P5:综合案例与度量
Easy Data x AI 课程 · 道篇 · 第五期
PM 路径的最后一课。我们用两个完整案例把前四期的概念串起来,并正式呈现一直在暗线中生长的核心框架——三层度量。
开场:拼图的最后一块
过去四期,我们一期解决一个问题。
P1 告诉你:先判断需求适不适合做 Agent,立项前先问“数据在哪”。P2 教你一棵归因决策树:用户说“AI 答得不好”,按步骤排查问题出在数据层、模型层还是业务层。P3 拆解了记忆系统的设计挑战——难的不是存,而是该忘什么。P4 指出 Skill 碎片化本质上是经验数据没有被统一管理的问题。
每期你拿到了一块拼图。今天我们做两件事:
第一,把拼图拼完整。通过两个综合案例,让你看到这些概念在一个真实产品里是怎么同时工作的——不是孤立的知识点,而是一个有机的系统。
第二,亮出底图。从 P2 开始,有一条暗线一直在生长:出了问题先判断在哪一层,解法就在哪一层。今天我们把它正式展开成一个完整的三层度量框架——这是你做 AI 产品最需要的诊断工具。
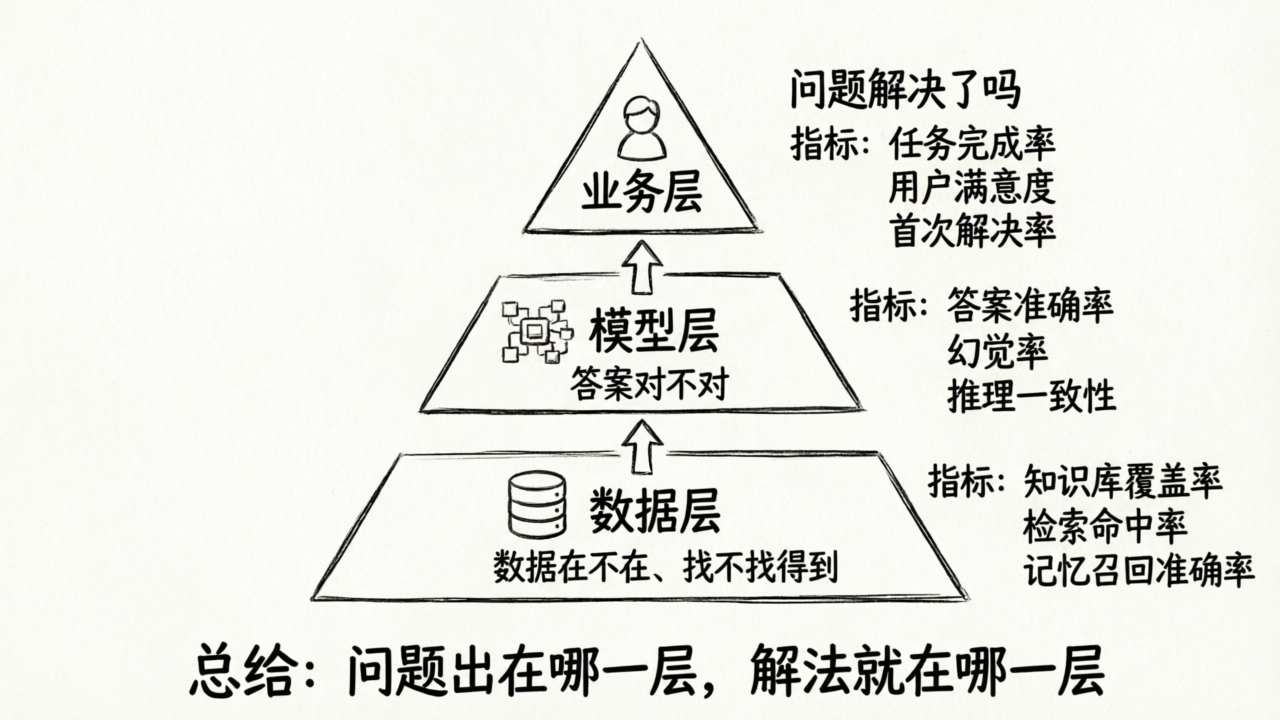
第一部分:三层度量框架
核心质量框架始终只有三层:数据层、模型层、业务层。运行层是三层质量框架的工程补充,不是第四个质量归因层;它关注系统能否稳定地把三层能力交付出来。
P2 中我们引入了三层归因的思路:数据层、模型层、业务层。当时的重点是“怎么判断问题出在哪”。今天我们往前走一步:怎么持续度量每一层的健康状况,而不是等用户投诉了再去排查。
好的度量体系不是等火烧起来才去救火,而是在烟刚冒出来的时候就能发现。
数据层指标:数据在不在、找得到找不到
数据层回答的核心问题是:Agent 需要的信息,存在吗?能被检索到吗?
三个关键指标:
- 知识库覆盖率:用户问的问题中,有多少能在知识库里找到对应的答案内容?如果用户问了 100 个问题,其中 40 个的答案在知识库里压根不存在——那你的覆盖率只有 60%。这意味着无论模型多强,这 40 个问题它都只能靠编,或者老实说“我不知道”。
- 检索命中率:知识库里明明有答案,但检索系统能把它找出来吗?P2 中我们讲过纯向量搜索在专有名词和精确信息上的盲区——即使答案存在,如果检索策略不对,Agent 可能拿到的是不相关的内容。检索命中率衡量的就是“知识存在且被正确找到”的比例。
- 记忆召回准确率:P3 讲的记忆系统同样面临检索问题——Agent 记住了用户的偏好,但在合适的时候能想起来吗?想起来的是当前最相关的记忆,还是三个月前已经过时的旧信息?
这三个指标有一个共同特征:它们衡量的都是数据从“存在”到“被 Agent 拿到”的链路是否通畅。链路断在任何一个环节,后面的模型再强也无能为力。
模型层指标:模型给的答案对不对
模型层回答的核心问题是:Agent 拿到了正确的数据,它的输出是否准确?
三个关键指标:
- 答案准确率:模型基于检索到的内容生成的回答,事实是否正确?有没有歪曲或遗漏检索结果中的关键信息?
- 幻觉率:模型有没有在回答中“添油加醋”——加入检索结果中不存在的信息?P2 中我们详细讨论过,这是大模型的原理性特征,不是 bug。幻觉率衡量的是这种“编造”发生的频率。
- 推理一致性:当用户用不同的方式问同一个问题时,模型给出的答案是否一致?如果同一个问题换个问法就得到截然不同的答案,用户会迅速失去信任。
注意:模型层指标只有在数据层是健康的前提下才有意义。如果数据层本身就有问题——知识库不全、检索不准——那模型层的指标再差也不能怪模型。先确认数据层没问题,再看模型层的表现。
业务层指标:最终业务结果好不好
业务层回答的核心问题是:用户的实际问题解决了吗?业务目标达成了吗?
三个关键指标:
- 任务完成率:用户带着一个具体目的来使用 Agent,最终目的达成了吗?比如用户想查一个退款政策——他最终拿到了准确的政策信息并完成了退款操作,还是中途放弃了?
- 用户满意度:用户对整体体验的主观评价。这包含了回答的准确性,也包含了回答的风格、速度、交互体验等数据层和模型层都不直接衡量的维度。
- 首次解决率:用户的问题是在第一次交互中就得到解决,还是需要反复追问、转人工、甚至换渠道?首次解决率越高,说明 Agent 作为一个完整产品的效果越好。
业务层指标是“最终考试成绩”。数据层和模型层是“平时作业和模考”——它们帮你提前发现问题,但最终产品好不好,还是要看业务结果。
三层之间的核心判断
三层度量框架的价值不只是“给你一堆指标”,而是帮你做出一个关键判断:
问题出在哪一层,解法就应该在哪一层。
这听起来像常识,但在实践中,绝大多数团队犯的最贵的错误就是层级误诊——把数据层的问题当成模型层的问题来解决。
还记得 P1 开场的那个案例吗?一家公司花了 200 万换模型,满意度只提升了不到 5%;另一家公司花了 20 万整理知识库数据,满意度提升了 40%。第一家公司的问题出在数据层(知识库内容缺失和过时),但他们把预算花在了模型层(更换更贵的模型)。
有了三层度量框架,这个误诊本来可以避免。如果他们在花钱换模型之前先看一眼数据层的指标——知识库覆盖率只有 60%、检索命中率也不高——就会意识到:问题根本不在模型。
把数据层问题误诊为模型层问题,是 AI 产品中最常见、最昂贵的错误。 三层度量框架的首要价值,就是帮你避免这种误诊。
第二部分:综合案例一——企业知识库助手
让我们用一个完整的案例把框架落地。
场景
某 B2B SaaS 公司要做一个面向客户的知识库问答助手。客户有产品使用问题时,先问 AI 助手;AI 回答不了的,再转人工客服。目标很明确:降低人工客服的工作量,同时提升客户自助解决问题的体验。
产品上线三个月了,客户反馈不断涌入。我们用三层度量框架来分析。
Agent 的工作流程
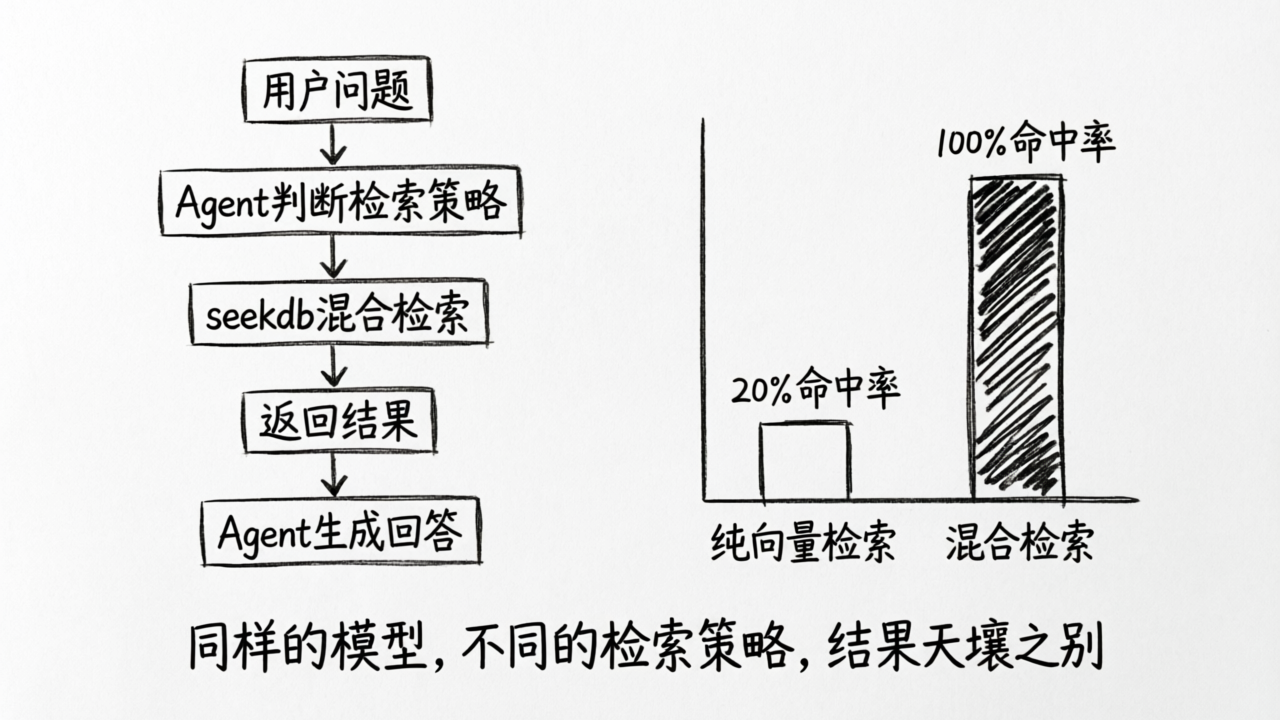
先理解这个 AI 助手是怎么工作的——这是一个典型的 Agentic RAG 系统:
- 客户提出问题:“OceanBase 4.2.1 版本支持哪些操作系统?”
- Agent 判断检索策略:这个问题涉及具体版本号,需要精确匹配和语义理解同时工作
- 从知识库中检索相关文档,返回最匹配的几段内容
- Agent 基于检索到的内容,生成一个针对性的回答
- 回答附带来源引用,方便客户验证
P2 中我们讲过,Agentic RAG 和传统 RAG 的区别在于第 2 步——Agent 会主动判断应该怎么搜、搜哪里、搜到的结果够不够用。但无论 Agent 的判断多聪明,它能给出的回答上限,取决于第 3 步知识库返回了什么。
检索效果对比
产品团队在优化过程中做了一次检索策略对比测试。他们选了 20 个真实客户问题,分别用纯向量搜索和混合搜索(向量 + 关键词)来检索,对比返回结果的质量。
以下是其中几个典型案例的对比:
| 客户问题 | 纯向量搜索返回的内容 | 混合搜索返回的内容 | 结果差异 |
|---|---|---|---|
| “OB-4.2.1 支持哪些操作系统?” | 返回了 OB-3.x 版本的操作系统兼容性文档(语义相近但版本错误) | 精确匹配到 OB-4.2.1 的兼容性文档 | 纯向量搜索版本匹配错误 |
| “ERR-40012 报错怎么解决?” | 返回了多个错误码的通用排查指南(语义相关但不针对具体错误码) | 精确命中 ERR-40012 的排查文档 | 纯向量搜索无法精确匹配错误码 |
| “如何配置主备集群的高可用?” | 返回了高可用架构概述文档(相关且有用) | 返回了同样的高可用架构文档,以及一篇具体的主备集群配置指南 | 两者都有用,混合搜索更完整 |
| “最近更新了什么功能?” | 返回了多个版本的更新日志(语义理解到位) | 返回了类似的更新日志内容 | 两者差异不大 |
20 个问题测完,产品团队发现了一个清晰的规律:凡是包含产品型号、版本号、错误码等精确信息的查询,纯向量搜索几乎必然“找错”;而对于纯语义类的查询,两种方式差异不大。
这正是 P2 中讨论过的向量搜索的结构性盲区——它理解”意思”,但不理解”精确”。在企业知识库这种充满专有名词和精确标识符的场景中,这个盲区会被反复放大。
用三层框架分析
现在用三层度量框架来诊断这个产品的问题:
数据层:知识库覆盖了大约 70% 的常见问题——还有 30% 的问题,客户问了但知识库里没有对应内容。这些缺失集中在最近两个版本的新功能文档和一些边缘场景的排查指南。检索命中率方面,切换到混合搜索后,涉及精确信息的查询命中率从 45% 提升到了 85%。
模型层:在检索结果正确的情况下,模型的回答准确率约 90%,幻觉率约 8%。这是一个相当不错的水平——主流模型在有良好参考资料时的表现差距不大。
业务层:整体首次解决率约 55%,用户满意度约 65 分(满分 100)。
诊断结论是什么?
首次解决率低,表面上看起来像是“AI 不够聪明”。但拆到三层来看:模型层的 90% 准确率和 8% 幻觉率都在合理范围内——模型不是瓶颈。真正拖后腿的是数据层:30% 的内容覆盖缺失 + 精确查询的检索命中率只有 45%。
这意味着什么?意味着客户的问题中有近一半,不是因为 AI 不聪明才答不好,而是因为AI 根本没拿到正确的参考资料。
解法也随之明确:第一优先级是补全知识库中缺失的 30% 的内容(尤其是新版本文档);第二优先级是将检索策略从纯向量搜索升级为混合搜索。这两件事都是数据层的工作,不需要换模型、不需要调参数、不需要重写 Prompt。
如果这个团队没有三层框架,他们最可能做什么? 大概率是去评估更贵的模型——然后花三个月时间和一大笔预算,得到和 P1 开场案例一模一样的结果:效果几乎不变。
把案例真正跑起来:从离线评测到 Dashboard
到这里,你已经知道应该看哪些指标,也知道如何根据指标判断问题出在哪一层。但在真实团队里,光有一个概念框架还不够。还需要把它变成一个每天都能看的系统。
本节用课程代码把刚才的企业知识库助手落到一个最小可运行的监控链路里。它不是生产系统的全部复杂度,但保留了生产系统最关键的骨架:
用户问题
-> Knowledge Agent
-> /ask API
-> /metrics
-> Prometheus
-> Grafana Dashboard你可以把这条链路理解成“从一次用户请求到一个管理者能看懂的仪表盘”的完整路径。
第一步:先用离线评测固定口径
接入 Prometheus 和 Grafana 前,先准备一个固定的评测集。这一步看起来朴素,却非常重要。
课程代码里有 30 条离线样本,覆盖六类场景:
| 类型 | 样本数 | 为什么要测 |
|---|---|---|
| 普通知识问答 | 8 | 验证知识库的基础覆盖能力 |
| 产品型号和版本 | 6 | 验证精确匹配,避免版本答错 |
| 错误码问题 | 5 | 验证错误码这类强精确字段能否命中 |
| 工具调用任务 | 5 | 验证 Agent 是否能模拟外部动作,并识别工具失败 |
| 知识缺失问题 | 4 | 验证 Agent 是否会老实转人工,而不是编答案 |
| 异常和边界任务 | 2 | 验证检索失败和幻觉样本是否能被单独识别 |
为什么先做离线评测?因为上线监控之前,团队必须先统一“什么叫好、什么叫坏”。
如果没有这一步,后面就会出现很典型的扯皮:模型工程师说“我觉得回答还行”,客服团队说“用户还是不满意”,产品经理说“Dashboard 上看不出问题”。离线评测集的作用,就是把争论从主观感受拉回到可复现样本。
运行方式很简单:
cd code/P5
python -m app.evaluation.run_eval它会生成两份报告:
outputs/evaluation_report.json
outputs/evaluation_report.md报告按核心三层和运行层补充展示指标:
- 数据层:知识覆盖率、检索命中率、检索故障率
- 模型层:回答准确率、幻觉率
- 业务层:任务成功率、转人工率、行为一致率
- 运行层补充:工具成功率、平均延迟、平均 Token 使用量
这里要注意一个教学重点:离线评测不是为了替代线上监控,而是为了给线上监控提供一套稳定口径。离线评测回答“在固定样本上表现如何”;线上监控回答“真实运行中表现是否持续稳定”。
第二步:把 Agent 暴露成 API
有了评测口径后,这个示例将 Mock Knowledge Agent 封装为一个 FastAPI 服务。服务提供三个最小接口:
GET /health
POST /ask
GET /metrics其中 /ask 是用户真正调用的 Agent API,/metrics 是 Prometheus 抓取指标的入口。
为什么要把 /ask 和 /metrics 分开?因为它们面向的是两类不同的读者:
/ask面向业务调用方,关心的是“这个问题答了什么、是否转人工、是否成功”;/metrics面向监控系统,关心的是“请求总量、成功率、延迟、成本这些可聚合数字”。
这一点很重要。用户的问题、回答正文、task_id 这些内容可以进入日志或 LangSmith Trace,但不能进入 Prometheus label。Prometheus 的 label 一旦放进高基数字段,时间序列数量会快速膨胀,监控系统会变慢甚至不可用。
因此,本示例的 Prometheus label 只使用这些低基数字段:
agent_version
environment
status
tool_name
error_type这是一条生产经验:Trace 负责看单条请求细节,Metrics 负责看整体趋势。不要让 Metrics 记录本该由 Trace 记录的东西。
第三步:理解每个指标属于哪一层
下表将课程代码中的 Prometheus 指标放回三层框架。读 Dashboard 时,先问“这个指标属于哪一层”,再判断“异常应该从哪里修”。
| 层级 | Prometheus 指标 | 计算方式 | 读法 |
|---|---|---|---|
| 数据层 | agent_knowledge_available_total / agent_knowledge_evaluated_total | 知识覆盖率 | 排除检索故障后,问题是否在知识库里有答案 |
| 数据层 | agent_retrieval_hit_total / agent_retrieval_total | 检索命中率 | 有答案时是否找到了正确文档 |
| 模型层 | agent_answer_correct_total / agent_answer_evaluated_total | 回答准确率 | 已标注流量中回答是否包含关键事实 |
| 模型层 | agent_answer_evaluated_total / agent_tasks_total | 回答评测覆盖率 | 准确率代表了多少线上流量 |
| 模型层 | agent_hallucination_total / agent_tasks_total | 幻觉率 | 没有依据却给确定答案的比例 |
| 业务层 | agent_task_success_total / agent_tasks_total | 任务成功率 | 用户任务是否由 Agent 独立完成 |
| 业务层 | agent_handoff_total / agent_tasks_total | 转人工率 | 有多少任务需要人工兜底 |
| 运行层 | agent_tool_calls_total - agent_tool_errors_total | 工具成功数 | 外部动作是否可靠 |
| 运行层 | agent_request_duration_seconds | P95 延迟 | 服务响应是否稳定 |
| 运行层 | agent_token_usage_total / agent_requests_total | 平均 Token | 单次请求大概消耗多少模型资源 |
| 运行层 | agent_cost_total | 成本累计 | 运行成本是否可控 |
这张表看起来像技术文档,但背后对应的是非常具体的产品决策:
- 知识覆盖率低:优先补知识库,不要先换模型。
- 检索命中率低:优先改检索策略,比如加入关键词、过滤条件或结构化索引。
- 回答准确率低但检索命中高:再看 Prompt、模型选择或回答模板。
- 幻觉率高:需要更严格的“无依据不回答”策略,必要时提高转人工。
- 转人工率高:先判断是数据缺失导致,还是工具失败导致,还是业务规则本身太复杂。
- 延迟和 Token 高:进入工程优化和成本控制问题。
第四步:用 Dashboard 做分层诊断
Grafana Dashboard 的意义不是把所有指标堆在一个页面上,而是帮助你形成固定的诊断顺序。
一个推荐读法是:
- 先看总体健康状态:请求量、任务成功率、转人工率、P95 延迟、错误率。如果这些指标都稳定,说明系统整体没有明显事故。
- 再看数据层:知识覆盖率和检索命中率是否下降。如果下降,优先怀疑知识库更新、索引构建、检索策略或文档质量。
- 再看模型层:回答准确率和幻觉率是否异常。如果数据层稳定但模型层恶化,再考虑 Prompt、模型版本或生成策略。
- 再看业务层:任务成功率和转人工率如何变化。如果模型回答没问题但业务成功率低,可能是流程、权限、工具或产品交互问题。
- 最后看运行层:延迟、错误率、Token 和成本是否变差。这些指标帮助你判断系统是否变慢、变贵或不稳定。
下面用几个典型异常来练习:
场景 A:任务成功率下降,知识覆盖率也下降。
这通常不是模型突然变笨了,而是知识库没有覆盖新的用户问题。比如产品刚上线一个新版本,但文档没有同步更新。正确动作是补文档、更新 FAQ、把新问题加入知识库,而不是急着换模型。
场景 B:知识覆盖率正常,检索命中率下降。
说明知识库里有答案,但 Agent 没找到。常见原因是索引没更新、关键词策略失效、版本号和错误码没有做精确匹配。正确动作是查检索链路。
场景 C:检索命中率正常,回答准确率下降,幻觉率上升。
这时才更像模型层问题。可能是 Prompt 约束变弱、模型版本变化、回答模板没有要求引用来源。正确动作是收紧生成策略,让 Agent 只基于检索结果回答。
场景 D:回答准确率正常,但转人工率上升。
这可能不是回答质量问题,而是业务层流程问题。比如工具调用失败、权限不足、某类任务必须人工确认。正确动作是看工具成功率和业务规则,不要只盯着文本回答。
场景 E:所有质量指标稳定,但成本快速上升。
这通常是运行层问题。可能是请求量上涨、平均 Token 变长、模型调用变贵。正确动作是做缓存、压缩上下文、限制无效请求,或者拆分低成本路径。
通过这些例子你会发现,Dashboard 不是“看数字好不好看”,而是训练团队形成一种肌肉记忆:先定位层级,再决定动作。
第五步:用 Demo Traffic 制造可观察变化
如果你刚启动 Dashboard,可能会发现面板是空的。这不是系统坏了,而是还没有流量。
课程代码提供了一个演示流量脚本:
cd code/P5
python -m app.observability.generate_traffic --count 100它会轮流制造七类请求:
- 成功任务
- 检索漏召回
- 检索服务故障
- 知识缺失
- 幻觉样本
- 工具失败
- 转人工
不要只发送成功请求。真实系统一定会遇到失败、知识缺失、工具不可用和幻觉风险;只有同时模拟这些情形,Dashboard 才能呈现每类问题会如何影响指标。
比如工具失败样本会让 agent_tool_errors_total 增长;幻觉样本会让 agent_hallucination_total 增长;知识缺失会提高 agent_handoff_total。这样你就能把“一个具体失败案例”和“Dashboard 上某个指标变化”对应起来。
实验观察:100 条请求发送后,应该去哪里看?
最短实验顺序是:安装依赖并运行离线评测;终端 A 执行 docker compose up --build; 终端 B 发送 Demo Traffic;依次查看 Agent /metrics、Prometheus、Grafana;最后在终端 A 按 Ctrl+C 并执行 docker compose down。Compose 周期性出现 /health、/metrics 就表示服务已持续运行。 端口冲突、镜像超时等排错统一见 code/P5/README.md。
Uvicorn 终端中的 POST /ask HTTP/1.1\" 200 OK 表示请求处理成功。流量发送后,打开 http://127.0.0.1:8000/metrics,或执行:
curl -s http://127.0.0.1:8000/metrics | rg '^agent_'这里可确认 agent_requests_total 等累计指标已增长。Grafana 图表需要先完成 docker compose up --build,再访问 http://localhost:3000。
第六步:LangSmith 看单条,Prometheus 看整体
除了 Prometheus,课程代码还提供了可选的 LangSmith Trace。默认不开启;没有 API Key 时,系统仍然可以完整运行。
开启后,每次 /ask 会形成一个 Trace:
Agent Trace
├── Retrieval Run
├── Generation Run
├── Tool Run(如果这次任务调用了工具)
└── Final Response这就是前面讲的分工:
- Prometheus / Grafana:看整体趋势,例如最近 5 分钟任务成功率是否下降。
- LangSmith Trace:点进一条失败请求,看它到底检索到了什么、生成了什么、工具是否失败。
在真实团队里,这两个工具通常是配合使用的。你先从 Grafana 发现“幻觉率突然上升”,再到 LangSmith 里筛选对应时间段的 Trace,逐条看模型为什么开始编造。一个负责发现异常,一个负责解释异常。
这也是三层度量框架落地时的关键原则:Metrics 告诉你哪里变坏了,Trace 告诉你为什么变坏。
从三层指标到 ROI:优化值不值得投入
三层指标告诉我们问题在哪里,但产品决策还要回答另一个问题:解决这个问题值不值得花钱?
以企业知识库助手为例,数据层的知识覆盖率和检索命中率、模型层的回答准确率、业务层的首次解决率,都是诊断指标。它们不能各自换算成一笔收益后相加,否则同一次问题解决会被重复计算。
正确链路是:
知识覆盖率提升
-> 检索命中率提升
-> 回答准确率提升
-> 转人工减少、成功任务增加、风险事件减少
-> 人工节省、收入提升、风险损失降低因此,ROI 的输入要明确区分两类数据:系统观测数据和业务假设。
| 类别 | 典型字段 | 来源 |
|---|---|---|
| 系统观测数据 | 月任务量、转人工率、任务成功率、风险事件率、单任务成本 | 运行日志、监控系统或离线评测汇总 |
| 业务假设 | 人工处理单价、成功任务价值、风险事件损失、开发和维护成本 | 客服、财务和业务负责人 |
首年累计的核心公式如下:
总成本(Total Cost, TotalCost)
= 初始投入(Initial Cost, InitialCost)
+ 12 × [月固定成本(Monthly Fixed Cost, MonthlyFixedCost)
+ 月可变成本(Monthly Variable Cost, MonthlyVariableCost)]
总收益(Total Benefit, TotalBenefit)
= 12 × [人力节省(Human Saving, HumanSaving)
+ 收入提升(Revenue Lift, RevenueLift)
+ 风险损失降低(Risk Reduction, RiskReduction)
+ 独立效率收益(Efficiency Gain, EfficiencyGain)]
净收益(Net Benefit, NetBenefit)= 总收益 - 总成本
投资回报率(Return on Investment, ROI)= 净收益 / 总成本 × 100%其中,“总成本”和“总收益”是最终决策指标;TotalCost、TotalBenefit 等英文名称是代码和 JSON 报告中的字段名。投资回收期(Payback Period)表示初始投入由月净收益覆盖所需的月数;盈亏平衡任务量(Break-even Monthly Task Volume)表示在首年口径下实现净收益为零所需的每月任务量。
课程代码提供了保守、基准、乐观三种情景的可复现计算器。运行一次命令即可同时计算三种情景,输出 Markdown、JSON 和 CSV 对比报告:
| 情景 | 月任务量 | 转人工率 | 任务成功率 | 单任务成本 | 首年 ROI | 解读 |
|---|---|---|---|---|---|---|
保守(conservative) | 80 | 35% | 68% | 2.5 元 | -24.46% | 业务量偏低、转人工和模型成本偏高,首年尚未回本 |
基准(base) | 100 | 20% | 80% | 2 元 | 67.65% | 课程案例的预期运营水平 |
乐观(optimistic) | 140 | 12% | 88% | 1.6 元 | 188.92% | 业务量增长,质量和成本均持续改善 |
基准情景假设 AI 将转人工率降至 20%、任务成功率从 60% 提升到 80%。在初始投入 4,000 元、每月固定成本 600 元和每任务成本 2 元的前提下,首年总成本为 13,600 元、总收益为 22,800 元、净收益为 9,200 元,ROI 约为 67.65%,投资回收期约为 3.64 个月。三种情景都是教学用假设,实际项目应以运营快照和业务负责人确认的价值参数替换。
运行方式见 P5 ROI 计算器 README。当后续监控体系上线后,只需将示例 YAML 中的运营快照替换为 Prometheus 或评测系统聚合出的真实数据;成本和业务价值假设仍需由业务负责人确认。
第三部分:综合案例二——有记忆的个人 AI 助手
第二个案例的重心从知识检索转向用户记忆。
场景
一款面向个人用户的 AI 助手产品,核心卖点是“越用越懂你”。它不只是回答问题,还会从每次对话中学习用户的偏好、习惯和背景,让后续的交互越来越个性化。
这里面的技术构成我们在 P3 中都讲过:语义记忆存用户的事实信息,情景记忆存过往的成功交互经验,程序记忆存用户偏好的行为方式。
但让我们看看这些概念在产品里是怎么具体工作的。
AI 如何积累对用户的了解
想象一个用户“小李”,她是一个创业公司的产品经理。
第一次对话(周一上午): 小李问:“帮我写一份竞品分析的大纲。”AI 给出了一个通用的竞品分析框架。小李说:“太学术了,我需要更落地的,直接能拿去和投资人聊的那种。”AI 调整了风格,给出了更商业化的版本。小李满意了。
这次对话中,AI 提炼了几条记忆:
- 语义记忆:小李是产品经理,在创业公司工作
- 情景记忆:小李要求“落地的、能和投资人聊”的风格时,从学术框架切换到商业化表达效果好
- 程序记忆:用户偏好直接、落地的回答风格,不喜欢太学术的表述
第三次对话(周三下午): 小李问:“帮我整理一下我们产品的核心亮点。”注意——AI 这次不需要再问“你做什么的”“给谁看的”。它从语义记忆中知道小李是创业公司的产品经理,从情景记忆中知道她可能需要面向投资人的商业化表达,直接给出了一个适合融资场景的产品亮点整理。
小李的反应:“这个角度挺好的,不过我们刚 pivot 了方向,现在做的是企业级市场,不是 C 端了。”
AI 立刻更新了语义记忆:小李的公司从 C 端转向了企业级市场。旧的“C 端产品”相关记忆开始降权,新的“企业级市场”记忆进入高权重状态。
第十次对话(两周后): 小李只说了一句:“帮我准备明天的投资人会议。”
AI 已经知道她是谁、做什么、公司最近 pivot 到了企业级市场、她偏好落地的商业化表达风格。它给出了一份完整的投资人会议准备材料——包括公司定位、市场分析、产品亮点、竞争优势——全部基于过去十次对话积累的上下文,用小李喜欢的风格呈现。
小李不需要重新解释任何背景。这就是“越用越懂你”。
用户如何感知和管理记忆
但“越用越懂你”也可能让用户不安。P3 中我们讲过——如果用户不知道 AI 记住了什么,不知道这些记忆会怎么影响 AI 的行为,信任就建立不起来。
好的产品设计需要做到几点:
第一,透明。当 AI 使用了某条记忆来个性化回答时,应该让用户能感知到。比如:“基于你之前提到公司最近转向了企业级市场,我用了 B2B 的视角来分析。”用户看到这句话,就知道 AI 为什么这么回答——这比莫名其妙地给出一个精准但来路不明的回答,更让人信任。
第二,可管理。用户应该能查看 AI 记住了什么,能修正错误的记忆(“不对,我们没有放弃 C 端,是两条线并行”),能删除不想被记住的信息。
第三,有边界。不是所有对话内容都应该被记住。如果小李在某次对话中随口吐槽了一下老板,她大概不希望 AI 在后续对话中提起这件事。记忆系统需要有判断力——什么值得存,什么应该忽略。
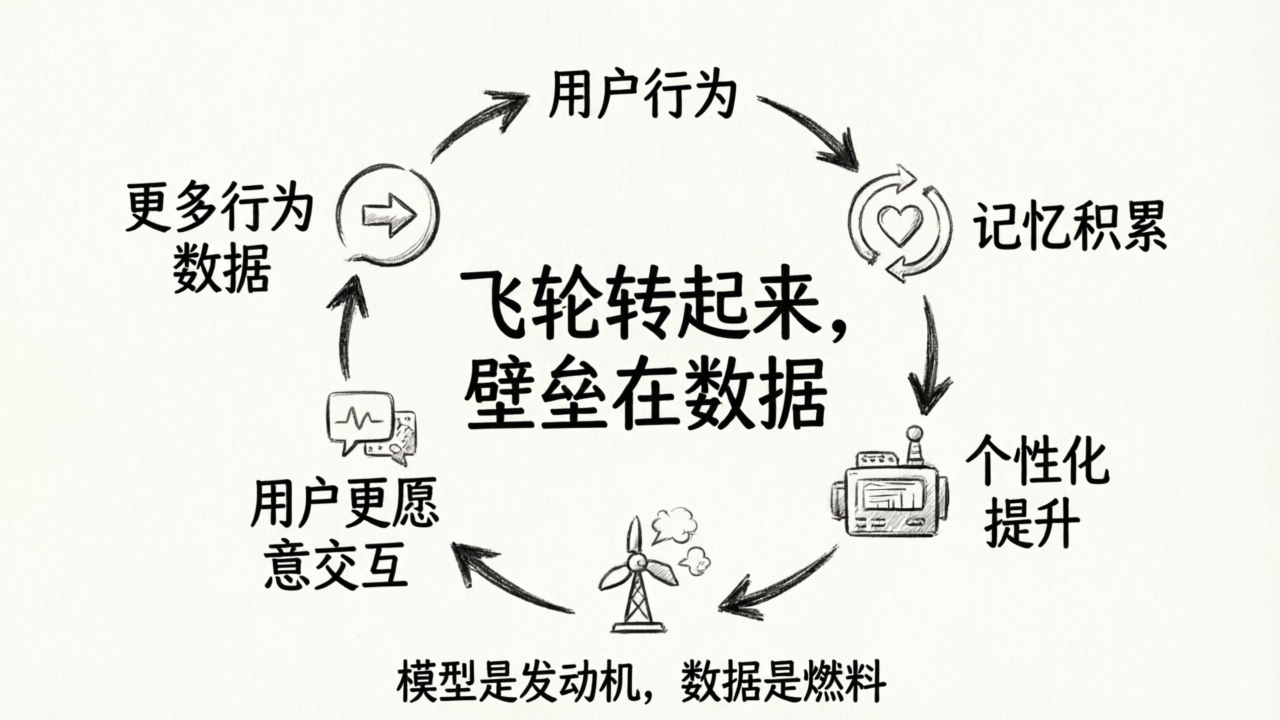
数据飞轮
这个案例最值得关注的产品逻辑是数据飞轮:
用户行为 → 记忆积累 → 个性化提升 → 用户更愿意交互 → 更多行为数据 → 更丰富的记忆 → 更好的个性化 → ……
这个飞轮一旦转起来,产品的壁垒就不再是模型(模型大家都能用),而是积累的用户数据。每个用户和 AI 的交互越多,AI 对这个用户的了解越深,切换到另一个没有记忆的产品的成本就越高。
但飞轮能不能转,取决于一个前提:记忆系统的数据质量够不够好。
如果记忆提炼不准确——把用户的随口一说当成了确定偏好,或者忽略了用户的重要变化——个性化就会出错。出错的个性化比没有个性化更糟:用户会觉得“这个 AI 不仅不懂我,还自以为懂我”,信任崩塌,飞轮停转。
所以,记忆助手的核心瓶颈和知识库助手一样——不在模型层,在数据层。模型的理解能力和生成能力已经足够好了;真正决定产品体验的,是记忆数据的提炼质量、检索策略和时效性管理。
我们的思考
两个案例,一个以 Agentic RAG 为主,一个以 Memory 为主。表面上看是两类完全不同的产品,但拆到底,它们呈现的是同一个底层逻辑:
AI 产品的迭代飞轮转不转,取决于数据层转不转。
知识库助手的飞轮是:数据补全 → 检索准确 → 回答质量提升 → 用户信任提高 → 更多使用场景 → 更多反馈数据 → 进一步优化数据。记忆助手的飞轮是:交互数据 → 记忆积累 → 个性化提升 → 用户黏性增强 → 更多交互数据。
两个飞轮的驱动引擎都不是模型——模型是发动机,但数据是燃料。发动机的马力已经足够大了,真正的瓶颈是油箱里有没有油、油管通不通、油品好不好。
但我们在实践中反复观察到一个资源错配:大多数团队把 80% 的精力花在模型层调优上——选模型、调参数、换 API、优化 Prompt——但真正制约产品效果的瓶颈往往在数据层。
为什么会这样?因为模型层的优化“看起来”更像是在做 AI——它涉及大模型、涉及前沿技术、涉及让人兴奋的新能力。而数据层的工作“看起来”很朴素——整理知识库、优化检索策略、设计记忆的提炼和降权机制——这些工作不性感,但它们决定了 AI 产品的天花板。
seekdb 和 PowerMem 就是基于这个判断做的。seekdb 解决的是知识数据的存储与检索——一个引擎同时支持向量语义搜索、关键词精确搜索和结构化条件过滤,让数据层不再是三套系统拼凑出来的脆弱架构。PowerMem 解决的是记忆数据的积累与召回——从认知科学中借鉴的遗忘曲线机制,让 Agent 的记忆不是无差别地堆积,而是像人脑一样有选择地保留和衰减。
底层逻辑是一样的:先把数据层的问题解决了,模型层的能力才能被充分释放。 就像再好的跑车,跑在坑洼不平的路上也发挥不出性能。先把路修好——这是我们选择的切入点。
这节课要留下的印象
如果这节课的所有内容你只记住一句话,记住这句:
AI 产品的问题通常出在数据层,但大多数团队把预算花在了模型层。三层度量框架帮你看清问题在哪——先量对了,再改对了。
课后行动
为你当前负责的 AI 产品(或正在规划的 AI 功能),完成以下练习:
列出三层指标,每层至少 2 个可度量的指标:
- 数据层:比如知识库覆盖率、检索命中率、记忆召回准确率
- 模型层:比如答案准确率、幻觉率、推理一致性
- 业务层:比如任务完成率、用户满意度、首次解决率
诚实地判断:当前你的产品最该优先改善的是哪一层?是数据层的覆盖和检索质量?是模型层的准确性?还是业务层的规则和体验?
审视资源投入:你的团队实际在哪一层投入了最多的时间和预算?这个投入方向和你第 2 步的判断一致吗?如果不一致——恭喜你,你可能刚刚发现了一个值得在下次团队会议上提出来的重要问题。
回顾整条 PM 路径
五期课走完了。让我们站远一点,看看这条路径的全貌。
P1 解决的是“要不要做”的问题。我们给了你一套场景判断方法(Agent 的三个甜区)和一份可行性评估 Checklist(数据可得性、任务可定义性、失败可承受性)。核心判断:90% 的 AI 功能失败不是模型不行,而是立项时没人问“数据在哪”。
P2 解决的是“答得不好怎么办”的问题。我们给了你三层归因框架和一棵决策树,帮你精准定位问题出在数据层、模型层还是业务层。核心判断:PM 的第一反应不应该是“换模型”,而是“数据层有没有问题”。
P3 解决的是“怎么让 AI 记住用户”的问题。我们介绍了 CoALA 框架下的三种记忆类型,拆解了“存什么、忘什么、给谁看”的设计挑战。核心判断:记忆系统难的不是存——难的是该忘什么、该想起什么,以及用户是否信任你的记忆管理。
P4 解决的是“怎么管理 Agent 的技能”的问题。我们指出 Skill 碎片化的本质是经验数据没有被统一管理,和知识库分散是同一类问题。核心判断:Agent 生态的下一个基础设施问题,是给技能建一个可检索的知识库。
P5——也就是今天——把前四期的拼图拼在一起,用两个综合案例展示它们如何协同工作,并正式呈现了三层度量框架作为你日常工作中的诊断工具。
五期课有一条主线从头贯穿到尾:数据视角。
不是说模型不重要——模型当然重要。但在当前这个阶段,主流模型之间的能力差距已经越来越小,而数据层的质量差距可以是天壤之别。一个好的知识库和一个烂的知识库,给同一个模型带来的效果差异,远大于在同一个知识库上换不同模型的效果差异。
如果这五期课程让你建立了一个习惯——遇到 AI 产品的问题,先想数据层——那这门课的目的就达到了。
这不是“数据比模型重要”的简单判断,而是一个更精确的判断:在大多数团队的资源配置中,数据层被系统性地低估了。 当你把视线从模型层转向数据层,你会发现很多看似困难的问题其实有很直接的解法——补数据、优化检索、设计记忆策略——这些工作不需要等下一代模型发布,现在就能开始做,而且往往能带来最显著的效果提升。
先量对了,再改对了。先看数据,再看模型。
这就是我们想传递的数据视角。感谢你走完了这条路径。
延伸阅读
如果你对本期提到的概念想做进一步了解,以下是一些推荐资源:
- 三层度量在实践中的应用:RAG 评估领域有多个开源框架(如 RAGAS、DeepEval)可以帮助你量化数据层和模型层的指标,感兴趣的读者可以搜索 “RAG evaluation framework” 了解更多
- 企业知识库助手的最佳实践:混合检索(向量 + 关键词)已经成为生产级 RAG 系统的标准配置,Dev 路径 D3 模块中有完整的对比实验代码可以参考
- 记忆系统的产品设计:ChatGPT Memory、Claude 的记忆功能都是值得研究的产品实践案例——重点关注它们在“透明性”和“用户控制”方面的设计选择
- LOCOMO Benchmark:github.com/Shopify/locomo,P3 中提到的 Agent 长期记忆评估基准,可以用来量化你的记忆系统的检索准确率
- 课程整体回顾:回看 F1-F2 的共同基础模块,你会发现 P1-P5 中讨论的每一个话题,都能在那张 Agent 能力地图中找到对应的位置——“Agent 的每一项能力,拆到底都是数据的存储与检索”
欢迎各位老师在 https://github.com/datawhalechina/easy-data-x-ai 参与课程共建。
也欢迎各位老师加入 Data x AI 交流群~
