D5:课程总结
Easy Data x AI 课程 · 术篇 · 第五期
走完术篇的旅程,回头看看你做了什么、学到了什么、以及这一切背后的那条主线。
开场:你已经走了多远
D1 你第一次用代码调用大模型,让它从"只能说"变成"能做事"。
D2 你搭建了一个能同时处理向量、全文和关系数据的数据层。
D3 你把 D1 和 D2 连起来,构建了一个知识库问答系统,并亲眼看到了检索策略对最终效果的影响。
D4 你给 Agent 加了记忆,体验了"有记忆"和"没记忆"的 Agent 在对话中的天壤之别。
四期课程,四个动手实验,一条主线贯穿始终。
这一期,我们不引入新技术——我们站远一点,把这四期的内容串起来,看清楚它们在解决同一个问题的不同层面。
第一部分:D1 回顾——Tool Use 是一切的起点
大模型只能"说"
D1 的核心认知是:大模型本身只能生成文本,它无法主动查数据库、调 API、执行代码。它的能力边界就是"说"。
Tool Use 打破了这个边界。你在代码里定义工具(函数),告诉模型"你可以调用这些工具",模型在推理时会声明"我需要调用某个工具",你的代码去执行,结果传回来,模型继续推理。
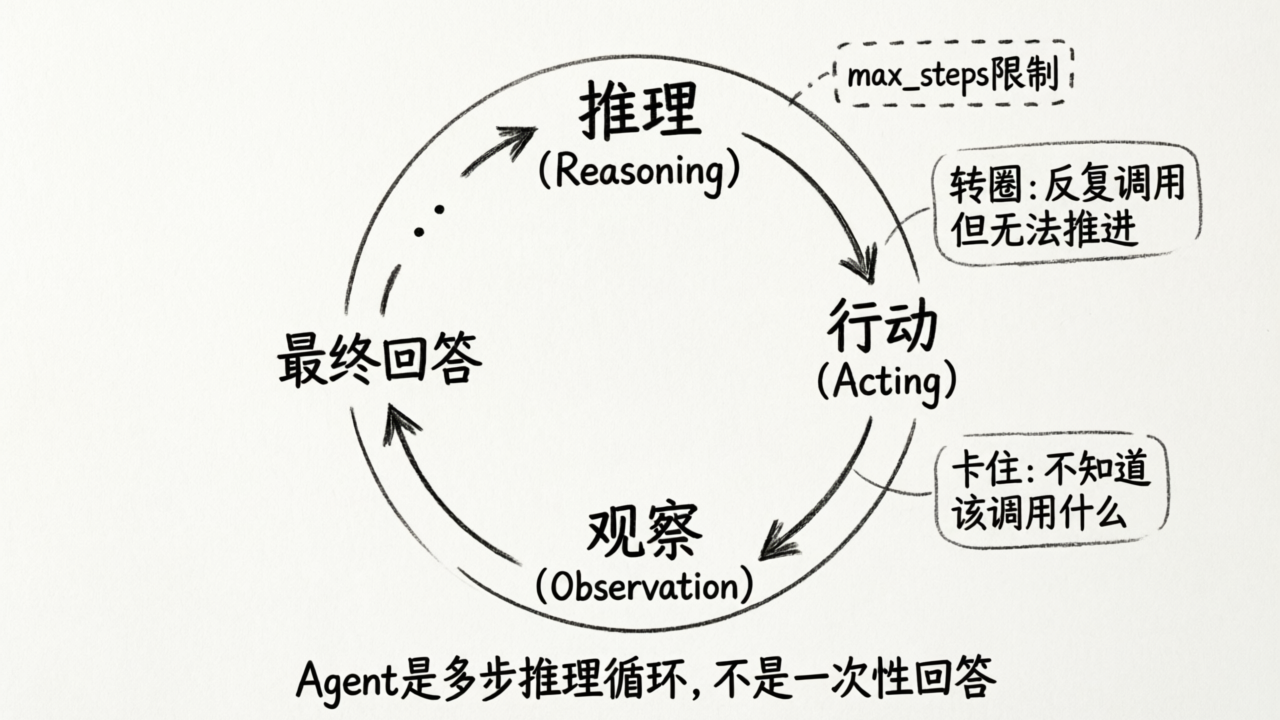
这个"声明→执行→传回"的循环,就是 Agent 与外部世界交互的核心机制。
从单次调用到 Agent 循环
D1 的代码演进路径是:
d1_1 基础调用 → 一问一答
d1_2 多轮对话 → 手动维护消息历史
d1_4 Tool Use Mock → 手动编排工具调用(假数据)
d1_5 Tool Use Real → 手动编排 + 真实检索
d1_6 Agent 循环 → 自动化的"推理→行动→观察"多轮循环d1_4/d1_5 里你手动写的那些 if/else 逻辑,在 d1_6 里被框架一行代码替代了。这不是偷懒——这是理解了底层机制之后,才能正确使用上层抽象。
D1 留下的判断
Agent 不是"更聪明的 ChatGPT",而是一个具有"感知→推理→行动"循环能力的系统。它的能力上限,取决于它能调用什么工具、工具能拿到什么数据。
第二部分:D2 回顾——数据层决定能力上限
为什么传统数据库不够用
AI 应用需要语义检索——用户问"有没有关于数据库性能优化的内容",不是在做关键词匹配,而是在做语义理解。传统数据库的全文搜索做不到这一点。
但纯向量搜索也有问题:遇到专有名词、版本号、错误码时,语义相似不等于内容正确。用户问"OceanBase 4.2 的 BUG-12345 怎么解决",纯向量搜索可能给你一个"语义相近但版本完全不对"的结果。
混合检索是完整方案
D2 的核心结论:向量检索 + 全文检索 + 关系过滤,三种能力缺一不可。
- 向量检索:处理语义模糊的查询
- 全文检索:精确匹配专有名词、版本号、错误码
- 关系过滤:按结构化字段(时间、分类、来源)缩小范围
seekdb 在一个引擎里原生支持三种能力,不需要三个系统拼凑。
D2 留下的判断
AI 应用的数据层,不是"存数据的地方",而是"决定 Agent 能拿到什么信息"的地方。数据层的质量,直接决定 Agent 回答的质量。
第三部分:D3 回顾——亲眼看到数据层的影响
对比实验是最好的说明
D3 最重要的不是代码,而是那个对比实验:同样的查询,纯向量检索和混合检索的结果差距是肉眼可见的。
特别是包含专有名词、版本号、错误码的查询——混合检索把正确答案排在第一位,纯向量搜索则可能给你一个"语义相近但完全错误"的结果。
这个实验验证了 P2 讲的核心判断:"AI 答得不好"的大多数根因在数据层,不在模型层。
Agentic RAG 的结构
D3 把 D1 的 Tool Use 和 D2 的数据层连接起来:
# Agent 通过 Tool Use 调用 seekdb 混合检索
tools = [hybrid_search_tool]
# 用户提问 → Agent 推理 → 调用检索工具 → 拿到结果 → 生成回答
response = agent.run(user_query, tools=tools)这个结构是后续所有模块的基础。D4 的记忆系统,也是在这个结构上叠加的。
D3 留下的判断
换更强的模型之前,先检查你的检索策略。大多数时候,问题出在数据层,不在模型层。
第四部分:D4 回顾——记忆系统是数据问题
失忆的 Agent
没有记忆的 Agent,每次对话都是全新的开始。你告诉它"我是 Python 开发者,喜欢简洁的回答",下次打开程序,它什么都不记得了。
这不是模型的问题——模型本身没有持久化存储。这是一个数据问题:用户信息需要被存储、检索、管理。
三种长期记忆的工程实现
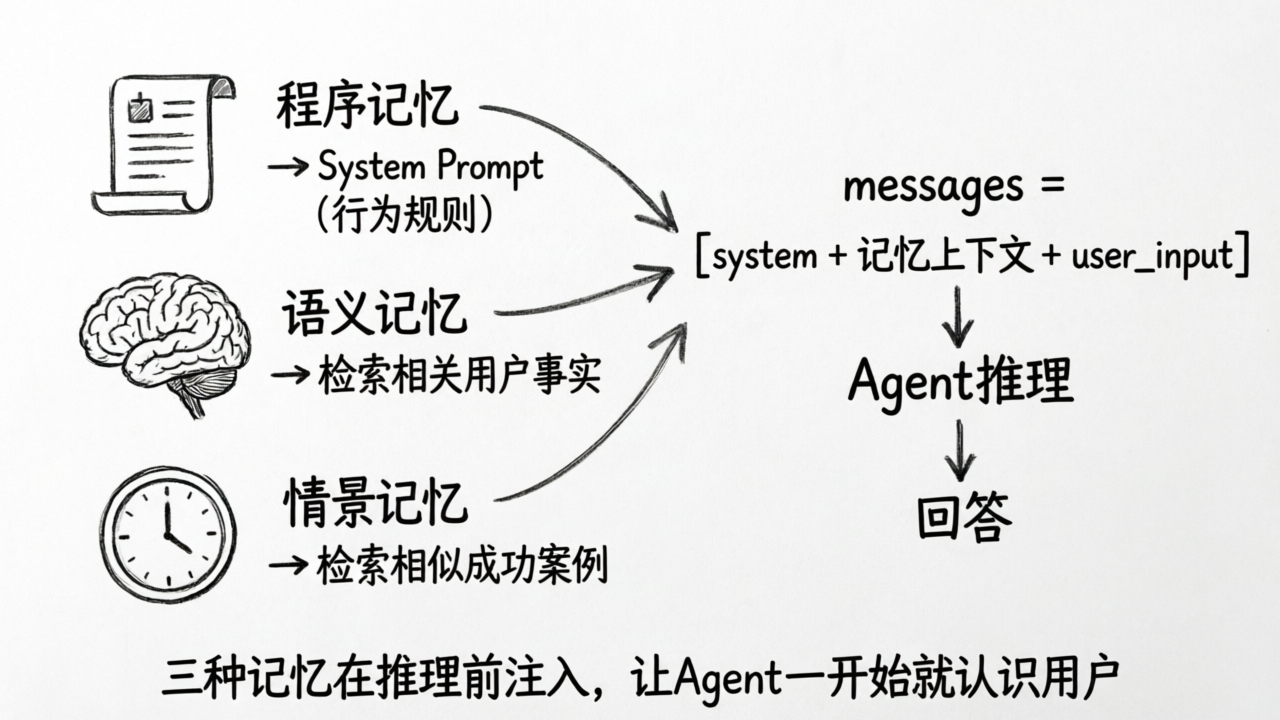
D4 把 P3 的产品概念落地成了工程实现:
| 记忆类型 | 存储内容 | 工程实现 |
|---|---|---|
| 语义记忆 | 用户事实与偏好 | 从对话中提炼关键事实,存入向量数据库,语义检索召回 |
| 情景记忆 | 过去的成功经验 | 存储历史案例,作为 few-shot 示例注入 Prompt |
| 程序记忆 | 行为规则 | System Prompt,Agent 可自我修改 |
三种记忆都在 Agent 推理循环之前注入到 Prompt 中——让 Agent 在开始推理时就已经"认识"这个用户。
记、忘、想起的数据挑战
- 记:不是存原文,而是提炼关键事实(LLM 完成)
- 想起:语义检索,和 RAG 是同一个机制
- 忘:艾宾浩斯遗忘曲线——旧记忆随时间降权,被使用时权重回升
PowerMem 在 LOCOMO 基准测试中准确率 78.7%,比"把所有历史对话塞进上下文"的暴力方案(52.9%)高出近 50%。把所有信息都"记住",效果反而不如有选择地记忆。
D4 留下的判断
记忆系统看起来是 AI 问题,拆到底是数据问题——怎么存、怎么查、怎么过期。
第五部分:一条主线贯穿始终
退一步看这四个模块:
D1 Tool Use → Agent 与数据的连接方式
D2 seekdb → 数据本身的存储与检索
D3 Agentic RAG → 用数据回答问题
D4 Memory → 用数据记住用户每一个模块,做的事情都不一样。但它们底层解决的是同一件事:
Agent 的每一项能力,拆到底都是数据的存储与检索。数据层的质量,决定了 Agent 能力的上限。
这是 F2 画的那张地图中一开始就写下的判断。走完四个模块之后,你不再需要"相信"这个判断——你已经用代码和实验亲手验证了它。
我们的思考
从 D1 到 D4,有一件事反复出现:当 Agent 表现不好,第一反应不应该是"换个更强的模型",而应该是"检查数据层"。
D3 的对比实验证明了这一点——同一个模型,换了检索策略,效果天壤之别。D4 的记忆实验也证明了这一点——同一个模型,加了记忆系统,对话体验完全不同。
Skill 进一步说明:经验流程也要先沉淀成可管理的数据,才能被迁移和复用。
模型是固定的,数据是你能控制的。投资数据层,是 ROI 最高的工程决策。
如果你在这门课中只带走一个工程判断,带走这个:
与其为 Agent 的每一项能力分别搭建数据基础设施,不如先投资一个统一的、高质量的数据层。数据层做对了,Agent 的每一项能力都受益。数据层做错了,任何一项能力都会被拖累。
这节课要留下的印象
D1 到 D4 分别完成 Tool Use、数据层、Agentic RAG 和记忆系统四项能力,D5 负责把它们串成一条工程主线。Skill 的产品设计在 P4,标准化工具实战可继续阅读 X5。
课后行动
回顾四组示例代码:从 D1 到 D4,你跑通了四组动手实验。花半小时回顾一遍,重点思考:
- 哪些模块的内容可以直接用在你当前的项目中?
- 你的项目中,Agent 最薄弱的环节是什么——是检索不准(D2-D3)、还是没有记忆(D4)、还是工具调用不稳定(D1)?
- 最薄弱的环节,对应的是数据层的什么问题?
做一个对比实验:在你自己的知识库上,分别用纯向量检索和混合检索跑同一组查询,记录结果差异。特别关注包含专有名词、版本号的查询。
给你的 Agent 加记忆:选一个你在用的 Agent 应用,用 PowerMem 给它加上跨会话记忆。观察加了记忆之后,对话体验有什么变化。
欢迎各位老师在 https://github.com/datawhalechina/easy-data-x-ai 参与课程共建。
也欢迎各位老师加入 Data x AI 交流群~
