D4:Agent 开发与记忆系统
Easy Data x AI 课程 · 术篇 · 第四期
上一期你构建了一个能查知识库的 RAG Agent。这一期,我们给它装一个大脑——让它记住你是谁、你说过什么、你需要什么。
开场:那个每次都失忆的 Agent
你在 D3 构建的 RAG Agent 已经能回答知识库相关的问题了。用户提问,Agent 通过 Tool Use 调用 seekdb 检索知识库,基于检索结果生成回答。效果不错。
但你有没有试过连续和它聊五轮以上?
第一轮你说:“我是 Python 开发者,最近在做一个数据分析项目。”Agent 回答得很好。
第二轮你问:“帮我推荐一个适合的数据库方案。”Agent 给了你一个通用的推荐列表——MySQL、PostgreSQL、MongoDB,什么都有。
等等,你刚刚告诉过它你是 Python 开发者在做数据分析项目啊?它为什么不直接推荐 pandas + seekdb 这种 Python 友好的方案?为什么要给你推荐一堆 Java 生态更常用的选项?
因为它根本不记得你说过什么。
更准确地说,在同一个对话窗口内,它能记住——因为你的代码把历史消息都放在 messages 列表里了。但一旦会话结束、程序重启,一切归零。下次你再来,它不知道你是谁、不知道你喜欢什么、不知道你上次的问题解决了没有。
P3 用了一个精确的类比:这就像一个每天早上都会彻底失忆的同事。他很聪明,但你每天都要重新做一次自我介绍。
今天,我们来解决这个问题。不只是“让 Agent 能记住”,而是让它智能地记住——记该记的,忘该忘的,想起该想起的。
第一部分:Agent 不是一次性回答机器
在动手加记忆之前,我们先理解一件很多开发者忽略的事:Agent 和你之前写的那些“调 API 拿回答”的代码,在架构上有本质区别。
Agent 的推理循环
D1 你学了 Tool Use,知道模型可以声明“我要调用一个工具”,你的代码去执行,结果传回来,模型继续推理。
但 D1 的例子是一个单次循环——用户提问 → 模型判断要不要调工具 → 调一次 → 拿到结果 → 回答。
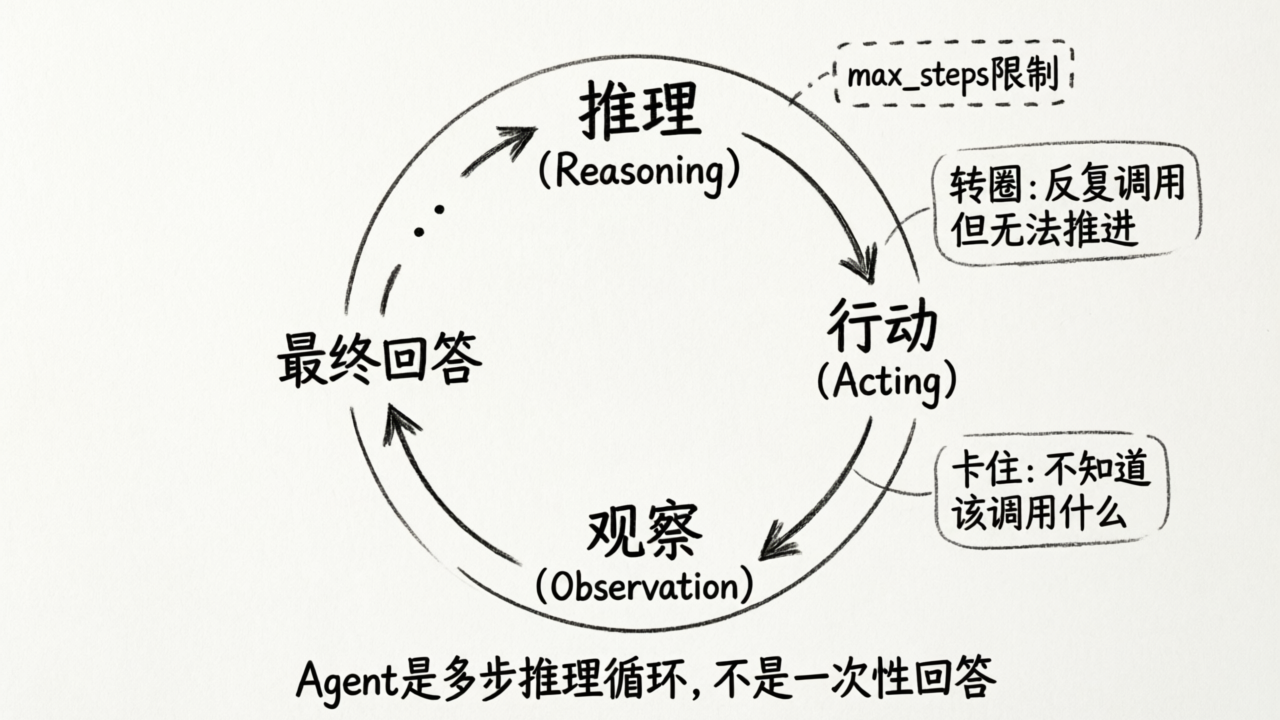
真实的 Agent 不是这么工作的。它是一个多步推理循环,业界称为 ReAct 模式(Reasoning + Acting):
推理 → 行动 → 观察 → 推理 → 行动 → 观察 → ... → 最终回答用伪代码表示:
def agent_loop(user_input, tools, max_steps=10):
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_input}
]
for step in range(max_steps):
response = llm.chat(messages=messages, tools=tools)
if response.has_tool_calls():
# 推理后决定行动:调用工具
for tool_call in response.tool_calls:
result = execute_tool(tool_call)
messages.append(tool_call_message)
messages.append(tool_result_message(result))
# 观察结果后继续循环,进入下一轮推理
else:
# 推理后决定:信息够了,直接回答
return response.content
return "抱歉,我无法完成这个任务。"一个关键细节:循环有最大步数限制(max_steps)。为什么?因为 Agent 有时候会“转圈”——它调用了工具,拿到的结果不够好,又调用一次,结果还是不够好,于是陷入循环。
理解了这个结构,你就能理解 Agent 的两个常见问题:
- Agent 转圈(Looping):它在循环中反复调用工具,但每次拿到的数据都不足以推进推理。根因通常是数据层的问题——检索结果不够相关,或者工具定义不够清晰。
- Agent 卡住(Getting Stuck):它不知道下一步该调用什么工具,或者所有工具都试过了但没有得到有用的信息。同样,根因往往在数据层。
这和 P1 讲的判断一致:Agent 表现不好,多半不是模型不够聪明,是它没拿到够好的数据。
现在,带着这个理解,我们来看记忆系统如何融入这个循环。
第二部分:记忆系统的工程实现
P3 用 CoALA 框架把 Agent 记忆分成了短期记忆和三种长期记忆(语义记忆、情景记忆、程序记忆)。那是产品设计视角的分类。现在我们从工程视角来看:这些概念在代码里长什么样?
短期记忆:你已经在用了
短期记忆就是当前会话的对话历史。你在 D1 就写过:
messages = [
{"role": "system", "content": "你是一个技术助手。"},
{"role": "user", "content": "什么是 RAG?"},
{"role": "assistant", "content": "RAG 是检索增强生成..."},
{"role": "user", "content": "它和微调有什么区别?"}
]这个 messages 列表就是短期记忆。它有两个特点:会话期间随用随取,会话结束就消失。
在 LangGraph 等框架中,短期记忆的管理被封装成 Checkpointer 的概念——它负责在每一步推理后保存当前状态,这样即使中途出错也能恢复。本质上就是对 messages 列表的持久化管理。
短期记忆的工程挑战不大,但有一个值得注意的点:随着对话轮数增加,messages 列表越来越长,迟早会撞上上下文窗口的限制。这时候你需要做截断或摘要——而怎么截断、保留哪些信息、丢弃哪些信息,本身就是一个数据决策。
长期记忆——语义记忆:这是重头戏
语义记忆存储的是关于用户的事实和偏好。P3 用了“百科全书”的类比——记的是“什么是什么”。
从工程角度,语义记忆要做三件事,对应 P3 讲的“记、忘、想起”:
第一步:提炼(记)
不是把对话原文存进去,而是从对话中提取关键事实。
比如一段对话:
用户:我最近在用 FastAPI 做后端,感觉比 Flask 好用多了。
Agent:FastAPI 确实在性能和类型提示方面有优势...
用户:对,我们团队前端用的是 React。从这段对话中应该提取的记忆是:
- “用户后端使用 FastAPI”
- “用户之前用过 Flask”
- “用户团队前端使用 React”
而不是把整段对话的原文存进去。这个提炼过程由 LLM 完成——让另一个 LLM 调用(或同一个模型的后台任务)从对话中萃取结构化的事实。
第二步:检索(想起)
存进去的记忆,需要在正确的时候被想起来。这个“想起来”的过程,本质上就是一个语义检索——和 D2、D3 讲的 RAG 是同一个问题。
当用户在新的对话中说“帮我推荐一个 ORM 框架”时,Agent 需要从记忆中检索出“用户后端使用 FastAPI”这条信息,然后推荐和 FastAPI 兼容的 ORM(比如 SQLAlchemy 或 Tortoise ORM),而不是推荐一堆 Java 的 ORM。
检索方式和 RAG 一样:把当前查询向量化,在记忆库中找语义最相关的条目。混合检索在这里同样有价值——如果用户说“我之前提到过 FastAPI”,全文搜索能精确匹配到“FastAPI”这个关键词,比纯语义检索更可靠。
第三步:降权(忘)
这是 P3 花了最多篇幅讲的部分,也是工程上最有挑战的部分。
三个月前用户说“我喜欢详细的解释”。最近他连续说了三次“太长了,简洁一点”。现在他问一个问题,Agent 应该用哪种风格回答?
如果所有记忆都是等权重的,Agent 会困惑——它同时看到“喜欢详细”和“要简洁”两条矛盾的信息。正确的做法是:旧的偏好随时间自然降权,新的偏好优先生效。这就是 P3 讲的“艾宾浩斯遗忘曲线”在工程上的应用。
长期记忆——情景记忆:成功经验的复用
情景记忆存的是过去的交互经历——什么方法有效、什么方案失败了。
在工程上,情景记忆最常见的实现方式是 few-shot 示例。当 Agent 遇到一个新问题时,从记忆中检索出类似问题的成功处理案例,放进当前的 Prompt 中作为参考。
# 伪代码:检索类似的历史成功案例
similar_episodes = memory.search_episodes(
query="用户问数据库部署方案",
top_k=2
)
# 把历史成功案例作为 few-shot 示例放进 Prompt
system_prompt = f"""你是一个技术助手。
以下是你过去成功帮助用户的案例,供参考:
{format_episodes(similar_episodes)}
请根据用户当前的问题给出建议。"""这样 Agent 就能从过往经验中学习,避免在同一类问题上反复试错。
长期记忆——程序记忆:可自我进化的行为规则
程序记忆就是 Agent 的 System Prompt 和行为规则。在代码里,它就是 messages[0]——那条 role: "system" 的消息。
有趣的是,程序记忆是三种长期记忆中唯一一种 Agent 可以自我修改的。如果用户反复给负面反馈(“你的回答太啰嗦了”),Agent 可以自动在自己的行为规则里加一条“回答要简洁”。
这和 D5 要讲的 Skill 直接相关——Skill 本质上就是结构化的程序记忆,是 Agent 的“操作手册”。D5 会展开。
三种长期记忆在代码中的位置
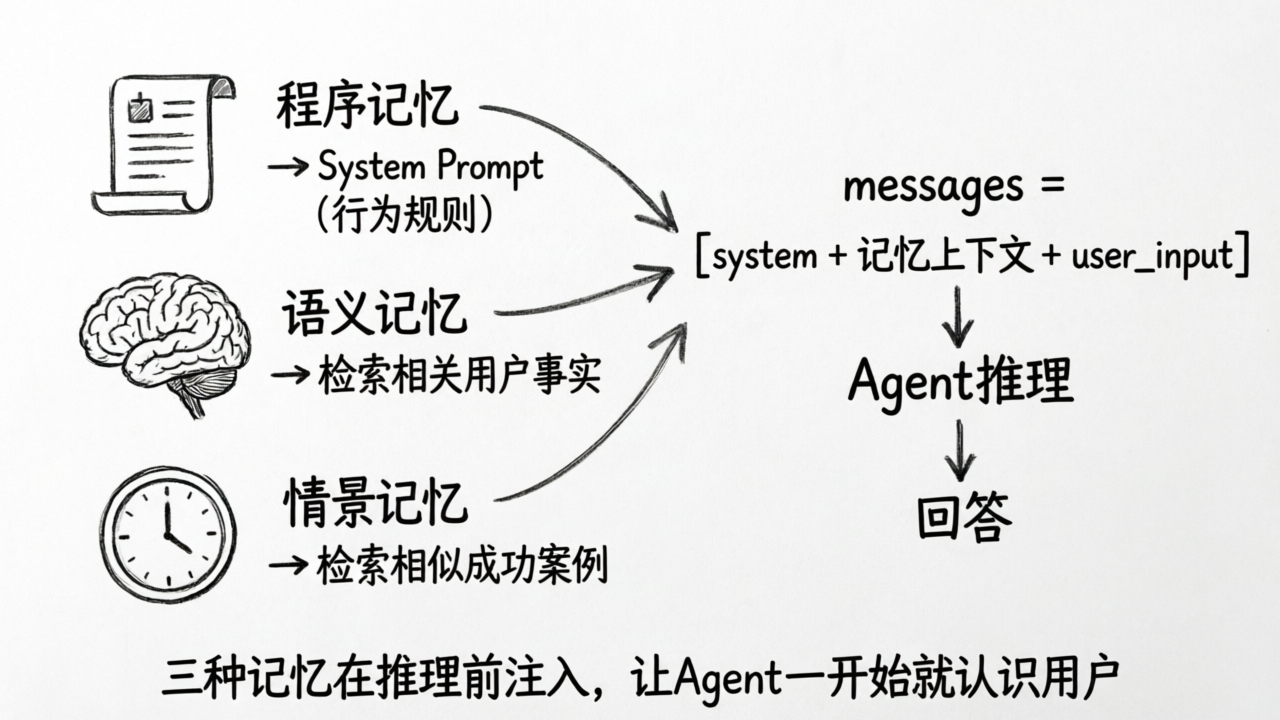
把它们放回 Agent 的推理循环中,就能看清楚每种记忆在什么时候发挥作用:
def agent_with_memory(user_input, tools, memory):
# 程序记忆 → System Prompt
system_prompt = memory.get_procedural_rules()
# 语义记忆 → 检索相关的用户事实
relevant_facts = memory.search_semantic(query=user_input, top_k=5)
# 情景记忆 → 检索相似的成功案例
similar_episodes = memory.search_episodic(query=user_input, top_k=2)
messages = [
{"role": "system", "content": f"""{system_prompt}
关于这位用户,你知道以下信息:
{format_facts(relevant_facts)}
以下是过去类似问题的处理经验:
{format_episodes(similar_episodes)}"""},
{"role": "user", "content": user_input}
]
# 进入 ReAct 推理循环
response = agent_loop(messages, tools)
# 对话结束后,提炼新的记忆
memory.extract_and_store(user_input, response)
return response看到了吗?三种长期记忆都是在 Agent 推理循环之前被注入到 Prompt 中的。它们的作用是让 Agent 在开始推理时就已经“认识”这个用户、“记得”过去的经验、“知道”自己该怎么做。
第三部分:用 PowerMem 给 Agent 装上记忆
理解了原理,我们来动手。
上面那段代码展示了记忆系统的逻辑结构,但真正实现起来有大量的工程细节:LLM 提取事实的 Prompt 怎么写?记忆的存储格式怎么定?时效性降权的算法怎么实现?检索用纯向量还是混合?
这些问题 PowerMem 已经封装好了。PowerMem 是基于 seekdb 构建的 Agent 记忆系统——它用 seekdb 做底层的数据存储和混合检索,用 LLM 做记忆的提炼和管理,用艾宾浩斯曲线做时效性降权。
先来看一个没有记忆的 Agent 是什么效果,再看加了 PowerMem 之后是什么效果。
没有记忆的 Agent
from openai import OpenAI
client = OpenAI()
def chat_without_memory(user_input):
"""无记忆的 Agent:每次对话都是全新的"""
messages = [
{"role": "system", "content": "你是一个友好的技术助手。根据用户的问题提供有针对性的建议。"},
{"role": "user", "content": user_input}
]
response = client.chat.completions.create(
model="gpt-4o",
messages=messages
)
return response.choices[0].message.content用这个 Agent 跑几轮对话:
print("--- 第 1 轮 ---")
print(chat_without_memory("我是一个 Python 开发者,主要做后端开发,喜欢简洁的回答。"))
print("\n--- 第 2 轮 ---")
print(chat_without_memory("帮我推荐一个 Web 框架"))
print("\n--- 第 3 轮 ---")
print(chat_without_memory("怎么给我的项目加缓存?"))你会看到:第 2 轮它不知道你是 Python 开发者,可能推荐 Java 的 Spring 或 JavaScript 的 Express;第 3 轮它不知道你喜欢简洁回答,可能给你一大段从基础讲起的长文。
每一轮都是一次全新的对话,上一轮说过的话全部消失。
有记忆的 Agent
from powermem import PowerMem
memory = PowerMem(user_id="developer_001")
def chat_with_memory(user_input):
"""有记忆的 Agent:能记住用户信息,跨会话持久化"""
# 从记忆中检索与当前问题相关的用户信息
relevant_memories = memory.search(query=user_input, top_k=5)
# 构建包含记忆的 System Prompt
memory_context = "\n".join([m["content"] for m in relevant_memories])
system_prompt = f"""你是一个友好的技术助手。根据用户的问题提供有针对性的建议。
你对这位用户有以下了解:
{memory_context if memory_context else "暂无已知信息,请在对话中了解用户。"}
请根据你了解的信息,提供个性化的回答。"""
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_input}
]
response = client.chat.completions.create(
model="gpt-4o",
messages=messages
)
assistant_reply = response.choices[0].message.content
# 对话结束后,提炼并存储新的记忆
memory.add(
messages=[
{"role": "user", "content": user_input},
{"role": "assistant", "content": assistant_reply}
]
)
return assistant_reply同样跑几轮:
print("--- 第 1 轮 ---")
print(chat_with_memory("我是一个 Python 开发者,主要做后端开发,喜欢简洁的回答。"))
print("\n--- 第 2 轮 ---")
print(chat_with_memory("帮我推荐一个 Web 框架"))
print("\n--- 第 3 轮 ---")
print(chat_with_memory("怎么给我的项目加缓存?"))这次效果完全不同:
- 第 2 轮:Agent 记得你是 Python 开发者,直接推荐 FastAPI 或 Django,不会给你推荐 Java 框架
- 第 3 轮:Agent 记得你喜欢简洁回答,直接给出核心建议——“用 Redis 做缓存,
pip install redis,三行代码搞定”,而不是从“什么是缓存”讲起
更重要的是,这些记忆是跨会话持久化的。你关掉程序、明天重新打开,Agent 仍然记得你是 Python 开发者、喜欢简洁回答。
两个版本对话效果对比
为了让差距更直观,我们把同一组问题分别交给两个版本,对比回答:
| 轮次 | 用户输入 | 无记忆 Agent | 有记忆 Agent |
|---|---|---|---|
| 1 | “我是 Python 开发者,喜欢简洁回答” | “好的,有什么可以帮你的?” | “好的,我记住了!有什么可以帮你的?” |
| 2 | “推荐一个 Web 框架” | 长篇介绍 Spring、Express、Django、Rails.。。 | “推荐 FastAPI——异步、类型安全、性能好,适合 Python 后端。” |
| 3 | “怎么部署到云上?” | 泛泛而谈各种云平台、各种语言的部署方案 | “FastAPI 部署推荐 Docker + 云平台。Dockerfile 三行搞定……” |
| 4 | “数据库怎么选?” | 列出所有主流数据库的优缺点对比 | “Python 后端推荐 PostgreSQL 或 seekdb。配合 SQLAlchemy ORM……” |
| 5 | “谢谢,今天先到这” | “不客气!” | “不客气!下次继续聊你的项目。” |
关掉程序,第二天重新打开——
| 轮次 | 用户输入 | 无记忆 Agent | 有记忆 Agent |
|---|---|---|---|
| 6 | “继续昨天的话题” | “抱歉,我不知道昨天聊了什么。” | “好的,昨天你在搭建 Python 后端项目。我们聊到了数据库选型,还需要继续吗?” |
天壤之别。

第四部分:框架集成——不需要重写你的架构
你可能在想:我已经用了 LangChain 或其他 Agent 框架,加 PowerMem 要改多少代码?
答案是:几乎不用改架构。
PowerMem 的设计思路是作为一个记忆层独立存在,而不是替代你的 Agent 框架。它通过两个接入点和你现有的 Agent 交互:
- 推理前注入:在构建 Prompt 时,调用
memory.search()检索相关记忆,拼到 System Prompt 里 - 推理后存储:对话结束后,调用
memory.add()提炼并存储新记忆
无论你用 LangChain、LlamaIndex、还是自己手写的 Agent 循环,这两个接入点的位置都是明确的。以 LangChain 为例:
from langchain.chat_models import ChatOpenAI
from langchain.agents import AgentExecutor, create_tool_calling_agent
from powermem import PowerMem
memory = PowerMem(user_id="user_001")
llm = ChatOpenAI(model="gpt-4o")
def build_prompt_with_memory(user_input):
"""在现有 Agent 的 Prompt 中注入记忆"""
memories = memory.search(query=user_input, top_k=5)
memory_text = "\n".join([m["content"] for m in memories])
return f"""你是一个技术助手。
你对当前用户有以下了解:
{memory_text}
请根据以上信息提供个性化的回答。"""
# 在你的 Agent 流程中,只需要修改两处:
# 1. Prompt 构建时加入 memory.search()
# 2. 对话结束后调用 memory.add()底层的数据存储和检索由 seekdb 处理——向量索引、全文索引、混合检索,都是 D2 讲过的那套能力。PowerMem 在 seekdb 之上增加了记忆特有的逻辑:LLM 自动提取关键事实、艾宾浩斯曲线管理时效性、记忆冲突检测与合并。
你不需要关心这些内部细节。从使用者的角度,memory.search() 和 memory.add() 就是你需要的全部 API。
第五部分:多用户 / 多租户记忆隔离
到这里,你的 Agent 已经能记住一个人了。但真实产品几乎从不上线“只有一个用户”的 Agent。
想象你做了一个技术问答机器人,Alice 和 Bob 都在用。Alice 说:“我是 Python 开发者,过敏原是花生。”Bob 说:“我是 Java 开发者,喜欢详细解释。”
如果记忆库里没有隔离——下一次 Bob 问“推荐个 Web 框架”,Agent 可能答:“推荐 FastAPI,顺便别碰花生。”
这不是“个性化过头”,这是数据串户。多用户场景下,记忆系统的第一个硬要求不是“记得更聪明”,而是:谁的记忆,只能被谁看见、被谁改。
问题本质:共享存储 + 独立视图
工程上,多用户记忆通常共用同一套存储(同一张表、同一个向量库),靠命名空间把视图切开。PowerMem 的做法是把隔离键做成存储层的一等公民:
user_id → agent_id → run_iduser_id:用户 / 租户维度(多用户隔离的主键)agent_id:Agent 维度(同一用户下,不同 Agent 也可再隔离)run_id:会话维度(可选,用于单次任务上下文)
关键点不在存的时候写上 user_id,而在查的时候必须带着 user_id 过滤。PowerMem 在构建查询时就把这些字段注入过滤条件,等价于 SQL 里的:
WHERE user_id = 'alice' AND agent_id = 'tech_assistant'过滤发生在数据库索引层,而不是“先全库搜一遍,再在应用代码里丢掉别人的记忆”。后者更慢,也更容易把别人的数据打进日志。
user_id 命名空间:写入带标签,检索带过滤
第三部分的示例里,你已经写过 PowerMem(user_id="developer_001")。那一行看起来像初始化参数,本质上是在告诉记忆层:之后所有读写,默认都落在这个命名空间里。
更显式的写法是每次调用都传入 user_id:
from powermem import Memory, auto_config
memory = Memory(config=auto_config())
# Alice 的记忆写入 alice 命名空间
memory.add(
"用户是 Python 开发者,喜欢简洁回答",
user_id="alice",
agent_id="tech_assistant",
)
# Bob 的记忆写入 bob 命名空间
memory.add(
"用户是 Java 开发者,喜欢详细解释",
user_id="bob",
agent_id="tech_assistant",
)
# 检索时必须带上 user_id——否则就失去了隔离边界
alice_hits = memory.search("推荐 Web 框架", user_id="alice")
bob_hits = memory.search("推荐 Web 框架", user_id="bob")alice_hits 里不应出现 Bob 的 Java 偏好;bob_hits 里也不应出现 Alice 的 Python 偏好。同一套 Agent 代码、同一套存储,靠 user_id 切成两个互不可见的记忆视图。
多租户场景同理:把 user_id 理解成租户 ID(或 tenant_id:user_id 组合键)即可。隔离规则不变——命名空间是边界,不是建议。
权限校验:隔离不够,还要拦越权操作
命名空间解决的是“看不见”。但真实系统还有写操作:更新、删除、分享。如果 Bob 拿到了 Alice 某条记忆的 ID,能不能删掉它?
答案必须是:不能。 所有权校验要发生在操作入口,而不是事后补救。
PowerMem 多用户模式下的基本规则很直接:
| 操作 | 本人记忆 | 他人记忆(未授权) | 他人记忆(已显式分享且授权) |
|---|---|---|---|
| 读 / 搜 | ✅ | ❌(命名空间过滤) | ✅(按授权权限) |
| 更新 | ✅ | ❌ PermissionError | 仅当授予 write |
| 删除 | ✅ | ❌ PermissionError | ❌(通常仅所有者) |
用伪代码表达权限门:
def delete_memory(store, memory_id, requester_id):
memory = store.get(memory_id)
if memory is None:
raise ValueError(f"Memory {memory_id} not found")
# 权限校验:只有所有者可以删除
if memory["user_id"] != requester_id:
raise PermissionError(
f"User {requester_id} cannot delete memory owned by {memory['user_id']}"
)
store.remove(memory_id)
return {"success": True, "deleted_id": memory_id}注意两件事:
- 先鉴权,再改数据。 不要先删再判断。
- 失败要显式。 用
PermissionError/ 403,而不是静默成功——静默会让调用方以为“删掉了”,实际留下脏状态。
如果业务需要跨用户共享(比如客服 Agent 把一条偏好分享给销售 Agent 对应的用户视图),必须走显式授权:记录 shared_with 和权限列表(read / write),读路径按授权放行,写路径仍默认拒绝。
接到 Agent 循环里长什么样
回到第三部分的记忆 Agent:以前是“一个全局 memory”,现在每个请求都要绑定当前登录用户:
def chat_with_memory(user_input, current_user_id):
# 推理前:只检索当前用户命名空间里的记忆
memories = memory.search(query=user_input, user_id=current_user_id, top_k=5)
memory_text = "\n".join([m["content"] for m in memories])
system_prompt = f"""你是一个友好的技术助手。
你对这位用户有以下了解:
{memory_text if memory_text else "暂无已知信息。"}
"""
reply = llm_chat(system_prompt, user_input)
# 推理后:新记忆必须写入当前用户命名空间
memory.add(
messages=[
{"role": "user", "content": user_input},
{"role": "assistant", "content": reply},
],
user_id=current_user_id,
)
return replycurrent_user_id 从哪来?从你的鉴权层来——登录态、API Token、租户上下文。绝不要让前端随便传一个 user_id 就信。 记忆隔离的前提是:请求身份可信。
配套可运行示例见 code/D4/d4_5_multi_user_isolation.py:用纯 Python 模拟命名空间过滤与权限门,不依赖外部 API,可以直接跑通 Alice / Bob 互不可见、越权删除被拒绝这两条核心断言。
第六部分:长期记忆的存储成本控制
到这里,你的 Agent 已经能记住、能隔离。但下一个问题随之而来:
记得多了,账单和延迟一起涨。
假设你的产品有 1 万日活用户,每人每天聊 20 轮,每轮对话再提炼出 1~2 条记忆。一个月下来,记忆条目轻松冲到百万级。每条记忆不止是一段文本,还有向量 embedding、索引、元数据、以及每次检索时被扫进候选集的计算开销。如果再把对话原文原样塞进库,成本会再乘一截。
P3 讲“忘”时,重点在用户体验:旧偏好该淡出,新偏好该占优。这一节更想说明的是,忘,也是成本控制。 工程上要做的,是让记忆库在“够用”和“可控”之间找到平衡——该压的压、该分层的分层、该清的清。
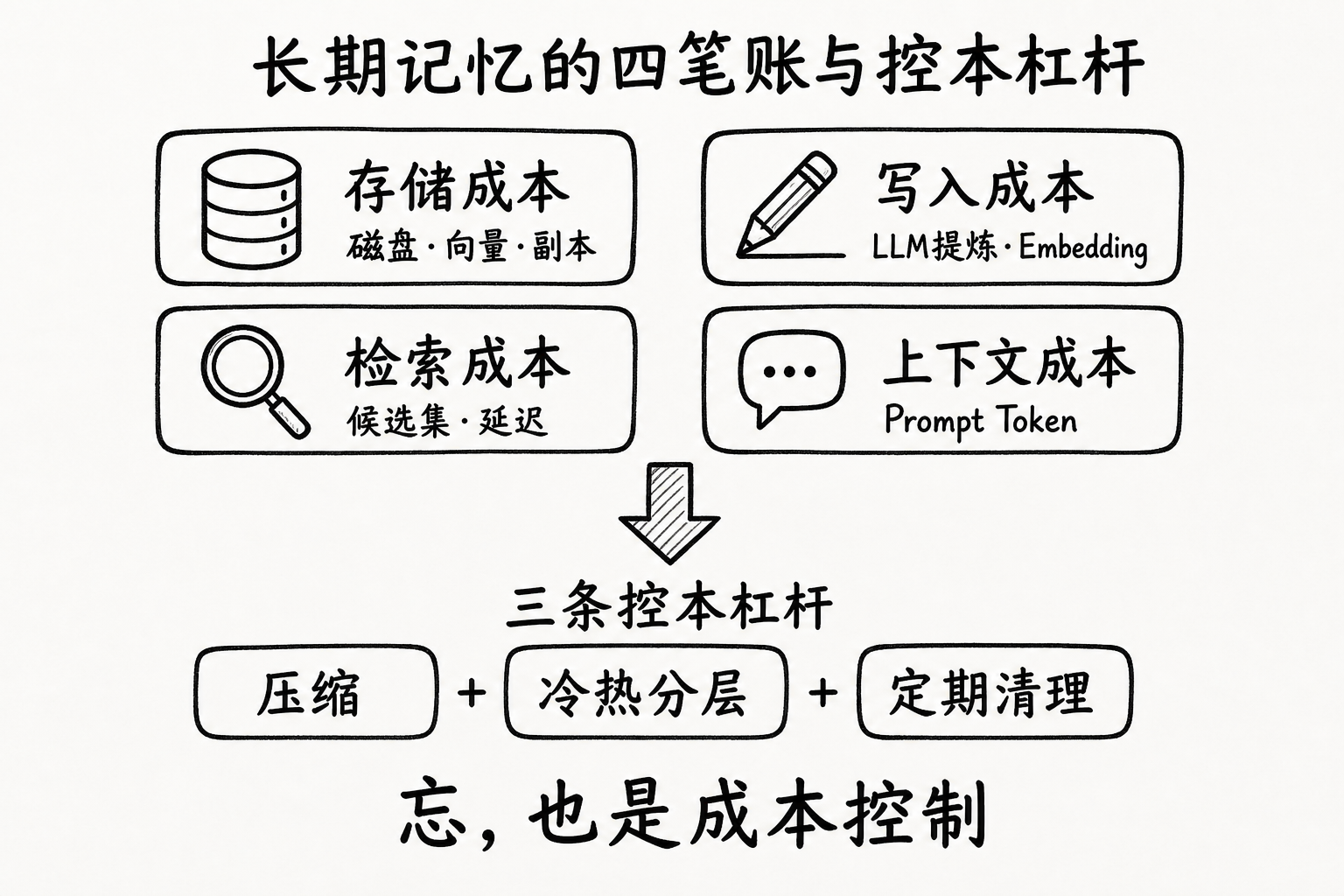
你在为记忆付什么钱
长期记忆的成本不止“磁盘占了多少 GB”。拆开来看,至少有四笔账:
| 成本项 | 发生时机 | 典型驱动因素 | 失控时的表现 |
|---|---|---|---|
| 存储成本 | 写入后持续占用 | 原文 / 事实条数、向量维度、副本数 | 磁盘与云存储账单线性上涨 |
| 写入成本 | 每次 memory.add() | LLM 提炼调用、embedding 计算 | 对话越活跃,后台费用越高 |
| 检索成本 | 每次 memory.search() | 候选集大小、索引类型、重排次数 | 延迟升高,Agent 变“钝” |
| 上下文成本 | 记忆注入 Prompt 后 | 召回条数 × 单条长度 | Token 费用暴涨,回答被噪声干扰 |
其中最容易被忽略的是后两项。很多人只盯着“库有多大”,却忘了:一条永远不会被想起的记忆,仍会拖慢每一次检索、挤占每一次 Prompt 预算。
所以成本控制不是“以后再说的运维问题”,而是记忆系统设计的一部分。做法可以收敛成三条工程实践:压缩、冷热分层、定期清理。
压缩策略:先少存,再好存
成本控制的第一刀不是删,而是别把不该进库的东西放进去。
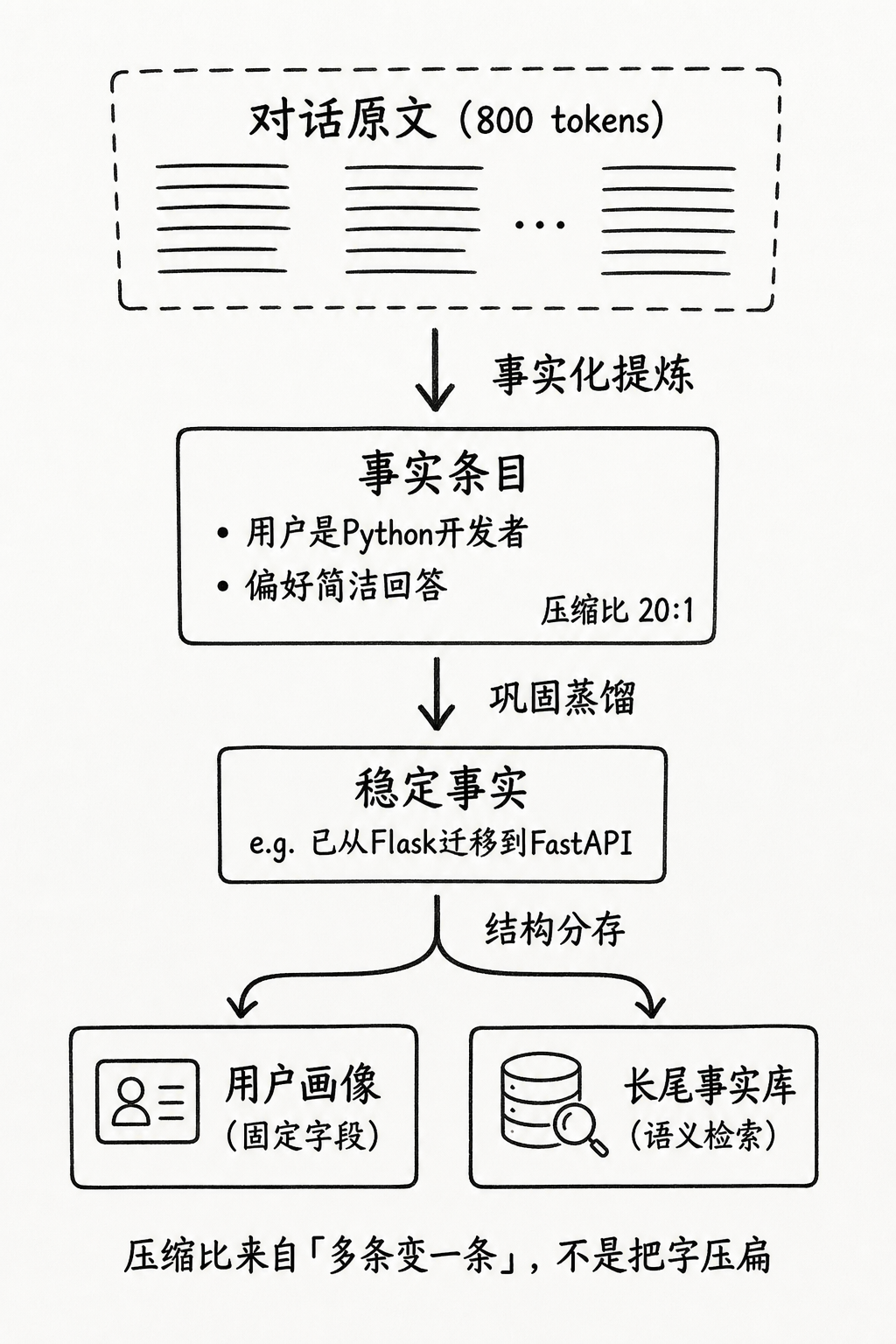
第二部分讲过:语义记忆存的是提炼后的事实,不是对话原文。这是最基础、也最有效的压缩——一段 800 token 的闲聊,可能只提炼出 2 条 20 token 的事实。压缩比轻松超过 20:1,而且检索质量通常更好,因为噪声更少。
在此之上,工程里还有三层常见压缩:
1. 写入时压缩:事实化,拒绝原文堆叠
# 坏做法:把整段对话原文塞进记忆库
memory.add(raw_transcript) # 800 tokens × N 轮 → 库爆炸
# 好做法:只存 LLM 提炼后的结构化事实
facts = extract_facts(user_input, assistant_reply)
# ["用户是 Python 后端开发者", "用户偏好简洁回答"]
for fact in facts:
memory.add(fact, user_id=current_user_id)PowerMem 的 memory.add() 默认就会走提炼路径。你自己实现时,也要守住这条边界:原文进日志归档(可选),事实进记忆检索面。
2. 存续中压缩:多条弱信号蒸馏成一条强事实
用户可能分五次说了类似的话:“在用 Flask”“Flask 有点慢”“准备迁 FastAPI”“FastAPI 上手了”“旧项目还留着一点 Flask”。如果每句各存一条,库里会堆出互相打架的碎片。更好的做法是定期(或达到频次阈值后)做一次巩固(consolidation):
def consolidate_topic(topic_memories):
"""把同一话题下的多条碎片记忆,蒸馏成一条稳定事实"""
if len(topic_memories) < 3:
return None # 证据不足,先不升格
distilled = llm_summarize(topic_memories)
# 例如:"用户后端已从 Flask 迁移到 FastAPI"
return distilled蒸馏之后,旧碎片可以降权或归档,长期检索面只保留那条稳定事实。在这里的工程结论就是,压缩比来自“多条变一条”,不是来自“把字压扁”。
3. 结构压缩:画像字段 + 长尾事实分开存
不是所有长期信息都适合丢进向量库。职业、主力语言、云平台这类变化慢、需要精确命中的字段,更适合做成结构化用户画像(按 key 读写);项目细节、某次排障经验这类长尾、语义模糊的内容,再进向量事实库。
# 画像:固定字段,覆盖写,体积可控
profile = {
"primary_language": "Python",
"role": "backend",
"cloud": "AWS",
"answer_style": "concise",
}
# 事实库:增量追加,靠检索召回长尾
facts = [
"曾用 FastAPI + Redis 做过会话缓存",
"团队淘汰过 RabbitMQ,觉得运维成本高",
]画像条目数通常是几十个字段的量级;事实库才是会增长的那一侧。两者拆开后,热路径上的确定性约束几乎零检索成本,向量库只服务真正需要语义匹配的部分。
配套可运行示例见 code/D4/d4_6_memory_compression.py:用同一段 10 轮对话对比「原文入库」与「事实化入库」的体积和 Top-5 Prompt 预算,并演示巩固蒸馏、画像/事实分存。不依赖外部 API,可以直接跑通。
冷热分层:不是所有记忆都配住在 SSD 上
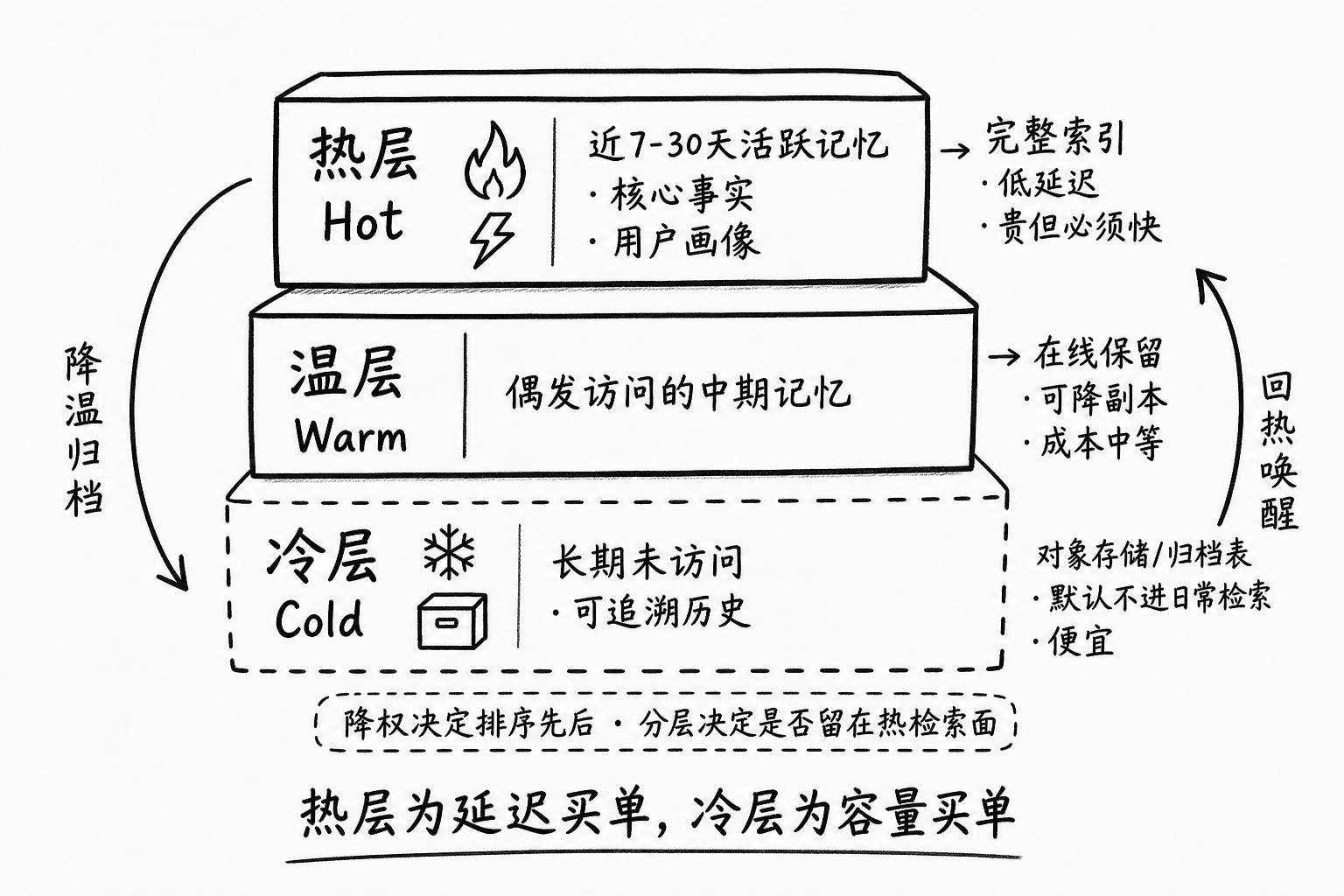
压缩解决的是“单条更瘦”。分层解决的是“不同命运的记忆,住不同成本的房子”。
P3 用便利贴 / 抽屉 / 档案柜做类比。落到存储工程上,可以粗分成三层:
| 层级 | 典型内容 | 访问特征 | 存储与索引策略 | 成本定位 |
|---|---|---|---|---|
| 热层(Hot) | 近 7~30 天活跃记忆、高权重核心事实、用户画像 | 高频读写 | 在线库 + 完整向量/全文索引,低延迟检索 | 贵,但必须快 |
| 温层(Warm) | 有一定保留价值、偶发被问起的中期记忆 | 中低频读 | 在线库保留,可降副本 / 延后重建索引 | 中等 |
| 冷层(Cold) | 长期未访问、已降权但仍可能被追溯的历史 | 极低频读 | 对象存储 / 归档表,默认不进日常检索 | 便宜,按需加载 |
分层的关键规则只有一条:热层为延迟买单,冷层为容量买单;绝不要让冷数据长期占用热索引。
用伪代码表达一次“按温度分流”的写入后处理:
def assign_tier(memory, retention, days_since_access):
"""根据保留率与访问新鲜度,决定记忆住哪一层"""
if memory["is_profile"] or retention >= 0.7:
return "hot"
if retention >= 0.3 and days_since_access <= 30:
return "warm"
return "cold"
def migrate_if_needed(store, memory):
tier = assign_tier(
memory,
retention=memory["retention"],
days_since_access=memory["days_since_access"],
)
if tier == memory["tier"]:
return
if tier == "cold":
# 移出热索引:文本进归档,向量索引删除或标记不可检索
store.archive(memory["id"])
store.drop_from_hot_index(memory["id"])
elif tier == "hot":
# 被重新唤醒:从冷层拉回,重建检索能力
store.restore_to_hot(memory["id"])
memory["tier"] = tier注意冷热分层和艾宾浩斯降权是配合关系,不是两套互斥逻辑:
- 降权决定“在热检索里排多前”
- 分层决定“还配不配留在热检索面里”
一条记忆可以先在热层里被降权排到很后面,再在某次巡检中被挪进冷层。用户某天突然问“我去年怎么部署的”,你再按需从冷层召回——日常 99% 的请求不必为那 1% 的追溯付热存储的钱。
配套可运行示例见 code/D4/d4_7_hot_cold_tier.py:实现 assign_tier / migrate_if_needed,验证日常检索不扫冷层、降温归档与回热唤醒。不依赖外部 API,可以直接跑通。
定期清理:把“遗忘”落成可运行的作业
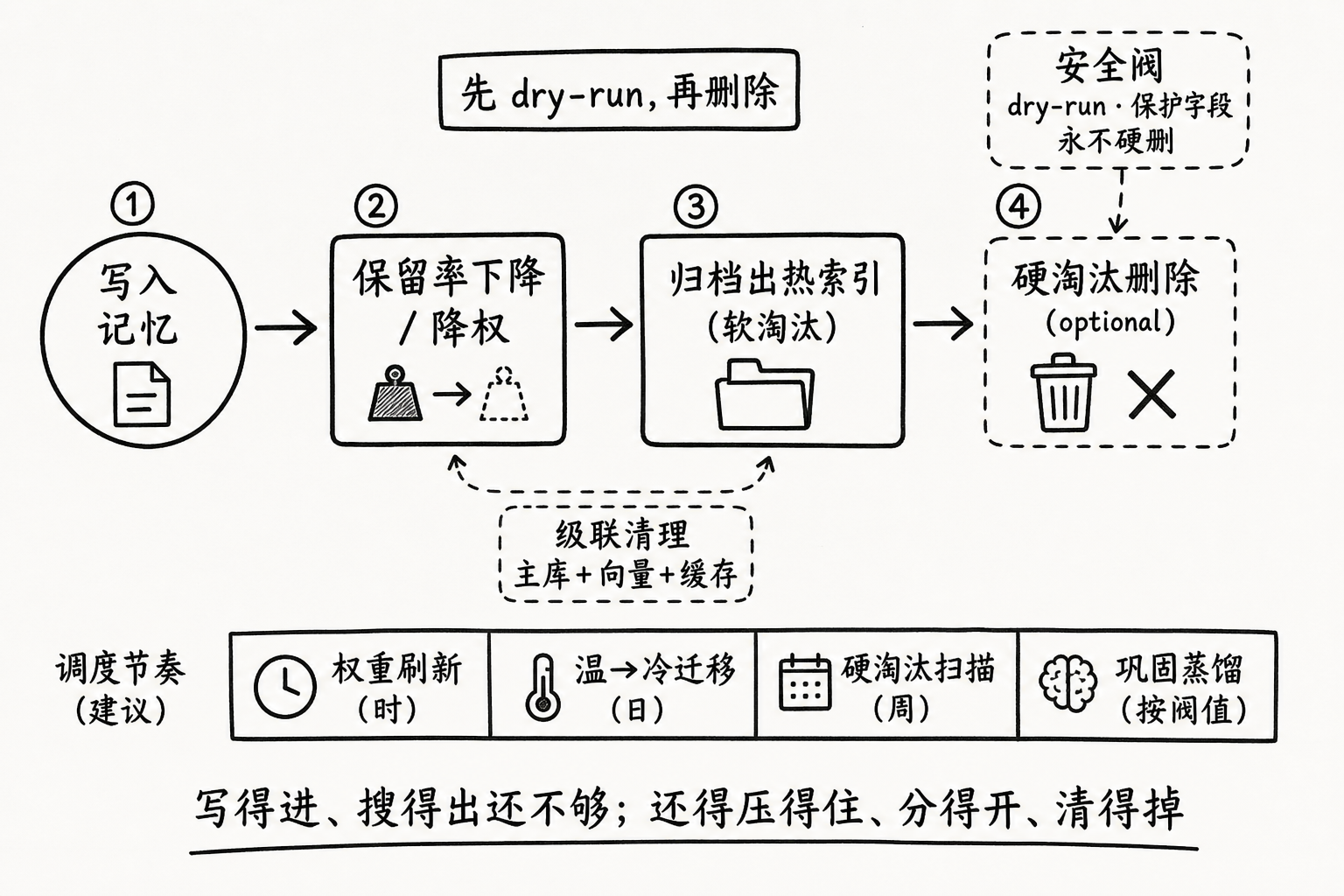
有了压缩和分层,还差最后一环:定期清理。否则温层会慢慢积成第二热层,冷层也会无限膨胀到失去“冷”的意义。
P3 给过处置阶梯:降权 → 归档 → 硬淘汰。工程上把它变成一条可调度的生命周期管线:
def cleanup_memories(store, now, dry_run=True):
"""
定期清理作业(建议每日 / 每周跑一次)。
dry_run=True 时只统计将要发生的动作,便于先观测再真正删除。
"""
stats = {"archived": 0, "deleted": 0}
for mem in store.iter_all():
retention = calc_retention(mem, now)
idle_days = (now - mem["last_accessed_at"]).days
# 安全阀:核心画像 / 合规字段永不硬删,最多归档
protected = mem.get("protected", False)
# 1) 硬淘汰:极低价值且长期零唤醒 —— 真正释放存储
if (not protected) and retention < 0.1 and idle_days >= 90:
stats["deleted"] += 1
if not dry_run:
store.delete(mem["id"]) # 主库 + 向量 + 缓存级联清理
continue
# 2) 软淘汰:移出日常检索,保留可追溯归档
if retention < 0.3 or idle_days >= 30:
stats["archived"] += 1
if not dry_run:
store.archive(mem["id"])
store.drop_from_hot_index(mem["id"])
continue
# 3) 仍可用:只更新权重,留给检索排序自然处理
# (降权已在 calc_retention / 检索精排中体现)
return stats落地时守住几条实践原则:
- 先 dry-run,再删除。 清理策略调错的代价,往往比多存一个月冷数据更贵。
- 分级,不要二元。 默认走归档;硬删除只留给“低保留率 + 长期零访问 + 非保护字段”。
- 级联清理。 删主库记录时,同步处理向量索引和缓存,否则会出现“库里没了、索引还能搜到幽灵记忆”。
- 按用户 / 租户隔离执行。 第五部分的
user_id边界在清理作业里同样生效——批量任务最容易误扫别人的数据。 - 观测指标先于直觉。 至少看:热层条目数、冷层占比、月度归档量、误删申诉率、
searchP95 延迟。延迟降下去了,清理才算有效,而不是“删得很爽”。
一个可参考的巡检节奏:
| 作业 | 频率 | 做什么 |
|---|---|---|
| 权重刷新 | 每次检索 / 每小时批处理 | 更新保留率,服务排序 |
| 温→冷迁移 | 每日 | 把长期未访问的温层记忆归档 |
| 硬淘汰扫描 | 每周 | 对冷层中极低价值条目做受控删除 |
| 巩固蒸馏 | 每日或按阈值触发 | 多条碎片压成稳定事实,反哺压缩 |
至此,三条杠杆形成闭环:压缩减少写入体积 → 冷热分层降低热检索面 → 定期清理回收长期占用。 艾宾浩斯曲线负责“分数怎么变”,这三条负责“分数变了之后,存储和索引怎么跟着变”。
配套可运行示例见 code/D4/d4_8_memory_cleanup.py:先 dry-run 再落盘,覆盖保护字段跳过硬删、主库/向量/缓存级联清理,以及按 user_id 隔离执行。不依赖外部 API,可以直接跑通。
一张表收束:控本手段怎么选
| 手段 | 优先解决的问题 | 对效果的影响 | 上手成本 | 什么时候上 |
|---|---|---|---|---|
| 事实化压缩 | 写入体积、Prompt 噪声 | 通常正向(噪声↓) | 低(PowerMem 默认就做) | 第一天就该有 |
| 巩固蒸馏 | 碎片膨胀、矛盾并存 | 正向(稳定事实↑) | 中(要话题聚类 + LLM) | 单用户记忆过千条后 |
| 画像 / 事实分存 | 热路径成本、精确约束漏检 | 正向 | 中 | 个性化字段稳定后 |
| 冷热分层 | 索引体积、检索延迟 | 中性偏正(需处理好回热) | 中高 | 热层扫描开始变慢时 |
| 定期清理 | 冷数据无限增长 | 取决于阈值是否保守 | 中 | 与分层一起上,先 dry-run |
经验法则很简单:先压缩,再分层,最后才硬删。 删是不可逆的;压和分大多可回滚。
更细的保留率公式、参数消融和巩固触发策略,见扩展篇 X1《探究 AI Agent 记忆系统》。D4 这一节要留下的工程直觉是:
记忆系统的成本,本质是数据生命周期没有闭环。写得进、搜得出,还不够;还得压得住、分得开、清得掉。
我们的思考
记忆系统看起来是个 AI 问题,但拆到底是个数据问题——怎么存、怎么查、怎么过期、怎么控成本。
我们在做 PowerMem 的过程中,最大的感受是:每一个“AI 层面”的设计决策,最终都落到了数据层面的实现上。
“记什么”是一个数据提炼问题。 从一段对话中提取关键事实,本质上是把非结构化数据(对话原文)变成结构化数据(事实条目)。LLM 负责理解语义和判断重要性,但提炼出来的结果要以什么格式存、怎么建索引,是数据层的决策。提炼本身,也是成本控制的第一刀——事实化压缩往往比事后删库更划算。
“想起什么”是一个数据检索问题。 和 RAG 完全是同一个机制——把当前查询向量化,在记忆库中做混合检索,返回最相关的条目。D2 和 D3 你花了大量时间研究的检索策略,在记忆系统中一模一样地适用。冷热分层要保证的是:日常检索只扫热面,而不是每次都在全量历史里捞针。
“忘什么”是一个数据生命周期管理问题。 PowerMem 用艾宾浩斯遗忘曲线来实现时效性管理:每条记忆有一个权重,随时间自然衰减;但如果这条记忆在后续对话中被再次提及,权重回升。经常被用到的记忆权重持续维持在高位,不再被提及的记忆自然淡出。落到存储上,淡出还要继续走完归档与清理,否则“逻辑上忘了、物理上还占着索引”。
这套机制在 LOCOMO 基准测试(Shopify 开发的 Agent 长期记忆评估基准)上取得了 78.7% 的准确率。作为对比,把所有历史对话直接塞进上下文窗口的“暴力方案”只有 52.9%。差距接近 50%。
这个数据说明了一件反直觉的事:把所有信息都“记住”,效果反而不如有选择地记忆。 信息过载会干扰检索——当上下文中塞满了过时的、无关的信息,模型反而找不到真正有用的那几条。成本侧也同理:全量死记会同时推高存储、延迟和 Token 账单。
还有一层经常被忽略的数据边界:多用户场景下,“记对了”之前,先要“记在正确的命名空间里”。 user_id 过滤和权限校验看起来像安全需求,本质上仍是数据层问题——共享存储如何切出互不串扰的视图,以及写操作如何在入口处拦住越权。没有隔离的记忆系统,个性化越强,串户风险越大。清理作业同样必须带着命名空间跑,批量任务比单次请求更容易误伤别人的数据。
PowerMem 封装了这些最佳实践。安装 powermem 之后,几十行代码就能给你的 Agent 加上智能记忆——自动提取关键事实、混合检索召回相关记忆、艾宾浩斯曲线管理时效性,以及按 user_id 做多用户隔离。你不需要自己实现这些机制,但你需要理解它们背后的逻辑——因为当记忆系统表现不够好,或账单和延迟开始失控时,问题几乎一定出在“记 / 忘 / 想起 / 隔离 / 控本”这几个环节中的某一个。
动手体验:构建你的记忆 Agent
环境准备
# 终端运行
# pip install openai powermem pyseekdb完整代码:一个有记忆的对话 Agent
from openai import OpenAI
from powermem import PowerMem
client = OpenAI()
memory = PowerMem(user_id="demo_user")
def chat(user_input):
# 1. 检索相关记忆
memories = memory.search(query=user_input, top_k=5)
memory_text = "\n".join([m["content"] for m in memories]) if memories else "暂无"
# 2. 构建带记忆的 Prompt
messages = [
{"role": "system", "content": f"""你是一个友好、专业的技术助手。
你对当前用户有以下了解:
{memory_text}
请根据你对用户的了解,提供个性化的、有针对性的回答。
如果用户提供了新的个人信息或偏好,自然地融入对话中。"""},
{"role": "user", "content": user_input}
]
# 3. 调用模型
response = client.chat.completions.create(
model="gpt-4o",
messages=messages
)
reply = response.choices[0].message.content
# 4. 提炼并存储新记忆
memory.add(
messages=[
{"role": "user", "content": user_input},
{"role": "assistant", "content": reply}
]
)
return reply
# 开始对话
while True:
user_input = input("\n你: ")
if user_input.lower() in ["quit", "exit", "退出"]:
break
print(f"\nAgent: {chat(user_input)}")试试这个对话序列
跑起来之后,按这个顺序输入,观察 Agent 的行为:
你: 我是一个 Python 开发者,在一家做 SaaS 产品的创业公司工作。
你: 我喜欢简洁的回答,不需要太多解释。
你: 帮我推荐一个适合的消息队列方案。
你: 我们团队之前试过 RabbitMQ,感觉配置太复杂了。
你: 那 Celery 呢?在第 3 轮,观察 Agent 是否直接推荐 Python 生态的方案(而不是泛泛列举所有语言的选项)。在第 4 轮之后,观察 Agent 是否避免再次推荐 RabbitMQ。在第 5 轮,观察 Agent 的回答是否简洁——因为你在第 2 轮说过“喜欢简洁的回答”。
然后,退出程序,重新启动,再输入:
你: 我之前说过我在哪种公司工作来着?
你: 帮我选一个数据库方案。如果记忆系统正常工作,Agent 应该记得你在 SaaS 创业公司工作,并且推荐 Python 友好、适合创业公司规模的数据库方案。
这节课要留下的印象
如果这节课的所有内容你只记住一句话,记住这句:
给 Agent 加记忆,难的不是代码——难的是该记什么、该忘什么、该想起什么;有了多个用户,还要先保证记在正确的命名空间里;而库一旦长大,还得压得住、分得开、清得掉,否则“记得全”会同时拖垮效果和账单。
课后行动
跑通 Notebook:运行本模块的代码,构建一个有记忆的对话 Agent,和它连续聊 5 轮以上。退出后重新启动,确认记忆跨会话保持。
做一个有趣的实验:在前几轮对话中,故意提供一些偏好信息和个人背景——
- “我喜欢简洁的回答”
- “我是 Python 开发者”
- “我们公司用的是 AWS”
- “上次你推荐的 FastAPI 方案我已经在用了”
然后在后续对话中,观察 Agent 是否在合适的时候自然地调用了这些信息。它有没有在你问 Web 框架时优先推荐 Python 的?有没有在你问部署方案时默认用 AWS 的?有没有记住你说过喜欢简洁、实际给出简洁的回答?
对比体验:用同样的对话序列分别测试“有记忆”和“无记忆”版本,直观感受差距。
多用户隔离实验:运行
d4_5_multi_user_isolation.py,确认 Alice / Bob 的记忆互不可见,并验证 Bob 无法删除 Alice 的记忆。然后试着故意去掉user_id过滤,观察“串户”是怎么发生的——体会为什么过滤必须发生在查询构建阶段。存储成本小实验:依次运行第六部分配套示例——
d4_6_memory_compression.py:对比原文入库 vs 事实化入库的体积与 Top-5 Prompt 预算,观察巩固蒸馏和画像/事实分存d4_7_hot_cold_tier.py:确认日常检索不扫冷层,并手动走一遍降温归档 / 回热唤醒d4_8_memory_cleanup.py:先看 dry-run 动作清单,再执行真正清理,确认保护字段不被硬删、Bob 的记忆不会被 Alice 的清理作业误伤
跑完后回头看你自己的记忆 Agent:有没有把原文塞进检索面?热索引里是不是堆着长期不访问的条目?清理有没有 dry-run?这三问比再多写两行
memory.add()更重要。
延伸阅读
如果你对本期提到的概念想做进一步了解,以下是一些推荐资源:
- ReAct 论文原文:ReAct: Synergizing Reasoning and Acting in Language Models,定义了 Agent “推理-行动”循环模式的经典论文
- CoALA 论文:Cognitive Architectures for Language Agents,系统定义了 Agent 记忆的分类框架(语义记忆、情景记忆、程序记忆),被 LangChain 等主流框架广泛采用
- LangGraph 记忆架构:LangGraph 的 Checkpointer 和 Memory Store 实现,是当前主流 Agent 框架中记忆管理的工程参考
- LOCOMO Benchmark:github.com/Shopify/locomo,Shopify 开发的 Agent 长期记忆评估基准,用于衡量记忆系统的检索准确率
- X1 扩展篇:探究 AI Agent 记忆系统:从遗忘曲线到永久记忆,在 D4 基础上深入保留率公式、巩固蒸馏与生命周期工程——想把第六部分的控本直觉落成可调参数时,从这里继续
下一期预告:D5 · 课程总结——今天讲的程序记忆告诉我们 Agent 需要”操作手册”。但当手册越来越多、分散在不同平台时,一个新问题出现了:经验数据的碎片化。后续 X5 会进一步用 MCP 把稳定 Skill 包装成标准化工具,让不同 Agent 客户端统一调用。
欢迎各位老师在 https://github.com/datawhalechina/easy-data-x-ai 参与课程共建。
也欢迎各位老师加入 Data x AI 交流群~
