Ollama 零基础环境部署(Ubuntu 24.04 + ROCm 7+)
本节介绍在 Ubuntu 24.04 + ROCm 7+ 环境下,如何安装和使用 Ollama(ROCm 版 llama.cpp 后端),并以 Gemma 4 E4B-it Q4_K_M 为例进行性能测试。
前置条件:已经完成 ROCm 7.1.0 环境准备(参考
env-prepare-ubuntu24-rocm7.md)。
1. 安装 Ollama(系统服务)
第一步:一键安装到 systemctl 中管理,会占用本地 11434 端口启动服务。
更多信息参考官方文档:https://docs.ollama.com/linux
安装命令:
bash
curl -fsSL https://ollama.com/install.sh | sh2. 验证服务连通性
安装完成后,可以用以下命令验证服务是否正常运行:
bash
curl http://localhost:11434若返回 JSON 信息(如版本号等),说明服务启动成功。
3. 基本使用命令
常用基础命令如下:
bash
# 列出所有模型
ollama list
# 下载模型(以 Gemma 4 E4B-it Q4_K_M 为例)
ollama pull gemma4:e4b-it-q4_K_M
# 测试模型运行(交互式)
ollama run gemma4:e4b-it-q4_K_M说明:Ollama 官方镜像库中 Gemma 4 的 tag 命名可能会随上游更新而变化,使用前请到 ollama.com/library/gemma4 确认最新 tag;若显存充裕,也可以切换为
gemma4:31b或gemma4:26b-a4b等更大变体。
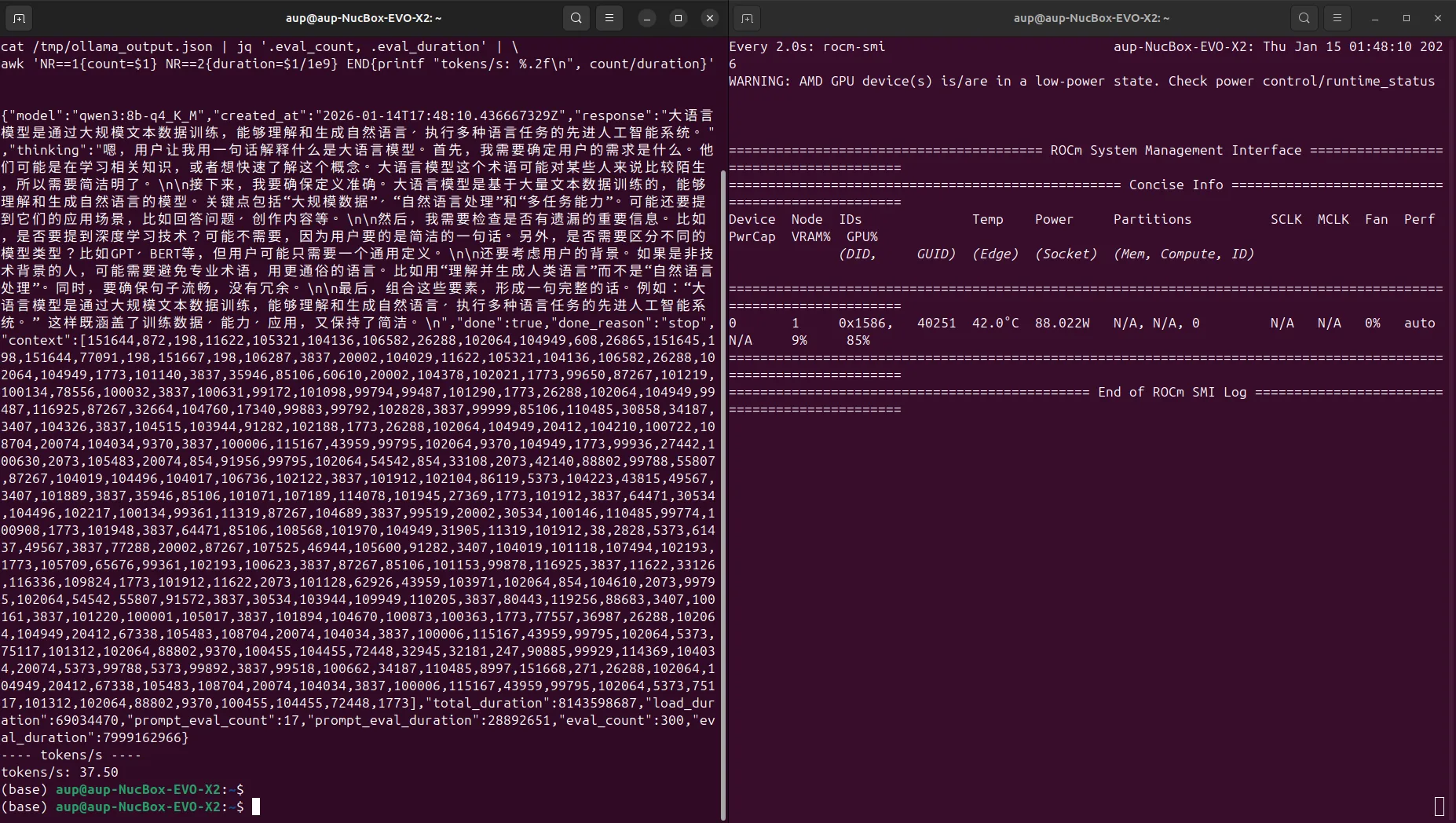
4. 使用 curl 测速(计算 tokens/s)
下面的命令示例将调用 Ollama 的 REST 接口,并使用 jq 解析返回中的评估信息,计算推理速度:
bash
curl -s -X POST http://localhost:11434/api/generate \
-H "Content-Type: application/json" \
-d '{
"model": "gemma4:e4b-it-q4_K_M",
"prompt": "用一句话解释什么是大语言模型",
"stream": false
}' | jq '.eval_count, .eval_duration' | \
awk 'NR==1{count=$1} NR==2{duration=$1/1e9} END{printf "tokens/s: %.2f\n", count/duration}'eval_count:推理产生的 token 数量eval_duration:推理耗时(单位:纳秒)tokens/s:通过count / (duration / 1e9)计算得到
5. Gemma 4 E4B-it Q4_K_M 性能示例
在上述环境中,对 Gemma 4 E4B-it Q4_K_M 模型进行测试(上下文长度 4096):
- tokens/s 以实际硬件测试为准(Gemma 4 E4B 推理时仅激活 4.5B 有效参数,相同 Q4_K_M 量化下通常比同级 8B 模型更快)
截图示例:
若需体验 Gemma 4 的多模态能力(图像 / 视频 / 音频输入),请选用 Ollama 中标注支持
vision/multimodal的 Gemma 4 tag,并通过/api/chat接口随消息传入images字段(Base64 编码图片)即可。具体参数请以 Ollama 最新文档为准。