LM Studio 零基础大模型部署(Ubuntu 24.04 + ROCm 7+)
本节介绍如何在 Ubuntu 24.04 上,基于 ROCm 7+ 使用 LM Studio + ROCm 版 llama.cpp 部署 Gemma 4,并给出 Gemma 4 E4B-it Q4_K_M 的性能示例。
在开始本节前,请确保已完成环境准备并正确安装 ROCm 7.1.0(参考
env-prepare-ubuntu24-rocm7.md)。
1. 使用 LM Studio(选择 ROCm 版本 llama.cpp 后端推理)
1.1 下载 LM Studio AppImage
首先从官网下载安装包:
https://lmstudio.ai/下载最新的 .AppImage 文件到本地。
示意图:
1.2 解压 AppImage
提取 AppImage 内容并解压到 squashfs-root 目录:
chmod u+x LM-Studio-*.AppImage
./LM-Studio-*.AppImage --appimage-extract1.3 修复 chrome-sandbox 权限
进入 squashfs-root 目录中,并为 chrome-sandbox 文件设置适当权限(该二进制文件是应用安全运行所需):
cd squashfs-root
sudo chown root:root chrome-sandbox
sudo chmod 4755 chrome-sandbox1.4 启动 LM Studio
在当前文件夹下启动 LM Studio 应用程序:
./lm-studio2. 安装 ROCm 版本 llama.cpp 后端推理
在 LM Studio 中选择 ROCm 版本的 llama.cpp 后端 安装:
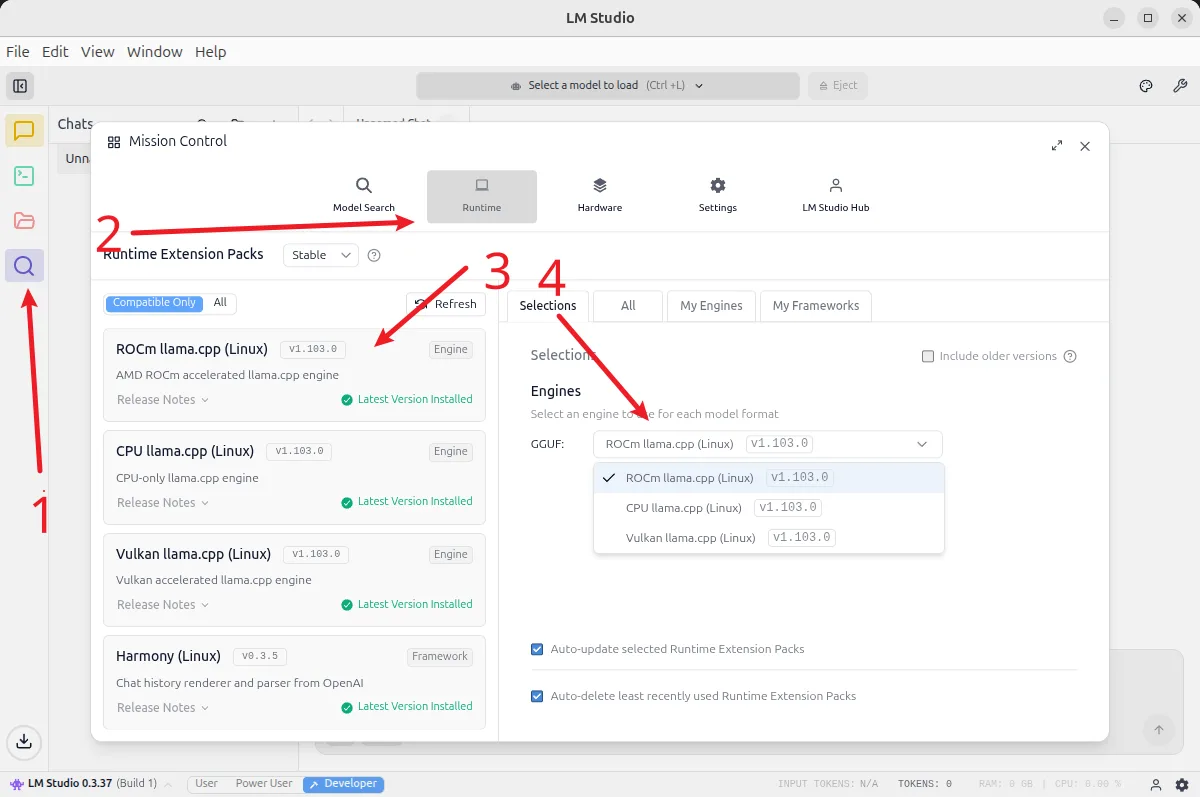
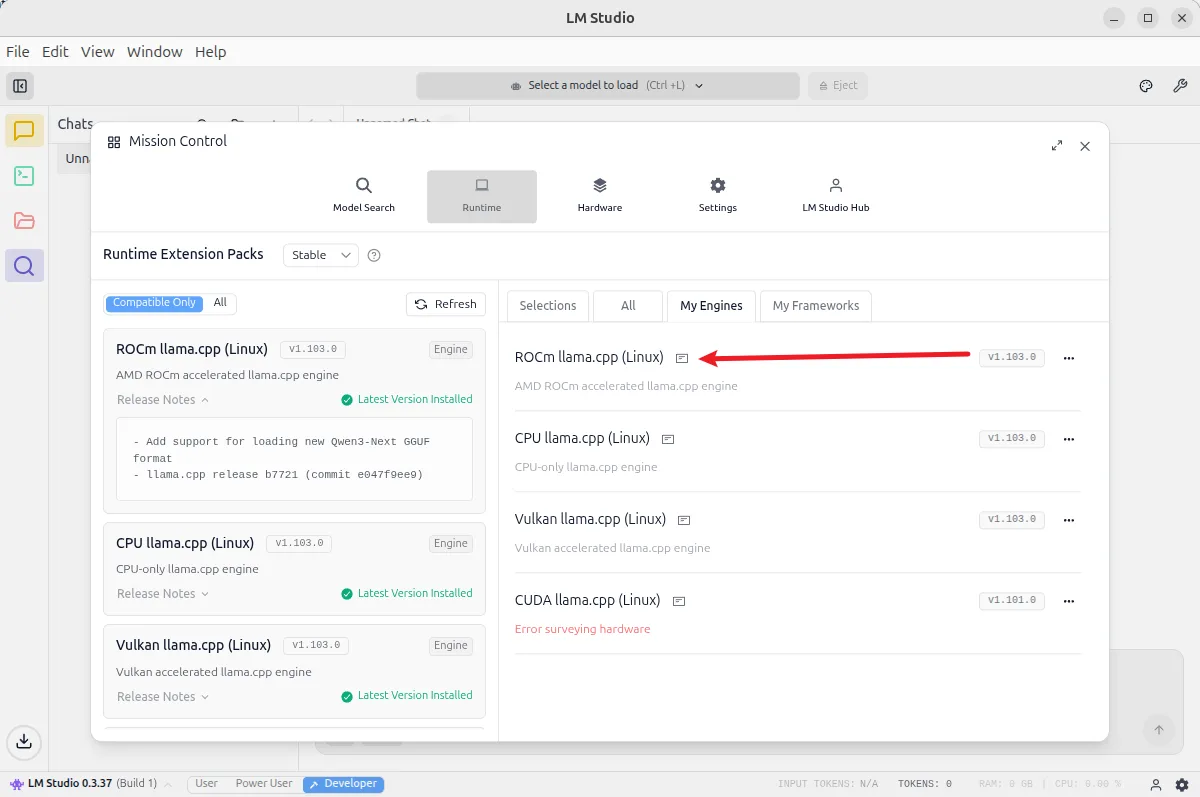
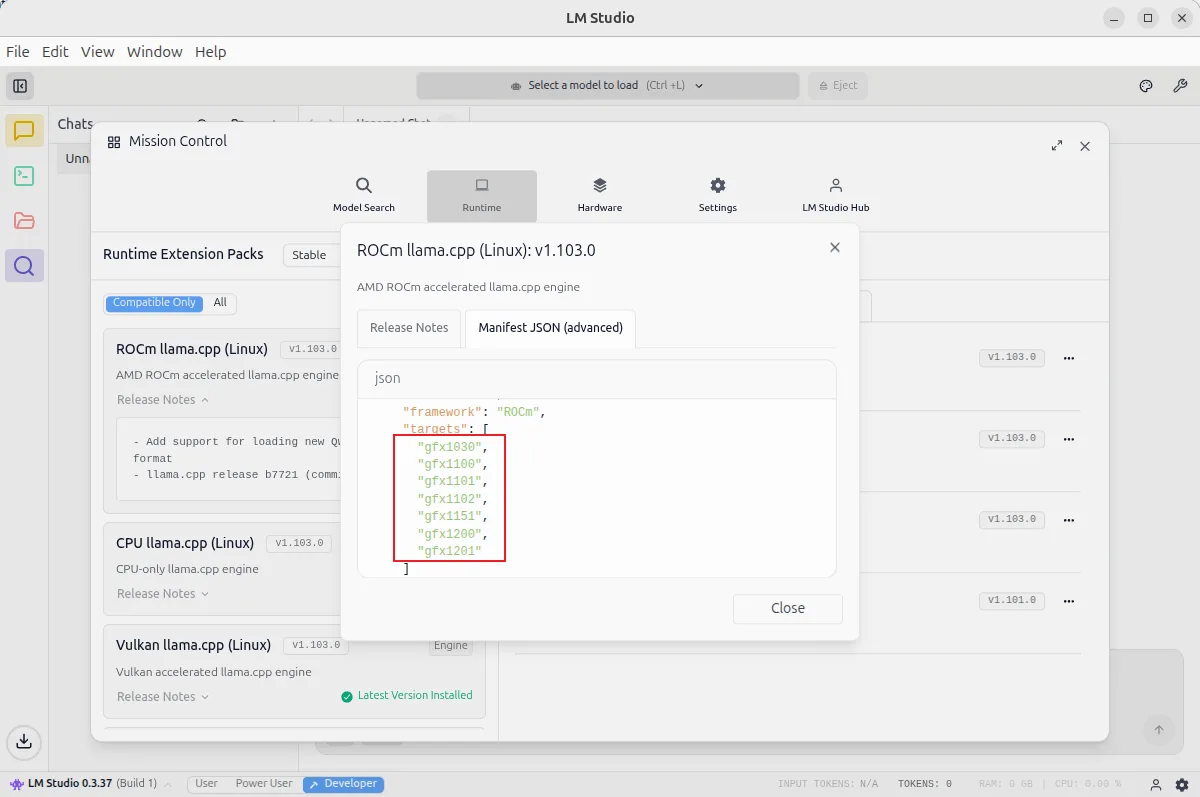
需要注意,目前 LM Studio 所提供的 ROCm 版本 llama.cpp 所支持的架构列表(不同 GPU 架构支持状况):
3. 加载 Gemma 4 E4B-it Q4_K_M 模型
在 LM Studio 的 Discover 页面直接搜索关键词:
gemma-4-E4B-it GGUF选择社区提供的 Q4_K_M 量化版本下载(例如 bartowski/google_gemma-4-E4B-it-GGUF 等可信仓库,具体以 LM Studio 最新目录为准)。
提示:
- 首次下载 Gemma 系列模型需要在 Hugging Face 上接受模型使用条款,并在 LM Studio 中登录 / 配置对应 Token。
- 若显存更大,可改用
gemma-4-26B-A4B-it或gemma-4-31B-it的 GGUF 量化版本。
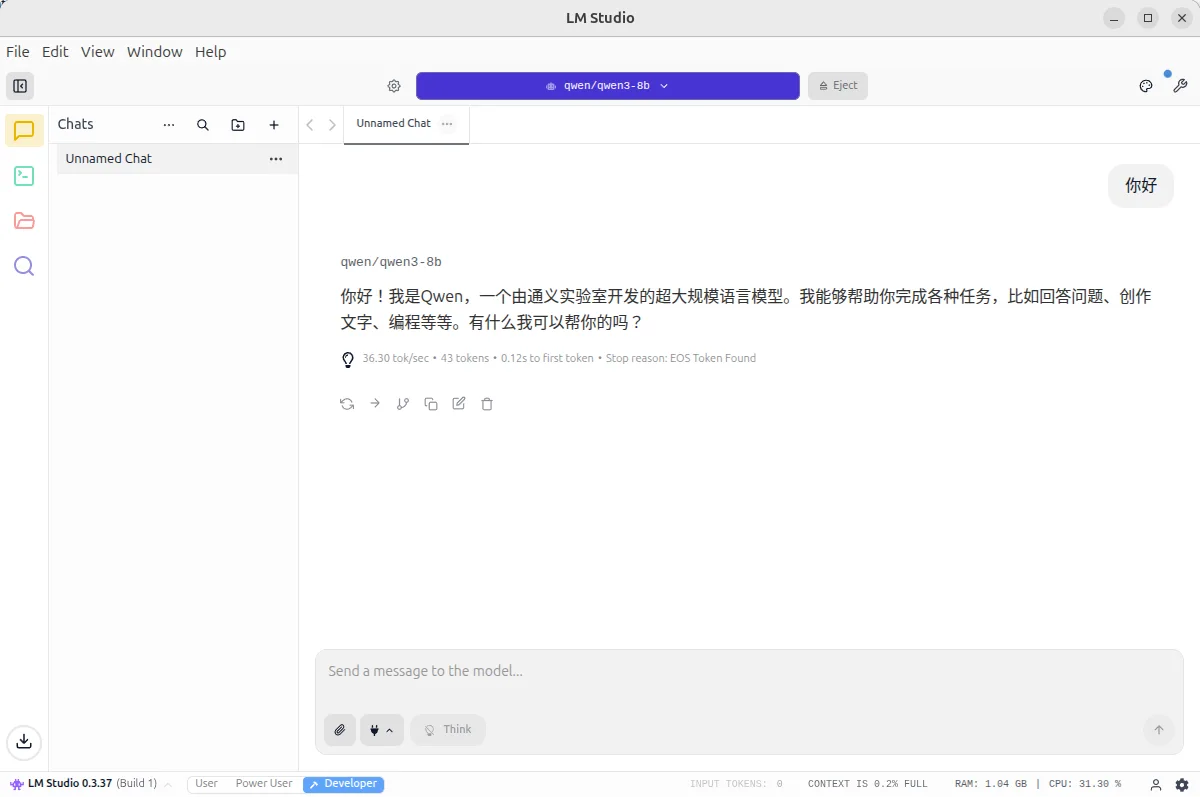
4. Gemma 4 E4B-it Q4_K_M 性能示例
在 LM Studio 中加载 Gemma 4 E4B-it Q4_K_M 模型,设置上下文长度为 4096(Gemma 4 E4B 原生支持 128K,可按显存逐步上调),即可进行对话与推理:
- tokens/s 以实际硬件测试为准(Gemma 4 E4B 推理时仅激活 4.5B 有效参数,在相同 Q4_K_M 量化下通常比同级 8B 模型更快)
截图示例:
若需体验 Gemma 4 的图像 / 视频 / 音频多模态能力,请使用 LM Studio 中标注支持 Vision / Multimodal 的 Gemma 4 GGUF 包(通常附带
mmproj投影文件),然后在对话窗口直接拖入图片或音频即可。