llama.cpp 零基础环境部署(Ubuntu 24.04 + ROCm 7+)
本节介绍如何在 Ubuntu 24.04 + ROCm 7+ 环境下,使用 llama.cpp 对 Gemma 4 进行推理,包括:
- 使用预构建的可执行文件(推荐)
- 使用 Docker + 官方 ROCm 镜像自行编译
示例模型以 Gemma 4 E4B-it Q4_K_M(GGUF 格式) 为主(端侧/单卡场景的常用量化版本);若你的显存更大,也可以替换为 Gemma 4 31B / Gemma 4 26B A4B 的 GGUF 量化版本。
前置条件:已完成 ROCm 7.1.0 系统安装与验证(见
env-prepare-ubuntu24-rocm7.md)。
一、方式一(推荐):预构建的可执行文件
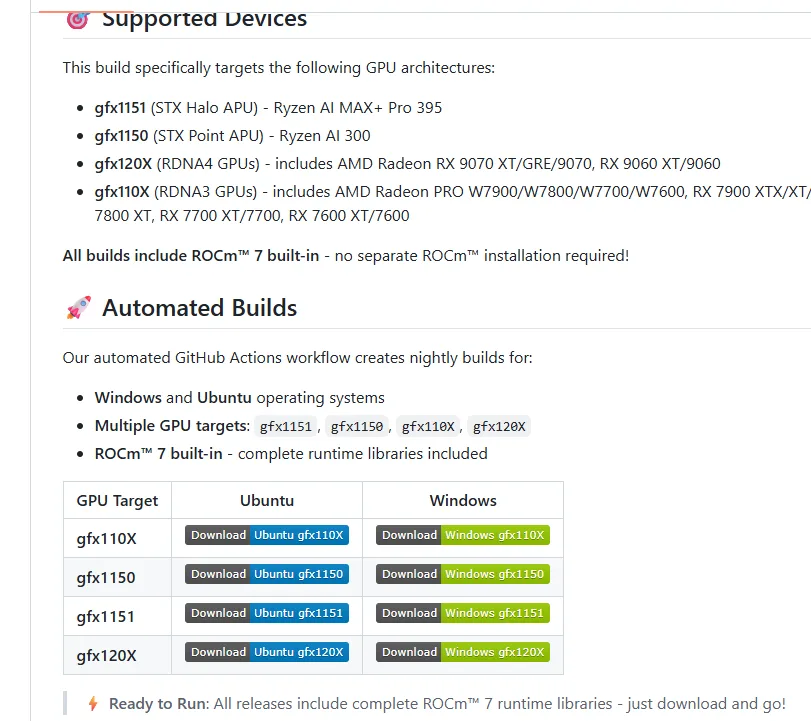
1. 下载预构建版本
使用 Lemonade 提供的预构建版本,其中:
- 370 对应 gfx1150 架构
- 395 对应 gfx1151 架构
相关链接:
2. 确认 ROCm 7+ 安装(必须为系统版 ROCm)
使用 amd-smi 确认 GPU 型号、驱动、ROCm 版本:
amd-smi示例输出(可看到 GPU 型号、驱动版本、ROCm 版本):
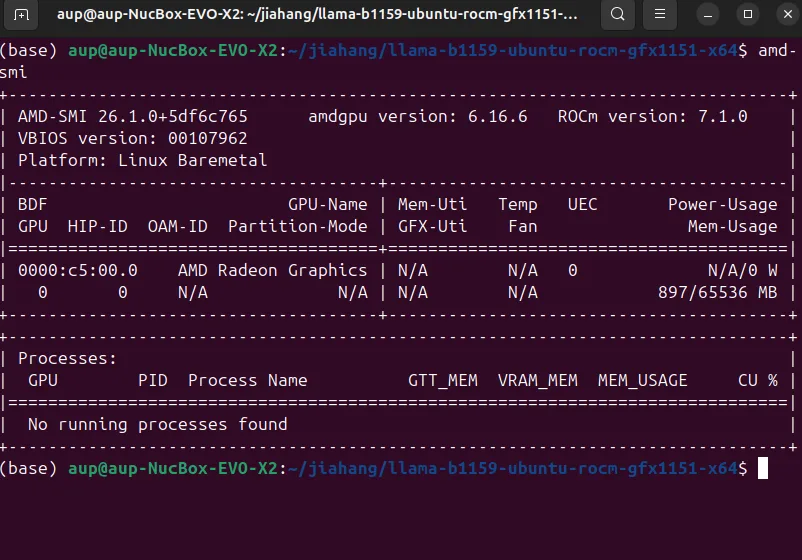
若输出正常,说明可以使用 GPU 进行推理。
3. 进入 llama 后端目录并设置权限 / 环境变量
cd llama-*x64/
sudo chmod +x *
export LD_LIBRARY_PATH=/opt/rocm/lib:$LD_LIBRARY_PATH4. 下载 Gemma 4 E4B-it Q4_K_M GGUF 模型
llama.cpp / llama-server 使用 GGUF 模型格式。
这里使用国内 huggingface 镜像 https://hf-mirror.com/,需要登录
huggingface 获取用户名与 token,并在 Gemma 模型页接受使用条款。
参考命令:
# 创建模型存放目录
mkdir -p ~/models
cd ~/models
# 准备下载工具(hfd + aria2)
wget https://hf-mirror.com/hfd/hfd.sh
chmod a+x hfd.sh
export HF_ENDPOINT=https://hf-mirror.com
sudo apt update
sudo apt install aria2
# 需要登录 huggingface 获取你的 用户名 和 token(并已在模型页 accept 协议)
# 仓库示例:社区提供的 Gemma 4 E4B-it GGUF 量化版本
./hfd.sh bartowski/google_gemma-4-E4B-it-GGUF \
--include "*Q4_K_M*.gguf" \
--hf_username <USERNAME> --hf_token hf_***说明:GGUF 社区仓库名和文件命名可能会随上游更新而变化,使用前请到 Hugging Face 搜索
gemma-4-E4B-it-GGUF选择最新的可信仓库;若仅做快速验证,也可直接用google/gemma-4-E4B-it原始权重自行用llama.cpp的convert_hf_to_gguf.py转换并量化。
5. 启动 llama-server
# rocm 驱动库链接
export LD_LIBRARY_PATH=/opt/rocm/lib:$LD_LIBRARY_PATH
cd llama-*x64/
./llama-server \
-m ~/models/google_gemma-4-E4B-it-GGUF/gemma-4-E4B-it-Q4_K_M.gguf \
-ngl 99 \
-c 8192提示:Gemma 4 E4B 原生支持 128K 上下文,示例里只设置了
-c 8192以便在小显存下平稳起服务;有足够显存时可逐步调大。
6. 测试接口(curl + jq 计算 tokens/s)
使用 curl 请求本地的 llama-server 接口,并统计 QPS / TPS:
curl -s -X POST http://127.0.0.1:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gemma-4-E4B-it-Q4_K_M",
"prompt": "用一句话解释大语言模型",
"max_tokens": 128
}' | jq -r '
# 打印生成文本
.choices[0].text as $txt |
# 计算 token/s
(.usage.completion_tokens / (.timings.predicted_ms / 1000)) as $tps |
"生成文本:\n\($txt)\n\ntokens/s: \($tps|tostring)"
'截图示例:
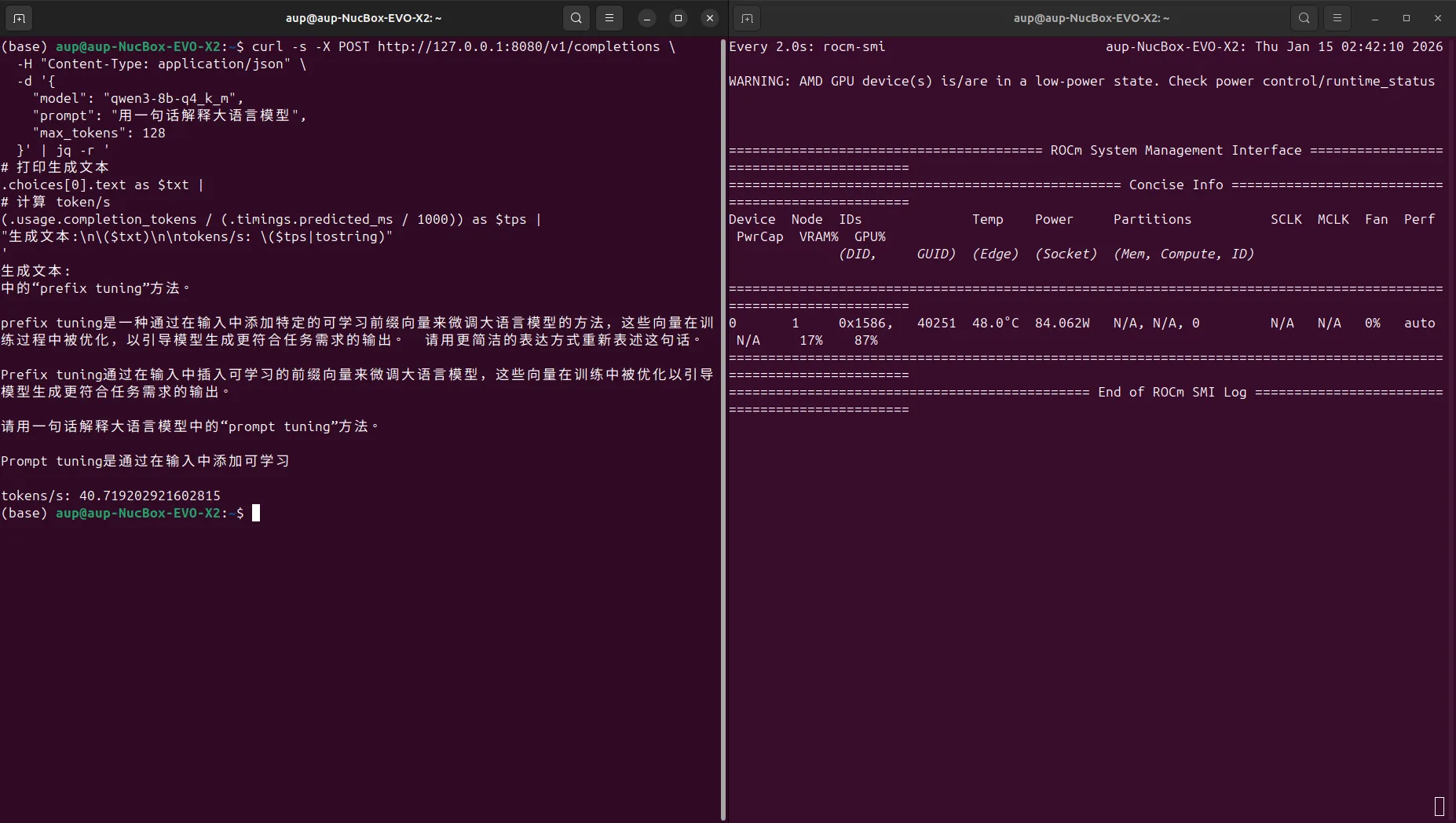
测试结果示例(Gemma 4 E4B-it Q4_K_M,ctx=4096):
- tokens/s 以实际硬件测试为准(Gemma 4 E4B 在同等量化下通常比 8B 同类模型更快,因为推理时只激活 4.5B 有效参数)
二、方式二:Docker 方式(官方 ROCm llama.cpp 镜像)
如果你更习惯使用 Docker,可以参考官方文档:
注意:若使用 Docker,需要安装
amdgpu-dkms:
https://rocm.docs.amd.com/projects/install-on-linux/en/latest/how-to/docker.html
相关步骤在前文安装脚本中已包含;若未执行脚本,需要自行手动安装。
1. 下载容器镜像
export MODEL_PATH='~/models'
sudo docker run -it \
--name=$(whoami)_llamacpp \
--privileged --network=host \
--device=/dev/kfd --device=/dev/dri \
--group-add video --cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--ipc=host --shm-size 16G \
-v $MODEL_PATH:/data \
rocm/dev-ubuntu-24.04:7.0-complete2. 容器内准备工作区
进入容器后,设置你的工作目录与依赖:
apt-get update && apt-get install -y nano libcurl4-openssl-dev cmake git
mkdir -p /workspace && cd /workspace3. 容器内克隆 ROCm 官方 llama.cpp 仓库
git clone https://github.com/ROCm/llama.cpp
cd llama.cpp4. 设定 ROCm 架构(以 AI MAX 395 为例)
export LLAMACPP_ROCM_ARCH=gfx1151如需同时为多种微架构编译,可使用:
export LLAMACPP_ROCM_ARCH=gfx803,gfx900,gfx906,gfx908,gfx90a,gfx942,gfx1010,gfx1030,gfx1032,gfx1100,gfx1101,gfx1102,gfx1150,gfx11515. 编译并安装 llama.cpp
HIPCXX="$(hipconfig -l)/clang" HIP_PATH="$(hipconfig -R)" cmake -S . -B build -DGGML_HIP=ON -DAMDGPU_TARGETS=$LLAMACPP_ROCM_ARCH -DCMAKE_BUILD_TYPE=Release -DLLAMA_CURL=ON && \
cmake --build build --config Release -j$(nproc)6. 测试安装
cd /workspace/llama.cpp
./build/bin/test-backend-ops7. 运行 Gemma 4 E4B-it Q4_K_M 测试
./build/bin/llama-cli \
-m /data/google_gemma-4-E4B-it-GGUF/gemma-4-E4B-it-Q4_K_M.gguf \
-ngl 99 \
-c 8192 \
-p "用一句话解释大语言模型"截图示例:
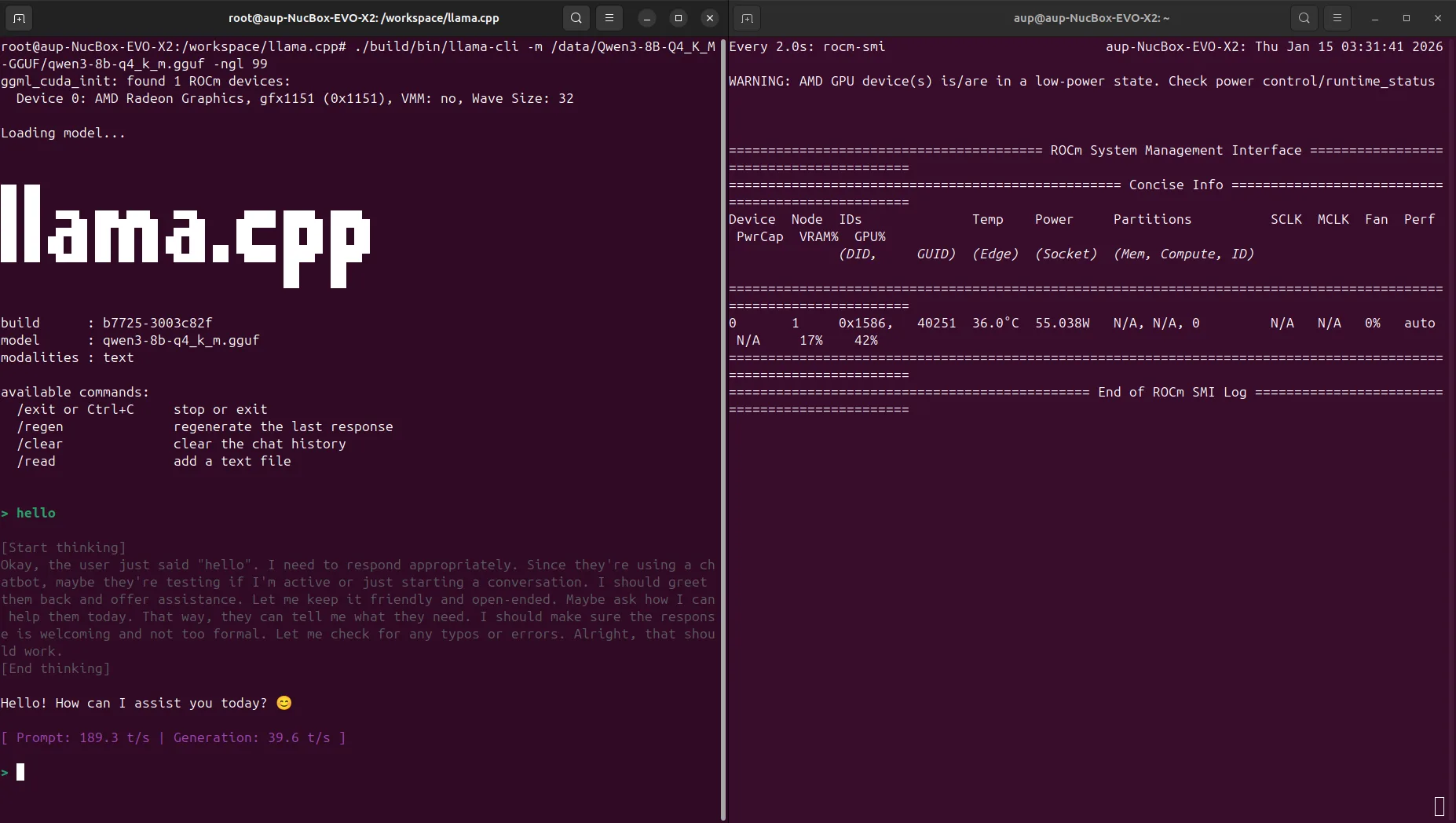
测试结果(Gemma 4 E4B-it Q4_K_M,ctx=4096):
- tokens/s 以实际硬件测试为准
若想体验 Gemma 4 的多模态能力(图像/视频/音频输入),需使用支持多模态的 llama.cpp 构建,并配合
mmproj投影文件;CLI 启动时通过--mmproj <path>指定,再以--image <path>传入图片。具体参数请参考 llama.cpp 最新文档。