Vector Index
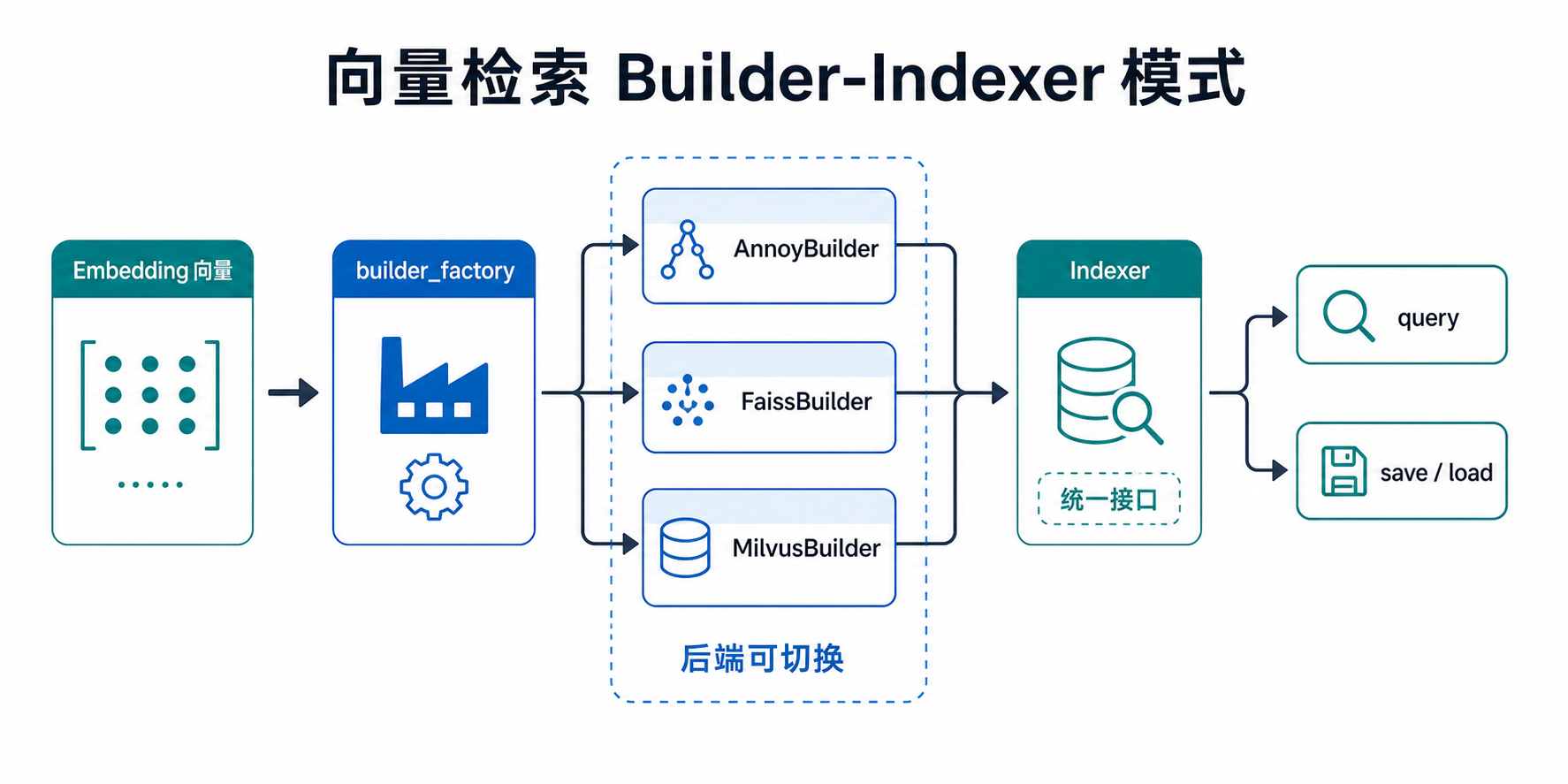
Torch-RecHub provides a unified vector retrieval interface supporting three mainstream Approximate Nearest Neighbor (ANN) search libraries: Annoy, FAISS, and Milvus. Through the standardized Builder-Indexer pattern, users can easily switch between different retrieval backends.
Quick Start
import torch
from torch_rechub.serving import builder_factory
# Prepare embeddings
item_embeddings = torch.randn(1000, 64, dtype=torch.float32) # 1000 items, 64 dimensions
user_embeddings = torch.randn(10, 64, dtype=torch.float32) # 10 users, 64 dimensions
# Create Builder and build index
builder = builder_factory("faiss", index_type="Flat", metric="L2")
with builder.from_embeddings(item_embeddings) as indexer:
# Query Top-K
ids, distances = indexer.query(user_embeddings, top_k=10)
# Save index
indexer.save("item.index")
# Load existing index
with builder.from_index_file("item.index") as indexer:
ids, distances = indexer.query(user_embeddings, top_k=10)Core Concepts
Builder-Indexer Pattern
- Builder: Responsible for index construction configuration, created via the
builder_factoryfactory function - Indexer: Responsible for query and save operations, obtained through the Builder's context manager
Factory Function
from torch_rechub.serving import builder_factory
builder = builder_factory(model, **builder_config)| Parameter | Type | Description |
|---|---|---|
model | str | Retrieval backend name: "annoy", "faiss", or "milvus" |
**builder_config | dict | Configuration parameters passed to the specific Builder |
Annoy
Annoy (Approximate Nearest Neighbors Oh Yeah) is an open-source approximate nearest neighbor search library by Spotify, featuring memory efficiency and file memory mapping support.
Installation
pip install annoy⚠️ Note: Annoy is a C++ library that requires compilation during installation. If your system lacks a C++ compilation environment (e.g., missing Visual Studio Build Tools on Windows), you may encounter compilation errors.
Solutions:
- Linux/macOS: Ensure
gcc/g++orclangis installed- Windows: Install Visual Studio Build Tools, or download pre-built wheel files:
- Pre-built wheels: https://github.com/Sprocketer/annoy-wheels
- Download the
.whlfile matching your Python version, then install locally:bashpip install annoy-1.17.3-cp311-cp311-win_amd64.whl
Parameters
builder = builder_factory(
"annoy",
d=64, # Vector dimension (required)
metric="angular", # Distance metric
n_trees=10, # Number of trees
threads=-1, # Number of threads for building
searchk=-1, # Number of nodes to inspect during search
)| Parameter | Type | Default | Description |
|---|---|---|---|
d | int | Required | Vector dimension |
metric | str | "angular" | Distance metric: "angular" (cosine), "euclidean", "dot" (dot product) |
n_trees | int | 10 | Number of trees to build; more trees = higher accuracy but slower build |
threads | int | -1 | Number of build threads; -1 uses all available cores |
searchk | int | -1 | Nodes to inspect during search; -1 means n_trees * top_k |
Usage Example
import torch
from torch_rechub.serving import builder_factory
item_embeddings = torch.randn(1000, 64, dtype=torch.float32)
user_embeddings = torch.randn(10, 64, dtype=torch.float32)
# Using cosine similarity
builder = builder_factory(
"annoy",
d=64,
metric="angular",
n_trees=50,
searchk=100,
)
with builder.from_embeddings(item_embeddings) as indexer:
ids, distances = indexer.query(user_embeddings, top_k=10)
indexer.save("annoy.index")
print(f"Retrieved item IDs: {ids}")
print(f"Distances: {distances}")FAISS
FAISS (Facebook AI Similarity Search) is Meta's open-source high-performance similarity search library, supporting GPU acceleration and multiple index types.
Installation
# CPU version
pip install faiss-cpu
# GPU version (requires CUDA)
pip install faiss-gpuSupported Index Types
| Index Type | Description | Use Case |
|---|---|---|
Flat | Brute-force search, exact results | Small-scale data (< 100K) |
HNSW | Graph-based approximate search | Medium-scale, high recall |
IVF | Inverted index, cluster-based | Large-scale data |
Parameters
Flat Index
builder = builder_factory(
"faiss",
index_type="Flat", # Index type
metric="L2", # Distance metric
)| Parameter | Type | Default | Description |
|---|---|---|---|
index_type | str | "Flat" | Index type |
metric | str | "L2" | Distance metric: "L2" (Euclidean), "IP" (Inner Product) |
HNSW Index
builder = builder_factory(
"faiss",
index_type="HNSW",
metric="L2",
m=32, # Maximum neighbors per node
efSearch=50, # Candidate nodes during search
)| Parameter | Type | Default | Description |
|---|---|---|---|
m | int | 32 | Maximum neighbors per node; higher = more accurate |
efSearch | int | None | Candidate nodes during search; higher = more accurate but slower |
IVF Index
builder = builder_factory(
"faiss",
index_type="IVF",
metric="L2",
nlists=100, # Number of cluster centers
nprobe=10, # Clusters to visit during search
)| Parameter | Type | Default | Description |
|---|---|---|---|
nlists | int | 100 | Number of cluster centers; recommended sqrt(n) to 4*sqrt(n) |
nprobe | int | None | Clusters to visit during search; higher = more accurate but slower |
Usage Example
import torch
from torch_rechub.serving import builder_factory
item_embeddings = torch.randn(10000, 128, dtype=torch.float32)
user_embeddings = torch.randn(100, 128, dtype=torch.float32)
# Using HNSW index
builder = builder_factory(
"faiss",
index_type="HNSW",
metric="IP", # Inner product, suitable for normalized vectors
m=32,
efSearch=64,
)
with builder.from_embeddings(item_embeddings) as indexer:
ids, distances = indexer.query(user_embeddings, top_k=20)
indexer.save("faiss_hnsw.index")Milvus
Milvus is a cloud-native vector database supporting distributed deployment and multiple indexing algorithms, suitable for production-grade large-scale vector retrieval.
Installation
pip install pymilvusNote: Using Milvus requires starting the Milvus service first. You can quickly start it with Docker:
bashdocker run -d --name milvus-standalone -p 19530:19530 milvusdb/milvus:latest
Supported Index Types
| Index Type | Description | Use Case |
|---|---|---|
FLAT | Brute-force search | Small-scale, exact results |
HNSW | Graph-based index | Medium-scale, high recall |
IVF_FLAT | Inverted index | Large-scale data |
Parameters
FLAT Index
builder = builder_factory(
"milvus",
d=64, # Vector dimension (required)
index_type="FLAT",
metric="L2", # Distance metric
)| Parameter | Type | Default | Description |
|---|---|---|---|
d | int | Required | Vector dimension |
metric | str | "L2" | Distance metric: "L2", "IP", "COSINE" |
HNSW Index
builder = builder_factory(
"milvus",
d=64,
index_type="HNSW",
metric="COSINE",
m=16, # Maximum neighbors per node
ef=50, # Candidate nodes during search
)| Parameter | Type | Default | Description |
|---|---|---|---|
m | int | 16 | Maximum neighbors per node |
ef | int | None | Candidate nodes during search |
IVF_FLAT Index
builder = builder_factory(
"milvus",
d=64,
index_type="IVF_FLAT",
metric="IP",
nlist=128, # Number of cluster centers
nprobe=16, # Clusters to visit during search
)| Parameter | Type | Default | Description |
|---|---|---|---|
nlist | int | 128 | Number of cluster centers |
nprobe | int | None | Clusters to visit during search |
Usage Example
import torch
from torch_rechub.serving import builder_factory
item_embeddings = torch.randn(10000, 64, dtype=torch.float32)
user_embeddings = torch.randn(100, 64, dtype=torch.float32)
# Using Milvus HNSW index
builder = builder_factory(
"milvus",
d=64,
index_type="HNSW",
metric="COSINE",
m=32,
ef=64,
)
with builder.from_embeddings(item_embeddings) as indexer:
ids, distances = indexer.query(user_embeddings, top_k=10)
# Note: Milvus indexes are stored on the server, local save is not supportedComplete Example: Retrieval Model Evaluation
Here's a complete example of dual-tower model vector retrieval evaluation:
import collections
import numpy as np
import pandas as pd
import torch
from torch_rechub.serving import builder_factory
from torch_rechub.basic.metric import topk_metrics
def match_evaluation(
user_embedding: torch.Tensor,
item_embedding: torch.Tensor,
test_user: dict,
all_item: dict,
user_col: str = 'user_id',
item_col: str = 'item_id',
raw_id_maps: str = "./raw_id_maps.npy",
topk: int = 10,
backend: str = "faiss",
**backend_kwargs,
):
"""
Perform retrieval evaluation using vector search
Args:
user_embedding: User embedding vectors (n_users, dim)
item_embedding: Item embedding vectors (n_items, dim)
test_user: Test user data dictionary
all_item: All item data dictionary
user_col: User ID column name
item_col: Item ID column name
raw_id_maps: ID mapping file path
topk: Number of items to retrieve
backend: Retrieval backend ("annoy", "faiss", "milvus")
**backend_kwargs: Additional parameters for builder_factory
Returns:
Evaluation metrics dictionary
"""
print(f"Performing vector retrieval evaluation using {backend}")
# 1. Create Builder
dim = item_embedding.shape[1]
if backend == "annoy":
builder = builder_factory("annoy", d=dim, n_trees=10, **backend_kwargs)
elif backend == "faiss":
builder = builder_factory("faiss", index_type="Flat", metric="L2", **backend_kwargs)
elif backend == "milvus":
builder = builder_factory("milvus", d=dim, index_type="FLAT", metric="L2", **backend_kwargs)
else:
raise ValueError(f"Unsupported backend: {backend}")
# 2. Ensure tensors are on CPU
item_embedding = item_embedding.cpu().float()
user_embedding = user_embedding.cpu().float()
# 3. Load ID mappings
user_map, item_map = np.load(raw_id_maps, allow_pickle=True)
# 4. Build index and query
match_res = collections.defaultdict(dict)
with builder.from_embeddings(item_embedding) as indexer:
ids, distances = indexer.query(user_embedding, topk)
ids_np = ids.numpy()
for i, user_id in enumerate(test_user[user_col]):
items_idx = ids_np[i]
predicted_item_ids = all_item[item_col][items_idx]
match_res[user_map[user_id]] = np.vectorize(item_map.get)(predicted_item_ids)
# 5. Build ground truth
data = pd.DataFrame({user_col: test_user[user_col], item_col: test_user[item_col]})
data[user_col] = data[user_col].map(user_map)
data[item_col] = data[item_col].map(item_map)
user_pos_item = data.groupby(user_col).agg(list).reset_index()
ground_truth = dict(zip(user_pos_item[user_col], user_pos_item[item_col]))
# 6. Compute metrics
out = topk_metrics(y_true=ground_truth, y_pred=match_res, topKs=[topk])
return out
# Usage example
# result = match_evaluation(
# user_embedding, item_embedding, test_user, all_item,
# topk=10, backend="faiss", index_type="HNSW", m=32
# )Performance Comparison & Selection Guide
| Feature | Annoy | FAISS | Milvus |
|---|---|---|---|
| Installation | Easy | Medium | Requires service |
| Memory Usage | Low | Medium | Depends on config |
| Build Speed | Slow | Fast | Fast |
| Query Speed | Medium | Fast | Fast |
| GPU Support | ❌ | ✅ | ✅ |
| Distributed | ❌ | ❌ | ✅ |
| Best For | Small-scale offline | Medium-large scale | Production environments |
Selection Recommendations
- Quick prototyping / Small datasets: Use Annoy - simple installation, memory efficient
- Medium-large scale offline computation: Use FAISS - excellent performance, GPU support
- Production environments / Online services: Use Milvus - distributed support, dynamic updates
API Reference
BaseBuilder
class BaseBuilder(abc.ABC):
def from_embeddings(self, embeddings: torch.Tensor) -> ContextManager[BaseIndexer]:
"""Build index from embedding vectors"""
def from_index_file(self, index_file: FilePath) -> ContextManager[BaseIndexer]:
"""Load index from file"""BaseIndexer
class BaseIndexer(abc.ABC):
def query(self, embeddings: torch.Tensor, top_k: int) -> tuple[torch.Tensor, torch.Tensor]:
"""
Query nearest neighbors
Args:
embeddings: Query vectors (n, d)
top_k: Number of nearest neighbors to return
Returns:
ids: Nearest neighbor IDs (n, top_k)
distances: Distances (n, top_k)
"""
def save(self, file_path: FilePath) -> None:
"""Save index to file"""