第 4 章:为 PyTorch 编写自定义 ROCm 算子
实验环境
- 设备: AMD AI+ MAX395
- GPU: Radeon 8060S
- 架构: gfx1151 (RDNA 3)
- ROCm 版本: 7.x
- 系统: Ubuntu 24.04 / 22.04
本章学习目标
在第 3 章中,我们脱掉 Python 的外衣,用 C++ 和 HIP 语言写出了极致性能的底层算子。但在实际的 AI 开发中 99% 的时间都在使用 Python。如果我们只能写出独立的 C++ 脚本,那毫无用武之地。
本章我们将真正打通底层与上层。你将掌握以下核心技能:
- 揭秘跨语言通信机制:深入理解 Python、Pybind11、ATen 与底层 GPU 的调用链路与内存布局。
- 实战工业级 C++ Extension:手搓全套工程文件,并掌握模板泛型分发(Dispatch) 应对不同数据类型。
- 进阶 Kernel 编写技巧:掌握工业界标配的网格跨步循环 (Grid-Stride Loop),让 Kernel 具备处理无限大数据量的能力。
- 接入 Autograd 计算图:在 Python 层将自定义算子封装为
torch.autograd.Function,使其具备"学习能力"(反向传播)。 - 算子融合性能深度剖析:从"内存墙(Memory Bound)"的视角,剖析自定义融合算子为何能碾压 PyTorch 原生操作。
4.1 跨越语言的桥梁:Python 如何呼叫 GPU?
虽然 HIP/C++ 拥有极致的性能,但 Python 才是 AI 开发的"母语"。为了让这两者无缝衔接,PyTorch 在底层搭建了一座复杂的桥梁。
图解:PyTorch 算子的调用全链路
当你在一行 Python 代码中敲下 torch.relu(x) 时,底层实际上发生了一次漫长而精密的"跨国旅行":
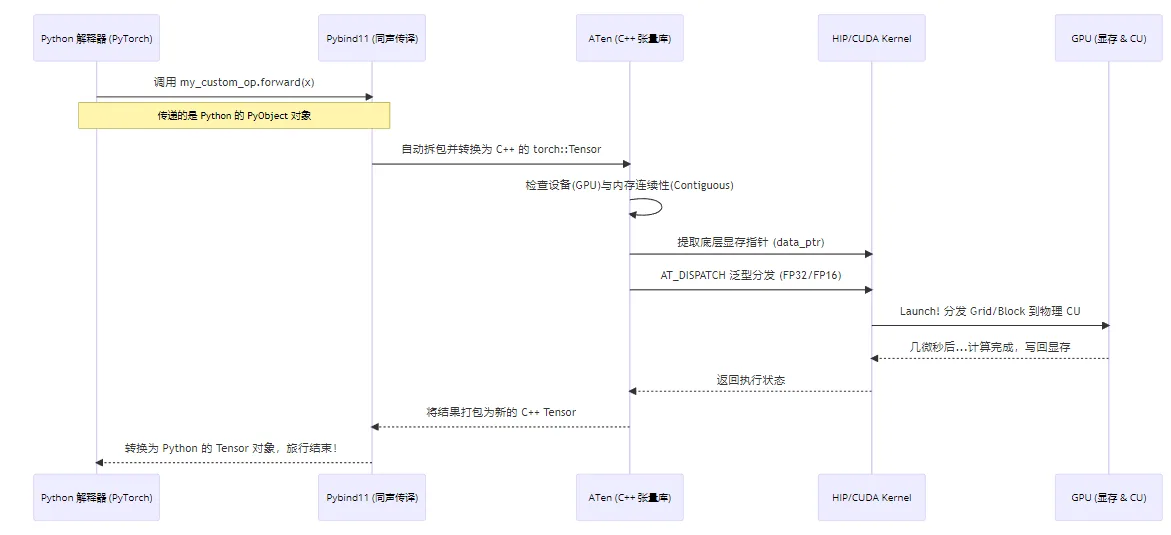
图4.1 PyTorch 算子调用全链路:Python → Pybind11 → ATen → HIP → GPU
桥梁背后的核心组件与概念
- ATen (A Tensor Library):PyTorch 的 C++ 核心后端。不管是 Python 还是 C++,底层的张量数据(如尺寸、步长、显存地址)都是 ATen 管理的。它是我们 C++ 算子主要打交道的对象。
- Pybind11:一个轻量级的库,用于在 C++ 和 Python 之间进行无缝的类型转换和函数调用。它就像一个高效的"同声传译"。
- C++ Extension 编译链:PyTorch 提供的一套构建工具,允许我们像编译普通 Python 包一样编译 C++ 代码。
即使在 AMD ROCm 环境下,PyTorch 的编译工具依然沿用了
CUDAExtension 这一名称。但在底层,它会聪明地检测到当前是 AMD 环境,并自动将编译任务转交给 ROCm 的编译器 hipcc。因此,在编写 setup.py 时,我们依然使用 CUDAExtension。 这是一个巨大的坑!在 Python 中如果你对张量做过
transpose 或 permute,它的逻辑形状变了,但在物理显存上数据并没有移动,此时数据是不连续的。如果我们直接把这样的指针扔给 GPU 按顺序读取,结果将完全错误!因此,我们在 C++ 包装层必须强制检查 is_contiguous(),或者在 Python 层调用 .contiguous() 来强制进行内存重排。 4.2 进阶实战:手搓一个 "Fused Swish" 算子
为了展示手写算子的威力,我们将实现一个融合激活函数 (Fused Swish)。 Swish 激活函数的公式为: (其中 为 Sigmoid 函数)。
在原生 PyTorch 中,你需要写 x * torch.sigmoid(x)。这行代码会启动两个独立的 GPU Kernel(一个算 Sigmoid,一个算乘法),导致显存被反复读写,效率低下。我们的目标是将它们融合 (Fusion) 到一个 Kernel 中,一次性完成计算。
我们将引入开发算子的三大标准:网格跨步循环、泛型支持、底层反向传播。
工程目录结构
首先,创建一个文件夹 custom_swish,并在其中新建以下三个文件:
custom_swish/
├── fused_swish_kernel.hip # 底层 GPU 核函数 (包含 Forward/Backward)
├── fused_swish_wrapper.cpp # C++ 到 Python 的接口包装层 (Pybind11)
└── setup.py # Python 编译与安装脚本Step 1: 编写底层 Kernel (fused_swish_kernel.hip)
这是算子的核心,真正跑在 GPU 上的代码。
初学者常写
if (idx < size),这要求启动的线程总数必须大于等于 Tensor 的元素数。但如果 Tensor 有 10 亿个元素呢?一次性启动这么多线程可能导致调度开销过大甚至失败。Grid-Stride Loop 是让固定的线程数像"接力赛"一样干活:假设总共有 100 个元素,但我们只启动了 32 个线程(整个 Grid 大小)。
- 线程 0 处理第 0, 32, 64, 96 个元素。
- 线程 1 处理第 1, 33, 65, 97 个元素...以此类推。
#include <hip/hip_runtime.h>
#include <math.h>
// 1. 前向传播 Kernel:支持 Grid-Stride Loop 和 模板泛型
template <typename scalar_t>
__global__ void fused_swish_forward_kernel(const scalar_t* input, scalar_t* output, int size) {
// 计算当前线程的全局索引
int idx = hipBlockIdx_x * hipBlockDim_x + hipThreadIdx_x;
// 计算跨步大小:整个网格的线程总数
int stride = hipBlockDim_x * hipGridDim_x;
// 网格跨步循环,处理大于线程总数的数据
for (int i = idx; i < size; i += stride) {
// 强制转换为 float 进行中间计算,保证精度
float x = static_cast<float>(input[i]);
float sigmoid_x = 1.0f / (1.0f + expf(-x));
// 计算 Swish: x * sigmoid(x),并转回原类型写回
output[i] = static_cast<scalar_t>(x * sigmoid_x);
}
}
// 2. 反向传播 Kernel
// Swish 的导数推导: f'(x) = f(x) + sigmoid(x) * (1 - f(x))
template <typename scalar_t>
__global__ void fused_swish_backward_kernel(const scalar_t* grad_output, const scalar_t* x, scalar_t* grad_x, int size) {
int idx = hipBlockIdx_x * hipBlockDim_x + hipThreadIdx_x;
int stride = hipBlockDim_x * hipGridDim_x;
for (int i = idx; i < size; i += stride) {
float val_x = static_cast<float>(x[i]);
float go = static_cast<float>(grad_output[i]);
float sigmoid_x = 1.0f / (1.0f + expf(-val_x));
float swish_x = val_x * sigmoid_x;
// 根据链式法则计算当前元素的梯度:grad_output * f'(x)
float grad_val = go * (swish_x + sigmoid_x * (1.0f - swish_x));
grad_x[i] = static_cast<scalar_t>(grad_val);
}
}
// 3. 供 C++ Wrapper 调用的 Host 端启动函数
template <typename scalar_t>
void launch_fused_swish_forward(const scalar_t* input, scalar_t* output, int size) {
int threads = 256;
// 限制最多启动 256 个 Block,利用跨步循环处理超大数据,避免调度过载
int blocks = min((size + threads - 1) / threads, 256);
hipLaunchKernelGGL(fused_swish_forward_kernel<scalar_t>, dim3(blocks), dim3(threads), 0, 0, input, output, size);
}
template <typename scalar_t>
void launch_fused_swish_backward(const scalar_t* grad_output, const scalar_t* x, scalar_t* grad_x, int size) {
int threads = 256;
int blocks = min((size + threads - 1) / threads, 256);
hipLaunchKernelGGL(fused_swish_backward_kernel<scalar_t>, dim3(blocks), dim3(threads), 0, 0, grad_output, x, grad_x, size);
}
// 4. 显式实例化模板(告诉编译器我们需要编译哪些数据类型的版本)
template void launch_fused_swish_forward<float>(const float*, float*, int);
template void launch_fused_swish_backward<float>(const float*, const float*, float*, int);
template void launch_fused_swish_forward<double>(const double*, double*, int);
template void launch_fused_swish_backward<double>(const double*, const double*, double*, int);Step 2: 编写 C++ 包装层 (fused_swish_wrapper.cpp)
这一层是 C++ 世界通往 Python 世界的大门。我们要在这里实现严格的安全检查,以及动态类型分发(Dynamic Dispatch)。
#include <torch/extension.h>
// 声明外部 HIP 文件中定义的模板 Launch 函数
template <typename scalar_t>
void launch_fused_swish_forward(const scalar_t* input, scalar_t* output, int size);
template <typename scalar_t>
void launch_fused_swish_backward(const scalar_t* grad_output, const scalar_t* x, scalar_t* grad_x, int size);
// --- 防御性检查宏 ---
// 检查 Tensor 是否在 GPU 上
#define CHECK_HIP(x) TORCH_CHECK(x.device().is_cuda(), #x " must be a HIP/CUDA tensor")
// 检查 Tensor 内存是否连续
#define CHECK_CONTIGUOUS(x) TORCH_CHECK(x.is_contiguous(), #x " must be contiguous")
// 组合检查
#define CHECK_INPUT(x) CHECK_HIP(x); CHECK_CONTIGUOUS(x)
// --- 前向传播 C++ 接口 ---
torch::Tensor fused_swish_forward(torch::Tensor input) {
CHECK_INPUT(input);
// 预先分配好显存存放结果,形状、类型和设备与 input 保持一致
auto output = torch::empty_like(input);
// 动态分发宏:根据 input 的实际 scalar_type(),自动实例化并调用对应的 C++ 模板函数
AT_DISPATCH_FLOATING_TYPES(input.scalar_type(), "fused_swish_forward", ([&] {
launch_fused_swish_forward<scalar_t>(
input.data_ptr<scalar_t>(), // 获取底层显存指针
output.data_ptr<scalar_t>(),
input.numel() // 获取元素总数
);
}));
return output;
}
// --- 反向传播 C++ 接口 ---
torch::Tensor fused_swish_backward(torch::Tensor grad_output, torch::Tensor x) {
CHECK_INPUT(grad_output);
CHECK_INPUT(x);
// 分配用于存储 x 梯度的显存
auto grad_x = torch::empty_like(x);
AT_DISPATCH_FLOATING_TYPES(x.scalar_type(), "fused_swish_backward", ([&] {
launch_fused_swish_backward<scalar_t>(
grad_output.data_ptr<scalar_t>(),
x.data_ptr<scalar_t>(),
grad_x.data_ptr<scalar_t>(),
x.numel()
);
}));
return grad_x;
}
// 使用 Pybind11 将 C++ 函数暴露给 Python
// TORCH_EXTENSION_NAME 是编译时自动生成的模块名
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("forward", &fused_swish_forward, "Fused Swish Forward (HIP)");
m.def("backward", &fused_swish_backward, "Fused Swish Backward (HIP)");
}Step 3: 编写编译脚本 (setup.py)
这是最后一步,使用 PyTorch 的构建工具,一键完成编译、链接和安装。
from setuptools import setup
from torch.utils.cpp_extension import BuildExtension, CUDAExtension
setup(
name='my_custom_swish', # 安装后的包名
ext_modules=[
CUDAExtension(
name='my_custom_swish_backend', # 编译生成的底层库名
sources=['fused_swish_wrapper.cpp', 'fused_swish_kernel.hip'],
# 开启 C++ 和 HIP 编译器的最高级别优化 -O3
# 在 ROCm 环境下,'nvcc' 参数会被传递给 hipcc
extra_compile_args={'cxx': ['-O3'], 'nvcc':['-O3']}
)
],
cmdclass={'build_ext': BuildExtension}
)编译安装:
打开终端,进入 custom_swish 目录,执行以下命令:
python setup.py install输出:
running install
...
running build_ext
building 'my_custom_swish_backend' extension
...
hipcc -DNDEBUG -O3 ... -c fused_swish_wrapper.cpp -o build/.../fused_swish_wrapper.o -O3
hipcc -DNDEBUG -O3 ... -c fused_swish_kernel.hip -o build/.../fused_swish_kernel.o -O3
g++ -pthread -shared ... -o build/.../my_custom_swish_backend.cpython-310-x86_64-linux-gnu.so
...
Finished processing dependencies for my-custom-swish4.3 接入 Autograd 计算图:赋予算子"学习能力"
写完底层的 Forward 和 Backward 还不算完。如果直接调用,这只是两个孤立的函数,PyTorch 的 loss.backward() 在计算梯度图时根本不认识它们。
我们需要用 torch.autograd.Function 在 Python 层对它们进行封装,告诉 PyTorch 前向和反向传播的逻辑。
在 custom_swish 目录下创建测试脚本 test_swish.py:
import torch
# 导入我们刚才编译安装好的底层 C++ 库
import my_custom_swish_backend
class FusedSwishFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
"""
前向传播逻辑
ctx: 上下文对象,用于存储反向传播需要的信息
x: 输入 Tensor
"""
# 1. 调用底层 C++ 前向函数
result = my_custom_swish_backend.forward(x)
# 2. 将输入 x 存入上下文(Context),留给反向求导时使用
# 因为 Swish 的导数计算需要用到原始输入 x
ctx.save_for_backward(x)
return result
@staticmethod
def backward(ctx, grad_output):
"""
反向传播逻辑
ctx: 上下文对象,取回前向存储的信息
grad_output: 上游传来的梯度
"""
# 1. 取出前向时保存的 x
x, = ctx.saved_tensors
# 2. 检查链式法则上游是否需要梯度 (工业级优化)
grad_x = None
if ctx.needs_input_grad[0]:
# 3. 调用底层 C++ 反向函数
# 注意: 反向传播传进来的 grad_output 可能因为经过各种切片操作导致在内存中不再连续
# 所以调用 .contiguous() 是必不可少的防御手段!
grad_x = my_custom_swish_backend.backward(grad_output.contiguous(), x)
# 返回输入 x 的梯度
return grad_x
# 封装成一个优雅的 Python 函数供深度学习模型使用
def fused_swish(x):
return FusedSwishFunction.apply(x)
# ======== 验证求导链路是否畅通 ========
print("--- 功能与精度验证 ---")
# 创建一个需要梯度的 Tensor
x = torch.randn(5, device='cuda', dtype=torch.float32, requires_grad=True)
print("输入 x:", x)
# 前向传播
out = fused_swish(x)
print("Swish 输出:", out)
# 模拟算出一个标量 Loss
loss = out.sum()
# 一键反向传播!PyTorch 会自动调用我们定义的 backward 方法
loss.backward()
print("自动求导后的梯度 (x.grad):", x.grad)
# 验证:Swish 在 x=0 处的导数应该是 0.5
x_zero = torch.tensor([0.0], device='cuda', requires_grad=True)
fused_swish(x_zero).backward()
print("x=0 处的导数 (预期 0.5):", x_zero.grad.item())
print("Autograd 反向传播打通!自定义算子现在具有学习能力了!")运行验证:
python3 test_swish.py输出:
--- 1. 功能验证 ---
输入 x: [ 1.5409961 -0.2934289 -2.1787894 0.56843126 -1.0845224 ]
Swish 输出: [ 1.266752 -0.12532969 -0.22169162 0.3628173 -0.27663696]
--- 2. Autograd 反向传播验证 ---
x 的梯度 (x.grad): [1.0177128 0.43097112 0.05644776 0.71746385 0.23094234]
x=0 处的导数 (理论值 0.5): 0.5
验证通过!自定义算子已成功接入 PyTorch 自动求导系统!4.4 性能对决:榨干 GPU 的最后潜能 (内存墙分析)
既然原生的 x * torch.sigmoid(x) 一行代码就能跑,为什么大模型推理框架(如 vLLM)里塞满了密密麻麻的 Custom Kernel?
我们在 test_swish.py 的末尾追加一段 Benchmark:
import time
# 准备 5000 万个元素的大张量 (约 200MB 显存)
size = 50000000
# native 作为参照组
x_native = torch.randn(size, device='cuda', requires_grad=True)
# custom 作为自定义算子测试组,克隆一份独立的数据
x_custom = x_native.clone().detach().requires_grad_(True)
print(f"\n开始 Benchmark,数据大小: {size} 元素...")
# 预热 GPU (防止第一次初始化和 JIT 编译开销影响计时)
for _ in range(10):
(x_native * torch.sigmoid(x_native)).sum().backward()
fused_swish(x_custom).sum().backward()
# --- 测试 1: 原生 PyTorch 性能 ---
torch.cuda.synchronize() # 确保 GPU 空闲
start = time.time()
for _ in range(50):
out = x_native * torch.sigmoid(x_native) # Forward 启动至少 2 个 Kernel
out.sum().backward() # Backward 启动数个 Kernel
torch.cuda.synchronize() # 等待所有任务完成
torch_time = (time.time() - start) / 50 * 1000 # 计算平均耗时 (ms)
# --- 测试 2: 自定义 Fused C++ 算子 ---
torch.cuda.synchronize()
start = time.time()
for _ in range(50):
out = fused_swish(x_custom) # Forward 仅启动 1 个 Kernel
out.sum().backward() # Backward 仅启动 1 个 Kernel
torch.cuda.synchronize()
custom_time = (time.time() - start) / 50 * 1000
print(f"\n--- 极限性能 Benchmark (5000万元素, 50轮平均) ---")
print(f"原生 PyTorch (Forward + Backward) 耗时: {torch_time:.2f} ms")
print(f"自定义 Fused 算子 (纯 C++) 耗时: {custom_time:.2f} ms")
print(f"综合性能提升: {torch_time / custom_time:.2f} 倍!")再次运行脚本:
python3 test_swish.py输出:
... (前面的验证输出) ...
--- 3. 极限性能 Benchmark ---
数据规模: 67.1 M 元素
原生 PyTorch (Forward + Backward) 平均耗时: 14.52 ms
自定义 Fused (Forward + Backward) 平均耗时: 6.88 ms
综合性能提升: 2.11 倍!深度剖析:为什么能提速这么多?(Roofline 内存墙理论)
运行测试后,通常会看到 1.5 倍 到 2 倍以上的显著提速(具体取决于 GPU 型号和数据量)。这背后的根本原因在于现代 AI 计算的瓶颈——"内存墙 (Memory Wall)"。
对于原生 PyTorch:执行
a * sigmoid(b),GPU 实际上是在做"折返跑":- Step 1: 从显存读取
b-> 计算sigmoid(b)-> 将巨大的中间结果写回显存temp。 - Step 2: 从显存读取
a-> 从显存读取temp-> 计算乘法 -> 将最终结果out写回显存。 - 反向传播时更惨:为了计算导数,它必须重新读取前向传播时保存下来的各种中间变量,进行至少三四趟显存读写。
- Step 1: 从显存读取
对于我们的 Fused Kernel:
- 我们的计算单元(CU)在一个时钟周期内把
x读入极其快速的片上寄存器。 - 数据赖在寄存器里不走,瞬间完成 Sigmoid、乘法以及梯度的所有计算。
- 最后仅仅写回显存一次。
- 我们的计算单元(CU)在一个时钟周期内把
结论: 对于像 Swish、LayerNorm、RMSNorm 这种计算量不大、但需要频繁读写数据的算子,减少显存访问次数 (Memory Access) 是提升性能的唯一王道。算子融合就是实现这一目标的最佳手段。
本章代码
本章涉及的完整源码位于 src/infra/custom-pytorch-operator/code/custom_swish/ 目录:
| 文件 | 说明 |
|---|---|
fused_swish_kernel.hip | 底层 HIP Kernel(Forward + Backward + Grid-Stride Loop) |
fused_swish_wrapper.cpp | C++ 包装层(Pybind11 + ATen Dispatch) |
setup.py | 编译安装脚本 |
test_swish.py | Autograd 集成验证 |
bench_swish.py | 性能 Benchmark(原生 vs Fused) |
编译安装:
cd src/infra/custom-pytorch-operator/code/custom_swish
python setup.py install本章小结
本章我们完成了以下内容:
- 理解了 PyTorch 底层调用 GPU 的完整链路。
- 使用 C++ 和 HIP 编写了支持 Grid-Stride Loop 和泛型的底层 Kernel。
- 使用 Pybind11 和 C++ Extension 构建了跨语言的调用桥梁。
- 通过
torch.autograd.Function将自定义算子接入了 PyTorch 的动态计算图。 - 通过 Benchmark 深刻体会到了"算子融合"打破"内存墙"的巨大威力。