대규모 언어 모델(LLM)이 더 널리 채택되면서, 기업은 매우 실용적인 문제에 직면하게 되었습니다: 질문이 내부 문서, 실시간 데이터 또는 도메인별 지식에 의존할 때 모델이 어떻게 정확하게 답변할 수 있을까요? 결국 모델의 학습 데이터는 제한적이고 시간적 한계가 있으므로, 회사별 비즈니스 지식이나 지속적으로 업데이트되는 정보를 포괄할 수 없습니다.
직관적인 아이디 중 하나는 이것입니다: 컨텍스트 창이 계속 커지고 있으니, 8K에서 128K, 그리고 지금은 백만 토큰 이상으로 늘어나는 상황에서, 관련 문서를 프롬프트에 넣고 모델이 그 자료에서 직접 답변하게 하면 되지 않을까요?
그러나 긴 컨텍스트를 처리할 수 있다는 것과 기업 시나리오에서 안정적이고 효율적이며 통제 가능하게 정확한 답변을 제공할 수 있다는 것은 전혀 다른 문제입니다. 긴 컨텍스트에 맹목적으로 의존하면 비용 폭증, 주의력 분산, 지식 업데이트 지연 등 심각한 도전 과제가 발생합니다.
이러한 문제점을 해결하기 위해 검색 증강 생성, 즉 RAG라는 기술이 등장했습니다. 모델이 답변을 생성하기 전에 RAG는 먼저 정확한 외부 지식을 검색합니다. 무작정 컨텍스트 길이를 확장하는 것과 비교하여, RAG는 더 낮은 비용, 더 높은 정확도, 더 강력한 통제력으로 기업의 사실적 정확성과 최신 지식에 대한 요구를 충족시킵니다. 따라서 신뢰할 수 있는 AI 애플리케이션 구축의 핵심 기반이 되었습니다.
이 튜토리얼에서는 RAG가 무엇인지 체계적으로 설명하고, 그 등장 배경과 핵심 원리를 추적한 다음, 기본 형태에서 고급 형태로의 발전과 향후 나아갈 방향을 탐구할 것입니다.
이번 강의에서 배울 내용
- RAG의 핵심 가치: 비용, 주의력, 지식 신선도라는 긴 컨텍스트의 핵심 문제를 어떻게 해결하는지 깊이 이해하기
- RAG의 작동 원리: 구체적인 예시를 통해 검색부터 생성까지 전체 루프가 어떻게 완성되는지 살펴보기
- RAG의 발전: 기본적인 Naive RAG에서 Advanced RAG, 그리고 Modular RAG로의 진화
- RAG를 위한 모델 선택: Embedding, Rerank, LLM의 세 가지 핵심 모델 유형을 평가하고 선택하는 방법 이해하기
- 기업용 RAG 실무: 데이터 전처리부터 시스템 배포 및 평가까지 전체 체인 구축 가이드 배우기
- RAG 평가 및 최적화: 핵심 지표, 주요 프레임워크, 지속적인 개선 방법 이해하기
- RAG의 최신 동향: RAG가 에이전트, 멀티모달리티 및 기타 새로운 기술과 어떻게 결합되고 있는지 탐구하기
이번 강의를 통해 얻을 수 있는 것
이 튜토리얼을 완료하면 RAG 기술에 대한 체계적인 초급 수준의 이해를 갖추게 될 것입니다. RAG가 무엇인지뿐만 아니라 왜 작동하는지도 알게 될 것입니다. 또한 기업의 요구를 충족하는 효율적이고 신뢰할 수 있으며 통제 가능한 RAG 시스템을 평가, 선택 및 설계하는 방법에 대한 명확한 청사진을 얻게 되어, 실제 기업급 RAG 애플리케이션 구축을 위한 탄탄한 기초를 다질 수 있습니다.
1. RAG가 필요한 이유
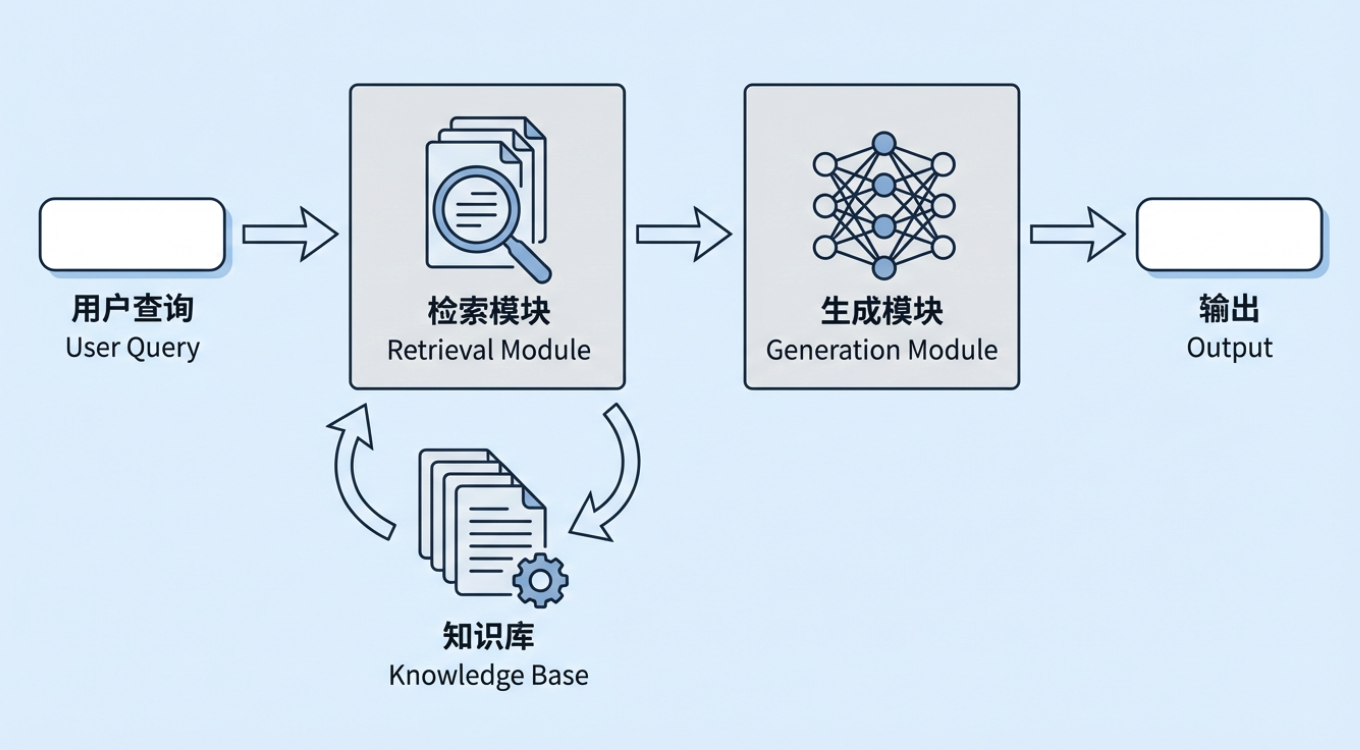
검색 증강 생성(RAG)은 오늘날 생성형 AI에서 가장 중요한 기술적 접근법 중 하나입니다. 기본 아이디어는 간단합니다: 대규모 모델에게 답변을 생성하도록 요청하기 전에 시스템이 먼저 사용자의 질문과 관련된 정보를 외부 지식 베이스에서 검색한 다음, 검색된 정보와 원래 질문을 모두 모델에 전달하여 모델이 실제 자료를 바탕으로 답변할 수 있도록 하는 것입니다. 그 외부 지식 베이스는 기업의 내부 정책, 프로세스 문서 및 제품 지식이거나, 산업 데이터베이스, 규정 코퍼스, 표준 라이브러리 등이 될 수 있습니다.
이 시점에서 자연스러운 질문이 등장합니다: 대규모 모델이 이미 "직접 질문에 답변"할 수 있다면, 왜 검색 증강 생성이라는 또 다른 계층을 추가해야 할까요? 특히 컨텍스트 창이 점점 더 커지고 있어서 관련 자료를 모두 모델에 전달하면 대부분의 요구를 해결할 수 있을 것처럼 보입니다.
진정한 차이는 "답변을 생성할 수 있다"는 것과 "실제 비즈니스 환경에서 지속적, 안정적, 통제 가능하게 올바른 답변을 생성할 수 있다"는 것이 완전히 다르다는 데 있습니다. 모델의 매개변수 메모리에만 의존하거나 대량의 문서를 긴 컨텍스트에 단순히 넣는 방식만으로는 기업 환경에서 적어도 세 가지 전형적인 문제가 여전히 발생합니다.
비용 및 효율성 문제: 컨텍스트 창이 계속 확장되고 있음에도 불구하고, 모든 문서를 한 번에 컨텍스트에 넣는다는 아이디어는 실제 시스템에서 여전히 비현실적입니다. 핵심 모순은 두 가지 측면에서 나타납니다:
추론 비용은 컨텍스트 길이와 강한 양의 상관관계가 있습니다. 컨텍스트가 길어질수록 추론 비용이 증가하며, 거의 선형적으로 때로는 초선형적으로 증가합니다. 단일 호출의 경우 8K 토큰과 200K 토큰은 완전히 다른 가격 및 지연 시간 범위에 있으며, 긴 컨텍스트는 훨씬 더 높은 비용 임계값을 가집니다.
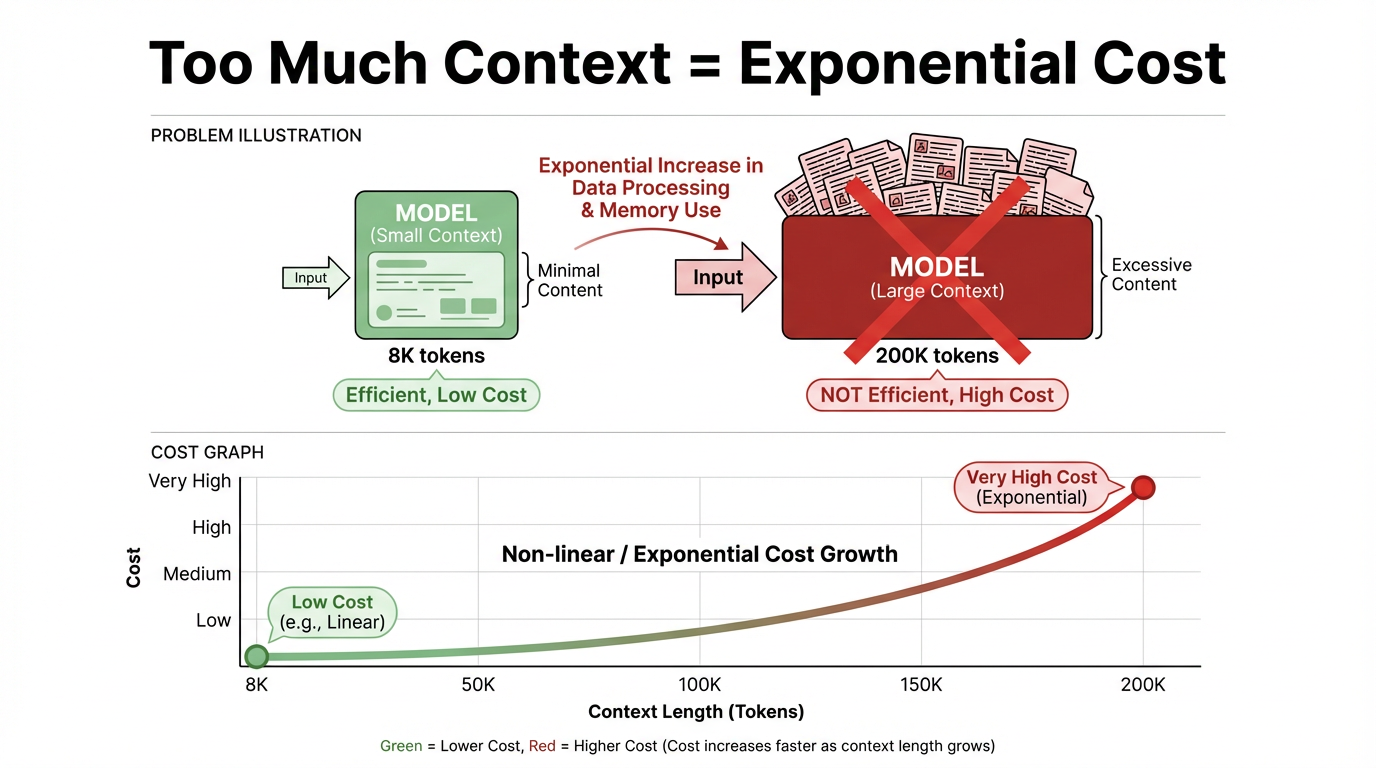
의미상 컨텍스트는 모델이 질문에 답변할 때 "참조하는" 배경 정보와 대화 기록입니다. 기술적으로 컨텍스트는 한 번의 추론을 위해 모델에 입력되는 전체 토큰 시퀀스로, 시스템 및 사용자 지침, 메시지 기록, 검색된 구절 등을 포함합니다.
"컨텍스트 창"은 해당 입력의 용량 한계입니다. 오늘날 주류 대규모 모델 아키텍처인 Transformer에서는 이러한 토큰들이 모든 계층에서 어텐션 연산에 참여합니다. 창이 길어지고 토큰 수가 증가하면 연산량과 비용이 기하급수적으로 증가할 수 있습니다.
대량의 연산이 낭비됩니다. 대부분의 작업은 현재 질문과 고도로 관련된 아주 적은 양의 정보만 필요로 합니다. 전체 문서 세트를 컨텍스트에 넣으면 심각한 유휴 및 연산 낭비가 발생하여 시스템 처리량이 감소하고 응답 속도가 느려지며 결국 사용자 경험이 저하됩니다.
주의력 및 집중력 문제: 대규모 모델은 초장문 컨텍스트를 "다룰" 수 있을지 모르지만, 모든 구간을 동일한 품질로 사용할 수는 없습니다. 컨텍스트 길이가 특정 임계값을 넘어서면 모델은 뚜렷한 주의력 편향을 보이기 시작합니다:
주의력 감소: 모델의 컨텍스트 초기 및 중간 부분에 대한 주의력이 점차 약해지고, 나중에 읽은 텍스트에 더 많이 의존하는 경향이 있어 초기의 중요한 정보가 효과적으로 무시될 수 있습니다.
정보 간섭: 모델은 컨텍스트 내의 관련 없거나 반복적이거나 심지어 충돌하는 정보에 의해 쉽게 궤도에서 벗어날 수 있습니다. 최종 답변은 논리적으로 일관되게 들리면서도 여전히 핵심 질문에서 벗어나 있어 정확도를 보장하기 어렵습니다. 검색 단계에서 관련성을 필터링하고 순위를 매기지 않으면, 컨텍스트가 길어질수록 답변이 진정으로 핵심적인 증거에 집중하기가 더 어려워집니다. 긴 컨텍스트의 장점은 정보 간섭으로 인해 완전히 상쇄될 수 있습니다.
지식 신선도 및 통제 가능성 문제: 모든 지식이 모델 매개변수에만 저장되거나 수동으로 프롬프트에 복사되는 경우, 피할 수 없는 두 가지 결함이 나타납니다:
지식 업데이트의 어려움: 정책 변경, 제품 반복 또는 가격 업데이트와 같이 지식이 변경되면 모델을 재학습시키거나 미세조정해야 하며, 이는 비용이 많이 들고 느립니다. 또는 프롬프트 템플릿을 수동으로 유지관리해야 하며, 이 역시 비용이 많이 들고 인적 오류가 발생하기 쉽습니다.
추적 가능성 부족: 모델이 답변할 때 블랙박스 매개변수나 긴 프롬프트에서 정확한 증거를 찾기가 종종 어렵습니다. 이로 인해 명확한 의사결정 근거가 필요한 규정 준수 감사, 위험 설명 및 기타 작업이 극도로 어려워집니다.
이러한 실제 제약 조건 하에서 RAG의 장점은 훨씬 더 명확해집니다. 핵심 접근 방식은 생성 전에 관련 있고 신뢰할 수 있는 정보를 찾는 것이며, 따라서 모델은 필요한 지식만을 바탕으로 답변합니다. 지식은 외부 지식 베이스에 독립적으로 저장될 수 있어 업데이트와 관리가 더 쉽습니다. 동시에 생성된 결과에는 인용 출처가 포함될 수 있어 해석 가능성과 신뢰성이 향상됩니다. 앞으로 컨텍스트 창이 계속 커지더라도 RAG는 여전히 상대적으로 낮은 비용으로 효율적인 지식 관리와 사용을 가능하게 하여, 프로세스가 관찰 가능하고 행동이 추적 가능한 기업급 지식 애플리케이션을 지원할 것입니다.
기업 요구의 관점에서 내부 매개변수에만 의존하는 전통적인 LLM과 비교하여 RAG는 주로 다음과 같은 실제 배포 문제를 해결합니다:
- 신선도: 전통적인 모델은 일반적으로 학습 중단 시점 이후에 등장한 새로운 규정, 제품 또는 워크플로우를 알지 못하지만, RAG는 최신 정책 문서, 비즈니스 데이터베이스 및 지식 베이스를 직접 읽을 수 있습니다. 빈번한 재학습 없이도 답변이 최신 비즈니스 상태와 동기화될 수 있습니다.
- 전문화: 의료, 화학, 금융과 같은 수직 도메인에서는 범용 모델이 충분히 깊이 이해하거나 정확하게 표현하지 못하는 경우가 많습니다. 기업 소유의 도메인 문서와 산업 표준을 연결한 후에는 답변이 권위 있는 자료를 기반으로 하여 실제 비즈니스 실무에 훨씬 더 가까워질 수 있습니다.
- 환각: 답변이 검색된 구절에 근거하고 인용을 제공하도록 요구함으로써, 시스템은 메커니즘 수준에서 근거 없는 허구를 줄일 수 있으며, "사실처럼 들림"을 "실제로 사실임"에 훨씬 더 가깝게 만들 수 있습니다.
- 설명 가능성 및 감사 가능성: 순수 매개변수 기반 모델은 종종 "이 결론이 어떤 규칙에서 도출되었는가?"라는 질문에 답할 수 없습니다. RAG는 각 답변을 특정 정책 조항, 비즈니스 문서 또는 과거 사례로 추적할 수 있게 합니다. 이는 비즈니스 담당자가 답변을 검사하고 수정하는 데 도움이 되며, 감사, 위험 및 규정 준수 팀에 필요한 추적 가능성을 제공합니다.
- 연산 비용 및 자원 효율성: 모델이 모든 기업 지식을 매개변수에 암기하게 하려면 일반적으로 더 큰 모델과 더 높은 추론 비용이 필요합니다. RAG는 대부분의 지식을 벡터 저장소와 문서 저장소에 모델 외부에 저장하고 필요에 따라 검색하여, 기업이 더 작은 모델과 제한된 연산으로도 더 넓은 범위와 더 정확한 세부 정보를 얻을 수 있게 합니다.
따라서 실제 비즈니스 시나리오에서 대규모 모델을 장기적, 안정적, 통제 가능하게 사용하고자 하는 기업에게 RAG는 선택적 강화가 아닙니다. 고품질 기업 지식 애플리케이션 시스템 구축을 위한 필수적인 기반 기술입니다.
2. RAG란 무엇인가
RAG, 즉 검색 증강 생성의 핵심 아이디어는 대규모 모델이 학습 중에 배운 정적 지식뿐만 아니라 런타임에 외부 지식 베이스에서 가져온 최신의 신뢰할 수 있는 정보를 바탕으로 질문에 답변하도록 하는 것입니다.
일반적인 RAG 시스템에서 사용자의 질문은 대규모 모델에 직접 전송되지 않습니다. 대신 검색 모듈이 먼저 기업 지식 베이스에서 가장 관련성 높은 문서 구절을 찾은 다음, 그 구절들을 원래 질문과 결합하여 완전한 컨텍스트를 구성하고, 마지막으로 이를 모델에 전달하여 답변을 생성합니다. 이 "먼저 검색하고, 그다음 생성하는" 패턴은 모델이 매개변수에 기억하는 것만 추측하는 대신 실제 참조 자료를 바탕으로 추론할 수 있게 합니다. 전형적인 사례를 살펴보겠습니다:
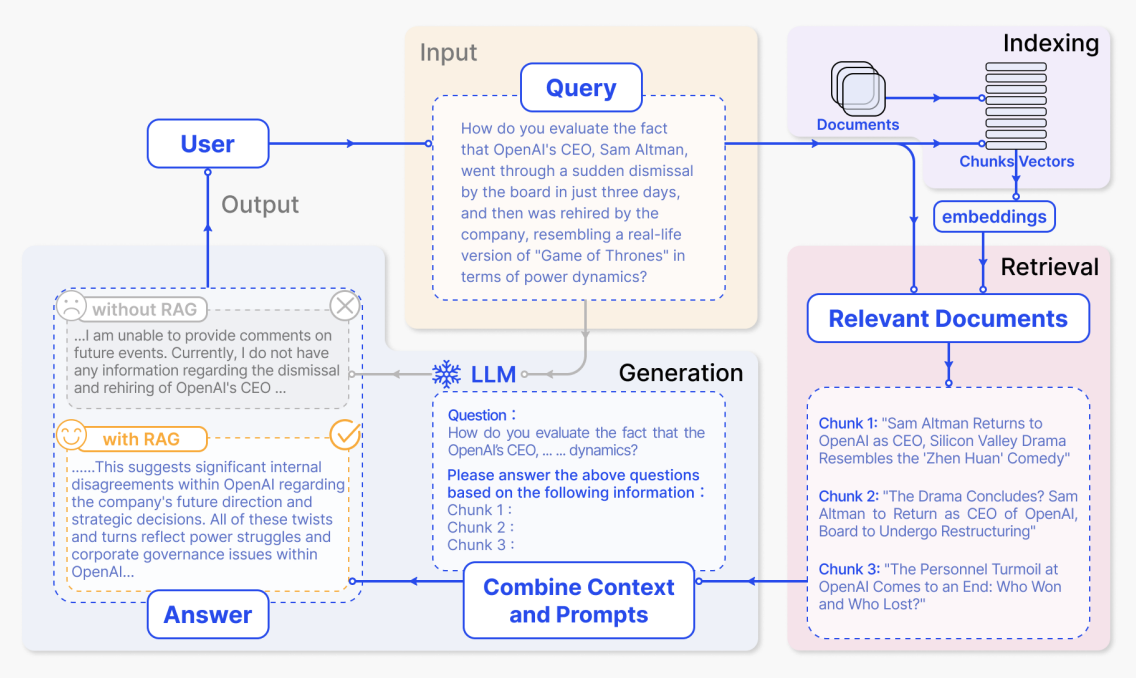
인덱싱 단계
인덱싱 단계에서 시스템은 먼저 내부 기업 문서, 웹 페이지, 보고서와 같은 원시 자료를 처리합니다. 이를 더 작은 의미론적 청크로 분할한 다음 임베딩 모델을 사용하여 각 청크에 대한 벡터 표현을 생성하고 인덱스를 구축합니다. 나중에 사용자 질문이 들어오면 시스템은 벡터 공간에서 가장 의미적으로 유사한 청크를 빠르게 찾을 수 있습니다.
다이어그램에서 이는 오른쪽 상단의 보라색 "Indexing" 영역에 해당합니다. "Documents"에서 "Chunks / Vectors"를 거쳐 "embeddings"까지의 경로는 문서가 청크로 분할되고, 벡터로 변환되며, 인덱스에 기록되는 과정을 보여줍니다. 더 구체적으로:
- 문서는 의미론적으로 일관된 청크 세트로 분할되며, 각 청크는 짧은 뉴스 구절, 설명 또는 분석에 해당할 수 있습니다.
- 각 청크는 임베딩 모델에 의해 고차원 벡터로 변환되어 벡터 인덱스에 저장됩니다.
- 이 인덱스는 나중에 유사도 기반 검색을 지원하여, 질문에 답변할 때 시스템이 참조할 수 있는 지식 베이스를 준비합니다.
검색 단계 및 검색 결과로부터의 답변 생성
사용자가 질문을 한 후 시스템은 먼저 인덱스에서 관련 콘텐츠를 검색한 다음 질문과 검색된 텍스트를 함께 대규모 모델에 전송하여 답변을 생성합니다. 그림에서 위에서 아래로, 오른쪽에서 왼쪽으로의 주요 영역은 정확히 이 전체 흐름에 해당합니다.
(1) 사용자 입력 질문: 노란색 Input - Query 영역
"OpenAI의 CEO 샘 알트만이 이사회에 의해 갑작스럽게 해임된 후 단 3일 만에 재고용된 사실을 어떻게 평가하시겠습니까? 이는 권력 역학 측면에서 '왕좌의 게임'의 실제 버전과 같습니다."
"OpenAI CEO 샘 알트만이 이사회에 의해 갑작스럽게 해임된 후 단 3일 만에 재고용되어 권력 투쟁이 실제 '왕좌의 게임'과 같다는 것을 어떻게 평가하시겠습니까?"
이 큰 텍스트 블록은 다이어그램에서 "Query" 상자 안의 내용으로, 사용자의 자연어 질문에 해당합니다. 시스템은 그 질문을 벡터화하고 이를 사용하여 오른쪽 상단 인덱스에서 관련 문서 청크를 검색합니다.
(2) 검색된 관련 문서: 오른쪽 하단의 분홍색 Relevant Documents 영역
검색 후 시스템은 질문과 가장 관련성이 높은 여러 문서 청크를 얻습니다. 다이어그램에서는 세 개의 청크로 표시됩니다:
"샘 알트만, OpenAI CEO로 복귀... 실리콘밸리 드라마, '궁중 음모' 코미디와 같아" "샘 알트만, OpenAI CEO로 복귀... 실리콘밸리 드라마, 궁중 음모 코미디와 같아"
"드라마 끝났나? 샘 알트만, OpenAI CEO로 복귀 예정... 이사회, 개편 예정" "드라마가 끝나가는가? 샘 알트만이 OpenAI CEO로 복귀할 예정이며, 이사회가 개편될 것입니다."
"OpenAI 인사 소동 끝났다: 누가 이겼고 누가 졌는가?" "OpenAI의 인사 소동이 끝났다: 누가 이겼고 누가 졌는가?"
(3) 프롬프트 결합 및 답변 생성: 파란색 LLM / Combine Context and Prompts 영역
그런 다음 시스템은 원래 사용자 질문과 검색된 청크를 결합하여 완전한 프롬프트를 구성하고 모델에 전송합니다. 그림 하단 중앙의 점선 상자는 프롬프트 예시를 보여줍니다:
"질문: OpenAI CEO의 ... 권력 역학을 어떻게 평가하시겠습니까?
다음 정보를 바탕으로 위 질문에 답변해 주세요: 청크 1: 청크 2: 청크 3:"
"질문: OpenAI CEO 사건에서의 권력 투쟁을 어떻게 평가하시겠습니까?
아래 정보를 바탕으로 위 질문에 답변해 주세요: 청크 1: 청크 2: 청크 3:"
(4) RAG 유무에 따른 답변 비교: 왼쪽 하단의 회색 및 노란색 Output - Answer 영역
마지막으로 모델은 제공된 정보를 바탕으로 답변을 생성합니다. 그림은 또한 RAG가 있는 경우와 없는 경우의 출력을 비교합니다. RAG가 없으면 모델은 외부 자료가 없어 모호한 응답만 제공할 수 있으며, 이는 회색 상자에 해당합니다:
"... 저는 미래 사건에 대해 논평할 수 없습니다. 현재 OpenAI CEO의 해임 및 재고용에 관한 정보가 없습니다 ..."
RAG가 있으면 모델은 검색된 뉴스와 분석을 사용하여 훨씬 더 유익한 답변을 생성할 수 있으며, 이는 노란색 상자에 해당합니다:
"... 이는 OpenAI 내부에 회사의 미래 방향과 전략적 결정에 대한 상당한 이견이 있음을 시사합니다. 이러한 모든 우여곡절은 OpenAI 내의 권력 투쟁과 기업 지배구조 문제를 반영합니다 ..."
위의 예시는 일반적인 RAG 시스템의 전체 흐름을 보여주며, 핵심 단계와 정보가 어떻게 흐르는지 이해하는 데 도움을 줍니다. 하지만 많은 중요한 기술적 세부 사항은 여전히 블랙박스 안에 있습니다: 벡터 매칭은 정확히 어떻게 수행되며, 검색된 콘텐츠를 모델이 더 효과적으로 사용할 수 있도록 프롬프트는 어떻게 구성해야 할까요? 이러한 세부 사항은 실제 RAG 품질을 크게 결정합니다. 다음으로, RAG의 내부 메커니즘을 더 깊이 파고들어 벡터화 원리와 유사도 계산에서 프롬프트 엔지니어링까지 단계별로 분해해 보겠습니다.
3. RAG의 작동 원리
"사과"에 대한 지식 베이스를 기반으로 한 간단한 질문-답변 예시를 통해 분해해 볼 수 있습니다.
3.1 문서 벡터화 단계
다음 세 개의 문서 구절을 포함하는 단순화된 지식 베이스가 있다고 가정해 보겠습니다:
- 구절 A: 애플 Inc.는 1976년 4월 1일 스티브 잡스, 스티브 워즈니악, 로널드 웨인에 의해 설립되었으며, 본사는 캘리포니아주 쿠퍼티노에 있습니다.
- 구절 B: 사과는 비타민 C와 식이섬유가 풍부한 과일로, 소화 및 면역 체계 건강에 도움이 됩니다.
- 구절 C: 애플 Inc.는 2007년에 최초의 iPhone을 출시하여 스마트폰 산업을 근본적으로 변화시켰습니다.
이 문서들을 임베딩 모델(예: OpenAI의 text-embedding-ada-002 또는 오픈소스 BGE 모델)로 처리하면 각 구절은 고차원 벡터로 변환되며, 일반적으로 768, 1024 또는 1536차원입니다.
벡터는 본질적으로 많은 숫자 값으로 이루어진 배열입니다. 각 차원은 텍스트의 의미론적 특징에 해당합니다. 예를 들어, "고양이"의 벡터는 포유류, 가정용 반려동물, 털이 있는 등과 관련된 차원을 포함할 수 있습니다. 최종 값 조합은 텍스트의 의미를 포착하여 컴퓨터가 텍스트 간의 관계를 "이해"할 수 있게 합니다.
단순화된 예시이며, 실제 벡터는 훨씬 더 높은 차원을 가집니다:
- 애플 설립에 대한 구절 A의 벡터:
[0.85, -0.23, 0.41, -0.56, 0.12, 0.78, ...] - 과일로서의 사과에 대한 구절 B의 벡터:
[-0.12, 0.95, -0.34, 0.67, -0.89, 0.05, ...] - iPhone 출시에 대한 구절 C의 벡터:
[0.79, -0.18, 0.52, -0.61, 0.23, 0.81, ...]
이 벡터들은 나중에 검색 및 회수를 위해 Pinecone, Weaviate 또는 FAISS와 같은 벡터 데이터베이스에 저장되어야 합니다.
데이터베이스는 데이터를 구조화된 방식으로 저장하고 관리하는 시스템으로, 체계적인 저장과 효율적인 검색을 가능하게 합니다. 일반적인 예로는 연락처 목록과 전자상거래 제품 카탈로그가 있습니다.
벡터 데이터베이스는 특수한 종류의 데이터베이스입니다. 텍스트, 테이블 및 기타 일반적인 데이터 구조를 저장하는 전통적인 데이터베이스와 달리, 벡터 데이터베이스는 벡터, 즉 고차원 숫자 배열을 저장하도록 특별히 설계되었으며, AI 시나리오에서의 유사도 검색에 최적화되어 있습니다.
3.2 사용자 질의, 검색 및 응답 단계
지식 베이스가 벡터화되어 저장되면 RAG 시스템은 실시간 사용자 질의를 지원할 수 있습니다. 사용자가 질문을 하면 시스템은 연속적인 흐름을 실행합니다: 먼저 질문을 벡터로 변환한 다음 유사도 계산을 사용하여 지식 베이스에서 가장 관련성 높은 정보를 검색하고, 마지막으로 해당 구절을 답변 생성의 기반으로 사용합니다. 세 가지 구체적인 질의로 이 과정을 설명할 수 있습니다.
질의 1: "애플 Inc.는 언제 설립되었나요?"
질의-벡터화 단계에서 질문은 임베딩 모델에 의해 의미론적 벡터로 변환됩니다(예: [0.82, -0.21, 0.38, -0.58, 0.15, 0.76, ...]). 이 숫자 패턴은 저장된 벡터 중 회사 설립에 대한 구절 A의 벡터와 매우 유사합니다.
그런 다음 시스템은 유사도 검색을 수행합니다. Top-K에서 K = 2로, 질의 벡터와 지식 베이스의 모든 문서 벡터 간의 코사인 유사도를 계산합니다. 결과는 다음과 같습니다:
- 구절 A(설립 구절)와의 유사도: 0.97, 고도로 관련됨
- 구절 C(iPhone 출시 구절)와의 유사도: 0.88, 회사에 대한 내용이므로 관련됨
- 구절 B(과일 영양 구절)와의 유사도: 0.12, 거의 관련 없음
Top-K는 벡터 검색에서 일반적인 선택 전략입니다. 모든 매치를 유사도가 높은 순에서 낮은 순으로 정렬하고 상위 K개의 결과만 유지하는 것을 의미합니다. K = 2는 시스템이 유사도 기준 상위 두 개의 문서 벡터만 유지하고 하위 순위의 것들은 필터링하여, 다음 단계에서 가장 관련성 높은 두 개의 문서 구절만을 바탕으로 답변이 생성되도록 합니다.
유사도로 필터링된 결과를 회수 결과라고 합니다. 시스템은 Top-2 구절을 증거로 반환합니다:
- 구절 A, 유사도 0.97: "애플 Inc.는 1976년 4월 1일 스티브 잡스, 스티브 워즈니악, 로널드 웨인에 의해 설립되었으며, 본사는 캘리포니아주 쿠퍼티노에 있습니다."
- 구절 C, 유사도 0.88: "애플 Inc.는 2007년에 최초의 iPhone을 출시하여 스마트폰 산업을 근본적으로 변화시켰습니다."
답변 생성 단계에서 시스템은 회수된 콘텐츠를 참조 정보 섹션에 배치하고 시스템 프롬프트와 함께 전송하여 완전한 구조화된 입력을 구성합니다:
[System Prompt]
당신은 전문적인 질문-답변 어시스턴트입니다. 사용자가 제공한 "참조 정보"를 엄격하게 따라 답변해 주세요.
참조 정보에 답변이 포함되어 있으면 그것을 바탕으로 직접 답변하세요.
참조 정보에 답변이 포함되어 있지 않으면 "현재 제공된 자료로는 질문에 답변할 수 없습니다"라고 명시하고, 정보를 조작하지 마세요.
답변이 어떤 정보를 바탕으로 했는지 표시해 주세요.
[Retrieved Context]
애플 Inc.는 1976년 4월 1일 스티브 잡스, 스티브 워즈니악, 로널드 웨인에 의해 설립되었으며, 본사는 캘리포니아주 쿠퍼티노에 있습니다.
애플 Inc.는 2007년에 최초의 iPhone을 출시하여 스마트폰 산업을 근본적으로 변화시켰습니다.
[User Query]
애플 Inc.는 언제 설립되었나요?이 구조화된 입력을 받은 후 LLM은 시스템 지침을 따르고 검색된 컨텍스트를 답변을 위한 유일한 신뢰할 수 있는 출처로 취급합니다. 최종 응답은 다음과 같을 것입니다:
제공된 참조 정보에 따르면, 애플 Inc.는 1976년 4월 1일에 설립되었습니다. [근거: 정보 1]
질의 2: "사과를 먹으면 어떤 이점이 있나요?"
질의-벡터화 단계에서 이 질문은 [-0.08, 0.92, -0.31, 0.71, -0.85, 0.08, ...]와 같은 의미론적 벡터로 변환됩니다. 이 숫자 패턴은 저장된 벡터 중 사과 영양에 대한 구절 B의 벡터와 매우 유사합니다.
시스템은 다시 K = 2로 Top-K 유사도 검색을 수행하고 코사인 유사도를 계산합니다:
- 구절 B(과일 영양)와의 유사도: 0.95, 고도로 관련됨
- 구절 C(iPhone 출시)와의 유사도: 0.18, 거의 관련 없음
- 구절 A(회사 설립)와의 유사도: 0.15, 거의 관련 없음
시스템은 Top-2 구절을 증거로 반환합니다:
- 구절 B, 유사도 0.95: "사과는 비타민 C와 식이섬유가 풍부한 과일로, 소화 및 면역 체계 건강에 도움이 됩니다."
- 구절 C, 유사도 0.18: "애플 Inc.는 2007년에 최초의 iPhone을 출시하여 스마트폰 산업을 근본적으로 변화시켰습니다." 이는 약하게만 관련되어 있어 실제로는 임계값에 의해 필터링되는 경우가 많습니다.
완전한 구조화된 입력은 다음과 같이 구성됩니다:
[System Prompt]
당신은 전문적인 질문-답변 어시스턴트입니다. 사용자가 제공한 "참조 정보"를 엄격하게 따라 답변해 주세요.
참조 정보에 답변이 포함되어 있으면 그것을 바탕으로 직접 답변하세요.
참조 정보에 답변이 포함되어 있지 않으면 "현재 제공된 자료로는 질문에 답변할 수 없습니다"라고 명시하고, 정보를 조작하지 마세요.
답변이 어떤 정보를 바탕으로 했는지 표시해 주세요.
[Retrieved Context]
사과는 비타민 C와 식이섬유가 풍부한 과일로, 소화 및 면역 체계 건강에 도움이 됩니다.
애플 Inc.는 2007년에 최초의 iPhone을 출시하여 스마트폰 산업을 근본적으로 변화시켰습니다.
[User Query]
사과를 먹으면 어떤 이점이 있나요?최종 응답은 다음과 같을 것입니다:
제공된 참조 정보에 따르면, 사과는 비타민 C와 식이섬유가 풍부하며, 사과를 섭취하면 소화 및 면역 체계 건강에 도움이 됩니다. [근거: 정보 1]
질의 3: "오늘 날씨가 어떤가요?"
질의-벡터화 단계에서 이 질문은 날씨 및 기상과 관련된 의미론적 벡터로 변환됩니다(예: [0.10, -0.05, 0.30, -0.12, 0.21, 0.08, ...]). 의미 공간에서 이 벡터는 회사든 과일이든 사과에 관한 모든 문서 벡터와 멀리 떨어져 있어 유의미한 유사도가 나타나지 않습니다.
시스템은 다시 K = 2로 Top-K 검색을 수행합니다. 질문 주제가 지식 베이스와 관련이 없기 때문에 전체 유사도 점수가 모두 매우 낮습니다:
- 구절 B(과일 영양)와의 유사도: 0.18, 매우 낮음
- 구절 C(iPhone 출시)와의 유사도: 0.10, 거의 관련 없음
- 구절 A(회사 설립)와의 유사도: 0.08, 거의 관련 없음
Top-K는 여전히 상위 K개의 결과를 반환하지만, 이 경우 그 결과는 유효한 증거를 제공하지 않습니다. 실제로 시스템은 종종 최소 유사도 임계값을 적용하고, 무관련 간섭을 줄이기 위해 빈 회수(즉, 유효한 결과 없음)를 직접 반환합니다.
반환된 두 구절은 여전히 다음과 같습니다:
- 구절 B, 유사도 0.18: "사과는 비타민 C와 식이섬유가 풍부한 과일로, 소화 및 면역 체계 건강에 도움이 됩니다."
- 구절 C, 유사도 0.10: "애플 Inc.는 2007년에 최초의 iPhone을 출시하여 스마트폰 산업을 근본적으로 변화시켰습니다."
전체 입력은 다음과 같을 것입니다:
[System Prompt]
당신은 전문적인 질문-답변 어시스턴트입니다. 사용자가 제공한 "참조 정보"를 엄격하게 따라 답변해 주세요.
참조 정보에 답변이 포함되어 있으면 그것을 바탕으로 직접 답변하세요.
참조 정보에 답변이 포함되어 있지 않으면 "현재 제공된 자료로는 질문에 답변할 수 없습니다"라고 명시하고, 정보를 조작하지 마세요.
답변이 어떤 정보를 바탕으로 했는지 표시해 주세요.
[Retrieved Context]
사과는 비타민 C와 식이섬유가 풍부한 과일로, 소화 및 면역 체계 건강에 도움이 됩니다.
애플 Inc.는 2007년에 최초의 iPhone을 출시하여 스마트폰 산업을 근본적으로 변화시켰습니다.
[User Query]
오늘 날씨가 어떤가요?LLM은 먼저 참조 정보에 직접적인 날씨 또는 실시간 기상 정보가 포함되어 있는지 판단할 것입니다. 포함되어 있지 않음을 확인한 후 지침에 따라 답변할 수 없다고 응답할 것입니다:
현재 제공된 자료로는 "오늘 날씨가 어떤가요?"라는 질문에 답변할 수 없습니다. 참조 정보에는 사과, 과일 영양 및 애플 Inc. 제품과 관련된 내용만 포함되어 있으며, 날씨 정보나 실시간 기상 데이터는 포함되어 있지 않기 때문입니다. [근거: 검색된 컨텍스트에 날씨 관련 정보가 존재하지 않음]
이 세 가지 예시에서 RAG 대화 단계의 핵심을 볼 수 있습니다. 시스템 프롬프트는 LLM의 역할과 응답 규칙을 정의하고, 검색된 증거는 구체적이고 신뢰할 수 있는 자료를 제공하며, 사용자의 질문은 작업 목표를 정의합니다. 이 구조화된 입력 패턴이야말로 RAG가 환각을 일으킬 수 있는 LLM을 효과적으로 안내하고 제약하여, 안정적이고 신뢰할 수 있는 답변을 생성하는 시스템으로 전환할 수 있게 하는 것입니다. 모델이 지원되지 않는 정보를 발명하는 대신 기존 정보를 이해하고 정리하는 데 사용되도록 보장합니다.
4. RAG의 진화
RAG는 대규모 모델 시대에 기원한 것은 아닙니다. 초기 연구에도 이미 동일한 아이디어의 프로토타입이 포함되어 있었습니다. 역사적 관점에서 RAG는 전통적인 LLM의 한계에 대한 인식에서 비롯되었습니다. 초기 대규모 언어 모델은 주로 사전 학습 데이터에 의존했으며, 학습이 완료되면 그 데이터는 고정되었습니다. 예를 들어 GPT-3와 같은 모델은 학습 데이터가 수집된 시점과 연결된 지식 중단일이 있었으며 이후의 지식을 얻을 수 없었습니다. 특정 도메인에 대해 LLM을 재학습하거나 미세조정하는 것도 많은 자원과 전문 지식이 필요하여 비용이 많이 들고 빠른 반복이 어려웠습니다.
RAG의 뿌리는 2017년 DrQA 프레임워크까지 추적할 수 있으며, 이는 처음으로 검색과 언어 모델의 결합을 시도했습니다. 그 후 2020년 Dense Passage Retrieval(DPR)에서 중요한 돌파구가 마련되었으며, 이는 TF-IDF 및 BM25와 같은 전통적인 단어 빈도 기반 방법 대신 사전 학습된 신경망 모델을 의미론적 검색에 사용했습니다. 2021년에는 RAG가 공식적으로 제안되고 체계화되어 LLM의 지식 중단 및 환각 문제를 해결하는 표준 방법이 되었습니다.
넓게 보면 RAG의 진화는 세 단계로 나눌 수 있습니다:
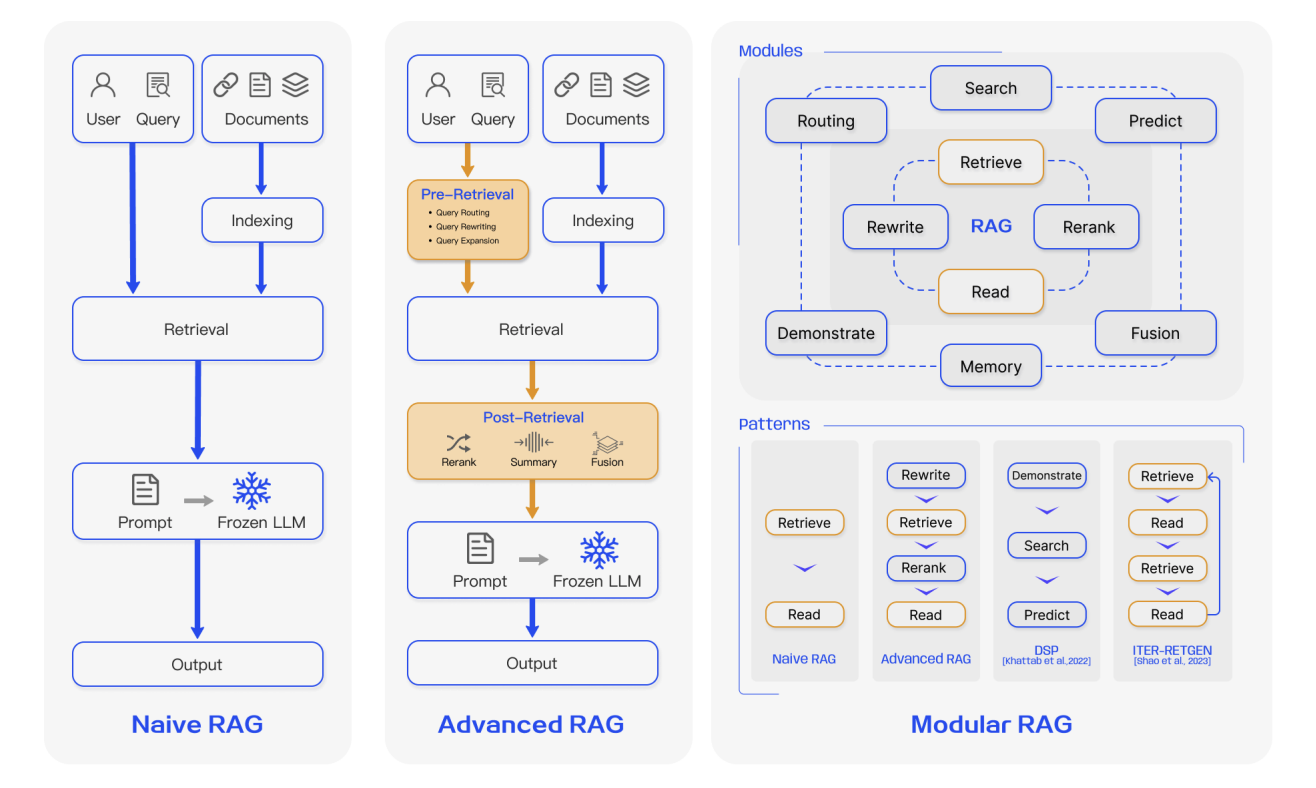
4.1 1세대 RAG: Naive RAG
Naive RAG는 RAG의 가장 기본적인 형태입니다. 엔지니어링 관점에서 매우 직접적인 3단계 흐름을 따릅니다:
- 문서 전처리 및 인덱싱. 원시 문서가 정리되고, 고정 길이 텍스트 청크로 분할되며, 임베딩 모델로 벡터로 인코딩되어 벡터 데이터베이스에 기록됩니다.
- 유사도 기반 검색. 사용자의 자연어 질문이 벡터로 인코딩되고, 시스템은 벡터 저장소에 대해 Top-K 유사도 검색을 수행합니다.
- 단순 검색 증강 생성. 검색된 청크가 원래 질문과 직접 연결되어 긴 프롬프트를 형성하며, 이를 LLM에 전송하여 답변을 생성합니다.
이 단계의 가치는 매우 낮은 장벽으로 "검색 후 답변"이 실제로 작동한다는 것을 검증한 데 있습니다. 모델의 내부 메모리에만 의존하는 것과 비교하여 지식 중단 문제와 일부 환각을 이미 상당히 줄였으며, 이것이 초기 프로토타입, 데모 및 입문 튜토리얼에서 중요한 역할을 한 이유입니다.
그러나 1세대 RAG의 한계도 명확합니다. 첫째, 청킹 전략이 보통 조잡합니다. 대부분의 시스템은 단순히 고정 길이로 분할하므로, 의미론적으로 일관된 단락이 중간에 잘리거나 하나의 청크에 여러 주제가 섞일 수 있습니다. 이는 검색 정확도를 떨어뜨리고 LLM의 이해를 더 어렵게 만듭니다. 둘째, 검색 신호가 너무 단순합니다. 순위 결정은 보통 벡터 유사도에만 의존하며, 키워드, 타임스탬프, 출처 신뢰도 또는 접근 권한과 같은 더 풍부한 구조적 단서를 사용하지 않습니다. 셋째, 검색 결과가 거의 관리되지 않습니다: 노이즈가 많거나 반복적이거나 심지어 모순된 청크가 변경 없이 컨텍스트에 들어가, 이미 제한된 컨텍스트 창에 대량의 저가치 정보가 차지하게 됩니다.
요컨대 1세대는 검색이 필요한지 여부라는 질문을 해결했습니다. 하지만 어떻게 더 잘 검색할 것인가, 그리고 검색된 정보를 어떻게 더 합리적으로 사용할 것인가라는 질문에서는 여전히 매우 원시적인 수준에 머물렀습니다.
4.2 2세대 RAG: Advanced RAG
RAG가 데모에서 실제 비즈니스 시나리오로 넘어가면서 안정성, 통제 가능성 및 출력 품질에 대한 요구가 급격히 높아졌습니다. 2세대는 보통 Advanced RAG라는 광범위한 이름으로 묶이며, 여전히 먼저 검색하고 나중에 생성하는 패턴을 따르지만, 검색 전후에 체계적인 개선을 도입합니다. 즉, 시스템은 단순히 무언가를 검색하는 데 만족하지 않습니다. 이제 올바른 것을 제대로 저장하고, 명확하게 올바른 질문을 하며, 검색된 컨텍스트를 신중하게 관리하는 것을 목표로 합니다.
검색 전에는 저장과 질문에 집중합니다:
인덱싱 측면에서 청킹은 고정 길이 분할에서 의미론적 인식 청킹 및 계층적 인덱싱으로 발전합니다. 시스템은 장, 절, 단락 또는 문장 경계를 따라 슬라이딩 윈도우 및 다중 세분성 인덱스 구조와 결합하여 청킹할 수 있습니다.
각 문서 청크는 출처, 타임스탬프, 작성자, 주제 및 문서 유형과 같은 풍부한 메타데이터를 포함할 수 있어, 나중에 필터링 및 순위 결정에 더 많은 차원을 제공합니다.
질의 측면에서 사용자의 원래 질문은 Query Rewrite, Multi-Query, Sub-Query 분해, Step-back Prompting과 같은 기술을 통해 재작성, 확장 또는 분해될 수 있으며, 모호하거나 대화형인 사용자 질의를 검색이 더 잘 이해할 수 있는 형태로 변환합니다.
- Query Rewrite
핵심 아이디어는 사용자의 모호하고 구어적이거나 비표준적인 질의를 검색 시스템이 더 쉽게 이해할 수 있는 정규화된 표현으로 변환하여, 핵심 정보를 보충하고 모호성을 해결하는 것입니다.
- 예를 들어, "내일 베이징 날씨 어떻게 확인하나요?"는 "베이징 내일 종일 실시간 날씨 조회"와 같이 더 표준화된 형태로 재작성될 수 있습니다.
- 또는 "좋은 영화 추천해 줘"는 사용자 기록을 참고하여 "2024년 고평점 서스펜스 영화 추천"으로 재작성될 수 있습니다.
- Multi-Query
시스템은 원래 질문에서 의미론적으로 관련되지만 다른 각도의 여러 질의를 생성하여 누락된 결과를 줄이고 사용자가 명시적으로 표현하지 않은 잠재적 요구를 포괄합니다.
- Sub-Query
여러 목표를 포함하는 복합 질문에 대해 시스템은 이를 더 작고 간단한 하위 질의로 분할하여 각 요구를 정밀하게 매칭할 수 있게 합니다.
- Step-back Prompting
시스템은 먼저 더 추상적이고 상위 수준의 질문을 생성한 다음, 그것을 사용하여 검색 방향을 안내함으로써 원래 질문의 세부 사항에 지나치게 집중하여 발생하는 편향을 줄입니다.
검색 후에는 검색된 것을 관리하는 데 집중합니다:
- 전용 리랭크 모델 또는 심지어 LLM이 후보 문서를 재순위 지정하여 가장 중요하고 질문과 관련성 높은 콘텐츠가 컨텍스트에 먼저 들어가도록 할 수 있습니다.
리랭크 모델은 정보 검색 파이프라인의 핵심 구성 요소입니다. 회수 단계에서 반환된 후보 결과에 대해 2단계 순위 지정을 수행하며, 종종 Transformer 아키텍처를 기반으로 한 더 강력한 의미론적 이해를 사용하여 첫 번째 단계의 의미론적 순위 오류를 수정하고 사용자 요구와 가장 일치하는 결과를 더 앞쪽으로 이동시킵니다.
- 검색된 구절은 필터링, 중복 제거 및 압축을 거쳐 명백히 관련 없거나 고도로 반복적인 청크를 제거하여, 긴 컨텍스트 시스템이 중간의 유용한 정보를 무시하는 경향을 줄일 수 있습니다.
- 필요한 경우 경량 모델 미세조정을 통해 LLM이 검색 증거를 바탕으로 답변하고 명시적인 인용이나 출처를 포함할 가능성을 높일 수 있습니다.
전반적으로 Advanced RAG는 검색이 필요한지 또는 무언가를 검색할 수 있는지에만 집중하지 않습니다. 대신 세 가지 더 큰 과제를 다룹니다: 진정으로 중요한 구절을 정확하게 찾을 수 있는지, 대규모 모델에 전달된 컨텍스트가 간결하고 잘 구조화되어 효율적으로 사용하기 쉬운지, 그리고 노이즈, 충돌 또는 다중 출처 정보 요구가 있는 상황에서도 전체 시스템이 안정적이고 신뢰할 수 있는지.
대량의 실험 및 엔지니어링 증거는 Advanced RAG가 답변 정확도, 환각 억제, 시스템 견고성 및 설명 가능성에서 Naive RAG를 상당히 능가한다는 것을 보여줍니다. 이것이 산업계에서 전통적인 기본 접근 방식을 점차 대체하고 오늘날 RAG 시스템 구축을 위한 주류 산업 패러다임이 된 이유입니다.
4.3 3세대 RAG: Modular RAG
복잡한 기업 애플리케이션에서 요구 사항은 종종 여러 도메인에 걸쳐 있습니다. 이러한 경우 검색, 리랭크, 생성의 단순한 선형 흐름만으로는 충분하지 않은 경우가 많습니다:
- 동일한 시스템이 단순한 FAQ, 긴 보고서 생성, 코드 검색 및 데이터베이스 호출을 모두 지원해야 할 수 있습니다.
- 벡터 저장소, 전문 검색, 관계형 데이터베이스, 지식 그래프 및 외부 검색 엔진을 동시에 연결해야 할 수 있습니다.
- 여러 라운드에 걸쳐 사용자 선호와 과거 결정을 유지하면서 규정 준수 검사와 답변 추적 가능성도 적용해야 할 수 있습니다.
이러한 배경에서 RAG는 모듈형 시스템 형태로 진화하기 시작했습니다. Modular RAG는 더 이상 고정된 파이프라인으로 간주되지 않습니다. 대신 필요에 따라 오케스트레이션할 수 있는 플러그형, 교체 가능 및 구성 가능한 기능 모듈의 집합으로 취급됩니다. 전형적인 모듈은 다음과 같습니다:
- 질의 이해 및 라우팅 이 모듈은 의도 인식, 질문 재작성, 하위 작업 분해 및 경로 선택을 처리합니다. 요청이 주로 내부 지식, 외부 검색 또는 특정 도구나 데이터베이스에 의존해야 하는지 결정합니다.
- 다중 출처 검색 및 융합 이 모듈은 벡터 데이터베이스, 전문 검색, 구조화된 데이터베이스 및 지식 그래프를 동시에 연결하고, 쿼리한 후 결과를 병합하고 재순위 지정하여 통합된 증거 세트를 만듭니다.
- 메모리 및 개인화 이 모듈은 장기 사용자 프로필, 단기 세션 메모리 및 도메인 지식 캐시를 유지하여 시스템이 과거 정보를 지속적으로 축적하고 사용할 수 있게 합니다.
- 작업 적응 및 거버넌스 이 모듈은 다양한 작업에 대해 다른 어댑터를 로드하고, 출력 형식, 어조 및 스타일을 제약하며, 팩트 체크, 위험 필터링 및 인용 정렬을 통해 출력을 관리합니다.
요컨대 전통적인 RAG는 종종 1회 검색과 1회 생성으로 끝납니다. Modular RAG는 이 단일 흐름 패턴을 깹니다. 생성 과정에서 정보가 여전히 충분하지 않다고 시스템이 발견하면 새로운 검색 라운드를 사전에 트리거할 수 있으며, 심지어 검색과 생성 사이를 여러 번 앞뒤로 이동하여 더 복잡한 작업을 완료할 수 있습니다.
나아가 모델은 스스로 결정을 내리는 법을 배울 수 있습니다: 확신이 높을 때는 내부 지식이나 짧은 컨텍스트에서 직접 답변하고, 불확실성이 높을 때만 검색이나 외부 도구 호출을 시작합니다. 이는 품질을 유지하면서 효율성을 높이고 자원을 절약합니다. 심하게 불충분하거나 불완전한 질의에 대해 모델은 먼저 가상의 중간 답변이나 초안 문서를 생성한 다음 그것을 추가 검색의 단서로 사용하여 점진적으로 신뢰할 수 있는 출처에 접근할 수 있습니다.
이 단계에서 RAG는 더 이상 대규모 모델에 몇 가지 참조 구절을 첨부하는 단순한 구성 요소가 아닙니다. 기업 지능형 애플리케이션 내부의 중앙 지식 오케스트레이션 계층이 되어 여러 데이터 소스, 여러 도구 및 여러 작업을 조정하고 있습니다.
5. 데모에서 기업급 RAG까지
기업 엔지니어링의 관점에서 RAG 시스템 구축은 검색 증강 생성에만 국한될 수 없습니다. 위의 내용은 여전히 데모 수준의 소개에 더 가깝습니다. 실제 비즈니스 시나리오에서는 데이터가 종종 노이즈가 많고 형식이 일관성이 없으므로, 전처리, 정제 및 수집에 더 많은 노력을 투자해야 하며, 모든 핵심 지점에서 모델 선택을 신중하게 처리해야 합니다.
완전한 기업급 RAG 시스템은 일반적으로 세 가지 핵심 모듈로 나눌 수 있습니다: 레이아웃 분석 및 지식 수집, 지식 베이스 구축, RAG 기반 질문-답변 서비스. 전체 기술 체인에서 임베딩 모델, 리랭크 모델, LLM을 포함한 여러 핵심 모델 선택 결정이 나타납니다. 각 단계에서 합리적인 기술적 선택이 있어야만 시스템이 전체적으로 강력한 결과를 달성할 수 있습니다.
레이아웃 분석 및 로컬 지식 파일 읽기
이 모듈은 다양한 형식의 로컬 지식 자산을 검색에 사용할 수 있는 텍스트로 변환합니다. 입력에는 PDF, TXT, HTML, Word, Excel, PPT 파일뿐만 아니라 PNG 및 JPG와 같은 스캔된 이미지 파일, 심지어 오디오 녹음이 포함될 수 있습니다.
시스템은 각 형식을 적절하게 구문 분석하고, 텍스트 문서에 대해 레이아웃 분석과 구조 추출을 수행하며, 제목, 본문, 표, 머리글 및 바닥글을 구분하고 합리적인 읽기 순서를 복원합니다. 이미지 파일에는 OCR을, 음성에는 ASR을 수행하며, 마지막으로 모든 것을 비교적 깨끗한 지식 텍스트로 변환하면서 파일 이름, 장, 페이지 번호 및 타임스탬프와 같은 기본 메타데이터를 보존하여 나중에 청킹 및 인덱싱에 사용할 수 있게 합니다.
지식 베이스 구축: 청킹, 임베딩 및 인덱싱
정제된 지식 텍스트를 얻은 후 시스템은 청킹을 수행하여 긴 문서를 적절한 길이의 의미론적으로 일관된 블록으로 분할합니다. 보통 단락, 제목 구조 또는 슬라이딩 윈도우를 사용하면서 각 청크의 출처와 메타데이터를 보존합니다.
그런 다음 선택한 임베딩 모델(예:
text-embedding-3-small, Sentence Transformers 또는 BGE)을 사용하여 각 청크에 대한 벡터 표현을 계산하고 Faiss, Milvus 또는 관리형 벡터 검색 서비스와 같은 도구를 사용하여 벡터 인덱스를 구축합니다. 이 시점에서 빠른 의미론적 검색을 지원하는 지식 베이스가 생성된 것입니다.RAG 기반 질문 답변: 회수, 리랭킹, 연결, 생성
온라인 QA 단계에서 사용자가 질의를 보냅니다. 시스템은 이를 질의 벡터로 임베딩하고, 벡터 인덱스에서 가장 유사한 텍스트 청크 배치를 검색하며, 이를 조정 순위 단계로 취급합니다. 그런 다음 BGE 리랭커와 같은 리랭크 모델 또는 리랭커 역할을 하는 LLM을 사용하여 질의-문서 쌍을 다시 평가하고 진정으로 가장 관련성 높은 Top-K 문서만을 지식 컨텍스트로 유지할 수 있습니다.
다음으로, "다음 자료를 엄격하게 바탕으로 답변해 주세요"와 같이 신중하게 설계된 시스템 프롬프트와 함께 사용자 질의와 검색된 문서 구절을 연결하여 병합된 프롬프트를 LLM에 전송합니다. 모델은 검색된 증거 조각들을 바탕으로 최종 답변을 생성하고, 필요할 때 인용이나 출처를 포함합니다.
5.1 모델 선택
다음으로 모델 선택에 집중해 보겠습니다. 완전한 RAG 시스템은 일반적으로 세 가지 핵심 모델 카테고리를 포함합니다: 임베딩 모델, 리랭크 모델 및 대규모 언어 모델. 각각의 역할이 있으며, 함께 검색부터 답변 생성까지의 전체 경로를 형성합니다. 임베딩 모델은 텍스트를 검색 가능한 의미론적 벡터로 변환하고, 리랭크 모델은 초기 검색 결과를 정제하며, LLM은 선택된 지식 컨텍스트를 바탕으로 최종 답변을 생성합니다.
5.1.1 임베딩 모델
RAG 시스템에서 임베딩 모델의 역할은 텍스트(예: 사용자 질의 및 지식 베이스 콘텐츠)를 고차원 벡터로 변환하는 것입니다. 의미론적으로 유사한 텍스트는 벡터 공간에서 더 가까이 배치되어 시스템이 유사도를 통해 관련 지식을 빠르게 찾을 수 있습니다. 따라서 올바른 임베딩 모델을 선택하는 것은 회수 품질을 직접적으로 결정하므로 고성능 RAG 시스템 구축에서 가장 중요한 단계 중 하나입니다.
강력한 모델을 선택하려면 체계적인 벤치마크를 사용하는 것이 도움이 됩니다. 가장 널리 사용되는 것 중 하나는 MTEB, 즉 Massive Text Embedding Benchmark입니다.
MTEB는 많은 임베딩 모델에 대한 통합되고 객관적인 평가 프레임워크를 제공합니다. 8개의 주요 작업 카테고리와 56개의 데이터셋을 통해 검색, 클러스터링, 분류, 리랭킹, 텍스트 매칭, 의미론적 유사도 등에서 성능을 평가합니다. 모델의 전체 MTEB 점수는 벡터 표현의 범용성과 견고성을 반영하며 모델 선택의 중요한 참고 자료가 될 수 있습니다. 최신 순위는 Hugging Face MTEB 리더보드에서 확인할 수 있습니다:
리더보드에 많은 모델이 있지만, 모든 것을 마스터할 필요는 없습니다. 실제로는 주요 모델 제공업체에서 번들로 제공하는 임베딩 모델을 선택하거나 많은 사람들이 이미 검증한 클라우드 서비스 모델을 사용하는 것이 일반적으로 안전한 선택입니다. 사이드바에서 카테고리나 언어별로 리더보드를 필터링할 수도 있습니다:
임베딩 모델을 필터링할 때 두 가지 매개변수가 특히 중요합니다. 이는 RAG 성능에 직접적인 영향을 미치기 때문입니다: 차원과 컨텍스트 길이.
차원은 벡터 출력의 차원수(예: 128, 768, 1536)입니다. 이는 벡터가 표현할 수 있는 의미론적 특징의 수를 대략적으로 반영합니다. 고차원 벡터는 더 풍부한 의미론적 세부 정보와 더 강한 변별력을 포착할 수 있습니다. 예를 들어 768차원 벡터는 "사과"를 품종, 맛, 원산지 등 수백 가지 각도에서 표현할 수 있어 의료나 법률과 같이 정밀한 검색이 필요한 전문 시나리오에 적합합니다. 저차원은 연산 및 저장 비용을 줄이고 검색 속도를 향상시켜 고동시성과 강력한 실시간 요구가 있는 대규모 범용 시나리오에 적합합니다.
컨텍스트 길이는 임베딩 모델이 한 번에 처리할 수 있는 최대 텍스트 길이로, 토큰 단위로 측정됩니다. 영어 토큰 1개는 대략 단어의 3/4에 해당하고, 한국어 토큰 1개는 대략 글자 1개에 해당합니다. 최대 길이를 초과하는 텍스트는 잘립니다. 이는 모델이 텍스트를 완전히 이해할 수 있는지를 직접적으로 결정합니다. 길이가 너무 짧아 중요한 정보가 손실되면 검색 정확도가 급격히 떨어집니다. 짧은 사용자 질의와 짧은 QA 쌍의 경우 512~1024 토큰이면 충분한 경우가 많습니다. 논문과 보고서와 같은 긴 텍스트의 경우 일반적으로 2048 토큰 이상이 필요합니다.
아래는 몇 가지 일반적인 임베딩 모델의 비교입니다. 실제로는 비용과 성능의 균형을 고려하여 선택해야 합니다. 모든 상황에 최고인 모델은 없으며, 자체 사용 사례에서 여러 옵션을 비교한 후 가장 적합한 모델만 있습니다.
| 모델명 | 모델 규모 | 핵심 강점 | 적합한 시나리오 |
|---|---|---|---|
OpenAI text-embedding-3-large | 클로즈드 API | MTEB 장기 리더, 성숙하고 안정적 | 극한의 성능을 우선시하고 충분한 예산이 있는 클라우드 API 시나리오 |
jina-embeddings-v2 | 최대 8K 컨텍스트의 긴 텍스트 지원 | 비동기 인코딩 설계로 긴 문서 검색에 강함 | 문서 분석, 법률 규정 준수, 학술 검색 |
multilingual-e5-large | 대규모 | 다국어 클래식 옵션 | 다국어 RAG, 글로벌 제품, 다국어 지원 시스템 |
Qwen/Qwen2-Embedding-8B | 8B 매개변수, 최대 4096 맞춤형 차원 | 이전 다국어 MTEB 최고 성능, 긴 텍스트 및 다국어 작업, 코드에 강함 | 고정밀 중국어-영어 RAG, 긴 문서 분석, 코드 검색 |
Qwen/Qwen2-Embedding-4B | 4B 매개변수 | 성능과 효율성의 강력한 균형 | 대규모 프로덕션 RAG 시스템 |
Qwen/Qwen2-Embedding-0.6B | 0.6B 매개변수 | 엣지 디바이스에 적합 | 자원이 제한되고 속도를 우선하는 시나리오 |
BAAI/bge-m3 | 하이브리드 검색 지원, dense + sparse + multi-vector | MIRACL과 같은 다국어 벤치마크에서 강함 | 하이브리드 검색이 필요한 복잡한 다국어 시나리오 |
BAAI/bge-large-zh-v1.5 | 대규모 | 강력한 커뮤니티 검증으로 안정적인 중국어 RAG 베이스라인 | 짧은 문서를 가진 순수 중국어 프로젝트 |
ZhipuAI Embedding-3 | 클로즈드 클라우드 API | 256에서 2048까지 맞춤형 차원 지원 | 클라우드 API를 선호하는 중국어 중심 애플리케이션 |
5.1.2 리랭크 모델
RAG 시스템에서 리랭크 모델은 초기 검색 결과를 정밀하게 재순위 지정하는 역할을 합니다. 사용자 질의와 후보 문서를 입력으로 받아 각 질의-문서 쌍에 대한 정확한 관련성 점수를 계산합니다. 점수가 높을수록 매치가 더 좋습니다. 따라서 임베딩 기반 회수 위에 리랭크 모델을 추가하는 것은 검색 정밀도를 향상시키는 핵심 단계입니다.
임베딩 모델의 경우 MTEB와 같은 벤치마크를 사용할 수 있습니다. 리랭크 모델의 경우 Agentset의 리랭커 리더보드가 유용한 참고 자료입니다:
Agentset 벤치마크는 먼저 FAISS를 사용하여 대규모 문서 저장소에서 50개의 가장 관련성 높은 후보 결과를 검색한 다음, 평가 중인 리랭크 모델에게 그 50개의 문서를 재순위 지정하도록 요청합니다. 이 벤치마크는 순위 품질과 지연 시간 모두에 주의를 기울입니다. 실제 애플리케이션에서 정밀도만 추구하고 속도를 무시하면 사용자 경험이 저하되고, 반대로 속도만 추구하고 순위 품질을 희생하면 유용성이 떨어집니다.
Agentset은 또한 ELO 평점 메커니즘을 도입합니다. 각 질의에 대해 GPT-5가 심판 역할을 하여 두 가지 다른 리랭크 모델의 순위 지정된 출력을 비교하고, 어느 것이 진정으로 관련성 있는 문서를 더 합리적인 순서로 배치하는지 결정합니다. 이러한 쌍별 비교를 대량으로 수행한 후 더 자주 승리하는 모델이 더 높은 ELO 점수를 받아 직관적인 전체 성능 지표를 제공합니다.
이 벤치마크는 또한 두 가지 보완적인 지표 그룹을 사용합니다:
nDCG@5/10: 관련 문서가 앞쪽에 배치되었는지 여부에 초점을 맞추어 순위 정밀도를 반영합니다.Recall@5/10: 모든 관련 문서를 찾을 수 있는지 여부에 초점을 맞추어 커버리지를 반영합니다.
이러한 지표들은 함께 리랭크 성능에 대한 더 완전한 그림을 제공합니다.
그럼에도 불구하고 실제로는 리랭크 모델을 리더보드에서만 선택할 필요는 없습니다. 산업적 유용성과 리더보드 점수가 항상 같은 것은 아닙니다. 실용적인 접근법은 클라우드 제공업체가 추천하는 리랭크 모델이나 주요 모델 제공업체의 기본 리랭크 API에서 시작하거나, 이미 사용 중인 모델 패밀리(예: 매칭되는 Qwen 리랭크 모델)를 테스트하는 것입니다.
5.1.3 LLM
임베딩 모델에 의한 의미론적 검색과 리랭크 모델에 의한 정밀한 필터링 후, 관련 문서 구절들이 사용자의 원래 질문과 결합되어 프롬프트를 형성합니다. 그런 다음 LLM은 독해력, 정보 통합 및 자연어 생성을 수행하여 컨텍스트에 맞는 일관되고 정확한 답변을 출력합니다.
구현 수준에서 RAG에서 LLM을 사용하는 두 가지 주요 방법이 있습니다:
- 사내 배포 대규모 모델. 데이터 프라이버시, 통제 가능한 비용 또는 심층적인 맞춤화를 중요시하는 시나리오에 적합합니다. Qwen, Llama, GLM과 같은 주류 오픈 모델은 RAG 작업에서 좋은 성능을 발휘합니다. 예를 들어 7B 또는 14B 범위의 Qwen2.5는 자원 사용을 적게 유지하면서도 좋은 지시 준수 능력과 중국어 이해력을 제공하여 로컬 기업 배포에 적합합니다. KIMI, Minimax, DeepSeek와 같은 모델도 특정 비즈니스 요구에 따라 고려할 수 있습니다.
- 클라우드 API 대규모 모델. 빠른 출시, 탄력적 확장 및 지속적인 모델 업그레이드를 우선시하는 시나리오에 적합합니다. OpenAI, Anthropic, Google, Alibaba, ZhipuAI와 같은 주요 제공업체 모두 안정적인 API 서비스를 제공합니다. 이러한 모델은 일반적으로 강력한 언어 이해 및 생성 능력을 가지며 RAG 시나리오에서 답변을 잘 종합할 수 있습니다.
클라우드 모델을 선택할 때는 다음 사항이 중요합니다: 답변 품질이 정확하고 유창한지, 가격이 합리적인지, 지연 시간이 허용 가능한지, 컨텍스트 창이 여러 검색된 문서를 담을 만큼 충분히 큰지. 실제로는 자체 데이터에서 여러 후보를 비교하여 어느 것이 가장 완전하고 정확한 답변을 제공하는지 확인해야 합니다. 비용이 우려되는 경우 유용한 접근법은 대형 및 소형 모델을 결합하는 것입니다: 간단한 질문에는 더 저렴한 소형 모델을 사용하고 어려운 경우에는 비싼 대형 모델을 예약합니다. 모델이 빠르게 업데이트되므로 정기적으로 후보를 재테스트하는 것도 현명합니다.
광범위한 대화 및 QA 능력에 대해 LMSYS Chatbot Arena, 현재 LMArena는 가장 널리 인정받는 평가 참고 자료 중 하나입니다:
이는 블라인드 쌍별 인간 비교를 사용하여 모델의 순위를 매깁니다. 이 순위는 유용한 첫 번째 필터를 제공하지만, 실제 RAG 선택에서는 출발점으로만 사용해야 합니다. 의학, 법률, 금융과 같은 전문 도메인에서는 일반 리더보드 순위가 실제 비즈니스 데이터에서의 성능과 상당히 다를 수 있습니다.
LLM 선택의 모범 사례는 20~30개의 전형적인 비즈니스 질문을 포함하는 작지만 대표적인 테스트 세트를 구축하고, 격리된 모델 벤치마크만 보는 대신 전체 엔드투엔드 RAG 파이프라인을 통해 후보 모델을 평가하는 것입니다. 추론 모델을 사용할지 비추론 모델을 사용할지, 또는 어느 모델 크기가 품질과 속도의 균형을 가장 잘 맞추는지와 같은 질문은 모두 자체 사용 사례에서 실제 테스트를 통해 가장 잘 답변됩니다.
5.2 실행 프레임워크
실제 엔지니어링 실무에서는 전체 RAG 시스템을 처음부터 구축할 필요가 없는 경우가 많습니다. 여러 성숙한 오픈소스 프레임워크가 이미 존재하며, 각각 아키텍처, 모듈 통합 및 개발 효율성에서 고유한 강점을 가지고 있습니다. 기업은 자체 기술 보유량과 비즈니스 시나리오에 따라 선택할 수 있습니다.
일반적인 프레임워크 유형은 다음과 같습니다:
로우코드 또는 시각적 플랫폼
- Dify: RAG 애플리케이션을 빠르게 구축하기 위한 직관적인 시각적 인터페이스를 제공하여 비기술 팀이나 빠른 프로토타입 검증에 적합합니다. 내장된 다중 모델 액세스, 워크플로우 오케스트레이션 및 프롬프트 관리가 포함되어 있습니다.
- Coze: 바이트댄스의 AI 봇 개발 플랫폼으로, 제로코드 시각적 구축을 제공합니다. 바이트댄스 모델 서비스와 깊게 통합되어 플러그인 마켓플레이스, 예약 작업 및 다중 채널 게시를 지원하여 소비자용 어시스턴트나 사내 엔터프라이즈 봇에 적합합니다.
- n8n: 오픈소스 노드 기반 워크플로우 자동화 플랫폼입니다. RAG 시나리오에서 복잡한 비즈니스 로직을 오케스트레이션하고 전처리, 벡터 데이터베이스 작업, 모델 호출 및 이메일 발송이나 티켓 업데이트와 같은 후속 작업을 하나의 자동화된 흐름으로 연결할 수 있습니다.
- RAGFlow: 심층적인 레이아웃 분석 및 지식 추출에 중점을 두고 다중 열 PDF 및 표가 많은 자료와 같은 복잡한 문서에서 좋은 성능을 발휘합니다.
- FastGPT: 지식 베이스 관리, 대화 오케스트레이션 및 애플리케이션 게시를 통합한 중국 오픈소스 솔루션으로, 강력한 중국어 문서화를 갖추고 있어 중국어 RAG 애플리케이션의 빠른 배포에 적합합니다.
코드 프레임워크 및 개발 라이브러리
아래의 도구들은 일반적으로 다양한 백엔드 언어로 구현되어 있습니다. 애플리케이션 스택에 맞는 해당 언어 버전을 선택할 수 있습니다.
- LlamaIndex: RAG를 위해 특별히 설계된 Python 프레임워크로, 풍부한 커넥터, 인덱스 구조 및 질의 엔진을 갖추고 있습니다. 모듈성으로 인해 깊이 맞춤화된 검색 전략이나 많은 데이터 소스와의 통합에 적합합니다.
- LangChain: RAG가 한 가지 사용 사례인 범용 LLM 애플리케이션 프레임워크입니다. 강점은 풍부한 생태계와 컴포넌트 커버리지이며, 복잡한 에이전트 및 워크플로우 오케스트레이션 지원을 포함하지만 학습 곡선이 더 가파릅니다.
팀의 기술 보유량이 제한적이고 속도가 가장 중요하다면 Dify, Coze 또는 FastGPT와 같은 로우코드 플랫폼을 첫 번째 선택으로 하는 것이 좋습니다. 깊은 맞춤화, 특수한 데이터 소스 통합 또는 상세한 성능 튜닝이 필요한 경우 LlamaIndex와 LangChain이 더 많은 유연성을 제공합니다. 실제로는 하이브리드 경로도 일반적입니다: 로우코드 플랫폼을 사용하여 빠른 실현 가능성 검증을 수행한 다음 프로덕션 배포 및 최적화를 위해 코드 프레임워크로 전환합니다. 이러한 프레임워크의 대부분은 주류 임베딩, 리랭크 및 LLM 모델과의 빠른 통합도 지원하여 위에서 논의한 모델 선택 원칙을 사용하여 유연하게 결합할 수 있습니다.
5.3 효과 평가
RAG 시스템을 배포하는 기업에게 가장 큰 과제는 종종 시스템 구축이 아니라 튜닝입니다. 프로덕션급 RAG는 검색과 생성이라는 두 가지 비결정론적 단계를 포함하므로 전통적인 소프트웨어 테스트만으로는 충분하지 않습니다. 이것이 과학적인 평가 시스템, 즉 RAG 평가를 구축하는 것이 그토록 중요한 이유입니다.
5.3.1 초급 예시: LLM 기반 RAG 평가
RAG 평가에 대한 직관적인 이해를 구축하는 데 도움이 되도록 LLM-as-a-judge 아이디어를 기반으로 한 간단한 자동화 파이프라인을 살펴보겠습니다:
https://huggingface.co/learn/cookbook/rag_evaluation
이 과정은 일반적으로 세 가지 핵심 단계를 포함합니다:
- 첫째, 지식 베이스에서 문서를 샘플링하고 LLM에게 고품질 질문-답변 쌍을 생성하도록 요청한 다음 관련성과 근거 기반 여부로 필터링하여 벤치마크 세트를 형성합니다.
- 둘째, 해당 테스트 세트의 각 질문에 대해 RAG 시스템을 실행하고 생성된 답변을 수집합니다.
- 셋째, 다른 LLM을 심판으로 호출하여 생성된 답변과 참조 답변을 비교하고 정확성 및 완전성과 같은 차원에 대해 정량적 점수를 부여합니다.
간단한 예시:
- 문제 생성. 지식 베이스에 "이 장치는 무선 충전을 지원하며 5000mAh 배터리를 장착하고 있습니다"라는 제품 매뉴얼 항목이 있다고 가정합니다. 한 모델에게 출제자 역할을 하도록 요청하여 "이 장치의 배터리 용량은 얼마입니까?"와 같은 질문을 생성합니다. 정답은 "5000mAh"입니다.
- 문제 해결. 이 질문을 RAG 시스템에 보내면 관련 자료를 검색하고 답변합니다(예: "이 장치는 5000mAh 배터리를 장착하고 있습니다").
- 채점. 다른 모델에게 채점자 역할을 하도록 요청하여 질문, 생성된 답변 및 참조 답변을 비교합니다(예: "생성된 답변이 올바른지 판단하세요. 올바름 또는 올바르지 않음만 출력하세요").
이 과정을 대규모로 실행하면 정확도와 같은 지표를 계산할 수 있습니다. 이는 평가, 최적화, 재평가의 실용적인 루프를 형성합니다.
RAG 평가에 대한 더 깊은 세부 정보(지표 정의, 프레임워크 사용법 및 벤치마크 데이터셋)를 원한다면 다음 두 가지 유용한 서베이 논문이 있습니다:
- https://arxiv.org/pdf/2504.14891, Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey
- https://arxiv.org/pdf/2405.07437, Evaluation of Retrieval-Augmented Generation: A Survey
5.3.2 평가 지표
RAG 평가는 근본적으로 두 가지 질문을 중심으로 회전합니다: 검색 모듈이 올바른 자료를 찾을 수 있는가, 그리고 생성 모듈이 그 자료로부터 고품질의 답변을 생성할 수 있는가? 이에 따라 평가 시스템은 검색 평가와 생성 평가로 나뉘며, LLM-as-a-judge 평가가 보충됩니다.
검색 평가: 회수 정확도 및 순위 품질
검색 모듈은 RAG 시스템의 첫 번째 관문입니다. 평가는 세 가지 차원에 초점을 맞춥니다: 올바른 것을 찾았는지, 충분히 찾았는지, 그리고 잘 순위를 매겼는지.
기본 회수 품질 지표
고전적인 기본 지표는 Recall@K, Precision@K 및 F1입니다:
- Recall@K는 상위 K개의 결과에서 회수된 관련 문서의 비율을 측정합니다. 관련 문서가 5개 있고 상위 10개에서 3개를 찾으면 Recall@10은 60%입니다. 이는 검색 커버리지가 얼마나 넓은지 알려줍니다.
- Precision@K는 상위 K개의 결과 중 진정으로 관련성 있는 것의 비율을 측정합니다. 상위 10개 중 3개가 관련성 있고 7개가 아니면 Precision@10은 30%입니다. 이는 검색 정밀도를 반영합니다.
- F1은 Recall과 Precision의 조화 평균으로 두 가지의 균형을 맞춥니다.
이러한 지표는 기준 회수 문제를 빠르게 진단하는 데 유용합니다. Recall이 낮으면 관련 문서를 전혀 찾지 못한 것입니다. Precision이 낮으면 검색 노이즈가 너무 높은 것입니다.
순위 품질 지표
관련 문서를 찾는 것은 첫 번째 단계일 뿐입니다. 가장 관련성 높은 것을 앞쪽에 배치하는 것이 더 중요합니다. 이를 위해 MRR, NDCG@K 및 MAP를 살펴봅니다:
- MRR(평균 역순위)는 첫 번째 관련 문서의 순위 위치 역수를 측정합니다. 첫 번째 관련 문서가 위치 3에 나타나면 역순위는 1/3입니다. MRR은 하나의 올바른 답만으로 충분한 시나리오에 특히 적합합니다.
- NDCG@K(정규화 할인 누적 이득)은 등급이 매겨진 관련성과 위치 할인을 모두 고려합니다. 문서가 관련성 있는지뿐만 아니라 얼마나 관련성 있는지도 묻고, 일찍 나타나는 고도로 관련성 있는 문서에 보상을 줍니다.
- MAP(평균 평균 정밀도)은 모든 관련 문서의 위치에 민감하며 전체적인 순위 품질을 반영합니다.
실제 엔지니어링에서 일반적인 조합은 Recall@K와 MRR@K입니다. 예를 들어 Recall@10이 80%이지만 MRR@10이 0.3에 불과하면 관련 문서를 찾고는 있지만 너무 깊이 묻혀 있다는 것을 의미하며, 이는 리랭킹 개선이 필요함을 시사합니다.
필요한 경우 Coverage 지표를 추가하여 지식 베이스 커버리지를 모니터링하고 체계적인 맹점을 파악할 수도 있습니다.
생성 품질 평가: 정확도 및 사실적 충실도
검색은 원재료를 제공합니다. 다음 질문은 생성 모듈이 그 자료로부터 고품질 답변을 생성할 수 있는지입니다. 핵심 차원은 답변 정확도와 검색된 증거에 대한 충실도입니다.
정확 일치 및 텍스트 유사도
가장 단순한 지표는 EM(Exact Match)로, 생성된 답변이 참조 답변과 정확히 일치해야 합니다. 이는 날짜나 본사 위치와 같이 고정된 형태의 유일하게 올바른 팩트 질문에 적합하지만, 다르지만 동등하게 올바른 표면 형태가 매치에 실패할 수 있어 너무 엄격합니다.
이것이 ROUGE, BLEU, METEOR와 같은 n-그램 오버랩 지표도 일반적으로 사용되는 이유입니다. 이들은 참조 답변과의 단어 오버랩을 비교하여 생성된 답변의 점수를 매깁니다. ROUGE-L은 최장 공통 부분수열에 주의를 기울이고, BLEU는 기계 번역에서 유래하여 정확성을 강조하며, METEOR는 동의어와 어간 추출 고려 사항을 추가합니다.
순수 단어 오버랩의 한계를 극복하기 위해 BERTScore 또는 직접적인 벡터 유사도를 사용할 수도 있습니다. 이들은 사전 학습된 의미론적 표현을 사용하므로 표면적 변형을 더 잘 허용합니다.
사실적 충실도 및 환각 탐지
RAG 시스템의 경우 답변-참조 유사도만으로는 충분하지 않습니다. 더 중요한 질문은 답변이 실제로 검색된 문서에 근거하고 있는지 또는 지원되지 않는 콘텐츠를 환각하고 있는지입니다.
이것이 환각 비율과 충실도와 같은 지표가 중요한 이유입니다. 두 번째 LLM이 팩트 체커 역할을 하고 생성된 답변을 문장별로 검사하여 각 주장이 검색된 문서에 의해 지원될 수 있는지 판단할 수 있습니다. 의료, 법률 및 금융과 같은 고위험 도메인에서는 이러한 유형의 지표가 특히 중요하며, 일부 기업은 환각 임계값을 프로덕션 출시 기준으로 강제하기도 합니다.
LLM-as-a-Judge: 다차원 평가
모든 자동 지표에는 한계가 있습니다. 대부분의 표면 형태 지표는 의미론적 품질이나 전체적인 유용성을 완전히 포착할 수 없습니다. 이것이 LLM-as-a-judge가 특히 가치 있는 이유입니다.
기본 접근법은 질문, 검색된 문서, 시스템 답변 및 참조 답변을 강력한 독립 모델(예: GPT-4 또는 Claude)에 입력으로 제공하고 다음과 같은 차원에서 평가하도록 요청하는 것입니다:
- 질문 관련성
- 정보 완전성
- 사실적 충실도
- 전체적 정확성
LLM 심판의 강점은 더 인간과 유사한 전체적 판단을 내릴 수 있다는 것입니다. 물론 심판 프롬프트는 여전히 신중한 설계와 인간이 라벨링한 예시에 대한 교정이 필요하여 평가의 일관성과 신뢰성을 유지해야 합니다.
실용적인 지표 조합 구축
사용 가능한 지표가 많으므로 팀은 어느 것을 사용할지 종종 궁금해합니다. 실용적인 추천은 간결한 조합으로 시작하여 점진적으로 확장하는 것입니다:
- 검색의 경우 Recall@K + MRR@K로 시작
- 생성의 경우 작업 유형에 따라 EM, ROUGE-L, BERTScore 중 한두 개의 기본 지표 선택
- 전체 평가의 경우 관련성, 완전성 및 충실도에 초점을 맞춘 LLM 심판 도입
그런 다음 평가, 문제 진단, 전략 조정 및 재평가의 루프를 통해 반복합니다.
5.3.3 평가 프레임워크
RAG가 빠르게 발전함에 따라 학계와 산업계 모두에서 많은 강력한 평가 프레임워크가 나왔습니다. 이러한 프레임워크는 공통 지표를 패키지할 뿐만 아니라 표준화된 데이터셋, 벤치마크 절차 및 엔드투엔드 워크플로우도 제공합니다.
프레임워크의 기본 분류
RAG 평가 프레임워크는 대략 세 가지 카테고리로 나눌 수 있습니다:
- 연구 프레임워크: 학술적 탐색과 세밀한 진단에 초점. 예: FiD-Light, Diversity Reranker
- 벤치마크 프레임워크: 시스템을 수평적으로 비교하기 위한 표준화된 테스트 세트와 워크플로우 제공. 예: RAGAS, ARES, RGB, MultiHop-RAG, CRUD-RAG
- 도구 프레임워크: 엔지니어링 사용성과 개발 프레임워크와의 통합 강조. 예: TruEra RAG Triad, LangChain Benchmarks, RECALL
최근에는 평가 프레임워크가 더 전문화되었습니다. 예를 들어 의학에는 MedRAG, 법률에는 LegalBench-RAG, 금융에는 자체적인 도메인별 프레임워크가 있습니다. 이러한 도메인 프레임워크는 종종 전문화된 데이터셋뿐만 아니라 의료 정확도나 법률 인용 관련성과 같은 전문화된 지표도 제공합니다.
실제로 좋은 경험 법칙은:
- 빠르게 기준을 잡아야 한다면 RAGAS와 같은 더 일반적인 프레임워크로 시작
- 특정 문제를 진단하는 경우 더 표적이 있는 프레임워크 선택
- 의학, 법률, 금융 또는 기타 전문 도메인에 있는 경우 가능하면 도메인 적응 프레임워크 선호
- 강력한 문서화와 반응이 좋은 커뮤니티를 가진 적극적으로 유지 관리되는 도구 선호
커뮤니티에서 일반적으로 추천하는 도구로는 Ragas, Continuous Eval, TruLens-Eval, LlamaIndex 내부의 평가 기능, Phoenix, DeepEval, LangSmith 및 OpenAI Evals가 있습니다.
5.3.4 평가 벤치마크
평가 벤치마크의 중요성은 종종 과소평가됩니다. 많은 팀이 소수의 직접 작성한 테스트 질문만으로 RAG 시스템을 평가하기 시작한 다음 실제 온라인 성능이 오프라인 인상과 크게 다르다는 것을 발견합니다. 근본 원인은 대표성 있고 체계적인 평가 데이터가 부족하다는 것입니다.
시스템 반복을 잘 지원하는 벤치마크는 일반적으로 세 가지 핵심 특성을 가집니다:
- 대표성: 고빈도 사용자 질문, 경계 사례 및 비정상 입력을 포괄
- 표준화: 질문 및 답변 형식, 난이도 수준 및 평가 규칙이 일관됨
- 진화성: 시스템 역량과 비즈니스 요구가 발전함에 따라 벤치마크가 업데이트될 수 있음
대부분의 기업에게 비즈니스 시나리오가 고유하기 때문에 최종 답은 일반적으로 자체 평가 데이터셋을 구축하는 것입니다.
- 비즈니스 로그에서 실제 사용자 질문을 추출하여 유형, 빈도 및 난이도별로 샘플링합니다.
- 간단한 경우에는 도메인 전문가가 직접 주석을 답니다. 더 복잡한 질문의 경우 강력한 LLM이 먼저 후보 답변을 생성하도록 한 다음 전문가가 수정합니다.
- 답변 자체 외에도 관련 문서, 답변 유형 및 난이도 수준과 같은 메타데이터를 라벨링합니다.
- 온라인에서 발견된 새로운 어려운 사례로 데이터셋을 정기적으로 업데이트합니다.
자원이 제한되어 있고 빠른 기준이 필요한 경우 공개 벤치마크는 여전히 유용한 출발점입니다. 2025년 현재 범용 및 수직 시나리오 모두에 대해 많은 공개 벤치마크가 존재합니다:
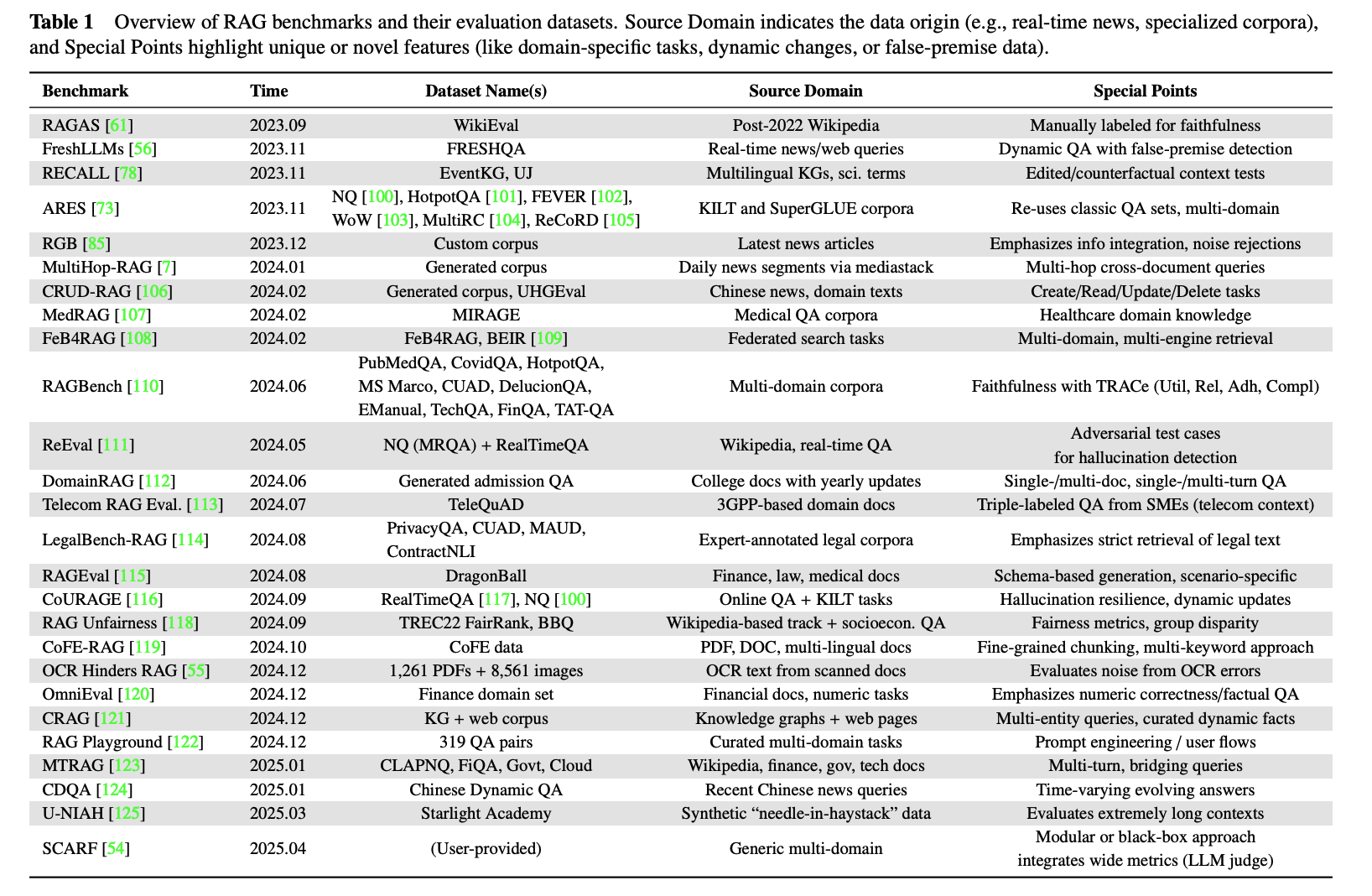
선택할 때 먼저 목표를 명확히 하세요. 기준을 설정하는 것인가, 아니면 출시 전에 시스템을 검증하는 것인가? 그런 다음 벤치마크가 관심 있는 시나리오와 난이도 프로필을 커버하는지 확인합니다. 뉴스나 금융과 같이 시간에 민감한 도메인의 경우 벤치마크에 시간 민감 테스트가 포함되어 있는지 확인하세요.
실제로는 자체 도메인 내 데이터셋과 공개 벤치마크를 결합하는 것이 종종 가장 견고한 경로입니다. 평가가 실제 비즈니스 요구에 가깝게 유지되면서도 수평적 비교 가능성을 일부 보존할 수 있기 때문입니다.
6. 심층 탐구: 대회 및 공개 튜토리얼에서 배우기 (선택 사항)
위의 원리와 기본 구현은 사용 가능한 프로토타입을 구축하는 데 충분하지만, 프로덕션에서 나타나는 더 어려운 문제를 해결하기에는 아직 거리가 있습니다. 더 실용적이고 실전 검증된 RAG 기술을 이해하고 싶다면 가장 효율적인 방법 중 하나는 수상 대회 솔루션과 우수한 공개 튜토리얼을 연구하는 것입니다. 이러한 솔루션은 종종 실제 시나리오에서 강력한 팀이 반복적인 시도를 통해 발견한 모범 사례를 집중적으로 보여줍니다.
아래의 예시는 대표적인 것이며 전체를 포괄하지는 않습니다. 실제로 특정 문제(예: PDF 파싱, 멀티모달 검색, 저지연 최적화)를 만나면 해당 문제와 관련된 대회를 검색하고 수상 팀의 기술 보고서와 공개 코드를 연구하는 것이 종종 효과적입니다.
6.1 의미론적 캐시: 고빈도 질의 최적화
Hugging Face는 Chroma 벡터 데이터베이스 위에 구축된 의미론적 캐시 구현을 제공합니다:
https://huggingface.co/learn/cookbook/semantic_cache_chroma_vector_database
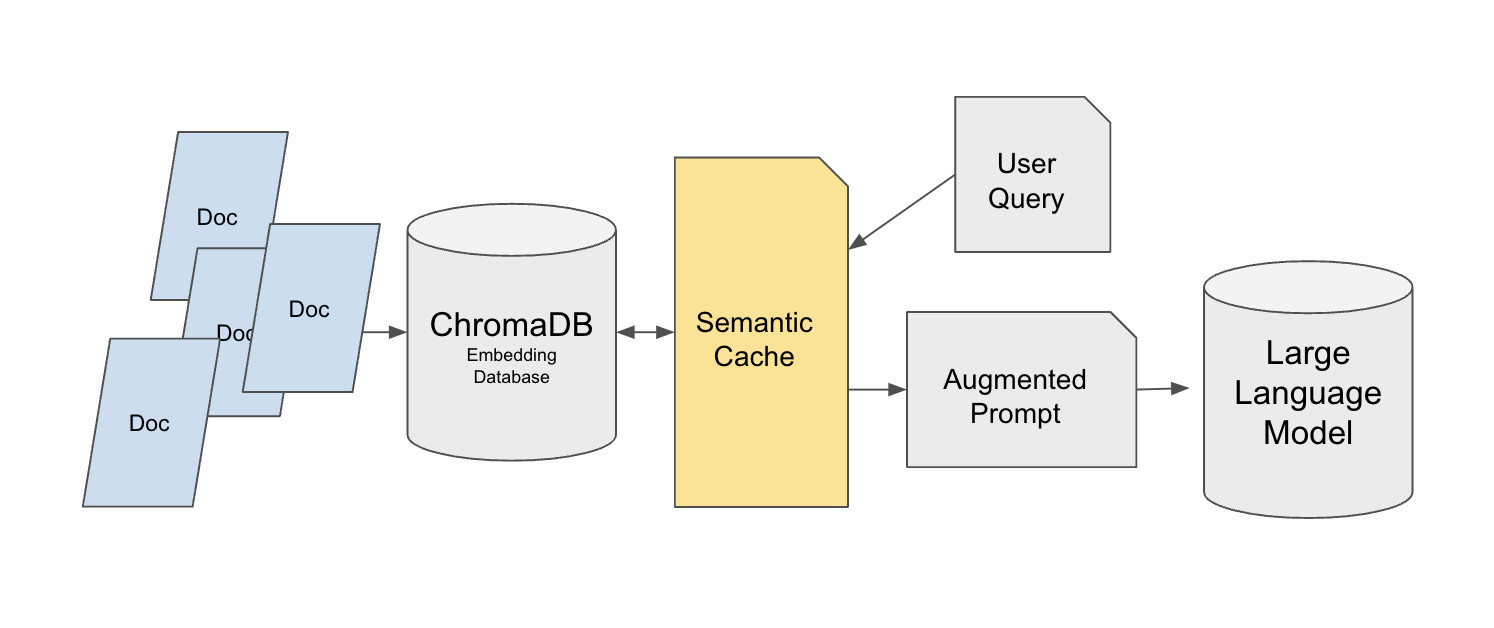
배경: 대부분의 튜토리얼 RAG 시스템은 단일 사용자 테스트를 위해 구축됩니다. 하지만 프로덕션에 배포되면 시스템은 수십 또는 수천 건의 반복된 질의를 받을 수 있습니다(예: 고객 지원 사용자가 환불 절차에 대해 반복적으로 질문). 반복된 질의가 있을 때마다 벡터 검색과 LLM 호출을 트리거하면 지연 시간과 비용이 빠르게 증가합니다. 의미론적 캐시 계층은 답변 품질을 유지하면서 원래 데이터 소스의 부하를 크게 줄일 수 있습니다.
이 설계는 2계층 검색 아키텍처를 사용합니다. 기본 계층은 Chroma에 원래 지식 베이스를 저장하며, MedQuad와 같은 데이터셋을 예시로 사용하고 정확한 참조를 위해 각 항목에 고유 ID를 할당합니다. 캐시 계층은 FAISS를 사용하여 FlatL2 인덱스로 구축됩니다. 의미론적 캐시는 사용자 질의와 Chroma 사이에 위치하며, LLM의 최종 답변을 직접 캐시하지 않습니다. 이 설계가 중요한 이유는 답변을 직접 캐시하면 "이것을 쉬운 언어로 설명해 줘"와 같은 개인화된 답변 요구 사항을 위반할 수 있기 때문입니다.
캐시 시스템은 all-mpnet-base-v2 SentenceTransformer를 사용하여 질의 벡터를 생성하고 유클리디안 거리를 사용하며 임계값 0.35로 질의가 유사한지 판단합니다. 캐시가 가득 차면 max_response 매개변수로 제어되며 가장 오래된 항목이 FIFO로 제거됩니다. 캐시 데이터는 JSON 파일로 저장하여 세션 간 재사용할 수도 있습니다.
소규모 테스트에서 "백신은 어떻게 작동하나요?"와 같은 첫 번째 질의는 Chroma에서 가져오는 데 0.057초가 걸렸으며, 유사한 질의를 캐시에서 제공하는 데는 0.016초밖에 걸리지 않았습니다. 대규모 프로덕션 시나리오에서 이 접근법은 반복이 많은 환경에서 90~95%의 성능 최적화를 달성할 수 있으며 벡터 저장소 및 API 비용을 상당히 줄일 수 있습니다.
6.2 비정형 데이터 처리: 다중 형식 문서를 위한 통합 파싱
또 다른 Hugging Face 튜토리얼은 Unstructured 라이브러리를 사용하여 비정형 문서 처리를 위한 전체 파이프라인을 구축하는 방법을 보여줍니다:
https://huggingface.co/learn/cookbook/rag_with_unstructured_data

배경: 기업 시나리오에서 지식은 종종 PDF, PowerPoint, EPUB, HTML 페이지 및 기타 여러 형식에 분산되어 있습니다. 전통적인 전처리 방법은 하나의 형식만 지원하거나 변환 중에 표와 제목 계층과 같은 중요한 구조적 정보를 잃습니다. 이로 인해 RAG 시스템이 콘텐츠를 올바르게 이해하고 검색하기 어렵습니다.
이 솔루션은 먼저 다중 형식 테스트 문서(예: 많은 표가 포함된 캐나다 농약 매뉴얼 PDF, 차트와 다단계 제목이 포함된 플로리다 대학 감귤 IPM PowerPoint 파일)를 다운로드합니다. 그런 다음 Unstructured의 Local Runner를 사용하여 파싱합니다. 구성에는 프로세서 구성, 더 강력한 OCR을 위해 API 파티션 모드를 선택적으로 사용할 수 있는 파티션 구성, 입력 경로를 정의하는 로컬 구성이 포함됩니다. 파싱된 문서는 본문, 제목, 표와 같은 유형이 지정된 요소를 포함하는 JSON으로 변환됩니다.
그런 다음 시스템은 chunk_by_title을 사용하고 최대 길이를 512자로 설정하며 200자 미만의 연속적인 조각을 병합하여 의미론적 일관성을 보존합니다. LangChain Document 객체로 변환하는 동안 복잡한 메타데이터 필드를 필터링하여 Chroma에 맞게 조정합니다. 벡터 단계에서는 BAAI/bge-base-en-v1.5 임베딩 모델을 4비트 양자화된 Llama-3-8B-Instruct 및 LangChain RetrievalQA 체인과 함께 사용하여 완전한 RAG 시스템을 구축합니다.
결과 시스템은 다중 형식 문서를 정확하게 처리할 수 있습니다. "진딧물은 해충인가요?"와 같은 질문에 대해 파싱된 문서에서 핵심 사실을 추출하고 관련 자료를 바탕으로 답변을 생성할 수 있습니다. 이는 여러 문서 유형을 처리해야 하는 기업 지식 베이스에 특히 유용합니다.
6.3 기업 문서 QA: 고정밀 및 추적 가능한 RAG
Enterprise RAG Challenge의 챔피언십 솔루션은 엄격한 시간과 정밀도 요구 사항 하에서 프로덕션급 RAG 시스템을 구축하는 방법을 보여줍니다:
- https://abdullin.com/ilya/how-to-build-best-rag/
- https://hustyichi.github.io/2025/07/03/rag-complete/
배경: 참가자들은 2.5시간 안에 100개의 실제 기업 연례 보고서 PDF를 파싱해야 했으며, 각 보고서는 최대 1000페이지이고 복잡한 재무 표, 다중 열 레이아웃 및 차트를 포함하고 있었습니다. 파싱 후 시스템은 예/아니오, 회사명, 정확한 수치 지표 또는 임원 직함과 같은 명시적인 답변 유형으로 100개의 정밀한 비즈니스 질문에 답변해야 했으며, 증거로 페이지 번호를 인용해야 했습니다.
수상 팀은 IBM의 오픈소스 Docling을 PDF 파서로 선택했으며, 복잡한 표와 다중 열 텍스트에서 가장 좋은 성능을 보였기 때문입니다. Docling 코드를 개선하여 메타데이터가 포함된 JSON과 Markdown-plus-HTML을 출력할 수 있게 했으며, 특히 표 파싱을 개선했습니다. 처리 속도를 높이기 위해 RTX 4090 GPU를 임대하고 40분 만에 100개 보고서 파싱을 완료했습니다.
텍스트 청킹은 의미론적 일관성을 보존하기 위해 50토큰 오버랩이 있는 300토큰 청크와 재귀적 분할을 사용했습니다. 회사 간 교차 오염을 피하기 위해 각 회사는 IndexFlatIP 인덱스를 사용하는 자체 FAISS 벡터 저장소를 가졌습니다. 검색은 세 단계를 따랐습니다: 벡터로 Top-30 청크를 검색하고, 여러 청크가 같은 페이지에서 올 수 있으므로 부모 페이지별로 중복 제거하고, GPT-4o-mini로 페이지를 리랭킹했습니다. 최종 순위는 0.3~0.7 가중치 분할로 벡터 검색과 LLM 리랭킹 점수를 혼합했습니다.
생성은 답변 유형에 따라 다른 프롬프트 템플릿을 사용했습니다. 연간 수익과 같은 수치 질문의 경우 시스템은 지표 매칭, 단위 일관성 및 교차 확인을 보장하기 위해 5단계 분석 프로세스를 사용했습니다. 출력은 추적 가능성을 위해 분석 과정과 페이지 참조를 포함하도록 구조화되었습니다.
이 시스템은 두 개의 상을 수상하고 리더보드에서 1위를 차지했습니다. 중요한 관찰은 Llama 8B와 같은 더 작은 모델도 참가자의 80% 이상을 능가했으며, Llama 3.3 70B는 GPT-4o-mini에 근접했다는 것으로, 좋은 시스템 설계가 정확성, 효율성 및 비용의 균형을 성공적으로 맞출 수 있음을 보여주었습니다.
6.4 AIOps 시나리오: 혼합 텍스트 및 이미지 데이터의 지능적 처리
AIOps RAG 대회에서의 EasyRAG 프로젝트는 운영 시나리오를 위한 QA에 초점을 맞추었습니다:
http://blog.csdn.net/hustyichi/article/details/143323746
배경: 운영 엔지니어는 종종 텍스트뿐만 아니라 모니터링 차트, 시스템 아키텍처 다이어그램 및 성능 곡선도 포함된 기술 문서를 읽어야 합니다. 예를 들어 시스템 문제를 진단할 때 "CPU 사용률이 80%를 초과하면 어떻게 해야 하나요?"에 대한 답변이 텍스트 설명과 모니터링 그래프 사이에 분산되어 있을 수 있습니다. 전통적인 텍스트 전용 RAG는 차트 추세와 값을 이해할 수 없어 답변이 불완전하게 됩니다.
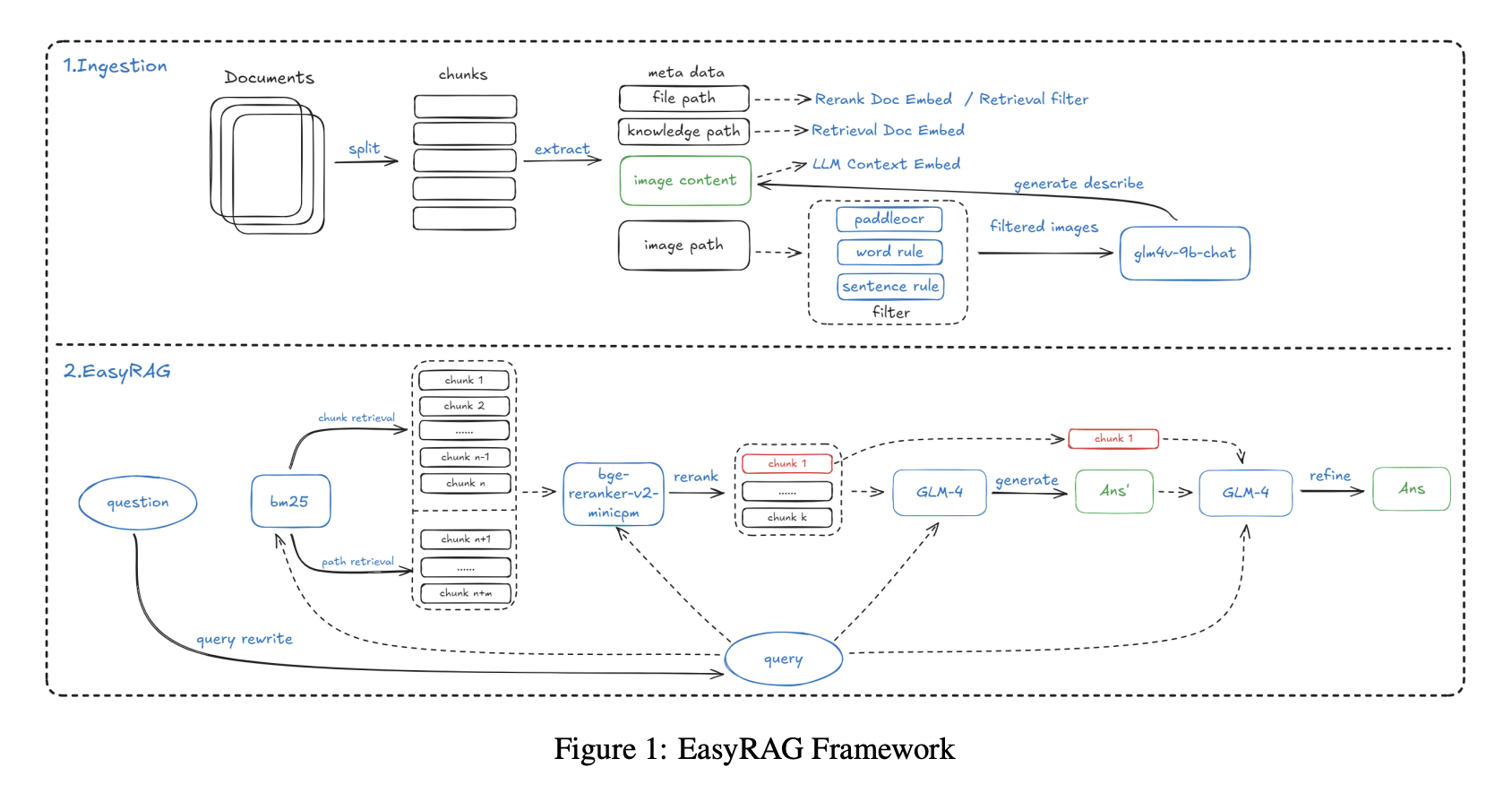
인덱싱 단계에서는 1024토큰 청크와 200토큰 오버랩이 있는 개선된 SentenceSplitter가 사용되었습니다. 핵심 혁신은 각 청크에 지식 베이스 경로 및 파일 경로와 같은 메타데이터를 추가한 것으로, 회수율이 2% 향상되었습니다. 이미지 데이터의 경우 시스템은 먼저 PaddleOCR을 사용하여 차트와 스크린샷에서 텍스트를 추출한 다음, 멀티모달 모델 GLM-4V-9B를 사용하여 이미지의 자연어 설명을 생성했습니다(예: 오후에 90%로 정점을 찍는 CPU 사용률 선 설명). OCR 텍스트와 이미지 설명은 모두 함께 인덱싱되었습니다.
검색은 광범위한 회수를 위해 BM25 + 벡터의 이중 경로 전략을 사용했습니다. BM25는 청크 검색과 경로 검색을 커버하여 파일 경로로 관련 없는 문서를 필터링하는 데 도움을 주었으며, 벡터 검색은 gte-Qwen2-7B-instruct를 사용했습니다. 리랭킹은 bge-reranker-v2-minicpm-layerwise를 사용했으며, 28계층 설정이 실험에서 가장 좋은 성능을 보였습니다.
답변 생성은 2단계 전략을 사용했습니다: 먼저 Top-6 문서에서 초안을 생성하여 정보 커버리지를 최대화한 다음, Top-1 가장 관련성 높은 문서로 답변을 최적화하여 핵심 답변을 강조했습니다.
수백 페이지의 완전한 운영 매뉴얼과 같은 긴 텍스트 시나리오를 처리하기 위해 시스템은 BM25 기반 컨텍스트 압축도 구현하여 문서를 문장으로 분할하고 질의와의 문장 유사도를 평가하며 가장 관련성 높은 문장만 연결했습니다. 50% 압축률에서 이 방법은 단 7.7초 만에 86.48%의 정확도를 달성했으며 LLMLingua와 같은 도구를 능가했습니다.
6.5 다중 출처 데이터 융합: 구조화 및 비정형 지식의 협업
KDD Cup 2024 Meta RAG 챌린지의 수상 솔루션은 비정형 웹 콘텐츠와 구조화된 지식 그래프를 통합하는 방법을 보여주었습니다:
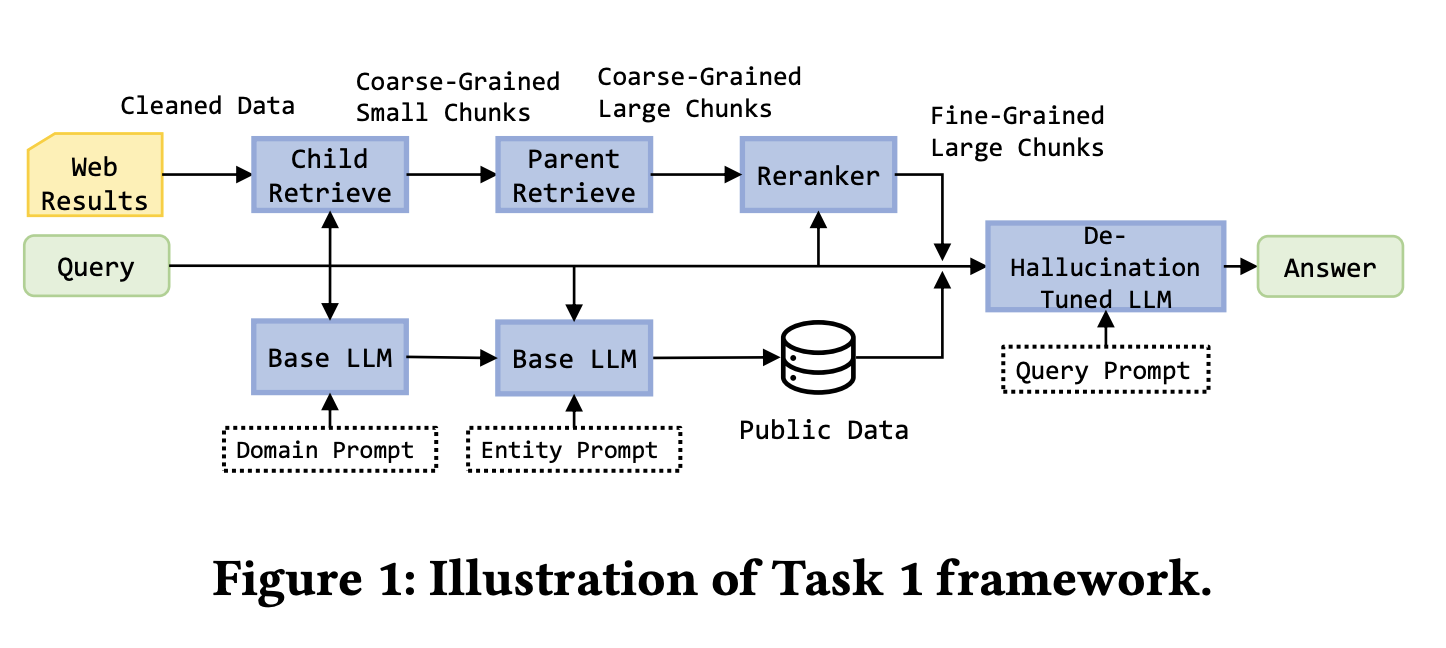
배경: 작업 1은 5개의 웹 페이지에서 검색 요약이 필요했습니다. 작업 2는 영화 데이터베이스 및 엔티티 관계와 같은 것에 직접 접근할 수 있는 구조화된 지식 그래프를 나타내는 목업 API가 추가되었습니다. 작업 3은 난이도를 높여 50개의 웹 페이지와 목업 API를 사용하여 박스 오피스가 5억 달러 이상인 놀란 감독 영화 식별과 같은 더 복잡한 질의에 답변해야 했습니다. 모든 질의는 30초 이내에 완료되어야 했습니다.
작업 1의 경우 수상 팀은 정교한 웹 처리 파이프라인을 구축했습니다. BeautifulSoup을 사용하여 페이지 텍스트를 추출하고 ParentDocumentRetriever를 사용하여 부모-자식 청크 관계를 관리했으며, 검색에는 200토큰 자식 청크를, 생성에는 500~2000토큰 부모 청크를 사용했습니다. 임베딩 모델은 bge-base-en-v1.5, 벡터 저장소는 Chroma, 리랭킹은 bge-reranker-v2-m3를 사용했습니다. 또한 공개 데이터셋에서 영화 및 금융 데이터를 보충하고 유효하지 않은 질문과 참조 답변이 포함된 학습 데이터로 Llama-3-8B-instruct를 LoRA로 미세조정했습니다.
작업 2와 3의 경우 핵심 혁신은 지식 그래프를 우선시하는 것이었습니다. 시스템은 필터링 및 정렬 지원과 함께 get_person 및 get_movie와 같은 표준화된 API 호출을 정의했습니다. 먼저 지식 그래프 API를 호출하고 그래프 결과가 누락되거나 유효하지 않은 경우에만 웹 검색으로 대체했습니다. 이는 속도와 답변 정확도를 모두 향상시켰습니다.
시스템이 지식 그래프를 우선시하고 구조화된 출력 형식을 사용했기 때문에 환각이 명확히 감소했습니다. 그래프가 결정론적인 답변을 직접 제공할 수 있으면 시스템은 생성 단계 없이 반환했습니다. 웹 검색이 필요한 경우 답변은 엄격한 인용 및 단계별 추론 규칙을 따라야 했습니다.
이 솔루션은 세 가지 작업 모두에서 1위를 차지했습니다. 주요 교훈은 구조화된 데이터와 비정형 데이터를 모두 포함하는 기업 시나리오에서 데이터 유형에 따라 검색 전략을 설계해야 한다는 것입니다: 결정론적인 구조화된 데이터를 먼저 사용하고 비정형 출처를 보충으로 취급하십시오.
이러한 실제 사례에서 몇 가지 공통 원칙이 반복적으로 나타납니다:
- 비즈니스 시나리오에 따라 캐싱, 검색 및 생성 전략 선택
- 다양한 형식과 모달리티에 대한 전용 파싱 및 인덱싱 경로 설계
- 하이브리드 검색 + 리랭킹을 표준 구성으로 취급
- 작업별 프롬프팅과 구조화된 출력을 사용하여 정확도와 추적 가능성 향상
이러한 실제 대회와 공개 프로젝트에서 얻은 교훈은 더 강력한 기업 RAG 시스템을 구축할 때 귀중한 참고 자료입니다.
7. 폭넓은 탐구: RAG의 미래 진화 (선택 사항)
RAG의 실용적인 기술과 최적화 방법을 배운 후에는 구체적인 시나리오에서 시스템 성능을 이미 향상시킬 수 있습니다. 하지만 지역적인 엔지니어링 기교만 이해하는 것으로는 RAG가 어디로 향하고 있는지에 대한 더 넓은 시야를 갖기에 충분하지 않습니다. 더 폭넓은 진화 방향도 살펴보아야 합니다.
RAG는 이제 전통적인 텍스트 청크 검색 후 생성 패턴을 빠르게 벗어나고 있습니다. 이 섹션에서는 그러한 경로 중 몇 가지에 초점을 맞춥니다: 청크 검색에서 그래프 구조 검색으로의 이동, 이미지와 오디오를 멀티모달 RAG에 결합, 벡터화된 후속 청킹을 통한 긴 문서 처리 개선, 그리고 RAG가 점차 에이전트 지향 시스템으로 진화하는 방식.
7.1 Graph RAG: 관계 네트워크로 심층 검색 재구성
관련 연구:
전통적인 RAG는 질문과 유사한 텍스트 구절을 찾는 방식으로 작동하며, 이는 자료 더미에서 가장 관련성 있어 보이는 몇 단락을 골라내는 것과 같습니다. 이는 직접적인 팩트 조회에 잘 작동합니다. 하지만 질문이 여러 문서를 연결하고 다른 단서들을 결합해야 하는 경우 성능이 떨어집니다.
예를 들어, 의사가 "이러한 사례와 최신 치료 가이드라인을 바탕으로 특정 약물이 노년 환자에게 미치는 이점과 위험을 어떻게 평가해야 할까요?"라고 질문할 수 있습니다. 또는 프로젝트 팀이 "지난 2년간의 요구사항 문서, 검토 기록 및 온라인 이슈 보고서를 종합해 볼 때, 우리 시스템 아키텍처의 어느 부분이 가장 자주 실패합니까?"라고 물을 수 있습니다. 이러한 질문은 단일 문장을 찾는 것이 아닙니다. 여러 자료에 흩어진 사람, 대상, 사건 및 관계를 식별하고 완전한 그림을 형성해야 합니다.
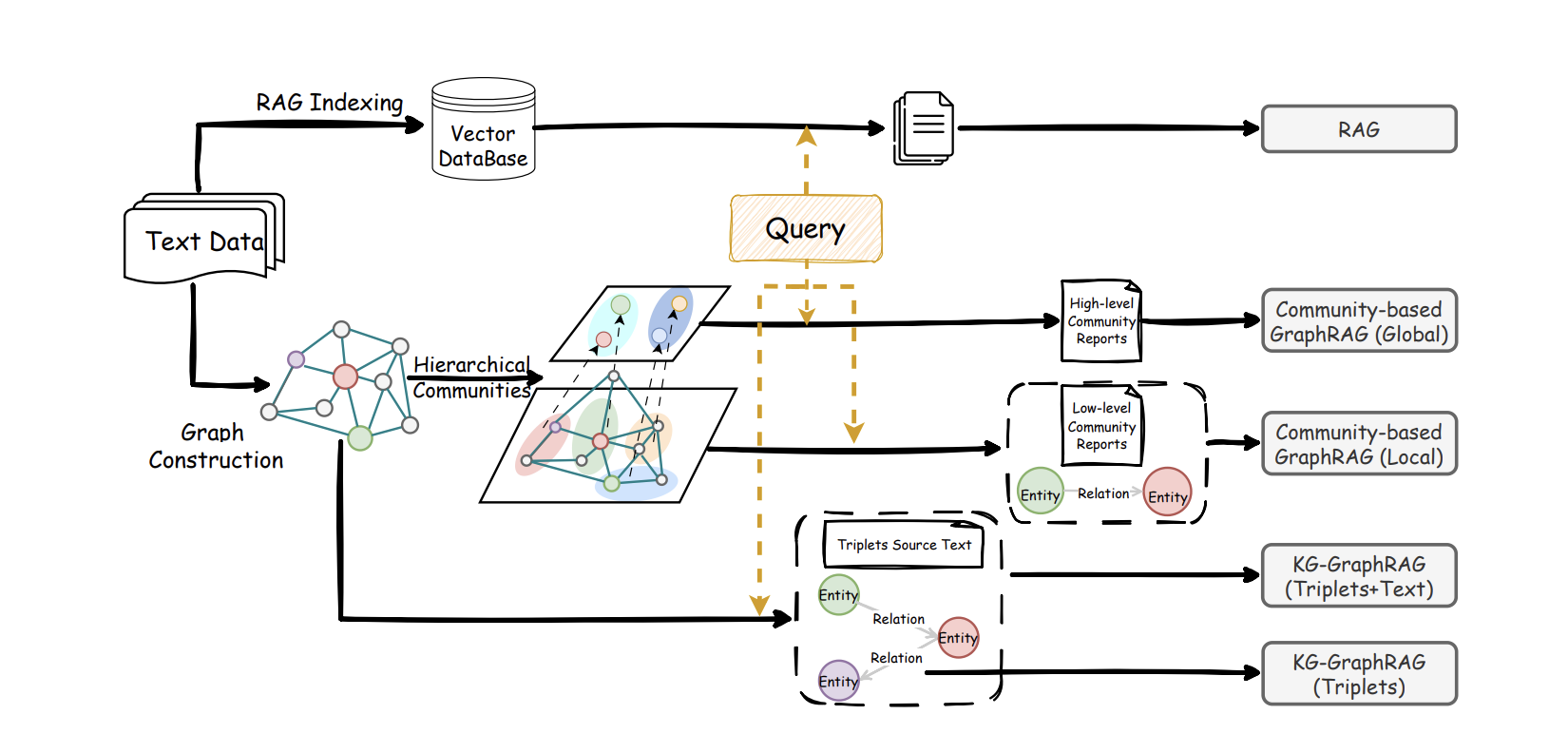
Graph RAG는 그 그림을 사전에 구축합니다. 시스템은 대규모 모델을 사용하여 텍스트에서 핵심 엔티티(예: 사람, 조직, 기능 모듈, 사건, 데이터)와 그 관계(예: 인과관계, 의존성, 변화, 모순)를 식별합니다. 그런 다음 더 많은 자료가 추가됨에 따라 성장하는 지식 네트워크를 구축합니다. 자동 그룹화를 통해 밀접하게 관련된 엔티티와 관계가 주제별로 조직되며, 각 주제는 사전에 요약될 수 있습니다. 사용자가 질문을 하면 시스템은 더 이상 유사해 보이는 텍스트 구절만 검색하지 않습니다. 먼저 가장 관련성 높은 엔티티와 로컬 그래프 구조를 찾고, 관련 주제 그룹을 통해 확장한 다음, 분석 경로, 노드 설명 및 출처 구절을 함께 LLM에 제공하여 추론합니다.
이 프레임워크에서 Graph RAG와 전통적인 RAG는 상호 보완적입니다. 전통적인 RAG는 한 단계에서 답변을 찾을 수 있는 세부 질문에서 여전히 강점이 있습니다. Graph RAG는 인간 연구자가 생각하는 방식에 더 가깝습니다: 먼저 전체 구조와 주제를 정리하고, 다음으로 증거를 채우고, 마지막으로 논리와 조건이 있는 결론을 도출합니다. 기존 비교에서는 멀티홉 추론 작업에서 Graph RAG가 종종 더 많은 핵심 콘텐츠를 커버하고 더 넓은 관점을 제공하는 것으로 나타났습니다. 두 접근 방식의 유연한 결합이 하나만 사용하는 것보다 종종 더 낫습니다.
7.2 멀티모달 RAG
관련 연구:
실제 데이터는 결코 텍스트만이 아닙니다. 서버 장애를 진단하는 엔지니어는 온도 곡선, 장치 스크린샷 및 로그를 함께 봐야 합니다. 진단을 내리는 의사는 CT 또는 MRI 이미지, 검사 보고서 및 전자 의료 기록을 동시에 필요로 합니다. 전통적인 텍스트 RAG는 기껏해야 "온도 이상" 또는 "폐 결절 의심"과 같은 문구를 검색할 수 있지만, 그 설명을 실제 차트 추세나 이미지 병변 형태와 연결하는 데는 어려움이 있으며, 이미지, 오디오 또는 비디오에서 문서나 지식을 역검색할 수도 없습니다.
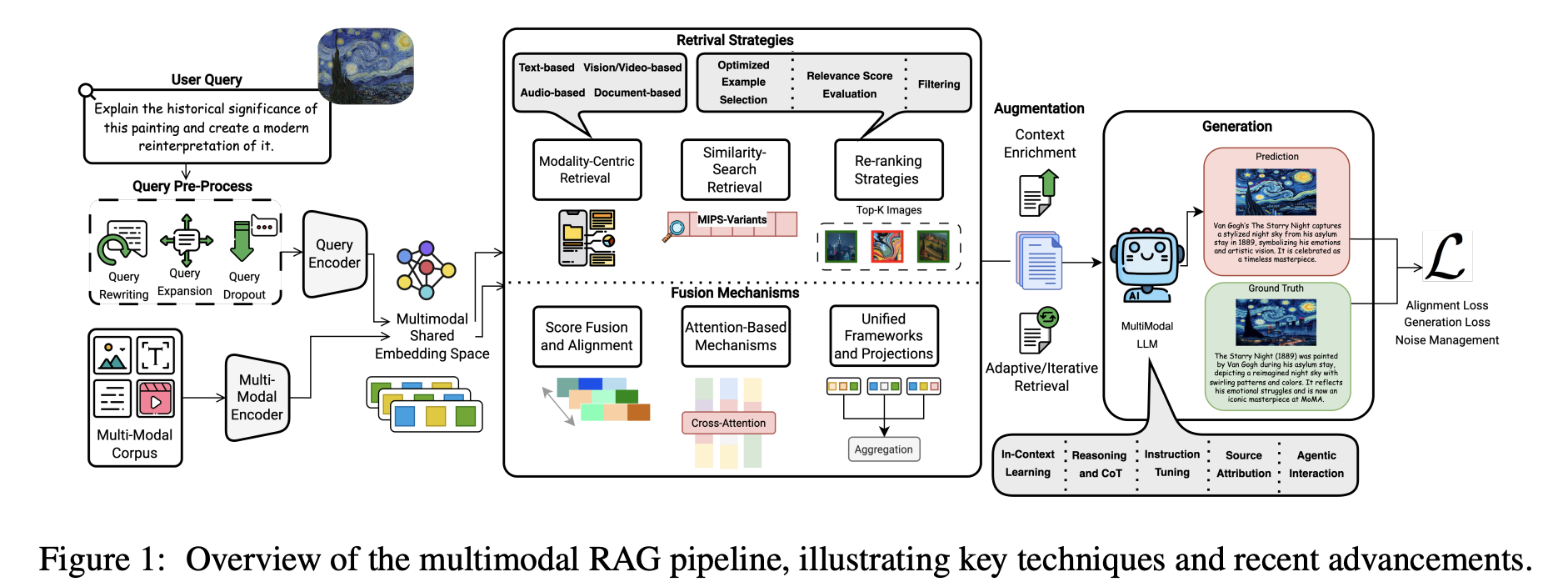
멀티모달 RAG는 서로 다른 모달리티가 서로를 "볼" 수 없는 문제를 해결합니다. 핵심은 교차 모달 의미론적 정렬입니다. 시스템은 이미지, 비디오, 오디오 및 텍스트에 적합한 인코더를 OCR, ASR 및 레이아웃 분석과 함께 사용하여 시각 및 오디오 소스에서 핵심 정보를 추출하고 다른 모달리티를 통합된 멀티모달 인덱스를 구축할 수 있는 공유 의미 공간에 매핑합니다.
검색 및 생성 시 사용자가 2023년 3분기에 판매 정점을 보여주는 차트를 요청하든 스케치나 조작 비디오를 업로드하든 시스템은 먼저 해당 통합 공간에서 가장 가까운 멀티모달 증거를 찾고, 텍스트 유사도 및 이미지 유사도와 같은 신호로 필터링하며, 가장 유용한 조각을 유지한 다음, 그 이미지, 텍스트 구절 및 표를 함께 멀티모달 LLM에 제공합니다. 모델은 모달리티 간의 증거를 결합하여 답변할 수 있으며, 이상적으로는 출처를 표시하거나 이미지나 문서의 관련 영역을 강조 표시할 수 있습니다.
텍스트 전용 RAG와 비교하여 멀티모달 RAG는 더 많은 종류의 증거를 사용할 수 있으며 종종 환각을 줄이면서 더 완전하고 검증 가능한 답변을 생성합니다.
7.3 Late Chunking: 긴 문서의 전체 컨텍스트 보존
관련 소개:
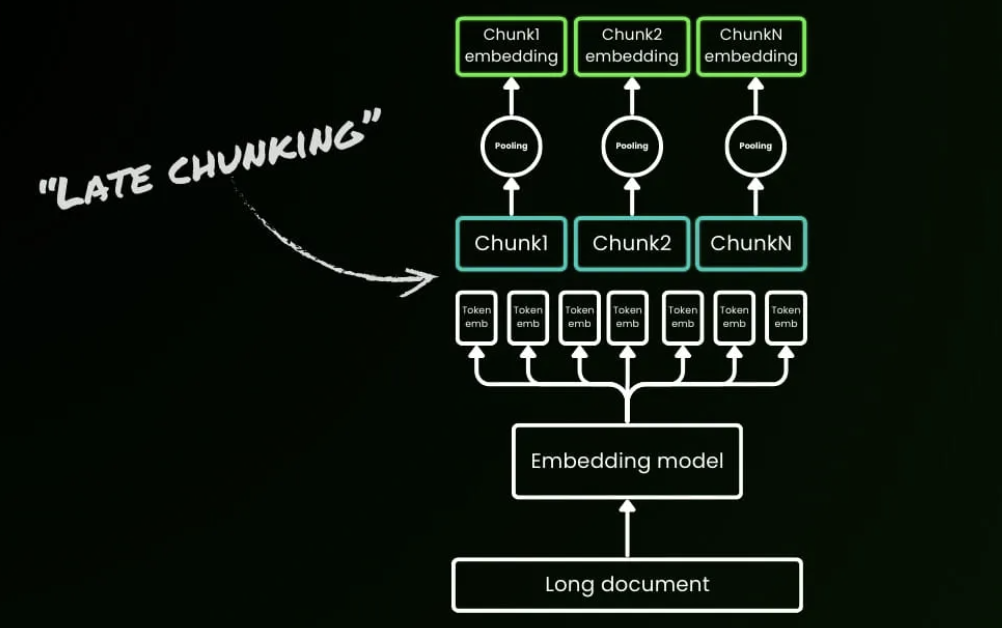
베를린에 대한 위키백과 문서를 읽는다고 상상해 보세요. 전통적인 RAG는 먼저 이를 독립적인 단락으로 자른 다음 각 청크를 임베딩합니다. 첫 번째 문장이 "베를린은 독일의 수도입니다"라고 말하는 경우, "이 도시" 또는 "그 인구"와 같은 이후의 구문은 분리되면 베를린과의 연결을 잃게 됩니다. "베를린의 인구는 얼마입니까?"와 같은 질의는 베를린이라는 용어와 인구 정보가 같은 청크 내에 나타나지 않았기 때문에 실패할 수 있습니다. 이 문제는 긴 문서에서 더욱 악화됩니다. 200페이지짜리 보험 계약서에서 면책금액의 정의는 5페이지에 나타나고 그것이 적용되는 조건은 30페이지에 나타날 수 있습니다. 고정 길이 청킹은 이러한 관련 조각들을 수십 개의 고립된 청크로 분할할 수 있으며, 실험에 따르면 이 경우 의미론적 유사도가 급격히 저하될 수 있습니다.
Late Chunking은 전통적인 먼저 청크한 후 임베딩하는 파이프라인을 뒤집고 대신 먼저 임베딩한 후 청크하는 방식을 따릅니다. 8192토큰과 같은 것을 처리할 수 있는 긴 컨텍스트 임베딩 모델을 사용하여 전체 문서를 먼저 Transformer에 통과시켜 전체 문서를 이미 본 토큰 수준의 임베딩을 생성합니다. 그 후에야 청크 경계에 따라 전역적으로 정보를 얻은 토큰 임베딩을 청크 임베딩으로 풀링합니다. 결과 청크는 더 이상 고립된 섬이 아닙니다. 문단 간 참조와 개념적 관계를 보존하는 컨텍스트 종속적 임베딩입니다.
BEIR 벤치마크 데이터셋에서 Late Chunking은 전통적인 청킹을 광범위하게 능가하며, 특히 더 긴 문서에서 강력한 이득을 보입니다. 짧은 텍스트 시나리오에서는 차이가 거의 사라지며, 이는 핵심 규칙을 확인합니다: 문서가 길수록 Late Chunking의 장점이 더 큽니다. 이 방법은 이제 Jina Embeddings v3에 통합되었습니다. 긴 문서를 먼저 인코딩하는 것이 추론 시간을 10~20% 증가시킬 수 있지만, 의료 기록, 법률 문서 및 기술 매뉴얼과 같은 시나리오에서 검색 이득은 그 비용을 쉽게 정당화할 수 있습니다.
Late Chunking은 이러한 시나리오에서 8K 이상의 긴 컨텍스트 임베딩 모델이 과도한 엔지니어링이 아님을 보여줍니다. 고품질 청크 임베딩을 생성하기 위해 종종 필요하며, 먼저 청크한 후 임베딩에서 먼저 임베딩한 후 청크로의 전환을 나타냅니다.
7.4 RAG에서 에이전트 시대의 RAG로
관련 논의:
- https://ragflow.io/blog/rag-at-the-crossroads-mid-2025-reflections-on-ai-evolution
- https://arxiv.org/pdf/2501.09136
- https://www.letta.com/blog/rag-vs-agent-memory
- https://www.linkedin.com/posts/richmondalake_100daysofagentmemory-rag-memorizz-activity-7348281860843577346-LM7Y/
- https://www.llamaindex.ai/blog/rag-is-dead-long-live-agentic-retrieval
RAG는 검색 증강 생성 도구에서 에이전트의 인지 아키텍처의 핵심 부분으로 발전했습니다. 전통적인 RAG는 단순한 질문, 검색, 답변 패턴을 기반으로 구축되었으며 근본적으로 수동적입니다. 질의를 기다리고 사전에 행동하지 않습니다. 이러한 수동성을 극복하고 더 복잡한 인지 작업을 처리하기 위해 RAG는 에이전트 역량과 깊이 결합되어 새로운 패러다임인 Agentic RAG를 탄생시켰습니다.
이 패러다임에서 RAG의 역할은 근본적으로 변화합니다. 더 이상 외부 지식의 수동적 제공자가 아닙니다. 대신 에이전트의 능동적 계획, 목표 방향성 및 자기 성찰 하에서 지능적 행동을 지원하는 핵심 처리 장치가 됩니다. 이 융합은 전체 시스템에 목표 지향성, 반복적 최적화 및 자율적 의사결정을 부여하여 인간-AI 상호작용의 질을 크게 심화시킵니다. Agentic RAG는 복잡한 작업을 이해하고 분해하며 검색 전략을 계획하고 초기 결과의 품질을 평가하여 더 깊은 탐색이 필요한지 결정할 수 있습니다.
이 능력의 핵심은 다계층 능동 루프입니다. 복잡한 질의에 직면하면 에이전트는 먼저 문제의 본질을 분석하고 하위 문제로 분해하며 각 하위 문제에 대한 정밀한 검색 전략을 설계합니다. 초기 결과를 받은 후 이를 평가하고 정보가 완전하고 관련성 있는지 판단하며 지식 격차를 식별하고 더 정밀한 새로운 질의를 동적으로 생성합니다. 이 반복 과정은 종종 멀티홉 검색을 포함하며, 한 라운드의 결과가 다음 라운드의 새로운 방향을 드러내어 인간 연구자가 작업하는 방식과 유사한 지식 탐색 체인을 생성합니다.
이러한 지속적이고 반복적인 지능적 행동을 지원하기 위해, 특히 개인화와 장기 지식 축적이 중요할 때, 단기 대화 컨텍스트만으로는 턱없이 부족합니다. 이것이 장기적이고 구조화된 메모리의 필요성으로 이어집니다.
이것이 바로 RAG가 점점 더 에이전트의 장기 메모리 시스템 역할을 부여받고 전체 외부 메모리 아키텍처를 구축하는 데 사용되는 이유입니다. 이 장기 메모리는 현재 대화 컨텍스트 유지를 담당하는 단기 메모리를 보완합니다. 장기 메모리 시스템은 세 가지 핵심 메커니즘에 의존합니다:
- 구조화된 인덱싱 능력: 이를 통해 에이전트는 방대한 양의 비정형 데이터에 대해 시간, 주제, 엔티티 관계 등에 따라 다차원 인덱스를 구축할 수 있어, 인간이 다른 단서를 통해 정보를 회상하는 것과 같이 여러 각도에서 효율적인 검색을 지원합니다.
- 지능적 망각: 가치 평가 알고리즘을 통해 시스템은 저빈도, 약하게 관련되거나 구식인 정보를 감쇠시키거나 선택적으로 폐기하여 메모리 시스템을 날렵하고 효율적으로 유지하며 과부하를 방지합니다.
- 지식 통합: 시스템은 흩어진 대화와 상호작용 경험을 구조화된 지식으로 정제합니다. 엔티티 인식, 관계 추출 및 의미론적 클러스터링을 통해 파편화된 정보를 지식 그래프로 연결하여 단기 경험을 장기 지식으로 전환합니다.
RAG 위에 구축된 이 외부 메모리 시스템은 에이전트의 인지 경계를 크게 확장할 뿐만 아니라, 지식을 지속적으로 학습하고 진화시키는 능력을 부여합니다. 에이전트가 장기 상호작용을 통해 경험을 축적하고, 개인화된 운영 패턴과 도메인 지식 시스템을 형성하며, 더 복잡하고 장기 실행되는 작업을 지원할 수 있게 합니다.
요약
검색 증강 생성은 대규모 모델의 환각과 지식 노후화를 보상하는 기술적 방법일 뿐만 아니라, 범용 AI 역량을 깊은 기업 가치로 전환하는 핵심 교량입니다. Naive RAG에서 모듈형 및 에이전트 형태로의 진화는 더 세밀한 데이터 처리, 임베딩, 리랭크 및 LLM 단계에 걸친 더 과학적인 모델 선택, 그리고 더 체계적인 평가를 포함하여 RAG의 모든 부분이 지속적으로 심화되어야 함을 보여줍니다. 이 모든 것은 통제 가능하고 신뢰할 수 있으며 효율적인 기업 지식 시스템을 구축하기 위한 필수적인 단계입니다. 동시에 대회와 엔지니어링 사례 연구에서 교훈을 얻는 것은 기술적 세부 사항에 대한 이해를 심화하는 가장 좋은 방법 중 하나입니다.
Graph RAG, 멀티모달 이해 및 Late Chunking이 계속 발전하고 결합됨에 따라 RAG는 꾸준히 예전의 검색과 생성 경계를 넘어 더 깊은 의미론적 연관과 더 지속 가능한 메모리 역량을 향해 나아가고 있습니다. 이 서베이 스타일의 글이 원리에서 실무까지, 평가에서 진화까지 전체 체인 방법론을 구축하는 데 도움이 되기를 바라며, 빠르게 변화하는 기술 환경에서 실제로 착지하여 복잡한 비즈니스 과제를 처리할 수 있는 고품질 지능형 애플리케이션을 구축할 수 있기를 바랍니다.
참고문헌
[1] Ask in Any Modality: A Comprehensive Survey on Multimodal Retrieval-Augmented Generation.
https://arxiv.org/pdf/2502.08826
[2] Retrieving Multimodal Information for Augmented Generation: A Survey.
https://arxiv.org/pdf/2303.10868
[3] A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models.
https://arxiv.org/pdf/2405.06211
[4] Retrieval-Augmented Generation for Large Language Models: A Survey.
https://arxiv.org/pdf/2312.10997
[5] LightRAG: Simple and Fast Retrieval-Augmented Generation.
https://arxiv.org/pdf/2410.05779
[6] Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG.
https://arxiv.org/pdf/2501.09136
[7] ERAGent: Enhancing Retrieval-Augmented Language Models with Improved Accuracy, Efficiency, and Personalization.
https://arxiv.org/pdf/2405.06683
[8] Graph Retrieval-Augmented Generation: A Survey.
https://www.arxiv.org/pdf/2408.08921
[9] Evaluation of Retrieval-Augmented Generation: A Survey.
https://arxiv.org/pdf/2405.07437
[10] Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey.
https://arxiv.org/pdf/2504.14891
[11] From Local to Global: A Graph RAG Approach to Query-Focused Summarization.
https://arxiv.org/pdf/2404.16130
[12] RAG vs. GraphRAG: A Systematic Evaluation and Key Insights.
https://arxiv.org/pdf/2502.11371
[13] Introduction to RAG | LlamaIndex Python Documentation.
https://developers.llamaindex.ai/python/framework/understanding/rag/
[14] All-in-RAG | A Full-Stack Guide to RAG in Large-Model Application Development.
https://datawhalechina.github.io/all-in-rag/#/en/
[15] Ilya Rice: How I Won the Enterprise RAG Challenge.
https://abdullin.com/ilya/how-to-build-best-rag/
[16] RAG Research Table - Awesome Generative AI Guide (GitHub).
[17] RAG is dead, long live agentic retrieval.
https://www.llamaindex.ai/blog/rag-is-dead-long-live-agentic-retrieval
[18] LLM/RAG Zoomcamp extra lesson 5: Common evaluation methods and market preferences in RAG evolution.
https://vip.studycamp.tw/t/llmrag-zoomcamp-課外補充-5:rag-evolution-常見評估方法和市場偏好/8185
[19] How to Evaluate Retrieval Augmented Generation (RAG) Applications.
https://zilliz.com.cn/blog/how-to-evaluate-rag-zilliz
[20] RAG is not Agent Memory.
https://www.letta.com/blog/rag-vs-agent-memory
[21] Richmond Alake. LinkedIn post on #100DaysOfAgentMemory, RAG and MemoRizz.