مع اعتماد النماذج اللغوية الكبيرة (LLMs) على نطاق أوسع، تواجه المؤسسات مشكلة عملية للغاية: كيف يمكن للنموذج الإجابة على الأسئلة بدقة عندما تعتمد هذه الأسئلة على وثائق داخلية أو بيانات في الوقت الفعلي أو معرفة متخصصة في مجال معين؟ في النهاية، بيانات تدريب النموذج محدودة ومقيدة زمنيًا، لذا لا يمكنها تغطية المعرفة المتعلقة بالأعمال الخاصة بالشركة أو المعلومات المحدثة باستمرار.
فكرة بديهية واحدة هي: نظرًا لأن نوافذ السياق تستمر في التوسع، من 8K إلى 128K والآن تتجاوز مليون رمز، لماذا لا نضع الوثائق ذات الصلة ببساطة في الموجه ونترك النموذج يجيب من تلك المواد مباشرة؟
ومع ذلك، القدرة على معالجة السياق الطويل والقدرة على تقديم إجابات صحيحة بشكل مستقر وفعال وقابل للتحكم في سيناريوهات المؤسسات هما أمران مختلفان تمامًا. الاعتماد الأعمى على السياق الطويل يجلب سلسلة من التحديات الشديدة، بما في ذلك التكلفة المتفاقمة، وتشتت الانتباه، وتحديثات المعرفة القديمة.
لحل هذه النقاط المؤلمة، ظهرت تقنية تسمى التوليد المعزز بالاسترجاع، أو RAG. قبل أن يقوم النموذج بتوليد إجابة، يقوم RAG أولاً باسترجاع المعرفة الخارجية الدقيقة. مقارنة ببساطة توسيع طول السياق بطريقة القوة الغاشمة، يلبي RAG متطلبات المؤسسات للدقة الواقعية والمعرفة الطازجة بتكلفة أقل، مع دقة أعلى وقابلية تحكم أقوى. لذلك أصبح أساسًا رئيسيًا لبناء تطبيقات ذكاء اصطناعي موثوقة.
في هذا البرنامج التعليمي، سنشرح بشكل منهجي ما هو RAG، وتتبع الخلفية وراء ظهوره ومبادئه الأساسية، ثم نستكشف تطوره من الأشكال الأساسية إلى الأشكال المتقدمة، إلى جانب أين قد يتجه بعد ذلك.
ما ستتعلمه في هذا الدرس
- القيمة الأساسية لـ RAG: فهم عميق لكيفية معالجة المشاكل المركزية للسياق الطويل من حيث التكلفة والانتباه وحداثة المعرفة
- كيف يعمل RAG: فهم من خلال أمثلة ملموسة كيف يكمل الحلقة الكاملة من الاسترجاع إلى التوليد
- تطور RAG: من Naive RAG الأساسي إلى Advanced RAG ثم إلى Modular RAG
- اختيار النموذج لـ RAG: فهم كيفية تقييم واختيار أنواع النماذج الرئيسية الثلاثة، Embedding وRerank وLLM
- ممارسة RAG للمؤسسات: تعلم دليل البناء الكامل للسلسلة من المعالجة المسبقة للبيانات إلى نشر النظام والتقييم
- تقييم RAG وتحسينه: فهم المقاييس الأساسية والأطر السائدة وطرق التحسين المستمر
- الاتجاهات الحدودية في RAG: استكشاف كيف يتحد RAG مع الوكلاء وتعدد الوسائط والتقنيات الناشئة الأخرى
ما ستكسبه
بعد إكمال هذا البرنامج التعليمي، ستبني فهمًا منهجيًا على مستوى المبتدئين لتقنية RAG. لن تعرف فقط ما هو، بل أيضًا لماذا يعمل. ستكسب أيضًا خريطة طريق واضحة لكيفية تقييم واختيار وتصميم نظام RAG فعال وموثوق وقابل للتحكم يلبي متطلبات المؤسسات، مما يضع أساسًا متينًا لبناء تطبيقات RAG حقيقية على مستوى المؤسسات.
1. لماذا يُحتاج RAG
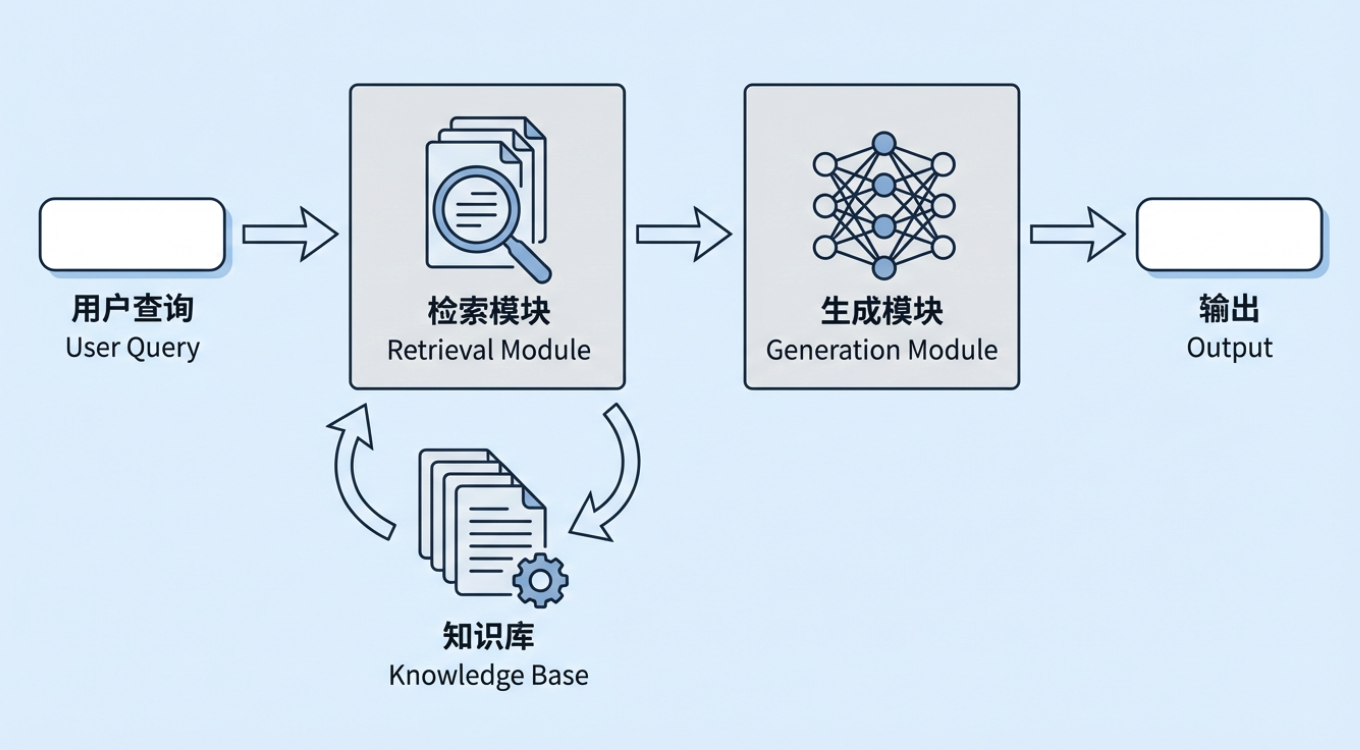
التوليد المعزز بالاسترجاع (RAG) هو أحد أهم المناهج التقنية في الذكاء الاصطناعي التوليدي اليوم. فكرته الأساسية بسيطة: قبل أن يُطلب من النموذج الكبير توليد إجابة، يقوم النظام أولاً باسترجاع المعلومات المتعلقة بسؤال المستخدم من قاعدة معرفة خارجية، ثم يمرر كل من المعلومات المسترجعة والسؤال الأصلي إلى النموذج حتى يتمكن النموذج من الإجابة بناءً على مواد حقيقية. يمكن أن تكون قاعدة المعرفة الخارجية هذه السياسات الداخلية للمؤسسة، ووثائق العمليات، والمعرفة بالمنتجات، أو قاعدة بيانات صناعية، ومجموعة اللوائح، ومكتبة المعايير، وما إلى ذلك.
في هذه المرحلة، يظهر سؤال طبيعي: إذا كانت النماذج الكبيرة يمكن بالفعل "الإجابة على الأسئلة مباشرة"، فلماذا نضيف طبقة أخرى تسمى التوليد المعزز بالاسترجاع؟ خاصة الآن مع استمرار نوافذ السياق في التوسع، قد يبدو وكأن مجرد تسليم كل المواد ذات الصلة للنموذج يجب أن يحل معظم الاحتياجات.
الفرق الحقيقي هو أن "القدرة على إنتاج إجابة" و"القدرة على إنتاج الإجابة الصحيحة بشكل مستمر ومستقر وقابل للتحكم في بيئة أعمال حقيقية" هما شيئان مختلفان تمامًا. إذا اعتمدت فقط على ذاكرة معلمات النموذج، أو فقط على إلقاء كميات كبيرة من الوثائق في سياق طويل، تظهر ثلاث مشاكل نموذجية على الأقل في الاستخدام المؤسسي.
مشاكل التكلفة والكفاءة: حتى مع استمرار توسع نوافذ السياق، فإن فكرة إلقاء جميع الوثائق في السياق دفعة واحدة لا تزال غير عملية في الأنظمة الحقيقية. التناقض المركزي يظهر في مكانين:
تكلفة الاستدلال مرتبطة بشكل إيجابي قوي بطول السياق. كلما طال السياق، زادت تكلفة الاستدلال، بشكل شبه خطي وأحيانًا حتى بشكل فوق خطي. لمكالمة واحدة، 8K رمز و200K رمز يعيشان في نطاقات سعر وزمن مختلفة تمامًا، والسياق الطويل له عتبة تكلفة أعلى بكثير.
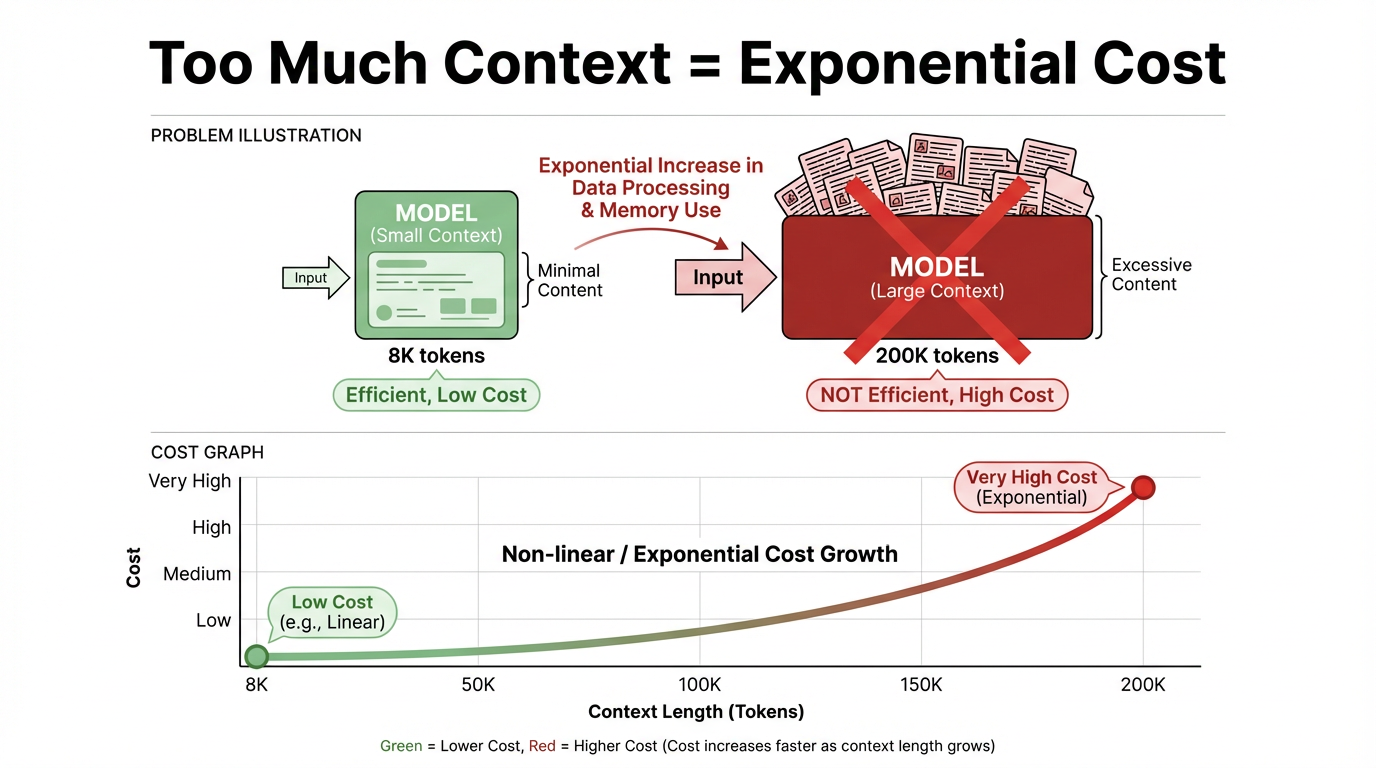
في المعنى، السياق هو المعلومات الأساسية وتاريخ المحادثة الذي "يرجع إليه" النموذج عند الإجابة على سؤال. من الناحية التقنية، هو تسلسل الرموز الكلي الذي يتم تغذيته في النموذج لاستنتاج واحد، مثل تعليمات النظام والمستخدم، وتاريخ الرسائل، والمقاطع المسترجعة.
"نافذة السياق" هي حد السعة لتلك المدخلات. في بنيات النماذج الكبيرة السائدة اليوم، مثل Transformers، تشارك تلك الرموز في حساب الانتباه في كل طبقة. بمجرد أن تصبح النافذة أطول وزاد عدد الرموز، ترتفع الحسابات والتكلفة بشكل مضاعف ويمكن أن تقترب حتى من النمو الأسي.
يتم إهدار كمية كبيرة من الحسابات. معظم المهام تحتاج فقط إلى كمية صغيرة جدًا من المعلومات ذات الصلة العالية بالسؤال الحالي. حشو مجموعة الوثائق الكاملة في السياق يخلق حسابات خاملة ومهدرة خطيرة، ويخفض إنتاجية النظام، ويبطئ سرعة الاستجابة، وفي النهاية يضر بتجربة المستخدم.
مشاكل الانتباه والتركيز: قد يتمكن النموذج الكبير من "تغطية" السياق الفائق الطول، لكنه لا يمكنه استخدام كل جزء بنفس الجودة. بمجرد أن يتجاوز طول السياق عتبة معينة، يبدأ النموذج في إظهار تحيز انتباه واضح:
اضمحلال الانتباه: يضعف انتباه النموذج إلى الأجزاء المبكرة والمتوسطة من السياق تدريجيًا، ويميل إلى الاعتماد أكثر على النص الذي قرأه لاحقًا، لذلك يمكن تجاهل المعلومات الحرجة المبكرة بشكل فعال.
تداخل المعلومات: يمكن سحب النموذج بسهولة خارج المسار بواسطة معلومات غير ذات صلة أو متكررة أو حتى متضاربة داخل السياق. قد تبدو الإجابة النهائية متماسكة منطقيًا بينما لا تزال تنحرف عن السؤال الأساسي، مما يجعل ضمان الدقة أمرًا صعبًا. بدون مرحلة استرجاع لتصفية وترتيب الصلة بالنيابة، كلما طال السياق، أصبح من الصعب إبقاء الإجابة مركزة على الأدلة الحقيقية الرئيسية. يمكن إلغاء ميزة السياق الطويل بالكامل بسبب تداخل المعلومات.
مشاكل حداثة المعرفة وقابلية التحكم: إذا تم تخزين كل المعرفة بالكامل في معلمات النموذج، أو نسخها يدويًا في الموجهات، يظهر عيبان لا يمكن تجنبهما:
تحديثات المعرفة صعبة: بمجرة تغير المعرفة، مثل التغييرات في السياسات، أو تكرارات المنتجات، أو تحديثات الأسعار، تحتاج إما إلى إعادة تدريب النموذج أو ضبطه بدقة، وهو مكلف وبطيء، أو الحفاظ على قوالب الموجهات يدويًا، وهو مكلف أيضًا وعرضة للخطأ البشري.
إمكانية التتبع ضعيفة: عندما يجيب النموذج، غالبًا ما يصعب تحديد الأدلة الدقيقة إما من المعلمات الصندوق الأسود أو الموجهات الطويلة. هذا يجعل عمليات التدقيق المتعلقة بالامتثال، وشروحات المخاطر، والمهام الأخرى التي تتطلب أسباب قرار واضحة أمرًا صعبًا للغاية.
في ظل هذه القيود الحقيقية، تصبح ميزة RAG أوضح بكثير. نهجه الأساسي هو تحديد المعلومات ذات الصلة والموثوقة قبل التوليد، لذلك يجيب النموذج فقط من المعرفة الضرورية. يمكن تخزين المعرفة بشكل مستقل في قاعدة معرفة خارجية، مما يسهل تحديثها وإدارتها. في نفس الوقت، يمكن أن تتضمن النتائج المولدة مصادر مقتبسة، مما يحسن القابلية للتفسير والثقة. حتى لو استمرت نوافذ السياق في النمو في المستقبل، سيظل RAG يمكّن الإدارة الفعالة للمعرفة واستخدامها بتكلفة منخفضة نسبيًا، داعمًا تطبيقات المعرفة على مستوى المؤسسات التي تكون عمليتها قابلة للملاحظة وسلوكها قابل للتتبع.
من منظور متطلبات المؤسسات، مقارنة مع LLM التقليدي الذي يعتمد فقط على معلماته الداخلية، يحل RAG بشكل أساسي مشاكل النشر الحقيقية التالية:
- الحداثة: النماذج التقليدية عادة لا تعرف اللوائح أو المنتجات أو سير العمل الجديدة التي ظهرت بعد تاريخ قطع تدريبها، لكن RAG يمكنه قراءة أحدث وثائق السياسات وقواعد بيانات الأعمال وقواعد المعرفة مباشرة. بدون إعادة تدريب متكررة، يمكن للإجابات البقاء متزامنة مع أحدث حالة للأعمال.
- التخصص: في المجالات العمودية مثل الرعاية الصحية أو الكيماويات أو المالية، غالبًا لا تفهم النماذج ذات الأغراض العامة بعمق كافٍ أو تتحدث بدقة كافية. بعد ربط وثائق المجال المملوكة للمؤسسة ومعايير الصناعة، يمكن أن تستند الإجابات إلى مواد موثوقة وتصبح أقرب بكثير إلى ممارسة الأعمال الحقيقية.
- الهلوسة: من خلال مطالبة الإجابات بالبقاء مبنية على المقاطع المسترجعة وتقديم الاستشهادات، يمكن للنظام تقليل التلفيق غير المدعوم على مستوى الآلية، مما يجعل "يبدو صحيحًا" أقرب بكثير إلى "صحيح فعلاً".
- القابلية للتفسير والتدقيق: النماذج القائمة على المعلمات بحتة غالبًا لا يمكنها الإجابة، "من أي قاعدة اشتُق هذا الاستنتاج؟" يتيح RAG تتبع كل إجابة إلى بند سياسة محدد، أو وثيقة أعمال، أو حالة تاريخية. ذلك يساعد موظفي الأعمال على فحص وتصحيح الإجابات ويعطي فرق التدقيق والمخاطر والامتثال إمكانية التتبع التي يحتاجونها.
- تكلفة الحسابات وكفاءة الموارد: جعل النموذج يحفظ كل معرفة المؤسسة في معلماته عادة يعني نموذجًا أكبر وتكلفة استدلال أعلى. يخزن RAG معظم المعرفة خارج النموذج في مخازن المتجهات ومخازن الوثائق ويسترجعها عند الطلب، مما يسمح للمؤسسات بالحصول على تغطية أوسع وتفاصيل أكثر دقة حتى مع نماذج أصغر وحسابات محدودة.
لذلك، بالنسبة للمؤسسات التي ترغب في استخدام النماذج الكبيرة في سيناريوهات الأعمال الحقيقية على المدى الطويل، بشكل مستقر وقابل للتحكم، RAG ليس تحسينًا اختياريًا. إنه تقنية أساسية ضرورية تقريبًا لبناء نظام تطبيق معرفة مؤسسي عالي الجودة.
2. ما هو RAG
الفكرة الأساسية لـ RAG، التوليد المعزز بالاسترجاع، هي السماح للنموذج الكبير بالإجابة على الأسئلة ليس فقط بالمعرفة الثابتة التي تعلمها أثناء التدريب، ولكن أيضًا بالمعلومات المحدثة والموثوقة المسحوبة من قاعدة معرفة خارجية في وقت التشغيل.
في نظام RAG نموذجي، لا يتم إرسال سؤال المستخدم مباشرة إلى النموذج الكبير. بدلاً من ذلك، تجد وحدة الاسترجاع أولاً مقاطع الوثائق الأكثر صلة من قاعدة معرفة المؤسسة، ثم تجمع تلك المقاطع مع السؤال الأصلي في سياق كامل، وتعطي ذلك أخيرًا للنموذج لتوليد إجابة. نمط "استرجع أولاً، ولد ثانيًا" هذا يسمح للنموذج بالاستنتاج من مواد مرجعية حقيقية بدلاً من التخمين فقط مما يتذكره في معلماته. يمكننا النظر في حالة نموذجية:
مرحلة الفهرسة
في مرحلة الفهرسة، يعالج النظام أولاً المواد الخام مثل الوثائق الداخلية للمؤسسة وصفحات الويب والتقارير. يقسمها إلى أجزاء دلالية أصغر، ثم يستخدم نموذج التضمين لتوليد تمثيلات متجهة لكل جزء ويبني فهرسًا. لاحقًا، عندما يصل سؤال مستخدم، يمكن للنظام العثور بسرعة على الأجزاء الأكثر تشابهًا دلاليًا في فضاء المتجهات.
في الرسم التخطيطي، يتوافق هذا مع منطقة "الفهرسة" البنفسجية في أعلى اليمين. المسار من "الوثائق" عبر "الأجزاء / المتجهات" إلى "التضمينات" يوضح تقسيم الوثائق إلى أجزاء، وتحويلها إلى متجهات، وكتابتها في الفهرس. بشكل أكثر تحديدًا:
- يتم تقسيم الوثائق إلى مجموعة من الأجزاء المتماسكة دلاليًا، كل منها قد يتوافق مع مقطع أخبار قصير، أو شرح، أو تحليل.
- يتم تحويل كل جزء إلى متجه عالي الأبعاد بواسطة نموذج التضمين وتخزينه في فهرس المتجهات.
- يدعم هذا الفهرس الاسترجاع القائم على التشابه لاحقًا، محضرًا قاعدة معرفة يمكن للنظام الرجوع إليها عند الإجابة على الأسئلة.
مرحلة الاسترجاع مع توليد الإجابة من النتائج المسترجعة
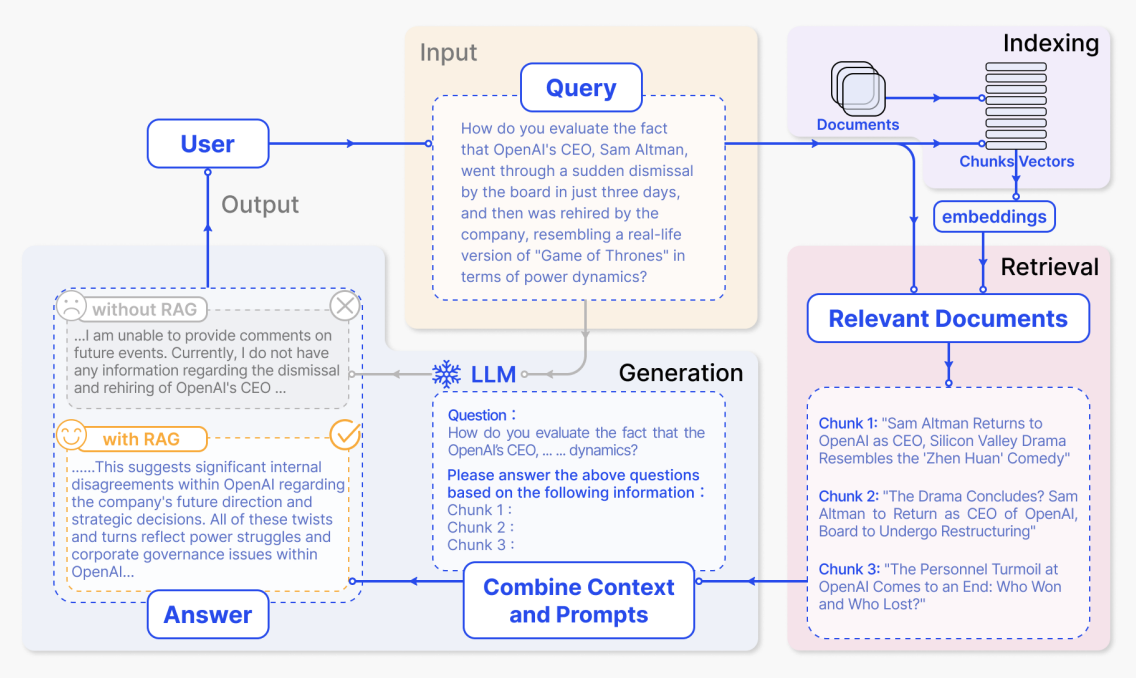
بعد أن يطرح المستخدم سؤالاً، يسترجع النظام أولاً المحتوى ذي الصلة من الفهرس، ثم يرسل السؤال والنص المسترجع معًا إلى النموذج الكبير لتوليد إجابة. في الشكل، تتوافق المناطق الرئيسية من أعلى إلى أسفل ومن اليمين إلى اليسار بالضبط مع هذا التدفق الكامل.
(1) سؤال إدخال المستخدم: منطقة الإدخال - الاستعلام الصفراء
"كيف تقيّم حقيقة أن الرئيس التنفيذي لشركة OpenAI، سام ألتمان، مرّ بفصل مفاجئ من قبل مجلس الإدارة في ثلاثة أيام فقط، ثم أعيد توظيفه من قبل الشركة، مما يشبه نسخة واقعية من 'لعبة العروش' من حيث ديناميكيات السلطة؟"
"كيف تقيّم حقيقة أن رئيس OpenAI التنفيذي سام ألتمان فُصل فجأة من قبل مجلس الإدارة ثم أُعيد توظيفه من قبل الشركة بعد ثلاثة أيام فقط، مما يجعل صراع السلطة يشبه نسخة واقعية من لعبة العروش؟"
هذه الكتلة الكبيرة من النص هي المحتوى داخل صندوق "الاستعلام" في الرسم التخطيطي، تتوافق مع سؤال المستخدم باللغة الطبيعية. يقوم النظام بتحويل هذا السؤال إلى متجه ويستخدمه للبحث في الفهرس في أعلى اليمين عن أجزاء الوثائق ذات الصلة.
(2) الوثائق ذات الصلة المسترجعة: منطقة الوثائق ذات الصلة الوردية في أسفل اليمين
بعد الاسترجاع، يحصل النظام على عدة أجزاء وثائق أكثر ارتباطًا بالسؤال. في الرسم التخطيطي، تظهر كثلاثة أجزاء:
"سام ألتمان يعود إلى OpenAI كرئيس تنفيذي، دراما وادي السيليكون تشبه كوميديا 'تشين هوان'" "سام ألتمان يعود كرئيس تنفيذي لـ OpenAI، وهذه الدراما في وادي السيليكون تشبه كوميديا مؤامرة البلاط."
"الدراما تنتهي؟ سام ألتمان سيعود كرئيس تنفيذي لـ OpenAI، مجلس الإدارة سيخضع لإعادة هيكلة" "هل تنتهي الدراما؟ سيعود سام ألتمان كرئيس تنفيذي لـ OpenAI، بينما سيتم إعادة هيكلة مجلس الإدارة."
"الاضطرابات الشخصية في OpenAI تنتهي: من فاز ومن خسر؟" "الاضطرابات الشخصية في OpenAI تنتهي: من فاز ومن خسر؟"
(3) دمج الموجه وتوليد الإجابة: منطقة LLM / دمج السياق والموجهات الزرقاء
ثم يجمع النظام سؤال المستخدم الأصلي والأجزاء المسترجعة في موجه كامل ويرسله إلى النموذج. يُظهر الصندوق المتقطع في وسط أسفل الشكل مثالًا على موجه:
"سؤال: كيف تقيّم حقيقة أن الرئيس التنفيذي لـ OpenAI، ... الديناميكيات؟
يرجى الإجابة على الأسئلة أعلاه بناءً على المعلومات التالية: الجزء 1: الجزء 2: الجزء 3:"
"سؤال: كيف تقيّم صراع السلطة في حادثة الرئيس التنفيذي لـ OpenAI؟
يرجى الإجابة على السؤال أعلاه بناءً على المعلومات أدناه: الجزء 1: الجزء 2: الجزء 3:"
(4) مقارنة الإجابة مع وبدون RAG: مناطق الإخراج - الإجابة الرمادية والصفراء في أسفل اليسار
أخيرًا، يولد النموذج إجابة بناءً على المعلومات المقدمة. يقارن الشكل أيضًا المخرجات مع وبدون RAG. بدون RAG، لا يمتلك النموذج مواد خارجية ويمكنه فقط تقديم استجابة غامضة، تتوافق مع الصندوق الرمادي:
"... لا أستطيع تقديم تعليقات حول الأحداث المستقبلية. حاليًا ليس لدي أي معلومات بخصوص فصل وإعادة توظيف الرئيس التنفيذي لـ OpenAI ..."
مع RAG، يمكن للنموذج استخدام الأخبار والتحليلات المسترجعة لإنتاج إجابة أكثر إفادة بكثير، تتوافق مع الصندوق الأصفر:
"... يشير هذا إلى خلافات داخلية كبيرة داخل OpenAI بشأن الاتجاه المستقبلي للشركة والقرارات الاستراتيجية. كل هذه التقلبات والتحولات تعكس صراعات السلطة وقضايا الحوكمة المؤسسية داخل OpenAI ..."
المثال أعلاه يوضح التدفق الكامل لنظام RAG نموذجي ويساعدنا على فهم مراحله الأساسية وكيف تتحرك المعلومات عبرها. لكن العديد من التفاصيل التقنية المهمة لا تزال داخل صندوق أسود: كيف يتم إجراء مطابقة المتجهات بالضبط، وكيف يجب تنظيم الموجه حتى يتمكن النموذج من استخدام المحتوى المسترجع بشكل أكثر فعالية؟ هذه التفاصيل تحدد جودة RAG الحقيقية إلى حد كبير. بعد ذلك، سنتعمق في الآلية الداخلية لـ RAG ونفككها خطوة بخطوة، من مبادئ التوجيه وحساب التشابه إلى هندسة الموجهات.
3. كيف يعمل RAG
يمكننا تفكيكه من خلال مثال بسيط للإجابة على الأسئلة مبني على قاعدة معرفة حول "تفاحة".
3.1 مرحلة تحويل الوثائق إلى متجهات
لنفترض أن لدينا قاعدة معرفة مبسطة تحتوي على هذه المقاطع الوثائقية الثلاثة:
- المقطع أ: تأسست شركة Apple Inc. في 1 أبريل 1976 على يد ستيف جوبز وستيف وزنياك ورونالد واين، ومقرها في كوبرتينو، كاليفورنيا.
- المقطع ب: التفاح فاكهة غنية بفيتامين C والألياف الغذائية، مما يساعد على الهضم وصحة الجهاز المناعي.
- المقطع ج: أطلقت شركة Apple Inc. أول iPhone في عام 2007، مما غيّر صناعة الهواتف الذكية جذريًا.
عندما نعالج هذه الوثائق بنموذج تضمين، مثل text-embedding-ada-002 من OpenAI أو نموذج BGE مفتوح المصدر، يتم تحويل كل مقطع إلى متجه عالي الأبعاد، غالبًا بأبعاد 768 أو 1024 أو 1536.
المتجه هو في الأساس مصفوفة مكونة من العديد من القيم العددية. كل بُعد يتوافق مع ميزة دلالية للنص. على سبيل المثال، قد يحتوي متجه "قطة" على أبعاد تتعلق بالثدييات، والحيوانات الأليفة المنزلية، والفرو. المزيج النهائي من القيم يلتقط المعنى الدلالي للنص بحيث يمكن للكمبيوتر "فهم" العلاقات بين النصوص.
أمثلة مبسطة، مع كون المتجهات الحقيقية أعلى بكثير في الأبعاد:
- متجه المقطع أ، عن تأسيس Apple:
[0.85, -0.23, 0.41, -0.56, 0.12, 0.78, ...] - متجه المقطع ب، عن التفاح كفاكهة:
[-0.12, 0.95, -0.34, 0.67, -0.89, 0.05, ...] - متجه المقطع ج، عن إطلاق iPhone:
[0.79, -0.18, 0.52, -0.61, 0.23, 0.81, ...]
تحتاج هذه المتجهات بعد ذلك إلى التخزين في قاعدة بيانات متجهات، مثل Pinecone أو Weaviate أو FAISS، للاسترجاع والاستدعاء لاحقًا.
قاعدة البيانات هي نظام يخزن ويدير البيانات بطريقة منظمة، مما يتيح التخزين المنظم والاسترجاع الفعال. تشمل الأمثلة الشائعة قوائم جهات الاتصال وكتالوجات منتجات التجارة الإلكترونية.
قاعدة بيانات المتجهات هي نوع متخصص من قواعد البيانات. على عكس قواعد البيانات التقليدية، التي تخزن النصوص والجداول وهياكل البيانات العادية الأخرى، تم تصميم قاعدة بيانات المتجهات خصيصًا لتخزين المتجهات، أي المصفوفات العددية عالية الأبعاد، وهي محسّنة للبحث عن التشابه في سيناريوهات الذكاء الاصطناعي.
3.2 مرحلة استعلام المستخدم والاسترجاع والاستجابة
بمجرد تحويل قاعدة المعرفة إلى متجهات وتخزينها، يمكن لنظام RAG دعم استعلامات المستخدم في الوقت الفعلي. عندما يطرح المستخدم سؤالاً، ينفذ النظام تدفقًا مستمرًا: يحول أولاً السؤال إلى متجه، ثم يستخدم حساب التشابه لاسترجاع المعلومات الأكثر صلة من قاعدة المعرفة، وأخيرًا يستخدم تلك المقاطع كأساس لتوليد الإجابة. يمكننا توضيح هذه العملية بثلاثة استعلامات ملموسة.
الاستعلام 1: "متى تأسست شركة Apple Inc.؟"
في مرحلة تحويل الاستعلام إلى متجهات، يتم تحويل السؤال بواسطة نموذج التضمين إلى متجه دلالي، على سبيل المثال [0.82, -0.21, 0.38, -0.58, 0.15, 0.76, ...]. هذا النمط العددي مشابه جدًا لمتجه المقطع أ المخزن، المقطع المتعلق بتأسيس الشركة.
ثم يقوم النظام بإجراء استرجاع بالتشابه، Top-K مع K = 2، عن طريق حساب تشابه جيب التمام بين متجه الاستعلام وجميع متجهات الوثائق في قاعدة المعرفة. تبدو النتيجة كالتالي:
- التشابه مع المقطع أ، مقطع التأسيس: 0.97، ذو صلة عالية
- التشابه مع المقطع ج، مقطع إطلاق iPhone: 0.88، ذو صلة لأنه يتعلق أيضًا بالشركة
- التشابه مع المقطع ب، مقطع تغذية الفاكهة: 0.12، غير ذي صلة تقريبًا
Top-K هي استراتيجية اختيار شائعة في استرجاع المتجهات. تعني ترتيب جميع التطابقات من الأعلى إلى الأقل تشابهًا والاحتفاظ بأفضل K نتائج. K = 2 يعني أن النظام يحتفظ فقط بأفضل متجهي وثائق من حيث التشابه ويصفية المرتبة الأقل، بحيث تولد المرحلة التالية الإجابة فقط من مقطعي الوثائق الأكثر صلة.
النتائج التي تم تصفيتها بالتشابه تسمى نتائج الاستدعاء. يعيد النظام أفضل مقطعين كأدلة:
- المقطع أ، تشابه 0.97: "تأسست شركة Apple Inc. في 1 أبريل 1976 على يد ستيف جوبز وستيف وزنياك ورونالد واين، ومقرها في كوبرتينو، كاليفورنيا."
- المقطع ج، تشابه 0.88: "أطلقت شركة Apple Inc. أول iPhone في عام 2007، مما غيّر صناعة الهواتف الذكية جذريًا."
في مرحلة توليد الإجابة، يبني النظام مدخلًا منظمًا كاملاً بوضع المحتوى المستدعى داخل قسم المعلومات المرجعية وإرساله معًا مع موجه نظام:
[موجه النظام]
أنت مساعد محترف للإجابة على الأسئلة. يرجى الإجابة بدقة وفقًا لـ "المعلومات المرجعية" التي قدمها المستخدم.
إذا كانت المعلومات المرجعية تحتوي على الإجابة، فأجب بناءً عليها مباشرة.
إذا لم تحتوِ المعلومات المرجعية على الإجابة، أخبر المستخدم بوضوح بأنه "لا يمكن الإجابة على السؤال بناءً على المواد المتاحة حاليًا"، ولا تلفق معلومات.
يرجى الإشارة إلى نقطة المعلومات التي تستند إليها إجابتك.
[السياق المسترجع]
تأسست شركة Apple Inc. في 1 أبريل 1976 على يد ستيف جوبز وستيف وزنياك ورونالد واين، ومقرها في كوبرتينو، كاليفورنيا.
أطلقت شركة Apple Inc. أول iPhone في عام 2007، مما غيّر صناعة الهواتف الذكية جذريًا.
[استعلام المستخدم]
متى تأسست شركة Apple Inc.؟بعد تلقي هذا المدخل المنظم، يتبع LLM تعليمات النظام ويعامل السياق المسترجع كمصدر موثوق وحيد للإجابة. ستكون استجابته النهائية كالتالي:
وفقًا للمعلومات المرجعية المقدمة، تأسست شركة Apple Inc. في 1 أبريل 1976. [الأساس: المعلومات 1]
الاستعلام 2: "ما هي فوائد أكل التفاح؟"
في مرحلة تحويل الاستعلام إلى متجهات، يتم تحويل هذا السؤال إلى متجه دلالي مثل [-0.08, 0.92, -0.31, 0.71, -0.85, 0.08, ...]. نمطه العددي مشابه جدًا لمتجه المقطع ب المخزن، المقطع المتعلق بتغذية التفاح.
يقوم النظام مرة أخرى بإجراء استرجاع بالتشابه Top-K مع K = 2 وحساب تشابه جيب التمام:
- التشابه مع المقطع ب، تغذية الفاكهة: 0.95، ذو صلة عالية
- التشابه مع المقطع ج، إطلاق iPhone: 0.18، غير ذي صلة تقريبًا
- التشابه مع المقطع أ، تأسيس الشركة: 0.15، غير ذي صلة تقريبًا
يعيد النظام أفضل مقطعين كأدلة:
- المقطع ب، تشابه 0.95: "التفاح فاكهة غنية بفيتامين C والألياف الغذائية، مما يساعد على الهضم وصحة الجهاز المناعي."
- المقطع ج، تشابه 0.18: "أطلقت شركة Apple Inc. أول iPhone في عام 2007، مما غيّر صناعة الهواتف الذكية جذريًا." هذا مرتبط بشكل ضعيف فقط وغالبًا ما يتم تصفيته بعتبة في الممارسة.
ثم يتم بناء المدخل المنظم الكامل على النحو التالي:
[موجه النظام]
أنت مساعد محترف للإجابة على الأسئلة. يرجى الإجابة بدقة وفقًا لـ "المعلومات المرجعية" التي قدمها المستخدم.
إذا كانت المعلومات المرجعية تحتوي على الإجابة، فأجب بناءً عليها مباشرة.
إذا لم تحتوِ المعلومات المرجعية على الإجابة، أخبر المستخدم بوضوح بأنه "لا يمكن الإجابة على السؤال بناءً على المواد المتاحة حاليًا"، ولا تلفق معلومات.
يرجى الإشارة إلى نقطة المعلومات التي تستند إليها إجابتك.
[السياق المسترجع]
التفاح فاكهة غنية بفيتامين C والألياف الغذائية، مما يساعد على الهضم وصحة الجهاز المناعي.
أطلقت شركة Apple Inc. أول iPhone في عام 2007، مما غيّر صناعة الهواتف الذكية جذريًا.
[استعلام المستخدم]
ما هي فوائد أكل التفاح؟ستكون استجابته النهائية كالتالي:
وفقًا للمعلومات المرجعية المقدمة، التفاح غني بفيتامين C والألياف الغذائية، وأكل التفاح يساعد على الهضم وصحة الجهاز المناعي. [الأساس: المعلومات 1]
الاستعلام 3: "كيف حال الطقس اليوم؟"
في مرحلة تحويل الاستعلام إلى متجهات، يصبح هذا السؤال متجهًا دلاليًا متعلقًا بالطقس والأرصاد الجوية، على سبيل المثال [0.10, -0.05, 0.30, -0.12, 0.21, 0.08, ...]. في الفضاء الدلالي، هذا المتجه بعيد عن جميع متجهات الوثائق عن التفاح، سواء الشركة أو الفاكهة، لذلك لا يظهر تشابه كبير.
يقوم النظام مرة أخرى بإجراء استرجاع Top-K مع K = 2. نظرًا لأن موضوع السؤال غير مرتبط بقاعدة المعرفة، فإن درجات التشابه الإجمالية منخفضة جدًا جميعها:
- التشابه مع المقطع ب، تغذية الفاكهة: 0.18، منخفض للغاية
- التشابه مع المقطع ج، إطلاق iPhone: 0.10، غير ذي صلة تقريبًا
- التشابه مع المقطع أ، تأسيس الشركة: 0.08، غير ذي صلة تقريبًا
لا يزال Top-K يعيد أفضل K نتيجة مرتبة، لكن في هذه الحالة تلك النتائج لا توفر أدلة فعالة. في الممارسة، يطبق النظام غالبًا عتبة تشابه أدنى ويعيد استدعاء فارغًا مباشرة، أي لا نتائج صالحة، لتقليل التدخل غير ذي الصلة.
سيكون المقطعان المعادان:
- المقطع ب، تشابه 0.18: "التفاح فاكهة غنية بفيتامين C والألياف الغذائية، مما يساعد على الهضم وصحة الجهاز المناعي."
- المقطع ج، تشابه 0.10: "أطلقت شركة Apple Inc. أول iPhone في عام 2007، مما غيّر صناعة الهواتف الذكية جذريًا."
سيكون المدخل الكامل:
[موجه النظام]
أنت مساعد محترف للإجابة على الأسئلة. يرجى الإجابة بدقة وفقًا لـ "المعلومات المرجعية" التي قدمها المستخدم.
إذا كانت المعلومات المرجعية تحتوي على الإجابة، فأجب بناءً عليها مباشرة.
إذا لم تحتوِ المعلومات المرجعية على الإجابة، أخبر المستخدم بوضوح بأنه "لا يمكن الإجابة على السؤال بناءً على المواد المتاحة حاليًا"، ولا تلفق معلومات.
يرجى الإشارة إلى نقطة المعلومات التي تستند إليها إجابتك.
[السياق المسترجع]
التفاح فاكهة غنية بفيتامين C والألياف الغذائية، مما يساعد على الهضم وصحة الجهاز المناعي.
أطلقت شركة Apple Inc. أول iPhone في عام 2007، مما غيّر صناعة الهواتف الذكية جذريًا.
[استعلام المستخدم]
كيف حال الطقس اليوم؟سيحكم LLM أولاً على ما إذا كانت المعلومات المرجعية تحتوي على معلومات طقس مباشرة أو أرصاد جوية في الوقت الفعلي. بعد التأكد من عدم وجودها، سيتبع التعليمات بالإجابة بأنه لا يمكنه الإجابة:
المواد المتاحة حاليًا لا يمكنها الإجابة على سؤال "كيف حال الطقس اليوم؟" لأن المعلومات المرجعية تحتوي فقط على محتوى متعلق بالتفاح وتغذية الفاكهة ومنتجات Apple Inc.، ولا تحتوي على معلومات طقس أو بيانات أرصاد جوية في الوقت الفعلي. [الأساس: لا توجد معلومات متعلقة بالطقس في السياق المسترجع]
من هذه الأمثلة الثلاثة، يمكننا رؤية مفتاح مرحلة حوار RAG. يحدد موجه النظام دور LLM وقواعد الاستجابة، وتوفر الأدلة المسترجعة مواد ملموسة وموثوقة، ويحدد سؤال المستخدم هدف المهمة. نمط المدخل المنظم هذا هو بالضبط ما يتيح لـ RAG توجيه وتقييد LLM بشكل فعال قد يهلوس بخلاف ذلك، وتحويله إلى نظام ينتج إجابات مستقرة وموثوقة. يضمن ذلك استخدام النموذج لفهم وتنظيم المعلومات الموجودة بدلاً من اختراع معلومات غير مدعومة.
4. تطور RAG
لم ينشأ RAG في عصر النماذج الكبيرة. الأبحاث المبكرة كانت تحتوي بالفعل على نماذج أولية لنفس الفكرة. من منظور تاريخي، نشأ RAG من الاعتراف بقيود LLMs التقليدية. اعتمدت النماذج اللغوية الكبيرة المبكرة بشكل أساسي على بيانات ما قبل التدريب، وأصبحت تلك البيانات ثابتة بمجرد انتهاء التدريب. على سبيل المثال، كان لدى نماذج مثل GPT-3 تواريخ قطع معرفي مرتبطة بوقت جمع بيانات التدريب ولم تتمكن من الحصول على معرفة لاحقة. كما أن إعادة تدريب أو ضبط LLMs بدقة لمجالات محددة يتطلب موارد كبيرة وخبرة متخصصة، مما يجعلها مكلفة وصعبة التكرار بسرعة.
يمكن تتبع جذور RAG إلى إطار عمل DrQA في عام 2017، الذي حاول لأول مرة الجمع بين الاسترجاع والنماذج اللغوية. ثم جاء اختراق كبير في عام 2020 مع Dense Passage Retrieval، أو DPR، الذي استخدم نماذج عصبية مدربة مسبقًا للاسترجاع الدلالي بدلاً من الطرق التقليدية القائمة على تكرار الكلمات مثل TF-IDF وBM25. في عام 2021، تم اقتراح RAG رسميًا وتنظيمه، ليصبح طريقة قياسية لمعالجة مشاكل قطع المعرفة والهلوسة في LLMs.
بشكل عام، يمكن تقسيم تطور RAG إلى ثلاث مراحل:
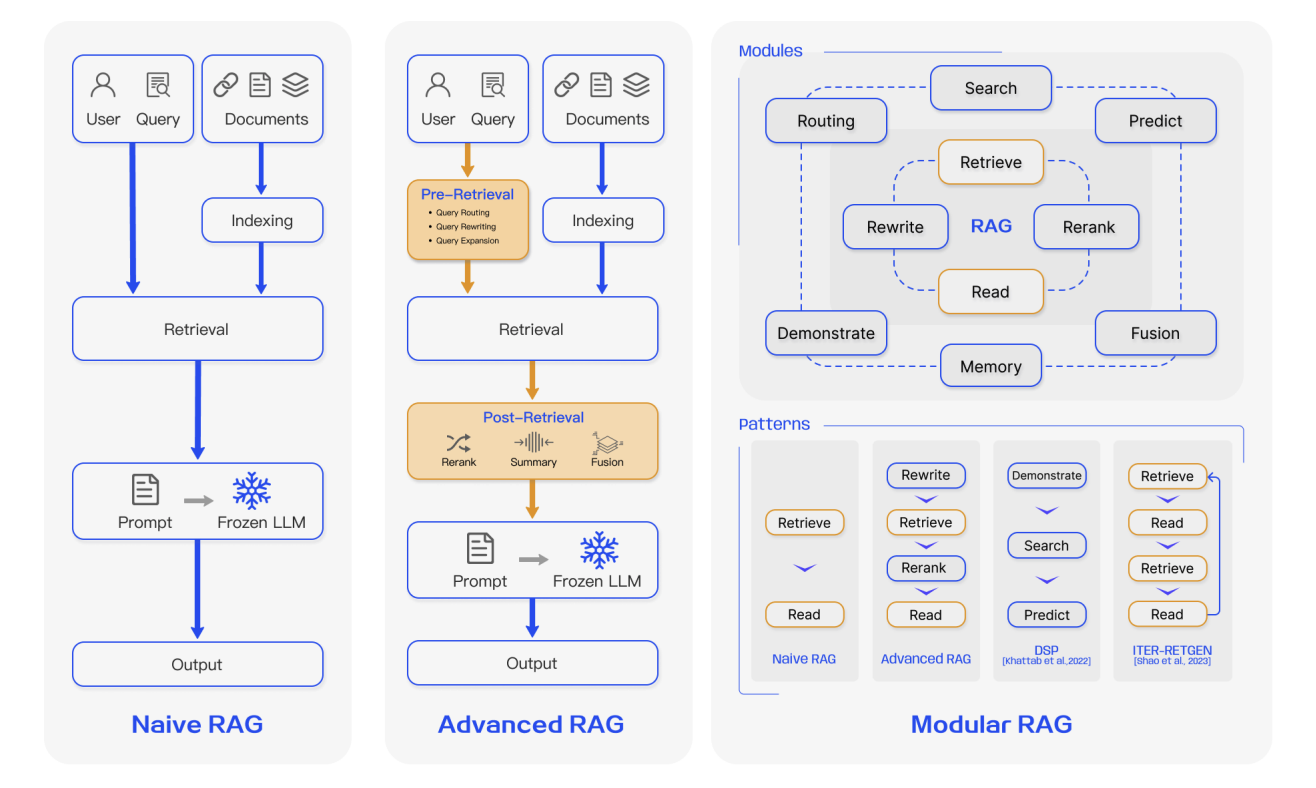
4.1 RAG من الجيل الأول: Naive RAG
Naive RAG هو الشكل الأساسي لـ RAG. من منظور هندسي، يتبع تدفقًا مباشرًا من ثلاث خطوات:
- المعالجة المسبقة للوثائق والفهرسة. يتم تنظيف الوثائق الخام، وتقسيمها إلى أجزاء نصية ذات طول ثابت، وتشفيرها إلى متجهات بنموذج تضمين، وكتابتها في قاعدة بيانات متجهات.
- الاسترجاع القائم على التشابه. يتم تشفير سؤال المستخدم باللغة الطبيعية إلى متجه، ويقوم النظام بإجراء بحث Top-K عن التشابه عبر مخزن المتجهات.
- التوليد المعزز بالاسترجاع البسيط. يتم ربط الأجزاء المسترجعة مباشرة مع السؤال الأصلي لتشكيل موجه طويل، يُرسل إلى LLM لتوليد الإجابة.
قيمة هذه المرحلة هي أنها تحققت، بحاجز منخفض جدًا، من أن "الاسترجاع قبل الإجابة" يعمل فعلاً. مقارنة بالاعتماد فقط على الذاكرة الداخلية للنموذج، قللت بالفعل بشكل كبير من مشاكل قطع المعرفة وبعض الهلوسة، وهو السبب في أنها لعبت دورًا مهمًا في النماذج الأولية المبكرة والعروض التوضيحية والدروس التمهيدية.
ومع ذلك، قيود RAG من الجيل الأول واضحة أيضًا. أولاً، استراتيجية التقسيم عادة ما تكون بدائية. معظم الأنظمة تقسم ببساطة حسب الطول الثابت، مما يمكن أن يقطع فقرة دلالية متماسكة في المنتصف أو يخلط مواضيع متعددة داخل جزء واحد. هذا يضر بدقة الاسترجاع ويجعل الفهم أصغر على LLM. ثانيًا، إشارة الاسترجاع بسيطة جدًا. يعتمد الترتيب عادة فقط على تشابه المتجهات ولا يستخدم أدلة منظمة أكثر ثراءً مثل الكلمات المفتاحية، والطوابع الزمنية، ومصداقية المصدر، أو أذونات الوصول. ثالثًا، نتائج الاسترجاع بالكاد تُحكم: الأجزاء الصاخبة والمتكررة وحتى المتناقضة يمكن أن تُحشر في السياق دون تغيير، مما يتسبب في احتلال كميات كبيرة من المعلومات منخفضة القيمة لنافذة سياق محدودة بالفعل.
باختصار، حل الجيل الأول مسألة ما إذا كان الاسترجاع ضروريًا. لكن في مسائل كيفية الاسترجاع بشكل أفضل، وكيفية استخدام المعلومات المسترجعة بشكل أكثر معقولية، لا يزال في مرحلة بدائية جدًا.
4.2 RAG من الجيل الثاني: Advanced RAG
مع انتقال RAG من العروض التوضيحية إلى سيناريوهات الأعمال الحقيقية، ارتفعت المتطلبات للاستقرار والقابلية للتحكم وجودة المخرجات بشكل حاد. الجيل الثاني، الذي يُجمع عادة تحت الاسم الواسع Advanced RAG، لا يزال يتبع نمط استرجع أولاً ولد ثانيًا، لكنه يقدم تحسينًا منهجيًا قبل الاسترجاع وبعده. بعبارة أخرى، النظام لم يعد راضيًا عن مجرد استرجاع شيء ما. يهدف الآن إلى تخزين الأشياء الصحيحة بشكل صحيح، وطرح الأسئلة الصحيحة بوضوح، والتحكم في السياق المسترجع بعناية.
قبل الاسترجاع، يكون التركيز على التخزين والسؤال الجيد:
على جانب الفهرسة، يتطور التقسيم من الانقسامات ذات الطول الثابت إلى التقسيم الواعي دلاليًا والفهرسة الهرمية. قد يقسم النظام على طول حدود الفصول والأقسام الفرعية والفقرات والجمل، مع نوافذ منزلقة وهياكل فهرس متعددة الدقة.
يمكن أن يحمل كل جزء وثيقة بيانات وصفية غنية مثل المصدر والطابع الزمني والمؤلف والموضوع ونوع الوثيقة، مما يوفر أبعادًا أكثر للتصفية والترتيب اللاحق.
على جانب الاستعلام، يمكن إعادة كتابة سؤال المستخدم الأصلي أو توسيعه أو تفكيكه من خلال تقنيات مثل Query Rewrite وMulti-Query وتفكيك Sub-Query وStep-back Prompting، لتحويل استعلامات المستخدم الغامضة أو المحادثية إلى أشكال يمكن للاسترجاع فهمها بشكل أفضل.
- Query Rewrite
الفكرة الأساسية هي تحويل استعلام المستخدم الغامض أو العامي أو غير القياسي إلى تعبير معياري يمكن لنظام الاسترجاع فهمه بسهولة أكبر، مع supplementing المعلومات الأساسية وحل الغموض.
- على سبيل المثال، "كيف أتحقق من طقس الغد في بكين؟" قد يُعاد كتابته إلى شيء أكثر معيارية مثل "استعلام عن طقس بكين الكامل ليوم غد في الوقت الفعلي."
- أو "أوصِ بأفلام جيدة" قد يُعاد كتابته، بعد النظر في تاريخ المستخدم، إلى "أوصِ بأفلام إثارة عالية التقييم من عام 2024."
- Multi-Query
يولد النظام استعلامات متعددة ذات صلة دلاليًا لكن بزوايا مختلفة من السؤال الأصلي لتقليل النتائج المفقودة وتغطية الاحتياجات الكامنة التي لم يذكرها المستخدم صراحةً.
- Sub-Query
بالنسبة للأسئلة المركبة التي تحتوي على عدة أهداف، يقسمها النظام إلى استعلامات فرعية أصغر وأبسط بحيث يمكن للاسترجاع مطابقة كل احتياج بدقة.
- Step-back Prompting
يولد النظام أولاً سؤالاً أكثر تجريدًا ومستوى أعلى، ثم يستخدمه لتوجيه اتجاه الاسترجاع، مما يقلل التحيز الناجم عن التركيز الضيق جدًا على التفاصيل في السؤال الأصلي.
بعد الاسترجاع، يكون التركيز على التحكم في ما تم استرجاعه:
- يمكن لنموذج إعادة الترتيب المخصص أو حتى LLM إعادة ترتيب الوثائق المرشحة بحيث يدخل المحتوى الأكثر أهمية والأكثر صلة بالسؤال السياق أولاً.
نموذج إعادة الترتيب هو مكون أساسي في خط أنابيب استرجاع المعلومات. يقوم بالترتيب الثاني لمرحلة النتائج المرشحة المعادة من مرحلة الاستدعاء، باستخدام فهم دلالي أقوى، غالبًا بناءً على بنيات Transformer، لإصلاح أخطاء الترتيب الدلالي من المرحلة الأولى وتقديم النتائج الأكثر توافقًا مع احتياجات المستخدم إلى الأمام.
- يمكن تصفية المقاطع المسترجعة وإزالة تكرارها وضغطها لإزالة الأجزاء غير ذات الصلة بوضوح أو المتكررة للغاية، مما يقلل من ميل أنظمة السياق الطويل لتجاهل المعلومات المفيدة في المنتصف.
- عند الضرورة، يمكن للضبط الدقيق الخفيف للنموذج أن يجعل LLM أكثر ميلًا للإجابة من أدلة الاسترجاع وتضمين استشهادات أو مصادر صريحة.
بشكل عام، لم يعد Advanced RAG يركز فقط على ما إذا كان الاسترجاع ضروريًا أو ما إذا كان يمكن استرجاع شيء ما. بل يعالج ثلاثة تحديات أكبر: ما إذا كان يمكن تحديد المقاطع الحرجة فعلًا بدقة، ما إذا كان السياق المقدم للنموذج الكبير موجزًا ومنظمًا جيدًا وسهل الاستخدام بكفاءة، وما إذا كان النظام بأكمله يظل مستقرًا وموثوقًا في وجود الضوضاء أو التعارض أو احتياجات المعلومات متعددة المصادر.
تظهر كميات كبيرة من الأدلة التجريبية والهندسية أن Advanced RAG يتفوق بشكل كبير على Naive RAG في دقة الإجابة وقمع الهلوسة ومتانة النظام والقابلية للتفسير. هذا هو السبب في أنه حل تدريجيًا محل النهج التقليدية الأساسية وأصبح النموذج الصناعي السائد لبناء أنظمة RAG اليوم.
4.3 RAG من الجيل الثالث: Modular RAG
في تطبيقات المؤسسات المعقدة، تمتد المتطلبات غالبًا عبر مجالات متعددة. في تلك الحالات، لا يكفي غالبًا تدفق خطي بسيط من استرجع وأعد الترتيب وولد:
- قد يحتاج نفس النظام إلى دعم الأسئلة الشائعة البسيطة، وتوليد التقارير الطويلة، واسترجاع الأكواد، واستدعاءات قاعدة البيانات.
- قد يحتاج إلى ربط مخازن المتجهات والاسترجاع النصي الكامل وقواعد البيانات العلائقية ورسوم المعرفة ومحركات البحث الخارجية في نفس الوقت.
- قد يحتاج إلى الحفاظ على تفضيلات المستخدم والقرارات التاريخية عبر جولات متعددة، مع تطبيق فحوصات الامتثال وإمكانية تتبع الإجابات.
على خلفية هذه المتطلبات، بدأ RAG يتطور نحو شكل نظام معياري. لم يعد يُنظر إلى Modular RAG كخط أنابيب ثابت. بل يُعامل بدلاً من ذلك كمجموعة من وحدات الوظائف القابلة للإدراج والاستبدال والتركيب التي يمكن تنسيقها حسب الحاجة. تشمل الوحدات النموذجية:
- فهم الاستعلام والتوجيه تتعامل هذه الوحدة مع التعرف على النية، وإعادة كتابة الأسئلة، وتفكيك المهام الفرعية، واختيار المسار. تقرر ما إذا كان يجب أن يعتمد الطلب بشكل أساسي على المعرفة الداخلية، أو الاسترجاع الخارجي، أو أداة محددة أو قاعدة بيانات.
- الاسترجاع متعدد المصادر والدمج تتصل هذه الوحدة بقواعد بيانات المتجهات والبحث النصي الكامل وقواعد البيانات المهيكلة ورسوم المعرفة في وقت واحد، وتستعلمها، وتدمج ويعيد ترتيب نتائجها في مجموعة أدلة موحدة.
- الذاكرة والتخصيص تحافظ هذه الوحدة على ملفات تعريف المستخدم طويلة الأمد وذاكرة الجلسة قصيرة الأمد وذاكرة التخزين المؤقت للمعرفة المجالية بحيث يمكن للنظام التراكم المستمر واستخدام المعلومات التاريخية.
- التكيف مع المهام والحوكمة تحمّل هذه الوحة محولات مختلفة لمهام مختلفة، وتقيد تنسيق المخرجات ونبرتها وأسلوبها، وتحكم المخرجات من خلال التحقق من الحقائق وتصفية المخاطر ومحاذاة الاستشهادات.
باختصار، RAG التقليدي ينتهي غالبًا بعد جولة استرجاع واحدة زائد جولة توليد واحدة. Modular RAG يكسر نمط التدفق الواحد هذا. إذا اكتشف النظام أثناء التوليد أن المعلومات لا تزال غير كافية، يمكنه بدء جولات استرجاع جديدة بشكل استباقي وحتى التنقل ذهابًا وإيابًا عدة مرات بين الاسترجاع والتوليد لإكمال مهمة أكثر تعقيدًا.
بالذهاب أبعد، يمكن للنموذج تعلم اتخاذ قراراته الخاصة: الإجابة مباشرة من المعرفة الداخلية أو السياق القصير عندما يكون الثقة عاليًا، وإطلاق الاسترجاع أو استدعاءات الأدوات الخارجية فقط عندما يكون عدم اليقين عاليًا. ذلك يحسن الكفاءة ويوفر الموارد مع الحفاظ على الجودة. بالنسبة للاستعلامات غير المحددة بشدة أو غير المكتملة، يمكن للنموذج حتى توليد إجابة وسيطة افتراضية أو وثيقة مسودة أولاً، ثم استخدامها كدليل لاسترجاع إضافي، مع الاقتراب تدريجيًا من مصادر موثوقة.
في هذه المرحلة، لم يعد RAG مجرد مكون بسيط يرفق بعض المقاطع المرجعية بنموذج كبير. بل أصبح طبقة تنسيق المعرفة المركزية داخل تطبيقات المؤسسات الذكية، تنسق مصادر بيانات متعددة وأدوات متعددة ومهام متعددة.
5. من العرض التوضيحي إلى RAG على مستوى المؤسسات
من منظور هندسة المؤسسات، لا يمكن أن يقتصر بناء نظام RAG على التوليد المعزز بالاسترجاع وحده. ما سبق لا يزال أقرب إلى مقدمة على مستوى العرض التوضيحي. في سيناريوهات الأعمال الحقيقية، البيانات غالبًا ما تكون صاخبة وغير متسقة في التنسيق، لذا يجب استثمار المزيد من الجهد في المعالجة المسبقة والتنظيف والاستيعاب، ويجب التعامل مع اختيار النموذج بعناية في كل نقطة رئيسية.
عادةً ما يمكن تقسيم نظام RAG كامل على مستوى المؤسسات إلى ثلاث وحدات أساسية: تحليل التخطيط واستيعاب المعرفة، وبناء قاعدة المعرفة، وخدمة الإجابة على الأسئلة القائمة على RAG. عبر السلسلة التقنية الكاملة، تظهر عدة قرارات رئيسية لاختيار النموذج، بما في ذلك نموذج التضمين، ونموذج إعادة الترتيب، وLLM. فقط بخيارات تقنية معقولة في كل مرحلة يمكن للنظام تحقيق نتائج قوية إجمالية.
تحليل التخطيط وقراءة ملفات المعرفة المحلية
تحول هذه الوحدة أصول المعرفة المحلية بتنسيقات مختلفة إلى نص قابل للاسترجاع. قد تشمل المدخلات ملفات PDF وTXT وHTML وWord وExcel وPPT، بالإضافة إلى ملفات الصور الممسوحة ضوئيًا مثل PNG وJPG، أو حتى التسجيلات الصوتية.
يحتاج النظام إلى تحليل كل تنسيق بشكل مناسب، وإجراء تحليل التخطيط والاستخراج الهيكلي للوثائق النصية، والتمييز بين العناوين والنص الرئيسي والجداول والرؤوس والتذييلات، واستعادة ترتيب قراءة معقول. يقوم بإجراء OCR على ملفات الصور وASR على الكلام، محولاً كل شيء في النهاية إلى نص معرفي نظيف نسبيًا مع الاحتفاظ بالبيانات الوصفية الأساسية مثل اسم الملف والفصل ورقم الصفحة والطابع الزمني للتقسيم والفهرسة اللاحقين.
بناء قاعدة المعرفة: التقسيم والتضمينات والفهرسة
بعد الحصول على نص المعرفة المنظف، يقوم النظام بالتقسيم، وتقسيم الوثائق الطويلة إلى كتل متماسكة دلاليًا بطول مناسب، عادةً حسب الفقرة أو بنية العناوين أو نافذة منزلقة، مع الحفاظ على مصدر وبيانات كل كتلة.
ثم يستخدم نموذج التضمين المختار، مثل
text-embedding-3-smallأو Sentence Transformers أو BGE، لحساب التمثيلات المتجهة لكل كتلة وبناء فهرس متجهات باستخدام أدوات مثل Faiss أو Milvus أو خدمات البحث المتجه المدارة. في تلك المرحلة، تكون قاعدة معرفة تدعم الاسترجاع الدلالي السريع قد أُنشئت.الإجابة على الأسئلة القائمة على RAG: الاستدعاء وإعادة الترتيب والربط والتوليد
في مرحلة الإجابة على الأسئلة عبر الإنترنت، يرسل المستخدم استعلامًا. يقوم النظام بتضمينه في متجه استعلام، ويسترجع دفعة من أكثر أجزاء النص تشابهًا من فهرس المتجهات، ويعامل ذلك كمرحلة ترتيب أولية. ثم يمكنه استخدام نموذج إعادة ترتيب مثل BGE reranker أو حتى LLM يعمل كمُعيد ترتيب لتسجيل أزواج الاستعلام-الوثيقة مرة أخرى والاحتفاظ فقط بأفضل K وثيقة التي هي الأكثر صلة فعلًا كسياق المعرفة.
بعد ذلك، مع موجه نظام مصمم بعناية مثل "يرجى الإجابة بدقة بناءً على المواد التالية"، يربط النظام استعلام المستخدم ومقاطع الوثائق المسترجعة ويرسل الموجه المدمج إلى LLM. يولد النموذج بعد ذلك الإجابة النهائية من تلك القطع الأثرية المسترجعة، وعند الحاجة، يتضمن استشهادات أو مصادر.
5.1 اختيار النموذج
بعد ذلك نركز على اختيار النموذج. نظام RAG كامل يتضمن عادةً ثلاث فئات نماذج أساسية: نماذج التضمين، ونماذج إعادة الترتيب، والنماذج اللغوية الكبيرة. لكل منها دورها الخاص، ومعًا تشكل المسار الكامل من الاسترجاع إلى توليد الإجابة. يحول نموذج التضمين النص إلى متجهات دلالية قابلة للبحث، ونموذج إعادة الترتيب يحسن نتائج الاسترجاع الأولية، وLLM يولد الإجابة النهائية بناءً على سياق المعرفة المحدد.
5.1.1 نماذج التضمين
في نظام RAG، وظيفة نموذج التضمين هي تحويل النص، مثل استعلامات المستخدم ومحتوى قاعدة المعرفة، إلى متجهات عالية الأبعاد. تُوضع النصوص المتشابهة دلاليًا أقرب معًا في فضاء المتجهات، مما يسمح للنظام بتحديد المعرفة ذات الصلة بسرعة عن طريق التشابه. لذلك فإن اختيار نموذج التضمين الصحيح هو أحد أهم الخطوات في بناء نظام RAG عالي الأداء لأنه يحدد جودة الاستدعاء بشكل مباشر.
ل اختيار نموذج قوي، يساعد استخدام معيار مرجعي منهجي. أحد أكثر المعايير استخدامًا هو MTEB، معيار تضمين النص الضخم.
يوفر MTEB إطار تقييم موحد وموضوعي للعديد من نماذج التضمين. من خلال ثماني فئات مهام رئيسية و56 مجموعة بيانات، يقيم الأداء عبر الاسترجاع والتجميع والتصنيف وإعادة الترتيب ومطابقة النص والتشابه الدلالي والمزيد. درجة MTEB الإجمالية للنموذج تعكس عمومية ومتانة تمثيلاته المتجهة ويمكن أن تعمل كمرجع مهم لاختيار النموذج. يمكن التحقق من أحدث ترتيب على لوحة المتصدرين MTEB على Hugging Face:
على الرغم من وجود العديد من النماذج على اللوحة، لا تحتاج إلى إتقانها جميعًا. في الممارسة، اختيار نموذج التضمين المقدم من مزود نموذج كبير، أو استخدام نموذج خدمة سحابية قام العديد من الأشخاص بالتحقق من صحته بالفعل، عادةً ما يكون خيارًا آمنًا. يمكنك أيضًا تصفية اللوحة حسب الفئة أو اللغة في الشريط الجانبي:
عند تصفية نماذج التضمين، هناك معلمان مهمان بشكل خاص لأنهما يؤثران بشكل مباشر على أداء RAG: البعد وطول السياق.
البعد هو أبعاد مخرجات المتجه، مثل 128 أو 768 أو 1536. يعكس تقريبًا عدد الميزات الدلالية التي يمكن للمتجه التعبير عنها. المتجهات ذات الأبعاد الأعلى يمكنها التقاط تفاصيل دلالية أكثر ثراءً وتمييز أقوى. على سبيل المثال، يمكن لمتجه 768-بعد أن يمثل "تفاحة" من مئات الزوايا مثل الصنف والطعم والمنشأ، مما يجعله مناسبًا للسيناريوهات المهنية مثل الرعاية الصحية أو القانون التي تحتاج استرجاع دقيق. الأبعاد الأقل تقلل من تكلفة الحسابات والتخزين وتحسن سرعة الاسترجاع، مما يجعلها مناسبة للسيناريوهات العامة واسعة النطاق مع التزامن العالي ومتطلبات الوقت الفعلي القوية.
طول السياق هو الحد الأقصى لطول النص الذي يمكن لنموذج التضمين معالجته في تمريرة واحدة، مقيسًا بالرموز. رمز إنجليزي واحد يساوي تقريبًا ثلاثة أرباع كلمة، ورمز صيني واحد يساوي تقريبًا حرف صيني واحد. أي شيء أطول من الحد الأقصى يُقطع. هذا يحدد مباشرة ما إذا كان النموذج يمكنه فهم النص بالكامل. إذا فُقدت معلومات مهمة لأن الطول قصير جدًا، تنخفض دقة الاسترجاع بشكل حاد. لاستعلامات المستخدم القصيرة وأزواج الأسئلة والأجوبة القصيرة، 512 إلى 1024 رمز غالبًا ما يكون كافيًا. للنصوص الأطول مثل الأوراق والتقارير، تحتاج عادةً إلى 2048 رمز أو أكثر.
فيما يلي مقارنة بين عدة نماذج تضمين شائعة. في الممارسة، تحتاج إلى الاختيار من خلال الموازنة بين التكلفة والأداء. لا يوجد نموذج الأفضل عالميًا، فقط النموذج الأكثر ملاءمة بعد مقارنة عدة خيارات في حالة الاستخدام الخاصة بك.
| اسم النموذج | حجم النموذج | نقطة القوة الأساسية | السيناريوهات المناسبة |
|---|---|---|---|
OpenAI text-embedding-3-large | API مغلق | متصدر طويل الأمد على MTEB، ناضج ومستقر | سيناريوهات API السحابية التي تعطي الأولوية للأداء المتطرف ولديها ميزانية كافية |
jina-embeddings-v2 | يدعم النص الطويل حتى 8K سياق | قوي لاسترجاع الوثائق الطويلة من خلال تصميم التشفير غير المتزامن | تحليل الوثائق، الامتثال القانوني، الاسترجاع الأكاديمي |
multilingual-e5-large | حجم كبير | خيار متعدد اللغات كلاسيكي | RAG عبر اللغات، المنتجات الدولية، أنظمة دعم متعددة اللغات |
Qwen/Qwen2-Embedding-8B | معلمات 8B، حتى 4096 بُعد مخصص | المتصدر السابق في MTEB متعدد اللغات، قوي على النص الطويل والمهام متعددة اللغات والأكواد | RAG صيني-إنجليزي عالي الدقة، تحليل الوثائق الطويلة، استرجاع الأكواد |
Qwen/Qwen2-Embedding-4B | معلمات 4B | توازن قوي بين الأداء والكفاءة | أنظمة RAG الإنتاجية واسعة النطاق |
Qwen/Qwen2-Embedding-0.6B | معلمات 0.6B | مناسب للأجهزة الطرفية | السيناريوهات المقيّدة الموارد، التي تعطي الأولوية للسرعة |
BAAI/bge-m3 | يدعم الاسترجاع الهجين، كثيف زائد متناثر زائد متعدد المتجهات | قوي على معايير متعددة اللغات مثل MIRACL | السيناريوهات متعددة اللغات المعقدة التي تحتاج استرجاع هجين |
BAAI/bge-large-zh-v1.5 | حجم كبير | خط أساس RAG صيني مستقر مع تحقق مجتمعي قوي | مشاريع صينية بحتة مع وثائق أقصر |
ZhipuAI Embedding-3 | API سحابي مغلق | يدعم أبعاد مخصصة من 256 إلى 2048 | التطبيقات التي تركز على الصينية وتفضل APIs السحابية |
5.1.2 نماذج إعادة الترتيب
في نظام RAG، يكون نموذج إعادة الترتيب مسؤولًا عن إعادة ترتيب نتائج الاسترجاع الأولية بدقة. يأخذ استعلام المستخدم والوثائق المرشحة كمدخل ويحسب درجة صلة دقيقة لكل زوج استعلام-وثيقة. كلما زادت الدرجة، كان التطابق أفضل. لذلك، فإن إضافة نموذج إعادة ترتيب فوق الاستدعاء القائم على التضمين هو خطوة رئيسية لتحسين دقة الاسترجاع.
بالنسبة لنماذج التضمين، يمكننا استخدام معايير مثل MTEB. بالنسبة لنماذج إعادة الترتيب، أحد المراجع المفيدة هو لوحة متصدري إعادة الترتيب من Agentset:
يسترجع معيار Agentset أولاً أفضل 50 نتيجة مرشحة ذات صلة من مخزن وثائق كبير باستخدام FAISS، ثم يطلب من نموذج إعادة الترتيب قيد التقييم إعادة ترتيب تلك الـ 50 وثيقة. ينتبه المعيار لكل من جودة الترتيب وزمن الاستجابة. في التطبيقات العملية، السعي للدقة مع تجاهل السرعة يضر بتجربة المستخدم، بينما السعي للسرعة مع التضحية بجودة الترتيب يضر بالفائدة.
يقدم Agentset أيضًا آلية تسجيل ELO. لكل استعلام، يعمل GPT-5 كحكم ويقارن المخرجات المرتبة لنموذجي إعادة ترتيب مختلفين، ويقرر أيهما يضع الوثائق ذات الصلة فعلًا في ترتيب أكثر معقولية. بعد أعداد كبيرة من هذه المقارنات الزوجية، النماذج التي تفوز أكثر تحصل على درجات ELO أعلى، مما يوفر إشارة أداء إجمالي بديهية.
يستخدم المعيار أيضًا مجموعتين من المقاييس المكملة:
nDCG@5/10، الذي يركز على ما إذا كانت الوثائق ذات الصلة موضوعة قريبًا من الأمام وبالتالي يعكس دقة الترتيبRecall@5/10، الذي يركز على ما إذا كان يمكن العثور على جميع الوثائق ذات الصلة وبالتالي يعكس التغطية
معًا توفر هذه المقاييس صورة أكثر اكتمالًا لأداء إعادة الترتيب.
ومع ذلك، في الممارسة، لا تحتاج إلى اختيار نماذج إعادة الترتيب فقط من لوحة متصدرين. الفائدة الصناعية ودرجة اللوحة ليست دائمًا نفس الشيء. نهج عملي هو البدء من نماذج إعادة الترتيب الموصى بها من قبل مزودي الخدمة السحابية لديك أو APIs إعادة الترتيب الافتراضية المقدمة من مزودي النماذج الكبار، أو اختبار عائلة نماذج تستخدمها بالفعل، مثل نموذج إعادة ترتيب Qwen مطابق.
5.1.3 النماذج اللغوية الكبيرة (LLMs)
بعد الاسترجاع الدلالي بواسطة نموذج التضمين والتصفية المحسنة بواسطة نموذج إعادة الترتيب، يتم دمج مقاطع الوثائق ذات الصلة مع سؤال المستخدم الأصلي في موجه. ثم يقوم LLM بفهم القراءة وتكامل المعلومات وتوليد اللغة الطبيعية لإخراج إجابة متماسكة ودقيقة تناسب السياق.
على مستوى التنفيذ، هناك طريقتان رئيسيتان لاستخدام LLMs في RAG:
- النماذج الكبيرة المنشورة خاصًا. هذه مناسبة للسيناريوهات التي تهتم بخصوصية البيانات، أو التكلفة القابلة للتحكم، أو التخصيص العميق. النماذج المفتوحة السائدة مثل Qwen وLlama وGLM تعمل بشكل جيد في مهام RAG. على سبيل المثال، Qwen2.5 في نطاق 7B أو 14B يقدم متابعة تعليمات جيدة وفهمًا صينيًا جيدًا مع الحفاظ على استخدام الموارد معتدلً، مما يجعله مناسبًا للنشر المحلي للمؤسسات. يمكن أيضًا النظر في نماذج مثل KIMI وMinimax وDeepSeek وفقًا لاحتياجات أعمال محددة.
- النماذج الكبيرة عبر API السحابية. هذه تناسب السيناريوهات التي تعطي الأولوية للإطلاق السريع والتوسع المرن والتحديثات المستمرة للنماذج. المزودون الرئيسيون مثل OpenAI وAnthropic وGoogle وAlibaba وZhipuAI يقدمون جميعًا خدمات API مستقرة. هذه النماذج عمومًا لديها قدرة قوية على فهم اللغة وتوليدها ويمكنها تجميع الإجابات بشكل جيد في سيناريوهات RAG.
عند اختيار النماذج السحابية، عدة نقاط مهمة: ما إذا كانت جودة الإجابة دقيقة وسلسة، ما إذا كان السعر معقول، ما إذا كان زمن الاستجابة مقبولً،ا وما إذا كانت نافذة السياق كبيرة بما يكفي لاحتواء وثائق مسترجعة متعددة. في الممارسة، يجب عليك مقارنة عدة مرشحين على بياناتك الخاصة ومعرفة أيها يعطي إجابات أكثر اكتمالًا ودقة. إذا كانت التكلفة مصدر قلق، فإن نهجًا مفيدًا هو الجمع بين النماذج الكبيرة والصغيرة: استخدام نماذج صغيرة أرخص للأسئلة البسيطة وحجز النماذج الكبيرة المكلفة للحالات الصعبة. نظرًا لأن النماذج تتحدث بسرعة، فمن الحكمة أيضًا إعادة اختبار المرشحين بشكل دوري.
للقدرة العامة على المحادثة والإجابة على الأسئلة، LMSYS Chatbot Arena، الآن LMArena، هي واحدة من أكثر مراجع التقييم المعترف بها على نطاق واسع:
تستخدم مقارنات بشرية زوجية معممة لترتيب النماذج. يوفر الترتيب مرشحًا أوليًا مفيدًا، لكن في اختيار RAG الفعلي يجب أن يكون فقط نقطة بداية. في المجالات المتخصصة مثل الطب والقانون والمالية، يمكن أن يختلف ترتيب اللوحة العامة بشكل كبير عن الأداء الحقيقي على بيانات أعمالك.
أفضل ممارسة لاختيار LLM هي بناء مجموعة اختبار صغيرة ولكن ممثلة تحتوي على 20 إلى 30 سؤال أعمال نموذجي وتقييم النماذج المرشحة من خلال خط أنابيب RAG الكامل من البداية إلى النهاية بدلاً من النظر فقط في معايير النموذج المعزولة. أسئلة مثل ما إذا كنت تستخدم نماذج الاستدلال أو نماذج عدم الاستدلال، أو أي حجم نموذج يوازن بشكل أفضل بين الجودة والسرعة، تُجاب بشكل أفضل من خلال الاختبار الحقيقي على حالة الاستخدام الخاصة بك.
5.2 أطر التنفيذ
في الممارسة الهندسية الحقيقية، لا تحتاج عادةً إلى بناء نظام RAG كامل من الصفر. يوجد عدد من الأطر مفتوحة المصدر الناضجة، لكل منها نقاط قوتها الخاصة في البنية والتكامل المعياري وكفاءة التطوير. يمكن للمؤسسات الاختيار وفقًا لاحتياطياتها التقنية وسيناريوهات أعمالها.
تشمل أنواع الأطر الشائعة:
منصات منخفضة الكود أو بصرية
- Dify: يوفر واجهة بصرية بديهية لبناء تطبيقات RAG بسرعة، مما يجعله مناسبًا للفرق غير التقنية أو التحقق السريع من النماذج الأولية. يتضمن وصول متعدد النماذج مدمج، وتنسيق سير العمل، وإدارة الموجهات.
- Coze: منصة تطوير روبوتات ذكاء اصطناعي من ByteDance تقدم بناء بصري بدون كود. تتكامل بعمق مع خدمات نماذج ByteDance، وتدعم سوق الإضافات، والمهام المجدولة، والنشر متعدد القنوات، مما يجعلها مناسبة للمساعدات الموجهة للمستهلكين أو روبوتات المؤسسات الداخلية.
- n8n: منصة أتمتة سير العمل مفتوحة المصدر قائمة على العقد. في سيناريوهات RAG، يمكنها تنسيق منطق الأعمال المعقد وربط المعالجة المسبقة وعمليات قاعدة بيانات المتجهات واستدعاءات النماذج والإجراءات اللاحقة مثل إرسال البريد الإلكتروني أو تحديث التذاكر في تدفق آلي واحد.
- RAGFlow: يركز على تحليل التخطيط العميق واستخراج المعرفة ويعمل بشكل جيد على الوثائق المعقدة مثل ملفات PDF متعددة الأعمدة والمواد الغنية بالجداول.
- FastGPT: حل مفتوح المصدر صيني يدمج إدارة قاعدة المعرفة وتنسيق الحوار ونشر التطبيقات، مع توثيق صيني قوي وملاءمة للنشر السريع لتطبيقات RAG الصينية.
أطر الكود ومكتبات التطوير
الأدوات أدناه عادةً لديها تطبيقات بلغات خلفية مختلفة. يمكنك اختيار إصدار اللغة المناسب لمكدس تطبيقك.
- LlamaIndex: إطار عمل Python مصمم خصيصًا لـ RAG، مع موصلات غنية وهياكل فهرس ومحركات استعلام. نمطيته تجعله مناسبًا لاستراتيجيات الاسترجاع المخصصة بعمق أو التكامل مع مصادر بيانات عديدة.
- LangChain: إطار عمل عام لتطبيقات LLM حيث RAG هو حالة استخدام واحدة فقط. نقطة قوته هي نظامه البيئي الغني وتغطية المكونات، بما في ذلك دعم الوكلاء المعقدين وتنسيق سير العمل، رغم أن منحنى التعلم أشد.
إذا كانت الاحتياطيات التقنية للفريق محدودة والسرعة هي الأهم، فإن المنصات منخفضة الكود مثل Dify وCoze وFastGPT هي خيارات أولى جيدة. إذا كنت تحتاج تخصيصًا عميقًا أو تكامل مصدر بيانات خاص أو ضبط أداء مفصل، فإن LlamaIndex وLangChain يوفران مرونة أكبر. في الممارسة، المسار الهجين شائع أيضًا: استخدام منصة منخفضة الكود للتحقق السريع من الجدوى، ثم الانتقال إلى أطر الكود للنشر الإنتاجي والتحسين. معظم هذه الأطر تدعم أيضًا التكامل السريع مع نماذج التضمين وإعادة الترتيب وLLM السائدة، مما يتيح لك الجمع بينها بمرونة باستخدام مبادئ اختيار النموذج المناقشة أعلاه.
5.3 تقييم الأثر
للمؤسسات التي تنشر أنظمة RAG، أكبر تحدٍ غالبًا ليس بناء النظام بل ضبطه. RAG على مستوى الإنتاج يحتوي على مرحلتين غير حتميتين، الاسترجاع والتوليد، لذلك اختبار البرمجيات التقليدية ليس كافيًا. هذا هو السبب في أن بناء نظام تقييم علمي، أو تقييم RAG، مهم جدًا.
5.3.1 مثال للمبتدئين: تقييم RAG القائم على LLM
للمساعدة في بناء فهم بديهي لتقييم RAG، يمكننا النظر في خط أنابيب آلي بسيط قائم على فكرة LLM كحكم:
https://huggingface.co/learn/cookbook/rag_evaluation
العملية عادةً تحتوي على ثلاث خطوات رئيسية:
- أولاً، تجميع مجموعة بيانات تقييم عن طريق أخذ عينات من الوثائق من قاعدة المعرفة وطلب LLM توليد أزواج أسئلة-إجابات عالية الجودة، ثم تصفيتها حسب الصلة والارتكاز لتشكيل مجموعة مرجعية.
- ثانيًا، تشغيل نظام RAG على كل سؤال في مجموعة الاختبار تلك وجمع الإجابات المولدة.
- ثالثًا، التسجيل الآلي عن طريق استدعاء LLM آخر كحكم، ومقارنة الإجابات المولدة مع الإجابات المرجعية، وإعطاء درجات كمية لأبعاد مثل الدقة والاكتمال.
مثال بسيط:
- توليد المشكلة. لنفترض أن قاعدة المعرفة تحتوي على سطر في دليل منتج يقول، "هذا الجهاز يدعم الشحن اللاسلكي وبطاريته 5000mAh." نطلب من نموذج واحد أن يعمل كواضع اختبار ويولد سؤالًا مثل، "ما هي سعة بطارية هذا الجهاز؟" الإجابة القياسية هي "5000mAh."
- حل المشكلة. نرسل ذلك السؤال إلى نظام RAG، الذي يسترجع المواد ذات الصلة ويجيب، على سبيل المثال، "الجهاز به بطارية 5000mAh."
- التقييم. نطلب من نموذج آخر أن يعمل كالمُقيّم بمقارنة السؤال والإجابة المولدة والإجابة المرجعية، باستخدام موجه مثل، "احكم على ما إذا كانت الإجابة المولدة صحيحة. أخرج فقط صحيحة أو غير صحيحة."
بتشغيل هذه العملية على نطاق واسع، يمكننا حساب مقاييس مثل الدقة. هذا يشكل حلقة عملية من تقييم وتحسين وإعادة تقييم.
إذا كنت تريد تفاصيل أعمق حول تقييم RAG، بما في ذلك تعريفات المقاييس واستخدام الأطر ومجموعات بيانات المعايير، فورقتان استطلاعيتان مفيدتان:
- https://arxiv.org/pdf/2504.14891، Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey
- https://arxiv.org/pdf/2405.07437، Evaluation of Retrieval-Augmented Generation: A Survey
5.3.2 مقاييس التقييم
يدور تقييم RAG بشكل أساسي حول سؤالين: هل يمكن لوحدة الاسترجاع العثور على المواد الصحيحة، وهل يمكن لوحدة التوليد إنتاج إجابة عالية الجودة من تلك الموارد؟ وفقًا لذلك، ينقسم نظام التقييم إلى تقييم الاسترجاع وتقييم التوليد، مدعومًا بتسجيل LLM كحكم.
تقييم الاسترجاع: دقة الاستدعاء وجودة الترتيب
وحدة الاسترجاع هي البوابة الأولى في نظام RAG. يركز تقييمها على ثلاثة أبعاد: هل تجد الأشياء الصحيحة، هل تجد ما يكفي منها، وهل ترتبها بشكل جيد.
مقاييس جودة الاستدعاء الأساسية
المقاييس الكلاسيكية الأساسية هي Recall@K وPrecision@K وF1:
- Recall@K يقيس نسبة الوثائق ذات الصلة المسترجعة في أفضل K نتيجة. إذا كانت هناك خمس وثائق ذات صلة وتم العثور على ثلاث في أفضل 10، فإن Recall@10 هو 60 بالمائة. هذا يخبرنا عن مدى اتساع تغطية الاسترجاع.
- Precision@K يقيس نسبة أفضل K نتيجة التي هي ذات صلة فعلًا. إذا كانت ثلاث من أفضل 10 ذات صلة وسبع ليست كذلك، فإن Precision@10 هو 30 بالمائة. هذا يعكس دقة الاسترجاع.
- F1 هو الوسط التوافقي لـ Recall وPrecision ويوازن بينهما.
هذه المقاييس مفيدة للتشخيص السريع لمشاكل الاستدعاء الأساسية. إذا كان Recall منخفضًا، لم يتم العثور على وثائق ذات صلة على الإطلاق. إذا كانت Precision منخفضة، فإن ضوضاء الاسترجاع عالية جدًا.
مقاييس جودة الترتيب
إيجاد الوثائق ذات الصلة هو الخطوة الأولى فقط. من الأهمية بمكان وضع الأكثر صلة في المقدمة. لذلك ننظر إلى MRR وNDCG@K وMAP:
- MRR، متوسط الرتبة المقلوبة، يقيس مقلوب موقع رتبة أول وثيقة ذات صلة. إذا ظهرت أول وثيقة ذات صلة في الموضع 3، فإن الرتبة المقلوبة هي 1/3. MRR مناسب بشكل خاص للسيناريوهات حيث إجابة واحدة صحيحة كافية.
- NDCG@K، المكاسب التراكمية المخفضة المعيارية، يأخذ في الاعتبار كل من الصلة المتدرجة وخصم الموضع. لا يسأل فقط ما إذا كانت الوثيقة ذات صلة، بل مدى صلتها، ويكافئ الوثائق ذات الصلة العالية التي تظهر مبكرًا.
- MAP، متوسط الدقة المتوسطة، حساس لمواضع جميع الوثائق ذات الصلة ويعكس جودة الترتيب الإجمالية.
في الممارسة الهندسية، مزيج شائع هو Recall@K مع MRR@K. على سبيل المثال، إذا كان Recall@10 هو 80 بالمائة لكن MRR@10 هو 0.3 فقط، يتم العثور على وثائق ذات صلة لكنها مدفونة عميقًا جدًا، مما يشير إلى أن إعادة الترتيب تحتاج إلى تحسين.
عند الحاجة، يمكن أيضًا إضافة مقياس Coverage لمراقبة تغطية قاعدة المعرفة وكشف النقاط العمياء المنهجية.
تقييم جودة التوليد: الدقة والالتزام الواقعي
يوفر الاسترجاع المواد الخام. السؤال التالي هو ما إذا كان يمكن لوحدة التوليد إنتاج إجابة عالية الجودة من تلك المواد. الأبعاد الأساسية هنا هي دقة الإجابة والالتزام بالأدلة المسترجعة.
المطابقة التامة والتشابه النصي
أبسط مقياس هو EM، المطابقة التامة، الذي يتطلب أن تتطابق الإجابة المولدة مع الإجابة المرجعية بالضبط. هذا مناسب لأسئلة الحقائق ذات الشكل الثابت والصحيح الوحيد مثل التواريخ أو مواقع المقرات، لكنه صارم جدًا لأن أشكال السطح المختلفة ولكن الصحيحة بنفس القدر قد تفشل في التطابق.
لذلك تستخدم أيضًا مقاييس تداخل n-gram مثل ROUGE وBLEU وMETEOR بشكل شائع. تسجل الإجابات المولدة عن طريق مقارنة تداخل الكلمات مع الإجابات المرجعية. ROUGE-L ينتبه إلى أطول المتتاليات المشتركة، وBLEU يأتي من الترجمة الآلية ويؤكد الدقة، وMETEOR يضيف اعتبارات المرادفات والجذور.
للتغلب على حدود تداخل الكلمات البحت، يمكننا أيضًا استخدام BERTScore أو تشابه المتجهات المباشر. هذه تستخدم تمثيلات دلالية مدربة مسبقًا وبالتالي تتحمل التباين السطحي بشكل أفضل.
الالتزام الواقعي وكشف الهلوسة
لأنظمة RAG، تشابه الإجابة مع المرجع ليس كافيًا. السؤال الأكثر أهمية هو ما إذا كانت الإجابة مبنية فعلًا على الوثائق المسترجعة أو هلوسة محتوى غير مدعوم.
لذلك فإن مقاييس مثل معدل الهلوسة والالتزام مهمة. يمكن لـ LLM ثانٍ أن يعمل كمدقق حقائق ويفحص الإجابة المولدة جملة بجملة، ويحكم على ما إذا كان كل ادعاء يمكن دعمه بالوثائق المسترجعة. للمجالات عالية المخاطر مثل الرعاية الصحية والقانون والمالية، هذا النوع من المقاييس مهم بشكل خاص، وبعض المؤسسات تطبق حتى عتبات الهلوسة كمعايير إطلاق الإنتاج.
LLM كحكم: التسجيل متعدد الأبعاد
كل مقياس آلي له حدود. معظم مقاييس الشكل السطحي لا يمكنها التقاط الجودة الدلالية أو الفائدة الإجمالية بالكامل. هذا هو المكان الذي يصبح فيه LLM كحكم ذا قيمة خاصة.
النهج الأساسي هو تغذية السؤال والوثائق المسترجعة وإجابة النظام والإجابة المرجعية في نموذج مستقل قوي، مثل GPT-4 أو Claude، وطلب منه التسجيل عبر أبعاد مثل:
- صلة السؤال
- اكتمال المعلومات
- الالتزام الواقعي
- الصحة الإجمالية
قوة حكم LLM هي أنه يمكنه إصدار حكم شامل أقرب إلى الإنسان. بالطبع، لا تزال موجهات الحكم تحتاج تصميمًا دقيقًا ومعايرة مقابل أمثلة موسومة بشريًا لإبقاء التسجيل متسقًا وموثوقًا.
بناء مجموعة مقاييس عملية
مع توفر العديد من المقاييس، تتساءل الفرق غالبًا أيها تستخدم. توصية عملية هي البدء بمجموعة مدمجة والتوسع تدريجيًا:
- للاسترجاع، ابدأ بـ Recall@K مع MRR@K
- للتوليد، اختر مقياسًا أساسيًا أو اثنين من EM وROUGE-L وBERTScore وفقًا لنوع المهمة
- للتقييم الإجمالي، أدخل حكم LLM يركز على الصلة والاكتمال والالتزام
ثم كرر من خلال حلقة من التقييم وتشخيص المشاكل وتعديل الاستراتيجية وإعادة التقييم.
5.3.3 أطر التقييم
مع التطور السريع لـ RAG، أنتجت كل من الأوساط الأكاديمية والصناعة العديد من أطر التقييم القوية. هذه الأطر لا تغلف فقط المقاييس الشائعة، بل تقدم أيضًا مجموعات بيانات معيارية وإجراءات قياس وتدفقات عمل شاملة من البداية إلى النهاية.
تصنيف أساسي للأطر
يمكننا تقسيم أطر تقييم RAG تقريبًا إلى ثلاث فئات:
- أطر البحث، التي تركز على الاستكشاف الأكاديمي والتشخيص الدقيق. تشمل الأمثلة FiD-Light وDiversity Reranker.
- أطر المعايير، التي توفر مجموعات اختبار معيارية وتدفقات عمل موحدة للمقارنة الأفقية بين الأنظمة. تشمل هذه أطرًا مثل RAGAS وARES وRGB وMultiHop-RAG وCRUD-RAG.
- أطر الأدوات، التي تؤكد قابلية الاستخدام الهندسي والتكامل مع أطر التطوير. تشمل الأمثلة TruEra RAG Triad وLangChain Benchmarks وRECALL.
في السنوات الأخيرة، أصبحت أطر التقييم أكثر تخصصًا. على سبيل المثال، الطب لديه MedRAG، والقانون لديه LegalBench-RAG، والمالية لديها أطرها المتخصصة. هذه الأطر المجالية غالبًا توفر ليس فقط مجموعات بيانات متخصصة بل أيضًا مقاييس متخصصة مثل الدقة الطبية أو صلة الاستشهاد القانوني.
في الممارسة، قاعدة جيدة هي:
- إذا كنت تحتاج خط أساس بسرعة، ابدأ بإطار أكثر عمومية مثل RAGAS.
- إذا كنت تشخص مشكلة محددة، اختر إطارًا أكثر استهدافًا.
- إذا كنت في الطب أو القانون أو المالية أو مجال مهني آخر، فضل الأطر المتكيفة مع المجال حيثما أمكن.
- فضل الأدوات التي تتم صيانتها بنشاط مع توثيق قوي ومجتمعات مستجيبة.
الأدوات الموصى بها شيوعًا في المجتمع تشمل Ragas وContinuous Eval وTruLens-Eval وميزات التقييم داخل LlamaIndex وPhoenix وDeepEval وLangSmith وOpenAI Evals.
5.3.4 معايير التقييم
غالبًا ما يُقلل من أهمية معايير التقييم. العديد من الفرق تبدأ تقييم نظام RAG مع عدد قليل فقط من أسئلة الاختبار المكتوبة يدويًا، ثم تكتشف أن الأداء الفعلي عبر الإنترنت يختلف بشكل كبير عن الانطباعات دون اتصال. السبب الجذري هو أنها تفتقر إلى بيانات تقييم تمثيلية ومنهجية.
معيار يدعم تكرار النظام بشكل جيد عادةً له ثلاث خصائص أساسية:
- التمثيلية، أي أنه يغطي أسئلة المستخدم عالية التكرار وحالات الحدود والمدخلات الشاذة
- المعيارية، أي أن تنسيقات الأسئلة والأجوبة ومستويات الصعوبة وقواعد التسجيل متسقة
- القابلية للتطور، أي أن المعيار يمكن تحديثه مع تطور قدرات النظام واحتياجات الأعمال
لمعظم المؤسسات، لأن سيناريوهات الأعمال فريدة، الإجابة النهائية عادةً هي بناء مجموعات بيانات تقييم خاصة بهم.
- ابدأ باستخراج أسئلة المستخدم الحقيقية من سجلات الأعمال وأخذ عينات منها حسب النوع والتكرار والصعوبة.
- للحالات البسيطة، دع خبراء المجال يوسمون مباشرة. للأسئلة الأكثر تعقيدًا، دع LLM قوي يولد إجابات مرشحة أولاً، ثم يقوم الخبراء بمراجعتها.
- إلى جانب الإجابة نفسها، أوسم البيانات الوصفية مثل الوثائق ذات الصلة ونوع الإجابة ومستوى الصعوبة.
- حدّث مجموعة البيانات بشكل دوري مع الحالات الصعبة الجديدة المكتشفة عبر الإنترنت.
إذا كانت الموارد محدودة وتحتاج خط أساس سريع، فإن المعايير العامة لا تزال نقطة بداية مفيدة. اعتبارًا من عام 2025، توجد العديد من المعايير العامة لكل من السيناريوهات العامة والعمودية:
عند الاختيار بينها، أوضح الهدف أولاً. هل تؤسس خط أساس، أم تتحقق من النظام قبل الإطلاق؟ ثم تحقق مما إذا كان المعيار يغطي السيناريوهات وملف الصعوبة الذي يهمك. للمجالات الحساسة للوقت مثل الأخبار أو المالية، تأكد من أن المعيار يتضمن اختبارات حساسة للوقت.
في الممارسة، الجمع بين مجموعة البيانات الداخلية الخاصة بك مع المعايير العامة غالبًا ما يكون المسار الأكثر متانة لأنه يبقي التقييم قريبًا من احتياجات الأعمال الحقيقية مع الحفاظ أيضًا على بعض المقارنة الأفقية.
6. تعمق: التعلم من المسابقات والدروس المفتوحة (اختياري)
المبادئ والتنفيذ الأساسي أعلاه كافية لمساعدتك في بناء نموذج أولي قابل للاستخدام، لكنها لا تزال على بعض المسافة من حل المشاكل الأصعب التي تظهر في الإنتاج. إذا كنت تريد فهم تقنيات RAG العملية والمختبرة في المعركة بشكل أفضل، فإن أحد أكثر الطرق كفاءة هو دراسة حلول المسابقات الفائزة والدروس المفتوحة القوية. هذه الحلول غالبًا ما تركز أفضل الممارسات التي اكتشفتها فرق قوية بعد محاولات متكررة في سيناريوهات حقيقية.
الأمثلة أدناه تمثيلية وليست شاملة. عندما تواجه مشكلة محددة في الممارسة، مثل تحليل PDF أو الاسترجاع متعدد الوسائط أو التحسين منخفض زمن الاستجابة، غالبًا ما يكون من الفعال البحث عن مسابقات متعلقة بتلك المشكلة ودراسة التقارير التقنية والأكواد المفتوحة من الفرق الفائزة.
6.1 الذاكرة المؤقتة الدلالية: تحسين الاستعلامات عالية التكرار
توفر Hugging Face تطبيقًا للذاكرة المؤقتة الدلالية مبنيًا على قاعدة بيانات المتجهات Chroma:
https://huggingface.co/learn/cookbook/semantic_cache_chroma_vector_database
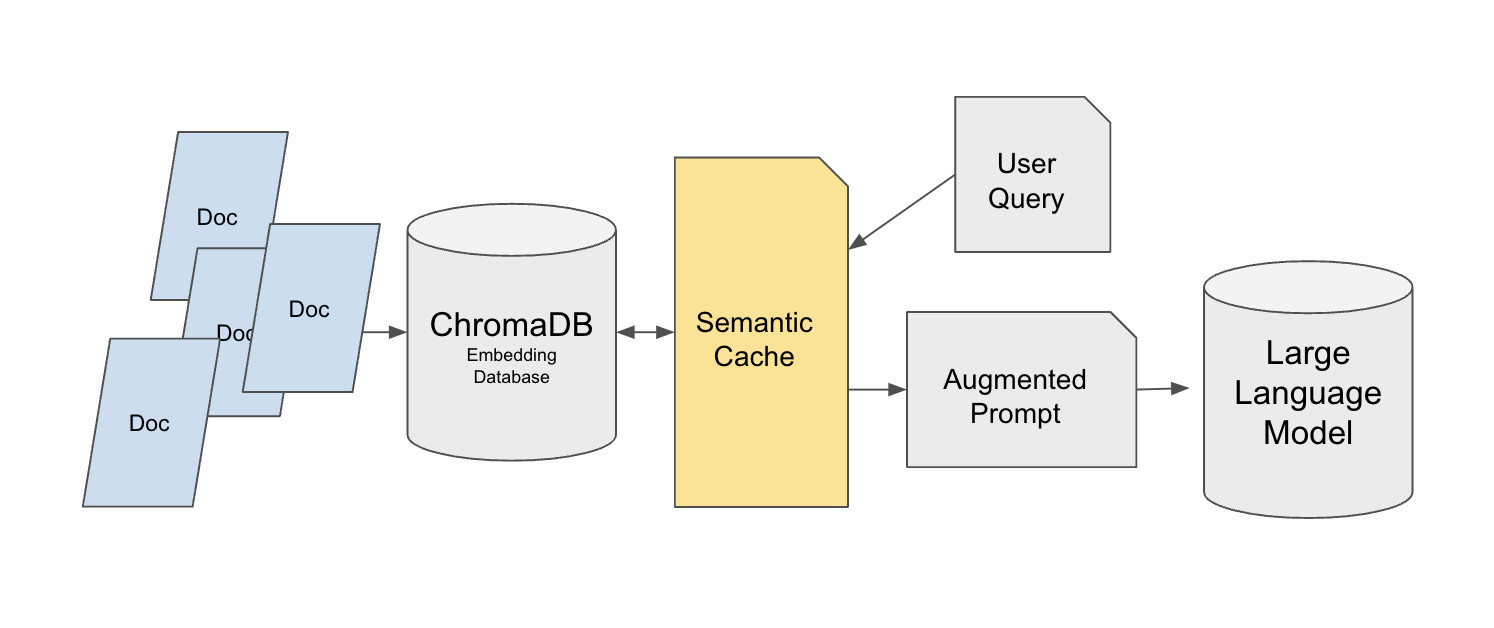
الخلفية: معظم أنظمة RAG التعليمية مبنية لاختبار مستخدم واحد. لكن بمجرد النشر في الإنتاج، قد يتلقى النظام عشرات أو آلاف الاستعلامات المتكررة، على سبيل المثال مستخدمو الدعم يسألون بشكل متكرر عن كيفية عمل الاستردادات. إذا كان كل استعلام متكرر لا يزال يحفز استرجاع المتجهات واستدعاء LLM، ترتفع التكلفة وزمن الاستجابة بسرعة. يمكن لطبقة ذاكرة مؤقتة دلالية أن تقلل بشكل حاد الضغط على مصادر البيانات الأصلية مع الحفاظ على جودة الإجابة.
يستخدم هذا التصميم بنية استرجاع من طبقتين. الطبقة الأساسية تخزن قاعدة المعرفة الأصلية في Chroma، باستخدام مجموعة بيانات مثل MedQuad كمثال وتعيين معرف فريد لكل إدخال للرجوع الدقيق. طبقة الذاكرة المؤقتة مبنية على FAISS باستخدام فهرس FlatL2. الذاكرة المؤقتة الدلالية تجلس بين استعلام المستخدم وChromا، بدلاً من تخزين الإجابة النهائية لـ LLM مؤقتًا مباشرة. ذلك التصميم مهم لأن التخزين المؤقت المباشر للإجابات يمكن أن يكسر متطلبات الإجابة المخصصة مثل "اشرح هذا بلغة بسيطة."
يستخدم نظام الذاكرة المؤقتة all-mpnet-base-v2 SentenceTransformer لتوليد متجهات الاستعلام ويستخدم المسافة الإقليدية، مع عتبة 0.35، للحكم على ما إذا كانت الاستعلامات متشابهة. عندما تمتلئ الذاكرة المؤقتة، التي يتحكم فيها معامل max_response، تُزال أقدم إدخال باستخدام FIFO. يمكن أيضًا حفظ بيانات الذاكرة المؤقتة في ملفات JSON لإعادة الاستخدام عبر الجلسات.
في الاختبارات صغيرة النطاق، استغرق استعلام أول مثل "كيف تعمل اللقاحات؟" 0.057 ثانية عند جلبه من Chroma، بينما استعلام مشابه خدم من الذاكرة المؤقتة استغرق 0.016 ثانية فقط. في سيناريوهات الإنتاج الكبيرة، يمكن لهذا النهج إنتاج تحسين أداء بنسبة 90 إلى 95 بالمائة في البيئات عالية التكرار وتقليل تكلفة مخزن المتجهات وAPI بشكل كبير.
6.2 معالجة البيانات غير المنظمة: تحليل موحد لوثائق متعددة التنسيقات
يوضح درس تعليمي آخر من Hugging Face كيفية استخدام مكتبة Unstructured لبناء خط أنابيب كامل لمعالجة الوثائق غير المنظمة:
https://huggingface.co/learn/cookbook/rag_with_unstructured_data

الخلفية: في سيناريوهات المؤسسات، المعرفة غالبًا ما تكون مبعثرة عبر ملفات PDF وعروض PowerPoint وEPUBs وصفحات HTML والعديد من التنسيقات الأخرى. طرق المعالجة المسبقة التقليدية إما تدعم تنسيقًا واحدًا فقط أو تفقد معلومات هيكلية حاسمة مثل الجداول والتسلسل الهرمي للعناوين أثناء التحويل. ذلك يجعل من الصعب على نظام RAG فهم واسترجاع المحتوى بشكل صحيح.
يقوم هذا الحل أولاً بتنزيل وثائق اختبار متعددة التنسيقات، مثل دليل مبيدات آفات كندي PDF يحتوي على العديد من الجداول وملف PowerPoint لإدارة الآفات الحمضية من جامعة فلوريدا يحتوي على رسوم بيانية وعناوين متعددة المستويات. ثم يستخدم Local Runner من Unstructured للتحليل. يتضمن التكوين تهيئة المعالج، وتهيئة القسم التي يمكنها اختياريًا استخدام وضع تقسيم API لـ OCR أقوى، وتهيئة محلية تحدد مسارات الإدخال. يتم تحويل الوثائق المحللة إلى JSON يحتوي على عناصر موسومة مثل النص الأساسي والعناوين والجداول.
يستخدم النظام بعد ذلك chunk_by_title، ويحدد حد أقصى للطول 512 حرف، ويدمج الأجزاء المتتالية الأقصر من 200 حرف للحفاظ على التماسك الدلالي. أثناء التحويل إلى كائنات LangChain Document، يتم تصفية حقول البيانات الوصفية المعقدة لتناسب Chroma. مرحلة المتجهات تستخدم نموذج التضمين BAAI/bge-base-en-v1.5، مع Llama-3-8B-Instruct المكمم 4-بت وسلسلة RetrievalQA من LangChain لبناء نظام RAG كامل.
يمكن للنظام الناتج التعامل مع وثائق متعددة التنسيقات بدقة. لأسئلة مثل "هل المن citrus آفة؟" يمكنه استخراج حقائق رئيسية من الوثائق المحللة وتوليد إجابات مبنية على المواد ذات الصلة. هذا مفيد بشكل خاص لقواعد معرفة المؤسسات التي تحتاج معالجة أنواع وثائق عديدة.
6.3 الإجابة على أسئلة وثائق المؤسسات: RAG عالي الدقة وقابل للتتبع
يُظهر حل البطولة في تحدي RAG للمؤسسات كيفية بناء نظام RAG على مستوى الإنتاج تحت متطلبات صارمة للوقت والدقة:
- https://abdullin.com/ilya/how-to-build-best-rag/
- https://hustyichi.github.io/2025/07/03/rag-complete/
الخلفية: كان على المتنافسين تحليل 100 تقرير سنوي حقيقي لمؤسسات كملفات PDF في 2.5 ساعة، كل تقرير يصل إلى 1000 صفحة ويحتوي على جداول مالية معقدة وتخطيطات متعددة الأعمدة ورسوم بيانية. بعد التحليل، كان على النظام الإجابة على 100 سؤال أعمال دقيق مع أنواع إجابات صريحة، مثل نعم-لا، أسماء شركات، مؤشرات رقمية دقيقة، أو مناصب تنفيذية، وكان عليه الاستشهاد بأرقام الصفحات كأدلة.
اختار الفريق الفائز Docling مفتوح المصدر من IBM كمحلل PDF لأنه كان الأفضل أداءً على الجداول المعقدة والنص متعدد الأعمدة. حسّنوا كود Docling حتى يتمكن من إخراج JSON وMarkdown-plus-HTML مع بيانات وصفية وخاصة تحسين تحليل الجداول. لتسريع المعالجة، استأجروا وحدات معالجة رسوميات RTX 4090 وأنهوا تحليل التقارير المائة في 40 دقيقة.
استخدم تقسيم النص أجزاء بحجم 300 رمز مع تداخل 50 رمز وتقسيمًا عوديًا للحفاظ على التماسك الدلالي. لتجنب التلوث عبر الشركات، كان لكل شركة مخزن متجهات FAISS خاص بها باستخدام فهرس IndexFlatIP. اتبع الاسترجاع بعد ذلك ثلاث مراحل: استرجاع أفضل 30 جزءًا بالمتجهات، وإزالة التكرار حسب الصفحات الأم لأن أجزاء متعددة قد تأتي من نفس الصفحة، وإعادة ترتيب الصفحات مع GPT-4o-mini. مزج الترتيب النهائي بين درجات استرجاع المتجهات وإعادة ترتيب LLM بتقسيم وزن 0.3 إلى 0.7.
استخدم التوليد قوالب موجهات مختلفة لأنواع إجابات مختلفة. للأسئلة الرقمية، مثل الإيرادات السنوية، استخدم النظام عملية تحليل من خمس خطوات لضمان مطابقة المؤشرات واتساق الوحدات والتحقق المتقاطع. كانت المخرجات منظمة لتتضمن عملية التحليل ومراجع الصفحات لإمكانية التتبع.
فاز النظام بجائزتين واحتل المركز الأول على لوحة المتصدرين. ملاحظة مهمة كانت أنه حتى النماذج الأصغر مثل Llama 8B تفوقت على أكثر من 80 بالمائة من المشاركين، بينما اقترب Llama 3.3 70B من GPT-4o-mini، مما يظهر أن تصميم نظام جيد يمكن أن يوازن بنجاح بين الدقة والكفاءة والتكلفة.
6.4 سيناريو AIOps: المعالجة الذكية لبيانات النص والصور المختلطة
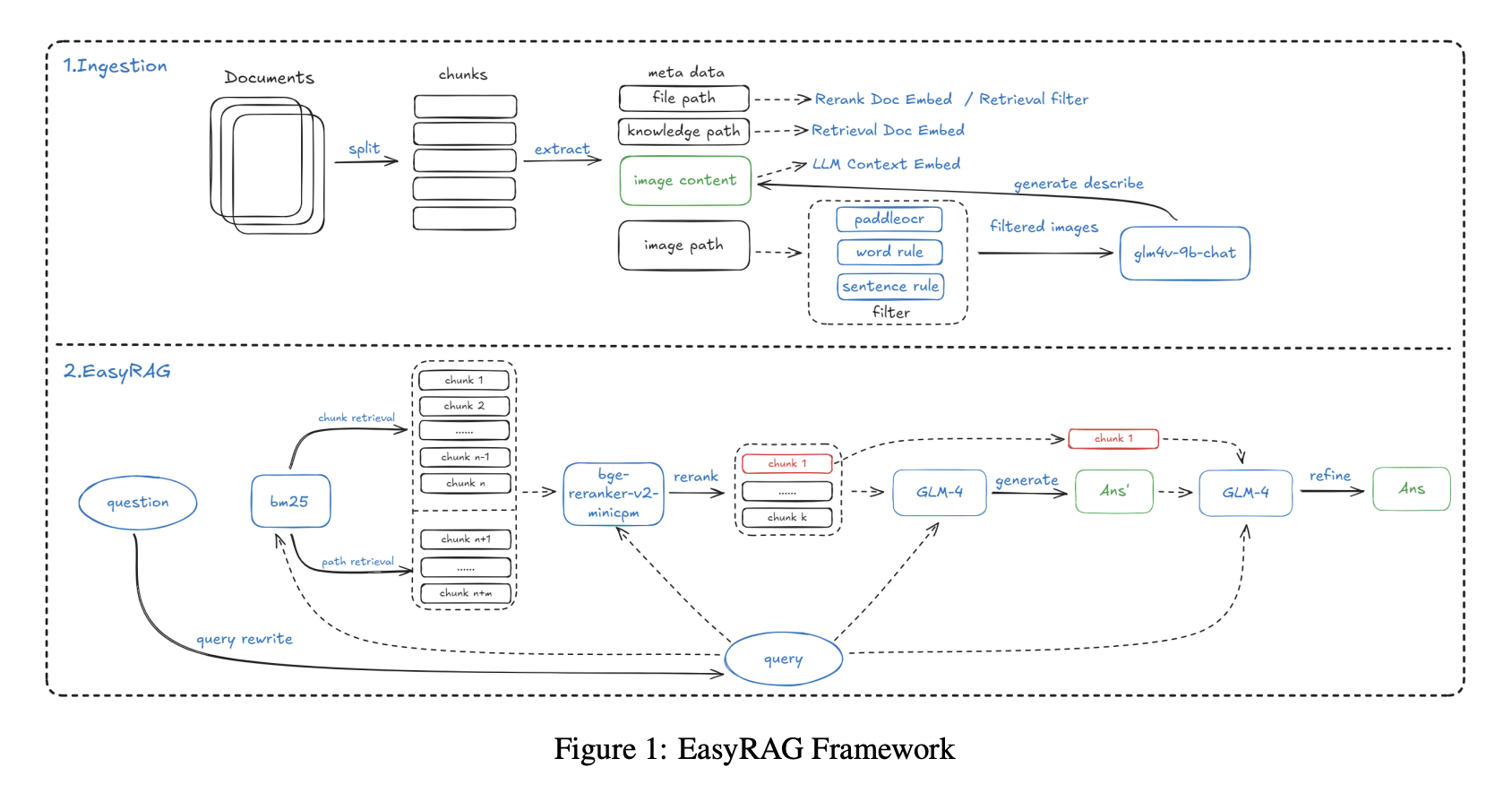
ركز مشروع EasyRAG في مسابقة RAG لـ AIOps على الإجابة على الأسئلة لسيناريوهات العمليات:
http://blog.csdn.net/hustyichi/article/details/143323746
الخلفية: يحتاج مهندسو العمليات غالبًا إلى قراءة وثائق تقنية تتضمن ليس فقط النص بل أيضًا رسوم المراقبة ومخططات بنية النظام ومنحنيات الأداء. على سبيل المثال، عند تشخيص مشكلة نظام، قد تكون إجابة "ماذا يجب أن أفعل عندما يتجاوز استخدام CPU 80 بالمائة؟" مبعثرة بين الأوصاف النصية ورسوم المراقبة. RAG النصي التقليدي لا يمكنه فهم اتجاهات وقيم الرسوم البيانية، لذلك تبقى الإجابات غير مكتملة.
استخدمت مرحلة الفهرسة SentenceSplitter محسنًا مع أجزاء بحجم 1024 رمز وتداخل 200 رمز. كانت ابتكارًا رئيسيًا إضافة بيانات وصفية مثل مسارات قاعدة المعرفة ومسارات الملفات إلى كل جزء، مما حسّن الاستدعاء بنسبة 2 بالمائة. لبيانات الصور، استخدم النظام أولاً PaddleOCR لاستخراج النص من الرسوم البيانية ولقطات الشاشة، ثم استخدم نموذجًا متعدد الوسائط، GLM-4V-9B، لتوليد أوصاف باللغة الطبيعية للصورة، على سبيل المثال وصف خط استخدام CPU يصل إلى ذروة 90 بالمائة في فترة ما بعد الظهر. تم فهرسة كل من نص OCR ووصف الصورة معًا.
استخدم الاسترجاع استراتيجية BM25 زائد المتجهات ثنائية المسار للاستدعاء الواسع. غطى BM25 استرجاع الأجزاء واسترجاع المسارات، مما ساعد في تصفية الوثائق غير ذات الصلة حسب مسار الملف، بينما استخدم استرجاع المتجهات gte-Qwen2-7B-instruct. استخدمت إعادة الترتيب bge-reranker-v2-minicpm-layerwise، وإعداد 28 طبقة كان الأفضل أداءً في التجارب.
استخدم توليد الإجابات استراتيجية من خطوتين: أولاً توليد مسودة من أفضل 6 وثائق لتعظيم تغطية المعلومات، ثم تحسين الإجابة مع الوثيقة الأكثر صلة (أفضل 1) للتأكيد على الإجابة الأساسية.
للتعامل مع سيناريوهات النص الطويل، مثل دليل عمليات كامل بمئات الصفحات، نفذ النظام أيضًا ضغط سياق قائم على BM25، تقسيم الوثائق إلى جمل، تسجيل تشابه الجمل مع الاستعلام، وربط الجمل الأكثر صلة فقط. عند ضغط 50 بالمائة، حققت هذه الطريقة دقة 86.48 بالمائة في 7.7 ثانية فقط وتفوقت على أدوات مثل LLMLingua.
6.5 دمج البيانات متعددة المصادر: تعاون المعرفة المنظمة وغير المنظمة
أظهر الحل الفائز في تحدي KDD Cup 2024 Meta RAG كيفية دمج محتوى الويب غير المنظم ورسوم المعرفة المنظمة:
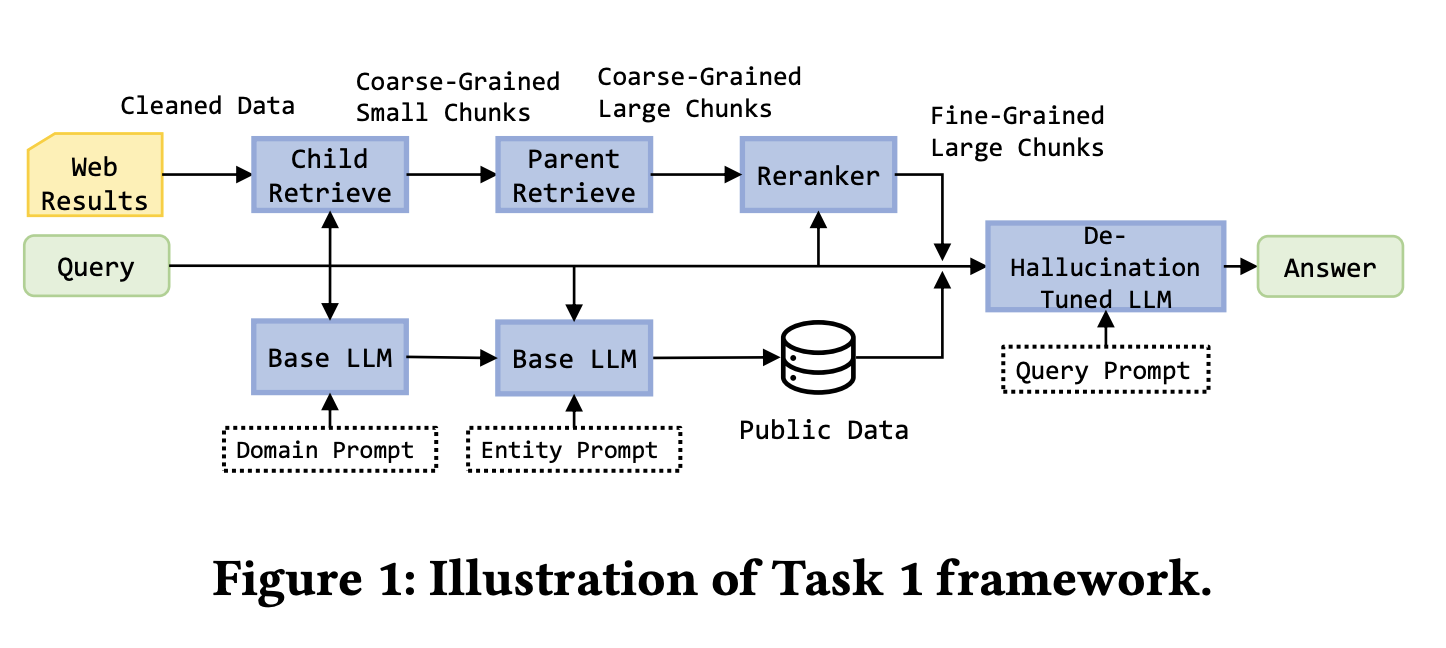
الخلفية: تطلب المهمة 1 تلخيص استرجاع من خمس صفحات ويب. أضافت المهمة 2 API وهمية تمثل رسم معرفة منظم، مما يتيح الوصول المباشر لأشياء مثل قواعد بيانات الأفلام وعلاقات الكيانات. رفعت المهمة 3 الصعوبة باستخدام خمسين صفحة ويب زائد API الوهمية للإجابة على استعلامات أكثر تعقيدًا، مثل تحديد أفلام أخرجها نولان بإيرادات تتجاوز 500 مليون دولار. كان يجب أن ينتهي كل استعلام في غضون 30 ثانية.
للمهمة 1، بنى الفريق الفائز خط أنابيب معالجة ويب محسن. استخدموا BeautifulSoup لاستخراج نص الصفحة وParentDocumentRetriever لإدارة علاقات الأجزاء الأم-الطفل، باستخدام أجزاء فرعية بحجم 200 رمز للاسترجاع وأجزاء أم بحجم 500 إلى 2000 رمز للتوليد. كان نموذج التضمين bge-base-en-v1.5، ومخزن المتجهات Chroma، وإعادة الترتيب استخدمت bge-reranker-v2-m3. كما زوّد الفريق بيانات الأفلام والمالية من مجموعات بيانات عامة وضبطوا بدقة Llama-3-8B-instruct مع LoRA على بيانات تدريب تضمنت أسئلة غير صالحة وإجابات مرجعية.
للمهام 2 و3، كان الابتكار الرئيسي هو إعطاء الأولوية لرسم المعرفة. حدد النظام استدعاءات API معيارية مثل get_person وget_movie، مع دعم التصفية والفرز. استدعى أولاً API رسم المعرفة ولم يلجأ إلى استرجاع الويب إلا إذا كانت نتائج الرسم مفقودة أو غير صالحة. هذا حسّن كل من السرعة ودقة الإجابة.
بسبب إعطاء الأولوية لرسم المعرفة واستخدام تنسيقات مخرجات منظمة، تم تقليل الهلوسة بوضوح. إذا كان يمكن للرسم تقديم إجابة حتمية مباشرة، أعادها النظام بدون خطوة توليدية. إذا كان استرجاع الويب مطلوبًا، كان يجب أن تتبع الإجابة قواعد استشهاد وتفكير تدريجي صارمة.
فاز الحل بالمركز الأول في جميع المهام الثلاث. الدرس الرئيسي هو أنه في سيناريوهات المؤسسات التي تحتوي على كل من البيانات المنظمة وغير المنظمة، يجب تصميم استراتيجية الاسترجاع وفقًا لنوع البيانات: استخدام البيانات المنظمة الحتمية أولاً ومعاملة المصادر غير المنظمة كمكملات.
عبر هذه الحالات العملية، تظهر عدة مبادئ مشتركة بشكل متكرر:
- اختيار استراتيجيات الذاكرة المؤقتة والاسترجاع والتوليد وفقًا لسيناريو الأعمال
- تصميم مسارات تحليل وفهرسة مخصصة لتنسيقات ووسائط مختلفة
- معاملة الاسترجاع الهجين زائد إعادة الترتيب كتكوين قياسي
- استخدام الموجهات المخصصة للمهام والمخرجات المنظمة لتحسين الدقة وإمكانية التتبع
هذه الدروس من المسابقات الحقيقية والمشاريع المفتوحة هي مراجع قيمة عند بناء أنظمة RAG مؤسسية أقوى.
7. استكشاف واسع: التطور المستقبلي لـ RAG (اختياري)
بمجرد أن تتعلم المهارات العملية وطرق تحسين RAG، يمكنك بالفعل تحسين أداء النظام في سيناريوهات محددة. لكن فهم حيل الهندسة المحلية فقط ليس كافيًا إذا كنت تريد فهمًا أوسع لأين يتجه RAG. نحتاج أيضًا إلى النظر في اتجاهات تطورية أوسع.
RAG الآن يكسر بسرعة نمط استرجع-أجزاء-النص-ثم-ولد التقليدي. في هذا القسم نركز على عدة من تلك المسارات: الانتقال من استرجاع الأجزاء إلى الاسترجاع القائم على بنية الرسم البياني، الجمع بين الصور والصوت في RAG متعدد الوسائط، تحسين التعامل مع الوثائق الطويلة من خلال التقسيم المتأخر إلى أجزاء متجهة، والطريقة التي يتطور بها RAG تدريجيًا نحو نظام موجه بالوكلاء.
7.1 Graph RAG: إعادة تشكيل الاسترجاع العميق بشبكات العلاقات
أبحاث ذات صلة:
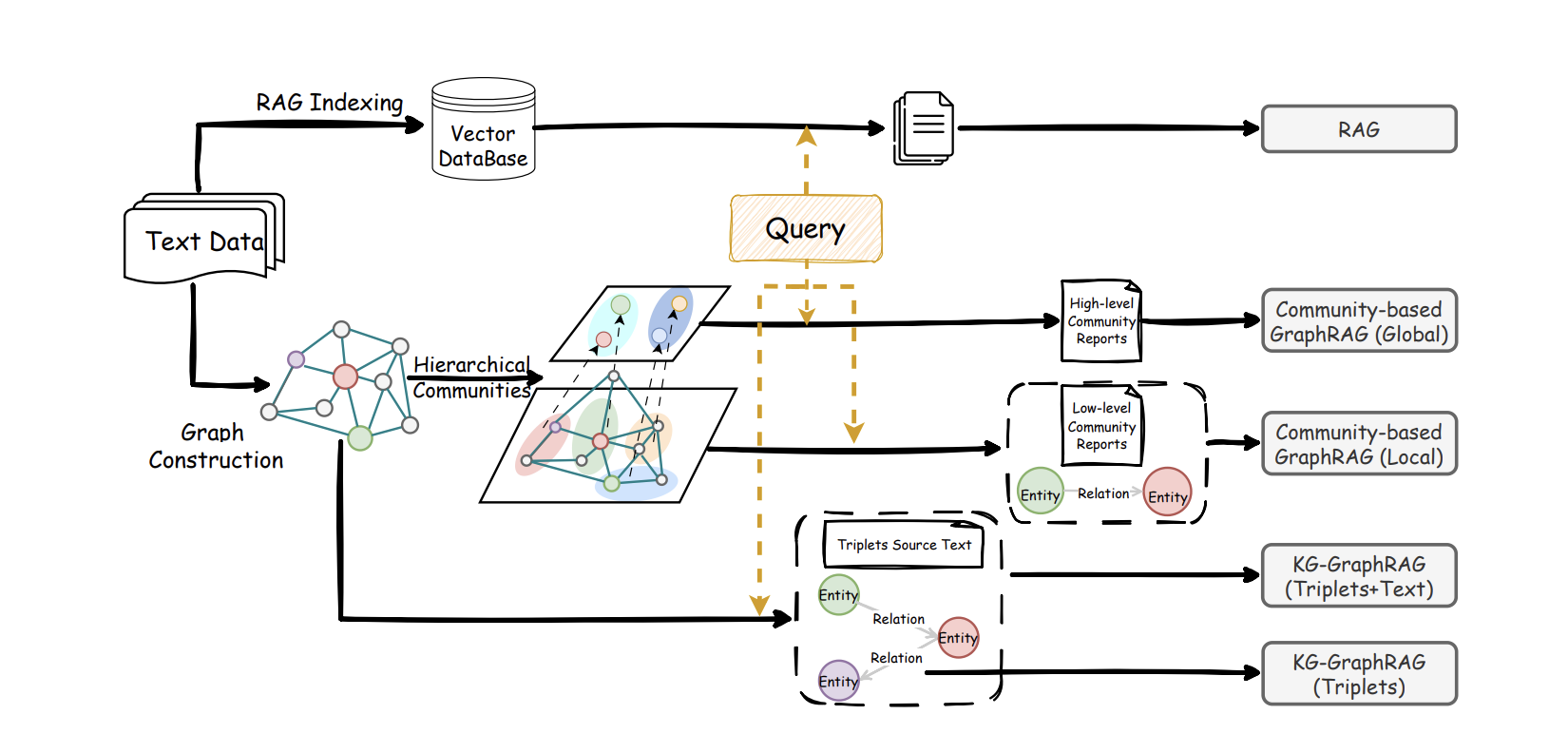
يعمل RAG التقليدي بإيجاد مقاطع نصية مشابهة للسؤال، وهو مثل انتقاء الفقرات القليلة التي تبدو الأكثر صلة من كومة من المواد. ذلك يعمل بشكل جيد للبحث عن الحقائق المباشرة. لكن إذا تطلب سؤال ربط وثائق متعددة والجمع بين أدلة مختلفة، ينخفض الأداء.
على سبيل المثال، قد يسأل طبيب، "بناءً على هذه الحالات وأحدث إرشادات العلاج، كيف يجب أن نقيم فوائد ومخاطر دواء معين للمرضى المسنين؟" أو قد يسأل فريق مشروع، "بالنظر عبر وثائق المتطلبات وسجلات المراجعة وتقارير المشكلات عبر الإنترنت على مدى العامين الماضيين، أي جزء من بنية نظامنا يفشل في أغلب الأحيان؟" أسئلة مثل هذه ليست حول إيجاد جملة واحدة. تتطلب تحديد الأشخاص والأشياء والأحداث والعلاقات المبعثرة عبر مواد متعددة وتشكيل صورة كاملة.
يبني Graph RAG تلك الصورة بشكل استباقي. يستخدم النظام نموذجًا كبيرًا لتحديد الكيانات الرئيسية من النص، مثل الأشخاص والمنظمات والوحدات الوظيفية والأحداث والبيانات، مع علاقاتها، مثل السببية والاعتماد والتغيير والتناقض. ثم يبني شبكة معرفية تنمو مع إضافة المزيد من المواد. من خلال التجميع التلقائي، تُنظم الكيانات والعلاقات الوثيقة الصلة في موضوعات، ويمكن تلخيص كل موضوع مقدمًا. عندما يطرح المستخدم سؤالاً، لم يعد النظام يبحث فقط عن مقاطع نصية تبدو مشابهة. بل يجد أولاً الكيانات الأكثر صلة وبنية الرسم المحلية، ثم يتوسع عبر مجموعات المواضيع ذات الصلة، ثم يعطي مسار التحليل وأوصاف العقد والمقاطع المصدر معًا إلى LLM للاستنتاج.
تحت هذا الإطار، يكمل Graph RAG وRAG التقليدي بعضهما البعض. يظل RAG التقليدي قويًا لأسئلة التفاصيل التي يمكن العثور على إجاباتها في خطوة واحدة. Graph RAG أقرب إلى طريقة تفكير باحث بشري: ينظم أولاً الهيكل العام والمواضيع، ثم يملأ الأدلة، وأخيرًا ينتج استنتاجًا بمنطق وشروط. المقارنات الموجودة تظهر أنه في مهام الاستدلال متعدد القفزات، يغطي Graph RAG غالبًا محتوى حرجًا أكثر ويوفر منظورًا أوسع. الجمع المرن بين النهجين غالبًا ما يكون أفضل من استخدام واحد فقط.
7.2 RAG متعدد الوسائط
أبحاث ذات صلة:
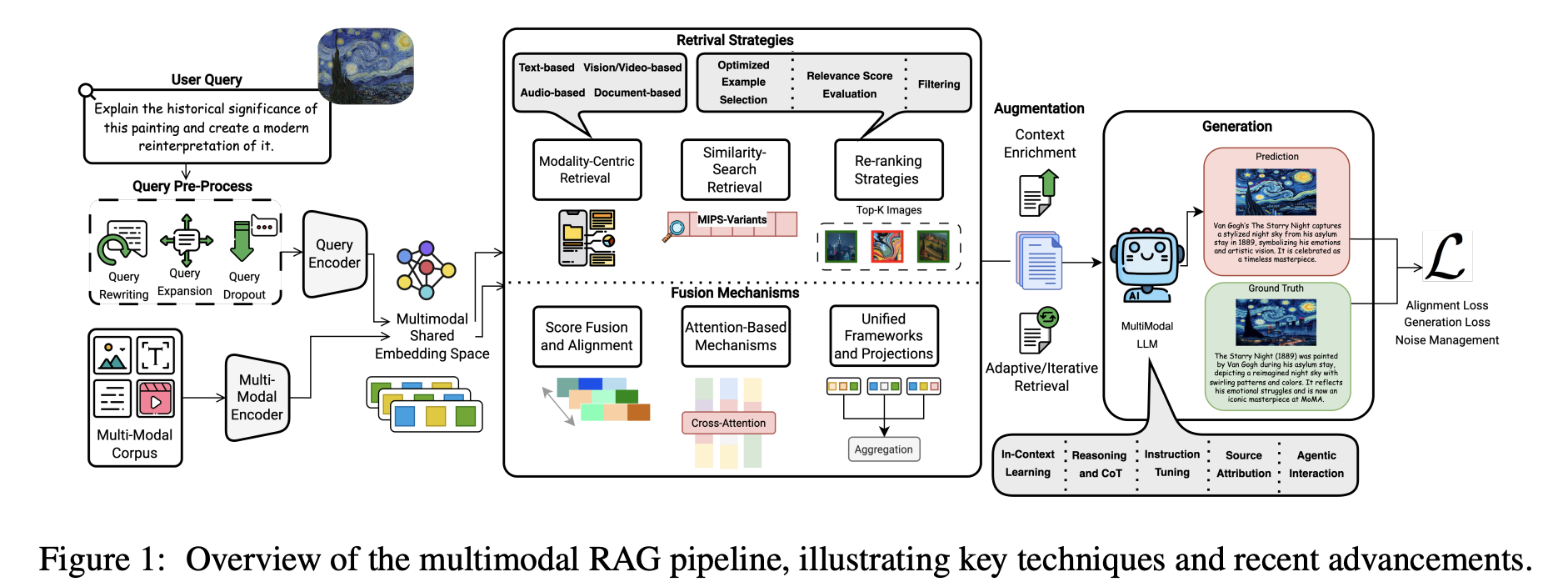
البيانات الحقيقية ليست نصًا فقط أبدًا. مهندسو تشخيص أعطال الخوادم يحتاجون النظر في منحنيات درجات الحرارة ولقطات شاشة الأجهزة والسجلات معًا. الأطباء الذين يقومون بالتشخيص يحتاجون صور CT أو MRI وتقارير الفحوص والسجلات الطبية الإلكترونية في نفس الوقت. RAG النصي التقليدي يمكنه في أحسن الأحوال استرجاع عبارات مثل "درجة حرارة غير طبيعية" أو "ورقة رئة مشتبهة"، لكنه يعاني من ربط تلك الأوصاف باتجاه الرسم البياني الفعلي أو شكل الآفة في الصورة، ولا يمكنه البحث العكسي عن وثائق أو معرفة من صور أو صوت أو فيديو.
يحل RAG متعدد الوسائط مشكلة عدم قدرة الوسائط المختلفة على "رؤية" بعضها البعض. جوهره هو المحاذاة الدلالية عبر الوسائط. يستخدم النظام مشفرات مناسبة للصور والفيديو والصوت والنص، مع OCR وASR وتحليل التخطيط، يستخرج معلومات رئيسية من المصادر البصرية والصوتية، ويخترن الوسائط المختلفة في فضاء دلالي مشترك حيث يمكن بناء فهرس متعدد الوسائط موحد.
في وقت الاسترجاع والتوليد، سواء سأل المستخدم عن رسم بياني يُظهر ذروة مبيعات في الربع الثالث من 2023 أو حمّل رسمًا تخطيطيًا أو فيديو تشغيلي، يجد النظام أولاً أقرب أدلة متعددة الوسائط في ذلك الفضاء الموحد، ويصفيها بإشارات مثل تشابه النص وتشابه الصورة، ويبقى على أكثر القطع فائدة، ثم يعطي تلك الصور ومقاطع النص والجداول معًا إلى LLM متعدد الوسائط. يمكن للنموذج بعد ذلك الإجابة بالجمع بين الأدلة عبر الوسائط وبشكل مثالي يشير إلى المصدر أو يسلط الضوء على المناطق ذات الصلة في الصورة أو الوثيقة.
مقارنة مع RAG النصي فقط، يمكن لـ RAG متعدد الوسائط استخدام أنواع أكثر من الأدلة وغالبًا ما يقلل الهلوسة بينما ينتج إجابات أكثر اكتمالًا وأكثر قابلية للتحقق.
7.3 التقسيم المتأخر: الحفاظ على السياق الكامل للوثائق الطويلة
مقدمة ذات صلة:
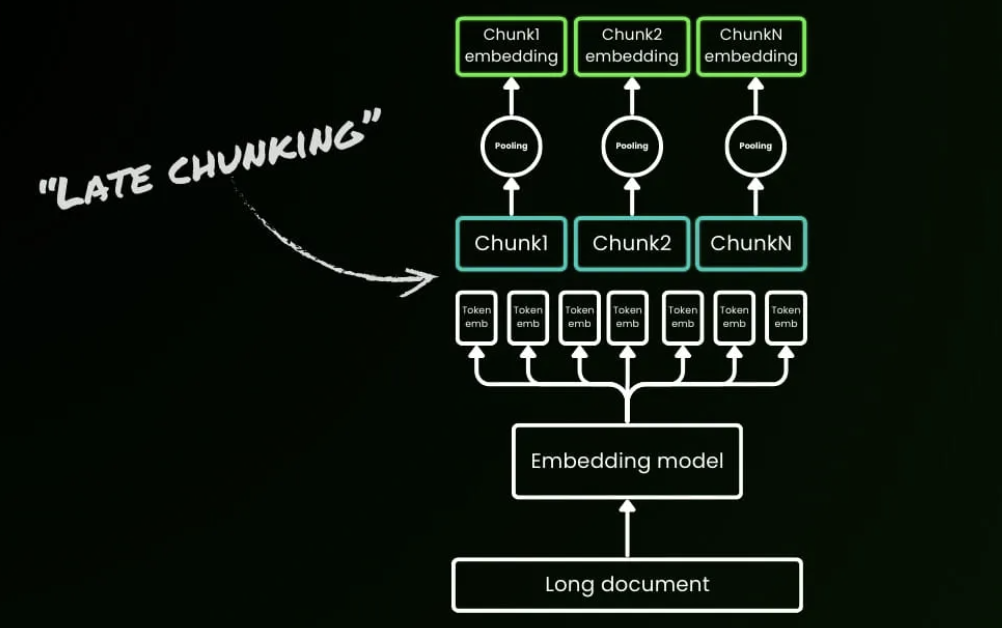
تخيل قراءة مقال ويكيبيديا عن برلين. RAG التقليدي سيقطعه أولاً إلى فقرات مستقلة ثم يضمّن كل جزء. إذا كانت الجملة الأولى تقول "برلين هي عاصمة ألمانيا"، فإن العبارات اللاحقة مثل "المدينة" أو "سكانها" تفقد اتصالها ببرلين بمجرد فصلها. استعلام مثل "ما هو عدد سكان برلين؟" قد يفشل لأن مصطلح برلين ومعلومات السكان لم يظهران داخل نفس الجزء أبدًا. تصبح هذه المشكلة أسوأ بالنسبة للوثائق الطويلة. في عقد تأمين من 200 صفحة، قد يظهر تعريف قابلية الخصم في الصفحة 5 بينما تظهر الشروط التي تنطبق عليها في الصفحة 30. التقسيم ذو الطول الثابت يمكن أن يقطع هذه الأجزاء المرتبطة إلى عشرات من الأجزاء المعزولة، وتظهر التجارب أن التشابه الدلالي يمكن أن ينهار بشكل حاد عندما يحدث ذلك.
يقلب التقسيم المتأخر خط أنابيب قسم-أولاً-ثم-ضمّن التقليدي ويتبع بدلاً من ذلك ضمّن-أولاً-ثم-قسم. مع نماذج تضمين السياق الطويل التي يمكنها التعامل مع شيء مثل 8192 رمز، يتم تمرير الوثيقة الكاملة أولاً عبر Transformer، منتجة تضمينات على مستوى الرموز التي رأت بالفعل الوثيقة الكاملة. فقط بعد ذلك يتم تجميع تضمينات الرموز المطلعة عالميًا تلك في تضمينات أجزاء وفقًا لحدود الأجزاء. الأجزاء الناتجة لم تعد جزرًا مستقلة. إنها تضمينات تعتمد على السياق تحافظ على المراجع عبر الفقرات والعلاقات المفاهيمية.
على مجموعات بيانات معيار BEIR، يتفوق التقسيم المتأخر على التقسيم التقليدي بشكل واسع، مع مكاسب خاصة قوية على الوثائق الأطول. في سيناريوهات النص القصير، يختفي الفرق إلى حد كبير، مما يؤكد قاعدة رئيسية: كلما طالت الوثيقة، زادت ميزة التقسيم المتأخر. الطريقة مدمجة الآن في Jina Embeddings v3. على الرغم من أن تشفير وثيقة طويلة كاملة أولاً يمكن أن يزيد وقت الاستدلال بنسبة 10 إلى 20 بالمائة، فإن مكاسب الاسترجاع في سيناريوهات مثل السجلات الطبية والوثائق القانونية والأدلة التقنية يمكن أن تبرر تلك التكلفة بسهولة.
يُظهر التقسيم المتأخر أن نماذج التضمين ذات السياق الطويل 8K فأكثر ليست مبالغة في الهندسة في هذه السيناريوهات. غالبًا ما تكون ضرورية لإنتاج تضمينات أجزاء عالية الجودة وتمثل تحولاً من قسم أولاً ثم ضمّن، إلى ضمّن أولاً ثم قسم.
7.4 من RAG إلى RAG في عصر الوكلاء
نقاشات ذات صلة:
- https://ragflow.io/blog/rag-at-the-crossroads-mid-2025-reflections-on-ai-evolution
- https://arxiv.org/pdf/2501.09136
- https://www.letta.com/blog/rag-vs-agent-memory
- https://www.linkedin.com/posts/richmondalake_100daysofagentmemory-rag-memorizz-activity-7348281860843577346-LM7Y/
- https://www.llamaindex.ai/blog/rag-is-dead-long-live-agentic-retrieval
تطور RAG من أداة توليد معززة بالاسترجاع إلى جزء رئيسي من بنية معرفية الوكيل. RAG التقليدي مبني على نمط اسأل واسترجع وأجب البسيط و سلبي بشكل أساسي. ينتظر استعلامًا ولا يتصرف بشكل استباقي. لاختراق تلك السلبية والتعامل مع مهام معرفية أكثر تعقيدًا، تم دمج RAG بعمق مع قدرات الوكلاء، مما أعطىrise إلى نموذج جديد: RAG الوكيل.
تحت هذا النموذج، يتغير دور RAG بشكل أساسي. لم يعد مجرد مزود سلبي للمعرفة الخارجية. بل يصبح وحدة المعالجة الأساسية التي تدعم السلوك الذكي تحت التخطيط النشط والاتجاه نحو الهدف والتأمل الذاتي للوكيل. هذا الاندماج يعطي النظام الكامل توجيهًا نحو الهدف، وتحسينًا تكراريًا، واتخاذ قرار مستقل، مما يعمق جودة التفاعل بين الإنسان والذكاء الاصطناعي بشكل كبير. يمكن لـ RAG الوكيل فهم المهام المعقدة، وتفكيكها، وتخطيط استراتيجيات الاسترجاع، وتقييم جودة النتائج الأولية لتحديد ما إذا كان الاستكشاف الأعمق مطلوبًا.
مفتاح هذه القدرة هو حلقة نشطة متعددة الطبقات. في مواجهة استعلام معقد، يحلل الوكيل أولاً طبيعة المشكلة، ويقسمها إلى مشاكل فرعية، ويصمم استراتيجيات استرجاع دقيقة لكل مشكلة فرعية. بعد تلقي النتائج الأولية، يقيّمها، ويحكم على ما إذا كانت المعلومات مكتملة وذات صلة، ويحدد فجوات المعرفة، ويولد بشكل ديناميكي استعلامات جديدة أكثر دقة. هذه العملية التكرارية غالبًا ما تتضمن استرجاع متعدد القفزات، حيث تكشف جولة واحدة من النتائج عن اتجاهات جديدة للجولة التالية، منتجة سلسلة استكشاف معرفي مشابهة لطريقة عمل باحث بشري.
لدعم هذا السلوك الذكي المستمر والتكراري، خاصة عندما يكون التخصيص وتراكم المعرفة طويل الأمد مهمين، سياق المحادثة قصيرة المدى وحدها بعيد عن أن يكون كافيًا. هذا يؤدي إلى الحاجة إلى ذاكرة طويلة المدى منظمة.
هذا بالضبط السبب في أن RAG يُعين بشكل متزايد دور نظام الذاكرة طويلة المدى للوكيل ويُستخدم لبناء بنية ذاكرة خارجية كاملة. هذه الذاكرة طويلة المدى تكمل الذاكرة قصيرة المدى، المسؤولة عن الحفاظ على سياق المحادثة الحالي. يعتمد نظام الذاكرة طويلة المدى على ثلاث آليات رئيسية:
- قدرة الفهرسة المنظمة: هذا يسمح للوكيل ببناء فهارس متعددة الأبعاد عبر كميات هائلة من البيانات غير المنظمة، حسب الوقت والموضوع وعلاقات الكيانات والمزيد، داعمًا استرجاعًا فعالًا من زوايا متعددة تشبه إلى حد كبير كيف يسترجع البشر المعلومات من خلال أدلة مختلفة.
- النسيان الذكي: من خلال خوارزميات تقييم القيمة، يمكن للنظام اضمحلال أو التخلص الانتقائي من المعلومات منخفضة التكرار أو الضعيفة الارتباط أو القديمة، مما يبقي نظام الذاكرة رشيقًا وفعالاً ويمنع الحمل الزائد.
- توطيد المعرفة: يصقل النظام تجربة المحادثة والتفاعل المبعثرة إلى معرفة منظمة. من خلال التعرف على الكيانات واستخراج العلاقات والتجميع الدلالي، يتم ربط المعلومات المجزأة في رسوم معرفية، تحويل التجربة قصيرة المدى إلى معرفة طويلة المدى.
نظام الذاكرة الخارجية هذا المبني على RAG لا يوسع الحد المعرفي للوكيل بشكل كبير فقط، بل يعطيه أيضًا القدرة على التعلم المستمر وتطوير معرفته. يسمح للوكيل بتراكم الخبرة عبر التفاعل طويل الأمد، وتكوين أنماط تشغيل مخصسة وأنظمة معرفة مجالية، ودعم مهام أكثر تعقيدًا وأطول تشغيلًا.
الملخص
التوليد المعزز بالاسترجاع ليس فقط طريقة تقنية للتعويض عن الهلوسة وقدم المعرفة في النماذج الكبيرة. إنه أيضًا جسر رئيسي لتحويل قدرات الذكاء الاصطناعي العامة إلى قيمة مؤسسية عميقة. التطور من Naive RAG إلى الأشكال المعيارية والوكيلة يُظهر أن كل جزء من RAG يحتاج إلى التعمق المستمر، بما في ذلك معالجة بيانات أدق، واختيار نماذج أكثر علمية عبر مراحل التضمين وإعادة الترتيب وLLM، وتقييم أكثر منهجية. كل هذه خطوات ضرورية نحو بناء أنظمة معرفة مؤسسية قابلة للتحكم وموثوقة وفعالة. في نفس الوقت، استخلاص الدروس من المسابقات والدراسات الهندسية هو أحد أفضل الطرق لتعميق فهم التفاصيل التقنية.
مع استمرار تطور Graph RAG والفهم متعدد الوسائط والتقسيم المتأخر ودمجها، يدفع RAG بثبات خارج حدود الاسترجاع والتوليد القديمة ويتحرك نحو ارتباط دلالي أعمق وقدرة ذاكرة أكثر استدامة. الأمل هو أن تساعد هذه المقالة الاستطلاعية في بناء منهجية سلسلة كاملة، من المبدأ إلى الممارسة ومن التقييم إلى التطور، بحيث في مشهد تقني سريع التغير يمكنك بناء تطبيقات ذكية عالية الجودة تهبط فعلًا في العالم الحقيقي ويمكنها التعامل مع تحديات الأعمال المعقدة.
المراجع
[1] Ask in Any Modality: A Comprehensive Survey on Multimodal Retrieval-Augmented Generation.
https://arxiv.org/pdf/2502.08826
[2] Retrieving Multimodal Information for Augmented Generation: A Survey.
https://arxiv.org/pdf/2303.10868
[3] A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models.
https://arxiv.org/pdf/2405.06211
[4] Retrieval-Augmented Generation for Large Language Models: A Survey.
https://arxiv.org/pdf/2312.10997
[5] LightRAG: Simple and Fast Retrieval-Augmented Generation.
https://arxiv.org/pdf/2410.05779
[6] Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG.
https://arxiv.org/pdf/2501.09136
[7] ERAGent: Enhancing Retrieval-Augmented Language Models with Improved Accuracy, Efficiency, and Personalization.
https://arxiv.org/pdf/2405.06683
[8] Graph Retrieval-Augmented Generation: A Survey.
https://www.arxiv.org/pdf/2408.08921
[9] Evaluation of Retrieval-Augmented Generation: A Survey.
https://arxiv.org/pdf/2405.07437
[10] Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey.
https://arxiv.org/pdf/2504.14891
[11] From Local to Global: A Graph RAG Approach to Query-Focused Summarization.
https://arxiv.org/pdf/2404.16130
[12] RAG vs. GraphRAG: A Systematic Evaluation and Key Insights.
https://arxiv.org/pdf/2502.11371
[13] Introduction to RAG | LlamaIndex Python Documentation.
https://developers.llamaindex.ai/python/framework/understanding/rag/
[14] All-in-RAG | A Full-Stack Guide to RAG in Large-Model Application Development.
https://datawhalechina.github.io/all-in-rag/#/en/
[15] Ilya Rice: How I Won the Enterprise RAG Challenge.
https://abdullin.com/ilya/how-to-build-best-rag/
[16] RAG Research Table - Awesome Generative AI Guide (GitHub).
[17] RAG is dead, long live agentic retrieval.
https://www.llamaindex.ai/blog/rag-is-dead-long-live-agentic-retrieval
[18] LLM/RAG Zoomcamp extra lesson 5: Common evaluation methods and market preferences in RAG evolution.
https://vip.studycamp.tw/t/llmrag-zoomcamp-課外補充-5:rag-evolution-常見評估方法和市場偏好/8185
[19] How to Evaluate Retrieval Augmented Generation (RAG) Applications.
https://zilliz.com.cn/blog/how-to-evaluate-rag-zilliz
[20] RAG is not Agent Memory.
https://www.letta.com/blog/rag-vs-agent-memory
[21] Richmond Alake. LinkedIn post on #100DaysOfAgentMemory, RAG and MemoRizz.