A mesure que les grands modeles de langage (LLM) sont adoptes plus largement, les entreprises font face a un probleme tres pratique : comment un modele peut-il repondre aux questions avec precision lorsque celles-ci dependent de documents internes, de donnees en temps reel ou de connaissances specifiques a un domaine ? Apres tout, les donnees d'entrainement d'un modele sont limitees et bornees dans le temps, il ne peut donc pas couvrir les connaissances metier specifiques a l'entreprise ou les informations constamment mises a jour.
Une idee intuitive est la suivante : puisque les fenetres de contexte ne cessent de s'agrandir, passant de 8K a 128K et maintenant au-dela d'un million de tokens, pourquoi ne pas simplement inserer les documents pertinents dans le prompt et laisser le modele repondre directement a partir de ces documents ?
Cependant, pouvoir traiter un contexte long et pouvoir fournir des reponses correctes de maniere stable, efficace et controlable dans des scenarios d'entreprise sont deux choses tres differentes. S'appuyer aveuglment sur le contexte long apporte une serie de defis severes, notamment l'explosion des couts, la dilution de l'attention et la actualisation des connaissances obsoletes.
Pour resoudre ces problemes, une technique appeleeee Generation Amelioree par la Recherche, ou RAG (Retrieval-Augmented Generation), a emerge. Avant que le modele ne genère une reponse, le RAG recupere d'abord des connaissances externes precises. Compare a l'expansion brute de la longueur du contexte, le RAG repond aux exigences des entreprises en matiere d'exactitude factuelle et de connaissances fraiches a un cout inferieur, avec une meilleure precision et une controlabilite renforcee. Il est donc devenu un fondement cle pour la construction d'applications IA dignes de confiance.
Dans ce tutoriel, nous expliquerons systematiquement ce qu'est le RAG, retracerons les antecedents de son emergence et ses principes fondamentaux, puis explorerons son evolution des formes basiques aux formes avancees, ainsi que les perspectives futures.
Ce que vous apprendrez dans cette lecon
- La valeur cle du RAG : comprendre en profondeur comment il resout les problemes centraux du contexte long que sont le cout, l'attention et la fraicheur des connaissances
- Le fonctionnement du RAG : voir a travers des exemples concrets comment il complete la boucle complete de la recherche a la generation
- L'evolution du RAG : du Naive RAG basique au Advanced RAG puis au Modular RAG
- La selection de modeles pour le RAG : comprendre comment evaluer et choisir les trois types de modeles cles, Embedding, Rerank et LLM
- La pratique du RAG en entreprise : apprendre le guide de construction complet de la chaine, du preprocessing des donnees au deploiement systeme et a l'evaluation
- L'evaluation et l'optimisation du RAG : comprendre les metriques cles, les frameworks dominants et les methodes d'amelioration continue
- Les tendances a la pointe du RAG : explorer comment le RAG se combine avec les agents, la multimodalite et d'autres techniques emergentes
Ce que vous retirerez
Apres avoir complete ce tutoriel, vous acquerrez une comprehension systematique de niveau debutant de la technologie RAG. Vous saurez non seulement ce que c'est, mais aussi pourquoi cela fonctionne. Vous acquerrez egalement une feuille de route claire pour evaluer, choisir et concevoir un systeme RAG efficace, fiable et controlable qui reponde aux exigences de l'entreprise, jetant ainsi des bases solides pour construire de veritables applications RAG de niveau entreprise.
1. Pourquoi le RAG est necessaire
La Generation Amelioree par la Recherche (Retrieval-Augmented Generation, RAG) est l'une des approches techniques les plus importantes de l'IA generative d'aujourd'hui. Son idee de base est simple : avant de demander a un grand modele de generer une reponse, le systeme recupere d'abord les informations liees a la question de l'utilisateur a partir d'une base de connaissances externe, puis transmet a la fois les informations recuperees et la question originale au modele pour que celui-ci puisse repondre sur la base de documents reels. Cette base de connaissances externe peut etre les politiques internes de l'entreprise, les documents de processus et les connaissances produit, ou une base de donnees sectorielle, un corpus reglementaire, une bibliotheque de normes, etc.
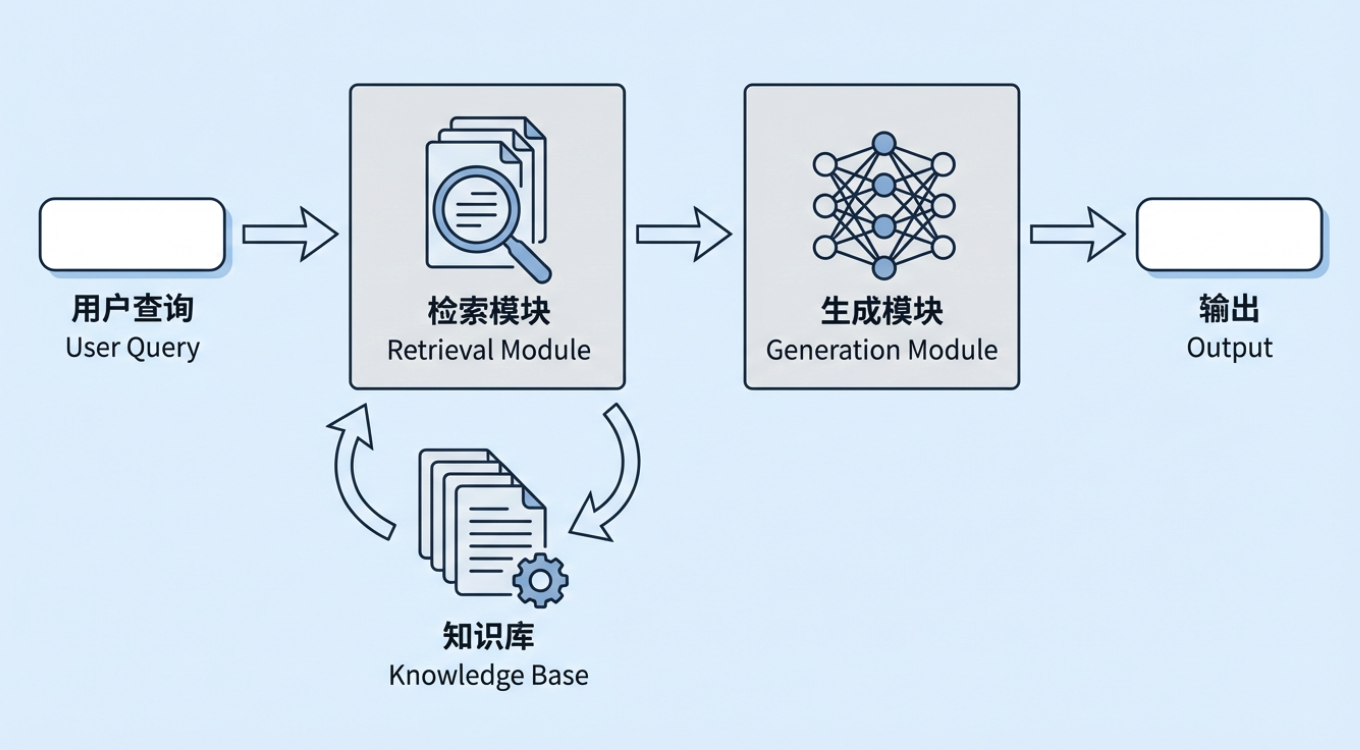
A ce stade, une question naturelle se pose : si les grands modeles peuvent deja "repondre directement aux questions", pourquoi ajouter une couche supplementaire appelee Generation Amelioree par la Recherche ? Surtout maintenant que les fenetres de contexte deviennent de plus en plus grandes, il peut sembler que simplement transmettre tout le document pertinent au modele devrait resoudre la plupart des besoins.
La veritable difference est que "pouvoir produire une reponse" et "pouvoir produire continuellement, de maniere stable et controlable la bonne reponse dans un environnement metier reel" sont deux choses completement differentes. Si vous vous fiez uniquement a la memoire parametrique du modele, ou uniquement au depot massif de documents dans un contexte long, au moins trois problemes typiques subsistent dans l'utilisation en entreprise.
Problemes de cout et d'efficacite : Meme si les fenetres de contexte continuent de s'etendre, l'idee de deposer tous les documents dans le contexte en une seule fois reste irrealisable dans les systemes reels. La contradiction centrale se manifeste de deux manieres :
Le cout d'inference est fortement et positivement correle a la longueur du contexte. Plus le contexte est long, plus le cout d'inference augmente, presque lineairement et parfois meme de maniere superlineaire. Pour un seul appel, 8K tokens et 200K tokens se situent dans des gammes de prix et de latence completement differentes, et le contexte long a un seuil de cout beaucoup plus eleve.
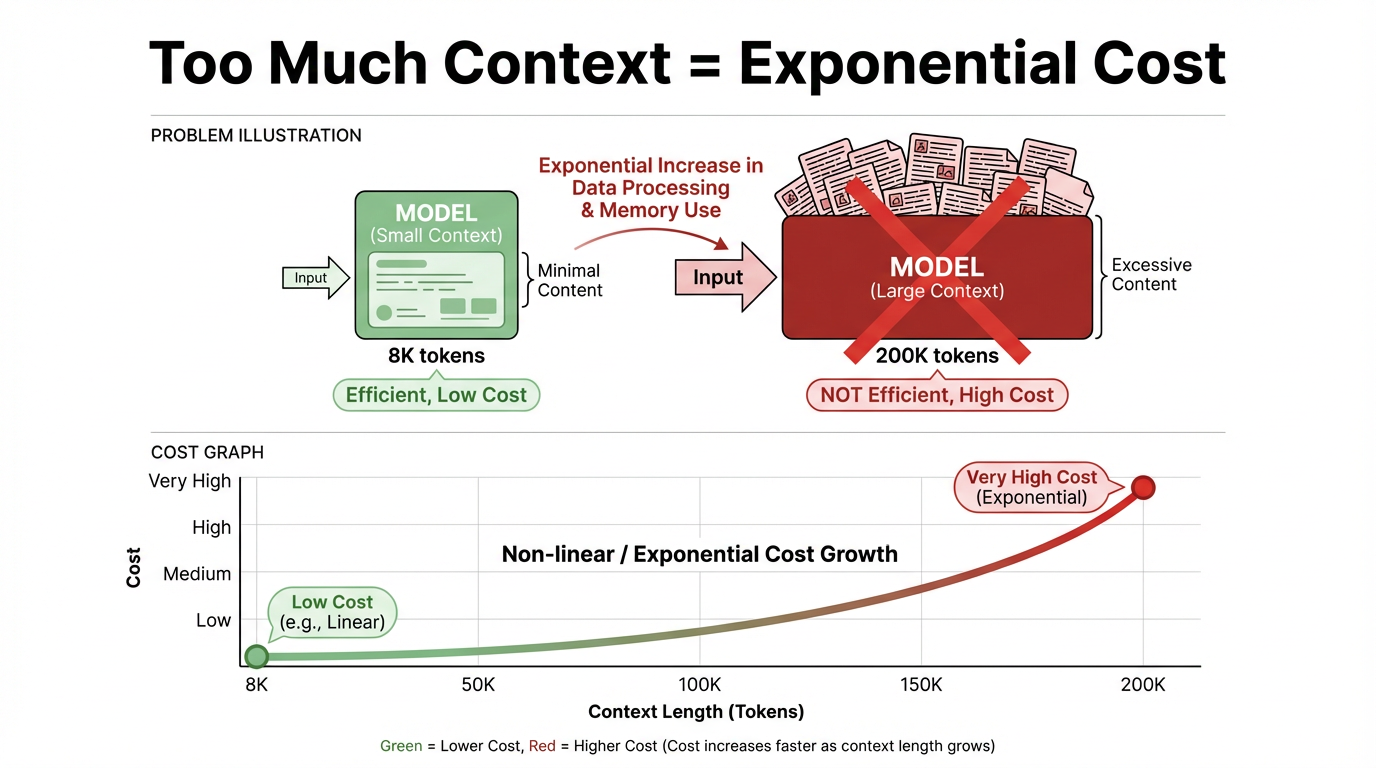
En substance, le contexte est les informations de fond et l'historique de conversation auxquels le modele "se refere" lorsqu'il repond a une question. En termes techniques, c'est la sequence totale de tokens alimentee au modele pour une inference, telle que les instructions systeme et utilisateur, l'historique des messages et les passages recuperes.
Une "fenetre de contexte" est la limite de capacite pour cette entree. Dans les architectures de grands modeles dominantes actuelles, telles que les Transformers, ces tokens participent au calcul d'attention a chaque couche. Une fois que la fenetre s'agrandit et que le nombre de tokens augmente, les calculs et les couts augmentent de maniere multiplicative et peuvent meme approcher une croissance exponentielle.
Une grande quantite de calcul est gaspillee. La plupart des taches n'ont besoin que d'une tres petite quantite d'informations hautement pertinentes pour la question actuelle. L'insertion de l'ensemble complet de documents dans le contexte cree un calcul inactif et gaspille serieux, reduit le debit du systeme, ralentit la vitesse de reponse et finit par nuire a l'experience utilisateur.
Problemes d'attention et de concentration : Un grand modele peut etre capable de "couvrir" un contexte ultra-long, mais il ne peut pas utiliser chaque segment avec la meme qualite. Une fois que la longueur du contexte depasse un certain seuil, le modele commence a montrer un biais d'attention evident :
Affaiblissement de l'attention : l'attention du modele aux parties initiales et intermediaires du contexte s'affaiblit progressivement, et il a tendance a s'appuyer davantage sur le texte lu ulterieurement, de sorte que les informations critiques initiales peuvent etre effectivement ignorees.
Interference informationnelle : le modele peut facilement etre detourne de son sujet par des informations non pertinentes, repetitives ou meme contradictoires a l'interieur du contexte. La reponse finale peut sembler logiquement coherente tout en s'eloignant de la question principale, rendant la precision difficile a garantir. Sans etape de recherche pour filtrer et classer la pertinence, plus le contexte devient long, plus il est difficile de garder la reponse concentree sur les veritables preuves cles. L'avantage du contexte long peut etre completement annule par l'interference informationnelle.
Problemes de fraicheur et de controlabilite des connaissances : Si toutes les connaissances sont stockees entierement dans les parametres du modele, ou copiees manuellement dans les prompts, deux defauts inevitables apparaissent :
Les mises a jour des connaissances sont difficiles : une fois que les connaissances changent, comme des modifications de politiques, des iterations de produits ou des mises a jour de prix, vous devez soit reentrainer ou affiner le modele, ce qui est couteux et lent, soit maintenir manuellement les modeles de prompt, ce qui est egalement couteux et sujet a l'erreur humaine.
La tracabilite est mauvaise : lorsqu'un modele repond, il est souvent difficile de localiser les elements de preuve exacts a partir de parametres en boite noire ou de prompts longs. Cela rend les audits de conformite, les explications de risque et d'autres taches necessitant des bases decisionnelles claires extremement difficiles.
Sous ces contraintes reelles, l'avantage du RAG devient beaucoup plus clair. Son approche centrale est de localiser les informations pertinentes et fiables avant la generation, de sorte que le modele reponde uniquement a partir des connaissances necessaires. Les connaissances peuvent etre stockees independamment dans une base de connaissances externe, facilitant les mises a jour et la gestion. En meme temps, les resultats generes peuvent inclure des sources citees, ameliorant l'interpretabilite et la fiabilite. Meme si les fenetres de contexte continuent de croitre a l'avenir, le RAG permettra toujours une gestion et une utilisation efficaces des connaissances a un cout relativement bas, en chargeant des applications de connaissances de niveau entreprise dont le processus est observable et le comportement tracable.
Du point de vue des exigences de l'entreprise, compare a un LLM traditionnel qui s'appuie uniquement sur ses parametres internes, le RAG resout principalement les problemes de deploiement reels suivants :
- Fraicheur : Les modeles traditionnels ne connaissent generalement pas les nouvelles reglementations, produits ou flux de travail apparus apres leur date limite d'entrainement, mais le RAG peut lire directement les derniers documents politiques, les bases de donnees metier et les bases de connaissances. Sans reentrainement frequent, les reponses peuvent rester synchronisees avec le dernier etat metier.
- Specialisation : Dans les domaines verticaux tels que la sante, la chimie ou la finance, les modeles generalistes ne comprennent souvent pas suffisamment en profondeur ou ne s'expriment pas assez precisement. Apres connexion aux documents de domaine detenus par l'entreprise et aux normes sectorielles, les reponses peuvent etre fondees sur des materiaux autorites et devenir beaucoup plus proches de la pratique metier reelle.
- Hallucinations : En exigeant que les reponses restent fondees sur les passages recuperes et fournissent des citations, le systeme peut reduire les fabrications non soutenues au niveau du mecanisme, rendant "semble vrai" beaucoup plus proche de "est effectivement vrai".
- Explicabilite et auditabilite : Les modeles purement bases sur les parametres ne peuvent souvent pas repondre a la question "De quelle regle cette conclusion est-elle derivee ?" Le RAG permet de retracer chaque reponse jusqu'a une clause politique specifique, un document metier ou un cas historique. Cela aide le personnel metier a inspecter et corriger les reponses et donne aux equipes d'audit, de risque et de conformite la tracabilite dont elles ont besoin.
- Cout de calcul et efficacite des ressources : Faire memoriser a un modele toutes les connaissances de l'entreprise dans ses parametres signifie generalement un modele plus grand et un cout d'inference plus eleve. Le RAG stocke la majorite des connaissances en dehors du modele dans des stores vectoriels et des stores de documents et les recupere a la demande, permettant aux entreprises d'obtenir une couverture plus large et des details plus precis meme avec des modeles plus petits et des ressources de calcul limitees.
Par consequent, pour les entreprises qui souhaitent utiliser les grands modeles dans de veritables scenarios metier sur le long terme, de maniere stable et controlable, le RAG n'est pas une amelioration facultative. C'est presque une technologie fondatrice essentielle pour construire un systeme de connaissances d'entreprise de haute qualite.
2. Ce qu'est le RAG
L'idee centrale du RAG, la Generation Amelioree par la Recherche, est de permettre a un grand modele de repondre aux questions non seulement avec les connaissances statiques apprises pendant l'entrainement, mais aussi avec des informations a jour et fiables tirees d'une base de connaissances externe au moment de l'execution.
Dans un systeme RAG typique, la question de l'utilisateur n'est pas envoyee directement au grand modele. Au lieu de cela, un module de recherche trouve d'abord les passages de documents les plus pertinents dans la base de connaissances de l'entreprise, puis combine ces passages avec la question originale dans un contexte complet, et enfin les transmet au modele pour generer une reponse. Ce modele "rechercher d'abord, generer ensuite" permet au modele de raisonner a partir de documents de reference reels au lieu de simplement deviner a partir de ce qu'il se souvient dans ses parametres. Nous pouvons examiner un cas typique :
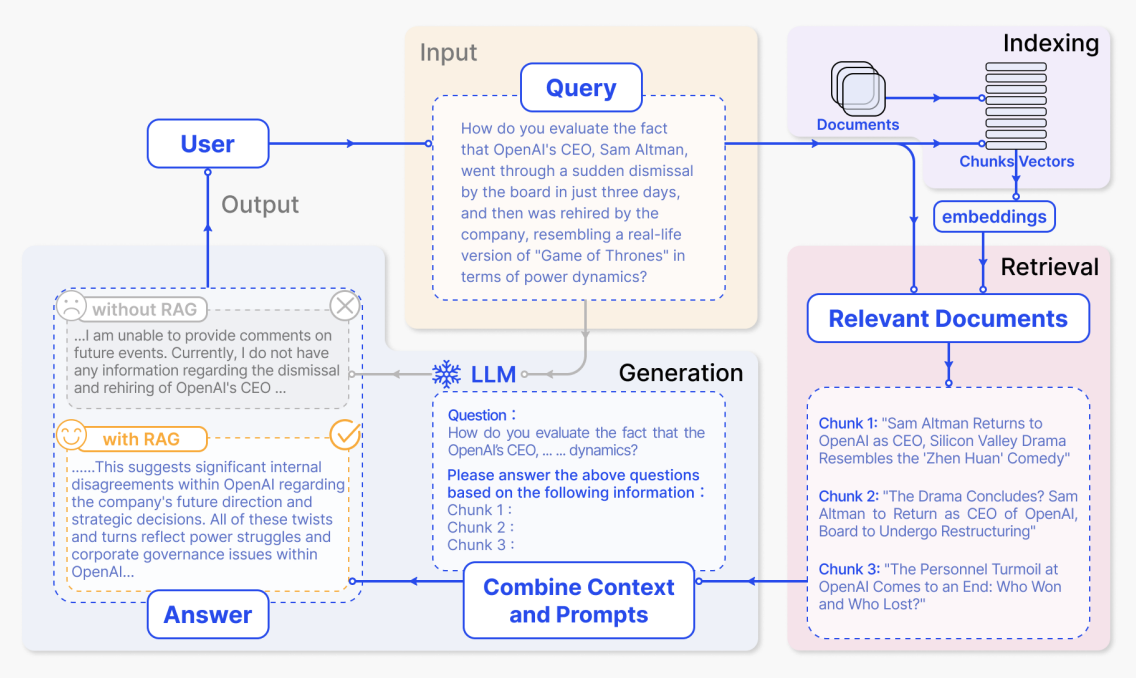
Etape d'indexation
Dans l'etape d'indexation, le systeme traite d'abord les documents bruts tels que les documents internes de l'entreprise, les pages web et les rapports. Il les divise en segments semantiques plus petits, puis utilise un modele d'embedding pour generer des representations vectorielles pour chaque segment et construit un index. Plus tard, lorsqu'une question utilisateur arrive, le systeme peut trouver rapidement les segments les plus semantiquement similaires dans l'espace vectoriel.
Dans le diagramme, cela correspond a la zone violette "Indexing" en haut a droite. Le chemin de "Documents" a travers "Chunks / Vectors" vers "embeddings" montre les documents etant decoupes, convertis en vecteurs et ecrits dans l'index. Plus concretement :
- Les documents sont divises en un ensemble de segments semantiquement coherents, chacun pouvant correspondre a un court passage de nouvelles, une explication ou une analyse.
- Chaque segment est converti en un vecteur de haute dimension par le modele d'embedding et stocke dans l'index vectoriel.
- Cet index prend en charge la recherche par similarite ulterieurement, preparant une base de connaissances que le systeme peut consulter lors de la reponse aux questions.
Etape de recherche plus generation de reponse a partir des resultats recuperes
Apres que l'utilisateur a pose une question, le systeme recupere d'abord le contenu pertinent de l'index, puis envoie la question et le texte recupere ensemble au grand modele pour generer une reponse. Dans la figure, les zones cles de haut en bas et de droite a gauche correspondent exactement a ce flux complet.
(1) Question saisie par l'utilisateur : la zone jaune Input - Query
"Comment evaluez-vous le fait que le PDG d'OpenAI, Sam Altman, a ete soudainement renvoye par le conseil d'administration en seulement trois jours, puis a ete reengage par l'entreprise, ressemblant a une version reelle de 'Game of Thrones' en termes de dynamiques de pouvoir ?"
"Comment evaluez-vous le fait que le PDG d'OpenAI, Sam Altman, a ete soudainement renvoye par le conseil d'administration puis reengage par l'entreprise seulement trois jours plus tard, faisant ressembler la lutte de pouvoir a une version reelle de Game of Thrones ?"
Ce grand bloc de texte est le contenu a l'interieur de la boite "Query" dans le diagramme, correspondant a la question en langage naturel de l'utilisateur. Le systeme vectorise cette question et l'utilise pour rechercher dans l'index en haut a droite les segments de documents connexes.
(2) Documents pertinents recuperes : la zone rose Relevant Documents en bas a droite
Apres la recherche, le systeme obtient plusieurs segments de documents les plus lies a la question. Dans le diagramme, ils sont montres comme trois segments :
"Sam Altman revient chez OpenAI en tant que PDG, le drame de la Silicon Valley ressemble a la comedie 'Zhen Huan'" "Sam Altman revient en tant que PDG d'OpenAI, et ce drame de la Silicon Valley ressemble a une comedie d'intrigue de cour."
"Le drame se termine ? Sam Altman va revenir en tant que PDG d'OpenAI, le Conseil sera restructure" "Le drame se termine-il ? Sam Altman reviendra en tant que PDG d'OpenAI, tandis que le conseil d'administration sera restructure."
"Les tourments personnels chez OpenAI prennent fin : qui a gagne et qui a perdu ?" "Les tourments personnels d'OpenAI prennent fin : qui a gagne et qui a perdu ?"
(3) Combiner le prompt et generer la reponse : la zone bleue LLM / Combine Context and Prompts
Le systeme combine ensuite la question originale de l'utilisateur et les segments recuperes dans un prompt complet et l'envoie au modele. La boite en pointilles au milieu en bas de la figure montre un exemple de prompt :
"Question : Comment evaluez-vous le fait que le PDG d'OpenAI, ... dynamiques ?
Veuillez repondre aux questions ci-dessus sur la base des informations suivantes : Segment 1 : Segment 2 : Segment 3 :"
"Question : Comment evaluez-vous la lutte de pouvoir dans l'incident du PDG d'OpenAI ?
Veuillez repondre a la question ci-dessus sur la base des informations ci-dessous : Segment 1 : Segment 2 : Segment 3 :"
(4) Comparaison des reponses avec et sans RAG : les zones grises et jaunes Output - Answer en bas a gauche
Enfin, le modele genere une reponse basee sur les informations fournies. La figure compare egalement les sorties avec et sans RAG. Sans RAG, le modele n'a pas de materiel externe et ne peut donner qu'une reponse vague, correspondant a la boite grise :
"... Je suis incapable de fournir des commentaires sur des evenements futurs. Actuellement, je n'ai aucune information concernant le renvoi et le reengagement du PDG d'OpenAI ..."
Avec le RAG, le modele peut utiliser les nouvelles et analyses recuperees pour produire une reponse beaucoup plus informative, correspondant a la boite jaune :
"... Cela suggere des desaccords internes significatifs au sein d'OpenAI concernant la direction future de l'entreprise et les decisions strategiques. Tous ces rebondissements refletent des luttes de pouvoir et des problemes de gouvernance d'entreprise au sein d'OpenAI ..."
L'exemple ci-dessus montre le flux complet d'un systeme RAG typique et nous aide a comprendre ses etapes cles et la maniere dont l'information y circule. Mais de nombreux details techniques importants restent dans une boite noire : comment exactement l'appariement vectoriel est-il effectue, et comment le prompt devrait-il etre organise pour que le modele puisse utiliser le contenu recupere plus efficacement ? Ces determinent en grande partie la qualite reelle du RAG. Ensuite, nous allons plonger plus profondement dans le mecanisme interne du RAG et le decomposer etape par etape, des principes de vectorisation et du calcul de similarite a l'ingenierie des prompts.
3. Comment le RAG fonctionne
Nous pouvons le decomposer a travers un exemple simple de question-reponse construit sur une base de connaissances sur "apple".
3.1 Etape de vectorisation des documents
Supposons que nous ayons une base de connaissances simplifiee contenant ces trois passages de documents :
- Passage A : Apple Inc. a ete fondee le 1er avril 1976 par Steve Jobs, Steve Wozniak et Ronald Wayne, et son siege social est a Cupertino, en Californie.
- Passage B : Les pommes sont un fruit riche en vitamine C et en fibres alimentaires, ce qui aide la digestion et la sante du systeme immunitaire.
- Passage C : Apple Inc. a lance le premier iPhone en 2007, changeant fondamentalement l'industrie des smartphones.
Lorsque nous traitons ces documents avec un modele d'embedding, comme le text-embedding-ada-002 d'OpenAI ou un modele BGE open source, chaque passage est converti en un vecteur de haute dimension, souvent avec 768, 1024 ou 1536 dimensions.
Un vecteur est essentiellement un tableau compose de nombreuses valeurs numeriques. Chaque dimension correspond a une caracteristique semantique du texte. Par exemple, le vecteur pour "chat" peut contenir des dimensions liees a mammifere, animal de compagnie et pelucheux. La combinaison finale des valeurs capture la signification semantique du texte afin que l'ordinateur puisse "comprendre" les relations entre les textes.
Exemples simplifies, les vrais vecteurs etant de dimension beaucoup plus elevee :
- Vecteur du passage A, sur la fondation d'Apple :
[0.85, -0.23, 0.41, -0.56, 0.12, 0.78, ...] - Vecteur du passage B, sur les pommes en tant que fruit :
[-0.12, 0.95, -0.34, 0.67, -0.89, 0.05, ...] - Vecteur du passage C, sur le lancement de l'iPhone :
[0.79, -0.18, 0.52, -0.61, 0.23, 0.81, ...]
Ces vecteurs doivent ensuite etre stockes dans une base de donnees vectorielle, comme Pinecone, Weaviate ou FAISS, pour une recherche et un rappel ulterieurs.
Une base de donnees est un systeme qui stocke et gere les donnees de maniere structuree, permettant un stockage organise et une recherche efficace. Des exemples courants incluent les listes de contacts et les catalogues de produits de commerce electronique.
Une base de donnees vectorielle est un type specialise de base de donnees. Contrairement aux bases de donnees traditionnelles qui stockent du texte, des tables et d'autres structures de donnees ordinaires, une base de donnees vectorielle est concue specifiquement pour stocker des vecteurs, c'est-a-dire des tableaux numeriques de haute dimension, et elle est optimisee pour la recherche par similarite dans les scenarios d'IA.
3.2 Etape de requete utilisateur, recherche et reponse
Une fois que la base de connaissances a ete vectorisee et stockee, un systeme RAG peut prendre en charge les requetes des utilisateurs en temps reel. Lorsqu'un utilisateur pose une question, le systeme execute un flux continu : il convertit d'abord la question en un vecteur, puis utilise le calcul de similarite pour recuperer les informations les plus pertinentes de la base de connaissances, et enfin utilise ces passages comme base pour la generation de la reponse. Nous pouvons illustrer ce processus avec trois requetes concretes.
Requete 1 : "Quand Apple Inc. a-t-elle ete fondee ?"
A l'etape de vectorisation de la requete, la question est convertie par le modele d'embedding en un vecteur semantique, par exemple [0.82, -0.21, 0.38, -0.58, 0.15, 0.76, ...]. Ce modele numerique est hautement similaire au vecteur stocke pour le passage A, celui sur la fondation de l'entreprise.
Le systeme effectue ensuite une recherche par similarite, Top-K avec K = 2, en calculant la similarite cosinus entre le vecteur de la requete et tous les vecteurs de documents dans la base de connaissances. Le resultat ressemble a ceci :
- Similarite avec le passage A, le passage sur la fondation : 0.97, hautement pertinent
- Similarite avec le passage C, le passage sur le lancement de l'iPhone : 0.88, pertinent car il concerne egalement l'entreprise
- Similarite avec le passage B, le passage sur la nutrition du fruit : 0.12, presque non pertinent
Top-K est une strategie de selection courante dans la recherche vectorielle. Elle signifie classer toutes les correspondances de la similarite la plus elevee a la plus basse et conserver les K meilleurs resultats. K = 2 signifie que le systeme ne conserve que les deux vecteurs de documents les mieux classes par similarite et filtre les moins bien classes, de sorte que l'etape suivante genere la reponse uniquement a partir des deux passages de documents les plus pertinents.
Les resultats filtres par similarite sont appeles resultats de rappel. Le systeme renvoie les 2 meilleurs passages comme preuves :
- Passage A, similarite 0.97 : "Apple Inc. a ete fondee le 1er avril 1976 par Steve Jobs, Steve Wozniak et Ronald Wayne, et son siege social est a Cupertino, en Californie."
- Passage C, similarite 0.88 : "Apple Inc. a lance le premier iPhone en 2007, changeant fondamentalement l'industrie des smartphones."
A l'etape de generation de la reponse, le systeme construit une entree structuree complete en placant le contenu rappele dans la section des informations de reference et en l'envoyant ensemble avec un prompt systeme :
[Prompt Systeme]
Vous etes un assistant professionnel de reponse aux questions. Veuillez repondre strictement selon les "informations de reference" fournies par l'utilisateur.
Si les informations de reference contiennent la reponse, repondez directement sur cette base.
Si les informations de reference ne contiennent pas la reponse, dites explicitement a l'utilisateur que "la question ne peut pas etre repondue sur la base des documents actuellement disponibles", et ne forgez pas d'informations.
Veuillez indiquer sur quel point d'information votre reponse est basee.
[Contexte Recupere]
Apple Inc. a ete fondee le 1er avril 1976 par Steve Jobs, Steve Wozniak et Ronald Wayne, et son siege social est a Cupertino, en Californie.
Apple Inc. a lance le premier iPhone en 2007, changeant fondamentalement l'industrie des smartphones.
[Requete Utilisateur]
Quand Apple Inc. a-t-elle ete fondee ?Apres avoir recu cette entree structuree, le LLM suit l'instruction systeme et traite le contexte recupere comme la seule source fiable pour repondre. Sa reponse finale ressemblerait a ceci :
Selon les informations de reference fournies, Apple Inc. a ete fondee le 1er avril 1976. [Base : Information 1]
Requete 2 : "Quels sont les bienfaits de manger des pommes ?"
A l'etape de vectorisation de la requete, cette question est convertie en un vecteur semantique tel que [-0.08, 0.92, -0.31, 0.71, -0.85, 0.08, ...]. Son modele numerique est hautement similaire au vecteur stocke pour le passage B, celui sur la nutrition des pommes.
Le systeme effectue a nouveau une recherche de similarite Top-K avec K = 2 et calcule la similarite cosinus :
- Similarite avec le passage B, nutrition du fruit : 0.95, hautement pertinent
- Similarite avec le passage C, lancement de l'iPhone : 0.18, presque non pertinent
- Similarite avec le passage A, fondation de l'entreprise : 0.15, presque non pertinent
Le systeme renvoie les 2 meilleurs passages comme preuves :
- Passage B, similarite 0.95 : "Les pommes sont un fruit riche en vitamine C et en fibres alimentaires, ce qui aide la digestion et la sante du systeme immunitaire."
- Passage C, similarite 0.18 : "Apple Inc. a lance le premier iPhone en 2007, changeant fondamentalement l'industrie des smartphones." Celui-ci est seulement faiblement lie et serait souvent filtre par un seuil en pratique.
L'entree structuree complete est ensuite construite comme suit :
[Prompt Systeme]
Vous etes un assistant professionnel de reponse aux questions. Veuillez repondre strictement selon les "informations de reference" fournies par l'utilisateur.
Si les informations de reference contiennent la reponse, repondez directement sur cette base.
Si les informations de reference ne contiennent pas la reponse, dites explicitement a l'utilisateur que "la question ne peut pas etre repondue sur la base des documents actuellement disponibles", et ne forgez pas d'informations.
Veuillez indiquer sur quel point d'information votre reponse est basee.
[Contexte Recupere]
Les pommes sont un fruit riche en vitamine C et en fibres alimentaires, ce qui aide la digestion et la sante du systeme immunitaire.
Apple Inc. a lance le premier iPhone en 2007, changeant fondamentalement l'industrie des smartphones.
[Requete Utilisateur]
Quels sont les bienfaits de manger des pommes ?Sa reponse finale ressemblerait alors a :
Selon les informations de reference fournies, les pommes sont riches en vitamine C et en fibres alimentaires, et manger des pommes aide la digestion et la sante du systeme immunitaire. [Base : Information 1]
Requete 3 : "Quel temps fait-il aujourd'hui ?"
A l'etape de vectorisation de la requete, cette question devient un vecteur semantique lie a la meteo et a la meteorologie, par exemple [0.10, -0.05, 0.30, -0.12, 0.21, 0.08, ...]. Dans l'espace semantique, ce vecteur est eloigne de tous les vecteurs de documents sur les pommes, qu'il s'agisse de l'entreprise ou du fruit, donc aucune similarite significative n'apparait.
Le systeme effectue a nouveau une recherche Top-K avec K = 2. Parce que le sujet de la question n'est pas lie a la base de connaissances, les scores de similarite globaux sont tous tres bas :
- Similarite avec le passage B, nutrition du fruit : 0.18, extremement bas
- Similarite avec le passage C, lancement de l'iPhone : 0.10, presque non pertinent
- Similarite avec le passage A, fondation de l'entreprise : 0.08, presque non pertinent
Top-K renvoie toujours les K resultats les mieux classes, mais dans ce cas, ces resultats ne fournissent pas de preuves efficaces. En pratique, le systeme applique souvent un seuil de similarite minimum et renvoie directement un rappel vide, c'est-a-dire aucun resultat valide, pour reduire les interferences non pertinentes.
Les deux passages renvoyees seraient quand meme :
- Passage B, similarite 0.18 : "Les pommes sont un fruit riche en vitamine C et en fibres alimentaires, ce qui aide la digestion et la sante du systeme immunitaire."
- Passage C, similarite 0.10 : "Apple Inc. a lance le premier iPhone en 2007, changeant fondamentalement l'industrie des smartphones."
L'entree complete serait alors :
[Prompt Systeme]
Vous etes un assistant professionnel de reponse aux questions. Veuillez repondre strictement selon les "informations de reference" fournies par l'utilisateur.
Si les informations de reference contiennent la reponse, repondez directement sur cette base.
Si les informations de reference ne contiennent pas la reponse, dites explicitement a l'utilisateur que "la question ne peut pas etre repondue sur la base des documents actuellement disponibles", et ne forgez pas d'informations.
Veuillez indiquer sur quel point d'information votre reponse est basee.
[Contexte Recupere]
Les pommes sont un fruit riche en vitamine C et en fibres alimentaires, ce qui aide la digestion et la sante du systeme immunitaire.
Apple Inc. a lance le premier iPhone en 2007, changeant fondamentalement l'industrie des smartphones.
[Requete Utilisateur]
Quel temps fait-il aujourd'hui ?Le LLM jugerait d'abord si les informations de reference contiennent des informations meteorologiques directes ou des donnees meteorologiques en temps reel. Apres avoir confirme qu'elles ne le contiennent pas, il suivrait l'instruction pour repondre qu'il ne peut pas repondre :
Les documents actuellement disponibles ne peuvent pas repondre a la question "Quel temps fait-il aujourd'hui ?" car les informations de reference ne contiennent que du contenu lie aux pommes, a la nutrition des fruits et aux produits Apple Inc., et ne contiennent pas d'informations meteorologiques ni de donnees meteorologiques en temps reel. [Base : Aucune information liee a la meteo n'existe dans le contexte recupere]
A partir de ces trois exemples, nous pouvons voir la cle de l'etape de dialogue du RAG. Le prompt systeme definit le role du LLM et les regles de reponse, les preuves recuperees fournissent un materiel concret et fiable, et la question de l'utilisateur definit l'objectif de la tache. Ce modele d'entree structuree est exactement ce qui permet au RAG de guider et de contraindre efficacement un LLM qui pourrait autrement halluciner, le transformant en un systeme qui produit des reponses stables et fiables. Il garantit que le modele est utilise pour comprendre et organiser les informations existantes plutot que d'inventer des informations non soutenues.
4. L'evolution du RAG
Le RAG ne trouve pas son origine dans l'ere des grands modeles. Des recherches anterieures contenaient deja des prototypes de la meme idee. D'un point de vue historique, le RAG est ne de la reconnaissance des limites des LLM traditionnels. Les premiers grands modeles de langage dependent principalement des donnees de pre-entrainement, et ces donnees deviennent fixes une fois l'entrainement termine. Par exemple, des modeles tels que GPT-3 avaient des dates limites de connaissances liees au moment ou les donnees d'entrainement ont ete collectees et ne pouvaient pas obtenir de connaissances ulterieures. Le reentrainement ou l'affinage des LLM pour des domaines specifiques necessitait egalement de grandes ressources et une expertise specialisee, ce qui rendait le processus couteux et difficile a iterer rapidement.
Les racines du RAG peuvent etre tracees jusqu'au framework DrQA en 2017, qui a tente pour la premiere fois de combiner la recherche avec les modeles de langage. Une avancee majeure est ensuite intervenue en 2020 avec la Dense Passage Retrieval, ou DPR, qui a utilise des modeles neuronaux pre-entraines pour la recherche semantique au lieu des methodes traditionnelles basees sur la frequence des mots telles que TF-IDF et BM25. En 2021, le RAG a ete formellement propose et systematise, devenant une maniere standard de resoudre les problemes de date limite des connaissances et d'hallucination dans les LLM.
De maniere generale, l'evolution du RAG peut etre divisee en trois etapes :
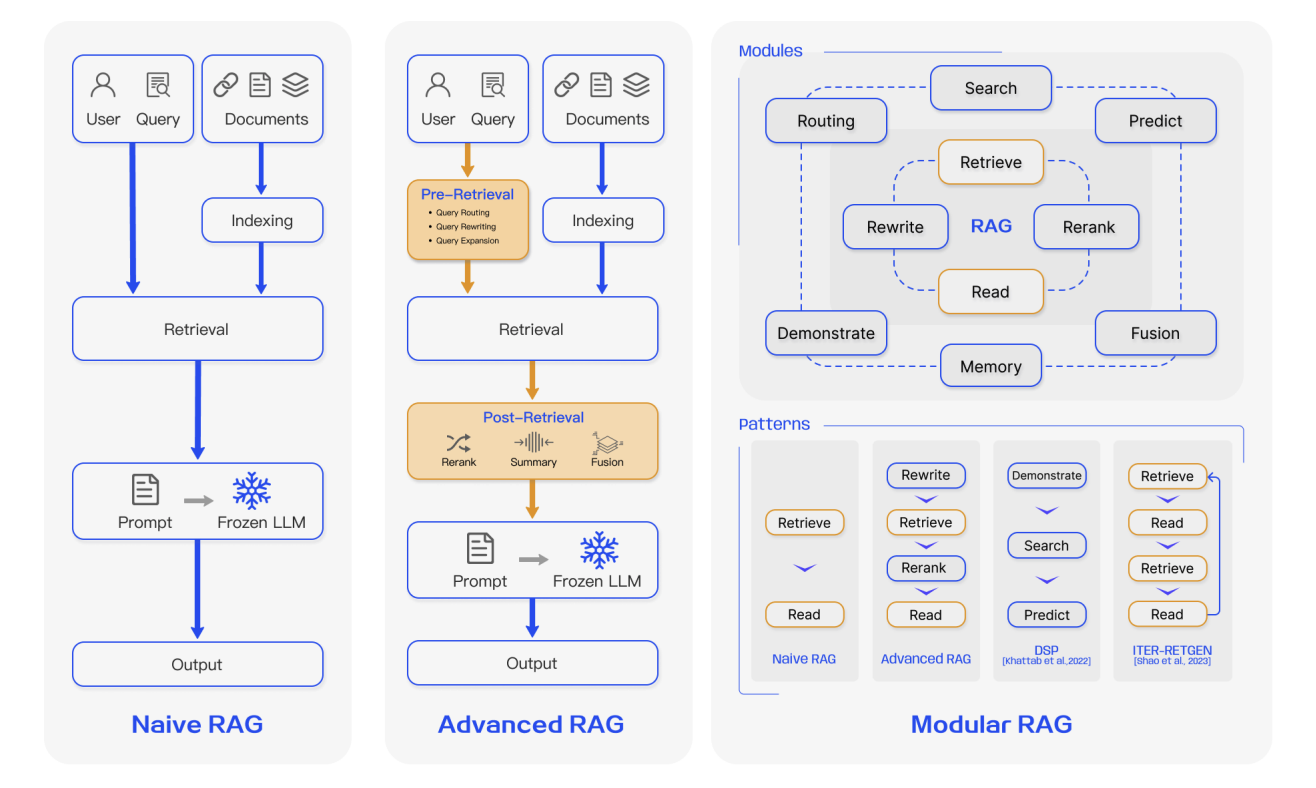
4.1 RAG de premiere generation : Naive RAG
Le Naive RAG est la forme la plus basique du RAG. D'un point de vue de l'ingenierie, il suit un flux en trois etapes tres direct :
- Pretraitement des documents et indexation. Les documents bruts sont nettoyes, divises en segments de texte de longueur fixe, encodes en vecteurs avec un modele d'embedding et ecrits dans une base de donnees vectorielle.
- Recherche basee sur la similarite. La question en langage naturel de l'utilisateur est encodee en un vecteur, et le systeme effectue une recherche de similarite Top-K sur le store vectoriel.
- Generation amelioree par la recherche simple. Les segments recuperes sont directement concatenes avec la question originale pour former un prompt long, qui est envoye au LLM pour la generation de la reponse.
La valeur de cette etape est d'avoir verifie, avec une barre tres basse, que "rechercher avant de repondre" fonctionne reellement. Compare a la seule dependance a la memoire interne du modele, il reduit deja significativement les problemes de date limite des connaissances et certaines hallucinations, ce qui explique le role important qu'il a joue dans les premiers prototypes, les demos et les tutoriels d'introduction.
Cependant, les limites du RAG de premiere generation sont also evidentes. Premierement, la strategie de decoupage est generalement grossiere. La plupart des systemes se contentent de diviser par longueur fixe, ce qui peut couper un paragraphe semantiquement coherent en son milieu ou melanger plusieurs sujets dans un seul segment. Cela nuit a la precision de la recherche et rend egalement la comprehension plus difficile pour le LLM. Deuxiemement, le signal de recherche est trop simple. Le classement depend generalement uniquement de la similarite vectorielle et n'utilise pas d'indices structures plus riches tels que les mots-cles, les horodatages, la credibilite de la source ou les autorisations d'acces. Troisiemement, les resultats de la recherche sont a peine geres : des segments bruyants, repetitifs et meme contradictoires peuvent etre inseres dans le contexte sans modification, provoquant l'occupation d'une fenetre de contexte deja limitee par de grandes quantites d'informations de faible valeur.
En resume, la premiere generation a resolu la question de savoir si la recherche est necessaire. Mais sur les questions de comment mieux rechercher et comment utiliser les informations recuperees plus raisonnablement, elle restait encore a un stade assez primitif.
4.2 RAG de deuxieme generation : Advanced RAG
A mesure que le RAG passait des demos aux veritables scenarios metier, les exigences de stabilite, de controlabilite et de qualite de sortie ont augmente de maniere drastique. La deuxieme generation, generalement regroupee sous le nom large d'Advanced RAG, suit toujours le modele de rechercher d'abord et generer ensuite, mais elle introduit un affinage systematique a la fois avant et apres la recherche. En d'autres termes, le systeme n'est plus satisfait de simplement recuperer quelque chose. Il vise maintenant a stocker correctement les bonnes choses, poser les bonnes questions clairement et gerer soigneusement le contexte recupere.
Avant la recherche, l'accent est mis sur bien stocker et bien poser :
Du cote de l'indexation, le decoupage evolue des divisions de longueur fixe vers un decoupage sensible a la semantique et une indexation hierarchique. Le systeme peut decouper le long des frontieres de chapitres, sous-sections, paragraphes ou phrases, combine avec des fenetres glissantes et des structures d'index multi-granularite.
Chaque segment de document peut comporter des metadonnees riches telles que la source, l'horodatage, l'auteur, le sujet et le type de document, fournissant plus de dimensions pour le filtrage et le classement ulterieurs.
Du cote de la requete, la question originale de l'utilisateur peut etre reecrite, etendue ou decomposee par des techniques telles que la Reecriture de Requete, la Multi-Requete, la decomposition en Sous-Requetes et le Step-back Prompting, transformant les requetes utilisateur vagues ou conversationnelles en formes que la recherche peut mieux comprendre.
- Reecriture de Requete (Query Rewrite)
L'idee centrale est de transformer la requete vague, familiere ou non standard de l'utilisateur en une expression normalisee que le systeme de recherche peut comprendre plus facilement, en supplementant les informations cles et en resolvent les ambiguites.
- Par exemple, "Comment puis-je verifier la meteo de demain a Beijing ?" pourrait etre reecrite en quelque chose de plus standardise comme "Rechercher la meteo en temps reel de toute la journee de demain a Beijing."
- Ou "Recommandez de bons films" peut etre reecrit, apres consultation de l'historique de l'utilisateur, en "Recommander des films a suspense de 2024 bien notes."
- Multi-Requete (Multi-Query)
Le systeme genere plusieurs requetes semantiquement liees mais sous des angles differents a partir de la question originale pour reduire les resultats manques et couvrir les besoins latents que l'utilisateur n'a pas explicitement exprimes.
- Sous-Requete (Sub-Query)
Pour les questions composees qui contiennent plusieurs objectifs, le systeme les divise en sous-requetes plus petites et plus simples pour que la recherche puisse correspondre a chaque besoin precisement.
- Step-back Prompting
Le systeme genere d'abord une question plus abstraite et de plus haut niveau, puis l'utilise pour guider la direction de la recherche, reduisant le biais cause par un focus trop etroit sur les details de la question originale.
Apres la recherche, l'accent est mis sur la gestion de ce qui a ete recupere :
- Un modele de rerank dedie ou meme un LLM peut reclasser les documents candidats afin que le contenu le plus important et le plus pertinent par rapport a la question entre en premier dans le contexte.
Un modele de rerank est un composant cle dans un pipeline de recherche d'information. Il effectue un classement de second niveau sur les resultats candidats renvoyes par la phase de rappel, utilisant une comprehension semantique plus forte, souvent basee sur des architectures Transformer, pour corriger les erreurs de classement semantique du premier niveau et faire avancer les resultats les plus alignes sur les besoins de l'utilisateur.
- Les passages recuperes peuvent etre filtres, dedupliques et compresses pour supprimer les segments clairement non pertinents ou hautement repetitifs, reduisant la tendance des systemes a contexte long a ignorer les informations utiles au milieu.
- Si necessaire, un leger ajustement du modele peut rendre le LLM plus susceptible de repondre a partir des preuves de recherche et d'inclure des citations ou sources explicites.
Dans l'ensemble, l'Advanced RAG ne se concentre plus uniquement sur le fait de savoir si la recherche est necessaire ou si quelque chose peut etre recupere. Il s'attaque plutot a trois defis plus vastes : si les passages veritablement critiques peuvent etre localises avec precision, si le contexte remis au grand modele est concis, bien structure et facile a utiliser efficacement, et si l'ensemble du systeme reste stable et fiable en presence de bruit, de conflit ou de besoins d'information multi-sources.
De grandes quantites de preuves experimentales et d'ingenierie montrent que l'Advanced RAG surpasse significativement le Naive RAG en matiere de precision des reponses, de suppression des hallucinations, de robustesse du systeme et d'explicabilite. C'est pourquoi il a progressivement remplace les approches basiques traditionnelles et est devenu le paradigme industriel dominant pour la construction de systemes RAG aujourd'hui.
4.3 RAG de troisieme generation : Modular RAG
Dans les applications d'entreprise complexes, les exigences s'etendent souvent sur plusieurs domaines. Dans ces cas, un simple flux lineaire de recherche, rerank et generation est souvent insuffisant :
- Le meme systeme peut avoir besoin de prendre en charge des FAQ simples, la generation de rapports longs, la recherche de code et des appels de base de donnees.
- Il peut avoir besoin de connecter des stores vectoriels, la recherche en texte integral, des bases de donnees relationnelles, des graphes de connaissances et des moteurs de recherche externes en meme temps.
- Il peut avoir besoin de preserver les preferences utilisateur et les decisions historiques sur plusieurs tours, tout en appliquant des verifications de conformite et la tracabilite des reponses.
Dans ce contexte, le RAG a commence a evoluer vers une forme de systeme modulaire. Le Modular RAG n'est plus vu comme un pipeline fixe. Il est traite plutot comme un ensemble de modules fonctionnels enfichables, remplacables et composables qui peuvent etre organises selon les besoins. Les modules typiques incluent :
- Comprehension et routage des requetes Ce module gere la reconnaissance d'intention, la reecriture des questions, la decomposition en sous-taches et la selection de chemin. Il decide si une requete doit s'appuyer principalement sur les connaissances internes, la recherche externe ou un outil ou une base de donnees specifique.
- Recherche et fusion multi-sources Ce module connecte simultanement des bases de donnees vectorielles, la recherche en texte integral, des bases de donnees structurees et des graphes de connaissances, les interroge, et fusionne et reclasse leurs resultats en un ensemble de preuves unifie.
- Memoire et personnalisation Ce module maintient des profils utilisateur a long terme, une memoire de session a court terme et des caches de connaissances de domaine pour que le systeme puisse accumuler et utiliser continuellement les informations historiques.
- Adaptation aux taches et gouvernance Ce module charge differents adaptateurs pour differentes taches, contraint le format de sortie, le ton et le style, et gouverne les sorties par la verification des faits, le filtrage des risques et l'alignement des citations.
En resume, le RAG traditionnel se termine souvent apres un cycle de recherche plus un cycle de generation. Le Modular RAG brise ce modele a flux unique. Si le systeme decouvre pendant la generation que les informations sont encore insuffisantes, il peut declencher proactivement de nouveaux cycles de recherche et meme aller et venir plusieurs fois entre la recherche et la generation pour completer une tache plus complexe.
Allant plus loin, le modele peut apprendre a prendre ses propres decisions : repondre directement a partir des connaissances internes ou d'un contexte court lorsque la confiance est elevee, et lancer la recherche ou des appels d'outils externes uniquement en cas d'incertitude. Cela ameliore l'efficacite et economise des ressources tout en preservant la qualite. Pour les requetes fortement sous-specifiees ou incompletes, le modele peut meme generer d'abord une reponse intermediaire hypothetique ou un document de brouillon, puis l'utiliser comme indice pour une recherche ulterieure, s'approchant progressivement de sources fiables.
A ce stade, le RAG n'est plus seulement un simple composant qui attache quelques passages de reference a un grand modele. Il devient la couche centrale d'orchestration des connaissances dans les applications intelligentes d'entreprise, coordonnant de multiples sources de donnees, de multiples outils et de multiples taches.
5. Du Demo au RAG de niveau entreprise
Du point de vue de l'ingenierie d'entreprise, construire un systeme RAG ne peut pas se limiter a la generation amelioree par la recherche seule. Le contenu ci-dessus est encore plus proche d'une introduction de niveau demo. Dans les veritables scenarios metier, les donnees sont souvent bruyantes et de format incoherent, il faut donc investir davantage d'efforts dans le pretraitement, le nettoyage et l'ingestion, et la selection des modeles doit etre geree avec soin a chaque point cle.
Un systeme RAG complet de niveau entreprise peut generalement etre divise en trois modules centraux : l'analyse de mise en page et l'ingestion de connaissances, la construction de la base de connaissances, et le service de question-reponse base sur le RAG. Sur toute la chaine technique, plusieurs decisions cles de selection de modeles apparaissent, y compris le modele d'embedding, le modele de rerank et le LLM. Ce n'est qu'avec des choix techniques sensibless a chaque etape que le systeme peut obtenir de bons resultats globaux.
Analyse de mise en page et lecture des fichiers de connaissances locaux
Ce module convertit les actifs de connaissances locaux dans differents formats en texte utilisable pour la recherche. Les entrees peuvent inclure des PDF, TXT, HTML, Word, Excel et PPT, ainsi que des fichiers d'images scannees tels que PNG et JPG, ou meme des enregistrements audio.
Le systeme doit analyser chaque format de maniere appropriee, effectuer une analyse de mise en page et une extraction structurelle pour les documents texte, distinguer les titres, le corps du texte, les tableaux, les en-tetes et les pieds de page, et restaurer un ordre de lecture logique. Il effectue l'OCR sur les fichiers image et l'ASR sur la parole, convertissant finalement tout en texte de connaissances relativement propre tout en conservant les metadonnees de base telles que le nom du fichier, le chapitre, le numero de page et l'horodatage pour le decoupage et l'indexation ulterieurs.
Construction de la base de connaissances : decoupage, embeddings et indexation
Apres avoir obtenu le texte de connaissances nettoye, le systeme effectue le decoupage, divisant les documents longs en blocs semantiquement coherents de longueur appropriee, generalement par paragraphe, structure de titre ou fenetre glissante, tout en preservant la source et les metadonnees de chaque bloc.
Il utilise ensuite le modele d'embedding choisi, comme
text-embedding-3-small, Sentence Transformers ou BGE, pour calculer les representations vectorielles de chaque bloc et construire un index vectoriel a l'aide d'outils tels que Faiss, Milvus ou des services de recherche vectorielle geres. A ce stade, une base de connaissances qui prend en charge la recherche semantique rapide a ete creee.Question-reponse basee sur le RAG : rappel, reranking, concatenation, generation
Dans l'etape de QA en ligne, l'utilisateur envoie une requete. Le systeme l'integre dans un vecteur de requete, recupere un lot des segments de texte les plus similaires de l'index vectoriel et traite cela comme une etape de classement grossier. Il peut ensuite utiliser un modele de rerank tel qu'un reranker BGE ou meme un LLM agissant comme reranker pour noter a nouveau les paires requete-document et ne conserver que les Top-K documents veritablement les plus pertinents comme contexte de connaissances.
Ensuite, avec un prompt systeme soigneusement concu comme "Veuillez repondre strictement sur la base des documents suivants", le systeme concatenne la requete utilisateur et les passages de documents recuperees et envoie le prompt fusionne au LLM. Le modele genere ensuite la reponse finale a partir de ces pieces de preuve recuperees et, si necessaire, inclut des citations ou des sources.
5.1 Selection des modeles
Nous nous concentrons ensuite sur la selection des modeles. Un systeme RAG complet implique generalement trois categories de modeles centraux : les modeles d'embedding, les modeles de rerank et les grands modeles de langage. Chacun a son propre role, et ensemble ils forment le chemin complet de la recherche a la generation de la reponse. Le modele d'embedding convertit le texte en vecteurs semantiques recherchables, le modele de rerank affine les resultats de recherche initiaux, et le LLM genere la reponse finale sur la base du contexte de connaissances selectionne.
5.1.1 Modeles d'Embedding
Dans un systeme RAG, le travail du modele d'embedding est de convertir le texte, comme les requetes utilisateur et le contenu de la base de connaissances, en vecteurs de haute dimension. Les textes semantiquement similaires sont places plus proches les uns des autres dans l'espace vectoriel, permettant au systeme de localiser rapidement les connaissances connexes par similarite. Choisir le bon modele d'embedding est donc l'une des etapes les plus critiques dans la construction d'un systeme RAG haute performance car il determine directement la qualite du rappel.
Pour choisir un modele performant, il est utile d'utiliser un benchmark systematique. L'un des plus largement utilises est MTEB, le Massive Text Embedding Benchmark.
MTEB fournit un cadre d'evaluation unifie et objectif pour de nombreux modeles d'embedding. A travers huit categories de taches majeures et 56 jeux de donnees, il evalue la performance en recherche, clustering, classification, reranking, correspondance de texte, similarite semantique, et plus encore. Le score MTEB global d'un modele reflete la generalite et la robustesse de ses representations vectorielles et peut servir de reference importante pour la selection des modeles. Le classement le plus recent peut etre consulte sur le classement Hugging Face MTEB :
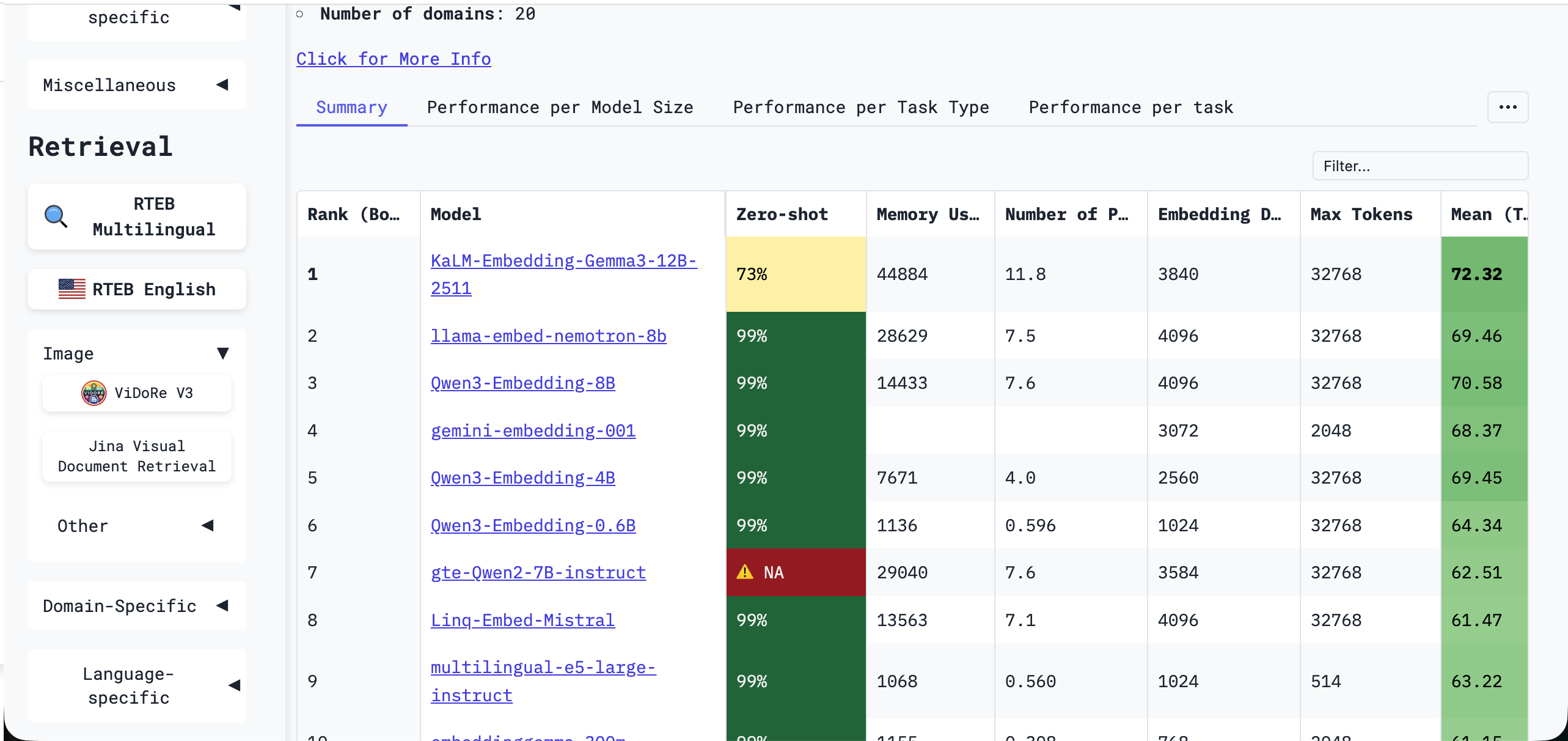
Bien qu'il y ait de nombreux modeles sur le classement, vous n'avez pas besoin de tous les maitriser. En pratique, choisir le modele d'embedding fourni par un fournisseur de modele majeur, ou utiliser un modele cloud deja valide par de nombreuses personnes, est generalement un choix sur. Vous pouvez egalement filtrer le classement par categorie ou langue dans la barre laterale :
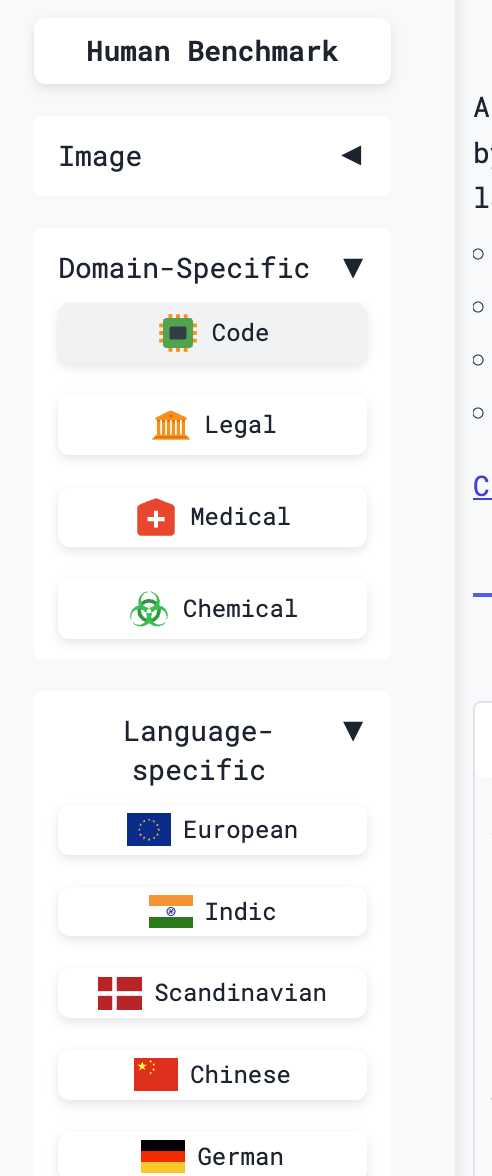
Lors du filtrage des modeles d'embedding, deux parametres sont particulierement importants car ils affectent directement la performance du RAG : la dimension et la longueur du contexte.
La dimension est la dimensionnalite de la sortie vectorielle, comme 128, 768 ou 1536. Elle reflete grossierement le nombre de caracteristiques semantiques que le vecteur peut exprimer. Les vecteurs de dimension superieure peuvent capturer des details semantiques plus riches et une discrimination plus forte. Par exemple, un vecteur a 768 dimensions peut representer "apple" sous des centaines d'angles tels que la variete, le gout et l'origine, ce qui le rend adapte aux scenarios professionnels comme la sante ou le droit necessitant une recherche precise. Les dimensions inferieures reduisent le cout de calcul et de stockage et ameliorent la vitesse de recherche, ce qui les rend adaptees aux scenarios generaux a grande echelle avec une forte concurrence et des exigences de temps reel elevees.
La longueur du contexte est la longueur maximale de texte que le modele d'embedding peut traiter en une seule passe, mesuree en tokens. Un token anglais correspond environ aux trois quarts d'un mot, et un token chinois correspond environ a un caractere chinois. Tout ce qui depasse le maximum est tronque. Cela determine directement si le modele peut comprendre pleinement le texte. Si des informations importantes sont perdues parce que la longueur est trop courte, la precision de la recherche chute brutalement. Pour les courtes requetes utilisateur et les courtes paires QA, 512 a 1024 tokens suffisent souvent. Pour les textes plus longs comme les articles et les rapports, vous avez generalement besoin de 2048 tokens ou plus.
Voici une comparaison de plusieurs modeles d'embedding courants. En pratique, vous devez choisir en equilibrant le cout et la performance. Il n'y a pas de modele universellement meilleur, seulement le modele le plus adapte apres avoir compare plusieurs options dans votre propre cas d'utilisation.
| Nom du modele | Echelle du modele | Force principale | Scenarios adaptes |
|---|---|---|---|
OpenAI text-embedding-3-large | API fermee | Leader de longue date sur MTEB, mature et stable | Scenarios API cloud qui priorisent la performance extreme et ont un budget suffisant |
jina-embeddings-v2 | Prend en charge le texte long jusqu'a 8K de contexte | Fort pour la recherche de documents longs grace a une conception d'encodage asynchrone | Analyse de documents, conformite juridique, recherche academique |
multilingual-e5-large | Grande echelle | Option multilingue classique | RAG multilingue, produits internationaux, systemes de support multilingue |
Qwen/Qwen2-Embedding-8B | 8B parametres, jusqu'a 4096 dimensions personnalisables | Ancien leader multilingue MTEB, fort sur le texte long, les taches multilingues et le code | RAG chinois-anglais de haute precision, analyse de documents longs, recherche de code |
Qwen/Qwen2-Embedding-4B | 4B parametres | Bon equilibre entre performance et efficacite | Systemes RAG de production a grande echelle |
Qwen/Qwen2-Embedding-0.6B | 0.6B parametres | Adapte aux appareils edge | Scenarios a ressources limitees, priorite a la vitesse |
BAAI/bge-m3 | Prend en charge la recherche hybride, dense plus creuse plus multi-vecteur | Fort sur les benchmarks multilingues tels que MIRACL | Scenarios multilingues complexes necessitant une recherche hybride |
BAAI/bge-large-zh-v1.5 | Grande echelle | Ligne de base RAG chinoise stable avec une validation communautaire forte | Projets purement chinois avec des documents plus courts |
ZhipuAI Embedding-3 | API cloud fermee | Prend en charge des dimensions personnalisables de 256 a 2048 | Applications chinoises preferant les API cloud |
5.1.2 Modeles de Rerank
Dans un systeme RAG, le modele de rerank est responsable du reclassement fin des resultats de recherche initiaux. Il prend la requete utilisateur et les documents candidats en entree et calcule un score de pertinence exact pour chaque paire requete-document. Plus le score est eleve, meilleure est la correspondance. Par consequent, ajouter un modele de rerank par-dessus le rappel base sur l'embedding est une etape cle pour ameliorer la precision de la recherche.
Pour les modeles d'embedding, nous pouvons utiliser des benchmarks comme MTEB. Pour les modeles de rerank, une reference utile est le classement de rerankers d'Agentset :
Le benchmark Agentset recupere d'abord les 50 resultats candidats les plus pertinents d'un grand store de documents en utilisant FAISS, puis demande au modele de rerank en evaluation de reclasser ces 50 documents. Le benchmark prete attention a la fois a la qualite du classement et a la latence. Dans les applications pratiques, poursuivre la precision en ignorant la vitesse nuit a l'experience utilisateur, tandis que poursuivre la vitesse en sacrifiant la qualite du classement nuit a l'utilite.
Agentset introduit egalement un mecanisme de score ELO. Pour chaque requete, GPT-5 agit comme juge et compare les sorties classees de deux modeles de rerank differents, decidant lequel place les documents veritablement pertinents dans un ordre plus logique. Apres un grand nombre de telles comparaisons par paires, les modeles qui gagnent plus souvent recoivent des scores ELO plus eleves, fournissant un signal global de performance intuit.
Le benchmark utilise egalement deux groupes de metriques complementaires :
nDCG@5/10, qui se concentre sur le fait que les documents pertinents sont places pres du debut et reflete donc la precision du classementRecall@5/10, qui se concentre sur la capacite a trouver tous les documents pertinents et reflete donc la couverture
Ensemble, ces metriques fournissent une image plus complete de la performance de rerank.
Neammoins, en pratique, vous n'avez pas besoin de selectionner les modeles de rerank uniquement a partir d'un classement. L'utilite industrielle et le score au classement ne sont pas toujours la meme chose. Une approche pratique est de commencer par les modeles de rerank recommandes par vos fournisseurs cloud ou les API de rerank par defaut fournies par les principaux fournisseurs de modeles, ou de tester une famille de modeles que vous utilisez deja, comme un modele de rerank Qwen correspondant.
5.1.3 LLM
Apres la recherche semantique par le modele d'embedding et le filtrage raffine par le modele de rerank, les passages de documents pertinents sont combines avec la question originale de l'utilisateur dans un prompt. Le LLM effectue ensuite la comprehension de lecture, l'integration d'informations et la generation en langage naturel pour produire une reponse coherente, precise et adaptee au contexte.
Au niveau de l'implementation, il existe deux principales facons d'utiliser les LLM dans le RAG :
- Grands modeles deployes en prive. Ceux-ci sont adaptes aux scenarios qui se soucient de la confidentialite des donnees, du cout controlable ou de la personnalisation approfondie. Les modeles open source dominants comme Qwen, Llama et GLM performent bien dans les taches RAG. Par exemple, Qwen2.5 dans la gamme 7B ou 14B offre un bon suivi d'instructions et une comprehension du chinois tout en gardant l'utilisation des ressources moderee, ce qui le rend adapte au deploiement local en entreprise. Des modeles tels que KIMI, Minimax et DeepSeek peuvent egalement etre envisages selon les besoins metier specifiques.
- Grands modeles API cloud. Ceux-ci conviennent aux scenarios qui priorisent le lancement rapide, la mise a l'echelle elastique et les mises a jour continues des modeles. Les principaux fournisseurs tels qu'OpenAI, Anthropic, Google, Alibaba et ZhipuAI offrent tous des services API stables. Ces modeles ont generalement une forte capacite de comprehension et de generation linguistique et peuvent synthetiser les reponses de maniere appropriee dans les scenarios RAG.
Lors de la selection des modeles cloud, plusieurs points sont importants : si la qualite des reponses est precise et fluide, si le prix est raisonnable, si la latence est acceptable et si la fenetre de contexte est assez grande pour contenir plusieurs documents recuperes. En pratique, vous devriez comparer plusieurs candidats sur vos propres donnees et voir lequel donne les reponses les plus completes et les plus precises. Si le cout est un probleme, une approche utile est de combiner grands et petits modeles : utiliser des petits modeles moins chers pour les questions simples et reserver les grands modeles couteux pour les cas difficiles. Comme les modeles se mettent a jour rapidement, il est egalement judicieux de retester les candidats periodiquement.
Pour la capacite generale de conversation et de QA, LMSYS Chatbot Arena, maintenant LMArena, est l'une des references d'evaluation les plus largement reconnues :
Elle utilise des comparaisons humaines a l'aveugle par paires pour classer les modeles. Le classement offre un premier filtre utile, mais dans la selection reelle du RAG, il ne devrait etre qu'un point de depart. Dans les domaines specialises tels que la medecine, le droit et la finance, le classement general peut diverger substantiellement de la performance reelle sur vos donnees metier.
La meilleure pratique pour la selection des LLM est de construire un petit jeu de test representatif contenant 20 a 30 questions metier typiques et d'evaluer les modeles candidats a travers le pipeline RAG complet de bout en bout plutot que de regarder uniquement les benchmarks isoles du modele. Des questions telles que s'il faut utiliser des modeles de raisonnement ou des modeles sans raisonnement, ou quelle taille de modele equilibre le mieux qualite et vitesse, sont toutes mieux repondues par des tests reels sur votre propre cas d'utilisation.
5.2 Frameworks d'execution
Dans la pratique reelle de l'ingenierie, vous n'avez generalement pas besoin de construire un systeme RAG entier a partir de zero. Un certain nombre de frameworks open source matures existent deja, chacun avec ses propres forces en matiere d'architecture, d'integration modulaire et d'efficacite de developpement. Les entreprises peuvent choisir en fonction de leurs propres reserves techniques et de leurs scenarios metier.
Les types de frameworks courants incluent :
Plateformes low-code ou visuelles
- Dify : fournit une interface visuelle intuitive pour construire rapidement des applications RAG, ce qui la rend adaptee aux equipes non techniques ou a la validation rapide de prototypes. Elle inclut un acces multi-modele integre, l'orchestration de flux de travail et la gestion des prompts.
- Coze : une plateforme de developpement de bots IA de ByteDance qui offre une construction visuelle zero code. Elle s'integre profondement avec les services de modeles de ByteDance, prend en charge un marche de plugins, des taches planifiees et la publication multi-canal, ce qui la rend adaptee aux assistants grand public ou aux bots d'entreprise internes.
- n8n : une plateforme d'automatisation de flux de travail basee sur des nœuds open source. Dans les scenarios RAG, elle peut orchestrer une logique metier complexe et connecter le pretraitement, les operations de base de donnees vectorielle, les appels de modele et les actions de suivi comme l'envoi d'emails ou la mise a jour de tickets dans un flux automatise.
- RAGFlow : se concentre sur l'analyse de mise en page approfondie et l'extraction de connaissances et performe bien sur les documents complexes tels que les PDF multi-colonnes et les documents riches en tableaux.
- FastGPT : une solution open source chinoise integrant la gestion de base de connaissances, l'orchestration de dialogue et la publication d'applications, avec une forte documentation chinoise et une adaptee pour le deploiement rapide d'applications RAG chinoises.
Frameworks de code et bibliotheques de developpement
Les outils ci-dessous ont generalement des implementations dans differents langages backend. Vous pouvez choisir la version de langue correspondante pour votre stack d'application.
- LlamaIndex : un framework Python concu specifiquement pour le RAG, avec des connecteurs riches, des structures d'index et des moteurs de requete. Sa modularite le rend adapte aux strategies de recherche profondement personnalisees ou a l'integration avec de nombreuses sources de donnees.
- LangChain : un framework general d'application LLM ou le RAG n'est qu'un cas d'utilisation. Sa force est son ecosystem riche et la couverture de ses composants, y compris le support pour des agents complexes et l'orchestration de flux de travail, bien que sa courbe d'apprentissage soit plus raide.
Si les reserves techniques de l'equipe sont limitees et que la vitesse est primordiale, les plateformes low-code comme Dify, Coze ou FastGPT sont de bons premiers choix. Si vous avez besoin d'une personnalisation approfondie, d'une integration de source de donnees speciales ou d'un reglage de performance detaille, LlamaIndex et LangChain offrent plus de flexibilite. En pratique, une route hybride est egalement courante : utiliser une plateforme low-code pour la validation rapide de faisabilite, puis passer aux frameworks de code pour le deploiement en production et l'optimisation. La plupart de ces frameworks prennent egalement en charge l'integration rapide avec les principaux modeles d'embedding, de rerank et de LLM, vous permettant de les combiner de maniere flexible en utilisant les principes de selection de modeles discutes ci-dessus.
5.3 Evaluation des effets
Pour les entreprises deployant des systemes RAG, le plus grand defi est souvent de construire le systeme, mais de le regler. Un RAG de niveau production contient deux etapes non deterministes, la recherche et la generation, donc les tests logiciels traditionnels ne suffisent pas. C'est pourquoi construire un systeme d'evaluation scientifique, ou evaluation du RAG, est si important.
5.3.1 Exemple pour debutants : evaluation du RAG basee sur le LLM
Pour aider a construire une comprehension intuitive de l'evaluation du RAG, nous pouvons regarder un pipeline automatise simple base sur l'idee du LLM-as-a-judge :
https://huggingface.co/learn/cookbook/rag_evaluation
Le processus contient generalement trois etapes cles :
- Premierement, synthetiser un jeu de donnees d'evaluation en echantillonnant des documents de la base de connaissances et en demandant a un LLM de generer des paires question-reponse de haute qualite, puis en les filtrant par pertinence et fondement pour former un jeu de reference.
- Deuxiemement, executer le systeme RAG sur chaque question de ce jeu de test et collecter les reponses generees.
- Troisiemement, automatiser la notation en appelant un autre LLM comme juge, comparant les reponses generees avec les reponses de reference et donnant des scores quantitatifs pour des dimensions telles que la precision et la completude.
Un exemple simple :
- Generation de problemes. Supposons que la base de connaissances contient une ligne du manuel d'un produit disant, "Cet appareil prend en charge la recharge sans fil et a une batterie de 5000 mAh." Nous demandons a un modele d'agir comme redacteur d'examen et de generer une question comme, "Quelle est la capacite de la batterie de cet appareil ?" La reponse standard est "5000 mAh."
- Resolution de problemes. Nous envoyons cette question au systeme RAG, qui recupere le materiel connexe et repond, par exemple, "L'appareil a une batterie de 5000 mAh."
- Notation. Nous demandons a un autre modele d'agir comme correcteur en comparant la question, la reponse generee et la reponse de reference, en utilisant un prompt comme, "Jugez si la reponse generee est correcte. Produisez uniquement correct ou incorrect."
En executant ce processus a grande echelle, nous pouvons calculer des metriques telles que la precision. Cela forme une boucle pratique d'evaluation, d'optimisation et de reevaluation.
Si vous souhaitez des details plus approfondis sur l'evaluation du RAG, y compris les definitions de metriques, l'utilisation des frameworks et les jeux de donnees de benchmark, deux articles de synthese utiles sont :
- https://arxiv.org/pdf/2504.14891, Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey
- https://arxiv.org/pdf/2405.07437, Evaluation of Retrieval-Augmented Generation: A Survey
5.3.2 Metriques d'evaluation
L'evaluation du RAG tourne fondamentalement autour de deux questions : le module de recherche peut-il trouver le bon materiel, et le module de generation peut-il produire une reponse de haute qualite a partir de ce materiel ? En consequence, le systeme d'evaluation est divise en evaluation de la recherche et evaluation de la generation, completee par la notation LLM-as-a-judge.
Evaluation de la recherche : precision du rappel et qualite du classement
Le module de recherche est la premiere porte dans un systeme RAG. Son evaluation se concentre sur trois dimensions : s'il trouve les bonnes choses, s'il en trouve assez, et s'il les classe bien.
Metriques de base de la qualite du rappel
Les metriques basiques classiques sont Recall@K, Precision@K et F1 :
- Recall@K mesure la proportion de documents pertinents recuperees dans les K premiers resultats. Si cinq documents pertinents existent et trois sont trouves dans les 10 premiers, Recall@10 est de 60 pour cent. Cela nous indique la largeur de la couverture de la recherche.
- Precision@K mesure la proportion des K premiers resultats qui sont veritablement pertinents. Si trois des 10 premiers sont pertinents et sept ne le sont pas, Precision@10 est de 30 pour cent. Cela reflete la precision de la recherche.
- F1 est la moyenne harmonique du Recall et de la Precision et equilibre les deux.
Ces metriques sont utiles pour diagnostiquer rapidement les problemes de rappel de base. Si le Recall est bas, les documents pertinents n'ont pas ete trouves du tout. Si la Precision est basse, le bruit de recherche est trop eleve.
Metriques de qualite du classement
Trouver les documents pertinents n'est que la premiere etape. Il est encore plus important de placer les plus pertinents pres du debut. Pour cela, nous examinons MRR, NDCG@K et MAP :
- MRR, Mean Reciprocal Rank, mesure l'inverse de la position de classement du premier document pertinent. Si le premier document pertinent apparait en position 3, le rang reciproque est 1/3. MRR est particulierement adapte aux scenarios ou une seule reponse correcte suffit.
- NDCG@K, Normalized Discounted Cumulative Gain, prend en compte a la fois la pertinence graduee et l'escompte de position. Il ne demande pas seulement si un document est pertinent, mais a quel point il est pertinent, et il recompense les documents fortement pertinents qui apparaissent tot.
- MAP, Mean Average Precision, est sensible aux positions de tous les documents pertinents et reflete la qualite globale du classement.
En ingenierie reelle, une combinaison courante est Recall@K plus MRR@K. Par exemple, si Recall@10 est de 80 pour cent mais que MRR@10 n'est que de 0.3, les documents pertinents sont trouves mais enterres trop profondement, ce qui suggere que le reranking a besoin d'amelioration.
Si necessaire, une metrique de couverture (Coverage) peut egalement etre ajoutee pour surveiller la couverture de la base de connaissances et reveler les angles morts systematiques.
Evaluation de la qualite de generation : precision et fidelite factuelle
La recherche fournit la matiere premiere. La question suivante est de savoir si le module de generation peut produire une reponse de haute qualite a partir de ces materiaux. Les dimensions centrales ici sont la precision de la reponse et la fidelite aux preuves recuperees.
Correspondance exacte et similarite textuelle
La metrique la plus simple est EM, Exact Match, qui exige que la reponse generee corresponde exactement a la reponse de reference. Cela est adapte aux questions de fait a forme fixe et reponse unique correcte comme les dates ou les localisations de siege social, mais elle est trop stricte car differentes formes de surface egalement correctes peuvent ne pas correspondre.
C'est pourquoi les metriques de chevauchement de n-grammes comme ROUGE, BLEU et METEOR sont aussi couramment utilisees. Elles notent les reponses generees en comparant le chevauchement de mots avec les reponses de reference. ROUGE-L prete attention aux plus longues sous-sequences communes, BLEU provient de la traduction automatique et met l'accent sur l'exactitude, et METEOR ajoute des considerations de synonymes et de racinisation.
Pour surmonter les limites du pur chevauchement de mots, nous pouvons egalement utiliser BERTScore ou la similarite vectorielle directe. Celles-ci utilisent des representations semantiques pre-entrainees et tolerent donc mieux les variations de surface.
Fidelite factuelle et detection des hallucinations
Pour les systemes RAG, la similarite reponse-reference ne suffit pas. La question la plus importante est de savoir si la reponse est effectivement fondee dans les documents recuperes ou si elle hallucine du contenu non soutenu.
C'est pourquoi des metriques comme le taux d'hallucination et la Fidelite sont importantes. Un second LLM peut agir comme verificateur de faits et inspecter la reponse generee phrase par phrase, jugeant si chaque affirmation peut etre soutenue par les documents recuperes. Pour les domaines a enjeux eleves comme la sante, le droit et la finance, ce type de metrique est particulierement important, et certaines entreprises imposent meme des seuils d'hallucination comme criteres de publication en production.
LLM-as-a-Judge : notation multi-dimensionnelle
Chaque metrique automatique a ses limites. La plupart des metriques de forme de surface ne peuvent pas capturer pleinement la qualite semantique ou l'utilite globale. C'est la que le LLM-as-a-judge devient particulierement precieux.
L'approche de base consiste a fournir la question, les documents recuperes, la reponse du systeme et la reponse de reference a un modele independant puissant, comme GPT-4 ou Claude, et a lui demander de noter sur des dimensions telles que :
- pertinence par rapport a la question
- completude de l'information
- fidelite factuelle
- correction globale
La force d'un juge LLM est qu'il peut porter un jugement holistique plus proche de celui d'un humain. Bien sur, les prompts du juge doivent encore etre concus avec soin et calibres par rapport a des exemples etiquetes par des humains pour garder la notation coherente et fiable.
Construire une combinaison de metriques pratiques
Avec autant de metriques disponibles, les equipes se demandent souvent lesquelles utiliser. Une recommandation pratique est de commencer avec une combinaison compacte et d'elargir progressivement :
- Pour la recherche, commencer avec Recall@K plus MRR@K
- Pour la generation, choisir une ou deux metriques de base parmi EM, ROUGE-L et BERTScore selon le type de tache
- Pour l'evaluation globale, introduire un juge LLM concentre sur la pertinence, la completude et la fidelite
Puis iterer a travers une boucle d'evaluation, de diagnostic des problemes, d'ajustement de strategie et de reevaluation.
5.3.3 Frameworks d'evaluation
A mesure que le RAG s'est developpe rapidement, tant le monde academique que l'industrie ont produit de nombreux frameworks d'evaluation solides. Ces frameworks non seulement empaquettent les metriques courantes, mais offrent aussi des jeux de donnees standardises, des procedures de benchmark et des flux de travail de bout en bout.
Une classification de base des frameworks
Nous pouvons diviser grossierement les frameworks d'evaluation RAG en trois categories :
- Frameworks de recherche, qui se concentrent sur l'exploration academique et le diagnostic a granularite fine. Des exemples incluent FiD-Light et Diversity Reranker.
- Frameworks de benchmark, qui fournissent des jeux de test standardises et des flux de travail pour comparer les systemes horizontalement. Ceux-ci incluent des frameworks comme RAGAS, ARES, RGB, MultiHop-RAG et CRUD-RAG.
- Frameworks d'outillage, qui mettent l'accent sur l'utilisabilite en ingenierie et l'integration avec les frameworks de developpement. Des exemples incluent TruEra RAG Triad, LangChain Benchmarks et RECALL.
Ces dernieres annees, les frameworks d'evaluation sont devenus plus specialises. Par exemple, la medecine a MedRAG, le droit a LegalBench-RAG, et la finance a ses propres frameworks specifiques au domaine. Ces frameworks de domaine fournissent souvent non seulement des jeux de donnees specialises mais aussi des metriques specialisees comme la precision medicale ou la pertinence des citations juridiques.
En pratique, une bonne regle empirique est :
- Si vous avez besoin d'une ligne de base rapidement, commencez avec un framework plus general comme RAGAS.
- Si vous diagnostiquez un probleme specifique, choisissez un framework plus cible.
- Si vous etes dans la medecine, le droit, la finance ou un autre domaine professionnel, preferez les frameworks adaptes au domaine dans la mesure du possible.
- Preferez les outils activement maintenus avec une forte documentation et des communautes reactives.
Les outils couramment recommandes dans la communaute incluent Ragas, Continuous Eval, TruLens-Eval, les fonctionnalites d'evaluation dans LlamaIndex, Phoenix, DeepEval, LangSmith et OpenAI Evals.
5.3.4 Benchmarks d'evaluation
L'importance des benchmarks d'evaluation est souvent sous-estimee. Beaucoup d'equipes commencent a evaluer un systeme RAG avec seulement une poignee de questions de test ecrites a la main, puis decouvrent que la performance en ligne reelle differe fortement des impressions hors ligne. La cause racine est qu'elles manquent de donnees d'evaluation representativess et systematiques.
Un benchmark qui soutient bien l'iteration du systeme a generalement trois caracteristiques centrales :
- la representativite, signifiant qu'il couvre les questions utilisateur a haute frequence, les cas aux limites et les entrees anormales
- la standardisation, signifiant que les formats de questions et de reponses, les niveaux de difficulte et les regles de notation sont coherents
- l'evolutivite, signifiant que le benchmark peut etre mis a jour a mesure que les capacites du systeme et les besoins metier evoluent
Pour la plupart des entreprises, parce que les scenarios metier sont uniques, la reponse finale est generalement de construire leurs propres jeux de donnees d'evaluation.
- Commencez par extraire les questions reelles des utilisateurs des journaux metier et echantillonnez-les par type, frequence et difficulte.
- Pour les cas simples, laissez les experts du domaine annoter directement. Pour les questions plus complexes, laissez d'abord un LLM puissant generer des reponses candidates, puis faites-les reviser par des experts.
- Outre la reponse elle-meme, etiquetez les metadonnees telles que les documents connexes, le type de reponse et le niveau de difficulte.
- Mettez a jour periodiquement le jeu de donnees avec de nouveaux cas difficiles decouverts en ligne.
Si les ressources sont limitees et que vous avez besoin d'une ligne de base rapide, les benchmarks publics restent un point de depart utile. En 2025, de nombreux benchmarks publics existent pour les scenarios generaux et verticaux :
Lors du choix parmi eux, clarifiez d'abord l'objectif. Etablissez-vous une ligne de base, ou validez-vous le systeme avant le lancement ? Verifiez ensuite si le benchmark couvre les scenarios et le profil de difficulte qui vous importent. Pour les domaines sensibles au temps comme l'actualite ou la finance, assurez-vous que le benchmark inclut des tests de sensibilite temporelle.
En pratique, combiner votre propre jeu de donnees intra-domaine avec des benchmarks publics est souvent la voie la plus robuste car elle maintient l'evaluation proche des veritables besoins metier tout en preservant une certaine comparabilite horizontale.
6. Plongee approfondie : apprendre des competitions et des tutoriels ouverts (Optionnel)
Les principes et l'implementation de base ci-dessus suffisent pour vous aider a construire un prototype utilisable, mais ils sont encore a une certaine distance des problemes plus difficiles qui apparaissent en production. Si vous voulez comprendre des techniques RAG plus pratiques et eprouvees au combat, l'une des voies les plus efficaces est d'etudier les solutions gagnantes de competitions et les solides tutoriels ouverts. Ces solutions concentrent souvent les meilleures pratiques decouvertes par des equipes fortes apres des tentatives repetees dans des scenarios reels.
Les exemples ci-dessous sont representatifs plutot qu'exhaustifs. Lorsque vous rencontrez un probleme specifique en pratique, comme l'analyse PDF, la recherche multimodale ou l'optimisation a faible latence, il est souvent efficace de rechercher des competitions liees a ce probleme et d'etudier les rapports techniques et le code ouvert des equipes gagnantes.
6.1 Cache semantique : optimisation des requetes a haute frequence
Hugging Face fournit une implementation de cache semantique construite sur la base de donnees vectorielle Chroma :
https://huggingface.co/learn/cookbook/semantic_cache_chroma_vector_database
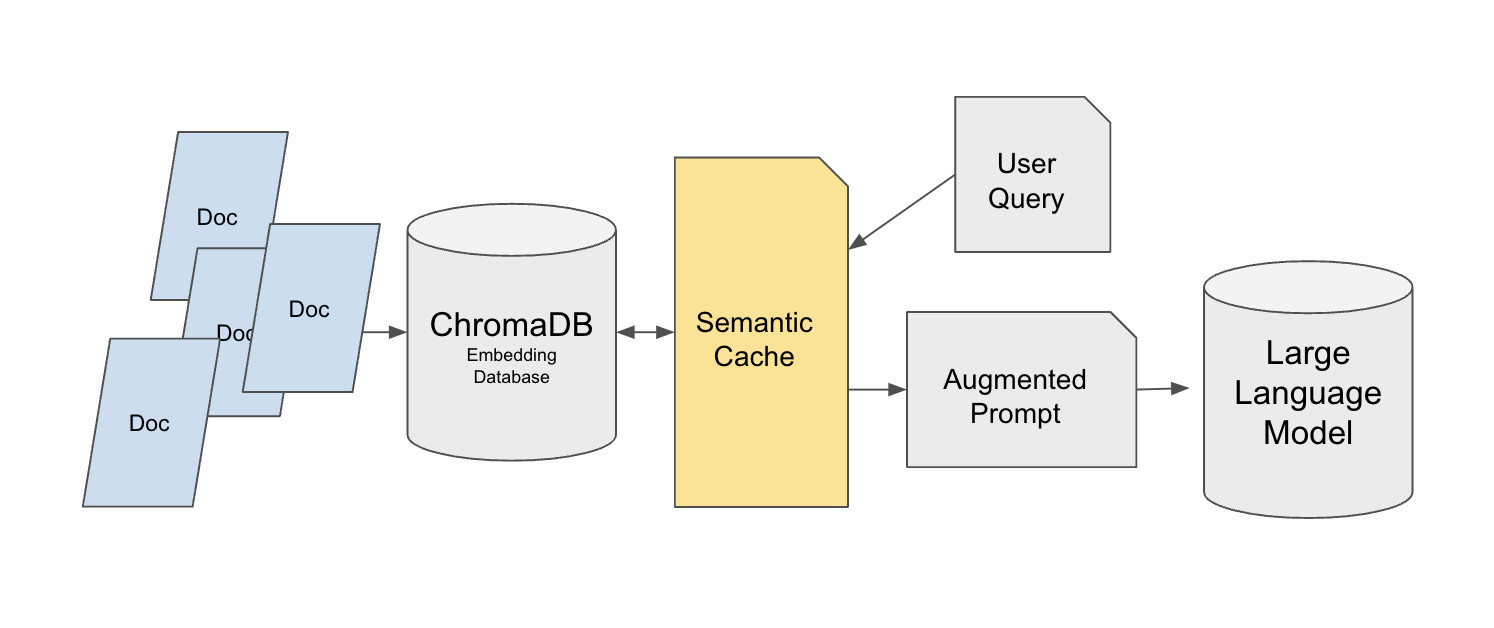
Contexte : La plupart des systemes RAG de tutoriel sont construits pour des tests mono-utilisateur. Mais une fois deployes en production, le systeme peut recevoir des dizaines ou des milliers de requetes repetees, par exemple des utilisateurs du support demandant repetitivement comment fonctionnent les remboursements. Si chaque requete repetee declenche encore une recherche vectorielle et un appel LLM, la latence et le cout augmentent rapidement. Une couche de cache semantique peut reduire fortement la pression sur les sources de donnees originales tout en preservant la qualite des reponses.
Cette conception utilise une architecture de recherche a deux couches. La couche de base stocke la base de connaissances originale dans Chroma, utilisant un jeu de donnees comme MedQuad comme exemple et attribuant a chaque entree un identifiant unique pour une reference precise. La couche de cache est construite sur FAISS utilisant un index FlatL2. Le cache semantique se situe entre la requete utilisateur et Chroma, plutot que de mettre en cache directement la reponse finale du LLM. Cette conception est importante car la mise en cache directe des reponses peut casser les exigences de reponses personnalisees comme "expliquez-moi ca en langage simple."
Le systeme de cache utilise le SentenceTransformer all-mpnet-base-v2 pour generer des vecteurs de requete et utilise la distance euclidienne, avec un seuil de 0.35, pour juger si les requetes sont similaires. Lorsque le cache est plein, controle par le parametre max_response, l'entree la plus ancienne est supprimee en utilisant FIFO. Les donnees du cache peuvent aussi etre sauvegardees dans des fichiers JSON pour une reutilisation inter-sessions.
Dans des tests a petite echelle, une premiere requete comme "Comment fonctionnent les vaccins ?" a pris 0.057 secondes lors de la recuperation depuis Chroma, tandis qu'une requete similaire servie depuis le cache n'a pris que 0.016 secondes. Dans des scenarios de production a grande echelle, cette approche peut produire une optimisation de performance de 90 a 95 pour cent dans des environnements a forte repetition et reduire significativement le cout du store vectoriel et des API.
6.2 Traitement des donnees non structurees : analyse unifiee pour les documents multi-formats
Un autre tutoriel Hugging Face montre comment utiliser la bibliotheque Unstructured pour construire un pipeline complet pour le traitement de documents non structures :
https://huggingface.co/learn/cookbook/rag_with_unstructured_data

Contexte : Dans les scenarios d'entreprise, les connaissances sont souvent dispersees a travers des PDF, des presentations PowerPoint, des EPUB, des pages HTML et de nombreux autres formats. Les methodes de pretraitement traditionnelles soit ne supportent qu'un seul format, soit perdent des informations structurelles cruciales comme les tableaux et la hierarchie des titres lors de la conversion. Cela rend difficile pour le systeme RAG de comprendre et de rechercher correctement le contenu.
Cette solution telecharge d'abord des documents de test multi-formats, comme un PDF de manuel canadien sur les pesticides contenant de nombreux tableaux et un fichier PowerPoint IPM sur les agrumes de l'Universite de Floride contenant des graphiques et des titres multi-niveaux. Elle utilise ensuite le Local Runner d'Unstructured pour l'analyse. La configuration inclut une configuration de processeur, une configuration de partition qui peut optionnellement utiliser le mode de partition API pour un OCR plus puissant, et une configuration locale definissant les chemins d'entree. Les documents analyses sont convertis en JSON contenant des elements types comme le corps du texte, les titres et les tableaux.
Le systeme utilise ensuite chunk_by_title, definit une longueur maximale de 512 caracteres et fusionne les fragments consecutifs de moins de 200 caracteres pour preserver la coherence semantique. Lors de la conversion en objets Document LangChain, les champs de metadonnees complexes sont filtres pour s'adapter a Chroma. L'etape vectorielle utilise le modele d'embedding BAAI/bge-base-en-v1.5, avec un Llama-3-8B-Instruct quantifie en 4 bits et une chaine RetrievalQA LangChain pour construire un systeme RAG complet.
Le systeme resultant peut gerer avec precision des documents multi-formats. Pour des questions comme "Les pucerons sont-ils un parasite ?" il peut extraire des faits cles des documents analyses et generer des reponses fondees sur le materiel pertinent. Cela est particulierement utile pour les bases de connaissances d'entreprise qui doivent traiter de nombreux types de documents.
6.3 QA de documents d'entreprise : RAG de haute precision et tracable
La solution championne du Enterprise RAG Challenge montre comment construire un systeme RAG de niveau production sous des exigences strictes de temps et de precision :
- https://abdullin.com/ilya/how-to-build-best-rag/
- https://hustyichi.github.io/2025/07/03/rag-complete/
Contexte : Les concurrents devaient analyser 100 PDF de rapports annuels d'entreprise reels en 2.5 heures, chaque rapport allant jusqu'a 1000 pages et contenant des tableaux financiers complexes, des mises en page multi-colonnes et des graphiques. Apres l'analyse, le systeme devait repondre a 100 questions commerciales precises avec des types de reponses explicites, comme oui-non, noms d'entreprises, indicateurs numeriques exacts ou titres de dirigeants, et citer les numeros de page comme preuves.
L'equipe gagnante a choisi Docling d'IBM open source comme analyseur PDF car il performait le mieux sur les tableaux complexes et le texte multi-colonnes. Ils ont ameliore le code Docling pour qu'il puisse produire du JSON et du Markdown-plus-HTML avec des metadonnees et ont surtout ameliore l'analyse des tableaux. Pour accelerer le traitement, ils ont loue des GPU RTX 4090 et termine l'analyse des 100 rapports en 40 minutes.
Le decoupage du texte utilisait des segments de 300 tokens avec un chevauchement de 50 tokens et un decoupage recursif pour preserver la coherence semantique. Pour eviter la contamination inter-entreprises, chaque entreprise avait son propre store vectoriel FAISS utilisant un index IndexFlatIP. La recherche suivait ensuite trois etapes : recuperer les Top-30 segments par vecteurs, dedupliquer par pages parentes car plusieurs segments peuvent provenir de la meme page, et reclasser les pages avec GPT-4o-mini. Le classement final melangeait les scores de recherche vectorielle et de reranking LLM avec une repartition de poids de 0.3 a 0.7.
La generation utilisait differents modeles de prompt pour differents types de reponses. Pour les questions numeriques, comme le chiffre d'affaires annuel, le systeme utilisait un processus d'analyse en cinq etapes pour assurer la correspondance des indicateurs, la coherence des unites et la verification croisee. Les sorties etaient structurees pour inclure le processus d'analyse et les references de page pour la tracabilite.
Le systeme a remporte deux prix et a pris la premiere place du classement. Une observation importante etait que meme des modeles plus petits comme Llama 8B surpassaient plus de 80 pour cent des participants, tandis que Llama 3.3 70B approchait GPT-4o-mini, montrant qu'une bonne conception de systeme peut equilibrer avec succes precision, efficacite et cout.
6.4 Scenario AIOps : traitement intelligent de donnees mixtes texte et image
Le projet EasyRAG dans une competition RAG AIOps s'est concentre sur la QA pour des scenarios d'operations :
http://blog.csdn.net/hustyichi/article/details/143323746
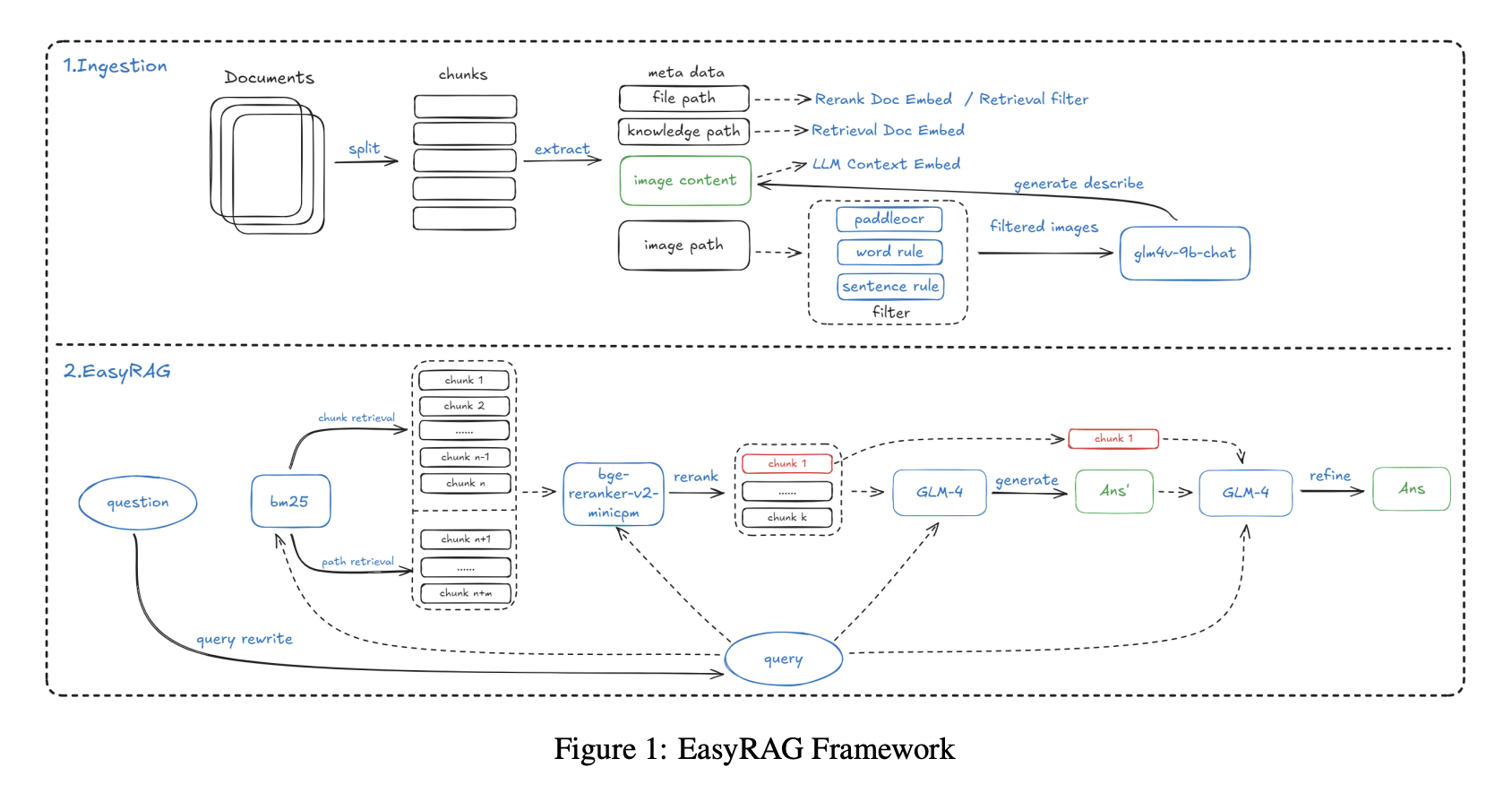
Contexte : Les ingenieurs d'operations doivent souvent lire des documents techniques qui incluent non seulement du texte mais aussi des graphiques de surveillance, des diagrammes d'architecture systeme et des courbes de performance. Par exemple, lors du diagnostic d'un probleme systeme, la reponse a "Que dois-je faire lorsque l'utilisation du CPU depasse 80 pour cent ?" peut etre dispersee entre des descriptions textuelles et des graphiques de surveillance. Le RAG traditionnel textuel ne peut pas comprendre les tendances et les valeurs des graphiques, donc les reponses restent incompletes.
L'etape d'indexation utilisait un SentenceSplitter ameliore avec des segments de 1024 tokens et un chevauchement de 200 tokens. Une innovation cle etait l'ajout de metadonnees comme les chemins de base de connaissances et les chemins de fichiers a chaque segment, ce qui a ameliore le rappel de 2 pour cent. Pour les donnees image, le systeme utilisait d'abord PaddleOCR pour extraire le texte des graphiques et des captures d'ecran, puis utilisait un modele multimodal, GLM-4V-9B, pour generer des descriptions en langage naturel de l'image, par exemple decrivant un pic de la ligne d'utilisation du CPU a 90 pour cent dans l'apres-midi. Le texte OCR et la description de l'image etaient ensuite indexes ensemble.
La recherche utilisait une strategie a deux voies BM25 plus vectorielle pour un rappel large. BM25 couvrait la recherche de segments et la recherche de chemins, aidant a filtrer les documents non pertinents par chemin de fichier, tandis que la recherche vectorielle utilisait gte-Qwen2-7B-instruct. Le reranking utilisait bge-reranker-v2-minicpm-layerwise, et un reglage a 28 couches performait le mieux dans les experiences.
La generation de reponses utilisait une strategie en deux etapes : generer d'abord un brouillon a partir des 6 meilleurs documents pour maximiser la couverture d'information, puis optimiser la reponse avec le document le plus pertinent pour mettre l'accent sur la reponse principale.
Pour gerer les scenarios de texte long, comme un manuel d'operations complet avec des centaines de pages, le systeme a aussi implemente une compression de contexte basee sur BM25, divisant les documents en phrases, scorant la similarite des phrases avec la requete et concatenant uniquement les phrases les plus pertinentes. A 50 pour cent de compression, cette methode a atteint une precision de 86.48 pour cent en seulement 7.7 secondes et a surpasse des outils comme LLMLingua.
6.5 Fusion de donnees multi-sources : collaboration entre connaissances structurees et non structurees
La solution gagnante du KDD Cup 2024 Meta RAG challenge a montre comment integrer du contenu web non structure et des graphes de connaissances structures :
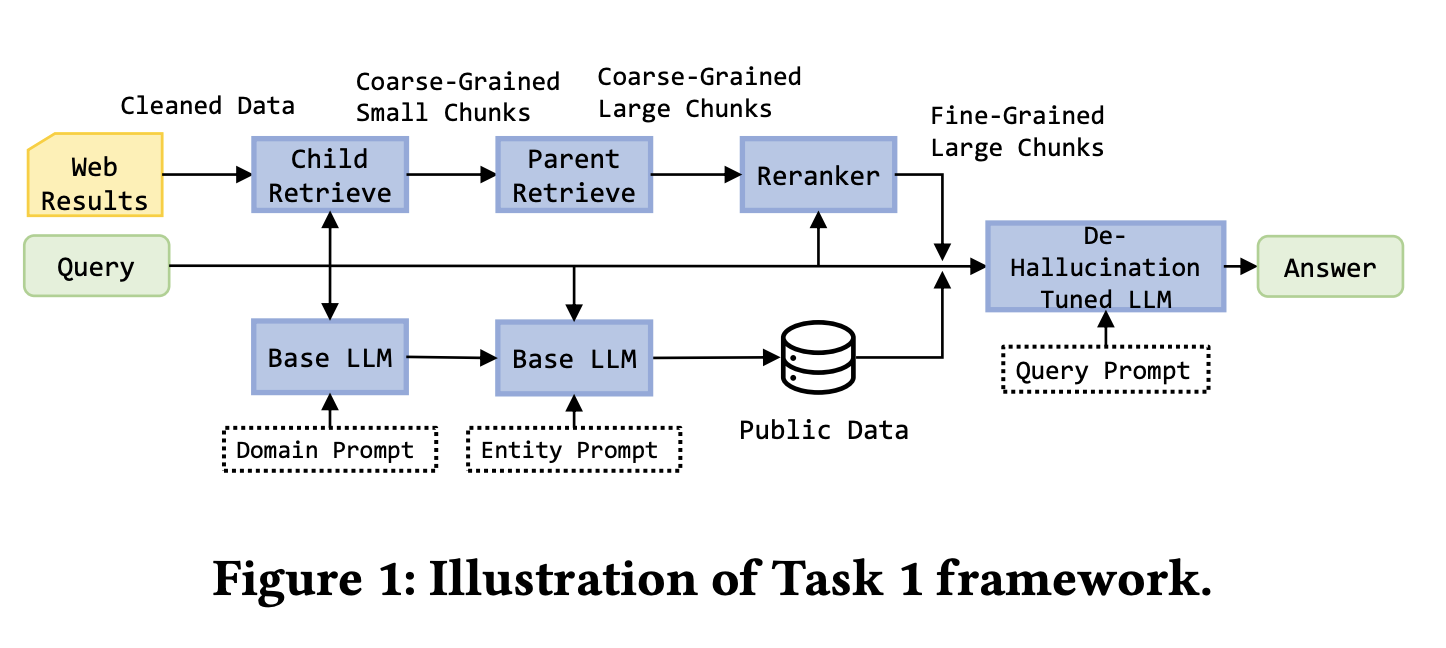
Contexte : La tache 1 necessitait un resume de recherche a partir de cinq pages web. La tache 2 ajoutait une API simulant un graphe de connaissances structure, permettant l'acces direct a des choses comme des bases de donnees de films et des relations d'entites. La tache 3 augmentait la difficulte en utilisant cinquante pages web plus l'API simulee pour repondre a des requetes plus complexes, comme identifier les films diriges par Nolan avec un box office superieur a 500 millions de dollars. Chaque requete devait se terminer en 30 secondes.
Pour la tache 1, l'equipe gagnante a construit un pipeline de traitement web raffine. Ils ont utilise BeautifulSoup pour extraire le texte des pages et ParentDocumentRetriever pour gerer les relations parent-enfant des segments, utilisant des segments enfants de 200 tokens pour la recherche et des segments parents de 500 a 2000 tokens pour la generation. Le modele d'embedding etait bge-base-en-v1.5, le store vectoriel etait Chroma, et le reranking utilisait bge-reranker-v2-m3. L'equipe a aussi complete les donnees de films et de finance a partir de jeux de donnees publics et a affine Llama-3-8B-instruct avec LoRA sur des donnees d'entrainement incluant des questions invalides et des reponses de reference.
Pour les taches 2 et 3, l'innovation cle etait la priorisation du graphe de connaissances. Le systeme definissait des appels API standardises comme get_person et get_movie, avec support de filtrage et de tri. Il appelait d'abord l'API du graphe de connaissances et ne revenait a la recherche web que si les resultats du graphe etaient manquants ou invalides. Cela ameliorait a la fois la vitesse et la precision des reponses.
Parce que le systeme priorisait le graphe de connaissances et utilisait des formats de sortie structures, l'hallucination etait clairement reduite. Si le graphe pouvait fournir une reponse deterministe directement, le systeme la renvoyait sans etape generative. Si la recherche web etait necessaire, la reponse devait suivre des regles strictes de citation et de raisonnement etape par etape.
La solution a remporte la premiere place dans les trois taches. La principale lecon est que dans les scenarios d'entreprise contenant a la fois des donnees structurees et non structurees, la strategie de recherche devrait etre concue selon le type de donnees : utiliser d'abord les donnees structurees deterministes et traiter les sources non structurees comme supplements.
A travers ces cas pratiques, plusieurs principes partages apparaissent repetitivement :
- choisir des strategies de cache, de recherche et de generation selon le scenario metier
- concevoir des chemins d'analyse et d'indexation dedies pour differents formats et modalites
- traiter la recherche hybride plus le reranking comme une configuration standard
- utiliser des prompts specifiques aux taches et des sorties structurees pour ameliorer la precision et la tracabilite
Ces lecons de veritables competitions et projets ouverts sont des references precieuses pour construire des systemes RAG d'entreprise plus performants.
7. Exploration large : l'evolution future du RAG (Optionnel)
Une fois que vous avez appris les competences pratiques et les methodes d'optimisation du RAG, vous pouvez deja ameliorer la performance du systeme dans des scenarios concrets. Mais comprendre seulement les astuces d'ingenierie locales ne suffit pas si vous voulez avoir une vision plus large de la direction du RAG. Nous devons aussi examiner des directions evolutives plus larges.
Le RAG depasse maintenant rapidement le modele traditionnel de recherche de segments de texte puis generation. Dans cette section, nous nous concentrons sur plusieurs de ces voies : passer de la recherche de segments a la recherche structuree en graphe, combiner images et audio dans le RAG multimodal, ameliorer la gestion des documents longs par le decoupage tardif vectorise, et la facon dont le RAG evolue progressivement vers un systeme oriente agent.
7.1 Graph RAG : remodeler la recherche profonde avec des reseaux de relations
Recherches connexes :
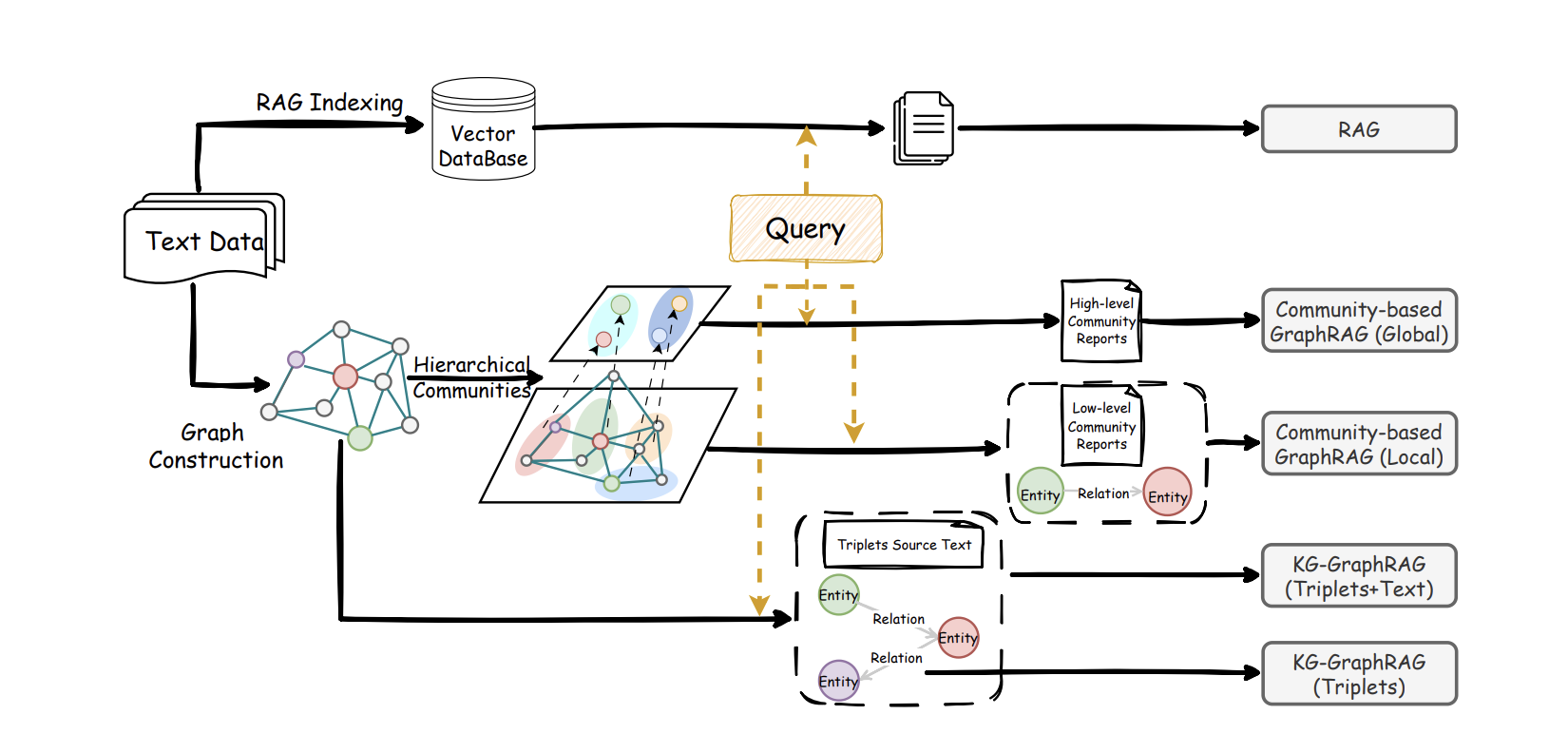
Le RAG traditionnel fonctionne en trouvant des passages de texte similaires a la question, ce qui revient a extraire les quelques paragraphes qui semblent les plus pertinents d'un tas de materiel. Cela fonctionne bien pour la recherche directe de faits. Mais si une question necessite de connecter plusieurs documents et de combiner differents indices, la performance chute.
Par exemple, un medecin pourrait demander, "Sur la base de ces cas et des dernieres directives de traitement, comment devrions-nous evaluer les benefices et les risques d'un certain medicament pour les patients ages ?" Ou une equipe projet pourrait demander, "En regardant a travers les deux dernieres annees de documents d'exigences, de comptes rendus de revue et de rapports d'incidents en ligne, quelle partie de notre architecture systeme echoue le plus souvent ?" Des questions comme celles-ci ne concernent pas la recherche d'une seule phrase. Elles necessitent d'identifier les personnes, les objets, les evenements et les relations dispersees a travers de multiples materiaux et de former une image complete.
Le Graph RAG construit cette image proactivement. Le systeme utilise un grand modele pour identifier les entites cles du texte, comme les personnes, les organisations, les modules fonctionnels, les evenements et les donnees, ainsi que leurs relations, comme la causalite, la dependance, le changement et la contradiction. Il construit ensuite un reseau de connaissances qui croit a mesure que davantage de materiel est ajoute. Par un regroupement automatique, les entites et relations etroitement liees sont organisees en themes, et chaque theme peut ete resume a l'avance. Lorsqu'un utilisateur pose une question, le systeme ne recherche plus seulement les passages de texte qui semblent similaires. Il trouve d'abord les entites et la structure de graphe locale les plus pertinentes, s'etend a travers les groupes de themes connexes, puis donne le chemin d'analyse, les descriptions de nœuds et les passages sources ensemble au LLM pour le raisonnement.
Sous ce cadre, le Graph RAG et le RAG traditionnel se completent mutuellement. Le RAG traditionnel reste fort pour les questions de detail dont les reponses peuvent etre trouvees en une seule etape. Le Graph RAG est plus proche de la facon dont un chercheur humain reflichit : organiser d'abord la structure globale et les themes, puis remplir les preuves, et enfin produire une conclusion avec logique et conditions. Les comparaisons existantes montrent que dans les taches de raisonnement multi-sauts, le Graph RAG couvre souvent plus de contenu critique et offre une perspective plus large. La combinaison flexible des deux approches est souvent meilleure que l'utilisation d'une seule.
7.2 RAG Multimodal
Recherches connexes :
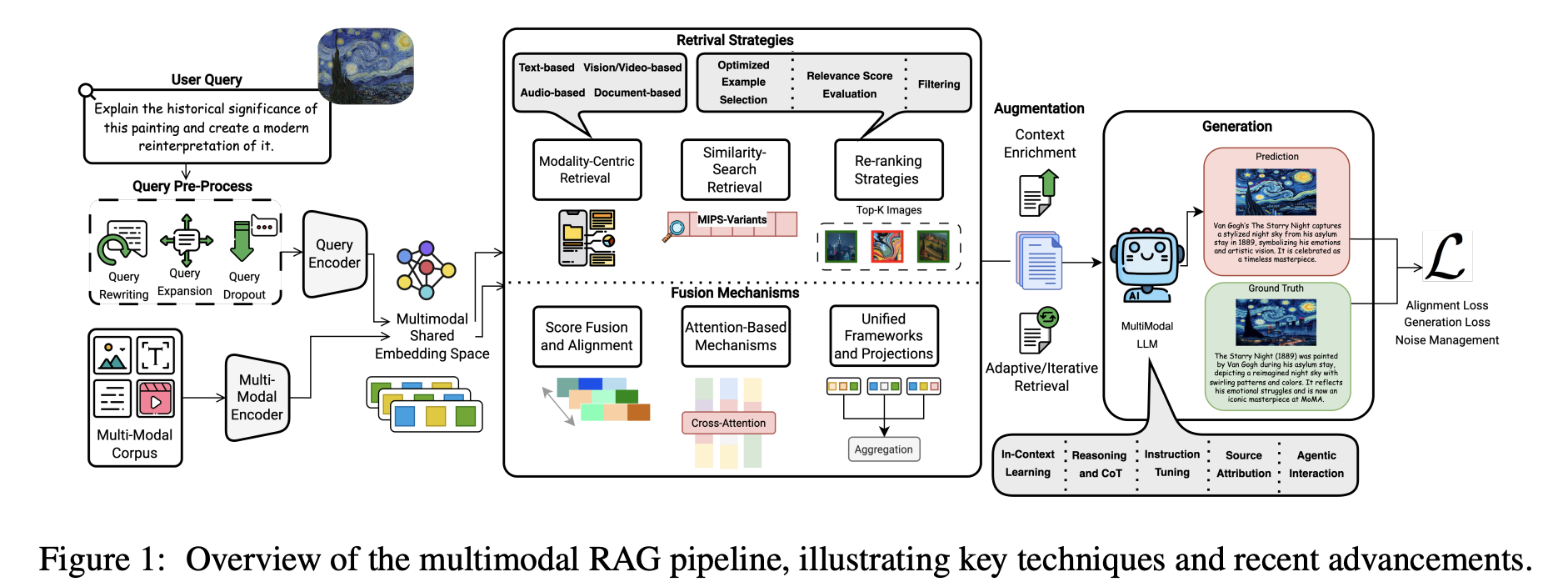
Les donnees du monde reel ne sont jamais seulement textuelles. Les ingenieurs diagnostiquant des pannes de serveur doivent regarder ensemble les courbes de temperature, les captures d'ecran d'appareils et les journaux. Les medecins faisant des diagnostics ont besoin d'images CT ou IRM, de rapports d'analyse et de dossiers medicaux electroniques en meme temps. Le RAG textuel traditionnel peut au mieux recuperer des phrases comme "anomalie de temperature" ou "suspect nodule pulmonaire", mais il a du mal a connecter ces descriptions a la tendance reelle du graphique ou a la forme de la lesion sur l'image, et il ne peut pas faire une recherche inverse de documents ou de connaissances a partir d'images, d'audio ou de video.
Le RAG multimodal resout ce probleme de differentes modalites incapables de "voir" les unes les autres. Son cœur est l'alignement semantique cross-modal. Le systeme utilise des encodeurs appropries pour les images, la video, l'audio et le texte, ainsi que l'OCR, l'ASR et l'analyse de mise en page, extrait les informations cles des sources visuelles et audio, et mappe differentes modalites dans un espace semantique partage ou un index multimodal unifie peut etre construit.
Au moment de la recherche et de la generation, que l'utilisateur demande un graphique montrant un pic de ventes au T3 2023 ou telecharge un croquis ou une video de fonctionnement, le systeme trouve d'abord les preuves multimodales les plus proches dans cet espace unifie, les filtre par des signaux comme la similarite textuelle et la similarite d'image, garde les pieces les plus utiles, puis donne ces images, passages de texte et tableaux ensemble a un LLM multimodal. Le modele peut alors repondre en combinant les preuves a travers les modalites et idealement indiquer la source ou mettre en evidence les zones pertinentes dans l'image ou le document.
Compare au RAG textuel uniquement, le RAG multimodal peut utiliser plus de types de preuves et reduit souvent les hallucinations tout en produisant des reponses plus completes et plus verifiables.
7.3 Late Chunking : preserver le contexte complet pour les documents longs
Introduction connexe :
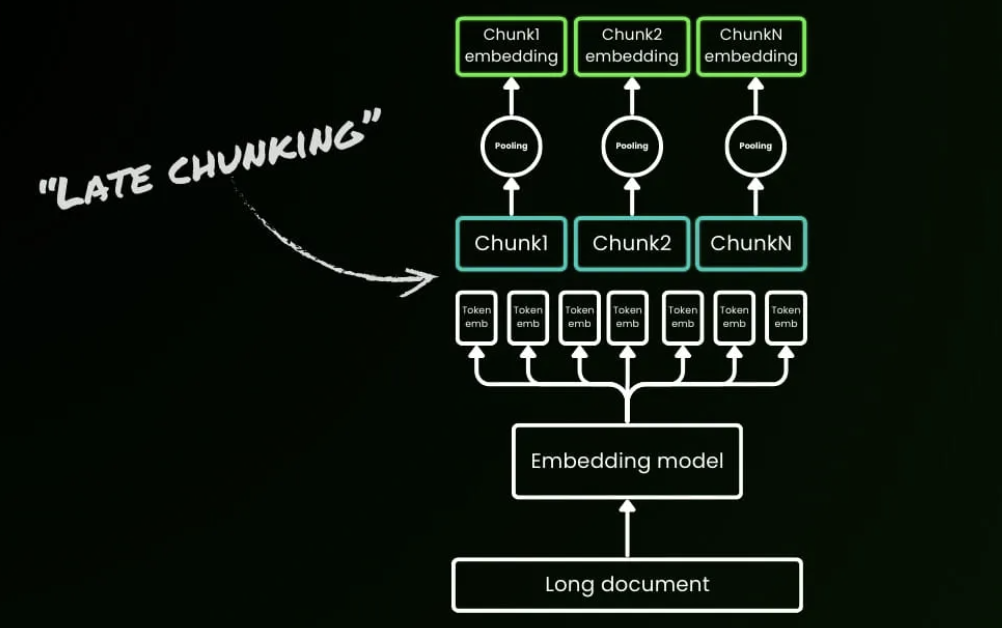
Imaginez lire un article Wikipedia sur Berlin. Le RAG traditionnel le couperait d'abord en paragraphes independants puis integrerait chaque segment. Si la premiere phrase dit "Berlin est la capitale de l'Allemagne", les expressions ulterieures comme "la ville" ou "sa population" perdent leur lien avec Berlin une fois separees. Une requete comme "Quelle est la population de Berlin ?" peut alors echouer parce que le terme Berlin et l'information sur la population ne sont jamais apparus dans le meme segment. Ce probleme devient encore pire pour les documents longs. Dans un contrat d'assurance de 200 pages, la definition d'une franchise peut apparaitre a la page 5 tandis que les conditions dans lesquelles elle s'applique apparaissent a la page 30. Le decoupage de longueur fixe peut diviser ces pieces liees en dizaines de segments isoles, et les experiences montrent que la similarite semantique peut s'effondrer brutalement lorsque cela se produit.
Le Late Chunking renverse le pipeline traditionnel de decouper-puis-integrer et suit plutot integrer-puis-decouper. Avec des modeles d'embedding a contexte long capables de traiter quelque chose comme 8192 tokens, tout le document est d'abord passe a travers le Transformer, produisant des embeddings au niveau du token qui ont deja vu le document complet. Ce n'est qu'apres coup que ces embeddings de token globalement informees sont regroupes en embeddings de segments selon les frontieres de segments. Les segments resultants ne sont plus des iles independantes. Ce sont des embeddings dependants du contexte qui preservent les references inter-paragraphes et les relations conceptuelles.
Sur les jeux de donnees du benchmark BEIR, le Late Chunking surpasse le decoupage traditionnel de maniere generale, avec des gains particulierement forts sur les documents plus longs. Dans les scenarios de texte court, la difference disparait largement, ce qui confirme une regle cle : plus le document est long, plus l'avantage du Late Chunking est grand. La methode est maintenant integree dans Jina Embeddings v3. Bien que l'encodage d'un document long complet en premier puisse augmenter le temps d'inference de 10 a 20 pour cent, les gains de recherche dans des scenarios comme les dossiers medicaux, les documents juridiques et les manuels techniques peuvent facilement justifier ce cout.
Le Late Chunking montre que les modeles d'embedding a contexte long de plus de 8K ne sont pas de la suringenierie dans ces scenarios. Ils sont souvent necessaires pour produire des embeddings de segments de haute qualite et representent un passage de decouper d'abord, puis integrer, a integrer d'abord, puis decouper.
7.4 Du RAG au RAG dans l'ere des Agents
Discussions connexes :
- https://ragflow.io/blog/rag-at-the-crossroads-mid-2025-reflections-on-ai-evolution
- https://arxiv.org/pdf/2501.09136
- https://www.letta.com/blog/rag-vs-agent-memory
- https://www.linkedin.com/posts/richmondalake_100daysofagentmemory-rag-memorizz-activity-7348281860843577346-LM7Y/
- https://www.llamaindex.ai/blog/rag-is-dead-long-live-agentic-retrieval
Le RAG a evolue d'un outil de generation amelioree par la recherche en une partie cle de l'architecture cognitive d'un agent. Le RAG traditionnel est construit sur un modele simple de demander, rechercher, repondre et est fondamentalement passif. Il attend une requete et n'agit pas proactivement. Pour percer cette passivite et gerer des taches cognitives plus complexes, le RAG a ete profondement combine avec les capacites des agents, donnant naissance a un nouveau paradigme : le RAG Agentique.
Sous ce paradigme, le role du RAG change fondamentalement. Il n'est plus seulement un fournisseur passif de connaissances externes. Au lieu de cela, il devient l'unite de traitement centrale qui soutient le comportement intelligent sous la planification active, la direction par objectifs et l'auto-reflexion de l'agent. Cette fusion donne au systeme global une orientation par objectifs, une optimisation iterative et une prise de decision autonome, approfondissant considerablement la qualite de l'interaction humain-IA. Le RAG Agentique peut comprendre des taches complexes, les decomposer, planifier des strategies de recherche et evaluer la qualite des resultats initiaux pour decider si une exploration plus approfondie est necessaire.
La cle de cette capacite est une boucle active a plusieurs couches. Face a une requete complexe, l'agent analyse d'abord la nature du probleme, le decompose en sous-problemes et concence des strategies de recherche precises pour chaque sous-probleme. Apres avoir recu les resultats initiaux, il les evalue, juge si l'information est complete et pertinente, identifie les lacunes de connaissances et genere dynamiquement de nouvelles requetes plus precises. Ce processus iteratif inclut souvent une recherche multi-sauts, ou les resultats d'un tour revelent de nouvelles directions pour le tour suivant, produisant une chaine d'exploration des connaissances similaire a la facon dont travaille un chercheur humain.
Pour soutenir ce comportement intelligent continu et iteratif, surtout lorsque la personnalisation et l'accumulation de connaissances a long terme comptent, le seul contexte de conversation a court terme est loin de suffire. Cela conduit au besoin de memoire a long terme structuree.
C'est exactement pourquoi le RAG est de plus en plus assigne au role de systeme de memoire a long terme d'un agent et utilise pour construire une architecture complete de memoire externe. Cette memoire a long terme complete la memoire a court terme, qui est responsable du maintien du contexte de dialogue actuel. Le systeme de memoire a long terme s'appuie sur trois mecanismes cles :
- Capacite d'indexation structuree : Cela permet a l'agent de construire des index multi-dimensionnels sur de grandes quantites de donnees non structurees, par temps, sujet, relations d'entites, et plus encore, supportant une recherche efficace sous plusieurs angles, un peu comme les humains se souviennent des informations a travers differents indices.
- Oubli intelligent : A travers des algorithmes d'evaluation de valeur, le systeme peut décroître ou se debarasser selectivement des informations a faible frequence, faiblement liees ou obsoletes, gardant le systeme de memoire mince et efficace et evitant la surcharge.
- Consolidation des connaissances : Le systeme raffine l'experience de dialogue et d'interaction dispersee en connaissances structurees. A travers la reconnaissance d'entites, l'extraction de relations et le clustering semantique, les informations fragmentees sont connectees en graphes de connaissances, transformant l'experience a court terme en connaissances a long terme.
Ce systeme de memoire externe construit sur le RAG non seulement etend significativement la frontiere cognitive d'un agent, mais lui donne aussi la capacite de continuer a apprendre et a faire evoluer ses connaissances. Il permet a l'agent d'accumuler de l'experience sur des interactions a long terme, de former des modes de fonctionnement personnalises et des systemes de connaissances de domaine, et de soutenir des taches plus complexes et plus longues.
Resume
La Generation Amelioree par la Recherche n'est pas seulement une methode technique pour compenser les hallucinations et l'obsolescence des connaissances dans les grands modeles. C'est aussi un pont cle pour transformer la capacite generale de l'IA en valeur profonde pour l'entreprise. L'evolution du Naive RAG aux formes modulaires et agentiques montre que chaque partie du RAG doit s'approfondir continuellement, y compris un traitement des donnees plus fin, une selection de modeles plus scientifique a travers les etapes d'embedding, de rerank et de LLM, et une evaluation plus systematique. Tous ces elements sont des etapes necessaires vers la construction de systemes de connaissances d'entreprise qui soient controlables, dignes de confiance et efficaces. En meme temps, tirer les lecons des competitions et des cas d'ingenierie est l'un des meilleurs moyens d'approfondir la comprehension des details techniques.
A mesure que le Graph RAG, la comprehension multimodale et le Late Chunking continuent de se developper et de se combiner, le RAG pousse regulierement au-dela de l'ancienne frontiere de recherche-et-generation et se deplace vers des associations semantiques plus profondes et une capacite de memoire plus durable. L'espoir est que cet article de synthese vous aide a construire une methodologie de chaine complete, du principe a la pratique et de l'evaluation a l'evolution, pour que dans un paysage technologique en rapide evolution vous puissiez construire des applications intelligentes de haute qualite qui atterrissent vraiment dans le monde reel et peuvent gerer des defis metier complexes.
References
[1] Ask in Any Modality: A Comprehensive Survey on Multimodal Retrieval-Augmented Generation.
https://arxiv.org/pdf/2502.08826
[2] Retrieving Multimodal Information for Augmented Generation: A Survey.
https://arxiv.org/pdf/2303.10868
[3] A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models.
https://arxiv.org/pdf/2405.06211
[4] Retrieval-Augmented Generation for Large Language Models: A Survey.
https://arxiv.org/pdf/2312.10997
[5] LightRAG: Simple and Fast Retrieval-Augmented Generation.
https://arxiv.org/pdf/2410.05779
[6] Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG.
https://arxiv.org/pdf/2501.09136
[7] ERAGent: Enhancing Retrieval-Augmented Language Models with Improved Accuracy, Efficiency, and Personalization.
https://arxiv.org/pdf/2405.06683
[8] Graph Retrieval-Augmented Generation: A Survey.
https://www.arxiv.org/pdf/2408.08921
[9] Evaluation of Retrieval-Augmented Generation: A Survey.
https://arxiv.org/pdf/2405.07437
[10] Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey.
https://arxiv.org/pdf/2504.14891
[11] From Local to Global: A Graph RAG Approach to Query-Focused Summarization.
https://arxiv.org/pdf/2404.16130
[12] RAG vs. GraphRAG: A Systematic Evaluation and Key Insights.
https://arxiv.org/pdf/2502.11371
[13] Introduction to RAG | LlamaIndex Python Documentation.
https://developers.llamaindex.ai/python/framework/understanding/rag/
[14] All-in-RAG | A Full-Stack Guide to RAG in Large-Model Application Development.
https://datawhalechina.github.io/all-in-rag/#/en/
[15] Ilya Rice: How I Won the Enterprise RAG Challenge.
https://abdullin.com/ilya/how-to-build-best-rag/
[16] RAG Research Table - Awesome Generative AI Guide (GitHub).
[17] RAG is dead, long live agentic retrieval.
https://www.llamaindex.ai/blog/rag-is-dead-long-live-agentic-retrieval
[18] LLM/RAG Zoomcamp extra lesson 5: Common evaluation methods and market preferences in RAG evolution.
https://vip.studycamp.tw/t/llmrag-zoomcamp-課外補充-5:rag-evolution-常見評估方法和市場偏好/8185
[19] How to Evaluate Retrieval Augmented Generation (RAG) Applications.
https://zilliz.com.cn/blog/how-to-evaluate-rag-zilliz
[20] RAG is not Agent Memory.
https://www.letta.com/blog/rag-vs-agent-memory
[21] Richmond Alake. LinkedIn post on #100DaysOfAgentMemory, RAG and MemoRizz.