大規模言語モデル(LLM)の普及が進む中、企業は非常に現実的な問題に直面しています。それは、社内文書やリアルタイムデータ、専門分野の知識に依存する質問に対して、モデルが正確に回答するにはどうすればよいかという問題です。結局のところ、モデルの学習データには限りと時間的な制約があり、企業固有のビジネス知識や常に更新される情報を網羅することはできません。
直感的なアイデアとして、コンテキストウィンドウが8Kから128K、さらには100万トークンを超えるまで拡大し続けているのだから、関連文書をプロンプトに詰め込んで、モデルに直接それらの資料から回答させるのはどうだろうか、というものがあります。
しかし、長いコンテキストを処理できることと、企業シナリオで正確な回答を安定して、効率的に、かつ制御可能に提供できることは、全く異なる二つのことです。長いコンテキストへの盲信は、コストの爆発、注意の希薄化、知識更新の陳腐化といった一連の深刻な課題をもたらします。
こうしたペインポイントを解決するため、Retrieval-Augmented Generation、略してRAGと呼ばれる技術が登場しました。RAGは、モデルが回答を生成する前に、まず外部の正確な知識を検索します。コンテキスト長を力技で拡大するだけのアプローチと比較して、RAGはより低いコストで、より高い精度と強い制御性で、企業の事実正確性と最新知識に対する要件を満たします。そのため、信頼できるAIアプリケーションを構築するための重要な基盤となっています。
本チュートリアルでは、RAGとは何かを体系的に説明し、その登場背景と核心的な原理をたどりながら、基本形から高度な形への進化、そして今後の方向性について探ります。
このレッスンで学ぶこと
- RAGの核心的価値:コスト、注意、知識の鮮度という長文脈の中心的問題にどう対処するかを深く理解する
- RAGの仕組み:具体的な例を通じて、検索から生成までの完全なループがどのように完了するかを見る
- RAGの進化:基本的なNaive RAGからAdvanced RAG、そしてModular RAGへ
- RAGのためのモデル選択:Embedding、Rerank、LLMという3つの主要なモデルタイプの評価と選択方法を理解する
- 企業RAGの実践:データ前処理からシステム展開・評価までのフルチェーン構築ガイドを学ぶ
- RAGの評価と最適化:コア指標、主要フレームワーク、継続的改善手法を理解する
- RAGの最前線トレンド:RAGがエージェント、マルチモーダル、その他の新興技術とどう組み合わされているかを探る
得られるもの
このチュートリアルを完了すると、RAG技術について体系的な初級レベルの理解が得られます。RAGが何であるかだけでなく、なぜ機能するのかも理解できるようになります。さらに、企業要件を満たす効率的で信頼性が高く制御可能なRAGシステムの評価、選択、設計方法について明確な青写真を得て、実際のエンタープライズグレードのRAGアプリケーション構築の堅固な基盤を築くことができます。
1. なぜRAGが必要なのか
Retrieval-Augmented Generation(RAG)は、今日の生成AIにおいて最も重要な技術的アプローチの一つです。その基本的な考え方はシンプルです。大規模モデルに回答を生成させる前に、システムがまずユーザーの質問に関連する情報を外部のナレッジベースから検索し、その検索された情報と元の質問の両方をモデルに渡すことで、モデルが実際の資料に基づいて回答できるようにするというものです。外部のナレッジベースは、企業の社内ポリシー、プロセス文書、製品知識であったり、業界データベース、規制コーパス、規格ライブラリなどであったりします。
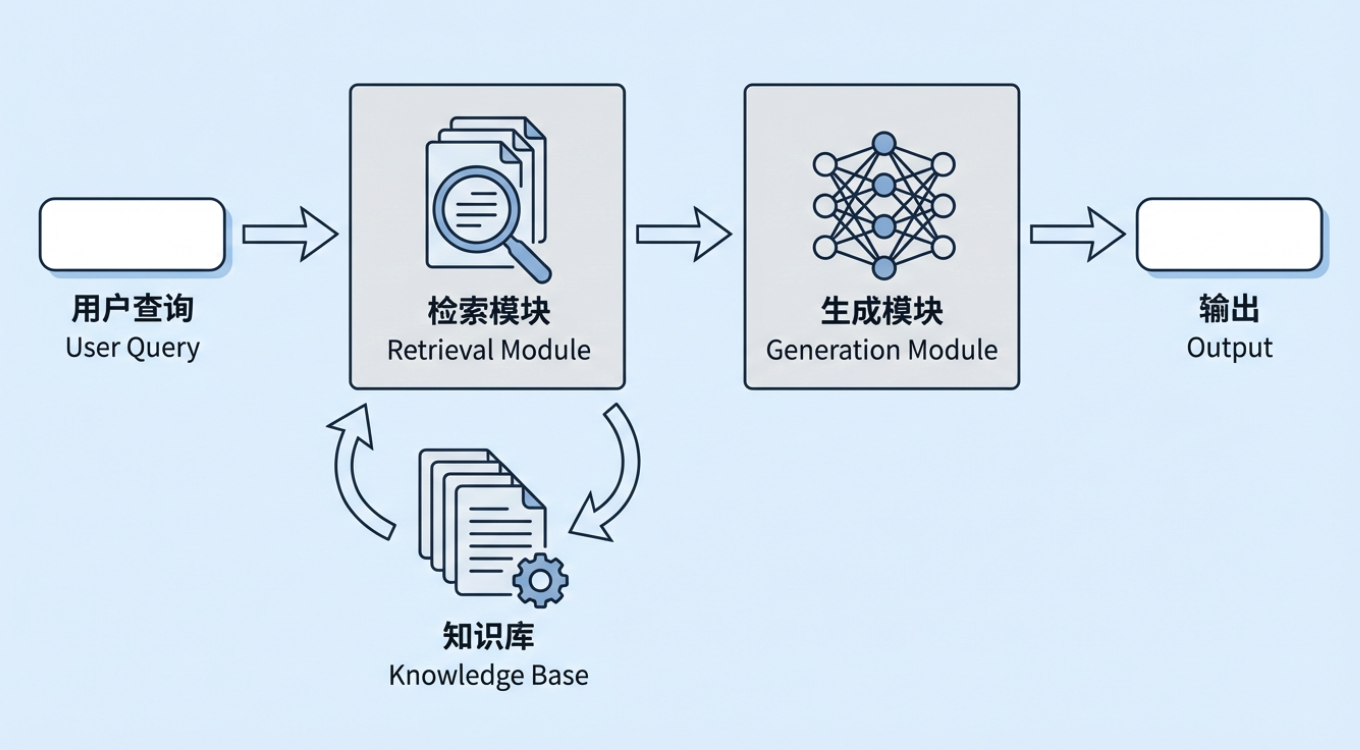
ここで自然な疑問が浮かびます。大規模モデルはすでに「直接質問に答える」ことができるのに、なぜRetrieval-Augmented Generationという別の層を追加する必要があるのか?特にコンテキストウィンドウがますます大きくなっている今、単に関連資料をすべてモデルに渡せば、ほとんどのニーズを解決できるように思えます。
本当の違いは、「回答を出力できること」と「実際のビジネス環境で継続的かつ安定して、制御可能に正しい回答を出力できること」が全く異なる二つのことであるという点にあります。モデルのパラメータメモリのみに頼る場合、あるいは大量の文書を長いコンテキストに詰め込むだけの場合、企業での利用において少なくとも3つの典型的な問題が依然として現れます。
コストと効率の問題: コンテキストウィンドウが拡大し続けても、全文書を一度にコンテキストに詰め込むという考え方は、実際のシステムでは依然として非現実的です。中心的な矛盾は2点に現れます:
推論コストはコンテキスト長と強い正の相関があります。コンテキストが長くなるほど推論コストが上昇し、ほぼ線形、時には超線形的に増加します。1回の呼び出しにおいて、8Kトークンと200Kトークンは全く異なる価格とレイテンシの範囲にあり、長いコンテキストははるかに高いコスト閾値を持ちます。
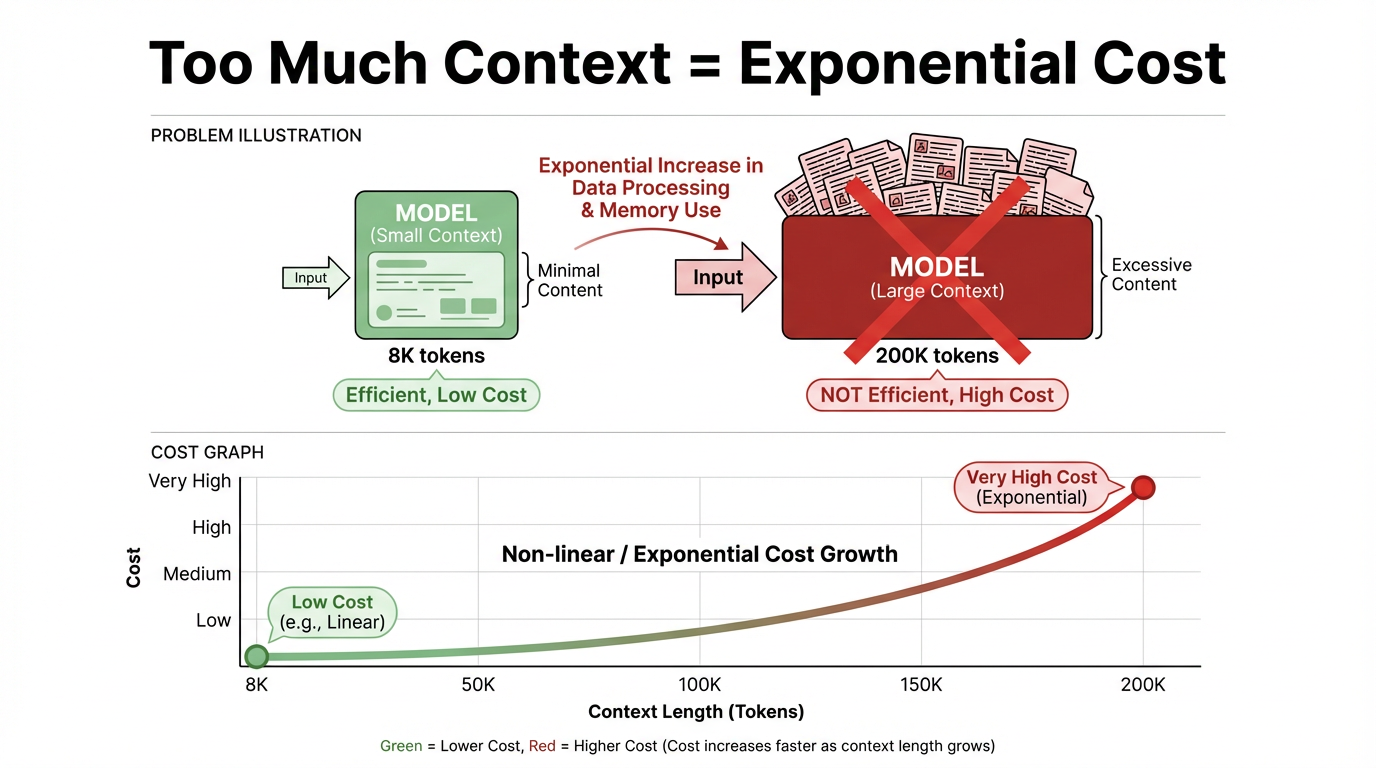
意味的には、コンテキストとは、モデルが質問に答える際に「参照する」背景情報と会話履歴です。技術的には、1回の推論でモデルに入力されるトークン列全体(システム指示、ユーザー指示、メッセージ履歴、検索された一節など)を指します。
「コンテキストウィンドウ」とは、その入力の容量制限です。Transformersなど、現在の主流の大規模モデルアーキテクチャでは、これらのトークンは各レイヤーでアテンション計算に参加します。ウィンドウが長くなりトークン数が増えると、計算量とコストは乗算的に増加し、指数関数的な成長に近づくことさえあります。
大量の計算が浪費されます。ほとんどのタスクは、現在の質問に高い関連性を持つごくわずかな情報のみを必要とします。全文書セットをコンテキストに詰め込むと、深刻なアイドルと計算の浪費が生じ、システムのスループットが低下し、応答速度が遅くなり、最終的にユーザー体験を損ないます。
注意と集中の問題: 大規模モデルは超長いコンテキストを「カバー」できても、すべてのセグメントを同等の品質で利用することはできません。コンテキスト長が一定の閾値を超えると、モデルは明らかな注意バイアスを示し始めます:
注意の減衰:コンテキストの前半と中間部分に対するモデルの注意が徐々に弱まり、後で読んだテキストに依存する傾向が強まるため、重要な初期情報が事実上無視される可能性があります。
情報干渉:モデルは、コンテキスト内の無関係、重複、あるいは矛盾する情報によって容易に軌道を外れます。最終的な回答は論理的に首尾一貫しているように聞こえながらも、核心的な質問から逸脱している可能性があり、精度の保証が困難になります。 検索段階で関連性をフィルタリングしてランク付けしなければ、コンテキストが長くなるほど、本当に重要な証拠に回答を集中させるのが難しくなります。長いコンテキストの利点は、情報干渉によって完全に相殺される可能性があります。
知識の鮮度と制御性の問題: すべての知識がモデルのパラメータに完全に保存されている場合、またはプロンプトに手動でコピーされている場合、2つの避けられない欠陥が現れます:
知識の更新が困難:ポリシーの変更、製品の反復、価格の更新など、知識が変化した場合、モデルの再学習またはファインチューニングが必要となり、コストが高く時間がかかるか、プロンプトテンプレートを手動で保守する必要があり、これもコストが高く人的エラーが発生しやすくなります。
トレーサビリティが低い:モデルが回答する際、ブラックボックスのパラメータや長いプロンプトから正確な証拠を特定することが困難です。これにより、コンプライアンス監査、リスク説明、その他の明確な決定根拠を必要とするタスクが極めて困難になります。
これらの現実的な制約の下で、RAGの利点ははるかに明確になります。その核心的なアプローチは、生成の前に、関連性が高く信頼できる情報を特定し、モデルが必要な知識のみから回答することです。知識は外部のナレッジベースに独立して保存でき、更新と管理が容易になります。同時に、生成された結果には引用元を含めることができ、解釈性と信頼性が向上します。将来、コンテキストウィンドウが拡大し続けても、RAGは依然として比較的低コストで効率的な知識管理と利用を可能にし、プロセスが観察可能で行動がトレース可能なエンタープライズグレードのナレッジアプリケーションを支援します。
企業要件の観点から、内部パラメータのみに依存する従来のLLMと比較して、RAGは主に以下の現実的な展開問題を解決します:
- 鮮度: 従来のモデルは通常、学習カットオフ以降に登場した新しい規制、製品、ワークフローを知りませんが、RAGは最新のポリシー文書、ビジネスデータベース、ナレッジベースを直接読み取ることができます。頻繁な再学習なしに、回答を最新のビジネス状態と同期させることができます。
- 専門性: 医療、化学、金融などの垂直ドメインでは、汎用モデルは深い理解や正確な表現が不十分な場合があります。企業所有のドメイン文書や業界標準に接続することで、回答を権威ある資料に基づかせ、実際のビジネス実践にはるかに近づけることができます。
- ハルシネーション: 回答を検索された一節に基づかせ、引用を提供することを要求することで、システムはメカニズムレベルで裏付けのない捏造を減らし、「真実らしく聞こえる」ことを「実際に真実である」ことに近づけることができます。
- 説明可能性と監査可能性: 純粋にパラメータベースのモデルは、「この結論はどのルールから導き出されたのか?」に答えることができません。RAGは各回答を特定のポリシー条項、ビジネス文書、または過去の事例に遡って追跡できます。これはビジネス担当者が回答を検査・修正するのに役立ち、監査、リスク、コンプライアンスチームに必要なトレーサビリティを提供します。
- 計算コストとリソース効率: 企業の全知識をモデルのパラメータに記憶させるには、通常、より大きなモデルとより高い推論コストが必要です。RAGは知識の大部分をベクトルストアやドキュメントストアにモデルの外部に保存し、オンデマンドで検索するため、より小さなモデルと限られた計算リソースでも、より広いカバレッジとより正確な詳細を得ることができます。
したがって、実際のビジネスシナリオで大規模モデルを長期的かつ安定的に制御可能に利用したい企業にとって、RAGはオプションの強化ではありません。それは高品質なエンタープライズナレッジアプリケーションシステムを構築するためのほぼ不可欠な基盤技術です。
2. RAGとは何か
RAG、すなわちRetrieval-Augmented Generationの核心的なアイデアは、大規模モデルに、学習中に獲得した静的な知識だけでなく、実行時に外部ナレッジベースから引き出した最新で信頼できる情報も使って質問に答えさせることです。
典型的なRAGシステムでは、ユーザーの質問は大規模モデルに直接送信されません。代わりに、検索モジュールがまず企業ナレッジベースから最も関連性の高い文書の段落を見つけ、それらの段落と元の質問を完全なコンテキストに組み合わせ、最終的にそれをモデルに渡して回答を生成させます。この「まず検索、次に生成」というパターンにより、モデルはパラメータに記憶していることから推測するだけでなく、実際の参照資料から推論できるようになります。典型的なケースを見てみましょう:
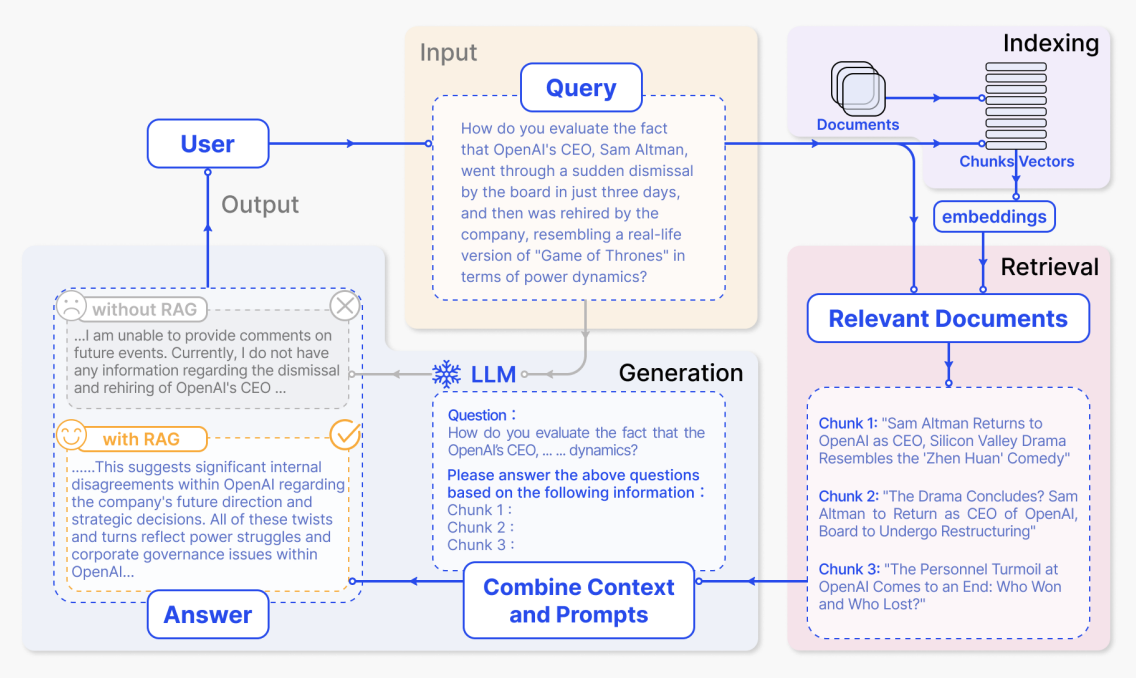
インデックス構築段階
インデックス構築段階では、システムは社内文書、ウェブページ、レポートなどの生素材を最初に処理します。それらを小さな意味的チャンクに分割し、埋め込みモデルを使用して各チャンクのベクトル表現を生成し、インデックスを構築します。後でユーザーの質問が届いたとき、システムはベクトル空間で最も意味的に類似したチャンクを素早く見つけることができます。
図では、これは右上の紫色の「Indexing」領域に対応しています。「Documents」から「Chunks / Vectors」を経て「embeddings」へのパスは、文書がチャンク化され、ベクトルに変換され、インデックスに書き込まれる過程を示しています。より具体的には:
- 文書は意味的に一貫したチャンクの集合に分割され、各チャンクは短いニュース記事、解説、分析に対応する場合があります。
- 各チャンクは埋め込みモデルによって高次元ベクトルに変換され、ベクトルインデックスに保存されます。
- このインデックスは後の類似性ベースの検索をサポートし、システムが質問に答える際に参照できるナレッジベースを準備します。
検索段階と検索結果からの回答生成
ユーザーが質問した後、システムはまずインデックスから関連コンテンツを検索し、質問と検索されたテキストを一緒に大規模モデルに送信して回答を生成します。図では、上から下、右から左への主要な領域がこの完全なフローに正確に対応しています。
(1) ユーザー入力質問:黄色のInput - Query領域
「OpenAIのCEO、Sam Altmanが、わずか3日間で取締役会による突然の解任を経て、その後会社に再雇用されたという事実をどう評価しますか?権力闘争の観点から、まさにリアル版の『ゲーム・オブ・スローンズ』のようですが。」
「OpenAIのCEO Sam Altmanが取締役会によって突然解任され、わずか3日後に会社に再雇用された事実をどう評価しますか?この権力闘争はリアル版のゲーム・オブ・スローンズのようですが。」
この大きなテキストブロックは、図の「Query」ボックス内の内容であり、ユーザーの自然言語の質問に対応しています。システムはその質問をベクトル化し、右上のインデックスから関連する文書チャンクを検索するために使用します。
(2) 検索された関連文書:右下のピンク色のRelevant Documents領域
検索後、システムは質問に最も関連するいくつかの文書チャンクを取得します。図では、3つのチャンクとして表示されています:
「Sam AltmanがCEOとしてOpenAIに復帰、シリコンバレーのドラマは『甄嬛伝』のコメディのよう」 「Sam AltmanがOpenAIのCEOとして復帰、このシリコンバレーのドラマは宮廷陰謀コメディのようです。」
「ドラマは終結?Sam AltmanがOpenAIのCEOに復帰予定、取締役会は再編へ」 「ドラマは終わるのか?Sam AltmanがOpenAIのCEOに復帰予定、取締役会は再編される予定。」
「OpenAIの人材騒動が終結:勝者と敗者は誰か?」 「OpenAIの人材騒動が終結:誰が勝ち、誰が負けたのか?」
(3) プロンプトの結合と回答生成:青色のLLM / Combine Context and Prompts領域
システムは元のユーザー質問と検索されたチャンクを完全なプロンプトに結合し、モデルに送信します。図の下部中央の点線ボックスにプロンプトの例が示されています:
「質問: OpenAIのCEOである...の権力闘争についてどう評価しますか?
以下の情報に基づいて上記の質問に答えてください: チャンク1: チャンク2: チャンク3:」
「質問: OpenAI CEO事件の権力闘争についてどう評価しますか?
以下の情報に基づいて上記の質問に答えてください: チャンク1: チャンク2: チャンク3:」
(4) RAGあり・なしの回答比較:左下の灰色と黄色のOutput - Answer領域
最後に、モデルは提供された情報に基づいて回答を生成します。図ではRAGあり・なしの出力も比較されています。RAGなしでは、モデルは外部資料がなく、曖昧な回答しかできず、灰色のボックスに対応します:
「...将来の出来事についてコメントすることはできません。現在、OpenAIのCEOの解任と再雇用に関する情報を一切持っていません...」
RAGありでは、モデルは検索されたニュースと分析を利用して、はるかに情報量の多い回答を生成でき、黄色のボックスに対応します:
「...これはOpenAI内に会社の将来の方向性と戦略的決定に関する重大な内部対立があることを示唆しています。これらすべての紆余曲折は、OpenAI内の権力闘争と企業ガバナンスの問題を反映しています...」
上記の例は、典型的なRAGシステムの完全なフローを示し、核心的な段階と情報がどのようにそれらを通じて移動するかを理解するのに役立ちます。しかし、多くの重要な技術的詳細は依然としてブラックボックスの中にあります。ベクトルマッチングは具体的にどのように実行されるのか、プロンプトはどのように構成すべきかでモデルが検索されたコンテンツをより効果的に活用できるのか。これらの詳細は実際のRAGの品質を大きく左右します。次に、RAGの内部メカニズムに深く入り込み、ベクトル化の原理と類似性計算からプロンプトエンジニアリングまで、段階的に解き明かしていきます。
3. RAGの仕組み
「りんご」に関するナレッジベースに基づいて構築されたシンプルな質問応答の例を通じて分解できます。
3.1 文書ベクトル化段階
以下の3つの文書段落を含む簡略化されたナレッジベースがあると仮定します:
- 段落A:Apple Inc.は1976年4月1日にSteve Jobs、Steve Wozniak、Ronald Wayneによって設立され、本社はカリフォルニア州クパチーノにあります。
- 段落B:りんごはビタミンCと食物繊維が豊富な果物で、消化と免疫システムの健康に役立ちます。
- 段落C:Apple Inc.は2007年に初代iPhoneを発売し、スマートフォン業界を根本的に変革しました。
これらの文書を埋め込みモデル(OpenAIのtext-embedding-ada-002やオープンソースのBGEモデルなど)で処理すると、各段落は高次元ベクトルに変換され、通常は768、1024、または1536次元を持ちます。
ベクトルとは本質的に、多くの数値からなる配列です。各次元はテキストの意味的な特徴に対応します。例えば、「猫」のベクトルには、哺乳類、家庭のペット、毛皮のようなに関連する次元が含まれる場合があります。値の最終的な組み合わせがテキストの意味的意味を捉え、コンピュータがテキスト間の関係を「理解」できるようにします。
簡略化された例(実際のベクトルははるかに高次元):
- Appleの設立に関する段落Aのベクトル:
[0.85, -0.23, 0.41, -0.56, 0.12, 0.78, ...] - 果物としてのりんごに関する段落Bのベクトル:
[-0.12, 0.95, -0.34, 0.67, -0.89, 0.05, ...] - iPhone発売に関する段落Cのベクトル:
[0.79, -0.18, 0.52, -0.61, 0.23, 0.81, ...]
これらのベクトルは、後の検索とリコールのために、Pinecone、Weaviate、FAISSなどのベクトルデータベースに保存する必要があります。
データベースとは、データを構造化された方法で保存・管理し、組織的な保存と効率的な検索を可能にするシステムです。一般的な例には連絡先リストやeコマースの製品カタログがあります。
ベクトルデータベースは特殊な種類のデータベースです。テキスト、テーブル、その他の通常のデータ構造を保存する従来のデータベースとは異なり、ベクトルデータベースはベクトル、つまり高次元の数値配列を保存するために特別に設計され、AIシナリオでの類似性検索に最適化されています。
3.2 ユーザークエリ、検索、応答の段階
ナレッジベースがベクトル化されて保存されると、RAGシステムはリアルタイムのユーザークエリをサポートできます。ユーザーが質問すると、システムは連続したフローを実行します。まず質問をベクトルに変換し、類似性計算を使用してナレッジベースから最も関連性の高い情報を検索し、最後にそれらの段落を回答生成の基礎として使用します。3つの具体的なクエリでこのプロセスを説明できます。
クエリ1:「Apple Inc.はいつ設立されましたか?」
クエリベクトル化段階では、質問は埋め込みモデルによって意味ベクトルに変換されます(例:[0.82, -0.21, 0.38, -0.58, 0.15, 0.76, ...])。この数値パターンは、会社の設立に関する段落Aの保存されたベクトルと高い類似性を持っています。
システムは類似性検索(Top-K、K = 2)を実行し、クエリベクトルとナレッジベース内のすべての文書ベクトル間のコサイン類似度を計算します。結果は以下のようになります:
- 段落A(設立段落)との類似度:0.97、高い関連性
- 段落C(iPhone発売段落)との類似度:0.88、会社に関するものなので関連
- 段落B(果物栄養段落)との類似度:0.12、ほぼ無関係
Top-Kはベクトル検索における一般的な選択戦略です。すべてのマッチを類似度の高い順にランク付けし、上位K件を保持することを意味します。K = 2は、システムが類似度によって上位2つの文書ベクトルのみを保持し、下位のものをフィルタリングし、次の段階が最も関連する2つの文書段落のみから回答を生成することを意味します。
類似度でフィルタリングされた結果はリコール結果と呼ばれます。システムはTop-2の段落を証拠として返します:
- 段落A、類似度0.97:「Apple Inc.は1976年4月1日にSteve Jobs、Steve Wozniak、Ronald Wayneによって設立され、本社はカリフォルニア州クパチーノにあります。」
- 段落C、類似度0.88:「Apple Inc.は2007年に初代iPhoneを発売し、スマートフォン業界を根本的に変革しました。」
回答生成段階では、システムはリコールされたコンテンツを参照情報セクションに配置し、システムプロンプトと一緒に送信することで、完全な構造化入力を構築します:
[System Prompt]
あなたはプロフェッショナルな質問応答アシスタントです。ユーザーが提供した「参照情報」に厳密に基づいて回答してください。
参照情報に回答が含まれている場合、それに直接基づいて回答してください。
参照情報に回答が含まれていない場合、「現在利用可能な資料に基づいて質問に回答することはできません」とユーザーに明確に伝え、情報を捏造しないでください。
回答がどの情報に基づいているかを示してください。
[Retrieved Context]
Apple Inc.は1976年4月1日にSteve Jobs、Steve Wozniak、Ronald Wayneによって設立され、本社はカリフォルニア州クパチーノにあります。
Apple Inc.は2007年に初代iPhoneを発売し、スマートフォン業界を根本的に変革しました。
[User Query]
Apple Inc.はいつ設立されましたか?この構造化入力を受け取った後、LLMはシステム指示に従い、検索されたコンテキストを回答のための唯一の信頼できる情報源として扱います。最終的な回答は次のようになります:
提供された参照情報によると、Apple Inc.は1976年4月1日に設立されました。[根拠:情報1]
クエリ2:「りんごを食べることの利点は何ですか?」
クエリベクトル化段階では、この質問は[-0.08, 0.92, -0.31, 0.71, -0.85, 0.08, ...]のような意味ベクトルに変換されます。その数値パターンは、りんごの栄養に関する段落Bの保存されたベクトルと高い類似性を持っています。
システムは再びTop-K類似性検索(K = 2)を実行し、コサイン類似度を計算します:
- 段落B(果物栄養)との類似度:0.95、高い関連性
- 段落C(iPhone発売)との類似度:0.18、ほぼ無関係
- 段落A(会社設立)との類似度:0.15、ほぼ無関係
システムはTop-2の段落を証拠として返します:
- 段落B、類似度0.95:「りんごはビタミンCと食物繊維が豊富な果物で、消化と免疫システムの健康に役立ちます。」
- 段落C、類似度0.18:「Apple Inc.は2007年に初代iPhoneを発売し、スマートフォン業界を根本的に変革しました。」これは弱い関連性しかなく、実際には閾値でフィルタリングされることが多いです。
完全な構造化入力は次のように構築されます:
[System Prompt]
あなたはプロフェッショナルな質問応答アシスタントです。ユーザーが提供した「参照情報」に厳密に基づいて回答してください。
参照情報に回答が含まれている場合、それに直接基づいて回答してください。
参照情報に回答が含まれていない場合、「現在利用可能な資料に基づいて質問に回答することはできません」とユーザーに明確に伝え、情報を捏造しないでください。
回答がどの情報に基づいているかを示してください。
[Retrieved Context]
りんごはビタミンCと食物繊維が豊富な果物で、消化と免疫システムの健康に役立ちます。
Apple Inc.は2007年に初代iPhoneを発売し、スマートフォン業界を根本的に変革しました。
[User Query]
りんごを食べることの利点は何ですか?最終的な回答は次のようになります:
提供された参照情報によると、りんごはビタミンCと食物繊維が豊富で、りんごを食べることは消化と免疫システムの健康に役立ちます。[根拠:情報1]
クエリ3:「今日の天気はどうですか?」
クエリベクトル化段階では、この質問は天気や気象学に関連する意味ベクトルになります(例:[0.10, -0.05, 0.30, -0.12, 0.21, 0.08, ...])。意味空間では、このベクトルは会社であれ果物であれ、りんごに関するすべての文書ベクトルから遠く離れているため、有意な類似性は現れません。
システムは再びTop-K検索(K = 2)を実行します。質問のトピックがナレッジベースと無関係であるため、全体の類似度スコアはすべて非常に低くなります:
- 段落B(果物栄養)との類似度:0.18、極めて低い
- 段落C(iPhone発売)との類似度:0.10、ほぼ無関係
- 段落A(会社設立)との類似度:0.08、ほぼ無関係
Top-Kは依然として上位K件の結果を返しますが、この場合、それらの結果は有効な証拠を提供しません。実際には、システムは最小類似度閾値を適用し、直接空のリコール、つまり有効な結果なしを返すことで、無関係な干渉を減らすことがよくあります。
返される2つの段落は依然として:
- 段落B、類似度0.18:「りんごはビタミンCと食物繊維が豊富な果物で、消化と免疫システムの健康に役立ちます。」
- 段落C、類似度0.10:「Apple Inc.は2007年に初代iPhoneを発売し、スマートフォン業界を根本的に変革しました。」
完全な入力は次のようになります:
[System Prompt]
あなたはプロフェッショナルな質問応答アシスタントです。ユーザーが提供した「参照情報」に厳密に基づいて回答してください。
参照情報に回答が含まれている場合、それに直接基づいて回答してください。
参照情報に回答が含まれていない場合、「現在利用可能な資料に基づいて質問に回答することはできません」とユーザーに明確に伝え、情報を捏造しないでください。
回答がどの情報に基づいているかを示してください。
[Retrieved Context]
りんごはビタミンCと食物繊維が豊富な果物で、消化と免疫システムの健康に役立ちます。
Apple Inc.は2007年に初代iPhoneを発売し、スマートフォン業界を根本的に変革しました。
[User Query]
今日の天気はどうですか?LLMはまず、参照情報に直接の天気やリアルタイムの気象情報が含まれているかどうかを判断します。含まれていないことを確認した後、指示に従って回答できないと答えます:
現在利用可能な資料では、「今日の天気はどうですか?」という質問に回答できません。参照情報はりんご、果物の栄養、Apple Inc.の製品に関連するコンテンツのみを含み、天気情報やリアルタイムの気象データは含まれていないためです。[根拠:検索されたコンテキストに天気関連情報は存在しません]
この3つの例から、RAG対話段階の鍵が見えます。システムプロンプトはLLMの役割と応答ルールを定義し、検索された証拠は具体的で信頼できる資料を提供し、ユーザーの質問はタスク目標を定義します。この構造化入力パターンこそが、RAGがそうでなければハルシネーションを起こす可能性のあるLLMを効果的に導き制約し、安定した信頼性の高い回答を生成するシステムに変えることを可能にしています。モデルが既存の情報の理解と整理に使用され、裏付けのない情報の発明に使用されないことを確保します。
4. RAGの進化
RAGは大規模モデルの時代に始まったものではありません。より初期の研究にも同じアイデアのプロトタイプが含まれていました。歴史的観点から見ると、RAGは従来のLLMの限界の認識から生まれました。初期の大規模言語モデルは主に事前学習データに依存しており、そのデータは学習が完了すると固定されました。例えば、GPT-3などのモデルは、学習データが収集された時期に関連する知識カットオフ日を持っており、それ以降の知識を取得できませんでした。特定のドメイン向けのLLMの再学習やファインチューニングも、大量のリソースと専門知識を必要とし、コストが高く迅速な反復が困難でした。
RAGの起源は2017年のDrQAフレームワークに遡ることができ、これは初めて検索と言語モデルの組み合わせを試みたものでした。その後、2020年にDense Passage Retrieval(DPR)が大きなブレイクスルーをもたらし、TF-IDFやBM25のような従来の単語頻度ベースの手法の代わりに、事前学習されたニューラルモデルを意味的検索に使用しました。2021年にはRAGが正式に提案され体系化され、LLMにおける知識カットオフとハルシネーションの問題に対処する標準的な方法となりました。
広義には、RAGの進化は3つの段階に分けることができます:
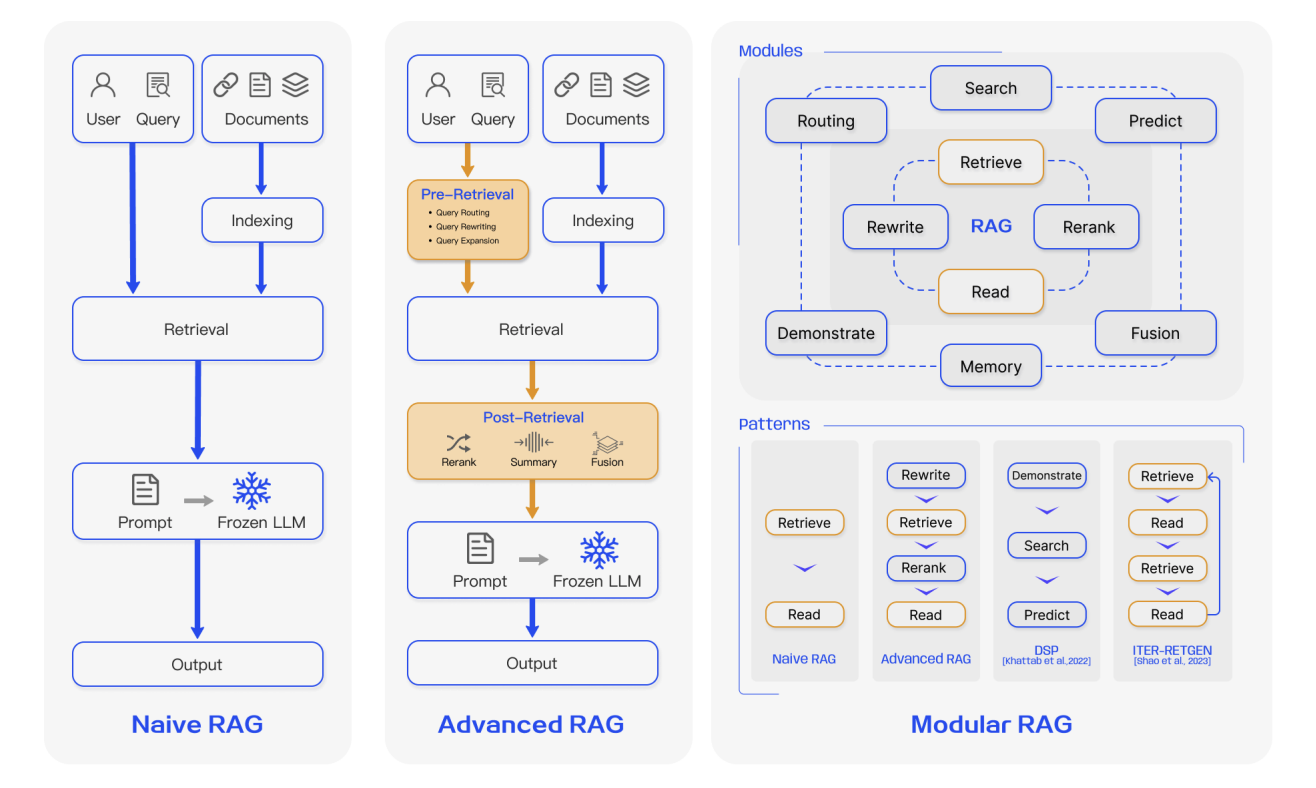
4.1 第一世代のRAG:Naive RAG
Naive RAGはRAGの最も基本的な形態です。エンジニアリングの観点からは、非常に直接的な3ステップのフローに従います:
- 文書の前処理とインデックス構築。生の文書はクリーニングされ、固定長のテキストチャンクに分割され、埋め込みモデルでベクトルにエンコードされ、ベクトルデータベースに書き込まれます。
- 類似性ベースの検索。ユーザーの自然言語の質問がベクトルにエンコードされ、システムがベクトルストア上でTop-K類似性検索を実行します。
- シンプルな検索拡張生成。検索されたチャンクは元の質問と直接連結されて長いプロンプトが形成され、LLMに送られて回答生成が行われます。
この段階の価値は、「回答する前に検索する」ことが実際に機能することを非常に低いハードルで検証したことです。モデルの内部メモリのみに頼るのと比較して、知識カットオフの問題と一部のハルシネーションをすでに大幅に削減しており、それが初期のプロトタイプ、デモ、入門チュートリアルで重要な役割を果たした理由です。
しかし、第一世代のRAGの限界も明確です。第一に、チャンキング戦略は通常粗雑です。ほとんどのシステムは単に固定長で分割するだけで、一貫した意味的段落の途中で切ってしまったり、1つのチャンクに複数のトピックを混ぜたりする可能性があります。これにより検索精度が低下し、LLMの理解も難しくなります。第二に、検索信号が単純すぎます。ランク付けは通常ベクトル類似度のみに依存し、キーワード、タイムスタンプ、ソースの信頼性、アクセス権限などのより豊かな構造化された手がかりを使用しません。第三に、検索結果はほとんど管理されていません。ノイズの多い、重複した、さらには矛盾するチャンクがそのままコンテキストに詰め込まれ、大量の低価値情報がすでに限られたコンテキストウィンドウを占有します。
要するに、第一世代は検索が必要かどうかという問題を解決しました。しかし、より良く検索するにはどうすればよいか、検索された情報をより合理的に利用するにはどうすればよいかという問題については、まだかなり原始的な段階にとどまっていました。
4.2 第二世代のRAG:Advanced RAG
RAGがデモから実際のビジネスシナリオに移行するにつれて、安定性、制御性、出力品質に対する要件が急激に高まりました。第二世代は通常、Advanced RAGという広い名称でグループ化されます。依然として「まず検索、次に生成」のパターンに従いますが、検索の前後に体系的な改良を導入しています。言い換えると、システムはもはや何かを検索することに満足していません。正しいものを適切に保存し、正しい質問を明確にし、検索されたコンテキストを注意深く管理することを目指しています。
検索前では、保存と質問の改善に焦点が当てられます:
インデックス側では、チャンキングは固定長の分割から意味認識チャンキングと階層的インデックス構築へと進化します。システムは章、節、段落、文の境界に沿って、スライディングウィンドウと多粒度インデックス構造を組み合わせてチャンキングする場合があります。
各文書チャンクには、ソース、タイムスタンプ、作成者、トピック、文書タイプなどの豊かなメタデータを付与でき、後のフィルタリングとランク付けにより多くの次元を提供します。
クエリ側では、ユーザーの元の質問は、Query Rewrite、Multi-Query、Sub-Query分解、Step-back Promptingなどの技術を通じて、書き換え、拡張、または分解され、曖昧または会話的なユーザークエリを検索がより理解しやすい形に変換します。
- Query Rewrite
核心的なアイデアは、ユーザーの曖昧な、口語的な、または非標準的なクエリを、検索システムがより理解しやすい正規化された表現に変換し、重要な情報を補足し、曖昧さを解決することです。
- 例えば、「明日の北京の天気をどうやって確認すればいいですか?」は、「北京の明日の終日のリアルタイム天気を照会する」のように、より標準化された形に書き換えられる場合があります。
- または「良い映画を勧めて」は、ユーザーの履歴を見た後、「高評価の2024年のサスペンス映画を勧める」に書き換えられる場合があります。
- Multi-Query
システムは元の質問から、意味的に関連するが異なる角度からの複数のクエリを生成し、見落としを減らし、ユーザーが明示的に述べていない潜在的なニーズをカバーします。
- Sub-Query
複数の目標を含む複合的な質問の場合、システムはそれらをより小さく、よりシンプルなサブクエリに分割し、検索が各ニーズに正確にマッチできるようにします。
- Step-back Prompting
システムはまず、より抽象的で高レベルな質問を生成し、それを使用して検索方向を導き、元の質問の細部に狭く集中しすぎることによるバイアスを減らします。
検索後では、検索されたものの管理に焦点が当てられます:
- 専用のリランキングモデルやLLMを使用して、候補文書を再ランク付けし、最も重要で質問に関連するコンテンツがコンテキストに最初に入るようにします。
リランキングモデルは、情報検索パイプラインにおける重要なコンポーネントです。リコールフェーズから返された候補結果に対して第二段階のランク付けを行い、通常はTransformerアーキテクチャに基づくより強力な意味理解を使用して、第一段階の意味的ランク付けエラーを修正し、ユーザーニーズに最も合致する結果を前に押し出します。
- 検索された一節は、明らかに無関係または高度に反復的なチャンクを除去するために、フィルタリング、重複排除、圧縮を行うことができ、長いコンテキストシステムが中間の有用な情報を無視する傾向を減らします。
- 必要に応じて、軽量なモデルファインチューニングにより、LLMが検索証拠から回答しやすくし、明示的な引用や情報源を含めることができます。
全体として、Advanced RAGはもはや検索が必要かどうか、何かを検索できるかどうかにのみ焦点を当てていません。代わりに、3つのより大きな課題に取り組みます:本当に重要な段落を正確に特定できるかどうか、大規模モデルに渡されるコンテキストが簡潔で、構造化され、効率的に使用しやすいかどうか、そしてシステム全体がノイズ、矛盾、またはマルチソースの情報ニーズの存在下で安定して信頼できるかどうかです。
大量の実験的およびエンジニアリング的証拠は、Advanced RAGが回答精度、ハルシネーション抑制、システムの堅牢性、説明可能性の点でNaive RAGを大幅に上回ることを示しています。そのため、従来の基本的なアプローチに徐々に取って代わり、今日のRAGシステム構築における主流の産業パラダイムとなっています。
4.3 第三世代のRAG:Modular RAG
複雑なエンタープライズアプリケーションでは、要件が複数のドメインにまたがることがよくあります。そのような場合、検索、リランキング、生成というシンプルな線形フローだけでは不十分です:
- 同じシステムが、シンプルなFAQ、長いレポート生成、コード検索、データベース呼び出しをサポートする必要がある場合があります。
- ベクトルストア、全文検索、リレーショナルデータベース、ナレッジグラフ、外部検索エンジンに同時に接続する必要がある場合があります。
- 複数のラウンドにわたってユーザーの好みと過去の決定を保持しつつ、コンプライアンスチェックと回答のトレーサビリティも適用する必要がある場合があります。
この背景に対して、RAGはモジュール化されたシステム形態へと進化し始めました。Modular RAGはもはや固定されたパイプラインとは見なされません。代わりに、プラグイン可能で、交換可能で、組み立て可能な機能モジュールのセットとして扱われ、必要に応じてオーケストレーションできます。典型的なモジュールには以下が含まれます:
- クエリ理解とルーティング このモジュールは、意図認識、質問の書き換え、サブタスク分解、パス選択を処理します。リクエストが主に内部知識、外部検索、または特定のツールやデータベースに依存すべきかどうかを決定します。
- マルチソース検索と融合 このモジュールは、ベクトルデータベース、全文検索、構造化データベース、ナレッジグラフに同時に接続し、それらをクエリし、結果を統合およびリランキングして統一された証拠セットにします。
- メモリとパーソナライゼーション このモジュールは、長期のユーザープロファイル、短期のセッションメモリ、ドメイン知識キャッシュを維持し、システムが継続的に履歴情報を蓄積・利用できるようにします。
- タスク適応とガバナンス このモジュールは異なるタスクに異なるアダプタを読み込み、出力形式、トーン、スタイルを制約し、事実確認、リスクフィルタリング、引用アライメントを通じて出力をガバナンスします。
要するに、従来のRAGは通常、1回の検索ラウンドと1回の生成ラウンドで終了します。Modular RAGはこの単一フローパターンを打ち破ります。生成中に情報がまだ不十分であることがシステムが発見した場合、新しい検索ラウンドを積極的にトリガーでき、検索と生成の間を複数回行き来して、より複雑なタスクを完了することさえできます。
さらに、モデルは自ら意思決定することを学ぶことができます。信頼度が高い場合には内部知識や短いコンテキストから直接回答し、不確実性が高い場合にのみ検索や外部ツールの呼び出しを開始します。これにより、品質を維持しながら効率が向上し、リソースが節約されます。定義が不十分または不完全なクエリの場合、モデルは最初に仮の中間回答やドラフト文書を生成し、それをさらなる検索の手がかりとして使用し、段階的に信頼できる情報源に近づくことさえできます。
この段階では、RAGはもはや大規模モデルにいくつかの参照段落を付加するだけのシンプルなコンポーネントではありません。それはエンタープライズインテリジェントアプリケーション内の中央のナレッジオーケストレーション層になり、複数のデータソース、複数のツール、複数のタスクを調整しています。
5. デモからエンタープライズグレードのRAGへ
エンタープライズエンジニアリングの観点から見ると、RAGシステムの構築は検索拡張生成のみに限定することはできません。上記の内容は依然としてデモレベルの入門に近いものです。実際のビジネスシナリオでは、データはノイズが多くフォーマットが不統一であることが多いため、前処理、クリーニング、インジェストにより多くの労力を投資する必要があり、各主要ポイントでのモデル選択を慎重に扱う必要があります。
完全なエンタープライズグレードのRAGシステムは、通常3つのコアモジュールに分けられます:レイアウト分析とナレッジインジェスト、ナレッジベース構築、RAGベースの質問応答サービスです。技術チェーン全体を通じて、埋め込みモデル、リランキングモデル、LLMを含むいくつかの主要なモデル選択の決定が現れます。各段階で適切な技術的選択を行ってのみ、システムは強力な全体的な結果を達成できます。
レイアウト分析とローカルナレッジファイルの読み取り
このモジュールは、異なる形式のローカルナレッジアセットを検索に使用できるテキストに変換します。入力にはPDF、TXT、HTML、Word、Excel、PPTファイル、スキャンされた画像ファイル(PNGやJPG)、さらには音声録音が含まれる場合があります。
システムは各フォーマットを適切に解析し、テキスト文書のレイアウト分析と構造抽出を行い、タイトル、本文、表、ヘッダー、フッターを区別し、適切な読書順序を復元します。画像ファイルにはOCRを、音声にはASRを実行し、最終的にすべてを比較的クリーンなナレッジテキストに変換しながら、ファイル名、章、ページ番号、タイムスタンプなどの基本メタデータを保持して、後のチャンキングとインデックス構築に備えます。
ナレッジベース構築:チャンキング、埋め込み、インデックス構築
クリーニングされたナレッジテキストを取得した後、システムはチャンキングを行い、長い文書を適切な長さの意味的に一貫したブロックに分割します。通常は段落、タイトル構造、またはスライディングウィンドウによって行い、各チャンクのソースとメタデータを保持します。
次に、選択した埋め込みモデル(
text-embedding-3-small、Sentence Transformers、BGEなど)を使用して各チャンクのベクトル表現を計算し、Faiss、Milvus、またはマネージドベクトル検索サービスなどのツールを使用してベクトルインデックスを構築します。その時点で、高速な意味的検索をサポートするナレッジベースが作成されます。RAGベースの質問応答:リコール、リランキング、結合、生成
オンラインQA段階では、ユーザーがクエリを送信します。システムはそれをクエリベクトルに埋め込み、ベクトルインデックスから最も類似したテキストチャンクのバッチを検索し、それを粗いランク付け段階として扱います。次に、BGEリランカーのようなリランキングモデルや、リランカーとして機能するLLMを使用して、クエリと文書のペアを再度スコアリングし、真に最も関連するTop-K文書のみをナレッジコンテキストとして保持します。
次に、「以下の資料に厳密に基づいて回答してください」のような注意深く設計されたシステムプロンプトと共に、ユーザークエリと検索された文書段落を結合し、マージされたプロンプトをLLMに送信します。モデルは検索された証拠から最終的な回答を生成し、必要に応じて引用や情報源を含めます。
5.1 モデル選択
次にモデル選択に焦点を当てます。完全なRAGシステムは通常、3つのコアモデルカテゴリに関与します:埋め込みモデル、リランキングモデル、大規模言語モデルです。それぞれに独自の役割があり、一緒に検索から回答生成までの完全なパスを形成します。埋め込みモデルはテキストを検索可能な意味ベクトルに変換し、リランキングモデルは初期の検索結果を洗練させ、LLMは選択されたナレッジコンテキストに基づいて最終的な回答を生成します。
5.1.1 埋め込みモデル
RAGシステムでは、埋め込みモデルの役割は、ユーザークエリやナレッジベースコンテンツなどのテキストを高次元ベクトルに変換することです。意味的に類似したテキストはベクトル空間でより近くに配置され、システムが類似性によって関連する知識を素早く特定できるようにします。したがって、適切な埋め込みモデルの選択は、高性能なRAGシステムを構築する上で最も重要なステップの一つであり、リコール品質を直接決定するからです。
強力なモデルを選ぶためには、体系的なベンチマークを使用することが役立ちます。最も広く使用されているベンチマークの一つは、MTEB(Massive Text Embedding Benchmark)です。
MTEBは、多くの埋め込みモデルに対する統一的で客観的な評価フレームワークを提供します。8つの主要なタスクカテゴリと56のデータセットを通じて、検索、クラスタリング、分類、リランキング、テキストマッチング、意味的類似性などにわたるパフォーマンスを評価します。モデルの全体的なMTEBスコアは、ベクトル表現の一般性と堅牢性を反映し、モデル選択の重要な参考となります。最新のランキングはHugging Face MTEBリーダーボードで確認できます:
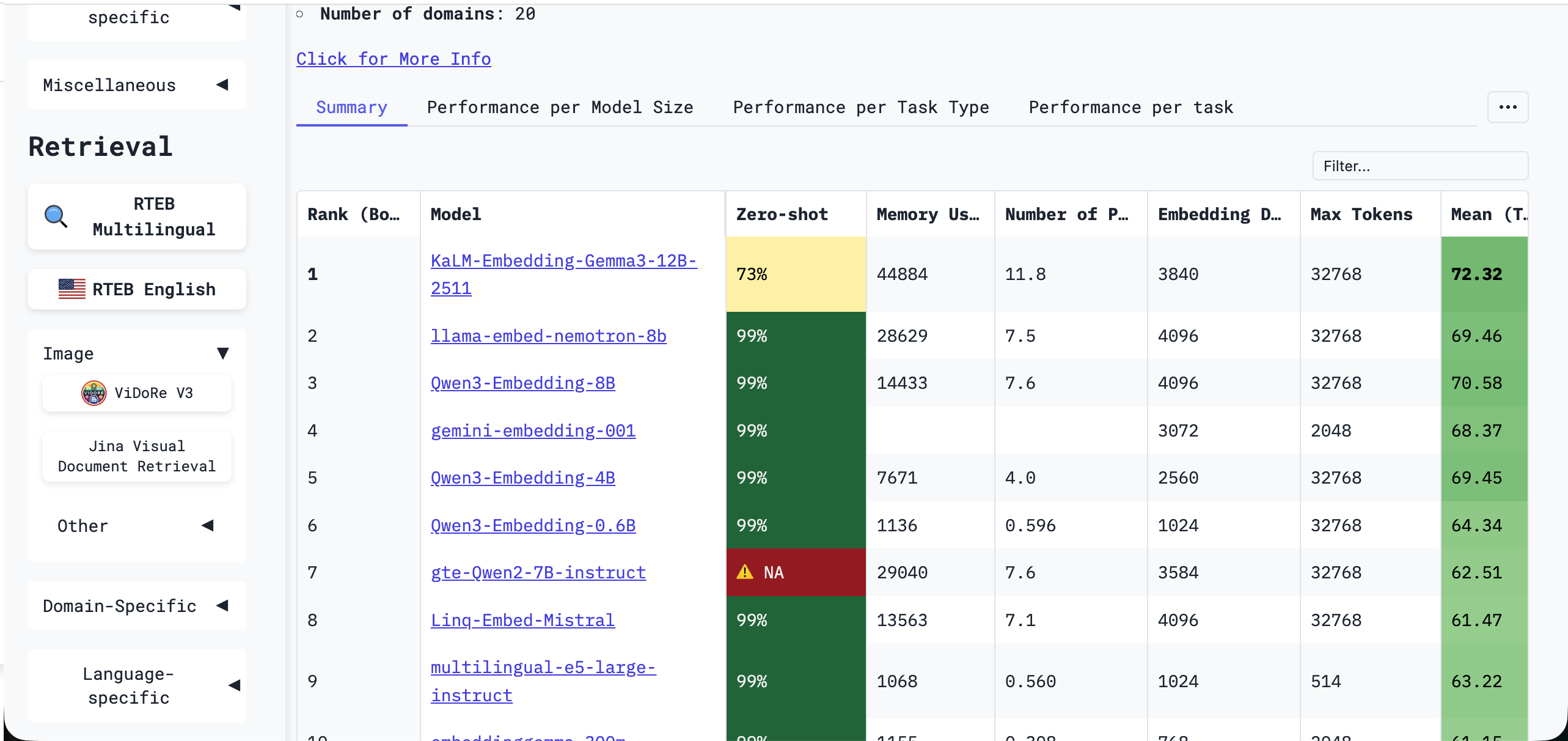
リーダーボードには多くのモデルがありますが、すべてを習得する必要はありません。実際には、大手モデルプロバイダーがバンドルしている埋め込みモデルを選ぶか、多くの人が既に検証しているクラウド提供モデルを使用するのが、通常は安全な選択です。サイドバーでカテゴリや言語でリーダーボードをフィルタリングすることもできます:
埋め込みモデルをフィルタリングする際、特に重要な2つのパラメータがあります。それらはRAGのパフォーマンスに直接影響するためです:次元とコンテキスト長です。
次元とは、ベクトル出力の次元数(128、768、1536など)です。これはベクトルが表現できる意味的特徴の数を大まかに反映します。より高次元のベクトルは、より豊かな意味的詳細とより強い識別力を捉えることができます。例えば、768次元のベクトルは「りんご」を品種、味、産地など数百の角度から表現でき、医療や法律などの正確な検索が必要な専門シナリオに適しています。低い次元は計算とストレージコストを削減し、検索速度を向上させ、高い同時性と強いリアルタイム要件を持つ大規模な汎用シナリオに適しています。
コンテキスト長とは、埋め込みモデルが1回で処理できる最大テキスト長であり、トークンで測定されます。英語の1トークンは約4分の3語に相当し、日本語の1トークンは約1文字に相当します。最大値を超えるものは切り詰められます。これはモデルがテキストを完全に理解できるかどうかを直接決定します。重要な情報が短すぎる長さのために失われると、検索精度が急激に低下します。短いユーザークエリと短いQAペアには、512から1024トークンが通常十分です。論文やレポートなどの長いテキストには、通常2048トークン以上が必要です。
以下は、いくつかの一般的な埋め込みモデルの比較です。実際には、コストとパフォーマンスのバランスを取りながら選択する必要があります。普遍的に最適なモデルはなく、自身のユースケースでいくつかの選択肢を比較した後に最も適したモデルのみがあります。
| モデル名 | モデル規模 | コアの強み | 適用シナリオ |
|---|---|---|---|
OpenAI text-embedding-3-large | クローズドAPI | MTEBでの長期リーダー、成熟して安定 | 極端なパフォーマンスを優先し十分な予算を持つクラウドAPIシナリオ |
jina-embeddings-v2 | 8Kまでの長いテキストをサポート | 非同期エンコーディング設計による長文書検索に強い | 文書分析、法的コンプライアンス、学術検索 |
multilingual-e5-large | 大規模 | クラシックな多言語オプション | クロスリンガルRAG、国際製品、多言語サポートシステム |
Qwen/Qwen2-Embedding-8B | 8Bパラメータ、最大4096カスタム次元 | 元MTEB多言語トップ、長テキスト、多言語タスク、コードに強い | 高精度の日中英RAG、長文書分析、コード検索 |
Qwen/Qwen2-Embedding-4B | 4Bパラメータ | パフォーマンスと効率の強いバランス | 大規模プロダクションRAGシステム |
Qwen/Qwen2-Embedding-0.6B | 0.6Bパラメータ | エッジデバイスに適している | リソース制約、速度優先のシナリオ |
BAAI/bge-m3 | ハイブリッド検索サポート、dense + sparse + multi-vector | MIRACLなどの多言語ベンチマークに強い | ハイブリッド検索が必要な複雑な多言語シナリオ |
BAAI/bge-large-zh-v1.5 | 大規模 | コミュニティ検証済みの安定した中国語RAGベースライン | 短い文書の純粋な中国語プロジェクト |
ZhipuAI Embedding-3 | クラウドAPI(クローズド) | 256から2048までのカスタム次元をサポート | クラウドAPIを好む中国語重視のアプリケーション |
5.1.2 リランキングモデル
RAGシステムでは、リランキングモデルは初期の検索結果を精緻に再ランク付けする役割を担います。ユーザークエリと候補文書を入力として受け取り、各クエリと文書のペアに対して正確な関連性スコアを計算します。スコアが高いほどマッチ度が良いことを示します。したがって、埋め込みベースのリコールの上にリランキングモデルを追加することは、検索精度を向上させるための重要なステップです。
埋め込みモデルについては、MTEBのようなベンチマークを使用できます。リランキングモデルについては、Agentsetのリランカーリーダーボードが有用な参考になります:
Agentsetベンチマークはまず、FAISSを使用して大規模な文書ストアから最も関連性の高い50の候補結果を検索し、評価対象のリランキングモデルにそれらの50文書をリランクさせます。ベンチマークはランク付け品質とレイテンシの両方に注目します。実際のアプリケーションでは、速度を無視して精度を追求するとユーザー体験を損ない、逆にランク付け品質を犠牲にして速度を追求すると有用性を損ないます。
AgentsetはELOスコアリングメカニズムも導入しています。各クエリについて、GPT-5が審判として機能し、2つの異なるリランキングモデルのランク付けされた出力を比較し、どちらが真に関連する文書をより合理的な順序に配置しているかを決定します。このようなペアワイズ比較の大量の繰り返しの後、より多く勝ったモデルが高いELOスコアを受け取り、直感的な全体的パフォーマンス指標を提供します。
ベンチマークはまた、2つの補完的な指標グループを使用しています:
nDCG@5/10:関連文書が前面に配置されているかどうかに焦点を当て、ランク付け精度を反映Recall@5/10:すべての関連文書を見つけられるかどうかに焦点を当て、カバレッジを反映
これらの指標は一緒に、リランキングパフォーマンスのより完全な像を提供します。
それでも実際には、リランキングモデルをリーダーボードからのみ選択する必要はありません。産業的有用性とリーダーボードスコアは常に同じではありません。実践的なアプローチは、クラウドベンダーが推奨するリランキングモデルや、大手モデルベンダーが提供するデフォルトのリランクAPIから始めるか、既に使用しているモデルファミリ(例えばマッチするQwenリランキングモデルなど)をテストすることです。
5.1.3 LLM
埋め込みモデルによる意味的検索とリランキングモデルによる洗練されたフィルタリングの後、関連する文書段落はユーザーの元の質問と組み合わされてプロンプトになります。LLMは読解、情報統合、自然言語生成を行い、文脈に合った一貫性のある正確な回答を出力します。
実装レベルでは、RAGでLLMを使用する主な方法が2つあります:
- プライベート展開の大規模モデル。 データプライバシー、制御可能なコスト、または深いカスタマイズを重視するシナリオに適しています。Qwen、Llama、GLMなどの主流のオープンモデルはRAGタスクで良好なパフォーマンスを発揮します。例えば、7Bまたは14Bの範囲のQwen2.5は、リソース使用を控えめに抑えながら良好な指示追従性と中国語理解を提供し、ローカルでのエンタープライズ展開に適しています。KIMI、Minimax、DeepSeekなどのモデルも、具体的なビジネスニーズに応じて検討できます。
- クラウドAPI大規模モデル。 高速なローンチ、弾力的なスケーリング、継続的なモデルアップグレードを優先するシナリオに適しています。OpenAI、Anthropic、Google、Alibaba、ZhipuAIなどの主要プロバイダーがすべて安定したAPIサービスを提供しています。これらのモデルは通常、強力な言語理解と生成能力を持ち、RAGシナリオで回答をうまく統合できます。
クラウドモデルの選択では、いくつかのポイントが重要です:回答品質が正確で流暢かどうか、価格が合理的かどうか、レイテンシが許容範囲かどうか、コンテキストウィンドウが複数の検索文書を収容するのに十分大きいかどうかです。実際には、独自のデータでいくつかの候補を比較し、どれが最も完全で正確な回答を提供するかを確認すべきです。コストが懸念される場合、大小のモデルの組み合わせが有用なアプローチです:簡単な質問にはより安価な小さなモデルを使用し、困難なケースには高価な大きなモデルを確保します。モデルの更新が速いため、定期的に候補を再テストすることも賢明です。
幅広い会話とQA能力については、LMSYS Chatbot Arena(現LMArena)が最も広く認識された評価参考の一つです:
これはブラインドペアワイズの人間の比較を使用してモデルをランク付けします。ランキングは有用な第一次フィルターとして機能しますが、実際のRAG選択では開始点にすぎません。医療、法律、金融などの専門ドメインでは、一般的なリーダーボードランキングとビジネスデータでの実際のパフォーマンスが大きく乖離する可能性があります。
LLM選択のベストプラクティスは、20〜30の典型的なビジネス質問を含む小規模だが代表的なテストセットを構築し、孤立したモデルベンチマークを見るだけでなく、完全なエンドツーエンドのRAGパイプラインを通じて候補モデルを評価することです。推論モデルを使用するか非推論モデルを使用するか、どのモデルサイズが品質と速度のバランスを最も良く取るかといった質問は、すべて自身のユースケースでの実際のテストを通じて最もよく回答されます。
5.2 実行フレームワーク
実際のエンジニアリングプラクティスでは、通常、RAGシステム全体をゼロから構築する必要はありません。多くの成熟したオープンソースフレームワークが既に存在し、それぞれアーキテクチャ、モジュラ統合、開発効率に独自の強みを持っています。企業は自身の技術蓄積とビジネスシナリオに応じて選択できます。
一般的なフレームワークの種類には以下が含まれます:
ローコードまたはビジュアルプラットフォーム
- Dify:直感的なビジュアルインターフェースを提供し、RAGアプリケーションを素早く構築でき、非技術チームや迅速なプロトタイプ検証に適しています。組み込みのマルチモデルアクセス、ワークフローオーケストレーション、プロンプト管理を含みます。
- Coze:ByteDanceのAIボット開発プラットフォームで、ゼロコードのビジュアル構築を提供します。ByteDanceのモデルサービスと深く統合され、プラグインマーケットプレイス、スケジュールタスク、マルチチャネルパブリッシングをサポートし、コンシューマー向けアシスタントやエンタープライズ内部ボットに適しています。
- n8n:オープンソースのノードベースのワークフロー自動化プラットフォーム。RAGシナリオでは、複雑なビジネスロジックをオーケストレーションし、前処理、ベクトルデータベース操作、モデル呼び出し、メール送信やチケット更新などのフォローアップアクションを1つの自動化フローに接続できます。
- RAGFlow:深いレイアウト分析とナレッジ抽出に注力し、複数段組みPDFや表が多い資料などの複雑な文書に良好なパフォーマンスを発揮します。
- FastGPT:中国のオープンソースソリューションで、ナレッジベース管理、対話オーケストレーション、アプリケーションパブリッシングを統合し、強力な中国語ドキュメントと中国語RAGアプリケーションの迅速な展開への適合性を持ちます。
コードフレームワークと開発ライブラリ
以下のツールは通常、異なるバックエンド言語での実装を持っています。アプリケーションスタックに応じて対応する言語版を選択できます。
- LlamaIndex:RAG専用に設計されたPythonフレームワークで、豊富なコネクタ、インデックス構造、クエリエンジンを持ちます。モジュール性により、深くカスタマイズされた検索戦略や多くのデータソースとの統合に適しています。
- LangChain:汎用LLMアプリケーションフレームワークで、RAGはユースケースの一つにすぎません。強みは豊かなエコシステムとコンポーネントカバレッジで、複雑なエージェントやワークフローオーケストレーションのサポートを含みますが、学習曲線はやや急です。
チームの技術蓄積が限られていてスピードが最も重要な場合、Dify、Coze、FastGPTのようなローコードプラットフォームが良い第一選択です。深いカスタマイズ、特別なデータソース統合、または詳細なパフォーマンスチューニングが必要な場合、LlamaIndexとLangChainがより多くの柔軟性を提供します。実際には、ハイブリッドルートも一般的です:ローコードプラットフォームで迅速な実現可能性検証を行い、その後コードフレームワークに移行してプロダクション展開と最適化を行います。これらのフレームワークのほとんどは、上記で議論したモデル選択の原則を使用して、主流の埋め込み、リランキング、LLMモデルとの迅速な統合もサポートしています。
5.3 効果評価
RAGシステムを展開する企業にとって、最大の課題は多くの場合、システムの構築ではなく調整です。プロダクショングレードのRAGには検索と生成という2つの非決定的段階が含まれるため、従来のソフトウェアテストだけでは不十分です。そのため、科学的な評価システム、つまりRAG評価の構築が非常に重要です。
5.3.1 初心者向けの例:LLMベースのRAG評価
RAG評価の直感的な理解を構築するために、LLM-as-a-judgeのアイデアに基づくシンプルな自動パイプラインを見てみましょう:
https://huggingface.co/learn/cookbook/rag_evaluation
プロセスは通常3つの主要なステップを含みます:
- 第一に、ナレッジベースから文書をサンプリングし、LLMに高品質の質問と回答のペアを生成させ、関連性と根拠性でフィルタリングしてベンチマークセットを形成することで、評価データセットを合成します。
- 第二に、そのテストセットの各質問に対してRAGシステムを実行し、生成された回答を収集します。
- 第三に、別のLLMを審判として呼び出して自動採点し、生成された回答と参照回答を比較し、正確性や完全性などの次元について定量的スコアを与えます。
シンプルな例:
- 問題生成。ナレッジベースに「このデバイスはワイヤレス充電をサポートし、5000mAhのバッテリーを搭載している」という製品マニュアルの行があるとします。あるモデルに出題者として機能するよう依頼し、「このデバイスのバッテリー容量は?」のような質問を生成します。標準回答は「5000mAh」です。
- 問題解決。その質問をRAGシステムに送信し、システムが関連資料を検索して回答します(例:「デバイスは5000mAhのバッテリーを搭載しています」)。
- 採点。別のモデルに採点者として機能するよう依頼し、質問、生成された回答、参照回答を比較し、「生成された回答が正しいかどうかを判断してください。正しいか不正確かのみを出力してください」というプロンプトを使用します。
このプロセスを大規模に実行することで、正確性などの指標を計算できます。これは、評価、最適化、再評価の実践的なループを形成します。
RAG評価についてより深い詳細を知りたい場合(指標の定義、フレームワークの使用法、ベンチマークデータセットなど)、2つの有用な調査論文があります:
- https://arxiv.org/pdf/2504.14891, Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey
- https://arxiv.org/pdf/2405.07437, Evaluation of Retrieval-Augmented Generation: A Survey
5.3.2 評価指標
RAG評価は根本的に2つの問いを中心に展開します:検索モジュールは正しい資料を見つけられるかどうか、生成モジュールはその資料から高品質の回答を生成できるかどうかです。これに従い、評価システムは検索評価と生成評価に分けられ、LLM-as-a-judgeのスコアリングが補完します。
検索評価:リコール精度とランク付け品質
検索モジュールはRAGシステムの最初のゲートです。その評価は3つの次元に焦点を当てます:正しいものを見つけられるかどうか、十分に見つけられるかどうか、そして適切にランク付けできるかどうかです。
基本的なリコール品質指標
古典的な基本指標はRecall@K、Precision@K、F1です:
- Recall@Kは、上位K件の結果で回収された関連文書の割合を測定します。5つの関連文書が存在し、上位10件で3つ見つかった場合、Recall@10は60パーセントです。これは検索カバレッジがどれほど広いかを示します。
- Precision@Kは、上位K件の結果のうち実際に関連するものの割合を測定します。上位10件のうち3件が関連し、7件が関連しない場合、Precision@10は30パーセントです。これは検索精度を反映します。
- F1はRecallとPrecisionの調和平均で、両者のバランスを取ります。
これらの指標は、ベースラインのリコール問題を迅速に診断するのに有用です。Recallが低い場合、関連文書が見つかっていません。Precisionが低い場合、検索ノイズが高すぎます。
ランク付け品質指標
関連文書を見つけることは最初のステップにすぎません。さらに重要なのは、最も関連するものを前面に配置することです。そのためにMRR、NDCG@K、MAPを見ます:
- MRR(Mean Reciprocal Rank)は、最初の関連文書のランク位置の逆数を測定します。最初の関連文書が位置3に現れた場合、逆数ランクは1/3です。MRRは正解が1つで十分なシナリオに特に適しています。
- NDCG@K(Normalized Discounted Cumulative Gain)は、段階的な関連性と位置割引の両方を考慮します。文書が関連しているかどうかだけでなく、どの程度関連しているかを問い、早く現れる高関連文書に報酬を与えます。
- MAP(Mean Average Precision)は、すべての関連文書の位置に敏感で、全体的なランク付け品質を反映します。
実際のエンジニアリングでは、Recall@K + MRR@Kが一般的な組み合わせです。例えば、Recall@10が80パーセントなのにMRR@10がわずか0.3の場合、関連文書は見つかっているが深く埋もれており、リランキングの改善が必要であることを示唆しています。
必要に応じて、ナレッジベースのカバレッジを監視し、体系的なブラインドスポットを明らかにするためのCoverage指標を追加することもできます。
生成品質評価:正確性と事実への忠実性
検索が原材料を提供します。次の問題は、生成モジュールがその原材料から高品質の回答を生成できるかどうかです。ここでのコアとなる次元は、回答の正確性と検索された証拠への忠実性です。
完全一致とテキスト類似度
最もシンプルな指標はEM(Exact Match)で、生成された回答が参照回答と正確に一致することを要求します。これは、日付や本社の場所など、固定形式で一意に正しい事実質問に適していますが、異なる表現であっても同様に正しい回答がマッチしない可能性があるため、厳しすぎます。
そのため、ROUGE、BLEU、METEORなどのn-gramオーバーラップ指標も一般的に使用されます。これらは参照回答との単語のオーバーラップを比較して生成された回答をスコアリングします。ROUGE-Lは最長共通部分列に注目し、BLEUは機械翻訳に由来し正確性を強調し、METEORは同義語と語幹の考慮を追加します。
純粋な単語オーバーラップの限界を克服するために、BERTScoreや直接的なベクトル類似度を使用することもできます。これらは事前学習された意味表現を使用するため、表面的な変動をより許容します。
事実への忠実性とハルシネーション検出
RAGシステムでは、回答と参照の類似性だけでは不十分です。さらに重要な問題は、回答が実際に検索された文書に基づいているのか、それとも裏付けのないコンテンツをハルシネーションしているのかです。
そのため、ハルシネーション率と忠実性のような指標が重要です。第二のLLMが事実確認者として機能し、生成された回答を文ごとに検査し、各主張が検索された文書によってサポートできるかどうかを判断します。医療、法律、金融などの高リスクドメインでは、このタイプの指標が特に重要であり、一部の企業はハルシネーション閾値をプロダクションリリース基準として施行しています。
LLM-as-a-Judge:多次元スコアリング
すべての自動指標には限界があります。ほとんどの表面形式の指標は、意味的品質や全体的な有用性を完全に捉えることができません。そこでLLM-as-a-judgeが特に価値を持ちます。
基本的なアプローチは、質問、検索された文書、システムの回答、参照回答を強力な独立モデル(GPT-4やClaudeなど)に入力し、以下の次元でスコアリングを依頼します:
- 質問への関連性
- 情報の完全性
- 事実への忠実性
- 全体的な正確性
LLM審判の強みは、人間に近い総合的判断ができることです。もちろん、審判プロンプトは依然として慎重な設計と人間のラベル付き例に対するキャリブレーションが必要で、スコアリングの一貫性と信頼性を保ちます。
実践的な指標の組み合わせの構築
多くの指標が利用可能な中、チームはどれを使用すべきか迷うことがよくあります。実践的な推奨は、コンパクトな組み合わせから始めて段階的に拡大することです:
- 検索については、Recall@K + MRR@Kから始める
- 生成については、タスクタイプに応じてEM、ROUGE-L、BERTScoreから1〜2つのベースライン指標を選ぶ
- 全体評価については、関連性、完全性、忠実性に焦点を当てたLLM審判を導入する
その後、評価、問題診断、戦略調整、再評価のループを繰り返します。
5.3.3 評価フレームワーク
RAGの急速な発展に伴い、学術界と産業界の双方から多くの強力な評価フレームワークが生み出されています。これらのフレームワークは一般的な指標をパッケージ化するだけでなく、標準化されたデータセット、ベンチマーク手順、エンドツーエンドのワークフローも提供します。
フレームワークの基本的な分類
RAG評価フレームワークは大まかに3つのカテゴリに分けられます:
- 研究フレームワーク:学術的探求ときめ細かい診断に焦点。例:FiD-Light、Diversity Reranker。
- ベンチマークフレームワーク:システムを横断的に比較するための標準化されたテストセットとワークフローを提供。RAGAS、ARES、RGB、MultiHop-RAG、CRUD-RAGなどが含まれます。
- ツールフレームワーク:エンジニアリングの使いやすさと開発フレームワークとの統合を強調。例:TruEra RAG Triad、LangChain Benchmarks、RECALL。
近年、評価フレームワークはより専門化しています。例えば、医療にはMedRAG、法律にはLegalBench-RAG、金融には独自のドメイン特化フレームワークがあります。これらのドメインフレームワークは通常、専門的なデータセットだけでなく、医療正確性や法的引用関連性などの専門的な指標も提供します。
実際には、良い経験則は以下の通りです:
- ベースラインを素早く必要とする場合、RAGASのようなより汎用的なフレームワークから始める。
- 特定の問題を診断する場合、よりターゲットを絞ったフレームワークを選ぶ。
- 医療、法律、金融、またはその他の専門ドメインにいる場合、可能であればドメイン適応フレームワークを優先する。
- 強力なドキュメントとレスポンシブなコミュニティを持つ、アクティブにメンテナンスされているツールを優先する。
コミュニティでよく推奨されるツールには、Ragas、Continuous Eval、TruLens-Eval、LlamaIndex内の評価機能、Phoenix、DeepEval、LangSmith、OpenAI Evalsがあります。
5.3.4 評価ベンチマーク
評価ベンチマークの重要性は過小評価されることがよくあります。多くのチームは少数の手書きのテスト問題のみでRAGシステムの評価を始め、その後、実際のオンラインパフォーマンスがオフラインの印象と大きく異なることに気づきます。根本的な原因は、代表的で体系的な評価データが不足していることです。
システムの反復をよくサポートするベンチマークは通常、3つのコア特性を持ちます:
- 代表性:高頻度のユーザー質問、境界ケース、異常入力をカバーしていること
- 標準化:質問と回答の形式、難易度レベル、採点ルールが一貫していること
- 進化性:システム能力とビジネスニーズの進化に伴いベンチマークが更新できること
ほとんどの企業にとって、ビジネスシナリオが固有であるため、最終的な回答は通常、独自の評価データセットを構築することです。
- ビジネスログから実際のユーザー質問を抽出し、タイプ、頻度、難易度でサンプリングする。
- 単純なケースについては、ドメイン専門家に直接アノテーションさせる。より複雑な質問については、強力なLLMに候補回答を生成させ、専門家に改訂させる。
- 回答自体に加えて、関連文書、回答タイプ、難易度レベルなどのメタデータもラベル付けする。
- オンラインで発見された新しい困難なケースでデータセットを定期的に更新する。
リソースが限られており、迅速なベースラインが必要な場合、公開ベンチマークは依然として有用な開始点です。2025年現在、汎用および垂直シナリオの両方について多くの公開ベンチマークが存在します:
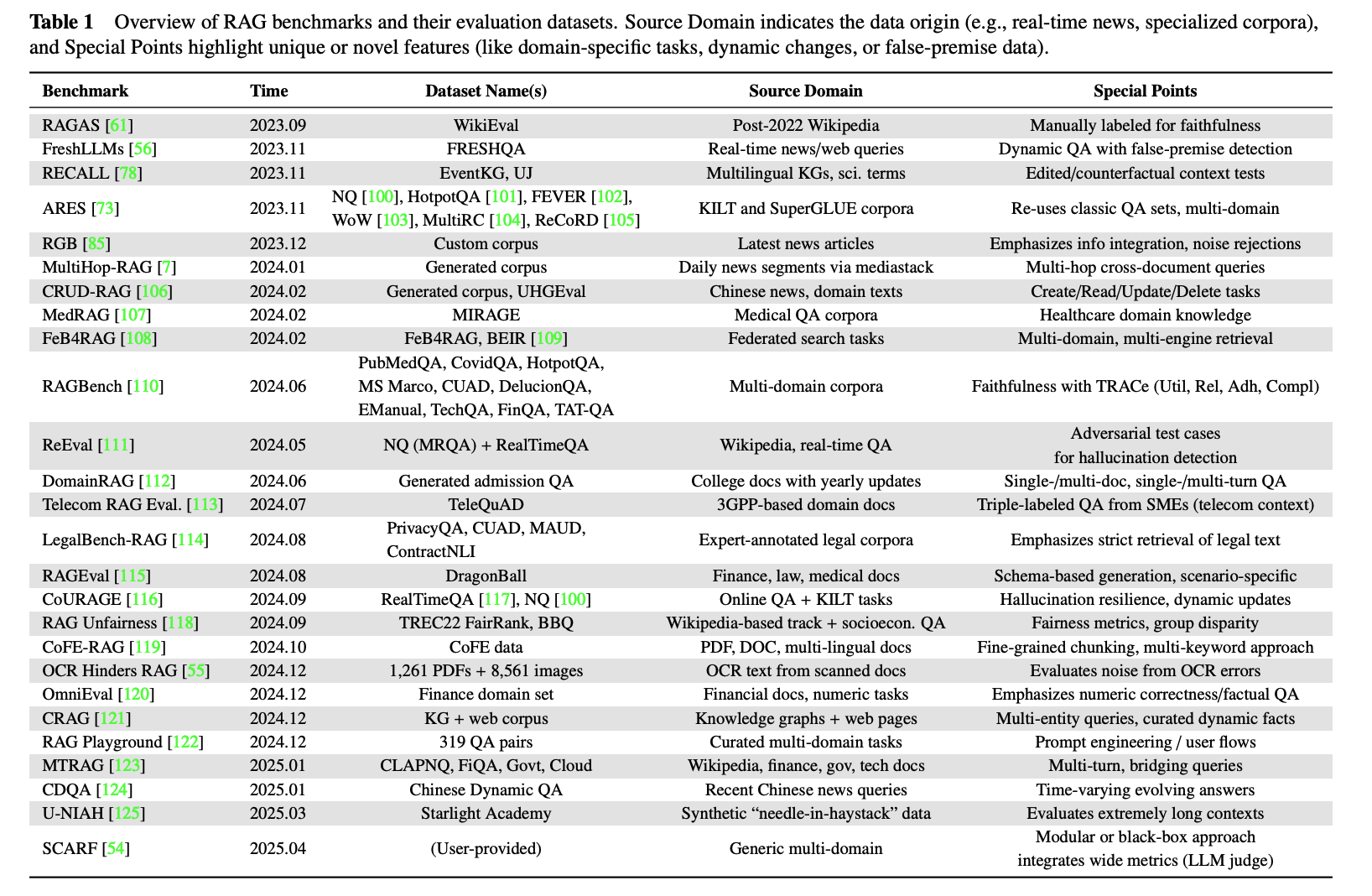
選択する際は、まず目標を明確にします。ベースラインを確立したいのか、それともローンチ前にシステムを検証したいのか。その後、ベンチマークが関心のあるシナリオと難易度プロファイルをカバーしているかを確認します。ニュースや金融などの時間に敏感なドメインでは、ベンチマークに時間に敏感なテストが含まれていることを確認してください。
実際には、独自のドメイン内データセットと公開ベンチマークを組み合わせることが、最も堅牢なアプローチであることが多いです。これは、評価を実際のビジネスニーズに近づけながら、ある程度の横断的な比較可能性も保持するからです。
6. ディープダイブ:コンペティションとオープンチュートリアルから学ぶ(オプション)
上記の原理とベースラインの実装は、使用可能なプロトタイプを構築するのに十分ですが、プロダクションで現れるより困難な問題を解決するにはまだ距離があります。より実践的で実戦でテストされたRAG技術を理解したい場合、最も効率的な方法の一つは、コンペティションの優勝ソリューションと強力なオープンチュートリアルを学ぶことです。これらのソリューションは、強力なチームが実際のシナリオで繰り返し試行した後に発見したベストプラクティスを集中して含んでいます。
以下の例は、包括的ではなく代表的なものです。実際に特定の問題(PDF解析、マルチモーダル検索、低レイテンシ最適化など)に遭遇した場合、その問題に関連するコンペティションを検索し、優勝チームの技術レポートとオープンコードを研究することが効果的な場合がよくあります。
6.1 Semantic Cache:高頻度クエリの最適化
Hugging Faceは、Chromaベクトルデータベース上に構築されたセマンティックキャッシュの実装を提供しています:
https://huggingface.co/learn/cookbook/semantic_cache_chroma_vector_database
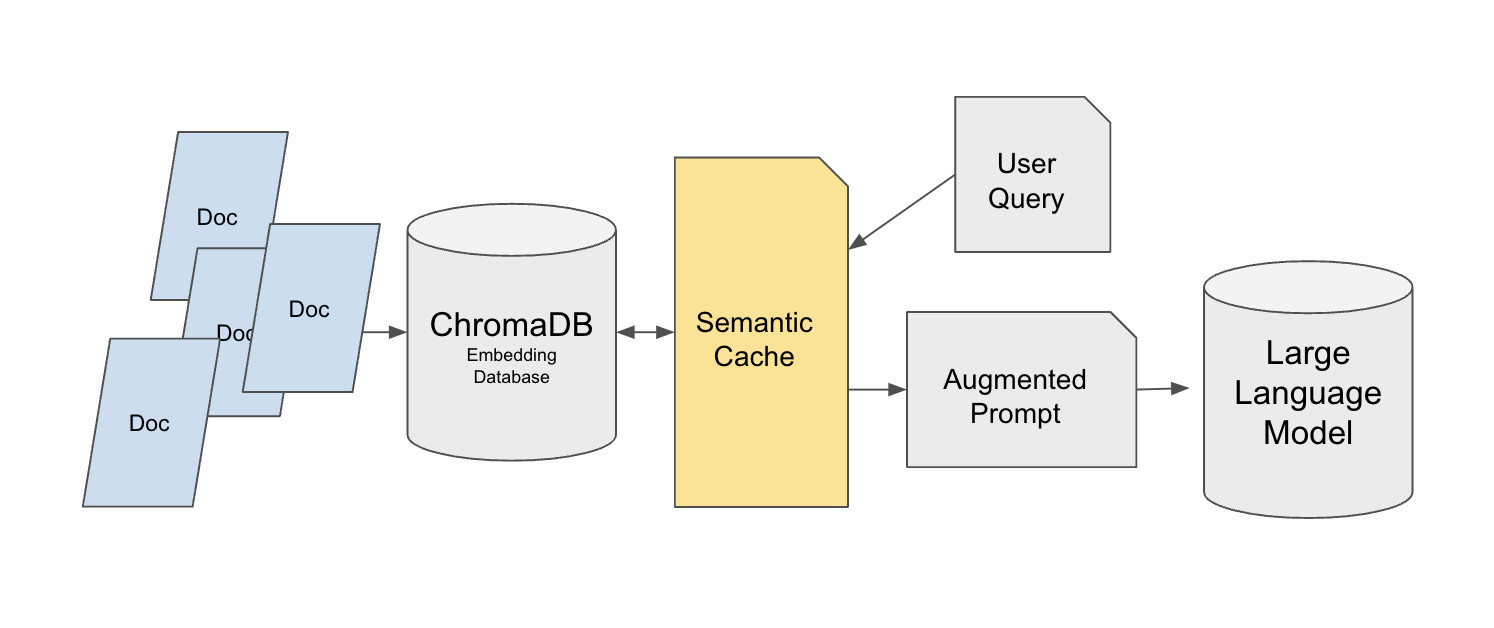
背景:ほとんどのチュートリアルRAGシステムは単一ユーザーのテスト用に構築されています。しかしプロダクションに展開されると、システムは数十または数千の繰り返しクエリを受ける可能性があります(例:サポートユーザーが繰り返し返金手続きについて質問する)。すべての繰り返しクエリがベクトル検索とLLM呼び出しをトリガーすると、レイテンシとコストが急速に上昇します。セマンティックキャッシュ層により、回答品質を維持しながら元のデータソースへの負荷を大幅に削減できます。
この設計は2層検索アーキテクチャを使用しています。ベース層はChromaに元のナレッジベースを保存し、MedQuadのようなデータセットを使用し、各エントリに正確な参照のための固有IDを割り当てます。キャッシュ層はFAISSを使用しFlatL2インデックスで構築されます。セマンティックキャッシュはユーザークエリとChromaの間に位置し、LLMの最終回答を直接キャッシュするわけではありません。この設計が重要なのは、回答を直接キャッシュすると、「簡単な言葉で説明して」のようなパーソナライズされた回答要件を破壊する可能性があるためです。
キャッシュシステムはSentenceTransformer all-mpnet-base-v2を使用してクエリベクトルを生成し、ユークリッド距離(閾値0.35)を使用してクエリが類似しているかどうかを判断します。キャッシュがいっぱいになった場合(max_responseパラメータで制御)、最も古いエントリがFIFOで削除されます。キャッシュデータはJSONファイルに保存してセッション間での再利用も可能です。
小規模テストでは、「ワクチンはどうやって機能しますか?」のような最初のクエリはChromaから取得するのに0.057秒かかりましたが、キャッシュから提供された類似クエリはわずか0.016秒でした。大規模なプロダクションシナリオでは、このアプローチは高反復環境で90〜95パーセントのパフォーマンス最適化を生み出し、ベクトルストアとAPIコストを大幅に削減できます。
6.2 非構造化データ処理:マルチフォーマット文書の統一解析
別のHugging Faceチュートリアルでは、Unstructuredライブラリを使用して非構造化文書処理のフルパイプラインを構築する方法を示しています:
https://huggingface.co/learn/cookbook/rag_with_unstructured_data

背景:エンタープライズシナリオでは、知識はPDF、PowerPoint、EPUB、HTMLページなど多くのフォーマットに散在しています。従来の前処理方法は、単一フォーマットのみをサポートするか、変換中に表やタイトル階層のような重要な構造情報を失います。これによりRAGシステムがコンテンツを正しく理解・検索することが困難になります。
このソリューションはまず、多くの表を含むカナダの農薬ハンドブックPDFや、チャートと多レベル見出しを含むフロリダ大学の柑橘類IPM PowerPointファイルなど、マルチフォーマットのテスト文書をダウンロードします。その後、UnstructuredのLocal Runnerを使用して解析を行います。設定にはプロセッサ設定、APIパーティションモードをオプションで使用できるパーティション設定、入力パスを定義するローカル設定が含まれます。解析された文書は、本文、タイトル、表などの型付き要素を含むJSONに変換されます。
システムはその後chunk_by_titleを使用し、最大長を512文字に設定し、200文字未満の連続フラグメントをマージして意味的一貫性を保持します。LangChain Documentオブジェクトへの変換中、複雑なメタデータフィールドがChromaに適合するようにフィルタリングされます。ベクトル段階ではBAAI/bge-base-en-v1.5埋め込みモデルを使用し、4ビット量子化されたLlama-3-8B-InstructとLangChain RetrievalQAチェーンと共に完全なRAGシステムを構築します。
結果として得られるシステムは、マルチフォーマット文書を正確に処理できます。「アブラムシは害虫ですか?」のような質問に対して、解析された文書から重要な事実を抽出し、関連資料に基づいて回答を生成できます。これは多くの文書タイプを処理する必要があるエンタープライズナレッジベースに特に有用です。
6.3 エンタープライズ文書QA:高精度でトレース可能なRAG
Enterprise RAG Challengeの優勝ソリューションは、厳格な時間と精度要件の下でプロダクショングレードのRAGシステムを構築する方法を示しています:
- https://abdullin.com/ilya/how-to-build-best-rag/
- https://hustyichi.github.io/2025/07/03/rag-complete/
背景:参加者は2.5時間で100の実際のエンタープライズ年次報告書PDFを解析する必要がありました。各報告書は最大1000ページで、複雑な財務表、多段レイアウト、チャートが含まれていました。解析後、システムは100の正確なビジネス質問に、明示的な回答タイプ(yes-no、会社名、正確な数値指標、役員名など)で回答し、証拠としてページ番号を引用する必要がありました。
優勝チームは、複雑な表と多段テキストで最も良いパフォーマンスを発揮したため、IBMのオープンソースDoclingをPDFパーサーとして選択しました。彼らはDoclingコードを改善し、メタデータ付きのJSONとMarkdown-plus-HTMLを出力できるようにし、特に表解析を改善しました。処理を高速化するため、RTX 4090 GPUをレンタルし、100報告書の解析を40分で完了しました。
テキストチャンキングは、意味的一貫性を保持するために50トークンのオーバーラップを持つ300トークンのチャンクと再帰的分割を使用しました。会社間のクロスコンタミネーションを避けるため、各会社はIndexFlatIPインデックスを使用する独自のFAISSベクトルストアを持ちました。検索は3つの段階に従いました:ベクトルでTop-30チャンクを検索し、複数のチャンクが同じページから来ている可能性があるため親ページで重複排除し、GPT-4o-miniでページをリランキングしました。最終ランク付けはベクトル検索とLLMリランキングスコアを0.3対0.7の重み付けで混ぜ合わせました。
生成では、異なる回答タイプに異なるプロンプトテンプレートを使用しました。数値の質問(年間収入など)では、指標マッチング、単位の一貫性、クロスチェックを確実にするために5ステップの分析プロセスを使用しました。出力はトレーサビリティのために分析プロセスとページ参照を含むように構造化されました。
システムは2つの賞を受賞し、リーダーボードで1位になりました。重要な観察として、Llama 8Bのようなより小さなモデルでさえ参加者の80パーセント以上を上回り、Llama 3.3 70BはGPT-4o-miniに近いパフォーマンスを示しました。これは、良いシステム設計が精度、効率、コストのバランスを取れることを示しています。
6.4 AIOpsシナリオ:テキストと画像の混在データのインテリジェント処理
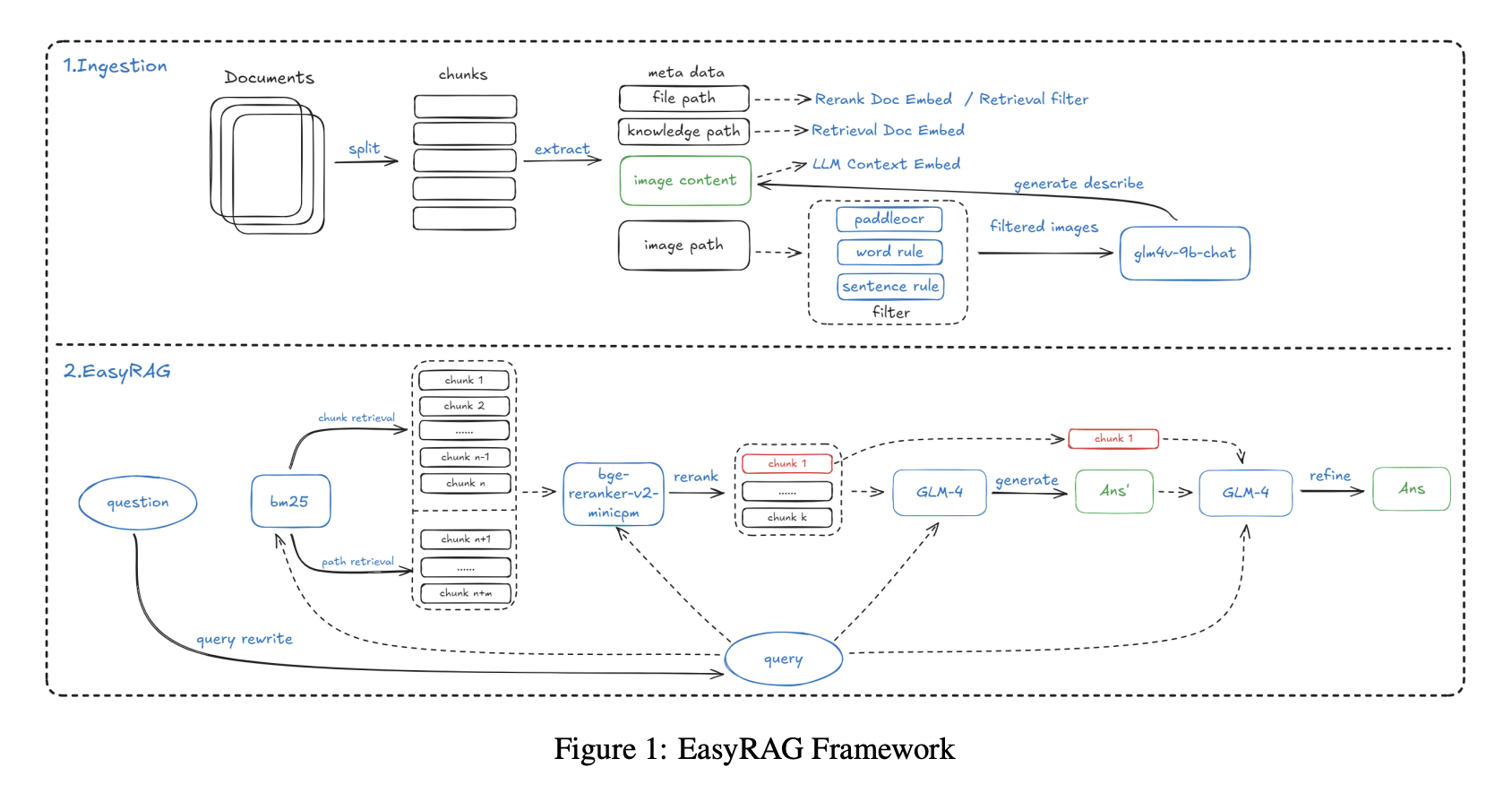
AIOps RAGコンペティションのEasyRAGプロジェクトは、運用シナリオでのQAに焦点を当てました:
http://blog.csdn.net/hustyichi/article/details/143323746
背景:運用エンジニアは多くの場合、テキストだけでなく監視チャート、システムアーキテクチャ図、パフォーマンス曲線を含む技術文書を読む必要があります。例えば、システム問題の診断時、「CPU使用率が80パーセントを超えたらどうすべきか?」の回答は、テキスト記述と監視グラフの間に散在している場合があります。従来のテキストのみのRAGはチャートの傾向と値を理解できないため、回答は不完全になります。
インデックス構築段階では、1024トークンのチャンクと200トークンのオーバーラップを持つ改善されたSentenceSplitterを使用しました。重要なイノベーションは、各チャンクにナレッジベースパスやファイルパスなどのメタデータを追加したことで、リコールが2パーセント向上しました。画像データについては、まずPaddleOCRを使用してチャートやスクリーンショットからテキストを抽出し、次にマルチモーダルモデルGLM-4V-9Bを使用して画像の自然言語記述を生成しました(例:午後にCPU使用率が90パーセントでピークに達するラインを記述する)。OCRテキストと画像記述の両方が一緒にインデックス化されました。
検索では広いリコールのためにBM25 + ベクトルの2パス戦略を使用しました。BM25はチャンク検索とパス検索をカバーし、ファイルパスで無関係な文書をフィルタリングし、ベクトル検索はgte-Qwen2-7B-instructを使用しました。リランキングはbge-reranker-v2-minicpm-layerwiseを使用し、28層の設定が実験で最も良いパフォーマンスを示しました。
回答生成では2ステップ戦略を使用しました:まずTop-6文書からドラフトを生成して情報カバレッジを最大化し、次にTop-1の最も関連する文書で回答を最適化してコア回答を強調しました。
長いテキストシナリオ(数百ページの完全な運用マニュアルなど)を処理するため、システムはBM25ベースのコンテキスト圧縮も実装しました。文書を文に分割し、クエリとの文の類似度をスコアリングし、最も関連する文のみを連結します。50パーセントの圧縮率で、この方法はわずか7.7秒で86.48パーセントの精度を達成し、LLMLinguaなどのツールを上回りました。
6.5 マルチソースデータ融合:構造化と非構造化知識の連携
KDD Cup 2024 Meta RAGチャレンジの優勝ソリューションは、非構造化ウェブコンテンツと構造化ナレッジグラフを統合する方法を示しました:
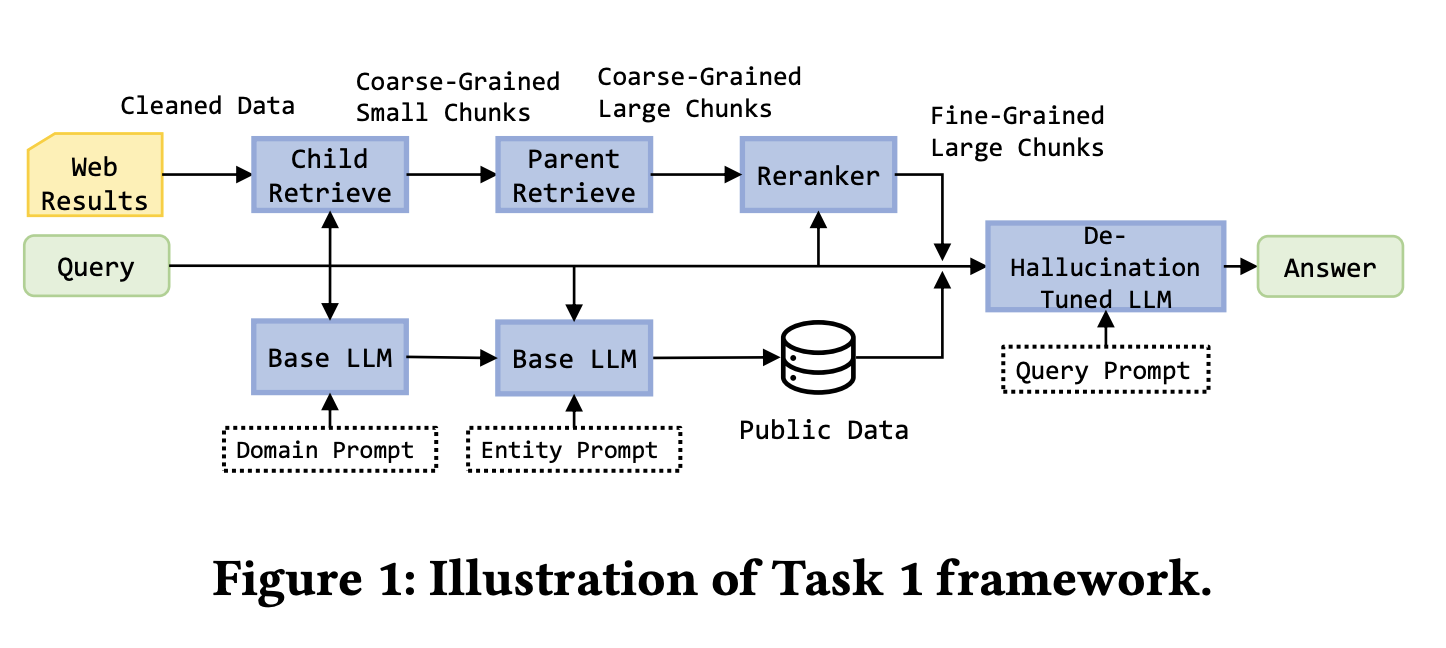
背景:タスク1では5つのウェブページからの検索要約が求められました。タスク2では構造化ナレッジグラフを表すモックAPIが追加され、映画データベースやエンティティ関係への直接アクセスが可能になりました。タスク3では、50のウェブページとモックAPIを使用してより複雑なクエリ(興行収入が5億ドルを超えるノーラン監督映画の特定など)に回答することで難易度が上がりました。各クエリは30秒以内に完了する必要がありました。
タスク1では、優勝チームは洗練されたウェブ処理パイプラインを構築しました。BeautifulSoupを使用してページテキストを抽出し、ParentDocumentRetrieverで親子チャンクの関係を管理し、検索に200トークンの子チャンク、生成に500〜2000トークンの親チャンクを使用しました。埋め込みモデルはbge-base-en-v1.5、ベクトルストアはChroma、リランキングはbge-reranker-v2-m3を使用しました。チームは公開データセットからの映画や金融データも補足し、無効な質問と参照回答を含む学習データでLlama-3-8B-instructをLoRAでファインチューニングしました。
タスク2と3では、重要なイノベーションはナレッジグラフの優先でした。システムはget_personやget_movieのような標準化されたAPI呼び出しを定義し、フィルタリングとソートをサポートしました。最初にナレッジグラフAPIを呼び出し、グラフの結果が欠落または無効な場合にのみウェブ検索にフォールバックしました。これにより速度と回答精度の両方が向上しました。
システムがナレッジグラフを優先し、構造化された出力フォーマットを使用したため、ハルシネーションが明確に削減されました。グラフが決定的な回答を直接提供できる場合、システムは生成ステップなしで返しました。ウェブ検索が必要な場合、回答は厳格な引用と段階的推論ルールに従う必要がありました。
ソリューションは3つのタスクすべてで1位を獲得しました。主な教訓は、構造化と非構造化データの両方を含むエンタープライズシナリオでは、データタイプに応じて検索戦略を設計すべきであることです:決定論的な構造化データを最初に使用し、非構造化ソースを補完として扱います。
これらの実践的なケースを通じて、いくつかの共通の原則が繰り返し現れます:
- ビジネスシナリオに応じてキャッシュ、検索、生成戦略を選択する
- 異なるフォーマットとモダリティに専用の解析とインデックスパスを設計する
- ハイブリッド検索 + リランキングを標準構成として扱う
- タスク固有のプロンプティングと構造化出力を使用して精度とトレーサビリティを向上させる
これらの実際のコンペティションとオープンプロジェクトからの教訓は、より強力なエンタープライズRAGシステムを構築する際の貴重な参考になります。
7. 広範な探求:RAGの将来の進化(オプション)
RAGの実践的なスキルと最適化手法を学んだ後、具体的なシナリオでのシステムパフォーマンスを向上させることができます。しかし、局所的なエンジニアリングのテクニックだけを理解するのでは、RAGがどこに向かっているのかについてのより広い把握を持つには不十分です。より広範な進化の方向も見る必要があります。
RAGは現在、従来のテキストチャンクを検索してから生成するパターンを急速に打ち破っています。このセクションでは、いくつかのパスに焦点を当てます:チャンク検索からグラフ構造検索への移行、画像と音声をマルチモーダルRAGに組み込むこと、ベクトル化されたLate Chunkingによる長文書処理の改善、そしてRAGがエージェント指向システムへと徐々に進化している方法です。
7.1 Graph RAG:関係ネットワークで深い検索を再構築する
関連研究:
従来のRAGは、質問に類似したテキスト段落を見つけることで機能します。これは資料の山から最も関連性が高そうな数段落を拾い出すようなものです。これは直接の事実検索にはうまく機能します。しかし、複数の文書を接続し、異なる手がかりを組み合わせる必要がある質問では、パフォーマンスが低下します。
例えば、医師が「これらの症例と最新の治療ガイドラインに基づいて、高齢患者に対するある薬の利益とリスクをどのように評価すべきか?」と尋ねるかもしれません。またはプロジェクトチームが「過去2年間の要件文書、レビュー記録、オンラインインシデントレポートを見渡して、システムアーキテクチャのどの部分が最も頻繁に故障しているか?」と尋ねるかもしれません。このような質問は単一の文を見つけることではありません。複数の資料に散在する人、物、出来事、関係を特定し、完全な像を形成することが求められます。
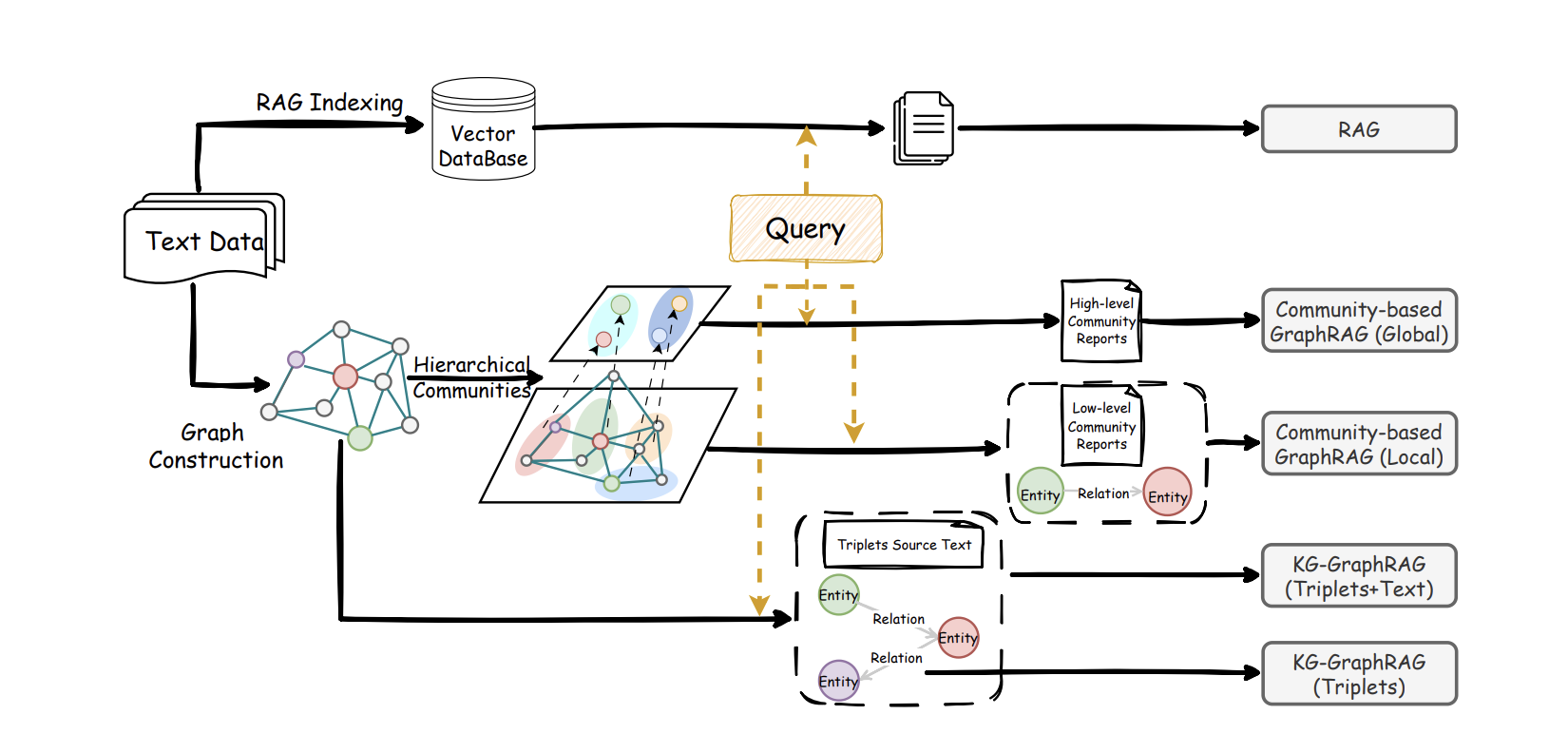
Graph RAGはその像を積極的に構築します。システムは大規模モデルを使用してテキストから主要なエンティティ(人、組織、機能モジュール、出来事、データなど)とその関係(因果関係、依存関係、変更、矛盾など)を特定します。その後、より多くの資料が追加されるにつれて成長するナレッジネットワークを構築します。自動グループ化を通じて、密接に関連するエンティティと関係がテーマに編成され、各テーマは事前に要約できます。ユーザーが質問すると、システムはもはや類似して見えるテキスト段落のみを検索しません。まず最も関連するエンティティとローカルグラフ構造を見つけ、関連するトピックグループを通じて拡張し、分析パス、ノード記述、ソース段落を一緒にLLMに与えて推論させます。
このフレームワークの下で、Graph RAGと従来のRAGは相互に補完します。従来のRAGは、ワンステップで回答が見つかる詳細な質問に依然として強いです。Graph RAGは人間の研究者の思考に近いです:まず全体構造とテーマを整理し、次に証拠を埋め、最後に論理と条件を伴う結論を生成します。既存の比較では、マルチホップ推論タスクにおいて、Graph RAGは多くの場合、より多くの重要なコンテンツをカバーし、より広い視点を提供することが示されています。2つのアプローチの柔軟な組み合わせは、1つのみを使用するよりも優れていることが多いです。
7.2 マルチモーダルRAG
関連研究:
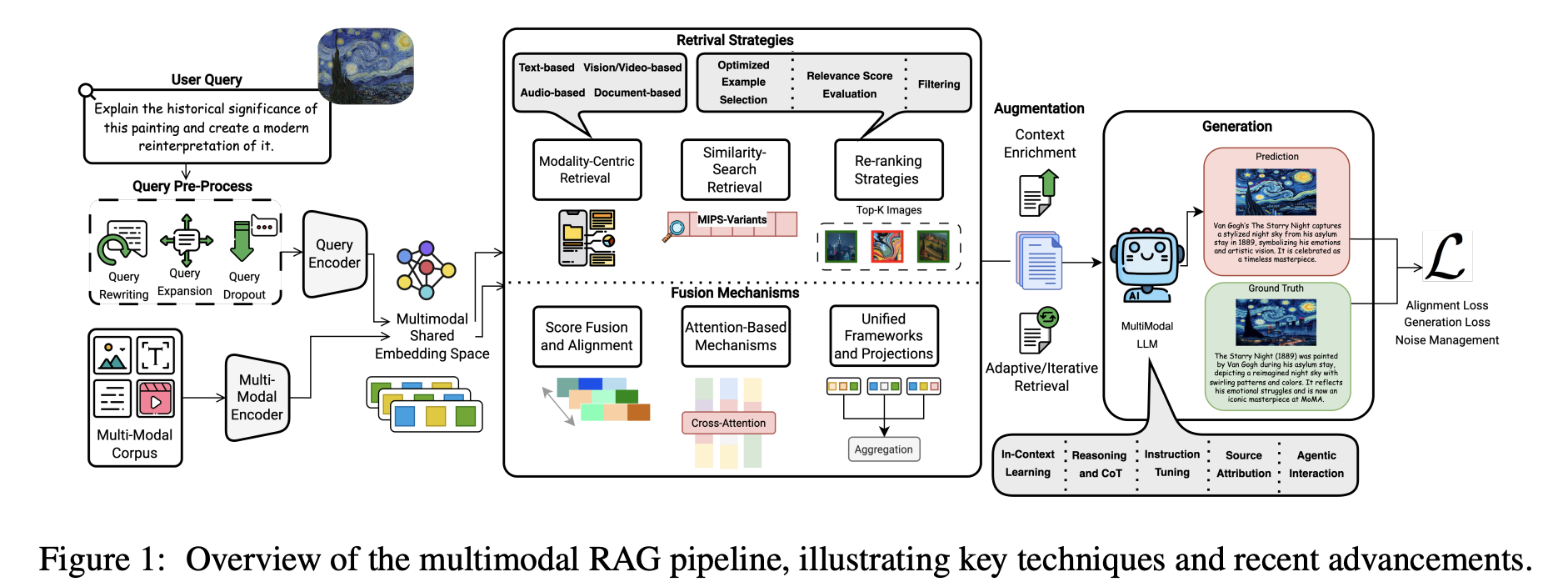
現実のデータは決してテキストだけではありません。サーバー障害を診断するエンジニアは、温度曲線、デバイスのスクリーンショット、ログを同時に見る必要があります。診断を行う医師は、CTやMRI画像、検査レポート、電子カルテを同時に必要とします。従来のテキストRAGはせいぜい「温度異常」や「肺結節の疑い」のようなフレーズを検索できますが、それらの記述を実際のチャートの傾向や画像の病変形状に関連付けることは困難であり、画像、音声、動画から文書や知識を逆検索することもできません。
マルチモーダルRAGは、この異なるモダリティが互いに「見る」ことができない問題を解決します。その核心はクロスモーダルな意味アライメントです。システムは、画像、動画、音声、テキストに適したエンコーダーをOCR、ASR、レイアウト分析と共に使用し、視覚および音声ソースから重要な情報を抽出し、異なるモダリティを統一されたマルチモーダルインデックスを構築できる共有意味空間にマッピングします。
検索と生成の際、ユーザーが2023年Q3の売上ピークを示すチャートを尋ねる場合でも、スケッチや操作動画をアップロードする場合でも、システムはまず統一空間で最も近いマルチモーダル証拠を見つけ、テキスト類似度や画像類似度などの信号でフィルタリングし、最も有用な部分を保持し、画像、テキスト段落、表を一緒にマルチモーダルLLMに与えます。モデルはモダリティをまたいで証拠を組み合わせて回答し、理想的には情報源を示したり、画像や文書の関連領域をハイライトしたりできます。
テキストのみのRAGと比較して、マルチモーダルRAGはより多くの種類の証拠を使用でき、ハルシネーションを減らしながらより完全で検証可能な回答を生成することが多いです。
7.3 Late Chunking:長文書の完全なコンテキストを保持
関連紹介:
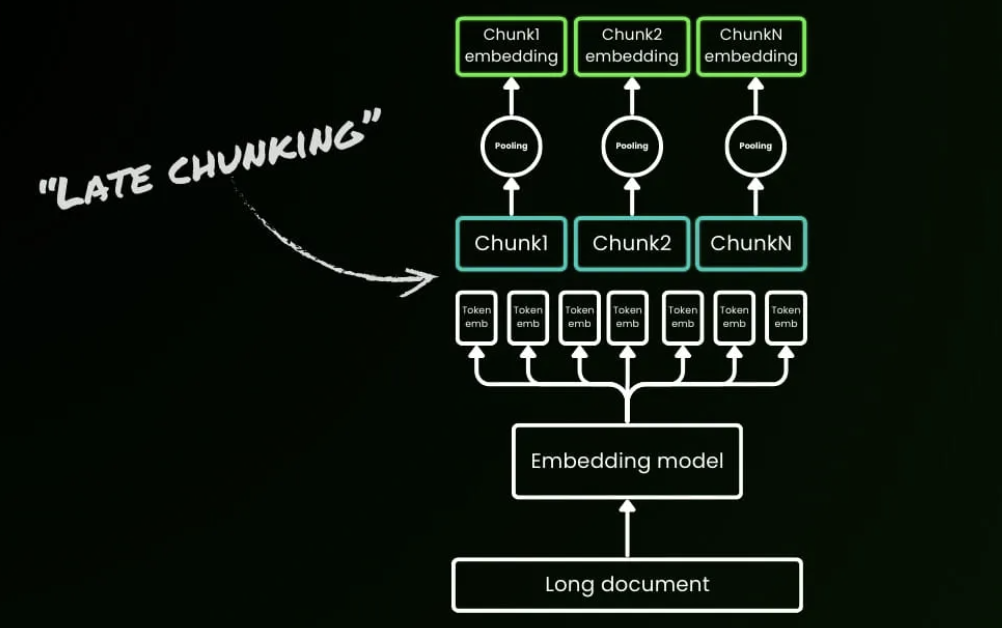
ベルリンに関するWikipediaの記事を読むことを想像してください。従来のRAGはまずそれを独立した段落に切り、次に各チャンクを埋め込みます。最初の文が「ベルリンはドイツの首都です」と言っている場合、「その都市」や「その人口」という後のフレーズは、切り離されるとベルリンとの関連を失います。そのため「ベルリンの人口は?」というクエリは、ベルリンという用語と人口情報が同じチャンク内に現れなかったため、失敗する可能性があります。この問題は長い文書ではさらに悪化します。200ページの保険契約では、免責額の定義が5ページ目にあり、適用条件が30ページ目にある場合があります。固定長のチャンキングはこれらの関連部分を数十の孤立したチャンクに分割する可能性があり、実験ではこの場合、意味的類似度が急激に崩壊することが示されています。
Late Chunkingは従来の「チャンクしてから埋め込む」パイプラインを覆し、代わりに「埋め込んでからチャンクする」に従います。8192トークンのような長いコンテキストを処理できる埋め込みモデルでは、文書全体が最初にTransformerを通じて渡され、文書全体を見たトークンレベルの埋め込みが生成されます。その後、それらのグローバルに情報を得たトークン埋め込みのみが、チャンク境界に従ってチャンク埋め込みにプールされます。結果として得られるチャンクはもはや独立した島ではありません。それらは段落間の参照や概念の関係を保持する、コンテキスト依存の埋め込みです。
BEIRベンチマークデータセットでは、Late Chunkingは広く従来のチャンキングを上回り、特に長い文書で強い成果を示しています。短いテキストのシナリオでは差はほぼ消失し、これは重要なルールを確認しています:文書が長いほど、Late Chunkingの利点が大きくなります。この方法は現在Jina Embeddings v3に統合されています。長い文書全体を最初にエンコードすることで推論時間が10〜20パーセント増加する可能性がありますが、医療記録、法的文書、技術マニュアルなどのシナリオでの検索の利益は、そのコストを容易に正当化できます。
Late Chunkingは、これらのシナリオでは8K以上の長いコンテキスト埋め込みモデルがオーバーエンジニアリングではなく、高品質のチャンク埋め込みを生成するために必要であることを示しています。そして「チャンクしてから埋め込む」から「埋め込んでからチャンクする」への移行を象徴しています。
7.4 RAGからエージェント時代のRAGへ
関連議論:
- https://ragflow.io/blog/rag-at-the-crossroads-mid-2025-reflections-on-ai-evolution
- https://arxiv.org/pdf/2501.09136
- https://www.letta.com/blog/rag-vs-agent-memory
- https://www.linkedin.com/posts/richmondalake_100daysofagentmemory-rag-memorizz-activity-7348281860843577346-LM7Y/
- https://www.llamaindex.ai/blog/rag-is-dead-long-live-agentic-retrieval
RAGは検索拡張生成ツールから、エージェントの認知アーキテクチャの重要な部分へと発展しました。従来のRAGはシンプルな「質問、検索、回答」パターンで構築され、根本的に受動的です。クエリを待ち、能動的に行動しません。この受動性を突破し、より複雑な認知タスクを処理するために、RAGはエージェント能力と深く組み合わされ、Agentic RAGという新しいパラダイムが生まれました。
このパラダイムの下で、RAGの役割は根本的に変化します。それはもはや外部知識の受動的な提供者ではありません。代わりに、エージェントの能動的な計画、目標方向付け、自己反省の下でインテリジェントな動作をサポートするコア処理ユニットになります。この融合は、システム全体に目標方向性、反復的最適化、自律的意思決定を与え、人間とAIの相互作用の品質を大幅に深めます。Agentic RAGは複雑なタスクを理解し、それらを分解し、検索戦略を計画し、初期結果の品質を評価して、より深い探求が必要かどうかを決定できます。
この能力の鍵は、多層の能動的ループです。複雑なクエリに直面すると、エージェントはまず問題の性質を分析し、それをサブ問題に分解し、各サブ問題に対して正確な検索戦略を設計します。初期結果を受け取った後、それらを評価し、情報が完全で関連しているかどうかを判断し、知識ギャップを特定し、より正確な新しいクエリを動的に生成します。この反復プロセスは多くの場合マルチホップ検索を含み、1回の結果が次の回の新しい方向を明らかにし、人間の研究者が働く方法に似た知識探索チェーンを生成します。
この継続的、反復的なインテリジェントな動作をサポートするため、特にパーソナライゼーションと長期的な知識蓄積が重要な場合、短期の会話コンテキストだけでは到底不十分です。これが長期的で構造化されたメモリの必要性につながります。
これこそまさに、RAGがエージェントの長期メモリシステムとしての役割をますます割り当てられ、完全な外部メモリアーキテクチャの構築に使用されている理由です。この長期メモリは、現在の対話コンテキストの維持を担当する短期メモリを補完します。長期メモリシステムは3つの主要なメカニズムに依存しています:
- 構造化インデックス能力: これによりエージェントは、時間、トピック、エンティティ関係などで、大量の非構造化データに多次元インデックスを構築でき、人間が異なる手がかりを通じて情報を想起するように、複数の角度からの効率的な検索をサポートします。
- インテリジェントな忘却: 価値評価アルゴリズムを通じて、システムは低頻度、弱い関連性、または古い情報を減衰または選択的に破棄し、メモリシステムをリーンかつ効率的に保ち、過負荷を防ぎます。
- 知識の統合: システムは散在する対話と相互作用の経験を構造化された知識に精製します。エンティティ認識、関係抽出、意味的クラスタリングを通じて、断片化された情報がナレッジグラフに接続され、短期の経験が長期の知識に変換されます。
RAG上に構築されたこの外部メモリシステムは、エージェントの認知境界を大幅に拡張するだけでなく、知識を継続的に学習し進化させる能力を与えます。エージェントが長期的な相互作用を通じて経験を蓄積し、パーソナライズされた動作パターンとドメイン知識システムを形成し、より複雑で長期にわたるタスクをサポートできるようにします。
まとめ
Retrieval-Augmented Generationは、大規模モデルのハルシネーションと知識の陳腐化を補う技術的手法であるだけでなく、一般的なAI能力を深いエンタープライズ価値に変えるための重要な架け橋です。Naive RAGからモジュラーおよびエージェント的な形態への進化は、RAGのすべての部分が継続的に深まる必要があることを示しています。より繊細なデータ処理、埋め込み、リランキング、LLM段階にわたるより科学的なモデル選択、より体系的な評価などがすべて、制御可能で信頼性が高く効率的なエンタープライズナレッジシステムの構築に向けて必要なステップです。同時に、コンペティションやエンジニアリングケーススタディから教訓を導き出すことは、技術的詳細の理解を深める最良の方法の一つです。
Graph RAG、マルチモーダル理解、Late Chunkingが引き続き発展し組み合わされるにつれて、RAGは着実に古い検索と生成の境界を押し広げ、より深い意味的関連付けとより持続可能なメモリ能力に向かって進んでいます。この調査スタイルの記事が、原理から実践、評価から進化に至るフルチェーンの方法論を構築する一助となり、急速に変化する技術環境の中で、実際の世界に着地し複雑なビジネス課題に対応できる高品質なインテリジェントアプリケーションを構築できることを願っています。
参考文献
[1] Ask in Any Modality: A Comprehensive Survey on Multimodal Retrieval-Augmented Generation.
https://arxiv.org/pdf/2502.08826
[2] Retrieving Multimodal Information for Augmented Generation: A Survey.
https://arxiv.org/pdf/2303.10868
[3] A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models.
https://arxiv.org/pdf/2405.06211
[4] Retrieval-Augmented Generation for Large Language Models: A Survey.
https://arxiv.org/pdf/2312.10997
[5] LightRAG: Simple and Fast Retrieval-Augmented Generation.
https://arxiv.org/pdf/2410.05779
[6] Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG.
https://arxiv.org/pdf/2501.09136
[7] ERAGent: Enhancing Retrieval-Augmented Language Models with Improved Accuracy, Efficiency, and Personalization.
https://arxiv.org/pdf/2405.06683
[8] Graph Retrieval-Augmented Generation: A Survey.
https://www.arxiv.org/pdf/2408.08921
[9] Evaluation of Retrieval-Augmented Generation: A Survey.
https://arxiv.org/pdf/2405.07437
[10] Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey.
https://arxiv.org/pdf/2504.14891
[11] From Local to Global: A Graph RAG Approach to Query-Focused Summarization.
https://arxiv.org/pdf/2404.16130
[12] RAG vs. GraphRAG: A Systematic Evaluation and Key Insights.
https://arxiv.org/pdf/2502.11371
[13] Introduction to RAG | LlamaIndex Python Documentation.
https://developers.llamaindex.ai/python/framework/understanding/rag/
[14] All-in-RAG | A Full-Stack Guide to RAG in Large-Model Application Development.
https://datawhalechina.github.io/all-in-rag/#/en/
[15] Ilya Rice: How I Won the Enterprise RAG Challenge.
https://abdullin.com/ilya/how-to-build-best-rag/
[16] RAG Research Table - Awesome Generative AI Guide (GitHub).
[17] RAG is dead, long live agentic retrieval.
https://www.llamaindex.ai/blog/rag-is-dead-long-live-agentic-retrieval
[18] LLM/RAG Zoomcamp extra lesson 5: Common evaluation methods and market preferences in RAG evolution.
https://vip.studycamp.tw/t/llmrag-zoomcamp-課外補充-5:rag-evolution-常見評估方法和市場偏好/8185
[19] How to Evaluate Retrieval Augmented Generation (RAG) Applications.
https://zilliz.com.cn/blog/how-to-evaluate-rag-zilliz
[20] RAG is not Agent Memory.
https://www.letta.com/blog/rag-vs-agent-memory
[21] Richmond Alake. LinkedIn post on #100DaysOfAgentMemory, RAG and MemoRizz.