A medida que los modelos de lenguaje grande (LLMs) se adoptan más ampliamente, las empresas enfrentan un problema muy práctico: ¿cómo puede un modelo responder preguntas con precisión cuando esas preguntas dependen de documentos internos, datos en tiempo real o conocimiento específico de un dominio? Después de todo, los datos de entrenamiento de un modelo son limitados y están acotados en el tiempo, por lo que no pueden cubrir el conocimiento de negocio específico de la empresa ni la información que se actualiza constantemente.
Una idea intuitiva es la siguiente: dado que las ventanas de contexto siguen creciendo, de 8K a 128K y ahora más de un millón de tokens, ¿por qué no simplemente introducir los documentos relevantes en el prompt y dejar que el modelo responda directamente a partir de esos materiales?
Sin embargo, ser capaz de procesar un contexto largo y ser capaz de ofrecer respuestas correctas de manera estable, eficiente y controlable en escenarios empresariales son dos cosas muy diferentes. Confiar ciegamente en el contexto largo trae una serie de desafíos severos, incluyendo costos explosivos, atención diluida y actualizaciones de conocimiento obsoletas.
Para resolver estos puntos débiles, surgió una técnica llamada Generación Aumentada por Recuperación, o RAG (Retrieval-Augmented Generation). Antes de que el modelo genere una respuesta, RAG primero recupera conocimiento externo preciso. Comparado con simplemente expandir la longitud del contexto de manera forzada, RAG satisface los requisitos empresariales de precisión factual y conocimiento fresco a menor costo, con mayor precisión y mayor controlabilidad. Por lo tanto, se ha convertido en una base clave para construir aplicaciones de IA confiables.
En este tutorial, explicaremos sistemáticamente qué es RAG, rastrearemos el contexto detrás de su surgimiento y sus principios fundamentales, y luego exploraremos su evolución desde formas básicas hasta formas avanzadas, junto con hacia dónde puede dirigirse en el futuro.
Lo que Aprenderás en Esta Lección
- El valor central de RAG: comprender profundamente cómo aborda los problemas centrales del contexto largo de costo, atención y frescura del conocimiento
- Cómo funciona RAG: ver a través de ejemplos concretos cómo completa el ciclo completo desde la recuperación hasta la generación
- La evolución de RAG: desde el Naive RAG básico hasta Advanced RAG y luego a Modular RAG
- Selección de modelos para RAG: comprender cómo evaluar y elegir los tres tipos de modelos clave, Embedding, Rerank y LLM
- Práctica empresarial de RAG: aprender la guía de construcción de cadena completa desde el preprocesamiento de datos hasta el despliegue y evaluación del sistema
- Evaluación y optimización de RAG: comprender las métricas centrales, los frameworks principales y los métodos de mejora continua
- Tendencias fronterizas en RAG: explorar cómo RAG se combina con agentes, multimodalidad y otras técnicas emergentes
Lo que Obtendrás
Después de completar este tutorial, construirás una comprensión sistemática a nivel principiante de la tecnología RAG. No solo sabrás qué es, sino también por qué funciona. También obtendrás un plan claro para cómo evaluar, elegir y diseñar un sistema RAG eficiente, confiable y controlable que cumpla con los requisitos empresariales, sentando una base sólida para construir aplicaciones RAG de nivel empresarial reales.
1. Por qué se Necesita RAG
La Generación Aumentada por Recuperación (RAG) es uno de los enfoques técnicos más importantes en la IA generativa actual. Su idea básica es simple: antes de pedir a un modelo grande que genere una respuesta, el sistema primero recupera información relacionada con la pregunta del usuario desde una base de conocimiento externa, y luego pasa tanto la información recuperada como la pregunta original al modelo para que pueda responder sobre la base de materiales reales. Esa base de conocimiento externa puede ser las políticas internas de una empresa, documentos de procesos y conocimiento de productos, o una base de datos de la industria, corpus regulatorio, biblioteca de estándares, etc.
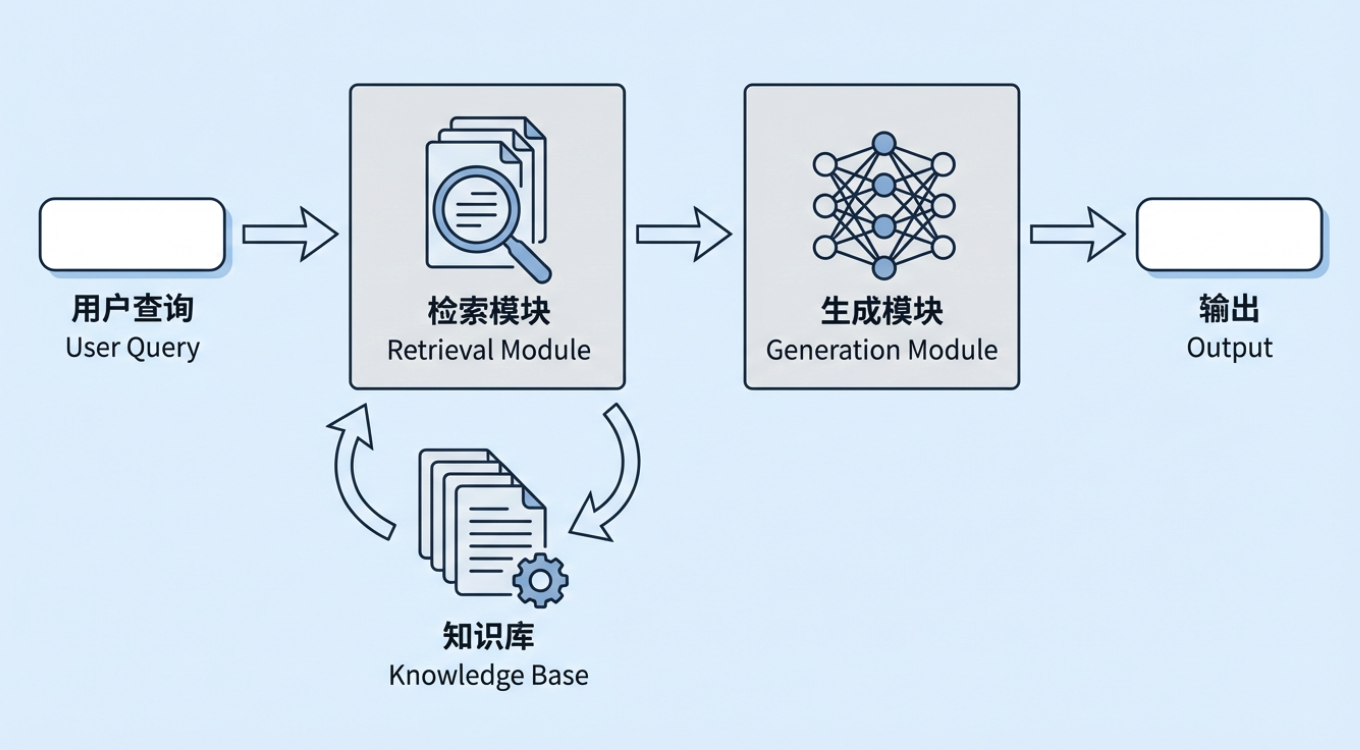
En este punto, aparece una pregunta natural: si los modelos grandes ya pueden "responder preguntas directamente", ¿por qué añadir otra capa llamada Generación Aumentada por Recuperación? Especialmente ahora que las ventanas de contexto son cada vez más grandes, puede parecer que simplemente entregar todo el material relevante al modelo debería resolver la mayoría de las necesidades.
La diferencia real es que "poder producir una respuesta" y "poder producir continua, estable y controlablemente la respuesta correcta en un entorno de negocio real" son dos cosas completamente diferentes. Si dependes solo de la memoria paramétrica del modelo, o solo de volcar grandes cantidades de documentos en un contexto largo, al menos tres problemas típicos siguen apareciendo en el uso empresarial.
Problemas de costo y eficiencia: Incluso cuando las ventanas de contexto siguen expandiéndose, la idea de volcar todos los documentos en el contexto de una vez sigue siendo impráctica en sistemas reales. La contradicción central se manifiesta en dos lugares:
El costo de inferencia está fuertemente correlacionado de forma positiva con la longitud del contexto. Cuanto más largo es el contexto, más aumenta el costo de inferencia, casi linealmente y a veces incluso superlinealmente. Para una sola llamada, 8K tokens y 200K tokens están en rangos de precio y latencia completamente diferentes, y el contexto largo tiene un umbral de costo mucho más alto.
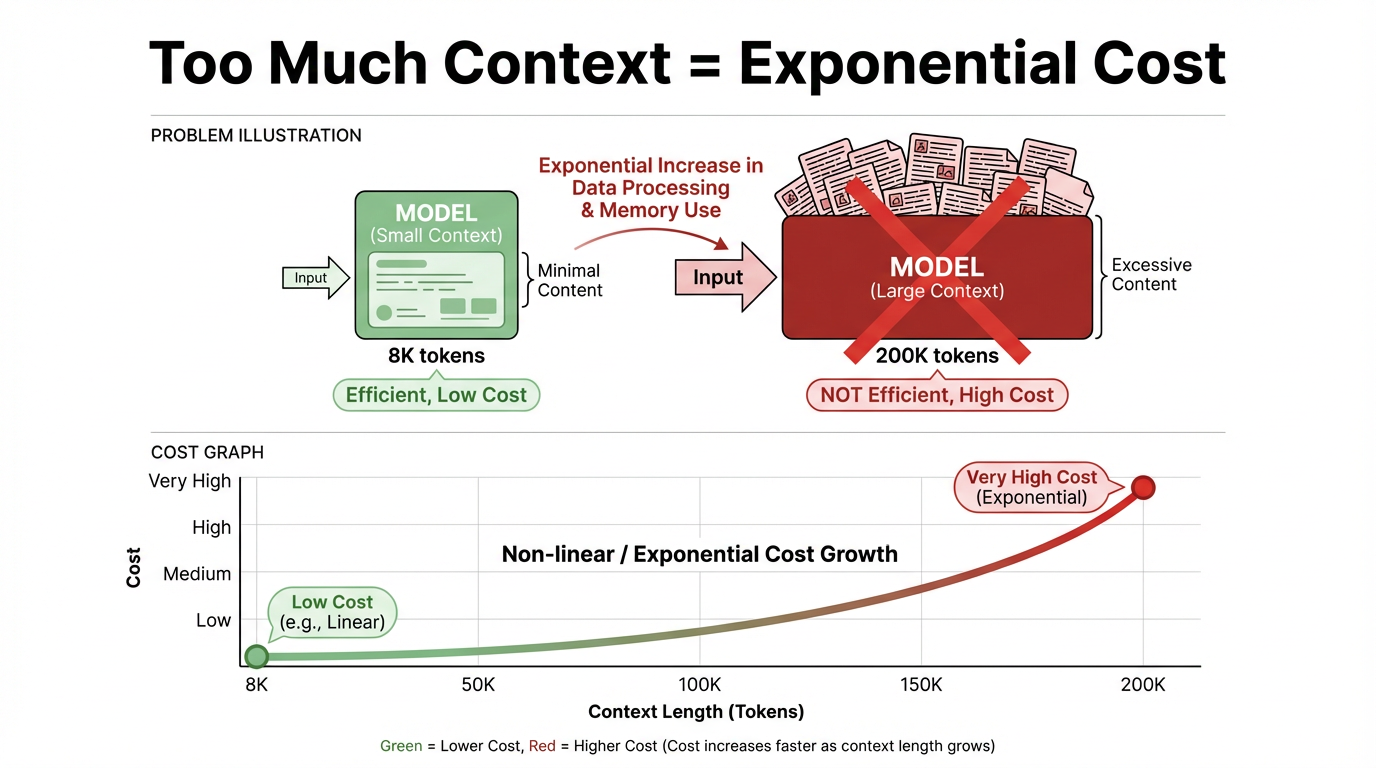
En términos de significado, el contexto es la información de fondo y el historial de conversación que el modelo "consulta" al responder una pregunta. En términos técnicos, es la secuencia total de tokens alimentada al modelo para una inferencia, como instrucciones del sistema y del usuario, historial de mensajes y pasajes recuperados.
Una "ventana de contexto" es el límite de capacidad para esa entrada. En las arquitecturas de modelos grandes dominantes actuales, como Transformers, esos tokens participan en el cálculo de atención en cada capa. Una vez que la ventana se hace más larga y la cantidad de tokens aumenta, el cómputo y el costo aumentan multiplicativamente y pueden incluso acercarse a un crecimiento exponencial.
Se desperdicia una gran cantidad de cómputo. La mayoría de las tareas necesitan solo una cantidad muy pequeña de información que está altamente relacionada con la pregunta actual. Introducir el conjunto completo de documentos en el contexto crea un serio desperdicio de cómputo inactivo, reduce el rendimiento del sistema, ralentiza la velocidad de respuesta y eventualmente perjudica la experiencia del usuario.
Problemas de atención y enfoque: Un modelo grande puede "cubrir" un contexto ultra largo, pero no puede usar cada segmento con la misma calidad. Una vez que la longitud del contexto cruza un cierto umbral, el modelo comienza a mostrar un sesgo de atención obvio:
Decaimiento de la atención: la atención del modelo a las partes tempranas y medias del contexto se debilita gradualmente, y tiende a depender más del texto que leyó después, por lo que la información crítica temprana puede ser efectivamente ignorada.
Interferencia de información: el modelo puede ser fácilmente arrastrado fuera de curso por información irrelevante, repetitiva o incluso conflictiva dentro del contexto. La respuesta final puede sonar lógicamente coherente mientras se desvía de la pregunta central, haciendo que la precisión sea difícil de garantizar. Sin una etapa de recuperación para filtrar y clasificar la relevancia, cuanto más largo se vuelve el contexto, más difícil es mantener la respuesta enfocada en la evidencia verdaderamente clave. La ventaja del contexto largo puede ser completamente cancelada por la interferencia de información.
Problemas de frescura y controlabilidad del conocimiento: Si todo el conocimiento se almacena completamente en los parámetros del modelo, o se copia manualmente en los prompts, aparecen dos defectos inevitables:
Las actualizaciones de conocimiento son difíciles: una vez que el conocimiento cambia, como cambios de políticas, iteraciones de productos o actualizaciones de precios, necesitas reentrenar o afinar el modelo, lo cual es costoso y lento, o mantener las plantillas de prompts manualmente, lo cual también es costoso y propenso a errores humanos.
La trazabilidad es pobre: cuando un modelo responde, a menudo es difícil ubicar las piezas exactas de evidencia ya sea desde parámetros de caja negra o prompts largos. Esto hace que las auditorías de cumplimiento, las explicaciones de riesgo y otras tareas que requieren fundamentos claros de decisión sean extremadamente difíciles.
Bajo estas restricciones reales, la ventaja de RAG se vuelve mucho más clara. Su enfoque central es localizar información relevante y confiable antes de la generación, para que el modelo responda solo a partir del conocimiento necesario. El conocimiento puede almacenarse independientemente en una base de conocimiento externa, facilitando su actualización y gestión. Al mismo tiempo, los resultados generados pueden incluir fuentes citadas, mejorando la interpretabilidad y la confiabilidad. Incluso si las ventanas de contexto siguen creciendo en el futuro, RAG seguirá permitiendo una gestión y uso eficiente del conocimiento a un costo relativamente bajo, respaldando aplicaciones de conocimiento de nivel empresarial cuyo proceso es observable y cuyo comportamiento es rastreable.
Desde la perspectiva de los requisitos empresariales, comparado con un LLM tradicional que depende solo de sus parámetros internos, RAG resuelve principalmente los siguientes problemas de despliegue en el mundo real:
- Frescura: Los modelos tradicionales generalmente no conocen las nuevas regulaciones, productos o flujos de trabajo que aparecieron después de su fecha límite de entrenamiento, pero RAG puede leer directamente los documentos de políticas más recientes, bases de datos de negocio y bases de conocimiento. Sin reentrenamiento frecuente, las respuestas pueden mantenerse sincronizadas con el estado de negocio más reciente.
- Especialización: En dominios verticales como salud, química o finanzas, los modelos de propósito general a menudo no comprenden con suficiente profundidad o no hablan con suficiente precisión. Después de conectar documentos de dominio propios de la empresa y estándares de la industria, las respuestas pueden basarse en materiales autorizados y acercarse mucho más a la práctica de negocio real.
- Alucinación: Al requerir que las respuestas se basen en los pasajes recuperados y proporcionen citas, el sistema puede reducir la fabricación no respaldada a nivel de mecanismo, haciendo que "suena verdadero" esté mucho más cerca de "es realmente verdadero".
- Explicabilidad y auditabilidad: Los modelos basados puramente en parámetros a menudo no pueden responder "¿A partir de qué regla se derivó esta conclusión?" RAG permite que cada respuesta sea rastreada hasta una cláusula de política específica, documento de negocio o caso histórico. Eso ayuda al personal de negocio a inspeccionar y corregir respuestas y da a los equipos de auditoría, riesgo y cumplimiento la trazabilidad que necesitan.
- Costo computacional y eficiencia de recursos: Hacer que un modelo memorice todo el conocimiento empresarial en sus parámetros generalmente significa un modelo más grande y un costo de inferencia más alto. RAG almacena la mayor parte del conocimiento fuera del modelo en almacenes de vectores y almacenes de documentos y lo recupera bajo demanda, permitiendo a las empresas obtener una cobertura más amplia y un detalle más preciso incluso con modelos más pequeños y recursos computacionales limitados.
Por lo tanto, para las empresas que desean usar modelos grandes en escenarios de negocio reales a largo plazo, de manera estable y controlable, RAG no es una mejora opcional. Es casi una tecnología fundacional esencial para construir un sistema de aplicación de conocimiento empresarial de alta calidad.
2. Qué es RAG
La idea central de RAG, Generación Aumentada por Recuperación, es permitir que un modelo grande responda preguntas no solo con el conocimiento estático aprendido durante el entrenamiento, sino también con información actualizada y confiable extraída de una base de conocimiento externa en tiempo de ejecución.
En un sistema RAG típico, la pregunta del usuario no se envía directamente al modelo grande. En su lugar, un módulo de recuperación primero encuentra los pasajes de documentos más relevantes de la base de conocimiento empresarial, luego combina esos pasajes con la pregunta original en un contexto completo, y finalmente se lo da al modelo para generar una respuesta. Este patrón de "recuperar primero, generar después" permite que el modelo razone a partir de material de referencia real en lugar de solo adivinar a partir de lo que recuerda en sus parámetros. Podemos ver un caso típico:
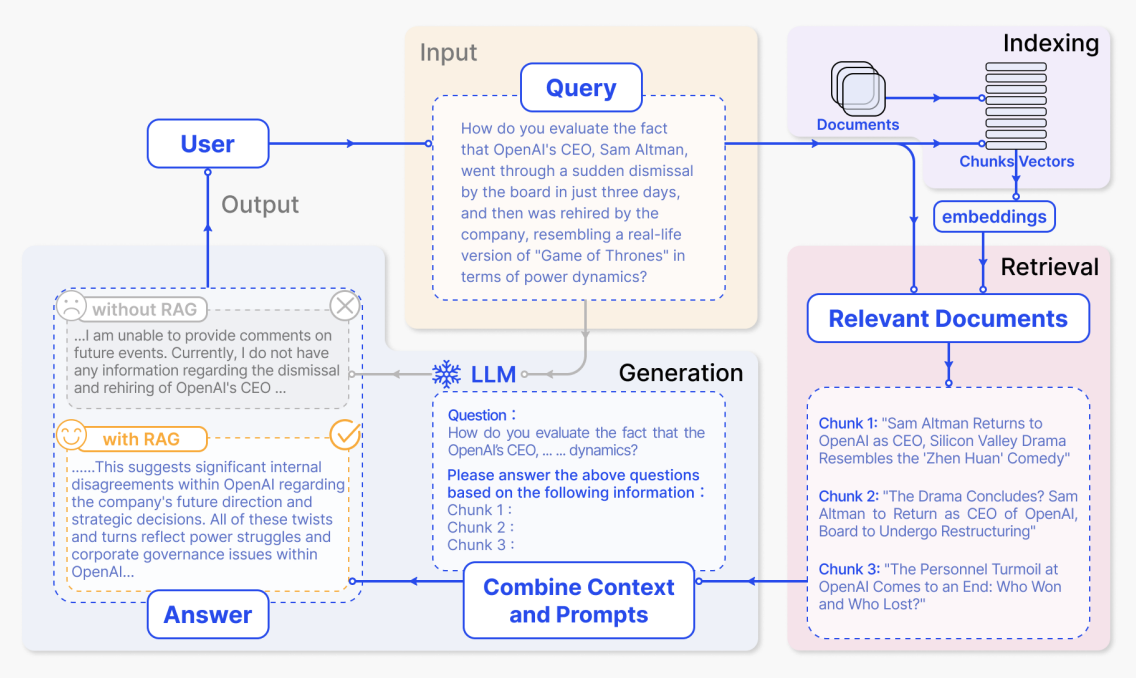
Etapa de indexación
En la etapa de indexación, el sistema primero procesa material en bruto como documentos internos de la empresa, páginas web e informes. Los divide en fragmentos semánticos más pequeños, luego usa un modelo de embedding para generar representaciones vectoriales para cada fragmento y construye un índice. Más tarde, cuando llega una pregunta de usuario, el sistema puede encontrar rápidamente los fragmentos más similares semánticamente en el espacio vectorial.
En el diagrama, esto corresponde al área púrpura "Indexing" en la parte superior derecha. La ruta desde "Documents" a través de "Chunks / Vectors" hasta "embeddings" muestra los documentos siendo fragmentados, convertidos en vectores y escritos en el índice. Más concretamente:
- Los documentos se dividen en un conjunto de fragmentos semánticamente coherentes, cada uno de los cuales puede corresponder a un breve pasaje de noticias, explicación o análisis.
- Cada fragmento se convierte en un vector de alta dimensionalidad por el modelo de embedding y se almacena en el índice vectorial.
- Este índice soporta recuperación basada en similitud posterior, preparando una base de conocimiento que el sistema puede consultar al responder preguntas.
Etapa de recuperación más generación de respuesta a partir de resultados recuperados
Después de que el usuario hace una pregunta, el sistema primero recupera contenido relevante del índice, luego envía la pregunta y el texto recuperado juntos al modelo grande para generar una respuesta. En la figura, las áreas clave de arriba a abajo y de derecha a izquierda corresponden exactamente a este flujo completo.
(1) Pregunta de entrada del usuario: el área amarilla Input - Query
"¿Cómo evalúas el hecho de que el CEO de OpenAI, Sam Altman, pasara por un despido repentino por parte de la junta directiva en solo tres días, y luego fuera recontratado por la empresa, pareciendo una versión real de 'Juego de Tronos' en términos de dinámicas de poder?"
"¿Cómo evalúas el hecho de que el CEO de OpenAI, Sam Altman, fuera despedido repentinamente por la junta directiva y luego recontratado por la empresa en solo tres días, haciendo que la lucha de poder se pareciera a una versión real de Juego de Tronos?"
Este bloque grande de texto es el contenido dentro de la caja "Query" en el diagrama, correspondiente a la pregunta en lenguaje natural del usuario. El sistema vectoriza esa pregunta y la usa para buscar en el índice de la parte superior derecha fragmentos de documentos relacionados.
(2) Documentos relevantes recuperados: el área rosa Relevant Documents en la parte inferior derecha
Después de la recuperación, el sistema obtiene varios fragmentos de documentos más relacionados con la pregunta. En el diagrama, se muestran como tres fragmentos:
"Sam Altman regresa a OpenAI como CEO, el drama de Silicon Valley se parece a la comedia 'Zhen Huan'" "Sam Altman regresa como CEO de OpenAI, y este drama de Silicon Valley se parece a una comedia de intrigas palaciegas."
"¿El drama concluye? Sam Altman regresará como CEO de OpenAI, la junta directiva será reestructurada" "¿Está terminando el drama? Sam Altman regresará como CEO de OpenAI, mientras la junta directiva será reestructurada."
"La agitación personal en OpenAI llega a su fin: ¿quién ganó y quién perdió?" "La agitación personal de OpenAI llega a su fin: ¿quién ganó y quién perdió?"
(3) Combinar el prompt y generar la respuesta: el área azul LLM / Combine Context and Prompts
El sistema entonces combina la pregunta original del usuario y los fragmentos recuperados en un prompt completo y lo envía al modelo. La caja punteada en la parte inferior central de la figura muestra un ejemplo de prompt:
"Pregunta: ¿Cómo evalúas el hecho de que el CEO de OpenAI, ... dinámicas?
Por favor responde las preguntas anteriores basándote en la siguiente información: Fragmento 1: Fragmento 2: Fragmento 3:"
"Pregunta: ¿Cómo evalúas la lucha de poder en el incidente del CEO de OpenAI?
Por favor responde la pregunta anterior basándote en la información a continuación: Fragmento 1: Fragmento 2: Fragmento 3:"
(4) Comparación de respuestas con y sin RAG: las áreas grises y amarillas Output - Answer en la parte inferior izquierda
Finalmente, el modelo genera una respuesta basándose en la información proporcionada. La figura también compara las salidas con y sin RAG. Sin RAG, el modelo no tiene material externo y solo puede dar una respuesta vaga, correspondiente a la caja gris:
"... No puedo proporcionar comentarios sobre eventos futuros. Actualmente no tengo ninguna información respecto al despido y recontratación del CEO de OpenAI ..."
Con RAG, el modelo puede usar las noticias y el análisis recuperados para producir una respuesta mucho más informativa, correspondiente a la caja amarilla:
"... Esto sugiere desacuerdos internos significativos dentro de OpenAI respecto a la dirección futura de la empresa y las decisiones estratégicas. Todos estos giros y vueltas reflejan luchas de poder y problemas de gobernanza corporativa dentro de OpenAI ..."
El ejemplo anterior muestra el flujo completo de un sistema RAG típico y nos ayuda a entender sus etapas centrales y cómo la información fluye a través de ellas. Pero muchos detalles técnicos importantes permanecen dentro de una caja negra: ¿cómo se realiza exactamente la coincidencia vectorial, y cómo debería organizarse el prompt para que el modelo pueda usar el contenido recuperado más efectivamente? Estos detalles determinan en gran medida la calidad real de RAG. A continuación, profundizaremos en el mecanismo interno de RAG y lo desglosaremos paso a paso, desde los principios de vectorización y cálculo de similitud hasta la ingeniería de prompts.
3. Cómo Funciona RAG
Podemos desglosarlo a través de un simple ejemplo de preguntas y respuestas construido sobre una base de conocimiento sobre "manzana".
3.1 Etapa de Vectorización de Documentos
Supongamos que tenemos una base de conocimiento simplificada que contiene estos tres pasajes de documentos:
- Pasaje A: Apple Inc. fue fundada el 1 de abril de 1976 por Steve Jobs, Steve Wozniak y Ronald Wayne, y su sede está en Cupertino, California.
- Pasaje B: Las manzanas son una fruta rica en vitamina C y fibra dietética, lo que ayuda a la digestión y la salud del sistema inmunológico.
- Pasaje C: Apple Inc. lanzó el primer iPhone en 2007, cambiando fundamentalmente la industria de los smartphones.
Cuando procesamos estos documentos con un modelo de embedding, como text-embedding-ada-002 de OpenAI o un modelo BGE de código abierto, cada pasaje se convierte en un vector de alta dimensionalidad, a menudo con 768, 1024 o 1536 dimensiones.
Un vector es esencialmente un arreglo compuesto por muchos valores numéricos. Cada dimensión corresponde a una característica semántica del texto. Por ejemplo, el vector para "gato" puede contener dimensiones relacionadas con mamífero, mascota del hogar y peludo. La combinación final de valores captura el significado semántico del texto para que la computadora pueda "entender" las relaciones entre textos.
Ejemplos simplificados, siendo los vectores reales de dimensionalidad mucho mayor:
- Vector del pasaje A, sobre la fundación de Apple:
[0.85, -0.23, 0.41, -0.56, 0.12, 0.78, ...] - Vector del pasaje B, sobre manzanas como fruta:
[-0.12, 0.95, -0.34, 0.67, -0.89, 0.05, ...] - Vector del pasaje C, sobre el lanzamiento del iPhone:
[0.79, -0.18, 0.52, -0.61, 0.23, 0.81, ...]
Estos vectores luego necesitan ser almacenados en una base de datos vectorial, como Pinecone, Weaviate o FAISS, para su posterior recuperación y recall.
Una base de datos es un sistema que almacena y gestiona datos de manera estructurada, permitiendo un almacenamiento organizado y una recuperación eficiente. Ejemplos comunes incluyen listas de contactos y catálogos de productos de comercio electrónico.
Una base de datos vectorial es un tipo especializado de base de datos. A diferencia de las bases de datos tradicionales, que almacienen texto, tablas y otras estructuras de datos ordinarias, una base de datos vectorial está diseñada específicamente para almacenar vectores, es decir, arreglos numéricos de alta dimensionalidad, y está optimizada para búsqueda por similitud en escenarios de IA.
3.2 Etapa de Consulta de Usuario, Recuperación y Respuesta
Una vez que la base de conocimiento ha sido vectorizada y almacenada, un sistema RAG puede soportar consultas de usuario en tiempo real. Cuando un usuario hace una pregunta, el sistema ejecuta un flujo continuo: primero convierte la pregunta en un vector, luego usa el cálculo de similitud para recuperar la información más relevante de la base de conocimiento, y finalmente usa esos pasajes como base para la generación de la respuesta. Podemos ilustrar este proceso con tres consultas concretas.
Consulta 1: "¿Cuándo fue fundada Apple Inc.?"
En la etapa de vectorización de la consulta, la pregunta se convierte por el modelo de embedding en un vector semántico, por ejemplo [0.82, -0.21, 0.38, -0.58, 0.15, 0.76, ...]. Este patrón numérico es altamente similar al vector almacenado del pasaje A, el de la fundación de la empresa.
El sistema entonces realiza recuperación por similitud, Top-K con K = 2, calculando la similitud coseno entre el vector de consulta y todos los vectores de documentos en la base de conocimiento. El resultado se ve así:
- Similitud con el pasaje A, el pasaje de la fundación: 0.97, altamente relevante
- Similitud con el pasaje C, el pasaje del lanzamiento del iPhone: 0.88, relevante porque también trata sobre la empresa
- Similitud con el pasaje B, el pasaje de nutrición de frutas: 0.12, casi irrelevante
Top-K es una estrategia de selección común en la recuperación vectorial. Significa clasificar todas las coincidencias de mayor a menor similitud y mantener los K resultados principales. K = 2 significa que el sistema retiene solo los dos vectores de documentos con mayor similitud y filtra los de menor ranking, para que la siguiente etapa genere la respuesta solo a partir de los dos pasajes de documentos más relevantes.
Los resultados filtrados por similitud se llaman resultados de recall. El sistema devuelve los pasajes Top-2 como evidencia:
- Pasaje A, similitud 0.97: "Apple Inc. fue fundada el 1 de abril de 1976 por Steve Jobs, Steve Wozniak y Ronald Wayne, y su sede está en Cupertino, California."
- Pasaje C, similitud 0.88: "Apple Inc. lanzó el primer iPhone en 2007, cambiando fundamentalmente la industria de los smartphones."
En la etapa de generación de respuesta, el sistema construye una entrada estructurada completa colocando el contenido recuperado dentro de la sección de información de referencia y enviándolo junto con un prompt del sistema:
[Prompt del Sistema]
Eres un asistente profesional de preguntas y respuestas. Por favor responde estrictamente de acuerdo con la "información de referencia" proporcionada por el usuario.
Si la información de referencia contiene la respuesta, responde directamente basándote en ella.
Si la información de referencia no contiene la respuesta, dile explícitamente al usuario que "la pregunta no puede ser respondida basándose en los materiales actualmente disponibles", y no fabriques información.
Por favor indica en qué punto de información se basa tu respuesta.
[Contexto Recuperado]
Apple Inc. fue fundada el 1 de abril de 1976 por Steve Jobs, Steve Wozniak y Ronald Wayne, y su sede está en Cupertino, California.
Apple Inc. lanzó el primer iPhone en 2007, cambiando fundamentalmente la industria de los smartphones.
[Consulta del Usuario]
¿Cuándo fue fundada Apple Inc.?Después de recibir esta entrada estructurada, el LLM sigue la instrucción del sistema y trata el contexto recuperado como la única fuente confiable para responder. Su respuesta final se vería así:
Según la información de referencia proporcionada, Apple Inc. fue fundada el 1 de abril de 1976. [Base: Información 1]
Consulta 2: "¿Cuáles son los beneficios de comer manzanas?"
En la etapa de vectorización de la consulta, esta pregunta se convierte en un vector semántico como [-0.08, 0.92, -0.31, 0.71, -0.85, 0.08, ...]. Su patrón numérico es altamente similar al vector almacenado del pasaje B, el de la nutrición de las manzanas.
El sistema nuevamente realiza recuperación de similitud Top-K con K = 2 y calcula la similitud coseno:
- Similitud con el pasaje B, nutrición de frutas: 0.95, altamente relevante
- Similitud con el pasaje C, lanzamiento del iPhone: 0.18, casi irrelevante
- Similitud con el pasaje A, fundación de la empresa: 0.15, casi irrelevante
El sistema devuelve los pasajes Top-2 como evidencia:
- Pasaje B, similitud 0.95: "Las manzanas son una fruta rica en vitamina C y fibra dietética, lo que ayuda a la digestión y la salud del sistema inmunológico."
- Pasaje C, similitud 0.18: "Apple Inc. lanzó el primer iPhone en 2007, cambiando fundamentalmente la industria de los smartphones." Esto está solo débilmente relacionado y a menudo sería filtrado por un umbral en la práctica.
La entrada estructurada completa se construye entonces de la siguiente manera:
[Prompt del Sistema]
Eres un asistente profesional de preguntas y respuestas. Por favor responde estrictamente de acuerdo con la "información de referencia" proporcionada por el usuario.
Si la información de referencia contiene la respuesta, responde directamente basándote en ella.
Si la información de referencia no contiene la respuesta, dile explícitamente al usuario que "la pregunta no puede ser respondida basándose en los materiales actualmente disponibles", y no fabriques información.
Por favor indica en qué punto de información se basa tu respuesta.
[Contexto Recuperado]
Las manzanas son una fruta rica en vitamina C y fibra dietética, lo que ayuda a la digestión y la salud del sistema inmunológico.
Apple Inc. lanzó el primer iPhone en 2007, cambiando fundamentalmente la industria de los smartphones.
[Consulta del Usuario]
¿Cuáles son los beneficios de comer manzanas?Su respuesta final se vería entonces así:
Según la información de referencia proporcionada, las manzanas son ricas en vitamina C y fibra dietética, y comer manzanas ayuda a la digestión y la salud del sistema inmunológico. [Base: Información 1]
Consulta 3: "¿Cómo está el clima hoy?"
En la etapa de vectorización de la consulta, esta pregunta se convierte en un vector semántico relacionado con el clima y la meteorología, por ejemplo [0.10, -0.05, 0.30, -0.12, 0.21, 0.08, ...]. En el espacio semántico, este vector está lejos de todos los vectores de documentos sobre manzanas, ya sea la empresa o la fruta, por lo que no aparece ninguna similitud significativa.
El sistema nuevamente realiza recuperación Top-K con K = 2. Debido a que el tema de la pregunta no está relacionado con la base de conocimiento, las puntuaciones generales de similitud son todas muy bajas:
- Similitud con el pasaje B, nutrición de frutas: 0.18, extremadamente baja
- Similitud con el pasaje C, lanzamiento del iPhone: 0.10, casi irrelevante
- Similitud con el pasaje A, fundación de la empresa: 0.08, casi irrelevante
Top-K sigue devolviendo los K resultados mejor clasificados, pero en este caso esos resultados no proporcionan evidencia efectiva. En la práctica, el sistema a menudo aplica un umbral mínimo de similitud y devuelve directamente un recall vacío, es decir, sin resultados válidos, para reducir la interferencia irrelevante.
Los dos pasajes devueltos seguirían siendo:
- Pasaje B, similitud 0.18: "Las manzanas son una fruta rica en vitamina C y fibra dietética, lo que ayuda a la digestión y la salud del sistema inmunológico."
- Pasaje C, similitud 0.10: "Apple Inc. lanzó el primer iPhone en 2007, cambiando fundamentalmente la industria de los smartphones."
La entrada completa sería entonces:
[Prompt del Sistema]
Eres un asistente profesional de preguntas y respuestas. Por favor responde estrictamente de acuerdo con la "información de referencia" proporcionada por el usuario.
Si la información de referencia contiene la respuesta, responde directamente basándote en ella.
Si la información de referencia no contiene la respuesta, dile explícitamente al usuario que "la pregunta no puede ser respondida basándose en los materiales actualmente disponibles", y no fabriques información.
Por favor indica en qué punto de información se basa tu respuesta.
[Contexto Recuperado]
Las manzanas son una fruta rica en vitamina C y fibra dietética, lo que ayuda a la digestión y la salud del sistema inmunológico.
Apple Inc. lanzó el primer iPhone en 2007, cambiando fundamentalmente la industria de los smartphones.
[Consulta del Usuario]
¿Cómo está el clima hoy?El LLM primero juzgaría si la información de referencia contiene información directa sobre el clima o datos meteorológicos en tiempo real. Después de confirmar que no lo hace, seguiría la instrucción para responder que no puede responder:
Los materiales actualmente disponibles no pueden responder la pregunta "¿Cómo está el clima hoy?" porque la información de referencia solo contiene contenido relacionado con manzanas, nutrición de frutas y productos de Apple Inc., y no contiene información meteorológica ni datos meteorológicos en tiempo real. [Base: No existe información relacionada con el clima en el contexto recuperado]
De estos tres ejemplos, podemos ver la clave de la etapa de diálogo RAG. El prompt del sistema define el rol y las reglas de respuesta del LLM, la evidencia recuperada proporciona material concreto y confiable, y la pregunta del usuario define el objetivo de la tarea. Este patrón de entrada estructurada es exactamente lo que permite a RAG guiar y constreñir efectivamente a un LLM que de otra manera podría alucinar, convirtiéndolo en un sistema que produce respuestas estables y confiables. Garantiza que el modelo se use para comprender y organizar información existente en lugar de inventar información no respaldada.
4. La Evolución de RAG
RAG no se originó en la era de los modelos grandes. Investigaciones anteriores ya contenían prototipos de la misma idea. Desde una perspectiva histórica, RAG surgió del reconocimiento de las limitaciones de los LLMs tradicionales. Los modelos de lenguaje grande tempranos dependían principalmente de los datos de preentrenamiento, y esos datos se fijaban una vez terminado el entrenamiento. Por ejemplo, modelos como GPT-3 tenían fechas límite de conocimiento vinculadas a cuándo se recopilaron los datos de entrenamiento y no podían obtener conocimiento posterior. Reentrenar o afinar LLMs para dominios específicos también requería grandes recursos y experiencia especializada, haciendo que fuera costoso y difícil de iterar rápidamente.
Las raíces de RAG se pueden rastrear hasta el framework DrQA en 2017, que fue el primer intento de combinar recuperación con modelos de lenguaje. Un avance importante llegó luego en 2020 con Dense Passage Retrieval, o DPR, que usó modelos neuronales preentrenados para recuperación semántica en lugar de métodos tradicionales basados en frecuencia de palabras como TF-IDF y BM25. En 2021, RAG fue formalmente propuesto y sistematizado, convirtiéndose en una forma estándar de abordar los problemas de fecha límite de conocimiento y alucinación en los LLMs.
En términos generales, la evolución de RAG se puede dividir en tres etapas:
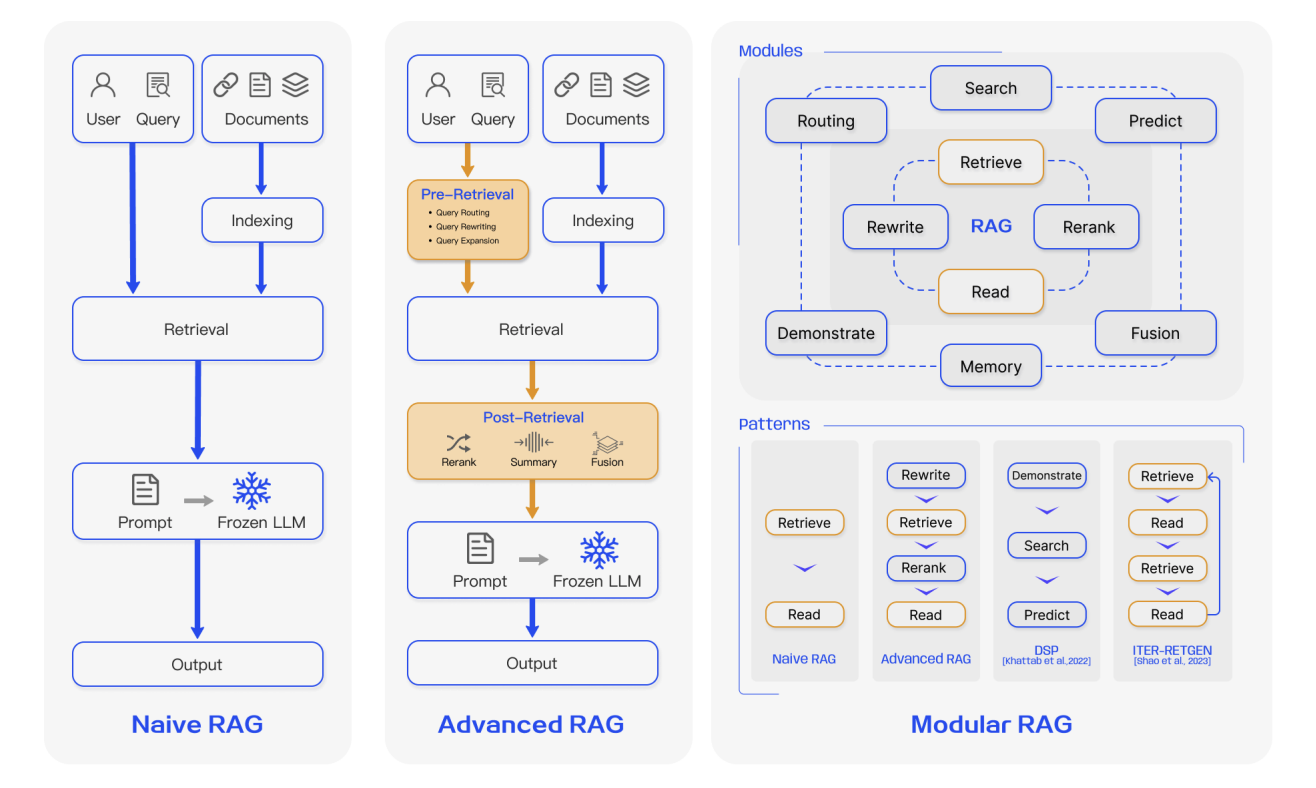
4.1 RAG de Primera Generación: Naive RAG
Naive RAG es la forma más básica de RAG. Desde una perspectiva de ingeniería, sigue un flujo de tres pasos muy directo:
- Preprocesamiento e indexación de documentos. Los documentos en bruto se limpian, se dividen en fragmentos de texto de longitud fija, se codifican en vectores con un modelo de embedding y se escriben en una base de datos vectorial.
- Recuperación basada en similitud. La pregunta en lenguaje natural del usuario se codifica en un vector, y el sistema realiza una búsqueda de similitud Top-K sobre el almacén vectorial.
- Generación aumentada por recuperación simple. Los fragmentos recuperados se concatenan directamente con la pregunta original para formar un prompt largo, que se envía al LLM para la generación de la respuesta.
El valor de esta etapa es que verificó, con una barrera muy baja, que "recuperar antes de responder" realmente funciona. Comparado con depender solo de la memoria interna del modelo, ya reduce significativamente los problemas de fecha límite de conocimiento y algunas alucinaciones, por lo que jugó un papel importante en prototipos tempranos, demos y tutoriales introductorios.
Sin embargo, las limitaciones del RAG de primera generación también son obvias. Primero, la estrategia de fragmentación suele ser burda. La mayoría de los sistemas simplemente dividen por longitud fija, lo que puede cortar un párrafo semánticamente coherente por la mitad o mezclar múltiples temas dentro de un fragmento. Esto perjudica la precisión de la recuperación y también hace que la comprensión sea más difícil para el LLM. Segundo, la señal de recuperación es demasiado simple. La clasificación generalmente depende solo de la similitud vectorial y no usa pistas estructuradas más ricas como palabras clave, marcas de tiempo, credibilidad de la fuente o permisos de acceso. Tercero, los resultados de la recuperación apenas se gobiernan: fragmentos ruidosos, repetitivos e incluso contradictorios pueden ser introducidos en el contexto sin cambios, causando que grandes cantidades de información de bajo valor ocupen una ventana de contexto ya limitada.
En resumen, la primera generación resolvió la pregunta de si la recuperación es necesaria. Pero en las preguntas de cómo recuperar mejor, y cómo usar la información recuperada de manera más razonable, todavía permanecía en una etapa bastante primitiva.
4.2 RAG de Segunda Generación: Advanced RAG
A medida que RAG pasó de demos a escenarios de negocio reales, los requisitos de estabilidad, controlabilidad y calidad de salida aumentaron bruscamente. La segunda generación, generalmente agrupada bajo el nombre amplio de Advanced RAG, sigue el patrón de recuperar primero y generar después, pero introduce un refinamiento sistemático tanto antes como después de la recuperación. En otras palabras, el sistema ya no está satisfecho con simplemente recuperar algo. Ahora aspira a almacenar las cosas correctas adecuadamente, hacer las preguntas correctas claramente y gobernar el contexto recuperado cuidadosamente.
Antes de la recuperación, el enfoque está en almacenar y preguntar bien:
En el lado de la indexación, la fragmentación evoluciona desde divisiones de longitud fija hacia fragmentación consciente del significado e indexación jerárquica. El sistema puede fragmentar a lo largo de los límites de capítulos, subsecciones, párrafos o oraciones, combinado con ventanas deslizantes y estructuras de índice de multigranularidad.
Cada fragmento de documento puede llevar metadatos ricos como fuente, marca de tiempo, autor, tema y tipo de documento, proporcionando más dimensiones para el filtrado y clasificación posteriores.
En el lado de la consulta, la pregunta original del usuario puede ser reescrita, expandida o descompuesta a través de técnicas como Query Rewrite, Multi-Query, descomposición Sub-Query y Step-back Prompting, transformando las consultas de usuario vagas o conversacionales en formas que la recuperación puede entender mejor.
- Query Rewrite
La idea central es transformar la consulta vaga, coloquial o no estándar del usuario en una expresión normalizada que el sistema de recuperación pueda entender más fácilmente, complementando información clave y resolviendo ambigüedades.
- Por ejemplo, "¿Cómo reviso el clima de mañana en Beijing?" podría ser reescrito en algo más estandarizado como "Consultar el clima en tiempo real de mañana para todo el día en Beijing."
- O "Recomienda buenas películas" puede ser reescrito, después de revisar el historial del usuario, como "Recomendar películas de suspenso de 2024 con altas calificaciones."
- Multi-Query
El sistema genera múltiples consultas semánticamente relacionadas pero con ángulos diferentes a partir de la pregunta original para reducir resultados omitidos y cubrir necesidades latentes que el usuario no expresó explícitamente.
- Sub-Query
Para preguntas compuestas que contienen varios objetivos, el sistema las divide en subconsultas más pequeñas y más simples para que la recuperación pueda coincidir con cada necesidad con precisión.
- Step-back Prompting
El sistema primero genera una pregunta más abstracta y de mayor nivel, luego usa esa para guiar la dirección de recuperación, reduciendo el sesgo causado por estar demasiado enfocado en los detalles de la pregunta original.
Después de la recuperación, el enfoque está en gobernar lo que fue recuperado:
- Un modelo rerank dedicado o incluso un LLM puede reclasificar los documentos candidatos para que el contenido más importante y relevante a la pregunta entre primero en el contexto.
Un modelo rerank es un componente clave en un pipeline de recuperación de información. Realiza una clasificación de segunda etapa sobre los resultados candidatos devueltos por la fase de recall, usando una comprensión semántica más fuerte, a menudo basada en arquitecturas Transformer, para corregir errores de clasificación semántica de la primera etapa y mover los resultados más alineados con las necesidades del usuario más adelante.
- Los pasajes recuperados pueden ser filtrados, deduplicados y comprimidos para eliminar fragmentos claramente irrelevantes o altamente repetitivos, reduciendo la tendencia de los sistemas de contexto largo a ignorar información útil en el medio.
- Cuando sea necesario, una afinación ligera del modelo puede hacer que el LLM sea más propenso a responder a partir de la evidencia de recuperación e incluir citas o fuentes explícitas.
En general, Advanced RAG ya no se enfoca solo en si la recuperación es necesaria o si algo puede ser recuperado. En cambio, aborda tres desafíos mayores: si los pasajes verdaderamente críticos pueden ser localizados con precisión, si el contexto entregado al modelo grande es conciso, bien estructurado y fácil de usar eficientemente, y si todo el sistema permanece estable y confiable en presencia de ruido, conflictos o necesidades de información de múltiples fuentes.
Grandes cantidades de evidencia experimental y de ingeniería muestran que Advanced RAG supera significativamente a Naive RAG en precisión de respuestas, supresión de alucinaciones, robustez del sistema y explicabilidad. Es por eso que gradualmente ha reemplazado los enfoques básicos tradicionales y se ha convertido en el paradigma industrial dominante para construir sistemas RAG hoy en día.
4.3 RAG de Tercera Generación: Modular RAG
En aplicaciones empresariales complejas, los requisitos a menudo abarcan múltiples dominios. En esos casos, un flujo lineal simple de recuperar, reclasificar y generar a menudo no es suficiente:
- El mismo sistema puede necesitar soportar preguntas frecuentes simples, generación de informes largos, recuperación de código y llamadas a bases de datos.
- Puede necesitar conectar almacenes vectoriales, recuperación de texto completo, bases de datos relacionales, grafos de conocimiento y motores de búsqueda externos al mismo tiempo.
- Puede necesitar preservar las preferencias del usuario y las decisiones históricas a lo largo de múltiples rondas, mientras aplica verificaciones de cumplimiento y trazabilidad de respuestas.
Against this background, RAG began evolving toward a modular system shape. Modular RAG is no longer viewed as a fixed pipeline. It is treated instead as a set of pluggable, replaceable, and composable function modules that can be orchestrated as needed. Typical modules include:
- Comprensión y enrutamiento de consultas Este módulo maneja el reconocimiento de intenciones, reescritura de preguntas, descomposición de subtareas y selección de rutas. Decide si una solicitud debe depender principalmente del conocimiento interno, la recuperación externa o una herramienta o base de datos específica.
- Recuperación y fusión multifuente Este módulo conecta bases de datos vectoriales, búsqueda de texto completo, bases de datos estructuradas y grafos de conocimiento simultáneamente, los consulta y fusiona y reclasifica sus resultados en un conjunto de evidencia unificado.
- Memoria y personalización Este módulo mantiene perfiles de usuario a largo plazo, memoria de sesión a corto plazo y cachés de conocimiento de dominio para que el sistema pueda acumular y usar continuamente información histórica.
- Adaptación de tareas y gobernanza Este módulo carga diferentes adaptadores para diferentes tareas, restringe el formato, tono y estilo de salida, y gobierna las salidas a través de verificación de hechos, filtrado de riesgos y alineación de citas.
En resumen, el RAG tradicional a menudo termina después de una ronda de recuperación más una ronda de generación. Modular RAG rompe ese patrón de flujo único. Si el sistema descubre durante la generación que la información aún es insuficiente, puede activar proactivamente nuevas rondas de recuperación e incluso moverse hacia atrás y hacia adelante múltiples veces entre recuperación y generación para completar una tarea más compleja.
Yendo más allá, el modelo puede aprender a tomar sus propias decisiones: responder directamente desde el conocimiento interno o el contexto corto cuando la confianza es alta, y lanzar recuperación o llamadas a herramientas externas solo cuando la incertidumbre es alta. Eso mejora la eficiencia y ahorra recursos mientras preserva la calidad. Para consultas muy subespecificadas o incompletas, el modelo puede incluso generar primero una respuesta intermedia hipotética o documento borrador, luego usar eso como pista para una recuperación posterior, aproximándose progresivamente a fuentes confiables.
En esta etapa, RAG ya no es solo un componente simple que adjunta algunos pasajes de referencia a un modelo grande. Se está convirtiendo en la capa central de orquestación de conocimiento dentro de las aplicaciones inteligentes empresariales, coordinando múltiples fuentes de datos, múltiples herramientas y múltiples tareas.
5. De Demo a RAG de Nivel Empresarial
Desde la perspectiva de la ingeniería empresarial, construir un sistema RAG no puede limitarse a la generación aumentada por recuperación por sí sola. El material anterior está más cerca de una introducción a nivel de demo. En escenarios de negocio reales, los datos a menudo son ruidosos e inconsistentes en formato, por lo que se debe invertir más esfuerzo en preprocesamiento, limpieza e ingestión, y la selección de modelos debe manejarse cuidadosamente en cada punto clave.
Un sistema RAG de nivel empresarial completo generalmente se puede dividir en tres módulos centrales: análisis de diseño e ingestión de conocimiento, construcción de base de conocimiento y servicio de preguntas y respuestas basado en RAG. A lo largo de la cadena técnica completa, aparecen varias decisiones clave de selección de modelos, incluyendo el modelo de embedding, el modelo rerank y el LLM. Solo con elecciones técnicas sensatas en cada etapa puede el sistema lograr resultados generales fuertes.
Análisis de diseño y lectura de archivos de conocimiento locales
Este módulo convierte activos de conocimiento local en diferentes formatos en texto utilizable para recuperación. Las entradas pueden incluir archivos PDF, TXT, HTML, Word, Excel y PPT, así como archivos de imágenes escaneadas como PNG y JPG, o incluso grabaciones de audio.
El sistema necesita analizar cada formato apropiadamente, realizar análisis de diseño y extracción estructural para documentos de texto, distinguir títulos, cuerpo principal, tablas, encabezados y pies de página, y restaurar un orden de lectura sensato. Realiza OCR en archivos de imagen y ASR en voz, finalmente convirtiendo todo en texto de conocimiento relativamente limpio mientras conserva metadatos básicos como nombre de archivo, capítulo, número de página y marca de tiempo para su posterior fragmentación e indexación.
Construcción de base de conocimiento: fragmentación, embeddings e indexación
Después de obtener el texto de conocimiento limpiado, el sistema realiza la fragmentación, dividiendo documentos largos en bloques semánticamente coherentes de longitud adecuada, generalmente por párrafo, estructura de títulos o ventana deslizante, mientras conserva la fuente y los metadatos de cada fragmento.
Luego usa el modelo de embedding elegido, como
text-embedding-3-small, Sentence Transformers o BGE, para calcular representaciones vectoriales para cada fragmento y construir un índice vectorial usando herramientas como Faiss, Milvus o servicios de búsqueda vectorial gestionados. En ese punto, se ha creado una base de conocimiento que soporta recuperación semántica rápida.Preguntas y respuestas basadas en RAG: recall, reranking, concatenación, generación
En la etapa de QA en línea, el usuario envía una consulta. El sistema la convierte en un vector de consulta, recupera un lote de los fragmentos de texto más similares del índice vectorial y lo trata como una etapa de clasificación gruesa. Luego puede usar un modelo rerank como un reranker BGE o incluso un LLM actuando como reranker para puntuar los pares consulta-documento nuevamente y conservar solo los documentos Top-K verdaderamente más relevantes como contexto de conocimiento.
A continuación, junto con un prompt de sistema cuidadosamente diseñado como "Por favor responde estrictamente basándote en los siguientes materiales", el sistema concatena la consulta del usuario y los pasajes de documentos recuperados y envía el prompt fusionado al LLM. El modelo entonces genera la respuesta final a partir de esas piezas de evidencia recuperadas y, cuando sea necesario, incluye citas o fuentes.
5.1 Selección de Modelos
A continuación nos enfocamos en la selección de modelos. Un sistema RAG completo generalmente involucra tres categorías de modelos centrales: modelos de embedding, modelos rerank y modelos de lenguaje grande. Cada uno tiene su propio rol, y juntos forman la ruta completa desde la recuperación hasta la generación de respuestas. El modelo de embedding convierte texto en vectores semánticos buscables, el modelo rerank refina los resultados de recuperación inicial, y el LLM genera la respuesta final basándose en el contexto de conocimiento seleccionado.
5.1.1 Modelos de Embedding
En un sistema RAG, el trabajo del modelo de embedding es convertir texto, como las consultas de usuario y el contenido de la base de conocimiento, en vectores de alta dimensionalidad. Los textos semánticamente similares se colocan más cerca en el espacio vectorial, lo que permite al sistema localizar conocimiento relacionado rápidamente por similitud. Elegir el modelo de embedding correcto es por lo tanto uno de los pasos más críticos en la construcción de un sistema RAG de alto rendimiento porque determina directamente la calidad del recall.
Para elegir un modelo fuerte, ayuda usar un benchmark sistemático. Uno de los más utilizados es MTEB, el Massive Text Embedding Benchmark.
MTEB proporciona un marco de evaluación unificado y objetivo para muchos modelos de embedding. A través de ocho categorías principales de tareas y 56 conjuntos de datos, evalúa el rendimiento en recuperación, clustering, clasificación, reranking, coincidencia de texto, similitud semántica y más. La puntuación MTEB general de un modelo refleja la generalidad y robustez de sus representaciones vectoriales y puede servir como una referencia importante para la selección de modelos. El ranking más reciente se puede consultar en el tablero de clasificación MTEB de Hugging Face:
Aunque hay muchos modelos en el tablero de clasificación, no necesitas dominarlos todos. En la práctica, elegir el modelo de embedding incluido por un proveedor de modelos importante, o usar un modelo servido en la nube que muchas personas ya han validado, suele ser una opción segura. También puedes filtrar el tablero de clasificación por categoría o idioma en la barra lateral:
Al filtrar modelos de embedding, dos parámetros importan especialmente porque afectan directamente el rendimiento de RAG: dimensionalidad y longitud del contexto.
La dimensionalidad es la dimensionalidad de la salida del vector, como 128, 768 o 1536. Refleja aproximadamente cuántas características semánticas puede expresar el vector. Los vectores de mayor dimensionalidad pueden capturar un detalle semántico más rico y una discriminación más fuerte. Por ejemplo, un vector de 768 dimensiones puede representar "manzana" desde cientos de ángulos como variedad, sabor y origen, haciéndolo adecuado para escenarios profesionales como salud o derecho que necesitan recuperación precisa. Dimensiones más bajas reducen el costo de cómputo y almacenamiento y mejoran la velocidad de recuperación, haciéndolas adecuadas para escenarios generales a gran escala con alta concurrencia y fuertes requisitos de tiempo real.
La longitud del contexto es la longitud máxima de texto que el modelo de embedding puede procesar en una sola pasada, medida en tokens. Un token en inglés es aproximadamente tres cuartos de una palabra, y un token en chino es aproximadamente un carácter chino. Cualquier cosa más larga que el máximo se trunca. Esto determina directamente si el modelo puede entender completamente el texto. Si se pierde información importante porque la longitud es demasiado corta, la precisión de la recuperación cae bruscamente. Para consultas de usuario cortas y pares de preguntas y respuestas cortos, 512 a 1024 tokens suelen ser suficientes. Para textos más largos como artículos e informes, generalmente necesitas 2048 tokens o más.
A continuación se presenta una comparación de varios modelos de embedding comunes. En la práctica, necesitas elegir equilibrando costo y rendimiento. No hay un modelo universalmente mejor, solo el modelo más adecuado después de comparar varias opciones en tu propio caso de uso.
| Nombre del Modelo | Escala del Modelo | Fortaleza Principal | Escenarios Adecuados |
|---|---|---|---|
OpenAI text-embedding-3-large | API cerrada | Líder a largo plazo en MTEB, maduro y estable | Escenarios de API en la nube que priorizan el rendimiento extremo y tienen presupuesto suficiente |
jina-embeddings-v2 | Soporta texto largo hasta 8K de contexto | Fuerte para recuperación de documentos largos a través de diseño de codificación asíncrona | Análisis de documentos, cumplimiento legal, recuperación académica |
multilingual-e5-large | Escala grande | Opción multilingüe clásica | RAG multilingüe, productos internacionales, sistemas de soporte multilingüe |
Qwen/Qwen2-Embedding-8B | Parámetros de 8B, hasta 4096 dimensiones personalizables | Antiguo líder multilingüe de MTEB, fuerte en texto largo, tareas multilingües y código | RAG chino-inglés de alta precisión, análisis de documentos largos, recuperación de código |
Qwen/Qwen2-Embedding-4B | Parámetros de 4B | Fuerte equilibrio de rendimiento y eficiencia | Sistemas RAG de producción a gran escala |
Qwen/Qwen2-Embedding-0.6B | Parámetros de 0.6B | Adecuado para dispositivos de borde | Escenarios con recursos limitados, prioridad de velocidad |
BAAI/bge-m3 | Soporta recuperación híbrida, densa más dispersa más multivector | Fuerte en benchmarks multilingües como MIRACL | Escenarios multilingües complejos que necesitan recuperación híbrida |
BAAI/bge-large-zh-v1.5 | Escala grande | Línea base estable de RAG chino con fuerte validación comunitaria | Proyectos puramente chinos con documentos más cortos |
ZhipuAI Embedding-3 | API de nube cerrada | Soporta dimensiones personalizadas de 256 a 2048 | Aplicaciones enfocadas en chino que prefieren APIs en la nube |
5.1.2 Modelos Rerank
En un sistema RAG, el modelo rerank es responsable de reclasificar finamente los resultados de recuperación inicial. Toma la consulta del usuario y los documentos candidatos como entrada y calcula una puntuación de relevancia exacta para cada par consulta-documento. Cuanto mayor sea la puntuación, mejor será la coincidencia. Por lo tanto, añadir un modelo rerank sobre el recall basado en embedding es un paso clave para mejorar la precisión de recuperación.
Para modelos de embedding, podemos usar benchmarks como MTEB. Para modelos rerank, una referencia útil es el tablero de clasificación de rerankers de Agentset:
El benchmark de Agentset primero recupera los 50 resultados candidatos más relevantes de un almacén de documentos grande usando FAISS, luego pide al modelo rerank bajo evaluación que reclasifique esos 50 documentos. El benchmark presta atención tanto a la calidad de clasificación como a la latencia. En aplicaciones prácticas, perseguir la precisión ignorando la velocidad perjudica la experiencia del usuario, mientras perseguir la velocidad sacrificando la calidad de clasificación perjudica la utilidad.
Agentset también introduce un mecanismo de puntuación ELO. Para cada consulta, GPT-5 actúa como juez y compara las salidas clasificadas de dos modelos rerank diferentes, decidiendo cuál coloca los documentos verdaderamente relevantes en un orden más sensato. Después de grandes números de tales comparaciones por pares, los modelos que ganan más a menudo reciben puntuaciones ELO más altas, proporcionando una señal de rendimiento general intuitiva.
El benchmark también usa dos grupos complementarios de métricas:
nDCG@5/10, que se enfoca en si los documentos relevantes se colocan cerca del frente y por lo tanto refleja la precisión de clasificaciónRecall@5/10, que se enfoca en si se pueden encontrar todos los documentos relevantes y por lo tanto refleja la cobertura
Juntas, estas métricas proporcionan una imagen más completa del rendimiento del rerank.
Aún así, en la práctica, no necesitas seleccionar modelos rerank solo de un tablero de clasificación. La utilidad industrial y la puntuación del tablero de clasificación no siempre son lo mismo. Un enfoque práctico es empezar por los modelos rerank recomendados por tus proveedores de nube o las APIs de rerank predeterminadas proporcionadas por los proveedores de modelos importantes, o probar una familia de modelos que ya estés usando, como un modelo rerank Qwen coincidente.
5.1.3 LLMs
Después de la recuperación semántica por el modelo de embedding y el filtrado refinado por el modelo rerank, los pasajes de documentos relevantes se combinan con la pregunta original del usuario en un prompt. El LLM luego realiza comprensión de lectura, integración de información y generación de lenguaje natural para producir una respuesta coherente, precisa que se ajusta al contexto.
A nivel de implementación, hay dos formas principales de usar LLMs en RAG:
- Modelos grandes desplegados privadamente. Estos son adecuados para escenarios que se preocupan por la privacidad de datos, el costo controlable o la personalización profunda. Modelos abiertos dominantes como Qwen, Llama y GLM funcionan bien en tareas RAG. Por ejemplo, Qwen2.5 en el rango de 7B o 14B ofrece un buen seguimiento de instrucciones y comprensión del chino mientras mantiene un uso de recursos modesto, haciéndolo adecuado para despliegue empresarial local. Modelos como KIMI, Minimax y DeepSeek también pueden considerarse según las necesidades de negocio específicas.
- Modelos grandes de API en la nube. Estos se ajustan a escenarios que priorizan el lanzamiento rápido, el escalado elástico y las actualizaciones continuas del modelo. Proveedores principales como OpenAI, Anthropic, Google, Alibaba y ZhipuAI ofrecen servicios API estables. Estos modelos generalmente tienen una fuerte comprensión y generación de lenguaje y pueden sintetizar respuestas bien en escenarios RAG.
Al seleccionar modelos en la nube, varios puntos importan: si la calidad de la respuesta es precisa y fluida, si el precio es razonable, si la latencia es aceptable y si la ventana de contexto es lo suficientemente grande para contener múltiples documentos recuperados. En la práctica, deberías comparar varios candidatos en tus propios datos y ver cuál da las respuestas más completas y precisas. Si el costo es una preocupación, un enfoque útil es combinar modelos grandes y pequeños: usar modelos pequeños más baratos para preguntas simples y reservar modelos grandes costosos para casos difíciles. Dado que los modelos se actualizan rápidamente, también es prudente reevaluar candidatos periódicamente.
Para capacidad general de conversación y QA, LMSYS Chatbot Arena, ahora LMArena, es una de las referencias de evaluación más ampliamente reconocidas:
Usa comparaciones humanas cegadas por pares para clasificar modelos. El ranking ofrece un primer filtro útil, pero en la selección real de RAG solo debería ser un punto de partida. En dominios especializados como medicina, derecho y finanzas, el ranking general del tablero de clasificación puede divergir sustancialmente del rendimiento real en tus datos de negocio.
La mejor práctica para la selección de LLM es construir un conjunto de prueba pequeño pero representativo que contenga de 20 a 30 preguntas de negocio típicas y evaluar los modelos candidatos a través del pipeline RAG completo de extremo a extremo en lugar de mirar solo benchmarks aislados del modelo. Preguntas como si usar modelos de razonamiento o no, o qué tamaño de modelo equilibra mejor calidad y velocidad, se responden mejor a través de pruebas reales en tu propio caso de uso.
5.2 Frameworks de Ejecución
En la práctica de ingeniería real, generalmente no necesitas construir un sistema RAG entero desde cero. Ya existen varios frameworks de código abierto maduros, cada uno con sus propias fortalezas en arquitectura, integración modular y eficiencia de desarrollo. Las empresas pueden elegir según sus propias reservas técnicas y escenarios de negocio.
Los tipos comunes de frameworks incluyen:
Plataformas de bajo código o visuales
- Dify: proporciona una interfaz visual intuitiva para construir rápidamente aplicaciones RAG, haciéndola adecuada para equipos no técnicos o validación rápida de prototipos. Incluye acceso multi-modelo integrado, orquestación de flujos de trabajo y gestión de prompts.
- Coze: una plataforma de desarrollo de bots de IA de ByteDance que ofrece construcción visual de cero código. Se integra profundamente con los servicios de modelos de ByteDance, soporta un marketplace de plugins, tareas programadas y publicación multicanal, haciéndola adecuada para asistentes orientados al consumidor o bots empresariales internos.
- n8n: una plataforma de automatización de flujos de trabajo basada en nodos de código abierto. En escenarios RAG, puede orquestar lógica de negocio compleja y conectar preprocesamiento, operaciones de base de datos vectorial, llamadas a modelos y acciones de seguimiento como envío de correos o actualización de tickets en un flujo automatizado.
- RAGFlow: se enfoca en análisis de diseño profundo y extracción de conocimiento y funciona bien en documentos complejos como PDFs multicol y materiales con muchas tablas.
- FastGPT: una solución de código abierto china que integra gestión de base de conocimiento, orquestación de diálogos y publicación de aplicaciones, con fuerte documentación en chino y idoneidad para despliegue rápido de aplicaciones RAG en chino.
Frameworks de código y bibliotecas de desarrollo
Las herramientas a continuación generalmente tienen implementaciones en diferentes lenguajes de backend. Puedes elegir la versión de lenguaje correspondiente para tu stack de aplicación.
- LlamaIndex: un framework en Python diseñado específicamente para RAG, con conectores ricos, estructuras de índice y motores de consulta. Su modularidad lo hace adecuado para estrategias de recuperación profundamente personalizadas o integración con muchas fuentes de datos.
- LangChain: un framework general de aplicaciones LLM donde RAG es solo un caso de uso. Su fortaleza es su ecosistema rico y cobertura de componentes, incluyendo soporte para agentes complejos y orquestación de flujos de trabajo, aunque su curva de aprendizaje es más pronunciada.
Si las reservas técnicas del equipo son limitadas y la velocidad es lo más importante, las plataformas de bajo código como Dify, Coze o FastGPT son buenas primeras opciones. Si necesitas personalización profunda, integración de fuentes de datos especiales o ajuste fino detallado del rendimiento, LlamaIndex y LangChain ofrecen más flexibilidad. En la práctica, una ruta híbrida también es común: usar una plataforma de bajo código para validación rápida de viabilidad, luego moverse a frameworks de código para despliegue de producción y optimización. La mayoría de estos frameworks también soportan integración rápida con modelos de embedding, rerank y LLM dominantes, permitiéndote combinarlos flexiblemente usando los principios de selección de modelos discutidos anteriormente.
5.3 Evaluación de Efecto
Para las empresas que despliegan sistemas RAG, el mayor desafío a menudo no es construir el sistema sino ajustarlo. El RAG de nivel producción contiene dos etapas no deterministas, recuperación y generación, por lo que las pruebas de software tradicionales no son suficientes. Es por eso que construir un sistema de evaluación científico, o evaluación RAG, es tan importante.
5.3.1 Ejemplo para Principiantes: Evaluación RAG Basada en LLM
Para ayudar a construir una comprensión intuitiva de la evaluación RAG, podemos ver un pipeline automatizado simple basado en la idea de LLM-as-a-judge:
https://huggingface.co/learn/cookbook/rag_evaluation
El proceso generalmente contiene tres pasos clave:
- Primero, sintetizar un conjunto de datos de evaluación muestreando documentos de la base de conocimiento y pidiendo a un LLM que genere pares de preguntas y respuestas de alta calidad, luego filtrarlos por relevancia y fundamentación para formar un conjunto de referencia.
- Segundo, ejecutar el sistema RAG en cada pregunta de ese conjunto de prueba y recopilar las respuestas generadas.
- Tercero, puntuación automatizada llamando a otro LLM como juez, comparando las respuestas generadas con las respuestas de referencia y dando puntuaciones cuantitativas para dimensiones como precisión y completitud.
Un ejemplo simple:
- Generación de problemas. Supongamos que la base de conocimiento contiene una línea del manual de un producto que dice, "Este dispositivo soporta carga inalámbrica y tiene una batería de 5000mAh." Pedimos a un modelo que actúe como creador de exámenes y genere una pregunta como, "¿Cuál es la capacidad de la batería de este dispositivo?" La respuesta estándar es "5000mAh."
- Resolución de problemas. Enviamos esa pregunta al sistema RAG, que recupera material relacionado y responde, por ejemplo, "El dispositivo tiene una batería de 5000mAh."
- Calificación. Pedimos a otro modelo que actúe como calificador comparando la pregunta, la respuesta generada y la respuesta de referencia, usando un prompt como, "Juzga si la respuesta generada es correcta. Produce solo correcta o incorrecta."
Al ejecutar este proceso a escala, podemos calcular métricas como la precisión. Esto forma un ciclo práctico de evaluar, optimizar y reevaluar.
Si deseas más detalles sobre la evaluación RAG, incluyendo definiciones de métricas, uso de frameworks y conjuntos de datos de benchmark, dos artículos de revisión útiles son:
- https://arxiv.org/pdf/2504.14891, Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey
- https://arxiv.org/pdf/2405.07437, Evaluation of Retrieval-Augmented Generation: A Survey
5.3.2 Métricas de Evaluación
La evaluación RAG gira fundamentalmente en torno a dos preguntas: ¿puede el módulo de recuperación encontrar el material correcto, y puede el módulo de generación producir una respuesta de alta calidad a partir de ese material? En consecuencia, el sistema de evaluación se divide en evaluación de recuperación y evaluación de generación, complementado por puntuación LLM-as-a-judge.
Evaluación de Recuperación: precisión de recall y calidad de clasificación
El módulo de recuperación es la primera puerta en un sistema RAG. Su evaluación se enfoca en tres dimensiones: si encuentra las cosas correctas, si encuentra suficientes, y si las clasifica bien.
Métricas básicas de calidad de recall
Las métricas básicas clásicas son Recall@K, Precision@K y F1:
- Recall@K mide la proporción de documentos relevantes recuperados en los K resultados principales. Si existen cinco documentos relevantes y tres se encuentran en los 10 principales, Recall@10 es 60 por ciento. Esto nos dice qué tan amplia es la cobertura de recuperación.
- Precision@K mide la proporción de los K resultados principales que son verdaderamente relevantes. Si tres de los 10 principales son relevantes y siete no lo son, Precision@10 es 30 por ciento. Esto refleja la precisión de recuperación.
- F1 es la media armónica de Recall y Precision y equilibra ambas.
Estas métricas son útiles para diagnosticar rápidamente problemas de recall de línea base. Si Recall es bajo, no se encontraron los documentos relevantes. Si Precision es bajo, el ruido de recuperación es demasiado alto.
Métricas de calidad de clasificación
Encontrar documentos relevantes es solo el primer paso. Es aún más importante poner los más relevantes cerca del frente. Para eso miramos MRR, NDCG@K y MAP:
- MRR, Mean Reciprocal Rank, mide el recíproco de la posición de clasificación del primer documento relevante. Si el primer documento relevante aparece en la posición 3, el rango recíproco es 1/3. MRR es especialmente adecuado para escenarios donde una respuesta correcta es suficiente.
- NDCG@K, Normalized Discounted Cumulative Gain, considera tanto la relevancia graduada como el descuento por posición. No solo pregunta si un documento es relevante, sino qué tan relevante es, y recompensa los documentos altamente relevantes que aparecen temprano.
- MAP, Mean Average Precision, es sensible a las posiciones de todos los documentos relevantes y refleja la calidad general de clasificación.
En la ingeniería real, una combinación común es Recall@K más MRR@K. Por ejemplo, si Recall@10 es 80 por ciento pero MRR@10 es solo 0.3, se están encontrando documentos relevantes pero enterrados demasiado profundo, lo que sugiere que el reranking necesita mejora.
Cuando sea necesario, también se puede añadir una métrica de Coverage para monitorear la cobertura de la base de conocimiento y revelar puntos ciegos sistemáticos.
Evaluación de calidad de generación: precisión y fidelidad factual
La recuperación proporciona la materia prima. La siguiente pregunta es si el módulo de generación puede producir una respuesta de alta calidad a partir de esos materiales. Las dimensiones centrales aquí son la precisión de la respuesta y la fidelidad a la evidencia recuperada.
Coincidencia exacta y similitud de texto
La métrica más simple es EM, Exact Match, que requiere que la respuesta generada coincida exactamente con la respuesta de referencia. Esto es adecuado para preguntas de hechos de forma fija y unívocamente correctas como fechas o ubicaciones de sedes, pero es demasiado estricta porque formas superficiales diferentes pero igualmente correctas pueden no coincidir.
Es por eso que las métricas de superposición de n-gramas como ROUGE, BLEU y METEOR también se usan comúnmente. Puntúan las respuestas generadas comparando la superposición de palabras con las respuestas de referencia. ROUGE-L presta atención a las subsecuencias comunes más largas, BLEU proviene de la traducción automática y enfatiza la exactitud, y METEOR añade consideraciones de sinónimos y lematización.
Para superar los límites de la superposición pura de palabras, también podemos usar BERTScore o similitud vectorial directa. Estas usan representaciones semánticas preentrenadas y por lo tanto toleran mejor la variación superficial.
Fidelidad factual y detección de alucinaciones
Para sistemas RAG, la similitud respuesta-referencia no es suficiente. La pregunta más importante es si la respuesta está realmente basada en los documentos recuperados o si alucina contenido no respaldado.
Es por eso que métricas como Tasa de alucinación y Fidelidad son importantes. Un segundo LLM puede actuar como verificador de hechos e inspeccionar la respuesta generada oración por oración, juzgando si cada afirmación puede ser respaldada por los documentos recuperados. Para dominios de alto riesgo como salud, derecho y finanzas, este tipo de métrica es especialmente importante, y algunas empresas incluso imponen umbrales de alucinación como criterios de lanzamiento a producción.
LLM-as-a-Judge: puntuación multidimensional
Cada métrica automática tiene límites. La mayoría de las métricas de forma superficial no pueden capturar completamente la calidad semántica o la utilidad general. Es ahí donde LLM-as-a-judge se vuelve especialmente valioso.
El enfoque básico es alimentar la pregunta, los documentos recuperados, la respuesta del sistema y la respuesta de referencia en un modelo independiente fuerte, como GPT-4 o Claude, y pedirle que puntúe a través de dimensiones como:
- relevancia de la pregunta
- completitud de la información
- fidelidad factual
- corrección general
La fortaleza de un juez LLM es que puede hacer un juicio holístico más similar al humano. Por supuesto, los prompts del juez aún necesitan un diseño cuidadoso y calibración contra ejemplos etiquetados por humanos para mantener la puntuación consistente y confiable.
Construir una combinación de métricas práctica
Con tantas métricas disponibles, los equipos a menudo se preguntan cuáles usar. Una recomendación práctica es empezar con una combinación compacta y expandir gradualmente:
- Para recuperación, comenzar con Recall@K más MRR@K
- Para generación, elegir una o dos métricas de línea base de EM, ROUGE-L y BERTScore según el tipo de tarea
- Para evaluación general, introducir un juez LLM enfocado en relevancia, completitud y fidelidad
Luego iterar a través de un ciclo de evaluación, diagnóstico de problemas, ajuste de estrategia y reevaluación.
5.3.3 Frameworks de Evaluación
A medida que RAG se ha desarrollado rápidamente, tanto la academia como la industria han producido muchos frameworks de evaluación fuertes. Estos frameworks no solo empaquetan métricas comunes, sino que también ofrecen conjuntos de datos estandarizados, procedimientos de benchmark y flujos de trabajo de extremo a extremo.
Una clasificación básica de frameworks
Podemos dividir aproximadamente los frameworks de evaluación RAG en tres categorías:
- Frameworks de investigación, que se enfocan en la exploración académica y el diagnóstico de grano fino. Ejemplos incluyen FiD-Light y Diversity Reranker.
- Frameworks de benchmark, que proporcionan conjuntos de prueba estandarizados y flujos de trabajo para comparar sistemas horizontalmente. Estos incluyen frameworks como RAGAS, ARES, RGB, MultiHop-RAG y CRUD-RAG.
- Frameworks de herramientas, que enfatizan la usabilidad de ingeniería y la integración con frameworks de desarrollo. Ejemplos incluyen TruEra RAG Triad, LangChain Benchmarks y RECALL.
En los últimos años, los frameworks de evaluación se han vuelto más especializados. Por ejemplo, la medicina tiene MedRAG, el derecho tiene LegalBench-RAG, y las finanzas tienen sus propios frameworks específicos de dominio. Estos frameworks de dominio a menudo proporcionan no solo conjuntos de datos especializados sino también métricas especializadas como precisión médica o relevancia de citas legales.
En la práctica, una buena regla general es:
- Si necesitas una línea base rápidamente, comienza con un framework más general como RAGAS.
- Si estás diagnosticando un problema específico, elige un framework más dirigido.
- Si estás en medicina, derecho, finanzas u otro dominio profesional, prefiere frameworks adaptados al dominio cuando sea posible.
- Prefiere herramientas mantenidas activamente con documentación fuerte y comunidades receptivas.
Herramientas comúnmente recomendadas en la comunidad incluyen Ragas, Continuous Eval, TruLens-Eval, las características de evaluación dentro de LlamaIndex, Phoenix, DeepEval, LangSmith y OpenAI Evals.
5.3.4 Benchmarks de Evaluación
La importancia de los benchmarks de evaluación a menudo se subestima. Muchos equipos comienzan a evaluar un sistema RAG con solo un puñado de preguntas de prueba escritas a mano, luego descubren que el rendimiento real en línea difiere bruscamente de las impresiones fuera de línea. La causa raíz es que carecen de datos de evaluación representativos y sistemáticos.
Un benchmark que soporta bien la iteración del sistema generalmente tiene tres características centrales:
- representatividad, lo que significa que cubre preguntas de usuario de alta frecuencia, casos límite e inputs anormales
- estandarización, lo que significa que los formatos de preguntas y respuestas, niveles de dificultad y reglas de puntuación son consistentes
- evolucionabilidad, lo que significa que el benchmark puede actualizarse a medida que la capacidad del sistema y las necesidades de negocio evolucionan
Para la mayoría de las empresas, debido a que los escenarios de negocio son únicos, la respuesta final suele ser construir sus propios conjuntos de datos de evaluación.
- Comienza extrayendo preguntas reales de usuarios de los logs de negocio y muestreándolas por tipo, frecuencia y dificultad.
- Para casos simples, deja que expertos del dominio anoten directamente. Para preguntas más complejas, deja que un LLM fuerte genere respuestas candidatas primero, luego haz que los expertos las revisen.
- Además de la respuesta en sí, etiqueta metadatos como documentos relacionados, tipo de respuesta y nivel de dificultad.
- Actualiza el conjunto de datos periódicamente con nuevos casos difíciles descubiertos en línea.
Si los recursos son limitados y necesitas una línea base rápida, los benchmarks públicos siguen siendo un punto de partida útil. A partir de 2025, existen muchos benchmarks públicos tanto para escenarios generales como verticales:
Al elegir entre ellos, primero aclara el objetivo. ¿Estás estableciendo una línea base, o validando el sistema antes del lanzamiento? Luego verifica si el benchmark cubre los escenarios y el perfil de dificultad que te importan. Para dominios sensibles al tiempo como noticias o finanzas, asegúrate de que el benchmark incluya pruebas sensibles al tiempo.
En la práctica, combinar tu propio conjunto de datos de dominio con benchmarks públicos es a menudo la ruta más robusta porque mantiene la evaluación cerca de las necesidades de negocio reales mientras preserva algo de comparabilidad horizontal.
6. Profundización: Aprender de Competiciones y Tutoriales Abiertos (Opcional)
Los principios y la implementación de línea base anteriores son suficientes para ayudarte a construir un prototipo utilizable, pero aún están a cierta distancia de resolver los problemas más difíciles que aparecen en producción. Si quieres entender técnicas RAG más prácticas y probadas en batalla, una de las formas más eficientes es estudiar las soluciones ganadoras de competiciones y tutoriales fuertes y abiertos. Estas soluciones a menudo concentran las mejores prácticas descubiertas por equipos fuertes después de intentos repetidos en escenarios reales.
Los ejemplos a continuación son representativos en lugar de exhaustivos. Cuando encuentres un problema específico en la práctica, como análisis de PDF, recuperación multimodal u optimización de baja latencia, a menudo es efectivo buscar competiciones relacionadas con ese problema y estudiar los informes técnicos y el código abierto de los equipos ganadores.
6.1 Caché Semántico: optimización de consultas de alta frecuencia
Hugging Face proporciona una implementación de caché semántico construida sobre la base de datos vectorial Chroma:
https://huggingface.co/learn/cookbook/semantic_cache_chroma_vector_database
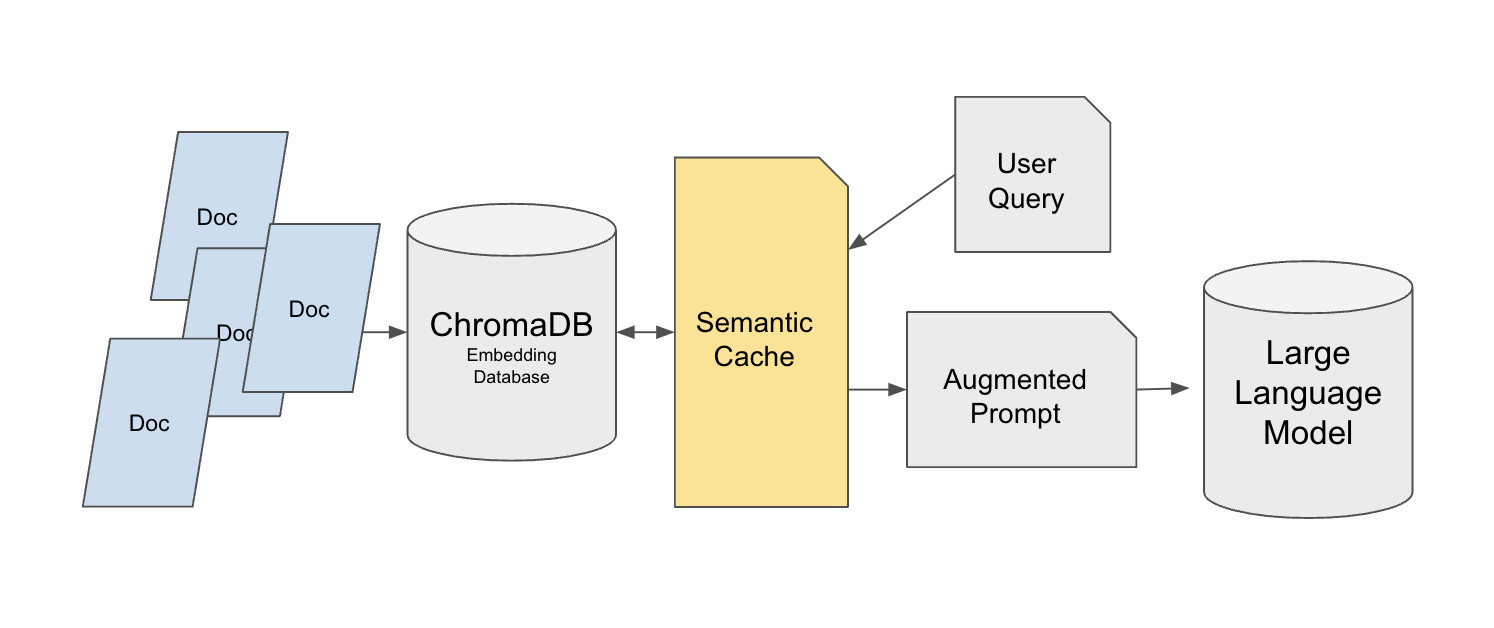
Contexto: La mayoría de los sistemas RAG de tutorial están construidos para pruebas de un solo usuario. Pero una vez desplegados en producción, el sistema puede recibir docenas o miles de consultas repetidas, por ejemplo usuarios de soporte preguntando repetidamente cómo funcionan los reembolsos. Si cada consulta repetida aún activa la recuperación vectorial y una llamada al LLM, la latencia y el costo aumentan rápidamente. Una capa de caché semántico puede reducir bruscamente la presión sobre las fuentes de datos originales mientras preserva la calidad de la respuesta.
Este diseño usa una arquitectura de recuperación de dos capas. La capa base almacena la base de conocimiento original en Chroma, usando un conjunto de datos como MedQuad como ejemplo y asignando a cada entrada un ID único para referencia precisa. La capa de caché se construye sobre FAISS usando un índice FlatL2. El caché semántico se sitúa entre la consulta del usuario y Chroma, en lugar de cachear directamente la respuesta final del LLM. Ese diseño importa porque cachear respuestas directamente puede romper los requisitos de respuestas personalizadas como "explica esto en lenguaje simple."
El sistema de caché usa el SentenceTransformer all-mpnet-base-v2 para generar vectores de consulta y usa distancia euclidiana, con un umbral de 0.35, para juzgar si las consultas son similares. Cuando el caché está lleno, controlado por el parámetro max_response, la entrada más antigua se elimina usando FIFO. Los datos del caché también pueden guardarse en archivos JSON para reuso entre sesiones.
En pruebas a pequeña escala, una primera consulta como "¿Cómo funcionan las vacunas?" tomó 0.057 segundos cuando se obtuvo de Chroma, mientras que una consulta similar servida desde el caché tomó solo 0.016 segundos. En escenarios de producción grandes, este enfoque puede producir una optimización de rendimiento del 90 al 95 por ciento en entornos de alta repetición y reducir significativamente el costo del almacén vectorial y la API.
6.2 Procesamiento de Datos No Estructurados: análisis unificado para documentos multiformato
Otro tutorial de Hugging Face muestra cómo usar la biblioteca Unstructured para construir un pipeline completo para el procesamiento de documentos no estructurados:
https://huggingface.co/learn/cookbook/rag_with_unstructured_data

Contexto: En escenarios empresariales, el conocimiento a menudo está disperso en PDFs, presentaciones de PowerPoint, EPUBs, páginas HTML y muchos otros formatos. Los métodos de preprocesamiento tradicionales o soportan solo un formato o pierden información estructural crucial como tablas y jerarquía de títulos durante la conversión. Esto hace difícil que el sistema RAG entienda y recupere el contenido correctamente.
Esta solución primero descarga documentos de prueba multiformato, como un manual de pesticidas canadiense en PDF que contiene muchas tablas y un archivo PowerPoint de IPM de cítricos de la Universidad de Florida que contiene gráficos y títulos multinivel. Luego usa el Local Runner de Unstructured para el análisis. La configuración incluye una configuración de procesador, una configuración de partición que puede usar opcionalmente el modo de partición API para OCR más fuerte, y una configuración local que define las rutas de entrada. Los documentos analizados se convierten en JSON que contiene elementos tipados como texto del cuerpo, títulos y tablas.
El sistema luego usa chunk_by_title, establece una longitud máxima de 512 caracteres y fusiona fragmentos consecutivos más cortos de 200 caracteres para preservar la coherencia semántica. Durante la conversión en objetos Document de LangChain, los campos de metadatos complejos se filtran para ajustarse a Chroma. La etapa vectorial usa el modelo de embedding BAAI/bge-base-en-v1.5, junto con un Llama-3-8B-Instruct cuantizado en 4 bits y una cadena RetrievalQA de LangChain para construir un sistema RAG completo.
El sistema resultante puede manejar documentos multiformato con precisión. Para preguntas como "¿Son los áfidos una plaga?", puede extraer hechos clave de los documentos analizados y generar respuestas basadas en el material relevante. Esto es especialmente útil para bases de conocimiento empresariales que necesitan procesar muchos tipos de documentos.
6.3 QA de Documentos Empresariales: RAG de alta precisión y rastreable
La solución ganadora del Enterprise RAG Challenge muestra cómo construir un sistema RAG de nivel producción bajo requisitos estrictos de tiempo y precisión:
- https://abdullin.com/ilya/how-to-build-best-rag/
- https://hustyichi.github.io/2025/07/03/rag-complete/
Contexto: Los concursantes tenían que analizar 100 PDFs de informes anuales empresariales reales en 2.5 horas, cada informe con hasta 1000 páginas y conteniendo tablas financieras complejas, diseños multicol y gráficos. Después del análisis, el sistema tenía que responder 100 preguntas de negocio precisas con tipos de respuesta explícitos, como sí-no, nombres de empresas, indicadores numéricos exactos o cargos de ejecutivos, y tenía que citar números de página como evidencia.
El equipo ganador eligió Docling de código abierto de IBM como el analizador de PDF porque funcionó mejor en tablas complejas y texto multicol. Mejoraron el código de Docling para que pudiera producir JSON y Markdown-plus-HTML con metadatos y especialmente mejoraron el análisis de tablas. Para acelerar el procesamiento, alquilaron GPUs RTX 4090 y terminaron el análisis de los 100 informes en 40 minutos.
La fragmentación de texto usó fragmentos de 300 tokens con superposición de 50 tokens y división recursiva para preservar la coherencia semántica. Para evitar la contaminación entre empresas, cada empresa tenía su propio almacén vectorial FAISS usando un índice IndexFlatIP. La recuperación luego siguió tres etapas: recuperar fragmentos Top-30 por vectores, desduplicar por páginas padre porque múltiples fragmentos pueden provenir de la misma página, y reclasificar páginas con GPT-4o-mini. La clasificación final mezcló puntuaciones de recuperación vectorial y reranking del LLM con una división de peso de 0.3 a 0.7.
La generación usó plantillas de prompt diferentes para diferentes tipos de respuesta. Para preguntas numéricas, como ingresos anuales, el sistema usó un proceso de análisis de cinco pasos para asegurar la coincidencia de indicadores, consistencia de unidades y verificación cruzada. Las salidas se estructuraron para incluir el proceso de análisis y referencias de página para trazabilidad.
El sistema ganó dos premios y ocupó el primer lugar en el tablero de clasificación. Una observación importante fue que incluso modelos más pequeños como Llama 8B superaron a más del 80 por ciento de los participantes, mientras que Llama 3.3 70B se acercó a GPT-4o-mini, mostrando que un buen diseño de sistema puede equilibrar exitosamente precisión, eficiencia y costo.
6.4 Escenario AIOps: manejo inteligente de datos mixtos de texto e imagen
El proyecto EasyRAG en una competición RAG de AIOps se enfocó en QA para escenarios de operaciones:
http://blog.csdn.net/hustyichi/article/details/143323746
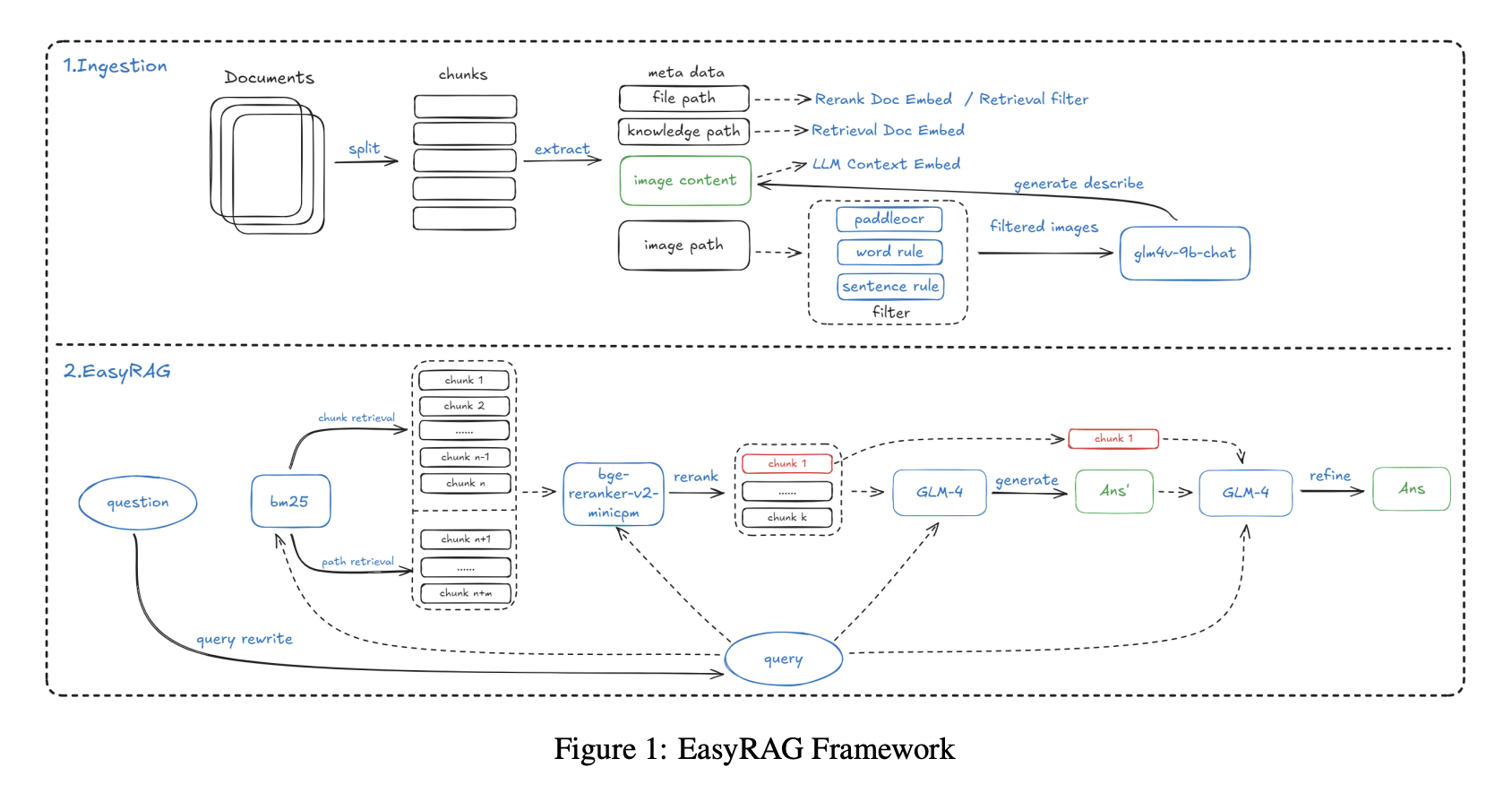
Contexto: Los ingenieros de operaciones a menudo necesitan leer documentos técnicos que incluyen no solo texto sino también gráficos de monitoreo, diagramas de arquitectura del sistema y curvas de rendimiento. Por ejemplo, al diagnosticar un problema del sistema, la respuesta a "¿Qué debería hacer cuando la utilización de la CPU excede el 80 por ciento?" puede estar dispersa entre descripciones de texto y gráficos de monitoreo. El RAG tradicional de solo texto no puede entender las tendencias y valores de los gráficos, por lo que las respuestas permanecen incompletas.
La etapa de indexación usó un SentenceSplitter mejorado con fragmentos de 1024 tokens y superposición de 200 tokens. Una innovación clave fue añadir metadatos como rutas de base de conocimiento y rutas de archivos a cada fragmento, lo que mejoró el recall en un 2 por ciento. Para datos de imagen, el sistema primero usó PaddleOCR para extraer texto de gráficos y capturas de pantalla, luego usó un modelo multimodal, GLM-4V-9B, para generar descripciones en lenguaje natural de la imagen, por ejemplo describiendo una línea de uso de CPU que alcanza un pico del 90 por ciento en la tarde. Tanto el texto OCR como la descripción de la imagen fueron entonces indexados juntos.
La recuperación usó una estrategia de dos vías BM25 más vectorial para recall amplio. BM25 cubrió recuperación de fragmentos y recuperación de rutas, ayudando a filtrar documentos irrelevantes por ruta de archivo, mientras que la recuperación vectorial usó gte-Qwen2-7B-instruct. El reranking usó bge-reranker-v2-minicpm-layerwise, y un ajuste de 28 capas funcionó mejor en los experimentos.
La generación de respuestas usó una estrategia de dos pasos: primero generar un borrador a partir de los documentos Top-6 para maximizar la cobertura de información, luego optimizar la respuesta con el documento Top-1 más relevante para enfatizar la respuesta central.
Para manejar escenarios de texto largo, como un manual de operaciones completo con cientos de páginas, el sistema también implementó compresión de contexto basada en BM25, dividiendo documentos en oraciones, puntuando la similitud de oraciones con la consulta y concatenando solo las oraciones más relevantes. Al 50 por ciento de compresión, este método logró una precisión del 86.48 por ciento en solo 7.7 segundos y superó herramientas como LLMLingua.
6.5 Fusión de Datos Multifuente: colaboración entre conocimiento estructurado y no estructurado
La solución ganadora en el desafío KDD Cup 2024 Meta RAG mostró cómo integrar contenido web no estructurado y grafos de conocimiento estructurados:
Contexto: La Tarea 1 requería resumen de recuperación de cinco páginas web. La Tarea 2 añadió una API mock que representaba un grafo de conocimiento estructurado, permitiendo acceso directo a cosas como bases de datos de películas y relaciones de entidades. La Tarea 3 elevó la dificultad usando cincuenta páginas web más la API mock para responder consultas más complejas, como identificar películas dirigidas por Nolan con taquilla mayor a 500 millones de dólares. Cada consulta tenía que terminar en 30 segundos.
Para la Tarea 1, el equipo ganador construyó un pipeline refinado de procesamiento web. Usaron BeautifulSoup para extraer texto de páginas y ParentDocumentRetriever para gestionar relaciones de fragmentos padre-hijo, usando fragmentos hijos de 200 tokens para recuperación y fragmentos padre de 500 a 2000 tokens para generación. El modelo de embedding fue bge-base-en-v1.5, el almacén vectorial fue Chroma, y el reranking usó bge-reranker-v2-m3. El equipo también complementó datos de películas y finanzas de conjuntos de datos públicos y afinó Llama-3-8B-instruct con LoRA en datos de entrenamiento que incluían preguntas inválidas y respuestas de referencia.
Para las Tareas 2 y 3, la innovación clave fue priorizar el grafo de conocimiento. El sistema definió llamadas API estandarizadas como get_person y get_movie, con soporte de filtrado y ordenamiento. Primero llamaba a la API del grafo de conocimiento y solo recurría a la recuperación web si los resultados del grafo faltaban o eran inválidos. Esto mejoró tanto la velocidad como la precisión de las respuestas.
Debido a que el sistema priorizó el grafo de conocimiento y usó formatos de salida estructurados, la alucinación se redujo claramente. Si el grafo podía proporcionar una respuesta determinista directamente, el sistema la devolvía sin un paso generativo. Si se requería recuperación web, la respuesta tenía que seguir reglas estrictas de citas y razonamiento paso a paso.
La solución ganó el primer lugar en las tres tareas. La lección principal es que en escenarios empresariales que contienen tanto datos estructurados como no estructurados, la estrategia de recuperación debería diseñarse según el tipo de datos: usar datos estructurados deterministas primero y tratar las fuentes no estructuradas como suplementos.
A través de estos casos prácticos, varios principios compartidos aparecen repetidamente:
- elegir estrategias de caché, recuperación y generación según el escenario de negocio
- diseñar rutas de análisis e indexación dedicadas para diferentes formatos y modalidades
- tratar la recuperación híbrida más reranking como una configuración estándar
- usar prompting específico de tarea y salidas estructuradas para mejorar precisión y trazabilidad
Estas lecciones de competiciones reales y proyectos abiertos son referencias valiosas al construir sistemas RAG empresariales más fuertes.
7. Exploración Amplia: La Evolución Futura de RAG (Opcional)
Una vez que hayas aprendido las habilidades prácticas y los métodos de optimización de RAG, ya puedes mejorar el rendimiento del sistema en escenarios concretos. Pero entender solo los trucos de ingeniería local no es suficiente si quieres tener una visión más amplia de hacia dónde se dirige RAG. También necesitamos mirar direcciones evolutivas más amplias.
RAG ahora está rompiendo rápidamente el patrón tradicional de recuperar-fragmentos-de-texto-luego-generar. En esta sección nos enfocamos en varias de esas rutas: pasar de la recuperación de fragmentos a la retrieval de estructura de grafos, combinar imágenes y audio en RAG multimodal, mejorar el manejo de documentos largos a través de la fragmentación tardía vectorizada, y la forma en que RAG gradualmente evoluciona hacia un sistema orientado a agentes.
7.1 Graph RAG: reformando la recuperación profunda con redes de relaciones
Investigación relacionada:
El RAG tradicional funciona encontrando pasajes de texto similares a la pregunta, lo que es como seleccionar los pocos párrafos que parecen más relevantes de una pila de material. Eso funciona bien para la búsqueda directa de hechos. Pero si una pregunta requiere conectar múltiples documentos y combinar diferentes pistas, el rendimiento cae.
Por ejemplo, un médico podría preguntar, "Basándonos en estos casos y las últimas guías de tratamiento, ¿cómo deberíamos evaluar los beneficios y riesgos de cierto medicamento para pacientes ancianos?" O un equipo de proyecto podría preguntar, "Mirando a través de los documentos de requisitos de los últimos dos años, registros de revisión e informes de problemas en línea, ¿qué parte de nuestra arquitectura de sistema falla más a menudo?" Preguntas como estas no se trata de encontrar una sola oración. Requieren identificar a las personas, objetos, eventos y relaciones dispersas en múltiples materiales y formar un cuadro completo.
Graph RAG construye ese cuadro proactivamente. El sistema usa un modelo grande para identificar entidades clave del texto, como personas, organizaciones, módulos funcionales, eventos y datos, junto con sus relaciones, como causalidad, dependencia, cambio y contradicción. Luego construye una red de conocimiento que crece a medida que se añade más material. A través de la agrupación automática, las entidades y relaciones estrechamente conectadas se organizan en temas, y cada tema puede resumirse por adelantado. Cuando un usuario hace una pregunta, el sistema ya no busca solo pasajes de texto que parezcan similares. Primero encuentra las entidades más relevantes y la estructura local del grafo, se expande a través de grupos de temas relacionados, y luego da la ruta de análisis, descripciones de nodos y pasajes fuente juntos al LLM para razonamiento.
Bajo este framework, Graph RAG y el RAG tradicional se complementan mutuamente. El RAG tradicional sigue siendo fuerte para preguntas de detalle cuyas respuestas pueden encontrarse en un paso. Graph RAG se acerca más a cómo piensa un investigador humano: primero organizar la estructura general y los temas, luego completar la evidencia, y finalmente producir una conclusión con lógica y condiciones. Las comparaciones existentes muestran que en tareas de razonamiento multi-salto, Graph RAG a menudo cubre más contenido crítico y proporciona una perspectiva más amplia. La combinación flexible de ambos enfoques es a menudo mejor que usar solo uno.
7.2 RAG Multimodal
Investigación relacionada:
Los datos del mundo real nunca son solo texto. Los ingenieros diagnosticando fallos de servidores necesitan mirar curvas de temperatura, capturas de pantalla de dispositivos y logs juntos. Los médicos haciendo diagnósticos necesitan imágenes de CT o MRI, informes de pruebas y registros médicos electrónicos al mismo tiempo. El RAG de texto tradicional puede a lo sumo recuperar frases como "anomalía de temperatura" o "posible nódulo pulmonar", pero le resulta difícil conectar esas descripciones con la tendencia real del gráfico o la forma de la lesión en la imagen, y no puede buscar inversamente documentos o conocimiento a partir de imágenes, audio o video.
El RAG multimodal resuelve este problema de diferentes modalidades que no pueden "verse" entre sí. Su núcleo es la alineación semántica transversal. El sistema usa codificadores adecuados para imágenes, video, audio y texto, junto con OCR, ASR y análisis de diseño, extrae información clave de fuentes visuales y auditivas, y mapea diferentes modalidades en un espacio semántico compartido donde se puede construir un índice multimodal unificado.
En el momento de la recuperación y generación, ya sea que el usuario pida un gráfico que muestre un pico de ventas en el Q3 de 2023 o suba un boceto o video de operación, el sistema primero encuentra la evidencia multimodal más cercana en ese espacio unificado, la filtra por señales como similitud de texto y similitud de imagen, mantiene las piezas más útiles, y luego da esas imágenes, pasajes de texto y tablas juntos a un LLM multimodal. El modelo puede entonces responder combinando evidencia a través de modalidades e idealmente indicar la fuente o resaltar áreas relevantes en la imagen o documento.
Comparado con el RAG de solo texto, el RAG multimodal puede usar más tipos de evidencia y a menudo reduce la alucinación mientras produce respuestas más completas y más verificables.
7.3 Late Chunking: preservando el contexto completo para documentos largos
Introducción relacionada:
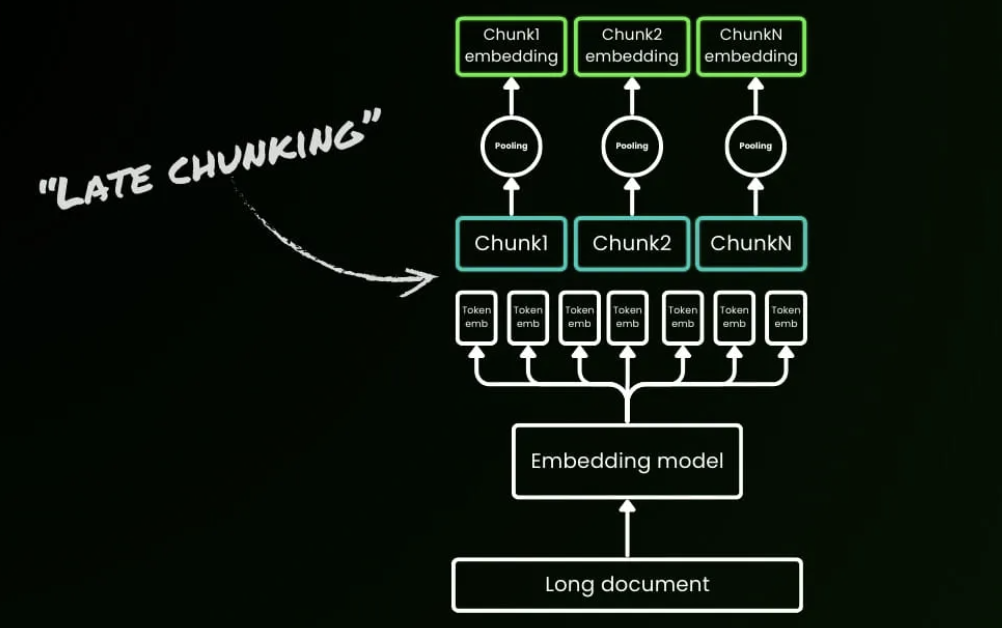
Imagina leer un artículo de Wikipedia sobre Berlín. El RAG tradicional primero lo cortaría en párrafos independientes y luego embebería cada fragmento. Si la primera oración dice "Berlín es la capital de Alemania", frases posteriores como "la ciudad" o "su población" pierden su conexión con Berlín una vez separadas. Una consulta como "¿Cuál es la población de Berlín?" puede entonces fallar porque el término Berlín y la información de población nunca aparecieron dentro del mismo fragmento. Este problema se vuelve aún peor para documentos largos. En un contrato de seguros de 200 páginas, la definición de un deducible puede aparecer en la página 5 mientras las condiciones bajo las cuales se aplica aparecen en la página 30. La fragmentación de longitud fija puede dividir estas piezas relacionadas en docenas de fragmentos aislados, y los experimentos muestran que la similitud semántica puede caer bruscamente cuando eso sucede.
Late Chunking invierte el pipeline tradicional de fragmentar-primero-luego-embeber y en su lugar sigue embeber-primero-luego-fragmentar. Con modelos de embedding de contexto largo que pueden manejar algo como 8192 tokens, todo el documento se pasa primero a través del Transformer, produciendo embeddings a nivel de token que ya han visto el documento completo. Solo después se agrupan esos embeddings de tokens informados globalmente en embeddings de fragmentos según los límites de fragmentos. Los fragmentos resultantes ya no son islas independientes. Son embeddings dependientes del contexto que preservan referencias transversales entre párrafos y relaciones conceptuales.
En los conjuntos de datos del benchmark BEIR, Late Chunking supera a la fragmentación tradicional ampliamente, con ganancias especialmente fuertes en documentos más largos. En escenarios de texto corto, la diferencia desaparece en gran medida, lo que confirma una regla clave: cuanto más largo es el documento, mayor es la ventaja de Late Chunking. El método ahora está integrado en Jina Embeddings v3. Aunque codificar primero un documento largo completo puede aumentar el tiempo de inferencia en un 10 a 20 por ciento, las ganancias de recuperación en escenarios como registros médicos, documentos legales y manuales técnicos pueden justificar fácilmente ese costo.
Late Chunking muestra que los modelos de embedding de contexto largo de 8K-plus no son exceso de ingeniería en estos escenarios. A menudo son necesarios para producir embeddings de fragmentos de alta calidad y representan un cambio de fragmentar primero, luego embeber, a embeber primero, luego fragmentar.
7.4 De RAG a RAG en la Era de los Agentes
Discusiones relacionadas:
- https://ragflow.io/blog/rag-at-the-crossroads-mid-2025-reflections-on-ai-evolution
- https://arxiv.org/pdf/2501.09136
- https://www.letta.com/blog/rag-vs-agent-memory
- https://www.linkedin.com/posts/richmondalake_100daysofagentmemory-rag-memorizz-activity-7348281860843577346-LM7Y/
- https://www.llamaindex.ai/blog/rag-is-dead-long-live-agentic-retrieval
RAG se ha desarrollado desde una herramienta de generación aumentada por recuperación hasta convertirse en una parte clave de la arquitectura cognitiva de un agente. El RAG tradicional está construido sobre un patrón simple de preguntar, recuperar, responder y es fundamentalmente pasivo. Espera una consulta y no actúa proactivamente. Para romper esa pasividad y manejar tareas cognitivas más complejas, RAG se ha combinado profundamente con capacidades de agente, dando lugar a un nuevo paradigma: Agentic RAG.
Bajo este paradigma, el rol de RAG cambia fundamentalmente. Ya no es solo un proveedor pasivo de conocimiento externo. En cambio, se convierte en la unidad de procesamiento central que soporta el comportamiento inteligente bajo la planificación activa, dirección por objetivos y autorreflexión del agente. Esta fusión da al sistema general orientación a objetivos, optimización iterativa y toma de decisiones autónoma, profundizando enormemente la calidad de la interacción humano-IA. Agentic RAG puede entender tareas complejas, descomponerlas, planificar estrategias de recuperación y evaluar la calidad de los resultados iniciales para decidir si se necesita una exploración más profunda.
La clave de esta capacidad es un bucle activo multicapa. Frente a una consulta compleja, el agente primero analiza la naturaleza del problema, lo descompone en subproblemas y diseña estrategias de recuperación precisas para cada subproblema. Después de recibir los resultados iniciales, los evalúa, juzga si la información es completa y relevante, identifica brechas de conocimiento y genera dinámicamente nuevas consultas más precisas. Este proceso iterativo a menudo incluye recuperación multi-salto, donde una ronda de resultados revela nuevas direcciones para la siguiente ronda, produciendo una cadena de exploración de conocimiento similar a cómo trabaja un investigador humano.
Para soportar este comportamiento inteligente continuo e iterativo, especialmente cuando la personalización y la acumulación de conocimiento a largo plazo importan, el contexto de conversación a corto plazo por sí solo está lejos de ser suficiente. Esto lleva a la necesidad de memoria estructurada a largo plazo.
Es exactamente por eso que RAG es cada vez más asignado al rol de sistema de memoria a largo plazo de un agente y usado para construir una arquitectura de memoria externa completa. Esta memoria a largo plazo complementa la memoria a corto plazo, que es responsable de mantener el contexto de diálogo actual. El sistema de memoria a largo plazo depende de tres mecanismos clave:
- Capacidad de indexación estructurada: Esto permite al agente construir índices multidimensionales sobre enormes cantidades de datos no estructurados, por tiempo, tema, relaciones de entidades y más, soportando recuperación eficiente desde múltiples ángulos de manera similar a cómo los humanos recuerdan información a través de diferentes pistas.
- Olvido inteligente: A través de algoritmos de evaluación de valor, el sistema puede decaer o descartar selectivamente información de baja frecuencia, débilmente relacionada u obsoleta, manteniendo el sistema de memoria esbelto y eficiente y previniendo la sobrecarga.
- Consolidación de conocimiento: El sistema refina la experiencia dispersa de diálogo e interacción en conocimiento estructurado. A través del reconocimiento de entidades, extracción de relaciones y clustering semántico, la información fragmentada se conecta en grafos de conocimiento, convirtiendo la experiencia a corto plazo en conocimiento a largo plazo.
Este sistema de memoria externa construido sobre RAG no solo expande significativamente el límite cognitivo de un agente, sino que también le da la capacidad de continuar aprendiendo y evolucionando su conocimiento. Permite al agente acumular experiencia a lo largo de la interacción a largo plazo, formar patrones operativos personalizados y sistemas de conocimiento de dominio, y soportar tareas más complejas y de mayor duración.
Resumen
La Generación Aumentada por Recuperación no es solo un método técnico para compensar la alucinación y la obsolescencia del conocimiento en modelos grandes. Es también un puente clave para transformar la capacidad general de IA en valor empresarial profundo. La evolución desde Naive RAG hasta formas modulares y agenticas muestra que cada parte de RAG necesita profundizarse continuamente, incluyendo un manejo de datos más fino, una selección de modelos más científica en las etapas de embedding, rerank y LLM, y una evaluación más sistemática. Todos estos son pasos necesarios hacia la construcción de sistemas de conocimiento empresariales que sean controlables, confiables y eficientes. Al mismo tiempo, extraer lecciones de competiciones y casos de ingeniería es una de las mejores formas de profundizar la comprensión de los detalles técnicos.
A medida que Graph RAG, la comprensión multimodal y Late Chunking continúan desarrollándose y combinándose, RAG está avanzando constantemente más allá del antiguo límite de recuperación-y-generación y moviéndose hacia una asociación semántica más profunda y una capacidad de memoria más sostenible. La esperanza es que este artículo de estilo revisión te ayude a construir una metodología de cadena completa, desde el principio hasta la práctica y desde la evaluación hasta la evolución, para que en un panorama técnico que cambia rápidamente puedas construir aplicaciones inteligentes de alta calidad que realmente aterricen en el mundo real y puedan manejar desafíos de negocio complejos.
Referencia
[1] Ask in Any Modality: A Comprehensive Survey on Multimodal Retrieval-Augmented Generation.
https://arxiv.org/pdf/2502.08826
[2] Retrieving Multimodal Information for Augmented Generation: A Survey.
https://arxiv.org/pdf/2303.10868
[3] A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models.
https://arxiv.org/pdf/2405.06211
[4] Retrieval-Augmented Generation for Large Language Models: A Survey.
https://arxiv.org/pdf/2312.10997
[5] LightRAG: Simple and Fast Retrieval-Augmented Generation.
https://arxiv.org/pdf/2410.05779
[6] Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG.
https://arxiv.org/pdf/2501.09136
[7] ERAGent: Enhancing Retrieval-Augmented Language Models with Improved Accuracy, Efficiency, and Personalization.
https://arxiv.org/pdf/2405.06683
[8] Graph Retrieval-Augmented Generation: A Survey.
https://www.arxiv.org/pdf/2408.08921
[9] Evaluation of Retrieval-Augmented Generation: A Survey.
https://arxiv.org/pdf/2405.07437
[10] Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey.
https://arxiv.org/pdf/2504.14891
[11] From Local to Global: A Graph RAG Approach to Query-Focused Summarization.
https://arxiv.org/pdf/2404.16130
[12] RAG vs. GraphRAG: A Systematic Evaluation and Key Insights.
https://arxiv.org/pdf/2502.11371
[13] Introduction to RAG | LlamaIndex Python Documentation.
https://developers.llamaindex.ai/python/framework/understanding/rag/
[14] All-in-RAG | A Full-Stack Guide to RAG in Large-Model Application Development.
https://datawhalechina.github.io/all-in-rag/#/en/
[15] Ilya Rice: How I Won the Enterprise RAG Challenge.
https://abdullin.com/ilya/how-to-build-best-rag/
[16] RAG Research Table - Awesome Generative AI Guide (GitHub).
[17] RAG is dead, long live agentic retrieval.
https://www.llamaindex.ai/blog/rag-is-dead-long-live-agentic-retrieval
[18] LLM/RAG Zoomcamp extra lesson 5: Common evaluation methods and market preferences in RAG evolution.
https://vip.studycamp.tw/t/llmrag-zoomcamp-課外補充-5:rag-evolution-常見評估方法和市場偏好/8185
[19] How to Evaluate Retrieval Augmented Generation (RAG) Applications.
https://zilliz.com.cn/blog/how-to-evaluate-rag-zilliz
[20] RAG is not Agent Memory.
https://www.letta.com/blog/rag-vs-agent-memory
[21] Richmond Alake. LinkedIn post on #100DaysOfAgentMemory, RAG and MemoRizz.