Mit der zunehmenden Verbreitung großer Sprachmodelle (LLMs) sehen sich Unternehmen einem sehr praktischen Problem gegenüber: Wie kann ein Modell Fragen präzise beantworten, wenn diese Fragen von internen Dokumenten, Echtzeitdaten oder domänenspezifischem Wissen abhängen? Die Trainingsdaten eines Modells sind schließlich begrenzt und zeitlich eingeschränkt, sodass sie unternehmensspezifisches Geschäftswissen oder ständig aktualisierte Informationen nicht abdecken können.
Ein naheliegender Gedanke ist: Da Kontextfenster immer größer werden – von 8K über 128K bis hin zu über einer Million Tokens –, warum nicht einfach die relevanten Dokumente in den Prompt einfügen und das Modell direkt aus diesen Materialien antworten lassen?
Allerdings sind die Fähigkeit, lange Kontexte zu verarbeiten, und die Fähigkeit, in Unternehmensszenarien stabil, effizient und kontrollierbar richtige Antworten zu liefern, zwei völlig unterschiedliche Dinge. Das blinde Verlassen auf lange Kontexte bringt eine Reihe schwerwiegender Herausforderungen mit sich, darunter explodierende Kosten, aufmerksamskeitsverdünnung und veraltete Wissensaktualisierungen.
Um diese Schmerzpunkte zu lösen, entstand eine Technik namens Retrieval-Augmented Generation, kurz RAG. Bevor das Modell eine Antwort generiert, ruft RAG zunächst präzises externes Wissen ab. Im Vergleich zur einfachen Brute-Force-Erweiterung der Kontextlänge erfüllt RAG die Unternehmensanforderungen an faktische Genauigkeit und frisches Wissen bei geringeren Kosten, höherer Präzision und stärkerer Kontrollierbarkeit. Daher ist es zu einer wichtigen Grundlage für den Aufbau vertrauenswürdiger KI-Anwendungen geworden.
In diesem Tutorial werden wir systematisch erklären, was RAG ist, den Hintergrund seiner Entstehung und seine Kernprinzipien nachverfolgen und dann seine Entwicklung von einfachen zu fortgeschrittenen Formen sowie seine möglichen weiteren Schritte untersuchen.
Was Sie in dieser Lektion lernen werden
- Der Kernwert von RAG: tiefes Verständnis, wie es die zentralen Probleme langer Kontexte bei Kosten, Aufmerksamkeit und Wissensfrische löst
- Wie RAG funktioniert: an konkreten Beispielen sehen, wie es die vollständige Schleife vom Abruf bis zur Generierung durchläuft
- Die Evolution von RAG: von einfachem Naive RAG über Advanced RAG bis hin zu Modular RAG
- Modellauswahl für RAG: verstehen, wie man die drei Schlüsselmodelltypen Embedding, Rerank und LLM bewertet und auswählt
- RAG in der Unternehmenspraxis: den Leitfaden zur Konstruktion der gesamten Kette von der Datenvorverarbeitung bis zur Systembereitstellung und -bewertung kennenlernen
- RAG-Bewertung und -Optimierung: Kernmetriken, etablierte Frameworks und Methoden zur kontinuierlichen Verbesserung verstehen
- Aktuelle Trends bei RAG: erkunden, wie RAG sich mit Agenten, Multimodalität und anderen aufstrebenden Techniken verbindet
Was Sie gewinnen werden
Nach Abschluss dieses Tutorials werden Sie ein systematisches Grundlagenverständnis der RAG-Technologie aufbauen. Sie werden nicht nur wissen, was es ist, sondern auch, warum es funktioniert. Sie werden außerdem eine klare Vorlage dafür erhalten, wie Sie ein effizientes, zuverlässiges und kontrollierbares RAG-System bewerten, auswählen und entwerfen können, das den Unternehmensanforderungen entspricht, und damit ein solides Fundament für den Aufbau echter unternehmensweiter RAG-Anwendungen legen.
1. Warum RAG benötigt wird
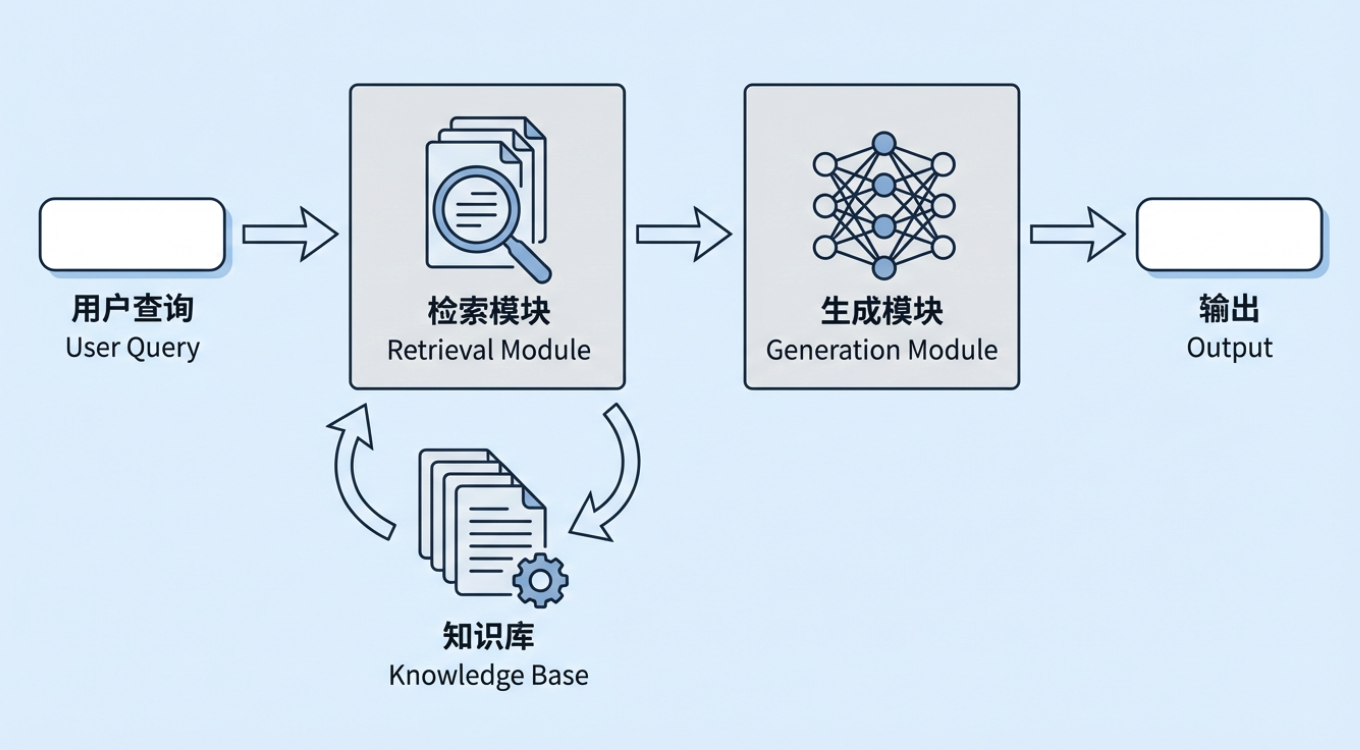
Retrieval-Augmented Generation (RAG) ist einer der wichtigsten technischen Ansätze in der generativen KI heute. Die Grundidee ist einfach: Bevor ein großes Modell aufgefordert wird, eine Antwort zu generieren, ruft das System zunächst Informationen ab, die mit der Frage des Benutzers zusammenhängen, aus einer externen Wissensbasis und übergibt dann sowohl die abgerufenen Informationen als auch die ursprüngliche Frage an das Modell, damit es auf der Grundlage realer Materialien antworten kann. Diese externe Wissensbasis kann interne Unternehmensrichtlinien, Prozessdokumente und Produktwissen sein oder eine Branchendatenbank, einen regulatorischen Korpus, eine Normenbibliothek usw.
An diesem Punkt stellt sich eine natürliche Frage: Wenn große Modelle bereits „Fragen direkt beantworten" können, warum eine zusätzliche Ebene namens Retrieval-Augmented Generation hinzufügen? Besonders da Kontextfenster immer größer werden, kann es so wirken, als ob die einfache Übergabe aller relevanten Materialien an das Modell die meisten Anforderungen lösen sollte.
Der eigentliche Unterschied besteht darin, dass „eine Antwort produzieren können" und „in einer realen Geschäftsumgebung kontinuierlich, stabil und kontrollierbar die richtige Antwort produzieren können" zwei völlig unterschiedliche Dinge sind. Wenn man sich nur auf das Parametergedächtnis eines Modells verlässt oder nur darauf, große Dokumentmengen in einen langen Kontext zu laden, treten in der Unternehmensnutzung mindestens drei typische Probleme auf.
Kosten- und Effizienzprobleme: Auch wenn Kontextfenster immer weiter wachsen, ist die Idee, alle Dokumente auf einmal in den Kontext zu laden, in realen Systemen weiterhin unpraktisch. Der zentrale Widerspruch zeigt sich an zwei Stellen:
Inferenzkosten korrelieren stark positiv mit der Kontextlänge. Je länger der Kontext, desto stärker steigen die Inferenzkosten, nahezu linear und manchmal sogar superlinear. Für einen einzelnen Aufruf liegen 8K Tokens und 200K Tokens in völlig unterschiedlichen Preis- und Latenzbereichen, und lange Kontexte haben eine deutlich höhere Kostenschwelle.
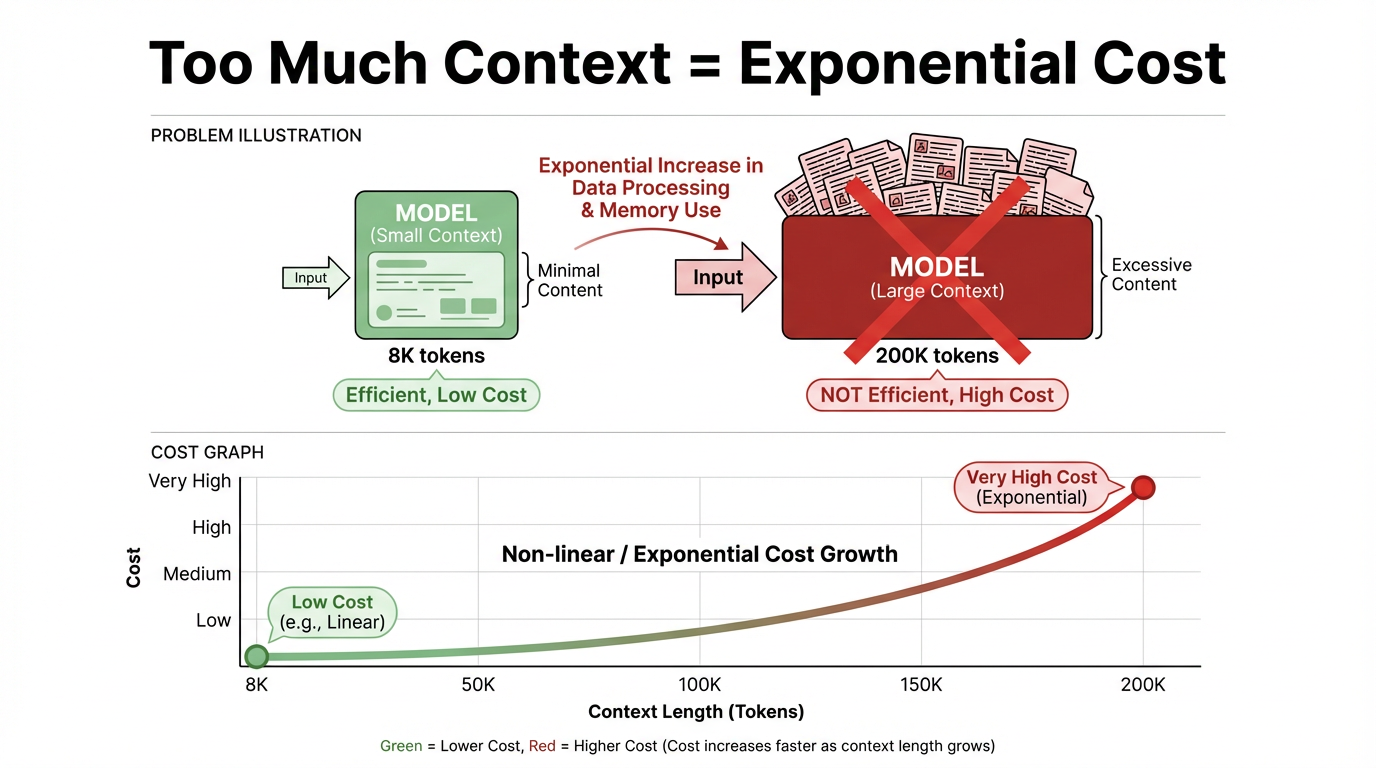
Im inhaltlichen Sinn ist der Kontext die Hintergrundinformation und Gesprächshistorie, auf die sich das Modell beim Beantworten einer Frage „bezieht". Technisch gesehen ist es die gesamte Token-Sequenz, die dem Modell für eine Inferenz übergeben wird, wie System- und Benutzeranweisungen, Nachrichtenhistorie und abgerufene Passagen.
Ein „Kontextfenster" ist die Kapazitätsbegrenzung für diese Eingabe. In heutigen gängigen Großmodellarchitekturen wie Transformatoren nehmen diese Token an jeder Schicht an der Attention-Berechnung teil. Sobald das Fenster länger und die Token-Anzahl steigt, steigen Rechenleistung und Kosten multiplikativ und können sogar exponentielles Wachstum erreichen.
Eine große Menge an Rechenleistung wird verschwendet. Die meisten Aufgaben benötigen nur einen sehr kleinen Anteil an Informationen, die für die aktuelle Frage hochrelevant sind. Das Einfügen des gesamten Dokumentbestands in den Kontext führt zu erheblicher Leerlauf- und verschwendeter Rechenleistung, senkt den Systemdurchsatz, verlangsamt die Antwortgeschwindigkeit und beeinträchtigt letztendlich die Benutzererfahrung.
Aufmerksamkeits- und Fokusprobleme: Ein großes Modell kann zwar ultralange Kontexte „abdecken", aber es kann nicht jedes Segment mit gleicher Qualität nutzen. Sobald die Kontextlänge einen bestimmten Schwellenwert überschreitet, zeigt das Modell eine deutliche Aufmerksamkeitsverzerrung:
Aufmerksamkeitsverfall: Die Aufmerksamkeit des Modells für frühe und mittlere Teile des Kontexts schwächt sich allmählich ab, und es neigt dazu, sich stärker auf Text zu verlassen, den es später gelesen hat, sodass frühzeitig kritische Informationen effektiv ignoriert werden können.
Informationsinterferenz: Das Modell kann leicht durch irrelevante, repetitive oder sogar widersprüchliche Informationen innerhalb des Kontexts vom Kurs abgebracht werden. Die endgültige Antwort mag logisch kohärent klingen, während sie dennoch vom Kern der Frage abweicht, was die Genauigkeit schwer garantiert. Ohne eine Abrufstufe zur Filterung und Rangordnung der Relevanz wird es umso schwerer, die Antwort auf die wirklich schlüssigen Beweise zu fokussieren, je länger der Kontext wird. Der Vorteil eines langen Kontexts kann durch Informationsinterferenz vollständig aufgehoben werden.
Probleme der Wissensfrische und Kontrollierbarkeit: Wenn das gesamte Wissen ausschließlich in Modellparametern gespeichert oder manuell in Prompts kopiert wird, treten zwei unvermeidbare Mängel auf:
Wissensaktualisierungen sind schwierig: Sobald sich das Wissen ändert – wie Richtlinienänderungen, Produktiterationen oder Preisaktualisierungen – muss man entweder das Modell neu trainieren oder feintunen, was kostspielig und langsam ist, oder Prompt-Vorlagen manuell pflegen, was ebenfalls kostspielig und fehleranfällig ist.
Rückverfolgbarkeit ist schlecht: Wenn ein Modell antwortet, ist es oft schwierig, die genauen Beweisstücke entweder aus Black-Box-Parametern oder langen Prompts zu lokalisieren. Dies macht Compliance-Audits, Risikoberichte und andere Aufgaben, die klare Entscheidungsgrundlagen erfordern, extrem schwierig.
Unter diesen realen Rahmenbedingungen wird der Vorteil von RAG viel klarer. Sein Kernansatz besteht darin, relevante und zuverlässige Informationen vor der Generierung zu lokalisieren, sodass das Modell nur aus notwendigem Wissen antwortet. Wissen kann unabhängig in einer externen Wissensbasis gespeichert werden, was Aktualisierung und Verwaltung erleichtert. Gleichzeitig können generierte Ergebnisse zitierte Quellen enthalten, was die Erklärbarkeit und Vertrauenswürdigkeit verbessert. Selbst wenn Kontextfenster in Zukunft weiter wachsen, wird RAG weiterhin ein effizientes Wissensmanagement und -nutzung zu relativ niedrigen Kosten ermöglichen und unternehmensweite Wissensanwendungen unterstützen, deren Prozess beobachtbar und deren Verhalten rückverfolgbar ist.
Aus der Perspektive der Unternehmensanforderungen löst RAG im Vergleich zu einem traditionellen LLM, das sich nur auf seine internen Parameter verlässt, hauptsächlich die folgenden realen Bereitstellungsprobleme:
- Frische: Traditionelle Modelle kennen neue Vorschriften, Produkte oder Arbeitsabläufe, die nach ihrem Trainingsabschluss erschienen sind, in der Regel nicht, aber RAG kann die neuesten Richtliniendokumente, Geschäftsdatenbanken und Wissensbasen direkt lesen. Ohne häufiges Neu-Training können die Antworten mit dem neuesten Geschäftsstand synchronisiert werden.
- Spezialisierung: In vertikalen Domänen wie Gesundheit, Chemie oder Finanzen verstehen Allzweckmodelle oft nicht tief genug oder sprechen nicht präzise genug. Nach der Anbindung unternehmenseigener Domänendokumente und Branchenstandards können Antworten auf autoritativen Materialien basieren und viel näher an der realen Geschäftspraxis sein.
- Halluzination: Indem das System verlangt, dass Antworten auf abgerufenen Passagen basieren und Quellenangaben liefern, kann es auf Mechanismusebene unbegründete Fälschungen reduzieren und macht „klingt wahr" viel näher an „ist tatsächlich wahr".
- Erklärbarkeit und Prüfbarkeit: Rein parameterbasierte Modelle können oft nicht die Frage beantworten: „Aus welcher Regel wurde diese Schlussfolgerung abgeleitet?" RAG ermöglicht es, jede Antwort auf eine bestimmte Richtlinienklausel, ein Geschäftsdokument oder einen historischen Fall zurückzuführen. Das hilft Geschäftspersonal bei der Überprüfung und Korrektur von Antworten und gibt Audit-, Risiko- und Compliance-Teams die benötigte Rückverfolgbarkeit.
- Rechenkosten und Ressourceneffizienz: Ein Modell dazu zu bringen, das gesamte Unternehmenswissen in seinen Parametern zu speichern, bedeutet in der Regel ein größeres Modell und höhere Inferenzkosten. RAG speichert das meiste Wissen außerhalb des Modells in Vektorspeichern und Dokumentenspeichern und ruft es bei Bedarf ab, sodass Unternehmen selbst mit kleineren Modellen und begrenzter Rechenleistung eine breitere Abdeckung und genauere Details erzielen können.
Daher ist RAG für Unternehmen, die große Modelle langfristig, stabil und kontrollierbar in realen Geschäftsszenarien einsetzen möchten, keine optionale Erweiterung. Es ist fast eine unverzichtbare Grundlagentechnologie für den Aufbau eines hochwertigen unternehmensweiten Wissensanwendungssystems.
2. Was RAG ist
Die Kernidee von RAG, Retrieval-Augmented Generation, besteht darin, ein großes Modell Fragen nicht nur mit dem statischen Wissen beantworten zu lassen, das während des Trainings gelernt wurde, sondern auch mit aktuellen und zuverlässigen Informationen, die zur Laufzeit aus einer externen Wissensbasis abgerufen werden.
In einem typischen RAG-System wird die Frage des Benutzers nicht direkt an das große Modell gesendet. Stattdessen sucht ein Abrufmodul zunächst die relevantesten Dokumentpassagen aus der Unternehmenswissensbasis, kombiniert diese Passagen dann mit der ursprünglichen Frage zu einem vollständigen Kontext und übergibt diesen schließlich dem Modell zur Generierung einer Antwort. Dieses Muster „zuerst abrufen, dann generieren" ermöglicht es dem Modell, aus echtem Referenzmaterial zu schlussfolgern, anstatt nur aus dem zu raten, was es in seinen Parametern gespeichert hat. Wir können uns ein typisches Beispiel ansehen:
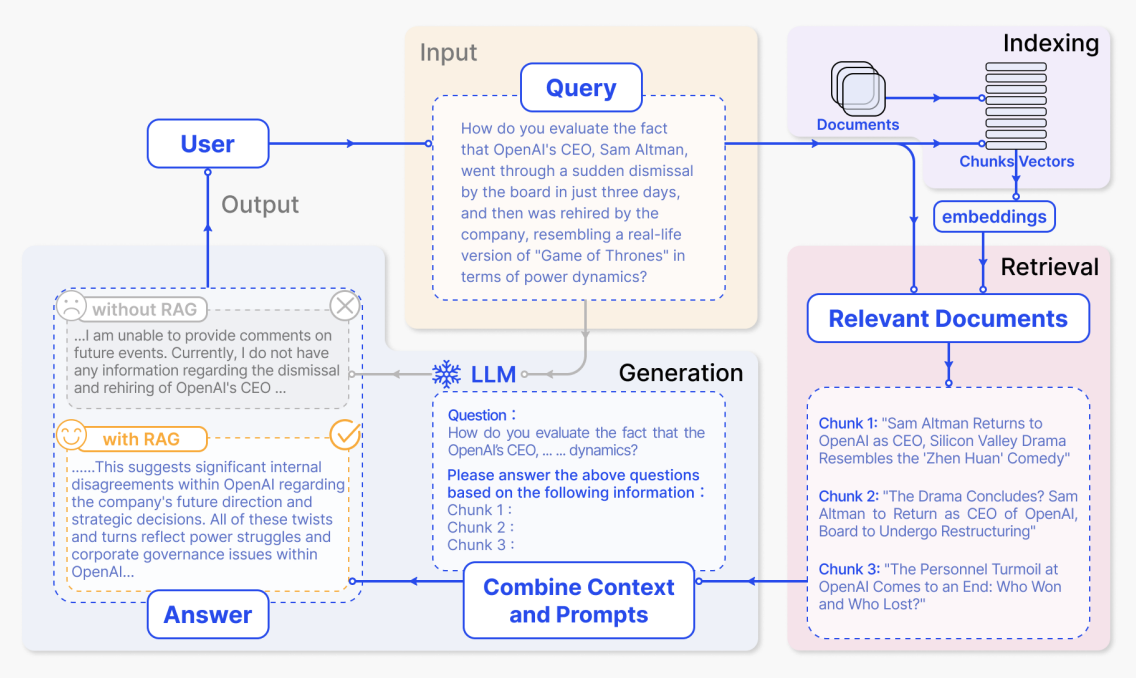
Indexierungsstufe
In der Indexierungsstufe verarbeitet das System zunächst Rohmaterial wie interne Unternehmensdokumente, Webseiten und Berichte. Es teilt sie in kleinere semantische Abschnitte auf, verwendet dann ein Embedding-Modell, um Vektordarstellungen für jeden Abschnitt zu generieren, und erstellt einen Index. Wenn später eine Benutzerfrage eingeht, kann das System schnell die semantisch ähnlichsten Abschnitte im Vektorraum finden.
Im Diagramm entspricht dies dem violetten „Indexing"-Bereich oben rechts. Der Pfad von „Documents" über „Chunks / Vectors" zu „embeddings" zeigt, wie Dokumente aufgeteilt, in Vektoren umgewandelt und in den Index geschrieben werden. Konkreter:
- Dokumente werden in eine Reihe semantisch kohärenter Abschnitte unterteilt, von denen jeder einer kurzen Nachricht, einer Erklärung oder einer Analyse entsprechen kann.
- Jeder Abschnitt wird durch das Embedding-Modell in einen hochdimensionalen Vektor umgewandelt und im Vektorindex gespeichert.
- Dieser Index unterstützt später die ähnlichkeitsbasierte Suche und bereitet eine Wissensbasis vor, die das System bei der Beantwortung von Fragen konsultieren kann.
Abrufstufe plus Antwortgenerierung aus abgerufenen Ergebnissen
Nachdem der Benutzer eine Frage gestellt hat, ruft das System zunächst relevante Inhalte aus dem Index ab und sendet dann die Frage und den abgerufenen Text zusammen an das große Modell, um eine Antwort zu generieren. In der Abbildung entsprechen die Schlüsselbereiche von oben nach unten und von rechts nach links genau diesem gesamten Ablauf.
(1) Benutzereingabe-Frage: der gelbe Input - Query-Bereich
„Wie bewerten Sie die Tatsache, dass OpenAIs CEO Sam Altman innerhalb von nur drei Tagen vom Vorstand plötzlich entlassen und dann vom Unternehmen wieder eingestellt wurde, ähnlich einer realen Version von 'Game of Thrones' in Bezug auf Machtdynamik?"
„Wie bewerten Sie die Tatsache, dass OpenAI-CEO Sam Altman vom Vorstand plötzlich entlassen und dann vom Unternehmen nur drei Tage später wieder eingestellt wurde, wodurch der Machtkampf einer realen Version von Game of Thrones gleicht?"
Dieser große Textblock ist der Inhalt innerhalb des „Query"-Kastens im Diagramm und entspricht der Frage des Benutzers in natürlicher Sprache. Das System vektorisiert diese Frage und nutzt sie, um im Index oben rechts nach verwandten Dokumentabschnitten zu suchen.
(2) Abgerufene relevante Dokumente: der rosa Relevant Documents-Bereich unten rechts
Nach dem Abruf erhält das System mehrere Dokumentabschnitte, die am stärksten mit der Frage zusammenhängen. Im Diagramm werden sie als drei Abschnitte dargestellt:
„Sam Altman kehrt als CEO zu OpenAI zurück, Silicon-Valley-Drama ähnelt der 'Zhen Huan'-Komödie" „Sam Altman kehrt als OpenAI-CEO zurück, und dieses Silicon-Valley-Drama ähnelt einer Hofintrigen-Komödie."
„Das Drama endet? Sam Altman wird als CEO von OpenAI zurückkehren, der Vorstand wird umstrukturiert" „Geht das Drama zu Ende? Sam Altman wird als CEO von OpenAI zurückkehren, während der Vorstand umstrukturiert wird."
„Das Personalturbulenzen bei OpenAI kommt zu einem Ende: Wer hat gewonnen und wer verloren?" „OpenAIs Personalturbulenzen kommen zu einem Ende: Wer hat gewonnen und wer verloren?"
(3) Prompt kombinieren und Antwort generieren: der blaue LLM / Combine Context and Prompts-Bereich
Das System kombiniert dann die ursprüngliche Benutzerfrage und die abgerufenen Abschnitte zu einem vollständigen Prompt und sendet ihn an das Modell. Der gestrichelte Kasten in der Mitte unten in der Abbildung zeigt ein Prompt-Beispiel:
„Frage: Wie bewerten Sie die Tatsache, dass OpenAIs CEO, ... Dynamik?
Bitte beantworten Sie die obigen Fragen basierend auf den folgenden Informationen: Chunk 1: Chunk 2: Chunk 3:"
„Frage: Wie bewerten Sie den Machtkampf im OpenAI-CEO-Vorfall?
Bitte beantworten Sie die obige Frage basierend auf den folgenden Informationen: Chunk 1: Chunk 2: Chunk 3:"
(4) Antwortvergleich mit und ohne RAG: die grauen und gelben Output - Answer-Bereiche unten links
Schließlich generiert das Modell eine Antwort basierend auf den bereitgestellten Informationen. Die Abbildung vergleicht auch die Ausgaben mit und ohne RAG. Ohne RAG hat das Modell kein externes Material und kann nur eine vage Antwort geben, entsprechend dem grauen Kasten:
„... Ich kann keine Kommentare zu zukünftigen Ereignissen abgeben. Derzeit verfüge ich über keine Informationen bezüglich der Entlassung und Wiedereinstellung von OpenAIs CEO ..."
Mit RAG kann das Modell die abgerufenen Nachrichten und Analysen nutzen, um eine viel informativere Antwort zu erstellen, entsprechend dem gelben Kasten:
„... Dies deutet auf erhebliche interne Meinungsverschiedenheiten innerhalb von OpenAI bezüglich der zukünftigen Richtung und strategischen Entscheidungen des Unternehmens hin. All diese Wendungen und Windungen spiegeln Machtkämpfe und Corporate-Governance-Probleme innerhalb von OpenAI wider ..."
Das obige Beispiel zeigt den vollständigen Ablauf eines typischen RAG-Systems und hilft uns, seine Kernstufen und die Informationsflussrichtung zu verstehen. Aber viele wichtige technische Details bleiben in einer Black Box: Wie genau wird die Vektorübereinstimmung durchgeführt, und wie sollte der Prompt organisiert werden, damit das Modell die abgerufenen Inhalte effektiver nutzen kann? Diese Details bestimmen weitgehend die tatsächliche RAG-Qualität. Als Nächstes werden wir tiefer in den internen Mechanismus von RAG eindringen und ihn Schritt für Schritt aufschlüsseln, von Vektorisierungsprinzipien und Ähnlichkeitsberechnung bis hin zu Prompt-Engineering.
3. Wie RAG funktioniert
Wir können es anhand eines einfachen Frage-Antwort-Beispiels aufschlüsseln, das auf einer Wissensbasis über „Apfel" aufbaut.
3.1 Dokumentvektorisierungsstufe
Angenommen, wir haben eine vereinfachte Wissensbasis mit diesen drei Dokumentpassagen:
- Passage A: Apple Inc. wurde am 1. April 1976 von Steve Jobs, Steve Wozniak und Ronald Wayne gegründet, und sein Hauptsitz befindet sich in Cupertino, Kalifornien.
- Passage B: Äpfel sind eine Frucht, die reich an Vitamin C und Ballaststoffen ist, was die Verdauung und die Gesundheit des Immunsystems fördert.
- Passage C: Apple Inc. brachte 2007 das erste iPhone auf den Markt und veränderte die Smartphone-Industrie grundlegend.
Wenn wir diese Dokumente mit einem Embedding-Modell verarbeiten, wie z. B. OpenAIs text-embedding-ada-002 oder einem Open-Source-BGE-Modell, wird jede Passage in einen hochdimensionalen Vektor umgewandelt, oft mit 768, 1024 oder 1536 Dimensionen.
Ein Vektor ist im Wesentlichen ein Array aus vielen numerischen Werten. Jede Dimension entspricht einem semantischen Merkmal des Textes. Zum Beispiel kann der Vektor für „Katze" Dimensionen enthalten, die mit Säugetier, Haustier und fellig zusammenhängen. Die endgültige Kombination von Werten erfasst die semantische Bedeutung des Textes, sodass der Computer Beziehungen zwischen Texten „verstehen" kann.
Vereinfachte Beispiele, wobei echte Vektoren viel höherdimensional sind:
- Vektor für Passage A, über Apples Gründung:
[0.85, -0.23, 0.41, -0.56, 0.12, 0.78, ...] - Vektor für Passage B, über Äpfel als Frucht:
[-0.12, 0.95, -0.34, 0.67, -0.89, 0.05, ...] - Vektor für Passage C, über den iPhone-Start:
[0.79, -0.18, 0.52, -0.61, 0.23, 0.81, ...]
Diese Vektoren müssen dann in einer Vektordatenbank wie Pinecone, Weaviate oder FAISS gespeichert werden, um späteren Abruf und Rückruf zu ermöglichen.
Eine Datenbank ist ein System, das Daten strukturiert speichert und verwaltet und eine organisierte Speicherung und effizienten Abruf ermöglicht. Häufige Beispiele sind Kontaktlisten und E-Commerce-Produktkataloge.
Eine Vektordatenbank ist eine spezielle Art von Datenbank. Im Gegensatz zu traditionellen Datenbanken, die Text, Tabellen und andere gewöhnliche Datenstrukturen speichern, ist eine Vektordatenbank speziell dafür konzipiert, Vektoren – also hochdimensionale numerische Arrays – zu speichern und für die Ähnlichkeitssuche in KI-Szenarien optimiert.
3.2 Benutzerabfrage-, Abruf- und Antwortstufe
Sobald die Wissensbasis vektorisiert und gespeichert wurde, kann ein RAG-System Echtzeit-Benutzerabfragen unterstützen. Wenn ein Benutzer eine Frage stellt, führt das System einen kontinuierlichen Ablauf aus: Es wandelt zunächst die Frage in einen Vektor um, nutzt dann die Ähnlichkeitsberechnung, um die relevantesten Informationen aus der Wissensbasis abzurufen, und verwendet schließlich diese Passagen als Grundlage für die Antwortgenerierung. Wir können diesen Prozess an drei konkreten Abfragen veranschaulichen.
Abfrage 1: „Wann wurde Apple Inc. gegründet?"
In der Abfragevektorisierungsstufe wird die Frage vom Embedding-Modell in einen semantischen Vektor umgewandelt, zum Beispiel [0.82, -0.21, 0.38, -0.58, 0.15, 0.76, ...]. Dieses Zahlenmuster ist dem gespeicherten Vektor für Passage A, dem über die Unternehmensgründung, sehr ähnlich.
Das System führt dann eine Ähnlichkeitssuche durch, Top-K mit K = 2, indem es die Kosinusähnlichkeit zwischen dem Abfragevektor und allen Dokumentvektoren in der Wissensbasis berechnet. Das Ergebnis sieht so aus:
- Ähnlichkeit mit Passage A, der Gründungspassage: 0.97, hochrelevant
- Ähnlichkeit mit Passage C, der iPhone-Start-Passage: 0.88, relevant, da sie ebenfalls das Unternehmen betrifft
- Ähnlichkeit mit Passage B, der Fruchternährungspassage: 0.12, fast irrelevant
Top-K ist eine gängige Auswahlstrategie beim Vektorabruf. Sie bedeutet, alle Treffer von der höchsten zur niedrigsten Ähnlichkeit zu rangieren und die obersten K Ergebnisse zu behalten. K = 2 bedeutet, dass das System nur die zwei Dokumentvektoren mit der höchsten Ähnlichkeit behält und niedriger rangierte herausfiltert, sodass die nächste Stufe die Antwort nur aus den zwei relevantesten Dokumentpassagen generiert.
Die durch Ähnlichkeit gefilterten Ergebnisse werden als Recall-Ergebnisse bezeichnet. Das System gibt die Top-2-Passagen als Beweis zurück:
- Passage A, Ähnlichkeit 0.97: „Apple Inc. wurde am 1. April 1976 von Steve Jobs, Steve Wozniak und Ronald Wayne gegründet, und sein Hauptsitz befindet sich in Cupertino, Kalifornien."
- Passage C, Ähnlichkeit 0.88: „Apple Inc. brachte 2007 das erste iPhone auf den Markt und veränderte die Smartphone-Industrie grundlegend."
In der Antwortgenerierungsstufe erstellt das System einen vollständigen strukturierten Input, indem es den zurückgerufenen Inhalt in den Referenzinformationsabschnitt platziert und ihn zusammen mit einem System-Prompt sendet:
[System Prompt]
Sie sind ein professioneller Frage-Antwort-Assistent. Bitte antworten Sie streng gemäß den vom Benutzer bereitgestellten „Referenzinformationen".
Wenn die Referenzinformationen die Antwort enthalten, antworten Sie direkt auf dieser Grundlage.
Wenn die Referenzinformationen die Antwort nicht enthalten, teilen Sie dem Benutzer ausdrücklich mit, dass „die Frage anhand der aktuell verfügbaren Materialien nicht beantwortet werden kann", und erfinden Sie keine Informationen.
Bitte geben Sie an, auf welchem Informationspunkt Ihre Antwort basiert.
[Retrieved Context]
Apple Inc. wurde am 1. April 1976 von Steve Jobs, Steve Wozniak und Ronald Wayne gegründet, und sein Hauptsitz befindet sich in Cupertino, Kalifornien.
Apple Inc. brachte 2007 das erste iPhone auf den Markt und veränderte die Smartphone-Industrie grundlegend.
[User Query]
Wann wurde Apple Inc. gegründet?Nach Erhalt dieses strukturierten Inputs befolgt das LLM die Systemanweisung und behandelt den abgerufenen Kontext als einzige vertrauenswürdige Quelle für die Antwort. Seine endgültige Antwort würde so aussehen:
Gemäß den bereitgestellten Referenzinformationen wurde Apple Inc. am 1. April 1976 gegründet. [Grundlage: Information 1]
Abfrage 2: „Was sind die Vorteile davon, Äpfel zu essen?"
In der Abfragevektorisierungsstufe wird diese Frage in einen semantischen Vektor umgewandelt, wie z. B. [-0.08, 0.92, -0.31, 0.71, -0.85, 0.08, ...]. Sein Zahlenmuster ist dem gespeicherten Vektor für Passage B, dem über Apfelernährung, sehr ähnlich.
Das System führt erneut eine Top-K-Ähnlichkeitssuche mit K = 2 durch und berechnet die Kosinusähnlichkeit:
- Ähnlichkeit mit Passage B, Fruchternährung: 0.95, hochrelevant
- Ähnlichkeit mit Passage C, iPhone-Start: 0.18, fast irrelevant
- Ähnlichkeit mit Passage A, Unternehmensgründung: 0.15, fast irrelevant
Das System gibt die Top-2-Passagen als Beweis zurück:
- Passage B, Ähnlichkeit 0.95: „Äpfel sind eine Frucht, die reich an Vitamin C und Ballaststoffen ist, was die Verdauung und die Gesundheit des Immunsystems fördert."
- Passage C, Ähnlichkeit 0.18: „Apple Inc. brachte 2007 das erste iPhone auf den Markt und veränderte die Smartphone-Industrie grundlegend." Dies ist nur schwach verwandt und würde in der Praxis oft durch einen Schwellenwert gefiltert.
Der vollständige strukturierte Input wird dann wie folgt erstellt:
[System Prompt]
Sie sind ein professioneller Frage-Antwort-Assistent. Bitte antworten Sie streng gemäß den vom Benutzer bereitgestellten „Referenzinformationen".
Wenn die Referenzinformationen die Antwort enthalten, antworten Sie direkt auf dieser Grundlage.
Wenn die Referenzinformationen die Antwort nicht enthalten, teilen Sie dem Benutzer ausdrücklich mit, dass „die Frage anhand der aktuell verfügbaren Materialien nicht beantwortet werden kann", und erfinden Sie keine Informationen.
Bitte geben Sie an, auf welchem Informationspunkt Ihre Antwort basiert.
[Retrieved Context]
Äpfel sind eine Frucht, die reich an Vitamin C und Ballaststoffen ist, was die Verdauung und die Gesundheit des Immunsystems fördert.
Apple Inc. brachte 2007 das erste iPhone auf den Markt und veränderte die Smartphone-Industrie grundlegend.
[User Query]
Was sind die Vorteile davon, Äpfel zu essen?Die endgültige Antwort würde dann so aussehen:
Gemäß den bereitgestellten Referenzinformationen sind Äpfel reich an Vitamin C und Ballaststoffen, und der Verzehr von Äpfeln fördert die Verdauung und die Gesundheit des Immunsystems. [Grundlage: Information 1]
Abfrage 3: „Wie ist das Wetter heute?"
In der Abfragevektorisierungsstufe wird diese Frage zu einem semantischen Vektor im Zusammenhang mit Wetter und Meteorologie, zum Beispiel [0.10, -0.05, 0.30, -0.12, 0.21, 0.08, ...]. Im semantischen Raum ist dieser Vektor weit von allen Dokumentvektoren über Äpfel entfernt – sowohl dem Unternehmen als auch der Frucht – sodass keine signifikante Ähnlichkeit auftritt.
Das System führt erneut eine Top-K-Suche mit K = 2 durch. Da das Thema der Frage nicht mit der Wissensbasis zusammenhängt, sind die Gesamtähnlichkeitsergebnisse alle sehr niedrig:
- Ähnlichkeit mit Passage B, Fruchternährung: 0.18, extrem niedrig
- Ähnlichkeit mit Passage C, iPhone-Start: 0.10, fast irrelevant
- Ähnlichkeit mit Passage A, Unternehmensgründung: 0.08, fast irrelevant
Top-K gibt weiterhin die bestplatzierten K-Ergebnisse zurück, aber in diesem Fall liefern diese Ergebnisse keinen wirksamen Beweis. In der Praxis wendet das System oft einen Mindestähnlichkeitsschwellenwert an und gibt direkt einen leeren Recall zurück, d. h. keine gültigen Ergebnisse, um irrelevante Störungen zu reduzieren.
Die beiden zurückgegebenen Passagen wären immer noch:
- Passage B, Ähnlichkeit 0.18: „Äpfel sind eine Frucht, die reich an Vitamin C und Ballaststoffen ist, was die Verdauung und die Gesundheit des Immunsystems fördert."
- Passage C, Ähnlichkeit 0.10: „Apple Inc. brachte 2007 das erste iPhone auf den Markt und veränderte die Smartphone-Industrie grundlegend."
Der vollständige Input wäre dann:
[System Prompt]
Sie sind ein professioneller Frage-Antwort-Assistent. Bitte antworten Sie streng gemäß den vom Benutzer bereitgestellten „Referenzinformationen".
Wenn die Referenzinformationen die Antwort enthalten, antworten Sie direkt auf dieser Grundlage.
Wenn die Referenzinformationen die Antwort nicht enthalten, teilen Sie dem Benutzer ausdrücklich mit, dass „die Frage anhand der aktuell verfügbaren Materialien nicht beantwortet werden kann", und erfinden Sie keine Informationen.
Bitte geben Sie an, auf welchem Informationspunkt Ihre Antwort basiert.
[Retrieved Context]
Äpfel sind eine Frucht, die reich an Vitamin C und Ballaststoffen ist, was die Verdauung und die Gesundheit des Immunsystems fördert.
Apple Inc. brachte 2007 das erste iPhone auf den Markt und veränderte die Smartphone-Industrie grundlegend.
[User Query]
Wie ist das Wetter heute?Das LLM würde zunächst beurteilen, ob die Referenzinformationen direkte Wetter- oder Echtzeit-Meteorologieinformationen enthalten. Nachdem bestätigt wurde, dass dies nicht der Fall ist, würde es der Anweisung folgen und antworten, dass es nicht antworten kann:
Die aktuell verfügbaren Materialien können die Frage „Wie ist das Wetter heute?" nicht beantworten, da die Referenzinformationen nur Inhalte enthalten, die mit Äpfeln, Fruchternährung und Apple Inc.-Produkten zusammenhängen, und keine Wetterinformationen oder Echtzeit-Meteorologiedaten enthalten. [Grundlage: Es existieren keine wetterbezogenen Informationen im abgerufenen Kontext]
Aus diesen drei Beispielen können wir das Wesentliche der RAG-Dialogstufe erkennen. Der System-Prompt definiert die Rolle und die Antwortregeln des LLM, die abgerufenen Beweise liefern konkretes und vertrauenswürdiges Material, und die Frage des Benutzers definiert das Aufgabenziel. Dieses strukturierte Eingabemuster ist genau das, was RAG ermöglicht, ein LLM, das andernfalls halluzinieren könnte, effektiv zu leiten und einzuschränken und es in ein System umzuwandeln, das stabile und zuverlässige Antworten produziert. Es stellt sicher, dass das Modell zum Verstehen und Organisieren vorhandener Informationen eingesetzt wird und nicht zum Erfinden unbegründeter Informationen.
4. Die Evolution von RAG
RAG entstand nicht erst in der Ära der großen Modelle. In früheren Forschungen gab es bereits Prototypen derselben Idee. Aus historischer Perspektive entstand RAG aus der Erkenntnis der Grenzen traditioneller LLMs. Frühe große Sprachmodelle dependierten hauptsächlich von Vortrainingsdaten, und diese Daten waren festgeschrieben, sobald das Training abgeschlossen war. Zum Beispiel hatten Modelle wie GPT-3 Wissenabschnittdaten, die an den Zeitpunkt der Trainingsdatenerhebung gebunden waren und kein späteres Wissen erhalten konnten. Das Neu-Training oder Feintunen von LLMs für bestimmte Domänen erforderte zudem große Ressourcen und spezialisiertes Fachwissen, was es teuer und schwer iterierbar machte.
Die Wurzeln von RAG lassen sich bis zum DrQA-Framework im Jahr 2017 zurückverfolgen, das erstmals versuchte, Abruf mit Sprachmodellen zu kombinieren. Ein großer Durchbruch kam dann 2020 mit Dense Passage Retrieval, oder DPR, das vortrainierte neuronale Modelle für die semantische Suche anstelle traditioneller wortfrequenzbasierter Methoden wie TF-IDF und BM25 verwendete. 2021 wurde RAG formal vorgeschlagen und systematisiert und wurde zu einer Standardmethode zur Adressierung der Wissensabschnitt- und Halluzinationsprobleme in LLMs.
Im Großen und Ganzen kann die Evolution von RAG in drei Stufen unterteilt werden:
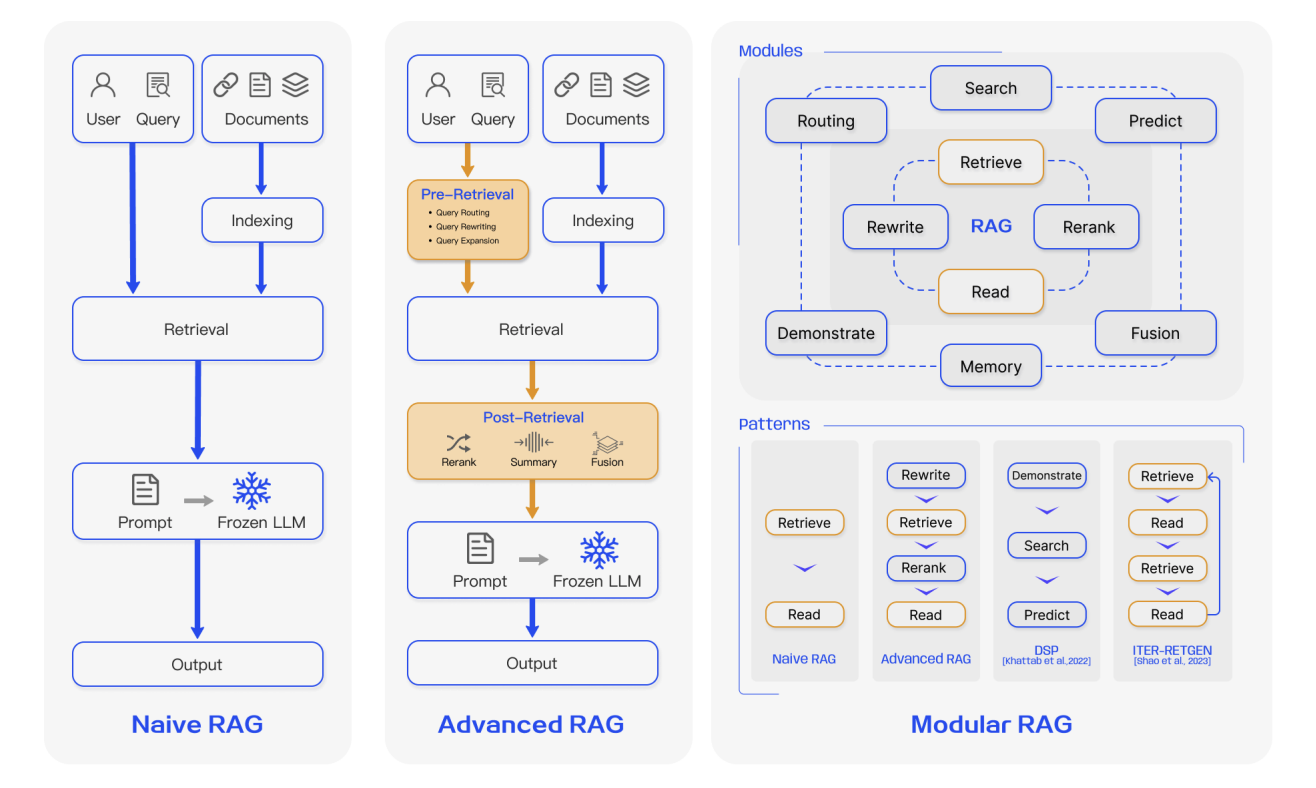
4.1 Erste Generation RAG: Naive RAG
Naive RAG ist die grundlegendste Form von RAG. Aus ingenieurtechnischer Perspektive folgt sie einem sehr direkten dreistufigen Ablauf:
- Dokumentvorverarbeitung und Indexierung. Rohdokumente werden bereinigt, in festlängige Textabschnitte aufgeteilt, mit einem Embedding-Modell in Vektoren kodiert und in eine Vektordatenbank geschrieben.
- Ähnlichkeitsbasierter Abruf. Die Frage des Benutzers in natürlicher Sprache wird in einen Vektor kodiert, und das System führt eine Top-K-Ähnlichkeitssuche über den Vektorspeicher durch.
- Einfache abrufaugmentierte Generierung. Die abgerufenen Abschnitte werden direkt mit der ursprünglichen Frage zu einem langen Prompt verkettet, der an das LLM zur Antwortgenerierung gesendet wird.
Der Wert dieser Stufe liegt darin, dass sie mit einer sehr niedrigen Einstiegshürde verifiziert hat, dass „zuerst abrufen, dann antworten" tatsächlich funktioniert. Im Vergleich zur alleinigen Nutzung des internen Gedächtnisses des Modells reduziert sie bereits Wissensabschnitt-Probleme und einige Halluzinationen erheblich, weshalb sie eine wichtige Rolle in frühen Prototypen, Demos und Einführungstutorials spielte.
Die Grenzen der RAG der ersten Generation sind jedoch ebenfalls offensichtlich. Erstens ist die Aufteilungsstrategie meist grob. Die meisten Systeme teilen einfach nach fester Länge, was einen kohärenten semantischen Abschnitt mitten durchschneiden oder mehrere Themen innerhalb eines Abschnitts vermischen kann. Dies beeinträchtigt die Abrufgenauigkeit und erschwert auch das Verständnis für das LLM. Zweitens ist das Abrufsignal zu einfach. Die Rangordnung hängt normalerweise nur von der Vektorähnlichkeit ab und nutzt keine reichhaltigeren strukturierten Hinweise wie Schlüsselwörter, Zeitstempel, Quellenvertrauenswürdigkeit oder Zugriffsrechte. Drittens werden die Abrufergebnisse kaum reguliert: verrauschte, repetitive und sogar widersprüchliche Abschnitte können unverändert in den Kontext gestopft werden, wodurch große Mengen an Informationen mit niedrigem Wert ein bereits begrenztes Kontextfenster belegen.
Kurz gesagt: Die erste Generation löste die Frage, ob Abruf notwendig ist. Aber bei den Fragen, wie man besser abruft und wie man abgerufene Informationen vernünftiger nutzt, blieb sie noch auf einem ziemlich primitiven Stand.
4.2 Zweite Generation RAG: Advanced RAG
Als RAG von Demos in reale Geschäftsszenarien überging, stiegen die Anforderungen an Stabilität, Kontrollierbarkeit und Ausgabequalität stark an. Die zweite Generation, die meist unter dem Sammelbegriff Advanced RAG zusammengefasst wird, folgt weiterhin dem Muster „zuerst abrufen, dann generieren", führt aber systematische Verfeinerungen sowohl vor als auch nach dem Abruf ein. Mit anderen Worten: Das System ist nicht mehr damit zufrieden, lediglich etwas abzurufen. Es zielt nun darauf ab, die richtigen Dinge ordnungsgemäß zu speichern, die richtigen Fragen klar zu stellen und den abgerufenen Kontext sorgfältig zu regulieren.
Vor dem Abruf liegt der Fokus auf gutem Speichern und Fragen:
Auf der Indexierungsseite entwickelt sich die Aufteilung von festen Längenteilungen hin zu semantisch bewusster Aufteilung und hierarchischer Indexierung. Das System kann entlang von Kapitel-, Unterabschnitts-, Absatz- oder Satzgrenzen aufteilen, kombiniert mit gleitenden Fenstern und multigranularen Indexstrukturen.
Jeder Dokumentabschnitt kann umfangreiche Metadaten wie Quelle, Zeitstempel, Autor, Thema und Dokumenttyp tragen, die weitere Dimensionen für spätere Filterung und Rangordnung bieten.
Auf der Abfrageseite kann die ursprüngliche Frage des Benutzers durch Techniken wie Query Rewrite, Multi-Query, Sub-Query-Zerlegung und Step-back Prompting umgeschrieben, erweitert oder zerlegt werden, um vage oder konversationelle Benutzerabfragen in Formen umzuwandeln, die der Abruf besser verstehen kann.
- Query Rewrite
Die Kernidee besteht darin, die vage, umgangssprachliche oder nicht standardisierte Abfrage des Benutzers in einen normalisierten Ausdruck umzuwandeln, den das Abrufsystem leichter verstehen kann, wobei Schlüsselinformationen ergänzt und Mehrdeutigkeiten aufgelöst werden.
- Zum Beispiel könnte „Wie überprüfe ich das morgige Wetter in Peking?" in etwas Standardisierteres umgeschrieben werden wie „Das morgige Ganztag-Echtzeit-Wetter in Peking abfragen."
- Oder „Gute Filme empfehlen" kann nach Durchsicht der Benutzerhistorie umgeschrieben werden in „Hochbewertete Spannungsfilme von 2024 empfehlen."
- Multi-Query
Das System generiert mehrere semantisch verwandte, aber unterschiedlich ausgerichtete Abfragen aus der ursprünglichen Frage, um verpasste Ergebnisse zu reduzieren und latente Bedürfnisse abzudecken, die der Benutzer nicht explizit geäußert hat.
- Sub-Query
Für zusammengesetzte Fragen, die mehrere Ziele enthalten, teilt das System sie in kleinere, einfachere Teilabfragen auf, sodass der Abruf jedes Bedürfnis präzise abgleichen kann.
- Step-back Prompting
Das System generiert zunächst eine abstraktere, übergeordnete Frage und nutzt diese dann, um die Abrufrichtung zu steuern, wodurch die Verzerrung reduziert wird, die durch eine zu enge Fokussierung auf Details in der ursprünglichen Frage entsteht.
Nach dem Abruf liegt der Fokus auf der Regulierung des Abgerufenen:
- Ein dediziertes Rerank-Modell oder sogar ein LLM kann Kandidatendokumente neu rangieren, sodass die wichtigsten und fragelevantesten Inhalte zuerst in den Kontext gelangen.
Ein Rerank-Modell ist eine Schlüsselkomponente in einer Informationsabrufpipeline. Es führt eine Zweitstufen-Rangordnung der Kandidatenergebnisse durch, die von der Recall-Phase zurückgegeben wurden, und nutzt ein stärkeres semantisches Verständnis, oft basierend auf Transformer-Architekturen, um semantische Rangordnungsfehler aus der ersten Stufe zu korrigieren und die Ergebnisse, die am besten mit den Benutzerbedürfnissen übereinstimmen, weiter nach vorne zu bringen.
- Abgerufene Passagen können gefiltert, dedupliziert und komprimiert werden, um eindeutig irrelevante oder hochrepetitive Abschnitte zu entfernen und die Tendenz von Langkontextsystemen zu reduzieren, nützliche Informationen in der Mitte zu ignorieren.
- Bei Bedarf kann leichtes Modell-Finetuning das LLM eher dazu bringen, aus Abrufbeweisen zu antworten und explizite Zitate oder Quellen anzugeben.
Insgesamt konzentriert sich Advanced RAG nicht mehr nur darauf, ob Abruf notwendig ist oder ob etwas abgerufen werden kann. Es adressiert stattdessen drei größere Herausforderungen: ob die wirklich kritischen Passagen präzise lokalisiert werden können, ob der an das große Modell übergebene Kontext prägnant, gut strukturiert und effizient nutzbar ist, und ob das gesamte System bei Vorhandensein von Rauschen, Konflikten oder Mehrquellen-Informationsbedürfnissen stabil und zuverlässig bleibt.
Große Mengen experimenteller und ingenieurtechnischer Evidenz zeigen, dass Advanced RAG bei Antwortgenauigkeit, Halluzinationsunterdrückung, Systemrobustheit und Erklärbarkeit Naive RAG deutlich übertrifft. Daher hat es traditionelle grundlegende Ansätze allmählich ersetzt und ist zum industriellen Mainstream-Paradigma für den Aufbau von RAG-Systemen heute geworden.
4.3 Dritte Generation RAG: Modular RAG
In komplexen Unternehmensanwendungen erstrecken sich die Anforderungen oft über mehrere Domänen. In diesen Fällen reicht ein einfacher linearer Ablauf von Abruf, Rerank und Generierung oft nicht aus:
- Dasselbe System muss möglicherweise einfache FAQs, lange Berichtsgenerierung, Codeabruf und Datenbankaufrufe unterstützen.
- Es muss möglicherweise gleichzeitig Vektorspeicher, Volltextabruf, relationale Datenbanken, Wissensgraphen und externe Suchmaschinen anbinden.
- Es muss möglicherweise Benutzerpräferenzen und historische Entscheidungen über mehrere Runden hinweg bewahren und gleichzeitig Compliance-Prüfungen und Antwort-Rückverfolgbarkeit anwenden.
Vor diesem Hintergrund begann sich RAG in Richtung eines modularen Systems zu entwickeln. Modular RAG wird nicht mehr als feste Pipeline betrachtet. Es wird stattdessen als ein Satz von einsteckbaren, austauschbaren und komponierbaren Funktionsmodulen behandelt, die nach Bedarf orchestriert werden können. Typische Module umfassen:
- Abfrageverständnis und Routing Dieses Modul verarbeitet Intent-Erkennung, Fragen-Umschreibung, Teilaufgabenzerlegung und Pfadauswahl. Es entscheidet, ob eine Anfrage hauptsächlich auf internes Wissen, externen Abruf oder ein spezifisches Werkzeug oder eine Datenbank zurückgreifen soll.
- Mehrquellen-Abruf und Fusion Dieses Modul verbindet gleichzeitig Vektordatenbanken, Volltextsuche, strukturierte Datenbanken und Wissensgraphen, fragt sie ab und fusioniert und rangordnet ihre Ergebnisse zu einem einheitlichen Beweissatz.
- Speicher und Personalisierung Dieses Modul verwaltet langfristige Benutzerprofile, Kurzzeit-Sitzungsspeicher und Domänenwissens-Caches, sodass das System historische Informationen kontinuierlich akkumulieren und nutzen kann.
- Aufgabenanpassung und Governance Dieses Modul lädt verschiedene Adapter für verschiedene Aufgaben, schränkt Ausgabeformat, Ton und Stil ein und reguliert Ausgaben durch Faktenprüfung, Risikofilterung und Zitatangleichung.
Kurz gesagt: Traditionelles RAG endet oft nach einer Abrufrunde plus einer Generierungsrunde. Modular RAG bricht dieses Einzelpipeline-Muster. Wenn das System während der Generierung feststellt, dass die Informationen noch unzureichend sind, kann es proaktiv neue Abrufrunden auslösen und sogar mehrmals zwischen Abruf und Generierung hin- und herwechseln, um eine komplexere Aufgabe zu erledigen.
Noch weitergehend kann das Modell lernen, eigene Entscheidungen zu treffen: direkt aus internem Wissen oder kurzem Kontext zu antworten, wenn die Konfidenz hoch ist, und Abruf oder externe Werkzeugaufrufe nur zu starten, wenn die Unsicherheit hoch ist. Das verbessert die Effizienz und spart Ressourcen, während die Qualität erhalten bleibt. Bei stark unterbestimmten oder unvollständigen Abfragen kann das Modell sogar zuerst eine hypothetische Zwischenantwort oder einen Entwurf erstellen und diese dann als Hinweis für weiteren Abruf nutzen, sich schrittweise zuverlässigen Quellen annähernd.
In dieser Stufe ist RAG nicht mehr nur eine einfache Komponente, die einige Referenzpassagen an ein großes Modell anhängt. Es wird zur zentralen Wissensorchestrierungsschicht innerhalb unternehmensweiter intelligenter Anwendungen, die mehrere Datenquellen, mehrere Werkzeuge und mehrere Aufgaben koordiniert.
5. Vom Demo zum Unternehmens-RAG
Aus der Perspektive des Unternehmensingenieurwesens kann der Aufbau eines RAG-Systems nicht auf abrufaugmentierte Generierung allein beschränkt sein. Das obige Material ist noch näher an einer Demo-Einführung. In realen Geschäftsszenarien sind Daten oft verrauscht und in der Format inkonsistent, sodass mehr Aufwand in Vorverarbeitung, Bereinigung und Ingestion investiert werden muss, und die Modellauswahl muss an jedem Schlüsselpunkt sorgfältig gehandhabt werden.
Ein vollständiges unternehmensweites RAG-System kann normalerweise in drei Kernmodule unterteilt werden: Layout-Analyse und Wissensingestion, Wissensbasiskonstruktion und RAG-basierter Frage-Antwort-Dienst. Über die gesamte technische Kette hinweg erscheinen mehrere Schlüsselentscheidungen zur Modellauswahl, darunter das Embedding-Modell, das Rerank-Modell und das LLM. Nur mit sinnvollen technischen Entscheidungen an jeder Stufe kann das System starke Gesamtergebnisse erzielen.
Layout-Analyse und lokales Wissensdatei-Lesen
Dieses Modul wandelt lokale Wissensressourcen in verschiedenen Formaten in für den Abruf nutzbaren Text um. Eingaben können PDFs, TXT, HTML, Word, Excel und PPT-Dateien sowie gescannte Bilddateien wie PNG und JPG oder sogar Audioaufnahmen umfassen.
Das System muss jedes Format angemessen parsen, Layout-Analyse und Struktur-Extraktion für Textdokumente durchführen, Titel, Haupttext, Tabellen, Kopf- und Fußzeilen unterscheiden und eine sinnvolle Lesereihenfolge wiederherstellen. Es führt OCR bei Bilddateien und ASR bei Sprache durch und konvertiert schließlich alles in relativ sauberen Wissenstext, während grundlegende Metadaten wie Dateiname, Kapitel, Seitennummer und Zeitstempel für spätere Aufteilung und Indexierung beibehalten werden.
Wissensbasiskonstruktion: Aufteilung, Embeddings und Indexierung
Nach Erhalt des bereinigten Wissenstexts führt das System die Aufteilung durch, wobei lange Dokumente in semantisch kohärente Blöcke geeigneter Länge aufgeteilt werden, normalerweise nach Absatz, Titelstruktur oder gleitendem Fenster, während die Quelle und Metadaten jedes Blocks erhalten bleiben.
Dann verwendet es das gewählte Embedding-Modell, wie z. B.
text-embedding-3-small, Sentence Transformers oder BGE, um Vektordarstellungen für jeden Block zu berechnen und einen Vektorindex mit Werkzeugen wie Faiss, Milvus oder verwalteten Vektorsuchdiensten zu erstellen. An diesem Punkt wurde eine Wissensbasis erstellt, die schnelle semantische Suche unterstützt.RAG-basiertes Frage-Antworten: Recall, Reranking, Verkettung, Generierung
In der Online-QA-Stufe sendet der Benutzer eine Abfrage. Das System bettet sie in einen Abfragevektor ein, ruft einen Stapel der ähnlichsten Textblöcke aus dem Vektorindex ab und behandelt dies als Grobrangordnungsstufe. Dann kann es ein Rerank-Modell wie einen BGE-Reranker oder sogar ein als Reranker fungierendes LLM verwenden, um Abfrage-Dokument-Paare erneut zu bewerten und nur die Top-K-Dokumente zu behalten, die wirklich am relevantesten sind, als den Wissenskontext.
Als Nächstes verkettet das System zusammen mit einem sorgfältig gestalteten System-Prompt wie „Bitte antworten Sie streng basierend auf den folgenden Materialien" die Benutzerabfrage und die abgerufenen Dokumentpassagen und sendet den zusammengeführten Prompt an das LLM. Das Modell generiert dann die endgültige Antwort aus diesen abgerufenen Beweisstücken und schließt bei Bedarf Zitate oder Quellen ein.
5.1 Modellauswahl
Als Nächstes konzentrieren wir uns auf die Modellauswahl. Ein vollständiges RAG-System umfasst normalerweise drei Kernmodellkategorien: Embedding-Modelle, Rerank-Modelle und große Sprachmodelle. Jedes hat seine eigene Rolle, und zusammen bilden sie den vollständigen Pfad vom Abruf bis zur Antwortgenerierung. Das Embedding-Modell wandelt Text in durchsuchbare semantische Vektoren um, das Rerank-Modell verfeinert die anfänglichen Abrufergebnisse, und das LLM generiert die endgültige Antwort basierend auf dem ausgewählten Wissenskontext.
5.1.1 Embedding-Modelle
In einem RAG-System besteht die Aufgabe des Embedding-Modells darin, Text – wie Benutzerabfragen und Wissensbaseninhalt – in hochdimensionale Vektoren umzuwandeln. Semantisch ähnliche Texte werden im Vektorraum näher beieinander platziert, wodurch das System verwandtes Wissen schnell durch Ähnlichkeit lokalisieren kann. Die Wahl des richtigen Embedding-Modells ist daher einer der kritischsten Schritte beim Aufbau eines leistungsstarken RAG-Systems, da es die Recall-Qualität direkt bestimmt.
Um ein starkes Modell auszuwählen, hilft die Nutzung eines systematischen Benchmarks. Einer der am weitesten verbreiteten ist MTEB, der Massive Text Embedding Benchmark.
MTEB bietet ein einheitliches und objektives Bewertungsframework für viele Embedding-Modelle. Durch acht Hauptaufgabenkategorien und 56 Datensätze bewertet es die Leistung über Abruf, Clustering, Klassifizierung, Reranking, Textabgleich, semantische Ähnlichkeit und mehr. Die Gesamt-MTEB-Punktzahl eines Modells spiegelt die Allgemeinheit und Robustheit seiner Vektordarstellungen wider und kann als wichtige Referenz für die Modellauswahl dienen. Die aktuelle Rangliste kann auf dem Hugging Face MTEB Leaderboard eingesehen werden:
Obwohl es viele Modelle auf dem Leaderboard gibt, müssen Sie nicht alle beherrschen. In der Praxis ist die Wahl des Embedding-Modells, das von einem großen Modellanbieter bereitgestellt wird, oder die Nutzung eines Cloud-Served-Modells, das bereits von vielen Menschen validiert wurde, normalerweise eine sichere Wahl. Sie können das Leaderboard auch nach Kategorie oder Sprache in der Seitenleiste filtern:
Bei der Filterung von Embedding-Modellen sind zwei Parameter besonders wichtig, da sie die RAG-Leistung direkt beeinflussen: Dimension und Kontextlänge.
Die Dimension ist die Dimensionalität der Vektorausgabe, wie z. B. 128, 768 oder 1536. Sie spiegelt ungefähr wider, wie viele semantische Merkmale der Vektor ausdrücken kann. Höherdimensionale Vektoren können reichhaltigere semantische Details und eine stärkere Diskriminierung erfassen. Zum Beispiel kann ein 768-dimensionaler Vektor „Apfel" aus hunderten von Blickwinkeln wie Sorte, Geschmack und Herkunft darstellen, was ihn für professionelle Szenarien wie Gesundheit oder Recht geeignet macht, die präzisen Abruf benötigen. Niedrigere Dimensionen reduzieren Rechen- und Speicherkosten und verbessern die Abrufgeschwindigkeit, was sie für groß angelegte allgemeine Szenarien mit hoher Nebenläufigkeit und starken Echtzeitanforderungen geeignet macht.
Die Kontextlänge ist die maximale Textlänge, die das Embedding-Modell in einem Durchgang verarbeiten kann, gemessen in Tokens. Ein englisches Token entspricht ungefähr drei Vierteln eines Wortes, und ein chinesisches Token entspricht ungefähr einem chinesischen Zeichen. Alles, was länger als das Maximum ist, wird abgeschnitten. Dies bestimmt direkt, ob das Modell den Text vollständig verstehen kann. Wenn wichtige Informationen verloren gehen, weil die Länge zu kurz ist, sinkt die Abrufgenauigkeit stark. Für kurze Benutzerabfragen und kurze QA-Paare reichen 512 bis 1024 Tokens oft aus. Für längere Texte wie Papiere und Berichte benötigen Sie normalerweise 2048 Tokens oder mehr.
Nachfolgend ein Vergleich mehrerer gängiger Embedding-Modelle. In der Praxis müssen Sie durch Abwägung von Kosten und Leistung wählen. Es gibt kein universell bestes Modell, nur das am besten geeignete Modell nach Vergleich mehrerer Optionen in Ihrem eigenen Anwendungsfall.
| Modellname | Modellskala | Kernstärke | Geeignete Szenarien |
|---|---|---|---|
OpenAI text-embedding-3-large | Geschlossene API | Langjähriger Leader auf MTEB, ausgereift und stabil | Cloud-API-Szenarien, die extreme Leistung priorisieren und ausreichend Budget haben |
jina-embeddings-v2 | Unterstützt langen Text bis zu 8K Kontext | Stark für langen Dokumentabruf durch asynchrones Encoding-Design | Dokumentanalyse, rechtliche Compliance, akademischer Abruf |
multilingual-e5-large | Große Skala | Klassische mehrsprachige Option | Mehrsprachiger RAG, internationale Produkte, mehrsprachige Supportsysteme |
Qwen/Qwen2-Embedding-8B | 8B Parameter, bis zu 4096 benutzerdefinierte Dimensionen | Ehemaliger Top-Mehrsprachig-MTEB-Performer, stark bei langem Text, mehrsprachigen Aufgaben und Code | Hochpräziser chinesisch-englischer RAG, Langdokumentanalyse, Codeabruf |
Qwen/Qwen2-Embedding-4B | 4B Parameter | Starke Balance aus Leistung und Effizienz | Groß angelegte produktive RAG-Systeme |
Qwen/Qwen2-Embedding-0.6B | 0.6B Parameter | Geeignet für Edge-Geräte | Ressourcenbeschränkte, geschwindigkeitspriorisierte Szenarien |
BAAI/bge-m3 | Unterstützt hybriden Abruf, Dense plus Sparse plus Multi-Vektor | Stark auf mehrsprachigen Benchmarks wie MIRACL | Komplexe mehrsprachige Szenarien, die hybriden Abruf benötigen |
BAAI/bge-large-zh-v1.5 | Große Skala | Stabile chinesische RAG-Baseline mit starker Community-Validierung | Rein chinesische Projekte mit kürzeren Dokumenten |
ZhipuAI Embedding-3 | Geschlossene Cloud-API | Unterstützt benutzerdefinierte Dimensionen von 256 bis 2048 | China-fokussierte Anwendungen, die Cloud-APIs bevorzugen |
5.1.2 Rerank-Modelle
In einem RAG-System ist das Rerank-Modell für die feine Neurangordnung der anfänglichen Abrufergebnisse verantwortlich. Es nimmt die Benutzerabfrage und Kandidatendokumente als Eingabe und berechnet eine genaue Relevanzpunktzahl für jedes Abfrage-Dokument-Paar. Je höher die Punktzahl, desto besser die Übereinstimmung. Daher ist das Hinzufügen eines Rerank-Modells über dem Embedding-basierten Recall ein Schlüsselschritt zur Verbesserung der Abrufpräzision.
Für Embedding-Modelle können wir Benchmarks wie MTEB verwenden. Für Rerank-Modelle ist eine nützliche Referenz das Agentset Reranker Leaderboard:
Der Agentset-Benchmark ruft zunächst die 50 relevantesten Kandidatenergebnisse aus einem großen Dokumentenspeicher mit FAISS ab und bittet dann das zu bewertende Rerank-Modell, diese 50 Dokumente neu zu rangieren. Der Benchmark achtet sowohl auf Rangordnungsqualität als auch auf Latenz. In praktischen Anwendungen schadet die Verfolgung von Präzision unter Ignorierung der Geschwindigkeit der Benutzererfahrung, während die Verfolgung von Geschwindigkeit unter Opferung der Rangordnungsqualität die Nützlichkeit beeinträchtigt.
Agentset führt auch einen ELO-Bewertungsmechanismus ein. Für jede Abfrage fungiert GPT-5 als Richter und vergleicht die rangordneten Ausgaben zweier verschiedener Rerank-Modelle und entscheidet, welches die wirklich relevanten Dokumente in einer sinnvolleren Reihenfolge platziert. Nach großen Mengen solcher paarweisen Vergleiche erhalten Modelle, die öfter gewinnen, höhere ELO-Punktzahlen, was ein intuitives Gesamtleistungssignal liefert.
Der Benchmark verwendet auch zwei komplementäre Metrikgruppen:
nDCG@5/10, das sich darauf konzentriert, ob relevante Dokumente nah am Anfang platziert sind, und daher die Rangordnungspräzision widerspiegeltRecall@5/10, das sich darauf konzentriert, ob alle relevanten Dokumente gefunden werden können, und daher die Abdeckung widerspiegelt
Zusammen bieten diese Metriken ein vollständigeres Bild der Rerank-Leistung.
Dennoch müssen Sie in der Praxis Rerank-Modelle nicht nur anhand eines Leaderboards auswählen. Industrielle Nützlichkeit und Leaderboard-Punktzahl sind nicht immer dasselbe. Ein praktischer Ansatz besteht darin, mit den von Ihren Cloud-Anbietern empfohlenen Rerank-Modellen oder den Standard-Rerank-APIs großer Modellanbieter zu beginnen oder eine Modellfamilie zu testen, die Sie bereits verwenden, wie ein passendes Qwen-Rerank-Modell.
5.1.3 LLMs
Nach dem semantischen Abruf durch das Embedding-Modell und der verfeinerten Filterung durch das Rerank-Modell werden die relevanten Dokumentpassagen mit der ursprünglichen Frage des Benutzers zu einem Prompt kombiniert. Das LLM führt dann Leseverständnis, Informationsintegration und natürliche Sprachgenerierung durch, um eine kohärente, präzise und zum Kontext passende Antwort auszugeben.
Auf der Implementierungsebene gibt es zwei Hauptwege, LLMs in RAG zu nutzen:
- Privat bereitgestellte große Modelle. Diese eignen sich für Szenarien, die sich um Datenschutz, kontrollierbare Kosten oder tiefe Anpassung kümmern. Mainstream-Open-Modelle wie Qwen, Llama und GLM performen gut in RAG-Aufgaben. Zum Beispiel bietet Qwen2.5 im 7B- oder 14B-Bereich gute Instruktionsbefolgung und chinesisches Verständnis, während der Ressourcenverbrauch moderat bleibt, was es für lokale Unternehmensbereitstellung geeignet macht. Modelle wie KIMI, Minimax und DeepSeek können ebenfalls je nach spezifischen Geschäftsanforderungen in Betracht gezogen werden.
- Cloud-API große Modelle. Diese passen zu Szenarien, die schnellen Start, elastische Skalierung und kontinuierliche Modellaktualisierungen priorisieren. Großanbieter wie OpenAI, Anthropic, Google, Alibaba und ZhipuAI bieten alle stabile API-Dienste an. Diese Modelle verfügen im Allgemeinen über starke Sprachverständnis- und Generierungsfähigkeiten und können in RAG-Szenarien gut Antworten synthetisieren.
Bei der Auswahl von Cloud-Modellen sind mehrere Punkte wichtig: ob die Antwortqualität präzise und flüssig ist, ob der Preis angemessen ist, ob die Latenz akzeptabel ist und ob das Kontextfenster groß genug ist, um mehrere abgerufene Dokumente aufzunehmen. In der Praxis sollten Sie mehrere Kandidaten an Ihren eigenen Daten vergleichen und sehen, welches die vollständigsten und präzisesten Antworten liefert. Wenn Kosten ein Anliegen sind, ist ein nützlicher Ansatz die Kombination großer und kleiner Modelle: Verwenden Sie günstigere kleine Modelle für einfache Fragen und reservieren Sie teure große Modelle für schwierige Fälle. Da sich Modelle schnell aktualisieren, ist es auch ratsam, Kandidaten regelmäßig neu zu testen.
Für allgemeine Konversations- und QA-Fähigkeiten ist LMSYS Chatbot Arena, jetzt LMArena, eine der am weitesten anerkannten Bewertungsreferenzen:
Sie verwendet verblindete paarweise menschliche Vergleiche zur Rangordnung von Modellen. Die Rangliste bietet einen nützlichen ersten Filter, sollte aber bei der tatsächlichen RAG-Auswahl nur ein Ausgangspunkt sein. In spezialisierten Domänen wie Medizin, Recht und Finanzen kann die allgemeine Leaderboard-Rangordnung erheblich von der tatsächlichen Leistung an Ihren Geschäftsdaten abweichen.
Best Practice für die LLM-Auswahl ist der Aufbau eines kleinen, aber repräsentativen Testsatzes mit 20 bis 30 typischen Geschäftsfragen und die Bewertung von Kandidatenmodellen durch die vollständige End-to-End-RAG-Pipeline anstatt nur isolierte Modell-Benchmarks zu betrachten. Fragen wie die Verwendung von Reasoning-Modellen oder Non-Reasoning-Modellen, oder welche Modellgröße Qualität und Geschwindigkeit am besten ausbalanciert, werden am besten durch reales Testen in Ihrem eigenen Anwendungsfall beantwortet.
5.2 Ausführungsframeworks
In der realen Ingenieurpraxis müssen Sie normalerweise kein gesamtes RAG-System von Grund auf neu aufbauen. Eine Reihe ausgereifter Open-Source-Frameworks existiert bereits, jedes mit eigenen Stärken in Architektur, modularer Integration und Entwicklungseffizienz. Unternehmen können nach ihren eigenen technischen Reserven und Geschäftsszenarien wählen.
Gängige Framework-Typen umfassen:
Low-Code- oder visuelle Plattformen
- Dify: bietet eine intuitive visuelle Schnittstelle zum schnellen Aufbau von RAG-Anwendungen, geeignet für nichttechnische Teams oder schnelle Prototyp-Validierung. Es enthält integrierten Multi-Modell-Zugang, Workflow-Orchestrierung und Prompt-Management.
- Coze: eine KI-Bot-Entwicklungsplattform von ByteDance, die Zero-Code-Visuellerstellung bietet. Sie integriert sich tief in ByteDance-Modelldienste, unterstützt ein Plugin-Marketplace, geplante Aufgaben und Mehrkanalveröffentlichung und eignet sich für verbraucherorientierte Assistenten oder interne Unternehmens-Bots.
- n8n: eine Open-Source-knotenbasierte Workflow-Automatisierungsplattform. In RAG-Szenarien kann sie komplexe Geschäftslogik orchestrieren und Vorverarbeitung, Vektordatenbankoperationen, Modellaufrufe und Folgeaktionen wie E-Mail-Versand oder Ticket-Updates in einen automatisierten Ablauf verbinden.
- RAGFlow: konzentriert sich auf tiefe Layout-Analyse und Wissens-Extraktion und performt gut bei komplexen Dokumenten wie mehrspaltigen PDFs und tabellenreichem Material.
- FastGPT: eine chinesische Open-Source-Lösung, die Wissensbasenmanagement, Dialog-Orchestrierung und Anwendungsveröffentlichung integriert, mit starker chinesischer Dokumentation und Eignung für die schnelle Bereitstellung chinesischer RAG-Anwendungen.
Code-Frameworks und Entwicklungsbibliotheken
Die folgenden Werkzeuge haben normalerweise Implementierungen in verschiedenen Backend-Sprachen. Sie können die entsprechende Sprachversion für Ihren Applikationsstack wählen.
- LlamaIndex: ein Python-Framework, das speziell für RAG entwickelt wurde, mit reichhaltigen Konnektoren, Indexstrukturen und Abfrage-Engines. Seine Modularität macht es für tief angepasste Abrufstrategien oder die Integration mit vielen Datenquellen geeignet.
- LangChain: ein allgemeines LLM-Anwendungsframework, bei dem RAG nur ein Anwendungsfall ist. Seine Stärke liegt in seinem reichen Ökosystem und der Komponentenabdeckung, einschließlich der Unterstützung für komplexe Agenten und Workflow-Orchestrierung, obwohl die Lernkurve steiler ist.
Wenn die technischen Reserven des Teams begrenzt sind und Geschwindigkeit am wichtigsten ist, sind Low-Code-Plattformen wie Dify, Coze oder FastGPT gute Erstwahlen. Wenn Sie tiefe Anpassung, spezielle Datenquellenintegration oder detailliertes Performance-Tuning benötigen, bieten LlamaIndex und LangChain mehr Flexibilität. In der Praxis ist auch ein hybrider Weg üblich: eine Low-Code-Plattform für schnelle Machbarkeitsvalidierung nutzen und dann zu Code-Frameworks für Produktionsbereitstellung und Optimierung wechseln. Die meisten dieser Frameworks unterstützen auch die schnelle Integration mit Mainstream-Embedding-, Rerank- und LLM-Modellen und ermöglichen flexible Kombination unter Verwendung der oben diskutierten Modellauswahlprinzipien.
5.3 Wirkungsevaluierung
Für Unternehmen, die RAG-Systeme bereitstellen, ist die größte Herausforderung oft nicht der Systemaufbau, sondern das Tuning. Produktions-RAG enthält zwei nichtdeterministische Stufen – Abruf und Generierung –, sodass traditionelle Softwaretests nicht ausreichen. Deshalb ist der Aufbau eines wissenschaftlichen Bewertungssystems, oder RAG-Bewertung, so wichtig.
5.3.1 Einsteigerbeispiel: LLM-basierte RAG-Bewertung
Um ein intuitives Verständnis der RAG-Bewertung aufzubauen, können wir uns eine einfache automatisierte Pipeline ansehen, die auf der Idee des LLM-as-a-judge basiert:
https://huggingface.co/learn/cookbook/rag_evaluation
Der Prozess enthält normalerweise drei Schlüsselschritte:
- Zuerst wird ein Bewertungsdatensatz synthetisiert, indem Dokumente aus der Wissensbasis entnommen und ein LLM beauftragt wird, hochwertige Frage-Antwort-Paare zu generieren, die dann nach Relevanz und Fundierung gefiltert werden, um einen Benchmark-Satz zu bilden.
- Zweitens wird das RAG-System für jede Frage in diesem Testsatz ausgeführt und die generierten Antworten gesammelt.
- Drittens erfolgt die automatisierte Bewertung, indem ein anderes LLM als Richter aufgerufen wird, das die generierten Antworten mit Referenzantworten vergleicht und quantitative Punktzahlen für Dimensionen wie Genauigkeit und Vollständigkeit vergibt.
Ein einfaches Beispiel:
- Problemgenerierung. Angenommen, die Wissensbasis enthält eine Produktmanualzeile: „Dieses Gerät unterstützt kabelloses Laden und hat einen 5000-mAh-Akku." Wir bitten ein Modell, als Prüfer zu fungieren und eine Frage zu generieren wie: „Was ist die Akkukapazität dieses Geräts?" Die Standardantwort ist „5000 mAh."
- Problemlösung. Wir senden diese Frage an das RAG-System, das verwandtes Material abruft und antwortet, zum Beispiel: „Das Gerät hat einen 5000-mAh-Akku."
- Benotung. Wir bitten ein anderes Modell, als Korrektor zu fungieren, indem es die Frage, die generierte Antwort und die Referenzantwort vergleicht, unter Verwendung eines Prompts wie: „Beurteilen Sie, ob die generierte Antwort korrekt ist. Geben Sie nur korrekt oder inkorrekt aus."
Durch die Ausführung dieses Prozesses in großem Maßstab können wir Metriken wie Genauigkeit berechnen. Dies bildet eine praktische Schleife aus Bewerten, Optimieren und Neubewerten.
Wenn Sie tiefere Details zur RAG-Bewertung wünschen, einschließlich Metrikdefinitionen, Framework-Nutzung und Benchmark-Datensätzen, sind zwei nützliche Übersichtsarbeiten:
- https://arxiv.org/pdf/2504.14891, Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey
- https://arxiv.org/pdf/2405.07437, Evaluation of Retrieval-Augmented Generation: A Survey
5.3.2 Bewertungsmetriken
Die RAG-Bewertung dreht sich grundlegend um zwei Fragen: Kann das Abrufmodul das richtige Material finden, und kann das Generierungsmodul aus diesem Material eine hochwertige Antwort produzieren? Dementsprechend ist das Bewertungssystem in Abrufbewertung und Generierungsbewertung unterteilt, ergänzt durch LLM-as-a-judge-Bewertung.
Abrufbewertung: Recall-Genauigkeit und Rangordnungsqualität
Das Abrufmodul ist das erste Tor in einem RAG-System. Seine Bewertung konzentriert sich auf drei Dimensionen: Findet es die richtigen Dinge, findet es genug davon und rangiert es sie gut.
Grundlegende Recall-Qualitätsmetriken
Die klassischen Grundmetriken sind Recall@K, Precision@K und F1:
- Recall@K misst den Anteil der relevanten Dokumente, die in den obersten K Ergebnissen zurückgewonnen wurden. Wenn fünf relevante Dokumente existieren und drei in den Top 10 gefunden werden, ist Recall@10 60 Prozent. Dies sagt uns, wie breit die Abrufabdeckung ist.
- Precision@K misst den Anteil der obersten K Ergebnisse, die wirklich relevant sind. Wenn drei der Top 10 relevant sind und sieben nicht, ist Precision@10 30 Prozent. Dies spiegelt die Abrufgenauigkeit wider.
- F1 ist das harmonische Mittel von Recall und Precision und balanciert die beiden.
Diese Metriken sind nützlich, um grundlegende Recall-Probleme schnell zu diagnostizieren. Wenn Recall niedrig ist, wurden relevante Dokumente überhaupt nicht gefunden. Wenn Precision niedrig ist, ist das Abrufrauschen zu hoch.
Rangordnungsqualitätsmetriken
Relevante Dokumente zu finden ist nur der erste Schritt. Es ist noch wichtiger, die relevantesten nah am Anfang zu platzieren. Dafür betrachten wir MRR, NDCG@K und MAP:
- MRR, Mean Reciprocal Rank, misst den Kehrwert der Rangposition des ersten relevanten Dokuments. Wenn das erste relevante Dokument an Position 3 erscheint, ist der reziproke Rang 1/3. MRR eignet sich besonders für Szenarien, in denen eine korrekte Antwort ausreicht.
- NDCG@K, Normalized Discounted Cumulative Gain, berücksichtigt sowohl abgestufte Relevanz als auch Positionsabzug. Es fragt nicht nur, ob ein Dokument relevant ist, sondern wie relevant, und belohnt hochrelevante Dokumente, die früh erscheinen.
- MAP, Mean Average Precision, ist sensibel für die Positionen aller relevanten Dokumente und spiegelt die Gesamt-Rangordnungsqualität wider.
In der tatsächlichen Ingenieurpraxis ist eine gängige Kombination Recall@K plus MRR@K. Wenn beispielsweise Recall@10 80 Prozent beträgt, aber MRR@10 nur 0.3, werden relevante Dokumente gefunden, aber zu tief begraben, was darauf hindeutet, dass das Reranking verbessert werden muss.
Bei Bedarf kann auch eine Coverage-Metrik hinzugefügt werden, um die Wissensbasenabdeckung zu überwachen und systematische blinde Flecken aufzudecken.
Generierungsqualitätsbewertung: Genauigkeit und faktische Treue
Der Abruf liefert das Rohmaterial. Die nächste Frage ist, ob das Generierungsmodul aus diesen Materialien eine hochwertige Antwort produzieren kann. Die Kerndimensionen hier sind Antwortgenauigkeit und Treue gegenüber den abgerufenen Beweisen.
Exakte Übereinstimmung und Textähnlichkeit
Die einfachste Metrik ist EM, Exact Match, die verlangt, dass die generierte Antwort exakt mit der Referenzantwort übereinstimmt. Dies eignet sich für festformatige, eindeutig korrekte Faktenfragen wie Datum oder Hauptsitzstandort, ist aber zu streng, da unterschiedliche, aber gleich korrekte Oberflächenformen möglicherweise nicht übereinstimmen.
Deshalb werden auch n-Gramm-Überlappungsmetriken wie ROUGE, BLEU und METEOR häufig verwendet. Sie bewerten generierte Antworten, indem sie die Wortüberlappung mit Referenzantworten vergleichen. ROUGE-L beachtet längste gemeinsame Teilsequenzen, BLEU stammt aus der maschinellen Übersetzung und betont Exaktheit, und METEOR fügt Synonym- und Stemming-Überlegungen hinzu.
Um die Grenzen reiner Wortüberlappung zu überwinden, können wir auch BERTScore oder direkte Vektorähnlichkeit verwenden. Diese nutzen vortrainierte semantische Repräsentationen und tolerieren daher Oberflächenvariation besser.
Faktische Treue und Halluzinationsdetektion
Für RAG-Systeme ist die Ähnlichkeit zwischen Antwort und Referenz nicht ausreichend. Die wichtigere Frage ist, ob die Antwort tatsächlich in den abgerufenen Dokumenten fundiert ist oder ob sie nicht unterstützten Inhalt halluziniert.
Deshalb sind Metriken wie Halluzinationsrate und Faithfulness wichtig. Ein zweites LLM kann als Faktenprüfer fungieren und die generierte Antwort Satz für Satz inspizieren und beurteilen, ob jede Behauptung durch die abgerufenen Dokumente gestützt werden kann. Für hochriskante Domänen wie Gesundheit, Recht und Finanzen ist diese Art von Metrik besonders wichtig, und einige Unternehmen setzen sogar Halluzinationsschwellenwerte als Produktionsfreigabekriterien durch.
LLM-as-a-Judge: mehrdimensionale Bewertung
Jede automatische Metrik hat Grenzen. Die meisten oberflächenformbezogenen Metriken können die semantische Qualität oder die Gesamtnützlichkeit nicht vollständig erfassen. Hier wird LLM-as-a-judge besonders wertvoll.
Der Grundansatz besteht darin, die Frage, die abgerufenen Dokumente, die Systemantwort und die Referenzantwort in ein starkes unabhängiges Modell wie GPT-4 oder Claude einzugeben und es zu bitten, über Dimensionen wie zu bewerten:
- Fragerelevanz
- Informationsvollständigkeit
- faktische Treue
- Gesamtkorrektheit
Die Stärke eines LLM-Richters liegt darin, dass er ein menschenähnlicheres ganzheitliches Urteil fällen kann. Natürlich müssen Richter-Prompts weiterhin sorgfältig gestaltet und anhand menschlich beschrifteter Beispiele kalibriert werden, um die Bewertung konsistent und zuverlässig zu halten.
Aufbau einer praktischen Metrikkombination
Mit so vielen verfügbaren Metriken fragen sich Teams oft, welche sie verwenden sollen. Eine praktische Empfehlung ist, mit einer kompakten Kombination zu beginnen und schrittweise zu erweitern:
- Für den Abruf mit Recall@K plus MRR@K beginnen
- Für die Generierung je nach Aufgabentyp ein oder zwei Baseline-Metriken aus EM, ROUGE-L und BERTScore wählen
- Für die Gesamtbewertung einen LLM-Richter einführen, der sich auf Relevanz, Vollständigkeit und Treue konzentriert
Dann durch eine Schleife aus Bewertung, Problemdiagnose, Strategieanpassung und Neubewertung iterieren.
5.3.3 Bewertungsframeworks
Da sich RAG schnell entwickelt hat, haben sowohl die Wissenschaft als auch die Industrie viele starke Bewertungsframeworks hervorgebracht. Diese Frameworks verpacken nicht nur gängige Metriken, sondern bieten auch standardisierte Datensätze, Benchmark-Verfahren und End-to-End-Workflows.
Eine grundlegende Klassifizierung von Frameworks
Wir können RAG-Bewertungsframeworks grob in drei Kategorien einteilen:
- Forschungsframeworks, die sich auf akademische Exploration und feinkörnige Diagnose konzentrieren. Beispiele sind FiD-Light und Diversity Reranker.
- Benchmark-Frameworks, die standardisierte Testsätze und Workflows für den horizontalen Systemvergleich bieten. Dazu gehören Frameworks wie RAGAS, ARES, RGB, MultiHop-RAG und CRUD-RAG.
- Tooling-Frameworks, die technische Nutzbarkeit und Integration mit Entwicklungsframeworks betonen. Beispiele sind TruEra RAG Triad, LangChain Benchmarks und RECALL.
In den letzten Jahren sind Bewertungsframeworks spezialisierter geworden. Zum Beispiel hat die Medizin MedRAG, das Recht hat LegalBench-RAG, und die Finanzen haben ihre eigenen domänenspezifischen Frameworks. Diese Domänenframeworks bieten oft nicht nur spezialisierte Datensätze, sondern auch spezialisierte Metriken wie medizinische Genauigkeit oder juristische Zitatrelevanz.
In der Praxis ist eine gute Faustregel:
- Wenn Sie schnell eine Baseline benötigen, beginnen Sie mit einem allgemeineren Framework wie RAGAS.
- Wenn Sie ein spezifisches Problem diagnostizieren, wählen Sie ein gezielteres Framework.
- Wenn Sie in der Medizin, im Recht, in den Finanzen oder einer anderen professionellen Domäne tätig sind, bevorzugen Sie nach Möglichkeit domänenangepasste Frameworks.
- Bevorzugen Sie aktiv gewartete Werkzeuge mit starker Dokumentation und reaktionsschnellen Communitys.
Häufig empfohlene Werkzeuge in der Community sind Ragas, Continuous Eval, TruLens-Eval, die Bewertungsfunktionen innerhalb von LlamaIndex, Phoenix, DeepEval, LangSmith und OpenAI Evals.
5.3.4 Bewertungsbenchmarks
Die Bedeutung von Bewertungsbenchmarks wird oft unterschätzt. Viele Teams beginnen die Bewertung eines RAG-Systems mit nur einer Handvoll handgeschriebener Testfragen und stellen dann fest, dass die reale Online-Leistung stark von den Offline-Eindrücken abweicht. Die Ursache ist, dass es an repräsentativen und systematischen Bewertungsdaten mangelt.
Ein Benchmark, der die Systemiteration gut unterstützt, hat normalerweise drei Kernmerkmale:
- Repräsentativität, d. h. er deckt hochfrequente Benutzerfragen, Grenzfälle und abnormale Eingaben ab
- Standardisierung, d. h. Frage- und Antwortformate, Schwierigkeitsgrade und Bewertungsregeln sind konsistent
- Entwickelbarkeit, d. h. der Benchmark kann aktualisiert werden, wenn Systemfähigkeiten und Geschäftsanforderungen sich weiterentwickeln
Für die meisten Unternehmen, da Geschäftsszenarien einzigartig sind, besteht die endgültige Antwort normalerweise darin, eigene Bewertungsdatensätze zu erstellen.
- Beginnen Sie damit, echte Benutzerfragen aus Geschäftsprotokollen zu extrahieren und nach Typ, Häufigkeit und Schwierigkeit zu sampeln.
- Für einfache Fälle lassen Sie Domänenexperten direkt annotieren. Für komplexere Fragen lassen Sie ein starkes LLM zunächst Kandidatenantworten generieren und lassen dann Experten diese überarbeiten.
- Neben der Antwort selbst Metadaten wie verwandte Dokumente, Antworttyp und Schwierigkeitsgrad kennzeichnen.
- Den Datensatz regelmäßig mit neuen, online entdeckten schweren Fällen aktualisieren.
Wenn die Ressourcen begrenzt sind und Sie eine schnelle Baseline benötigen, sind öffentliche Benchmarks dennoch ein nützlicher Ausgangspunkt. Stand 2025 existieren viele öffentliche Benchmarks für sowohl allgemeine als auch vertikale Szenarien:
Wählen Sie unter ihnen, indem Sie zunächst das Ziel klären. Möchten Sie eine Baseline erstellen oder das System vor dem Launch validieren? Prüfen Sie dann, ob der Benchmark die Szenarien und das Schwierigkeitsprofil abdeckt, das Sie interessiert. Für zeitempfindliche Domänen wie Nachrichten oder Finanzen stellen Sie sicher, dass der Benchmark zeitempfindliche Tests enthält.
In der Praxis ist die Kombination Ihres eigenen domäneninternen Datensatzes mit öffentlichen Benchmarks oft der robusteste Weg, da die Bewertung nah an realen Geschäftsanforderungen bleibt und gleichzeitig eine gewisse horizontale Vergleichbarkeit gewahrt wird.
6. Vertiefung: Lernen aus Wettbewerben und offenen Tutorials (Optional)
Die obigen Prinzipien und die Baseline-Implementierung reichen aus, um Ihnen beim Aufbau eines nutzbaren Prototyps zu helfen, aber sie sind noch etwas von der Lösung der schwierigeren Probleme entfernt, die in der Produktion auftreten. Wenn Sie praktischere und kampferprobtere RAG-Techniken verstehen möchten, ist eine der effizientesten Methoden, Gewinnerlösungen von Wettbewerben und starke offene Tutorials zu studieren. Diese Lösungen konzentrieren oft die Best Practices, die von starken Teams nach wiederholten Versuchen in realen Szenarien entdeckt wurden.
Die folgenden Beispiele sind repräsentativ und nicht erschöpfend. Wenn Sie in der Praxis ein spezifisches Problem treffen, wie PDF-Parsing, multimodalen Abruf oder latenzarme Optimierung, ist es oft effektiv, nach Wettbewerben zu suchen, die mit diesem Problem zusammenhängen, und die technischen Berichte und den offenen Code der Gewinner-Teams zu studieren.
6.1 Semantischer Cache: Optimierung hochfrequenter Abfragen
Hugging Face bietet eine Semantik-Cache-Implementierung, die auf der Chroma-Vektordatenbank aufbaut:
https://huggingface.co/learn/cookbook/semantic_cache_chroma_vector_database
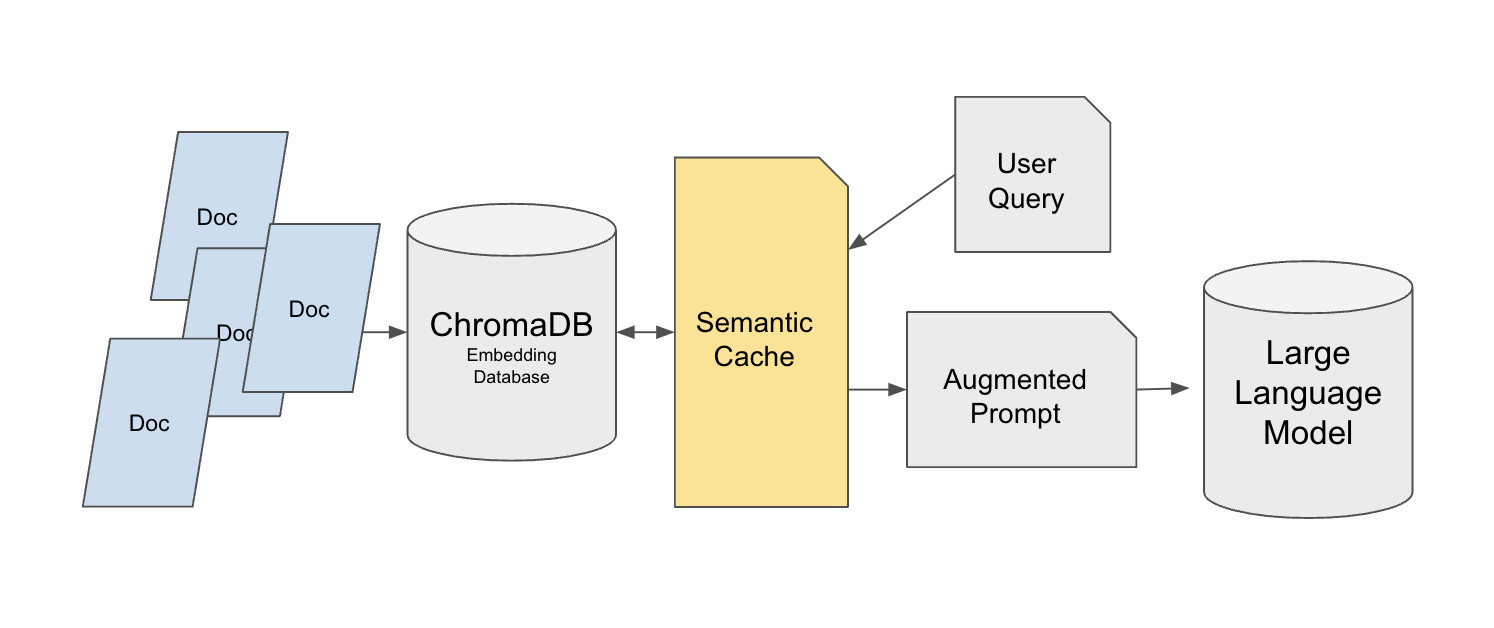
Hintergrund: Die meisten Tutorial-RAG-Systeme sind für Einbenutzer-Tests erstellt. Aber sobald sie in der Produktion bereitgestellt werden, kann das System Dutzende oder Tausende von wiederholten Abfragen erhalten, zum Beispiel Support-Benutzer, die wiederholt fragen, wie Rückerstattungen funktionieren. Wenn jede wiederholte Abfrage weiterhin Vektorabruf und einen LLM-Aufruf auslöst, steigen Latenz und Kosten schnell. Eine semantische Cache-Schicht kann den Druck auf die ursprünglichen Datenquellen drastisch reduzieren, während die Antwortqualität erhalten bleibt.
Dieses Design verwendet eine zweischichtige Abrufarchitektur. Die Basisschicht speichert die ursprüngliche Wissensbasis in Chroma unter Verwendung eines Datensatzes wie MedQuad als Beispiel und weist jedem Eintrag eine eindeutige ID für präzise Referenz zu. Die Cache-Schicht wird auf FAISS mit einem FlatL2-Index aufgebaut. Der semantische Cache sitzt zwischen der Benutzerabfrage und Chroma, anstatt die endgültige Antwort des LLMs direkt zu cachen. Dieses Design ist wichtig, weil das direkte Cachen von Antworten personalisierte Antwortanforderungen wie „erklären Sie dies in einfacher Sprache" brechen kann.
Das Cache-System verwendet den all-mpnet-base-v2 SentenceTransformer, um Abfragevektoren zu generieren, und verwendet euklidische Distanz mit einem Schwellenwert von 0.35, um zu beurteilen, ob Abfragen ähnlich sind. Wenn der Cache voll ist, gesteuert durch den max_response-Parameter, wird der älteste Eintrag nach FIFO entfernt. Cache-Daten können auch in JSON-Dateien für die sitzungsübergreifende Wiederverwendung gespeichert werden.
In kleinskaligen Tests dauerte eine erste Abfrage wie „Wie funktionieren Impfstoffe?" 0.057 Sekunden, als sie aus Chroma abgerufen wurde, während eine ähnliche Abfrage aus dem Cache nur 0.016 Sekunden dauerte. In großen Produktionsszenarien kann dieser Ansatz eine 90- bis 95-prozentige Leistungsoptimierung in Umgebungen mit hoher Wiederholungsrate erzeugen und die Vektorspeicher- und API-Kosten signifikant reduzieren.
6.2 Unstrukturierte Datenverarbeitung: einheitliches Parsing für Mehrformat-Dokumente
Ein weiteres Hugging-Face-Tutorial zeigt, wie man die Unstructured-Bibliothek verwendet, um eine vollständige Pipeline für die Verarbeitung nicht-strukturierter Dokumente aufzubauen:
https://huggingface.co/learn/cookbook/rag_with_unstructured_data

Hintergrund: In Unternehmensszenarien ist Wissen oft über PDFs, PowerPoint-Präsentationen, EPUBs, HTML-Seiten und viele andere Formate verstreut. Traditionelle Vorverarbeitungsmethoden unterstützen entweder nur ein Format oder verlieren während der Konvertierung entscheidende Strukturinformationen wie Tabellen und Titelhierarchie. Das macht es dem RAG-System schwer, den Inhalt korrekt zu verstehen und abzurufen.
Diese Lösung lädt zunächst Mehrformat-Testdokumente herunter, wie z. B. ein kanadisches Pestizidhandbuch-PDF mit vielen Tabellen und eine University-of-Florida-Citrus-IPM-PowerPoint-Datei mit Diagrammen und mehrstufigen Überschriften. Es verwendet dann Unstructureds Local Runner zum Parsing. Die Konfiguration umfasst eine Processor-Konfiguration, eine Partition-Konfiguration, die optional den API-Partitionsmodus für stärkeres OCR nutzen kann, und eine lokale Konfiguration, die Eingabepfade definiert. Geparste Dokumente werden in JSON konvertiert, das typisierte Elemente wie Fließtext, Titel und Tabellen enthält.
Das System verwendet dann chunk_by_title, setzt eine maximale Länge von 512 Zeichen und verschmilzt aufeinanderfolgende Fragmente von weniger als 200 Zeichen, um die semantische Kohärenz zu erhalten. Während der Konvertierung in LangChain-Dokumentobjekte werden komplexe Metadatenfelder gefiltert, um zu Chroma zu passen. Die Vektorstufe verwendet das BAAI/bge-base-en-v1.5 Embedding-Modell zusammen mit einem 4-bit-quantisierten Llama-3-8B-Instruct und einer LangChain-RetrievalQA-Kette, um ein vollständiges RAG-System aufzubauen.
Das resultierende System kann Mehrformat-Dokumente präzise verarbeiten. Für Fragen wie „Sind Blattläuse ein Schädling?" kann es Schlüsselfakten aus den geparsten Dokumenten extrahieren und Antworten generieren, die auf dem relevanten Material fundieren. Dies ist besonders nützlich für Unternehmenswissensbasen, die viele Dokumenttypen verarbeiten müssen.
6.3 Unternehmensdokument-QA: hochpräzises und rückverfolgbares RAG
Die Meisterschaftslösung des Enterprise RAG Challenge zeigt, wie man ein produktionsreifes RAG-System unter strengen Zeit- und Präzisionsanforderungen aufbaut:
- https://abdullin.com/ilya/how-to-build-best-rag/
- https://hustyichi.github.io/2025/07/03/rag-complete/
Hintergrund: Die Teilnehmer mussten 100 echte Unternehmensjahresberichts-PDFs in 2.5 Stunden parsen, jeder Bericht mit bis zu 1000 Seiten und enthaltend komplexe Finanztabellen, mehrspaltige Layouts und Diagramme. Nach dem Parsing musste das System 100 präzise Geschäftsfragen mit expliziten Antworttypen beantworten – wie Ja-Nein, Firmennamen, exakte numerische Indikatoren oder Führungskräftebezeichnungen – und Seitenzahlen als Beweis angeben.
Das Siegerteam wählte IBMs Open-Source-Docling als PDF-Parser, da er bei komplexen Tabellen und mehrspaltigem Text am besten performte. Sie verbesserten den Docling-Code, sodass er JSON und Markdown-plus-HTML mit Metadaten ausgeben konnte, und verbesserten insbesondere das Tabellen-Parsing. Um die Verarbeitung zu beschleunigen, mieteten sie RTX-4090-GPUs und beendeten den 100-Berichte-Parse in 40 Minuten.
Die Textaufteilung verwendete 300-Token-Abschnitte mit 50-Token-Überlappung und rekursiver Aufteilung, um die semantische Kohärenz zu erhalten. Um unternehmensübergreifende Kontamination zu vermeiden, hatte jedes Unternehmen seinen eigenen FAISS-Vektorspeicher unter Verwendung eines IndexFlatIP-Index. Der Abruf folgte dann drei Stufen: Top-30-Abschnitte nach Vektoren abrufen, nach übergeordneten Seiten deduplizieren, da mehrere Abschnitte von derselben Seite stammen können, und Seiten mit GPT-4o-mini reranken. Die endgültige Rangordnung mischte Vektorabruf- und LLM-Reranking-Punktzahlen mit einer 0.3 bis 0.7 Gewichtungsaufteilung.
Die Generierung verwendete verschiedene Prompt-Vorlagen für verschiedene Antworttypen. Für numerische Fragen, wie Jahresumsatz, verwendete das System einen fünfstufigen Analyseprozess, um Indikatorabgleich, Einheitenkonsistenz und Kreuzprüfung sicherzustellen. Ausgaben waren strukturiert und enthielten Analyseprozess und Seitenreferenzen für Rückverfolgbarkeit.
Das System gewann zwei Auszeichnungen und belegte den ersten Platz auf dem Leaderboard. Eine wichtige Beobachtung war, dass selbst kleinere Modelle wie Llama 8B mehr als 80 Prozent der Teilnehmer übertrafen, während Llama 3.3 70B nahe an GPT-4o-mini herankam, was zeigt, dass ein gutes Systemdesign Genauigkeit, Effizienz und Kosten erfolgreich ausbalancieren kann.
6.4 AIOps-Szenario: intelligente Verarbeitung gemischter Text- und Bilddaten
Das EasyRAG-Projekt in einem AIOps-RAG-Wettbewerb konzentrierte sich auf QA für Betriebsszenarien:
http://blog.csdn.net/hustyichi/article/details/143323746
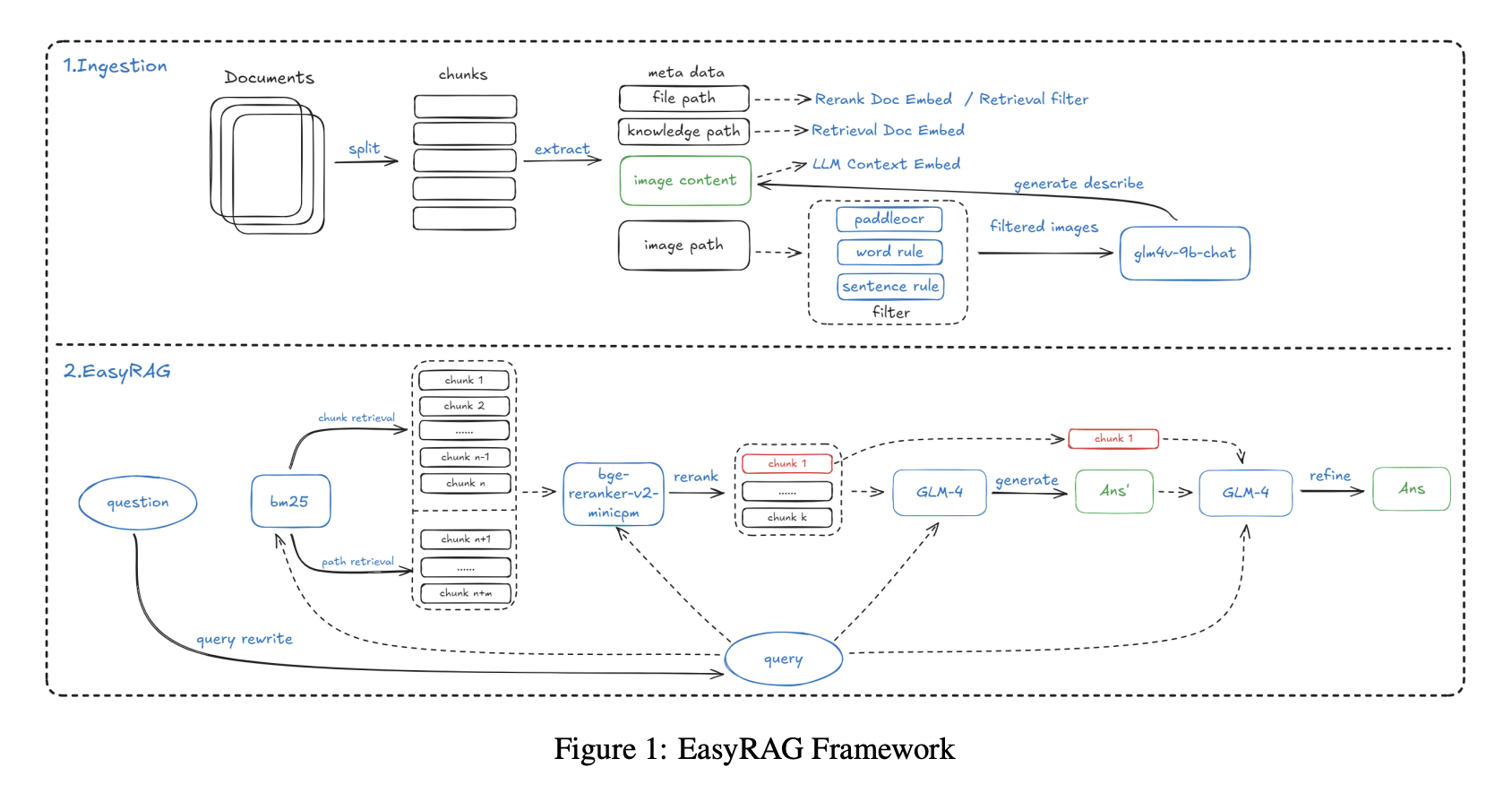
Hintergrund: Betriebsingenieure müssen oft technische Dokumente lesen, die nicht nur Text, sondern auch Überwachungsdiagramme, Systemarchitekturdiagramme und Leistungskurven enthalten. Zum Beispiel kann bei der Diagnose eines Systemproblems die Antwort auf „Was soll ich tun, wenn die CPU-Auslastung 80 Prozent übersteigt?" zwischen Textbeschreibungen und Überwachungsgraphen verstreut sein. Traditioneller reiner Text-RAG kann Diagrammtrends und -werte nicht verstehen, sodass Antworten unvollständig bleiben.
Die Indexierungsstufe verwendete einen verbesserten SentenceSplitter mit 1024-Token-Abschnitten und 200-Token-Überlappung. Eine Schlüsselinnovation war das Hinzufügen von Metadaten wie Wissensbasispfaden und Dateipfaden zu jedem Abschnitt, was den Recall um 2 Prozent verbesserte. Für Bilddaten verwendete das System zunächst PaddleOCR, um Text aus Diagrammen und Screenshots zu extrahieren, und verwendete dann ein multimodales Modell, GLM-4V-9B, um natürlichsprachige Beschreibungen des Bildes zu generieren, zum Beispiel eine CPU-Auslastungslinie zu beschreiben, die nachmittags bei 90 Prozent spitzt. Sowohl der OCR-Text als auch die Bildbeschreibung wurden dann zusammen indexiert.
Der Abruf verwendete eine zweipfadige BM25-plus-Vektor-Strategie für breiten Recall. BM25 deckte Abschnittsabruf und Pfadabruf ab, was half, irrelevante Dokumente nach Dateipfad zu filtern, während der Vektorabruf gte-Qwen2-7B-instruct verwendete. Reranking verwendete bge-reranker-v2-minicpm-layerwise, und eine 28-Schicht-Einstellung performte in Experimenten am besten.
Die Antwortgenerierung verwendete eine zweistufige Strategie: Zuerst einen Entwurf aus den Top-6-Dokumenten generieren, um die Informationsabdeckung zu maximieren, dann die Antwort mit dem Top-1-relevantesten Dokument optimieren, um die Kernantwort zu betonen.
Um langen Text-Szenarien zu handhaben, wie z. B. ein vollständiges Betriebshandbuch mit hunderten von Seiten, implementierte das System auch BM25-basierte Kontextkompression, wobei Dokumente in Sätze aufgeteilt, die Satzähnlichkeit mit der Abfrage bewertet und nur die relevantesten Sätze verkettet wurden. Bei 50-prozentiger Kompression erreichte diese Methode 86.48-prozentige Genauigkeit in nur 7.7 Sekunden und übertraf Werkzeuge wie LLMLingua.
6.5 Mehrquellen-Datenfusion: Zusammenarbeit zwischen strukturiertem und unstrukturiertem Wissen
Die Siegerlösung im KDD Cup 2024 Meta RAG Challenge zeigte, wie man unstrukturierte Webinhalte und strukturierte Wissensgraphen integriert:
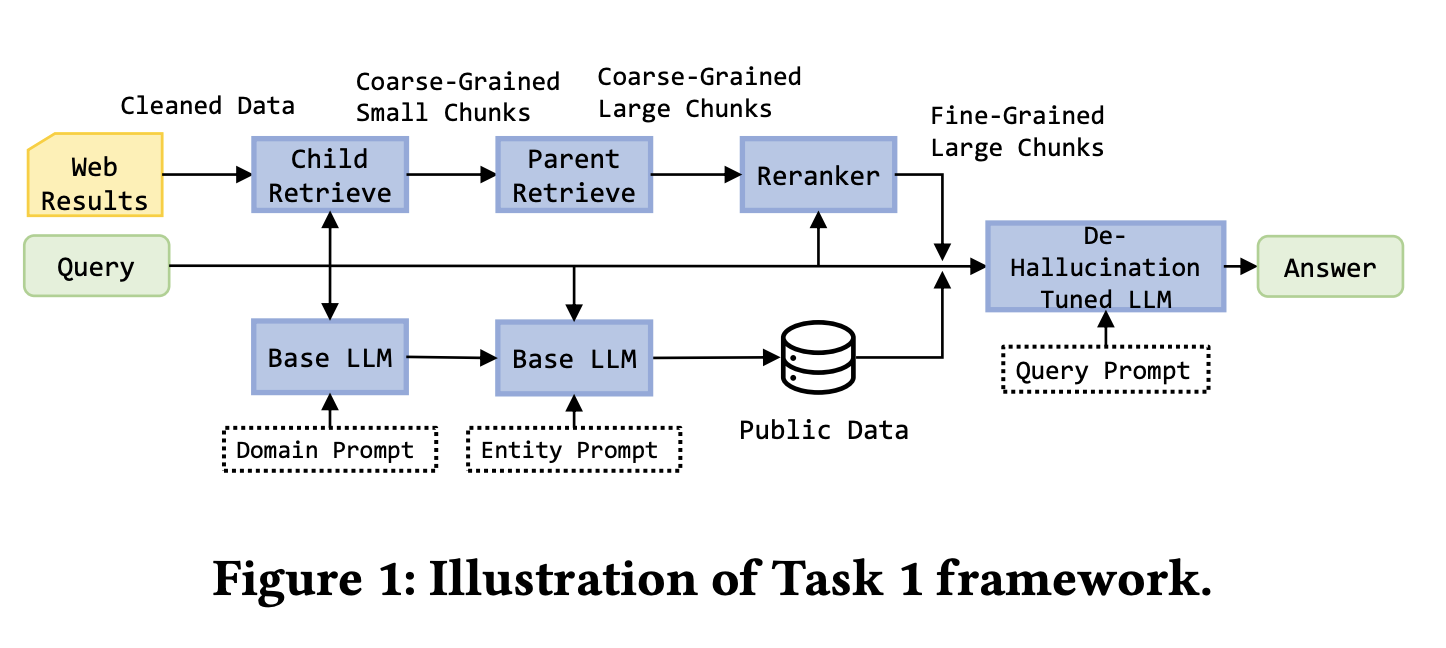
Hintergrund: Aufgabe 1 erforderte Abrufzusammenfassung von fünf Webseiten. Aufgabe 2 fügte eine Mock-API hinzu, die einen strukturierten Wissensgraphen repräsentierte und den direkten Zugriff auf Dinge wie Filmdatenbanken und Entitätsbeziehungen ermöglichte. Aufgabe 3 erhöhte die Schwierigkeit, indem fünfzig Webseiten plus die Mock-API verwendet wurden, um komplexere Abfragen zu beantworten, wie z. B. die Identifizierung von Nolan-regierten Filmen mit einem Einspielergebnis von mehr als 500 Millionen Dollar. Jede Abfrage musste innerhalb von 30 Sekunden abgeschlossen sein.
Für Aufgabe 1 baute das Siegerteam eine verfeinerte Web-Verarbeitungspipeline auf. Es verwendete BeautifulSoup, um Seitentext zu extrahieren, und ParentDocumentRetriever, um Eltern-Kind-Abschnittsbeziehungen zu verwalten, mit 200-Token-Kind-Abschnitten für den Abruf und 500 bis 2000-Token-Eltern-Abschnitten für die Generierung. Das Embedding-Modell war bge-base-en-v1.5, der Vektorspeicher war Chroma, und das Reranking verwendete bge-reranker-v2-m3. Das Team ergänzte auch Film- und Finanzdaten aus öffentlichen Datensätzen und feintunte Llama-3-8B-instruct mit LoRA auf Trainingsdaten, die ungültige Fragen und Referenzantworten enthielten.
Für die Aufgaben 2 und 3 war die Schlüsselinnovation die Priorisierung des Wissensgraphen. Das System definierte standardisierte API-Aufrufe wie get_person und get_movie mit Filter- und Sortierunterstützung. Es rief zuerst die Wissensgraph-API auf und fiel nur auf den Web-Abruf zurück, wenn die Graph-Ergebnisse fehlten oder ungültig waren. Dies verbesserte sowohl die Geschwindigkeit als auch die Antwortgenauigkeit.
Da das System den Wissensgraphen priorisierte und strukturierte Ausgabeformate verwendete, wurde die Halluzination deutlich reduziert. Wenn der Graph eine deterministische Antwort direkt liefern konnte, gab das System sie ohne generativen Schritt zurück. Wenn der Web-Abruf erforderlich war, musste die Antwort strengen Zitier- und schrittweisen Schlussfolgerungsregeln folgen.
Die Lösung gewann den ersten Platz in allen drei Aufgaben. Die wichtigste Lektion ist, dass in Unternehmensszenarien, die sowohl strukturierte als auch unstrukturierte Daten enthalten, die Abrufstrategie nach Datentyp gestaltet werden sollte: zuerst deterministische strukturierte Daten verwenden und unstrukturierte Quellen als Ergänzung behandeln.
Über diese praktischen Fälle hinweg erscheinen mehrere gemeinsame Prinzipien wiederholt:
- Caching-, Abruf- und Generierungsstrategien gemäß dem Geschäftsszenario wählen
- dedizierte Parsing- und Indexierungspfade für verschiedene Formate und Modalitäten entwerfen
- hybriden Abruf plus Reranking als Standardkonfiguration behandeln
- aufgabenspezifisches Prompting und strukturierte Ausgaben verwenden, um Genauigkeit und Rückverfolgbarkeit zu verbessern
Diese Lektionen aus realen Wettbewerben und offenen Projekten sind wertvolle Referenzen beim Aufbau stärkerer Unternehmens-RAG-Systeme.
7. Breite Exploration: Die zukünftige Evolution von RAG (Optional)
Sobald Sie die praktischen Fähigkeiten und Optimierungsmethoden von RAG gelernt haben, können Sie die Systemleistung in konkreten Szenarien bereits verbessern. Aber das Verständnis nur lokaler Ingenieurtricks reicht nicht aus, wenn Sie einen breiteren Blick darauf haben möchten, wohin sich RAG entwickelt. Wir müssen auch breitere Entwicklungsrichtungen betrachten.
RAG bricht jetzt schnell über das traditionelle Muster „Textabschnitte-abrufen-dann-generieren" hinaus. In diesem Abschnitt konzentrieren wir uns auf mehrere dieser Wege: den Übergang vom Abschnittsabruf zum graphstrukturierten Abruf, die Kombination von Bildern und Audio zu multimodalem RAG, die Verbesserung der Langdokumentverarbeitung durch vektorisiertes Late Chunking und die Art und Weise, wie sich RAG allmählich zu einem agentenorientierten System entwickelt.
7.1 Graph RAG: Umgestaltung des tiefen Abrufs mit Beziehungsnetzwerken
Verwandte Forschung:
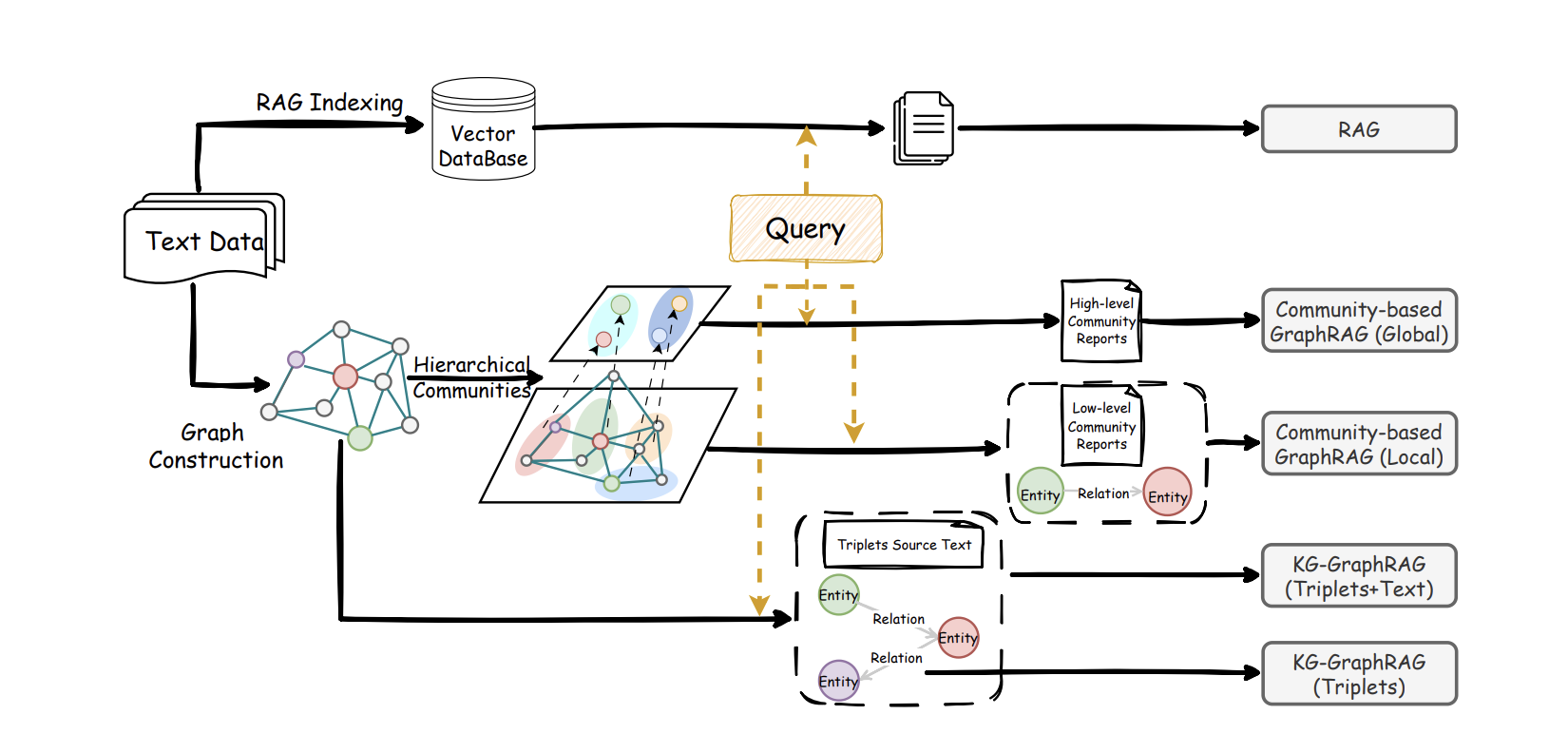
Traditionelles RAG funktioniert, indem es Textpassagen findet, die der Frage ähnlich sind, was wie das Herauspicken der wenigen Absätze ist, die am relevantesten aussehen, aus einem Stapel Material. Das funktioniert gut für direkte Faktenabfragen. Wenn jedoch eine Frage erfordert, mehrere Dokumente zu verbinden und verschiedene Hinweise zu kombinieren, sinkt die Leistung.
Zum Beispiel könnte ein Arzt fragen: „Basierend auf diesen Fällen und den neuesten Behandlungsrichtlinien, wie sollten wir die Vorteile und Risiken eines bestimmten Medikaments für ältere Patienten bewerten?" Oder ein Projektteam könnte fragen: „Wenn man die Anforderungsdokumente der letzten zwei Jahre, Überprüfungsprotokolle und Online-Problemmeldungen betrachtet, welcher Teil unserer Systemarchitektur versagt am häufigsten?" Solche Fragen drehen sich nicht um das Finden eines einzelnen Satzes. Sie erfordern die Identifizierung der Personen, Objekte, Ereignisse und Beziehungen, die über mehrere Materialien verstreut sind, und die Bildung eines vollständigen Bildes.
Graph RAG baut dieses Bild proaktiv auf. Das System verwendet ein großes Modell, um Schlüsselentitäten aus Text zu identifizieren – wie Personen, Organisationen, funktionale Module, Ereignisse und Daten – zusammen mit ihren Beziehungen – wie Kausalität, Abhängigkeit, Veränderung und Widerspruch. Es baut dann ein Wissensnetzwerk auf, das wächst, wenn mehr Material hinzugefügt wird. Durch automatische Gruppierung werden eng verwandte Entitäten und Beziehungen in Themen organisiert, und jedes Thema kann im Voraus zusammengefasst werden. Wenn ein Benutzer eine Frage stellt, sucht das System nicht mehr nur nach Textpassagen, die ähnlich aussehen. Es findet zuerst die relevantesten Entitäten und die lokale Graphstruktur, erweitert durch verwandte Themengruppen und gibt dann den Analysepfad, Knotenbeschreibungen und Quellpassagen zusammen an das LLM zum Schlussfolgern.
Unter diesem Framework ergänzen sich Graph RAG und traditionelles RAG. Traditionelles RAG bleibt stark für Detailfragen, deren Antworten in einem Schritt gefunden werden können. Graph RAG ist näher daran, wie ein menschlicher Forscher denkt: zuerst die Gesamtstruktur und Themen organisieren, dann Beweise ausfüllen und schließlich eine Schlussfolgerung mit Logik und Bedingungen erstellen. Bestehende Vergleiche zeigen, dass Graph RAG bei Multi-Hop-Schlussfolgerungsaufgaben oft mehr kritische Inhalte abdeckt und eine breitere Perspektive bietet. Flexible Kombination beider Ansätze ist oft besser als die alleinige Verwendung nur eines.
7.2 Multimodaler RAG
Verwandte Forschung:
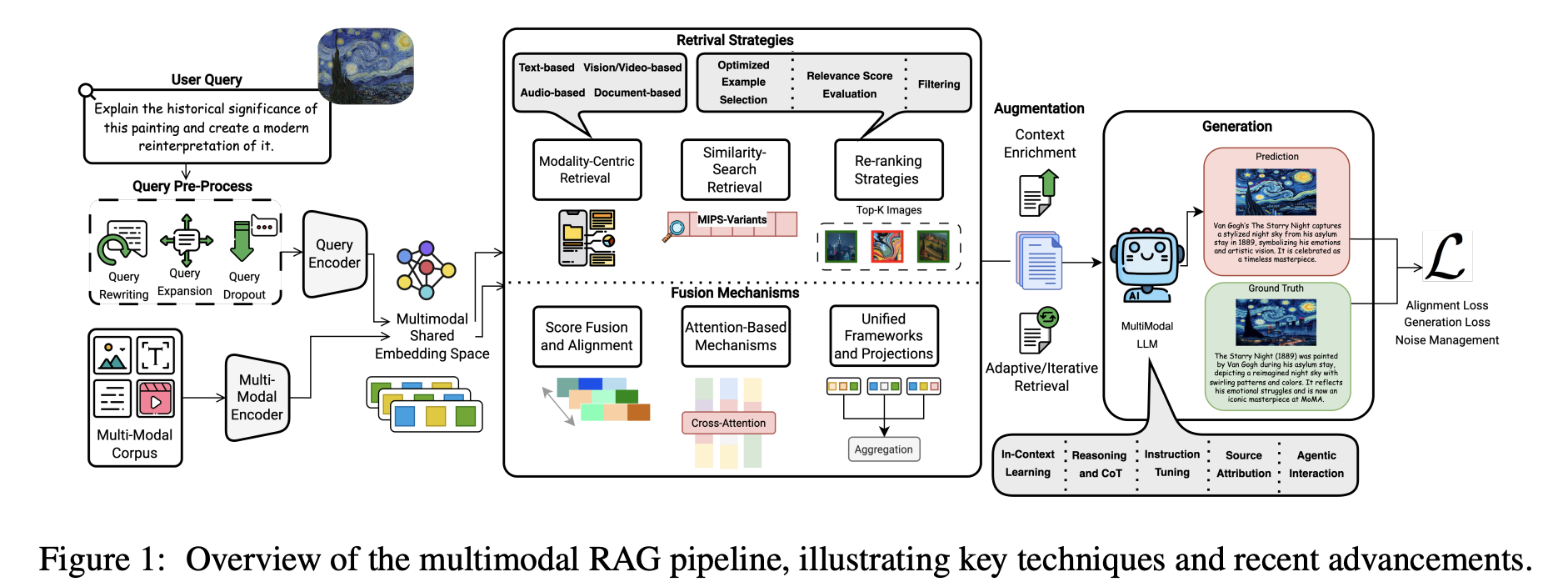
Echte Daten sind nie nur Text. Ingenieure, die Serverausfälle diagnostizieren, müssen Temperaturkurven, Geräte-Screenshots und Protokolle zusammen betrachten. Ärzte bei Diagnosen benötigen CT- oder MRT-Bilder, Testberichte und elektronische Krankenakten gleichzeitig. Traditioneller Text-RAG kann höchstens Phrasen wie „Temperaturanomalie" oder „Verdacht auf Lungenknoten" abrufen, aber er tut sich schwer, diese Beschreibungen mit dem tatsächlichen Diagrammtrend oder der Bildläsionsform zu verbinden, und kann keine Dokumente oder Wissen aus Bildern, Audio oder Video rückwärts suchen.
Multimodaler RAG löst dieses Problem verschiedener Modalitäten, die einander nicht „sehen" können. Sein Kern ist die cross-modale semantische Ausrichtung. Das System verwendet geeignete Encoder für Bilder, Video, Audio und Text zusammen mit OCR, ASR und Layout-Analyse, extrahiert Schlüsselinformationen aus visuellen und auditiven Quellen und bildet verschiedene Modalitäten in einem gemeinsamen semantischen Raum ab, wo ein einheitlicher multimodaler Index erstellt werden kann.
Zum Zeitpunkt des Abrufs und der Generierung, ob der Benutzer nach einem Diagramm fragt, das eine Umsatzspitze im Q3 2023 zeigt, oder eine Skizze oder ein Betriebsvideo hochlädt, findet das System zuerst den nächsten multimodalen Beweis in diesem einheitlichen Raum, filtert ihn nach Signalen wie Textähnlichkeit und Bildähnlichkeit, behält die nützlichsten Stücke und gibt dann diese Bilder, Textpassagen und Tabellen zusammen an ein multimodales LLM. Das Modell kann dann antworten, indem es Beweise über Modalitäten hinweg kombiniert und idealerweise die Quelle angibt oder relevante Bereiche im Bild oder Dokument hervorhebt.
Im Vergleich zu reinem Text-RAG kann multimodaler RAG mehr Arten von Beweisen nutzen und reduziert oft Halluzination, während vollständigere und überprüfbarere Antworten produziert werden.
7.3 Late Chunking: Erhaltung des vollständigen Kontexts für lange Dokumente
Verwandte Einführung:
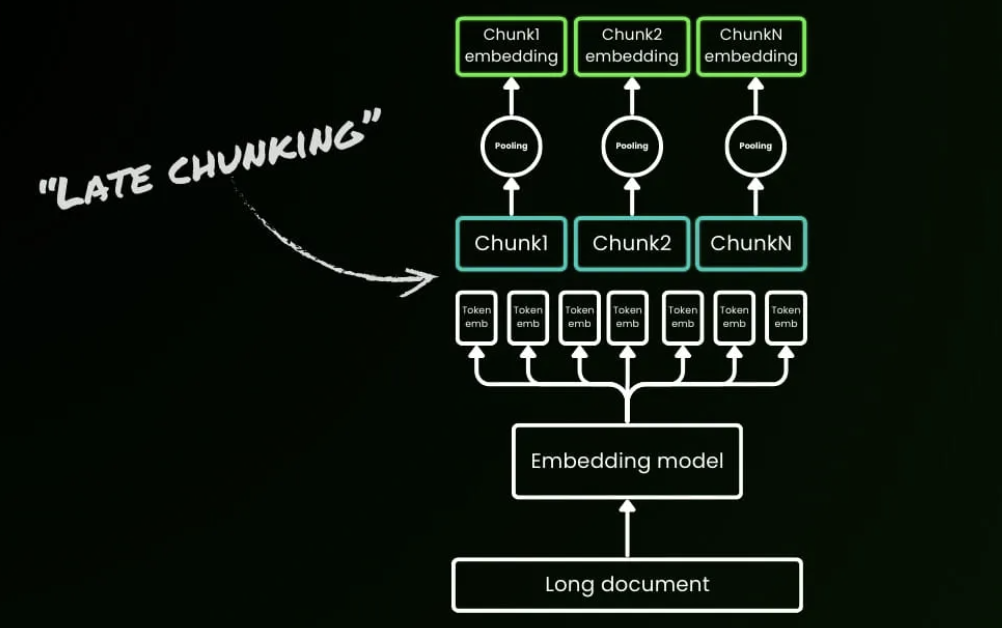
Stellen Sie sich vor, Sie lesen einen Wikipedia-Artikel über Berlin. Traditionelles RAG würde ihn zuerst in unabhängige Absätze schneiden und dann jeden Abschnitt einbetten. Wenn der erste Satz lautet „Berlin ist die Hauptstadt von Deutschland", verlieren spätere Phrasen wie „die Stadt" oder „ihre Bevölkerung" ihre Verbindung zu Berlin, sobald sie getrennt sind. Eine Abfrage wie „Wie hoch ist die Bevölkerung von Berlin?" kann dann fehlschlagen, weil der Begriff Berlin und die Bevölkerungsinformationen niemals innerhalb desselben Abschnitts erschienen. Dieses Problem wird bei langen Dokumenten noch schlimmer. In einem 200-seitigen Versicherungsvertrag kann die Definition einer Selbstbeteiligung auf Seite 5 erscheinen, während die Bedingungen, unter denen sie gilt, auf Seite 30 stehen. Festlängenaufteilung kann diese verwandten Stücke in Dutzende isolierter Abschnitte aufteilen, und Experimente zeigen, dass die semantische Ähnlichkeit stark einbrechen kann, wenn das passiert.
Late Chunking kehrt die traditionelle Pipeline „zuerst aufteilen, dann einbetten" um und folgt stattdessen „zuerst einbetten, dann aufteilen". Mit Langkontext-Embedding-Modellen, die etwas wie 8192 Tokens verarbeiten können, wird das gesamte Dokument zuerst durch den Transformer geleitet, wodurch Token-Level-Embeddings entstehen, die das gesamte Dokument bereits gesehen haben. Erst danach werden diese global informierten Token-Embeddings gemäß Abschnittsgrenzen in Abschnitts-Embeddings gepoolt. Die resultierenden Abschnitte sind keine unabhängigen Inseln mehr. Es sind kontextabhängige Embeddings, die absatzübergreifende Referenzen und konzeptionelle Beziehungen erhalten.
Auf BEIR-Benchmark-Datensätzen übertrifft Late Chunking traditionelle Aufteilung breit, mit besonders starken Gewinnen bei längeren Dokumenten. In Kurztext-Szenarien verschwindet der Unterschied weitgehend, was eine Schlüsselregel bestätigt: Je länger das Dokument, desto größer der Vorteil von Late Chunking. Die Methode ist jetzt in Jina Embeddings v3 integriert. Obwohl das erste Encodieren eines ganzen langen Dokuments die Inferenzzeit um 10 bis 20 Prozent erhöhen kann, können die Abrufgewinne in Szenarien wie Krankenakten, juristischen Dokumenten und technischen Handbüchern diese Kosten leicht rechtfertigen.
Late Chunking zeigt, dass 8K-plus-Langkontext-Embedding-Modelle in diesen Szenarien keine Überdimensionierung sind. Sie sind oft notwendig, um hochwertige Abschnitts-Embeddings zu produzieren, und repräsentieren einen Wechsel von „zuerst aufteilen, dann einbetten" zu „zuerst einbetten, dann aufteilen".
7.4 Von RAG zu RAG in der Agenten-Ära
Verwandte Diskussionen:
- https://ragflow.io/blog/rag-at-the-crossroads-mid-2025-reflections-on-ai-evolution
- https://arxiv.org/pdf/2501.09136
- https://www.letta.com/blog/rag-vs-agent-memory
- https://www.linkedin.com/posts/richmondalake_100daysofagentmemory-rag-memorizz-activity-7348281860843577346-LM7Y/
- https://www.llamaindex.ai/blog/rag-is-dead-long-live-agentic-retrieval
RAG hat sich von einem Abruf-augmentierten Generierungswerkzeug zu einem wichtigen Bestandteil der kognitiven Architektur eines Agenten entwickelt. Traditionelles RAG basiert auf einem einfachen Muster aus Fragen, Abrufen, Antworten und ist grundsätzlich passiv. Es wartet auf eine Abfrage und handelt nicht proaktiv. Um diese Passivität zu durchbrechen und komplexere kognitive Aufgaben zu bewältigen, wurde RAG tief mit Agentenfähigkeiten kombiniert, was ein neues Paradigma hervorbrachte: Agentic RAG.
Unter diesem Paradigma ändert sich die Rolle von RAG grundlegend. Es ist nicht mehr nur ein passiver Anbieter externen Wissens. Stattdessen wird es zur Kernverarbeitungseinheit, die intelligentes Verhalten unter der aktiven Planung, Zielrichtung und Selbstreflexion des Agenten unterstützt. Diese Fusion gibt dem Gesamtsystem Zielorientierung, iterative Optimierung und autonome Entscheidungsfindung und vertieft die Qualität der Mensch-KI-Interaktion erheblich. Agentic RAG kann komplexe Aufgaben verstehen, sie zerlegen, Abrufstrategien planen und die Qualität der anfänglichen Ergebnisse bewerten, um zu entscheiden, ob eine tiefere Exploration erforderlich ist.
Der Schlüssel zu dieser Fähigkeit ist eine mehrschichtige aktive Schleife. Angesichts einer komplexen Abfrage analysiert der Agent zuerst die Natur des Problems, zerlegt es in Teilprobleme und entwirft präzise Abrufstrategien für jedes Teilproblem. Nach Erhalt der anfänglichen Ergebnisse bewertet er sie, beurteilt, ob die Informationen vollständig und relevant sind, identifiziert Wissenslücken und generiert dynamisch präzisere neue Abfragen. Dieser iterative Prozess umfasst oft Multi-Hop-Abruf, wo eine Runde von Ergebnissen neue Richtungen für die nächste Runde aufdeckt und eine Wissensexplorationskette ähnlich der Arbeitsweise eines menschlichen Forschers erzeugt.
Um dieses kontinuierliche, iterative intelligente Verhalten zu unterstützen, insbesondere wenn Personalisierung und langfristige Wissensakkumulation wichtig sind, reicht der kurzfristige Gesprächskontext allein bei weitem nicht aus. Dies führt zum Bedarf an langfristigem, strukturiertem Speicher.
Genau deshalb wird RAG zunehmend die Rolle des langfristigen Speichersystems eines Agenten zugewiesen und verwendet, um eine vollständige externe Speicherarchitektur aufzubauen. Dieser langfristige Speicher ergänzt den Kurzzeitspeicher, der für die Aufrechterhaltung des aktuellen Dialogkontexts verantwortlich ist. Das langfristige Speichersystem stützt sich auf drei Schlüsselmechanismen:
- Strukturierte Indexierungsfähigkeit: Dies ermöglicht es dem Agenten, mehrdimensionale Indizes über große Mengen unstrukturierter Daten aufzubauen – nach Zeit, Thema, Entitätsbeziehungen und mehr – und unterstützt effizienten Abruf aus mehreren Blickwinkeln, ähnlich wie Menschen sich Informationen durch verschiedene Hinweise ins Gedächtnis rufen.
- Intelligentes Vergessen: Durch Werbevaluationsalgorithmen kann das System Informationen mit niedriger Frequenz, schwacher Relevanz oder veraltetem Inhalt abklingen oder selektiv verwerfen, wodurch das Speichersystem schlank und effizient bleibt und Überlastung verhindert wird.
- Wissenskonsolidierung: Das System verfeinert verstreute Dialog- und Interaktionserfahrung zu strukturiertem Wissen. Durch Entitätserkennung, Relations-Extraktion und semantisches Clustering werden fragmentierte Informationen zu Wissensgraphen verbunden, die kurzfristige Erfahrung in langfristiges Wissen umwandeln.
Dieses auf RAG basierende externe Speichersystem erweitert nicht nur die kognitive Grenze eines Agenten erheblich, sondern gibt ihm auch die Fähigkeit, Wissen kontinuierlich zu lernen und weiterzuentwickeln. Es ermöglicht dem Agenten, Erfahrung über langfristige Interaktion zu akkumulieren, personalisierte Betriebsmuster und Domänenwissenssysteme zu bilden und komplexere und länger laufende Aufgaben zu unterstützen.
Zusammenfassung
Retrieval-Augmented Generation ist nicht nur eine technische Methode zur Kompensation von Halluzination und Wissensveraltung in großen Modellen. Es ist auch eine Schlüsselbrücke, um allgemeine KI-Fähigkeit in tiefen Unternehmenswert umzuwandeln. Die Evolution von Naive RAG zu modularen und agentenorientierten Formen zeigt, dass jeder Teil von RAG sich kontinuierlich vertiefen muss, einschließlich feinerer Datenverarbeitung, wissenschaftlicherer Modellauswahl über Embedding-, Rerank- und LLM-Stufen hinweg und systematischerer Bewertung. All dies sind notwendige Schritte hin zum Aufbau unternehmensweiter Wissenssysteme, die kontrollierbar, vertrauenswürdig und effizient sind. Gleichzeitig ist das Ziehen von Lehren aus Wettbewerben und Ingenieurfallstudien einer der besten Wege, das Verständnis der technischen Details zu vertiefen.
Da Graph RAG, multimodales Verständnis und Late Chunking sich weiterentwickeln und kombinieren, verschiebt RAG stetig die alte Abruf-und-Generationsgrenze und bewegt sich hin zu tieferer semantischer Assoziation und nachhaltigerer Speicherfähigkeit. Die Hoffnung ist, dass dieser Übersichtsartikel Ihnen hilft, eine Vollketten-Methodologie aufzubauen – vom Prinzip zur Praxis und von der Bewertung zur Evolution –, sodass Sie in einer sich schnell bewegenden technologischen Landschaft hochwertige intelligente Anwendungen aufbauen können, die tatsächlich in der realen Welt ankommen und komplexe Geschäftsanforderungen bewältigen können.
Referenzen
[1] Ask in Any Modality: A Comprehensive Survey on Multimodal Retrieval-Augmented Generation.
https://arxiv.org/pdf/2502.08826
[2] Retrieving Multimodal Information for Augmented Generation: A Survey.
https://arxiv.org/pdf/2303.10868
[3] A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models.
https://arxiv.org/pdf/2405.06211
[4] Retrieval-Augmented Generation for Large Language Models: A Survey.
https://arxiv.org/pdf/2312.10997
[5] LightRAG: Simple and Fast Retrieval-Augmented Generation.
https://arxiv.org/pdf/2410.05779
[6] Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG.
https://arxiv.org/pdf/2501.09136
[7] ERAGent: Enhancing Retrieval-Augmented Language Models with Improved Accuracy, Efficiency, and Personalization.
https://arxiv.org/pdf/2405.06683
[8] Graph Retrieval-Augmented Generation: A Survey.
https://www.arxiv.org/pdf/2408.08921
[9] Evaluation of Retrieval-Augmented Generation: A Survey.
https://arxiv.org/pdf/2405.07437
[10] Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey.
https://arxiv.org/pdf/2504.14891
[11] From Local to Global: A Graph RAG Approach to Query-Focused Summarization.
https://arxiv.org/pdf/2404.16130
[12] RAG vs. GraphRAG: A Systematic Evaluation and Key Insights.
https://arxiv.org/pdf/2502.11371
[13] Introduction to RAG | LlamaIndex Python Documentation.
https://developers.llamaindex.ai/python/framework/understanding/rag/
[14] All-in-RAG | A Full-Stack Guide to RAG in Large-Model Application Development.
https://datawhalechina.github.io/all-in-rag/#/en/
[15] Ilya Rice: How I Won the Enterprise RAG Challenge.
https://abdullin.com/ilya/how-to-build-best-rag/
[16] RAG Research Table - Awesome Generative AI Guide (GitHub).
[17] RAG is dead, long live agentic retrieval.
https://www.llamaindex.ai/blog/rag-is-dead-long-live-agentic-retrieval
[18] LLM/RAG Zoomcamp extra lesson 5: Common evaluation methods and market preferences in RAG evolution.
https://vip.studycamp.tw/t/llmrag-zoomcamp-課外補充-5:rag-evolution-常見評估方法和市場偏好/8185
[19] How to Evaluate Retrieval Augmented Generation (RAG) Applications.
https://zilliz.com.cn/blog/how-to-evaluate-rag-zilliz
[20] RAG is not Agent Memory.
https://www.letta.com/blog/rag-vs-agent-memory
[21] Richmond Alake. LinkedIn post on #100DaysOfAgentMemory, RAG and MemoRizz.