Khi các mô hình ngôn ngữ lớn (LLM) được áp dụng ngày càng rộng rãi, các doanh nghiệp phải đối mặt với một vấn đề rất thực tế: làm thế nào để mô hình có thể trả lời chính xác các câu hỏi khi những câu hỏi đó phụ thuộc vào tài liệu nội bộ, dữ liệu theo thời gian thực hoặc kiến thức chuyên ngành? Suy cho cùng, dữ liệu huấn luyện của mô hình là có giới hạn và bị ràng buộc về mặt thời gian, nên không thể bao phủ toàn bộ kiến thức nghiệp vụ đặc thù của doanh nghiệp hay thông tin liên tục được cập nhật.
Một ý tưởng trực quan là: vì cửa sổ ngữ cảnh ngày càng mở rộng, từ 8K lên 128K và nay đã vượt quá một triệu token, tại sao không nhét toàn bộ tài liệu liên quan vào prompt và để mô hình trả lời trực tiếp dựa trên những tài liệu đó?
Tuy nhiên, việc có thể xử lý ngữ cảnh dài và việc có thể đưa ra câu trả lời chính xác một cách ổn định, hiệu quả và có thể kiểm soát trong các tình huống doanh nghiệp là hai vấn đề hoàn toàn khác nhau. Việc mù quáng dựa vào ngữ cảnh dài mang lại một loạt thách thức nghiêm trọng, bao gồm chi phí bùng nổ, sự phân tán sự chú ý và việc cập nhật kiến thức lỗi thời.
Để giải quyết những điểm nghẽn này, một kỹ thuật gọi là Retrieval-Augmented Generation, hay RAG, đã ra đời. Trước khi mô hình tạo ra câu trả lời, RAG truy xuất kiến thức bên ngoài một cách chính xác. So với việc chỉ đơn giản mở rộng độ dài ngữ cảnh một cách vũ lực, RAG đáp ứng các yêu cầu của doanh nghiệp về độ chính xác thực tế và kiến thức mới với chi phí thấp hơn, độ chính xác cao hơn và khả năng kiểm soát mạnh mẽ hơn. Do đó, nó đã trở thành nền tảng quan trọng để xây dựng các ứng dụng AI đáng tin cậy.
Trong hướng dẫn này, chúng tôi sẽ giải thích một cách có hệ thống RAG là gì, truy nguyên bối cảnh đằng sau sự ra đời của nó và các nguyên lý cốt lõi, sau đó khám phá sự tiến hóa của RAG từ hình thức cơ bản đến nâng cao, cùng với những hướng phát triển trong tương lai.
Bạn sẽ học được gì trong bài học này
- Giá trị cốt lõi của RAG: hiểu sâu cách nó giải quyết các vấn đề trung tâm về chi phí, sự chú ý và độ mới của kiến thức trong ngữ cảnh dài
- Cách RAG hoạt động: xem qua các ví dụ cụ thể cách nó hoàn thành vòng lặp đầy đủ từ truy xuất đến tạo sinh
- Sự tiến hóa của RAG: từ Naive RAG cơ bản đến Advanced RAG và sau đó là Modular RAG
- Lựa chọn mô hình cho RAG: hiểu cách đánh giá và chọn ba loại mô hình chính: Embedding, Rerank và LLM
- Thực hành RAG doanh nghiệp: tìm hiểu hướng dẫn xây dựng toàn chuỗi từ tiền xử lý dữ liệu đến triển khai và đánh giá hệ thống
- Đánh giá và tối ưu hóa RAG: hiểu các chỉ số cốt lõi, framework phổ biến và phương pháp cải tiến liên tục
- Xu hướng tiền tuyến của RAG: khám phá cách RAG kết hợp với agent, đa phương thức và các kỹ thuật mới nổi khác
Bạn sẽ đạt được gì
Sau khi hoàn thành hướng dẫn này, bạn sẽ xây dựng được nền tảng hiểu biết cơ bản có hệ thống về công nghệ RAG. Bạn không chỉ biết RAG là gì mà còn hiểu tại sao nó hoạt động. Bạn cũng sẽ có một bản thiết kế rõ ràng về cách đánh giá, chọn và thiết kế một hệ thống RAG hiệu quả, đáng tin cậy và có thể kiểm soát đáp ứng yêu cầu doanh nghiệp, tạo nền tảng vững chắc cho việc xây dựng các ứng dụng RAG cấp doanh nghiệp thực tế.
1. Tại sao cần RAG
Retrieval-Augmented Generation (RAG) là một trong những phương pháp kỹ thuật quan trọng nhất trong AI tạo sinh hiện nay. Ý tưởng cơ bản của nó rất đơn giản: trước khi yêu cầu mô hình lớn tạo câu trả lời, hệ thống truy xuất thông tin liên quan đến câu hỏi của người dùng từ cơ sở kiến thức bên ngoài, sau đó chuyển cả thông tin đã truy xuất và câu hỏi gốc cho mô hình để mô hình trả lời dựa trên tài liệu thực tế. Cơ sở kiến thức bên ngoài đó có thể là chính sách nội bộ, tài liệu quy trình và kiến thức sản phẩm của doanh nghiệp, hoặc cơ sở dữ liệu ngành, bộ văn bản quy định, thư viện tiêu chuẩn, v.v.
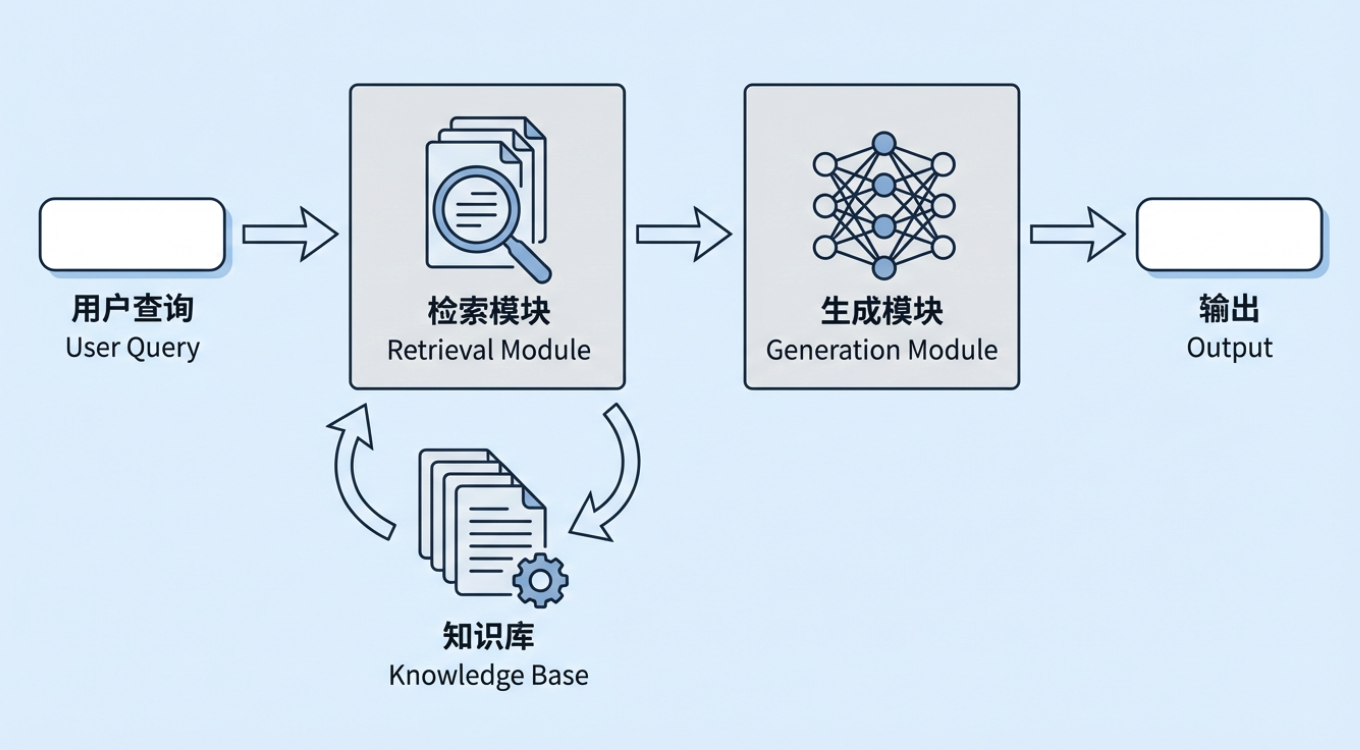
Lúc này, một câu hỏi tự nhiên xuất hiện: nếu các mô hình lớn đã có thể "trả lời câu hỏi trực tiếp", tại sao phải thêm một lớp gọi là Retrieval-Augmented Generation? Đặc biệt là khi cửa sổ ngữ cảnh ngày càng lớn hơn, có vẻ như chỉ cần đưa toàn bộ tài liệu liên quan cho mô hình là có thể giải quyết hầu hết nhu cầu.
Điểm khác biệt thực sự là "có thể đưa ra câu trả lời" và "có thể liên tục, ổn định và có thể kiểm soát đưa ra câu trả lời đúng trong môi trường kinh doanh thực tế" là hai việc hoàn toàn khác nhau. Nếu bạn chỉ dựa vào bộ nhớ tham số của mô hình, hoặc chỉ đổ một lượng lớn tài liệu vào ngữ cảnh dài, ít nhất ba vấn đề điển hình vẫn xuất hiện trong sử dụng doanh nghiệp.
Vấn đề chi phí và hiệu quả: Ngay cả khi cửa sổ ngữ cảnh tiếp tục mở rộng, ý tưởng đổ toàn bộ tài liệu vào ngữ cảnh cùng lúc vẫn không thực tế trong hệ thống thực tế. Mâu thuẫn cốt lõi thể hiện ở hai điểm:
Chi phí suy luận có tương quan dương mạnh với độ dài ngữ cảnh. Ngữ cảnh càng dài, chi phí suy luận càng tăng, gần như tuyến tính và đôi khi siêu tuyến tính. Đối với một lần gọi, 8K token và 200K token nằm trong các phạm vi giá cả và độ trễ hoàn toàn khác nhau, và ngữ cảnh dài có ngưỡng chi phí cao hơn nhiều.
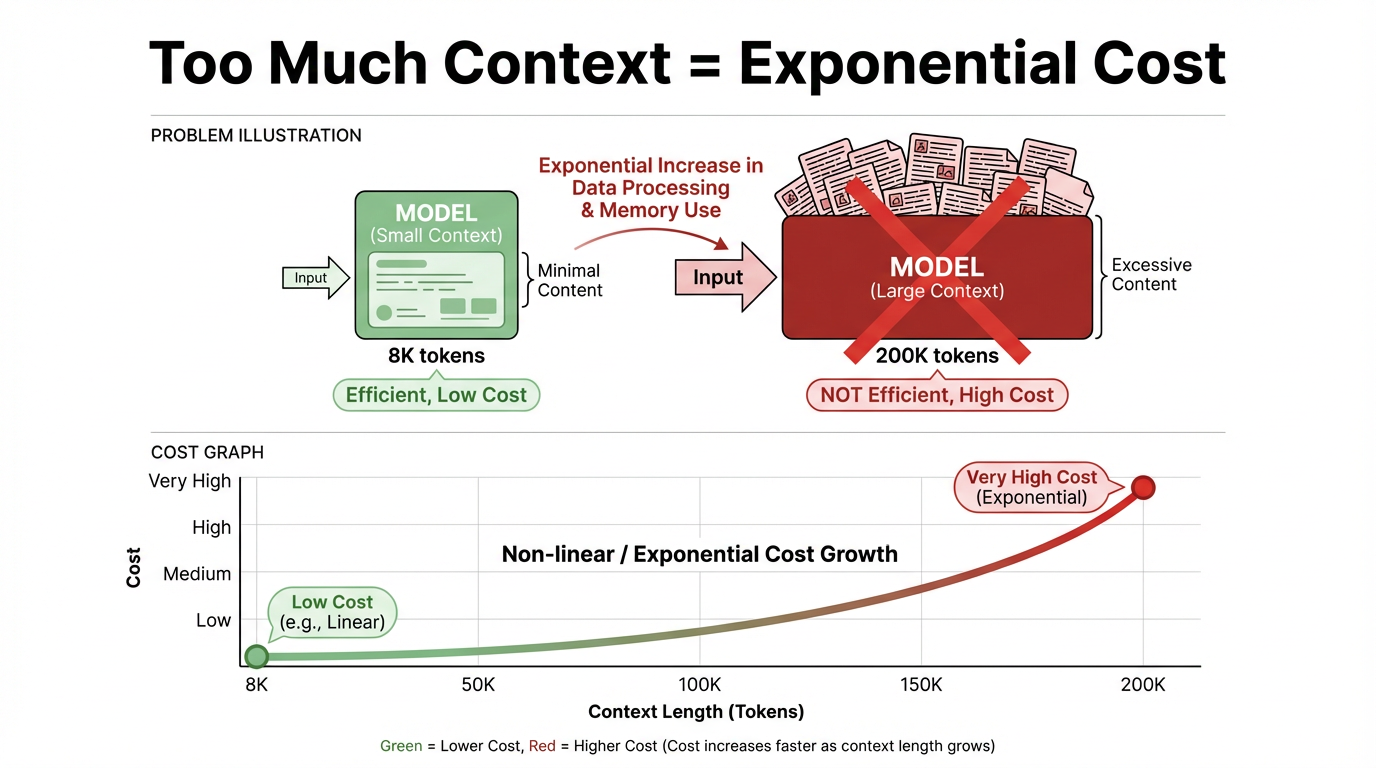
Về mặt ý nghĩa, ngữ cảnh là thông tin nền và lịch sử hội thoại mà mô hình "tham chiếu" khi trả lời câu hỏi. Về mặt kỹ thuật, đó là tổng chuỗi token được đưa vào mô hình cho một lần suy luận, chẳng hạn như hướng dẫn hệ thống và người dùng, lịch sử tin nhắn và các đoạn văn bản đã truy xuất.
"Cửa sổ ngữ cảnh" là giới hạn dung lượng cho đầu vào đó. Trong các kiến trúc mô hình lớn phổ biến hiện nay, như Transformers, các token đó tham gia vào tính toán attention ở mỗi lớp. Khi cửa sổ trở nên dài hơn và số lượng token tăng lên, tính toán và chi phí tăng theo cấp số nhân và thậm chí có thể tiếp cận tăng trưởng theo cấp số mũ.
Một lượng lớn tính toán bị lãng phí. Hầu hết các tác vụ chỉ cần một lượng rất nhỏ thông tin có liên quan cao đến câu hỏi hiện tại. Nhét toàn bộ bộ tài liệu vào ngữ cảnh tạo ra tính toán nhàn rỗi và lãng phí nghiêm trọng, giảm thông lượng hệ thống, làm chậm tốc độ phản hồi và cuối cùng ảnh hưởng đến trải nghiệm người dùng.
Vấn đề sự chú ý và tập trung: Một mô hình lớn có thể "bao phủ" ngữ cảnh siêu dài, nhưng không thể sử dụng mọi đoạn văn bản với chất lượng đồng đều. Khi độ dài ngữ cảnh vượt qua một ngưỡng nhất định, mô hình bắt đầu thể hiện thiên kiến chú ý rõ rệt:
Suy giảm chú ý: sự chú ý của mô hình đến các phần đầu và giữa của ngữ cảnh dần yếu đi, và nó có xu hướng dựa nhiều hơn vào văn bản đọc được sau này, do đó thông tin quan trọng ở đầu có thể bị bỏ qua hiệu quả.
Nhiễu loạn thông tin: mô hình dễ bị kéo lệch bởi thông tin không liên quan, lặp lại hoặc thậm chí mâu thuẫn trong ngữ cảnh. Câu trả lời cuối cùng có vẻ logic mạch lạc nhưng vẫn lệch khỏi câu hỏi cốt lõi, khiến độ chính xác khó đảm bảo. Nếu không có giai đoạn truy xuất để lọc và xếp hạng mức độ liên quan, ngữ cảnh càng dài thì càng khó giữ cho câu trả lời tập trung vào bằng chứng thực sự quan trọng. Lợi thế của ngữ cảnh dài có thể bị triệt tiêu hoàn toàn bởi nhiễu loạn thông tin.
Vấn đề độ mới và khả năng kiểm soát kiến thức: Nếu toàn bộ kiến thức được lưu trữ hoàn toàn trong tham số mô hình, hoặc được sao chép thủ công vào prompt, hai khiếm khuyết không thể tránh khỏi xuất hiện:
Cập nhật kiến thức khó khăn: khi kiến thức thay đổi, chẳng hạn như thay đổi chính sách, lặp lại sản phẩm hoặc cập nhật giá, bạn cần huấn luyện lại hoặc tinh chỉnh mô hình, tốn kém và chậm chạp, hoặc duy trì mẫu prompt thủ công, cũng tốn kém và dễ sai sót do con người.
Khả năng truy xuất nguồn gốc kém: khi mô hình trả lời, thường khó xác định các bằng chứng chính xác từ các tham số hộp đen hoặc prompt dài. Điều này làm cho các cuộc kiểm toán tuân thủ, giải thích rủi ro và các tác vụ khác yêu cầu căn cứ quyết định rõ ràng trở nên cực kỳ khó khăn.
Trong những ràng buộc thực tế này, lợi thế của RAG trở nên rõ ràng hơn nhiều. Phương pháp cốt lõi của nó là định vị thông tin liên quan và đáng tin cậy trước khi tạo sinh, để mô hình chỉ trả lời dựa trên kiến thức cần thiết. Kiến thức có thể được lưu trữ độc lập trong cơ sở kiến thức bên ngoài, giúp dễ dàng cập nhật và quản lý hơn. Đồng thời, kết quả tạo sinh có thể bao gồm nguồn trích dẫn, cải thiện khả năng giải thích và độ tin cậy. Ngay cả khi cửa sổ ngữ cảnh tiếp tục tăng trong tương lai, RAG vẫn sẽ cho phép quản lý và sử dụng kiến thức hiệu quả với chi phí tương đối thấp, hỗ trợ các ứng dụng kiến thức cấp doanh nghiệp có quy trình có thể quan sát và hành vi có thể truy xuất.
Từ góc độ yêu cầu doanh nghiệp, so với LLM truyền thống chỉ dựa vào tham số nội bộ, RAG chủ yếu giải quyết các vấn đề triển khai thực tế sau:
- Độ mới: Các mô hình truyền thống thường không biết các quy định, sản phẩm hoặc quy trình mới xuất hiện sau thời điểm cắt huấn luyện, nhưng RAG có thể đọc trực tiếp các tài liệu chính sách, cơ sở dữ liệu nghiệp vụ và cơ sở kiến thức mới nhất. Không cần huấn luyện lại thường xuyên, câu trả lời vẫn đồng bộ với trạng thái nghiệp vụ mới nhất.
- Chuyên môn hóa: Trong các lĩnh vực chuyên ngành như y tế, hóa chất hoặc tài chính, các mô hình đa dụng thường không hiểu đủ sâu hoặc nói đủ chính xác. Sau khi kết nối tài liệu lĩnh vực sở hữu của doanh nghiệp và tiêu chuẩn ngành, câu trả lời có thể dựa trên tài liệu có thẩm quyền và trở nên gần với thực hành kinh doanh thực tế hơn nhiều. 3.Ảo giác: Bằng cách yêu cầu câu trả lời dựa trên các đoạn văn bản đã truy xuất và cung cấp trích dẫn, hệ thống có thể giảm việc bịa đặt không có căn cứ ở cấp độ cơ chế, làm cho "nghe có vẻ đúng" gần hơn với "thực sự đúng."
- Khả năng giải thích và kiểm toán: Các mô hình chỉ dựa vào tham số thường không thể trả lời, "Quy tắc nào đã dẫn đến kết luận này?" RAG cho phép mỗi câu trả lời được truy xuất về một điều khoản chính sách cụ thể, tài liệu nghiệp vụ hoặc trường hợp lịch sử. Điều đó giúp nhân viên nghiệp vụ kiểm tra và sửa đổi câu trả lời và cung cấp cho các nhóm kiểm toán, rủi ro và tuân thủ khả năng truy xuất nguồn gốc mà họ cần.
- Chi phí tính toán và hiệu quả tài nguyên: Việc bắt mô hình ghi nhớ toàn bộ kiến thức doanh nghiệp trong tham số thường đồng nghĩa với mô hình lớn hơn và chi phí suy luận cao hơn. RAG lưu trữ phần lớn kiến thức bên ngoài mô hình trong kho lưu trữ vector và kho tài liệu, truy xuất theo nhu cầu, cho phép doanh nghiệp có được độ bao phủ rộng hơn và chi tiết chính xác hơn ngay cả với mô hình nhỏ hơn và tính toán hạn chế.
Do đó, đối với các doanh nghiệp muốn sử dụng mô hình lớn trong các tình huống kinh doanh thực tế trong dài hạn, ổn định và có thể kiểm soát, RAG không phải là một cải tiến tùy chọn. Nó gần như là công nghệ nền tảng thiết yếu để xây dựng một hệ thống ứng dụng kiến thức doanh nghiệp chất lượng cao.
2. RAG là gì
Ý tưởng cốt lõi của RAG, Retrieval-Augmented Generation, là cho phép mô hình lớn trả lời câu hỏi không chỉ với kiến thức tĩnh học được trong quá trình huấn luyện, mà còn với thông tin cập nhật và đáng tin cậy được lấy từ cơ sở kiến thức bên ngoài tại thời điểm chạy.
Trong một hệ thống RAG điển hình, câu hỏi của người dùng không được gửi trực tiếp đến mô hình lớn. Thay vào đó, một module truy xuất trước tiên tìm các đoạn tài liệu liên quan nhất từ cơ sở kiến thức doanh nghiệp, sau đó kết hợp các đoạn văn bản đó với câu hỏi gốc thành một ngữ cảnh hoàn chỉnh, và cuối cùng đưa cho mô hình để tạo câu trả lời. Mô hình "truy xuất trước, tạo sau" này cho phép mô hình lập luận từ tài liệu tham khảo thực tế thay vì chỉ đoán từ những gì nó ghi nhớ trong tham số. Chúng ta có thể xem một trường hợp điển hình:
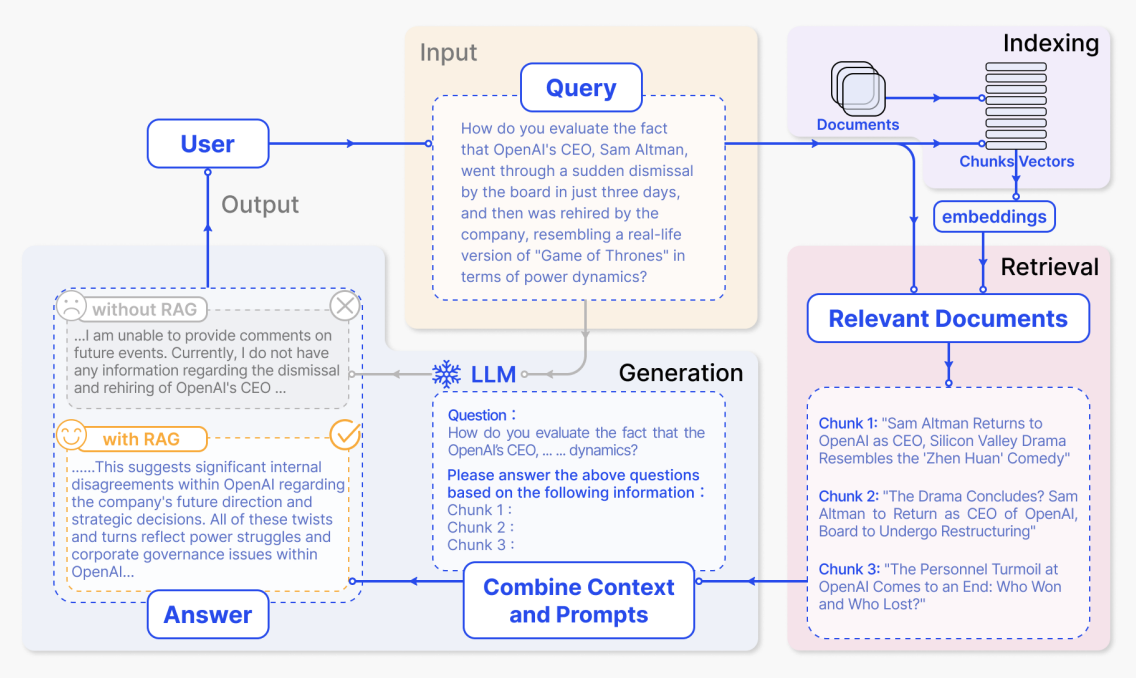
Giai đoạn lập chỉ mục
Trong giai đoạn lập chỉ mục, hệ thống xử lý tài liệu thô như tài liệu nội bộ doanh nghiệp, trang web và báo cáo. Nó chia nhỏ chúng thành các đoạn ngữ nghĩa nhỏ hơn, sau đó sử dụng mô hình embedding để tạo biểu diễn vector cho mỗi đoạn và xây dựng chỉ mục. Sau đó, khi câu hỏi của người dùng đến, hệ thống có thể nhanh chóng tìm các đoạn có độ tương đồng ngữ nghĩa cao nhất trong không gian vector.
Trong sơ đồ, điều này tương ứng với vùng "Indexing" màu tím ở góc trên bên phải. Đường dẫn từ "Documents" qua "Chunks / Vectors" đến "embeddings" cho thấy tài liệu được chia nhỏ, chuyển đổi thành vector và ghi vào chỉ mục. Cụ thể hơn:
- Tài liệu được chia thành một tập hợp các đoạn ngữ nghĩa mạch lạc, mỗi đoạn có thể tương ứng với một đoạn tin tức ngắn, giải thích hoặc phân tích.
- Mỗi đoạn được chuyển đổi thành vector nhiều chiều bởi mô hình embedding và lưu trữ trong chỉ mục vector.
- Chỉ mục này hỗ trợ truy xuất dựa trên độ tương đồng sau này, chuẩn bị một cơ sở kiến thức mà hệ thống có thể tham khảo khi trả lời câu hỏi.
Giai đoạn truy xuất cộng với tạo câu trả lời từ kết quả truy xuất
Sau khi người dùng đặt câu hỏi, hệ thống trước tiên truy xuất nội dung liên quan từ chỉ mục, sau đó gửi câu hỏi và văn bản đã truy xuất cùng nhau đến mô hình lớn để tạo câu trả lời. Trong hình, các vùng chính từ trên xuống dưới và từ phải sang trái tương ứng chính xác với quy trình đầy đủ này.
(1) Câu hỏi đầu vào của người dùng: vùng Input - Query màu vàng
"Bạn đánh giá thế nào về việc CEO của OpenAI, Sam Altman, bị hội đồng quản trị sa thải đột ngột chỉ trong ba ngày, và sau đó được công ty tuyển dụng lại, giống như một phiên bản thực tế của 'Game of Thrones' về mặt động lực quyền lực?"
"Bạn đánh giá thế nào về việc CEO OpenAI Sam Altman bị hội đồng quản trị sa thải đột ngột và sau đó được công ty tuyển dụng lại chỉ ba ngày sau, khiến cuộc đấu tranh quyền lực giống như một phiên bản thực tế của Game of Thrones?"
Khối văn bản lớn này là nội dung bên trong hộp "Query" trong sơ đồ, tương ứng với câu hỏi ngôn ngữ tự nhiên của người dùng. Hệ thống vector hóa câu hỏi đó và sử dụng nó để tìm kiếm các đoạn tài liệu liên quan trong chỉ mục phía trên bên phải.
(2) Tài liệu liên quan đã truy xuất: vùng Relevant Documents màu hồng ở phía dưới bên phải
Sau khi truy xuất, hệ thống nhận được một số đoạn tài liệu liên quan nhất đến câu hỏi. Trong sơ đồ, chúng được hiển thị dưới dạng ba đoạn:
"Sam Altman quay lại OpenAI với tư cách CEO, kịch bản Thung lũng Silicon giống vở hài 'Chân Hoàn'" "Sam Altman quay lại với tư cách CEO OpenAI, và kịch bản Thung lũng Silicon này giống một bộ phim hài cung đấu."
"Kịch đã kết thúc? Sam Altman sẽ quay lại làm CEO của OpenAI, Hội đồng quản trị sẽ tái cấu trúc" "Kịch có kết thúc không? Sam Altman sẽ quay lại làm CEO của OpenAI, trong khi hội đồng quản trị sẽ được tái cấu trúc."
"Biến động nhân sự tại OpenAI đi đến kết thúc: Ai thắng ai thua?" "Biến động nhân sự của OpenAI đi đến kết thúc: ai thắng ai thua?"
(3) Kết hợp prompt và tạo câu trả lời: vùng LLM / Combine Context and Prompts màu xanh
Hệ thống sau đó kết hợp câu hỏi gốc của người dùng và các đoạn đã truy xuất thành một prompt hoàn chỉnh và gửi cho mô hình. Hộp nét đứt ở phần dưới giữa của hình hiển thị một ví dụ prompt:
"Câu hỏi: Bạn đánh giá thế nào về việc CEO của OpenAI, ... động lực?
Vui lòng trả lời các câu hỏi trên dựa trên thông tin sau: Đoạn 1: Đoạn 2: Đoạn 3:"
"Câu hỏi: Bạn đánh giá thế nào về cuộc đấu tranh quyền lực trong sự cố CEO OpenAI?
Vui lòng trả lời câu hỏi trên dựa trên thông tin dưới đây: Đoạn 1: Đoạn 2: Đoạn 3:"
(4) So sánh câu trả lời có và không có RAG: các vùng Output - Answer màu xám và vàng ở phía dưới bên trái
Cuối cùng, mô hình tạo câu trả lời dựa trên thông tin được cung cấp. Hình cũng so sánh kết quả đầu ra có và không có RAG. Không có RAG, mô hình không có tài liệu bên ngoài và chỉ có thể đưa ra phản hồi mơ hồ, tương ứng với hộp màu xám:
"... Tôi không thể đưa ra bình luận về các sự kiện tương lai. Hiện tại, tôi không có bất kỳ thông tin nào về việc sa thải và tuyển dụng lại CEO của OpenAI ..."
Với RAG, mô hình có thể sử dụng các tin tức và phân tích đã truy xuất để tạo ra câu trả lời nhiều thông tin hơn nhiều, tương ứng với hộp màu vàng:
"... Điều này cho thấy bất đồng nội bộ đáng kể trong OpenAI về định hướng tương lai và các quyết định chiến lược của công ty. Tất cả những twists and turns này phản ánh cuộc đấu tranh quyền lực và các vấn đề quản trị doanh nghiệp trong OpenAI ..."
Ví dụ trên cho thấy quy trình đầy đủ của một hệ thống RAG điển hình và giúp chúng ta hiểu các giai đoạn cốt lõi và cách thông tin di chuyển qua chúng. Nhưng nhiều chi tiết kỹ thuật quan trọng vẫn nằm trong hộp đen: đối sánh vector được thực hiện chính xác như thế nào, và prompt nên được tổ chức ra sao để mô hình sử dụng nội dung đã truy xuất hiệu quả hơn? Những chi tiết này phần lớn quyết định chất lượng RAG thực tế. Tiếp theo, chúng ta sẽ đi sâu vào cơ chế nội bộ của RAG và phân tích từng bước, từ nguyên lý vector hóa và tính toán độ tương đồng đến kỹ thuật prompt.
3. Cách RAG hoạt động
Chúng ta có thể phân tích thông qua một ví dụ hỏi-đáp đơn giản được xây dựng trên cơ sở kiến thức về "táo."
3.1 Giai đoạn vector hóa tài liệu
Giả sử chúng ta có một cơ sở kiến thức đơn giản chứa ba đoạn tài liệu sau:
- Đoạn A: Apple Inc. được thành lập vào ngày 1 tháng 4 năm 1976 bởi Steve Jobs, Steve Wozniak và Ronald Wayne, và trụ sở chính nằm ở Cupertino, California.
- Đoạn B: Táo là một loại trái cây giàu vitamin C và chất xơ, giúp tiêu hóa và sức khỏe hệ miễn dịch.
- Đoạn C: Apple Inc. ra mắt chiếc iPhone đầu tiên vào năm 2007, thay đổi căn bản ngành công nghiệp điện thoại thông minh.
Khi chúng ta xử lý các tài liệu này bằng mô hình embedding, chẳng hạn như text-embedding-ada-002 của OpenAI hoặc mô hình BGE mã nguồn mở, mỗi đoạn được chuyển đổi thành một vector nhiều chiều, thường với 768, 1024 hoặc 1536 chiều.
Vector về bản chất là một mảng được tạo thành từ nhiều giá trị số. Mỗi chiều tương ứng với một đặc trưng ngữ nghĩa của văn bản. Ví dụ, vector cho "mèo" có thể chứa các chiều liên quan đến động vật có vú, thú cưng trong nhà và có lông. Sự kết hợp cuối cùng của các giá trị nắm bắt ý nghĩa ngữ nghĩa của văn bản để máy tính có thể "hiểu" mối quan hệ giữa các văn bản.
Các ví dụ đơn giản hóa, với vector thực tế có nhiều chiều hơn nhiều:
- Vector cho đoạn A, về việc thành lập Apple:
[0.85, -0.23, 0.41, -0.56, 0.12, 0.78, ...] - Vector cho đoạn B, về táo như trái cây:
[-0.12, 0.95, -0.34, 0.67, -0.89, 0.05, ...] - Vector cho đoạn C, về việc ra mắt iPhone:
[0.79, -0.18, 0.52, -0.61, 0.23, 0.81, ...]
Các vector này sau đó cần được lưu trữ trong cơ sở dữ liệu vector, chẳng hạn như Pinecone, Weaviate hoặc FAISS, để truy xuất và thu hồi sau này.
Cơ sở dữ liệu là một hệ thống lưu trữ và quản lý dữ liệu theo cách có cấu trúc, cho phép lưu trữ có tổ chức và truy xuất hiệu quả. Các ví dụ phổ biến bao gồm danh bạ liên lạc và danh mục sản phẩm thương mại điện tử.
Cơ sở dữ liệu vector là một loại cơ sở dữ liệu chuyên biệt. Khác với cơ sở dữ liệu truyền thống lưu trữ văn bản, bảng và các cấu trúc dữ liệu thông thường khác, cơ sở dữ liệu vector được thiết kế đặc biệt để lưu trữ vector, tức là các mảng số nhiều chiều, và được tối ưu hóa cho tìm kiếm tương đồng trong các kịch bản AI.
3.2 Giai đoạn truy vấn, truy xuất và phản hồi của người dùng
Sau khi cơ sở kiến thức đã được vector hóa và lưu trữ, một hệ thống RAG có thể hỗ trợ truy vấn người dùng theo thời gian thực. Khi người dùng đặt câu hỏi, hệ thống thực thi một quy trình liên tục: đầu tiên chuyển đổi câu hỏi thành vector, sau đó sử dụng tính toán độ tương đồng để truy xuất thông tin liên quan nhất từ cơ sở kiến thức, và cuối cùng sử dụng các đoạn văn bản đó làm cơ sở cho việc tạo câu trả lời. Chúng ta có thể minh họa quy trình này bằng ba truy vấn cụ thể.
Truy vấn 1: "Apple Inc. được thành lập khi nào?"
Ở giai đoạn vector hóa truy vấn, câu hỏi được chuyển đổi bởi mô hình embedding thành một vector ngữ nghĩa, ví dụ [0.82, -0.21, 0.38, -0.58, 0.15, 0.76, ...]. Mẫu số này có độ tương đồng cao với vector đã lưu của đoạn A, đoạn về việc thành lập công ty.
Hệ thống sau đó thực hiện truy xuất tương đồng, Top-K với K = 2, bằng cách tính độ tương đồng cosine giữa vector truy vấn và tất cả vector tài liệu trong cơ sở kiến thức. Kết quả trông như sau:
- Độ tương đồng với đoạn A, đoạn về việc thành lập: 0.97, liên quan cao
- Độ tương đồng với đoạn C, đoạn về việc ra mắt iPhone: 0.88, liên quan vì cũng nói về công ty
- Độ tương đồng với đoạn B, đoạn về dinh dưỡng trái cây: 0.12, gần như không liên quan
Top-K là một chiến lược lựa chọn phổ biến trong truy xuất vector. Nó có nghĩa là xếp hạng tất cả các kết quả đối sánh từ độ tương đồng cao nhất đến thấp nhất và giữ lại K kết quả hàng đầu. K = 2 có nghĩa là hệ thống chỉ giữ lại hai vector tài liệu hàng đầu theo độ tương đồng và lọc bỏ các kết quả xếp hạng thấp hơn, do đó giai đoạn tiếp theo chỉ tạo câu trả lời từ hai đoạn tài liệu liên quan nhất.
Các kết quả được lọc theo độ tương đồng được gọi là kết quả thu hồi. Hệ thống trả về các đoạn Top-2 làm bằng chứng:
- Đoạn A, độ tương đồng 0.97: "Apple Inc. được thành lập vào ngày 1 tháng 4 năm 1976 bởi Steve Jobs, Steve Wozniak và Ronald Wayne, và trụ sở chính nằm ở Cupertino, California."
- Đoạn C, độ tương đồng 0.88: "Apple Inc. ra mắt chiếc iPhone đầu tiên vào năm 2007, thay đổi căn bản ngành công nghiệp điện thoại thông minh."
Ở giai đoạn tạo câu trả lời, hệ thống xây dựng một đầu vào có cấu trúc hoàn chỉnh bằng cách đặt nội dung đã thu hồi vào phần thông tin tham khảo và gửi cùng với prompt hệ thống:
[System Prompt]
Bạn là một trợ lý hỏi đáp chuyên nghiệp. Vui lòng trả lời nghiêm ngặt theo "thông tin tham khảo" do người dùng cung cấp.
Nếu thông tin tham khảo chứa câu trả lời, hãy trả lời trực tiếp dựa trên nó.
Nếu thông tin tham khảo không chứa câu trả lời, hãy nói rõ với người dùng rằng "không thể trả lời câu hỏi dựa trên các tài liệu hiện có," và không được bịa đặt thông tin.
Vui lòng cho biết câu trả lời của bạn dựa trên thông tin nào.
[Retrieved Context]
Apple Inc. được thành lập vào ngày 1 tháng 4 năm 1976 bởi Steve Jobs, Steve Wozniak và Ronald Wayne, và trụ sở chính nằm ở Cupertino, California.
Apple Inc. ra mắt chiếc iPhone đầu tiên vào năm 2007, thay đổi căn bản ngành công nghiệp điện thoại thông minh.
[User Query]
Apple Inc. được thành lập khi nào?Sau khi nhận được đầu vào có cấu trúc này, LLM tuân theo hướng dẫn hệ thống và coi ngữ cảnh đã truy xuất là nguồn đáng tin cậy duy nhất để trả lời. Phản hồi cuối cùng của nó sẽ trông như thế này:
Theo thông tin tham khảo được cung cấp, Apple Inc. được thành lập vào ngày 1 tháng 4 năm 1976. [Căn cứ: Thông tin 1]
Truy vấn 2: "Ăn táo có lợi ích gì?"
Ở giai đoạn vector hóa truy vấn, câu hỏi này được chuyển đổi thành một vector ngữ nghĩa như [-0.08, 0.92, -0.31, 0.71, -0.85, 0.08, ...]. Mẫu số của nó có độ tương đồng cao với vector đã lưu của đoạn B, đoạn về dinh dưỡng táo.
Hệ thống lại thực hiện truy xuất tương đồng Top-K với K = 2 và tính toán độ tương đồng cosine:
- Độ tương đồng với đoạn B, dinh dưỡng trái cây: 0.95, liên quan cao
- Độ tương đồng với đoạn C, ra mắt iPhone: 0.18, gần như không liên quan
- Độ tương đồng với đoạn A, thành lập công ty: 0.15, gần như không liên quan
Hệ thống trả về các đoạn Top-2 làm bằng chứng:
- Đoạn B, độ tương đồng 0.95: "Táo là một loại trái cây giàu vitamin C và chất xơ, giúp tiêu hóa và sức khỏe hệ miễn dịch."
- Đoạn C, độ tương đồng 0.18: "Apple Inc. ra mắt chiếc iPhone đầu tiên vào năm 2007, thay đổi căn bản ngành công nghiệp điện thoại thông minh." Điều này chỉ liên quan yếu và thường sẽ bị lọc bởi ngưỡng trong thực tế.
Đầu vào có cấu trúc hoàn chỉnh sau đó được xây dựng như sau:
[System Prompt]
Bạn là một trợ lý hỏi đáp chuyên nghiệp. Vui lòng trả lời nghiêm ngặt theo "thông tin tham khảo" do người dùng cung cấp.
Nếu thông tin tham khảo chứa câu trả lời, hãy trả lời trực tiếp dựa trên nó.
Nếu thông tin tham khảo không chứa câu trả lời, hãy nói rõ với người dùng rằng "không thể trả lời câu hỏi dựa trên các tài liệu hiện có," và không được bịa đặt thông tin.
Vui lòng cho biết câu trả lời của bạn dựa trên thông tin nào.
[Retrieved Context]
Táo là một loại trái cây giàu vitamin C và chất xơ, giúp tiêu hóa và sức khỏe hệ miễn dịch.
Apple Inc. ra mắt chiếc iPhone đầu tiên vào năm 2007, thay đổi căn bản ngành công nghiệp điện thoại thông minh.
[User Query]
Ăn táo có lợi ích gì?Phản hồi cuối cùng của nó sẽ trông như sau:
Theo thông tin tham khảo được cung cấp, táo giàu vitamin C và chất xơ, và ăn táo giúp tiêu hóa và sức khỏe hệ miễn dịch. [Căn cứ: Thông tin 1]
Truy vấn 3: "Hôm nay thời tiết thế nào?"
Ở giai đoạn vector hóa truy vấn, câu hỏi này trở thành một vector ngữ nghĩa liên quan đến thời tiết và khí tượng, ví dụ [0.10, -0.05, 0.30, -0.12, 0.21, 0.08, ...]. Trong không gian ngữ nghĩa, vector này nằm xa tất cả các vector tài liệu về táo, dù là công ty hay trái cây, do đó không có độ tương đồng đáng kể nào xuất hiện.
Hệ thống lại thực hiện truy xuất Top-K với K = 2. Vì chủ đề câu hỏi không liên quan đến cơ sở kiến thức, điểm tương đồng tổng thể đều rất thấp:
- Độ tương đồng với đoạn B, dinh dưỡng trái cây: 0.18, cực kỳ thấp
- Độ tương đồng với đoạn C, ra mắt iPhone: 0.10, gần như không liên quan
- Độ tương đồng với đoạn A, thành lập công ty: 0.08, gần như không liên quan
Top-K vẫn trả về K kết quả xếp hàng đầu, nhưng trong trường hợp này những kết quả đó không cung cấp bằng chứng hiệu quả. Trong thực tế, hệ thống thường áp dụng ngưỡng tương đồng tối thiểu và trực tiếp trả về kết quả thu hồi trống, tức là không có kết quả hợp lệ, để giảm nhiễu loạn không liên quan.
Hai đoạn được trả về vẫn sẽ là:
- Đoạn B, độ tương đồng 0.18: "Táo là một loại trái cây giàu vitamin C và chất xơ, giúp tiêu hóa và sức khỏe hệ miễn dịch."
- Đoạn C, độ tương đồng 0.10: "Apple Inc. ra mắt chiếc iPhone đầu tiên vào năm 2007, thay đổi căn bản ngành công nghiệp điện thoại thông minh."
Đầu vào đầy đủ sau đó sẽ là:
[System Prompt]
Bạn là một trợ lý hỏi đáp chuyên nghiệp. Vui lòng trả lời nghiêm ngặt theo "thông tin tham khảo" do người dùng cung cấp.
Nếu thông tin tham khảo chứa câu trả lời, hãy trả lời trực tiếp dựa trên nó.
Nếu thông tin tham khảo không chứa câu trả lời, hãy nói rõ với người dùng rằng "không thể trả lời câu hỏi dựa trên các tài liệu hiện có," và không được bịa đặt thông tin.
Vui lòng cho biết câu trả lời của bạn dựa trên thông tin nào.
[Retrieved Context]
Táo là một loại trái cây giàu vitamin C và chất xơ, giúp tiêu hóa và sức khỏe hệ miễn dịch.
Apple Inc. ra mắt chiếc iPhone đầu tiên vào năm 2007, thay đổi căn bản ngành công nghiệp điện thoại thông minh.
[User Query]
Hôm nay thời tiết thế nào?LLM sẽ trước tiên đánh giá xem thông tin tham khảo có chứa thông tin thời tiết trực tiếp hoặc khí tượng thời gian thực hay không. Sau khi xác nhận rằng không có, nó sẽ tuân theo hướng dẫn để trả lời rằng không thể trả lời:
Các tài liệu hiện có không thể trả lời câu hỏi "Hôm nay thời tiết thế nào?" vì thông tin tham khảo chỉ chứa nội dung liên quan đến táo, dinh dưỡng trái cây và sản phẩm của Apple Inc., và không chứa thông tin thời tiết hoặc dữ liệu khí tượng thời gian thực. [Căn cứ: Không có thông tin liên quan đến thời tiết trong ngữ cảnh đã truy xuất]
Từ ba ví dụ này, chúng ta có thể thấy điểm then chốt của giai đoạn đối thoại RAG. Prompt hệ thống xác định vai trò và quy tắc phản hồi của LLM, bằng chứng đã truy xuất cung cấp tài liệu cụ thể và đáng tin cậy, và câu hỏi của người dùng xác định mục tiêu tác vụ. Mô hình đầu vào có cấu trúc này chính xác là điều cho phép RAG hướng dẫn và ràng buộc hiệu quả một LLM có thể tạo ảo giác, biến nó thành một hệ thống tạo ra câu trả lời ổn định và đáng tin cậy. Nó đảm bảo rằng mô hình được sử dụng để hiểu và tổ chức thông tin hiện có thay vì phát minh ra thông tin không có căn cứ.
4. Sự tiến hóa của RAG
RAG không bắt nguồn từ kỷ nguyên mô hình lớn. Các nghiên cứu trước đó đã chứa các nguyên mẫu của cùng ý tưởng này. Từ góc độ lịch sử, RAG phát sinh từ việc nhận ra những hạn chế của LLM truyền thống. Các mô hình ngôn ngữ lớn ban đầu chủ yếu phụ thuộc vào dữ liệu tiền huấn luyện, và dữ liệu đó trở nên cố định một khi huấn luyện kết thúc. Ví dụ, các mô hình như GPT-3 có ngày cắt kiến thức gắn liền với thời điểm thu thập dữ liệu huấn luyện và không thể có được kiến thức mới hơn. Việc huấn luyện lại hoặc tinh chỉnh LLM cho các lĩnh vực cụ thể cũng đòi hỏi tài nguyên lớn và chuyên môn chuyên biệt, khiến nó tốn kém và khó lặp lại nhanh chóng.
Nguồn gốc của RAG có thể được truy ngược lại framework DrQA năm 2017, lần đầu tiên thử nghiệm kết hợp truy xuất với mô hình ngôn ngữ. Một bước đột phá lớn sau đó đến vào năm 2020 với Dense Passage Retrieval, hay DPR, sử dụng các mô hình nơ-ron được tiền huấn luyện cho truy xuất ngữ nghĩa thay vì các phương pháp dựa trên tần suất từ truyền thống như TF-IDF và BM25. Năm 2021, RAG được chính thức đề xuất và hệ thống hóa, trở thành một phương pháp tiêu chuẩn để giải quyết các vấn đề cắt kiến thức và ảo giác trong LLM.
Nói rộng ra, sự tiến hóa của RAG có thể được chia thành ba giai đoạn:
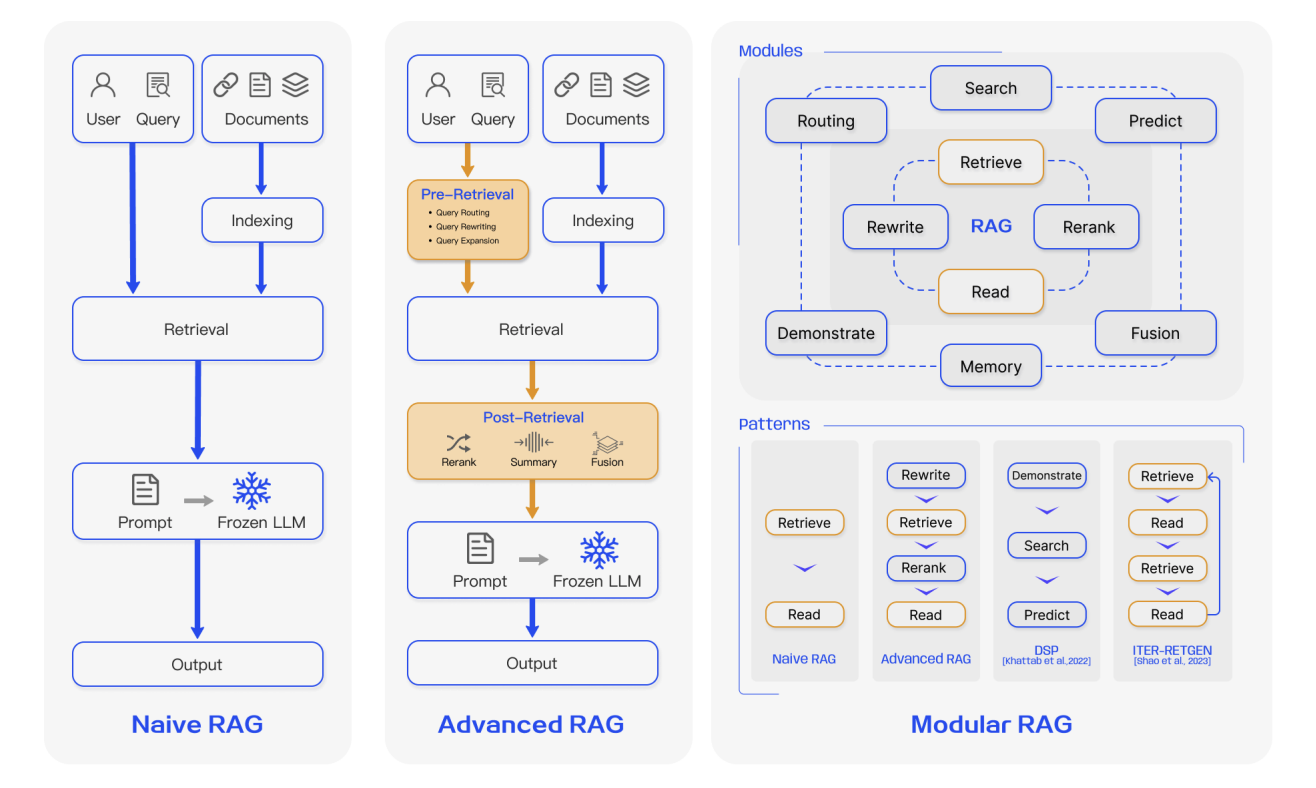
4.1 RAG thế hệ đầu tiên: Naive RAG
Naive RAG là hình thức cơ bản nhất của RAG. Từ góc độ kỹ thuật, nó tuân theo quy trình ba bước rất trực tiếp:
- Tiền xử lý tài liệu và lập chỉ mục. Tài liệu thô được làm sạch, chia thành các đoạn văn bản có độ dài cố định, mã hóa thành vector bằng mô hình embedding và ghi vào cơ sở dữ liệu vector.
- Truy xuất dựa trên độ tương đồng. Câu hỏi ngôn ngữ tự nhiên của người dùng được mã hóa thành vector và hệ thống thực hiện tìm kiếm tương đồng Top-K trên kho lưu trữ vector.
- Tạo sinh tăng cường truy xuất đơn giản. Các đoạn đã truy xuất được nối trực tiếp với câu hỏi gốc để tạo thành một prompt dài, sau đó gửi đến LLM để tạo câu trả lời.
Giá trị của giai đoạn này là nó đã xác minh, với rào cản rất thấp, rằng "truy xuất trước khi trả lời" thực sự hoạt động. So với việc chỉ dựa vào bộ nhớ nội bộ của mô hình, nó đã giảm đáng kể các vấn đề cắt kiến thức và một số ảo giác, đó là lý do tại sao nó đóng vai trò quan trọng trong các nguyên mẫu sớm, bản demo và hướng dẫn nhập môn.
Tuy nhiên, những hạn chế của RAG thế hệ đầu tiên cũng rõ ràng. Đầu tiên, chiến lược chia đoạn thường thô sơ. Hầu hết các hệ thống chỉ đơn giản chia theo độ dài cố định, điều này có thể cắt một đoạn văn ngữ nghĩa mạch lạc ở giữa hoặc trộn nhiều chủ đề trong một đoạn. Điều này làm giảm độ chính xác truy xuất và cũng làm cho việc hiểu khó hơn đối với LLM. Thứ hai, tín hiệu truy xuất quá đơn giản. Xếp hạng thường chỉ phụ thuộc vào độ tương đồng vector và không sử dụng các manh mối có cấu trúc phong phú hơn như từ khóa, dấu thời gian, độ tin cậy nguồn hoặc quyền truy cập. Thứ ba, kết quả truy xuất gần như không được quản lý: các đoạn ồn ào, lặp lại và thậm chí mâu thuẫn có thể được nhét vào ngữ cảnh không thay đổi, khiến một lượng lớn thông tin giá trị thấp chiếm dụng cửa sổ ngữ cảnh vốn đã hạn chế.
Tóm lại, thế hệ đầu tiên đã giải quyết câu hỏi liệu truy xuất có cần thiết hay không. Nhưng về các câu hỏi làm thế nào để truy xuất tốt hơn, và làm thế nào để sử dụng thông tin đã truy xuất hợp lý hơn, nó vẫn ở giai đoạn khá nguyên thủy.
4.2 RAG thế hệ thứ hai: Advanced RAG
Khi RAG chuyển từ bản demo sang các kịch bản kinh doanh thực tế, các yêu cầu về tính ổn định, khả năng kiểm soát và chất lượng đầu ra tăng mạnh. Thế hệ thứ hai, thường được nhóm dưới tên gọi chung Advanced RAG, vẫn tuân theo mô hình truy xuất trước và tạo sau, nhưng nó giới thiệu tinh chỉnh có hệ thống cả trước và sau truy xuất. Nói cách khác, hệ thống không còn thỏa mãn với việc chỉ truy xuất được thứ gì đó. Nó giờ đây hướng đến việc lưu trữ đúng thứ đúng cách, đặt đúng câu hỏi rõ ràng và quản lý ngữ cảnh đã truy xuất cẩn thận.
Trước khi truy xuất, trọng tâm là lưu trữ và đặt câu hỏi tốt:
Về phía lập chỉ mục, việc chia đoạn tiến hóa từ chia theo độ dài cố định sang chia đoạn nhận thức ngữ nghĩa và lập chỉ mục phân cấp. Hệ thống có thể chia dọc theo ranh giới chương, tiểu mục, đoạn văn hoặc câu, kết hợp với cửa sổ trượt và cấu trúc chỉ mục đa mức.
Mỗi đoạn tài liệu có thể mang metadata phong phú như nguồn gốc, dấu thời gian, tác giả, chủ đề và loại tài liệu, cung cấp nhiều chiều hơn cho việc lọc và xếp hạng sau này.
Về phía truy vấn, câu hỏi gốc của người dùng có thể được viết lại, mở rộng hoặc phân giải thông qua các kỹ thuật như Query Rewrite, Multi-Query, phân giải Sub-Query và Step-back Prompting, chuyển đổi các truy vấn người dùng mơ hồ hoặc hội thoại thành các dạng mà truy xuất có thể hiểu tốt hơn.
- Query Rewrite
Ý tưởng cốt lõi là chuyển đổi truy vấn mơ hồ, thông tục hoặc không chuẩn của người dùng thành biểu thức chuẩn hóa mà hệ thống truy xuất có thể hiểu dễ dàng hơn, bổ sung thông tin chính và giải quyết sự mơ hồ.
- Ví dụ, "Làm thế nào để tôi kiểm tra thời tiết ngày mai ở Hà Nội?" có thể được viết lại thành thứ chuẩn hóa hơn như "Truy vấn thời tiết thời gian thực cả ngày mai ở Hà Nội."
- Hoặc "Gợi ý phim hay" có thể được viết lại, sau khi xem lịch sử người dùng, thành "Gợi ý phim ly kỳ đánh giá cao năm 2024."
- Multi-Query
Hệ thống tạo nhiều truy vấn liên quan ngữ nghĩa nhưng từ các góc độ khác nhau từ câu hỏi gốc để giảm kết quả bị bỏ sót và bao phủ nhu cầu tiềm ẩn mà người dùng không nêu rõ.
- Sub-Query
Đối với các câu hỏi phức hợp chứa nhiều mục tiêu, hệ thống chia chúng thành các truy vấn con nhỏ hơn, đơn giản hơn để truy xuất có thể đối sánh chính xác từng nhu cầu.
- Step-back Prompting
Hệ thống trước tiên tạo một câu hỏi trừu tượng hơn, cấp cao hơn, sau đó sử dụng nó để hướng dẫn hướng truy xuất, giảm thiên kiến do quá tập trung vào chi tiết trong câu hỏi gốc.
Sau khi truy xuất, trọng tâm là quản lý những gì đã được truy xuất:
- Một mô hình rerank chuyên dụng hoặc thậm chí LLM có thể xếp hạng lại các tài liệu ứng viên để nội dung quan trọng và liên quan nhất đến câu hỏi đi vào ngữ cảnh trước tiên.
Mô hình rerank là một thành phần chính trong pipeline truy xuất thông tin. Nó thực hiện xếp hạng giai đoạn hai trên các kết quả ứng viên được trả về bởi giai đoạn thu hồi, sử dụng khả năng hiểu ngữ nghĩa mạnh hơn, thường dựa trên kiến trúc Transformer, để sửa lỗi xếp hạng ngữ nghĩa từ giai đoạn đầu và đẩy các kết quả phù hợp nhất với nhu cầu người dùng lên phía trước.
- Các đoạn đã truy xuất có thể được lọc, loại bỏ trùng lặp và nén để loại bỏ các đoạn rõ ràng không liên quan hoặc lặp lại cao, giảm xu hướng của hệ thống ngữ cảnh dài bỏ qua thông tin hữu ích ở giữa.
- Khi cần thiết, tinh chỉnh mô hình nhẹ có thể làm cho LLM có khả năng trả lời dựa trên bằng chứng truy xuất nhiều hơn và bao gồm trích dẫn hoặc nguồn rõ ràng.
Nhìn chung, Advanced RAG không còn chỉ tập trung vào việc truy xuất có cần thiết hay không hay có thể truy xuất được thứ gì đó không. Thay vào đó, nó giải quyết ba thách thức lớn hơn: liệu các đoạn thực sự quan trọng có thể được định vị chính xác hay không, liệu ngữ cảnh được chuyển cho mô hình lớn có súc tích, có cấu trúc tốt và dễ sử dụng hiệu quả hay không, và liệu toàn bộ hệ thống có duy trì ổn định và đáng tin cậy trong điều kiện nhiễu loạn, xung đột hoặc nhu cầu thông tin đa nguồn hay không.
Một lượng lớn bằng chứng thực nghiệm và kỹ thuật cho thấy Advanced RAG vượt trội hơn Naive RAG đáng kể về độ chính xác câu trả lời, đàn áp ảo giác, tính mạnh mẽ của hệ thống và khả năng giải thích. Đó là lý do tại sao nó đã dần thay thế các phương pháp cơ bản truyền thống và trở thành mô hình công nghiệp phổ biến để xây dựng hệ thống RAG ngày nay.
4.3 RAG thế hệ thứ ba: Modular RAG
Trong các ứng dụng doanh nghiệp phức tạp, yêu cầu thường trải dài nhiều lĩnh vực. Trong những trường hợp đó, một quy trình tuyến tính đơn giản gồm truy xuất, xếp hạng lại và tạo sinh thường là không đủ:
- Cùng một hệ thống có thể cần hỗ trợ FAQ đơn giản, tạo báo cáo dài, truy xuất mã và gọi cơ sở dữ liệu.
- Nó có thể cần kết nối kho lưu trữ vector, truy xuất toàn văn, cơ sở dữ liệu quan hệ, đồ thị kiến thức và công cụ tìm kiếm bên ngoài cùng lúc.
- Nó có thể cần bảo tồn tùy chọn người dùng và quyết định lịch sử qua nhiều vòng, đồng thời áp dụng kiểm tra tuân thủ và truy xuất nguồn gốc câu trả lời.
Trước bối cảnh đó, RAG bắt đầu tiến hóa theo hướng hệ thống module. Modular RAG không còn được xem là một pipeline cố định. Nó được xử lý thay vào đó như một tập hợp các module chức năng có thể cắm thêm, thay thế và kết hợp có thể được sắp xếp theo nhu cầu. Các module điển hình bao gồm:
- Hiểu truy vấn và định tuyến Module này xử lý nhận diện ý định, viết lại câu hỏi, phân giải tác vụ con và lựa chọn đường dẫn. Nó quyết định liệu một yêu cầu nên dựa chủ yếu vào kiến thức nội bộ, truy xuất bên ngoài hay một công cụ hoặc cơ sở dữ liệu cụ thể.
- Truy xuất và hợp nhất đa nguồn Module này kết nối đồng thời cơ sở dữ liệu vector, tìm kiếm toàn văn, cơ sở dữ liệu có cấu trúc và đồ thị kiến thức, truy vấn chúng, hợp nhất và xếp hạng lại kết quả thành một tập bằng chứng thống nhất.
- Bộ nhớ và cá nhân hóa Module này duy trì hồ sơ người dùng dài hạn, bộ nhớ phiên ngắn hạn và bộ nhớ đệm kiến thức lĩnh vực để hệ thống có thể liên tục tích lũy và sử dụng thông tin lịch sử.
- Thích ứng tác vụ và quản trị Module này tải các adapter khác nhau cho các tác vụ khác nhau, ràng buộc định dạng đầu ra, giọng điệu và phong cách, và quản trị đầu ra thông qua kiểm tra sự thật, lọc rủi ro và căn chỉnh trích dẫn.
Tóm lại, RAG truyền thống thường kết thúc sau một vòng truy xuất cộng với một vòng tạo sinh. Modular RAG phá vỡ mô hình đơn luồng đó. Nếu hệ thống phát hiện trong quá trình tạo sinh rằng thông tin vẫn không đủ, nó có thể chủ động kích hoạt các vòng truy xuất mới và thậm chí di chuyển qua lại nhiều lần giữa truy xuất và tạo sinh để hoàn thành một tác vụ phức tạp hơn.
Đi xa hơn, mô hình có thể học cách tự ra quyết định: trả lời trực tiếp từ kiến thức nội bộ hoặc ngữ cảnh ngắn khi độ tin cậy cao, và chỉ khởi chạy truy xuất hoặc gọi công cụ bên ngoài khi mức độ không chắc chắn cao. Điều đó cải thiện hiệu quả và tiết kiệm tài nguyên trong khi vẫn duy trì chất lượng. Đối với các truy vấn được định nghĩa không đầy đủ hoặc không hoàn chỉnh, mô hình thậm chí có thể tạo một câu trả lời trung gian giả định hoặc tài liệu nháp trước, sau đó sử dụng nó làm manh mối cho truy xuất tiếp theo, tiệm cận dần các nguồn đáng tin cậy.
Ở giai đoạn này, RAG không còn chỉ là một thành phần đơn giản gắn thêm một vài đoạn tham chiếu vào mô hình lớn. Nó đang trở thành lớp điều phối kiến thức trung tâm trong các ứng dụng thông minh doanh nghiệp, điều phối nhiều nguồn dữ liệu, nhiều công cụ và nhiều tác vụ.
5. Từ bản Demo đến RAG cấp doanh nghiệp
Từ góc độ kỹ thuật doanh nghiệp, việc xây dựng hệ thống RAG không thể chỉ giới hạn ở tạo sinh tăng cường truy xuất. Nội dung phía trên vẫn gần hơn với giới thiệu cấp bản demo. Trong các kịch bản kinh doanh thực tế, dữ liệu thường ồn ào và không đồng nhất về định dạng, do đó nhiều nỗ lực hơn phải được đầu tư vào tiền xử lý, làm sạch và nhập dữ liệu, và việc lựa chọn mô hình phải được xử lý cẩn thận tại mỗi điểm chính.
Một hệ thống RAG cấp doanh nghiệp hoàn chỉnh thường có thể được chia thành ba module cốt lõi: phân tích bố cục và nhập kiến thức, xây dựng cơ sở kiến thức và dịch vụ hỏi đáp dựa trên RAG. Trên toàn bộ chuỗi kỹ thuật, một số quyết định lựa chọn mô hình chính xuất hiện, bao gồm mô hình embedding, mô hình rerank và LLM. Chỉ với các lựa chọn kỹ thuật hợp lý ở mỗi giai đoạn, hệ thống mới có thể đạt được kết quả tổng thể mạnh mẽ.
Phân tích bố cục và đọc tài liệu kiến thức cục bộ
Module này chuyển đổi các tài sản kiến thức cục bộ ở các định dạng khác nhau thành văn bản có thể sử dụng cho truy xuất. Đầu vào có thể bao gồm PDF, TXT, HTML, Word, Excel và tệp PPT, cũng như tệp hình ảnh quét như PNG và JPG, hoặc thậm chí bản ghi âm.
Hệ thống cần phân tích cú pháp từng định dạng phù hợp, thực hiện phân tích bố cục và trích xuất cấu trúc cho tài liệu văn bản, phân biệt tiêu đề, nội dung chính, bảng, đầu trang và chân trang, khôi phục thứ tự đọc hợp lý. Nó thực hiện OCR trên tệp hình ảnh và ASR trên giọng nói, cuối cùng chuyển đổi mọi thứ thành văn bản kiến thức tương đối sạch trong khi vẫn giữ metadata cơ bản như tên tệp, chương, số trang và dấu thời gian để chia đoạn và lập chỉ mục sau này.
Xây dựng cơ sở kiến thức: chia đoạn, embedding và lập chỉ mục
Sau khi có văn bản kiến thức đã làm sạch, hệ thống thực hiện chia đoạn, chia tài liệu dài thành các đoạn ngữ nghĩa mạch lạc có độ dài phù hợp, thường theo đoạn văn, cấu trúc tiêu đề hoặc cửa sổ trượt, trong khi vẫn giữ nguồn gốc và metadata của mỗi đoạn.
Sau đó nó sử dụng mô hình embedding đã chọn, như
text-embedding-3-small, Sentence Transformers hoặc BGE, để tính toán biểu diễn vector cho mỗi đoạn và xây dựng chỉ mục vector bằng các công cụ như Faiss, Milvus hoặc dịch vụ tìm kiếm vector được quản lý. Tại thời điểm đó, một cơ sở kiến thức hỗ trợ truy xuất ngữ nghĩa nhanh đã được tạo ra.Hỏi đáp dựa trên RAG: thu hồi, xếp hạng lại, nối và tạo sinh
Trong giai đoạn hỏi đáp trực tuyến, người dùng gửi truy vấn. Hệ thống nhúng nó thành một vector truy vấn, truy xuất một loạt đoạn văn bản tương tự nhất từ chỉ mục vector và coi đó là giai đoạn xếp hạng thô. Sau đó nó có thể sử dụng mô hình rerank như BGE reranker hoặc thậm chí LLM đóng vai trò reranker để chấm điểm các cặp truy vấn-tài liệu và chỉ giữ lại Top-K tài liệu thực sự liên quan nhất làm ngữ cảnh kiến thức.
Tiếp theo, cùng với một prompt hệ thống được thiết kế cẩn thận như "Vui lòng trả lời nghiêm ngặt dựa trên các tài liệu sau," hệ thống nối truy vấn người dùng và các đoạn tài liệu đã truy xuất và gửi prompt đã hợp nhất đến LLM. Mô hình sau đó tạo câu trả lời cuối cùng từ các bằng chứng đã truy xuất và, khi cần thiết, bao gồm trích dẫn hoặc nguồn.
5.1 Lựa chọn mô hình
Tiếp theo chúng ta tập trung vào việc lựa chọn mô hình. Một hệ thống RAG hoàn chỉnh thường bao gồm ba loại mô hình cốt lõi: mô hình embedding, mô hình rerank và mô hình ngôn ngữ lớn. Mỗi loại có vai trò riêng và cùng nhau chúng tạo thành đường dẫn đầy đủ từ truy xuất đến tạo câu trả lời. Mô hình embedding chuyển đổi văn bản thành vector ngữ nghĩa có thể tìm kiếm được, mô hình rerank tinh chỉnh kết quả truy xuất ban đầu và LLM tạo câu trả lời cuối cùng dựa trên ngữ cảnh kiến thức đã chọn.
5.1.1 Mô hình Embedding
Trong hệ thống RAG, nhiệm vụ của mô hình embedding là chuyển đổi văn bản, như truy vấn người dùng và nội dung cơ sở kiến thức, thành vector nhiều chiều. Các văn bản tương đồng về mặt ngữ nghĩa được đặt gần nhau hơn trong không gian vector, cho phép hệ thống định vị kiến thức liên quan nhanh chóng bằng độ tương đồng. Việc chọn mô hình embedding phù hợp do đó là một trong những bước quan trọng nhất trong việc xây dựng hệ thống RAG hiệu năng cao vì nó trực tiếp quyết định chất lượng thu hồi.
Để chọn một mô hình mạnh, sẽ hữu ích khi sử dụng một benchmark có hệ thống. Một trong những benchmark được sử dụng rộng rãi nhất là MTEB, Massive Text Embedding Benchmark.
MTEB cung cấp một framework đánh giá thống nhất và khách quan cho nhiều mô hình embedding. Thông qua tám loại tác vụ chính và 56 bộ dữ liệu, nó đánh giá hiệu suất trên truy xuất, phân cụm, phân loại, xếp hạng lại, đối sánh văn bản, tương đồng ngữ nghĩa và hơn thế nữa. Điểm MTEB tổng thể của mô hình phản ánh tính tổng quát và tính mạnh mẽ của biểu diễn vector và có thể phục vụ như một tài liệu tham khảo quan trọng cho việc lựa chọn mô hình. Bảng xếp hạng mới nhất có thể được kiểm tra trên bảng xếp hạng Hugging Face MTEB:
Mặc dù có nhiều mô hình trên bảng xếp hạng, bạn không cần phải nắm vững tất cả. Trong thực tế, việc chọn mô hình embedding được cung cấp kèm bởi một nhà cung cấp mô hình lớn, hoặc sử dụng mô hình đám mây mà nhiều người đã xác nhận, thường là một lựa chọn an toàn. Bạn cũng có thể lọc bảng xếp hạng theo danh mục hoặc ngôn ngữ trong thanh bên:
Khi lọc mô hình embedding, hai tham số đặc biệt quan trọng vì chúng ảnh hưởng trực tiếp đến hiệu suất RAG: chiều và độ dài ngữ cảnh.
Chiều là số chiều của đầu ra vector, như 128, 768 hoặc 1536. Nó phản ánh đại khái số lượng đặc trưng ngữ nghĩa mà vector có thể biểu diễn. Vector chiều cao hơn có thể nắm bắt chi tiết ngữ nghĩa phong phú hơn và khả năng phân biệt mạnh hơn. Ví dụ, vector 768 chiều có thể biểu diễn "táo" từ hàng trăm góc độ như giống, vị và xuất xứ, phù hợp cho các kịch bản chuyên nghiệp như y tế hoặc pháp lý cần truy xuất chính xác. Chiều thấp hơn giảm chi phí tính toán và lưu trữ và cải thiện tốc độ truy xuất, phù hợp cho các kịch bản quy mô lớn đa dụng với đồng thời cao và yêu cầu thời gian thực mạnh.
Độ dài ngữ cảnh là độ dài văn bản tối đa mà mô hình embedding có thể xử lý trong một lần, đo bằng token. Một token tiếng Anh tương đương khoảng ba phần tư từ, và một token tiếng Việt tương đương khoảng một ký tự. Bất cứ thứ gì dài hơn mức tối đa sẽ bị cắt ngắn. Điều này trực tiếp quyết định liệu mô hình có thể hiểu đầy đủ văn bản hay không. Nếu thông tin quan trọng bị mất vì độ dài quá ngắn, độ chính xác truy xuất giảm mạnh. Đối với các truy vấn người dùng ngắn và cặp hỏi đáp ngắn, 512 đến 1024 token thường là đủ. Đối với văn bản dài hơn như bài báo và báo cáo, bạn thường cần 2048 token trở lên.
Dưới đây là so sánh một số mô hình embedding phổ biến. Trong thực tế, bạn cần chọn bằng cách cân bằng chi phí và hiệu suất. Không có mô hình nào tốt nhất một cách phổ quát, chỉ có mô hình phù hợp nhất sau khi so sánh một số tùy chọn trong trường hợp sử dụng của riêng bạn.
| Tên mô hình | Quy mô mô hình | Điểm mạnh cốt lõi | Kịch bản phù hợp |
|---|---|---|---|
OpenAI text-embedding-3-large | API đóng | Dẫn đầu lâu dài trên MTEB, trưởng thành và ổn định | Kịch bản API đám mây ưu tiên hiệu suất tối đa và có ngân sách đủ |
jina-embeddings-v2 | Hỗ trợ văn bản dài lên đến ngữ cảnh 8K | Mạnh cho truy xuất tài liệu dài thông qua thiết kế mã hóa không đồng bộ | Phân tích tài liệu, tuân thủ pháp lý, truy xuất học thuật |
multilingual-e5-large | Quy mô lớn | Lựa chọn đa ngôn ngữ kinh điển | RAG xuyên ngôn ngữ, sản phẩm quốc tế, hệ thống hỗ trợ đa ngôn ngữ |
Qwen/Qwen2-Embedding-8B | 8B tham số, lên đến 4096 chiều tùy chỉnh | Cựu thủ lĩnh MTEB đa ngôn ngữ, mạnh trên văn bản dài, tác vụ đa ngôn ngữ và mã | RAG Trung-Anh độ chính xác cao, phân tích tài liệu dài, truy xuất mã |
Qwen/Qwen2-Embedding-4B | 4B tham số | Cân bằng mạnh giữa hiệu suất và hiệu quả | Hệ thống RAG sản xuất quy mô lớn |
Qwen/Qwen2-Embedding-0.6B | 0.6B tham số | Phù hợp cho thiết bị biên | Kịch bản hạn chế tài nguyên, ưu tiên tốc độ |
BAAI/bge-m3 | Hỗ trợ truy xuất hỗn hợp, dense cộng sparse cộng multi-vector | Mạnh trên các benchmark đa ngôn ngữ như MIRACL | Kịch bản đa ngôn ngữ phức tạp cần truy xuất hỗn hợp |
BAAI/bge-large-zh-v1.5 | Quy mô lớn | Baseline RAG tiếng Trung ổn định với xác nhận cộng đồng mạnh | Dự án thuần tiếng Trung với tài liệu ngắn hơn |
ZhipuAI Embedding-3 | API đám mây đóng | Hỗ trợ chiều tùy chỉnh từ 256 đến 2048 | Ứng dụng tập trung vào tiếng Trung ưu tiên API đám mây |
5.1.2 Mô hình Rerank
Trong hệ thống RAG, mô hình rerank chịu trách nhiệm xếp hạng lại tinh tế kết quả truy xuất ban đầu. Nó lấy truy vấn người dùng và tài liệu ứng viên làm đầu vào và tính toán điểm liên quan chính xác cho mỗi cặp truy vấn-tài liệu. Điểm càng cao, độ phù hợp càng tốt. Do đó, việc thêm mô hình rerank trên đầu thu hồi dựa trên embedding là một bước chính để cải thiện độ chính xác truy xuất.
Đối với mô hình embedding, chúng ta có thể sử dụng các benchmark như MTEB. Đối với mô hình rerank, một tài liệu tham khảo hữu ích là bảng xếp hạng reranker của Agentset:
Benchmark Agentset trước tiên truy xuất 50 kết quả ứng viên liên quan nhất từ một kho tài liệu lớn bằng FAISS, sau đó yêu cầu mô hình rerank đang được đánh giá xếp hạng lại 50 tài liệu đó. Benchmark chú ý đến cả chất lượng xếp hạng và độ trễ. Trong các ứng dụng thực tế, theo đuổi độ chính xác trong khi bỏ qua tốc độ ảnh hưởng đến trải nghiệm người dùng, trong khi theo đuổi tốc độ trong khi hy sinh chất lượng xếp hạng ảnh hưởng đến tính hữu ích.
Agentset cũng giới thiệu cơ chế chấm điểm ELO. Đối với mỗi truy vấn, GPT-5 đóng vai trò thẩm phán và so sánh đầu ra đã xếp hạng của hai mô hình rerank khác nhau, quyết định mô hình nào đặt các tài liệu liên quan thực sự theo thứ tự hợp lý hơn. Sau một số lượng lớn so sánh cặp như vậy, các mô hình thắng nhiều hơn nhận điểm ELO cao hơn, cung cấp tín hiệu hiệu suất tổng thể trực quan.
Benchmark cũng sử dụng hai nhóm chỉ số bổ sung:
nDCG@5/10, tập trung vào việc liệu các tài liệu liên quan có được đặt gần phía trước hay không và do đó phản ánh độ chính xác xếp hạngRecall@5/10, tập trung vào việc liệu tất cả các tài liệu liên quan có thể được tìm thấy hay không và do đó phản ánh độ bao phủ
Cùng nhau, các chỉ số này cung cấp một bức tranh hoàn chỉnh hơn về hiệu suất rerank.
Tuy nhiên, trong thực tế, bạn không cần phải chọn mô hình rerank chỉ từ bảng xếp hạng. Tính hữu dụng công nghiệp và điểm bảng xếp hạng không phải lúc nào cũng giống nhau. Một cách tiếp cận thực tế là bắt đầu từ các mô hình rerank được khuyến nghị bởi nhà cung cấp đám mây của bạn hoặc API rerank mặc định được cung cấp bởi các nhà cung cấp mô hình lớn, hoặc thử nghiệm một họ mô hình mà bạn đã sử dụng, như mô hình rerank Qwen phù hợp.
5.1.3 LLM
Sau khi truy xuất ngữ nghĩa bởi mô hình embedding và lọc tinh chỉnh bởi mô hình rerank, các đoạn tài liệu liên quan được kết hợp với câu hỏi gốc của người dùng thành một prompt. LLM sau đó thực hiện đọc hiểu, tích hợp thông tin và tạo ngôn ngữ tự nhiên để xuất một câu trả lời mạch lạc, chính xác phù hợp với ngữ cảnh.
Ở cấp độ triển khai, có hai cách chính để sử dụng LLM trong RAG:
- Mô hình lớn triển khai riêng. Những mô hình này phù hợp cho các kịch bản quan tâm đến quyền riêng tư dữ liệu, chi phí có thể kiểm soát hoặc tùy chỉnh sâu. Các mô hình mở phổ biến như Qwen, Llama và GLM hoạt động tốt trong các tác vụ RAG. Ví dụ, Qwen2.5 trong phạm vi 7B hoặc 14B cung cấp khả năng tuân thủ hướng dẫn và hiểu tiếng Trung tốt trong khi vẫn giữ mức sử dụng tài nguyên khiêm tốn, phù hợp cho triển khai doanh nghiệp cục bộ. Các mô hình như KIMI, Minimax và DeepSeek cũng có thể được xem xét theo nhu cầu nghiệp vụ cụ thể.
- Mô hình lớn API đám mây. Những mô hình này phù hợp cho các kịch bản ưu tiên ra mắt nhanh, mở rộng linh hoạt và nâng cấp mô hình liên tục. Các nhà cung cấp lớn như OpenAI, Anthropic, Google, Alibaba và ZhipuAI đều cung cấp dịch vụ API ổn định. Các mô hình này thường có khả năng hiểu và tạo ngôn ngữ mạnh và có thể tổng hợp câu trả lời tốt trong các kịch bản RAG.
Khi chọn mô hình đám mây, một số điểm quan trọng: chất lượng câu trả lời có chính xác và trôi chảy không, giá cả có hợp lý không, độ trễ có chấp nhận được không, và cửa sổ ngữ cảnh có đủ lớn để chứa nhiều tài liệu đã truy xuất không. Trong thực tế, bạn nên so sánh một số ứng viên trên dữ liệu của riêng mình và xem cái nào đưa ra câu trả lời hoàn chỉnh và chính xác nhất. Nếu chi phí là mối quan tâm, một cách tiếp cận hữu ích là kết hợp mô hình lớn và nhỏ: sử dụng mô hình nhỏ rẻ hơn cho câu hỏi đơn giản và dành mô hình lớn đắt tiền cho các trường hợp khó. Vì các mô hình cập nhật nhanh, cũng khôn ngoan khi kiểm tra lại các ứng viên định kỳ.
Đối với khả năng hội thoại và hỏi đáp rộng rãi, LMSYS Chatbot Arena, nay là LMArena, là một trong những tài liệu tham khảo đánh giá được công nhận rộng rãi nhất:
Nó sử dụng so sánh cặp mù giữa con người để xếp hạng các mô hình. Bảng xếp hạng cung cấp một bộ lọc đầu tiên hữu ích, nhưng trong lựa chọn RAG thực tế, nó chỉ nên là một điểm khởi đầu. Trong các lĩnh vực chuyên ngành như y tế, pháp lý và tài chính, xếp hạng bảng xếp hạng tổng quát có thể khác biệt đáng kể với hiệu suất thực tế trên dữ liệu kinh doanh của bạn.
Thực hành tốt nhất cho việc lựa chọn LLM là xây dựng một tập kiểm thử nhỏ nhưng đại diện chứa 20 đến 30 câu hỏi kinh doanh điển hình và đánh giá các mô hình ứng_candidate thông qua pipeline RAG đầu-cuối đầy đủ thay vì chỉ xem các benchmark mô hình đơn lẻ. Các câu hỏi như có nên sử dụng mô hình suy luận hay mô hình không suy luận, hoặc kích thước mô hình nào cân bằng tốt nhất chất lượng và tốc độ, đều được trả lời tốt nhất thông qua kiểm tra thực tế trên trường hợp sử dụng của riêng bạn.
5.2 Framework triển khai
Trong thực tiễn kỹ thuật thực tế, bạn thường không cần xây dựng toàn bộ hệ thống RAG từ con số không. Một số framework mã nguồn mở trưởng thành đã tồn tại, mỗi cái có điểm mạnh riêng về kiến trúc, tích hợp module và hiệu quả phát triển. Các doanh nghiệp có thể chọn theo dự trữ kỹ thuật và kịch bản kinh doanh của riêng mình.
Các loại framework phổ biến bao gồm:
Nền tảng low-code hoặc trực quan
- Dify: cung cấp giao diện trực quan trực quan để xây dựng nhanh ứng dụng RAG, phù hợp cho các nhóm phi kỹ thuật hoặc xác chứng nguyên mẫu nhanh. Nó bao gồm truy cập đa mô hình tích hợp, điều phối quy trình làm việc và quản lý prompt.
- Coze: nền tảng phát triển bot AI từ ByteDance cung cấp xây dựng trực quan zero-code. Nó tích hợp sâu với dịch vụ mô hình của ByteDance, hỗ trợ thị trường plugin, tác vụ theo lịch và xuất bản đa kênh, phù hợp cho trợ lý hướng đến người tiêu dùng hoặc bot nội bộ doanh nghiệp.
- n8n: nền tảng tự động hóa quy trình làm việc dựa trên node mã nguồn mở. Trong các kịch bản RAG, nó có thể điều phối logic nghiệp vụ phức tạp và kết nối tiền xử lý, hoạt động cơ sở dữ liệu vector, gọi mô hình và hành động theo dõi như gửi email hoặc cập nhật ticket thành một quy trình tự động.
- RAGFlow: tập trung vào phân tích bố cục sâu và trích xuất kiến thức và hoạt động tốt trên tài liệu phức tạp như PDF đa cột và tài liệu nhiều bảng.
- FastGPT: giải pháp mã nguồn mở Trung Quốc tích hợp quản lý cơ sở kiến thức, điều phối đối thoại và xuất bản ứng dụng, với tài liệu tiếng Trung mạnh và phù hợp cho triển khai nhanh các ứng dụng RAG tiếng Trung.
Framework mã và thư viện phát triển
Các công cụ dưới đây thường có triển khai bằng các ngôn ngữ backend khác nhau. Bạn có thể chọn phiên bản ngôn ngữ tương ứng cho ngăn xếp ứng dụng của mình.
- LlamaIndex: framework Python được thiết kế đặc biệt cho RAG, với các connector, cấu trúc chỉ mục và công cụ truy vấn phong phú. Tính module hóa của nó phù hợp cho các chiến lược truy xuất được tùy chỉnh sâu hoặc tích hợp với nhiều nguồn dữ liệu.
- LangChain: framework ứng dụng LLM tổng quát nơi RAG chỉ là một trường hợp sử dụng. Điểm mạnh của nó là hệ sinh thái phong phú và độ bao phủ thành phần, bao gồm hỗ trợ cho các agent phức tạp và điều phối quy trình làm việc, mặc dù đường cong học tập của nó dốc hơn.
Nếu dự trữ kỹ thuật của nhóm hạn chế và tốc độ quan trọng nhất, các nền tảng low-code như Dify, Coze hoặc FastGPT là lựa chọn đầu tiên tốt. Nếu bạn cần tùy chỉnh sâu, tích hợp nguồn dữ liệu đặc biệt hoặc điều chỉnh hiệu suất chi tiết, LlamaIndex và LangChain cung cấp nhiều linh hoạt hơn. Trong thực tế, một lộ trình kết hợp cũng phổ biến: sử dụng nền tảng low-code để xác chứng khả năng nhanh chóng, sau đó chuyển sang framework mã để triển khai sản xuất và tối ưu hóa. Hầu hết các framework này cũng hỗ trợ tích hợp nhanh với các mô hình embedding, rerank và LLM phổ biến, cho phép bạn kết hợp chúng linh hoạt bằng các nguyên tắc lựa chọn mô hình đã thảo luận ở trên.
5.3 Đánh giá hiệu quả
Đối với các doanh nghiệp triển khai hệ thống RAG, thách thức lớn nhất thường không phải là xây dựng hệ thống mà là tinh chỉnh nó. RAG cấp sản xuất chứa hai giai đoạn không xác định, truy xuất và tạo sinh, do đó kiểm thử phần mềm truyền thống là không đủ. Đó là lý do tại sao việc xây dựng một hệ thống đánh giá khoa học, hay đánh giá RAG, lại quan trọng như vậy.
5.3.1 Ví dụ nhập môn: Đánh giá RAG dựa trên LLM
Để giúp xây dựng hiểu biết trực quan về đánh giá RAG, chúng ta có thể xem một pipeline tự động đơn giản dựa trên ý tưởng LLM-as-a-judge:
https://huggingface.co/learn/cookbook/rag_evaluation
Quy trình thường chứa ba bước chính:
- Đầu tiên, tổng hợp tập dữ liệu đánh giá bằng cách lấy mẫu tài liệu từ cơ sở kiến thức và yêu cầu LLM tạo các cặp câu hỏi-trả lời chất lượng cao, sau đó lọc chúng theo mức độ liên quan và độ tin cậy để tạo thành tập chuẩn.
- Thứ hai, chạy hệ thống RAG trên mỗi câu hỏi trong tập kiểm thử và thu thập các câu trả lời đã tạo.
- Thứ ba, tự động chấm điểm bằng cách gọi một LLM khác làm thẩm phán, so sánh các câu trả lời đã tạo với câu trả lời tham khảo và đưa ra điểm định lượng cho các chiều như độ chính xác và tính đầy đủ.
Một ví dụ đơn giản:
- Tạo vấn đề. Giả sử cơ sở kiến thức chứa một dòng hướng dẫn sản phẩm nói, "Thiết bị này hỗ trợ sạc không dây và có pin 5000mAh." Chúng tôi yêu cầu một mô hình đóng vai người ra đề và tạo câu hỏi như, "Dung lượng pin của thiết bị này là bao nhiêu?" Câu trả lời chuẩn là "5000mAh."
- Giải quyết vấn đề. Chúng tôi gửi câu hỏi đó đến hệ thống RAG, hệ thống truy xuất tài liệu liên quan và trả lời, ví dụ, "Thiết bị có pin 5000mAh."
- Chấm điểm. Chúng tôi yêu cầu một mô hình khác đóng vai người chấm bằng cách so sánh câu hỏi, câu trả lời đã tạo và câu trả lời tham khảo, sử dụng prompt như, "Đánh giá xem câu trả lời đã tạo có đúng không. Chỉ xuất đúng hoặc sai."
Bằng cách chạy quy trình này ở quy mô lớn, chúng ta có thể tính toán các chỉ số như độ chính xác. Điều này tạo thành một vòng lặp thực tế gồm đánh giá, tối ưu hóa và đánh giá lại.
Nếu bạn muốn chi tiết sâu hơn về đánh giá RAG, bao gồm định nghĩa chỉ số, sử dụng framework và tập dữ liệu benchmark, hai bài khảo sát hữu ích là:
- https://arxiv.org/pdf/2504.14891, Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey
- https://arxiv.org/pdf/2405.07437, Evaluation of Retrieval-Augmented Generation: A Survey
5.3.2 Chỉ số đánh giá
Đánh giá RAG về cơ bản xoay quanh hai câu hỏi: module truy xuất có thể tìm được tài liệu đúng không, và module tạo sinh có thể tạo câu trả lời chất lượng cao từ tài liệu đó không? Theo đó, hệ thống đánh giá được chia thành đánh giá truy xuất và đánh giá tạo sinh, được bổ sung bởi chấm điểm LLM-as-a-judge.
Đánh giá truy xuất: độ chính xác thu hồi và chất lượng xếp hạng
Module truy xuất là cánh cửa đầu tiên trong hệ thống RAG. Đánh giá của nó tập trung vào ba chiều: có tìm được đúng thứ không, có tìm đủ không, và có xếp hạng tốt không.
Chỉ số chất lượng thu hồi cơ bản
Các chỉ số cơ bản kinh điển là Recall@K, Precision@K và F1:
- Recall@K đo tỷ lệ tài liệu liên quan được thu hồi trong K kết quả hàng đầu. Nếu tồn tại năm tài liệu liên quan và ba được tìm thấy trong top 10, Recall@10 là 60 phần trăm. Điều này cho chúng ta biết độ bao phủ truy xuất rộng đến đâu.
- Precision@K đo tỷ lệ K kết quả hàng đầu thực sự liên quan. Nếu ba trong số top 10 liên quan và bảy không, Precision@10 là 30 phần trăm. Điều này phản ánh độ chính xác truy xuất.
- F1 là trung bình điều hòa của Recall và Precision và cân bằng hai yếu tố.
Các chỉ số này hữu ích để chẩn đoán nhanh các vấn đề thu hồi cơ bản. Nếu Recall thấp, tài liệu liên quan không được tìm thấy. Nếu Precision thấp, nhiễu loạn truy xuất quá cao.
Chỉ số chất lượng xếp hạng
Tìm tài liệu liên quan chỉ là bước đầu tiên. Còn quan trọng hơn là đặt những tài liệu liên quan nhất lên phía trước. Để làm điều đó, chúng ta xem xét MRR, NDCG@K và MAP:
- MRR, Mean Reciprocal Rank, đo nghịch đảo của vị trí xếp hạng của tài liệu liên quan đầu tiên. Nếu tài liệu liên quan đầu tiên xuất hiện ở vị trí 3, xếp hạng nghịch đảo là 1/3. MRR đặc biệt phù hợp cho các kịch bản mà một câu trả lời đúng là đủ.
- NDCG@K, Normalized Discounted Cumulative Gain, xem xét cả mức độ liên quan theo bậc và chiết khấu vị trí. Nó không chỉ hỏi liệu một tài liệu có liên quan hay không, mà mức độ liên quan như thế nào, và nó thưởng cho các tài liệu liên quan cao xuất hiện sớm.
- MAP, Mean Average Precision, nhạy cảm với vị trí của tất cả các tài liệu liên quan và phản ánh chất lượng xếp hạng tổng thể.
Trong kỹ thuật thực tế, một sự kết hợp phổ biến là Recall@K cộng với MRR@K. Ví dụ, nếu Recall@10 là 80 phần trăm nhưng MRR@10 chỉ là 0.3, tài liệu liên quan đang được tìm thấy nhưng bị chôn quá sâu, cho thấy xếp hạng lại cần cải thiện.
Khi cần, một chỉ số Coverage cũng có thể được thêm để giám sát độ bao phủ cơ sở kiến thức và tiết lộ các điểm mù hệ thống.
Đánh giá chất lượng tạo sinh: độ chính xác và độ trung thành thực tế
Truy xuất cung cấp nguyên liệu thô. Câu hỏi tiếp theo là liệu module tạo sinh có thể tạo câu trả lời chất lượng cao từ những nguyên liệu đó không. Các chiều cốt lõi ở đây là độ chính xác câu trả lời và độ trung thành với bằng chứng đã truy xuất.
Đối sánh chính xác và tương đồng văn bản
Chỉ số đơn giản nhất là EM, Exact Match, yêu cầu câu trả lời đã tạo phải khớp chính xác với câu trả lời tham khảo. Điều này phù hợp cho các câu hỏi sự thực có dạng cố định, duy nhất đúng như ngày tháng hoặc địa điểm trụ sở, nhưng nó quá nghiêm ngặt vì các dạng bề mặt khác nhau nhưng đúng như nhau có thể không khớp.
Đó là lý do tại sao các chỉ số trùng lặp n-gram như ROUGE, BLEU và METEOR cũng thường được sử dụng. Chúng chấm điểm câu trả lời đã tạo bằng cách so sánh trùng lặp từ với câu trả lời tham khảo. ROUGE-L chú ý đến các dãy con chung dài nhất, BLEU đến từ dịch máy và nhấn mạnh độ chính xác, và METEOR thêm các xem xét về từ đồng nghĩa và gốc từ.
Để vượt qua các giới hạn của trùng lặp từ thuần túy, chúng ta cũng có thể sử dụng BERTScore hoặc tương đồng vector trực tiếp. Chúng sử dụng biểu diễn ngữ nghĩa được tiền huấn luyện và do đó chịu đựng biến thể bề mặt tốt hơn.
Độ trung thành thực tế và phát hiện ảo giác
Đối với các hệ thống RAG, tương đồng câu trả lời-tham khảo là chưa đủ. Câu hỏi quan trọng hơn là liệu câu trả lời thực sự dựa trên các tài liệu đã truy xuất hay nó tạo ảo giác nội dung không có căn cứ.
Đó là lý do tại sao các chỉ số như Tỷ lệ ảo giác và Độ trung thành lại quan trọng. Một LLM thứ hai có thể đóng vai trò kiểm tra sự thật và kiểm tra câu trả lời đã tạo từng câu, đánh giá xem mỗi tuyên bố có thể được hỗ trợ bởi các tài liệu đã truy xuất hay không. Đối với các lĩnh vực rủi ro cao như y tế, pháp lý và tài chính, loại chỉ số này đặc biệt quan trọng và một số doanh nghiệp thậm chí áp dụng ngưỡng ảo giác làm tiêu chí phát hành sản xuất.
LLM-as-a-Judge: chấm điểm đa chiều
Mọi chỉ số tự động đều có giới hạn. Hầu hết các chỉ số dạng bề mặt không thể nắm bắt đầy đủ chất lượng ngữ nghĩa hoặc tính hữu dụng tổng thể. Đó là nơi LLM-as-a-judge trở nên đặc biệt có giá trị.
Cách tiếp cận cơ bản là cung cấp câu hỏi, tài liệu đã truy xuất, câu trả lời hệ thống và câu trả lời tham khảo cho một mô hình độc lập mạnh, như GPT-4 hoặc Claude, và yêu cầu nó chấm điểm trên các chiều như:
- mức độ liên quan đến câu hỏi
- tính đầy đủ thông tin
- độ trung thành thực tế
- độ chính xác tổng thể
Điểm mạnh của thẩm phán LLM là nó có thể đưa ra phán xét tổng thể giống con người hơn. Tất nhiên, prompt thẩm phán vẫn cần thiết kế cẩn thận và hiệu chuẩn với các ví dụ do con người gán nhãn để giữ cho việc chấm điểm nhất quán và đáng tin cậy.
Xây dựng kết hợp chỉ số thực tế
Với nhiều chỉ số có sẵn, các nhóm thường thắc mắc nên sử dụng cái nào. Một khuyến nghị thực tế là bắt đầu với một kết hợp nhỏ gọn và mở rộng dần:
- Đối với truy xuất, bắt đầu với Recall@K cộng với MRR@K
- Đối với tạo sinh, chọn một hoặc hai chỉ số cơ bản từ EM, ROUGE-L và BERTScore theo loại tác vụ
- Đối với đánh giá tổng thể, giới thiệu thẩm phán LLM tập trung vào mức độ liên quan, tính đầy đủ và độ trung thành
Sau đó lặp qua một vòng đánh giá, chẩn đoán vấn đề, điều chỉnh chiến lược và đánh giá lại.
5.3.3 Framework đánh giá
Khi RAG phát triển nhanh chóng, cả giới học thuật và công nghiệp đều đã tạo ra nhiều framework đánh giá mạnh mẽ. Các framework này không chỉ đóng gói các chỉ số phổ biến mà còn cung cấp tập dữ liệu chuẩn, quy trình benchmark và quy trình làm việc đầu-cuối.
Phân loại cơ bản các framework
Chúng ta có thể chia framework đánh giá RAG thành ba loại:
- Framework nghiên cứu, tập trung vào khám phá học thuật và chẩn đoán chi tiết. Ví dụ bao gồm FiD-Light và Diversity Reranker.
- Framework benchmark, cung cấp tập kiểm thử chuẩn và quy trình làm việc để so sánh hệ thống theo chiều ngang. Chúng bao gồm các framework như RAGAS, ARES, RGB, MultiHop-RAG và CRUD-RAG.
- Framework công cụ, nhấn mạnh tính khả dụng kỹ thuật và tích hợp với framework phát triển. Ví dụ bao gồm TruEra RAG Triad, LangChain Benchmarks và RECALL.
Trong những năm gần đây, các framework đánh giá đã trở nên chuyên biệt hơn. Ví dụ, y tế có MedRAG, pháp lý có LegalBench-RAG và tài chính có framework chuyên biệt riêng. Các framework lĩnh vực này thường cung cấp không chỉ tập dữ liệu chuyên biệt mà còn các chỉ số chuyên biệt như độ chính xác y tế hoặc mức độ liên quan trích dẫn pháp lý.
Trong thực tế, một quy tắc kinh nghiệm tốt là:
- Nếu bạn cần một baseline nhanh, bắt đầu với một framework tổng quát hơn như RAGAS.
- Nếu bạn đang chẩn đoán một vấn đề cụ thể, chọn một framework có mục tiêu hơn.
- Nếu bạn ở y tế, pháp lý, tài chính hoặc một lĩnh vực chuyên nghiệp khác, ưu tiên framework thích ứng lĩnh vực khi có thể.
- Ưu tiên các công cụ được duy trì tích cực với tài liệu mạnh và cộng đồng phản hồi nhanh.
Các công cụ thường được khuyến nghị trong cộng đồng bao gồm Ragas, Continuous Eval, TruLens-Eval, các tính năng đánh giá bên trong LlamaIndex, Phoenix, DeepEval, LangSmith và OpenAI Evals.
5.3.4 Benchmark đánh giá
Tầm quan trọng của benchmark đánh giá thường bị đánh giá thấp. Nhiều nhóm bắt đầu đánh giá hệ thống RAG chỉ với một vài câu hỏi kiểm tra viết tay, sau đó phát hiện rằng hiệu suất trực tuyến thực tế khác biệt đáng kể so với ấn tượng ngoại tuyến. Nguyên nhân gốc rễ là họ thiếu dữ liệu đánh giá đại diện và có hệ thống.
Một benchmark hỗ trợ lặp hệ thống tốt thường có ba đặc điểm cốt lõi:
- tính đại diện, nghĩa là nó bao phủ các câu hỏi người dùng tần suất cao, trường hợp biên và đầu vào bất thường
- tính chuẩn hóa, nghĩa là định dạng câu hỏi và câu trả lời, mức độ khó và quy tắc chấm điểm nhất quán
- tính tiến hóa, nghĩa là benchmark có thể được cập nhật khi khả năng hệ thống và nhu cầu kinh doanh phát triển
Đối với hầu hết các doanh nghiệp, vì các kịch bản kinh doanh là duy nhất, câu trả lời cuối cùng thường là xây dựng tập dữ liệu đánh giá của riêng mình.
- Bắt đầu bằng cách trích xuất các câu hỏi người dùng thực từ nhật ký kinh doanh và lấy mẫu theo loại, tần suất và mức độ khó.
- Đối với các trường hợp đơn giản, để chuyên gia lĩnh vực gán nhãn trực tiếp. Đối với các câu hỏi phức tạp hơn, để một LLM mạnh tạo câu trả lời ứng viên trước, sau đó có chuyên gia sửa đổi.
- Ngoài câu trả lời, gán nhãn metadata như tài liệu liên quan, loại câu trả lời và mức độ khó.
- Cập nhật tập dữ liệu định kỳ với các trường hợp khó mới được phát hiện trực tuyến.
Nếu tài nguyên hạn chế và bạn cần một baseline nhanh, các benchmark công khai vẫn là một điểm khởi đầu hữu ích. Tính đến năm 2025, nhiều benchmark công khai tồn tại cho cả kịch bản tổng quát và chuyên ngành:
Khi chọn trong số chúng, trước tiên hãy làm rõ mục tiêu. Bạn đang thiết lập baseline hay xác nhận hệ thống trước khi ra mắt? Sau đó kiểm tra xem benchmark có bao phủ các kịch bản và phân phối mức độ khó mà bạn quan tâm không. Đối với các lĩnh vực nhạy cảm với thời gian như tin tức hoặc tài chính, đảm bảo benchmark bao gồm các kiểm tra nhạy cảm thời gian.
Trong thực tế, kết hợp tập dữ liệu trong lĩnh vực của riêng bạn với các benchmark công khai thường là con đường mạnh mẽ nhất vì nó giữ cho đánh giá gần với nhu cầu kinh doanh thực tế trong khi cũng bảo tồn một số tính so sánh theo chiều ngang.
6. Đào sâu: Học hỏi từ các cuộc thi và hướng dẫn mở (Tùy chọn)
Các nguyên lý và triển khai baseline phía trên là đủ để giúp bạn xây dựng một nguyên mẫu sử dụng được, nhưng chúng vẫn còn một khoảng cách so với việc giải quyết các vấn đề khó hơn xuất hiện trong sản xuất. Nếu bạn muốn hiểu các kỹ thuật RAG thực tế và đã được kiểm chứng hơn, một trong những cách hiệu quả nhất là nghiên cứu các giải pháp chiến thắng cuộc thi và các hướng dẫn mở mạnh mẽ. Các giải pháp này thường tập trung các thực tiễn tốt nhất được phát hiện bởi các đội mạnh sau nhiều lần thử nghiệm trong các kịch bản thực tế.
Các ví dụ dưới đây mang tính đại diện chứ không đầy đủ. Khi bạn gặp một vấn đề cụ thể trong thực tế, như phân tích PDF, truy xuất đa phương thức hoặc tối ưu hóa độ trễ thấp, thường hiệu quả khi tìm kiếm các cuộc thi liên quan đến vấn đề đó và nghiên cứu các báo cáo kỹ thuật và mã nguồn mở từ các đội chiến thắng.
6.1 Semantic Cache: tối ưu hóa truy vấn tần suất cao
Hugging Face cung cấp một triển khai semantic-cache được xây dựng trên cơ sở dữ liệu vector Chroma:
https://huggingface.co/learn/cookbook/semantic_cache_chroma_vector_database
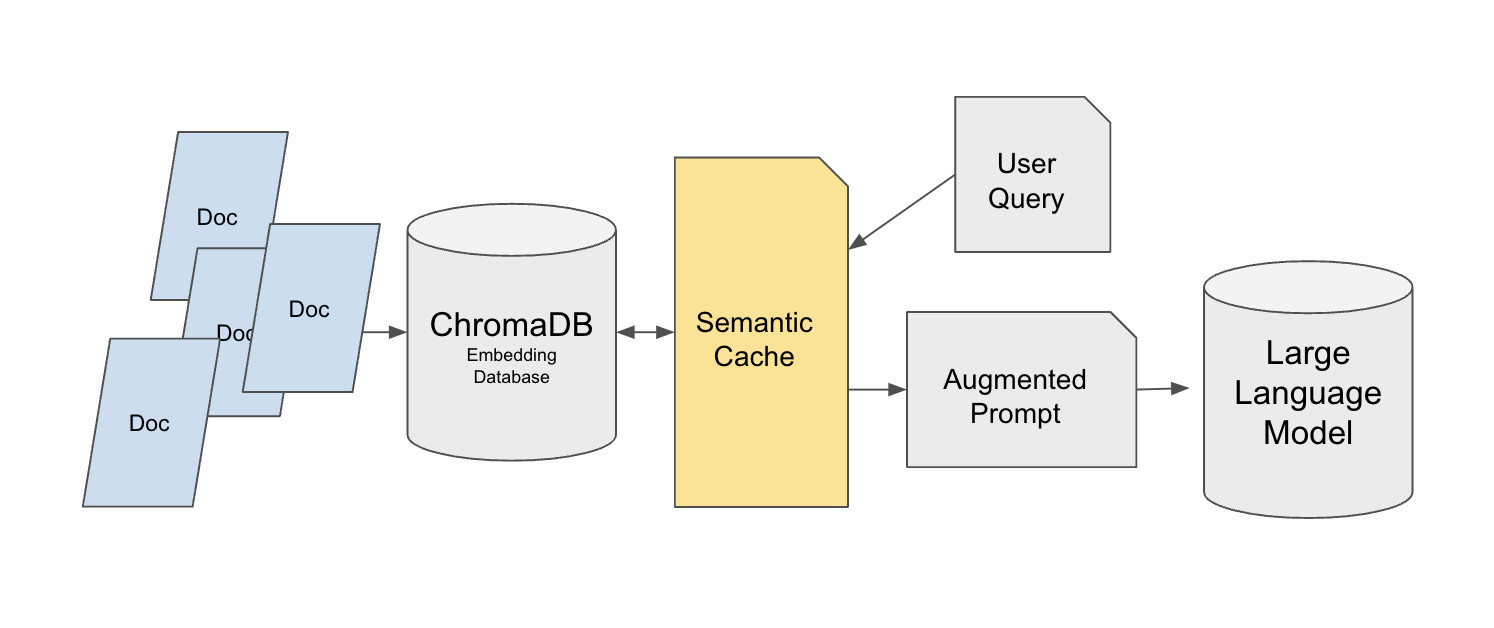
Bối cảnh: Hầu hết các hệ thống RAG trong hướng dẫn được xây dựng cho kiểm thử single-user. Nhưng khi triển khai lên sản xuất, hệ thống có thể nhận hàng chục hoặc hàng ngàn truy vấn lặp lại, ví dụ người dùng hỗ trợ liên tục hỏi về quy trình hoàn tiền. Nếu mỗi truy vấn lặp lại vẫn kích hoạt truy xuất vector và gọi LLM, độ trễ và chi phí tăng nhanh. Một lớp semantic cache có thể giảm mạnh áp lực lên các nguồn dữ liệu gốc trong khi vẫn duy trì chất lượng câu trả lời.
Thiết kế này sử dụng kiến trúc truy xuất hai lớp. Lớp cơ sở lưu trữ cơ sở kiến thức gốc trong Chroma, sử dụng tập dữ liệu như MedQuad làm ví dụ và gán cho mỗi mục một ID duy nhất để tham chiếu chính xác. Lớp cache được xây dựng trên FAISS sử dụng chỉ mục FlatL2. Semantic cache nằm giữa truy vấn người dùng và Chroma, thay vì cache câu trả lời cuối cùng của LLM trực tiếp. Thiết kế đó quan trọng vì cache trực tiếp câu trả lời có thể phá vỡ yêu cầu câu trả lời cá nhân hóa như "giải thích điều này bằng ngôn ngữ đơn giản."
Hệ thống cache sử dụng SentenceTransformer all-mpnet-base-v2 để tạo vector truy vấn và sử dụng khoảng cách Euclid, với ngưỡng 0.35, để đánh giá xem các truy vấn có tương tự hay không. Khi cache đầy, được kiểm soát bởi tham số max_response, mục cũ nhất được loại bỏ bằng FIFO. Dữ liệu cache cũng có thể được lưu vào tệp JSON để tái sử dụng xuyên phiên.
Trong kiểm thử quy mô nhỏ, một truy vấn đầu tiên như "Vaccine hoạt động như thế nào?" mất 0.057 giây khi lấy từ Chroma, trong khi một truy vấn tương tự được phục vụ từ cache chỉ mất 0.016 giây. Trong các kịch bản sản xuất lớn, cách tiếp cận này có thể tạo ra tối ưu hóa hiệu suất 90 đến 95 phần trăm trong môi trường lặp lại cao và giảm đáng kể chi phí kho lưu trữ vector và API.
6.2 Xử lý dữ liệu phi cấu trúc: phân tích cú pháp thống nhất cho tài liệu đa định dạng
Một hướng dẫn khác của Hugging Face cho thấy cách sử dụng thư viện Unstructured để xây dựng pipeline đầy đủ cho xử lý tài liệu phi cấu trúc:
https://huggingface.co/learn/cookbook/rag_with_unstructured_data

Bối cảnh: Trong các kịch bản doanh nghiệp, kiến thức thường nằm rải rác trên PDF, PowerPoint, EPUB, trang HTML và nhiều định dạng khác. Các phương pháp tiền xử lý truyền thống hoặc chỉ hỗ trợ một định dạng hoặc mất thông tin cấu trúc quan trọng như bảng và hệ thống phân cấp tiêu đề trong quá trình chuyển đổi. Điều này làm cho hệ thống RAG khó hiểu và truy xuất nội dung chính xác.
Giải pháp này đầu tiên tải xuống các tài liệu kiểm thử đa định dạng, như PDF hướng dẫn thuốc trừ sâu của Canada chứa nhiều bảng và tệp PowerPoint IPM trái cây họ cam của Đại học Florida chứa biểu đồ và tiêu đề đa cấp. Sau đó nó sử dụng Local Runner của Unstructured để phân tích cú pháp. Cấu hình bao gồm cấu hình processor, cấu hình partition có thể tùy chọn sử dụng chế độ partition API cho OCR mạnh hơn và cấu hình cục bộ xác định đường dẫn đầu vào. Tài liệu đã phân tích được chuyển đổi thành JSON chứa các phần tử có kiểu như nội dung chính, tiêu đề và bảng.
Hệ thống sau đó sử dụng chunk_by_title, đặt độ dài tối đa 512 ký tự và hợp nhất các đoạn liên tiếp ngắn hơn 200 ký tự để bảo tồn tính mạch lạc ngữ nghĩa. Trong quá trình chuyển đổi thành đối tượng LangChain Document, các trường metadata phức tạp được lọc để phù hợp với Chroma. Giai đoạn vector sử dụng mô hình embedding BAAI/bge-base-en-v1.5, cùng với Llama-3-8B-Instruct lượng tử hóa 4-bit và chuỗi RetrievalQA của LangChain để xây dựng hệ thống RAG hoàn chỉnh.
Hệ thống kết quả có thể xử lý tài liệu đa định dạng chính xác. Đối với các câu hỏi như "Rệp có phải là dịch hại không?" nó có thể trích xuất các sự kiện chính từ các tài liệu đã phân tích và tạo câu trả lời dựa trên tài liệu liên quan. Điều này đặc biệt hữu ích cho các cơ sở kiến thức doanh nghiệp cần xử lý nhiều loại tài liệu.
6.3 Hỏi đáp tài liệu doanh nghiệp: RAG độ chính xác cao và có thể truy xuất nguồn gốc
Giải pháp vô địch của Enterprise RAG Challenge cho thấy cách xây dựng hệ thống RAG cấp sản xuất dưới yêu cầu thời gian và độ chính xác nghiêm ngặt:
- https://abdullin.com/ilya/how-to-build-best-rag/
- https://hustyichi.github.io/2025/07/03/rag-complete/
Bối cảnh: Người tham gia phải phân tích cú pháp 100 PDF báo cáo thường niên doanh nghiệp thực trong 2.5 giờ, mỗi báo cáo lên đến 1000 trang và chứa bảng tài chính phức tạp, bố cục đa cột và biểu đồ. Sau khi phân tích, hệ thống phải trả lời 100 câu hỏi nghiệp vụ chính xác với loại câu trả lời rõ ràng, như có-không, tên công ty, chỉ số số chính xác hoặc chức danh điều hành, và phải trích dẫn số trang làm bằng chứng.
Đội vô địch chọn Docling mã nguồn mở của IBM làm trình phân tích PDF vì nó hoạt động tốt nhất trên bảng phức tạp và văn bản đa cột. Họ cải thiện mã Docling để nó có thể xuất JSON và Markdown-plus-HTML với metadata và đặc biệt cải thiện phân tích bảng. Để tăng tốc xử lý, họ thuê GPU RTX 4090 và hoàn thành phân tích 100 báo cáo trong 40 phút.
Chia đoạn văn bản sử dụng đoạn 300 token với 50 token chồng lấp và chia đệ quy để bảo tồn tính mạch lạc ngữ nghĩa. Để tránh nhiễm chéo giữa các công ty, mỗi công ty có kho lưu trữ vector FAISS riêng sử dụng chỉ mục IndexFlatIP. Truy xuất sau đó theo ba giai đoạn: truy xuất Top-30 đoạn theo vector, loại bỏ trùng lặp theo trang gốc vì nhiều đoạn có thể đến từ cùng một trang, và xếp hạng lại trang bằng GPT-4o-mini. Xếp hạng cuối cùng trộn điểm truy xuất vector và xếp hạng lại LLM với tỷ lệ trọng số 0.3 đến 0.7.
Tạo sinh sử dụng các mẫu prompt khác nhau cho các loại câu trả lời khác nhau. Đối với câu hỏi số, như doanh thu hàng năm, hệ thống sử dụng quy trình phân tích năm bước để đảm bảo đối sánh chỉ số, nhất quán đơn vị và kiểm tra chéo. Đầu ra được cấu trúc để bao gồm quy trình phân tích và tham chiếu trang để truy xuất nguồn gốc.
Hệ thống đã giành hai giải thưởng và đứng đầu bảng xếp hạng. Một quan sát quan trọng là ngay cả các mô hình nhỏ hơn như Llama 8B cũng vượt trội hơn 80 phần trăm người tham gia, trong khi Llama 3.3 70B tiến gần đến GPT-4o-mini, cho thấy rằng thiết kế hệ thống tốt có thể cân bằng thành công độ chính xác, hiệu quả và chi phí.
6.4 Kịch bản AIOps: xử lý thông minh dữ liệu hỗn hợp văn bản và hình ảnh
Dự án EasyRAG trong một cuộc thi RAG AIOps tập trung vào hỏi đáp cho các kịch bản vận hành:
http://blog.csdn.net/hustyichi/article/details/143323746
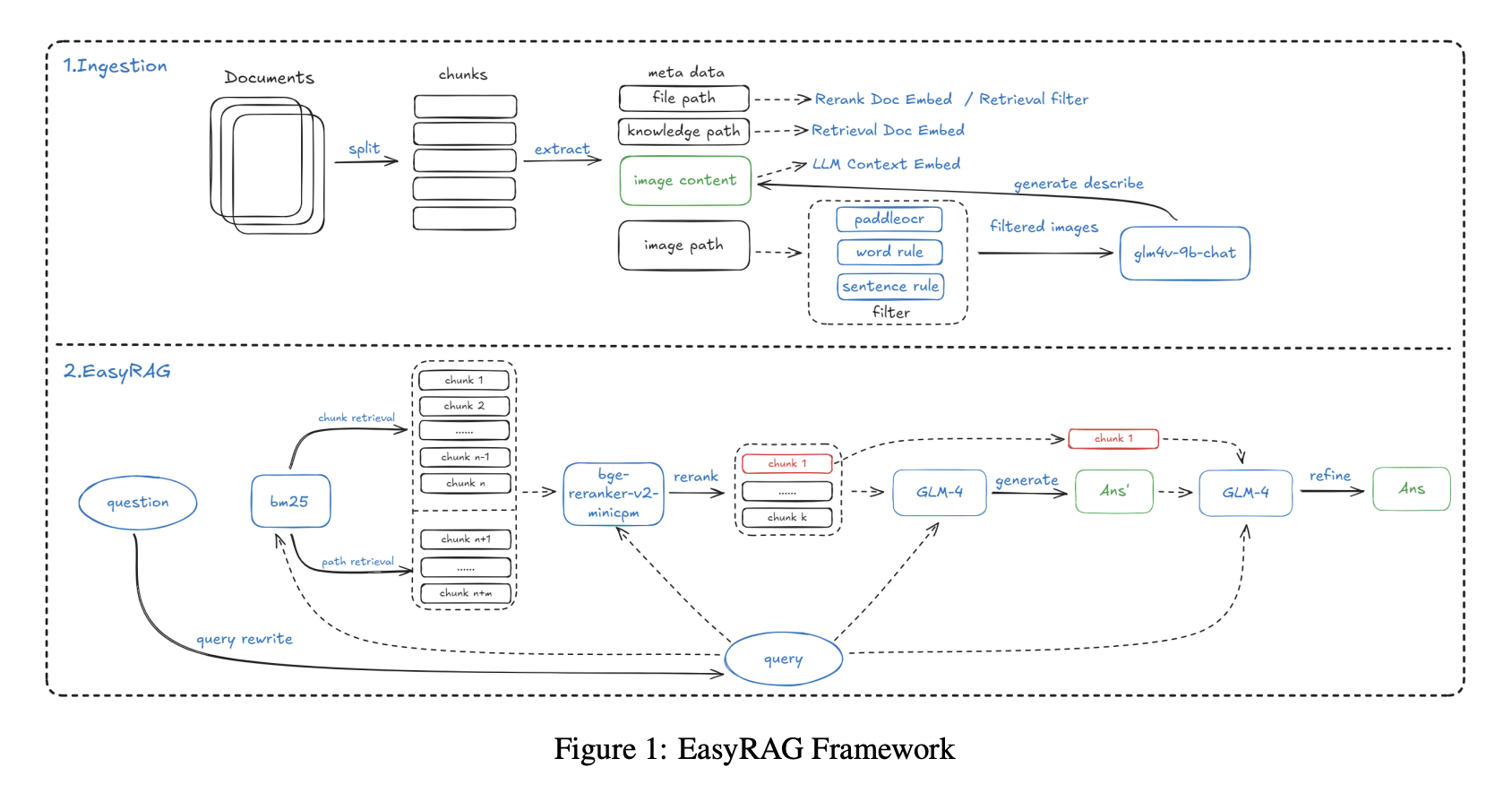
Bối cảnh: Kỹ sư vận hành thường cần đọc tài liệu kỹ thuật bao gồm không chỉ văn bản mà còn biểu đồ giám sát, sơ đồ kiến trúc hệ thống và đường cong hiệu suất. Ví dụ, khi chẩn đoán vấn đề hệ thống, câu trả lời cho "Tôi nên làm gì khi sử dụng CPU vượt quá 80 phần trăm?" có thể nằm rải rác giữa mô tả văn bản và biểu đồ giám sát. RAG chỉ văn bản truyền thống không thể hiểu xu hướng và giá trị biểu đồ, do đó câu trả lời vẫn không đầy đủ.
Giai đoạn lập chỉ mục sử dụng SentenceSplitter cải tiến với đoạn 1024 token và 200 token chồng lấp. Một đổi mới chính là thêm metadata như đường dẫn cơ sở kiến thức và đường dẫn tệp cho mỗi đoạn, cải thiện thu hồi thêm 2 phần trăm. Đối với dữ liệu hình ảnh, hệ thống đầu tiên sử dụng PaddleOCR để trích xuất văn bản từ biểu đồ và ảnh chụp màn hình, sau đó sử dụng mô hình đa phương thức, GLM-4V-9B, để tạo mô tả ngôn ngữ tự nhiên của hình ảnh, ví dụ mô tả đường sử dụng CPU đạt đỉnh 90 phần trăm vào buổi chiều. Cả văn bản OCR và mô tả hình ảnh sau đó được lập chỉ mục cùng nhau.
Truy xuất sử dụng chiến lược hai đường BM25 cộng với vector để thu hồi rộng. BM25 bao phủ truy xuất đoạn và truy xuất đường dẫn, giúp lọc tài liệu không liên quan theo đường dẫn tệp, trong khi truy xuất vector sử dụng gte-Qwen2-7B-instruct. Xếp hạng lại sử dụng bge-reranker-v2-minicpm-layerwise và cài đặt 28 lớp hoạt động tốt nhất trong các thử nghiệm.
Tạo câu trả lời sử dụng chiến lược hai bước: đầu tiên tạo nháp từ 6 tài liệu hàng đầu để tối đa hóa độ bao phủ thông tin, sau đó tối ưu câu trả lời với 1 tài liệu liên quan nhất để nhấn mạnh câu trả lời cốt lõi.
Để xử lý kịch bản văn bản dài, như một hướng dẫn vận hành hoàn chỉnh với hàng trăm trang, hệ thống cũng triển khai nén ngữ cảnh dựa trên BM25, chia tài liệu thành câu, chấm điểm tương đồng câu với truy vấn và nối chỉ các câu liên quan nhất. Ở mức nén 50 phần trăm, phương pháp này đạt độ chính xác 86.48 phần trăm chỉ trong 7.7 giây và vượt trội hơn các công cụ như LLMLingua.
6.5 Hợp nhất dữ liệu đa nguồn: hợp tác giữa kiến thức có cấu trúc và phi cấu trúc
Giải pháp chiến thắng trong thử thách KDD Cup 2024 Meta RAG đã cho thấy cách tích hợp nội dung web phi cấu trúc và đồ thị kiến thức có cấu trúc:
Bối cảnh: Tác vụ 1 yêu cầu tóm tắt truy xuất từ năm trang web. Tác vụ 2 thêm API mô phỏng đại diện cho đồ thị kiến thức có cấu trúc, cho phép truy cập trực tiếp đến những thứ như cơ sở dữ liệu phim và quan hệ thực thể. Tác vụ 3 nâng độ khó bằng cách sử dụng năm mươi trang web cộng với API mô phỏng để trả lời các truy vấn phức tạp hơn, như xác định phim do Nolan đạo diễn có doanh thu lớn hơn 500 triệu đô la. Mỗi truy vấn phải hoàn thành trong vòng 30 giây.
Đối với Tác vụ 1, đội chiến thắng đã xây dựng một pipeline xử lý web tinh chỉnh. Họ sử dụng BeautifulSoup để trích xuất văn bản trang và ParentDocumentRetriever để quản lý quan hệ đoạn cha-con, sử dụng đoạn con 200 token để truy xuất và đoạn cha 500 đến 2000 token để tạo sinh. Mô hình embedding là bge-base-en-v1.5, kho lưu trữ vector là Chroma và xếp hạng lại sử dụng bge-reranker-v2-m3. Đội cũng bổ sung dữ liệu phim và tài chính từ các tập dữ liệu công khai và tinh chỉnh Llama-3-8B-instruct với LoRA trên dữ liệu huấn luyện bao gồm câu hỏi không hợp lệ và câu trả lời tham khảo.
Đối với Tác vụ 2 và 3, đổi mới chính là ưu tiên đồ thị kiến thức. Hệ thống xác định các lệnh gọi API chuẩn hóa như get_person và get_movie, với hỗ trợ lọc và sắp xếp. Nó đầu tiên gọi API đồ thị kiến thức và chỉ quay lại truy xuất web nếu kết quả đồ thị bị thiếu hoặc không hợp lệ. Điều này cải thiện cả tốc độ và độ chính xác câu trả lời.
Vì hệ thống ưu tiên đồ thị kiến thức và sử dụng định dạng đầu ra có cấu trúc, ảo giác được giảm rõ rệt. Nếu đồ thị có thể cung cấp câu trả lời xác định trực tiếp, hệ thống trả về mà không cần bước tạo sinh. Nếu truy xuất web được yêu cầu, câu trả lời phải tuân theo quy tắc trích dẫn và lập luận từng bước nghiêm ngặt.
Giải pháp đã giành vị trí đầu trong cả ba tác vụ. Bài học chính là trong các kịch bản doanh nghiệp chứa cả dữ liệu có cấu trúc và phi cấu trúc, chiến lược truy xuất nên được thiết kế theo loại dữ liệu: sử dụng dữ liệu có cấu trúc xác định trước và coi các nguồn phi cấu trúc như bổ sung.
Trong các trường hợp thực tế này, một số nguyên tắc chung xuất hiện lặp đi lặp lại:
- chọn chiến lược cache, truy xuất và tạo sinh theo kịch bản kinh doanh
- thiết kế đường dẫn phân tích cú pháp và lập chỉ mục chuyên dụng cho các định dạng và phương thức khác nhau
- coi truy xuất hỗn hợp cộng xếp hạng lại như một cấu hình tiêu chuẩn
- sử dụng prompting theo tác vụ và đầu ra có cấu trúc để cải thiện độ chính xác và truy xuất nguồn gốc
Những bài học từ các cuộc thi thực tế và dự án mở này là tài liệu tham khảo có giá trị khi xây dựng hệ thống RAG doanh nghiệp mạnh mẽ hơn.
7. Khám phá rộng: Sự tiến hóa tương lai của RAG (Tùy chọn)
Khi bạn đã học các kỹ năng thực tế và phương pháp tối ưu hóa của RAG, bạn đã có thể cải thiện hiệu suất hệ thống trong các kịch bản cụ thể. Nhưng chỉ hiểu các kỹ thuật kỹ thuật cục bộ là chưa đủ nếu bạn muốn có cái nhìn rộng hơn về hướng đi của RAG. Chúng ta cũng cần xem xét các hướng tiến hóa rộng hơn.
RAG hiện đang nhanh chóng vượt ra ngoài mô hình truy xuất-đoạn-văn-bản-rồi-tạo-sinh truyền thống. Trong phần này, chúng ta tập trung vào một số con đường đó: chuyển từ truy xuất đoạn sang truy xuất có cấu trúc đồ thị, kết hợp hình ảnh và âm thanh thành RAG đa phương thức, cải thiện xử lý tài liệu dài thông qua vectorized late chunking và cách RAG đang dần tiến hóa thành một hệ thống hướng agent.
7.1 Graph RAG: định hình lại truy xuất sâu với mạng lưới quan hệ
Nghiên cứu liên quan:
RAG truyền thống hoạt động bằng cách tìm các đoạn văn bản tương tự với câu hỏi, giống như chọn ra vài đoạn trông liên quan nhất từ một đống tài liệu. Điều này hoạt động tốt cho tra cứu sự thực trực tiếp. Nhưng nếu một câu hỏi yêu cầu kết nối nhiều tài liệu và kết hợp các manh mối khác nhau, hiệu suất giảm.
Ví dụ, một bác sĩ có thể hỏi, "Dựa trên các ca bệnh này và hướng dẫn điều trị mới nhất, chúng ta nên đánh giá lợi ích và rủi ro của một loại thuốc nhất định cho bệnh nhân cao tuổi như thế nào?" Hoặc một nhóm dự án có thể hỏi, "Nhìn xuyên suốt hai năm tài liệu yêu cầu, biên bản đánh giá và báo cáo sự cố trực tuyến, phần nào của kiến trúc hệ thống của chúng ta thất bại thường xuyên nhất?" Những câu hỏi như thế này không phải là tìm một câu đơn lẻ. Chúng đòi hỏi xác định con người, đối tượng, sự kiện và mối quan hệ nằm rải rác trên nhiều tài liệu và hình thành một bức tranh hoàn chỉnh.
Graph RAG xây dựng bức tranh đó một cách chủ động. Hệ thống sử dụng mô hình lớn để xác định các thực thể chính từ văn bản, như con người, tổ chức, module chức năng, sự kiện và dữ liệu, cùng với các mối quan hệ của chúng, như quan hệ nhân quả, sự phụ thuộc, thay đổi và mâu thuẫn. Sau đó nó xây dựng một mạng lưới kiến thức phát triển khi thêm tài liệu. Thông qua nhóm tự động, các thực thể và mối quan hệ liên quan chặt chẽ được tổ chức thành chủ đề và mỗi chủ đề có thể được tóm tắt trước. Khi người dùng đặt câu hỏi, hệ thống không chỉ tìm các đoạn văn bản trông tương tự. Nó đầu tiên tìm các thực thể và cấu trúc đồ thị cục bộ liên quan nhất, mở rộng qua các nhóm chủ đề liên quan, và sau đó cung cấp đường dẫn phân tích, mô tả node và đoạn nguồn cùng cho LLM để lập luận.
Dưới framework này, Graph RAG và RAG truyền thống bổ sung cho nhau. RAG truyền thống vẫn mạnh cho các câu hỏi chi tiết có câu trả lời có thể tìm trong một bước. Graph RAG gần với cách một nhà nghiên cứu con người nghĩ: đầu tiên tổ chức cấu trúc tổng thể và chủ đề, sau đó điền bằng chứng và cuối cùng tạo kết luận với logic và điều kiện. Các so sánh hiện có cho thấy trong các tác vụ lập luận đa bước, Graph RAG thường bao phủ nhiều nội dung quan trọng hơn và cung cấp góc nhìn rộng hơn. Kết hợp linh hoạt hai cách tiếp cận thường tốt hơn việc chỉ sử dụng một.
7.2 RAG đa phương thức
Nghiên cứu liên quan:
Dữ liệu thực tế không bao giờ chỉ là văn bản. Kỹ sư chẩn đoán lỗi máy chủ cần xem đường cong nhiệt độ, ảnh chụp màn hình thiết bị và nhật ký cùng lúc. Bác sĩ chẩn đoán cần hình ảnh CT hoặc MRI, báo cáo xét nghiệm và hồ sơ bệnh án điện tử đồng thời. RAG văn bản truyền thống tối đa chỉ có thể truy xuất các cụm từ như "bất thường nhiệt độ" hoặc "nghi ngờ nốt phổi," nhưng nó gặp khó khăn trong việc kết nối các mô tả đó với xu hướng biểu đồ thực tế hoặc hình dạng tổn thương hình ảnh, và nó không thể tìm kiếm tài liệu hoặc kiến thức ngược từ hình ảnh, âm thanh hoặc video.
RAG đa phương thức giải quyết vấn đề các phương thức khác nhau không thể "nhìn thấy" lẫn nhau. Cốt lõi của nó là căn chỉnh ngữ nghĩa xuyên phương thức. Hệ thống sử dụng các encoder phù hợp cho hình ảnh, video, âm thanh và văn bản, cùng với OCR, ASR và phân tích bố cục, trích xuất thông tin chính từ nguồn hình ảnh và âm thanh, và ánh xạ các phương thức khác nhau vào một không gian ngữ nghĩa chung nơi một chỉ mục đa phương thức thống nhất có thể được xây dựng.
Tại thời điểm truy xuất và tạo sinh, dù người dùng hỏi về biểu đồ cho thấy đỉnh doanh số trong Q3 2023 hay tải lên bản phác thảo hoặc video vận hành, hệ thống đầu tiên tìm bằng chứng đa phương thức gần nhất trong không gian thống nhất đó, lọc theo các tín hiệu như tương đồng văn bản và tương đồng hình ảnh, giữ lại các phần hữu ích nhất, và sau đó cung cấp hình ảnh, đoạn văn bản và bảng cùng cho một LLM đa phương thức. Mô hình sau đó có thể trả lời bằng cách kết hợp bằng chứng xuyên phương thức và lý tưởng là chỉ ra nguồn hoặc tô sáng các vùng liên quan trong hình ảnh hoặc tài liệu.
So với RAG chỉ văn bản, RAG đa phương thức có thể sử dụng nhiều loại bằng chứng hơn và thường giảm ảo giác trong khi tạo câu trả lời hoàn chỉnh và có thể xác minh hơn.
7.3 Late Chunking: bảo tồn ngữ cảnh đầy đủ cho tài liệu dài
Giới thiệu liên quan:
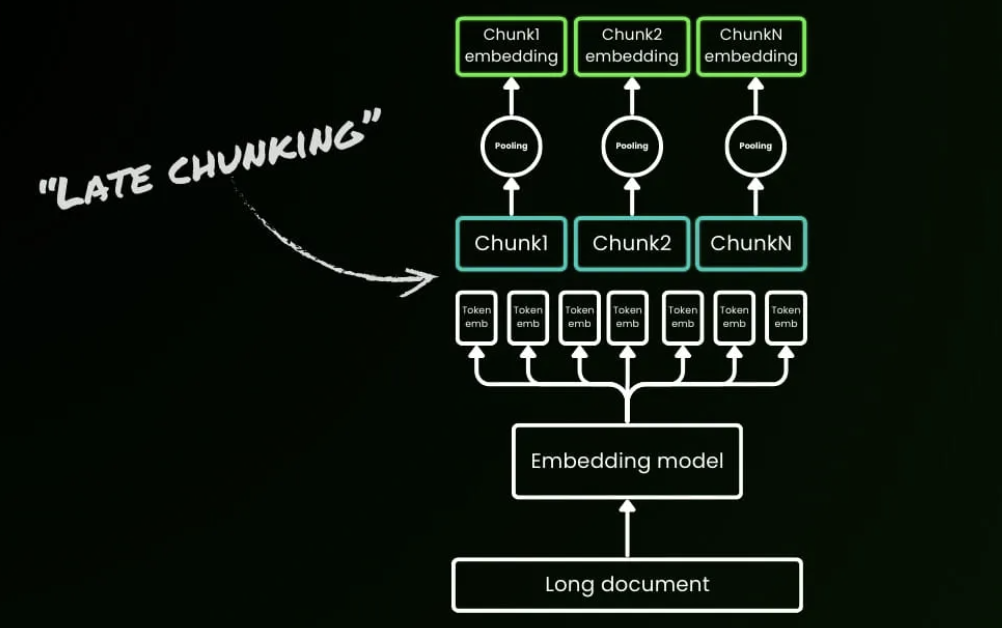
Hãy tưởng tượng đọc một bài viết Wikipedia về Berlin. RAG truyền thống sẽ đầu tiên cắt nó thành các đoạn độc lập và sau đó nhúng mỗi đoạn. Nếu câu đầu tiên nói "Berlin là thủ đô của Đức," các cụm từ sau như "thành phố" hoặc "dân số của nó" mất kết nối với Berlin khi bị tách ra. Một truy vấn như "Dân số của Berlin là bao nhiêu?" có thể thất bại vì thuật ngữ Berlin và thông tin dân số không bao giờ xuất hiện trong cùng một đoạn. Vấn đề này trở nên tồi tệ hơn đối với tài liệu dài. Trong một hợp đồng bảo hiểm 200 trang, định nghĩa về mức miễn thường có thể xuất hiện ở trang 5 trong khi điều kiện áp dụng xuất hiện ở trang 30. Chia đoạn theo độ dài cố định có thể chia các phần liên quan này thành hàng chục đoạn cô lập và các thử nghiệm cho thấy tương đồng ngữ nghĩa có thể sụp đổ mạnh khi điều đó xảy ra.
Late Chunking lật ngược pipeline chia-trước-rồi-nhúng-sau truyền thống và thay vào đó theo nhúng-trước-rồi-chia-sau. Với các mô hình embedding ngữ cảnh dài có thể xử lý khoảng 8192 token, toàn bộ tài liệu được đưa qua Transformer trước, tạo ra các embedding cấp token đã thấy toàn bộ tài liệu. Chỉ sau đó các embedding token đã được thông tin toàn cầu mới được gộp thành các embedding đoạn theo ranh giới đoạn. Các đoạn kết quả không còn là các hòn đảo độc lập. Chúng là các embedding phụ thuộc ngữ cảnh bảo tồn các tham chiếu xuyên đoạn văn và mối quan hệ khái niệm.
Trên các tập dữ liệu benchmark BEIR, Late Chunking vượt trội hơn chia đoạn truyền thống rộng rãi, với lợi ích đặc biệt mạnh trên tài liệu dài hơn. Trong các kịch bản văn bản ngắn, sự khác biệt phần lớn biến mất, xác nhận một quy tắc chính: tài liệu càng dài, lợi thế của Late Chunking càng lớn. Phương pháp hiện được tích hợp vào Jina Embeddings v3. Mặc dù mã hóa toàn bộ tài liệu dài trước có thể tăng thời gian suy luận 10 đến 20 phần trăm, lợi ích truy xuất trong các kịch bản như hồ sơ y tế, tài liệu pháp lý và hướng dẫn kỹ thuật có thể dễ dàng biện minh cho chi phí đó.
Late Chunking cho thấy các mô hình embedding ngữ cảnh dài 8K trở lên không phải là overengineering trong các kịch bản này. Chúng thường cần thiết để tạo ra các embedding đoạn chất lượng cao và đại diện cho sự chuyển dịch từ chia trước rồi nhúng sang nhúng trước rồi chia.
7.4 Từ RAG đến RAG trong kỷ nguyên Agent
Thảo luận liên quan:
- https://ragflow.io/blog/rag-at-the-crossroads-mid-2025-reflections-on-ai-evolution
- https://arxiv.org/pdf/2501.09136
- https://www.letta.com/blog/rag-vs-agent-memory
- https://www.linkedin.com/posts/richmondalake_100daysofagentmemory-rag-memorizz-activity-7348281860843577346-LM7Y/
- https://www.llamaindex.ai/blog/rag-is-dead-long-live-agentic-retrieval
RAG đã phát triển từ công cụ tạo sinh tăng cường truy xuất thành một phần chính trong kiến trúc nhận thức của agent. RAG truyền thống được xây dựng trên mô hình hỏi-truy xuất-trả lời đơn giản và về cơ bản là bị động. Nó chờ truy vấn và không hành động chủ động. Để đột phá tính bị động đó và xử lý các tác vụ nhận thức phức tạp hơn, RAG đã được kết hợp sâu với khả năng agent, tạo ra một mô hình mới: Agentic RAG.
Dưới mô hình này, vai trò của RAG thay đổi căn bản. Nó không còn chỉ là nhà cung cấp kiến thức bên ngoài bị động. Thay vào đó, nó trở thành đơn vị xử lý cốt lõi hỗ trợ hành vi thông minh dưới quy hoạch chủ động, hướng mục tiêu và tự phản hồi của agent. Sự hợp nhất này cung cấp cho hệ thống tổng thể định hướng mục tiêu, tối ưu hóa lặp và ra quyết định tự chủ, đào sâu đáng kể chất lượng tương tác người-AI. Agentic RAG có thể hiểu các tác vụ phức tạp, phân giải chúng, lên kế hoạch chiến lược truy xuất và đánh giá chất lượng kết quả ban đầu để quyết định liệu cần khám phá sâu hơn hay không.
Điểm mấu chốt của khả năng này là một vòng lặp chủ động nhiều lớp. Đối mặt với một truy vấn phức tạp, agent đầu tiên phân tích bản chất của vấn đề, chia nó thành các vấn đề con và thiết kế chiến lược truy xuất chính xác cho mỗi vấn đề con. Sau khi nhận kết quả ban đầu, nó đánh giá chúng, đánh giá xem thông tin đã đầy đủ và liên quan chưa, xác định khoảng trống kiến thức và động thái tạo các truy vấn mới chính xác hơn. Quá trình lặp này thường bao gồm truy xuất đa bước, nơi một vòng kết quả tiết lộ hướng mới cho vòng tiếp theo, tạo ra một chuỗi khám phá kiến thức tương tự cách một nhà nghiên cứu con người làm việc.
Để hỗ trợ hành vi thông minh liên tục, lặp này, đặc biệt khi cá nhân hóa và tích lũy kiến thức dài hạn quan trọng, ngữ cảnh hội thoại ngắn hạn một mình là không đủ. Điều này dẫn đến nhu cầu về bộ nhớ có cấu trúc dài hạn.
Đó chính xác là lý do tại sao RAG ngày càng được giao vai trò hệ thống bộ nhớ dài hạn của agent và được sử dụng để xây dựng kiến trúc bộ nhớ bên ngoài đầy đủ. Bộ nhớ dài hạn này bổ sung cho bộ nhớ ngắn hạn, chịu trách nhiệm duy trì ngữ cảnh đối thoại hiện tại. Hệ thống bộ nhớ dài hạn dựa vào ba cơ chế chính:
- Khả năng lập chỉ mục có cấu trúc: Điều này cho phép agent xây dựng các chỉ mục đa chiều trên lượng lớn dữ liệu phi cấu trúc, theo thời gian, chủ đề, quan hệ thực thể và hơn thế nữa, hỗ trợ truy xuất hiệu quả từ nhiều góc độ giống như cách con người gợi nhớ thông tin qua các manh mối khác nhau.
- Quên thông minh: Thông qua thuật toán đánh giá giá trị, hệ thống có thể phân rã hoặc loại bỏ có chọn lọc thông tin tần suất thấp, liên quan yếu hoặc lỗi thời, giữ cho hệ thống bộ nhớ tinh gọn và hiệu quả và ngăn ngừa quá tải.
- Củng cố kiến thức: Hệ thống tinh luyện trải nghiệm đối thoại và tương tác rải rác thành kiến thức có cấu trúc. Thông qua nhận diện thực thể, trích xuất quan hệ và phân cụm ngữ nghĩa, thông tin phân mảnh được kết nối thành đồ thị kiến thức, biến trải nghiệm ngắn hạn thành kiến thức dài hạn.
Hệ thống bộ nhớ bên ngoài được xây dựng trên RAG này không chỉ mở rộng đáng kể ranh giới nhận thức của agent mà còn cho nó khả năng tiếp tục học hỏi và tiến hóa kiến thức. Nó cho phép agent tích lũy kinh nghiệm qua tương tác dài hạn, hình thành mô hình vận hành cá nhân hóa và hệ thống kiến thức lĩnh vực, và hỗ trợ các tác vụ phức tạp hơn và chạy dài hơn.
Tóm tắt
Retrieval-Augmented Generation không chỉ là phương pháp kỹ thuật để bù đắp ảo giác và kiến thức lỗi thời trong mô hình lớn. Nó còn là cầu nối chính để biến khả năng AI tổng quát thành giá trị doanh nghiệp sâu sắc. Sự tiến hóa từ Naive RAG sang các hình thức module và agent cho thấy mọi phần của RAG cần được đào sâu liên tục, bao gồm xử lý dữ liệu tinh tế hơn, lựa chọn mô hình khoa học hơn xuyên qua các giai đoạn embedding, rerank và LLM và đánh giá có hệ thống hơn. Tất cả những điều này là các bước cần thiết hướng tới xây dựng hệ thống kiến thức doanh nghiệp có thể kiểm soát, đáng tin cậy và hiệu quả. Đồng thời, rút ra bài học từ các cuộc thi và nghiên cứu tình huống kỹ thuật là một trong những cách tốt nhất để đào sâu hiểu biết về các chi tiết kỹ thuật.
Khi Graph RAG, hiểu đa phương thức và Late Chunking tiếp tục phát triển và kết hợp, RAG đang vững bước vượt ra ngoài ranh giới truy xuất-và-tạo-sinh cũ và tiến về phía liên kết ngữ nghĩa sâu hơn và khả năng bộ nhớ bền vững hơn. Hy vọng rằng bài khảo sát kiểu này giúp bạn xây dựng phương pháp luận chuỗi đầy đủ, từ nguyên lý đến thực tiễn và từ đánh giá đến tiến hóa, để trong một bối cảnh kỹ thuật thay đổi nhanh bạn có thể xây dựng các ứng dụng thông minh chất lượng cao thực sự hạ cánh trong thế giới thực và có thể xử lý các thách thức kinh doanh phức tạp.
Tài liệu tham khảo
[1] Ask in Any Modality: A Comprehensive Survey on Multimodal Retrieval-Augmented Generation.
https://arxiv.org/pdf/2502.08826
[2] Retrieving Multimodal Information for Augmented Generation: A Survey.
https://arxiv.org/pdf/2303.10868
[3] A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models.
https://arxiv.org/pdf/2405.06211
[4] Retrieval-Augmented Generation for Large Language Models: A Survey.
https://arxiv.org/pdf/2312.10997
[5] LightRAG: Simple and Fast Retrieval-Augmented Generation.
https://arxiv.org/pdf/2410.05779
[6] Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG.
https://arxiv.org/pdf/2501.09136
[7] ERAGent: Enhancing Retrieval-Augmented Language Models with Improved Accuracy, Efficiency, and Personalization.
https://arxiv.org/pdf/2405.06683
[8] Graph Retrieval-Augmented Generation: A Survey.
https://www.arxiv.org/pdf/2408.08921
[9] Evaluation of Retrieval-Augmented Generation: A Survey.
https://arxiv.org/pdf/2405.07437
[10] Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey.
https://arxiv.org/pdf/2504.14891
[11] From Local to Global: A Graph RAG Approach to Query-Focused Summarization.
https://arxiv.org/pdf/2404.16130
[12] RAG vs. GraphRAG: A Systematic Evaluation and Key Insights.
https://arxiv.org/pdf/2502.11371
[13] Introduction to RAG | LlamaIndex Python Documentation.
https://developers.llamaindex.ai/python/framework/understanding/rag/
[14] All-in-RAG | A Full-Stack Guide to RAG in Large-Model Application Development.
https://datawhalechina.github.io/all-in-rag/#/en/
[15] Ilya Rice: How I Won the Enterprise RAG Challenge.
https://abdullin.com/ilya/how-to-build-best-rag/
[16] RAG Research Table - Awesome Generative AI Guide (GitHub).
[17] RAG is dead, long live agentic retrieval.
https://www.llamaindex.ai/blog/rag-is-dead-long-live-agentic-retrieval
[18] LLM/RAG Zoomcamp extra lesson 5: Common evaluation methods and market preferences in RAG evolution.
https://vip.studycamp.tw/t/llmrag-zoomcamp-課外補充-5:rag-evolution-常見評估方法和市場偏好/8185
[19] How to Evaluate Retrieval Augmented Generation (RAG) Applications.
https://zilliz.com.cn/blog/how-to-evaluate-rag-zilliz
[20] RAG is not Agent Memory.
https://www.letta.com/blog/rag-vs-agent-memory
[21] Richmond Alake. LinkedIn post on #100DaysOfAgentMemory, RAG and MemoRizz.