第 11 章 上下文截断与压缩——主动管理每一轮的信息预算
在上一章中,我们看到了 GA 如何通过分层记忆管理跨任务的知识——只注入索引,按需加载详情。但即使有了记忆分层,单次任务内的对话依然会越来越长:每一轮工具调用都会返回新的数据,推理过程会产生新的思考记录,历史轮次不断累积。
许多 Agent 框架选择依赖扩展的上下文窗口(高达 1M token),假设更多上下文意味着更好的推理。但实践表明,这种做法不仅成本高昂,还会引入更多幻觉。论文将当前模型在不产生幻觉的前提下能有效利用的上下文上限称为无幻觉上下文长度(hallucination-free context length),其量级大约比名义窗口小一个数量级。因此,GA 选择了一条截然不同的路径:将预算控制在 30k token 以内,投资于压缩而非扩展——把高密度信息装进更小的窗口,优于把稀释的内容灌入更大的窗口。
这一战略选择决定了本章的核心主题:GA 如何在"不丢关键信息"和"不超预算"之间取得平衡?
11.1 上下文预算的量化模型
11.1.1 直觉理解:信用卡额度
把上下文窗口想象成一张信用卡的额度。每一轮对话都是一笔"消费":用户消息、模型推理、工具调用、工具返回——每一项都在消耗额度。如果不主动管理,几十轮下来就会"刷爆额度",模型将无法接收新的信息。
GA 的做法不是"等到刷爆再处理",而是主动记账、提前瘦身——在每一笔大额消费发生时就控制支出,在余额不足时主动清理旧账单。
11.1.2 深入理解:字符域预算公式
由于 GA 无法直接获得精确的 token 计数,它使用一个字符域启发式公式(Character-Domain Heuristic) 来管理上下文预算:
其中:
是当前对话历史 中所有消息 的字符总长度(JSON 序列化后) 是配置的 token 窗口大小 是字符/token 的经验转换系数 是字符域预算 - 当
时,触发压缩或驱逐机制
所有预算比较都在字符域完成,不会转换回 token 数。这使得预算管理完全独立于具体的 tokenizer 实现,支撑了 GA 的模型无关设计。
关于
的设计权衡:对于英文为主的内容,实际的字符/token 比率约为 4:1,这意味着 会略微高估 token 消耗,导致提前驱逐——这是一种安全的失效模式(宁可少放一些,也不要超出窗口)。但对于中日韩(CJK)内容,每个字符通常消耗 1-2 个 token, 反而会低估 token 消耗 3-6 倍,存在延迟驱逐的风险。这是当前实现的一个已知局限。
11.2 四阶段压缩流水线
GA 的上下文管理不是单一策略,而是一条四阶段流水线(Four-Stage Pipeline),从细粒度到粗粒度依次处理。我们用一个比喻来理解:
想象你在整理一个越来越满的行李箱:
- Stage 1:先把每件衣服卷紧(减少单件体积)
- Stage 2:把旧的、不常穿的衣服折叠得更小(压缩旧物品)
- Stage 3:实在装不下了,把最旧的衣服拿出来(移除旧物品)
- Stage 4:在行李箱外面贴一张清单,记录被拿出去的东西是什么(保留索引)
11.2.1 Stage 1:工具级截断——控制每件"物品"的大小
第一道防线作用在每个工具的返回值上。在工具执行结果进入对话历史之前,GA 会根据预设的阈值进行截断。
截断策略采用对称头尾保留(Symmetric Head-Tail Policy):当输出超过阈值
为什么保留头和尾而不是只保留头部?因为在很多场景下,尾部信息同样关键:
- 代码执行的错误信息通常出现在输出末尾
- 文件内容的结尾可能包含关键的总结或签名
- 日志的最新条目在底部
各工具的截断阈值如下:
| 工具 / 模式 | 截断阈值 | 说明 |
|---|---|---|
code_run | 10,000 | 标准代码输出截断 |
web_execute_js | 8,000 | 使用 save_to_file 时全量写磁盘,仅短预览入上下文 |
web_scan(纯文本) | 10,000 | 头尾截断 |
web_scan(HTML) | 35,000 | DOM 级子树裁剪,非头尾截断 |
file_read | ~1,280/行;总计 20,000 | 行级 + 总量双重控制 |
注意
web_scan的 HTML 模式使用的是 DOM 级字符预算而不是简单的头尾截断。这是因为 HTML 是树形结构,简单的字符截断会破坏标签的完整性。GA 在 DOM 层面进行子树裁剪,确保返回的 HTML 始终是结构完整的。我们将在 11.3 节详细讨论浏览器层的选择性提取。
11.2.2 Stage 2:Tag 级压缩——压缩旧轮次的"包装"
即使每个工具返回值都被截断了,随着对话推进,历史消息中仍然会累积大量结构化标签内容:推理痕迹(<thinking>)、工具调用记录(<tool_use>)、工具返回结果(<tool_result>)、以及过期的工作记忆快照(<history>、<key_info>)。
Tag 级压缩大约每 5 轮执行一次(以摊销计算成本)。这个间隔还带来了一个额外收益:未被修改的旧消息在相邻轮次之间保持不变,使得约 80% 的轮次能够命中 prompt-cache,显著降低了推理成本。处理方式分两类:
第一类:替换过期的工作记忆块。 <history> 和 <key_info> 标签的内容只有最新的一份是有意义的——旧的快照已经被新快照覆盖。因此,旧轮次中的这些标签会被替换为简短的占位符 [...]。
第二类:截短推理和工具标签。 旧轮次中的 <thinking>、<tool_use>、<tool_result> 标签内容会被截断到约 800 字符的头尾窗口。这保留了推理的开头(通常包含策略判断)和结尾(通常包含结论),丢弃中间的详细推导过程。
关键保护机制:最近的消息(默认 10 条)不受 Stage 2 压缩的影响。这确保了模型对最近几轮交互拥有完整的上下文,不会因为压缩而丢失刚刚发生的关键信息。
11.2.3 Stage 3:消息驱逐——当"瘦身"不够时"断舍离"
当
第一步:更激进地重跑 Stage 2。 这次只豁免最近 4 条消息(而非正常的 10 条),对更多历史消息进行 Tag 级压缩。
第二步:FIFO 驱逐。 如果压缩后仍然超预算,按先进先出顺序从最早的消息开始移除,直到
为什么目标是
而不是刚好 ? 这个 60% 目标是刻意的"过度修剪",目的是为后续轮次预留空间。如果每次都只修剪到刚好不超预算,那么下一轮新消息进来后立即又要触发驱逐,导致频繁的压缩开销。60% 的目标提供了约 40% 的缓冲区。
驱逐后的结构修复:消息被移除后,剩余的历史可能出现结构问题——比如开头是一条孤立的 tool_result 消息,却没有对应的 tool_use。GA 会进行轻量级的结构修复:
- 重新对齐历史,确保以用户消息开头
- 将孤立的
tool_result转换为纯文本,避免 API 协议错误
一个关键的设计选择:Stage 3 不做摘要。被驱逐的消息就是被丢弃了,GA 不会尝试用 LLM 生成一段"之前发生了什么"的摘要。这是因为:
- 摘要需要额外的 LLM 调用,增加延迟和成本
- 摘要本身也占用上下文空间
- 摘要的质量难以保证,可能引入错误信息
但论文强调,被驱逐的内容并不会完全丧失:Stage 4 的工作记忆锚点保留了关键的任务状态,而 Stage 2 的压缩机制确保了即使在不到 30k token 的上下文窗口内,也能容纳数十轮历史交互的压缩信息。GA 正是用这两层机制来弥补驱逐造成的信息损失。
11.2.4 Stage 4:工作记忆锚点——驱逐后的唯一长程记忆
Stage 4 是整个压缩流水线的"安全网"。在每次工具调用之后,GA 会在下一条用户消息中注入一个锚点提示(Anchor Prompt),包含三部分内容:
- 最近 20 条单行轮次摘要:每条约 100 字符,记录了"第 N 轮做了什么、结果如何"。摘要的来源有两种:优先使用模型在推理过程中提供的
<summary>字段;如果模型未提供,则从该轮的实际工具操作中自动生成一条简要描述 - 当前轮次编号:让模型知道任务已经进行了多少轮
- 持久化 key_info 块:通过
update_working_checkpoint工具维护的结构化笔记,包含当前目标、关键发现、约束条件等。这里有一个重要的机制区分——key_info 是由 Agent 显式更新的(模型主动调用工具写入),但写入后由系统自动携带到后续每一轮的上下文中。它不是后台自动改写的机制,而是"写一次,自动传播"的设计
这个锚点是消息驱逐后唯一的长程记忆保留机制。当 Stage 3 把早期的对话全部清除之后,模型依靠这个锚点来"知道之前发生了什么"。
注意这里的巧妙之处:因为锚点被注入到每条用户消息中,所以 Stage 2 会自动将旧的锚点副本压缩为占位符
[...],只保留最新的一份完整内容。这避免了锚点自身造成的上下文膨胀。
11.2.5 四阶段协作的全景
让我们把四个阶段放在一起,看看它们如何协作:
消息产生 ──→ Stage 1: 工具级截断 ──→ 进入对话历史
│
每 ~5 轮触发
│
▼
Stage 2: Tag 级压缩
(旧标签缩短,旧快照替换)
│
超预算时触发
│
▼
Stage 3: 消息驱逐
(激进压缩 → FIFO移除 → 结构修复)
│
每轮自动注入
│
▼
Stage 4: 锚点注入
(20条摘要 + 轮次号 + key_info)Stage 1 控制增量(每条新消息的大小),Stage 2 控制存量(旧消息的膨胀),Stage 3 控制总量(整体预算),Stage 4 补偿损失(驱逐后的记忆恢复)。四个阶段形成了一个完整的信息生命周期管理系统。
11.3 浏览器层的选择性提取
在四阶段流水线之外,GA 还在信息进入系统之前就进行了一次重要的过滤——这就是浏览器工具 web_scan 的语义结构化处理。
11.3.1 为什么不能直接把网页塞进上下文
一个典型网页的完整 HTML 可能有几十万甚至上百万字符,其中大部分是对 Agent 决策毫无价值的内容:CSS 样式、JavaScript 代码、隐藏元素、广告栏、页脚导航等。如果把原始 HTML 直接送入上下文,信息密度将极其低下。
11.3.2 DOM 语义压缩的效果
正如第 9 章 §9.2.3 所介绍的,web_scan 在返回页面内容之前会执行一套 DOM 级的选择性提取——克隆 DOM 树、计算元素可见性、区分主/非主内容区域、移除遮挡和隐藏元素,最终在 35,000 字符的 DOM 级预算内优先保留主要内容。
从上下文压缩的角度来看,论文指出这种处理将 token 消耗降低了一个数量级——原始 DOM 可能包含数十万字符,经过 web_scan 的语义提取后通常压缩到数万字符以内,且关键信息完整保留。
这里体现了 GA 信息密度最大化原则的又一个实例:不是在信息进入上下文后再压缩,而是在源头就只提取有价值的信息。 Stage 1 的工具级截断是"入口把关",而
web_scan的 DOM 处理则是"源头净化"——两者共同构成了信息进入上下文之前的两道过滤。
11.4 工具 Schema 省略优化
除了对话内容的压缩,GA 还对一个容易被忽视的上下文开销进行了优化——工具定义(Tool Schema)。
9 个工具的完整 Schema 定义(包括参数说明、类型描述等)大约占用 2000-3000 字符。在文本协议路径下,如果每轮都发送完整的 Schema,这部分开销就是纯粹的浪费——因为工具定义在相邻轮次之间通常不会变化。
GA 的优化策略是:
- 相邻轮次 Schema 不变时省略:用一句简短的自然语言提醒替代完整定义(如"工具定义与上轮相同")
- 定期重发完整 Schema:每隔若干轮,或当累积提示词长度超过安全阈值时,重新发送完整定义,防止模型因长时间未见完整 Schema 而产生工具调用格式漂移
这个优化在原生 API 路径下不适用——因为 API 协议要求每次调用都携带完整的工具定义。它主要服务于文本协议场景,每轮可节省约 2000-3000 字符的固定开销。
11.5 实验印证:压缩与记忆协同下的效率收敛
本章介绍的压缩机制并非孤立运作——它与记忆层和自我进化层协同工作,共同产生了一个显著的效率收敛效果。论文在 §4.3.1(Memory System Effectiveness 下的 Continuous Efficiency Improvement)中报告了这一实验。
实验设置:以 GPT-5.4 为骨干模型,比较 CodeX、Claude Code、OpenClaw 和 GA 在 HuggingFace 数据集下载任务上的表现。实验包含五个不同的数据集,每轮实验在全新的独立会话中执行,以严格避免残留上下文的干扰。
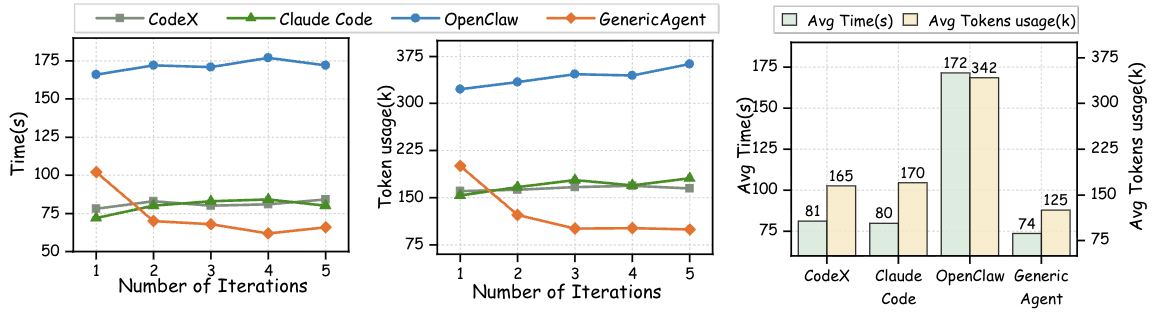
图 11-1:不同 Agent 系统在五轮重复实验中的操作时间和 token 消耗趋势。CodeX、Claude Code 和 OpenClaw 在各轮之间基本保持稳定,而 GA 展现出明显的效率收敛模式——运行时间和 token 消耗均随轮次稳步下降,表明任务经验被成功转化为可复用的记忆。(来源:论文 Figure 4)
实验结果:
- CodeX、Claude Code、OpenClaw 的操作时间和 token 消耗在各轮之间基本保持稳定,没有明显的改善趋势
- GA 的操作时间从第一轮的 102 秒下降到后续轮次的约 66 秒,token 消耗从 200,439 降至约 100,000
论文将这种稳步下降归因于 GA 的记忆系统:GA 不是简单地累积历史,而是将任务经验转化为可复用的 L3 SOP,从而在后续运行中减少了重复理解、不必要的推理和决策开销。效率的提升不是因为"存了更多内容",而是因为只保留了模型尚未掌握的、直接影响行为的高价值信息。
需要注意的是,这个收敛效果是压缩层、记忆层和进化层三者协同的结果:压缩机制确保每轮上下文不膨胀,为高密度信息留出空间;记忆机制确保经验被结构化保存在 L2/L3 中;进化机制(将在第 12 章详细讨论)负责将经验蒸馏为更精炼的 SOP 和代码。三者缺一不可。
11.6 本章小结
本章详细展示了 GA 如何主动管理每一轮的上下文预算。核心要点:
- 压缩优于扩展:GA 不依赖扩大上下文窗口,而是将预算控制在 30k token 以内——因为当前模型的无幻觉上下文长度远小于名义窗口
- 字符域预算公式以
的启发式系数将 token 窗口转换为字符预算,实现模型无关的预算管理 - 四阶段压缩流水线从细到粗逐层处理:工具级截断(控制增量)→ Tag 级压缩(控制存量)→ 消息驱逐(控制总量)→ 锚点注入(补偿损失)
- 浏览器层的 DOM 语义提取在信息源头就将 token 消耗降低了一个数量级
- 工具 Schema 省略减少了每轮的固定开销
这套机制的设计哲学可以概括为:与其让模型在一堆冗余信息中艰难寻找关键内容,不如主动确保模型看到的每一个字符都物有所值。
现在,我们已经理解了 GA 的工具层(第 9 章)、记忆层(第 10 章)和压缩层(本章)如何协同工作来最大化上下文信息密度。但这三个机制都在解决"当前任务如何高效执行"的问题。还有一个更深层的挑战尚未触及——跨任务的能力增长。GA 能不能像一个经验丰富的员工一样,把过去的成功经验转化为未来的效率?
这就是下一章的主题——自我进化。