第 7 章 上下文信息密度——GenericAgent 的第一性原理
在第一部分的应用篇中,我们已经学会了如何使用 GenericAgent(GA)来完成各种实际任务——从文件管理到网页操作,从定时任务到子代理协作。但你是否好奇过:GA 的底层到底是怎么设计的?为什么它能在长时间、多步骤的复杂任务中依然保持稳定的表现?
从本章开始,我们将进入原理篇,深入剖析 GA 的设计哲学与核心机制。而一切的起点,需要从长期运行 Agent 面临的两大根本挑战说起。
两大挑战:为什么现有 Agent 不够用?
当 LLM 从单轮问答的"文本生成器"转变为在终端、文件系统、浏览器中持续运作的目标驱动型 Agent,两个根本性的系统挑战随之浮现:
挑战一:上下文爆炸(Context Explosion)。随着 Agent 与环境交互,提示词不断膨胀——工具定义、检索到的记忆、中间观察结果、历史轨迹、网页原始内容层层堆叠。虽然这些组件在产生时各有用途,但它们对下一步决策的价值参差不齐。那些与当前推理无关的内容不仅被浪费,还会主动稀释模型的注意力,引发约束遗漏、状态混淆和幻觉等错误。
挑战二:经验无法有效积累与复用(Experience Accumulation)。在真实的长期运行环境中,大量有价值的知识并非一开始就存在,而是通过与特定用户的文件系统、工作流程和外部服务的反复交互中逐渐浮现的。如果 Agent 无法蒸馏和保留这些经验,每次遇到类似任务都得从头探索——耗费大量 token 却毫无能力增长。久而久之,系统陷入一种停滞循环(Stagnation Loop):尽管持续交互,性能却纹丝不动。
那么,要同时应对这两大挑战,关键的设计支点是什么?答案是一个看似简单却极其关键的问题:LLM 的上下文到底应该塞什么?
7.1 一个反直觉的事实:上下文越长,表现越差
7.1.1 直觉理解
想象你正在参加一场闭卷考试。你被允许带一张 A4 大小的"小抄"进考场。你会怎么写这张小抄?
- 方案 A:把课本的每一页都缩印上去,字小到几乎看不清
- 方案 B:只写你最容易忘记的公式和关键概念,字大清晰
显然,大多数人会选择方案 B。虽然方案 A 包含了"所有信息",但在考试的有限时间内,你根本来不及从密密麻麻的文字中找到需要的内容。更糟糕的是,过多的无关信息反而会干扰你的判断。
LLM Agent 面临的处境与此极其相似。虽然现代 LLM 的上下文窗口越来越大(从 4K 到 200K 甚至更长),但有效上下文远小于名义窗口。塞进去的信息越多,不代表模型的决策质量越高——恰恰相反,大量无关信息会显著降低模型的推理准确率。这个答案或许反直觉,但已被多项研究证实。接下来我们看看背后的三个技术原因。
7.1.2 深入理解:LLM 的三重上下文陷阱
研究者们发现,LLM 在处理长上下文时存在三种相互叠加的失效模式:
第一重陷阱:位置偏差(Lost-in-the-Middle)
LLM 对上下文中不同位置的信息关注度并不均匀。它们倾向于更好地利用上下文开头和结尾的信息,而中间部分的信息往往被"遗忘"。这意味着,即使关键信息确实存在于上下文中,只要它恰好落在中间位置,模型就可能视而不见。
这个现象被形象地称为"Lost-in-the-Middle"——信息迷失在上下文的中间地带。Liu et al. (2024) 的实验表明,当关键信息从上下文的开头/结尾移到中间位置时,模型的准确率会显著下降。
第二重陷阱:注意力稀释(Attention Dilution)
LLM 的注意力机制是一种有限资源。当上下文中充斥着大量无关内容时,模型分配给每条关键信息的注意力就会被稀释。这就好比在嘈杂的鸡尾酒派对上试图听清一个人说话——背景噪音越大,越难捕捉到有价值的信号。需要强调的是,无关内容不仅仅是被浪费了——它会主动干扰模型对关键证据的利用。
第三重陷阱:有效窗口远小于名义窗口
一个标称 128K token 上下文窗口的模型,其"有效利用"的上下文可能远小于这个数字。随着上下文增长,模型的推理能力会逐渐退化。换句话说,上下文窗口的"名义容量"和"有效容量"之间存在巨大鸿沟。
7.1.3 恶性循环:三重陷阱如何相互强化
这三重陷阱并非简单并列——它们在实践中形成一个相互强化的恶性循环。我们可以追踪这个循环的因果链条:
- 上下文不断增长 → 无关内容占比上升
- 无关内容增多 → 注意力被稀释,模型更难从中间位置检索关键信息(位置偏差加剧)
- 位置偏差加剧 → 模型越来越依赖开头和结尾的信息,有效窗口进一步收缩
- 有效窗口收缩 → 为补偿信息损失,系统倾向于注入更多"可能有用"的上下文
- 回到第 1 步 → 上下文进一步膨胀,循环加剧
这个恶性循环的核心启示是:超过某个临界点后,增加更多上下文不仅无法提升性能,反而会降低表现。
这一洞察对 Agent 系统设计有直接启示。现有的一些 Agent 框架采用整块式提示词组装策略——把脚手架文本、控制指令和大量边际相关的交互历史一股脑塞进上下文。这种做法不是在暴露当前决策真正需要的信息,而是把最需要的证据挤出了有效上下文窗口。结果就是:上下文在体量上更大了,但在效用上反而更低了,同时推理成本还在持续攀升。
那么,"上下文爆炸"到底有多严重?我们可以看一组实际数据。在安装了 20 个技能并经过长时间使用后,仅对一个最简单的 "Hello" 请求,各系统的完整提示词长度如下(数据来源:论文 Table 7):
| 系统 | 完整提示词长度(tokens) |
|---|---|
| OpenClaw | 43,321 |
| CodeX | 23,932 |
| Claude Code | 22,821 |
| GA | 2,298 |
GA 的提示词长度只有其他系统的 1/10 到 1/20。这就是系统性控制上下文信息密度的效果——即使经过长期使用和大量技能积累,GA 的上下文也不会失控膨胀。
7.2 GenericAgent 的核心设计约束:上下文信息密度最大化
7.2.1 直觉理解
既然"塞得多"不等于"用得好",那 GA 的设计哲学就很清晰了:不追求上下文的长度,而追求上下文的信息密度(Information Density)。
什么是信息密度?我们可以用一个简单的比喻来理解:
- 低信息密度上下文 = 一份冗长的会议记录,包含了每个人的寒暄、跑题讨论和重复发言
- 高信息密度上下文 = 一份精炼的会议纪要,只保留了决策事项、关键结论和行动计划
GA 的所有设计决策,都围绕一个核心目标展开:在有限的上下文预算内,最大化每一个 token 对当前决策的贡献。我们可以用一个形式化的视角来表达这个设计目标:
其中:
是当前上下文的内容组合 是上下文的信息密度 - 分子衡量"有用信息有多少"——对应完备性
- 分母衡量"总共塞了多少"——对应简洁性
需要说明的是,这个公式是教程为便于理解而构造的形式化表达,用于直觉地传达 GA 的设计理念。在实际系统中,GA 并不显式地计算信息密度,而是通过多层机制从不同角度来逼近这个目标。
7.2.2 深入理解:完备性与简洁性的权衡
从上下文工程(Context Engineering) 的视角来看,上下文质量可以用两个主要需求和一个辅助约束来刻画:
完备性(Completeness):当前决策所需的所有信息都必须显式地出现在上下文中,防止模型依赖隐含假设或产生幻觉补全。如果关键信息被遗漏,模型就会"巧妇难为无米之炊"。
简洁性(Conciseness):无关和冗余的信息必须被清除,使注意力始终聚焦在决策关键的信号上。每多一条无关信息,就多一分注意力稀释。
自然性(Naturalness):上下文应当保持合理的自然语言形态和语义可读性。但需要指出,自然性是一个重要但次要的约束——在大多数 Agent 失败场景中,主要的失败模式不是"措辞不够自然",而是完备性或简洁性的丧失。
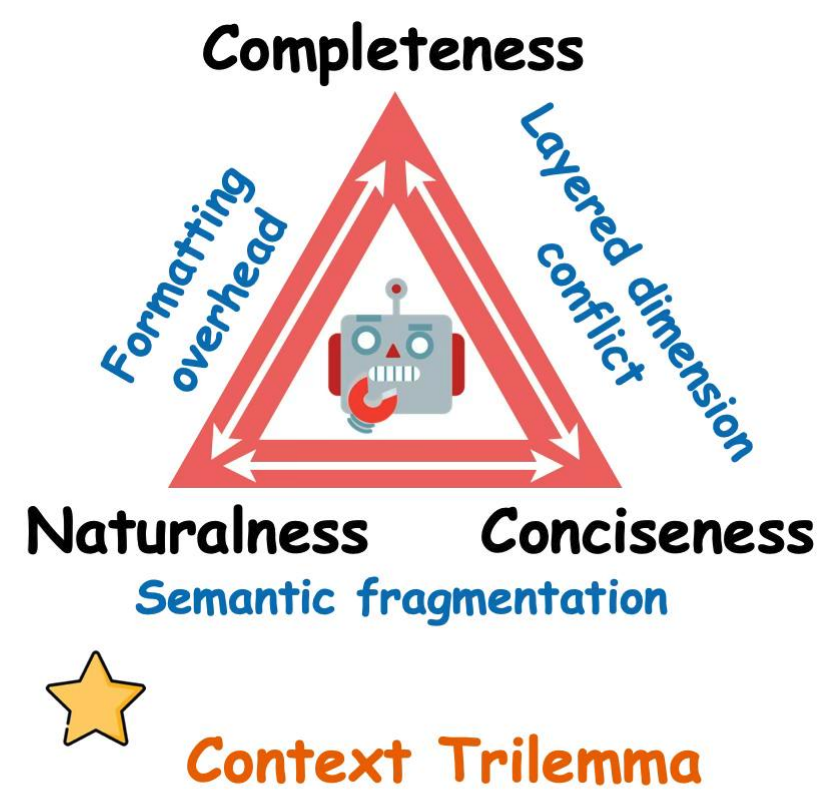
图 7-1:完备性与简洁性定义了上下文设计的核心权衡,而自然性作为有效表征的辅助约束。左图完备但过度冗长,关键信息被淹没;右图简洁但遗漏关键信息;中间为 GA 的平衡方案——完备且简洁,自然性自然跟随。
上下文工程的核心挑战,在于平衡完备性与简洁性。其他常被讨论的维度——如时效性(Recency)和相关性(Relevance)——可以在这个框架下自然理解:时效性同时服务于完备性(最新状态往往是当前决策所必需的)和简洁性(过时信息通常不再相关);相关性则是一个横切关注点,完备性和简洁性都需要基于"什么是相关的"来做判断。
7.2.3 核心洞察:结构性张力而非预算问题
理解了完备性和简洁性之后,我们来到本章最关键的洞察。
完备性和简洁性之间存在一个根本性的张力。你可能会以为:这个矛盾只是因为上下文窗口太小了——等模型有了无限大的窗口,问题就解决了。但事实并非如此。即使上下文窗口是无限大的,这个张力依然存在。这是一个结构性矛盾,而非仅仅是资源预算问题。
为什么?至少有三个原因:
- 加入更多可能相关的信息,提升了完备性,却削弱了简洁性——因为"可能相关"并不等于"当前需要",多余的信息必然稀释注意力
- 摘要和压缩提升了简洁性,却可能损害完备性——任何压缩都有信息损失的风险,可能恰好丢弃了下一步决策需要的关键细节
- 自然性在某些情况下会加剧这个权衡——高度压缩或人工编码的表示可能更难被模型解读,但这通常是次要效应而非主要约束
有限的有效上下文窗口 把这个结构性张力进一步激化为一个硬约束——但底层的冲突是结构性的,而非单纯的资源驱动。在这种结构性张力下,上下文工程不应被看作完备性-简洁性-自然性的三元等价博弈,而是以平衡完备性与简洁性为核心、以自然性为辅助表征约束的约束优化问题。
7.3 四层信息密度优化:GA 的系统性解法
那么,GA 具体是如何在系统层面应对完备性与简洁性的结构性张力,最大化上下文信息密度的?答案是通过四个核心机制,分别在信息生命周期的不同阶段进行优化:
机制一:最小原子工具集——减少"先天噪声"
在每一轮对话中,LLM Agent 都需要在上下文中包含工具定义(告诉模型有哪些工具可用、每个工具的参数是什么)。工具越多,这些定义占用的 token 就越多——而且这些 token 每轮都会重复出现。
GA 的策略是极端克制:只保留 9 个原子工具,覆盖文件操作、代码执行、网页交互、记忆管理和人机协作五大能力类。通过最小化工具数量,GA 从源头上减少了上下文中的"固定开销"——在任务执行开始之前,就让低价值的接口信息不再占用上下文预算。
我们将在第 9 章详细展开工具集的设计原理。
机制二:分层按需记忆——只加载"当前需要的"
传统的 Agent 要么不保留历史(每次从零开始),要么把所有历史都塞进上下文(信息爆炸)。GA 采用了一种分层记忆架构:将长期知识按重要性和类型分为多个层次,只在需要时按需加载到上下文中。
这就好比一个图书馆:你不会把所有书搬到桌上才开始工作,而是先查目录(索引层),再去书架取需要的那本(事实层/SOP层)。这种设计决定了哪些信息随时间持久保留,而不是让所有保留的信息都自动成为提示词的一部分。
我们将在第 10 章详细介绍分层记忆的设计。
机制三:上下文截断与压缩——主动"瘦身"
即使工具定义和记忆加载都经过了精心控制,随着对话轮次的增加,上下文仍然会不断膨胀。GA 通过一套四阶段的压缩流水线,在工具返回值截断、历史轮次压缩、消息驱逐、工作记忆锚点注入等多个层面主动"瘦身",确保活跃上下文在对话过程中始终保持简洁和任务相关。
我们将在第 11 章详细剖析这套压缩机制。
机制四:反思驱动的自我进化——让"未来的上下文"更精炼
GA 最独特的机制之一是自我进化:它能将成功的任务经验蒸馏为可复用的 SOP、代码和技能,存入长期记忆。这意味着,当下次遇到类似任务时,GA 不需要在上下文中重新探索整个解决方案,而是直接调用之前积累的精炼经验——将交互轨迹逐步转化为紧凑的、结构化的能力。
这正是对"挑战二——经验无法积累"的系统性回应。没有进化机制时,Agent 在重复任务上面临两难:要么重放更长的探索过程(削弱简洁性),要么从更短但信息不足的提示词开始(削弱完备性)。自我进化创造了一种打破这个两难的途径。
我们将在第 12 章深入探讨自我进化的原理。
下面这张图展示了四个机制如何在信息生命周期的不同阶段协同工作:
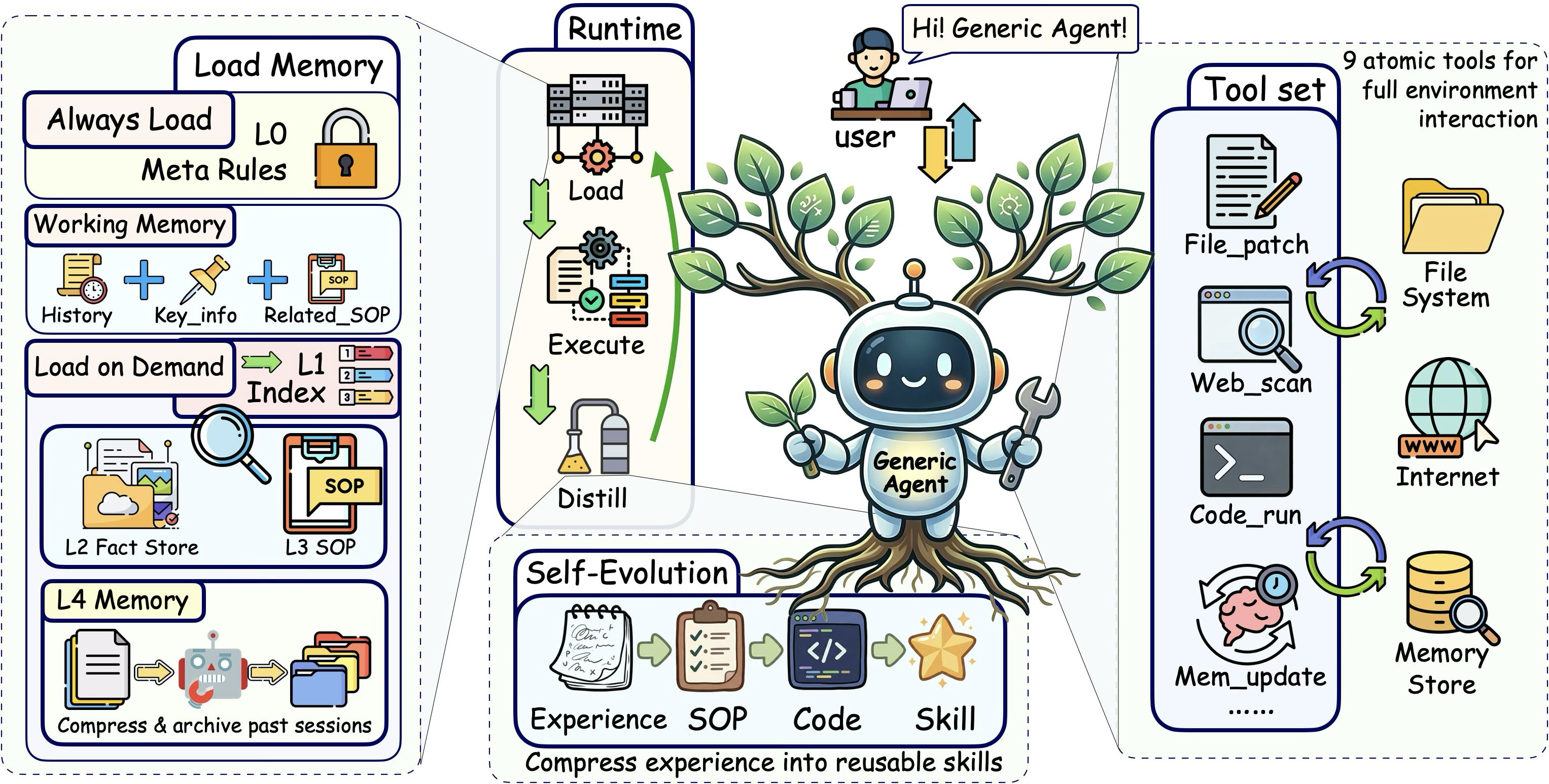
图 7-2:GenericAgent 整体框架。GA 围绕统一 Agent 循环构建,从当前任务和记忆中组装执行上下文,生成输出或工具调用,并通过结构化反馈更新系统状态。四大核心机制——最小原子工具集(右侧)、分层记忆(左侧)、自我进化(底部)和上下文截断与压缩(贯穿运行时)——在信息生命周期的不同阶段协同优化信息密度。
7.4 从"Prompt Engineering"到"Context Engineering"
在看过四大机制的全景之后,我们可以从更高的视角来理解 GA 的设计——它代表的是一种范式转变。
在 LLM 应用的早期阶段,大家关注的是提示工程(Prompt Engineering)——如何写出更好的提示词来引导模型输出。这在单轮问答或简单任务中非常有效。
但在 Agent 场景下,仅靠一段精心设计的提示词已经远远不够。Agent 的上下文不仅包含用户指令,还包含工具定义、历史对话、记忆内容、工具返回值等多种组件。如何系统性地管理这些组件的注入、压缩和替换,才是决定 Agent 长期表现的关键。
这种更高层次的设计思维,就是从"Prompt Engineering"到上下文工程(Context Engineering) 的转变。GA 的整个设计理念,正是"Context Engineering"思想的一种系统性实践。
如果说 Prompt Engineering 是在优化"一句话怎么说",那么 Context Engineering 就是在优化"每一轮对话中,模型看到的所有信息应该是什么"。正如我们在 7.2 节中所分析的,这本质上是一个以平衡完备性与简洁性为核心的约束优化问题。GA 通过工具层、记忆层、压缩层和进化层四个维度,将 Context Engineering 落实为具体的系统机制。
7.5 本章小结
本章介绍了 GenericAgent 最核心的设计原则——上下文信息密度最大化。
核心洞察是:完备性与简洁性之间的张力是结构性的——即使上下文窗口无限大,这个矛盾依然存在。GA 的所有设计都是围绕如何在这一结构性张力下最大化信息密度展开的。
围绕这一原则,GA 设计了四个核心机制,分别在信息生命周期的不同阶段优化信息密度:
| 机制 | 作用阶段 | 核心策略 | 详见章节 |
|---|---|---|---|
| 最小原子工具集 | 工具定义注入时 | 用 9 个工具覆盖全部能力,减少固定开销 | 第 9 章 |
| 分层按需记忆 | 记忆加载时 | 按层次存储,按需检索,不预加载 | 第 10 章 |
| 上下文截断与压缩 | 对话过程中 | 四阶段流水线,主动"瘦身" | 第 11 章 |
| 反思驱动自我进化 | 跨任务经验蒸馏 | 经验蒸馏为 SOP/代码/技能,优化未来上下文 | 第 12 章 |
在接下来的章节中,我们将首先俯瞰 GA 的系统全貌,然后逐一深入每个机制的设计原理。那么,让我们先从一个问题开始:GA 整体长什么样?