Case 2:登录态围观热榜 + 礼貌评论
学完本章,你将掌握如何让 GA 借用你已经登录的浏览器,把任意社交平台的「最热一条」读到「能聊一句」的程度,再起草 N 条候选评论让你审稿后发出。聪明的读者一定会触类旁通——把同一套流程用在你想用的内容平台上(B 站、知乎、X、小红书、Reddit……)。
📍 For GA · 给智能体看的输入
text读取最热门的一个帖子或者视频的信息(包含点赞数、回复评论、弹幕等等),并总结一下,然后发表一个相关评论。上面这段是用户原话,直接复制粘贴给 GA 就能跑——读者无需关心 GA 怎么拆解。 下面是给人类读者看的章节解析:GA 把这一句话拆成了哪些步、为什么这么拆、踩了哪些坑。
🎯 学习目标
- 理解 GA 在登录态浏览器里"读 + 评"的通用思路
- 学会「找 tab → 抓榜首 → 抓 metrics → 抓评论与弹幕 → 蒸馏总结 → 起草候选 → ask_user 双确认 → 发送 → OCR 双验证」九步流程
- 掌握「人在回路(human-in-loop)」的工程化手势——任何对外发出的动作必须 ask_user 二次确认
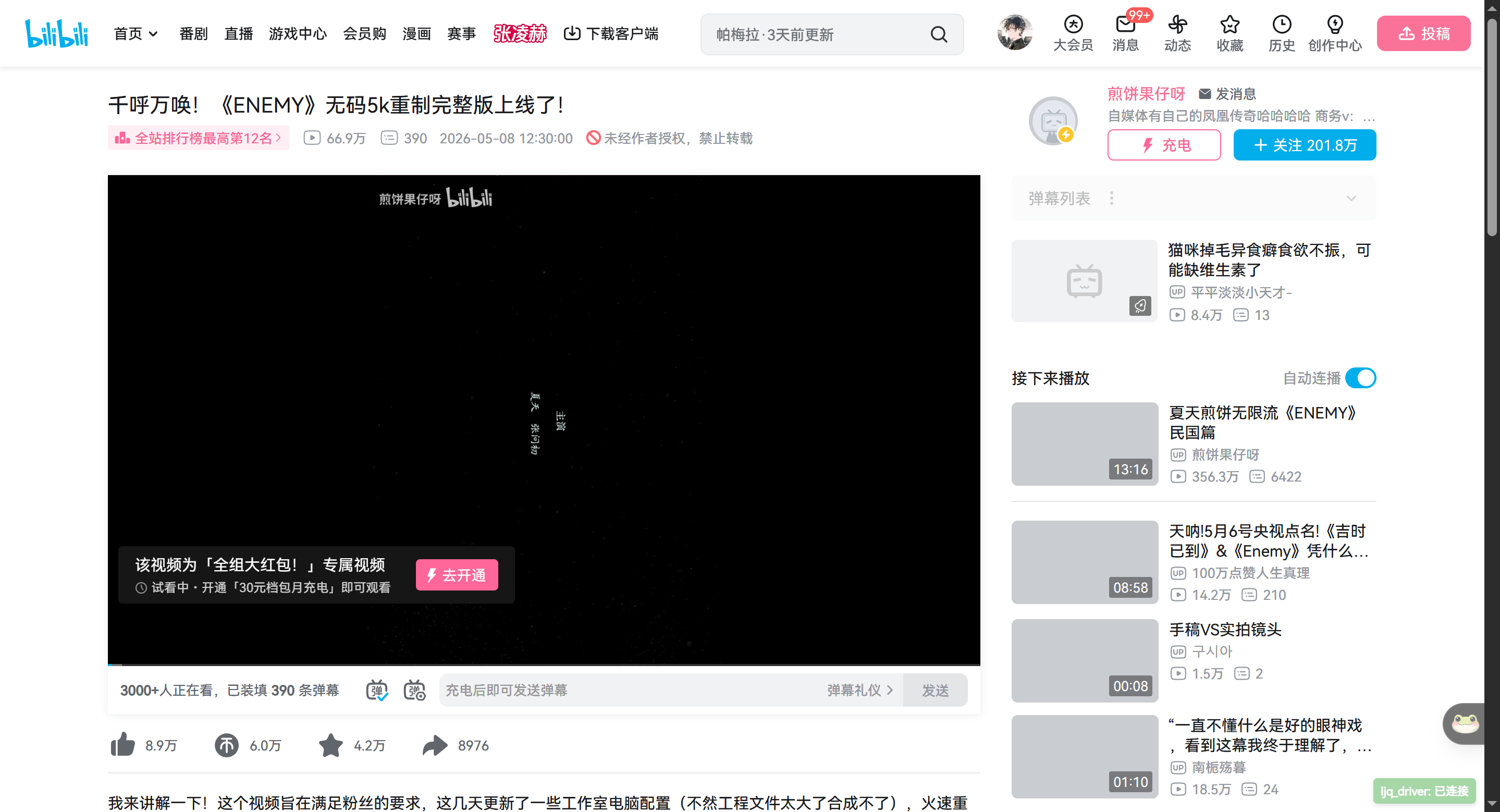
上图是 2026-05-09 GA 实跑当天抓到的 B 站榜首视频 (《ENEMY》5K 重制完整版,UP:煎饼果仔呀),CDP 整页快照。 注意页面正中的 "试看中 · 开通 30 元档包月充电" 付费墙—— 它就是 GA 在 result.md 里识别出
control.input_disable=true的可视化证据。
15.1 适用场景
💡 本章介绍的方法适用于 任何提供网页登录态的内容平台。当你想做"读最热的一条 + 留一句不水的评论"这种"网感速通"任务时,本章流程都能套用。
如果你只想读不想评,省掉最后三步即可;如果是 CLI / 官方 API 友好的平台(比如飞书机器人那种),优先走 API 而不是浏览器复用——更稳更快。
15.2 整体流程概览
不管是哪个平台,自动「读一条 + 评一句」的核心步骤都是一样的:
┌─────────────┐
│ Step 1 │ 找已登录 tab:通过 web_tabs 枚举当前 Chrome 已开窗口
│ 探测平台 │ 确认是否登录、是否在合适页面
└──────┬──────┘
▼
┌─────────────┐
│ Step 2 │ 抓榜首与 metrics:在已登录 tab 内 fetch 同源 API
│ 拿主对象 │ 拿 BV/标题/UP/三连/弹幕数/评论数 ...
└──────┬──────┘
▼
┌─────────────┐
│ Step 3 │ 抓 Top N 热评 + 弹幕样本:按热度排序,不要全量
│ 拿网感素材 │ 评论翻 1-2 页就够,弹幕取 30+ 条采样
└──────┬──────┘
▼
┌─────────────┐
│ Step 4 │ 蒸馏总结:reasoning 模型读 raw_top.json
│ 写 300 字 │ 钩子 + 三段式(视频是啥/评论氛围/弹幕梗)
└──────┬──────┘
▼
┌─────────────┐
│ Step 5 │ 起草 N 条候选:走心 / 玩梗 / 提问 三种风格
│ 写 draft │ 每条 ≤ 100 字、emoji ≤ 1
└──────┬──────┘
▼
┌─────────────┐
│ Step 6 │ ask_user N 选 1 → ask_user 二次确认
│ 双确认 │ 任一次"否 / 都不发"立即收尾
└──────┬──────┘
▼
┌─────────────┐
│ Step 7 │ 发送 + 双验证:rapid_ocr 截图 OCR + DOM 查询
│ 确认上墙 │ 两路都过 → 写 result;任一失败 → 写失败原因
└─────────────┘⚠️ 安全原则:Step 6 的两次
ask_user是不可省的合规底线。任何"GA 自动发评论"的优化都不能动这两次确认——它是这条 case 能光明正大公开发布的唯一原因。
15.3 本案用到的能力(动手前先看一眼)
GA 内置能力(开箱即用,不需要额外安装)
web_tabs/web_scan/web_execute_js:枚举 Chrome 已登录 tab、在已登录 tab 内fetch(..., credentials:'include')同源调用,cookie 不出浏览器web_cdp Page.captureScreenshot:评论上墙后视觉验证用ocr_image()(来自memory/ocr_utils.py,后端rapidocr_onnxruntime):~1s/次本地 OCR,对中文极准ask_user:人在回路二次确认——发评论的合规底线
本案专属 SOP(已打包到 sop/)
| 文件 | 用途 |
|---|---|
sop/human_in_loop.md | ask_user 双确认范式:发评论前两次确认(先选哪条 → 再确认内容) |
sop/login_read_comment.md | 弱模型 fallback SOP(链路一图 + 10 条避坑 + 完整润色后 prompt) |
外部 SKILL(本案不需要)
无——这条 case 全程走 GA 内置能力 + 一个 reasoning 模型 + 一张人在回路 SOP。
15.4 Step 1:找到已登录 tab
第一步不是开新窗口,而是找用户当前 Chrome 里已经开着的、已登录的 tab:
# GA 内置 web_tabs() 列出所有 tab
tabs = web_tabs()
bili_tabs = [t for t in tabs if 'bilibili.com' in t['url']]💡 小知识:登录态的 cookie 永远在浏览器里。Python 端不应该也不需要知道它长啥样——后续所有"需要登录"的请求都通过
web_execute_js在已登录 tab 内fetch(..., credentials:'include')发出,浏览器自动带 cookie。这种"借力"姿势,是这条 case 能合规跑的根。
如果当前没有已登录 tab,用 ask_user 让用户提供入口 —— 不要"猜"。
15.5 Step 2:抓榜首与 metrics
不要 web_navigate 跳走(会污染用户当前在看的视频),而是在已登录 tab 内同源 fetch 平台公开 API:
// web_execute_js
const r = await fetch('/x/web-interface/popular?ps=1&pn=1', {credentials:'include'});
const j = await r.json();
return j.data.list[0]; // 榜首一条拿到 BV 后再调一次详情页 API,把播放/点赞/投币/收藏/转发/弹幕数/评论数全收齐,落盘到 raw_top.json。
⚠️ 不要走 wbi_sign:B 站 wbi 签名是反 Python 端伪造的设计,走浏览器 fetch 天然规避。能
web_execute_js解决就不要去手撕 sign。
15.6 Step 3:抓 Top N 热评 + 弹幕样本
热评走 /x/v2/reply?type=1&oid={aid}&sort=2(sort=2 按热度,不是 sort=0 按时间——后者全是新留的水贴)。弹幕走 /x/v1/dm/list.so?oid={cid} 的 XML 接口。
🎯 采样而非全量:评论翻 1–2 页够 Top 20 即可,弹幕从 305 条里取 30+ 条等距样本。目标不是数据集,是"够你聊一句"。
// raw_top.json 关键字段
{
"stat": {"view": 664444, "like": 88807, "coin": 59794, /* ... */},
"top_comments": [{"user":"...","like":937,"content":"..."}, /* … 19 more … */],
"danmaku_sample": [{"t": 12.4, "text": "有一股强劲的音乐响起"}, /* … */],
"control": {"input_disable": true, "reason": "需充值 30 元档包月充电才能评论"}
}15.7 Step 4:蒸馏总结
把 raw_top.json 喂给一个 reasoning 模型(glm-5.1 / minimax-m2.7 / gpt-5.5 任选,优先选便宜的),让它写一段 ≤ 300 字的「钩子 + 三段式(视频是啥 / 评论氛围 / 弹幕梗)」总结。
💡 总结质量 > 抓取广度:第一版让 GA 抓全部评论 + 全部弹幕,结果 reasoning 模型 input 撑爆且摘要变成"流水账"。改成"Top 20 评论 + 30 条采样弹幕 + 显式聚类"后,输出从 1500 字流水账压到 300 字的"网感速读",反而更像真人写的。
15.8 Step 5:起草 N 条候选评论
风格固定为走心 / 玩梗 / 提问 三种,每条 ≤ 100 字、不带 @、不挂链接、emoji ≤ 1。
| 风格 | 长度 | 钩子 |
|---|---|---|
| 走心 | ≤ 100 字 | 提一个具体时间点 / 画面 / 句子 |
| 玩梗 | ≤ 50 字 | 不引用敏感梗、不引用其他平台 |
| 提问 | ≤ 80 字 | 引导 UP 主真实回答(避免假问题) |
落盘 draft_comments.md,准备进入双确认环节。
15.9 Step 6:ask_user 双确认 → 发送
这是这条 case 的合规底线。详细范式见 sop/human_in_loop.md。
# 步骤 1:N 选 1
choice = ask_user(
candidates=["走心款", "玩梗款", "提问款", "都不发"],
question="挑一条评论,或者都不发"
)
if choice == "都不发":
return "user_aborted"
# 步骤 2:二次确认(必须含具体内容)
confirm = ask_user(
candidates=["确认发送", "改一下", "算了不发"],
question=f"最终发送『{drafts[choice]}』,确认?"
)
if confirm != "确认发送":
return "user_aborted"
# 步骤 3:真发送
send_comment(drafts[choice])⚠️ 任何一次 ask_user 收到"否 / 都不发"必须立即收尾,不能把"重试 3 次"当作"用户没拒绝"。
15.10 Step 7:rapid_ocr + DOM 双验证
发送后做两路验证:
- DOM 路:
web_execute_js查询.reply-item .user-name是否含自己的昵称 - 视觉路:
web_cdp Page.captureScreenshot截评论区底部,再用 GA 内置的ocr_image()(memory/ocr_utils.py,后端是rapidocr_onnxruntime)做本地 OCR,匹配关键词
from memory.ocr_utils import ocr_image
result = ocr_image(screenshot_path) # ~1s/次,中英文都准
ok = my_keyword in result['text']💡 为什么 rapid_ocr 而不是 vision API:本地、~1s、免费、对中文极准。只有 OCR 都失败时才考虑 vision 兜底——没必要为这件事去花 token。
两路都过 → 写 result.json {ok: true, comment_id, ts};任一失败 → 写失败原因。
15.11 实战:2026-05-09 真实跑一遍
我们用一句最朴素、最口语化的 prompt 喂给 GA:
读取最热门的一个帖子或者视频的信息(包含点赞数、回复评论、弹幕等等),
并总结一下,然后发表一个相关评论。40 个字,没有任何"先做什么再做什么"的拆解。GA 自己拆出了 10 个 turn,5 分钟跑完:
| 阶段 | 耗时 | 关键证据 |
|---|---|---|
| 探测 + 翻 tab | ~30 s | turn 1-2:web_scan(tabs_only=True) 找到已登录 B 站 tab |
| 拿榜首 + metrics | ~30 s | turn 4-5:在已登录 tab 内 fetch('/x/web-interface/popular?ps=1&pn=1', credentials:'include') 拿到 BV1VXdcBwEVT《千呼万唤!《ENEMY》无码 5k 重制完整版上线了!》 |
| Top20 热评 + 弹幕 | ~60 s | turn 6-8:/x/v2/reply?sort=2(按热度)+ /x/v1/dm/list.so?oid={cid} XML,305 条弹幕取 35+ 条样本 |
| 蒸馏总结 + 起草 | ~60 s | turn 9-10:写 summary.md(300 字钩子+三段式)+ draft_comments.md(走心/玩梗/提问 三选一) |
| 安全收尾 | ~5 s | 未发送任何评论——按 prompt 的 headless 演示约束跳过 ask_user 二次确认 |
🎓 彩蛋:GA 在 result.md 里指出该视频开了「30 元档包月充电后才能评论」(API 字段
control.input_disable=true)——也就是说即便允许 GA 真发,前端也会被付费墙拦住。这是真实世界给 case1 安全约束打的一记最佳注脚。
实跑产物全部落 assets/,可以直接打开看 GA 跑出来什么:
assets/
├── screenshot_01_hero.png # CDP 整页快照
├── ga_input_prompt.txt # 喂给 GA 的 prompt 全文
├── ga_run_trace.txt # 10 个 turn 的逐步执行轨迹
├── raw_top.json # 原始抓取字段
├── summary.md # 300 字总结
├── draft_comments.md # 三条候选评论
└── result.md # 最终执行报告 + 安全自检将经验沉淀为 SOP
实战成功后,把这次成功的经验固化为一份 SOP,存入 GA 的记忆中:
你:刚才"读热榜+评一句"的流程跑通了,请把这次的经验整理成一份 SOP,
保存到 memory 目录里。GA 会自动把本次实践中用到的具体参数(榜首 API 路径、sort=2 按热度、弹幕 XML 接口、双确认范式)和踩过的坑一起写入 SOP。下次同样的任务,GA 直接读这份 SOP,不需要重新摸索。
15.12 避坑指南
🚫 绝对禁止的操作
| 操作 | 后果 | 替代方案 |
|---|---|---|
| 导出 cookie 给 Python 用 | 风控 + 一旦泄漏不可控 | 全程 web_execute_js 内 fetch,cookie 不出浏览器 |
| 走 wbi_sign 自己签名 | 平台一改算法立刻失效 | 借浏览器登录态走同源请求 |
一次 ask_user 就发 | 误发评论 | 必须两次 —— 选哪条 + 内容确认 |
| 失败重试当成"用户没拒绝" | 把误发当 transient error | 任一 ask_user 收到"否"立即收尾 |
| 写 cron 自动追热榜 + 评论 | 同 IP 高频 + 机器评论质量低 | 一次性任务,不留 cron |
💡 实用技巧
- 频控 > 速度:评论页和弹幕接口不要一次拉空,分两次、间隔几秒。
control.input_disable必查:B 站充电墙、知乎付费专栏、小红书私密笔记都会让评论框disabled——起草前先检查,不然写完三条草稿才发现发不出。- OCR 用本地 rapidocr:
memory/ocr_utils.py的ocr_image()一次约 1s + 中英文都准 + 不走云。 - 触类旁通时按平台改 Step 2:popular API → 知乎
topstory/recommend/ XHomeTimeline.json/ 小红书explore/feed_v2,其余 step 几乎不用改。
15.13 本章小结
本章通过「读 B 站热榜首条 + 起草礼貌评论」这个 Case,学习了 GA 在登录态浏览器里安全做事的完整流程:
| 核心概念 | 说明 |
|---|---|
| 借登录态 ≠ 偷 cookie | cookie 一直在浏览器里,Python 端永远不知道它长啥样 |
| 七步流程 | 找 tab → 抓主对象 → 抓网感素材 → 蒸馏 → 起草 → 双确认 → 双验证 |
| 人在回路 | 任何"对外发出去 / 不可撤销"动作必须 ask_user 二次确认 |
| 采样而非全量 | "够你聊一句" > "数据集",Top 20 评论 + 30 条弹幕样本 |
| OCR 走 rapid_ocr | 本地 / 1s / 免费,比 vision API 更适合验证场景 |
| 抽象层在 prompt | "读最热的一条然后评一句"——抽象层在自然语言里,不在代码里 |
🎓 举一反三:这套「找 tab → 借登录态抓 → reasoning 蒸馏 → 双确认 → 双验证」的姿势,不仅适用于 B 站,任何登录态内容平台的"读评流"都可以套用。后面两章我们会看到同样的"借登录态"姿势用在更复杂的任务上(自我画像 / 视频离线下载)。
📎 给"模型能力一般"的读者
如果你的 GA 装的是中小模型,仅凭一句 40 字的 prompt 它可能拆不出 7 个步骤。去看 sop/login_read_comment.md:
- 链路一图 + 10 条踩过的避坑 + 凭证 / 工具索引 + 实战参考
- 末尾附完整的「润色后 prompt」——把全部约束写明,直接复制粘贴给 GA。