第 8 章 GenericAgent 系统全貌
在上一章中,我们建立了 GenericAgent(GA)的第一性原理——上下文信息密度最大化(Contextual Information Density Maximization),并了解了 LLM 在处理长上下文时面临的三重陷阱。我们还预告了 GA 通过四个核心机制来优化信息密度。
那么,GA 究竟是如何围绕这个原则构建整个系统的?在深入每个机制之前,我们先来鸟瞰 GA 的全貌——看看它的整体架构长什么样,各模块之间如何协作。本章的目标是为你建立一张"系统地图",后续章节则相当于逐个区域深入探索。
GA 的一个重要设计决策是模型无关(Model-Agnostic):底层的推理引擎(Claude、GPT、Gemini 等)可以替换,而不影响执行逻辑、工具接口或记忆架构。这意味着,当更强的模型出现时,整体架构不需要改变,只需替换推理引擎即可获得能力提升。GA 的系统设计与具体模型的能力完全解耦。
8.1 统一 Agent 循环
8.1.1 直觉理解:像人一样工作
在理解 GA 的架构之前,我们先想想一个人是怎么完成一项复杂工作的:
- 接到任务:老板说"帮我整理一份季度报告"
- 回忆相关经验:你想起上次做报告时用了哪个模板、数据放在哪个文件夹
- 思考策略:先收集数据,再填模板,最后排版
- 动手执行:打开电脑,查找文件,复制数据
- 观察结果:看看填进去的数据对不对,格式是否正确
- 决定下一步:如果数据有误,回去重查;如果没问题,继续下一节
这个"接任务→调记忆→想策略→动手做→看结果→下一步"的循环会一直重复,直到任务完成。
GA 的工作方式与此极其相似。它的核心是一个统一 Agent 循环(Unified Agent Loop)——一个连续的"推理→行动→观察"闭环,驱动 GA 完成从简单文件操作到复杂多步任务的一切工作。
8.1.2 深入理解:执行上下文的构建
让我们更精确地看看这个循环的每一步发生了什么。
第一步:构建执行上下文(Execution Context)
每一轮循环开始时,GA 将全局记忆与当前任务规格组合,构建执行上下文。这个上下文不是简单地把用户输入转发给 LLM,而是由多个组件精心组装而成:
执行上下文 = 系统提示词(System Prompt)
+ 始终在线记忆(Always-on Memory:元记忆 + L1 索引 + 工作目录上下文)
+ 工具定义(9 个原子工具的 Schema)
+ 当前任务规格(用户指令 + 约束条件)
+ 历史对话(经过压缩的交互记录)
+ 工作记忆(当前目标、约束、进度)注意这里的每个组件都经过了信息密度的考量:始终在线记忆只注入索引层而非全量知识,工具定义只有 9 个而非几十个,历史对话经过了截断和压缩。这正是第 7 章所讲的"上下文信息密度最大化"原则在实践中的体现。
第二步:LLM 推理与决策
构建好的执行上下文被送入 LLM。模型基于这些信息进行推理,产出两种可能的结果:
- 直接输出:模型认为可以直接回答用户问题,不需要使用工具(比如解释一个概念)
- 工具调用(Tool Call):模型决定调用一个或多个工具来获取信息或执行操作(比如读取一个文件、运行一段代码)
第三步:工具执行与结构化反馈
如果模型发出了工具调用请求,统一分发器(Unified Dispatcher) 会将请求路由到对应的本地执行器。执行完成后,结果以结构化信号(Structured Signal) 的形式返回,更新系统状态。
这里的"结构化"很关键——工具不是简单地返回一段原始文本,而是返回经过格式化的结果,包含执行状态(成功/失败)、核心输出内容、以及可能的元数据(如页面变化提示)。这使得模型可以快速判断执行结果,而不需要从一大段原始输出中"猜"发生了什么。
第四步:状态更新与循环继续
工具返回的结构化信号被追加到对话历史中,成为下一轮执行上下文的一部分。模型据此决定是否需要继续执行(再调一个工具)、调整策略(换一种方法),还是任务已经完成(向用户汇报结果)。任务完成后,执行轨迹会被压缩为结构化的长期表征,存入共享记忆,使积累的经验可以通过压缩和复用来改善未来的执行。
这个循环创建了推理与环境反馈之间的持续交互,论文将其称为工具锚定的迭代执行(Tool-Grounded Iterative Execution)。我们可以用一个流程图来概括:
┌──────────────────────┐
│ 构建执行上下文 │
│ (记忆+工具+任务+历史) │
└──────────┬───────────┘
│
▼
┌──────────────────────┐
│ LLM 推理决策 │
└──────┬───────┬───────┘
│ │
直接输出│ │工具调用
▼ ▼
┌──────┐ ┌──────────────┐
│ 回复 │ │ 统一分发器 │
│ 用户 │ │ → 本地执行器 │
└──────┘ └──────┬───────┘
│
▼
┌──────────────┐
│ 结构化反馈 │
│ 更新系统状态 │
└──────┬───────┘
│
▼
继续下一轮循环这个循环看起来简洁,但它的威力在于通用性:无论是读写文件、操作浏览器、执行代码、还是管理记忆,所有任务都通过同一个循环来驱动。不需要为不同类型的任务设计不同的执行流程。
8.2 两种执行模式
GA 的统一循环支持两种不同的启动方式,论文称之为两种执行模式(Execution Modes):
8.2.1 交互模式(Interact Mode)
这是最常见的模式——用户发起任务,GA 响应执行。你在第一部分应用篇中使用的所有场景都属于交互模式:
- 用户说"帮我把桌面的 PDF 按年份整理到文件夹"
- GA 接收指令,开始执行 Agent 循环
- 每完成一步,GA 可能向用户汇报进度或请求确认
- 任务完成后,GA 返回结果
交互模式的特点是用户驱动:需要用户指令来触发,涵盖代码执行、信息检索、文件操作等任务。GA 在执行过程中可以随时通过 ask_user 请求人类介入。
8.2.2 反射模式(Reflect Mode)
这是 GA 的另一面——无需用户指令,自动触发的后台任务。反射模式持续监控环境变化,当检测到特定条件或事件时自动触发相应任务,包括两种触发方式:
- 看门狗(Watchdog):监控环境变化(如新文件出现、错误日志产生),一旦检测到就立即触发 GA 任务
- 定时任务(Scheduled Task):基于时间规则在特定间隔或精确时间点生成 GA 任务
反射模式的实现机制非常简洁:一个轻量级脚本定期检查条件,当规则被触发时,脚本将返回的字符串作为标准任务分发给 GA CLI。
关键设计决策:两种模式共享同一套基础设施。 交互模式和反射模式使用完全相同的 Agent 循环和记忆系统,仅在触发方式和输出处理上有所不同。这意味着:
- 反射模式可以使用与交互模式完全相同的工具来读写文件、执行代码
- 反射模式产生的结果和记忆更新,会在下一次交互执行中被自动利用
- 不需要维护两套独立的系统
8.2.3 执行边界与可控性
为了支持长期运行,GA 定义了明确的执行边界(Execution Bounds),在保持可中断性和范围约束的同时确保可控性:
- 轮次上限:每次任务执行有最大轮次限制,超过后强制终止或请求用户介入
- 故障升级策略:当执行遇到失败时,GA 遵循三步渐进升级——① 分析错误信息,做小幅修正后重试;② 若持续失败,切换到全新策略或搜索环境中缺失的信息;③ 若所有自动化尝试均失败,暂停并请求人类介入
- 可中断性:用户可以随时中断执行,GA 会保存当前进度到工作记忆
这些边界确保了 GA 在拥有强大自主能力的同时,始终处于可控范围内。
8.3 四大核心机制预览
在统一循环和两种执行模式的基础上,GA 围绕"上下文信息密度最大化"这一核心目标,设计了四个协同工作的核心机制。下表给出每个机制的一句话定位:
| 机制 | 核心问题 | 一句话定位 | 详见章节 |
|---|---|---|---|
| 最小原子工具集 | Agent 需要多少工具? | 用 9 个原子工具覆盖完整能力环,从源头减少上下文固定开销 | 第 9 章 |
| 分层记忆架构 | 如何管理跨任务知识? | 四层分级存储 + 按需加载,让"记住更多"不再等于"上下文更长" | 第 10 章 |
| 上下文截断与压缩 | 对话越来越长怎么办? | 四阶段流水线主动"瘦身",确保每轮上下文都在预算之内 | 第 11 章 |
| 反思驱动的自我进化 | 能不能越用越聪明? | 将成功经验蒸馏为可复用的 SOP 和代码,让未来的上下文更精炼 | 第 12 章 |
这四个机制不是独立拼凑的功能模块,而是围绕同一目标协同设计的有机整体。它们分别在信息生命周期的不同阶段发挥作用:
信息的生命周期
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
① 注入阶段 ② 加载阶段 ③ 运行阶段 ④ 沉淀阶段
┌────────────┐ ┌────────────┐ ┌────────────┐ ┌────────────┐
│ 最小工具集 │ │ 分层记忆 │ │ 截断与压缩 │ │ 自我进化 │
│ (第 9 章) │ │ (第 10 章) │ │ (第 11 章) │ │ (第 12 章) │
└────────────┘ └────────────┘ └────────────┘ └────────────┘
│ │ │ │
减少工具定义的 控制记忆注入的 压缩历史对话的 将经验蒸馏为
固定 token 开销 按需 token 开销 累积 token 开销 未来可复用的
精炼知识下面这张图展示了 GA 的整体架构,以及四个核心机制如何在统一循环中协同工作:
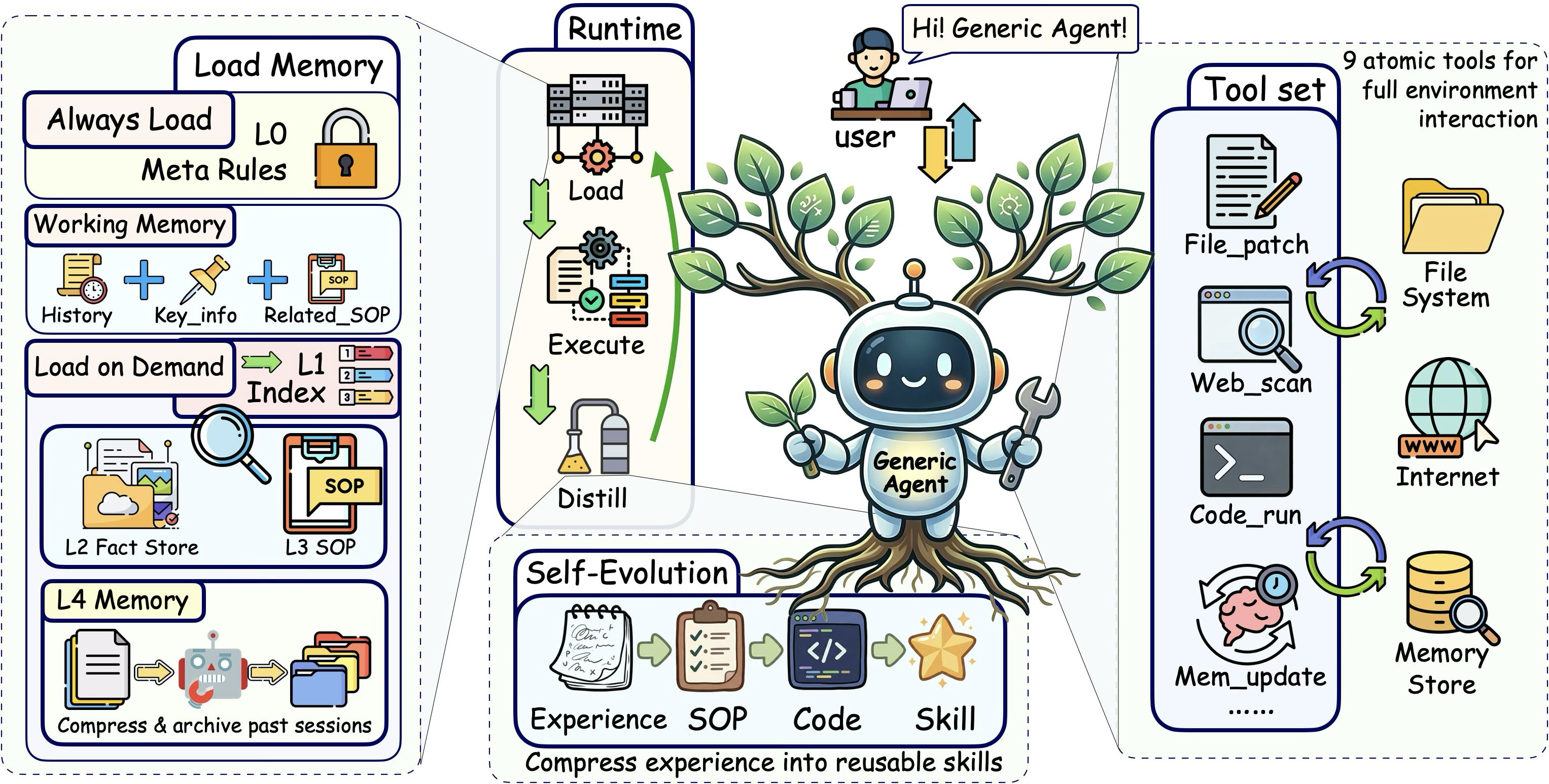
图 8-1:GenericAgent 整体框架。GA 围绕统一 Agent 循环构建,从当前任务和记忆中组装执行上下文,生成输出或工具调用,并通过结构化反馈更新系统状态。四大核心机制——最小原子工具集(右侧)、分层记忆(左侧)、自我进化(底部)和上下文截断与压缩(贯穿运行时)——在信息生命周期的不同阶段协同优化信息密度。(来源:论文 Figure 2)
8.4 从全貌到细节:一个具体例子
为了让上面的抽象架构更加具体,我们来追踪一个完整的任务执行过程,看看各个模块是如何协作的。
场景:用户说"帮我从 HuggingFace 下载 IMDB 数据集"。
第一轮循环:
- 构建上下文:系统注入始终在线记忆(L1 索引中包含"HuggingFace 下载"相关的 SOP 指针)、9 个工具的 Schema、用户指令
- LLM 推理:模型发现 L1 索引中有相关 SOP,决定先读取它
- 工具调用:
file_read(path="memory/L3/huggingface_download_sop.md") - 结构化反馈:返回 SOP 内容(经 file_read 截断控制,只返回相关部分)
这里模型通过 L1 索引中的指针定位到 L3 层的 SOP 文件,然后用
file_read按需加载——这就是第 10 章将详细介绍的 L1→L3 路由链。
第二轮循环:
- 构建上下文:上一轮的工具返回结果被追加到历史中
- LLM 推理:模型根据 SOP 中的步骤,决定执行下载代码
- 工具调用:
code_run(script="from datasets import load_dataset; ds = load_dataset('imdb')...") - 结构化反馈:返回执行结果(成功/失败 + 输出摘要)
第三轮循环:
- 模型确认下载成功,向用户汇报结果
- 任务完成
幕后(自我进化):
- 如果这是 GA 第一次执行 HuggingFace 下载任务,GA 会在任务成功完成后通过
start_long_term_update将这次成功的执行经验蒸馏为一条新的 SOP,存入 L3 记忆层 - 下次遇到类似任务时,L1 索引会路由到这条 SOP,GA 可以直接按 SOP 执行,跳过探索阶段
注意在这个例子中,四个机制都参与了工作:工具集提供了
file_read和code_run两个原子操作;分层记忆让 GA 快速定位到相关 SOP;对话历史经过截断与压缩控制在合理范围内;自我进化将成功经验沉淀为可复用的 SOP 知识。
8.5 本章小结
本章从全局视角介绍了 GA 的系统架构。我们了解到:
- 统一 Agent 循环是 GA 的执行引擎——"构建上下文→LLM 推理→工具执行→结构化反馈"的闭环驱动所有任务
- 两种执行模式(交互模式 + 反射模式)共享同一套基础设施,分别负责用户驱动的任务执行和环境驱动的自动触发
- 四大核心机制(工具集、记忆、压缩、进化)围绕信息密度最大化协同设计,在信息生命周期的不同阶段分别发挥作用
现在,你已经拥有了 GA 的"系统地图"。从下一章开始,我们将沿着信息生命周期的顺序,逐一深入每个核心机制。
第一站,是 GA 最引人注目的设计选择:为什么只用 9 个工具就够了?