
Part B: Latent Dynamics
The Encoder Is Not Enough: We Need to Predict the Future
With a VAE encoder, we can compress the current frame
In latent space, given the current state
and action , predict the next state .
This prediction capability lets the agent "simulate" the future internally, enabling planning without actually executing actions in the environment. This is the key reason world models reduce sample complexity.
The Simplest Dynamics Model: GRU
The Gated Recurrent Unit (GRU) is a foundational tool for sequence modeling. As a dynamics model, the GRU takes
📖 GRU internals (brief): A GRU controls information flow through two gates: the reset gate decides "how much of the past to forget", and the update gate decides "how much of the old state to retain vs. how much new information to write in". Gate values lie between 0 and 1, determined jointly by the current input and the previous hidden state. This allows the GRU to selectively retain long-term dependencies while discarding irrelevant information, making it better at handling longer sequences than a plain RNN. Compared to an LSTM, the GRU has one fewer gate (no separate memory cell), fewer parameters, and trains faster.
The GRU's strengths are simplicity and stable training. Its limitation is that it produces deterministic predictions and cannot express uncertainty. In real environments, the same action can lead to multiple different outcomes (for example, pushing a box might succeed or might get stuck).
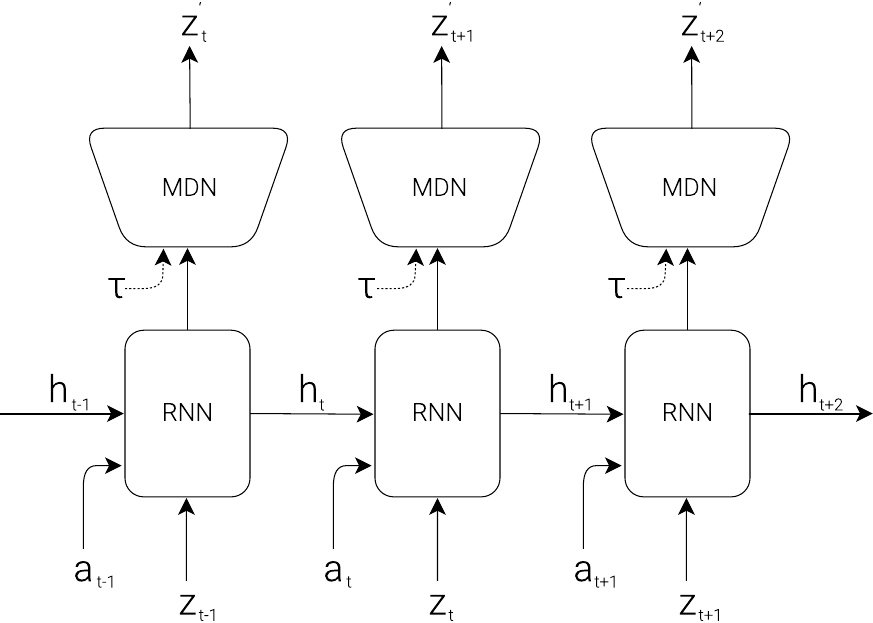
MDN-RNN: Modeling Uncertainty
MDN-RNN (Mixture Density Network + RNN), proposed in Ha & Schmidhuber (2018), models uncertainty over the next state using a mixture of Gaussians:
Gaussian components, each with its own mean (center of the distribution) and variance (width of the distribution) - Mixture weights
: the probability mass of the -th Gaussian component, satisfying , . These can be read as "the probability that the -th future occurs". The network outputs values and normalizes them through softmax to ensure the weights sum to 1.
MDN-RNN can capture multimodal distributions: the environment may transition to several distinct next states, and the model can represent all of them.
RSSM: Separating Deterministic and Stochastic Components
The RSSM (Recurrent State Space Model) is the core innovation of the Dreamer series. It splits the state into two parts:
- Deterministic hidden state
: maintained by an RNN, aggregating information from the historical trajectory, with no stochasticity - Stochastic latent state
: sampled from a distribution conditioned on , expressing current uncertainty
Core equations of the RSSM:
📖 Subscript
(phi): the subscript in , , denotes "this function has parameters ", i.e., the learnable weights of the neural network. is read as "function parameterized by ". During training, gradient descent updates so that the predictions of these functions become increasingly accurate. Similarly, (theta) that appears later is another commonly used symbol for a distinct set of learnable parameters.
📖 Prior vs. posterior: these are fundamental concepts in Bayesian statistics. The prior is "belief before seeing data", the RSSM's guess about the current state
based on historical memory . The posterior is "belief updated after seeing data", refining the prior with real observation to obtain a more accurate estimate. During training, the posterior generates and the KL loss is computed (measuring the gap between prior and posterior). During inference and imagination, only the prior is available (there is no real ), so the RSSM rolls forward using the prior alone.
Why separate them?
| State | Role | Property |
|---|---|---|
| Memory | Deterministic, aggregates history | |
| Perception | Stochastic, expresses uncertainty |
After separation, the model can roll forward using only the prior
The PlaNet paper (Hafner et al., ICML 2019) verified this design through ablation studies (systematically removing one component of the model and observing the change in performance, thereby confirming the component's necessity): a purely stochastic path (no deterministic
Comparison of Three Dynamics Models
| Model | Uncertainty Modeling | Memory Mechanism | Primary Use |
|---|---|---|---|
| GRU | None (deterministic output) | Fixed-dimension hidden state | Simple sequence prediction, rapid prototyping |
| MDN-RNN | Mixture of Gaussians (multimodal) | Fixed-dimension hidden state | Multimodal uncertainty, Ha & Schmidhuber M-module |
| RSSM | Separated prior/posterior (Gaussian) | Dual-track: deterministic | Core of Dreamer, supports pure-imagination planning |
The three form a progression: GRU establishes the foundation for sequence modeling, MDN-RNN introduces uncertainty, and RSSM further decouples "memory" from "perceptual uncertainty", enabling the model to roll forward and plan without real observations.