
Debate 3: Are World Models and LLMs Competitors or Complements?
Xie Saining's Division-of-Labor Logic
On this point, Xie Saining is surprisingly moderate. He does not say "LLMs are a dead end." Instead:
"Without LLMs, Vision would have no way to expand into the truly multimodal, large-scale intelligence we have today."
His AMI Labs does not reject LLMs; it explicitly credits them for the progress they enabled. LLMs solved language understanding and instruction following, two critical problems, giving visual systems a "language interface" so that world models can accept natural-language commands.
His position is that the two paradigms handle different dimensions of information, each with its own domain of strength.
| Paradigm | Domain of strength |
|---|---|
| LLM | Reasoning in digital space, code, text generation, knowledge retrieval |
| World model | Prediction of the physical world, robot control, industrial perception, embodied intelligence |
| WAM | Unification of both: joint modeling of video and action, understanding physics while accepting language commands |
Dreamer V3 sits squarely in the world model row: it consumes actions, predicts latent states, and has been demonstrated across 7 domains with a single set of hyperparameters.
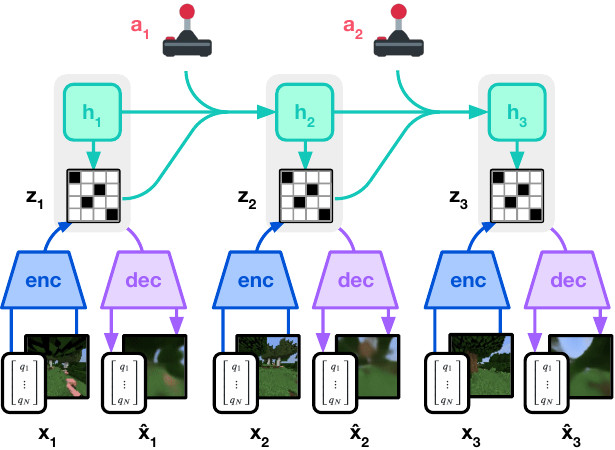
WAM: The Joint-Modeling Approach
The concept of WAM (World Action Model) deserves separate explanation.
📖 WAM (World Action Model): A class of architectures that jointly model video prediction and action prediction. The core idea is not merely to "understand the world" but to "understand the world and know how to act within it." Video frames provide physical constraints; action signals provide causal annotation. A model trained jointly on both understands the consequences of actions better than a combination of separately trained modules.
Traditional world models and policies are two separate modules: first model the world state, then plan inside the world model. WAM breaks this division: video itself serves as the supervisory signal for action learning, without requiring explicit reward functions or manual annotation.
To understand the existing world models with a matrix, consider the horizontal axis as "does the model consume action signals" and the vertical axis as "what does the model predict":
- Dreamer (RSSM + latent Actor-Critic, see L02-L03): consumes actions, predicts latent states, a narrow-sense world model and active decision-maker
- STORM (Stochastic Transformer-based wORld Models, categorical VAE + Transformer dynamics, see L03): consumes actions (actions concatenated as tokens into the sequence), predicts next-frame latent tokens, interactive
- WAM: consumes actions while simultaneously understanding semantics, a unification of both
These three paradigms were compared from an engineering perspective in L03. The question here is different: what assumption is WAM betting on? World models and policies should not be two separate modules; video itself is the supervisory signal for action learning. If this assumption holds, joint training will dissolve the division between model foundation and policy learning, producing new emergent capabilities.
JEPA: A Different Path
LeCun's JEPA (Joint Embedding Predictive Architecture, LeCun 2022) takes a different direction.
📖 JEPA (Joint Embedding Predictive Architecture): An architectural principle proposed by LeCun in 2022. The core idea is that prediction should happen at the level of abstract representations, not pixels. Rather than having a model predict every pixel of the future (extremely difficult, and full of irrelevant noise), the model predicts future semantic representations. V-JEPA 2 is the video version of this approach.
JEPA does not generate pixels; it only predicts semantic representations. This choice reflects a clear stance: pixels are noise, semantics are signal. A model that generates no images at all may actually acquire structural understanding of the physical world faster than diffusion-based world models.
LeCun has put a concrete timestamp on this bet. In a May 2026 interview, he stated that by early 2027 the entire field will recognize that the paradigm must change, and that within five years JEPA-style architectures will become the foundational standard in AI the way Linux became the standard in operating systems.
The sharpest version of his argument comes from comparing two kinds of learners. A VLA (Vision-Language-Action) model takes visual input plus a language instruction and directly outputs actions, which is the approach behind most current end-to-end robotic and autonomous driving systems. Tesla's Autopilot follows this logic: trained on millions of hours of driving footage, it maps perception to steering. But LeCun's critique is that VLA is fundamentally the wrong direction: it memorizes an enormous catalog of situations but has no internal model for predicting consequences. When it encounters a genuinely novel situation, it has no principled way to reason about what will happen next.
A 17-year-old learning to drive in 20 hours does not memorize road situations. The learner builds an internal model of how vehicles, physics, and other drivers behave, and uses that model to anticipate and plan. That is the capability JEPA is designed to develop: not token-by-token output, but structured prediction of future representations that enables deliberate planning.
JEPA and WAM represent another debate within the world-model camp: in which space should prediction happen? Prediction in pixel space is interpretable but computationally expensive and easily distracted by irrelevant details. Prediction in representation space is efficient, but the quality of the representation determines everything.
The Central Tension: Will They Converge?
There is a question that makes both camps uncomfortable: if world models ultimately need to connect to language (accepting natural-language commands), and LLMs ultimately need to connect to vision (processing images and video), will the two eventually converge into the same thing?
GPT-4o (OpenAI's multimodal large language model released in 2024, capable of simultaneously processing text, image, and audio inputs and generating corresponding outputs, where "o" stands for "omni") can see images, hear sounds, and generate images. V-JEPA 2 generates no pixels, only predicts semantic representations, but also requires language to describe tasks. The two paths are approaching the same point from opposite directions.
Perhaps the "LLM vs. world model" debate is fundamentally about core design philosophy, not about the final product form: do you start from language and expand toward physical understanding? Or do you start from physical perception and expand toward a language interface?
The starting point may differ, leading to fundamental differences in system architecture, training data, and evaluation metrics, even if the final capabilities look similar.
Xie Saining's answer to this question is embodied in AMI Labs' technical choices: start from physical perception, use language as an interface rather than as a foundation. The cost of this choice is clear: you need a completely different kind of data, not Common Crawl, but sensor recordings from the physical world.
For You to Consider
V-JEPA 2 generates no pixels, only predicts semantic representations. GPT-4o can see images and generate them. Do you think these two paths will still be separate five years from now?
If they converge, who "wins": the language camp or the world-model camp? Or is the question itself framed wrong?