
Part A: RNN, Transformer, and Diffusion Architectures
Review: You Already Have an RNN Baseline
The RSSM from P02 has two parallel paths:
- Deterministic path (GRU):
, capturing smooth dynamic trends - Stochastic path:
, sampling the uncertainty at the current timestep in latent space
This design, validated in Dreamer V1/V2, achieves solid policy performance on continuous control tasks at very low computational cost. Its limitation is equally clear: GRU memory capacity degrades as sequences grow longer, making it inadequate for tasks requiring reasoning across hundreds of steps.
The five architecture families that follow each address this limitation, but take different directions.
Architecture 1: RNN / RSSM (Your Baseline)
Representative systems: Ha & Schmidhuber World Models (2018), Dreamer V1 (2019), Dreamer V2 (2020)
The GRU incrementally updates the hidden state with O(1) per-step cost, independent of sequence length. RSSM builds on this by splitting out the stochastic path
Learning paradigm: Interactive. Collects
Applicable scenarios: Simple to moderately complex continuous control tasks (e.g., DMControl, the DeepMind Control Suite, a set of standard continuous control benchmarks based on the MuJoCo physics engine, including Cheetah running, Cartpole balancing, Reacher goal reaching, and similar tasks; Atari, a set of classic video game benchmarks covering 57 games used to evaluate general decision-making capability), and latency-sensitive online reinforcement learning.
Limitations: Weak long-term memory, with the effective memory window of the GRU hidden state typically between 50-100 steps; generation quality inferior to Diffusion; data collection on real robots remains expensive.
Architecture 2: Transformer-based (2022, 2023)
Representative systems: IRIS (2022), STORM (2023)
Core Mechanism
Replace the GRU with a Transformer, tokenize the historical observation sequence
📖 softmax function: Converts an arbitrary real-valued vector
into a probability distribution (all elements non-negative, summing to 1): . Larger values yield larger output probabilities; smaller values yield probabilities near zero. The attention mechanism uses softmax to convert relevance scores into weights, giving the "most relevant positions" the highest weight.
📖 Q, K, V in self-attention: Each position's vector is linearly projected into three roles: Query (Q): what the current position is "asking"; Key (K): what information other positions "offer"; Value (V): the actual information content carried.
computes pairwise relevance scores between positions, divided by (the dimension of the Key vector, used to prevent the dot product from becoming too large as dimensionality grows, which would cause softmax output to be overly peaked and gradients to vanish), then normalized by softmax into attention weights, and finally used to compute a weighted sum of . Each position "asks" (Q) all other positions which of their answers (K) are relevant, then extracts their content (V) weighted by relevance.
Every position can directly "see" any historical timestep in the sequence, no longer constrained by the GRU's hidden state bottleneck.
IRIS: Turning Images into "Sentences"
IRIS (Imagination with auto-Regression over an Inner Speech, ICLR 2023) centers on VQ-VAE quantization, converting continuous image frames into discrete token sequences. GPT can predict "the next word" because words are discrete and finite, and the probability distribution can be modeled precisely with softmax. By converting images into discrete units analogous to "words," one can directly apply a GPT-style autoregressive Transformer to predict "the next visual word."
📖 VQ (vector quantization) works as follows: (1) the encoder maps an image patch to a continuous vector
; (2) the closest vector in the codebook is found ( ); (3) the index of replaces the continuous vector and is passed to the Transformer. During backpropagation, the straight-through estimator is used: the forward pass uses the quantized discrete vector, while the backward pass pretends the quantization operation does not exist and passes gradients straight through.
The Transformer in IRIS receives a sequence of interleaved frame tokens and actions: each frame is encoded by VQ-VAE into
IRIS processes each frame as a pipeline: VQ-VAE encodes the raw frame into a discrete token sequence, the Transformer autoregressively predicts the next-frame token sequence, and VQ-VAE decodes it back into a reconstructed image.
STORM's Key Improvement: Single-Token Stochastic Latent Variable
STORM (Stochastic Transformer-based wORld Models, NeurIPS 2023) differs from IRIS mainly in its latent variable design. IRIS uses VQ-VAE to represent one frame as multiple discrete tokens (
The Transformer processes the sequence with causal masking, and
📖 Teacher Forcing: During training, the model conditions on real historical frames at each timestep rather than its own previous predictions. This makes training more stable and convergence faster, but creates a distribution gap: "always having correct historical frames during training, only having the model's own predicted frames during inference." For autoregressive world models, this is the most common source of error accumulation. In STORM's evaluation metrics, long-horizon PSNR is specifically designed to quantify this gap (see the STORM metrics section in L04).
Compared to DreamerV3's GRU-based RSSM, STORM's Transformer sequence model is stronger at long-sequence modeling and supports parallel training. The trade-off is the removal of RSSM's recurrent hidden state
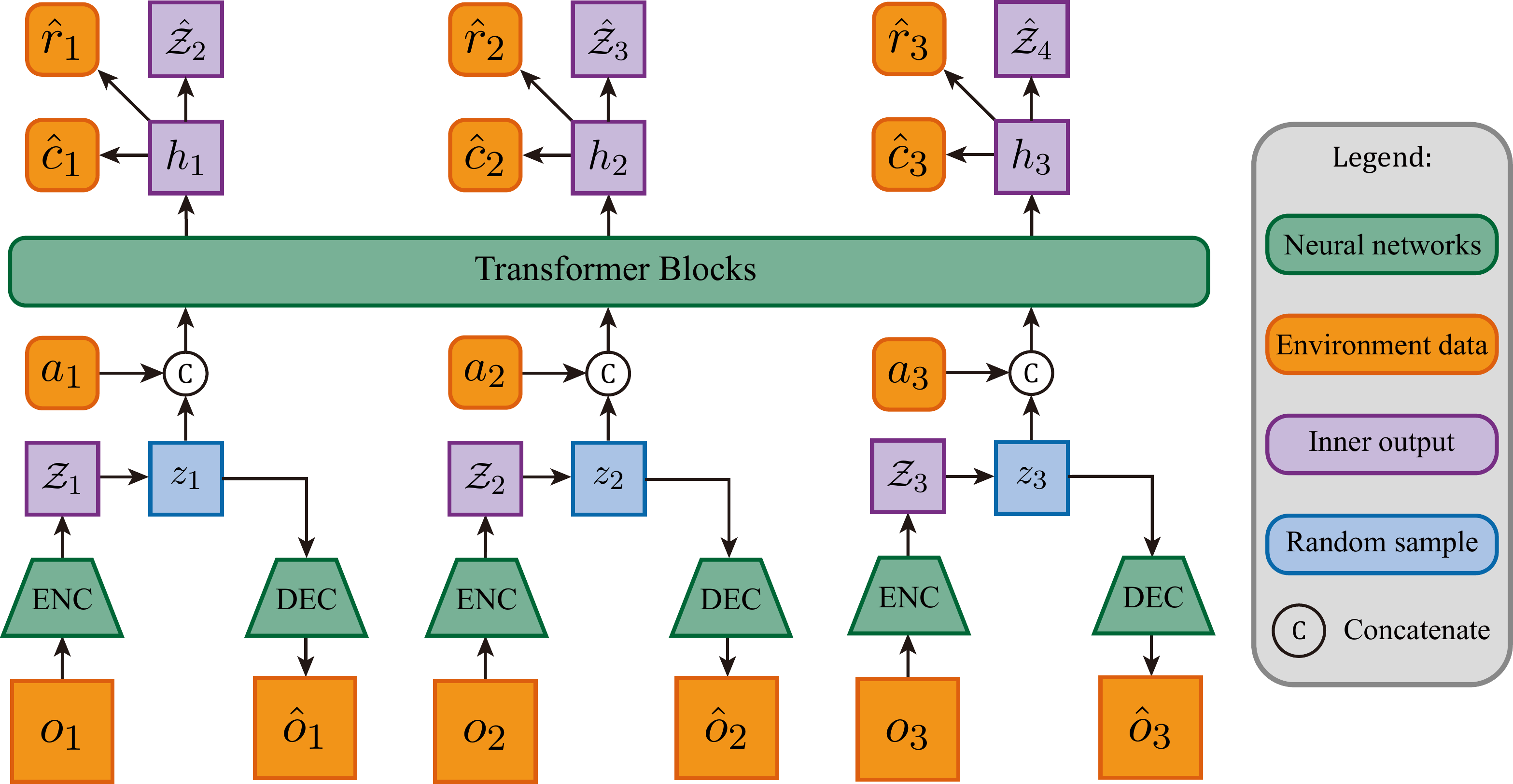
Learning paradigm: Interactive (action-conditioned). Action
Applicable scenarios: Complex games (long Atari games, strategy games), tasks requiring multi-step planning; the preferred choice when sufficient compute and data are available.
Limitations: Computation scales quadratically with sequence length (
Architecture 3: Diffusion-based (2023, 2024)
Representative systems: Diamond (2024), GameNGen (Google, 2024)
Core Mechanism
Diffusion models generate outputs through iterative denoising: Gaussian noise is added to real frames, and the network is trained to predict the noise:
In the world model setting, conditioned on historical frames and actions, the diffusion model iteratively "denoises" the next frame. Each denoising step is a full forward pass through the neural network, guided by "action conditioning" to determine "where to remove noise."
📖 U-Net: A convolutional neural network with an encoder-decoder structure, named for its "U" shape. The encoder progressively reduces spatial resolution (extracting features), and the decoder progressively restores resolution (recovering details), with skip connections that pass features from each encoder layer directly to the corresponding decoder layer to preserve high-frequency detail. The bottleneck is the lowest layer of the U-shape, where resolution is minimal and information is highly compressed before being gradually expanded. Diffusion world models use U-Net at each denoising step to process images and predict progressively clearer frames.
GameNGen (2024) is the first system to run a complete game engine in real time using a neural network, simulating DOOM at 20fps. The model itself is the game engine. Generating each frame requires 10-100 denoising iterations, each a full U-Net forward pass, making diffusion world models extremely expensive in online RL training loops.
Diamond: A World Model Combining the Diffusion Process with the RL Training Loop
Diamond (NeurIPS 2024) directly integrates the diffusion process with the reinforcement learning training loop. Conditioned on a number of past frames and the current action, it uses a U-Net to denoise and generate the next frame, with the full generation chain serving as an environment simulator for policy training.
Diamond's key design decision: action information is injected via cross-attention (a variant of self-attention where the Query comes from one sequence and the Key and Value come from another, aligning two different sources of information; here used to let image features "query" action information) into every resolution layer of the U-Net, rather than only into the bottleneck (the lowest-resolution layer at the bottom of the U-Net), which tightly aligns the generated frames with the action instructions. On the Atari 100k benchmark, Diamond achieves an average HNS of 1.46, surpassing all prior world model methods while maintaining excellent visual generation quality.
The inherent challenge for diffusion world models is object persistence: each frame is denoised independently, and the model does not maintain explicit object state, causing the identity, position, and occlusion relationships of objects to quietly drift in long sequences. Diamond mitigates this by limiting the number of rollout steps and adding a depth consistency penalty to the loss (for more diagnostic methods, see L04).
Learning paradigm: Interactive (Diamond is action-conditioned) or observation-only (pure video diffusion models). Observation-only diffusion models are trained on large-scale internet video, learning the visual regularities of the world without action conditioning, and cannot answer "what would happen if I took a different action."
Applicable scenarios: Offline video prediction, high-fidelity simulators, film and game content generation; not suitable for RL scenarios requiring real-time closed-loop control.
Limitations: Slow inference (10-100 denoising steps); difficult to interface directly with policy optimization (the sampling process is non-differentiable); object persistence is hard to maintain; training and inference costs are substantial.