
Part B:潜在动力学
编码器不够用,我们需要预测未来
有了 VAE 编码器,我们能把当前帧
在潜在空间中,给定当前状态
和动作 ,预测下一时刻的状态 。
这个预测能力让智能体可以在脑海中"模拟"未来,从而在不真实执行动作的情况下规划决策,这正是世界模型节省样本的关键所在。
最简单的动力学:GRU
门控循环单元(GRU,Gated Recurrent Unit) 是序列建模的基础工具。作为动力学模型,GRU 接收
📖 GRU 内部机制(简要):GRU 通过两个"门"控制信息流:**重置门(reset gate)**决定"遗忘多少过去",**更新门(update gate)**决定"保留多少旧状态 vs 写入新信息"。门的值介于 0-1 之间,由当前输入和上一隐状态共同决定。这使 GRU 能够选择性地记住长期依赖,同时忘记无关信息,比普通 RNN 更擅长处理较长序列。相比 LSTM,GRU 少一个门(无单独的记忆细胞),参数更少,训练更快。
GRU 的优点是简单、训练稳定;缺点是输出确定性预测,无法表达不确定性。真实环境中,同一动作可能导致多种不同结果(例如:推箱子可能成功,也可能被卡住)。
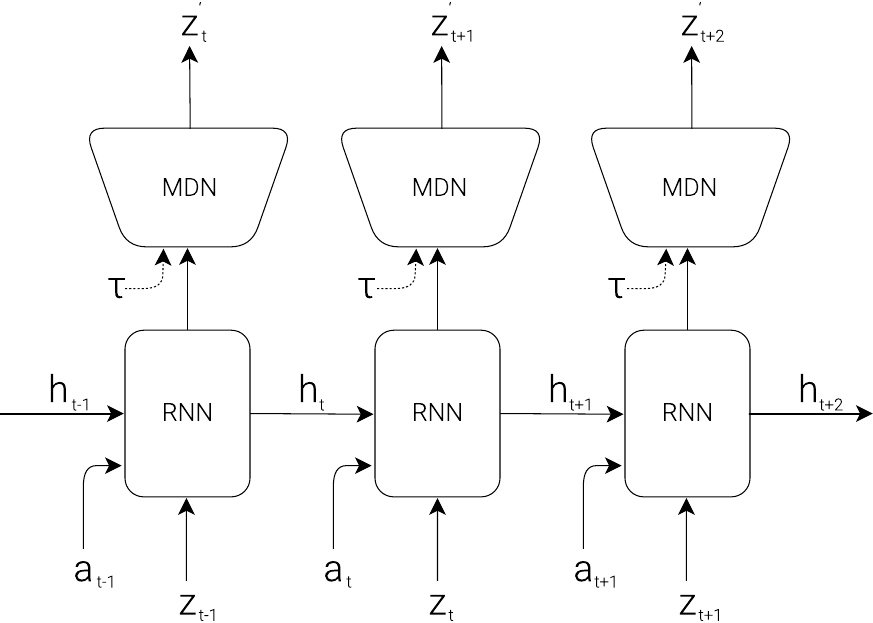
MDN-RNN:建模不确定性
MDN-RNN(Mixture Density Network + RNN) 在 Ha & Schmidhuber(2018) 的 World Models 论文中提出,用混合高斯分布对下一状态的不确定性建模:
个高斯分量,每个有自己的均值 (分布中心)、方差 (分布宽度) - 混合权重
:第 个高斯分量的概率质量,满足 , 。可以理解为"第 种未来发生的概率"。网络输出 后通过 softmax 函数归一化,确保所有权重之和为 1。
MDN-RNN 能捕捉多峰分布:环境可能跳到多个不同的下一状态,模型都能表达。
RSSM:分离确定性与随机性
RSSM(Recurrent State Space Model,循环状态空间模型) 是 Dreamer 系列论文的核心创新,它将状态分为两部分:
- 确定性隐藏状态
:由 RNN 维护,汇聚历史轨迹信息,没有随机性 - 随机潜在状态
:从以 为条件的分布中采样,表达当前的不确定性
RSSM 的核心方程:
📖 参数下标
(phi):公式中的 、 、 里的下标 表示"这个函数的参数是 ",即神经网络的可学习权重。 读作"以 为参数的函数 "。训练时,梯度下降更新 ,让这些函数的预测越来越准确。同理,后面出现的 (theta)也是另一组可学习参数的常用符号。
📖 先验 vs 后验:这是贝叶斯统计的基本概念。先验(prior)是"看到数据之前的信念",RSSM 依据历史记忆
对当前状态 的猜测。后验(posterior)是"看到数据之后更新的信念",用真实观测 修正先验,得到更准确的估计。训练时用后验产生 并计算 KL 损失(衡量先验与后验的差距);推理/想象时只有先验可用(没有真实 ),RSSM 纯靠先验向前滚动。
为什么要分离?
| 状态 | 角色 | 特性 |
|---|---|---|
| 记忆 | 确定性,汇聚历史 | |
| 感知 | 随机性,表达不确定性 |
分离后,模型可以在没有真实观测的情况下,仅用先验
PlaNet 论文(Hafner et al., ICML 2019)通过消融实验(ablation study,系统性地去掉模型的某一个组件,观察性能如何变化,从而验证该组件的必要性)明确验证了这一设计:纯随机路径(无确定性
三种动力学模型对比
| 模型 | 不确定性建模 | 记忆机制 | 主要用途 |
|---|---|---|---|
| GRU | 无(确定性输出) | 固定维度隐状态 | 简单序列预测,快速原型 |
| MDN-RNN | 混合高斯(多峰分布) | 固定维度隐状态 | 多峰不确定性,Ha & Schmidhuber M 模块 |
| RSSM | 先验/后验分离(高斯) | 确定性 | Dreamer 核心,支持纯想象规划 |
三者是递进关系:GRU 奠定序列建模基础,MDN-RNN 引入不确定性,RSSM 进一步把"记忆"和"感知不确定性"解耦,让模型可以在没有真实观测的情况下向前滚动规划。