
Part A:RNN、Transformer 与 Diffusion 架构
回顾:你已经有了一个 RNN 基线
P02 的 RSSM 有两条并行路径:
- 确定性路径(GRU):
,捕捉平滑的动态趋势 - 随机路径:
,在潜空间里采样当前时刻的不确定性
这个设计在 Dreamer V1/V2 中得到验证,能以很低的计算开销在连续控制任务上取得不错的策略性能。它的局限也很明确:GRU 的记忆容量随序列变长而衰减,对需要跨越数百步推理的任务力不从心。
接下来五个架构族,都是为了突破这一限制,只是各自选择了不同的方向。
架构一:RNN / RSSM(你的基线)
代表系统:Ha & Schmidhuber World Models (2018)、Dreamer V1 (2019)、Dreamer V2 (2020)
GRU 逐步更新隐状态,单步计算开销 O(1),与序列长度无关。RSSM 在此基础上拆出随机路径
学习范式:交互型。收集
适用场景:简单到中等复杂度的连续控制任务(如 DMControl,DeepMind Control Suite,一套基于 MuJoCo 物理引擎的标准连续控制基准,包含 Cheetah 奔跑、Cartpole 平衡、Reacher 到达目标等任务;Atari,一套经典电子游戏基准,包含 57 款游戏,用于评估通用决策能力),对延迟敏感的在线强化学习。
局限:长时记忆弱,GRU 隐状态的有效记忆窗口通常在 50-100 步之间;生成质量不如 Diffusion;数据采集在真实机器人上仍然昂贵。
架构二:Transformer-based(2022, 2023)
代表系统:IRIS (2022)、STORM (2023)
核心机制
用 Transformer 替换 GRU,将历史观测序列
📖 softmax 函数:将一个任意实数向量
转换为概率分布(所有元素非负且之和为 1): 。较大的 对应较大的输出概率,较小的 对应接近零的概率。注意力机制用 softmax 将相关性得分转换为权重,使"最相关的位置"获得最大权重。
📖 自注意力中的 Q、K、V:每个序列位置的向量被线性变换为三个角色,Query(查询,Q):当前位置想"问什么";Key(键,K):其他位置"提供什么信息";Value(值,V):实际携带的信息内容。
计算每对位置之间的相关性得分,除以 ( 是 Key 向量的维度,除以它防止点积随维度增大而过大,导致 softmax 输出过于尖锐、梯度消失),再用 softmax 归一化为注意力权重,最后加权求和 。每个位置都在"问"(Q)其他所有位置,哪些位置的答案(K)与我相关,然后按相关性加权提取它们的内容(V)。
每个位置都能直接"看到"序列里任意一个历史时刻,不再受限于 GRU 的隐状态瓶颈。
IRIS:把图像变成"句子"
IRIS(Imagination with auto-Regression over an Inner Speech,ICLR 2023)的核心是 VQ-VAE 量化,把连续的图像帧变成离散 token 序列。GPT 能预测"下一个词",因为词是离散的、有限的,概率分布可以用 softmax 精确建模。把图像也变成类似"词"的离散单元,就可以直接用 GPT 风格的自回归 Transformer 预测"下一个视觉词"。
📖 VQ(向量量化)的工作原理:①编码器将图像块映射为连续向量
;②在 codebook 中找到与 最近的向量 ( );③用 的索引 代替连续向量,传入 Transformer。反向传播时用直通估计器(straight-through estimator):前向传播用量化后的离散向量,反向传播时假装量化操作不存在,梯度直接流过。
IRIS 的 Transformer 接收的是帧 token 与动作交错的序列:每帧被 VQ-VAE 编码为
IRIS 的处理流程是单向管道:VQ-VAE 将原始帧编码为离散 token 序列,Transformer 自回归预测下一帧 token 序列,VQ-VAE 再将其解码还原为重建图像。
STORM 的核心改进:单 token 随机潜变量
STORM(Stochastic Transformer-based wORld Models,NeurIPS 2023)与 IRIS 的主要区别在于潜变量设计。IRIS 用 VQ-VAE 把一帧图像表示为多个离散 token(
Transformer 以因果掩码处理序列,
📖 Teacher Forcing:训练时,模型在每个时间步都以真实的历史帧作为条件输入,而非使用模型自身上一步的预测。这让训练更稳定、收敛更快,但产生了"训练时总有正确历史帧、推理时只有自己的预测帧"的分布差距。对于自回归世界模型,这是最常见的误差累积来源。STORM 的评估指标中,长时域 PSNR 正是为量化这一差距而设计(详见 L04 STORM 指标一节)。
与 DreamerV3 的 GRU-based RSSM 相比,STORM 的 Transformer 序列模型在长序列建模上更强,训练可并行;代价是去掉了 RSSM 的循环隐状态
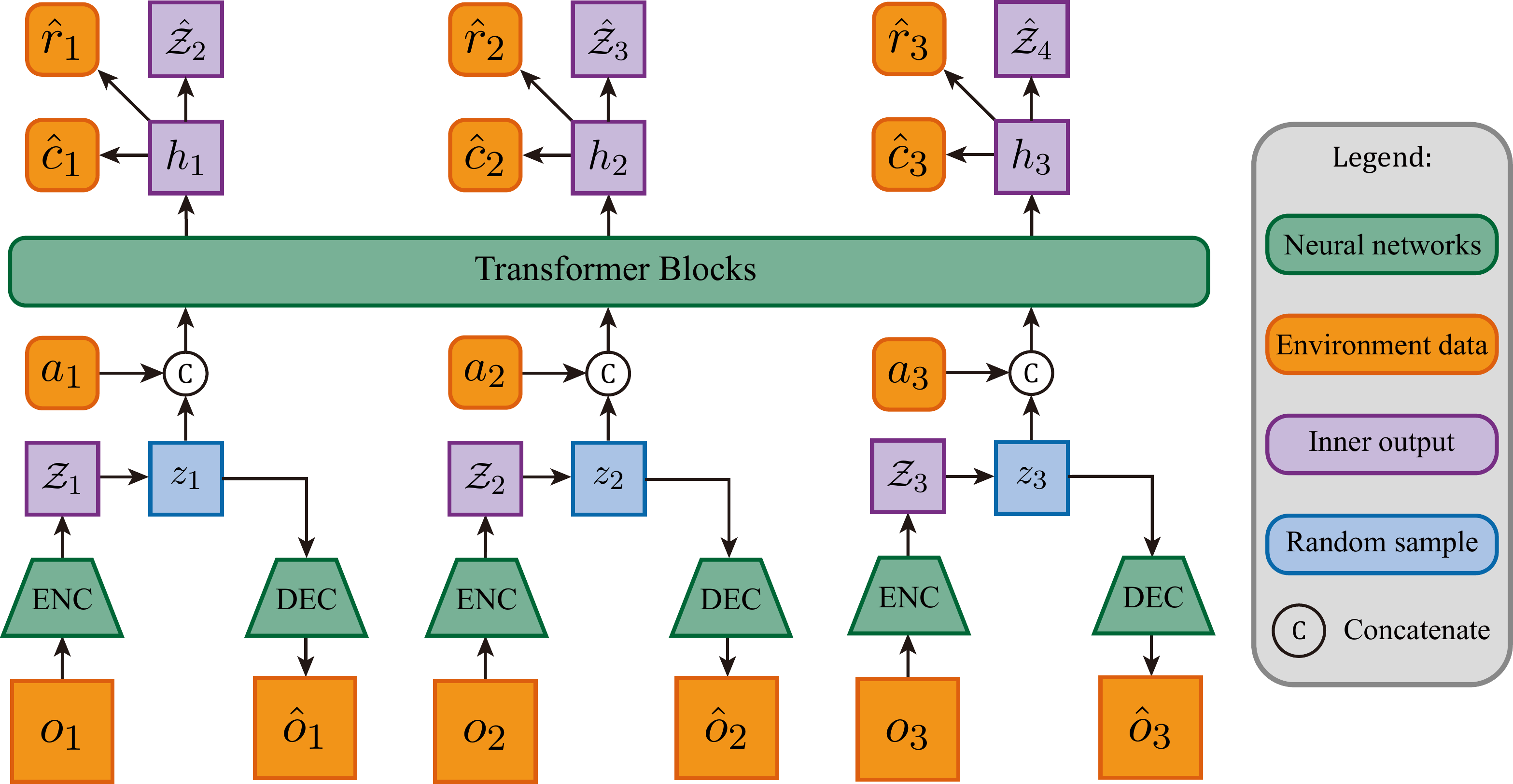
学习范式:交互型(带动作条件)。动作
适用场景:复杂游戏(Atari 长游、策略游戏)、需要多步规划的任务;有充足算力和数据时的首选。
局限:计算量随序列长度二次增长(
架构三:Diffusion-based(2023, 2024)
代表系统:Diamond (2024)、GameNGen (Google, 2024)
核心机制
扩散模型通过逐步去噪生成输出:先向真实帧添加高斯噪声,再训练网络预测噪声:
在世界模型场景中,以历史帧和动作为条件,扩散模型逐步"去噪"出下一帧。每一步去噪都是一次完整的神经网络前向传播,网络在"动作条件"的引导下决定"把哪里的噪声去掉"。
📖 U-Net:一种编码器-解码器结构的卷积神经网络,因形似字母"U"而得名。编码器逐步压缩空间分辨率(提取特征),解码器逐步恢复分辨率(还原细节),并通过跳跃连接(skip connections)将编码器各层的特征直接送入解码器对应层,保留高频细节。Bottleneck(瓶颈层)是 U 形结构最底部、分辨率最低的层,信息在此高度压缩后再逐步展开。扩散世界模型用 U-Net 在每一步去噪中处理图像,对逐渐清晰的帧进行预测。
GameNGen (2024) 是第一个用神经网络实时运行完整游戏引擎的系统,以 20fps 的速度模拟《毁灭战士》(DOOM)。模型本身就是游戏引擎。每生成一帧,扩散模型需要 10-100 步去噪迭代,每步都是一次完整的 U-Net 前向传播,这导致扩散世界模型在在线 RL 训练循环里非常昂贵。
Diamond:将扩散过程与强化学习训练循环结合的世界模型
Diamond(NeurIPS 2024)将扩散过程与强化学习训练循环直接结合。它以过去若干帧和当前动作为条件,用 U-Net 去噪生成下一帧,整条生成链作为环境模拟器供策略训练。
Diamond 的关键设计决策:动作信息通过交叉注意力(cross-attention,自注意力的变体,Query 来自一个序列,Key 和 Value 来自另一个序列,使两个不同来源的信息相互对齐,这里用于让图像特征"查询"动作信息)注入 U-Net 的每一个分辨率层,而非只注入 bottleneck(瓶颈层,U-Net 最底部分辨率最低的层),这使生成帧与动作指令的对齐更紧密。在 Atari 100k 基准上,Diamond 以平均 HNS 1.46 超越了之前所有世界模型方法,同时维持了出色的视觉生成质量。
扩散世界模型的固有挑战是物体持久性(object persistence):每帧独立去噪,模型不维护显式的物体状态,导致长序列中物体的身份、位置和遮挡关系会悄悄漂移。Diamond 通过限制展开步数和在损失中加入深度一致性惩罚来缓解这一问题(更多诊断方法见 L04)。
学习范式:交互型(Diamond 带动作条件)或观察型(纯视频扩散模型)。观察型扩散模型在海量互联网视频上训练,学到的是世界的视觉规律,不包含动作条件,无法回答"如果我换一个动作,世界会怎样"。
适用场景:离线视频预测、高保真仿真器、影视/游戏内容生成;不适合需要实时闭环控制的 RL 场景。
局限:推理慢(10-100 步去噪);难与策略优化直接对接(采样过程不可微);物体持久性维护困难;训练和推理开销巨大。