
争论三:世界模型和 LLM 是竞争关系还是互补?
谢赛宁的分工逻辑
在这一点上,谢赛宁出人意料地温和。他没有说"LLM 是死路",而是说:
"没有 LLM,Vision 也没办法拓展到现在这种真正的多模态智能的大的范畴。"
他的 AMI Labs 不排斥 LLM,甚至明确感谢 LLM 带来的进步。LLM 解决了语言理解和指令跟随这两个关键问题,让视觉系统有了"语言接口",世界模型才能接受自然语言指令。
他的判断是:两者处理的是不同维度的信息,各有主场。
| 范式 | 主场 |
|---|---|
| LLM | 数字空间的推理、代码、文本生成、知识检索 |
| 世界模型 | 物理世界的预测、机器人控制、工业感知、具身智能 |
| WAM | 两者的统一:video + action 联合建模,理解物理并接受语言指令 |
Dreamer V3 处于世界模型这一行:吃动作,预测潜在状态,已在 7 个领域用同一套超参数跑通。
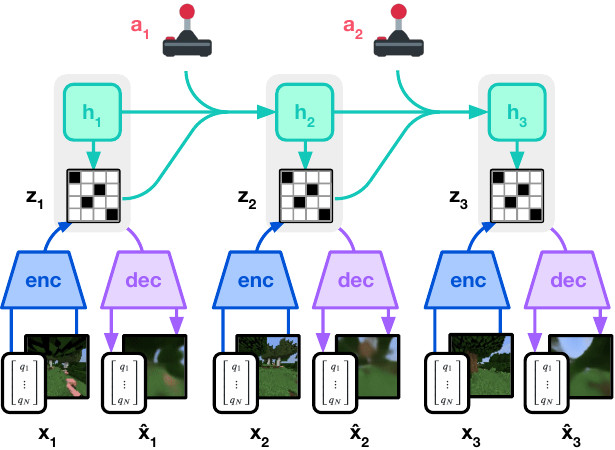
WAM:联合建模的思路
这个"WAM"(World Action Model,世界动作模型)的概念值得单独说明。
📖 WAM(World Action Model):一类将视频预测和动作预测联合建模的架构。它的核心思路是:不只是"看懂世界",而是"看懂世界并知道怎么在里面行动"。视频帧提供物理约束,动作信号提供因果标注,两者联合训练出来的模型,比分开训练的组合更能理解行动的后果。
传统的世界模型和策略是两个分离的模块,先建模世界状态,再在世界模型里做规划。WAM 的思路是打破这个分工:视频本身就是动作学习的监督信号,不需要显式的奖励函数或人工标注。
如果用一个矩阵来理解现有的世界模型,横轴是"吃不吃动作信号",纵轴是"预测什么":
- Dreamer(RSSM + 潜在 Actor-Critic,详见 L02–L03):吃动作,预测潜在状态,狭义世界模型,主动决策者
- STORM(Stochastic Transformer-based wORld Models,分类 VAE + Transformer 动力学,详见 L03):吃动作(动作作为 token 拼入序列),预测下一帧 latent token,交互型
- WAM:吃动作,同时理解语义,两者的统一
这三种范式在 L03 已经从工程角度比较过。这里的问题不同:WAM 押注的是什么假设?世界模型和策略不应该是两个分离的模块,视频本身就是动作学习的监督信号。 如果这个假设成立,联合训练会打破模型基础和策略学习之间的分工,产生新的涌现能力。
JEPA 的另一条路
LeCun 提出的 JEPA(Joint Embedding Predictive Architecture,LeCun 2022)走了一条不同的方向。
📖 JEPA(Joint Embedding Predictive Architecture):LeCun 2022 年提出的架构原则。核心想法是:预测应该发生在抽象表示层,而不是像素层。与其让模型预测未来的每一个像素(极其困难,且充满无关的噪声),不如让模型预测未来的语义表征。V-JEPA 2 就是这个思路的视频版本。
JEPA 不生成像素,只预测语义表征。这个选择背后有一个明确的立场:像素是噪声,语义才是信号。 一个不生成任何画面的模型,反而可能比扩散式世界模型更快获得对物理世界的结构性理解。
LeCun 在 2026 年 5 月的一次访谈里,给这个赌注设了一个具体的时间节点:2027 年初,整个行业都会意识到必须换范式;五年之内,JEPA 类架构会像 Linux 成为操作系统底层标准一样,成为 AI 的基础标准。这不是随口的预言,他说这是用自己的职业生涯在押注。
他对这场范式之争的最尖锐表达,来自对两种学习者的比较。VLA(Vision-Language-Action)模型接收视觉输入加语言指令,直接输出动作,是目前大多数端到端机器人和自动驾驶系统的主流路线。特斯拉 Autopilot 就是这个思路:用数百万小时的驾驶数据训练,把感知映射到方向盘。但 LeCun 的批评是:VLA 走的是错误方向。它记住了海量的情境,但内部没有对"后果"的建模。遇到真正没见过的场景,它没有任何推理后果的能力,只能蒙。
一个 17 岁的孩子用 20 小时学会开车,靠的不是背熟所有路况,而是建立起一套对车辆、物理规律、其他驾驶者行为的内部模型,用这个模型去预判和规划。这正是 JEPA 要发展的能力:不是逐 token 蹦词,而是在表征空间里结构性地预测未来,从而支撑有目的的规划。
JEPA 和 WAM 代表了世界模型内部的另一场争论:在哪个空间里做预测?像素空间的预测可解释,但计算昂贵,且容易被无关细节分散注意力。表征空间的预测高效,但表征的质量决定了一切。
关键张力:最终会收敛吗?
这里有一个让双方都不舒服的问题:如果世界模型最终都要接语言(接受自然语言指令),LLM 最终都要接视觉(处理图像和视频),两者会不会最终收敛成同一个东西?
GPT-4o(OpenAI 2024 年发布的多模态大语言模型,能同时处理文本、图像、音频输入并生成对应输出,"o"代表"omni"即全模态)能看图、能听声音、能生成图像。V-JEPA 2 不生成像素,只预测语义表征,但也需要语言来描述任务。两条路正在从两个方向接近同一个点。
也许"LLM vs 世界模型"的争论,本质上是关于核心设计哲学的争论,而不是关于最终产品形态的争论:你是从语言出发,往物理理解扩展?还是从物理感知出发,往语言接口扩展?
出发点不同,可能导致系统架构、训练数据、评估指标上的根本差异,即使最终功能看起来相似。
谢赛宁对这个问题的回答,体现在 AMI Labs 的技术选择里:从物理感知出发,用语言作为接口,而不是用语言作为基底。这个选择的代价是:你需要一套完全不同的数据,不是 Common Crawl,而是物理世界里的传感器记录。
留给你
V-JEPA 2 不生成像素,只预测语义表征。GPT-4o 能看图、能生成图。你觉得五年后这两条路还是分开的吗?
如果它们收敛了,是谁"赢"了,语言派还是世界模型派?还是说,这个问题本身就问错了?