As large language models (LLMs) are adopted more widely, enterprises face a very practical problem: how can a model answer questions accurately when those questions depend on internal documents, real-time data, or domain-specific knowledge? After all, a model's training data is limited and time-bounded, so it cannot cover company-specific business knowledge or constantly updated information.
One intuitive idea is this: since context windows keep getting larger, from 8K to 128K and now beyond one million tokens, why not just stuff the relevant documents into the prompt and let the model answer from those materials directly?
However, being able to process long context and being able to deliver correct answers stably, efficiently, and controllably in enterprise scenarios are two very different things. Blindly relying on long context brings a series of severe challenges, including exploding cost, diluted attention, and stale knowledge updates.
To solve these pain points, a technique called Retrieval-Augmented Generation, or RAG, emerged. Before the model generates an answer, RAG first retrieves precise external knowledge. Compared with simply expanding the context length in a brute-force way, RAG meets enterprise requirements for factual accuracy and fresh knowledge at lower cost, with higher accuracy and stronger controllability. It has therefore become a key foundation for building trustworthy AI applications.
In this tutorial, we will systematically explain what RAG is, trace the background behind its emergence and its core principles, and then explore its evolution from basic forms to advanced forms, along with where it may go next.
What You Will Learn in This Lesson
- The core value of RAG: deeply understand how it addresses the central long-context problems of cost, attention, and knowledge freshness
- How RAG works: see through concrete examples how it completes the full loop from retrieval to generation
- The evolution of RAG: from basic Naive RAG to Advanced RAG and then to Modular RAG
- Model selection for RAG: understand how to evaluate and choose the three key model types, Embedding, Rerank, and LLM
- Enterprise RAG practice: learn the full-chain construction guide from data preprocessing to system deployment and evaluation
- RAG evaluation and optimization: understand core metrics, mainstream frameworks, and continuous improvement methods
- Frontier trends in RAG: explore how RAG is combining with agents, multimodality, and other emerging techniques
What You Will Gain
After completing this tutorial, you will build a systematic beginner-level understanding of RAG technology. You will not only know what it is, but also why it works. You will also gain a clear blueprint for how to evaluate, choose, and design an efficient, reliable, and controllable RAG system that meets enterprise requirements, laying a solid foundation for building real enterprise-grade RAG applications.
1. Why RAG Is Needed
Retrieval-Augmented Generation (RAG) is one of the most important technical approaches in generative AI today. Its basic idea is simple: before asking a large model to generate an answer, the system first retrieves information related to the user's question from an external knowledge base, and then passes both the retrieved information and the original question to the model so the model can answer on top of real materials. That external knowledge base can be an enterprise's internal policies, process documents, and product knowledge, or an industry database, regulatory corpus, standards library, and so on.
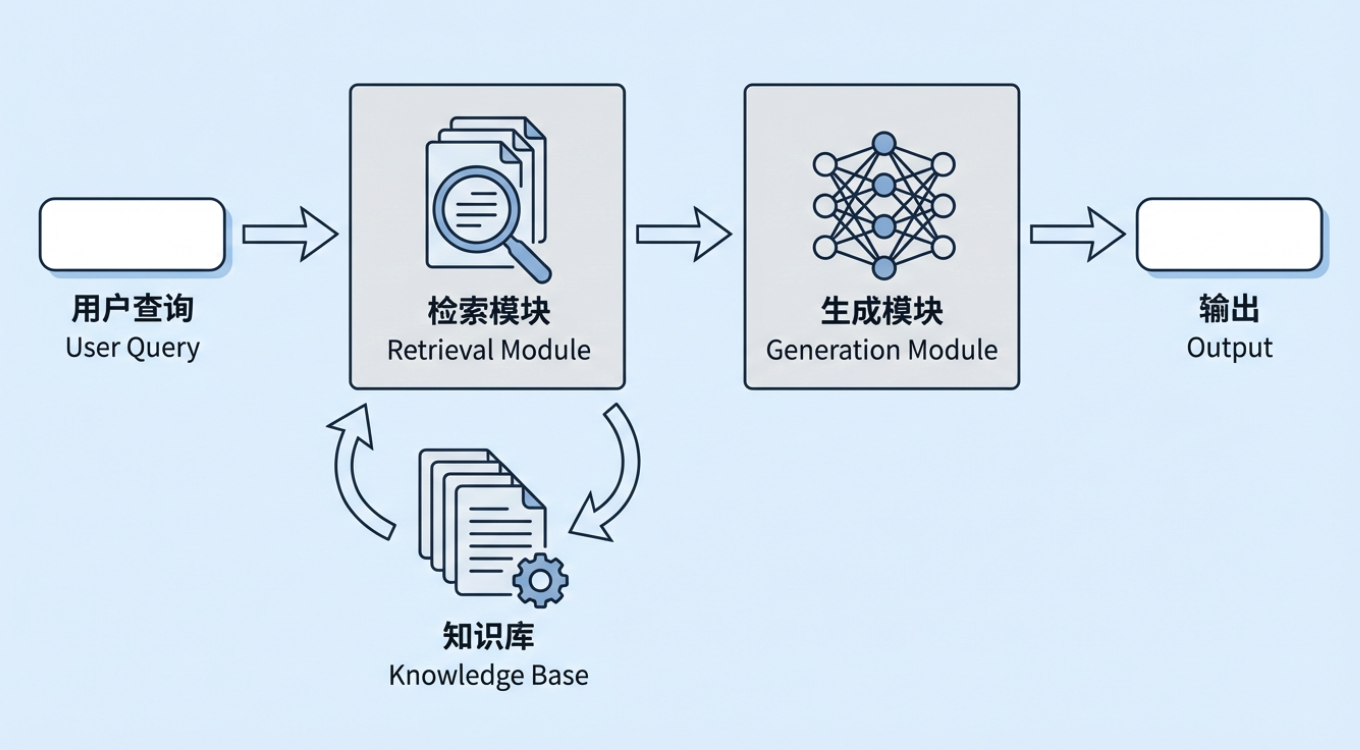
At this point, a natural question appears: if large models can already "answer questions directly," why add another layer called Retrieval-Augmented Generation? Especially now that context windows are getting larger and larger, it can seem as if simply handing all relevant material to the model ought to solve most needs.
The real difference is that "being able to produce an answer" and "being able to continuously, stably, and controllably produce the right answer in a real business environment" are two completely different things. If you rely only on a model's parameter memory, or only on dumping large amounts of documents into a long context, at least three typical problems still appear in enterprise use.
Cost and efficiency problems: Even as context windows keep expanding, the idea of dumping all documents into the context at once is still impractical in real systems. The central contradiction shows up in two places:
Inference cost is strongly positively correlated with context length. The longer the context, the more inference cost rises, almost linearly and sometimes even superlinearly. For a single call, 8K tokens and 200K tokens live in completely different price and latency ranges, and long context has a much higher cost threshold.
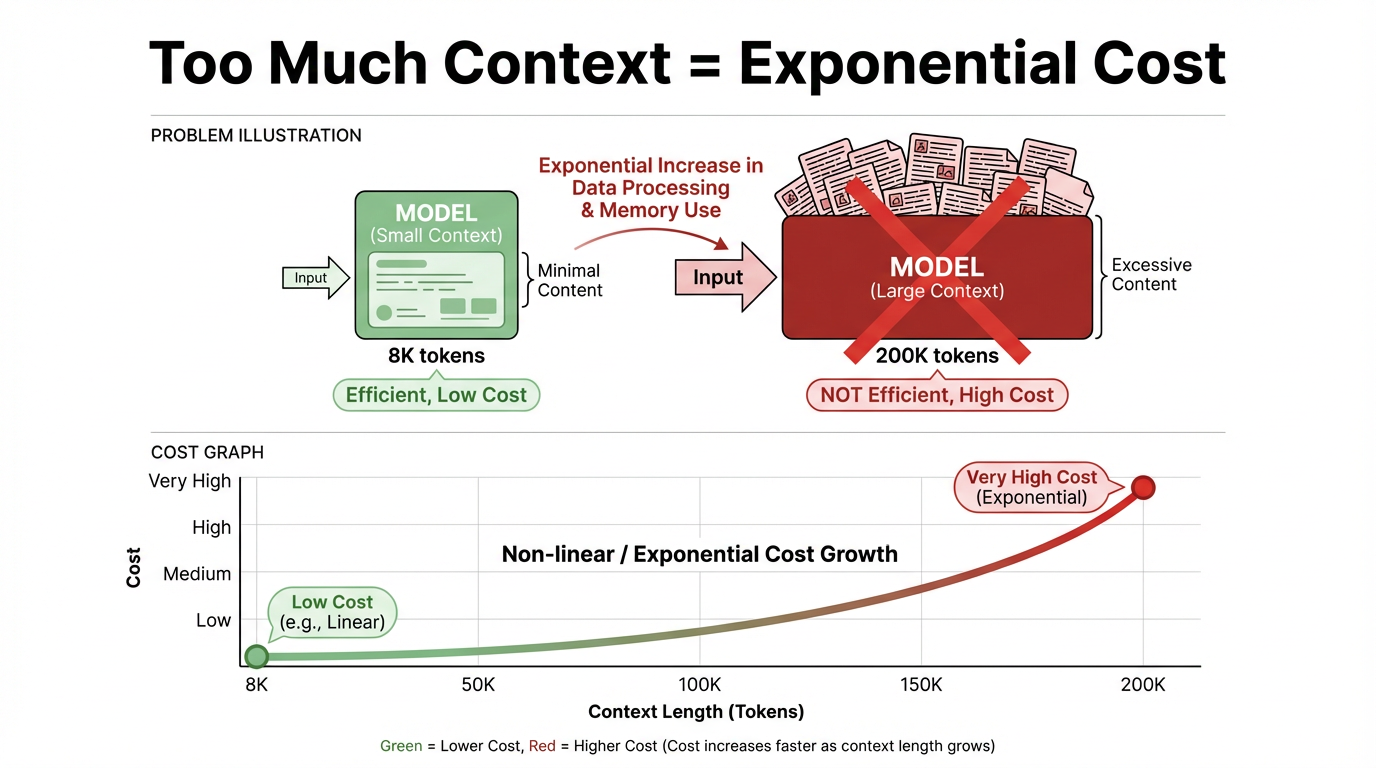
In meaning, context is the background information and conversation history the model "refers to" when answering a question. In technical terms, it is the total token sequence fed into the model for one inference, such as system and user instructions, message history, and retrieved passages.
A "context window" is the capacity limit for that input. In mainstream large-model architectures today, such as Transformers, those tokens participate in attention computation at every layer. Once the window becomes longer and the token count increases, compute and cost rise multiplicatively and can even approach exponential growth.
A large amount of compute is wasted. Most tasks need only a very small amount of information that is highly relevant to the current question. Stuffing the full document set into the context creates serious idle and wasted computation, lowers system throughput, slows response speed, and eventually harms user experience.
Attention and focus problems: A large model may be able to "cover" ultra-long context, but it cannot use every segment with equal quality. Once context length crosses a certain threshold, the model begins to show obvious attention bias:
Attention decay: the model's attention to early and middle parts of the context gradually weakens, and it tends to rely more on text it read later, so early critical information can be effectively ignored.
Information interference: the model can easily be dragged off course by irrelevant, repetitive, or even conflicting information inside the context. The final answer may sound logically coherent while still drifting away from the core question, making accuracy hard to guarantee. Without a retrieval stage to filter and rank relevance, the longer the context becomes, the harder it is to keep the answer focused on the truly key evidence. The advantage of long context can be fully canceled out by information interference.
Knowledge freshness and controllability problems: If all knowledge is stored entirely in model parameters, or manually copied into prompts, two unavoidable defects appear:
Knowledge updates are difficult: once the knowledge changes, such as policy changes, product iterations, or price updates, you either need to retrain or fine-tune the model, which is costly and slow, or maintain prompt templates manually, which is also costly and prone to human error.
Traceability is poor: when a model answers, it is often difficult to locate the exact pieces of evidence from either black-box parameters or long prompts. This makes compliance audits, risk explanations, and other tasks that require clear decision grounds extremely difficult.
Under these real constraints, the advantage of RAG becomes much clearer. Its core approach is to locate relevant and reliable information before generation, so the model answers only from necessary knowledge. Knowledge can be stored independently in an external knowledge base, making it easier to update and manage. At the same time, generated results can include cited sources, improving interpretability and trustworthiness. Even if context windows keep growing in the future, RAG will still enable efficient knowledge management and use at relatively low cost, supporting enterprise-grade knowledge applications whose process is observable and whose behavior is traceable.
From the perspective of enterprise requirements, compared with a traditional LLM that relies only on its internal parameters, RAG mainly solves the following real-world deployment problems:
- Freshness: Traditional models usually do not know new regulations, products, or workflows that appeared after their training cutoff, but RAG can directly read the latest policy documents, business databases, and knowledge bases. Without frequent retraining, answers can stay synchronized with the latest business state.
- Specialization: In vertical domains such as healthcare, chemicals, or finance, general-purpose models often do not understand deeply enough or speak precisely enough. After connecting enterprise-owned domain documents and industry standards, answers can be grounded in authoritative materials and become much closer to real business practice.
- Hallucination: By requiring answers to stay grounded in retrieved passages and provide citations, the system can reduce unsupported fabrication at the mechanism level, making "sounds true" much closer to "is actually true."
- Explainability and auditability: Pure parameter-based models often cannot answer, "Which rule was this conclusion derived from?" RAG lets each answer be traced back to a specific policy clause, business document, or historical case. That helps business staff inspect and correct answers and gives audit, risk, and compliance teams the traceability they need.
- Compute cost and resource efficiency: Making a model memorize all enterprise knowledge in its parameters usually means a larger model and higher inference cost. RAG stores most knowledge outside the model in vector stores and document stores and retrieves it on demand, allowing enterprises to get broader coverage and more accurate detail even with smaller models and limited compute.
Therefore, for enterprises that want to use large models in real business scenarios over the long term, stably and controllably, RAG is not an optional enhancement. It is almost an essential foundational technology for building a high-quality enterprise knowledge application system.
2. What RAG Is
The core idea of RAG, Retrieval-Augmented Generation, is to let a large model answer questions not only with static knowledge learned during training, but also with up-to-date and reliable information pulled from an external knowledge base at runtime.
In a typical RAG system, the user's question is not sent directly to the large model. Instead, a retrieval module first finds the most relevant document passages from the enterprise knowledge base, then combines those passages with the original question into a complete context, and finally gives that to the model to generate an answer. This "retrieve first, generate second" pattern allows the model to reason from real reference material instead of only guessing from what it remembers in its parameters. We can look at a typical case:
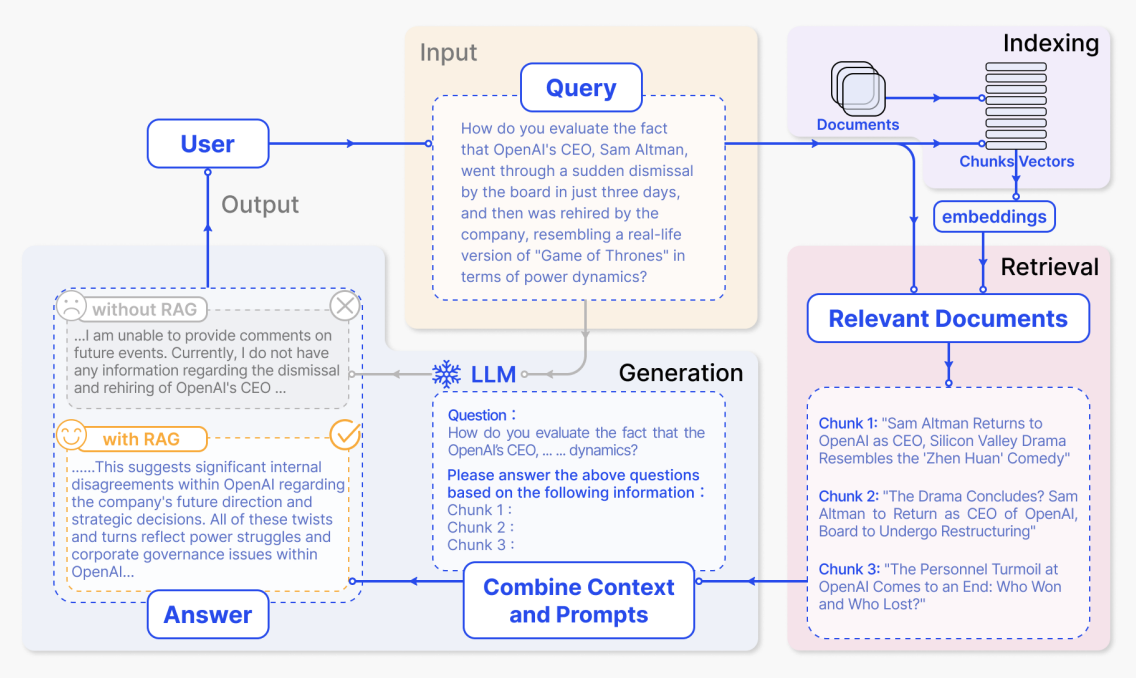
Indexing stage
In the indexing stage, the system first processes raw material such as internal enterprise documents, web pages, and reports. It splits them into smaller semantic chunks, then uses an embedding model to generate vector representations for each chunk and builds an index. Later, when a user question arrives, the system can quickly find the most semantically similar chunks in vector space.
In the diagram, this corresponds to the purple "Indexing" area in the upper right. The path from "Documents" through "Chunks / Vectors" to "embeddings" shows documents being chunked, converted into vectors, and written into the index. More concretely:
- Documents are divided into a set of semantically coherent chunks, each of which may correspond to a short news passage, explanation, or analysis.
- Each chunk is converted into a high-dimensional vector by the embedding model and stored in the vector index.
- This index supports similarity-based retrieval later, preparing a knowledge base the system can consult when answering questions.
Retrieval stage plus answer generation from retrieved results
After the user asks a question, the system first retrieves relevant content from the index, then sends the question and retrieved text together to the large model to generate an answer. In the figure, the key areas from upper to lower and right to left correspond exactly to this full flow.
(1) User input question: the yellow Input - Query area
"How do you evaluate the fact that OpenAI's CEO, Sam Altman, went through a sudden dismissal by the board in just three days, and then was rehired by the company, resembling a real-life version of 'Game of Thrones' in terms of power dynamics?"
"How do you evaluate the fact that OpenAI CEO Sam Altman was suddenly dismissed by the board and then rehired by the company just three days later, making the power struggle resemble a real-life version of Game of Thrones?"
This large block of text is the content inside the "Query" box in the diagram, corresponding to the user's natural-language question. The system vectorizes that question and uses it to search the upper-right index for related document chunks.
(2) Retrieved relevant documents: the pink Relevant Documents area at the lower right
After retrieval, the system gets several document chunks most related to the question. In the diagram, they are shown as three chunks:
"Sam Altman Returns to OpenAI as CEO, Silicon Valley Drama Resembles the 'Zhen Huan' Comedy" "Sam Altman returns as OpenAI CEO, and this Silicon Valley drama resembles a court-intrigue comedy."
"The Drama Concludes? Sam Altman to Return as CEO of OpenAI, Board to Undergo Restructuring" "Is the drama ending? Sam Altman will return as CEO of OpenAI, while the board will be restructured."
"The Personnel Turmoil at OpenAI Comes to an End: Who Won and Who Lost?" "OpenAI's personnel turmoil comes to an end: who won and who lost?"
(3) Combine the prompt and generate the answer: the blue LLM / Combine Context and Prompts area
The system then combines the original user question and the retrieved chunks into a complete prompt and sends it to the model. The dashed box in the lower middle of the figure shows a prompt example:
"Question: How do you evaluate the fact that the OpenAI's CEO, ... dynamics?
Please answer the above questions based on the following information: Chunk 1: Chunk 2: Chunk 3:"
"Question: How do you evaluate the power struggle in the OpenAI CEO incident?
Please answer the above question based on the information below: Chunk 1: Chunk 2: Chunk 3:"
(4) Answer comparison with and without RAG: the gray and yellow Output - Answer areas in the lower left
Finally, the model generates an answer based on the provided information. The figure also compares outputs with and without RAG. Without RAG, the model has no external material and can only give a vague response, corresponding to the gray box:
"... I am unable to provide comments on future events. Currently, I do not have any information regarding the dismissal and rehiring of OpenAI's CEO ..."
With RAG, the model can use the retrieved news and analysis to produce a much more informative answer, corresponding to the yellow box:
"... This suggests significant internal disagreements within OpenAI regarding the company's future direction and strategic decisions. All of these twists and turns reflect power struggles and corporate governance issues within OpenAI ..."
The example above shows the full flow of a typical RAG system and helps us understand its core stages and how information moves through them. But many important technical details remain inside a black box: how exactly is vector matching performed, and how should the prompt be organized so the model can use the retrieved content more effectively? These details largely determine real RAG quality. Next, we will go deeper into RAG's internal mechanism and break it down step by step, from vectorization principles and similarity computation to prompt engineering.
3. How RAG Works
We can break it down through a simple question-answering example built on a knowledge base about "apple."
3.1 Document Vectorization Stage
Suppose we have a simplified knowledge base containing these three document passages:
- Passage A: Apple Inc. was founded on April 1, 1976 by Steve Jobs, Steve Wozniak, and Ronald Wayne, and its headquarters are in Cupertino, California.
- Passage B: Apples are a fruit rich in vitamin C and dietary fiber, which helps digestion and immune-system health.
- Passage C: Apple Inc. launched the first iPhone in 2007, fundamentally changing the smartphone industry.
When we process these documents with an embedding model, such as OpenAI's text-embedding-ada-002 or an open-source BGE model, each passage is converted into a high-dimensional vector, often with 768, 1024, or 1536 dimensions.
A vector is essentially an array made of many numeric values. Each dimension corresponds to a semantic feature of the text. For example, the vector for "cat" may contain dimensions related to mammal, household pet, and furry. The final combination of values captures the semantic meaning of the text so the computer can "understand" relationships between texts.
Simplified examples, with real vectors being much higher-dimensional:
- Vector for passage A, about Apple's founding:
[0.85, -0.23, 0.41, -0.56, 0.12, 0.78, ...] - Vector for passage B, about apples as fruit:
[-0.12, 0.95, -0.34, 0.67, -0.89, 0.05, ...] - Vector for passage C, about the iPhone launch:
[0.79, -0.18, 0.52, -0.61, 0.23, 0.81, ...]
These vectors then need to be stored in a vector database, such as Pinecone, Weaviate, or FAISS, for later retrieval and recall.
A database is a system that stores and manages data in a structured way, enabling organized storage and efficient retrieval. Common examples include contact lists and e-commerce product catalogs.
A vector database is a specialized kind of database. Unlike traditional databases, which store text, tables, and other ordinary data structures, a vector database is designed specifically to store vectors, that is, high-dimensional numeric arrays, and it is optimized for similarity search in AI scenarios.
3.2 User Query, Retrieval, and Response Stage
Once the knowledge base has been vectorized and stored, a RAG system can support real-time user queries. When a user asks a question, the system executes a continuous flow: it first converts the question into a vector, then uses similarity computation to retrieve the most relevant information from the knowledge base, and finally uses those passages as the basis for answer generation. We can illustrate this process with three concrete queries.
Query 1: "When was Apple Inc. founded?"
At the query-vectorization stage, the question is converted by the embedding model into a semantic vector, for example [0.82, -0.21, 0.38, -0.58, 0.15, 0.76, ...]. This numeric pattern is highly similar to the stored vector for passage A, the one about the company's founding.
The system then performs similarity retrieval, Top-K with K = 2, by computing cosine similarity between the query vector and all document vectors in the knowledge base. The result looks like this:
- Similarity with passage A, the founding passage: 0.97, highly relevant
- Similarity with passage C, the iPhone launch passage: 0.88, relevant because it is also about the company
- Similarity with passage B, the fruit nutrition passage: 0.12, almost irrelevant
Top-K is a common selection strategy in vector retrieval. It means ranking all matches from highest to lowest similarity and keeping the top K results. K = 2 means the system retains only the top two document vectors by similarity and filters out lower-ranked ones, so the next stage generates the answer only from the two most relevant document passages.
The results filtered by similarity are called recall results. The system returns the Top-2 passages as evidence:
- Passage A, similarity 0.97: "Apple Inc. was founded on April 1, 1976 by Steve Jobs, Steve Wozniak, and Ronald Wayne, and its headquarters are in Cupertino, California."
- Passage C, similarity 0.88: "Apple Inc. launched the first iPhone in 2007, fundamentally changing the smartphone industry."
At the answer-generation stage, the system builds a complete structured input by placing the recalled content inside the reference information section and sending it together with a system prompt:
[System Prompt]
You are a professional question-answering assistant. Please answer strictly according to the "reference information" provided by the user.
If the reference information contains the answer, answer directly based on it.
If the reference information does not contain the answer, explicitly tell the user that "the question cannot be answered based on the currently available materials," and do not fabricate information.
Please indicate which information point your answer is based on.
[Retrieved Context]
Apple Inc. was founded on April 1, 1976 by Steve Jobs, Steve Wozniak, and Ronald Wayne, and its headquarters are in Cupertino, California.
Apple Inc. launched the first iPhone in 2007, fundamentally changing the smartphone industry.
[User Query]
When was Apple Inc. founded?After receiving this structured input, the LLM follows the system instruction and treats the retrieved context as the only trustworthy source for answering. Its final response would look like this:
According to the provided reference information, Apple Inc. was founded on April 1, 1976. [Basis: Information 1]
Query 2: "What are the benefits of eating apples?"
At the query-vectorization stage, this question is converted into a semantic vector such as [-0.08, 0.92, -0.31, 0.71, -0.85, 0.08, ...]. Its numerical pattern is highly similar to the stored vector for passage B, the one about apple nutrition.
The system again performs Top-K similarity retrieval with K = 2 and computes cosine similarity:
- Similarity with passage B, fruit nutrition: 0.95, highly relevant
- Similarity with passage C, iPhone launch: 0.18, almost irrelevant
- Similarity with passage A, company founding: 0.15, almost irrelevant
The system returns the Top-2 passages as evidence:
- Passage B, similarity 0.95: "Apples are a fruit rich in vitamin C and dietary fiber, which helps digestion and immune-system health."
- Passage C, similarity 0.18: "Apple Inc. launched the first iPhone in 2007, fundamentally changing the smartphone industry." This is only weakly related and would often be filtered by a threshold in practice.
The complete structured input is then built as follows:
[System Prompt]
You are a professional question-answering assistant. Please answer strictly according to the "reference information" provided by the user.
If the reference information contains the answer, answer directly based on it.
If the reference information does not contain the answer, explicitly tell the user that "the question cannot be answered based on the currently available materials," and do not fabricate information.
Please indicate which information point your answer is based on.
[Retrieved Context]
Apples are a fruit rich in vitamin C and dietary fiber, which helps digestion and immune-system health.
Apple Inc. launched the first iPhone in 2007, fundamentally changing the smartphone industry.
[User Query]
What are the benefits of eating apples?Its final response would then look like:
According to the provided reference information, apples are rich in vitamin C and dietary fiber, and eating apples helps digestion and immune-system health. [Basis: Information 1]
Query 3: "How is the weather today?"
At the query-vectorization stage, this question becomes a semantic vector related to weather and meteorology, for example [0.10, -0.05, 0.30, -0.12, 0.21, 0.08, ...]. In semantic space, this vector is far away from all document vectors about apples, whether the company or the fruit, so no significant similarity appears.
The system again performs Top-K retrieval with K = 2. Because the question topic is unrelated to the knowledge base, overall similarity scores are all very low:
- Similarity with passage B, fruit nutrition: 0.18, extremely low
- Similarity with passage C, iPhone launch: 0.10, almost irrelevant
- Similarity with passage A, company founding: 0.08, almost irrelevant
Top-K still returns the top-ranked K results, but in this case those results do not provide effective evidence. In practice, the system often applies a minimum similarity threshold and directly returns empty recall, that is, no valid results, to reduce irrelevant interference.
The two returned passages would still be:
- Passage B, similarity 0.18: "Apples are a fruit rich in vitamin C and dietary fiber, which helps digestion and immune-system health."
- Passage C, similarity 0.10: "Apple Inc. launched the first iPhone in 2007, fundamentally changing the smartphone industry."
The full input would then be:
[System Prompt]
You are a professional question-answering assistant. Please answer strictly according to the "reference information" provided by the user.
If the reference information contains the answer, answer directly based on it.
If the reference information does not contain the answer, explicitly tell the user that "the question cannot be answered based on the currently available materials," and do not fabricate information.
Please indicate which information point your answer is based on.
[Retrieved Context]
Apples are a fruit rich in vitamin C and dietary fiber, which helps digestion and immune-system health.
Apple Inc. launched the first iPhone in 2007, fundamentally changing the smartphone industry.
[User Query]
How is the weather today?The LLM would first judge whether the reference information contains direct weather or real-time meteorological information. After confirming that it does not, it would follow the instruction to answer that it cannot answer:
The currently available materials cannot answer the question "How is the weather today?" because the reference information only contains content related to apples, fruit nutrition, and Apple Inc. products, and does not contain weather information or real-time meteorological data. [Basis: No weather-related information exists in the retrieved context]
From these three examples, we can see the key to the RAG dialogue stage. The system prompt defines the LLM's role and response rules, retrieved evidence provides concrete and trustworthy material, and the user's question defines the task objective. This structured-input pattern is exactly what lets RAG effectively guide and constrain an LLM that might otherwise hallucinate, turning it into a system that produces stable and reliable answers. It ensures that the model is used for understanding and organizing existing information rather than inventing unsupported information.
4. The Evolution of RAG
RAG did not originate in the era of large models. Earlier research already contained prototypes of the same idea. From a historical perspective, RAG arose from recognition of the limitations of traditional LLMs. Early large language models depended mainly on pretraining data, and that data became fixed once training finished. For example, models such as GPT-3 had knowledge cutoff dates tied to when the training data was collected and could not obtain later knowledge. Retraining or fine-tuning LLMs for specific domains also required large resources and specialized expertise, making it expensive and hard to iterate quickly.
The roots of RAG can be traced back to the DrQA framework in 2017, which first attempted to combine retrieval with language models. A major breakthrough then came in 2020 with Dense Passage Retrieval, or DPR, which used pretrained neural models for semantic retrieval instead of traditional word-frequency-based methods such as TF-IDF and BM25. In 2021, RAG was formally proposed and systematized, becoming a standard way to address the knowledge-cutoff and hallucination problems in LLMs.
Broadly speaking, the evolution of RAG can be divided into three stages:
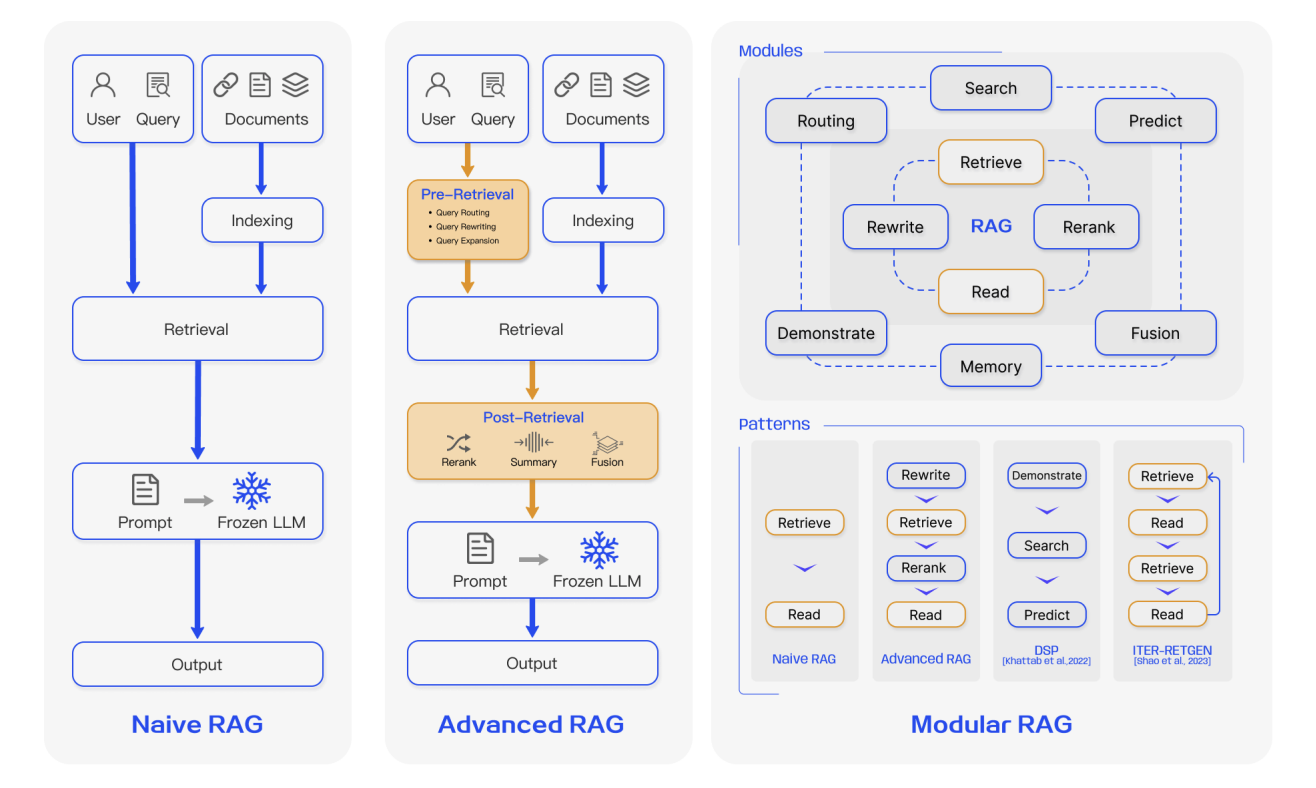
4.1 First-Generation RAG: Naive RAG
Naive RAG is the most basic form of RAG. From an engineering perspective, it follows a very direct three-step flow:
- Document preprocessing and indexing. Raw documents are cleaned, split into fixed-length text chunks, encoded into vectors with an embedding model, and written into a vector database.
- Similarity-based retrieval. The user's natural-language question is encoded into a vector, and the system performs a Top-K similarity search over the vector store.
- Simple retrieval-augmented generation. The retrieved chunks are directly concatenated with the original question to form a long prompt, which is sent to the LLM for answer generation.
The value of this stage is that it verified, with a very low barrier, that "retrieve before answering" actually works. Compared with relying only on the model's internal memory, it already significantly reduces knowledge-cutoff issues and some hallucinations, which is why it played an important role in early prototypes, demos, and introductory tutorials.
However, the limitations of first-generation RAG are also obvious. First, the chunking strategy is usually crude. Most systems simply split by fixed length, which can cut a coherent semantic paragraph in the middle or mix multiple topics inside one chunk. This hurts retrieval accuracy and also makes comprehension harder for the LLM. Second, the retrieval signal is too simple. Ranking usually depends only on vector similarity and does not use richer structured clues such as keywords, timestamps, source credibility, or access permissions. Third, retrieval results are barely governed at all: noisy, repetitive, and even contradictory chunks can be stuffed into the context unchanged, causing large amounts of low-value information to occupy an already limited context window.
In short, the first generation solved the question of whether retrieval is needed. But on the questions of how to retrieve better, and how to use retrieved information more reasonably, it still remained at a rather primitive stage.
4.2 Second-Generation RAG: Advanced RAG
As RAG moved from demos into real business scenarios, the requirements for stability, controllability, and output quality rose sharply. The second generation, usually grouped under the broad name Advanced RAG, still follows the pattern of retrieve first and generate second, but it introduces systematic refinement both before and after retrieval. In other words, the system is no longer satisfied with merely retrieving something. It now aims to store the right things properly, ask the right questions clearly, and govern the retrieved context carefully.
Before retrieval, the focus is on storing and asking well:
On the indexing side, chunking evolves from fixed-length splits to semantically aware chunking and hierarchical indexing. The system may chunk along chapter, subsection, paragraph, or sentence boundaries, combined with sliding windows and multi-granularity index structures.
Each document chunk can carry rich metadata such as source, timestamp, author, topic, and document type, providing more dimensions for later filtering and ranking.
On the query side, the user's original question can be rewritten, expanded, or decomposed through techniques such as Query Rewrite, Multi-Query, Sub-Query decomposition, and Step-back Prompting, transforming vague or conversational user queries into forms that retrieval can understand better.
- Query Rewrite
The core idea is to transform the user's vague, colloquial, or nonstandard query into a normalized expression that the retrieval system can understand more easily, supplementing key information and resolving ambiguity.
- For example, "How do I check tomorrow's weather in Beijing?" might be rewritten into something more standardized such as "Query tomorrow's full-day real-time weather in Beijing."
- Or "Recommend good movies" may be rewritten, after looking at user history, into "Recommend high-rated 2024 suspense movies."
- Multi-Query
The system generates multiple semantically related but differently angled queries from the original question to reduce missed results and cover latent needs the user did not explicitly state.
- Sub-Query
For compound questions that contain several goals, the system splits them into smaller, simpler sub-queries so retrieval can match each need precisely.
- Step-back Prompting
The system first generates a more abstract, higher-level question, then uses that to guide retrieval direction, reducing bias caused by being too narrowly focused on details in the original question.
After retrieval, the focus is on governing what was retrieved:
- A dedicated rerank model or even an LLM can rerank candidate documents so the most important and question-relevant content enters the context first.
A rerank model is a key component in an information-retrieval pipeline. It performs second-stage ranking on candidate results returned by the recall phase, using stronger semantic understanding, often based on Transformer architectures, to fix semantic ranking errors from the first stage and move the results most aligned with user needs further forward.
- Retrieved passages can be filtered, deduplicated, and compressed to remove clearly irrelevant or highly repetitive chunks, reducing the tendency of long-context systems to ignore useful information in the middle.
- When necessary, light model fine-tuning can make the LLM more likely to answer from retrieval evidence and include explicit citations or sources.
Overall, Advanced RAG is no longer focused only on whether retrieval is necessary or whether something can be retrieved. It instead addresses three larger challenges: whether the truly critical passages can be located precisely, whether the context handed to the large model is concise, well-structured, and easy to use efficiently, and whether the whole system remains stable and reliable in the presence of noise, conflict, or multi-source information needs.
Large amounts of experimental and engineering evidence show that Advanced RAG significantly outperforms Naive RAG on answer accuracy, hallucination suppression, system robustness, and explainability. That is why it has gradually replaced traditional basic approaches and become the mainstream industrial paradigm for building RAG systems today.
4.3 Third-Generation RAG: Modular RAG
In complex enterprise applications, requirements often span multiple domains. In those cases, a simple linear flow of retrieve, rerank, and generate is often not enough:
- The same system may need to support simple FAQs, long report generation, code retrieval, and database calls.
- It may need to connect vector stores, full-text retrieval, relational databases, knowledge graphs, and external search engines at the same time.
- It may need to preserve user preferences and historical decisions over multiple rounds, while also applying compliance checks and answer traceability.
Against this background, RAG began evolving toward a modular system shape. Modular RAG is no longer viewed as a fixed pipeline. It is treated instead as a set of pluggable, replaceable, and composable function modules that can be orchestrated as needed. Typical modules include:
- Query understanding and routing This module handles intent recognition, question rewriting, subtask decomposition, and path selection. It decides whether a request should rely mainly on internal knowledge, external retrieval, or a specific tool or database.
- Multi-source retrieval and fusion This module connects vector databases, full-text search, structured databases, and knowledge graphs simultaneously, queries them, and merges and reranks their results into a unified evidence set.
- Memory and personalization This module maintains long-term user profiles, short-term session memory, and domain knowledge caches so the system can continuously accumulate and use historical information.
- Task adaptation and governance This module loads different adapters for different tasks, constrains output format, tone, and style, and governs outputs through fact checking, risk filtering, and citation alignment.
In short, traditional RAG often ends after one retrieval round plus one generation round. Modular RAG breaks that single-flow pattern. If the system discovers during generation that information is still insufficient, it can proactively trigger new retrieval rounds and even move back and forth multiple times between retrieval and generation to complete a more complex task.
Going further, the model can learn to make its own decisions: answer directly from internal knowledge or short context when confidence is high, and launch retrieval or external tool calls only when uncertainty is high. That improves efficiency and saves resources while preserving quality. For heavily underspecified or incomplete queries, the model can even generate a hypothetical intermediate answer or draft document first, then use that as a clue for further retrieval, progressively approaching reliable sources.
At this stage, RAG is no longer just a simple component that attaches a few reference passages to a large model. It is becoming the central knowledge-orchestration layer inside enterprise intelligent applications, coordinating multiple data sources, multiple tools, and multiple tasks.
5. From Demo to Enterprise-Grade RAG
From the perspective of enterprise engineering, building a RAG system cannot be limited to retrieval-augmented generation alone. The material above is still closer to a demo-level introduction. In real business scenarios, data is often noisy and inconsistent in format, so more effort must be invested into preprocessing, cleaning, and ingestion, and model selection must be handled carefully at every key point.
A complete enterprise-grade RAG system can usually be divided into three core modules: layout analysis and knowledge ingestion, knowledge-base construction, and RAG-based question-answering service. Across the full technical chain, several key model-selection decisions appear, including the embedding model, rerank model, and LLM. Only with sensible technical choices at each stage can the system achieve strong overall results.
Layout analysis and local knowledge-file reading
This module converts local knowledge assets in different formats into text usable for retrieval. Inputs may include PDFs, TXT, HTML, Word, Excel, and PPT files, as well as scanned image files such as PNG and JPG, or even audio recordings.
The system needs to parse each format appropriately, perform layout analysis and structural extraction for text documents, distinguish titles, main body, tables, headers, and footers, and restore a sensible reading order. It performs OCR on image files and ASR on speech, finally converting everything into relatively clean knowledge text while retaining basic metadata such as file name, chapter, page number, and timestamp for later chunking and indexing.
Knowledge-base construction: chunking, embeddings, and indexing
After obtaining cleaned knowledge text, the system performs chunking, splitting long documents into semantically coherent blocks of suitable length, usually by paragraph, title structure, or sliding window, while preserving each chunk's source and metadata.
Then it uses the chosen embedding model, such as
text-embedding-3-small, Sentence Transformers, or BGE, to calculate vector representations for each chunk and build a vector index using tools such as Faiss, Milvus, or managed vector-search services. At that point, a knowledge base that supports fast semantic retrieval has been created.RAG-based question answering: recall, reranking, concatenation, generation
In the online QA stage, the user sends a query. The system embeds it into a query vector, retrieves a batch of the most similar text chunks from the vector index, and treats that as a coarse ranking stage. Then it can use a rerank model such as a BGE reranker or even an LLM acting as a reranker to score query-document pairs again and keep only the Top-K documents that are truly most relevant as the knowledge context.
Next, together with a carefully designed system prompt such as "Please answer strictly based on the following materials," the system concatenates the user query and retrieved document passages and sends the merged prompt to the LLM. The model then generates the final answer from those retrieved pieces of evidence and, when needed, includes citations or sources.
5.1 Model Selection
Next we focus on model selection. A complete RAG system usually involves three core model categories: embedding models, rerank models, and large language models. Each has its own role, and together they form the full path from retrieval to answer generation. The embedding model converts text into searchable semantic vectors, the rerank model refines initial retrieval results, and the LLM generates the final answer based on the selected knowledge context.
5.1.1 Embedding Models
In a RAG system, the job of the embedding model is to convert text, such as user queries and knowledge-base content, into high-dimensional vectors. Semantically similar texts are placed closer together in vector space, allowing the system to locate related knowledge quickly by similarity. Choosing the right embedding model is therefore one of the most critical steps in building a high-performance RAG system because it directly determines recall quality.
To choose a strong model, it helps to use a systematic benchmark. One of the most widely used is MTEB, the Massive Text Embedding Benchmark.
MTEB provides a unified and objective evaluation framework for many embedding models. Through eight major task categories and 56 datasets, it evaluates performance across retrieval, clustering, classification, reranking, text matching, semantic similarity, and more. A model's overall MTEB score reflects the generality and robustness of its vector representations and can serve as an important reference for model selection. The latest ranking can be checked on the Hugging Face MTEB leaderboard:
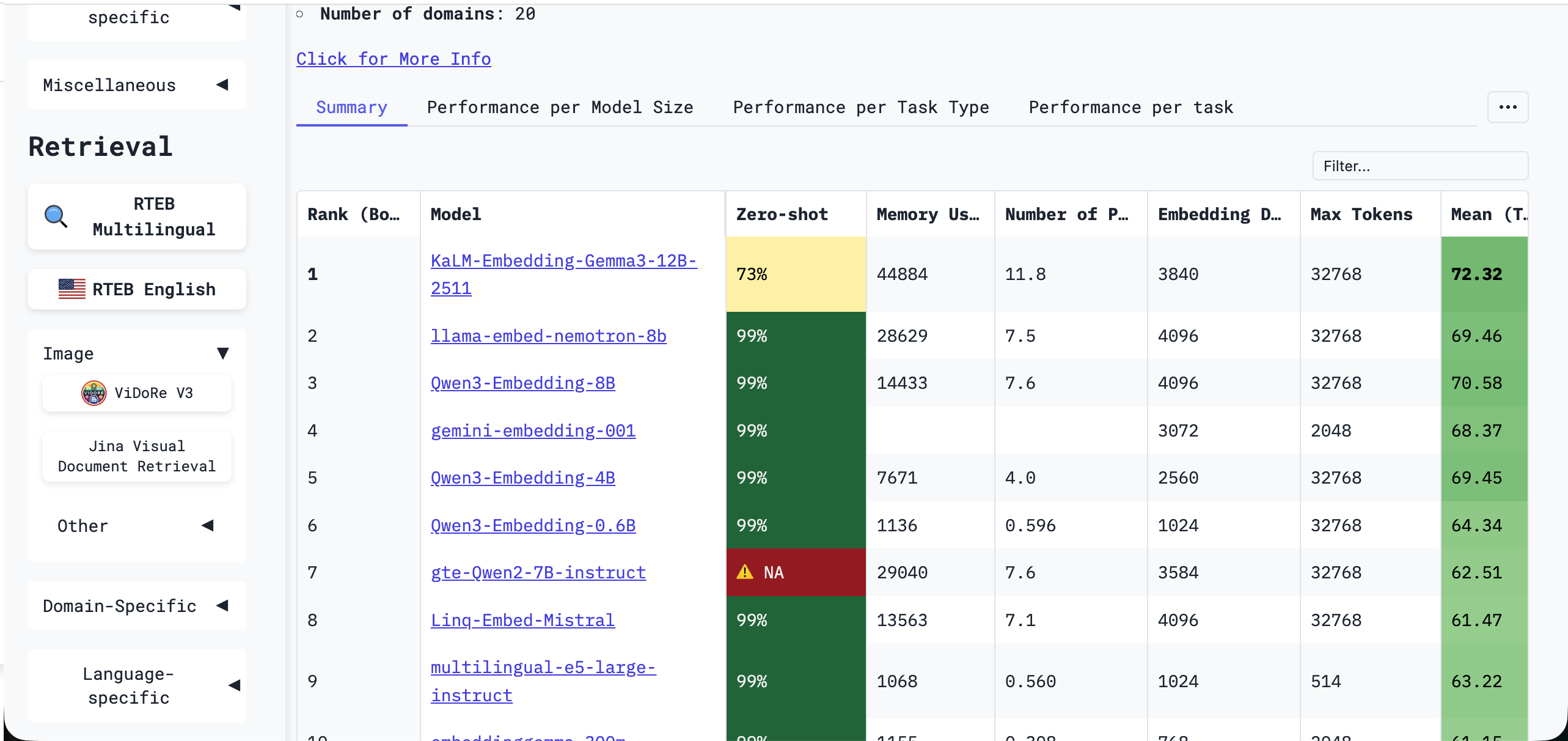
Although there are many models on the leaderboard, you do not need to master all of them. In practice, choosing the embedding model bundled by a major model provider, or using a cloud-served model that many people have already validated, is usually a safe choice. You can also filter the leaderboard by category or language in the sidebar:
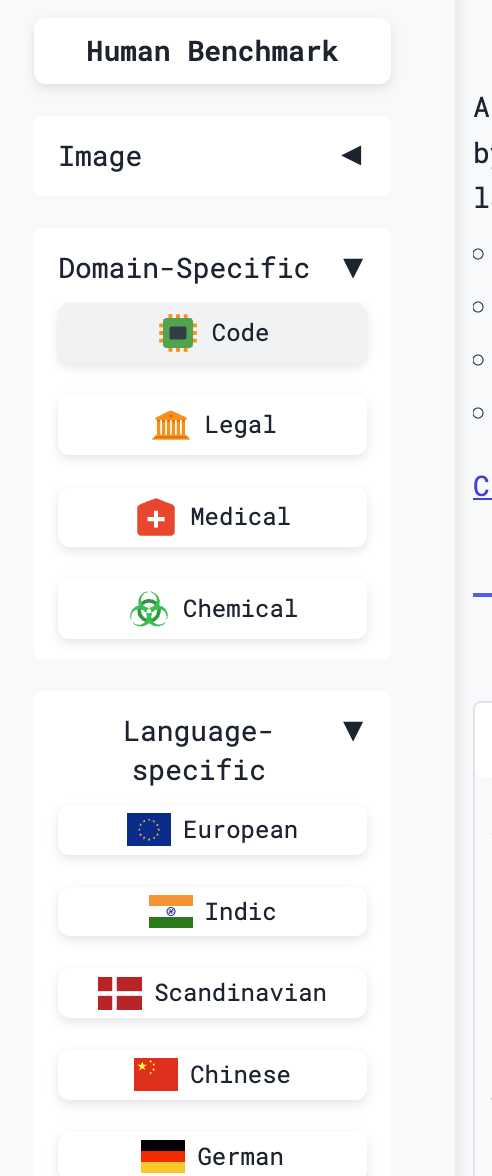
When filtering embedding models, two parameters matter especially because they directly affect RAG performance: dimension and context length.
Dimension is the dimensionality of the vector output, such as 128, 768, or 1536. It roughly reflects how many semantic features the vector can express. Higher-dimensional vectors can capture richer semantic detail and stronger discrimination. For example, a 768-dimensional vector can represent "apple" from hundreds of angles such as variety, taste, and origin, making it suitable for professional scenarios like healthcare or law that need precise retrieval. Lower dimensions reduce computation and storage cost and improve retrieval speed, making them suitable for large-scale general scenarios with high concurrency and strong real-time requirements.
Context length is the maximum text length the embedding model can process in one pass, measured in tokens. One English token is roughly three quarters of a word, and one Chinese token is roughly one Chinese character. Anything longer than the maximum is truncated. This directly determines whether the model can fully understand the text. If important information is lost because the length is too short, retrieval accuracy drops sharply. For short user queries and short QA pairs, 512 to 1024 tokens is often enough. For longer texts such as papers and reports, you usually need 2048 tokens or more.
Below is a comparison of several common embedding models. In practice, you need to choose by balancing cost and performance. There is no universally best model, only the most suitable model after comparing several options in your own use case.
| Model Name | Model Scale | Core Strength | Suitable Scenarios |
|---|---|---|---|
OpenAI text-embedding-3-large | Closed API | Long-term leader on MTEB, mature and stable | Cloud API scenarios that prioritize extreme performance and have enough budget |
jina-embeddings-v2 | Supports long text up to 8K context | Strong for long-document retrieval through asynchronous encoding design | Document analysis, legal compliance, academic retrieval |
multilingual-e5-large | Large scale | Classic multilingual option | Cross-lingual RAG, international products, multilingual support systems |
Qwen/Qwen2-Embedding-8B | 8B parameters, up to 4096 custom dimensions | Former top multilingual MTEB performer, strong on long text, multilingual tasks, and code | High-precision Chinese-English RAG, long-document analysis, code retrieval |
Qwen/Qwen2-Embedding-4B | 4B parameters | Strong balance of performance and efficiency | Large-scale production RAG systems |
Qwen/Qwen2-Embedding-0.6B | 0.6B parameters | Suitable for edge devices | Resource-constrained, speed-first scenarios |
BAAI/bge-m3 | Supports hybrid retrieval, dense plus sparse plus multi-vector | Strong on multilingual benchmarks such as MIRACL | Complex multilingual scenarios that need hybrid retrieval |
BAAI/bge-large-zh-v1.5 | Large scale | Stable Chinese RAG baseline with strong community validation | Pure Chinese projects with shorter documents |
ZhipuAI Embedding-3 | Closed cloud API | Supports custom dimensions from 256 to 2048 | Chinese-focused applications preferring cloud APIs |
5.1.2 Rerank Models
In a RAG system, the rerank model is responsible for finely reranking initial retrieval results. It takes the user query and candidate documents as input and computes an exact relevance score for each query-document pair. The higher the score, the better the match. Therefore, adding a rerank model on top of embedding-based recall is a key step for improving retrieval precision.
For embedding models, we can use benchmarks like MTEB. For rerank models, one useful reference is Agentset's reranker leaderboard:
The Agentset benchmark first retrieves the 50 most relevant candidate results from a large document store using FAISS, then asks the rerank model under evaluation to rerank those 50 documents. The benchmark pays attention to both ranking quality and latency. In practical applications, pursuing precision while ignoring speed hurts user experience, while pursuing speed while sacrificing ranking quality harms usefulness.
Agentset also introduces an ELO scoring mechanism. For each query, GPT-5 acts as a judge and compares the ranked outputs of two different rerank models, deciding which one places truly relevant documents in a more sensible order. After large numbers of such pairwise comparisons, models that win more often receive higher ELO scores, providing an intuitive overall performance signal.
The benchmark also uses two complementary groups of metrics:
nDCG@5/10, which focuses on whether relevant documents are placed near the front and therefore reflects ranking precisionRecall@5/10, which focuses on whether all relevant documents can be found and therefore reflects coverage
Together these metrics provide a more complete picture of rerank performance.
Still, in practice, you do not need to select rerank models only from a leaderboard. Industrial usefulness and leaderboard score are not always the same thing. A practical approach is to start from the rerank models recommended by your cloud vendors or default rerank APIs provided by major model vendors, or to test a model family you are already using, such as a matching Qwen rerank model.
5.1.3 LLMs
After semantic retrieval by the embedding model and refined filtering by the rerank model, the relevant document passages are combined with the user's original question into a prompt. The LLM then performs reading comprehension, information integration, and natural-language generation to output a coherent, accurate answer that fits the context.
At the implementation level, there are two main ways to use LLMs in RAG:
- Privately deployed large models. These are suitable for scenarios that care about data privacy, controllable cost, or deep customization. Mainstream open models such as Qwen, Llama, and GLM perform well in RAG tasks. For example, Qwen2.5 in the 7B or 14B range offers good instruction-following and Chinese understanding while keeping resource use modest, making it suitable for local enterprise deployment. Models such as KIMI, Minimax, and DeepSeek can also be considered according to specific business needs.
- Cloud API large models. These fit scenarios that prioritize fast launch, elastic scaling, and continuous model upgrades. Major providers such as OpenAI, Anthropic, Google, Alibaba, and ZhipuAI all offer stable API services. These models generally have strong language understanding and generation ability and can synthesize answers well in RAG scenarios.
When selecting cloud models, several points matter: whether answer quality is accurate and fluent, whether price is reasonable, whether latency is acceptable, and whether the context window is large enough to hold multiple retrieved documents. In practice, you should compare several candidates on your own data and see which one gives the most complete and accurate answers. If cost is a concern, a useful approach is to combine large and small models: use cheaper small models for simple questions and reserve expensive large models for difficult cases. Since models update quickly, it is also wise to retest candidates periodically.
For broad conversation and QA ability, LMSYS Chatbot Arena, now LMArena, is one of the most widely recognized evaluation references:
It uses blinded pairwise human comparisons to rank models. The ranking offers a useful first filter, but in actual RAG selection it should only be a starting point. In specialized domains such as medicine, law, and finance, general leaderboard ranking can diverge substantially from real performance on your business data.
Best practice for LLM selection is to build a small but representative test set containing 20 to 30 typical business questions and evaluate candidate models through the full end-to-end RAG pipeline rather than looking only at isolated model benchmarks. Questions such as whether to use reasoning models or non-reasoning models, or which model size best balances quality and speed, are all best answered through real testing on your own use case.
5.2 Execution Frameworks
In real engineering practice, you usually do not need to build an entire RAG system from zero. A number of mature open-source frameworks already exist, each with its own strengths in architecture, modular integration, and development efficiency. Enterprises can choose according to their own technical reserves and business scenarios.
Common framework types include:
Low-code or visual platforms
- Dify: provides an intuitive visual interface for quickly building RAG applications, making it suitable for nontechnical teams or rapid prototype validation. It includes built-in multi-model access, workflow orchestration, and prompt management.
- Coze: an AI bot development platform from ByteDance that offers zero-code visual construction. It integrates deeply with ByteDance model services, supports a plugin marketplace, scheduled tasks, and multichannel publishing, making it suitable for consumer-facing assistants or internal enterprise bots.
- n8n: an open-source node-based workflow automation platform. In RAG scenarios, it can orchestrate complex business logic and connect preprocessing, vector database operations, model calls, and follow-up actions such as email sending or ticket updates into one automated flow.
- RAGFlow: focuses on deep layout analysis and knowledge extraction and performs well on complex documents such as multi-column PDFs and table-heavy materials.
- FastGPT: a Chinese open-source solution integrating knowledge-base management, dialogue orchestration, and application publishing, with strong Chinese documentation and suitability for fast deployment of Chinese RAG applications.
Code frameworks and development libraries
The tools below usually have implementations in different backend languages. You can choose the corresponding language version for your application stack.
- LlamaIndex: a Python framework designed specifically for RAG, with rich connectors, index structures, and query engines. Its modularity makes it suitable for deeply customized retrieval strategies or integration with many data sources.
- LangChain: a general LLM application framework where RAG is only one use case. Its strength is its rich ecosystem and component coverage, including support for complex agents and workflow orchestration, though its learning curve is steeper.
If the team's technical reserves are limited and speed matters most, low-code platforms such as Dify, Coze, or FastGPT are good first choices. If you need deep customization, special data-source integration, or detailed performance tuning, LlamaIndex and LangChain offer more flexibility. In practice, a hybrid route is also common: use a low-code platform for rapid feasibility validation, then move to code frameworks for production deployment and optimization. Most of these frameworks also support rapid integration with mainstream embedding, rerank, and LLM models, letting you combine them flexibly using the model-selection principles discussed above.
5.3 Effect Evaluation
For enterprises deploying RAG systems, the biggest challenge is often not building the system but tuning it. Production-grade RAG contains two nondeterministic stages, retrieval and generation, so traditional software testing is not enough. That is why building a scientific evaluation system, or RAG evaluation, is so important.
5.3.1 Beginner Example: LLM-Based RAG Evaluation
To help build an intuitive understanding of RAG evaluation, we can look at a simple automated pipeline based on the idea of LLM-as-a-judge:
https://huggingface.co/learn/cookbook/rag_evaluation
The process usually contains three key steps:
- First, synthesize an evaluation dataset by sampling documents from the knowledge base and asking an LLM to generate high-quality question-answer pairs, then filter them by relevance and groundedness to form a benchmark set.
- Second, run the RAG system on each question in that test set and collect the generated answers.
- Third, automate scoring by calling another LLM as a judge, comparing the generated answers with reference answers, and giving quantitative scores for dimensions such as accuracy and completeness.
A simple example:
- Problem generation. Suppose the knowledge base contains a product manual line saying, "This device supports wireless charging and has a 5000mAh battery." We ask one model to act as an exam setter and generate a question such as, "What is the battery capacity of this device?" The standard answer is "5000mAh."
- Problem solving. We send that question to the RAG system, which retrieves related material and answers, for example, "The device has a 5000mAh battery."
- Grading. We ask another model to act as the grader by comparing the question, the generated answer, and the reference answer, using a prompt such as, "Judge whether the generated answer is correct. Output only correct or incorrect."
By running this process at scale, we can compute metrics such as accuracy. This forms a practical loop of evaluate, optimize, and reevaluate.
If you want deeper detail on RAG evaluation, including metric definitions, framework usage, and benchmark datasets, two useful survey papers are:
- https://arxiv.org/pdf/2504.14891, Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey
- https://arxiv.org/pdf/2405.07437, Evaluation of Retrieval-Augmented Generation: A Survey
5.3.2 Evaluation Metrics
RAG evaluation fundamentally revolves around two questions: can the retrieval module find the right material, and can the generation module produce a high-quality answer from that material? Accordingly, the evaluation system is divided into retrieval evaluation and generation evaluation, supplemented by LLM-as-a-judge scoring.
Retrieval Evaluation: recall accuracy and ranking quality
The retrieval module is the first gate in a RAG system. Its evaluation focuses on three dimensions: whether it finds the right things, whether it finds enough of them, and whether it ranks them well.
Basic recall quality metrics
The classic basic metrics are Recall@K, Precision@K, and F1:
- Recall@K measures the proportion of relevant documents recovered in the top K results. If five relevant documents exist and three are found in the top 10, Recall@10 is 60 percent. This tells us how broad retrieval coverage is.
- Precision@K measures the proportion of top K results that are truly relevant. If three of the top 10 are relevant and seven are not, Precision@10 is 30 percent. This reflects retrieval accuracy.
- F1 is the harmonic mean of Recall and Precision and balances the two.
These metrics are useful for quickly diagnosing baseline recall problems. If Recall is low, relevant documents were not found at all. If Precision is low, retrieval noise is too high.
Ranking quality metrics
Finding relevant documents is only the first step. It is even more important to put the most relevant ones near the front. For that we look at MRR, NDCG@K, and MAP:
- MRR, Mean Reciprocal Rank, measures the reciprocal of the rank position of the first relevant document. If the first relevant document appears in position 3, the reciprocal rank is 1/3. MRR is especially suitable for scenarios where one correct answer is enough.
- NDCG@K, Normalized Discounted Cumulative Gain, considers both graded relevance and position discount. It not only asks whether a document is relevant, but how relevant it is, and it rewards highly relevant documents that appear early.
- MAP, Mean Average Precision, is sensitive to the positions of all relevant documents and reflects overall ranking quality.
In actual engineering, a common combination is Recall@K plus MRR@K. For example, if Recall@10 is 80 percent but MRR@10 is only 0.3, relevant documents are being found but buried too deep, which suggests reranking needs improvement.
When needed, a Coverage metric can also be added to monitor knowledge-base coverage and reveal systematic blind spots.
Generation quality evaluation: accuracy and factual faithfulness
Retrieval provides the raw material. The next question is whether the generation module can produce a high-quality answer from those materials. The core dimensions here are answer accuracy and faithfulness to the retrieved evidence.
Exact match and text similarity
The simplest metric is EM, Exact Match, which requires the generated answer to match the reference answer exactly. This is suitable for fixed-form, uniquely correct fact questions such as dates or headquarters locations, but it is too strict because different but equally correct surface forms may fail to match.
That is why n-gram-overlap metrics such as ROUGE, BLEU, and METEOR are also commonly used. They score generated answers by comparing word overlap with reference answers. ROUGE-L pays attention to longest common subsequences, BLEU comes from machine translation and emphasizes exactness, and METEOR adds synonym and stemming considerations.
To overcome the limits of pure word overlap, we can also use BERTScore or direct vector similarity. These use pretrained semantic representations and therefore tolerate surface variation better.
Factual faithfulness and hallucination detection
For RAG systems, answer-reference similarity is not enough. The more important question is whether the answer is actually grounded in the retrieved documents or whether it hallucinates unsupported content.
That is why metrics such as Hallucination rate and Faithfulness are important. A second LLM can act as a fact checker and inspect the generated answer sentence by sentence, judging whether each claim can be supported by the retrieved documents. For high-stakes domains such as healthcare, law, and finance, this type of metric is especially important, and some enterprises even enforce hallucination thresholds as production release criteria.
LLM-as-a-Judge: multi-dimensional scoring
Every automatic metric has limits. Most surface-form metrics cannot fully capture semantic quality or overall usefulness. That is where LLM-as-a-judge becomes especially valuable.
The basic approach is to feed the question, retrieved documents, system answer, and reference answer into a strong independent model, such as GPT-4 or Claude, and ask it to score across dimensions such as:
- question relevance
- information completeness
- factual faithfulness
- overall correctness
The strength of an LLM judge is that it can make a more human-like holistic judgment. Of course, judge prompts still need careful design and calibration against human-labeled examples to keep the scoring consistent and reliable.
Building a practical metric combination
With so many metrics available, teams often wonder which ones to use. A practical recommendation is to start with a compact combination and expand gradually:
- For retrieval, begin with Recall@K plus MRR@K
- For generation, choose one or two baseline metrics from EM, ROUGE-L, and BERTScore according to task type
- For overall evaluation, introduce an LLM judge focused on relevance, completeness, and faithfulness
Then iterate through a loop of evaluation, problem diagnosis, strategy adjustment, and reevaluation.
5.3.3 Evaluation Frameworks
As RAG has developed rapidly, both academia and industry have produced many strong evaluation frameworks. These frameworks not only package common metrics, but also offer standardized datasets, benchmark procedures, and end-to-end workflows.
A basic classification of frameworks
We can roughly divide RAG evaluation frameworks into three categories:
- Research frameworks, which focus on academic exploration and fine-grained diagnosis. Examples include FiD-Light and Diversity Reranker.
- Benchmark frameworks, which provide standardized test sets and workflows for comparing systems horizontally. These include frameworks such as RAGAS, ARES, RGB, MultiHop-RAG, and CRUD-RAG.
- Tooling frameworks, which emphasize engineering usability and integration with development frameworks. Examples include TruEra RAG Triad, LangChain Benchmarks, and RECALL.
In recent years, evaluation frameworks have become more specialized. For example, medicine has MedRAG, law has LegalBench-RAG, and finance has its own domain-specific frameworks. These domain frameworks often provide not only specialized datasets but also specialized metrics such as medical accuracy or legal citation relevance.
In practice, a good rule of thumb is:
- If you need a baseline quickly, start with a more general framework such as RAGAS.
- If you are diagnosing a specific problem, choose a more targeted framework.
- If you are in medicine, law, finance, or another professional domain, prefer domain-adapted frameworks where possible.
- Prefer actively maintained tools with strong documentation and responsive communities.
Commonly recommended tools in the community include Ragas, Continuous Eval, TruLens-Eval, the evaluation features inside LlamaIndex, Phoenix, DeepEval, LangSmith, and OpenAI Evals.
5.3.4 Evaluation Benchmarks
The importance of evaluation benchmarks is often underestimated. Many teams start assessing a RAG system with only a handful of hand-written test questions, then discover that real online performance differs sharply from offline impressions. The root cause is that they lack representative and systematic evaluation data.
A benchmark that supports system iteration well usually has three core characteristics:
- representativeness, meaning it covers high-frequency user questions, boundary cases, and abnormal inputs
- standardization, meaning question and answer formats, difficulty levels, and scoring rules are consistent
- evolvability, meaning the benchmark can be updated as system capability and business needs evolve
For most enterprises, because business scenarios are unique, the final answer is usually to build their own evaluation datasets.
- Start by extracting real user questions from business logs and sampling them by type, frequency, and difficulty.
- For simple cases, let domain experts annotate directly. For more complex questions, let a strong LLM generate candidate answers first, then have experts revise them.
- Besides the answer itself, label metadata such as related documents, answer type, and difficulty level.
- Update the dataset periodically with new hard cases discovered online.
If resources are limited and you need a fast baseline, public benchmarks are still a useful starting point. As of 2025, many public benchmarks exist for both general and vertical scenarios:
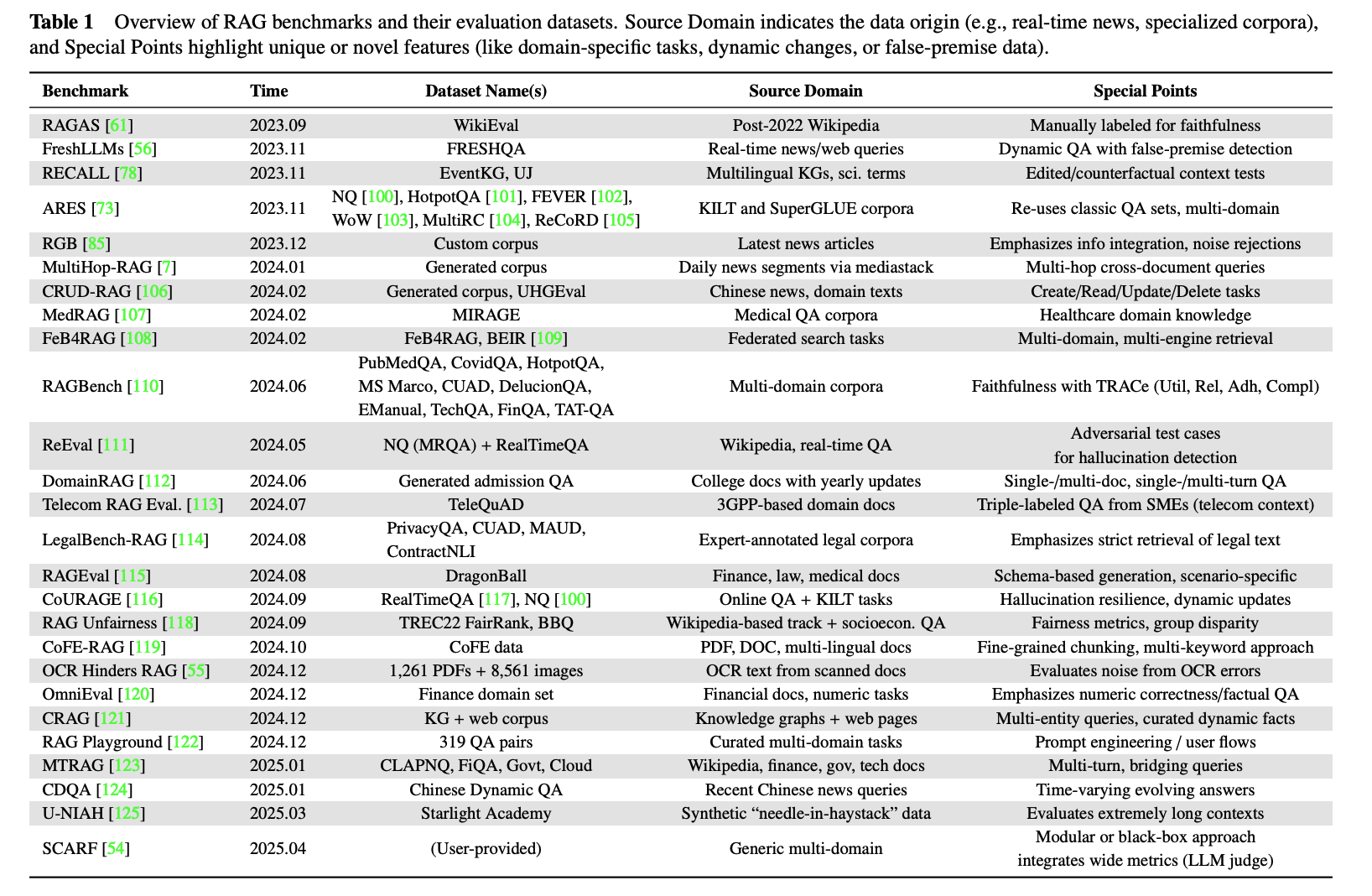
When choosing among them, first clarify the goal. Are you establishing a baseline, or validating the system before launch? Then check whether the benchmark covers the scenarios and difficulty profile you care about. For time-sensitive domains such as news or finance, make sure the benchmark includes time-sensitive tests.
In practice, combining your own in-domain dataset with public benchmarks is often the most robust path because it keeps evaluation close to real business needs while also preserving some horizontal comparability.
6. Deep Dive: Learning from Competitions and Open Tutorials (Optional)
The principles and baseline implementation above are enough to help you build a usable prototype, but they are still some distance away from solving the harder problems that appear in production. If you want to understand more practical and battle-tested RAG techniques, one of the most efficient ways is to study winning competition solutions and strong open tutorials. These solutions often concentrate the best practices discovered by strong teams after repeated attempts in real scenarios.
The examples below are representative rather than exhaustive. When you meet a specific problem in practice, such as PDF parsing, multimodal retrieval, or low-latency optimization, it is often effective to search for competitions related to that problem and study the technical reports and open code from winning teams.
6.1 Semantic Cache: optimizing high-frequency queries
Hugging Face provides a semantic-cache implementation built on top of the Chroma vector database:
https://huggingface.co/learn/cookbook/semantic_cache_chroma_vector_database
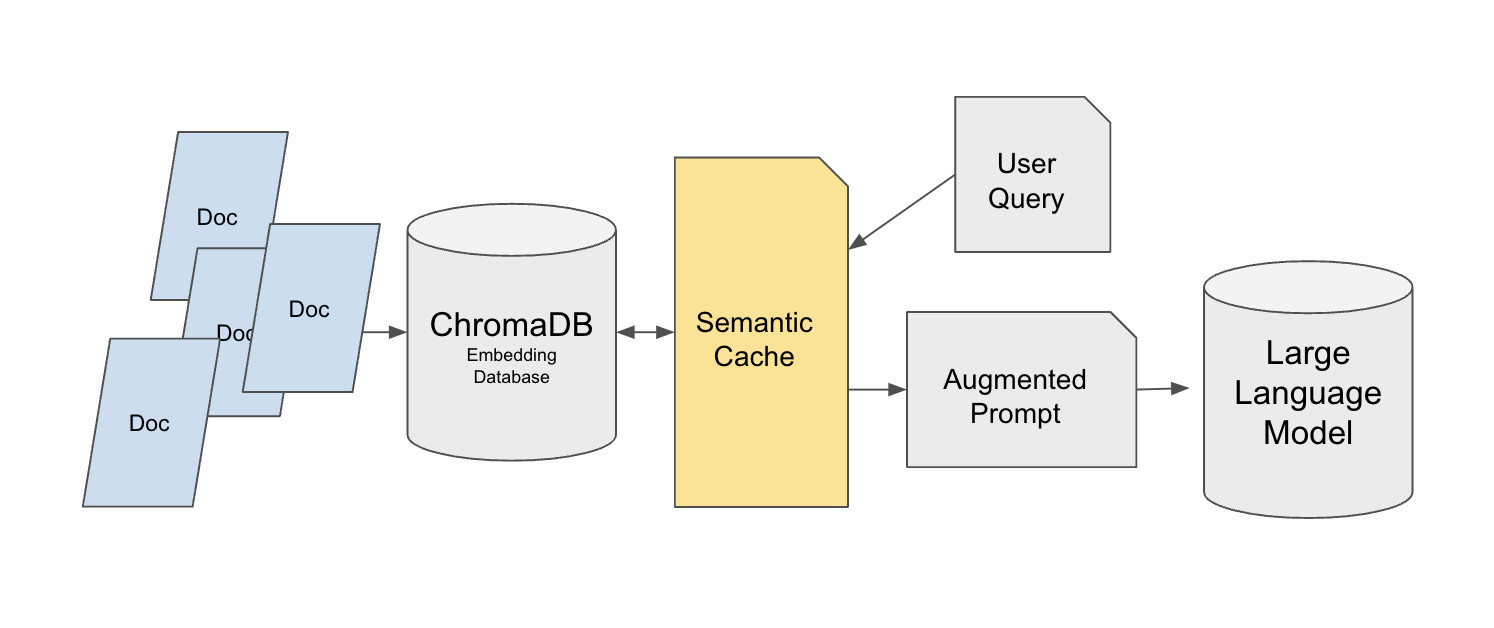
Background: Most tutorial RAG systems are built for single-user testing. But once deployed to production, the system may receive dozens or thousands of repeated queries, for example support users repeatedly asking how refunds work. If every repeated query still triggers vector retrieval and an LLM call, latency and cost rise quickly. A semantic cache layer can sharply reduce pressure on the original data sources while preserving answer quality.
This design uses a two-layer retrieval architecture. The base layer stores the original knowledge base in Chroma, using a dataset such as MedQuad as an example and assigning each entry a unique ID for precise reference. The cache layer is built on FAISS using a FlatL2 index. The semantic cache sits between the user query and Chroma, rather than caching the LLM's final answer directly. That design matters because directly caching answers can break personalized answer requirements such as "explain this in simple language."
The cache system uses the all-mpnet-base-v2 SentenceTransformer to generate query vectors and uses Euclidean distance, with a threshold of 0.35, to judge whether queries are similar. When the cache is full, controlled by the max_response parameter, the oldest entry is removed using FIFO. Cache data can also be saved into JSON files for cross-session reuse.
In small-scale testing, a first query such as "How do vaccines work?" took 0.057 seconds when fetched from Chroma, while a similar query served from cache took only 0.016 seconds. In large production scenarios, this approach can produce 90 to 95 percent performance optimization in high-repeat environments and significantly reduce vector-store and API cost.
6.2 Unstructured Data Processing: unified parsing for multi-format documents
Another Hugging Face tutorial shows how to use the Unstructured library to build a full pipeline for non-structured document processing:
https://huggingface.co/learn/cookbook/rag_with_unstructured_data

Background: In enterprise scenarios, knowledge is often scattered across PDFs, PowerPoint decks, EPUBs, HTML pages, and many other formats. Traditional preprocessing methods either support only one format or lose crucial structural information such as tables and title hierarchy during conversion. That makes it difficult for the RAG system to understand and retrieve the content correctly.
This solution first downloads multi-format test documents, such as a Canadian pesticide handbook PDF containing many tables and a University of Florida citrus IPM PowerPoint file containing charts and multi-level headings. It then uses Unstructured's Local Runner for parsing. The configuration includes a processor config, a partition config that can optionally use API partition mode for stronger OCR, and a local config defining input paths. Parsed documents are converted into JSON containing typed elements such as body text, titles, and tables.
The system then uses chunk_by_title, sets a max length of 512 characters, and merges consecutive fragments shorter than 200 characters to preserve semantic coherence. During conversion into LangChain Document objects, complex metadata fields are filtered to fit Chroma. The vector stage uses the BAAI/bge-base-en-v1.5 embedding model, together with a 4-bit quantized Llama-3-8B-Instruct and a LangChain RetrievalQA chain to build a complete RAG system.
The resulting system can handle multi-format documents accurately. For questions such as "Are aphids a pest?" it can extract key facts from the parsed documents and generate answers grounded in the relevant material. This is especially useful for enterprise knowledge bases that need to process many document types.
6.3 Enterprise document QA: high-precision and traceable RAG
The championship solution of the Enterprise RAG Challenge shows how to build a production-grade RAG system under strict time and precision requirements:
- https://abdullin.com/ilya/how-to-build-best-rag/
- https://hustyichi.github.io/2025/07/03/rag-complete/
Background: Contestants had to parse 100 real enterprise annual-report PDFs in 2.5 hours, each report with up to 1000 pages and containing complex financial tables, multi-column layouts, and charts. After parsing, the system had to answer 100 precise business questions with explicit answer types, such as yes-no, company names, exact numerical indicators, or executive titles, and it had to cite page numbers as evidence.
The winning team chose IBM's open-source Docling as the PDF parser because it performed best on complex tables and multi-column text. They improved the Docling code so it could output JSON and Markdown-plus-HTML with metadata and especially improved table parsing. To accelerate processing, they rented RTX 4090 GPUs and finished the 100-report parse in 40 minutes.
Text chunking used 300-token chunks with 50-token overlap and recursive splitting to preserve semantic coherence. To avoid cross-company contamination, each company had its own FAISS vector store using an IndexFlatIP index. Retrieval then followed three stages: retrieve Top-30 chunks by vectors, deduplicate by parent pages because multiple chunks may come from the same page, and rerank pages with GPT-4o-mini. Final ranking mixed vector retrieval and LLM reranking scores with a 0.3 to 0.7 weight split.
Generation used different prompt templates for different answer types. For numeric questions, such as annual revenue, the system used a five-step analysis process to ensure indicator matching, unit consistency, and cross-checking. Outputs were structured to include analysis process and page references for traceability.
The system won two awards and took first place on the leaderboard. An important observation was that even smaller models such as Llama 8B outperformed more than 80 percent of participants, while Llama 3.3 70B came close to GPT-4o-mini, showing that a good system design can successfully balance accuracy, efficiency, and cost.
6.4 AIOps scenario: intelligent handling of mixed text-and-image data
The EasyRAG project in an AIOps RAG competition focused on QA for operations scenarios:
http://blog.csdn.net/hustyichi/article/details/143323746
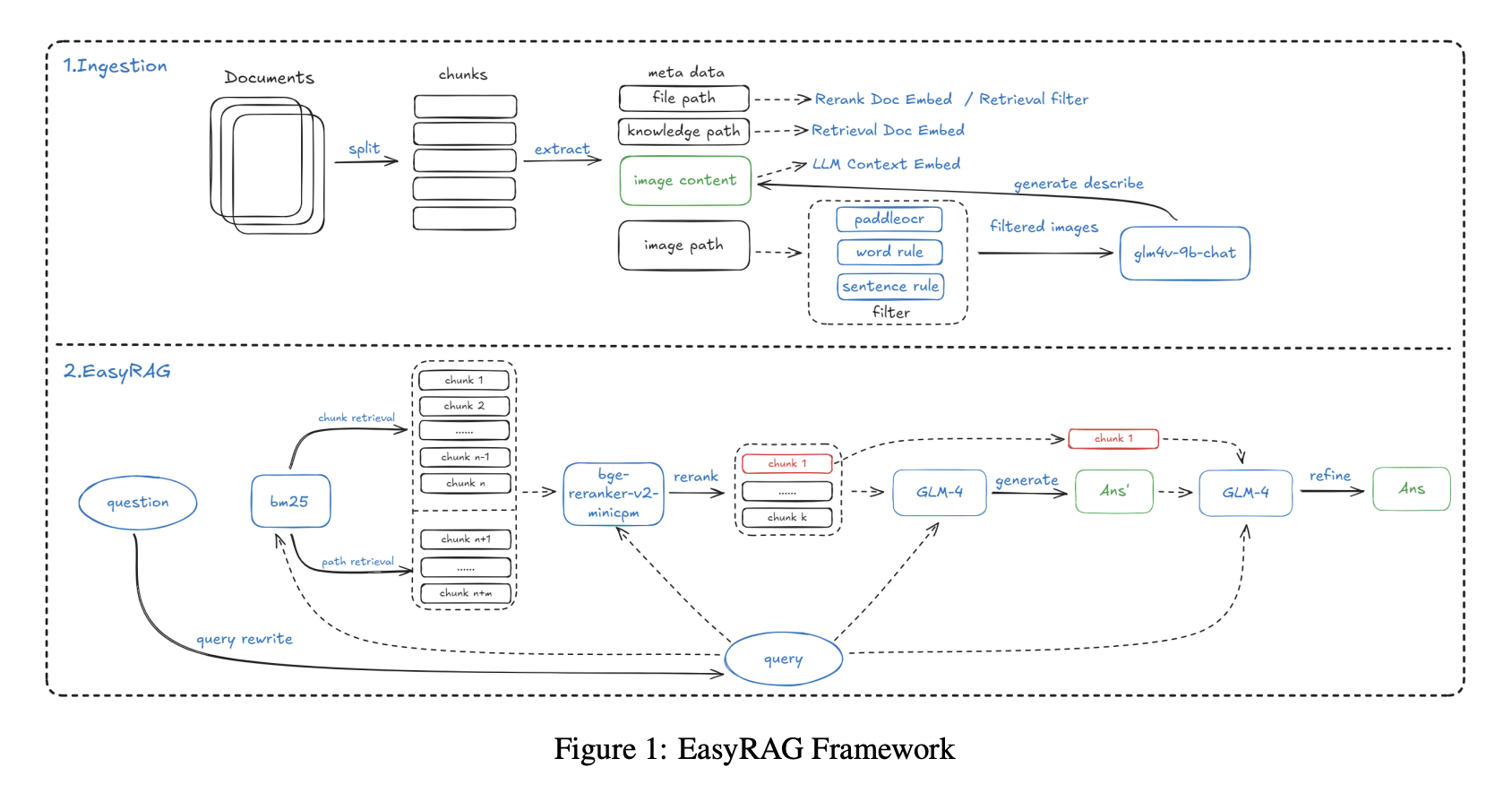
Background: Operations engineers often need to read technical documents that include not only text but also monitoring charts, system architecture diagrams, and performance curves. For example, when diagnosing a system problem, the answer to "What should I do when CPU utilization exceeds 80 percent?" may be scattered between text descriptions and monitoring graphs. Traditional text-only RAG cannot understand chart trends and values, so answers remain incomplete.
The indexing stage used an improved SentenceSplitter with 1024-token chunks and 200-token overlap. A key innovation was adding metadata such as knowledge-base paths and file paths to each chunk, which improved recall by 2 percent. For image data, the system first used PaddleOCR to extract text from charts and screenshots, then used a multimodal model, GLM-4V-9B, to generate natural-language descriptions of the image, for example describing a CPU usage line peaking at 90 percent in the afternoon. Both the OCR text and image description were then indexed together.
Retrieval used a two-path BM25 plus vector strategy for broad recall. BM25 covered chunk retrieval and path retrieval, helping filter irrelevant documents by file path, while vector retrieval used gte-Qwen2-7B-instruct. Reranking used bge-reranker-v2-minicpm-layerwise, and a 28-layer setting performed best in experiments.
Answer generation used a two-step strategy: first generate a draft from the Top-6 documents to maximize information coverage, then optimize the answer with the Top-1 most relevant document to emphasize the core answer.
To handle long-text scenarios, such as a complete operations manual with hundreds of pages, the system also implemented BM25-based context compression, splitting documents into sentences, scoring sentence similarity to the query, and concatenating only the most relevant sentences. At 50 percent compression, this method achieved 86.48 percent accuracy in only 7.7 seconds and outperformed tools such as LLMLingua.
6.5 Multi-source data fusion: collaboration between structured and unstructured knowledge
The winning solution in the KDD Cup 2024 Meta RAG challenge showed how to integrate unstructured web content and structured knowledge graphs:
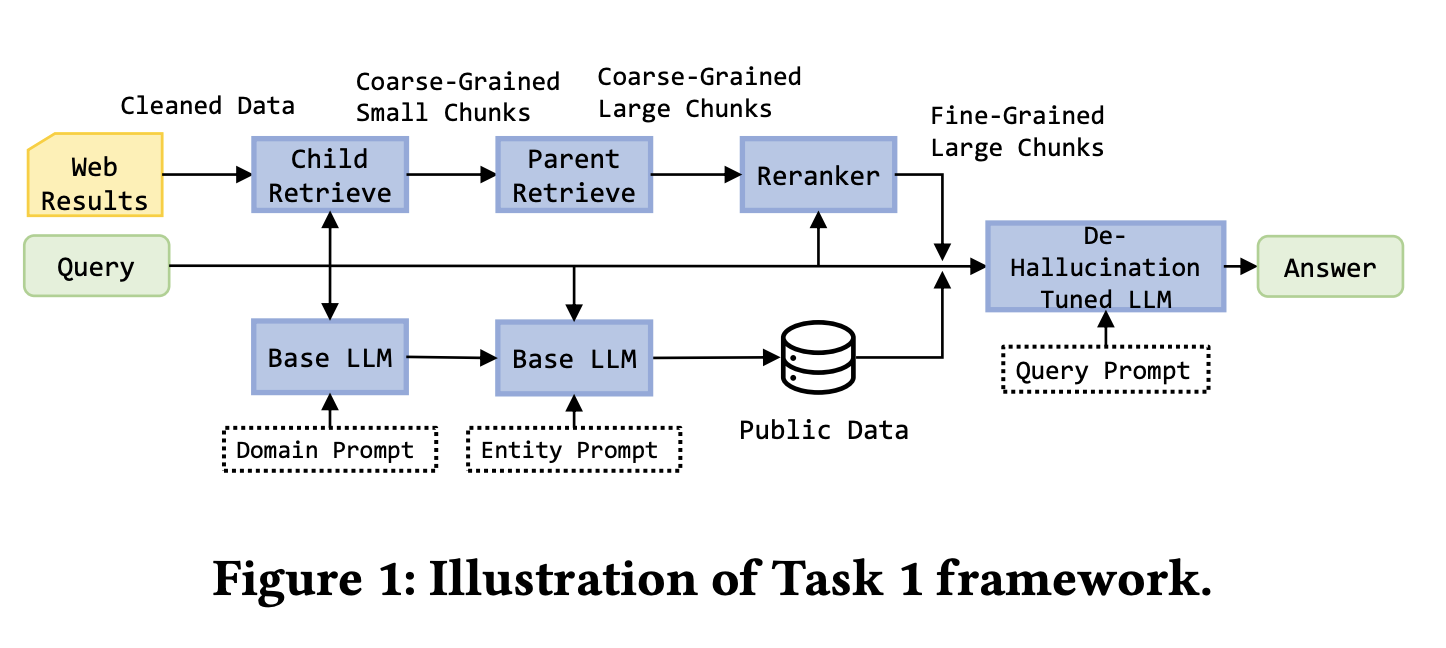
Background: Task 1 required retrieval summarization from five web pages. Task 2 added a mock API representing a structured knowledge graph, enabling direct access to things like movie databases and entity relationships. Task 3 raised the difficulty by using fifty web pages plus the mock API to answer more complex queries, such as identifying Nolan-directed films with box office greater than 500 million dollars. Every query had to finish within 30 seconds.
For Task 1, the winning team built a refined web-processing pipeline. They used BeautifulSoup to extract page text and ParentDocumentRetriever to manage parent-child chunk relationships, using 200-token child chunks for retrieval and 500 to 2000-token parent chunks for generation. The embedding model was bge-base-en-v1.5, the vector store was Chroma, and reranking used bge-reranker-v2-m3. The team also supplemented movie and finance data from public datasets and fine-tuned Llama-3-8B-instruct with LoRA on training data that included invalid questions and reference answers.
For Tasks 2 and 3, the key innovation was prioritizing the knowledge graph. The system defined standardized API calls such as get_person and get_movie, with filtering and sorting support. It first called the knowledge graph API and only fell back to web retrieval if the graph results were missing or invalid. This improved both speed and answer accuracy.
Because the system prioritized the knowledge graph and used structured output formats, hallucination was clearly reduced. If the graph could provide a deterministic answer directly, the system returned it without a generative step. If web retrieval was required, the answer had to follow strict citation and stepwise reasoning rules.
The solution won first place in all three tasks. The main lesson is that in enterprise scenarios containing both structured and unstructured data, retrieval strategy should be designed according to data type: use deterministic structured data first and treat unstructured sources as supplements.
Across these practical cases, several shared principles appear repeatedly:
- choose caching, retrieval, and generation strategies according to the business scenario
- design dedicated parsing and indexing paths for different formats and modalities
- treat hybrid retrieval plus reranking as a standard configuration
- use task-specific prompting and structured outputs to improve accuracy and traceability
These lessons from real competitions and open projects are valuable references when building stronger enterprise RAG systems.
7. Broad Exploration: The Future Evolution of RAG (Optional)
Once you have learned the practical skills and optimization methods of RAG, you can already improve system performance in concrete scenarios. But understanding only local engineering tricks is not enough if you want a wider grasp of where RAG is heading. We also need to look at broader evolutionary directions.
RAG is now rapidly breaking beyond the traditional retrieve-text-chunks-then-generate pattern. In this section we focus on several of those paths: moving from chunk retrieval to graph-structured retrieval, combining images and audio into multimodal RAG, improving long-document handling through vectorized late chunking, and the way RAG is gradually evolving into an agent-oriented system.
7.1 Graph RAG: reshaping deep retrieval with relationship networks
Related research:
Traditional RAG works by finding text passages similar to the question, which is like picking out the few paragraphs that look most relevant from a pile of material. That works well for direct fact lookup. But if a question requires connecting multiple documents and combining different clues, performance drops.
For example, a doctor might ask, "Based on these cases and the latest treatment guidelines, how should we evaluate the benefits and risks of a certain drug for elderly patients?" Or a project team might ask, "Looking across the past two years of requirements documents, review records, and online issue reports, which part of our system architecture fails most often?" Questions like these are not about finding a single sentence. They require identifying the people, objects, events, and relationships scattered across multiple materials and forming a complete picture.
Graph RAG builds that picture proactively. The system uses a large model to identify key entities from text, such as people, organizations, functional modules, events, and data, together with their relationships, such as causality, dependence, change, and contradiction. It then builds a knowledge network that grows as more material is added. Through automatic grouping, closely related entities and relationships are organized into themes, and each theme can be summarized in advance. When a user asks a question, the system no longer searches only for text passages that look similar. It first finds the most relevant entities and local graph structure, expands through related topic groups, and then gives the analysis path, node descriptions, and source passages together to the LLM for reasoning.
Under this framework, Graph RAG and traditional RAG complement one another. Traditional RAG remains strong for detail questions whose answers can be found in one step. Graph RAG is closer to how a human researcher thinks: first organize the overall structure and themes, then fill in evidence, and finally produce a conclusion with logic and conditions. Existing comparisons show that in multi-hop reasoning tasks, Graph RAG often covers more critical content and provides a broader perspective. Flexible combination of the two approaches is often better than using only one.
7.2 Multimodal RAG
Related research:
Real-world data is never only text. Engineers diagnosing server failures need to look at temperature curves, device screenshots, and logs together. Doctors making diagnoses need CT or MRI images, test reports, and electronic medical records at the same time. Traditional text RAG can at best retrieve phrases such as "temperature anomaly" or "suspected lung nodule," but it struggles to connect those descriptions to the actual chart trend or image lesion shape, and it cannot reverse-search documents or knowledge from images, audio, or video.
Multimodal RAG solves this problem of different modalities being unable to "see" one another. Its core is cross-modal semantic alignment. The system uses suitable encoders for images, video, audio, and text, together with OCR, ASR, and layout analysis, extracts key information from visual and audio sources, and maps different modalities into a shared semantic space where a unified multimodal index can be built.
At retrieval and generation time, whether the user asks for a chart showing a sales peak in Q3 2023 or uploads a sketch or operating video, the system first finds the closest multimodal evidence in that unified space, filters it by signals such as text similarity and image similarity, keeps the most useful pieces, and then gives those images, text passages, and tables together to a multimodal LLM. The model can then answer by combining evidence across modalities and ideally indicate the source or highlight relevant areas in the image or document.
Compared with text-only RAG, multimodal RAG can use more kinds of evidence and often reduces hallucination while producing more complete and more verifiable answers.
7.3 Late Chunking: preserving full context for long documents
Related introduction:
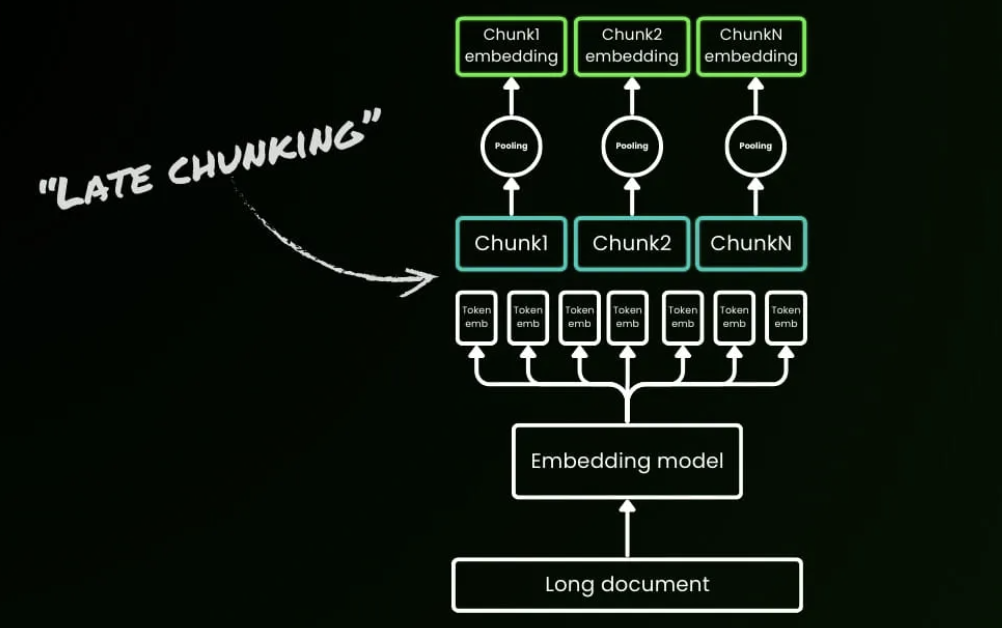
Imagine reading a Wikipedia article about Berlin. Traditional RAG would first cut it into independent paragraphs and then embed each chunk. If the first sentence says "Berlin is the capital of Germany," later phrases such as "the city" or "its population" lose their connection to Berlin once separated. A query such as "What is the population of Berlin?" may then fail because the term Berlin and the population information never appeared inside the same chunk. This problem becomes even worse for long documents. In a 200-page insurance contract, the definition of a deductible may appear on page 5 while the conditions under which it applies appear on page 30. Fixed-length chunking can split these related pieces into dozens of isolated chunks, and experiments show that semantic similarity can collapse sharply when that happens.
Late Chunking overturns the traditional chunk-first-then-embed pipeline and instead follows embed-first-then-chunk. With long-context embedding models that can handle something like 8192 tokens, the whole document is first passed through the Transformer, producing token-level embeddings that have already seen the full document. Only afterward are those globally informed token embeddings pooled into chunk embeddings according to chunk boundaries. The resulting chunks are no longer independent islands. They are context-dependent embeddings that preserve cross-paragraph references and conceptual relationships.
On BEIR benchmark datasets, Late Chunking outperforms traditional chunking broadly, with especially strong gains on longer documents. In short-text scenarios, the difference largely disappears, which confirms a key rule: the longer the document, the bigger the advantage of Late Chunking. The method is now integrated into Jina Embeddings v3. Although encoding a whole long document first can increase inference time by 10 to 20 percent, the retrieval gains in scenarios such as medical records, legal documents, and technical manuals can easily justify that cost.
Late Chunking shows that 8K-plus long-context embedding models are not overengineering in these scenarios. They are often necessary for producing high-quality chunk embeddings and represent a shift from chunk first, then embed, to embed first, then chunk.
7.4 From RAG to RAG in the Agent Era
Related discussions:
- https://ragflow.io/blog/rag-at-the-crossroads-mid-2025-reflections-on-ai-evolution
- https://arxiv.org/pdf/2501.09136
- https://www.letta.com/blog/rag-vs-agent-memory
- https://www.linkedin.com/posts/richmondalake_100daysofagentmemory-rag-memorizz-activity-7348281860843577346-LM7Y/
- https://www.llamaindex.ai/blog/rag-is-dead-long-live-agentic-retrieval
RAG has developed from a retrieval-augmented generation tool into a key part of an agent's cognitive architecture. Traditional RAG is built on a simple ask, retrieve, answer pattern and is fundamentally passive. It waits for a query and does not act proactively. To break through that passivity and handle more complex cognitive tasks, RAG has been deeply combined with agent capabilities, giving rise to a new paradigm: Agentic RAG.
Under this paradigm, the role of RAG changes fundamentally. It is no longer only a passive provider of external knowledge. Instead, it becomes the core processing unit that supports intelligent behavior under the agent's active planning, goal direction, and self-reflection. This fusion gives the overall system goal orientation, iterative optimization, and autonomous decision-making, greatly deepening the quality of human-AI interaction. Agentic RAG can understand complex tasks, decompose them, plan retrieval strategies, and evaluate the quality of initial results to decide whether deeper exploration is needed.
The key to this capability is a multi-layered active loop. Faced with a complex query, the agent first analyzes the nature of the problem, breaks it into subproblems, and designs precise retrieval strategies for each subproblem. After receiving initial results, it evaluates them, judges whether the information is complete and relevant, identifies knowledge gaps, and dynamically generates more precise new queries. This iterative process often includes multi-hop retrieval, where one round of results reveals new directions for the next round, producing a knowledge exploration chain similar to how a human researcher works.
To support this ongoing, iterative intelligent behavior, especially when personalization and long-term knowledge accumulation matter, short-term conversation context alone is far from enough. This leads to the need for long-term, structured memory.
That is exactly why RAG is increasingly assigned the role of an agent's long-term memory system and used to build a full external memory architecture. This long-term memory complements short-term memory, which is responsible for maintaining the current dialogue context. The long-term memory system relies on three key mechanisms:
- Structured indexing ability: This allows the agent to build multi-dimensional indexes over huge amounts of unstructured data, by time, topic, entity relations, and more, supporting efficient retrieval from multiple angles much like humans recall information through different clues.
- Intelligent forgetting: Through value-evaluation algorithms, the system can decay or selectively discard low-frequency, weakly related, or outdated information, keeping the memory system lean and efficient and preventing overload.
- Knowledge consolidation: The system refines scattered dialogue and interaction experience into structured knowledge. Through entity recognition, relation extraction, and semantic clustering, fragmented information is connected into knowledge graphs, turning short-term experience into long-term knowledge.
This external memory system built on RAG not only expands an agent's cognitive boundary significantly, but also gives it the ability to continue learning and evolving its knowledge. It allows the agent to accumulate experience over long-term interaction, form personalized operating patterns and domain knowledge systems, and support more complex and longer-running tasks.
Summary
Retrieval-Augmented Generation is not only a technical method for compensating for hallucination and knowledge staleness in large models. It is also a key bridge for turning general AI capability into deep enterprise value. The evolution from Naive RAG to modular and agentic forms shows that every part of RAG needs to deepen continuously, including finer data handling, more scientific model selection across embedding, rerank, and LLM stages, and more systematic evaluation. All of these are necessary steps toward building enterprise knowledge systems that are controllable, trustworthy, and efficient. At the same time, drawing lessons from competitions and engineering case studies is one of the best ways to deepen understanding of the technical details.
As Graph RAG, multimodal understanding, and Late Chunking continue to develop and combine, RAG is steadily pushing beyond the old retrieval-and-generation boundary and moving toward deeper semantic association and more sustainable memory capability. The hope is that this survey-style article helps you build a full-chain methodology, from principle to practice and from evaluation to evolution, so that in a fast-moving technical landscape you can build high-quality intelligent applications that truly land in the real world and can handle complex business challenges.
Reference
[1] Ask in Any Modality: A Comprehensive Survey on Multimodal Retrieval-Augmented Generation.
https://arxiv.org/pdf/2502.08826
[2] Retrieving Multimodal Information for Augmented Generation: A Survey.
https://arxiv.org/pdf/2303.10868
[3] A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models.
https://arxiv.org/pdf/2405.06211
[4] Retrieval-Augmented Generation for Large Language Models: A Survey.
https://arxiv.org/pdf/2312.10997
[5] LightRAG: Simple and Fast Retrieval-Augmented Generation.
https://arxiv.org/pdf/2410.05779
[6] Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG.
https://arxiv.org/pdf/2501.09136
[7] ERAGent: Enhancing Retrieval-Augmented Language Models with Improved Accuracy, Efficiency, and Personalization.
https://arxiv.org/pdf/2405.06683
[8] Graph Retrieval-Augmented Generation: A Survey.
https://www.arxiv.org/pdf/2408.08921
[9] Evaluation of Retrieval-Augmented Generation: A Survey.
https://arxiv.org/pdf/2405.07437
[10] Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey.
https://arxiv.org/pdf/2504.14891
[11] From Local to Global: A Graph RAG Approach to Query-Focused Summarization.
https://arxiv.org/pdf/2404.16130
[12] RAG vs. GraphRAG: A Systematic Evaluation and Key Insights.
https://arxiv.org/pdf/2502.11371
[13] Introduction to RAG | LlamaIndex Python Documentation.
https://developers.llamaindex.ai/python/framework/understanding/rag/
[14] All-in-RAG | A Full-Stack Guide to RAG in Large-Model Application Development.
https://datawhalechina.github.io/all-in-rag/#/en/
[15] Ilya Rice: How I Won the Enterprise RAG Challenge.
https://abdullin.com/ilya/how-to-build-best-rag/
[16] RAG Research Table - Awesome Generative AI Guide (GitHub).
[17] RAG is dead, long live agentic retrieval.
https://www.llamaindex.ai/blog/rag-is-dead-long-live-agentic-retrieval
[18] LLM/RAG Zoomcamp extra lesson 5: Common evaluation methods and market preferences in RAG evolution.
https://vip.studycamp.tw/t/llmrag-zoomcamp-課外補充-5:rag-evolution-常見評估方法和市場偏好/8185
[19] How to Evaluate Retrieval Augmented Generation (RAG) Applications.
https://zilliz.com.cn/blog/how-to-evaluate-rag-zilliz
[20] RAG is not Agent Memory.
https://www.letta.com/blog/rag-vs-agent-memory
[21] Richmond Alake. LinkedIn post on #100DaysOfAgentMemory, RAG and MemoRizz.