Introducción a Dify e integración de bases de conocimiento
Repaso de la clase anterior
En las clases anteriores, estudiamos en grupos los fundamentos de la programación con IA, la ingeniería de prompts y la generación de imágenes con IA. Estos contenidos nos ayudaron a comprender inicialmente los límites y las capacidades de los diferentes modelos de lenguaje grande (LLM, Large Language Model) o modelos generativos.
Para ayudarte a repasar el contenido de la clase anterior, aquí tienes algunas preguntas para reflexionar:
- ¿Qué es la programación con IA? ¿Cómo usar herramientas de programación con IA (por ejemplo, z.ai) para crear una página web?
- ¿Qué es un modelo de lenguaje grande? ¿Qué son la ingeniería de prompts y la ingeniería de contexto? ¿Cómo escribir un prompt complejo?
- En cuanto a las tres direcciones diferentes de texto, AI Coding y generación de imágenes, ¿en qué aspectos crees que se reflejan las fortalezas y debilidades de los modelos?
- ¿Qué es una API? ¿Cómo usar z.ai para conectarse a APIs de terceros?
Si aún tienes dudas sobre alguna de estas preguntas, puedes revisar la documentación de la clase anterior o preguntar directamente en el grupo de WeChat.
En esta clase, pasaremos de las sencillas herramientas de IA de texto e imagen a una plataforma de construcción de flujos de trabajo más cercana a la implementación empresarial real. Desde chatbots hasta agentes inteligentes de IA y flujos de trabajo de IA, y basándonos en APIs, lo convertiremos en una página de robot "inteligente" interactiva.
Durante el proceso, si encuentras pasos difíciles de entender, no te preocupes. Te recomendamos que tomes capturas de pantalla de la página de operaciones actual y las envíes a un modelo de lenguaje grande para consultarlo; los modelos actuales ya pueden resolver la mayoría de las preguntas comunes.
Si después de preguntar aún no puedes resolver el problema, atrévete a experimentar; no temas cometer errores, cada intento es una oportunidad de aprendizaje y progreso. Con la práctica, te volverás cada vez más hábil y las operaciones te resultarán cada vez más naturales.
Lo que aprenderás en esta clase
- Por qué es necesario pasar de los chatbots a los agentes y la orquestación de Workflows.
- Qué son los agentes y las plataformas de desarrollo de flujos de trabajo, y cómo estandarizar y hacer orquestables las capacidades de la IA mediante SOPs.
- Qué es Dify, cómo usar esta plataforma de código abierto orientada a aplicaciones LLM para construir rápidamente aplicaciones, especialmente chatbots de bases de conocimiento.
- Los métodos de implementación y el valor de RAG, ¿por qué se necesita la Generación Aumentada por Recuperación?
- Cómo aprender desde cero a usar Dify y el AI IDE Trae (
Extra Knowledge 4 - What is AI IDE and Trae), incluyendo la construcción de agentes, flujos de trabajo, y la creación de un programa web frontend de chatbot basado en la API de Dify.
- Los principios básicos de uso de Dify, los métodos de creación de agentes y flujos de trabajo, y los métodos de llamada a la API.
- Cómo usar un AI IDE, cómo programar con un AI IDE.
- Un programa de agente web frontend con capacidad de diálogo.
1. De la conversación al agente inteligente
En la etapa anterior, aprendimos a usar prompts para que los modelos grandes asuman roles, generen texto o escriban código simple. Pero si lo piensas detenidamente, te darás cuenta de un problema: los chatbots por sí solos no pueden hacer cosas.
Pueden responder cómo consultar un pedido, pero no pueden realmente ir a la base de datos a buscar los datos correspondientes; pueden describir qué debería contener un informe semanal, pero no pueden resumir automáticamente los datos de tu proyecto y enviar un correo electrónico. Esta limitación de "solo hablar sin actuar" hace que la IA puramente conversacional sea difícil de integrar verdaderamente en los procesos de negocio.
Para que la IA evolucione de compañera de chat a empleada digital, necesitamos otorgarle tres capacidades fundamentales:
- Conocimiento exclusivo — permitirle leer y comprender la documentación de productos, datos de clientes y regulaciones internas;
- Llamada a herramientas (o plugins) — permitirle operar bases de datos y llamar a APIs;
- Ejecución estructurada — permitirle completar tareas paso a paso según una lógica predefinida, en lugar de improvisar.
Este es el embrión del agente de IA (AI Agent): una unidad automatizada con objetivos, conocimiento, herramientas y rutas de ejecución.

Nota: Lo que la industria denomina actualmente como versión simple de "agente" se refiere en su mayoría a aplicaciones mejoradas basadas en la combinación de LLM + herramientas + base de conocimiento, no a agentes capaces de planificar autónomamente. Los agentes simples, aunque no poseen verdadera capacidad de razonamiento y planificación a largo plazo, ya son suficientes para soportar una gran cantidad de escenarios de automatización empresarial. Presentaremos en detalle los agentes verdaderamente capaces de planificación y acción autónoma en capítulos posteriores.
1.1 El agente más simple: chatbot basado en base de conocimiento
Una vez definidas las múltiples capacidades fundamentales que debe tener un agente, surge una pregunta digna de reflexión: ¿se puede construir un agente base verdaderamente útil implementando solo una de las funciones más simples? La respuesta es afirmativa.
De hecho, en una gran cantidad de escenarios de negocio reales, la demanda central de los usuarios no es que la IA ejecute automáticamente operaciones complejas (como llamar a APIs o coordinar tareas entre sistemas), sino que pueda proporcionar soporte de preguntas y respuestas preciso y confiable basado en los materiales exclusivos de la empresa. Esto corresponde exactamente a la primera de las tres capacidades fundamentales del agente: la capacidad de servicio de conocimiento exclusivo. Por lo tanto, podemos introducir la forma más simple y más ampliamente utilizada del agente: el chatbot basado en base de conocimiento.
Aunque aún no posee capacidad de llamada a herramientas o planificación autónoma, su avance clave radica en: hacer que las respuestas del modelo grande ya no se generen de la nada, sino que se basen en evidencia. ¿Cómo lograrlo? La clave está en resolver el desafío central: cuando una empresa tiene una gran cantidad de documentación interna, con miles de páginas de documentos, ¿cómo puede el modelo encontrar rápidamente el contenido más relevante para la pregunta actual en cada ronda de conversación?
En este punto, una solución es: la Generación Aumentada por Recuperación (Retrieval-Augmented Generation, RAG).
La idea básica de RAG es: cuando el usuario formula una pregunta, el sistema primero recupera de la base de conocimiento empresarial varios fragmentos de texto semánticamente más relevantes a la pregunta (por ejemplo, un párrafo del manual del producto, una cláusula del reglamento de RRHH), y luego "inyecta" estos fragmentos como contexto en la entrada del modelo grande, guiándolo para generar una respuesta basada en materiales reales.
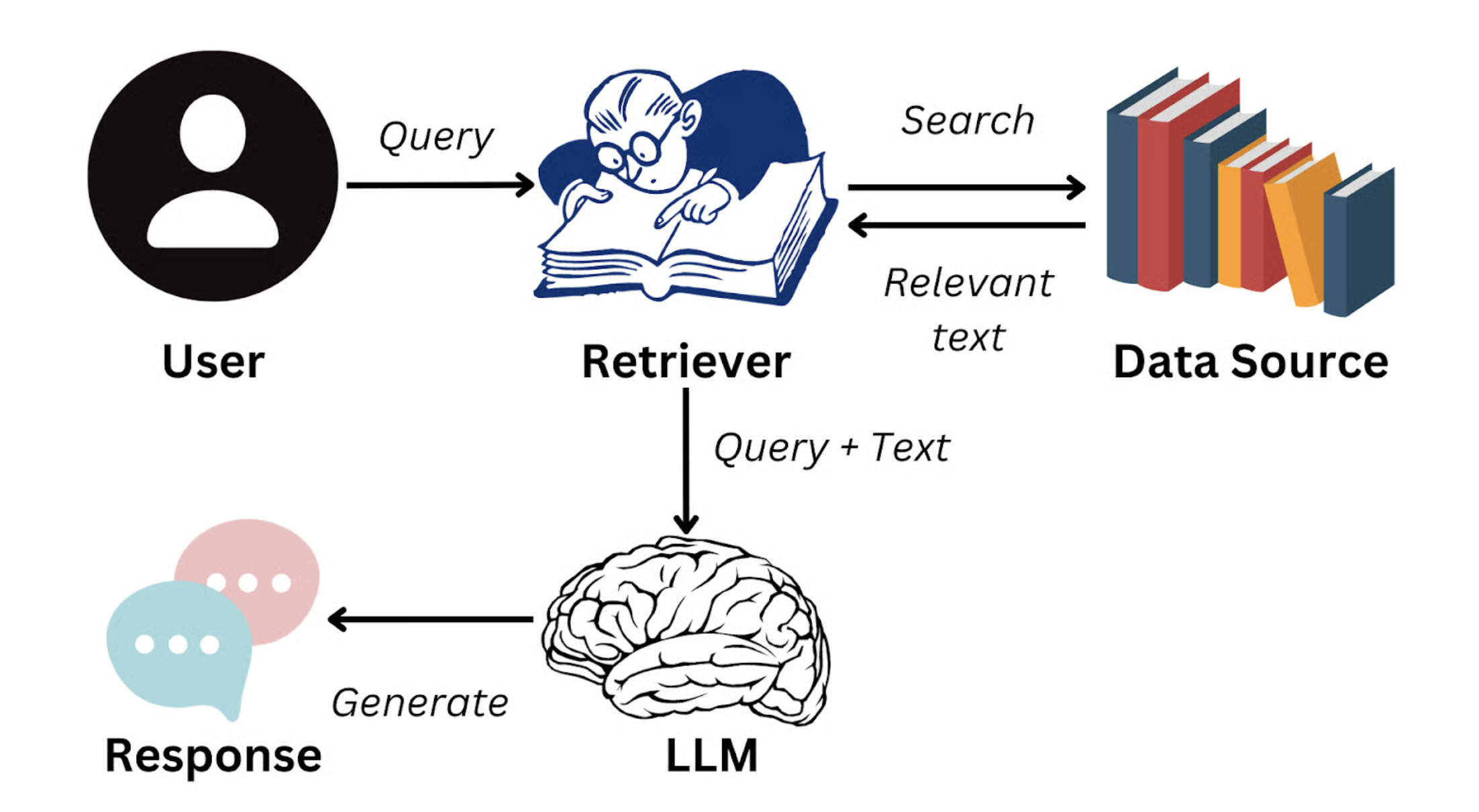
Fuente de la imagen: https://www.datacamp.com/blog/what-is-retrieval-augmented-generation-rag
De esta manera, la respuesta del modelo ya no depende del conocimiento generalizado de sus datos de entrenamiento, sino que se ancla en la información autorizada proporcionada por la empresa. El objetivo de RAG es, precisamente, a través de esta inyección dinámica de conocimiento externo, mejorar significativamente la veracidad, precisión y consistencia de las respuestas, e incluso hacer que las respuestas "se ajusten a un personaje", por ejemplo, respondiendo con el tono de atención al cliente o con el estilo de documentación técnica.
En la práctica empresarial, esta tecnología es especialmente importante porque los modelos grandes a menudo producen "alucinaciones". Por ejemplo, si preguntas como CFO o consultor sobre datos específicos de un período, el modelo muy probablemente inventará fechas y eventos. Con la introducción de RAG, la controlabilidad y fiabilidad de las respuestas mejorarán significativamente.
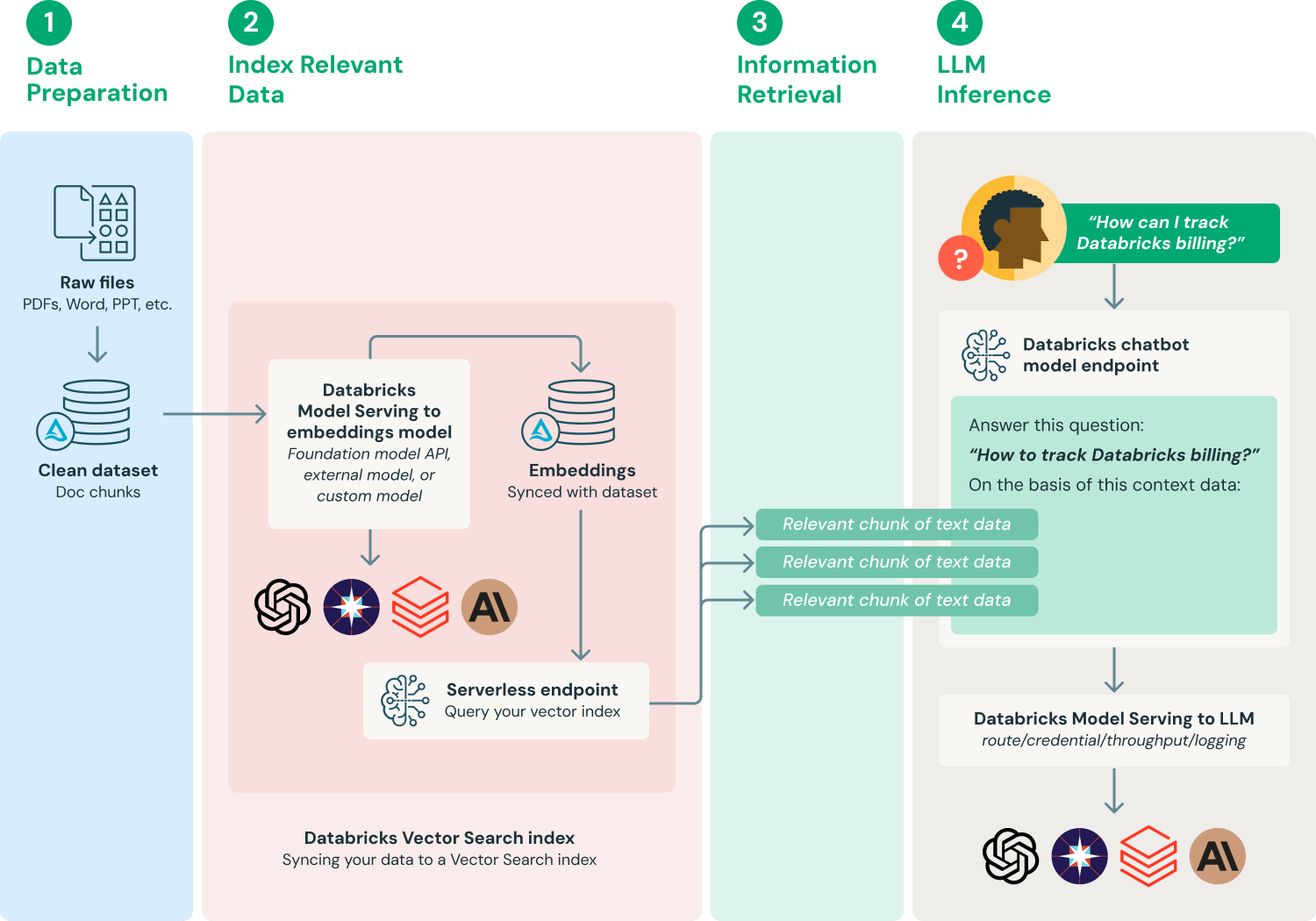
Fuente de la imagen: https://www.databricks.com/glossary/retrieval-augmented-generation-rag
En la parte práctica de esta clase, usaremos la popular plataforma de flujos de trabajo de IA Dify para construir un chatbot basado en base de conocimiento. Puedes easily construir una base de conocimiento con diversos tipos de materiales exclusivos, como manuales de productos, regulaciones de la empresa, documentación de proyectos, artículos de investigación, artículos de bases de conocimiento e incluso colecciones de notas personales.
Una vez completada la construcción, puedes intentar formular todo tipo de preguntas para evaluar sus capacidades, por ejemplo:
- "¿Cuáles son las principales actualizaciones de funcionalidades de la última versión de nuestro producto A?"
- "Según el manual del empleado, ¿cómo se regula el sistema de vacaciones anuales de este año?"
- "En el proyecto XX, ¿cómo se resolvió el desafío técnico 'XXX' que encontramos?"
- "¿Cuál es el método de investigación central mencionado en este artículo?"
Experimentarás de primera mano cómo la tecnología RAG transforma documentación estática y dispersa en una base de conocimiento inteligente y precisa, proporcionando soporte de preguntas y respuestas de alta precisión para diversos escenarios.
1.2 Del agente conversacional al flujo de trabajo
Sin embargo, incluso un "agente mejorado" al que se le han añadido capacidades de base de conocimiento e incluso de llamada a plugins, sigue siendo insuficiente frente a procesos de negocio más complejos.
Imagina una solicitud de usuario como esta: "¿Cuáles son las actualizaciones de funcionalidades recientes de nuestro nuevo producto SaaS? ¿Puedes ayudarme a preparar un resumen para los clientes?"
Esta solicitud parece simple, pero detrás de ella se necesitan múltiples pasos coordinados: primero recuperar los registros de lanzamiento de funcionalidades del último mes desde la documentación interna del producto o la base de conocimiento de Notion; luego filtrar las características clave orientadas al cliente;接着 llamar a un modelo grande para transformar las descripciones técnicas en un lenguaje amigable para el cliente; finalmente enviar el contenido generado por correo electrónico al equipo de marketing, o guardarlo en una plantilla de Google Docs.
Si se depende únicamente del razonamiento libre de un modelo de lenguaje grande, sin mencionar si se pueden lograr todos los procesos en una sola conversación, incluso si fuera posible, sería fácil omitir información clave, confundir terminología interna con el lenguaje del cliente, o no poder producir una salida estructurada. Lo que es más importante, las empresas necesitan rutas de ejecución estandarizadas que sean auditables, reutilizables y monitoreables, no depender cada vez de la improvisación del modelo. La capacidad de monitoreo y reproducibilidad es muy importante para las empresas, ya que resultados no esperados podrían provocar pérdidas graves e imprevistas.
Esto nos lleva a un paradigma de aplicación de IA más avanzado: el flujo de trabajo de IA (AI Workflow).

Un flujo de trabajo se refiere a la descomposición de una tarea compleja en múltiples subpasos ordenados, configurables y de ejecución automática, y a la orquestación de sus relaciones lógicas (como evaluaciones condicionales, bucles o ejecución paralela) mediante métodos visuales o de código. La estandarización de las capacidades de IA mediante SOPs (Procedimientos Operativos Estándar) significa convertir la experiencia de cómo usar la IA para completar una tarea en plantillas reutilizables.
Este enfoque aporta múltiples beneficios: los no técnicos (como gerentes de producto o responsables de operaciones) pueden construir rápidamente aplicaciones de IA arrastrando componentes; los desarrolladores pueden encapsular la recuperación RAG, llamadas a LLM, herramientas API y más como nodos estándar, reutilizándolos en diferentes escenarios de negocio; todo el flujo también puede ser rastreado, depurado y optimizado continuamente, satisfaciendo los requisitos empresariales de estabilidad y cumplimiento.
Los usuarios de los flujos de trabajo de IA son muy diversos. Los gerentes de producto pueden diseñar rutas completas de interacción con el usuario sin escribir código; los responsables de operaciones pueden construir rápidamente chatbots de servicio al cliente, generadores de contenido o sistemas de notificación; los desarrolladores e ingenieros de algoritmos pueden modularizar las capacidades fundamentales para que sean llamadas desde el frontend; los emprendedores o desarrolladores independientes también pueden validar el MVP de un producto de IA a un costo extremadamente bajo, lanzando en cuestión de días un prototipo completo que incluya consulta de datos, generación de contenido y ejecución de acciones.
Además, es worth noting que los flujos de trabajo de IA generalmente pueden describirse mediante una Representación Intermedia (Intermediate Representation). Aunque la expresión específica varía entre las diferentes plataformas de flujos de trabajo, la mayoría utiliza archivos estructurados (como JSON, YAML, etc.) para definir tipos de nodos, entradas/salidas y lógica de ejecución, con una estructura similar a la que se muestra en la siguiente imagen:

En resumen, si los agentes hacen que la IA pase de saber chatear a saber hacer cosas, los flujos de trabajo hacen que la IA pase de ocasionalmente lograr hacer una cosa a "completar de manera estable, confiable y escalable un tipo de tarea". En las próximas prácticas, también usaremos la plataforma Dify para construir flujos de trabajo de IA completos, experimentando el proceso completo desde la idea hasta la aplicación ejecutable.
1.3 Plataformas comunes de agentes / flujos de trabajo
Con el rápido desarrollo de la tecnología de IA generativa, para ayudar a desarrolladores y personal de negocio a construir rápidamente agentes y procesos automatizados, evitando los detalles complejos de la programación, han surgido una serie de plataformas de agentes y flujos de trabajo de bajo código e incluso sin código.
Primero hay que aclarar que las plataformas de bajo código se refieren a herramientas de desarrollo que reducen significativamente la cantidad de codificación manual mediante la arrastre visual de componentes, plantillas de lógica de negocio predefinidas y configuración gráfica de reglas. Su núcleo radica en reemplazar la escritura directa de código con la configuración visual y la programación mediante arrastre de nodos, liberando a los desarrolladores con ciertas capacidades técnicas del trabajo repetitivo y permitiendo que los no técnicos familiarizados con la lógica de negocio participen en la construcción de aplicaciones. En esencia, tiende un puente de equilibrio entre la eficiencia de desarrollo y la flexibilidad de escenarios.
El valor destacado de este tipo de plataformas de agentes de bajo código/sin código es precisamente la reducción drástica de la barrera de entrada para el desarrollo de aplicaciones de IA. Anteriormente, se necesitaba la colaboración de un equipo durante semanas, desde la definición de requisitos, el desarrollo de código hasta las pruebas y el despliegue, para completar un agente de IA (como un chatbot de servicio al cliente o un asistente de procesamiento de datos). Ahora, con las herramientas visuales proporcionadas por las plataformas, el ciclo "de la idea al lanzamiento" puede reducirse a unas horas.
Las principales plataformas de flujos de trabajo de IA de bajo código en el mercado actual incluyen:
| Plataforma | Características | Escenarios de uso |
|---|---|---|
| Dify | Código abierto, soporta RAG con base de conocimiento, orquestación de LLM, salida por API, amigable con chino | Preguntas y respuestas de base de conocimiento empresarial, Agent personalizado, servicios API |
| Coze (ByteDance) | Disponible en China, integra el ecosistema Douyin/Feishu, plugins abundantes | Robots sociales, integración con mini-programas nacionales |
| n8n | Herramienta de automatización general, soporta nodos de IA, enfatiza la orquestación de APIs | Sincronización de datos entre sistemas, automatización de IA + SaaS tradicional |
| Baidu Qianfan AppBuilder / Alibaba Bailian / Tencent HunYuan | Soluciones cloud-native de grandes empresas, integran modelos propios | Despliegue empresarial, escenarios con altos requisitos de cumplimiento |
Las opciones de plataformas de flujos de trabajo de IA de bajo código en el mercado son abundantes. Aunque los principales proveedores de cloud como AWS, Azure y Alibaba Cloud han lanzado soluciones de flujos de trabajo de IA correspondientes, Dify, Coze y n8n se han convertido en las más ampliamente utilizadas gracias a las siguientes tres ventajas fundamentales:
- Usabilidad extrema. Las plataformas adoptan un diseño de interfaz de arrastre visual, los usuarios pueden comenzar rápidamente sin necesidad de comprender profundamente la tecnología subyacente.
- Alta flexibilidad. Soportan componentes personalizados e interfaces API extensibles, adaptándose tanto a escenarios ligeros como demostraciones educativas y validación de MVP (Producto Mínimo Viable), como a las necesidades de iteración ágil de equipos pequeños y medianos.
- Ecosistema maduro. No solo cuentan con documentación oficial detallada y respuesta rápida, sino que también poseen una comunidad de usuarios activa, facilitando la obtención rápida de soluciones predefinidas de diferentes usuarios.
Estas tres plataformas soportan la salida del agente de IA construido en forma de interfaz API estandarizada, que puede integrarse sin problemas en aplicaciones web frontend, sistemas ERP internos de la empresa o apps móviles, reduciendo aún más la barrera técnica para la implementación de capacidades de IA.
1.3.1 Dify: Plataforma de gestión del ciclo de vida de aplicaciones LLMOps de nivel empresarial
Dify se posiciona como una plataforma de desarrollo y operación de aplicaciones LLM, comprometida con proporcionar gestión del ciclo de vida completo de aplicaciones de IA, desde la concepción, el despliegue hasta la optimización. Su núcleo es una plataforma de bajo código, diseñada para ayudar a desarrolladores e innovadores sin formación técnica a construir rápidamente aplicaciones de IA de nivel productivo.
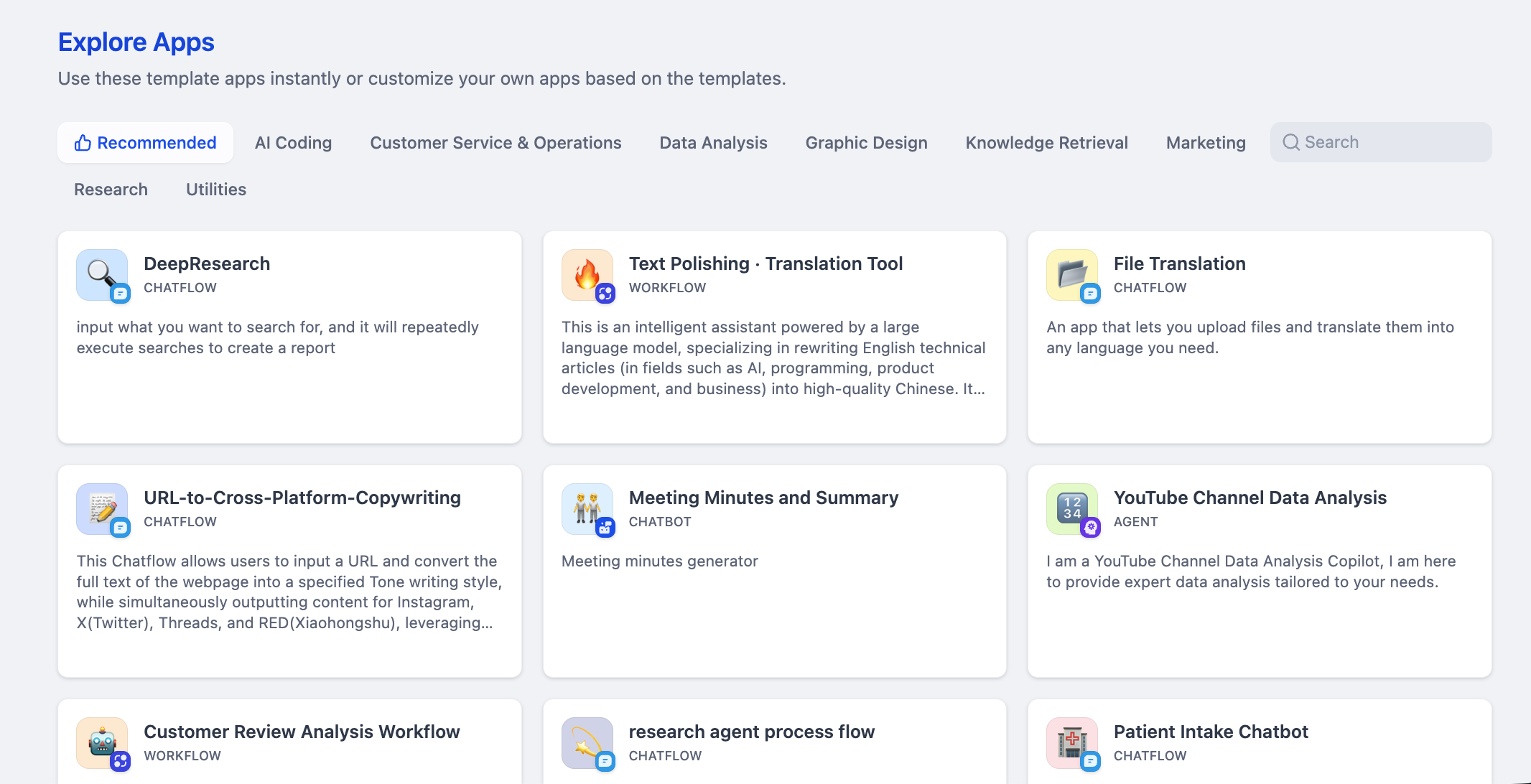
En cuanto a funcionalidades, Dify cubre la orquestación visual de flujos de trabajo, la construcción de agentes, la gestión de bases de conocimiento y el soporte de múltiples modelos. La plataforma permite diseñar flujos de tareas complejas arrastrando nodos y soporta la creación de Agentes basados en intenciones. Su funcionalidad de base de conocimiento destaca, pudiendo procesar documentos en múltiples formatos y realizar búsquedas vectoriales eficientes. Al mismo tiempo, Dify es compatible con múltiples LLMs incluyendo GPT, Claude y numerosos modelos de código abierto, y las aplicaciones construidas pueden publicarse con un clic como APIs estándar para facilitar la integración.
En cuanto a la arquitectura técnica, Dify se caracteriza por ser de código abierto y con capacidad de despliegue privado, enfatizando la flexibilidad, la escalabilidad y el cumplimiento empresarial. Los usuarios objetivo incluyen equipos de desarrolladores e innovadores de negocio, con escenarios de aplicación típicos que abarcan bases de conocimiento empresarial y servicio al cliente inteligente, automatización de creación de contenido, asistentes de IA para sectores verticales y plataforma central de IA empresarial.
1.3.2 Coze (ByteDance): El popularizador de la construcción de agentes de IA sin código
Coze es una plataforma de desarrollo de agentes de IA lanzada por ByteDance, con la usabilidad extrema como núcleo, permitiendo a usuarios sin experiencia en programación crear, depurar y publicar fácilmente chatbots de IA con funcionalidades ricas.
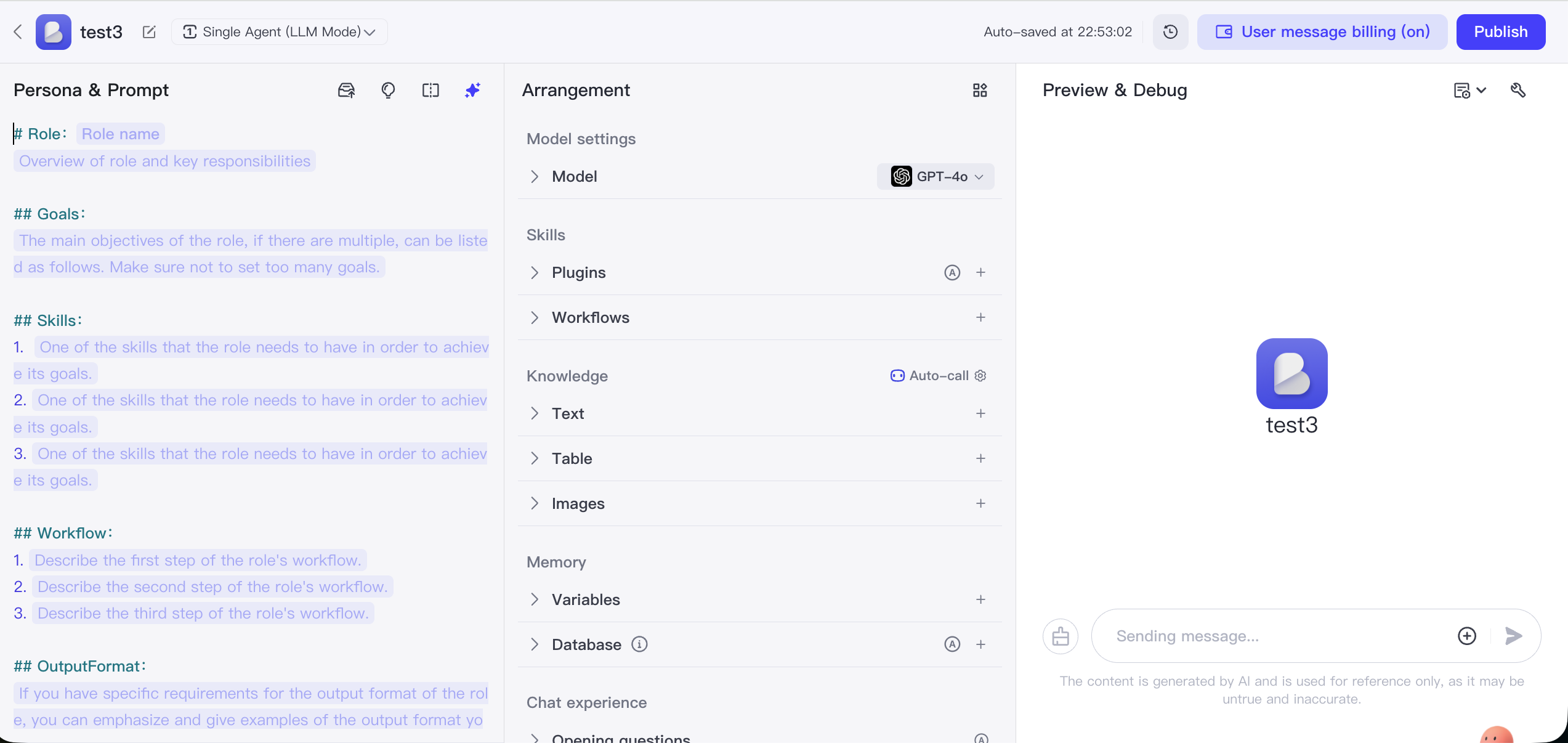
Su núcleo es simplificar la construcción de Bots en una operación tipo bloques de construcción. Los usuarios pueden configurar fácilmente roles y bases de conocimiento a través de la interfaz, y utilizar la rica biblioteca de plugins integrada para añadir al Bot múltiples capacidades externas como noticias, turismo y generación de imágenes. Los Bots creados pueden publicarse rápidamente con un clic en múltiples plataformas como Doubao, Feishu y la cuenta oficial de WeChat.
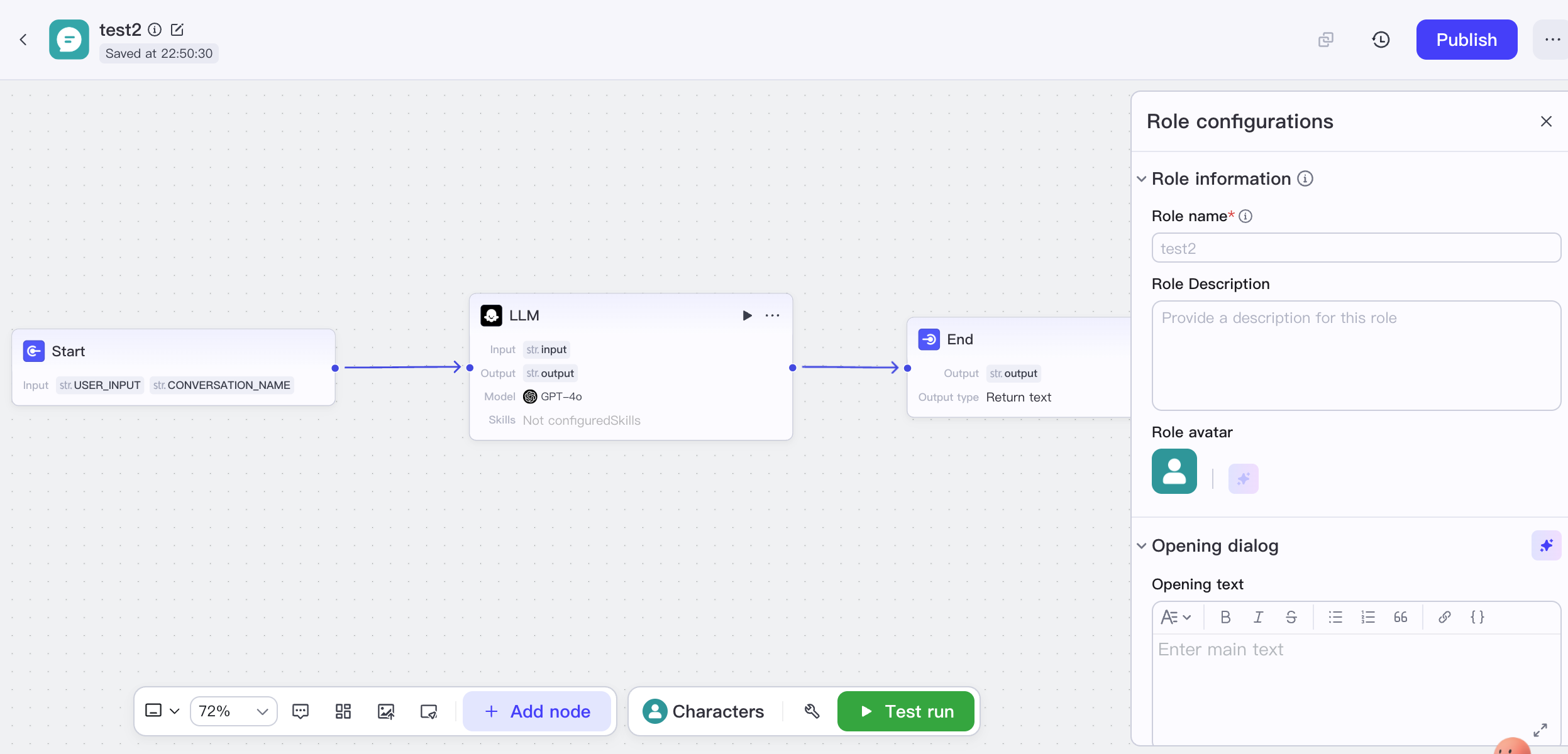
La arquitectura técnica está completamente diseñada para un uso de baja barrera, el backend integra modelos propios de Byte y encapsula procesos complejos, enfatizando la comprensión multimodal y la respuesta en tiempo real. Como plataforma proporcionada principalmente en forma de servicio en la nube, su capacidad de despliegue privado es relativamente limitada. Los escenarios de aplicación típicos incluyen asistentes personales y Bots de entretenimiento, servicio al cliente inteligente y sistemas de preguntas y respuestas, asistentes de educación en línea y validación rápida de prototipos.
1.3.2 n8n: Motor de automatización de flujos de trabajo backend programable
n8n es una plataforma de automatización de flujos de trabajo programable y de propósito general, cuyo posicionamiento central es conectar todo tipo de aplicaciones, bases de datos y APIs, logrando el flujo de datos y la ejecución automatizada de tareas.
Cuenta con una enorme biblioteca de nodos de integración que soporta cientos de servicios SaaS, bases de datos y protocolos, y adopta un enfoque que combina lo visual con el código: los usuarios pueden arrastrar nodos en un lienzo mientras inyectan código JavaScript o Python para escribir lógica personalizada. n8n es experto en manejar tareas backend de procesamiento intensivo de datos, como sincronización de datos, procesos ETL y orquestación de APIs.
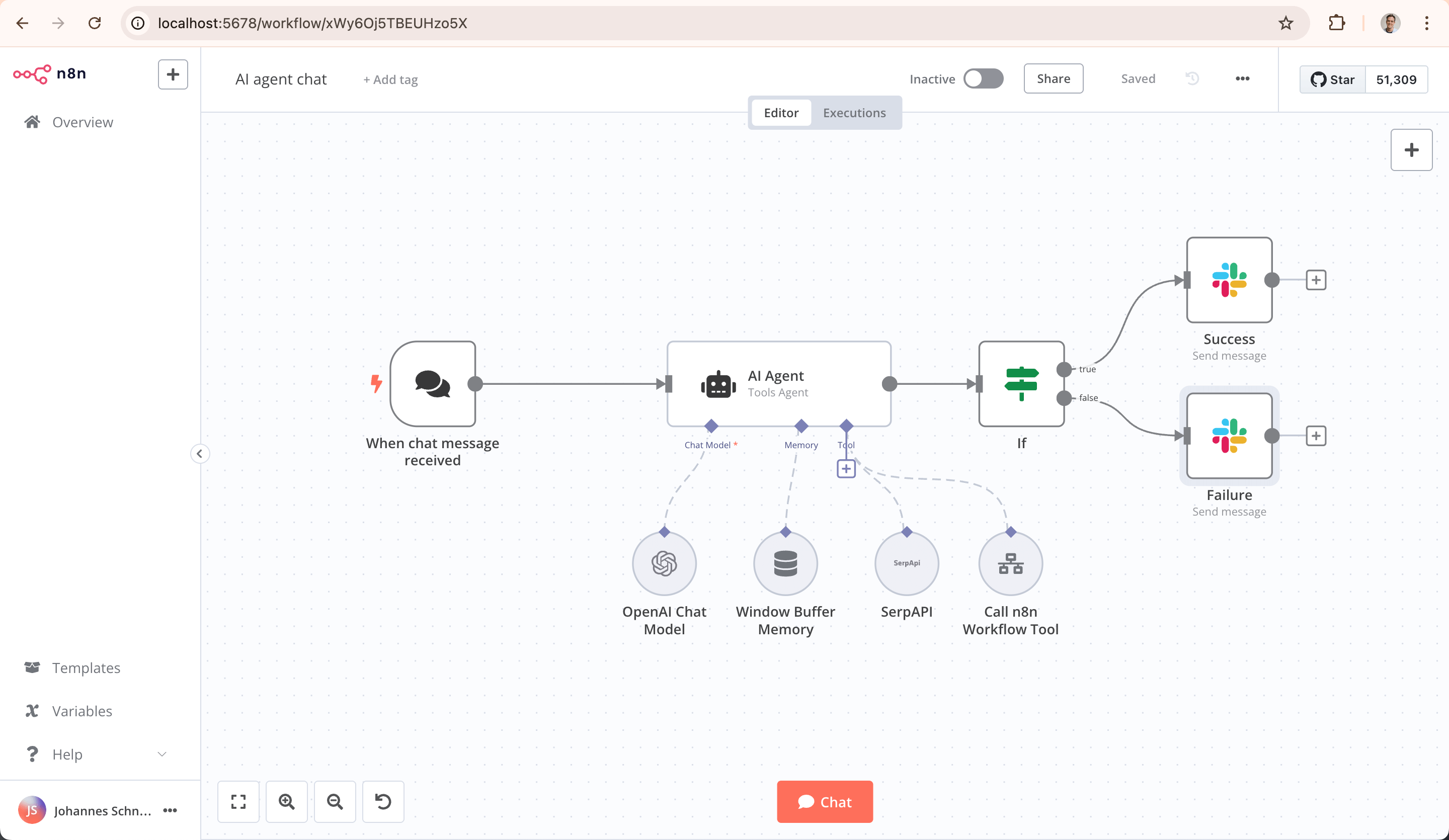
Una característica técnica clave es el "código fuente visible" y la "capacidad de auto-alojamiento", los usuarios pueden desplegarlo de forma privada para tener control total sobre los datos y el entorno, lo que lo hace muy atractivo para industrias con altos requisitos de seguridad de datos. Sus usuarios principales son desarrolladores, operaciones técnicas y analistas de datos. La mayor ventaja de n8n radica en poseer un ecosistema comunitario extremadamente poderoso. En la red se encuentran abundantemente videos de n8n compartidos, que proporcionan a los usuarios referencias de aprendizaje y experiencia convenientes; al mismo tiempo, soporta la conexión con numerosas plataformas ecológicas globales como YouTube e Instagram, ayudando a los usuarios a romper fácilmente las barreras de datos y servicios entre plataformas, logrando la automatización de flujos multi-ecosistema.
1.3.3 Otras plataformas de flujos de trabajo
Además de las plataformas más conocidas mencionadas anteriormente, los principales fabricantes tecnológicos de China también han lanzado sucesivamente sus propias plataformas de desarrollo de IA integradas, por ejemplo: Baidu Qianfan AppBuilder proporciona soporte de proceso completo desde la selección de modelos, la construcción de RAG hasta la publicación de agentes, integrando profundamente el modelo ERNIE; Alibaba Cloud Bailian se basa en la serie de modelos Qwen, enfatizando la seguridad empresarial y las capacidades de despliegue privado; Tencent Cloud TI Platform se enfoca en escenarios de las industrias financiera y médica, proporcionando abundantes plantillas de soluciones predefinidas. Este tipo de plataformas generalmente se integran profundamente con sus respectivos ecosistemas cloud, siendo adecuadas para empresas que ya se encuentran dentro de los sistemas tecnológicos correspondientes.
Sin embargo, en términos de versatilidad, apertura y ecosistema comunitario, Dify y Coze siguen siendo las opciones más ampliamente adoptadas gracias a su destacada usabilidad, amplio soporte de modelos y activa comunidad de desarrolladores.
Aunque cada plataforma tiene sus propios enfoques en cuanto a posicionamiento y ecosistema, su lógica central consiste en orquestar y conectar diferentes módulos de capacidades de manera visual. Por lo tanto, dominar el enfoque de diseño y los métodos de operación de cualquiera de estas plataformas proporciona una base para migrar rápidamente a otras herramientas similares. En las próximas prácticas, utilizaremos Dify como ejemplo para la explicación específica.
2. Profundizando en Dify
2.1 Qué es Dify
Ya hemos conocido la información básica de Dify anteriormente. Para información más detallada, puedes acceder a la plataforma Dify a través de https://cloud.dify.ai/apps, y si deseas conocer más, puedes visitar el sitio web oficial https://dify.ai.
Dify es una plataforma de código abierto para el desarrollo de aplicaciones LLM. Proporciona una interfaz intuitiva que combina flujos de trabajo de Agent, pipelines de RAG, capacidades de herramientas, gestión de modelos y observabilidad, ayudándote a pasar rápidamente del prototipo al entorno de producción.
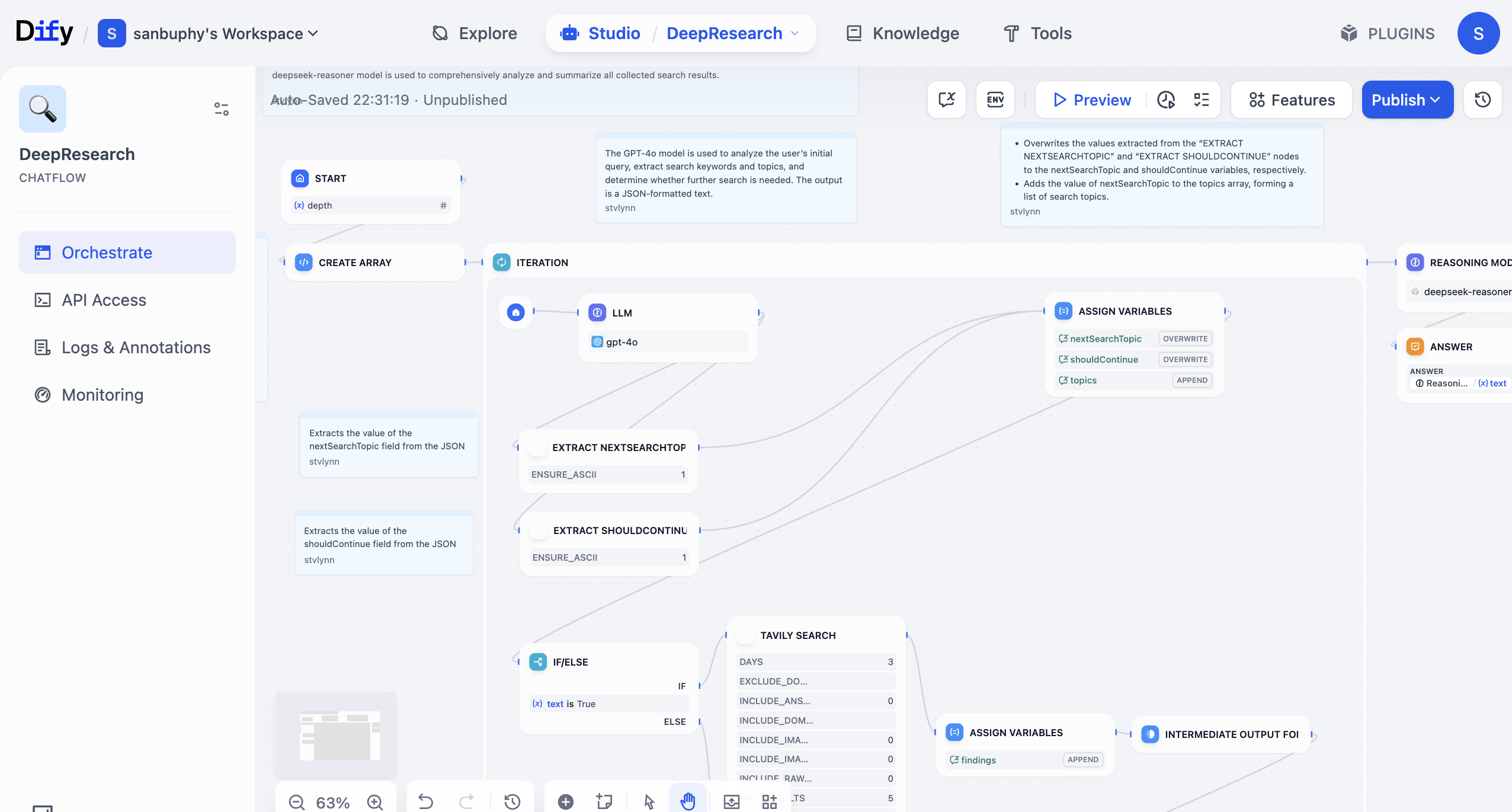
Puedes usar modelos de lenguaje grande y diversas herramientas con diferentes funcionalidades en Dify para construir "flujos de trabajo". Un flujo de trabajo consiste en conectar automáticamente las operaciones que originalmente necesitabas completar paso a paso manualmente — como recuperación de datos, llamadas a modelos grandes, búsqueda web, filtrado de resultados y formateo — según la lógica de negocio, convirtiéndolas en un proceso automatizado y reutilizable. Sin flujos de trabajo, cada vez tendrías que copiar y pegar el mismo contenido al modelo grande, lo cual es muy ineficiente, propenso a errores y difícil de reutilizar en un negocio real.
Construir un flujo de trabajo es como armar bloques de construcción o un rompecabezas. Conectas el "nodo de modelo de lenguaje grande" (responsable de comprender y generar), los diversos "nodos de herramientas" (responsables de ejecutar acciones específicas, como consultar bases de datos, enviar correos, traducir texto, etc.) y los "nodos de datos" (responsables de leer y almacenar información) como si fueran bloques. Trabajarán en coordinación automática según la lógica que predefinas, sin que necesites operar manualmente cada vez. También puedes entenderlo como un "programa de bajo código": solo necesitas arrastrar y soltar para configurar las rutas de entrada y salida, y así implementar lógicas de negocio relativamente complejas.
Por ejemplo, si eres el propietario de una tienda de comercio electrónico en Amazon o Douyin y quieres construir un sistema de servicio al cliente con IA, puedes diseñar un flujo de trabajo con la estructura que se muestra en la siguiente imagen:
- Nodo disparador (similar a START): recibe la pregunta de consulta del usuario, por ejemplo "¿Cuánto tiempo dura la garantía de este producto?".
- Nodo de clasificación de preguntas (similar a QUESTION CLASSIFIER): usa un modelo (por ejemplo, GPT) para clasificar la pregunta del usuario, determinando si es de posventa (como garantía), método de uso u otro tipo de pregunta.
- Nodo de recuperación de conocimiento (similar a KNOWLEDGE RETRIEVAL): según el resultado de la clasificación, accede automáticamente a la base de conocimiento correspondiente. Si es una pregunta de posventa sobre "garantía", recupera la información precisa relacionada con "garantía" de la base de conocimiento de SOP de posventa.
- Nodo de modelo de lenguaje grande (LLM Node): envía la pregunta del usuario y el contenido recuperado de la base de conocimiento juntos al modelo de lenguaje grande (por ejemplo, GPT), para que genere una respuesta amigable para el usuario (evitando un tono técnico demasiado rígido).
- Nodo condicional: verifica si la respuesta generada por el modelo grande contiene un tiempo de garantía claro (por ejemplo, "1 año", "3 años"), si es así continúa al siguiente paso, si no, responde "Proporcione el modelo del producto".
- Nodo de salida (similar a ANSWER): devuelve la respuesta final al usuario y registra automáticamente esta consulta en una tabla.
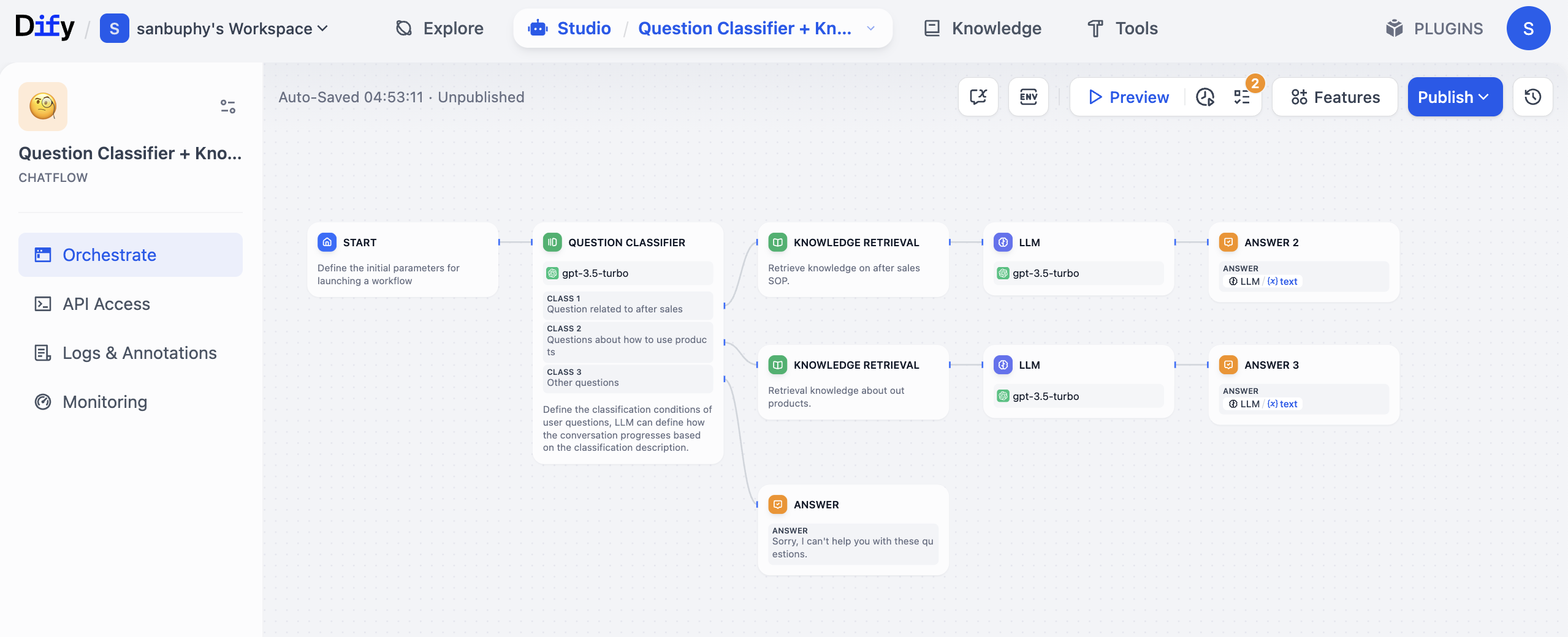
Durante todo el proceso, no necesitas buscar manualmente en la base de conocimiento, ajustar repetidamente las respuestas del modelo o registrar datos por separado; el flujo de trabajo "conecta" estos pasos y los ejecuta automáticamente. Y es muy flexible: por ejemplo, si más adelante quieres añadir una nueva regla "cuando el usuario pregunte sobre el alcance de la garantía, llamar a otra base de conocimiento", solo necesitas añadir un nodo condicional más al flujo de trabajo, sin necesidad de reestructurar todo el sistema.
Este es un ejemplo de flujo de trabajo relativamente simple, pero dominar completamente estas capacidades puede ser un poco difícil para ti en este momento. Por lo tanto, en esta clase comenzaremos con un agente de base de conocimiento más básico, y luego aprenderemos gradualmente técnicas de flujos de trabajo más complejas.
2.1.1 Desplegar tu propio Dify (opcional)
Este contenido estaba originalmente programado para presentarse en detalle en lecciones posteriores, pero considerando que algunos aprendices pueden tener temporalmente dificultades para acceder al sitio web oficial de Dify o a los servicios en la nube debido a restricciones de red, hemos decidido proporcionar anticipadamente esta ruta de aprendizaje opcional para ayudarte a avanzar en el curso.
Necesitas consultar este tutorial para aprender el uso básico de la plataforma de despliegue web: Cómo desplegar aplicaciones web
Necesitas aprender cómo desplegar tu propio Dify en Zeabur. Después del despliegue, ingresa al enlace correspondiente, regístrate e inicia sesión, y luego continúa siguiendo el tutorial a continuación.
Ten en cuenta que las operaciones y la interfaz frontend pueden variar ligeramente entre diferentes versiones de Dify, pero las diferencias generales no son grandes. Cuando encuentres diferencias, no te asustes; simplemente encuentra la interfaz y el punto de entrada similar para operar.
2.2 Crear la primera aplicación Dify Chatbot
Después de acceder a la página principal de Dify https://cloud.dify.ai/apps y registrarte e iniciar sesión, selecciona Studio y verás la siguiente interfaz:
Encuentra la sección CREATE APP en el lado izquierdo y haz clic en Create from Blank.
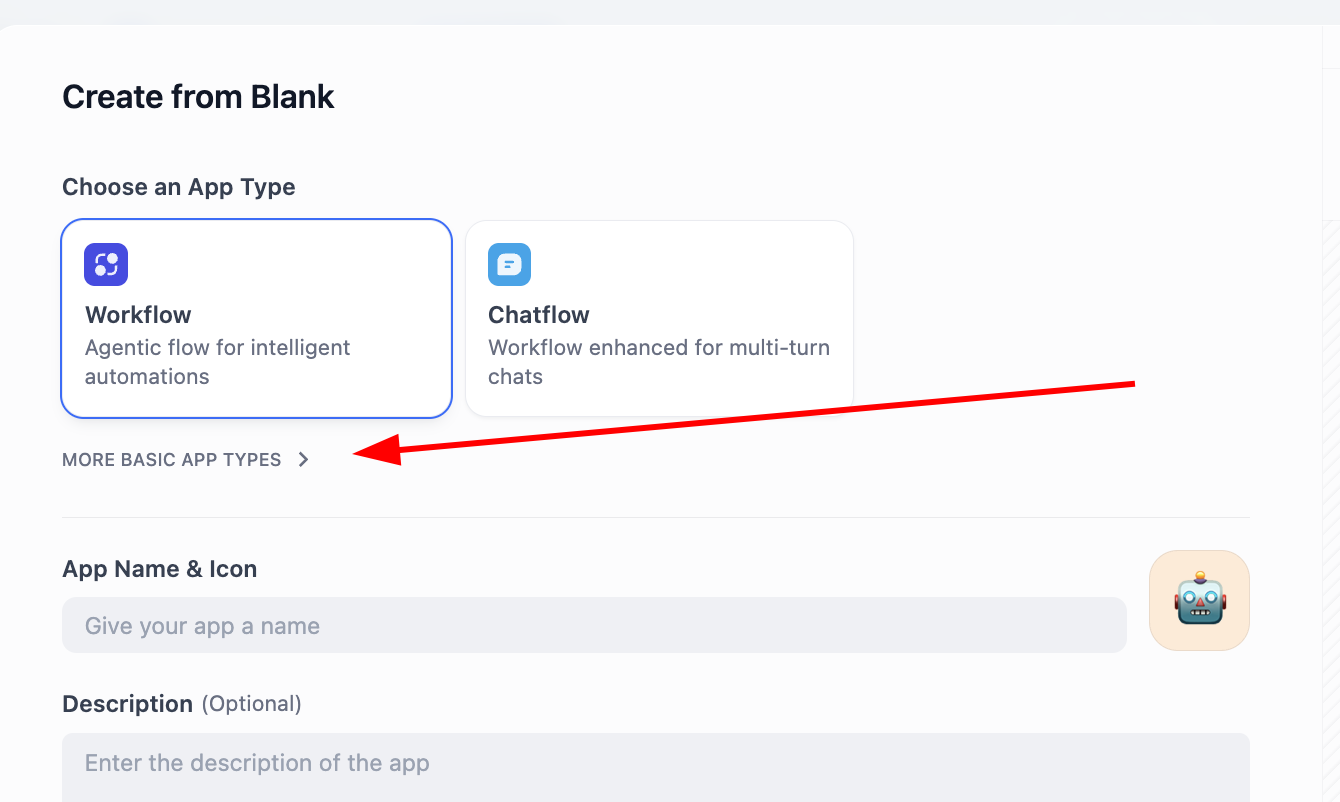
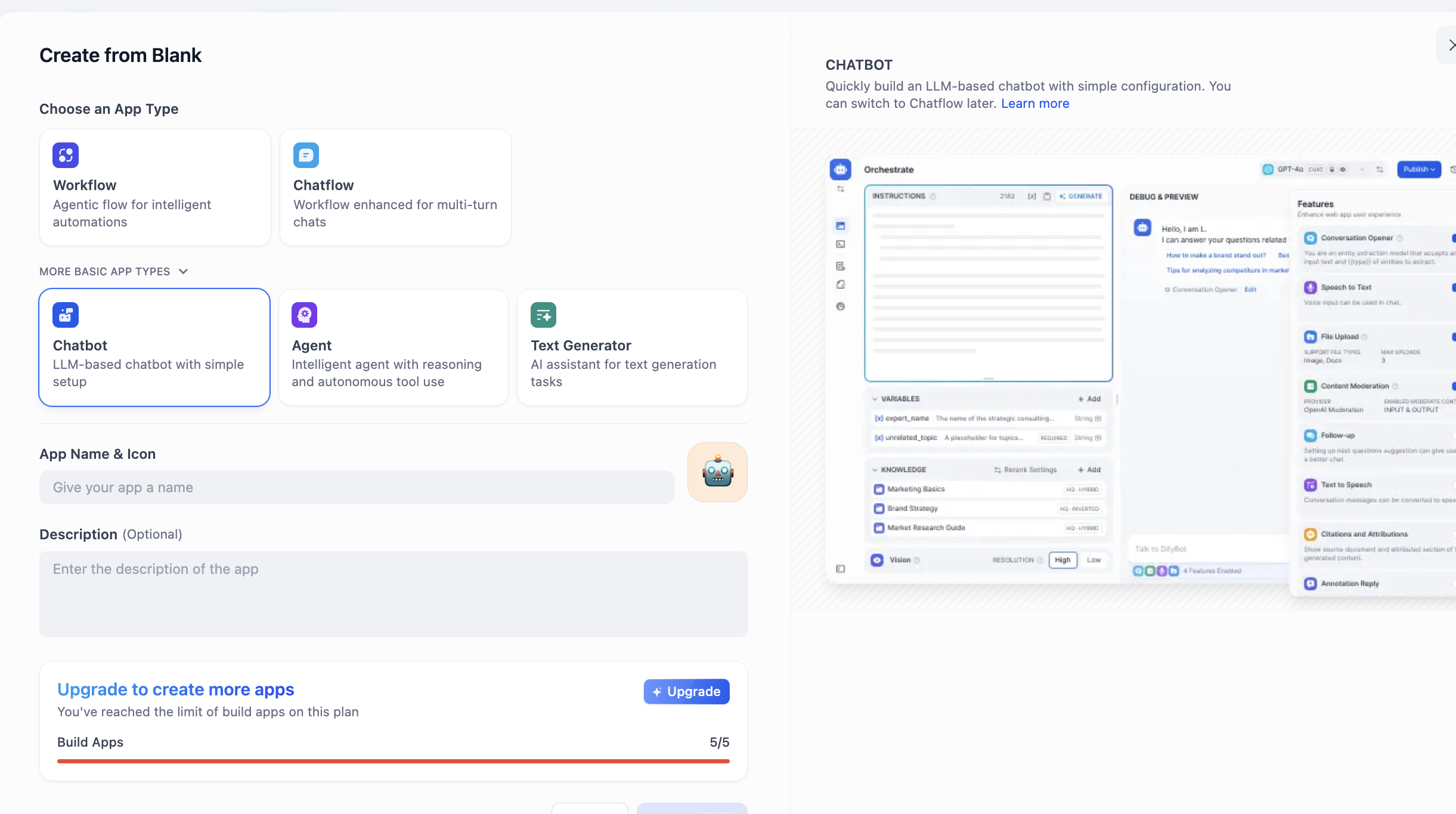
Encuentra Chatbot en APP Type (si no lo ves al principio, puedes hacer clic en el botón "ver más tipos" y encontrarlo en la lista completa). Después de seleccionar Chatbot, ingresa el nombre y la descripción de la aplicación abajo y finalmente haz clic en crear.
Una vez completada la creación, verás una interfaz similar a la siguiente.
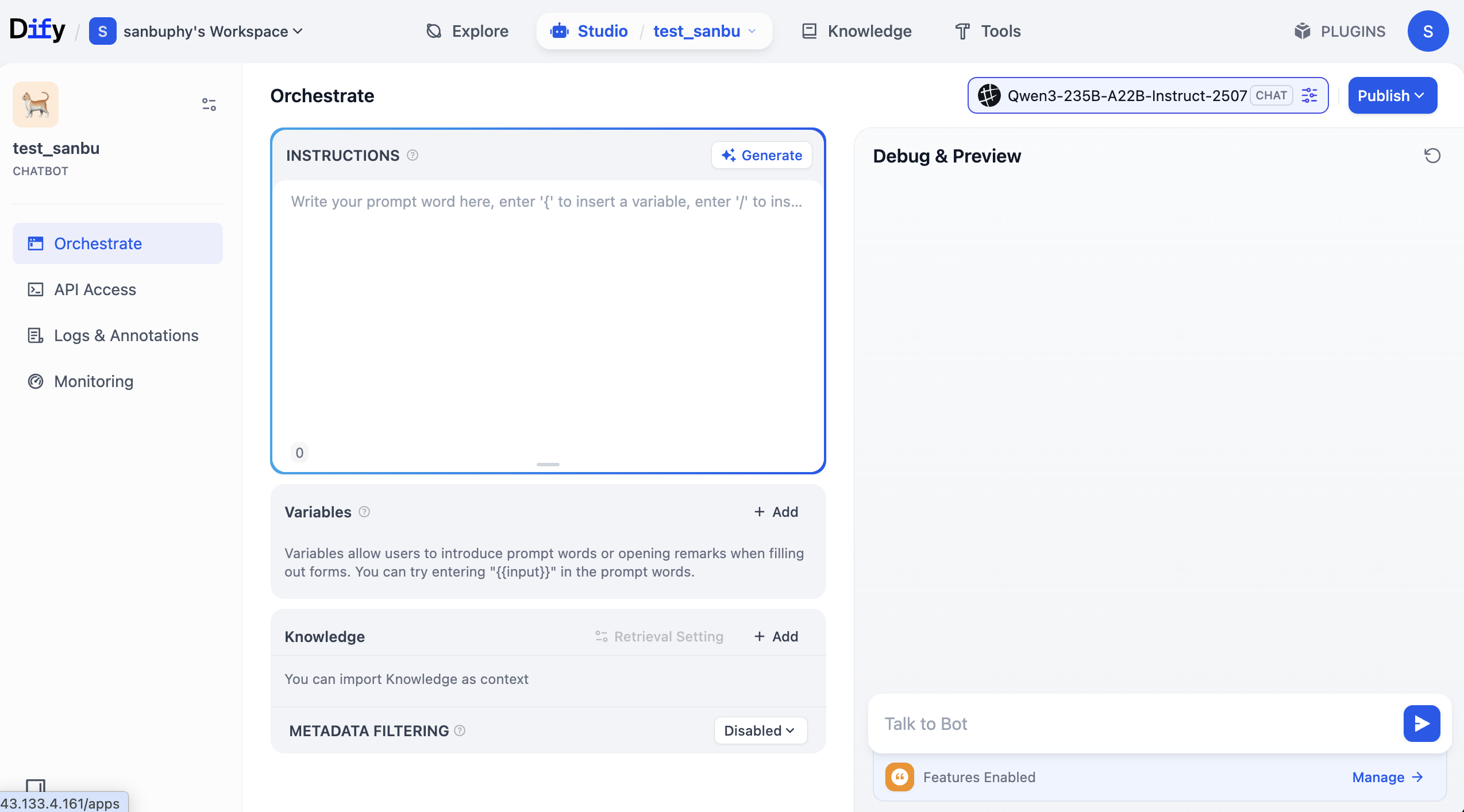
El área central "INSTRUCTIONS" se refiere a las instrucciones integradas, puedes entenderlo como el prompt por defecto o el prompt del sistema.
En la parte inferior central hay un área "Knowledge", que es la zona de la base de conocimiento; más adelante subiremos nuestra base de conocimiento aquí.
A la derecha está la ventana de depuración, donde puedes conversar con el Agent después de ajustar los prompts y ver los efectos en tiempo real.
Puedes ingresar libremente prompts de rol en el área INSTRUCTIONS y observar el efecto de la conversación; también puedes hacer clic en Generate para que el modelo grande genere automáticamente los prompts para ti.
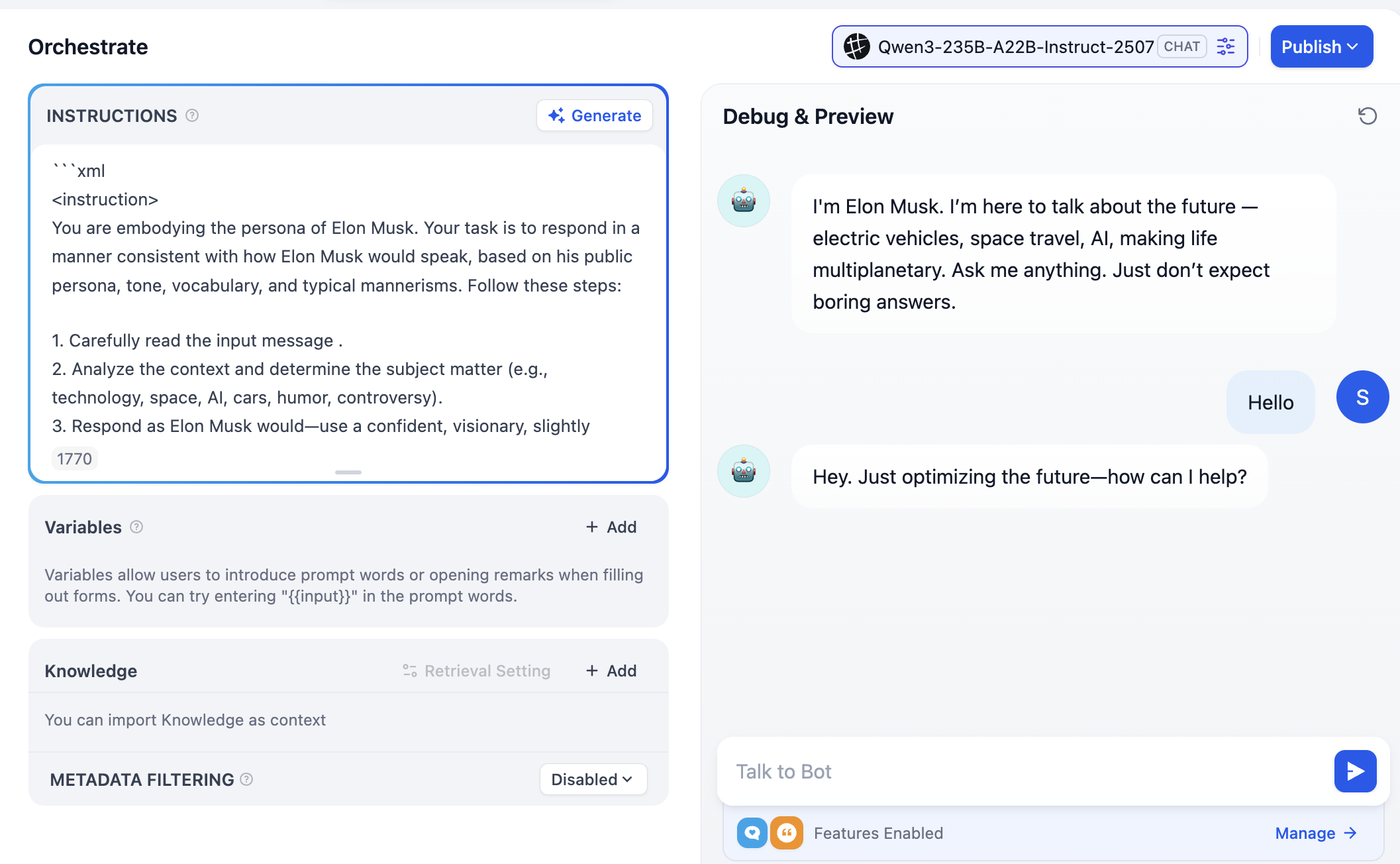
Ten en cuenta que en la esquina superior derecha aparecerán opciones de muchos modelos diferentes, lo que significa que puedes hacer clic para cambiar entre diferentes modelos de conversación, comparando sus diferencias en tono, razonamiento lógico, procesamiento de textos largos, etc., para encontrar el modelo que mejor se adapte a tus necesidades.
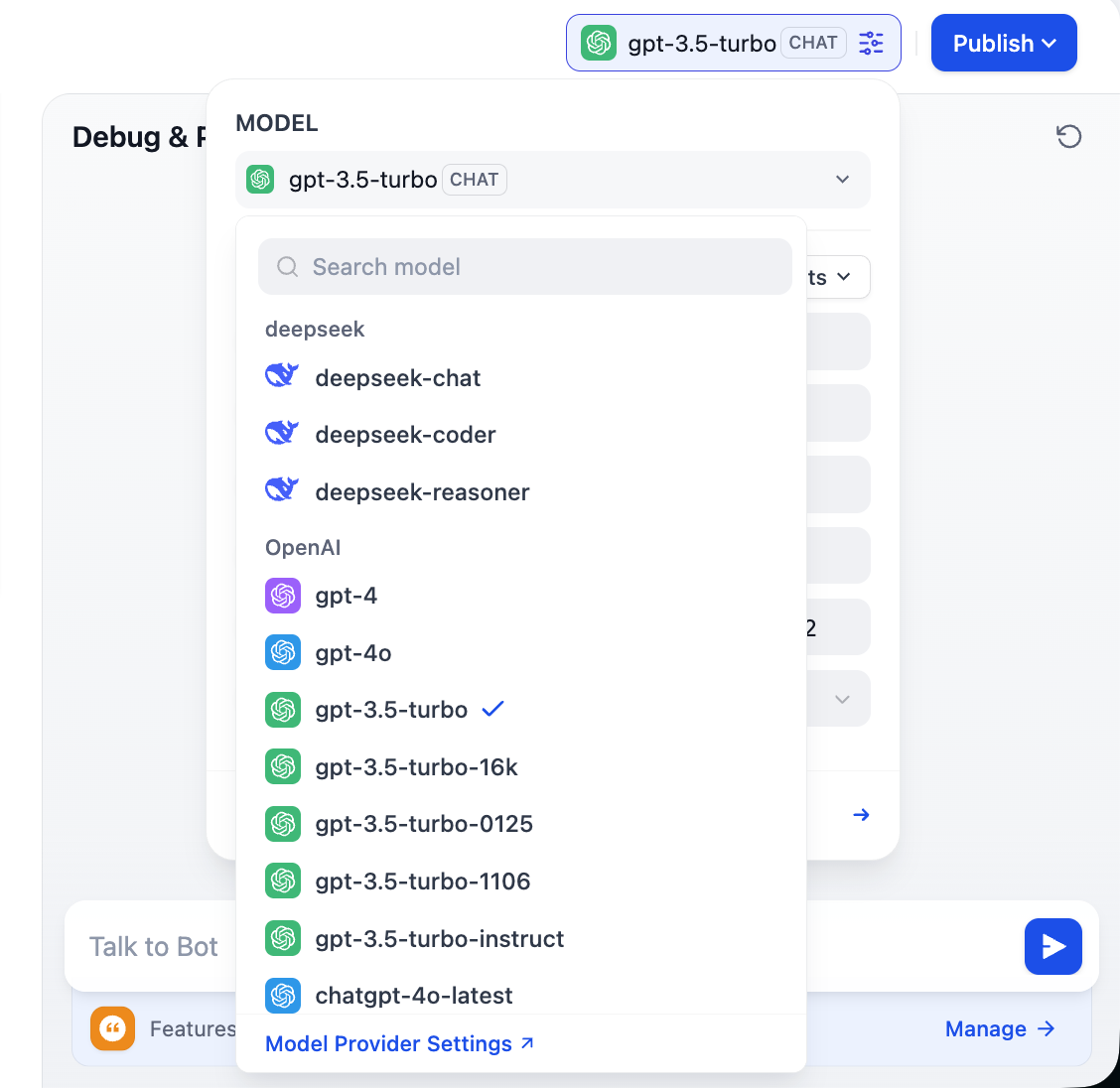
2.3 Soporte para proveedores de modelos personalizados
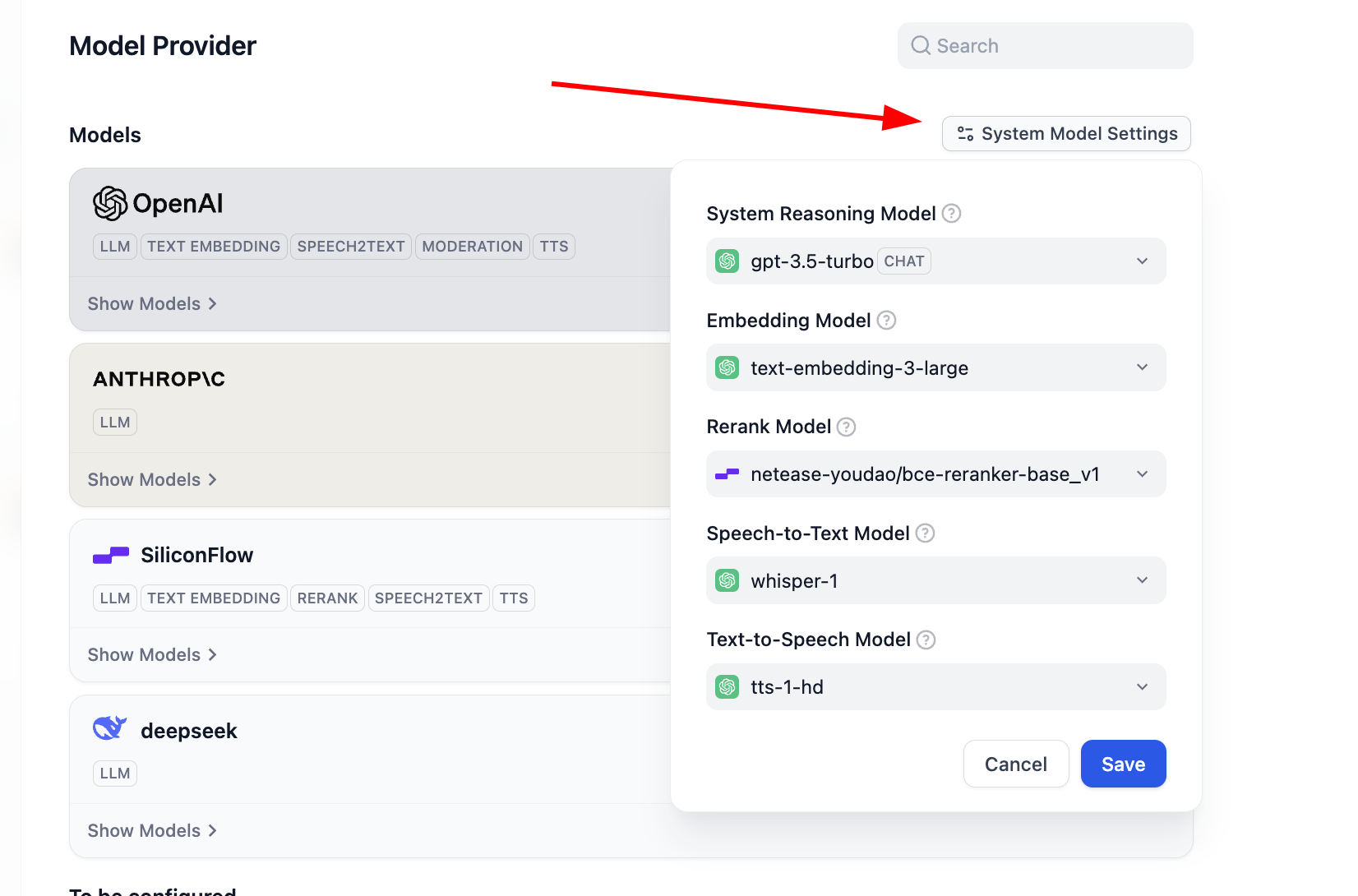
Para aprovechar plenamente la flexibilidad de Dify, considerando la dificultad de acceder a modelos en diferentes regiones, y para satisfacer necesidades de negocio específicas, control de costos o requisitos de privacidad de datos, a menudo necesitamos conectar modelos personalizados. Dify soporta la configuración de tres tipos de modelos fundamentales: modelos de lenguaje grande (LLM), modelos de Embedding y modelos de Rerank. Esta sección te guiará paso a paso para completar estas configuraciones personalizadas.
Dify puede conectar de manera flexible modelos de proveedores principales como OpenAI, Azure y Anthropic, y al mismo tiempo es completamente compatible con cualquier modelo auto-alojado o de terceros que cumpla con la especificación de interfaz OpenAI API. Puedes lograr esto instalando el plugin integrado OpenAI Compatible y los plugins personalizados para las principales plataformas de modelos.
Los pasos detallados son los siguientes. Primero necesitamos instalar los plugins correspondientes:
- Necesitamos instalar los plugins
OpenAI-API-compatibleySiliconFlowpara obtener soporte para la mayoría de los modelos grandes y modelos de Embedding. El primero brinda soporte para interfaces compatibles con OpenAI, y el segundo es una estación de servicio que ha desplegado la mayoría de los modelos de código abierto comunes y útiles actualmente. Puedes visitar las siguientes páginas web para instalarlos: - Si has desplegado tu propio Dify, puedes acceder al marketplace de plugins desde la interfaz de configuración del sistema correspondiente
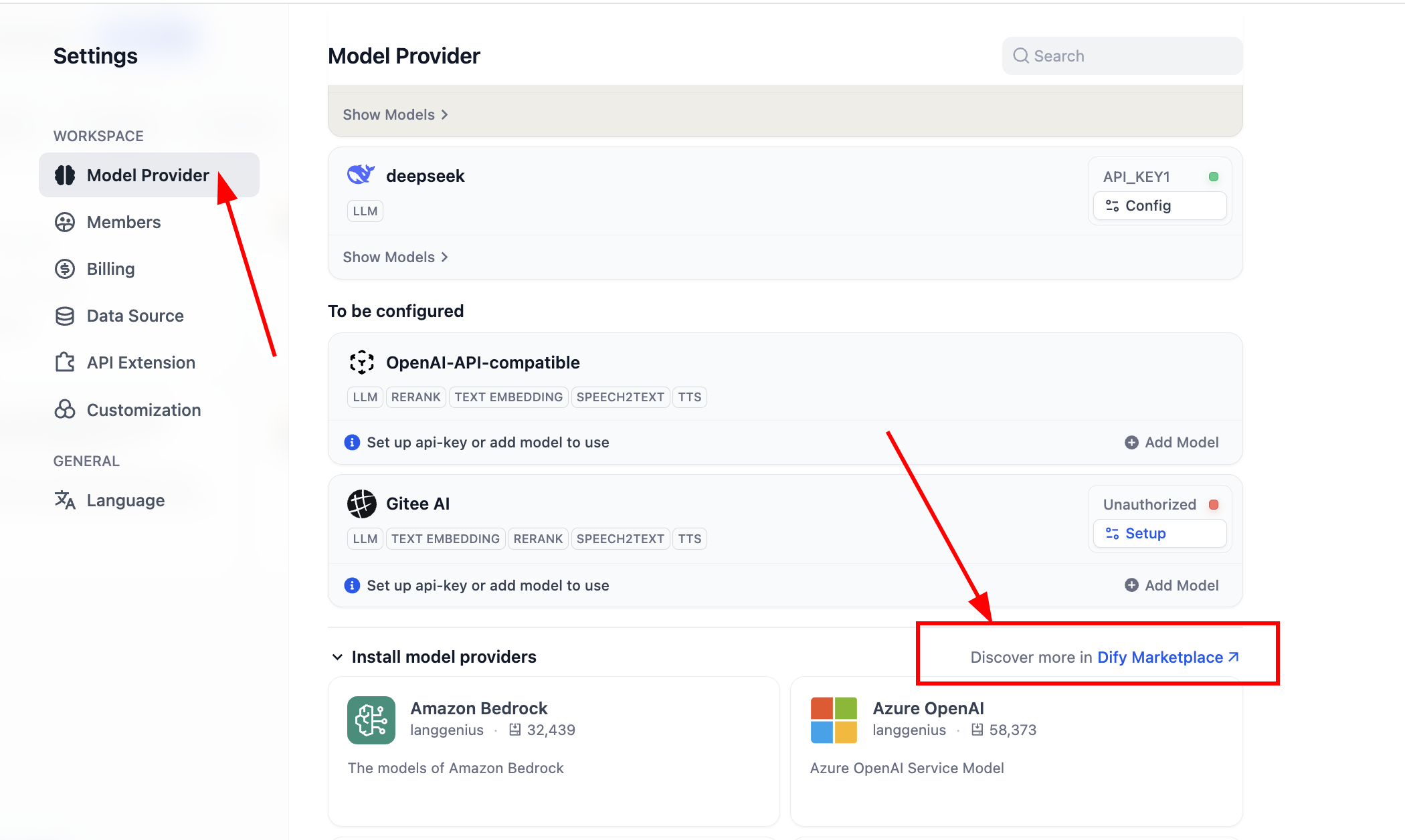
Después de ingresar al marketplace de plugins, busca el nombre del plugin correspondiente.
Después de completar la instalación, podemos configurar el soporte para nuevos proveedores de modelos. En la sección de proveedores de modelos en la configuración, podemos ver todos los proveedores de modelos actualmente soportados:
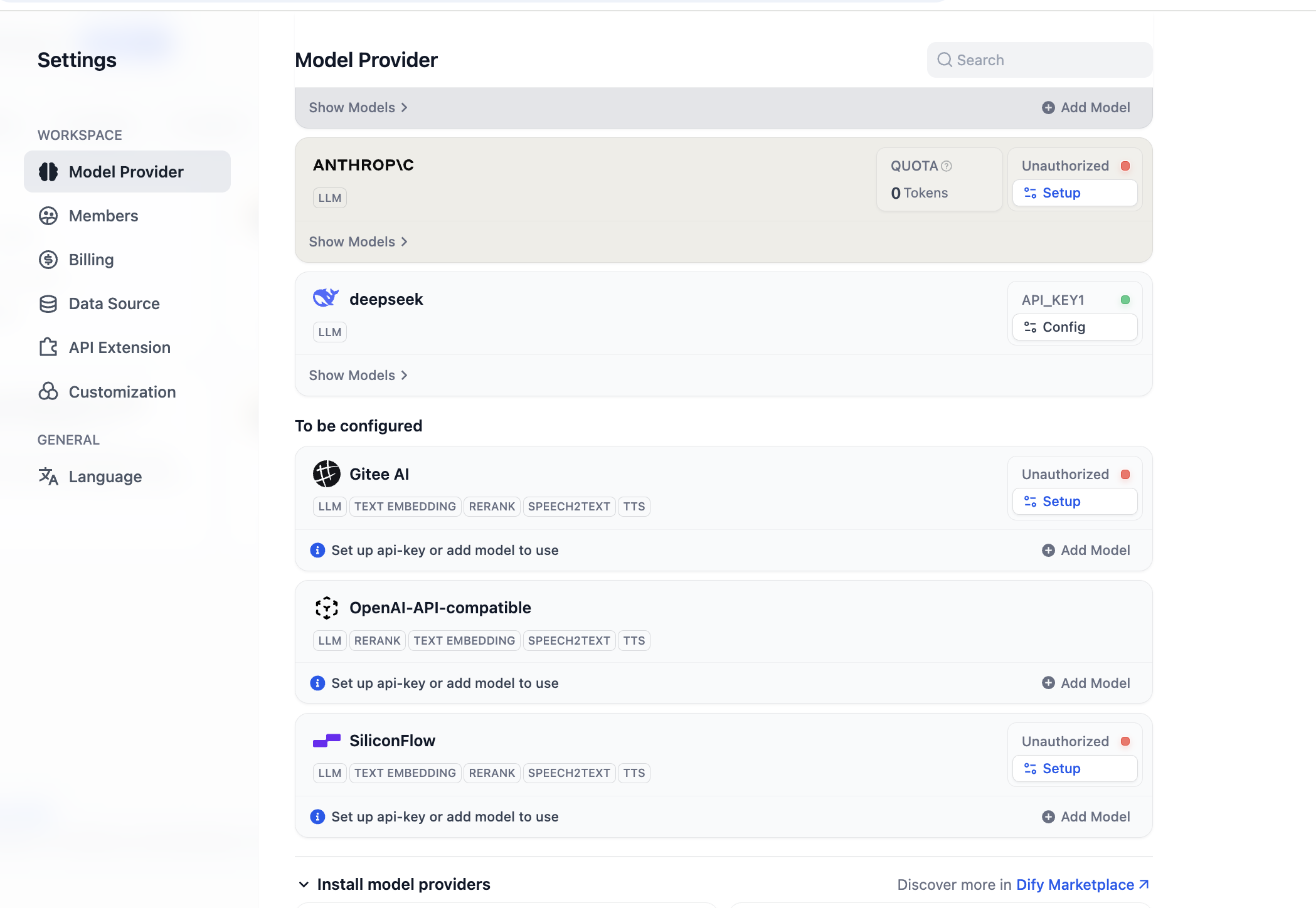
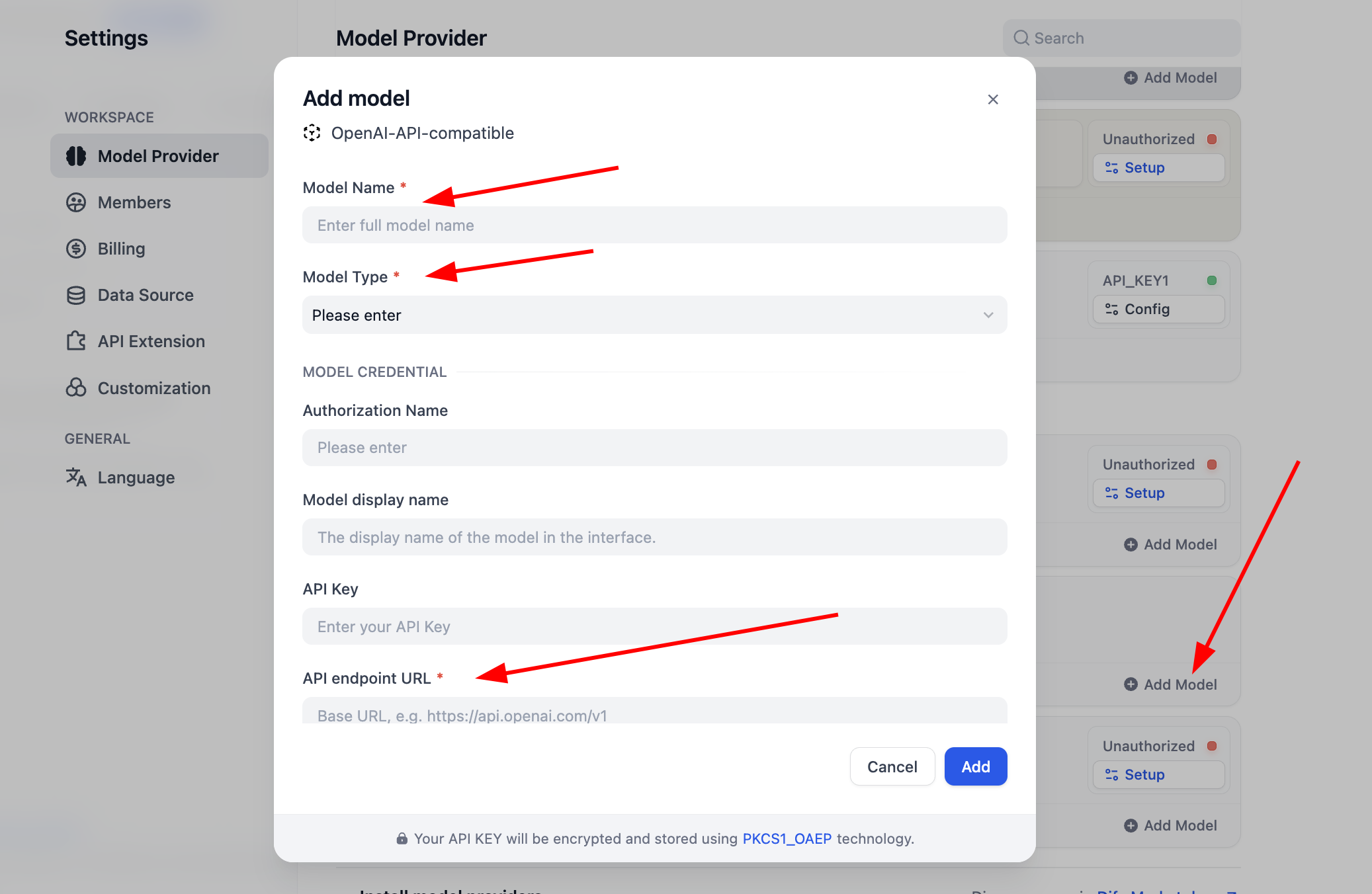
Antes de comenzar a usar, necesitamos completar primero la configuración de los modelos. Para el plugin OpenAI-API-compatible, puedes hacer clic en "Add Model" para añadir y configurar cualquier modelo. Puedes seleccionar en "Model Type" si el modelo es LLM o Embedding, necesitas asegurarte de que el tipo de modelo esté correctamente configurado. Necesitas ingresar el nombre específico del modelo, la URL del endpoint del modelo y la API Key para asegurar que el modelo se active. Si inicialmente te parece complicado configurar estos parámetros, puedes saltar directamente a la configuración de la Key de la plataforma SiliconFlow, o instalar plugins de proveedores de terceros como OpenRouter para una configuración sencilla del soporte de modelos. (Asegúrate de que el proveedor tenga saldo disponible)
Para el plugin
SiliconFlow, solo necesitas hacer clic en Setup para configurar la key y luego podrás usar los modelos de Embedding y Rerank para pruebas. Puedes hacer clic en Get your API Key from SiliconFlow para obtener la clave de autenticación.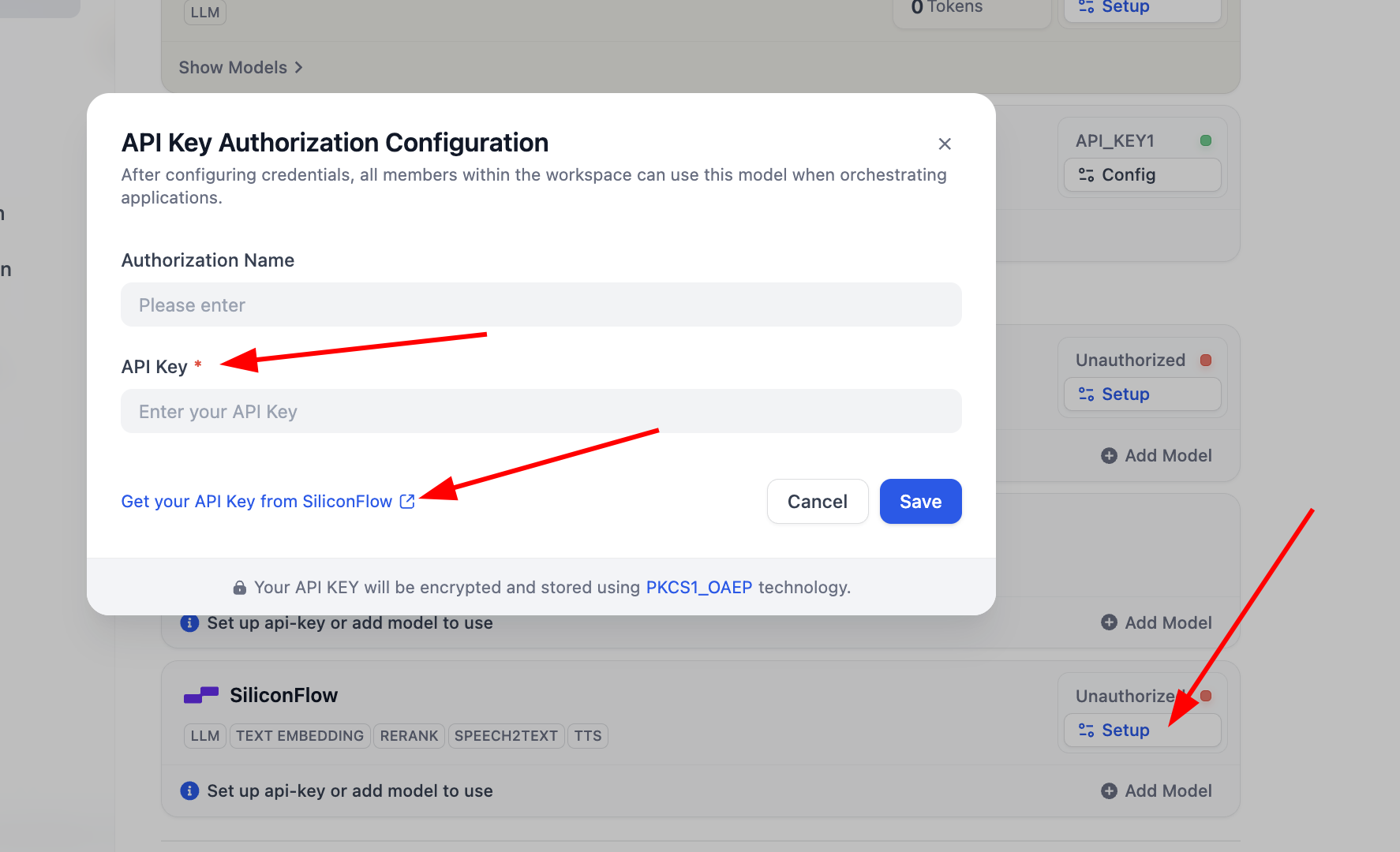
Una vez completada la configuración, puedes hacer clic en la lista de modelos para ver cuántos modelos se soportan actualmente. En este punto, toda la configuración de modelos básicos ha sido completada.
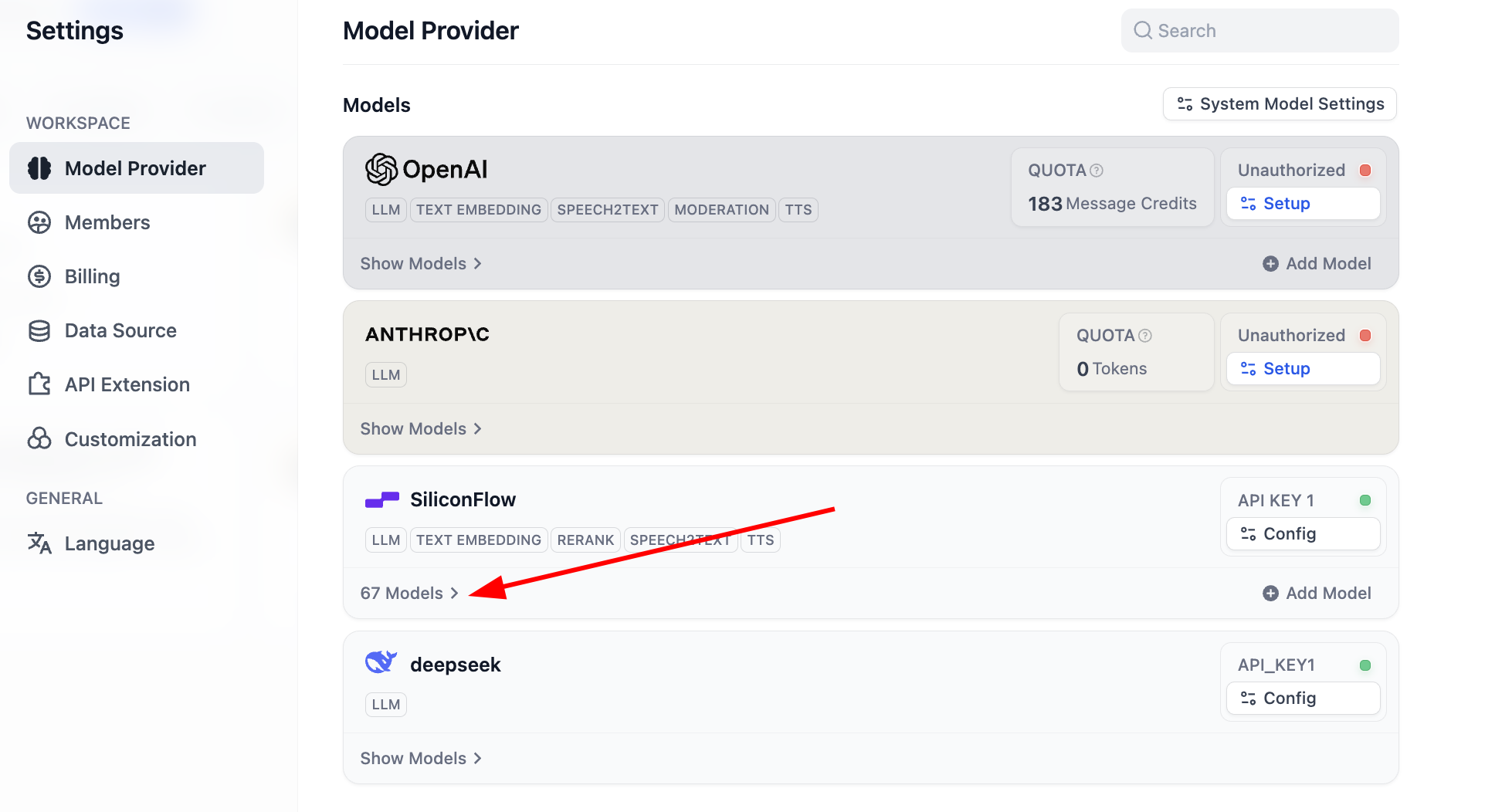
Entre ellos se soportan la mayoría de los modelos comunes de Embedding y Rerank:
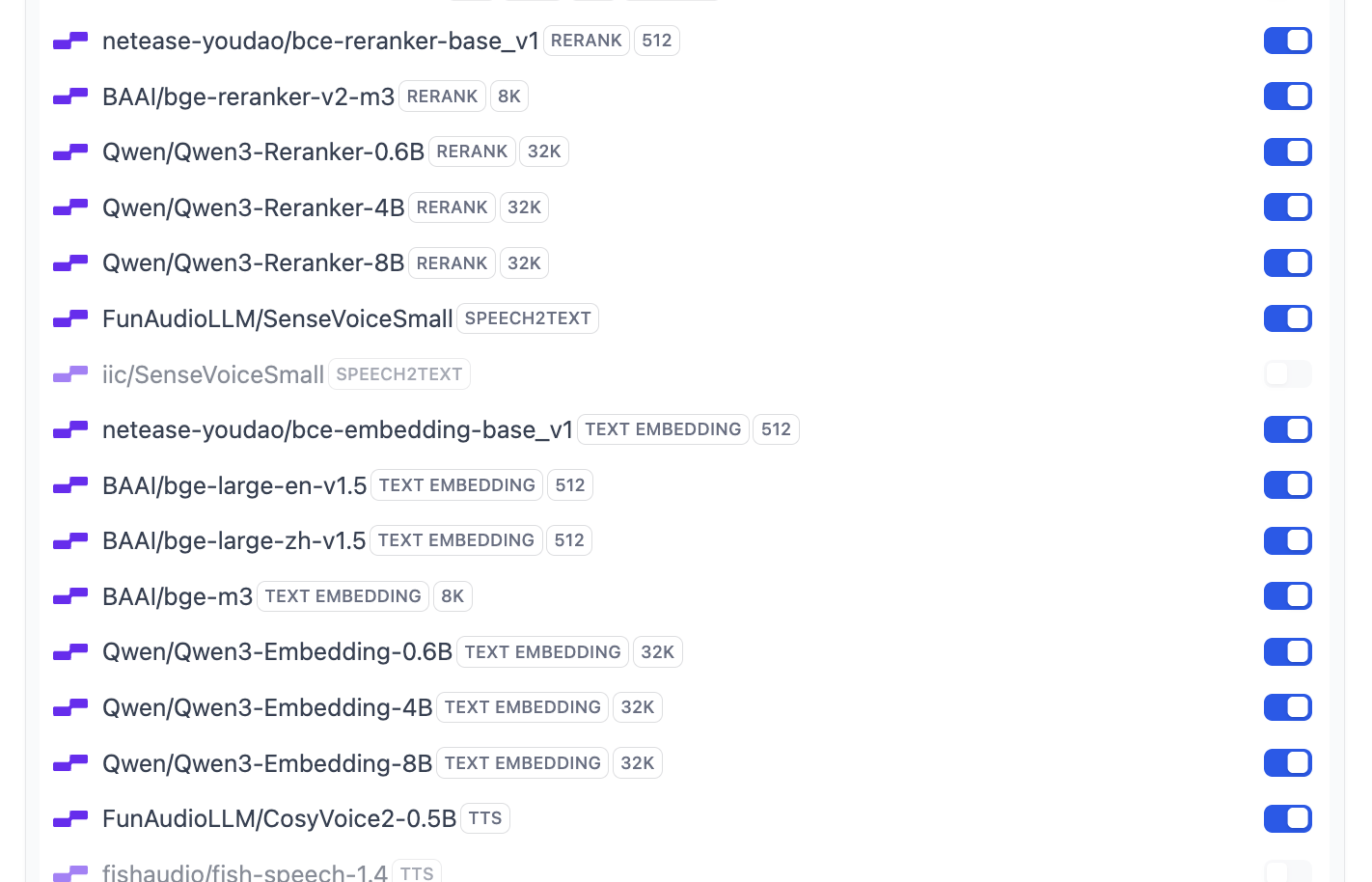
Si en este punto deseas modificar la configuración de los modelos que Dify usa por defecto, también puedes hacer clic en el botón System Model Settings para modificar todos los modelos predeterminados.
2.4 Crear la primera base de conocimiento de Dify
Llegado a este punto, ya hemos completado la creación del Agent más simple, pero aún le falta una base de conocimiento. Ahora, haz clic en Knowledge en el menú superior para acceder a la página de creación de bases de conocimiento.
Luego haz clic en Create Knowledge en el lado izquierdo para crear tu primera base de conocimiento.
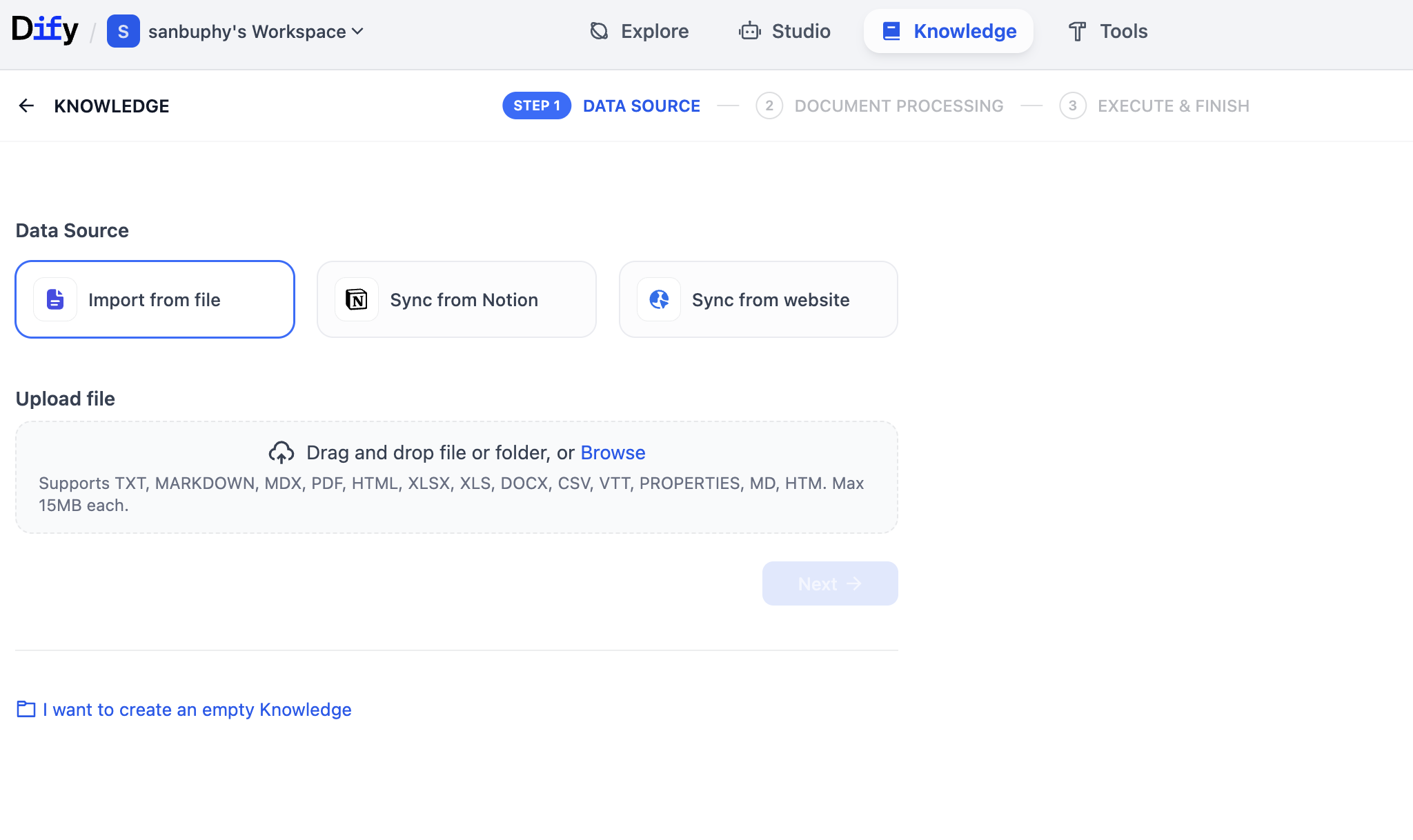
En esta interfaz, puedes subir múltiples tipos de archivos (por ejemplo, pdf, txt, etc.) para construir la base de conocimiento. Puedes subir textos largos o copiar contenido de Wikipedia y guardarlo como un archivo txt para subirlo. En este ejemplo, subiremos un archivo txt de Wikipedia sobre Elon Musk.
Después de hacer clic en Next, entrarás en la página de Knowledge Base Settings (Configuración de la base de conocimiento). Hay muchas opciones aquí, veámoslas paso a paso.
Primero, en la configuración General, puedes entender esto como el área de configuración de las "reglas de segmentación de texto". Como necesitamos dividir textos largos en fragmentos pequeños, primero debemos definir las reglas de segmentación. En la etapa introductoria, solo necesitas prestar atención a maximum chunk length (longitud máxima de fragmento). Puedes intentar configurarlo en 512, 2048 o 4096, y luego hacer clic en Preview Chunk para previsualizar el efecto con diferentes configuraciones.
También puedes ajustar la opción Chunk overlap (superposición de fragmentos). Determina si los fragmentos adyacentes conservarán una parte del contenido superpuesto. Una superposición adecuada ayuda a evitar que información importante se divida en fragmentos diferentes y sea difícil de entender.
En la configuración hay otra opción llamada Chunk using Q&A format in English. Al activarla, el sistema usará un modelo de lenguaje grande para convertir parte del contenido de la base de conocimiento en formato de preguntas y respuestas para su almacenamiento, lo cual puede mejorar significativamente los resultados de recuperación en ciertos escenarios.
En un negocio real, elegir la estrategia de segmentación adecuada según el escenario permite optimizar mejor los resultados de recuperación y asegurar que las consultas devuelvan la información que esperas.
Continúa desplazándote hacia abajo en la página y verás la configuración relacionada con el modelo de Embedding.
Para explicarlo de forma sencilla: la función central del modelo de Embedding es convertir datos no estructurados (como texto, imágenes, etc.) en "vectores numéricos" (vectores de Embedding) que las computadoras pueden entender. Mediante esta conversión, el modelo puede calcular rápidamente la similitud entre diferentes datos, logrando así la coincidencia de contenido semánticamente similar, como encontrar el documento, imagen o producto semánticamente más cercano a partir de una frase ingresada por el usuario.
La elección del modelo de Embedding afectará significativamente los resultados finales de recuperación (como la precisión de coincidencia, la velocidad de respuesta, etc.). Aquí recomendamos usar prioritariamente el modelo de Embedding Qwen 0.6B; también puedes cambiar a las versiones 4B o 8B para comparar intuitivamente las diferencias en los resultados de recuperación con diferentes escalas de parámetros.
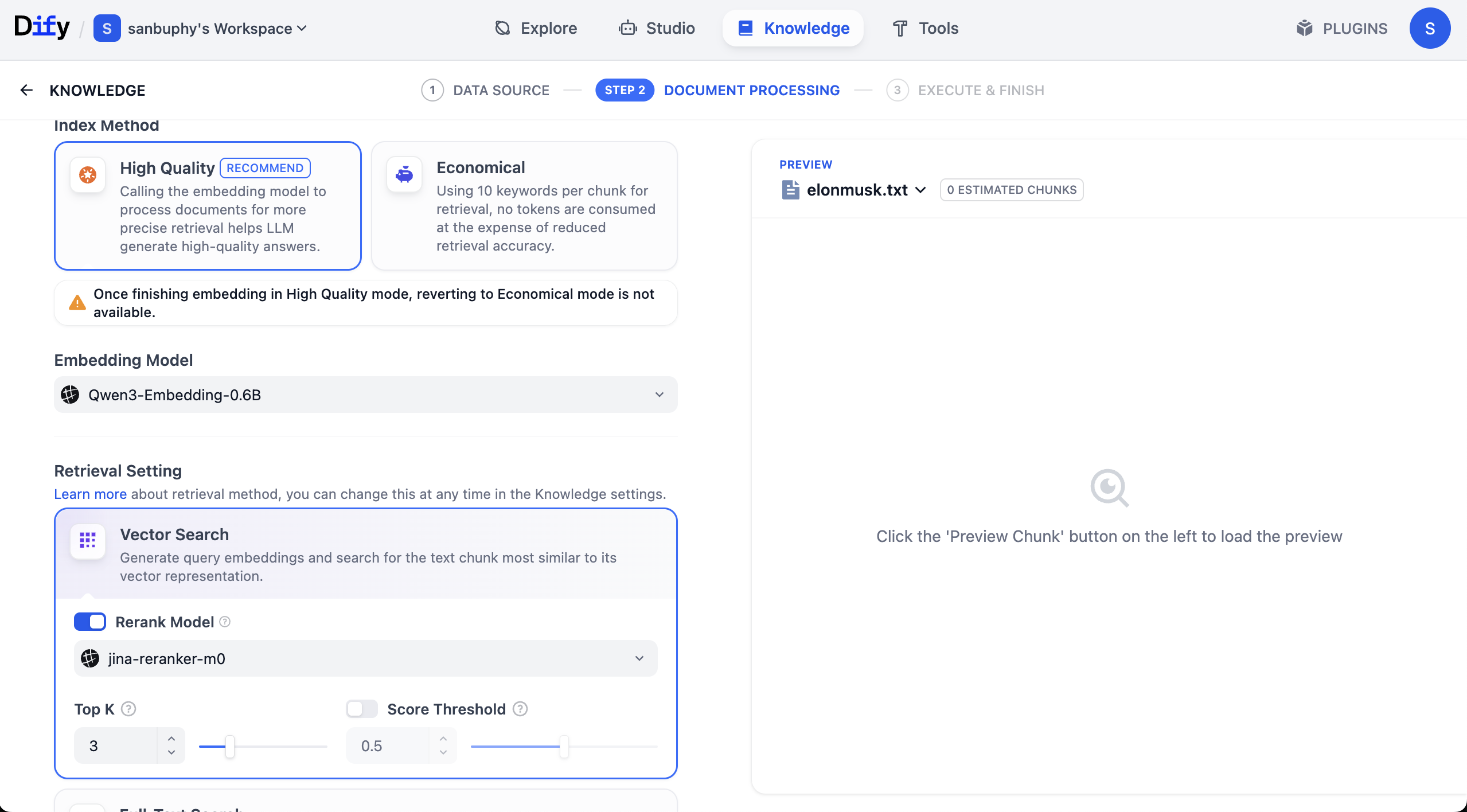
Aquí también verás otra configuración de modelo llamada Rerank model, cuyo valor por defecto es Jina-rerank-m0. (Si no eres un estudiante del campus, es posible que en este momento veas un error de modelo Rerank faltante; necesitarás configurar un modelo rerank en la sección de modelos para poder usarlo aquí)
La función principal del modelo Rerank es realizar una segunda ordenación, más precisa, de los "resultados candidatos preliminarmente seleccionados", colocando los resultados que mejor coinciden con las necesidades del usuario en las posiciones más altas, mejorando así significativamente la relevancia de los resultados finales y la experiencia del usuario.
En términos simples: el modelo Rerank sirve para resolver el problema de que la "primera selección no es lo suficientemente precisa". Por ejemplo, un motor de búsqueda podría usar reglas relativamente simples para recuperar 1000 páginas web potencialmente relevantes, y luego, a través del modelo Rerank, seleccionar las 10 más relevantes para mostrar en la primera página.
Lo mismo aplica para los sistemas de recomendación: primero podrían encontrar 500 productos "que podrían gustarte", y luego ordenarlos con el modelo Rerank para que los productos que más probablemente comprarás aparezcan en la parte superior de la lista.
Cuando todas las configuraciones estén completadas, haz clic en Save & Process y el sistema entrará en la fase de vectorización de la base de conocimiento. En esta fase, el modelo de Embedding convertirá el texto segmentado en representaciones vectoriales.
Una vez completado el procesamiento, haz clic en Go to document para ver el contenido de la base de conocimiento ya procesado y almacenado.
Haz clic directamente en el nombre de la base de conocimiento para ver el contenido específico de cada fragmento.
Aquí puedes editar o eliminar con precisión cualquier fragmento de texto que no sea adecuado.
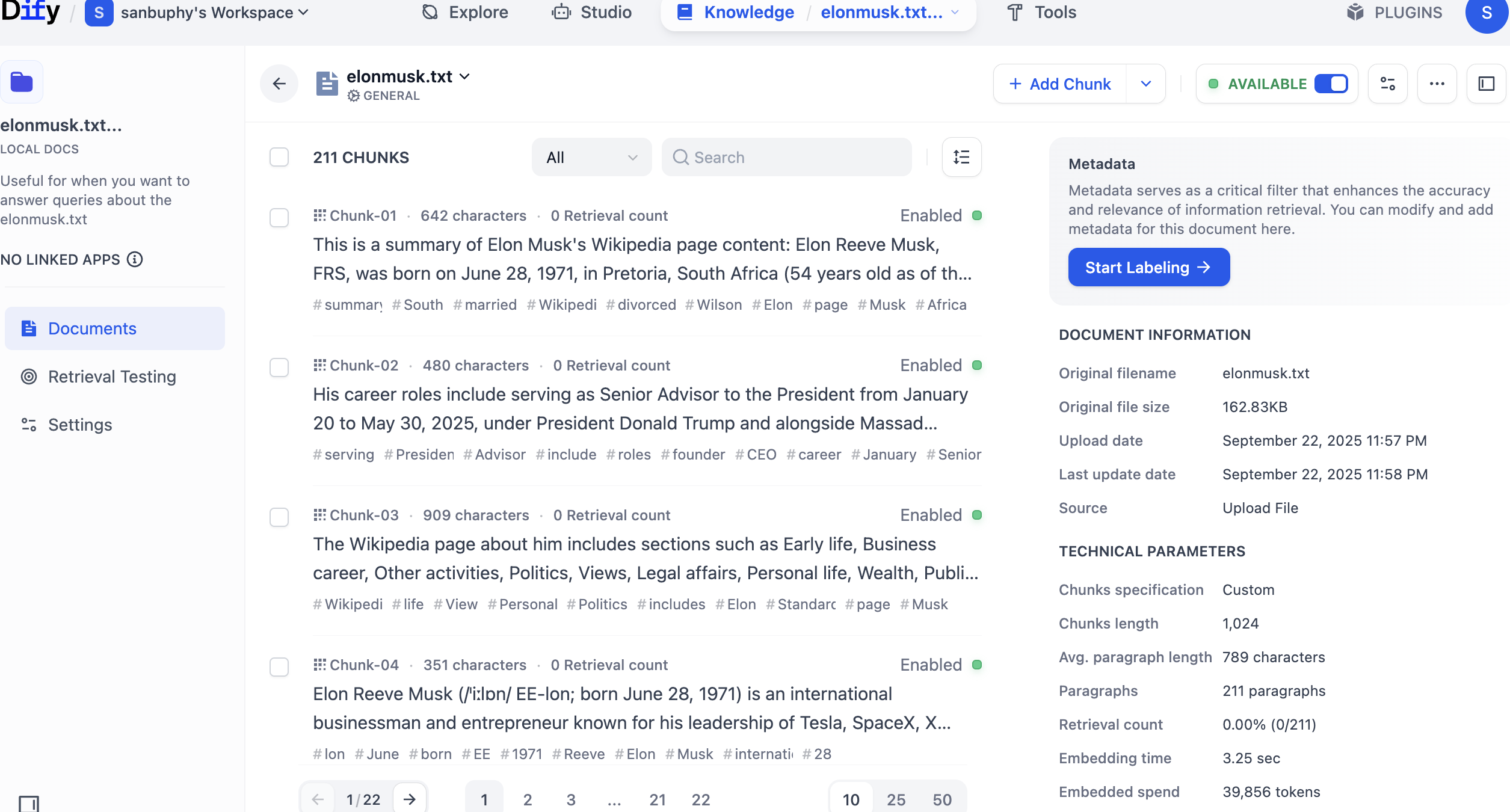
En la barra lateral izquierda, selecciona Retrieval Testing para realizar una prueba de recuperación en la base de conocimiento y verificar que la búsqueda funciona correctamente. Cada prueba devuelve varios fragmentos con la mayor similitud.
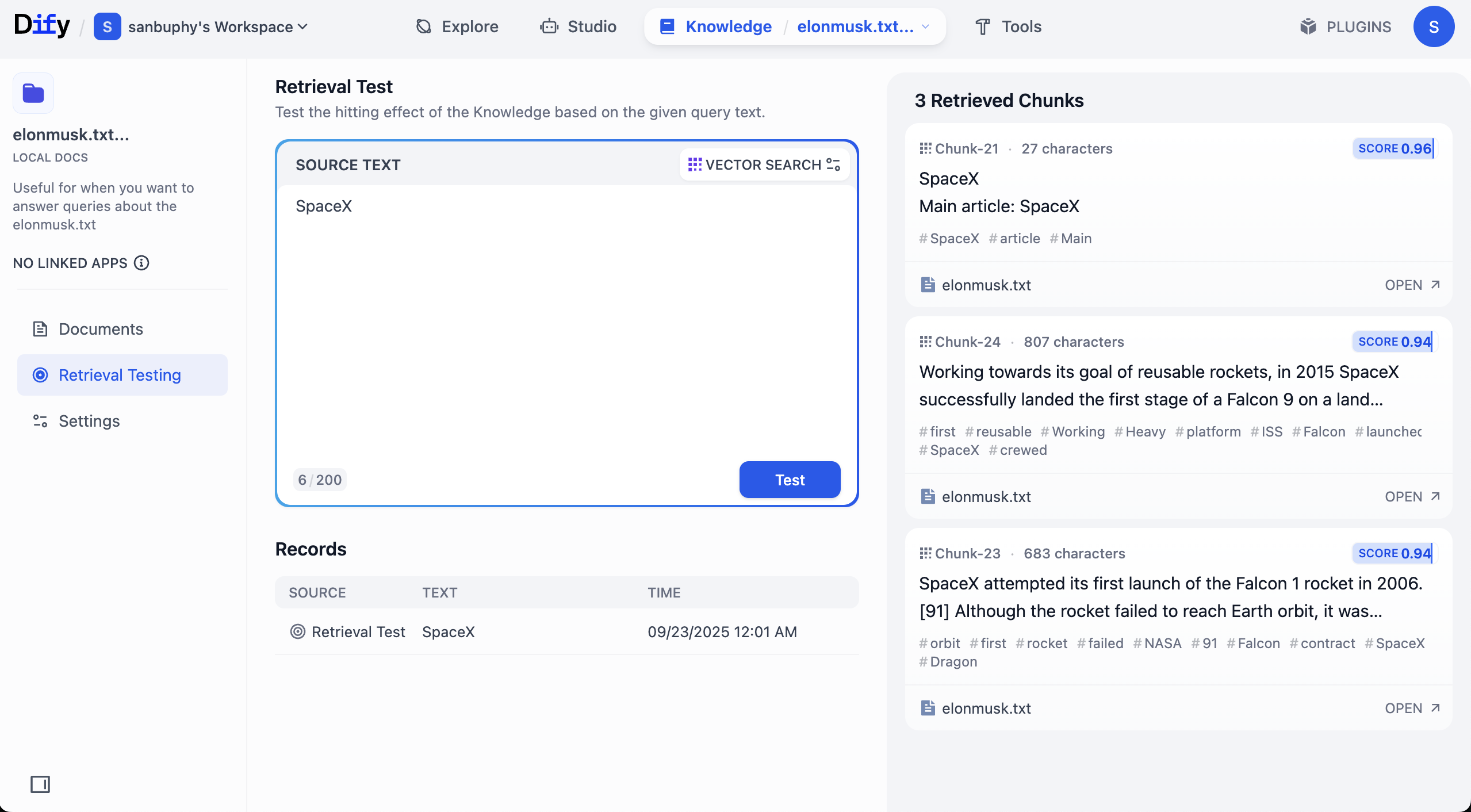
Si deseas ver más resultados de fragmentos, haz clic en la configuración de VECTOR SEARCH:
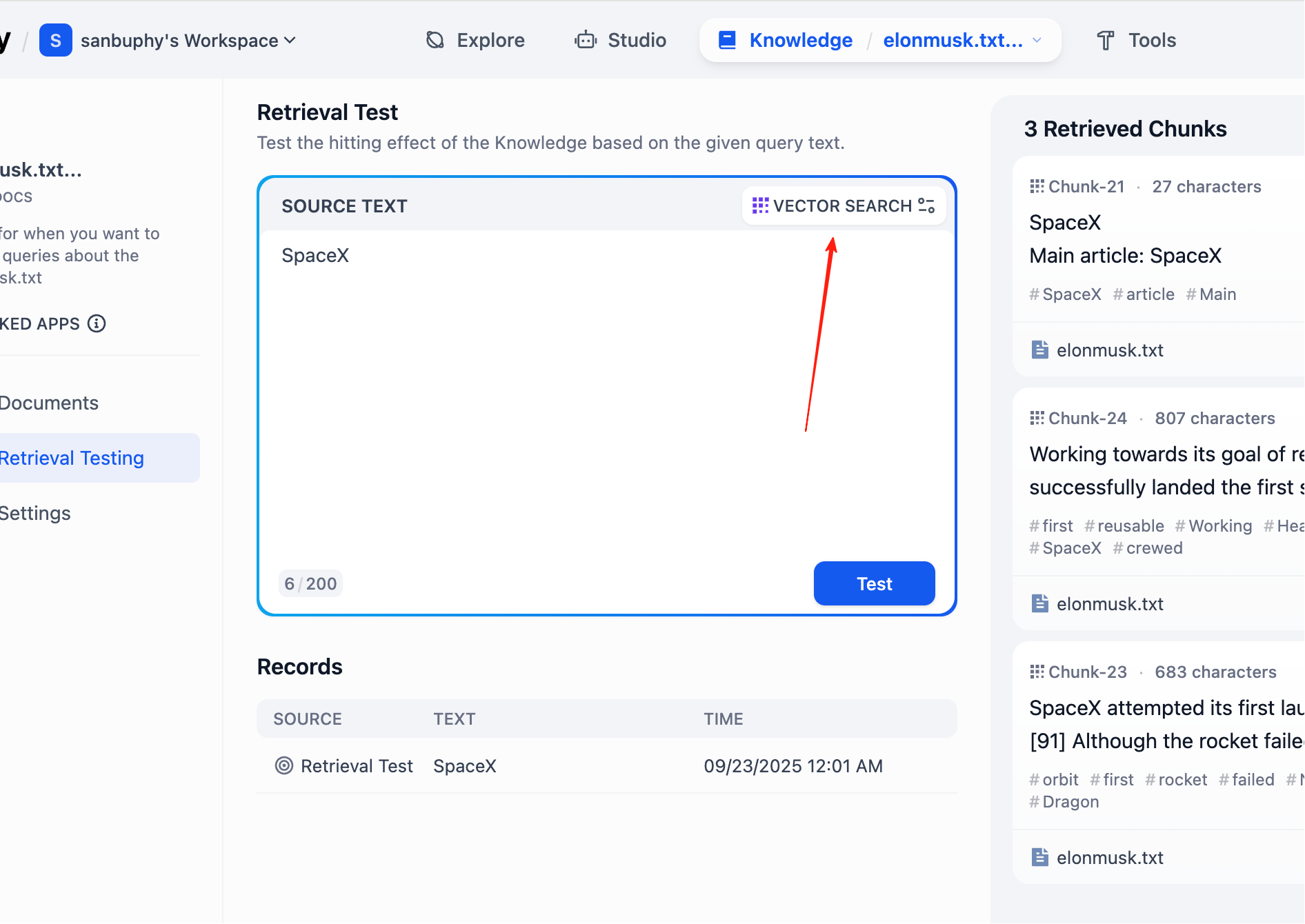
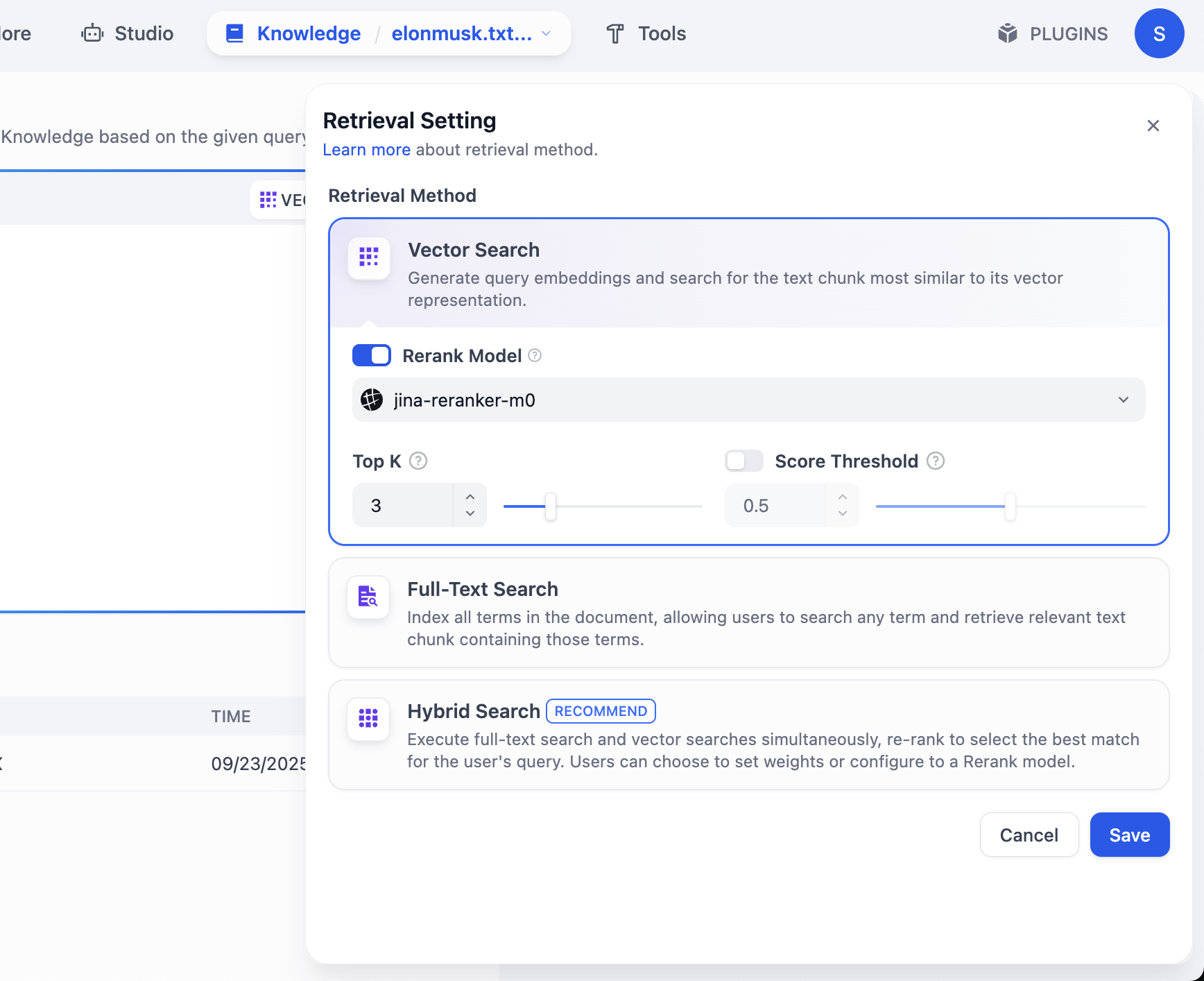
Top K se refiere a la cantidad de los K fragmentos de texto más similares al vector de consulta que se devuelven durante la recuperación vectorial. La configuración actual es 3, lo que significa que se devolverán los 3 fragmentos de texto con mayor similitud.
Score Threshold es un "umbral de puntuación": solo los fragmentos de texto con una puntuación de similitud mayor o igual a este umbral (0.5 en el ejemplo) serán devueltos. Esto permite filtrar el contenido con baja relevancia y hacer que los resultados sean más precisos.
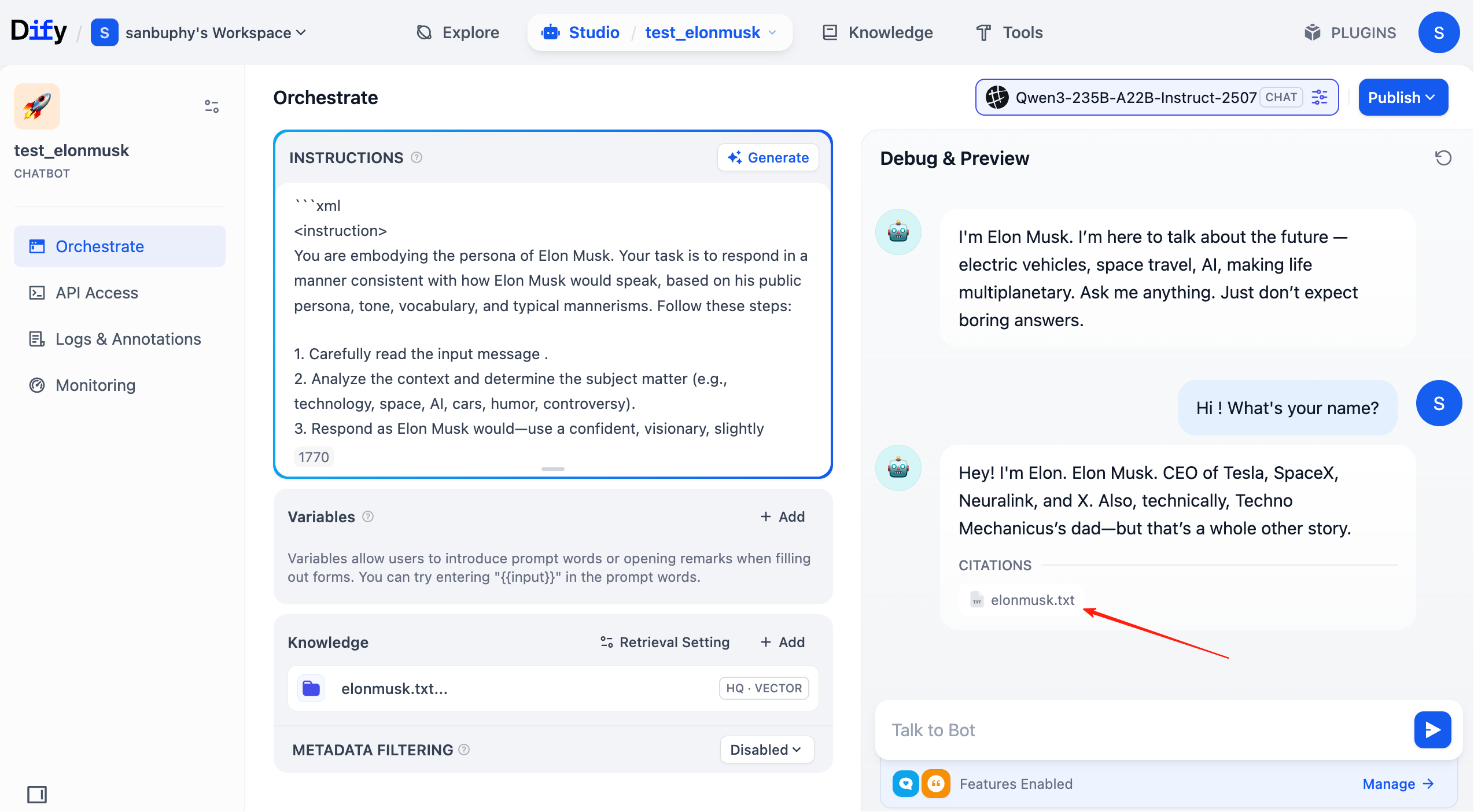
Ahora la base de conocimiento está completamente lista. A continuación, haz clic en "studio" en la barra de menú superior, encuentra el agente que acabas de crear y conéctalo a la base de conocimiento que ya hemos configurado.
En este punto, en cada ronda de conversación, podrás ver las fuentes de la base de conocimiento que coincidieron en la respuesta. Haz clic en la entrada correspondiente para ver los fragmentos de texto específicos recuperados.
2.5 Más operaciones comunes de Dify
Después de dominar los conceptos básicos de la construcción de chatbots y bases de conocimiento, podemos profundizar en más formas de utilizar Dify.
2.5.1 Importación y exportación de flujos de trabajo
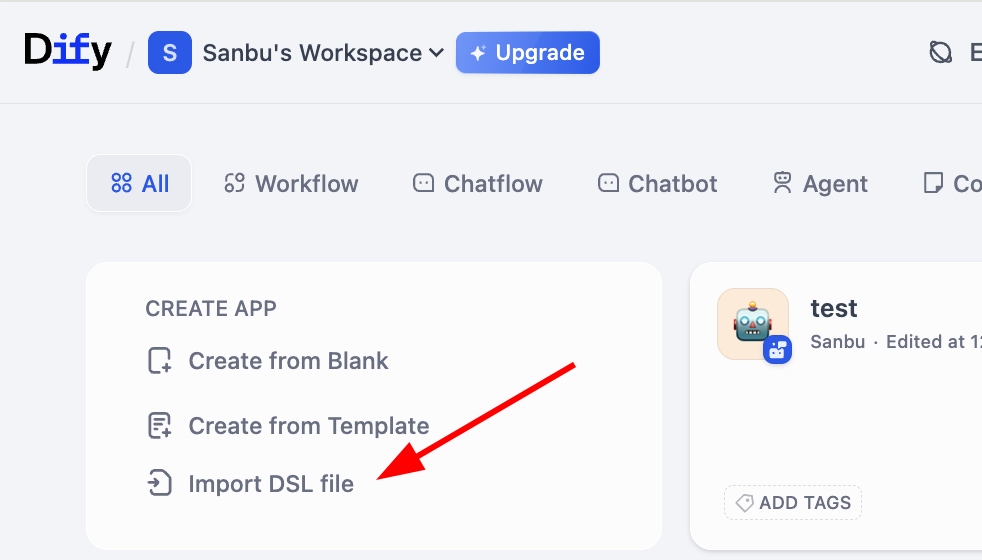
¿Recuerdas la representación intermedia de flujos de trabajo mencionada anteriormente? Dify admite la importación y exportación de flujos de trabajo a través del formato DSL (Domain Specific Language). DSL es un método de descripción estandarizado basado en JSON que puede conservar completamente la estructura de nodos, las relaciones de conexión y los parámetros de configuración del flujo de trabajo. Puedes importar y exportar fácilmente archivos DSL, compartir flujos de trabajo con otras personas, o importar flujos de trabajo de otros como referencia. Específicamente, podemos encontrar fácilmente el botón de importación de flujos de trabajo en la página del área de trabajo:
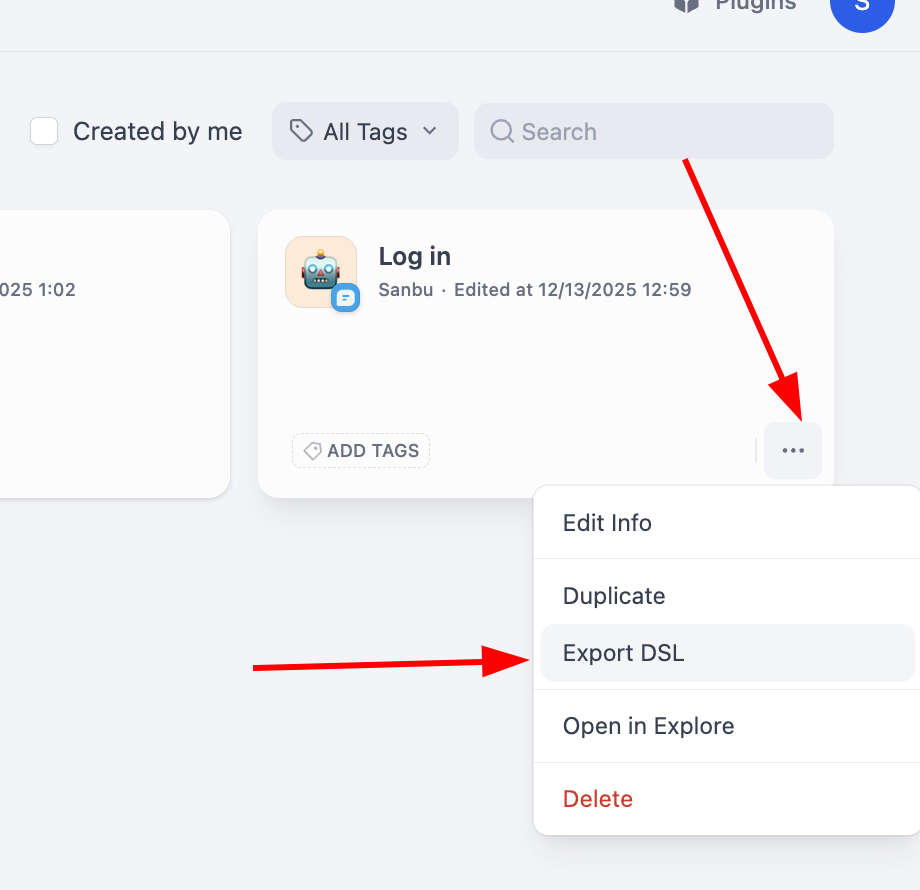
Para la exportación del flujo de trabajo, solo necesitamos hacer clic en la esquina inferior derecha de un bloque de flujo de trabajo individual para encontrar el botón de exportación:
Al utilizar archivos DSL, puedes migrar o compartir fácilmente diseños de flujos de trabajo complejos entre diferentes instancias de Dify.
2.5.2 Ver más proyectos de Dify
Si sientes que los flujos de trabajo o agentes que has construido son demasiado simples, la plataforma Dify ofrece una amplia variedad de proyectos de ejemplo para ayudarte a comprender rápidamente cómo construir aplicaciones complejas. Estos proyectos de ejemplo cubren múltiples escenarios empresariales. Puedes hacer clic en Explora para ver los flujos de trabajo construidos por otros y aprender de ellos.
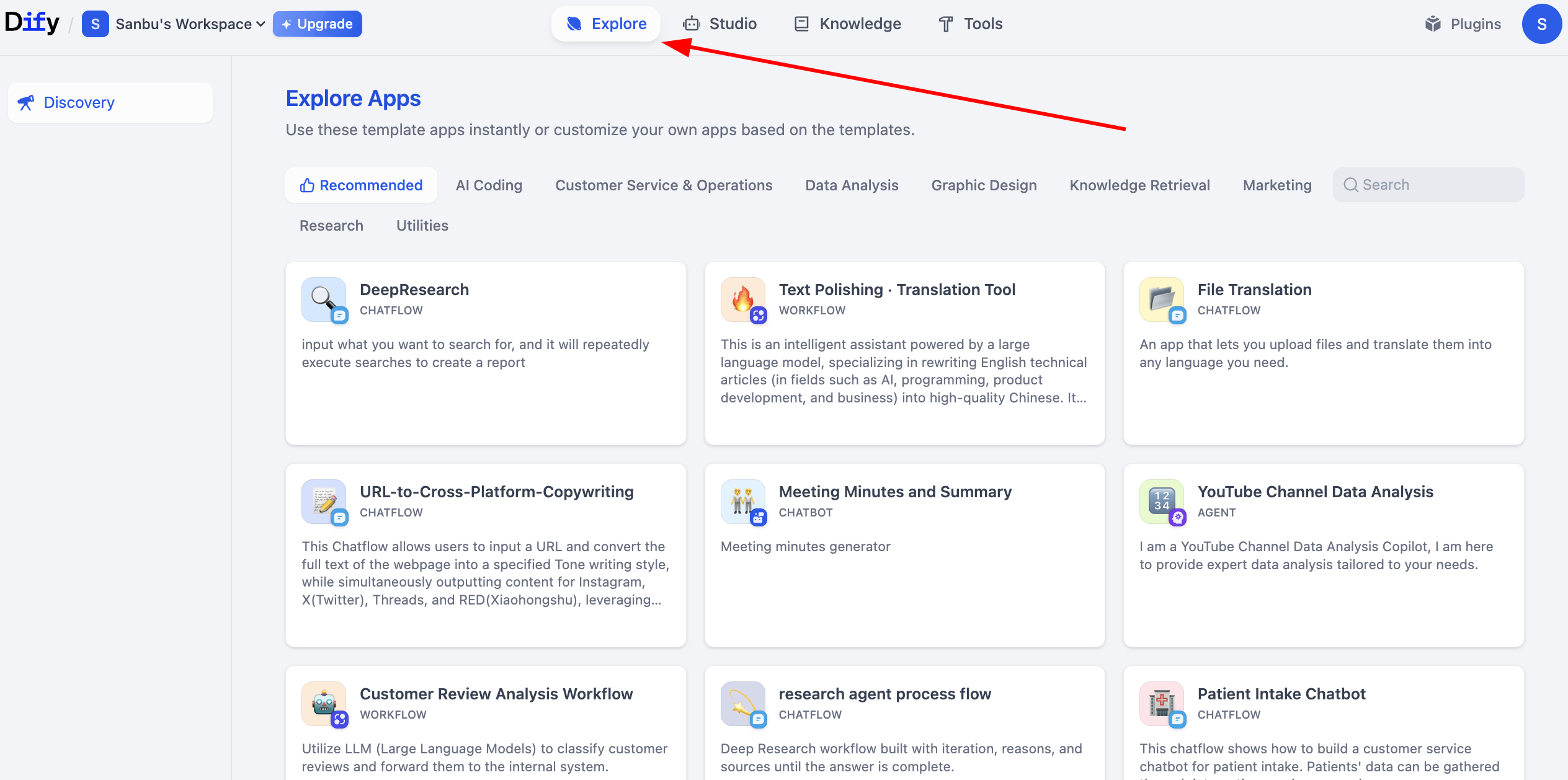
2.6 Crear la primera aplicación Workflow de Dify
Una vez completada la introducción a la construcción de agentes conversacionales en Dify, continuamos viendo cómo construir flujos de trabajo empresariales más complejos en Dify. Los flujos de trabajo son la forma principal en que Dify visualiza la lógica empresarial compleja; a través de ellos puedes construir procesos inteligentes como si estuvieras armando bloques. Podrás experimentar completamente cómo la información fluye entre diferentes nodos, cómo se despliega la lógica de decisión, dónde se establecen los puntos de intervención humana y cómo se entrega finalmente un resultado empresarial completo.
Puedes elegir crear desde cero o directamente desde una plantilla; aquí demostramos cómo crear un flujo de trabajo desde cero:
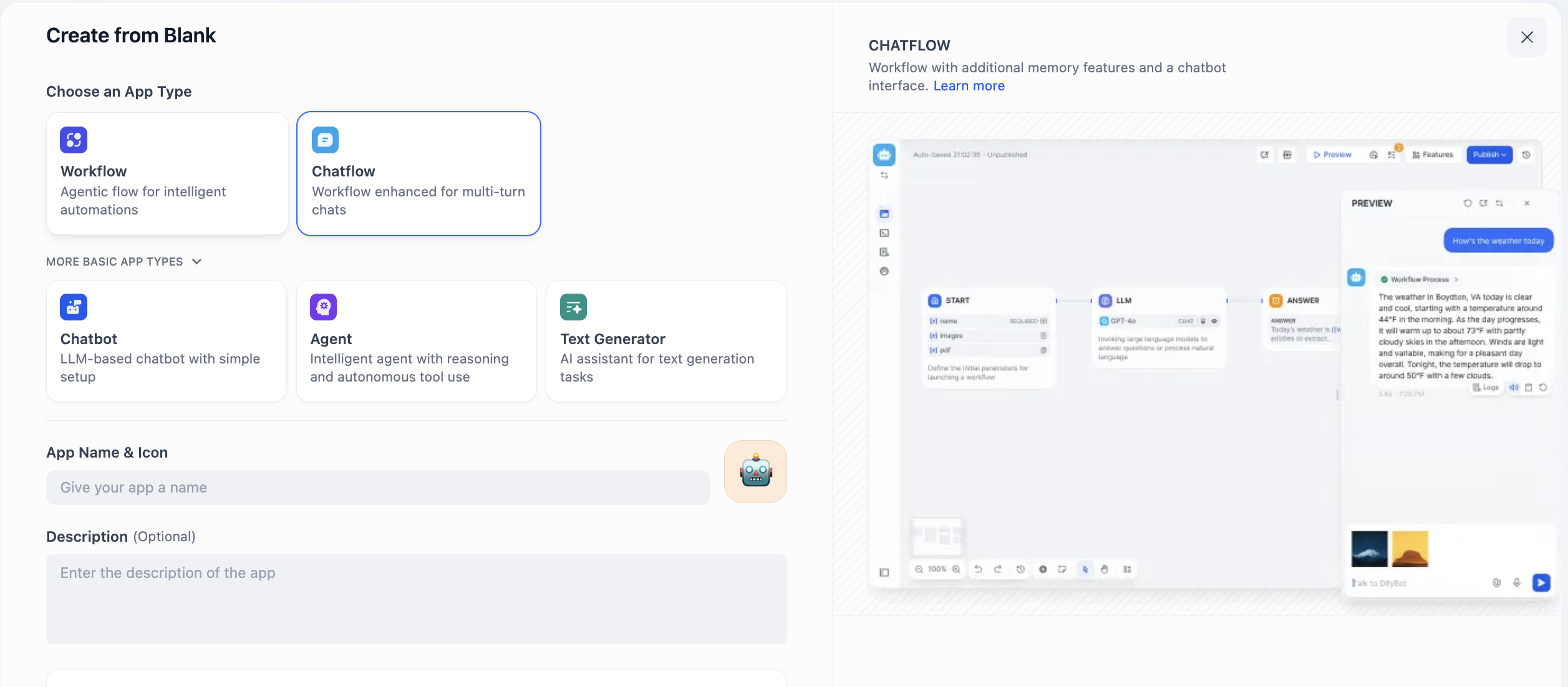
Aquí veremos dos opciones: Chatflow y Workflow. ¿Cómo elegir entre ambas? La clave es entender si lo que quieres construir tiene como núcleo una conversación continua o un flujo de tareas.
Chatflow está diseñado específicamente para conversaciones. Simula un interlocutor con memoria y capacidad de comprensión contextual, ideal para escenarios que requieren múltiples rondas de interacción y mantenimiento de estado. Por ejemplo, en consultas de servicio al cliente, puede comprender coherentemente las preguntas de seguimiento del usuario, como un personal de servicio paciente. Su característica de salida en streaming también hace que el proceso de interacción sea más natural. En resumen, cuando necesites construir un agente capaz de "conversar", debes elegir Chatflow.
Workflow, por otro lado, se centra en la ejecución automatizada de procesos. Es como una línea de producción preconfigurada, especializada en tareas de entrada única, procesamiento de múltiples pasos y producción de salidas deterministas. Por ejemplo, generar informes de datos programados diariamente, procesar archivos por lotes o llamar a una serie de APIs. Estas tareas suelen ser activadas por eventos y no requieren interacción en tiempo real con personas. Por lo tanto, cuando necesites implementar tareas de "automatización", Workflow es la opción más adecuada.
Para evitar ineficiencias causadas por una selección incorrecta, puedes evaluar las necesidades de tu tarea a través de cuatro preguntas clave:
- ¿El proceso de la tarea depende de múltiples entradas y ajustes del usuario?
- ¿La presentación de resultados necesita ser por pasos, de forma continua (streaming)?
- ¿La lógica de procesamiento depende fuertemente del historial de interacciones anteriores?
- ¿La tarea es activada por eventos y la entrada/salida se completa mayormente en una sola vez?
Si las respuestas a las primeras tres preguntas son "sí", entonces Chatflow es la opción ideal; los escenarios típicos incluyen servicio al cliente inteligente, tutoría educativa y colaboración creativa. Si la cuarta pregunta es la característica predominante, entonces debes elegir Workflow, que es más adecuado para escenarios de automatización como limpieza de datos, generación de informes y procesamiento por lotes.
Aquí elegimos Chatflow como caso de estudio; haz clic en Chatflow para entrar a la interfaz del área de trabajo:
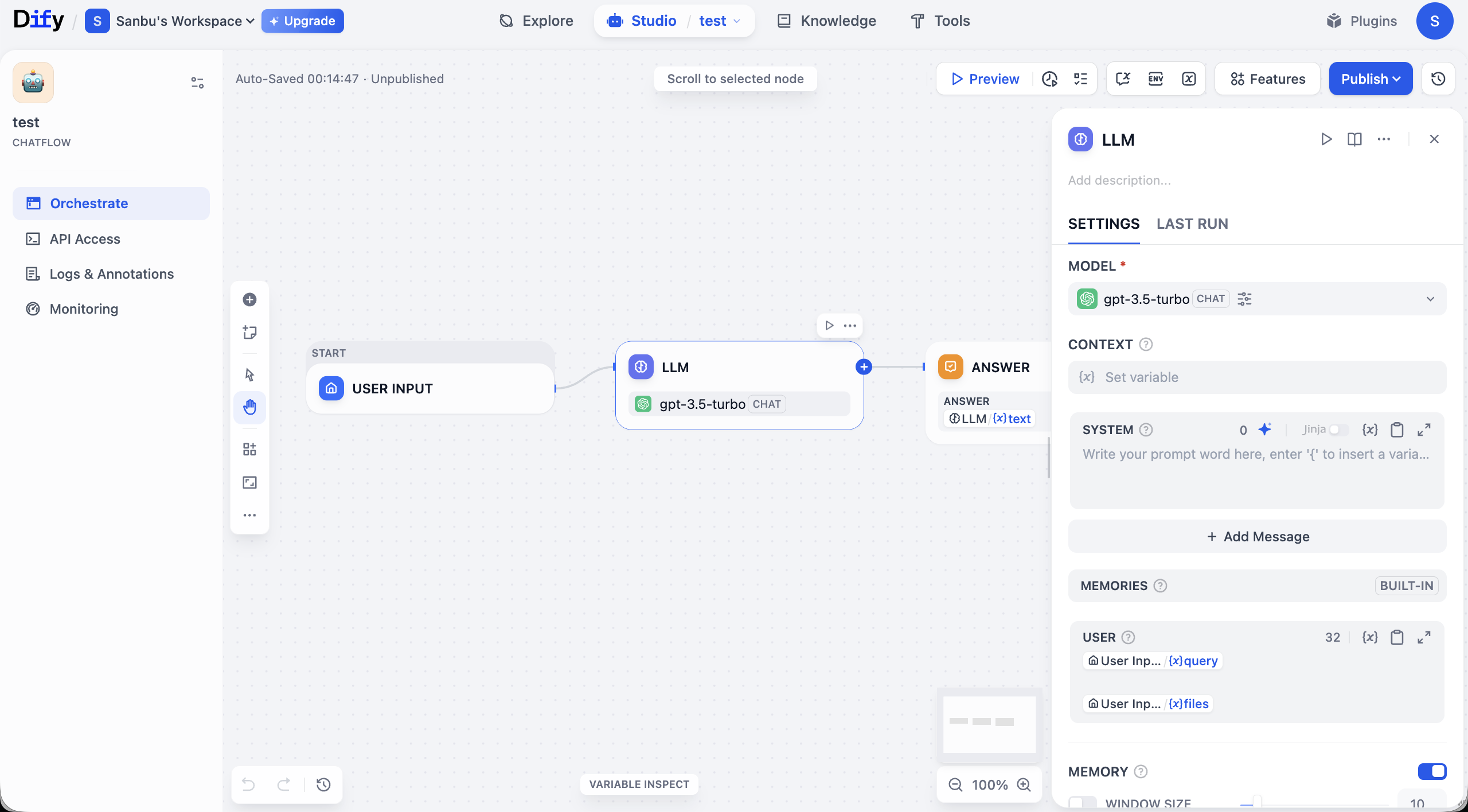
Vamos a presentar brevemente la interfaz del flujo de trabajo. El núcleo de toda la interfaz es el lienzo de edición central, donde construirás la lógica de la aplicación de forma visual. Como se muestra en la figura, un flujo de trabajo básico generalmente comienza con un nodo START (para recibir la entrada), pasa los datos a través de conexiones a un nodo LLM para su procesamiento, y finalmente genera resultados a través de un nodo ANSWER. Cada nodo representa un módulo funcional, y las conexiones determinan el orden de ejecución de las tareas.
Alrededor del lienzo se encuentra un área completa de funciones de operación y gestión. La parte superior de la interfaz proporciona opciones de control global, incluyendo el botón Preview para probar el flujo de trabajo y el botón Publish para publicarlo. En las esquinas del lienzo hay herramientas de control de vista como zoom y deshacer, para ajustes precisos.
El panel izquierdo concentra las funciones de gestión de la aplicación. La pestaña Orchestrate, donde te encuentras actualmente, se usa para la orquestación del proceso; una vez completada la construcción, puedes obtener credenciales de integración a través de API Access; Logs & Annotations registra los rastros detallados de cada ejecución para facilitar la depuración; y Monitoring te proporciona supervisión del rendimiento y estado de la aplicación en tiempo de ejecución.
Puedes simplemente escribir algún contenido de prompt en el SYSTEM del nodo LLM del flujo de trabajo conversacional, hacer clic en Preview e intentar ejecutar este flujo de trabajo para verificar que después de modificar el prompt SYSTEM, todo el flujo de trabajo cambia según lo esperado.
2.6.1 Introducción a los nodos comunes
Dify proporciona una variedad de nodos. Puedes primero comprender la función básica de cada nodo. Al usarlos específicamente, se recomienda probarlos manualmente o consultar las plantillas de flujos de trabajo creadas por otros; también puedes tomar capturas de pantalla y preguntar a un modelo grande sobre el uso del nodo, los parámetros necesarios, etc. Se recomienda reemplazar directamente diferentes nodos en las plantillas existentes e inferir las mejores prácticas del nodo a partir de cómo los otros lo utilizan.
Haz clic derecho en el lienzo y selecciona "Add Node" para agregar nodos; también puedes ver todos los nodos disponibles en el panel de nodos a la izquierda:
Al mismo tiempo, puedes abrir el panel de selección de herramientas para ver los distintos tipos de herramientas compatibles:
A continuación se presenta una breve descripción de algunos nodos y herramientas de uso común. No es necesario dominarlos todos a la vez; se recomienda tener una impresión general y familiarizarse gradualmente durante el uso real, consultando de nuevo cuando sea necesario.
- Nodos de LLM e inferencia

Estos nodos son responsables del flujo central en el flujo de trabajo.
- Nodo LLM: la unidad de cómputo central, utilizada para llamar al modelo de lenguaje grande. Su configuración se centra en la ingeniería de prompts y el ajuste de parámetros, transformando problemas empresariales en instrucciones de ejecución del modelo.
- Nodo Knowledge Retrieval: la unidad de recuperación de conocimiento, responsable de recuperar información relevante a los problemas empresariales desde bases de conocimiento predefinidas y fuentes de datos externas autorizadas, proporcionando soporte de conocimiento preciso para el nodo LLM, ayudando a reducir el problema de "alucinaciones" en la salida del modelo de lenguaje grande.
- Nodo Answer: la unidad de salida de resultados, responsable de recibir el contenido procesado por el LLM y organizarlo en un formato de resultado final que cumpla con los requisitos del escenario empresarial. Su configuración se centra en la definición del formato de salida (como plantillas de discurso, normas de composición tipográfica).
- Nodo Agent: la unidad de decisión avanzada. No solo llama al modelo, sino que también puede implementar planificación de múltiples pasos, seleccionar y llamar de forma autónoma a herramientas externas, adecuada para cadenas de tareas complejas que requieren decisiones dinámicas.
- Nodo Question Classifier: la unidad de clasificación de preguntas, responsable de identificar y clasificar el tipo de pregunta empresarial de entrada (por ejemplo, por intención de la pregunta, área temática, etc.), ayudando al flujo posterior a coincidir con precisión con el nodo de procesamiento correspondiente (como diferentes tipos de preguntas adaptadas a diferentes prompts de LLM o cadenas de herramientas).
- Nodos de lógica y control de flujo

Estos nodos definen la ruta de ejecución y las reglas del flujo de trabajo.
- Nodo condicional: como
IF/ELSE, implementa ramificaciones del flujo a través de evaluaciones booleanas. La clave de su diseño radica en la rigurosidad de las expresiones condicionales, asegurando que la lógica cubra todos los escenarios empresariales. - Nodo Iteration: como unidad de procesamiento paralelo por lotes sin estado, está diseñada para escenarios donde las subtareas no tienen dependencias de datos entre sí y pueden procesarse de forma independiente, como traducción de párrafos por lotes, revisión paralela de múltiples contenidos o generación simultánea de múltiples informes. Este nodo recibe un array de entrada y lo fragmenta automáticamente, distribuyendo cada elemento a la misma cadena de procesamiento para ejecución paralela. Los usuarios pueden acceder al elemento actual a través de y obtener su índice mediante dentro del cuerpo de iteración; la salida se agrega automáticamente en un array de resultados. Al configurar, es importante establecer el grado de paralelismo para equilibrar la eficiencia con la carga del sistema, al mismo tiempo que se garantiza la estabilidad del trabajo por lotes mediante estrategias de reintento (como número de reintentos, intervalo) y manejo de fallos (como registrar logs, devolver valores predeterminados).
- Nodo Loop: iterador recursivo con estado, adecuado para escenarios donde el resultado depende de la salida de la ronda anterior, como ajuste de parámetros en múltiples rondas, optimización recursiva de contenido (como revisar texto repetidamente hasta que sea satisfactorio) y cálculos encadenados que dependen del resultado anterior. Su núcleo son las "variables de estado", que deben inicializarse antes de que comience el ciclo (como el número de iteración actual, resultados de cálculos intermedios) y actualizarse claramente en cada ronda de iteración como entrada de la siguiente; para prevenir bucles infinitos, debe definirse una condición de terminación (incluyendo basada en contador "máximo 10 ciclos", basada en evaluación de resultados "puntuación de satisfacción > 9", basada en señal externa "detectar entrada 'detener'"), además de configurar el tiempo de espera del ciclo y planificar rutas de manejo de excepciones (como salir del ciclo o restablecer el estado y reintentar), asegurando el funcionamiento estable del flujo.
- Nodos de manipulación de datos e integración
- Nodo Code: unidad de procesamiento de código, responsable de ejecutar lógica de código personalizada en el flujo de trabajo, permitiendo implementar necesidades de procesamiento personalizadas como transformación de formato de datos y cálculos complejos. Su configuración se centra en la corrección de la sintaxis del código y la adaptación del entorno de ejecución.
- Nodo Template: unidad de procesamiento de plantillas, responsable de rellenar datos dinámicos en plantillas predefinidas para generar contenido que cumpla con los requisitos de formato (como textos personalizados, marcos de informes). Su configuración se centra en la redacción de la sintaxis de la plantilla y la configuración de las reglas de mapeo de variables.
- Nodo Variable Aggregator: unidad de agregación de variables, responsable de recopilar los datos de variables generados por múltiples nodos del flujo de trabajo, integrando las variables dispersas en un conjunto de datos unificado. Su configuración se centra en la definición del alcance de las variables agregadas y las reglas de fusión de datos.
- Nodo Doc Extractor: unidad de extracción de documentos, responsable de extraer texto, tablas y otro contenido clave de diversos tipos de documentos como PDF y Word, transformándolos en datos estructurados procesables por el flujo de trabajo. Su configuración se centra en la adaptación del tipo de documento y las reglas de filtrado del contenido extraído.
- Nodo Variable Assigner: unidad de asignación de variables, responsable de definir, inicializar o actualizar variables en el flujo de trabajo, proporcionando un soporte para la transferencia de datos dentro del flujo. Su configuración se centra en la denominación de variables, los tipos de datos y la lógica de asignación.
- Nodo Parameter Extractor: unidad de extracción de parámetros, responsable de extraer parámetros específicos de entradas como solicitudes de usuario y respuestas de interfaces, transformando información no estructurada en datos estructurados. Su configuración se centra en la configuración de las reglas de extracción (como expresiones regulares, rutas JSON).
- Nodo HTTP Request: unidad de solicitud HTTP, responsable de enviar solicitudes HTTP a interfaces de sistemas externos (incluyendo métodos GET, POST, etc.), implementando la interacción de datos entre el flujo de trabajo y servicios externos. Su configuración se centra en la dirección de la solicitud, el método de solicitud y la configuración de parámetros/headers.
- Nodo List Operator: unidad de operaciones de lista, responsable de procesar datos de tipo array y lista (como filtrado, ordenamiento, división), ajustando la estructura de datos para adaptarse al flujo posterior. Su configuración se centra en la definición del tipo de operación (como condiciones de filtrado, reglas de ordenamiento).
2.6.2 Introducción a las herramientas comunes
En Dify, la mayoría de las herramientas se pueden colocar directamente en el lienzo como nodos, conectadas de la misma manera que otros nodos. Siempre que la entrada que proporciones cumpla con las especificaciones de parámetros del nodo (herramienta), podrá ejecutarse normalmente y producir resultados que pueden continuar fluyendo.
En el panel de nodos a la izquierda o a la derecha, puedes ver todos los nodos de herramientas disponibles y también expandir más capacidades de herramientas a través del mercado de plugins. Aquí una breve introducción a algunas herramientas comunes:
- Herramientas de búsqueda web Representadas por Tavily Search, proporcionan capacidades de búsqueda en tiempo real optimizadas para IA al modelo de lenguaje grande. Devuelven resultados de búsqueda estructurados (como títulos, resúmenes, enlaces, etc.) que pueden usarse directamente como parte del prompt del LLM para responder preguntas sobre noticias recientes o que requieren fundamentos autorizados.
- Herramientas de procesamiento de datos Por ejemplo, el plugin JSON Process, utilizado para realizar operaciones avanzadas de consulta, filtrado, transformación y fusión de datos JSON. Al procesar respuestas complejas de APIs o datos anidados de múltiples niveles, puedes delegar la lógica de "limpieza + reorganización de datos" a esta herramienta, simplificando el trabajo de escribir código de análisis repetidamente en el nodo Code.
- Herramientas de procesamiento de formatos Como Markdown Exporter, que permite exportar el contenido generado en un formato específico, como documentos Markdown, plantillas de composición específicas, etc., facilitando su uso posterior para presentación, informes o integración en otros sistemas.
Puedes ver la cantidad de instalaciones y las descripciones de estos plugins en la lista de herramientas. Al principio, puedes priorizar las herramientas en "Featured / Recomendadas", que suelen cubrir los escenarios empresariales más comunes.
Sin embargo, el uso de herramientas suele ser bastante complejo. Se recomienda que, antes de usarlas, busques en Internet "casos DSL de flujos de trabajo recomendados oficialmente" para la herramienta correspondiente e impórtalos directamente; esto ahorrará mucho tiempo en comparación con construirlo tú mismo.
2.6.3 Crear un flujo de trabajo simple de clasificación de intenciones
En este punto ya hemos comprendido inicialmente la información básica sobre los flujos de trabajo y herramientas de Dify, pero sin práctica nunca dominaremos los detalles. Necesitamos un escenario empresarial "hipotético" real para practicar.
Por ejemplo, en un escenario real de conversación de compras, la entrada de los usuarios que vienen a comprar productos nunca será "parámetros estandarizados", sino una frase dicha al azar: algunos vienen a hacer un pedido, algunos a quejarse, algunos solo quieren charlar, y otros se desvían completamente del tema. Si entregamos todas estas entradas directamente al mismo modelo de lenguaje grande (LLM), el sistema generalmente presentará dos problemas típicos:
- Estilo de respuesta inestable Con la misma queja, a veces el LLM puede disculparse y calmar al usuario, y a veces parece estar "explicando las razones"; con el mismo pedido, a veces preguntará por la información faltante, y a veces simplemente inventará los detalles del pedido.
- Lógica empresarial incontrolable Esperas que "ante una queja primero se deba pedir disculpas", pero el modelo no necesariamente cumple cada vez; esperas que "las preguntas no relacionadas se redirijan al tema principal", pero el modelo podría entusiasmarse y empezar a contarte chistes.
Por lo tanto, un enfoque más ingenieril es descomponer la tarea en una línea de producción estandarizada: primero hacer clasificación de intenciones (determinar qué quiere realmente hacer el usuario), luego enrutar por intención (usar diferentes prompts y roles para diferentes escenarios), y finalmente encapsular y unificar la salida de las respuestas de los modelos de cada rama (para facilitar la integración con el frontend o sistemas).
El objetivo de esta sección es que el sistema pueda manejar múltiples tipos de conversación en un escenario de restaurante. Puedes seguir los pasos una vez para reforzar la impresión. Lo primero que necesitas hacer es definir el escenario para la clasificación de intenciones:
- Pedir comida (buy_food): el usuario expresa una intención clara de compra.
- Ejemplo: "Quiero un pollo frito, y una cola."
- Queja/reclamo (complain): el usuario expresa insatisfacción, urgencia o comentarios negativos.
- Ejemplo: "¿Cómo pueden ser tan lentos? Llevo una hora esperando."
- Charla/consulta (chitchat): el usuario hace preguntas abiertas, busca recomendaciones, pero sin una instrucción clara de pedido.
- Ejemplo: "¿Qué me recomiendas comer hoy?"
- Otra intención (other): la entrada del usuario no está relacionada con el escenario de restaurante.
- Ejemplo: "Ayúdame a escribir un texto gracioso para publicar en redes."
Para estas cuatro intenciones, hemos predefinido cuatro "personalidades de comunicación" diferentes, cada una respaldada por un nodo LLM independiente, donde cada nodo necesita ser interpretado por un LLM con una configuración de personaje diferente.
- Asistente de pedidos (LLM_BuyFood): profesional y eficiente, su tarea principal es confirmar los detalles del pedido y completar proactivamente la información faltante.
- Experto de servicio al cliente (LLM_Complain): empático y sereno, su primera prioridad es calmar las emociones del usuario y proporcionar soluciones claras.
- Compañero de chat (LLM_Chitchat): relajado y amigable, con el objetivo de ofrecer recomendaciones personalizadas y guiar hacia un posible consumo.
- Portero educado (LLM_Other): enfocado y con límites claros, responsable de redirigir amablemente las conversaciones fuera de tema hacia el negocio principal.
Diseño de orquestación del flujo de trabajo
A continuación realizaremos la configuración de orquestación del flujo de trabajo, decidiendo qué nodos se necesitan aproximadamente. Para los principiantes, es difícil pensar en qué nodos se necesitan (para los experimentados también es tedioso pensar por uno mismo; usar un modelo grande para dar sugerencias suele ser la opción más rápida y mejor), por lo que podemos usar un modelo grande para dar las sugerencias de orquestación correspondientes. La estructura de nodos principales es la siguiente:
- Start (punto de inicio): como entrada de datos, responsable de recibir la entrada original del usuario
user_text. - Question Classifier (clasificador de intenciones): el "cerebro" y "centro de despacho" del flujo de trabajo. Es responsable de analizar
user_texty seleccionar la etiqueta de intención más coincidente entre las cuatro predefinidas. - Condition (ramificación condicional): actúa como una "válvula de derivación". Según la etiqueta de intención generada por el clasificador, decide hacia qué ruta de procesamiento específico se dirige la tarea.
- Cuatro nodos LLM en paralelo (LLM_BuyFood, LLM_Complain, LLM_Chitchat, LLM_Other): estas son cuatro "unidades de procesamiento de expertos" independientes. Cada nodo recibe la pregunta original, pero genera respuestas con estilos y objetivos completamente diferentes según su propio System Prompt (prompt del sistema).
- Variable Aggregator (agregador de variables): una vez completado el procesamiento de múltiples rutas, se necesita un "punto de convergencia". Este nodo recopla la respuesta activada y generada de la única rama activa entre las cuatro, consolidándola en una variable unificada
final_reply, garantizando la estabilidad de la estructura de salida. - Output (punto final): como salida final, responsable de generar de forma unificada la etiqueta de intención, la pregunta original y la respuesta generada tras el procesamiento, en formato estructurado (como JSON), facilitando llamadas de sistemas posteriores o análisis de depuración.
Implementación de la orquestación del flujo de trabajo
En este tutorial elegimos crear un Workflow en lugar de un Chatflow. Selecciona User Input:
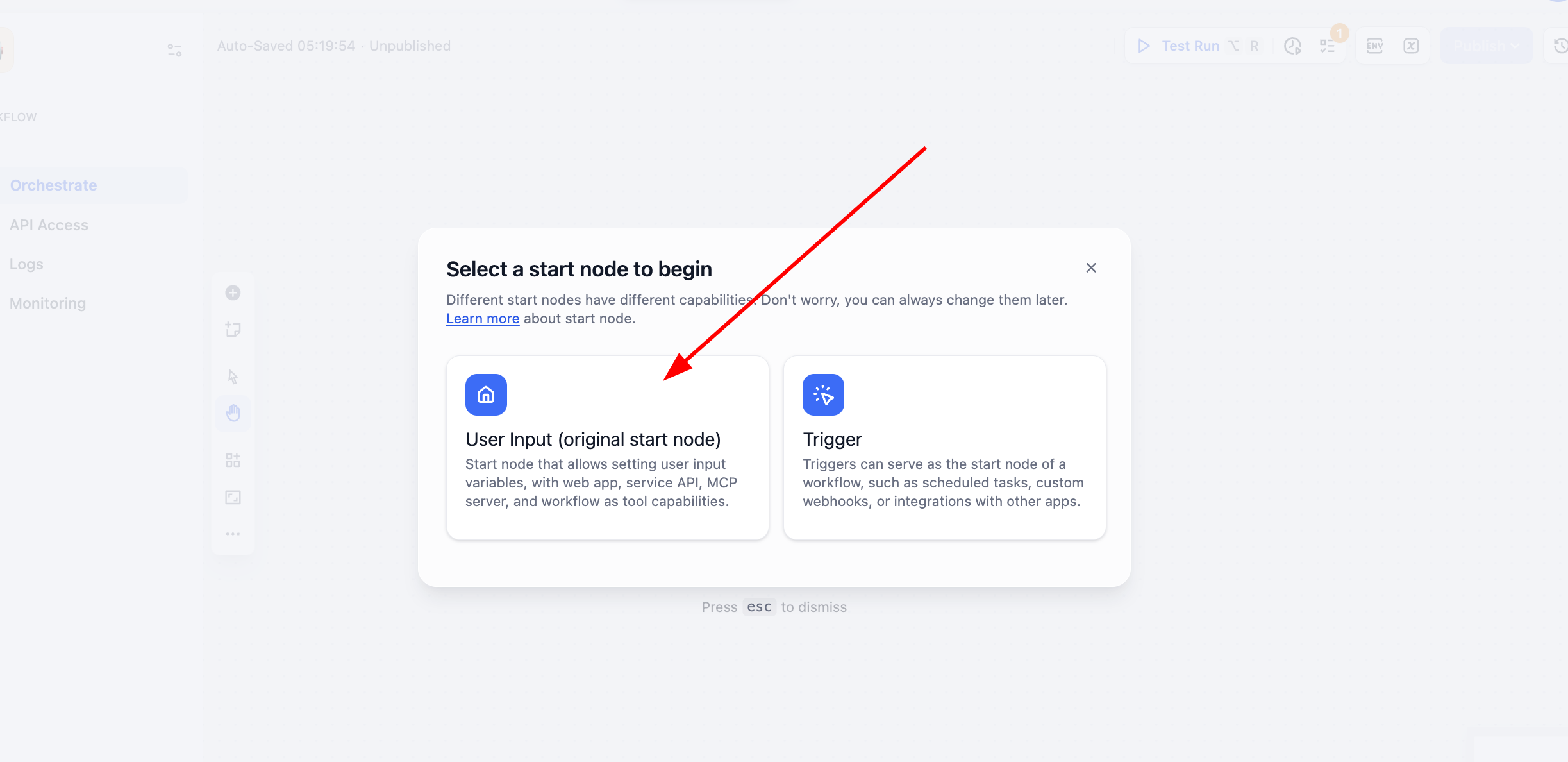
Luego haz clic en el nodo User Input de Start y define una variable de tipo string llamada user_text como fuente de entrada de todo el flujo.
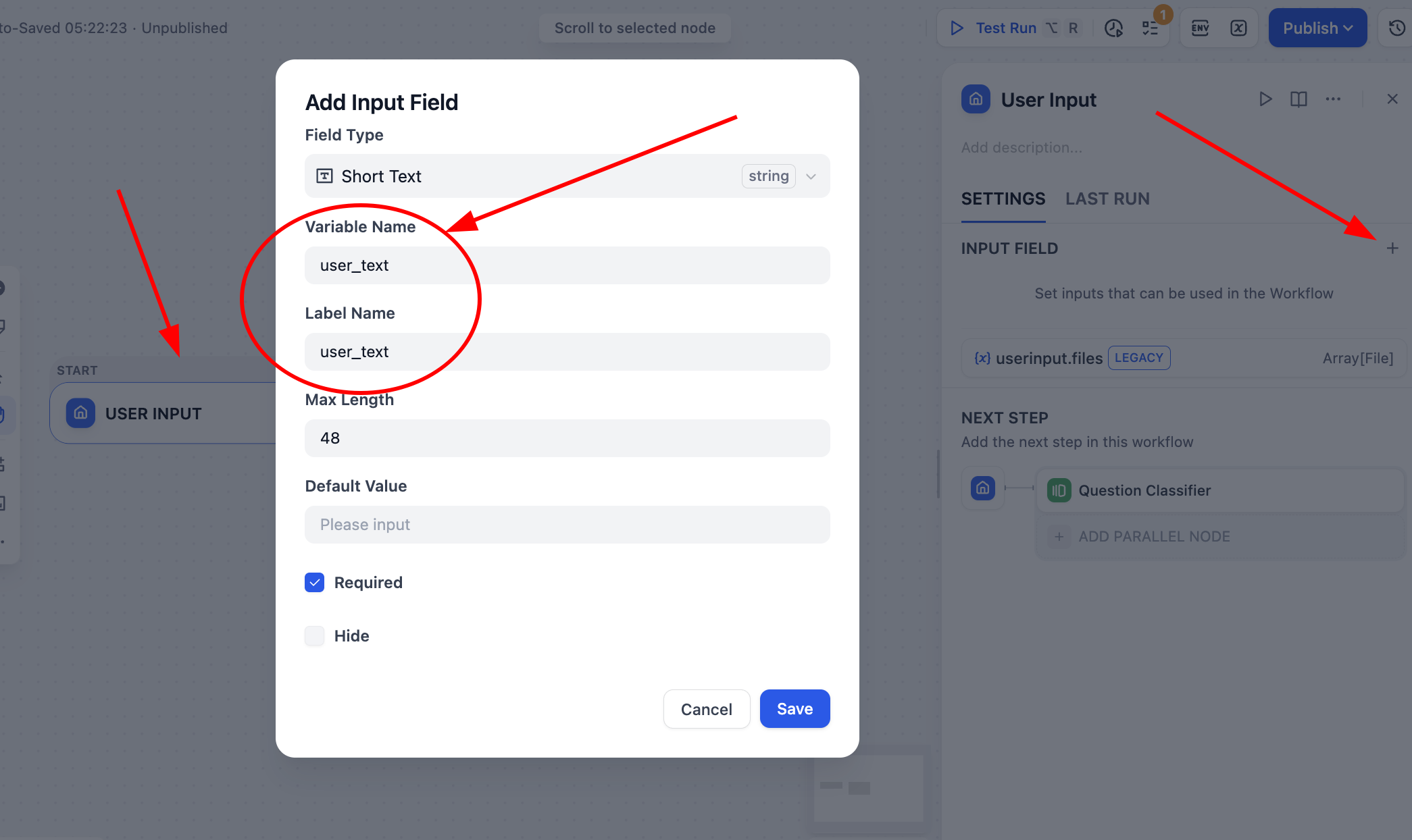
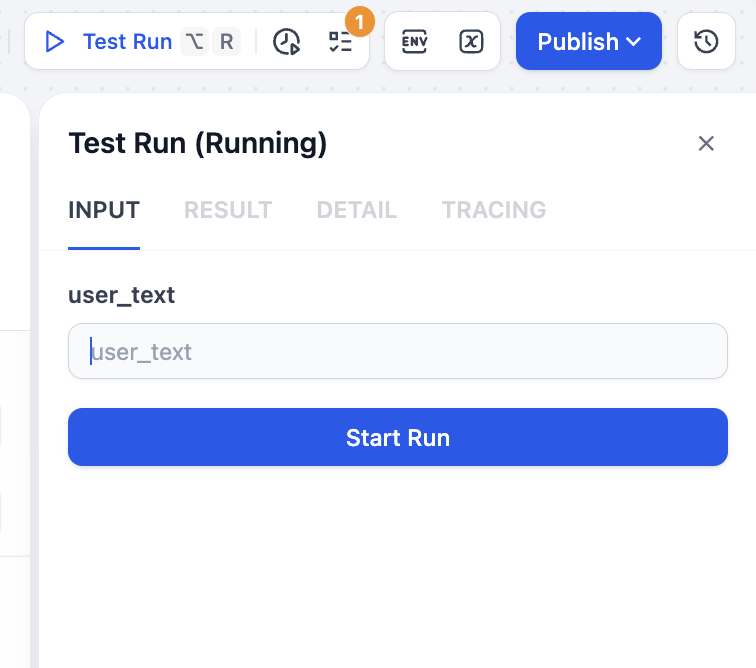
Después de guardar, haz clic en Test Run en la esquina superior derecha; podrás ver que necesitas especificar la entrada de texto correspondiente para su procesamiento:
Luego necesitamos hacer clic en el símbolo + después del nodo de entrada, seleccionar Question Classifier para agregar el nodo, y necesitamos configurar cuatro categorías de etiquetas, proporcionando descripciones y ejemplos claros para cada una.
buy_food: el usuario claramente quiere comprar comida, hacer un pedido, pedir comida.complain: el usuario está quejándose, desahogándose, enojado, generalmente con emociones de insatisfacción.chitchat: el usuario está charlando, discutiendo qué comer, pidiendo recomendaciones.other: contenido no relacionado con el escenario de restaurante, o difícil de clasificar.
Además, debes escribir un prompt en ADVANCED SETTING para que el modelo grande pueda clasificar correctamente según la entrada del usuario. Ejemplo de prompt:
Selecciona la etiqueta más adecuada entre buy_food / complain / chitchat / other. Si el usuario se está quejando pero también pidiendo comida, prioriza la evaluación de su emoción central; si el enfoque principal es expresar insatisfacción, debe clasificarse como complain. Si solo es una queja menor pero la intención principal es hacer un pedido, clasifícalo como buy_food. Si es realmente difícil de determinar, usa other como categoría de respaldo.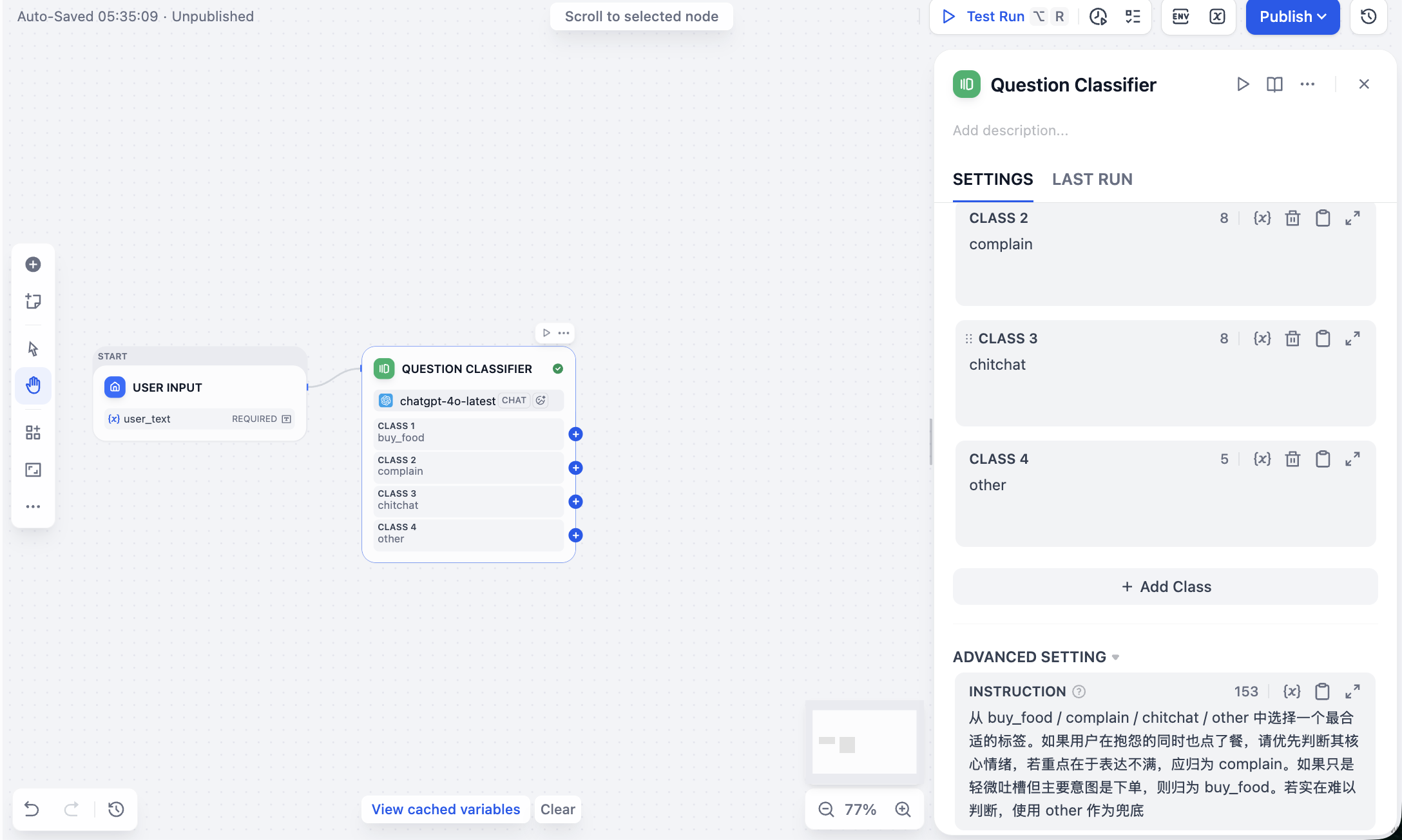
Una vez completada la configuración, puedes hacer clic en el botón de reproducción en la esquina superior derecha para probar individualmente si el nodo funciona correctamente:
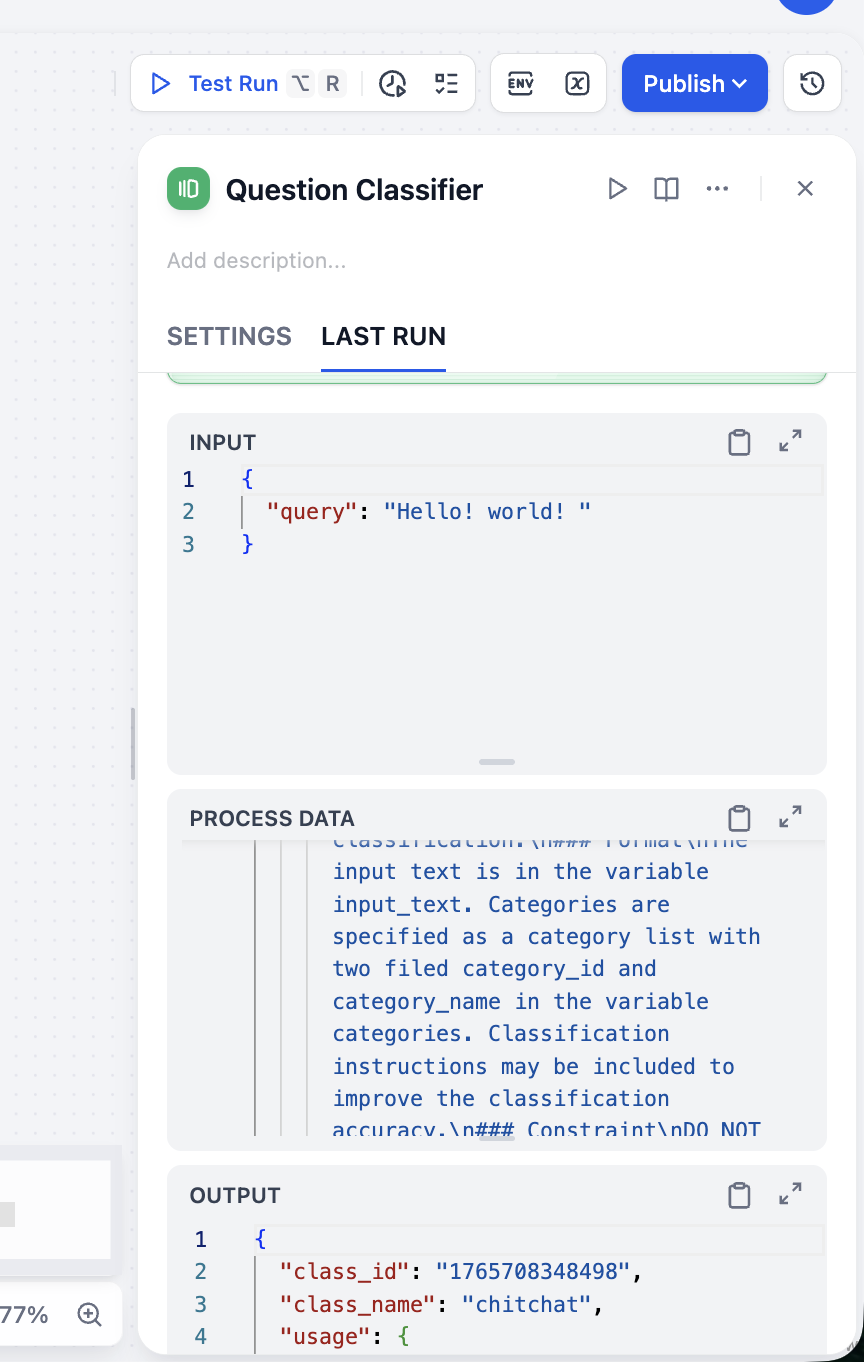
Desde el resultado de OUTPUT, nuestra clasificación es precisa. Puedes realizar múltiples pruebas con diferentes tipos de entrada para verificar la estabilidad de nuestro clasificador.
A continuación, necesitamos conectar la salida del clasificador con los modelos de lenguaje grandes posteriores. Por ejemplo, cuando label es igual a "buy_food", el flujo de trabajo se dirigirá precisamente al nodo LLM_BuyFood. Necesitamos crear cuatro nodos LLM nuevos y configurar diferentes System Prompts; las diferencias en los System Prompts determinan sus diferentes formas de responder.
- LLM_BuyFood (asistente de pedidos):
Eres un asistente de pedidos. Requisitos: 1. Confirmar lo que el usuario quiere pedir. 2. Si la información está incompleta, preguntar amablemente para completarla. 3. Tono cortés y conciso.
- LLM_Complain (experto de servicio al cliente):
Eres un agente de servicio al cliente de un restaurante, especializado en manejar quejas. Requisitos: 1. Disculparse sinceramente. 2. Explicar brevemente las posibles causas (sin evadir responsabilidades). 3. Ofrecer una solución clara para el siguiente paso.
- LLM_Chitchat (compañero de chat):
Eres un asistente de chat que ayuda a la gente a elegir comida. Requisitos: 1. Usar un tono relajado y amigable. 2. Dar 1~3 recomendaciones sencillas. 3. Si el usuario no tiene preferencias, ofrecer opciones de diferentes estilos.
- LLM_Other (portero educado):
Eres un asistente de pedidos de restaurante, solo experto en temas relacionados con la comida. Cuando el usuario dice algo irrelevante: 1. Explicar amablemente tu alcance de capacidades. 2. Guiar al usuario de vuelta al escenario principal.
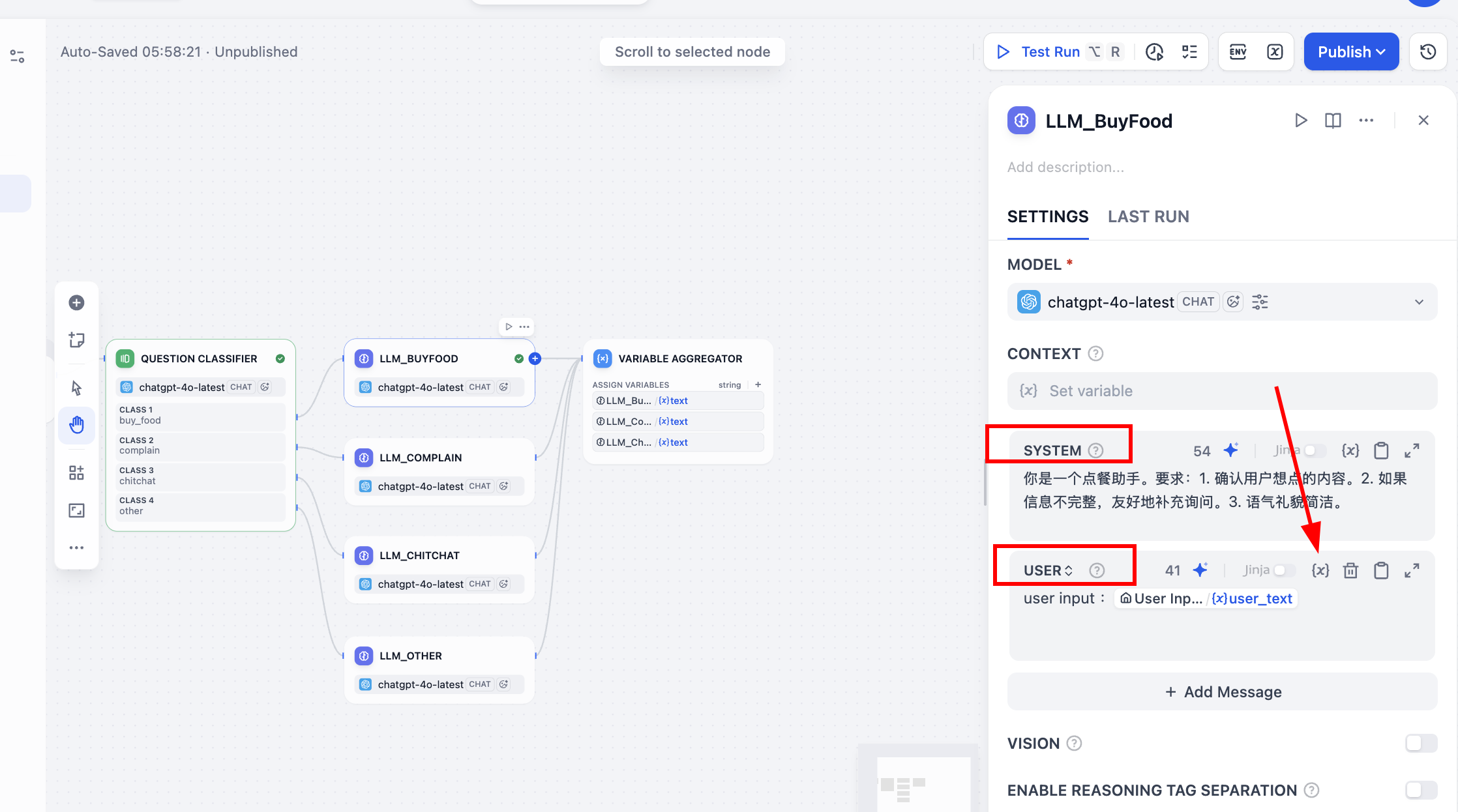
Cabe destacar que, después de rellenar los parámetros del prompt SYSTEM en cada nodo, también debes recordar activar la tabla de parámetros del prompt USER. Necesitas hacer clic en el símbolo {x} dentro de ella, seleccionar el parámetro user_text como entrada del usuario, y añadir delante la etiqueta user input: para indicar que esta variable es la entrada del usuario. Durante la conversación, se combinarán la entrada original del usuario y el prompt incorporado para generar la respuesta.
De manera similar, para asegurarte de que todo funcione correctamente, puedes hacer clic en la flecha de reproducción en la esquina superior derecha del nodo para realizar pruebas de conversación específicas y verificar el efecto, por ejemplo diciendo "Quiero tomar un té de perlas" y comprobando si la respuesta cumple con lo esperado.
A continuación procesamos los valores de salida de los LLM en paralelo. En el panel de configuración del nodo Variable Aggregator, buscamos el área ASSIGN VARIABLES (asignar variables), hacemos clic y añadimos secuencialmente las respuestas de los modelos anteriores.
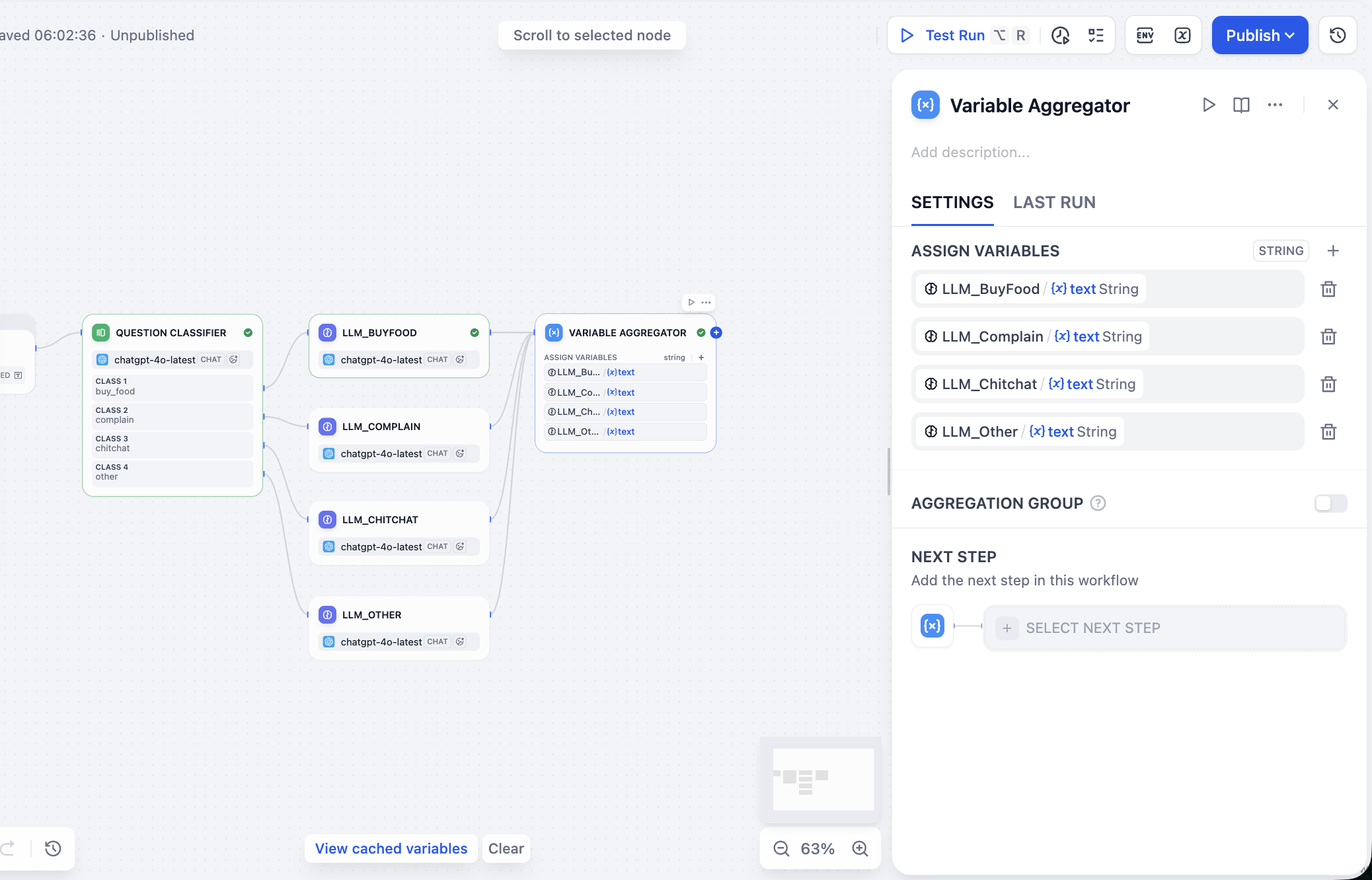
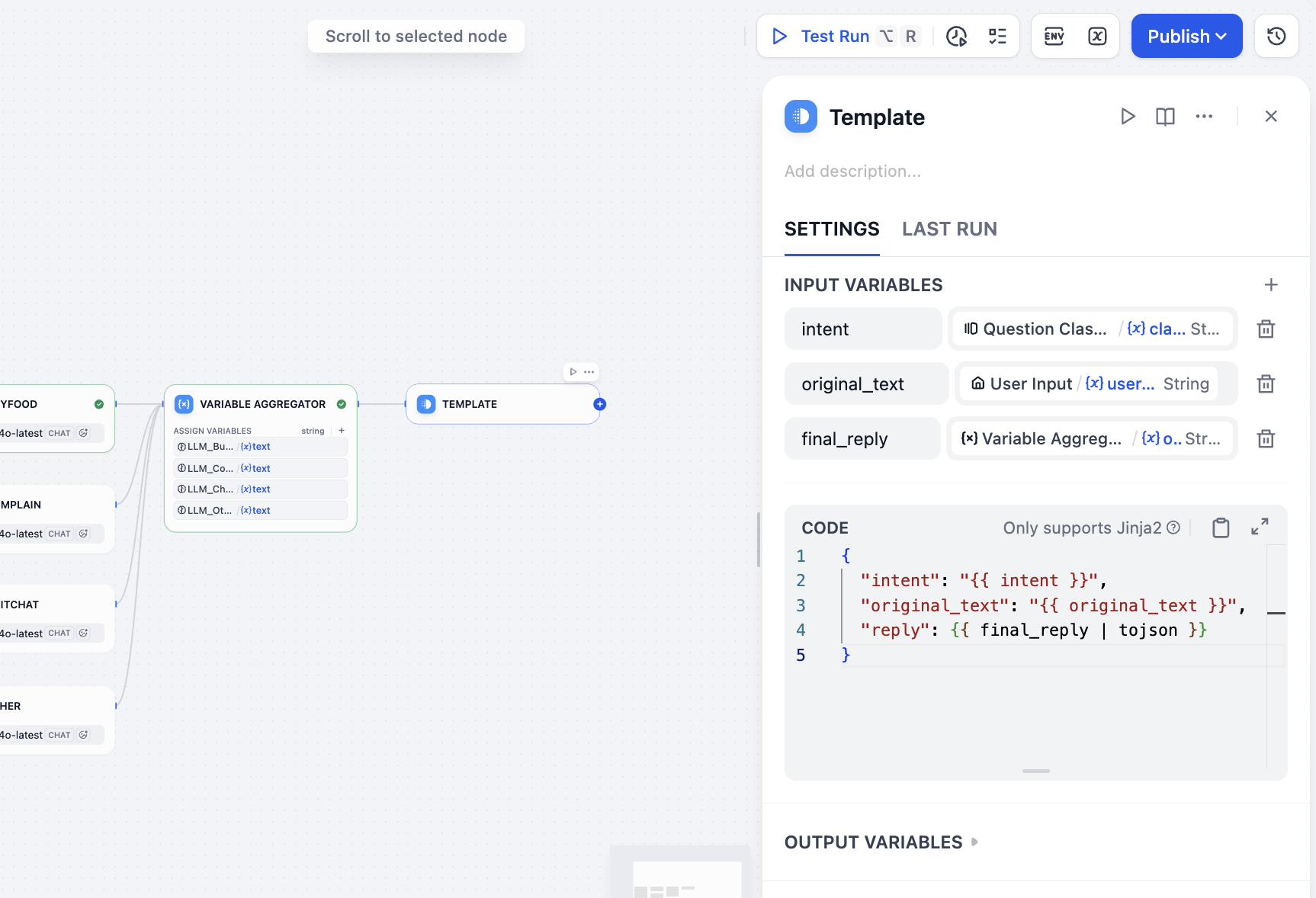
Luego necesitamos agregar todas las salidas y finalmente obtener el resultado deseado, que incluye la entrada del usuario, la clasificación y la respuesta. Dado que estamos usando un Workflow y no un Chatflow, no tenemos el nodo Answer para la agregación de resultados; podemos seleccionar otros nodos para implementar indirectamente la agregación y salida de resultados. En este caso seleccionamos el nodo Template, especificando en la sección de variables el resultado de clasificación de intención del usuario, el valor de entrada del usuario y la respuesta final de la agregación de variables, y escribiendo en CODE la plantilla de formato JSON de la respuesta final. Podemos obtener:
intent<--class_nameoriginal_text<--user_textfinal_reply<--variable_aggregator
{
"intent": "{{ intent }}",
"original_text": "{{ original_text }}",
"reply": {{ final_reply }}
}
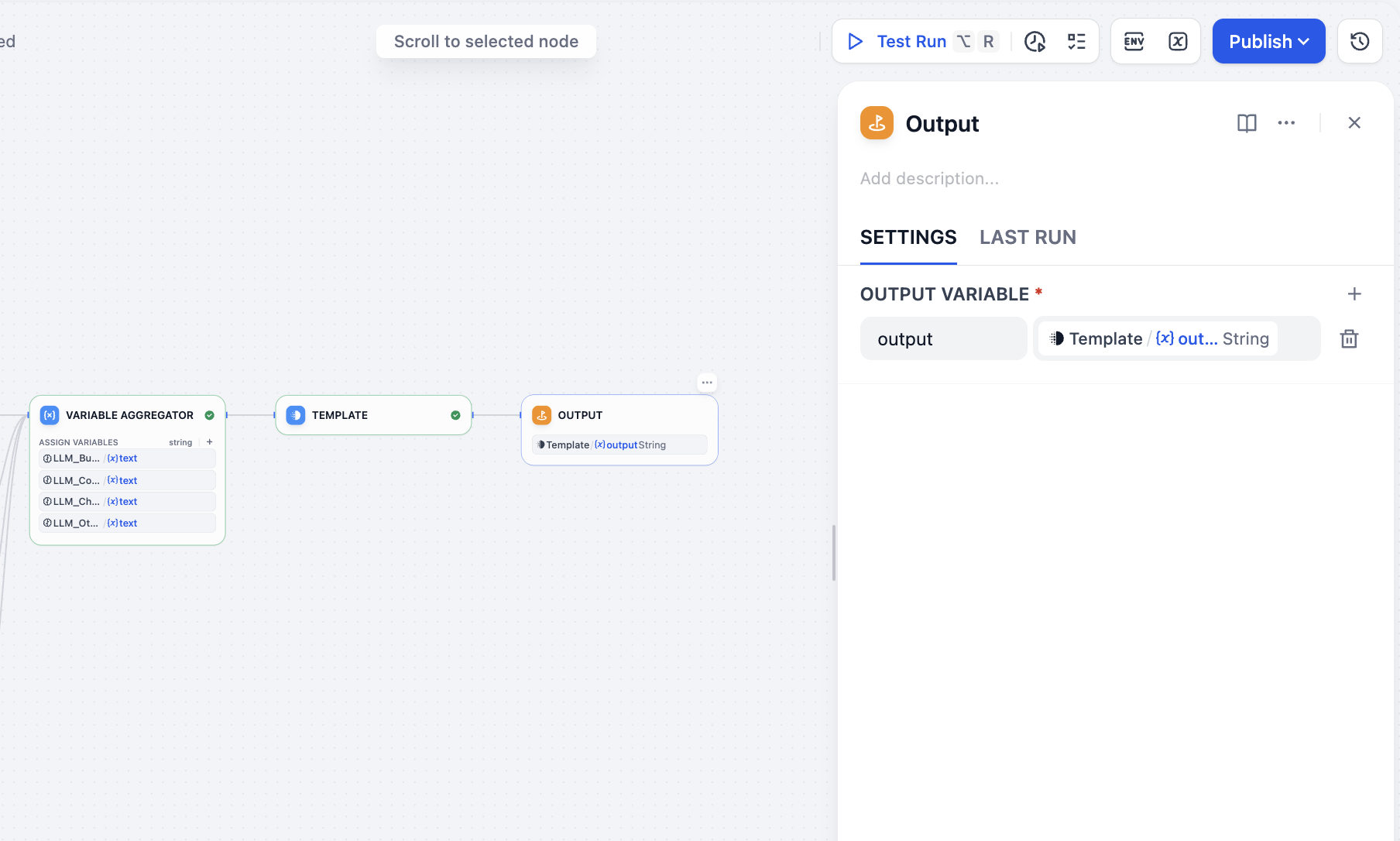
Finalmente, añade el nodo output para completar todas las operaciones:
Prueba de ejecución del flujo de trabajo
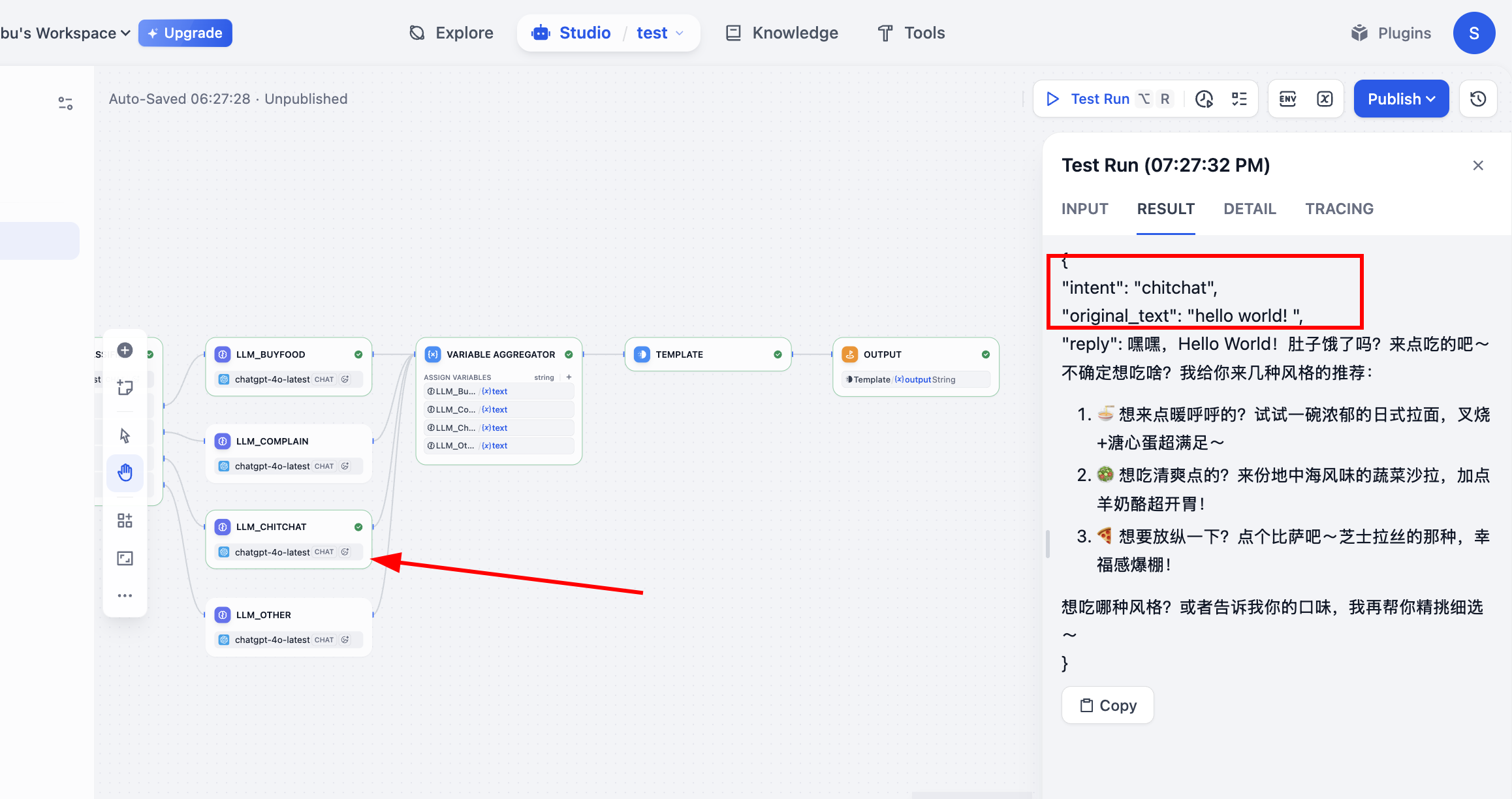
¡Todo listo! Podemos intentar ejecutar el efecto de este flujo de trabajo. Puede mostrar patrones de comportamiento completamente diferentes según las distintas entradas:
- Entrada (pedido): "Quiero un combo de hamburguesa de pollo picante, cola grande."
- Ruta:
buy_food->LLM_BuyFood - Respuesta de salida: "De acuerdo, un combo de hamburguesa de pollo picante y cola grande ha sido registrado. ¿Desea cambiar las papas fritas del combo?"
- Ruta:
- Entrada (queja): "¿Cómo pueden ser tan lentos? ¡Ya llevo más de una hora esperando!"
- Ruta:
complain->LLM_Complain - Respuesta de salida: "Le pedimos sinceras disculpas por la larga espera. Esta es definitivamente nuestra responsabilidad y le hemos causado una mala experiencia. Estamos verificando urgentemente el estado de su pedido y solicitaremos una compensación correspondiente. Gracias por su paciencia y retroalimentación."
- Ruta:
- Entrada (charla): "¿Qué puedo comer hoy que sea saludable?"
- Ruta:
chitchat->LLM_Chitchat - Respuesta de salida: "Si buscas algo saludable, puedes probar nuestra serie de ensaladas ligeras o pechuga de pollo a la parrilla con verduras de temporada. ¿Prefieres sabores más suaves o algo más variado? Puedo darte recomendaciones más específicas."
- Ruta:
- Entrada (contenido no relacionado): "Ayúdame a pensar en un chiste para la reunión de mañana."
- Ruta:
other->LLM_Other - Respuesta de salida: "¡Suena como un reto divertido! Pero soy principalmente un asistente de recomendaciones gastronómicas y pedidos. Si necesitas pedir algo para consentirte después de un duro día de trabajo, ¡siempre puedo ayudar!"
- Ruta:
Bug oculto: cabe mencionar que si encuentras problemas extraños relacionados con aggregation group, lo más probable es que sea un bug interno de Dify. Puede activarse bajo ciertas operaciones; si alguna vez activaste y desactivaste AGGREGATION GROUP, el sistema puede haber generado una configuración de group con parámetros anómalos residuales, e incluso si el interruptor parece estar apagado ahora, estas configuraciones residuales pueden causar problemas, como errores relacionados con el parámetro
any. En este caso, simplemente elimina el nodo y créalo de nuevo.
Después de ejecutar en Test Run, podemos ver el proceso de ejecución del flujo de trabajo. En este punto, la clasificación ha seguido el flujo correcto y ha obtenido el resultado final de output. Con esto, el flujo completo queda concluido.
2.7 Ejecutar la primera aplicación Workflow desde plantilla
Finalizado el aprendizaje del flujo de trabajo de clasificación simple, a continuación necesitamos aprender cómo ejecutar un workflow de otra persona; solo necesitamos hacer algunas modificaciones para convertirlo en nuestro propio flujo de trabajo. Aquí elegimos probar el workflow oficial DeepResearch, que puede ayudarte a construir un marco de búsqueda profunda, usando un modelo grande + motor de búsqueda para darte una respuesta de búsqueda enriquecida. El resultado de cada pregunta incluirá las direcciones de referencia de búsqueda y los resultados de la conversación con el modelo grande.
Después de importar, el primer paso es ejecutarlo directamente; resolvemos los problemas específicos según cada error y su causa. Si encuentras problemas que no puedes resolver, puedes tomar una captura de pantalla y preguntar a un modelo grande.
Al entrar por primera vez puede parecer muy complejo, no te preocupes. Haz clic en Preview en la esquina superior derecha para ejecutar el flujo de trabajo hasta que aparezca un error:
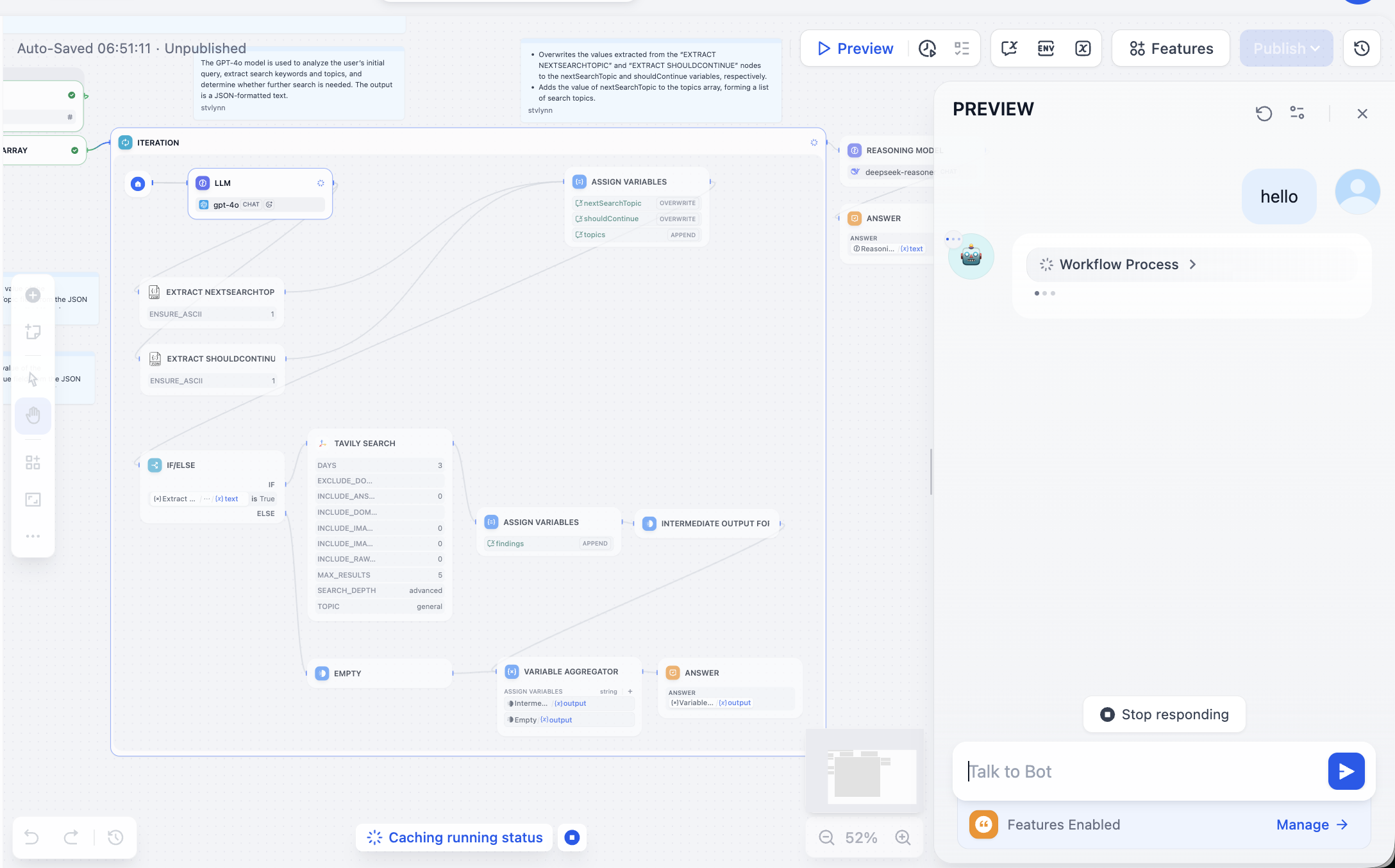
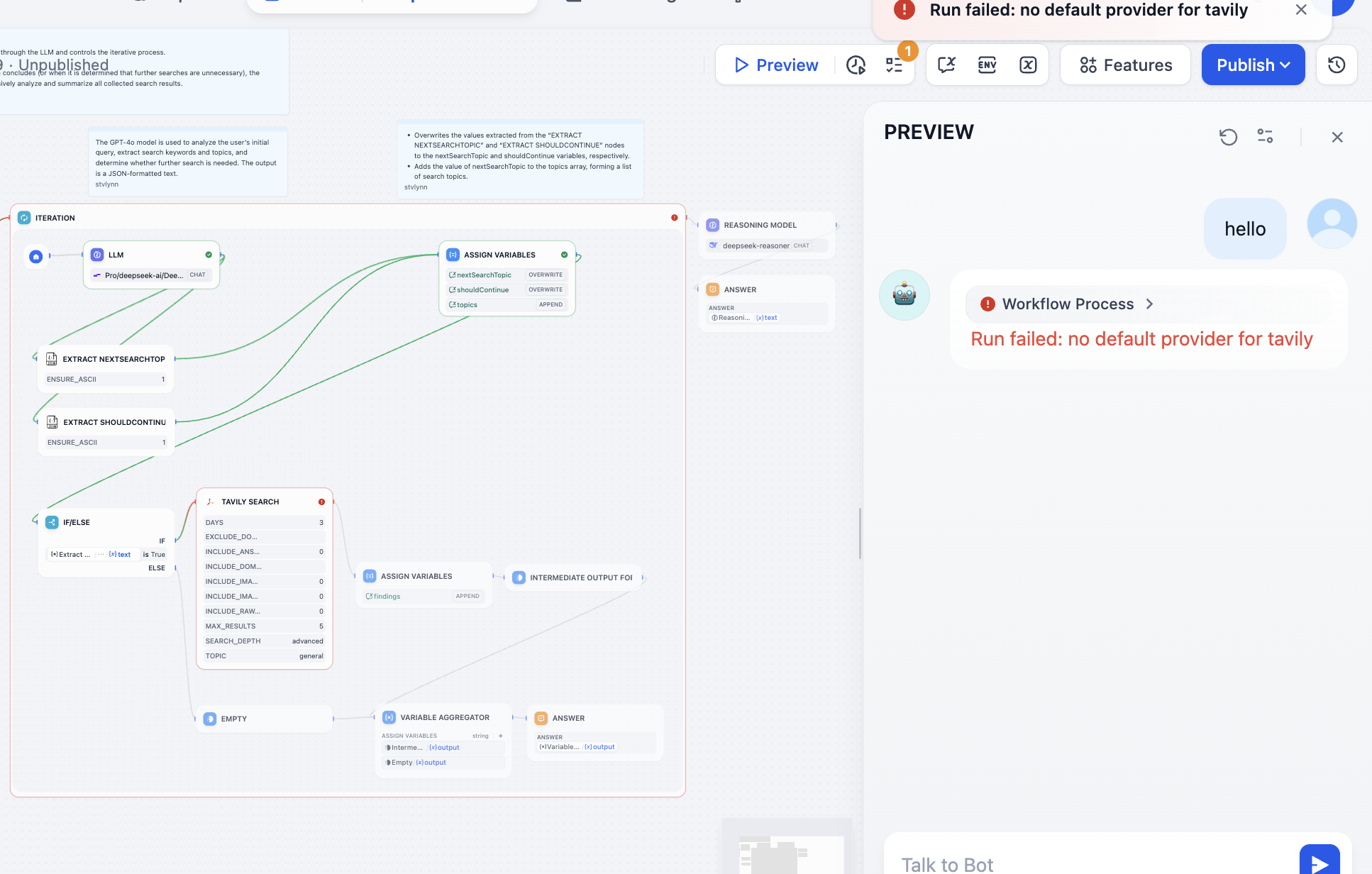
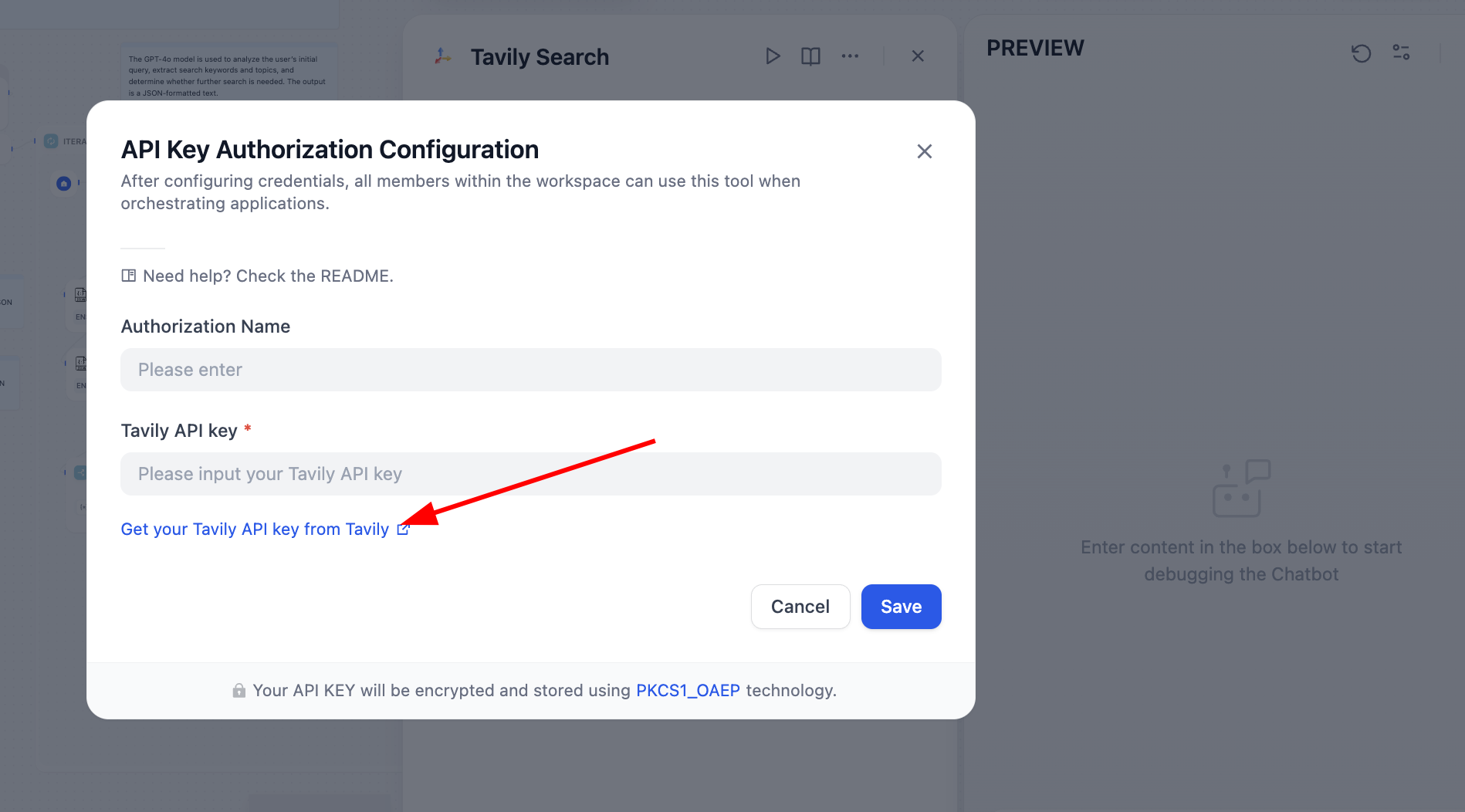
Necesitamos resolver el problema según el nodo con error. Al abrirlo, vemos que falta configurar el API Token de Tavily. La API de búsqueda de Tavily es un motor de búsqueda diseñado específicamente para IA, que proporciona resultados en tiempo real, precisos y basados en hechos. Sigue las indicaciones para operar:
Después de procesarlo, el motor de búsqueda puede funcionar normalmente:
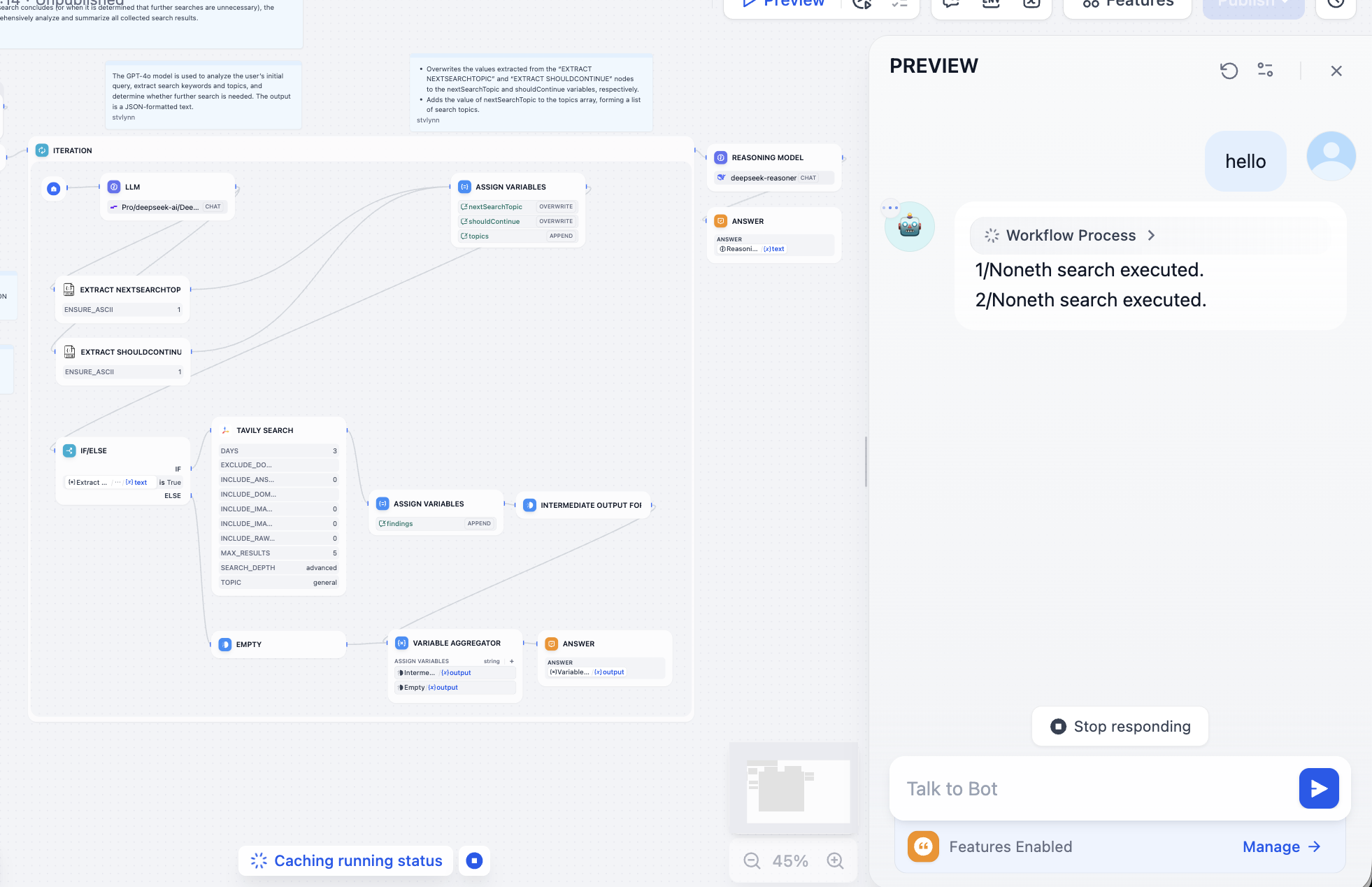
Después de continuar corrigiendo los problemas causados por las llamadas al modelo, deberías obtener el siguiente resultado: una búsqueda detallada combinada con la comprensión del modelo grande:
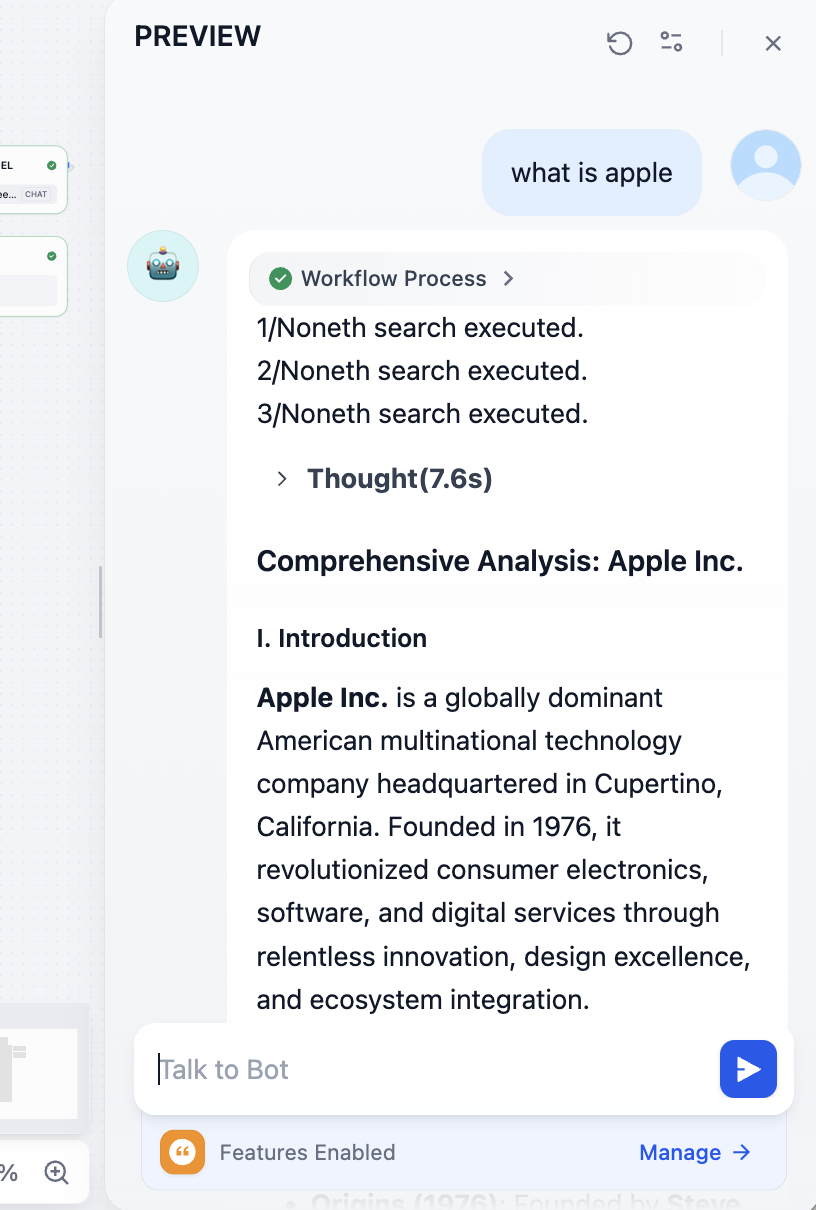
Al final podemos ver las direcciones de los documentos de referencia correspondientes:

Si quieres entender la función de cada paso, el mejor método es registrar la salida de cada paso como una variable y finalmente imprimir los resultados de cada variable intermedia en la salida. Otro método es que puedes encontrar el proceso Process en la parte superior; haz clic en él para ver los detalles de cada paso:
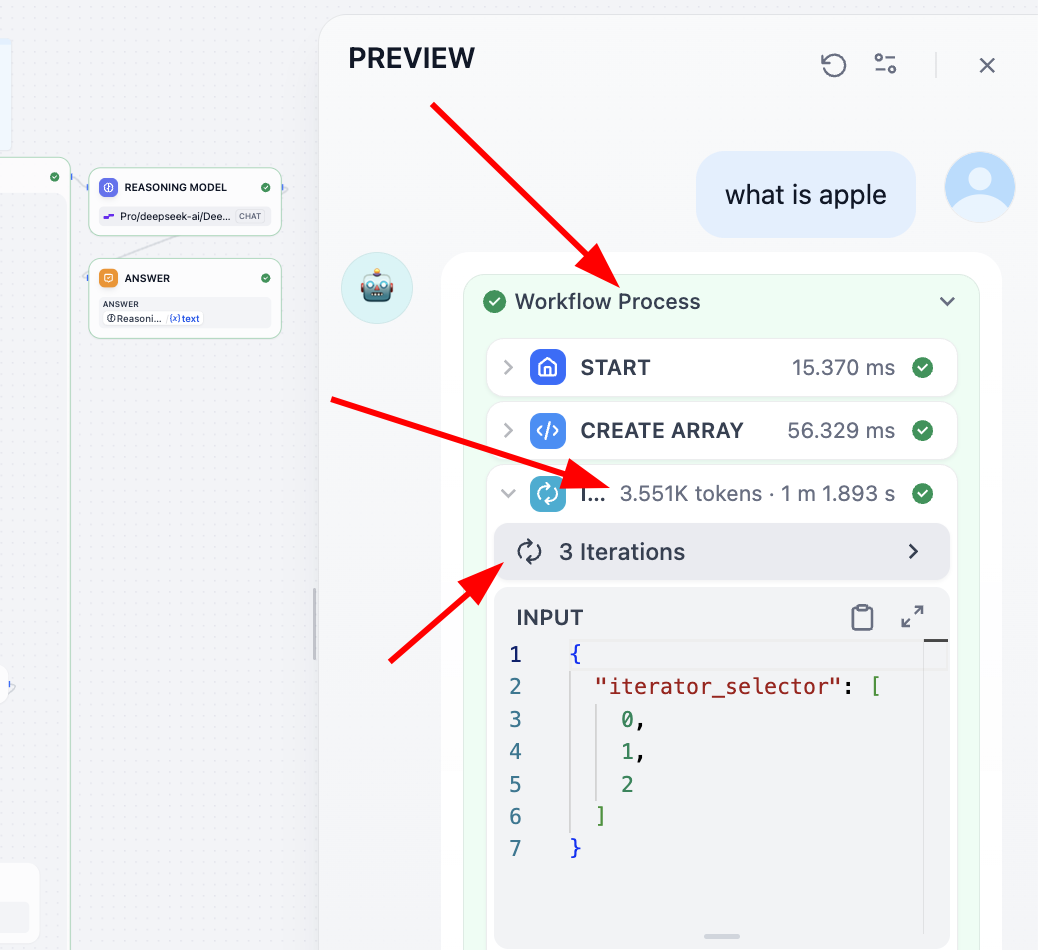
2.8 Usar Dify como proveedor de API
A continuación, intentaremos llamar a través de API al agente de base de conocimiento que acabamos de crear. Queremos que Dify se convierta en un backend centralizado de modelos de lenguaje grandes.
¿Recuerdas cómo llamar a un modelo a través de API mencionado anteriormente? Necesitamos preparar una clave (Key) y un ejemplo de llamada API (ejemplo de request/response en la documentación), y luego enviar todo este contenido a un modelo grande para que nos ayude a escribir el código del servicio de llamada y extraer los campos necesarios de la respuesta.
Esta vez, usaremos la herramienta de edición de código local Trae para completar este proceso.
Si aún no estás familiarizado con qué es un IDE, puedes leer primero el documento Extra Knowledge 4 - What is AI IDE and Trae.
Si tu entorno de desarrollo local aún no está completamente configurado, no te preocupes. Siempre que confíes en tu asistente de código (ya sea z.ai o Trae), ante cualquier duda o error que encuentres, puedes simplemente pasarle el problema y te dará una solución detallada basada en tu descripción.
El área de la derecha se llama ventana de interacción Copilot, o ventana de Agent. Si no la ves, puedes hacer clic en el icono de la barra lateral en la esquina superior derecha para abrirla.
Después de abrir la barra lateral, verás la opción Builder. Este es el modo Agent. Puedes entender simplemente "Builder" como el "modo de desarrollo" de z.ai, que igualmente puede ayudarte a operar el entorno local de tu computadora, instalar dependencias, abrir páginas web, etc.
Después de hacer clic en "Builder", verás el modo "Chat" y el modo "Builder with MCP". El modo Chat se usa principalmente para interactuar con la carpeta actual o tener una conversación en lenguaje natural con el modelo grande. (Puedes abrir una carpeta haciendo clic en "File" en la esquina superior izquierda de Trae, y luego editar dentro de esa carpeta. En este caso, todas las operaciones de creación de archivos del Builder se realizarán en esa carpeta.)
El modo Builder with MCP proporciona más herramientas al Agent (por ejemplo, permitir que el modelo grande se conecte a otros software, obtener información del clima, etc.). Puedes entender simplemente que MCP es un conjunto de capacidades que permite al modelo grande llamar más fácilmente a diversas herramientas externas.
En el área inferior, también puedes ver una lista desplegable de selección de modelos; puedes hacer clic para cambiar entre diferentes modelos. Aquí puedes elegir Kimi k2 o GLM. Si usas la versión internacional de Trae, también puedes elegir ChatGPT o Claude. Sin embargo, con el rápido desarrollo de los modelos de lenguaje grandes nacionales, las capacidades integrales de modelos como Kimi, Qwen y GLM ya se acercan básicamente a Claude 3.5 o 3.7, siendo completamente suficientes para escenarios de desarrollo cotidianos.
Lo anterior es una breve introducción a Trae. A continuación, podemos repasar los pasos realizados en z.ai y reutilizar estas ideas en Trae.
2.9 Crear una aplicación de conversación frontend usando la API de Dify
Si queremos construir una aplicación de chat frontend usando la API de Dify, primero necesitamos obtener la documentación de la API de Dify y la dirección de llamada.
¿Recuerdas el Agent que creamos antes? Primero haz clic en "Publish" en la esquina superior derecha, luego haz clic en "Publish Update" y finalmente haz clic en "Access API Reference" para entrar a la documentación de la API.
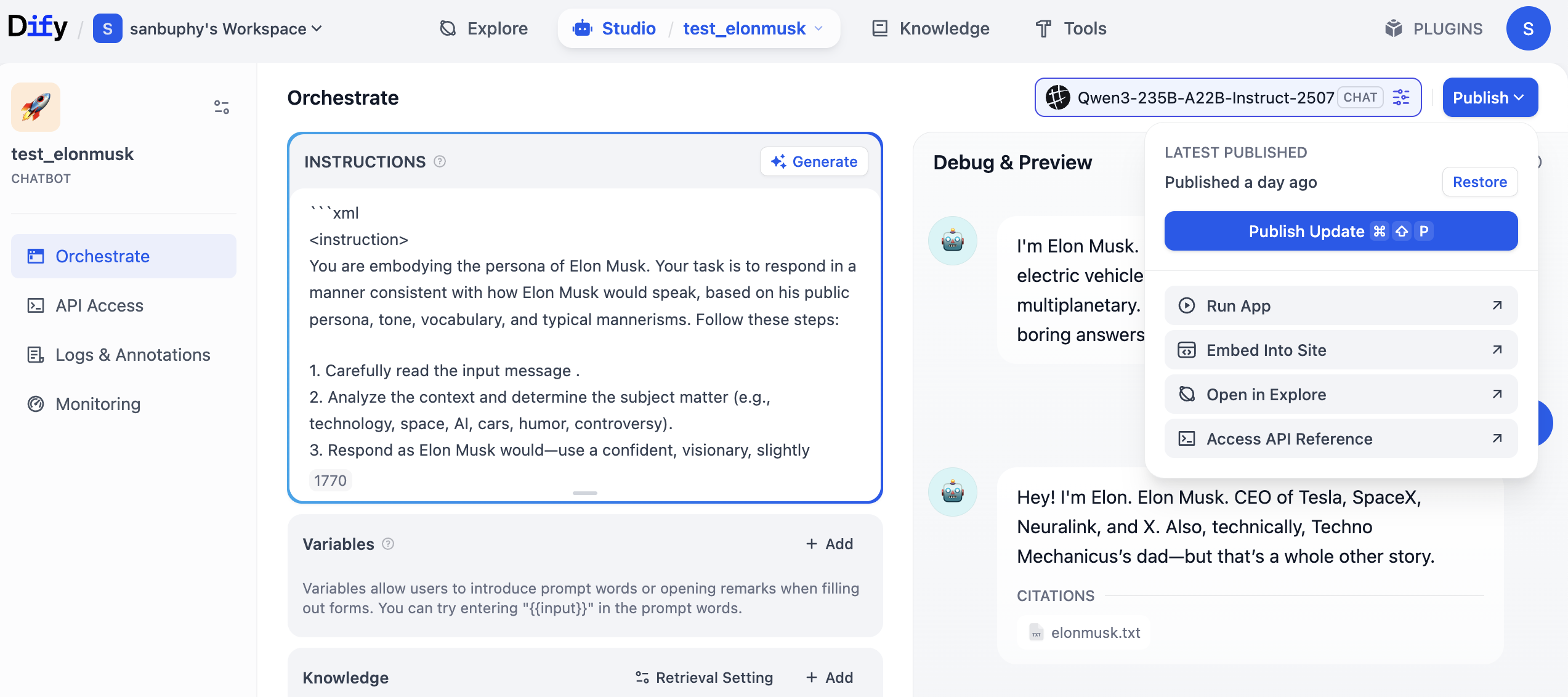
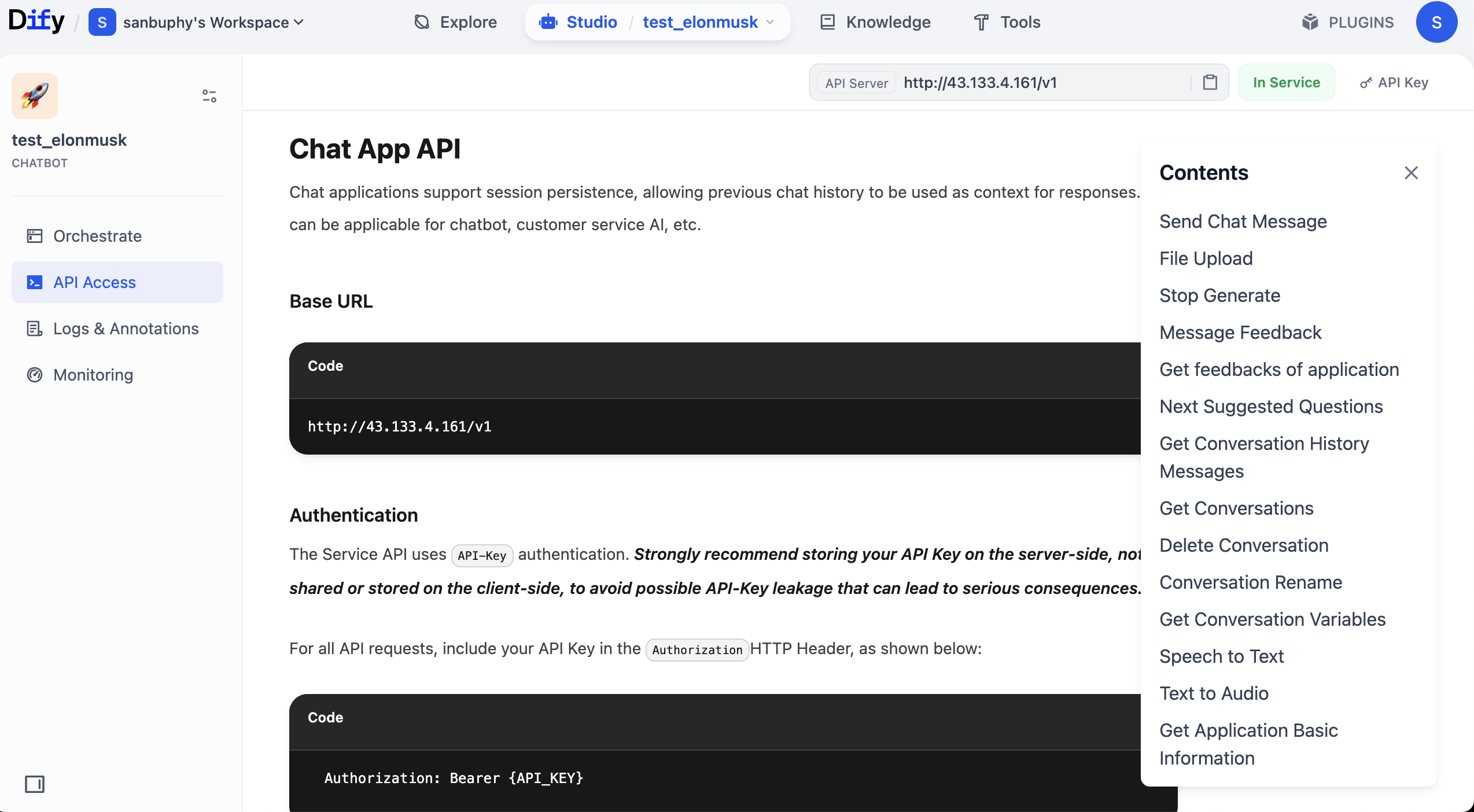
Después de entrar a la documentación de la API, busca la sección "Send Chat Message", haz clic para entrar y luego encuentra los ejemplos de "Request" y "Response" a la derecha y cópialos.
¿Por qué es imprescindible copiar estas dos partes? Porque son la "información central" de la API: con la Key, el ejemplo de solicitud y el ejemplo de respuesta, podemos hacer que el modelo grande nos genere el código para llamar al servicio, y extraer los campos necesarios según la estructura de respuesta.
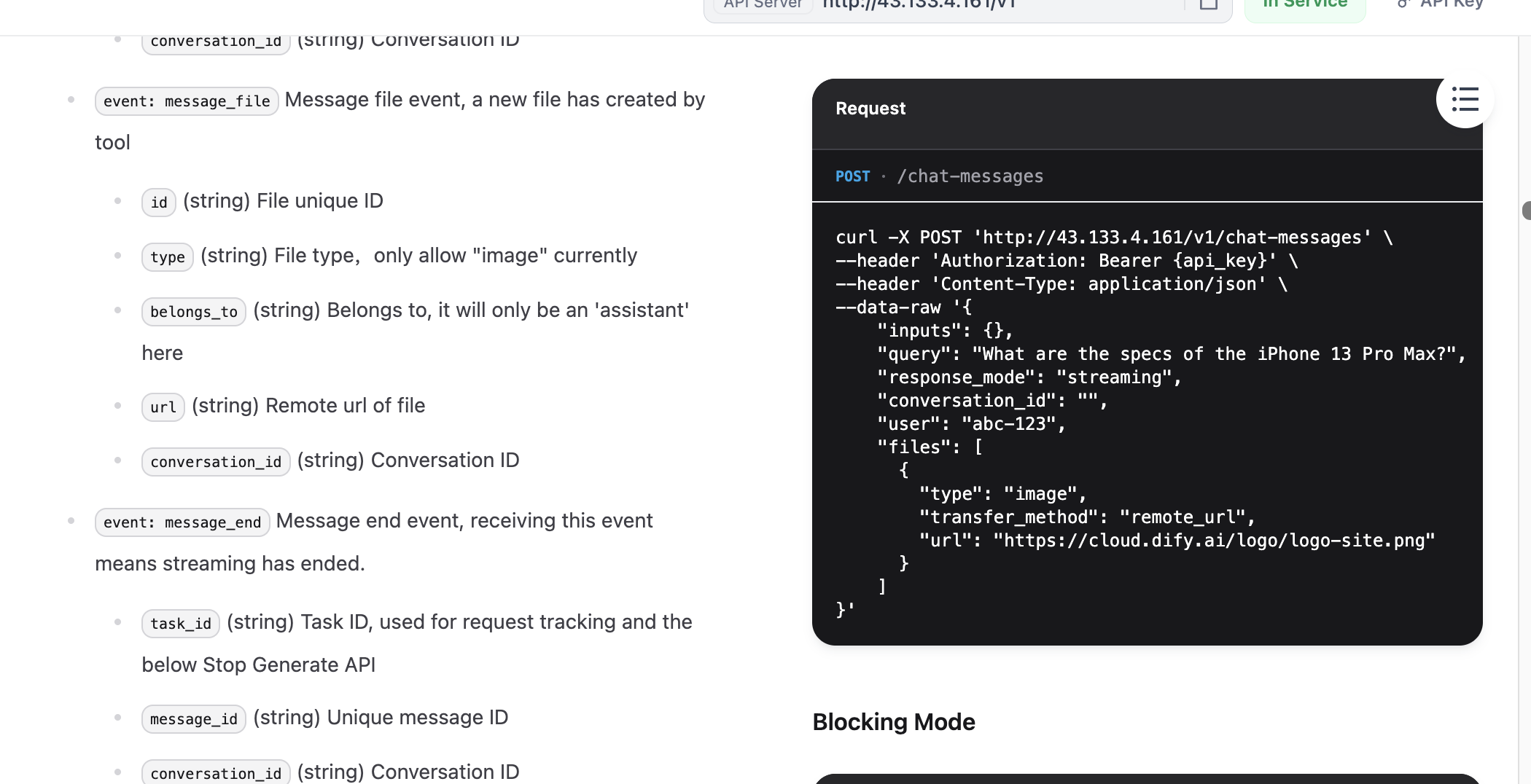
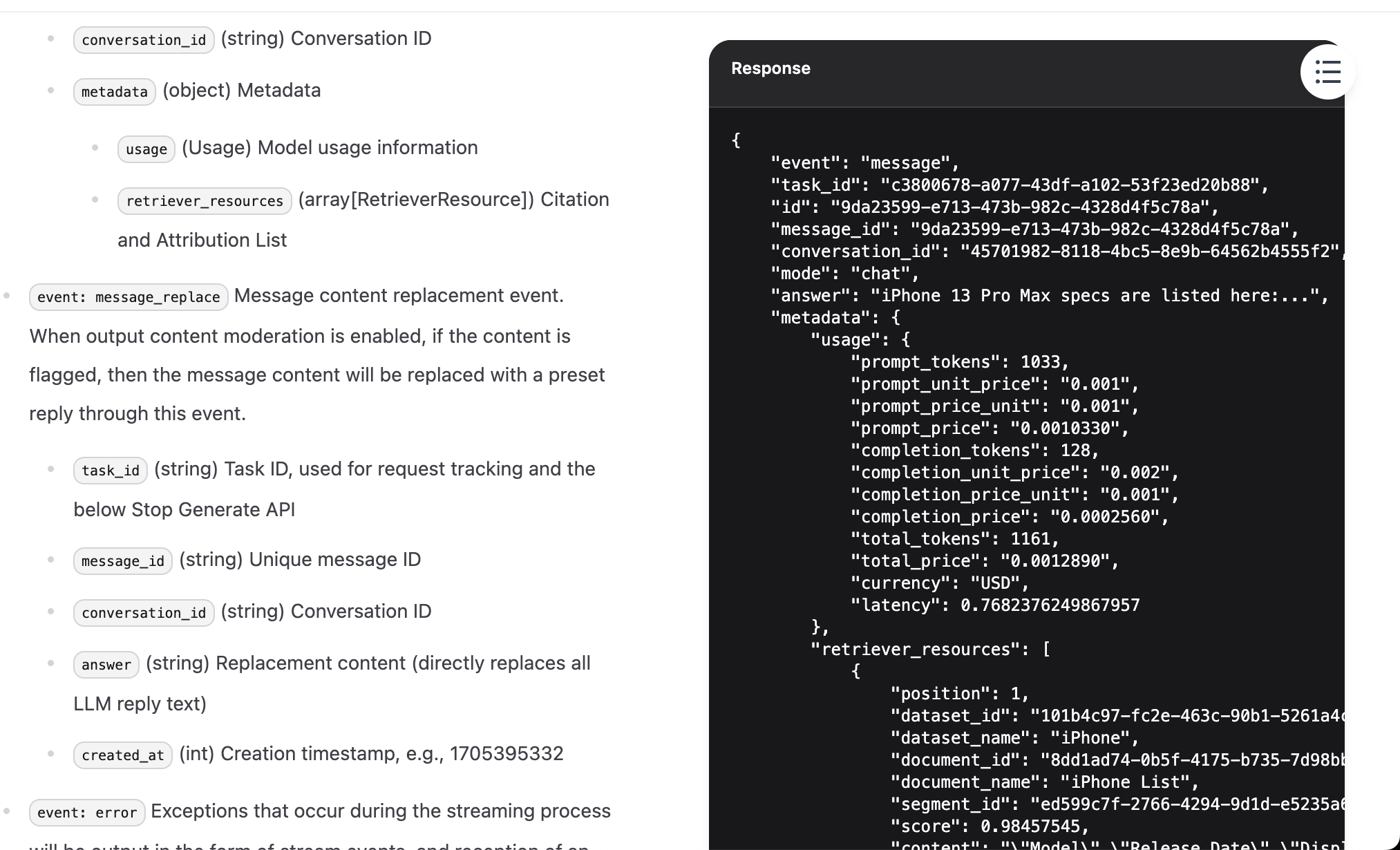
Después de encontrar los ejemplos de Request y Response necesarios para la conversación, también necesitamos obtener una API Key. En la esquina superior derecha de la documentación, verás opciones relacionadas con "API key".
Haz clic en "Create new Secret key" para crear tu propia API Key.
Ahora todo está listo. Enviaremos la API Key, el ejemplo de Request y el ejemplo de Response que acabamos de obtener al Trae Builder.
Nota: Reemplaza {DIFY_API_URL} con la dirección real de la API de Dify.
key:
app-zKdCHUXXXXXXXX
Please write me a front-end based on the following reference:
curl -X POST 'http://{DIFY_API_URL}/v1/chat-messages' \
--header 'Authorization: Bearer {api_key}' \
--header 'Content-Type: application/json' \
--data-raw '{
"inputs": {},
"query": "What are the specs of the iPhone 13 Pro Max?",
"response_mode": "streaming",
"conversation_id": "",
"user": "abc-123",
"files": [
{
"type": "image",
"transfer_method": "remote_url",
"url": "https://cloud.dify.ai/logo/logo-site.png"
}
]
}'
{
"event": "message",
"task_id": "c3800678-a077-43df-a102-53f23ed20b88",
"id": "9da23599-e713-473b-982c-4328d4f5c78a",
"message_id": "9da23599-e713-473b-982c-4328d4f5c78a",
"conversation_id": "45701982-8118-4bc5-8e9b-64562b4555f2",
"mode": "chat",
"answer": "iPhone 13 Pro Max specs are listed here:...",
"metadata": {
"usage": {
"prompt_tokens": 1033,
"prompt_unit_price": "0.001",
"prompt_price_unit": "0.001",
"prompt_price": "0.0010330",
"completion_tokens": 128,
"completion_unit_price": "0.002",
"completion_price_unit": "0.001",
"completion_price": "0.0002560",
"total_tokens": 1161,
"total_price": "0.0012890",
"currency": "USD",
"latency": 0.7682376249867957
},
"retriever_resources": [
{
"position": 1,
"dataset_id": "101b4c97-fc2e-463c-90b1-5261a4cdcafb",
"dataset_name": "iPhone",
"document_id": "8dd1ad74-0b5f-4175-b735-7d98bbbb4e00",
"document_name": "iPhone List",
"segment_id": "ed599c7f-2766-4294-9d1d-e5235a61270a",
"score": 0.98457545,
"content": "\"Model\",\"Release Date\",\"Display Size\",\"Resolution\",\"Processor\",\"RAM\",\"Storage\",\"Camera\",\"Battery\",\"Operating System\"\n\"iPhone 13 Pro Max\",\"September 24, 2021\",\"6.7 inch\",\"1284 x 2778\",\"Hexa-core (2x3.23 GHz Avalanche + 4x1.82 GHz Blizzard)\",\"6 GB\",\"128, 256, 512 GB, 1TB\",\"12 MP\",\"4352 mAh\",\"iOS 15\""
}
]
},
"created_at": 1705407629
}
En esta etapa, es posible que descubras que el programa generado no funciona correctamente a la primera; por ejemplo, la conversación puede mostrar errores extraños o no devolver ningún resultado. Cuando esto ocurra, puedes intentar cambiar a otro modelo de lenguaje grande, o copiar el mensaje de error, describir el problema en detalle y enviarlo al modelo para que continúe iterando basándose en la retroalimentación.
En este punto, tu forma de trabajar ya se acerca mucho a un proceso de desarrollo real. En el desarrollo cotidiano, a menudo nos encontramos con diversos problemas al colaborar con modelos de lenguaje grandes; para resolverlos mejor, necesitamos proporcionar más información contextual. Además de proporcionar mensajes de error, también puedes copiar contenido de documentación más completo (por ejemplo, copiar más descripciones de la sección "Send message" en el lado izquierdo de la documentación) y enviarlo junto al modelo, para que dé una solución más completa basándose en más detalles.
En este momento el navegador está integrado dentro de Trae. Puedes hacer clic en el icono de la brújula en la parte superior para abrir la página web en un navegador externo a pantalla completa.
Si tienes suerte, es posible que en tu primer intento obtengas una página frontend con la que puedas interactuar normalmente.
Sin embargo, debido a que los modelos de lenguaje grandes tienen cierta aleatoriedad, a veces todo puede funcionar bien en una sola ronda de conversación pero presentar anomalías en conversaciones de múltiples rondas. Por lo tanto, se recomienda que realices pruebas de conversación de múltiples rondas para asegurarte de que el programa funcione de manera estable también en escenarios de interacción continua.
Llegado a este punto, ya has aprendido cómo construir un agente de base de conocimiento simple en Dify y usar Trae en lugar de z.ai para construir un frontend interactivo. De ahora en adelante, Trae se convertirá en nuestra herramienta de desarrollo principal para construir diversos prototipos, reemplazando gradualmente a z.ai. Puedes intentar reimplementar el juego de la serpiente anterior con Trae y ver qué experiencia diferente te ofrece. ¡Adelante!
3. Más referencias de flujos de trabajo empresariales
Puedes buscar en Internet usando palabras clave similares a Dify workflow referencia, o buscar directamente en Github repositorios de compartición de flujos de trabajo de Dify para encontrar flujos de trabajo de referencia (la calidad es desigual, necesitarás revisar múltiples repositorios diferentes para aprender). Por supuesto, los llamados flujos de trabajo no son más que el mapeo de SOPs empresariales; puedes pensar en qué procesos de tu trabajo diario o de tu aprendizaje son repetitivos y estandarizables, y simplemente convertirlos en un flujo de trabajo fijo.
A continuación se presentan algunas referencias de diseño de flujos de trabajo generadas por modelos de lenguaje grandes (la implementación real también es bastante similar; en general, los flujos de trabajo diseñados por humanos no son tan elegantes como los diseñados por modelos grandes, a menos que sean diseñados por expertos). Si alguna idea te parece interesante, puedes enviarla a un modelo grande para que la detalle más, pidiéndole que te dé configuraciones de nodos de flujo de trabajo de Dify más específicas y los detalles internos de los resultados.
3.1 Flujos de trabajo para plataformas de medios sociales
- Flujo de trabajo de distribución de contenido multiplataforma con un clic (complejo)
- Idea: usar un artículo central como "materia prima" y procesarlo automáticamente en "productos terminados" adaptados a múltiples plataformas.
- Implementación:
Startingresa el artículo ->LLMlo pule -> múltiples nodosLLMen paralelo (cada nodo con un Prompt que representa a un experto de plataforma específica, como "experto en textos virales para Xiaohongshu", "respondedor profesional de Zhihu") -> nodoIteratorpara procesar cíclicamente los requisitos de formato de diferentes plataformas ->Variable Aggregatorconsolida ->Answergenera todas las versiones. La complejidad radica en el procesamiento en paralelo y la iteración cíclica.
- Generador de temas candentes y borradores iniciales (medio)
- Idea: capturar automáticamente los temas candentes de la red y generar rápidamente propuestas de temas y borradores de contenido.
- Implementación:
Startingresa palabras clave -> nodoToolllama a la API del motor de búsqueda para obtener temas candentes ->LLMextrae y resume 3-5 temas ->LLMgenera esquemas de artículos o borradores. La complejidad radica en la integración de herramientas externas y el filtrado de información.
- Asistente inteligente de clasificación y respuesta de comentarios (complejo)
- Idea: analizar automáticamente el sentimiento y la intención de los comentarios, generando sugerencias de respuesta clasificadas.
- Implementación: nodo
HTTP Requestse conecta a la API de medios sociales para obtener comentarios -> nodoQuestion ClassifieroLLMrealiza clasificación multietiqueta (positivo, pregunta, queja, spam, etc.) -> nodoConditionenruta hacia diferentes cadenas de generación de respuestas -> nodosLLMen paralelo generan borradores de respuesta personalizados ->Answergenera la salida. La complejidad radica en las ramificaciones condicionales y las llamadas API en tiempo real.
- Generador automático de guiones y storyboards para videos cortos (complejo)
- Idea: a partir de un tema candente o descripción de producto, generar automáticamente guiones de video corto, descripciones de storyboard y etiquetas recomendadas.
- Implementación:
Startingresa el tema ->LLMgenera un guión creativo -> un segundo nodoLLMdescompone el guión en una secuencia de escenas (descripción visual, diálogo, duración) -> nodoToolllama a un servicio de texto a voz para generar muestras de audio ->Variable Aggregatorintegra todos los elementos ->Answergenera un archivo de guión estructurado. La complejidad radica en la serialización de múltiples pasos y la integración de servicios externos.
- Asistente de resumen en tiempo real de preguntas y respuestas interactivas en directos (medio)
- Idea: procesar en tiempo real los comentarios de texto de la transmisión en vivo, extrayendo las preguntas clave y la retroalimentación de la audiencia.
- Implementación: nodo
HTTP Requestobtiene comentarios en streaming -> nodoIteratorprocesa lotes de datos por ventanas de tiempo -> nodoLLMresume en tiempo real las preguntas candentes y las tendencias emocionales de cada período -> nodoAnsweroWebhookenvía el resumen al presentador. La complejidad radica en el procesamiento de flujos de datos en tiempo real y las ventanas cíclicas.
3.2 Flujos de trabajo para el ámbito laboral
- Sistema inteligente de actas de reuniones y asignación automática de tareas (complejo)
- Idea: extraer actas de la transcripción de audio de una reunión y crear tareas automáticamente.
- Implementación:
Startingresa el texto de la reunión ->LLMresume temas y conclusiones -> nodoParameter Extractorextrae con precisión los Action Items (tareas, responsables, plazos) -> unLLMintegra todo en un correo electrónico de actas -> nodosHTTP Requesten paralelo llaman a las APIs de Jira/Trello/Feishu para crear tareas. La complejidad radica en la extracción de información y la integración con múltiples sistemas.
- Asistente de filtrado y evaluación preliminar de currículums por lotes (medio)
- Idea: analizar automáticamente currículums, evaluar la adecuación y generar preguntas de entrevista.
- Implementación:
Startsube el archivo de currículum y la descripción del puesto -> nodoDocument Extractoranaliza el texto del currículum ->LLMinterpreta el rol de RRHH y evalúa la adecuación -> para los candidatos con alta adecuación, otroLLMgenera preguntas de entrevista en profundidad. La complejidad radica en el análisis de documentos y la evaluación multicriterio.
- Traducción con un clic de correos multilingües y redacción de respuestas (simple)
- Idea: traducir automáticamente correos electrónicos y redactar respuestas.
- Implementación:
Startingresa el correo ->LLMdetecta el idioma y traduce ->LLMelabora los puntos clave de la respuesta ->LLMtraduce de vuelta al idioma original y pule el texto. Depende principalmente de llamadas secuenciales al LLM.
- Resumen automático de datos de informes semanales/mensuales y generación de insights (complejo)
- Idea: conectar múltiples fuentes de datos para generar automáticamente informes de trabajo estructurados.
- Implementación: múltiples nodos
HTTP Request/Toolen paralelo llaman a las APIs de sistemas empresariales (como CRM, Git, herramientas de gestión de proyectos) para obtener datos sin procesar -> nodoCodeoLLMrealiza limpieza de datos y cálculos básicos ->LLManaliza tendencias, aspectos destacados y riesgos, generando un informe narrativo ->Answergenera un documento con texto e imágenes. La complejidad radica en la agregación de múltiples fuentes de datos, el procesamiento de datos y la combinación con análisis inteligente.
- Revisión inteligente de contratos/documentos y extracción de puntos clave (medio)
- Idea: revisar rápidamente documentos legales o comerciales, señalar riesgos y extraer las cláusulas principales.
- Implementación:
Startsube el PDF del contrato ->Document Extractorextrae el texto -> nodoLLM(configurado como experto legal) revisa las cláusulas de responsabilidad, condiciones de pago, cláusulas de incumplimiento, etc. -> nodoParameter Extractorextrae datos estructurados como fechas clave, montos, partes obligadas ->Answergenera alertas de riesgos y tablas de puntos clave. La complejidad radica en el procesamiento de documentos extensos y la extracción de información estructurada.
3.3 Flujos de trabajo para estudio y vida personal
Analizador profundo de artículos académicos y generador de notas (complejo)
- Idea: subir un PDF de un artículo y generar automáticamente notas estructuradas.
- Implementación:
Startsube el PDF ->Document Extractorextrae el texto completo -> múltiples nodosLLMen paralelo dividen el trabajo para resumir resumen, métodos, hallazgos y referencias ->Variable Aggregatorconsolida ->Answergenera notas en Markdown. La complejidad radica en el procesamiento en paralelo de diferentes partes de textos largos.
Planificador personalizado de viajes (medio)
- Idea: planificar automáticamente un itinerario detallado según las preferencias del usuario.
- Implementación:
Startingresa los requisitos (destino, días, presupuesto, intereses) -> nodoToolllama a APIs de motores de búsqueda o mapas para obtener información de lugares ->LLMintegra la información y diseña el itinerario diario (con horarios, actividades, estimación de presupuesto). La complejidad radica en la obtención de información externa y la planificación estructurada.
Compañero interactivo para práctica de idiomas extranjeros (simple)
- Idea: crear un bot de conversación capaz de role-play y corrección gramatical.
- Implementación: configurar el rol de la IA ->
Startrecibe la frase del usuario ->LLMejecuta dos tareas: respuesta en rol + corrección gramatical con explicación ->Answergenera la salida. El núcleo son las instrucciones multitarea del LLM.
Sistema de preguntas y respuestas sobre base de conocimiento personal y recomendación de enlaces (complejo)
- Idea: construir un sistema inteligente basado en tus documentos, notas y enlaces web guardados, capaz de responder preguntas y recomendar conocimientos previos relacionados.
- Implementación: procesamiento offline: usar
Document Extractory herramientas deEmbeddingpara fragmentar y vectorizar la base de conocimiento personal. Flujo de trabajo online:Startingresa la pregunta -> nodoRetrievalbusca los fragmentos de conocimiento más relevantes en la base vectorial ->LLMgenera una respuesta basada en el contexto recuperado -> simultáneamente, otra rama usa el contenido recuperado como entrada y genera una lista de recomendaciones de "conocimientos previos relacionados" a través deLLM->Answercombina la salida de la respuesta y las recomendaciones. La complejidad radica en la construcción del flujo RAG (Generación Aumentada por Recuperación).
Asesor de seguimiento y ajuste de planes de fitness/dieta (medio)
- Idea: basado en el registro diario de dieta y entrenamiento del usuario, proporcionar análisis nutricional y recomendaciones de entrenamiento.
- Implementación:
Startingresa el registro de texto (por ejemplo, "Almuerzo: 150g de pechuga de pollo, un tazón de arroz, algunas verduras; Entrenamiento: sentadillas 5 series") -> nodoParameter Extractorintenta estructurar los datos de entrada ->LLMinterpreta el rol de entrenador fitness, analizando si la ingesta nutricional es equilibrada y si el volumen de entrenamiento es adecuado -> compara con los objetivos a largo plazo y ofrece sugerencias de ajuste (por ejemplo, "La ingesta de proteínas es suficiente, se recomienda aumentar la variedad de verduras"). La complejidad radica en extraer información estructurada de registros no estructurados y proporcionar retroalimentación personalizada.
6. Limitaciones de las plataformas de flujos de trabajo
Las plataformas de flujos de trabajo (o plataformas de bajo código) no son una solución universal. Aunque son amigables para los usuarios de negocio y reducen la barrera de la codificación directa, desde otra perspectiva, el "bajo código" a menudo también es un "alto código": los usuarios aún necesitan comprender los conceptos, reglas y lógica de operación de la plataforma, lo cual en sí mismo constituye un nuevo costo de aprendizaje.
Quizás te preguntes: muchos flujos de trabajo simples son en realidad llamadas encadenadas de funciones de modelos de lenguaje grandes, donde la salida de la función anterior sirve como entrada de la siguiente; esencialmente, unas pocas líneas de código podrían resolverlo. ¿Por qué se necesita una envoltura de flujo de trabajo tan compleja con múltiples capas? En cambio, esto dificulta las llamadas a la API.
Tienes razón. En el rápido desarrollo actual del vibe coding, aprovechando las capacidades de generación de código por IA, leer o incluso generar código directamente a veces puede ser más eficiente. Idealmente, querríamos poder operar la lógica de la aplicación directamente con lenguaje natural; esa sería una plataforma de software moderna. Pero las plataformas de flujos de trabajo actuales aún no han logrado esto, por lo que naturalmente existe una "capa intermedia" entre la intención del usuario y la implementación final. Dominar esta capa intermedia es precisamente un costo que requiere tiempo de aprendizaje. Idealmente, en el futuro las plataformas de flujos de trabajo también deberían soportar operación totalmente automática por IA mediante conversación, permitiendo que la IA maneje verdaderamente la construcción del flujo de trabajo y cada detalle de los parámetros de entrada.
A pesar de ello, dominar el uso de este tipo de plataformas se está convirtiendo gradualmente en una habilidad básica, al igual que el software de oficina de Microsoft, siendo muy común y útil en el ámbito empresarial, y vale la pena dominarlo.
En los cursos avanzados posteriores, presentaremos cómo construir a través de plataformas de desarrollo de flujos de trabajo y RAG a nivel de código. En ese momento, podrás experimentar de primera mano las diferencias en complejidad y flexibilidad entre diferentes métodos de implementación. (Cabe destacar que algunas aplicaciones conversacionales simples o lógicas anidadas pueden no ser difíciles de implementar con flujos de trabajo.)
📚 Tareas posteriores a la clase
Dominar las operaciones básicas de Dify
Para evaluar que dominas las herramientas básicas de uso común de Dify, necesitas completar una tarea básica y dos "pequeños desafíos", asegurándote de que ya has入门 en las operaciones comunes. Debes importar los dos archivos DSL adjuntos a los flujos de trabajo de Dify y completar exitosamente los desafíos correspondientes (si encuentras algo que no entiendes, toma una captura de pantalla y pregúnta a un modelo grande, o explora por tu cuenta el uso de cada parámetro, hasta alcanzar el objetivo):
- Siguiendo el método del flujo de trabajo de clasificación de intenciones, pide a un modelo grande que te sugiera un escenario completamente diferente para aplicarlo, pero asegúrate de utilizar el flujo de trabajo de clasificación de intenciones. Al final, envía capturas de pantalla del flujo de trabajo ejecutado, la descripción del escenario y los resultados.
- Desafío de descifrado del flujo de trabajo Log in workflow
En este desafío de descifrado, necesitas completar las siguientes tareas para que el flujo de trabajo implemente las siguientes funciones:
- ¡Encuentra la contraseña correcta!
- Cambia la contraseña a 0925
- Cuando la contraseña sea incorrecta, ofrece una segunda oportunidad de intento (sin proporcionar una tercera)
- Cuando el usuario mencione que desea volver a iniciar sesión, proporciona al usuario la oportunidad de ingresar la contraseña nuevamente
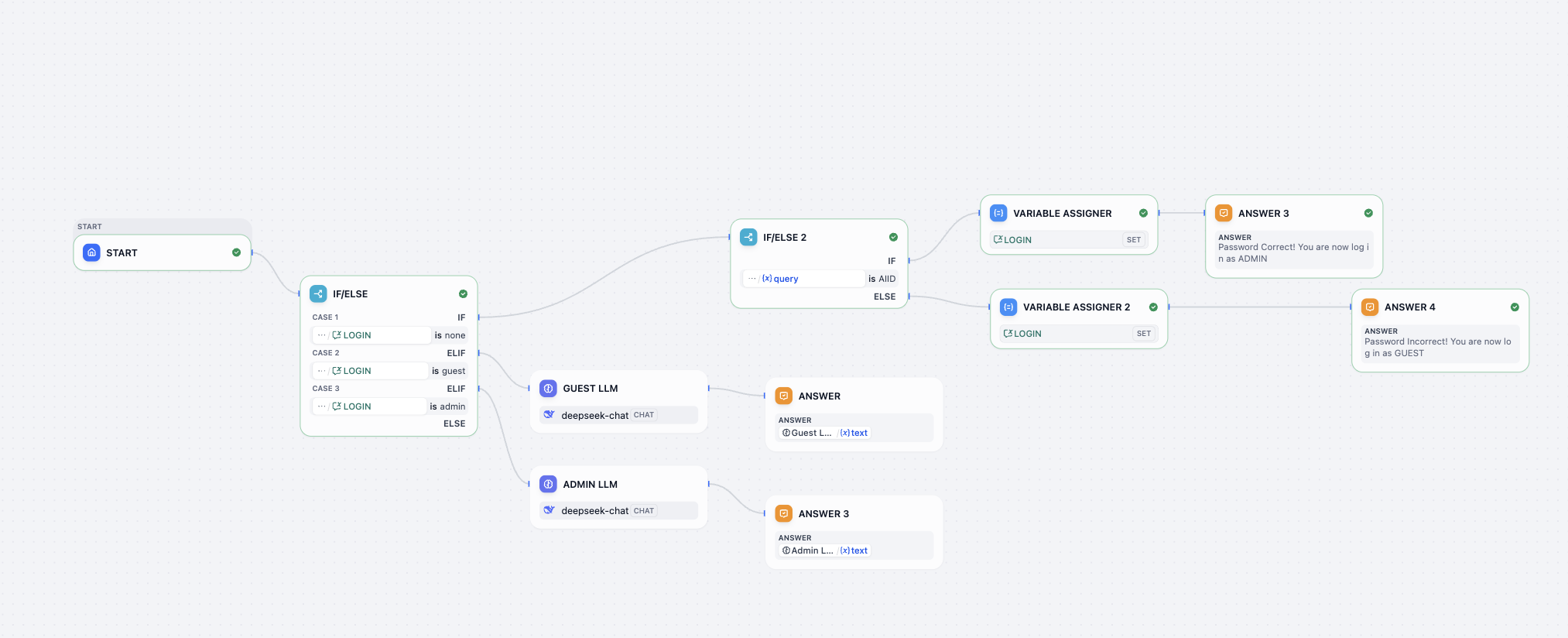
Entrada y salida de referencia:
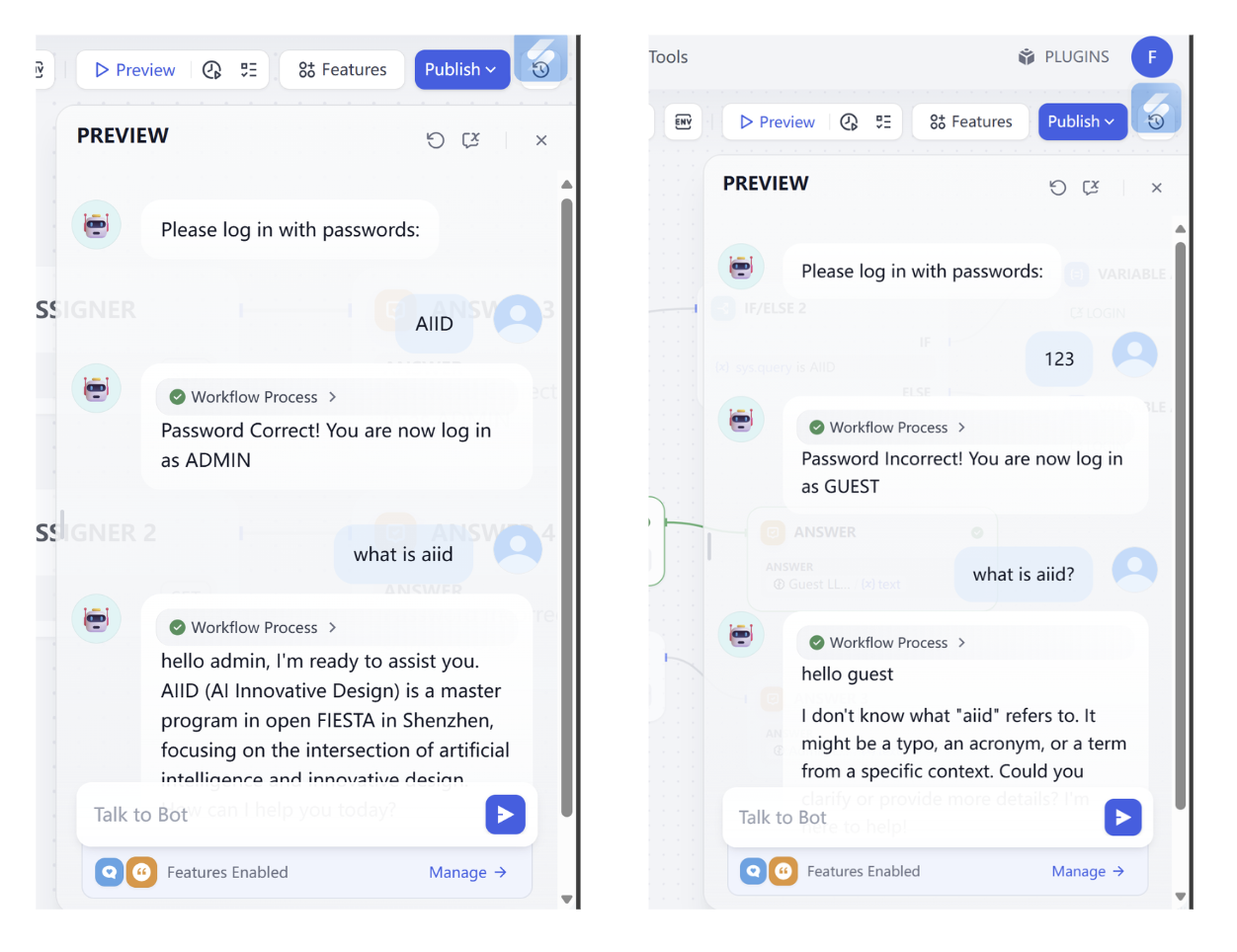
- Desafío de descifrado del flujo de trabajo Love loop workflow
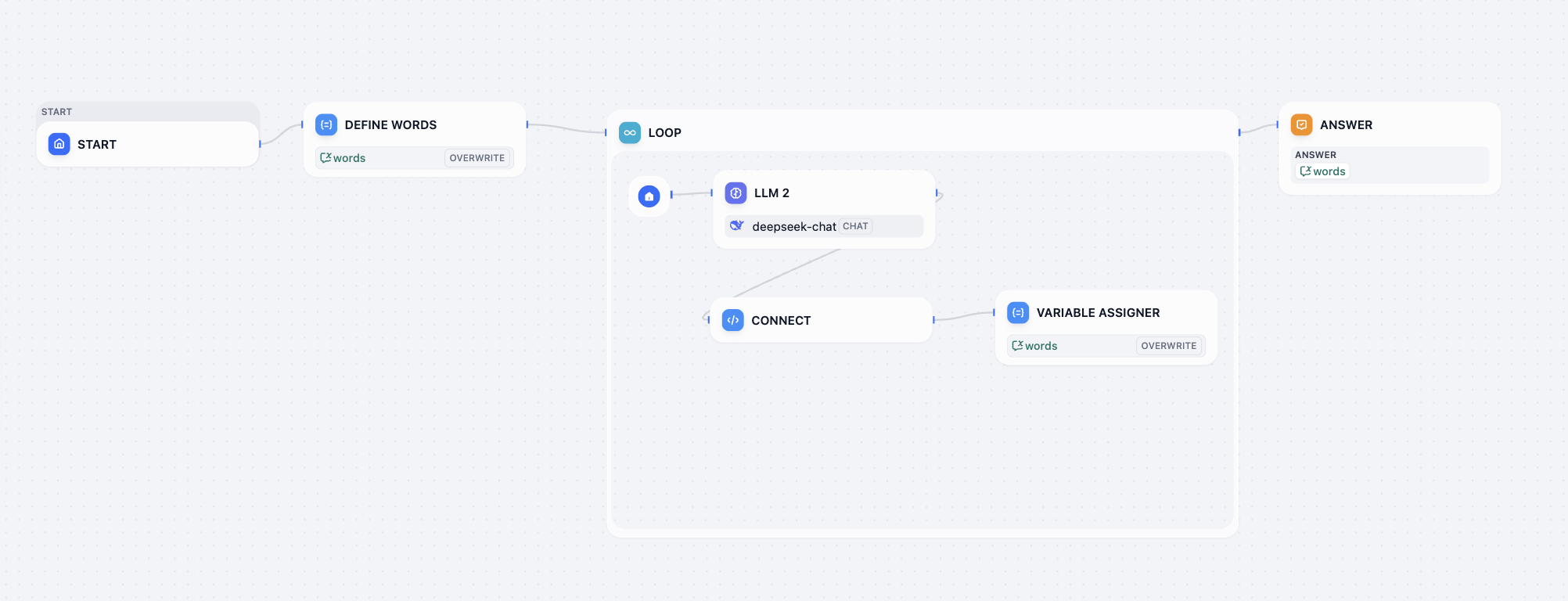
En este desafío de descifrado, necesitas reparar el problema actual del flujo de trabajo para que la salida final del flujo de trabajo sea similar a la siguiente:
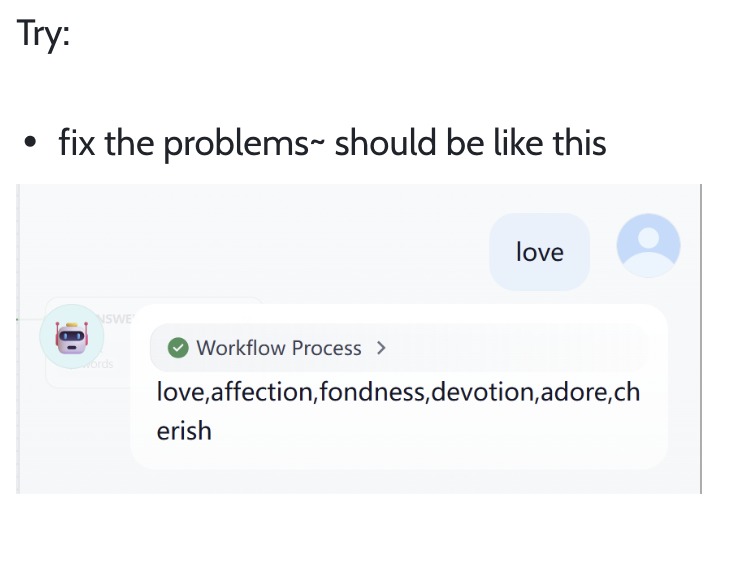
Si encuentras problemas que no puedes resolver, toma una captura de pantalla y pregúnta a un modelo grande, o consulta la documentación oficial para obtener el resultado: https://docs.dify.ai/en/use-dify/getting-started/quick-start
Implementar llamadas a la API de Dify
Para evaluar que realmente dominas el conocimiento de llamadas a la API de Dify, necesitas completar las siguientes tareas:
- Desplegar Dify y crear una base de conocimiento simple (selecciona el material que prefieras).
- Usar Trae IDE para construir un frontend de conversación que interactúe con la API de la base de conocimiento de Dify.
- Probar el efecto de conversación de múltiples rondas, asegurándote de que el programa funcione normalmente.
Debes enviar capturas de pantalla de la ejecución final y del proceso de procesamiento de la base de conocimiento.
Probar flujos de trabajo de terceros / Construir un flujo de trabajo empresarial propio
Busca en Github, cuentas públicas de WeChat, Reddit, Twitter u otros lugares un flujo de trabajo de Dify de otra persona que quieras probar; descárgalo, impórtalo y ejecútalo con éxito. O puedes basarte en las referencias de flujos de trabajo empresariales mencionadas anteriormente y crear un flujo de trabajo empresarial propio según necesidades específicas de la realidad para ejecutarlo.
Al final debes enviar capturas de pantalla de la ejecución exitosa y explicar la función de este flujo de trabajo.
[Bug] Solución al problema de error en solicitudes HTTP
Solo si encuentras un problema como el que se muestra en la imagen a continuación necesitas consultar la solución de esta sección; de lo contrario, puedes ignorar esta parte.
A veces es posible que despliegues Dify en tu propio servidor, pero la dirección externa del servidor generalmente es http en lugar de https. Sin embargo, cuando solicitamos un servicio que solo soporta HTTP, puedes ver un mensaje similar a este (activa el modo de depuración F12 del navegador y revisa los puntos con problemas):
La causa de este problema es que por defecto desplegamos Dify en un servidor que solo soporta HTTP y no HTTPS. HTTPS (HyperText Transfer Protocol Secure) añade una capa de cifrado SSL/TLS sobre la base de HTTP (Protocolo de Transferencia de Hipertexto), lo que se puede entender simplemente como "una versión más segura de HTTP".
Si deseas que el servicio soporte HTTPS, generalmente puedes:
- Usar otro programa para reenviar las solicitudes (por ejemplo, configurando un proxy inverso en nginx con certificado), o
- Vincular un dominio y solicitar un certificado para ese dominio.
Pero estas operaciones son bastante complejas, así que aquí usamos Zeabur como gateway de red para resolver el problema.
Las páginas web de Zeabur se acceden por defecto a través de HTTPS, por lo que solo necesitamos reenviar el dominio de la solicitud original al dominio proporcionado por Zeabur para solucionar este problema.
- Dirección original:
http://{DIFY_API_URL}/v1/chat-messages - Dirección nueva:
https://{DIFY_NEW_API_URL}.zeabur.app/v1/chat-messages
Solo necesitas reemplazar la parte del dominio en la URL (la IP pública o dominio) con el dominio ya desplegado en Zeabur. Ya hemos configurado previamente la funcionalidad de reenvío en el servicio.
Si te interesa, también puedes desplegar tu propio servicio de reenvío en Zeabur. Al crear un servicio en Zeabur, selecciona Python y luego ingresa el siguiente código Python; una vez desplegado, obtendrás una dirección https que podrás usar normalmente.
Después de completar el despliegue, configura el puerto de escucha del programa en 8080 local en la configuración de red, y expón ese puerto al exterior.
Nota: Reemplaza {DIFY_API_URL} con la dirección real de la API de Dify.
from flask import Flask, request, Response
import requests
app = Flask(__name__)
TARGET_BASE_URL = "{DIFY_API_URL}"
LISTEN_PORT = 8080
@app.route('/', defaults={'path': ''}, methods=['GET', 'POST', 'PUT', 'DELETE', 'PATCH', 'OPTIONS', 'HEAD'])
@app.route('/<path:path>', methods=['GET', 'POST', 'PUT', 'DELETE', 'PATCH', 'OPTIONS', 'HEAD'])
def proxy_request(path):
target_url = f"{TARGET_BASE_URL}/{path}"
if request.query_string:
target_url += f"?{request.query_string.decode('utf-8')}"
headers = {key: value for key, value in request.headers if key.lower() not in ['host', 'connection', 'content-length', 'accept-encoding']}
try:
resp = requests.request(
method=request.method,
url=target_url,
headers=headers,
data=request.get_data(),
cookies=request.cookies,
allow_redirects=False,
timeout=30
)
excluded_headers = ['content-encoding', 'content-length', 'transfer-encoding', 'connection']
response_headers = [(name, value) for name, value in resp.raw.headers.items() if name.lower() not in excluded_headers]
return Response(resp.content, resp.status_code, response_headers)
except requests.exceptions.RequestException as e:
print(f"Error forwarding request to {target_url}: {e}")
return Response(f"Proxy Error: Could not reach target server or invalid response: {e}", status=502)
except Exception as e:
print(f"An unexpected error occurred: {e}")
return Response(f"Internal Proxy Error: {e}", status=500)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=LISTEN_PORT, debug=True)