Dify 入門とナレッジベース統合
前回のレッスンの振り返り
これまでのレッスンでは、AI プログラミング、プロンプトエンジニアリング、AI 画像生成の基礎知識をグループに分けて学びました。これらの内容を通じて、異なる大規模言語モデル(LLM、Large Language Model)や生成モデルの能力の境界について初步的な理解を深めました。
前回のレッスンの内容を振り返るために、以下の質問について考えてみましょう。
- AI プログラミングとは何か?AI プログラミングツール(例:z.ai)を使ってウェブページを作成するにはどうすればよいか?
- 大規模言語モデルとは何か?プロンプトエンジニアリングとコンテキストエンジニアリングとは何か?複雑なプロンプトはどのように書くべきか?
- テキスト、AI Coding、画像生成の3つの異なる方向において、モデルの能力の強弱はそれぞれどこに現れているか?
- API とは何か?z.ai からサードパーティ API に接続するにはどうすればよいか?
どれか一つでも疑問が残る場合は、前回のレッスンの資料を見直すか、WeChat の学習グループで質問してください。
今回のレッスンでは、シンプルな AI テキスト・画像ツールから、企業の業務実装に近いワークフロー構築プラットフォームへと進みます。チャットボットから AI エージェント、AI ワークフローへと発展させ、API を使ってインタラクティブな「インテリジェント」ボットページを作ります。
操作中に理解しにくいステップに遭遇しても心配しないでください。現在の操作画面をスクリーンショットして大規模モデルに送信し質問することをお勧めします。現在の大規模モデルは、一般的な質問の大部分に回答できます。
質問しても解決できない場合は、思い切って操作を試してみてください。間違いを恐れる必要はありません。すべての試行は学習と進歩の機会です。実践を重ねることで、ますます上達し、操作もよりスムーズになります。
このレッスンで学ぶこと
- なぜチャットボットからエージェントや Workflow のオーケストレーションへと移行する必要があるのか。
- エージェントやワークフロー開発プラットフォームとは何か。AI の能力を SOP 化し、オーケストレーション可能にする方法。
- Dify とは何か。LLM アプリケーション向けのこのオープンソースプラットフォームを使って、特にナレッジベース Q&A ボットを迅速に構築する方法。
- RAG の実装方法とその価値。なぜ検索強化生成(Retrieval-Augmented Generation)が必要なのか。
- Dify と AI IDE Trae(
Extra Knowledge 4 - What is AI IDE and Trae)をゼロから使いこなす方法。エージェントやワークフローの構築、そして Dify API を使ったフロントエンドチャットボットウェブアプリケーションの作成。
- Dify の基本的な使用原理、エージェントやワークフローの作成方法、API 呼び出し方法
- AI IDE の使用方法と AI IDE でのプログラミング
- チャット可能なフロントエンドウェブエージェントアプリケーション
1. チャットからエージェントへ
前の段階では、プロンプトを使って大規模モデルにロールを演じさせたり、テキストを生成させたり、シンプルなコードを書かせたりする方法を学びました。しかし、よく考えると一つの問題に気づくでしょう。チャットボット自体は何も実行できないのです。
「注文の確認方法は?」と聞かれれば答えることはできますが、実際にデータベースにアクセスして該当する数値を調べることはできません。週報に何を含めるべきかを説明することはできますが、プロジェクトデータを自動で集計してメールを送信することはできません。この「言うだけでやらない」限界により、純粋なチャット式 AI は業務プロセスに真に組み込むことが困難です。
AI をチャットパートナーからデジタル従業員にレベルアップさせるには、3つのコア能力を与える必要があります。
- 専門知識——製品ドキュメント、顧客情報、社内制度を読んで理解させる
- ツール呼び出し(プラグインとも呼ばれます)——データベースを操作し、API を呼び出せるようにする
- 構造化実行——あらかじめ設定されたロジックに従って段階的にタスクを完了させ、自由な発想に任せない
これが AI エージェント(AI Agent)の原型です。目標、知識、ツール、実行パスを備えた自動化ユニットです。

注意:現在の業界で言及される「シンプル版のエージェント」は、主に LLM + ツール + ナレッジベースの組み合わせによる拡張型アプリケーションを指しており、自律的に計画を立てるエージェントを意味するものではありません。シンプルなエージェントは真の推論や長期計画能力を持っていませんが、大量のエンタープライズレベルの自動化シナリオを支えるには十分です。真の自律計画と行動能力を持つエージェントについては、後の章で詳しく説明します。
1.1 最もシンプルなエージェント:ナレッジベースベースの Q&A ボット
エージェントが持つべき複数のコア能力が明確になった後、一つの問いが浮かびます。その中のたった一つの最もシンプルな機能を実装するだけで、本当に使える基礎的なエージェントを構築できるのでしょうか?答えは「はい」です。
実際、多くの実際の業務シナリオにおいて、ユーザーのコアニーズは AI に複雑な操作(API の呼び出しやシステム間の連携など)を自動実行させることではなく、企業独自の資料に基づいた正確で信頼性の高い Q&A サポートです。これはまさに、エージェントの3つのコア能力のうち、最初の「専門知識サービス能力」に対応します。したがって、最もシンプルでありながら最も広く応用されているエージェントの形態である「ナレッジベースベースの Q&A ボット」を導入できます。
これはまだツール呼び出しや自律計画の能力を持っていませんが、重要なブレイクスルーは、大規模モデルの回答を無根拠な生成ではなく、確かな裏付けに基づかせる点にあります。どのように?その鍵となる課題——企業内に大量のドキュメントナレッジがあり、何千何万ページものドキュメントが存在する時、モデルはどうやって各ラウンドの対話で現在の質問に最も関連する内容を素早く見つけるのか——を解決することです。
ここでの解決策が、検索強化生成(Retrieval-Augmented Generation, RAG)です。
RAG の基本的な考え方は、ユーザーが質問した時に、システムがまず企業のナレッジベースから質問の意味に最も関連する複数のテキスト断片(例:製品マニュアルのある段落、HR 制度のある条項)を検索し、これらの断片をコンテキストとして大規模モデルの入力に「注入」し、実際の資料に基づいた回答の生成を促すというものです。
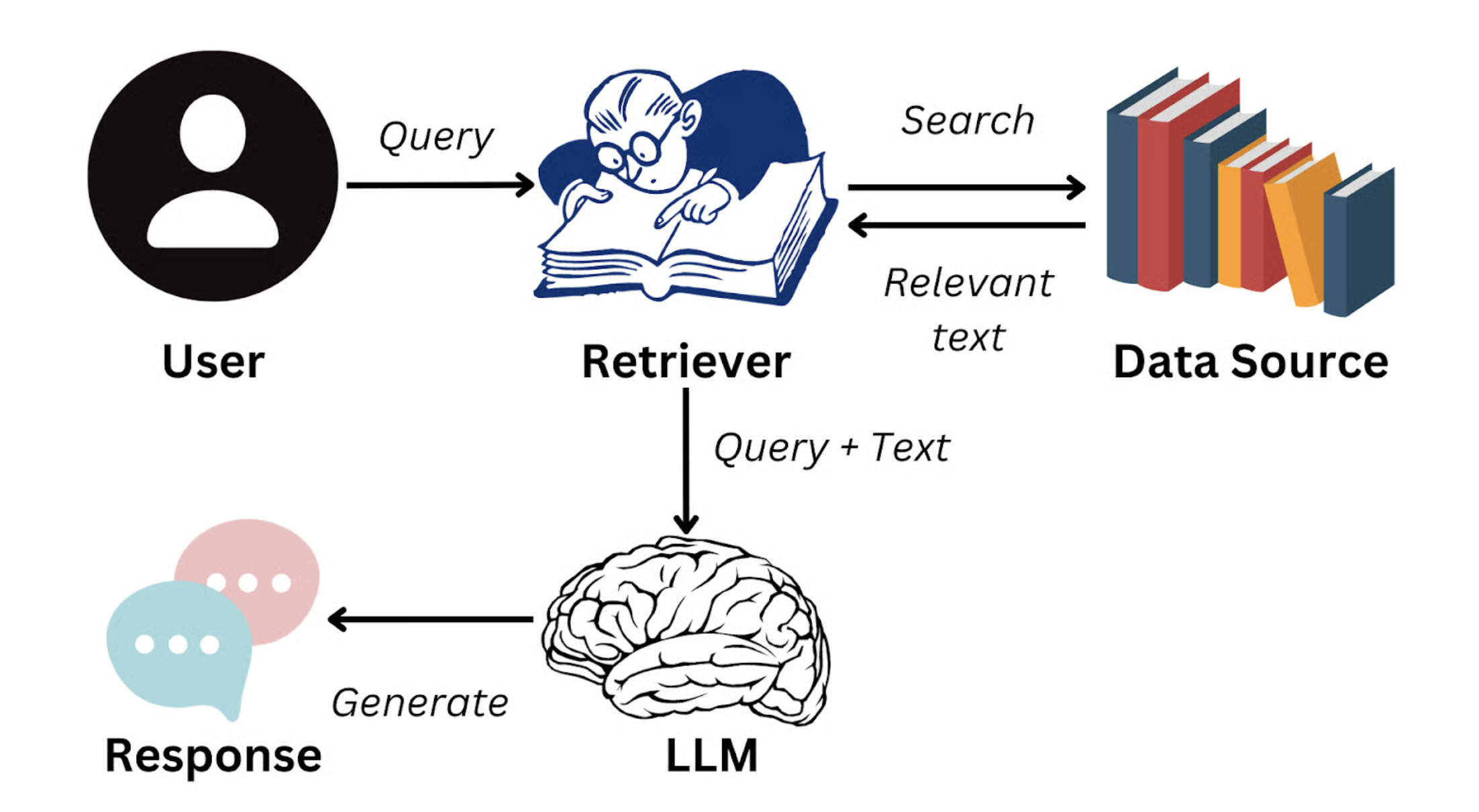
画像出典:https://www.datacamp.com/blog/what-is-retrieval-augmented-generation-rag
これにより、モデルの回答はもはや訓練データ中の一般化された知識に依存するのではなく、企業が提供する信頼性の高い情報に固定されます。RAG の目標は、このような外部知識の動的注入を通じて、回答の真実性、正確性、一貫性を大幅に向上させることです。回答を「キャラクター設定に合わせる」ことも可能です。例えば、カスタマーサポートのトーンや技術ドキュメントのスタイルで回答させることができます。
実際の業務では、この技術は特に重要です。大規模モデルはしばしば「ハルシネーション(幻覚)」を起こすからです。例えば、CFO やコンサルタントとしてある期間の具体的なデータを尋ねた場合、モデルが日付や出来事をでっち上げる可能性があります。RAG を導入することで、回答の制御性と信頼性が大幅に向上します。
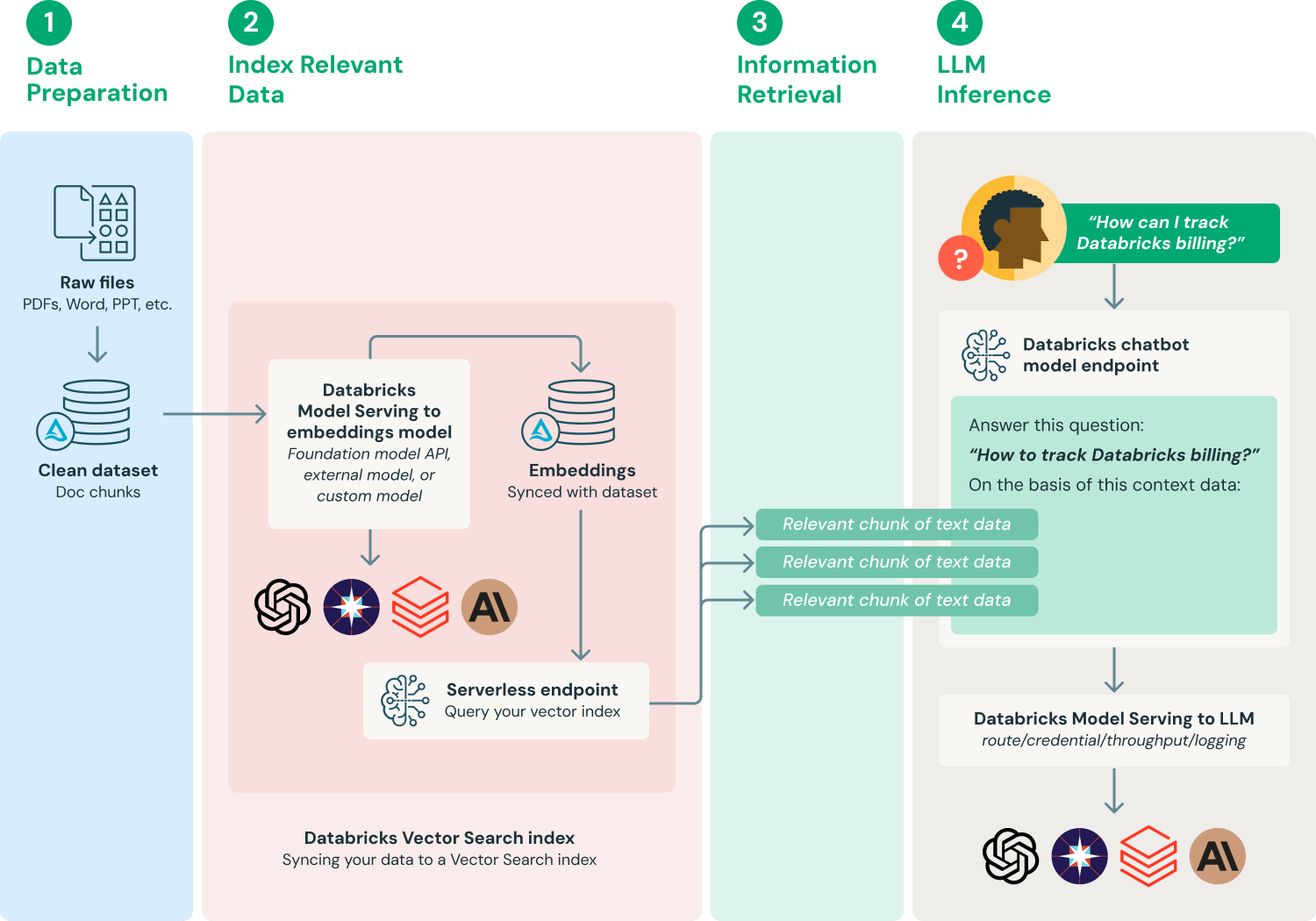
画像出典:https://www.databricks.com/glossary/retrieval-augmented-generation-rag
今回のレッスンの実践パートでは、人気の AI ワークフロープラットフォームである Dify を使って、ナレッジベースベースの Q&A ボットを構築します。製品マニュアル、社内制度、プロジェクトドキュメント、研究論文、ナレッジベース記事、さらには個人のメモ集など、様々なタイプの専用資料を簡単にナレッジベースとして構築できます。
構築完了後、様々な質問をしてその能力をテストできます。例えば:
- 「製品 A の最新バージョンの主な機能アップデートは何か?」
- 「従業員マニュアルに基づいて、今年の年次休暇制度はどのように規定されているか?」
- 「XX プロジェクトにおいて、技術的課題 'XXX' はどのように解決されたか?」
- 「この論文で述べられているコアの研究方法は何か?」
RAG 技術がどのように静的で散在する文書資料を、高精度な Q&A サポートを提供するインテリジェントナレッジベースに変換するかを、実際に体験できます。
1.2 チャットエージェントからワークフローへ
しかし、ナレッジベースやプラグイン呼び出し機能を追加した「拡張型エージェント」であっても、より複雑な業務プロセスに直面するとまだ力不足です。
次のようなユーザーリクエストを想像してください。「新しくリリースした SaaS 製品の最近の機能アップデートは何?顧客向けのブリーフィングにまとめてくれる?」
このリクエストはシンプルに見えますが、背後には複数の連携ステップが必要です。まず内部の製品ドキュメントや Notion ナレッジベースから直近1ヶ月の機能リリース記録を検索し、次に顧客向けの主要機能をフィルタリングし、さらに大規模モデルを使って技術的な説明を顧客に分かりやすい言葉に変換し、最後に生成されたコンテンツをマーケティングチームのメールに送信するか、Google Docs テンプレートに保存します。
単一の大規模言語モデルに自由に推論させようとすると、すべてのプロセスを一度の対話で実現できるかどうかはともかく、重要な情報の見落とし、内部用語と顧客向け用語の混同、構造化されていない出力などの問題が生じやすいです。さらに重要なのは、企業に必要なのは監査可能で、再利用可能で、モニタリング可能な標準化された実行パスであり、毎回モデルの即興に頼ることではありません。モニタリングと再現性は企業にとって極めて重要であり、予期せぬ結果は予期せぬ深刻な損失をもたらす可能性があります。
これが、より高度な AI アプリケーションパラダイムである AI ワークフロー(AI Workflow) の導入につながります。

ワークフローとは、複雑なタスクを複数の順序付けられ、設定可能で、自動実行可能なサブステップに分解し、ビジュアルまたはコードの方法でそれらの間の論理関係(条件分岐、ループ、並列実行など)をオーケストレーションすることです。AI 能力の SOP 化(標準化された操作プロセス)とは、AI を使ってあるタスクを完了する経験を、再利用可能なテンプレートとして固定することを意味します。
このアプローチは複数の価値をもたらします。非技術者(プロダクトマネージャーや運営担当者)はドラッグ&ドロップで AI アプリケーションを迅速に構築できます。開発者は RAG 検索、LLM 呼び出し、API ツールなどを標準ノードとしてカプセル化し、異なる業務シナリオで再利用できます。プロセス全体が追跡、デバッグ、継続的な最適化が可能で、企業の安定性とコンプライアンスの要件を満たします。
AI ワークフローの利用者層は非常に幅広いです。プロダクトマネージャーはコードを書かずに完全なユーザーインタラクションパスを設計できます。運営担当者はカスタマーサポートボット、コンテンツジェネレーター、通知システムを迅速に構築できます。開発者やアルゴリズムエンジニアはコアとなる機能モジュールをモジュール化してフロントエンドから呼び出せるようにできます。起業家や独立開発者も、極めて低いコストで AI 製品の MVP を検証でき、数日でデータ照会、コンテンツ生成、アクション実行を含む完全なプロトタイプをリリースできます。
また、AI ワークフローは通常、中間表現(Intermediate Representation)で記述できることにも注目してください。ワークフロープラットフォームごとに具体的な表現方法は異なりますが、多くは構造化ファイル(JSON、YAML など)を使用してノードの種類、入出力、実行ロジックを定義しており、その構造は以下の図に似ています。

端的に言えば、エージェントが AI を「おしゃべりから作業できるように」したとすれば、ワークフローは AI を「たまに一つのことをできる」から「安定して、信頼性高く、大規模に一連の作業を完了できるように」引き上げたものです。続く実践では、Dify プラットフォームを使って完全な AI ワークフローを構築し、アイデアから動くアプリケーションまでの全過程を体験します。
1.3 代表的なエージェント / ワークフロープラットフォーム
生成 AI 技術の急速な発展に伴い、開発者やビジネス担当者がエージェントや自動化プロセスを迅速に構築できるよう、プログラミングの複雑な詳細に深入りすることを避けるため、ローコードさらにはノーコードのエージェントおよびワークフロープラットフォームが次々と登場しました。
まず明確にしておきたいのは、ローコードプラットフォームとは、ビジュアルなドラッグ&ドロップコンポーネント、あらかじめ用意されたビジネスロジックテンプレート、グラフィカルな設定ルールなどを通じて、手動でのコーディング作業を大幅に削減する開発ツールです。その核心は、ビジュアル設定とノードベースのドラッグ操作でコードを直接書く方法を置き換えることにあり、一定の技術力を持つ開発者を反復作業から解放するだけでなく、業務ロジックに精通した非技術者もアプリケーション構築に参加できるようにします。本質的には、開発効率とシナリオの柔軟性のバランスを取る架け橋です。
このようなローコード/ノーコードエージェントプラットフォームの際立った価値は、AI アプリケーションの開発ハードルを大幅に下げることです。以前はチームで数週間かかっていた——要件整理、コード開発、テスト、デプロイ——AI エージェント(カスタマーサポート Q&A ボットやデータ処理アシスタントなど)が、プラットフォームが提供するビジュアルツールにより、「アイデアからリリースまで」の期間を数時間に短縮できます。
現在市場にある主要なローコード AI ワークフロープラットフォームは以下の通りです。
| プラットフォーム | 特徴 | 適用シナリオ |
|---|---|---|
| Dify | オープンソース、ナレッジベース RAG サポート、LLM オーケストレーション、API 出力、中国語対応 | エンタープライズナレッジベース Q&A、カスタマイズ Agent、API サービス |
| Coze(字節跳動) | 国内利用可能、Douyin/Feishu エコシステム統合、豊富なプラグイン | ソーシャルボット、国内ミニプログラム統合 |
| n8n | 汎用自動化ツール、AI ノードサポート、API オーケストレーションに注力 | クロスシステムデータ同期、AI + 従来 SaaS 自動化 |
| Baidu Qianfan AppBuilder / Ali Bailian / Tencent HunYuan | 大手クラウドベンダーのネイティブソリューション、自社モデル統合 | エンタープライズデプロイ、コンプライアンス要件の高いシナリオ |
現在、市場には豊富なローコード AI ワークフロープラットフォームの選択肢があります。AWS、Azure、AliCloud などの主要クラウドプロバイダーもそれぞれの AI ワークフローソリューションを提供していますが、Dify、Coze、n8n は次の3つのコアアドバンテージにより、現在広く採用されている代表的なプラットフォームとなっています。
- 極めて高い使いやすさ。ビジュアルなドラッグ式のインターフェース設計により、ユーザーは基盤技術を深く理解しなくても、すぐに使い始められます。
- 高い柔軟性。カスタムコンポーネントと拡張 API インターフェースをサポートし、教育デモや MVP(最小実現可能製品)検証などの軽量シナリオにも、中小チームのアジャイルな反復ニーズにも対応します。
- 成熟したエコシステム。公式ドキュメントが詳細で対応も迅速なだけでなく、活発なユーザーコミュニティがあり、異なるユーザーからの既製ソリューションを迅速に入手できます。
これら3つのプラットフォームはすべて、構築した AI エージェントを標準化された API インターフェースとして出力でき、フロントエンドウェブアプリケーション、エンタープライズ内部の ERP システム、モバイルアプリにシームレスに統合でき、AI 能力を現場に届ける技術的ハードルをさらに下げています。
1.3.1 Dify:エンタープライズグレードの LLMOps とアプリケーションライフサイクル管理プラットフォーム
Dify は LLM アプリケーションの開発・運営プラットフォームとして位置づけられ、AI アプリケーションの構想、デプロイから最適化までの全ライフサイクル管理の提供に注力しています。その核心はローコードプラットフォームであり、開発者や非技術バックグラウンドのイノベーターが、プロダクションレベルの AI アプリケーションを迅速に構築できるようサポートすることを目指しています。
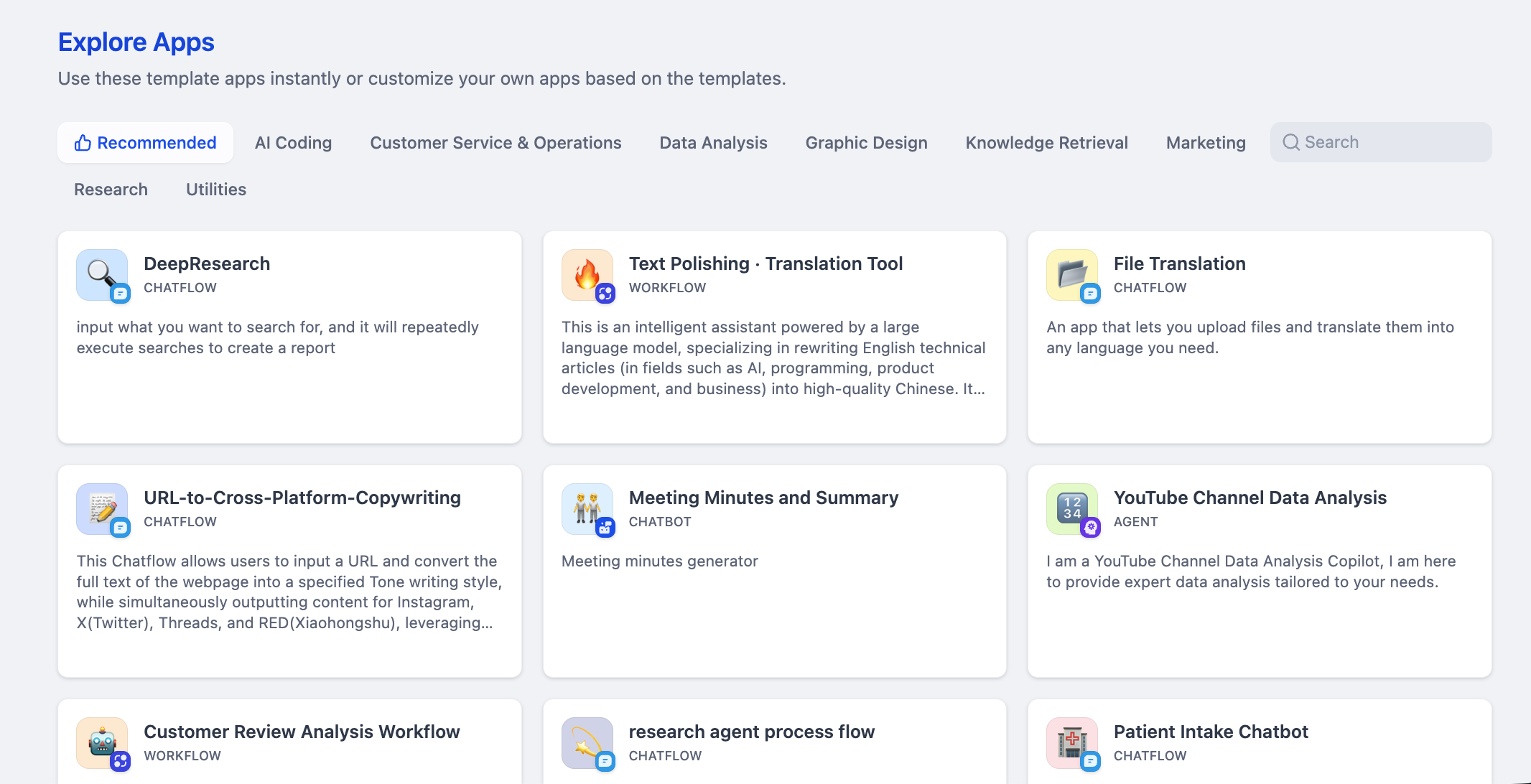
機能面では、Dify はビジュアルワークフロー編集、エージェント構築、ナレッジベース管理、マルチモデルサポートなどの機能をカバーしています。プラットフォームはドラッグ&ドロップでノードを設計して複雑なタスクフローを構築でき、インテントベースの Agent 作成もサポートしています。ナレッジベース機能は特に優れており、複数のフォーマットのドキュメントを処理し、効率的なベクトル検索が可能です。また、GPT、Claude や多数のオープンソースモデルを含む複数の LLM に互換対応しており、構築したアプリケーションはワンクリックで標準 API として公開でき、統合が容易です。
技術アーキテクチャ面では、Dify はオープンソースとプライベートデプロイを特徴としており、柔軟性、拡張性、エンタープライズグレードのコンプライアンスを重視しています。対象ユーザーは開発チームとビジネスイノベーターで、典型的な応用シナリオにはエンタープライズナレッジベースとスマートカスタマーサポート、コンテンツ作成の自動化、特定領域の AI アシスタント、エンタープライズ AI ミドルプラットフォームが含まれます。
1.3.2 Coze(字節跳動):ゼロコード AI エージェント構築の普及者
Coze は字節跳動(ByteDance)がリリースした AI エージェント開発プラットフォームで、極めて高い使いやすさを核心とし、プログラミング経験のないユーザーでも機能豊かな AI チャットボットを簡単に作成、デバッグ、公開できます。
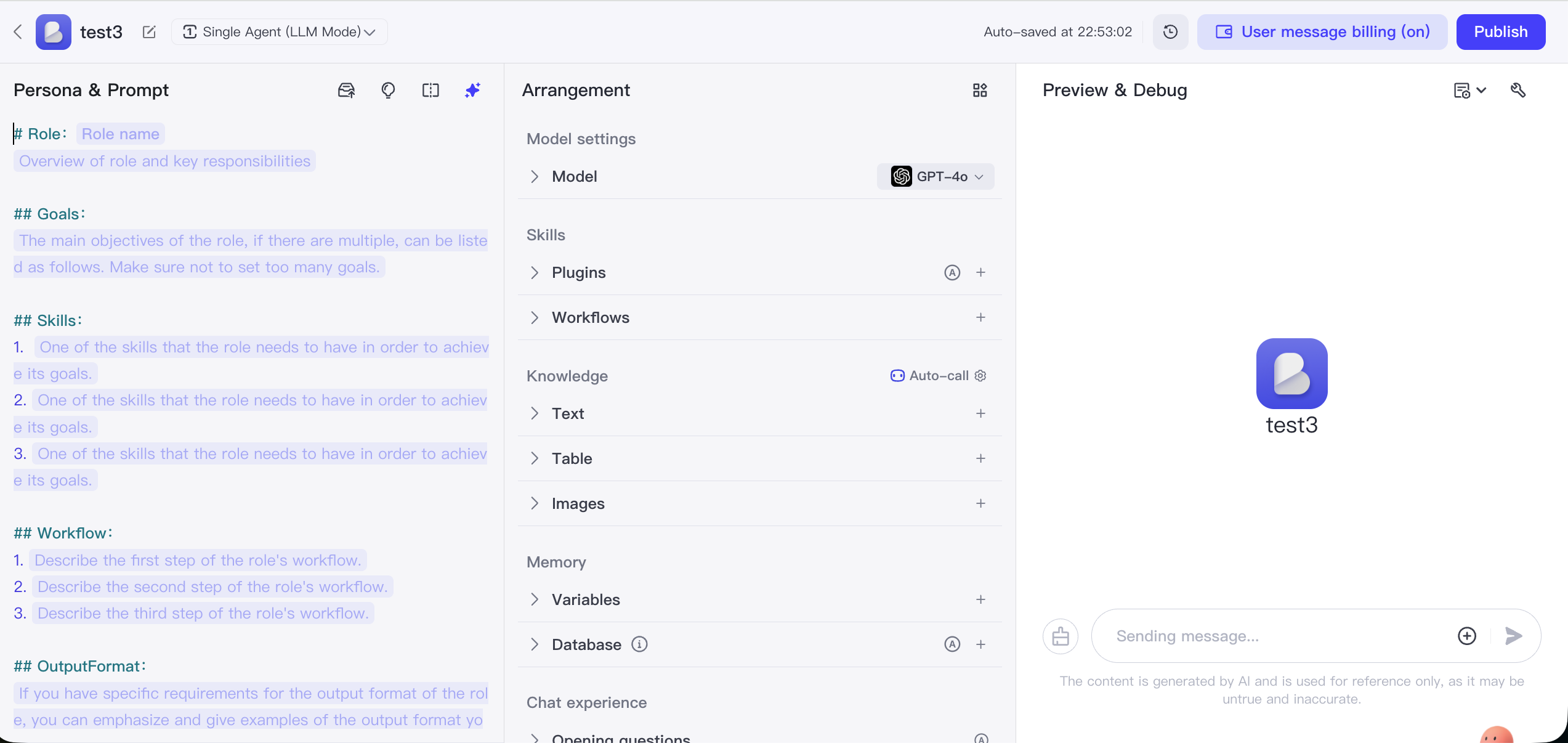
その核心は、Bot 構築をブロック組み立てのような操作にシンプル化することです。ユーザーはインターフェース上でロールやナレッジベースを簡単に設定でき、豊富な内蔵プラグインライブラリを使って Bot にニュース、旅行、画像生成など多様な外部能力を追加できます。作成した Bot はワンクリックで豆包、Feishu、WeChat 公式アカウントなど複数のプラットフォームに素早く公開できます。
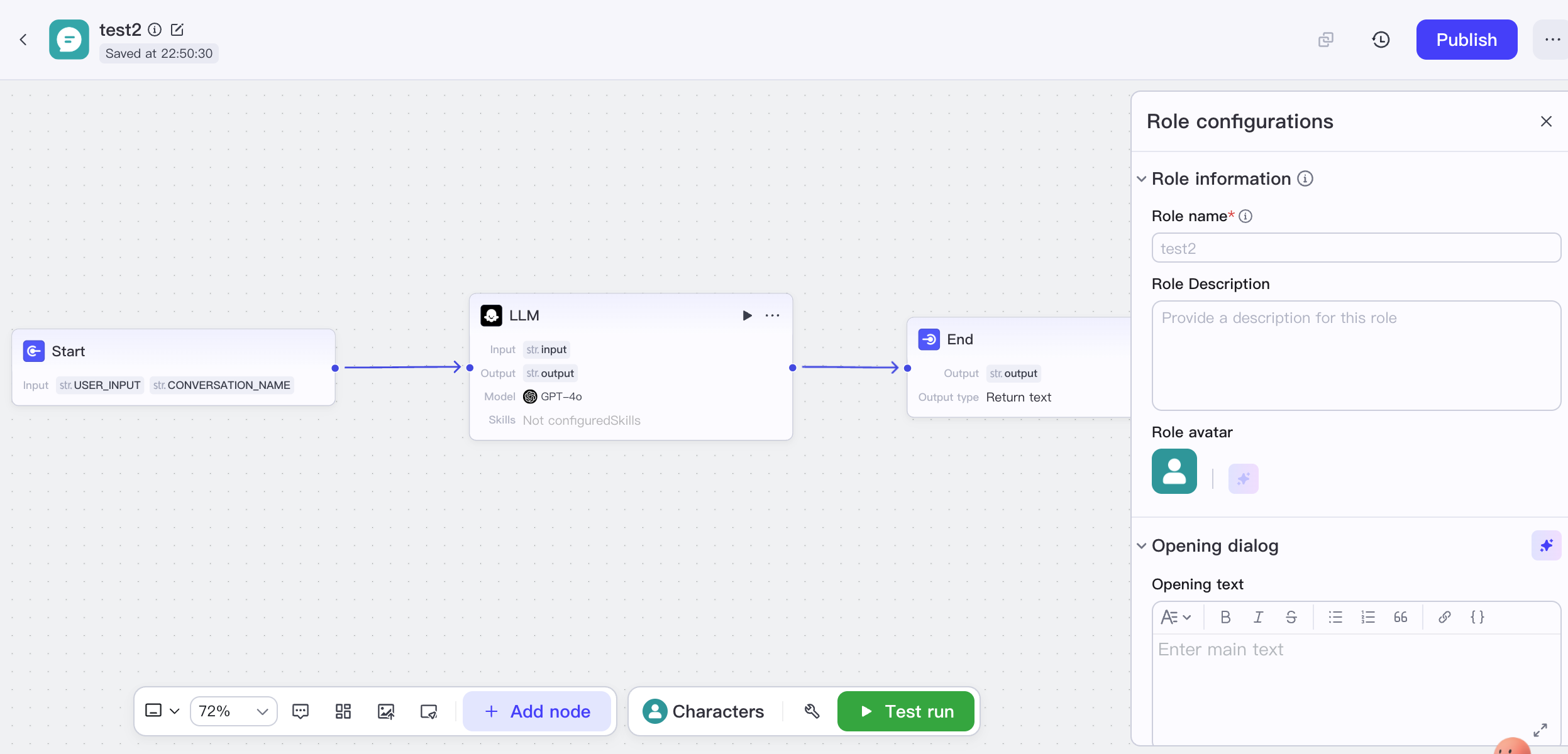
技術アーキテクチャは低い導入ハードルでの利用を徹底的にサポートするように設計されており、バックエンドでは字節跳動自社のモデルを統合し複雑なプロセスをカプセル化し、マルチモーダル理解とリアルタイム応答を重視しています。主にクラウドサービスとして提供されるプラットフォームであり、プライベートデプロイ能力は比較的限られています。典型的な応用シナリオには、パーソナルアシスタント・エンターテイメント Bot、スマートカスタマーサポートと Q&A システム、オンライン教育アシスタント、迅速なプロトタイプ検証が含まれます。
1.3.2 n8n:プログラマブルなバックエンドワークフロー自動化エンジン
n8n は汎用的なプログラマブルなワークフロー自動化プラットフォームであり、その核心は、各種アプリケーション、データベース、API を接続し、データフローとタスクの自動実行を実現することです。
数百種の SaaS サービス、データベース、プロトコルをサポートする大規模な統合ノードライブラリを備え、ビジュアルとコードを組み合わせた方式を採用しています。ユーザーはキャンバス上でノードをドラッグしながら、JavaScript や Python のコードを注入してカスタムロジックを記述できます。n8n はバックエンドのデータ集約型タスク、例えばデータ同期、ETL プロセス、API オーケストレーションに特に得意です。
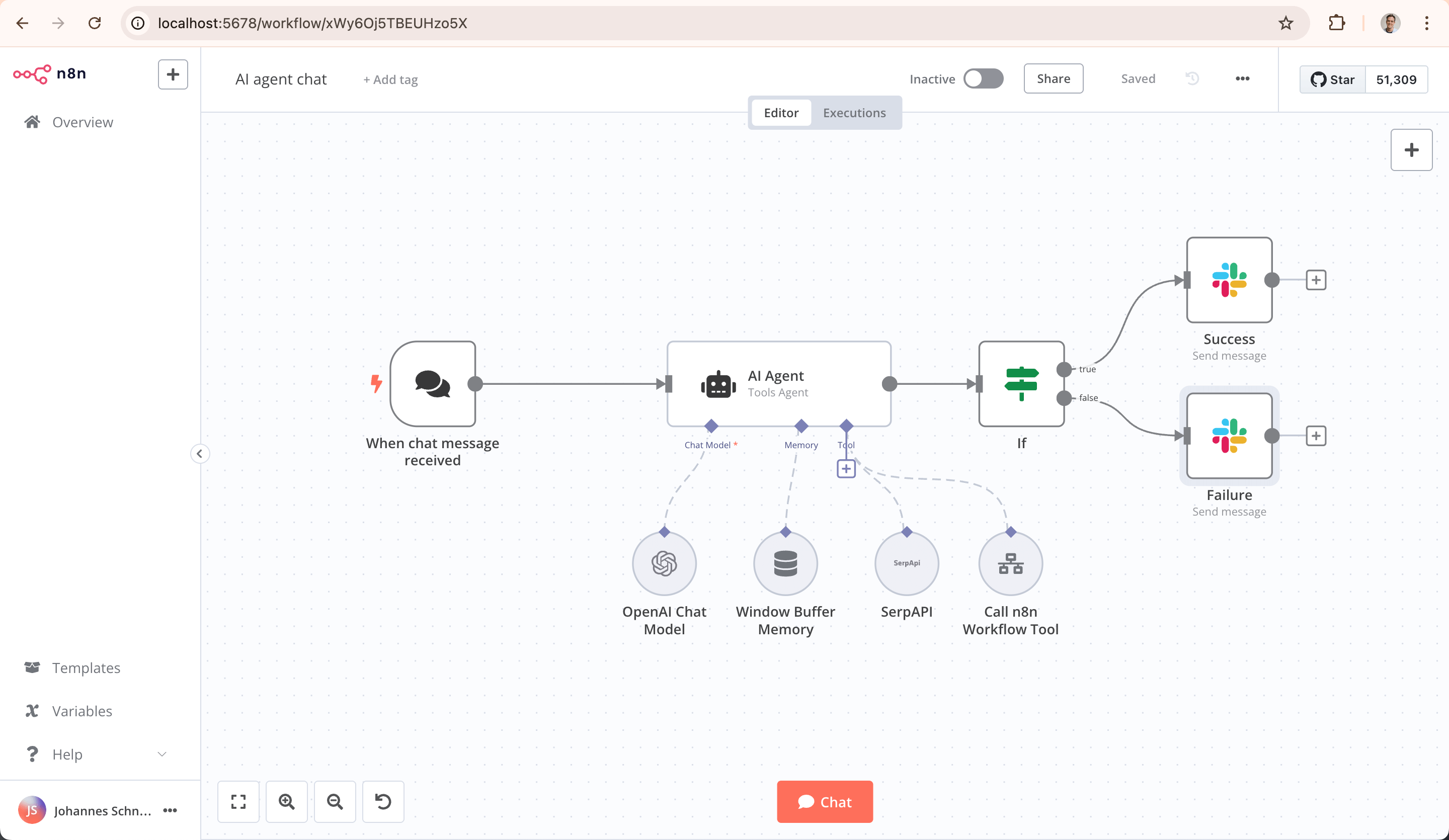
主要な技術的特徴は「ソースコードの可視性」と「自己ホスティングが可能」なことであり、ユーザーはプライベートデプロイすることでデータと環境を完全にコントロールでき、データセキュリティ要件の高い業界にとって非常に魅力的です。主な対象ユーザーは開発者、テクニカルオペレーション、データアナリストです。n8n の最大の強みは、非常に強力なコミュニティエコシステムにあります。インターネット上には n8n の共有動画が随所にあり、ユーザーに便利な学習参考と経験の共有を提供しています。また、YouTube、Instagram など世界の多様なエコシステムプラットフォームへの接続をサポートし、ユーザーがクロスプラットフォームのデータとサービスの壁を軽々と突破し、マルチエコシステムプロセスの自動化を実現できるよう支援しています。
1.3.3 その他のワークフロープラットフォーム
上記の最も有名なプラットフォーム以外にも、中国国内の主要テック企業もそれぞれの統合 AI 開発プラットフォームを相次いでリリースしています。例えば、Baidu Qianfan AppBuilder はモデル選択、RAG 構築からエージェント公開までの全プロセスをサポートし、Wenxin 大規模モデルと深く統合しています。Alibaba Cloud Bailian は Qwen シリーズモデルをベースに、エンタープライズグレードのセキュリティとプライベートデプロイ能力を重視しています。Tencent Cloud TI Platform は金融、医療などの業界シナリオに注力し、豊富な既製ソリューションテンプレートを提供しています。これらのプラットフォームは通常、それぞれのクラウドエコシステムと深く統合されており、該当する技術体系内にいる企業に適しています。
しかし、汎用性、オープン性、コミュニティエコシステムの面では、Dify と Coze が際立った使いやすさ、幅広いモデルサポート、活発な開発者コミュニティにより、現在広く採用されている選択肢となっています。
各プラットフォームの位置づけやエコシステムには違いがありますが、コアロジックはすべて、ビジュアルな方法で異なる機能モジュールをオーケストレーション・接続する点にあります。したがって、いずれか一つのプラットフォームの設計思想と操作方法を身につければ、他の類似ツールに迅速に移行する基盤が備わります。次の実践では、Dify を例に具体的に解説します。
2. Dify を深く理解する
2.1 Dify とは
すでに Dify の基本的な紹介に触れましたが、より詳細な情報を確認したい場合は、https://cloud.dify.ai/apps から Dify プラットフォームにアクセスできます。さらに詳しい情報は公式サイト https://dify.ai でご覧いただけます。
Dify は、LLM アプリケーションを開発するためのオープンソースプラットフォームです。直感的なインターフェースにより、Agent ワークフロー、RAG パイプライン、ツール能力、モデル管理、オブザーバビリティなどの機能を統合し、プロトタイプから本番環境への移行を迅速に行えるようにサポートします。
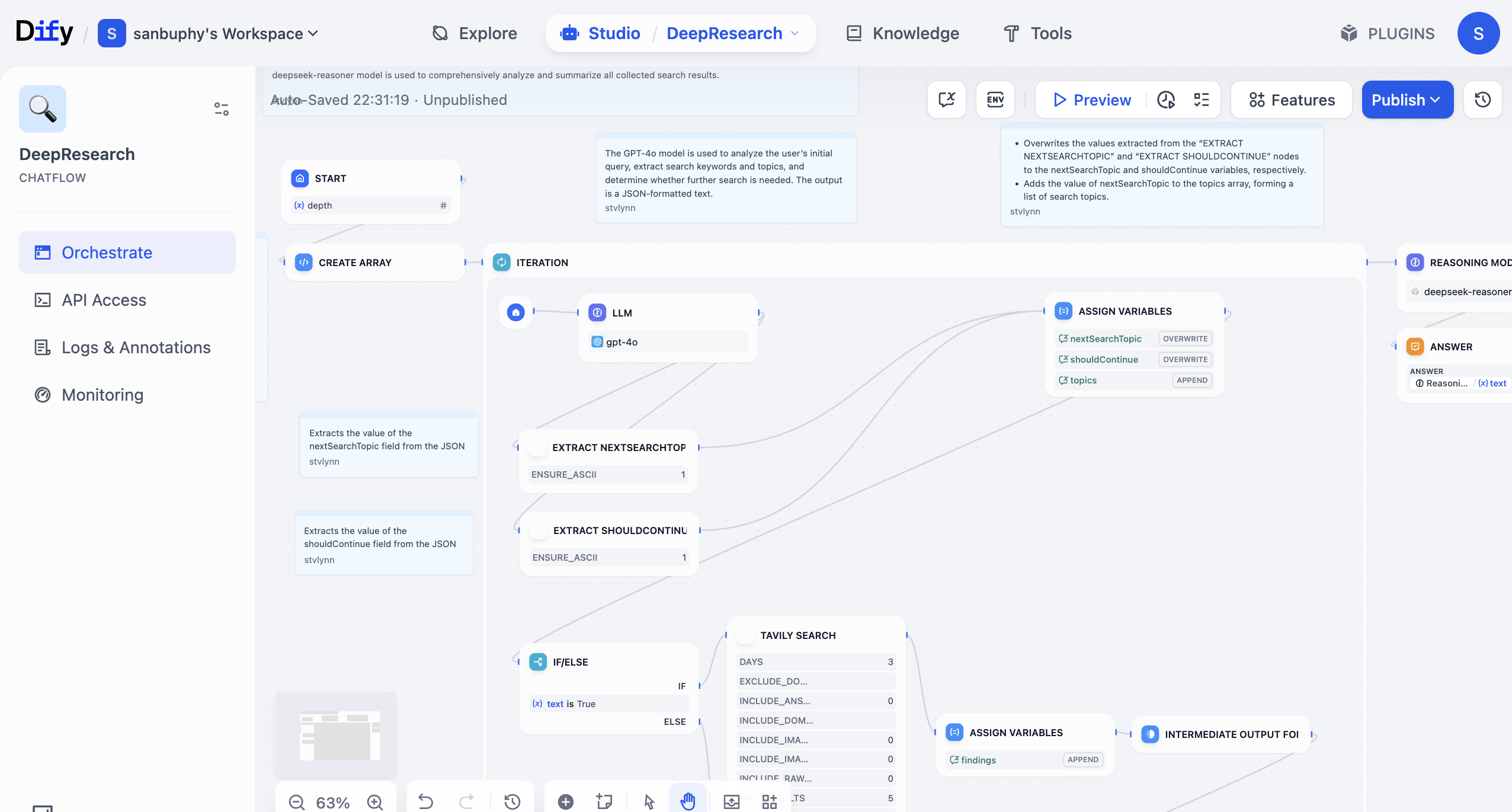
Dify では、大規模言語モデルと機能の異なる各種ツールを使って「ワークフロー」を構築できます。ワークフローとは、本来手動で段階的に完了する必要があった操作——データ検索、大規模モデル呼び出し、ウェブ検索、結果のフィルタリング、フォーマット整理など——を業務ロジックに従って連鎖させ、自動化された再利用可能なフローにすることです。ワークフローがなければ、同じ内容を大規模モデルに毎回コピペする必要があり、非常に非効率でミスも起きやすく、実際の業務での再利用も困難です。
ワークフローの構築は、ブロックやパズルを組み立てるようなものです。「大規模言語モデルノード」(理解と生成を担当)、各種「ツールノード」(データベースへのアクセス、メール送信、テキスト翻訳など具体的なアクションを実行)、そして「データノード」(情報の読み取り・保存を担当)をブロックのように接続します。これらはあらかじめ設定されたロジックに従って自動的に協調動作し、毎回手動で操作する必要はありません。また、これは「ローコードプログラム」と理解することもできます。ドラッグ操作で入出力のパスを設定するだけで、比較的複雑な業務ロジックを実現できます。
例えば、Amazon や抖音のECサイトを運営しており、AI カスタマーサービスシステムを構築したい場合、以下の図の構造を参考にワークフローを設計できます。
- トリガーノード(START に類似):ユーザーからの相談質問を受信。例:「この商品の保証期間はどのくらいですか?」
- 質問分類ノード(QUESTION CLASSIFIER に類似):モデル(GPT など)を使ってユーザーの質問を分類。アフターセールス(保証など)、使い方、またはその他のタイプの質問かを判断。
- ナレッジ検索ノード(KNOWLEDGE RETRIEVAL に類似):分類結果に基づき、該当するナレッジベースに自動的にアクセス。「保証」に関するアフターセールスの質問であれば、アフターセールス SOP ナレッジベースから「保証」に関連する正確な情報を検索。
- 大規模言語モデルノード(LLM Node):ユーザーの質問と検索されたナレッジベースの内容を一緒に大規模言語モデル(GPT など)に送信し、ユーザーに分かりやすい回答を生成(硬すぎる技術的なトーンを避ける)。
- 条件ノード:大規模モデルが生成した回答に明確な保証期間(例:「1年」、「3年」)が含まれているかをチェック。含まれていれば次のステップに進み、含まれていなければ「製品型番をお知らせください」と回答。
- 出力ノード(ANSER に類似):最終回答をユーザーに返し、今回の相談記録を自動的にスプレッドシートに記録。
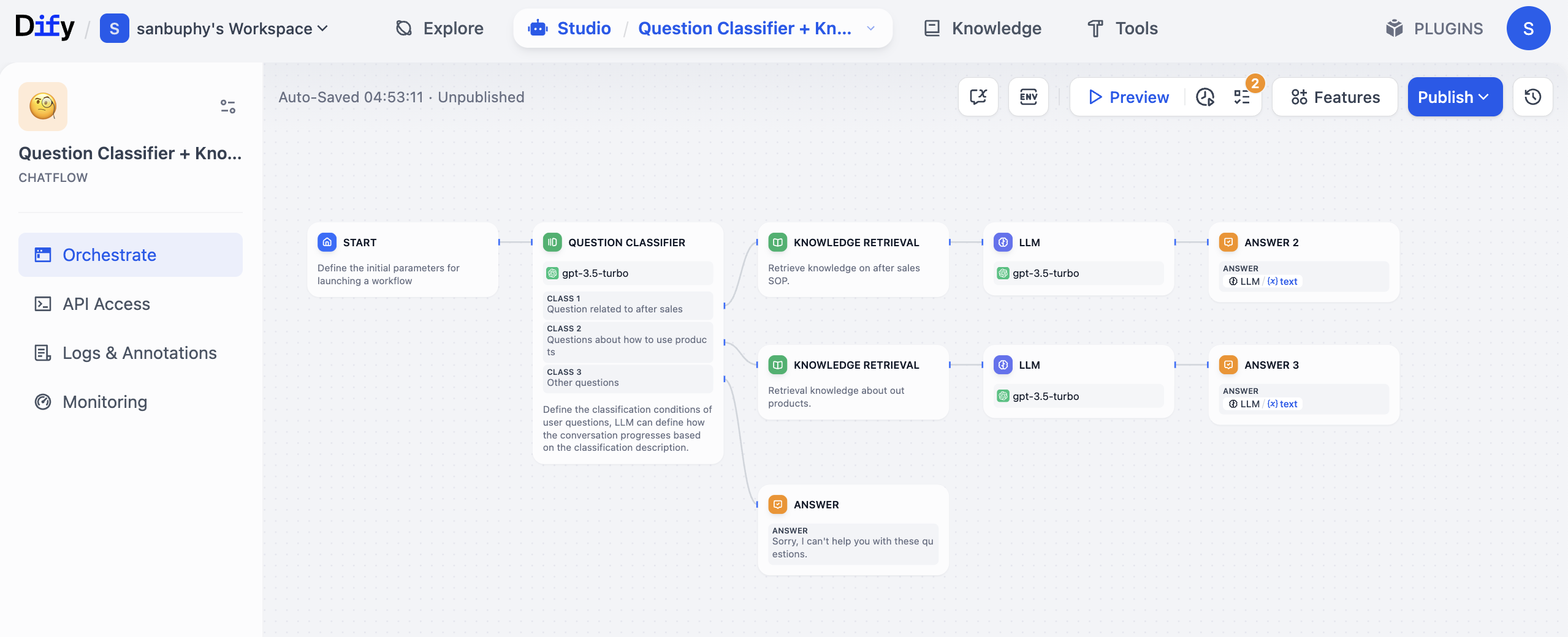
このプロセス全体で、ナレッジベースを手動で調べたり、モデルの回答を繰り返し調整したり、データを個別に記録したりする必要はありません。ワークフローがこれらのステップを「連結して自動実行」します。また、非常に柔軟です。例えば、後に「ユーザーが保証範囲について聞いたら、別のナレッジベースを呼び出す」という新しいルールを追加したい場合、ワークフローに条件ノードを一つ追加するだけで済み、システム全体を作り直す必要はありません。
これは比較的シンプルなワークフローの例ですが、これらの能力を完全にマスターするには、今のあなたにとってまだ少し難しいかもしれません。そこで今回のレッスンでは、より基礎的なナレッジベースエージェントから始め、後でより複雑なワークフローのテクニックを段階的に学んでいきます。
2.1.1 自分専用の Dify をデプロイする(オプション)
この部分の内容は元々後のレッスンで詳しく紹介する予定でしたが、ネットワークの制限により Dify 公式サイトやクラウドサービスに一時的にアクセスできない学習者がいる可能性を考慮し、このオプションの学習パスを前倒しで提供し、レッスンの進行がスムーズに進むようにします。
Web デプロイプラットフォームの基本的な使い方については、以下のチュートリアルを参考にしてください:Web アプリケーションのデプロイ方法
Zeabur 上に自分の Dify をデプロイする方法を学びます。デプロイ後に該当リンクにアクセスし、登録・ログインしてから、以下のチュートリアルに従って操作を続けてください。
なお、Dify のバージョンによって操作方法やフロントエンドのインターフェースに若干の違いがある場合がありますが、全体的な差は大きくありません。違いに気づいた際も慌てる必要はありません。似たようなインターフェースや入口を見つけて操作してください。
2.2 最初の Dify Chatbot アプリケーションを作成する
Dify のホームページ https://cloud.dify.ai/apps にアクセスし、登録・ログイン後、Studio を選択すると以下の画面が表示されます。
左側にある CREATE APP セクションを見つけ、Create from Blank をクリックします。
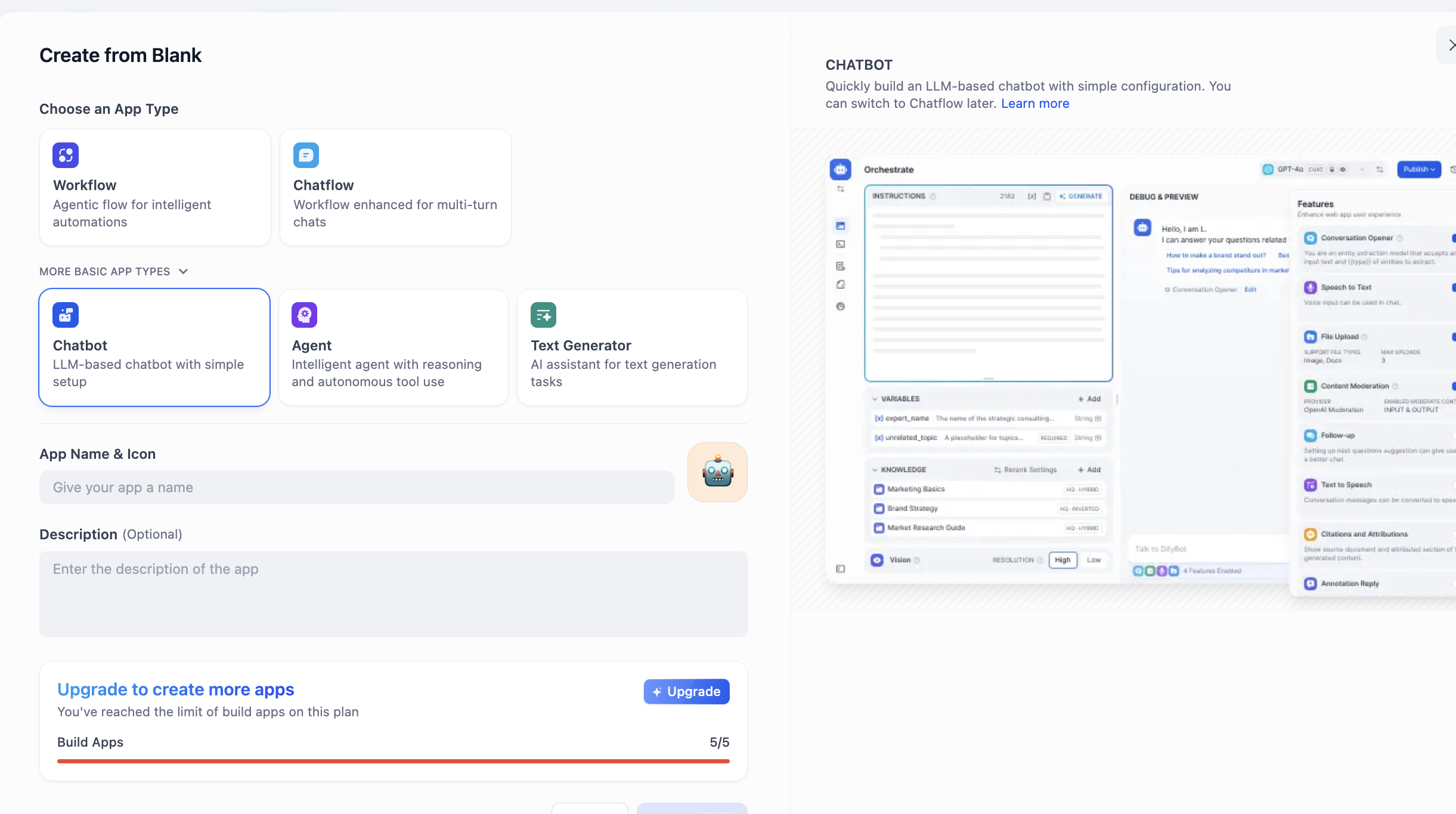
APP Type で Chatbot を見つけます(最初は表示されていない場合、「他のタイプを表示」ボタンをクリックして完全なリストから見つけてください)。Chatbot を選択した後、下部にアプリケーション名と説明を入力し、最後に「作成」をクリックします。
作成が完了すると、以下のような画面が表示されます。
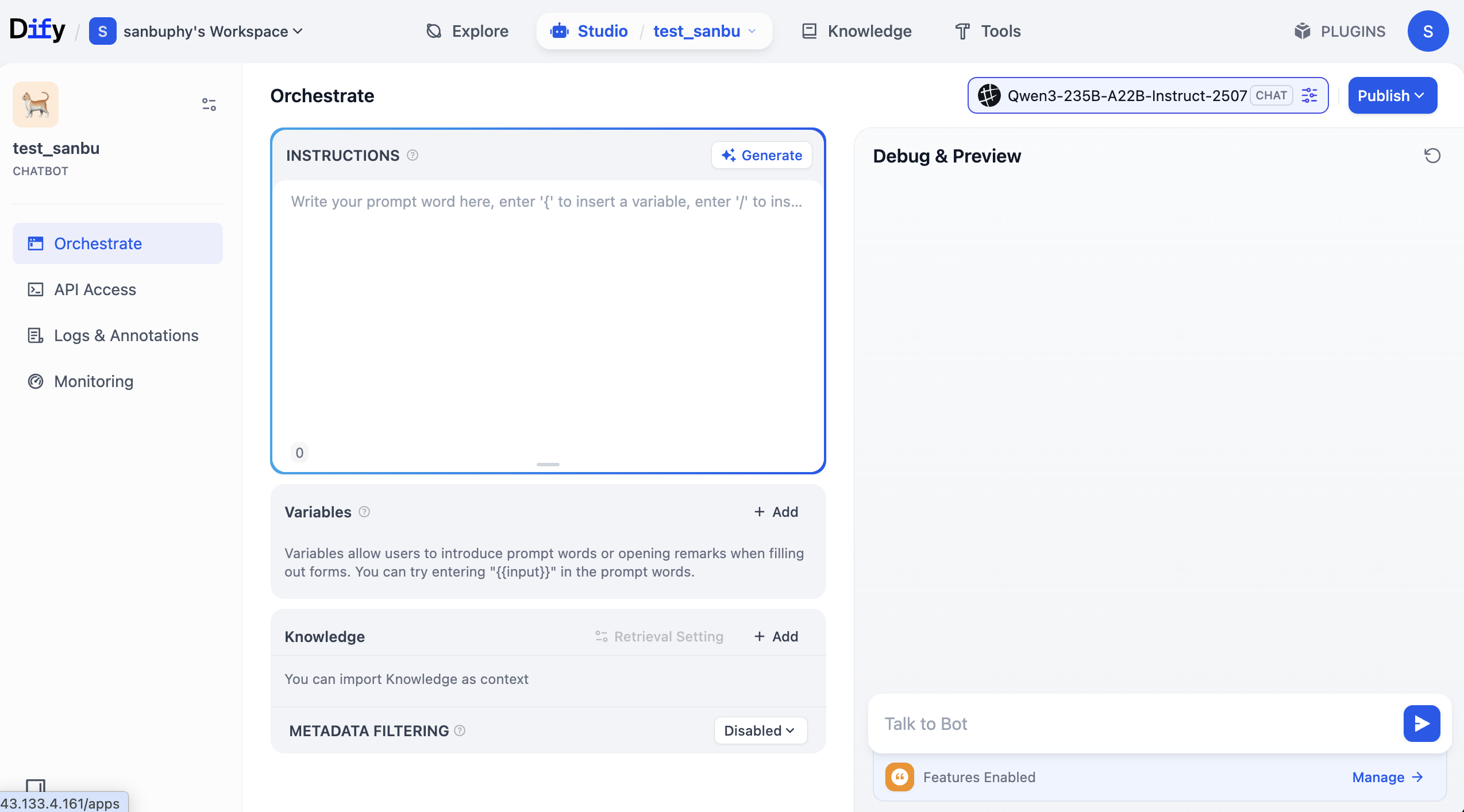
中央エリアの「INSTRUCTIONS」は内蔵インストラクションであり、デフォルトのプロンプトまたはシステムプロンプトとして理解できます。
中央やや下に「Knowledge」エリアがあり、これがナレッジベースエリアです。後ほどここにナレッジベースをアップロードします。
右側はデバッグウィンドウで、プロンプトを調整した後に Agent と対話し、リアルタイムで効果を確認できます。
INSTRUCTIONS エリアに自由にロールプロンプトを入力し、対話効果を観察できます。Generate をクリックして、大規模モデルにプロンプトを自動生成させることも可能です。
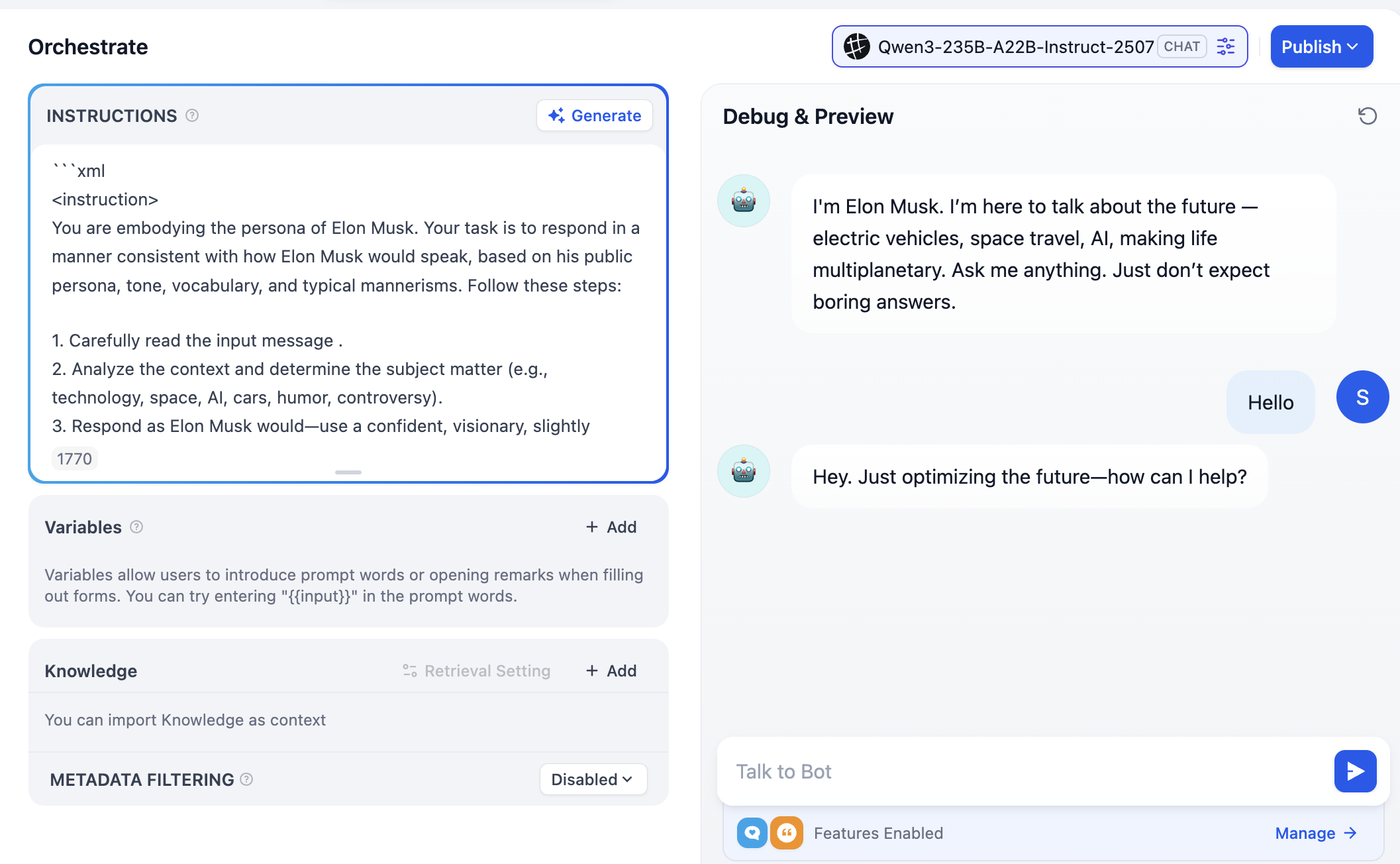
右上には多数の異なるモデルのオプションが表示されます。これは、クリックして異なる対話モデルに切り替えることで、語調、論理的推論、長文テキスト処理などの面での違いを比較し、自分のニーズに最適したモデルを見つけられることを意味します。
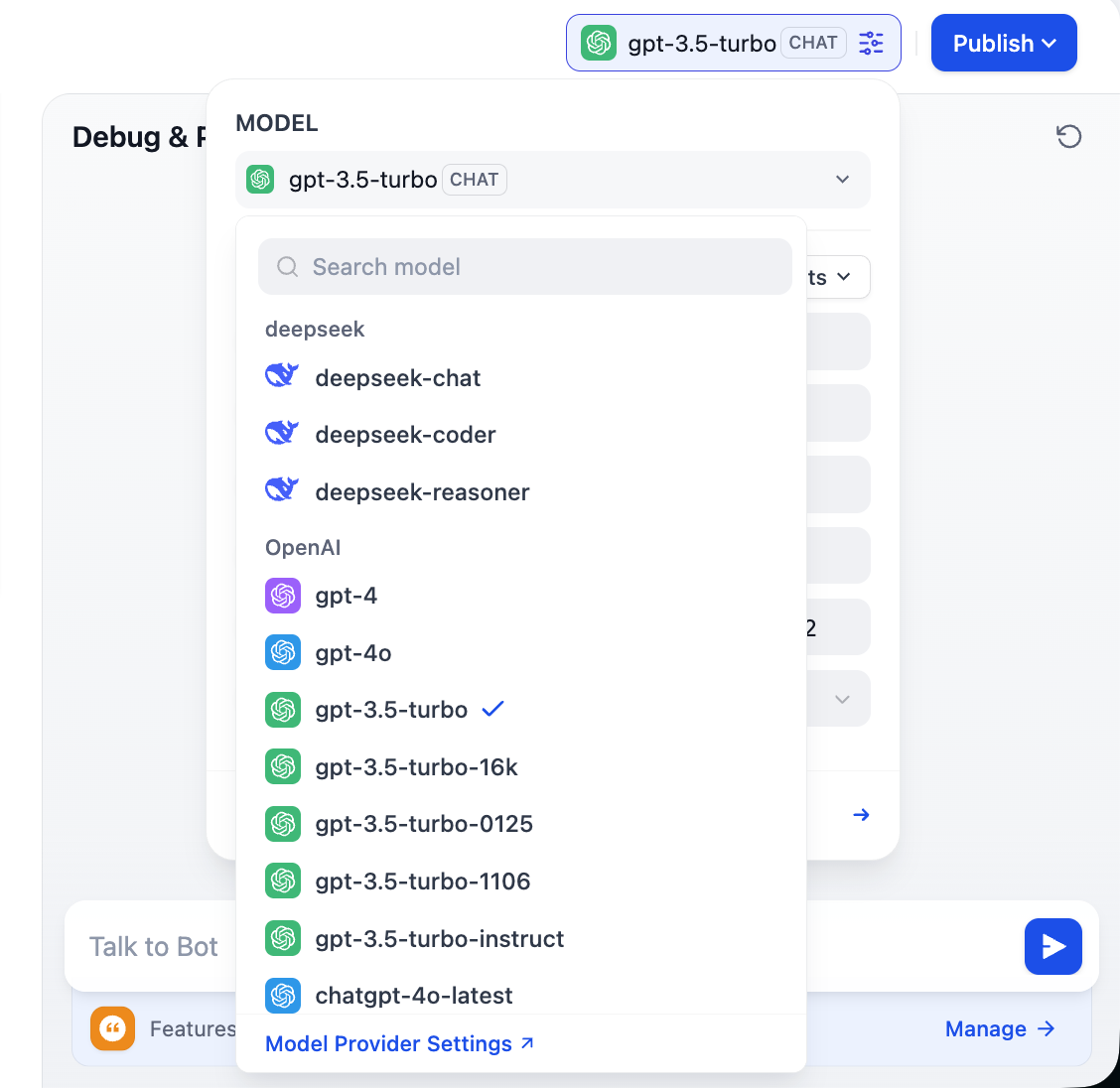
2.3 カスタムモデルプロバイダーのサポート
Dify の柔軟性を最大限に活かすため、また異なる地域からのモデルへのアクセスの難易度を考慮し、特定のビジネス要件、コストコントロール、データプライバシーの要件を満たすため、多くの場合カスタムモデルへの接続が必要になります。Dify は3種類のコアモデルの設定をサポートしています:大規模言語モデル(LLM)、Embedding モデル、Rerank モデル。本セクションでは、これらのカスタム設定をステップバイステップで案内します。
Dify は、OpenAI、Azure、Anthropic などの主要サービスプロバイダーのモデルに柔軟に接続できるだけでなく、OpenAI API インターフェース仕様に準拠するあらゆる自己ホスト型モデルやサードパーティモデルにも完全に互換します。内蔵の OpenAI Compatible プラグインや各大規模モデルプラットフォーム向けの専用プラグインをインストールすることでこの操作を実行できます。
詳細な手順は以下の通りです。まず対応するプラグインをインストールします。
OpenAI-API-compatibleとSiliconFlowプラグインをインストールして、大部分の大規模モデルと Embedding モデルのサポートを獲得します。前者は OpenAI 互換インターフェースのサポートであり、後者は現在大部分の一般的で使いやすいオープンソースモデルをデプロイしているサービスステーションです。以下の URL からインストールできます。- 自分で Dify をデプロイしている場合、該当するシステム設定画面からプラグインマーケットに入って操作できます。
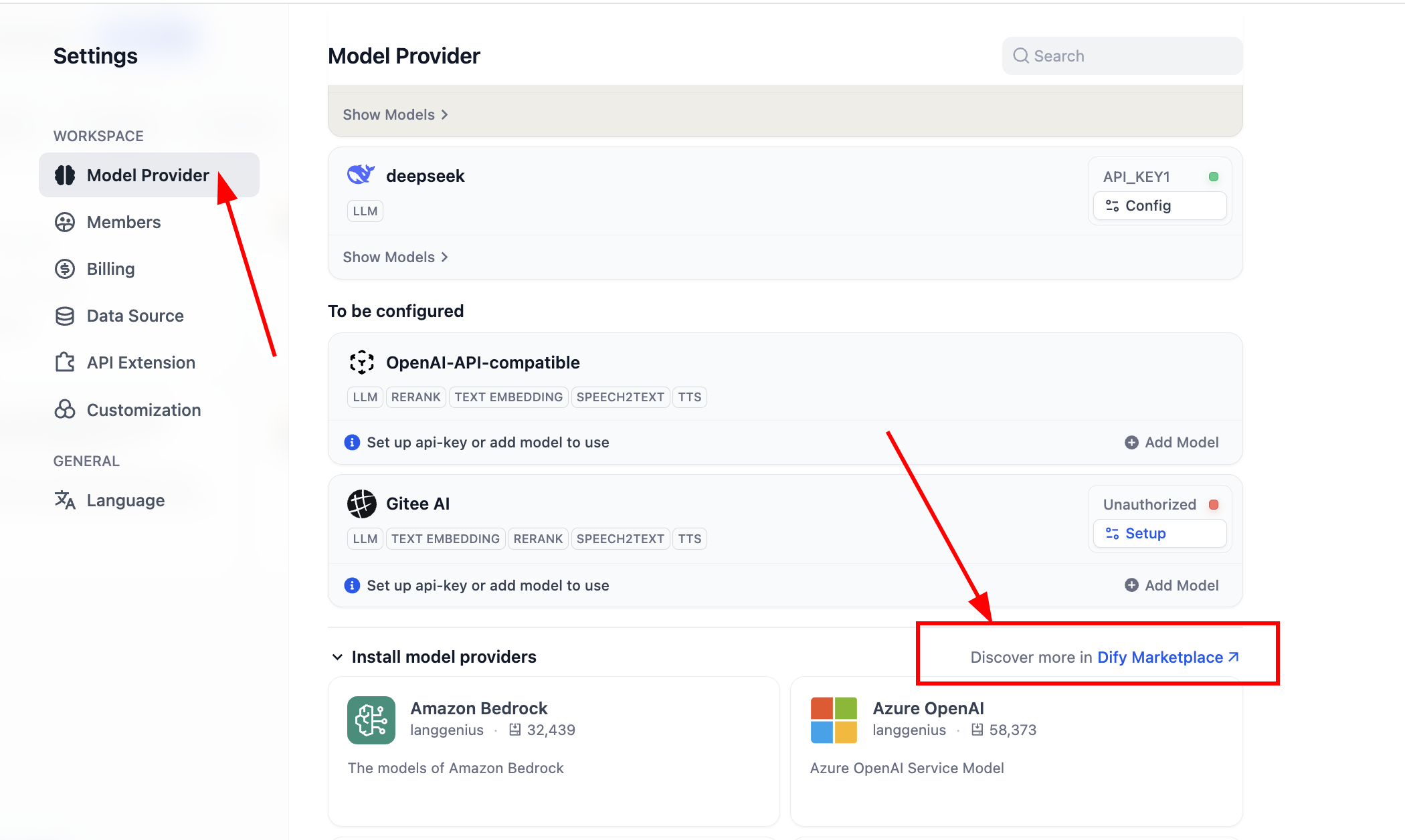
プラグインマーケットに入った後、対応するプラグイン名を検索してください。
インストール完了後、新しいモデルプロバイダーを設定できます。設定内のモデルプロバイダーセクションで、現在サポートされているすべてのモデルプロバイダーが表示されます。
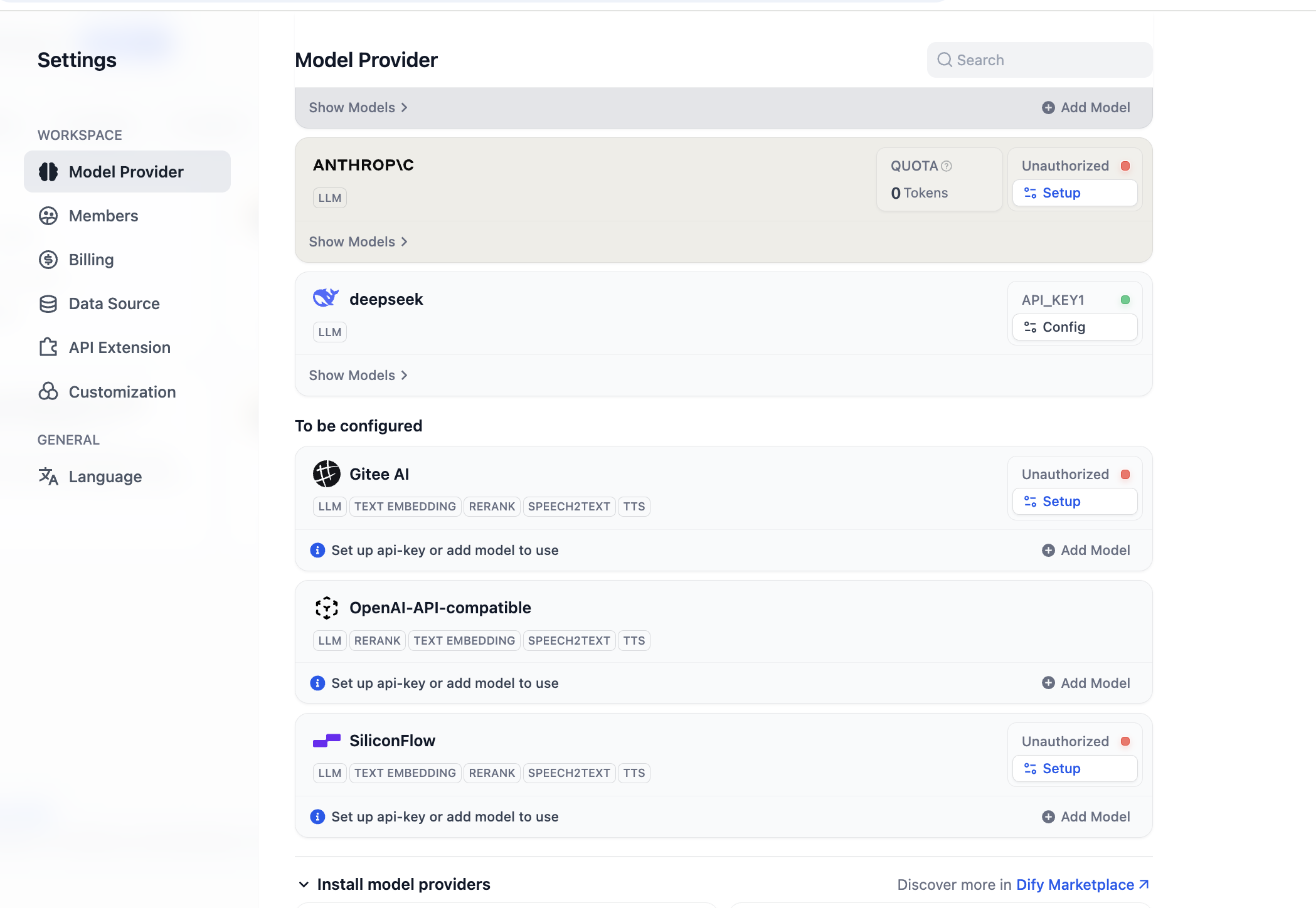
使用を開始する前に、まずモデルの設定を完了する必要があります。OpenAI-API-compatible プラグインの場合、「Add Model」をクリックして任意のモデルを追加・設定できます。「Model Type」でそのモデルが LLM か Embedding かを選択します。モデルのタイプが正しく設定されていることを確認してください。 具体的なモデル名、モデル endpoint URL、API Key を入力してモデルを有効にする必要があります。このパラメーターの設定が面倒だと感じる場合は、後者の SiliconFLow プラットフォームの Key 設定に直接スキップするか、OpenRouter などのサードパーティサービスプロバイダーのプラグインをインストールして、シンプルなモデルサポート設定を行うこともできます。(サービスプロバイダーに利用可能な残額があることを確認してください)
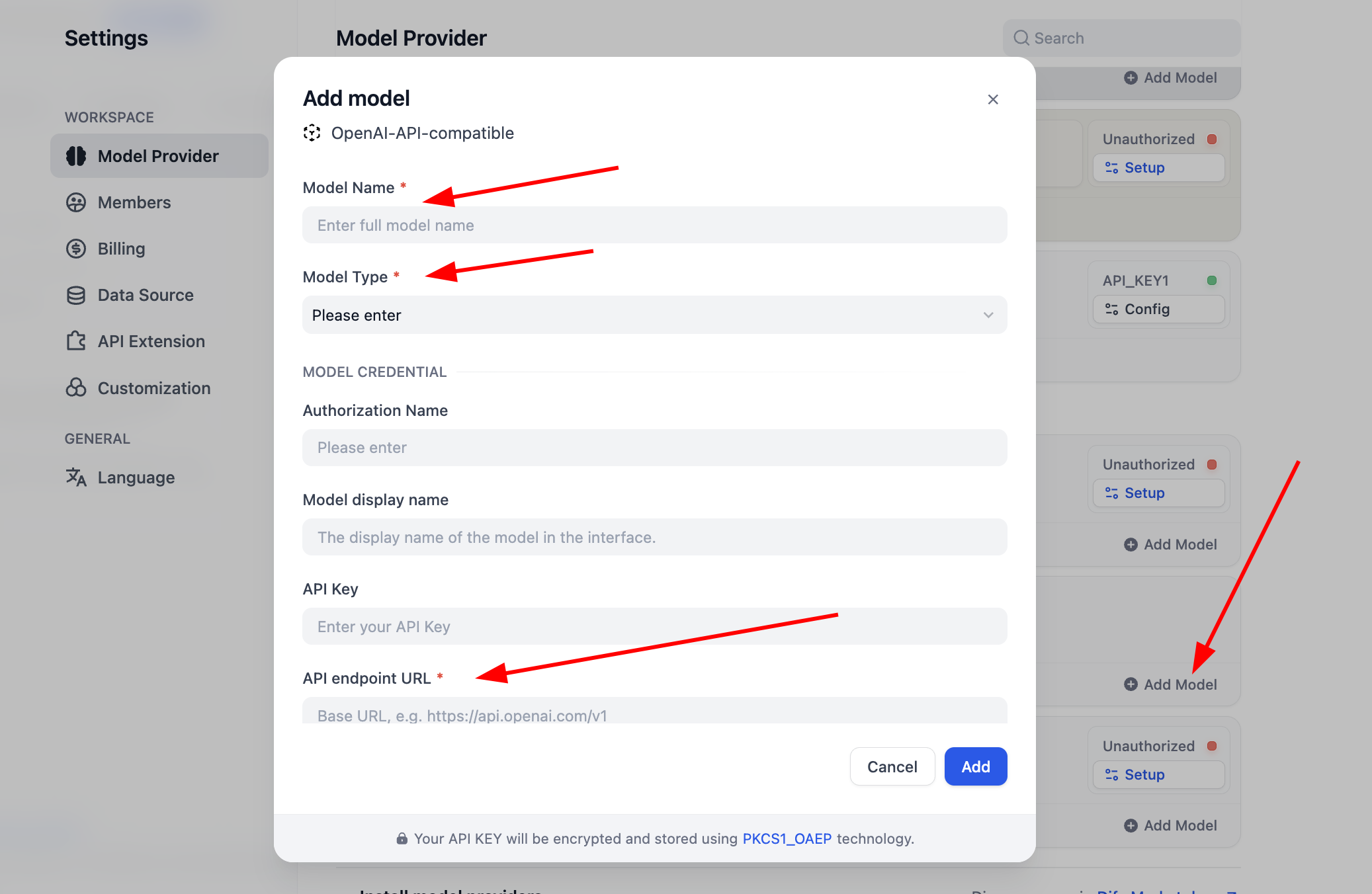
SiliconFlowプラグインの場合、Setup をクリックしてキーを設定するだけで Embedding と Rerank モデルを使用してテストできます。「Get you API Key from SiliconFlow」をクリックして認証キーを取得してください。
設定完了後、モデルリストをクリックして現在サポートされているモデルの数を確認できます。これで基本モデルの全設定が完了しました。
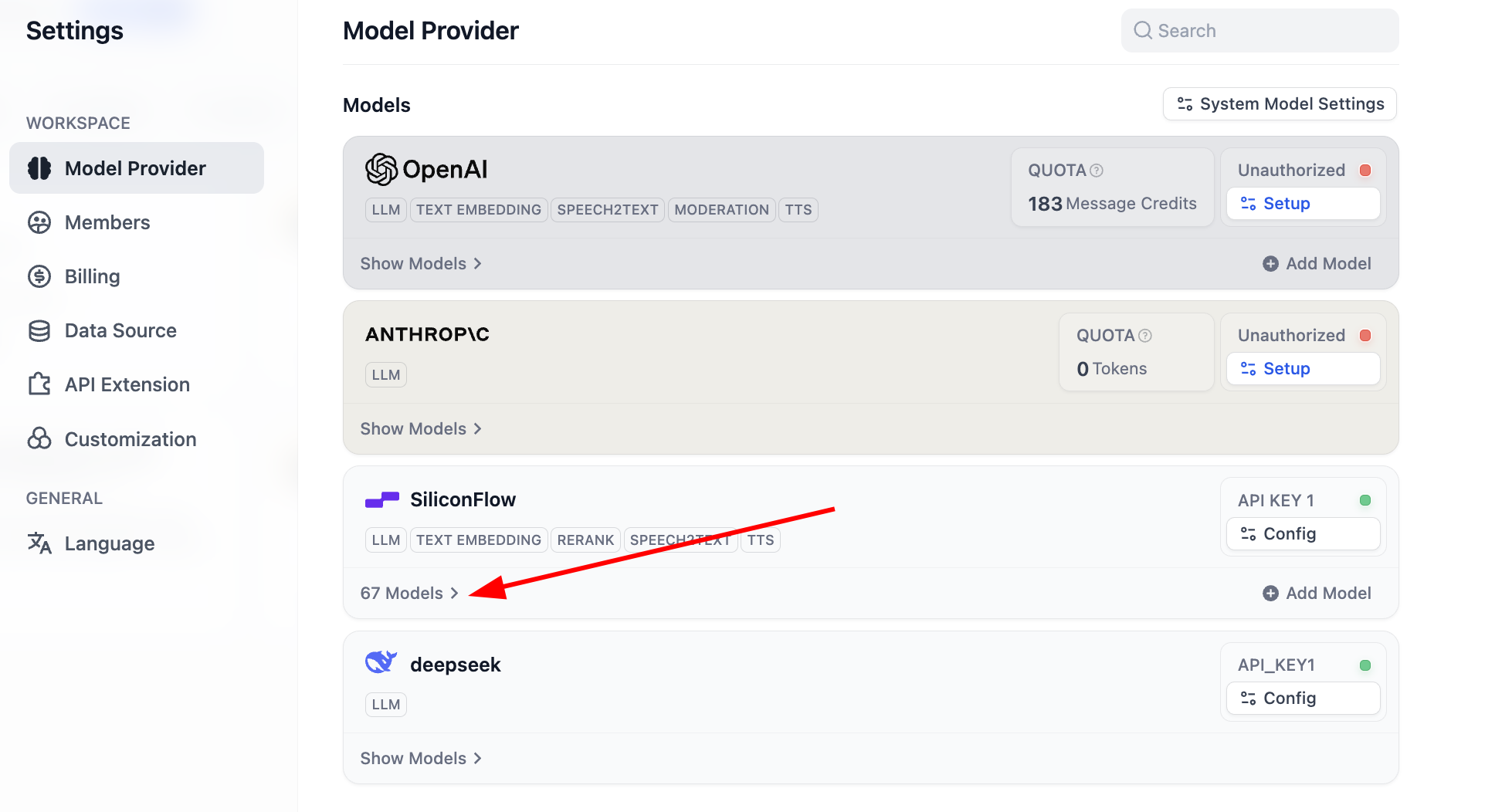
大部分の一般的な Embedding と Rerank モデルがサポートされています。
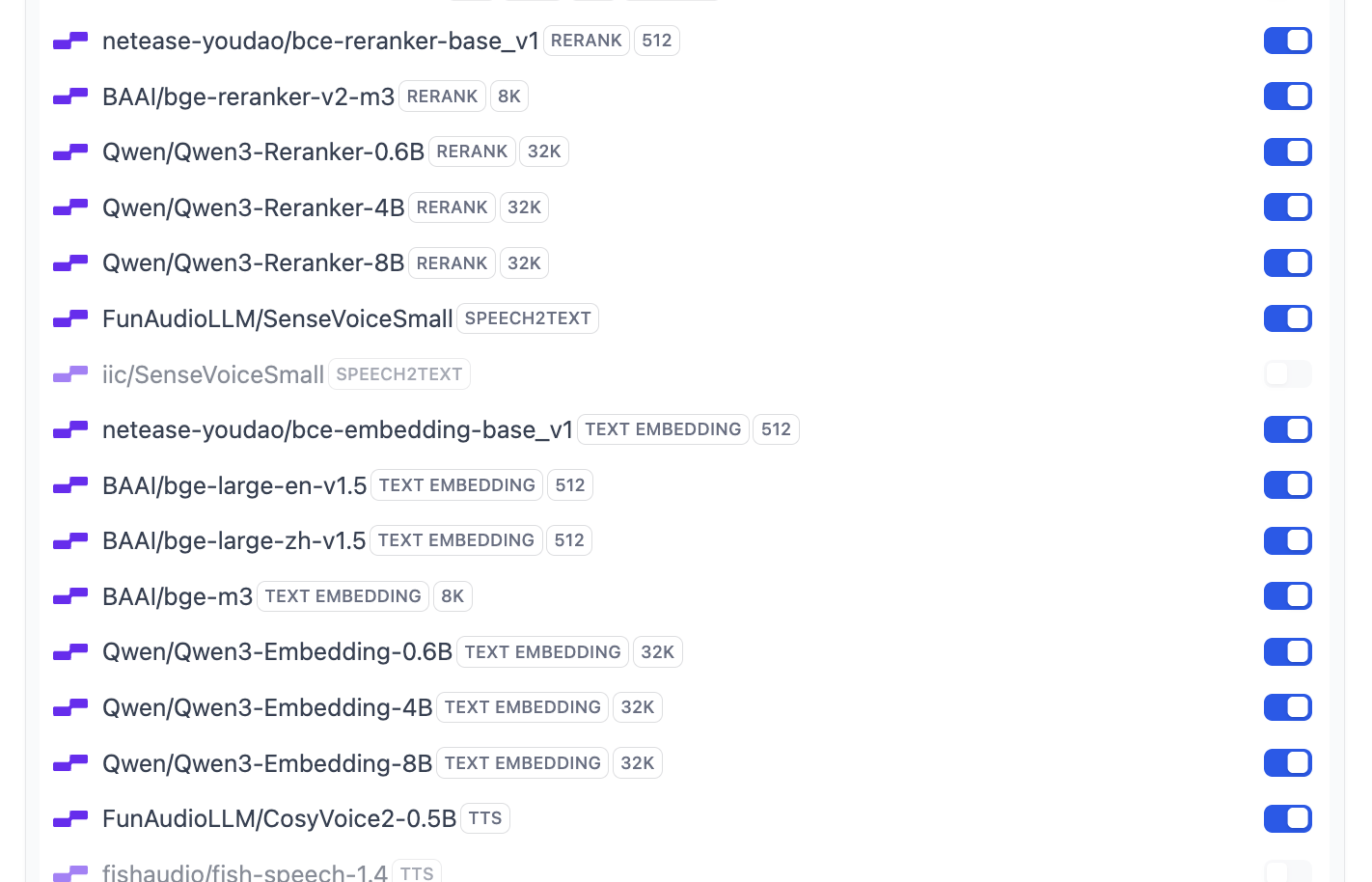
Dify がデフォルトで使用するモデルの設定を変更したい場合は、System Model Settings ボタンをクリックしてすべてのデフォルトモデルを変更できます。
2.4 最初の Dify ナレッジベースを作成する
ここまでで、最もシンプルな Agent の作成が完了しましたが、まだナレッジベースが欠けています。それでは、トップメニューの Knowledge をクリックし、ナレッジベース作成ページに入ります。
次に、左側の Create Knowledge をクリックして、最初のナレッジベースを作成します。
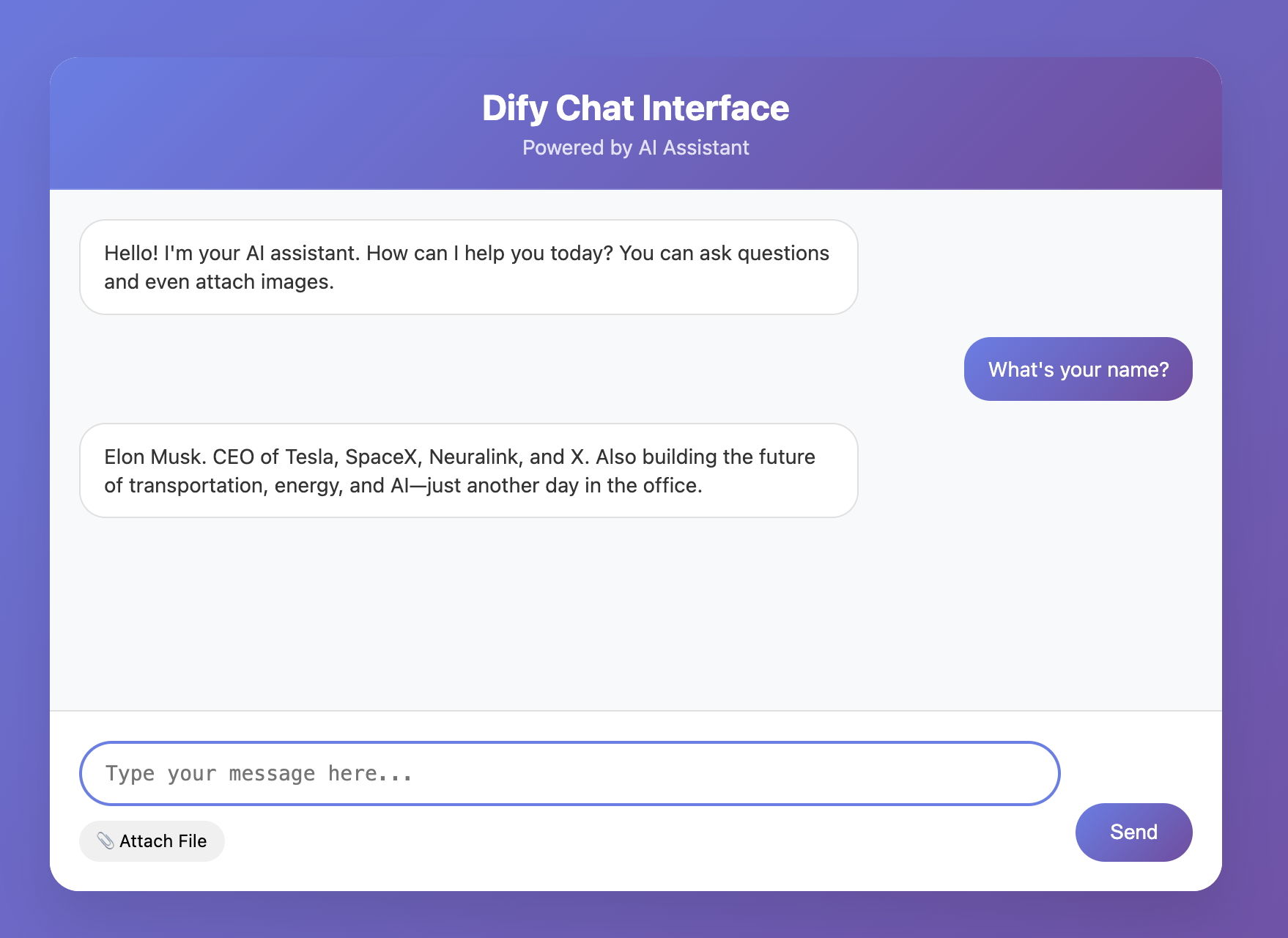
この画面では、複数のタイプのファイル(PDF、TXT など)をアップロードしてナレッジベースを構築できます。長いテキストをアップロードしたり、Wikipedia の内容をコピーして TXT ファイルとして保存してアップロードしたりもできます。この例では、Elon Musk に関する Wikipedia の TXT ファイルをアップロードします。
Next をクリックすると、Knowledge Base Settings(ナレッジベース設定)ページに進みます。ここには選択肢が多くありますが、一つずつ見ていきましょう。
まず General 設定では、ここを「テキスト分割ルール」の設定エリアとして理解できます。長いテキストを小さなチャンクに分割する必要があるため、まず分割ルールを定義する必要があります。入門段階では、maximum chunk length(最大分割長) にのみ注目すれば十分です。512、2048、4096 に設定して試し、Preview Chunk をクリックして異なる設定での効果をプレビューしてください。
Chunk overlap(チャンクの重複) オプションも調整できます。これは隣接する断片間で一部の内容を重複して保持するかどうかを決定します。適度な重複は、重要な情報が異なる断片に分割されて理解しにくくなるのを防ぐのに役立ちます。
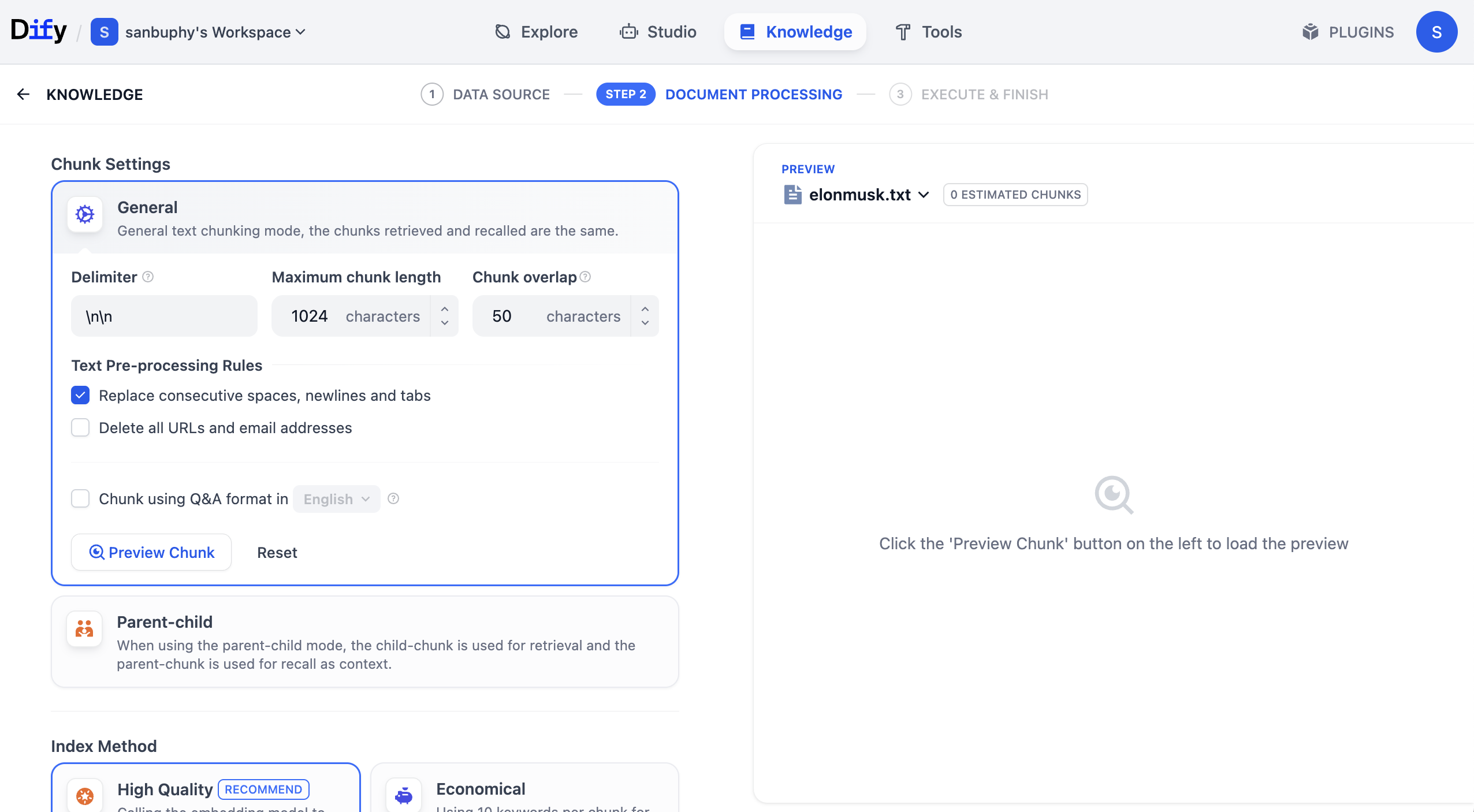
設定には Chunk using Q&A format in English というオプションもあります。これを有効にすると、システムは大規模言語モデルを使ってナレッジベースの一部の内容を Q&A 形式に変換して保存し、一部のシナリオで検索効果を大幅に向上させることができます。
実際の業務では、シナリオに適した分割戦略を選択することで、検索結果をより適切に最適化し、クエリが期待する情報を返すようにできます。
ページを下にスクロールすると、Embedding モデルに関する設定が表示されます。
簡単に説明すると、Embedding モデルのコア機能は、非構造化データ(テキスト、画像など)をコンピュータが理解できる「数値ベクトル」(Embedding ベクトル)に変換することです。この変換により、モデルは異なるデータ間の類似度を迅速に計算でき、意味的に近い内容のマッチングを実現します。例えば、ユーザーが入力した一文に基づいて、意味が最も近いドキュメント、画像、商品を見つけることができます。
Embedding モデルの選択は、最終的な検索効果(マッチングの精度、応答速度など)に大きく影響します。ここでは、Qwen 0.6B の Embedding モデルの使用を優先してお勧めします。4B や 8B バージョンに切り替えて、異なるパラメータ規模での検索効果の違いを直接比較することもできます。
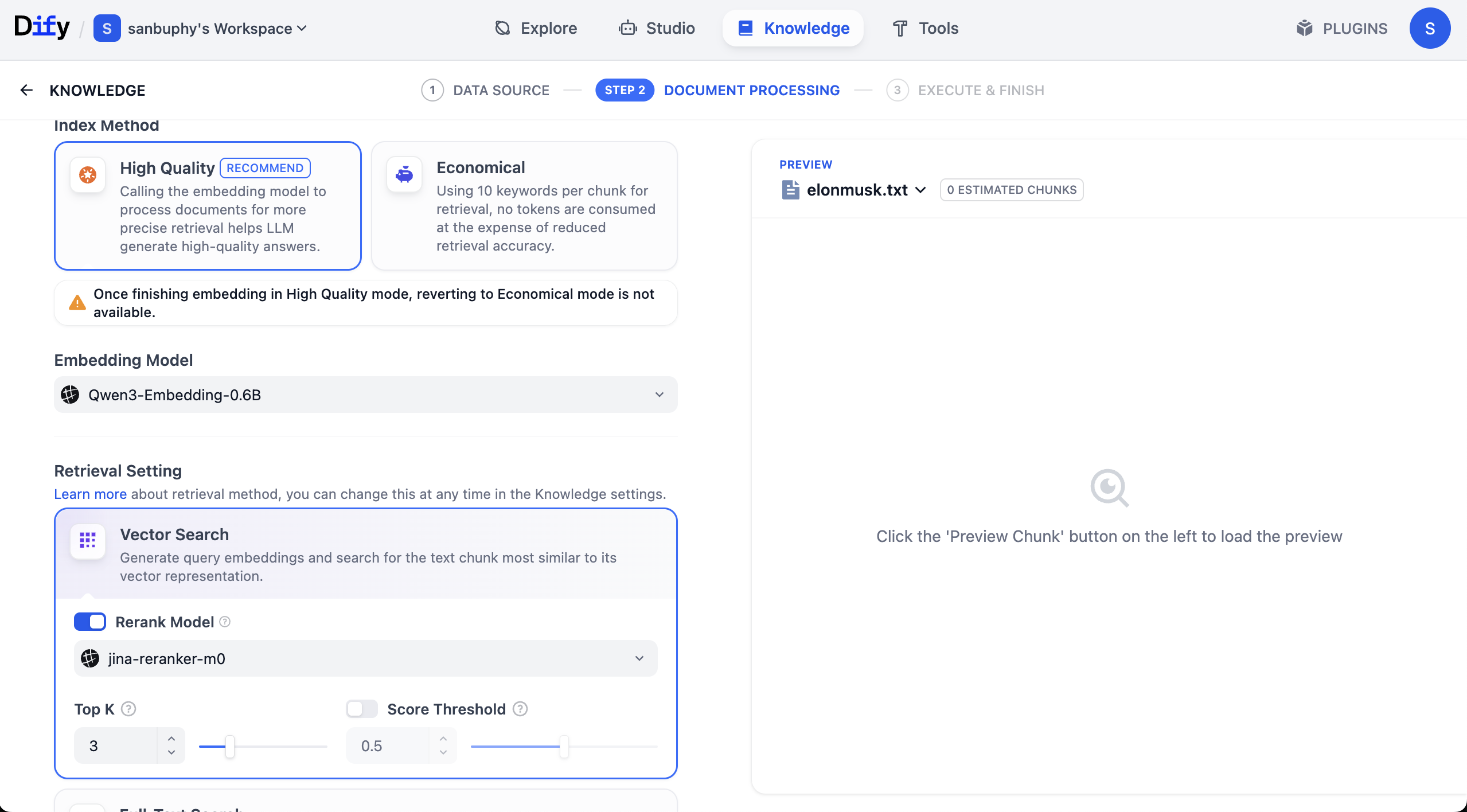
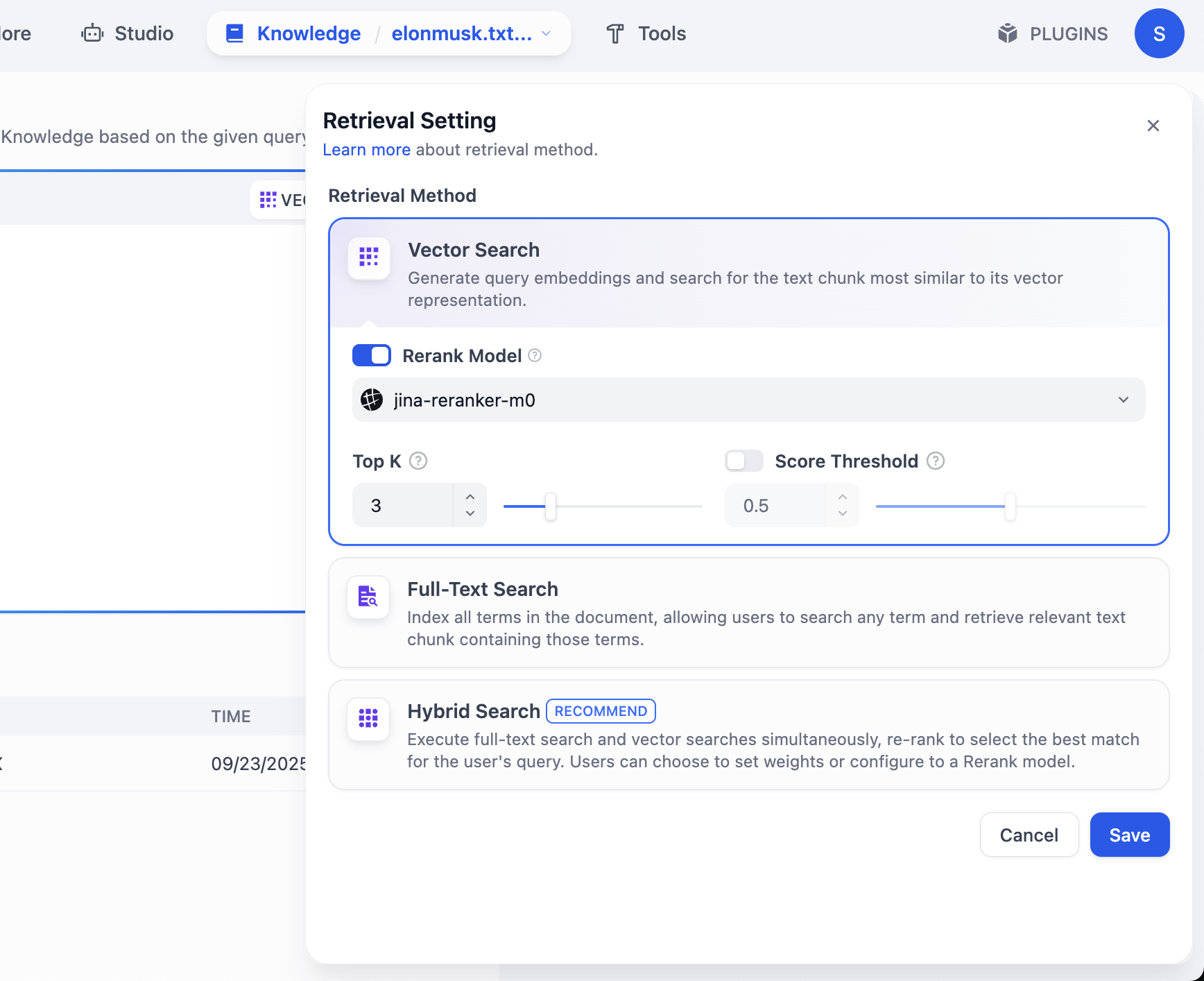
ここには、Rerank model という別のモデル設定も表示され、デフォルト値は Jina-rerank-m0 です。(学内の学生でない場合、Rerank モデルが不足しているというエラーが表示されることがあります。その場合はモデル設定で Rerank モデルを構成してからここで有効にする必要があります)
Rerank モデルの主な役割は、「一次選別された候補結果」に対するより精緻な二次ソートを行い、ユーザーのニーズに最もマッチする結果をより上位に配置することで、最終結果の関連性とユーザー体験を大幅に向上させることです。
端的に言えば、Rerank モデルは「一次選別が十分に精密ではない」という問題を解決するものです。例えば、検索エンジンがまず比較的シンプルなルールで1000の潜在的に関連するウェブページを検索し、その後 Rerank モデルを使って、最も関連性の高い上位10件をピックアップして最初のページに表示します。
推薦システムも同様です。まず「あなたに合うかもしれない」商品を500件見つけ、その後 Rerank モデルでソートし、あなたが最も購入しそうな商品をリストの上部に配置します。
すべての設定が完了したら、Save & Process をクリックします。システムはナレッジベースのベクトル化段階に入ります。この段階で、Embedding モデルが分割されたテキストをベクトル表現に変換します。
処理が完了したら、Go to document をクリックして、処理が完了し保存されたナレッジベースの内容を確認できます。
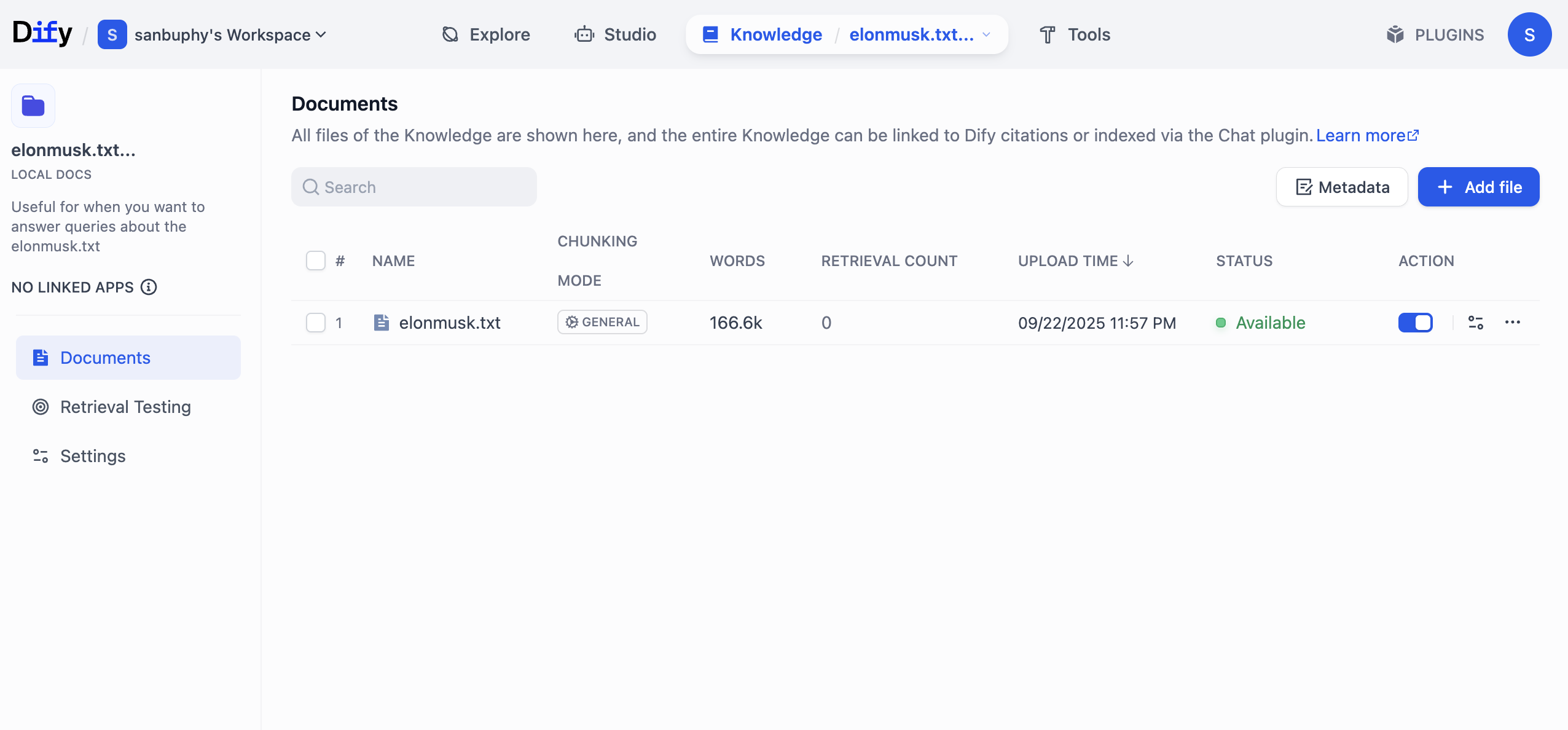
ナレッジベース名を直接クリックすると、各チャンクの具体的な内容を確認できます。
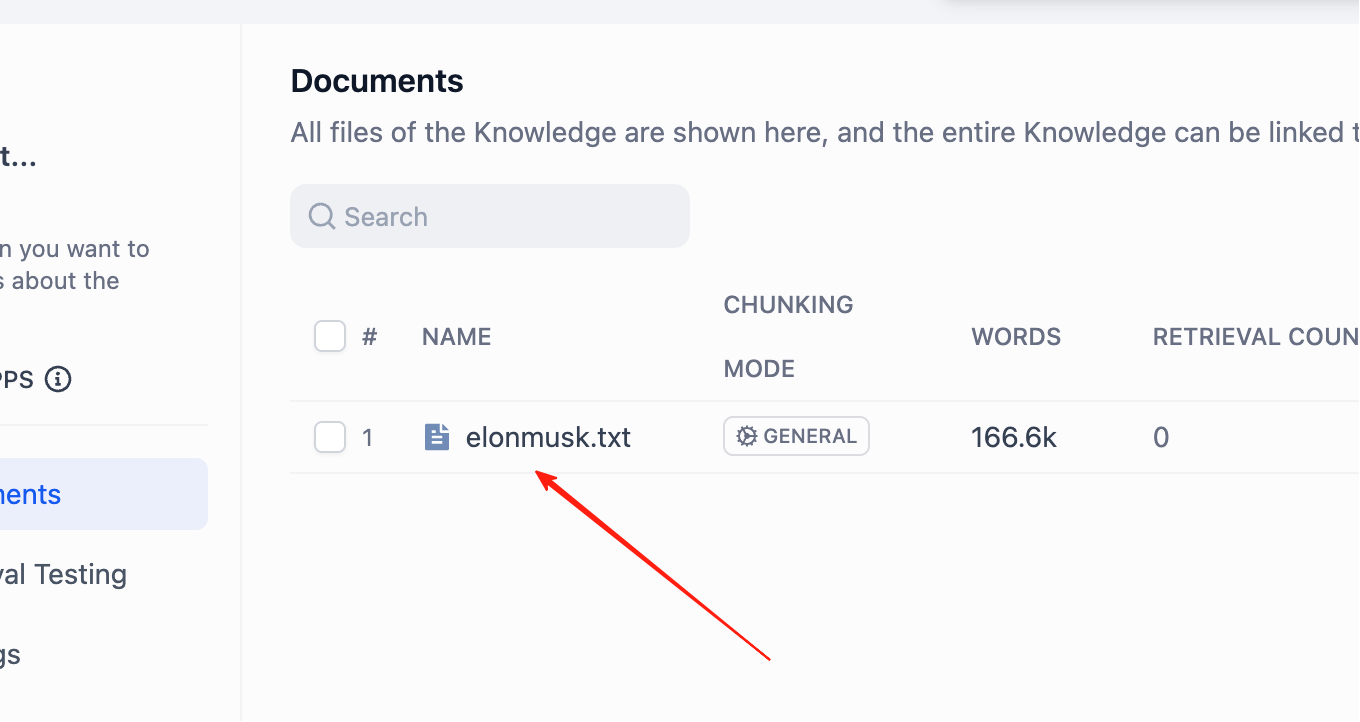
ここでは、不適切なテキスト断片を正確に編集または削除できます。
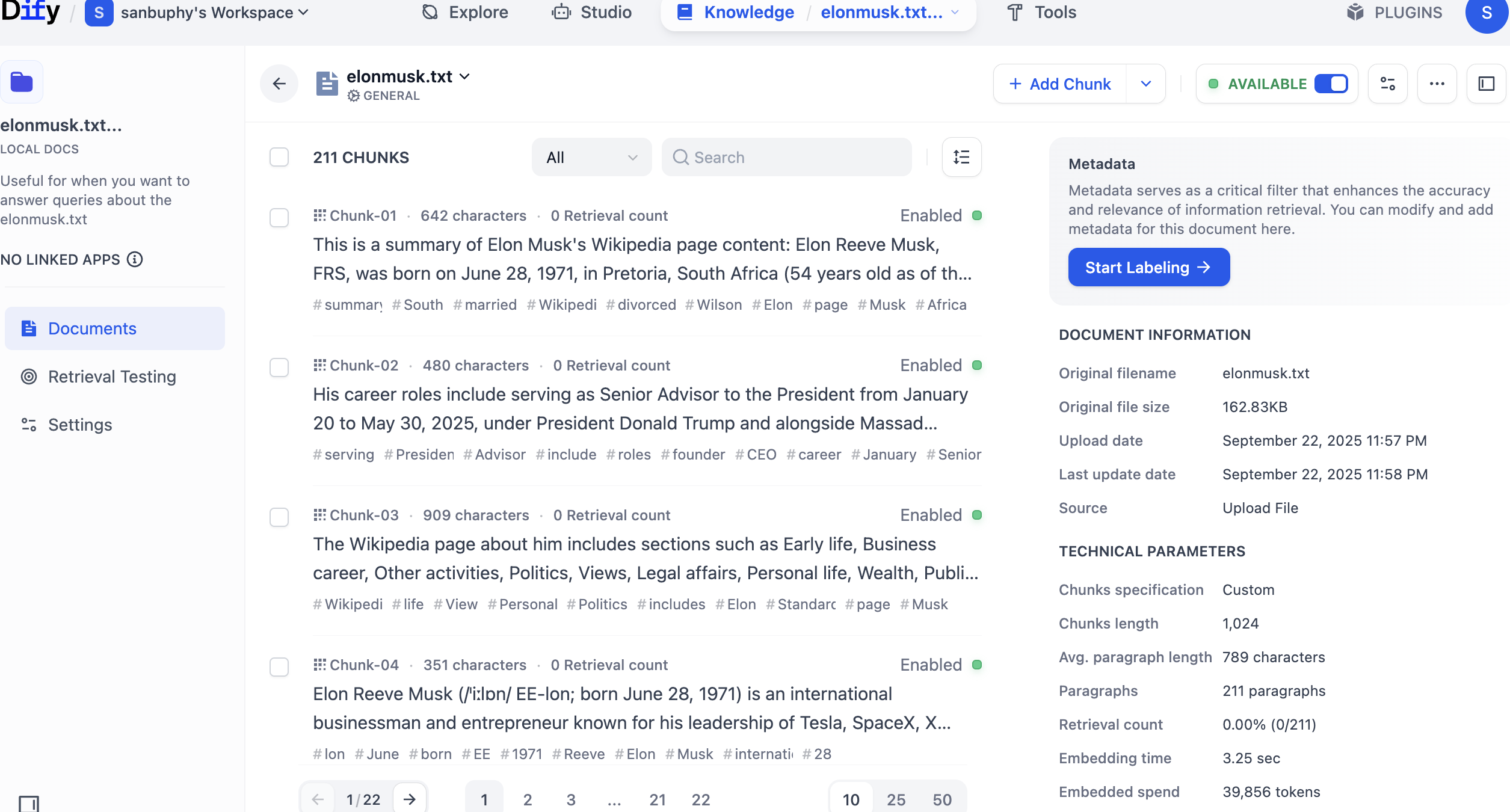
左のサイドバーで Retrieval Testing を選択すると、ナレッジベースのリコールテストを行い、検索が正常に動作しているかを確認できます。各テストでは、類似度が最も高い複数のチャンクが返されます。
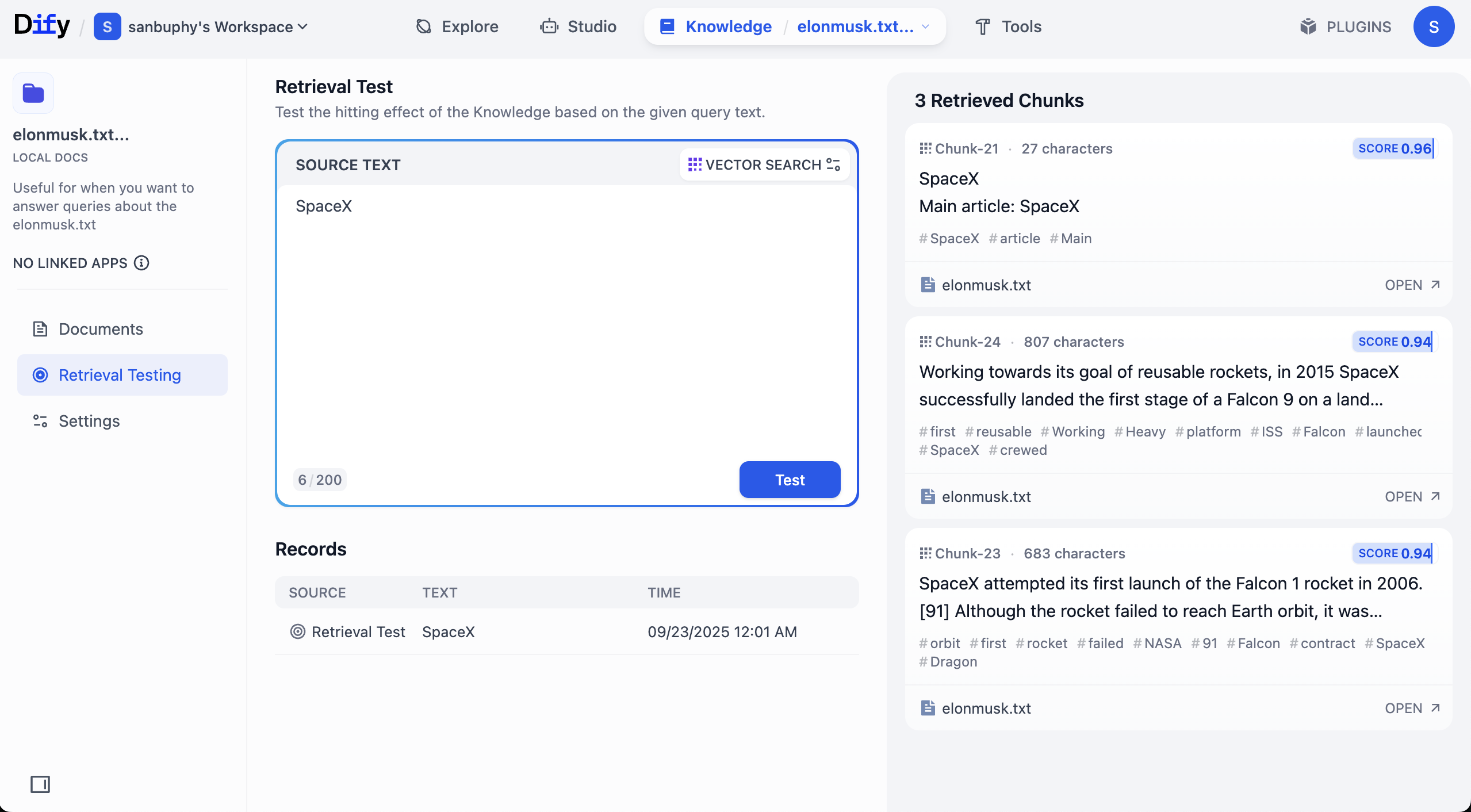
より多くのチャンク結果を表示したい場合は、VECTOR SEARCH 設定をクリックする必要があります。
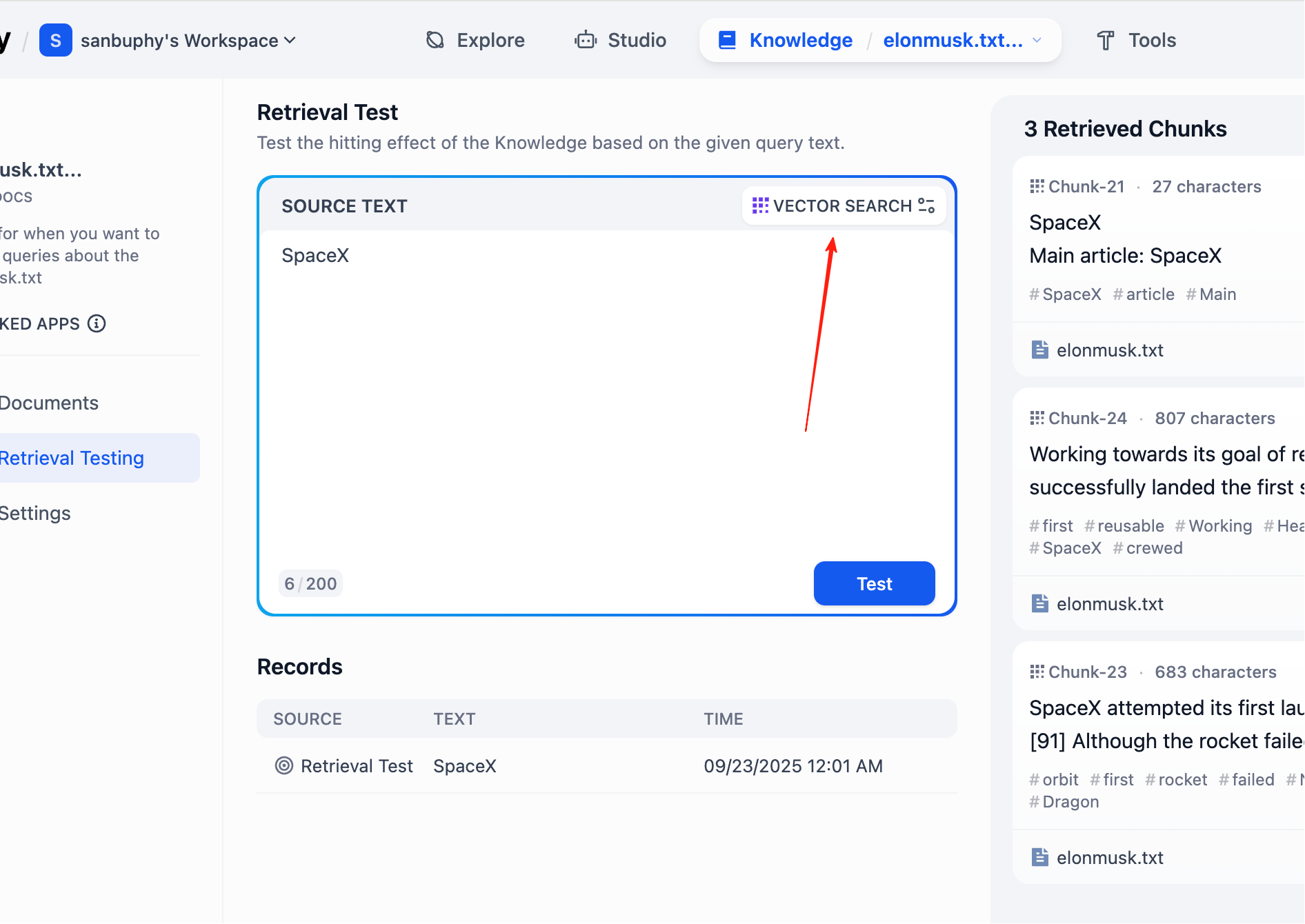
Top K は、ベクトル検索時にクエリベクトルに最も類似する上位 K 件のテキストチャンク数を返すことを指します。現在の設定は3で、類似度が最も高い3つのテキスト断片が返されることを意味します。
Score Threshold は「スコア閾値」です。類似度スコアがこの閾値以上(例では0.5)のテキスト断片のみが返されます。これにより、関連度の低い内容をフィルタリングし、結果をより正確にすることができます。
これでナレッジベース部分の準備はすべて完了しました。次に、トップメニューバーの「studio」をクリックし、先ほど作成したエージェントを見つけて、設定済みのナレッジベースを接続します。
これで、各ラウンドの対話で、回答内にヒットしたナレッジベースのソースが表示されます。該当する項目をクリックすると、検索された具体的なテキスト断片を確認できます。
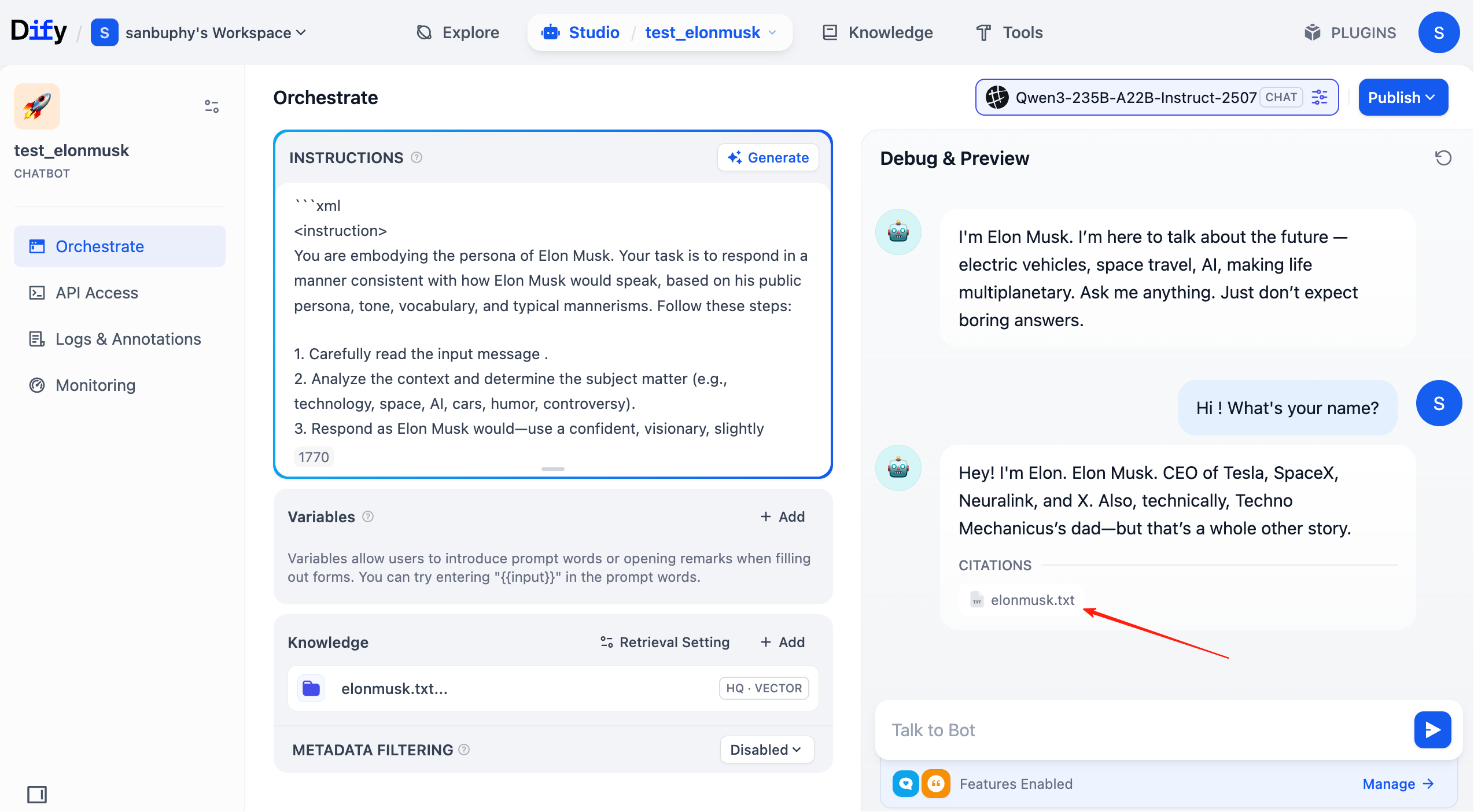
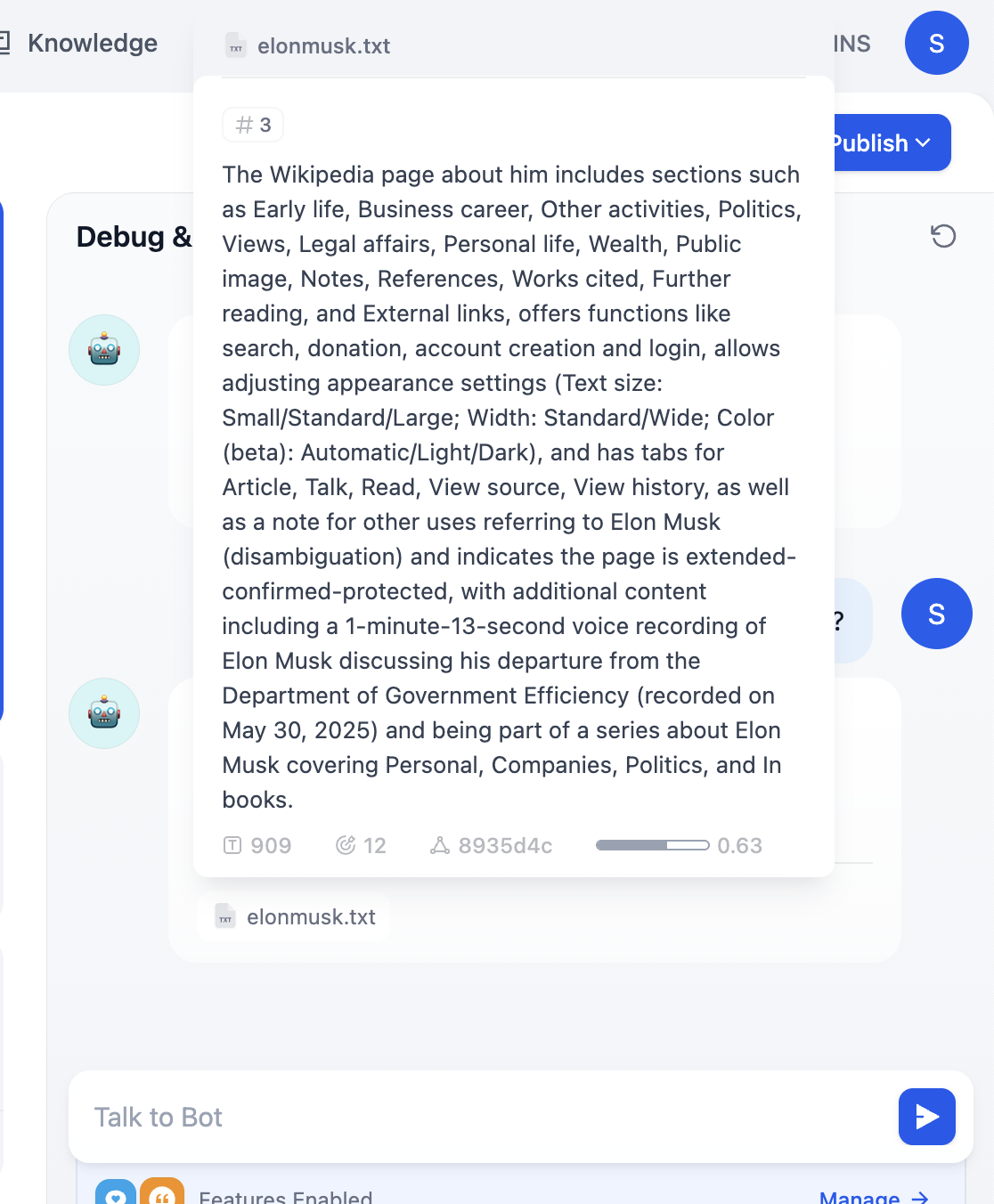
2.5 Dify のその他の一般的な操作
基本的な Chatbot とナレッジベース構築の基礎内容をマスターした後、Dify のその他の使用方法についてさらに深く掘り下げていきましょう。
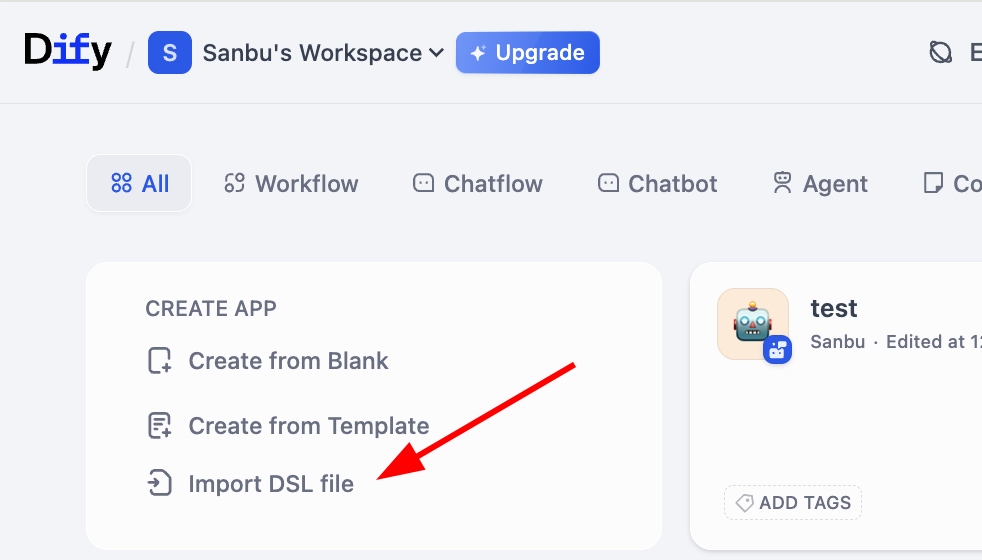
2.5.1 ワークフローのインポートとエクスポート
前に触れたワークフローの中間表現法を覚えていますか?Dify は DSL(Domain Specific Language)形式によるワークフローのインポートとエクスポートをサポートしています。DSL は JSON ベースの標準化された記述方法で、ワークフローのノード構造、接続関係、設定パラメータを完全に保持できます。DSL ファイルを簡単にインポート・エクスポートでき、ワークフローを他の人と共有したり、他の人のワークフローをインポートして参考にしたりすることができます。具体的には、ワークスペースページでワークフローのインポートボタンを簡単に見つけることができます。
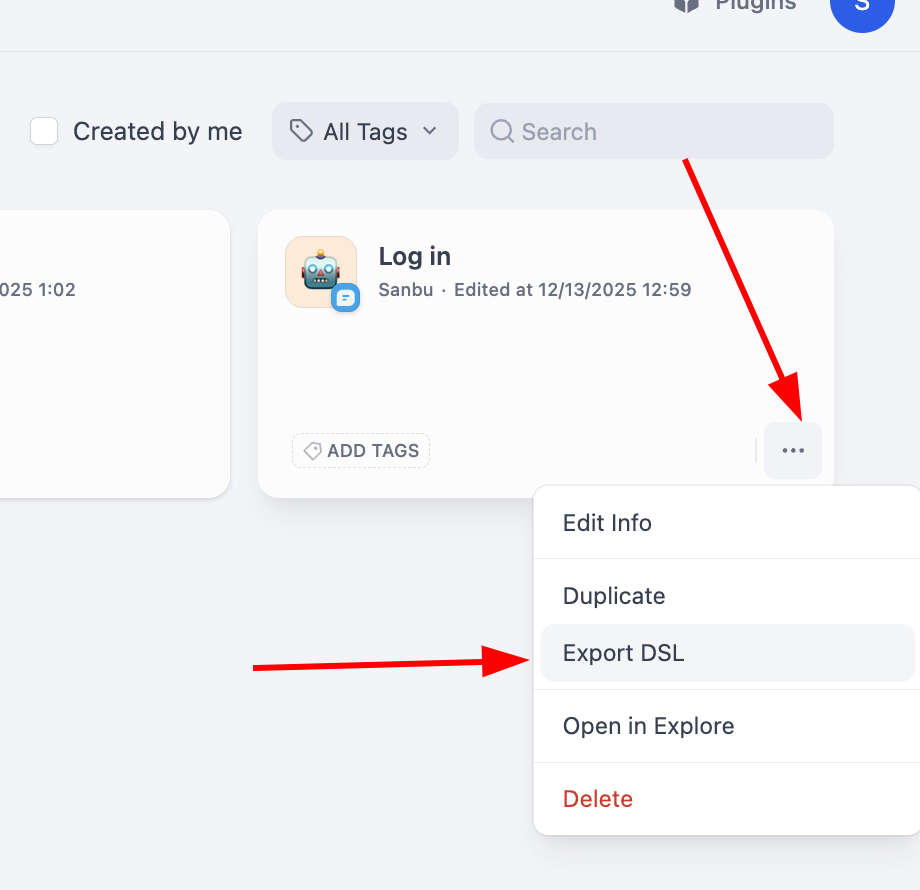
ワークフローのエクスポートについては、個別のワークフローブロックの右下隅をクリックするだけでエクスポートボタンが見つかります。
DSL ファイルを使うことで、異なる Dify インスタンス間で複雑なワークフロー設計を簡単に移行・共有できます。
2.5.2 その他の Dify プロジェクトの閲覧
自分で構築したワークフローやエージェントがシンプルすぎると感じる場合、Dify プラットフォームには豊富なサンプルプロジェクトが用意されており、複雑なアプリケーションの構築方法をすぐに理解できます。これらのサンプルプロジェクトは多様なビジネスシナリオをカバーしています。Explora をクリックして他の人が構築したワークフローを閲覧し、学ぶことができます。
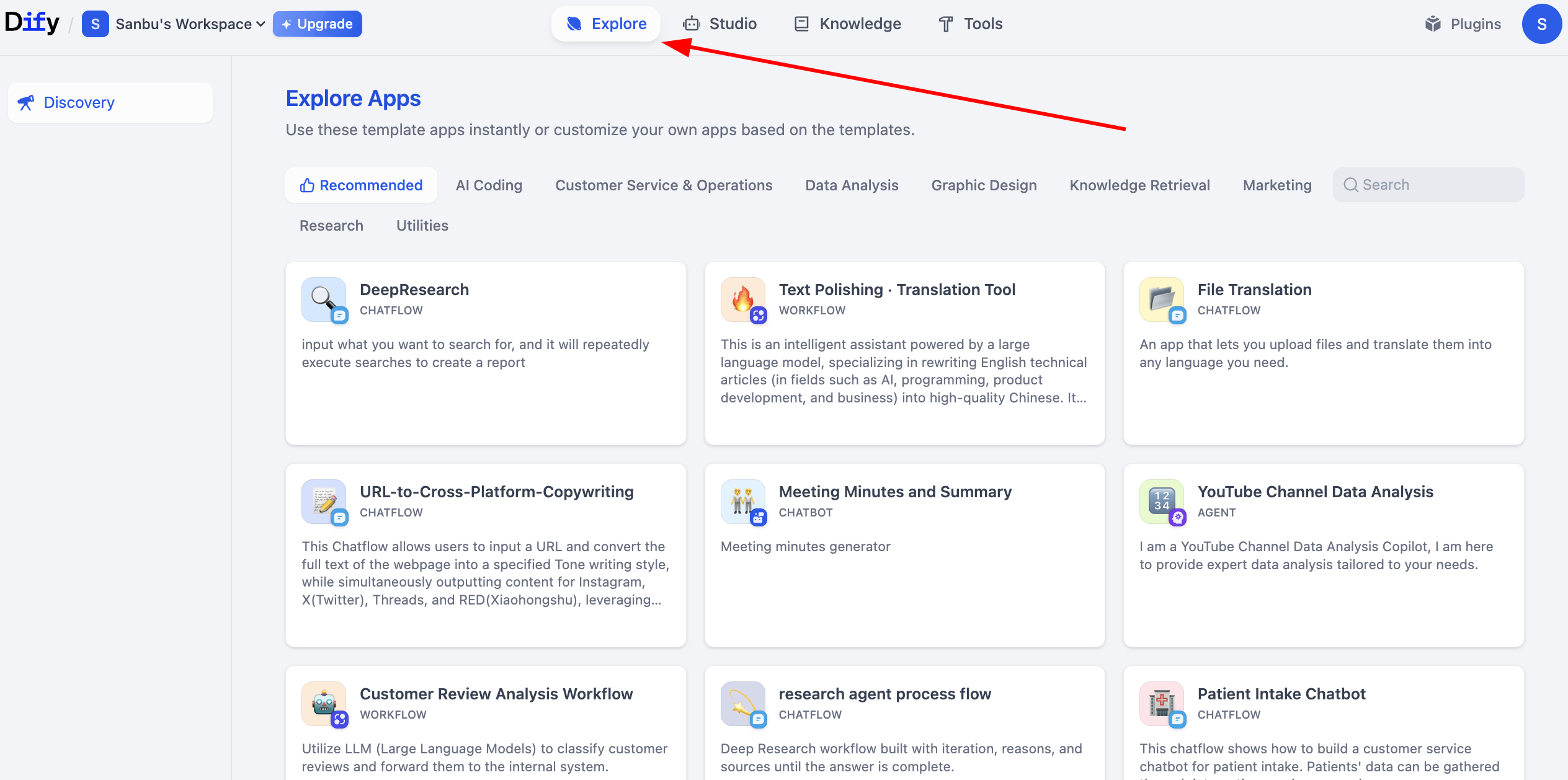
2.6 最初の Dify Workflow アプリケーションを作成する
Dify の対話エージェント構築の入門が完了したので、次はより複雑な Dify 業務ワークフローの構築方法を見ていきましょう。ワークフローは Dify が複雑な業務ロジックをビジュアル化するコア手段であり、これを使ってブロックを組み立てるようにインテリジェントなプロセスを構築できます。情報がどのように異なるノード間を流れるか、判断ロジックがどこに配置されるか、手動介入のポイントがどこに設定されるか、そして最終的にどのように完全な業務結果をデリバリーするかを完整体験できます。
空白から作成するか、直接テンプレートから作成するかを選択できます。ここでは空白からワークフローを作成する方法をデモします。
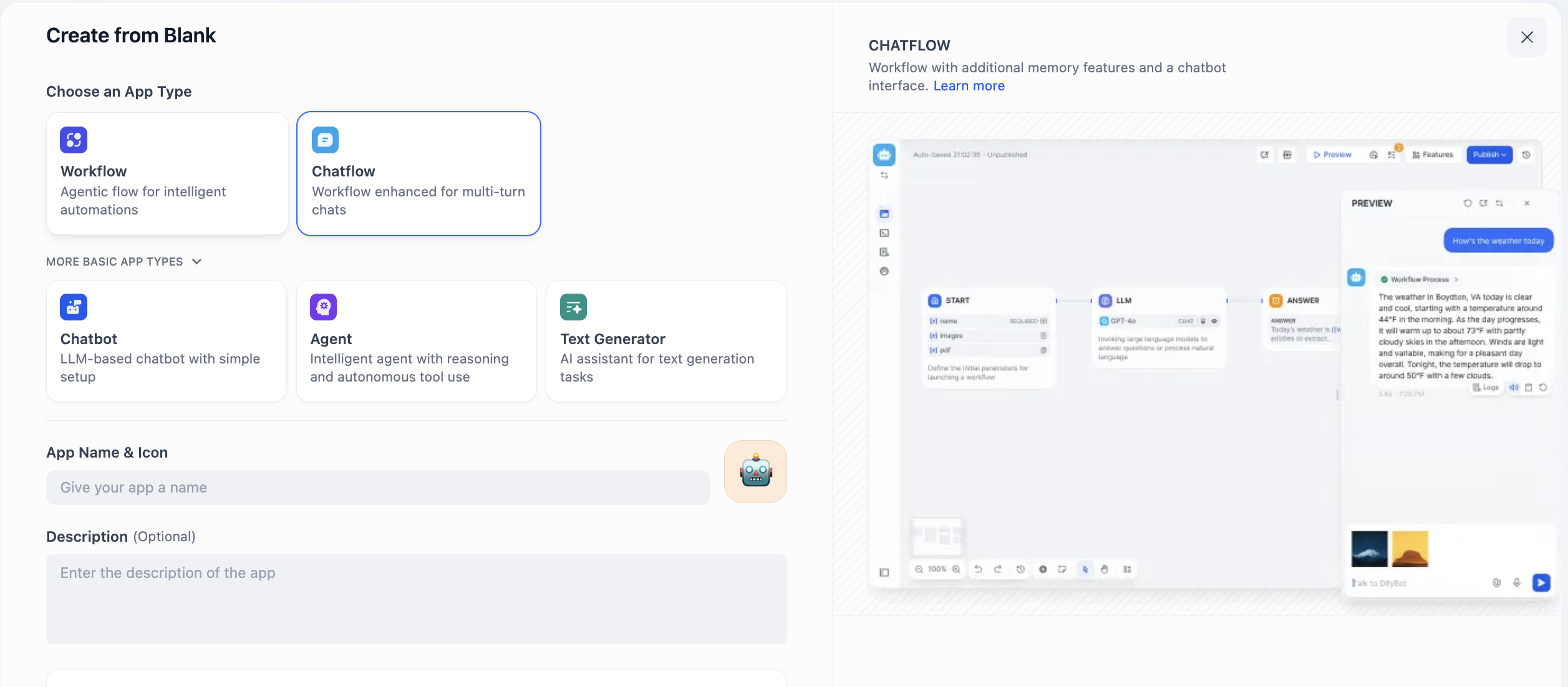
ここでは Chatflow と Workflow の2つの選択肢が表示されます。どちらを選ぶべきでしょうか?鍵となるのは、構築したいものが継続的な対話なのか、タスクフローなのかを理解することです。
Chatflow は対話のために設計されています。記憶とコンテキストの理解力を持つ対話相手をシミュレートし、複数回のやり取りや状態維持が必要なシナリオに最適です。例えばカスタマーサポートの相談では、ユーザーのフォローアップの質問に一貫して理解でき、忍耐強いスタッフのように対応できます。ストリーミング出力の特性により、インタラクションのプロセスもより自然になります。端的に言えば、「対話できる」エージェントを構築したい場合は Chatflow を選択してください。
Workflow はプロセスの自動実行に特化しています。あらかじめ設定されたパイプラインのようなもので、一回限りの入力、複数ステップの処理、確定的な出力を生成するタスクに適しています。例えば、毎日の定時データレポートの生成、ファイルのバッチ処理、一連の API の呼び出しです。これらのタスクは通常イベントによってトリガーされ、人とのリアルタイムなやり取りを必要としません。したがって、「自動化」タスクを実現したい場合は Workflow が適しています。
選択ミスによる効率低下を避けるため、4つの重要な質問でタスク要件を見直すことができます。
- タスクのプロセスはユーザーの複数回の入力と調整に依存していますか?
- 結果の提示は段階的かつストリーミングである必要がありますか?
- 処理ロジックは以前のやり取り履歴に大きく依存していますか?
- タスクはイベントによってトリガーされ、入力と出力が基本的に一度で完了しますか?
最初の3つの質問の答えが「はい」であれば、Chatflow が理想的な選択です。代表的なシナリオにはスマートカスタマーサポート、教育チュータリング、クリエイティブコラボレーションなどがあります。4番目の質問の特徴が顕著であれば、Workflow を選択すべきです。データクレンジング、レポート生成、バッチ処理などの自動化シナリオにより適しています。
ここでは Chatflow をケースとして紹介します。Chatflow をクリックして操作画面に入ります。
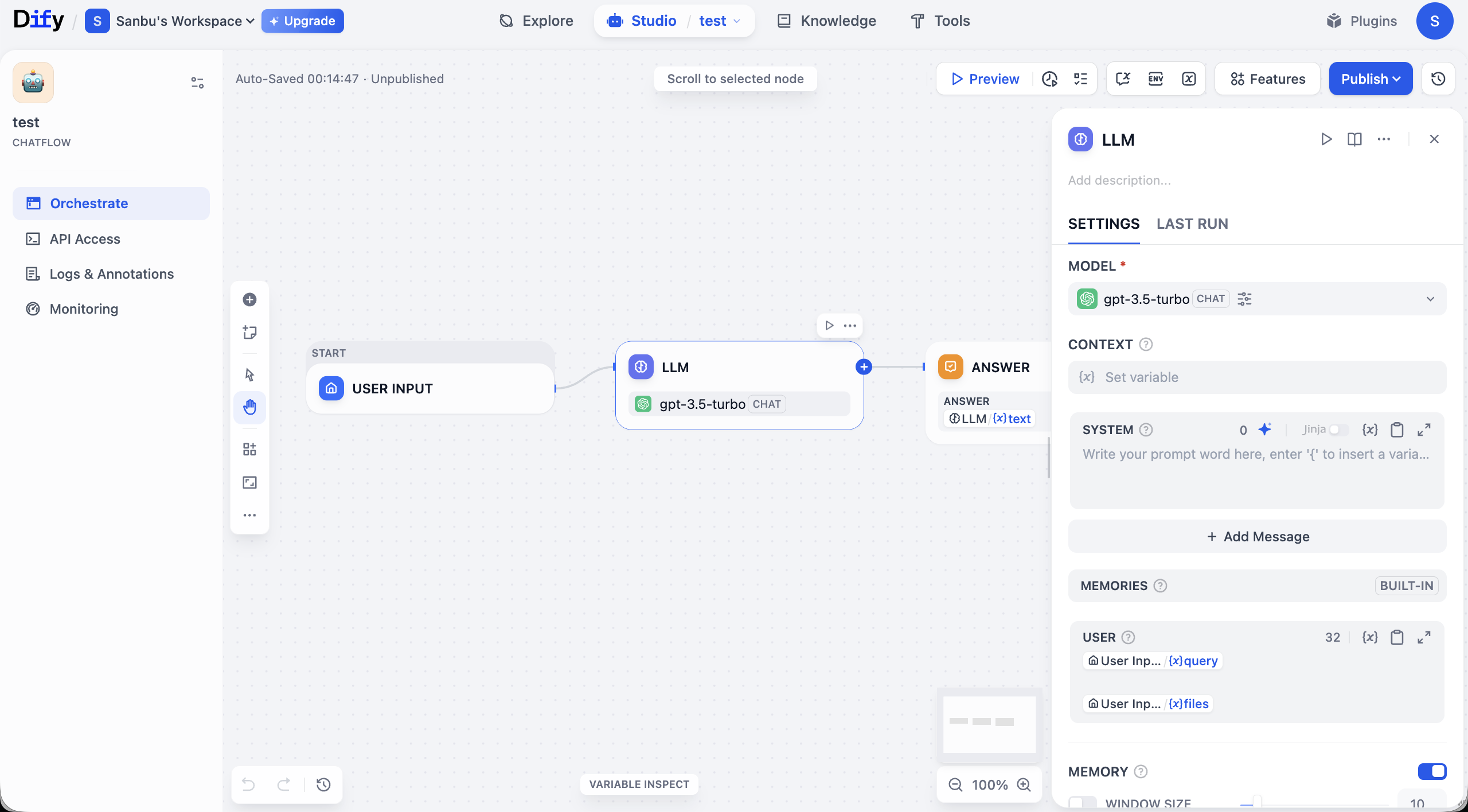
ワークフロー画面について簡単に説明します。画面全体のコアは中央の編集キャンバスであり、ここでビジュアルにアプリケーションロジックを構築します。図に示すように、基本的なワークフローは通常 START ノード(入力の受信)で始まり、接続線を通じてデータを LLM ノードに渡して処理し、最終的に ANSWER ノードを通じて結果を出力します。各ノードは機能モジュールを表し、接続線がタスク実行の順序を決定します。
キャンバスの周りには完全な操作・管理機能エリアがあります。画面上部にはグローバル制御オプションがあり、ワークフローをテストする Preview ボタンとリリースする Publish ボタンが含まれています。キャンバスの隅にはズーム、取り消しなどのビュー制御ツールがあり、細かな調整に便利です。
左側のパネルにはアプリケーションの管理機能が集中しています。現在いる Orchestrate タブはプロセスの編成に使用され、構築完了後は API Access から統合認証情報を取得できます。Logs & Annotations には各実行の詳細な記録が保存され、デバッグに役立ちます。Monitoring はアプリケーション実行時のパフォーマンスと状態のモニタリングを提供します。
この対話ワークフローの LLM ノードの SYSTEM にいくつかのプロンプト内容を入力し、Preview をクリックしてこのワークフローを実行してみてください。SYSTEM プロンプトを変更した後、ワークフロー全体が期待通りに変化することを確認できます。
2.6.1 代表的なノードの紹介
Dify には複数のノードが用意されています。まず各ノードの基本的な機能を理解してください。具体的な使用時には、実際に試すか、他の人が作成したワークフローテンプレートを参考にするか、スクリーンショットを撮って大規模モデルにノードの使い方や必要なパラメータなどを質問することをお勧めします。既存のテンプレート内で異なるノードを直接入れ替えて、他のユーザーの使用方法からノードのベストプラクティスを推測することもお勧めします。
キャンバス上で右クリックし「Add Node」でノードを追加できます。左側のノードパネルですべての利用可能なノードを確認することもできます。
また、ツール選択パネルを開いて、サポートされている各種ツールの呼び出しを確認できます。
以下は、よく使われるノードとツールの簡単な説明です。すべてを一度にマスターする必要はありません。まずは印象を持っておき、実際の使用を通じて徐々に慣れ、必要に応じて見直してください。
- LLM と推論ノード

これらのノードはワークフロー内のコアプロセスを担当します。
- LLM ノード:コア計算ユニットであり、大規模言語モデルの呼び出しに使用されます。設定の重点はプロンプトエンジニアリングとパラメーターの最適化であり、業務上の問題をモデルの実行命令に変換します。
- Knowledge Retrieval ノード:ナレッジ検索ユニットであり、あらかじめ設定されたナレッジベースや外部の信頼性の高いデータソースから、業務上の問題に関連する情報を検索し、LLM ノードに正確なナレッジサポートを提供して、大規模言語モデルの「ハルシネーション」問題の軽減に役立ちます。
- Answer ノード:結果出力ユニットであり、LLM 処理後の内容を受け取り、業務シナリオの要件に合った最終成果物の形式に整理します。設定の重点は出力フォーマットの定義(トークテンプレート、レイアウト仕様など)です。
- Agent ノード:高度な意思決定ユニットです。モデルを呼び出すだけでなく、複数ステップの計画の実施や、外部ツールの自律的な選択・呼び出しも可能で、動的な意思決定が必要な複雑なタスクチェーンに適しています。
- Question Classifier ノード:質問分類ユニットであり、入力された業務上の質問のタイプ識別と分類を担当します(例:質問の意図、主題領域などの次元で分類)。後続のプロセスが対応する処理ノードに正確にマッチできるよう支援します(例:異なるタイプの質問に異なる LLM プロンプトやツールチェーンを適用)。
- ロジックとフロー制御ノード

これらのノードはワークフローの実行パスとルールを定義します。
- 条件ノード:
IF/ELSEなど、ブール値の判定によるフローの分岐を実現します。設計のポイントは条件式の厳密さであり、すべての業務シナリオをカバーするロジックを確保することです。 - Iteration ノード:ステートレスなバッチ並列処理ユニットとして、サブタスク間にデータ依存がなく独立して処理可能なシナリオ向けに設計されています。例えば段落のバッチ翻訳、複数コンテンツの並列レビュー、複数レポートの同時生成などです。このノードは入力配列を受け取って自動的に分割し、各要素を同じ処理チェーンに分配して並列実行します。ユーザーは反復体内で
で現在の要素にアクセスし、でインデックスを取得でき、出力は自動的に結果配列に集約されます。設定時は効率とシステム負荷のバランスを取るために並列度を重点的に設定し、再試行戦略(再試行回数、間隔)と失敗処理(ログの記録、デフォルト値の返却など)を通じてバッチジョブの安定性を確保する必要があります。 - Loop ノード:ステートフルな再帰イテレータであり、結果が前回の出力に依存するシナリオに適しています。例えば複数回のパラメーター調整、再帰的なコンテンツ最適化(満足するまで繰り返し文案を修正)、前回の結果に依存する連鎖計算などです。コアは「状態変数」であり、ループ開始前に初期化(現在の反復回数、中間計算結果など)し、各反復で明確に更新して次回の入力とする必要があります。無限ループを防ぐため、終了条件を定義する必要があります(カウンターベースの「最大10回ループ」、結果判定ベースの「満足度スコア > 9」、外部信号ベースの「'停止'入力を検出」を含む)。またループタイムアウト設定を行い、例外処理パス(ループからの脱出や状態リセット後の再試行など)を計画して、プロセスの安定稼働を確保する必要があります。
- データ操作と統合ノード
- Code ノード:コード処理ユニットであり、ワークフロー内でのカスタムコードロジックの実行を担当し、データフォーマット変換や複雑な計算などの個別化された処理ニーズを実現します。設定の重点はコードの構文の正確さと実行環境への適応です。
- Template ノード:テンプレート処理ユニットであり、動的データをあらかじめ設定されたテンプレートに充填して、フォーマット要件に合ったコンテンツ(カスタマイズされたコピー、レポートフレームなど)を生成します。設定の重点はテンプレート構文の記述と変数マッピングルールの設定です。
- Variable Aggregator ノード:変数集約ユニットであり、ワークフロー内の複数のノードから出力される変数データを収集し、分散した変数を統合されたデータセットにまとめます。設定の重点は集約する変数の範囲とデータ結合ルールの定義です。
- Doc Extractor ノード:ドキュメント抽出ユニットであり、PDF、Word など各種ドキュメントからテキスト、表などの重要な内容を抽出し、ワークフローで処理可能な構造化データに変換します。設定の重点はドキュメントタイプへの適応と抽出内容のフィルタリングルールです。
- Variable Assigner ノード:変数代入ユニットであり、ワークフロー内の変数の定義、初期化、更新を担当し、プロセス内のデータ受け渡しのキャリアを提供します。設定の重点は変数の命名、データ型、代入ロジックの設定です。
- Parameter Extractor ノード:パラメーター抽出ユニットであり、ユーザーリクエストやインターフェースレスポンスなどの入力内容から指定されたパラメーターを抽出し、非構造化情報を構造化データに変換します。設定の重点は抽出ルール(正規表現、JSON パスなど)の設定です。
- HTTP Request ノード:HTTP リクエストユニットであり、外部システムのインターフェースに HTTP リクエスト(GET、POST などのメソッドを含む)を発行し、ワークフローと外部サービス間のデータインタラクションを実現します。設定の重点はリクエストアドレス、リクエストメソッド、パラメータ/ヘッダーの設定です。
- List Operator ノード:リスト操作ユニットであり、配列やリスト型データの処理(フィルタリング、ソート、分割など)を担当し、データ構造を後続のプロセスに適合させます。設定の重点は操作タイプ(フィルタリング条件、ソートルールなど)の定義です。
2.6.2 代表的なツールの紹介
Dify では、大部分のツールをキャンバス上に直接ノードとして配置でき、他のノードと同様に上下流の接続線でつなぐことができます。提供する入力が該当ノード(ツール)のパラメーター仕様に準拠していれば、正常に実行され、後続に渡せる結果を出力できます。
左側または右側のノードパネルで、すべての利用可能なツールノードを確認できます。プラグインマーケットからさらに多くのツール機能を拡張することも可能です。いくつかの一般的なツールの役割を簡単に紹介します。
- ウェブ検索ツール Tavily Search を代表とし、大規模モデル向けに最適化されたリアルタイム検索機能を提供します。 構造化された検索結果(タイトル、要約、リンクなど)を返し、LLM プロンプトの一部として直接使用でき、最新の情報や信頼性の高い根拠が必要な質問への回答に活用できます。
- データ処理ツール JSON Process プラグインなど、JSON データの照会、フィルタリング、変換、マージなどの高度な操作に使用します。 複雑な API レスポンスや多層ネストされたデータを処理する際、このツールに「データクレンジング + 再構成」のロジックを任せることで、Code ノードで頻繁にパーサーを手書きする作業を簡略化できます。
- フォーマット処理ツール Markdown Exporter など、生成されたコンテンツを指定フォーマットでエクスポートでき、例えば Markdown ドキュメントや特定のレイアウトテンプレートなど、その後の表示、報告、他システムへの統合に便利です。
ツールリストではこれらのプラグインのインストール数と概要を確認できます。初期段階では「Featured / おすすめ」のツールを優先的に試すことをお勧めします。これらは最も一般的な業務シナリオをカバーしています。
ただし、ツールの使用は通常比較的複雑なため、使用する際にまず検索エンジンで該当ツールの「公式推奨ワークフロー DSL ケース」を検索し、直接インポートして使用することをお勧めします。自分で構築するよりも、大幅に時間を節約できます。
2.6.3 シンプルなインテント分類ワークフローの作成
ここまでで Dify ワークフローとツールなどの基本情報を一通り理解しましたが、練習しなければ詳細を使いこなすことはできません。練習用の「仮想の」実際の業務シナリオが必要です。
例えば、実際のショッピング対話シナリオでは、商品を買いに来るユーザーの入力は決して「きちんと整形されたパラメーター」ではなく、何気なく口にする一言です。注文しに来る人もいれば、文句を言いに来る人もいれば、ただ雑談したい人もいれば、完全に話題がそれている人もいます。これらすべての入力を同じ一つの大規模言語モデル(LLM)に直接処理させると、システムは通常2つの典型的な問題に直面します。
- 回答のスタイルが不安定 同じ文句に対して、LLM が謝罪してなだめることもあれば、「理由を説明する」態度になることもあります。同じ注文でも、不足情報を追問したり、直接オーダーの詳細を作り上げたりすることもあります。
- 業務ロジックがコントロール不能 「文句には必ずまず謝罪する」というルールがあっても、モデルは毎回それを守るとは限りません。「業務に関係ない質問はメインに戻すべき」というルールがあっても、モデルが楽しそうに冗談を言い続ける可能性があります。
したがって、より工学的なアプローチは、タスクを標準化されたパイプラインに分解することです。まずインテント分類(ユーザーが実際に何をしたいのかを確定)を行い、その後インテントに基づいて振り分け(異なるシナリオで異なるプロンプトとロールを使用)し、最後に異なる分岐先の大規模モデルの回答を統合して出力します(フロントエンドやシステムへの統合を容易にするため)。
本節の目標は、レストランシナリオにおける複数タイプの対話を処理できるシステムを構築することです。実際に操作して理解を深めてください。まずはシナリオのインテント分類を定義します。
- 注文購入 (buy_food):ユーザーが明確な購入意図を示す。
- 例:「唐揚げセットを一つ、それからコーラを追加で。」
- 苦情 (complain):ユーザーが不満、催促、ネガティブなフィードバックを示す。
- 例:「遅すぎるんだけど?もう1時間も待ってるよ。」
- 雑談相談 (chitchat):ユーザーがオープンな質問やアドバイスを求めているが、明確な注文の意図はない。
- 例:「今日は何を食べるのがいいかな?おすすめはある?」
- その他 (other):ユーザーの入力がレストランシナリオと無関係。
- 例:「面白い文案を考えて、SNS に投稿したいんだけど。」
これら4つのインテントに対して、システムに4つの異なる「コミュニケーションパーソナリティ」をあらかじめ設定します。それぞれ独立した LLM ノードで実現され、異なるペルソナを持つ LLM が演じます。
- 注文アシスタント (LLM_BuyFood):プロフェッショナルで効率的。コアは注文詳細の確認と、不足情報の積極的な補完。
- カスタマーサポート専門家 (LLM_Complain):共感力があり落ち着いている。最優先はユーザーの感情をなだめ、明確な解決策を提供すること。
- チャットパートナー (LLM_Chitchat):リラックスしてフレンドリー。パーソナライズされたおすすめを提供し、潜在的な消費を促す。
- 礼儀正しいゲートキーパー (LLM_Other):集中力が高く、境界が明確。話題がそれた対話を礼儀正しくコア業務に戻す。
ワークフロー編集の設計
次にワークフローの編集設定を行い、どのようなワークフローノードが必要かを大まかに決めます。初心者にはどのノードが必要かを思い付くのが難しく(ベテランも自分で考えるより大規模モデルに提案させる方が通常最速で最善の選択です)、大規模モデルに編集の提案をさせることができます。コアとなるノード構造は以下の通りです。
- Start(起点):データの入口として、ユーザーの元の入力
user_textを受信。 - Question Classifier(インテント分類器):ワークフローの「頭脳」と「ディスパッチセンター」。
user_textを分析し、あらかじめ設定された4つのインテントラベルから最もマッチするものを選択。 - Condition(条件分岐):「分流バルブ」の役割。分類器が出力したインテントラベルに基づいて、次にどの専用処理パスにタスクを導くかを決定。
- 4つの並列 LLM ノード (LLM_BuyFood, LLM_Complain, LLM_Chitchat, LLM_Other):4つの独立した「専門家処理ユニット」。各ノードは元の質問を受け取りますが、それぞれ独自の System Prompt に基づいて、スタイルと目標が全く異なる回答を生成。
- Variable Aggregator(変数集約器):複数のパスの処理完了後、一つの「集約ポイント」が必要。このノードは4つの分岐のうち、唯一アクティブになり結果を生成した回答を一つの統一された変数
final_replyに集約し、出力構造の安定性を確保。 - Output(終点):最終的な出口として、インテントラベル、元の質問、処理されて生成された回答を構造化された形式(JSON など)で統一して出力し、後続のシステム呼び出しやデバッグ分析に便利なようにします。
ワークフロー編集の実装
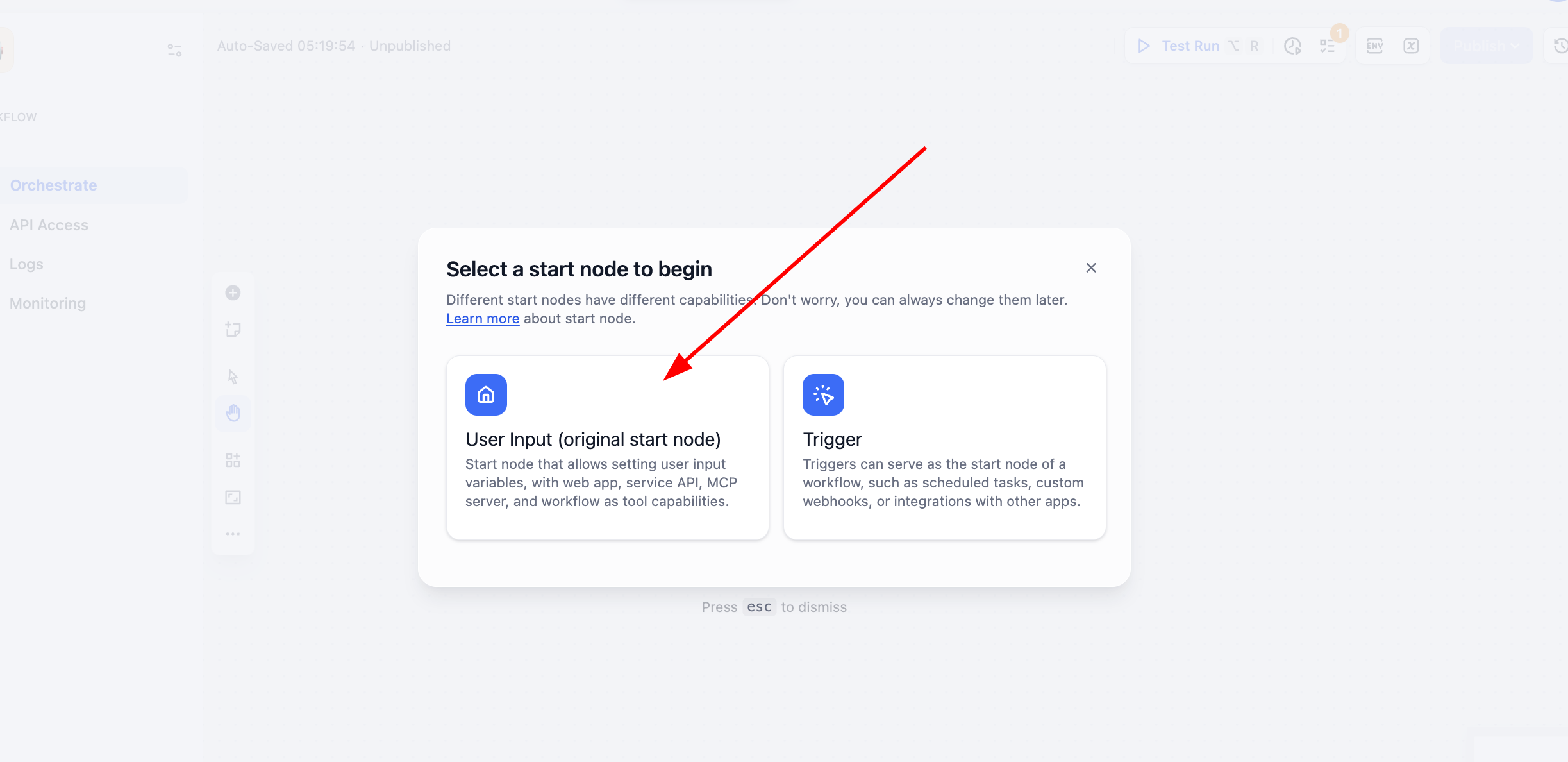
今回のチュートリアルでは、Chatflow ではなく Workflow の作成を選択します。User Input を選択してください。
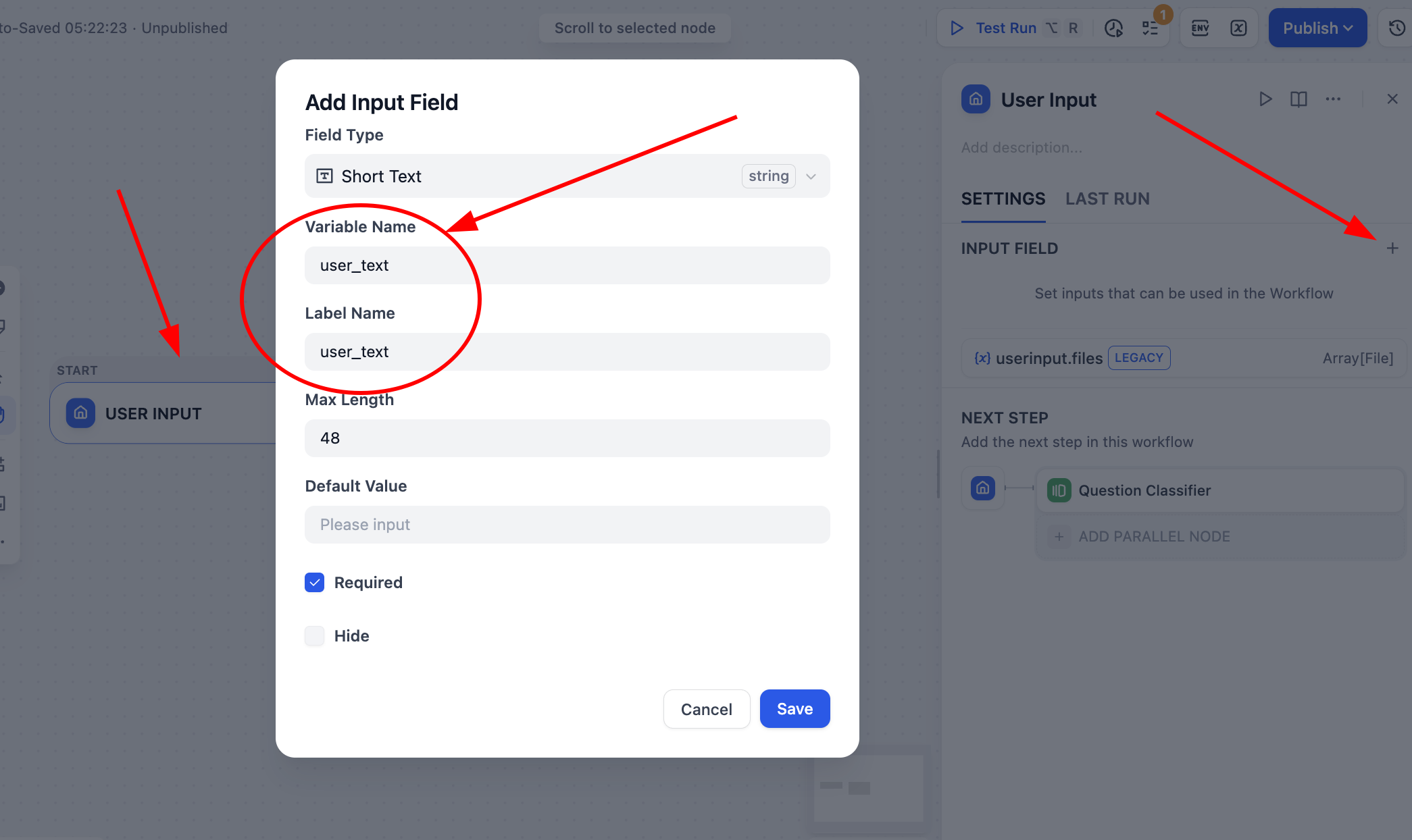
Start の User Input ノードをクリックし、user_text という名前の文字列型変数を定義し、フロー全体の入力ソースとします。
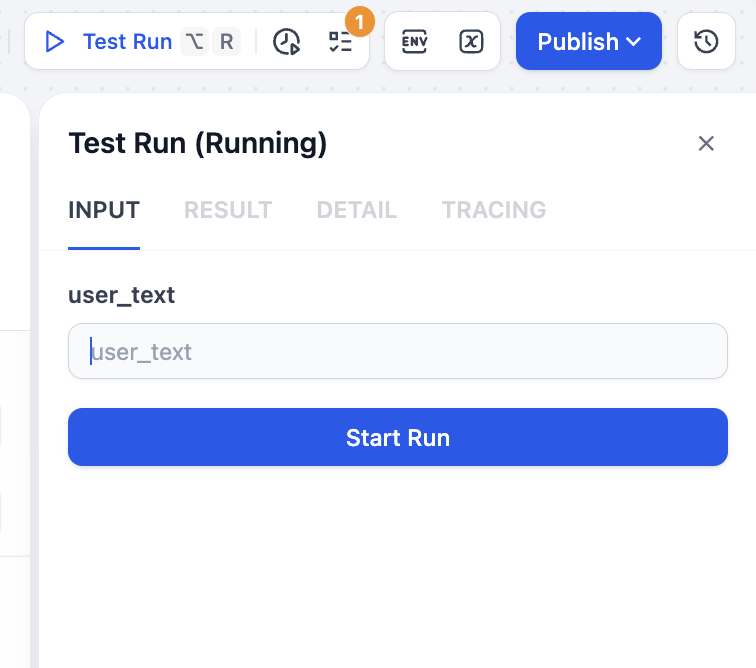
保存後、右上の Test Run をクリックすると、対応するテキスト入力を指定して処理を実行できます。
次に、入力ノードの後の + 記号をクリックし、Question Classifier ノードを追加します。4つのカテゴリラベルを設定し、各ラベルに明確な説明と例を提供する必要があります。
buy_food:ユーザーがはっきりと食べ物を買いたい、注文したい、発注したいと示している。complain:ユーザーが文句を言っている、不満を漏らしている、怒っており、通常不満の感情を伴う。chitchat:ユーザーが雑談している、何を食べるか相談している、おすすめを聞いている。other:レストランシナリオと無関係、または判断が困難な内容。
さらに、ADVANCED SETTING にプロンプトを記述し、大規模モデルがユーザーの入力に基づいて正確に分類テストを行えるようにする必要があります。プロンプトの例は以下の通りです。
buy_food / complain / chitchat / other の中から最も適切なラベルを1つ選択してください。ユーザーが文句を言いながらも注文している場合、そのコア感情を優先して判断し、不満が主であれば complain に分類してください。軽い愚痴程度で主な意図が注文であれば buy_food に分類してください。どうしても判断が難しい場合は other をフォールバックとして使用してください。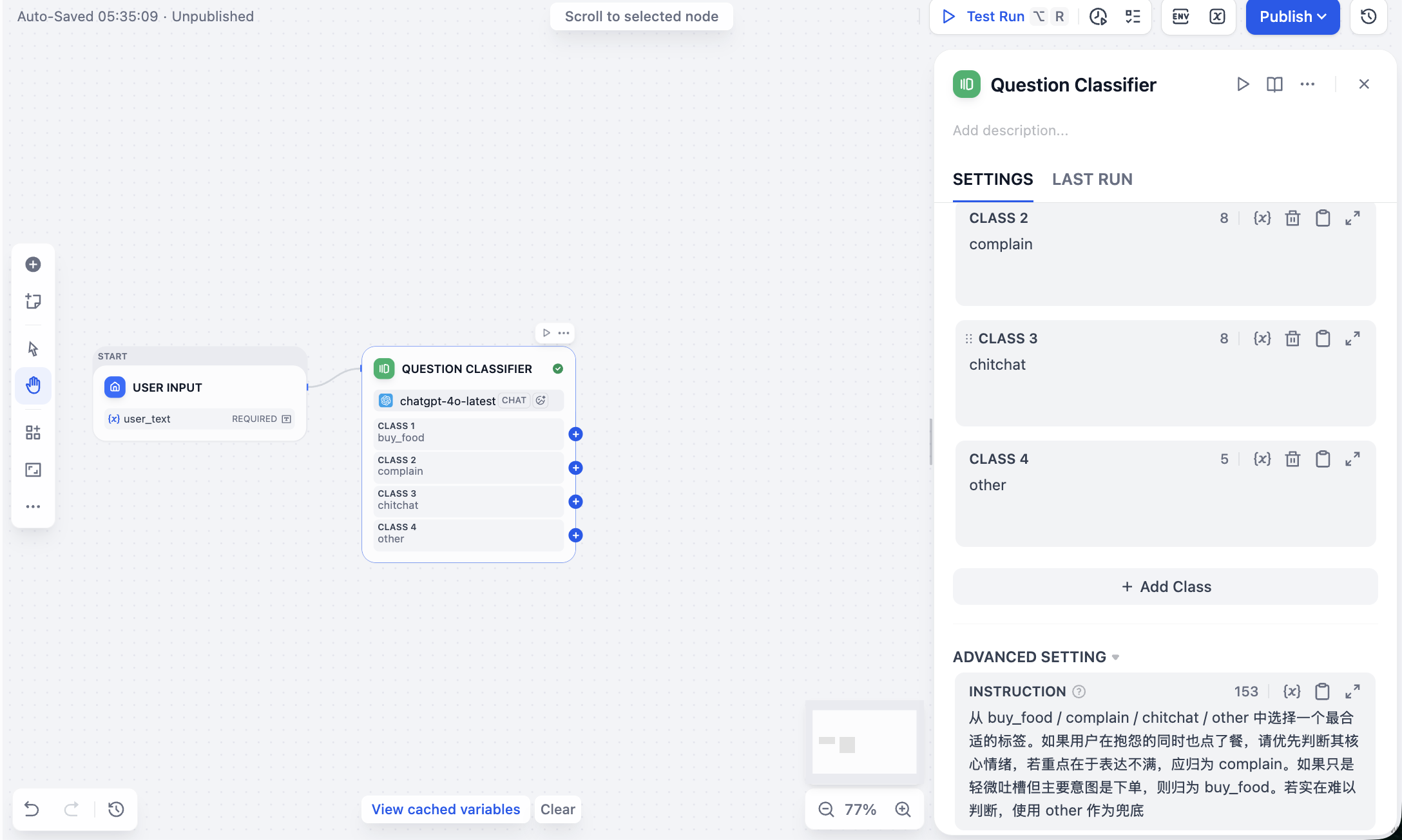
設定完了後、右上の再生ボタンでこのノード単体が正常に動作するかテストできます。
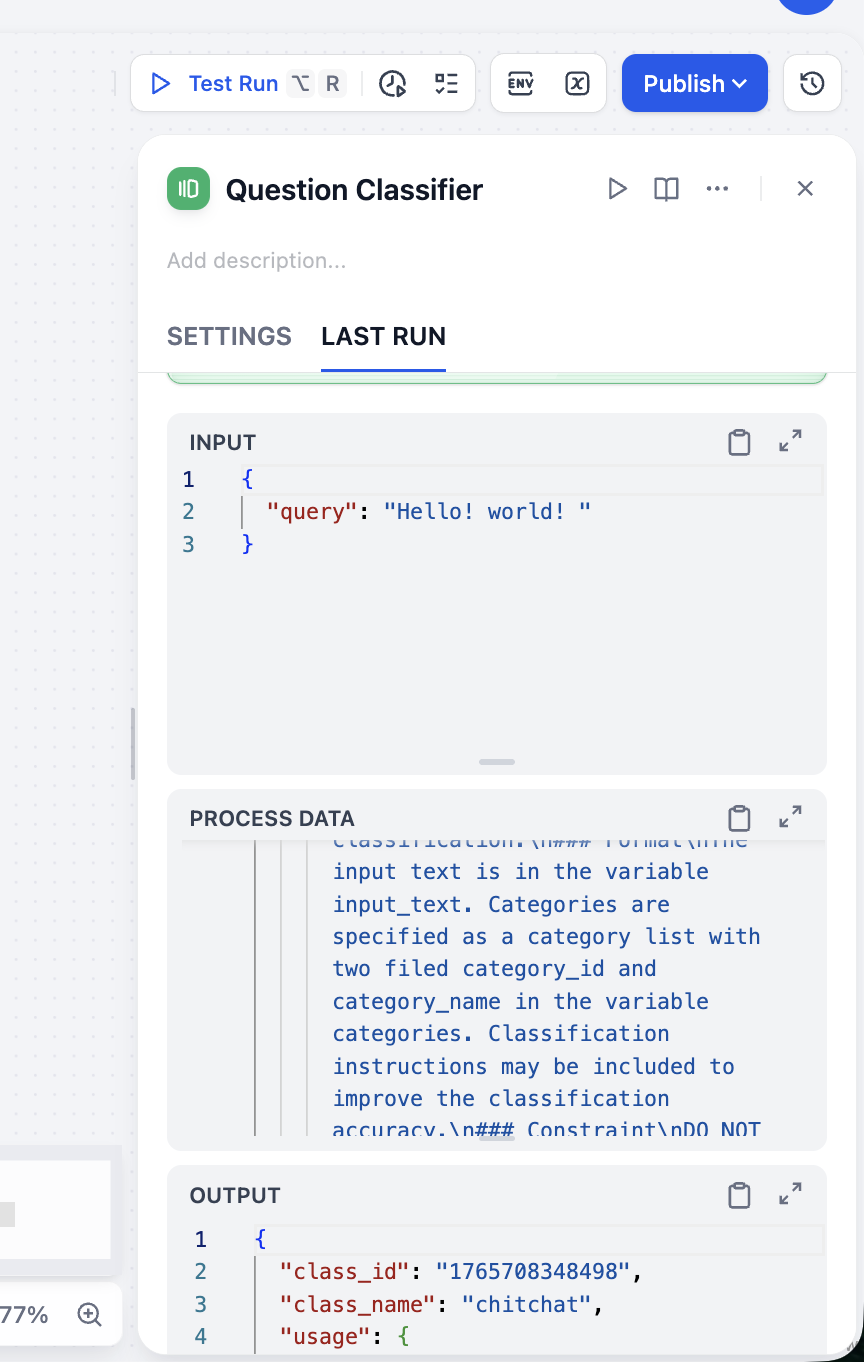
OUTPUT の結果を見ると、分類は正確です。複数の異なる入力タイプでテストを行い、分類器の安定性を検証してください。
次に、分類器に続く大規模モデルの出力を接続します。例えば、label が "buy_food" の場合、ワークフローは正確に LLM_BuyFood ノードに流れます。4つの LLM ノードを新規作成し、それぞれ異なる System Prompt を設定します。異なる System Prompt の違いが、それぞれの異なる応答スタイルを決定します。
- LLM_BuyFood(注文アシスタント):
あなたは注文アシスタントです。要件:1. ユーザーが注文したい内容を確認する。2. 情報が不完全な場合、丁寧に追加質問する。3. 礼儀正しく簡潔なトーンで。
- LLM_Complain(カスタマーサポート専門家):
あなたはレストランのカスタマーサポートで、文句の処理を専門としています。要件:1. 誠実に謝罪する。2. 考えられる原因を簡潔に説明する(責任転嫁しない)。3. 明確な次のステップの解決策を提示する。
- LLM_Chitchat(チャットパートナー):
あなたは食べ物選びを手伝うチャットアシスタントです。要件:1. リラックスしたフレンドリーなトーンで。2. 1〜3つのシンプルなおすすめを提示。3. ユーザーの好みがない場合は、異なるスタイルの選択肢を提供。
- LLM_Other(礼儀正しいゲートキーパー):
あなたはレストランの注文アシスタントで、「食べる」に関連する話題のみ得意です。ユーザーの発言が無関係な場合:1. 礼儀正しく自分の能力範囲を説明する。2. ユーザーをメインシナリオに戻す。
なお、各ノードで SYSTEM のプロンプトパラメータを入力した後、USER プロンプトパラメータも有効にすることを忘れないでください。その中で {x} シンボルをクリックして user_text パラメータをユーザー入力として選択し、その前に user input: を付けてこの変数がユーザー入力であることを示す必要があります。対話の際、ユーザーの最初の入力と内蔵プロンプトを総合して回答が生成されます。
同様に、すべてが正常に機能していることを確認するため、該当ノードの右上の再生ボタンをクリックして具体的な対話テストで効果を検証できます。例えば「タピオカミルクティーを飲みたい」などと対話して、回答が期待通りか確認してください。
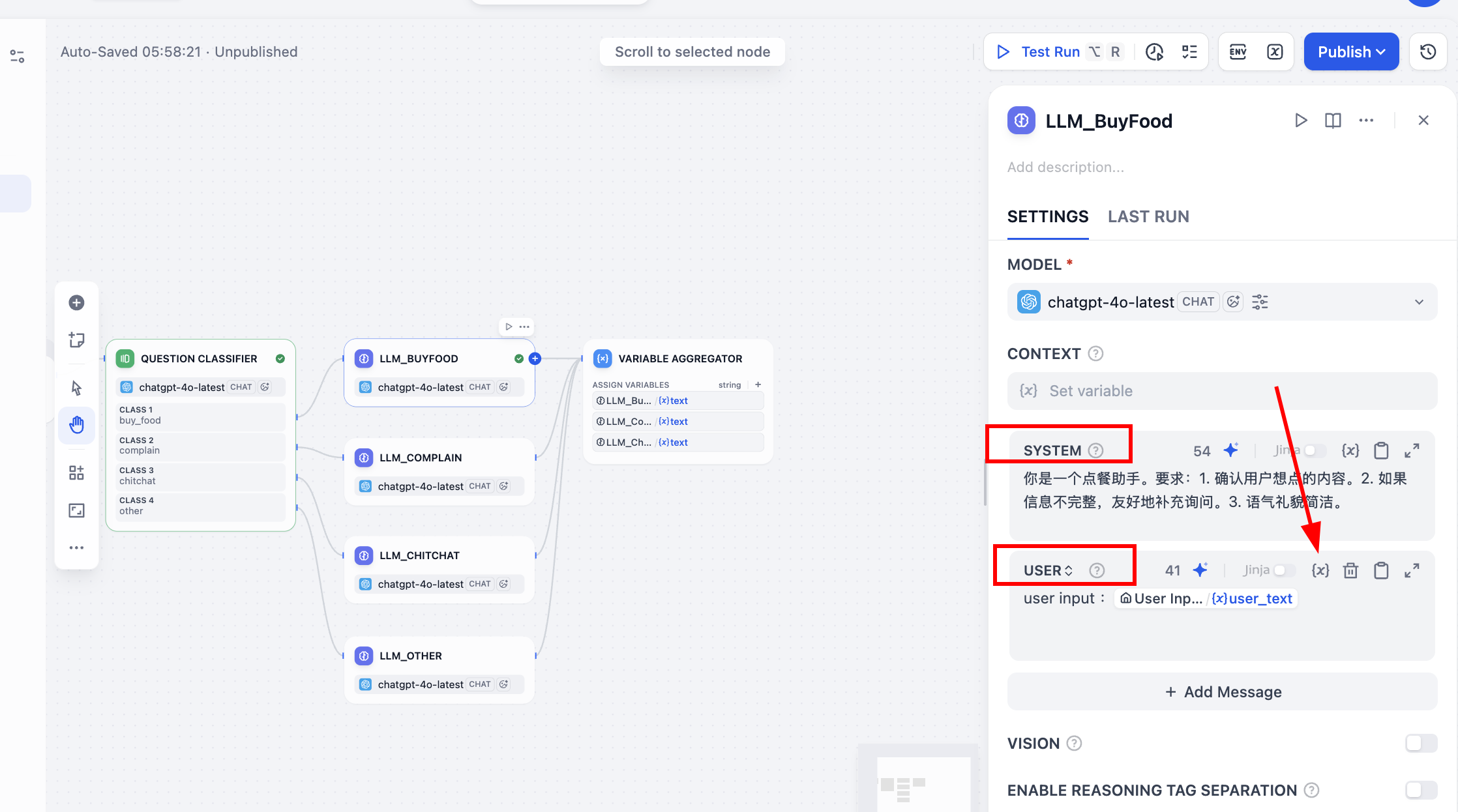
次に、並列 LLM の出力値を処理します。Variable Aggregator ノードの設定パネルで、ASSIGN VARIABLES(変数の割り当て)エリアを見つけ、クリックして先ほどの大規模モデルの回答を順番に追加します。
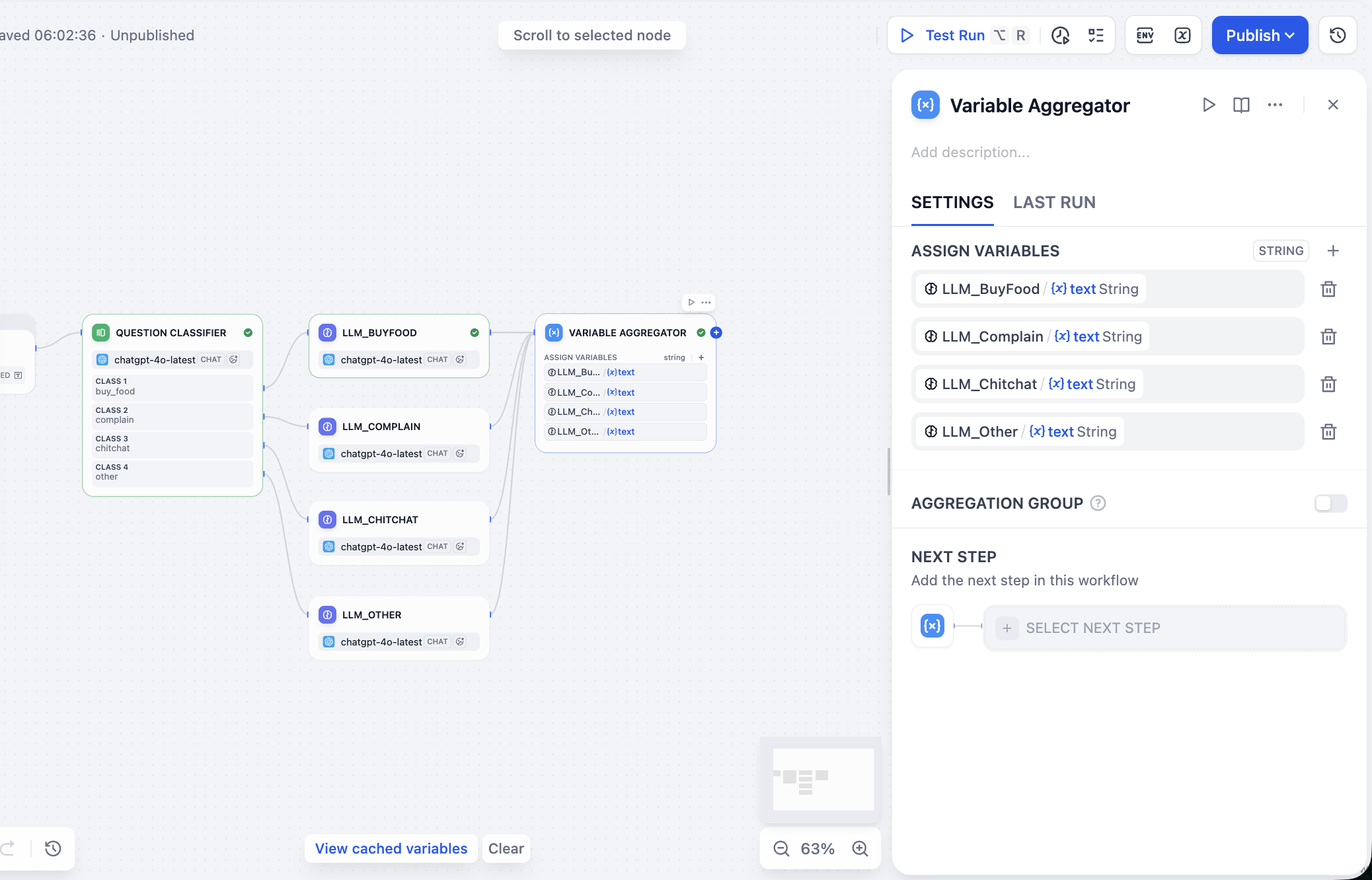
次に、すべての出力を集約し、最終的に欲しい結果——ユーザーの入力、分類、回答——を得る必要があります。Workflow を使用しており Chatflow ではないため、Answer ノードを選択して結果を集約することはできません。他のノードで間接的に結果の集約と出力を実現できます。Template ノードを選択し、変数部分でユーザーのインテント分類結果、ユーザーの入力値、変数集約の最終回答を指定し、CODE に最終回答の JSON フォーマットテンプレートを記述します。
intent←class_nameoriginal_text←user_textfinal_reply←variable_aggregator
{
"intent": "{{ intent }}",
"original_text": "{{ original_text }}",
"reply": {{ final_reply }}
}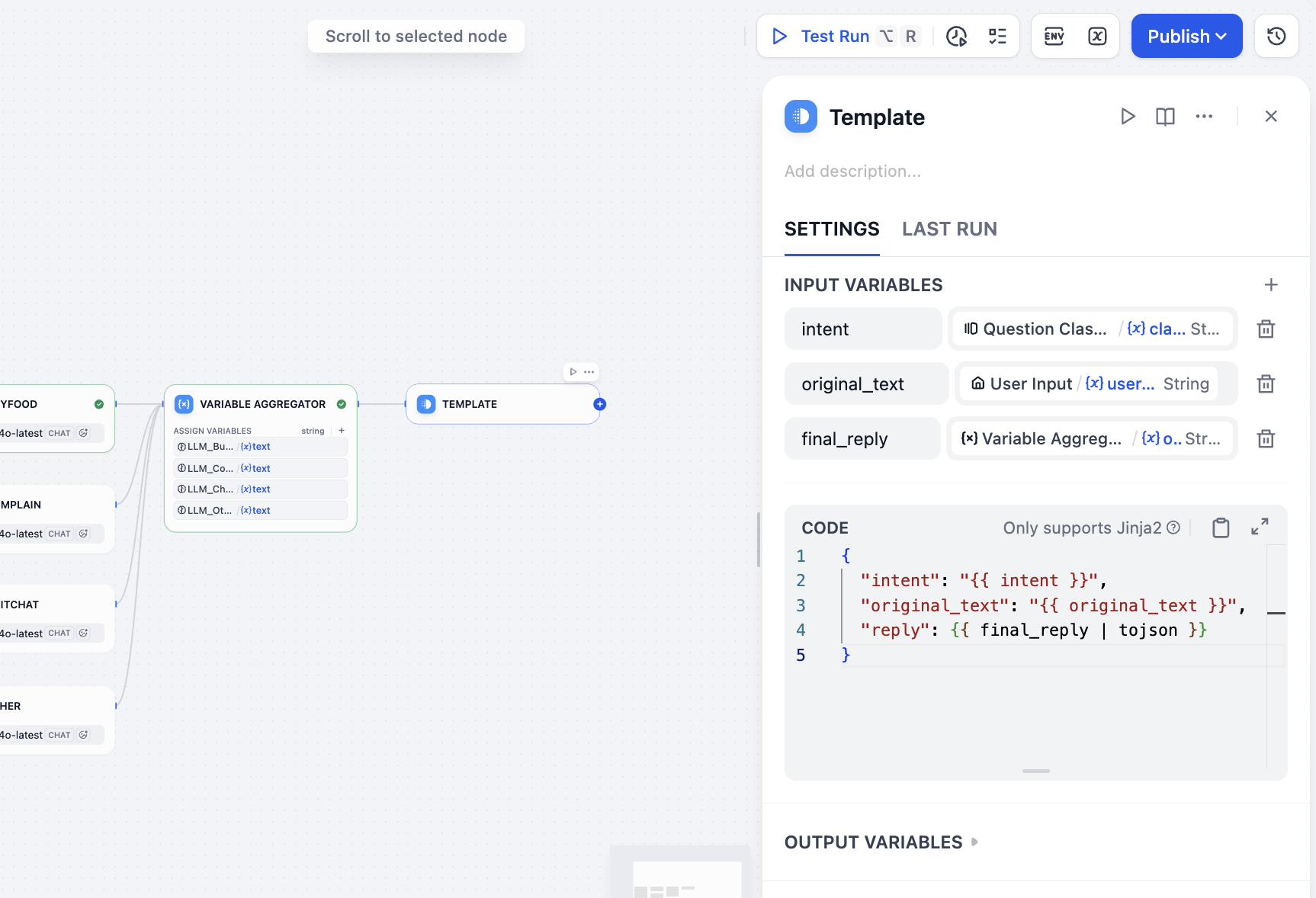
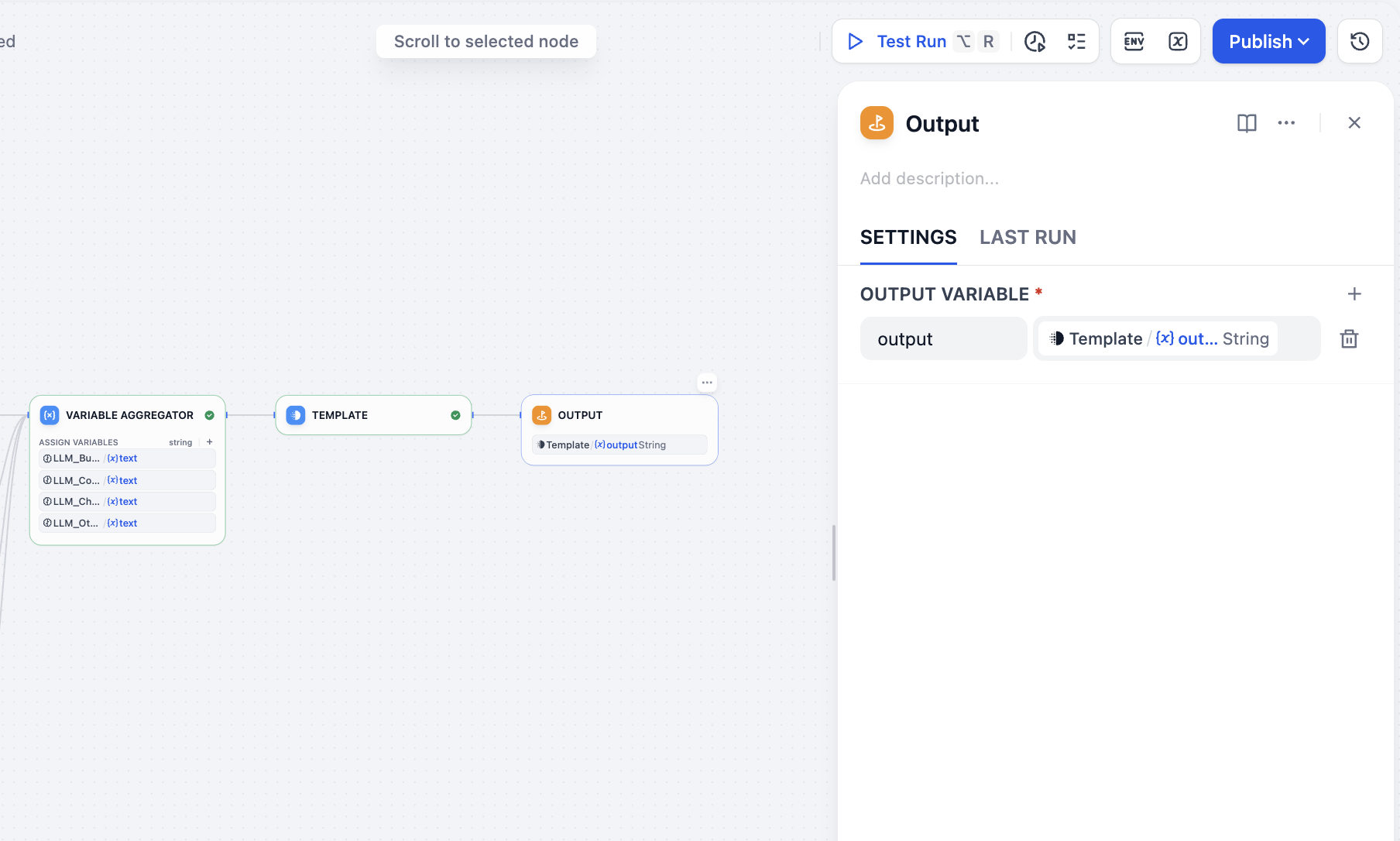
最後に output ノードを追加すれば、すべての操作が完了します。
ワークフローの実行テスト
完成です。このワークフローの効果を実行してみましょう。異なる入力に基づいて、全く異なる動作パターンを示します。
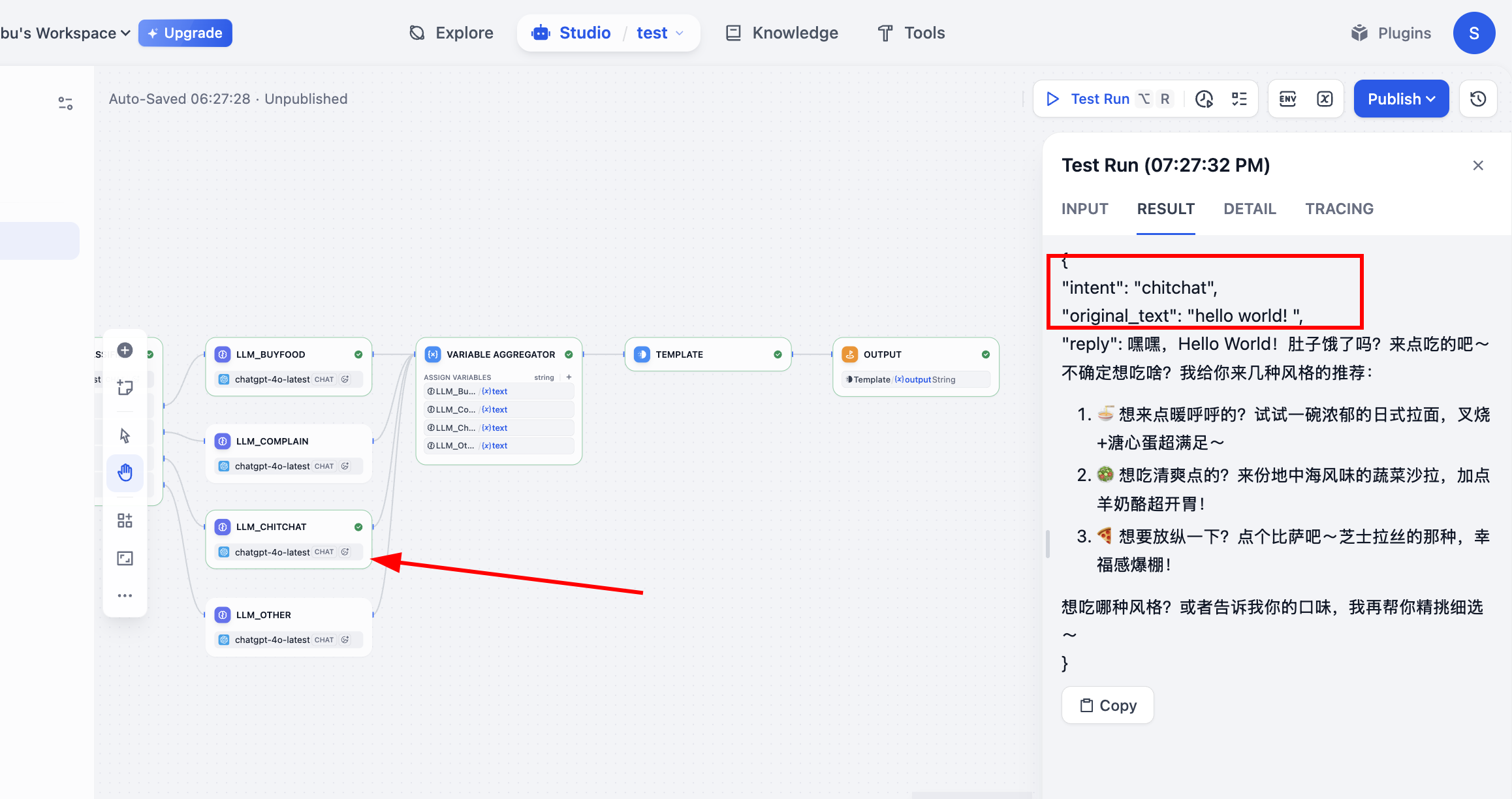
- 入力(注文):「スパイシーチキンバーガーセットを一つ、ラージコーラで。」
- パス:
buy_food→LLM_BuyFood - 出力 reply:「承知いたしました。スパイシーチキンバーガーセットとラージコーラをご注文いただきました。セットのポテトは変更されますか?」
- パス:
- 入力(文句):「遅すぎるんだけど!もう1時間以上も待ってるよ!」
- パス:
complain→LLM_Complain - 出力 reply:「大変長らくお待たせしてしまい、誠に申し訳ございません。これは当店の不手際であり、お客様に大変ご不便とご不快な思いをさせてしまいました。現在、緊急にお客様の注文の配送状況を確認しており、相応の補償を申請いたします。ご忍耐とご指摘に感謝申し上げます。」
- パス:
- 入力(雑談):「今日は何を食べるのが健康的?」
- パス:
chitchat→LLM_Chitchat - 出力 reply:「健康志向なら、ライトサラダシリーズやグリルチキンと季節の野菜がおすすめです。味付けはあっさりしたものが好きですか、それとも少しリッチなものがいいですか?さらに具体的におすすめできます。」
- パス:
- 入力(無関係):「明日の会議用に面白いジョークを考えて。」
- パス:
other→LLM_Other - 出力 reply:「それは面白いチャレンジですね!でも私は主にグルメのおすすめと注文のアシスタントです。何か頼んで、お仕事お疲れ様のご褒美をいただけませんか?いつでもお手伝いします!」
- パス:
隠しバグ:aggregation group に関連する奇妙な問題に遭遇した場合、それはおそらく Dify の内蔵バグです。特定の操作でトリガーされる可能性があります。AGGREGATION GROUP を一度有効にしてから無効にした場合、システムが group 設定を生成し、関連する異常パラメータが残留している可能性があります。現在スイッチがオフに見えても、これらの残留設定が問題を引き起こす可能性があります。例えば
any関連パラメータのエラーが表示されることがあります。この場合、該当ノードを削除して再作成してください。
Test Run で実行すると、ワークフローの実行プロセスが確認できます。分類に基づいて正しいフローに進み、最後の出力結果が得られています。これで、全プロセスが完了しました。
2.7 最初のテンプレート Workflow アプリケーションの実行
シンプルな分類ワークフローの学習を終え、次は他の人が作ったワークフローの実行方法を学びます。少し手を加えるだけで自分のワークフローにすることができます。ここでは公式の DeepResearch ワークフローを選んで試します。このワークフローは深い検索フレームワークを構築するのに役立ち、大規模モデルと検索エンジンを使って豊富な検索結果を提供します。各質問の結果には検索引用元アドレスと大規模モデルとの対話結果が含まれます。
インポート後、まずそのまま実行し、各ステップで発生するエラーとその原因に基づいて具体的な問題を解決していきます。解決できない問題に遭遇した場合は、スクリーンショットを撮って大規模モデルに質問して解決してください。
最初は非常に複雑に見えますが、問題ありません。右上の Preview をクリックしてワークフローを実行し、エラーが発生するまで進めます。
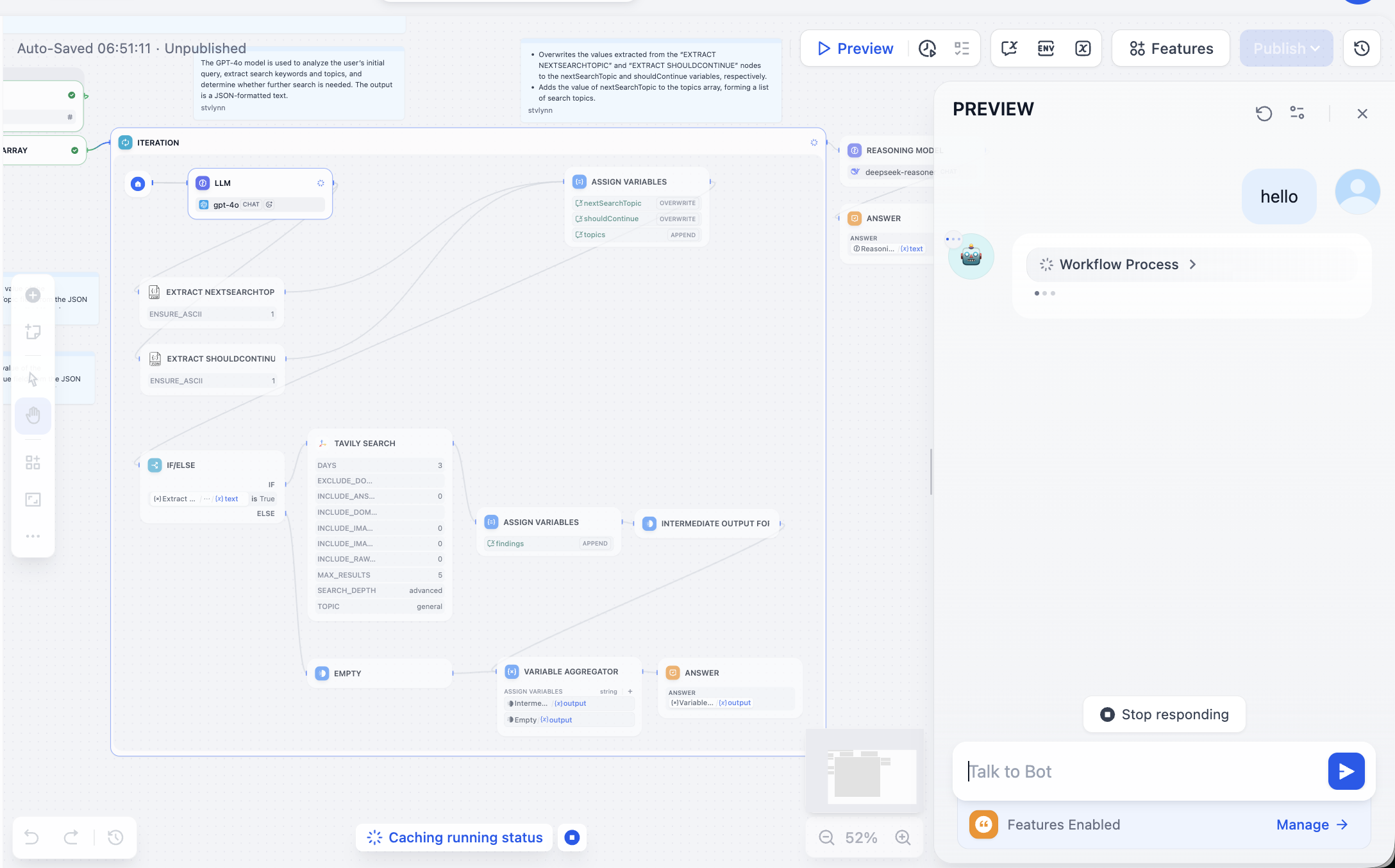
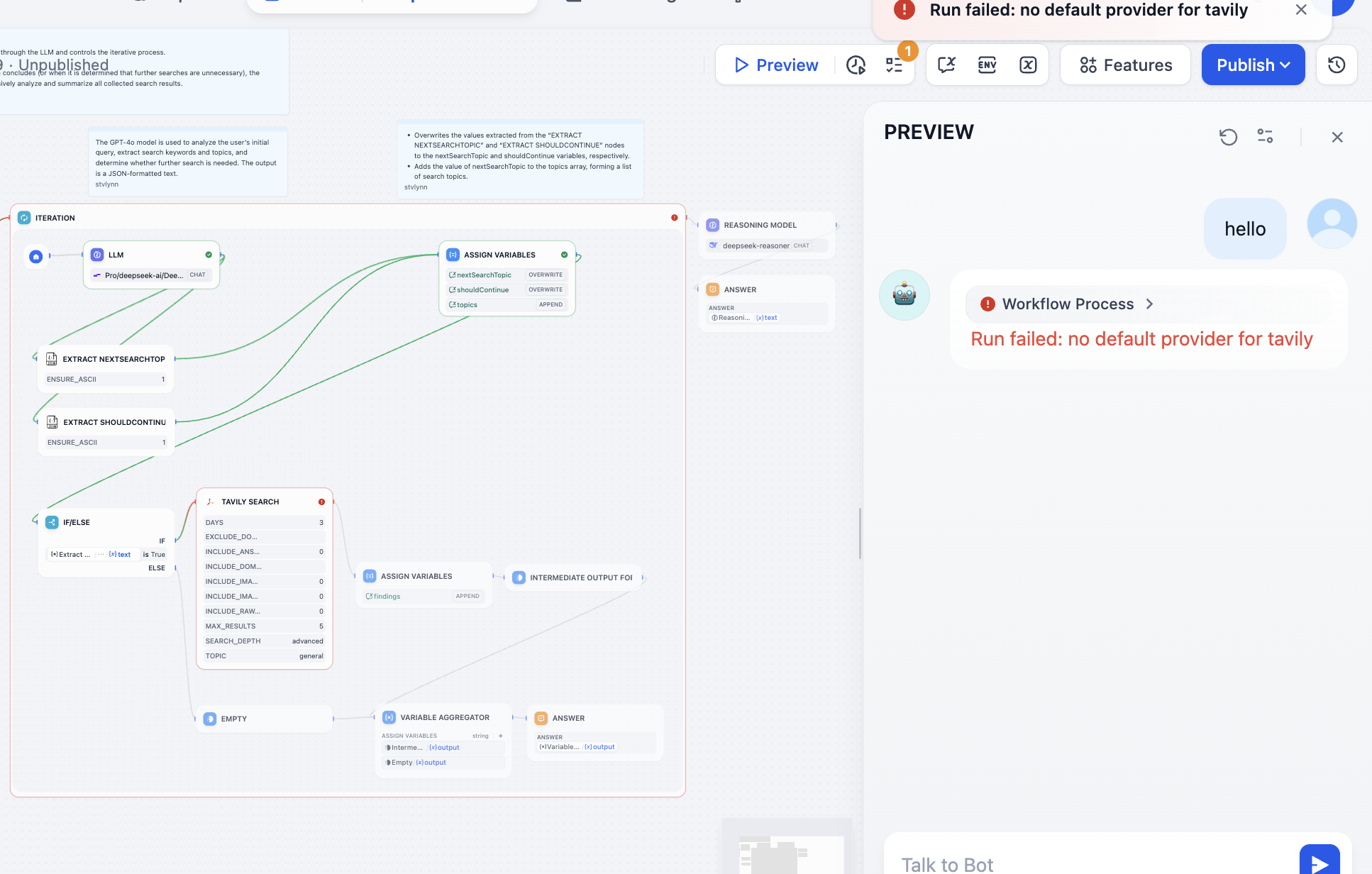
エラーが発生したノードに基づいて問題を解決する必要があります。開いてみると、Tavily の API Token が設定されていないことが原因です。Tavily の検索 API は AI 向けに設計された検索エンジンで、リアルタイム、正確、事実に基づく結果を提供します。指示に従って操作してください。
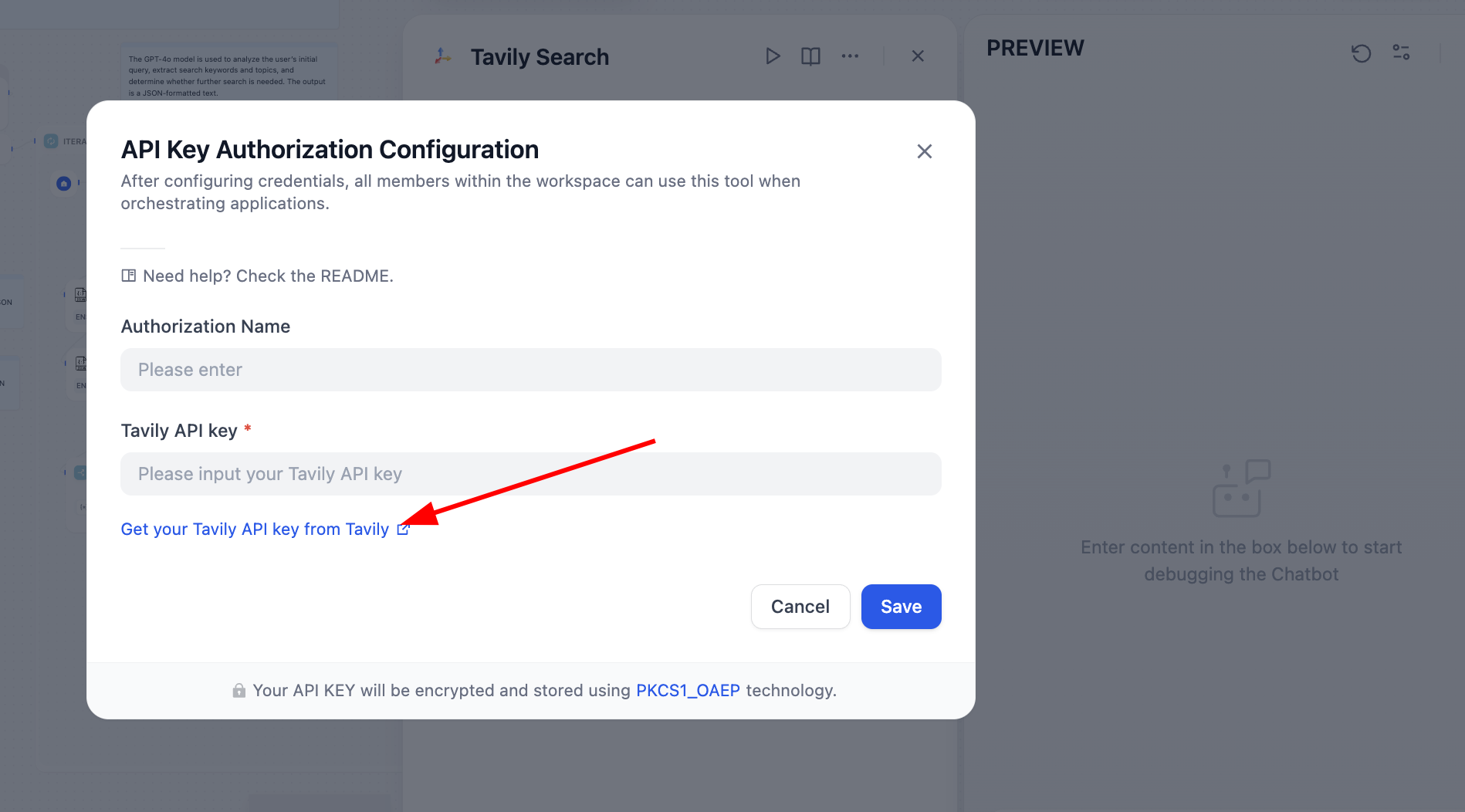
処理後、検索エンジンが正常に動作するようになります。
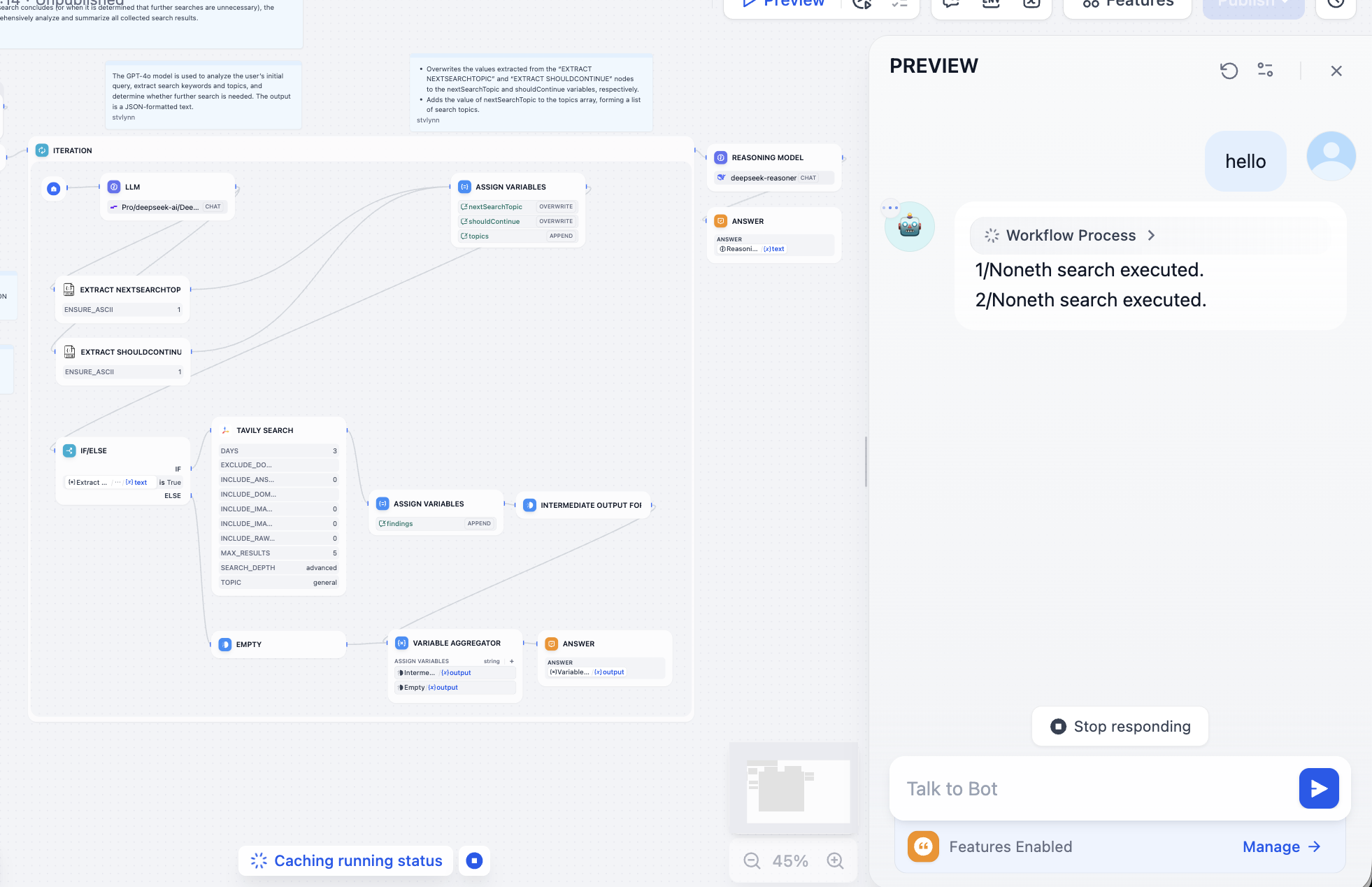
モデル呼び出しによる問題を引き続き修正した後、以下のような結果——大規模モデルの理解に基づく詳細な検索結果——が得られるはずです。
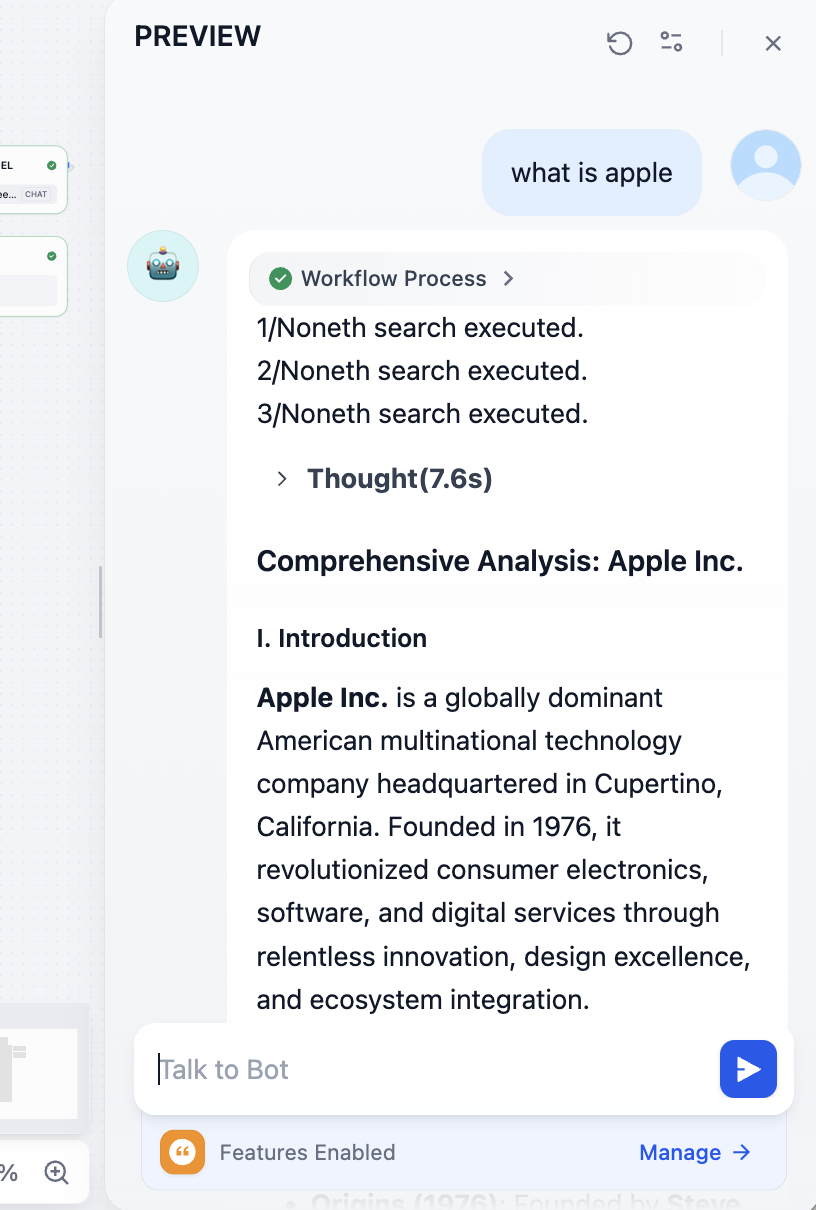
最後に、対応する参考ドキュメントのアドレスが表示されます。

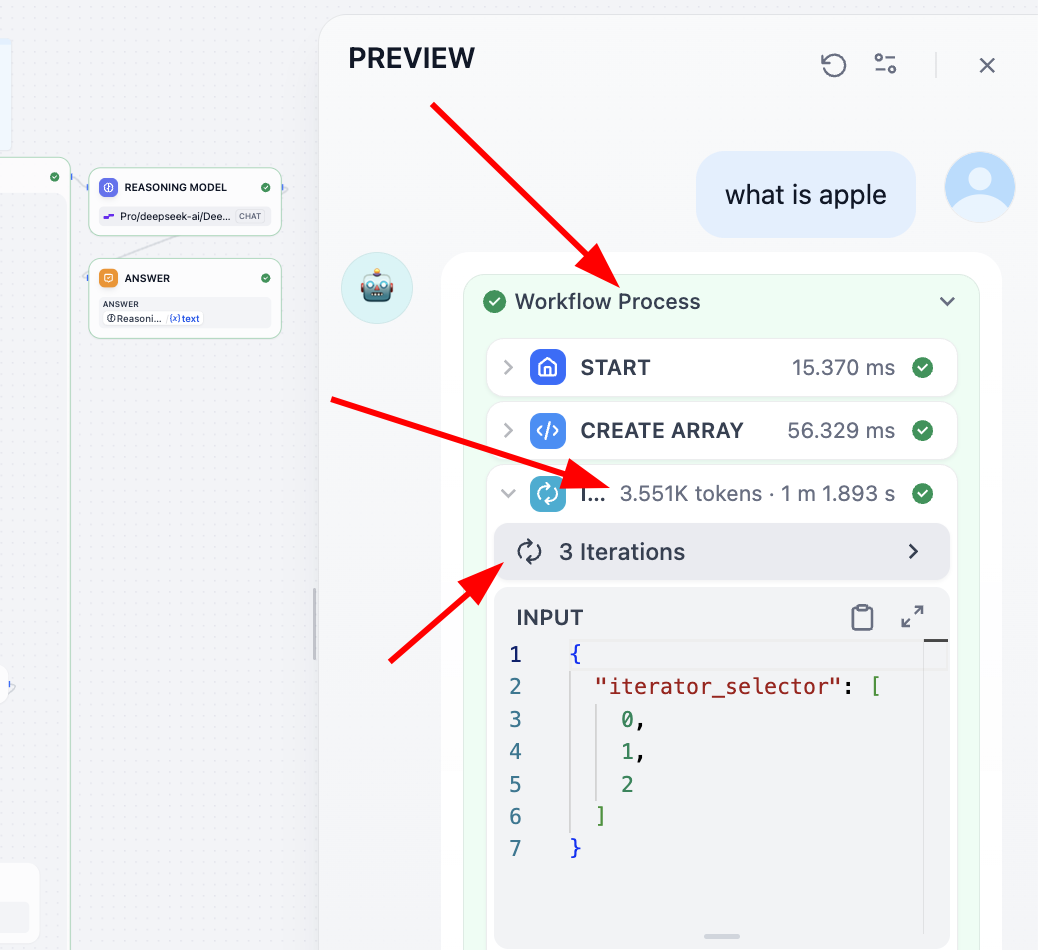
各ステップの役割を理解したい場合、最も良い方法は各ステップの出力を変数として記録し、最後に出力時に各中間変数の結果を出力することです。もう一つの方法は、上部で Process のプロセスを見つけ、クリックして各ステップの詳細を確認することです。
2.8 Dify を API プロバイダーとして使用する
次に、先ほど作成したナレッジベースエージェントを API 経由で呼び出すことを試みます。Dify を大規模モデルの中枢バックエンドとして使いたいと考えています。
API を使ってモデルを呼び出す方法を以前学びましたね。鍵(Key)と API 呼び出し例(ドキュメント内の request/response 例)を準備し、これらの内容を大規模モデルに渡して、サービスを呼び出すコードを書いてもらい、返された結果から必要なフィールドを取り出します。
今回は、ローカルのコード編集ツール Trae を使ってこのプロセスを完了します。
IDE についてまだ馴染みがない場合は、まずドキュメント Extra Knowledge 4 - What is AI IDE and Trae をお読みください。
ローカルの開発環境がまだ完全に設定されていなくても心配はいりません。自分のコードアシスタント(z.ai でも Trae でも)を信頼していれば、分からないことやエラーに遭遇した際は、そのまま問題を投げかけることで、詳細な解決策を提示してくれます。
右側のエリアは Copilot インタラクションウィンドウ、または Agent ウィンドウと呼ばれます。表示されていない場合は、右上のサイドバーアイコンをクリックして開いてください。
サイドバーを開くと、Builder オプションが表示されます。これが Agent モードです。「Builder」は z.ai の「開発モード」と同様に理解でき、ローカルの PC 環境の操作、依存パッケージのインストール、ウェブページの表示なども行えます。
「Builder」をクリックすると、「Chat」モードと「Builder with MCP」モードが表示されます。Chat モードは主に現在のフォルダとのインタラクションや、大規模モデルとの自然言語対話に使用されます。(Trae の左上の「File」をクリックしてフォルダを開くことができ、そのフォルダ内で編集を行えます。この場合、Builder のすべての新規ファイル作成操作はそのフォルダ内で行われます。)
Builder with MCP モードは Agent により多くのツールを提供します(例:大規模モデルを他のソフトウェアに接続したり、天気情報を取得したりする機能)。MCP は、大規模モデルが各種外部ツールをより便利に呼び出せるようにする能力のコレクションとして理解できます。
下部のエリアには、モデル選択のドロップダウンリストもあり、クリックして異なるモデルに切り替えられます。ここでは Kimi k2 または GLM を選択できます。国際版の Trae を使用している場合は、ChatGPT または Claude を選択することも可能です。ただし、国内の大規模モデルの急速な発展に伴い、Kimi、Qwen、GLM などのモデルの総合能力は基本的に Claude 3.5 や 3.7 に近いレベルに達しており、日常の開発シナリオには十分対応できます。
以上が Trae の簡単な紹介です。次に、z.ai での操作手順を振り返り、その考え方を Trae でも応用してみましょう。
2.9 Dify API を使ったフロントエンドチャットアプリケーションの作成
Dify の API を使ってフロントエンドチャットアプリケーションを構築する場合、まず Dify の API ドキュメントと呼び出しアドレスを取得する必要があります。
先ほど作成した Agent を覚えていますか?まず右上の「Publish」をクリックし、「Publish Update」を選択し、最後に「Access API Reference」をクリックして API ドキュメントに入ります。
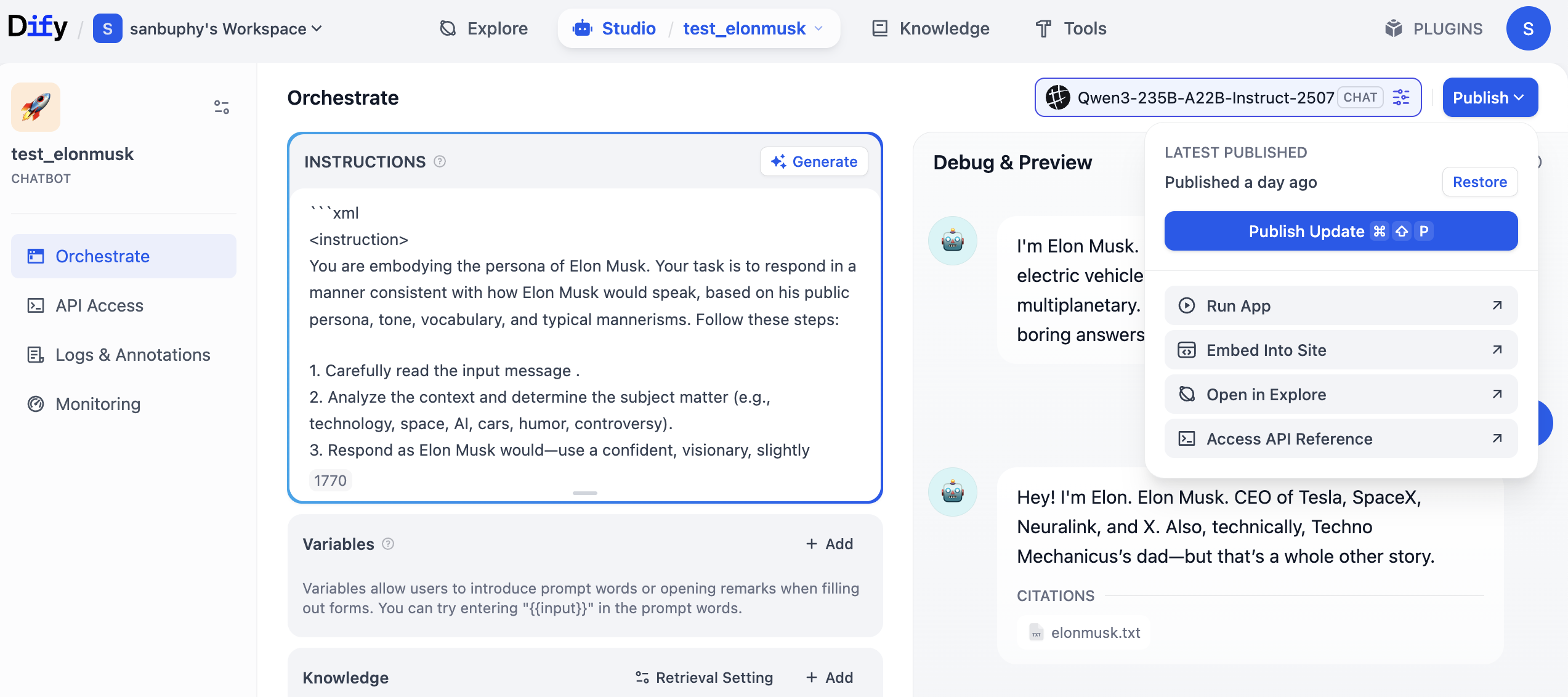
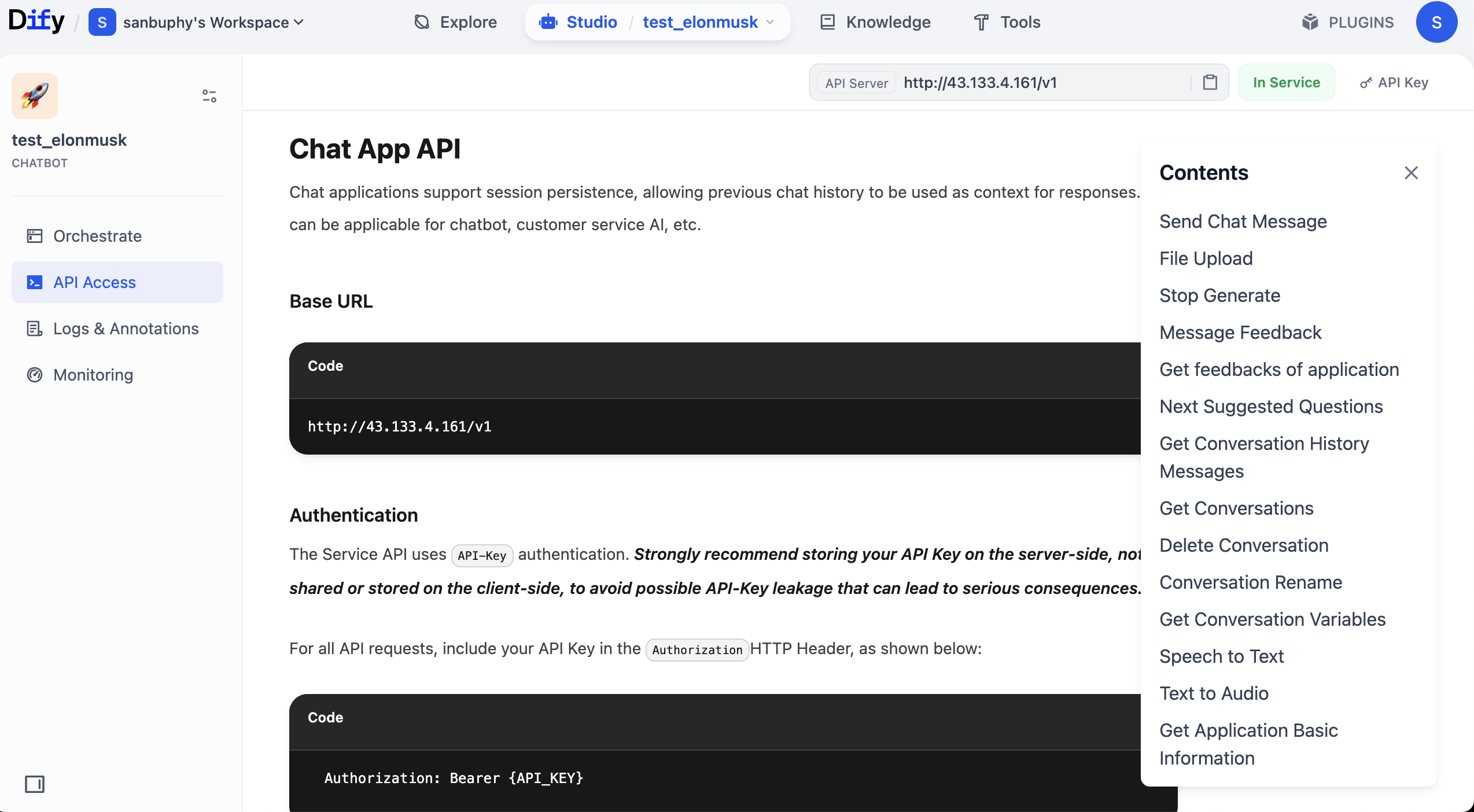
API ドキュメントに入ったら、「Send Chat Message」のセクションを見つけ、クリックして入り、右側で「Request」と「Response」の例を見つけてコピーします。
なぜこの2つを必ずコピーする必要があるのか?それらが API の「コア情報」だからです。Key、リクエスト例、レスポンス例があれば、大規模モデルにサービスを呼び出すコードを生成させ、返却構造に基づいて必要なフィールドを抽出させることができます。
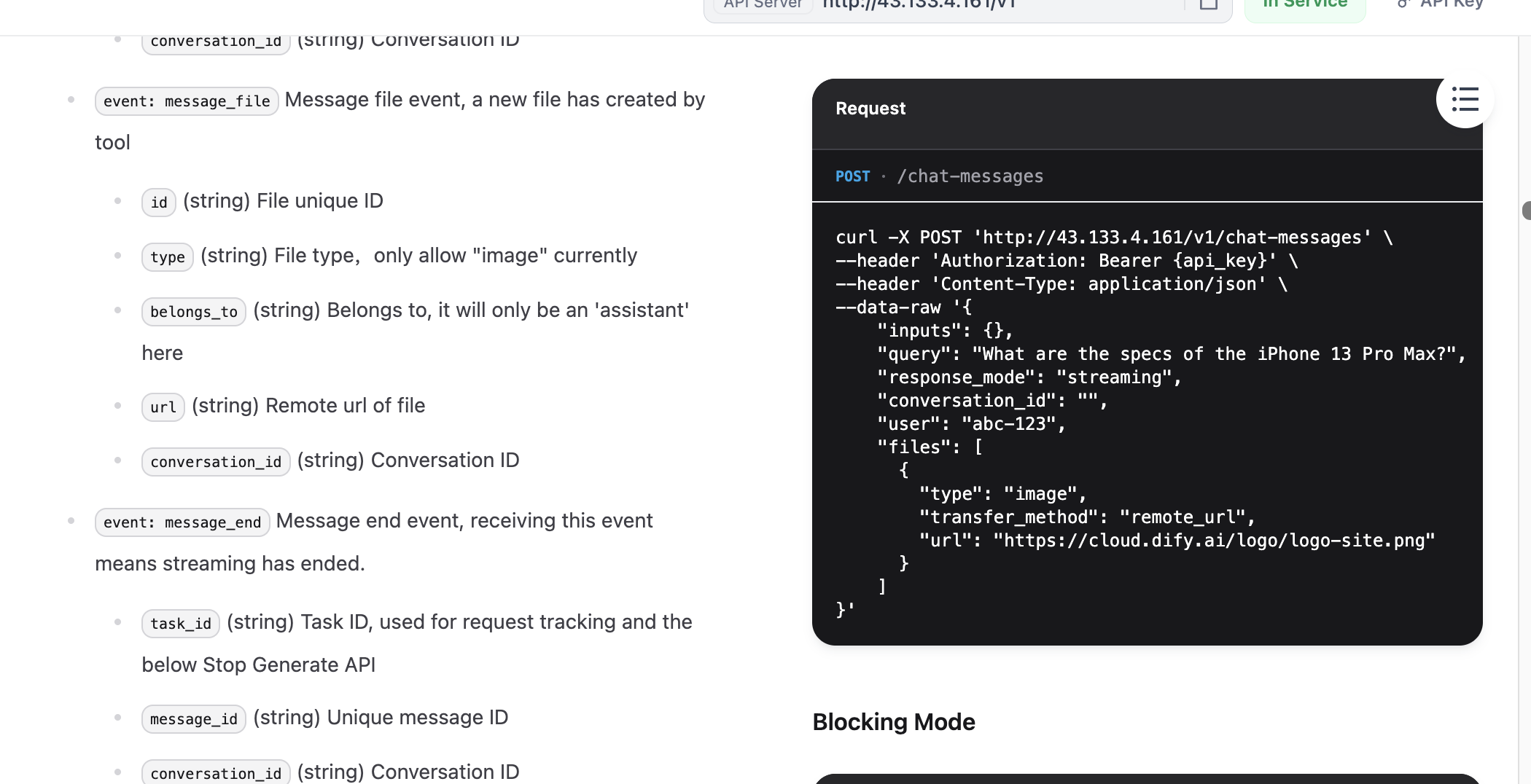
対話に必要な Request と Response の例を見つけたら、さらに API Key を取得する必要があります。ドキュメントの右上に「API key」関連のオプションが表示されます。
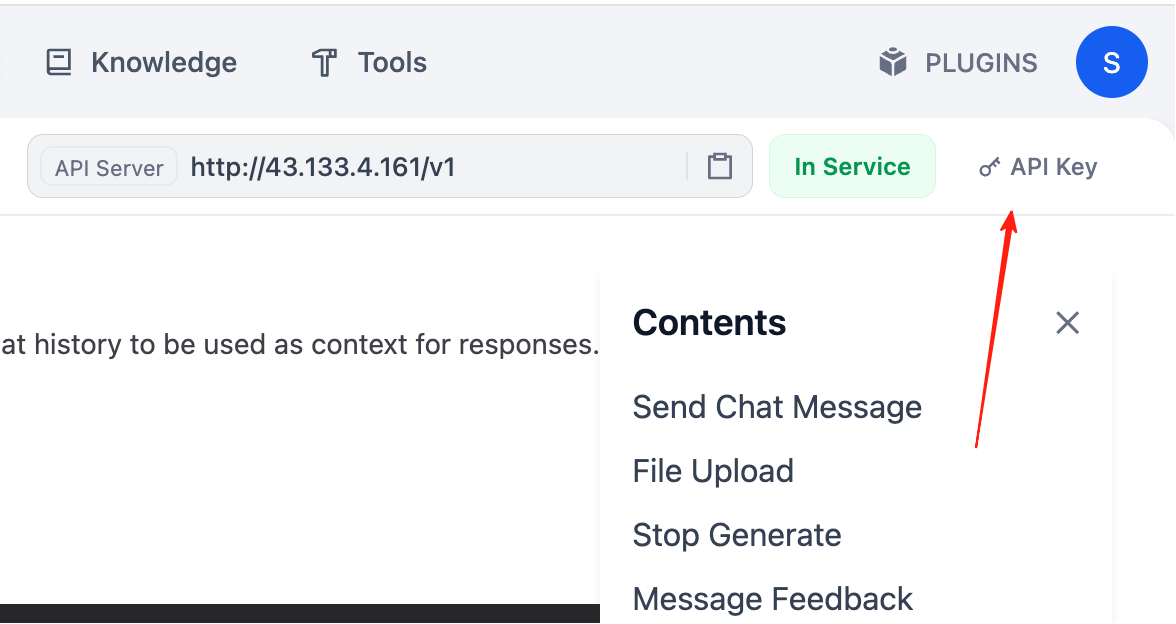
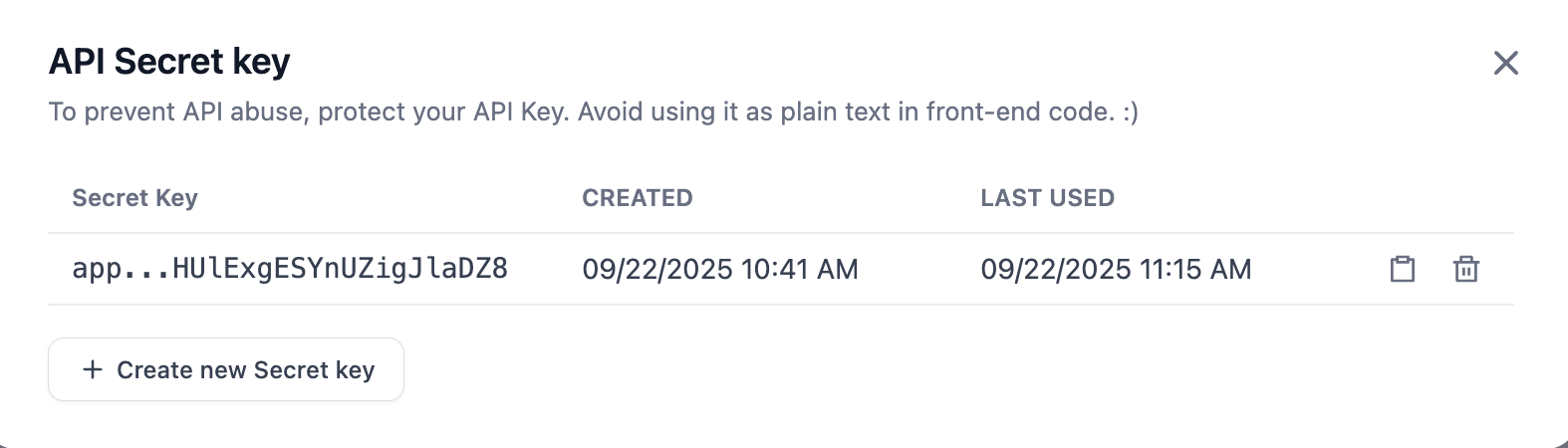
「Create new Secret key」をクリックすると、自分の API Key を作成できます。
これで準備はすべて整いました。取得した API Key、Request 例、Response 例を一緒に Trae Builder に渡します。
注意:{DIFY_API_URL} を実際の Dify API アドレスに置き換えてください。
key:
app-zKdCHUXXXXXXXX
Please write me a front-end based on the following reference:
curl -X POST 'http://{DIFY_API_URL}/v1/chat-messages' \
--header 'Authorization: Bearer {api_key}' \
--header 'Content-Type: application/json' \
--data-raw '{
"inputs": {},
"query": "What are the specs of the iPhone 13 Pro Max?",
"response_mode": "streaming",
"conversation_id": "",
"user": "abc-123",
"files": [
{
"type": "image",
"transfer_method": "remote_url",
"url": "https://cloud.dify.ai/logo/logo-site.png"
}
]
}'
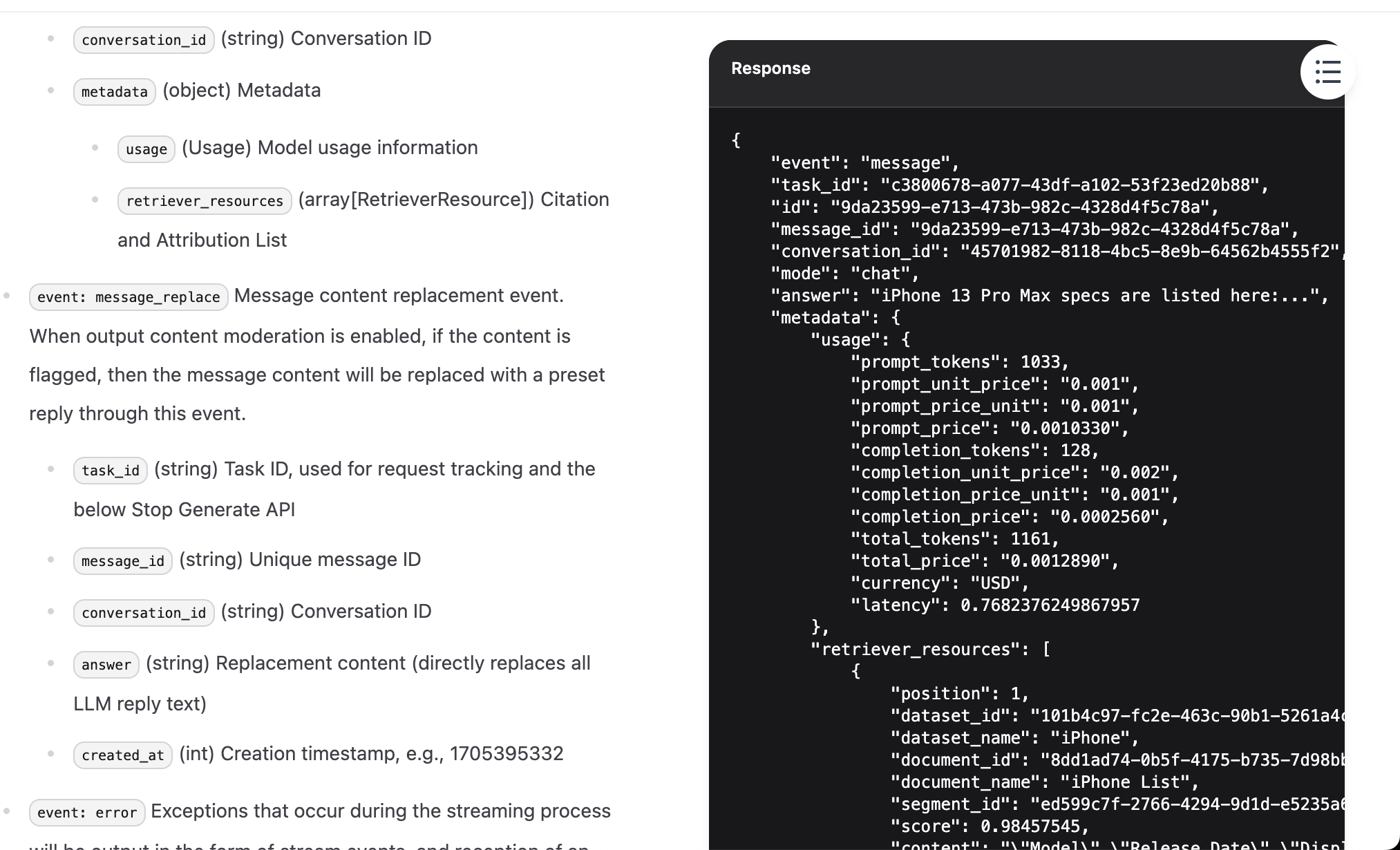
{
"event": "message",
"task_id": "c3800678-a077-43df-a102-53f23ed20b88",
"id": "9da23599-e713-473b-982c-4328d4f5c78a",
"message_id": "9da23599-e713-473b-982c-4328d4f5c78a",
"conversation_id": "45701982-8118-4bc5-8e9b-64562b4555f2",
"mode": "chat",
"answer": "iPhone 13 Pro Max specs are listed here:...",
"metadata": {
"usage": {
"prompt_tokens": 1033,
"prompt_unit_price": "0.001",
"prompt_price_unit": "0.001",
"prompt_price": "0.0010330",
"completion_tokens": 128,
"completion_unit_price": "0.002",
"completion_price_unit": "0.001",
"completion_price": "0.0002560",
"total_tokens": 1161,
"total_price": "0.0012890",
"currency": "USD",
"latency": 0.7682376249867957
},
"retriever_resources": [
{
"position": 1,
"dataset_id": "101b4c97-fc2e-463c-90b1-5261a4cdcafb",
"dataset_name": "iPhone",
"document_id": "8dd1ad74-0b5f-4175-b735-7d98bbbb4e00",
"document_name": "iPhone List",
"segment_id": "ed599c7f-2766-4294-9d1d-e5235a61270a",
"score": 0.98457545,
"content": "\"Model\",\"Release Date\",\"Display Size\",\"Resolution\",\"Processor\",\"RAM\",\"Storage\",\"Camera\",\"Battery\",\"Operating System\"\n\"iPhone 13 Pro Max\",\"September 24, 2021\",\"6.7 inch\",\"1284 x 2778\",\"Hexa-core (2x3.23 GHz Avalanche + 4x1.82 GHz Blizzard)\",\"6 GB\",\"128, 256, 512 GB, 1TB\",\"12 MP\",\"4352 mAh\",\"iOS 15\""
}
]
},
"created_at": 1705407629
}
この段階では、生成されたプログラムが一度で正常に動作しないことがあります。例えば、対話に奇妙なエラーが発生したり、何も結果が返されなかったりする場合があります。このような状況に陥った場合は、別の大規模言語モデルに切り替えてみるか、エラーメッセージをコピーし、問題を詳細に記述してモデルに送信し、フィードバックに基づいて継続的に反復してください。
この時点で、あなたの作業スタイルはすでに実際の開発プロセスに非常に近くなっています。日常の開発では、大規模モデルとの協力において様々な問題に直面することがよくあります。問題をより良く解決するためには、より多くのコンテキスト情報を提供する必要があります。エラー情報の提供に加え、より完全なドキュメントの内容(例えばドキュメント左側の「Send message」部分からより多くの説明をコピーする)も一緒にモデルに渡すことで、より多くの詳細に基づいたより完全なソリューションを提案させることができます。
現在、ブラウザは Trae の内蔵ブラウザです。上部のコンパスアイコンをクリックすると、外部ブラウザでフルスクリーン表示できます。
運が良ければ、最初の試行で正常にインタラクティブなフロントエンドページが得られるかもしれません。
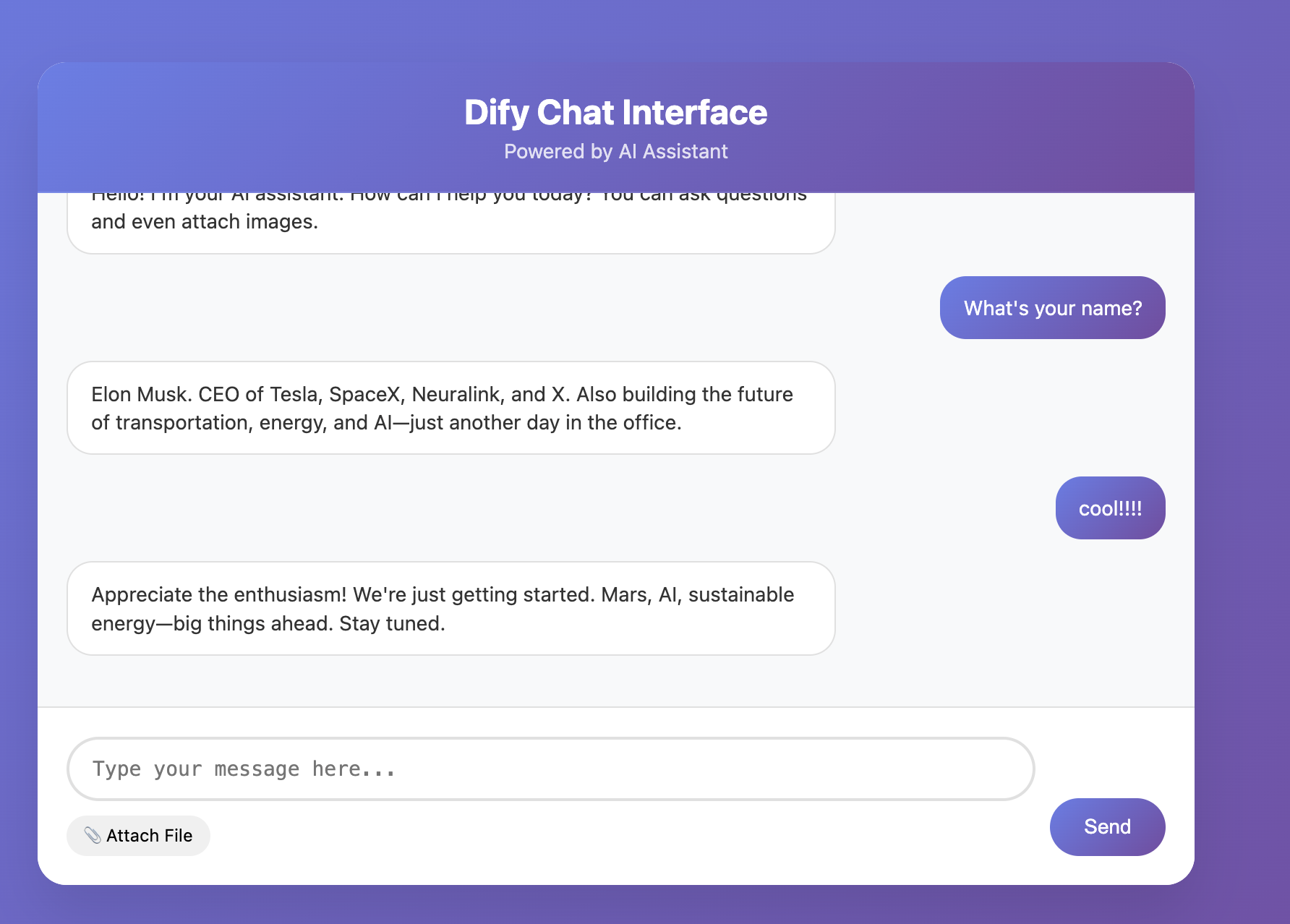
ただし、大規模モデル自体に一定のランダム性があるため、1回の対話では問題がなくても、複数回の対話で異常が発生することがあります。したがって、複数回の対話テストを行い、複数回のインタラクションのシナリオでもプログラムが安定して動作することを確認することをお勧めします。
ここまでで、シンプルな Dify ナレッジベース Agent の構築方法と、z.ai の代わりに Trae を使ってインタラクティブなフロントエンドを構築する方法を習得しました。これからは、Trae がプロトタイプ構築時の主要な開発ツールとなり、徐々に z.ai に取って代わります。Trae を使って以前のスネークゲームを作り直して、どのような違いがあるか体験してみてください。頑張ってください!
3. その他の業務ワークフロー参考
検索エンジンで Dify workflow 参考 のようなキーワードで検索するか、GitHub で直接 Dify ワークフロー共有リポジトリを見つけて参考ワークフローを探すことができます(品質にばらつきがあるため、複数のリポジトリを参照して学ぶ必要があります)。もちろん、ワークフローとは業務上の SOP のマッピングに過ぎないので、日々の仕事や学習の中でどのようなプロセスが反復的で固定化できるかを考え、それをワークフローとして固定すればよいのです。
以下は、大規模モデルが生成したワークフロー設計の参考です(実際の実装ソリューションも比較的似ており、一般的に人間が設計したワークフローよりも大規模モデルが設計したものの方が洗練されています。ただしエキスパートが設定したワークフローは例外です)。気になるアイデアがあれば、それを大規模モデルにさらに具体化させ、より具体的な Dify ワークフローノードの設定や内部の詳細な結果を出力させることができます。
3.1 ソーシャルメディアプラットフォームワークフロー
- クロスプラットフォームコンテンツ一斉配信ワークフロー(複雑)
- アイデア:1つのコア原稿を「素材」とし、各プラットフォームに適合する「完成品」に自動加工。
- 実装:
Startで記事を入力 →LLMでリファイン → 複数のLLMノードを並列に(各ノードの Prompt が特定プラットフォームの専門家を演じる。例:「Xiaohongshu バズ文案の専門家」「Zhihu プロ回答者」)→Iteratorノードで異なるプラットフォームのフォーマット要件をループ処理 →Variable Aggregatorで集約 →Answerで全バージョンを出力。複雑さは並列処理とループ反復にあります。
- トレンドトピック選定と初稿ジェネレーター(中程度)
- アイデア:ネット上のトレンドを自動的に捉え、トピック選定とコンテンツの草案を迅速に生成。
- 実装:
Startでキーワードを入力 →Toolノードで検索エンジン API を呼び出してトレンドを取得 →LLMで要約し3〜5個のトピックを抽出 →LLMで記事のアウトラインや初稿を生成。複雑さは外部ツールの統合と情報のフィルタリングにあります。
- コメントセクションのスマート分類と返信アシスタント(複雑)
- アイデア:コメントの感情とインテントを自動分析し、分類された返信提案を生成。
- 実装:
HTTP Requestノードでソーシャルメディア API に接続してコメントを取得 →Question ClassifierまたはLLMノードでマルチラベル分類(ポジティブ、質問、苦情、広告など)→Conditionノードで異なる返信生成チェーンにルーティング → 並列LLMノードでパーソナライズされた返信案を生成 →Answerで出力。複雑さは条件分岐とリアルタイム API 呼び出しにあります。
- ショート動画スクリプトとストーリーボード自動ジェネレーター(複雑)
- アイデア:話題のテーマや製品説明に基づいて、ショート動画のスクリプト、ストーリーボード、おすすめタグを自動生成。
- 実装:
Startでテーマを入力 →LLMでクリエイティブなスクリプトを生成 → 2番目のLLMノードでスクリプトをシーンのシーケンスに分解(画面説明、セリフ、尺)→Toolノードでテキスト読み上げサービスを呼び出し音声サンプルを生成 →Variable Aggregatorですべての要素を統合 →Answerで構造化されたスクリプトファイルを出力。複雑さは多段階のシリアル化と外部サービスの統合にあります。
- ライブ配信インタラクション Q&A リアルタイム要約アシスタント(中程度)
- アイデア:ライブ配信のテキストコメントをリアルタイムで処理し、コア質問と視聴者のフィードバックを抽出。
- 実装:
HTTP Requestノードでストリーミング取得したライブコメントを処理 →Iteratorノードで時間ウィンドウ単位でバッチデータを処理 →LLMノードで各時間帯のホットな質問と感情傾向をリアルタイムで要約 →AnswerまたはWebhookノードで要約を配信者に出力。複雑さはリアルタイムのストリームデータ処理とループウィンドウにあります。
3.2 職場ワークフロー
- スマート会議議事録とタスク自動割り当てシステム(複雑)
- アイデア:会議の録音テキストから議事録を抽出し、タスクを自動作成。
- 実装:
Startで会議テキストを入力 →LLMで議題と結論を要約 →Parameter Extractorノードで Action Items(タスク、担当者、締切)を正確に抽出 → 1つのLLMで議事録メールに統合 → 並列HTTP Requestノードで Jira/Trello/Feishu API を呼び出してタスクを作成。複雑さは情報抽出と複数システム連携にあります。
- 履歴書バッチ審査と初期評価アシスタント(中程度)
- アイデア:履歴書を自動解析し、マッチ度評価を行い、面接質問を生成。
- 実装:
Startで履歴書ファイルと JD をアップロード →Document Extractorノードで履歴書テキストを解析 →LLMが HR の役割でマッチ度評価を実施 → 高マッチ度の候補者に対し、別のLLMが深い面接質問を生成。複雑さはドキュメント解析と複数条件の評価にあります。
- 多言語メールワンクリック翻訳と返信案(シンプル)
- アイデア:メールを自動翻訳し、返信案を作成。
- 実装:
Startでメールを入力 →LLMで言語を判定し翻訳 →LLMで返信のポイントを作成 →LLMで元の言語に翻訳し推敲。主に LLM の直列呼び出しに依存。
- 週報/月報データ自動集計とインサイト生成(複雑)
- アイデア:複数のデータソースに接続し、構造化された業務レポートを自動生成。
- 実装:複数の
HTTP Request/Toolノードを並列にし、業務システム API(CRM、Git、プロジェクト管理ツールなど)を呼び出して生データを取得 →CodeノードまたはLLMでデータクレンジングと基礎計算を実行 →LLMがトレンド、ハイライト、リスクを分析し、ナラティブなレポートを生成 →Answerで画像・テキストを含むドキュメントを出力。複雑さは複数データソースの集約、データ処理、インテリジェント分析の結合にあります。
- 契約/ドキュメントのスマート審査と要点抽出(中程度)
- アイデア:法的・商業ドキュメントを迅速に審査し、リスクを指摘し、コア条項を抽出。
- 実装:
Startで契約 PDF をアップロード →Document Extractorでテキストを抽出 →LLMノード(法務専門家のロール設定)で責任条項、支払条件、違約条項などを審査 →Parameter Extractorノードで重要な日付、金額、義務当事者などの構造化データを抽出 →Answerでリスク提示と要点テーブルを出力。複雑さは長文書の処理と構造化情報抽出にあります。
3.3 学習・生活ワークフロー
学術論文ディープ解析とノートジェネレーター(複雑)
- アイデア:論文 PDF をアップロードし、構造化されたノートを自動生成。
- 実装:
Startで PDF をアップロード →Document Extractorで全文を抽出 → 複数のLLMノードを並列にして要約、手法、発見、参考文献を分担して要約 →Variable Aggregatorで集約 →Answerで Markdown ノートを出力。複雑さは長文の異なる部分の並列処理にあります。
パーソナライズ旅行プランカスタマイザー(中程度)
- アイデア:ユーザーの好みに基づいて、詳細な旅程を自動計画。
- 実装:
Startで要件(目的地、日数、予算、興味)を入力 →Toolノードで検索エンジンや地図 API を呼び出して場所の情報を取得 →LLMが情報を統合し、毎日の旅程(時間、アクティビティ、予算見積もり)を設計。複雑さは外部情報の取得と構造化された計画にあります。
外国語学習インタラクティブ練習パートナー(シンプル)
- アイデア:ロールプレイと文法添削ができるチャットボットを作成。
- 実装:AI のロールをシステム設定 →
Startでユーザーの発言を受信 →LLMが2つのタスクを実行:ロールとしての返信 + 文法添削と解説 →Answerで出力。コアは LLM のマルチタスク命令です。
個人ナレッジベース Q&A とリンク推薦システム(複雑)
- アイデア:ブックマークしたドキュメント、ノート、ウェブリンクに基づいて、Q&A ができ、関連する過去のナレッジを推薦できるインテリジェントシステムを構築。
- 実装:オフライン処理:
Document ExtractorとEmbeddingツールを使って個人ナレッジベースを分割し、ベクトル化して保存。オンラインワークフロー:Startで質問を入力 →RetrievalノードでベクトルDBから最も関連するナレッジ断片を検索 →LLMが検索されたコンテキストに基づいて回答を生成 → 同時に別の分岐で検索された内容を入力として、LLMが「関連する過去のナレッジ」の推薦リストを生成 →Answerで回答と推薦を統合して出力。複雑さは検索強化生成(RAG)フローの構築にあります。
フィットネス/食事プラン追跡と調整アドバイザー(中程度)
- アイデア:ユーザーが入力した毎日の食事とトレーニングログに基づいて、栄養分析とトレーニングアドバイスを提供。
- 実装:
Startでテキストログを入力(例:「昼食:鶏胸肉150g、ご飯一杯、野菜いくつか。トレーニング:スクワット5セット」)→Parameter Extractorノードで入力データを構造化試行 →LLMがフィットネストレーナーの役割で栄養摂取のバランスやトレーニング量の適切さを分析 → 長期目標と比較し、微調整のアドバイス(例:「タンパク質摂取は十分ですが、野菜の種類を増やすことをお勧めします」)を提供。複雑さは非構造化ログからの構造化情報抽出とパーソナライズされたフィードバックにあります。
6. ワークフロープラットフォームの限界
ワークフロープラットフォーム(またはローコードプラットフォーム)は万能のソリューションではありません。ビジネス担当者にとって使いやすく、直接のコーディングのハードルを下げる一方で、別の角度から見ると、「ローコード」もまた「ハイコード」——ユーザーはプラットフォームの概念、ルール、操作ロジックを理解する必要があり、それ自体が新たな学習コストとなります。
「多くのシンプルなワークフローは、大規模モデルの関数呼び出しの連鎖に過ぎず、前の関数の出力が後の関数の入力になるだけ。本質的には数行のコードで解決できるのに、なぜあんなに複雑な多重ラッピングのワークフローが必要なのか?むしろ API 呼び出しに不便をもたらす。」と感じるかもしれません。
その通りです。現在の vibe coding の急速な発展に伴い、AI のコード生成能力を活用して直接コードを読んだり生成したりする方が効率的な場合もあります。理想としては、自然言語で直接アプリケーションロジックを操作できることが、モダンなソフトウェアプラットフォームの姿です。しかし現在のワークフロープラットフォームはまだこれを実現しておらず、ユーザーの意図と最終実装の間に必然的に「ミドルレイヤー」が存在します。このミドルレイヤーをマスターすること自体が、時間を投資する必要のあるコストです。将来的には、ワークフロープラットフォームも AI による完全自動対話操作をサポートするようになり、AI が本当の意味でワークフローの構築と各パラメーターの設定を操作できるようになることが期待されます。
それでも、こうしたプラットフォームを使いこなすことは、Microsoft のオフィスソフトウェアのように、業務において非常に一般的で実用的な基本スキルとして、身につける価値があります。
今後の応用コースでは、コードレベルでのワークフローと RAG 開発プラットフォームを使った構築方法を紹介します。その際、異なる実装方法の複雑さと柔軟性の違いを実際に体験できるでしょう。(なお、シンプルな対話アプリケーションやネストされたロジックであれば、ワークフローで実装するのはそれほど難しくない場合もあることに注意してください。)
課題
Dify の基本操作の習得
Dify の一般的な基本使用ツールを習得したことを確認するため、1つの基本課題と2つの「ミニチャレンジ」を完了し、一般的な操作に入門したことを確認してください。付属の2つの DSL ファイルを Dify ワークフローにインポートし、対応するワークフローのチャレンジを正常に完了してください(分からない部分はスクリーンショットを撮って大規模モデルに質問するか、各パラメーターの使い方を自分で探索し、最終的に目標を達成してください)。
- インテント分類ワークフローの方法を参考に、大規模モデルに完全に異なるシナリオを提案させ、必ずインテント分類ワークフローを使用するようにしてください。最後に、実行したワークフローのスクリーンショット、シナリオの説明、結果を提出してください。
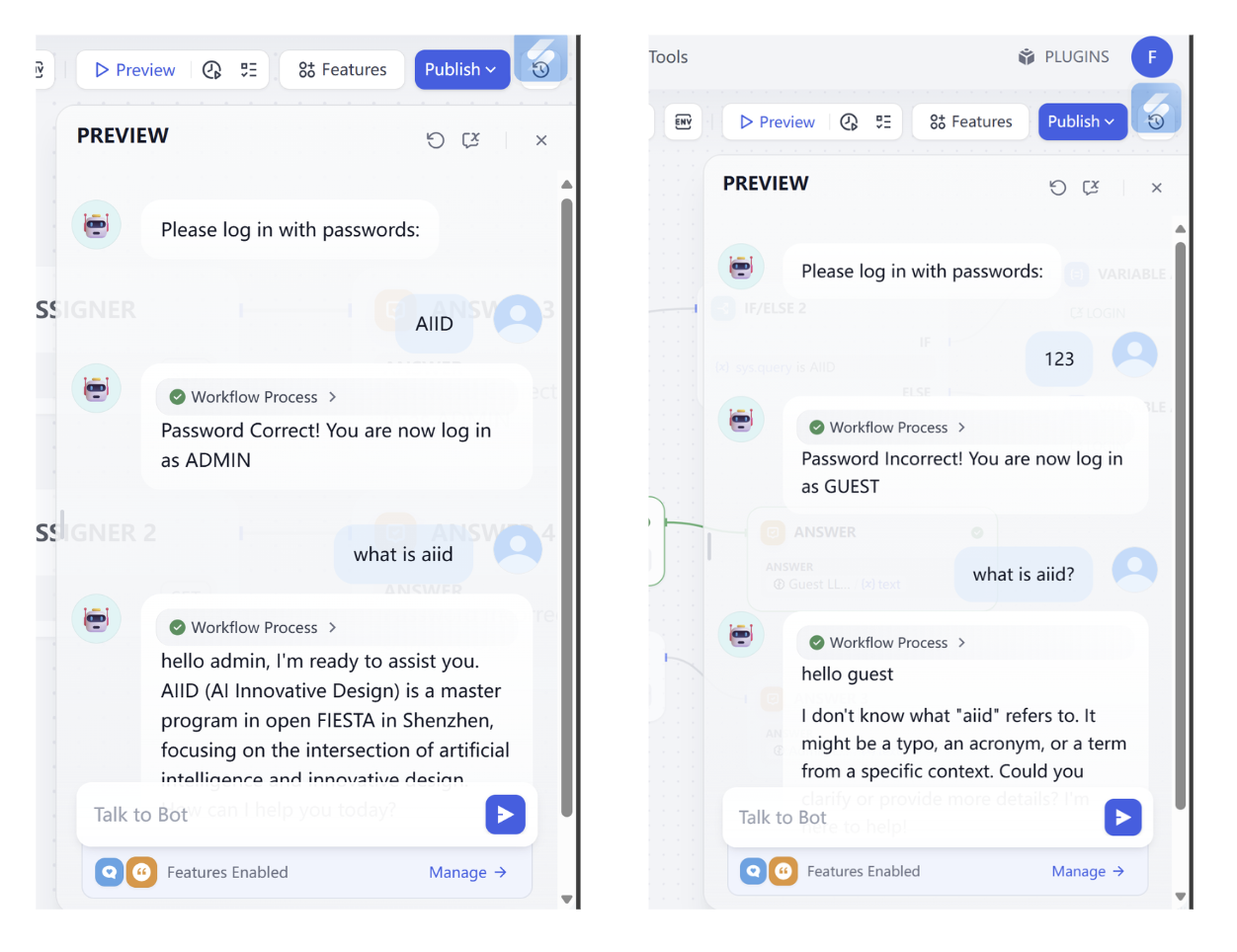
- Log in workflow ワークフロー解読チャレンジ
この解読チャレンジでは、以下のチャレンジを完了して、ワークフローに次の機能を実装させる必要があります。
- 正しいパスワードを見つける!
- パスワードを 0925 に変更する
- パスワードが正しくない場合、2回目の試行機会を提供する(3回目は提供しない)
- ユーザーが再度ログインしたいと言及した場合、パスワード再入力の機会を提供する
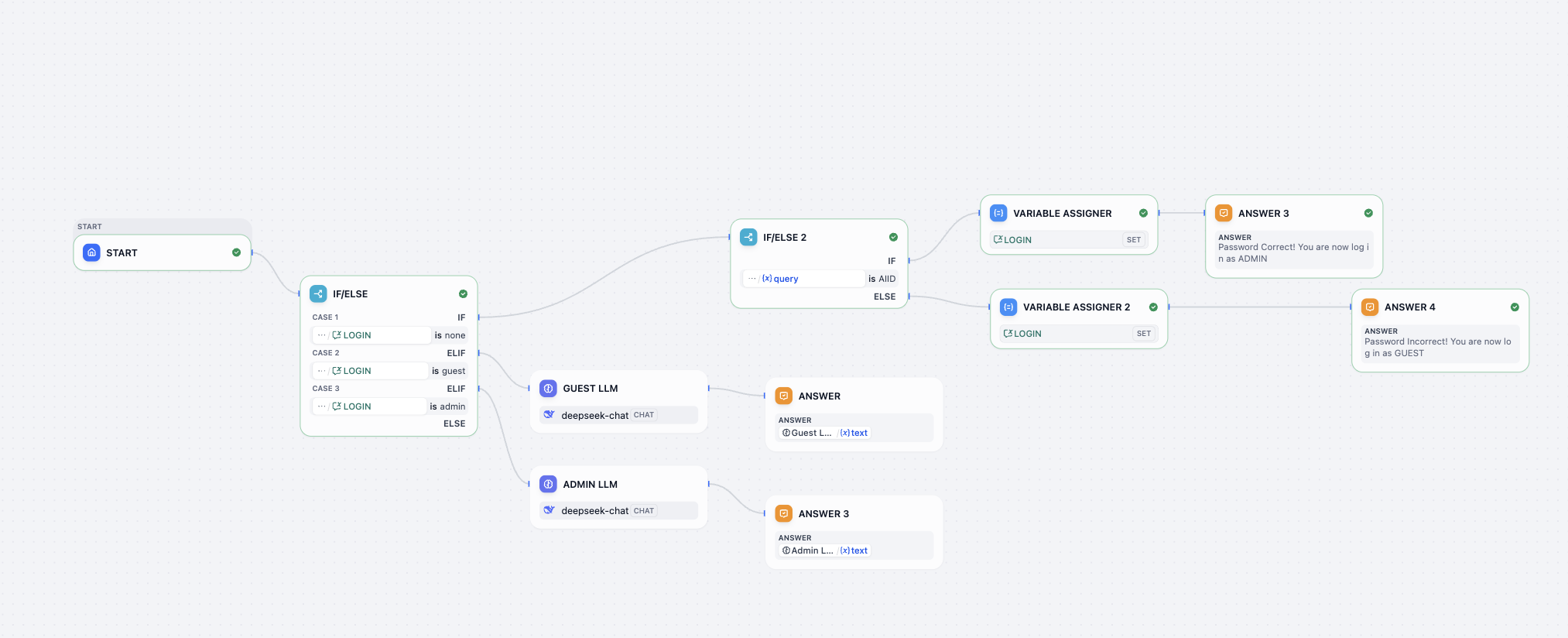
参考入出力:
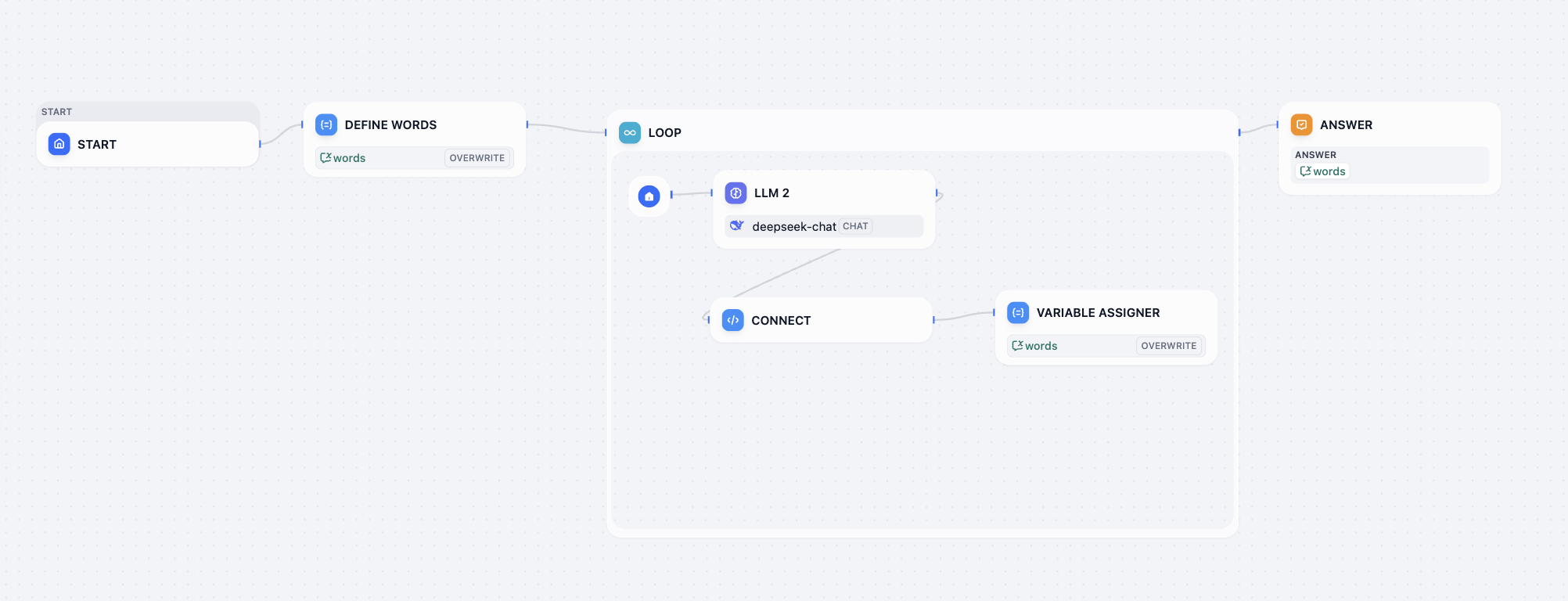
- Love loop workflow ワークフロー解読チャレンジ
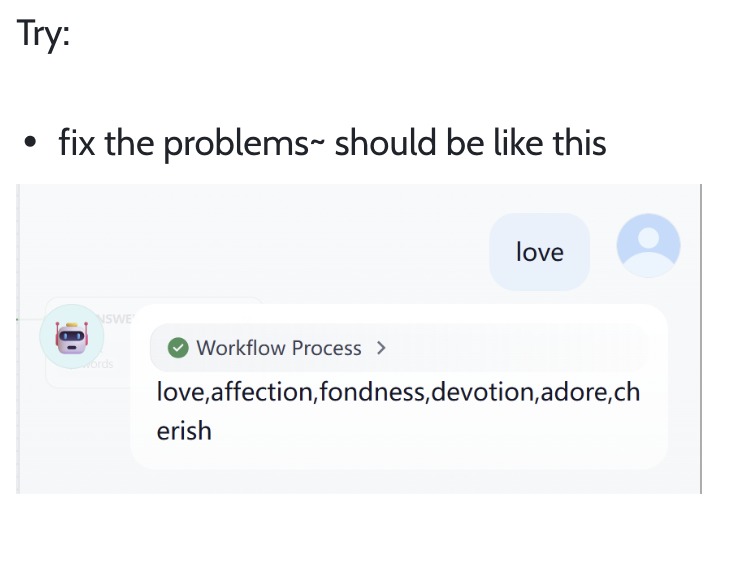
この解読チャレンジでは、現在のワークフローの問題を修正し、ワークフローの最終出力が以下のように表示されるようにしてください。
解決できない問題に遭遇した場合は、スクリーンショットを撮って大規模モデルに質問するか、公式ドキュメントを参照して結果を得てください:https://docs.dify.ai/en/use-dify/getting-started/quick-start
Dify API 呼び出しの実装
Dify の API 呼び出しの知識を本当に習得したことを確認するため、以下のタスクを完了してください。
- Dify をデプロイし、シンプルなナレッジベースを作成する(好きな資料を選んでください)。
- Trae IDE を使ってチャットフロントエンドを構築し、Dify ナレッジベースと API インタラクションを行う。
- 複数回の対話の効果をテストし、プログラムが正常に動作することを確認する。
最終的な実行スクリーンショットとナレッジベースの処理プロセスのスクリーンショットを提出してください。
サードパーティのワークフローの試用 / 自分の業務ワークフローの構築
GitHub、WeChat 公式アカウント、Reddit、Twitter などあらゆる場所で試してみたい他の人の Dify ワークフローを探し、ダウンロードしてインポート後に正常に実行してください。または、上記の業務ワークフロー参考に基づいて、現実の具体的なニーズから自分自身の業務ワークフローを作成して実行してください。
最後に、実行成功のスクリーンショットを提出し、そのワークフローの役割を説明してください。
[Bug] HTTP リクエストエラー問題の解決方法
以下の図に示すような問題に遭遇した場合のみ、本セクションの方案を参考にしてください。それ以外の場合は無視して構いません。
Dify を自分のサーバーにデプロイした場合、サーバーの外部アドレスは通常 HTTP であり HTTPS ではありません。HTTP のみをサポートするサービスにリクエストを送信する際、以下のようなメッセージが表示されることがあります(F12 ブラウザデバッグモードを有効にして、問題のある箇所を確認してください)。
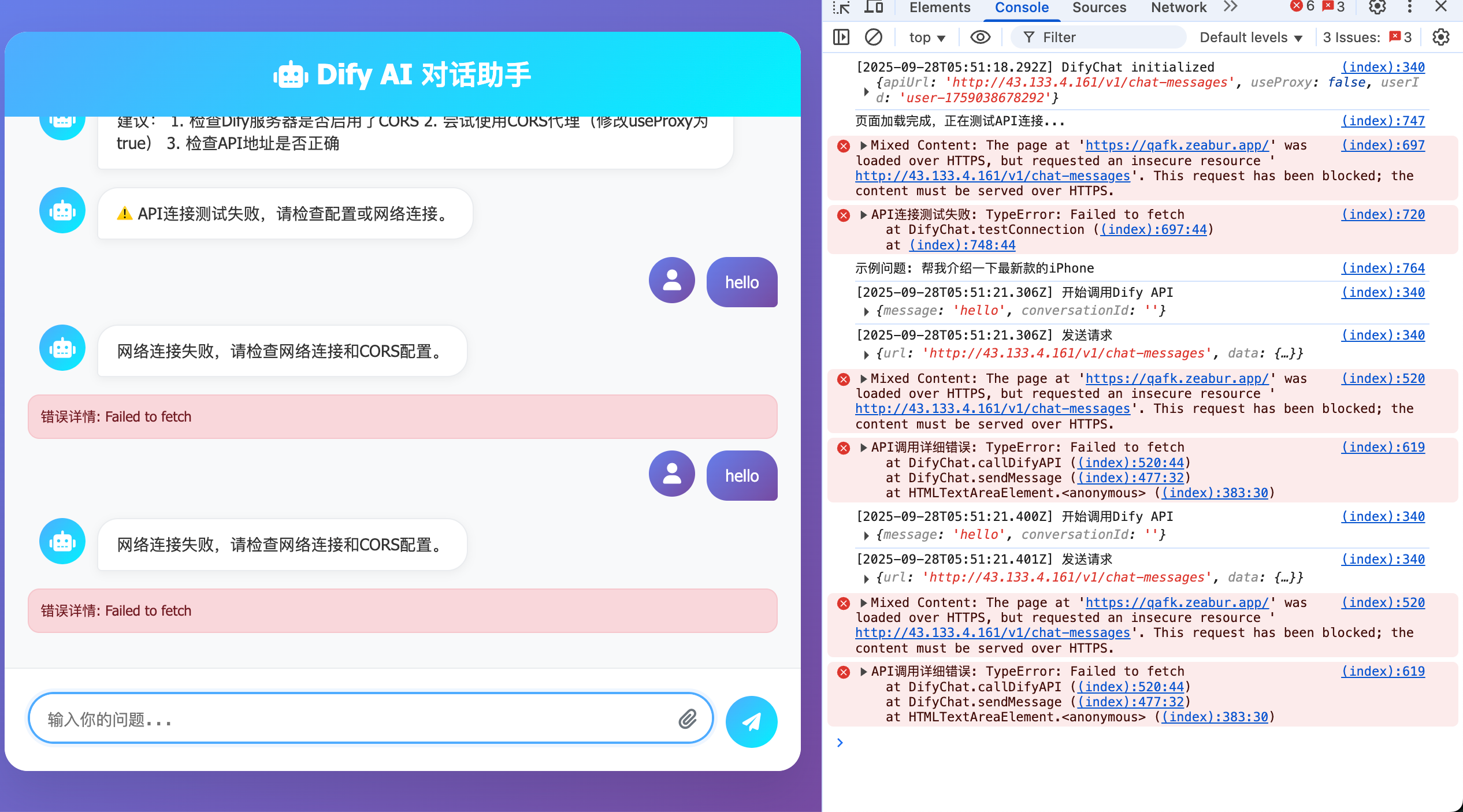
この問題が発生する原因は、Dify を HTTPS ではなく HTTP のみをサポートするサーバーにデプロイしたためです。HTTPS(HyperText Transfer Protocol Secure)は HTTP(HyperText Transfer Protocol)に SSL/TLS 暗号化レイヤーを追加したもので、「より安全な版の HTTP」と理解できます。
サービスで HTTPS をサポートさせるには、一般的に以下の方法があります。
- 他のプログラムを使ってリクエストを転送する(例:証明書がある nginx でリバースプロキシを行う)
- ドメイン名をバインドし、そのドメイン名の証明書を申請する
しかしこれらの操作は比較的複雑なため、ここでは Zeabur をネットワーク転送ゲートウェイとして使用して問題を解決します。
Zeabur のウェブページはデフォルトで HTTPS を通じてアクセスされるため、元々リクエストしていたドメインを Zeabur が提供するドメインに転送するだけで、この問題を修正できます。
- 元のアドレス:
http://{DIFY_API_URL}/v1/chat-messages - 変更後のアドレス:
https://{DIFY_NEW_API_URL}.zeabur.app/v1/chat-messages
URL 内のドメイン部分(パブリック IP またはドメイン)を、Zeabur にデプロイ済みのドメインに置き換えるだけで済みます。サービス内には転送機能があらかじめ設定されています。
興味がある場合は、自分で Zeabur に転送サービスをデプロイすることもできます。Zeabur でサービスを作成する際に Python を選択し、以下の Python コードを入力してデプロイすると、HTTPS アドレスが取得でき、HTTPS が正常に使用できるようになります。
デプロイ完了後、ネットワーク設定でプログラムのリスニングポートをローカル 8080 に設定し、そのポートを外部に公開してください。
注意:{DIFY_API_URL} を実際の Dify API アドレスに置き換えてください。
from flask import Flask, request, Response
import requests
app = Flask(__name__)
TARGET_BASE_URL = "{DIFY_API_URL}"
LISTEN_PORT = 8080
@app.route('/', defaults={'path': ''}, methods=['GET', 'POST', 'PUT', 'DELETE', 'PATCH', 'OPTIONS', 'HEAD'])
@app.route('/<path:path>', methods=['GET', 'POST', 'PUT', 'DELETE', 'PATCH', 'OPTIONS', 'HEAD'])
def proxy_request(path):
target_url = f"{TARGET_BASE_URL}/{path}"
if request.query_string:
target_url += f"?{request.query_string.decode('utf-8')}"
headers = {key: value for key, value in request.headers if key.lower() not in ['host', 'connection', 'content-length', 'accept-encoding']}
try:
resp = requests.request(
method=request.method,
url=target_url,
headers=headers,
data=request.get_data(),
cookies=request.cookies,
allow_redirects=False,
timeout=30
)
excluded_headers = ['content-encoding', 'content-length', 'transfer-encoding', 'connection']
response_headers = [(name, value) for name, value in resp.raw.headers.items() if name.lower() not in excluded_headers]
return Response(resp.content, resp.status_code, response_headers)
except requests.exceptions.RequestException as e:
print(f"Error forwarding request to {target_url}: {e}")
return Response(f"Proxy Error: Could not reach target server or invalid response: {e}", status=502)
except Exception as e:
print(f"An unexpected error occurred: {e}")
return Response(f"Internal Proxy Error: {e}", status=500)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=LISTEN_PORT, debug=True)