Nhập môn Dify và tích hợp cơ sở tri thức
Ôn tập bài trước
Trong các bài học trước, chúng ta đã học theo nhóm về kiến thức cơ bản của lập trình AI, kỹ thuật prompt và tạo ảnh bằng AI. Những nội dung này giúp chúng ta bước đầu hiểu được ranh giới và khả năng của các mô hình ngôn ngữ lớn (LLM, Large Language Model) hoặc các mô hình sinh khác nhau.
Để giúp bạn ôn tập nội dung bài trước, dưới đây có một số câu hỏi nhỏ để suy nghĩ:
- Lập trình AI là gì? Làm thế nào để sử dụng công cụ lập trình AI (ví dụ z.ai) để tạo một trang web?
- Mô hình ngôn ngữ lớn là gì? Kỹ thuật prompt và kỹ thuật ngữ cảnh là gì? Bạn nên viết một prompt phức tạp như thế nào?
- Đối với ba hướng khác nhau: văn bản, AI Coding, tạo ảnh, bạn nghĩ điểm mạnh của khả năng mô hình nằm ở đâu cho mỗi hướng?
- API là gì? Làm thế nào để sử dụng z.ai để tích hợp API bên thứ ba?
Nếu bạn còn băn khoăn về bất kỳ câu hỏi nào, có thể xem lại tài liệu bài trước, hoặc trực tiếp đặt câu hỏi trong nhóm WeChat.
Trong bài học này, chúng ta sẽ đi từ các công cụ văn bản ảnh AI đơn giản, bước vào nền tảng xây dựng quy trình làm việc gần với triển khai kinh doanh thực tế hơn. Từ chatbot tiến tới AI Agent, AI workflow, và dựa trên API biến nó thành trang "robot thông minh" có thể tương tác.
Trong quá trình thao tác, nếu gặp bước khó hiểu, đừng lo lắng, chúng tôi khuyến nghị bạn chụp màn hình trang thao tác hiện tại bất kỳ lúc nào, gửi cho mô hình lớn để hỏi; các mô hình lớn hiện tại đã có thể giải đáp hầu hết các vấn đề phổ biến.
Nếu sau khi hỏi vẫn không giải quyết được, hãy mạnh dạn thử thao tác; đừng sợ sai, mỗi lần thử đều là cơ hội học hỏi và tiến bộ. Khi số lần thực hành tăng lên, bạn sẽ ngày càng thành thạo và thao tác càng dễ dàng hơn!
Nội dung bạn sẽ học trong bài này
- Tại sao cần đi từ chatbot tới Agent và编排 Workflow.
- Agent và nền tảng phát triển workflow là gì, làm thế nào để chuẩn hóa (SOP) và编排 hóa khả năng AI.
- Dify là gì, làm thế nào để sử dụng nền tảng mã nguồn mở hướng tới ứng dụng LLM này để nhanh chóng xây dựng ứng dụng, đặc biệt là chatbot hỏi đáp dựa trên cơ sở tri thức.
- Phương pháp thực hiện và giá trị của RAG, tại sao cần Retrieval-Augmented Generation?
- Làm thế nào để từ 0 đến 1 học cách sử dụng Dify và AI IDE Trae (
Extra Knowledge 4 - What is AI IDE and Trae), bao gồm xây dựng Agent, workflow, và dựa trên API Dify tạo chương trình trang web chatbot frontend.
- Nguyên lý sử dụng cơ bản của Dify và phương pháp tạo Agent, workflow, phương pháp gọi API.
- Phương pháp sử dụng AI IDE, làm thế nào để lập trình bằng AI IDE.
- Một chương trình agent frontend có thể trò chuyện.
1. Từ hội thoại tới Agent
Ở giai đoạn trước, chúng ta đã học cách sử dụng prompt để khiến mô hình lớn đóng vai, tạo văn bản hoặc viết code đơn giản. Nhưng nếu bạn suy nghĩ kỹ, sẽ phát hiện một vấn đề: chatbot bản thân không thể hành động.
Nó có thể trả lời "làm thế nào để tra cứu đơn hàng?", nhưng không thể thực sự vào cơ sở dữ liệu để tra các con số tương ứng; nó có thể mô tả một báo cáo tuần nên chứa những gì, nhưng không thể tự động tổng hợp dữ liệu dự án và gửi email. Hạn chế "chỉ nói không làm" này khiến AI thuần túy hội thoại khó thực sự tích hợp vào quy trình kinh doanh.
Để nâng cấp AI từ đối tác trò chuyện thành "nhân viên kỹ thuật số", chúng ta cần trang bị cho nó ba khả năng cốt lõi:
- Kiến thức chuyên属 — để nó có thể đọc hiểu tài liệu sản phẩm, hồ sơ khách hàng, quy định nội bộ;
- Gọi công cụ (hoặc plugin) — để nó có thể thao tác cơ sở dữ liệu, gọi API;
- Thực thi có cấu trúc — để nó hoàn thành nhiệm vụ theo logic đã định trước, thay vì tự do phát huy.
Đây chính là dạng ban đầu của AI Agent (Tác nhân AI): một đơn vị tự động hóa có mục tiêu, kiến thức, công cụ và đường dẫn thực thi.

Lưu ý: "Agent" phiên bản đơn giản mà ngành hiện tại nhắc đến, chủ yếu chỉ các ứng dụng tăng cường dựa trên sự kết hợp LLM + công cụ + cơ sở tri thức, không phải là Agent có khả năng tự lập kế hoạch. Agent đơn giản tuy không có khả năng suy luận và lập kế hoạch dài hạn thực sự, nhưng đã đủ để hỗ trợ lượng lớn các kịch bản tự động hóa cấp doanh nghiệp. Chúng ta sẽ giới thiệu chi tiết về Agent thực sự có khả năng tự lập kế hoạch và hành động trong các chương sau.
1.1 Agent đơn giản nhất: Chatbot hỏi đáp dựa trên cơ sở tri thức
Sau khi xác định nhiều khả năng cốt lõi mà Agent nên có, một câu hỏi đáng suy nghĩ nảy sinh: liệu có thể chỉ thông qua việc thực hiện một trong những chức năng đơn giản nhất, đã có thể xây dựng một Agent cơ sở thực sự sử dụng được? Câu trả lời là có.
Trên thực tế, trong rất nhiều kịch bản kinh doanh thực tế, nhu cầu cốt lõi của người dùng không phải là để AI tự động thực hiện các thao tác phức tạp (như gọi API hoặc điều phối nhiệm vụ liên hệ thống), mà là hy vọng nó có thể cung cấp hỗ trợ hỏi đáp chính xác và đáng tin cậy dựa trên tài liệu chuyên属 của doanh nghiệp. Điều này tương ứng chính xác với khả năng cốt lõi đầu tiên trong ba khả năng của Agent — khả năng dịch vụ kiến thức chuyên属. Do đó, chúng ta có thể dẫn ra hình thái đơn giản nhất và được ứng dụng rộng rãi nhất của Agent: chatbot hỏi đáp dựa trên cơ sở tri thức.
Mặc dù nó chưa có khả năng gọi công cụ hoặc tự lập kế hoạch, nhưng đột phá quan trọng nằm ở: khiến câu trả lời của mô hình lớn không còn được tạo ra từ hư vô, mà có cơ sở dựa trên. Làm thế nào để thực hiện? Điểm mấu chốt nằm ở việc giải quyết thách thức cốt lõi: doanh nghiệp có lượng lớn tài liệu kiến thức nội bộ, khi có hàng nghìn trang tài liệu, làm thế nào để mô hình nhanh chóng tìm thấy nội dung liên quan nhất đến câu hỏi hiện tại trong mỗi vòng hội thoại?
Giải pháp lúc này là: Retrieval-Augmented Generation (RAG).
Ý tưởng cơ bản của RAG là: khi người dùng đặt câu hỏi, hệ thống đầu tiên truy xuất một số đoạn văn bản có ngữ nghĩa liên quan nhất đến câu hỏi từ cơ sở tri thức doanh nghiệp (ví dụ một đoạn trong sổ tay sản phẩm, một điều khoản trong quy định nhân sự), sau đó chèn các đoạn này làm ngữ cảnh vào đầu vào của mô hình lớn, hướng dẫn nó tạo câu trả lời dựa trên tài liệu thực tế.
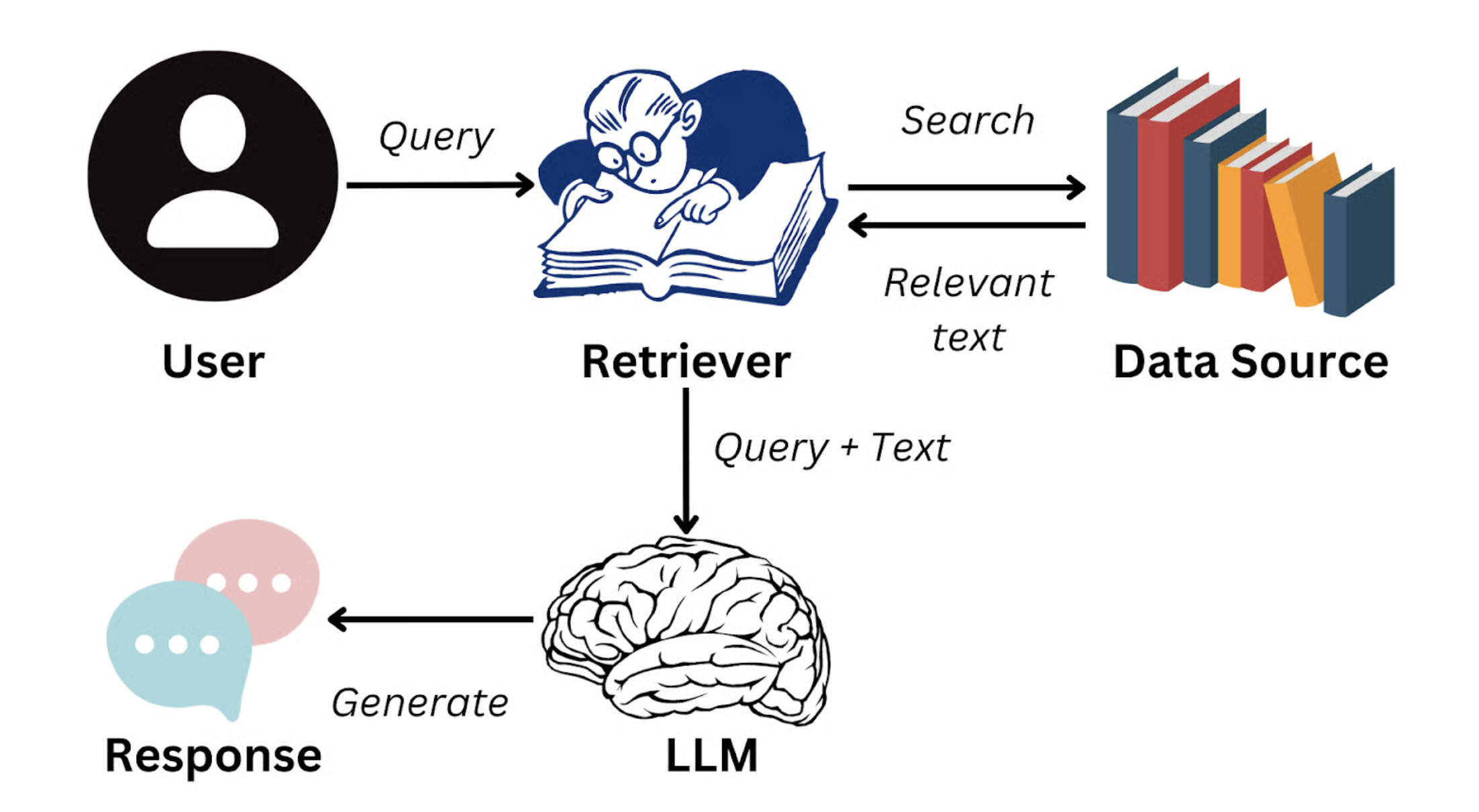
Nguồn hình: https://www.datacamp.com/blog/what-is-retrieval-augmented-generation-rag
Như vậy, câu trả lời của mô hình không còn phụ thuộc vào kiến thức tổng hợp trong dữ liệu huấn luyện, mà được neo trên thông tin uy tín do doanh nghiệp cung cấp. Mục tiêu của RAG chính là thông qua việc chèn động kiến thức bên ngoài này, nâng cao đáng kể tính chân thực, chính xác và nhất quán của câu trả lời — thậm chí có thể khiến câu trả lời "phù hợp với nhân vật", ví dụ trả lời theo phong cách chăm sóc khách hàng hoặc văn phong tài liệu kỹ thuật.
Trong kinh doanh thực tế, công nghệ này đặc biệt quan trọng, vì mô hình lớn thường xuyên tạo ra "ảo giác". Ví dụ, nếu bạn hỏi một số liệu cụ thể trong khoảng thời gian nào đó với tư cách CFO hoặc cố vấn, mô hình rất có thể bịa ra ngày tháng và sự kiện. Sau khi đưa RAG vào, tính kiểm soát và độ tin cậy của câu trả lời sẽ được nâng cao đáng kể.
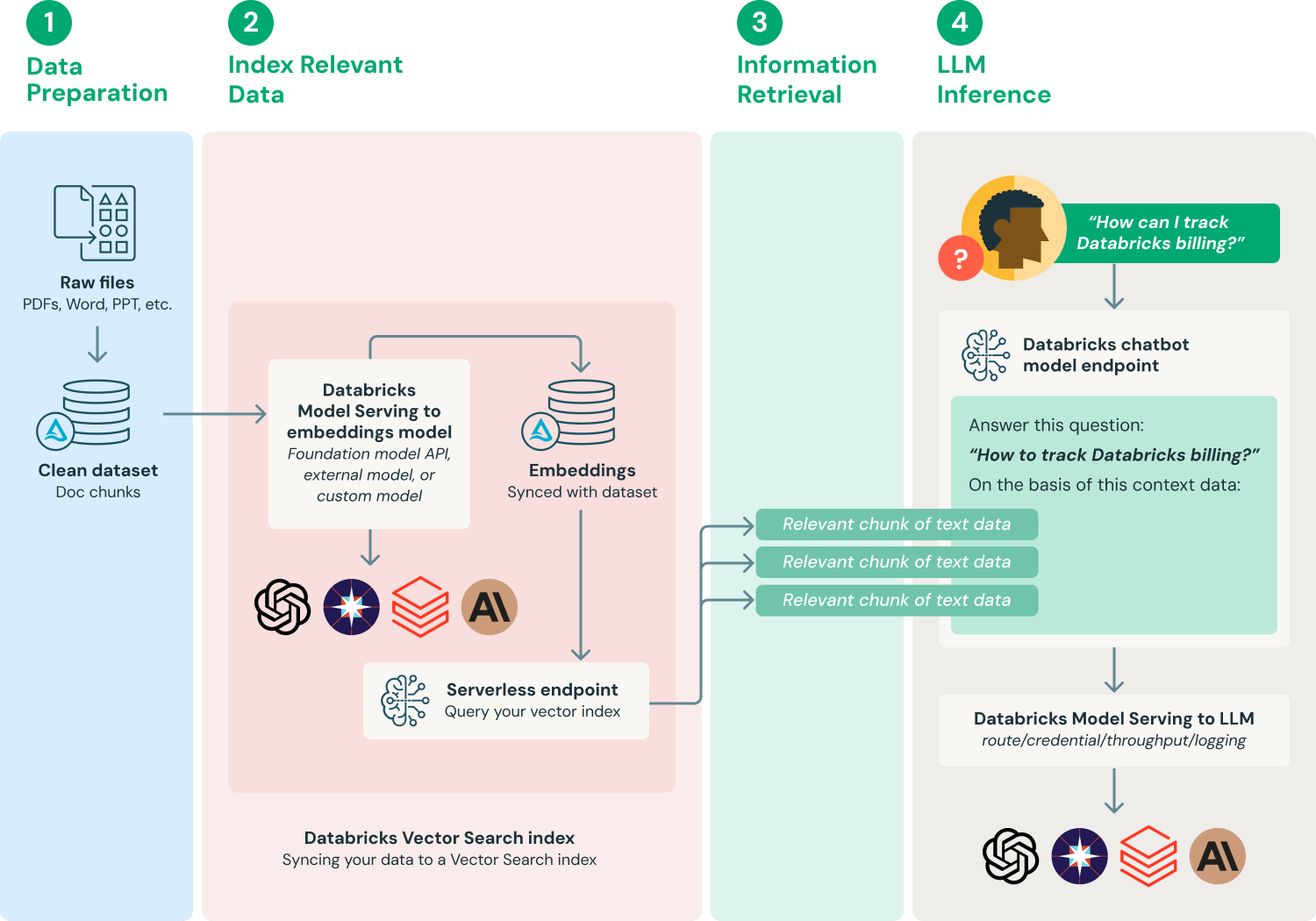
Nguồn hình: https://www.databricks.com/glossary/retrieval-augmented-generation-rag
Trong phần thực hành của bài học này, chúng ta sẽ sử dụng nền tảng AI workflow phổ biến Dify, thực hành xây dựng một chatbot hỏi đáp dựa trên cơ sở tri thức. Bạn có thể dễ dàng xây dựng cơ sở tri thức từ nhiều loại tài liệu chuyên属 khác nhau, như sổ tay sản phẩm, quy định công ty, tài liệu dự án, bài báo nghiên cứu, bài viết cơ sở tri thức, thậm chí là bộ ghi chú cá nhân.
Sau khi hoàn thành xây dựng, bạn có thể thử đặt các câu hỏi khác nhau để kiểm tra khả năng của nó, ví dụ:
- "Phiên bản mới nhất của sản phẩm A của chúng ta có những nâng cấp tính năng chính nào?"
- "Vui lòng theo sổ tay nhân viên, giải thích quy định nghỉ phép năm nay như thế nào?"
- "Trong dự án XX, thách thức kỹ thuật 'XXX' mà chúng ta gặp phải đã được giải quyết như thế nào?"
- "Phương pháp nghiên cứu cốt lõi được đề cập trong bài báo này là gì?"
Bạn sẽ trải nghiệm trực tiếp cách công nghệ RAG chuyển đổi tài liệu tĩnh phân tán thành một cơ sở tri thức thông minh chính xác, cung cấp hỗ trợ hỏi đáp độ chính xác cao cho nhiều kịch bản khác nhau.
1.2 Từ Agent hội thoại tới Workflow
Tuy nhiên, ngay cả khi đã bổ sung cơ sở tri thức và thậm chí khả năng gọi plugin, "Agent tăng cường" vẫn tỏ ra chưa đủ khi đối mặt với các quy trình kinh doanh phức tạp hơn.
Hãy tưởng tượng một yêu cầu người dùng như sau: "Sản phẩm SaaS mới ra mắt của chúng ta gần đây có những cập nhật tính năng nào? Có thể giúp tôi tổng hợp thành một bản tóm tắt cho khách hàng không?"
Yêu cầu này có vẻ đơn giản, nhưng đằng sau cần nhiều bước phối hợp: đầu tiên truy xuất bản ghi phát hành tính năng trong tháng gần nhất từ tài liệu sản phẩm nội bộ hoặc cơ sở tri thức Notion; sau đó lọc ra các tính năng chính hướng tới khách hàng; tiếp theo gọi mô hình lớn chuyển mô tả kỹ thuật thành ngôn ngữ thân thiện với khách hàng; cuối cùng đẩy nội dung đã tạo đến email của đội ngũ marketing, hoặc lưu vào mẫu Google Docs.
Nếu chỉ dựa vào một mô hình ngôn ngữ lớn tự do suy luận, chưa nói đến việc có thể thực hiện tất cả các bước trong một lần hội thoại hay không, ngay cả khi có thì cũng dễ bỏ sót thông tin quan trọng, nhầm lẫn thuật ngữ nội bộ với ngôn ngữ khách hàng, hoặc không thể xuất có cấu trúc. Quan trọng hơn, doanh nghiệp cần một đường dẫn thực thi tiêu chuẩn có thể kiểm toán, tái sử dụng và giám sát, chứ không phải mỗi lần đều dựa vào sự tự do phát huy của mô hình. Khả năng giám sát và tái lập rất quan trọng đối với doanh nghiệp, kết quả không mong đợi rất có thể mang lại tổn thất nghiêm trọng ngoài dự kiến.
Điều này dẫn ra mô hình ứng dụng AI cao cấp hơn: AI Workflow.

Workflow là việc chia một nhiệm vụ phức tạp thành nhiều bước con có thứ tự, có thể cấu hình, có thể tự động thực thi, và thông qua phương thức trực quan hoặc code để编排 quan hệ logic giữa chúng, như判断 điều kiện, vòng lặp hoặc thực thi song song. Đưa khả năng AI vào SOP (Standard Operating Procedure) có nghĩa là cố định hóa kinh nghiệm về cách sử dụng AI hoàn thành một nhiệm vụ thành một mẫu có thể tái sử dụng.
Cách làm này mang lại nhiều giá trị: nhân viên phi kỹ thuật (như quản lý sản phẩm hoặc vận hành) có thể nhanh chóng xây dựng ứng dụng AI thông qua kéo thả thành phần; nhà phát triển có thể đóng gói truy xuất RAG, gọi LLM, công cụ API thành các nút tiêu chuẩn, tái sử dụng trong các kịch bản kinh doanh khác nhau; toàn bộ quy trình còn có thể được theo dõi đầy đủ, gỡ lỗi và tối ưu hóa liên tục, đáp ứng yêu cầu về tính ổn định và tuân thủ của doanh nghiệp.
Người sử dụng AI Workflow rất đa dạng. Quản lý sản phẩm không cần viết code, đã có thể thiết kế đường dẫn tương tác người dùng hoàn chỉnh; nhân viên vận hành có thể nhanh chóng xây dựng chatbot chăm sóc khách hàng, trình tạo nội dung hoặc hệ thống thông báo; nhà phát triển và kỹ sư thuật toán có thể module hóa khả năng cốt lõi để frontend gọi; doanh nhân hoặc nhà phát triển độc lập cũng có thể xác minh MVP sản phẩm AI với chi phí cực thấp, đưa lên mạng một nguyên mẫu hoàn chỉnh bao gồm truy vấn dữ liệu, tạo nội dung và thực thi hành động trong vài ngày.
Ngoài ra, đáng chú ý là AI Workflow thường có thể được mô tả bằng một dạng biểu diễn trung gian (Intermediate Representation). Cách biểu diễn cụ thể của các nền tảng workflow khác nhau có khác biệt, nhưng hầu hết sử dụng file có cấu trúc (như JSON, YAML, v.v.) để định nghĩa loại nút, đầu vào/đầu ra và logic thực thi, cấu trúc tương tự như hình dưới:

Nói tóm lại, nếu Agent khiến AI đi từ biết trò chuyện tới có thể làm việc, thì workflow khiến AI từ thỉnh thoảng hoàn thành một việc tiến tới "hoàn thành một loại công việc một cách ổn định, đáng tin cậy và quy mô lớn". Trong thực hành tiếp theo, chúng ta sẽ sử dụng nền tảng Dify, trực tay xây dựng AI Workflow hoàn chỉnh, trải nghiệm toàn bộ quá trình từ ý tưởng đến ứng dụng có thể chạy được.
1.3 Các nền tảng Agent / Workflow phổ biến
Cùng với sự phát triển nhanh chóng của công nghệ AI sinh, để giúp nhà phát triển và nhân viên kinh doanh nhanh chóng xây dựng Agent và quy trình tự động hóa, tránh sa vào chi tiết phức tạp của lập trình, một loạt các nền tảng Agent và Workflow mã nguồn thấp (low-code) thậm chí không cần code (no-code) đã ra đời.
Trước tiên cần làm rõ, nền tảng mã nguồn thấp là công cụ phát triển giảm đáng kể khối lượng lập trình thủ công thông qua kéo thả thành phần trực quan, mẫu logic kinh doanh tích hợp sẵn, cấu hình quy tắc bằng đồ họa, v.v. Cốt lõi của nó là thay thế cách viết code trực tiếp bằng cách cấu hình trực quan, kéo thả theo nút, vừa giải phóng nhà phát triển có năng lực kỹ thuật nhất định khỏi lao động lặp lại, vừa cho phép nhân viên phi kỹ thuật am hiểu logic kinh doanh tham gia vào việc xây dựng ứng dụng. Về bản chất, nó là một cây cầu cân bằng giữa hiệu quả phát triển và tính linh hoạt của kịch bản.
Giá trị nổi bật của các nền tảng Agent mã nguồn thấp/không cần code này chính là giảm đáng kể ngưỡng phát triển ứng dụng AI. Trước đây cần đội nhóm phối hợp nhiều tuần — từ tổng hợp nhu cầu, phát triển code đến kiểm thử triển khai — mới có thể hoàn thành Agent AI (như chatbot hỏi đáp chăm sóc khách hàng, trợ thủ xử lý dữ liệu), nay借助 công cụ trực quan do nền tảng cung cấp, có thể rút ngắn chu kỳ "từ ý tưởng đến triển khai" xuống chỉ còn vài giờ.
Hiện tại, các nền tảng AI workflow mã nguồn thấp phổ biến trên thị trường bao gồm:
| Nền tảng | Đặc điểm | Kịch bản phù hợp |
|---|---|---|
| Dify | Mã nguồn mở, hỗ trợ RAG cơ sở tri thức,编排 LLM, xuất API, thân thiện tiếng Trung | Hỏi đáp cơ sở tri thức doanh nghiệp, Agent tùy chỉnh, dịch vụ API |
| Coze (ByteDance) | Sử dụng được tại Trung Quốc, tích hợp hệ sinh thái Douyin/Feishu, plugin phong phú | Bot mạng xã hội, tích hợp tiểu trình trong nước |
| n8n | Công cụ tự động hóa phổ dụng, hỗ trợ nút AI, nhấn mạnh编排 API | Đồng bộ dữ liệu liên hệ thống, tự động hóa AI + SaaS truyền thống |
| Baidu Qianfan AppBuilder / Alibaba Bailian / Tencent HunYuan | Giải pháp cloud-native từ các ông lớn, tích hợp mô hình riêng | Triển khai cấp doanh nghiệp, kịch bản yêu cầu tuân thủ cao |
Hiện tại sự lựa chọn nền tảng AI workflow mã nguồn thấp trên thị trường rất phong phú. Mặc dù các nhà cung cấp cloud chính thống như AWS, Azure, Alibaba Cloud đều đã đưa ra giải pháp AI workflow tương ứng, nhưng Dify, Coze và n8n凭借 ba ưu điểm cốt lõi sau đã trở thành những đại diện được ứng dụng rộng rãi nhất hiện nay:
- Tính dễ sử dụng cực độ. Nền tảng采用 thiết kế giao diện kéo thả trực quan, người dùng không cần hiểu sâu về công nghệ nền tảng, đã có thể nhanh chóng bắt đầu sử dụng.
- Tính linh hoạt cao. Hỗ trợ thành phần tùy chỉnh và mở rộng giao diện API, vừa thích hợp các kịch bản nhẹ như demo giảng dạy, xác minh MVP (Minimum Viable Product), vừa đáp ứng nhu cầu lặp nhanh của đội nhóm vừa và nhỏ.
- Hệ sinh thái trưởng thành. Không chỉ tài liệu chính thức chi tiết, phản hồi kịp thời, mà còn có cộng đồng người dùng hoạt động tích cực, dễ dàng tiếp thu các giải pháp đặt sẵn từ nhiều người dùng khác nhau.
Cả ba nền tảng này đều hỗ trợ xuất Agent AI đã xây dựng dưới dạng giao diện API tiêu chuẩn, có thể tích hợp liền mạch vào ứng dụng Web frontend, hệ thống ERP nội bộ doanh nghiệp hoặc APP di động, tiếp tục giảm ngưỡng kỹ thuật để đưa khả năng AI vào thực tế.
1.3.1 Dify: Nền tảng quản lý vòng đời ứng dụng và LLMOps cấp doanh nghiệp
Định vị của Dify là nền tảng phát triển và vận hành ứng dụng LLM, cam kết cung cấp quản lý vòng đời toàn diện cho ứng dụng AI từ构思, triển khai đến tối ưu. Cốt lõi là một nền tảng mã nguồn thấp, nhằm giúp nhà phát triển và nhà đổi mới phi kỹ thuật nhanh chóng xây dựng ứng dụng AI cấp sản xuất.
Về chức năng, Dify bao quát编排 workflow trực quan, xây dựng Agent, quản lý cơ sở tri thức, hỗ trợ đa mô hình, v.v. Nền tảng cho phép thiết kế quy trình nhiệm vụ phức tạp thông qua kéo thả nút, và hỗ trợ tạo Agent dựa trên ý định. Chức năng cơ sở tri thức nổi bật, có thể xử lý nhiều định dạng tài liệu và thực hiện truy xuất vector hiệu quả. Đồng thời, Dify tương thích và hỗ trợ nhiều LLM bao gồm GPT, Claude và nhiều mô hình mã nguồn mở, ứng dụng đã xây dựng có thể phát hành thành API tiêu chuẩn bằng một cú nhấp để dễ dàng tích hợp.
Về kiến trúc kỹ thuật, Dify nổi bật với đặc điểm mã nguồn mở và có thể triển khai riêng, nhấn mạnh tính linh hoạt, khả năng mở rộng và tuân thủ cấp doanh nghiệp. Đối tượng người dùng mục tiêu bao gồm đội nhóm nhà phát triển và nhà đổi mới kinh doanh, kịch bản ứng dụng điển hình bao gồm cơ sở tri thức doanh nghiệp và chăm sóc khách hàng thông minh, tự động hóa sáng tạo nội dung, trợ lý AI lĩnh vực chuyên biệt và trung tâm AI doanh nghiệp.
1.3.2 Coze (ByteDance): Người phổ cập xây dựng Agent AI không cần code
Coze là nền tảng phát triển Agent AI do ByteDance推出, với tính dễ sử dụng cực độ làm cốt lõi, cho phép người dùng không có kinh nghiệm lập trình cũng có thể dễ dàng tạo, gỡ lỗi và phát hành chatbot AI chức năng phong phú.
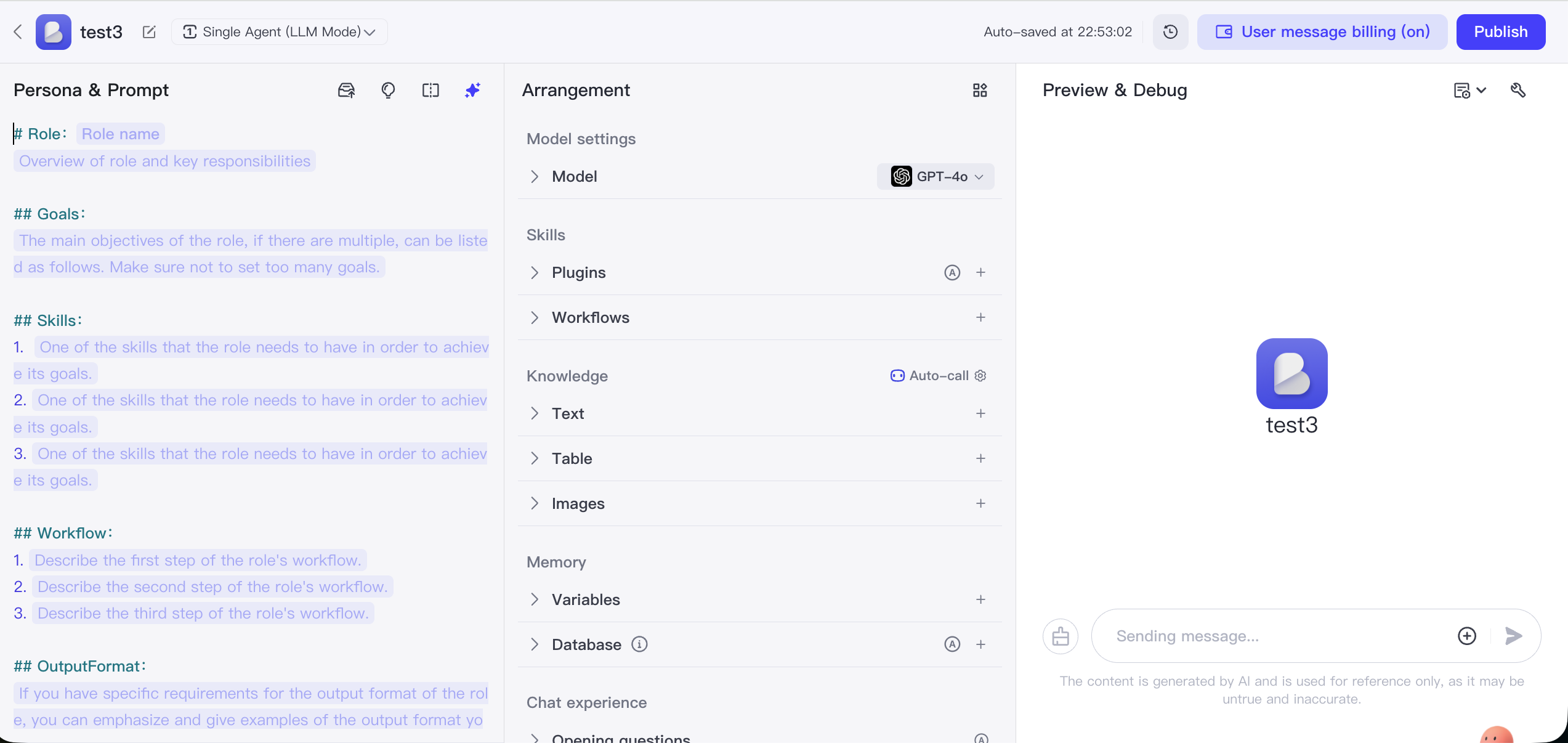
Điểm cốt lõi là đơn giản hóa việc xây dựng Bot thành thao tác kiểu xếp khối. Người dùng có thể dễ dàng cấu hình vai trò và cơ sở tri thức thông qua giao diện, và tận dụng thư viện plugin tích hợp phong phú để thêm nhiều khả năng bên ngoài như tin tức, du lịch, tạo ảnh, v.v. cho Bot. Bot đã tạo có thể nhanh chóng phát hành bằng một cú nhấp đến nhiều nền tảng như Doubao, Feishu, tài khoản chính thức WeChat, v.v.
Kiến trúc kỹ thuật hoàn toàn phục vụ việc sử dụng với ngưỡng thấp, backend tích hợp mô hình riêng của Byte và đóng gói quy trình phức tạp, nhấn mạnh hiểu đa phương thức và phản hồi thời gian thực. Là một nền tảng chủ yếu được cung cấp dưới dạng dịch vụ cloud, khả năng triển khai riêng tương đối hạn chế. Kịch bản ứng dụng điển hình bao gồm trợ lý cá nhân và Bot giải trí, hệ thống chăm sóc khách hàng và hỏi đáp thông minh, trợ lý giáo dục trực tuyến và xác minh nguyên mẫu nhanh.
1.3.2 n8n: Engine tự động hóa workflow backend có thể lập trình
n8n là một nền tảng tự động hóa workflow có thể lập trình phổ dụng, định vị cốt lõi là kết nối các ứng dụng, cơ sở dữ liệu và API khác nhau, thực hiện luồng dữ liệu và tự động hóa thực thi nhiệm vụ.
Nó hỗ trợ hàng trăm dịch vụ SaaS, cơ sở dữ liệu và giao thức thông qua thư viện nút tích hợp khổng lồ, và采用 phương thức kết hợp trực quan và code: người dùng có thể kéo thả nút trên canvas, đồng thời chèn code JavaScript hoặc Python để viết logic tùy chỉnh. n8n đặc biệt giỏi xử lý các nhiệm vụ backend chuyên về dữ liệu, như đồng bộ dữ liệu, quy trình ETL và编排 API.
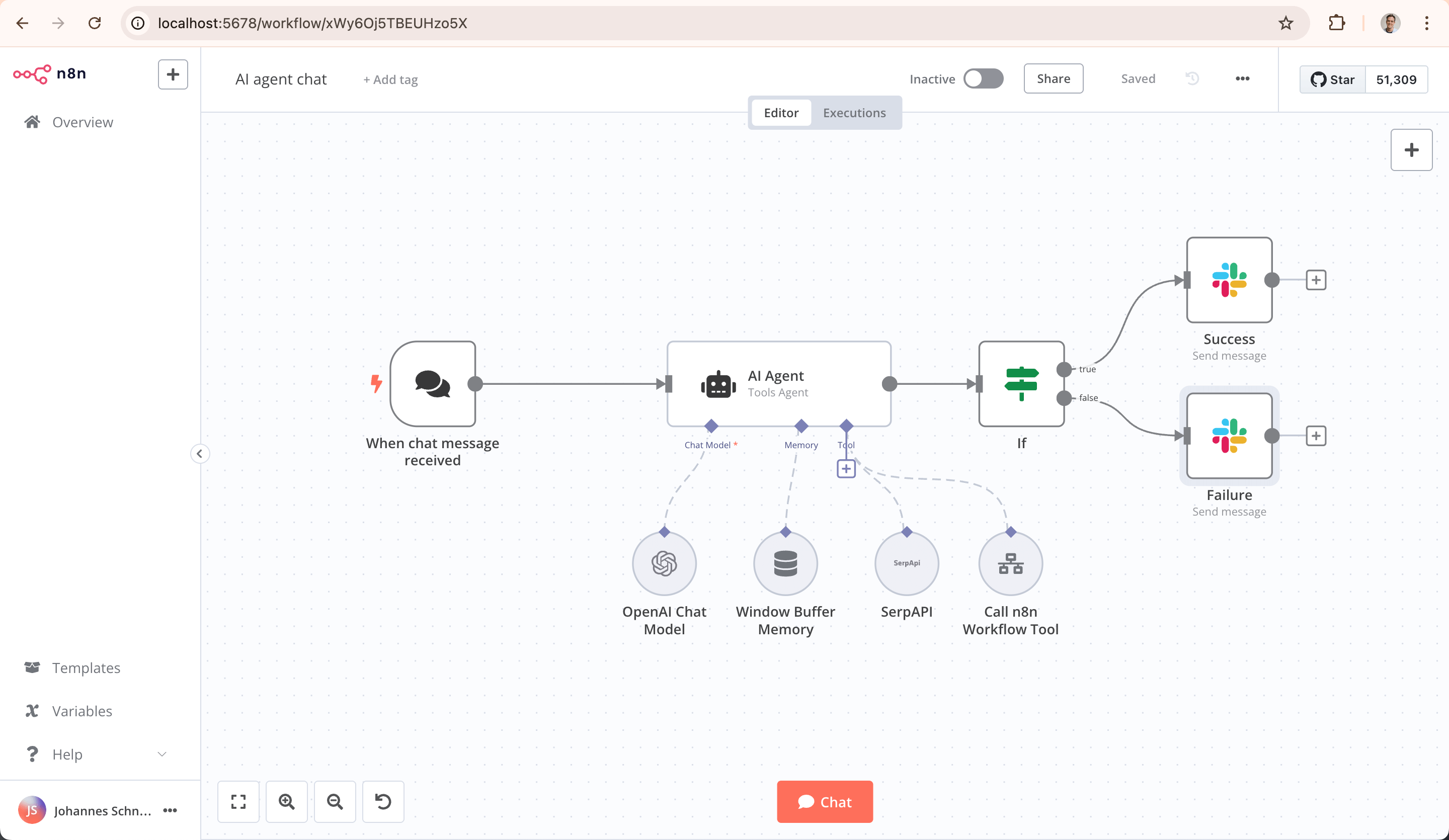
Đặc tính kỹ thuật quan trọng là "có thể xem mã nguồn" và "có thể tự lưu trữ", người dùng có thể triển khai riêng để hoàn toàn kiểm soát dữ liệu và môi trường, điều này khiến nó cực kỳ hấp dẫn đối với các ngành có yêu cầu cao về bảo mật dữ liệu. Đối tượng người dùng chính là nhà phát triển, vận hành kỹ thuật và nhà phân tích dữ liệu. Ưu điểm lớn nhất của n8n nằm ở hệ sinh thái cộng đồng cực kỳ mạnh mẽ. Trên mạng có vô số video chia sẻ n8n phong phú, cung cấp tài liệu tham khảo học tập và kinh nghiệm cho người dùng; đồng thời, nó hỗ trợ kết nối nhiều nền tảng hệ sinh thái toàn cầu khác nhau như YouTube, Instagram, v.v., có thể giúp người dùng dễ dàng phá vỡ rào cản dữ liệu và dịch vụ liên nền tảng, thực hiện tự động hóa luồng quy trình đa hệ sinh thái.
1.3.3 Các nền tảng workflow khác
Ngoài vài nền tảng nổi tiếng nhất ở trên, các nhà công nghệ chính tại Trung Quốc cũng lần lượt推出 các nền tảng phát triển AI tích hợp riêng, ví dụ: Baidu Qianfan AppBuilder cung cấp hỗ trợ toàn quy trình từ lựa chọn mô hình, xây dựng RAG đến phát hành Agent, tích hợp sâu mô hình văn tâm; Alibaba Cloud Bailian dựa trên loạt mô hình Tongyi Qianwen, tập trung vào bảo mật cấp doanh nghiệp và khả năng triển khai riêng; Tencent Cloud TI Platform tập trung vào các kịch bản ngành tài chính, y tế, v.v., cung cấp nhiều mẫu giải pháp đặt sẵn phong phú. Các nền tảng này thường tích hợp sâu với hệ sinh thái cloud tương ứng, phù hợp với các doanh nghiệp đã nằm trong hệ thống kỹ thuật tương ứng.
Tuy nhiên, về tính phổ dụng, tính mở và hệ sinh thái cộng đồng, Dify và Coze vẫn凭借 tính dễ sử dụng nổi bật, hỗ trợ mô hình rộng rãi và cộng đồng nhà phát triển hoạt động tích cực, trở thành lựa chọn được chấp nhận rộng rãi hơn hiện nay.
Mặc dù các nền tảng có trọng tâm khác nhau về định vị và hệ sinh thái, logic cốt lõi đều là编排 và kết nối các module khả năng khác nhau thông qua phương thức trực quan. Do đó, nắm vững tư tưởng thiết kế và phương pháp thao tác của bất kỳ nền tảng nào, đã có nền tảng để nhanh chóng chuyển sang các công cụ tương tự khác. Trong thực hành tiếp theo, chúng ta sẽ lấy Dify làm ví dụ để giải thích cụ thể.
2. Giải thích sâu về Dify
2.1 Dify là gì
Chúng ta đã tìm hiểu thông tin giới thiệu cơ bản về Dify trước đó, để biết thông tin chi tiết hơn, bạn có thể truy cập nền tảng Dify qua https://cloud.dify.ai/apps, nếu muốn tìm hiểu thêm, có thể truy cập trang chủ https://dify.ai.
Dify là một nền tảng mã nguồn mở dùng để phát triển ứng dụng LLM. Nó cung cấp giao diện trực quan, kết hợp Agent workflow, pipeline RAG, khả năng công cụ, quản lý mô hình, khả năng quan sát, v.v., giúp bạn nhanh chóng đi từ nguyên mẫu đến môi trường sản xuất.
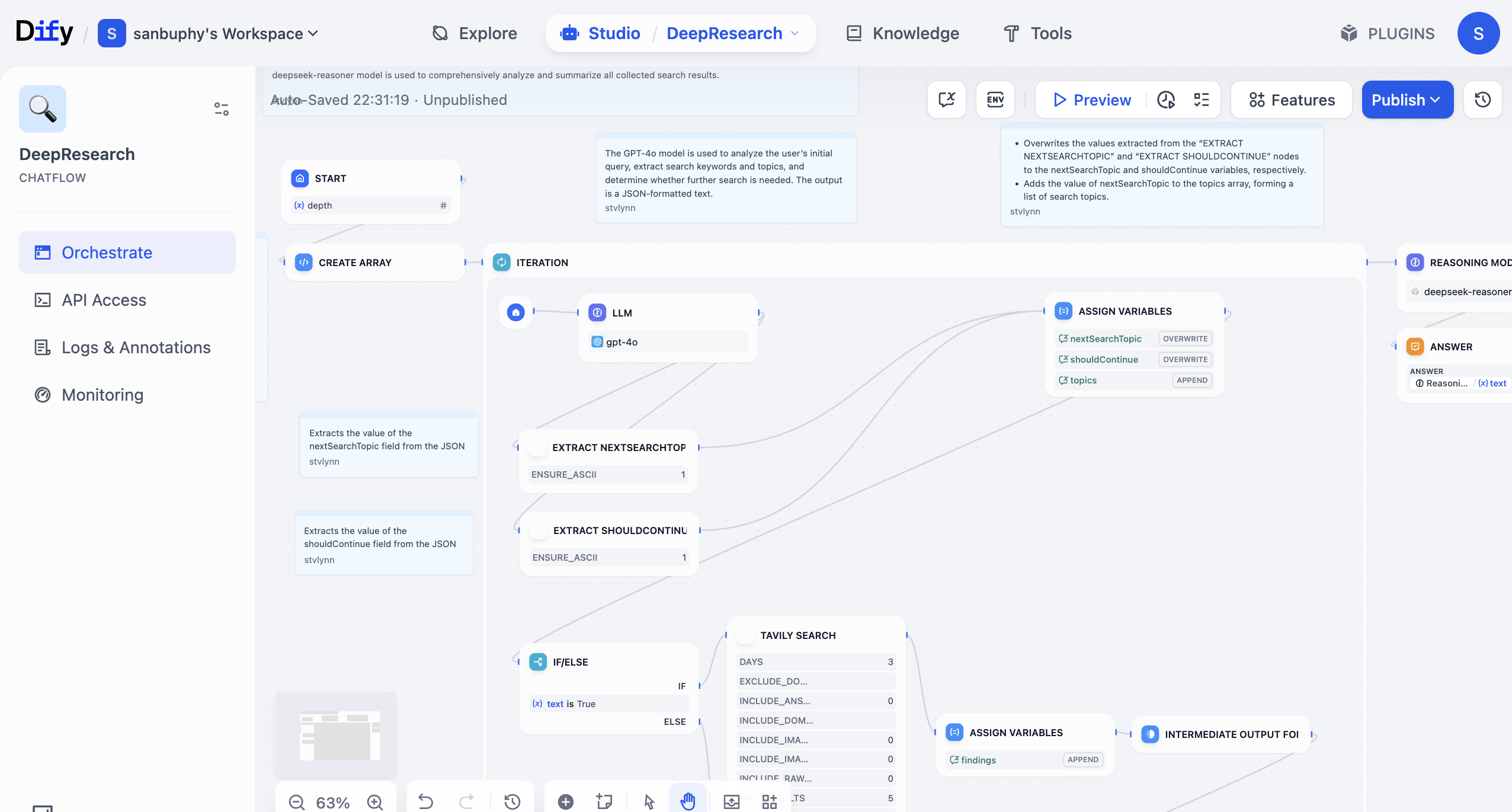
Bạn có thể sử dụng mô hình ngôn ngữ lớn và nhiều công cụ có chức năng khác nhau trong Dify để xây dựng "workflow". Sở dĩ gọi là workflow, là vì nó nối串 các thao tác — ví dụ truy xuất dữ liệu, gọi mô hình lớn, tìm kiếm web, lọc kết quả, định dạng, v.v. — theo logic kinh doanh thành một quy trình tự động, có thể tái sử dụng. Nếu không có workflow, mỗi lần bạn đều phải sao chép dán cùng một nội dung cho mô hình lớn, rất kém hiệu quả, dễ sai và khó tái sử dụng trong kinh doanh thực tế.
Xây dựng một workflow giống như xếp khối hoặc xếp tranh ghép. Bạn kết nối "nút mô hình ngôn ngữ lớn" (phụ trách hiểu và tạo), các "nút công cụ" (phụ trách thực thi hành động cụ thể, ví dụ truy vấn cơ sở dữ liệu, gửi email, dịch văn bản, v.v.), và "nút dữ liệu" (phụ trách đọc, lưu trữ thông tin) lại với nhau như các khối. Chúng sẽ tự động phối hợp làm việc theo logic bạn đặt trước, mà không cần bạn thao tác thủ công mỗi lần. Bạn cũng có thể hiểu nó là một "chương trình mã nguồn thấp": bạn chỉ cần kéo thả, cấu hình đường dẫn đầu vào và đầu ra, đã có thể thực hiện logic kinh doanh khá phức tạp.
Ví dụ, nếu bạn là chủ một cửa hàng thương mại điện tử Amazon hoặc Douyin, muốn xây dựng một hệ thống chăm sóc khách hàng AI, có thể tham khảo cấu trúc như hình dưới để thiết kế một workflow:
- Nút kích hoạt (tương tự START): nhận câu hỏi tư vấn của người dùng, ví dụ "thời gian bảo hành sản phẩm này là bao lâu?".
- Nút phân loại câu hỏi (tương tự QUESTION CLASSIFIER): sử dụng một mô hình (ví dụ GPT) để phân loại câu hỏi người dùng,判断 đây là vấn đề hậu mãi (ví dụ bảo hành), phương pháp sử dụng, hay loại câu hỏi khác.
- Nút truy xuất kiến thức (tương tự KNOWLEDGE RETRIEVAL): dựa trên kết quả phân loại, tự động truy cập cơ sở tri thức tương ứng. Nếu là vấn đề hậu mãi về "bảo hành", thì truy xuất thông tin chính xác liên quan đến "bảo hành" từ cơ sở tri thức SOP hậu mãi.
- Nút mô hình ngôn ngữ lớn (LLM Node): gửi câu hỏi người dùng và nội dung cơ sở tri thức đã truy xuất cùng lúc cho mô hình ngôn ngữ lớn (ví dụ GPT), để nó tạo một câu trả lời thân thiện với người dùng (tránh giọng điệu kỹ thuật quá cứng nhắc).
- Nút điều kiện: kiểm tra xem câu trả lời do mô hình lớn tạo có chứa thời gian bảo hành rõ ràng hay không (ví dụ "1 năm", "3 năm"), nếu có thì tiếp tục bước tiếp theo, nếu không thì yêu cầu trả lời "vui lòng cung cấp mã sản phẩm".
- Nút đầu ra (tương tự ANSWER): trả về câu trả lời cuối cùng cho người dùng, và tự động ghi lại bản ghi tư vấn lần này vào bảng.
Trong toàn bộ quá trình, bạn không cần phải tự tra cơ sở tri thức, điều chỉnh liên tục câu trả lời của mô hình, hay ghi chép dữ liệu riêng — workflow sẽ "nối" các bước này để "chạy tự động". Và nó rất linh hoạt: ví dụ, nếu sau này bạn muốn thêm một quy tắc mới "khi người dùng hỏi về phạm vi bảo hành, gọi một cơ sở tri thức khác", chỉ cần thêm một nút điều kiện vào workflow, mà không cần tái cấu trúc toàn bộ hệ thống.
Đây là một ví dụ workflow khá đơn giản, nhưng để nắm vững hoàn toàn các khả năng này, với bạn hiện tại có thể còn hơi khó. Do đó trong bài học này, chúng ta bắt đầu từ agent cơ sở tri thức cơ bản hơn, sau đó sẽ dần học các kỹ thuật workflow phức tạp hơn.
2.1.1 Triển khai Dify riêng (tùy chọn)
Nội dung phần này ban đầu được sắp xếp giới thiệu chi tiết trong khóa học sau, nhưng cân nhắc rằng một số người học hiện tại có thể tạm thời không thể truy cập trang web chính thức hoặc dịch vụ cloud của Dify do hạn chế mạng, chúng tôi quyết định cung cấp trước lộ trình học tùy chọn này, giúp bạn thuận lợi tiến triển khóa học.
Bạn cần tham khảo hướng dẫn này để làm quen cách sử dụng cơ bản của nền tảng triển khai web: Cách triển khai ứng dụng Web
Bạn cần học cách triển khai một Dify riêng trên Zeabur, sau khi triển khai xong, truy cập liên kết tương ứng, đăng ký và đăng nhập, sau đó tiếp tục làm theo hướng dẫn dưới đây.
Lưu ý, các phiên bản Dify khác nhau có thể có một chút khác biệt về thao tác và giao diện frontend, nhưng nhìn chung không khác nhiều, khi bạn phát hiện sự khác biệt đừng hoảng hốt, hãy tìm giao diện và điểm vào tương tự để thao tác.
2.2 Tạo ứng dụng Chatbot Dify đầu tiên
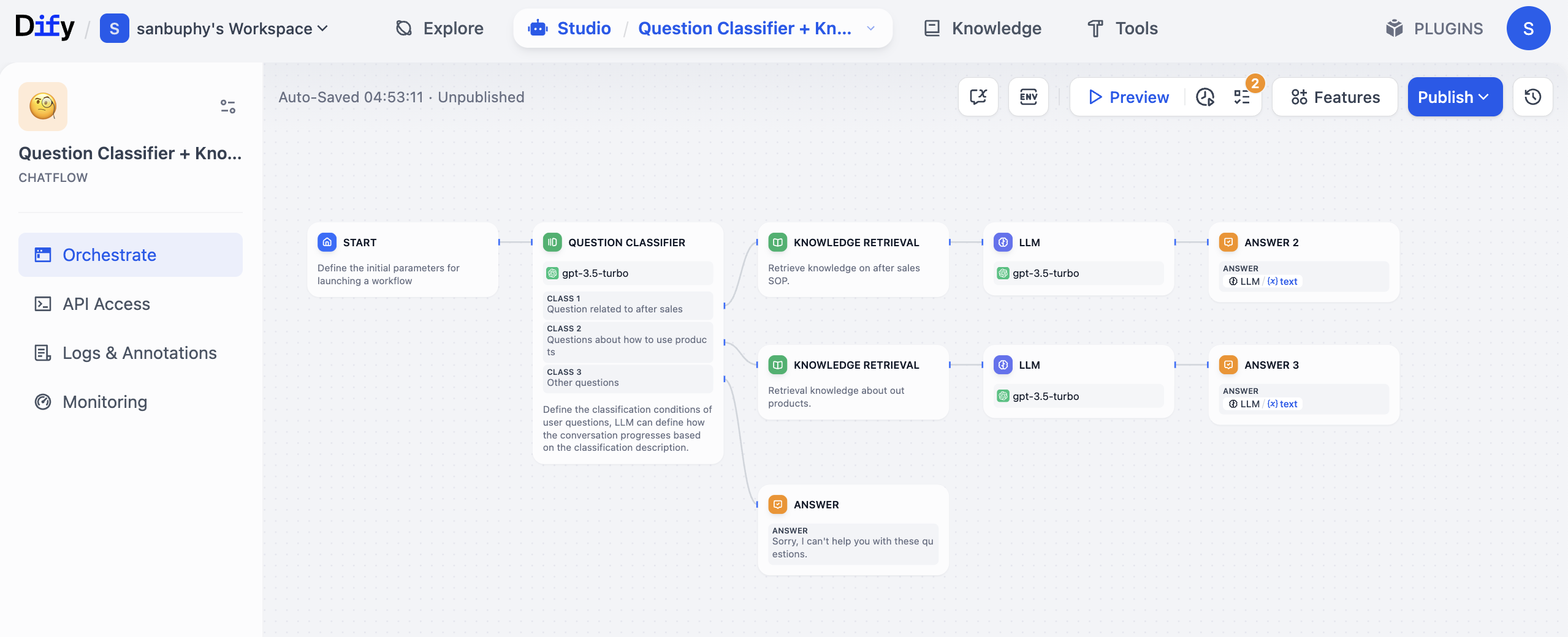
Truy cập trang chủ Dify https://cloud.dify.ai/apps, sau khi đăng ký và đăng nhập, chọn Studio, bạn sẽ thấy giao diện như sau:
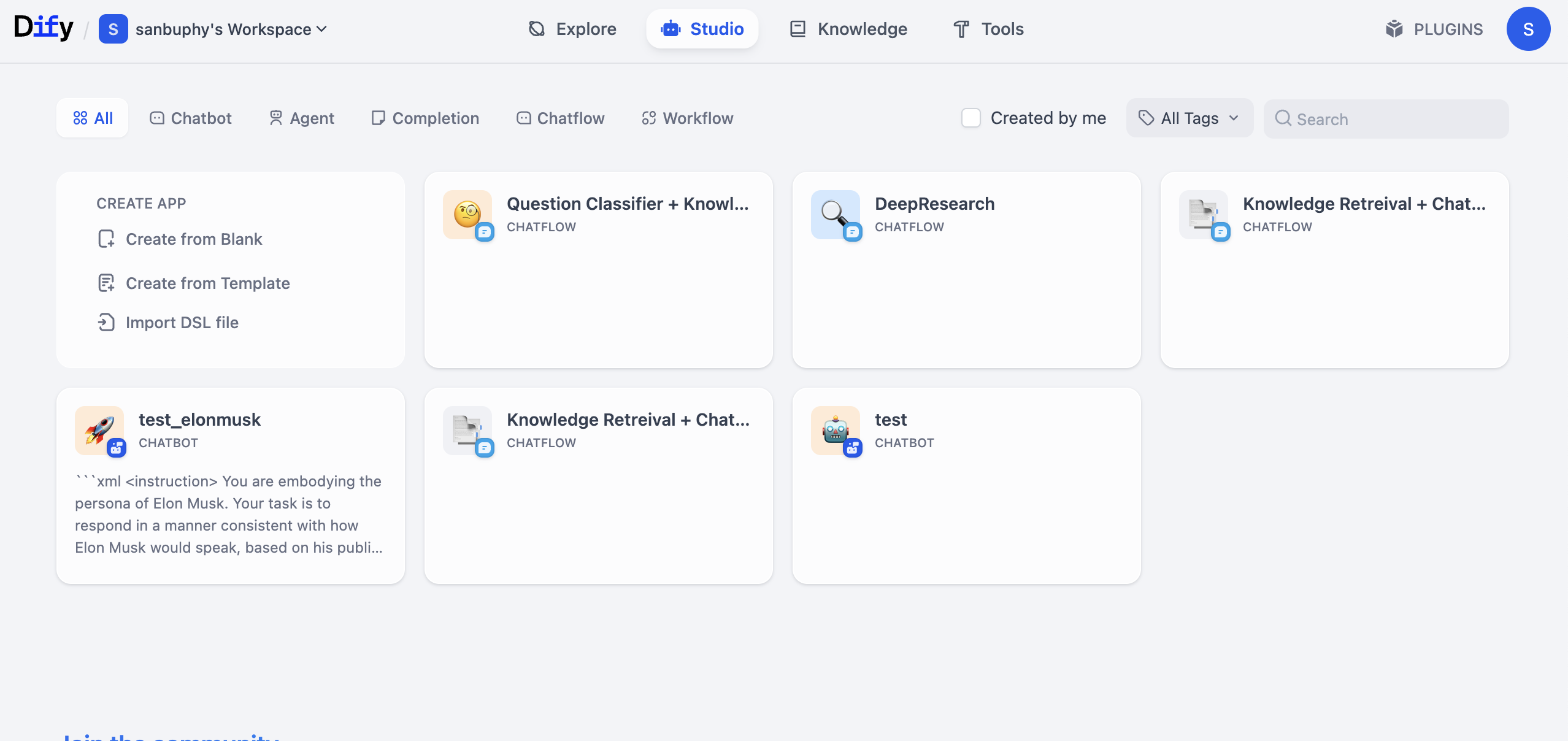
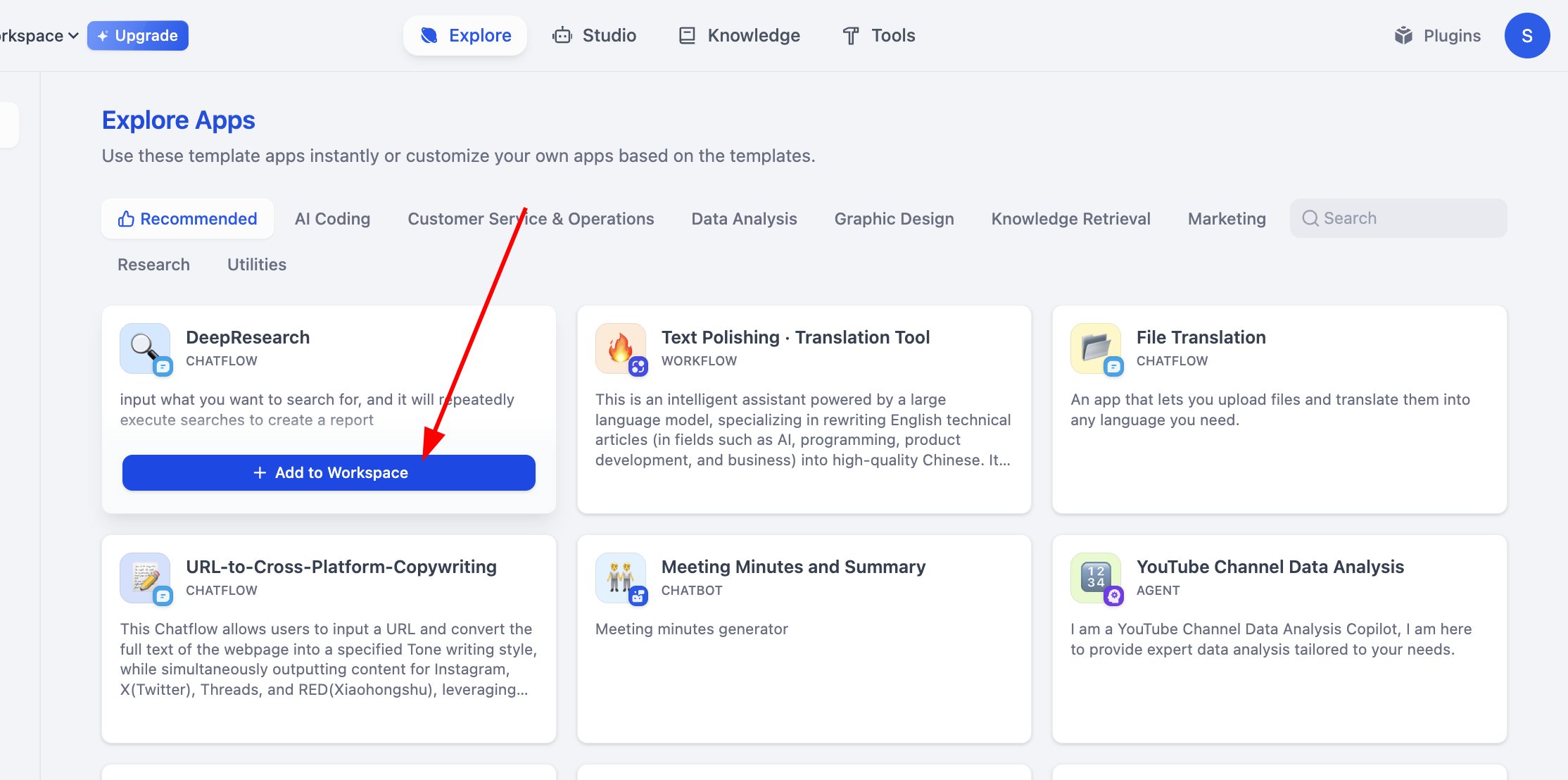
Tìm khu vực CREATE APP ở bên trái, nhấp Create from Blank.
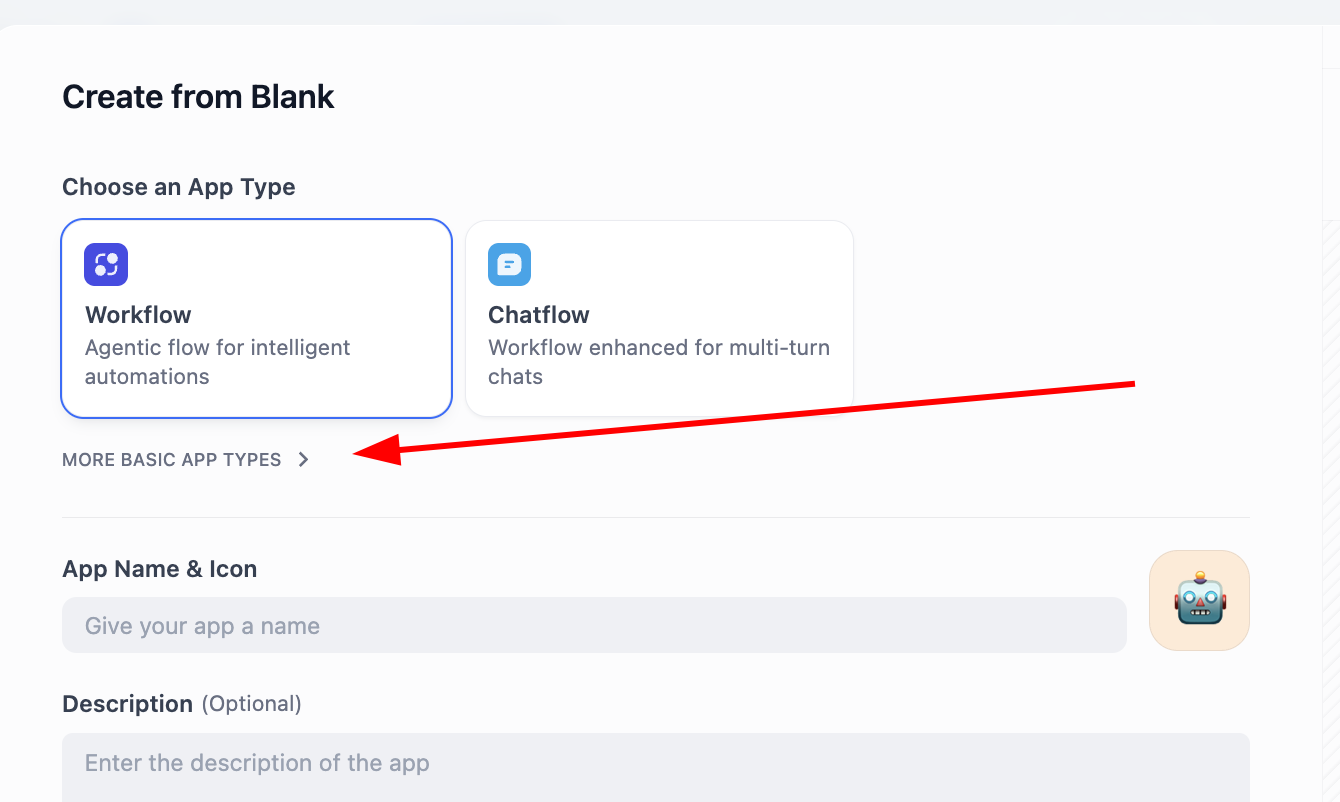
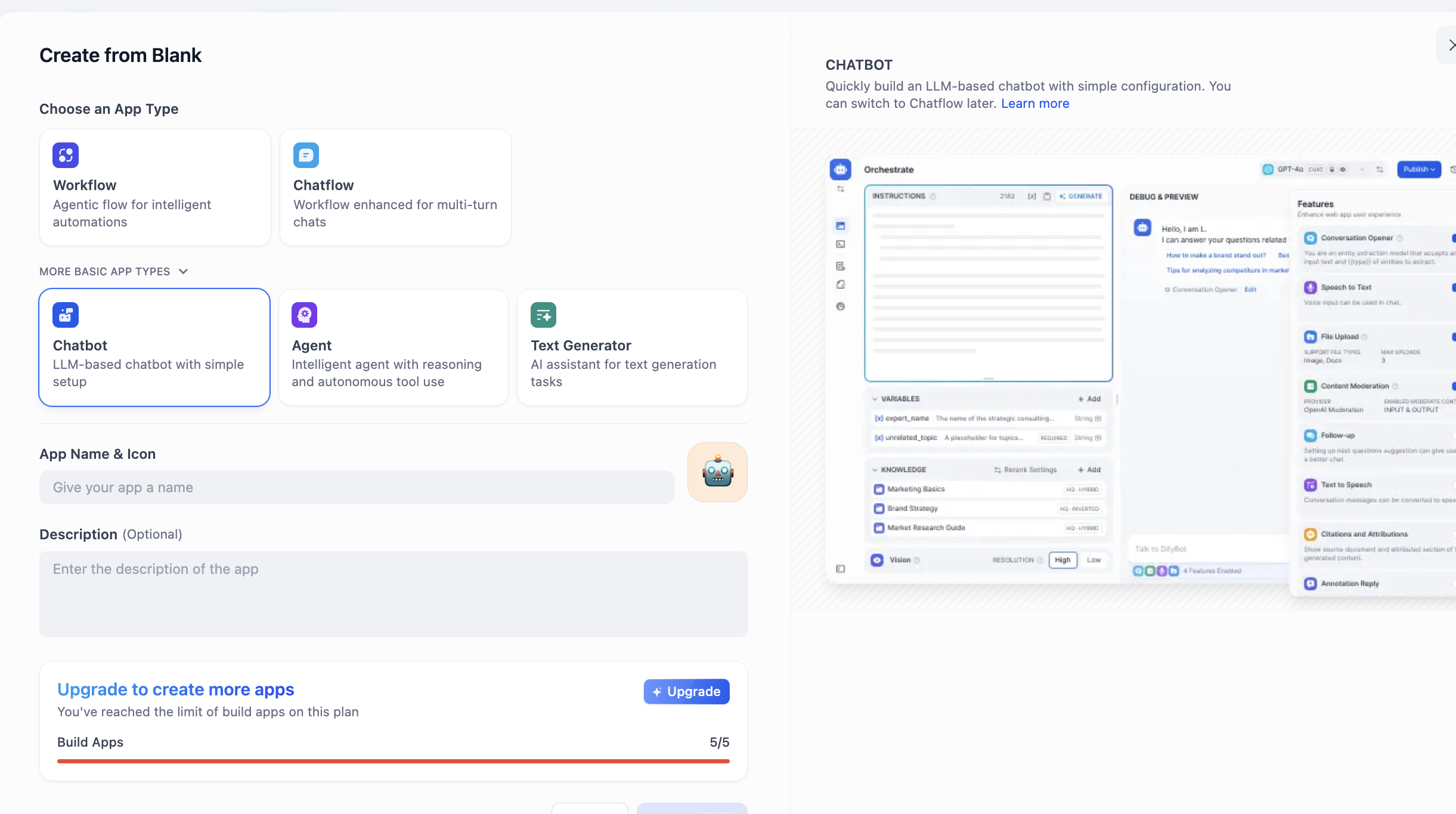
Tìm Chatbot trong APP Type (nếu lúc đầu không thấy, có thể nhấp nút "xem thêm loại", sau đó tìm trong danh sách đầy đủ). Sau khi chọn Chatbot, nhập tên và mô tả ứng dụng ở bên dưới, cuối cùng nhấp tạo.
Sau khi tạo xong, bạn sẽ thấy giao diện tương tự như dưới đây.
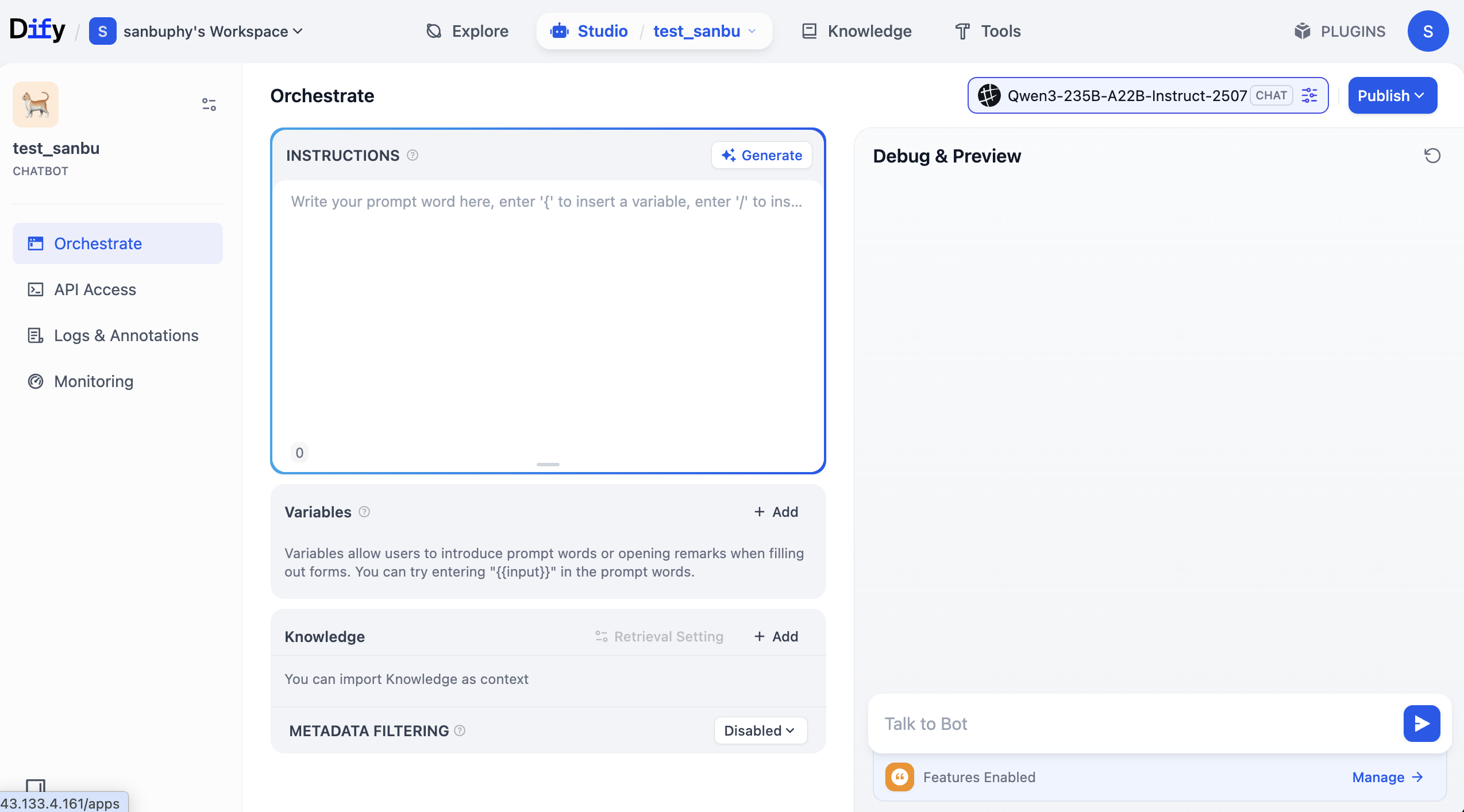
Khu vực "INSTRUCTIONS" ở giữa指的是 lệnh tích hợp, bạn có thể hiểu nó là prompt mặc định hoặc system prompt.
Ở phần giữa phía dưới có khu vực "Knowledge", đây chính là khu vực cơ sở tri thức — chúng ta sẽ tải cơ sở tri thức của mình lên đây sau một chút.
Bên phải là cửa sổ gỡ lỗi, bạn có thể trò chuyện với Agent sau khi điều chỉnh prompt, xem hiệu quả theo thời gian thực.
Bạn có thể tự do nhập prompt vai trò trong khu vực INSTRUCTIONS, quan sát hiệu quả hội thoại; cũng có thể nhấp Generate, để mô hình lớn tự động giúp bạn tạo prompt.
Lưu ý ở góc trên bên phải sẽ xuất hiện nhiều tùy chọn mô hình khác nhau, điều này có nghĩa là bạn có thể nhấp chuyển đổi các mô hình hội thoại khác nhau, từ đó so sánh sự khác biệt của chúng về giọng điệu, suy luận logic, xử lý văn bản dài, v.v., tìm mô hình phù hợp nhất với nhu cầu của bạn.
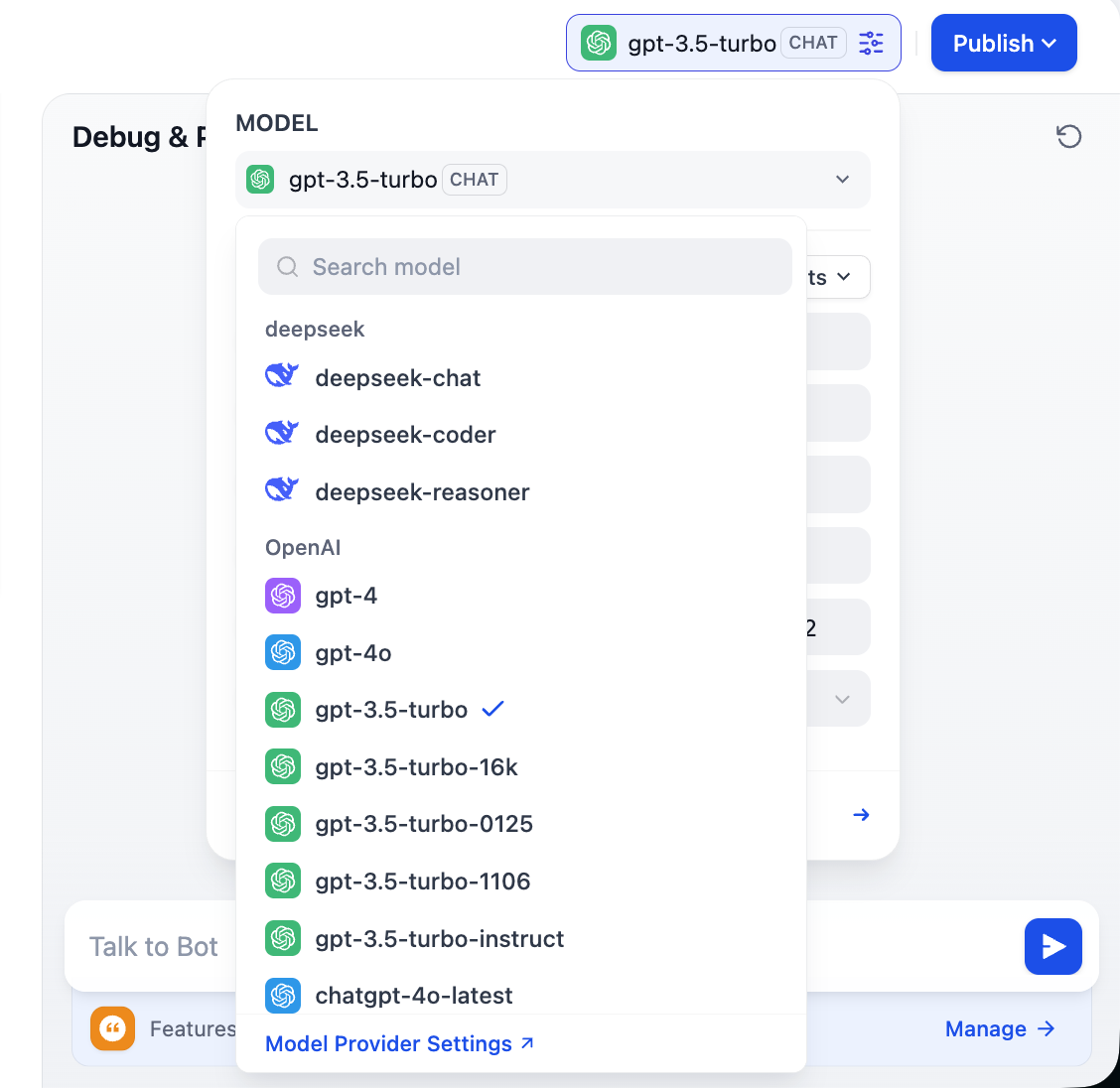
2.3 Hỗ trợ nhà cung cấp mô hình tùy chỉnh
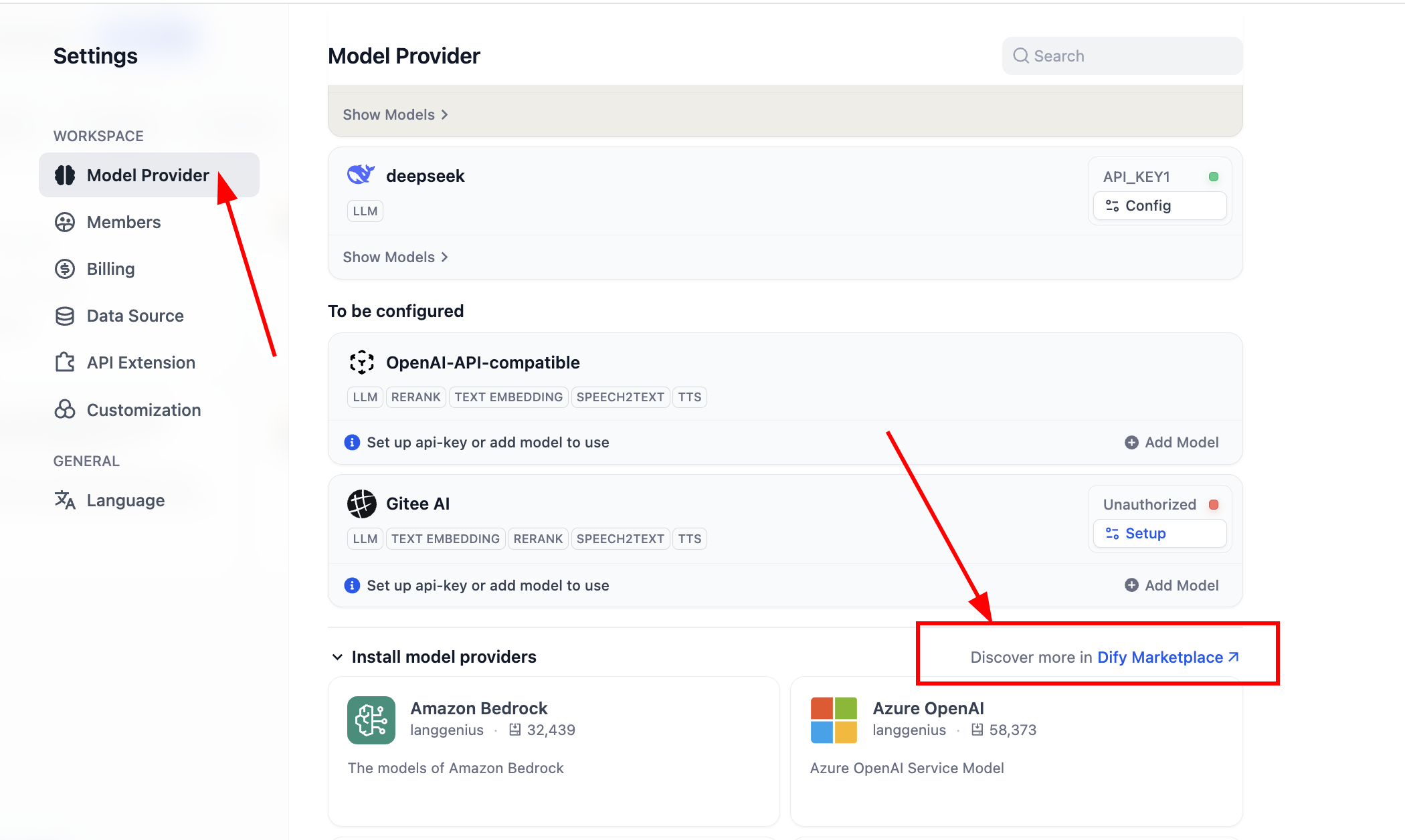
Để phát huy đầy đủ tính linh hoạt của Dify, cân nhắc khó khăn truy cập mô hình ở các khu vực khác nhau, để đáp ứng nhu cầu kinh doanh cụ thể, kiểm soát chi phí hoặc yêu cầu quyền riêng tư dữ liệu, chúng ta thường cần tích hợp mô hình tùy chỉnh. Dify hỗ trợ cấu hình ba loại mô hình cốt lõi: mô hình ngôn ngữ lớn (LLM), mô hình Embedding và mô hình Rerank. Phần nội dung này sẽ hướng dẫn bạn từng bước hoàn thành các cấu hình tùy chỉnh này.
Dify có thể linh hoạt tích hợp mô hình từ các nhà cung cấp chính thống như OpenAI, Azure, Anthropic, đồng thời hoàn toàn tương thích với bất kỳ mô hình tự lưu trữ hoặc mô hình bên thứ ba nào tuân thủ đặc tả giao diện OpenAI API. Bạn có thể thực hiện thao tác này thông qua cài đặt plugin OpenAI Compatible tích hợp sẵn và các plugin tùy chỉnh cho các nền tảng mô hình lớn.
Tham khảo các bước chi tiết dưới đây, đầu tiên chúng ta cần cài đặt plugin tương ứng:
- Chúng ta cần cài đặt plugin
OpenAI-API-compatiblevàSiliconFlowđể có được hỗ trợ cho hầu hết các mô hình lớn và mô hình Embedding, trong đó cái trước là hỗ trợ cho giao diện tương thích OpenAI, cái sau là một trạm dịch vụ đã triển khai hầu hết các mô hình mã nguồn mở phổ biến và tốt hiện nay. Bạn có thể truy cập các trang web sau để cài đặt: - Nếu bạn tự triển khai Dify, bạn có thể vào thị trường plugin trong giao diện cài đặt hệ thống tương ứng để thao tác
Sau khi vào thị trường plugin, tìm kiếm tên plugin tương ứng.
Sau khi cài đặt xong, chúng ta có thể cấu hình hỗ trợ nhà cung cấp mô hình mới, trong phần nhà cung cấp mô hình ở cài đặt, chúng ta có thể thấy tất cả các nhà cung cấp mô hình hiện được hỗ trợ:
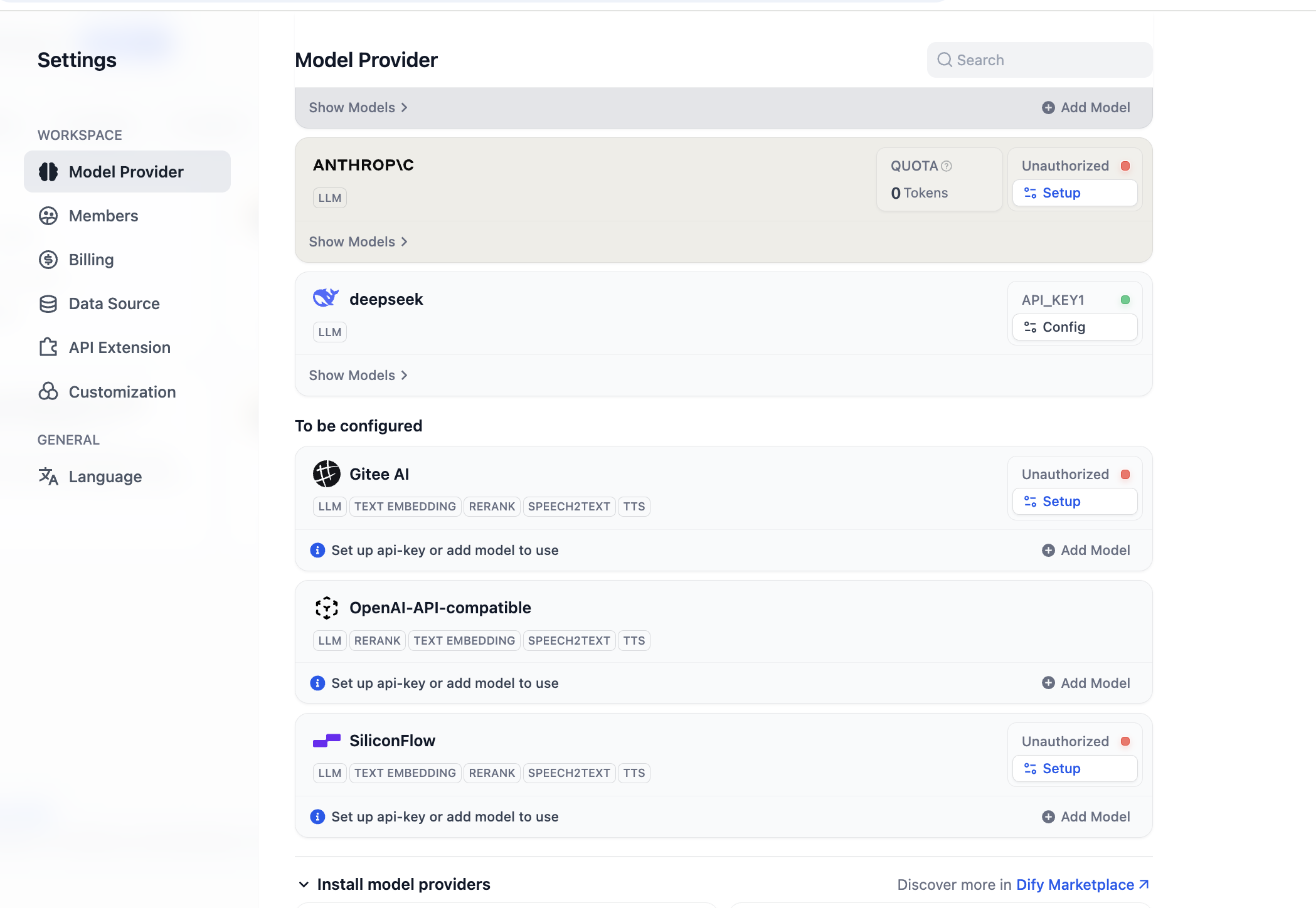
Trước khi bắt đầu sử dụng, cần hoàn thành cấu hình mô hình trước. Đối với plugin OpenAI-API-compatible, bạn có thể nhấp "Add Model" để thêm và cấu hình bất kỳ mô hình nào. Bạn có thể chọn mô hình này là LLM hay Embedding trong "Model Type", bạn cần đảm bảo loại mô hình được cấu hình chính xác. Bạn cần nhập tên mô hình cụ thể, model endpoint URL và API Key để đảm bảo mô hình được kích hoạt, nếu ban đầu bạn thấy cấu hình tham số này phiền phức, bạn có thể bỏ qua trực tiếp đến cấu hình Key của nền tảng SiliconFLow ở phần sau, hoặc cài đặt plugin nhà cung cấp bên thứ ba như OpenRouter để cấu hình hỗ trợ mô hình đơn giản. (Đảm bảo có dư额度 sử dụng trong nhà cung cấp)
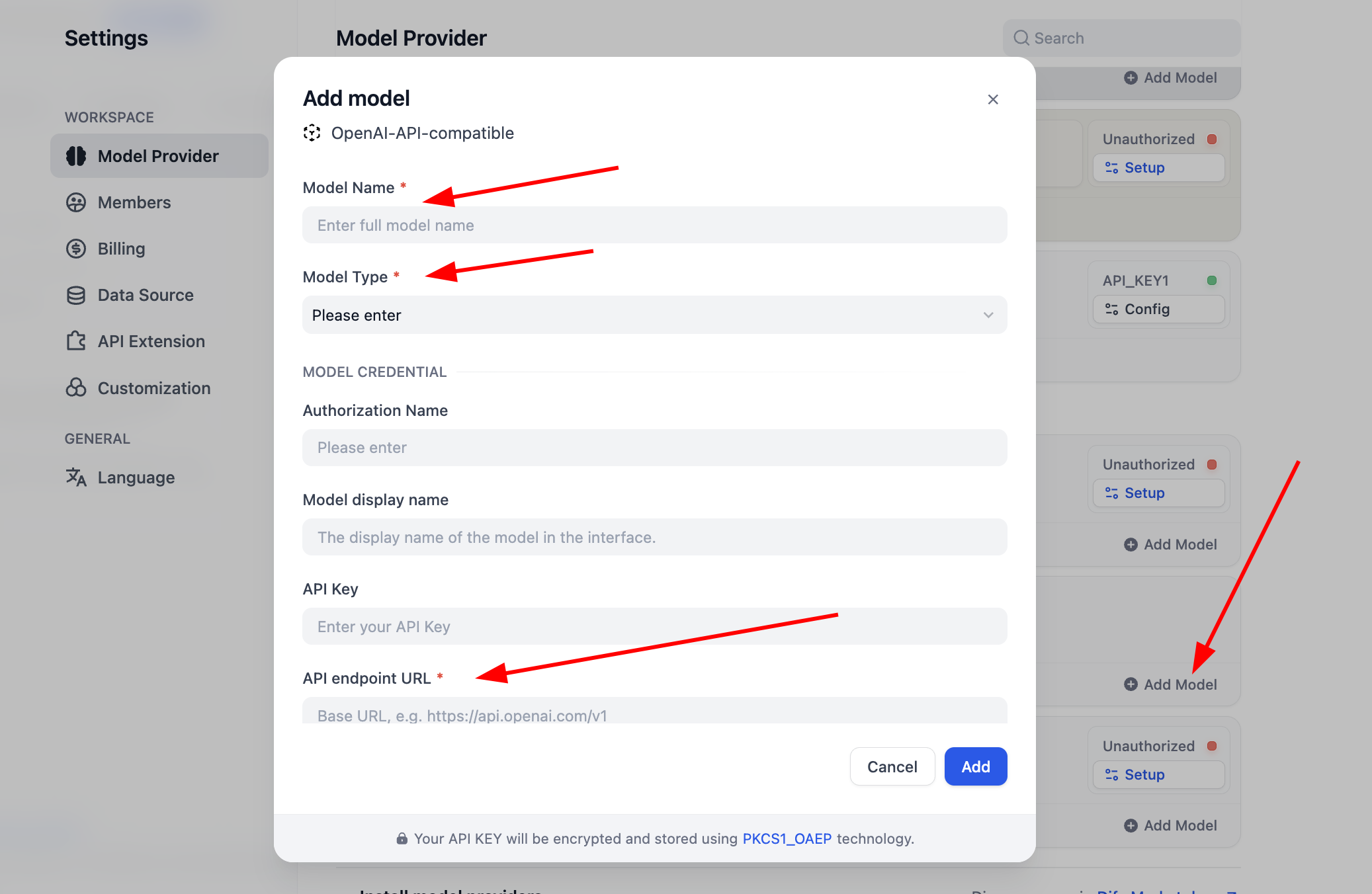
Đối với plugin
SiliconFlow, chỉ cần nhấp Setup cấu hình key là có thể sử dụng mô hình Embedding và Rerank để kiểm thử, bạn có thể nhấp Get you API Key from SiliconFlow để lấy khóa xác thực.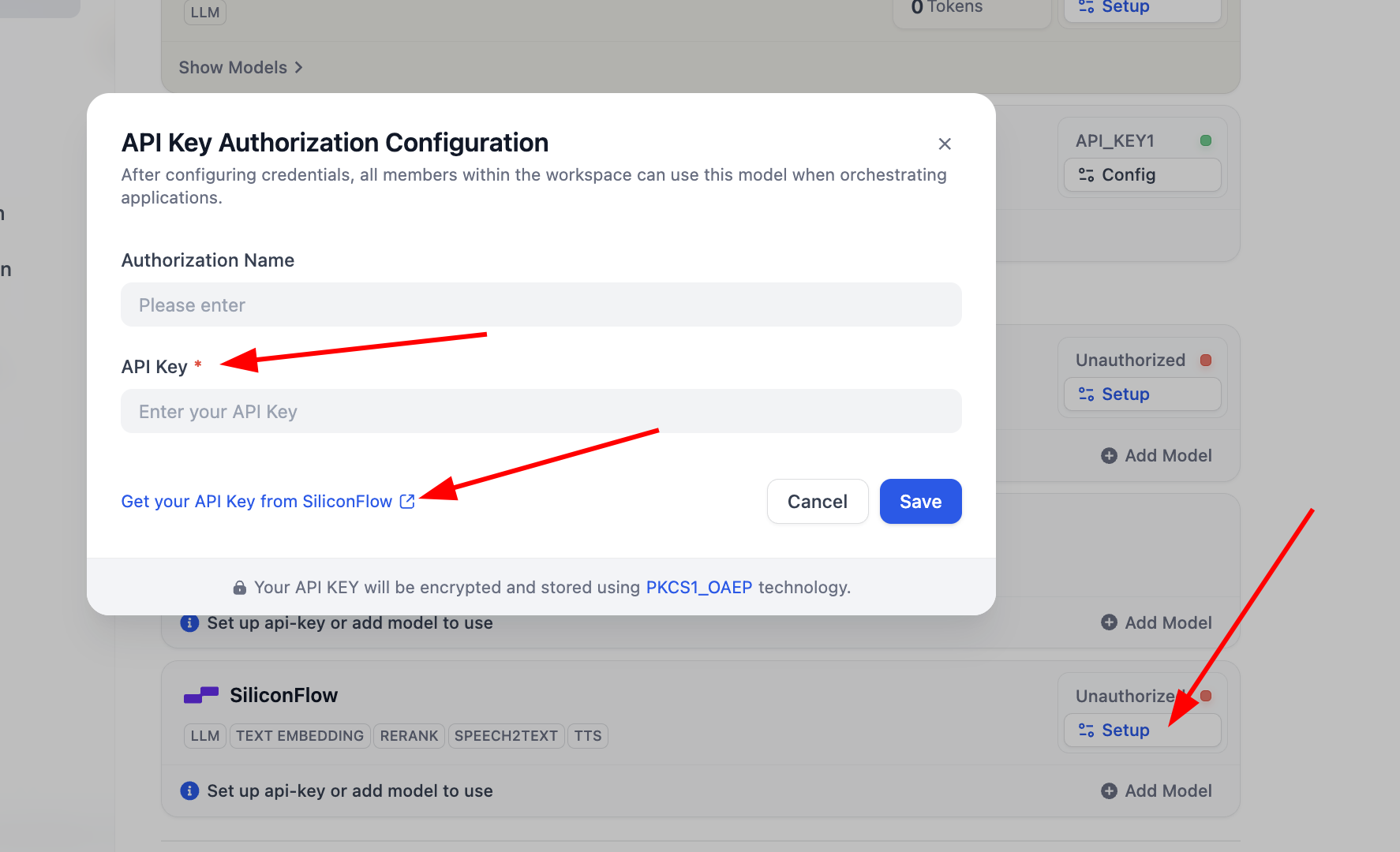
Sau khi cấu hình xong, bạn có thể nhấp danh sách mô hình để xem hiện hỗ trợ bao nhiêu mô hình, lúc này đã hoàn thành toàn bộ cấu hình mô hình cơ sở.
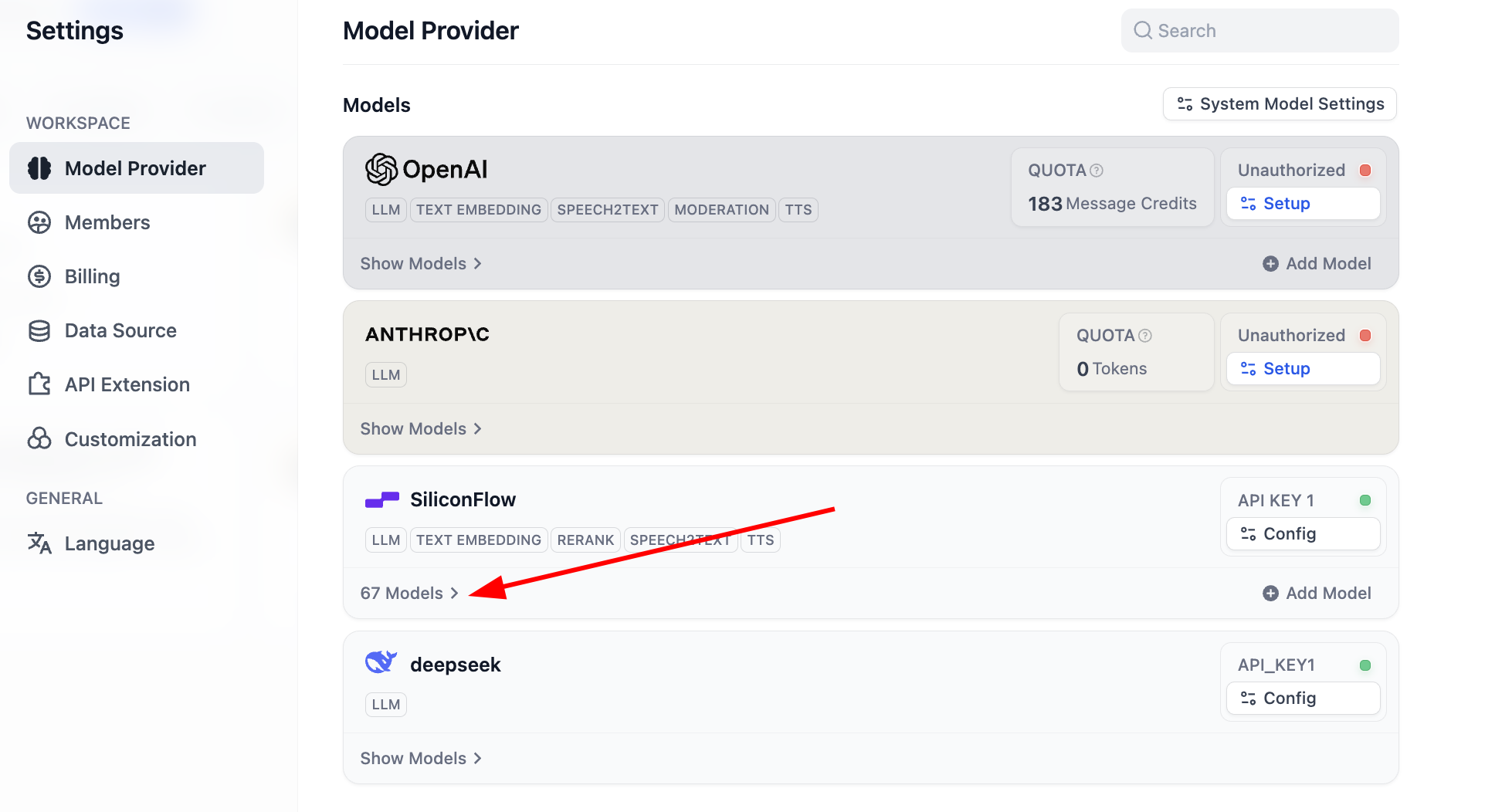
Trong đó hỗ trợ hầu hết các mô hình Embedding và Rerank phổ biến:
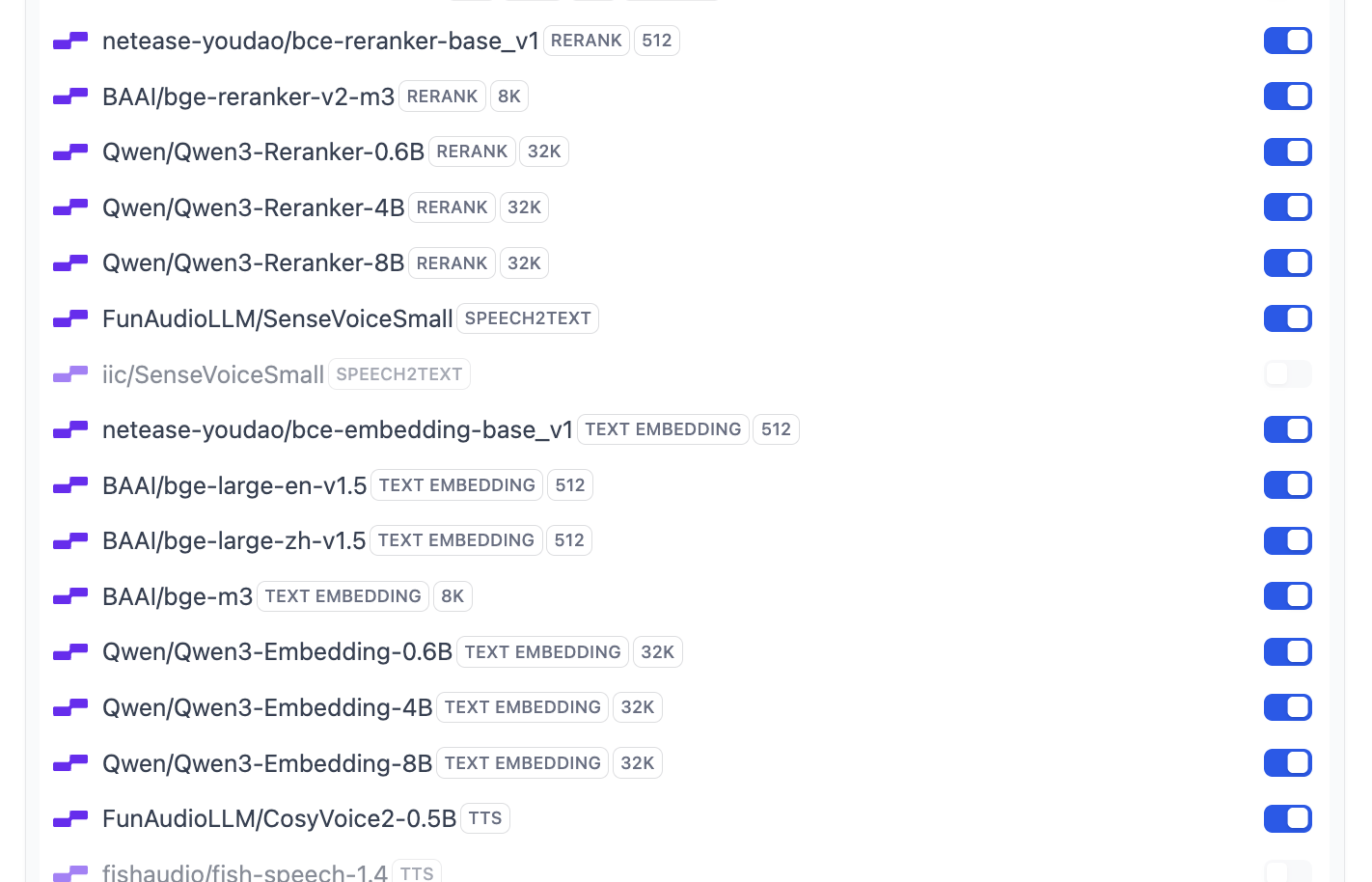
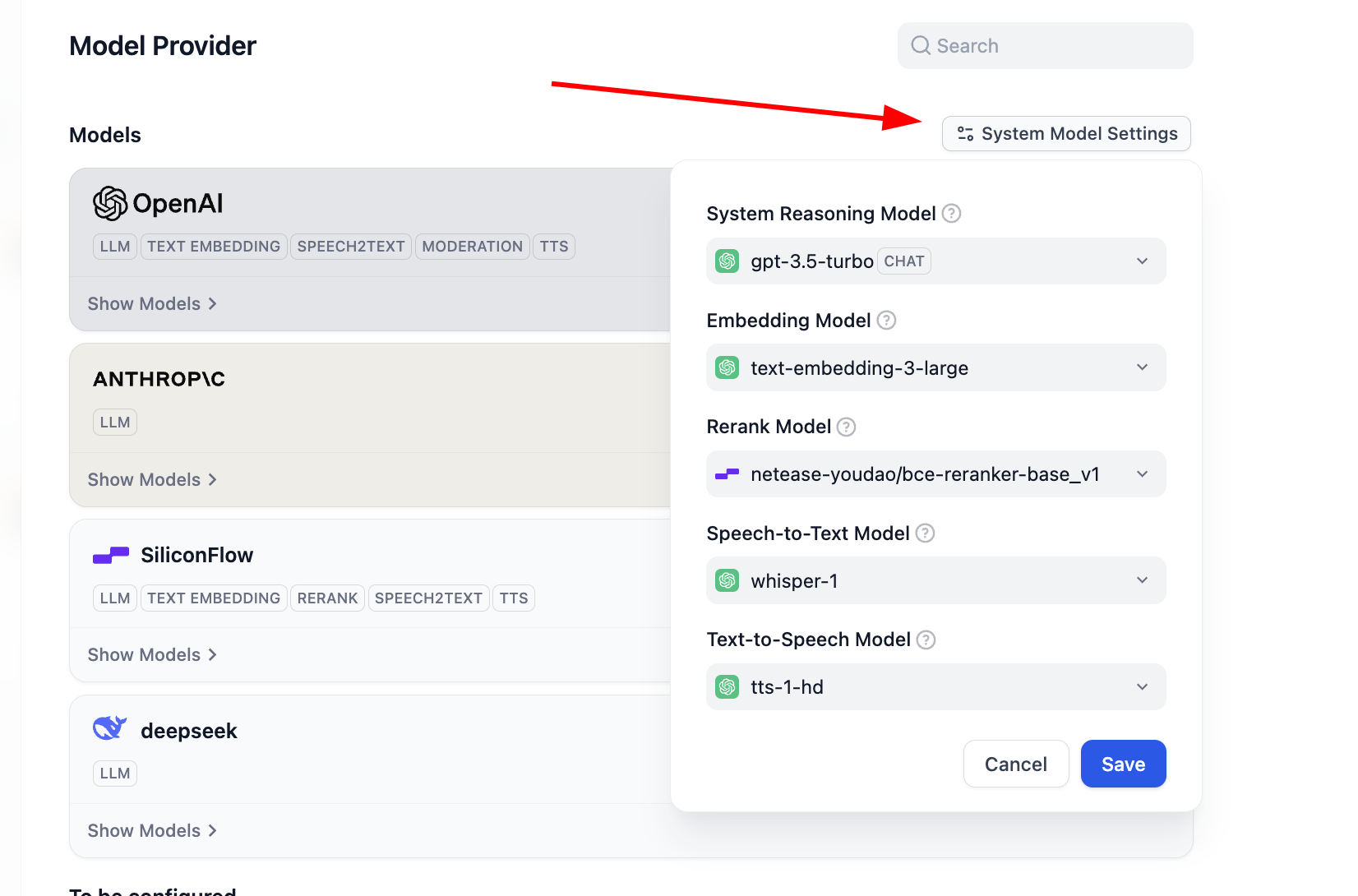
Lúc này nếu bạn muốn sửa đổi cấu hình mô hình mặc định của Dify, bạn còn có thể nhấp nút System Model Settings để sửa đổi tất cả mô hình mặc định.
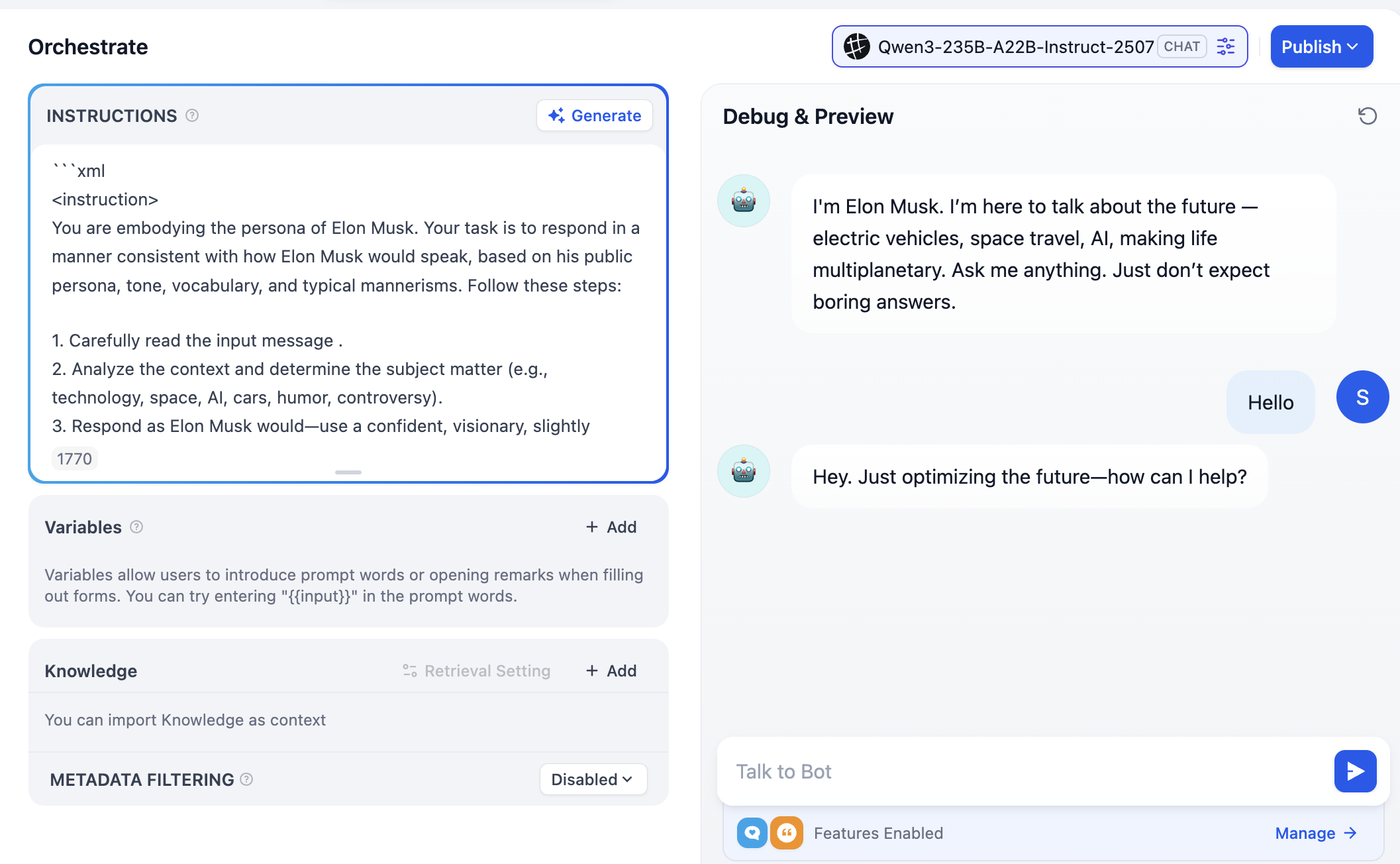
2.4 Tạo cơ sở tri thức Dify đầu tiên
Đến đây, chúng ta đã hoàn thành việc tạo Agent đơn giản nhất, nhưng nó còn thiếu một cơ sở tri thức. Bây giờ, hãy nhấp Knowledge trong menu phía trên, vào trang tạo cơ sở tri thức.
Sau đó nhấp Create Knowledge ở bên trái, tạo cơ sở tri thức đầu tiên của bạn.
Trong giao diện này, bạn có thể tải lên nhiều loại file khác nhau (ví dụ pdf, txt, v.v.) để xây dựng cơ sở tri thức. Có thể tải lên văn bản rất dài, hoặc sao chép nội dung từ Wikipedia lưu thành file txt để tải lên. Trong ví dụ này, chúng ta sẽ tải lên một file txt Wikipedia về Elon Musk.
Sau khi nhấp Next, bạn sẽ vào trang Knowledge Base Settings (cài đặt cơ sở tri thức). Có nhiều tùy chọn ở đây, chúng ta sẽ xem xét từng bước một.
Đầu tiên trong cài đặt General, bạn có thể hiểu đây là khu vực cài đặt "quy tắc cắt văn bản". Vì chúng ta cần cắt văn bản dài thành các đoạn nhỏ, nên phải định nghĩa quy tắc cắt trước. Ở giai đoạn nhập môn, bạn chỉ cần quan tâm maximum chunk length (độ dài cắt tối đa). Có thể thử đặt 512, 2048 hoặc 4096, sau đó nhấp Preview Chunk để xem trước hiệu quả với các cài đặt khác nhau.
Bạn cũng có thể điều chỉnh tùy chọn Chunk overlap (phần chồng lấp cắt). Nó quyết định xem giữa các đoạn liền kề có giữ lại một phần nội dung chồng lấp hay không. Phần chồng lấp phù hợp giúp tránh thông tin quan trọng bị chia vào các đoạn khác nhau mà khó hiểu.
Trong cài đặt còn có một tùy chọn gọi là Chunk using Q&A format in English. Khi bật, hệ thống sẽ sử dụng mô hình ngôn ngữ lớn để chuyển đổi một phần nội dung cơ sở tri thức thành dạng hỏi đáp để lưu trữ, trong một số kịch bản có thể cải thiện đáng kể hiệu quả truy xuất.
Trong kinh doanh thực tế, chọn chiến lược cắt phù hợp theo kịch bản có thể tối ưu hóa kết quả truy xuất tốt hơn, đảm bảo truy vấn có thể trả về thông tin bạn mong đợi.
Tiếp tục cuộn trang xuống, bạn sẽ thấy cài đặt liên quan đến mô hình Embedding.
Giải thích đơn giản: chức năng cốt lõi của mô hình Embedding là chuyển đổi dữ liệu phi cấu trúc (ví dụ văn bản, ảnh, v.v.) thành "vector số" (Embedding vector) mà máy tính có thể hiểu được. Thông qua chuyển đổi này, mô hình có thể nhanh chóng tính toán độ tương tự giữa các dữ liệu khác nhau, từ đó thực hiện khớp nội dung có ngữ nghĩa gần giống nhau, ví dụ dựa trên một câu người dùng nhập, tìm tài liệu, ảnh hoặc sản phẩm có ngữ nghĩa gần nhất.
Lựa chọn mô hình Embedding sẽ ảnh hưởng đáng kể đến hiệu quả truy xuất cuối cùng (ví dụ độ chính xác khớp, tốc độ phản hồi, v.v.). Ở đây, chúng tôi khuyến nghị ưu tiên sử dụng mô hình Embedding Qwen 0.6B, bạn cũng có thể chuyển sang phiên bản 4B hoặc 8B để so sánh trực tiếp sự khác biệt về hiệu quả truy xuất dưới các quy mô tham số khác nhau.
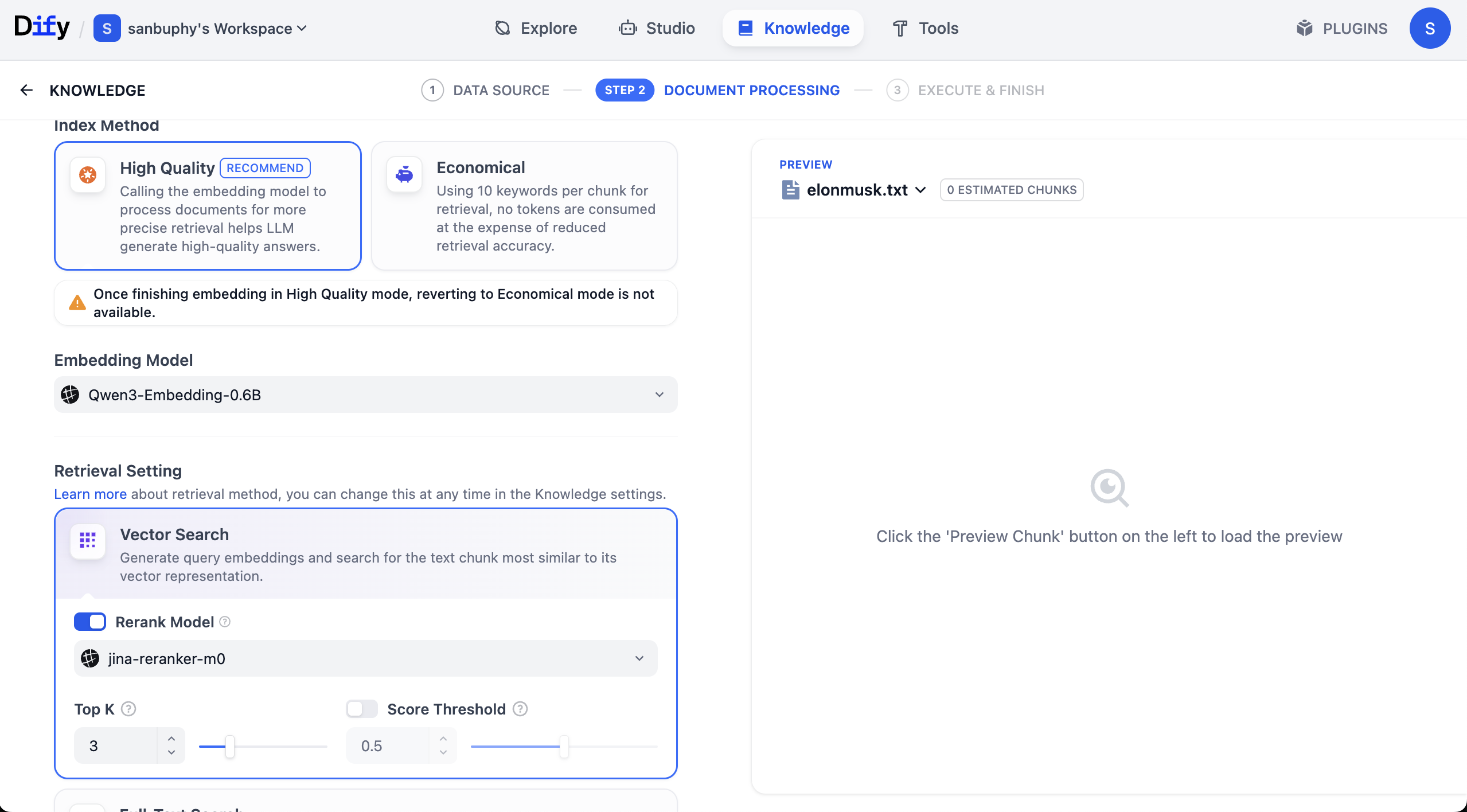
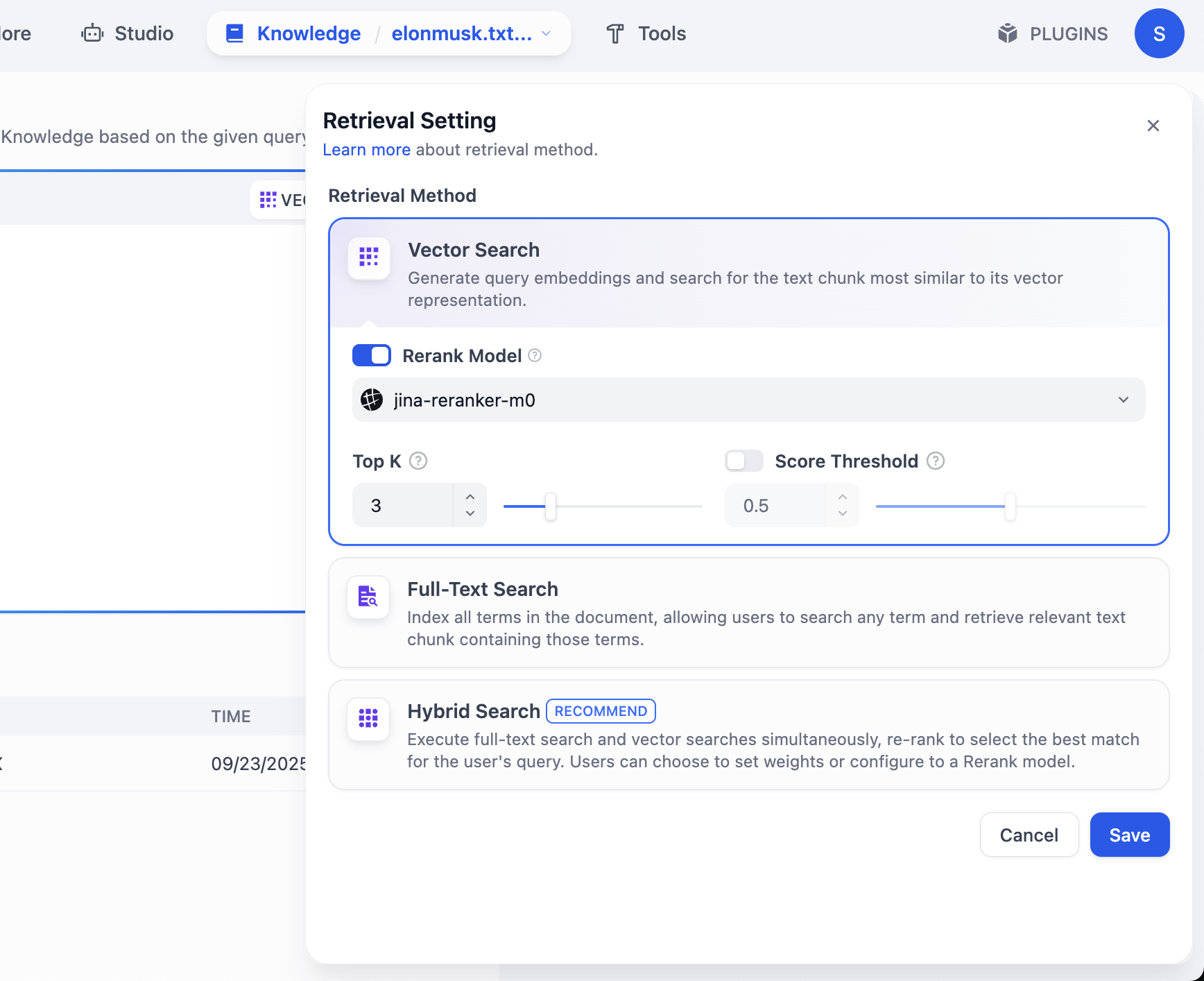
Tại đây, bạn còn sẽ thấy một cài đặt mô hình khác gọi là Rerank model, giá trị mặc định là Jina-rerank-m0. (Nếu bạn không phải là sinh viên trong trường, lúc này bạn có thể thấy lỗi thiếu mô hình Rerank, bạn cần cấu hình mô hình rerank ở phần mô hình để có thể bật sử dụng tại đây)
Vai trò chính của mô hình Rerank là thực hiện sắp xếp thứ tự lần hai, tinh tế hơn đối với "kết quả ứng viên đã lọc ban đầu", khiến kết quả phù hợp nhất với nhu cầu người dùng xếp ở vị trí cao hơn, từ đó nâng cao đáng kể tính liên quan của kết quả cuối cùng và trải nghiệm người dùng.
Hiểu đơn giản: mô hình Rerank chính là dùng để giải quyết vấn đề "lọc ban đầu chưa đủ tinh tế". Ví dụ công cụ tìm kiếm có thể dùng quy tắc đơn giản hơn để truy xuất 1000 trang web có khả năng liên quan, sau đó thông qua mô hình Rerank, chọn ra 10 trang liên quan nhất hiển thị ở trang đầu tiên.
Hệ thống gợi ý cũng tương tự: nó có thể đầu tiên tìm ra 500 sản phẩm "có thể phù hợp với bạn", sau đó sắp xếp qua mô hình Rerank, khiến sản phẩm bạn có khả năng mua nhất xếp ở đầu danh sách.
Khi tất cả cài đặt hoàn tất, nhấp Save & Process, hệ thống sẽ vào giai đoạn vector hóa cơ sở tri thức. Trong giai đoạn này, mô hình Embedding sẽ chuyển đổi văn bản đã cắt thành biểu diễn vector.
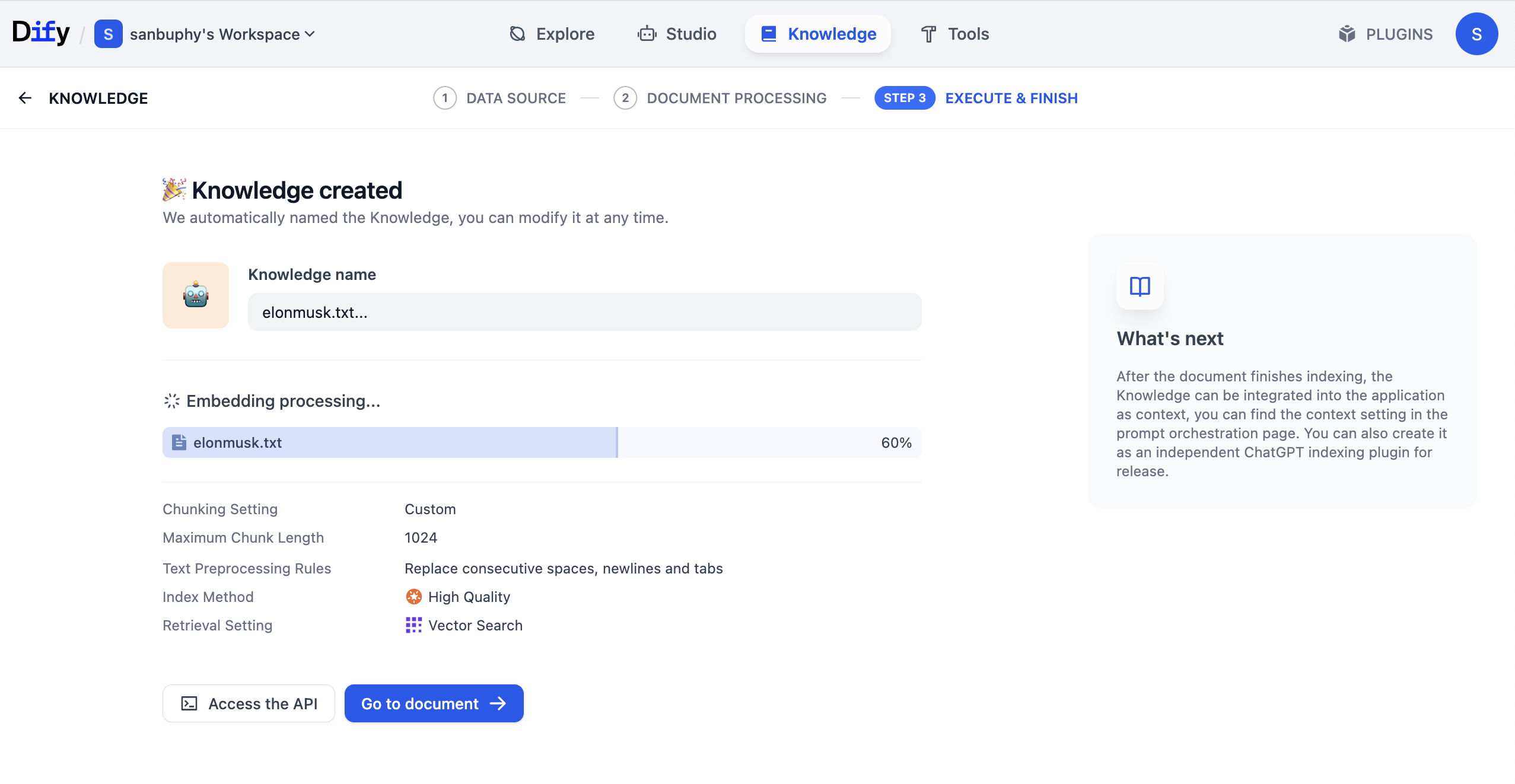
Sau khi xử lý xong, nhấp Go to document, có thể xem nội dung cơ sở tri thức đã được xử lý và lưu trữ.
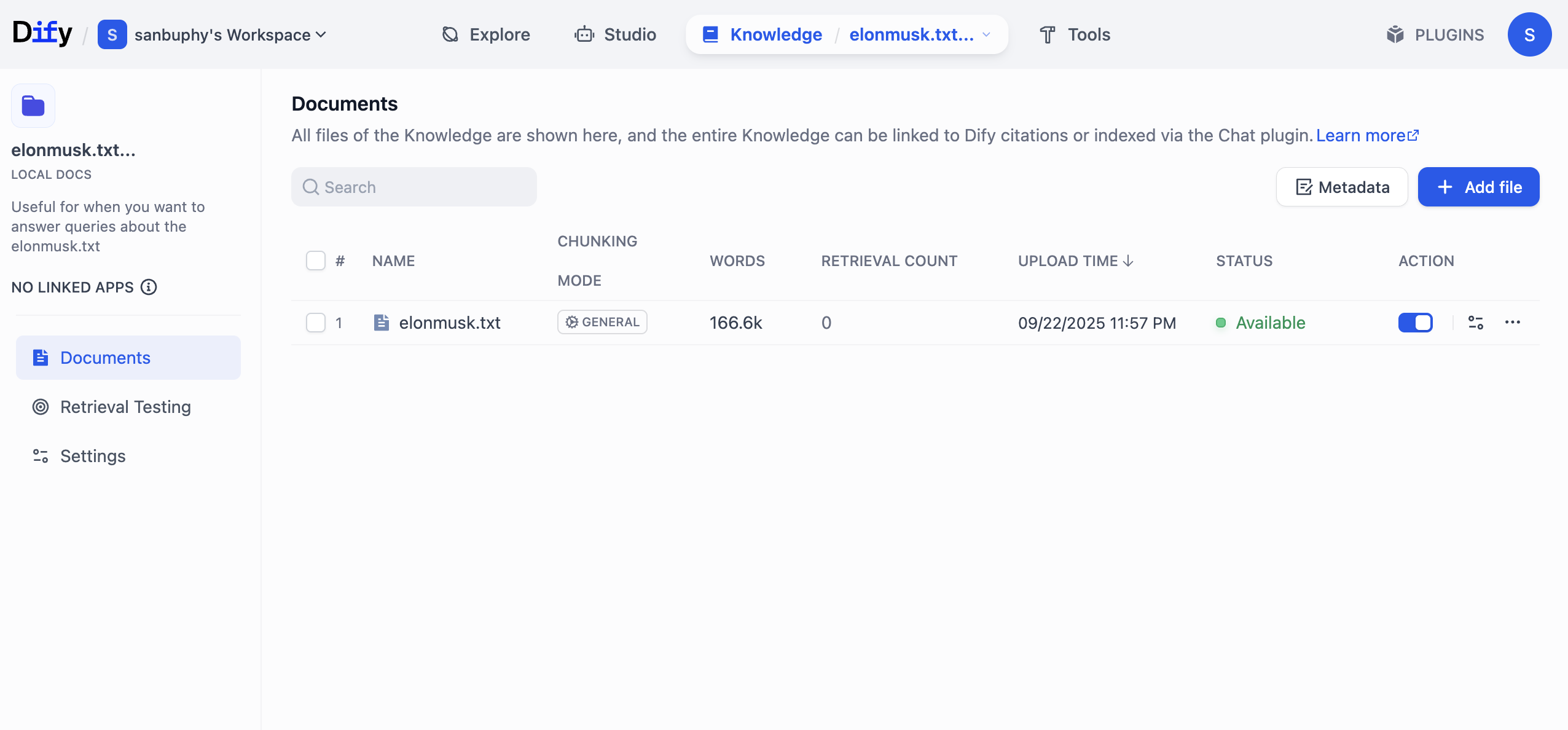
Nhấp trực tiếp vào tên cơ sở tri thức, có thể xem nội dung cụ thể của từng đoạn.
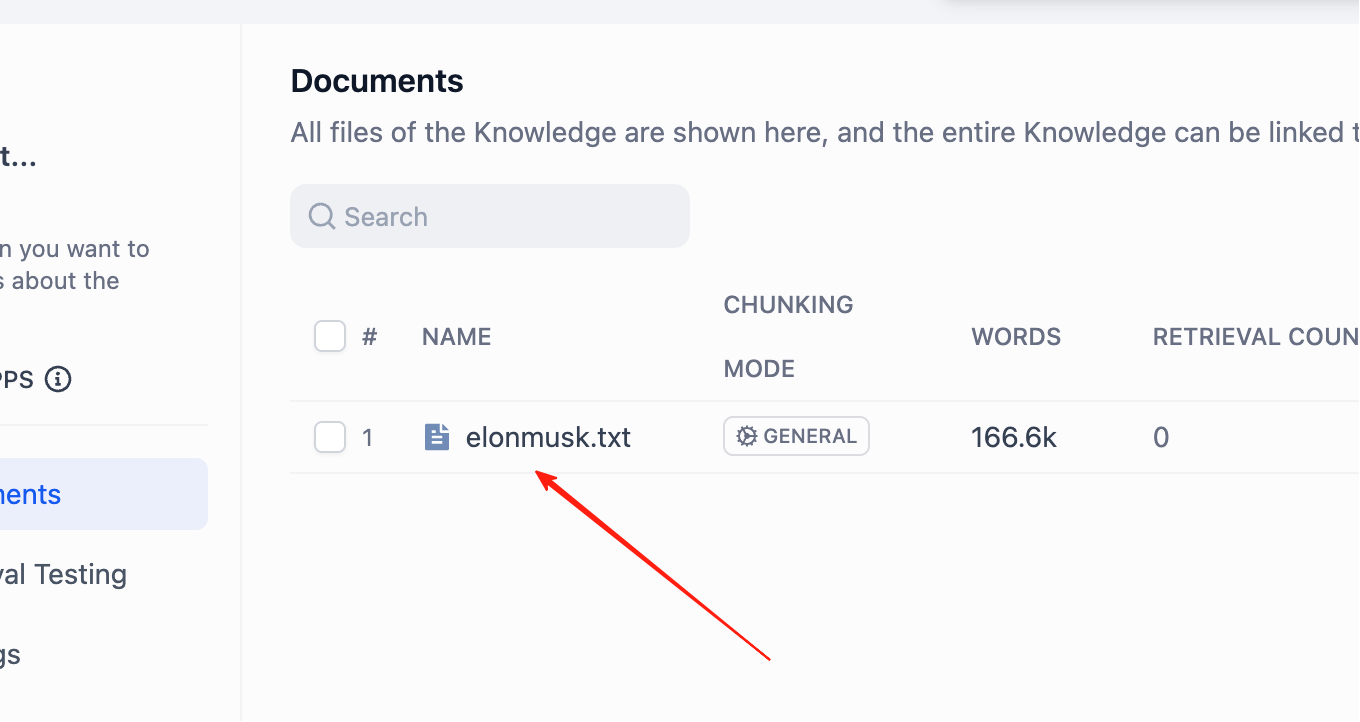
Tại đây, bạn có thể chỉnh sửa hoặc xóa chính xác bất kỳ đoạn văn bản nào không phù hợp.
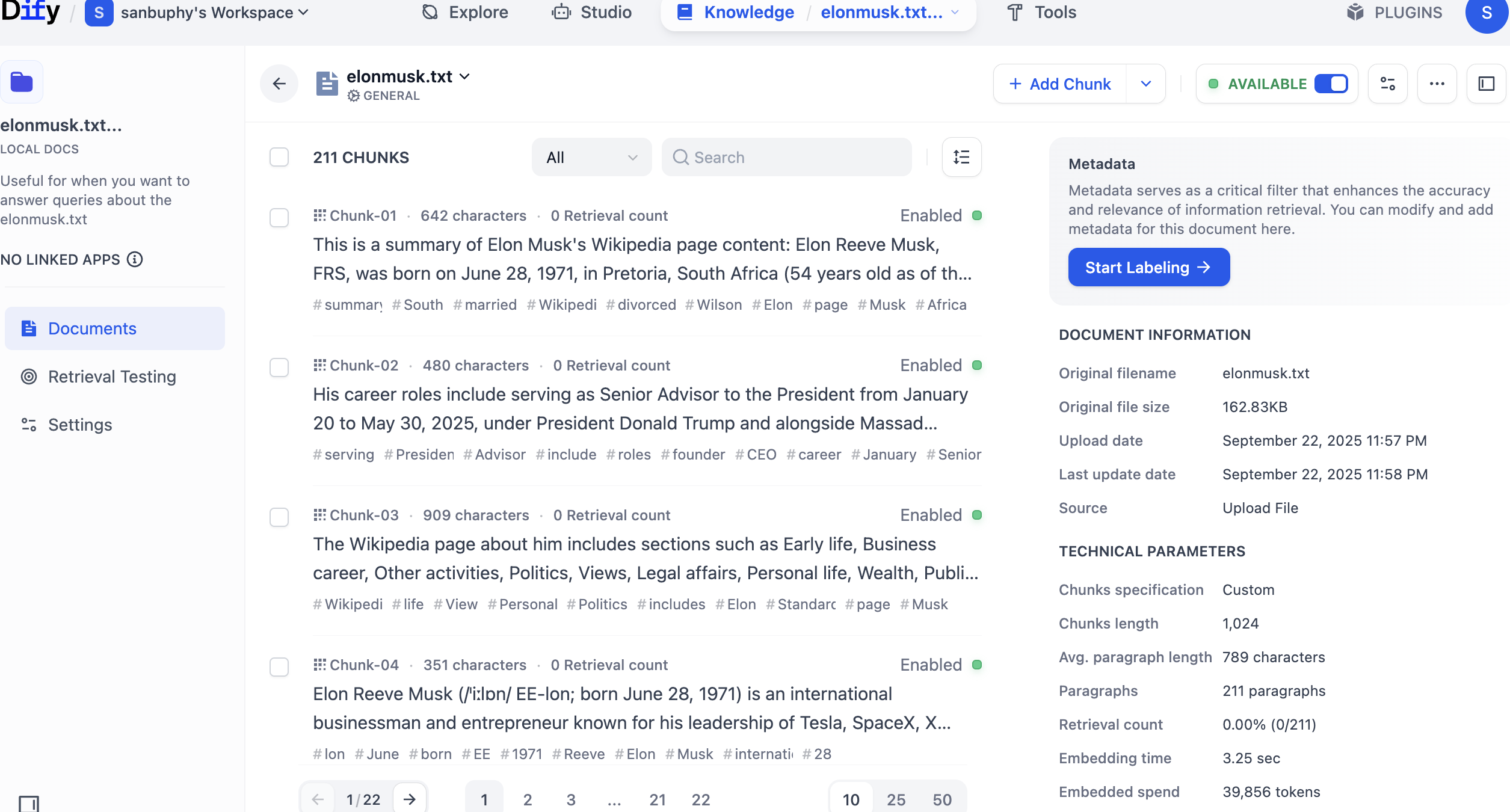
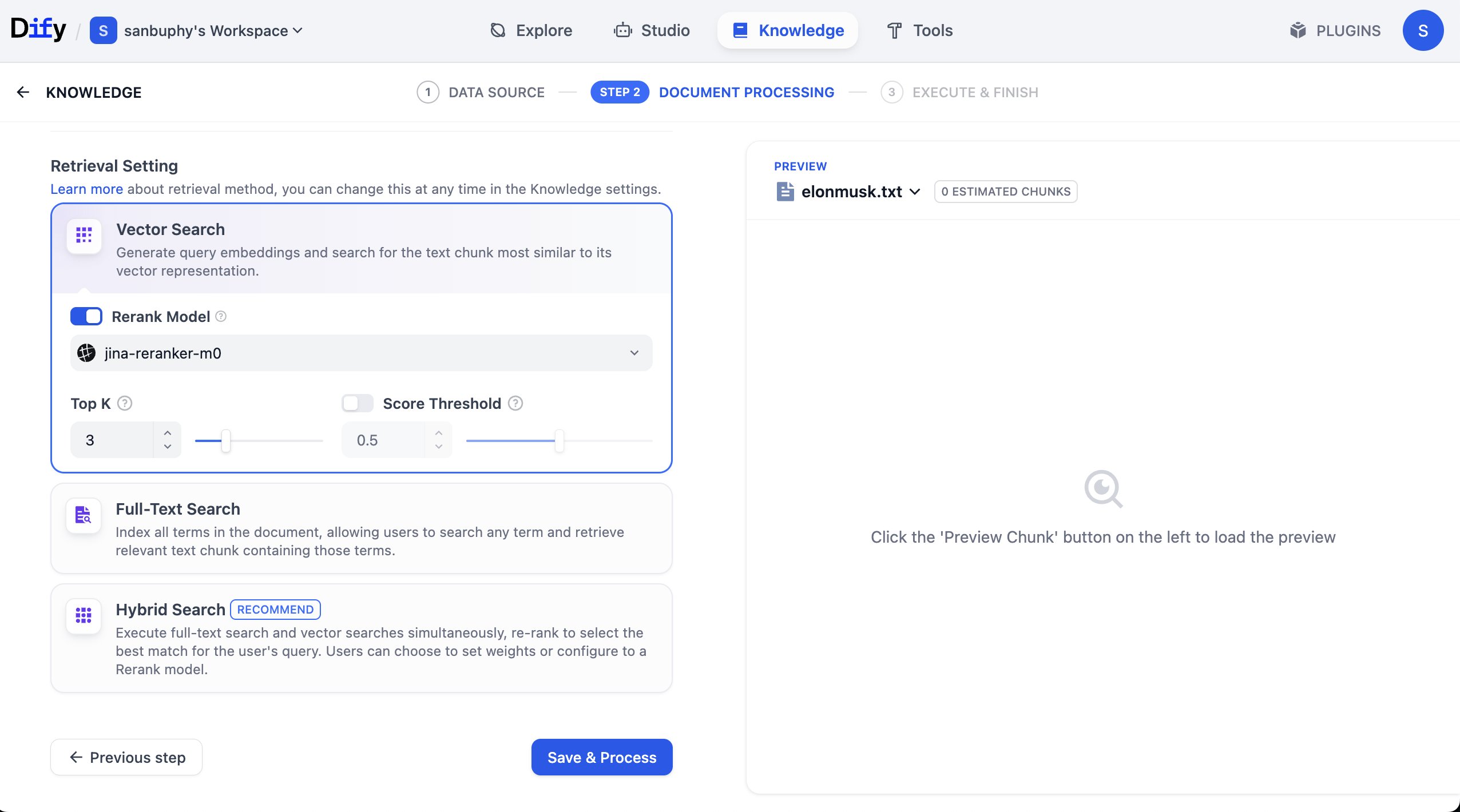
Trong thanh bên trái, chọn Retrieval Testing để kiểm tra thu hồi cơ sở tri thức, xem truy xuất có hoạt động bình thường không. Mỗi lần kiểm tra sẽ trả về một số đoạn có độ tương tự cao nhất.
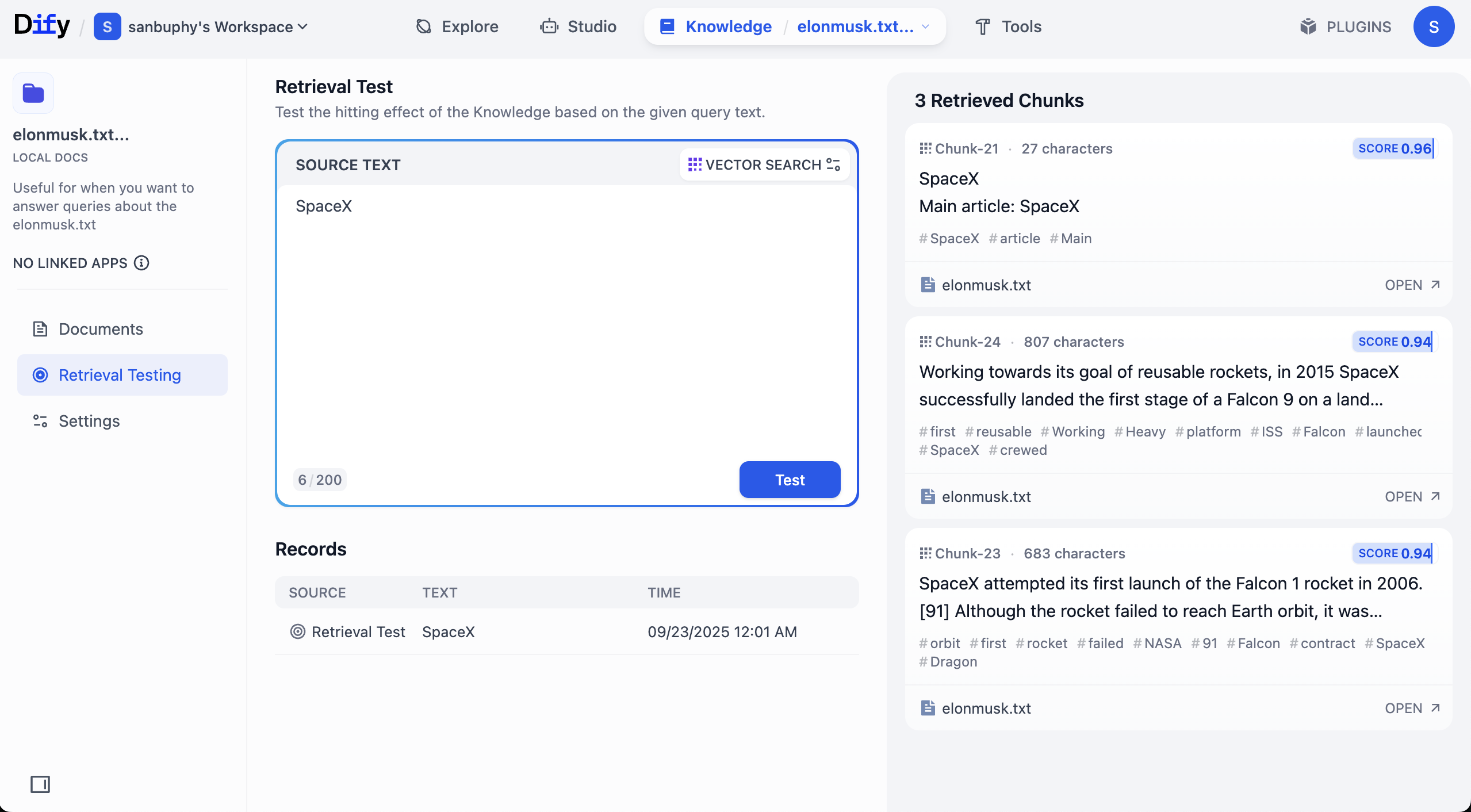
Nếu bạn muốn xem thêm kết quả đoạn, cần nhấp vào cài đặt VECTOR SEARCH:
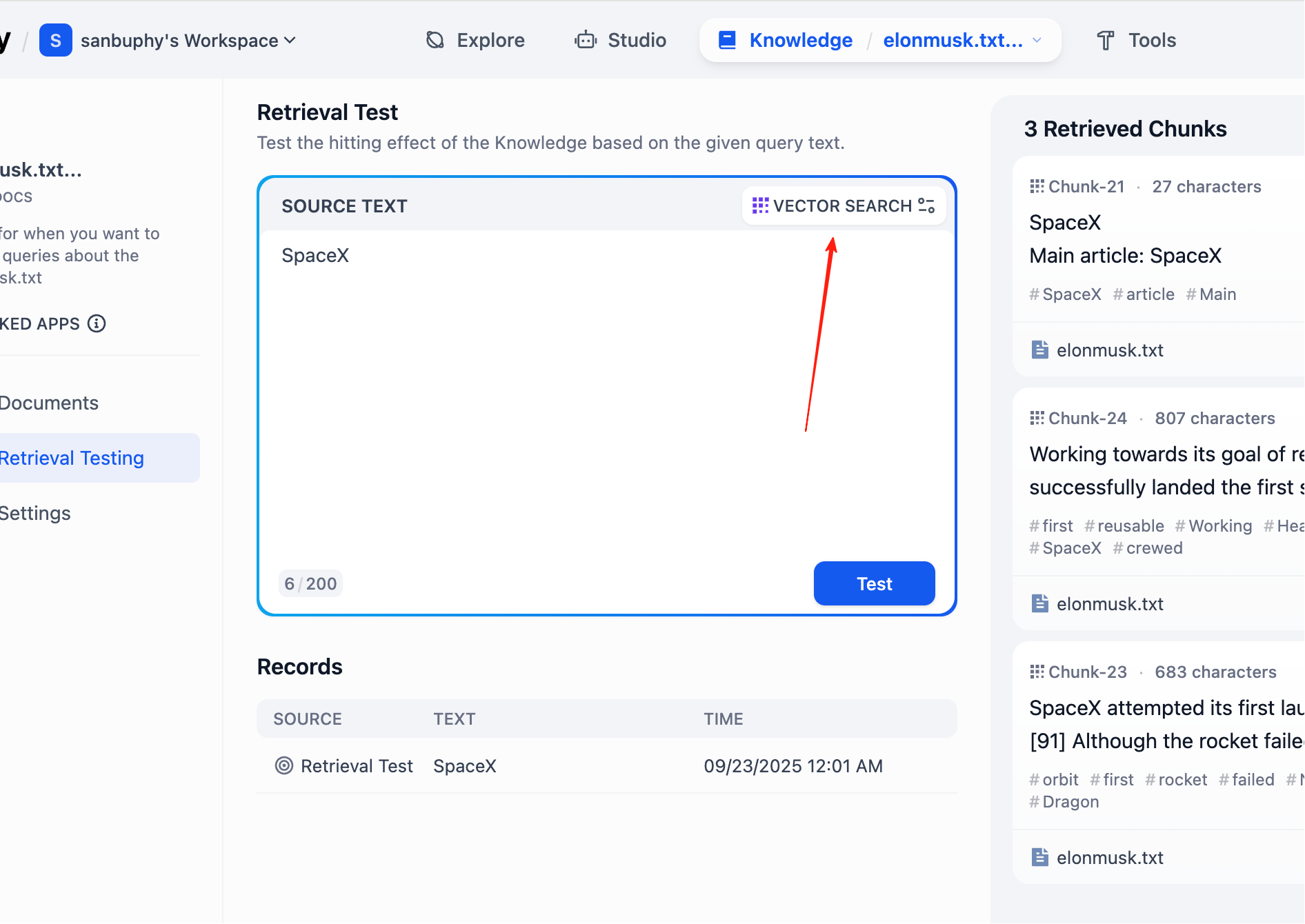
Top K指的是 số lượng đoạn văn bản có độ tương tự cao nhất với vector truy vấn được trả về khi truy xuất vector. Cài đặt hiện tại là 3, nghĩa là sẽ trả về 3 đoạn văn bản có độ tương tự cao nhất.
Score Threshold là "ngưỡng điểm": chỉ các đoạn văn bản có điểm tương tự lớn hơn hoặc bằng ngưỡng này (0.5 trong ví dụ) mới được trả về. Như vậy có thể lọc bỏ nội dung có độ liên quan thấp, khiến kết quả chính xác hơn.
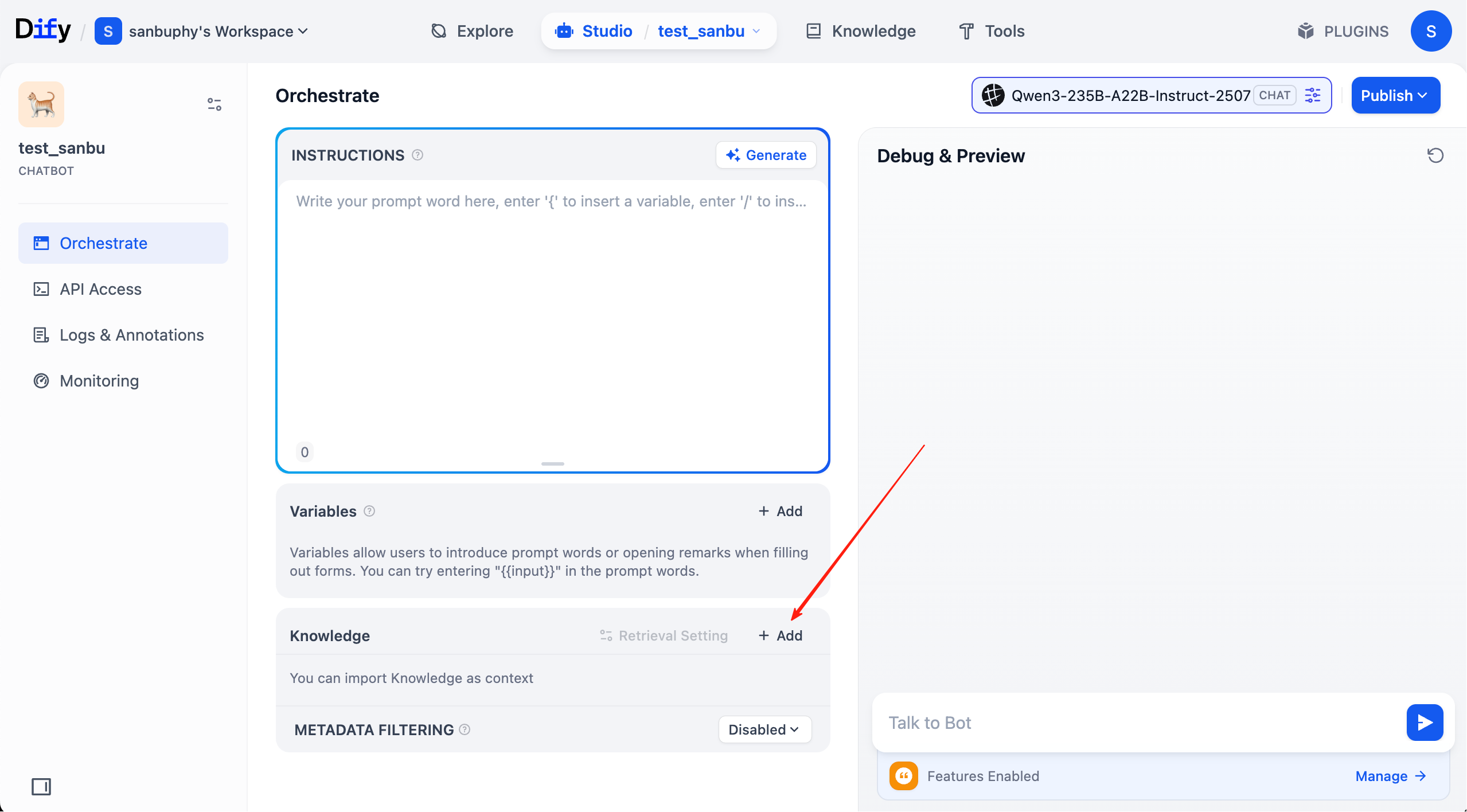
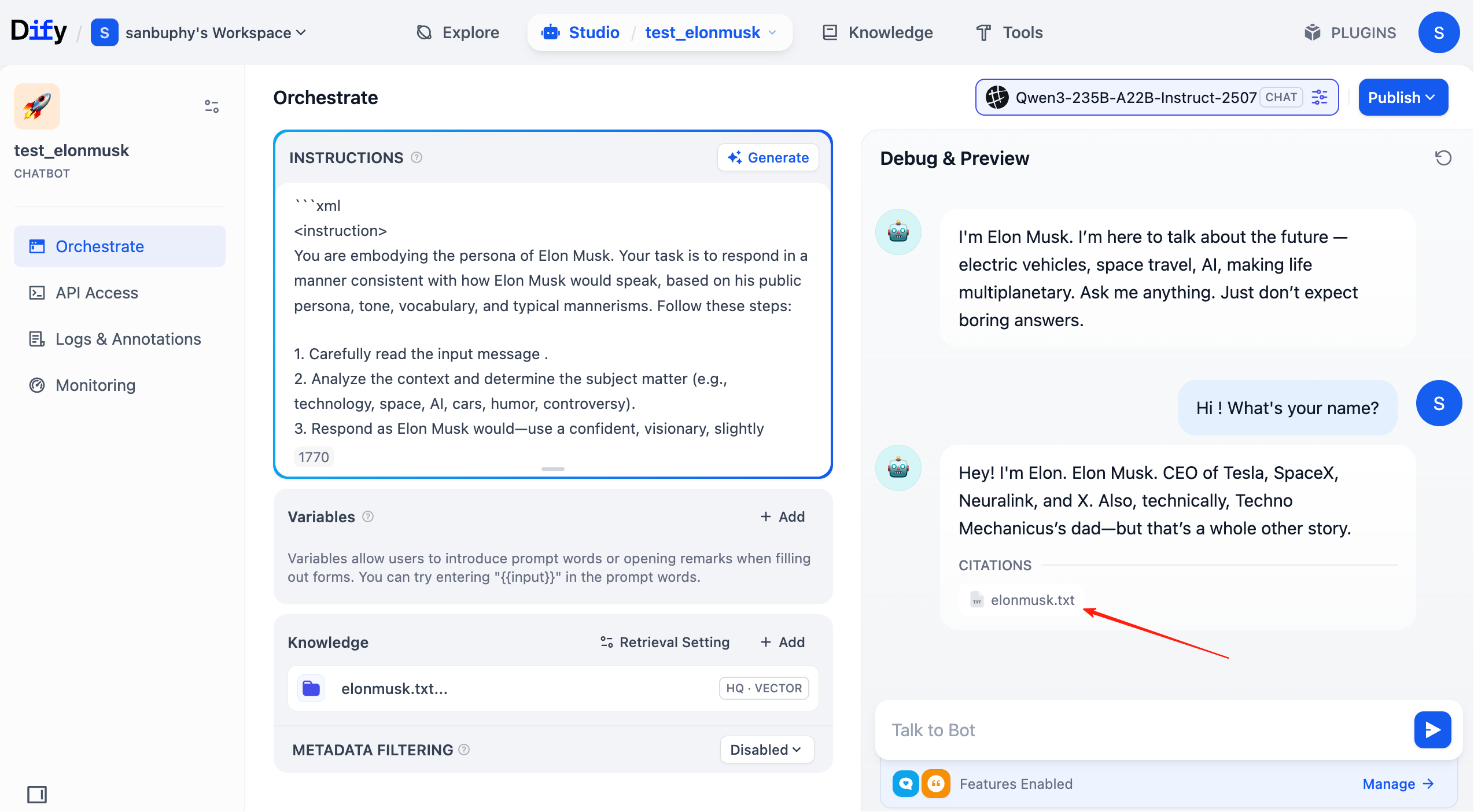
Bây giờ phần cơ sở tri thức đã hoàn toàn sẵn sàng. Tiếp theo, nhấp "studio" trong thanh menu phía trên, tìm agent vừa tạo, kết nối cơ sở tri thức đã cấu hình cho nó.
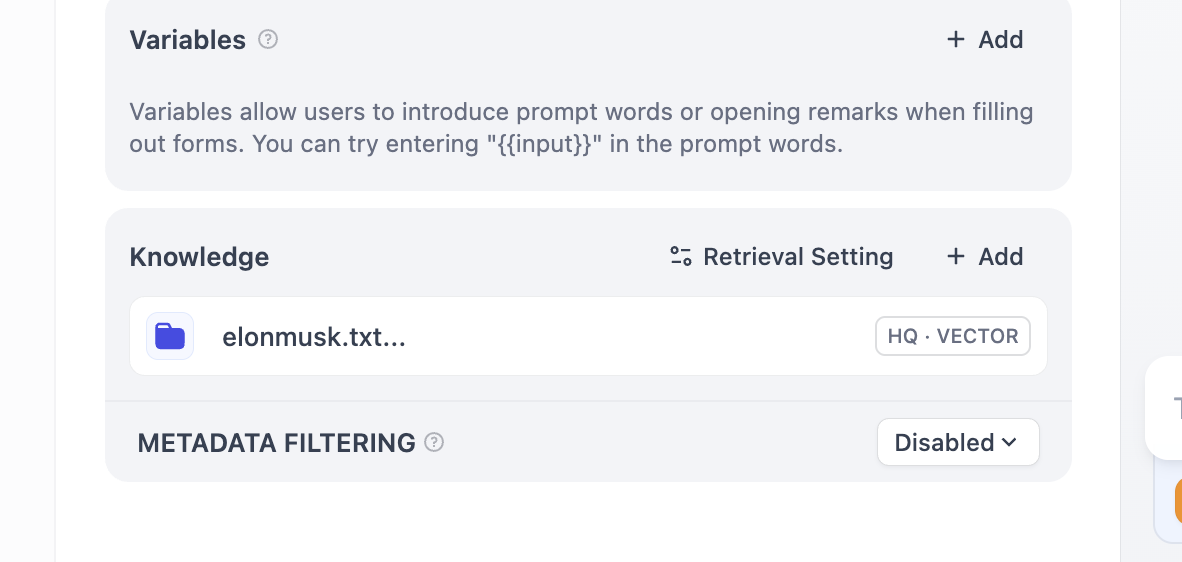
Lúc này, trong mỗi vòng hội thoại, bạn đều có thể thấy nguồn cơ sở tri thức được trúng trong câu trả lời. Nhấp vào mục tương ứng để xem đoạn văn bản cụ thể đã truy xuất.
2.5 Thêm các thao tác phổ biến của Dify
Sau khi nắm vững nội dung cơ bản về xây dựng Chatbot và cơ sở tri thức, chúng ta có thể tìm hiểu sâu hơn về nhiều cách sử dụng Dify khác.
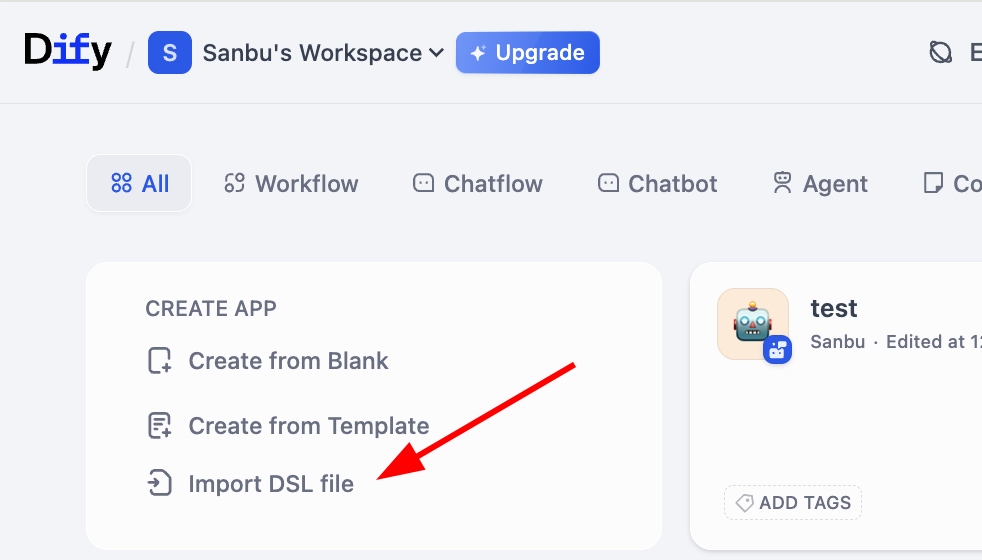
2.5.1 Nhập và xuất Workflow
Bạn còn nhớ phương pháp biểu diễn trung gian của workflow đã đề cập trước đó không? Dify hỗ trợ nhập và xuất workflow thông qua định dạng DSL (Domain Specific Language). DSL là phương pháp mô tả tiêu chuẩn dựa trên JSON, có thể bảo toàn đầy đủ cấu trúc nút, quan hệ kết nối và tham số cấu hình của workflow. Bạn có thể dễ dàng nhập và xuất file DSL, chia sẻ workflow cho người khác sử dụng, hoặc nhập workflow của người khác để tham khảo. Cụ thể, chúng ta có thể dễ dàng thấy nút nhập workflow trên trang bảng làm việc:
Còn đối với xuất workflow, chúng ta chỉ cần nhấp vào góc dưới bên phải của một khối workflow đơn lẻ là có thể tìm thấy nút xuất:
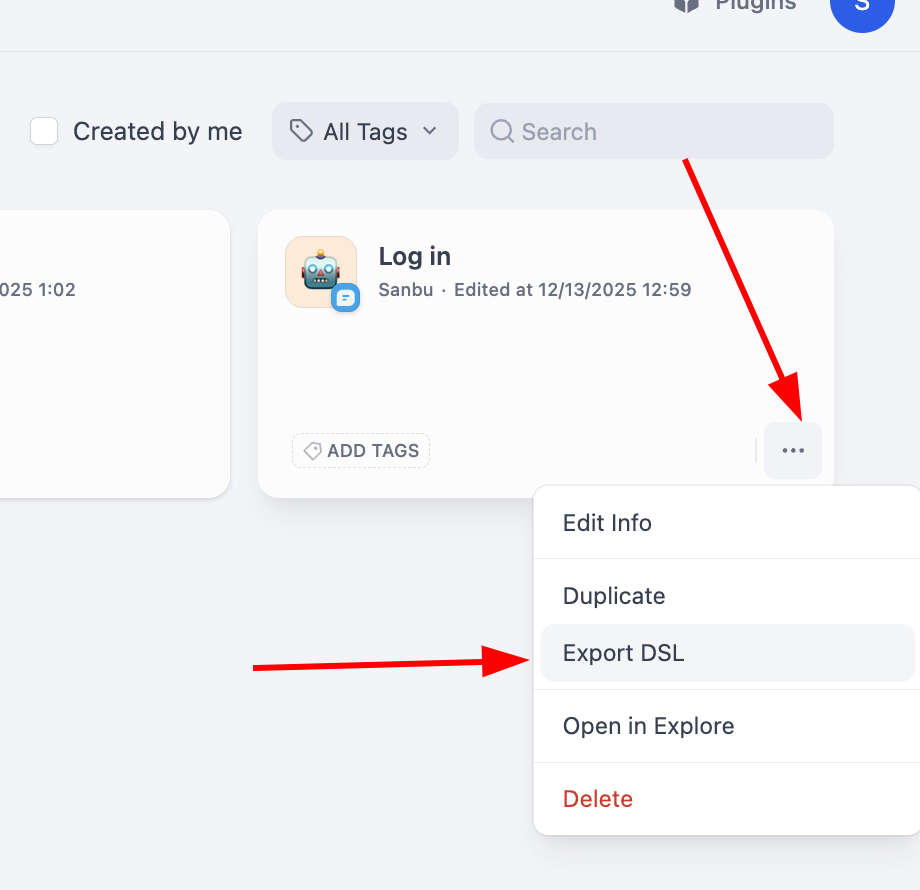
Thông qua việc sử dụng file DSL, bạn có thể dễ dàng di chuyển hoặc chia sẻ thiết kế workflow phức tạp giữa các instance Dify khác nhau.
2.5.2 Xem thêm dự án Dify
Nếu bạn cảm thấy workflow hoặc agent mình xây dựng quá đơn giản, nền tảng Dify cung cấp nhiều dự án mẫu phong phú, giúp bạn nhanh chóng hiểu cách xây dựng ứng dụng phức tạp. Các dự án mẫu này bao quát nhiều kịch bản kinh doanh khác nhau. Bạn có thể nhấp Explora để xem workflow người khác xây dựng để học hỏi.
2.6 Tạo ứng dụng Dify Workflow đầu tiên
Sau khi hoàn thành nhập môn xây dựng Agent hội thoại của Dify, chúng ta tiếp tục xem cách xây dựng workflow kinh doanh Dify phức tạp hơn. Workflow là cách cốt lõi mà Dify trực quan hóa logic kinh doanh phức tạp, thông qua nó bạn có thể xây dựng quy trình thông minh như xếp khối. Bạn có thể trải nghiệm hoàn chỉnh cách thông tin luân chuyển giữa các nút khác nhau, logic判断 được triển khai như thế nào, điểm can thiệp thủ công được đặt ở đâu, và cuối cùng cách giao kết quả kinh doanh hoàn chỉnh.
Bạn có thể chọn tạo từ trắng, hoặc trực tiếp tạo từ mẫu, ở đây demo cách tạo workflow từ trắng:
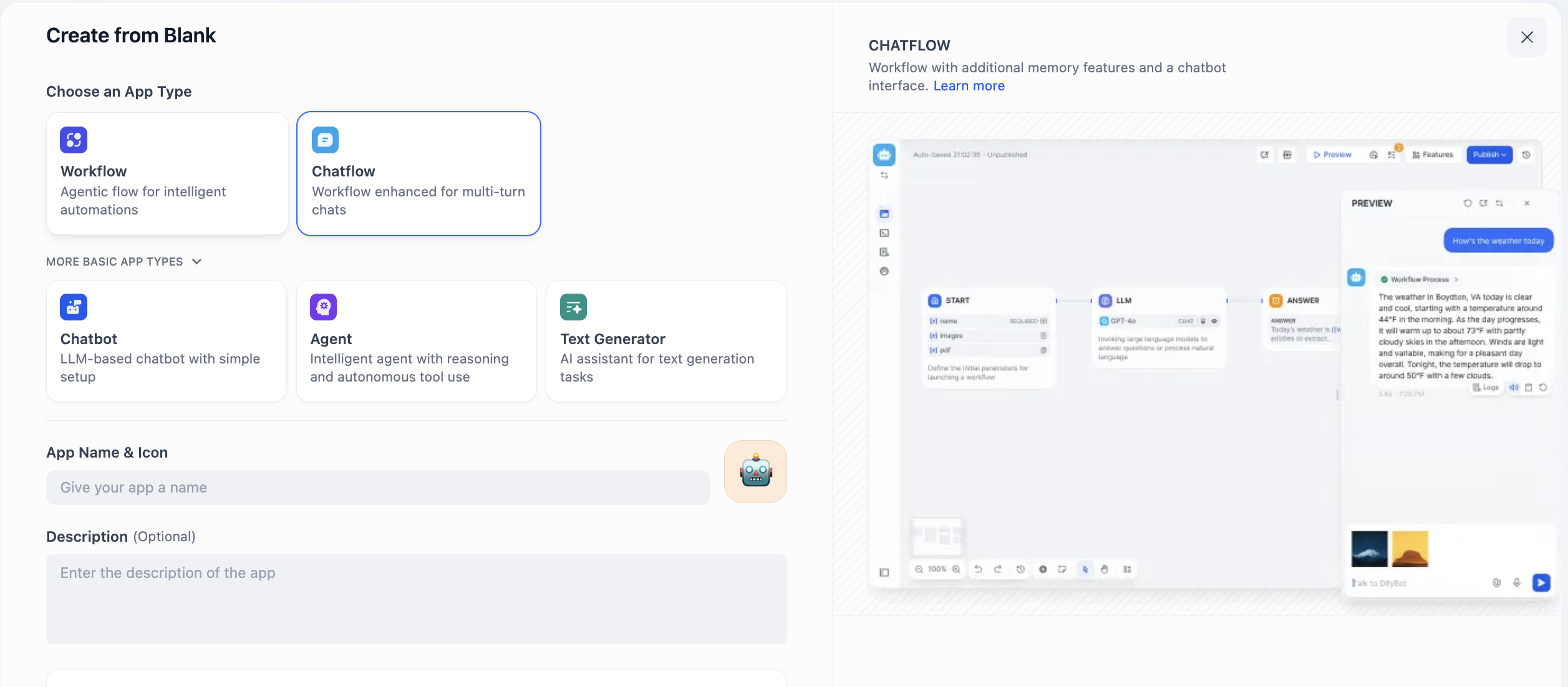
Ở đây chúng ta sẽ thấy hai lựa chọn,分别是 Chatflow và Workflow, làm thế nào để chọn giữa hai cái này? Điểm mấu chốt là bạn cần hiểu điều bạn muốn xây dựng, cốt lõi là hội thoại liên tục hay quy trình nhiệm vụ.
Chatflow được thiết kế riêng cho hội thoại. Nó mô phỏng một người hội thoại có khả năng ghi nhớ và hiểu ngữ cảnh, rất phù hợp cho các kịch bản cần tương tác nhiều vòng, duy trì trạng thái. Ví dụ trong tư vấn chăm sóc khách hàng, nó có thể hiểu liền mạch các câu hỏi theo sau của người dùng, giống như một nhân viên dịch vụ kiên nhẫn. Tính năng xuất luồng (streaming output) của nó cũng khiến quá trình tương tác tự nhiên hơn. Nói tóm lại, khi bạn cần xây dựng một agent có thể "giao tiếp", hãy chọn Chatflow.
Workflow tập trung vào tự động hóa thực thi quy trình. Nó giống một đường dây chuyền đặt trước, giỏi xử lý các nhiệm vụ đầu vào một lần, xử lý nhiều bước, và tạo đầu ra xác định. Ví dụ, tạo báo cáo dữ liệu theo lịch hàng ngày, xử lý file hàng loạt hoặc gọi chuỗi API. Các nhiệm vụ này thường được kích hoạt bởi sự kiện, không cần tương tác với người theo thời gian thực. Do đó, khi bạn cần thực hiện nhiệm vụ "tự động hóa", Workflow là lựa chọn phù hợp hơn.
Để tránh sai lầm chọn loại gây kém hiệu quả, bạn có thể xem xét nhu cầu nhiệm vụ của mình thông qua bốn câu hỏi quan trọng:
- Quá trình nhiệm vụ có cần dựa vào nhiều lần đầu vào và điều chỉnh của người dùng không?
- Việc trình bày kết quả có cần tiến hành theo từng bước, theo luồng không?
- Logic xử lý có phụ thuộc nghiêm trọng vào lịch sử tương tác trước đó không?
- Nhiệm vụ có được kích hoạt bởi sự kiện, và đầu vào/đầu ra chủ yếu hoàn thành trong một lần không?
Nếu câu trả lời cho ba câu hỏi đầu là "có", thì Chatflow là lựa chọn lý tưởng, kịch bản điển hình bao gồm chăm sóc khách hàng thông minh, gia sư giáo dục, hợp tác sáng tạo, v.v. Nếu đặc trưng câu hỏi thứ tư rõ rệt, thì nên chọn Workflow, nó phù hợp hơn cho các kịch bản tự động hóa như làm sạch dữ liệu, tạo báo cáo, xử lý hàng loạt.
Ở đây chúng ta chọn Chatflow làm ví dụ để giới thiệu, sau khi nhấp Chatflow sẽ vào giao diện bảng thao tác:
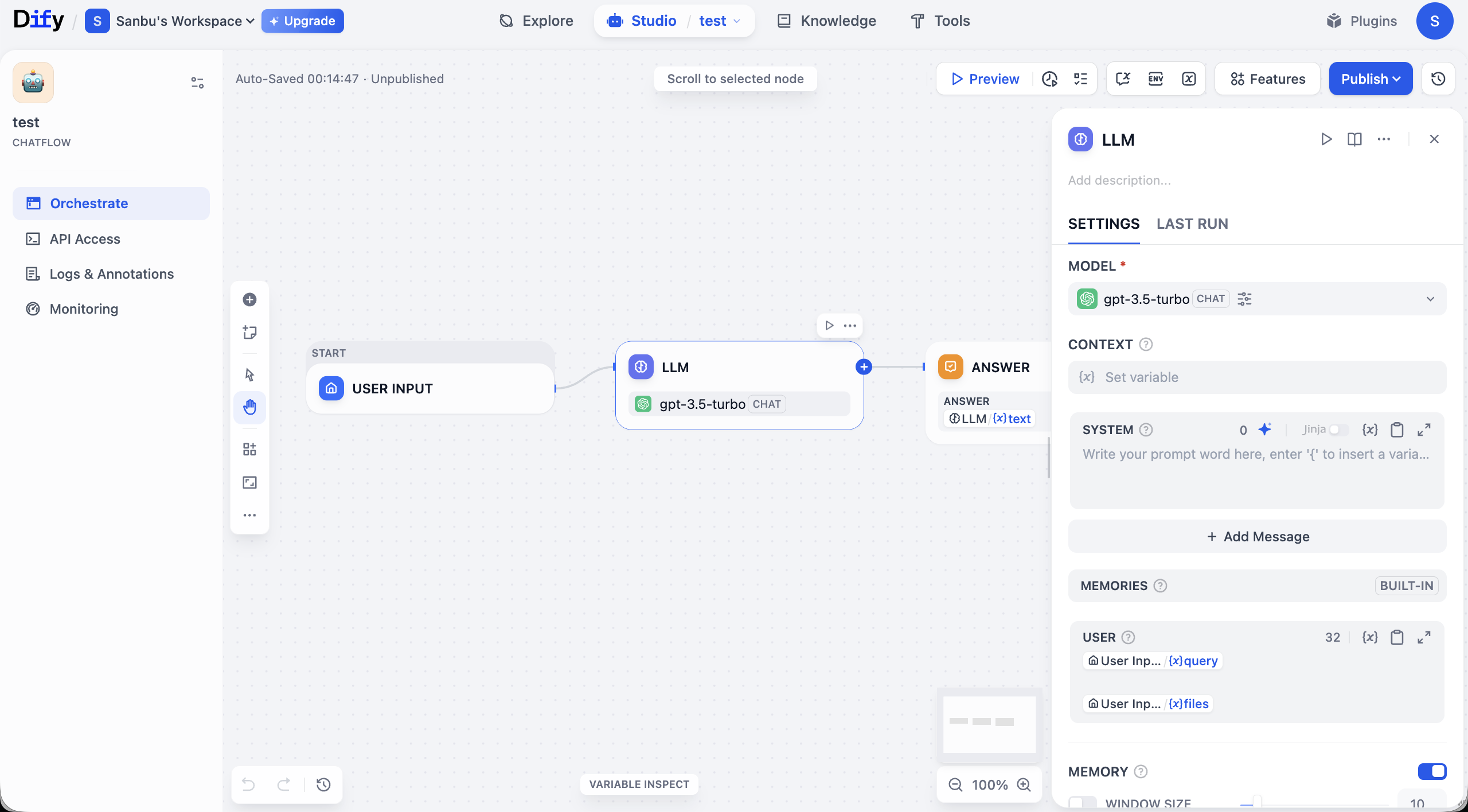
Chúng ta hãy giới thiệu đơn giản về giao diện trang workflow. Trong đó cốt lõi của toàn bộ giao diện là canvas chỉnh sửa ở trung tâm, bạn sẽ xây dựng logic ứng dụng tại đây theo phương thức trực quan. Như hình所示, một workflow cơ sở thường bắt đầu từ nút START (dùng để nhận đầu vào), qua đường dây truyền dữ liệu đến nút LLM để xử lý, cuối cùng xuất kết quả qua nút ANSWER. Mỗi nút đại diện cho một module chức năng, còn đường dây quyết định thứ tự thực thi nhiệm vụ.
Quanh canvas là khu vực chức năng quản lý và thao tác hoàn chỉnh. Phía trên giao diện cung cấp tùy chọn kiểm soát toàn cục, bao gồm nút Preview để kiểm thử workflow và nút Publish để đưa lên mạng. Góc canvas có công cụ điều chỉnh视图 như thu phóng, hoàn tác, v.v., thuận tiện cho tinh chỉnh.
Bảng bên trái tập trung các chức năng quản lý ứng dụng. Tab Orchestrate mà bạn đang ở dùng để编排 quy trình; sau khi xây dựng xong, có thể lấy chứng chỉ tích hợp qua API Access; Logs & Annotations ghi lại dấu vết chi tiết của mỗi lần thực thi, thuận tiện gỡ lỗi; còn Monitoring cung cấp giám sát hiệu suất và trạng thái runtime của ứng dụng cho bạn.
Bạn có thể nhập đơn giản một số nội dung prompt trong SYSTEM của nút LLM trong workflow hội thoại này, nhấp Preview sau đó thử chạy workflow này, xem sau khi sửa SYSTEM prompt toàn bộ workflow có thực sự thay đổi theo mong đợi hay không.
2.6.1 Giới thiệu các nút phổ biến
Dify cung cấp nhiều loại nút, bạn có thể tìm hiểu chức năng cơ bản của mỗi nút trước. Khi sử dụng cụ thể, khuyến nghị tự tay thử, hoặc tham khảo mẫu workflow người khác tạo, cũng có thể chụp màn hình và hỏi mô hình lớn về cách sử dụng nút, tham số cần thiết, v.v. Khuyến nghị trực tiếp thay các nút khác nhau trong mẫu hiện có, thông qua cách sử dụng của người khác để suy luận thực hành tốt nhất cho nút.
Nhấp chuột phải trên canvas chọn "Add Node" là có thể thêm nút, cũng có thể xem tất cả các nút khả dụng trong bảng nút bên trái:
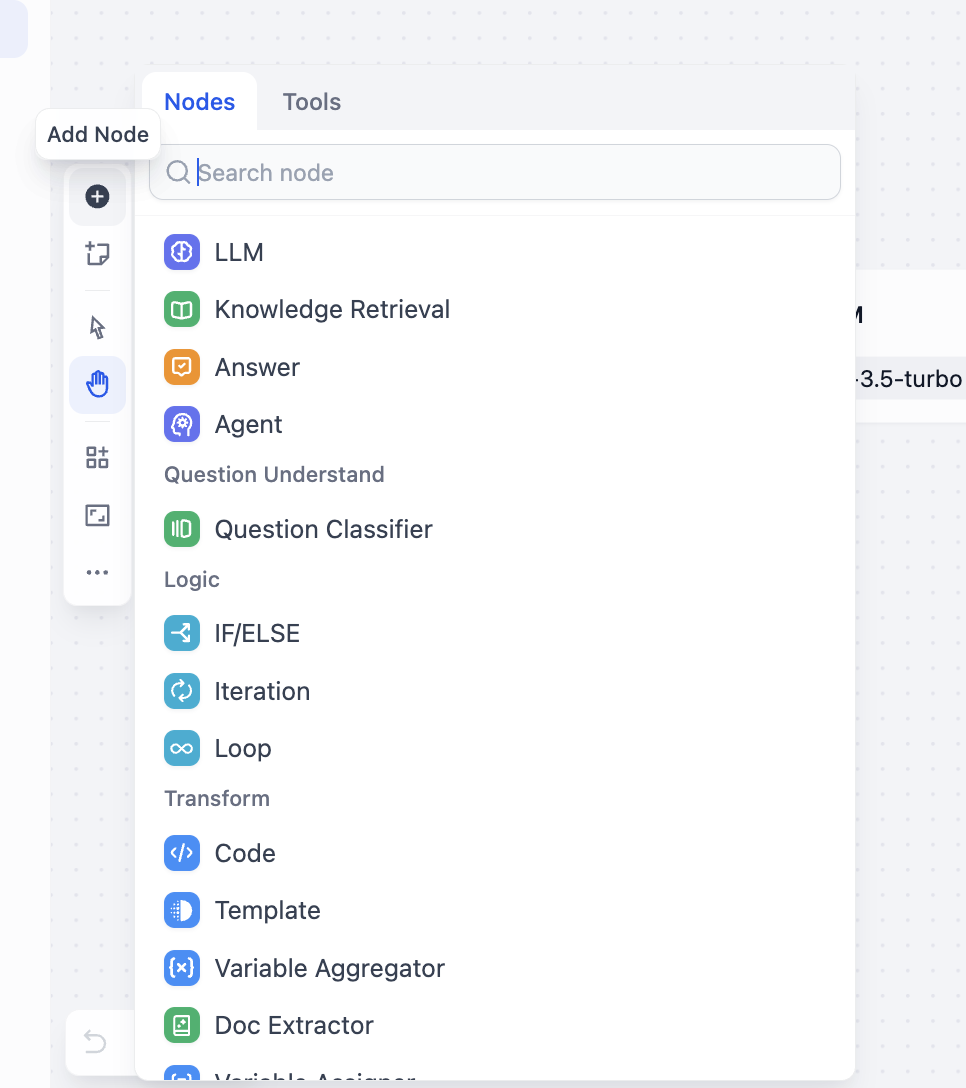
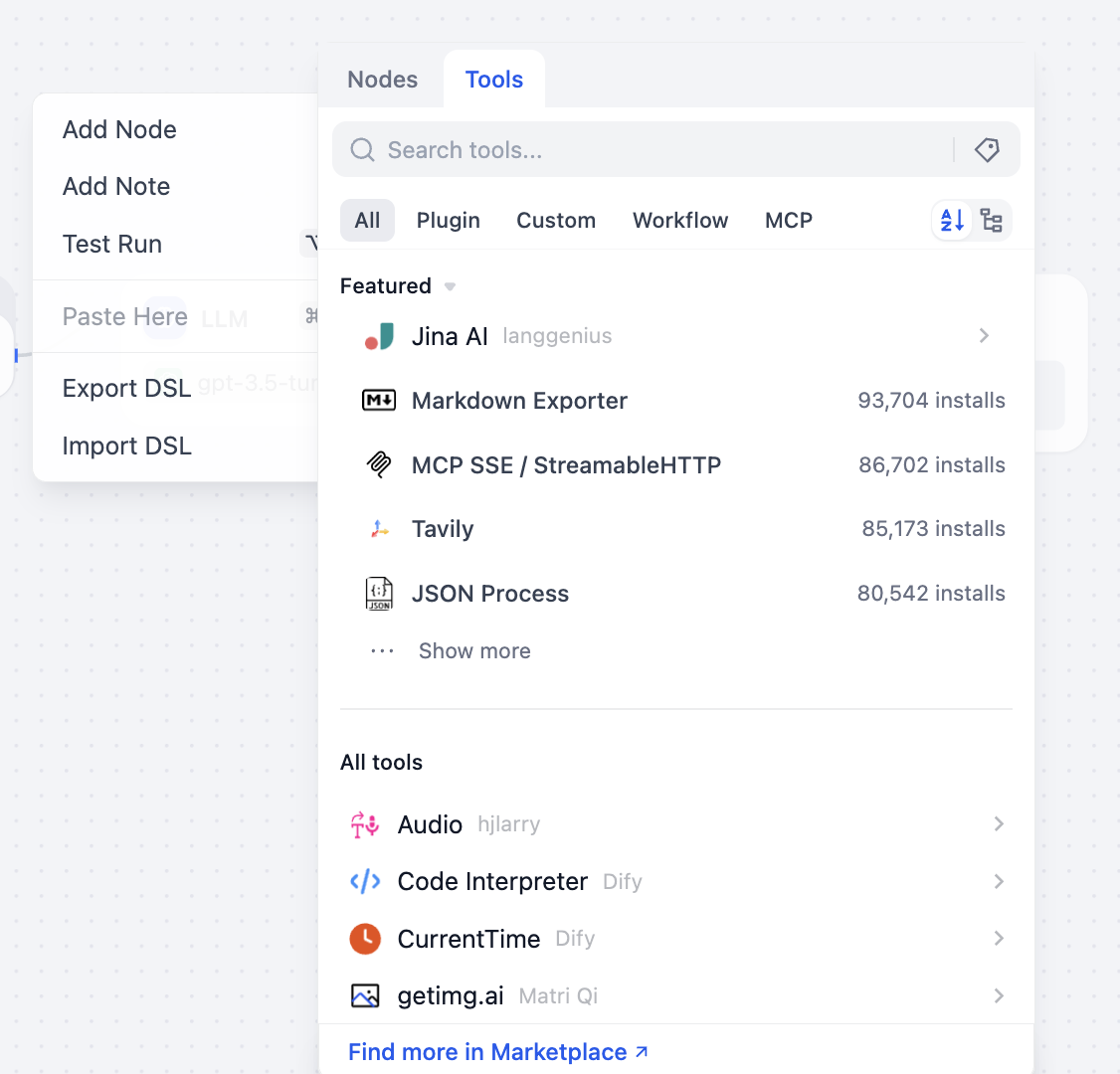
Đồng thời, có thể mở bảng chọn công cụ, xem các loại công cụ hỗ trợ gọi:
Dưới đây là mô tả ngắn về một số nút và công cụ phổ biến. Không cần nắm tất cả cùng một lúc, khuyến nghị để lại ấn tượng trước, dần làm quen trong quá trình sử dụng thực tế, cần thì quay lại tra cứu.
- Nút LLM và suy luận

Loại nút này phụ trách quy trình cốt lõi trong workflow.
- Nút LLM: đơn vị tính toán cốt lõi, dùng để gọi mô hình ngôn ngữ lớn. Trọng tâm cấu hình nằm ở kỹ thuật prompt và tinh chỉnh tham số, chuyển vấn đề kinh doanh thành lệnh thực thi cho mô hình.
- Nút Knowledge Retrieval: đơn vị truy xuất kiến thức, phụ trách truy xuất thông tin liên quan đến vấn đề kinh doanh từ cơ sở tri thức đặt trước, nguồn dữ liệu uy tín bên ngoài, cung cấp hỗ trợ kiến thức chính xác cho nút LLM, giúp giảm vấn đề "ảo giác" trong đầu ra của mô hình ngôn ngữ lớn.
- Nút Answer: đơn vị xuất kết quả, phụ trách nhận nội dung đã xử lý bởi LLM, tổ chức thành hình thức thành quả cuối cùng phù hợp với nhu cầu kịch bản kinh doanh. Trọng tâm cấu hình nằm ở định nghĩa định dạng đầu ra (như mẫu văn phòng, quy tắc trình bày).
- Nút Agent: đơn vị quyết định cao cấp. Nó không chỉ gọi mô hình, mà còn có thể thực hiện lập kế hoạch nhiều bước, tự chọn và gọi công cụ bên ngoài, phù hợp cho chuỗi nhiệm vụ phức tạp cần quyết định động.
- Nút Question Classifier: đơn vị phân loại câu hỏi, phụ trách nhận dạng loại và phân loại câu hỏi kinh doanh đầu vào (ví dụ phân loại theo ý định câu hỏi, lĩnh vực chủ đề, v.v.), giúp quy trình sau khớp chính xác với nút xử lý tương ứng (như các loại câu hỏi khác nhau khớp với prompt LLM hoặc chuỗi công cụ khác nhau).
- Nút điều khiển logic và quy trình

Loại nút này định nghĩa đường dẫn thực thi và quy tắc của workflow.
- Nút điều kiện: như
IF/ELSE, thực hiện phân nhánh quy trình thông qua判断 boolean. Điểm then chốt thiết kế nằm ở tính chặt chẽ của biểu thức điều kiện, đảm bảo logic bao phủ tất cả các kịch bản kinh doanh. - Nút Iteration: là đơn vị xử lý song song hàng loạt không trạng thái, được thiết kế riêng cho các kịch bản mà nhiệm vụ con không phụ thuộc dữ liệu lẫn nhau, có thể xử lý độc lập, ví dụ dịch hàng loạt đoạn văn bản, duyệt song song nhiều nội dung hoặc đồng thời tạo nhiều báo cáo. Nút này nhận một mảng đầu vào và tự động chia nhỏ, phân phối mỗi phần tử đến cùng một chuỗi xử lý thực thi song song, người dùng có thể truy cập phần tử hiện tại qua và lấy chỉ mục qua trong thân lặp, đầu ra sẽ tự động tổng hợp thành mảng kết quả; khi cấu hình cần tập trung thiết lập độ song song để cân bằng hiệu quả và tải hệ thống, đồng thời đảm bảo ổn định của tác vụ hàng loạt thông qua chiến lược thử lại (như số lần thử lại, khoảng thời gian) và xử lý lỗi (như ghi log, trả về giá trị mặc định).
- Nút Loop: bộ lặp đệ quy có trạng thái, phù hợp cho các kịch bản mà kết quả phụ thuộc vào đầu ra của vòng trước, ví dụ tinh chỉnh tham số nhiều vòng, tối ưu hóa nội dung đệ quy (như sửa đổi bản sao lặp lại đến khi hài lòng) và tính toán chuỗi phụ thuộc kết quả lần trước. Cốt lõi của nó là "biến trạng thái", cần khởi tạo trước khi bắt đầu vòng lặp (như số lần lặp hiện tại, kết quả tính toán trung gian), và cập nhật rõ ràng trong mỗi vòng làm đầu vào cho vòng tiếp theo; để tránh vòng lặp vô hạn, phải định nghĩa điều kiện kết thúc (bao gồm "lặp tối đa 10 lần" dựa trên bộ đếm, "điểm hài lòng > 9" dựa trên判断 kết quả, "phát hiện đầu vào 'dừng'" dựa trên tín hiệu bên ngoài), đồng thời cần thiết lập cấu hình timeout vòng lặp, và lập kế hoạch đường dẫn xử lý ngoại lệ (như thoát vòng lặp hoặc đặt lại trạng thái rồi thử lại), đảm bảo quy trình vận hành ổn định.
- Nút thao tác dữ liệu và tích hợp
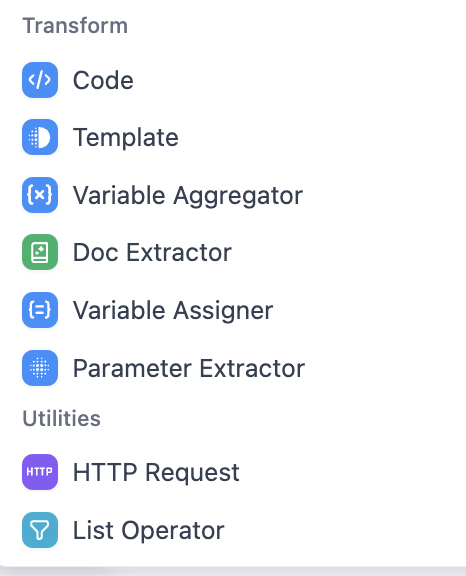
- Nút Code: đơn vị xử lý code, phụ trách thực thi logic code tùy chỉnh trong workflow, có thể thực hiện chuyển đổi định dạng dữ liệu, tính toán phức tạp, v.v. Trọng tâm cấu hình nằm ở tính chính xác của cú pháp code và sự phù hợp với môi trường thực thi.
- Nút Template: đơn vị xử lý mẫu, phụ trách điền dữ liệu động vào mẫu đặt trước, tạo nội dung phù hợp yêu cầu định dạng (như bản sao tùy chỉnh, khung báo cáo). Trọng tâm cấu hình nằm ở viết cú pháp mẫu và cài đặt quy tắc ánh xạ biến.
- Nút Variable Aggregator: đơn vị tổng hợp biến, phụ trách thu thập dữ liệu biến đầu ra từ nhiều nút trong workflow, tích hợp các biến phân tán thành tập dữ liệu thống nhất. Trọng tâm cấu hình nằm ở phạm vi biến tổng hợp và định nghĩa quy tắc hợp nhất dữ liệu.
- Nút Doc Extractor: đơn vị trích xuất tài liệu, phụ trách trích xuất văn bản, bảng biểu, v.v. từ các loại tài liệu PDF, Word, v.v., chuyển thành dữ liệu có cấu trúc mà workflow có thể xử lý. Trọng tâm cấu hình nằm ở thích ứng loại tài liệu và quy tắc sàng lọc nội dung trích xuất.
- Nút Variable Assigner: đơn vị gán biến, phụ trách định nghĩa, khởi tạo hoặc cập nhật biến trong workflow, cung cấp载体 cho truyền dữ liệu trong quy trình. Trọng tâm cấu hình nằm ở đặt tên biến, loại dữ liệu và logic gán.
- Nút Parameter Extractor: đơn vị trích xuất tham số, phụ trách trích xuất tham số chỉ định từ nội dung đầu vào như yêu cầu người dùng, trả về giao diện, v.v., chuyển thông tin phi cấu trúc thành dữ liệu có cấu trúc. Trọng tâm cấu hình nằm ở cấu hình quy tắc trích xuất (như biểu thức chính quy, đường dẫn JSON).
- Nút HTTP Request: đơn vị yêu cầu HTTP, phụ trách gửi yêu cầu HTTP (bao gồm GET, POST, v.v.) đến giao diện hệ thống bên ngoài, thực hiện tương tác dữ liệu giữa workflow và dịch vụ bên ngoài. Trọng tâm cấu hình nằm ở cài đặt địa chỉ yêu cầu, phương thức yêu cầu và tham số/headers.
- Nút List Operator: đơn vị thao tác danh sách, phụ trách xử lý dữ liệu loại mảng, danh sách (như lọc, sắp xếp, chia nhỏ), điều chỉnh cấu trúc dữ liệu để phù hợp với quy trình tiếp theo. Trọng tâm cấu hình nằm ở định nghĩa loại thao tác (như điều kiện lọc, quy tắc sắp xếp).
2.6.2 Giới thiệu công cụ phổ biến
Trong Dify, hầu hết các công cụ đều có thể trực tiếp đặt trên canvas như một nút, được nối với dòng lên xuống như các nút khác, miễn là đầu vào bạn cung cấp phù hợp với quy范 tham số của nút (công cụ) đó, nó sẽ thực thi bình thường và tạo kết quả có thể tiếp tục luân chuyển.
Trong bảng nút bên trái hoặc bên phải, có thể xem tất cả các nút công cụ khả dụng, cũng có thể mở rộng thêm khả năng công cụ thông qua thị trường plugin. Giới thiệu ngắn gọn vài công cụ phổ biến:
- Công cụ tìm kiếm web Điển hình là Tavily Search, cung cấp khả năng truy xuất thời gian thực được tối ưu hóa cho AI dành cho mô hình lớn. Nó sẽ trả về kết quả tìm kiếm có cấu trúc (như tiêu đề, tóm tắt, liên kết, v.v.), có thể trực tiếp dùng làm một phần prompt của LLM, dùng để trả lời các câu hỏi về tin tức mới nhất hoặc cần cơ sở uy tín.
- Công cụ xử lý dữ liệu Ví dụ plugin JSON Process, dùng để thực hiện các thao tác nâng cao như truy vấn, lọc, chuyển đổi, hợp nhất dữ liệu JSON. Khi xử lý phản hồi API phức tạp hoặc dữ liệu lồng nhau nhiều lớp, bạn có thể giao logic "làm sạch + tái cấu trúc dữ liệu" cho công cụ này, từ đó đơn giản hóa việc phải thường xuyên viết code phân tích thủ công trong nút Code.
- Công cụ xử lý định dạng Như Markdown Exporter, có thể xuất nội dung đã tạo theo định dạng chỉ định, ví dụ tài liệu Markdown, mẫu trình bày cụ thể, v.v., thuận tiện cho việc sử dụng sau này để hiển thị, báo cáo hoặc tích hợp vào hệ thống khác.
Bạn có thể thấy số lượng cài đặt và mô tả tóm tắt của các plugin này trong danh sách công cụ, ban đầu có thể ưu tiên thử cài đặt các công cụ trong "Featured / Đề xuất", thường bao phủ các kịch bản kinh doanh phổ biến nhất.
Tuy nhiên, việc sử dụng công cụ thường khá phức tạp, khuyến nghị khi sử dụng bạn có thể tìm kiếm trước "ví dụ DSL workflow được khuyến nghị chính thức" của công cụ tương ứng trên công cụ tìm kiếm, nhập trực tiếp để sử dụng, sẽ tiết kiệm được nhiều thời gian hơn so với tự xây dựng.
2.6.3 Tạo workflow phân loại ý định đơn giản
Lúc này chúng ta đã tìm hiểu sơ bộ về thông tin cơ bản của workflow và công cụ Dify, nhưng nếu không thực hành chúng ta sẽ không bao giờ thành thạo trong việc sử dụng chi tiết, chúng ta cần một kịch bản kinh doanh "giả định" thực tế để luyện tập.
Ví dụ, trong kịch bản đối thoại mua sắm thực tế, đầu vào của người dùng đến mua hàng không bao giờ là "tham số chuẩn hóa", mà là một câu nói bộc phát: có người đến đặt hàng, có người đến phàn nàn, có người chỉ muốn trò chuyện, cũng có người hoàn toàn lạc đề. Nếu chúng ta đưa tất cả các đầu vào này trực tiếp cho cùng một mô hình ngôn ngữ lớn (LLM) xử lý, hệ thống thường sẽ xuất hiện hai vấn đề điển hình:
- Phong cách phản hồi không ổn định Cũng là phàn nàn, đôi khi LLM có thể xin lỗi và xoa dịu, đôi khi lại giống như đang "giải thích nguyên nhân"; cũng là gọi món, đôi khi sẽ hỏi thêm thông tin còn thiếu, đôi khi lại tự bịa ra chi tiết đơn hàng.
- Logic kinh doanh không thể kiểm soát Bạn muốn "phàn nàn phải xin lỗi trước", nhưng mô hình không nhất thiết mỗi lần đều tuân thủ; bạn muốn "câu hỏi không liên quan đến kinh doanh phải hướng về chủ đề chính", nhưng mô hình có thể hào hứng trò chuyện về những câu chuyện vui với bạn.
Do đó, cách làm mang tính kỹ thuật hơn là chia nhiệm vụ thành một đường dây chuyền tiêu chuẩn hóa, đầu tiên phân loại ý định (xác định người dùng thực sự muốn làm gì), sau đó phân luồng theo ý định (các kịch bản khác nhau sử dụng prompt và vai trò khác nhau), cuối cùng đóng gói thống nhất đầu ra của mô hình lớn sau phân luồng (thuận tiện cho tích hợp frontend hoặc hệ thống).
Mục tiêu của phần này là giúp hệ thống có thể xử lý nhiều loại đối thoại trong một kịch bản nhà hàng. Bạn có thể làm theo thao tác một lần để ghi nhớ sâu hơn. Đầu tiên cần định nghĩa kịch bản thành các phân loại ý định:
- Đặt hàng mua đồ (buy_food): Người dùng thể hiện ý định mua hàng rõ ràng.
- Ví dụ: "Cho tôi một phần gà rán, thêm một ly cola."
- Phàn nàn khiếu nại (complain): Người dùng đang thể hiện sự không hài lòng, hối thúc hoặc phản hồi tiêu cực.
- Ví dụ: "Các bạn也太 chậm rồi? Đợi một tiếng rồi."
- Trò chuyện tư vấn (chitchat): Người dùng đang hỏi mở, tìm kiếm đề xuất, nhưng không có chỉ dẫn đặt hàng rõ ràng.
- Ví dụ: "Hôm nay ăn gì cho ngon, bạn có gợi ý gì không?"
- Ý định khác (other): Đầu vào của người dùng không liên quan đến kịch bản nhà hàng.
- Ví dụ: "Giúp tôi viết một caption hài hước đăng Facebook."
Đối với bốn loại ý định này, chúng ta đã đặt trước bốn "nhân cách giao tiếp" khác nhau cho hệ thống, lần lượt được gánh bởi bốn nút LLM độc lập, mỗi nút đều cần LLM với các nhân thiết khác nhau để đóng vai.
- Trợ lý đặt hàng (LLM_BuyFood): Chuyên nghiệp, hiệu quả, nhiệm vụ cốt lõi là xác nhận chi tiết đơn hàng, và chủ động bổ sung thông tin còn thiếu.
- Chuyên gia chăm sóc khách hàng (LLM_Complain): Thấu cảm, điềm tĩnh, ưu tiên hàng đầu là xoa dịu cảm xúc người dùng, và cung cấp giải pháp rõ ràng.
- Bạn trò chuyện (LLM_Chitchat): Thư giãn, thân thiện, nhằm cung cấp đề xuất cá nhân hóa, hướng dẫn tiêu dùng tiềm năng.
- Người gác cửa lịch sự (LLM_Other): Tập trung, ranh giới rõ ràng, phụ trách hướng dẫn lịch sự các cuộc đối thoại lệch chủ đề quay về nghiệp vụ cốt lõi.
Thiết kế编排 workflow
Tiếp theo chúng ta tiến hành thiết lập编排 workflow, quyết định đại loại cần có những nút workflow nào. Đối với người mới, rất khó nghĩ ra cần có những nút nào (đối với người giàu kinh nghiệm cũng lười tự suy nghĩ, dùng mô hình lớn để đưa ra gợi ý thường là lựa chọn nhanh và tốt nhất), nên chúng ta có thể sử dụng mô hình lớn để đưa ra gợi ý编排 tương ứng, cấu trúc nút cốt lõi như sau:
- Start (điểm bắt đầu): Là đầu vào dữ liệu, phụ trách nhận đầu vào gốc
user_textcủa người dùng. - Question Classifier (bộ phân loại ý định): Là "bộ não" và "trung tâm điều phối" của workflow. Nó phụ trách phân tích
user_text, và chọn nhãn ý định phù hợp nhất trong bốn loại nhãn ý định đã đặt trước. - Condition (nhánh điều kiện): Đóng vai trò "van phân luồng". Nó quyết định hướng nhiệm vụ tới đường xử lý chuyên biệt nào tiếp theo dựa trên nhãn ý định do bộ phân loại đầu ra.
- Bốn nút LLM song song (LLM_BuyFood, LLM_Complain, LLM_Chitchat, LLM_Other): Đây là bốn "đơn vị xử lý chuyên gia" độc lập. Mỗi nút đều nhận câu hỏi gốc, nhưng dựa trên System Prompt (prompt hệ thống) riêng biệt để tạo phản hồi có phong cách và mục tiêu hoàn toàn khác nhau.
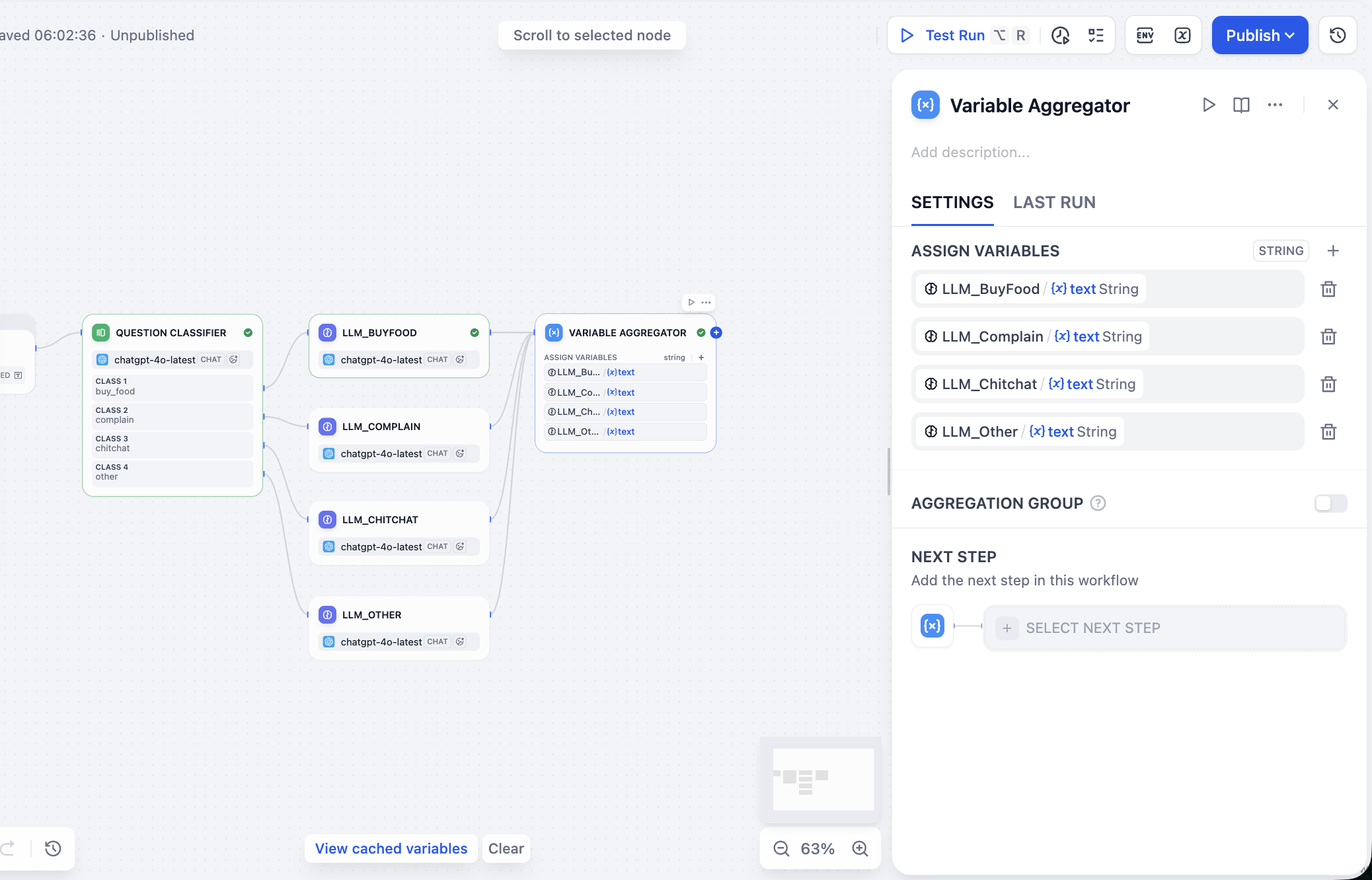
- Variable Aggregator (bộ tổng hợp biến): Sau khi nhiều đường xử lý hoàn tất, cần một "điểm tập hợp". Nút này sẽ thu thập phản hồi duy nhất được kích hoạt và tạo kết quả trong bốn nhánh thành một biến thống nhất
final_reply, đảm bảo tính ổn định của cấu trúc đầu ra. - Output (điểm kết thúc): Là đầu ra cuối cùng, phụ trách xuất nhãn ý định, câu hỏi gốc và phản hồi đã được xử lý tạo ra dưới dạng có cấu trúc (như JSON) thống nhất, thuận tiện cho hệ thống gọi hoặc phân tích gỡ lỗi sau này.
Thực hiện编排 workflow
Trong hướng dẫn lần này chúng ta chọn tạo Workflow thay vì Chatflow, chọn User Input:
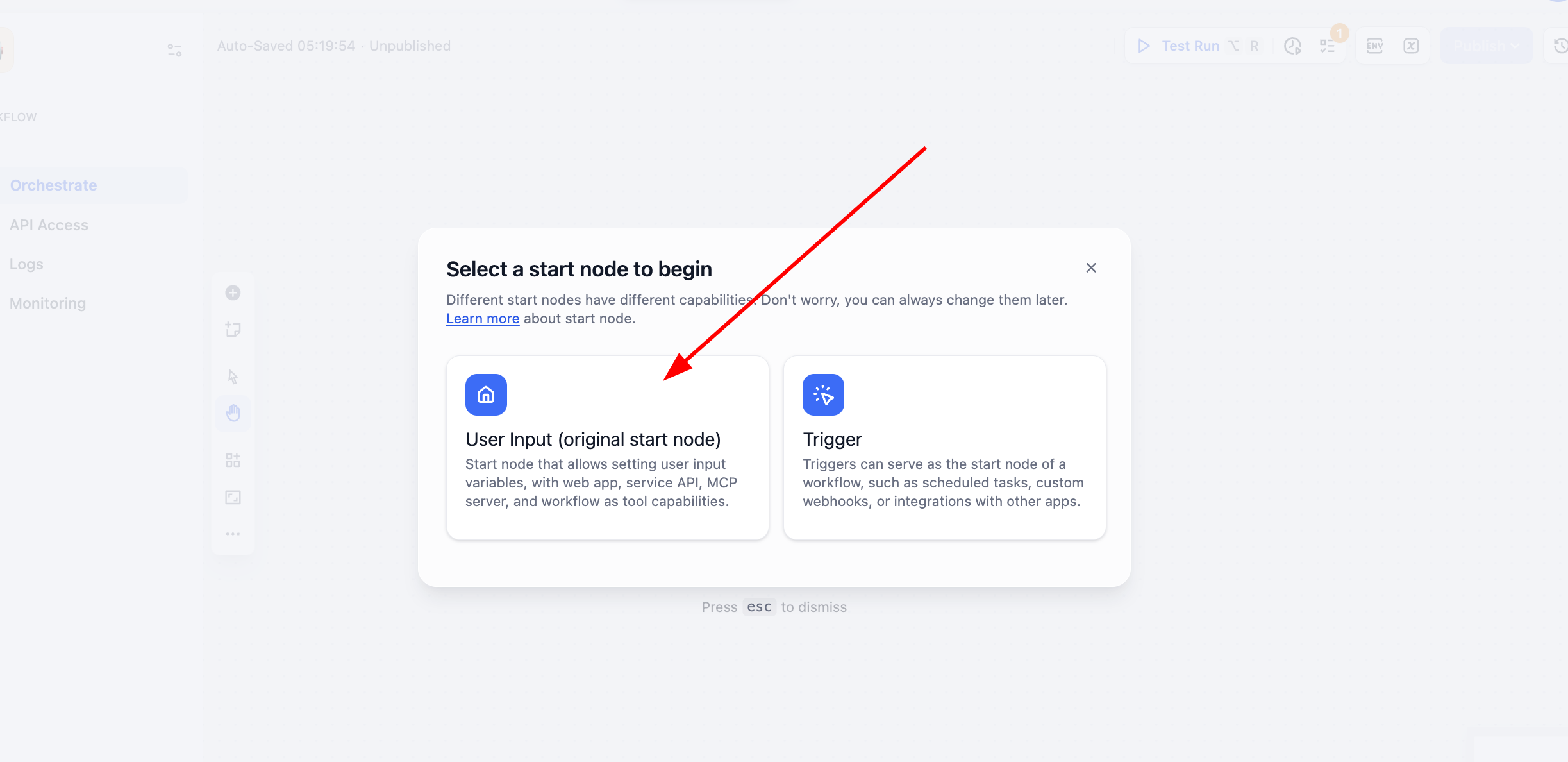
Sau đó nhấp vào nút User Input của Start, định nghĩa một biến loại chuỗi tên user_text, làm nguồn đầu vào của toàn bộ quy trình.
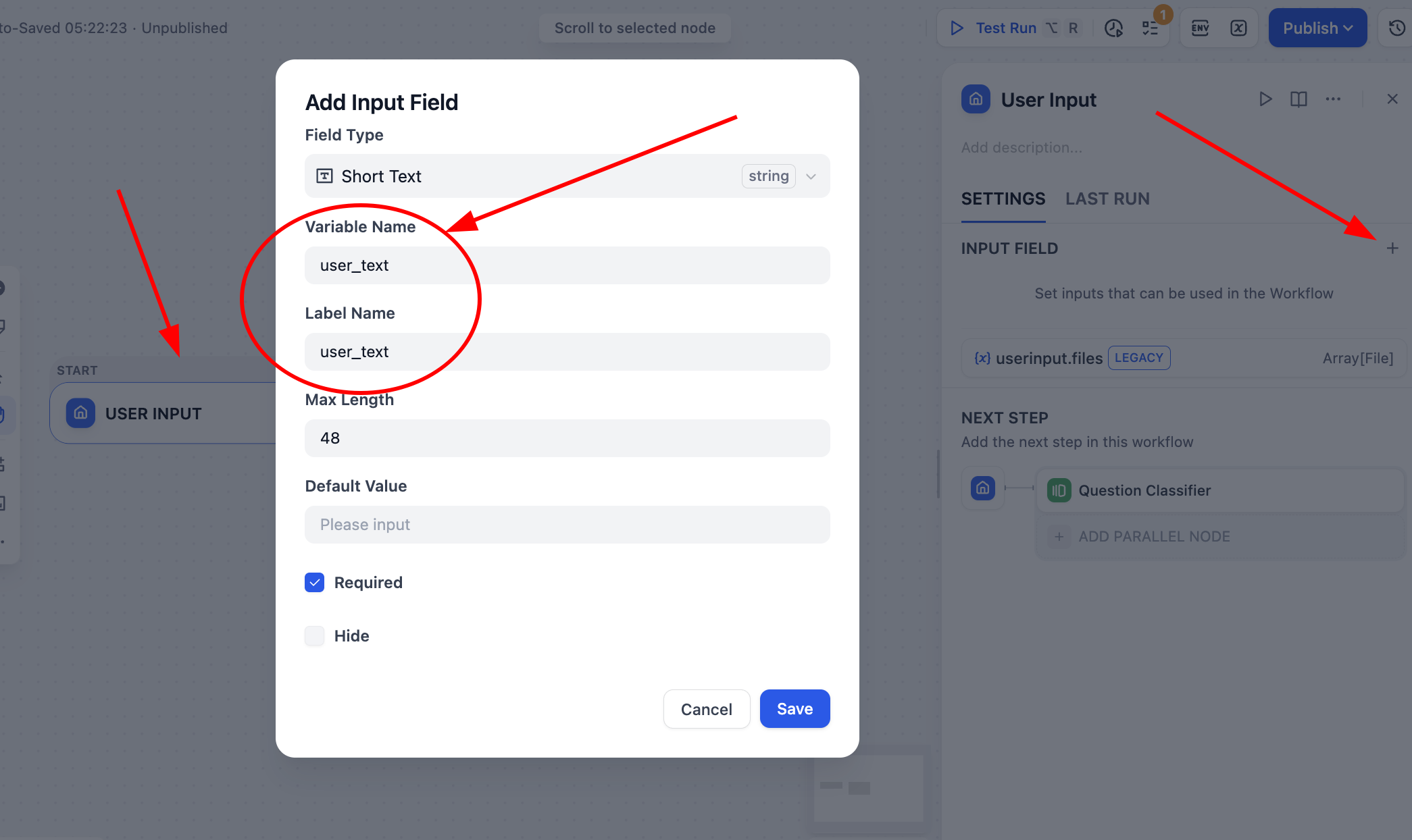
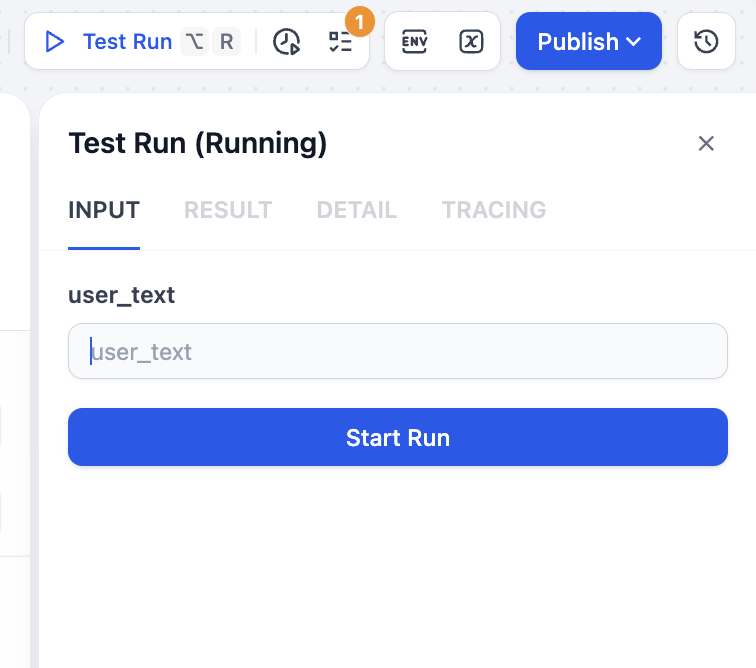
Sau khi lưu, nhấp Test Run ở góc trên bên phải, bạn có thể thấy cần chỉ định đầu vào văn bản tương ứng để xử lý:
Tiếp theo chúng ta cần nhấp vào dấu + sau nút đầu vào, chọn thêm nút Question Classifier, và chúng ta cần cấu hình bốn loại nhãn cho nó, cung cấp mô tả và ví dụ rõ ràng cho mỗi nhãn.
buy_food: Người dùng rõ ràng muốn mua đồ, gọi món, đặt hàng.complain: Người dùng đang phàn nàn,吐槽, tức giận, thường mang cảm xúc không hài lòng.chitchat: Người dùng đang trò chuyện, thảo luận ăn gì, tư vấn đề xuất.other: Không liên quan đến kịch bản nhà hàng, hoặc nội dung khó xác định.
Ngoài ra, bạn còn cần viết prompt trong ADVANCED SETTING, để mô hình lớn có thể phân loại chính xác dựa trên đầu vào của người dùng. Prompt mẫu như sau:
Chọn một nhãn phù hợp nhất từ buy_food / complain / chitchat / other. Nếu người dùng vừa phàn nàn vừa gọi món, hãy ưu tiên xác định cảm xúc cốt lõi, nếu trọng tâm là bày tỏ sự không hài lòng, nên phân vào complain. Nếu chỉ là than vãn nhẹ nhưng ý định chính là đặt hàng, thì phân vào buy_food. Nếu thực sự khó xác định, sử dụng other làm phương án dự phòng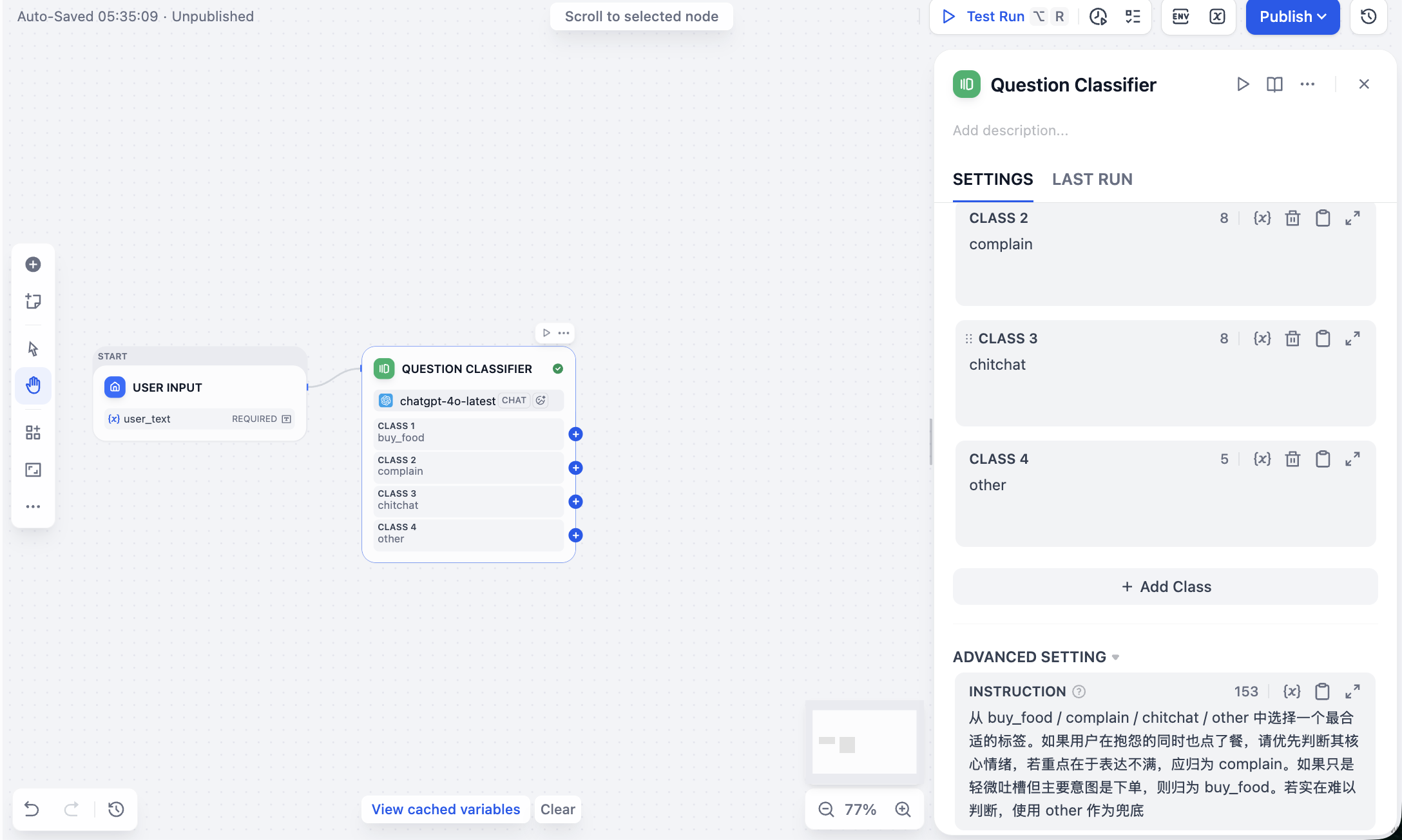
Sau khi thiết lập xong, bạn có thể nhấp nút phát ở góc trên bên phải để kiểm tra riêng nút này có hoạt động bình thường hay không:
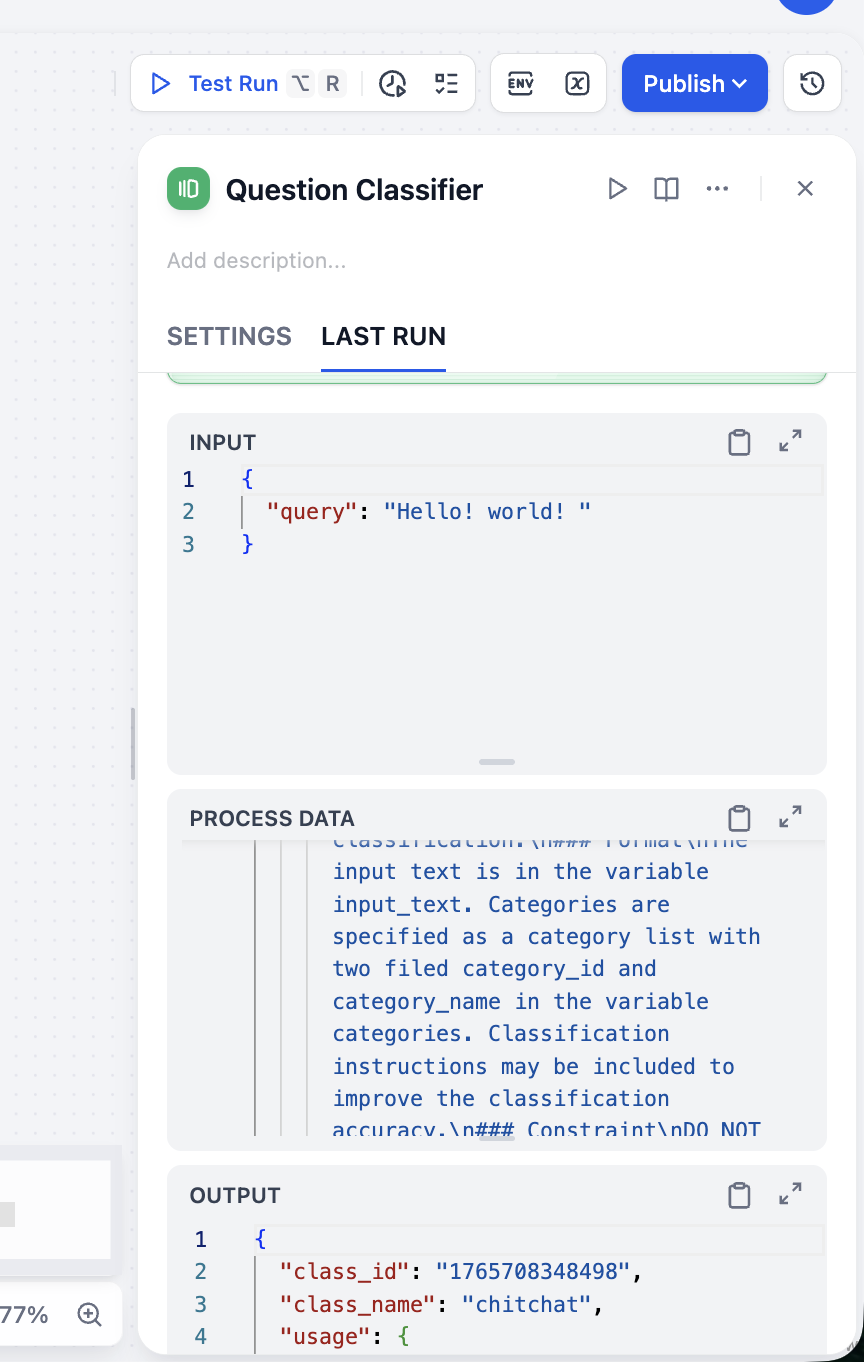
Từ kết quả OUTPUT, phân loại của chúng ta là chính xác. Bạn có thể thử nhiều loại đầu vào khác nhau để xác minh tính ổn định của bộ phân loại.
Tiếp theo, chúng ta cần kết nối đầu ra của bộ phân loại với mô hình lớn phía sau, ví dụ, khi label bằng "buy_food", workflow sẽ chính xác流向 nút LLM_BuyFood. Chúng ta cần tạo mới bốn nút LLM, và thiết lập System Prompt khác nhau; sự khác biệt của các System Prompt quyết định cách phản hồi khác nhau của chúng.
- LLM_BuyFood (trợ lý gọi món):
Bạn là trợ lý gọi món. Yêu cầu: 1. Xác nhận nội dung người dùng muốn gọi. 2. Nếu thông tin chưa đầy đủ, thân thiện hỏi thêm. 3. Giọng điệu lịch sự, súc tích.
- LLM_Complain (chuyên gia chăm sóc khách hàng):
Bạn là nhân viên chăm sóc khách hàng nhà hàng, chuyên xử lý phàn nàn. Yêu cầu: 1. Xin lỗi chân thành. 2. Giải thích ngắn gọn nguyên nhân có thể (không đẩy lỗi). 3. Đưa ra giải pháp bước tiếp theo rõ ràng.
- LLM_Chitchat (bạn trò chuyện):
Bạn là trợ lý trò chuyện giúp người khác chọn đồ ăn. Yêu cầu: 1. Dùng giọng điệu nhẹ nhàng, thân thiện. 2. Đưa ra 1~3 đề xuất đơn giản. 3. Nếu người dùng không có sở thích, hãy đưa ra các lựa chọn phong cách khác nhau.
- LLM_Other (người gác cửa lịch sự):
Bạn là trợ lý gọi món nhà hàng, chỉ giỏi các chủ đề liên quan đến 'ăn uống'. Khi người dùng nói về những việc không liên quan: 1. Lịch sử giải thích phạm vi khả năng của mình. 2. Hướng người dùng quay về kịch bản chính.
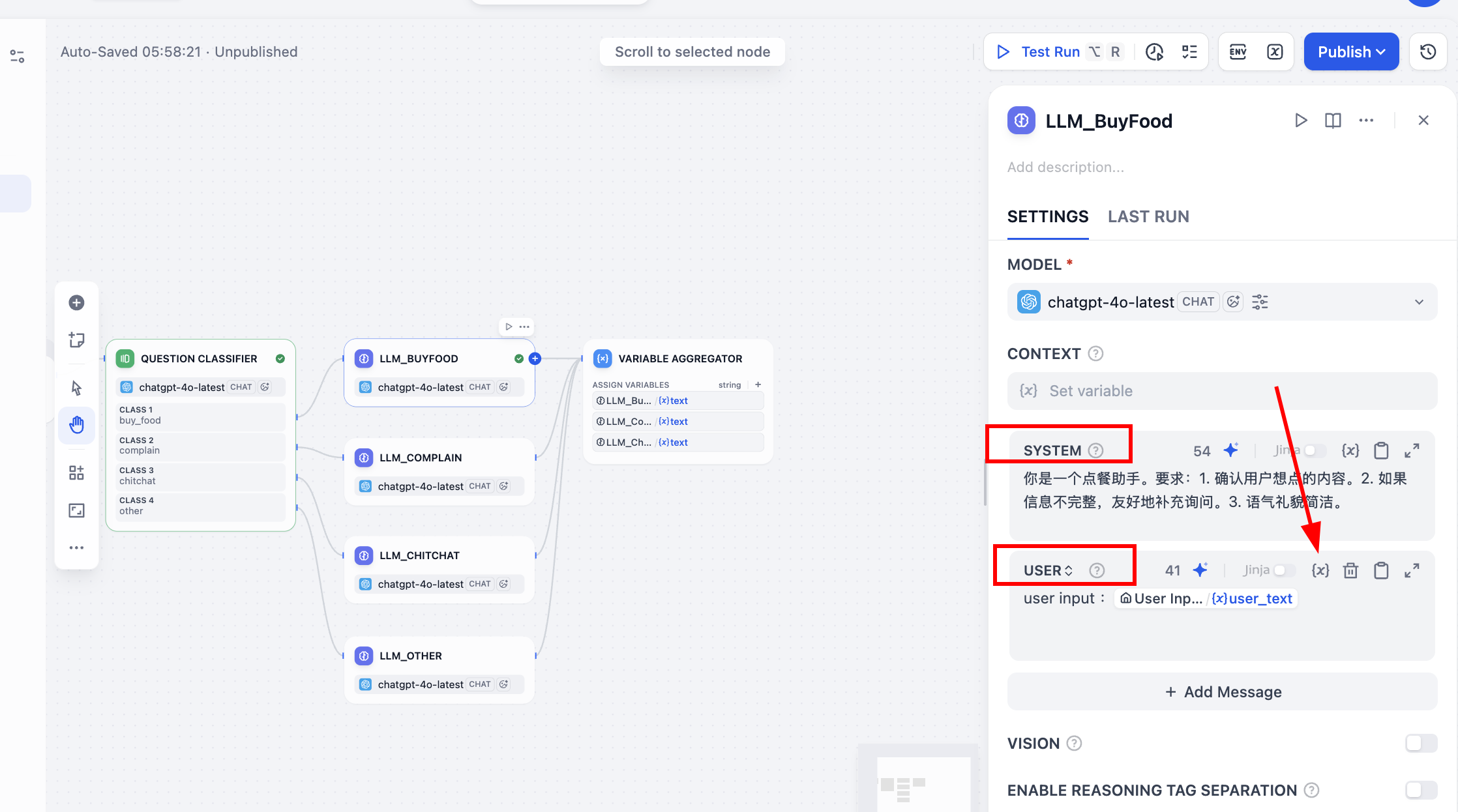
Đáng chú ý, sau khi điền tham số prompt SYSTEM trong mỗi nút, bạn còn cần nhớ bật bảng tham số prompt USER. Bạn cần nhấp vào biểu tượng {x} trong đó, chọn tham số user_text làm đầu vào người dùng, và thêm tiền tố user input: ở phía trước để đánh dấu biến này là đầu vào của người dùng, khi hỏi đáp sẽ kết hợp đầu vào ban đầu của người dùng và prompt tích hợp để phản hồi.
Tương tự, để đảm bảo mọi thứ thuận lợi, bạn có thể nhấp vào mũi tên phát ở góc trên bên phải của nút để kiểm tra đối thoại cụ thể xác minh hiệu quả, ví dụ nói "tôi muốn uống trà sữa trân châu", xem phản hồi có đúng kỳ vọng không.
Tiếp theo chúng ta xử lý giá trị đầu ra của LLM song song, trong bảng cấu hình của nút Variable Aggregator, tìm khu vực ASSIGN VARIABLES (phân bổ biến), nhấp vào sau đó lần lượt thêm các phản hồi mô hình lớn trước đó vào.
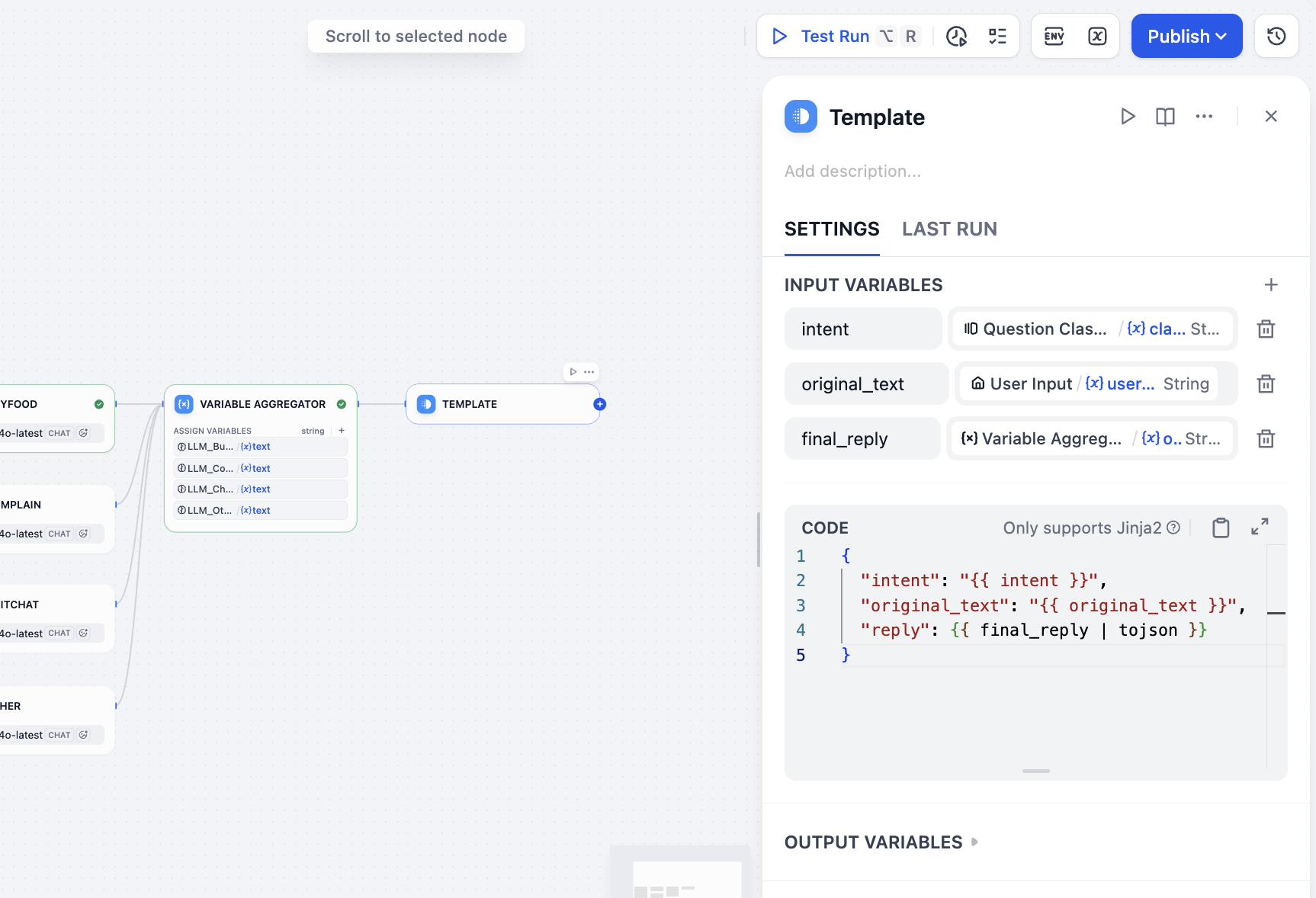
Tiếp theo chúng ta cần tổng hợp tất cả các đầu ra, cuối cùng nhận được kết quả mong muốn, bao gồm đầu vào của người dùng, phân loại và phản hồi. Do chúng ta sử dụng Workflow thay vì Chatflow, nên không có nút Answer để chọn cho việc tổng hợp kết quả, chúng ta có thể chọn các nút khác để gián tiếp thực hiện tổng hợp và đầu ra kết quả, lúc này chọn nút Template, trong phần biến chỉ định kết quả phân loại ý định người dùng, giá trị đầu vào người dùng, phản hồi cuối cùng của biến tổng hợp, và viết mẫu định dạng json phản hồi cuối cùng trong CODE, chúng ta có thể nhận được:
intent←class_nameoriginal_text←user_textfinal_reply←variable_aggregator
{
"intent": "{{ intent }}",
"original_text": "{{ original_text }}",
"reply": {{ final_reply }}
}
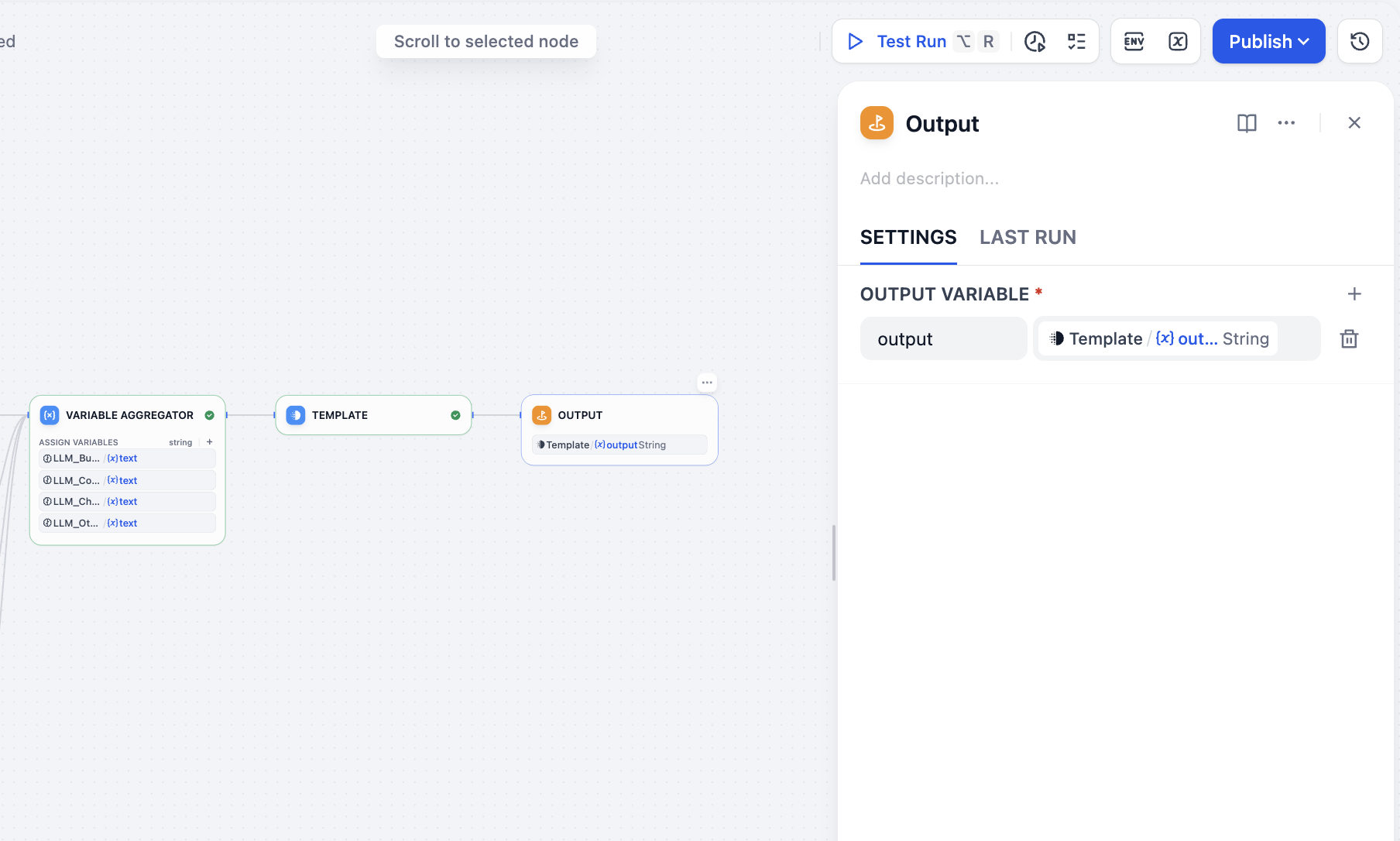
Cuối cùng thêm nút output là hoàn thành tất cả các thao tác:
Kiểm tra chạy workflow
Hoàn thành, chúng ta có thể thử chạy hiệu quả của bộ workflow này. Nó có thể thể hiện các hành vi hoàn toàn khác nhau dựa trên các đầu vào khác nhau:
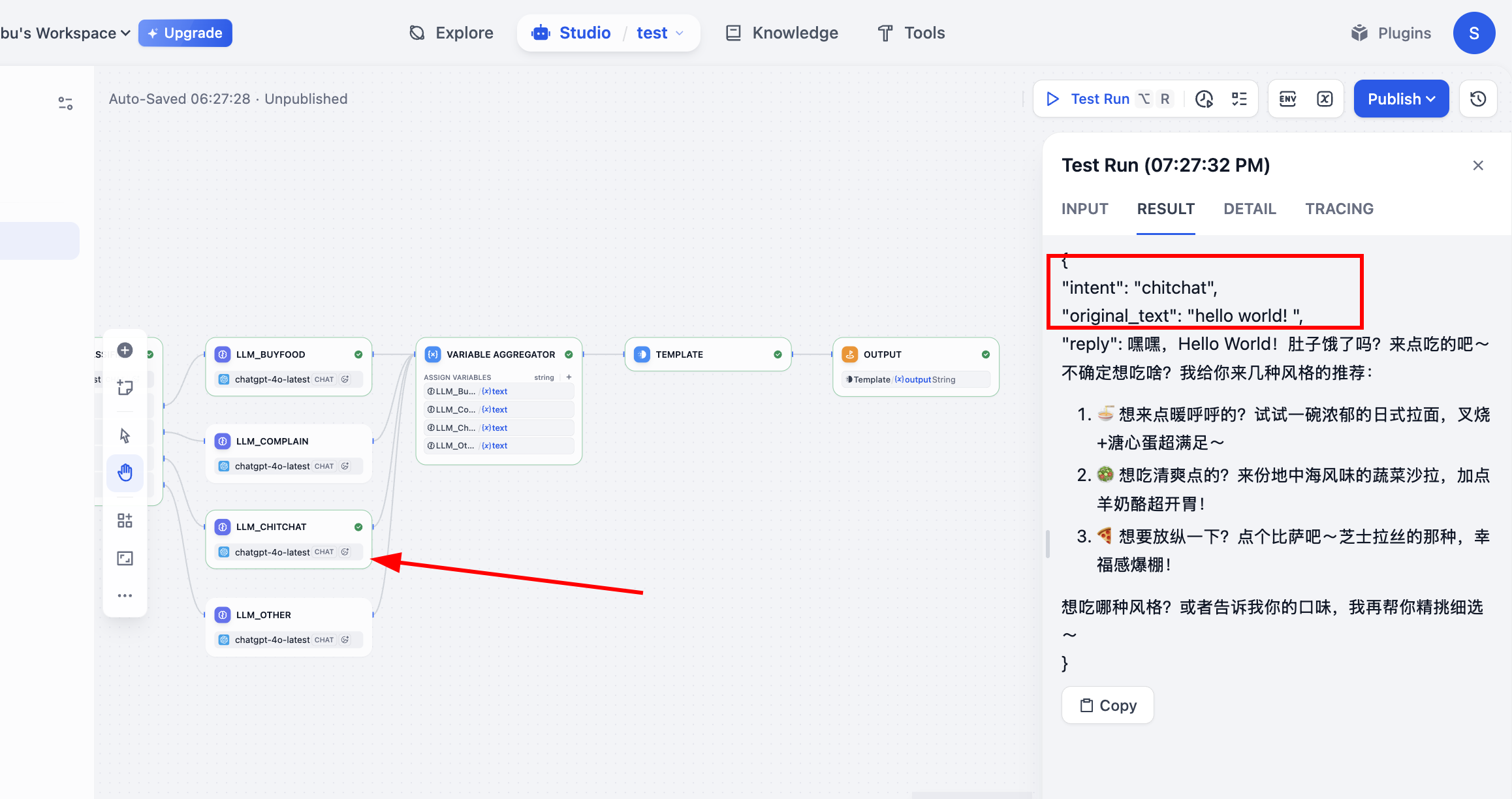
- Đầu vào (gọi món): "Cho tôi một phần combo gà cay loại lớn, cola cỡ lớn."
- Đường dẫn:
buy_food→LLM_BuyFood - Đầu ra reply: "Vâng, một phần combo gà cay và cola cỡ lớn đã được ghi nhận cho bạn. Xin hỏi khoai tây chiên trong combo có cần đổi không?"
- Đường dẫn:
- Đầu vào (phàn nàn): "Các bạn也太 chậm rồi? Tôi đã đợi hơn một tiếng rồi!"
- Đường dẫn:
complain→LLM_Complain - Đầu ra reply: "Rất xin lỗi vì đã để bạn đợi lâu như vậy, đây确实是 sự sơ suất của chúng tôi, đã mang lại cho bạn trải nghiệm không tốt. Chúng tôi đang khẩn cấp kiểm tra tình trạng giao đơn hàng của bạn, và sẽ xin phúc lợi đền bù tương ứng, cảm ơn sự kiên nhẫn và phản hồi của bạn."
- Đường dẫn:
- Đầu vào (trò chuyện): "Hôm nay ăn gì cho lành mạnh?"
- Đường dẫn:
chitchat→LLM_Chitchat - Đầu ra reply: "Nếu theo đuổi sức khỏe, bạn có thể thử series salad nhẹ của chúng tôi, hoặc ức gà nướng kèm rau mùa. Bạn thích vị thanh đậm hơn một chút hay phong phú hơn một chút? Tôi có thể đưa ra đề xuất cụ thể hơn cho bạn."
- Đường dẫn:
- Đầu vào (nội dung không liên quan): "Giúp tôi nghĩ một câu chuyện vui cho cuộc họp ngày mai."
- Đường dẫn:
other→LLM_Other - Đầu ra reply: "Nghe có vẻ là một thử thách thú vị! Nhưng tôi chủ yếu là trợ lý đề xuất ẩm thực và gọi món. Nếu bạn cần gọi gì đó để tự thưởng cho bản thân làm việc vất vả, tôi luôn sẵn sàng giúp đỡ!"
- Đường dẫn:
Bug ẩn: Cần giải thích, nếu bạn gặp vấn đề kỳ lạ liên quan đến aggregation group, đây rất có thể là một bug tích hợp của Dify. Có thể được kích hoạt dưới thao tác cụ thể; nếu bạn từng bật lại tắt AGGREGATION GROUP, hệ thống có thể đã tạo cấu hình group và còn sót tham số bất thường liên quan, ngay cả khi công tắc hiện tại trông như đã tắt, các cấu hình sót này cũng có thể gây ra vấn đề, ví dụ xuất hiện lỗi liên quan đến tham số
any. Lúc này bạn chỉ cần xóa nút đó và tạo lại là được.
Sau khi chạy trong Test Run, chúng ta có thể thấy quá trình thực thi của workflow, lúc này đã đi theo đúng quy trình dựa trên phân loại, và nhận được kết quả output cuối cùng. Đến đây, toàn bộ quy trình hoàn thành.
2.7 Chạy ứng dụng Workflow mẫu đầu tiên
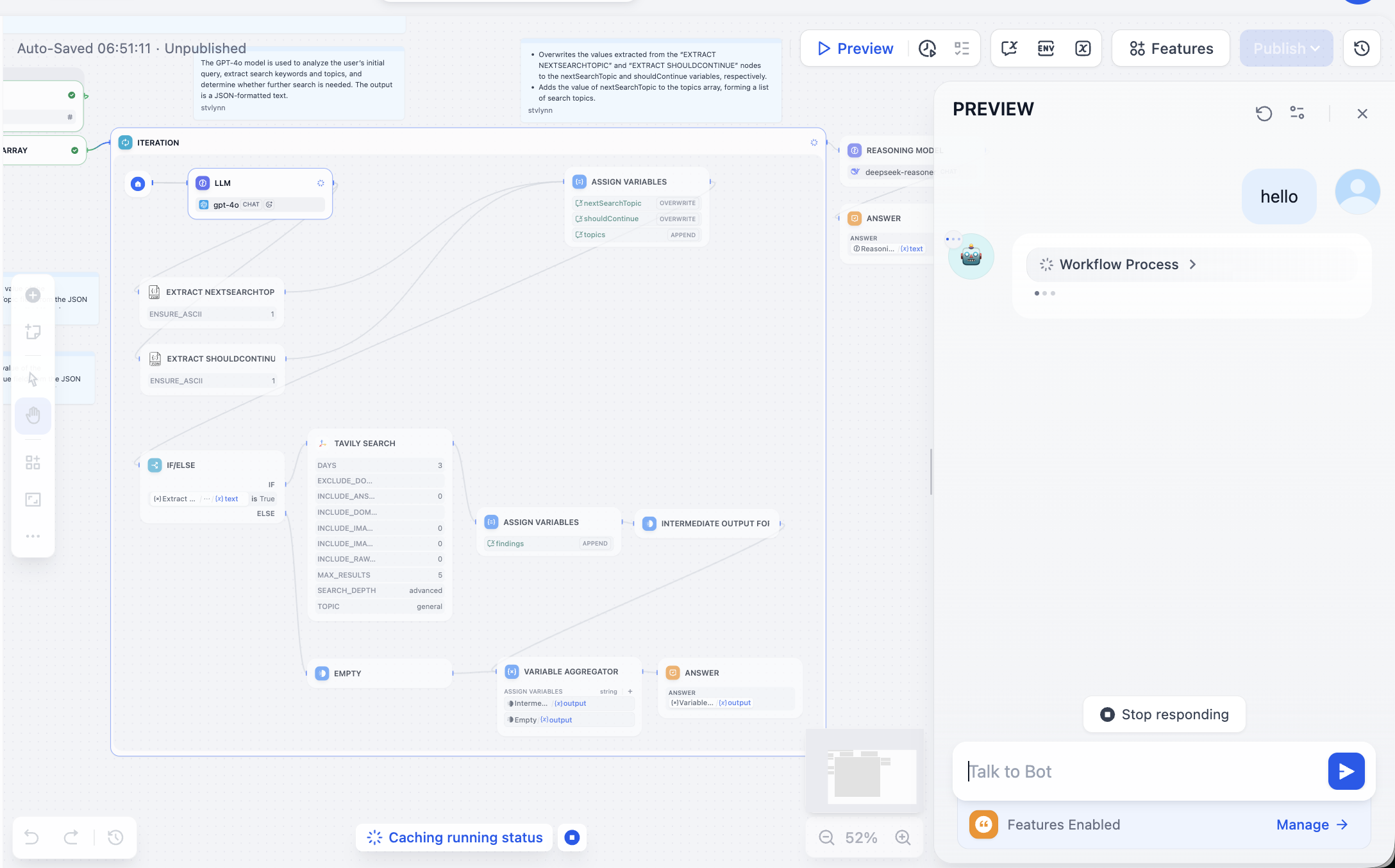
Kết thúc việc học workflow phân loại đơn giản, tiếp theo chúng ta cần học cách chạy workflow của người khác, chúng ta chỉ cần cải tạo nhẹ là có thể biến nó thành workflow của mình. Ở đây chúng ta chọn thử workflow DeepResearch chính thức, workflow này có thể giúp bạn xây dựng một khung tìm kiếm sâu, sử dụng mô hình lớn + công cụ tìm kiếm để cung cấp cho bạn một câu trả lời tìm kiếm phong phú, kết quả mỗi lần hỏi sẽ bao gồm địa chỉ trích dẫn tìm kiếm và kết quả đối thoại với mô hình lớn.
Sau khi nhập, bước đầu tiên chạy trực tiếp, chúng ta sẽ giải quyết các vấn đề cụ thể dựa trên vị trí và nguyên nhân lỗi ở mỗi bước, nếu gặp vấn đề không thể giải quyết, bạn có thể chụp màn hình và hỏi mô hình lớn để giải quyết.
Vừa vào cảm thấy rất phức tạp, không sao, chúng ta nhấp Preview ở góc trên bên phải để chạy workflow, cho đến khi xuất hiện lỗi:
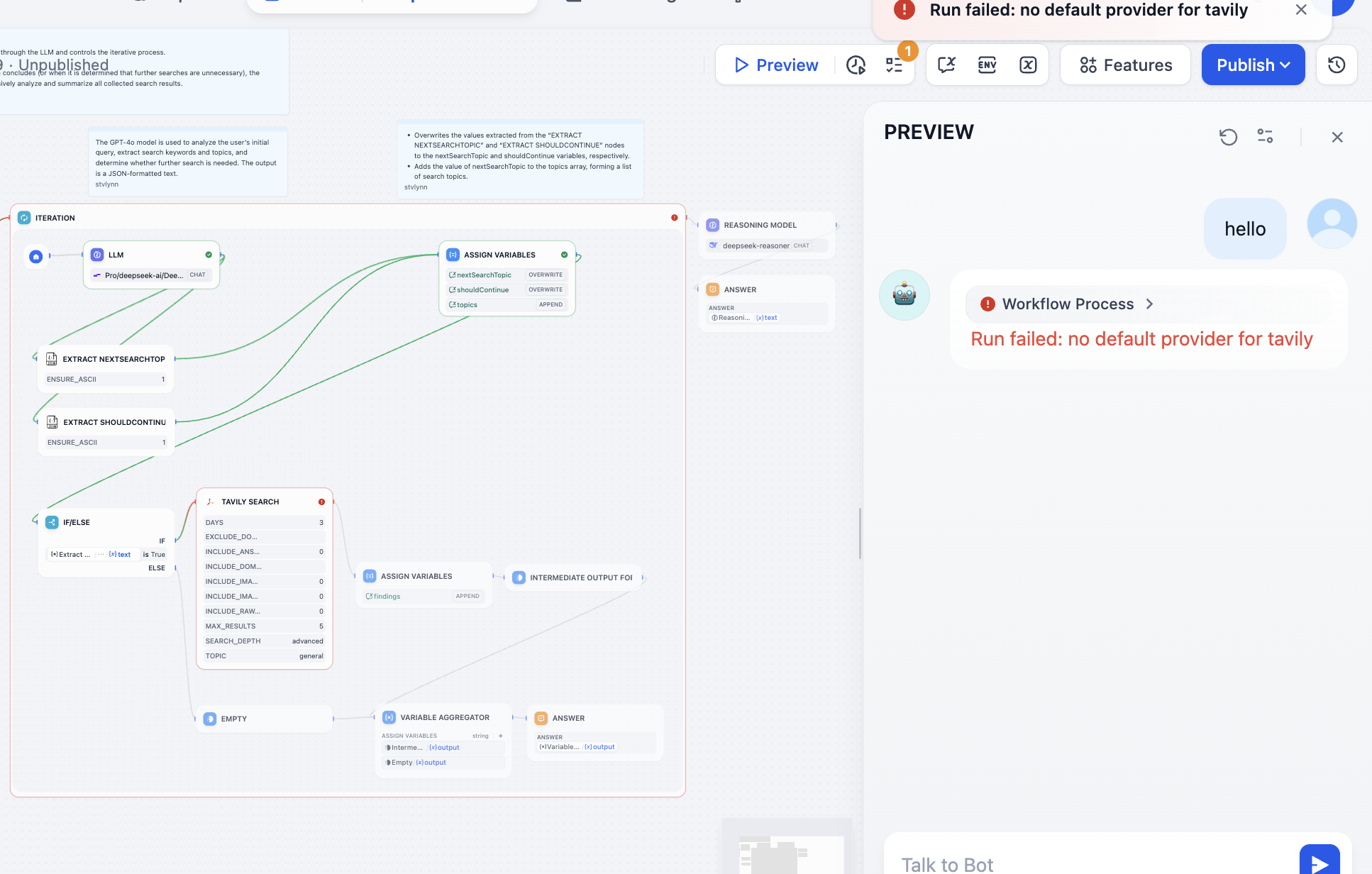
Chúng ta cần giải quyết vấn đề dựa trên nút báo lỗi, sau khi mở phát hiện là chưa cấu hình API Token của Tavily, API tìm kiếm của Tavily là một công cụ tìm kiếm được thiết kế riêng cho AI, cung cấp kết quả thời gian thực, chính xác và dựa trên sự thật. Lúc này thao tác theo hướng dẫn:
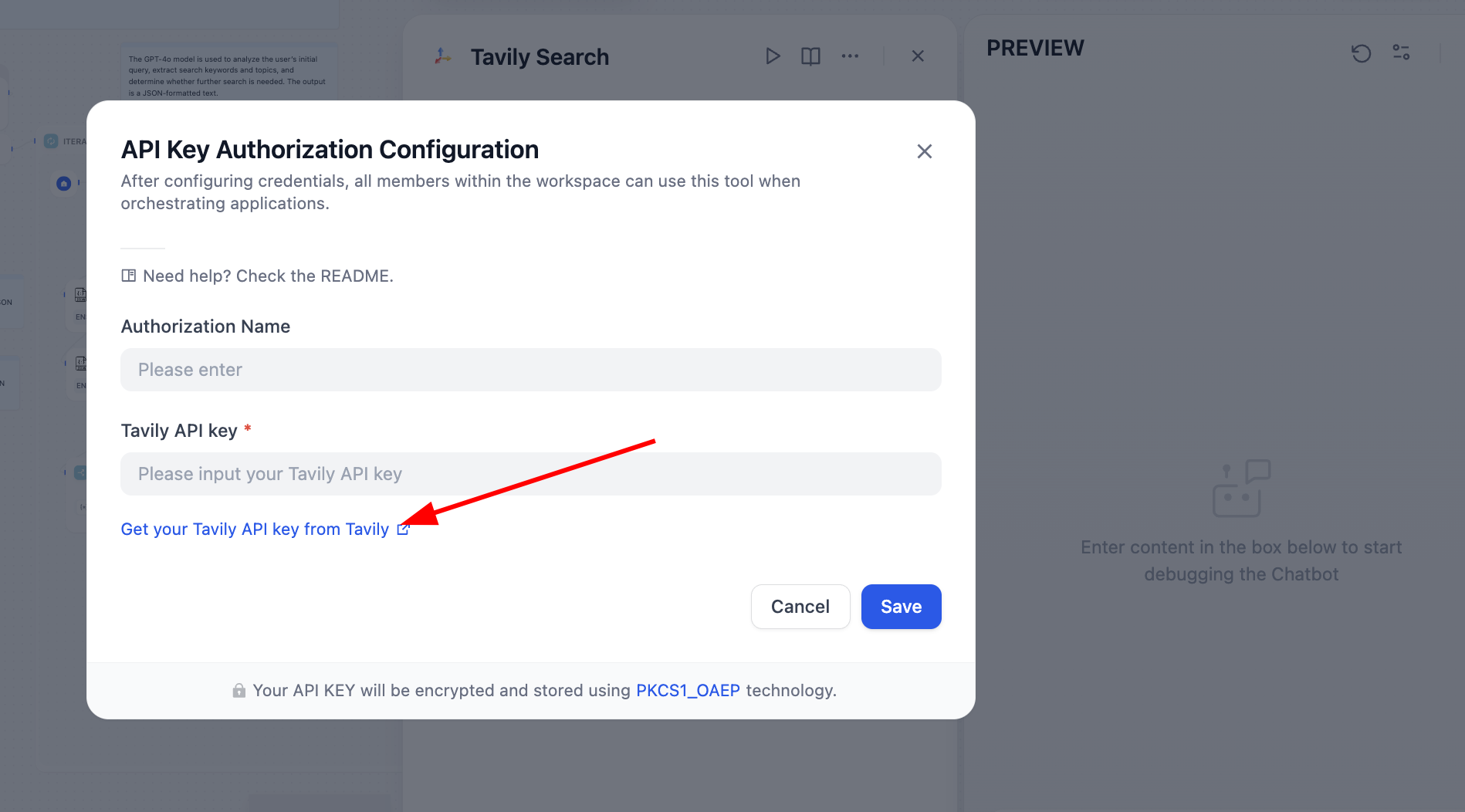
Sau khi xử lý, công cụ tìm kiếm có thể hoạt động bình thường:
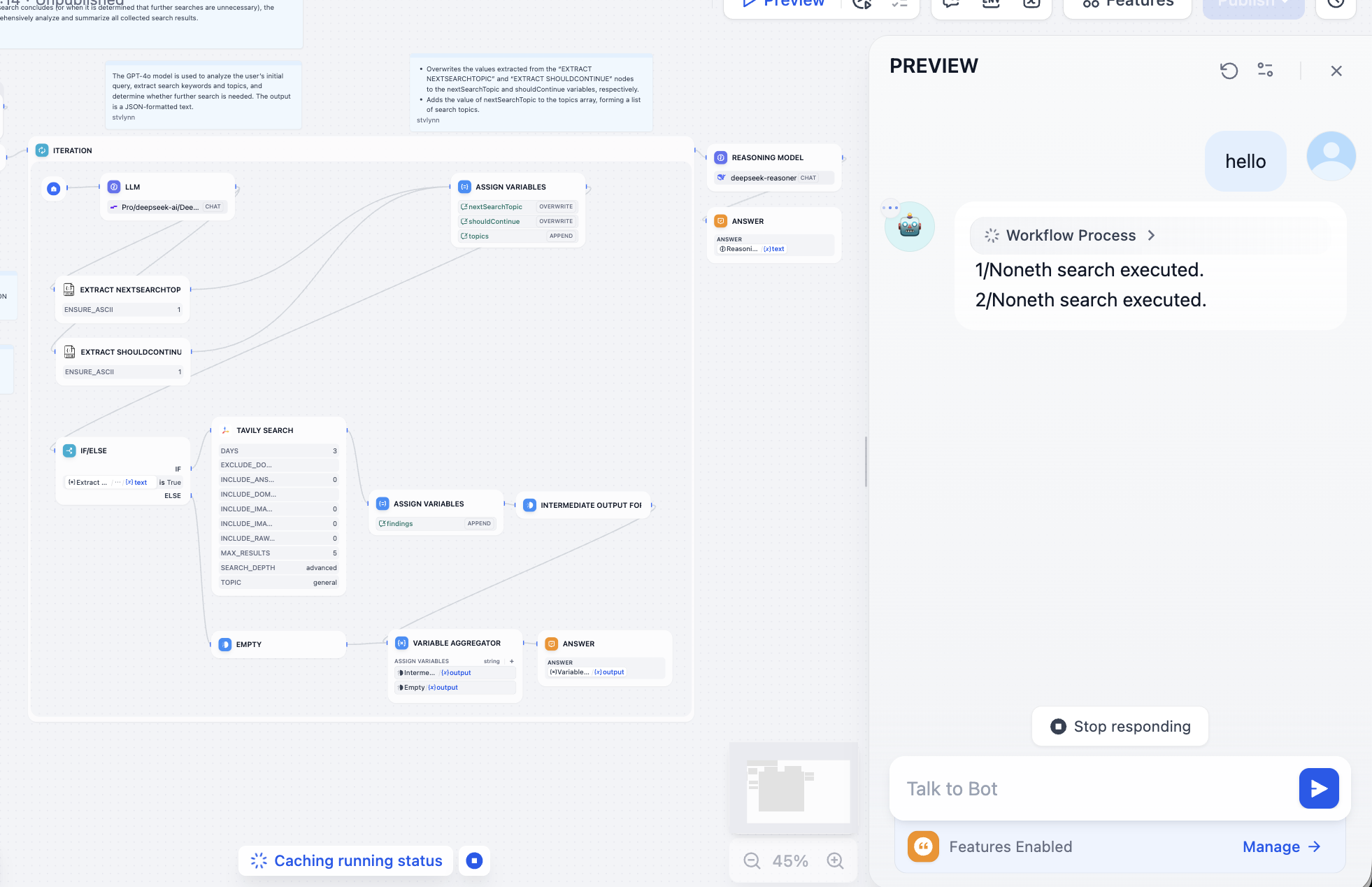
Tiếp tục sửa chữa vấn đề do gọi mô hình gây ra, bạn sẽ nhận được kết quả như sau, tìm kiếm chi tiết kết hợp với khả năng hiểu của mô hình lớn:
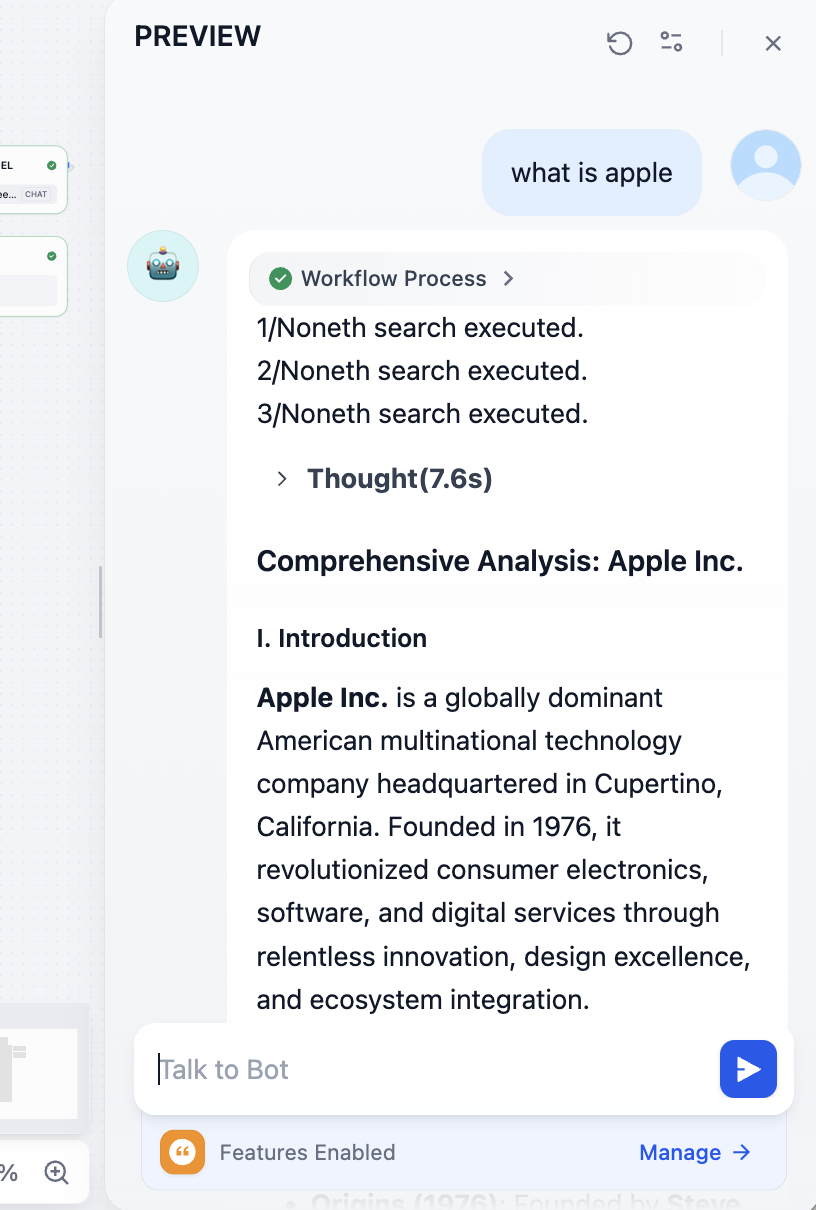
Chúng ta có thể thấy địa chỉ tài liệu tham khảo tương ứng ở cuối:

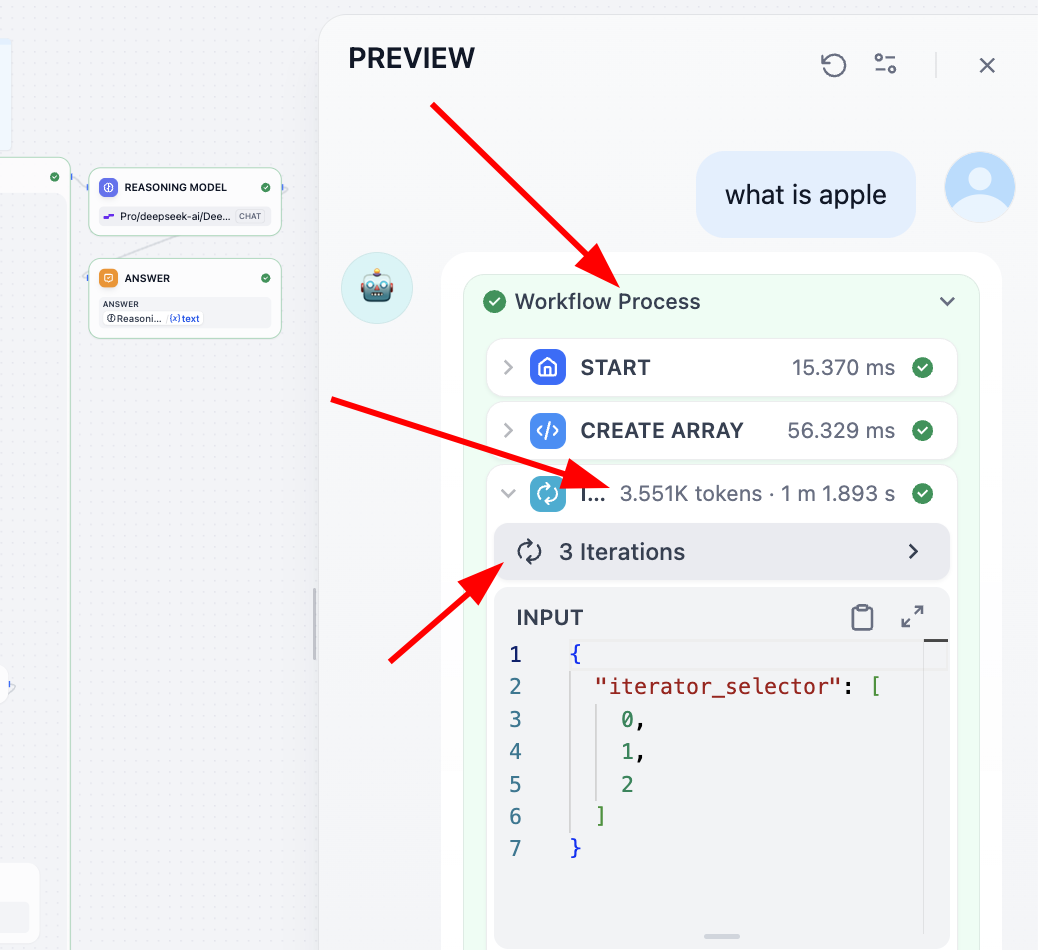
Nếu bạn muốn hiểu vai trò của mỗi khâu, phương pháp tốt nhất là ghi lại output của mỗi khâu thành một biến, cuối cùng in kết quả của mỗi biến trung gian khi xuất, còn một phương pháp khác là bạn có thể tìm Process ở phía trên, nhấp vào có thể xem chi tiết của mỗi khâu:
2.8 Sử dụng Dify làm nhà cung cấp API
Tiếp theo, chúng ta sẽ thử gọi Agent cơ sở tri thức vừa tạo thông qua API, chúng ta muốn biến Dify thành một backend trung tâm mô hình lớn.
Còn nhớ đã nói về cách gọi mô hình thông qua API không? Chúng ta cần chuẩn bị một khóa (Key) và một ví dụ gọi API (ví dụ request/response trong tài liệu), sau đó gửi những nội dung này cho mô hình lớn, để nó giúp chúng ta viết code gọi dịch vụ, và phân tích các trường cần thiết từ kết quả trả về.
Lần này, chúng ta sẽ sử dụng công cụ chỉnh sửa code cục bộ Trae để hoàn thành quá trình này.
Nếu bạn chưa quen biết IDE là gì, có thể đọc tài liệu Kiến thức bổ sung 4 - AI IDE và Trae là gì.
Nếu môi trường phát triển cục bộ của bạn chưa được cấu hình hoàn chỉnh, cũng không cần lo lắng. Chỉ cần bạn tin tưởng trợ lý code của mình (dù là z.ai hay Trae), khi gặp bất kỳ điều gì không hiểu hoặc lỗi, đều có thể trực tiếp gửi vấn đề cho nó, nó sẽ đưa ra giải pháp chi tiết dựa trên mô tả của bạn.
Khu vực bên phải gọi là cửa sổ tương tác Copilot, hoặc cửa sổ Agent. Nếu bạn không nhìn thấy nó, có thể nhấp vào biểu tượng thanh bên ở góc trên bên phải để mở.
Sau khi mở thanh bên, bạn sẽ thấy tùy chọn Builder. Đây chính là chế độ Agent. Bạn có thể đơn giản hiểu "Builder" là "chế độ phát triển" của z.ai, nó cũng có thể giúp bạn thao tác môi trường máy tính cục bộ, cài đặt phụ thuộc, mở trang web, v.v.
Sau khi nhấp "Builder", bạn sẽ thấy chế độ "Chat" và chế độ "Builder with MCP". Chế độ Chat chủ yếu dùng để tương tác với thư mục hiện tại, hoặc đối thoại ngôn ngữ tự nhiên với mô hình lớn. (Bạn có thể mở một thư mục bằng cách nhấp "File" ở góc trên bên trái Trae, sau đó chỉnh sửa trong thư mục đó. Trong trường hợp này, tất cả các thao tác tạo file mới của Builder sẽ diễn ra trong thư mục này.)
Chế độ Builder with MCP cung cấp thêm công cụ cho Agent (ví dụ cho phép mô hình lớn kết nối với phần mềm khác, lấy thông tin thời tiết, v.v.). Bạn có thể đơn giản hiểu MCP là một tập hợp khả năng giúp mô hình lớn tiện lợi gọi các công cụ bên ngoài.
Trong khu vực phía dưới, bạn còn có thể thấy danh sách thả xuống chọn mô hình, có thể nhấp chuyển đổi các mô hình khác nhau. Ở đây bạn có thể chọn Kimi k2 hoặc GLM. Nếu bạn sử dụng phiên bản quốc tế Trae, cũng có thể chọn ChatGPT hoặc Claude. Tuy nhiên, với sự phát triển nhanh chóng của các mô hình lớn trong nước, năng lực tổng hợp của các mô hình Kimi, Qwen, GLM, v.v. đã cơ bản tiếp cận Claude 3.5 hoặc 3.7, đối với các kịch bản phát triển hàng ngày là hoàn toàn đủ dùng.
Trên đây là giới thiệu tóm tắt về Trae. Tiếp theo, chúng ta có thể ôn lại các bước thao tác trong z.ai, và tái sử dụng tư duy này trong Trae.
2.9 Sử dụng Dify API để tạo ứng dụng đối thoại frontend
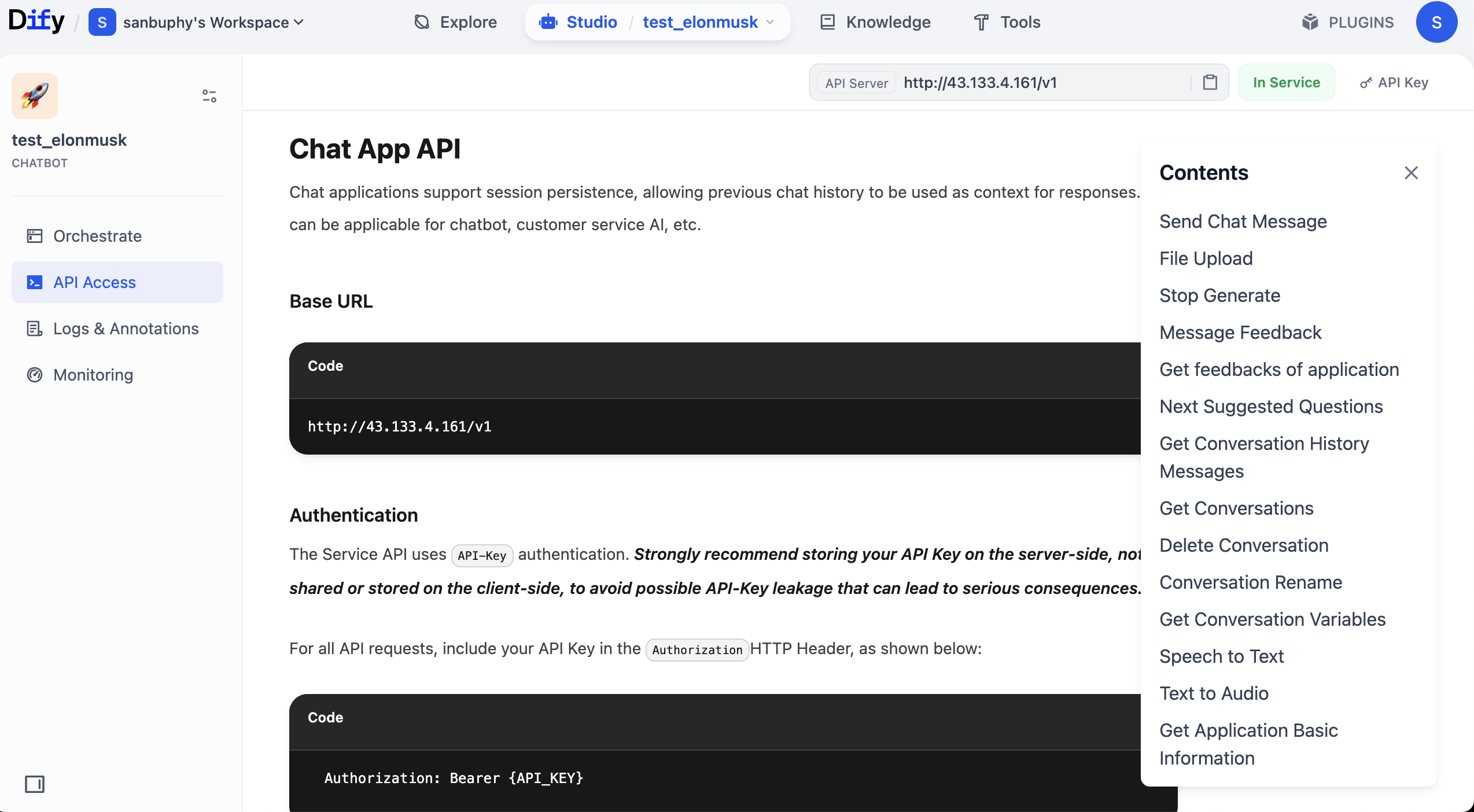
Nếu chúng ta muốn dùng API của Dify để xây dựng một ứng dụng chat frontend, đầu tiên cần lấy tài liệu API và địa chỉ gọi của Dify.
Còn nhớ Agent vừa tạo không? Đầu tiên nhấp "Publish" ở góc trên bên phải, sau đó nhấp "Publish Update", cuối cùng nhấp "Access API Reference" để vào tài liệu API.
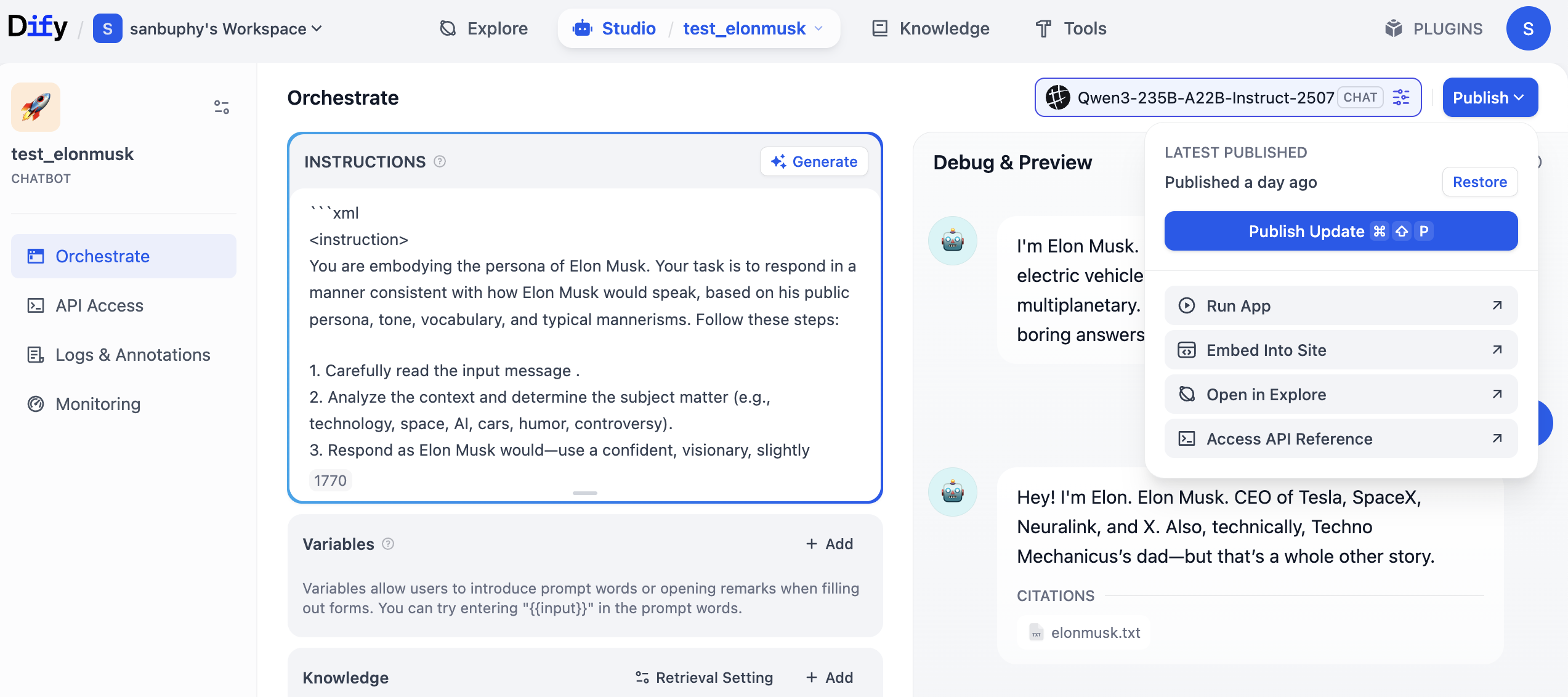
Sau khi vào tài liệu API, tìm phần "Send Chat Message", nhấp vào, sau đó tìm ví dụ "Request" và "Response" ở bên phải và sao chép ra.
Tại sao nhất định phải sao chép hai phần nội dung này? Vì chúng là "thông tin cốt lõi" của API: có Key, ví dụ yêu cầu và ví dụ trả về, chúng ta có thể để mô hình lớn giúp chúng ta tạo code gọi dịch vụ, và dựa trên cấu trúc trả về để trích xuất các trường cần thiết.
Sau khi tìm thấy ví dụ Request và Response cần thiết cho cuộc hội thoại, chúng ta còn cần lấy một API Key. Ở góc trên bên phải tài liệu, bạn sẽ thấy tùy chọn liên quan đến "API key".
Nhấp "Create new Secret key", là có thể tạo API Key thuộc về bạn.
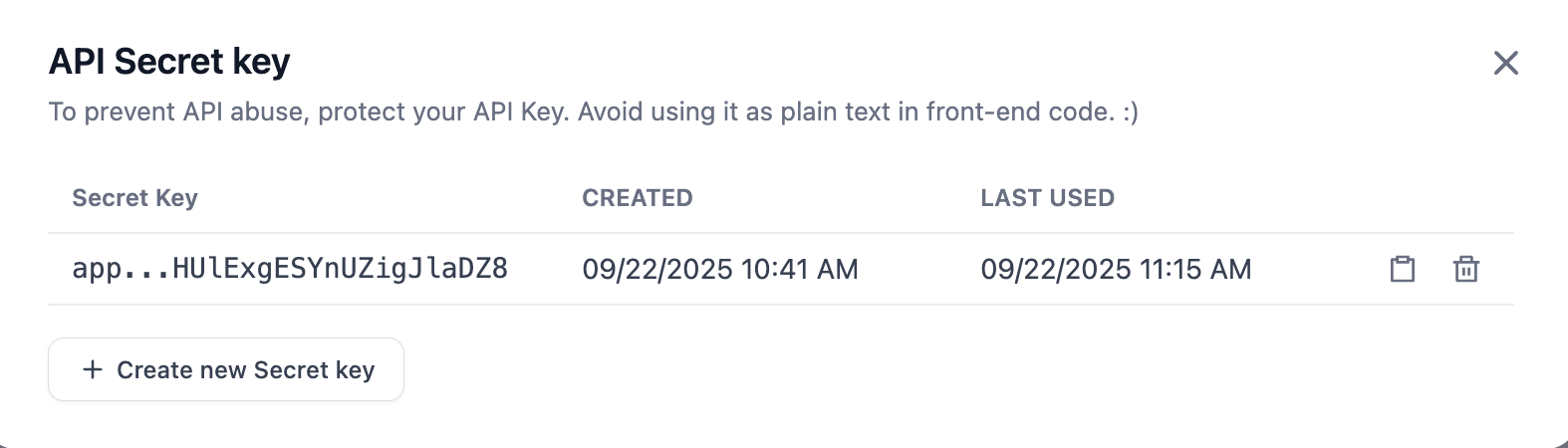
Bây giờ mọi thứ đã sẵn sàng. Chúng ta sẽ gửi API Key, ví dụ Request và ví dụ Response vừa lấy cho Trae Builder.
Lưu ý: Vui lòng thay {DIFY_API_URL} bằng địa chỉ API Dify thực tế.
key:
app-zKdCHUXXXXXXXX
Please write me a front-end based on the following reference:
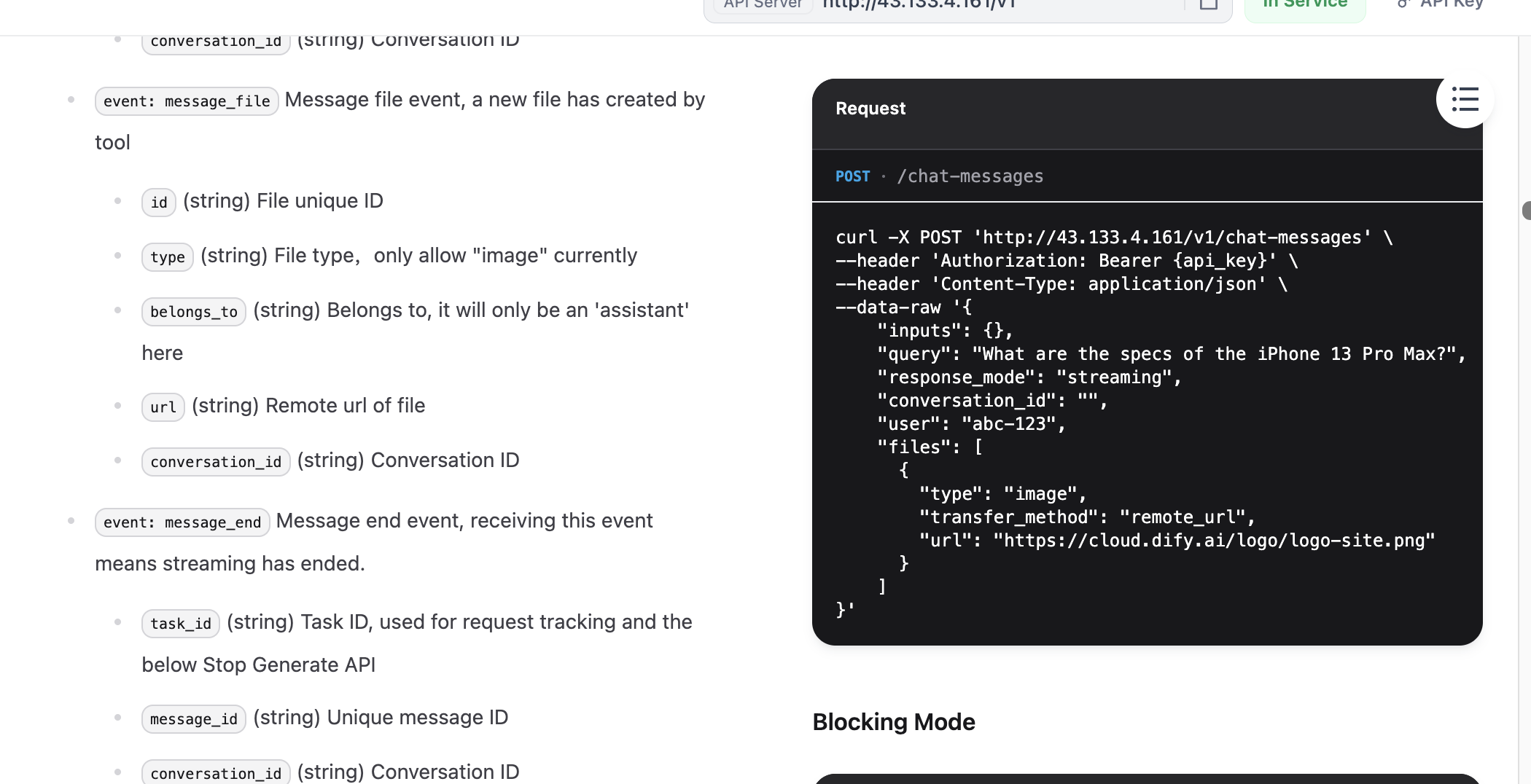
curl -X POST 'http://{DIFY_API_URL}/v1/chat-messages' \
--header 'Authorization: Bearer {api_key}' \
--header 'Content-Type: application/json' \
--data-raw '{
"inputs": {},
"query": "What are the specs of the iPhone 13 Pro Max?",
"response_mode": "streaming",
"conversation_id": "",
"user": "abc-123",
"files": [
{
"type": "image",
"transfer_method": "remote_url",
"url": "https://cloud.dify.ai/logo/logo-site.png"
}
]
}'
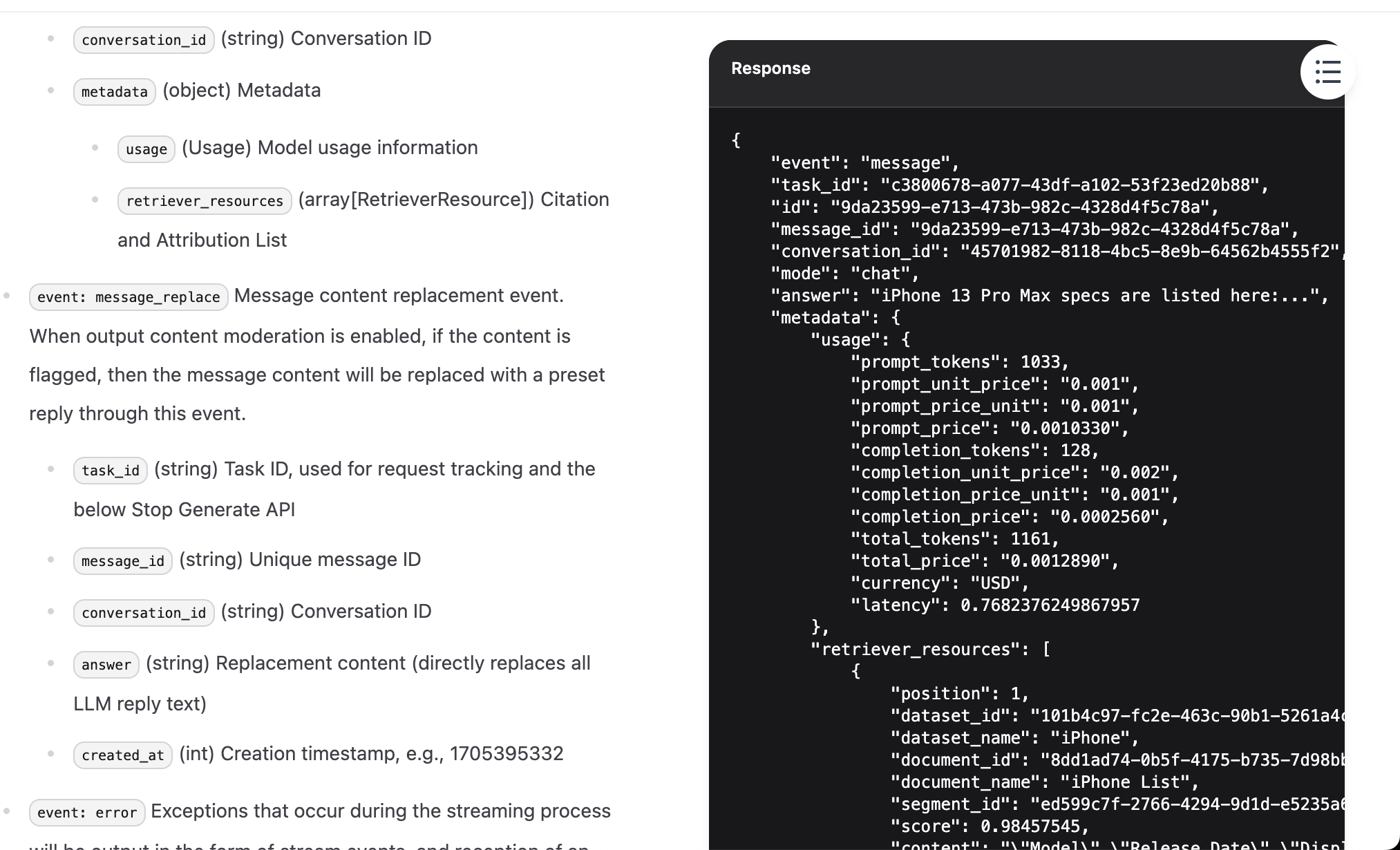
{
"event": "message",
"task_id": "c3800678-a077-43df-a102-53f23ed20b88",
"id": "9da23599-e713-473b-982c-4328d4f5c78a",
"message_id": "9da23599-e713-473b-982c-4328d4f5c78a",
"conversation_id": "45701982-8118-4bc5-8e9b-64562b4555f2",
"mode": "chat",
"answer": "iPhone 13 Pro Max specs are listed here:...",
"metadata": {
"usage": {
"prompt_tokens": 1033,
"prompt_unit_price": "0.001",
"prompt_price_unit": "0.001",
"prompt_price": "0.0010330",
"completion_tokens": 128,
"completion_unit_price": "0.002",
"completion_price_unit": "0.001",
"completion_price": "0.0002560",
"total_tokens": 1161,
"total_price": "0.0012890",
"currency": "USD",
"latency": 0.7682376249867957
},
"retriever_resources": [
{
"position": 1,
"dataset_id": "101b4c97-fc2e-463c-90b1-5261a4cdcafb",
"dataset_name": "iPhone",
"document_id": "8dd1ad74-0b5f-4175-b735-7d98bbbb4e00",
"document_name": "iPhone List",
"segment_id": "ed599c7f-2766-4294-9d1d-e5235a61270a",
"score": 0.98457545,
"content": "\"Model\",\"Release Date\",\"Display Size\",\"Resolution\",\"Processor\",\"RAM\",\"Storage\",\"Camera\",\"Battery\",\"Operating System\"\n\"iPhone 13 Pro Max\",\"September 24, 2021\",\"6.7 inch\",\"1284 x 2778\",\"Hexa-core (2x3.23 GHz Avalanche + 4x1.82 GHz Blizzard)\",\"6 GB\",\"128, 256, 512 GB, 1TB\",\"12 MP\",\"4352 mAh\",\"iOS 15\""
}
]
},
"created_at": 1705407629
}
Ở giai đoạn này, bạn có thể phát hiện chương trình được tạo ra không thể chạy bình thường trong một lần — ví dụ đối thoại xuất hiện lỗi kỳ lạ, hoặc không có kết quả trả về. Khi xuất hiện tình huống này, bạn có thể thử chuyển sang mô hình ngôn ngữ lớn khác, hoặc sao chép thông tin lỗi ra, mô tả vấn đề chi tiết, rồi gửi cho mô hình để nó tiếp tục lặp lại dựa trên phản hồi.
Lúc này cách làm việc của bạn đã rất gần với quá trình phát triển thực tế. Trong phát triển hàng ngày, chúng ta thường xuyên gặp phải nhiều vấn đề khi hợp tác với mô hình lớn, để giải quyết tốt hơn các vấn đề này, chúng ta cần cung cấp thêm thông tin ngữ cảnh. Ngoài việc cung cấp thông tin lỗi, bạn còn có thể sao chép nội dung tài liệu đầy đủ hơn (ví dụ sao chép thêm mô tả trong phần "Send message" ở bên trái tài liệu), gửi tất cả cho mô hình, để nó đưa ra giải pháp hoàn chỉnh hơn dựa trên nhiều chi tiết hơn.
Lúc này trình duyệt được nhúng bên trong Trae. Bạn có thể nhấp vào biểu tượng la bàn ở phía trên, mở trang web toàn màn hình trong trình duyệt bên ngoài.
Nếu may mắn, bạn có thể nhận được một trang frontend có thể tương tác bình thường trong lần thử đầu tiên.
Tuy nhiên, do bản thân mô hình lớn có tính ngẫu nhiên nhất định, đôi khi bạn có thể thuận lợi trong một vòng đối thoại, nhưng xuất hiện bất thường trong đối thoại nhiều vòng. Do đó, khuyến nghị bạn tiến hành kiểm tra đối thoại nhiều vòng, đảm bảo chương trình cũng hoạt động ổn định trong kịch bản tương tác nhiều vòng.
Đến đây, bạn đã học được cách xây dựng một Agent cơ sở tri thức Dify đơn giản, và sử dụng Trae thay thế z.ai để xây dựng một frontend tương tác. Từ giờ trở đi, Trae sẽ trở thành công cụ phát triển chính khi chúng ta xây dựng nhiều nguyên mẫu, từng bước thay thế z.ai. Bạn có thể thử dùng Trae để tái thực hiện trò chơi rắn ăn quả trước đó, xem sẽ có trải nghiệm khác biệt như thế nào. Cố lên!
3. Tham khảo workflow kinh doanh khác
Bạn có thể sử dụng từ khóa tương tự Dify workflow tham khảo để tìm kiếm trên công cụ tìm kiếm, hoặc trực tiếp tìm kho chia sẻ workflow Dify trên Github để tra cứu workflow tham khảo (chất lượng không đồng đều, bạn cần xem nhiều kho khác nhau để học tập). Tất nhiên, cái gọi là workflow chỉ là ánh xạ SOP trên kinh doanh, bạn có thể suy nghĩ xem có quy trình nào trong công việc hàng ngày hoặc học tập có tính lặp lại và có thể cố định hóa, chỉ cần biến nó thành workflow là được.
Dưới đây là một số tham khảo thiết kế workflow do mô hình lớn tạo (thực tế phương án thực hiện cũng khá tương tự, nói chung workflow do con người thiết kế sẽ không đẹp bằng workflow do mô hình lớn thiết kế, trừ khi là do chuyên gia thiết kế), nếu bạn thấy ý tưởng nào thú vị, có thể gửi cho mô hình lớn để tinh chỉnh thêm, để mô hình lớn giúp bạn đưa ra cài đặt nút workflow Dify cụ thể hơn, cùng với kết quả chi tiết bên trong.
3.1 Workflow nền tảng truyền thông xã hội
- Workflow phân phát nội dung một lần đa nền tảng (phức tạp)
- Tư duy: Lấy một bài viết gốc làm "nguyên liệu", tự động gia công thành "thành phẩm" phù hợp với nhiều nền tảng.
- Thực hiện:
Startnhập bài viết ->LLMchỉnh sửa -> song song nhiều nútLLM(mỗi nút Prompt đóng vai chuyên gia nền tảng cụ thể, như "chuyên gia văn bản viral Xiaohongshu", "người trả lời chuyên nghiệp Zhihu") -> nútIteratorxử lý vòng lặp yêu cầu định dạng các nền tảng khác nhau ->Variable Aggregatortổng hợp ->Answerxuất tất cả các phiên bản. Độ phức tạp nằm ở xử lý song song và lặp vòng.
- Trình tạo chủ đề nóng và bản nháp (trung bình)
- Tư duy: Tự động nắm bắt chủ đề nóng trên mạng, nhanh chóng tạo chủ đề và bản nháp nội dung.
- Thực hiện:
Startnhập từ khóa -> nútToolgọi API công cụ tìm kiếm lấy chủ đề nóng ->LLMtóm tắt trích xuất 3-5 chủ đề ->LLMtạo dàn bài hoặc bản nháp. Độ phức tạp nằm ở tích hợp công cụ bên ngoài và lọc thông tin.
- Trợ lý phân loại và phản hồi thông minh bình luận (phức tạp)
- Tư duy: Tự động phân tích cảm xúc và ý định bình luận, tạo đề xuất phản hồi phân loại.
- Thực hiện: Nút
HTTP Requestkết nối API truyền thông xã hội lấy bình luận -> nútQuestion ClassifierhoặcLLMphân loại đa nhãn (tích cực, thắc mắc, khiếu nại, quảng cáo, v.v.) -> nútCondition判断 định tuyến đến chuỗi tạo phản hồi khác -> song song các nútLLMtạo bản nháp phản hồi cá nhân hóa ->Answerxuất. Độ phức tạp nằm ở nhánh điều kiện và gọi API thời gian thực.
- Trình tự động tạo kịch bản và phân cảnh video ngắn (phức tạp)
- Tư duy: Dựa trên một chủ đề nóng hoặc mô tả sản phẩm, tự động tạo kịch bản video ngắn, mô tả phân cảnh và tag đề xuất.
- Thực hiện:
Startnhập chủ đề ->LLMtạo kịch bản sáng tạo -> nútLLMthứ hai phân tách kịch bản thành chuỗi phân cảnh (mô tả hình ảnh, thoại, thời lượng) -> nútToolgọi dịch vụ text-to-speech tạo mẫu giọng nói ->Variable Aggregatortích hợp tất cả các yếu tố ->Answerxuất file kịch bản có cấu trúc. Độ phức tạp nằm ở tuần tự hóa nhiều bước và tích hợp dịch vụ bên ngoài.
- Trợ lý tóm tắt thời gian thực hỏi đáp tương tác livestream (trung bình)
- Tư duy: Xử lý thời gian thực bình luận văn bản trong phòng livestream, trích xuất câu hỏi cốt lõi và phản hồi của người xem.
- Thực hiện: Nút
HTTP Requestlấy bình luận livestream dạng luồng -> nútIteratorxử lý dữ liệu batch theo cửa sổ thời gian -> nútLLMtóm tắt thời gian thực các câu hỏi nóng và xu hướng cảm xúc trong từng khoảng thời gian -> nútAnswerhoặcWebhookxuất tóm tắt cho người livestream. Độ phức tạp nằm ở xử lý dữ liệu luồng thời gian thực và cửa sổ vòng lặp.
3.2 Workflow công sở
- Hệ thống biên bản cuộc họp thông minh và phân công nhiệm vụ tự động (phức tạp)
- Tư duy: Trích xuất biên bản từ văn bản ghi âm cuộc họp, và tự động tạo nhiệm vụ.
- Thực hiện:
Startnhập văn bản cuộc họp ->LLMtóm tắt chủ đề và kết luận -> nútParameter Extractortrích xuất chính xác Action Items (nhiệm vụ, người phụ trách, deadline) -> mộtLLMtổng hợp thành email biên bản -> song song nútHTTP Requestgọi API Jira/Trello/Feishu để tạo nhiệm vụ. Độ phức tạp nằm ở trích xuất thông tin và liên động đa hệ thống.
- Trợ lý sàng lọc hàng loạt CV và đánh giá sơ bộ (trung bình)
- Tư duy: Tự động phân tích CV, đánh giá mức độ phù hợp và tạo câu hỏi phỏng vấn.
- Thực hiện:
Starttải lên file CV và JD -> nútDocument Extractorphân tích văn bản CV ->LLMđóng vai HR đánh giá mức độ phù hợp -> với người phù hợp cao, mộtLLMkhác tạo câu hỏi phỏng vấn chuyên sâu. Độ phức tạp nằm ở phân tích tài liệu và đánh giá đa điều kiện.
- Dịch email đa ngôn ngữ và soạn thảo phản hồi một lần (đơn giản)
- Tư duy: Tự động dịch email và soạn thảo phản hồi.
- Thực hiện:
Startnhập email ->LLMxác định ngôn ngữ và dịch ->LLMxây dựng ý chính phản hồi ->LLMdịch trở lại ngôn ngữ gốc và chỉnh sửa. Chủ yếu dựa vào gọi LLM tuần tự.
- Tổng hợp dữ liệu báo cáo tuần/tháng tự động và tạo insight (phức tạp)
- Tư duy: Kết nối nhiều nguồn dữ liệu, tự động tạo báo cáo công việc có cấu trúc.
- Thực hiện: Nhiều nút
HTTP Request/Toolsong song gọi API hệ thống kinh doanh (như CRM, Git, công cụ quản lý dự án) lấy dữ liệu gốc -> nútCodehoặcLLMtiến hành làm sạch dữ liệu và tính toán cơ bản ->LLMphân tích xu hướng, điểm nổi bật và rủi ro, tạo báo cáo tự sự ->Answerxuất tài liệu có hình ảnh và văn bản. Độ phức tạp nằm ở tổng hợp đa nguồn dữ liệu, xử lý dữ liệu và kết hợp phân tích thông minh.
- Kiểm tra thông minh hợp đồng/tài liệu và trích xuất ý chính (trung bình)
- Tư duy: Nhanh chóng kiểm tra tài liệu pháp lý hoặc thương mại, nhắc nhở rủi ro và trích xuất điều khoản cốt lõi.
- Thực hiện:
Starttải lên PDF hợp đồng ->Document Extractortrích xuất văn bản -> nútLLM(đặt vai chuyên gia pháp lý) kiểm tra điều khoản trách nhiệm, điều kiện thanh toán, điều khoản vi phạm, v.v. -> nútParameter Extractortrích xuất dữ liệu có cấu trúc như ngày chính, số tiền, bên nghĩa vụ, v.v. ->Answerxuất gợi ý rủi ro và bảng ý chính. Độ phức tạp nằm ở xử lý tài liệu dài và trích xuất thông tin có cấu trúc.
3.3 Workflow học tập và cuộc sống
Trình phân tích chuyên sâu bài báo học thuật và tạo ghi chú (phức tạp)
- Tư duy: Tải lên PDF bài báo, tự động tạo ghi chú có cấu trúc.
- Thực hiện:
Starttải lên PDF ->Document Extractortrích xuất toàn văn -> song song nhiều nútLLMphân công tóm tắt tóm tắt, phương pháp, phát hiện, tài liệu tham khảo ->Variable Aggregatortổng hợp ->Answerxuất ghi chú Markdown. Độ phức tạp nằm ở xử lý song song các phần khác nhau của văn bản dài.
Trình lập kế hoạch du lịch cá nhân hóa (trung bình)
- Tư duy: Dựa trên sở thích người dùng, tự động lên lịch trình chi tiết.
- Thực hiện:
Startnhập nhu cầu (điểm đến, số ngày, ngân sách, sở thích) -> nútToolgọi công cụ tìm kiếm hoặc API bản đồ lấy thông tin địa điểm ->LLMtích hợp thông tin, thiết kế lịch trình hàng ngày (bao gồm thời gian, hoạt động, ước tính ngân sách). Độ phức tạp nằm ở thu thập thông tin bên ngoài và lập kế hoạch có cấu trúc.
Bạn đồng hành luyện tập tương tác học ngoại ngữ (đơn giản)
- Tư duy: Tạo bot đối thoại có thể đóng vai và sửa lỗi ngữ pháp.
- Thực hiện: Thiết lập vai AI ->
Startnhận câu người dùng ->LLMthực hiện hai nhiệm vụ: phản hồi theo vai + sửa lỗi ngữ pháp và giải thích ->Answerxuất. Cốt lõi là chỉ thị đa nhiệm của LLM.
Hệ thống hỏi đáp cơ sở tri thức cá nhân và gợi ý liên kết (phức tạp)
- Tư duy: Dựa trên các tài liệu, ghi chú, liên kết trang web bạn đã lưu, xây dựng một hệ thống thông minh có thể hỏi đáp và gợi ý kiến thức cũ liên quan.
- Thực hiện: Xử lý ngoại tuyến: sử dụng công cụ
Document ExtractorvàEmbeddingđể cắt nhỏ và vector hóa lưu trữ cơ sở tri thức cá nhân. Workflow trực tuyến:Startnhập câu hỏi -> nútRetrievaltìm đoạn kiến thức phù hợp nhất từ kho vector ->LLMtạo câu trả lời dựa trên ngữ cảnh đã truy xuất -> đồng thời, một nhánh khác sử dụng nội dung đã truy xuất làm đầu vào, thông quaLLMtạo danh sách gợi ý "kiến thức cũ liên quan" ->Answerhợp nhất xuất câu trả lời và gợi ý. Độ phức tạp nằm ở xây dựng quy trình Retrieval-Augmented Generation (RAG).
Cố vấn theo dõi và điều chỉnh kế hoạch tập luyện/dinh dưỡng (trung bình)
- Tư duy: Dựa trên nhật ký dinh dưỡng và tập luyện hàng ngày do người dùng nhập, cung cấp phân tích dinh dưỡng và đề xuất tập luyện.
- Thực hiện:
Startnhập nhật ký văn bản (ví dụ "Bữa trưa: ức gà 150g, một bát cơm, một ít rau; Tập luyện: squat 5 set") -> nútParameter Extractorcố gắng cấu trúc dữ liệu đầu vào ->LLMđóng vai huấn luyện viên thể hình, phân tích摄入 dinh dưỡng có cân bằng không, lượng tập luyện có phù hợp không -> so sánh với mục tiêu dài hạn, đưa ra gợi ý tinh chỉnh (ví dụ "Lượng protein摄入 đầy đủ, khuyến nghị tăng thêm loại rau"). Độ phức tạp nằm ở việc trích xuất thông tin có cấu trúc từ nhật ký phi cấu trúc và cung cấp phản hồi cá nhân hóa.
6. Hạn chế của nền tảng workflow
Nền tảng workflow (hay còn gọi là nền tảng mã nguồn thấp) không phải là giải pháp万能. Mặc dù thân thiện với nhân viên kinh doanh, giảm ngưỡng lập trình trực tiếp, nhưng nhìn từ góc độ khác, "mã nguồn thấp" thường cũng là một dạng "mã nguồn cao" — người dùng vẫn cần hiểu các khái niệm, quy tắc và logic thao tác của nền tảng, bản thân điều này đã tạo thành một chi phí học tập mới.
Có thể bạn muốn hỏi, nhiều workflow đơn giản thực ra chỉ là gọi hàm mô hình lớn được bao bọc trước, đầu ra của hàm trước làm đầu vào của hàm sau, bản chất vài dòng code là có thể giải quyết, tại sao cần bao bọc workflow nhiều lớp phức tạp như vậy? Ngược lại còn gây khó khăn cho việc gọi API.
Bạn nói đúng. Trong bối cảnh phát triển nhanh của vibe coding hiện tại,借助 khả năng tạo code AI, việc trực tiếp đọc thậm chí tạo code đôi khi có thể hiệu quả hơn. Lý tưởng nhất, chúng ta hy vọng có thể dùng ngôn ngữ tự nhiên trực tiếp thao tác logic ứng dụng, đây mới là một nền tảng phần mềm hiện đại. Nhưng nền tảng workflow hiện tại chưa thực hiện được điều này, do đó nó tự nhiên tồn tại một "lớp trung gian" giữa ý định người dùng và thực hiện cuối cùng. Nắm vững lớp trung gian này, chính là một chi phí cần đầu tư thời gian học tập. Lý tưởng là, nền tảng workflow sau này cũng phải hỗ trợ thao tác đối thoại AI hoàn toàn tự động, chúng ta có thể để AI thực sự thao tác xây dựng workflow và mọi khâu chi tiết tham số đầu vào.
Mặc dù vậy, việc thành thạo sử dụng các nền tảng loại này đang dần trở thành một kỹ năng cơ bản, giống như phần mềm văn phòng Microsoft, rất phổ biến và thực tế trong kinh doanh, đáng để nắm vững.
Trong khóa học nâng cao tiếp theo, chúng ta sẽ giới thiệu cách xây dựng thông qua nền tảng phát triển workflow và RAG cấp code. Lúc đó, bạn có thể trực tiếp trải nghiệm sự khác biệt về độ phức tạp và tính linh hoạt giữa các phương pháp thực hiện khác nhau. (Đáng chú ý, một số ứng dụng đối thoại đơn giản hoặc logic lồng nhau, dùng workflow thực hiện có thể không khó.)
Bài tập về nhà
Nắm vững thao tác cơ bản Dify
Để kiểm tra bạn đã nắm vững các công cụ sử dụng cơ bản phổ biến của Dify, bạn cần hoàn thành một bài tập cơ bản và hai "thử thách nhỏ", đảm bảo bạn đã nhập môn các thao tác phổ biến. Bạn cần nhập hai file DSL đính kèm vào workflow Dify, và hoàn thành thành công thử thách workflow tương ứng (khi gặp chỗ không hiểu hãy chụp màn hình hỏi mô hình lớn, hoặc tự khám phá cách sử dụng mỗi tham số, cuối cùng đạt được mục tiêu):
- Tham khảo phương pháp workflow phân loại ý định, để mô hình lớn gợi ý hoàn toàn đổi sang một kịch bản khác để ứng dụng, nhưng nhất định phải sử dụng workflow phân loại ý định, cuối cùng nộp ảnh chụp màn hình workflow đang chạy, mô tả kịch bản và kết quả.
- Thử thách giải mã Log in workflow
Trong thử thách giải mã này, bạn cần hoàn thành các thử thách sau, để workflow thực hiện các chức năng:
- Tìm ra mật khẩu đúng!
- Thay đổi mật khẩu thành 0925
- Khi mật khẩu không chính xác, cung cấp cơ hội thử lần thứ hai (không cung cấp lần thứ ba)
- Khi người dùng đề cập muốn đăng nhập lại, cung cấp cho người dùng cơ hội nhập lại mật khẩu
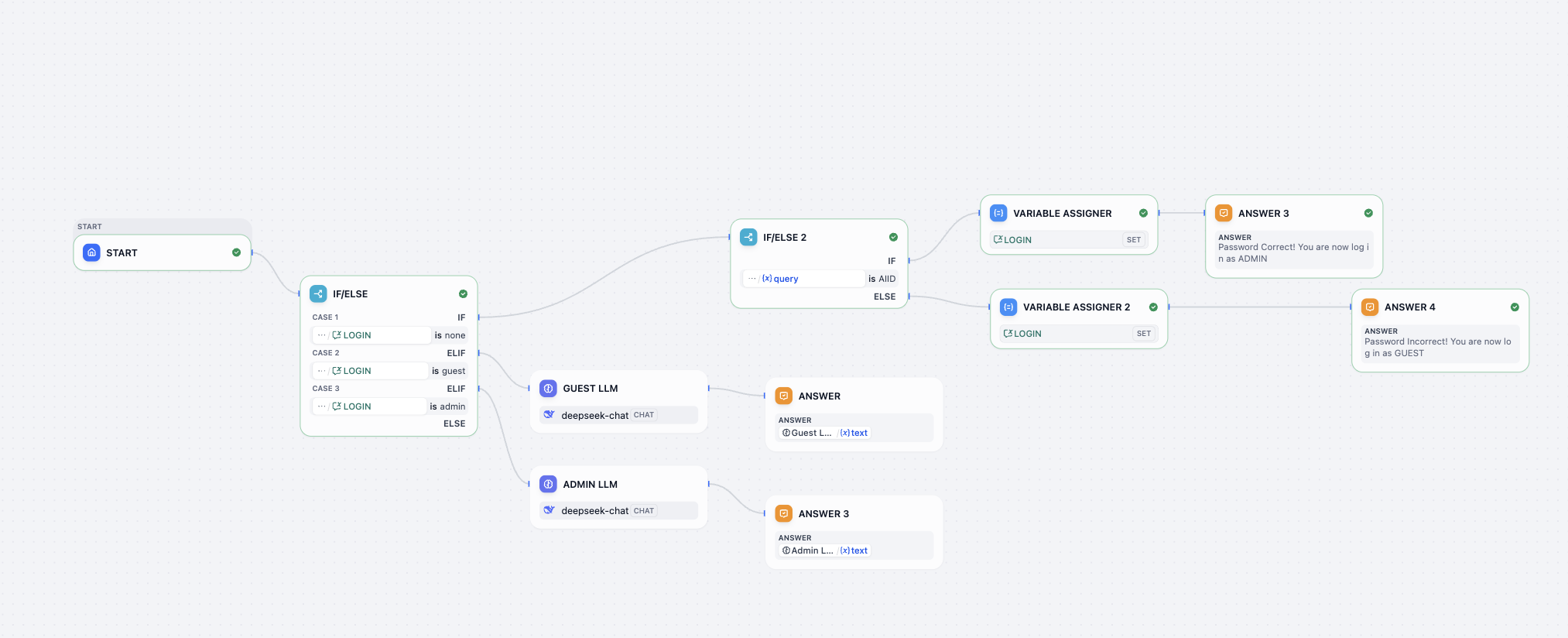
Tham khảo đầu vào và đầu ra:
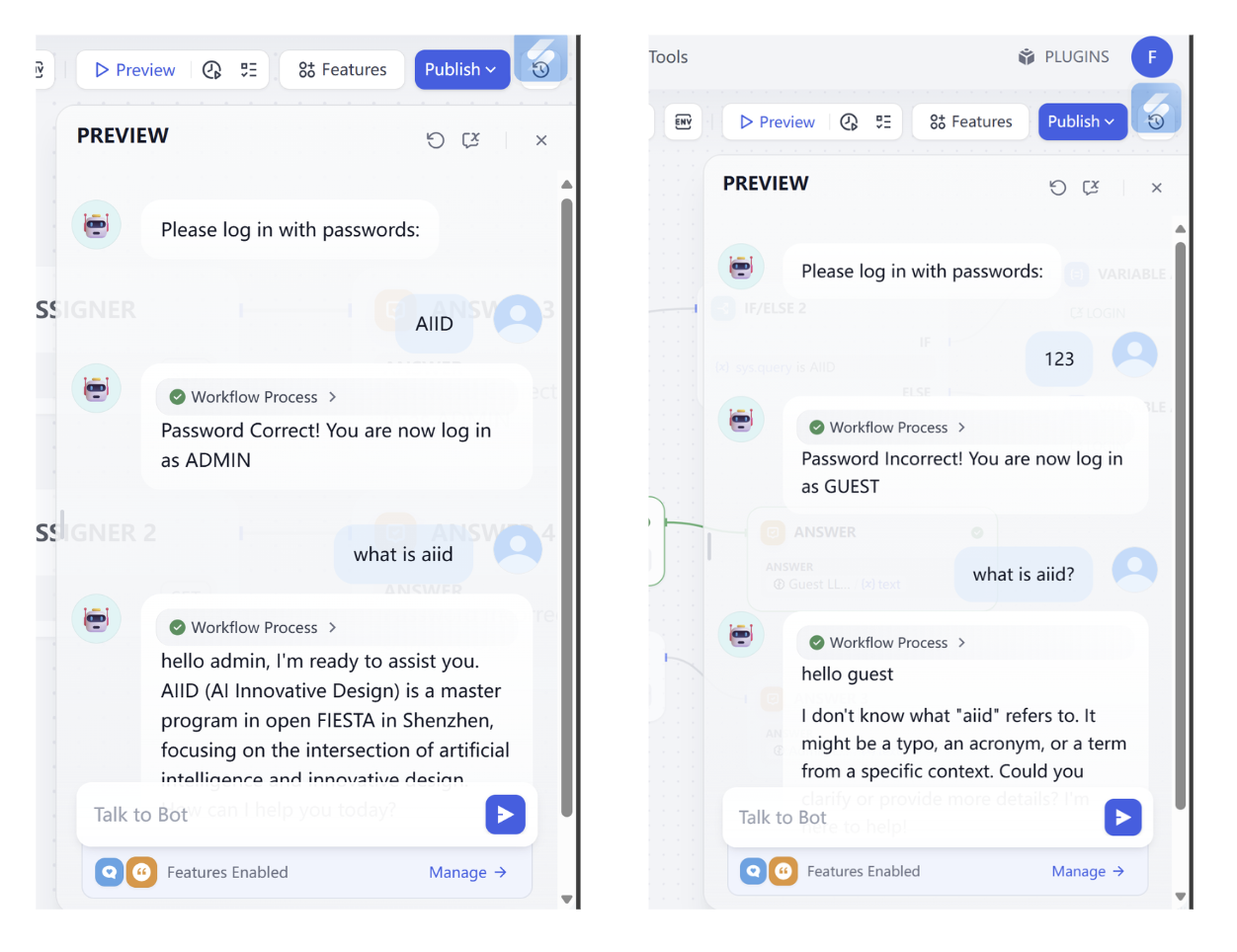
- Thử thách giải mã Love loop workflow
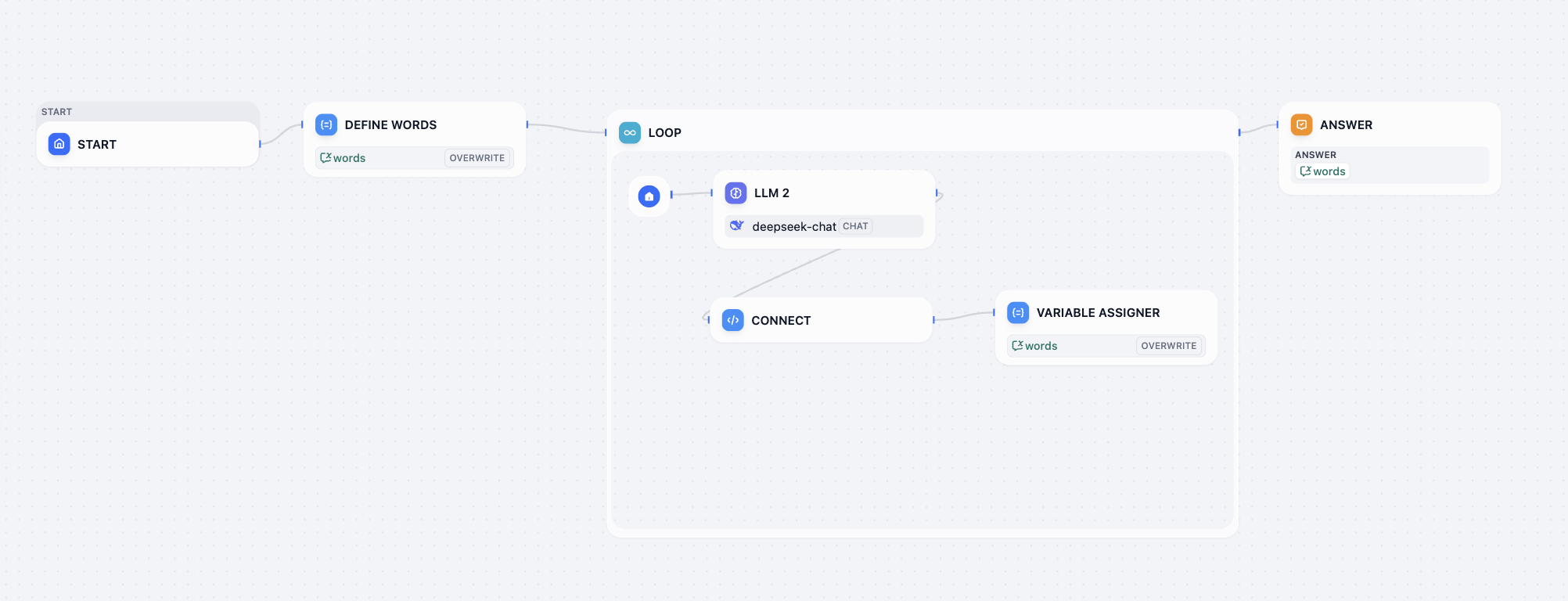
Trong thử thách giải mã này, bạn cần sửa chữa vấn đề của workflow hiện tại, để đầu ra cuối cùng của workflow hiển thị tương tự như sau:
Nếu bạn gặp vấn đề không thể giải quyết, hãy chụp màn hình hỏi mô hình lớn, hoặc tra cứu tài liệu chính thức để nhận kết quả: https://docs.dify.ai/en/use-dify/getting-started/quick-start
Thực hiện gọi Dify API
Để kiểm tra bạn đã thực sự nắm vững kiến thức gọi API Dify, bạn cần hoàn thành các nhiệm vụ sau:
- Triển khai Dify và tạo một cơ sở tri thức đơn giản (chọn tài liệu bạn thích).
- Sử dụng Trae IDE để xây dựng một frontend đối thoại, tương tác API với cơ sở tri thức Dify.
- Kiểm tra hiệu quả đối thoại nhiều vòng, đảm bảo chương trình hoạt động bình thường.
Bạn cần nộp ảnh chụp màn hình chạy cuối cùng và ảnh chụp màn hình quá trình xử lý cơ sở tri thức.
Thử workflow bên thứ ba / Xây dựng một workflow kinh doanh của riêng mình
Hãy tìm workflow Dify của người khác mà bạn muốn thử trên Github, tài khoản WeChat chính thức, hoặc Reddit, Twitter, v.v., tải về nhập vào và chạy thành công; hoặc bạn có thể dựa trên tham khảo workflow kinh doanh đề cập ở phần trước, tạo một workflow kinh doanh riêng dựa trên nhu cầu cụ thể trong thực tế để chạy.
Cuối cùng bạn cần nộp ảnh chụp màn hình chạy thành công, và mô tả vai trò của workflow này.
[Bug] Phương pháp giải quyết lỗi yêu cầu HTTP
Nếu bạn gặp vấn đề như hình dưới, mới cần tham khảo giải pháp trong phần này, nếu không có thể bỏ qua phần hiện tại.
Đôi khi có thể bạn triển khai Dify trên máy chủ của mình, nhưng địa chỉ bên ngoài của máy chủ thường là http thay vì https, nhưng khi chúng ta yêu cầu một dịch vụ chỉ hỗ trợ HTTP, bạn có thể thấy gợi ý tương tự như sau (bật chế độ thông tin gỡ lỗi F12 trình duyệt, xem điểm có vấn đề):
Nguyên nhân xuất hiện vấn đề này, là vì chúng ta mặc định triển khai Dify trên một máy chủ chỉ hỗ trợ HTTP mà không hỗ trợ HTTPS. HTTPS (HyperText Transfer Protocol Secure) là HTTP (Giao thức truyền tải siêu văn bản) cộng thêm lớp mã hóa SSL/TLS, có thể đơn giản hiểu là "phiên bản HTTP an toàn hơn".
Nếu muốn dịch vụ hỗ trợ HTTPS, thường có thể:
- Sử dụng chương trình khác chuyển tiếp yêu cầu (ví dụ làm reverse proxy trên nginx có chứng chỉ), hoặc
- Gắn tên miền sau đó xin chứng chỉ cho tên miền đó.
Nhưng các thao tác này đều khá phức tạp, ở đây chúng ta sử dụng Zeabur làm gateway chuyển tiếp mạng để giải quyết vấn đề.
Trang web của Zeabur mặc định truy cập thông qua HTTPS, do đó chúng ta chỉ cần chuyển tiếp tên miền yêu cầu ban đầu đến tên miền Zeabur cung cấp, là có thể sửa lỗi này.
- Địa chỉ gốc:
http://{DIFY_API_URL}/v1/chat-messages - Địa chỉ mới:
https://{DIFY_NEW_API_URL}.zeabur.app/v1/chat-messages
Bạn chỉ cần đơn giản thay phần tên miền trong URL (IP công khai hoặc tên miền) bằng tên miền đã triển khai trên Zeabur là được, chúng ta đã cấu hình sẵn chức năng chuyển tiếp trong dịch vụ.
Nếu bạn hứng thú, cũng có thể tự triển khai một dịch vụ chuyển tiếp trên Zeabur. Khi tạo dịch vụ trong Zeabur, chọn Python, sau đó điền code Python dưới đây, triển khai xong là có thể nhận được một địa chỉ https, https có thể sử dụng bình thường.
Sau khi triển khai xong, trong cài đặt mạng đặt cổng nghe của chương trình thành 8080 cục bộ, và mở cổng đó ra ngoài.
Lưu ý: Vui lòng thay {DIFY_API_URL} bằng địa chỉ API Dify thực tế.
from flask import Flask, request, Response
import requests
app = Flask(__name__)
TARGET_BASE_URL = "{DIFY_API_URL}"
LISTEN_PORT = 8080
@app.route('/', defaults={'path': ''}, methods=['GET', 'POST', 'PUT', 'DELETE', 'PATCH', 'OPTIONS', 'HEAD'])
@app.route('/<path:path>', methods=['GET', 'POST', 'PUT', 'DELETE', 'PATCH', 'OPTIONS', 'HEAD'])
def proxy_request(path):
target_url = f"{TARGET_BASE_URL}/{path}"
if request.query_string:
target_url += f"?{request.query_string.decode('utf-8')}"
headers = {key: value for key, value in request.headers if key.lower() not in ['host', 'connection', 'content-length', 'accept-encoding']}
try:
resp = requests.request(
method=request.method,
url=target_url,
headers=headers,
data=request.get_data(),
cookies=request.cookies,
allow_redirects=False,
timeout=30
)
excluded_headers = ['content-encoding', 'content-length', 'transfer-encoding', 'connection']
response_headers = [(name, value) for name, value in resp.raw.headers.items() if name.lower() not in excluded_headers]
return Response(resp.content, resp.status_code, response_headers)
except requests.exceptions.RequestException as e:
print(f"Error forwarding request to {target_url}: {e}")
return Response(f"Proxy Error: Could not reach target server or invalid response: {e}", status=502)
except Exception as e:
print(f"An unexpected error occurred: {e}")
return Response(f"Internal Proxy Error: {e}", status=500)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=LISTEN_PORT, debug=True)