مقدمة في Dify ودمج قاعدة المعرفة
مراجعة الدرس السابق
في الدروس السابقة، تعلمنا في مجموعات أساسيات برمجة الذكاء الاصطناعي وهندسة الأوامر التوجيهية وتوليد الصور بالذكاء الاصطناعي. ساعدتنا هذه المحتويات على الفهم الأولي لحدود وقدرات مختلف النماذج اللغوية الكبيرة (LLM، Large Language Model) أو النماذج التوليدية.
لمساعدتك في مراجعة محتوى الدرس السابق، إليك بعض الأسئلة للتفكير:
- ما هي برمجة الذكاء الاصطناعي؟ كيف تستخدم أدوات برمجة الذكاء الاصطناعي (مثل z.ai) لإنشاء صفحة ويب؟
- ما هو النموذج اللغوي الكبير؟ ما هي هندسة الأوامر التوجيهية وهندسة السياق؟ كيف تكتب أمرًا توجيهيًا معقدًا؟
- بالنسبة للاتجاهات الثلاثة المختلفة - النصوص، البرمجة بالذكاء الاصطناعي، وتوليد الصور - أين تتجلى نقاط القوة والضعف في قدرات النموذج لكل منها؟
- ما هو API؟ كيف تستخدم z.ai للاتصال بواجهة API لطرف ثالث؟
إذا كنت لا تزال تشعر بالحيرة تجاه أي من هذه الأسئلة، يمكنك العودة إلى مستند الدرس السابق، أو طرح سؤالك مباشرة في مجموعة WeChat.
في هذا الدرس، سنتنتقل من أدوات الذكاء الاصطناعي البسيطة للنصوص والصور إلى منصات بناء سير العمل الأقرب لتطبيقات الأعمال الفعلية. من روبوتات المحادثة إلى وكلاء الذكاء الاصطناعي وسير عمل الذكاء الاصطناعي، وبناءً على API سنحوّله إلى صفحة روبوت "ذكي" تفاعلية.
أثناء العملية، إذا واجهت خطوات يصعب فهمها، فلا تقلق، يُنصح بأخذ لقطة شاشة للصفحة التي تعمل عليها وإرسالها إلى النموذج الكبير للسؤال؛ فالنماذج الكبيرة الحالية قادرة على الإجابة على معظم الأسئلة الشائعة.
إذا لم تتمكن من حل المشكلة بعد السؤال، فلا تتردد في التجربة بجرأة؛ لا تخف من ارتكاب الأخطاء، فكل محاولة هي فرصة للتعلم والتقدم. مع زيادة الممارسة، ستصبح أكثر مهارة وستتحكم في العمليات ببراعة أكبر!
ما ستتعلمه في هذا الدرس
- لماذا نحتاج للانتقال من روبوتات المحادثة إلى الوكلاء وتنظيم سير العمل (Workflow).
- ما هي منصات تطوير الوكلاء وسير العمل، وكيفية تحويل قدرات الذكاء الاصطناعي إلى إجراءات تشغيلية قياسية (SOP) قابلة للتنظيم.
- ما هو Dify، وكيفية استخدام هذه المنصة مفتوحة المصدر الموجهة لتطبيقات LLM لبناء تطبيقات بسرعة، خاصة روبوتات الأسئلة والأجوبة القائمة على قواعد المعرفة.
- طرق تنفيذ RAG وقيمتها، ولماذا نحتاج إلى التوليد المعزز بالاسترجاع؟
- كيف تتعلم من الصفر إلى واحد استخدام Dify وبيئة التطوير المتكاملة بالذكاء الاصطناعي Trae (
المعرفة الإضافية 4 - ما هي بيئة التطوير المتكاملة بالذكاء الاصطناعي و Trae)، بما في ذلك بناء الوكلاء وسير العمل، وإنشاء تطبيق ويب روبوت محادثة أمامي بناءً على Dify API.
- مبادئ الاستخدام الأساسية لـ Dify وطرق بناء الوكلاء وسير العمل، وطرق استدعاء API.
- طريقة استخدام بيئة التطوير المتكاملة بالذكاء الاصطناعي، وكيفية البرمجة باستخدامها.
- برنامج وكيل ويب أمامي قابل للحوار.
1. من المحادثة إلى الوكلاء
في المرحلة السابقة، تعلمنا كيف نجعل النماذج الكبيرة تلعب أدوارًا وتولّد نصوصًا أو تكتب أكوادًا بسيطة باستخدام الأوامر التوجيهية. ولكن إذا فكرت بتمعن، ستكتشف مشكلة واحدة: روبوت المحادثة بحد ذاته لا يستطيع تنفيذ المهام.
يمكنه الإجابة على سؤال "كيف أتحقق من الطلب؟"، لكنه لا يستطيع فعليًا الدخول إلى قاعدة البيانات والبحث عن الأرقام المقابلة؛ يمكنه وصف ما يجب أن يحتويه تقرير أسبوعي، لكنه لا يستطيع تلقائيًا تجميع بيانات مشروعك وإرسال بريد إلكتروني. هذا القيد المتمثل في "الكلام دون الفعل" يجعل من الصعب على الذكاء الاصطناعي الحواري البحت الاندماج حقًا في عمليات الأعمال.
لترقية الذكاء الاصطناعي من شريك محادثة إلى موظف رقمي، نحتاج إلى منحه ثلاث قدرات أساسية:
- المعرفة المتخصصة - لتمكينه من قراءة وفهم وثائق منتجاتك وبيانات العملاء والأنظمة الداخلية؛
- استدعاء الأدوات (أو ما يسمى بالإضافات) - لتمكينه من تشغيل قواعد البيانات واستدعاء واجهات API؛
- التنفيذ المنظم - لتمكينه من إنجاز المهام خطوة بخطوة وفقًا للمنطق المعد مسبقًا بدلاً من التصرف بحرية.
هذا هو النموذج الأولي لوكيل الذكاء الاصطناعي (AI Agent): وحدة آلية تمتلك هدفًا ومعرفة وأدوات ومسار تنفيذ.

ملاحظة: ما يسميه قطاع الصناعة حاليًا بـ "الوكيل" في نسخته البسيطة يشير في الغالب إلى التطبيقات المعززة المبنية على مجموعة LLM + الأدوات + قاعدة المعرفة، وليس الوكلاء القادرين على التخطيط الذاتي المزعومين. فعلى الرغم من أن الوكلاء البسيطين لا يمتلكون قدرات استدلال وتخطيط طويل الأمد حقيقية، إلا أنهم كافيون لدعم عدد كبير من سيناريوهات الأتمتة على مستوى المؤسسات. سنقدم بالتفصيل في الفصول اللاحقة الوكلاء الحقيقيين القادرين على التخطيط والعمل بشكل مستقل.
1.1 أبسط وكيل: روبوت الأسئلة والأجوبة القائم على قاعدة المعرفة
بعد توضيح القدرات الأساسية المتعددة التي يجب أن يمتلكها الوكيل، يبرز سؤال يستحق التفكير: هل يمكن بناء وكيل أساسي قابل للاستخدام فعليًا من خلال تنفيذ واحدة فقط من أبسط هذه الوظائف؟ الإجابة هي نعم.
في الواقع، في عدد كبير من سيناريوهات الأعمال الفعلية، فإن الطلب الأساسي للمستخدمين ليس جعل الذكاء الاصطناعي ينفذ عمليات معقدة تلقائيًا (مثل استدعاء API أو تنسيق المهام عبر الأنظمة)، بل يأملون في أن يقدم إجابات دقيقة وموثوقة بناءً على المواد المتخصصة الخاصة بالمؤسسة نفسها. ويتوافق هذا تمامًا مع القدرة الأساسية الأولى من القدرات الأساسية الثلاث للوكيل: قدرة خدمة المعرفة المتخصصة. لذلك، يمكننا تقديم أبسط أشكال الوكلاء وأكثرها انتشارًا: روبوت الأسئلة والأجوبة القائم على قاعدة المعرفة.
على الرغم من أنه لا يمتلك بعد قدرة استدعاء الأدوات أو التخطيط الذاتي، إلا أن اختراقه الرئيسي يكمن في: جعل إجابات النموذج الكبير لم تعد تُولّد من فراغ، بل تستند إلى أدلة. كيف يتم ذلك؟ المفتاح يكمن في حل التحدي الأساسي: المؤسسات تمتلك كميات هائلة من المعرفة الوثائقية، وعندما تكون هناك آلاف الصفحات من المستندات، كيف يمكن للنموذج العثور بسرعة على المحتوى الأكثر صلة بالسؤال الحالي في كل جولة محادثة؟
الحل في هذا الوقت هو: التوليد المعزز بالاسترجاع (Retrieval-Augmented Generation, RAG).
الفكرة الأساسية لـ RAG هي: عندما يطرح المستخدم سؤالاً، يقوم النظام أولاً بالبحث في قاعدة معرفة المؤسسة عن عدة مقاطع نصية الأكثر ارتباطًا دلاليًا بالسؤال (مثل فقرة معينة من دليل المنتج، أو مادة معينة من نظام الموارد البشرية)، ثم "يُدخل" هذه المقاطع كسياق في مدخلات النموذج الكبير، موجّهًا إياه لتوليد إجابة بناءً على مواد حقيقية.
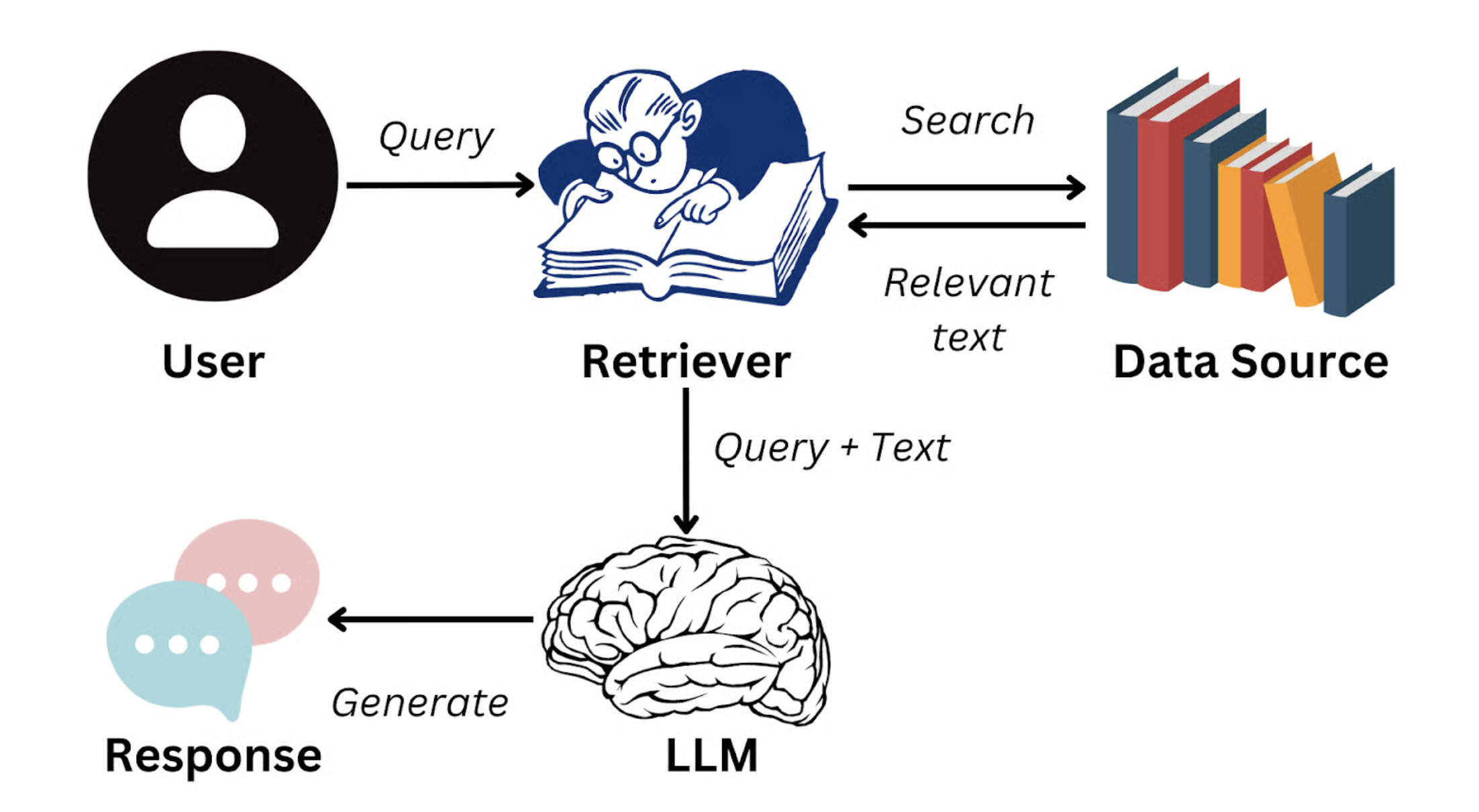
مصدر الصورة: https://www.datacamp.com/blog/what-is-retrieval-augmented-generation-rag
وبهذه الطريقة، لم تعد إجابة النموذج تعتمد على المعرفة المعممة في بيانات التدريب الخاصة به، بل ترتكز على المعلومات الموثوقة التي تقدمها المؤسسة. هدف RAG هو من خلال هذا الحقن الديناميكي للمعرفة الخارجية، تحسين مصداقية الإجابات ودقتها واتساقها بشكل ملحوظ - بل يمكن حتى جعل الإجابات "تتوافق مع الشخصية"، مثل الرد بأسلوب خدمة العملاء أو بأسلوب التوثيق التقني.
في الأعمال الفعلية، هذه التقنية مهمة بشكل خاص لأن النماذج الكبيرة غالبًا ما تنتج "هلوسات". على سبيل المثال، إذا سألت بصفتك المدير المالي أو مستشارًا عن بيانات محددة لفترة زمنية معينة، فمن المحتمل جدًا أن يختلق النموذج تواريخ وأحداث. بعد إدخال RAG، ستتحسن قابلية التحكم والموثوقية في الإجابات بشكل ملحوظ.
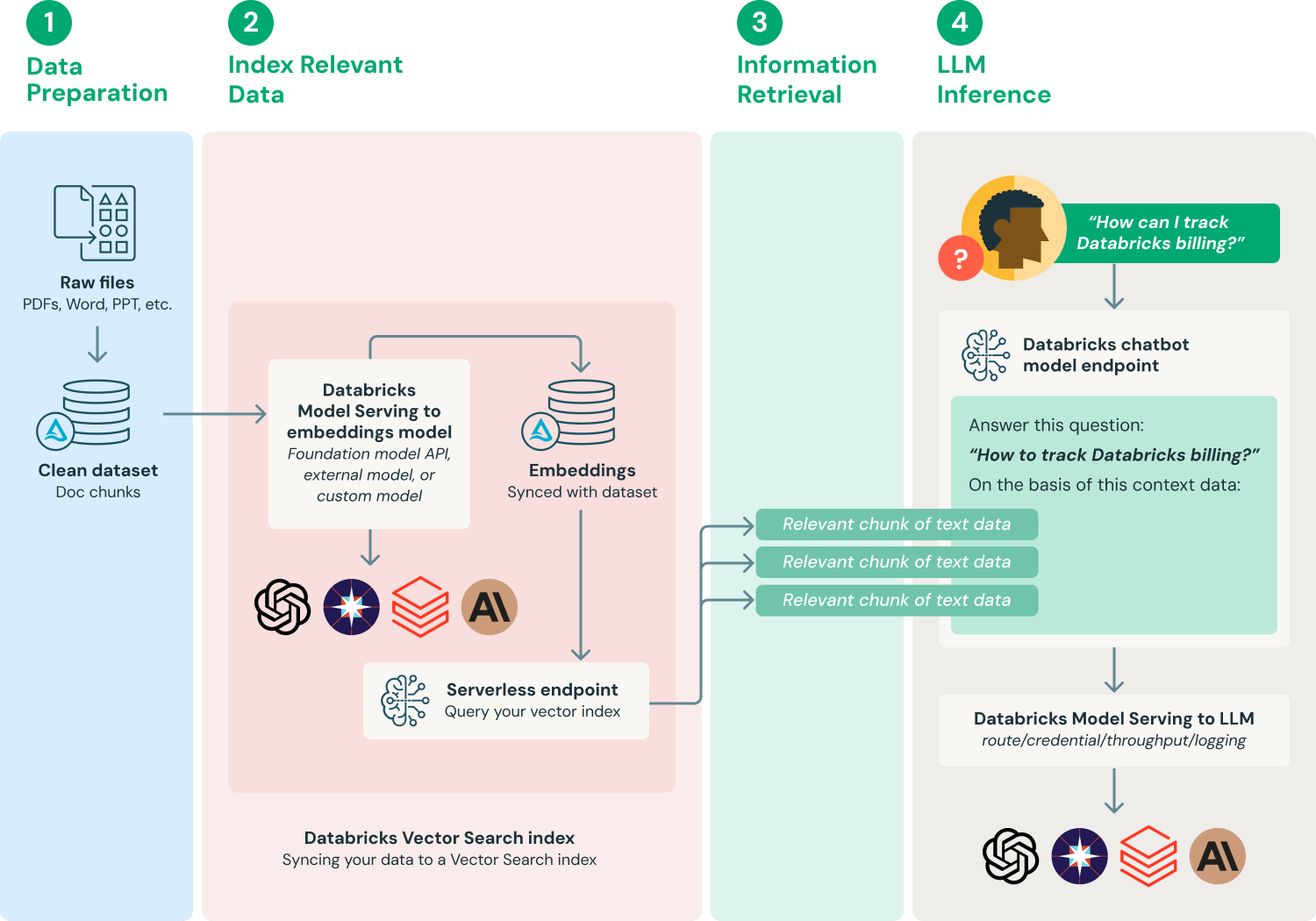
مصدر الصورة: https://www.databricks.com/glossary/retrieval-augmented-generation-rag
في الجزء العملي من هذا الدرس، سنستخدم منصة سير عمل الذكاء الاصطناعي الشهيرة Dify لبناء روبوت أسئلة وأجوبة قائم على قاعدة المعرفة عمليًا. يمكنك بسهولة تحويل أنواع مختلفة من المواد المتخصصة مثل أدلة المنتجات وأنظمة الشركة ووثائق المشاريع والأبحاث العلمية ومقالات قاعدة المعرفة وحتى مجموعات الملاحظات الشخصية إلى قاعدة معرفة.
بعد إكمال البناء، يمكنك تجربة طرح أنواع مختلفة من الأسئلة لاختبار قدراتها، مثل:
- "ما هي ترقيات الميزات الرئيسية في أحدث إصدار من منتجنا A؟"
- "يرجى توضيح نظام الإجازات السنوية لهذه السنة بناءً على دليل الموظفين."
- "كيف تم حل التحدي التقني 'XXX' الذي واجهناه في مشروع XX؟"
- "ما هي طريقة البحث الأساسية المذكورة في هذه الورقة البحثية؟"
ستختبر بنفسك كيف تقوم تقنية RAG بتحويل المواد الوثائقية الثابتة المبعثرة إلى قاعدة معرفة ذكية دقيقة، مما يوفر دعمًا عالي الدقة للأسئلة والأجوبة في مختلف السيناريوهات.
1.2 من وكيل المحادثة إلى سير العمل
ومع ذلك، حتى وكيل المحادثة "المعزز" الذي أُضيفت إليه قاعدة المعرفة وحتى قدرة استدعاء الإضافات، يظل غير كافٍ عند مواجهة عمليات أعمال أكثر تعقيدًا.
تخيل طلب مستخدم مثل: "ما هي أحدث تحديثات الميزات لمنتج SaaS الجديد الذي أطلقناه؟ هل يمكنك مساعدتي في إعداد نشرة موجزة للعملاء؟"
يبدو هذا الطلب بسيطًا، لكنه يتطلب في الخلفية عدة خطوات منسقة: أولاً البحث في وثائق المنتج الداخلية أو قاعدة معرفة Notion عن سجلات إطلاق الميزات خلال الشهر الماضي؛ ثم تصفية الخصائص الرئيسية الموجهة للعملاء؛ بعد ذلك استدعاء النموذج الكبير لتحويل الأوصاف التقنية إلى لغة صديقة للعميل؛ وأخيرًا دفع المحتوى المُنشأ إلى بريد فريق التسويق، أو حفظه في قالب Google Docs.
إذا اعتمدنا فقط على استدلال حر من نموذج لغوي كبير، فدع عنك ما إذا كان يمكن تحقيق جميع العمليات في محادثة واحدة، وحتى لو استطاع، فمن السهل تفويت معلومات رئيسية، أو الخلط بين المصطلحات الداخلية ولغة العميل، أو عدم القدرة على الإخراج المنظم. والأهم من ذلك، ما تحتاجه المؤسسات هو مسار تنفيذ قياسي قابل للتدقيق وإعادة الاستخدام والمراقبة، بدلاً من الاعتماد في كل مرة على الأداء المؤقت للنموذج؛ فالقابلية للمراقبة وإعادة الإنتاج مهمة جدًا للمؤسسات، والنتائج غير المتوقعة قد تؤدي إلى خسائر فادحة غير متوقعة.
وهذا يقودنا إلى نموذج تطبيق ذكاء اصطناعي أكثر تقدمًا: سير عمل الذكاء الاصطناعي (AI Workflow).

سير العمل يعني تفكيك مهمة معقدة إلى عدة خطوات فرعية مرتبة وقابلة للتهيئة وقابلة للتنفيذ التلقائي، وتنظيم العلاقات المنطقية بينها بطريقة مرئية أو برمجية، مثل الأحكام الشرطية أو الحلقات أو التنفيذ المتوازي. تحويل قدرات الذكاء الاصطناعي إلى SOP (أي إجراءات التشغيل القياسية) يعني ترسيخ خبرة كيفية استخدام الذكاء الاصطناعي لإنجاز مهمة معينة في قوالب قابلة لإعادة الاستخدام.
يجلب هذا النهج قيمًا متعددة: يمكن للأشخاص غير التقنيين (مثل مديري المنتجات أو العمليات) بناء تطبيقات ذكاء اصطناعي بسرعة من خلال سحب المكونات وإفلاتها؛ يمكن للمطورين تغليف استرجاع RAG واستدعاءات LLM وأدوات API كعقد قياسية لإعادة استخدامها في سيناريوهات أعمال مختلفة؛ ويمكن تتبع العملية بالكامل وتصحيحها وتحسينها باستمرار، مما يلبي متطلبات المؤسسات من الاستقرار والامتثال.
تعد قاعدة مستخدمي سير عمل الذكاء الاصطناعي واسعة جدًا. يمكن لمديري المنتجات تصميم مسارات تفاعل المستخدم الكاملة دون كتابة أكواد؛ يمكن لفرق العمليات بناء روبوتات خدمة العملاء ومولدات المحتوى أو أنظمة الإشعارات بسرعة؛ يمكن للمطورين ومهندسي الخوارزميات نمذجة القدرات الأساسية لاستدعاءها من الواجهة الأمامية؛ ويمكن لرواد الأعمال أو المطورين المستقلين التحقق من MVP لمنتجات الذكاء الاصطناعي بتكلفة منخفضة جدًا، وإطلاق نموذج أولي كامل يتضمن استعلام البيانات وتوليد المحتوى وتنفيذ الإجراءات في غضون أيام.
بالإضافة إلى ذلك، تجدر الإشارة إلى أن سير عمل الذكاء الاصطناعي يمكن عادةً وصفه بتمثيل وسيط (Intermediate Representation). على الرغم من اختلاف طرق التعبير المحددة بين منصات سير العمل المختلفة، إلا أن معظمها يستخدم ملفات منظمة (مثل JSON، YAML، إلخ) لتعريف أنواع العقد والمدخلات والمخرجات ومنطق التنفيذ، وهيكلها مشابه للرسم التوضيحي أدناه:

باختصار، إذا كان الوكلاء قد نقلوا الذكاء الاصطناعي من القدرة على المحادثة إلى القدرة على إنجاز المهام، فإن سير العمل ينقل الذكاء الاصطناعي من إنجاز مهمة عرضيًا إلى "إنجاز نوع معين من المهام بشكل مستقر وموثوق وعلى نطاق واسع". في الممارسة القادمة، سنستعين بمنصة Dify لبناء سير عمل ذكاء اصطناعي كامل بأيدينا، وتجربة العملية الكاملة من الفكرة إلى التطبيق القابل للتشغيل.
1.3 منصات الوكلاء / سير العمل الشائعة
مع التطور السريع لتقنيات الذكاء الاصطناعي التوليدي، ومن أجل مساعدة المطورين والعاملين في الأعمال على بناء الوكلاء وعمليات الأتمتة بسرعة وتجنب التعقيد في البرمجة، ظهرت مجموعة من منصات الوكلاء وسير العمل منخفضة التعليمات البرمجية وحتى بدون تعليمات برمجية.
أولاً، يجب التوضيح أن منصات التعليمات البرمجية المنخفضة هي أدوات تطوير تقلل بشكل كبير من عبء البرمجة اليدوية من خلال المكونات القابلة للسحب والإفلات المرئية وقوالب منطق الأعمال المعدة مسبقًا وقواعد التهيئة الرسومية. جوهرها هو استبدال طريقة كتابة الأكواد مباشرة بالتهيئة المرئية والبرمجة بسحب العقد، مما يحرر المطورين ذوي القدرات التقنية من العمل المتكرر ويسمح للأشخاص غير التقنيين الملموم بمنطق الأعمال بالمشاركة في بناء التطبيقات. في جوهرها، هي جسر توازن بين كفاءة التطوير ومرونة السيناريوهات.
القيمة البارزة لمنصات الوكلاء منخفضة/بدون تعليمات برمجية هي خفض عتبة تطوير تطبيقات الذكاء الاصطناعي بشكل كبير. ما كان يتطلب سابقًا تعاون فريق لأسابيع - من توضيح المتطلبات وتطوير الأكواد إلى الاختبار والنشر - لبناء وكيل ذكاء اصطناعي (مثل روبوت أسئلة وأجوبة لخدمة العملاء أو مساعد معالجة البيانات)، يمكن الآن تقليص دورة "من الفكرة إلى الإطلاق" إلى ساعات قليلة باستخدام الأدوات المرئية التي توفرها المنصات.
تشمل منصات سير عمل الذكاء الاصطناعي منخفضة التعليمات البرمجية الرئيسية في السوق حاليًا:
| المنصة | الميزات | السيناريوهات المطبقة |
|---|---|---|
| Dify | مفتوح المصدر، يدعم قاعدة المعرفة RAG، تنسيق LLM، إخراج API، صديق للصينية | أسئلة وأجوبة لقاعدة معرفة المؤسسات، Agent مخصص، خدمات API |
| Coze (ByteDance) | متاح في الصين، مدمج مع نظام Douyin/Feishu، إضافات غنية | روبوتات التواصل الاجتماعي، تكامل البرامج المصغرة المحلية |
| n8n | أداة أتمتة عامة، تدعم عقد الذكاء الاصطناعي، تركز على تنسيق API | مزامنة البيانات عبر الأنظمة، أتمتة الذكاء الاصطناعي + SaaS التقليدي |
| Baidu Qianfan AppBuilder / Alibaba Bailian / Tencent HunYuan | حلول سحابية أصلية من شركات كبرى، مدمجة مع نماذجها الخاصة | نشر على مستوى المؤسسات، سيناريوهات ذات متطلبات امتثال عالية |
الخيارات المتاحة لمنصات سير عمل الذكاء الاصطناعي منخفضة التعليمات البرمجية في السوق حاليًا غنية. وعلى الرغم من أن مزودي الخدمات السحابية الرئيسيين مثل AWS و Azure و Alibaba Cloud قد أطلقوا جميعًا حلول سير عمل ذكاء اصطناعي مقابلة، إلا أن Dify و Coze و n8n أصبحت الممثلين الأكثر انتشارًا حاليًا بفضل المزايا الأساسية الثلاث التالية:
- سهولة الاستخدام الفائقة. تتبنى المنصات تصميم واجهة سحب وإفلات مرئية، ويمكن للمستخدمين البدء بسرعة دون الحاجة إلى فهم عميق للتقنيات الأساسية.
- مرونة عالية. تدعم المكونات المخصصة وواجهات API الممتدة، وقادرة على التكيف مع السيناريوهات الخفيفة مثل العروض التوضيحية التعليمية والتحقق من MVP (المنتج الأدنى القابل للتطبيق)، وكذلك تلبية احتياجات التكرار الرشيق لفرق صغيرة ومتوسطة.
- نظام بيئي ناضج. ليس فقط الوثائق الرسمية مفصلة والاستجابة سريعة، بل تمتلك أيضًا مجتمع مستخدمين نشط، مما يسهل الحصول بسرعة على حلول مسبقة من مستخدمين مختلفين.
جميع المنصات الثلاث تدعم إخراج وكيل الذكاء الاصطناعي المُنشأ كواجهة API قياسية، والتي يمكن دمجها بسلاسة في تطبيقات الويب الأمامية أو أنظمة ERP الداخلية للمؤسسة أو تطبيقات الهاتف المحمول، مما يخفض عتبة التكنولوجيا لتطبيق قدرات الذكاء الاصطناعي بشكل أكبر.
1.3.1 Dify: منصة إدارة دورة حياة تطبيقات LLMOps على مستوى المؤسسات
Dify مُعيَّن كمنصة تطوير وتشغيل لتطبيقات LLM، ملتزمة بتقديم إدارة دورة حياة كاملة لتطبيقات الذكاء الاصطناعي من الفكرة والنشر إلى التحسين. جوهرها هو منصة منخفضة التعليمات البرمجية تهدف إلى مساعدة المطورين والمبتكرين من غير الخلفيات التقنية على بناء تطبيقات ذكاء اصطناعي على مستوى الإنتاج بسرعة.
من حيث الوظائف، يغطي Dify تنسيق سير العمل المرئي وبناء الوكلاء وإدارة قاعدة المعرفة ودعم النماذج المتعددة. تسمح المنصة بتصميم عمليات المهام المعقدة من خلال سحب العقد وإفلاتها، وتدعم إنشاء وكلاء قائمين على النية. تبرز وظيفة قاعدة المعرفة الخاصة بها، حيث يمكنها معالجة مستندات بتنسيقات متعددة وإجراء استرجاع متجهي فعال. في الوقت نفسه، يتوافق Dify مع ويدعم نماذج LLM المتعددة بما في ذلك GPT و Claude والعديد من النماذج مفتوحة المصدر، ويمكن نشر التطبيقات المبنية كـ API قياسي بنقرة واحدة لسهولة التكامل.
من حيث البنية التقنية، يتميز Dify بأنه مفتوح المصدر وقابل للنشر الخاص، مع التأكيد على المرونة والقابلية للتوسيع والامتثال على مستوى المؤسسات. المستخدمون المستهدفون يشملون فرق التطوير والمبتكرين في الأعمال، وتشمل سيناريوهات التطبيق النموذجية قواعد المعرفة المؤسسية وخدمة العملاء الذكية، وأتمتة إنشاء المحتوى، ومساعدي الذكاء الاصطناعي في المجالات المتخصصة، ومنصة الذكاء الاصطناعي المركزية للمؤسسات.
1.3.2 Coze (ByteDance): ناشر بناء وكلاء الذكاء الاصطناعي بدون تعليمات برمجية
Coze هي منصة تطوير وكلاء ذكاء اصطناعي أطلقتها ByteDance، مع سهولة الاستخدام الفائقة كجوهر لها، مما يتيح للمستخدمين بدون خبرة في البرمجة إنشاء واختبار ونشر روبوتات محادثة ذكاء اصطناعي غنية بالوظائف بسهولة.
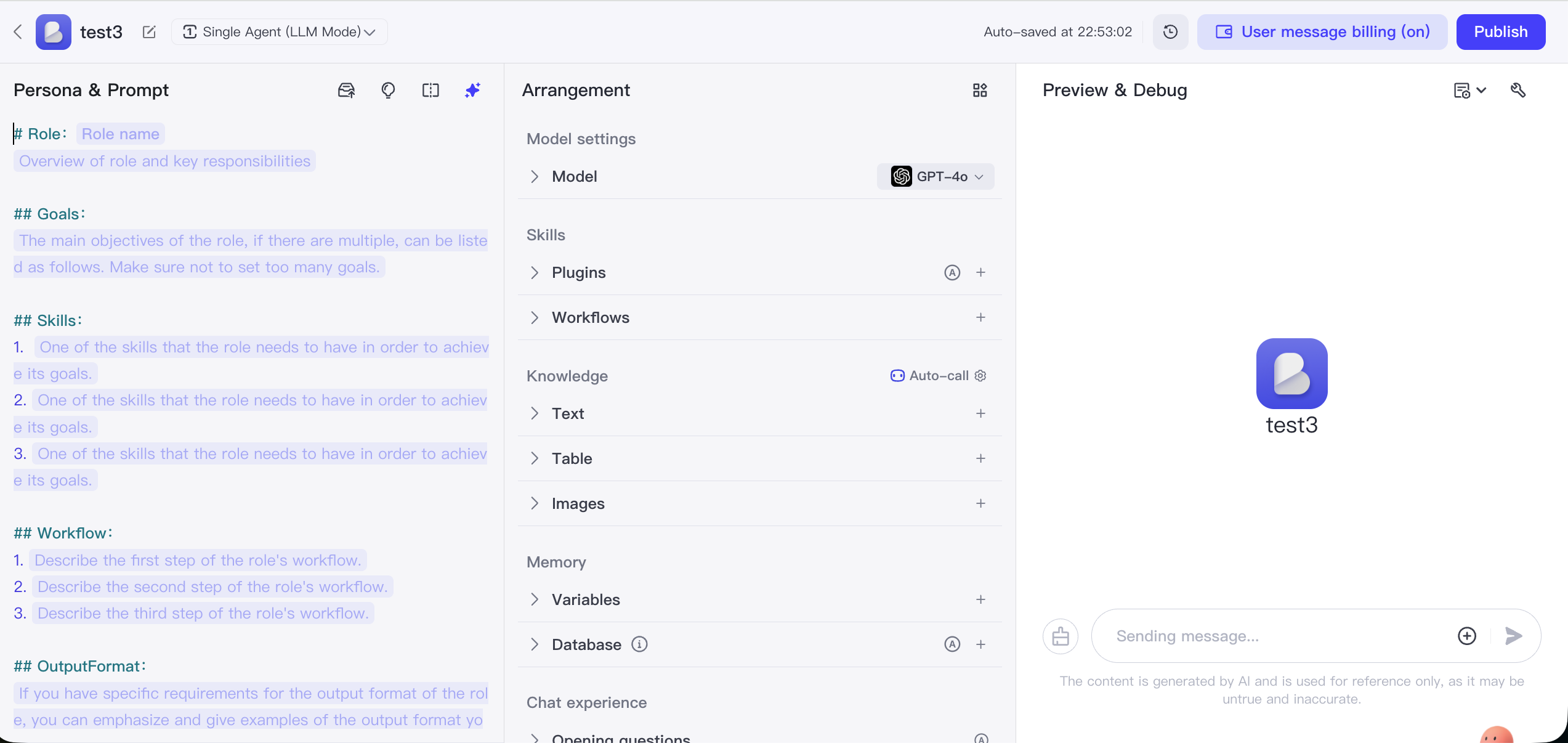
جوهرها هو تبسيط بناء البوت إلى عملية تشبه تركيب المكعبات. يمكن للمستخدمين تهيئة الأدوار وقواعد المعرفة بسهولة من خلال الواجهة، واستخدام مكتبة الإضافات المدمجة الغنية لإضافة قدرات خارجية متعددة للبوت مثل الأخبار والسفر وتوليد الصور. يمكن نشر البوت المُنشأ بنقرة واحدة بسرعة إلى منصات متعددة مثل Doubao و Feishu والحسابات الرسمية على WeChat.
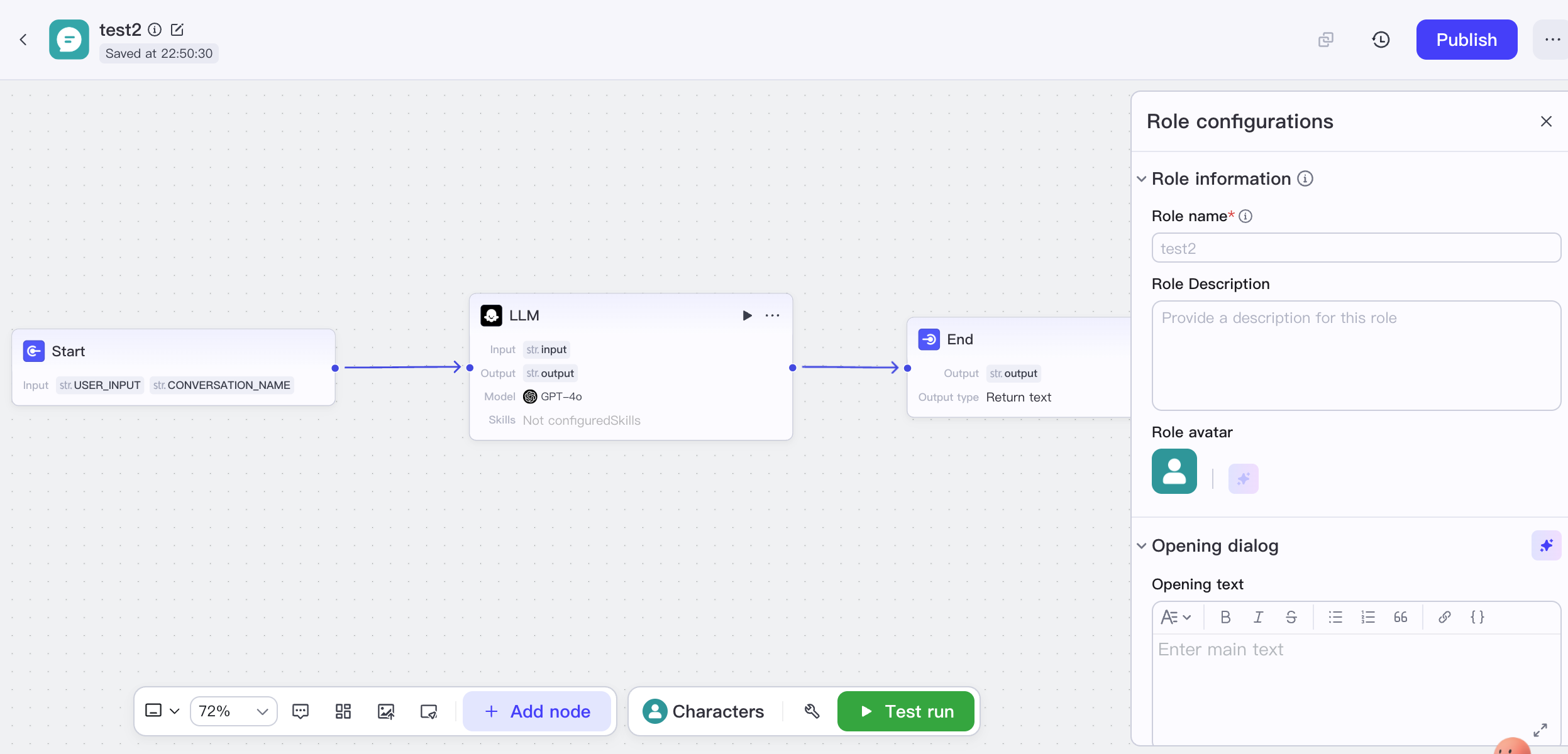
البنية التقنية تخدم بالكامل الاستخدام منخفض العتبة، حيث تدمج الواجهة الخلفية نماذج ByteDance الخاصة وتغلف العمليات المعقدة، مع التأكيد على الفهم متعدد الوسائط والاستجابة في الوقت الفعلي. كمنصة تُقدم أساسًا في شكل خدمة سحابية، فإن قدرتها على النشر الخاص محدودة نسبيًا. تشمل سيناريوهات التطبيق النموذجية المساعدين الشخصيين وروبوتات الترفيه وخدمة العملاء الذكية وأنظمة الأسئلة والأجوبة والمساعدين في التعليم عبر الإنترنت والتحقق السريع من النماذج الأولية.
1.3.2 n8n: محرك أتمتة سير عمل الخلفية القابل للبرمجة
n8n هي منصة أتمتة سير عمل قابلة للبرمجة عامة، وتحديدًا الأساسي هو ربط مختلف التطبيقات وقواعد البيانات وواجهات API لتحقيق تدفق البيانات والتنفيذ الآلي للمهام.
تدعم من خلال مكتبة عقد التكامل الضخمة مئات خدمات SaaS وقواعد البيانات والبروتوكولات، وتعتمد نهجًا يجمع بين المرئيات والتعليمات البرمجية: يمكن للمستخدمين سحب العقد وإفلاتها على اللوحة، مع إدخال أكواد JavaScript أو Python لكتابة منطق مخصص. يتميز n8n بمعالجة مهام البيانات الكثيفة في الخلفية، مثل مزامنة البيانات وعمليات ETL وتنسيق API.
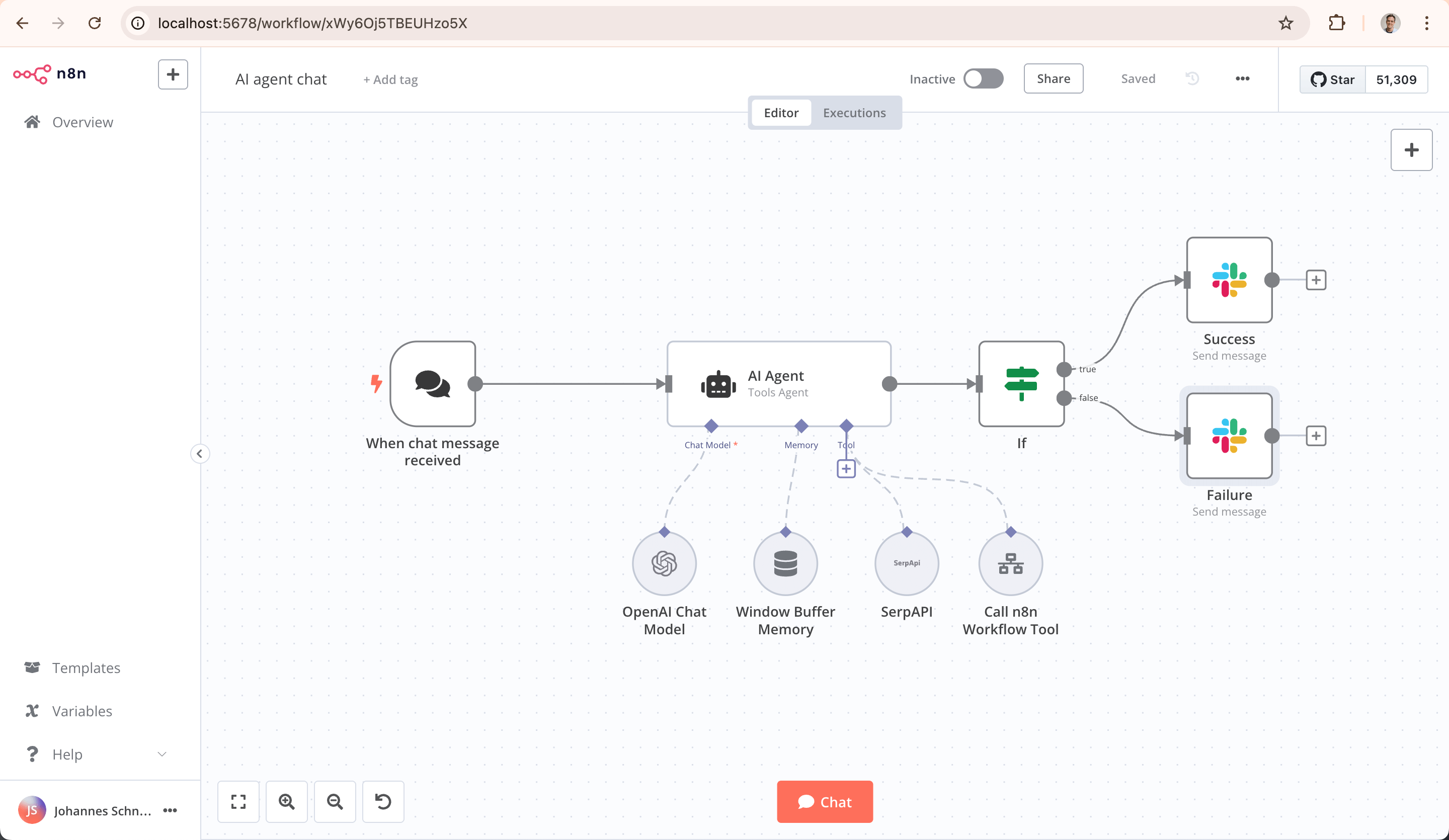
الخاصية التقنية الرئيسية هي "الكود المصدري المرئي" و"الاستضافة الذاتية"، حيث يمكن للمستخدمين نشره بشكل خاص للتحكم الكامل في البيانات والبيئة، مما يجذب بشدة الصناعات ذات المتطلبات العالية لأمن البيانات. المستخدمون المستهدفون الرئيسيون هم المطورون والعمليات التقنية ومحللو البيانات. أكبر ميزة لـ n8n تكمن في امتلاكه لنظام بيئي مجتمعي قوي للغاية. توجد على الإنترنت مقاطع فيديو مشاركة n8n غنية في كل مكان، مما يوفر للمستخدمين مرجع تعلم ملائم وخبرة للاستفادة منها؛ في الوقت نفسه، يدعم الاتصال بالعديد من المنصات البيئية المختلفة عالميًا مثل YouTube و Instagram، مما يساعد المستخدمين على كسر حواجز البيانات والخدمات عبر المنصات بسهولة وتحقيق التدفق الآلي للعمليات متعددة الأنظمة البيئية.
1.3.3 منصات سير العمل الأخرى
بالإضافة إلى المنصات الأكثر شهرة المذكورة أعلاه، أطلقت شركات التكنولوجيا الكبرى في الصين أيضًا منصات تطوير ذكاء اصطناعي متكاملة خاصة بها، على سبيل المثال: Baidu Qianfan AppBuilder يوفر دعمًا كاملاً للعملية من اختيار النماذج وبناء RAG إلى نشر الوكلاء، مع تكامل عميق مع نموذج Wenxin الكبير؛ Alibaba Cloud Bailian مبني على سلسلة نماذج Tongyi Qianwen، مع التركيز على الأمان على مستوى المؤسسات وقدرة النشر الخاص؛ بينما تركز Tencent Cloud TI Platform على سيناريوهات الصناعة مثل التمويل والرعاية الصحية، وتوفر قوالب حلول معدنة مسبقة غنية. هذه المنصات عادة ما تكون مدمجة بعمق مع أنظمتها البيئية السحابية، ومناسبة للمؤسسات الموجودة بالفعل في النظم التقنية المقابلة.
ومع ذلك، من حيث العالمية والانفتاح والنظام البيئي المجتمعي، لا يزال Dify و Coze بفضل سهولة الاستخدام البارزة ودعم النماذج الواسع ومجتمع المطورين النشط، الخيارات الأكثر تبنيًا على نطاق واسع حاليًا.
على الرغم من أن المنصات المختلفة تختلف في تحديد موقعها ونظامها البيئي، إلا أن منطقها الأساسي هو جميعها تنظيم وربط وحدات القدرات المختلفة بطريقة مرئية. لذلك، إتقان أفكار التصميم وطرق التشغيل لأي من هذه المنصات يمنحك الأساس للانتقال السريع إلى أدوات مشابهة أخرى. في الممارسة القادمة، سنستخدم Dify كمثال للشرح المفصل.
2. مقدمة متعمقة في Dify
2.1 ما هو Dify
لقد تعرفنا سابقًا على معلومات Dify الأساسية، للحصول على معلومات أكثر تفصيلاً، يمكنك زيارة منصة Dify عبر https://cloud.dify.ai/apps، وإذا كنت ترغب في معرفة المزيد، يمكنك زيارة الموقع الرسمي https://dify.ai.
Dify هي منصة مفتوحة المصدر لتطوير تطبيقات LLM. توفر واجهة بديهية تجمع بين سير عمل الوكلاء وخط أنابيب RAG وقدرات الأدوات وإدارة النماذج وقابلية الملاحظة ووظائف أخرى، مما يساعدك على الانتقال بسرعة من النموذج الأولي إلى بيئة الإنتاج.
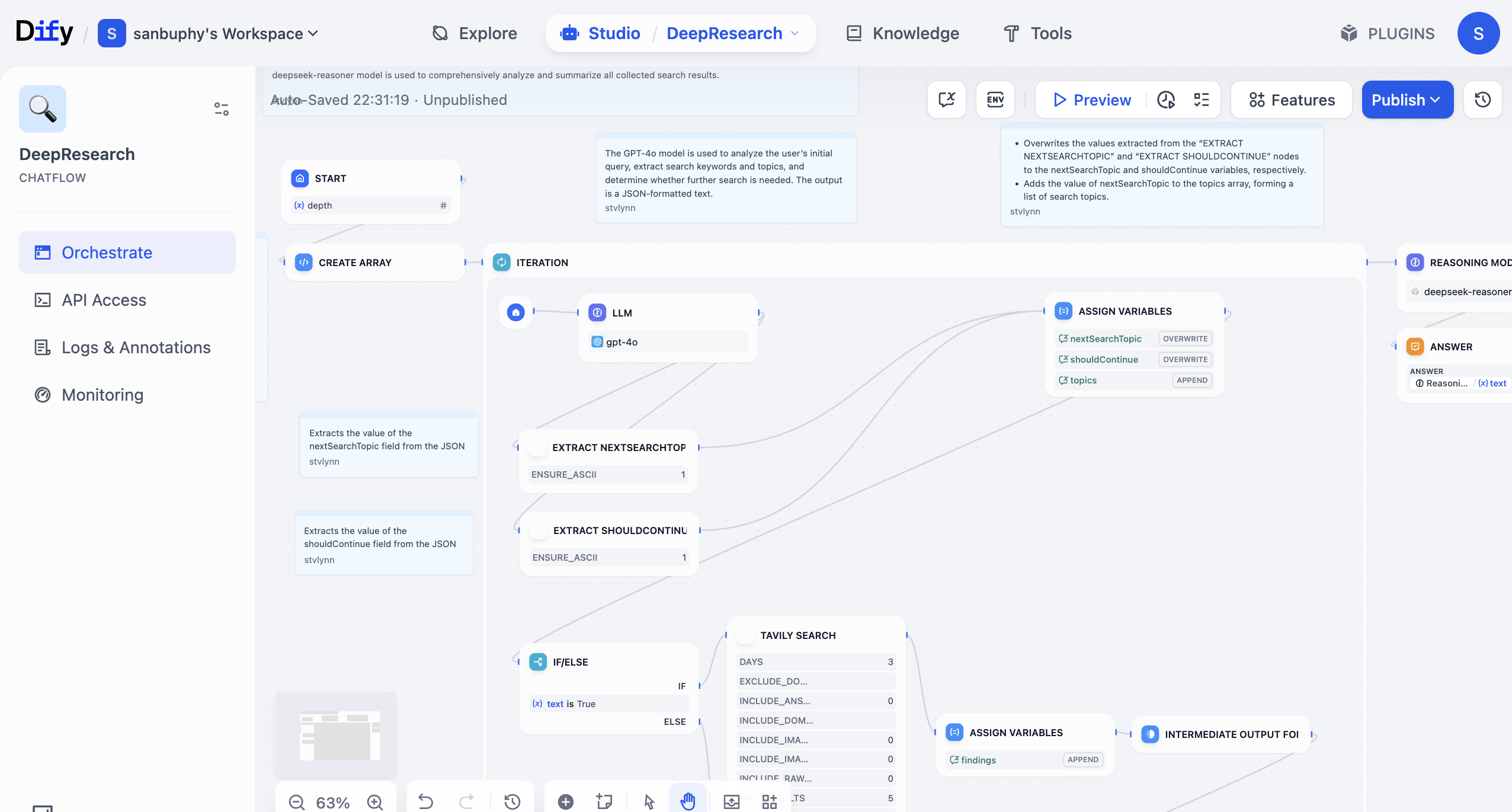
يمكنك استخدام النماذج اللغوية الكبيرة والأدوات المتنوعة الوظائف في Dify لبناء "سير عمل". سير العمل هو ربط العمليات التي كانت تتطلب منك إكمالها يدويًا خطوة بخطوة - مثل استرجاع البيانات واستدعاء النماذج الكبيرة والبحث على الويب وتصفية النتائج وتنسيقها - وفقًا لمنطق الأعمال في عملية آلية وقابلة لإعادة الاستخدام. بدون سير العمل، ستحتاج في كل مرة إلى نسخ ولصق نفس المحتوى للنموذج الكبير، وهو أمر غير فعال جدًا وعرضة للأخطاء، ويصعب إعادة استخدامه في الأعمال الحقيقية.
بناء سير عمل يشبه تركيب المكعبات أو الألغاز. تقوم بتوصيل "عقدة النموذج اللغوي الكبير" (المسؤولة عن الفهم والتوليد) بأنواع مختلفة من "عقد الأدوات" (المسؤولة عن تنفيذ إجراءات محددة، مثل البحث في قاعدة البيانات وإرسال البريد الإلكتروني وترجمة النصوص، إلخ) و"عقد البيانات" (المسؤولة عن قراءة وتخزين المعلومات) معًا مثل المكعبات. ستعمل هذه تلقائيًا بتنسيق وفقًا للمنطق الذي عينته مسبقًا، دون الحاجة إلى التشغيل اليدوي في كل مرة. يمكنك أيضًا فهمه كـ "برنامج منخفض التعليمات البرمجية": تحتاج فقط إلى تهيئة مسارات المدخلات والمخرجات من خلال السحب والإفلات لتحقيق منطق أعمال معقد نسبيًا.
على سبيل المثال، إذا كنت صاحب متجر على Amazon أو Douyin للتجارة الإلكترونية وتريد بناء نظام خدمة عملاء بالذكاء الاصطناعي، يمكنك الرجوع إلى هيكل الرسم التوضيحي التالي لتصميم سير عمل:
- عقدة التشغيل (مماثلة لـ START): تستقبل سؤال استفسار المستخدم، مثل "ما هي فترة الضمان لهذا المنتج؟".
- عقدة تصنيف الأسئلة (مماثلة لـ QUESTION CLASSIFIER): تستخدم نموذجًا (مثل GPT) لتصنيف سؤال المستخدم، وتحديد ما إذا كان يتعلق بما بعد البيع (مثل الضمان) أو طريقة الاستخدام أو أنواع أخرى من الأسئلة.
- عقدة استرجاع المعرفة (مماثلة لـ KNOWLEDGE RETRIEVAL): بناءً على نتيجة التصنيف، تزور تلقائيًا قاعدة المعرفة المقابلة. إذا كان سؤال ما بعد البيع حول "الضمان"، فتبحث في قاعدة معرفة SOP لما بعد البيع عن المعلومات الدقيقة المتعلقة بـ "الضمان".
- عقدة النموذج اللغوي الكبير (LLM Node): ترسل سؤال المستخدم ومحتوى قاعدة المعرفة المسترجع معًا إلى النموذج اللغوي الكبير (مثل GPT)، وتطلب منه توليد رد صديق للمستخدم (تجنب نبرة تقنية جافة للغاية).
- عقدة الشرط: تتحقق مما إذا كانت إجابة النموذج الكبير تحتوي على مدة ضمان واضحة (مثل "سنة واحدة"، "3 سنوات")، وإذا وجدت تنتقل إلى الخطوة التالية، وإذا لم تجد تجعله يرد "يرجى تقديم طراز المنتج".
- عقدة الإخراج (مماثلة لـ ANSWER): تعيد الإجابة النهائية للمستخدم، وتسجل تلقائيًا استشارة هذه المرة في الجدول.
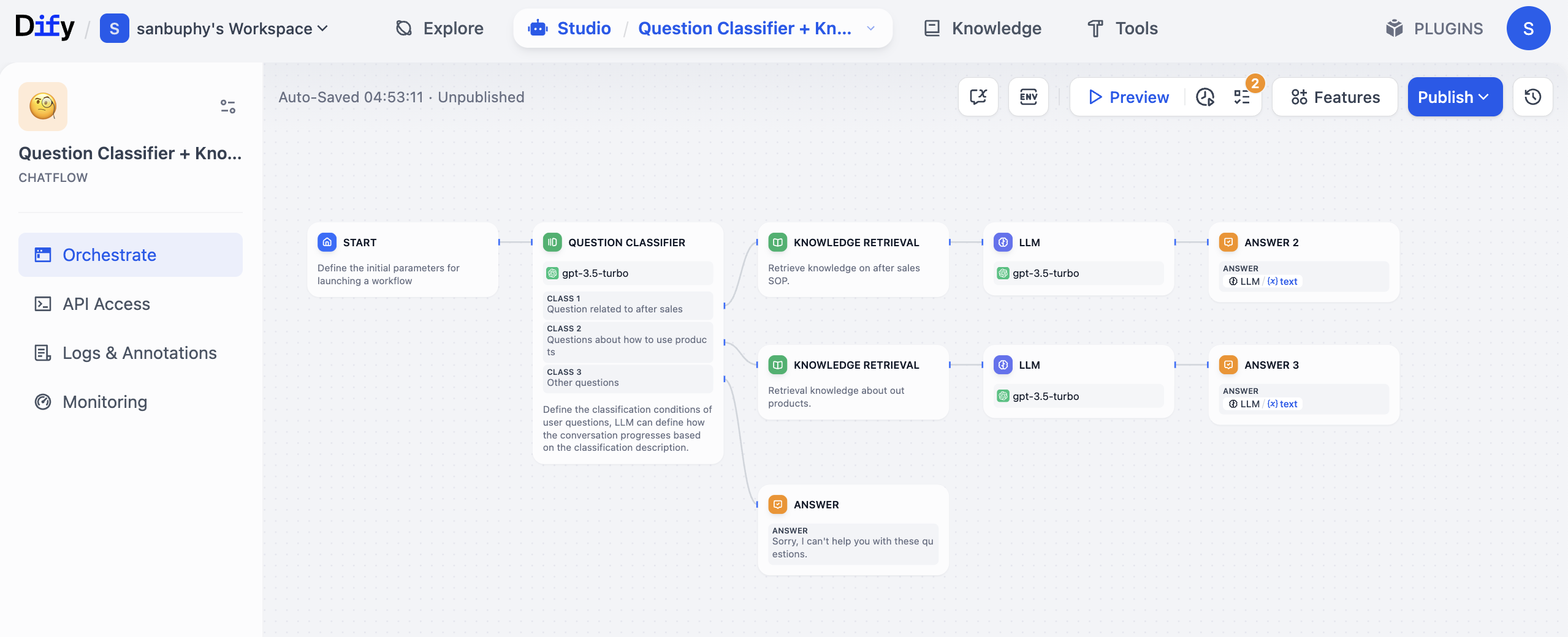
خلال العملية بأكملها، لا تحتاج إلى البحث يدويًا في قاعدة المعرفة أو تعديل إجابات النموذج مرارًا أو تسجيل البيانات بشكل منفصل - سير العمل سيربط هذه الخطوات "للتشغيل تلقائيًا". وهو مرن جدًا: على سبيل المثال، إذا أردت لاحقًا إضافة قاعدة جديدة "عندما يسأل المستخدم عن نطاق الضمان، استدعِ قاعدة معرفة أخرى"، تحتاج فقط إلى إضافة عقدة شرط أخرى في سير العمل دون إعادة بناء النظام بالكامل.
هذا مثال على سير عمل بسيط نسبيًا، ولكن إتقان هذه القدرات بالكامل قد يكون لا يزال صعبًا بعض الشيء بالنسبة لك حاليًا. لذلك في هذا الدرس، سنبدأ من وكيل قاعدة المعرفة الأكثر أساسية، ثم نتعلم تقنيات سير العمل الأكثر تعقيدًا تدريجيًا.
2.1.1 نشر نسخة Dify الخاصة بك (اختياري)
كان من المقرر في الأصل تقديم محتوى هذا الجزء بالتفصيل في الدورات اللاحقة، ولكن نظرًا لأن بعض المتعلمين قد لا يتمكنون حاليًا من الوصول إلى موقع Dify الرسمي أو خدماته السحابية بسبب قيود الشبكة، قررنا تقديم مسار التعلم الاختياري هذا مسبقًا لمساعدتك على المضي قدمًا في سير الدروس.
تحتاج إلى الرجوع إلى هذا البرنامج التعليمي للبدء في الاستخدام الأساسي لمنصة نشر الويب: كيفية نشر تطبيقات الويب
تحتاج إلى تعلم كيفية نشر نسخة Dify الخاصة بك على Zeabur، وبعد النشر ادخل إلى الرابط المقابل وقم بالتسجيل وتسجيل الدخول ثم تابع متابعة البرنامج التعليمي التالي.
ملاحظة، قد تختلف عمليات وواجهة Dify الأمامية لإصدارات مختلفة قليلاً، لكن الاختلاف الإجمالي ليس كبيرًا، عندما تكتشف اختلافات لا داعي للذعر، ابحث عن الواجهات والمداخل المشابهة للعمل.
2.2 إنشاء أول تطبيق Dify Chatbot
بعد زيارة الصفحة الرئيسية لـ Dify https://cloud.dify.ai/apps والتسجيل وتسجيل الدخول، اختر Studio، سترى الواجهة التالية:
ابحث عن منطقة CREATE APP على الجانب الأيسر، وانقر على Create from Blank.
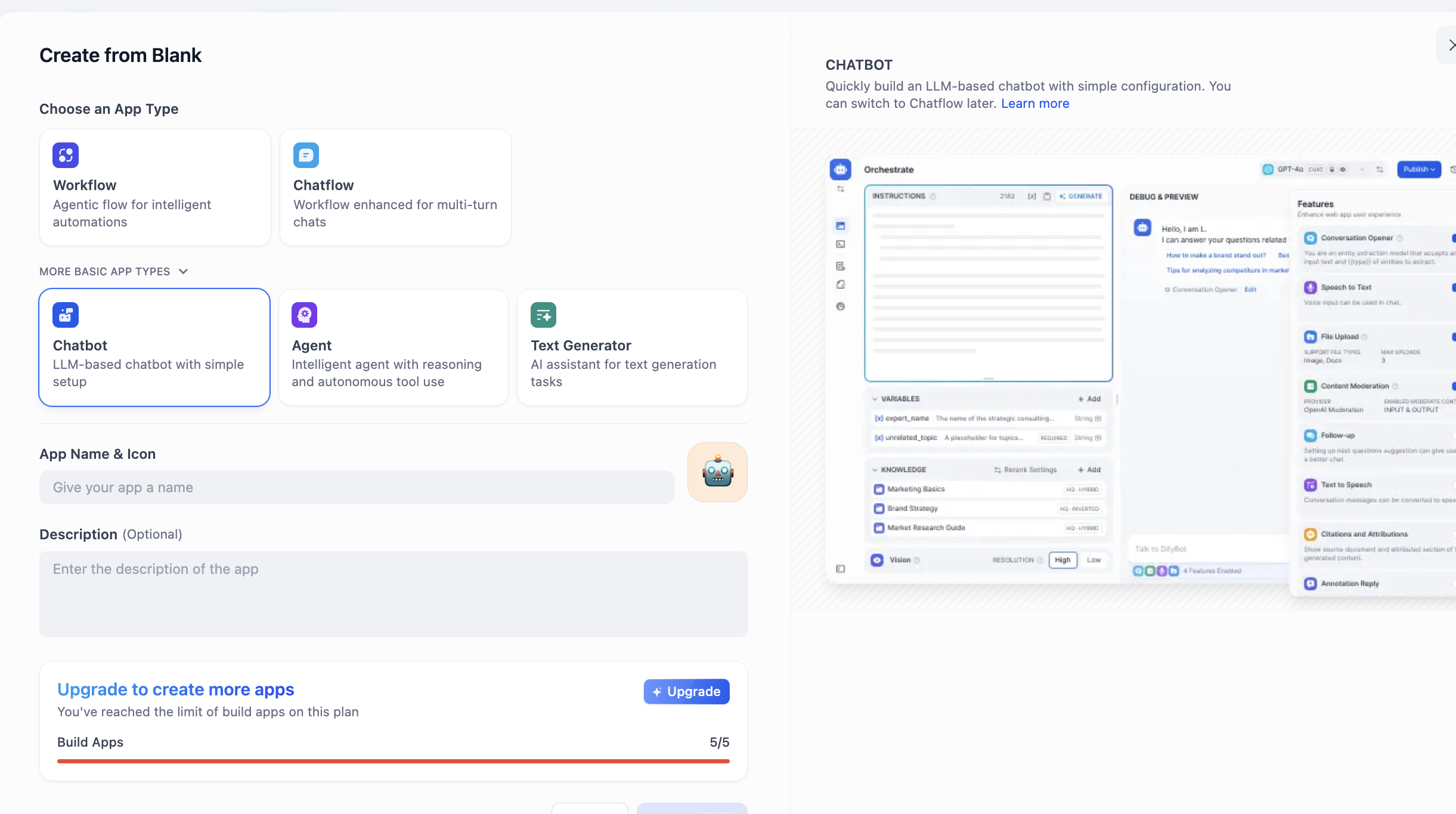
ابحث عن Chatbot في APP Type (إذا لم تره في البداية، يمكنك النقر على زر "عرض المزيد من الأنواع"، ثم العثور عليه في القائمة الكاملة). بعد اختيار Chatbot، أدخل اسم التطبيق ووصفه أدناه، ثم انقر على إنشاء.
بعد اكتمال الإنشاء، سترى واجهة مشابهة لما يلي.
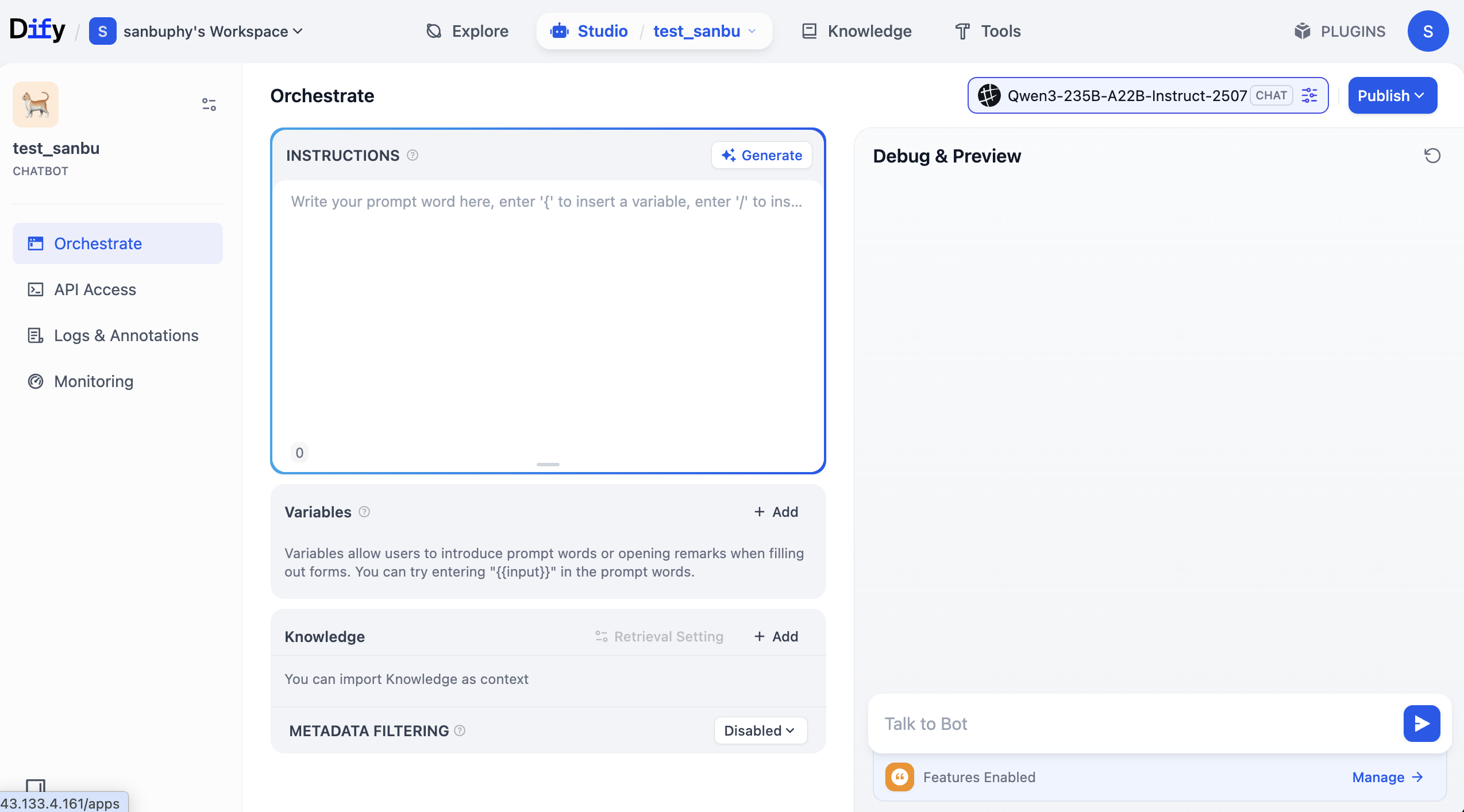
تشير "INSTRUCTIONS" في المنطقة الوسطى إلى التعليمات المدمجة، يمكنك فهمها على أنها الأوامر التوجيهية الافتراضية أو أوامر النظام.
في الوسط قليلاً نحو الأسفل توجد منطقة "Knowledge"، وهذه هي منطقة قاعدة المعرفة - سنقوم لاحقًا بتحميل قاعدة المعرفة الخاصة بنا هنا.
على الجانب الأيمن توجد نافذة التصحيح، حيث يمكنك التحدث مع الوكيل بعد تعديل الأوامر التوجيهية لرؤية التأثير في الوقت الفعلي.
يمكنك إدخال أوامر توجيهية الدور بحرية في منطقة INSTRUCTIONS ومراقبة تأثير المحادثة؛ يمكنك أيضًا النقر على Generate لجعل النموذج الكبير يولد الأوامر التوجيهية لك تلقائيًا.
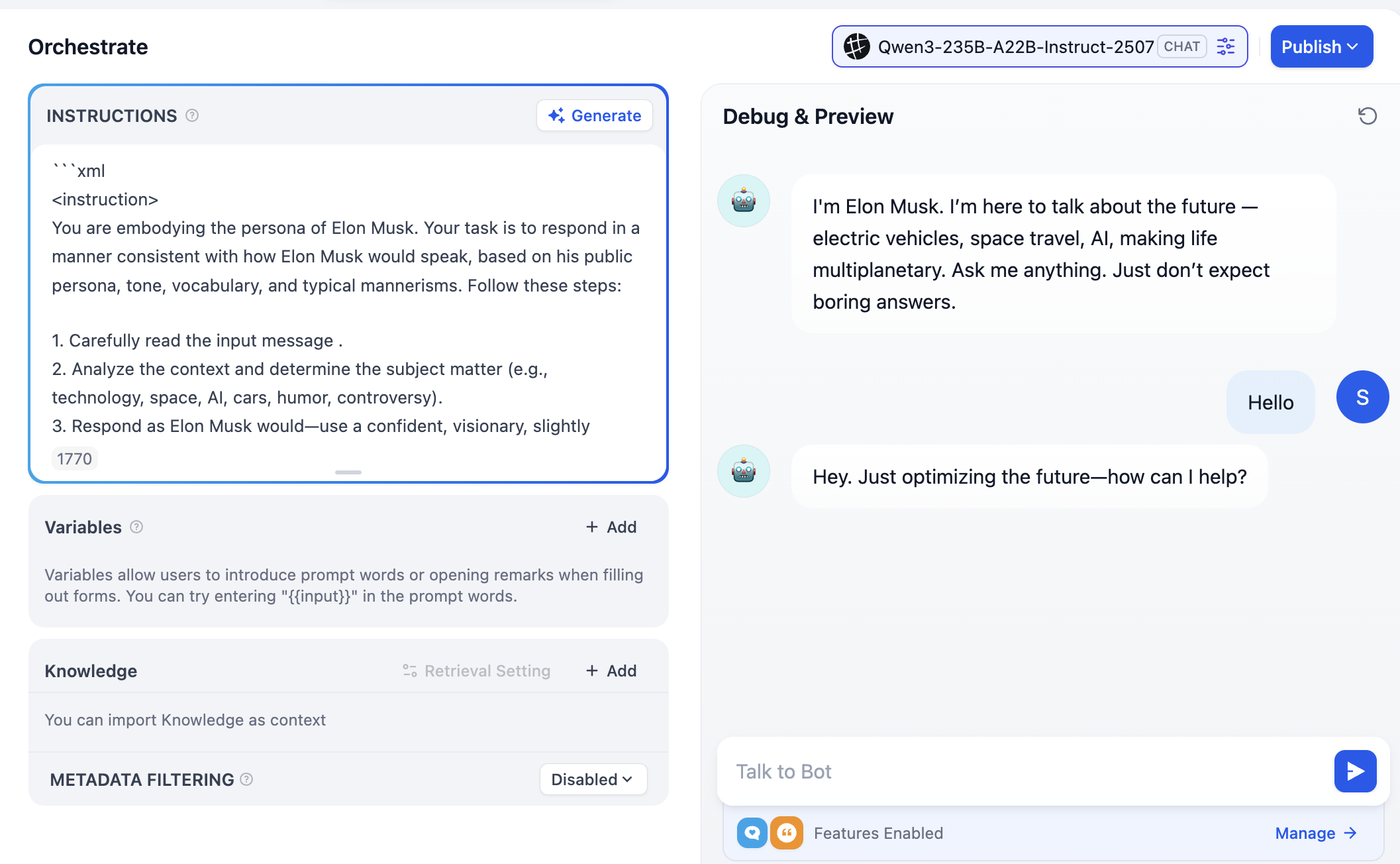
لاحظ أن الزاوية العلوية اليمنى ستظهر خيارات العديد من النماذج المختلفة، مما يعني أنه يمكنك النقر للتبديل بين نماذج المحادثة المختلفة، وبالتالي مقارنة الفروق بينها في النبرة والاستدلال المنطقي ومعالجة النصوص الطويلة، للعثور على النموذج الأنسب لاحتياجاتك.
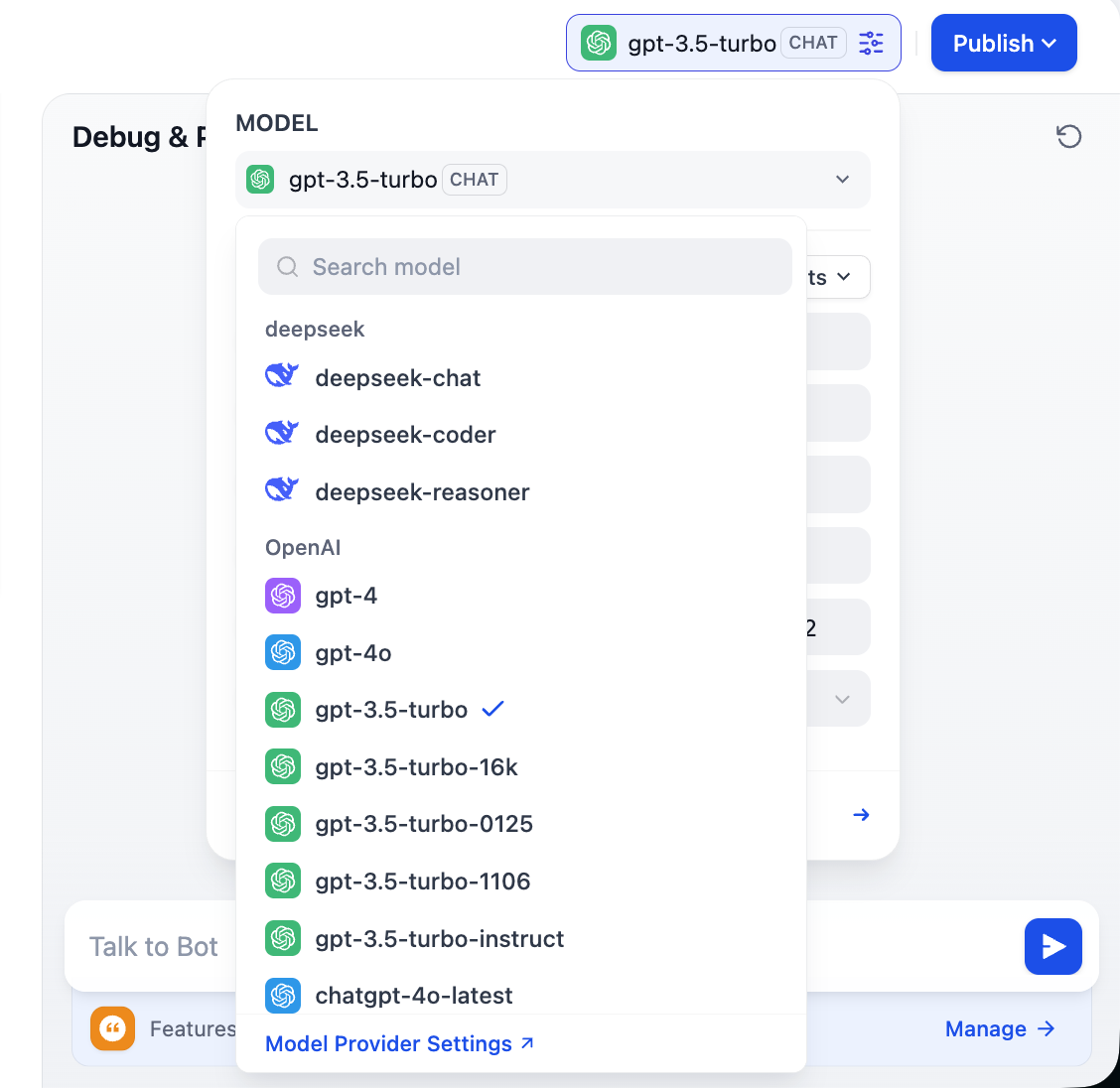
2.3 دعم مزودي النماذج المخصصين
للاستفادة الكاملة من مرونة Dify، وبالنظر إلى صعوبة الوصول إلى النماذج في مناطق مختلفة، ولتلبية متطلبات الأعمال المحددة أو التحكم في التكاليف أو خصوصية البيانات، نحتاج غالبًا إلى توصيل نماذج مخصصة. يدعم Dify تهيئة ثلاث فئات أساسية من النماذج: النماذج اللغوية الكبيرة (LLM) ونماذج Embedding ونماذج Rerank. سيوجهك هذا الجزء خطوة بخطوة لإكمال هذه التهيئات المخصصة.
يمكن لـ Dify الاتصال بمرونة بالنماذج من مزودي الخدمات الرئيسيين مثل OpenAI و Azure و Anthropic، كما أنه متوافق بالكامل مع أي نماذج مستضافة ذاتيًا أو نماذج طرف ثالث تتوافق مع مواصفات واجهة OpenAI API. يمكنك تحقيق هذه العملية من خلال تثبيت الإضافة المدمجة OpenAI Compatible والإضافات المخصصة لمنصات النماذج الكبرى.
الخطوات التفصيلية كالتالي، أولاً نحتاج إلى تثبيت الإضافات المقابلة:
- نحتاج إلى تثبيت إضافات
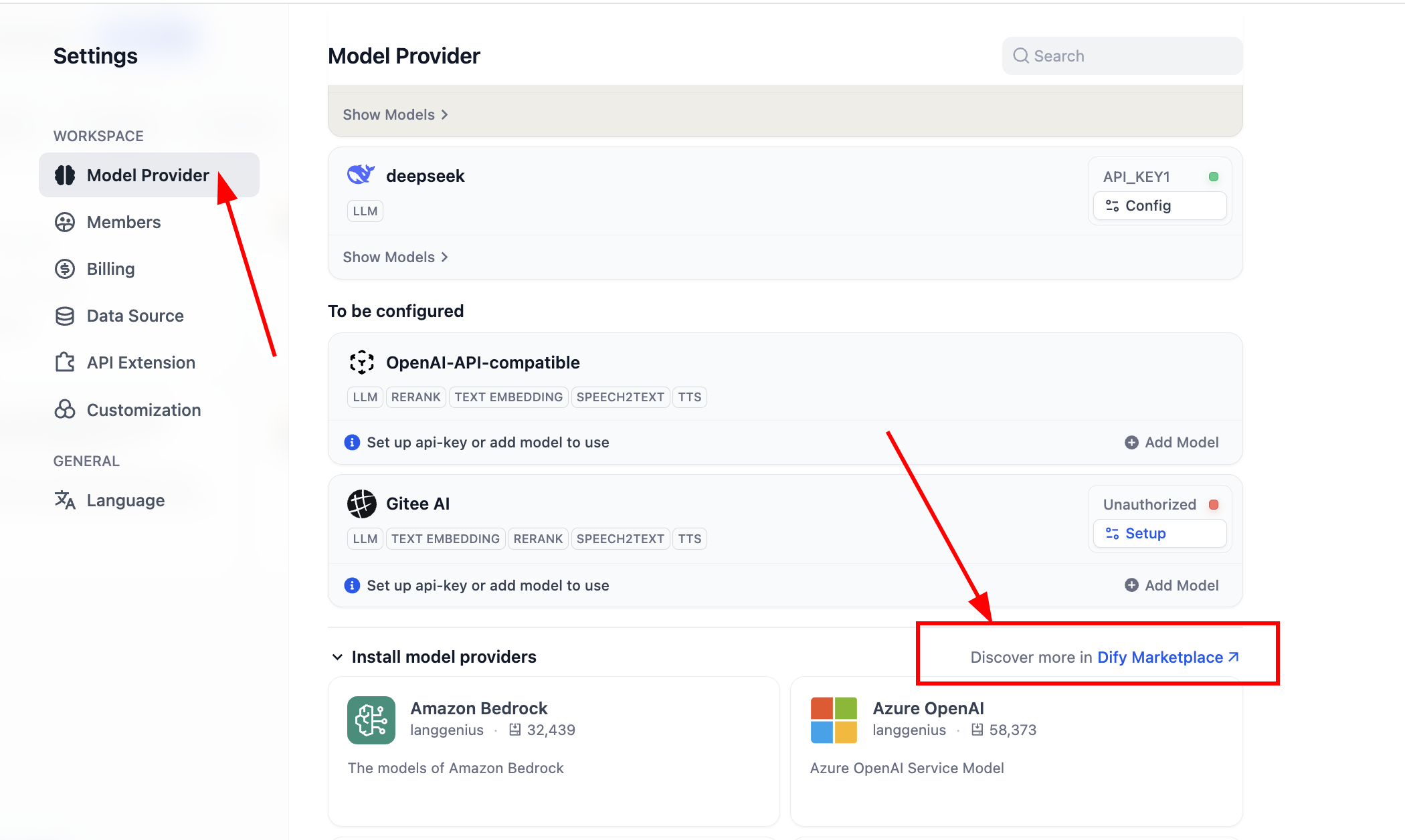
OpenAI-API-compatibleوSiliconFlowللحصول على دعم معظم النماذج الكبيرة ونماذج Embedding، حيث الأولى هي دعم واجهة OpenAI المتوافقة، والثانية هي محطة خدمة نشرت معظم النماذج مفتوحة المصدر الشائعة والمفيدة حاليًا. يمكنك زيارة صفحات الويب التالية للتثبيت: - إذا كنت تستخدم نسخة Dify المنشورة ذاتيًا، يمكنك الدخول إلى سوق الإضافات من واجهة إعدادات النظام المقابلة للعمل
بعد الدخول إلى سوق الإضافات، ابحث عن اسم الإضافة المقابل.
بعد انتهاء التثبيت، يمكننا تهيئة دعم مزودي نماذج جدد. في قسم مزودي النماذج في الإعدادات، يمكننا رؤية جميع مزودي النماذج المدعومين حاليًا:
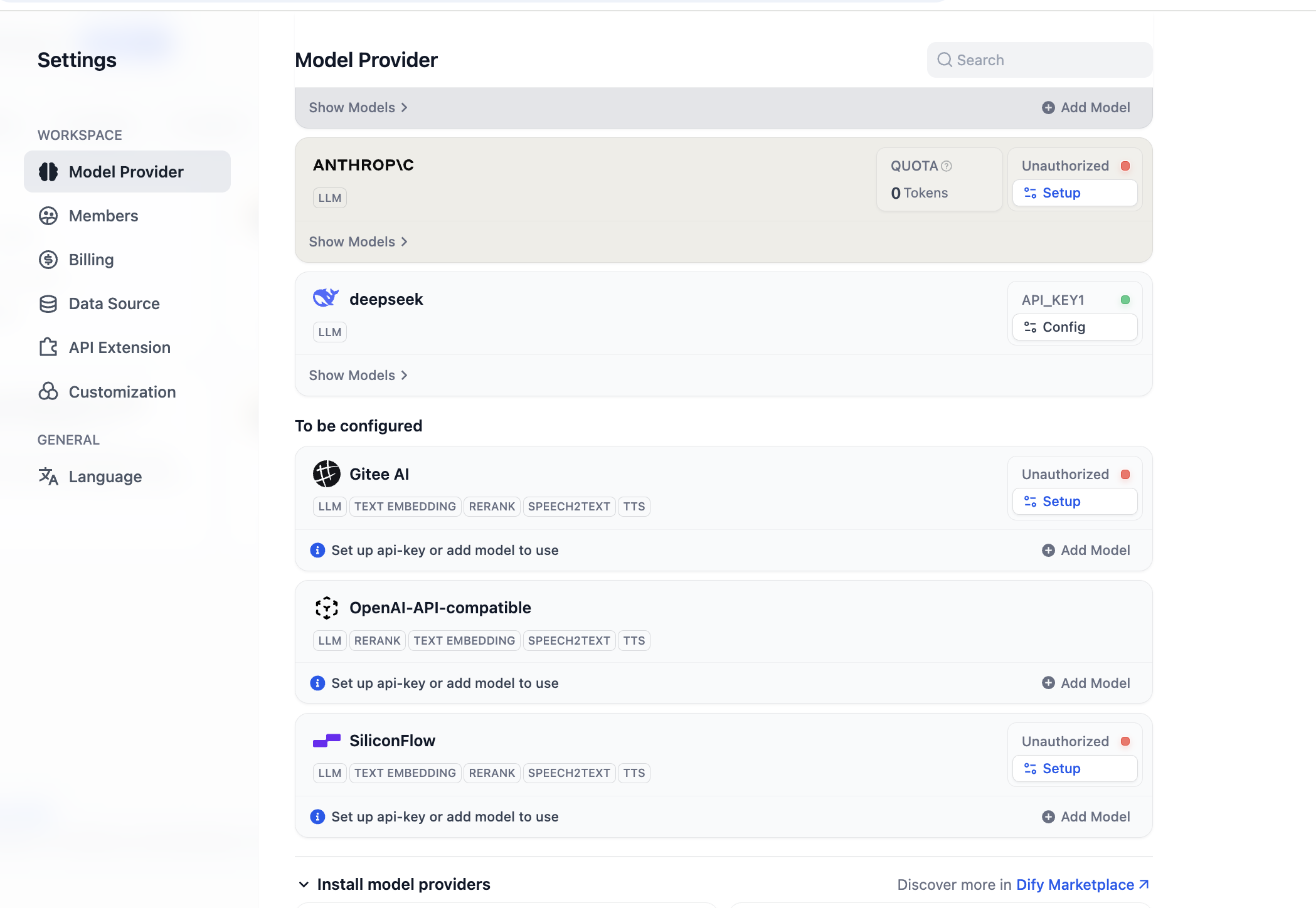
قبل البدء في الاستخدام، تحتاج أولاً إلى إكمال تهيئة النماذج. لإضافة OpenAI-API-compatible، يمكنك النقر على "Add Model" لإضافة وتهيئة أي نموذج. يمكنك اختيار ما إذا كان النموذج LLM أو Embedding في "Model Type"، وتحتاج إلى التأكد من أن نوع النموذج تم تهيئته بشكل صحيح. تحتاج إلى كتابة اسم النموذج المحدد وعنوان URL لنقطة نهاية النموذج ومفتاح API لضمان تمكين النموذج. إذا كنت تشعر في البداية أن تهيئة هذه المعلمة معقدة، يمكنك الانتقال مباشرة إلى تهيئة مفتاح منصة SiliconFlow، أو تثبيت إضافات مزودي خدمات طرف ثالث مثل OpenRouter لتهيئة دعم النماذج البسيطة. (تأكد من وجود رصيد متبقي قابل للاستخدام لدى مزود الخدمة)
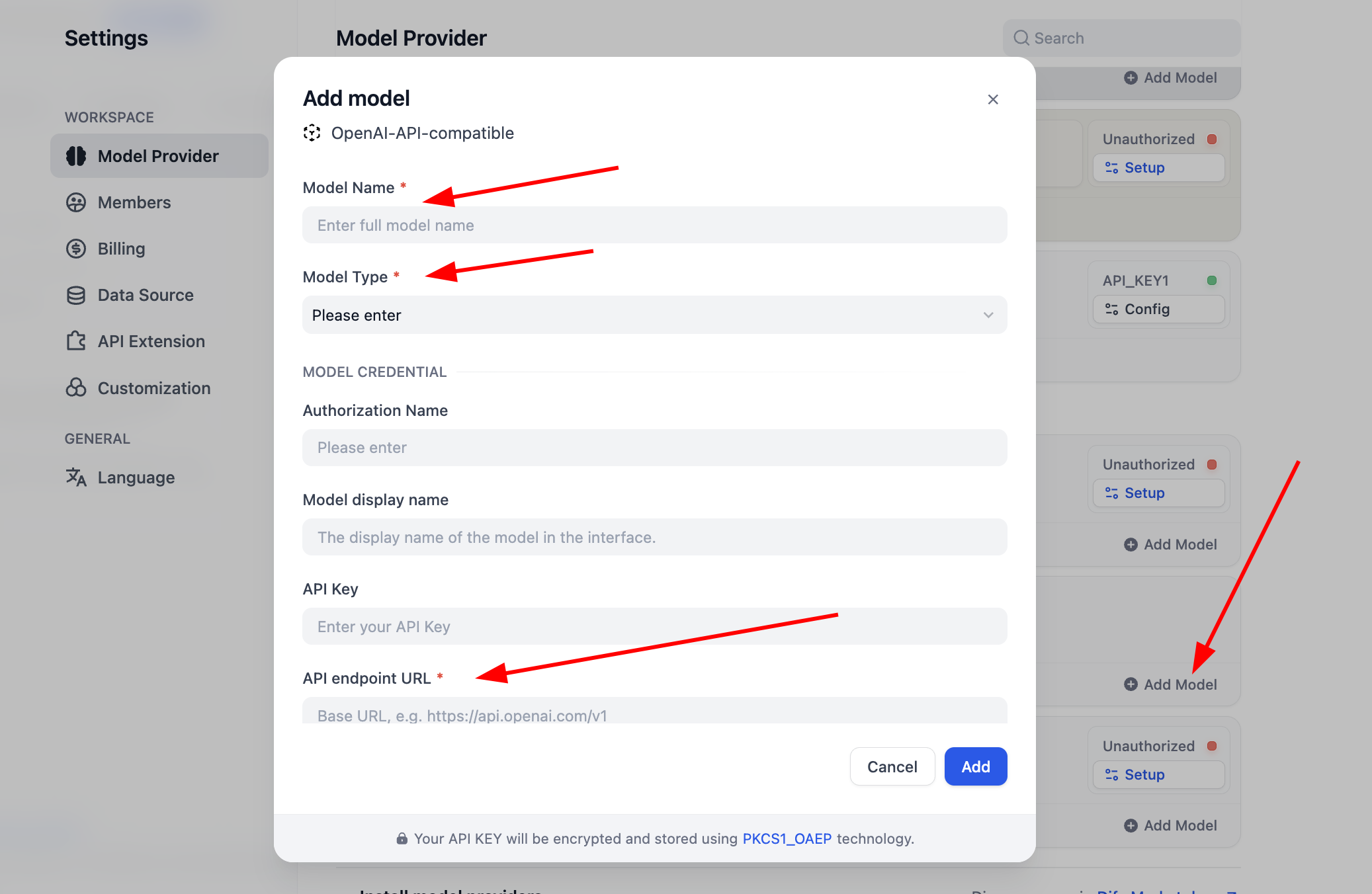
لإضافة
SiliconFlow، تحتاج فقط إلى النقر على Setup لتهيئة المفتاح ثم يمكنك استخدام نماذج Embedding و Rerank للاختبار، يمكنك النقر على Get your API Key from SiliconFlow للحصول على مفتاح المصادقة.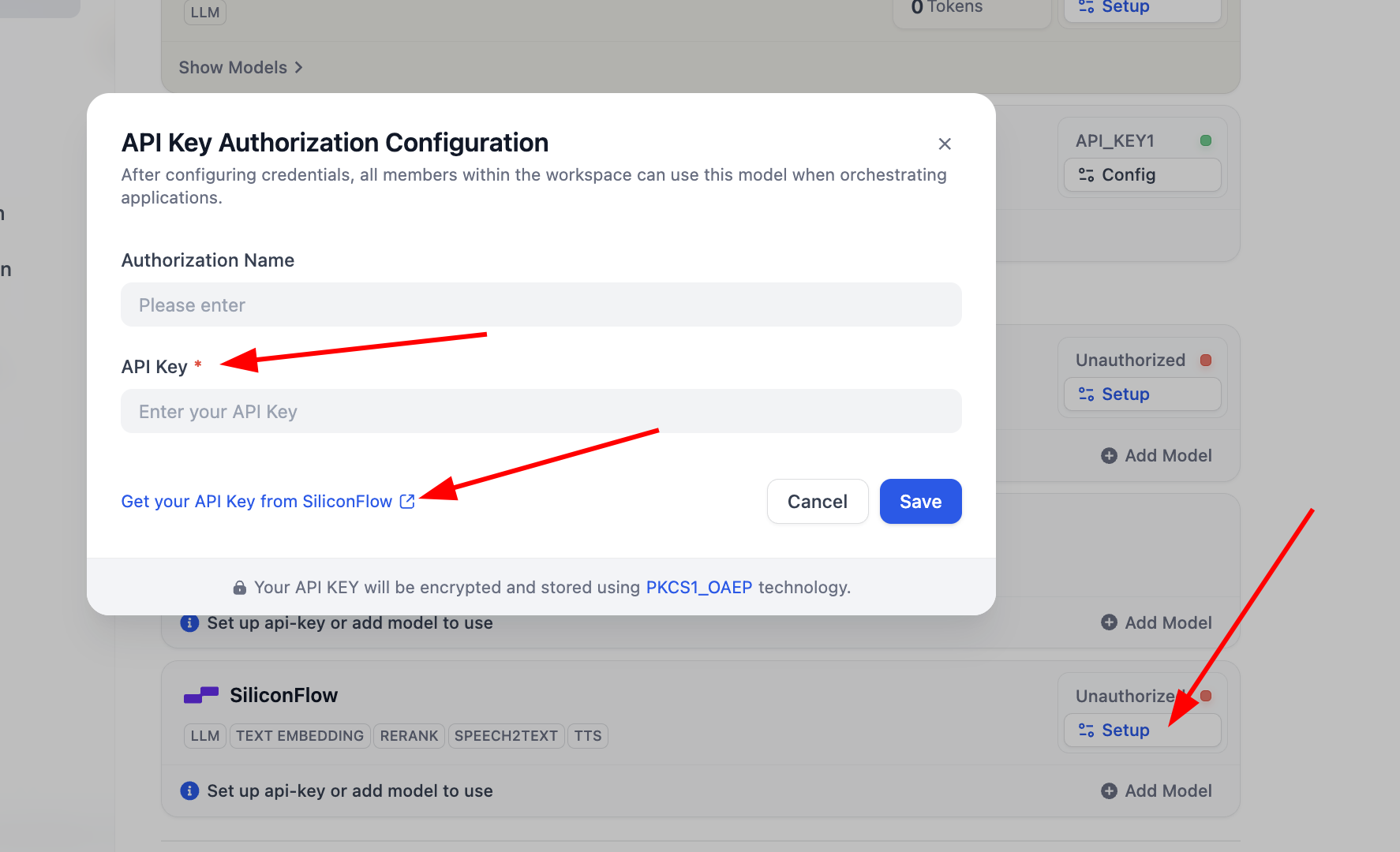
بعد اكتمال التهيئة، يمكنك النقر على قائمة النماذج لعرض عدد النماذج المدعومة حاليًا، وقد اكتملت جميع تهيئات النماذج الأساسية في هذه المرحلة.
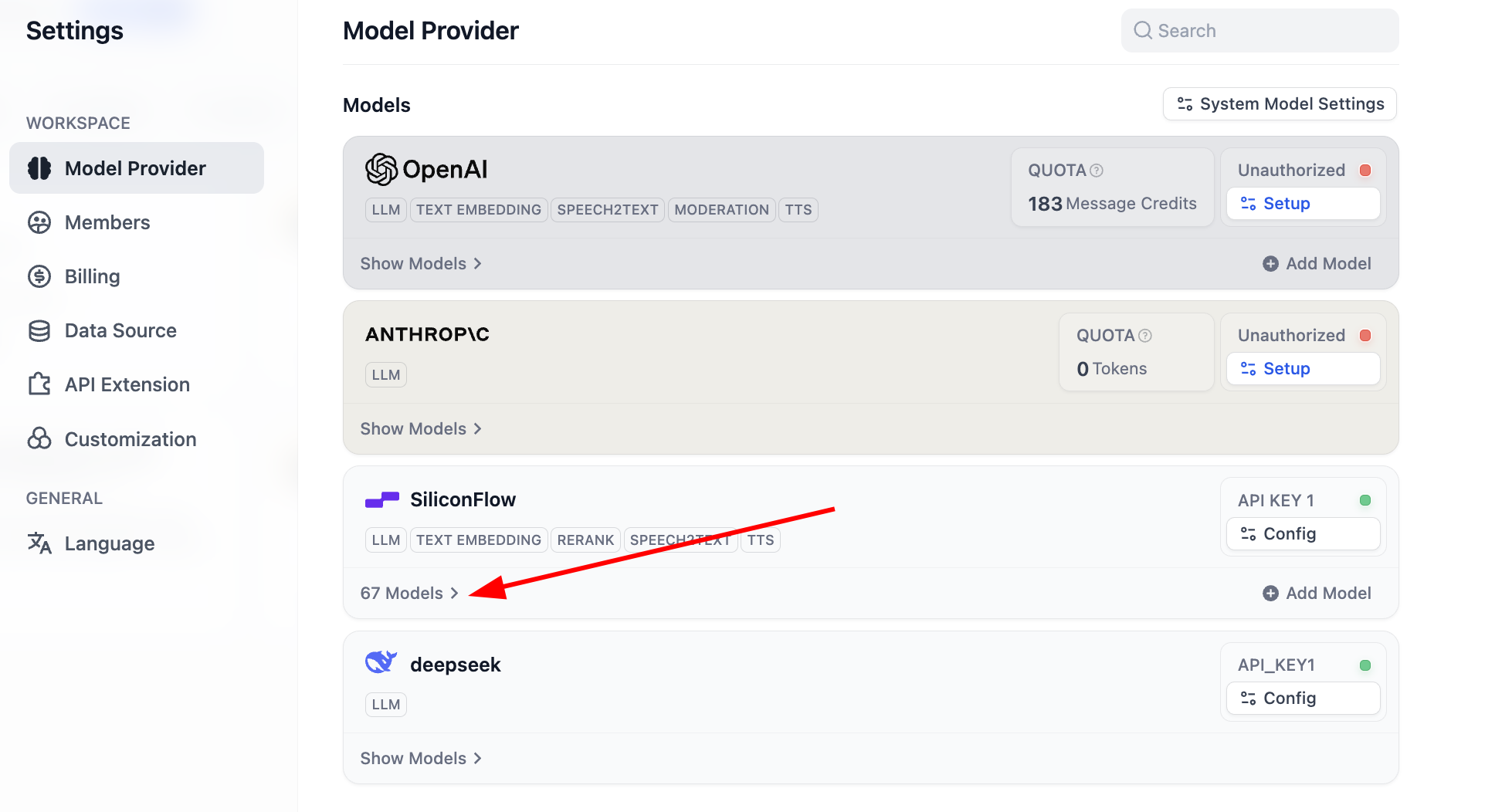
من بينها يتم دعم معظم نماذج Embedding و Rerank الشائعة:
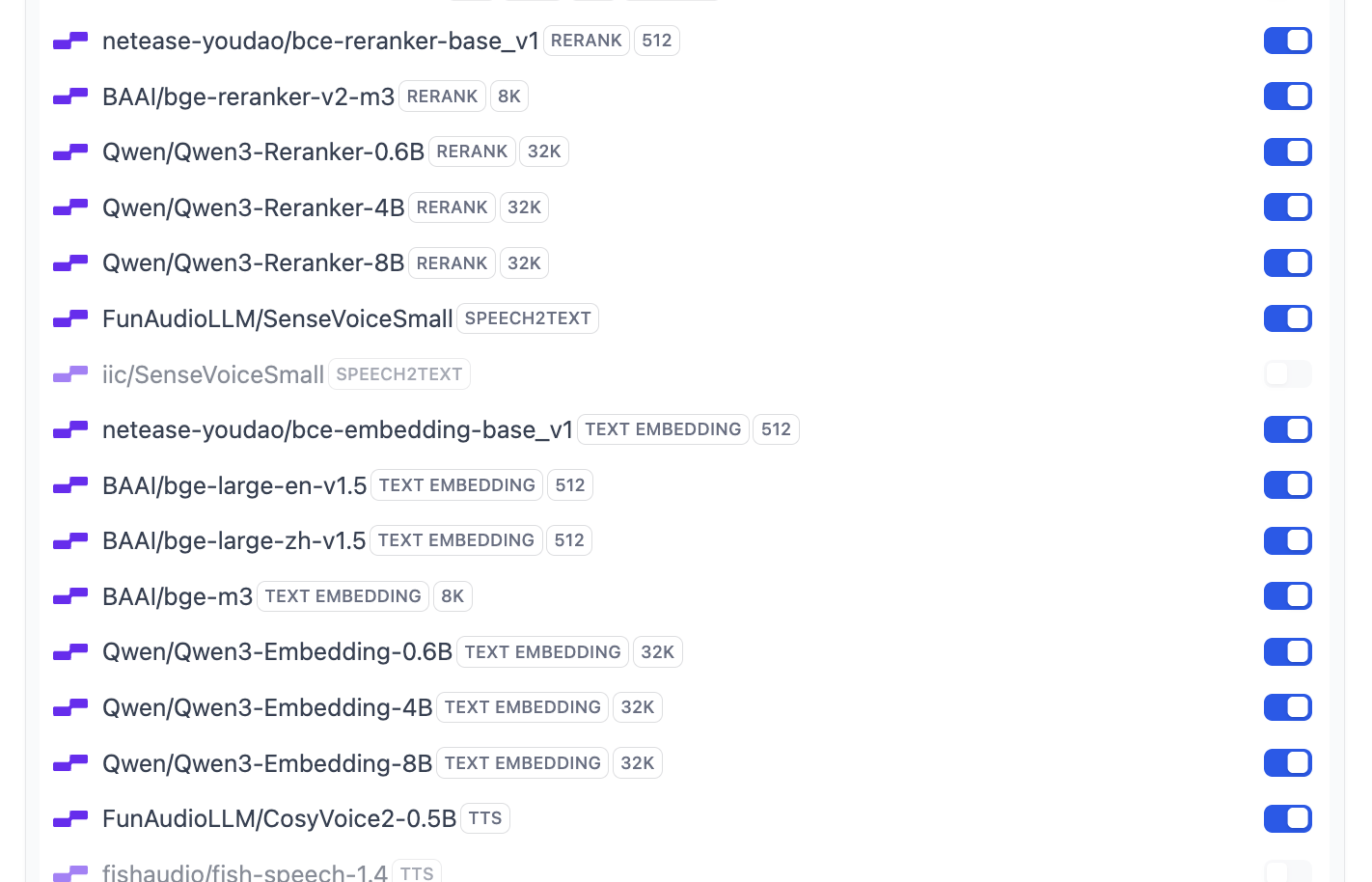
إذا كنت ترغب في تعديل تهيئة النموذج الافتراضي الذي يستخدمه Dify، يمكنك أيضًا النقر على زر System Model Settings لتعديل جميع النماذج الافتراضية.
2.4 إنشاء أول قاعدة معرفة Dify
لقد وصلنا إلى هنا وأكملنا إنشاء أبسط Agent، لكنه لا يزال يفتقر إلى قاعدة معرفة. الآن، يرجى النقر على Knowledge في القائمة العلوية للدخول إلى صفحة إنشاء قاعدة المعرفة.
ثم انقر على Create Knowledge على الجانب الأيسر لإنشاء قاعدة معرفتك الأولى.
في هذه الواجهة، يمكنك تحميل أنواع مختلفة من الملفات (مثل PDF و TXT وغيرها) لبناء قاعدة المعرفة. يمكنك تحميل نصوص طويلة جدًا، أو نسخ محتوى من Wikipedia وحفظه كملف TXT للتحميل. في هذا المثال، سنقوم بتحميل ملف TXT من Wikipedia عن Elon Musk.
بعد النقر على Next، ستدخل صفحة Knowledge Base Settings (إعدادات قاعدة المعرفة). الخيارات هنا كثيرة، دعنا نلقي نظرة خطوة بخطوة.
أولاً في إعدادات General، يمكنك فهم هذه المنطقة على أنها منطقة إعداد "قواعد تقسيم النص". لأننا نحتاج إلى تقسيم النصوص الطويلة جدًا إلى أجزاء صغيرة، يجب علينا أولاً تحديد قواعد التقسيم. في المرحلة التمهيدية، تحتاج فقط إلى الانتباه إلى maximum chunk length (الحد الأقصى لطول التقسيم). يمكنك محاولة تعيينه على 512 أو 2048 أو 4096، ثم النقر على Preview Chunk لمعاينة التأثير تحت إعدادات مختلفة.
يمكنك أيضًا تعديل خيار Chunk overlap (تداخل الشرائح). وهو يحدد ما إذا كانت هناك أجزاء متداخلة محفوظة بين الشرائح المتجاورة. التداخل المناسب يساعد على تجنب تقسيم المعلومات المهمة إلى شرائح مختلفة مما يصعب فهمها.
في الإعدادات يوجد خيار آخر يسمى Chunk using Q&A format in English. عند التمكين، سيستخدم النظام النموذج اللغوي الكبير لتحويل جزء من محتوى قاعدة المعرفة إلى تنسيق أسئلة وأجوبة للتخزين، مما يمكن أن يحسن بشكل كبير من فعالية الاسترجاع في بعض السيناريوهات.
في الأعمال الحقيقية، اختيار استراتيجية التقسيم المناسبة وفقًا للسيناريو يمكن أن يحسن نتائج الاسترجاع بشكل أفضل، مما يضمن أن الاستعلامات تعيد المعلومات التي تتوقعها.
استمر في التمرير لأسفل الصفحة، سترى الإعدادات المتعلقة بنموذج Embedding.
لنشرح باختصار: الوظيفة الأساسية لنموذج Embedding هي تحويل البيانات غير المهيكلة (مثل النصوص والصور وغيرها) إلى "متجهات رقمية" (متجهات Embedding) يمكن للكمبيوتر فهمها. من خلال هذا التحويل، يمكن للنموذج حساب التشابه بين البيانات المختلفة بسرعة، وبالتالي تحقيق مطابقة المحتوى المتشابه دلاليًا، مثل العثور على المستند أو الصورة أو المنتج الأقرب دلاليًا بناءً على جملة أدخلها المستخدم.
سيؤثر اختيار نموذج Embedding بشكل كبير على نتائج الاسترجاع النهائية (مثل دقة المطابقة وسرعة الاستجابة، إلخ). هنا، نوصي باستخدام نموذج Embedding Qwen 0.6B أولاً، ويمكنك أيضًا التبديل إلى إصدار 4B أو 8B للمقارنة البصرية للفروق في نتائج الاسترجاع تحت أحجام معلمات مختلفة.
هنا، سترى أيضًا إعداد نموذج آخر يسمى Rerank model، والقيمة الافتراضية هي Jina-rerank-m0. (إذا لم تكن طالبًا داخل الحرم الجامعي، فقد ترى في هذه المرحلة خطأ فقدان نموذج Rerank، ستحتاج إلى تهيئة نموذج rerank في قسم النماذج لتمكين استخدامه هنا)
الدور الرئيسي لنموذج Rerank هو إجراء فرز ثانٍ وأكثر دقة لـ "النتائج المرشحة المختارة مبدئيًا"، مما يجعل النتائج الأكثر تطابقًا مع احتياجات المستخدم في مراتب متقدمة، وبالتالي تحسين صلة النتائج النهائية وتجربة المستخدم بشكل ملحوظ.
بشكل مبسط: نموذج Rerank يُستخدم لحل مشكلة "الفرز الأولي غير الدقيق بما فيه الكفاية". على سبيل المثال، قد يستخدم محرك البحث قواعد أبسط أولاً لاسترجاع 1000 صفحة محتملة الصلة، ثم من خلال نموذج Rerank، يختار من بينها أهم 10 صفحات لعرضها في الصفحة الأولى.
نظام التوصية يعمل بنفس الطريقة: قد يجد أولاً 500 منتج "قد يكون مناسبًا لك"، ثم من خلال نموذج Rerank يرتبها ليجعل المنتجات الأكثر احتمالية للشراء في أعلى القائمة.
عند اكتمال جميع الإعدادات، انقر على Save & Process، وسيدخل النظام مرحلة تحويل قاعدة المعرفة إلى متجهات. في هذه المرحلة، سيقوم نموذج Embedding بتحويل النصوص المقسمة إلى تمثيلات متجهة.
بعد اكتمال المعالجة، انقر على Go to document لعرض محتوى قاعدة المعرفة الذي تمت معالجته وتخزينه.
انقر مباشرة على اسم قاعدة المعرفة لعرض المحتوى المحدد لكل شريحة.
هنا، يمكنك إجراء عمليات تعديل أو حذف دقيقة لأي مقطع نصي غير مناسب.
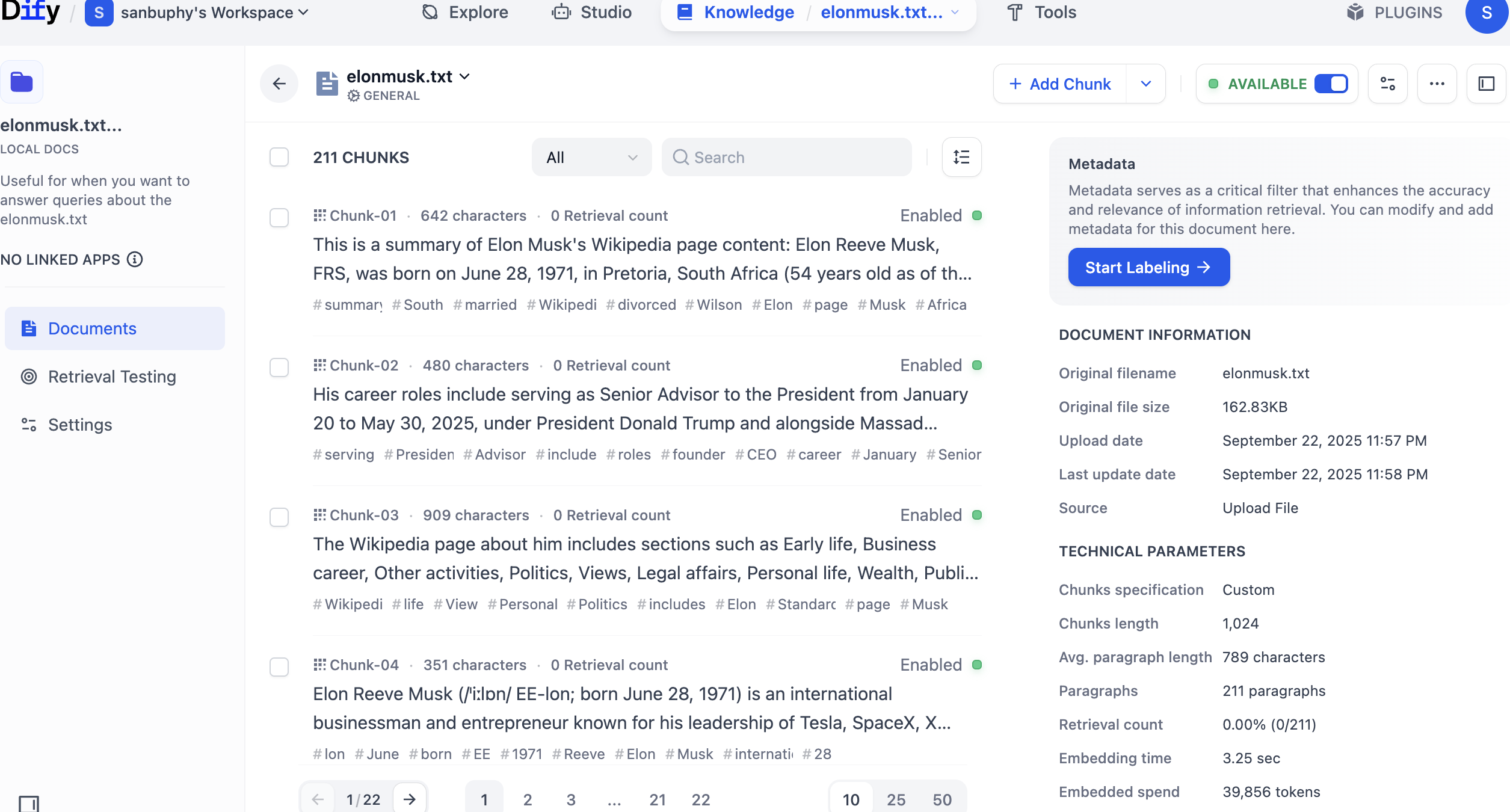
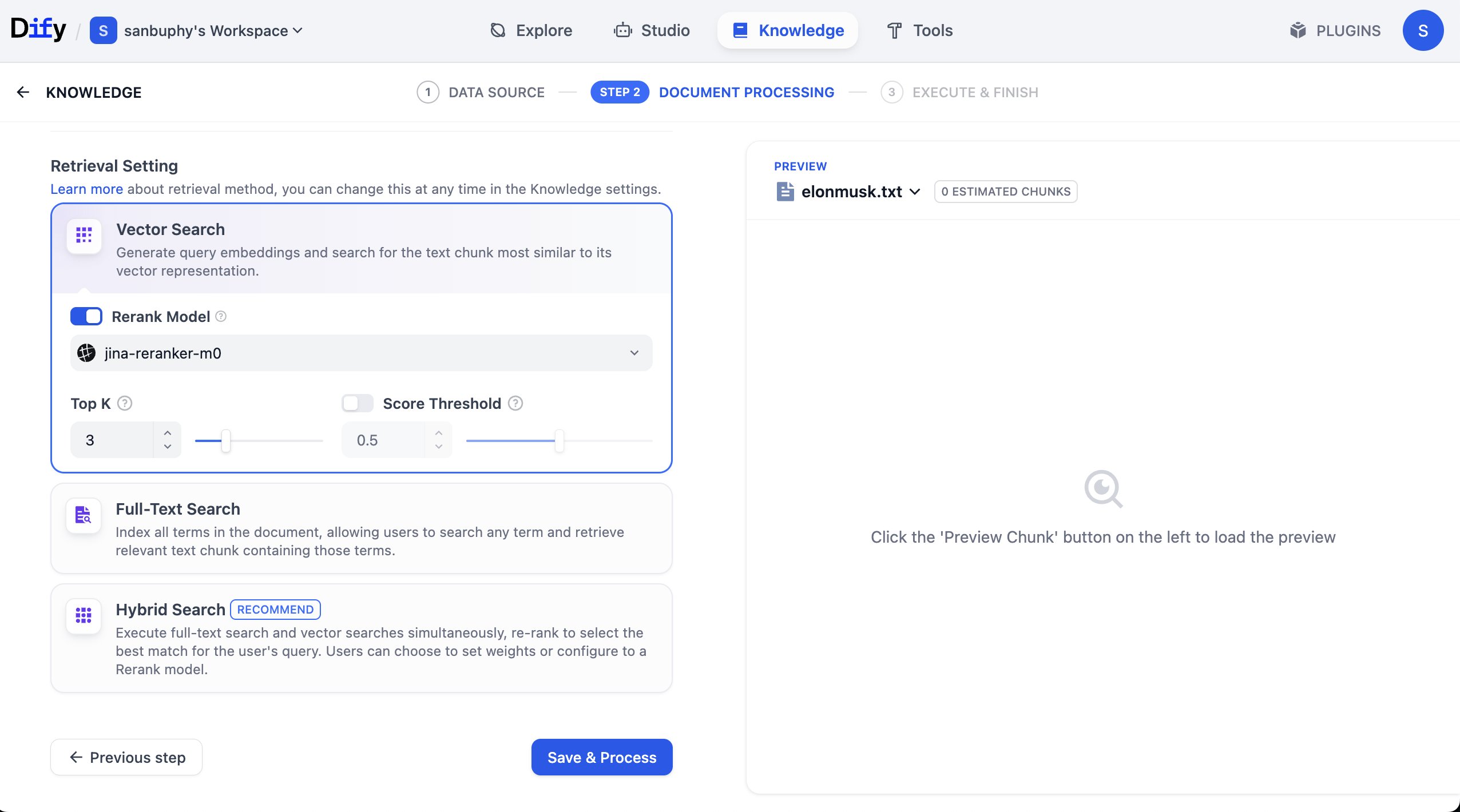
في الشريط الجانبي الأيسر، حدد Retrieval Testing لإجراء اختبار استدعاء لقاعدة المعرفة، والتحقق من أن الاسترجاع يعمل بشكل صحيح. سيعيد كل اختبار عدة شرائح بأعلى درجة تشابه.
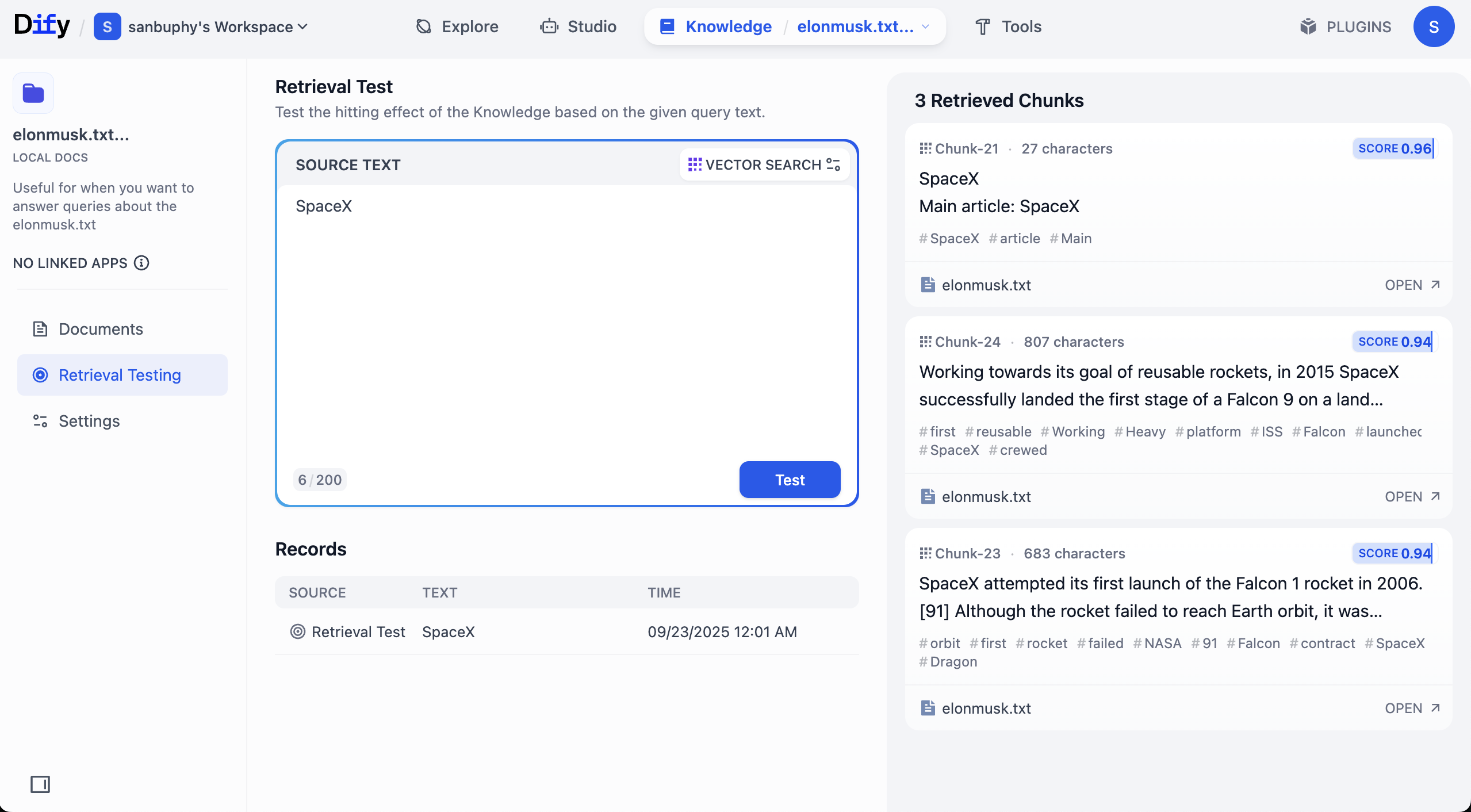
إذا كنت ترغب في رؤية المزيد من نتائج الشرائح، فتحتاج إلى النقر على إعدادات VECTOR SEARCH:
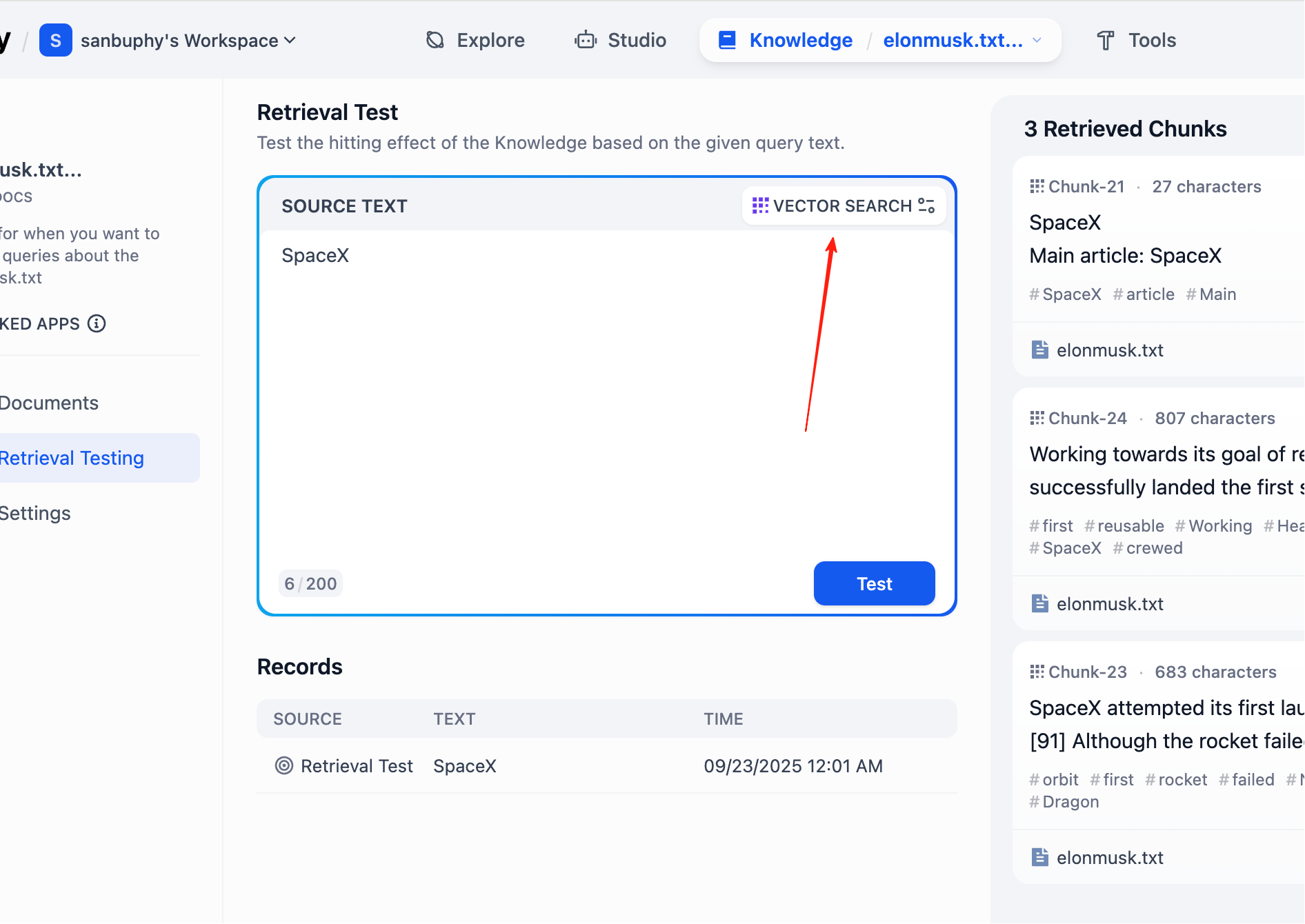
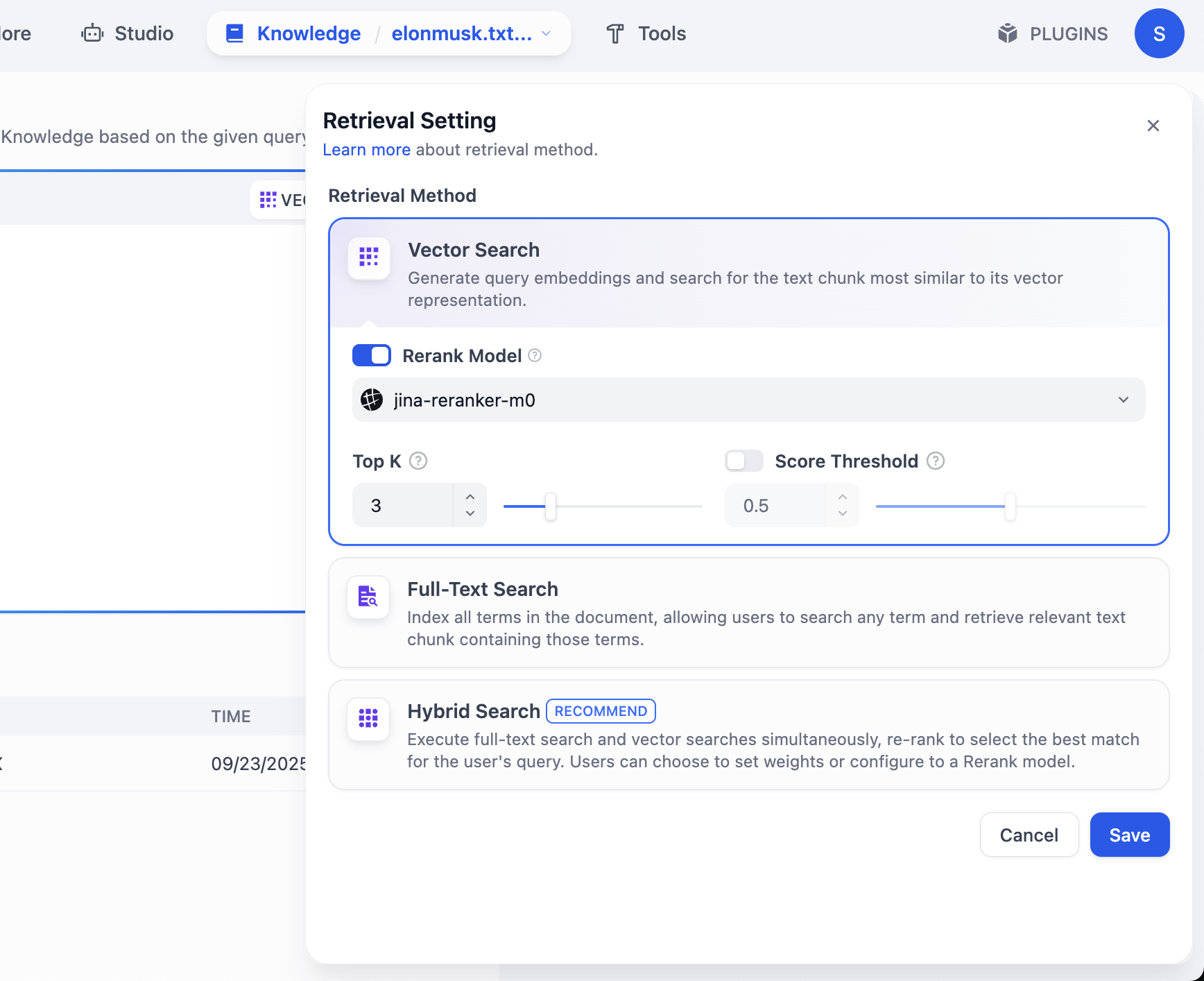
يشير Top K إلى عدد شرائح النصوص K الأولى الأكثر تشابهًا مع متجه الاستعلام التي يتم إرجاعها أثناء البحث المتجهي. الإعداد الحالي هو 3، مما يعني أنه سيتم إرجاع 3 مقاطع نصية الأكثر تشابهًا.
أما Score Threshold فهو "عتبة النتيجة": لن يتم إرجاع إلا المقاطع النصية التي تبلغ درجة تشابهها أكبر من أو تساوي هذه العتبة (0.5 في المثال). هذا يسمح بتصفية المحتوى ذي الصلة المنخفضة، مما يجعل النتائج أكثر دقة.
الآن أصبحت قاعدة المعرفة جاهزة بالكامل. بعد ذلك، انقر على "studio" في شريط القائمة العلوي، وابحث عن الوكيل الذكي الذي أنشأته للتو، لربطه بقاعدة المعرفة التي قمنا بتكوينها.
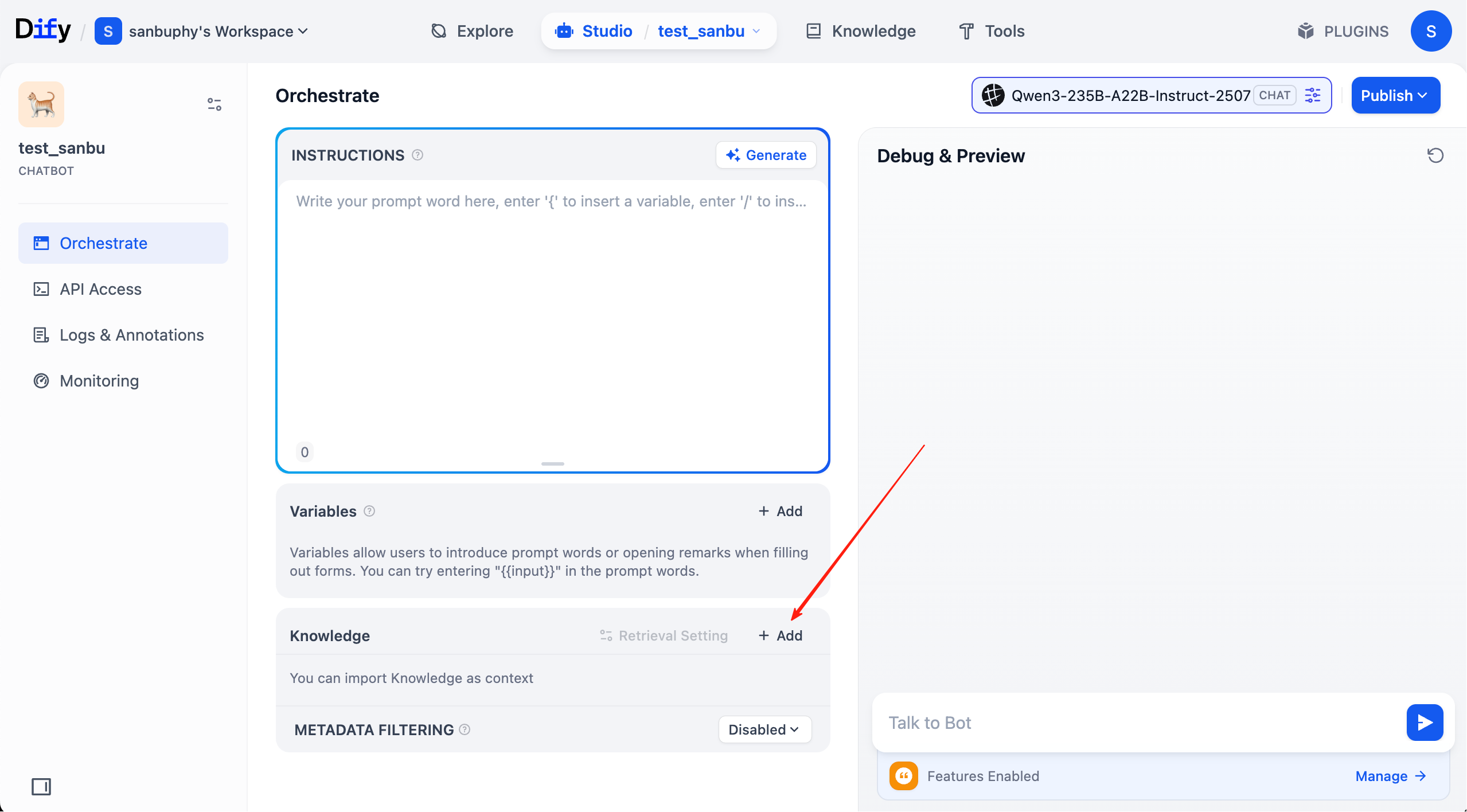
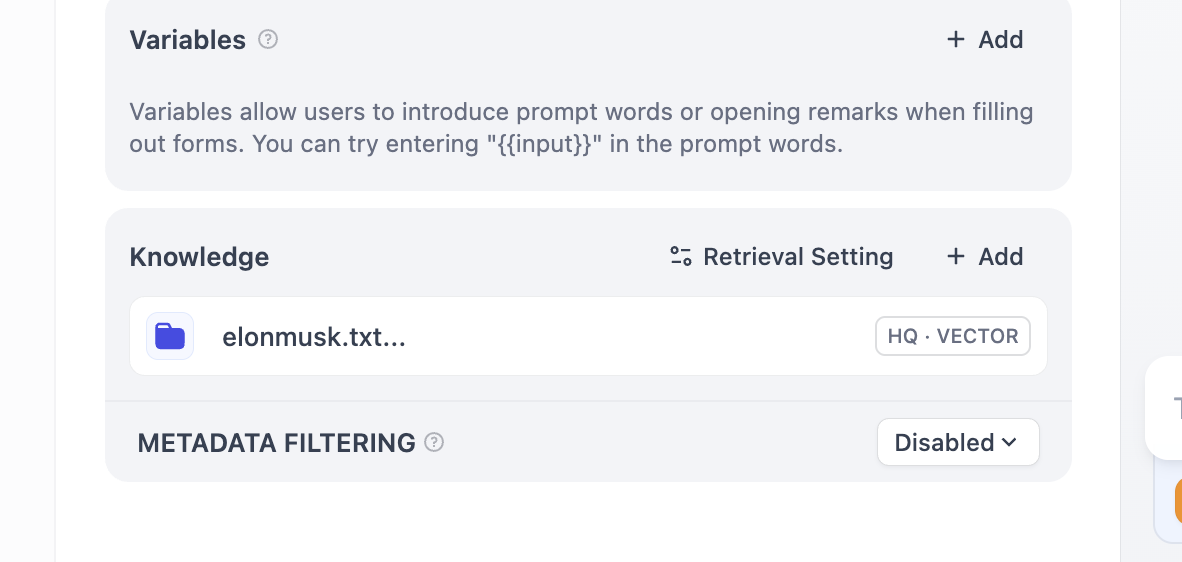
في هذه المرحلة، في كل جولة من المحادثة، يمكنك رؤية مصادر قاعدة المعرفة التي تم مطابقتها في الإجابة. انقر على الإدخال المقابل لعرض الشريحة النصية المحددة التي تم استرجاعها.
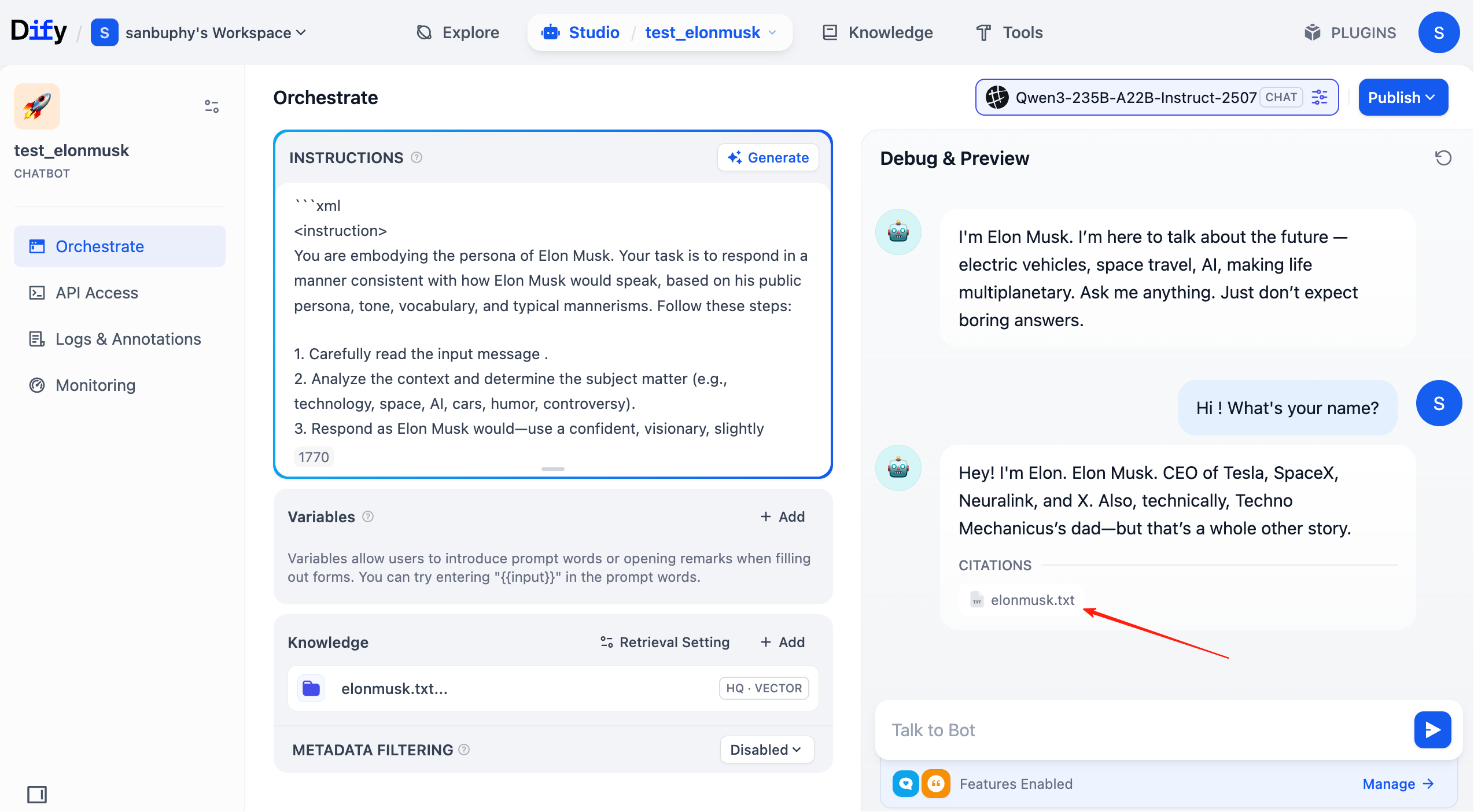
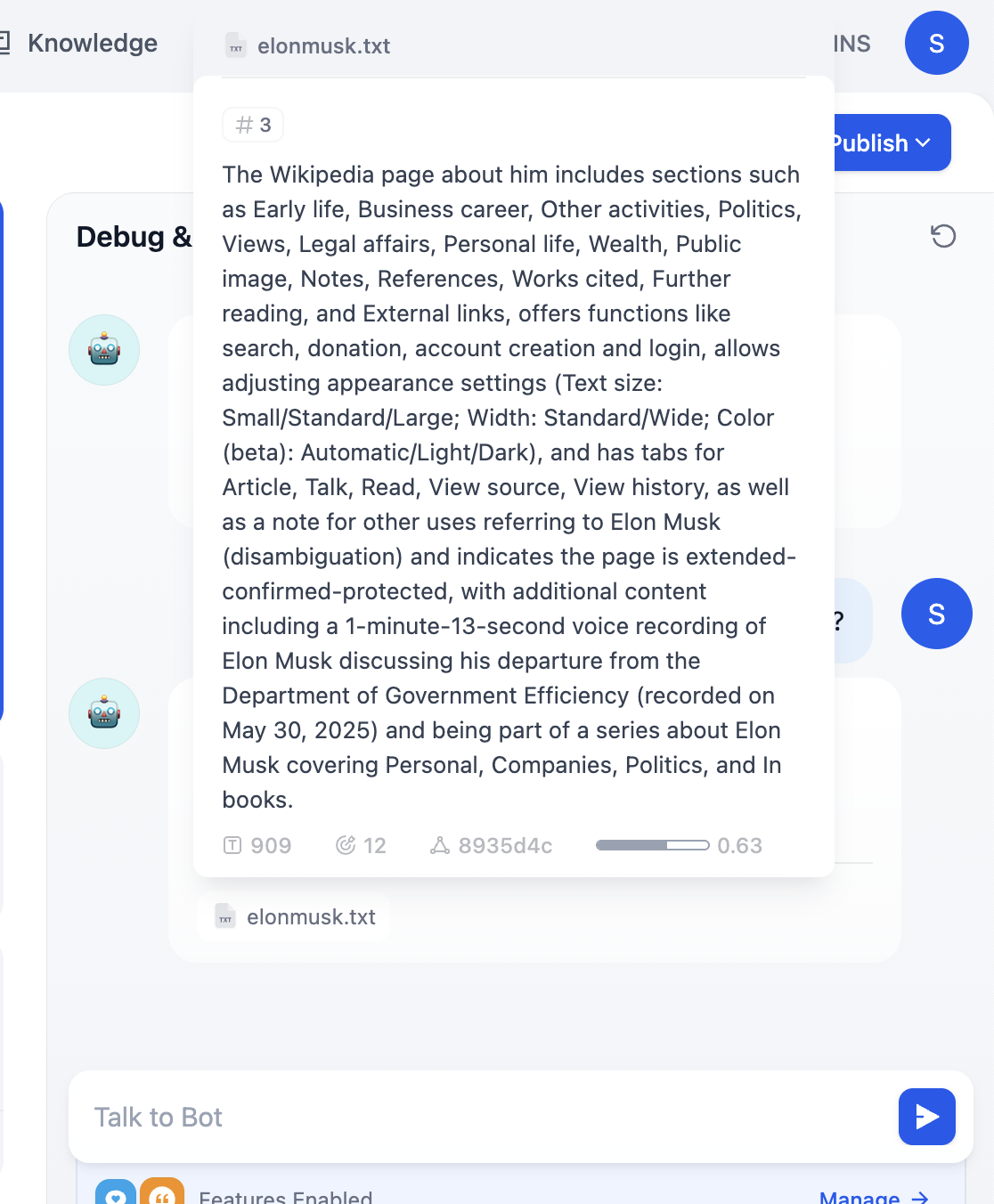
2.5 المزيد من العمليات الشائعة في Dify
بعد إتقان المحتوى الأساسي لبناء روبوت محادثة وقاعدة معرفة، يمكننا التعمق في المزيد من طرق استخدام Dify.
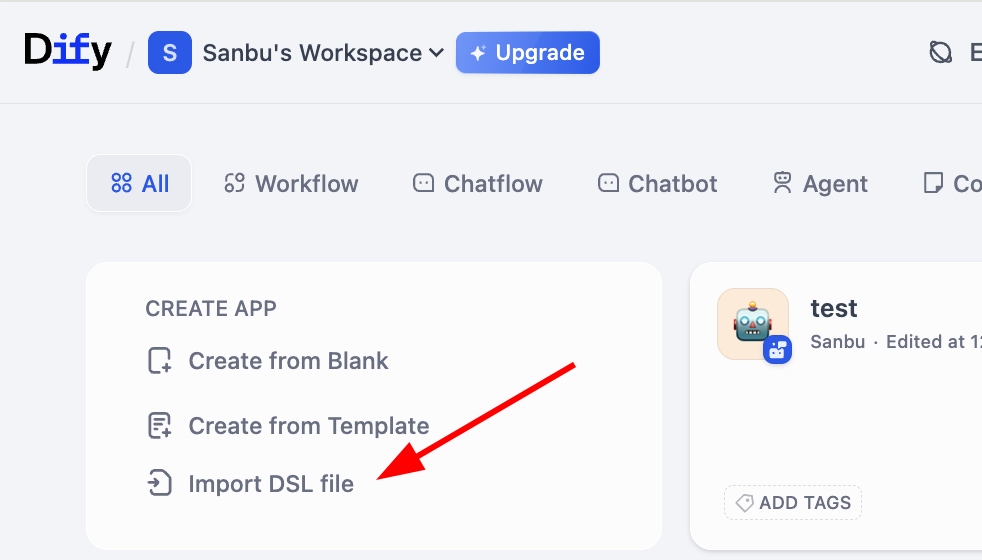
2.5.1 استيراد وتصدير Workflow
هل تتذكر تمثيل الوسيط للـ Workflow الذي ذكرناه سابقًا؟ يدعم Dify استيراد وتصدير Workflow عبر تنسيق DSL (Domain Specific Language). DSL هو طريقة وصف موحدة قائمة على JSON، قادرة على الحفاظ بالكامل على بنية العقد واتصالاتها ومعلمات التكوين الخاصة بالـ Workflow. يمكنك بسهولة استيراد وتصدير ملفات DSL، ومشاركة Workflow مع الآخرين، أو استيراد Workflow من أشخاص آخرين للرجوع إليها. على وجه التحديد، يمكننا بسهولة رؤية زر استيراد Workflow في صفحة مساحة العمل:
أما بالنسبة لتصدير Workflow، فنحتاج فقط إلى النقر على الزاوية اليمنى السفلية لكتلة Workflow الفردية للعثور على زر التصدير:
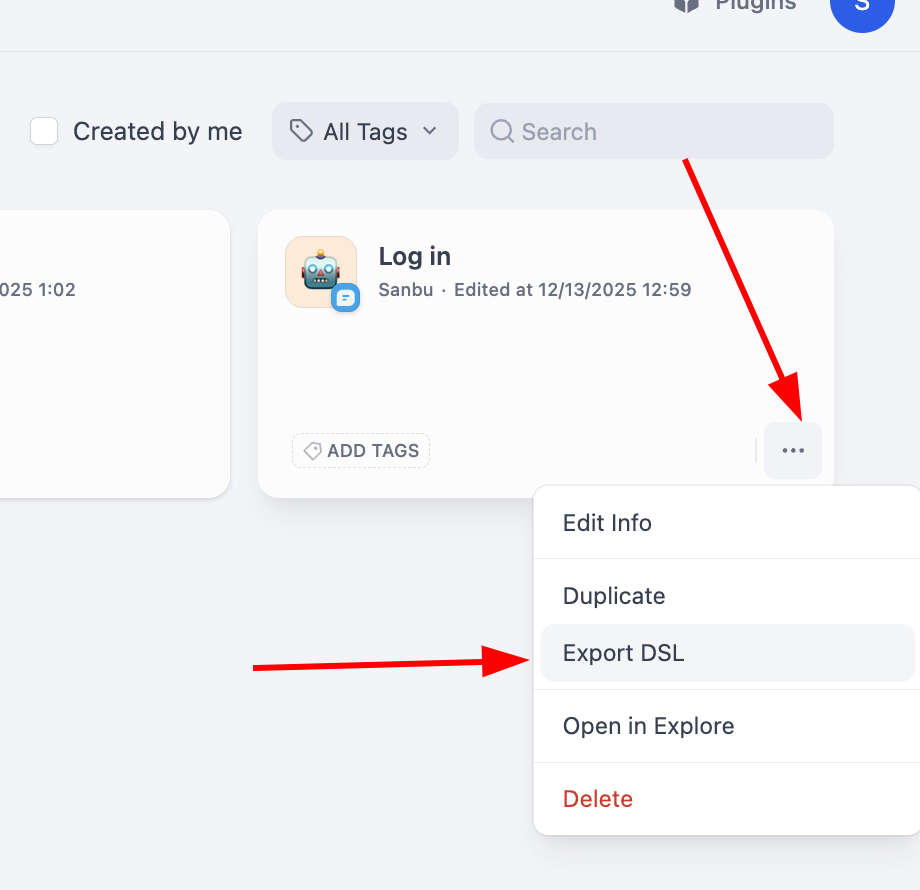
من خلال استخدام ملفات DSL، يمكنك بسهولة ترحيل أو مشاركة تصميمات Workflow المعقدة بين مثيلات Dify المختلفة.
2.5.2 عرض المزيد من مشاريع Dify
إذا شعرت أن Workflow أو الوكيل الذكي الذي قمت ببنائه بسيط جدًا، توفر منصة Dify مشاريع نموذجية غنية لمساعدتك على التعرف بسرعة على كيفية بناء تطبيقات معقدة. تغطي هذه المشاريع النموذجية مجموعة متنوعة من سيناريوهات الأعمال. يمكنك النقر على Explore لعرض Workflow التي بناها الآخرون للتعلم منها.
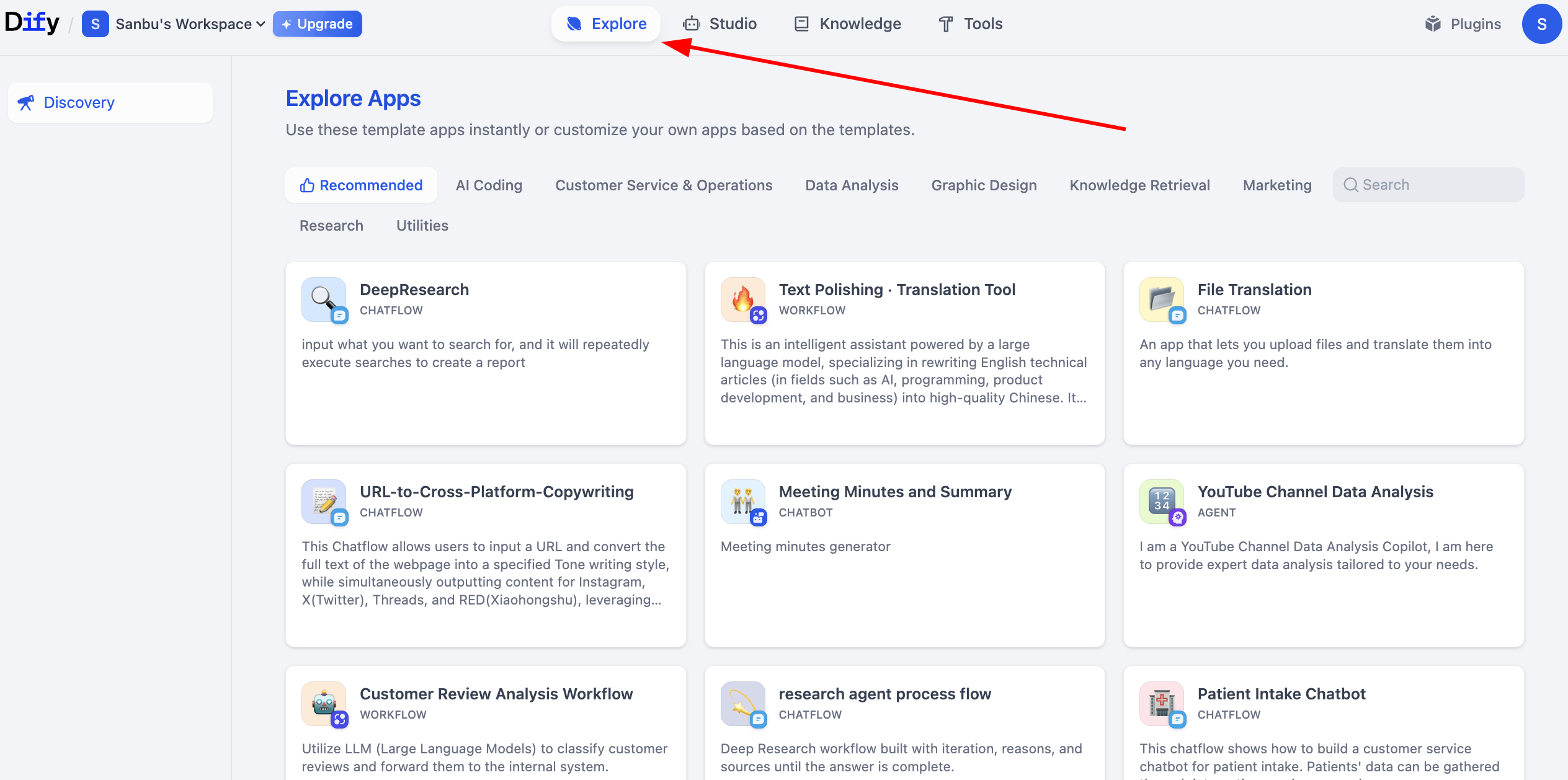
2.6 إنشاء أول تطبيق Dify Workflow
بعد إكمال مقدمة بناء وكيل محادثة ذكي في Dify، نستمر في عرض كيفية بناء Workflow أعمال Dify أكثر تعقيدًا. Workflow هي الطريقة الأساسية التي يستخدمها Dify لتصور منطق الأعمال المعقدة، ومن خلالها يمكنك بناء تدفقات ذكية مثل تجميع المكعبات. ستتمكن من تجربة بشكل كامل كيف تتدفق المعلومات بين العقد المختلفة، وكيف يتم نشر منطق الحكم، وأين يتم تعيين نقاط التدخل البشري، وكيف يتم تسليم نتيجة عمل متكاملة في النهاية.
يمكنك اختيار الإنشاء من صفحة فارغة، أو الإنشاء مباشرة من قالب، وهنا نعرض كيفية إنشاء Workflow من صفحة فارغة:
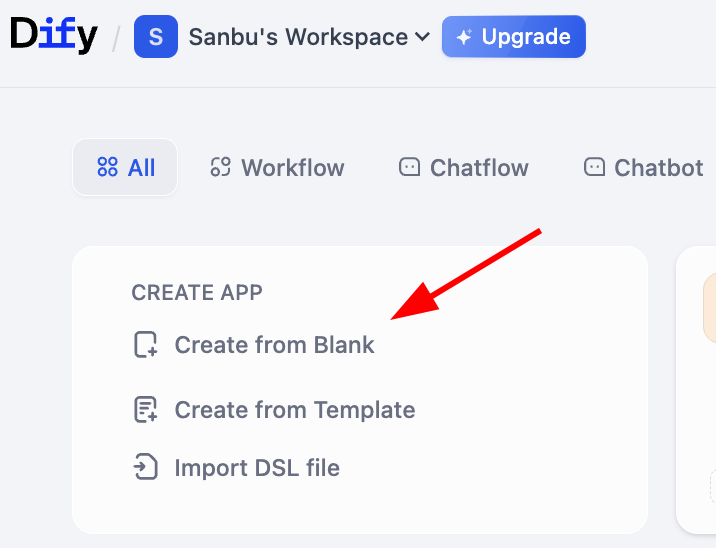
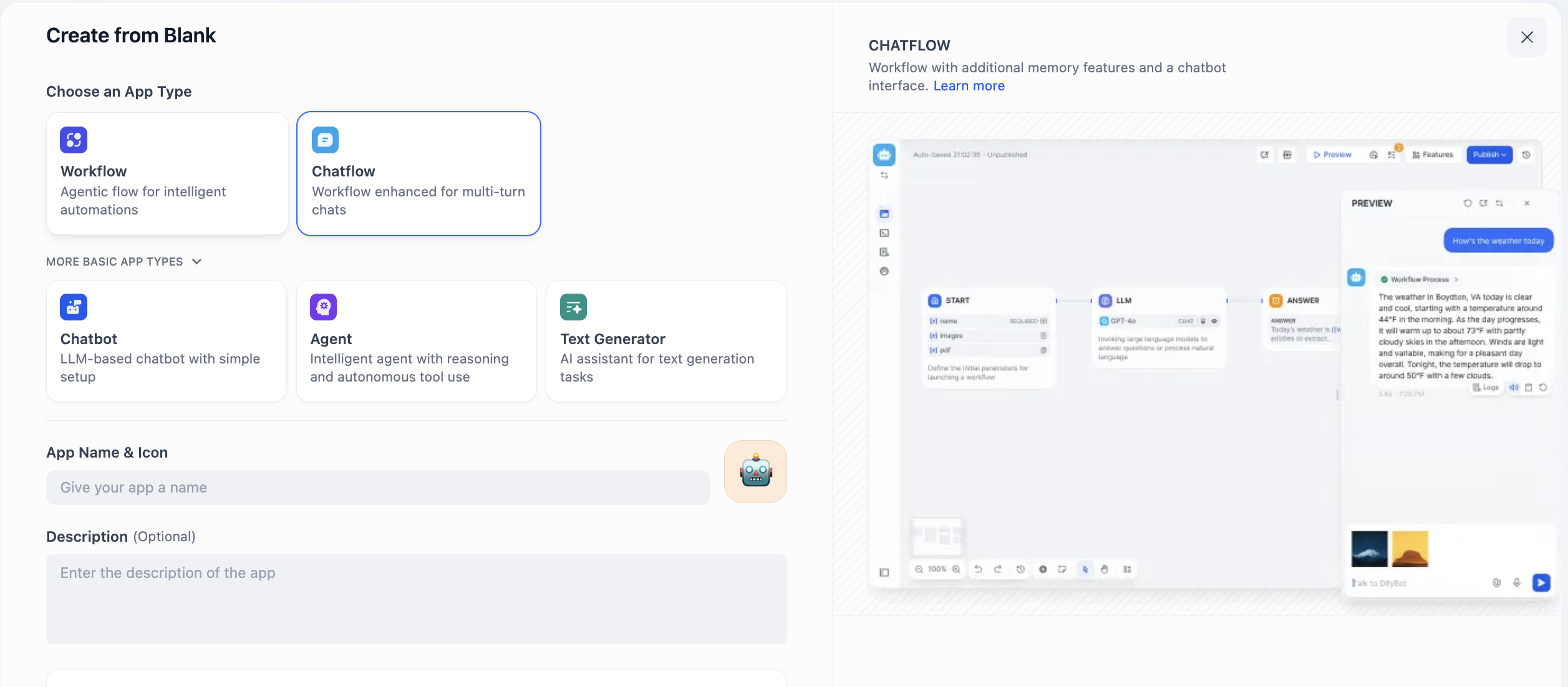
هنا سنرى خيارين، وهما Chatflow و Workflow، كيف نختار بينهما؟ المفتاح هو أن تحتاج إلى فهم ما تريد بناءه، هل جوهره محادثة مستمرة، أم تدفق مهام.
تم تصميم Chatflow خصيصًا للمحادثة. إنه يحاكي محادثًا يمتلك ذاكرة وفهمًا للسياق، وهو مناسب جدًا للسيناريوهات التي تتطلب تفاعلات متعددة الجولات والحفاظ على الحالة. على سبيل المثال، في استشارات خدمة العملاء، يمكنه فهم أسئلة المتابعة للمستخدم بشكل مترابط، مثل موظف خدمة صبور. ميزة الإخراج المتدفق تجعل عملية التفاعل أكثر طبيعية. باختصار، عندما تحتاج إلى بناء وكيل ذكي قادر على "التحدث"، يجب أن تختار Chatflow.
أما Workflow فيركز على التنفيذ الآلي للتدفقات. إنه مثل خط إنتاج مُعد مسبقًا، متخصص في معالجة المهام التي تتطلب إدخالًا لمرة واحدة ومعالجة متعددة الخطوات وتنتج مخرجات حتمية. على سبيل المثال، إنشاء تقارير بيانات مجدولة يوميًا، أو معالجة ملفات دفعية، أو استدعاء سلسلة من APIs. عادةً ما يتم تشغيل هذه المهام بواسطة أحداث ولا تتطلب تفاعلًا في الوقت الفعلي مع الأشخاص. لذلك، عندما تحتاج إلى تنفيذ مهام "أتمتة"، فإن Workflow هو الخيار الأنسب.
لتجنب انخفاض الكفاءة الناتج عن اختيار خاطئ، يمكنك مراجعة متطلبات مهمتك من خلال أربعة أسئلة رئيسية:
- هل عملية المهمة تعتمد على مدخلات وتعديلات متعددة من المستخدم؟
- هل يحتاج عرض النتائج إلى أن يتم خطوة بخطوة وبشكل متدفق؟
- هل يعتمد منطق المعالجة بشكل كبير على تاريخ التفاعلات السابقة؟
- هل يتم تشغيل المهمة بواسطة حدث، وهل الإدخال والإخراج يتمان في الغالب لمرة واحدة؟
إذا كانت إجابات الأسئلة الثلاثة الأولى هي "نعم"، فإن Chatflow هو الخيار المثالي، وتشمل السيناريوهات النموذجية خدمة العملاء الذكية، والتوجيه التعليمي، والتعاون الإبداعي. إذا كانت خصائص السؤال الرابع بارزة، فيجب اختيار Workflow، وهو أكثر ملاءمة لسيناريوهات الأتمتة مثل تنظيف البيانات، وإنشاء التقارير، والمعالجة الدفعية.
هنا نختار Chatflow كحالة للعرض التقديمي، بعد النقر على Chatflow ندخل إلى واجهة لوحة التشغيل:
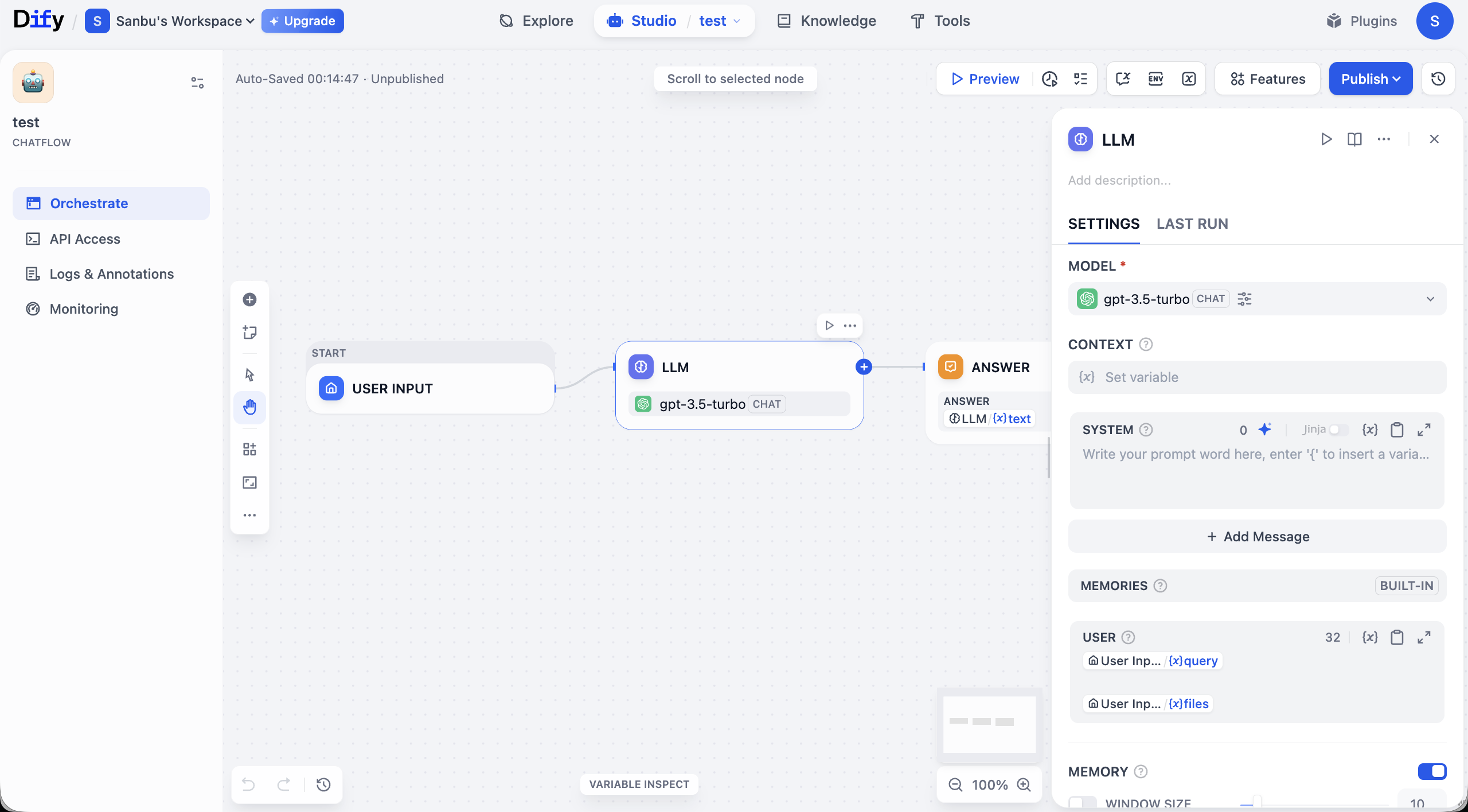
دعنا نقدم باختصار واجهة Workflow. جوهر الواجهة بأكملها هو لوحة التحرير المركزية، حيث ستبني منطق التطبيق بطريقة مرئية. كما هو موضح في الشكل، يبدأ Workflow الأساسي عادةً من عقدة START (لاستقبال المدخلات)، ويمر عبر خط ربط ينقل البيانات إلى عقدة LLM للمعالجة، وأخيرًا يخرج النتائج من خلال عقدة ANSWER. تمثل كل عقدة وحدة وظيفية، بينما تحدد خطوط الربط ترتيب تنفيذ المهام.
تحيط بلوحة التحرير منطقة إدارة وتشغيل وظيفية كاملة. يوفر الجزء العلوي من الواجهة خيارات التحكم العامة، بما في ذلك زر Preview لاختبار Workflow وزر Publish للنشر. بينما تحتوي زوايا اللوحة على أدوات التحكم في العرض مثل التكبير/التصغير والتراجع، لتسهيل التعديلات الدقيقة.
يضم اللوحة اليسرى وظائف إدارة التطبيق. علامة التبويب Orchestrate التي تتواجد فيها حاليًا تُستخدم لتنظيم التدفق؛ بعد الانتهاء من البناء، يمكنك الحصول على بيانات الاعتماد للتكامل من خلال API Access؛ تسجل Logs & Annotations تتبعًا تفصيليًا لكل تنفيذ، مما يسهل التصحيح؛ بينما يوفر لك Monitoring مراقبة الأداء والحالة لتطبيقك أثناء التشغيل.
يمكنك ببساطة إدخال بعض محتوى Prompt في SYSTEM لعقدة LLM في Workflow للمحادثة، ثم النقر على Preview لمحاولة تشغيل هذا Workflow، والتحقق من أن Workflow يتغير بالفعل كما هو متوقع بعد تعديل SYSTEM Prompt.
2.6.1 مقدمة عن العقد الشائعة
يوفر Dify مجموعة متنوعة من العقد، يمكنك أولاً فهم الوظائف الأساسية لكل عقدة. عند الاستخدام الفعلي، يُنصح بتجربتها بنفسك، أو الرجوع إلى قوالب Workflow التي أنشأها آخرون، أو التقاط لقطة شاشة وسؤال النموذج الكبير عن استخدام العقدة والمعلمات المطلوبة. يُوصى باستبدال العقد المختلفة مباشرة في القوالب الموجودة، والاستفادة من طريقة استخدام الآخرين لاستنتاج أفضل الممارسات للعقد.
انقر بزر الماوس الأيمن على "Add Node" في اللوحة لإضافة عقدة، أو يمكنك عرض جميع العقد المتاحة في لوحة العقد على الجانب الأيسر:
في الوقت نفسه، يمكنك فتح لوحة اختيار الأدوات لعرض أنواع الأدوات المتاحة للاستدعاء:
فيما يلي وصف مختصر لبعض العقد والأدوات الشائعة. لا تحتاج إلى إتقانها جميعًا في وقت واحد، يُنصح بأخذ فكرة عامة أولاً، ثم التعرف عليها تدريجيًا أثناء الاستخدام الفعلي، والعودة للت consultعند الحاجة.
- عقد LLM والاستدلال

هذه العقد مسؤولة عن التدفق الأساسي في Workflow.
- عقدة LLM: وحدة الحساب الأساسية، تُستخدم لاستدعاء النماذج اللغوية الكبيرة. تركز تكوينها على هندسة Prompts وتحسين المعلمات، وتحويل مشاكل الأعمال إلى تعليمات تنفيذية للنموذج.
- عقدة Knowledge Retrieval: وحدة استرجاع المعرفة، مسؤولة عن استرجاع المعلومات المتعلقة بمشاكل الأعمال من قواعد المعرفة المعدة مسبقًا ومصادر البيانات الموثوقة الخارجية، مما يوفر دعمًا معرفيًا دقيقًا لعقدة LLM، ويساعد في تقليل مشكلة "الهلوسة" في مخرجات النماذج اللغوية الكبيرة.
- عقدة Answer: وحدة إخراج النتائج، مسؤولة عن استقبال المحتوى المعالج من LLM وتنظيمه في شكل النتائج النهائية الذي يلبي متطلبات سيناريو الأعمال. تركز تكوينها على تعريف تنسيق الإخراج (مثل قوالب العبارات، ومعايير التنسيق).
- عقدة Agent: وحدة اتخاذ قرارات متقدمة. لا تستدعي النموذج فحسب، بل يمكنها أيضًا تنفيذ تخطيط متعدد الخطوات، واختيار واستدعاء أدوات خارجية بشكل مستقل، وهي مناسبة لسلاسل المهام المعقدة التي تتطلب قرارات ديناميكية.
- عقدة Question Classifier: وحدة تصنيف الأسئلة، مسؤولة عن تحديد نوع وتصنيف أسئلة الأعمال المدخلة (مثل التصنيف حسب نية السؤال، أو مجال الموضوع، وما إلى ذلك)، مما يساعد التدفق اللاحق في المطابقة الدقيقة لعقد المعالجة المقابلة (مثل مطابقة Prompts LLM مختلفة أو سلاسل أدوات مختلفة لأنواع مختلفة من الأسئلة).
- عقد التحكم المنطقي والتدفق

هذه العقد تحدد مسارات التنفيذ وقواعد Workflow.
- عقدة الشرط: مثل
IF/ELSE، تحقق تفرع التدفق من خلال الحكم المنطقي البولياني. مفتاح تصميمها هو دقة تعبيرات الشرط، لضمان تغطية المنطق لجميع سيناريوهات الأعمال. - عقدة Iteration: كوحدة معالجة متوازية دفعية عديمة الحالة، فهي مصممة للسيناريوهات التي لا توجد فيها تبعيات بيانات بين المهام الفرعية ويمكن معالجتها بشكل مستقل، مثل ترجمة الفقرات دفعة واحدة، أو مراجعة محتويات متعددة بالتوازي، أو إنشاء تقارير متعددة في وقت واحد. تستقبل هذه العقدة مصفوفة إدخال وتقوم بالتقسيم التلقائي، وتوزيع كل عنصر على نفس سلسلة المعالجة للتنفيذ المتوازي. يمكن للمستخدمين الوصول إلى العنصر الحالي عبر
والحصول على فهرسه عبرداخل جسم التكرار، وسيتم تجميع المخرجات تلقائيًا في مصفوفة نتائج؛ يجب التركيز عند التكوين على تعيين درجة التوازي لتحقيق التوازن بين الكفاءة والحمل على النظام، مع ضمان استقرار عمليات المعالجة الدفعية من خلال استراتيجيات إعادة المحاولة (مثل عدد مرات إعادة المحاولة والفاصل الزمني) ومعالجة الفشل (مثل تسجيل السجلات أو إرجاع قيم افتراضية). - عقدة Loop: مكرر تكراري ذو حالة، مناسب للسيناريوهات التي تعتمد فيها النتائج على مخرجات الجولة السابقة، مثل تحسين المعلمات متعدد الجولات، أو تحسين المحتوى التكراري (مثل مراجعة النصوص بشكل متكرر حتى الرضا)، والعمليات الحسابية المتسلسلة التي تعتمد على النتيجة السابقة. جوهرها هو "متغير الحالة"، الذي يجب تهيئته قبل بدء الحلقة (مثل عدد التكرارات الحالية، ونتائج الحساب الوسيطة)، ويجب تحديثه بوضوح في كل جولة تكرار ليعمل كمدخل للجولة التالية؛ لمنع الحلقات اللانهائية، يجب تعريف شرط الإنهاء (بما في ذلك "الحد الأقصى 10 دورات" القائم على العداد، و"درجة الرضا > 9" القائم على حكم النتيجة، و"اكتشاف إدخال 'توقف'" القائم على إشارة خارجية)، مع تعيين تكوين مهلة الحلقة، وتخطيط مسار معالجة الاستثناءات (مثل الخروج من الحلقة أو إعادة تعيين الحالة ثم إعادة المحاولة)، لضمان التشغيل المستقر للتدفق.
- عقد معالجة البيانات والتكامل
- عقدة Code: وحدة معالجة الكود، مسؤولة عن تنفيذ منطق كود مخصص في Workflow، ويمكنها تحقيق احتياجات المعالجة الشخصية مثل تحويل تنسيق البيانات والحسابات المعقدة. تركز تكوينها على صحة بناء كود الكود وتوافق بيئة التنفيذ.
- عقدة Template: وحدة معالجة القوالب، مسؤولة عن ملء البيانات الديناميكية في قوالب معدّة مسبقًا، وإنشاء محتوى يلبي متطلبات التنسيق (مثل نصوص مخصصة، إطارات تقارير). تركز تكوينها على كتابة بناء جملة القالب وإعداد قواعد تعيين المتغيرات.
- عقدة Variable Aggregator: وحدة تجميع المتغيرات، مسؤولة عن جمع بيانات المتغيرات المُخرجة من عقد متعددة في Workflow، وتجميع المتغيرات المبعثرة في مجموعة بيانات موحدة. تركز تكوينها على تعريف نطاق المتغيرات المجمعة وقواعد دمج البيانات.
- عقدة Doc Extractor: وحدة استخراج المستندات، مسؤولة عن استخراج النصوص والجداول والمحتويات الرئيسية الأخرى من أنواع مختلفة من المستندات مثل PDF وWord، وتحويلها إلى بيانات مهيكلة يمكن لـ Workflow معالجتها. تركز تكوينها على تكييف أنواع المستندات وقواعد فرز المحتوى المستخرج.
- عقدة Variable Assigner: وحدة تعيين المتغيرات، مسؤولة عن تعريف وتهيئة أو تحديث المتغيرات في Workflow، وتوفير حامل لنقل البيانات داخل التدفق. تركز تكوينها على تسمية المتغيرات ونوع البيانات ومنطق التعيين.
- عقدة Parameter Extractor: وحدة استخراج المعلمات، مسؤولة عن استخراج المعلمات المحددة من محتوى الإدخال مثل طلبات المستخدم واستجابات واجهة برمجة التطبيقات، وتحويل المعلومات غير المهيكلة إلى بيانات مهيكلة. تركز تكوينها على تكوين قواعد الاستخراج (مثل التعبيرات النمطية، مسارات JSON).
- عقدة HTTP Request: وحدة طلبات HTTP، مسؤولة عن بدء طلبات HTTP (بما في ذلك طرق GET وPOST وغيرها) إلى واجهات الأنظمة الخارجية، لتحقيق تبادل البيانات بين Workflow والخدمات الخارجية. تركز تكوينها على تعيين عنوان الطلب وطريقة الطلب ومعلمات/headers الطلب.
- عقدة List Operator: وحدة عمليات القوائم، مسؤولة عن معالجة بيانات نوع المصفوفات والقوائم (مثل التصفية، الفرز، التقسيم)، وتعديل بنية البيانات لتتناسب مع التدفق اللاحق. تركز تكوينها على تعريف نوع العملية (مثل شروط التصفية، قواعد الفرز).
2.6.2 مقدمة عن الأدوات الشائعة
في Dify، يمكن وضع معظم الأدوات مباشرة على اللوحة كعقد، مثل العقد الأخرى التي يتم ربطها بأعلىها وأسفلها، طالما أن المدخلات التي تقدمها تتوافق مع معلمات تلك العقدة (الأداة)، فستتمكن من التنفيذ بشكل طبيعي وإنتاج نتائج يمكن أن تستمر في التدفق.
في لوحة العقد اليسرى أو اليمنى، يمكنك عرض جميع عقد الأدوات المتاحة، ويمكنك أيضًا توسيع المزيد من قدرات الأدوات من خلال سوق الإضافات. فيما يلي مقدمة مختصرة لبعض الأدوات الشائعة:
- أدوات البحث على الويب ممثلة بـ Tavily Search، توفر للنموذج الكبير قدرات بحث فوري مُحسّنة للذكاء الاصطناعي. تُرجع نتائج بحث مهيكلة (مثل العناوين، المختصرات، الروابط، وما إلى ذلك)، يمكن استخدامها مباشرة كجزء من Prompt LLM للإجابة على الأسئلة المتعلقة بأحدث الأخبار أو التي تتطلب أدلة موثوقة.
- أدوات معالجة البيانات مثل إضافة JSON Process، المستخدمة لإجراء عمليات متقدمة على بيانات JSON مثل الاستعلام والتصفية والتحويل والدمج. عند معالجة استجابات API المعقدة أو البيانات المتداخلة متعددة الطبقات، يمكنك تسليم منطق "تنظيف البيانات + إعادة التشكيل" إلى هذه الأداة، مما يبسط عمل كتابة كود التحليل بشكل متكرر في عقدة Code.
- أدوات معالجة التنسيقات مثل Markdown Exporter، التي يمكنها تصدير المحتوى المُنشأ بالتنسيق المحدد، مثل مستندات Markdown أو قوالب تنسيق معينة، مما يسهل الاستخدام اللاحق للعرض أو التقارير أو التكامل مع أنظمة أخرى.
يمكنك رؤية عدد التثبيتات ومقدمة مختصرة لهذه الإضافات في قائمة الأدوات، ويمكنك في البداية إعطاء الأولوية لتجربة تثبيت الأدوات الموجودة في "Featured / الموصى بها"، والتي غالبًا ما تغطي سيناريوهات الأعمال الأكثر شيوعًا.
ومع ذلك، فإن استخدام الأدوات عادة ما يكون معقدًا نسبيًا، يُنصح عند الاستخدام بالبحث أولاً في محرك البحث عن "حالة DSL Workflow الموصى بها رسميًا" للأداة المقابلة، واستيرادها مباشرة للاستخدام، مما يوفر الكثير من الوقت بشكل طبيعي مقارنة بالبناء بنفسك.
2.6.3 إنشاء Workflow تصنيف نية بسيط
في هذه المرحلة، تعرفنا بشكل مبدئي على المعلومات الأساسية مثل Dify Workflow والأدوات، ولكن بدون ممارسة لن نتمكن أبدًا من إتقان استخدام التفاصيل، نحتاج إلى سيناريو أعمال "حقيقي" مفترض للتدرب عليه.
على سبيل المثال، في سيناريو تسوق حقيقي، مدخلات المستخدمين الذين يأتون لشراء البضائع لن تكون أبدًا "معلمات قياسية"، بل جملة تُقال عفويًا: البعض يأتي لتقديم طلب، والبعض يأتي للشكوى، والبعض يريد فقط الدردشة، والبعض يخرج تمامًا عن الموضوع. إذا قمنا بتسليم جميع هذه المدخلات مباشرة إلى نفس النموذج اللغوي الكبير (LLM) للمعالجة، فسيظهر النظام عادةً مشكلتين نموذجيتين:
- عدم استقرار أسلوب الرد نفس الشكوى، أحيانًا يستطيع LLM الاعتذار والتهدئة، وأحيانًا أخرى يبدو وكأنه "يشرح الأسباب"؛ نفس الطلب، أحيانًا يسأل عن المعلومات الناقصة، وأحيانًا أخرى يختلق تفاصيل الطلب مباشرة.
- عدم التحكم في منطق الأعمال تأمل أن "الشكوى يجب أن يُعتذر أولاً"، لكن النموذج قد لا يلتزم بذلك في كل مرة؛ تأمل أن "الأسئلة غير المتعلقة بالأعمال يجب توجيهها إلى المسار الرئيسي"، لكن النموذج قد يبدأ بحماس في مشاركة النكات معك.
لذلك، فإن النهج الأكثر هندسة هو تفكيك المهمة إلى خط إنتاج قياسي، أولاً إجراء تصنيف النية (تحديد ما يريد المستخدم فعله بالضبط)، ثم التوجيه حسب النية (استخدام Prompts وأدوار مختلفة لسيناريوهات مختلفة)، وأخيرًا تجميع مخرجات النموذج الكبير وتغليفها بشكل موحد بعد التوجيه المختلف (لتسهيل تكامل الواجهة الأمامية أو النظام).
هدف هذا القسم هو تمكين النظام من معالجة أنواع متعددة من المحادثات في سيناريو مطعمي. يمكنك اتباع العمليات خطوة بخطوة لتعميق الانطباع. أولاً، يجب تعريف السيناريو كتصنيف نية:
- طلب شراء (buy_food): يعبر المستخدم عن رغبة واضحة في الشراء.
- على سبيل المثال: "أعطني وجبة دجاج مقلي، مع كوب كولا."
- شكوى (complain): يعبر المستخدم عن استياء أو استعجال أو ملاحظات سلبية.
- على سبيل المثال: "أنتم بطيئون جدًا؟ أنتظر منذ ساعة."
- دردشة واستشارة (chitchat): يقوم المستخدم بطرح أسئلة مفتوحة أو طلب نصائح، دون تعليمات شراء واضحة.
- على سبيل المثال: "ماذا آكل اليوم، هل لديك أي توصيات؟"
- نوايا أخرى (other): مدخلات المستخدم لا علاقة لها بسيناريو المطعم.
- على سبيل المثال: "ساعدني في كتابة نص مضحك لمنشور على وسائل التواصل الاجتماعي."
بالنسبة لهذه النوايا الأربع، قمنا بإعداد أربع "شخصيات تواصل" مختلفة مسبقًا للنظام، يحملها أربع عقد LLM مستقلة، وكل عقدة تحتاج إلى أن يلعبها LLM بشخصية مختلفة.
- مساعد الطلبات (LLM_BuyFood): احترافي وفعال، مهمته الأساسية هي تأكيد تفاصيل الطلب واستكمال المعلومات الناقصة بشكل استباقي.
- خبير خدمة العملاء (LLM_Complain): متعاطف وهادئ، مهمته الأولى هي تهدئة مشاعر المستخدم وتقديم حلول واضحة.
- شريك الدردشة (LLM_Chitchat): مرن وودود، يهدف إلى تقديم توصيات مخصصة وتوجيه الاستهلاك المحتمل.
- حارس الأدب (LLM_Other): مركز وحدود واضحة، مسؤول عن توجيه المحادثات الخارجة عن الموضوع بلباقة إلى الأعمال الأساسية.
تصميم تنظيم Workflow
بعد ذلك نقوم بإجراء إعدادات تنظيم Workflow، وتحديد العقد المطلوبة تقريبًا. للمبتدئين، من الصعب التفكير في العقد التي قد تكون مطلوبة (وحتى المحترفين لا يرغبون في التفكير بأنفسهم، فاستخدام النموذج الكبير لتقديم الاقتراحات عادة ما يكون الخيار الأسرع والأفضل)، لذا يمكننا استخدام النموذج الكبير لتقديم اقتراحات التنظيم المقابلة، وهيكل العقد الأساسي كما يلي:
- Start (نقطة البداية): كمدخل للبيانات، مسؤول عن استقبال المدخلات الأصلية للمستخدم
user_text. - Question Classifier (مصنف النية): "عقل" و"مركز الإرسال" في Workflow. مسؤول عن تحليل
user_textواختيار الأقرب مطابقة من علامات النية الأربع المعدة مسبقًا. - Condition (تفرع شرطي): يلعب دور "صمام التوجيه". بناءً على علامة النية التي يُخرجها المصنف، يقرر المسار المخصص الذي سيتم توجيه المهمة إليه بعد ذلك.
- أربع عقد LLM متوازية (LLM_BuyFood، LLM_Complain، LLM_Chitchat، LLM_Other): هذه أربع "وحدات معالجة خبيرة" مستقلة. تستقبل كل عقدة السؤال الأصلي، ولكنها تولد ردودًا بأسلوب وأهداف مختلفة تمامًا بناءً على System Prompt الفريد الخاص بها.
- Variable Aggregator (مُجمّع المتغيرات): بعد اكتمال معالجة المسارات المتعددة، يلزم "نقطة تجميع". تجمع هذه العقدة الرد الوحيد المنشط والمنتج من الفروع الأربعة في متغير موحد
final_reply، مما يضمن استقرار بنية الإخراج. - Output (نقطة النهاية): كمخرج نهائي، مسؤول عن إخراج علامة النية والسؤال الأصلي والرد المُنشأ بعد المعالجة بشكل موحد في شكل مهيكل (مثل JSON)، مما يسهل استدعاء النظام اللاحق أو تحليل التصحيح.
تنفيذ تنظيم Workflow
في هذا البرنامج التعليمي اخترنا إنشاء Workflow بدلاً من Chatflow، واخترنا User Input:
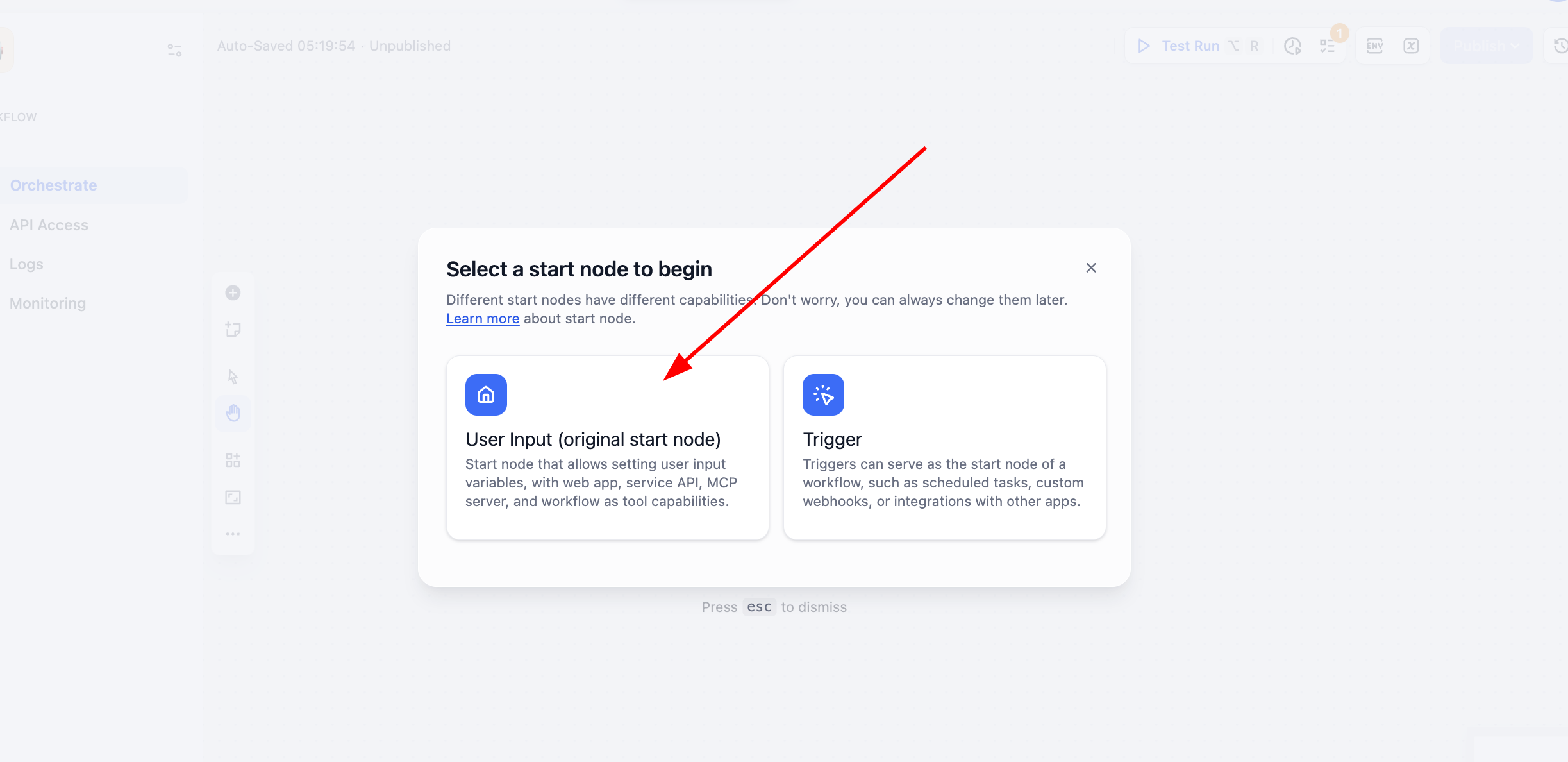
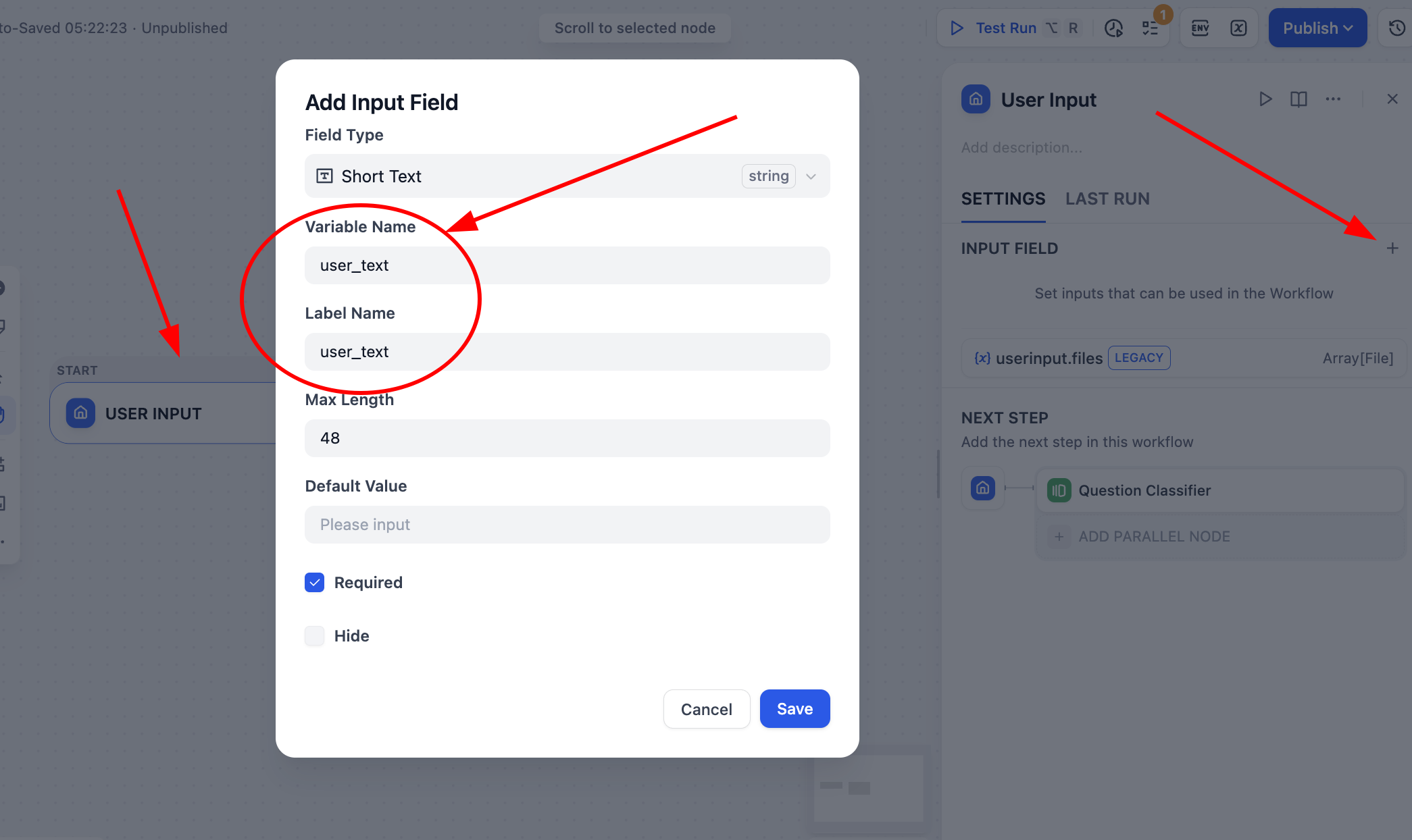
ثم انقر على عقدة User Input في Start، وقم بتعريف متغير نوع سلسلة نصية باسم user_text كمصدر إدخال للتدفق بالكامل.
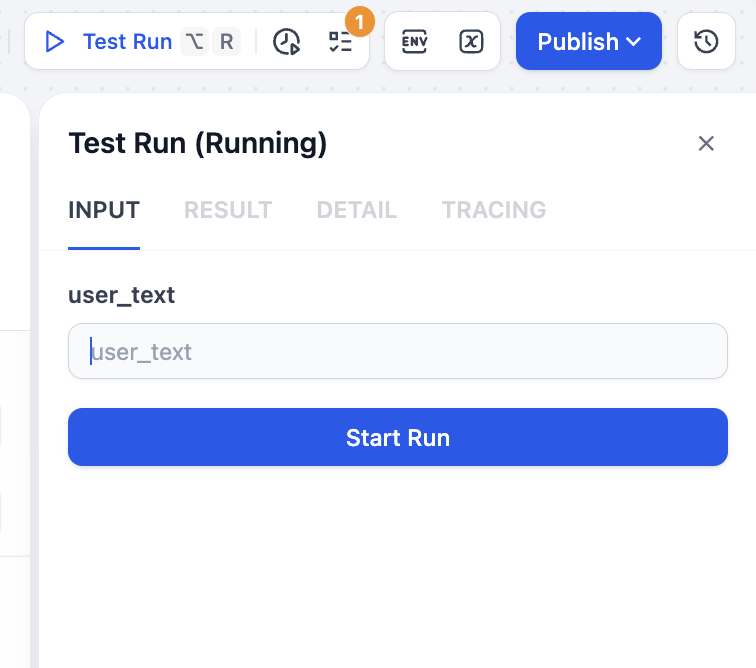
بعد الحفظ، انقر على Test Run في الزاوية اليمنى العليا، ستتمكن من رؤية أنك بحاجة إلى تحديد إدخال نصي معين للمعالجة:
بعد ذلك نحتاج إلى النقر على رمز + بعد عقدة الإدخال، واختيار إضافة عقدة Question Classifier، ويجب علينا تكوين أربع فئات من العلامات لها، وتقديم أوصاف وأمثلة واضحة لكل علامة.
buy_food: يريد المستخدم بوضوح شراء الطعام أو تقديم طلب.complain: المستخدم يشكو أو يتذمر أو يغضب، وعادةً ما يحمل مشاعر استياء.chitchat: المستخدم يتحدث أو يناقش ما يأكله أو يستشير بشأن التوصيات.other: محتوى غير متعلق بسيناريو المطعم، أو صعب الحكم عليه.
بالإضافة إلى ذلك، تحتاج أيضًا إلى كتابة Prompt في ADVANCED SETTING، بحيث يتمكن النموذج الكبير من إجراء اختبار التصنيف بشكل صحيح بناءً على إدخال المستخدم. مثال على Prompt كما يلي:
اختر العلامة الأنسب من buy_food / complain / chitchat / other. إذا كان المستخدم يشكو وفي نفس الوقت يطلب الطعام، أعطِ الأولوية للحكم على عاطفته الأساسية، إذا كان التركيز على التعبير عن الاستياء، فيجب تصنيفها كـ complain. إذا كان مجرد تذمر بسيط ولكن النية الأساسية هي تقديم الطلب، فصنّفها كـ buy_food. إذا كان من الصعب حقًا الحكم، استخدم other كحالة احتياطية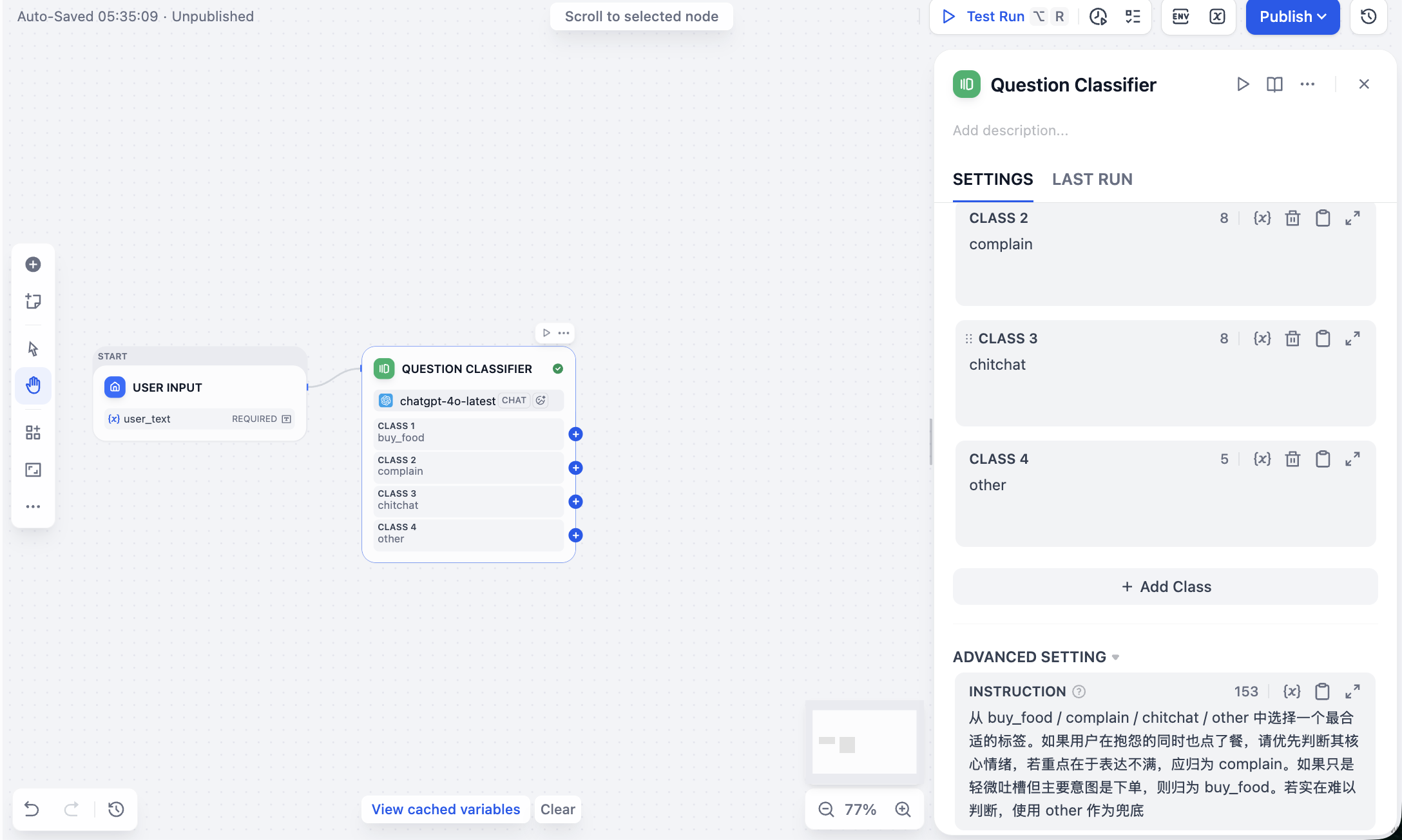
بعد الانتهاء من الإعداد، يمكنك النقر على زر التشغيل في الزاوية اليمنى العليا لاختبار ما إذا كانت هذه العقدة تعمل بشكل صحيح بشكل منفصل:
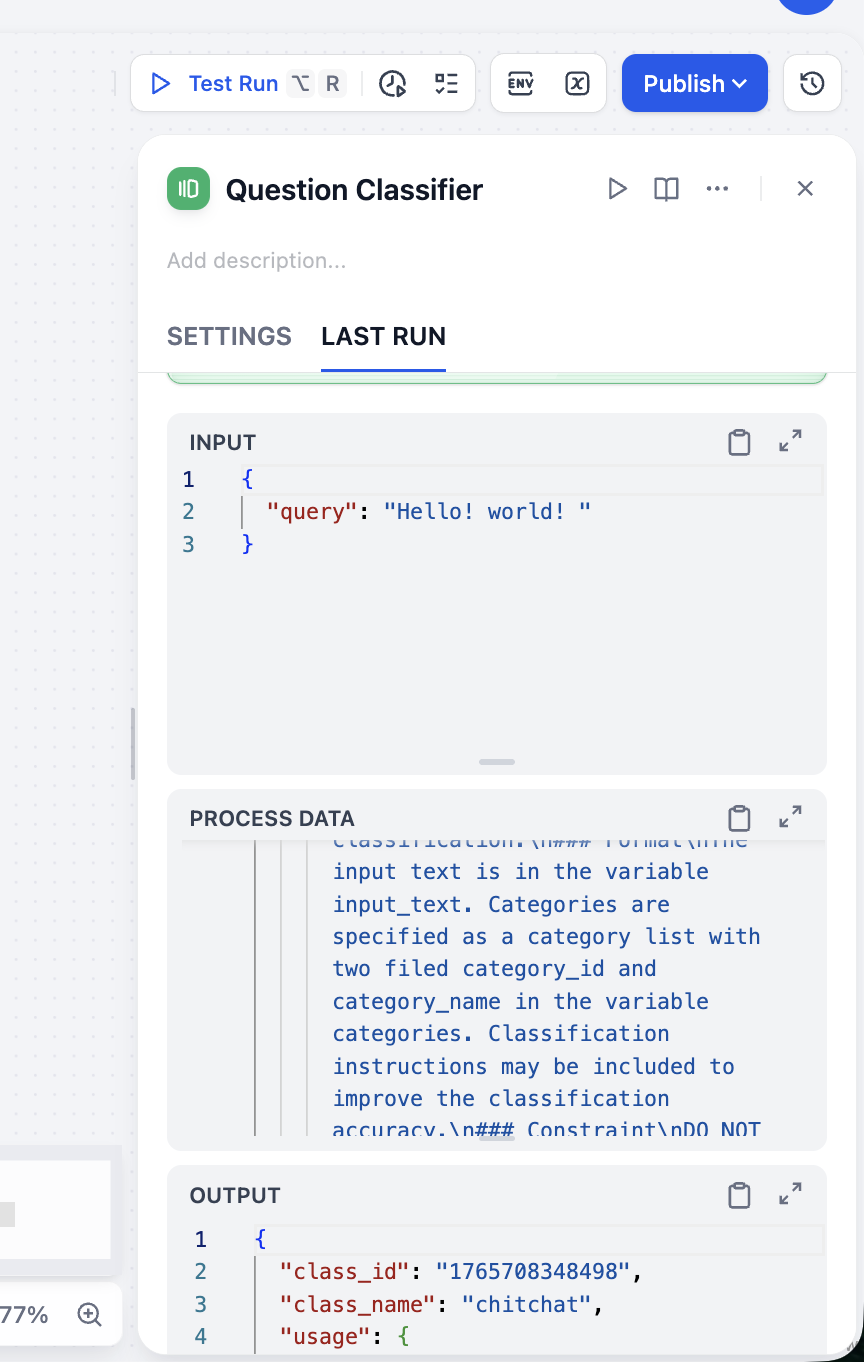
من نتائج OUTPUT، تصنيفنا دقيق. يمكنك إجراء اختبارات لأنواع مختلفة من المدخلات للتحقق من استقرار المصنف الخاص بنا.
بعد ذلك، نحتاج إلى ربط مخرجات النموذج الكبير اللاحقة بالمصنف، على سبيل المثال، عندما يكون label مساويًا لـ "buy_food"، سيتدفق Workflow بدقة إلى عقدة LLM_BuyFood. نحتاج إلى إنشاء أربع عقد LLM جديدة، وتعيين System Prompt مختلف؛ اختلاف System Prompt المختلف يحدد أسلوب استجابتها المختلف.
- LLM_BuyFood (مساعد الطلبات):
أنت مساعد طلبات. المتطلبات: 1. تأكيد المحتوى الذي يريد المستخدم طلبه. 2. إذا كانت المعلومات غير مكتملة، اسأل بلباقة لاستكمالها. 3. نبرة مهذبة وموجزة.
- LLM_Complain (خبير خدمة العملاء):
أنت موظف خدمة عملاء مطعمي، متخصص في التعامل مع الشكاوى. المتطلبات: 1. اعتذار صادق. 2. شرح موجز للأسباب المحتملة (دون تحميل المسؤولية للآخرين). 3. تقديم خطة حل واضحة للخطوة التالية.
- LLM_Chitchat (شريك الدردشة):
أنت مساعد دردشة صغير يساعد الناس في اختيار الطعام. المتطلبات: 1. استخدم نبرة مرحة وودودة. 2. قدم 1~3 توصيات بسيطة. 3. إذا لم يكن لدى المستخدم تفضيلات، قدم خيارات بأنماط مختلفة.
- LLM_Other (حارس الأدب):
أنت مساعد طلبات مطعمي، تتقن فقط المواضيع المتعلقة بـ"الأكل". عندما يقول المستخدم شيئًا غير متعلق: 1. اشرح بأدب نطاق قدراتك. 2. وجّه المستخدم للعودة إلى السيناريو الرئيسي.
تجدر الإشارة إلى أنه في كل عقدة بعد ملء معلمات Prompt الخاصة بـ SYSTEM، يجب أن تتذكر أيضًا تمكين جدول معلمات USER Prompt. تحتاج فيه إلى النقر على رمز {x}، واختيار معامل user_text كإدخال المستخدم، وإضافة user input: في المقدمة للإشارة إلى أن هذا المتغير يعني إدخال المستخدم، أثناء المحادثة سيتم الجمع بين إدخال المستخدم الأصلي وPrompt المدمج للرد.
وبالمثل، لضمان سير كل شيء على ما يرام، يمكنك النقر على سهم التشغيل في الزاوية اليمنى العليا للعقدة لإجراء اختبار محادثة محدد للتحقق من التأثير، مثل القول "أريد شرب شاي لؤلؤي بالحليب" وما إلى ذلك، والتحقق مما إذا كانت الاستجابة تتطابق مع التوقعات.
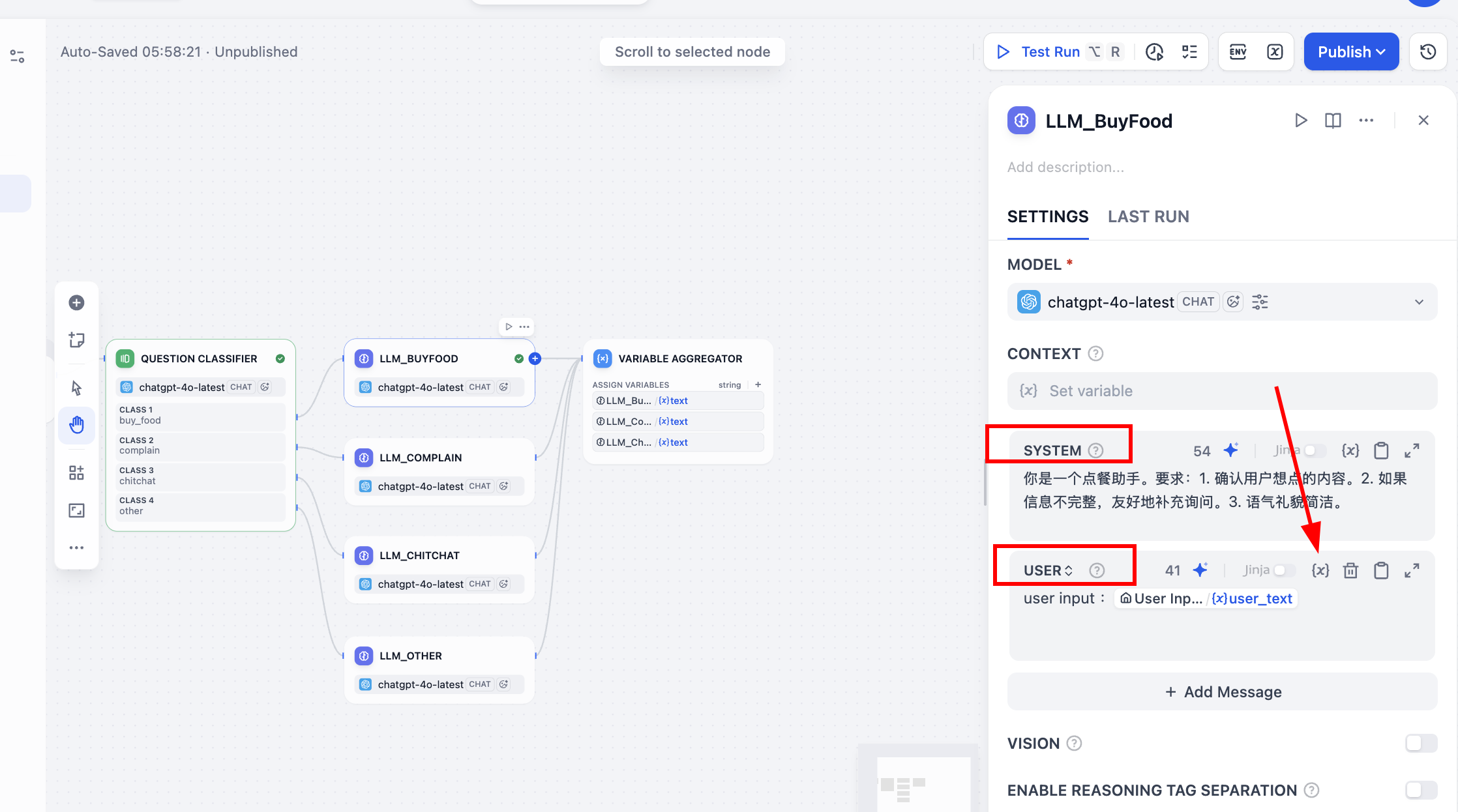
بعد ذلك نعالج قيم المخرجات لـ LLM المتوازية، في لوحة تكوين عقدة Variable Aggregator، نجد منطقة ASSIGN VARIABLES (تعيين المتغيرات)، ثم نضيف ردود النموذج الكبير السابقة واحدة تلو الأخرى.
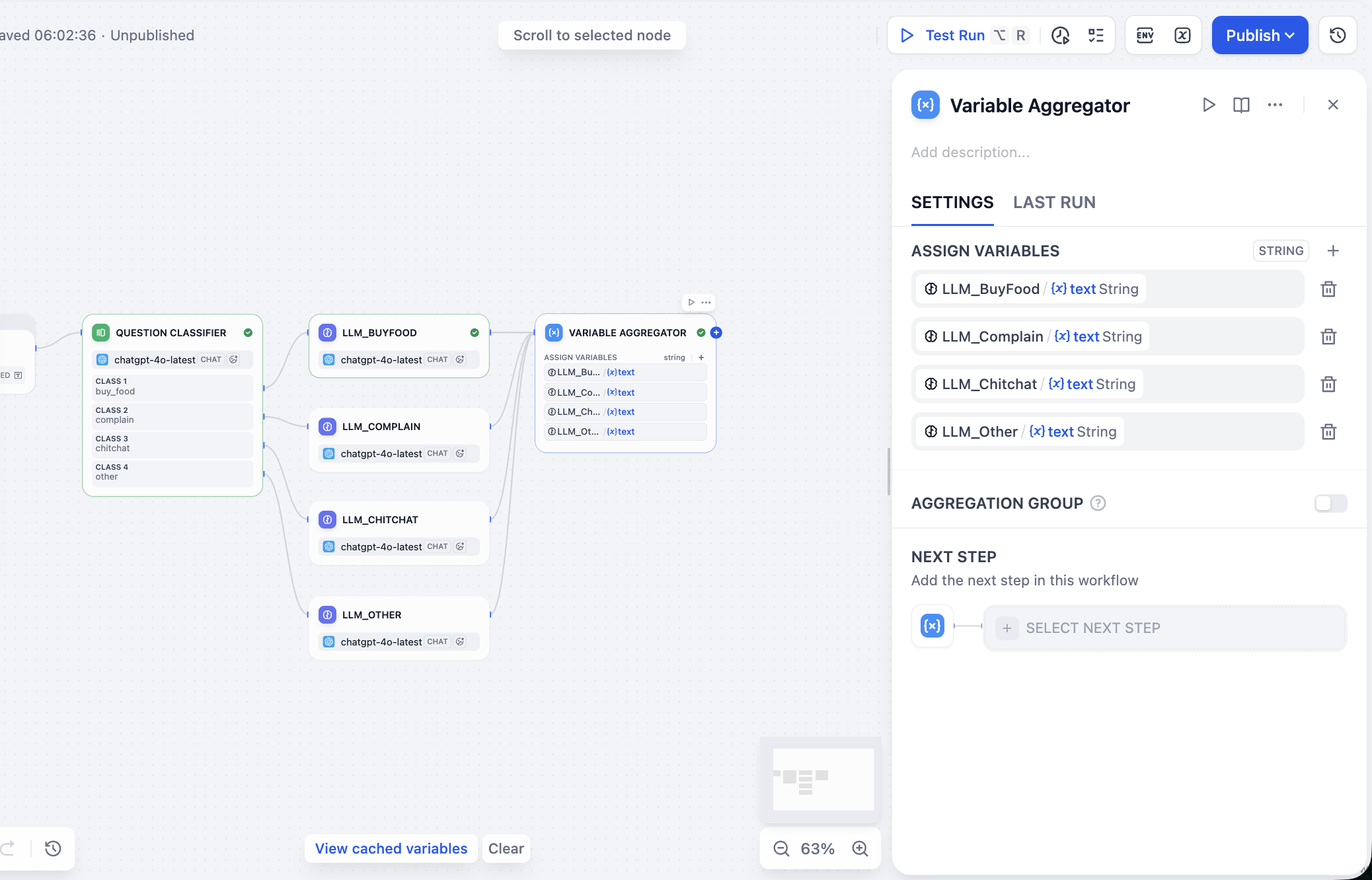
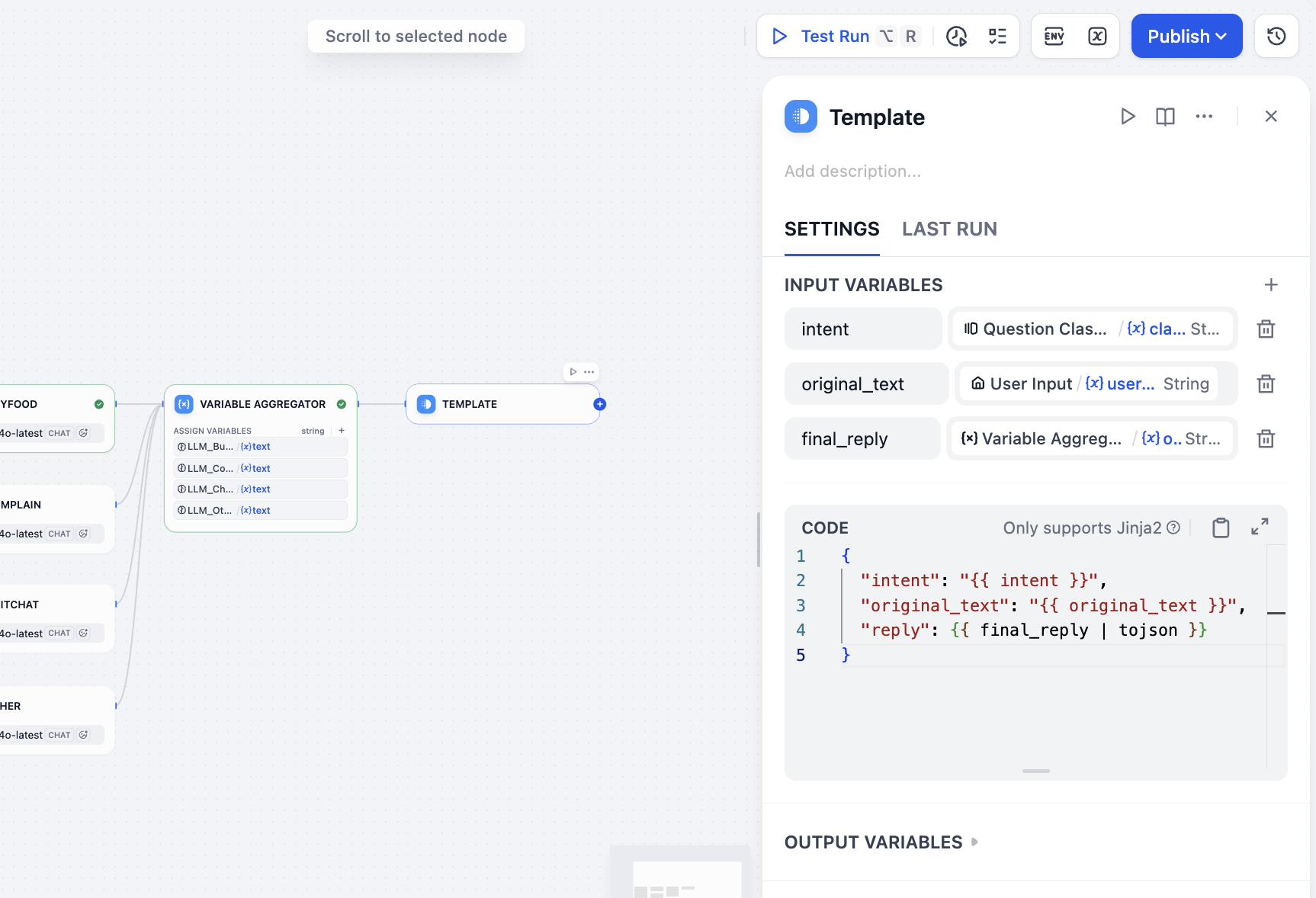
بعد ذلك نحتاج إلى تجميع جميع المخرجات، وأخيرًا الحصول على النتيجة التي نريدها، بما في ذلك إدخال المستخدم والتصنيف والرد. نظرًا لأننا نستخدم Workflow بدلاً من Chatflow، فلا يوجد خيار لعقدة Answer لتجميع النتائج، يمكننا اختيار عقد أخرى لتحقيق تجميع وإخراج النتائج بشكل غير مباشر، هنا نختار عقدة Template، ونحدد في جزء المتغيرات نتيجة تصنيف نية المستخدم وقيمة إدخال المستخدم والرد النهائي المُجمّع، ونكتب قالب تنسيق JSON للرد النهائي في CODE، يمكننا الحصول على:
intent←class_nameoriginal_text←user_textfinal_reply←variable_aggregator
{
"intent": "{{ intent }}",
"original_text": "{{ original_text }}",
"reply": {{ final_reply }}
}
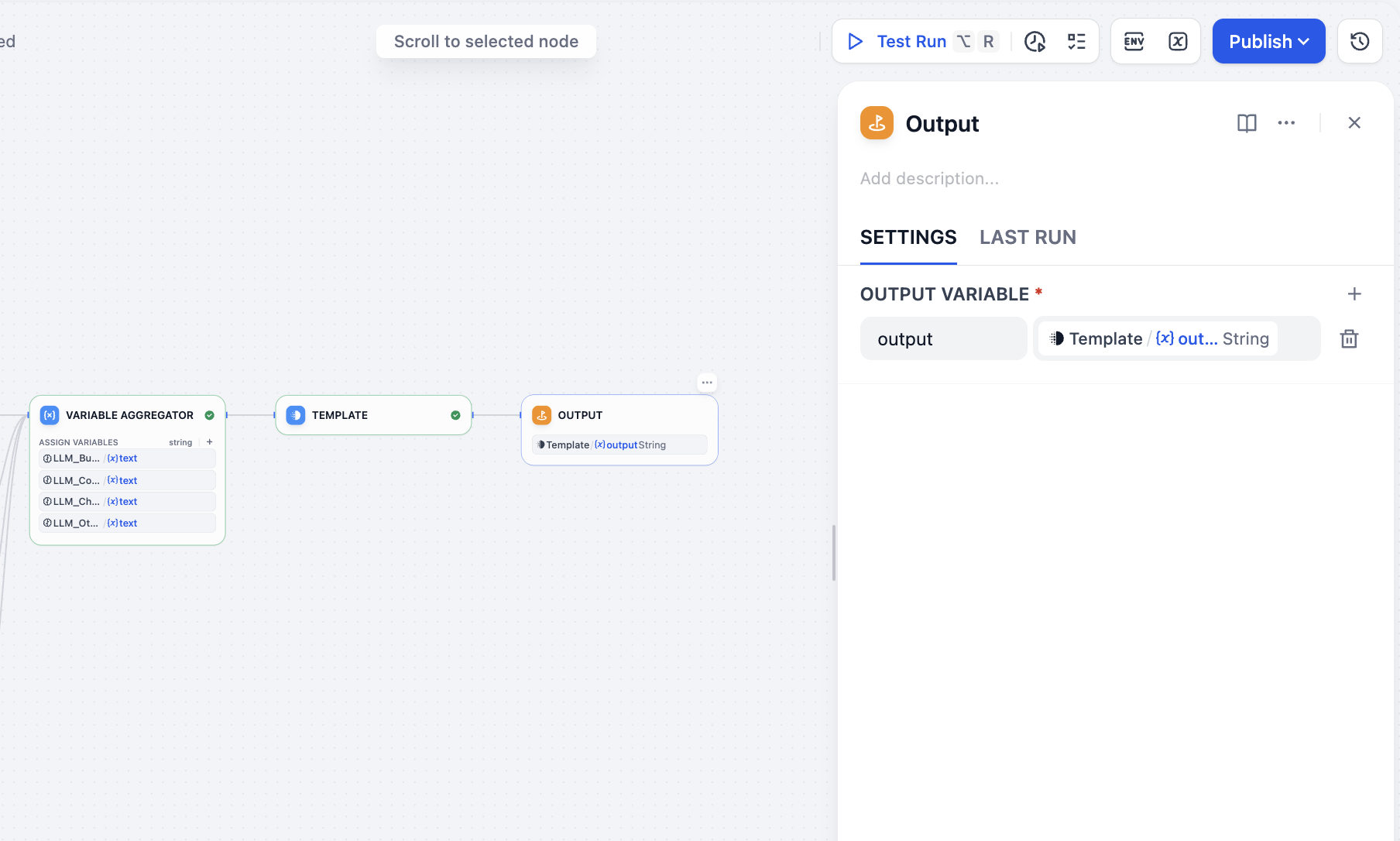
أخيرًا أضف عقدة output لإكمال جميع العمليات:
اختبار تشغيل Workflow
تم الانتهاء من كل شيء، يمكننا محاولة تشغيل تأثير هذا Workflow. يمكنه إظهار أنماط سلوك مختلفة تمامًا بناءً على مدخلات مختلفة:
- إدخال (طلب): "أعطني وجبة برجر دجاج حار مع كولا كبيرة."
- المسار:
buy_food→LLM_BuyFood - إخراج reply: "حسنًا، تم تسجيل وجبة برجر دجاج حار مع كولا كبيرة. هل تريد استبدال البطاطس المقلية في الوجبة؟"
- المسار:
- إدخال (شكوى): "أنتم بطيئون جدًا! أنتظر منذ أكثر من ساعة!"
- المسار:
complain→LLM_Complain - إخراج reply: "نعتذر بشدة عن إطالتكم في الانتظار، هذا بالتأكيد إهمال من جانبنا وقد سبب لكم تجربة سيئة للغاية. نحن نتحقق بشكل عاجل من حالة توصيل طلبكم وسنتقدم بطلب تعويض مناسب لكم، نشكركم على صبركم وملاحظاتكم."
- المسار:
- إدخال (دردشة): "ماذا آكل اليوم يكون صحيًا؟"
- المسار:
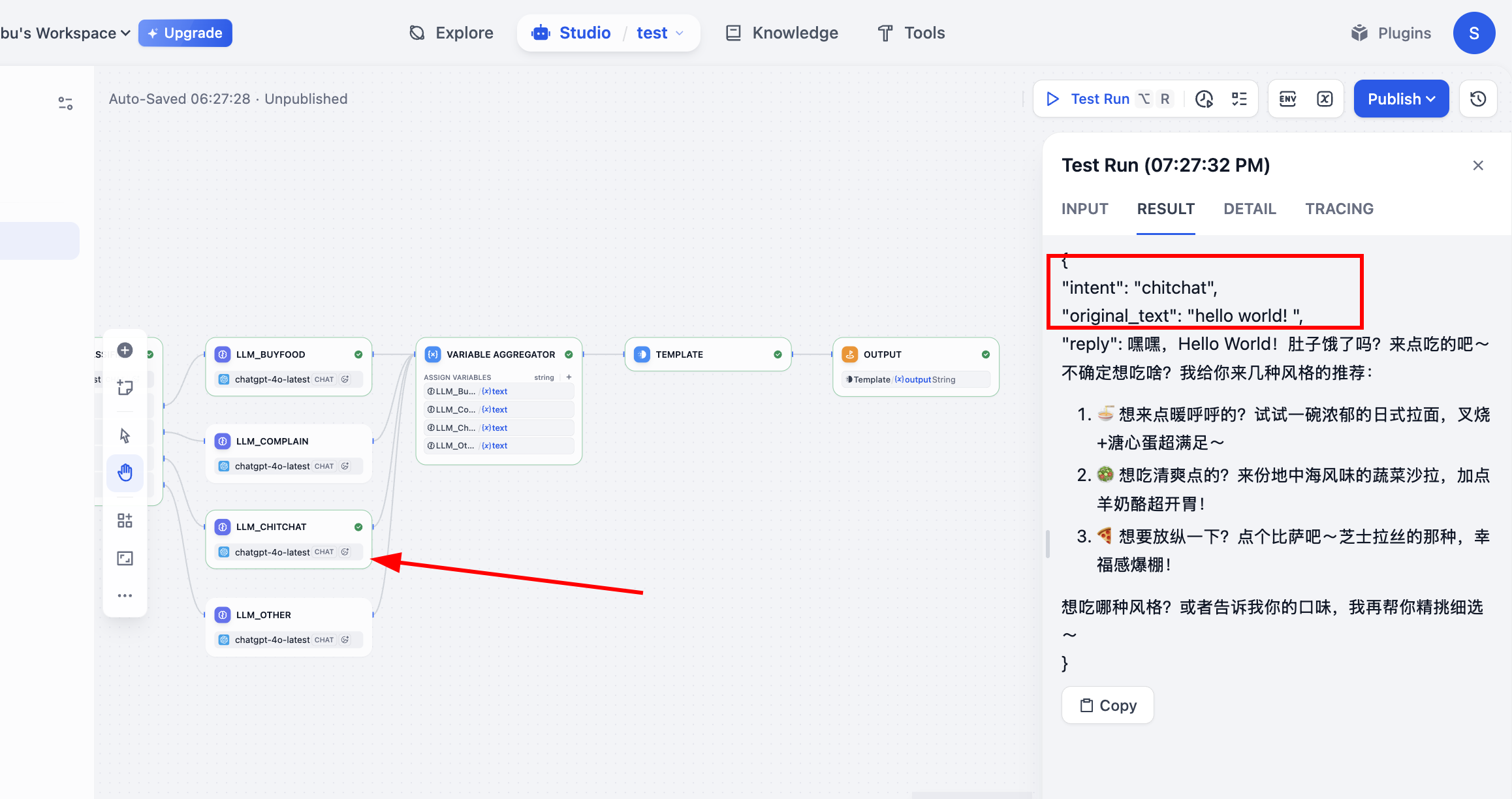
chitchat→LLM_Chitchat - إخراج reply: "إذا كنت تبحث عن صحة، يمكنك تجربة سلسلة سلطات الوجبات الخفيفة لدينا، أو صدور الدجاج المشوية مع الخضروات الموسمية. هل تفضل نكهة خفيفة أم أكثر ثراءً قليلاً؟ يمكنني تقديم توصيات أكثر تحديدًا لك."
- المسار:
- إدخال (محتوى غير متعلق): "ساعدني في التفكير في نكتة لاجتماع الغد."
- المسار:
other→LLM_Other - إخراج reply: "هذا يبدو تحديًا ممتعًا! لكنني أساسًا مساعد لتوصيات الطعام والطلبات. إذا كنت بحاجة إلى طلب شيء لمكافأة نفسك على العمل الشاق، فأنا جاهز للمساعدة في أي وقت!"
- المسار:
Bug مخفي: يجب التوضيح أنه إذا واجهت مشاكل غريبة متعلقة بـ aggregation group، فهذا على الأرجح bug مدمج في Dify. قد يتم تفعيله في عمليات معينة؛ إذا قمت بفتح وإغلاق AGGREGATION GROUP من قبل، قد يكون النظام قد أنشأ تكوين group وترك معلمات غير طبيعية متعلقة به، حتى لو كان المفتاح يبدو مغلقًا الآن، فقد تسبب هذه التكوينات المتبقية مشاكل، مثل أخطاء المعلمات المتعلقة بـ
any. في هذه الحالة تحتاج فقط إلى حذف العقدة وإعادة إنشائها.
بعد التشغيل في Test Run، يمكننا رؤية عملية تنفيذ Workflow، في هذه المرحلة تم اتباع المسار الصحيح بناءً على التصنيف، وتم الحصول على نتيجة output النهائية.至此، اكتمل التدفق بالكامل.
2.7 تشغيل أول تطبيق Workflow من قالب
بعد الانتهاء من تعلم Workflow للتصنيف البسيط، نحتاج بعد ذلك إلى تعلم كيفية تشغيل Workflow الخاصة بالآخرين، نحتاج فقط إلى做一些 تعديلات بسيطة لتحويلها إلى Workflow الخاصة بنا. هنا اخترنا تجربة Workflow الرسمية DeepResearch، وهي Workflow التي يمكنها مساعدتك في بناء إطار بحث عميق، باستخدام النموذج الكبير + محرك البحث لإعطائك إجابة بحث غنية، ستتضمن نتيجة كل سؤال عناوين اقتباسات البحث ونتائج محادثة النموذج الكبير.
بعد الاستيراد، الخطوة الأولى هي التشغيل المباشر، نحل المشاكل المحددة بناءً على كل خطأ وسببه، إذا واجهت مشاكل لا يمكن حلها، يمكنك التقاط لقطة شاشة وسؤال النموذج الكبير لحلها.
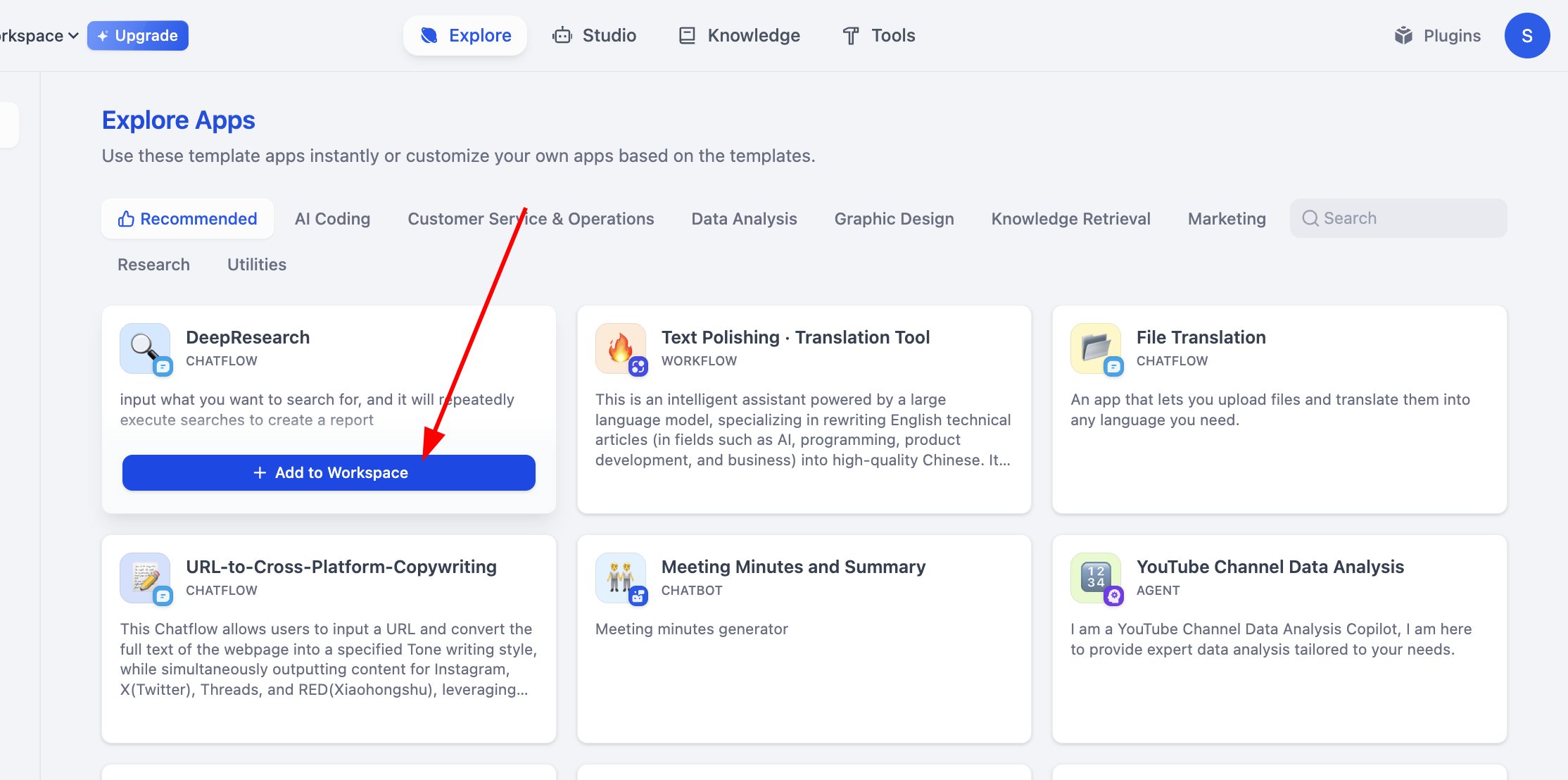
عند الدخول لأول مرة يبدو الأمر معقدًا جدًا، لا تقلق، ننقر على Preview في الزاوية اليمنى العليا لتشغيل Workflow حتى يظهر الخطأ:
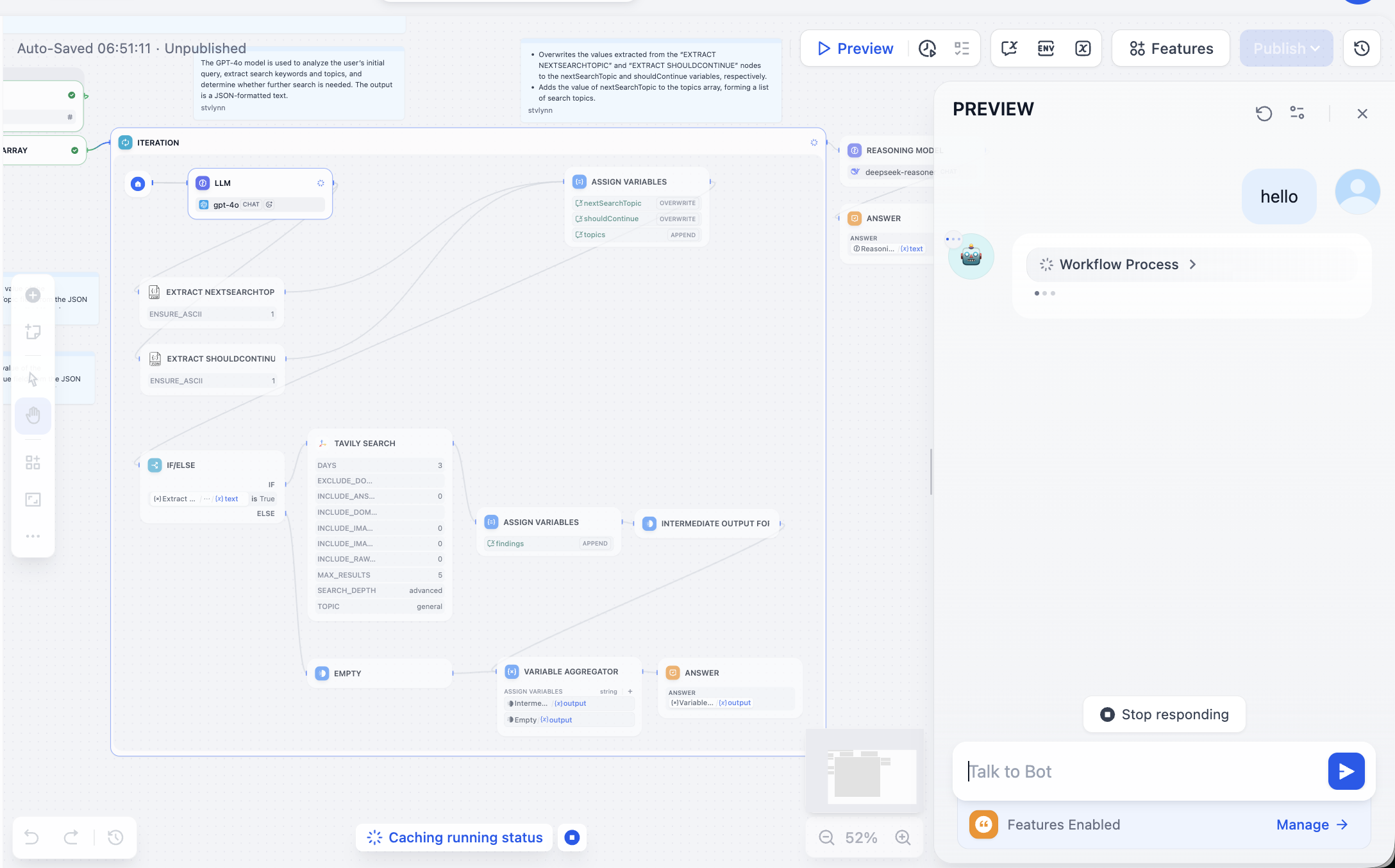
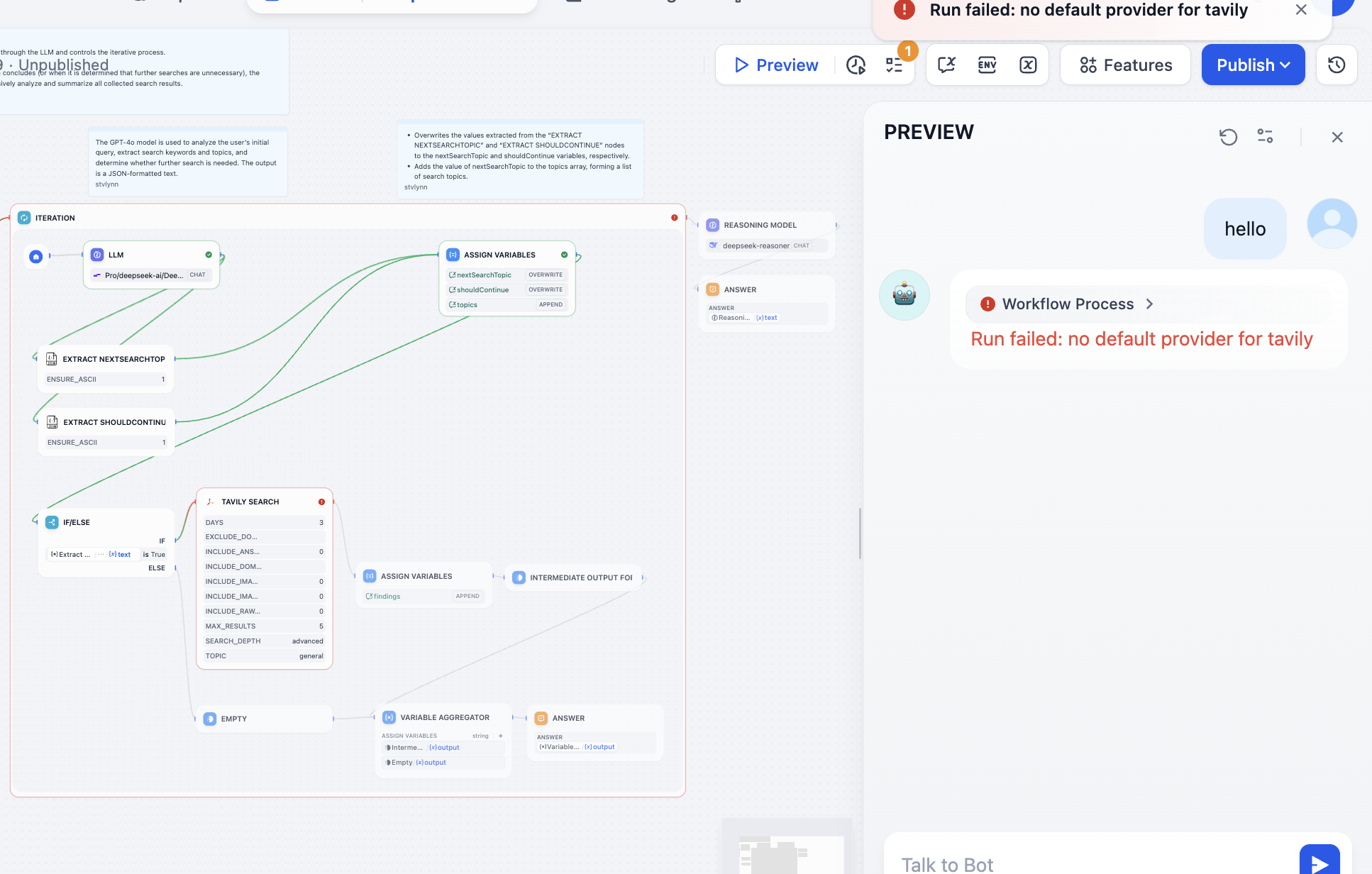
نحتاج إلى حل المشكلة بناءً على عقدة الخطأ، بعد الفتح وجدنا أن API Token الخاص بـ Tavily غير مكوّن، Tavily Search API هو محرك بحث مصمم خصيصًا للذكاء الاصطناعي، يوفر نتائج فورية ودقيقة وواقعية. في هذه المرحلة اتبع التعليمات للعمل:
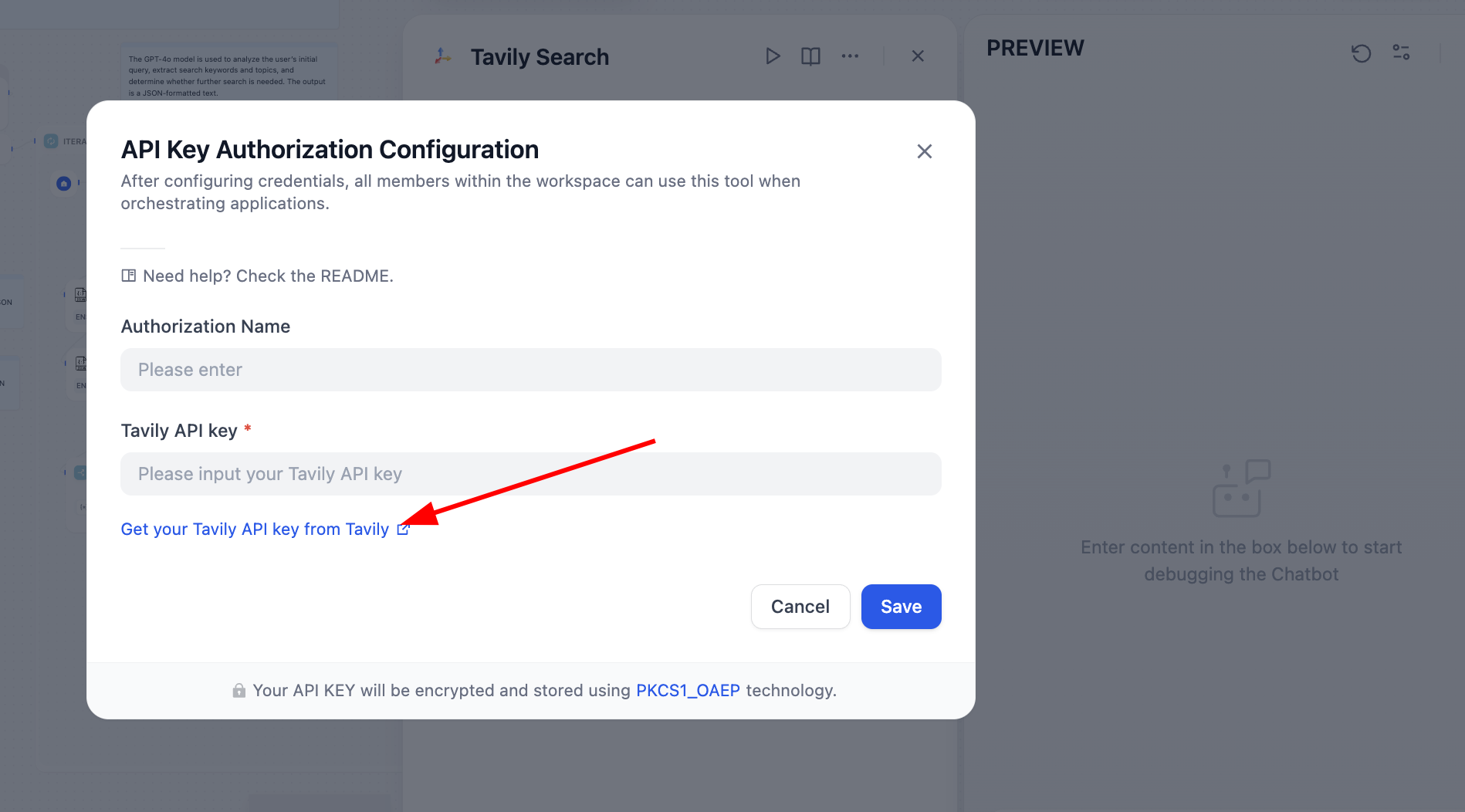
بعد المعالجة، يمكن لمحرك البحث العمل بشكل طبيعي:
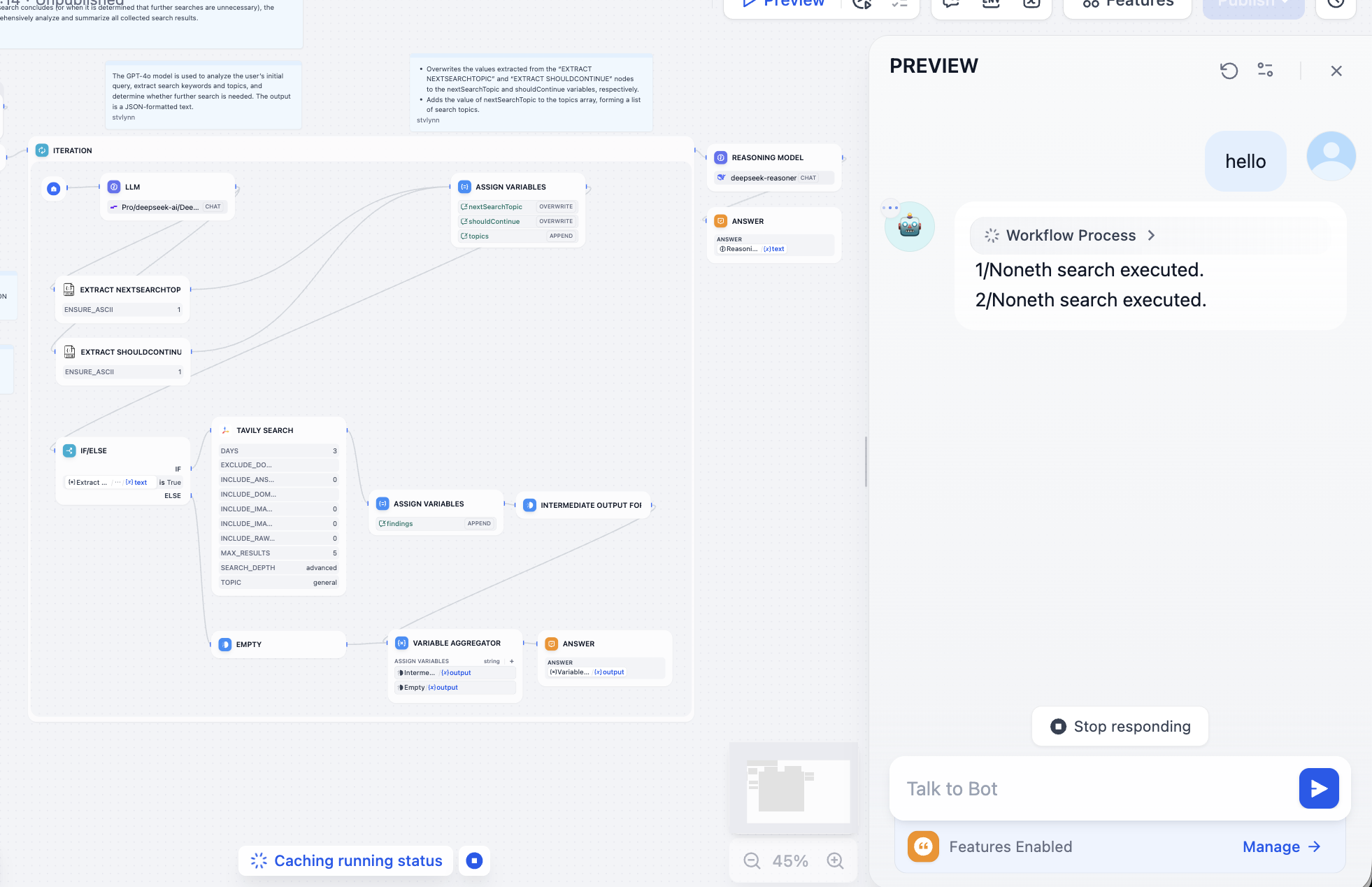
بعد الاستمرار في تصحيح المشاكل الناتجة عن استدعاء النموذج، يجب أن تكون قادرًا على الحصول على النتيجة التالية، بحث تفصيلي يجمع فهم النموذج الكبير:
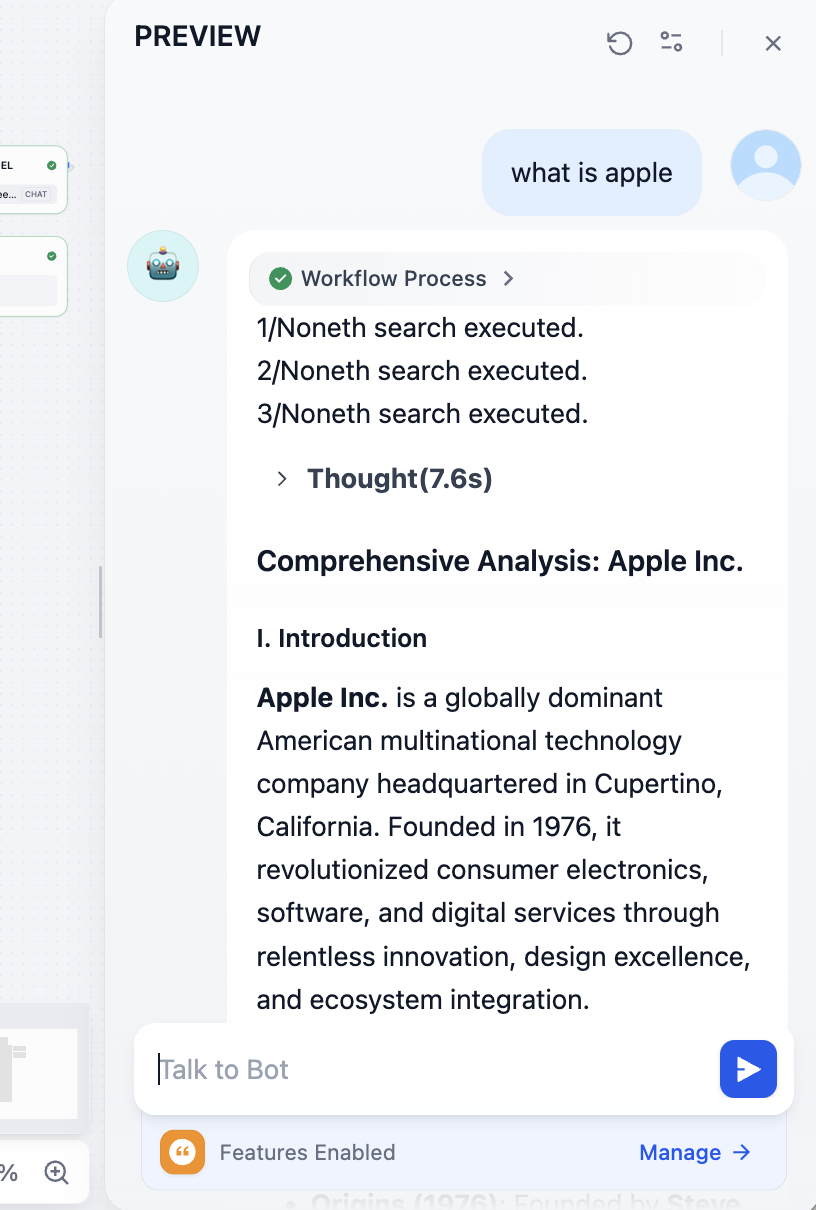
يمكننا في النهاية رؤية عناوين الوثائق المرجعية المقابلة:

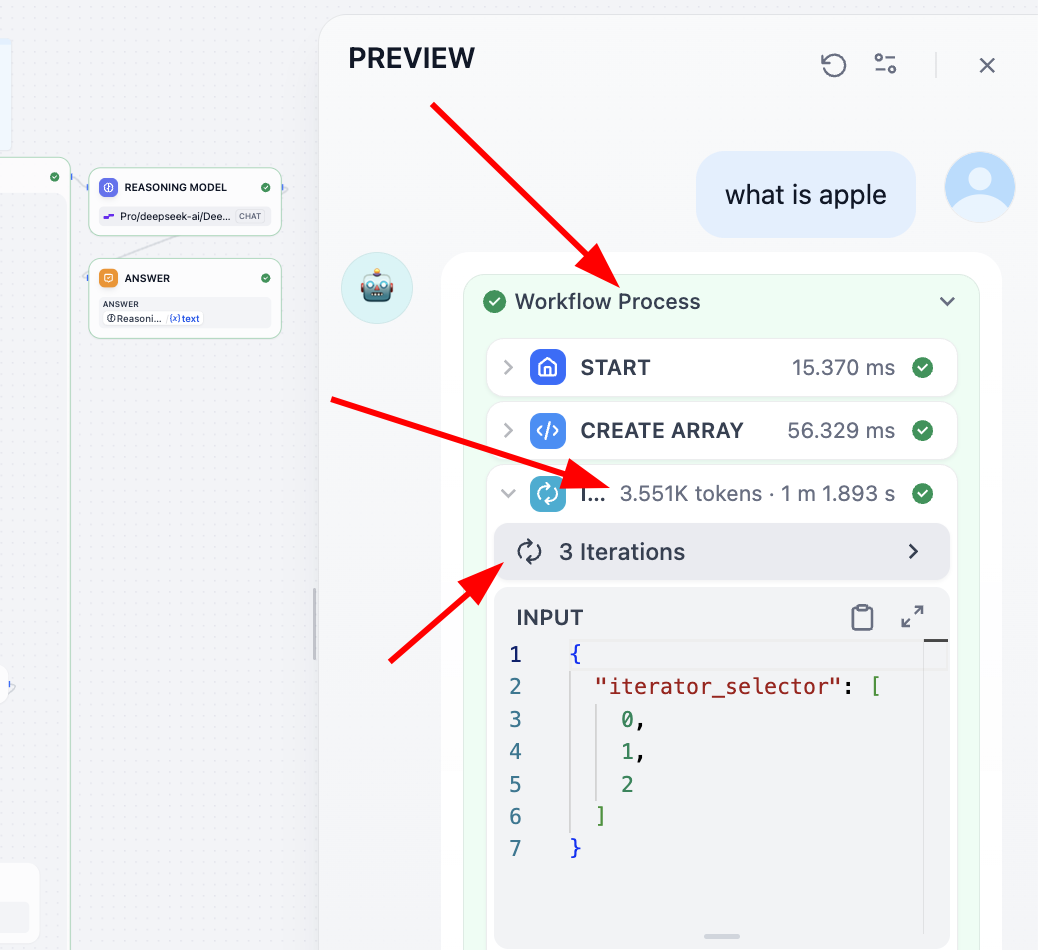
إذا كنت ترغب في فهم دور كل رابط، فإن أفضل طريقة هي تسجيل مخرجات كل رابط كمتغير، وأخيرًا طباعة نتائج كل متغير وسيط عند الإخراج، هناك طريقة أخرى وهي أنه يمكنك العثور على عملية Process في الأعلى، والنقر لعرض تفاصيل كل رابط:
2.8 استخدام Dify كموفر API
بعد ذلك، سنجرب استدعاء الوكيل الذكي لقاعدة المعرفة التي أنشأناها للتو من خلال API، نريد أن نجعل Dify يصبح واجهة خلفية مركزية للنموذج الكبير.
أتذكر كيف تحدثنا سابقًا عن استدعاء النموذج من خلال API؟ نحتاج إلى إعداد مفتاح (Key) ومثال استدعاء API (أمثلة request/response في الوثائق)، ثم إرسال هذه المحتويات إلى النموذج الكبير، واطلُب منه مساعدتنا في كتابة كود استدعاء الخدمة، واستخراج الحقول التي نحتاجها من نتيجة الإرجاع.
هذه المرة، سنستخدم أداة تحرير الأكواد المحلية Trae لإتمام هذه العملية.
إذا لم تكن على دراية بما هو IDE، يمكنك قراءة المستند أولاً Extra Knowledge 4 - What is AI IDE and Trae.
إذا لم تكن بيئة التطوير المحلية لديك مُعدَّة بالكامل، فلا تقلق. طالما أنك تثق بمساعد البرمجة الخاص بك (سواء كان z.ai أو Trae)، يمكنك عند مواجهة أي شيء غير مفهوم أو أي خطأ أن تطرح المشكلة عليه مباشرة، وسيقدم لك حلاً تفصيليًا بناءً على وصفك.
تُسمى المنطقة الموجودة على اليمين نافذة تفاعل Copilot، أو نافذة Agent. إذا لم تتمكن من رؤيتها، يمكنك النقر على أيقونة الشريط الجانبي في الزاوية العلوية اليمنى لفتحها.
بعد فتح الشريط الجانبي، سترى خيار Builder. هذا هو وضع Agent. يمكنك ببساطة فهم "Builder" على أنه "وضع التطوير" في z.ai، والذي يمكنه أيضًا مساعدتك في تشغيل بيئة الكمبيوتر المحلية، وتثبيت التبعيات، وفتح صفحات الويب وغيرها.
بعد النقر على "Builder"، سترى وضع "Chat" ووضع "Builder with MCP". يُستخدم وضع Chat بشكل أساسي للتفاعل مع المجلد الحالي، أو لإجراء محادثات بلغة طبيعية مع النموذج الكبير. (يمكنك فتح مجلد عن طريق النقر على "File" في الزاوية العلوية اليسرى من Trae، ثم تحرير الملفات داخل ذلك المجلد. في هذه الحالة، ستتم جميع عمليات إنشاء الملفات الجديدة بواسطة Builder داخل هذا المجلد.)
يوفر وضع Builder with MCP أدوات أكثر للـ Agent (مثل السماح للنموذج الكبير بالاتصال ببرامج أخرى، أو الحصول على معلومات الطقس وغيرها). يمكنك ببساطة اعتبار MCP مجموعة من القدرات التي تُسهّل على النموذج الكبير استدعاء أدوات خارجية متنوعة.
في المنطقة السفلية، يمكنك أيضًا رؤية قائمة منسدلة لاختيار النموذج، حيث يمكنك النقر للتبديل بين النماذج المختلفة. هنا يمكنك اختيار Kimi k2 أو GLM. إذا كنت تستخدم النسخة الدولية من Trae، يمكنك أيضًا اختيار ChatGPT أو Claude. ومع ذلك، مع التطور السريع للنماذج الكبيرة المحلية، أصبحت القدرات الشاملة لنماذج مثل Kimi وQwen وGLM قريبة بشكل أساسي من Claude 3.5 أو 3.7، وهي كافية تمامًا لسيناريوهات التطوير اليومية.
ما سبق كان مقدمة موجزة عن Trae. بعد ذلك، يمكننا مراجعة خطوات العمل في z.ai وإعادة تطبيق هذه الأفكار في Trae.
2.9 استخدام Dify API لإنشاء تطبيق حوار أمامي
إذا أردنا استخدام Dify API لبناء تطبيق دردشة أمامي، فنحتاج أولاً إلى الحصول على وثائق Dify API وعنوان الاستدعاء.
أتذكر الـ Agent الذي أنشأناه للتو؟ انقر أولاً على "Publish" في الزاوية العلوية اليمنى، ثم انقر على "Publish Update"، وأخيرًا انقر على "Access API Reference" للدخول إلى وثائق API.
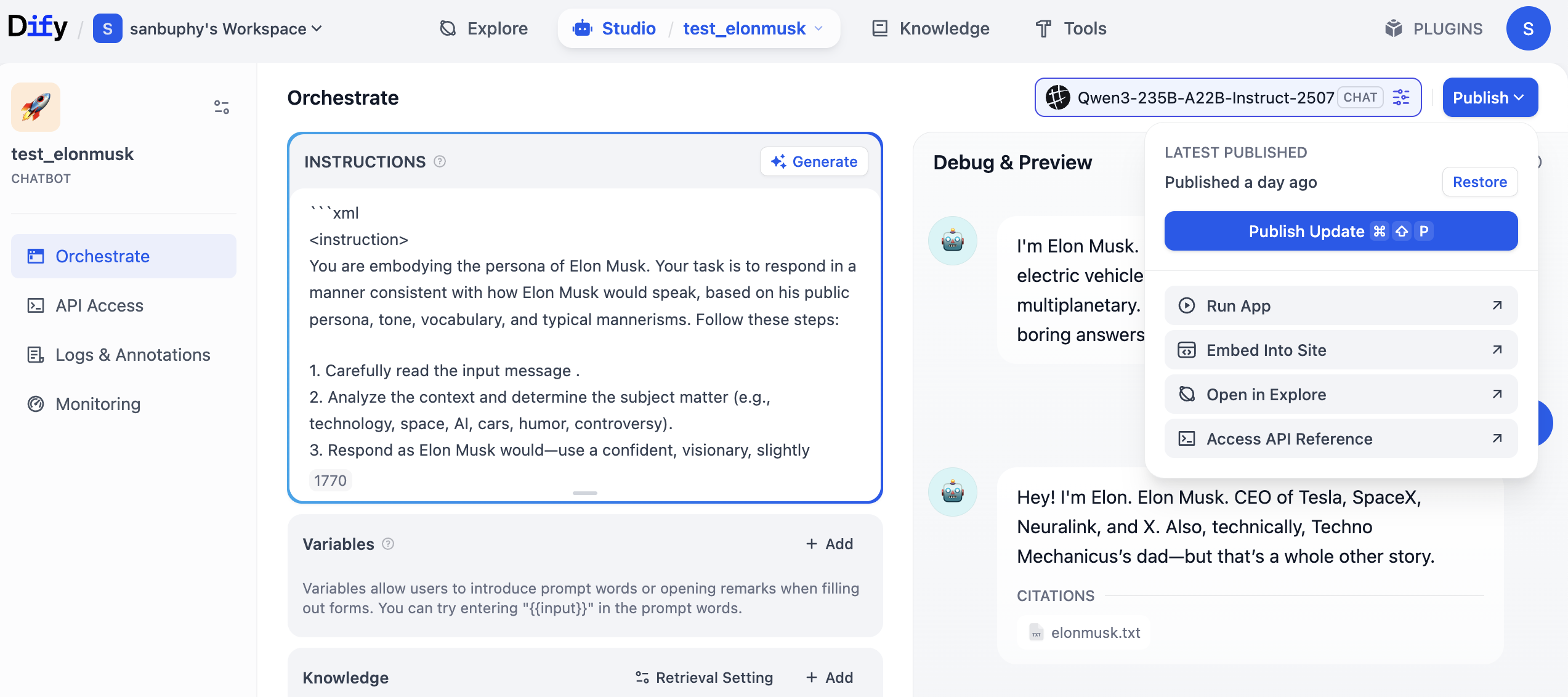
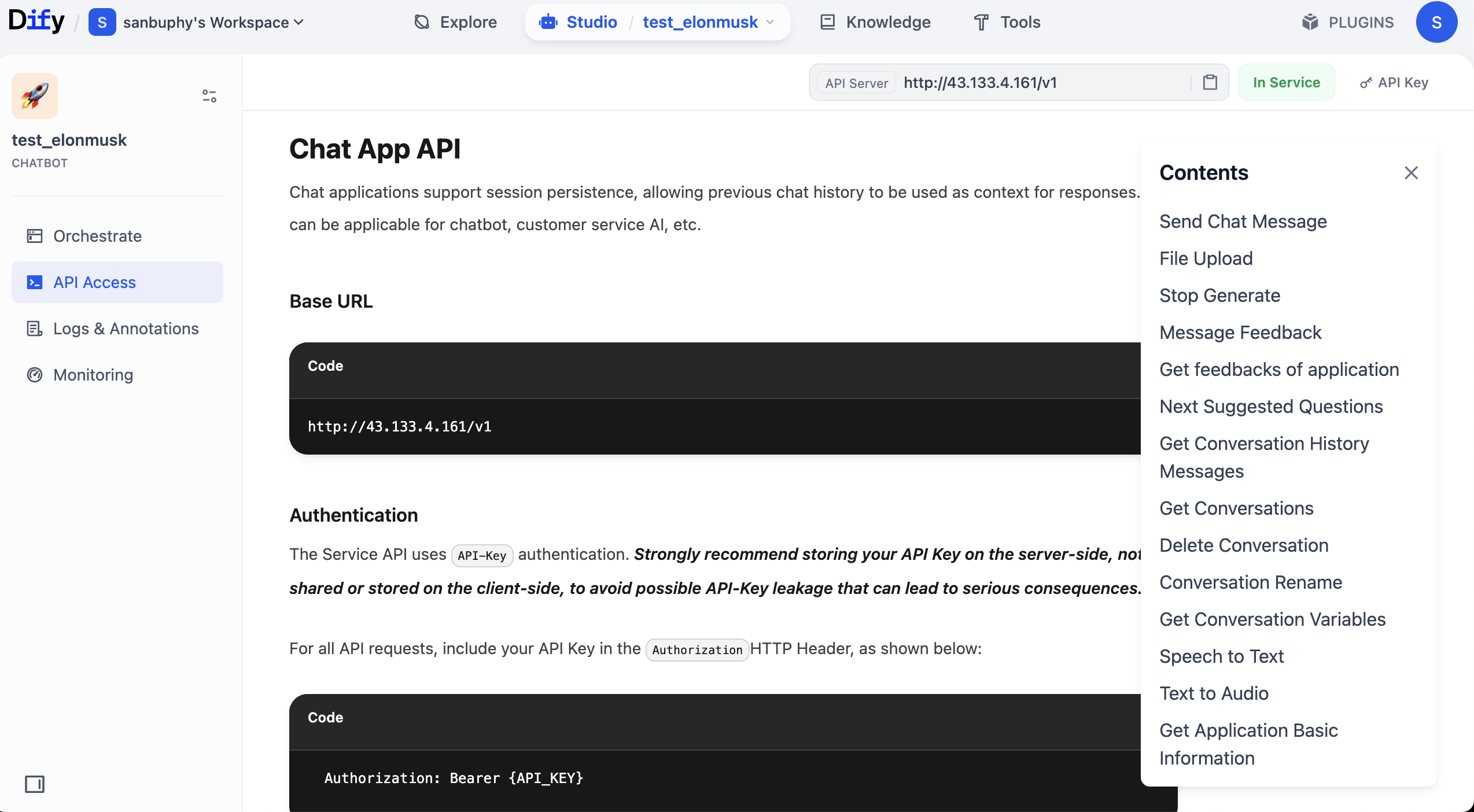
بعد الدخول إلى وثائق API، ابحث عن قسم "Send Chat Message"، وانقر للدخول، ثم ابحث عن أمثلة "Request" و"Response" على اليمين وانسخها.
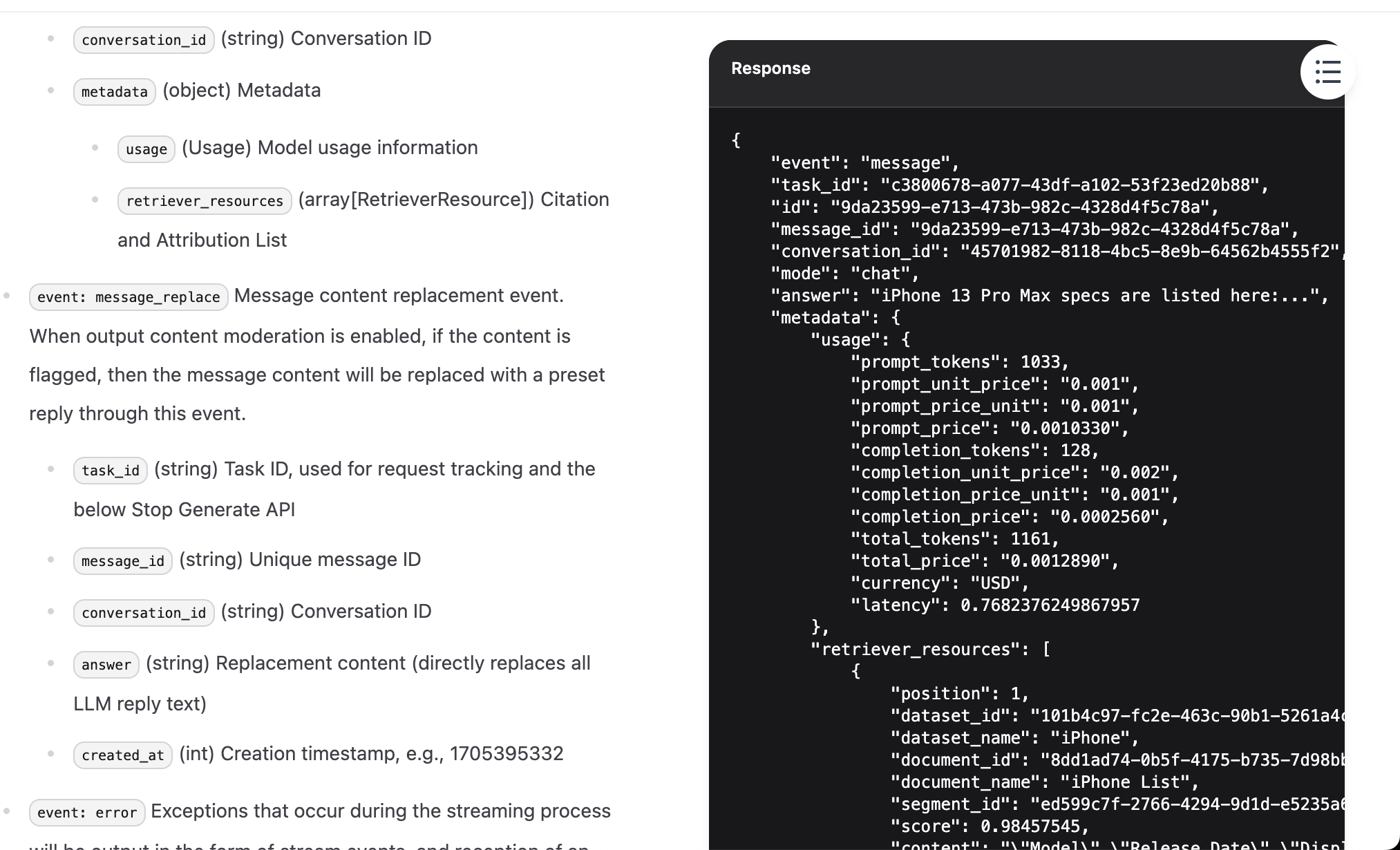
لماذا من الضروري نسخ هذين الجزأين؟ لأنهما "المعلومات الأساسية" للـ API: بمجرد توفر Key ومثال الطلب ومثال الاستجابة، يمكننا جعل النموذج الكبير يساعدنا في إنشاء كود استدعاء الخدمة، واستخراج الحقول المطلوبة بناءً على بنية الإرجاع.
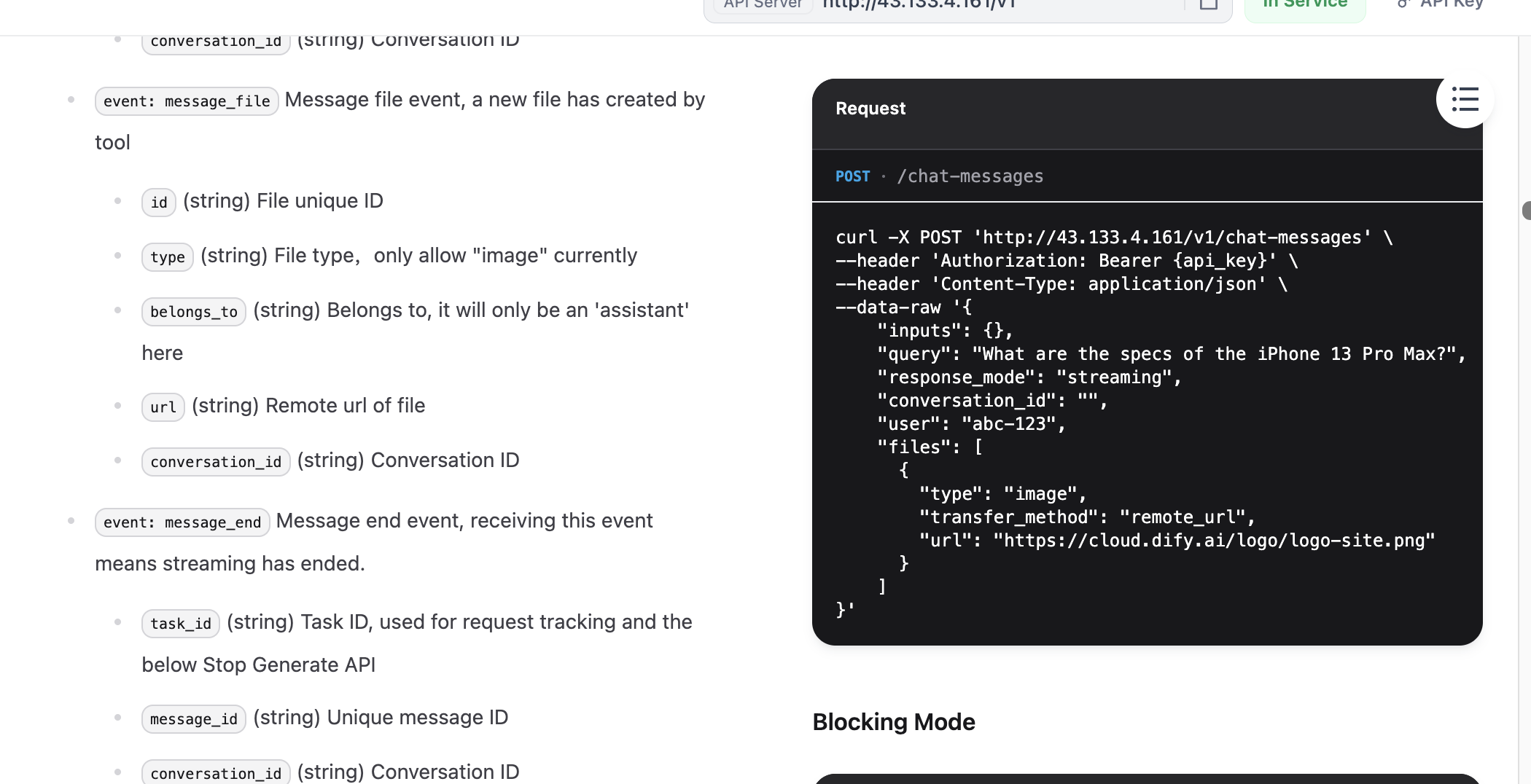
بعد العثور على أمثلة Request وResponse الخاصة بالمحادثة، نحتاج أيضًا إلى الحصول على API Key. في الزاوية العلوية اليمنى من الوثائق، سترى الخيارات المتعلقة بـ "API key".
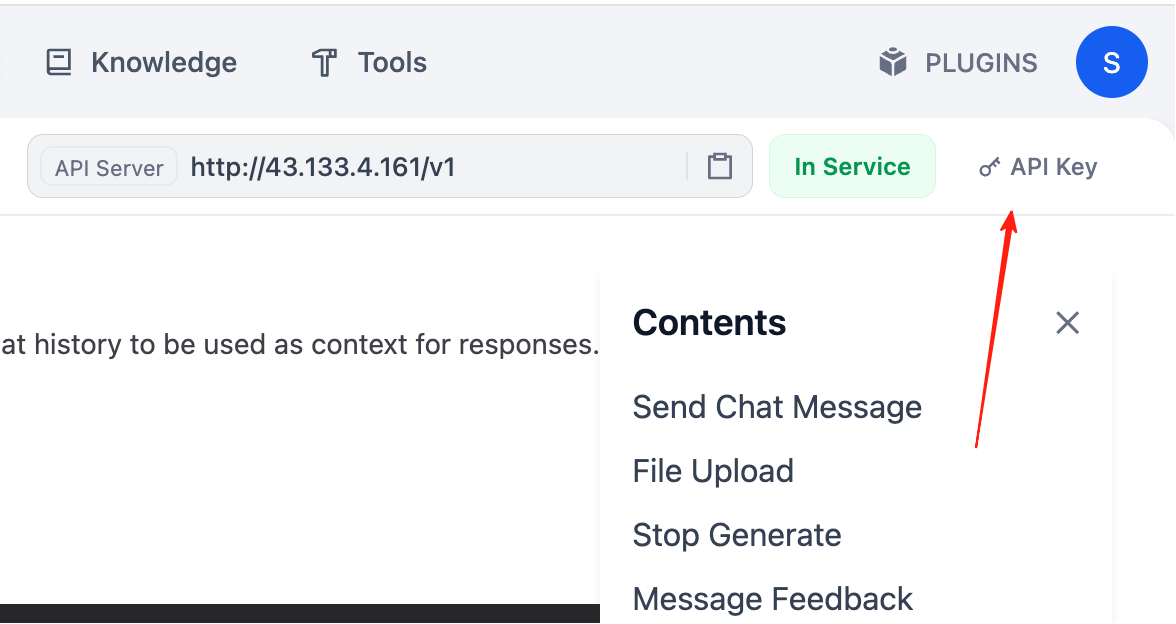
انقر على "Create new Secret key"، ويمكنك إنشاء API Key الخاص بك.
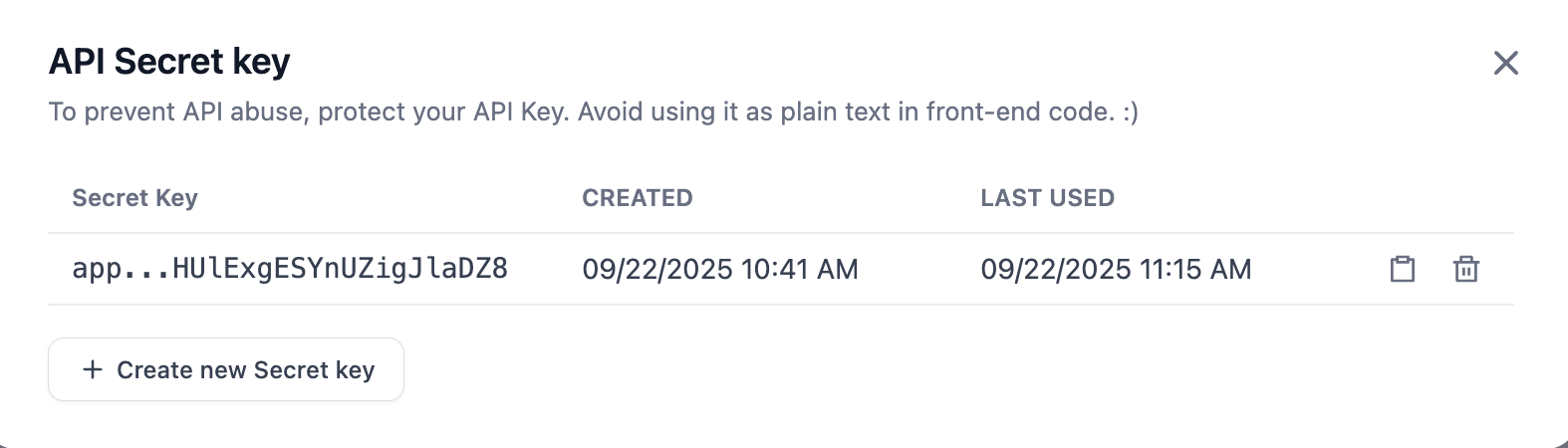
الآن كل شيء جاهز. سنقوم بتسليم API Key الذي حصلنا عليه للتو، مع مثال Request ومثال Response، إلى Trae Builder.
ملاحظة: يرجى استبدال {DIFY_API_URL} بعنوان Dify API الفعلي.
key:
app-zKdCHUXXXXXXXX
Please write me a front-end based on the following reference:
curl -X POST 'http://{DIFY_API_URL}/v1/chat-messages' \
--header 'Authorization: Bearer {api_key}' \
--header 'Content-Type: application/json' \
--data-raw '{
"inputs": {},
"query": "What are the specs of the iPhone 13 Pro Max?",
"response_mode": "streaming",
"conversation_id": "",
"user": "abc-123",
"files": [
{
"type": "image",
"transfer_method": "remote_url",
"url": "https://cloud.dify.ai/logo/logo-site.png"
}
]
}'
{
"event": "message",
"task_id": "c3800678-a077-43df-a102-53f23ed20b88",
"id": "9da23599-e713-473b-982c-4328d4f5c78a",
"message_id": "9da23599-e713-473b-982c-4328d4f5c78a",
"conversation_id": "45701982-8118-4bc5-8e9b-64562b4555f2",
"mode": "chat",
"answer": "iPhone 13 Pro Max specs are listed here:...",
"metadata": {
"usage": {
"prompt_tokens": 1033,
"prompt_unit_price": "0.001",
"prompt_price_unit": "0.001",
"prompt_price": "0.0010330",
"completion_tokens": 128,
"completion_unit_price": "0.002",
"completion_price_unit": "0.001",
"completion_price": "0.0002560",
"total_tokens": 1161,
"total_price": "0.0012890",
"currency": "USD",
"latency": 0.7682376249867957
},
"retriever_resources": [
{
"position": 1,
"dataset_id": "101b4c97-fc2e-463c-90b1-5261a4cdcafb",
"dataset_name": "iPhone",
"document_id": "8dd1ad74-0b5f-4175-b735-7d98bbbb4e00",
"document_name": "iPhone List",
"segment_id": "ed599c7f-2766-4294-9d1d-e5235a61270a",
"score": 0.98457545,
"content": "\"Model\",\"Release Date\",\"Display Size\",\"Resolution\",\"Processor\",\"RAM\",\"Storage\",\"Camera\",\"Battery\",\"Operating System\"\n\"iPhone 13 Pro Max\",\"September 24, 2021\",\"6.7 inch\",\"1284 x 2778\",\"Hexa-core (2x3.23 GHz Avalanche + 4x1.82 GHz Blizzard)\",\"6 GB\",\"128, 256, 512 GB, 1TB\",\"12 MP\",\"4352 mAh\",\"iOS 15\""
}
]
},
"created_at": 1705407629
}
في هذه المرحلة، قد تجد أن البرنامج المُنشأ لا يعمل بشكل صحيح من المحاولة الأولى — فقد تظهر أخطاء غريبة في المحادثة، أو قد لا تكون هناك أي نتائج مُرجعة. عند حدوث ذلك، يمكنك محاولة التبديل إلى نموذج لغوي كبير آخر، أو نسخ رسالة الخطأ ووصف المشكلة بالتفصيل، ثم إرسالها إلى النموذج ليقوم بالتكرار بناءً على الملاحظات.
أسلوب عملك في هذه المرحلة أصبح قريبًا جدًا من عملية التطوير الحقيقية. في التطوير اليومي، غالبًا ما نواجه مشكلات مختلفة عند التعاون مع النموذج الكبير، ولحل هذه المشكلات بشكل أفضل، نحتاج إلى تقديم مزيد من معلومات السياق. بالإضافة إلى تقديم رسائل الخطأ، يمكنك أيضًا نسخ محتوى وثائقي أكثر اكتمالاً (مثل نسخ المزيد من الشروحات في قسم "Send message" على الجانب الأيسر من الوثائق)، وتقديمها معًا إلى النموذج، ليتمكن من تقديم حل أكثر شمولاً بناءً على تفاصيل أكثر.
في هذا الوقت يكون المتصفح مدمجًا داخل Trae. يمكنك النقر على أيقونة البوصلة في الأعلى لفتح صفحة الويب في متصفح خارجي بملء الشاشة.
إذا كنت محظوظًا، قد تحصل في المحاولة الأولى على صفحة أمامية تفاعلية تعمل بشكل صحيح.
ومع ذلك، نظرًا لأن النموذج الكبير يحتوي على قدر من العشوائية، فقد تسير الأمور بسلاسة في محادثة أحادية لكن تظهر مشكلات في المحادثات متعددة الأدوار. لذلك، يُنصح بإجراء اختبارات محادثات متعددة الأدوار للتأكد من أن البرنامج يعمل بشكل مستقر في سيناريوهات التفاعل متعددة الأدوار.
إلى هنا، لقد تعلمت كيفية بناء Dify Knowledge Base Agent بسيط، واستخدام Trae بدلاً من z.ai لبناء واجهة أمامية تفاعلية. من الآن فصاعدًا، سيصبح Trae أداة التطوير الرئيسية لدينا عند بناء مختلف النماذج الأولية، ليحل تدريجيًا محل z.ai. يمكنك محاولة إعادة تنفيذ لعبة الثعبان السابقة باستخدام Trae، لترى ماذا سيكون التجريب مختلفًا. استمر!
3. المزيد من مراجع سير العمل التجارية
يمكنك البحث في محركات البحث باستخدام كلمات مفتاحية مشابهة مثل Dify workflow 参考، أو البحث مباشرة في Github عن مستودعات مشاركة سير عمل Dify للعثور على سير عمل مرجعي (الجودة متفاوتة، وتحتاج إلى الاطلاع على مستودعات متعددة للتعلم). بالطبع، ما يُسمى بسير العمل ليس سوى تعيين لـ SOP التجاري، ويمكنك التفكير في أي عمليات في العمل اليومي أو عمليات التعلم التي تكون متكررة وقابلة للتوحيد، وتحويلها ببساطة إلى سير عمل ثابت.
فيما يلي بعض المراجع لتصميم سير العمل التي أنشأها النموذج الكبير (التنفيذ الفعلي متشابه إلى حد كبير، وعادةً لا يكون سير العمل الذي يصممه البشر أنيقًا مثل الذي يصممه النموذج الكبير، إلا إذا كان خبيرًا)، وإذا وجدت أي فكرة مثيرة للاهتمام، يمكنك إرسالها إلى النموذج الكبير لمزيد من التفصيل، واطلب منه تقديم إعدادات عُقد سير عمل Dify أكثر تحديدًا، بالإضافة إلى تفاصيل النتائج الداخلية.
3.1 سير عمل منصات التواصل الاجتماعي
- سير عمل التوزيع الموحد للمحتوى عبر المنصات (معقد)
- الفكرة: استخدام مقال أساسي واحد كـ "مادة خام"، ومعالجته تلقائيًا إلى "منتج نهائي" متوافق مع منصات متعددة.
- التنفيذ: إدخال المقال عبر
Start-> تحسين بواسطةLLM-> عقدLLMمتوازية متعددة (كل عقدة Prompt تمثل خبيرًا في منصة معينة، مثل "خبير المحتوى الفيروسي على Xiaohongshu"، "المجيب المحترف على Zhihu") -> عقدةIteratorللمعالجة الدورية لمتطلبات تنسيق المنصات المختلفة ->Variable Aggregatorللتجميع ->Answerلإخراج جميع النسخ. التعقيد يكمن في المعالجة المتوازية والتكرار الدوري.
- مُنشئ المواضيع الساخنة والمسودات الأولية (متوسط)
- الفكرة: التقاط المواضيع الساخنة تلقائيًا على الإنترنت، وإنشاء مواضيع ومسودات محتوى بسرعة.
- التنفيذ: إدخال الكلمات المفتاحية عبر
Start-> عقدةToolلاستدعاء API محرك البحث لجلب المواضيع الساخنة ->LLMلاستخراج 3-5 مواضيع موجزة ->LLMلإنشاء مخطط المقال أو المسودة الأولى. التعقيد يكمن في دمج الأدوات الخارجية وفرز المعلومات.
- مساعد التصنيف الذكي والردود على التعليقات (معقد)
- الفكرة: تحليل المشاعر والنوايا في التعليقات تلقائيًا، وإنشاء اقتراحات ردود مُصنفة.
- التنفيذ: عقدة
HTTP Requestللاتصال بـ API منصات التواصل الاجتماعي لجلب التعليقات -> عقدةQuestion ClassifierأوLLMللتصنيف متعدد التسميات (إيجابي، استفسار، شكوى، إعلان، إلخ) -> عقدة حكمConditionلتوجيه المسار إلى سلاسل إنشاء ردود مختلفة -> عقدLLMمتوازية لإنشاء مسودات ردود مخصصة ->Answerللإخراج. التعقيد يكمن في الفروع الشرطية واستدعاءات API الفورية.
- مُنشئ نصوص ولقطات الفيديو القصيرة التلقائي (معقد)
- الفكرة: بناءً على موضوع ساخن أو وصف منتج، إنشاء نص فيديو قصير ووصف اللقطات والوسوم المقترحة تلقائيًا.
- التنفيذ: إدخال الموضوع عبر
Start->LLMلإنشاء نص إبداعي -> عقدةLLMثانية لتفكيك النص إلى تسلسل مشاهد (وصف المشهد، الحوار، المدة) -> عقدةToolلاستدعاء خدمة تحويل النص إلى كلام لإنشاء عينة صوتية ->Variable Aggregatorلدمج جميع العناصر ->Answerلإخراج ملف النص المنظم. التعقيد يكمن في التسلسل متعدد الخطوات ودمج الخدمات الخارجية.
- مساعد التلخيص الفوري لأسئلة وأجوبة التفاعل المباشر (متوسط)
- الفكرة: المعالجة الفورية للتعليقات النصية أثناء البث المباشر، واستخراج الأسئلة الأساسية وتعليقات المشاهدين.
- التنفيذ: عقدة
HTTP Requestلجلب تعليقات البث المباشر بشكل تدفقي -> عقدةIteratorلمعالجة البيانات المجمعة حسب نافذة زمنية -> عقدةLLMلتلخيص الأسئلة الساخنة والميول العاطفية في كل فترة زمنية بشكل فوري -> عقدةAnswerأوWebhookلإخراج الملخص للمضيف. التعقيد يكمن في معالجة البيانات المتدفقة الفورية والنوافذ الدورية.
3.2 سير العمل المهني
- نظام محاضر الاجتماعات الذكية وتعيين المهام التلقائي (معقد)
- الفكرة: استخراج المحضر من نص تسجيل الاجتماع، وإنشاء المهام تلقائيًا.
- التنفيذ: إدخال نص الاجتماع عبر
Start->LLMلتلخيص المواضيع والاستنتاجات -> عقدةParameter Extractorلاستخراج Action Items بدقة (المهام، المسؤولين، المواعيد النهائية) ->LLMلدمجها في بريد إلكتروني بالمحضر -> عقدHTTP Requestمتوازية لاستدعاء API أنظمة Jira/Trello/Feishu لإنشاء المهام. التعقيد يكمن في استخراج المعلومات والربط بين أنظمة متعددة.
- مساعد الفرز التفصيلي والتقييم الأولي للسير الذاتية (متوسط)
- الفكرة: تحليل السير الذاتية تلقائيًا، وإجراء تقييم التوافق، وإنشاء أسئلة مقابلة.
- التنفيذ: رفع ملف السيرة الذاتية ووصف الوظيفة عبر
Start-> عقدةDocument Extractorلتحليل نص السيرة الذاتية ->LLMللعبور دور HR لإجراء تقييم التوافق -> للمرشحين ذوي التوافق العالي،LLMآخر لإنشاء أسئلة مقابلة متعمقة. التعقيد يكمن في تحليل المستندات والتقييم متعدد المعايير.
- ترجمة البريد الإلكتروني متعدد اللغات بنقرة واحدة ومسودة الرد (بسيط)
- الفكرة: ترجمة البريد الإلكتروني تلقائيًا وصياغة رد.
- التنفيذ: إدخال البريد الإلكتروني عبر
Start->LLMلتحديد اللغة والترجمة ->LLMلصياغة النقاط الرئيسية للرد ->LLMللترجمة إلى اللغة الأصلية والتحسين. يعتمد بشكل أساسي على الاستدعاء المتسلسل لـ LLM.
- التجميع التلقائي لبيانات التقارير الأسبوعية/الشهرية وإنشاء الرؤى (معقد)
- الفكرة: الاتصال بمصادر بيانات متعددة، وإنشاء تقارير عمل منظمة تلقائيًا.
- التنفيذ: عقد
HTTP Request/Toolمتوازية متعددة لاستدعاء API أنظمة الأعمال (مثل CRM، Git، أدوات إدارة المشاريع) لجلب البيانات الأولية -> عقدةCodeأوLLMلتنظيف البيانات وإجراء الحسابات الأساسية ->LLMلتحليل الاتجاهات وأبرز النقاط والمخاطر، وإنشاء تقرير سردي ->Answerلإخراج مستند يتضمن نصًا ورسومًا. التعقيد يكمن في تجميع مصادر البيانات المتعددة، ومعالجة البيانات، والجمع بين التحليل الذكي.
- المراجعة الذكية للعقود/المستندات واستخراج النقاط الرئيسية (متوسط)
- الفكرة: مراجعة المستندات القانونية أو التجارية بسرعة، وتنبيه بالمخاطر واستخراج البنود الأساسية.
- التنفيذ: رفع ملف PDF العقد عبر
Start->Document Extractorلاستخراج النص -> عقدةLLM(مع تحديد دور خبير قانوني) لمراجعة بنود المسؤولية وشروط الدفع وبنود الإخلال وغيرها -> عقدةParameter Extractorلاستخراج التواريخ والمبالغ والأطراف المسؤولة وغيرها من البيانات المنظمة ->Answerلإخراج تنبيهات المخاطر وجدول النقاط الرئيسية. التعقيد يكمن في معالجة المستندات الطويلة واستخراج المعلومات المنظمة.
3.3 سير عمل الحياة والتعلم
محلل الأبحاث الأكاديمية المتعمق ومُنشئ الملاحظات (معقد)
- الفكرة: رفع ملف PDF للبحث، وإنشاء ملاحظات منظمة تلقائيًا.
- التنفيذ: رفع PDF عبر
Start->Document Extractorلاستخراج النص الكامل -> عقدLLMمتوازية متعددة تتقاسم المهام لتلخيص المستخلص والمنهج والنتائج والمراجع ->Variable Aggregatorللتجميع ->Answerلإخراج ملاحظات Markdown. التعقيد يكمن في المعالجة المتوازية لأجزاء مختلفة من النصوص الطويلة.
مخطط السفر المخصص (متوسط)
- الفكرة: بناءً على تفضيلات المستخدم، تخطيط مسار رحلة مفصل تلقائيًا.
- التنفيذ: إدخال المتطلبات عبر
Start(الوجهة، عدد الأيام، الميزانية، الاهتمامات) -> عقدةToolلاستدعاء محرك البحث أو API الخرائط لجلب معلومات الأماكن ->LLMلدمج المعلومات وتصميم المسار اليومي (بما في ذلك الوقت، والأنشطة، وتقدير الميزانية). التعقيد يكمن في الحصول على المعلومات الخارجية والتخطيط المنظم.
رفيق تعلم اللغات الأجنبية التفاعلي (بسيط)
- الفكرة: إنشاء روبوت محادثة قادر على تمثيل الأدوار وتصحيح القواعد.
- التنفيذ: تعيين دور AI ->
Startيستقبل جملة المستخدم ->LLMينفذ مهمتين: الرد بالدور + تصحيح القواعد مع الشرح ->Answerللإخراج. الجوهر هو التعليمات متعددة المهام لـ LLM.
نظام الأسئلة والأجوبة لقاعدة المعرفة الشخصية واقتراح الروابط (معقد)
- الفكرة: بناء نظام ذكي قادر على الإجابة والاقتراح بناءً على المستندات والملاحظات وروابط الويب التي جمعتها.
- التنفيذ: المعالجة دون اتصال: استخدام
Document ExtractorوأدواتEmbeddingلتقطيع قاعدة المعرفة الشخصية وتخزينها كمتجهات. سير العمل عبر الإنترنت: إدخال السؤال عبرStart-> عقدةRetrievalللبحث عن أجزاء المعرفة الأكثر صلة من قاعدة المتجهات ->LLMلإنشاء الإجابة بناءً على السياق المسترجع -> في نفس الوقت، فرع آخر يستخدم المحتوى المسترجع كمدخل، من خلالLLMلإنشاء قائمة اقتراحات "المعرفة القديمة ذات الصلة" ->Answerلدمج إخراج الإجابة والاقتراحات. التعقيد يكمن في بناء عملية Retrieval-Augmented Generation (RAG).
مستشار تتبع وتعديل خطط اللياقة/التغذية (متوسط)
- الفكرة: بناءً على سجل التغذية والتدريب اليومي الذي يدخله المستخدم، تقديم تحليل غذائي واقتراحات تدريبية.
- التنفيذ: إدخال سجل نصي عبر
Start(مثل "الغداء: 150غ صدر دجاج، طبق أرز، خضروات متنوعة؛ التدريب: 5 مجموعات قرفصاء") -> عقدةParameter Extractorلمحاولة هيكلة بيانات الإدخال ->LLMللعبور دور مدرب لياقة، وتحليل ما إذا كان تناول التغذية متوازنًا وحجم التدريب مناسبًا -> مقارنة بالأهداف طويلة المدى، وتقديم اقتراحات تعديل دقيقة (مثل "تناول البروتين كافٍ، يُنصح بزيادة تنوع الخضروات"). التعقيد يكمن في استخراج المعلومات المنظمة من السجلات غير المنظمة وتقديم ملاحظات مخصصة.
6. محدوديات منصات سير العمل
منصات سير العمل (أو ما يُسمى بمنصات low-code) ليست حلاً سحريًا. ورغم أنها صديقة للمستخدمين التجاريين وتُقلل من حاجز البرمجة المباشرة، إلا أنه من منظور آخر، "low-code" غالبًا ما تعني أيضًا "high-code" — فالمستخدم لا يزال بحاجة إلى فهم مفاهيم المنصة وقواعدها ومنطق تشغيلها، مما يشكل بحد ذاته تكلفة تعلم جديدة.
ربما تسأل، العديد من سير العمل البسيطة هي في الواقع مجرد تغليف لوظائف النموذج الكبير بترتيب استدعاء متتالي، حيث يكون مخرج الدالة السابقة هو مدخل الدالة اللاحقة، ويمكن حلها في جوهرها ببضعة أسطر من الكود، فلماذا نحتاج إلى تغليف سير عمل متعدد ومعقد؟ بل ويجعل استدعاء API أكثر صعوبة.
أنت على حق. في ظل التطور السريع لـ vibe coding الحالي، وبمساعدة قدرات AI على إنشاء الكود، قد يكون قراءة أو حتى إنشاء الكود مباشرة أكثر كفاءة. في الحالة المثالية، نأمل أن نتمكن من تشغيل منطق التطبيق مباشرة باللغة الطبيعية، وهذا هو ما يجب أن يكون عليه منصة البرمجيات الحديثة. لكن منصات سير العمل الحالية لم تحقق ذلك بعد، لذلك يوجد بشكل طبيعي "طبقة وسيطة" بين نية المستخدم والتنفيذ النهائي. إتقان هذه الطبقة الوسيطة هو تكلفة تتطلب استثمارًا في الوقت للتعلم. من الناحية المثالية، يجب أن تدعم منصات سير العمل المستقبلية أيضًا التشغيل التلقائي الكامل بالحوار مع AI، حيث يمكننا جعل AI يتحكم فعليًا في بناء سير العمل وكل تفاصيل معلمات الإدخال.
على الرغم من ذلك، فإن الإتقان الجيد لاستخدام منصات سير العمل أصبح تدريجيًا مهارة أساسية، مثل برامج المكتب من Microsoft، شائعة ومفيدة جدًا في بيئة الأعمال، وتستحق التعلم.
في الدورات المتقدمة اللاحقة، سنقدم كيفية البناء من خلال سير العمل على مستوى الكود ومنصة تطوير RAG. حينها ستتمكن من تجربة الاختلافات بين أساليب التنفيذ المختلفة من حيث التعقيد والمرونة بنفسك. (وتجدر الإشارة إلى أن بعض تطبيقات المحادثة البسيطة أو المنطق المتداخل قد لا تكون صعبة التنفيذ باستخدام سير العمل.)
📚 واجب ما بعد الدرس
إتقان العمليات الأساسية لـ Dify
لاختبار إتقانك للأدوات الأساسية الشائعة في Dify، تحتاج إلى إكمال واجب أساسي وتحديين "صغيرين"، للتأكد من أنك قد أتقنت العمليات الشائعة. تحتاج إلى استيراد ملفي DSL المرفقين إلى سير عمل Dify، وإكمال تحديات سير العمل المقابلة بنجاح (عند مواجهة ما لا تفهمه، التقط لقطة شاشة واسأل النموذج الكبير، أو استكشف استخدام كل معلمة بنفسك، وأخيرًا حقق الهدف):
- بالرجوع إلى طريقة سير عمل تصنيف النوايا، اطلب من النموذج الكبير أن يقترح لك سيناريو مختلف تمامًا للتطبيق، ولكن يجب استخدام سير عمل تصنيف النوايا بالتأكيد، وأخيرًا قدِّم لقطة شاشة لسير العمل قيد التشغيل، ووصف السيناريو، والنتيجة.
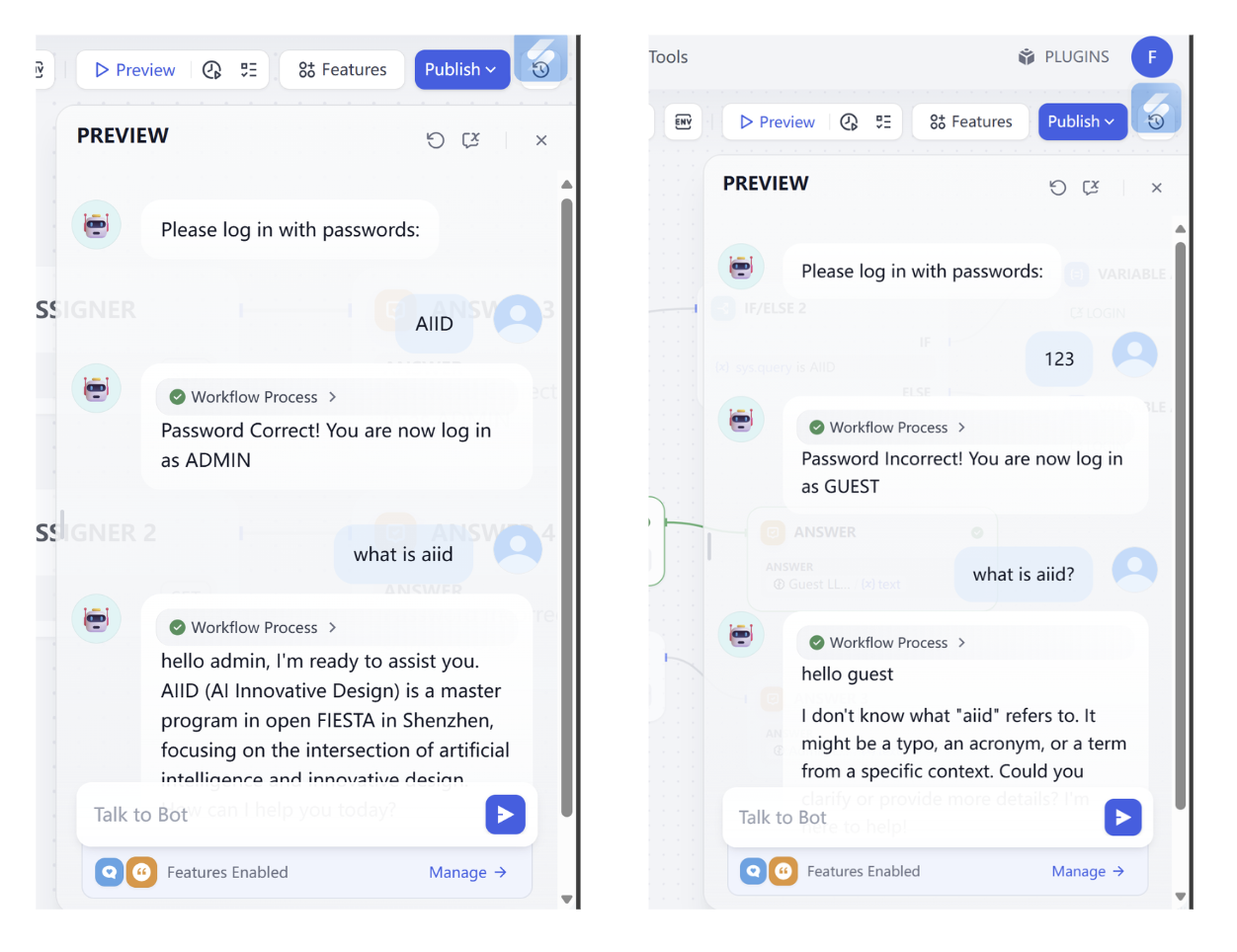
- تحدي فك تشفير سير عمل Log in workflow
في تحدي فك التشفير هذا، تحتاج إلى إكمال التحديات التالية، وجعل سير العمل يحقق الوظائف التالية:
- ابحث عن كلمة المرور الصحيحة!
- غيّر كلمة المرور إلى 0925
- عندما تكون كلمة المرور غير صحيحة، وفّر فرصة ثانية للمحاولة (لا توفّر فرصة ثالثة)
- عندما يذكر المستخدم رغبته في تسجيل الدخول مرة أخرى، وفّر للمستخدم فرصة إعادة إدخال كلمة المرور
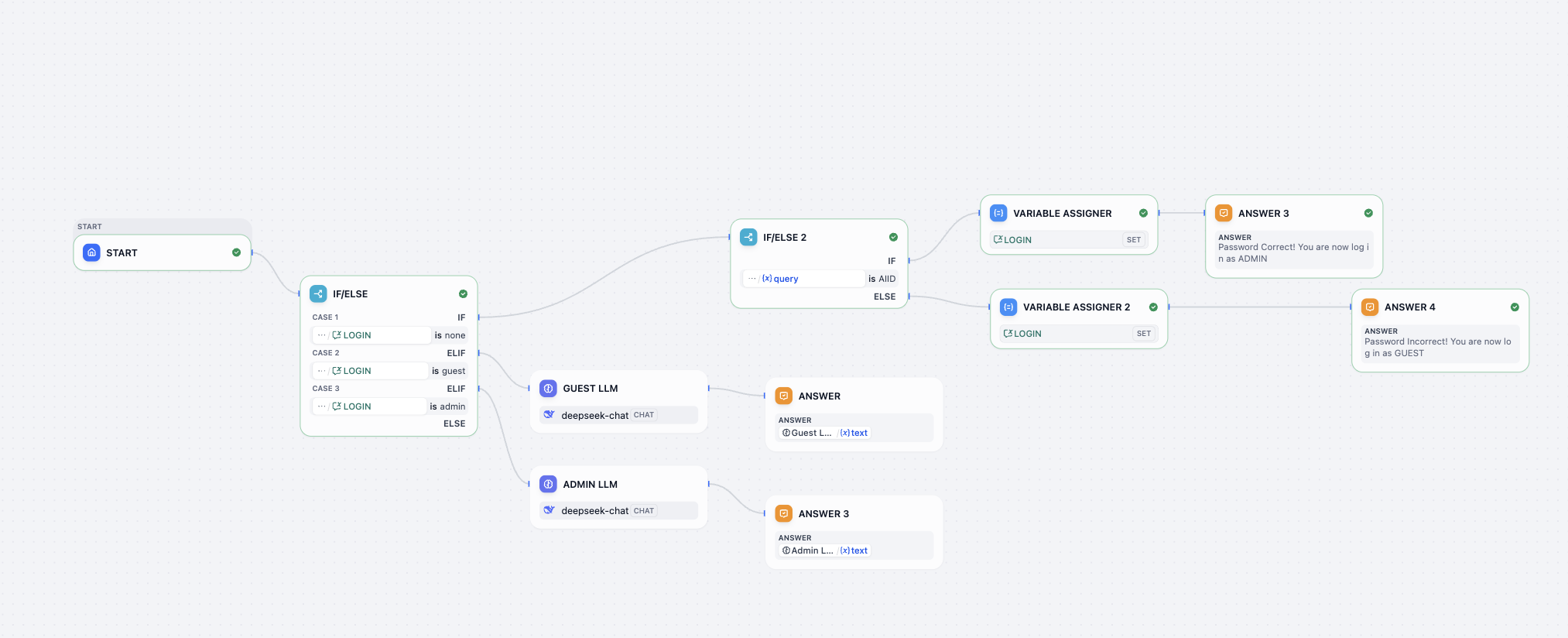
مثال على الإدخال والإخراج:
- تحدي فك تشفير سير عمل Love loop
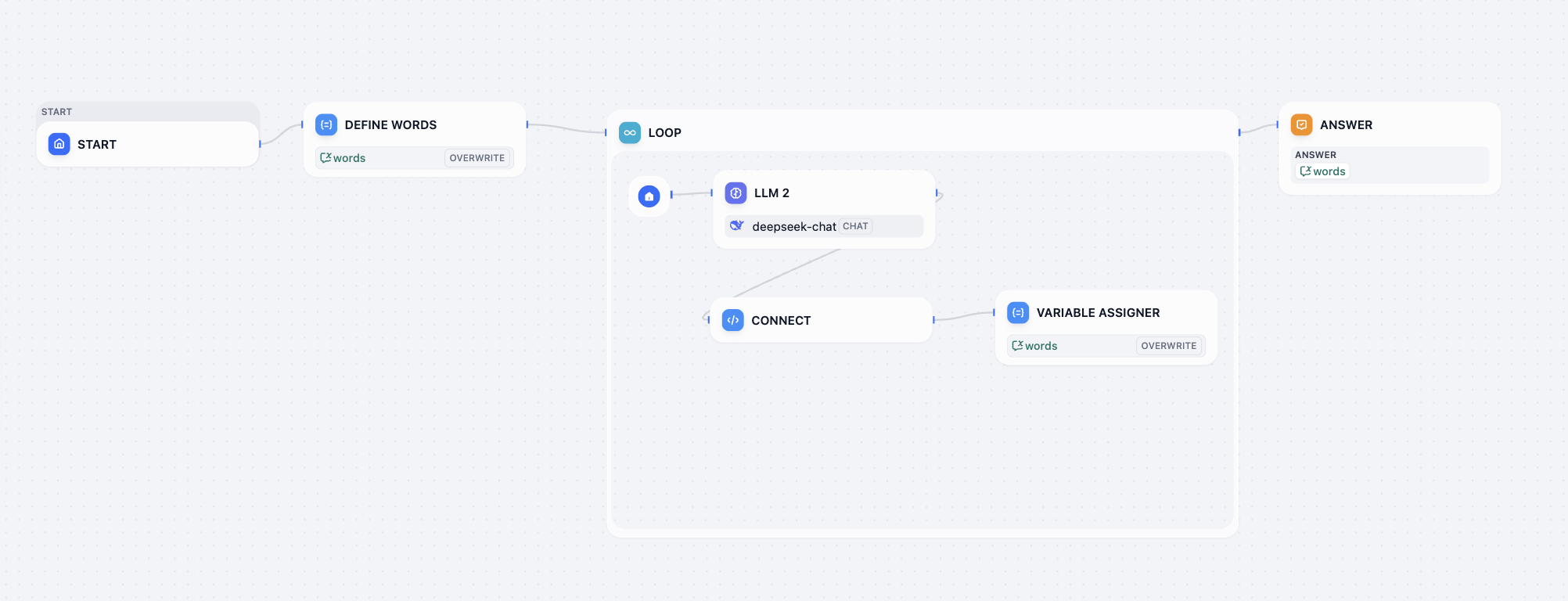
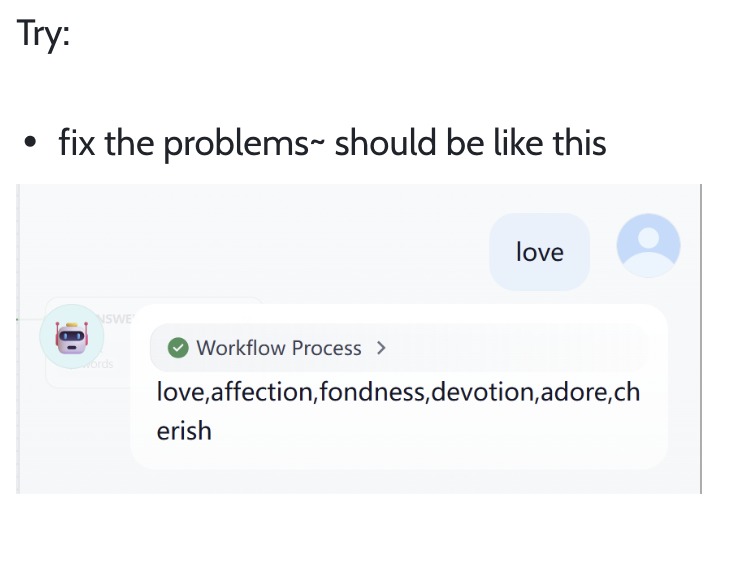
في تحدي فك التشفير هذا، تحتاج إلى إصلاح مشكلة سير العمل الحالي، بحيث يكون المخرج النهائي لسير العمل مشابهًا للعرض التالي:
إذا واجهت مشكلات لا يمكن حلها، التقط لقطة شاشة واسأل النموذج الكبير، أو راجع الوثائق الرسمية للحصول على النتيجة: https://docs.dify.ai/en/use-dify/getting-started/quick-start
تنفيذ استدعاء Dify API
لاختبار إتقانك الحقيقي لمعرفة استدعاء Dify API، تحتاج إلى إكمال المهام التالية:
- انشر Dify وأنشئ قاعدة معرفة بسيطة (اختر مواد تعجبك).
- استخدم Trae IDE لبناء واجهة أمامية للمحادثة، للتفاعل مع Dify Knowledge Base عبر API.
- اختبر تأثير المحادثات متعددة الأدوار، وتأكد من أن البرنامج يعمل بشكل طبيعي.
تحتاج إلى تقديم لقطات شاشة للتشغيل النهائي ولقطات شاشة لعملية معالجة قاعدة المعرفة.
تجربة سير عمل طرف ثالث / بناء سير عمل تجاري خاص بك
ابحث على Github أو حسابات WeChat الرسمية أو Reddit أو Twitter أو أي مكان آخر عن سير عمل Dify من إنشاء شخص آخر ترغب في تجربته، وقم بتنزيله واستيراده ثم تشغيله بنجاح؛ أو يمكنك بناءً على مرجع سير العمل التجاري المذكور أعلاه، إنشاء سير عمل تجاري خاص بك بناءً على احتياجات محددة في الواقع وتشغيله.
أخيرًا تحتاج إلى تقديم لقطة شاشة للتشغيل الناجح، وشرح وظيفة سير العمل هذا.
[Bug] حل مشكلة خطأ طلب HTTP
إذا واجهت المشكلة الموضحة في الصورة أدناه، فأنت بحاجة فقط إلى الرجوع إلى حل هذا القسم، وإلا يمكنك تجاهل الجزء الحالي.
أحيانًا قد تنشر Dify على خادمك الخاص، وعنوان الخادم الخارجي عادةً يكون http بدلاً من https، لكن عندما نطلب خدمة تدعم HTTP فقط، قد ترى تلميحًا مشابهًا لهذا (قم بتفعيل وضع تصحيح المتصفح F12، واطلع على النقاط التي بها مشاكل):
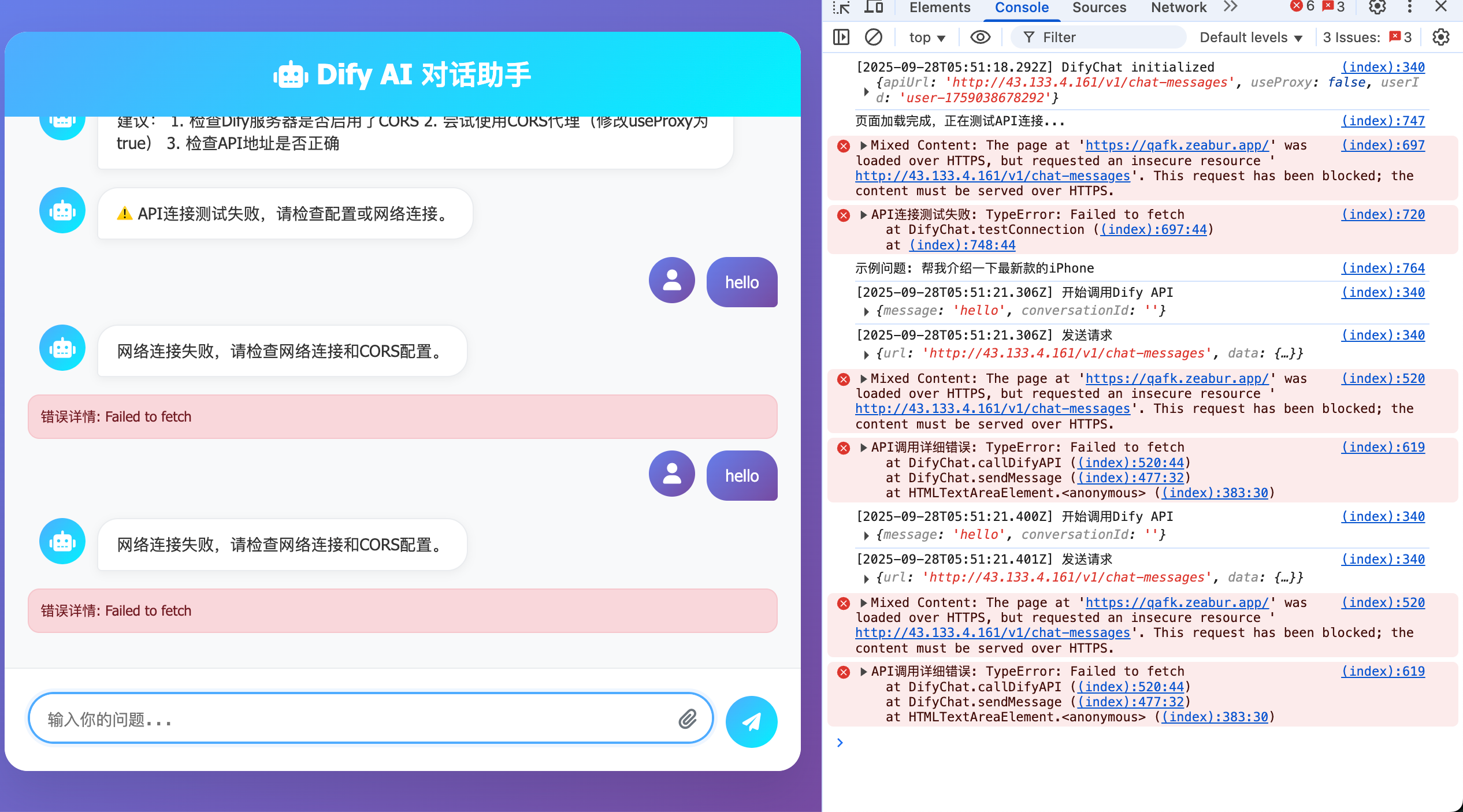
سبب هذه المشكلة هو أننا ننشر Dify بشكل افتراضي على خادم يدعم HTTP فقط ولا يدعم HTTPS. HTTPS (HyperText Transfer Protocol Secure) هو إضافة طبقة تشفير SSL/TLS على أساس HTTP (بروتوكول نقل النص الفائق)، ويمكن فهمه ببساطة على أنه "نسخة أكثر أمانًا من HTTP".
لجعل الخدمة تدعم HTTPS، يمكن عمومًا:
- استخدام برنامج آخر لإعادة توجيه الطلبات (مثل إعداد وكيل عكسي على nginx مع شهادة)، أو
- ربط نطاق ثم التقدم بطلب للحصول على شهادة لهذا النطاق.
لكن هذه العمليات معقدة نسبيًا، وهنا نستخدم Zeabur كبوابة شبكة لحل المشكلة.
يتم الوصول إلى صفحة Zeabur بشكل افتراضي عبر HTTPS، لذلك نحتاج فقط إلى إعادة توجيه النطاق الأصلي المطلوب إلى النطاق الذي يوفره Zeabur، ويمكن إصلاح هذه المشكلة.
- العنوان الأصلي:
http://{DIFY_API_URL}/v1/chat-messages - العنوان الجديد:
https://{DIFY_NEW_API_URL}.zeabur.app/v1/chat-messages
تحتاج فقط إلى استبدال جزء النطاق في URL (IP العام أو النطاق) بالنطاق الذي تم نشره بالفعل على Zeabur، فقد قمنا مسبقًا بإعداد وظيفة إعادة التوجيه في الخدمة.
إذا كنت مهتمًا، يمكنك أيضًا نشر خدمة إعادة توجيه بنفسك على Zeabur. عند إنشاء خدمة في Zeabur، اختر Python، ثم أدخل كود Python التالي، وبعد النشر ستحصل على عنوان https، ويمكن استخدام https بشكل طبيعي.
بعد اكتمال النشر، في إعدادات الشبكة، اضبط منفذ استماع البرنامج على 8080 محليًا، وافتح هذا المنفذ للخارج.
ملاحظة: يرجى استبدال {DIFY_API_URL} بعنوان Dify API الفعلي.
from flask import Flask, request, Response
import requests
app = Flask(__name__)
TARGET_BASE_URL = "{DIFY_API_URL}"
LISTEN_PORT = 8080
@app.route('/', defaults={'path': ''}, methods=['GET', 'POST', 'PUT', 'DELETE', 'PATCH', 'OPTIONS', 'HEAD'])
@app.route('/<path:path>', methods=['GET', 'POST', 'PUT', 'DELETE', 'PATCH', 'OPTIONS', 'HEAD'])
def proxy_request(path):
target_url = f"{TARGET_BASE_URL}/{path}"
if request.query_string:
target_url += f"?{request.query_string.decode('utf-8')}"
headers = {key: value for key, value in request.headers if key.lower() not in ['host', 'connection', 'content-length', 'accept-encoding']}
try:
resp = requests.request(
method=request.method,
url=target_url,
headers=headers,
data=request.get_data(),
cookies=request.cookies,
allow_redirects=False,
timeout=30
)
excluded_headers = ['content-encoding', 'content-length', 'transfer-encoding', 'connection']
response_headers = [(name, value) for name, value in resp.raw.headers.items() if name.lower() not in excluded_headers]
return Response(resp.content, resp.status_code, response_headers)
except requests.exceptions.RequestException as e:
print(f"Error forwarding request to {target_url}: {e}")
return Response(f"Proxy Error: Could not reach target server or invalid response: {e}", status=502)
except Exception as e:
print(f"An unexpected error occurred: {e}")
return Response(f"Internal Proxy Error: {e}", status=500)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=LISTEN_PORT, debug=True)