Dify Einführung und Wissensdatenbank-Integration
Rückblick auf die letzte Lektion
In den vergangenen Lektionen haben wir in Gruppen die Grundlagen von KI-Programmierung, Prompt-Engineering und KI-Bildgenerierung kennengelernt. Diese Inhalte haben uns geholfen, ein erstes Verständnis für die Grenzen und Fähigkeiten verschiedener Großer Sprachmodelle (LLMs, Large Language Models) bzw. generativer Modelle zu entwickeln.
Um dir bei der Wiederholung des letzten Unterrichts zu helfen, sind hier einige Fragen zum Nachdenken:
- Was ist KI-Programmierung? Wie verwendet man KI-Programmierwerkzeuge (z. B. z.ai), um eine Webseite zu erstellen?
- Was ist ein Großes Sprachmodell? Was sind Prompt-Engineering und Context-Engineering? Wie schreibst du einen komplexen Prompt?
- In Bezug auf die drei verschiedenen Richtungen Text, KI-Coding und Bildgenerierung – wo siehst du jeweils die Stärken und Schwächen der Modelle?
- Was ist eine API? Wie verwendet man z.ai, um auf Drittanbieter-APIs zuzugreifen?
Wenn du bei einer dieser Fragen noch Unsicherheit hast, kannst du die Unterlagen der letzten Lektion noch einmal durchsehen oder einfach in der WeChat-Gruppe fragen.
In dieser Lektion werden wir von einfachen KI-Text- und Bild-Tools zu einer Workflow-Plattform übergehen, die näher an realen Unternehmensanwendungen ist. Vom Chatbot hin zum KI-Agenten und KI-Workflow – und über eine API wird daraus eine interaktive „intelligente" Bot-Seite.
Falls du bei einzelnen Schritten Schwierigkeiten hast, mach dir keine Sorgen. Es empfiehlt sich, jederzeit einen Screenshot der aktuellen Oberfläche zu machen und diesen einem Großen Sprachmodell zur Analyse vorzulegen. Aktuelle Modelle können die meisten häufigen Fragen bereits beantworten.
Wenn auch nach dem Fragen keine Lösung gefunden wird, scheue dich nicht, einfach etwas auszuprobieren. Keine Angst vor Fehlern – jeder Versuch ist eine Gelegenheit zu lernen und Fortschritte zu machen. Mit zunehmender Praxis wirst du immer sicherer und die Bedienung immer flüssiger!
Was du in dieser Lektion lernen wirst
- Warum der Übergang vom Chatbot zum Agenten und zur Workflow-Orchestrierung notwendig ist.
- Was Agenten- und Workflow-Entwicklungsplattformen sind und wie man KI-Fähigkeiten als standardisierte, orchestrierbare Prozesse (SOPs) aufbaut.
- Was Dify ist und wie man mit dieser Open-Source-Plattform für LLM-Anwendungen schnell Anwendungen erstellt, insbesondere Wissensdatenbank-Frage-Antwort-Bots.
- Die Implementierungsmethoden und den Wert von RAG – warum Retrieval-Augmented Generation benötigt wird.
- Wie du von Grund auf Dify und die KI IDE Trae erlernst (
Extra Knowledge 4 - What is AI IDE and Trae), einschließlich der Erstellung von Agenten, Workflows und der Entwicklung einer Frontend-Chatbot-Webanwendung basierend auf der Dify API.
- Grundlegende Verwendung von Dify sowie Methoden zur Erstellung von Agenten und Workflows, API-Aufrufmethoden.
- Verwendung einer KI IDE und wie man mit einer KI IDE programmiert.
- Eine interaktive Frontend-Webanwendung als Agenten-Programm.
1. Vom Dialog zum Agenten
In der vorherigen Phase haben wir gelernt, wie man mit Prompts große Modelle dazu bringt, Rollen zu spielen, Texte zu generieren oder einfachen Code zu schreiben. Wenn du jedoch genauer nachdenkst, erkennst du ein Problem: Ein Chatbot allein kann keine echten Aufgaben erledigen.
Er kann die Frage „Wie prüfe ich eine Bestellung?" beantworten, aber nicht wirklich in einer Datenbank nach den entsprechenden Daten suchen; er kann beschreiben, was ein Wochenbericht enthalten sollte, aber nicht automatisch deine Projektdaten zusammenfassen und eine E-Mail senden. Diese Einschränkung des „nur Redens, kein Handelns" macht es für reine dialogbasierte KI schwierig, in echte Geschäftsprozesse integriert zu werden.
Um KI vom Chat-Partner zum digitalen Mitarbeiter zu machen, müssen wir ihr drei Kernfähigkeiten verleihen:
- Exklusives Wissen – die Fähigkeit, Produktdokumentation, Kundendaten und interne Richtlinien zu lesen und zu verstehen;
- Werkzeugnutzung (oder Plugins) – die Fähigkeit, Datenbanken zu bedienen und APIs aufzurufen;
- Strukturierte Ausführung – die Fähigkeit, Aufgaben nach vordefinierter Logik Schritt für Schritt zu erledigen statt frei zu improvisieren.
Dies ist der Grundentwurf eines KI-Agenten (AI Agent): eine automatisierte Einheit mit Ziel, Wissen, Werkzeugen und Ausführungspfad.

Hinweis: Was in der aktuellen Branche als einfache Version eines „Agenten" bezeichnet wird, meist meist eine erweiterte Anwendung, die auf der Kombination aus LLM + Werkzeugen + Wissensdatenbank basiert, und keinen selbstständig planenden Agenten im eigentlichen Sinne. Einfache Agenten verfügen zwar nicht über echte Schlussfolgerungs- und Langzeitplanungsfähigkeiten, reichen jedoch aus, um eine Vielzahl von Automatisierungsszenarien im Unternehmensumfeld zu unterstützen. Wir werden in späteren Kapiteln ausführlich auf echte, selbstständig planende und handelnde Agenten eingehen.
1.1 Der einfachste Agent: Frage-Antwort-Bot auf Basis einer Wissensdatenbank
Nachdem die vielfältigen Kernfähigkeiten eines Agenten definiert sind, stellt sich eine interessante Frage: Kann man allein durch die Umsetzung einer einzigen, einfachsten Funktion einen tatsächlich nutzbaren Basis-Agenten erstellen? Die Antwort lautet: Ja.
Tatsächlich ist das Kernanliegen der Nutzer in vielen realen Geschäftsszenarien nicht, dass KI automatisch komplexe Operationen ausführt (wie API-Aufrufe oder die Koordination von Aufgaben über Systeme hinweg), sondern dass sie auf der Grundlage unternehmenseigener Dokumente präzise und zuverlässige Fragen beantwortet. Dies entspricht genau der ersten der drei Kernfähigkeiten eines Agenten: der Fähigkeit zur Bereitstellung von exklusivem Wissen. Daraus ergibt sich die einfachste und am weitesten verbreitete Form eines Agenten: der Frage-Antwort-Bot auf Basis einer Wissensdatenbank.
Obwohl er noch nicht über Werkzeugnutzung oder autonome Planungsfähigkeiten verfügt, liegt der entscheidende Durchbruch darin, dass die Antworten des großen Modells nicht mehr frei erfunden werden, sondern auf belegbaren Grundlagen beruhen. Wie wird das erreicht? Die Lösung des Kernproblems lautet: Wenn ein Unternehmen über Tausende von Dokumentseiten verfügt, wie findet das Modell bei jedem Gesprächsdialog schnell die Inhalte, die für die aktuelle Frage am relevantesten sind?
Eine Lösung hierfür ist: Retrieval-Augmented Generation (RAG).
Der Grundgedanke von RAG ist: Wenn ein Nutzer eine Frage stellt, sucht das System zunächst in der Unternehmens-Wissensdatenbank nach den Textfragmenten, die semantisch am stärksten mit der Frage verwandt sind (z. B. ein Abschnitt aus dem Produkthandbuch oder eine Klausel aus den HR-Richtlinien). Diese Fragmente werden dann als Kontext in die Eingabe des großen Modells „eingefügt", um es dazu zu bringen, die Antwort auf der Grundlage realer Dokumente zu generieren.
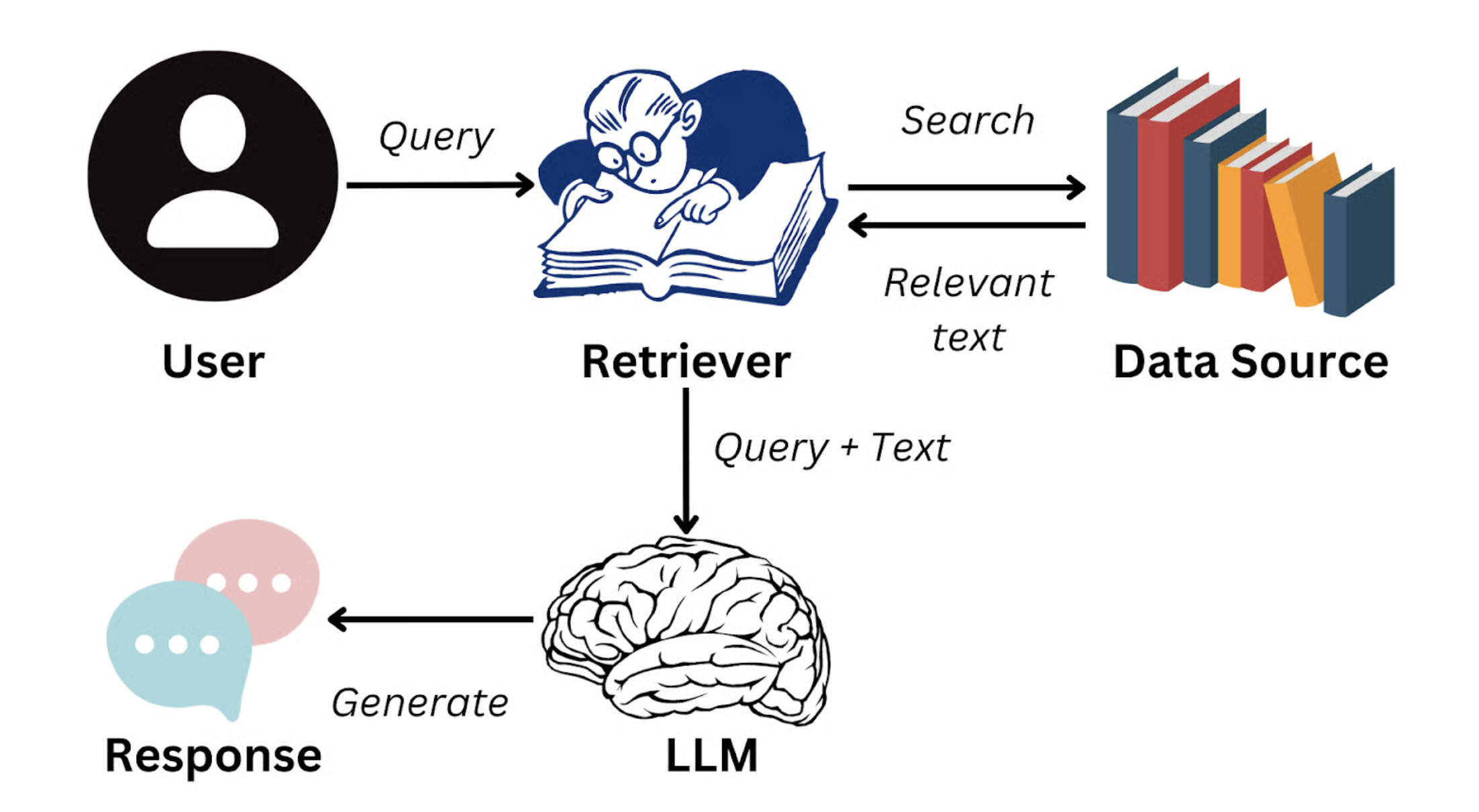
Bildquelle: https://www.datacamp.com/blog/what-is-retrieval-augmented-generation-rag
So beruht die Antwort des Modells nicht mehr auf dem verallgemeinerten Wissen seiner Trainingsdaten, sondern wird auf den von dem Unternehmen bereitgestellten verlässlichen Informationen verankert. Das Ziel von RAG ist es, durch diese dynamische Einbindung externen Wissens die Authentizität, Genauigkeit und Konsistenz der Antworten deutlich zu steigern – sogar dahingehend, dass Antworten „zur Rolle passen", beispielsweise im Kundenservice-Jargon oder im Stil einer technischen Dokumentation.
In der geschäftlichen Praxis ist diese Technologie besonders wichtig, da große Modelle häufig „Halluzinationen" erzeugen. Wenn du beispielsweise als CFO oder Berater nach konkreten Daten eines bestimmten Zeitraums fragst, könnte das Modell Datumsangaben und Ereignisse erfinden. Durch die Einführung von RAG werden die Kontrollierbarkeit und Zuverlässigkeit der Antworten deutlich verbessert.
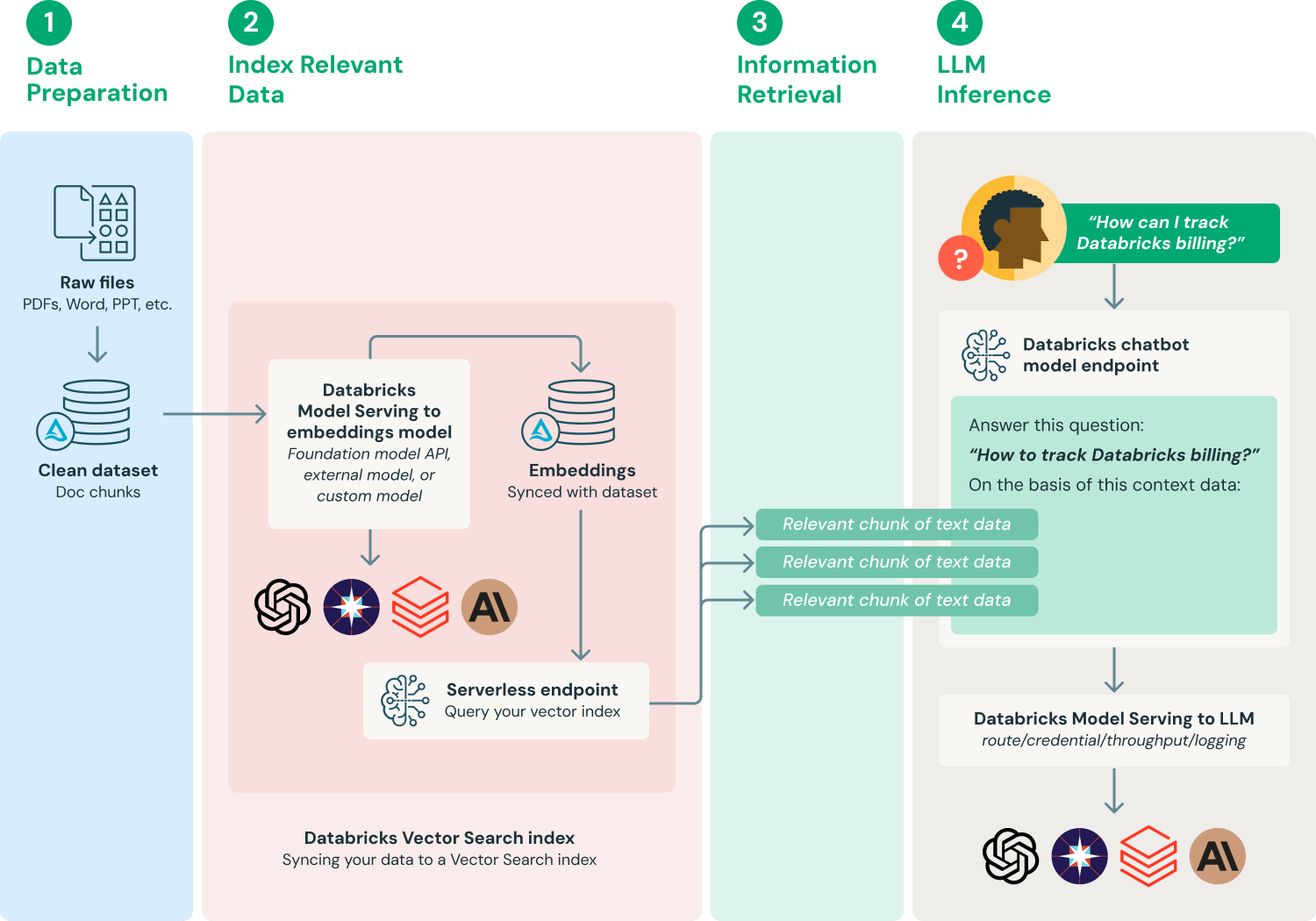
Bildquelle: https://www.databricks.com/glossary/retrieval-augmented-generation-rag
Im praktischen Teil dieser Lektion werden wir die beliebte KI-Workflow-Plattform Dify verwenden, um Schritt für Schritt einen Frage-Antwort-Bot auf Basis einer Wissensdatenbank zu erstellen. Du kannst problemlos verschiedene Arten von exklusivem Material in eine Wissensdatenbank umwandeln, wie Produkthandbücher, Unternehmensrichtlinien, Projektdokumentation, Forschungsarbeiten, Knowledge-Base-Artikel oder sogar persönliche Notizensammlungen.
Nach Abschluss der Einrichtung kannst du verschiedene Fragen stellen, um die Fähigkeiten zu testen, zum Beispiel:
- „Welche wesentlichen Funktions-Upgrades hat die neueste Version unseres Produkts A?"
- „Bitte erkläre mir anhand des Mitarbeiterhandbuchs, wie die Urlaubsregelungen für dieses Jahr festgelegt sind."
- „Wie wurde die technische Herausforderung ‚XXX', auf die wir im Projekt XX gestoßen sind, gelöst?"
- „Welche Kernforschungsmethode wird in dieser Arbeit beschrieben?"
Du wirst aus erster Hand erleben, wie die RAG-Technologie statische, verteilte Dokumentationen in eine präzise, intelligente Wissensdatenbank verwandelt, die hochpräzise Frage-Antwort-Unterstützung für unterschiedlichste Szenarien bietet.
1.2 Vom dialogbasierten Agenten zum Workflow
Selbst ein „erweiterter Agent" mit Wissensdatenbank und Plugin-Aufruffähigkeiten stößt bei komplexeren Geschäftsprozessen noch an seine Grenzen.
Stell dir folgende Nutzeranfrage vor: „Welche Funktionsupdates hat unser neues SaaS-Produkt kürzlich erhalten? Kannst du mir eine Kundenübersicht zusammenstellen?"
Diese Anfrage wirkt einfach, erfordert jedoch im Hintergrund mehrere koordinierte Schritte: Zunächst müssen die Funktionsveröffentlichungen des letzten Monats aus der internen Produktdokumentation oder der Notion-Wissensdatenbank abgerufen werden; dann die kundenrelevanten Kernfunktionen herausgefiltert werden; anschließend ein großes Modell die technischen Beschreibungen in kundenfreundliche Sprache übersetzt; und schließlich der generierte Inhalt an das Marketing-Team per E-Mail gesendet oder in einer Google Docs-Vorlage gespeichert wird.
Wenn man sich nur auf die freie Schlussfolgerung eines großen Sprachmodells verlässt, ist nicht einmal sicher, ob ein einziger Dialog alle Schritte abschließen kann. Selbst wenn, werden leicht wichtige Informationen übersehen, interne Begriffe mit Kundensprache verwechselt oder die Ausgabe ist nicht strukturiert. Noch wichtiger ist: Unternehmen benötigen überprüfbare, wiederverwendbare und überwachbare standardisierte Ausführungspfade – nicht die improvisierte Leistung eines Modells bei jedem Durchlauf. Überwachbarkeit und Reproduzierbarkeit sind für Unternehmen von entscheidender Bedeutung; unerwartete Ergebnisse können zu unvorhergesehenen und schwerwiegenden Verlusten führen.
Dies führt zu einem fortgeschritteneren KI-Anwendungsparadigma: dem KI-Workflow (AI Workflow).

Ein Workflow bedeutet, eine komplexe Aufgabe in mehrere geordnete, konfigurierbare und automatisch ausführbare Teilschritte zu zerlegen und ihre logischen Beziehungen – wie Bedingungsprüfungen, Schleifen oder Parallelausführung – visuell oder per Code zu orchestrieren. Die Standardisierung von KI-Fähigkeiten als SOP (Standard Operating Procedure) bedeutet, die Erfahrung, wie eine Aufgabe mit KI erledigt wird, als wiederverwendbare Vorlage zu fixieren.
Diese Vorgehensweise bringt vielfältigen Mehrwert: Nicht-Techniker (wie Produktmanager oder Marketing-Mitarbeiter) können durch Drag-and-Drop-Komponenten schnell KI-Anwendungen erstellen; Entwickler können RAG-Retrieval, LLM-Aufrufe, API-Tools usw. als Standardknoten verpacken und in verschiedenen Geschäftsszenarien wiederverwenden; der gesamte Prozess kann vollständig nachverfolgt, debuggt und kontinuierlich optimiert werden, was den Anforderungen von Unternehmen an Stabilität und Compliance gerecht wird.
KI-Workflows richten sich an eine breite Nutzerschaft. Produktmanager können ohne Programmierung komplette Nutzerinteraktionspfade entwerfen; Marketing-Mitarbeiter können schnell Kundenservice-Bots, Content-Generatoren oder Benachrichtigungssysteme aufbauen; Entwickler und Algorithmus-Ingenieure können Kernfähigkeiten modularisieren und für Frontend-Aufrufe bereitstellen; Gründer oder Solo-Entwickler können mit minimalen Kosten ein KI-Produkt-MVP validieren und innerhalb weniger Tage einen vollständigen Prototyp mit Datenabfrage, Inhaltserstellung und Aktionsausführung online stellen.
Darüber hinaus ist erwähnenswert, dass KI-Workflows in der Regel durch eine Zwischendarstellung (Intermediate Representation) beschrieben werden können. Die konkrete Ausdrucksweise variiert zwar zwischen den verschiedenen Workflow-Plattformen, aber die meisten verwenden strukturierte Dateien (wie JSON, YAML usw.), um Knotentypen, Ein- und Ausgaben sowie Ausführungslogik zu definieren, ähnlich der folgenden Darstellung:

Kurz gesagt: Wenn Agenten die KI vom „Können-Reden" zum „Können-Handeln" bringen, dann lassen Workflows die KI vom „gelegentlich eine Sache schaffen" zum „stabilen, zuverlässigen und skalierbaren Erledigen einer ganzen Aufgabengattung" übergehen. In der kommenden Praxis werden wir die Dify-Plattform nutzen, um selbst einen vollständigen KI-Workflow zu erstellen und den gesamten Prozess von der Idee bis zur lauffähigen Anwendung zu erleben.
1.3 Gängige Agenten-/Workflow-Plattformen
Mit der rasanten Entwicklung der generativen KI-Technologie sind eine Reihe von Low-Code- und sogar No-Code-Agenten- und Workflow-Plattformen entstanden, die Entwicklern und Fachanwendern helfen sollen, schnell Agenten und automatisierte Prozesse zu erstellen, ohne sich in die Komplexität der Programmierung vertiefen zu müssen.
Zunächst ist zu klären: Low-Code-Plattformen sind Entwicklungswerkzeuge, die durch visuelles Ziehen von Komponenten, vordefinierte Geschäftslogik-Vorlagen und grafische Regelkonfiguration den manuellen Programmieraufwand deutlich reduzieren. Ihr Kern besteht darin, visuelle Konfiguration und knotenbasiertes Drag-and-Drop-Programmieren als Ersatz für direktes Code-Schreiben zu nutzen. Dies befreit Entwickler mit technischen Fähigkeiten von repetitiver Arbeit und ermöglicht es gleichzeitig Nicht-Technikern mit Geschäftslogik-Kenntnissen, an der Anwendungserstellung teilzunehmen. Im Wesentlichen bilden sie eine Brücke zwischen Entwicklungseffizienz und Szenario-Flexibilität.
Der herausragende Wert solcher Low-/No-Code-Agentenplattformen liegt darin, die Einstiegshürde für KI-Anwendungen erheblich zu senken. Früher benötigte ein Team Wochen kooperativer Arbeit – von der Anforderungsanalyse über Code-Entwicklung bis hin zu Test und Bereitstellung –, um einen KI-Agenten (wie einen Kundenservice-QA-Bot oder einen Datenverarbeitungsassistenten) fertigzustellen. Mit den visuellen Werkzeugen der Plattformen lässt sich die Zeitspanne „von der Idee bis zum Live-Betrieb" auf wenige Stunden verkürzen.
Die derzeit gängigsten Low-Code-KI-Workflow-Plattformen auf dem Markt umfassen:
| Plattform | Merkmale | Anwendungsbereiche |
|---|---|---|
| Dify | Open Source, Wissensdatenbank-RAG, LLM-Orchestrierung, API-Ausgabe, chinesischfreundlich | Unternehmens-Wissensdatenbank-QA, maßgeschneiderte Agenten, API-Dienste |
| Coze (ByteDance) | In China verfügbar, Integration des Douyin/Feishu-Ökosystems, umfangreiche Plugins | Social-Bots, Integration chinesischer Mini-Programme |
| n8n | Universelles Automatisierungstool, KI-Knoten-Unterstützung, Fokus auf API-Orchestrierung | Systemübergreifende Datensynchronisation, KI + traditionelle SaaS-Automatisierung |
| Baidu Qianfan AppBuilder / Alibaba Bailian / Tencent HunYuan | Cloud-native Lösungen großer Anbieter, Integration eigener Modelle | Unternehmensweite Bereitstellung, Szenarien mit hohen Compliance-Anforderungen |
Die Auswahl an Low-Code-KI-Workflow-Plattformen auf dem Markt ist reichhaltig. Obwohl Mainstream-Cloud-Anbieter wie AWS, Azure und Alibaba Cloud entsprechende KI-Workflow-Lösungen anbieten, zeichnen sich Dify, Coze und n8n durch die folgenden drei Kernvorteile als die derzeit am weitesten verbreiteten Vertreter aus:
- Höchste Benutzerfreundlichkeit. Die Plattformen verwenden visuelle Drag-and-Drop-Oberflächen, sodass Nutzer ohne tiefes technisches Verständnis schnell starten können.
- Hohe Flexibilität. Unterstützung für benutzerdefinierte Komponenten und erweiterbare API-Schnittstellen, die sowohl für leichtgewichtige Szenarien wie Lehrdemonstrationen und MVP-Validierungen als auch für agile Iterationen kleiner und mittlerer Teams geeignet sind.
- Ausgereiftes Ökosystem. Nicht nur die offizielle Dokumentation ist detailliert und die Reaktionszeiten kurz, sondern auch die aktive Nutzergemeinschaft erleichtert den schnellen Zugriff auf vorgefertigte Lösungen unterschiedlicher Nutzer.
Alle drei Plattformen unterstützen die Ausgabe der erstellten KI-Agenten als standardisierte API-Schnittstellen, die nahtlos in Frontend-Webanwendungen, unternehmensinterne ERP-Systeme oder mobile Apps integriert werden können, was die technische Einstiegshürde für die praktische Umsetzung von KI-Fähigkeiten weiter senkt.
1.3.1 Dify: Unternehmensweite LLMOps- und Anwendungslebenszyklus-Management-Plattform
Dify positioniert sich als LLM-Anwendungsentwicklungs- und betriebsplattform mit dem Ziel, das gesamte Lebenszyklusmanagement von KI-Anwendungen – von der Konzeption über die Bereitstellung bis zur Optimierung – anzubieten. Der Kern ist eine Low-Code-Plattform, die Entwicklern und innovativen Nicht-Technikern helfen soll, schnell produktionsreife KI-Anwendungen zu erstellen.
Funktional deckt Dify visuelles Workflow-Design, Agenten-Erstellung, Wissensdatenbank-Verwaltung und Multi-Modell-Unterstützung ab. Die Plattform ermöglicht die Gestaltung komplexer Aufgabenabläufe durch Drag-and-Drop-Knoten und unterstützt die Erstellung intentionbasierter Agenten. Die Wissensdatenbank-Funktionalität sticht besonders hervor: Sie kann Dokumente in verschiedenen Formaten verarbeiten und eine effiziente Vektor-Suche durchführen. Gleichzeitig ist Dify mit zahlreichen LLMs kompatibel, darunter GPT, Claude und verschiedene Open-Source-Modelle. Die erstellten Anwendungen können per Klick als Standard-API veröffentlicht und einfach integriert werden.
Hinsichtlich der technischen Architektur zeichnet sich Dify durch Open Source und die Möglichkeit der privaten Bereitstellung aus, mit Fokus auf Flexibilität, Skalierbarkeit und Unternehmens-Compliance. Die Zielnutzer umfassen Entwicklerteams und Business-Innovatoren; typische Anwendungsszenarien reichen von Unternehmens-Wissensdatenbanken und intelligentem Kundenservice über automatisierte Inhaltserstellung bis hin zu branchenspezifischen KI-Assistenten und unternehmensweiten KI-Plattformen.
1.3.2 Coze (ByteDance): Wegbereiter der No-Code-KI-Agenten-Erstellung
Coze ist eine von ByteDance herausgegebene KI-Agenten-Entwicklungsplattform, die mit maximaler Benutzerfreundlichkeit als Kern auch Nutzer ohne Programmiererfahrung in die Lage versetzt, funktionsreiche KI-Chatbots einfach zu erstellen, zu testen und zu veröffentlichen.
Ihr Kernprinzip ist die Vereinfachung der Bot-Erstellung zu einer Art Baukasten-Prinzip. Nutzer können über die Oberfläche mühelos Rollen und Wissensdatenbanken konfigurieren und die umfangreiche integrierte Plugin-Bibliothek nutzen, um dem Bot externe Fähigkeiten wie Nachrichten, Reisen oder Bildgenerierung hinzuzufügen. Der erstellte Bot kann per Klick schnell auf Plattformen wie Doubao, Feishu und WeChat-öffentliche Konten veröffentlicht werden.
Die technische Architektur ist vollständig auf niedrige Einstiegshürden ausgerichtet; das Backend integriert Bytedances eigene Modelle und kapselt komplexe Abläufe, wobei multimodales Verständnis und Echtzeit-Antworten im Vordergrund stehen. Als primär als Cloud-Angebot betriebene Plattform sind die Möglichkeiten zur privaten Bereitstellung relativ begrenzt. Typische Anwendungsszenarien umfassen persönliche Assistenten und Unterhaltungs-Bots, intelligenten Kundenservice und QA-Systeme, Online-Bildungsassistenten und schnelle Prototyp-Validierung.
1.3.2 n8n: Programmierbare Backend-Workflow-Automatisierungs-Engine
n8n ist eine universelle, programmierbare Workflow-Automatisierungsplattform, deren Kernpositionierung darin besteht, verschiedene Anwendungen, Datenbanken und APIs miteinander zu verbinden und Datenflüsse sowie automatisierte Aufgabenausführung zu realisieren.
Über eine umfangreiche Bibliothek von Integrationsknoten unterstützt sie Hunderte von SaaS-Diensten, Datenbanken und Protokollen und verbindet visuelle und codebasierte Ansätze: Nutzer können Knoten auf einer Leinwand ziehen und gleichzeitig JavaScript- oder Python-Code einfügen, um benutzerdefinierte Logik zu schreiben. n8n ist besonders stark bei datenintensiven Backend-Aufgaben wie Datensynchronisation, ETL-Prozessen und API-Orchestrierung.
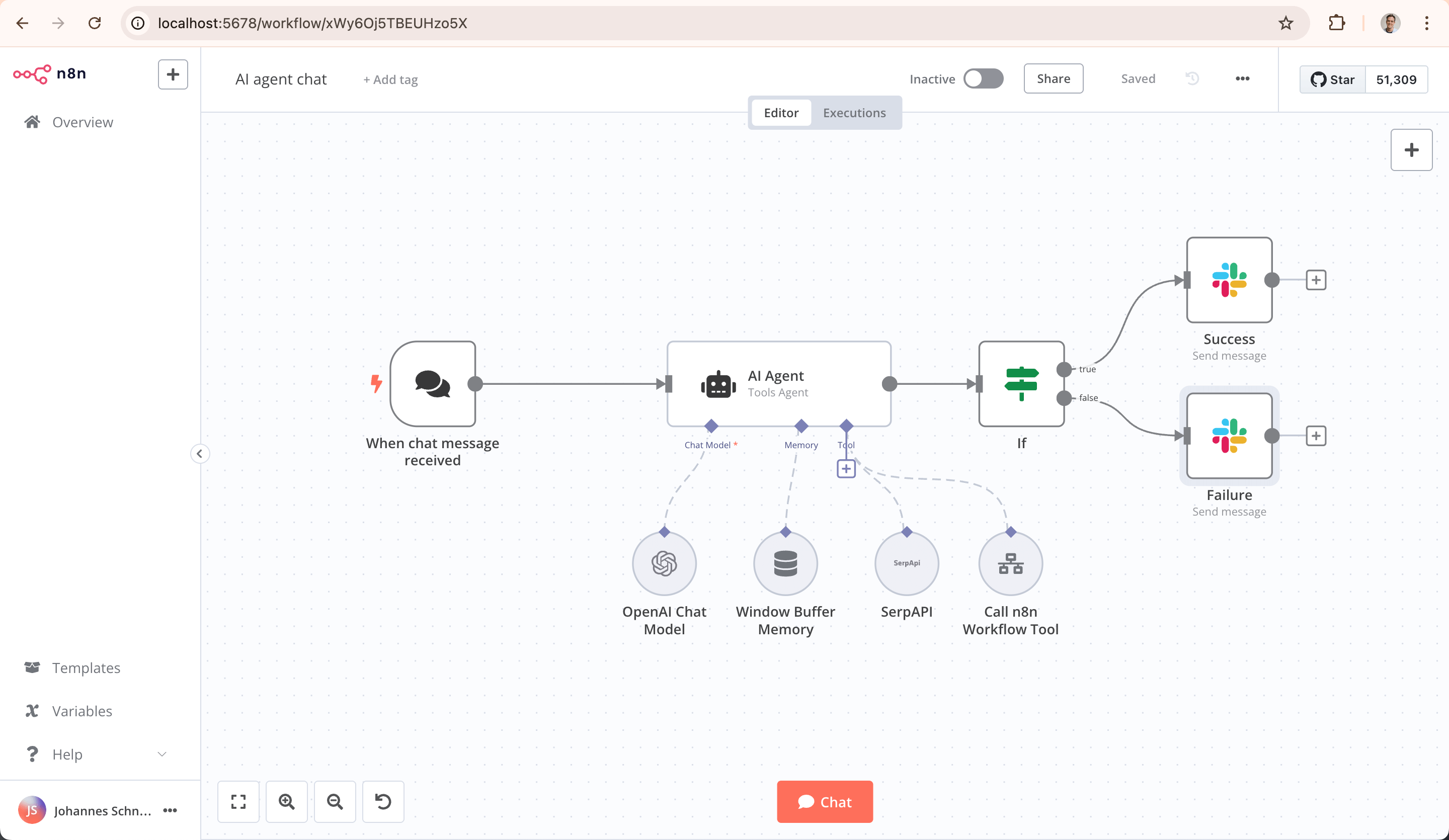
Ein Schlüsselmerkmal ist „quelloffen" und „selbst hostbar": Nutzer können die Plattform privat bereitstellen und volle Kontrolle über Daten und Umgebung behalten, was sie für Branchen mit hohen Datensicherheitsanforderungen besonders attraktiv macht. Die Hauptzielgruppe sind Entwickler, technisch versierte Betriebsmitarbeiter und Datenanalysten. Der größte Vorteil von n8n liegt in seinem äußerst starken Community-Ökosystem. Im Internet findet man eine Fülle von n8n-Tutorials und Erfahrungsberichten, die Nutzern praktische Lernreferenzen und Inspiration bieten. Gleichzeitig unterstützt es die Verbindung mit zahlreichen globalen Plattform-Ökosystemen wie YouTube und Instagram und hilft Nutzern dabei, plattformübergreifende Daten- und Servicebarrieren mühelos zu überwinden und automatisierte Multi-Ökosystem-Workflows zu realisieren.
1.3.3 Weitere Workflow-Plattformen
Neben den oben genannten bekanntesten Plattformen haben die großen Technologieunternehmen in China jeweils ihre eigenen integrierten KI-Entwicklungsplattformen auf den Markt gebracht: Baidu Qianfan AppBuilder bietet durchgehende Unterstützung von der Modellauswahl über den RAG-Aufbau bis zur Agenten-Veröffentlichung, mit tiefer Integration des ERNIE-Modells; Alibaba Cloud Bailian basiert auf der Tongyi Qianwen-Modellreihe mit Fokus auf Unternehmenssicherheit und private Bereitstellung; Tencent Cloud TI Platform konzentriert sich auf Branchenszenarien wie Finanzwesen und Gesundheitswesen und bietet umfangreiche vorkonfigurierte Lösungsvorlagen. Diese Plattformen sind in der Regel tief in ihr jeweiliges Cloud-Ökosystem integriert und eignen sich für Unternehmen, die bereits im entsprechenden Technologieumfeld tätig sind.
In Bezug auf Universalität, Offenheit und Community-Ökosystem bleiben Dify und Coze jedoch aufgrund ihrer herausragenden Benutzerfreundlichkeit, breiten Modellunterstützung und aktiven Entwickler-Communitys die derzeit am weitesten verbreiteten Wahlmöglichkeiten.
Obwohl sich die Plattformen in ihrer Positionierung und ihrem Ökosystem unterscheiden, ist ihre Kernlogik stets die visuelle Orchestrierung und Verbindung verschiedener Fähigkeitsmodule. Wer daher das Designkonzept und die Bedienung einer dieser Plattformen beherrscht, verfügt über die Grundlage, um schnell zu ähnlichen Werkzeugen zu wechseln. In der folgenden Praxis werden wir Dify als konkretes Beispiel verwenden.
2. Dify im Detail
2.1 Was ist Dify
Wir haben bereits grundlegende Informationen zu Dify kennengelernt. Für weitere Details kannst du über https://cloud.dify.ai/apps auf die Dify-Plattform zugreifen. Wenn du mehr erfahren möchtest, besuche die offizielle Website unter https://dify.ai.
Dify ist eine Open-Source-Plattform zur Entwicklung von LLM-Anwendungen. Sie bietet eine intuitive Oberfläche, die Agenten-Workflows, RAG-Pipelines, Werkzeugfähigkeiten, Modellverwaltung, Observabilität und weitere Funktionen vereint und dir hilft, schnell vom Prototyp in die Produktionsumgebung zu gelangen.
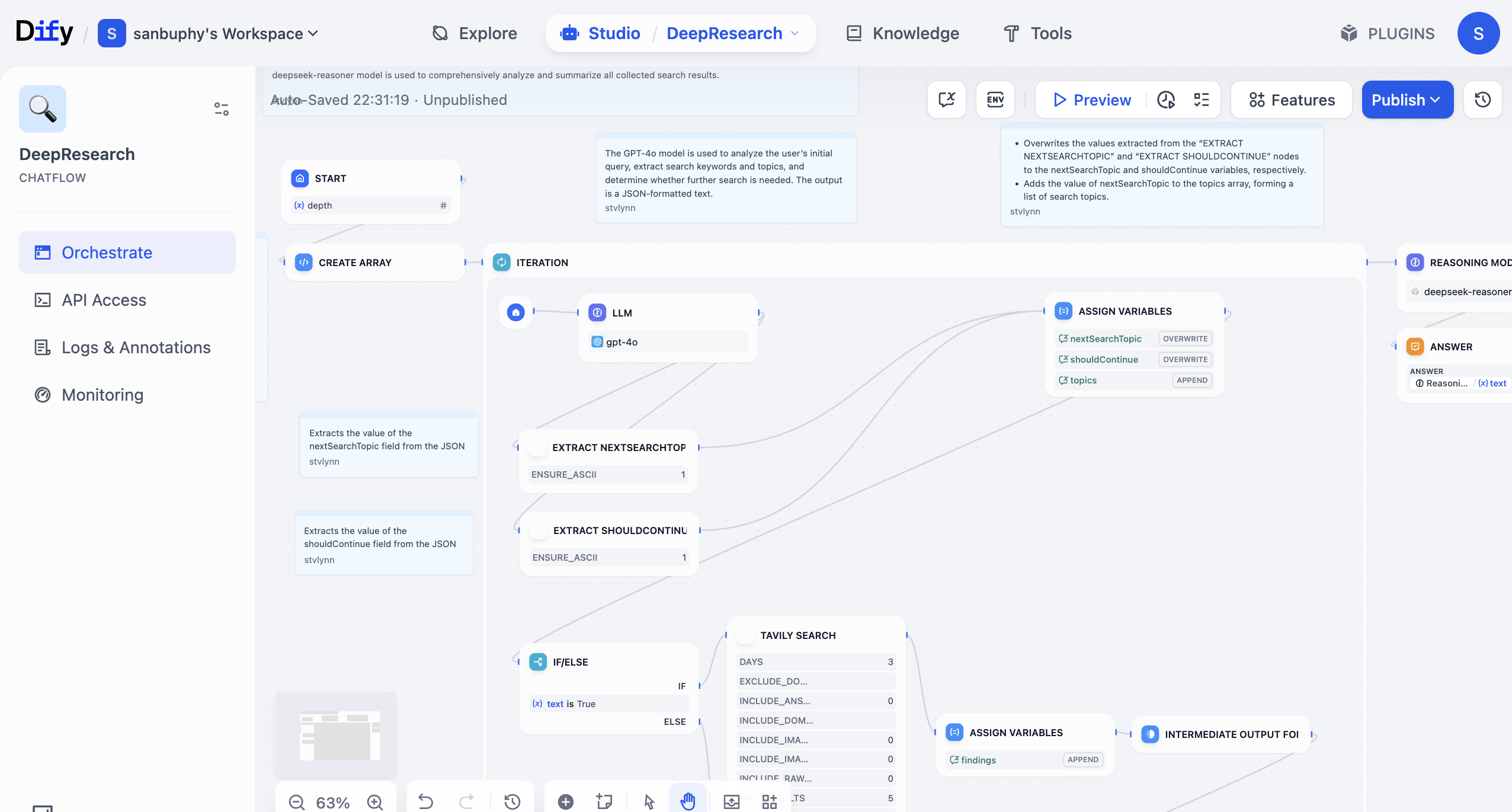
In Dify kannst du Große Sprachmodelle und verschiedene Werkzeuge nutzen, um „Workflows" zu erstellen. Ein Workflow verknüpft Schritte, die du sonst manuell ausführen müsstest – wie Datenabfrage, LLM-Aufrufe, Websuche, Ergebnisfilterung, Formatierung usw. – gemäß einer Geschäftslogik zu einem automatisierten, wiederverwendbaren Prozess. Ohne Workflows müsstest du bei jedem Durchlauf dieselben Inhalte per Copy & Paste an das große Modell übergeben – ineffizient, fehleranfällig und in realen Geschäftsabläufen kaum reproduzierbar.
Die Erstellung eines Workflows ist wie das Zusammenbauen von Bausteinen oder Puzzleteilen. Du verbindest „LLM-Knoten" (für das Verstehen und Generieren), verschiedene „Werkzeugknoten" (für konkrete Aktionen wie Datenbankabfragen, E-Mail-Versand, Textübersetzung usw.) sowie „Datenknoten" (für das Lesen und Speichern von Informationen) wie Bausteine miteinander. Sie arbeiten automatisch nach der von dir vorgegebenen Logik zusammen, ohne dass du bei jedem Durchlauf manuell eingreifen musst. Du kannst es dir auch als eine Art „Low-Code-Programm" vorstellen: Du musst lediglich per Drag-and-Drop die Ein- und Ausgabepfade konfigurieren, um relativ komplexe Geschäftslogik umzusetzen.
Ein Beispiel: Wenn du ein Amazon- oder Douyin-E-Commerce-Shopbesitzer bist und ein KI-Kundenservice-System aufbauen möchtest, kannst du einen Workflow nach der folgenden Struktur entwerfen:
- Trigger-Knoten (ähnlich START): Empfängt die Kundenanfrage, z. B. „Wie lange ist die Garantiezeit für dieses Produkt?".
- Fragenklassifikations-Knoten (ähnlich QUESTION CLASSIFIER): Verwendet ein Modell (z. B. GPT), um die Nutzerfrage zu klassifizieren und zu bestimmen, ob es sich um After-Sales (z. B. Garantie), Nutzungshinweise oder eine andere Kategorie handelt.
- Wissensabfrage-Knoten (ähnlich KNOWLEDGE RETRIEVAL): Greift basierend auf der Klassifikation automatisch auf die entsprechende Wissensdatenbank zu. Wenn es sich um eine Garantiefrage handelt, werden die präzisen Informationen zum Thema „Garantie" aus der After-Sales-SOP-Wissensdatenbank abgerufen.
- LLM-Knoten (LLM Node): Sendet die Nutzerfrage zusammen mit den abgerufenen Wissensdatenbank-Inhalten an das Große Sprachmodell (z. B. GPT), das eine nutzerfreundliche Antwort generiert (ohne zu technischen Jargon).
- Bedingungsknoten: Prüft, ob die vom großen Modell generierte Antwort eine klare Garantiezeit (z. B. „1 Jahr", „3 Jahre") enthält. Wenn ja, wird der nächste Schritt ausgeführt; wenn nicht, wird „Bitte geben Sie die Produktmodellnummer an" ausgegeben.
- Ausgabeknoten (ähnlich ANSWER): Gibt die endgültige Antwort an den Nutzer zurück und protokolliert automatisch die Beratungsaufzeichnung in einer Tabelle.
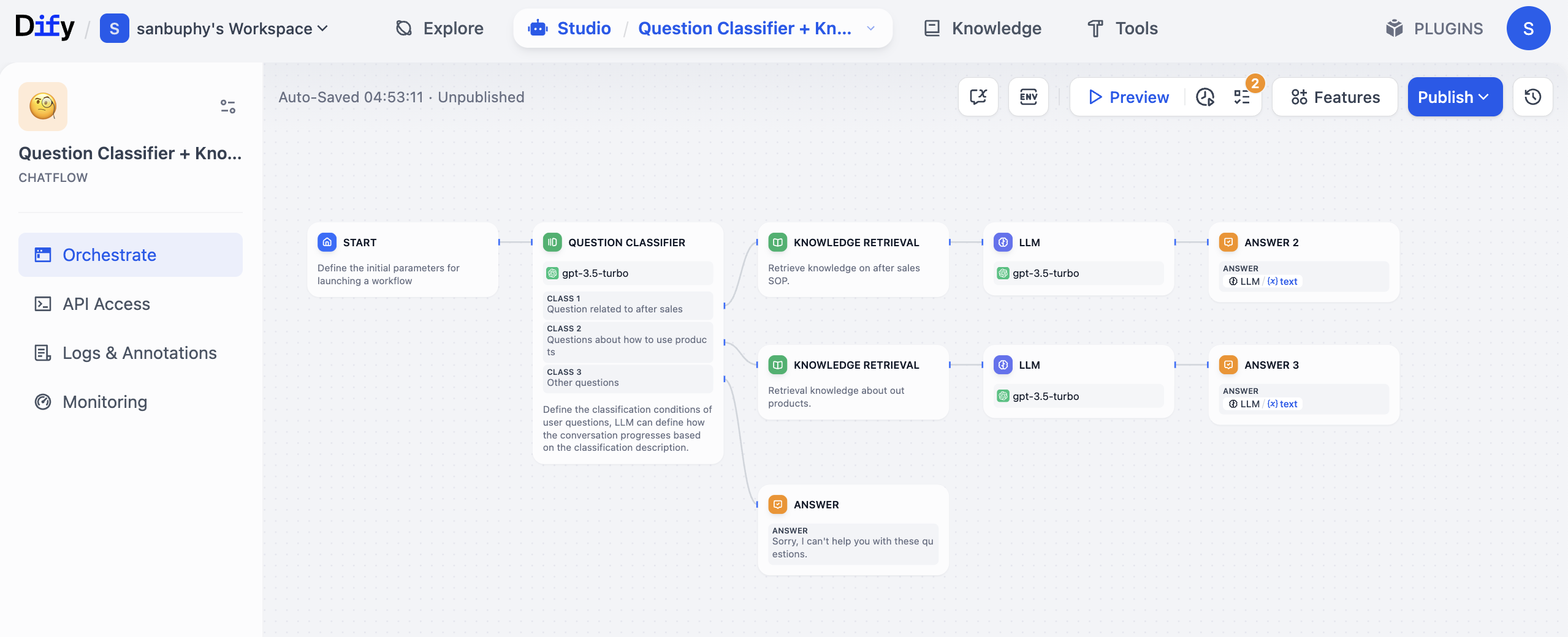
Während des gesamten Prozesses musst du nicht manuell die Wissensdatenbank durchsuchen, die Modellantworten wiederholt anpassen oder Daten separat erfassen – der Workflow verknüpft diese Schritte und „läuft automatisch ab". Und er ist sehr flexibel: Wenn du beispielsweise später eine neue Regel hinzufügen möchtest („Wenn der Nutzer nach dem Garantieumfang fragt, eine andere Wissensdatenbank abfragen"), fügst du einfach einen weiteren Bedingungsknoten im Workflow hinzu, ohne das gesamte System neu zu strukturieren.
Dies ist ein relativ einfaches Workflow-Beispiel, aber diese Fähigkeiten vollständig zu beherrschen, kann für dich momentan noch eine Herausforderung darstellen. Deshalb beginnen wir in dieser Lektion mit einem grundlegenderen Wissensdatenbank-Agenten und werden später schrittweise komplexere Workflow-Techniken erlernen.
2.1.1 Bereitstellung einer eigenen Dify-Instanz (optional)
Dieser Inhalt war ursprünglich für eine spätere Lektion geplant. Da jedoch einige Lernende möglicherweise aufgrund von Netzwerkbeschränkungen vorübergehend nicht auf die offizielle Dify-Website oder den Cloud-Dienst zugreifen können, bieten wir diesen optionalen Lernpfad vorab an, damit du deinen Lernfortschritt reibungslos fortsetzen kannst.
Du musst dieses Tutorial als Einführung in die grundlegende Verwendung von Web-Bereitstellungsplattformen heranziehen: Wie man Web-Anwendungen bereitstellt
Du lernst, wie man eine eigene Dify-Instanz auf Zeabur bereitstellt. Nach der Bereitstellung registrierst und meldest du dich unter dem entsprechenden Link an und folgst dann dem nachfolgenden Tutorial.
Beachte, dass verschiedene Dify-Versionen leichte Unterschiede in der Bedienung und der Benutzeroberfläche aufweisen können, die Gesamtstruktur jedoch ähnlich bleibt. Wenn du Unterschiede feststellst, keine Panik – suche einfach nach den entsprechenden Schnittstellen und Einstiegspunkten, um fortzufahren.
2.2 Erstellen der ersten Dify-Chatbot-Anwendung
Nach dem Aufruf der Dify-Startseite https://cloud.dify.ai/apps und der Registrierung/Anmeldung wählst du Studio und siehst die folgende Oberfläche:
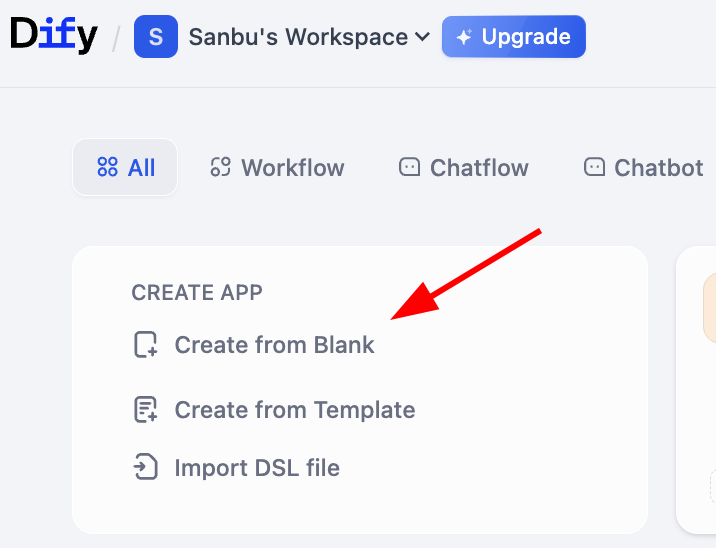
Finde den Bereich CREATE APP auf der linken Seite und klicke auf Create from Blank.
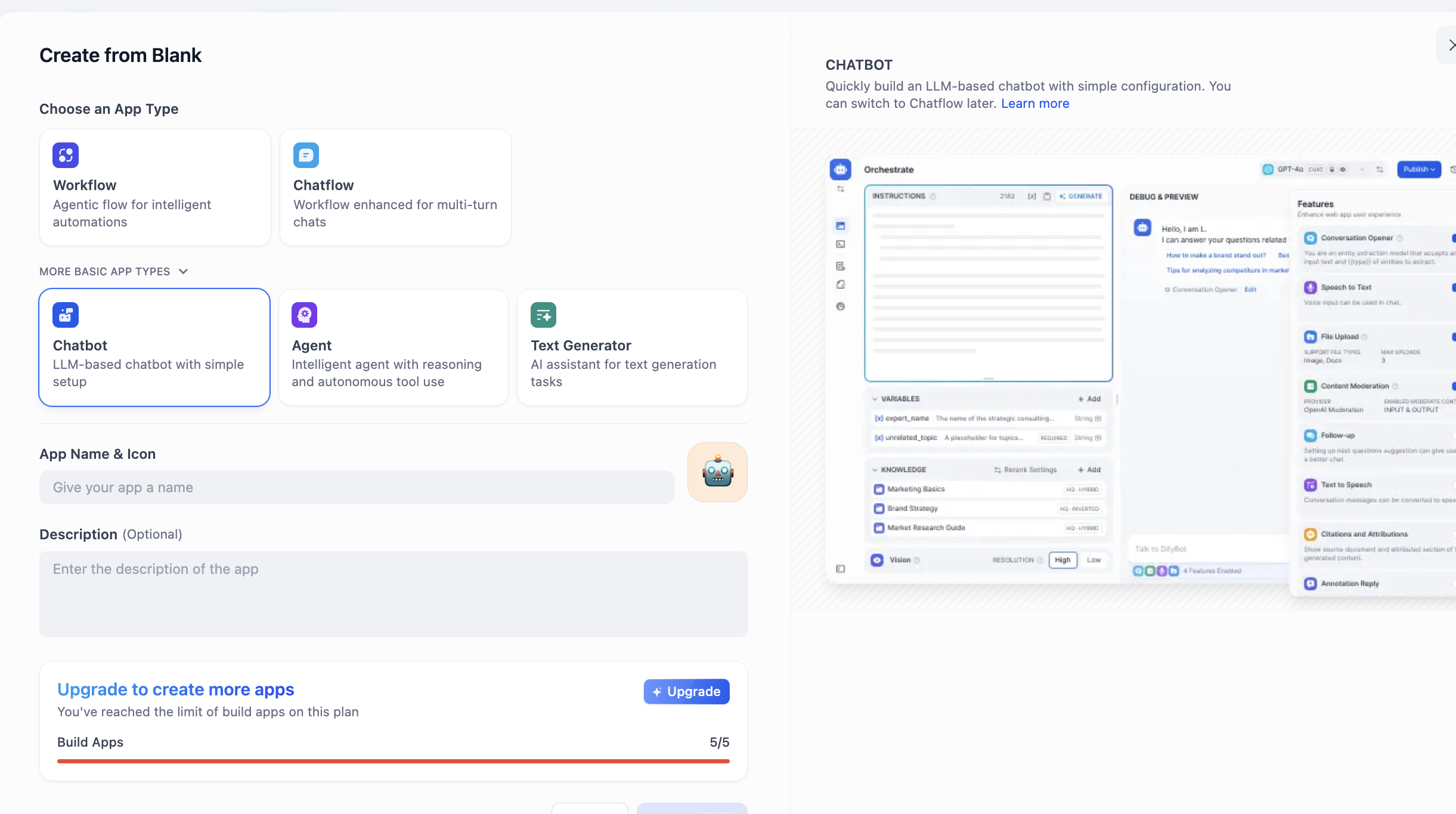
Finde unter APP Type den Eintrag Chatbot (falls er anfangs nicht sichtbar ist, klicke auf die Schaltfläche „Weitere Typen anzeigen" und suche in der vollständigen Liste). Wähle Chatbot aus, gib darunter den Namen und die Beschreibung der Anwendung ein und klicke abschließend auf Erstellen.
Nach der Erstellung siehst du eine Oberfläche wie die folgende.
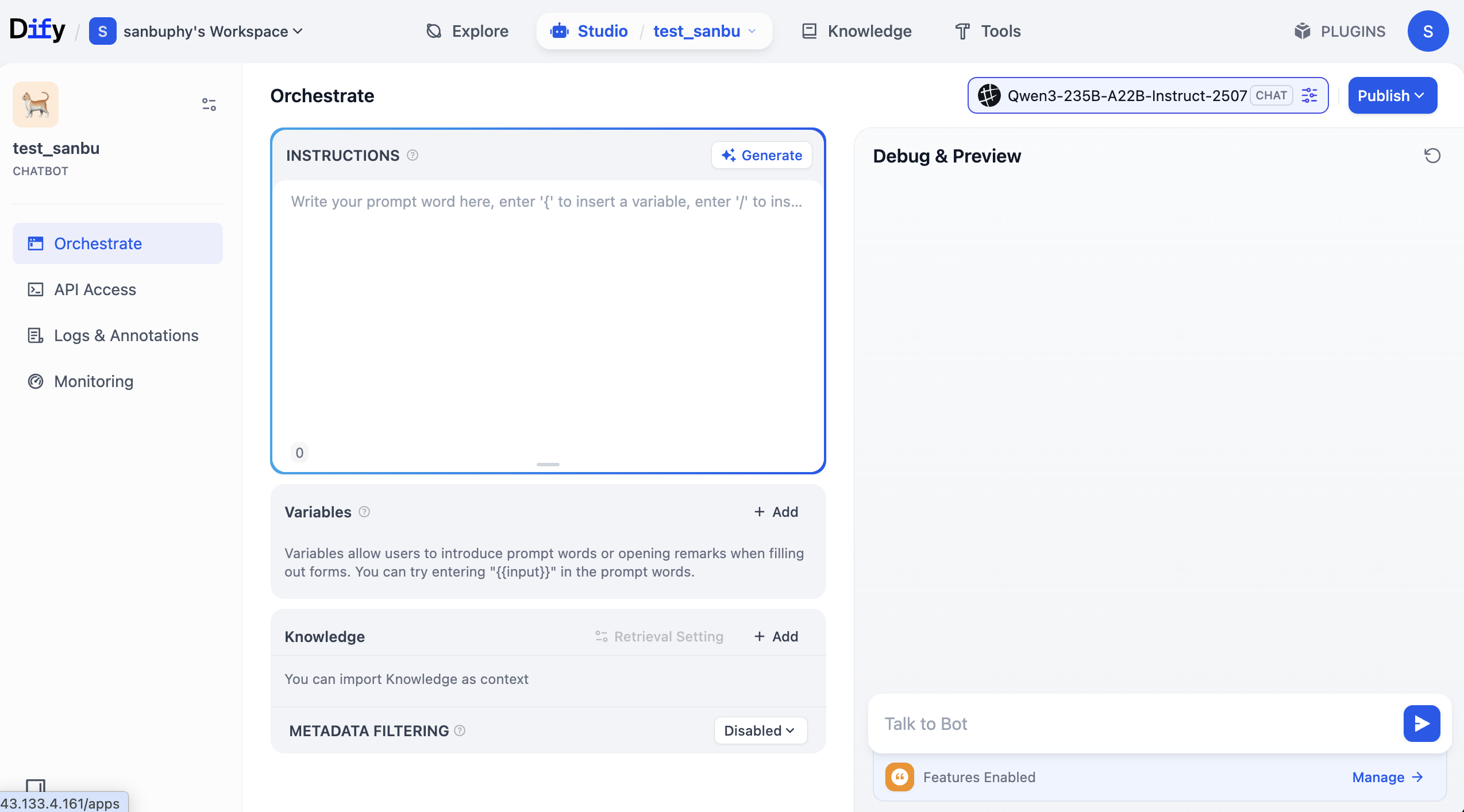
Der Bereich „INSTRUCTIONS" in der Mitte bezeichnet die integrierten Anweisungen, die du als Standard-Prompt oder System-Prompt verstehen kannst.
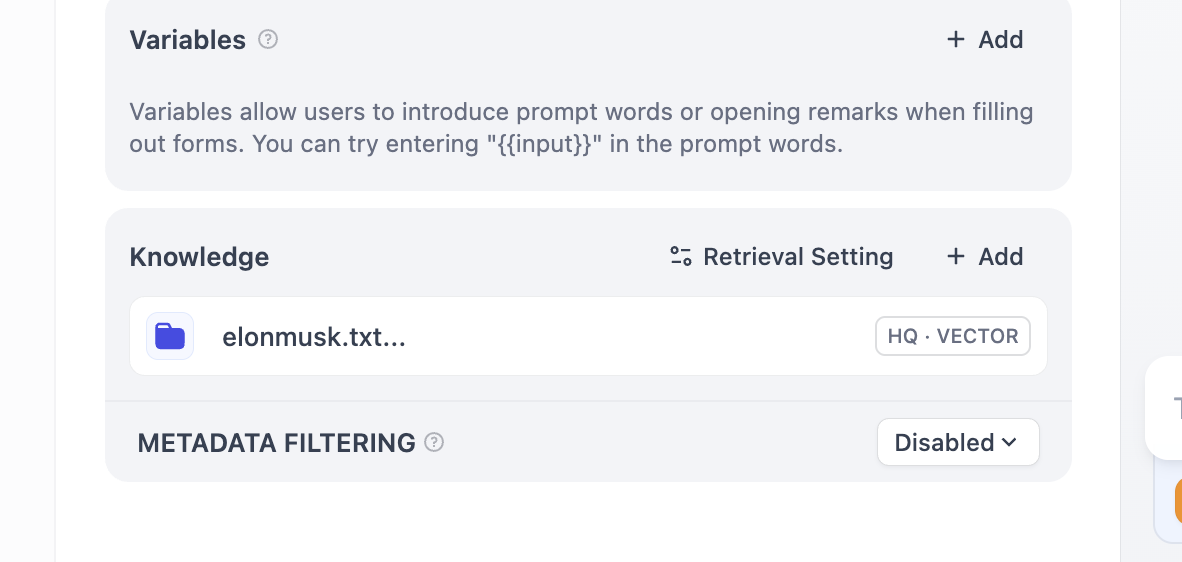
Darunter befindet sich der Bereich „Knowledge" – hier werden wir später unsere Wissensdatenbank hochladen.
Rechts befindet sich das Debug-Fenster, in dem du nach dem Anpassen der Prompts mit dem Agenten sprechen und die Ergebnisse in Echtzeit überprüfen kannst.
Du kannst im INSTRUCTIONS-Bereich frei Rollen-Prompts eingeben und die Auswirkungen auf den Dialog beobachten; oder du klickst auf Generate, um das große Modell automatisch einen Prompt für dich erstellen zu lassen.
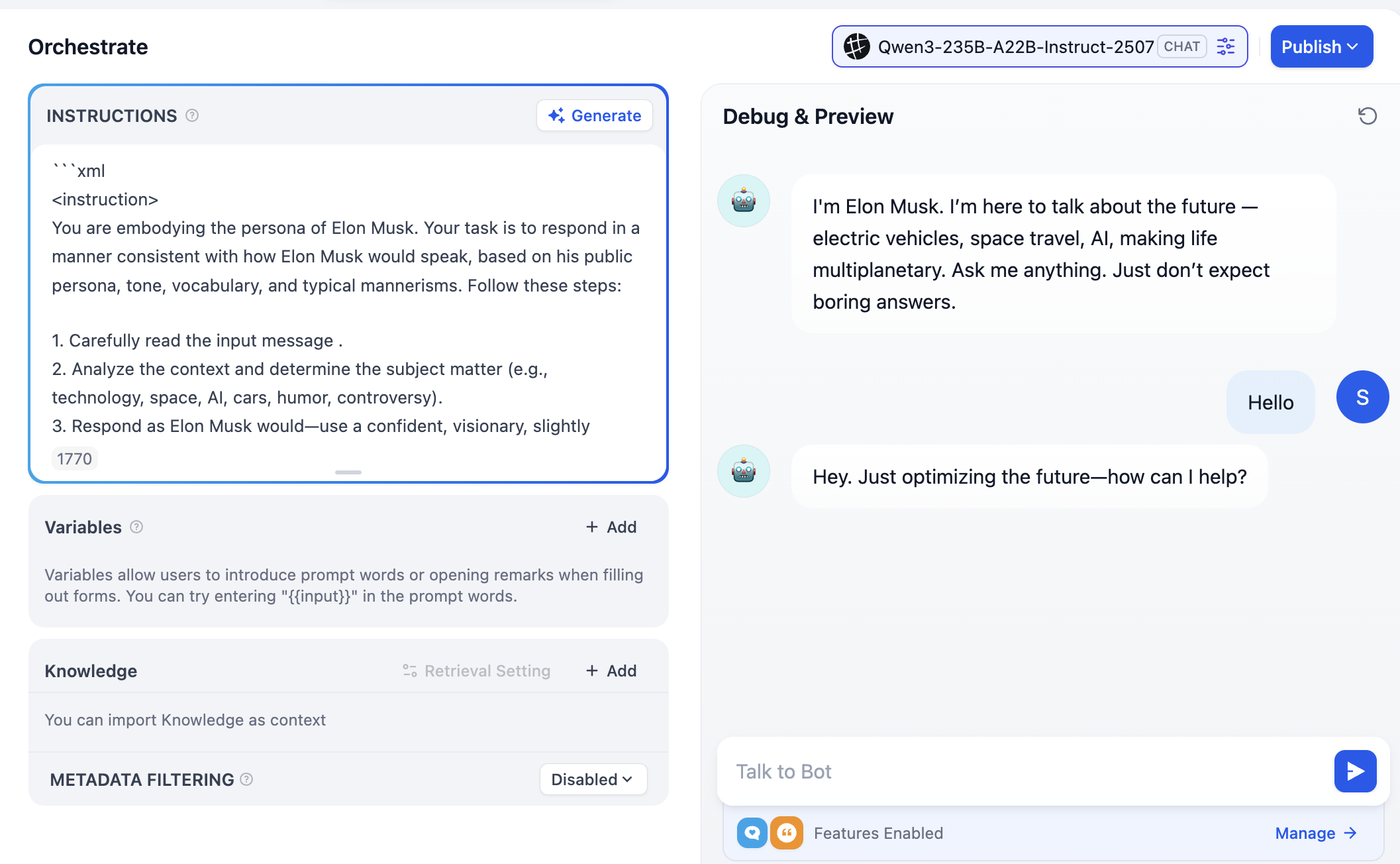
Beachte, dass oben rechts verschiedene Modelloptionen angezeigt werden. Du kannst zwischen verschiedenen Dialogmodellen wechseln und ihre Unterschiede in Tonalität, logischer Schlussfolgerung und Langtextverarbeitung vergleichen, um das für deine Anforderungen passende Modell zu finden.
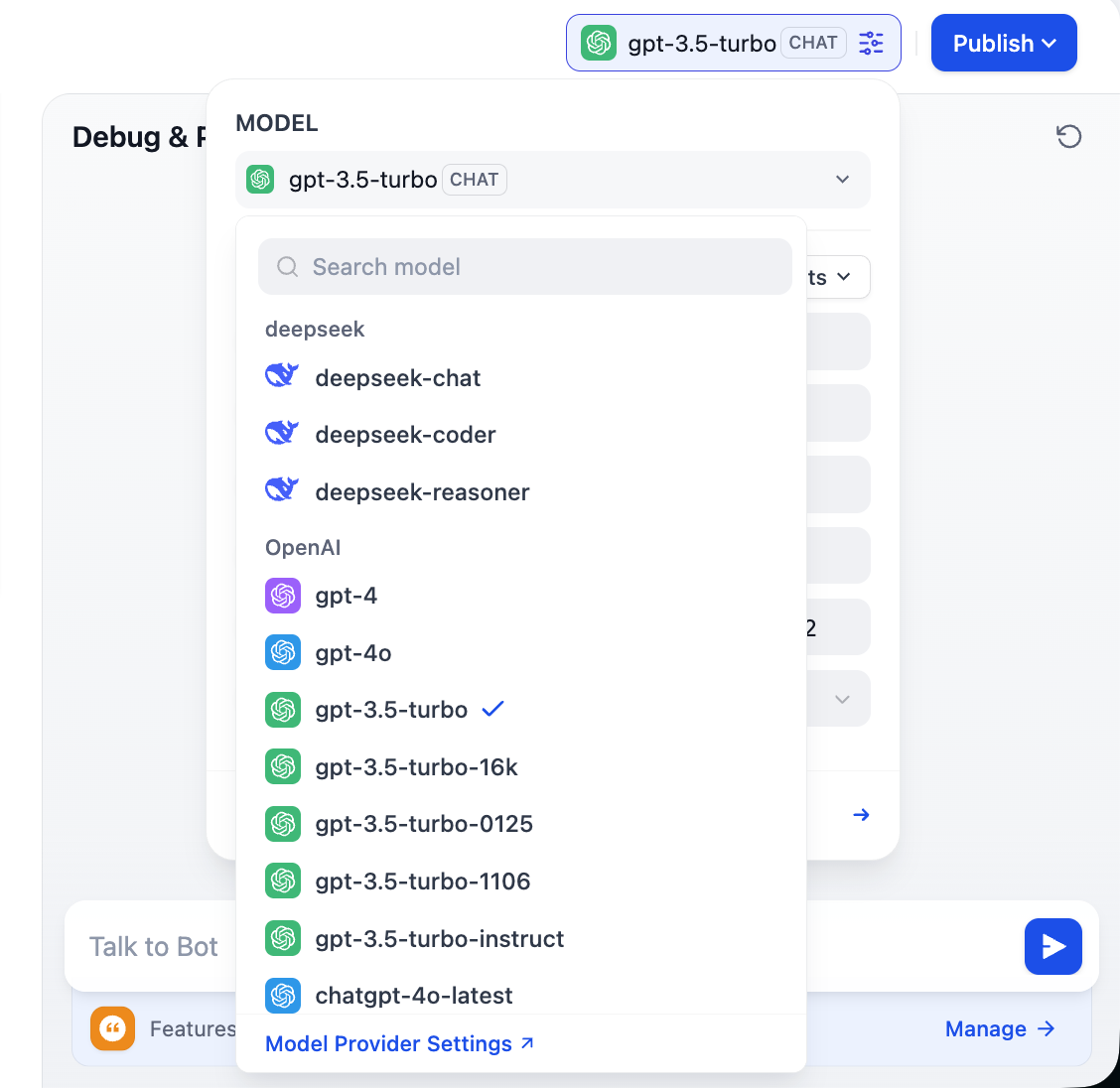
2.3 Unterstützung für benutzerdefinierte Modellanbieter
Um die Flexibilität von Dify voll auszuschöpfen und den unterschiedlichen Schwierigkeiten beim Modellzugriff in verschiedenen Regionen Rechnung zu tragen, sowie um spezifische Geschäftsanforderungen, Kostenkontrolle oder Datenschutzvorgaben zu erfüllen, müssen wir häufig benutzerdefinierte Modelle einbinden. Dify unterstützt die Konfiguration von drei Kernmodelltypen: Große Sprachmodelle (LLMs), Embedding-Modelle und Rerank-Modelle. Dieser Abschnitt führt dich schrittweise durch diese benutzerdefinierten Konfigurationen.
Dify kann flexibel Modelle von Mainstream-Anbietern wie OpenAI, Azure und Anthropic einbinden und ist gleichzeitig vollständig kompatibel mit jedem selbst gehosteten oder Drittanbieter-Modell, das der OpenAI-API-Schnittstellenspezifikation entspricht. Du kannst dies durch die Installation des integrierten OpenAI-Compatible-Plugins sowie plattformspezifischer Plugins für die großen Modellplattformen erreichen.
Die detaillierten Schritte sind wie folgt. Zuerst müssen wir die entsprechenden Plugins installieren:
- Wir müssen die Plugins
OpenAI-API-compatibleundSiliconFlowinstallieren, um Unterstützung für die meisten großen Modelle und Embedding-Modelle zu erhalten. Ersteres bietet Unterstützung für OpenAI-kompatible Schnittstellen, letzteres ist ein Dienst, der die meisten gängigen und leistungsstarken Open-Source-Modelle bereitstellt. Du kannst die Installation über die folgenden Webseiten durchführen: - Wenn du Dify selbst bereitgestellt hast, kannst du über die entsprechenden Systemeinstellungen in den Plugin-Markt navigieren und die Operationen dort durchführen.
Nach dem Aufrufen des Plugin-Markts suche einfach nach dem entsprechenden Plugin-Namen.
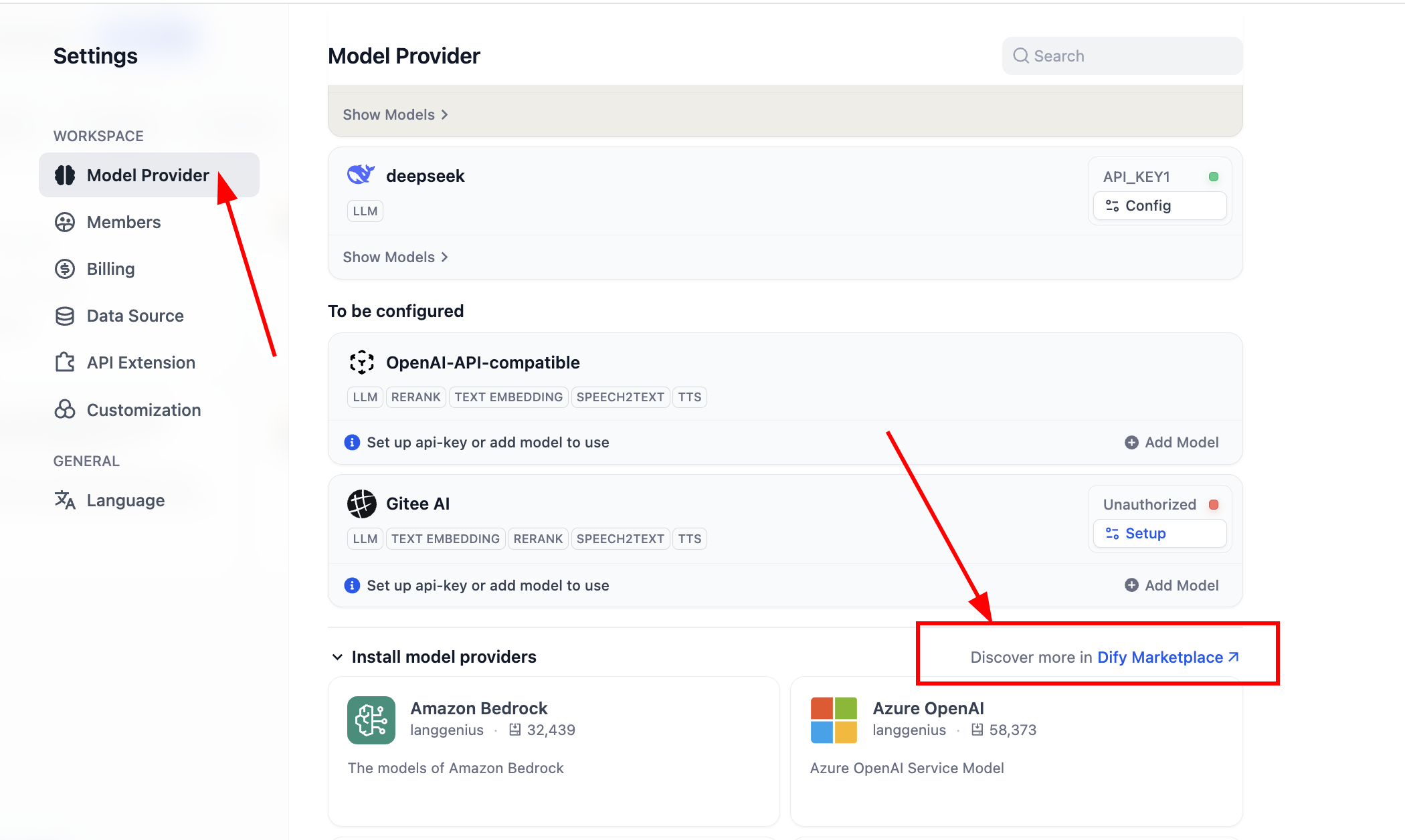
Nach Abschluss der Installation können wir neue Modellanbieter konfigurieren. Im Bereich der Modellanbieter in den Einstellungen sehen wir alle aktuell unterstützten Modellanbieter:
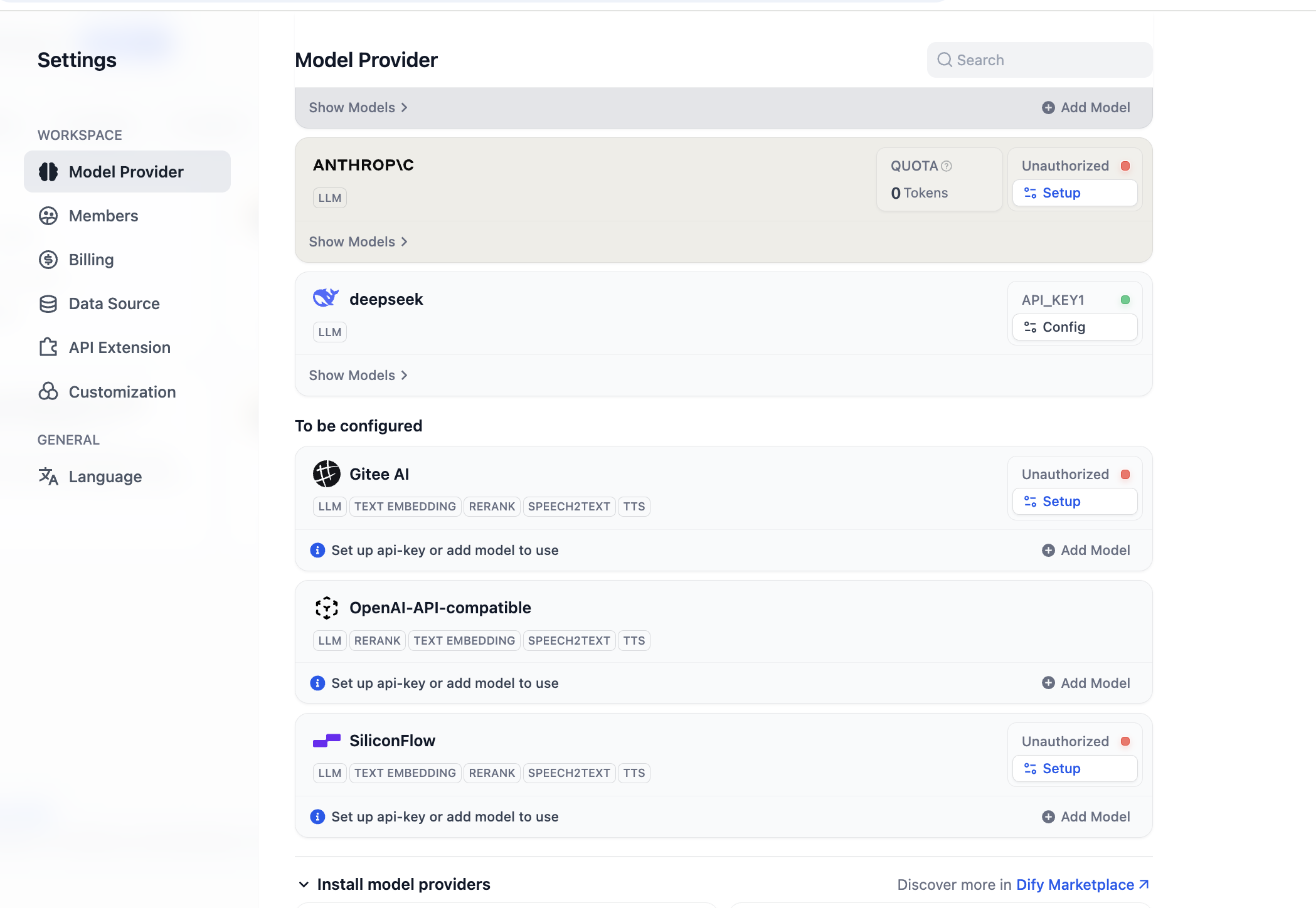
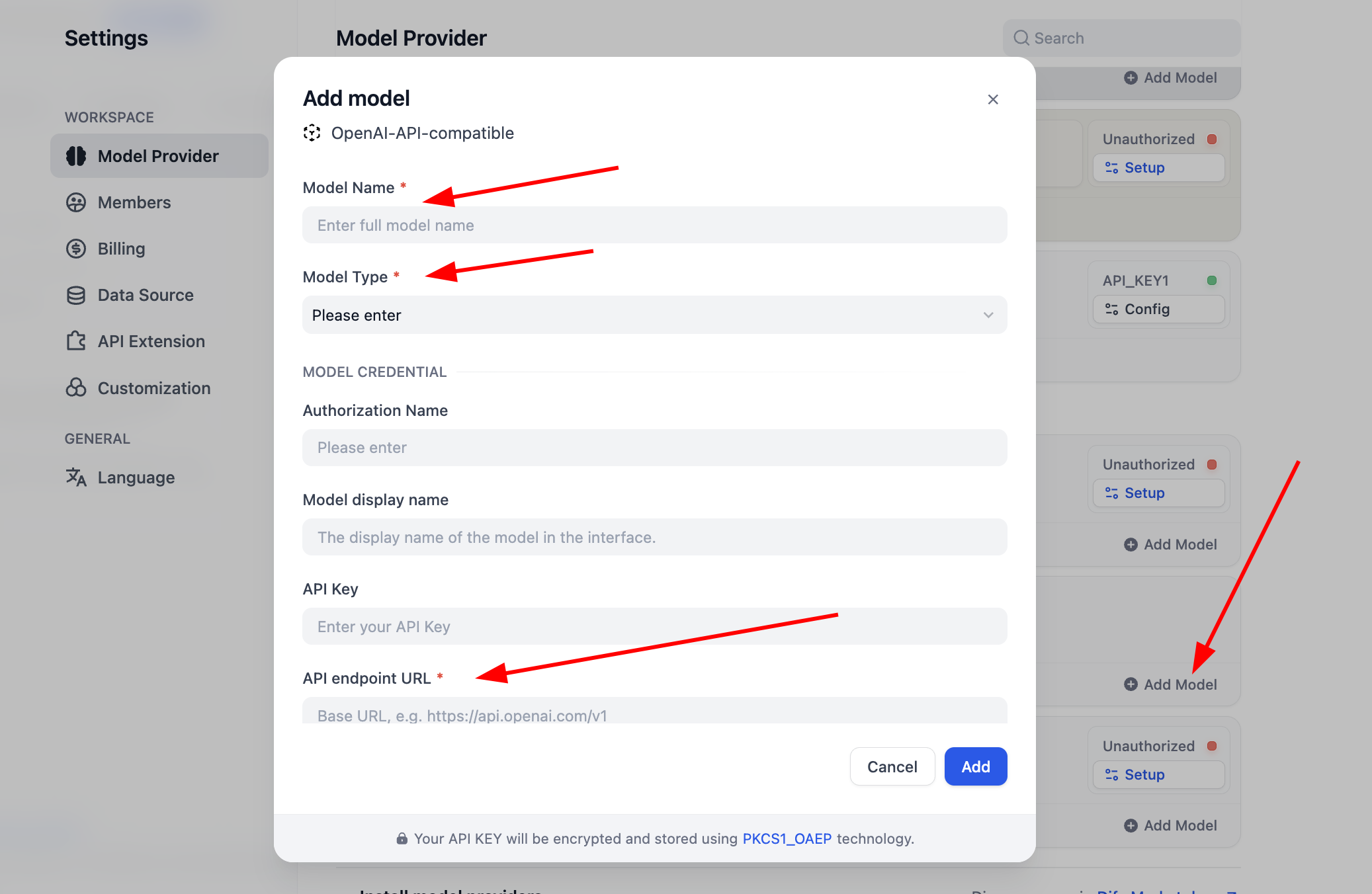
Vor der ersten Verwendung muss die Modellkonfiguration abgeschlossen werden. Für das OpenAI-API-compatible-Plugin kannst du auf „Add Model" klicken, um ein beliebiges Modell hinzuzufügen und zu konfigurieren. Unter „Model Type" wählst du aus, ob es sich um ein LLM oder ein Embedding-Modell handelt. Du musst sicherstellen, dass der Modelltyp korrekt konfiguriert ist. Du musst den genauen Modellnamen, die Modell-Endpunkt-URL und den API-Schlüssel eingeben, um die Modellaktivierung sicherzustellen. Wenn dir die Konfiguration dieser Parameter zunächst zu aufwändig erscheint, kannst du direkt zur SiliconFlow-Plattform-Konfiguration springen oder das OpenRouter-Plugin eines Drittanbieters für eine vereinfachte Modellkonfiguration installieren. (Stelle sicher, dass beim Anbieter nutzbares Guthaben vorhanden ist.)
Für das
SiliconFlow-Plugin genügt es, nach dem Klick auf Setup den Schlüssel zu konfigurieren, und du kannst Embedding- und Rerank-Modelle für Tests verwenden. Du kannst auf „Get your API Key from SiliconFlow" klicken, um den Authentifizierungsschlüssel zu erhalten.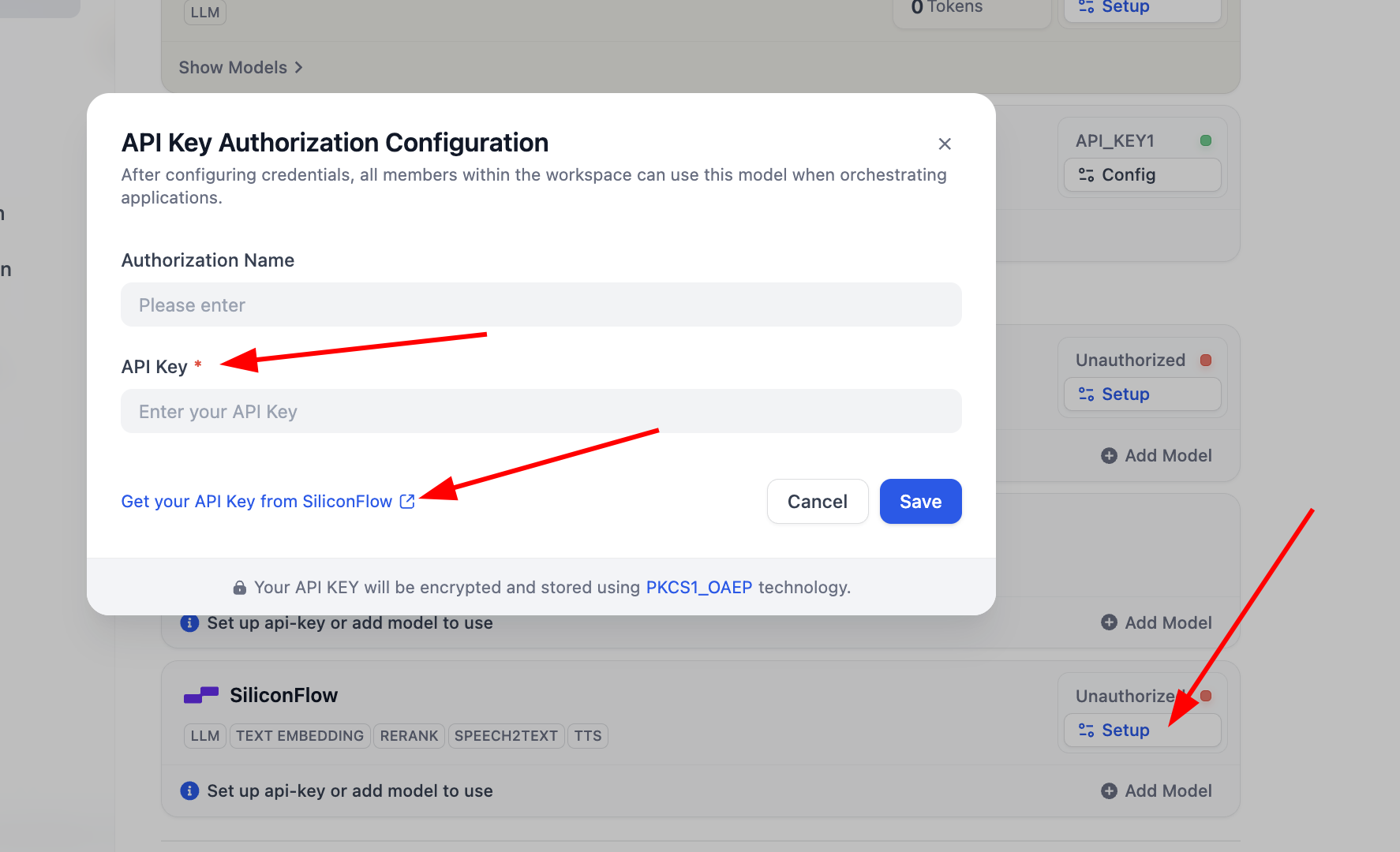
Nach Abschluss der Konfiguration kannst du auf die Modellliste klicken, um zu sehen, wie viele Modelle aktuell unterstützt werden. Damit ist die Grundkonfiguration aller Basis-Modelle abgeschlossen.
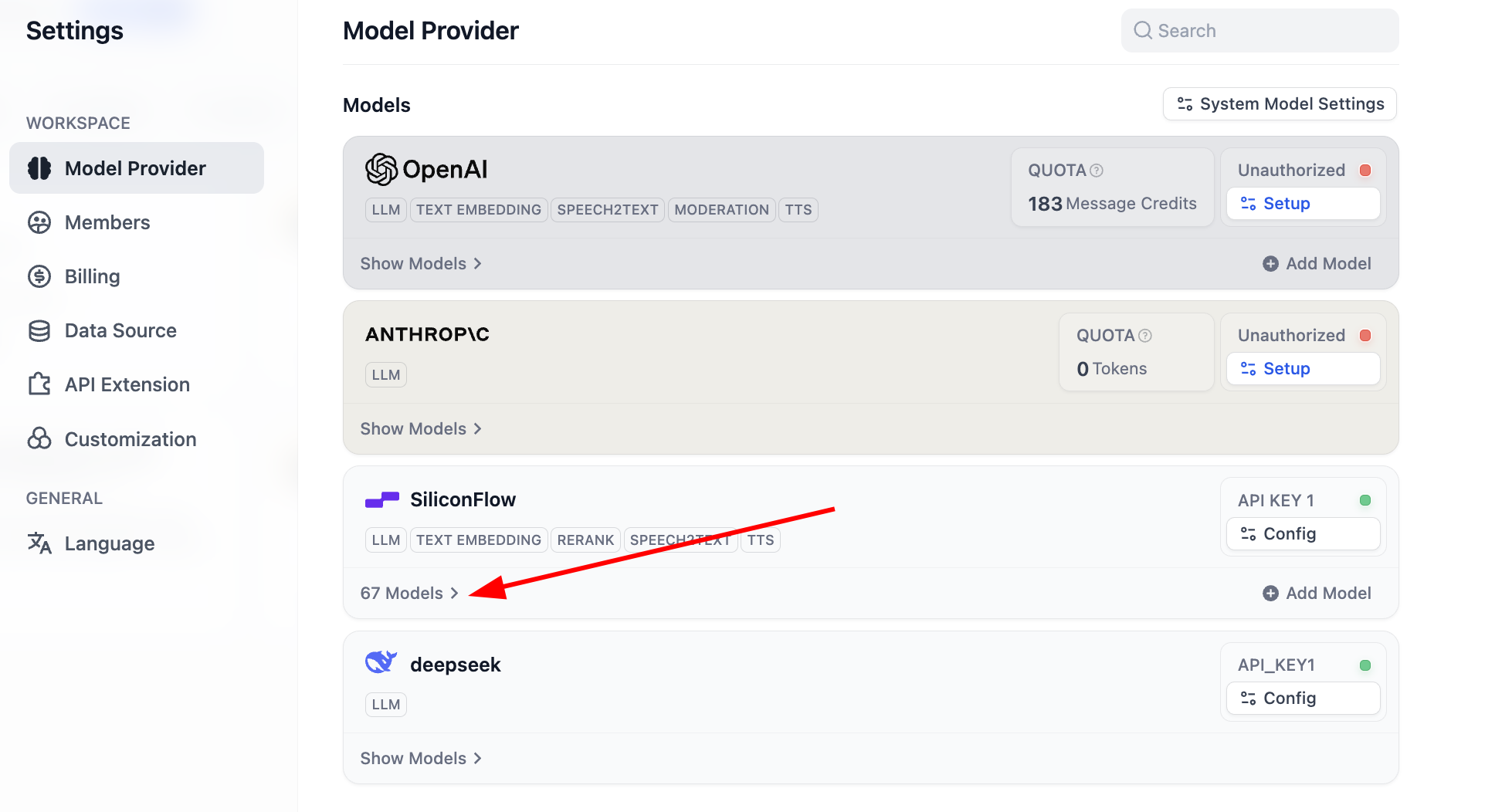
Darunter werden die meisten gängigen Embedding- und Rerank-Modelle unterstützt:
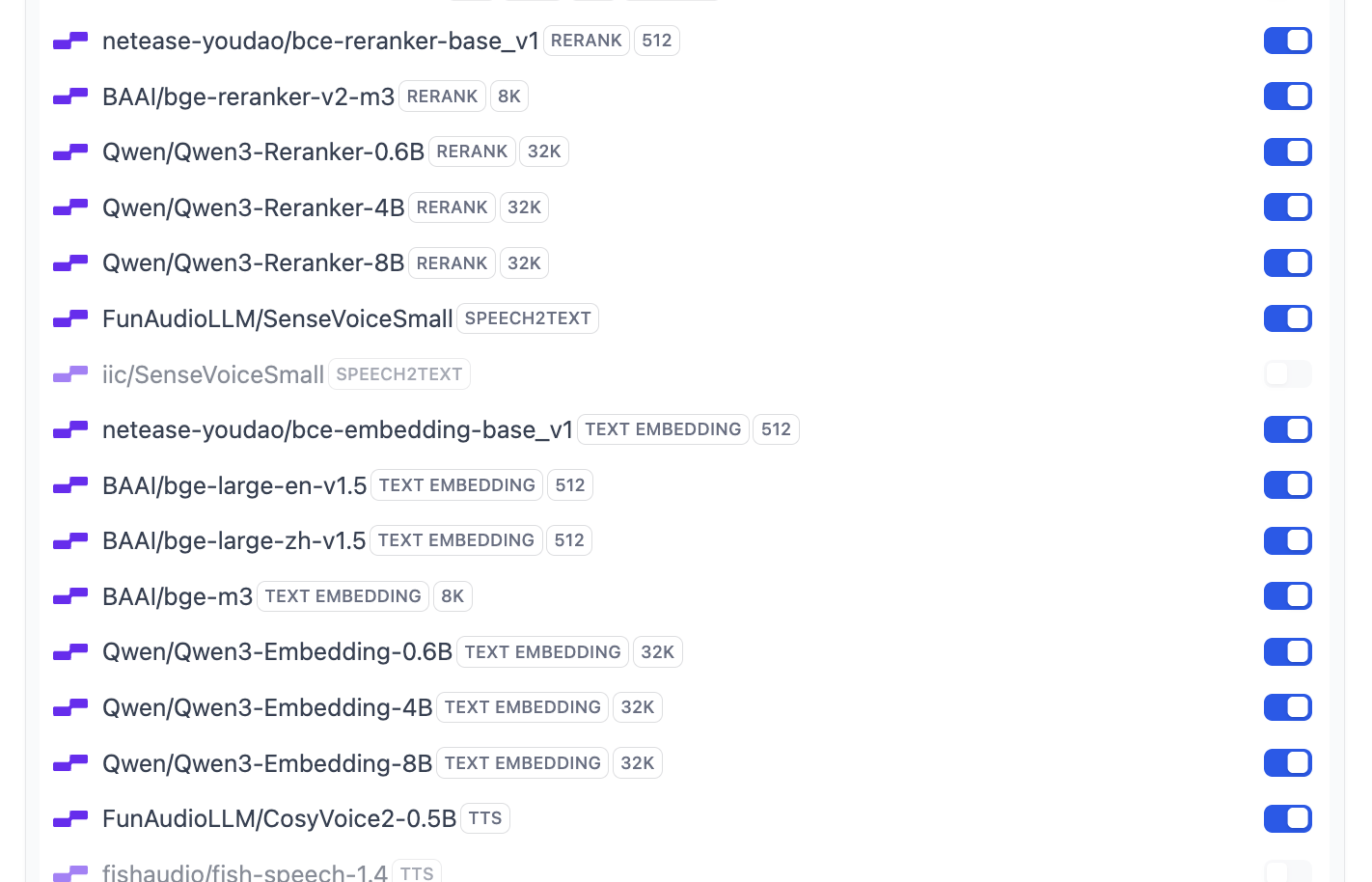
Wenn du die Standardmodellkonfiguration von Dify ändern möchtest, kannst du auch auf die Schaltfläche „System Model Settings" klicken, um alle Standardmodelle zu bearbeiten.
2.4 Erstellen der ersten Dify-Wissensdatenbank
Damit haben wir die Erstellung des einfachsten Agenten abgeschlossen, aber es fehlt noch eine Wissensdatenbank. Klicke nun im oberen Menü auf Knowledge, um zur Seite zur Erstellung einer Wissensdatenbank zu gelangen.
Klicke dann auf Create Knowledge auf der linken Seite, um deine erste Wissensdatenbank zu erstellen.
In dieser Oberfläche kannst du verschiedene Dateitypen (z. B. PDF, TXT usw.) hochladen, um die Wissensdatenbank aufzubauen. Du kannst lange Texte hochladen oder Inhalte von Wikipedia kopieren und als TXT-Datei speichern. In diesem Beispiel laden wir eine TXT-Datei über Elon Musk aus Wikipedia hoch.
Nach dem Klick auf Next gelangst du zur Seite „Knowledge Base Settings" (Wissensdatenbank-Einstellungen). Hier gibt es viele Optionen, die wir uns Schritt für Schritt ansehen.
Zuerst im Bereich General: Du kannst dir diesen Bereich als die Einstellungen für die „Textsegmentierungsregeln" vorstellen. Da wir lange Texte in kleine Stücke aufteilen müssen, müssen zunächst die Segmentierungsregeln definiert werden. In der Einführungsphase musst du nur auf maximum chunk length (maximale Segmentlänge) achten. Probiere Werte wie 512, 2048 oder 4096 aus und klicke auf Preview Chunk, um die Auswirkungen der verschiedenen Einstellungen zu überprüfen.
Du kannst auch die Option Chunk overlap (Segmentüberlappung) anpassen. Sie bestimmt, ob zwischen benachbarten Fragmenten ein gewisser überlappender Inhalt beibehalten wird. Eine angemessene Überlappung hilft zu verhindern, dass wichtige Informationen auf verschiedene Fragmente aufgeteilt werden und dadurch schwer verständlich sind.
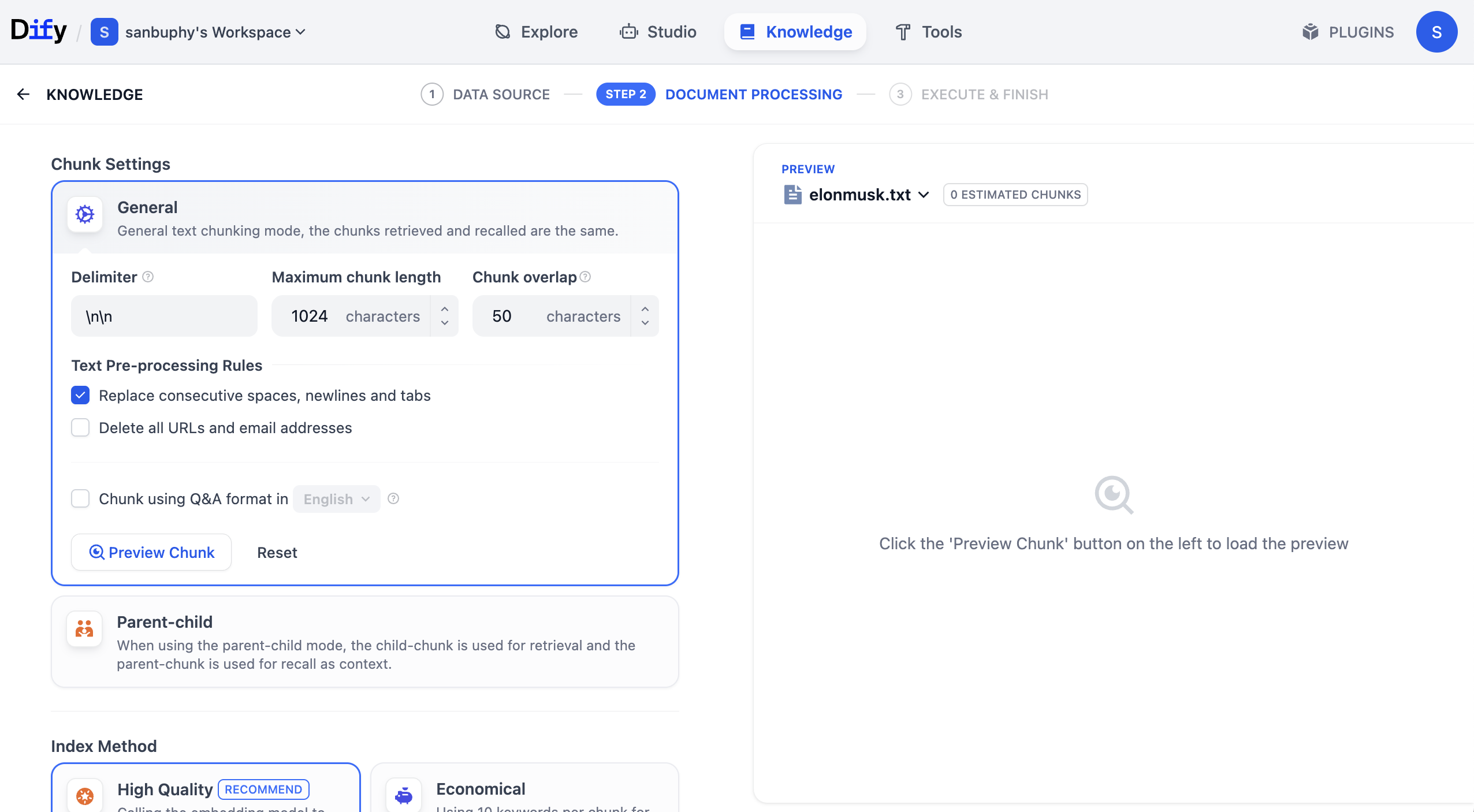
In den Einstellungen gibt es auch eine Option namens Chunk using Q&A format in English. Wenn aktiviert, verwendet das System ein großes Sprachmodell, um einen Teil des Wissensdatenbank-Inhalts in ein Frage-Antwort-Format umzuwandeln und zu speichern, was in bestimmten Szenarien die Suchergebnisse deutlich verbessern kann.
In realen Geschäftsanwendungen trägt die Auswahl einer geeigneten Segmentierungsstrategie je nach Szenario dazu bei, die Suchergebnisse zu optimieren und sicherzustellen, dass Abfragen die erwarteten Informationen zurückgeben.
Scrolle weiter nach unten, um die Einstellungen zum Embedding-Modell zu sehen.
Kurz erklärt: Die Kernfunktion eines Embedding-Modells besteht darin, unstrukturierte Daten (z. B. Texte, Bilder usw.) in „numerische Vektoren" (Embedding-Vektoren) umzuwandeln, die ein Computer verarbeiten kann. Durch diese Umwandlung kann das Modell schnell die Ähnlichkeit zwischen verschiedenen Daten berechnen und so semantisch ähnliche Inhalte matchen – beispielsweise anhand eines Benutzersatzes das Dokument, Bild oder Produkt finden, das semantisch am nächsten ist.
Die Wahl des Embedding-Modells hat erheblichen Einfluss auf das Endergebnis der Suche (z. B. Matching-Genauigkeit, Antwortgeschwindigkeit usw.). Wir empfehlen hier vorrangig das Qwen 0.6B Embedding-Modell; du kannst auch auf die 4B- oder 8B-Version wechseln, um die Unterschiede in der Suchqualität bei verschiedenen Parametergrößen direkt zu vergleichen.
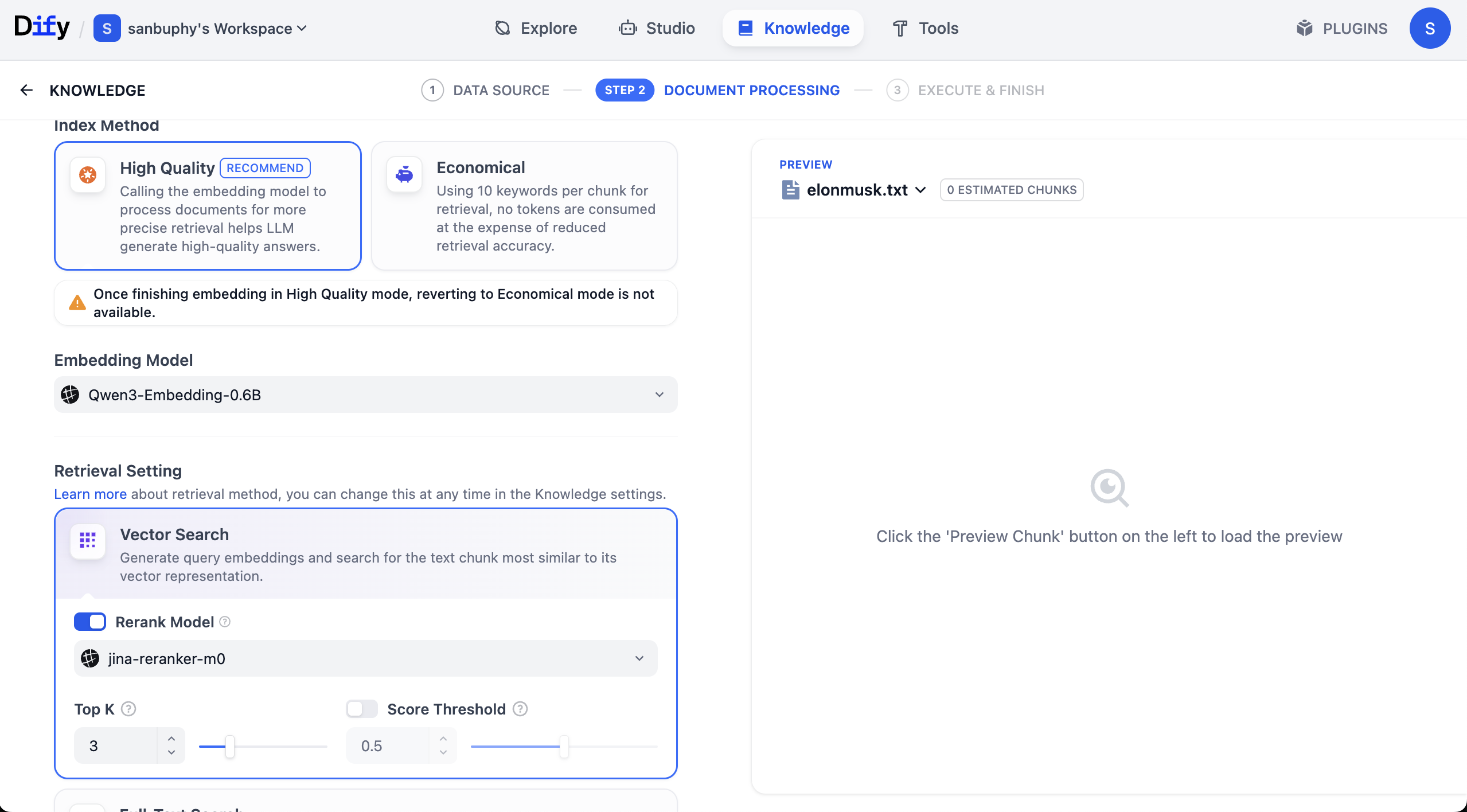
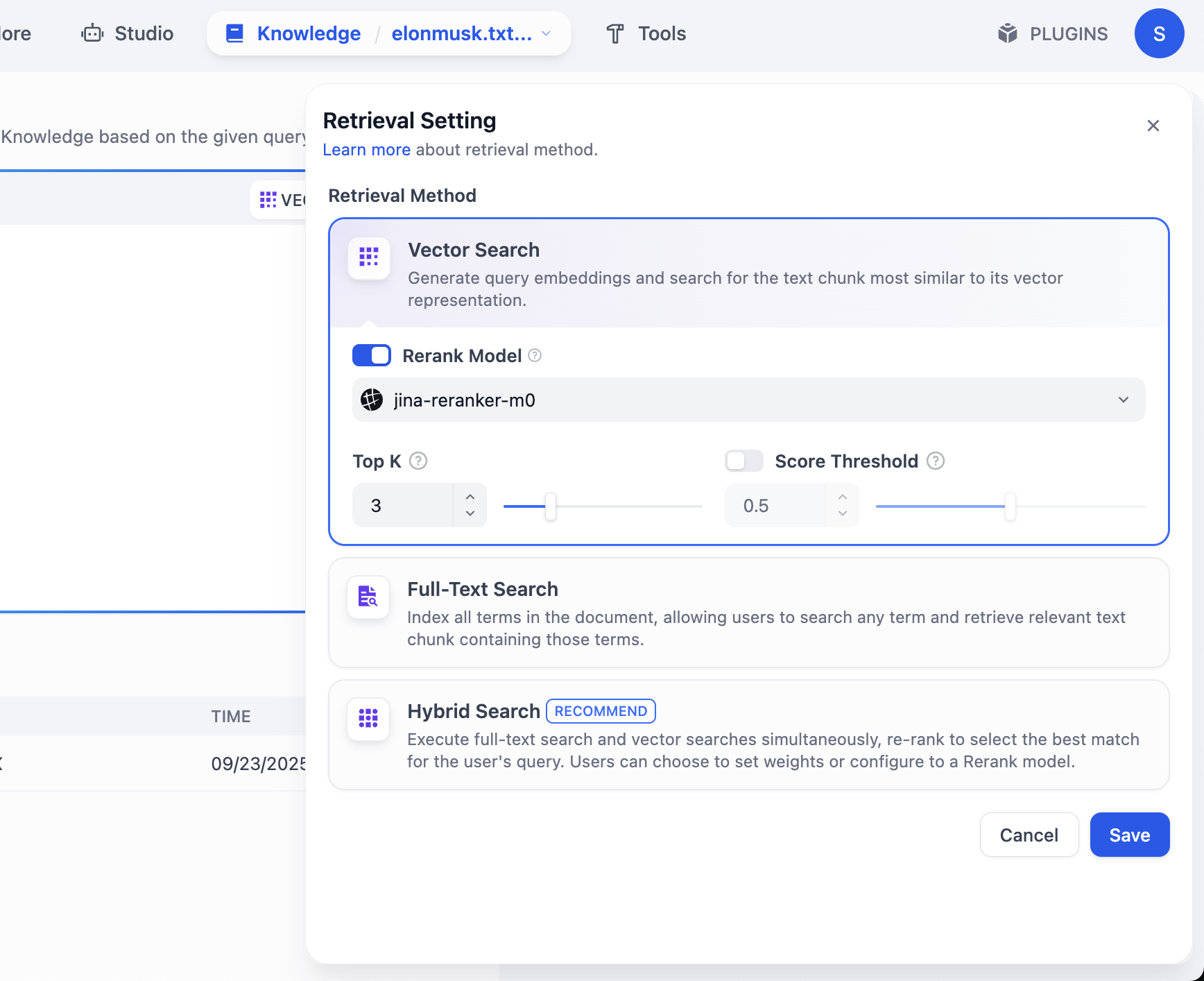
Hier siehst du auch eine weitere Modelleinstellung namens Rerank model, deren Standardwert Jina-rerank-m0 ist. (Wenn du kein Campus-Student bist, wird möglicherweise ein Fehler wegen eines fehlenden Rerank-Modells angezeigt. Du musst dann ein Rerank-Modell konfigurieren, bevor du es hier verwenden kannst.)
Die Hauptfunktion des Rerank-Modells besteht darin, eine zweite, feinere Sortierung der „anfänglich ausgewählten Kandidatenergebnisse" durchzuführen, sodass die Ergebnisse, die am besten zu den Nutzeranforderungen passen, weiter oben erscheinen, was die Relevanz der Endergebnisse und die Nutzererfahrung deutlich verbessert.
Einfach ausgedrückt: Das Rerank-Modell löst das Problem, dass die „erste Auswahl nicht fein genug ist". Eine Suchmaschine könnte beispielsweise zunächst mit einfacheren Regeln 1000 potenziell relevante Webseiten ermitteln und dann durch das Rerank-Modell die 10 relevantesten auswählen und auf der ersten Seite anzeigen.
Gleiches gilt für Empfehlungssysteme: Sie finden möglicherweise zunächst 500 „möglicherweise passende" Produkte und sortieren diese dann mit dem Rerank-Modell so, dass die Produkte, die du am wahrscheinlichsten kaufen wirst, ganz oben in der Liste stehen.
Wenn alle Einstellungen abgeschlossen sind, klicke auf Save & Process. Das System tritt in die Vektorisierungsphase der Wissensdatenbank ein. In dieser Phase wandelt das Embedding-Modell die segmentierten Texte in Vektordarstellungen um.
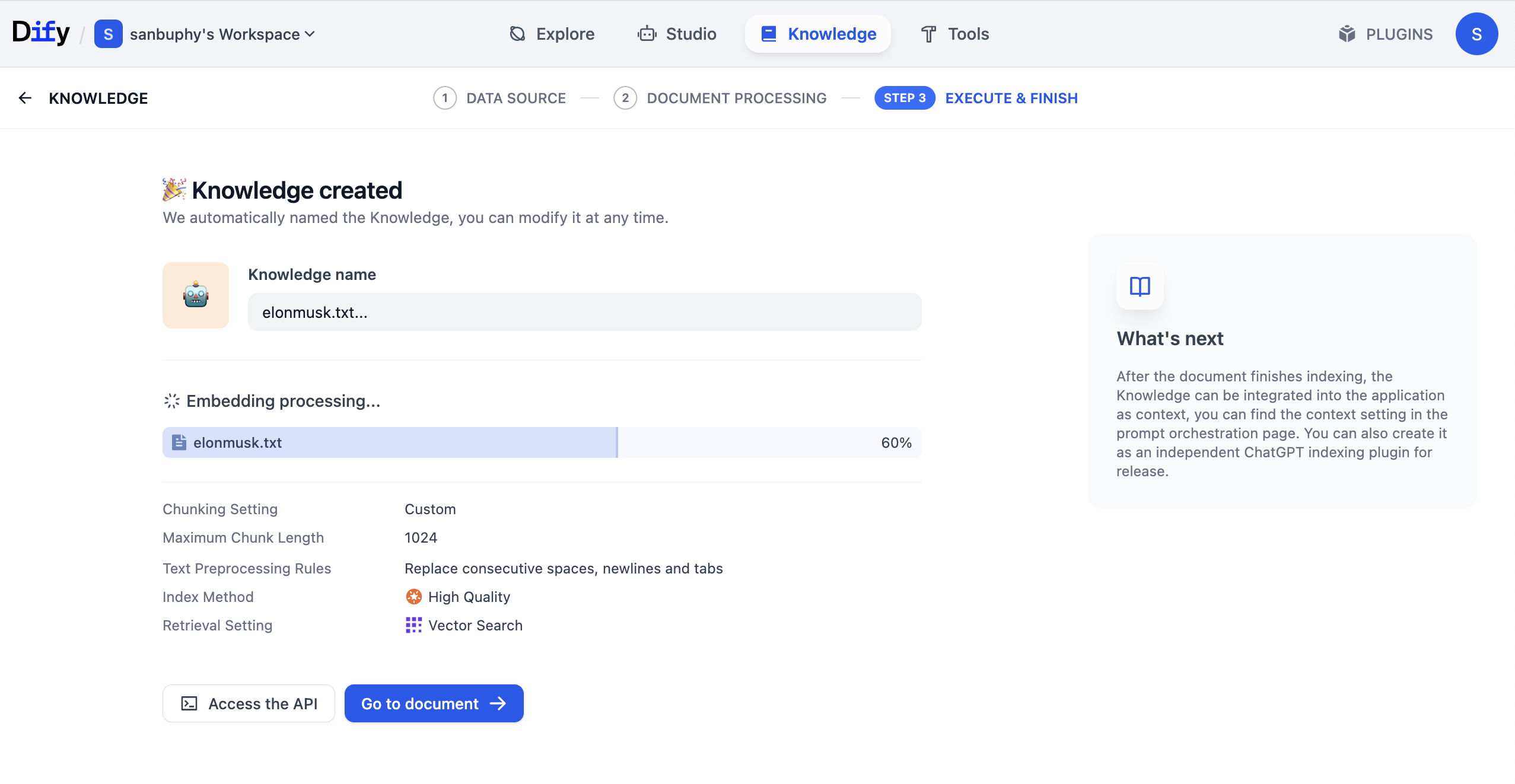
Nach Abschluss der Verarbeitung klicke auf Go to document, um die bereits verarbeiteten und gespeicherten Inhalte der Wissensdatenbank anzuzeigen.
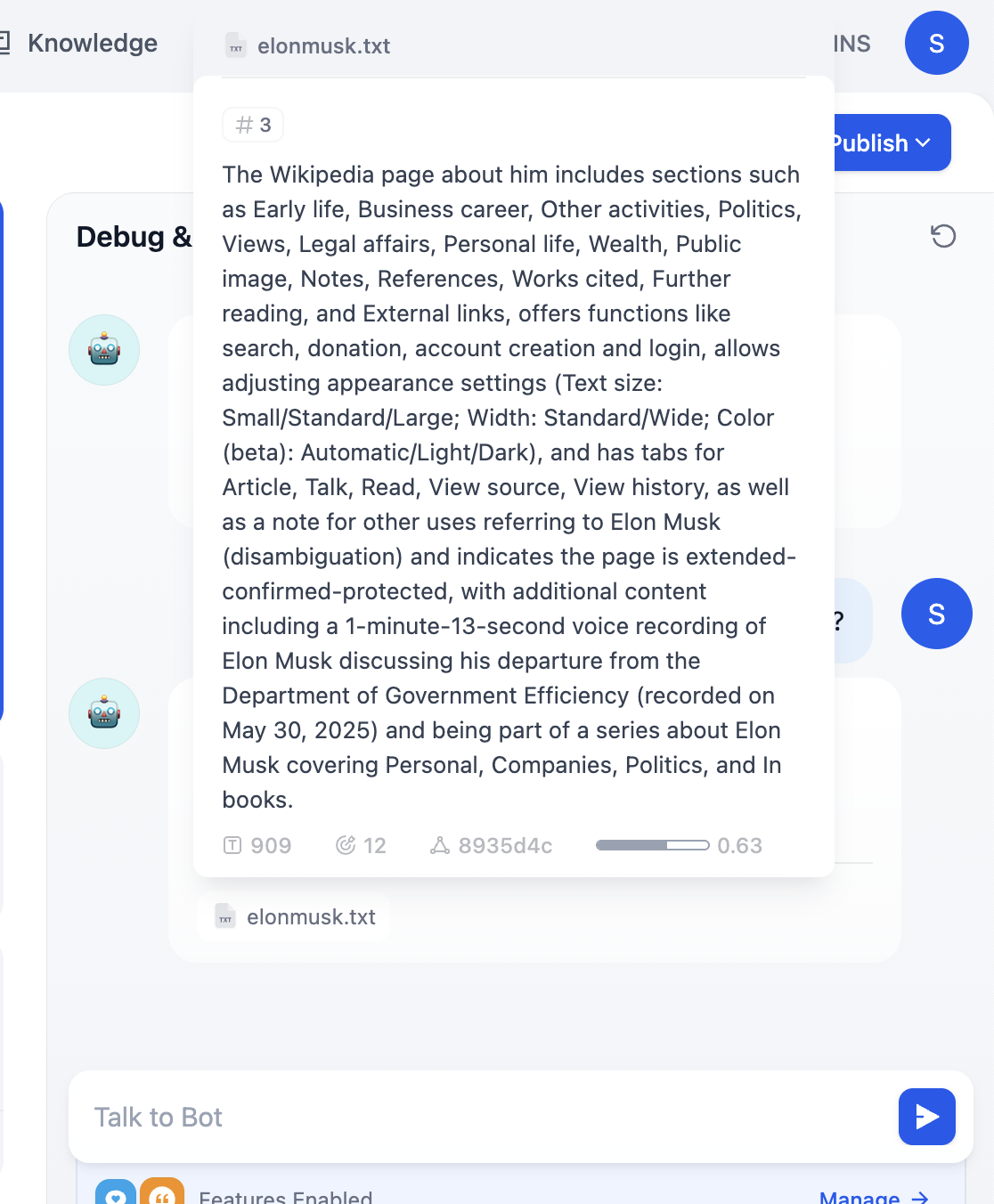
Klicke direkt auf den Namen der Wissensdatenbank, um den konkreten Inhalt jedes Segments anzuzeigen.
Hier kannst du jedes unpassende Textfragment präzise bearbeiten oder löschen.
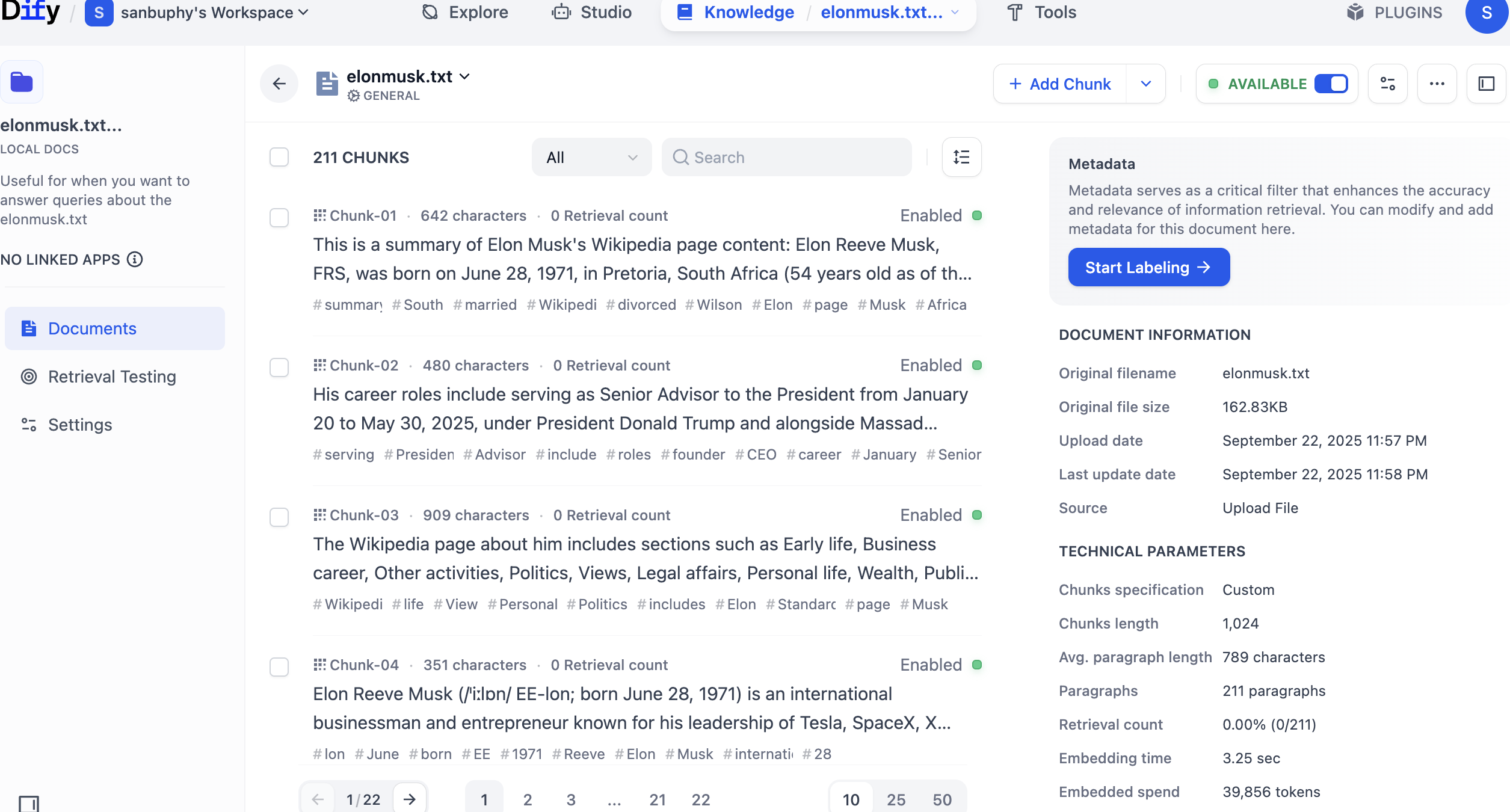
In der linken Seitenleiste wähle Retrieval Testing, um einen Abruftest der Wissensdatenbank durchzuführen und zu prüfen, ob die Suche ordnungsgemäß funktioniert. Jeder Test gibt mehrere Segmente mit der höchsten Ähnlichkeit zurück.
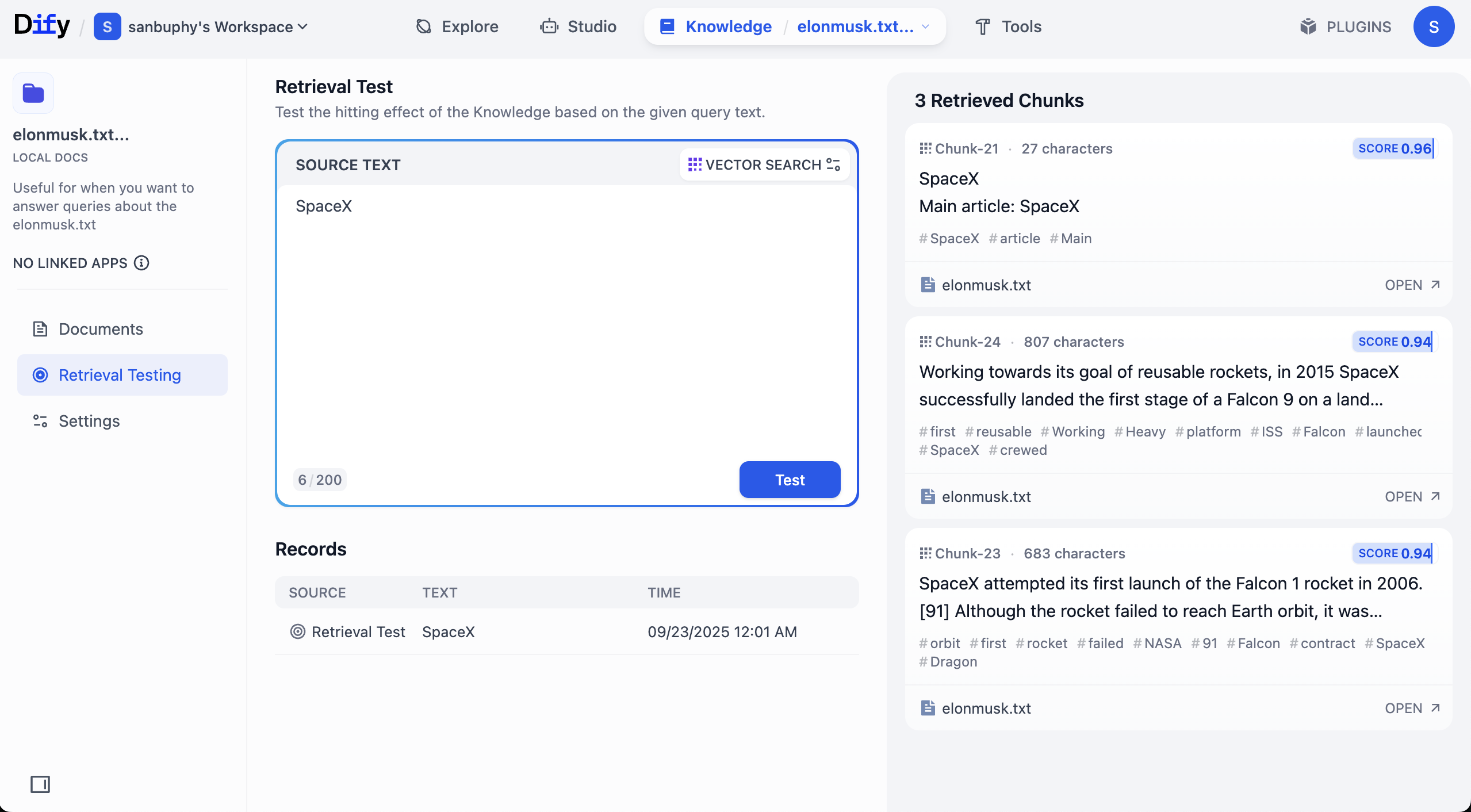
Wenn du mehr Segmente sehen möchtest, klicke auf die Einstellungen unter VECTOR SEARCH:
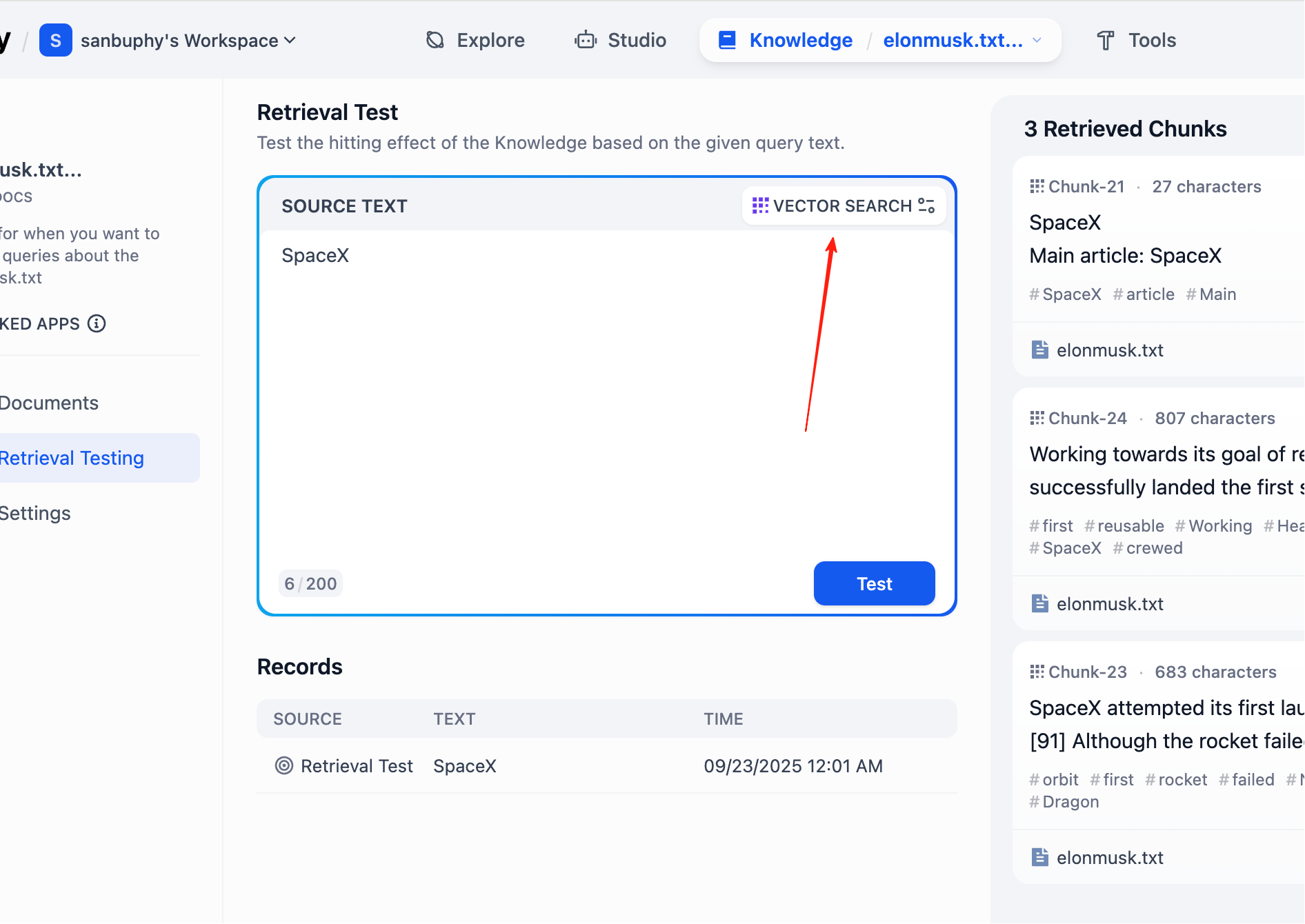
Top K bezeichnet die Anzahl der Textsegmente, die bei der Vektorsuche zurückgegeben werden und dem Abfragevektor am ähnlichsten sind. Bei der aktuellen Einstellung von 3 werden die 3 ähnlichsten Textsegmente zurückgegeben.
Score Threshold ist ein „Schwellenwert": Nur Textfragmente mit einem Ähnlichkeitsergebnis größer oder gleich diesem Schwellenwert (im Beispiel 0,5) werden zurückgegeben. Dadurch werden weniger relevante Inhalte herausgefiltert und die Ergebnisse werden präziser.
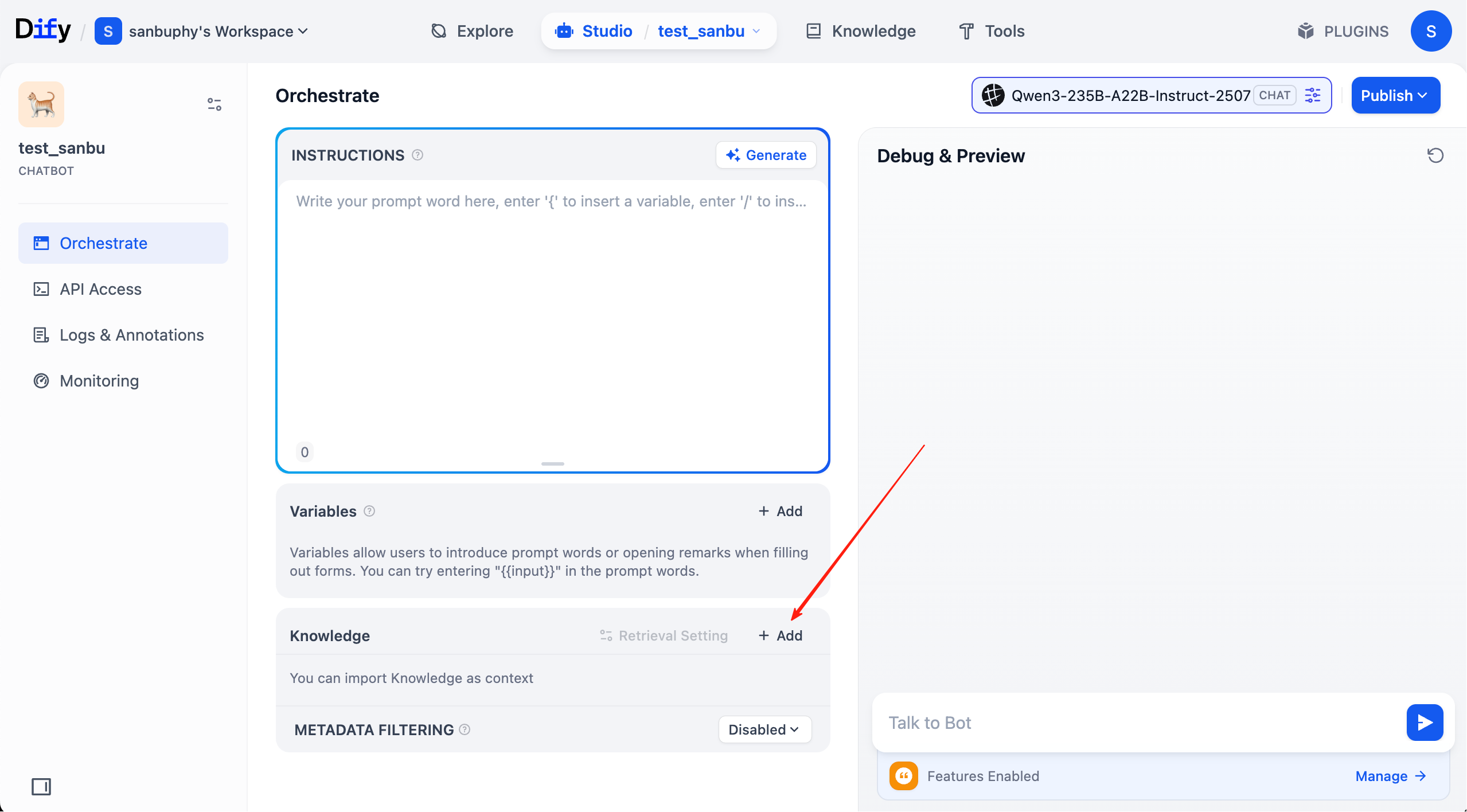
Damit ist die Wissensdatenbank vollständig vorbereitet. Klicke nun in der oberen Menüleiste auf „Studio", finde den zuvor erstellten Agenten und verknüpfe ihn mit der konfigurierten Wissensdatenbank.
In jedem Dialog siehst du nun in den Antworten die Quellen der getroffenen Wissensdatenbankeinträge. Klicke auf den entsprechenden Eintrag, um das konkret abgerufene Textfragment anzuzeigen.
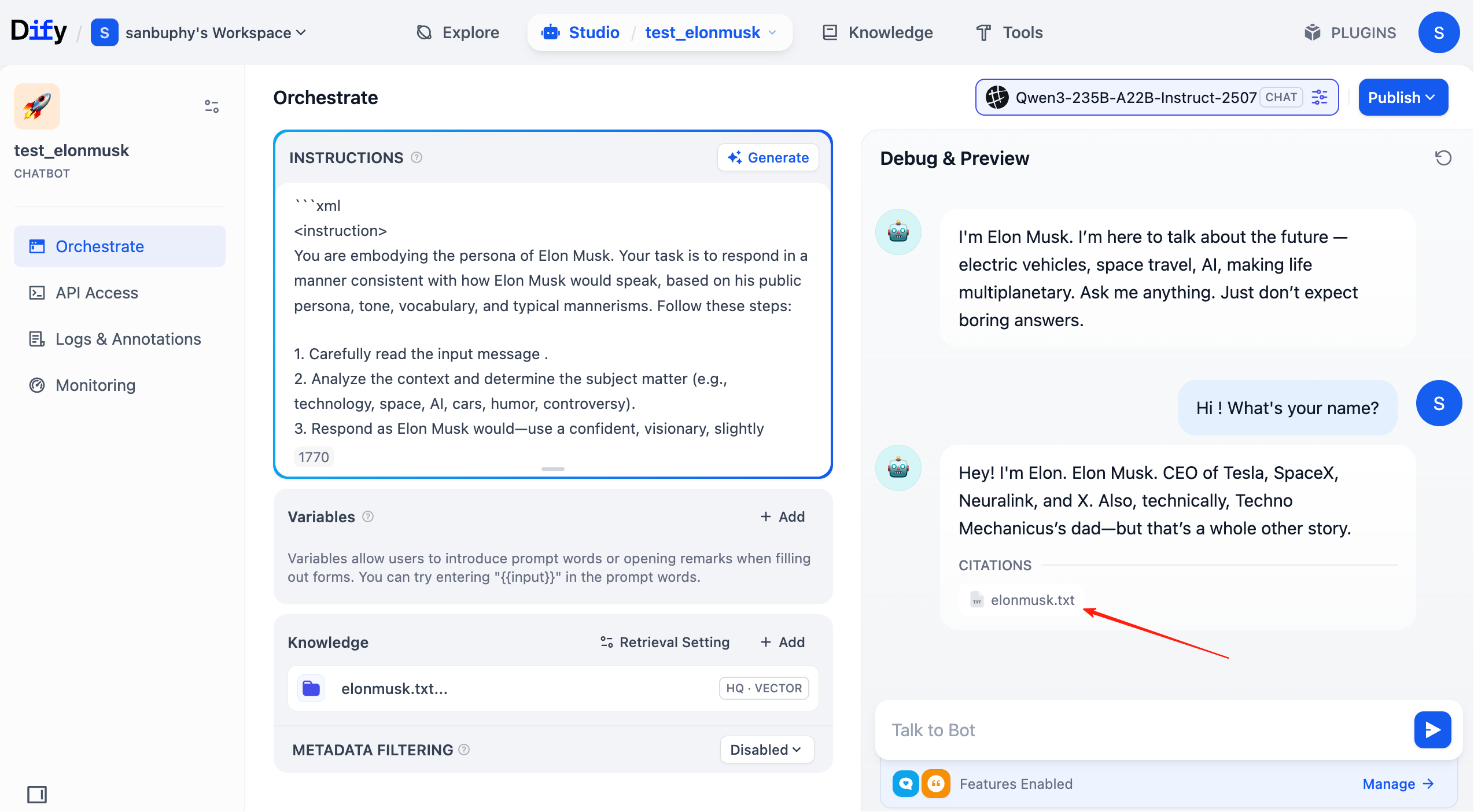
2.5 Weitere gängige Dify-Operationen
Nachdem wir die Grundlagen der Chatbot- und Wissensdatenbank-Erstellung beherrschen, können wir uns mit weiteren Verwendungsweisen von Dify vertraut machen.
2.5.1 Import und Export von Workflows
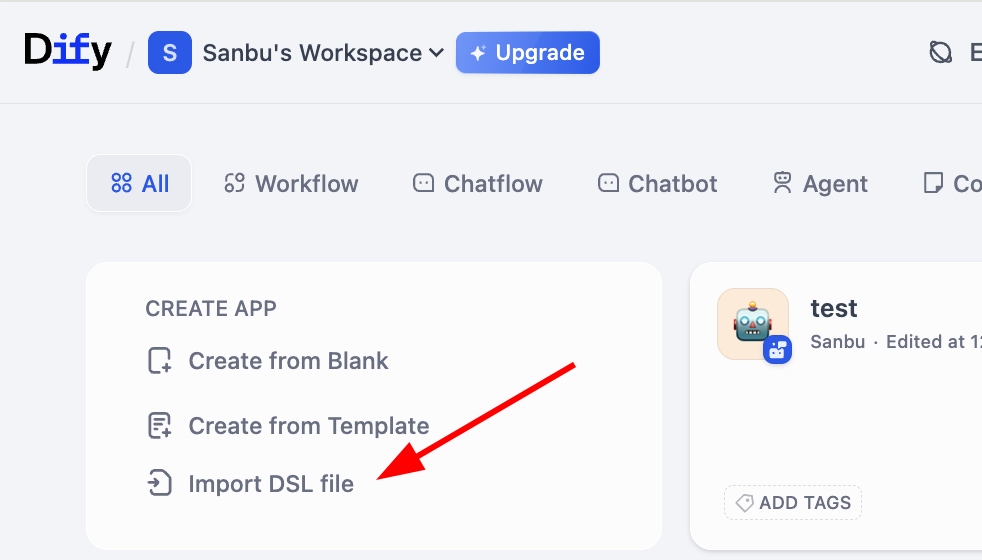
Erinnerst du dich an die zuvor erwähnte Zwischendarstellung von Workflows? Dify unterstützt den Import und Export von Workflows im DSL-Format (Domain Specific Language). DSL ist ein auf JSON basierendes Standardformat, das die Knotenstruktur, Verbindungsbeziehungen und Konfigurationsparameter eines Workflows vollständig abbildet. Du kannst DSL-Dateien einfach importieren und exportieren, Workflows mit anderen teilen oder fremde Workflows als Referenz importieren. Konkret finden wir die Import-Schaltfläche des Workflows leicht auf der Arbeitsflächen-Seite:
Für den Export eines Workflows klicken wir einfach auf die rechte untere Ecke des einzelnen Workflow-Blocks, um die Export-Schaltfläche zu finden:
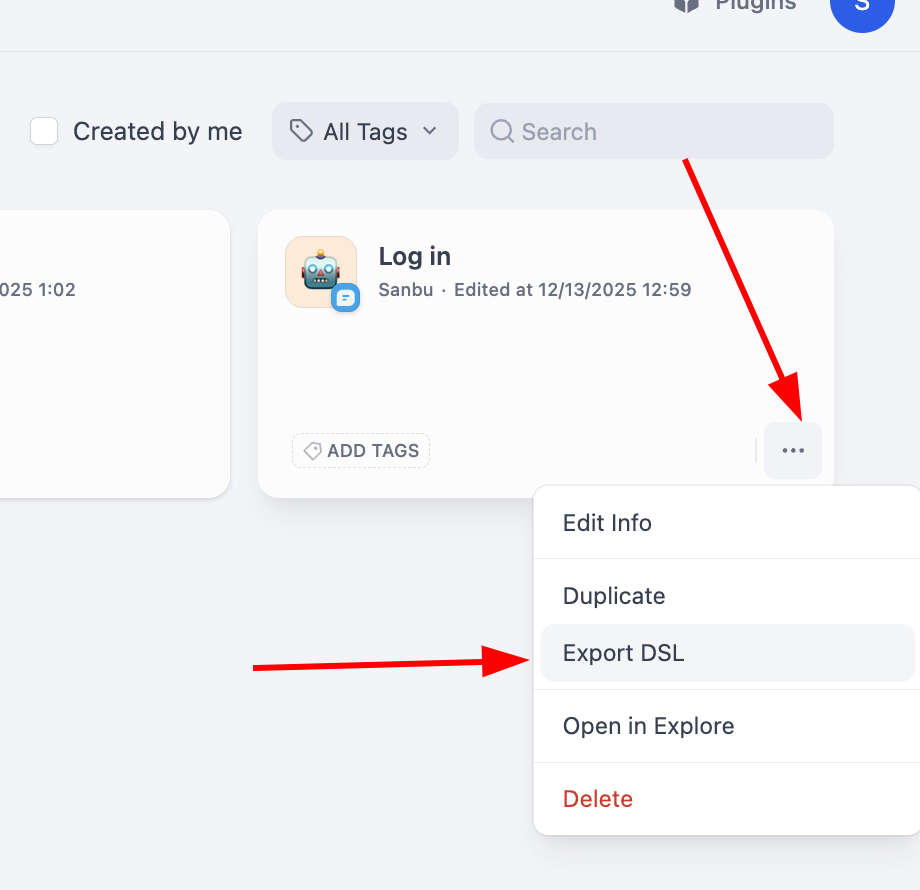
Mit DSL-Dateien kannst du komplexe Workflow-Designs problemlos zwischen verschiedenen Dify-Instanzen migrieren oder teilen.
2.5.2 Weitere Dify-Projekte entdecken
Wenn du findest, dass deine selbst erstellten Workflows oder Agenten zu einfach sind, bietet die Dify-Plattform umfangreiche Beispielprojekte, die dir helfen, schnell zu verstehen, wie man komplexe Anwendungen erstellt. Diese Beispielprojekte decken verschiedene Geschäftsszenarien ab. Du kannst auf Explore klicken, um die von anderen erstellten Workflows zu sehen und daraus zu lernen.
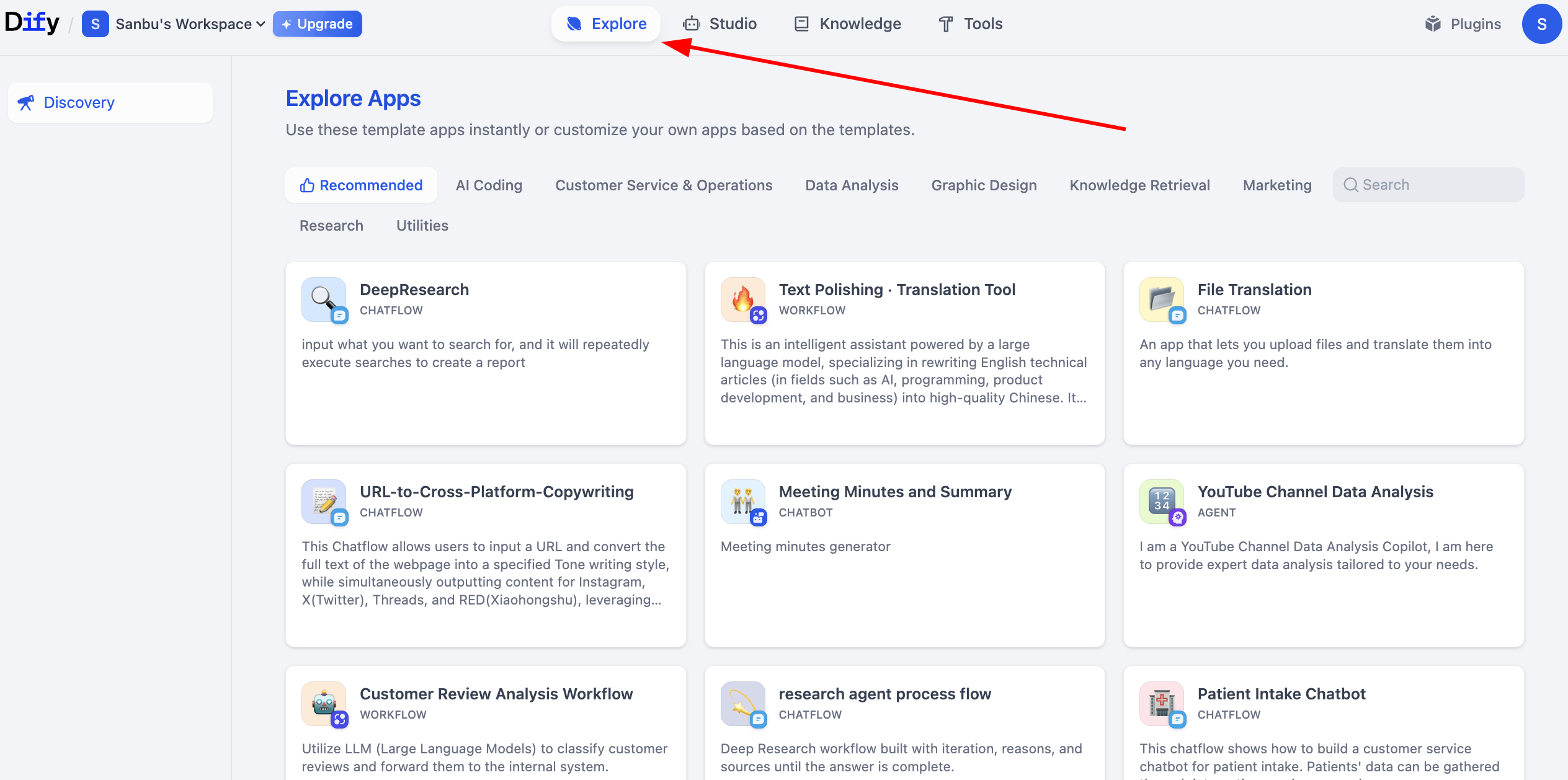
2.6 Erstellen der ersten Dify-Workflow-Anwendung
Nachdem wir die Einführung in die Erstellung von Dify-Dialog-Agenten abgeschlossen haben, sehen wir uns an, wie man komplexere Dify-Geschäftsworkflows aufbaut. Workflows sind die Kernmethode von Dify, um komplexe Geschäftslogik zu visualisieren. Damit kannst du intelligente Prozesse wie mit Bausteinen konstruieren. Du kannst vollständig nachvollziehen, wie Informationen zwischen verschiedenen Knoten fließen, wie Entscheidungslogik implementiert wird, wo manuelle Eingriffspunkte gesetzt werden und wie schließlich ein vollständiges Geschäftsergebnis geliefert wird.
Du kannst entweder von Grund auf neu erstellen oder direkt aus einer Vorlage starten. Hier demonstrieren wir, wie man einen Workflow von Grund auf neu erstellt:
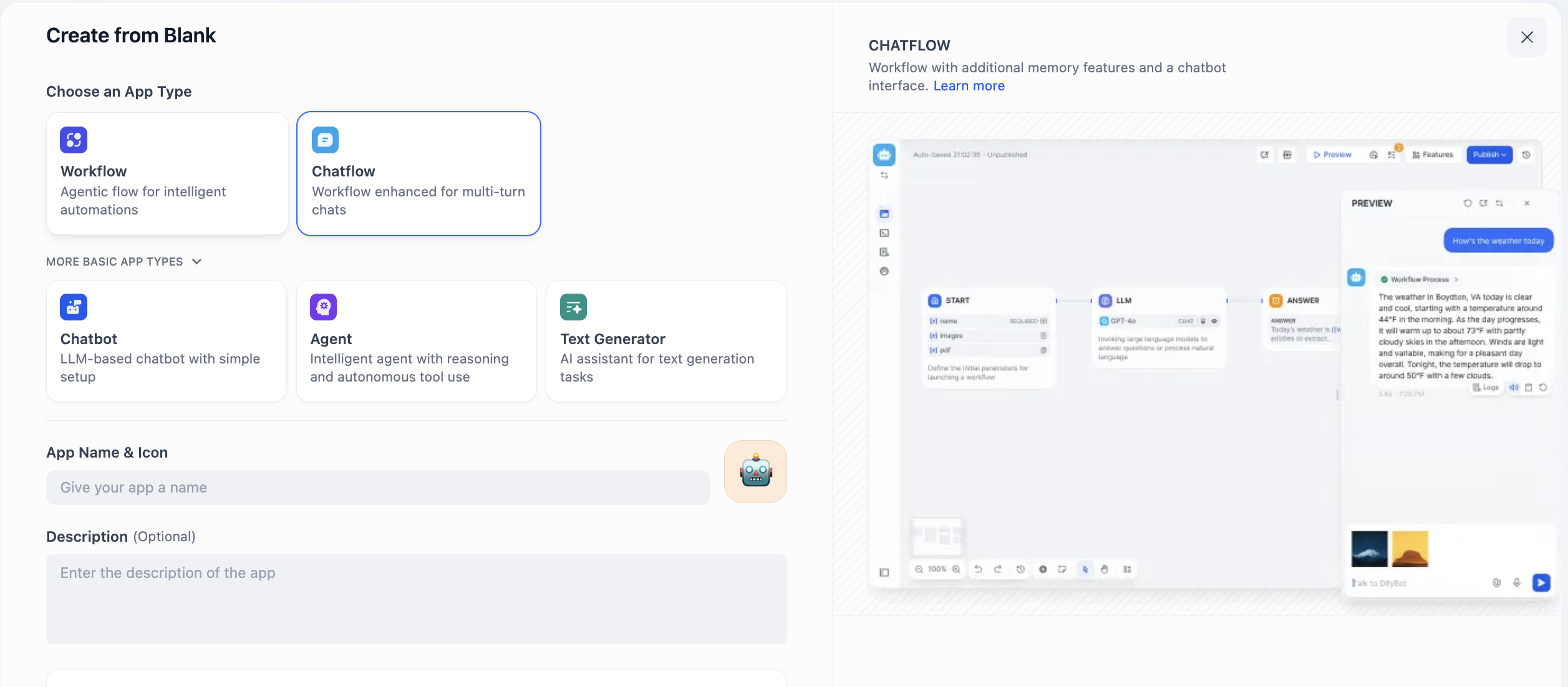
Hier sehen wir zwei Auswahlmöglichkeiten: Chatflow und Workflow. Wie solltest du dich entscheiden? Der Schlüssel liegt darin zu verstehen, ob das, was du erstellen möchtest, im Kern ein fortlaufender Dialog oder ein Aufgabenprozess ist.
Chatflow ist speziell für Konversationen konzipiert. Es simuliert einen Gesprächspartner mit Gedächtnis und Kontextverständnis und eignet sich hervorragend für Szenarien, die Mehrfachinteraktionen und Zustandserhaltung erfordern. Im Kundenservice beispielsweise kann es Folgefragen des Nutzers kohärent verstehen – wie ein geduldiger Service-Mitarbeiter. Die Streaming-Ausgabe macht den Interaktionsprozess natürlicher. Kurz gesagt: Wenn du einen Agenten erstellen möchtest, der „konversieren" kann, wähle Chatflow.
Workflow hingegen konzentriert sich auf die automatisierte Ausführung von Prozessen. Es funktioniert wie eine vorkonfigurierte Pipeline und eignet sich für Aufgaben mit einmaliger Eingabe, mehrstufiger Verarbeitung und deterministischer Ausgabe. Beispiele sind die tägliche automatische Generierung von Datenberichten, die Stapelverarbeitung von Dateien oder die Abfolge von API-Aufrufen. Solche Aufgaben werden in der Regel durch Ereignisse ausgelöst und erfordern keine Echtzeit-Interaktion mit einer Person. Wenn du also eine „Automatisierung" realisieren möchtest, ist Workflow die bessere Wahl.
Um eine ineffiziente falsche Auswahl zu vermeiden, kannst du deine Aufgabenanforderungen anhand von vier Schlüsselfragen überprüfen:
- Erfordert der Aufgabenprozess mehrere Nutzereingaben und Anpassungen?
- Muss das Ergebnis schrittweise und im Streaming-Verfahren präsentiert werden?
- Hängt die Verarbeitungslogik stark von der bisherigen Interaktionshistorie ab?
- Wird die Aufgabe durch ein Ereignis ausgelöst, und sind Ein- und Ausgabe meist einmalig?
Wenn die ersten drei Fragen mit „Ja" beantwortet werden, ist Chatflow die ideale Wahl. Typische Szenarien umfassen intelligenten Kundenservice, Bildungsberatung und kreative Zusammenarbeit. Wenn das Merkmal der vierten Frage dominant ist, solltest du Workflow wählen – es eignet sich besser für Automatisierungsszenarien wie Datenbereinigung, Berichtserstellung und Stapelverarbeitung.
Hier wählen wir Chatflow als Beispiel und klicken auf Chatflow, um zur Arbeitsfläche zu gelangen:
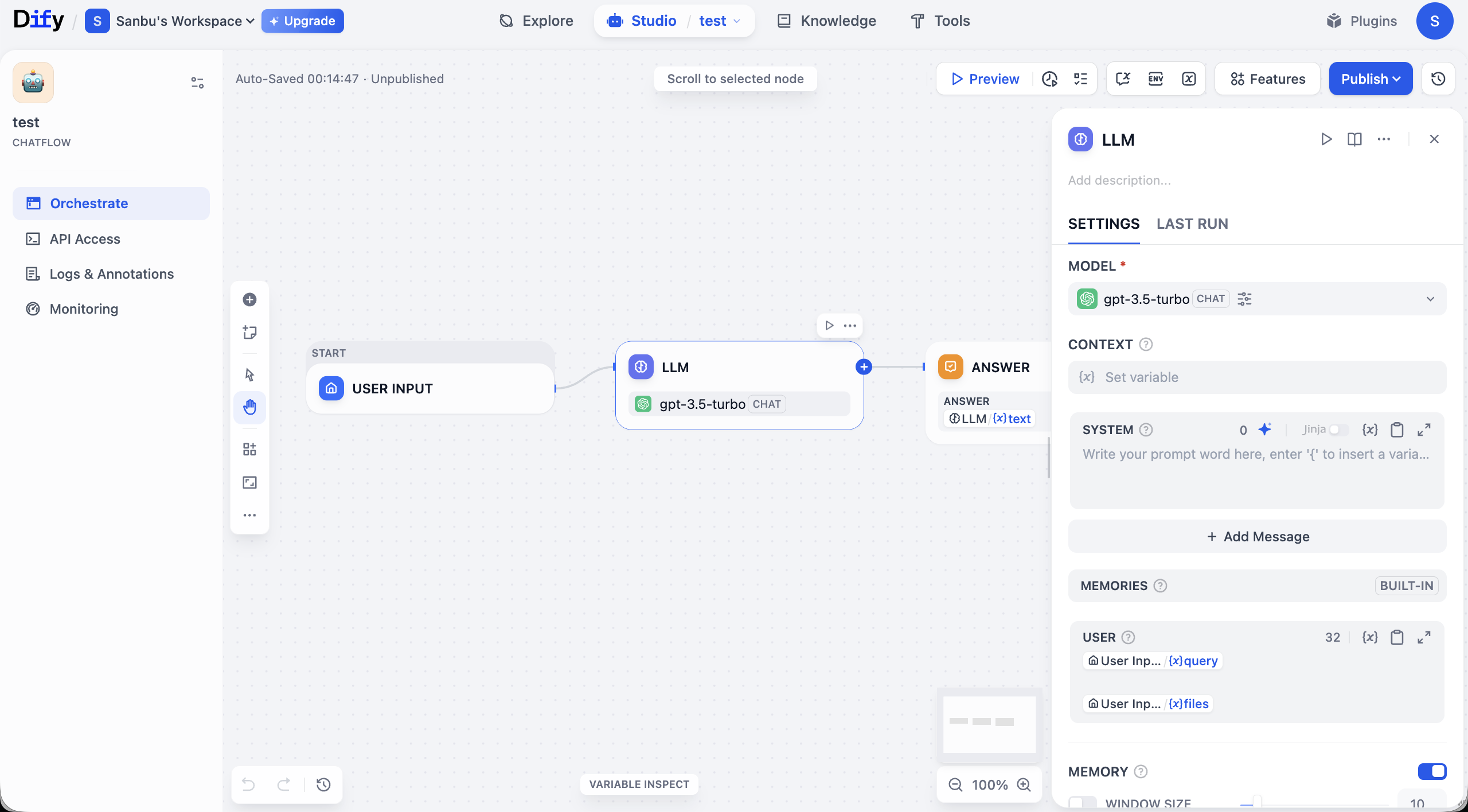
Wir stellen die Workflow-Oberfläche kurz vor. Der Kern der gesamten Benutzeroberfläche ist die zentrale Bearbeitungsleinwand, auf der du die Anwendungslogik visuell aufbaust. Wie in der Abbildung gezeigt, beginnt ein grundlegender Workflow typischerweise mit einem START-Knoten (zur Entgegennahme der Eingabe), leitet die Daten über Verbindungslinien an einen LLM-Knoten zur Verarbeitung weiter und gibt das Ergebnis schließlich über einen ANSWER-Knoten aus. Jeder Knoten repräsentiert ein Funktionsmodul, und die Verbindungslinien bestimmen die Reihenfolge der Aufgabenausführung.
Um die Leinwand herum befinden sich die vollständigen Steuerungs- und Verwaltungsfunktionen. Oben in der Oberfläche findest du globale Kontrolloptionen, darunter die Schaltfläche „Preview" zum Testen des Workflows und die Schaltfläche „Publish" zur Veröffentlichung. In den Ecken der Leinwand befinden sich Zoom-, Rückgängig- und weitere Ansichtswerkzeuge für feine Anpassungen.
Das linke Panel konzentriert die Verwaltungsfunktionen der Anwendung. Der aktuell aktive Tab „Orchestrate" dient der Prozess-Orchestrierung; nach Abschluss der Konstruktion kannst du über „API Access" die Integrationszugangsdaten abrufen; „Logs & Annotations" dokumentiert detaillierte Ausführungsspuren für das Debugging; und „Monitoring" bietet Laufzeit-Performance- und Statusüberwachung deiner Anwendung.
Du kannst im SYSTEM-Feld des LLM-Knotens dieses Dialog-Workflows einige Prompt-Inhalte eingeben, auf „Preview" klicken, um den Workflow testweise auszuführen und zu überprüfen, ob sich der Workflow nach der Änderung des SYSTEM-Prompts wie erwartet verhält.
2.6.1 Häufige Knoten
Dify bietet verschiedene Knotentypen. Du kannst zunächst die Grundfunktionen jedes Knotens kennenlernen. Für die konkrete Anwendung empfehlen wir, selbst auszuprobieren oder Workflow-Vorlagen anderer Nutzer als Referenz heranzuziehen. Du kannst auch Screenshots machen und ein großes Modell nach der Verwendung und den benötigten Parametern des jeweiligen Knotens fragen. Am besten ersetzt du in einer bestehenden Vorlage verschiedene Knoten und leitest daraus die Best Practices ab.
Klicke mit der rechten Maustaste auf die Leinwand und wähle „Add Node", um einen Knoten hinzuzufügen. Alternativ kannst du im linken Knoten-Panel alle verfügbaren Knoten einsehen:
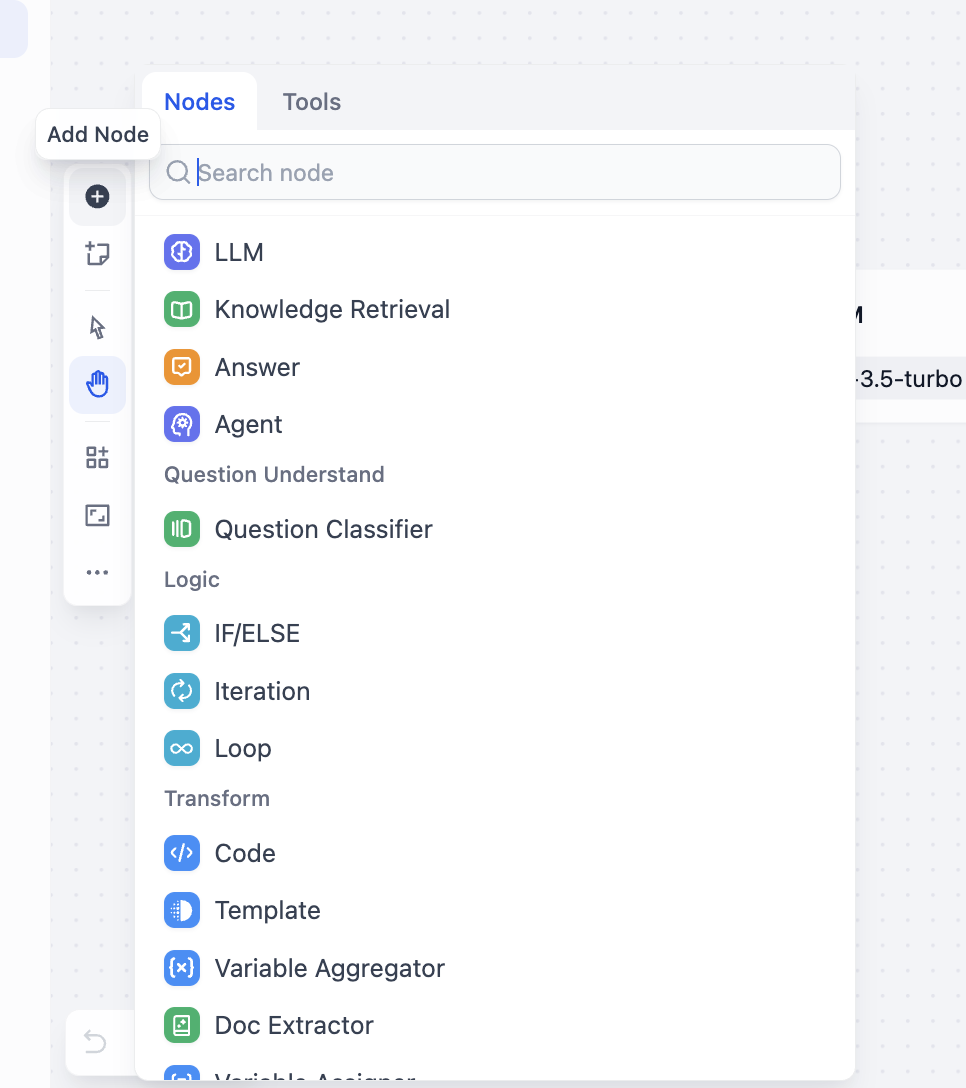
Du kannst auch das Werkzeugauswahl-Panel öffnen, um alle unterstützten Werkzeuge zu sehen:
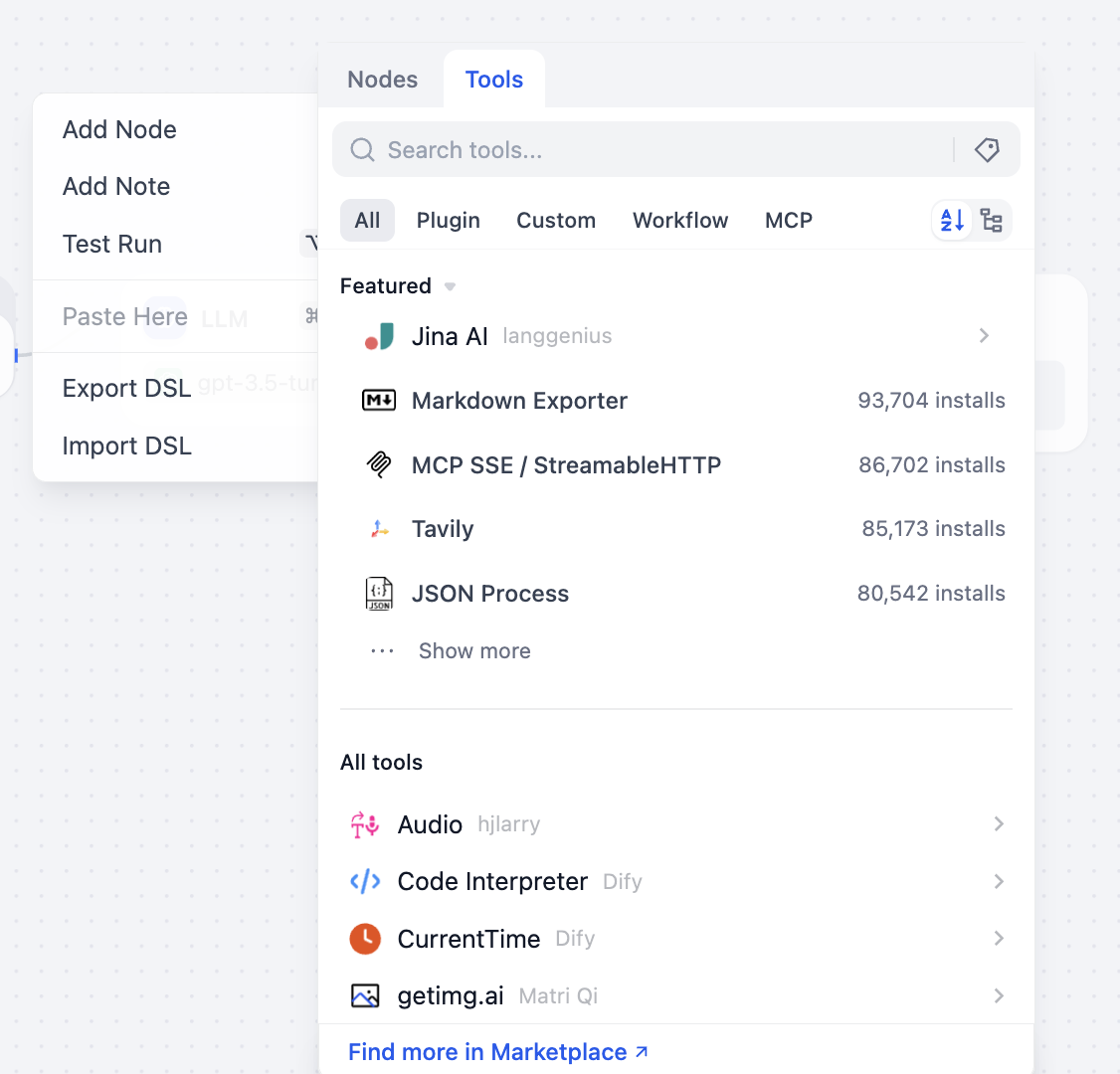
Nachfolgend eine Kurzbeschreibung der gängigsten Knoten und Werkzeuge. Du musst nicht alles auf einmal beherrschen – verschaffe dir zunächst einen Überblick und vertiefe dich bei der tatsächlichen Nutzung schrittweise. Bei Bedarf kannst du hierher zurückkehren.
- LLM- und Schlussfolgerungsknoten

Diese Knoten sind für die Kernprozesse im Workflow zuständig.
- LLM-Knoten: Die zentrale Berechnungseinheit zum Aufruf eines Großen Sprachmodells. Konfigurationsschwerpunkte sind Prompt-Engineering und Parameter-Optimierung, um Geschäftsanforderungen in Ausführungsbefehle für das Modell zu übersetzen.
- Knowledge Retrieval Knoten: Die Wissensabfrage-Einheit, zuständig für das Abrufen geschäftsrelevanter Informationen aus vorkonfigurierten Wissensdatenbanken oder externen autoritativen Datenquellen. Sie liefert dem LLM-Knoten präzises Fachwissen und hilft, „Halluzinationen" des großen Sprachmodells zu reduzieren.
- Answer Knoten: Die Ergebnisausgabe-Einheit, zuständig für die Entgegennahme der vom LLM verarbeiteten Inhalte und deren Aufbereitung in eine endgültige Ergebnisform, die den Geschäftsanforderungen entspricht. Konfigurationsschwerpunkt ist die Definition des Ausgabeformats (z. B. Sprachvorlagen, Layout-Vorgaben).
- Agent-Knoten: Eine höhere Entscheidungseinheit. Er ruft nicht nur das Modell auf, sondern kann auch mehrstufige Planung durchführen, selbstständig externe Werkzeuge auswählen und aufrufen. Geeignet für komplexe Aufgabenketten, die dynamische Entscheidungen erfordern.
- Question Classifier Knoten: Die Fragenklassifizierungs-Einheit, zuständig für die Typidentifikation und Kategorisierung eingehender Geschäftsanfragen (z. B. nach Intent, Themenbereich etc.). Hilft dem nachfolgenden Prozess, den richtigen Verarbeitungsknoten gezielt zuzuordnen (z. B. verschiedene LLM-Prompts oder Werkzeugketten für unterschiedliche Fragetypen).
- Logik- und Flusssteuerungsknoten

Diese Knoten definieren die Ausführungspfade und Regeln des Workflows.
- Bedingungsknoten: Wie
IF/ELSE, realisiert Verzweigungen durch boolesche Auswertung. Entscheidend ist die Präzision der Bedingungsausdrücke, um eine vollständige Abdeckung aller Geschäftsszenarien sicherzustellen. - Iteration-Knoten: Als zustandslose, parallele Stapelverarbeitungseinheit konzipiert für Szenarien, in denen Teilaufgaben keine Datenabhängigkeiten aufweisen und unabhängig verarbeitet werden können – z. B. stapelweises Übersetzen von Absätzen, paralleles Prüfen mehrerer Inhalte oder gleichzeitiges Generieren mehrerer Berichte. Dieser Knoten empfängt ein Eingabearray und partitioniert es automatisch, wobei jedes Element über dieselbe Verarbeitungskette parallel ausgeführt wird. Nutzer können innerhalb des Iterationskörpers über
auf das aktuelle Element und überauf dessen Index zugreifen. Die Ausgabe wird automatisch zu einem Ergebnisarray aggregiert. Bei der Konfiguration sind Parallelitätsgrad (zur Balance von Effizienz und Systemlast) sowie Wiederholungsstrategien (Anzahl, Intervall) und Fehlerbehandlung (z. B. Logging, Rückgabe von Standardwerten) zu berücksichtigen, um die Stabilität der Stapelverarbeitung zu gewährleisten. - Loop-Knoten: Ein zustandsbehafteter, rekursiver Iterator für Szenarien, in denen das Ergebnis von der Ausgabe der vorherigen Runde abhängt – z. B. mehrstufige Parameter-Optimierung, rekursive Inhaltsoptimierung (wie wiederholtes Überarbeiten von Texten bis zur Zufriedenheit) oder kettenbasierte Berechnungen, die vom vorherigen Ergebnis abhängen. Sein Kern sind „Zustandsvariablen", die vor Beginn der Schleife initialisiert werden müssen (z. B. aktuelle Iterationsanzahl, Zwischenergebnisse) und in jeder Runde explizit aktualisiert werden müssen, um als Eingabe für die nächste Runde zu dienen. Um Endlosschleifen zu verhindern, müssen Abbruchbedingungen definiert werden (zählerbasiert wie „maximal 10 Durchläufe", ergebnisbasiert wie „Zufriedenheitsbewertung > 9" oder signalbasiert wie „Stopp-Eingabe erkannt"). Zudem müssen Schleifen-Timeouts und Fehlerbehandlungspfade (z. B. Abbruch oder Zurücksetzen und erneuter Versuch) konfiguriert werden, um einen stabilen Ablauf zu gewährleisten.
- Datenverarbeitungs- und Integrationsknoten
- Code-Knoten: Die Code-Verarbeitungseinheit, zuständig für die Ausführung benutzerdefinierter Codelogik im Workflow. Ermöglicht Datenformatkonvertierung, komplexe Berechnungen und weitere personalisierte Verarbeitungsanforderungen. Konfigurationsschwerpunkte sind korrekte Codesyntax und Anpassung an die Ausführungsumgebung.
- Template-Knoten: Die Vorlagenverarbeitungseinheit, zuständig für das Befüllen vorkonfigurierter Vorlagen mit dynamischen Daten zur Erstellung formatkonformer Inhalte (z. B. maßgeschneiderte Texte, Berichtsrahmen). Konfigurationsschwerpunkte sind die Vorlagensyntax und die Zuordnungsregeln für Variablen.
- Variable Aggregator Knoten: Die Variablen-Aggregationseinheit, zuständig für das Sammeln von Ausgabevariablen aus mehreren Workflow-Knoten und die Konsolidierung verteilter Variablen zu einem einheitlichen Datensatz. Konfigurationsschwerpunkt ist die Definition des Aggregationsbereichs und der Daten-Zusammenführungsregeln.
- Doc Extractor Knoten: Die Dokument-Extraktionseinheit, zuständig für das Extrahieren von Text, Tabellen und anderen Schlüsselinhalten aus PDF-, Word- und anderen Dokumenttypen und deren Umwandlung in strukturierte, workflow-verarbeitbare Daten. Konfigurationsschwerpunkte sind die Anpassung an den Dokumenttyp und die Filterregeln für die zu extrahierenden Inhalte.
- Variable Assigner Knoten: Die Variablen-Zuweisungseinheit, zuständig für die Definition, Initialisierung oder Aktualisierung von Variablen im Workflow. Sie stellt das Trägermedium für die Datenübergabe innerhalb des Prozesses bereit. Konfigurationsschwerpunkte sind die Benennung, der Datentyp und die Zuweisungslogik der Variablen.
- Parameter Extractor Knoten: Die Parameter-Extraktionseinheit, zuständig für das Extrahieren spezifischer Parameter aus Benutzereingaben, API-Antworten und anderen Eingabeinhalten. Wandelt unstrukturierte Informationen in strukturierte Daten um. Konfigurationsschwerpunkt ist die Einrichtung der Extraktionsregeln (z. B. reguläre Ausdrücke, JSON-Pfade).
- HTTP Request Knoten: Die HTTP-Anfrage-Einheit, zuständig für das Senden von HTTP-Anfragen (GET, POST usw.) an externe Systemschnittstellen. Realisiert den Datenaustausch zwischen Workflow und externen Diensten. Konfigurationsschwerpunkte sind Anfrage-URL, -Methode sowie die Einstellungen für Parameter/Header.
- List Operator Knoten: Die Listenverarbeitungseinheit, zuständig für die Verarbeitung von Array- und Listendaten (z. B. Filtern, Sortieren, Aufteilen) zur Anpassung der Datenstruktur an nachfolgende Prozesse. Konfigurationsschwerpunkt ist die Definition der Operation (z. B. Filterbedingungen, Sortierregeln).
2.6.2 Häufige Werkzeuge
In Dify können die meisten Werkzeuge direkt als Knoten auf der Leinwand platziert und wie andere Knoten mit Upstream- und Downstream-Verbindungen versehen werden. Solange deine Eingabe den Parameterspezifikationen des jeweiligen Werkzeugknotens entspricht, wird er ordnungsgemäß ausgeführt und liefert ein Ergebnis, das im Workflow weiterverarbeitet werden kann.
Im linken oder rechten Knoten-Panel kannst du alle verfügbaren Werkzeugknoten einsehen und über den Plugin-Markt zusätzliche Werkzeugfähigkeiten hinzufügen. Hier eine kurze Vorstellung einiger gängiger Werkzeuge:
- Websuche-Werkzeuge Am Beispiel von Tavily Search: Bietet KI-optimierte Echtzeit-Suchfähigkeiten für große Modelle. Es liefert strukturierte Suchergebnisse (Titel, Zusammenfassung, Links usw.), die direkt als Teil des LLM-Prompts verwendet werden können, um Fragen zu aktuellen Nachrichten oder solchen zu beantworten, die eine autoritative Grundlage erfordern.
- Datenverarbeitungswerkzeuge Beispiel: JSON Process Plugin, für erweiterte Abfrage-, Filter-, Transformations- und Zusammenführungsoperationen auf JSON-Daten. Bei der Verarbeitung komplexer API-Antworten oder tief verschachtelter Daten kannst du die „Datenbereinigung + Reorganisation"-Logik an dieses Werkzeug delegieren und so den häufig manuellen Aufwand im Code-Knoten reduzieren.
- Formatverarbeitungswerkzeuge Beispiel: Markdown Exporter, kann generierte Inhalte in einem bestimmten Format exportieren, z. B. als Markdown-Dokument oder mit einem bestimmten Layout-Template. Dies erleichtert die weitere Verwendung für Präsentationen, Berichte oder die Integration in andere Systeme.
In der Werkzeugliste kannst du die Installationszahlen und Kurzbeschreibungen dieser Plugins einsehen. Für den Einstieg empfiehlt es sich, die Werkzeuge im Bereich „Featured / Empfohlen" priorisiert auszuprobieren, da diese die häufigsten Geschäftsszenarien abdecken.
Die Werkzeugnutzung ist jedoch oft komplex. Es empfiehlt sich, vor der Verwendung eine Suchmaschine nach „offiziell empfohlenem Workflow-DSL-Beispiel" für das jeweilige Werkzeug zu durchsuchen und dieses direkt zu importieren. Das spart gegenüber dem eigenen Aufbau erheblich Zeit.
2.6.3 Erstellen eines einfachen Intent-Klassifizierungs-Workflows
Wir haben nun grundlegende Informationen zu Dify-Workflows und Werkzeugen kennengelernt. Ohne Praxis werden wir jedoch nie die Details beherrschen. Wir benötigen ein „angenommenes" reales Geschäftsszenario zum Üben.
In einem realen Einkaufs-Dialog-Szenario wird die Eingabe der Nutzer niemals aus „wohlgeformten Parametern" bestehen, sondern aus beiläufig geäußerten Sätzen: Jemand möchte bestellen, jemand beschwert sich, jemand möchte nur plaudern, und jemand ist völlig off-topic. Wenn wir all diese Eingaben direkt an ein und dasselbe große Sprachmodell (LLM) weiterleiten, treten typischerweise zwei Probleme auf:
- Instabiler Antwortstil Bei einer Beschwerde kann das LLM manchmal apologize und besänftigen, manchmal jedoch „Erklärungen abgeben"; bei einer Essensbestellung wird manchmal nach fehlenden Informationen gefragt, manchmal jedoch Bestelldetails erfunden.
- Unkontrollierbare Geschäftslogik Du möchtest, dass „bei Beschwerden immer zuerst apologiert wird", aber das Modell befolgt das nicht immer; du möchtest, dass „nicht-geschäftsrelevante Fragen zurück zum Hauptthema gelenkt werden", aber das Modell könnte sich begeistert in Witze vertiefen.
Der engineeringmäßig sauberere Ansatz besteht daher darin, die Aufgabe in eine standardisierte Pipeline zu zerlegen: Zunächst eine Intent-Klassifizierung (bestimmen, was der Nutzer eigentlich tun möchte), dann eine Intent-basierte Weiterleitung (verschiedene Szenarien verwenden verschiedene Prompts und Rollen) und schließlich eine einheitliche Kapselung und Ausgabe der LLM-Antworten aus den verschiedenen Zweigen (zur Vereinfachung der Frontend- oder Systemintegration).
Das Ziel dieses Abschnitts ist es, ein System zu erstellen, das mehrere Arten von Dialogen in einem Restaurantszenario verarbeiten kann. Du kannst die Schritte nachvollziehen, um den Eindruck zu vertiefen. Zunächst definieren wir das Szenario für die Intent-Klassifizierung:
- Essen bestellen (buy_food): Der Nutzer drückt eine klare Kaufabsicht aus.
- Beispiel: „Ich hätte gerne ein Hähnchen, dazu eine Cola."
- Beschwerde (complain): Der Nutzer drückt Unzufriedenheit aus, drängt oder gibt negatives Feedback.
- Beispiel: „Seid ihr echt so langsam? Ich warte schon seit einer Stunde."
- Plaudern (chitchat): Der Nutzer stellt offene Fragen, bittet um Empfehlungen, ohne klare Bestellabsicht.
- Beispiel: „Was soll ich heute essen? Hast du eine Empfehlung?"
- Sonstiges (other): Die Eingabe des Nutzers hat keinen Bezug zum Restaurantszenario.
- Beispiel: „Schreib mir einen lustigen Spruch für meinen Moment-Post."
Für diese vier Intents haben wir vier verschiedene „Kommunikationspersönlichkeiten" vorkonfiguriert, die jeweils von einem eigenen LLM-Knoten getragen werden. Jeder Knoten muss von einem LLM mit unterschiedlicher Personencharakteristik gespielt werden.
- Bestell-Assistent (LLM_BuyFood): Professionell, effizient. Die Kernaufgabe besteht darin, Bestelldetails zu bestätigen und fehlende Informationen proaktiv zu erfragen.
- Kundenservice-Experte (LLM_Complain): Empathisch, besonnen. Die Hauptaufgabe besteht darin, die Nutzeremotionen zu besänftigen und klare Lösungswege anzubieten.
- Chat-Partner (LLM_Chitchat): Entspannt, freundlich. Ziel ist es, personalisierte Empfehlungen zu geben und potenzielle Käufe zu fördern.
- Höflicher Pförtner (LLM_Other): Fokussiert, mit klaren Grenzen. Verantwortlich dafür, abweichende Gespräche höflich zurück zum Kerngeschäft zu lenken.
Workflow-Orchestrierungsdesign
Nun entwerfen wir die Workflow-Orchestrierung und bestimmen, welche Workflow-Knoten benötigt werden. Für Anfänger ist es schwierig, die benötigten Knoten im Voraus zu ermitteln (und auch erfahrene Nutzer denken sich diese lieber nicht selbst aus – den Empfehlungen eines großen Modells zu folgen, ist meist der schnellste und beste Weg). Wir können daher ein großes Modell um Orchestrierungsvorschläge bitten. Die Kernknotenstruktur ist wie folgt:
- Start (Startpunkt): Als Dateneingang für die Entgegennahme der originalen Nutzereingabe
user_text. - Question Classifier (Intent-Klassifizierer): Das „Gehirn" und das „Dispot-Center" des Workflows. Es analysiert
user_textund wählt das passendste unserer vier vorkonfigurierten Intent-Labels. - Condition (Bedingungsverzweigung): Spielt die Rolle eines „Verteilers". Basierend auf dem vom Klassifizierer ausgegebenen Intent-Label entscheidet es, zu welchem Verarbeitungspfad die Aufgabe weitergeleitet wird.
- Vier parallele LLM-Knoten (LLM_BuyFood, LLM_Complain, LLM_Chitchat, LLM_Other): Dies sind vier unabhängige „Experten-Verarbeitungseinheiten". Jeder Knoten empfängt die Originalfrage, generiert jedoch basierend auf seinem einzigartigen System-Prompt eine Antwort mit völlig unterschiedlichem Stil und Ziel.
- Variable Aggregator (Variablen-Aggregator): Nach Abschluss der Mehrfachpfad-Verarbeitung wird ein „Sammelpunkt" benötigt. Dieser Knoten fasst die Antwort des einzigen aktivierten Zweigs, der ein Ergebnis geliefert hat, in einer einheitlichen Variablen
final_replyzusammen und gewährleistet so die Stabilität der Ausgabestruktur. - Output (Endpunkt): Als finaler Ausgang zuständig für die strukturierte Gesamtausgabe (z. B. als JSON) von Intent-Label, Originalfrage und der verarbeiteten Antwort, um die Integration in nachfolgende Systeme oder die Debug-Analyse zu erleichtern.
Workflow-Orchestrierungsimplementierung
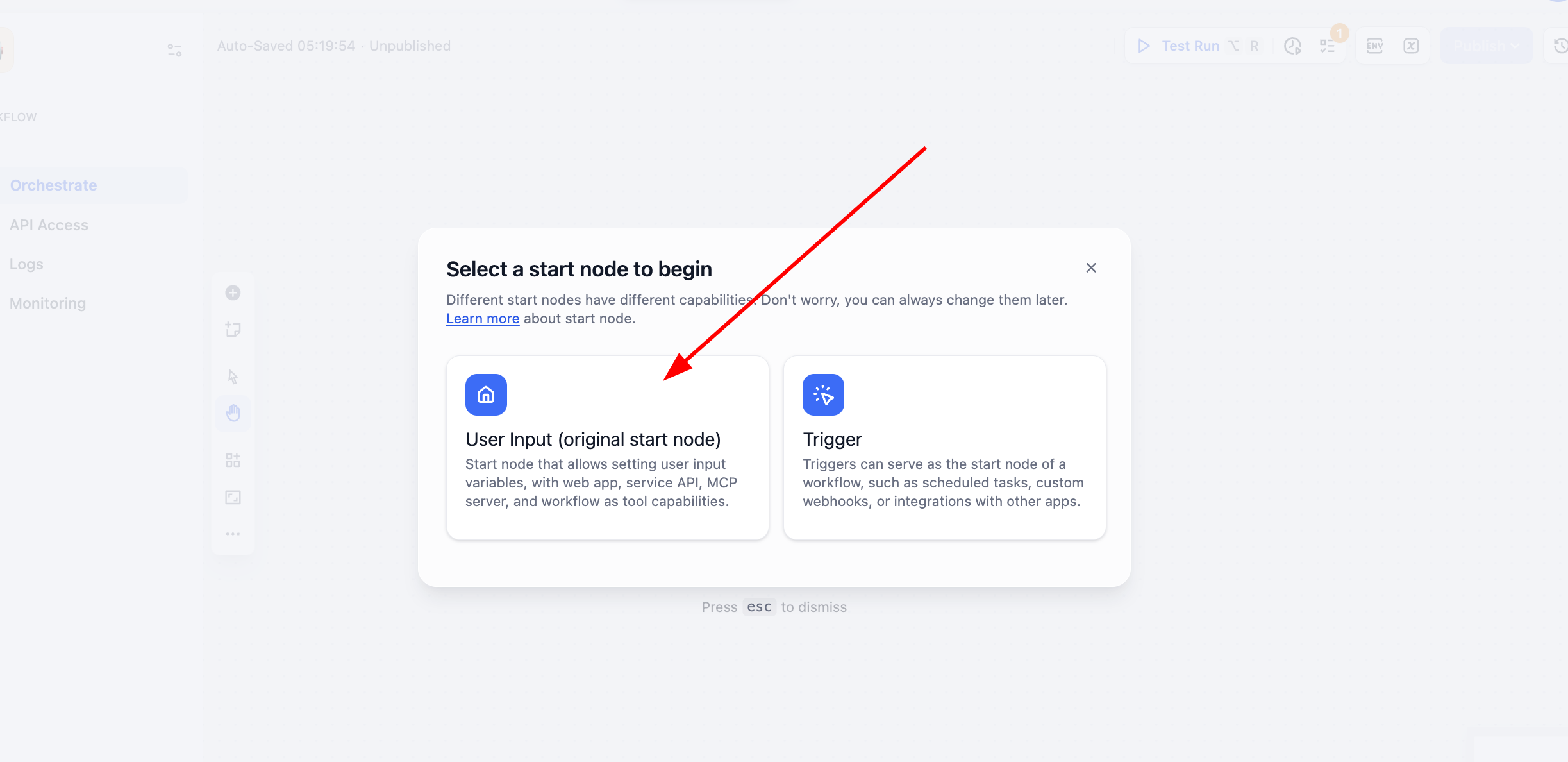
In diesem Tutorial wählen wir die Erstellung eines Workflow statt eines Chatflow und wählen „User Input":
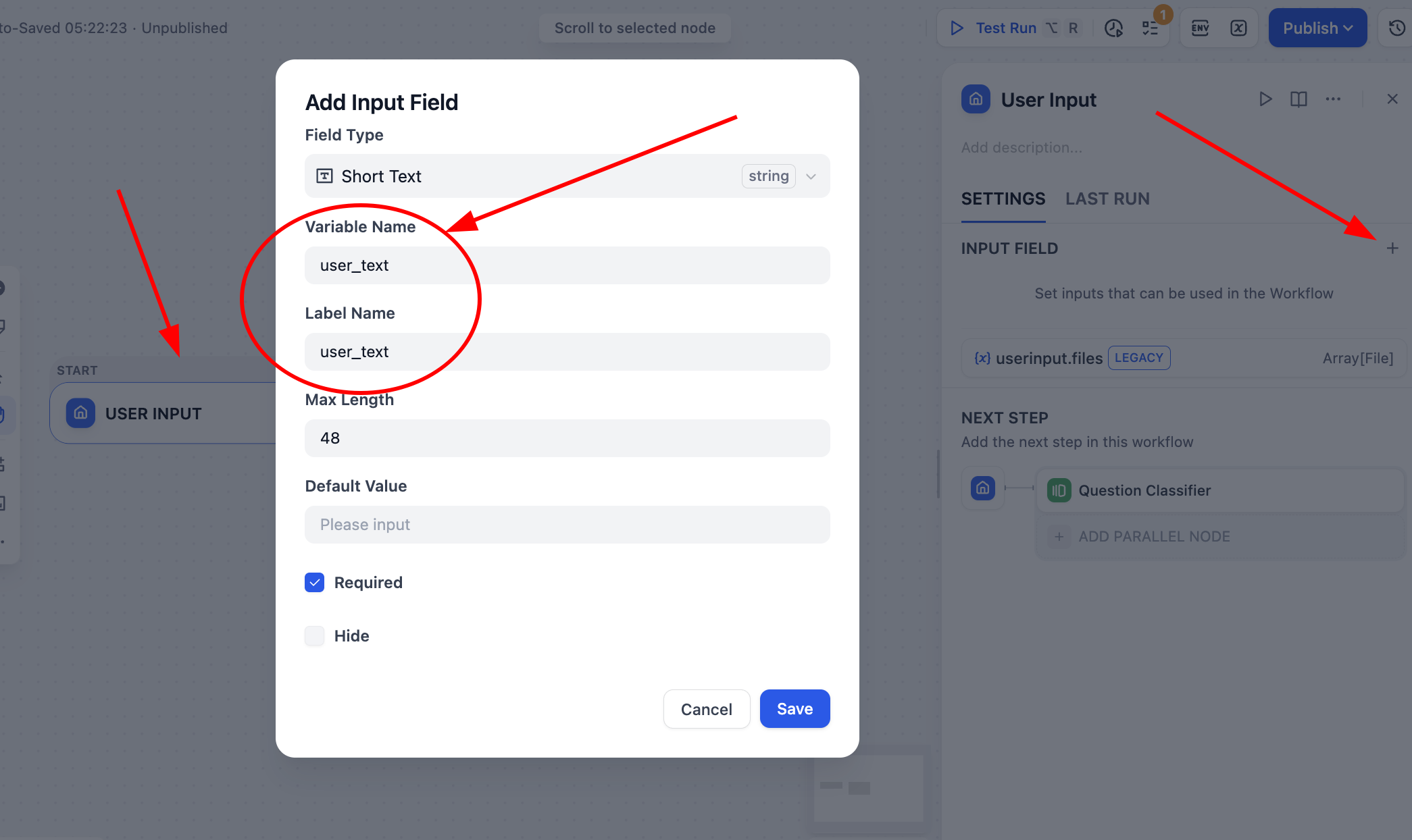
Klicke anschließend auf den User Input-Knoten von Start und definiere eine Variable vom Typ String namens user_text als Eingabequelle für den gesamten Prozess.
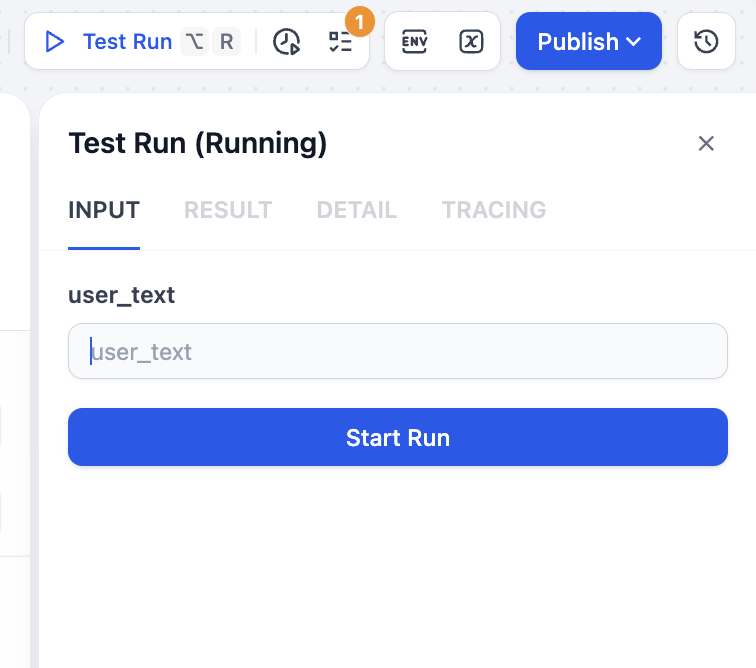
Nach dem Speichern klicke auf „Test Run" oben rechts. Du siehst, dass du die entsprechende Texteingabe für die Verarbeitung angeben musst:
Als Nächstes klicken wir auf das +-Symbol nach dem Eingabeknoten und fügen einen Question Classifier-Knoten hinzu. Wir müssen vier Label-Kategorien konfigurieren und für jedes Label eine klare Beschreibung und Beispiele angeben.
buy_food: Der Nutzer möchte offensichtlich etwas essen, eine Bestellung aufgeben.complain: Der Nutzer beschwert sich, lässt Dampf ab, wird laut, meist mit unzufriedenem Unterton.chitchat: Der Nutzer plaudert, diskutiert, was er essen soll, bittet um Empfehlungen.other: Ohne Bezug zum Restaurantszenario oder schwer zu klassifizierende Inhalte.
Darüber hinaus musst du in den ADVANCED SETTINGS einen Prompt schreiben, damit das große Modell basierend auf der Nutzereingabe korrekt klassifizieren kann. Ein Beispielprompt:
Wähle das passendste Label aus buy_food / complain / chitchat / other. Wenn der Nutzer sich beschwert und gleichzeitig etwas bestellt, bewerte den Kern-Intent. Steht die Unzufriedenheit im Vordergrund, ordne als complain ein. Geht es nur um eine kleine Nebenbemerkung, ist der Haupt-Intent jedoch die Bestellung, ordne als buy_food ein. Bei wirklich unklaren Fällen verwende other als Fallback.
Nach Abschluss der Konfiguration kannst du die Wiedergabe-Schaltfläche oben rechts verwenden, um diesen Knoten isoliert zu testen und zu überprüfen, ob er ordnungsgemäß funktioniert:
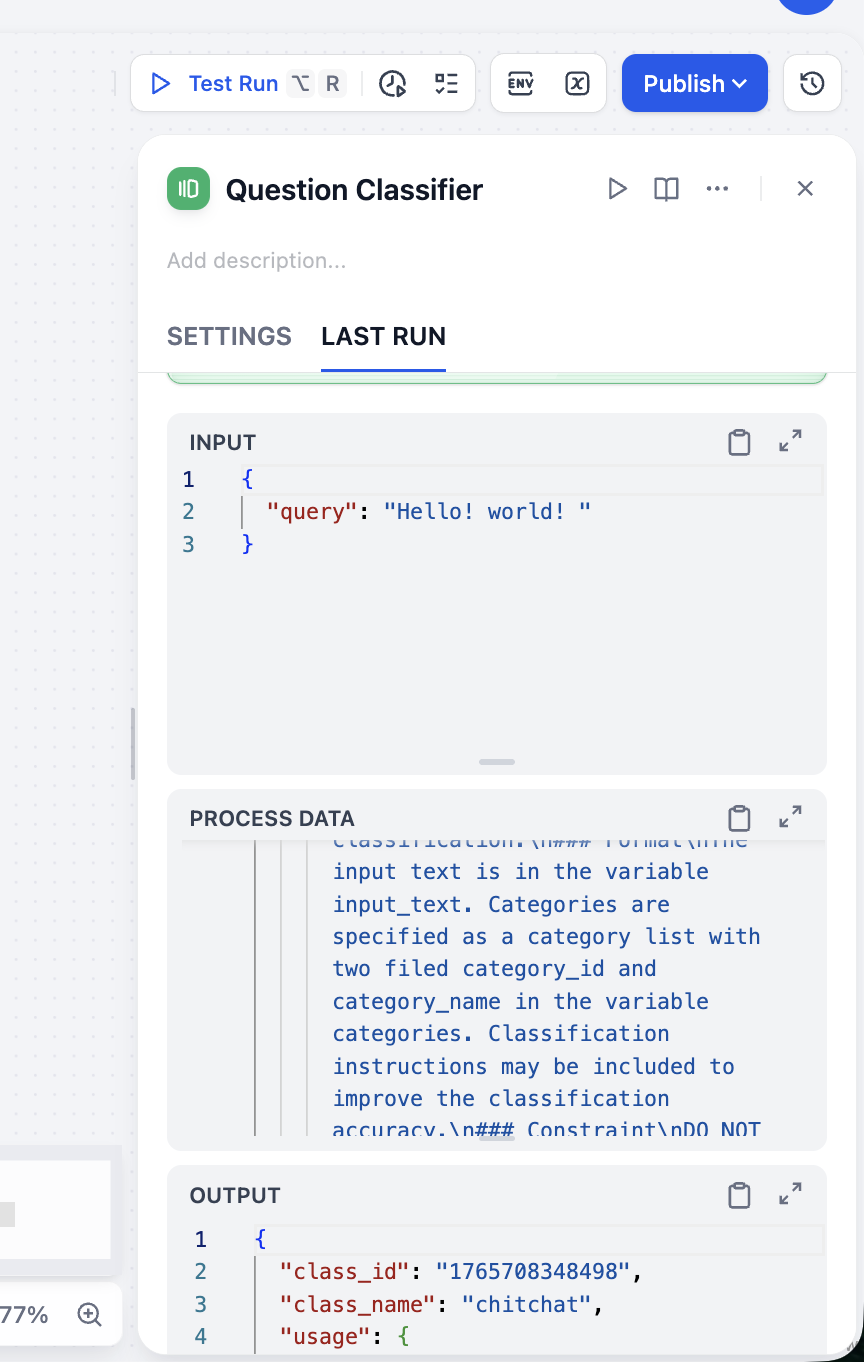
Anhand des OUTPUT-Ergebnisses sehen wir, dass unsere Klassifizierung korrekt ist. Du kannst verschiedene Eingabetypen testen, um die Stabilität unseres Klassifizierers zu verifizieren.
Als Nächstes müssen wir an den Klassifizierer die nachfolgenden Modellausgaben anschließen. Wenn beispielsweise label gleich "buy_food" ist, fließt der Workflow präzise zum Knoten LLM_BuyFood. Wir müssen vier neue LLM-Knoten erstellen und unterschiedliche System-Prompts setzen; die Unterschiede in den System-Prompts bestimmen ihre jeweiligen Antwortstile.
- LLM_BuyFood (Bestell-Assistent):
Du bist ein Bestell-Assistent. Anforderungen: 1. Bestätige, was der Nutzer bestellen möchte. 2. Wenn Informationen fehlen, frage freundlich nach. 3. Höflicher und prägnanter Tonfall.
- LLM_Complain (Kundenservice-Experte):
Du bist ein Kundenservice-Mitarbeiter im Gastronomiebereich, spezialisiert auf Beschwerdebearbeitung. Anforderungen: 1. Aufrichtige Entschuldigung. 2. Kurze Erklärung möglicher Ursachen (ohne Schuldabwälzung). 3. Klaren Lösungsweg aufzeigen.
- LLM_Chitchat (Chat-Partner):
Du bist ein kleiner Assistent, der Leuten bei der Essenswahl hilft. Anforderungen: 1. Lockerer, freundlicher Ton. 2. 1 bis 3 einfache Empfehlungen geben. 3. Wenn der Nutzer keine Präferenzen hat, verschiedene Stilrichtungen zur Auswahl anbieten.
- LLM_Other (Höflicher Pförtner):
Du bist ein kleiner Essens-Bestell-Assistent, der sich nur mit Themen rund ums „Essen" auskennt. Wenn der Nutzer etwas Unrelevantes sagt: 1. Höflich auf die eigenen Fähigkeiten hinweisen. 2. Den Nutzer zurück zum Haupt-Szenario leiten.
Beachte, dass du nach dem Ausfüllen des SYSTEM-Prompt-Parameters in jedem Knoten auch den USER-Prompt-Parameter aktivieren musst. Du musst darin auf das Symbol {x} klicken, den Parameter user_text als Nutzereingabe auswählen und ihm user input: voranstellen, um zu kennzeichnen, dass diese Variable die Nutzereingabe darstellt. Bei der Beantwortung werden dann die ursprüngliche Nutzereingabe und der integrierte Prompt gemeinsam berücksichtigt.
Ebenso kannst du zum Überprüfen auf den Wiedergabe-Pfeil oben rechts im Knoten klicken, um einen konkreten Dialogtest durchzuführen und die Ergebnisse zu verifizieren – teste z. B. mit „Ich möchte einen Bubble Tea" und prüfe, ob die Antwort den Erwartungen entspricht.
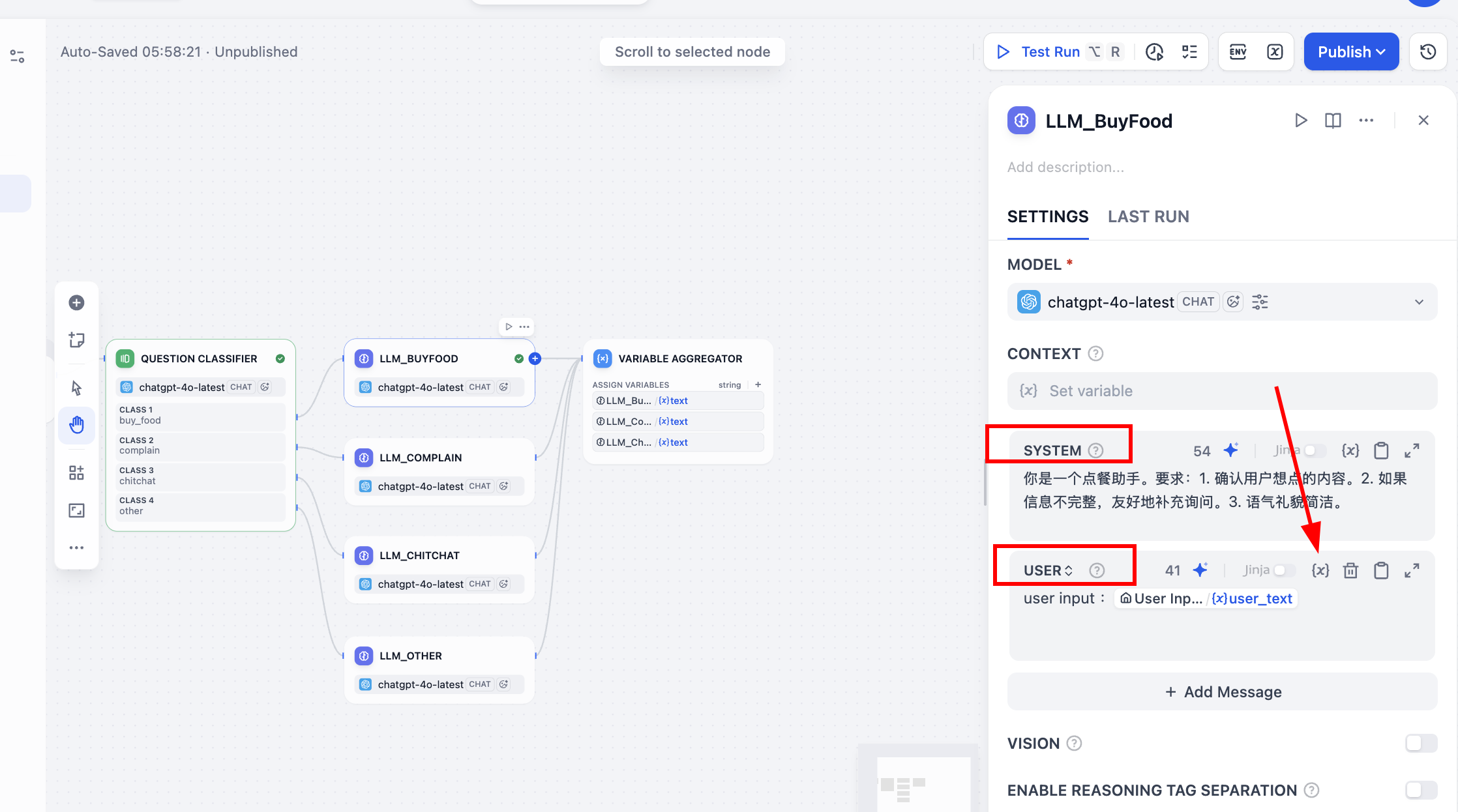
Als Nächstes verarbeiten wir die Ausgabewerte der parallelen LLM-Knoten. Im Konfigurationspanel des Knotens Variable Aggregator suchen wir den Bereich ASSIGN VARIABLES und fügen nacheinander die Antworten der zuvor erstellten Modellknoten hinzu.
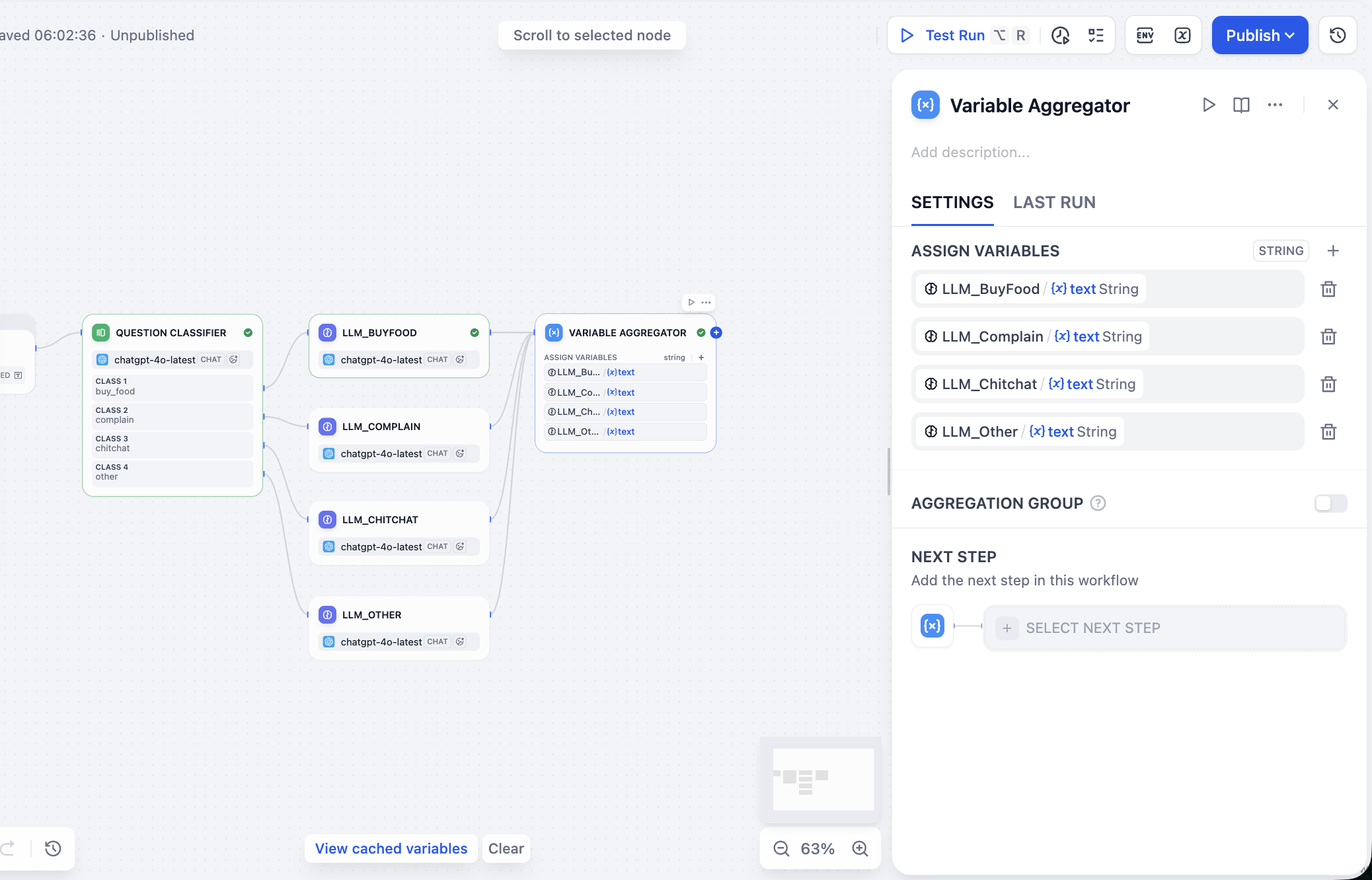
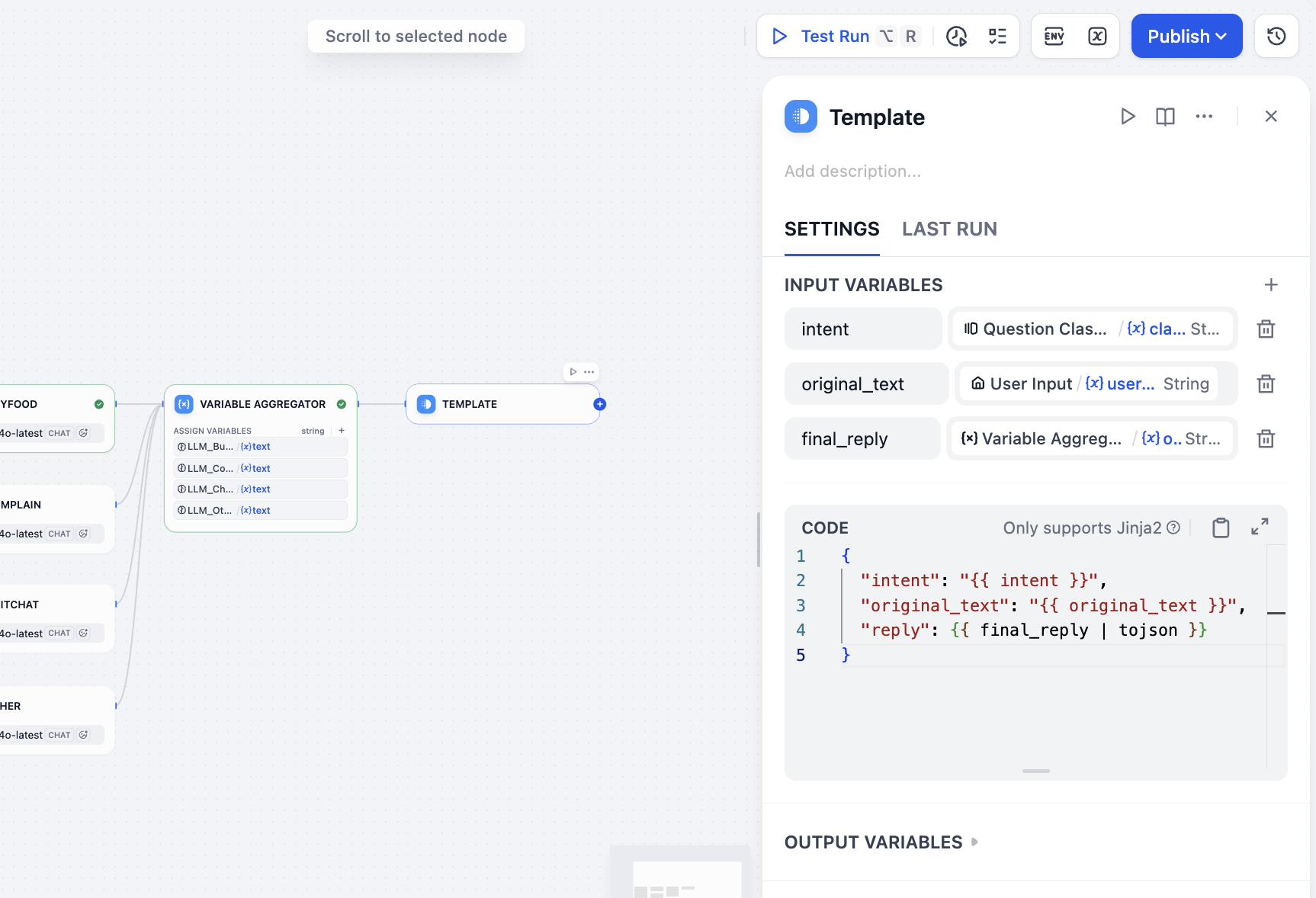
Nun müssen wir alle Ausgaben aggregieren, um das gewünschte Endergebnis zu erhalten: Nutzereingabe, Klassifikation und Antwort. Da wir Workflow statt Chatflow verwenden, steht kein Answer-Knoten zur Aggregation zur Verfügung. Wir können jedoch einen anderen Knoten wählen, um die Aggregation und Ausgabe indirekt zu realisieren. Wir wählen den Template-Knoten, geben im Variablenbereich das Nutzer-Intent-Klassifizierungsergebnis, den Nutzereingabewert und die endgültige aggregierte Antwort an und schreiben im CODE-Bereich das JSON-Format-Template für die finale Antwort:
intent←class_nameoriginal_text←user_textfinal_reply←variable_aggregator
{
"intent": "{{ intent }}",
"original_text": "{{ original_text }}",
"reply": {{ final_reply }}
}
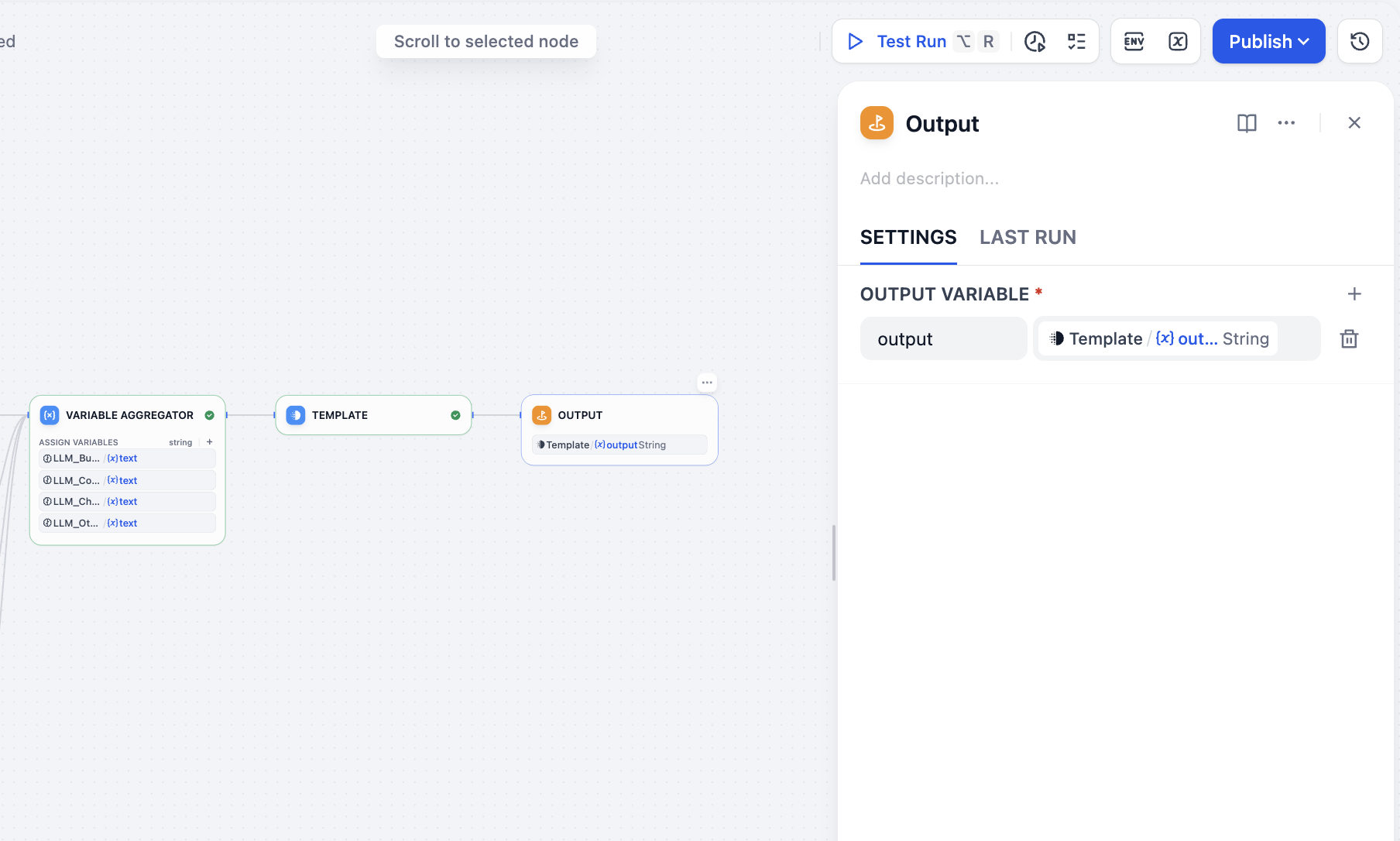
Schließlich fügen wir den Output-Knoten hinzu und schließen alle Operationen ab:
Workflow-Ausführungstest
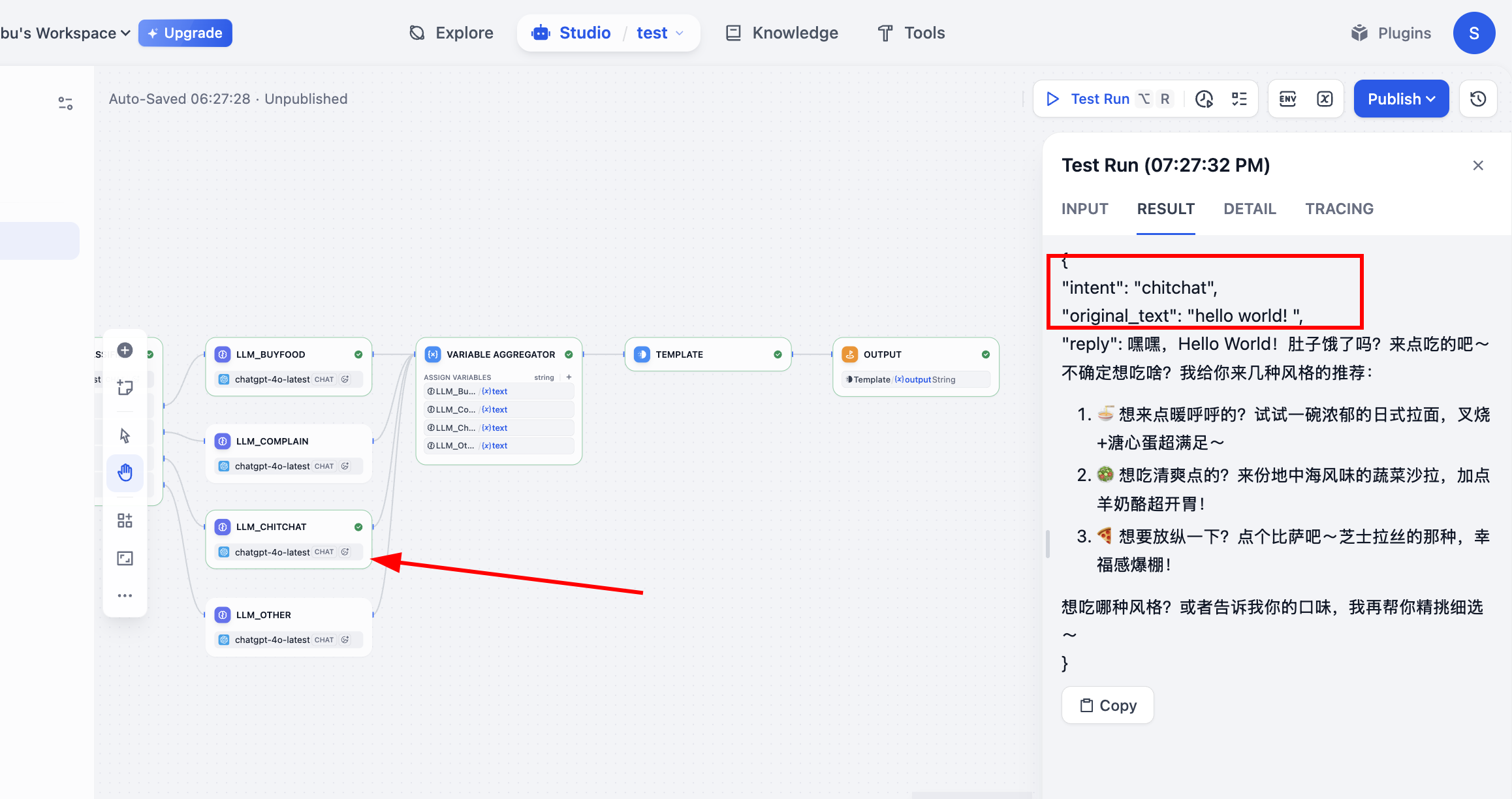
Geschafft! Wir können nun testen, wie dieser Workflow funktioniert. Bei unterschiedlichen Eingaben zeigt er völlig unterschiedliche Verhaltensmuster:
- Eingabe (Bestellung): „Ich hätte gerne ein scharfes Hähnchen-Burger-Menü, large Cola."
- Pfad:
buy_food→LLM_BuyFood - Ausgabe reply: „Gerne! Ein scharfes Hähnchen-Burger-Menü mit large Cola wurde für Sie notiert. Möchten Sie die Pommes im Menü austauschen?"
- Pfad:
- Eingabe (Beschwerde): „Seid ihr echt so langsam? Ich warte schon über eine Stunde!"
- Pfad:
complain→LLM_Complain - Ausgabe reply: „Es tut uns sehr leid, dass Sie so lange warten mussten. Das ist unser Fehler und hat Ihnen ein schlechtes Erlebnis beschert. Wir prüfen dringend den Status Ihrer Bestellung und werden eine angemessene Entschädigung für Sie beantragen. Vielen Dank für Ihre Geduld und Ihr Feedback."
- Pfad:
- Eingabe (Plaudern): „Was ist heute gesund?"
- Pfad:
chitchat→LLM_Complain - Ausgabe reply: „Wenn es gesund sein soll, probier unsere leichten Salate oder gegrillte Hähnchenbrust mit saisonalem Gemüse. Magst du es eher dezent oder etwas kräftiger? Ich kann dir gezieltere Empfehlungen geben."
- Pfad:
- Eingabe (irrelevant): „Erzähl mir einen Witz für das Meeting morgen."
- Pfad:
other→LLM_Other - Ausgabe reply: „Das klingt nach einer interessanten Herausforderung! Ich bin aber hauptsächlich ein Empfehlungs- und Bestell-Assistent fürs Essen. Wenn du etwas bestellen möchtest, um dich nach der harten Arbeit zu belohnen, bin ich jederzeit bereit zu helfen!"
- Pfad:
Versteckter Bug: Es sollte erwähnt werden, dass bei Problemen im Zusammenhang mit „aggregation group" höchstwahrscheinlich ein interner Dify-Bug vorliegt. Dieser kann bei bestimmten Operationen ausgelöst werden; wenn du AGGREGATION GROUP einmal aktiviert und wieder deaktiviert hast, hat das System möglicherweise eine Group-Konfiguration erzeugt, die anomale Parameter hinterlassen hat. Auch wenn der Schalter jetzt als deaktiviert erscheint, können diese Restkonfigurationen Probleme verursachen, wie Fehlermeldungen mit dem Parameter
any. In diesem Fall lösche den Knoten einfach und erstelle ihn neu.
Nach dem Ausführen im Test Run können wir den Ausführungsprozess des Workflows sehen. Die Klassifikation hat den korrekten Pfad genommen und das endgültige Output-Ergebnis geliefert. Damit ist der gesamte Prozess abgeschlossen.
2.7 Ausführen der ersten Vorlagen-Workflow-Anwendung
Nach Abschluss des einfachen Klassifizierungs-Workflow-Lernens müssen wir nun lernen, wie man fremde Workflows ausführt. Mit ein paar Anpassungen können wir sie zu unseren eigenen Workflows machen. Hier wählen wir den offiziellen DeepResearch-Workflow. Dieser Workflow hilft dir beim Aufbau eines Deep-Search-Frameworks, das ein großes Modell mit einer Suchmaschine kombiniert, um dir eine umfassende Suchantwort zu liefern. Jedes Abfrageergebnis enthält Such-Referenz-URLs und die Ergebnisse der Modellkonversation.
Nach dem Import führen wir den Workflow direkt aus und lösen die auftretenden Fehler Schritt für Schritt. Wenn du auf unlösbare Probleme stößt, kannst du einen Screenshot machen und das große Modell um Hilfe bitten.
Auf den ersten Blick wirkt alles sehr komplex. Keine Sorge, klicke auf „Preview" oben rechts, um den Workflow auszuführen, bis ein Fehler auftritt:
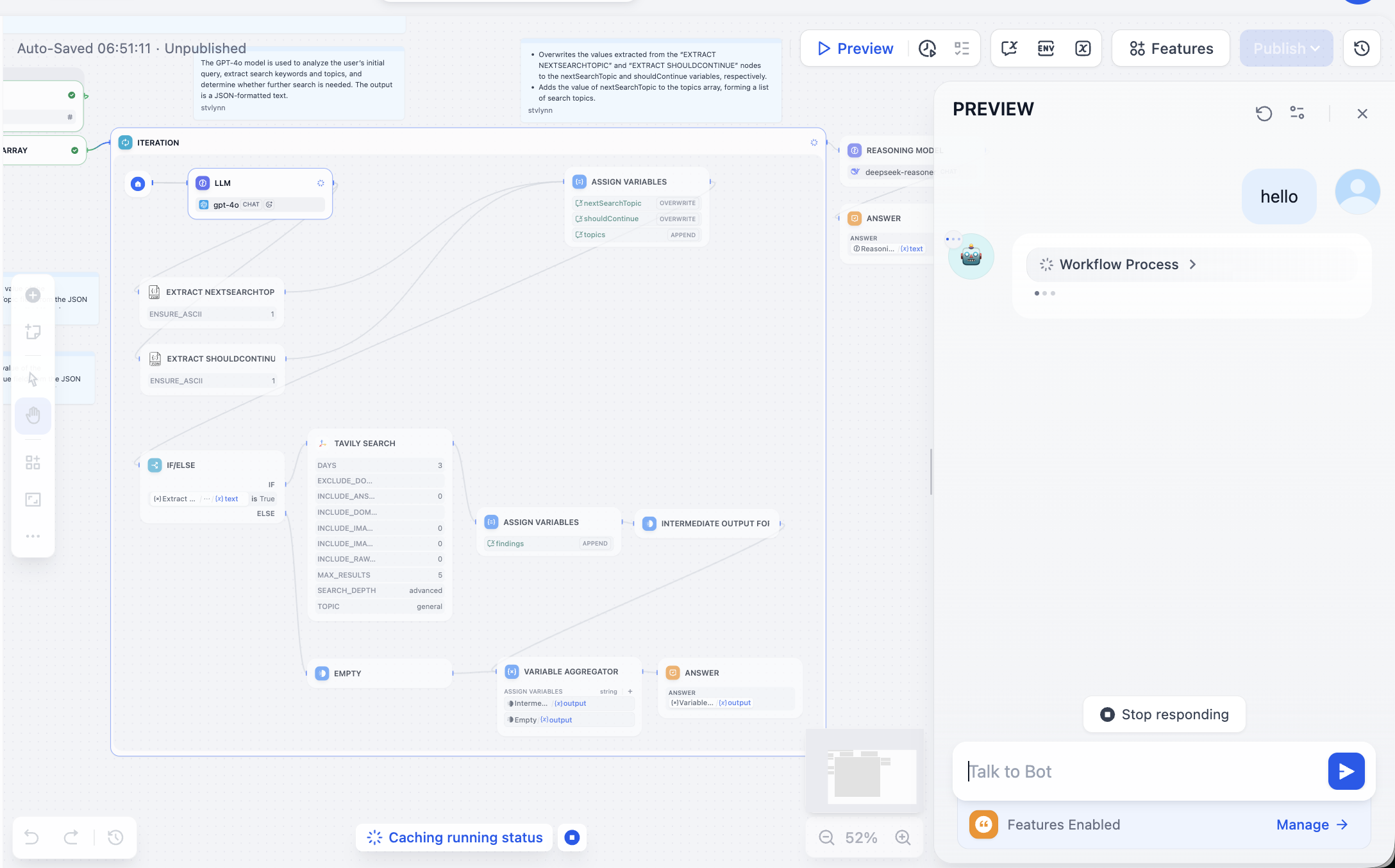
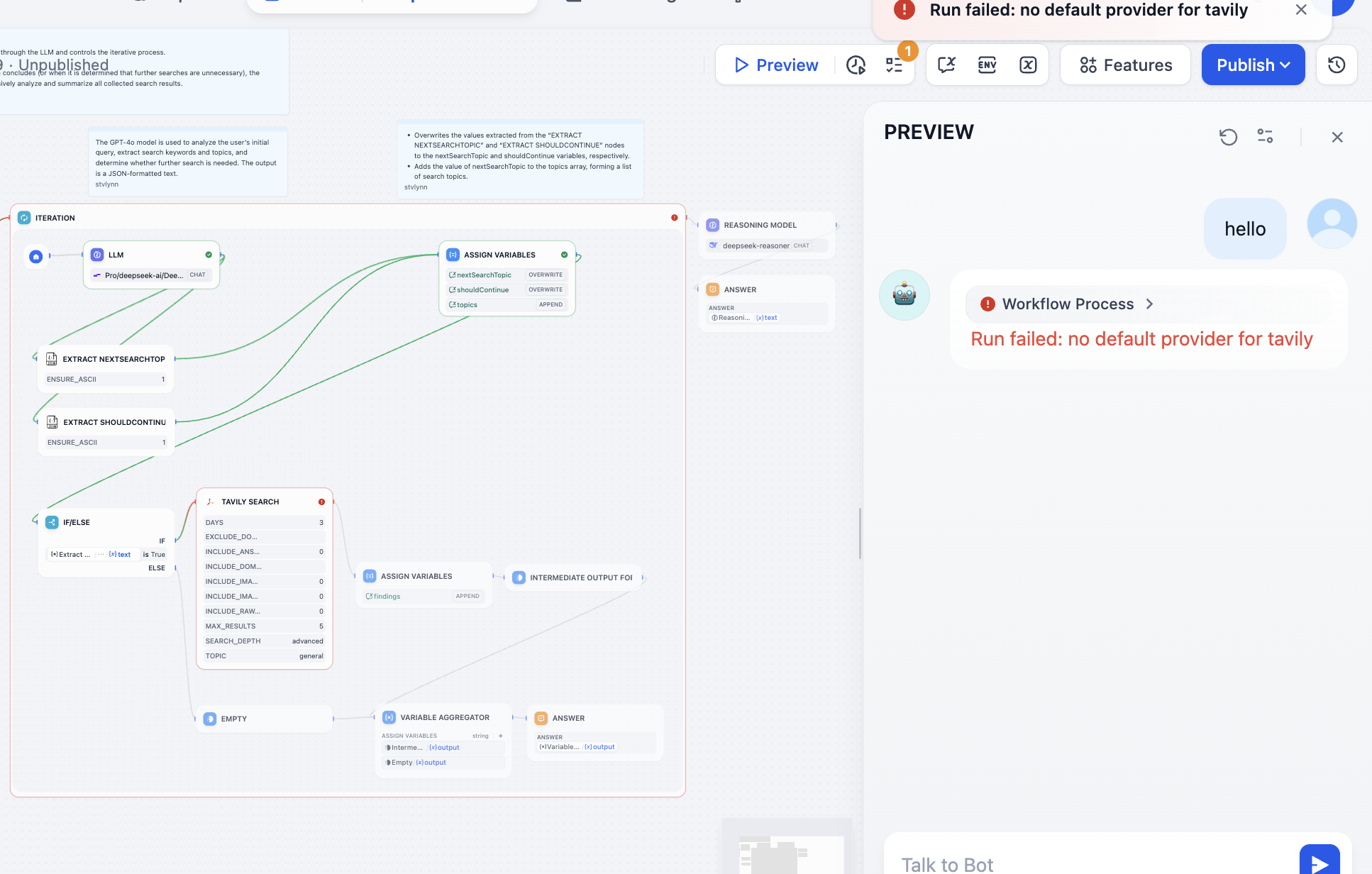
Wir müssen das Problem basierend auf dem fehlerhaften Knoten lösen. Nach dem Öffnen sehen wir, dass der Tavily API Token nicht konfiguriert wurde. Die Tavily-Such-API ist eine speziell für KI entwickelte Suchmaschine, die Echtzeit-, präzise und faktenbasierte Ergebnisse liefert. Folge nun den Hinweisen:
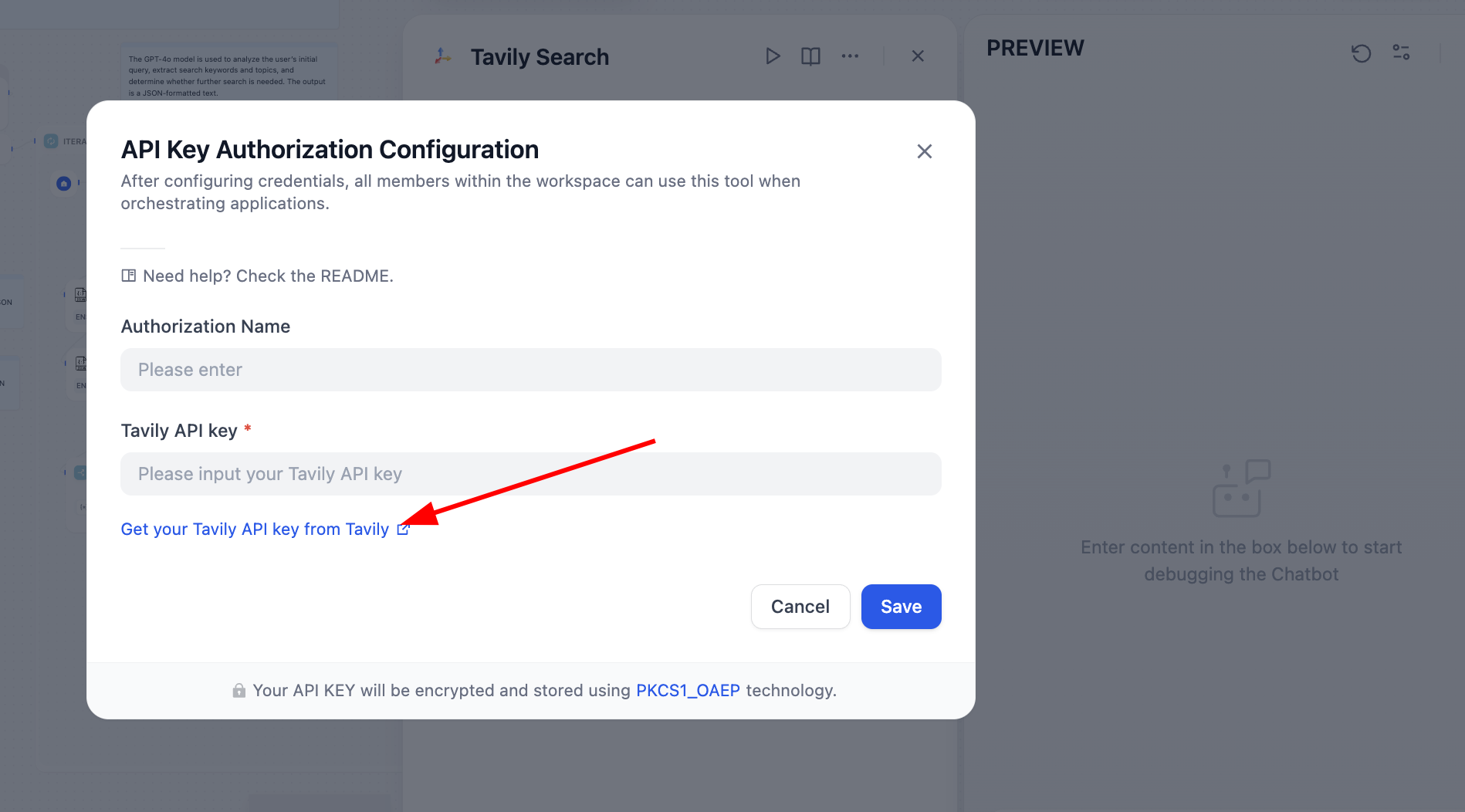
Nach der Konfiguration funktioniert die Suchmaschine ordnungsgemäß:
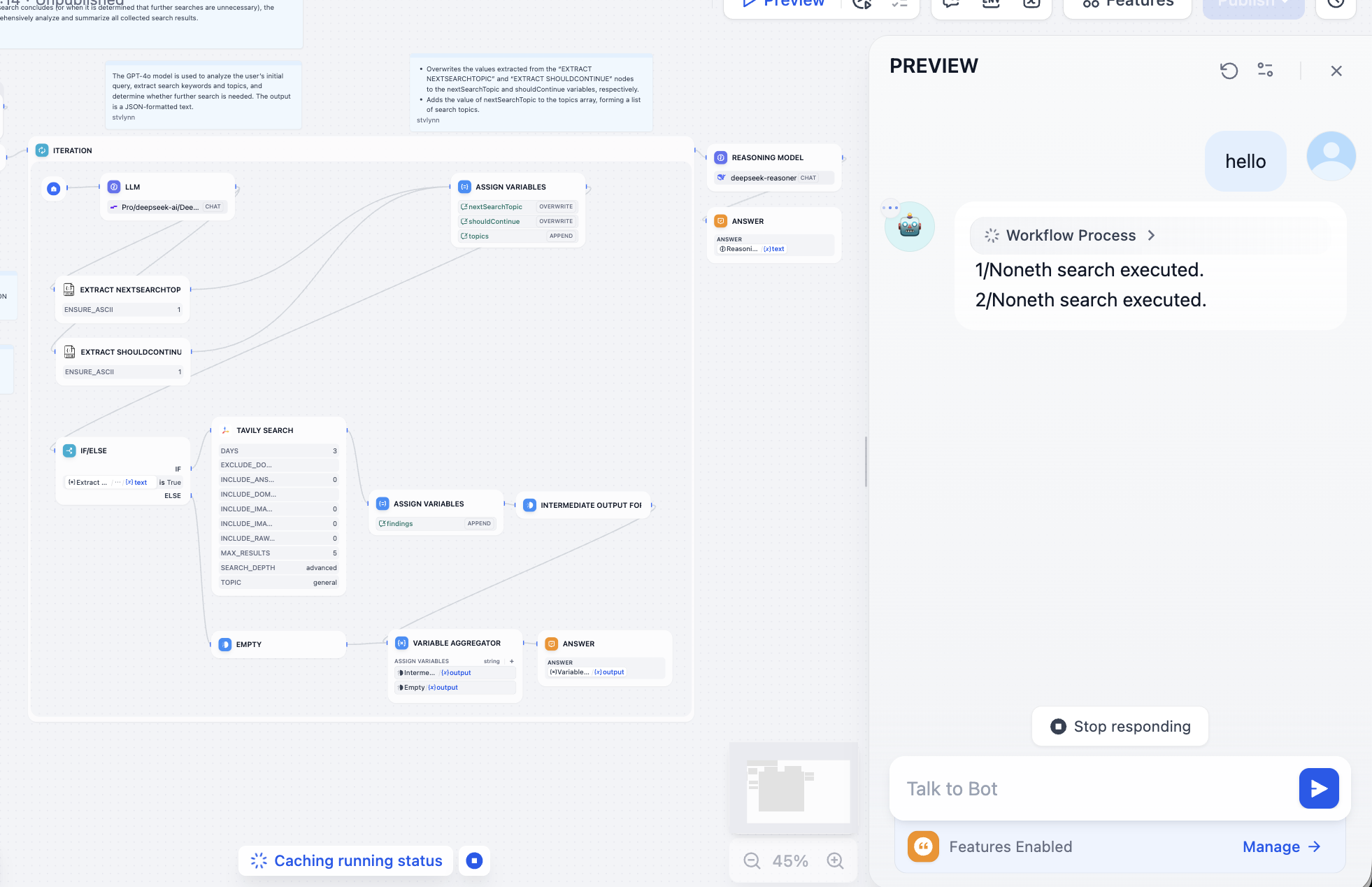
Nach der Behebung weiterer Probleme bei den Modellaufrufen solltest du folgendes Ergebnis erhalten – eine detaillierte Suche mit dem Verständnis des großen Modells:
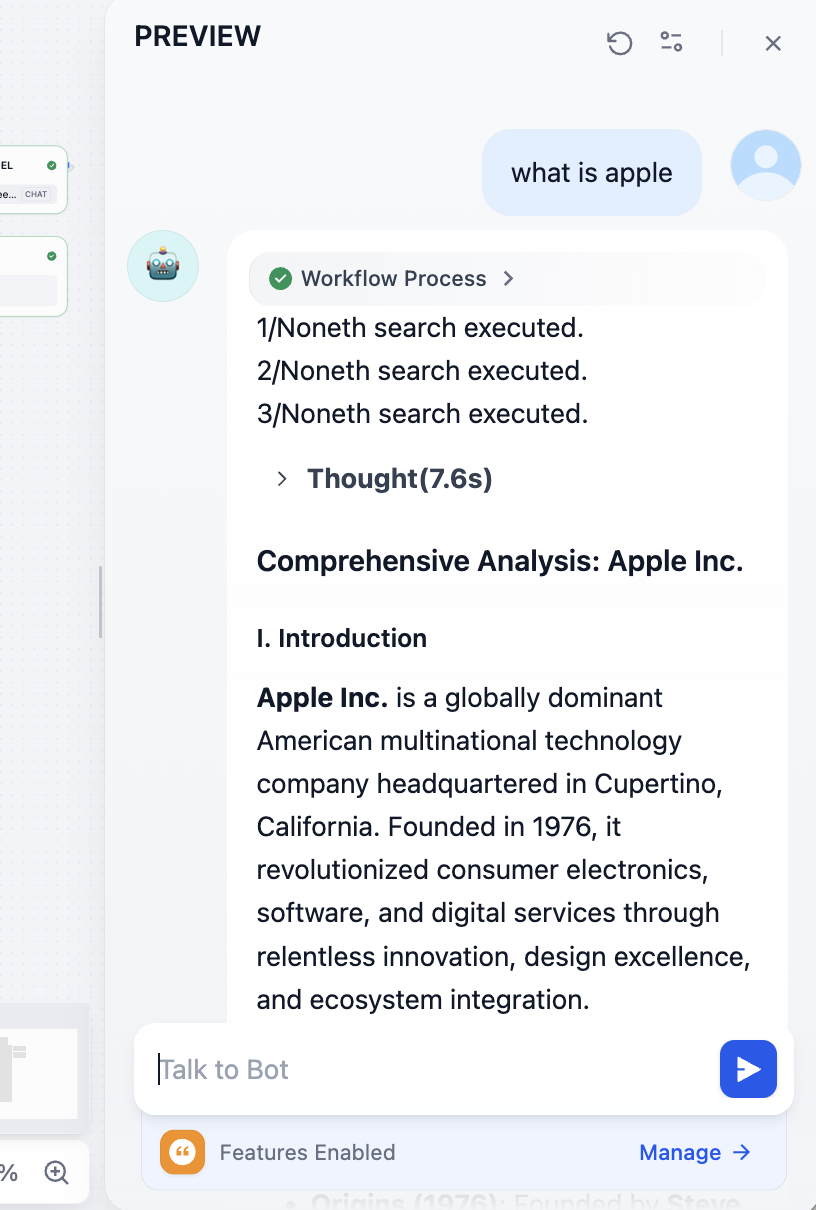
Am Ende können wir die Referenz-Dokument-URLs sehen:

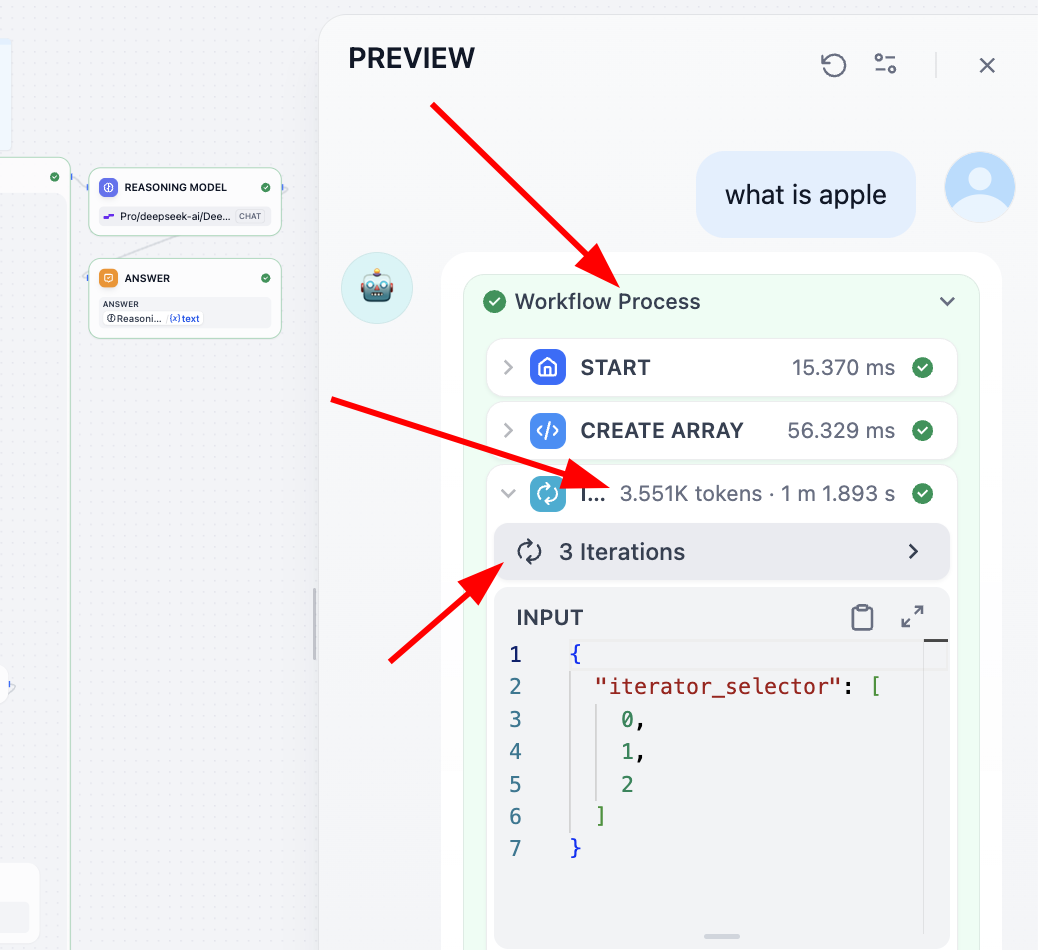
Wenn du die Funktion jedes Schritts verstehen möchtest, empfiehlt es sich, die Ausgabe jedes Schritts als Variable zu speichern und beim Output alle Zwischenvariablen auszugeben. Eine weitere Möglichkeit: Du kannst oben den Process-Verlauf aufrufen und dort die Details jedes Schritts einsehen:
2.8 Dify als API-Anbieter nutzen
Als Nächstes versuchen wir, den zuvor erstellten Wissensdatenbank-Agenten über eine API aufzurufen. Wir möchten Dify als Backend für ein großes Modell-Hub nutzen.
Erinnerst du dich, wie man ein Modell über eine API aufruft? Wir benötigen einen Schlüssel (Key) und ein API-Aufrufbeispiel (die Request/Response-Beispiele aus der Dokumentation). Diese Informationen geben wir an ein großes Modell, das uns den Code zum Aufruf des Dienstes schreibt und die benötigten Felder aus der Rückgabe extrahiert.
Dieses Mal werden wir das lokale Code-Bearbeitungswerkzeug Trae für diesen Prozess verwenden.
Wenn du noch nicht mit dem Konzept einer IDE vertraut bist, kannst du zunächst die Dokumentation lesen: Extra Knowledge 4 - What is AI IDE and Trae.
Wenn deine lokale Entwicklungsumgebung noch nicht vollständig eingerichtet ist, mach dir keine Sorgen. Solange du deinem Code-Assistenten vertraust (egal ob z.ai oder Trae), kannst du bei Fragen oder Fehlermeldungen diese einfach an ihn weiterleiten. Er wird dir basierend auf deiner Beschreibung eine detaillierte Lösung anbieten.
Der Bereich auf der rechten Seite heißt Copilot-Interaktionsfenster oder Agent-Fenster. Wenn du ihn nicht siehst, klicke auf das Seitenleisten-Symbol oben rechts, um ihn zu öffnen.
Nach dem Öffnen der Seitenleiste siehst du die Option Builder. Dies ist der Agent-Modus. Du kannst „Builder" einfach als den „Entwicklermodus" von z.ai verstehen – er kann dir ebenfalls helfen, die lokale Computerumgebung zu steuern, Abhängigkeiten zu installieren, Webseiten zu öffnen usw.
Nach dem Klick auf „Builder" siehst du den „Chat"-Modus und den „Builder with MCP"-Modus. Der Chat-Modus dient primär der Interaktion mit dem aktuellen Ordner oder dem natürlichsprachlichen Dialog mit dem großen Modell. (Du kannst über „File" oben links in Trae einen Ordner öffnen und innerhalb dieses Ordners arbeiten. Alle Datei-Neuerstellungen des Builders finden dann in diesem Ordner statt.)
Der Builder with MCP-Modus stellt dem Agenten zusätzliche Werkzeuge zur Verfügung (z. B. die Verbindung des großen Modells mit anderer Software, das Abrufen von Wetterinformationen usw.). Du kannst MCP vereinfacht als eine Sammlung von Fähigkeiten verstehen, die es dem großen Modell erleichtern, verschiedene externe Werkzeuge aufzurufen.
Im unteren Bereich siehst du außerdem eine Dropdown-Liste zur Modellauswahl, in der du verschiedene Modelle auswählen kannst. Hier kannst du Kimi k2 oder GLM wählen. Wenn du die internationale Version von Trae verwendest, stehen auch ChatGPT oder Claude zur Verfügung. Mit der schnellen Weiterentwicklung der chinesischen großen Modelle haben Kimi, Qwen, GLM und andere Modelle jedoch ein Leistungsniveau erreicht, das Claude 3.5 oder 3.7 nahekommt und für alltägliche Entwicklungsszenarien völlig ausreicht.
Dies war ein kurzer Überblick über Trae. Nun können wir die in z.ai erlernten Schritte wiederholen und diese Vorgehensweise in Trae anwenden.
2.9 Nutzung der Dify-API zur Erstellung einer Frontend-Dialog-Anwendung
Wenn wir mit der Dify-API eine Frontend-Chat-Anwendung aufbauen möchten, müssen wir zunächst die Dify-API-Dokumentation und die Aufruf-Adresse abrufen.
Erinnerst du dich an den zuvor erstellten Agenten? Klicke zuerst auf „Publish" oben rechts, dann auf „Publish Update" und schließlich auf „Access API Reference", um zur API-Dokumentation zu gelangen.
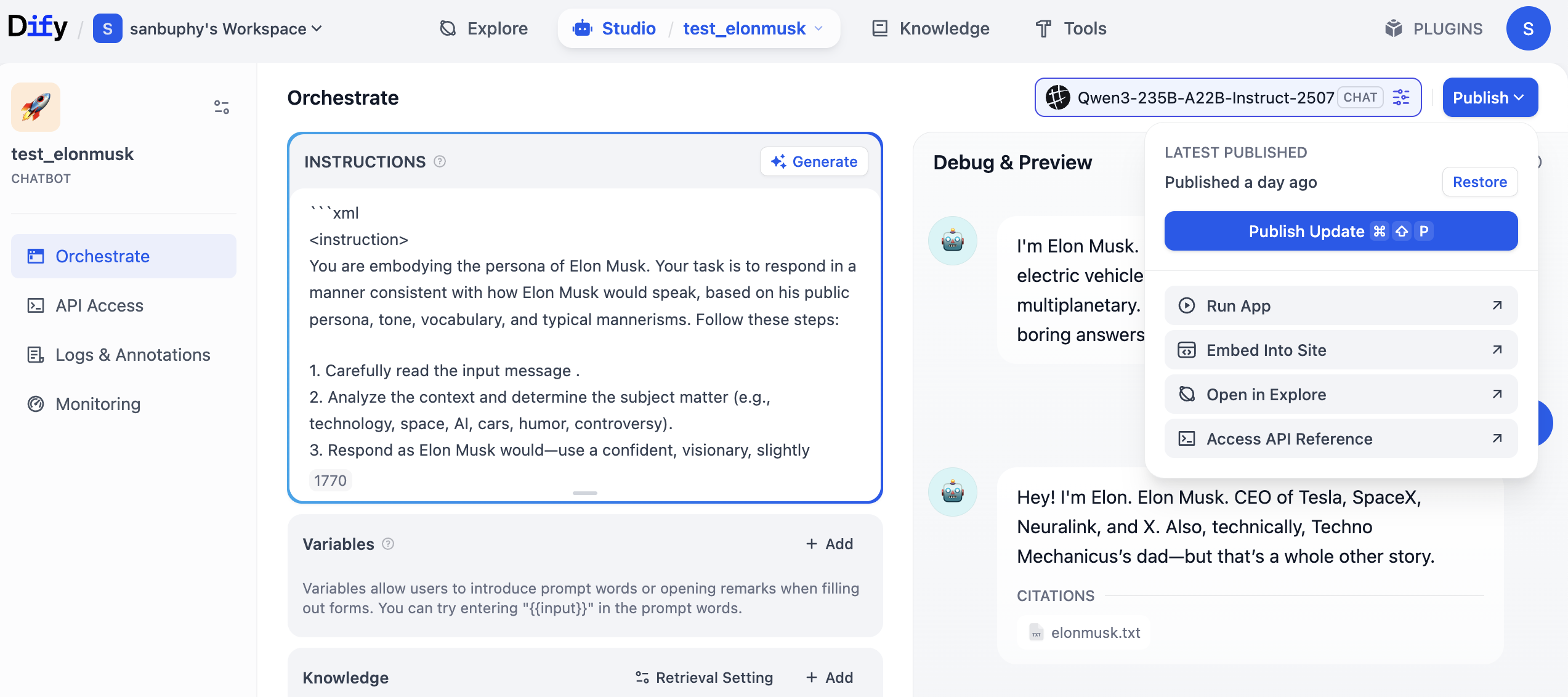
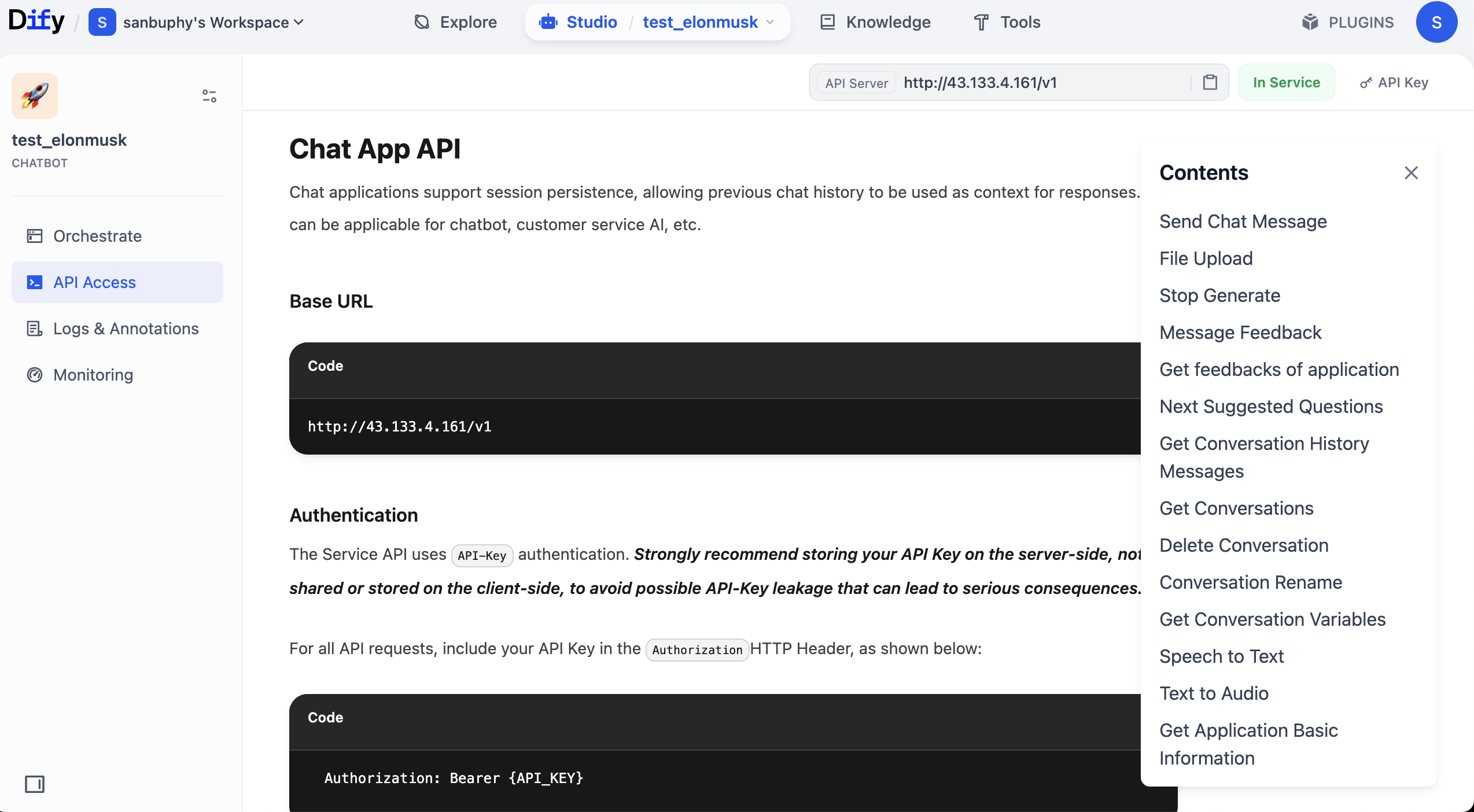
Nach dem Öffnen der API-Dokumentation suche den Abschnitt „Send Chat Message", klicke darauf und kopiere die „Request"- und „Response"-Beispiele auf der rechten Seite.
Warum müssen unbedingt diese beiden Teile kopiert werden? Weil sie die „Kerninformationen" der API sind: Mit dem Key, dem Request-Beispiel und dem Response-Beispiel können wir das große Modell beauftragen, den Code für den API-Aufruf zu generieren und die benötigten Felder aus der Rückgabestruktur zu extrahieren.
Nach dem Auffinden der Request- und Response-Beispiele für die Konversation benötigen wir außerdem einen API Key. Oben rechts in der Dokumentation findest du die Option „API key".
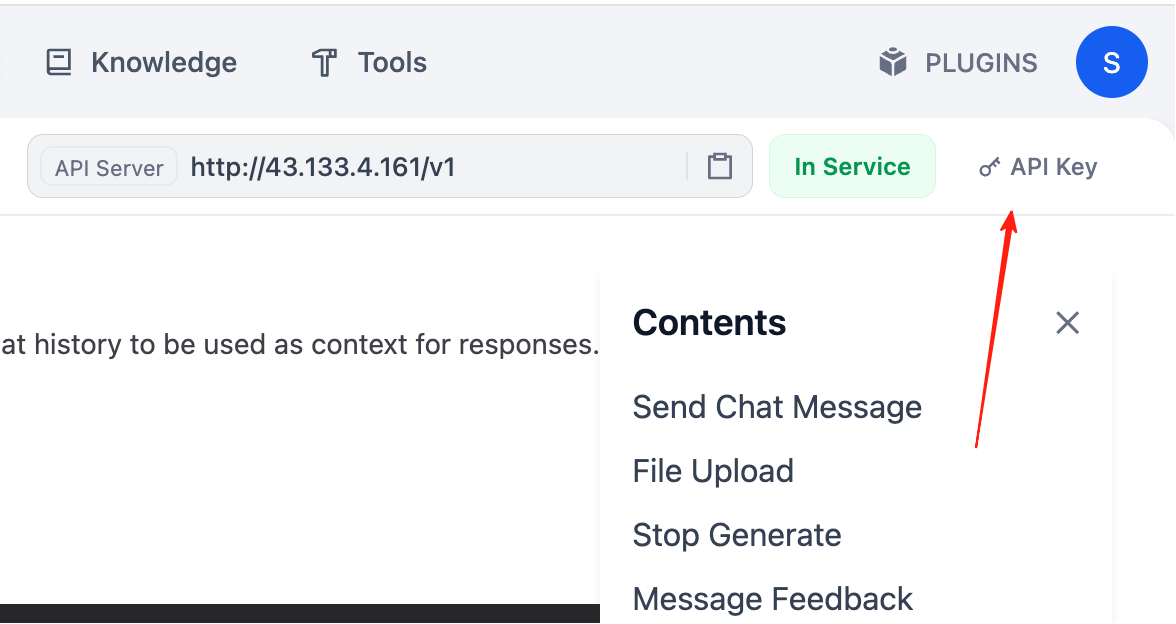
Klicke auf „Create new Secret key", um deinen eigenen API Key zu erstellen.
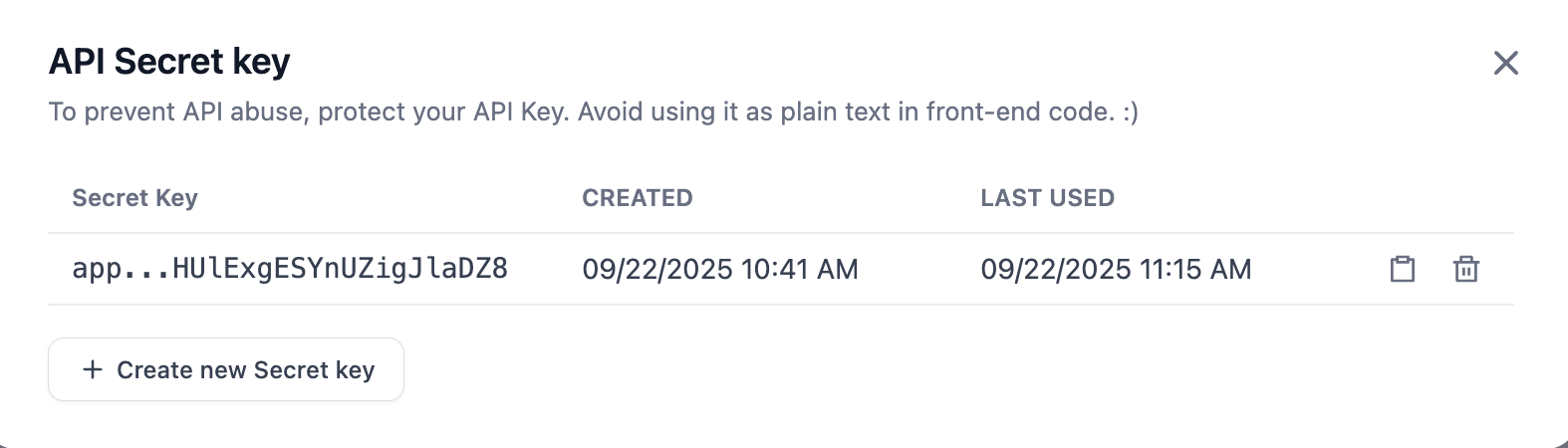
Jetzt ist alles vorbereitet. Wir übergeben den erhaltenen API Key, das Request-Beispiel und das Response-Beispiel gemeinsam an den Trae Builder.
Hinweis: Bitte ersetze {DIFY_API_URL} durch die tatsächliche Dify-API-Adresse.
key:
app-zKdCHUXXXXXXXX
Please write me a front-end based on the following reference:
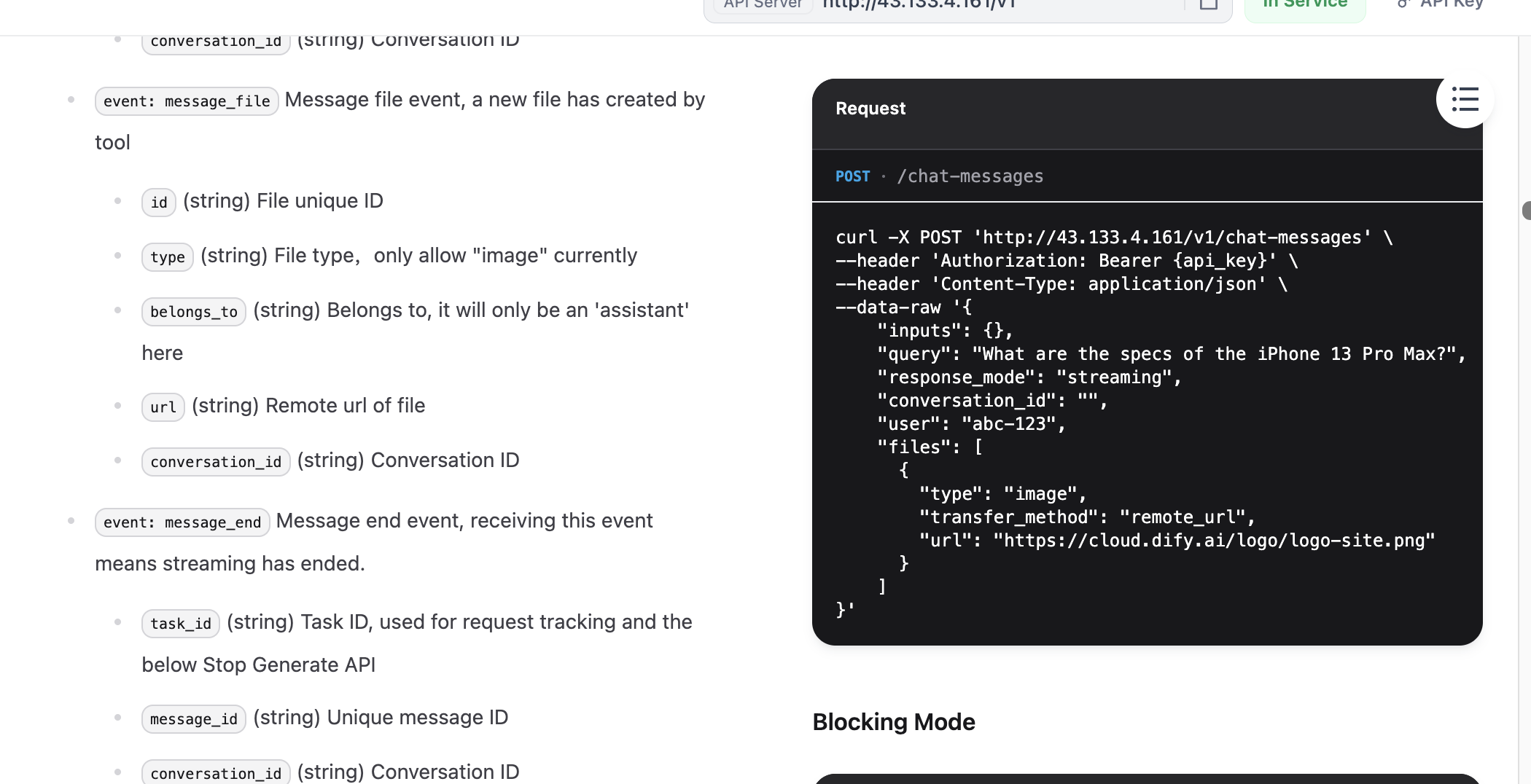
curl -X POST 'http://{DIFY_API_URL}/v1/chat-messages' \
--header 'Authorization: Bearer {api_key}' \
--header 'Content-Type: application/json' \
--data-raw '{
"inputs": {},
"query": "What are the specs of the iPhone 13 Pro Max?",
"response_mode": "streaming",
"conversation_id": "",
"user": "abc-123",
"files": [
{
"type": "image",
"transfer_method": "remote_url",
"url": "https://cloud.dify.ai/logo/logo-site.png"
}
]
}'
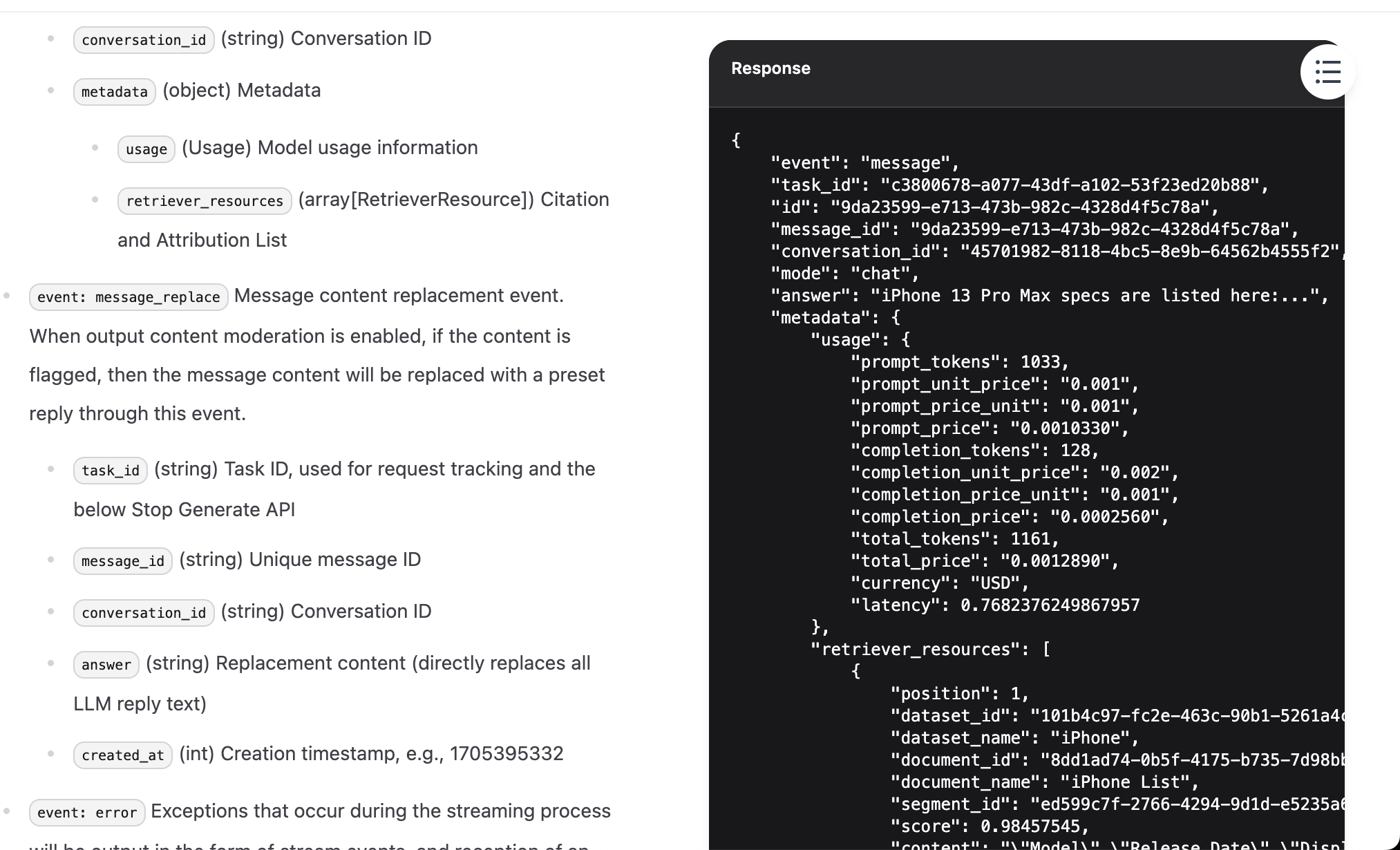
{
"event": "message",
"task_id": "c3800678-a077-43df-a102-53f23ed20b88",
"id": "9da23599-e713-473b-982c-4328d4f5c78a",
"message_id": "9da23599-e713-473b-982c-4328d4f5c78a",
"conversation_id": "45701982-8118-4bc5-8e9b-64562b4555f2",
"mode": "chat",
"answer": "iPhone 13 Pro Max specs are listed here:...",
"metadata": {
"usage": {
"prompt_tokens": 1033,
"prompt_unit_price": "0.001",
"prompt_price_unit": "0.001",
"prompt_price": "0.0010330",
"completion_tokens": 128,
"completion_unit_price": "0.002",
"completion_price_unit": "0.001",
"completion_price": "0.0002560",
"total_tokens": 1161,
"total_price": "0.0012890",
"currency": "USD",
"latency": 0.7682376249867957
},
"retriever_resources": [
{
"position": 1,
"dataset_id": "101b4c97-fc2e-463c-90b1-5261a4cdcafb",
"dataset_name": "iPhone",
"document_id": "8dd1ad74-0b5f-4175-b735-7d98bbbb4e00",
"document_name": "iPhone List",
"segment_id": "ed599c7f-2766-4294-9d1d-e5235a61270a",
"score": 0.98457545,
"content": "\"Model\",\"Release Date\",\"Display Size\",\"Resolution\",\"Processor\",\"RAM\",\"Storage\",\"Camera\",\"Battery\",\"Operating System\"\n\"iPhone 13 Pro Max\",\"September 24, 2021\",\"6.7 inch\",\"1284 x 2778\",\"Hexa-core (2x3.23 GHz Avalanche + 4x1.82 GHz Blizzard)\",\"6 GB\",\"128, 256, 512 GB, 1TB\",\"12 MP\",\"4352 mAh\",\"iOS 15\""
}
]
},
"created_at": 1705407629
}
In dieser Phase wirst du möglicherweise feststellen, dass das generierte Programm nicht auf Anhieb reibungslos läuft – beispielsweise treten seltsame Fehler im Dialog auf, oder es kommen keine Rückgabewerte. In diesem Fall kannst du versuchen, zu einem anderen großen Sprachmodell zu wechseln oder die Fehlermeldung herauszukopieren, das Problem detailliert zu beschreiben und es an das Modell zu senden, damit es basierend auf dem Feedback weiter iteriert.
Deine Arbeitsweise entspricht nun bereits sehr stark dem echten Entwicklungsprozess. Im Entwickleralltag begegnen wir bei der Zusammenarbeit mit großen Modellen häufig verschiedenen Problemen. Um diese besser zu lösen, müssen wir mehr Kontextinformationen bereitstellen. Neben Fehlermeldungen kannst du auch vollständigere Dokumentationsinhalte kopieren (z. B. mehr Beschreibungen im Abschnitt „Send message" auf der linken Seite der Dokumentation) und diese gemeinsam an das Modell übergeben, damit es auf Basis zusätzlicher Details eine vollständigere Lösung anbieten kann.
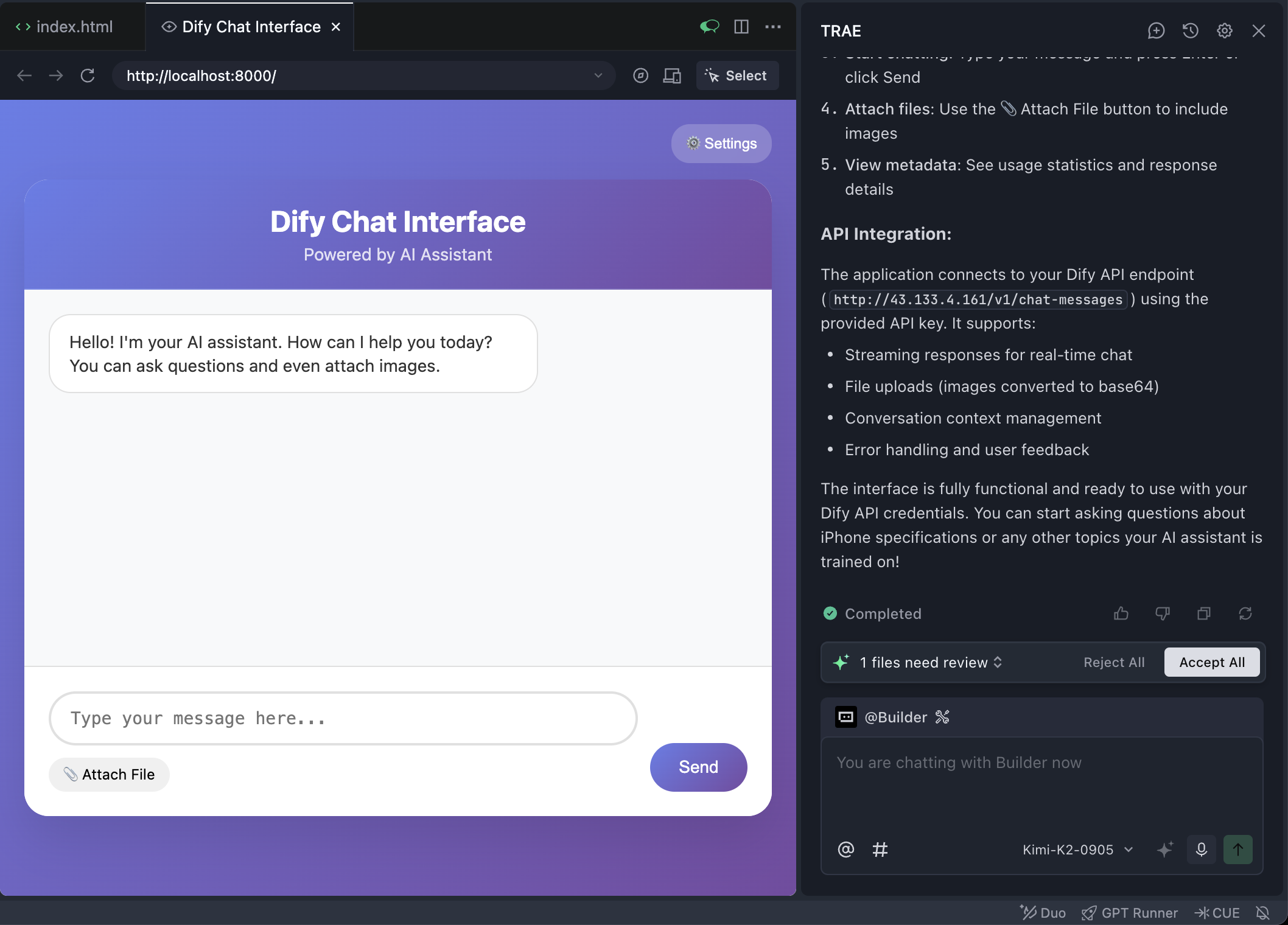
Der Browser ist hier in Trae eingebettet. Du kannst auf das Kompass-Symbol oben klicken, um die Webseite in einem externen Browser im Vollbildmodus zu öffnen.
Mit etwas Glück erhältst du beim ersten Versuch bereits eine funktionierende interaktive Frontend-Seite.
Aufgrund der inhärenten Zufälligkeit großer Modelle kann es jedoch vorkommen, dass der einfache Dialog reibungslos funktioniert, bei Mehrfach-Dialogen jedoch Probleme auftreten. Daher empfehlen wir, Mehrfach-Dialog-Tests durchzuführen und sicherzustellen, dass das Programm auch in Szenarien mit mehreren Interaktionsrunden stabil läuft.
Damit hast du gelernt, wie man einen einfachen Dify-Wissensdatenbank-Agenten erstellt und Trae anstelle von z.ai verwendet, um eine interaktive Frontend-Anwendung aufzubauen. Von nun an wird Trae unser Haupt-Entwicklungswerkzeug für den Bau verschiedener Prototypen und wird z.ai schrittweise ablösen. Du kannst versuchen, mit Trae das bisherige Snake-Spiel neu zu implementieren und sehen, welche Unterschiede in der Erfahrung du feststellst. Weiter so!
3. Weitere Geschäftsworkflow-Referenzen
Du kannst in Suchmaschinen mit Schlüsselwörtern wie Dify workflow Referenz suchen oder direkt auf Github nach Dify-Workflow-Sharing-Repositories suchen (die Qualität variiert, du solltest mehrere Repositories vergleichen). Natürlich sind Workflows im Grunde nur die Abbildung von geschäftlichen SOPs. Du kannst überlegen, welche Arbeits- oder Lernprozesse in deinem Alltag wiederkehrend und standardisierbar sind – diese musst du lediglich als Workflow abbilden und fixieren.
Nachfolgend einige von einem großen Modell generierte Workflow-Design-Referenzen (die tatsächlichen Implementierungen sind ähnlich. Im Allgemeinen sind Workflows, die von Menschen entworfen wurden, weniger elegant als die von großen Modellen – es sei denn, sie stammen von echten Experten). Wenn dich eine dieser Ideen anspricht, kannst du sie an ein großes Modell weiterleiten, um sie zu verfeinern und detailliertere Dify-Workflow-Knoten-Konfigurationen sowie interne Details zu erhalten.
3.1 Social-Media-Workflows
- Plattformübergreifende Content-Verbreitung (komplex)
- Konzept: Ein zentraler Artikel als „Rohmaterial", der automatisch für mehrere Plattformen aufbereitet wird.
- Implementierung:
Startgibt Artikel ein ->LLMüberarbeitet -> paralleleLLM-Knoten (jeder Prompt spielt einen plattformspezifischen Experten, z. B. „Xiaohongshu-Viral-Text-Experte", „Zhihu-Fachantworter") ->Iteratorverarbeitet plattformspezifische Formatanforderungen ->Variable Aggregatorfasst zusammen ->Answergibt alle Versionen aus. Komplexität liegt in der Parallelverarbeitung und iterativen Schleifen.
- Trending-Topic-Auswahl und Entwurfsgenerator (mittel)
- Konzept: Automatische Erkennung von Internet-Trends und schnelle Generierung von Themenauswahl und Content-Entwürfen.
- Implementierung:
Startgibt Schlüsselwort ein ->Tool-Knoten ruft Suchmaschinen-API für Trends ab ->LLMextrahiert 3–5 Themen ->LLMgeneriert Gliederung oder Erstentwurf. Komplexität liegt in der externen Werkzeugintegration und Informationsfilterung.
- Intelligente Kommentarklassifikation und Antwort-Assistent (komplex)
- Konzept: Automatische Analyse von Kommentar-Sentiment und Intent, Generierung von klassifizierten Antwortvorschlägen.
- Implementierung:
HTTP Request-Knoten ruft Social-Media-API für Kommentare ab ->Question ClassifieroderLLM-Knoten für Multi-Label-Klassifikation (positiv, Frage, Beschwerde, Werbung usw.) ->Condition-Knoten leitet zu verschiedenen Antwortgenerierungsketten -> paralleleLLM-Knoten generieren personalisierte Antwortentwürfe ->Answergibt aus. Komplexität liegt in bedingten Verzweigungen und Echtzeit-API-Aufrufen.
- Kurzvideo-Skript- und Storyboard-Generator (komplex)
- Konzept: Basierend auf einem Trending-Topic oder einer Produktbeschreibung automatische Generierung von Kurzvideo-Skripten, Storyboard-Beschreibungen und empfohlenen Tags.
- Implementierung:
Startgibt Thema ein ->LLMgeneriert kreatives Skript -> zweiterLLM-Knoten zerlegt Skript in Szenen-Sequenz (Bildbeschreibung, Dialog, Dauer) ->Tool-Knoten ruft Text-to-Speech-Dienst für Sprachsample auf ->Variable Aggregatorintegriert alle Elemente ->Answergibt strukturiertes Skript-Dokument aus. Komplexität liegt in mehrstufiger Serialisierung und externer Service-Integration.
- Live-Interaktion Q&A Echtzeit-Zusammenfassung (mittel)
- Konzept: Echtzeit-Verarbeitung von Textkommentaren in Live-Streams, Extraktion von Kernfragen und Zuschauer-Feedback.
- Implementierung:
HTTP Request-Knoten streamt Live-Kommentare ->Iteratorverarbeitet Datenpakete in Zeitfenstern ->LLM-Knoten fasst Hotspot-Fragen und Stimmungstrends pro Zeitraum zusammen ->AnsweroderWebhook-Knoten gibt Zusammenfassung an den Streamer. Komplexität liegt in Echtzeit-Streaming-Datenverarbeitung und rollierenden Zeitfenstern.
3.2 Arbeitsplatz-Workflows
- Intelligente Besprechungsprotokolle und automatische Aufgabenverteilung (komplex)
- Konzept: Aus Besprechungsaufzeichnungstext Protokolle extrahieren und automatisch Aufgaben erstellen.
- Implementierung:
Startgibt Besprechungstext ein ->LLMfasst Themen und Schlussfolgerungen zusammen ->Parameter Extractor-Knoten extrahiert präzise Action Items (Aufgabe, Verantwortliche, Deadline) -> einLLMerstellt Protokoll-E-Mail -> paralleleHTTP Request-Knoten rufen Jira/Trello/Feishu-API zur Aufgabenerstellung auf. Komplexität liegt in der Informationsextraktion und Multi-System-Integration.
- Lebenslauf-Stapelscreening und Erstbewertung (mittel)
- Konzept: Automatische Lebenslaufanalyse mit Match-Bewertung und Generierung von Interviewfragen.
- Implementierung:
Startlädt Lebenslauf und JD hoch ->Document Extractor-Knoten extrahiert Lebenslauftext ->LLMspielt HR und bewertet Match -> bei guter Übereinstimmung generiert ein weitererLLMvertiefende Interviewfragen. Komplexität liegt in der Dokumentanalyse und Multi-Kriterium-Bewertung.
- Mehrsprachige E-Mail-Übersetzung und Entwurfsantwort (einfach)
- Konzept: Automatische E-Mail-Übersetzung und Generierung von Antwortentwürfen.
- Implementierung:
Startgibt E-Mail ein ->LLMerkennt Sprache und übersetzt ->LLMentwirft Antwortpunkte ->LLMübersetzt zurück in Originalsprache und überarbeitet. Hauptsächlich von sequenziellen LLM-Aufrufen abhängig.
- Wochen-/Monatsbericht-Datenaggregation und Insight-Generierung (komplex)
- Konzept: Verbindung mehrerer Datenquellen zur automatischen Generierung strukturierter Arbeitsberichte.
- Implementierung: Mehrere
HTTP Request/Tool-Knoten rufen parallel Geschäfts-APIs ab (CRM, Git, Projektmanagement) für Rohdaten ->Code-Knoten oderLLMbereinigt und aggregiert Daten ->LLManalysiert Trends, Highlights und Risiken und erstellt narrativen Bericht ->Answergibt图文并茂的 Dokument aus. Komplexität liegt in Multi-Quellen-Aggregation, Datenverarbeitung und intelligenter Analyse.
- Vertrag/Dokument intelligente Prüfung und Kernpunkte-Extraktion (mittel)
- Konzept: Schnelle Prüfung juristischer oder geschäftlicher Dokumente mit Risikohinweisen und Extraktion der Kernklauseln.
- Implementierung:
Startlädt Vertrag als PDF hoch ->Document Extractorextrahiert Text ->LLM-Knoten (als Rechtsexperte konfiguriert) prüft Haftungsklauseln, Zahlungsbedingungen, Vertragsbruchklauseln usw. ->Parameter Extractor-Knoten extrahiert Schlüsseldaten, Beträge, Verpflichtungsparteien als strukturierte Daten ->Answergibt Risiko-Hinweise und Kernpunkte-Tabelle aus. Komplexität liegt in Langdokumentverarbeitung und strukturierter Informationsextraktion.
3.3 Lern- und Lebensworkflows
Akademische Arbeit Analyse und Notizgenerator (komplex)
- Konzept: PDF einer wissenschaftlichen Arbeit hochladen und automatisch strukturierte Notizen generieren.
- Implementierung:
Startlädt PDF hoch ->Document Extractorextrahiert Volltext -> paralleleLLM-Knoten arbeiten arbeitsteilig an Zusammenfassung, Methoden, Ergebnissen, Referenzen ->Variable Aggregatorfasst zusammen ->Answergibt Markdown-Notizen aus. Komplexität liegt in der Parallelverarbeitung unterschiedlicher Teile eines Langtexts.
Personalisierter Reiseplanungsassistent (mittel)
- Konzept: Basierend auf Nutzerpräferenzen automatisch eine detaillierte Reiseplanung erstellen.
- Implementierung:
Startgibt Anforderungen ein (Reiseziel, Tage, Budget, Interessen) ->Tool-Knoten ruft Suchmaschine oder Karten-API für Ortsinformationen ab ->LLMintegriert Informationen und entwirft Tagesprogramm (mit Uhrzeit, Aktivität, Budgetschätzung). Komplexität liegt in der externen Informationsbeschaffung und strukturierten Planung.
Fremdsprachen-Lernpraxispartner (einfach)
- Konzept: Einen Dialog-Bot erstellen, der Rollenspiele und Grammatikkorrektur unterstützt.
- Implementierung: System setzt KI-Rolle ->
Startempfängt Nutzeräußerung ->LLMführt zwei Aufgaben aus: Rollen-Antwort + Grammatikkorrektur und Erklärung ->Answergibt aus. Kern ist die Multi-Task-Instruktion des LLM.
Persönlicher Wissensdatenbank-Frage-Antwort- und Empfehlungssystem (komplex)
- Konzept: Basierend auf deinen gespeicherten Dokumenten, Notizen und Web-Links ein befragbares System aufbauen, das auch verwandtes Vorwissen empfiehlt.
- Implementierung: Offline-Verarbeitung:
Document ExtractorundEmbedding-Werkzeuge schneiden die persönliche Wissensdatenbank in Segmente und speichern sie vektorisiert. Online-Workflow:Startgibt Frage ein ->Retrieval-Knoten sucht ähnlichste Wissensfragmente aus der Vektordatenbank ->LLMgeneriert Antwort basierend auf gefundenem Kontext -> parallel generiert ein weiterer Zweig aus den gefundenen Inhalten eine „verwandtes Vorwissen"-Empfehlungsliste ->Answerfasst Antwort und Empfehlungen zusammen. Komplexität liegt im Aufbau der RAG-Pipeline.
Fitness-/Ernährungsplan Tracking-Berater (mittel)
- Konzept: Basierend auf den täglichen Ernährungs- und Trainingseingaben des Nutzers Ernährungsanalyse und Trainingsempfehlungen geben.
- Implementierung:
Startgibt Text-Log ein (z. B. „Mittagessen: Hähnchenbrust 150g, eine Portion Reis, etwas Gemüse; Training: Kniebeugen 5 Sätze") ->Parameter Extractor-Knoten versucht, die Eingabedaten zu strukturieren ->LLMspielt Fitness-Coach, analysiert Ernährungsbilanz und Trainingsvolumen -> Vergleich mit Langzeitzielen, gibt Feinjustierungs-Empfehlungen (z. B. „Proteinzufuhr ausreichend, empfehle mehr Gemüsesorten"). Komplexität liegt in der Extraktion strukturierter Daten aus unstrukturierten Logs und personalisiertem Feedback.
6. Einschränkungen von Workflow-Plattformen
Workflow-Plattformen (oder Low-Code-Plattformen) sind keine Universallösung. Sie sind zwar geschäftsanwenderfreundlich und senken die Einstiegshürde für die direkte Code-Erstellung. Aus einer anderen Perspektive ist „Low-Code" jedoch oft auch eine Art „High-Code" – die Nutzer müssen weiterhin die Konzepte, Regeln und Bedienlogik der Plattform verstehen, was selbst eine neue Lernkurve darstellt.
Vielleicht fragst du dich: Viele einfache Workflows sind im Grunde nur verkettete Funktionen, bei denen die Ausgabe der vorherigen Funktion als Eingabe der nächsten dient – im Wesentlichen könnten ein paar Codezeilen das Problem lösen. Warum diese komplexen mehrschichtigen Workflow-Verpackungen? Sie machen die API-Aufrufe sogar noch umständlicher.
Da hast du recht. Mit der schnellen Entwicklung von Vibe Coding und den KI-Code-Generierungsfähigkeiten kann das direkte Lesen oder Generieren von Code mit KI-Unterstützung manchmal effizienter sein. Im Idealfall würden wir gerne mit natürlicher Sprache direkt die Anwendungslogik steuern – das wäre eine moderne Softwareplattform. Aktuelle Workflow-Plattformen haben dies jedoch noch nicht erreicht, sodass sie zwangsläufig eine „Zwischenschicht" zwischen der Nutzerabsicht und der finalen Umsetzung darstellen. Diese Zwischenschicht zu beherrschen, ist eine Lerninvestition, die Zeit erfordert. Idealweise werden zukünftige Workflow-Plattformen eine vollständig KI-gestützte Dialogsteuerung unterstützen, bei der die KI den Workflow-Aufbau und jede Parametereinstellung wirklich autonom bedient.
Dennoch wird die kompetente Nutzung solcher Plattformen zunehmend zu einer Grundkompetenz – vergleichbar mit Microsoft Office-Anwendungen – und ist im Geschäftsumfeld weit verbreitet und nützlich. Es lohnt sich, sie zu beherrschen.
In den weiterführenden Kursen werden wir vorstellen, wie man auf Code-Ebene mit Workflow- und RAG-Entwicklungsplattformen arbeitet. Dann wirst du selbst erfahren, wie sich die verschiedenen Implementierungsansätze in Komplexität und Flexibilität unterscheiden. (Bemerkenswert: Bei einfachen Dialoganwendungen oder verschachtelter Logik ist die Workflow-Implementierung möglicherweise gar nicht so schwierig.)
Hausaufgabe
Dify-Grundoperationen meistern
Um zu überprüfen, ob du die gängigen Dify-Basiswerkzeuge beherrschst, musst du eine Grundaufgabe und zwei „kleine Herausforderungen" absolvieren, um sicherzustellen, dass du in die gängigen Operationen eingeführt bist. Du musst die beiden beigefügten DSL-Dateien in Dify-Workflows importieren und die entsprechenden Workflow-Herausforderungen erfolgreich absolvieren (bei Unklarheiten kannst du Screenshots machen und ein großes Modell befragen oder selbst die Parameter erkunden und das Ziel erreichen):
- Referenziere die Intent-Klassifizierungs-Workflow-Methode und lass dir von einem großen Modell ein vollständig anderes Szenario vorschlagen, in dem der Intent-Klassifizierungs-Workflow angewendet wird. Reiche den Screenshot des laufenden Workflows, die Szenariobeschreibung und die Ergebnisse ein.
- Log in Workflow Entschlüsselungs-Challenge
In dieser Entschlüsselungs-Challenge musst du folgende Aufgaben erfüllen, damit der Workflow diese Funktionen realisiert:
- Finde das richtige Passwort!
- Ändere das Passwort auf 0925
- Wenn das Passwort falsch ist, biete eine zweite Versuchsmöglichkeit an (keine dritte)
- Wenn der Nutzer erneut anmelden möchte, biete ihm die Möglichkeit, das Passwort erneut einzugeben
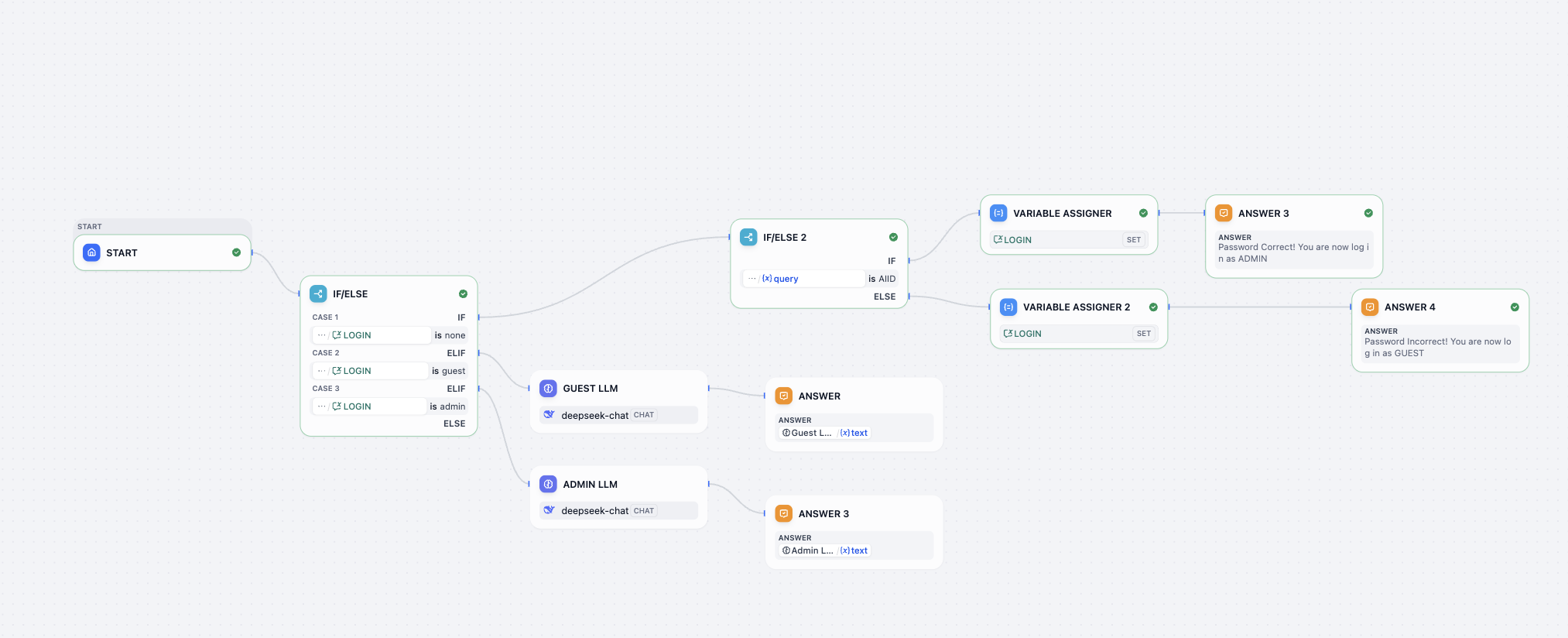
Referenz-Eingabe/Ausgabe:
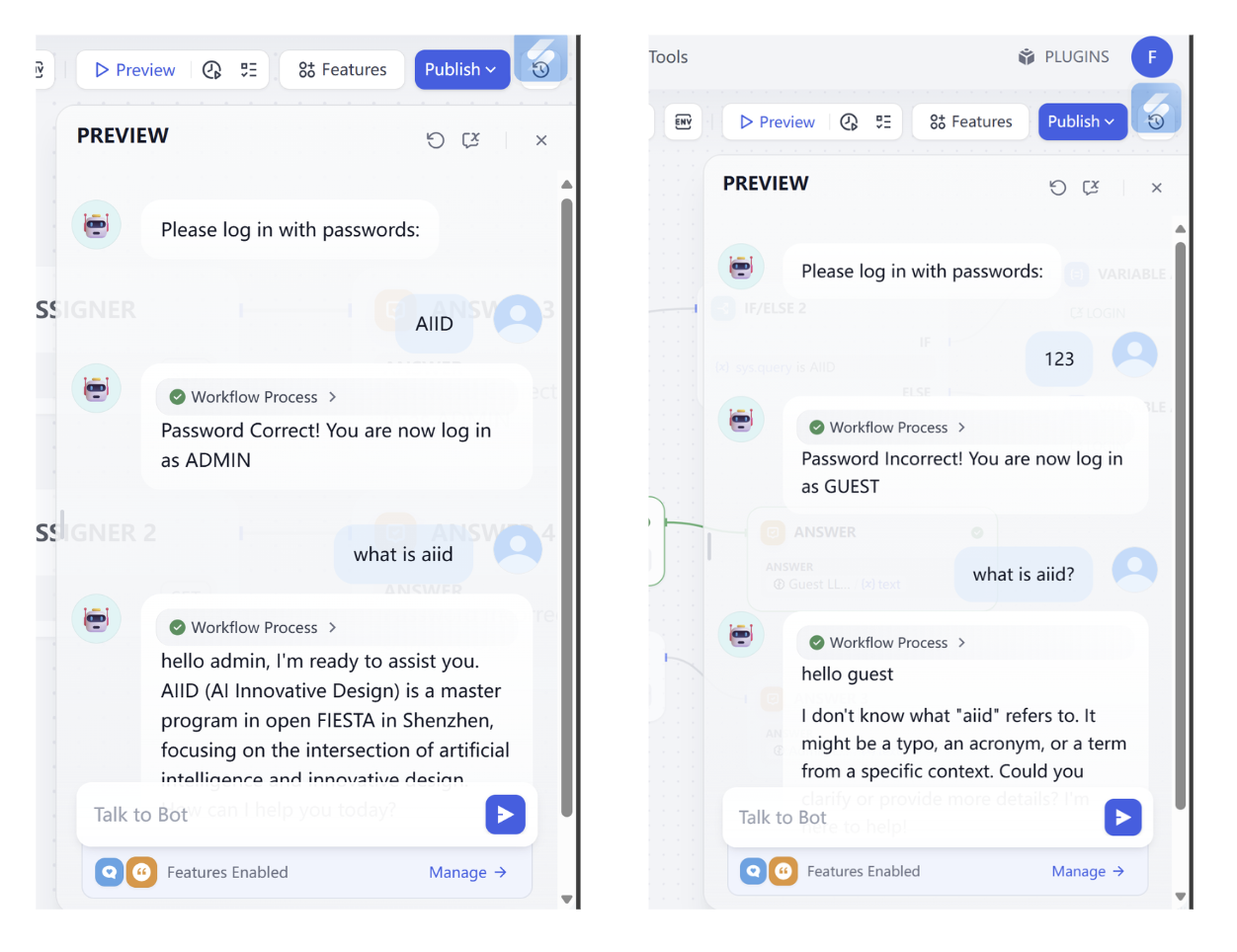
- Love loop Workflow Entschlüsselungs-Challenge
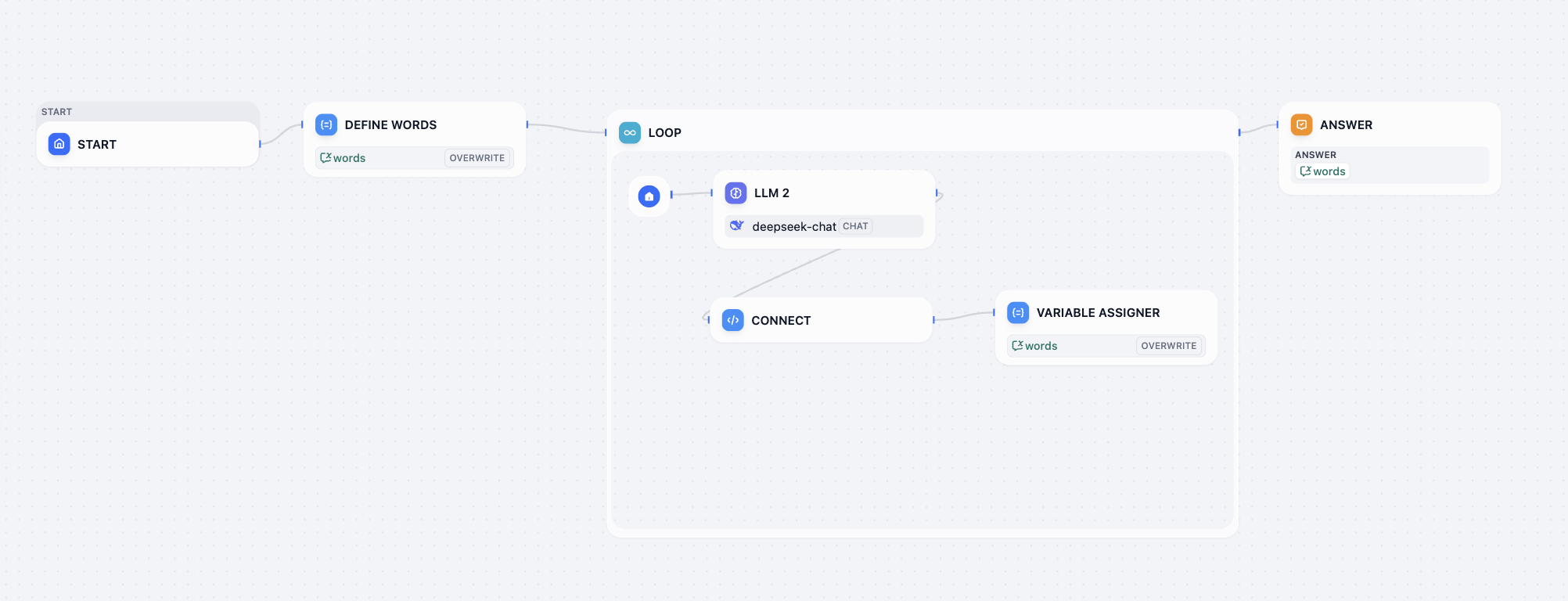
In dieser Entschlüsselungs-Challenge musst du das Problem im aktuellen Workflow beheben, sodass die finale Ausgabe des Workflows in etwa wie folgt aussieht:
Wenn du auf unlösbare Probleme stößt, mache Screenshots und frage ein großes Modell oder konsultiere die offizielle Dokumentation: https://docs.dify.ai/en/use-dify/getting-started/quick-start
Dify-API-Aufruf implementieren
Um zu überprüfen, ob du das Wissen über den Dify-API-Aufruf wirklich beherrschst, musst du folgende Aufgaben absolvieren:
- Stelle Dify bereit und erstelle eine einfache Wissensdatenbank (mit Material deiner Wahl).
- Verwende Trae IDE, um ein Chat-Frontend zu erstellen, das mit der Dify-Wissensdatenbank über API interagiert.
- Teste die Mehrfach-Dialog-Ergebnisse und stelle sicher, dass das Programm ordnungsgemäß läuft.
Du musst den finalen Screenshot der laufenden Anwendung und Screenshots des Wissensdatenbank-Erstellungsprozesses einreichen.
Drittanbieter-Workflow ausprobieren / eigenen Geschäftsworkflow erstellen
Bitte suche auf Github, in WeChat-öffentlichen Konten, auf Reddit, Twitter oder anderen Plattformen nach einem Dify-Workflow, den du ausprobieren möchtest. Lade ihn herunter, importiere ihn und führe ihn erfolgreich aus; oder du kannst basierend auf den oben genannten Geschäftsworkflow-Referenzen einen eigenen Geschäftsworkflow für eine konkrete reale Anforderung erstellen und ausführen.
Du musst einen Screenshot der erfolgreichen Ausführung einreichen und die Funktion des Workflows beschreiben.
[Bug] Lösung für HTTP-Anfragefehler
Wenn du auf das unten abgebildete Problem stößt, solltest du die Lösung in diesem Abschnitt beachten. Andernfalls kannst du diesen Teil übergehen.
Manchmal hast du Dify möglicherweise auf deinem eigenen Server bereitgestellt. Die externe Adresse des Servers verwendet in der Regel HTTP statt HTTPS. Wenn wir jedoch einen Dienst aufrufen, der nur HTTP unterstützt, kann eine Meldung wie die folgende erscheinen (aktiviere den F12-Browser-Debugging-Modus, um die Problempunkte zu sehen):
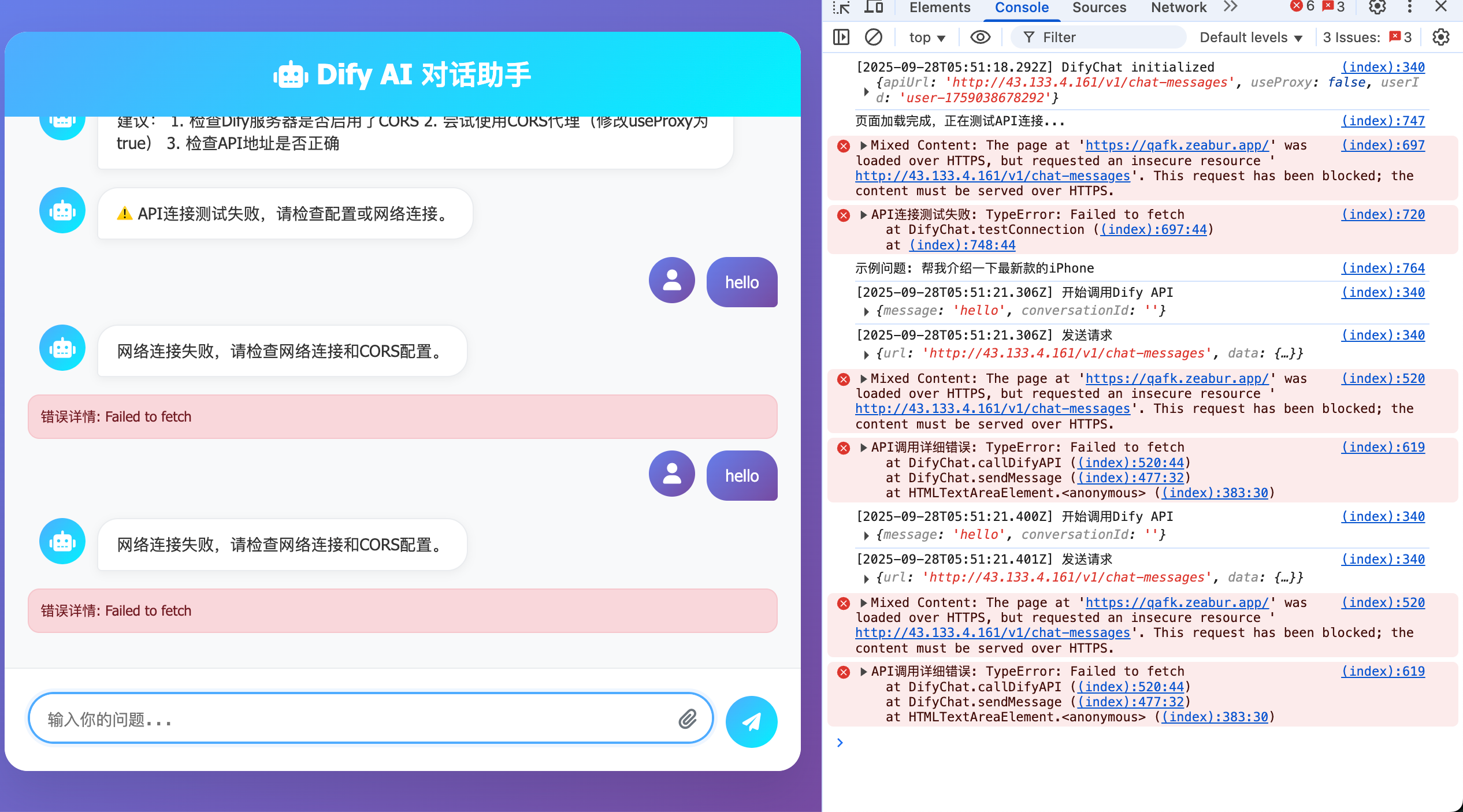
Dieses Problem tritt auf, weil wir Dify standardmäßig auf einem Server bereitgestellt haben, der nur HTTP und nicht HTTPS unterstützt. HTTPS (HyperText Transfer Protocol Secure) fügt HTTP (HyperText Transfer Protocol) eine SSL/TLS-Verschlüsselungsschicht hinzu – vereinfacht gesagt eine „sicherere Version von HTTP".
Um den Dienst HTTPS-fähig zu machen, gibt es im Allgemeinen zwei Möglichkeiten:
- Andere Programme zur Weiterleitung der Anfragen verwenden (z. B. einen Reverse Proxy auf einem Nginx-Server mit Zertifikat), oder
- Eine Domain binden und für diese ein Zertifikat beantragen.
Diese Operationen sind jedoch relativ komplex. Hier verwenden wir Zeabur als Netzwerk-Weiterleitungs-Gateway zur Problemlösung.
Zeabur-Webseiten werden standardmäßig über HTTPS aufgerufen. Wir müssen lediglich die ursprünglich angefragte Domain auf die von Zeabur bereitgestellte Domain weiterleiten, um das Problem zu beheben.
- Originaladresse:
http://{DIFY_API_URL}/v1/chat-messages - Neue Adresse:
https://{DIFY_NEW_API_URL}.zeabur.app/v1/chat-messages
Du musst einfach den Domain-Teil in der URL (öffentliche IP oder Domain) durch die auf Zeabur bereitgestellte Domain ersetzen. Die Weiterleitungsfunktionalität haben wir bereits im Dienst vorkonfiguriert.
Wenn du interessiert bist, kannst du auch selbst einen Weiterleitungsdienst auf Zeabur bereitstellen. Bei der Erstellung eines Dienstes in Zeabur wähle Python und gib den folgenden Python-Code ein. Nach der Bereitstellung erhältst du eine HTTPS-Adresse, die dann normal verwendet werden kann.
Stelle nach der Bereitstellung in den Netzwerkeinstellungen den Überwachungsport des Programms auf den lokalen Port 8080 ein und exponiere diesen Port nach außen.
Hinweis: Bitte ersetze {DIFY_API_URL} durch die tatsächliche Dify-API-Adresse.
from flask import Flask, request, Response
import requests
app = Flask(__name__)
TARGET_BASE_URL = "{DIFY_API_URL}"
LISTEN_PORT = 8080
@app.route('/', defaults={'path': ''}, methods=['GET', 'POST', 'PUT', 'DELETE', 'PATCH', 'OPTIONS', 'HEAD'])
@app.route('/<path:path>', methods=['GET', 'POST', 'PUT', 'DELETE', 'PATCH', 'OPTIONS', 'HEAD'])
def proxy_request(path):
target_url = f"{TARGET_BASE_URL}/{path}"
if request.query_string:
target_url += f"?{request.query_string.decode('utf-8')}"
headers = {key: value for key, value in request.headers if key.lower() not in ['host', 'connection', 'content-length', 'accept-encoding']}
try:
resp = requests.request(
method=request.method,
url=target_url,
headers=headers,
data=request.get_data(),
cookies=request.cookies,
allow_redirects=False,
timeout=30
)
excluded_headers = ['content-encoding', 'content-length', 'transfer-encoding', 'connection']
response_headers = [(name, value) for name, value in resp.raw.headers.items() if name.lower() not in excluded_headers]
return Response(resp.content, resp.status_code, response_headers)
except requests.exceptions.RequestException as e:
print(f"Error forwarding request to {target_url}: {e}")
return Response(f"Proxy Error: Could not reach target server or invalid response: {e}", status=502)
except Exception as e:
print(f"An unexpected error occurred: {e}")
return Response(f"Internal Proxy Error: {e}", status=500)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=LISTEN_PORT, debug=True)Wenn du findest, dass deine selbst erstellten Workflows oder Agenten zu einfach sind, bietet die Dify-Plattform umfangreiche Beispielprojekte, die dir helfen, schnell zu verstehen, wie man komplexe Anwendungen erstellt. Diese Beispielprojekte decken verschiedene Geschäftsszenarien ab. Du kannst auf Explore klicken, um die von anderen erstellten Workflows zu sehen und daraus zu lernen.
2.6 Erste Dify Workflow-Anwendung erstellen
Nachdem wir die Grundlagen der Dify-Konversationsagenten kennengelernt haben, schauen wir uns an, wie man komplexere Dify-Geschäftsworkflows erstellt. Workflows sind die Kernmethode von Dify, um komplexe Geschäftslogik zu visualisieren. Damit kannst du intelligente Prozesse wie beim Bau mit Bausteinen erstellen. Du kannst nachvollziehen, wie Informationen zwischen verschiedenen Knoten fließen, wie Entscheidungslogik implementiert wird, wo manuelle Eingriffspunkte gesetzt werden und wie schließlich ein vollständiges Geschäftsergebnis geliefert wird.
Du kannst wählen, ob du von Grund auf neu erstellen oder direkt aus einer Vorlage starten möchtest. Hier demonstrieren wir, wie man einen Workflow von Grund auf neu erstellt:
Hier sehen wir zwei Auswahlmöglichkeiten: Chatflow und Workflow. Wie soll man sich entscheiden? Der Schlüssel liegt darin, zu verstehen, ob das, was du erstellen möchtest, im Kern ein fortlaufender Dialog oder ein Aufgabenprozess ist.
Chatflow ist speziell für Konversationen konzipiert. Es simuliert einen Gesprächspartner mit Gedächtnis und Kontextverständnis und eignet sich hervorragend für Szenarien, die mehrfache Interaktionen und Zustandserhaltung erfordern. Zum Beispiel kann es im Kundenservice aufeinanderfolgende Rückfragen des Benutzers kohärent verstehen, wie ein geduldiger Dienstleister. Die Streaming-Ausgabe macht den Interaktionsprozess natürlicher. Kurz gesagt: Wenn du einen intelligenten Agenten erstellen möchtest, der „konversieren" kann, solltest du Chatflow wählen.
Workflow hingegen konzentriert sich auf die automatisierte Ausführung von Prozessen. Es ist wie eine voreingestellte Fließbandstraße, die sich darauf spezialisiert hat, Aufgaben mit einmaliger Eingabe, mehrstufiger Verarbeitung und deterministischer Ausgabe zu bearbeiten. Zum Beispiel: tägliche automatische Generierung von Datenberichten, stapelweises Verarbeiten von Dateien oder Aufrufen einer Reihe von APIs. Solche Aufgaben werden normalerweise durch Ereignisse ausgelöst, ohne dass eine Echtzeit-Interaktion mit Menschen erforderlich ist. Wenn du also „Automatisierungs"-Aufgaben umsetzen möchtest, ist Workflow die bessere Wahl.
Um Fehler bei der Auswahl zu vermeiden, kannst du deine Aufgabenanforderungen anhand von vier Schlüsselfragen überprüfen:
- Erfordert der Aufgabenprozess mehrfache Benutzereingaben und Anpassungen?
- Muss das Ergebnis schrittweise und im Streaming-Verfahren präsentiert werden?
- Hängt die Verarbeitungslogik stark vom bisherigen Interaktionsverlauf ab?
- Wird die Aufgabe durch Ereignisse ausgelöst, und sind Ein- und Ausgabe meist einmaliger Natur?
Wenn die ersten drei Fragen mit „Ja" beantwortet werden, ist Chatflow die ideale Wahl. Typische Szenarien umfassen intelligenten Kundenservice, Bildungsberatung, kreative Zusammenarbeit usw. Wenn die vierte Frage besonders zutreffend ist, solltest du Workflow wählen, das besser für automatisierte Szenarien wie Datenbereinigung, Berichtsgenerierung und Stapelverarbeitung geeignet ist.
Hier wählen wir Chatflow als Beispiel. Nach dem Klick auf Chatflow gelangen wir zur Arbeitsfläche:
Lassen Sie uns die Workflow-Oberfläche kurz vorstellen. Der Kern der gesamten Benutzeroberfläche ist die zentrale Bearbeitungsleinwand, auf der du die Anwendungslogik visuell erstellst. Wie in der Abbildung gezeigt, beginnt ein grundlegender Workflow normalerweise mit dem START-Knoten (zur Entgegennahme der Eingabe), gibt die Daten über Verbindungslinien an den LLM-Knoten zur Verarbeitung weiter und gibt die Ergebnisse schließlich über den ANSWER-Knoten aus. Jeder Knoten stellt ein Funktionsmodul dar, während die Verbindungslinien die Ausführungsreihenfolge bestimmen.
Um die Leinwand herum befinden sich die vollständigen Bedien- und Verwaltungsfunktionen. Oben in der Benutzeroberfläche befinden sich globale Steuerungsoptionen, einschließlich der Preview-Schaltfläche zum Testen des Workflows und der Publish-Schaltfläche für die Veröffentlichung. In den Ecken der Leinwand befinden sich Zoom-, Rückgängig- und andere Ansichtssteuerungswerkzeuge für feine Anpassungen.
Das linke Panel konzentriert die Verwaltungsfunktionen der Anwendung. Der aktuelle Orchestrate-Tab dient der Prozessorganisation; nach Abschluss der Erstellung kannst du über API Access die Integrationszugangsdaten abrufen; Logs & Annotations zeichnen detaillierte Ausführungsspuren auf, die beim Debugging helfen; und Monitoring bietet dir Performance- und Statusüberwachung der Anwendung zur Laufzeit.
Du kannst einfach einige Prompt-Inhalte im SYSTEM des LLM-Knotens dieses Dialog-Workflows eingeben, auf Preview klicken, um den Workflow testweise auszuführen und zu überprüfen, ob der Workflow nach der Änderung des SYSTEM-Prompts wie erwartet funktioniert.
2.6.1 Häufige Knoten vorgestellt
Dify bietet verschiedene Knoten. Du kannst zunächst die Grundfunktionen jedes Knotens kennenlernen. Bei der konkreten Verwendung wird empfohlen, es selbst auszuprobieren oder Workflow-Vorlagen von anderen zu referenzieren. Du kannst auch Screenshots machen und das Große Sprachmodell nach der Verwendung, den benötigten Parametern usw. fragen. Es wird empfohlen, direkt in vorhandenen Vorlagen verschiedene Knoten auszutauschen und die Best Practices der Knoten aus der Verwendung durch andere abzuleiten.
Klicke mit der rechten Maustaste auf die Leinwand und wähle „Add Node", um Knoten hinzuzufügen. Du kannst auch im linken Knoten-Panel alle verfügbaren Knoten einsehen:
Gleichzeitig kannst du das Werkzeugauswahl-Panel öffnen, um alle unterstützten Werkzeuge zu sehen:
Im Folgenden finden Sie eine kurze Beschreibung einiger häufig verwendeter Knoten und Werkzeuge. Du musst nicht alle auf einmal beherrschen. Es wird empfohlen, sich zunächst einen Überblick zu verschaffen und sie in der praktischen Anwendung schrittweise kennenzulernen.
- LLM- und Inferenzknoten
Diese Knoten sind für den Kernprozess im Workflow verantwortlich.
- LLM-Knoten: Die Kernberechnungseinheit, die zum Aufruf des großen Sprachmodells dient. Der Konfigurationsschwerpunkt liegt beim Prompt-Engineering und der Parameteroptimierung, um Geschäftsprobleme in Ausführungsanweisungen für das Modell umzuwandeln.
- Knowledge Retrieval-Knoten: Die Wissensabfrage-Einheit, die für die Suche nach geschäftsrelevanten Informationen aus voreingestellten Wissensdatenbanken und externen autoritativen Datenquellen verantwortlich ist. Sie bietet dem LLM-Knoten präzise Wissensunterstützung und hilft, das „Halluzinations"-Problem bei der Ausgabe großer Sprachmodelle zu reduzieren.
- Answer-Knoten: Die Ergebnis-Ausgabeeinheit, die für die Entgegennahme des vom LLM verarbeiteten Inhalts verantwortlich ist und diesen in eine endgültige Ergebnisform umwandelt, die den Geschäftsanforderungen entspricht. Der Konfigurationsschwerpunkt liegt bei der Definition des Ausgabeformats (z. B. Gesprächsvorlagen, Layout-Standards).
- Agent-Knoten: Eine fortgeschrittene Entscheidungseinheit. Er ruft nicht nur das Modell auf, sondern kann auch mehrstufige Planungen durchführen, automatisch externe Werkzeuge auswählen und aufrufen. Geeignet für komplexe Aufgabenketten, die dynamische Entscheidungen erfordern.
- Question Classifier-Knoten: Die Fragenklassifizierungseinheit, die für die Typidentifikation und Kategorisierung der eingegebenen Geschäftsfragen verantwortlich ist (z. B. nach Frageabsicht, Themenbereich usw.). Sie hilft dem nachfolgenden Prozess, die entsprechenden Verarbeitungsknoten präzise zuzuordnen (z. B. verschiedene Typen von Fragen mit verschiedenen LLM-Prompts oder Werkzeugketten).
- Logik- und Prozesssteuerungsknoten
Diese Knoten definieren die Ausführungspfade und Regeln des Workflows.
- Bedingungsknoten: Wie
IF/ELSE, das durch boolesche Beurteilung eine Prozessverzweigung realisiert. Der Designschwerpunkt liegt bei der Präzision der Bedingungsausdrücke, um sicherzustellen, dass die Logik alle Geschäftsszenarien abdeckt. - Iteration-Knoten: Als zustandslose parallele Stapelverarbeitungseinheit ist er für Szenarien konzipiert, in denen keine Datenabhängigkeit zwischen Unteraufgaben besteht und diese unabhängig verarbeitet werden können, z. B. stapelweises Übersetzen von Absätzen, paralleles Prüfen mehrerer Inhalte oder gleichzeitiges Generieren mehrerer Berichte. Dieser Knoten empfängt ein Eingabearray und partitioniert es automatisch, verteilt jedes Element an dieselbe Verarbeitungskette zur parallelen Ausführung. Benutzer können über auf das aktuelle Element und über auf seinen Index zugreifen. Die Ausgabe wird automatisch zu einem Ergebnisarray aggregiert. Bei der Konfiguration sollte der Parallelitätsgrad festgelegt werden, um Effizienz und Systemlast auszubalancieren. Gleichzeitig wird die Stabilität der Stapelverarbeitung durch Wiederholungsstrategien (wie Anzahl der Wiederholungen, Intervalle) und Fehlerbehandlung (wie Protokollierung, Rückgabe von Standardwerten) sichergestellt.
- Loop-Knoten: Ein zustandsbehafteter rekursiver Iterator, geeignet für Szenarien, in denen das Ergebnis von der Ausgabe der vorherigen Runde abhängt, z. B. mehrstufige Parameteroptimierung, rekursive Inhaltsoptimierung (wie wiederholtes Überarbeiten von Texten bis zur Zufriedenheit) und kettenbasierte Berechnungen, die vom vorherigen Ergebnis abhängen. Der Kern sind „Zustandsvariablen", die vor Beginn der Schleife initialisiert werden müssen (wie aktuelle Iterationsanzahl, Zwischenergebnisse) und in jeder Iteration explizit aktualisiert werden müssen, um als Eingabe für die nächste Runde zu dienen. Um Endlosschleifen zu vermeiden, müssen Abbruchbedingungen definiert werden (einschließlich zählerbasierter „maximal 10 Zyklen", ergebnisbasierter „Zufriedenheitsbewertung > 9" und externer Signal-basierter „'Stopp'-Eingabe erkannt"). Gleichzeitig muss ein Schleifen-Timeout konfiguriert und ein Fehlerbehandlungspfad geplant werden (wie Verlassen der Schleife oder Zurücksetzen des Zustands und erneuter Versuch), um einen stabilen Prozessablauf zu gewährleisten.
- Datenoperations- und Integrationsknoten
- Code-Knoten: Die Code-Verarbeitungseinheit, die für die Ausführung benutzerdefinierter Codelogik im Workflow verantwortlich ist. Sie kann Datenformatkonvertierung, komplexe Berechnungen und andere personalisierte Verarbeitungsanforderungen realisieren. Der Konfigurationsschwerpunkt liegt bei der Korrektheit der Codesyntax und der Anpassung an die Ausführungsumgebung.
- Template-Knoten: Die Vorlagen-Verarbeitungseinheit, die für das Befüllen dynamischer Daten in voreingestellte Vorlagen verantwortlich ist, um Inhalte zu generieren, die den Formatanforderungen entsprechen (z. B. maßgeschneiderte Texte, Berichtsrahmen). Der Konfigurationsschwerpunkt liegt beim Schreiben der Vorlagensyntax und dem Festlegen der Variablenzuordnungsregeln.
- Variable Aggregator-Knoten: Die Variablen-Aggregationseinheit, die für das Sammeln der von mehreren Knoten im Workflow ausgegebenen Variablendaten verantwortlich ist und die verstreuten Variablen zu einem einheitlichen Datensatz zusammenfasst. Der Konfigurationsschwerpunkt liegt bei der Definition des Aggregationsbereichs und der Daten-Zusammenführungsregeln.
- Doc Extractor-Knoten: Die Dokument-Extraktionseinheit, die für das Extrahieren von Text, Tabellen und anderen Schlüsselinhalten aus verschiedenen Dokumenten wie PDF, Word usw. verantwortlich ist und diese in strukturierte Daten umwandelt, die vom Workflow verarbeitet werden können. Der Konfigurationsschwerpunkt liegt bei der Anpassung an den Dokumenttyp und den Extraktionsregeln.
- Variable Assigner-Knoten: Die Variablen-Zuweisungseinheit, die für die Definition, Initialisierung oder Aktualisierung von Variablen im Workflow verantwortlich ist und einen Träger für die Datenübertragung innerhalb des Prozesses bereitstellt. Der Konfigurationsschwerpunkt liegt beim Festlegen der Variablenbenennung, Datentypen und Zuweisungslogik.
- Parameter Extractor-Knoten: Die Parameter-Extraktionseinheit, die für das Extrahieren angegebener Parameter aus Benutzereingaben, Schnittstellenantworten und anderen Eingabeinhalten verantwortlich ist und unstrukturierte Informationen in strukturierte Daten umwandelt. Der Konfigurationsschwerpunkt liegt bei der Konfiguration der Extraktionsregeln (wie reguläre Ausdrücke, JSON-Pfade).
- HTTP Request-Knoten: Die HTTP-Anforderungseinheit, die für das Senden von HTTP-Anfragen an externe Systemschnittstellen (einschließlich GET, POST und andere Methoden) verantwortlich ist und den Datenaustausch zwischen Workflow und externen Diensten realisiert. Der Konfigurationsschwerpunkt liegt bei der Einstellung der Anforderungsadresse, -methode und der Parameter/Headers.
- List Operator-Knoten: Die Listen-Operationseinheit, die für die Verarbeitung von Array- und Listendaten verantwortlich ist (wie Filtern, Sortieren, Aufteilen) und die Datenstruktur an den nachfolgenden Prozess anpasst. Der Konfigurationsschwerpunkt liegt bei der Definition des Operationstyps (wie Filterbedingungen, Sortierregeln).
2.6.2 Häufige Werkzeuge vorgestellt
In Dify können die meisten Werkzeuge direkt als Knoten auf der Leinwand platziert werden, die wie andere Knoten mit Upstream- und Downstream-Verbindungen verbunden werden. Solange die bereitgestellte Eingabe den Parameterspezifikationen des jeweiligen Knotens (Werkzeugs) entspricht, kann er normal ausgeführt werden und Ergebnisse liefern, die weiterfließen können.
Im linken oder rechten Knoten-Panel kannst du alle verfügbaren Werkzeugknoten einsehen und über den Plugin-Marketplace weitere Werkzeugfunktionen erweitern. Hier eine kurze Einführung einiger häufig verwendeter Werkzeuge:
- Websuch-Werkzeug Vertreten durch Tavily Search, bietet es dem großen Modell eine auf KI optimierte Echtzeit-Suchfähigkeit. Es gibt strukturierte Suchergebnisse zurück (wie Titel, Zusammenfassungen, Links usw.), die direkt als Teil des LLM-Prompts verwendet werden können, um aktuelle Nachrichten oder Fragen zu beantworten, die eine autoritative Grundlage erfordern.
- Datenverarbeitungs-Werkzeug Zum Beispiel das JSON Process Plugin, das für erweiterte Operationen wie Abfragen, Filtern, Transformieren und Zusammenführen von JSON-Daten verwendet wird. Bei der Verarbeitung komplexer API-Antworten oder mehrfach verschachtelter Daten kannst du die Logik „Datenbereinigung + Reorganisation" diesem Werkzeug überlassen und so die häufige manuelle Erstellung von Parsing-Code im Code-Knoten vereinfachen.
- Formatverarbeitungs-Werkzeug Wie der Markdown Exporter, der generierte Inhalte in einem bestimmten Format exportieren kann, z. B. Markdown-Dokumente, bestimmte Layout-Vorlagen usw., was die spätere Verwendung für Präsentation, Berichterstattung oder Integration in andere Systeme erleichtert.
Du kannst die Installationszahlen und Kurzbeschreibungen dieser Plugins in der Werkzeugliste sehen. Für den Einstieg wird empfohlen, zuerst die Werkzeuge unter „Featured / Empfohlen" auszuprobieren, da diese oft die häufigsten Geschäftsszenarien abdecken.
Allerdings ist die Verwendung von Werkzeugen oft recht komplex. Es wird empfohlen, bei der Verwendung zunächst eine Suchmaschine zu nutzen, um nach „offiziell empfohlenen Workflow-DSL-Beispielen" für das entsprechende Werkzeug zu suchen und diese direkt zu importieren, was viel Zeit im Vergleich zum Selberbauen spart.
2.6.3 Erstellen eines einfachen Intent-Classification-Workflows
Jetzt haben wir grundlegende Informationen über Dify-Workflows und Werkzeuge kennengelernt, aber ohne Übung werden wir die Details nie beherrschen. Wir benötigen ein „angenommenes" reales Geschäftsszenario zum Üben.
In einem realen Einkaufsdialog-Szenario beispielsweise ist die Eingabe von Benutzern, die zum Kauf kommen, niemals ein „standardisierter Parameter", sondern ein beiläufiger Satz: Manche kommen zum Bestellen, manche zum Beschweren, manche wollen nur plaudern, und andere sind völlig vom Thema abgekommen. Wenn wir alle diese Eingaben direkt an dasselbe große Sprachmodell (LLM) weiterleiten, treten in der Regel zwei typische Probleme auf:
- Instabiler Antwortstil Bei derselben Beschwerde kann das LLM manchmal Entschuldigen und Beruhigen, manchmal scheint es nur „Erklärungen abzugeben"; bei derselben Bestellung wird manchmal nach fehlenden Informationen gefragt, manchmal werden Bestelldetails einfach erfunden.
- Nicht kontrollierbare Geschäftslogik Du möchtest, dass „bei Beschwerden zuerst entschuldigt wird", aber das Modell befolgt dies nicht unbedingt jedes Mal; du möchtest, dass „Nicht-Geschäftsfragen zum Hauptthema zurückgeführt werden", aber das Modell könnte begeistert Witze mit dir erzählen.
Ein ingenieurtechnisch besserer Ansatz besteht daher darin, die Aufgabe in eine standardisierte Pipeline zu zerlegen: zuerst Intent-Classification (bestimmen, was der Benutzer wirklich tun möchte), dann nach Intent aufteilen (verschiedene Szenarien verwenden verschiedene Prompts und Rollen), und schließlich die Antworten der verschiedenen LLM-Pfade einheitlich verpacken und ausgeben (zur Erleichterung der Frontend- oder Systemintegration).
Das Ziel dieses Abschnitts ist es, das System zu befähigen, mehrere Arten von Dialogen in einem Gastronomieszenario zu verarbeiten. Du kannst den Vorgängen folgen, um dir einen tieferen Eindruck zu verschaffen. Zunächst müssen wir die Szene für die Intent-Classification definieren:
- Bestellung (buy_food): Der Benutzer drückt eine klare Kaufabsicht aus.
- Beispiel: „Ich hätte gerne ein Hähnchen und noch eine Cola."
- Beschwerde (complain): Der Benutzer drückt Unzufriedenheit aus, drängt oder gibt negatives Feedback.
- Beispiel: „Seid ihr auch so langsam? Ich warte schon seit einer Stunde."
- Plaudern (chitchat): Der Benutzer stellt offene Fragen, sucht Rat, hat aber keine klare Bestellabsicht.
- Beispiel: „Was soll ich heute essen? Hast du Empfehlungen?"
- Sonstige (other): Die Eingabe des Benutzers hat keinen Bezug zum Gastronomieszenario.
- Beispiel: „Schreib mir einen lustigen Spruch für meinen Social-Media-Post."
Für diese vier Intents haben wir dem System vier verschiedene „Kommunikationspersönlichkeiten" voreingestellt, die jeweils von vier unabhängigen LLM-Knoten getragen werden. Jeder Knoten muss von einem LLM mit unterschiedlichem Persona gespielt werden.
- Bestellassistent (LLM_BuyFood): Professionell, effizient, die Hauptaufgabe ist die Bestätigung der Bestelldetails und das proaktive Vervollständigen fehlender Informationen.
- Kundendienstexperte (LLM_Complain): Empathisch, besonnen, die oberste Priorität ist die Beruhigung der Benutzeremotionen und die Bereitstellung klarer Lösungsvorschläge.
- Chat-Partner (LLM_Chitchat): Locker, freundlich, zielt darauf ab, personalisierte Empfehlungen zu geben und potenzielle Käufe zu fördern.
- Höflicher Pförtner (LLM_Other): Fokussiert, mit klaren Grenzen, verantwortlich dafür, vom Thema abgekommene Gespräche höflich zum Kerngeschäft zurückzuführen.
Workflow-Orchestrierungsdesign
Als Nächstes werden wir die Workflow-Orchestrierung festlegen und bestimmen, welche Workflow-Knoten benötigt werden. Für Anfänger ist es schwierig, sich alle benötigten Knoten auszudenken (und auch erfahrene Benutzer denken oft nicht gerne selbst nach — das große Modell um Rat zu bitten ist meist die schnellste und beste Wahl). Daher können wir das große Modell um entsprechende Orchestrierungsvorschläge bitten. Die Kernknotenstruktur ist wie folgt:
- Start (Startpunkt): Als Dateneingang verantwortlich für die Entgegennahme der ursprünglichen Benutzereingabe
user_text. - Question Classifier (Intent-Klassifikator): Das „Gehirn" und das „Verteilungszentrum" des Workflows. Es ist für die Analyse von
user_textund die Auswahl des am besten passenden der vier voreingestellten Intent-Tags verantwortlich. - Condition (Bedingungsverzweigung): Spielt die Rolle eines „Verteilungsventils". Es bestimmt basierend auf dem vom Klassifikator ausgegebenen Intent-Tag, an welchen speziellen Verarbeitungspfad die Aufgabe als Nächstes weitergeleitet wird.
- Vier parallele LLM-Knoten (LLM_BuyFood, LLM_Complain, LLM_Chitchat, LLM_Other): Dies sind vier unabhängige „Experten-Verarbeitungseinheiten". Jeder Knoten empfängt die ursprüngliche Frage, generiert aber basierend auf seinem einzigartigen System Prompt Antworten mit völlig unterschiedlichem Stil und Ziel.
- Variable Aggregator (Variablen-Aggregator): Nach Abschluss der Verarbeitung mehrerer Pfade wird ein „Sammelpunkt" benötigt. Dieser Knoten fasst die Antwort des einzigen aktivierten und ergebnisproduzierenden Zweigs in einer einheitlichen Variable
final_replyzusammen und gewährleistet so die Stabilität der Ausgabestruktur. - Output (Endpunkt): Als endgültiger Ausgang verantwortlich für die strukturierte Gesamtausgabe des Intent-Tags, der ursprünglichen Frage und der generierten Antwort (z. B. als JSON), um die nachfolgende Systemintegration oder Debug-Analyse zu erleichtern.
Workflow-Orchestrierungsimplementierung
In diesem Tutorial wählen wir die Erstellung eines Workflows statt eines Chatflows. Wähle User Input:
Klicke dann auf den User Input-Knoten von Start und definiere eine Variable vom Typ String namens user_text als Eingabequelle für den gesamten Prozess.
Nach dem Speichern klicke auf Test Run oben rechts. Du siehst, dass du die entsprechende Texteingabe für die Verarbeitung angeben musst:
Als Nächstes müssen wir auf das +-Symbol nach dem Eingabeknoten klicken, den Question Classifier-Knoten hinzufügen und vier Arten von Tags konfigurieren. Für jedes Tag müssen klare Beschreibungen und Beispiele angegeben werden.
buy_food: Der Benutzer möchte eindeutig Essen kaufen, eine Bestellung aufgeben.complain: Der Benutzer beschwert sich, flucht, wird wütend, meist mit unzufriedener Stimmung.chitchat: Der Benutzer plaudert, diskutiert über das Essen, fragt nach Empfehlungen.other: Ohne Bezug zum Gastronomieszenario oder schwer zu beurteilender Inhalt.
Außerdem musst du in ADVANCED SETTING einen Prompt schreiben, damit das große Modell basierend auf der Benutzereingabe korrekt klassifizieren kann. Ein Beispiel-Prompt sieht wie folgt aus:
Wähle das passendste Label aus buy_food / complain / chitchat / other. Wenn der Benutzer sich beschwert und gleichzeitig bestellt, bewerte die Kernemotion. Steht die Unzufriedenheit im Vordergrund, ordne es als complain ein. Handelt es sich nur um eine leichte Kritik, aber die Hauptabsicht ist die Bestellung, ordne es als buy_food ein. Wenn es wirklich schwer zu beurteilen ist, verwende other als Standard
Nach Abschluss der Konfiguration kannst du oben rechts auf die Play-Taste klicken, um den Knoten separat zu testen und zu überprüfen, ob er ordnungsgemäß funktioniert:
Aus dem OUTPUT-Ergebnis ist ersichtlich, dass unsere Klassifizierung korrekt ist. Du kannst verschiedene Eingabetypen testen, um die Stabilität unseres Klassifikators zu überprüfen.
Als Nächstes müssen wir den Klassifikator mit der nachfolgenden Modellausgabe verbinden. Wenn beispielsweise label gleich "buy_food" ist, fließt der Workflow präzise zum LLM_BuyFood-Knoten. Wir müssen vier neue LLM-Knoten erstellen und verschiedene System Prompts festlegen; die Unterschiede in den System Prompts bestimmen ihre unterschiedlichen Antwortweisen.
- LLM_BuyFood (Bestellassistent):
Du bist ein Bestellassistent. Anforderungen: 1. Bestätige, was der Benutzer bestellen möchte. 2. Wenn die Informationen unvollständig sind, frage freundlich nach. 3. Höflicher und knapper Ton.
- LLM_Complain (Kundendienstexperte):
Du bist ein Kundendienstmitarbeiter im Gastgewerbe, spezialisiert auf Beschwerdebearbeitung. Anforderungen: 1. Aufrichtig entschuldigen. 2. Kurz mögliche Ursachen erläutern (ohne Verantwortung abzuschieben). 3. Klar die nächsten Lösungsschritte aufzeigen.
- LLM_Chitchat (Chat-Partner):
Du bist ein kleiner Chat-Assistent, der bei der Essenswahl hilft. Anforderungen: 1. Lockerer und freundlicher Ton. 2. Gib 1-3 einfache Empfehlungen. 3. Wenn der Benutzer keine Präferenzen hat, biete verschiedene Stiloptionen an.
- LLM_Other (Höflicher Pförtner):
Du bist ein kleiner Essens-Bestellassistent, der sich nur mit Themen rund ums „Essen" auskennt. Wenn der Benutzer etwas sagt, das nicht relevant ist: 1. Erkläre höflich deinen Kompetenzbereich. 2. Führe den Benutzer zurück zum Hauptszenario.
Beachte, dass du nach dem Ausfüllen der SYSTEM-Prompt-Parameter in jedem Knoten auch den USER-Prompt-Parameter aktivieren musst. Du musst darin auf das {x}-Symbol klicken, den Parameter user_text als Benutzereingabe auswählen und ihm user input: voranstellen, um zu kennzeichnen, dass diese Variable die Benutzereingabe ist. Bei der Frage-Antwort werden die ursprüngliche Eingabe des Benutzers und der eingebaute Prompt kombiniert, um die Antwort zu generieren.
Ebenso kannst du zur Überprüfung auf den Pfeil oben rechts am Knoten klicken, um spezifische Dialogtests durchzuführen, z. B. „Ich möchte Bubble-Tee trinken" eingeben und prüfen, ob die Antwort den Erwartungen entspricht.
Als Nächstes verarbeiten wir die Ausgabewerte der parallelen LLMs. Im Konfigurations-Panel des Variable Aggregator-Knotens finden wir den Bereich ASSIGN VARIABLES. Klicke darauf und füge nacheinander die vorherigen Modellantworten hinzu.
Als Nächstes müssen wir alle Ausgaben aggregieren und schließlich das gewünschte Ergebnis erhalten, einschließlich der Benutzereingabe, der Klassifizierung und der Antwort. Da wir Workflow statt Chatflow verwenden, steht uns kein Answer-Knoten zur Aggregation der Ergebnisse zur Verfügung. Wir können jedoch andere Knoten wählen, um die Aggregation und Ausgabe der Ergebnisse indirekt zu realisieren. Wähle hier den Template-Knoten, gib im Variablenbereich das Ergebnis der Benutzer-Intent-Klassifizierung, den Eingabewert des Benutzers und die endgültige Antwort der Variablenaggregation an und schreibe im CODE-Bereich die JSON-Formatvorlage der endgültigen Antwort. Wir erhalten:
intent←class_nameoriginal_text←user_textfinal_reply←variable_aggregator
{
"intent": "{{ intent }}",
"original_text": "{{ original_text }}",
"reply": {{ final_reply }}
}
Füge abschließend den Output-Knoten hinzu, um alle Vorgänge abzuschließen:
Workflow-Ausführungstest
Geschafft! Wir können nun versuchen, die Ergebnisse dieses Workflows zu testen. Er zeigt bei verschiedenen Eingaben völlig unterschiedliche Verhaltensmuster:
- Eingabe (Bestellung): „Ich hätte gerne ein scharfes Hähnchen-Menü und eine große Cola."
- Pfad:
buy_food→LLM_BuyFood - Ausgabe reply: „Gerne! Ein scharfes Hähnchen-Menü und eine große Cola wurden für dich notiert. Möchtest du die Pommes im Menü austauschen?"
- Pfad:
- Eingabe (Beschwerde): „Seid ihr auch so langsam? Ich warte schon über eine Stunde!"
- Pfad:
complain→LLM_Complain - Ausgabe reply: „Es tut uns sehr leid, dass Sie so lange warten mussten. Das ist unser Fehler und hat Ihnen eine schlechte Erfahrung beschert. Wir prüfen dringend den Status Ihrer Bestellung und werden eine entsprechende Entschädigung für Sie beantragen. Vielen Dank für Ihre Geduld und Ihr Feedback."
- Pfad:
- Eingabe (Plaudern): „Was ist heute gesund zum Essen?"
- Pfad:
chitchat→LLM_Chitchat - Ausgabe reply: „Wenn es gesund sein soll, kannst du unsere leichte Salatserie oder gegrillte Hähnchenbrust mit Gemüse probieren. Magst du es eher dezent oder etwas kräftiger? Ich kann dir gezieltere Empfehlungen geben."
- Pfad:
- Eingabe (Irrelevant): „Fällt dir ein lustiger Witz für die morgige Besprechung ein?"
- Pfad:
other→LLM_Other - Ausgabe reply: „Das klingt nach einer spannenden Herausforderung! Aber ich bin hauptsächlich ein Empfehlungs- und Bestellassistent für Essen. Wenn du etwas bestellen möchtest, um dich nach der harten Arbeit zu belohnen, bin ich jederzeit bereit zu helfen!"
- Pfad:
Versteckter Bug: Es sollte erwähnt werden, dass wenn du auf seltsame Probleme im Zusammenhang mit der Aggregation Group stößt, dies höchstwahrscheinlich ein eingebauter Bug in Dify ist. Er kann durch bestimmte Operationen ausgelöst werden; wenn du die AGGREGATION GROUP einmal aktiviert und dann wieder deaktiviert hast, hat das System möglicherweise eine Group-Konfiguration erstellt und entsprechende anomale Parameter hinterlassen. Auch wenn der Schalter jetzt deaktiviert aussieht, können diese Restkonfigurationen Probleme verursachen, wie z. B. Fehler bezüglich des
any-Parameters. In diesem Fall musst du nur den Knoten löschen und neu erstellen.
Nach dem Ausführen von Test Run können wir den Ausführungsprozess des Workflows sehen. Die Klassifizierung hat den korrekten Pfad gewählt und das endgültige Output-Ergebnis erhalten. Damit ist der gesamte Prozess abgeschlossen.
2.7 Erste Vorlagen-Workflow-Anwendung ausführen
Nach Abschluss des einfachen Klassifizierungs-Workflow-Lernens müssen wir als Nächstes lernen, wie man Workflows von anderen ausführt. Wir müssen sie nur geringfügig anpassen, um sie zu unseren eigenen Workflows zu machen. Hier wählen wir den offiziellen DeepResearch-Workflow. Dieser Workflow kann dir helfen, ein Deep-Search-Framework zu erstellen, das ein großes Modell + Suchmaschine nutzt, um dir umfangreiche Suchergebnisse zu liefern. Jedes Abfrageergebnis enthält Suchreferenz-URLs und die Ergebnisse der großen Modellkonversation.
Nach dem Import im ersten Schritt direkt ausführen. Wir lösen dann die spezifischen Probleme basierend auf den Fehlern und Ursachen in jedem Schritt. Wenn du auf ungelöste Probleme stößt, kannst du einen Screenshot machen und das große Modell um Hilfe bitten.
Auf den ersten Blick wirkt alles sehr komplex. Keine Sorge, klicke einfach oben rechts auf Preview, um den Workflow auszuführen, bis ein Fehler auftritt:
Wir müssen das Problem basierend auf dem fehlerhaften Knoten lösen. Nach dem Öffnen sehen wir, dass der Tavily API Token nicht konfiguriert ist. Die Tavily Search API ist eine speziell für KI entwickelte Suchmaschine, die Echtzeit-, genaue und faktenbasierte Ergebnisse liefert. Folge nun den Anweisungen:
Nach der Verarbeitung funktioniert die Suchmaschine ordnungsgemäß:
Nach der weiteren Behebung von Problemen durch Modellaufrufe solltest du folgendes Ergebnis erhalten — eine detaillierte Suche mit dem Verständnis des großen Modells:
Am Ende können wir die entsprechenden Referenzdokument-Adressen sehen:
Wenn du die Funktion jedes Schritts verstehen möchtest, ist die beste Methode, den Output jedes Schritts als Variable zu speichern und beim endgültigen Output die Ergebnisse jeder Zwischenvariable auszugeben. Eine andere Methode besteht darin, oben den Process-Verlauf zu finden und darauf zu klicken, um die Details jedes Schritts einzusehen:
2.8 Dify als API-Anbieter nutzen
Als Nächstes werden wir versuchen, den zuvor erstellten Knowledge-Base-Agenten über eine API aufzurufen. Wir möchten Dify zu einem zentralen Backend für große Modelle machen.
Erinnerst du dich, wie wir früher Modelle über APIs aufgerufen haben? Wir müssen einen Schlüssel (Key) und ein API-Aufrufbeispiel (die Request/Response-Beispiele in der Dokumentation) vorbereiten und diese Inhalte dann an das große Modell senden, damit es uns den Code zum Aufrufen des Dienstes schreibt und die benötigten Felder aus dem Rückgabeergebnis extrahiert.
Dieses Mal werden wir das lokale Code-Bearbeitungswerkzeug Trae verwenden, um diesen Prozess abzuschließen.
Wenn du noch nicht vertraut mit dem Begriff IDE bist, kannst du zuerst die Dokumentation Extra Knowledge 4 - What is AI IDE and Trae lesen.
Wenn deine lokale Entwicklungsumgebung noch nicht vollständig eingerichtet ist, mach dir keine Sorgen. Solange du deinem Code-Assistenten vertraust (egal ob z.ai oder Trae), kannst du bei allem, was du nicht verstehst, oder bei Fehlern einfach das Problem an ihn weitergeben. Er wird dir basierend auf deiner Beschreibung eine detaillierte Lösung anbieten.
Der Bereich auf der rechten Seite wird Copilot-Interaktionsfenster oder Agent-Fenster genannt. Wenn du ihn nicht siehst, kannst du oben rechts auf das Seitenleistensymbol klicken, um ihn zu öffnen.
Nach dem Öffnen der Seitenleiste siehst du die Option Builder. Dies ist der Agent-Modus. Du kannst „Builder" einfach als den „Entwicklermodus" von z.ai verstehen, der dir ebenfalls helfen kann, die lokale Computerumgebung zu bedienen, Abhängigkeiten zu installieren, Webseiten zu öffnen usw.
Nach dem Klick auf „Builder" siehst du den „Chat"-Modus und den „Builder with MCP"-Modus. Der Chat-Modus wird hauptsächlich für die Interaktion mit dem aktuellen Ordner oder für natürlichsprachliche Gespräche mit dem großen Modell verwendet. (Du kannst über „File" oben links in Trae einen Ordner öffnen und dann innerhalb dieses Ordners arbeiten. In diesem Fall finden alle neuen Datei-Operationen von Builder in diesem Ordner statt.)
Der Builder with MCP-Modus bietet dem Agenten weitere Werkzeuge (z. B. die Verbindung des großen Modells mit anderer Software, das Abrufen von Wetterinformationen usw.). Du kannst MCP einfach als eine Sammlung von Fähigkeiten verstehen, die es dem großen Modell erleichtern, verschiedene externe Werkzeuge aufzurufen.
Im unteren Bereich kannst du auch die Dropdown-Liste zur Modellauswahl sehen und zwischen verschiedenen Modellen wechseln. Hier kannst du Kimi k2 oder GLM auswählen. Wenn du die internationale Version von Trae verwendest, kannst du auch ChatGPT oder Claude wählen. Mit der raschen Entwicklung heimischer großer Modelle hat die Gesamtleistung von Modellen wie Kimi, Qwen und GLM jedoch das Niveau von Claude 3.5 oder 3.7 im Wesentlichen erreicht und ist für tägliche Entwicklungsszenarien völlig ausreichend.
Oben haben wir eine kurze Einführung zu Trae gegeben. Als Nächstes können wir die in z.ai gelernten Bedienungsschritte rekapitulieren und diese Denkweise in Trae anwenden.
2.9 Frontend-Dialoganwendung mit Dify API erstellen
Wenn wir eine Frontend-Chat-Anwendung mit der Dify-API erstellen möchten, müssen wir zunächst die Dify-API-Dokumentation und die Aufrufadresse abrufen.
Erinnerst du dich an den zuvor erstellten Agenten? Klicke zuerst oben rechts auf „Publish", dann auf „Publish Update" und schließlich auf „Access API Reference", um zur API-Dokumentation zu gelangen.
Nach dem Öffnen der API-Dokumentation suche den Abschnitt „Send Chat Message", klicke darauf und finde rechts die „Request"- und „Response"-Beispiele und kopiere sie.
Warum ist es zwingend erforderlich, diese beiden Teile zu kopieren? Weil sie die „Kerninformationen" der API sind: Mit Key, Request-Beispiel und Response-Beispiel können wir das große Modell bitten, den Code zum Aufrufen des Dienstes zu generieren und die benötigten Felder basierend auf der Rückgabestruktur zu extrahieren.
Nachdem wir die Request- und Response-Beispiele für die Konversation gefunden haben, müssen wir noch einen API Key abrufen. Oben rechts in der Dokumentation findest du die Option „API key".
Klicke auf „Create new Secret key", um deinen eigenen API Key zu erstellen.
Jetzt ist alles bereit. Wir übergeben den erhaltenen API Key, das Request-Beispiel und das Response-Beispiel an den Trae Builder.
Hinweis: Bitte ersetze {DIFY_API_URL} durch die tatsächliche Dify-API-Adresse.
key:
app-zKdCHUXXXXXXXX
Please write me a front-end based on the following reference:
curl -X POST 'http://{DIFY_API_URL}/v1/chat-messages' \
--header 'Authorization: Bearer {api_key}' \
--header 'Content-Type: application/json' \
--data-raw '{
"inputs": {},
"query": "What are the specs of the iPhone 13 Pro Max?",
"response_mode": "streaming",
"conversation_id": "",
"user": "abc-123",
"files": [
{
"type": "image",
"transfer_method": "remote_url",
"url": "https://cloud.dify.ai/logo/logo-site.png"
}
]
}'
{
"event": "message",
"task_id": "c3800678-a077-43df-a102-53f23ed20b88",
"id": "9da23599-e713-473b-982c-4328d4f5c78a",
"message_id": "9da23599-e713-473b-982c-4328d4f5c78a",
"conversation_id": "45701982-8118-4bc5-8e9b-64562b4555f2",
"mode": "chat",
"answer": "iPhone 13 Pro Max specs are listed here:...",
"metadata": {
"usage": {
"prompt_tokens": 1033,
"prompt_unit_price": "0.001",
"prompt_price_unit": "0.001",
"prompt_price": "0.0010330",
"completion_tokens": 128,
"completion_unit_price": "0.002",
"completion_price_unit": "0.001",
"completion_price": "0.0002560",
"total_tokens": 1161,
"total_price": "0.0012890",
"currency": "USD",
"latency": 0.7682376249867957
},
"retriever_resources": [
{
"position": 1,
"dataset_id": "101b4c97-fc2e-463c-90b1-5261a4cdcafb",
"dataset_name": "iPhone",
"document_id": "8dd1ad74-0b5f-4175-b735-7d98bbbb4e00",
"document_name": "iPhone List",
"segment_id": "ed599c7f-2766-4294-9d1d-e5235a61270a",
"score": 0.98457545,
"content": "\"Model\",\"Release Date\",\"Display Size\",\"Resolution\",\"Processor\",\"RAM\",\"Storage\",\"Camera\",\"Battery\",\"Operating System\"\n\"iPhone 13 Pro Max\",\"September 24, 2021\",\"6.7 inch\",\"1284 x 2778\",\"Hexa-core (2x3.23 GHz Avalanche + 4x1.82 GHz Blizzard)\",\"6 GB\",\"128, 256, 512 GB, 1TB\",\"12 MP\",\"4352 mAh\",\"iOS 15\""
}
]
},
"created_at": 1705407629
}
In dieser Phase stellst du möglicherweise fest, dass das generierte Programm nicht beim ersten Mal reibungslos funktioniert — zum Beispiel können seltsame Fehler im Dialog auftreten oder es gibt keine Rückgabeergebnisse. Wenn dies passiert, kannst du versuchen, zu einem anderen großen Sprachmodell zu wechseln oder die Fehlermeldung zu kopieren, das Problem detailliert zu beschreiben und es dann an das Modell zu senden, damit es basierend auf dem Feedback weiter iteriert.
Deine Arbeitsweise ist jetzt bereits sehr nahe an einem echten Entwicklungsprozess. In der täglichen Entwicklung treffen wir bei der Zusammenarbeit mit großen Modellen oft auf verschiedene Probleme. Um diese besser zu lösen, müssen wir mehr Kontextinformationen bereitstellen. Neben der Bereitstellung von Fehlerinformationen kannst du auch vollständigere Dokumentationsinhalte kopieren (z. B. mehr Erklärungen im Abschnitt „Send message" auf der linken Seite der Dokumentation) und diese dem Modell übergeben, damit es auf Basis weiterer Details eine vollständigere Lösung anbieten kann.
Der Browser ist zu diesem Zeitpunkt in Trae eingebettet. Du kannst oben auf das Kompass-Symbol klicken, um die Webseite in einem externen Browser im Vollbild zu öffnen.
Mit etwas Glück erhältst du beim ersten Versuch eine funktionsfähige interaktive Frontend-Seite.
Aufgrund der inhärenten Zufälligkeit großer Modelle kann es jedoch vorkommen, dass in einem Einzel-Dialog alles reibungslos verläuft, bei Mehrfach-Dialogen jedoch Anomalien auftreten. Daher wird empfohlen, Mehrfach-Dialog-Tests durchzuführen, um sicherzustellen, dass das Programm auch in Mehrfach-Interaktions-Szenarien stabil läuft.
Damit hast du gelernt, wie man einen einfachen Dify Knowledge-Base-Agenten erstellt und Trae anstelle von z.ai verwendet, um ein interaktives Frontend zu erstellen. Von nun an wird Trae unser wichtigstes Entwicklungswerkzeug beim Bau verschiedener Prototypen und wird z.ai schrittweise ersetzen. Du kannst versuchen, das frühere Snake-Spiel mit Trae neu zu implementieren und sehen, welche Unterschiede es gibt. Viel Erfolg!
3. Weitere Geschäftsworkflow-Referenzen
Du kannst in Suchmaschinen mit ähnlichen Schlagwörtern wie Dify Workflow Referenz suchen oder direkt auf Github nach Dify-Workflow-Sharing-Repositories suchen (die Qualität variiert, du solltest mehrere Repositories vergleichen). Natürlich sind Workflows lediglich eine Abbildung von SOPs (Standard Operating Procedures) im Geschäftsumfeld. Du kannst darüber nachdenken, welche Prozesse in deiner täglichen Arbeit oder deinem Lernalltag sich wiederholen und standardisieren lassen — du musst sie nur in einen Workflow umwandeln und fixieren.
Im Folgenden findest du einige von großen Modellen generierte Workflow-Design-Referenzen (die tatsächlichen Implementierungsansätze sind recht ähnlich; im Allgemeinen sind von Menschen entworfene Workflows nicht so elegant wie die von großen Modellen, es sei denn, sie stammen von Experten). Wenn du eine Idee interessant findest, kannst du sie an das große Modell weitergeben, um sie weiter zu verfeinern und detailliertere Dify-Workflow-Knoteneinstellungen sowie interne Detailergebnisse zu erhalten.
3.1 Social-Media-Plattform-Workflows
- Ein-Klick-Inhaltsverteilung über Plattformen (komplex)
- Ansatz: Einen Kernartikel als „Rohmaterial" nehmen und automatisch für mehrere Plattformen anpassen.
- Implementierung:
Startgibt Artikel ein ->LLMverfeinert -> paralleleLLM-Knoten (jeder Knoten-Prompt spielt einen bestimmten Plattform-Experten, wie „Xiaohongshu-Viral-Text-Experte", „Zhihu-Fachantworter") ->Iterator-Knoten verarbeitet zyklisch verschiedene Plattform-Formatanforderungen ->Variable Aggregatorfasst zusammen ->Answergibt alle Versionen aus. Die Komplexität liegt in der Parallelverarbeitung und zyklischen Iteration.
- Trending-Topic-Auswahl und Erstentwurf-Generator (mittel)
- Ansatz: Automatisch Internet-Trends erfassen und schnell Themen und Inhaltsentwürfe generieren.
- Implementierung:
Startgibt Schlüsselwörter ein ->Tool-Knoten ruft Suchmaschinen-API auf, um Trends zu erfassen ->LLMfasst 3-5 Themen zusammen ->LLMgeneriert Artikelgliederung oder Erstentwurf. Die Komplexität liegt in der externen Werkzeugintegration und Informationsfilterung.
- Intelligente Kommentarklassifikation und Antwort-Assistent (komplex)
- Ansatz: Automatisch Stimmung und Intent von Kommentaren analysieren und kategorisierte Antwortvorschläge generieren.
- Implementierung:
HTTP Request-Knoten verbindet Social-Media-API zum Abrufen von Kommentaren ->Question ClassifieroderLLM-Knoten führt Multi-Label-Klassifikation durch (positiv, Frage, Beschwerde, Werbung usw.) ->Condition-Knoten leitet zu verschiedenen Antwortgenerierungsketten -> paralleleLLM-Knoten generieren personalisierte Antwortentwürfe ->Answergibt aus. Die Komplexität liegt in den Bedingungsverzweigungen und Echtzeit-API-Aufrufen.
- Kurzvideo-Skript und Storyboard-Generator (komplex)
- Ansatz: Basierend auf einem Trend-Thema oder einer Produktbeschreibung automatisch ein Kurzvideo-Skript, Storyboard-Beschreibungen und empfohlene Tags generieren.
- Implementierung:
Startgibt Thema ein ->LLMgeneriert kreatives Skript -> zweiterLLM-Knoten zerlegt das Skript in eine Szenenfolge (Bildbeschreibung, Dialoge, Dauer) ->Tool-Knoten ruft Text-to-Speech-Service auf, um Sprachproben zu generieren ->Variable Aggregatorintegriert alle Elemente ->Answergibt strukturierte Skriptdatei aus. Die Komplexität liegt in der mehrstufigen Serialisierung und externen Serviceintegration.
- Echtzeit-Zusammenfassungsassistent für Live-Stream-Interaktion (mittel)
- Ansatz: Textkommentare aus Live-Streams in Echtzeit verarbeiten und Kernfragen und Zuschauerfeedback extrahieren.
- Implementierung:
HTTP Request-Knoten streamt Live-Kommentare ->Iterator-Knoten verarbeitet Batch-Daten in Zeitfenstern ->LLM-Knoten fasst Echtzeit-Trends und Stimmungstendenzen pro Zeitraum zusammen ->AnsweroderWebhook-Knoten gibt Zusammenfassung an den Streamer aus. Die Komplexität liegt in der Echtzeit-Stream-Datenverarbeitung und zyklischen Fensterung.
3.2 Arbeitsplatz-Workflows
- Intelligentes Meeting-Protokoll und automatische Aufgabenverteilung (komplex)
- Ansatz: Aus Meeting-Aufnahme-Texten Protokolle extrahieren und automatisch Aufgaben erstellen.
- Implementierung:
Startgibt Meeting-Text ein ->LLMfasst Themen und Schlussfolgerungen zusammen ->Parameter Extractor-Knoten extrahiert präzise Action Items (Aufgaben, Verantwortliche, Fristen) -> einLLMerstellt Protokoll-E-Mail -> paralleleHTTP Request-Knoten rufen Jira/Trello/Feishu-API auf, um Aufgaben zu erstellen. Die Komplexität liegt in der Informationsextraktion und Mehrsystem-Integration.
- Stapelweise Lebenslauf-Vorauswahl und Ersteinschätzung (mittel)
- Ansatz: Automatisch Lebensläufe analysieren, Passung bewerten und Interviewfragen generieren.
- Implementierung:
Startlädt Lebenslaufdatei und Stellenbeschreibung hoch ->Document Extractor-Knoten extrahiert Lebenslauftext ->LLMspielt HR und bewertet Passung -> für gut passende Kandidaten generiert ein weitererLLMtiefe Interviewfragen. Die Komplexität liegt in der Dokumentenanalyse und Mehrfach-Bewertung.
- Mehrsprachige E-Mail-Übersetzung und Antwortentwurf mit einem Klick (einfach)
- Ansatz: Automatisch E-Mails übersetzen und Antworten entwerfen.
- Implementierung:
Startgibt E-Mail ein ->LLMerkennt Sprache und übersetzt ->LLMentwirft Antwortpunkte ->LLMübersetzt zurück in die Originalsprache und verfeinert. Hauptsächlich abhängig von sequenziellen LLM-Aufrufen.
- Automatische Wochen-/Monatsbericht-Datenzusammenfassung und Insight-Generierung (komplex)
- Ansatz: Mehrere Datenquellen verbinden und automatisch strukturierte Arbeitsberichte generieren.
- Implementierung: Mehrere
HTTP Request/Tool-Knoten rufen parallel Business-System-APIs auf (wie CRM, Git, Projektmanagement-Tools), um Rohdaten abzurufen ->Code-Knoten oderLLMführen Datenbereinigung und Basisberechnungen durch ->LLManalysiert Trends, Highlights und Risiken und generiert narrativen Bericht ->Answergibt illustriertes Dokument aus. Die Komplexität liegt in der Multi-Datenquellen-Aggregation, Datenverarbeitung und Kombination mit intelligenter Analyse.
- Intelligente Vertrag-/Dokumentenprüfung und Kernpunkte-Extraktion (mittel)
- Ansatz: Schnelle Prüfung juristischer oder Geschäftsdokumente, Risikohinweise und Extraktion von Kernklauseln.
- Implementierung:
Startlädt Vertrags-PDF hoch ->Document Extractorextrahiert Text ->LLM-Knoten (als Jurist-Rolle konfiguriert) prüft Haftungsklauseln, Zahlungsbedingungen, Vertragsbruchklauseln usw. ->Parameter Extractor-Knoten extrahiert Schlüsseldaten, Beträge, Pflichtparteien als strukturierte Daten ->Answergibt Risikohinweise und Kernpunkte-Tabelle aus. Die Komplexität liegt in der Langdokumentverarbeitung und strukturierten Informationsextraktion.
3.3 Lern- und Lebensworkflows
Tiefenanalyse wissenschaftlicher Arbeiten und Notizgenerator (komplex)
- Ansatz: PDF einer wissenschaftlichen Arbeit hochladen und automatisch strukturierte Notizen generieren.
- Implementierung:
Startlädt PDF hoch ->Document Extractorextrahiert Volltext -> paralleleLLM-Knoten teilen sich die Arbeit: Zusammenfassung, Methoden, Ergebnisse, Referenzen ->Variable Aggregatorfasst zusammen ->Answergibt Markdown-Notizen aus. Die Komplexität liegt in der Parallelverarbeitung verschiedener Teile eines Langtextes.
Personalisierter Reiseplan-Designer (mittel)
- Ansatz: Basierend auf Benutzerpräferenzen automatisch eine detaillierte Reiseroute planen.
- Implementierung:
Startgibt Anforderungen ein (Reiseziel, Tage, Budget, Interessen) ->Tool-Knoten ruft Suchmaschine oder Karten-API auf, um Ortsinformationen abzurufen ->LLMintegriert Informationen und entwirft täglichen Reiseplan (mit Zeiten, Aktivitäten, Budgetschätzung). Die Komplexität liegt beim Abruf externer Informationen und der strukturierten Planung.
Interaktiver Fremdsprachen-Lernpartner (einfach)
- Ansatz: Einen Dialog-Bot erstellen, der Rollenspiele und Grammatikkorrektur durchführen kann.
- Implementierung: System definiert AI-Rolle ->
Startempfängt Benutzersatz ->LLMführt zwei Aufgaben aus: Rollenantwort + Grammatikkorrektur und Erklärung ->Answergibt aus. Der Kern liegt in den Multi-Task-Anweisungen des LLM.
Persönlicher Wissensdatenbank-Frage-Antwort- und Link-Empfehlungssystem (komplex)
- Ansatz: Basierend auf deinen gespeicherten Dokumenten, Notizen und Web-Links ein befragbares System aufbauen, das auch verwandtes altes Wissen empfehlen kann.
- Implementierung: Offline-Verarbeitung:
Document ExtractorundEmbedding-Werkzeuge verwenden, um persönliche Wissensdatenbank zu segmentieren und vektorisiert zu speichern. Online-Workflow:Startgibt Frage ein ->Retrieval-Knoten sucht relevanteste Wissensfragmente aus der Vektordatenbank ->LLMgeneriert Antwort basierend auf gefundenem Kontext -> gleichzeitig generiert ein anderer Zweig basierend auf gefundenen Inhalten überLLMeine „verwandtes altes Wissen"-Empfehlungsliste ->Answergibt Antwort und Empfehlungen kombiniert aus. Die Komplexität liegt im Aufbau des RAG-Prozesses (Retrieval-Augmented Generation).
Fitness-/Ernährungsplan-Tracking und Anpassungsberater (mittel)
- Ansatz: Basierend auf den täglichen Ernährungs- und Trainingseinträgen des Benutzers Ernährungsanalysen und Trainingsempfehlungen geben.
- Implementierung:
Startgibt Textprotokoll ein (z. B. „Mittagessen: Hähnchenbrust 150g, Reis eine Portion, Gemüse etwas; Training: Kniebeugen 5 Sätze") ->Parameter Extractor-Knoten versucht, die Eingabedaten zu strukturieren ->LLMspielt Fitness-Trainer, analysiert ob die Nährstoffaufnahme ausgewogen und das Trainingsvolumen angemessen ist -> Vergleich mit langfristigen Zielen, gibt Feinanpassungsempfehlungen (z. B. „Proteinaufnahme ausreichend, empfehle mehr Gemüsesorten"). Die Komplexität liegt in der Extraktion strukturierter Informationen aus unstrukturierten Protokollen und der Bereitstellung personalisierten Feedbacks.
6. Grenzen von Workflow-Plattformen
Workflow-Plattformen (auch Low-Code-Plattformen genannt) sind keine universelle Lösung. Obwohl sie geschäftsorientierten Benutzern entgegenkommen und die Hürde für direktes Codieren senken, ist „Low-Code" aus einer anderen Perspektive oft auch eine Art „High-Code" — Benutzer müssen weiterhin die Konzepte, Regeln und Bedienungslogik der Plattform verstehen, was selbst eine neue Lernkurve darstellt.
Vielleicht fragst du dich: Viele einfache Workflows sind eigentlich nur hintereinander geschaltete Aufrufe von großen Modellfunktionen, bei denen die Ausgabe der vorherigen Funktion als Eingabe der nächsten dient. Im Wesentlichen ließen sich diese mit wenigen Codezeilen lösen. Warum braucht man so komplex verschachtelte Workflows? Das erschwert sogar API-Aufrufe.
Du hast damit recht. Angesichts der raschen Entwicklung von Vibe Coding und den Code-Generierungsfähigkeiten von AI ist es manchmal effizienter, Code direkt zu lesen oder sogar zu generieren. Im Idealfall möchten wir Anwendungslogik direkt in natürlicher Sprache steuern — das wäre eine moderne Softwareplattform. Aktuelle Workflow-Plattformen haben dies jedoch noch nicht erreicht, daher gibt es naturgemäß eine „Zwischenschicht" zwischen der Benutzerabsicht und der endgültigen Implementierung. Diese Zwischenschicht zu beherrschen, ist eine Fähigkeit, die Zeitinvestition erfordert. Idealweise sollten zukünftige Workflow-Plattformen auch vollständige AI-gesteuerte Dialogoperationen unterstützen, sodass AI den Workflow-Aufbau und die Parametereingabe in jedem Detail tatsächlich selbst steuern kann.
Dennoch wird die kompetente Nutzung solcher Plattformen allmählich zu einer Grundfähigkeit, ähnlich wie Microsoft Office-Software — sie ist im Geschäftsalltag weit verbreitet und praktisch und es lohnt sich, sie zu beherrschen.
In den fortgeschrittenen Kursen werden wir vorstellen, wie man auf Code-Ebene mit Workflow- und RAG-Entwicklungsplattformen arbeitet. Dann kannst du selbst erleben, wie sich verschiedene Implementierungsansätze in Komplexität und Flexibilität unterscheiden. (Bemerkenswert ist, dass einige einfache Dialoganwendungen oder verschachtelte Logik mit Workflows möglicherweise gar nicht so schwierig umzusetzen sind.)
📚 Hausaufgaben
Dify-Grundlagen beherrschen
Um zu testen, ob du die häufigsten Dify-Basistools beherrschst, musst du eine Grundaufgabe und zwei „kleine Herausforderungen" absolvieren, um sicherzustellen, dass du die gängigen Operationen gemeistert hast. Du musst die beiden beigefügten DSL-Dateien in den Dify-Workflow importieren und die entsprechenden Workflow-Herausforderungen erfolgreich absolvieren (bei Unklarheiten Screenshots machen und das große Modell fragen, oder selbst die Verwendung der einzelnen Parameter erkunden und schließlich das Ziel erreichen):
- Referenziere die Methode des Intent-Classification-Workflows und lass dir vom großen Modell ein komplett neues Szenario vorschlagen. Du musst jedoch zwingend den Intent-Classification-Workflow verwenden. Reiche am Ende Screenshots des laufenden Workflows, die Szenariobeschreibung und die Ergebnisse ein.
- Log in workflow Workflow-Entschlüsselungs-Challenge
In dieser Entschlüsselungs-Challenge musst du folgende Herausforderungen absolvieren, damit der Workflow folgende Funktionen erfüllt:
- Finde das richtige Passwort!
- Ändere das Passwort auf 0925
- Wenn das Passwort falsch ist, biete eine zweite Versuchsmöglichkeit an (keine dritte)
- Wenn der Benutzer erwähnt, dass er sich erneut anmelden möchte, biete ihm die Möglichkeit, das Passwort erneut einzugeben
Referenz-Ein-/Ausgabe:
- Love loop workflow Workflow-Entschlüsselungs-Challenge
In dieser Entschlüsselungs-Challenge musst du die Probleme des aktuellen Workflows beheben, damit der Workflow am Ende eine Ausgabe ähnlich der folgenden zeigt:
Wenn du auf ungelöste Probleme stößt, mach bitte Screenshots und frage das große Modell oder konsultiere die offizielle Dokumentation: https://docs.dify.ai/en/use-dify/getting-started/quick-start
Dify API-Aufruf implementieren
Um zu testen, ob du das Wissen über den Dify-API-Aufruf wirklich beherrschst, musst du folgende Aufgaben absolvieren:
- Deploye Dify und erstelle eine einfache Wissensdatenbank (wähle Materialien, die dir gefallen).
- Verwende die Trae IDE, um ein Dialog-Frontend zu erstellen, das mit der Dify-Wissensdatenbank über API interagiert.
- Teste die Wirkung von Mehrfach-Dialogen und stelle sicher, dass das Programm ordnungsgemäß funktioniert.
Du musst Screenshots der endgültigen Ausführung und des Wissensdatenbank-Verarbeitungsprozesses einreichen.
Drittanbieter-Workflow ausprobieren / eigenen Geschäftsworkflow erstellen
Bitte suche auf Github, in WeChat-Offiziellen Accounts, Reddit, Twitter oder überall sonst nach einem Dify-Workflow, den du ausprobieren möchtest. Lade ihn herunter, importiere ihn und führe ihn erfolgreich aus; oder du kannst basierend auf den oben genannten Geschäftsworkflow-Referenzen einen eigenen Geschäftsworkflow basierend auf konkreten Anforderungen aus der Realität erstellen und ausführen.
Am Ende musst du einen Screenshot der erfolgreichen Ausführung einreichen und die Funktion dieses Workflows beschreiben.
[Bug] Lösung für HTTP-Anforderungsfehler
Nur wenn du auf das in der folgenden Abbildung gezeigte Problem stößt, solltest du die Lösung in diesem Abschnitt beachten. Andernfalls kannst du diesen Teil ignorieren.
Manchmal hast du Dify möglicherweise auf deinem eigenen Server deployt, aber die externe Adresse des Servers ist normalerweise HTTP statt HTTPS. Wenn wir jedoch einen Dienst anfordern, der nur HTTP unterstützt, siehst du möglicherweise einen Hinweis wie diesen (aktiviere den F12-Browser-Debug-Modus und überprüfe die problematische Stelle):
Dieses Problem tritt auf, weil wir Dify standardmäßig auf einem Server deployen, der nur HTTP und nicht HTTPS unterstützt. HTTPS (HyperText Transfer Protocol Secure) fügt HTTP (HyperText Transfer Protocol) eine SSL/TLS-Verschlüsselungsschicht hinzu. Man kann es sich einfach als eine „sicherere Version von HTTP" vorstellen.
Um den Dienst HTTPS-fähig zu machen, kann man generell:
- Ein anderes Programm zur Weiterleitung der Anfragen verwenden (z. B. Reverse Proxy auf einem Nginx mit Zertifikat), oder
- Eine Domain binden und ein Zertifikat für diese Domain beantragen.
Diese Operationen sind jedoch relativ komplex. Hier verwenden wir Zeabur als Netzwerk-Forwarding-Gateway, um das Problem zu lösen.
Die Zeabur-Webseite wird standardmäßig über HTTPS aufgerufen. Daher müssen wir nur die ursprünglich angeforderte Domain an die von Zeabur bereitgestellte Domain weiterleiten, um dieses Problem zu beheben.
- Ursprüngliche Adresse:
http://{DIFY_API_URL}/v1/chat-messages - Neue Adresse:
https://{DIFY_NEW_API_URL}.zeabur.app/v1/chat-messages
Du musst einfach den Domain-Teil in der URL (öffentliche IP oder Domain) durch die auf Zeabur bereits deployte Domain ersetzen. Wir haben den Forwarding-Dienst bereits im Voraus konfiguriert.
Wenn du interessiert bist, kannst du auch selbst einen Forwarding-Dienst auf Zeabur deployen. Beim Erstellen eines Dienstes auf Zeabur wähle Python aus und gib den folgenden Python-Code ein. Nach dem Deployment erhältst du eine HTTPS-Adresse, die dann normal verwendet werden kann.
Konfiguriere nach Abschluss des Deployments in den Netzwerkeinstellungen den lokalen Überwachungs-Port des Programms auf 8080 und exponiere diesen Port nach außen.
Hinweis: Bitte ersetze {DIFY_API_URL} durch die tatsächliche Dify-API-Adresse.
from flask import Flask, request, Response
import requests
app = Flask(__name__)
TARGET_BASE_URL = "{DIFY_API_URL}"
LISTEN_PORT = 8080
@app.route('/', defaults={'path': ''}, methods=['GET', 'POST', 'PUT', 'DELETE', 'PATCH', 'OPTIONS', 'HEAD'])
@app.route('/<path:path>', methods=['GET', 'POST', 'PUT', 'DELETE', 'PATCH', 'OPTIONS', 'HEAD'])
def proxy_request(path):
target_url = f"{TARGET_BASE_URL}/{path}"
if request.query_string:
target_url += f"?{request.query_string.decode('utf-8')}"
headers = {key: value for key, value in request.headers if key.lower() not in ['host', 'connection', 'content-length', 'accept-encoding']}
try:
resp = requests.request(
method=request.method,
url=target_url,
headers=headers,
data=request.get_data(),
cookies=request.cookies,
allow_redirects=False,
timeout=30
)
excluded_headers = ['content-encoding', 'content-length', 'transfer-encoding', 'connection']
response_headers = [(name, value) for name, value in resp.raw.headers.items() if name.lower() not in excluded_headers]
return Response(resp.content, resp.status_code, response_headers)
except requests.exceptions.RequestException as e:
print(f"Error forwarding request to {target_url}: {e}")
return Response(f"Proxy Error: Could not reach target server or invalid response: {e}", status=502)
except Exception as e:
print(f"An unexpected error occurred: {e}")
return Response(f"Internal Proxy Error: {e}", status=500)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=LISTEN_PORT, debug=True)