Dify 입문과 지식 베이스 통합
이전 수업 복습
이전 몇 차시 수업에서 우리는 조별로 AI 프로그래밍, 프롬프트 엔지니어링, AI 이미지 생성의 기초 지식을 학습했습니다. 이러한 내용은 다양한 대형 언어 모델(LLM, Large Language Model) 또는 생성형 모델의 한계와 능력을 이해하는 데 도움을 주었습니다.
이전 수업 내용을 복습하기 위해 아래 몇 가지 질문을 생각해 보세요:
- AI 프로그래밍이란 무엇인가요? AI 프로그래밍 도구(예: z.ai)를 사용하여 웹페이지를 만들려면 어떻게 해야 하나요?
- 대형 언어 모델이란 무엇인가요? 프롬프트 엔지니어링과 컨텍스트 엔지니어링이란 무엇이며, 복잡한 프롬프트는 어떻게 작성하나요?
- 텍스트, AI Coding, 이미지 생성 세 가지 방향에 대해, 모델 능력의 강약이 각각 어디에 나타난다고 생각하시나요?
- API란 무엇인가요? z.ai를 통해 서드파티 API에 어떻게 연결하나요?
이 중 어떤 질문에 대해 아직 의문이 있다면, 이전 수업의 문서를 다시 확인하거나 WeChat 그룹에서 직접 질문하셔도 좋습니다.
이번 수업에서는 간단한 AI 텍스트/이미지 도구에서 기업 실무 적용에 더 가까운 워크플로우 구축 플랫폼으로 나아갑니다. 대화형 챗봇에서 AI 에이전트, AI 워크플로우로 발전하고, API를 기반으로 상호작용 가능한 "지능형" 봇 페이지로 만들어 보겠습니다.
실습 과정에서 이해하기 어려운 단계가 있다면 걱정하지 마세요. 현재 보고 있는 조작 화면을 스크린샷으로 찍어 대형 모델에게 질문하는 것을 추천합니다. 현재 대형 모델은 대부분의 일반적인 질문에 답변할 수 있을 정도로 충분히 발전했습니다.
질문 후에도 해결되지 않는다면, 과감하게 직접 조작해 보세요. 실수를 두려워할 필요가 없습니다. 모든 시도는 학습이자 성장의 기회입니다. 실습 횟수가 늘어날수록 점점 익숙해지고, 조작도 더욱 자연스러워질 것입니다!
이번 수업에서 배울 내용
- 챗봇에서 에이전트와 Workflow 편성으로 나아가야 하는 이유
- 에이전트와 워크플로우 개발 플랫폼이란 무엇이며, AI의 능력을 SOP화하고 편성 가능하게 만드는 방법
- Dify란 무엇이며, LLM 애플리케이션을 위한 이 오픈소스 플랫폼으로 지식 베이스 Q&A 봇을 빠르게 구축하는 방법
- RAG의 구현 방법과 가치, 검색 증강 생성이 필요한 이유
- 0부터 1까지 Dify와 AI IDE Trae(
Extra Knowledge 4 - What is AI IDE and Trae)를 사용하는 방법, 에이전트 및 워크플로우 구축, Dify API를 기반으로 한 프론트엔드 대화형 봇 웹 프로그램 제작 포함
- Dify의 기본 사용 원리와 에이전트, 워크플로우 제작 방법, API 호출 방법
- AI IDE의 사용 방법과 AI IDE로 프로그래밍하는 방법
- 대화가 가능한 프론트엔드 웹 에이전트 프로그램
1. 대화에서 에이전트로
이전 단계에서 우리는 프롬프트를 통해 대형 모델이 역할을 수행하거나, 텍스트를 생성하거나, 간단한 코드를 작성하도록 하는 방법을 배웠습니다. 하지만 잘 생각해 보면 한 가지 문제를 발견할 수 있습니다. 챗봇 자체로는 실제로 어떤 일도 할 수 없다는 것입니다.
"주문을 어떻게 조회하나요?"라는 질문에는 답할 수 있지만, 실제로 데이터베이스에서 해당 데이터를 조회할 수는 없습니다. 주간 보고서에 무엇이 포함되어야 하는지 설명할 수 있지만, 프로젝트 데이터를 자동으로 취합하여 이메일을 발송할 수는 없습니다. 이러한 "말만 하고 실행하지 않는" 한계 때문에 순수 대화형 AI는 실제 업무 프로세스에 통합되기 어렵습니다.
AI를 단순한 대화 상대에서 디지털 직원으로 업그레이드하려면, 세 가지 핵심 능력을 부여해야 합니다:
- 전용 지식 -- 제품 문서, 고객 정보, 내부 규정을 읽고 이해할 수 있는 능력
- 도구 호출(또는 플러그인) -- 데이터베이스 조작, API 호출 능력
- 구조화된 실행 -- 자유로운 발휘가 아닌, 미리 설정된 논리에 따라 단계별로 작업을 완료하는 능력
이것이 바로 AI 에이전트(AI Agent)의 초기 형태입니다. 목표, 지식, 도구, 실행 경로를 갖춘 자동화 단위입니다.

참고: 현재 업계에서 말하는 간단한 버전의 "에이전트"는 대부분 LLM + 도구 + 지식 베이스의 조합으로 구성된 향상형 애플리케이션을 의미하며, 자율적으로 계획을 수립할 수 있는 에이전트를 말하는 것은 아닙니다. 간단한 에이전트는 진정한 추론과 장기 계획 능력은 갖추지 못했지만, 이미 많은 기업급 자동화 시나리오를 지원하기에 충분합니다. 자율 계획 및 행동 능력을 갖춘 진정한 에이전트에 대해서는 이후 장에서 자세히 다루겠습니다.
1.1 가장 간단한 에이전트: 지식 베이스 기반 Q&A 봇
에이전트가 갖춰야 할 여러 핵심 능력을 명확히 한 후, 한 가지 생각할 만한 질문이 생깁니다: 그 중 가장 간단한 기능 하나만 구현하는 것만으로도 실제로 사용 가능한 기본 에이전트를 구축할 수 있을까요? 대답은 "가능하다"입니다.
사실, 많은 실제 업무 시나리오에서 사용자의 핵심 요구는 AI가 복잡한 작업(예: API 호출이나 시스템 간 작업 조정)을 자동으로 실행하는 것이 아니라, 기업 자체의 전용 자료를 바탕으로 정확하고 신뢰할 수 있는 질문답변 지원을 제공하는 것입니다. 이는 에이전트의 세 가지 핵심 능력 중 첫 번째인 전용 지식 서비스 능력에 정확히 해당합니다. 따라서 우리는 에이전트의 가장 간단하면서도 널리 사용되는 형태인 지식 베이스 기반 Q&A 봇을 소개할 수 있습니다.
아직 도구 호출이나 자율 계획 능력은 갖추지 못했지만, 핵심적인 돌파구는 대형 모델의 답변이 더 이상 근거 없이 생성되는 것이 아니라 확실한 근거에 기반하게 된다는 것입니다. 어떻게 구현할까요? 핵심은 기업 내부에 대량의 문서 지식이 존재할 때, 수천 수만 페이지의 문서 중에서 매 대화마다 현재 질문과 가장 관련성이 높은 내용을 빠르게 찾아내는 핵심 과제를 해결하는 것입니다.
이때 하나의 해결책이 검색 증강 생성(Retrieval-Augmented Generation, RAG)입니다.
RAG의 기본 아이디어는 사용자가 질문할 때, 시스템이 먼저 기업 지식 베이스에서 질문의 의미와 가장 관련성이 높은 여러 텍스트 조각(예: 제품 매뉴얼의 특정 단락, HR 규정의 특정 조항)을 검색한 후, 이러한 조각을 컨텍스트로서 대형 모델의 입력에 "주입"하여, 실제 자료를 바탕으로 답변을 생성하도록 유도하는 것입니다.
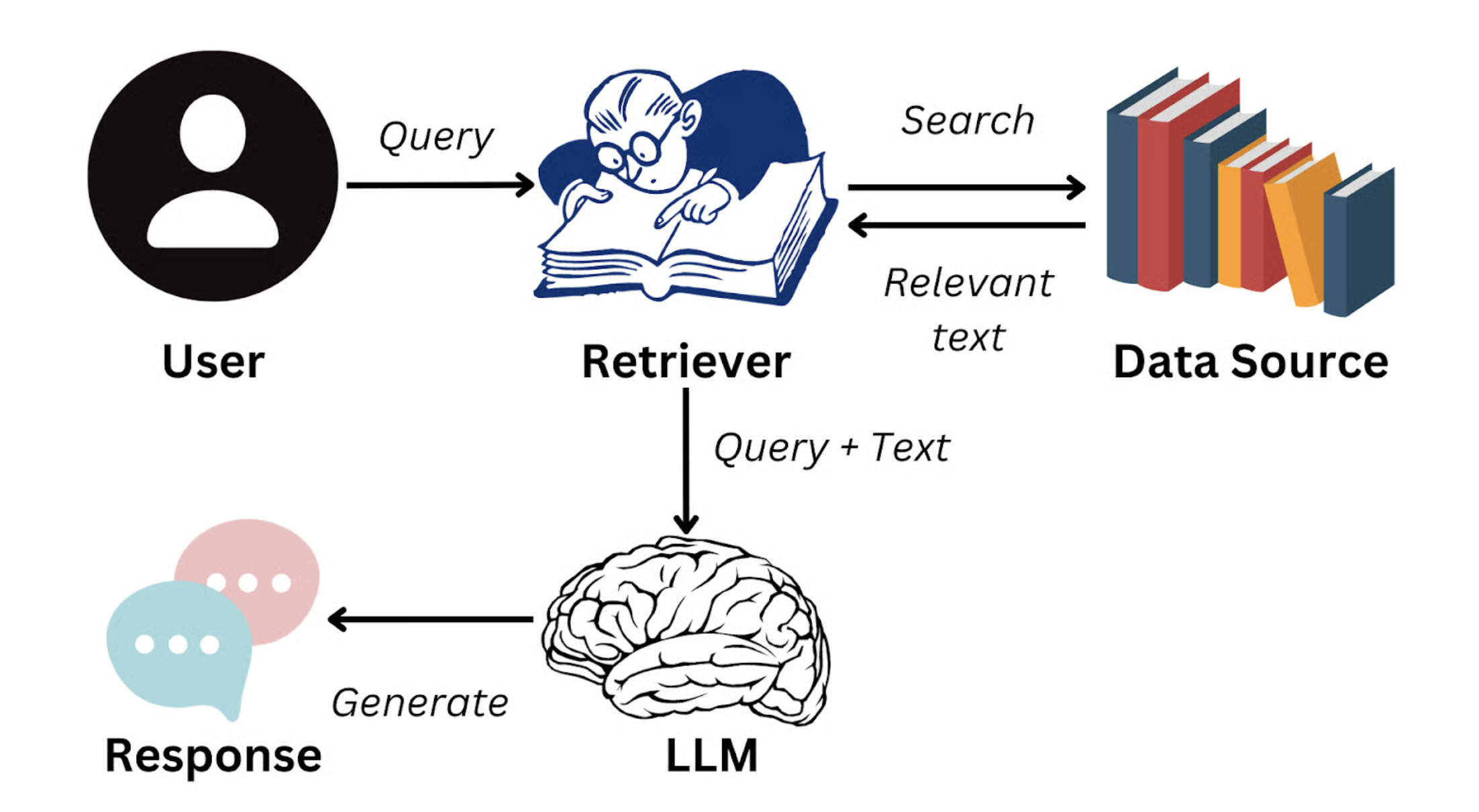
이미지 출처: https://www.datacamp.com/blog/what-is-retrieval-augmented-generation-rag
이렇게 하면 모델의 답변은 더 이상 학습 데이터의 일반화된 지식에 의존하지 않고, 기업이 제공한 권위 있는 정보에 고정됩니다. RAG의 목표는 바로 이러한 외부 지식의 동적 주입을 통해 답변의 진실성, 정확성, 일관성을 크게 향상시키는 것입니다. 심지어 답변이 "페르소나에 맞게" 할 수도 있습니다. 예를 들어 고객 서비스 어조나 기술 문서 스타일로 답변하는 것이 가능합니다.
실제 업무에서 이 기술은 특히 중요한데, 대형 모델이 종종 "환각(hallucination)"을 일으키기 때문입니다. 예를 들어, CFO나 컨설턴트의 신분으로 특정 기간의 구체적인 데이터를 질문하면, 모델이 날짜와 이벤트를 조작할 가능성이 높습니다. RAG를 도입하면 답변의 통제 가능성과 신뢰성이 크게 향상됩니다.
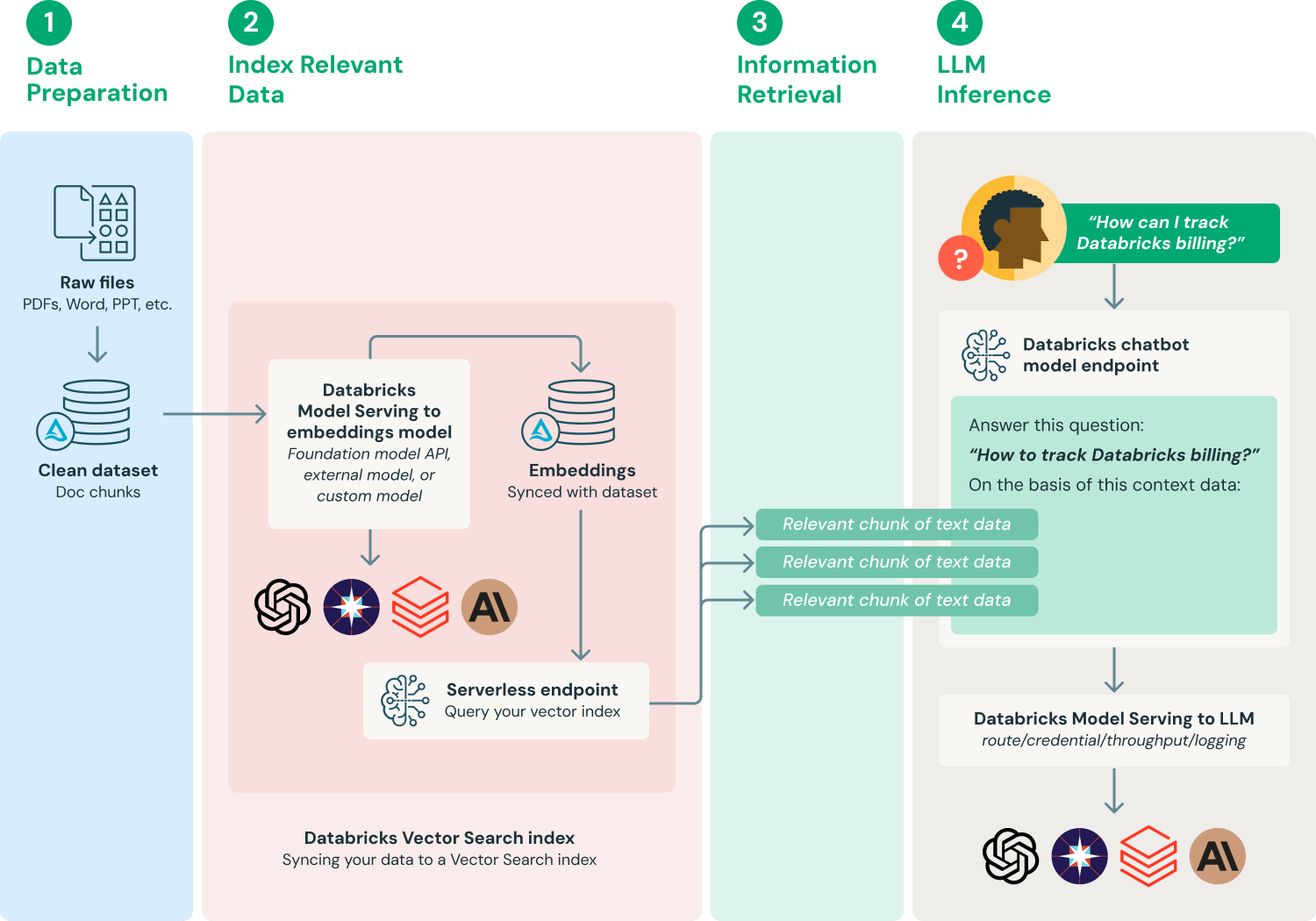
이미지 출처: https://www.databricks.com/glossary/retrieval-augmented-generation-rag
이번 수업의 실습에서는 인기 있는 AI 워크플로우 플랫폼인 Dify를 사용하여 지식 베이스 기반 Q&A 봇을 직접 구축해 보겠습니다. 제품 매뉴얼, 회사 규정, 프로젝트 문서, 연구 논문, 지식 베이스 문서, 심지어 개인 메모 모음 등 다양한 유형의 전용 자료를 지식 베이스로 쉽게 구축할 수 있습니다.
구축이 완료되면, 다양한 질문을 통해 그 능력을 테스트해 볼 수 있습니다. 예를 들어:
- "우리 제품 A의 최신 버전에는 어떤 주요 기능 업그레이드가 있나요?"
- "직원 매뉴얼에 따르면, 올해 연차 제도는 어떻게 규정되어 있나요?"
- "XX 프로젝트에서 우리가 겪은 기술적 과제 'XXX'는 어떻게 해결되었나요?"
- "이 논문에서 언급된 핵심 연구 방법은 무엇인가요?"
RAG 기술이 정적이고 분산된 문서 자료를 어떻게 정확한 지능형 지식 베이스로 변환하여, 다양한 시나리오에 고정밀 Q&A 지원을 제공하는지 직접 체험해 보세요.
1.2 대화형 에이전트에서 워크플로우로
하지만, 지식 베이스는 물론 플러그인 호출 능력까지 갖춘 "향상형 에이전트"라 할지라도, 더 복잡한 업무 프로세스 앞에서는 여전히 부족합니다.
다음과 같은 사용자 요청을 상상해 보세요: "새로 출시한 SaaS 제품의 최근 기능 업데이트는 무엇인가요? 고객용 브리핑으로 정리해 줄 수 있나요?"
이 요청은 간단해 보이지만, 배경에는 여러 협업 단계가 필요합니다. 먼저 내부 제품 문서나 Notion 지식 베이스에서 최근 한 달간의 기능 출시 기록을 검색하고, 고객 대상 핵심 기능을 필터링한 후, 대형 모델을 호출하여 기술적 설명을 고객 친화적인 언어로 변환하고, 마지막으로 생성된 콘텐츠를 마케팅 팀의 이메일로 전송하거나 Google Docs 템플릿에 저장합니다.
단순히 하나의 대형 언어 모델이 자유롭게 추론하는 것에만 의존한다면, 한 번의 대화로 모든 과정을 구현할 수 있는지는 차치하더라도, 그 과정에서 핵심 정보가 누락되거나, 내부 용어와 고객 용어가 혼동되거나, 구조화된 출력이 불가능할 가능성이 높습니다. 더 중요한 것은, 기업에는 감사 가능하고, 재사용 가능하며, 모니터링 가능한 표준화된 실행 경로가 필요하다는 것입니다. 매번 모델의 임의적인 발휘에 의존하는 것이 아니라, 모니터링 가능하고 재현 가능한 것이 기업에 매우 중요합니다. 예상치 못한 결과는 예상치 못한 심각한 손실을 초래할 수 있기 때문입니다.
이것이 더 높은 수준의 AI 애플리케이션 패러다임인 AI 워크플로우(AI Workflow)로 이어집니다.

워크플로우란 복잡한 작업을 여러 개의 순서가 있고, 구성 가능하며, 자동 실행 가능한 하위 단계로 분해하고, 조건 판단, 루프 또는 병렬 실행과 같은 논리적 관계를 시각적 또는 코드 방식으로 편성하는 것을 말합니다. AI 능력의 SOP화(즉, 표준화된 작업 프로세스)란 AI로 특정 작업을 완료하는 방법의 경험을 재사용 가능한 템플릿으로 고정하는 것을 의미합니다.
이러한 방식은 여러 가지 가치를 가져옵니다: 비기술자(예: 제품 관리자나 운영자)는 드래그 앤 드롭으로 AI 애플리케이션을 빠르게 구축할 수 있습니다. 개발자는 RAG 검색, LLM 호출, API 도구 등을 표준 노드로 캡슐화하여, 다양한 업무 시나리오에서 재사용할 수 있습니다. 전체 프로세스는 완전히 추적, 디버깅 및 지속적인 최적화가 가능하여, 기업의 안정성 및 규정 준수 요구사항을 충족합니다.
AI 워크플로우의 사용자층은 매우 넓습니다. 제품 관리자는 코드를 작성할 필요 없이 완전한 사용자 상호작용 경로를 설계할 수 있습니다. 운영자는 고객 서비스 봇, 콘텐츠 생성기 또는 알림 시스템을 빠르게 구축할 수 있습니다. 개발자와 알고리즘 엔지니어는 핵심 기능을 모듈화하여 프론트엔드에서 호출할 수 있도록 제공할 수 있습니다. 창업자나 독립 개발자도 매우 낮은 비용으로 AI 제품의 MVP를 검증하고, 며칠 안에 데이터 조회, 콘텐츠 생성, 액션 실행을 포함한 완전한 프로토타입을 출시할 수 있습니다.
또한, AI 워크플로우는 일반적으로 중간 표현(Intermediate Representation)으로 설명할 수 있다는 점도 주목할 만합니다. 워크플로우 플랫폼마다 구체적인 표현 방식에는 차이가 있지만, 대부분 구조화된 파일(예: JSON, YAML 등)을 사용하여 노드 유형, 입력/출력 및 실행 논리를 정의하며, 그 구조는 아래 그림과 유사합니다:

간단히 말해, 에이전트가 AI를 "대화만 할 수 있는" 상태에서 "실제로 일을 할 수 있는" 상태로 만들었다면, 워크플로우는 AI를 "가끔 한 가지 일을 해내는" 수준에서 "안정적이고, 신뢰할 수 있으며, 대규모로 한 유형의 작업을 완수하는" 수준으로 끌어올립니다. 다음 실습에서는 Dify 플랫폼을 활용하여 완전한 AI 워크플로우를 직접 구축하고, 아이디어에서 실행 가능한 애플리케이션까지의 전체 과정을 체험해 보겠습니다.
1.3 주요 에이전트 / 워크플로우 플랫폼
생성형 AI 기술의 급속한 발전에 따라, 개발자와 업무 담당자가 에이전트와 자동화 프로세스를 빠르게 구축하고 프로그래밍의 복잡한 세부 사항에 빠지지 않도록 돕기 위해, 로우코드 또는 노코드 에이전트 및 워크플로우 플랫폼이 등장했습니다.
먼저 명확히 해야 할 것은, 로우코드 플랫폼이란 시각적 드래그 앤 드롭 구성 요소, 사전 구축된 업무 논리 템플릿, 그래픽 규칙 구성 등의 방식을 통해 수동 코딩 작업량을 크게 줄여주는 개발 도구를 의미합니다. 그 핵심은 시각적 구성과 노드식 드래그 앤 드롭 방식이 직접 코드를 작성하는 방식을 대체하는 것으로, 일정한 기술 능력을 갖춘 개발자를 반복 작업에서 해방시킬 뿐만 아니라, 업무 논리에 익숙한 비기술자도 애플리케이션 구축에 참여할 수 있게 합니다. 본질적으로, 이는 개발 효율성과 시나리오 유연성 사이의 균형을 잡는 다리입니다.
이러한 로우코드/노코드 에이전트 플랫폼의 뚜렷한 가치는 바로 AI 애플리케이션의 개발 진입 장벽을 크게 낮춘다는 것입니다. 이전에는 팀의 협업이 수 주 걸리던 — 요구사항 정리, 코드 개발, 테스트 및 배포까지 — AI 에이전트(예: 고객 서비스 Q&A 봇, 데이터 처리 어시스턴트)가, 이제는 플랫폼에서 제공하는 시각적 도구를 활용하여 "아이디어에서 출시까지"의 주기를 몇 시간으로 단축할 수 있습니다.
현재 시장에서 주요 로우코드 AI 워크플로우 플랫폼은 다음과 같습니다:
| 플랫폼 | 특징 | 적용 시나리오 |
|---|---|---|
| Dify | 오픈소스, 지식 베이스 RAG 지원, LLM 편성, API 출력, 한국어 친화적 | 기업 지식 베이스 Q&A, 맞춤형 Agent, API 서비스 |
| Coze(바이트댄스) | 중국 내 사용 가능, Douyin/Feishu 생태계 통합, 풍부한 플러그인 | 소셜 봇, 중국 내 미니 프로그램 통합 |
| n8n | 범용 자동화 도구, AI 노드 지원, API 편성 강조 | 크로스 시스템 데이터 동기화, AI + 기존 SaaS 자동화 |
| 바이두 첸판 AppBuilder / 알리 바이리안 / 텐센트 HunYuan | 대형 클라우드 네이티브 솔루션, 자사 모델 통합 | 기업급 배포, 높은 규정 준수 요구 시나리오 |
현재 시장의 로우코드 AI 워크플로우 플랫폼 선택지는 매우 다양합니다. AWS, Azure, 알리클라우드 등 주류 클라우드 공급업체 모두 해당 AI 워크플로우 솔루션을 출시했지만, Dify, Coze, n8n은 다음 세 가지 핵심 이점으로 인해 현재 가장 널리 사용되는 대표 플랫폼이 되었습니다:
- 극강의 사용 편의성. 플랫폼은 시각적 드래그 앤 드롭 인터페이스 설계를 채택하여, 사용자가 기반 기술을 깊이 이해하지 않고도 빠르게 시작할 수 있습니다.
- 높은 유연성. 사용자 정의 구성 요소와 확장 API 인터페이스를 지원하여, 교육 데모, MVP(최소 기능 제품) 검증 등 가벼운 시나리오에도 적합하고, 중소 규모 팀의 민첩한 반복 요구도 충족할 수 있습니다.
- 성숙한 생태계. 공식 문서가 상세하고 응답이 빠를 뿐만 아니라, 활발한 사용자 커뮤니티를 보유하고 있어 다양한 사용자의 사전 구축 솔루션을 빠르게 얻을 수 있습니다.
이 세 가지 플랫폼 모두 구축된 AI 에이전트를 표준화된 API 인터페이스 형태로 출력하는 것을 지원하여, 프론트엔드 웹 애플리케이션, 기업 내부 ERP 시스템 또는 모바일 앱에 원활하게 통합할 수 있으며, AI 능력의 실제 적용 기술 장벽을 더욱 낮춥니다.
1.3.1 Dify: 기업급 LLMOps 및 애플리케이션 라이프사이클 관리 플랫폼
Dify는 LLM 애플리케이션 개발 및 운영 플랫폼으로, AI 애플리케이션의 구상, 배포, 최적화까지 전체 라이프사이클 관리를 제공하는 데 전념합니다. 핵심은 로우코드 플랫폼으로, 개발자와 비기술적 배경의 혁신가가 프로덕션급 AI 애플리케이션을 빠르게 구축할 수 있도록 돕는 것을 목표로 합니다.
기능적으로 Dify는 시각적 워크플로우 편성, 에이전트 구축, 지식 베이스 관리, 다중 모델 지원 등을 포함합니다. 플랫폼은 드래그 앤 드롭 노드를 통해 복잡한 작업 흐름을 설계할 수 있게 하며, 의도 기반 Agent 생성도 지원합니다. 지식 베이스 기능이 뛰어나, 다양한 형식의 문서를 처리하고 효율적인 벡터 검색을 수행할 수 있습니다. 동시에 Dify는 GPT, Claude 및 수많은 오픈소스 모델을 포함한 다양한 LLM과 호환되며, 구축된 애플리케이션은 원클릭으로 표준 API로 게시하여 통합하기 쉽습니다.
기술 아키텍처 측면에서, Dify는 오픈소스와 사설 배포 가능을 특징으로 하며, 유연성, 확장성 및 기업급 규정 준수를 강조합니다. 대상 사용자는 개발자 팀과 업무 혁신가이며, 전형적인 적용 시나리오는 기업 지식 베이스 및 스마트 고객 서비스, 콘텐츠 제작 자동화, 특정 분야 AI 어시스턴트, 기업 AI 허브 등입니다.
1.3.2 Coze(바이트댄스): 제로코드 AI 에이전트 구축의 대중화자
Coze는 바이트댄스가 출시한 AI 에이전트 개발 플랫폼으로, 극강의 사용 편의성을 핵심으로, 프로그래밍 경험이 없는 사용자도 기능이 풍부한 AI 챗봇을 쉽게 생성, 디버깅 및 게시할 수 있게 합니다.
핵심은 Bot 구축을 블록 조립식 조작으로 단순화하는 것입니다. 사용자는 인터페이스를 통해 역할과 지식 베이스를 쉽게 구성하고, 풍부한 내장 플러그인 라이브러리를 활용하여 Bot에 뉴스, 여행, 이미지 생성 등 다양한 외부 기능을 추가할 수 있습니다. 생성된 Bot은 Doubao, Feishu, WeChat 공식 계정 등 여러 플랫폼에 원클릭으로 빠르게 게시할 수 있습니다.
기술 아키텍처는 완전히 낮은 진입 장벽 사용에 맞춰져 있으며, 백엔드는 바이트댄스 자체 모델을 통합하고 복잡한 프로세스를 캡슐화하며, 멀티모달 이해와 실시간 응답을 강조합니다. 주로 클라우드 서비스 형태로 제공되는 플랫폼으로서 사설 배포 능력은 상대적으로 제한적입니다. 전형적인 적용 시나리오는 개인 비서 및 엔터테인먼트 Bot, 스마트 고객 서비스 및 Q&A 시스템, 온라인 교육 어시스턴트, 빠른 프로토타입 검증 등입니다.
1.3.2 n8n: 프로그래밍 가능한 백엔드 워크플로우 자동화 엔진
n8n은 범용 프로그래밍 가능 워크플로우 자동화 플랫폼으로, 핵심 포지셔닝은 다양한 애플리케이션, 데이터베이스 및 API를 연결하여 데이터 흐름과 작업 자동화 실행을 실현하는 것입니다.
방대한 통합 노드 라이브러리를 통해 수백 종의 SaaS 서비스, 데이터베이스 및 프로토콜을 지원하며, 시각적 방식과 코드 방식의 결합을 채택합니다: 사용자는 캔버스에서 노드를 드래그하는 동시에 JavaScript나 Python 코드를 주입하여 사용자 정의 논리를 작성할 수 있습니다. n8n은 백엔드 데이터 집약형 작업(예: 데이터 동기화, ETL 프로세스, API 편성)을 처리하는 데 뛰어납니다.
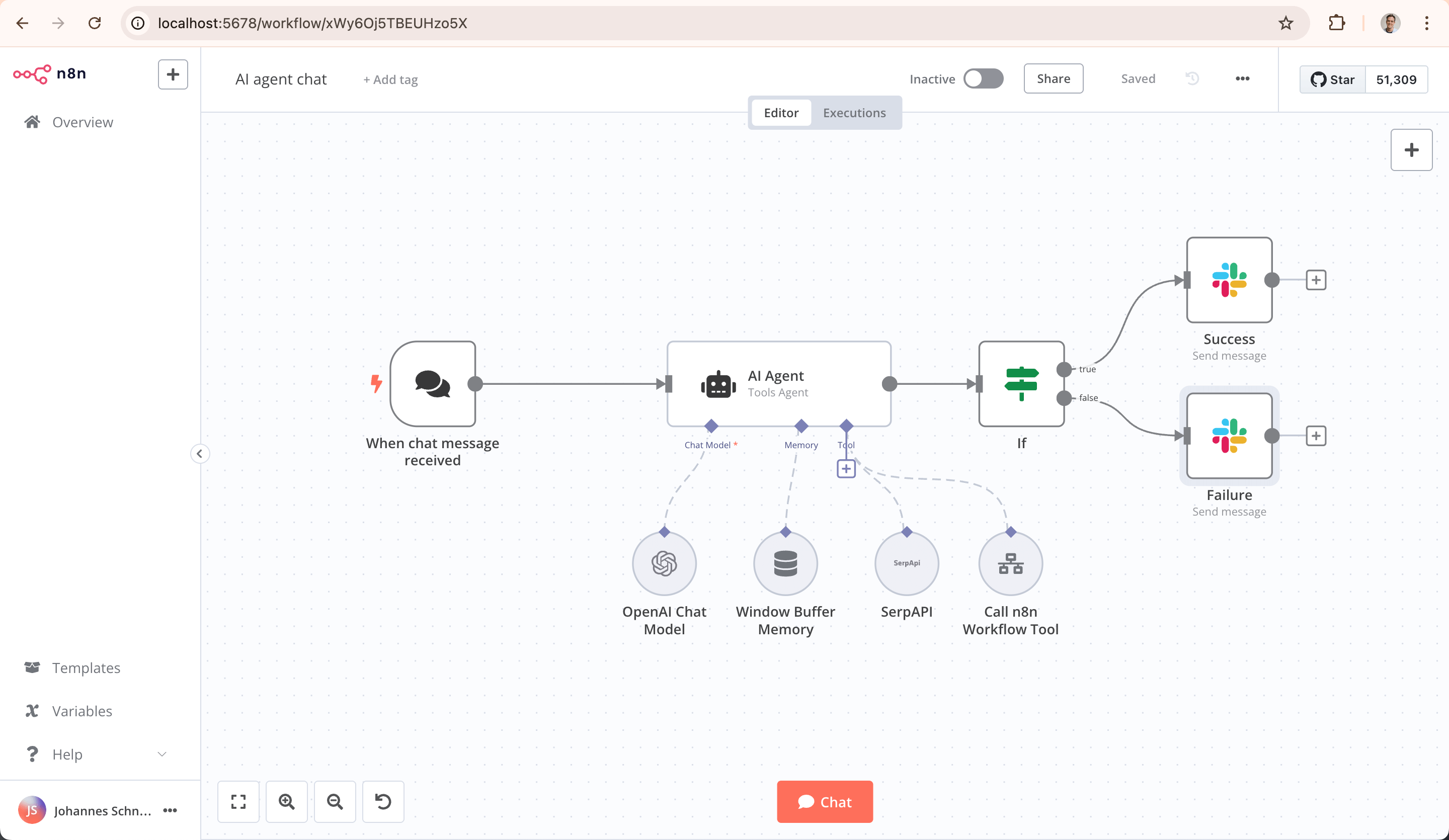
핵심 기술 특징은 "소스 코드 공개"와 "자체 호스팅 가능"으로, 사용자가 사설 배포하여 데이터와 환경을 완전히 통제할 수 있어, 데이터 보안 요구가 높은 산업에 매우 매력적입니다. 주요 대상 사용자는 개발자, 기술 운영 및 데이터 분석가입니다. n8n의 가장 큰 장점은 매우 강력한 커뮤니티 생태계에 있습니다. 인터넷에는 어디서나 찾을 수 있는 풍부한 n8n 공유 영상이 있어, 사용자에게 편리한 학습 참고 자료와 경험 공유를 제공합니다. 또한 YouTube, Instagram 등 전 세계 다양한 생태 플랫폼 연결을 지원하여, 사용자가 크로스 플랫폼 데이터 및 서비스의 장벽을 쉽게 허물고 다양한 생태 프로세스의 자동화 흐름을 실현할 수 있게 돕습니다.
1.3.3 기타 워크플로우 플랫폼
위에서 언급한 가장 유명한 플랫폼 외에도, 중국의 주요 기술 기업들도 각자의 통합 AI 개발 플랫폼을 잇달아 출시했습니다. 예를 들어: 바이두 첸판 AppBuilder는 모델 선택, RAG 구축부터 에이전트 게시까지의 전체 프로세스 지원을 제공하며, Wenxin 대형 모델과 깊이 통합되어 있습니다. 알리클라우드 바이리안은 Tongyi Qianwen 시리즈 모델을 기반으로, 기업급 보안 및 사설 배포 능력에 중점을 둡니다. 텐센트 클라우드 TI 플랫폼은 금융, 의료 등 산업 시나리오에 초점을 맞추어, 풍부한 사전 구축 솔루션 템플릿을 제공합니다. 이러한 플랫폼은 일반적으로 각자의 클라우드 생태와 깊이 통합되어 있어, 해당 기술 체계에 이미 속해 있는 기업에 적합합니다.
하지만, 범용성, 개방성, 커뮤니티 생태 측면에서 Dify와 Coze는 여전히 뛰어난 사용 편의성, 폭넓은 모델 지원, 활발한 개발자 커뮤니티를 바탕으로 현재 가장 널리 채택되는 선택지로 자리 잡고 있습니다.
각 플랫폼은 포지셔닝과 생태에서 각기 다른 측면에 중점을 두고 있지만, 핵심 논리는 모두 시각적 방식으로 다양한 기능 모듈을 편성하고 연결하는 것입니다. 따라서 이 중 하나의 플랫폼이라도 설계 사고와 조작 방법을 습득하면, 다른 유사한 도구로 빠르게 전환할 수 있는 기초를 갖추게 됩니다. 다음 실습에서는 Dify를 예로 구체적으로 설명하겠습니다.
2. Dify 깊이 있게 이해하기
2.1 Dify란 무엇인가
이미 기본적인 Dify 정보 소개를 확인했습니다. 더 자세한 정보는 https://cloud.dify.ai/apps를 통해 Dify 플랫폼에 접속할 수 있으며, 더 많은 정보를 원하시면 공식 웹사이트 https://dify.ai를 방문하세요.
Dify는 LLM 애플리케이션 개발을 위한 오픈소스 플랫폼입니다. 직관적인 인터페이스를 제공하여, Agent 워크플로우, RAG 파이프라인, 도구 능력, 모델 관리, 관측 가능성 등의 기능을 결합하여, 프로토타입에서 프로덕션 환경까지 빠르게 전환할 수 있도록 돕습니다.
Dify에서 대형 언어 모델과 다양한 기능의 도구를 사용하여 "워크플로우"를 구축할 수 있습니다. 워크플로우란 원래 수동으로 단계별로 완료해야 했던 조작(예: 데이터 검색, 대형 모델 호출, 웹 검색, 결과 필터링, 형식 정리 등)을 업무 논리에 따라 연결하여 자동화되고 재사용 가능한 프로세스로 만드는 것입니다. 워크플로우가 없다면, 매번 같은 내용을 대형 모델에 복사해서 붙여넣어야 하므로, 매우 비효율적이고 오류가 발생하기 쉬우며, 실제 업무에서 재사용하기 어렵습니다.
워크플로우를 구축하는 것은 블록을 조립하거나 퍼즐을 맞추는 것과 같습니다. "대형 언어 모델 노드"(이해 및 생성 담당), 다양한 "도구 노드"(특정 액션 실행 담당, 예: 데이터베이스 조회, 이메일 발송, 텍스트 번역 등), 그리고 "데이터 노드"(정보 읽기 및 저장 담당)를 블록처럼 연결합니다. 이들은 미리 설정된 논리에 따라 자동으로 협업하므로, 매번 수동으로 조작할 필요가 없습니다. 이를 "로우코드 프로그램"으로 이해할 수도 있습니다: 드래그 앤 드롭 방식으로 입력과 출력 경로만 구성하면, 비교적 복잡한 업무 논리를 구현할 수 있습니다.
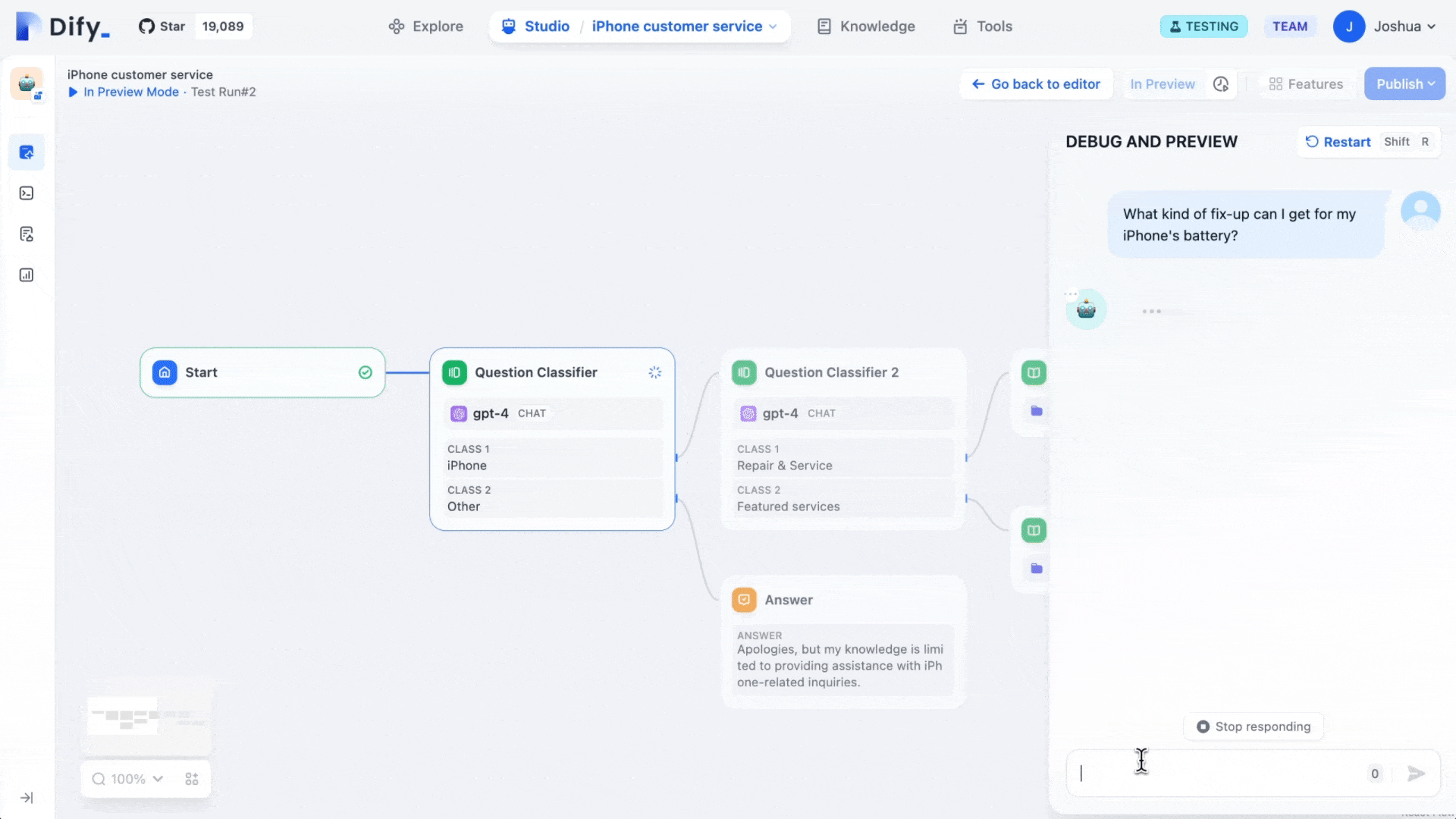
예를 들어, 아마존이나 Douyin 전자상거래 매장의 사장이라면, AI 고객 서비스 시스템을 구축하고 싶을 때 아래 그림의 구조를 참고하여 워크플로우를 설계할 수 있습니다:
- 트리거 노드(START와 유사): 사용자의 문의 질문을 수신합니다. 예: "이 상품의 보증 기간은 얼마인가요?"
- 질문 분류 노드(QUESTION CLASSIFIER와 유사): 모델(예: GPT)을 사용하여 사용자 질문을 분류합니다. A/S(예: 보증), 사용 방법, 또는 기타 유형의 질문인지 판단합니다.
- 지식 검색 노드(KNOWLEDGE RETRIEVAL와 유사): 분류 결과에 따라 해당 지식 베이스에 자동으로 접근합니다. "보증"에 관한 A/S 질문인 경우, A/S SOP 지식 베이스에서 "보증"과 관련된 정확한 정보를 검색합니다.
- 대형 언어 모델 노드(LLM Node): 사용자 질문과 검색된 지식 베이스 내용을 함께 대형 언어 모델(예: GPT)에 전송하여, 사용자 친화적인 답변을 생성합니다(지나치게 딱딱한 기술적 어조를 피함).
- 조건 노드: 대형 모델이 생성한 답변에 명확한 보증 기간(예: "1년", "3년")이 포함되어 있는지 확인합니다. 포함되어 있으면 다음 단계로 진행하고, 포함되어 있지 않으면 "제품 모델명을 알려주세요"라고 응답합니다.
- 출력 노드(ANSWER와 유사): 최종 답변을 사용자에게 반환하고, 이번 문의 기록을 자동으로 스프레드시트에 저장합니다.
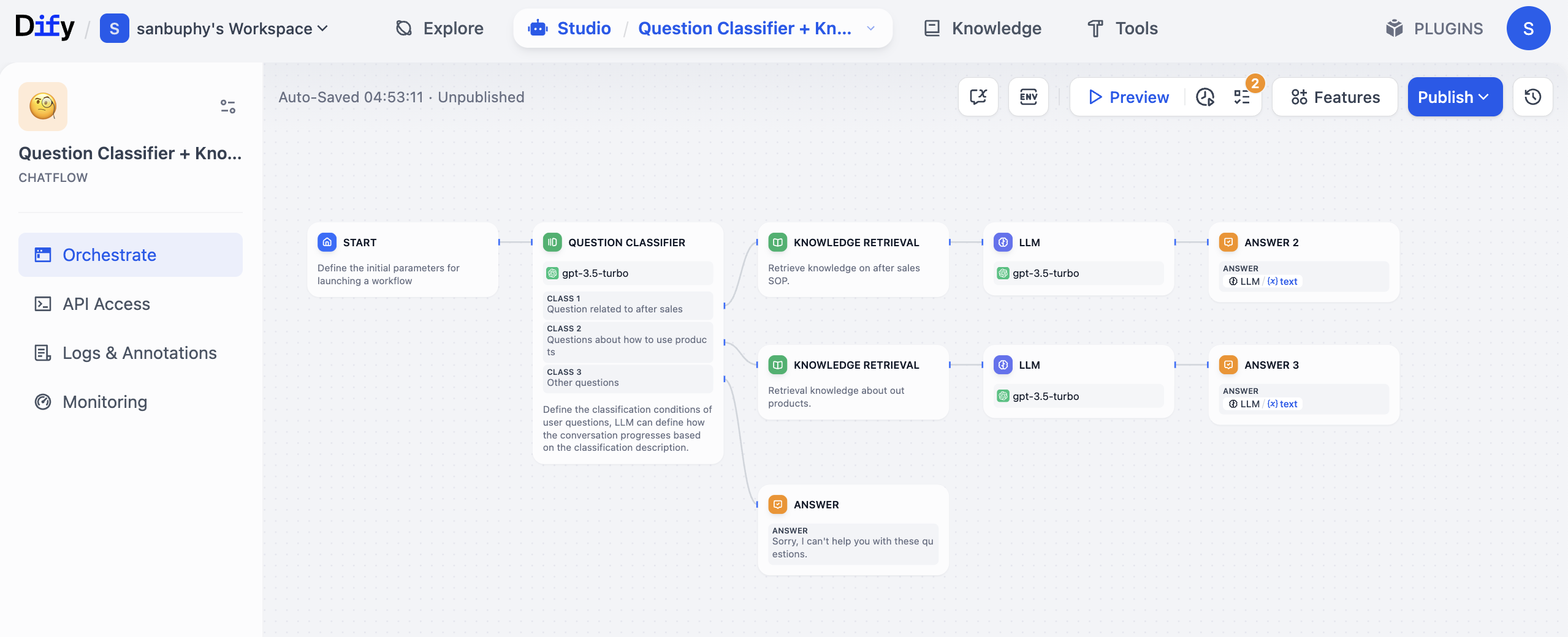
전체 과정에서 지식 베이스를 수동으로 찾거나, 모델의 답변을 반복 조정하거나, 데이터를 별도로 기록할 필요가 없습니다 — 워크플로우가 이러한 단계들을 "연결하여 자동으로 실행"합니다. 또한 매우 유연합니다: 예를 들어, 나중에 "사용자가 보증 범위를 물어볼 때, 다른 지식 베이스를 호출한다"는 새로운 규칙을 추가하고 싶다면, 워크플로우에 조건 노드를 하나 더 추가하기만 하면 되며, 전체 시스템을 재구축할 필요가 없습니다.
이것은 비교적 간단한 워크플로우 예시이지만, 이러한 능력을 완전히 마스터하는 것은 현재로서는 아직 조금 어려울 수 있습니다. 따라서 이번 수업에서는 더 기본적인 지식 베이스 에이전트부터 시작하고, 나중에 더 복잡한 워크플로우 기술을 점진적으로 학습하겠습니다.
2.1.1 나만의 Dify 배포하기(선택 사항)
이 부분의 내용은 원래 이후 과정에서 자세히 소개할 예정이었지만, 현재 일부 학습자가 네트워크 제한으로 인해 Dify 공식 웹사이트나 클라우드 서비스에 일시적으로 접근하지 못할 수 있다는 점을 고려하여, 과정 진행을 원활하게 하기 위해 이 선택적 학습 경로를 미리 제공하기로 결정했습니다.
웹 배포 플랫폼의 기본 사용 방법은 다음 튜토리얼을 참조하세요: 웹 애플리케이션 배포 방법
Zeabur에 나만의 Dify를 배포하는 방법을 학습해야 합니다. 배포 후 해당 링크로 들어가 회원가입 및 로그인한 후 아래 튜토리얼에 따라 계속 진행하면 됩니다.
참고로, Dify 버전에 따라 조작 방식과 프론트엔드 인터페이스에 약간의 차이가 있을 수 있지만, 전반적으로 큰 차이는 없습니다. 차이를 발견하더라도 당황하지 마시고, 비슷한 인터페이스와 진입점을 찾아 조작하시면 됩니다.
2.2 첫 번째 Dify Chatbot 애플리케이션 만들기
Dify 홈페이지 https://cloud.dify.ai/apps에 접속하여 회원가입 및 로그인 후, Studio를 선택하면 다음과 같은 인터페이스가 나타납니다:
왼쪽에서 CREATE APP 영역을 찾아, Create from Blank를 클릭합니다.
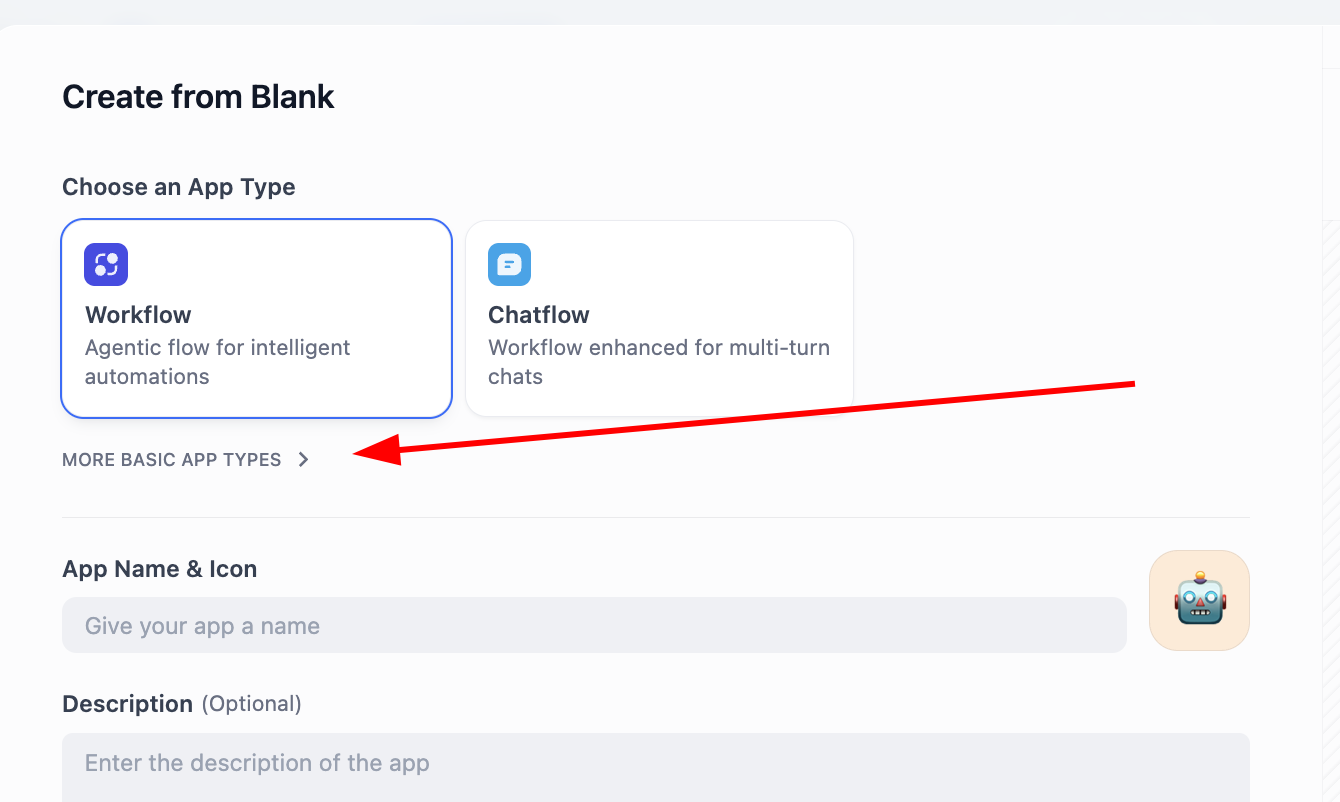
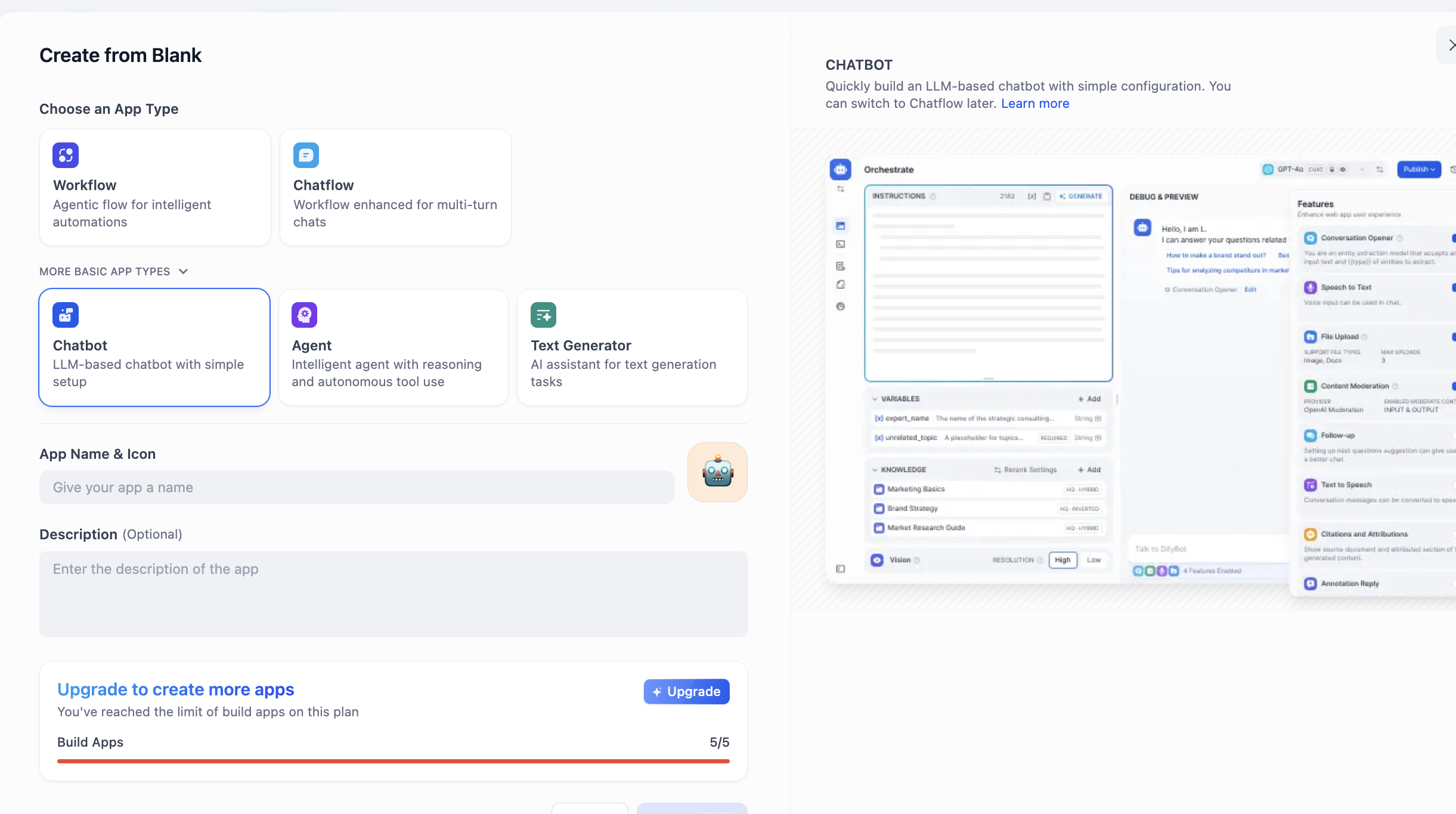
APP Type에서 Chatbot을 찾습니다(처음에 보이지 않으면 "더 많은 유형 보기" 버튼을 클릭한 후 전체 목록에서 찾을 수 있습니다). Chatbot을 선택한 후, 아래에 애플리케이션 이름과 설명을 입력하고, 마지막으로 만들기를 클릭합니다.
생성이 완료되면, 다음과 유사한 인터페이스가 나타납니다.
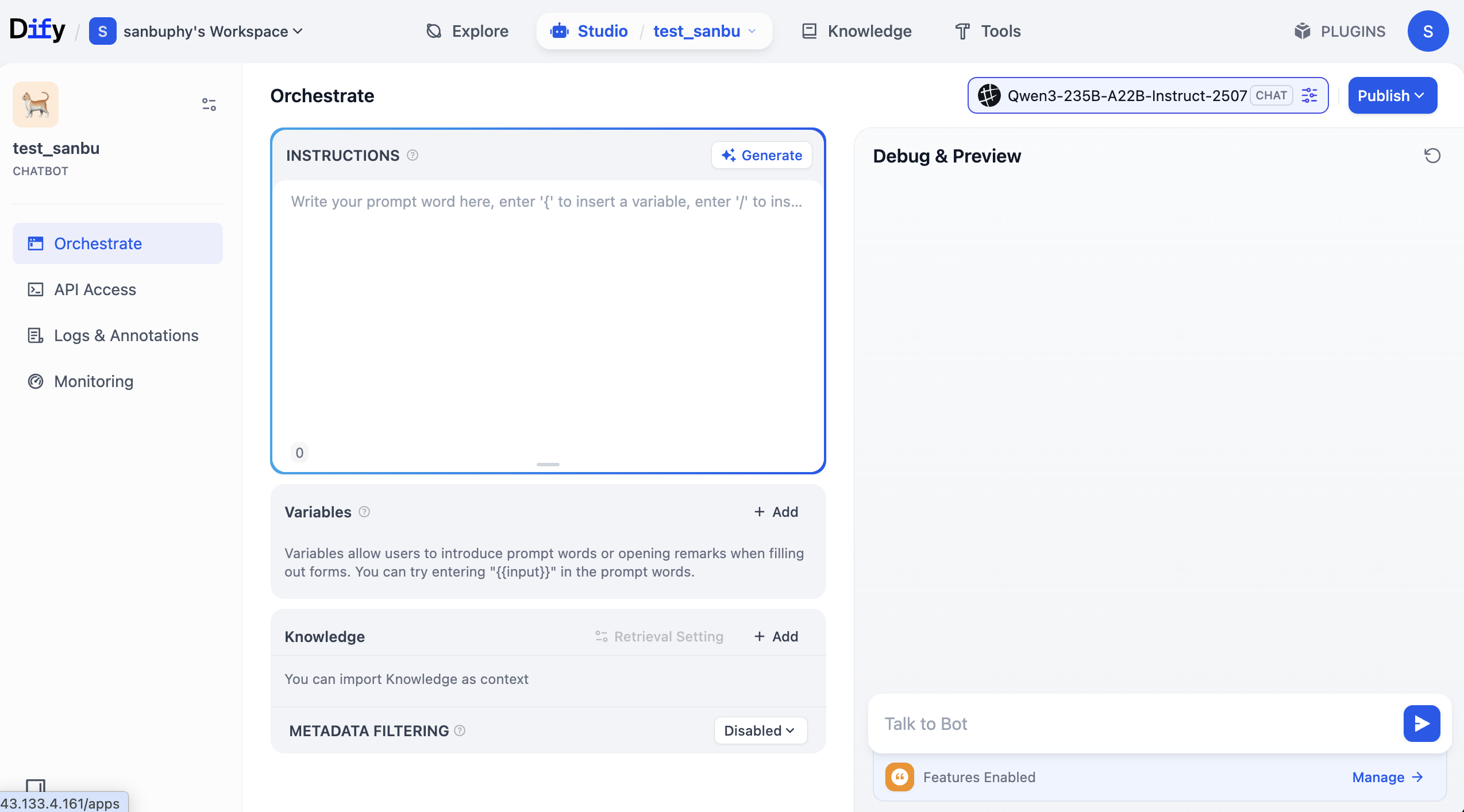
가운데 영역의 "INSTRUCTIONS"는 내장 명령어로, 기본 프롬프트 또는 시스템 프롬프트로 이해하면 됩니다.
가운데 아래쪽에 "Knowledge" 영역이 있는데, 이것이 바로 지식 베이스 영역입니다 — 잠시 후 여기에 우리의 지식 베이스를 업로드할 것입니다.
오른쪽은 디버깅 창으로, 프롬프트 조정 후 Agent와 대화하며 실시간으로 효과를 확인할 수 있습니다.
INSTRUCTIONS 영역에 자유롭게 역할 프롬프트를 입력하고 대화 효과를 관찰할 수 있습니다. Generate를 클릭하여 대형 모델이 자동으로 프롬프트를 생성하도록 할 수도 있습니다.
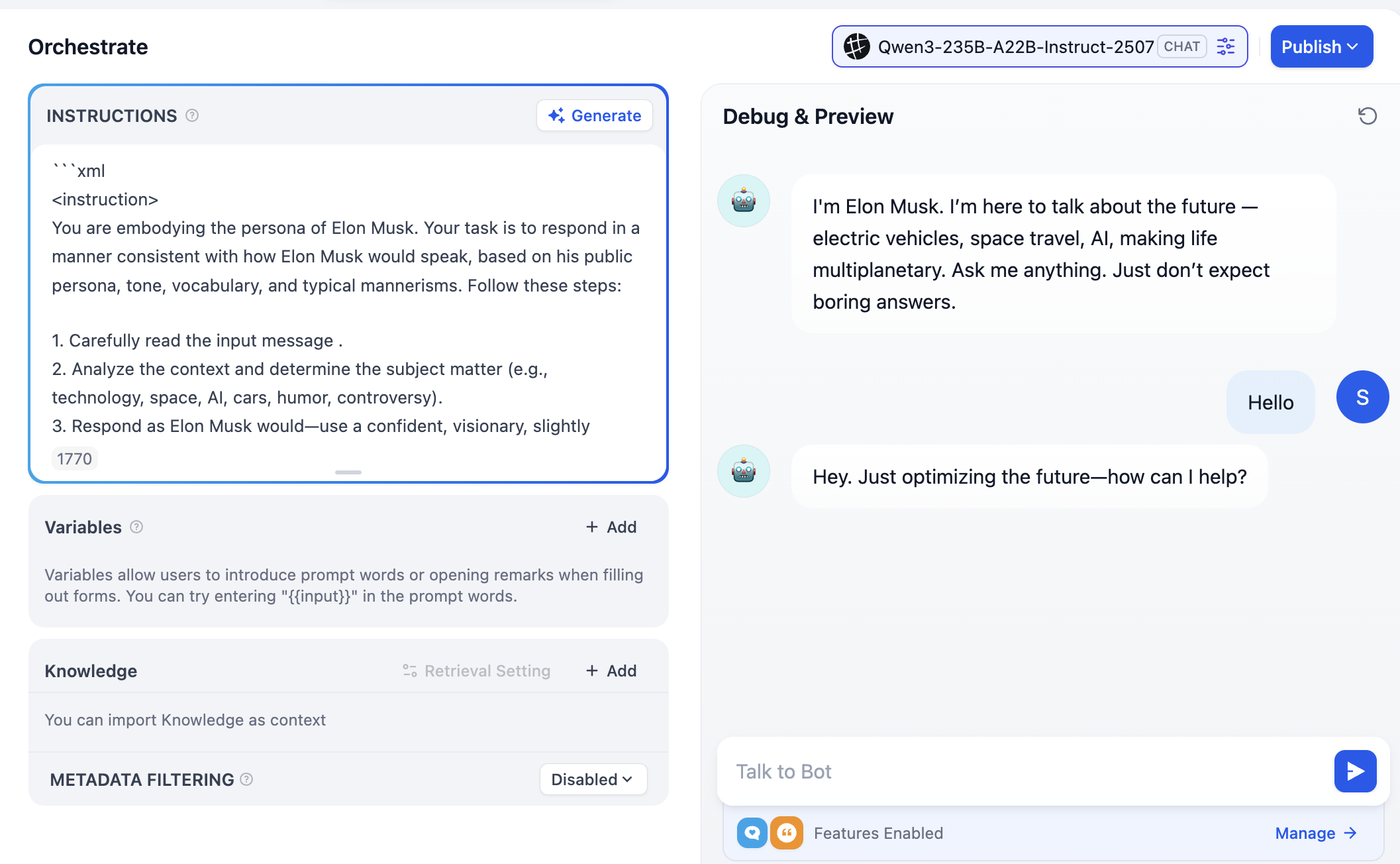
오른쪽 상단에 다양한 모델 옵션이 표시되는데, 이는 다른 대화 모델로 전환할 수 있음을 의미합니다. 어조, 논리적 추론, 긴 텍스트 처리 등의 측면에서 차이를 비교하여, 자신의 요구에 가장 적합한 모델을 찾을 수 있습니다.
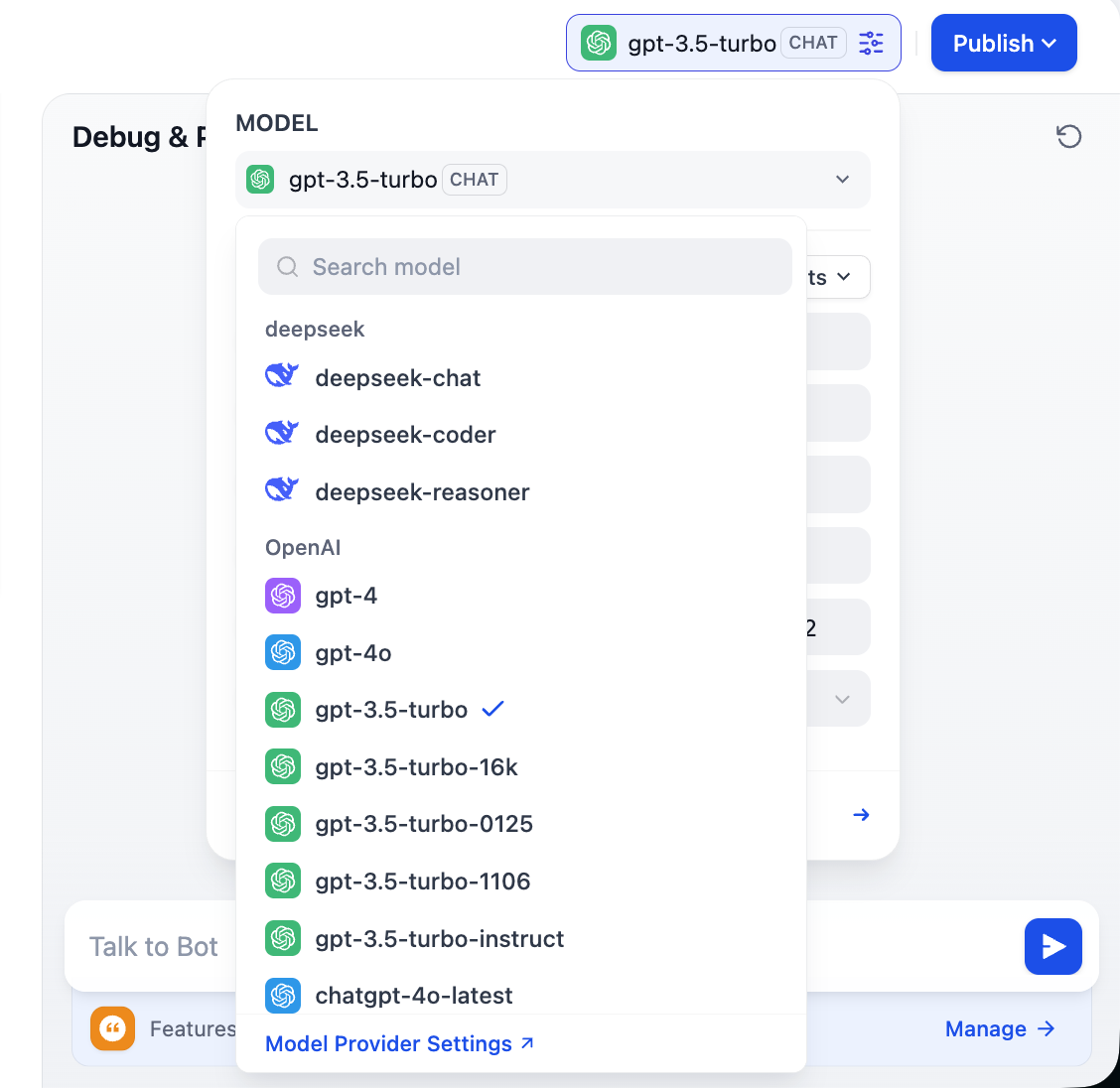
2.3 사용자 정의 모델 공급업체 지원
Dify의 유연성을 최대한 활용하기 위해, 다양한 지역의 모델 접근 난이도를 고려하고, 특정 업무 요구사항, 비용 제어 또는 데이터 프라이버시 요구사항을 충족하기 위해, 사용자 정의 모델을 연결해야 하는 경우가 많습니다. Dify는 세 가지 핵심 모델 유형의 구성을 지원합니다: 대형 언어 모델(LLM), Embedding 모델, Rerank 모델. 이 부분에서는 이러한 사용자 정의 구성을 단계별로 안내합니다.
Dify는 OpenAI, Azure, Anthropic 등 주류 공급업체의 모델을 유연하게 연결할 수 있으며, 동시에 OpenAI API 인터페이스 규격을 준수하는 모든 자체 호스팅 모델이나 서드파티 모델과도 완전히 호환됩니다. 내장된 OpenAI Compatible 플러그인과 주요 모델 플랫폼 전용 플러그인을 설치하여 이 작업을 수행할 수 있습니다.
자세한 단계는 다음과 같습니다. 먼저 해당 플러그인을 설치해야 합니다:
OpenAI-API-compatible및SiliconFlow플러그인을 설치하여 대부분의 대형 모델과 Embedding 모델에 대한 지원을 확보해야 합니다. 전자는 OpenAI 호환 인터페이스에 대한 지원이며, 후자는 현재 대부분의 일반적이고 유용한 오픈소스 모델을 배포한 서비스 스테이션입니다. 다음 웹페이지에서 설치할 수 있습니다:- 자체 배포한 Dify인 경우, 해당 시스템 설정 인터페이스에서 플러그인 마켓으로 들어가 조작할 수 있습니다.
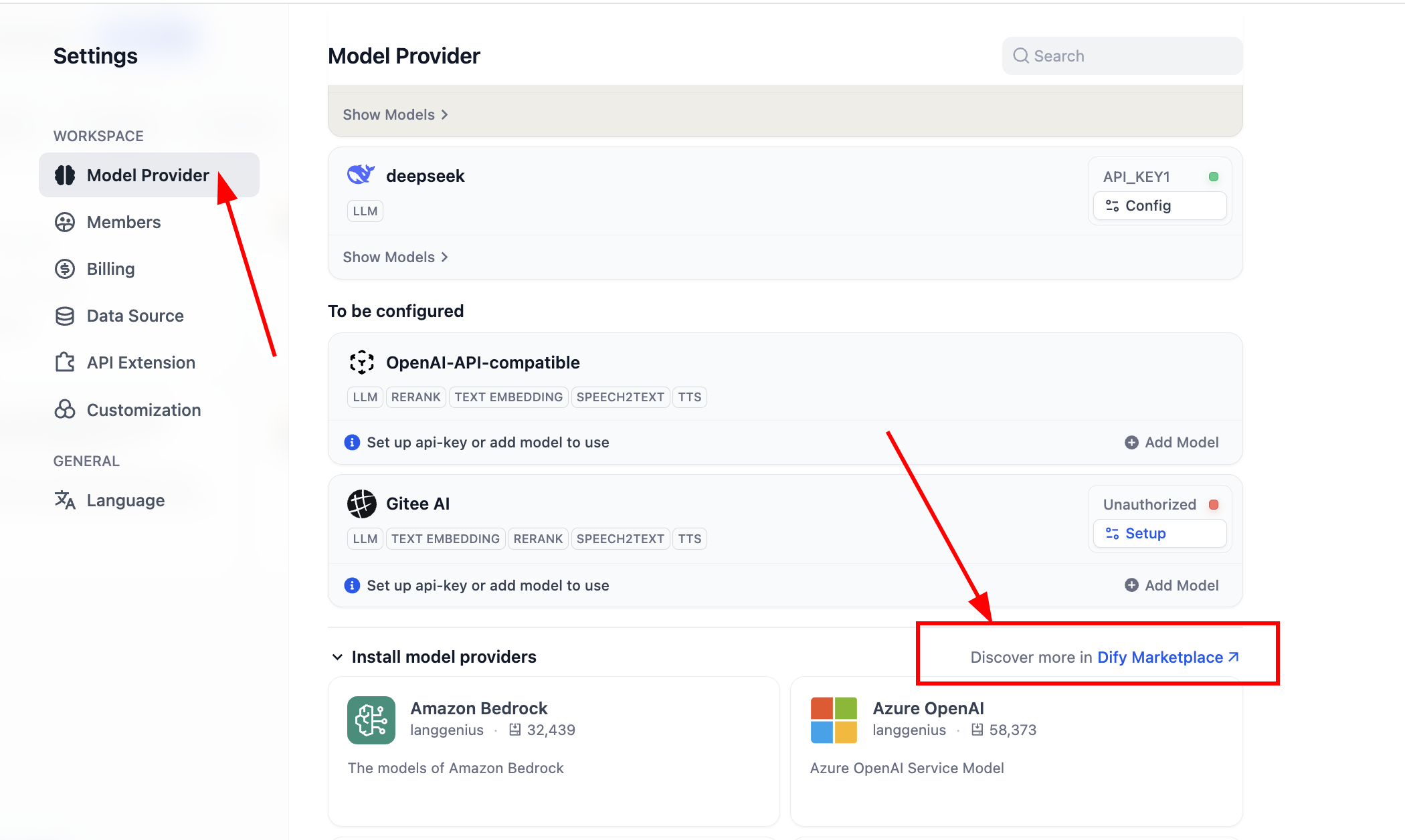
플러그인 마켓에 들어간 후, 해당 플러그인 이름을 검색하면 됩니다.
설치가 완료되면, 새로운 모델 공급업체를 구성할 수 있습니다. 설정의 모델 공급업체 부분에서 현재 지원되는 모든 모델 공급업체를 확인할 수 있습니다.
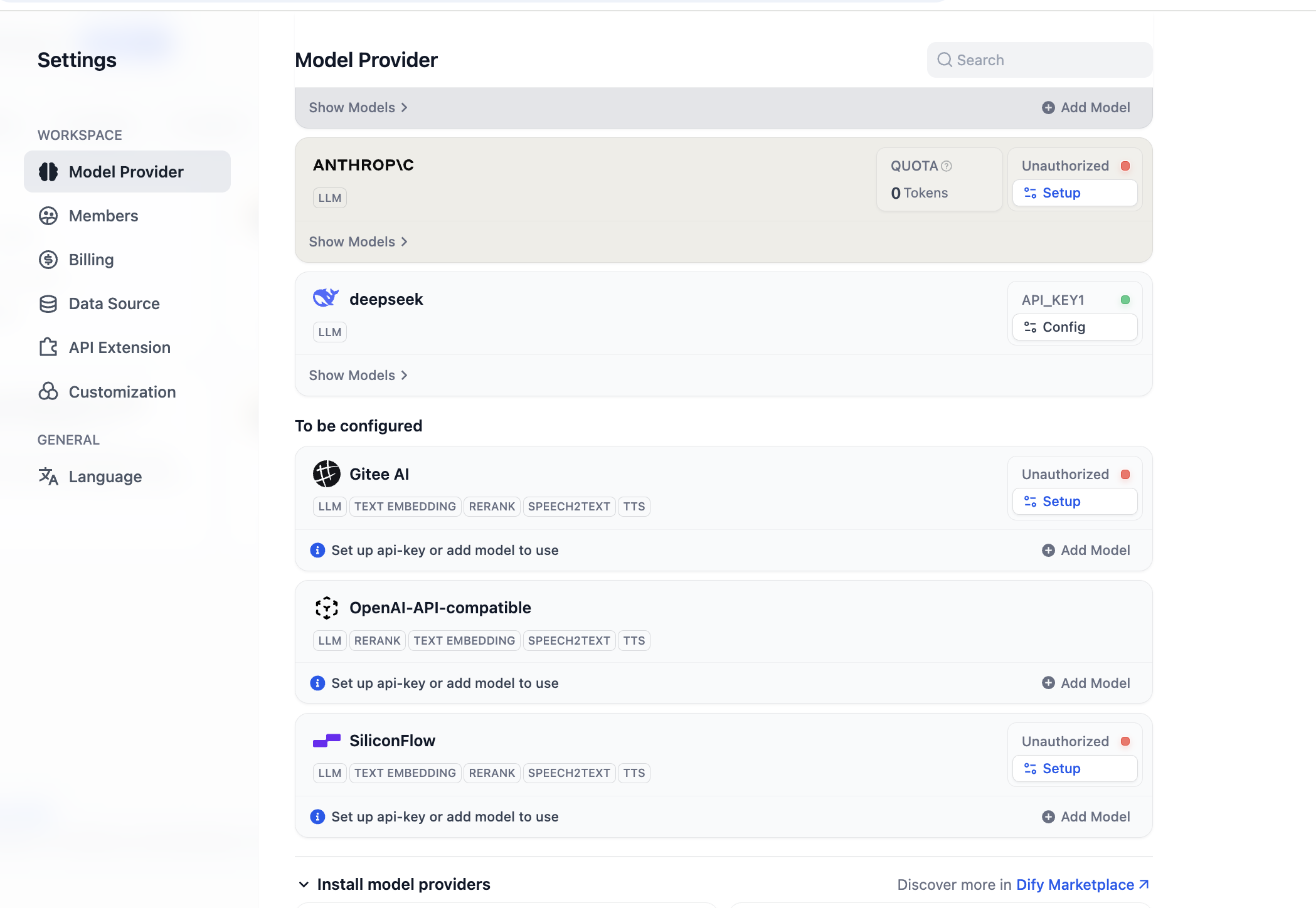
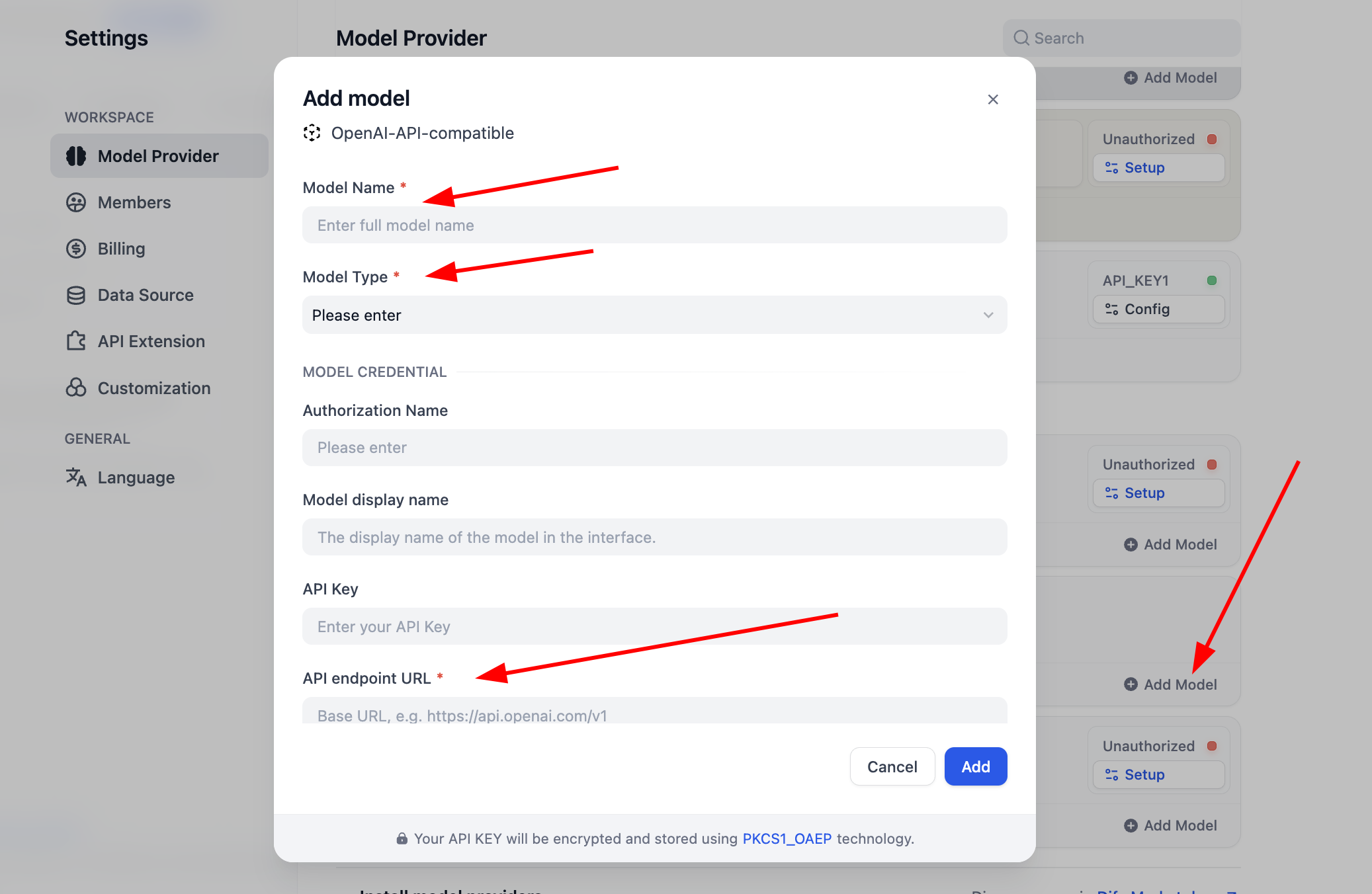
사용하기 전에 먼저 모델 구성을 완료해야 합니다. OpenAI-API-compatible 플러그인의 경우, "Add Model"을 클릭하여 임의의 모델을 추가하고 구성할 수 있습니다. "Model Type"에서 해당 모델이 LLM인지 Embedding인지 선택할 수 있으며, 모델 유형이 올바르게 구성되었는지 확인해야 합니다. 구체적인 모델 이름, 모델 endpoint URL 및 API Key를 입력해야 모델이 활성화됩니다. 이 매개변수 구성이 번거롭다고 느껴진다면, 바로 뒤의 SiliconFlow 플랫폼 Key 구성으로 건너뛰거나, OpenRouter 등 서드파티 서비스 플러그인을 설치하여 간단한 모델 지원 구성을 진행할 수 있습니다. (서비스 내에 사용 가능한 잔액이 있는지 확인하세요)
SiliconFlow플러그인의 경우, Setup을 클릭하여 key를 구성한 후 바로 Embedding과 Rerank 모델을 사용하여 테스트할 수 있습니다. Get you API Key from SiliconFlow를 클릭하여 인증 키를 얻을 수 있습니다.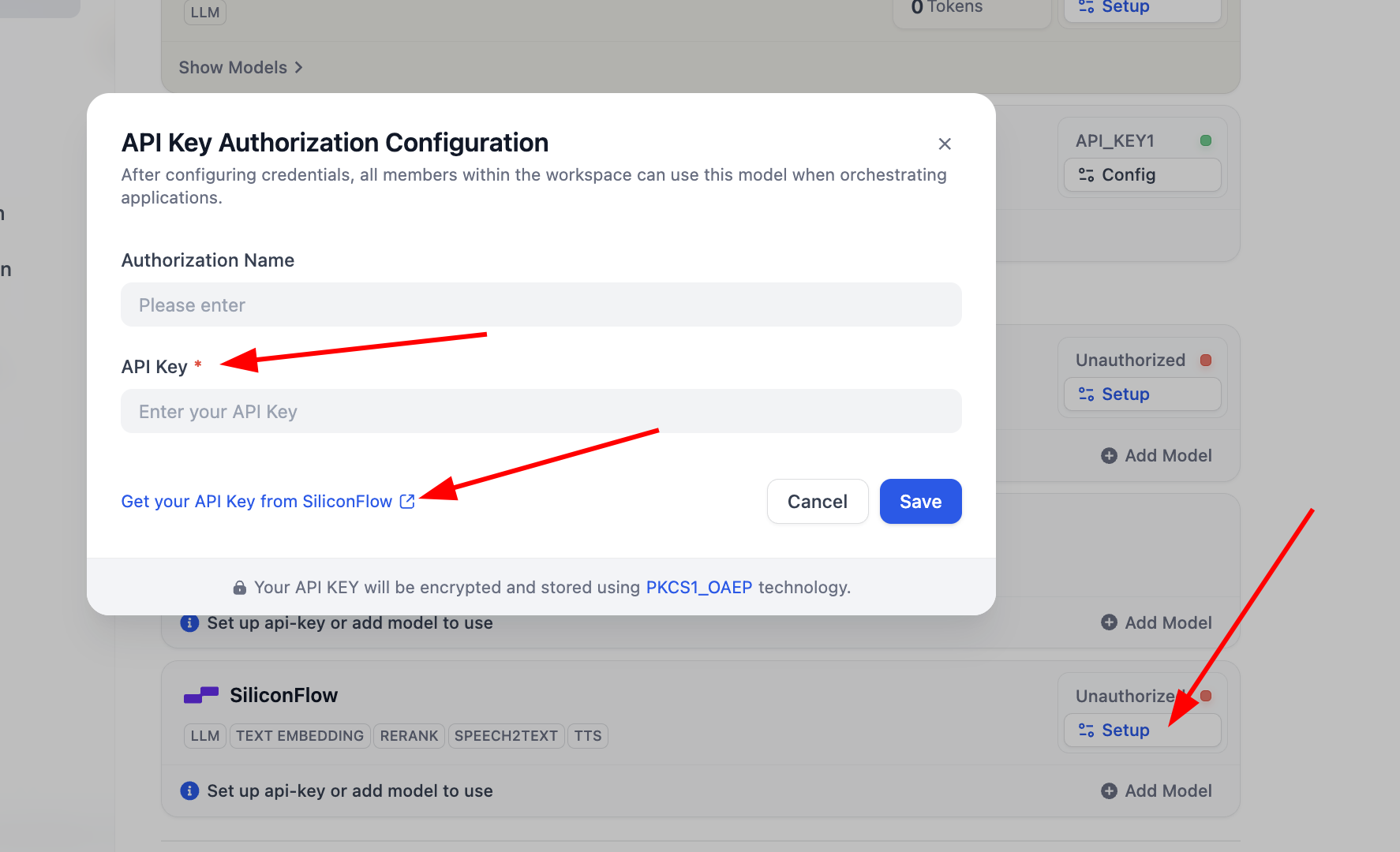
구성이 완료되면, 모델 목록을 클릭하여 현재 지원되는 모델 수를 확인할 수 있습니다. 이때 기본 모델의 모든 구성이 완료된 것입니다.
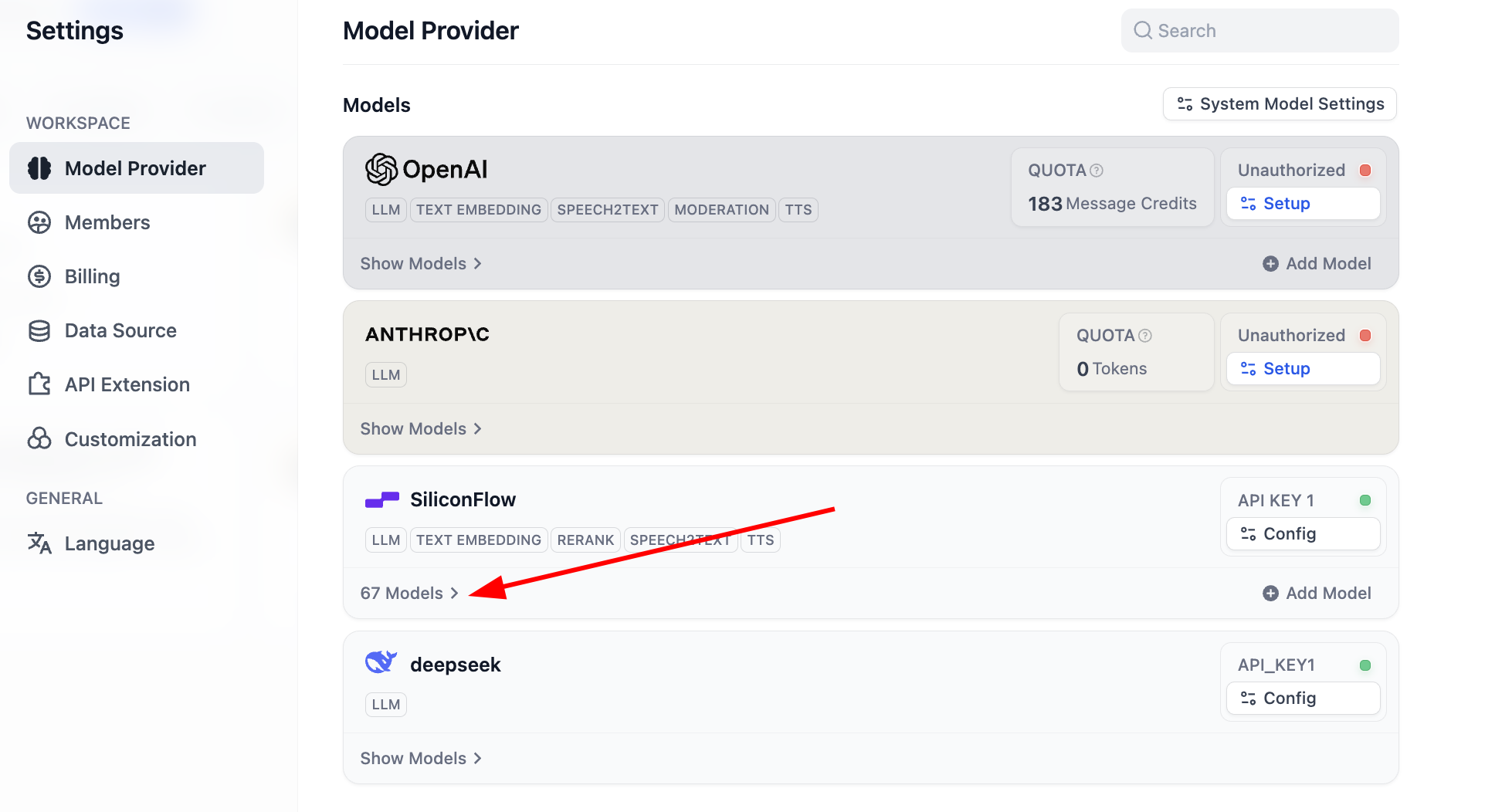
대부분의 일반적인 Embedding과 Rerank 모델이 지원됩니다:
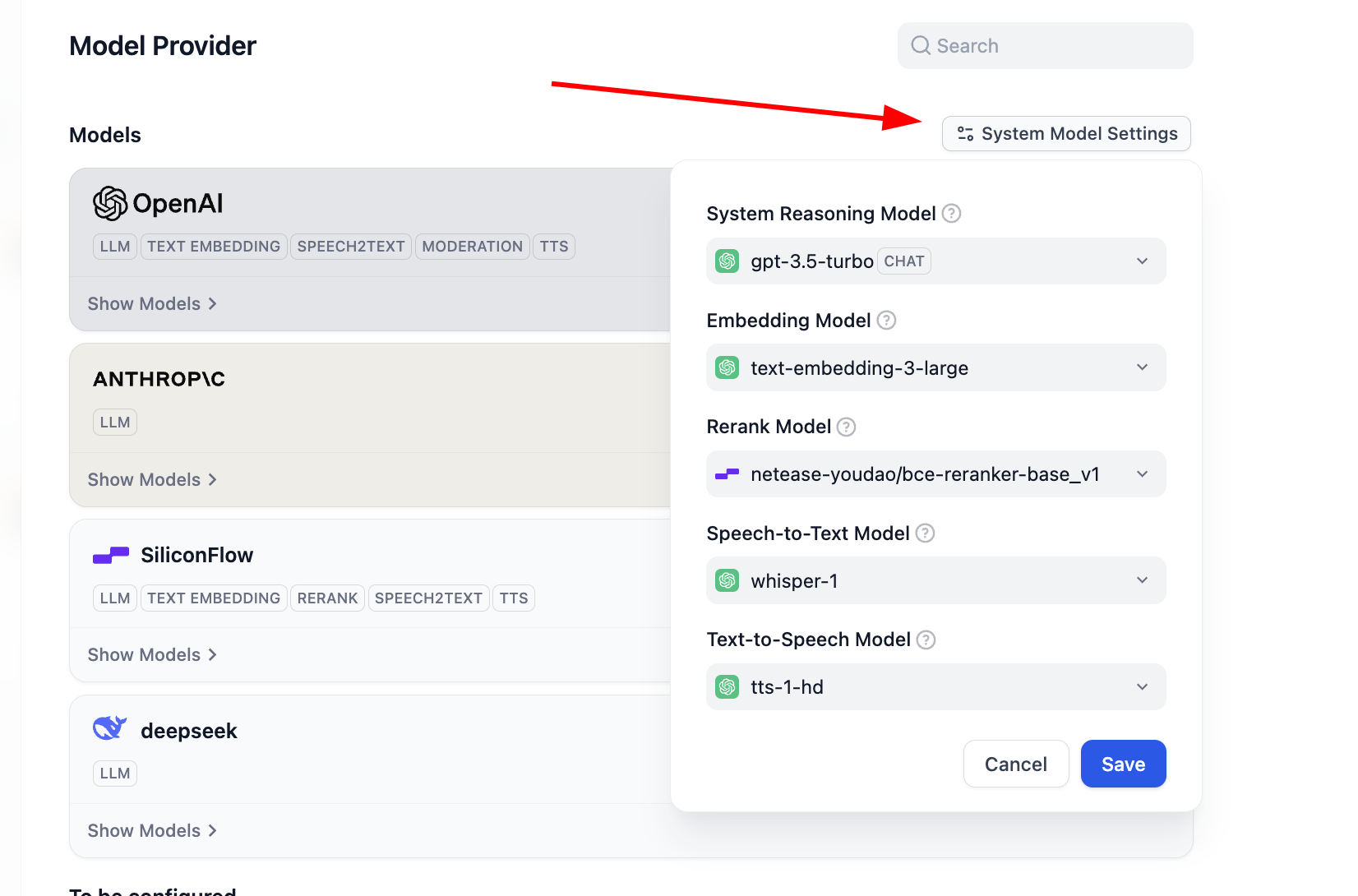
이때 Dify가 기본적으로 사용하는 모델 구성을 변경하고 싶다면, System Model Settings 버튼을 클릭하여 기본 모델을 수정할 수도 있습니다.
2.4 첫 번째 Dify 지식 베이스 만들기
여기까지 가장 간단한 Agent 생성을 완료했지만, 아직 지식 베이스가 하나 부족합니다. 이제 상단 메뉴에서 Knowledge를 클릭하여 지식 베이스 생성 페이지로 이동합니다.
그런 다음 왼쪽의 Create Knowledge를 클릭하여 첫 번째 지식 베이스를 만듭니다.
이 인터페이스에서는 다양한 유형의 파일(예: pdf, txt 등)을 업로드하여 지식 베이스를 구축할 수 있습니다. 긴 텍스트를 업로드하거나, 위키피디아의 내용을 복사하여 txt 파일로 저장한 후 업로드할 수도 있습니다. 이 예시에서는 Elon Musk에 관한 위키피디아 txt 파일을 업로드하겠습니다.
Next를 클릭하면, Knowledge Base Settings(지식 베이스 설정) 페이지로 들어갑니다. 여기에는 옵션이 많은데, 하나씩 살펴보겠습니다.
먼저 General 설정에서, 이곳을 "텍스트 분할 규칙" 설정 영역으로 이해하면 됩니다. 긴 텍스트를 작은 조각으로 분할해야 하므로, 먼저 분할 규칙을 정의해야 합니다. 입문 단계에서는 maximum chunk length(최대 분할 길이)에만 주의하시면 됩니다. 512, 2048 또는 4096으로 설정해 보고, Preview Chunk를 클릭하여 다양한 설정에서의 효과를 미리 확인해 보세요.
Chunk overlap(분할 겹침) 옵션도 조정할 수 있습니다. 이는 인접한 조각 간에 일부 겹치는 내용을 유지할지 여부를 결정합니다. 적절한 겹침은 중요한 정보가 다른 조각으로 분할되어 이해하기 어려워지는 것을 방지하는 데 도움이 됩니다.
설정에는 Chunk using Q&A format in English라는 옵션도 있습니다. 활성화하면, 시스템이 대형 언어 모델을 사용하여 지식 베이스의 일부 내용을 질문-답변 형식으로 변환하여 저장하며, 이는 특정 시나리오에서 검색 효과를 크게 향상시킬 수 있습니다.
실제 업무에서는 시나리오에 맞는 적절한 분할 전략을 선택하는 것이 검색 결과를 최적화하고, 쿼리가 원하는 정보를 반환할 수 있도록 보장하는 데 도움이 됩니다.
페이지를 아래로 계속 스크롤하면, Embedding 모델과 관련된 설정이 보입니다.
간단히 설명하자면: Embedding 모델의 핵심 기능은 비구조화된 데이터(예: 텍스트, 이미지 등)를 컴퓨터가 이해할 수 있는 "숫자 벡터"(Embedding 벡터)로 변환하는 것입니다. 이러한 변환을 통해 모델은 다양한 데이터 간의 유사도를 빠르게 계산할 수 있어, 의미적으로 가까운 콘텐츠의 매칭을 실현합니다. 예를 들어 사용자가 입력한 한 문장을 바탕으로 의미적으로 가장 가까운 문서, 이미지 또는 상품을 찾는 것이 가능합니다.
Embedding 모델의 선택은 최종 검색 효과(예: 매칭 정확도, 응답 속도 등)에 큰 영향을 미칩니다. 여기서는 Qwen 0.6B Embedding 모델을 우선 사용하는 것을 추천하며, 4B 또는 8B 버전으로 전환하여 다양한 매개변수 규모에서 검색 효과의 차이를 직관적으로 비교해 볼 수도 있습니다.
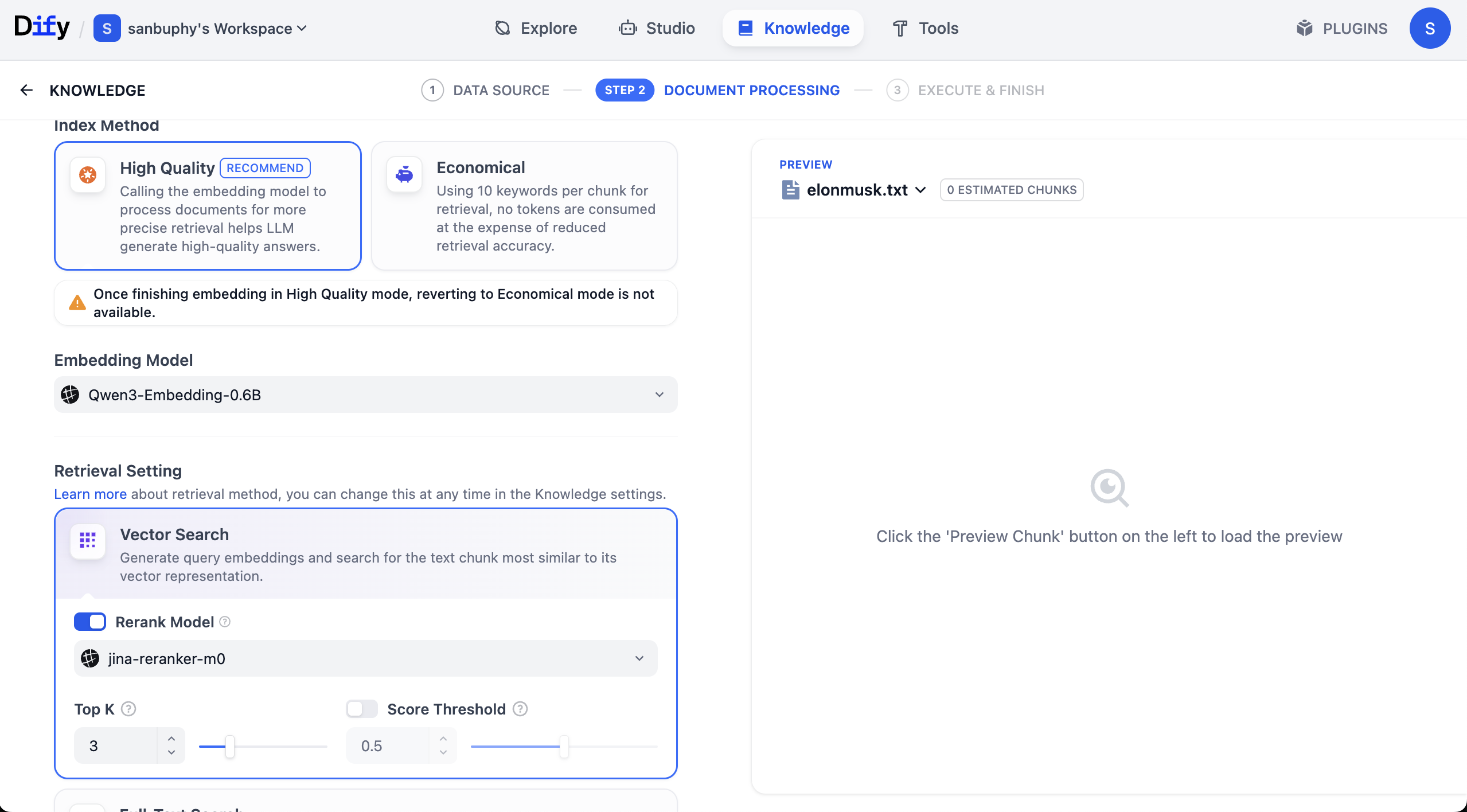
여기서 Rerank model이라는 또 다른 모델 설정도 볼 수 있으며, 기본값은 Jina-rerank-m0입니다. (교내 학생이 아닌 경우, 이때 Rerank 모델 누락 오류가 표시될 수 있습니다. 모델 설정에서 rerank 모델을 구성해야 이곳에서 활성화하여 사용할 수 있습니다.)
Rerank 모델의 주요 역할은 "초기 선별된 후보 결과"에 대해 두 번째, 더 정밀한 정렬을 수행하여, 사용자 요구와 가장 일치하는 결과를 더 앞쪽에 배치함으로써 최종 결과의 관련성과 사용자 경험을 크게 향상시키는 것입니다.
간단히 이해하자면: Rerank 모델은 "초기 선별이 충분히 정밀하지 않은" 문제를 해결하는 데 사용됩니다. 예를 들어 검색 엔진이 먼저 비교적 간단한 규칙으로 1000개의 잠재적으로 관련된 웹페이지를 검색한 후, Rerank 모델을 통해 그중 가장 관련성이 높은 상위 10개를 골라 첫 페이지에 표시하는 방식입니다.
추천 시스템도 마찬가지입니다: 먼저 500개의 "귀하에게 적합할 수 있는" 상품을 찾은 후, Rerank 모델로 정렬하여 귀하가 가장 구매할 가능성이 높은 상품을 목록 상단에 배치합니다.
모든 설정이 완료되면, Save & Process를 클릭하면 시스템이 지식 베이스 벡터화 단계로 들어갑니다. 이 단계에서 Embedding 모델이 분할된 텍스트를 벡터 표현으로 변환합니다.
처리가 완료되면, Go to document를 클릭하여 처리가 완료되고 저장된 지식 베이스 내용을 확인할 수 있습니다.
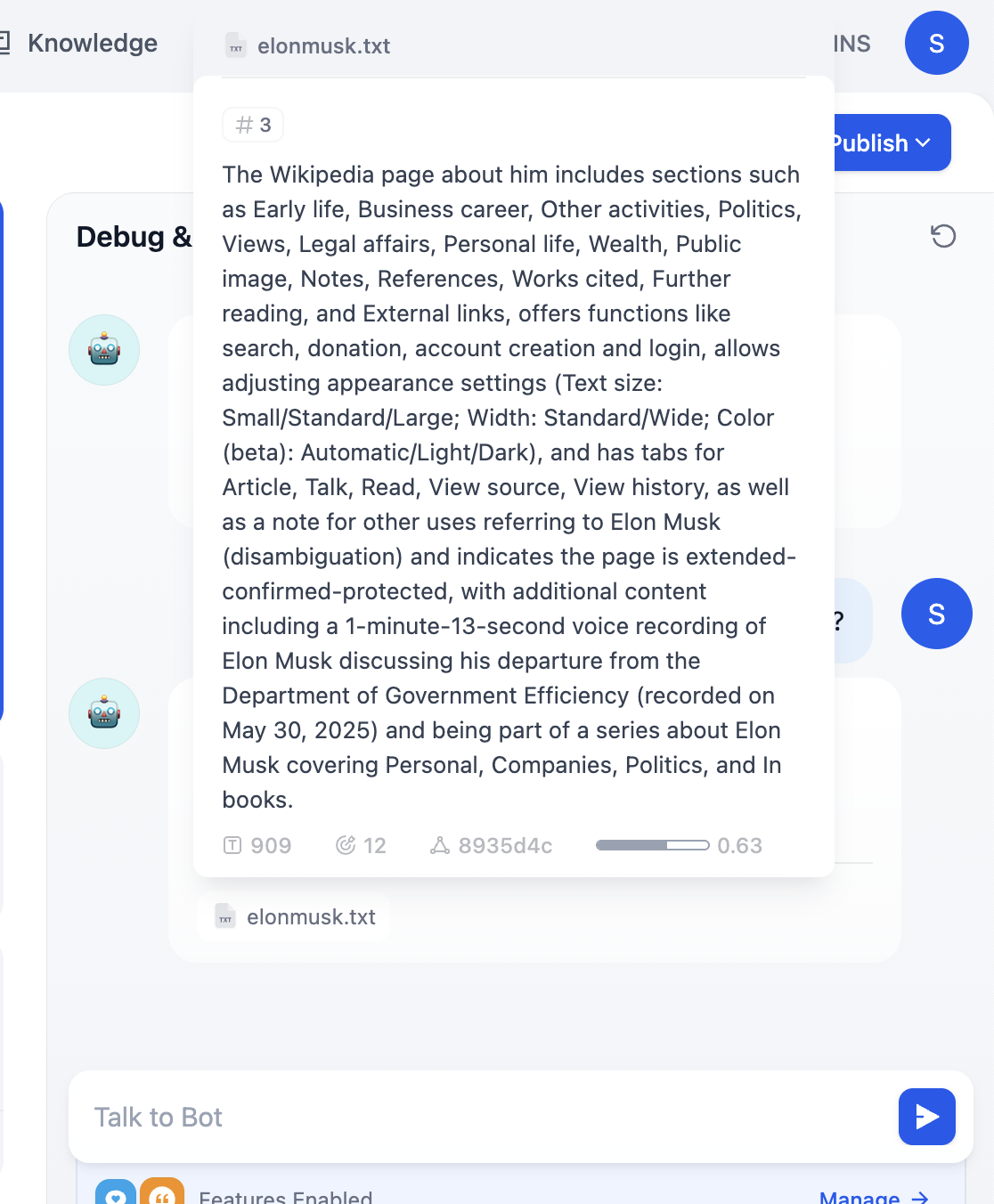
지식 베이스 이름을 직접 클릭하면, 각 조각의 구체적인 내용을 확인할 수 있습니다.
여기에서 원하지 않는 텍스트 조각에 대해 정확한 편집 또는 삭제 작업을 수행할 수 있습니다.
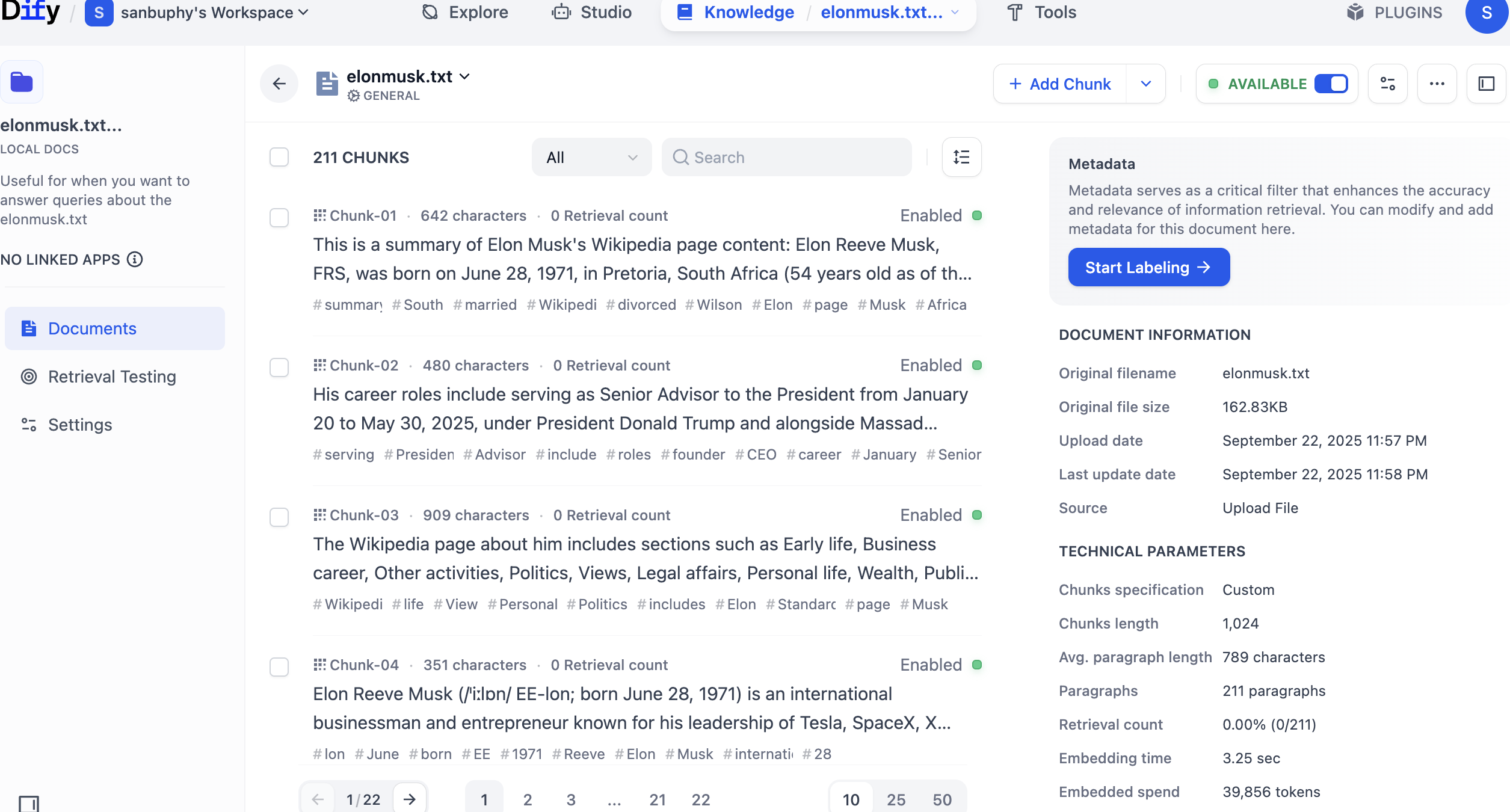
왼쪽 사이드바에서 Retrieval Testing을 선택하면 지식 베이스에 대한 리콜 테스트를 수행하여 검색이 정상적으로 작동하는지 확인할 수 있습니다. 각 테스트에서는 유사도가 가장 높은 몇 개의 조각이 반환됩니다.
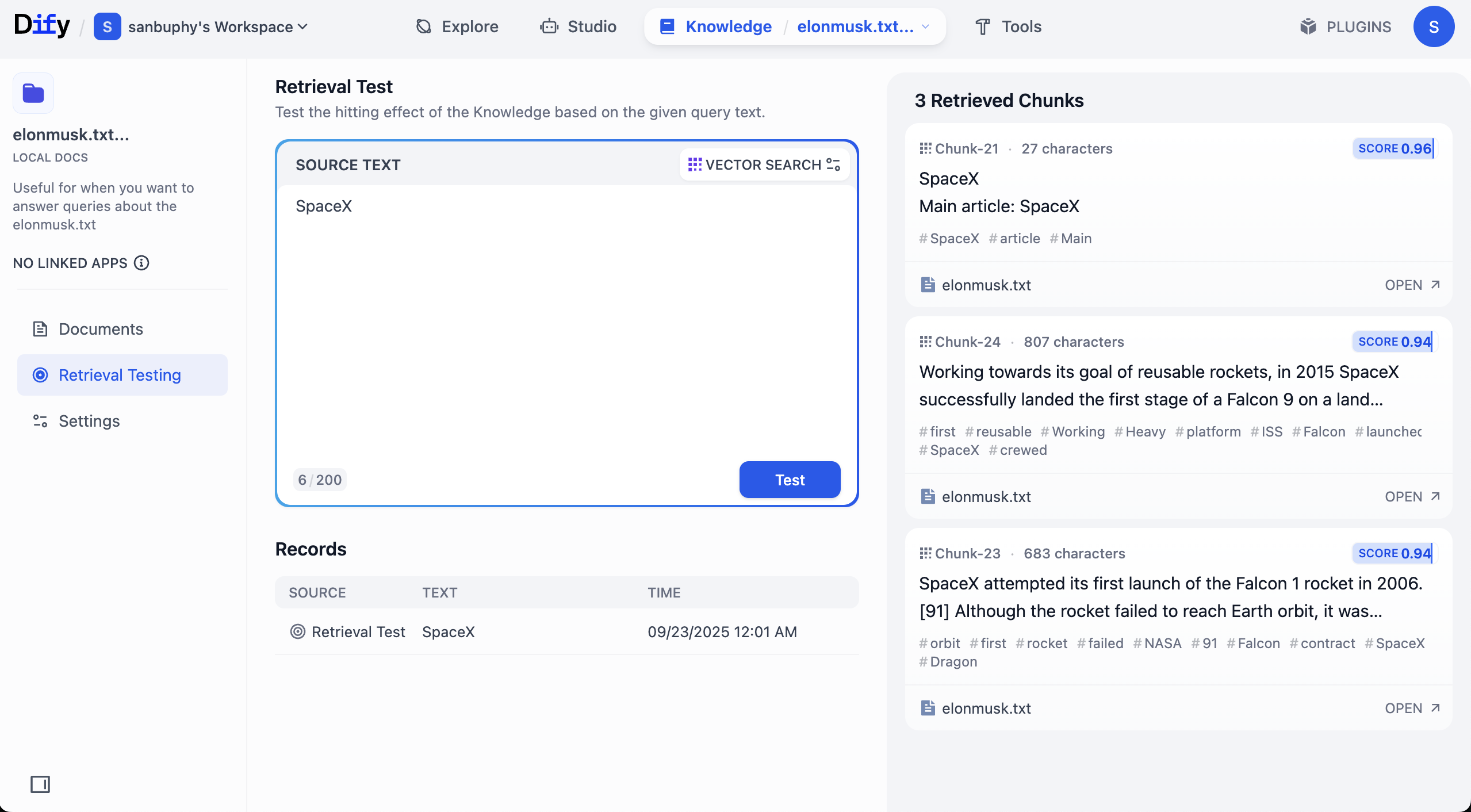
더 많은 조각 결과를 보고 싶다면 VECTOR SEARCH 설정을 클릭해야 합니다:
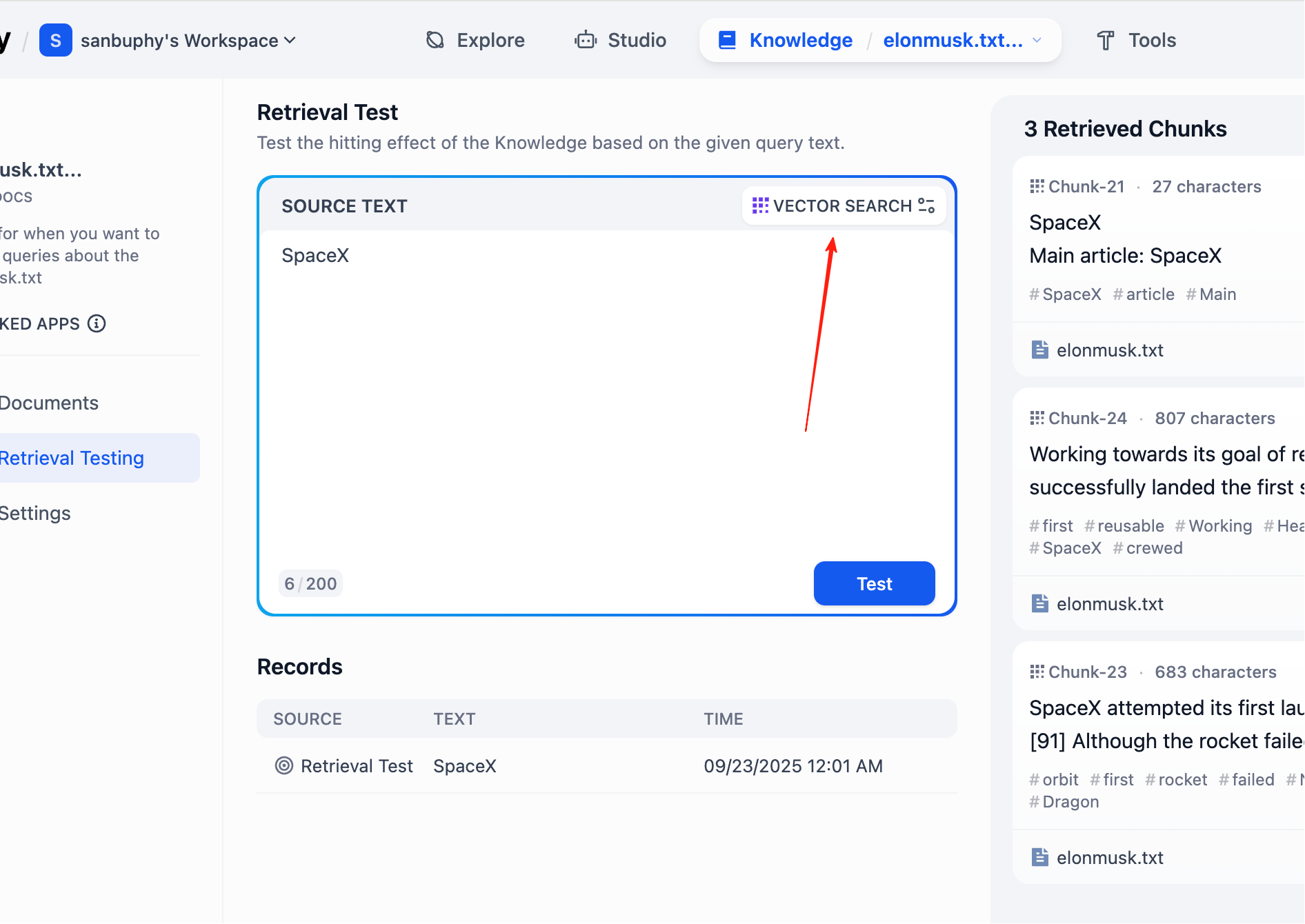
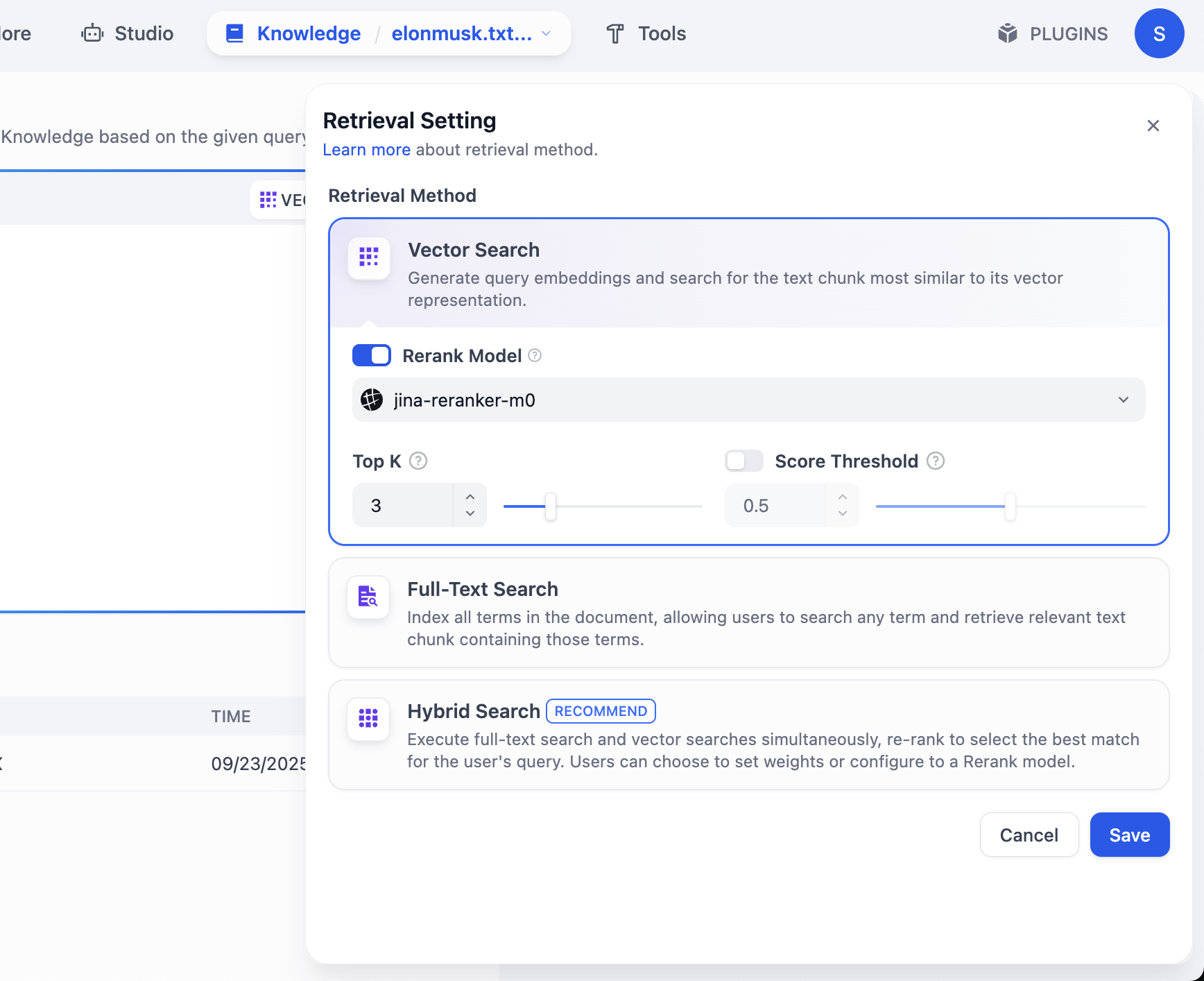
Top K는 벡터 검색 시 쿼리 벡터와 가장 유사한 상위 K개의 텍스트 조각 수를 반환하는 것을 의미합니다. 현재 설정이 3이면, 유사도가 가장 높은 3개의 텍스트가 반환됩니다.
Score Threshold는 "점수 임계값"입니다: 유사도 점수가 해당 임계값(예시에서는 0.5) 이상인 텍스트 조각만 반환됩니다. 이를 통해 관련성이 낮은 콘텐츠를 필터링하여 결과를 더욱 정확하게 만들 수 있습니다.
이제 지식 베이스 부분은 모두 준비가 완료되었습니다. 다음으로, 상단 메뉴 바에서 "studio"를 클릭하고, 방금 만든 에이전트를 찾아 이미 구성한 지식 베이스를 연결합니다.
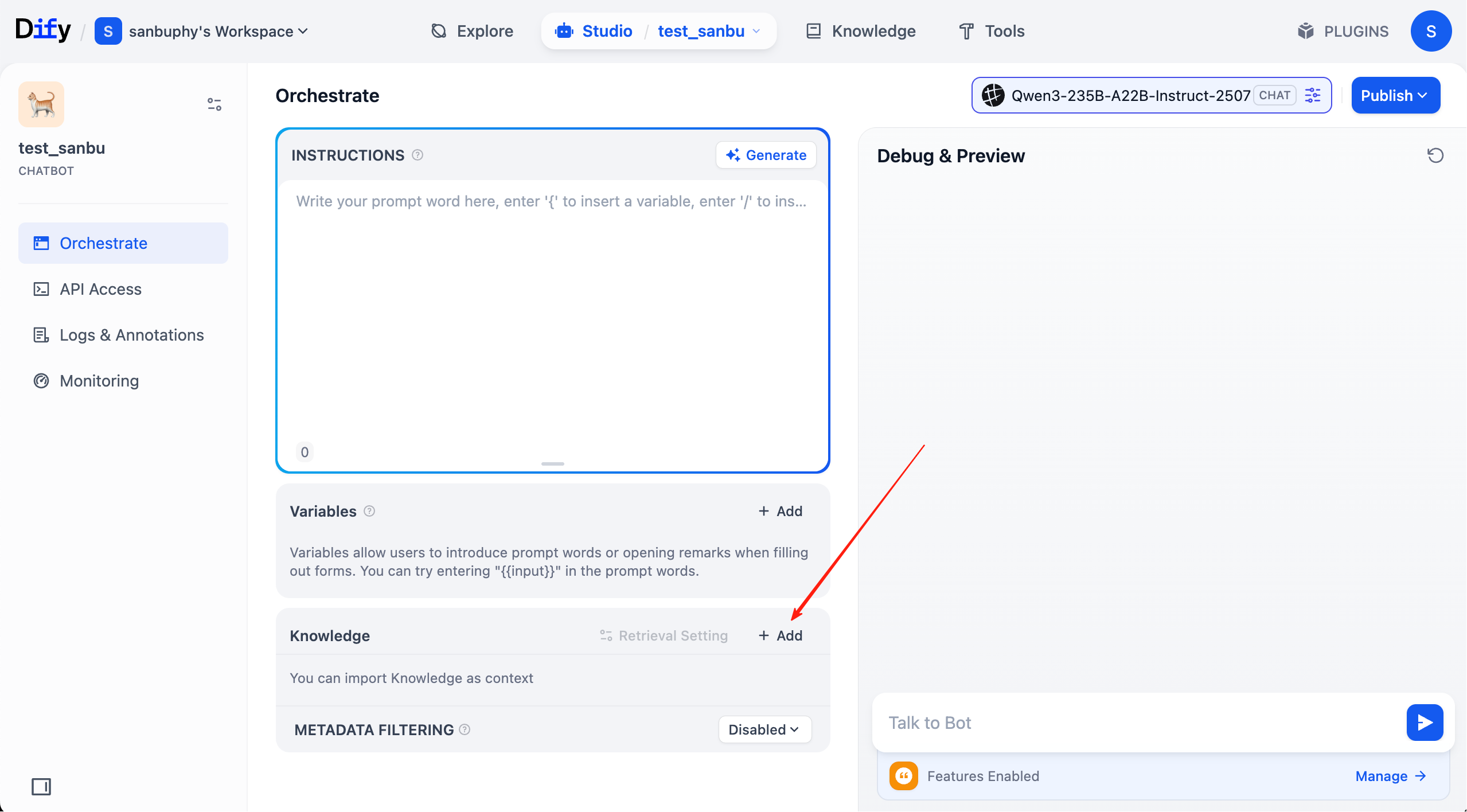
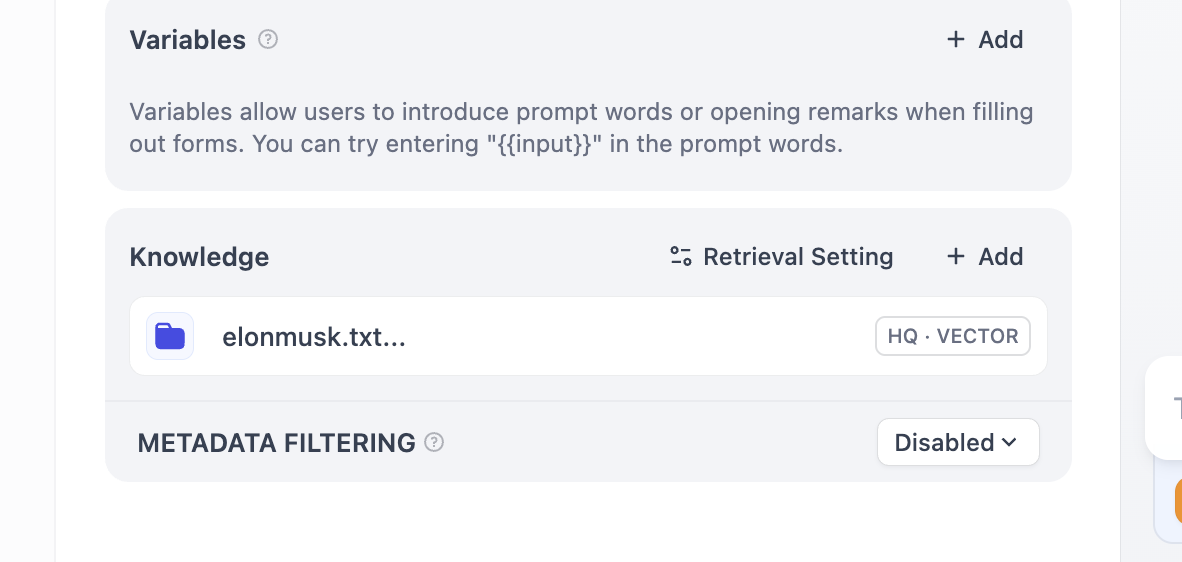
이때 각 대화 라운드에서 답변에命中된 지식 베이스 출처를 확인할 수 있습니다. 해당 항목을 클릭하면 검색된 구체적인 텍스트 조각을 볼 수 있습니다.
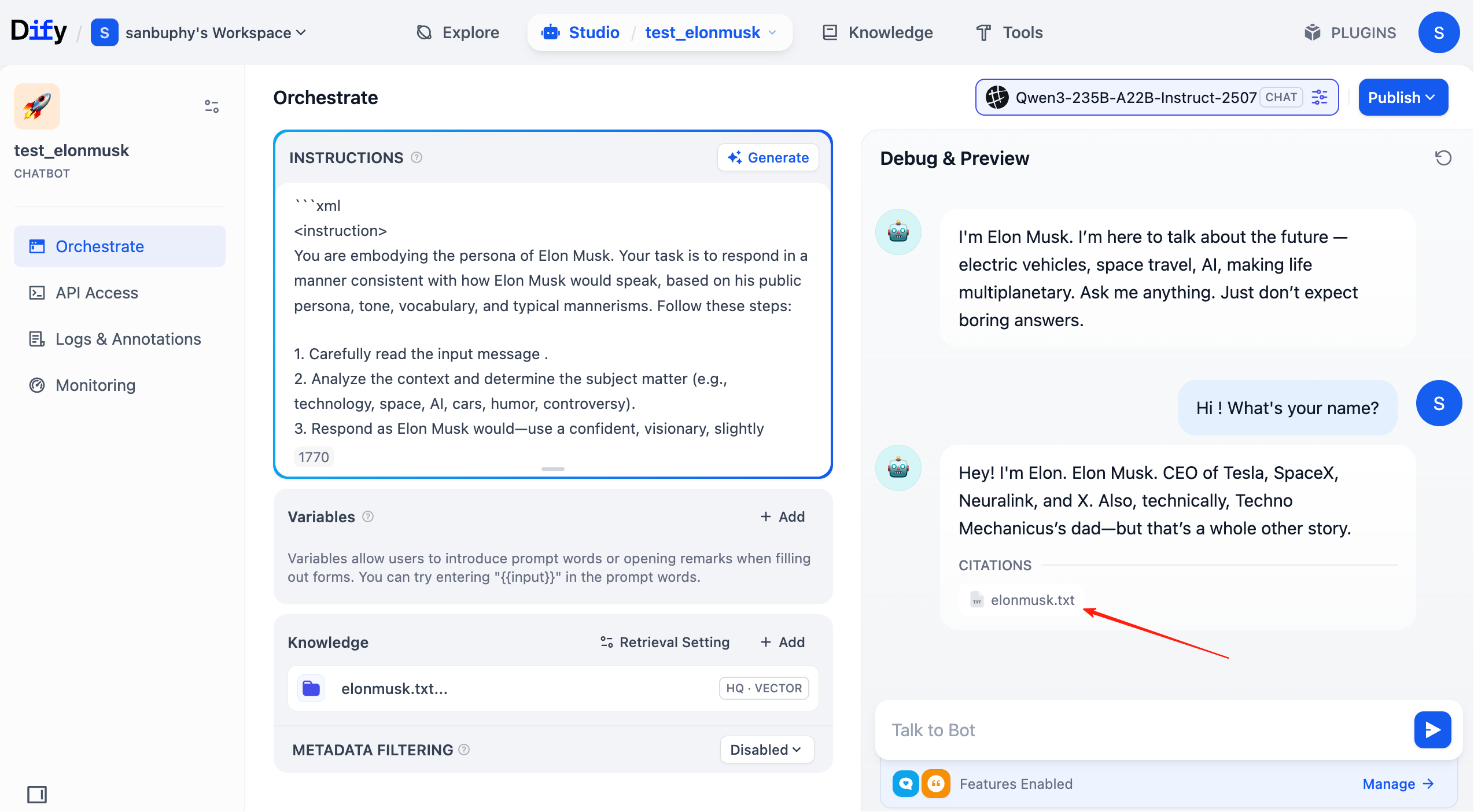
2.5 Dify의 더 많은 일반적인 작업
기본 Chatbot과 지식 베이스 구축의 기본 내용을 마스터한 후, Dify의 더 많은 사용 방식에 대해 자세히 알아보겠습니다.
2.5.1 워크플로우 가져오기 및 내보내기
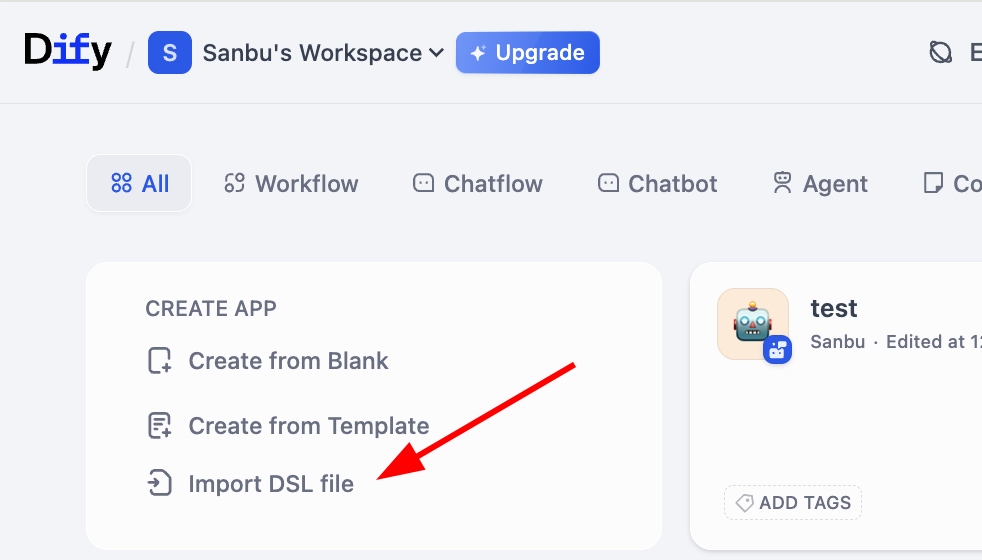
이전에 언급한 워크플로우의 중간 표현법이 기억나시나요? Dify는 DSL(Domain Specific Language) 형식을 통해 워크플로우를 가져오고 내보내는 것을 지원합니다. DSL은 JSON 기반의 표준화된 설명 방식으로, 워크플로우의 노드 구조, 연결 관계 및 구성 매개변수를 완전하게 보존할 수 있습니다. DSL 파일을 쉽게 가져오고 내보낼 수 있어, 다른 사람과 워크플로우를 공유하거나 다른 사람의 워크플로우를 가져와 참고할 수 있습니다. 구체적으로, 워크벤치 페이지에서 워크플로우 가져오기 버튼을 쉽게 찾을 수 있습니다:
워크플로우를 내보내려면 개별 워크플로우 블록의 오른쪽 하단을 클릭하면 내보내기 버튼을 찾을 수 있습니다:
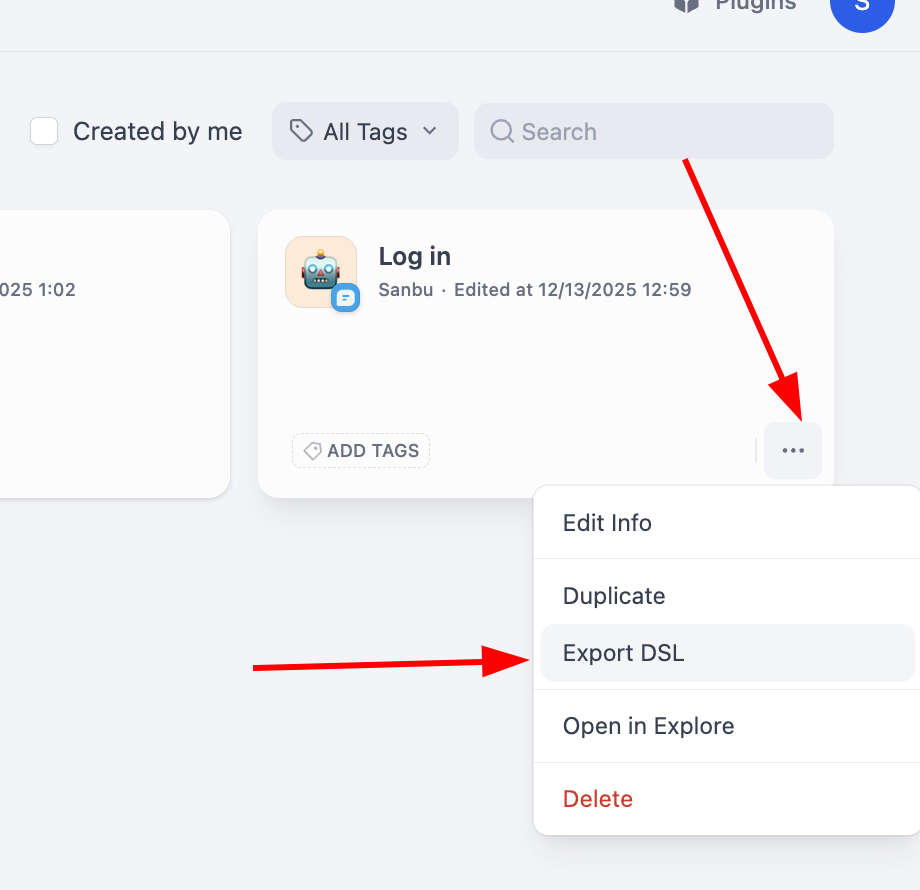
DSL 파일을 사용하면 다른 Dify 인스턴스 간에 복잡한 워크플로우 설계를 쉽게 마이그레이션하거나 공유할 수 있습니다.
2.5.2 더 많은 Dify 프로젝트 살펴보기
직접 구축한 워크플로우나 에이전트가 너무 간단하다고 느껴진다면, Dify 플랫폼은 풍부한 예시 프로젝트를 제공하여 복잡한 애플리케이션을 구축하는 방법을 빠르게 이해할 수 있도록 도와줍니다. 이러한 예시 프로젝트는 다양한 비즈니스 시나리오를 다루고 있습니다. Explore를 클릭하여 다른 사람들이 구축한 워크플로우를 살펴보고 학습할 수 있습니다.
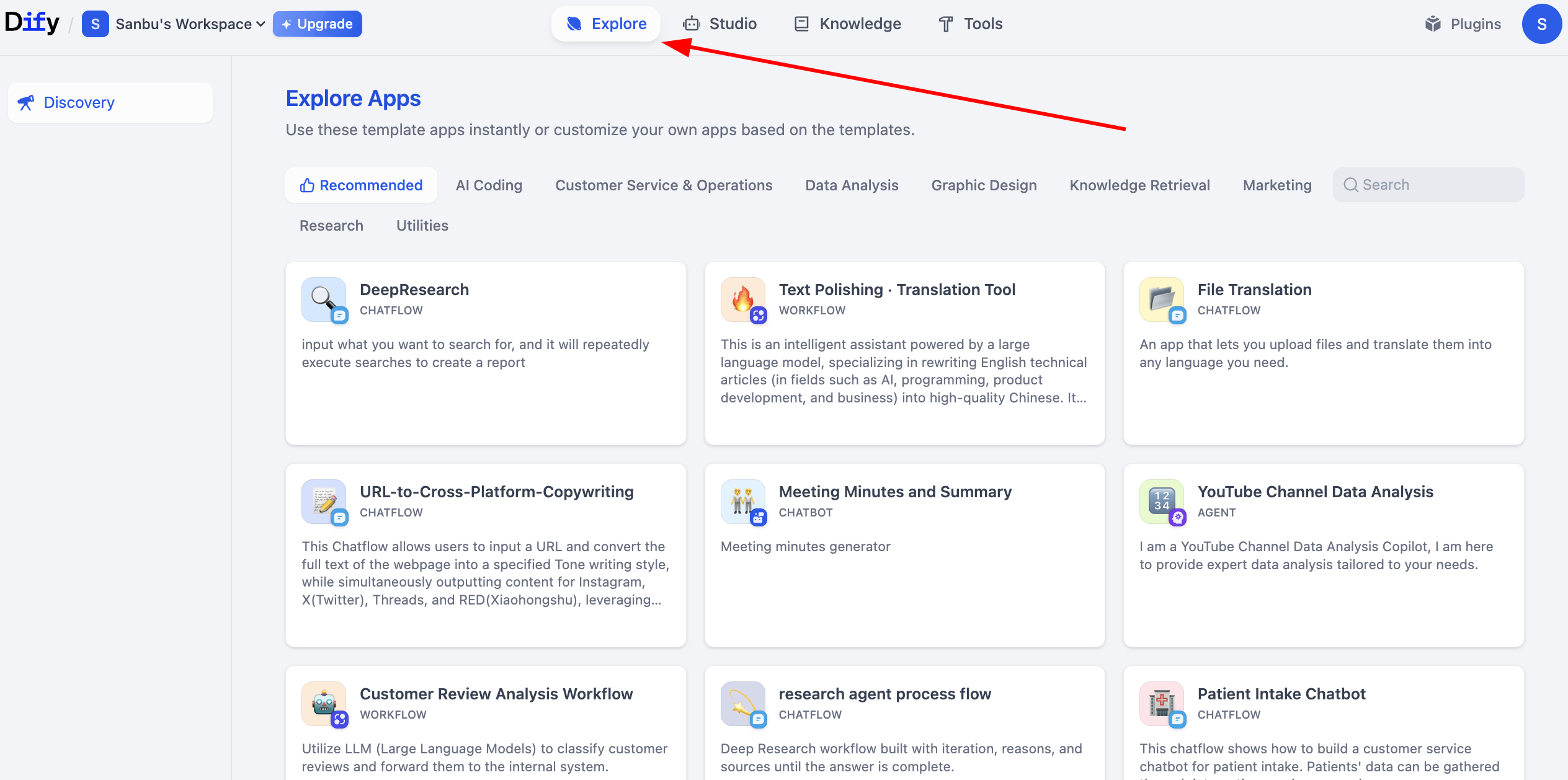
2.6 첫 번째 Dify Workflow 애플리케이션 만들기
Dify 대화형 에이전트 구축 입문을 완료한 후, 더 복잡한 Dify 비즈니스 워크플로우를 구축하는 방법을 계속 살펴보겠습니다. 워크플로우는 Dify가 복잡한 비즈니스 논리를 시각화하는 핵심 방법으로, 이를 통해 블록 조립하듯 지능형 프로세스를 구축할 수 있습니다. 정보가 다른 노드 간에 어떻게 흐르는지, 판단 논리가 어떻게 배포되는지, 수동 개입 지점이 어디에 설정되는지, 그리고 최종적으로 어떻게 완전한 비즈니스 결과를 전달하는지 완전히 경험할 수 있습니다.
빈 공간에서 새로 만들거나 템플릿에서 직접 만들 수 있습니다. 여기서는 빈 공간에서 워크플로우를 만드는 방법을 시연합니다:
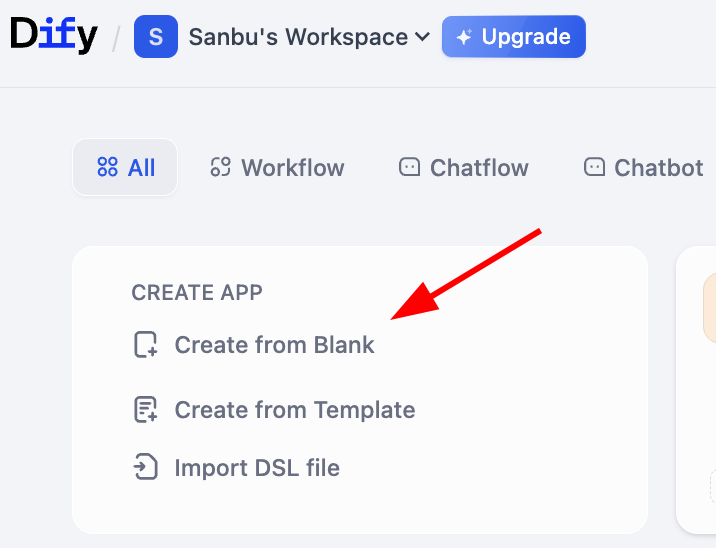
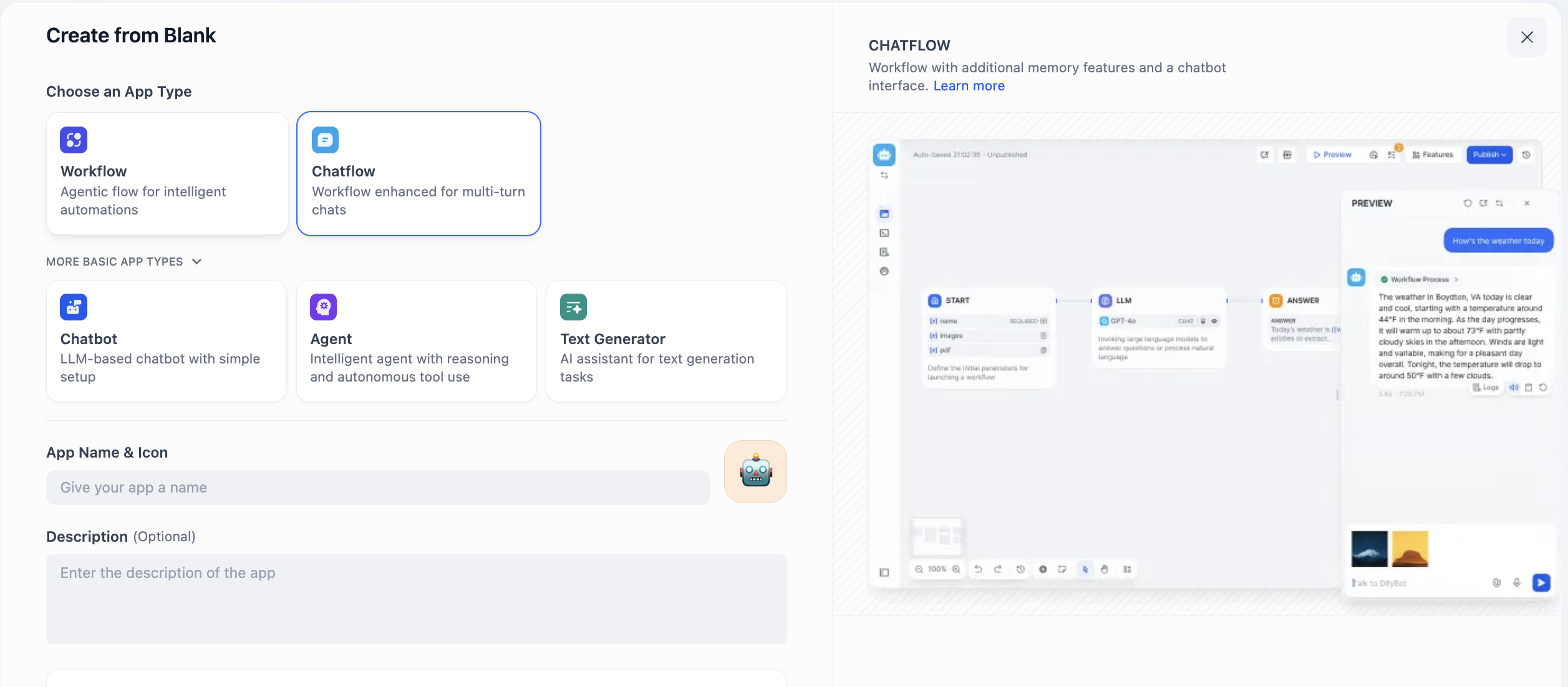
여기서 Chatflow와 Workflow라는 두 가지 선택지를 볼 수 있습니다. 이 둘 중 어떤 것을 선택해야 할까요? 핵심은 구축하려는 것의 본질이 지속적인 대화인지, 아니면 작업 프로세스인지 이해하는 것입니다.
Chatflow는 대화를 위해 설계되었습니다. 기억과 맥락 이해 능력을 갖춘 대화자를 시뮬레이션하여, 다중 라운드 상호작용과 상태 유지가 필요한 시나리오에 매우 적합합니다. 예를 들어 고객 서비스 상담에서 후속 질문을 일관되게 이해할 수 있으며, 마치 인내심 있는 서비스 담당자와 같습니다. 스트리밍 출력 기능은 상호작용 과정을 더욱 자연스럽게 만듭니다. 요약하자면, "대화"할 수 있는 에이전트를 구축하고자 할 때 Chatflow를 선택해야 합니다.
Workflow는 프로세스의 자동화 실행에 집중합니다. 미리 설정된 조립 라인과 같아서, 일회성 입력, 다단계 처리, 그리고 확정적인 출력을 생성하는 작업에 뛰어납니다. 예를 들어 매일 정기적으로 데이터 보고서를 생성하거나, 파일을 일괄 처리하거나, 일련의 API를 호출하는 작업 등입니다. 이러한 작업은 일반적으로 이벤트에 의해 트리거되며, 실시간으로 사람과 상호작용할 필요가 없습니다. 따라서 "자동화" 작업을 구현하고자 할 때 Workflow가 더 적합한 선택입니다.
선택 오류로 인한 비효율성을 피하기 위해, 네 가지 핵심 질문으로 작업 요구사항을 검토할 수 있습니다:
- 작업 과정이 여러 번의 사용자 입력과 조정에 의존해야 합니까?
- 결과 제시가 단계별, 스트리밍 방식으로 이루어져야 합니까?
- 처리 논리가 이전 상호작용 기록에 크게 의존합니까?
- 작업이 이벤트에 의해 트리거되며, 입력과 출력이 대부분 일회성으로 완료됩니까?
앞의 세 질문에 대한 답이 "예"라면 Chatflow가 이상적인 선택이며, 대표적인 시나리오로는 스마트 고객 서비스, 교육 지도, 창의적 협업 등이 있습니다. 네 번째 질문의 특징이 두드러진다면 Workflow를 선택해야 하며, 데이터 정제, 보고서 생성, 일괄 처리 등 자동화 시나리오에 더 적합합니다.
여기서는 Chatflow를 예시로 선택하여 소개하겠습니다. Chatflow를 클릭하면 작업대 인터페이스로 진입합니다:
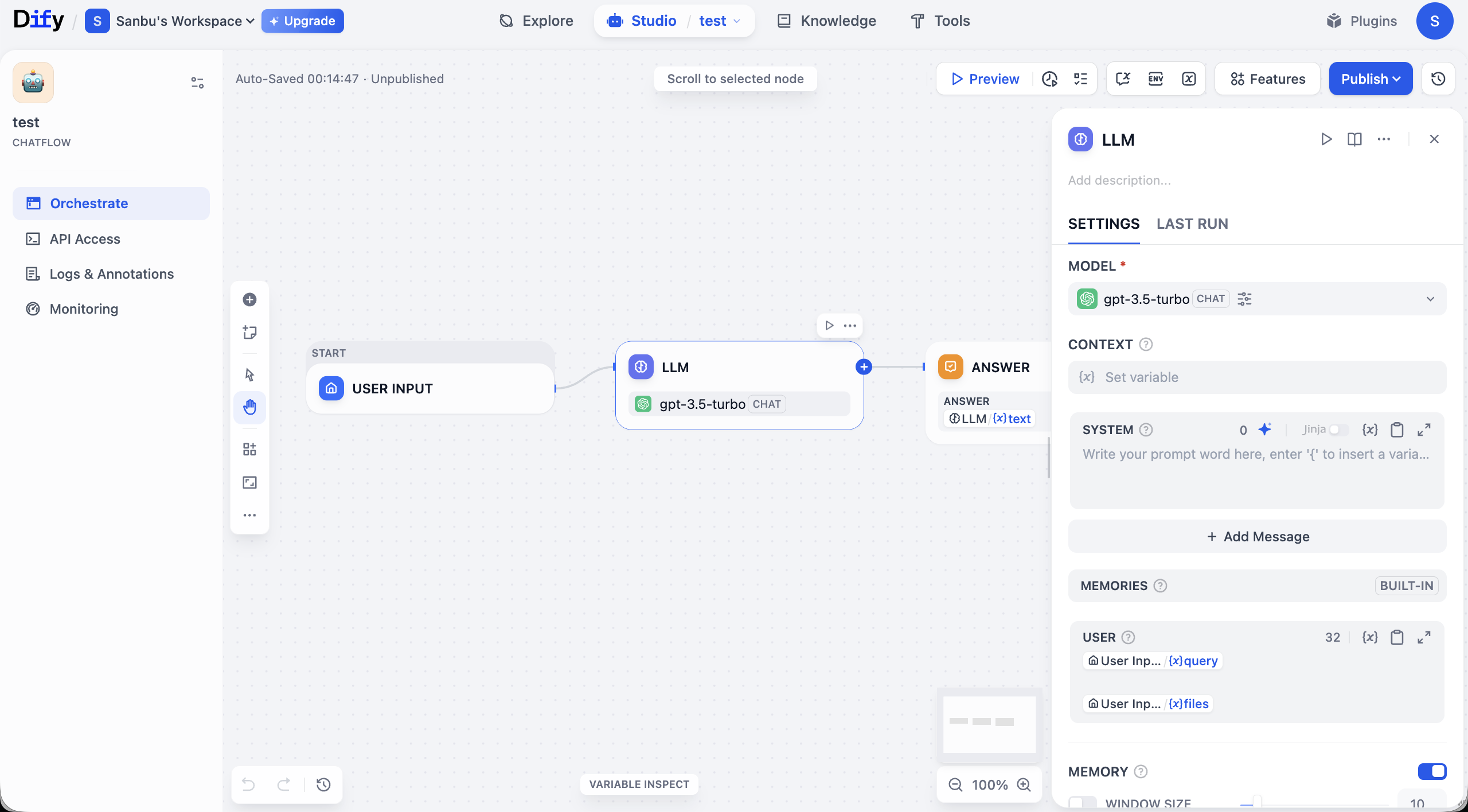
워크플로우 인터페이스의 페이지를 간단히 소개하겠습니다. 전체 인터페이스의 핵심은 중앙의 편집 캔버스이며, 여기서 시각적 방식으로 애플리케이션 논리를 구축합니다. 그림과 같이 기본 워크플로우는 일반적으로 START 노드(입력 수신용)에서 시작하여, 연결선을 통해 데이터를 LLM 노드로 전달하여 처리하고, 최종적으로 ANSWER 노드를 통해 결과를 출력합니다. 각 노드는 하나의 기능 모듈을 나타내며, 연결선은 작업 실행 순서를 결정합니다.
캔버스 주변에는 완전한 작업 및 관리 기능 영역이 있습니다. 인터페이스 상단에는 워크플로우 테스트를 위한 Preview 버튼과 서비스 배포를 위한 Publish 버튼을 포함한 전역 제어 옵션이 제공됩니다. 캔버스 모서리에는 확대/축소, 실행 취소 등의 뷰 제어 도구가 있어 세밀한 조정이 가능합니다.
왼쪽 패널에는 애플리케이션 관리 기능이 집중되어 있습니다. 현재 있는 Orchestrate 탭은 프로세스 편성에 사용됩니다. 구축이 완료되면 API Access를 통해 통합 자격 증명을 얻을 수 있습니다. Logs & Annotations는 각 실행의 상세한 추적 기록을 제공하여 디버깅에 도움을 줍니다. Monitoring은 애플리케이션 실행 시의 성능 및 상태 모니터링을 제공합니다.
이 대화 워크플로우의 LLM 노드 SYSTEM에 간단한 프롬프트 내용을 입력한 후, Preview를 클릭하여 워크플로우를 실행해 보고, SYSTEM 프롬프트 수정 후 전체 워크플로우가 예상대로 변화하는지 확인할 수 있습니다.
2.6.1 일반적인 노드 소개
Dify에는 다양한 노드가 제공됩니다. 각 노드의 기본 기능을 먼저 이해하는 것이 좋습니다. 실제 사용 시에는 직접 시도해 보거나, 다른 사람이 만든 워크플로우 템플릿을 참고하거나, 스크린샷을 찍어 대형 모델에게 해당 노드의 용도와 필요한 매개변수 등을 문의하는 것도 좋은 방법입니다. 기존 템플릿에서 다른 노드로 교체해 보고, 다른 사람의 사용 방식을 통해 노드의 모범 사례를 추론하는 것을 추천합니다.
캔버스에서 우클릭하여 "Add Node"를 클릭하면 노드를 추가할 수 있으며, 왼쪽 노드 패널에서 모든 사용 가능한 노드를 확인할 수도 있습니다:
또한 도구 선택 패널을 열어 호출 가능한 다양한 도구를 확인할 수 있습니다:
다음은 자주 사용되는 노드와 도구에 대한 간략한 설명입니다. 한 번에 모두 마스터할 필요는 없으며, 먼저 대략적인 인상을 남겨두고 실제 사용에서 점차 익숙해지며, 필요할 때 다시 돌아와 참고하시면 됩니다.
- LLM 및 추론 노드

이러한 노드는 워크플로우의 핵심 프로세스를 담당합니다.
- LLM 노드: 핵심 컴퓨팅 단위로, 대형 언어 모델을 호출하는 데 사용됩니다. 구성의 핵심은 프롬프트 엔지니어링과 매개변수 최적화에 있으며, 비즈니스 문제를 모델의 실행 명령으로 변환합니다.
- Knowledge Retrieval 노드: 지식 검색 단위로, 사전 설정된 지식 베이스와 외부 권위 있는 데이터 소스에서 비즈니스 문제와 관련된 정보를 검색하여 LLM 노드에 정확한 지식 지원을 제공하며, 대형 언어 모델 출력의 "환각(hallucination)" 문제를 줄이는 데 도움을 줍니다.
- Answer 노드: 결과 출력 단위로, LLM 처리 후의 콘텐츠를 수신하여 비즈니스 시나리오 요구에 맞는 최종 결과 형식으로 정리합니다. 구성의 핵심은 출력 형식의 정의(예: 화술 템플릿, 레이아웃 규격)에 있습니다.
- Agent 노드: 고급 의사결정 단위입니다. 모델을 호출할 뿐만 아니라, 다단계 계획을 수립하고 외부 도구를 자율적으로 선택하여 호출할 수 있으며, 동적 의사결정이 필요한 복잡한 작업 체인에 적합합니다.
- Question Classifier 노드: 질문 분류 단위로, 입력된 비즈니스 질문을 유형 식별 및 분류(예: 질문 의도, 주제 영역 등의 차원에 따라 분류)하는 역할을 담당하며, 후속 프로세스가 해당 처리 노드와 정확하게 매칭되도록 돕습니다(예: 다른 유형의 질문에 다른 LLM 프롬프트나 도구 체인 적용).
- 논리 및 프로세스 제어 노드

이러한 노드는 워크플로우의 실행 경로와 규칙을 정의합니다.
- 조건 노드:
IF/ELSE와 같이 부울 판단을 통해 프로세스 분기를 구현합니다. 설계의 핵심은 조건 표현식의 엄밀성으로, 모든 비즈니스 시나리오를 논리적으로 커버해야 합니다. - Iteration 노드: 상태 없는 일괄 병렬 처리 단위로, 하위 작업 간에 데이터 의존성이 없고 독립적으로 처리할 수 있는 시나리오를 위해 설계되었습니다. 예를 들어 문단 일괄 번역, 여러 콘텐츠 병렬 심사 또는 여러 보고서 동시 생성 등이 있습니다. 이 노드는 입력 배열을 수신하여 자동으로 분할하고, 각 요소를 동일한 처리 체인으로 분산하여 병렬 실행합니다. 사용자는 반복 본체에서 을 통해 현재 요소에 접근하고, 로 인덱스를 얻을 수 있으며, 출력은 자동으로 결과 배열로 집계됩니다. 구성 시 효율성과 시스템 부하의 균형을 위해 병렬도를 설정하는 것이 중요하며, 동시에 재시도 전략(예: 재시도 횟수, 간격)과 실패 처리(예: 로그 기록, 기본값 반환)를 통해 일괄 작업의 안정성을 보장해야 합니다.
- Loop 노드: 상태가 있는 재귀 반복자로, 결과가 이전 라운드 출력에 의존하는 시나리오에 적합합니다. 예를 들어 다중 라운드 매개변수 최적화, 재귀적 콘텐츠 개선(예: 만족할 때까지 문안 반복 수정) 및 이전 결과에 의존하는 체인식 계산 등입니다. 핵심은 "상태 변수"로, 루프 시작 전에 초기화해야 하며(예: 현재 반복 횟수, 중간 계산 결과), 각 반복에서 다음 라운드 입력으로 사용하도록 명확하게 업데이트해야 합니다. 무한 루프를 방지하기 위해 종료 조건을 정의해야 합니다(카운터 기반 "최대 10회 반복", 결과 판정 기반 "만족도 점수 > 9", 외부 신호 기반 "'정지' 입력 감지" 포함). 동시에 루프 타임아웃 구성을 설정하고, 예외 처리 경로를 계획하여(예: 루프에서 벗어나거나 상태를 재설정한 후 재시도) 프로세스의 안정적인 실행을 보장해야 합니다.
- 데이터 조작 및 통합 노드
- Code 노드: 코드 처리 단위로, 워크플로우에서 사용자 정의 코드 논리를 실행하는 데 사용되며, 데이터 형식 변환, 복잡한 계산 등 개인화된 처리 요구를 구현할 수 있습니다. 구성의 핵심은 코드 구문의 정확성과 실행 환경의 적응에 있습니다.
- Template 노드: 템플릿 처리 단위로, 동적 데이터를 미리 설정된 템플릿에 채워 형식 요구사항에 맞는 콘텐츠(예: 맞춤형 문안, 보고서 프레임워크)를 생성합니다. 구성의 핵심은 템플릿 구문 작성과 변수 매핑 규칙 설정에 있습니다.
- Variable Aggregator 노드: 변수 집계 단위로, 워크플로우 내 여러 노드에서 출력된 변수 데이터를 수집하여 분산된 변수를 통일된 데이터 세트로 통합합니다. 구성의 핵심은 집계할 변수 범위와 데이터 병합 규칙의 정의에 있습니다.
- Doc Extractor 노드: 문서 추출 단위로, PDF, Word 등 다양한 문서에서 텍스트, 표 등 핵심 콘텐츠를 추출하여 워크플로우가 처리할 수 있는 구조화된 데이터로 변환합니다. 구성의 핵심은 문서 유형 적응과 추출 콘텐츠 필터링 규칙에 있습니다.
- Variable Assigner 노드: 변수 할당 단위로, 워크플로우 내 변수를 정의, 초기화 또는 업데이트하여 프로세스 내 데이터 전달을 위한 매개체를 제공합니다. 구성의 핵심은 변수 명명, 데이터 유형 및 할당 논리 설정에 있습니다.
- Parameter Extractor 노드: 매개변수 추출 단위로, 사용자 요청, 인터페이스 반환 등의 입력 콘텐츠에서 지정된 매개변수를 추출하여 비구조화된 정보를 구조화된 데이터로 변환합니다. 구성의 핵심은 추출 규칙(예: 정규 표현식, JSON 경로)의 구성에 있습니다.
- HTTP Request 노드: HTTP 요청 단위로, 외부 시스템 인터페이스에 HTTP 요청(GET, POST 등 메서드 포함)을 발행하여 워크플로우와 외부 서비스 간의 데이터 상호작용을 구현합니다. 구성의 핵심은 요청 주소, 요청 메서드 및 매개변수/headers 설정에 있습니다.
- List Operator 노드: 리스트 조작 단위로, 배열, 리스트 유형의 데이터를 처리(예: 필터링, 정렬, 분할)하여 후속 프로세스에 맞게 데이터 구조를 조정합니다. 구성의 핵심은 조작 유형(예: 필터링 조건, 정렬 규칙)의 정의에 있습니다.
2.6.2 일반적인 도구 소개
Dify에서 대부분의 도구는 캔버스에 직접 노드로 배치할 수 있으며, 다른 노드와 마찬가지로 상하류 연결선으로 연결할 수 있습니다. 제공한 입력이 해당 노드(도구)의 매개변수 사양을 충족하면 정상적으로 실행되어 계속 전달할 수 있는 결과를 산출합니다.
왼쪽 또는 오른쪽 노드 패널에서 모든 사용 가능한 도구 노드를 확인할 수 있으며, 플러그인 마켓을 통해 더 많은 도구 기능을 확장할 수도 있습니다. 몇 가지 일반적인 도구의 역할을 간단히 소개합니다:
- 웹 검색 도구 Tavily Search를 대표로, 대형 모델에 AI 최적화된 실시간 검색 기능을 제공합니다. 구조화된 검색 결과(예: 제목, 요약, 링크 등)를 반환하며, LLM 프롬프트의 일부로 직접 사용하여 최신 뉴스나 권위 있는 근거가 필요한 질문에 답변하는 데 활용할 수 있습니다.
- 데이터 처리 도구 예를 들어 JSON Process 플러그인은 JSON 데이터에 대한 쿼리, 필터링, 변환, 병합 등의 고급 조작에 사용됩니다. 복잡한 API 응답이나 다층 중첩 데이터를 처리할 때 "데이터 정제 + 재구성" 논리를 이 도구에 맡겨, Code 노드에서 파싱 코드를 반복해서 수동으로 작성하는 작업을 간소화할 수 있습니다.
- 형식 처리 도구 예를 들어 Markdown Exporter는 생성된 콘텐츠를 지정된 형식(예: Markdown 문서, 특정 레이아웃 템플릿 등)으로 내보낼 수 있어, 후속 전시, 보고 또는 다른 시스템과의 통합에 편리합니다.
도구 목록에서 이러한 플러그인의 설치 수와 소개를 확인할 수 있습니다. 초기에는 "Featured / 추천"에 있는 도구를 우선적으로 설치해 보는 것을 권장하며, 이러한 도구는 보통 가장 일반적인 비즈니스 시나리오를 다루고 있습니다.
다만, 도구 사용은 일반적으로 비교적 복잡하므로, 사용하기 전에 검색 엔진에서 해당 도구의 "공식 추천 워크플로우 DSL 사례"를 먼저 검색하여 직접 가져와 사용하는 것이 직접 구축하는 것보다 훨씬 시간을 절약할 수 있습니다.
2.6.3 간단한 의도 분류 워크플로우 만들기
이제 Dify 워크플로우와 도구 등의 기본 정보를초보적으로 이해했지만, 연습 없이는 세부 사항을 숙달할 수 없습니다. "가상"의 실제 비즈니스 시나리오를 통해 연습해 보겠습니다.
예를 들어, 실제 쇼핑 대화 시나리오에서 상품을 구매하러 온 사용자의 입력은 결코 "규격화된 매개변수"가 아니며, 무심코 던진 한마디입니다. 어떤 사람은 주문을 하고, 어떤 사람은 불만을 토로하고, 어떤 사람은 그저 잡담을 하고 싶어 하며, 어떤 사람은 완전히 엉뚱한 이야기를 합니다. 이 모든 입력을 동일한 대형 언어 모델(LLM)에 직접 전달하면, 시스템은 일반적으로 두 가지 전형적인 문제가 발생합니다:
- 응답 스타일 불안정 불만 사항에 대해서도 어떤 때는 LLM이 사과하고 위로하지만, 어떤 때는 "원인을 설명"하는 것처럼 일관성이 없습니다. 주문에 대해서도 어떤 때는 누락된 정보를 추가로 묻지만, 어떤 때는 주문 세부 사항을 임의로 만들어냅니다.
- 비즈니스 논리 통제 불가 "불만에는 반드시 먼저 사과해야 한다"는 규칙을 원하지만, 모델이 매번 이를 준수하지 않을 수 있습니다. "비즈니스와 관련 없는 질문은 본론으로 유도해야 한다"는 규칙도 모델이 흥미롭게 농담을 이어갈 수 있습니다.
따라서, 더 공학적인 접근 방식은 작업을 표준화된 파이프라인으로 분해하는 것입니다. 먼저 의도 분류(사용자가 실제로 무엇을 원하는지 파악)를 수행한 후, 의도에 따라 분기(다른 시나리오에 다른 프롬프트와 역할 사용)하고, 마지막으로 각 분기에서 대형 모델의 응답을 통합하여 출력(프론트엔드나 시스템 통합에 편리)합니다.
이 절의 목표는 시스템이 식당 시나리오에서의 다양한 유형 대화를 처리할 수 있게 하는 것입니다. 직접 따라 해보며 인상을 깊게 할 수 있습니다. 먼저 장면을 의도 분류로 정의해야 합니다:
- 주문 구매 (buy_food): 사용자가 명확한 구매 의사를 표현합니다.
- 예: "치킨 한 부분 주시고, 콜라도 하나 추가해 주세요."
- 불만 접수 (complain): 사용자가 불만, 재촉 또는 부정적인 피드백을 표현합니다.
- 예: "너무 느린 거 아니에요? 한 시간이나 기다렸어요."
- 잡담 상담 (chitchat): 사용자가 개방형 질문, 조언을 구하지만 명확한 주문 지시는 없습니다.
- 예: "오늘 뭐 먹으면 좋을까요? 추천해 주실 수 있나요?"
- 기타 의도 (other): 사용자의 입력이 식당 시나리오와 무관합니다.
- 예: "웃긴 글귀 하나 써서 모멘트에 올리고 싶어요."
이 네 가지 의도에 대해 시스템에 네 가지 다른 "소통 페르소나"를 사전 설정하며, 각각 네 개의 독립적인 LLM 노드로 구성되고, 각 노드는 서로 다른 페르소나를 가진 LLM이 연기를 담당합니다.
- 주문 도우미 (LLM_BuyFood): 전문적이고 효율적이며, 핵심 임무는 주문 세부 사항을 확인하고 누락된 정보를 능동적으로 보완하는 것입니다.
- 고객 서비스 전문가 (LLM_Complain): 공감하고 차분하며, 첫 번째 임무는 사용자 감정을 안정시키고 명확한 해결책을 제공하는 것입니다.
- 대화 파트너 (LLM_Chitchat): 가볍고 친근하며, 개인화된 추천을 제공하고 잠재적 소비를 유도하는 것을 목표로 합니다.
- 정중한 문지기 (LLM_Other): 집중적이고 경계가 명확하며, 주제에서 벗어난 대화를 정중하게 핵심 비즈니스로 유도하는 역할을 담당합니다.
워크플로우 편성 설계
다음으로 워크플로우의 편성 설정을 진행하여, 대략적으로 어떤 워크플로우 노드가 필요한지 결정합니다. 초보자에게는 어떤 노드가 필요한지 생각하기 어려울 수 있습니다(숙련자도 직접 생각하는 것을 귀찮아하며, 대형 모델에게 조언을 구하는 것이 보통 가장 빠르고 좋은 선택입니다). 따라서 대형 모델을 사용하여 해당 편성 조언을 얻을 수 있으며, 핵심 노드 구조는 다음과 같습니다:
- Start (시작점): 데이터 입구로, 사용자의 원본 입력
user_text를 수신합니다. - Question Classifier (의도 분류기): 워크플로우의 "두뇌"이자 "스케줄링 센터"입니다.
user_text를 분석하고, 사전 설정된 네 가지 의도 레이블 중 가장 일치하는 것을 선택합니다. - Condition (조건 분기): "분배 밸브" 역할을 합니다. 분류기가 출력한 의도 레이블에 따라 다음에 작업을 어느 전용 처리 경로로 보낼지 결정합니다.
- 네 개의 병렬 LLM 노드 (LLM_BuyFood, LLM_Complain, LLM_Chitchat, LLM_Other): 네 개의 독립적인 "전문가 처리 단위"입니다. 각 노드는 원본 질문을 수신하지만, 자체적으로 고유한 System Prompt(시스템 프롬프트)에 따라 스타일과 목표가 완전히 다른 응답을 생성합니다.
- Variable Aggregator (변수 집계기): 여러 경로의 처리가 완료된 후 "수집 지점"이 필요합니다. 이 노드는 네 개의 분기 중 유일하게 활성화되어 결과를 생성한 응답을 통합 변수
final_reply로 수집하여 출력 구조의 안정성을 보장합니다. - Output (종점): 최종 출구로, 의도 레이블, 원본 질문, 그리고 처리를 거쳐 생성된 응답을 구조화된 형식(예: JSON)으로 통합 출력하여, 후속 시스템 호출이나 디버깅 분석에 편리합니다.
워크플로우 편성 구현
이번 튜토리얼에서는 Chatflow가 아닌 Workflow를 생성하기로 선택하며, User Input을 선택합니다:
그런 다음 Start의 User Input 노드를 클릭하고, user_text라는 문자열 유형 변수를 정의하여 전체 프로세스의 입력 소스로 사용합니다.
저장 후 오른쪽 상단의 Test Run을 클릭하면, 해당 텍스트 입력을 지정하여 처리하는 것을 볼 수 있습니다:
다음으로 입력 노드 뒤의 + 기호를 클릭하고, Question Classifier 노드를 추가하도록 선택합니다. 그리고 네 가지 유형의 레이블을 구성하고, 각 레이블에 명확한 설명과 예시를 제공해야 합니다.
buy_food: 사용자가 명확하게 음식을 사고 싶어 하거나, 주문하거나, 주문을 넣으려는 경우.complain: 사용자가 불만을 토로하거나, 불평하거나, 화를 내며, 보통 불만족스러운 감정이 동반됩니다.chitchat: 사용자가 잡담을 하거나, 뭘 먹을지 논의하거나, 추천을 상담하는 경우.other: 식당 시나리오와 무관하거나, 판단하기 어려운 콘텐츠.
또한, ADVANCED SETTING에 프롬프트를 작성하여 대형 모델이 사용자 입력에 따라 올바르게 분류 테스트를 수행할 수 있도록 해야 합니다. 예시 프롬프트는 다음과 같습니다:
buy_food / complain / chitchat / other 중에서 가장 적합한 레이블을 하나 선택하세요. 사용자가 불만을 토로하면서 동시에 주문도 한 경우, 핵심 감정을 우선적으로 판단하세요. 불만 표현이 주된 목적이라면 complain으로 분류해야 합니다. 가벼운 불평이지만 주된 의도가 주문이라면 buy_food로 분류하세요. 정말 판단하기 어려운 경우 other를 기본값으로 사용하세요.
설정이 완료되면, 오른쪽 상단의 재생 버튼을 클릭하여 해당 노드가 정상적으로 실행되는지 개별적으로 테스트할 수 있습니다:
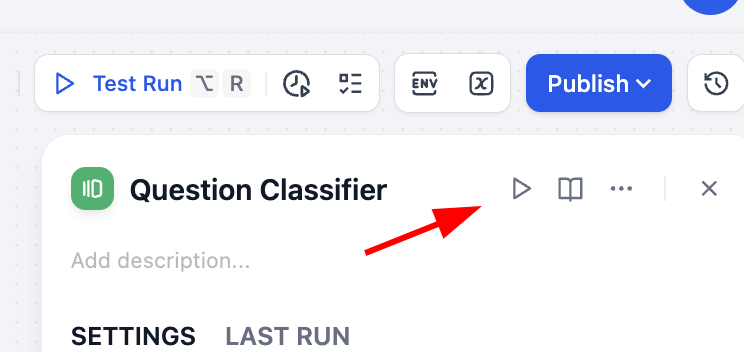
OUTPUT 결과를 보면 분류가 정확한 것을 확인할 수 있습니다. 다양한 유형의 입력으로 여러 번 테스트하여 분류기의 안정성을 검증할 수 있습니다.
다음으로, 분류기에 후속 대형 모델 출력을 연결해야 합니다. 예를 들어, label이 "buy_food"와 같으면 워크플로우는 정확하게 LLM_BuyFood 노드로 흐르게 됩니다. 네 개의 새로운 LLM 노드를 만들고 각각 다른 System Prompt를 설정해야 합니다. 다른 System Prompt의 차이가 각각 다른 응답 방식을 결정합니다.
- LLM_BuyFood (주문 도우미):
당신은 주문 도우미입니다. 요구사항: 1. 사용자가 주문하려는 내용을 확인합니다. 2. 정보가 불완전한 경우 친절하게 추가 질문합니다. 3. 정중하고 간결한 어조를 사용합니다.
- LLM_Complain (고객 서비스 전문가):
당신은 식당 고객 서비스 담당자로, 불만 처리를 전문으로 합니다. 요구사항: 1. 진심으로 사과합니다. 2. 가능한 원인을 간단히 설명합니다(책임을 전가하지 않음). 3. 명확한 다음 단계 해결책을 제시합니다.
- LLM_Chitchat (대화 파트너):
당신은 식품 추천 대화 도우미입니다. 요구사항: 1. 가볍고 친근한 어조를 사용합니다. 2. 1~3개의 간단한 추천을 제공합니다. 3. 사용자가 선호하는 것이 없으면 다양한 스타일의 선택지를 제공합니다.
- LLM_Other (정중한 문지기):
당신은 식당 주문 도우미로, '음식'과 관련된 주제에만 능숙합니다. 사용자가 관련 없는 말을 할 때: 1. 정중하게 자신의 능력 범위를 설명합니다. 2. 사용자를 핵심 시나리오로 유도합니다.
주의할 점은, 각 노드에서 SYSTEM 프롬프트 매개변수를 채운 후, USER 프롬프트 매개변수 표도 활성화하는 것을 잊지 마세요. 그 안에서 {x} 기호를 클릭하여 user_text 매개변수를 사용자 입력으로 선택하고, 앞에 user input:을 추가하여 이 변수가 사용자 입력임을 표시해야 합니다. 질의응답 시 사용자의 최초 입력과 내장 프롬프트를 종합하여 응답하게 됩니다.
마찬가지로, 모든 것이 순조로운지 확인하기 위해 해당 노드의 오른쪽 상단 재생 버튼을 클릭하여 구체적인 대화 테스트로 효과를 검증할 수 있습니다. 예를 들어 "탕후루 마시고 싶어요" 등의 대화로 응답이 예상에 부합하는지 확인합니다.
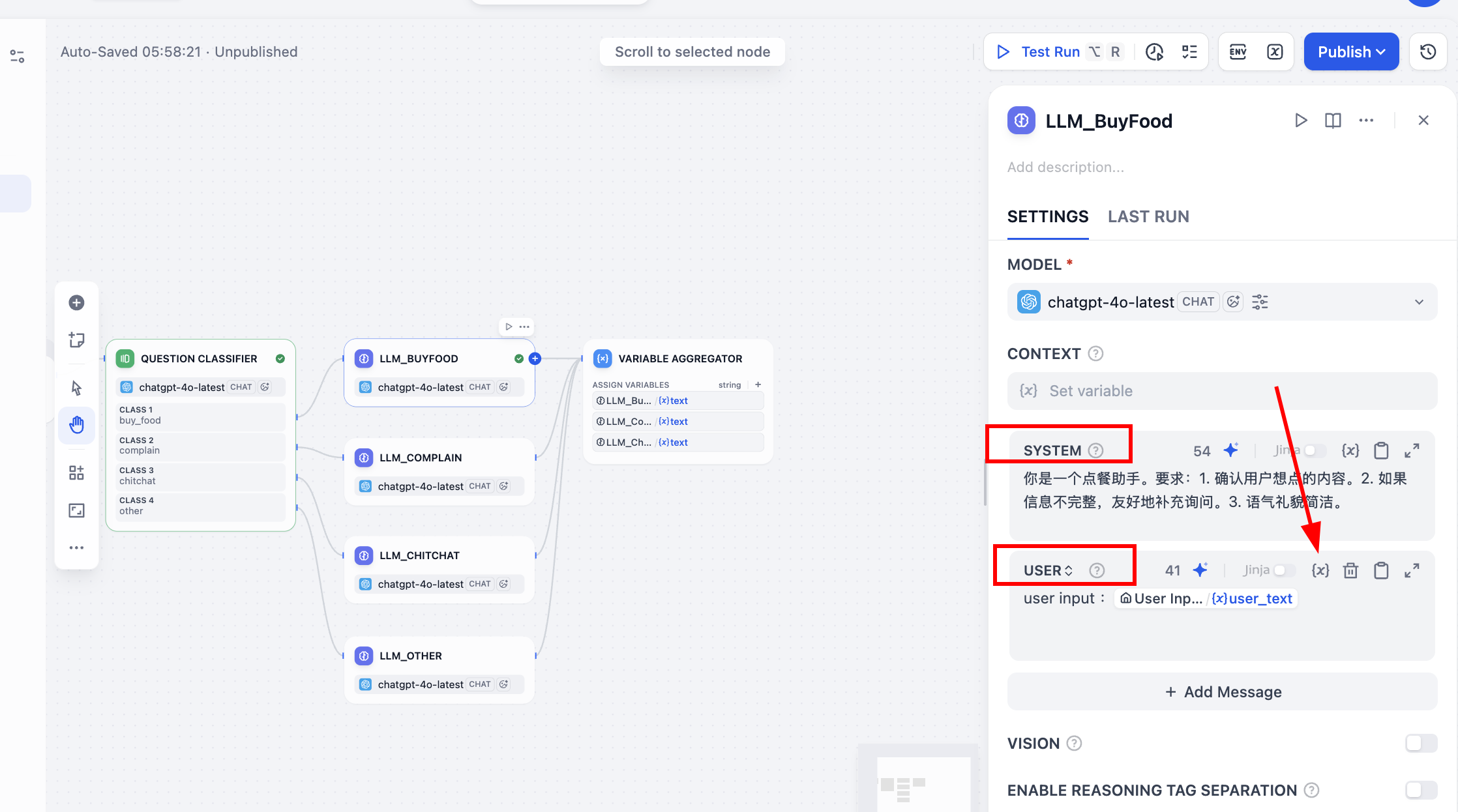
다음으로 병렬 LLM의 출력 값을 처리합니다. Variable Aggregator 노드의 구성 패널에서 ASSIGN VARIABLES(변수 할당) 영역을 찾아 클릭한 후, 이전의 대형 모델 응답을 순서대로 추가하면 됩니다.
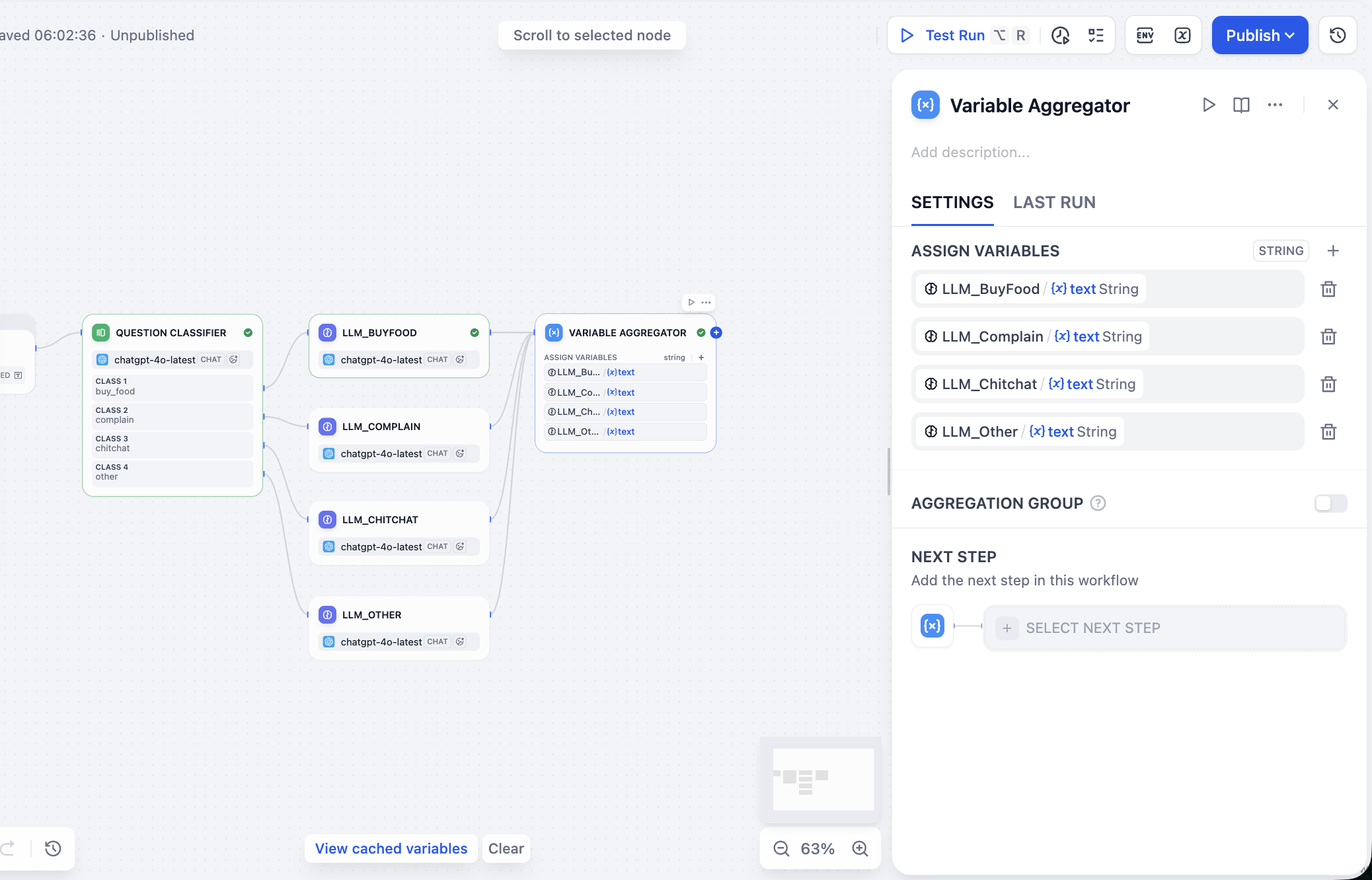
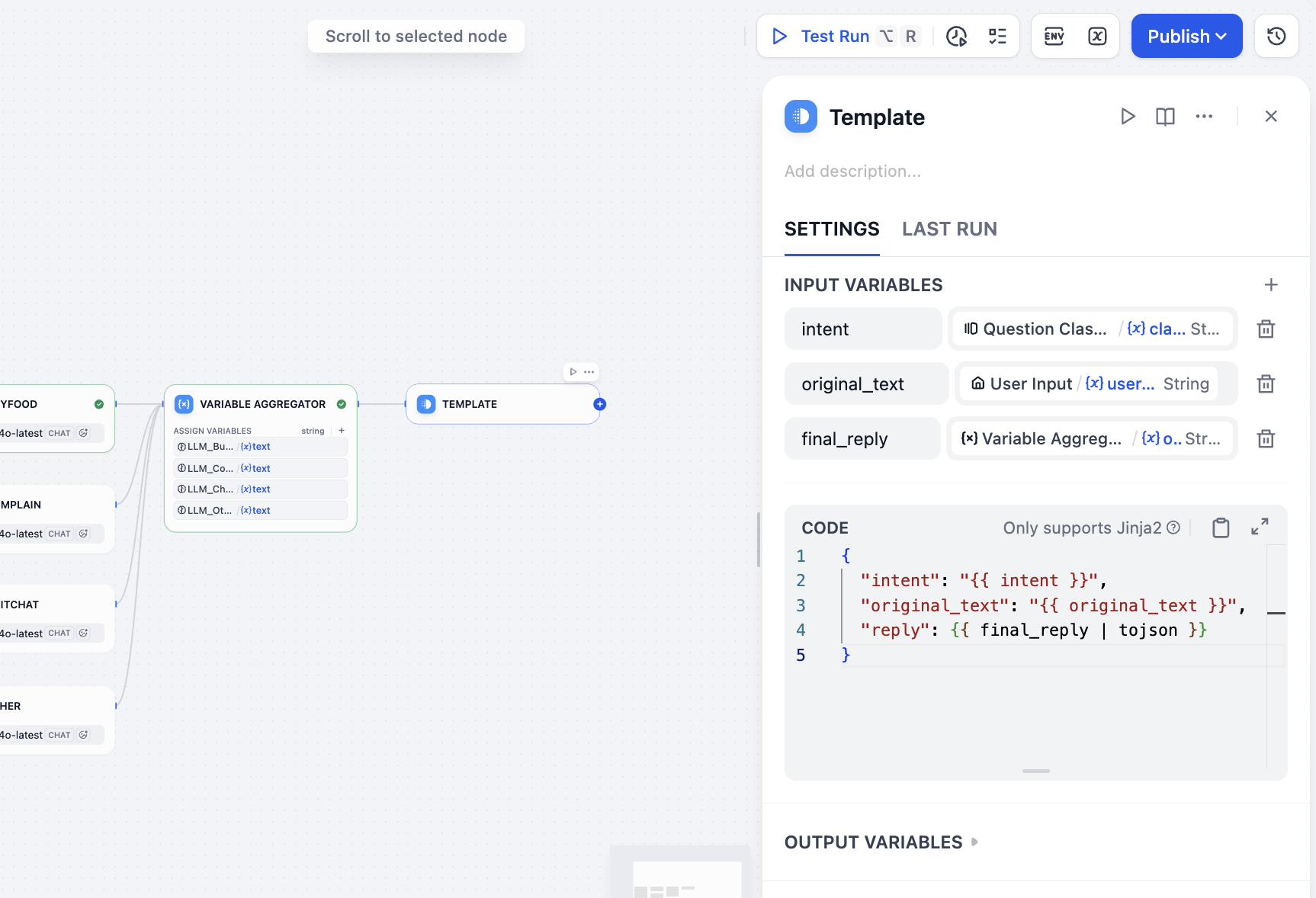
다음으로 모든 출력을 집계하여 최종적으로 원하는 결과(사용자 입력, 분류 및 응답 포함)를 얻어야 합니다. 우리가 사용하는 것은 Chatflow가 아닌 Workflow이므로, Answer 노드를 선택하여 결과를 집계할 수 없습니다. 다른 노드를 선택하여 간접적으로 결과의 집계와 출력을 구현할 수 있습니다. 이때 Template 노드를 선택하고, 변수 부분에 사용자 의도 분류 결과, 사용자 입력 값, 변수 집계의 최종 응답을 지정하며, CODE에 최종 응답의 json 형식 템플릿을 작성합니다. 다음과 같이 얻을 수 있습니다:
intent←class_nameoriginal_text←user_textfinal_reply←variable_aggregator
{
"intent": "{{ intent }}",
"original_text": "{{ original_text }}",
"reply": {{ final_reply }}
}
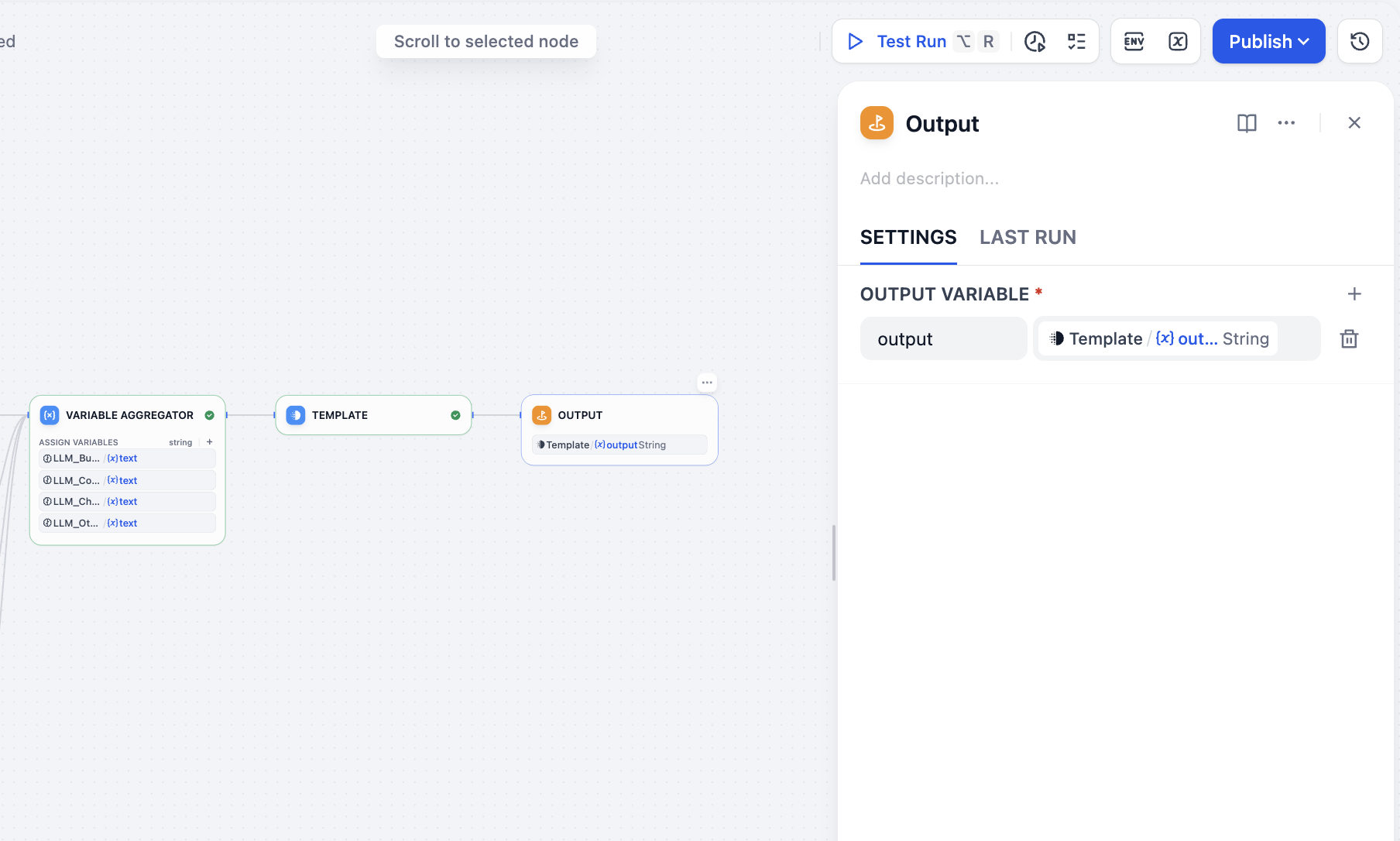
마지막으로 output 노드를 추가하면 모든 작업이 완료됩니다:
워크플로우 실행 테스트
완성되었습니다. 이 워크플로우의 효과를 실행해 볼 수 있습니다. 다른 입력에 따라 완전히 다른 행동 패턴을 보여줍니다:
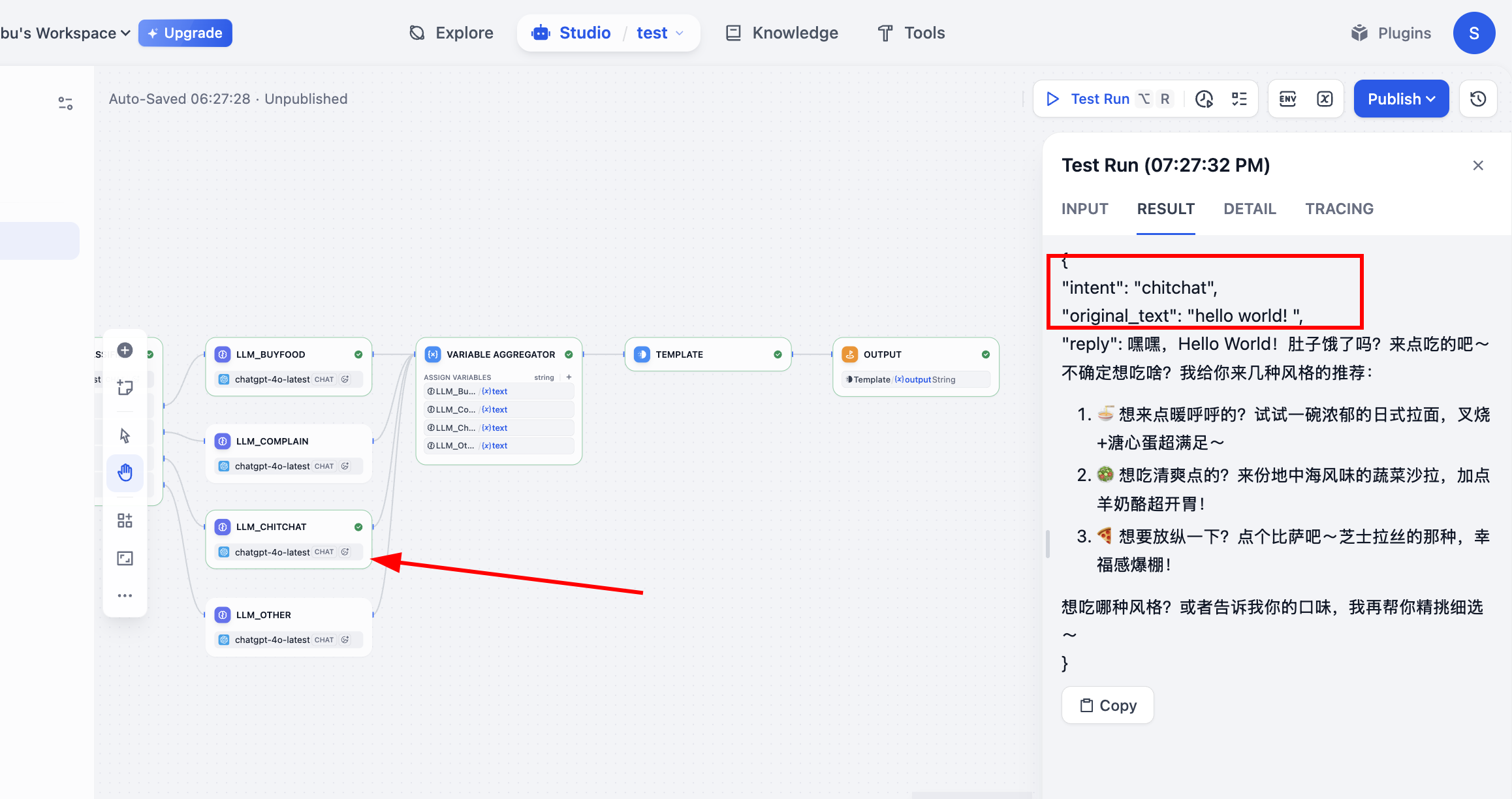
- 입력 (주문): "스파이시 치킨 버거 세트 하나, 라지 콜라 주세요."
- 경로:
buy_food→LLM_BuyFood - 출력 reply: "네, 스파이시 치킨 버거 세트와 라지 콜라를 확인했습니다. 세트의 감자튀김은 교환하시겠습니까?"
- 경로:
- 입력 (불만): "너무 느린 거 아니에요? 한 시간이 넘게 기다렸어요!"
- 경로:
complain→LLM_Complain - 출력 reply: "오랜 시간 기다리게 하여 진심으로 사과드립니다. 이는 저희의 불찰이며, 좋지 않은 경험을 드렸습니다. 현재 고객님의 주문 배송 상황을 긴급하게 확인 중이며, 상응하는 보상을 신청해 드리겠습니다. 인내와 피드백에 감사드립니다."
- 경로:
- 입력 (잡담): "오늘 뭐 먹으면 건강할까요?"
- 경로:
chitchat→LLM_Complain - 출력 reply: "건강을 추구하신다면, 저희 라이트 샐러드 시리즈나 구운 닭가슴살과 시즈 채소를 추천합니다. 담백한 맛을 선호하시나요, 아니면 조금 풍미 있는 것을 선호하시나요? 더 구체적인 추천을 드릴 수 있습니다."
- 경로:
- 입력 (관련 없음): "내일 회의에서 쓸 농담 하나 생각해 줘."
- 경로:
other→LLM_Other - 출력 reply: "재미있는 도전 같네요! 하지만 저는 주로 미식 추천과 주문 도우미입니다. 열심히 일하신 자신을 위해 뭔가 시켜드실 필요가 있다면 언제든 도와드릴 수 있습니다!"
- 경로:
숨겨진 Bug: aggregation group과 관련된 이상한 문제가 발생한다면, 이는 대부분 Dify의 내장 버그일 가능성이 높습니다. 특정 조작에서 트리거될 수 있으며, AGGREGATION GROUP을 켰다가 끈 적이 있다면, 시스템이 group 구성을 생성하고 관련 비정상 매개변수가 남아 있을 수 있습니다. 현재 스위치가 꺼져 있는 것처럼 보이더라도 이러한 잔여 구성이 문제를 일으킬 수 있습니다(예:
any관련 매개변수 오류). 이 경우 해당 노드를 삭제하고 다시 만들면 됩니다.
Test Run에서 실행한 후 워크플로우의 실행 과정을 볼 수 있습니다. 분류에 따라 올바른 프로세스로 진행되었으며, 마지막 output 결과를 얻었습니다. 이로써 전체 프로세스가 완료되었습니다.
2.7 첫 번째 템플릿 Workflow 애플리케이션 실행하기
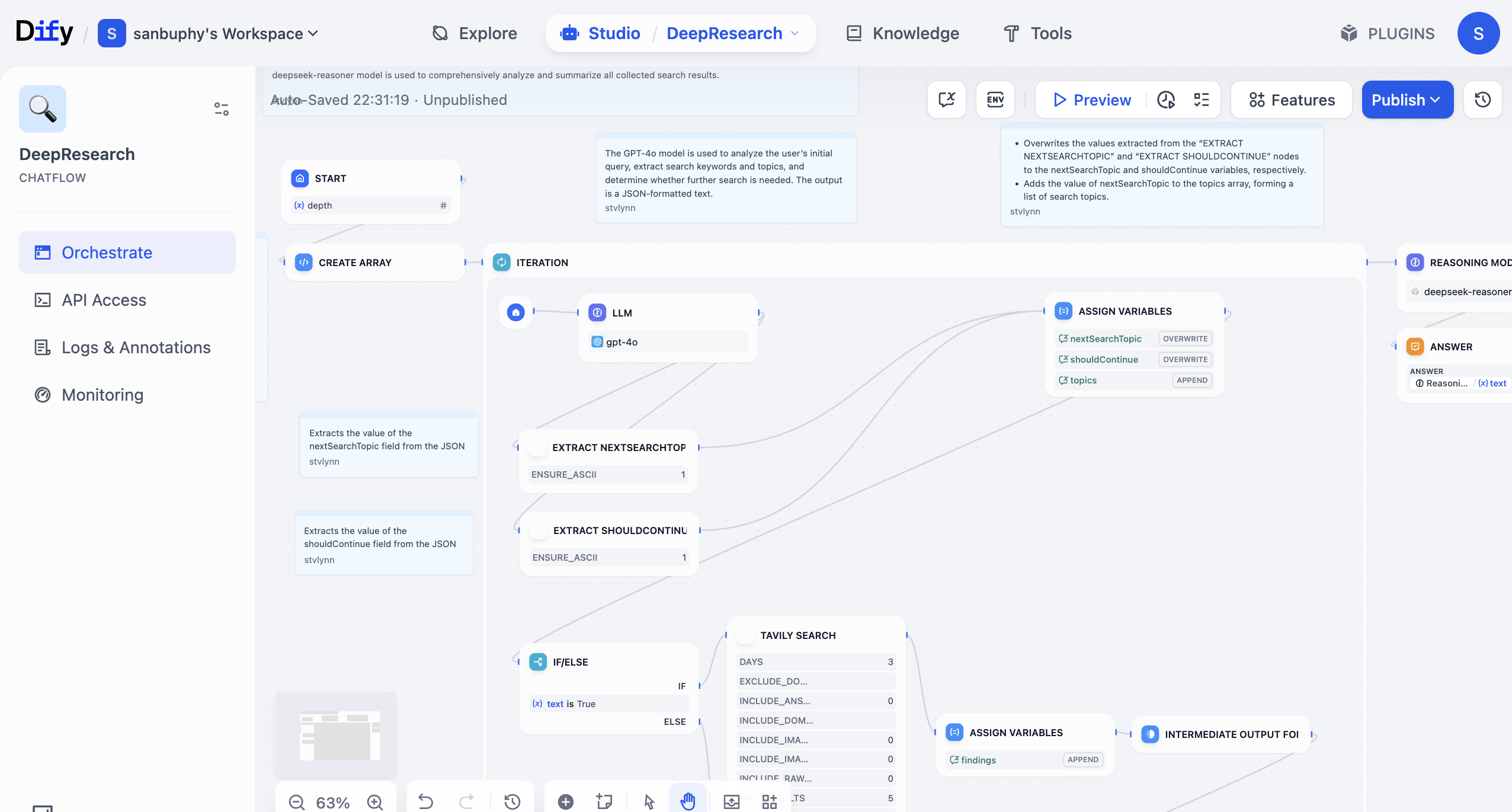
간단한 분류 워크플로우 학습을 마친 후, 다음으로 다른 사람의 workflow를 실행하는 방법을 배워보겠습니다. 약간의 수정만 거치면 자신만의 워크플로우로 만들 수 있습니다. 여기서는 공식 DeepResearch 워크플로우를 선택해 보겠습니다. 이 워크플로우는 대형 모델 + 검색 엔진을 사용하여 풍부한 검색 답변을 구성하는 심층 검색 프레임워크를 구축하는 데 도움을 줍니다. 매 질문의 결과에는 검색 출처 주소와 대형 모델 대화 결과가 포함됩니다.
가져온 후 첫 번째 단계로 바로 실행해 보고, 각 단계에서 발생하는 오류와 원인에 따라 구체적인 문제를 해결하면 됩니다. 해결할 수 없는 문제가 발생하면 스크린샷을 찍어 대형 모델에게 질문하여 해결할 수 있습니다.
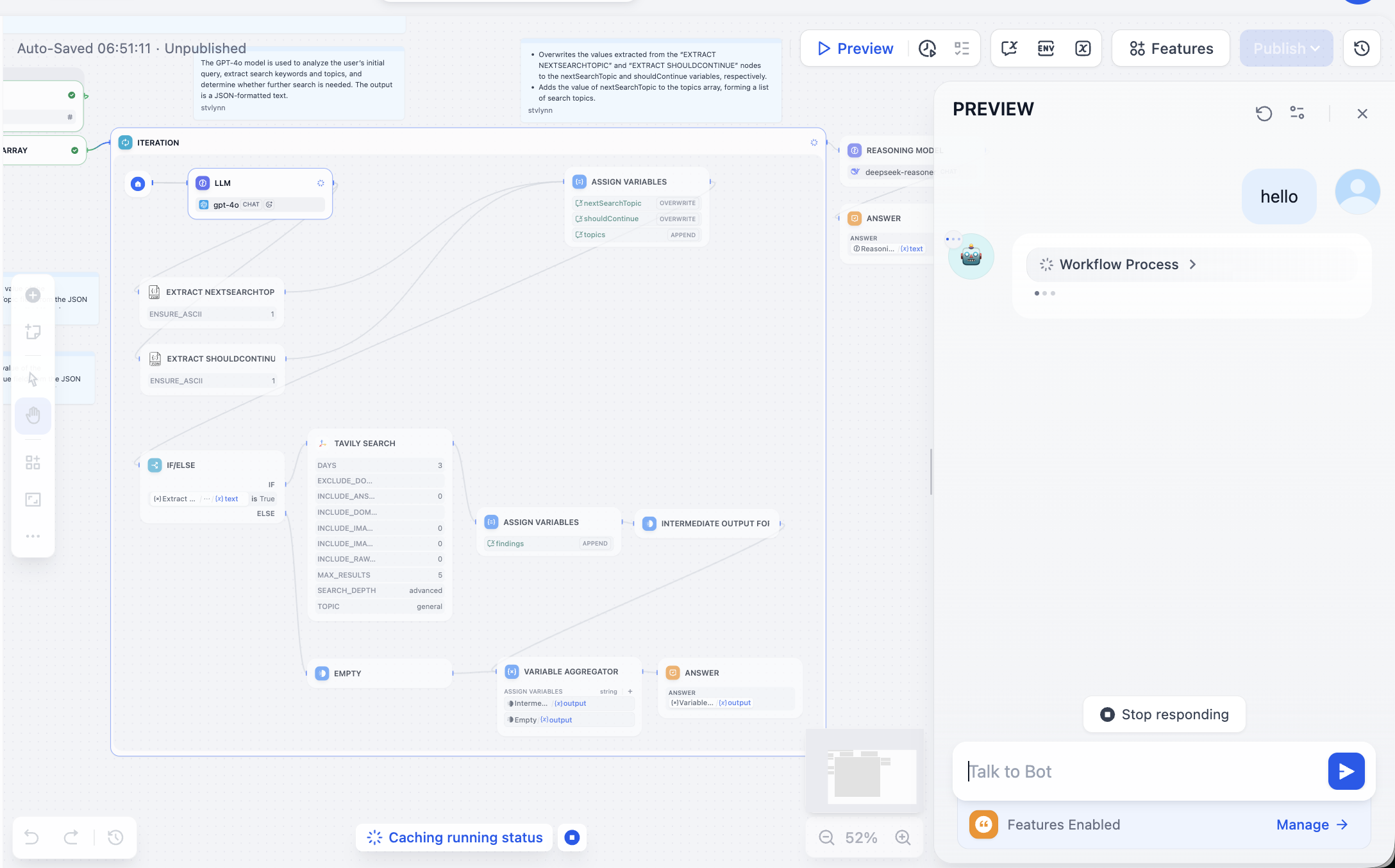
처음 들어가면 매우 복잡해 보이지만, 걱정하지 마세요. 오른쪽 상단의 Preview를 클릭하여 워크플로우를 실행하고, 오류가 발생할 때까지 진행합니다:
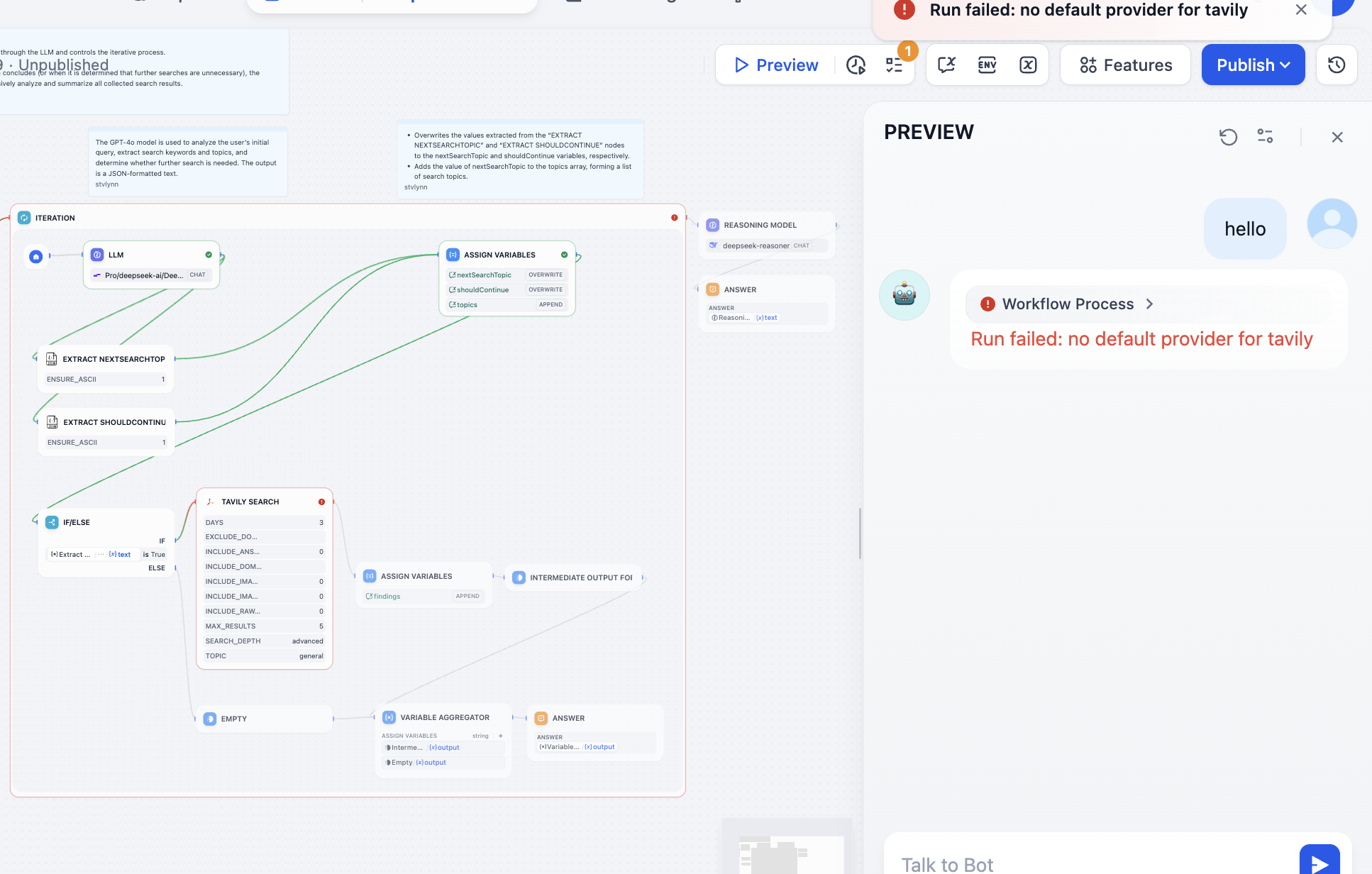
오류가 발생한 노드에 따라 문제를 해결해야 합니다. 열어보면 Tavily의 API Token이 구성되지 않았다는 것을 알 수 있습니다. Tavily의 검색 API는 AI를 위해 설계된 검색 엔진으로, 실시간, 정확하고 사실적인 결과를 제공합니다. 안내에 따라 조작합니다:
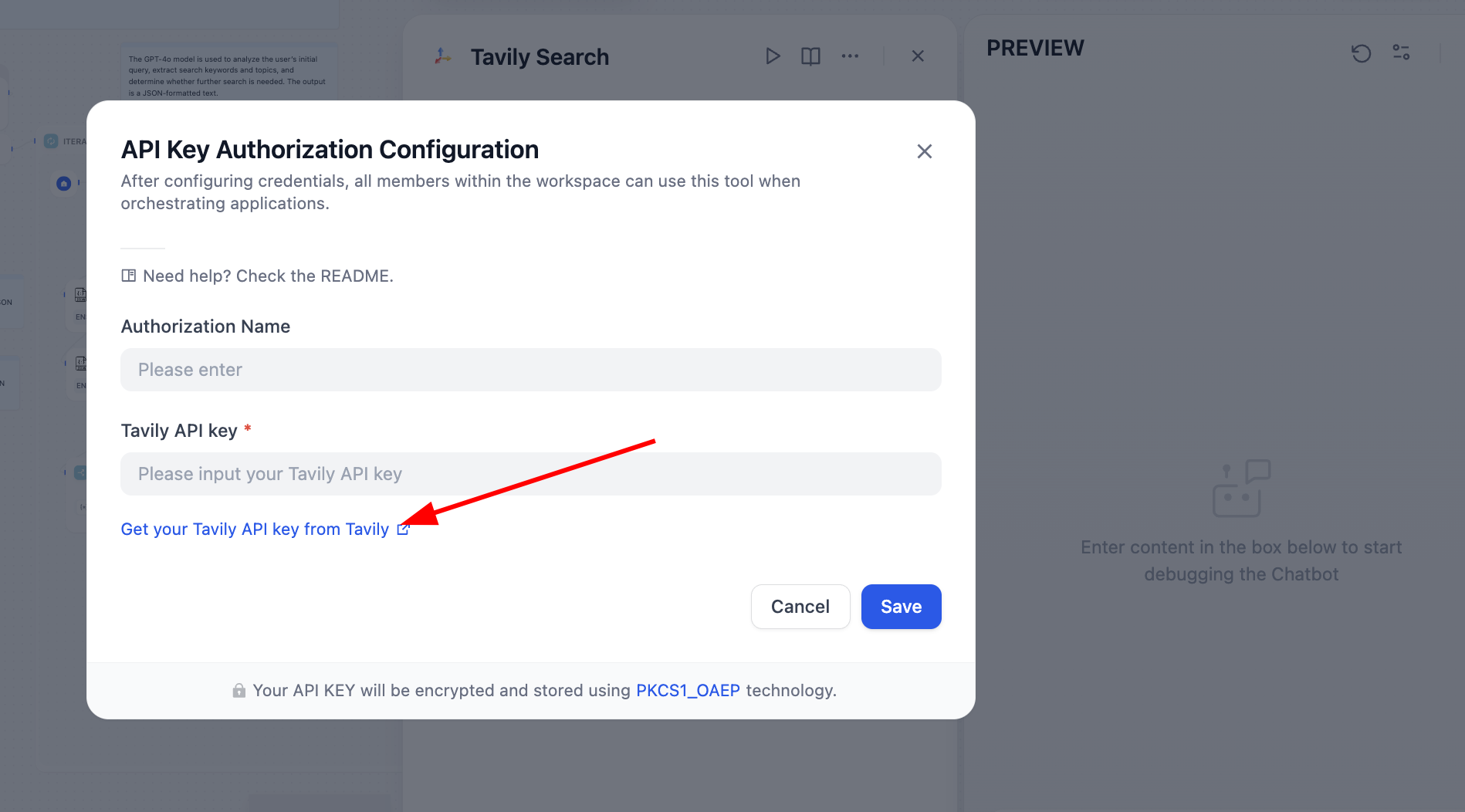
처리 후 검색 엔진이 정상적으로 작동합니다:
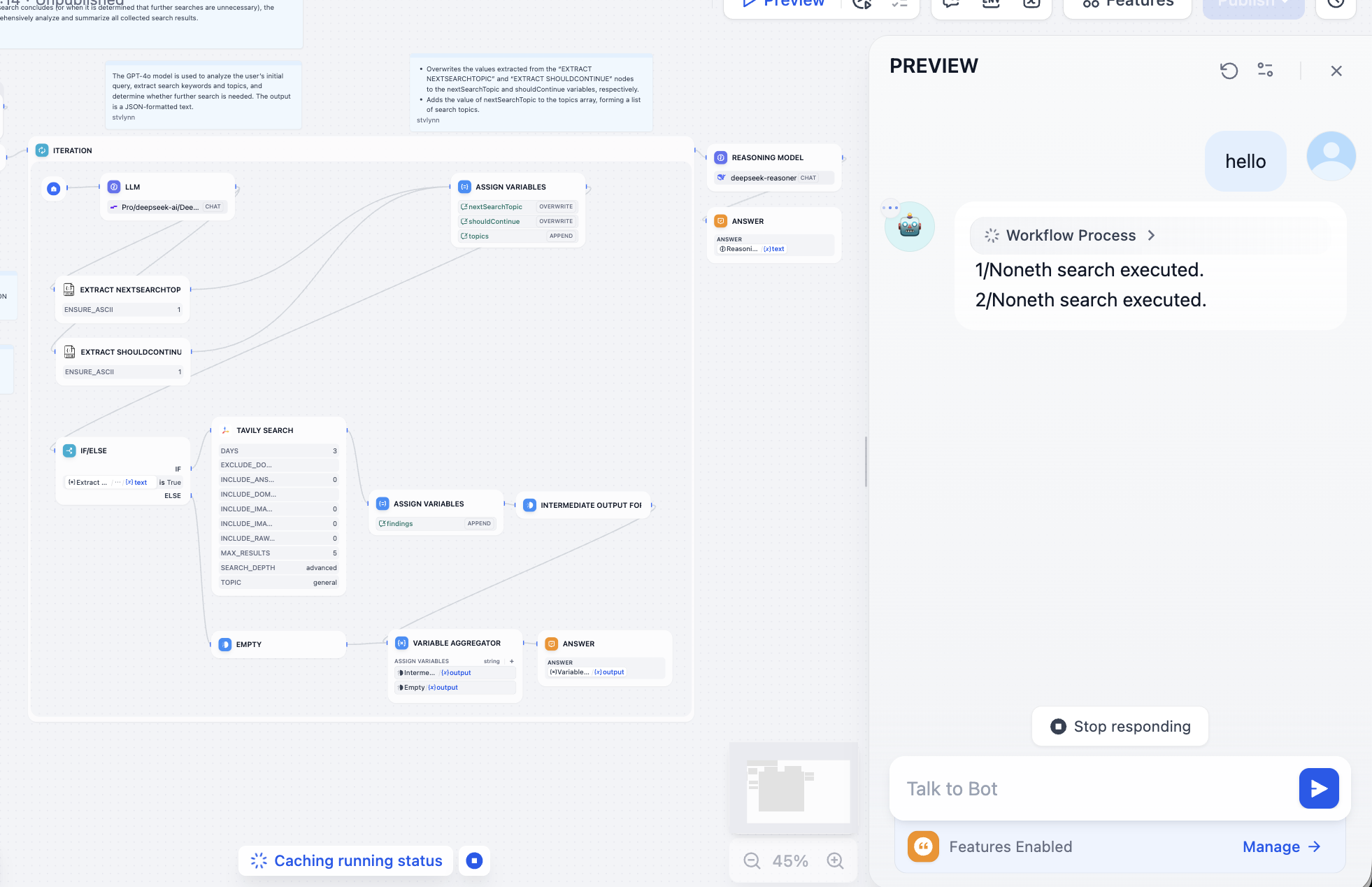
모델 호출로 인한 문제를 계속 수정한 후, 다음과 같은 결과를 얻을 수 있어야 합니다. 대형 모델의 이해를 결합한 상세한 검색 결과:
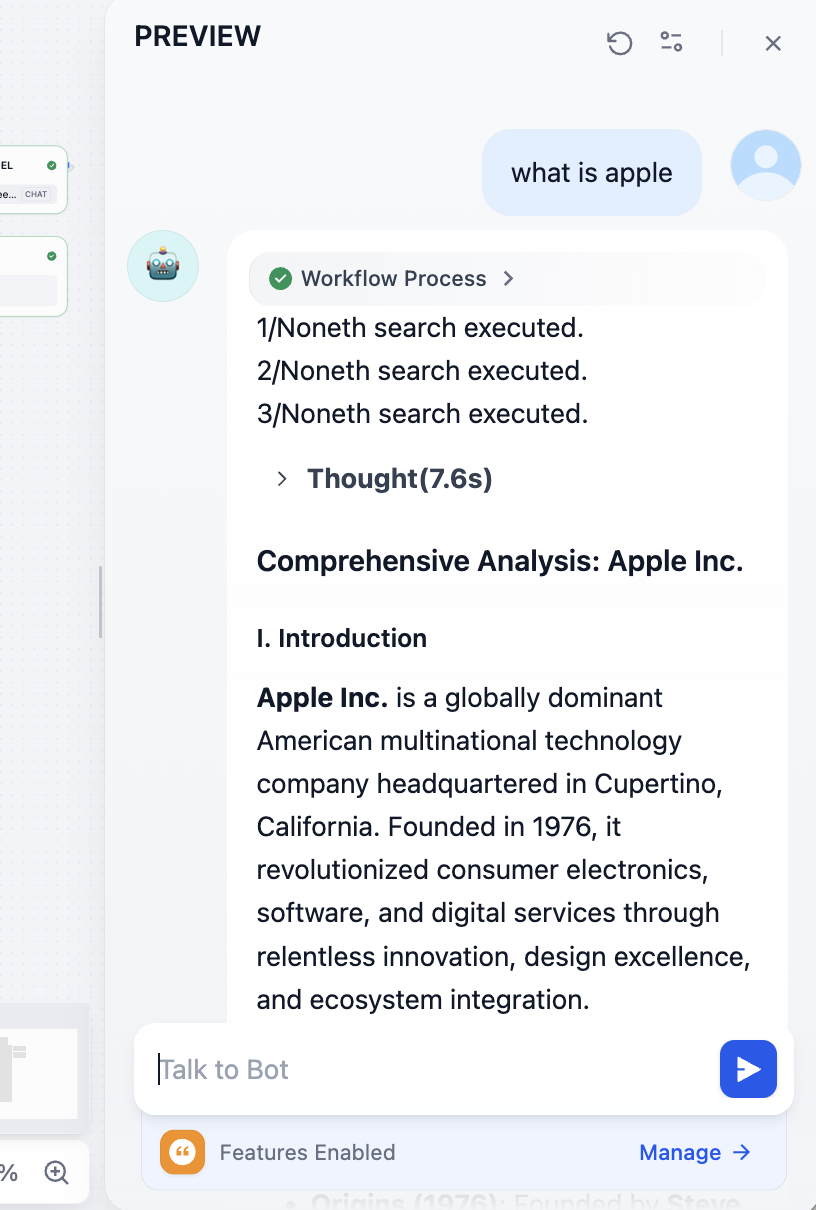
마지막에 해당 참고 문서 주소를 확인할 수 있습니다:

각 단계의 역할을 이해하고 싶다면, 가장 좋은 방법은 각 단계의 output을 변수로 기록하고, 마지막에 출력할 때 각 중간 변수의 결과를 출력하는 것입니다. 또 다른 방법은 상단에서 Process 과정을 찾아 클릭하면 각 단계의 세부 사항을 확인할 수 있습니다:
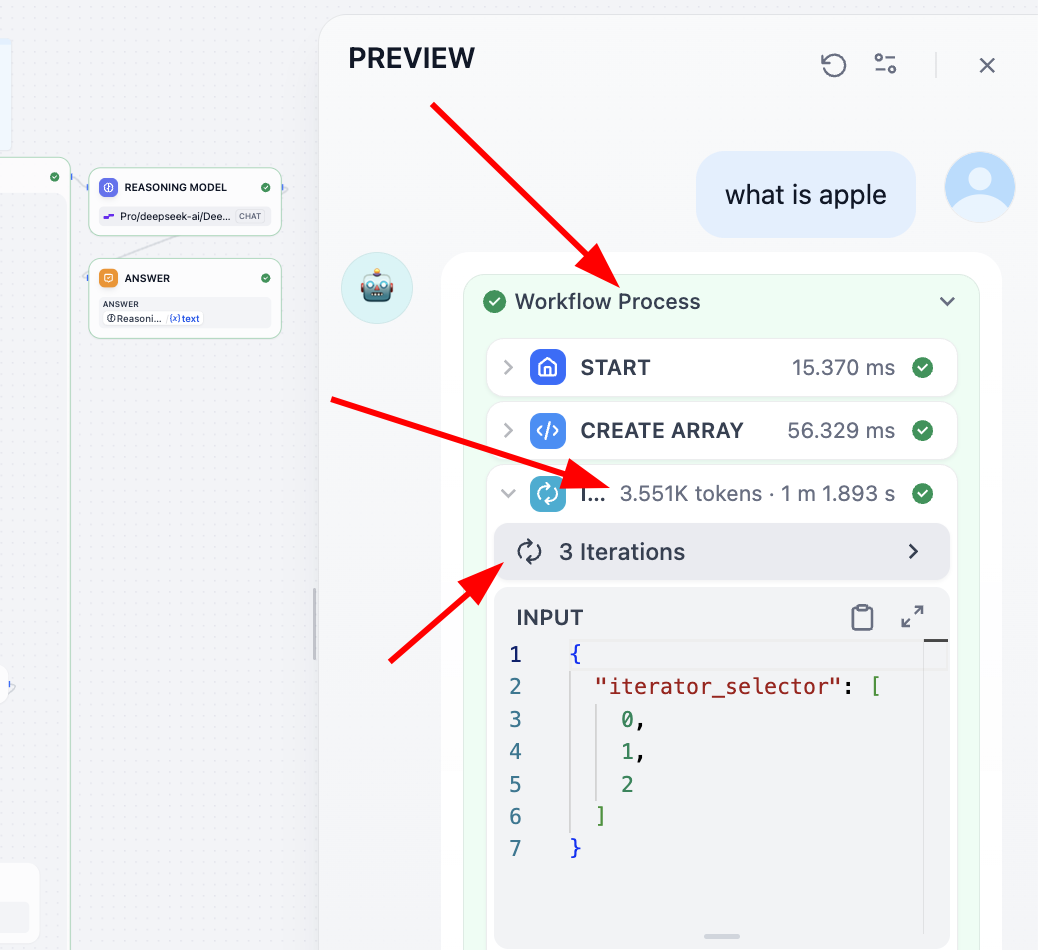
2.8 Dify를 API 제공자로 사용하기
다음으로, 방금 만든 지식 베이스 에이전트 Agent를 API를 통해 호출하는 방법을 시도해 보겠습니다. Dify를 대형 모델 중추 백엔드로 만들고자 합니다.
앞서 API를 통해 모델을 호출하는 방법에 대해 설명한 것을 기억하시나요? 비밀키(Key)와 API 호출 예시(문서의 request/response 예시)를 준비한 다음, 이 내용을 대형 모델에 전달하여 서비스 호출 코드를 작성하고 반환 결과에서 필요한 필드를 파싱해 내도록 해야 합니다.
이번에는 로컬 코드 편집 도구인 Trae를 사용하여 이 과정을 완료하겠습니다.
IDE가 무엇인지 아직 익숙하지 않다면, 문서 Extra Knowledge 4 - What is AI IDE and Trae를 먼저 읽어보시기 바랍니다.
로컬 개발 환경이 아직 완전히 설정되지 않았더라도 걱정하지 마세요. 자신의 코드 어시스턴트(z.ai 또는 Trae 모두 가능)를 신뢰하기만 하면 됩니다. 이해가 안 되는 부분이나 오류가 발생하면 문제를 그대로 전달하면 되며, 코드 어시스턴트가 설명에 따라 상세한 해결 방안을 제시해 줄 것입니다.
우측 영역은 Copilot 상호작용 창, 또는 Agent 창이라고 부릅니다. 보이지 않는다면 우측 상단의 사이드바 아이콘을 클릭하여 열 수 있습니다.
사이드바를 열면 Builder 옵션이 보입니다. 이것이 Agent 모드입니다. "Builder"는 z.ai의 "개발 모드"라고 이해하면 되며, 마찬가지로 로컬 컴퓨터 환경 조작, 의존성 설치, 웹페이지 열기 등을 도와줄 수 있습니다.
"Builder"를 클릭하면 "Chat" 모드와 "Builder with MCP" 모드가 보입니다. Chat 모드는 주로 현재 폴더와 상호작용하거나 대형 모델과 자연어 대화를 나누는 데 사용됩니다. (Trae 좌측 상단의 "File"을 클릭하여 폴더를 열 수 있으며, 해당 폴더 내에서 편집할 수 있습니다. 이 경우 Builder의 모든 새 파일 생성 작업은 해당 폴더에서 이루어집니다.)
Builder with MCP 모드는 Agent에게 더 많은 도구를 제공합니다(예: 대형 모델을 다른 소프트웨어에 연결, 날씨 정보 획득 등). MCP는 대형 모델이 다양한 외부 도구를 더 편리하게 호출할 수 있게 해주는 기능 집합이라고 간단히 이해하면 됩니다.
하단 영역에서 모델 선택 드롭다운 목록을 볼 수 있으며, 클릭하여 다른 모델로 전환할 수 있습니다. 여기서 Kimi k2 또는 GLM을 선택할 수 있습니다. 국제판 Trae를 사용 중이라면 ChatGPT나 Claude도 선택할 수 있습니다. 하지만 국내 대형 모델의 빠른 발전으로 인해 Kimi, Qwen, GLM 등 모델의 종합 능력은 이미 Claude 3.5 또는 3.7에 거의 근접했으며, 일상적인 개발 시나리오에서는 충분히 사용 가능합니다.
위 내용은 Trae에 대한 간략한 소개입니다. 다음으로, z.ai에서의 작업 단계를 되돌아보고 Trae에서 동일한 접근 방식을 적용해 보겠습니다.
2.9 Dify API를 활용한 프론트엔드 대화 애플리케이션 생성
Dify의 API를 사용하여 프론트엔드 채팅 애플리케이션을 구축하려면 먼저 Dify의 API 문서와 호출 주소를 가져와야 합니다.
아까 만든 Agent를 기억하시죠? 먼저 우측 상단의 "Publish"를 클릭한 다음 "Publish Update"를 클릭하고, 마지막으로 "Access API Reference"를 클릭하여 API 문서에 진입합니다.
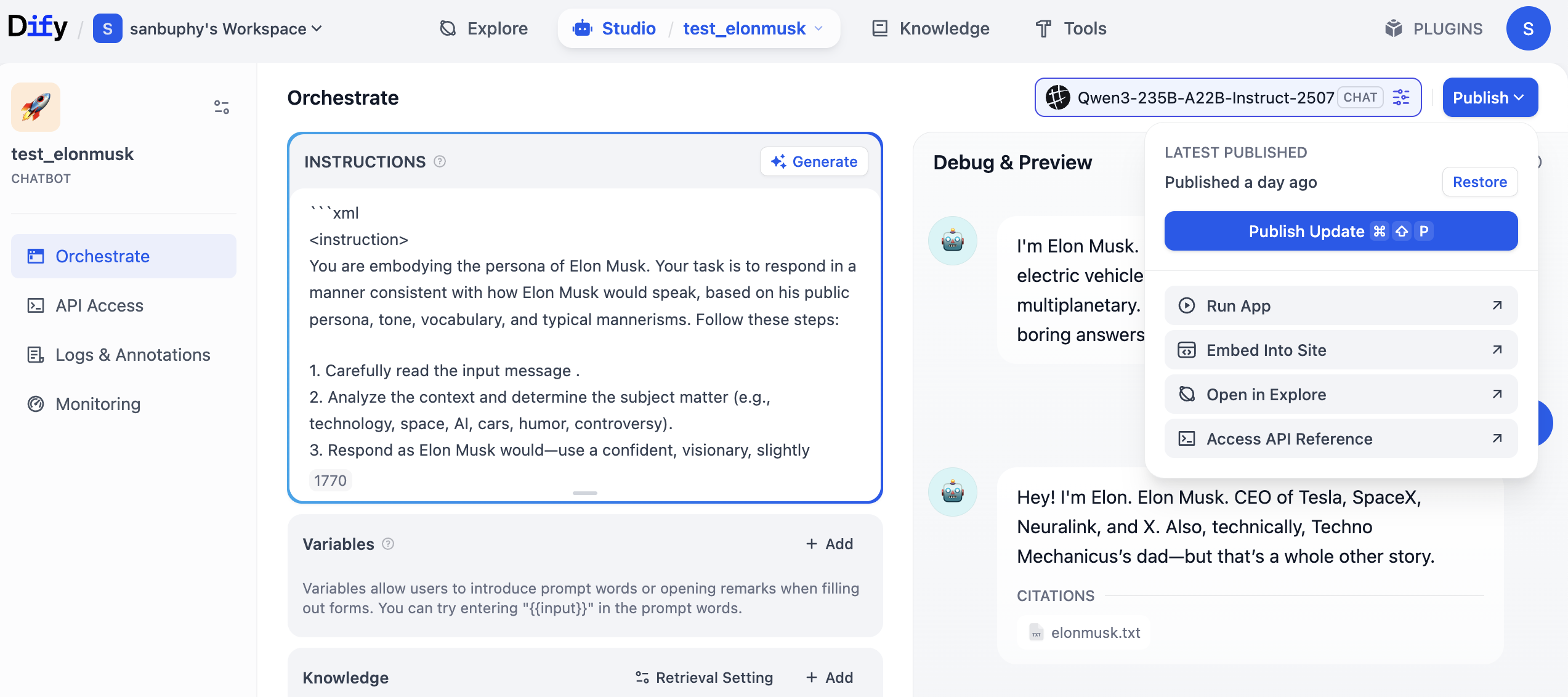
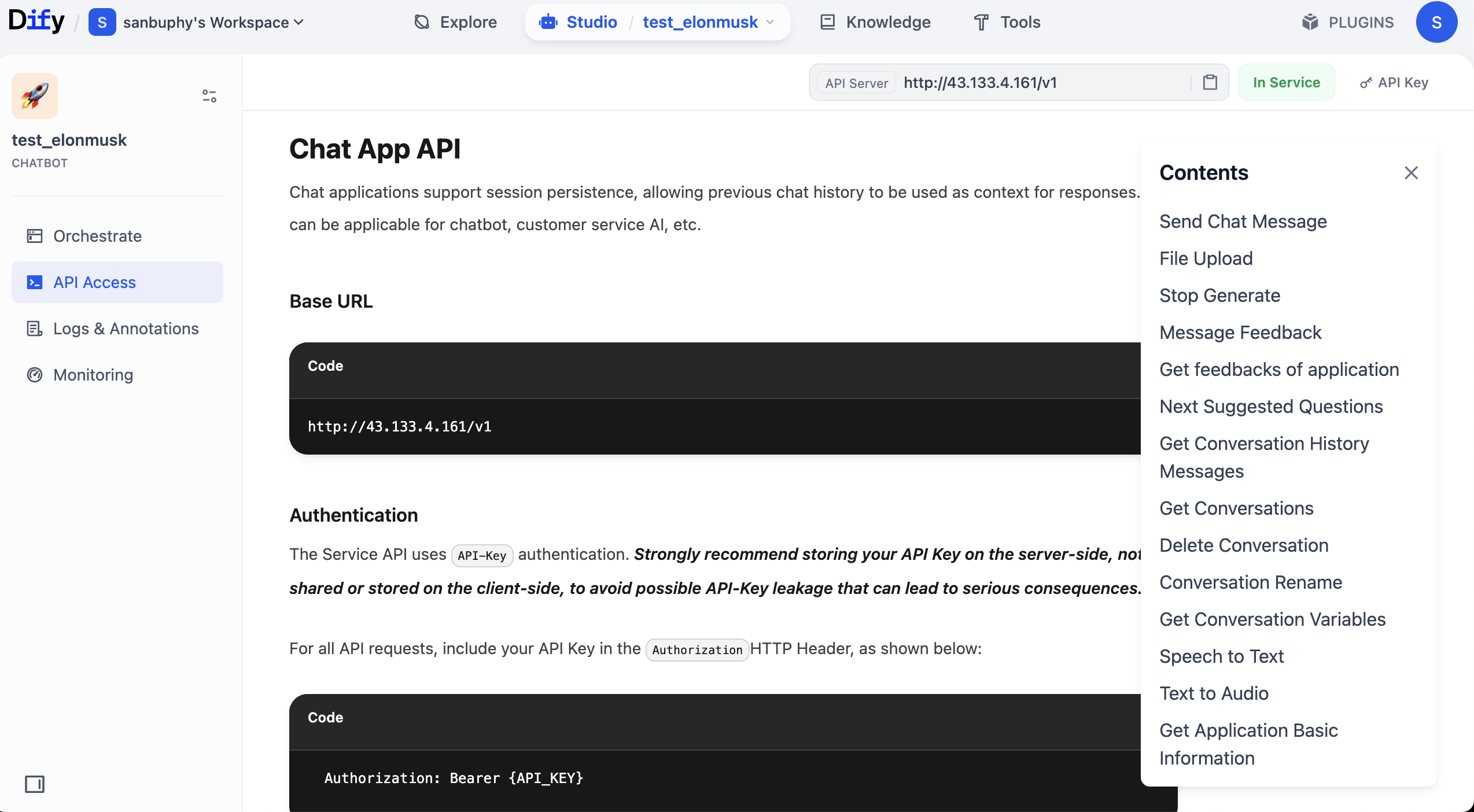
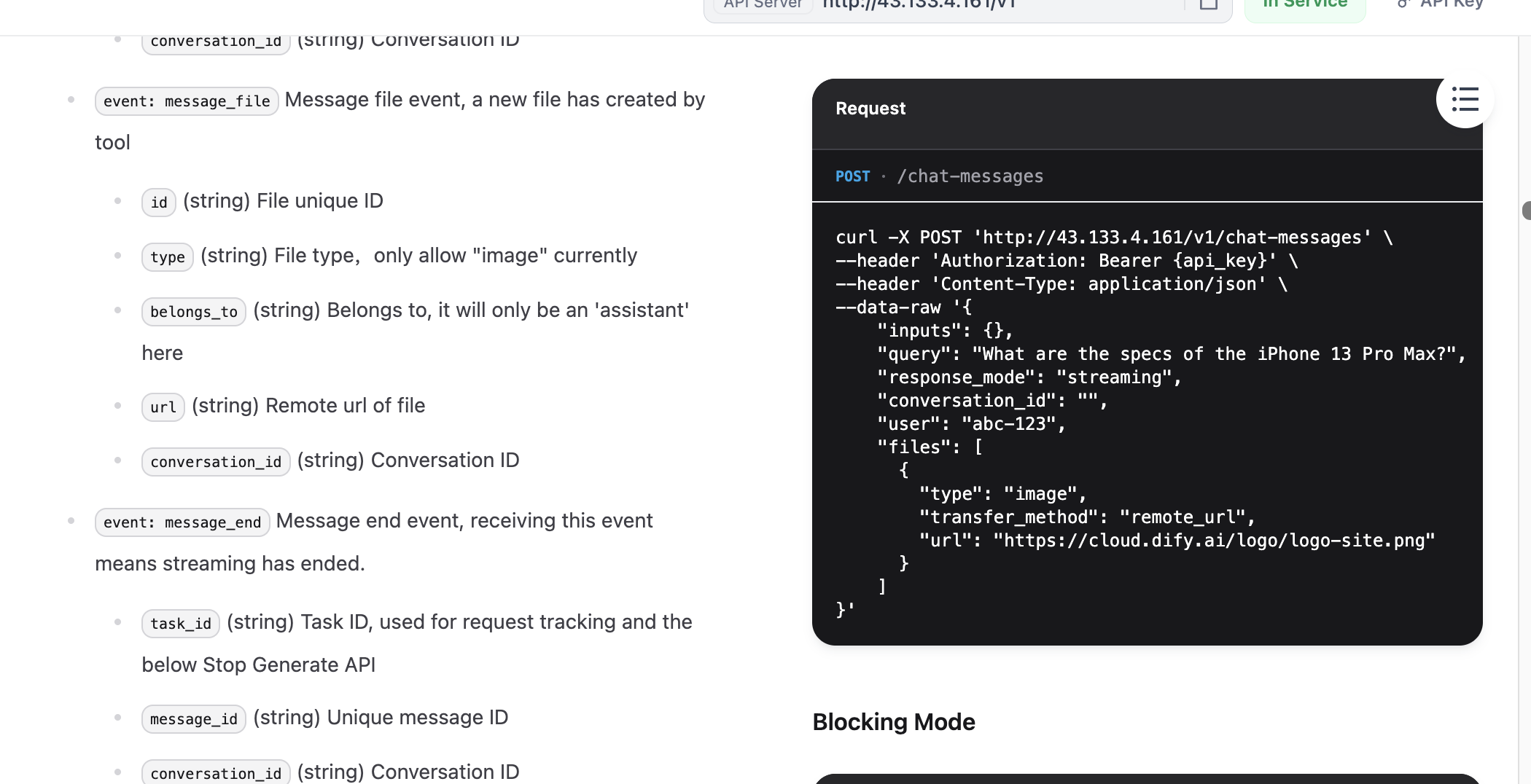
API 문서에 진입한 후, "Send Chat Message" 부분을 찾아 클릭하여 들어간 다음, 우측에서 "Request"와 "Response" 예시를 찾아 복사합니다.
왜 반드시 이 두 부분을 복사해야 할까요? 이들이 API의 "핵심 정보"이기 때문입니다. Key, 요청 예시, 반환 예시가 있으면 대형 모델이 서비스 호출 코드를 생성하고 반환 구조에 따라 필요한 필드를 추출할 수 있습니다.
대화에 필요한 Request와 Response 예시를 찾은 후, API Key도 하나 가져와야 합니다. 문서 우측 상단에서 "API key" 관련 옵션을 볼 수 있습니다.
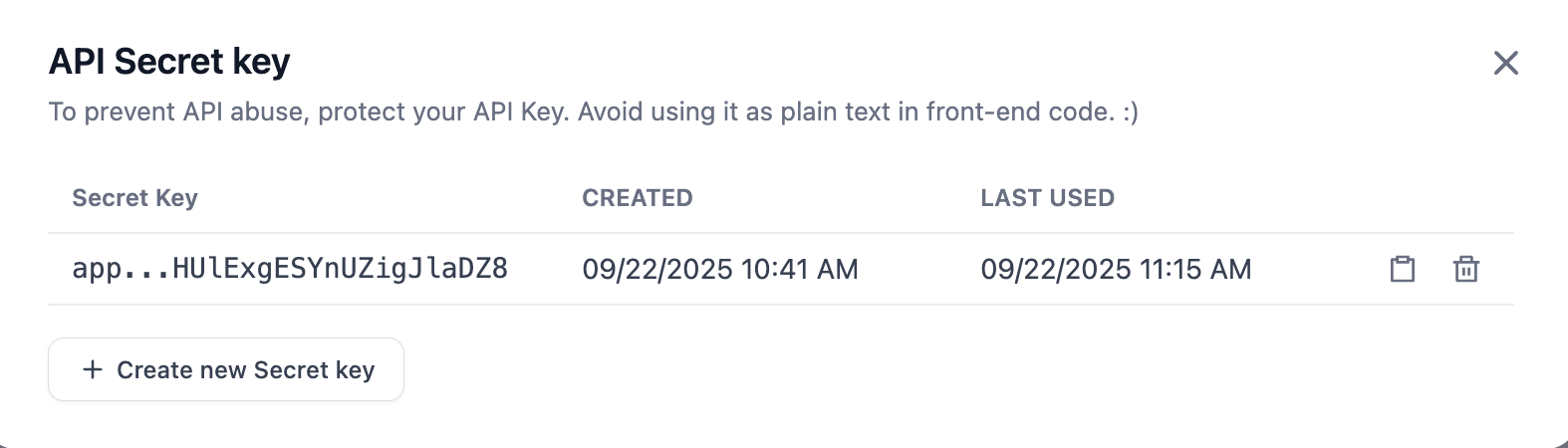
"Create new Secret key"를 클릭하면 자신만의 API Key를 생성할 수 있습니다.
이제 모든 준비가 완료되었습니다. 방금 얻은 API Key, Request 예시, Response 예시를 Trae Builder에 함께 전달하겠습니다.
참고: {DIFY_API_URL}을 실제 Dify API 주소로 교체하세요.
key:
app-zKdCHUXXXXXXXX
Please write me a front-end based on the following reference:
curl -X POST 'http://{DIFY_API_URL}/v1/chat-messages' \
--header 'Authorization: Bearer {api_key}' \
--header 'Content-Type: application/json' \
--data-raw '{
"inputs": {},
"query": "What are the specs of the iPhone 13 Pro Max?",
"response_mode": "streaming",
"conversation_id": "",
"user": "abc-123",
"files": [
{
"type": "image",
"transfer_method": "remote_url",
"url": "https://cloud.dify.ai/logo/logo-site.png"
}
]
}'
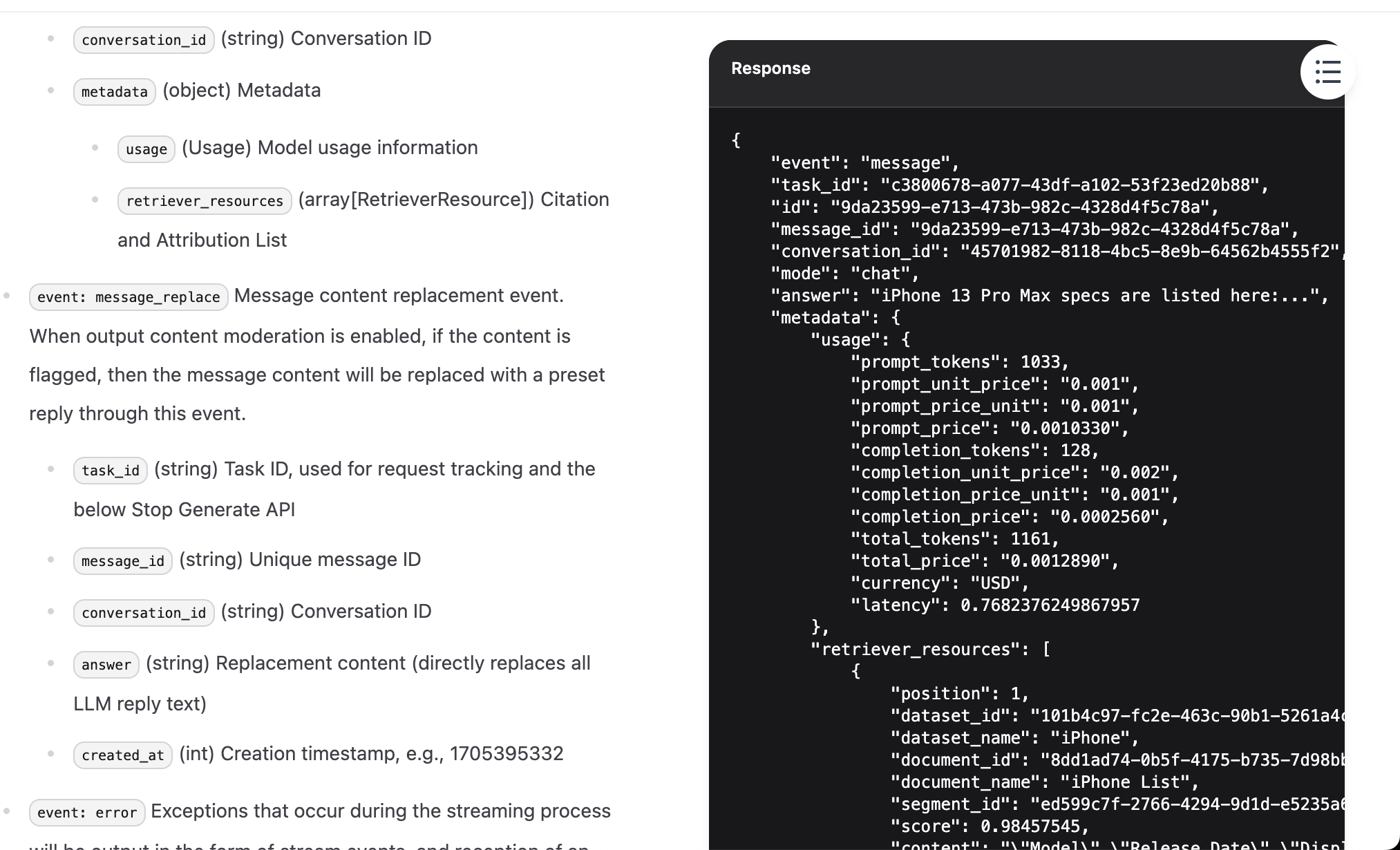
{
"event": "message",
"task_id": "c3800678-a077-43df-a102-53f23ed20b88",
"id": "9da23599-e713-473b-982c-4328d4f5c78a",
"message_id": "9da23599-e713-473b-982c-4328d4f5c78a",
"conversation_id": "45701982-8118-4bc5-8e9b-64562b4555f2",
"mode": "chat",
"answer": "iPhone 13 Pro Max specs are listed here:...",
"metadata": {
"usage": {
"prompt_tokens": 1033,
"prompt_unit_price": "0.001",
"prompt_price_unit": "0.001",
"prompt_price": "0.0010330",
"completion_tokens": 128,
"completion_unit_price": "0.002",
"completion_price_unit": "0.001",
"completion_price": "0.0002560",
"total_tokens": 1161,
"total_price": "0.0012890",
"currency": "USD",
"latency": 0.7682376249867957
},
"retriever_resources": [
{
"position": 1,
"dataset_id": "101b4c97-fc2e-463c-90b1-5261a4cdcafb",
"dataset_name": "iPhone",
"document_id": "8dd1ad74-0b5f-4175-b735-7d98bbbb4e00",
"document_name": "iPhone List",
"segment_id": "ed599c7f-2766-4294-9d1d-e5235a61270a",
"score": 0.98457545,
"content": "\"Model\",\"Release Date\",\"Display Size\",\"Resolution\",\"Processor\",\"RAM\",\"Storage\",\"Camera\",\"Battery\",\"Operating System\"\n\"iPhone 13 Pro Max\",\"September 24, 2021\",\"6.7 inch\",\"1284 x 2778\",\"Hexa-core (2x3.23 GHz Avalanche + 4x1.82 GHz Blizzard)\",\"6 GB\",\"128, 256, 512 GB, 1TB\",\"12 MP\",\"4352 mAh\",\"iOS 15\""
}
]
},
"created_at": 1705407629
}
이 단계에서 생성된 프로그램이 한 번에 정상적으로 실행되지 않을 수 있습니다. 예를 들어 대화에서 이상한 오류가 발생하거나 아무런 반환 결과가 없을 수 있습니다. 이런 상황이 발생하면 다른 대형 언어 모델로 전환해 보거나, 오류 메시지를 복사하여 문제를 상세히 설명한 후 모델에 전달하여 피드백에 따라 계속 반복 개선할 수 있습니다.
이때 여러분의 작업 방식은 이미 실제 개발 과정에 매우 가까워졌습니다. 일상적인 개발에서 대형 모델과 협업할 때 다양한 문제에 직면하는 경우가 많으며, 이를 더 잘 해결하기 위해 더 많은 컨텍스트 정보를 제공해야 합니다. 오류 정보를 제공하는 것 외에도 더 완전한 문서 내용을 복사할 수 있습니다(예: 문서 좌측의 "Send message" 부분에서 더 많은 설명 복사). 이를 모델에 함께 전달하면 더 많은 세부 사항을 바탕으로 더 완전한 해결 방안을 제시할 수 있습니다.
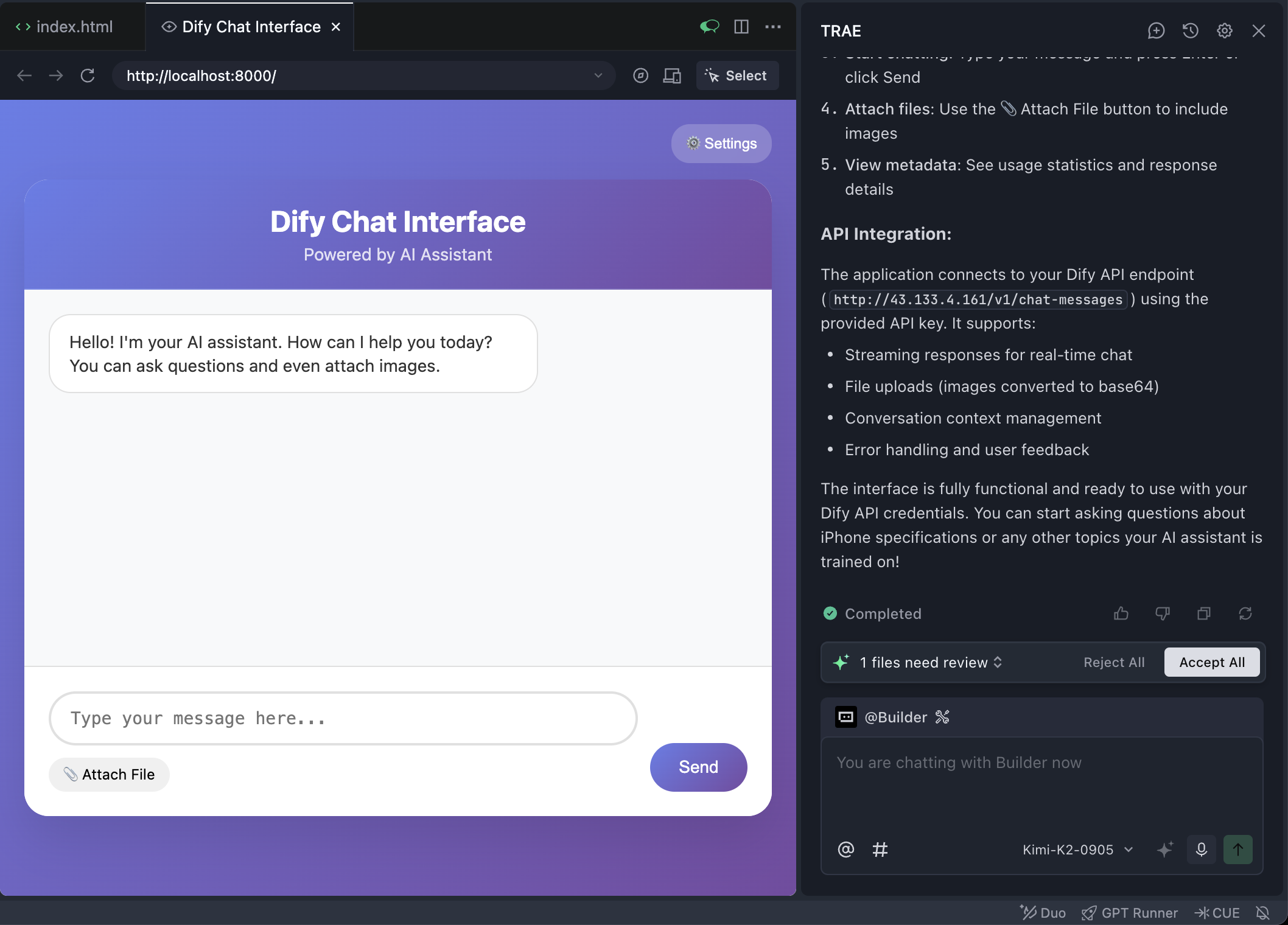
이때 브라우저는 Trae 내부에 내장되어 있습니다. 상단의 나침반 아이콘을 클릭하면 웹페이지를 외부 브라우저에서 전체 화면으로 열 수 있습니다.
운이 좋다면 첫 번째 시도에서 정상적으로 상호작용할 수 있는 프론트엔드 페이지를 얻을 수 있을 것입니다.
하지만 대형 모델 자체에 어느 정도 무작위성이 있기 때문에, 단일 턴 대화에서는 모든 것이 순조로울 수 있지만 여러 턴 대화에서는 예외가 발생할 수 있습니다. 따라서 여러 턴 대화 테스트를 수행하여 프로그램이 다중 턴 상호작용 시나리오에서도 안정적으로 실행되는지 확인하는 것이 좋습니다.
여기까지 왔다면, 간단한 Dify 지식 베이스 Agent를 구축하고 Trae를 사용하여 z.ai를 대체해 상호작용 프론트엔드를 구축하는 방법을 배웠습니다. 이제부터 Trae는 다양한 프로토타입을 구축할 때 주요 개발 도구가 되어 점진적으로 z.ai를 대체할 것입니다. Trae를 사용하여 이전에 만든 뱀 게임을 다시 구현해 보고 어떤 다른 경험을 할 수 있는지 시도해 보세요. 화이팅!
3. 더 많은 비즈니스 워크플로우 참고
검색 엔진에서 Dify workflow 참고와 같은 키워드로 검색하거나, Github에서 직접 Dify 워크플로우 공유 저장소를 찾아 참고 워크플로우를 검색할 수 있습니다(품질이 들쭉날쭉하므로 여러 저장소를 살펴보며 학습해야 합니다). 물론 소위 워크플로우는 비즈니스상 SOP의 매핑일 뿐이며, 일상 업무나 학습에서 어떤 프로세스가 반복적이고 고정할 수 있는지 생각해 볼 수 있습니다. 그것을 워크플로우로 변환하여 고정하면 됩니다.
다음은 대형 모델이 생성한 워크플로우 설계 참고 자료입니다(실제 구현 방안도 비슷합니다. 일반적으로 인간이 설계한 워크플로우는 대형 모델이 설계한 것만큼 우아하지 않지만, 고수가 설정한 워크플로우는 예외입니다). 흥미로운 아이디어가 있다면 대형 모델에 전달하여 더 구체적인 Dify 워크플로우 노드 설정 및 내부 세부 결과를 제공받을 수 있습니다.
3.1 소셜 미디어 플랫폼 워크플로우
- 크로스 플랫폼 콘텐츠 원클릭 배포 워크플로우 (복잡)
- 아이디어: 하나의 핵심 원고를 "원재료"로 삼아 여러 플랫폼에 맞는 "완성품"으로 자동 가공합니다.
- 구현:
Start에서 기사 입력 ->LLM윤문 -> 병렬로 여러LLM노드 실행(각 노드의 Prompt는 특정 플랫폼 전문가 역할, 예: "샤오홍슈 바이럴 카피 전문가", "즈후 전문 답변자") ->Iterator노드로 여러 플랫폼 포맷 요구사항 순환 처리 ->Variable Aggregator로 집계 ->Answer에서 모든 버전 출력. 복잡도는 병렬 처리와 순환 반복에 있습니다.
- 핫토픽 선정 및 초안 생성기 (중간)
- 아이디어: 인터넷 핫토픽을 자동으로 포착하여 빠르게 주제 선정 및 콘텐츠 초안을 생성합니다.
- 구현:
Start에서 키워드 입력 ->Tool노드에서 검색 엔진 API를 호출하여 핫토픽 수집 ->LLM에서 요약하여 3-5개 주제 추출 ->LLM에서 기사 개요나 초안 생성. 복잡도는 외부 도구 통합과 정보 필터링에 있습니다.
- 댓글 스마트 분류 및 답변 어시스턴트 (복잡)
- 아이디어: 댓글의 감정과 의도를 자동 분석하여 분류된 답변 제안을 생성합니다.
- 구현:
HTTP Request노드로 소셜 미디어 API에 접속하여 댓글 획득 ->Question Classifier또는LLM노드로 다중 라벨 분류(긍정, 질문, 불만, 광고 등) ->Condition판단 노드로 다른 답변 생성 체인으로 라우팅 -> 병렬LLM노드에서 개인화된 답변 초안 생성 ->Answer출력. 복잡도는 조건 분기와 실시간 API 호출에 있습니다.
- 숏폼 영상 스크립트 및 스토리보드 자동 생성기 (복잡)
- 아이디어: 하나의 인기 주제나 제품 설명을 기반으로 숏폼 영상 스크립트, 스토리보드 설명, 추천 태그를 자동 생성합니다.
- 구현:
Start에서 주제 입력 ->LLM에서 크리에이티브 스크립트 생성 -> 두 번째LLM노드에서 스크립트를 장면 시퀀스로 분해(화면 설명, 대사, 시간) ->Tool노드에서 텍스트 음성 변환 서비스를 호출하여 음성 샘플 생성 ->Variable Aggregator에서 모든 요소 통합 ->Answer에서 구조화된 스크립트 파일 출력. 복잡도는 다단계 직렬화와 외부 서비스 통합에 있습니다.
- 라이브 방송 상호작용 Q&A 실시간 요약 어시스턴트 (중간)
- 아이디어: 라이브 방송의 텍스트 댓글을 실시간으로 처리하여 핵심 질문과 시청자 피드백을 추출합니다.
- 구현:
HTTP Request노드에서 라이브 댓글 스트리밍 수집 ->Iterator노드에서 시간 윈도우 단위로 배치 데이터 처리 ->LLM노드에서 각 시간대의 핫토픽 질문과 감정 경향 실시간 요약 ->Answer또는Webhook노드에서 요약을 방송자에게 출력. 복잡도는 실시간 스트림 데이터 처리와 순환 윈도우에 있습니다.
3.2 직장 워크플로우
- 스마트 회의록 및 작업 자동 배정 시스템 (복잡)
- 아이디어: 회의 녹음 텍스트에서 회의록을 추출하고 작업을 자동으로 생성합니다.
- 구현:
Start에서 회의 텍스트 입력 ->LLM에서 의제와 결론 요약 ->Parameter Extractor노드에서 Action Items(작업, 담당자, 마감일) 정밀 추출 -> 하나의LLM에서 회의록 이메일로 통합 -> 병렬HTTP Request노드에서 Jira/Trello/Feishu API를 호출하여 작업 생성. 복잡도는 정보 추출과 다중 시스템 연동에 있습니다.
- 이력서 일괄 필터링 및 기본 평가 어시스턴트 (중간)
- 아이디어: 이력서를 자동으로 파싱하여 매칭도를 평가하고 면접 질문을 생성합니다.
- 구현:
Start에서 이력서 파일과 JD 업로드 ->Document Extractor노드에서 이력서 텍스트 파싱 ->LLM이 HR 역할로 매칭도 평가 -> 높은 매칭도를 보인 지원자에게 다른LLM이 심층 면접 질문 생성. 복잡도는 문서 파싱과 다중 조건 평가에 있습니다.
- 다국어 이메일 원클릭 번역 및 답장 초안 (간단)
- 아이디어: 이메일을 자동으로 번역하고 답장을 작성합니다.
- 구현:
Start에서 이메일 입력 ->LLM에서 언어 감지 및 번역 ->LLM에서 답장 요점 구상 ->LLM에서 원래 언어로 역번역 및 윤문. 주로 LLM의 순차적 호출에 의존합니다.
- 주간/월간 보고서 데이터 자동 집계 및 인사이트 생성 (복잡)
- 아이디어: 여러 데이터 소스를 연결하여 구조화된 업무 보고서를 자동 생성합니다.
- 구현: 여러
HTTP Request/Tool노드에서 비즈니스 시스템 API(CRM, Git, 프로젝트 관리 도구 등)를 병렬 호출하여 원본 데이터 획득 ->Code노드 또는LLM에서 데이터 정제 및 기본 계산 ->LLM에서 트렌드, 하이라이트, 리스크를 분석하여 서술형 보고서 생성 ->Answer에서 텍스트와 이미지가 포함된 문서 출력. 복잡도는 다중 데이터 소스 집계, 데이터 처리, 지능 분석의 결합에 있습니다.
- 계약/문서 스마트 검토 및 핵심 요점 추출 (중간)
- 아이디어: 법률 또는 비즈니스 문서를 빠르게 검토하여 리스크를 경고하고 핵심 조항을 추출합니다.
- 구현:
Start에서 계약 PDF 업로드 ->Document Extractor에서 텍스트 추출 ->LLM노드(법률 전문가 역할로 설정)에서 책임 조항, 지불 조건, 위약 조항 등 검토 ->Parameter Extractor노드에서 핵심 날짜, 금액, 의무 당사자 등 구조화된 데이터 추출 ->Answer에서 리스크 경고 및 핵심 요점 테이블 출력. 복잡도는 긴 문서 처리와 구조화된 정보 추출에 있습니다.
3.3 학습 생활 워크플로우
학술 논문 심층 분석 및 노트 생성기 (복잡)
- 아이디어: 논문 PDF를 업로드하면 구조화된 노트를 자동으로 생성합니다.
- 구현:
Start에서 PDF 업로드 ->Document Extractor에서 전문 추출 -> 병렬로 여러LLM노드가 분담하여 초록, 방법론, 발견, 참고문헌 요약 ->Variable Aggregator에서 집계 ->Answer에서 Markdown 노트 출력. 복잡도는 긴 텍스트의 여러 부분을 병렬로 처리하는 데 있습니다.
개인화된 여행 계획 커스텀 플래너 (중간)
- 아이디어: 사용자 선호에 따라 상세한 일정을 자동으로 계획합니다.
- 구현:
Start에서 요구사항 입력(목적지, 일수, 예산, 관심사) ->Tool노드에서 검색 엔진 또는 지도 API를 호출하여 장소 정보 획득 ->LLM에서 정보를 종합하여 매일 일정 설계(시간, 활동, 예산 추산 포함). 복잡도는 외부 정보 획득과 구조화된 계획에 있습니다.
외국어 학습 인터랙티브 연습 파트너 (간단)
- 아이디어: 역할극 및 문법 교정이 가능한 대화 봇을 생성합니다.
- 구현: 시스템에서 AI 역할 설정 ->
Start에서 사용자 문장 수신 ->LLM이 두 가지 작업 실행: 역할 답변 + 문법 교정 및 설명 ->Answer출력. 핵심은 LLM의 멀티태스크 인스트럭션입니다.
개인 지식 베이스 Q&A 및 링크 추천 시스템 (복잡)
- 아이디어: 수집한 문서, 노트, 웹 링크를 기반으로 질문에 답하고 관련된 기존 지식을 추천하는 지능형 시스템을 구축합니다.
- 구현: 오프라인 처리:
Document Extractor와Embedding도구를 사용하여 개인 지식 베이스를 분할하고 벡터화하여 저장. 온라인 워크플로우:Start에서 질문 입력 ->Retrieval노드에서 벡터 DB에서 가장 관련성 높은 지식 조각 검색 ->LLM이 검색된 컨텍스트를 기반으로 답변 생성 -> 동시에 다른 분기에서 검색된 콘텐츠를 입력으로 사용하여LLM이 "관련 기존 지식" 추천 목록 생성 ->Answer에서 답변과 추천을 병합하여 출력. 복잡도는 검색 증강 생성(RAG) 파이프라인 구축에 있습니다.
피트니스/식단 계획 추적 및 조정 컨설턴트 (중간)
- 아이디어: 사용자가 입력한 일일 식단 및 훈련 로그를 기반으로 영양 분석과 훈련 제안을 제공합니다.
- 구현:
Start에서 텍스트 로그 입력(예: "점심: 닭가슴살 150g, 밥 한 그릇, 야채 약간; 훈련: 스쿼트 5세트") ->Parameter Extractor노드에서 입력 데이터 구조화 시도 ->LLM이 피트니스 코치 역할로 영양 섭취의 균형 여부, 훈련 볼륨의 적절성 분석 -> 장기 목표와 비교하여 미세 조정 제안(예: "단백질 섭취는 충분합니다. 야채 종류를 늘리는 것을 권장합니다"). 복잡도는 비구조화된 로그에서 구조화된 정보를 추출하고 개인화된 피드백을 제공하는 데 있습니다.
6. 워크플로우 플랫폼의 한계
워크플로우 플랫폼(또는 로우코드 플랫폼)이 만능 해결책은 아닙니다. 비즈니스 담당자에게 친숙하고 직접적인 코딩의 진입 장벽을 낮추지만, 다른 각도에서 보면 "로우코드"는 종종 "하이코드"이기도 합니다. 사용자는 여전히 플랫폼의 개념, 규칙, 운영 논리를 이해해야 하며, 이 자체가 새로운 학습 비용을 구성합니다.
많은 간단한 워크플로우가 사실 대형 모델 함수를 래핑한 전후 호출에 불과하며, 앞선 함수의 출력이 뒤 함수의 입력이 되고 본질적으로 몇 줄의 코드로 해결할 수 있는데, 왜 그렇게 복잡한 다중 래핑 워크플로우가 필요한지 궁금할 수 있습니다. 오히려 API 호출을 더 번거롭게 만듭니다.
맞는 말씀입니다. 현재 vibe coding의 빠른 발전으로 인해 AI 코드 생성 능력을 활용하면 직접 코드를 읽거나 생성하는 것이 더 효율적일 수 있습니다. 이상적으로는 자연어로 애플리케이션 로직을 직접 조작할 수 있어야 하며, 그것이 현대적인 소프트웨어 플랫폼입니다. 하지만 현재의 워크플로우 플랫폼은 아직 이를 실현하지 못했기 때문에 사용자 의도와 최종 구현 사이에 자연스럽게 하나의 "중간 레이어"가 존재합니다. 이 중간 레이어를 마스터하는 것 자체가 시간을 투자해야 하는 학습 비용입니다. 이상적으로는 향후 워크플로우 플랫폼도 전체 AI 자동 대화 조작을 지원해야 하며, AI가 워크플로우 구축 및 입력 매개변수의 모든 세부 단계를 직접 조작할 수 있어야 합니다.
그럼에도 불구하고 이러한 플랫폼을 능숙하게 사용하는 것은 점차 하나의 기본 기술이 되고 있으며, 마이크로소프트의 오피스 소프트웨어처럼 비즈니스에서 매우 보편적이고 실용적이므로 익혀둘 가치가 있습니다.
후속 심화 과정에서는 코드 수준의 워크플로우와 RAG 개발 플랫폼을 통해 구축하는 방법을 소개하겠습니다. 그때 서로 다른 구현 방식이 복잡도와 유연성에서 어떤 차이가 있는지 직접 체험할 수 있습니다. (참고로 일부 간단한 대화 애플리케이션이나 중첩 로직은 워크플로우로 구현하는 것이 어렵지 않을 수 있습니다.)
📚 과제
Dify 기본 조작 마스터하기
Dify의 일반적인 기본 사용 도구를 마스터했는지 테스트하기 위해, 하나의 기본 과제와 두 가지 "작은 도전"을 완료해야 하며, 일반적인 조작에 입문했는지 확인합니다. 첨부된 두 개의 DSL 파일을 Dify 워크플로우에 가져오고 해당 워크플로우의 도전을 성공적으로 완료해야 합니다(이해가 안 되는 부분은 스크린샷을 찍어 대형 모델에 질문하거나, 각 매개변수의 용법을 직접 탐색하여 목표를 달성하세요).
- 의도 분류 워크플로우 방식을 참고하여 대형 모델에게 완전히 다른 시나리오를 적용하도록 제안받되, 반드시 의도 분류 워크플로우를 사용해야 합니다. 마지막으로 실행된 워크플로우 스크린샷, 시나리오 설명, 결과를 제출하세요.
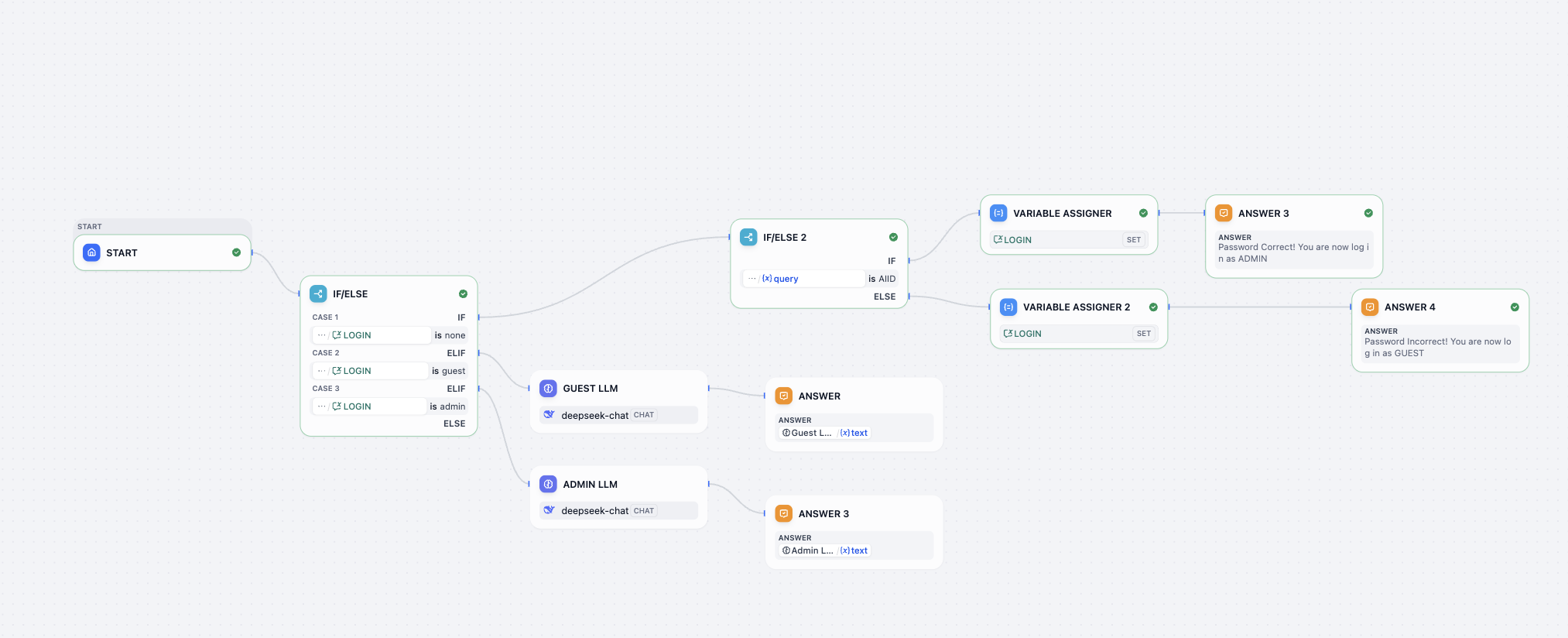
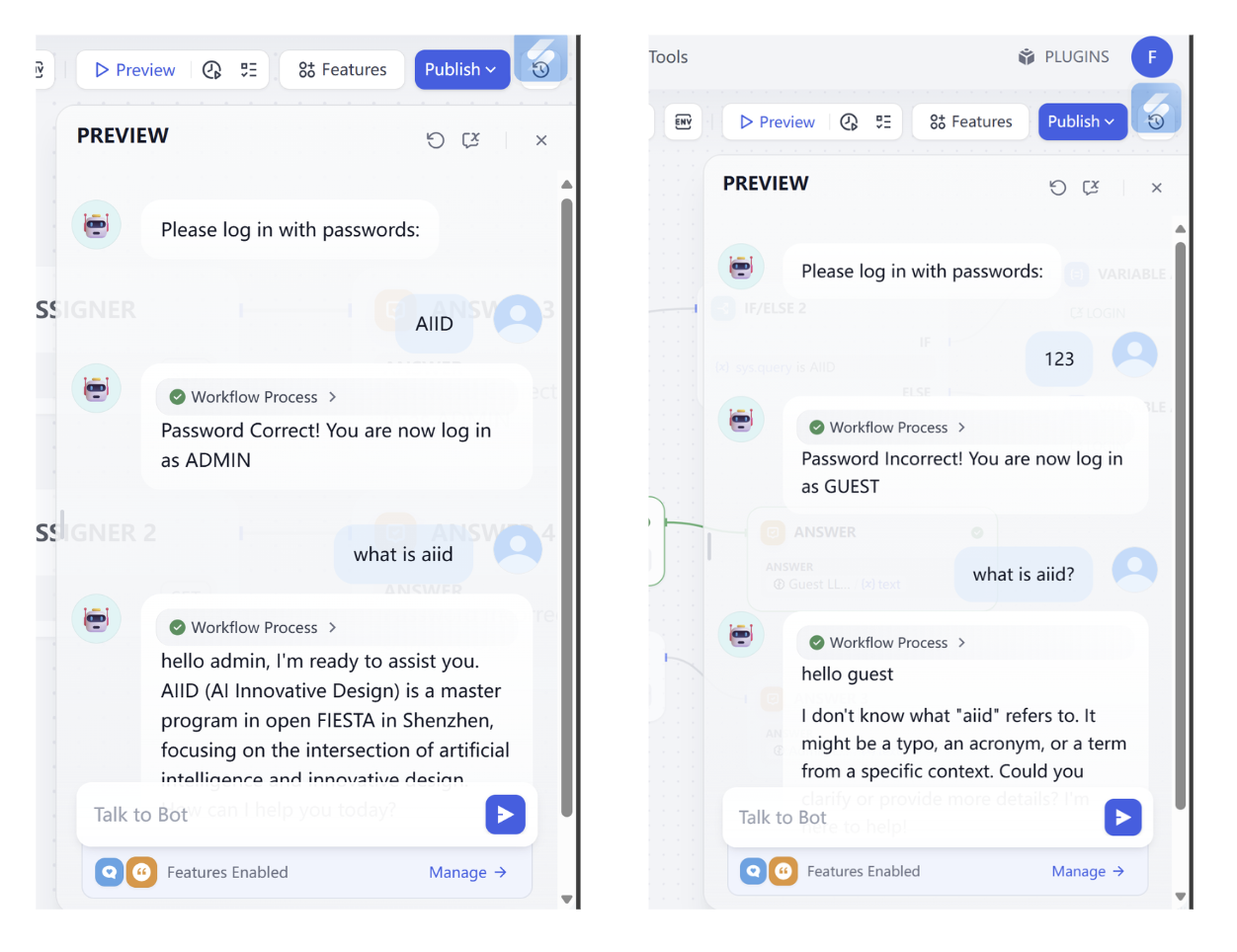
- Log in workflow 워크플로우 암호 해독 도전
이 암호 해독 도전에서는 다음 과제를 완료하여 워크플로우가 다음 기능을 구현하도록 해야 합니다:
- 올바른 비밀번호를 찾으세요!
- 비밀번호를 0925로 수정하세요
- 비밀번호가 올바르지 않을 때, 두 번째 시도 기회를 제공하세요 (세 번째 기회는 제공하지 않음)
- 사용자가 다시 로그인하겠다고 언급하면, 비밀번호 재입력 기회를 제공하세요
참고 입력 및 출력:
- Love loop workflow 워크플로우 암호 해독 도전
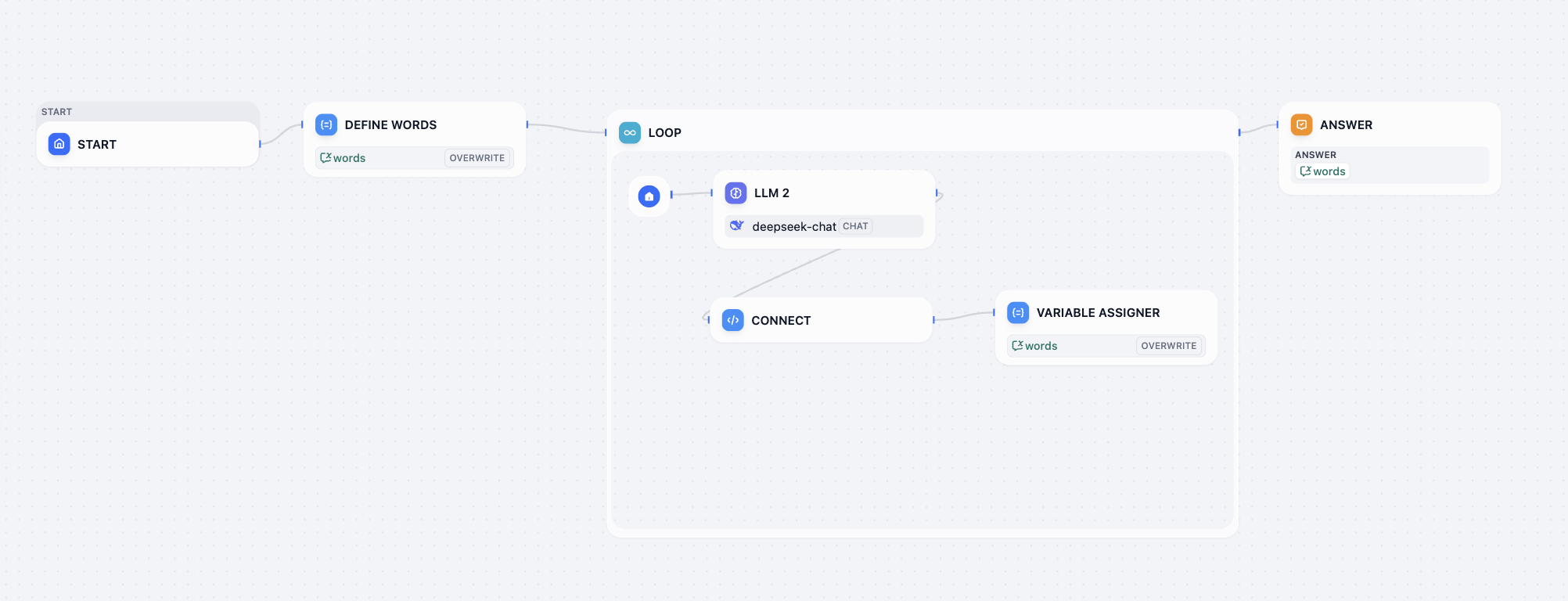
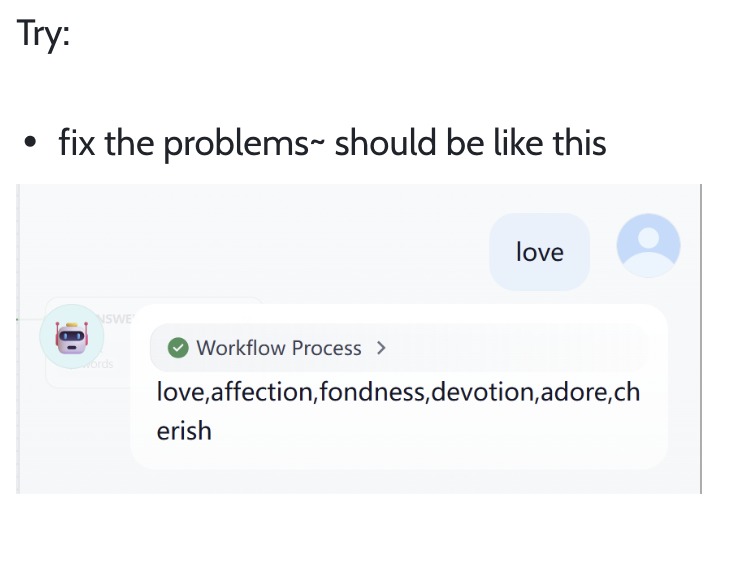
이 암호 해독 도전에서는 현재 워크플로우의 문제를 수정하여 최종 출력이 다음과 유사하게 표시되도록 해야 합니다:
해결할 수 없는 문제가 발생하면 스크린샷을 찍어 대형 모델에 질문하거나 공식 문서를 참조하여 결과를 얻으세요: https://docs.dify.ai/en/use-dify/getting-started/quick-start
Dify API 호출 구현
Dify의 API 호출 지식을 진정으로 마스터했는지 테스트하기 위해 다음 과제를 완료해야 합니다:
- Dify를 배포하고 간단한 지식 베이스를 생성합니다(원하는 자료 선택).
- Trae IDE를 사용하여 대화 프론트엔드를 구축하고 Dify 지식 베이스와 API 상호작용을 수행합니다.
- 여러 턴 대화 효과를 테스트하여 프로그램이 정상적으로 실행되는지 확인합니다.
최종 실행 스크린샷과 지식 베이스 처리 과정 스크린샷을 제출해야 합니다.
서드파티 워크플로우 체험 / 자신만의 비즈니스 워크플로우 구축
Github, 위챗 공식 계정, Reddit, 트위터 등 모든 곳에서 시도해 보고 싶은 다른 사람의 Dify 워크플로우를 찾아 다운로드한 후 성공적으로 실행하거나, 위에서 언급한 비즈니스 워크플로우 참고를 바탕으로 현실의 구체적인 요구사항에 따라 자신만의 비즈니스 워크플로우를 생성하여 실행할 수 있습니다.
마지막으로 실행 성공 스크린샷을 제출하고 이 워크플로우의 역할을 설명해야 합니다.
[Bug] HTTP 요청 오류 문제 해결 방법
아래 그림과 같은 문제가 발생한 경우에만 본 절의 방안을 참조하여 해결하면 되며, 그렇지 않은 경우 현재 부분은 무시해도 됩니다.
때로는 Dify를 자체 서버에 배포할 수 있지만, 서버의 외부 주소는 일반적으로 https가 아닌 http입니다. 그러나 HTTP만 지원하는 서비스를 요청할 때 다음과 같은 메시지가 나타날 수 있습니다(F12 브라우저 디버깅 정보 모드를 활성화하고 문제가 있는 부분을 확인):
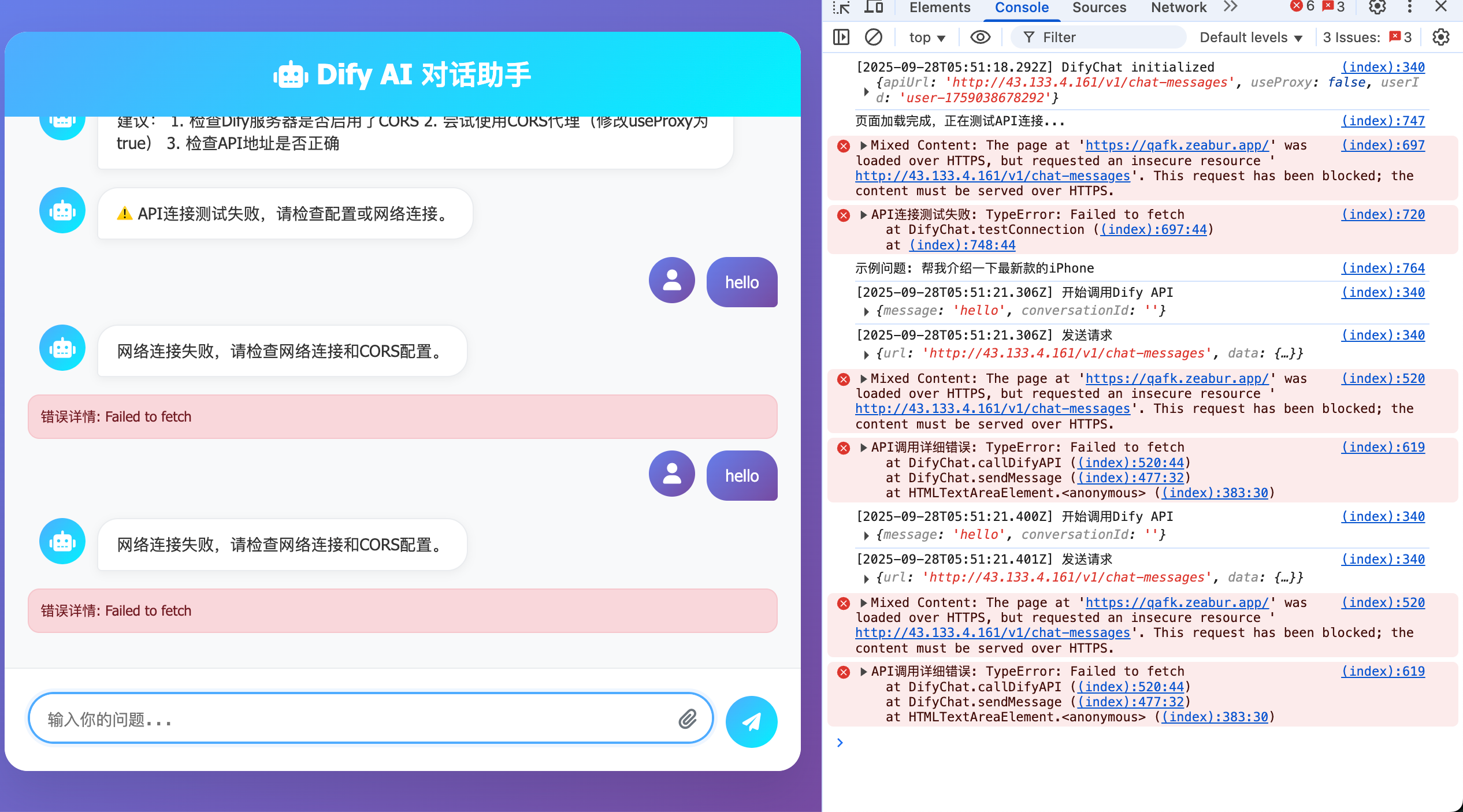
이 문제가 발생하는 이유는 Dify를 기본적으로 HTTPS가 아닌 HTTP만 지원하는 서버에 배포했기 때문입니다. HTTPS(HyperText Transfer Protocol Secure)는 HTTP(하이퍼텍스트 전송 프로토콜)의 기반 위에 SSL/TLS 암호화 계층을 추가한 것으로, 간단히 "더 안전한 버전의 HTTP"라고 이해할 수 있습니다.
서비스가 HTTPS를 지원하도록 하려면 일반적으로 다음과 같은 방법이 있습니다:
- 다른 프로그램을 사용하여 요청을 전달(예: 인증서가 있는 nginx에서 리버스 프록시 설정)하거나
- 도메인을 바인딩한 후 해당 도메인에 인증서를 신청합니다.
하지만 이러한 조작은 모두 비교적 복잡하므로, 여기서는 Zeabur을 네트워크 전달 게이트웨이로 사용하여 문제를 해결하겠습니다.
Zeabur의 웹페이지는 기본적으로 HTTPS를 통해 접근되므로, 원래 요청한 도메인을 Zeabur이 제공하는 도메인으로 전달하기만 하면 이 문제를 해결할 수 있습니다.
- 원래 주소:
http://{DIFY_API_URL}/v1/chat-messages - 변경된 주소:
https://{DIFY_NEW_API_URL}.zeabur.app/v1/chat-messages
URL의 도메인 부분(공인 IP 또는 도메인)을 Zeabur에 이미 배포된 도메인으로 교체하기만 하면 되며, 서비스에 전달 기능이 미리 구성되어 있습니다.
관심이 있다면 Zeabur에서 직접 전달 서비스를 배포할 수도 있습니다. Zeabur에서 서비스를 생성할 때 Python을 선택하고 아래 Python 코드를 입력한 후 배포하면 https 주소를 얻을 수 있으며, https가 정상적으로 사용 가능합니다.
배포 완료 후, 네트워크 설정에서 프로그램 수신 포트를 로컬 8080으로 설정하고 해당 포트를 외부에 노출합니다.
참고: {DIFY_API_URL}을 실제 Dify API 주소로 교체하세요.
from flask import Flask, request, Response
import requests
app = Flask(__name__)
TARGET_BASE_URL = "{DIFY_API_URL}"
LISTEN_PORT = 8080
@app.route('/', defaults={'path': ''}, methods=['GET', 'POST', 'PUT', 'DELETE', 'PATCH', 'OPTIONS', 'HEAD'])
@app.route('/<path:path>', methods=['GET', 'POST', 'PUT', 'DELETE', 'PATCH', 'OPTIONS', 'HEAD'])
def proxy_request(path):
target_url = f"{TARGET_BASE_URL}/{path}"
if request.query_string:
target_url += f"?{request.query_string.decode('utf-8')}"
headers = {key: value for key, value in request.headers if key.lower() not in ['host', 'connection', 'content-length', 'accept-encoding']}
try:
resp = requests.request(
method=request.method,
url=target_url,
headers=headers,
data=request.get_data(),
cookies=request.cookies,
allow_redirects=False,
timeout=30
)
excluded_headers = ['content-encoding', 'content-length', 'transfer-encoding', 'connection']
response_headers = [(name, value) for name, value in resp.raw.headers.items() if name.lower() not in excluded_headers]
return Response(resp.content, resp.status_code, response_headers)
except requests.exceptions.RequestException as e:
print(f"Error forwarding request to {target_url}: {e}")
return Response(f"Proxy Error: Could not reach target server or invalid response: {e}", status=502)
except Exception as e:
print(f"An unexpected error occurred: {e}")
return Response(f"Internal Proxy Error: {e}", status=500)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=LISTEN_PORT, debug=True)