De la base de datos a Supabase
En la leccion anterior, aprendimos el uso basico de las herramientas de diseno UI MasterGo y Figma, pudimos usar GitHub para la obtencion de codigo y gestion de versiones, y desplegar sitios web a traves de Zeabur para que nuestra aplicacion / sitio web llegara a mas usuarios.
Para ayudar a todos a conectar mejor los conocimientos, antes de comenzar con el nuevo contenido de esta leccion sobre herramientas de diseno y despliegue, repasemos rapidamente los puntos clave de la leccion anterior con algunas preguntas sencillas:
- Que son las herramientas de diseno frontend, la definicion y uso de Figma y MasterGo.
- Los metodos basicos para convertir disenos en codigo.
- Que es GitHub, como configurar SSH, como crear tu primer repositorio.
- Que significa despliegue, como usar Zeabur, como desplegar codigo desde GitHub o localmente a la red publica para que todos puedan acceder.
Si alguno de estos puntos te resulta borroso, te recomendamos revisar primero la documentacion y los apuntes de la leccion anterior. No dudes en hacer preguntas en el grupo de estudio de WeChat en cualquier momento.
En esta leccion, aprenderemos como transformar una APP / sitio web que simplemente funciona en algo mas cercano a un producto real en produccion: ademas de usar una base de datos para gestionar los diversos cambios de datos durante la ejecucion del programa, tambien necesitamos un sistema de usuarios completo (registro, inicio de sesion, permisos, etc.) y otras capacidades clave del backend. Tomaremos Supabase como plataforma de servicios backend principal, primero usandola para implementar las dos funciones basicas de "base de datos + sistema de usuarios", y luego, usando los componentes proporcionados por Supabase como referencia, entenderemos mas a fondo los modulos centrales que generalmente incluyen los servicios backend en la nube modernos, asi como las funciones especificas y la logica operativa de cada modulo.
Lo que aprenderas
- Que son los datos, que es una base de datos, bases de datos comunes y metodos de uso
- Que es Supabase, como usar Supabase para operaciones basicas de base de datos
- Como usar Supabase para agregar funcionalidad basica de gestion de usuarios a una aplicacion
- Aprender las funciones avanzadas de Supabase: realtime, storage, edge function
- Aprender a agregar soporte de inicio de sesion con Google y GitHub a Supabase
- Una aplicacion basica que admite registro / inicio de sesion de usuarios y puede almacenar datos en una base de datos en linea
- Un conjunto de plantillas de codigo backend reutilizables de Supabase (base de datos + gestion de usuarios, etc.) para uso directo en proyectos posteriores
1. Que es una base de datos
1.1 Que son los datos
En el mundo digital, los datos (Data) estan en todas partes. En terminos simples, los datos son el soporte de la informacion. Los contactos de tus amigos, un articulo de WeChat, un video corto, el nivel de un personaje en un juego, todos estos son datos. En nuestra aplicacion, los datos son toda la informacion que necesita ser registrada y gestionada, como los perfiles de usuario, el historial de pedidos, la configuracion del programa, etc.
Generalmente, los datos tienen diferentes formas de representacion en un programa, la mas simple son las variables, podemos usar diferentes variables para registrar numeros simples:
# Python variable definition examples
# Integer variable: stores age information
age = 30
# Boolean variable: stores status (whether active)
is_active = True # True means active, False means inactive
# List variable: stores a set of score data
scores = [85, 92, 78, 90] # Contains 4 integer elements representing different scores
# Dictionary variable: stores multiple related information of a user
user_info = {
"age": 30, # Key "age" corresponds to the value of age
"height": 1.80, # Key "height" corresponds to the value of height (unit: meter)
"login_count": 156 # Key "login_count" corresponds to the value of login times
}Para datos complejos como los perfiles personales y el historial de pedidos mencionados anteriormente, podemos usar tablas mas complejas para representar los datos:
| user_id | name | |
|---|---|---|
| 1001 | Alice | alice@example.com |
| 1002 | Bob | bob@example.com |
| order_id | user_id | amount | status |
|---|---|---|---|
| 901 | 1001 | 29.99 | completed |
| 902 | 1002 | 15.50 | pending |
Sin embargo, para datos con estructura compleja, relaciones jerarquicas o campos no fijos, podemos usar el formato JSON para describirlos — es un formato intermedio de datos universal en Internet que casi todos los programas pueden leer y analizar, lo que facilita la transmision de datos entre sistemas. Por ejemplo, un pedido puede contener multiples productos, y cada producto tiene su propio nombre, cantidad y precio. Representarlo con tablas tradicionales seria muy torpe: tendrias que dividirlo en multiples tablas como "tabla de pedidos" y "tabla de productos", confiando en campos de relacion para reflejar la relacion de "el pedido contiene productos"; o en una sola tabla usar campos redundantes como "nombre del producto 1, precio del producto 1, nombre del producto 2...", lo cual es imposible de adaptar cuando la cantidad de productos no es fija; JSON puede usar directamente una estructura anidada para aclarar la jerarquia de "pedido - producto - atributos del producto", siendo intuitivo y flexible.
{
"order_id": 901,
"user_id": 1001,
"amount": 29.99,
"status": "completed",
"items": [
{ "sku": "BG-001", "name": "牛肉汉堡", "quantity": 1, "price": 18.00 },
{ "sku": "SD-003", "name": "炸薯条", "quantity": 1, "price": 6.99 },
{ "sku": "DK-002", "name": "可乐", "quantity": 1, "price": 5.00 }
],
"shipping_address": {
"street": "科技园路123号",
"city": "深圳",
"zip_code": "518057"
}
}Yendo un paso mas alla, si consideramos datos codificados como vectores (Vector), los datos vectoriales suelen ser representaciones numericas obtenidas al procesar datos no estructurados como texto, imagenes o audio a traves de modelos de IA (como modelos de Embedding). Su forma de representacion podria ser:
[0.123, -0.456, 0.789, ..., -0.234] (un array compuesto por cientos o incluso miles de numeros de punto flotante)
En resumen, en el mundo real hay demasiados datos de diferentes formas y propositos que merecen un analisis detallado, y cada tipo de datos podria necesitar una base de datos especializada para su almacenamiento. Para mas detalles, consulta la siguiente imagen — parece que son muchos, verdad?
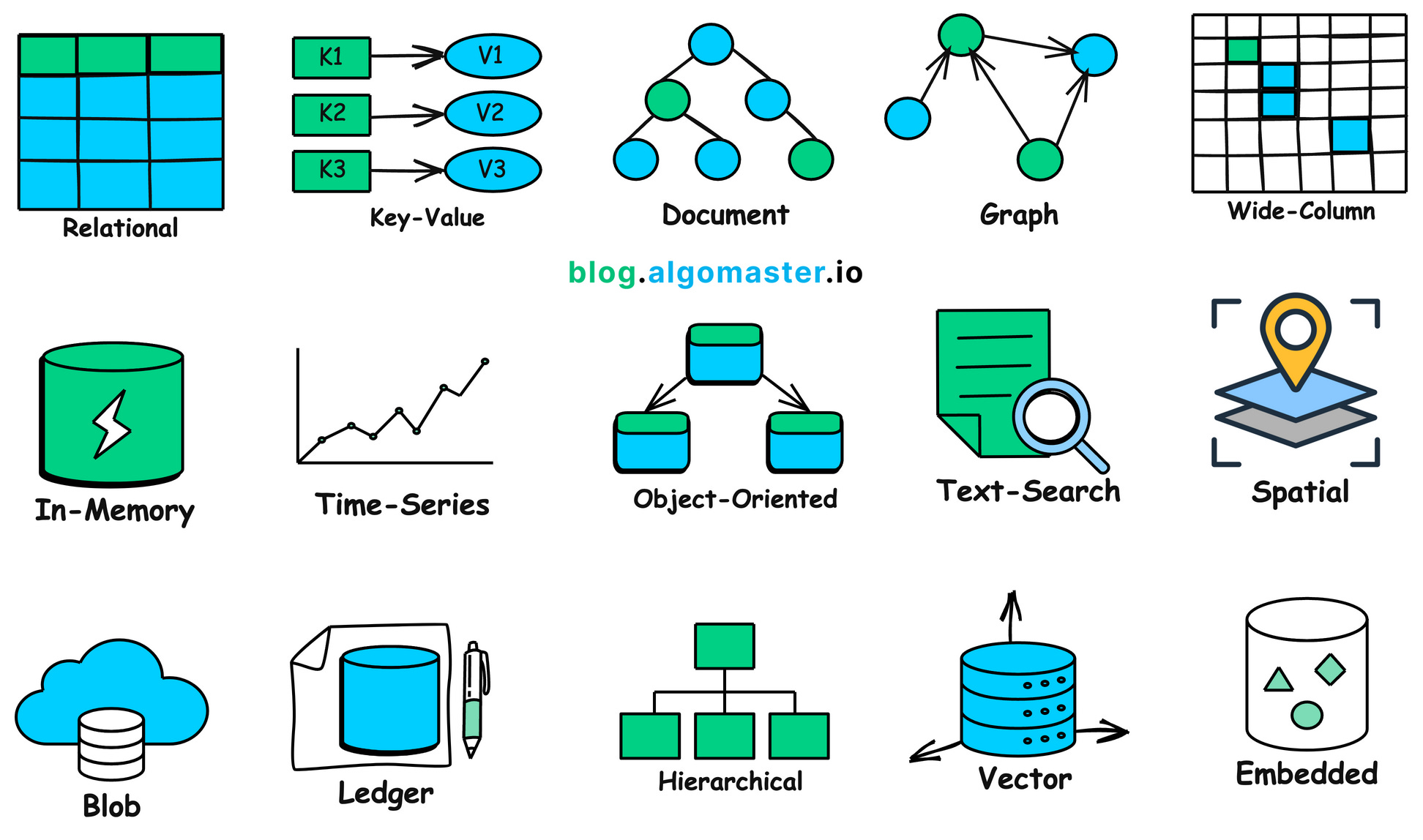
1.2 Por que necesitamos una base de datos
Ya hemos entendido que los datos del mundo real suelen tener estructuras complejas. Para almacenar y usar estos datos de manera eficiente, necesitamos un programa o contenedor especializado para gestionarlos — este es el proposito original de las bases de datos (Database). Una base de datos es esencialmente un programa especial cuya funcion principal es organizar, almacenar de forma segura y gestionar sistematicamente los datos, asi como soportar consultas y llamadas eficientes.
Imagina que pasaria con los datos de la aplicacion sin una base de datos: cuando un usuario cierra el navegador o sale de la aplicacion, toda la informacion cargada temporalmente se pierde directamente; no podemos guardar permanentemente el estado de uso del usuario (como informacion de inicio de sesion, configuracion personalizada), ni compartir datos clave entre diferentes usuarios (como inventario de productos, registros de pedidos). Necesitamos un dispositivo que nos ayude a almacenar todos los datos.
Lo mas flexible es que el metodo de despliegue de la base de datos se puede elegir segun las necesidades: se puede desplegar en un servidor local para satisfacer las necesidades de gestion local de datos; tambien se puede desplegar en la nube, donde las bases de datos en la nube soportan escalado elastico (Scale), pueden expandir sus capacidades a medida que crecen el volumen de datos y el trafico de acceso, soportando grandes volumenes de datos y alta concurrencia, e incluso si el numero de usuarios aumenta significativamente, se puede garantizar una experiencia de uso normal para los usuarios.
En resumen, las bases de datos, con su eficiente almacenamiento persistente, gestion precisa y capacidades de consulta rapida, resuelven principalmente los siguientes problemas centrales:
- Almacenamiento persistente de datos: Sin una base de datos, los datos solo existirian en la memoria de la aplicacion, y una vez que se cierra la aplicacion, los datos se perderian. La base de datos resuelve este problema almacenando datos de forma persistente en medios de almacenamiento como discos duros, asegurando la preservacion a largo plazo de los datos y reduciendo el riesgo de perdida.
- Consulta y analisis de datos conveniente: Las bases de datos proporcionan lenguajes de consulta potentes (como SQL) que permiten a los usuarios realizar facilmente y de manera eficiente consultas, filtrados y analisis complejos sobre grandes volumenes de datos, ayudando a las empresas a tomar decisiones mas inteligentes. Sin una base de datos, buscar informacion especifica en una gran cantidad de archivos desordenados seria una tarea extremadamente lenta y dificil.
- Soporte para alto rendimiento y acceso de alta concurrencia: Las bases de datos, a traves de tecnologias como optimizacion de indices, cache de consultas, pools de conexion y arquitecturas distribuidas, pueden responder a solicitudes de consulta en milisegundos y soportar el acceso concurrente de miles de usuarios. Esto es crucial para las aplicaciones de Internet modernas (como las actividades flash de plataformas de comercio electronico, las actualizaciones en tiempo real de redes sociales), asegurando la velocidad de respuesta del sistema y la experiencia del usuario. Sin el soporte de alto rendimiento de las bases de datos, el sistema experimentaria graves retrasos o incluso se colapsaria ante solicitudes masivas de usuarios.
- Garantia de integridad y consistencia de los datos: Las bases de datos aseguran la precision y consistencia de los datos a traves de una serie de mecanismos (como restricciones, triggers). Esto significa que los datos en la base de datos deben cumplir con reglas predefinidas, por ejemplo, la edad del usuario debe ser un numero, el numero de pedido debe ser unico, previniendo efectivamente la generacion de datos ilegales o invalidos.
- Seguridad de los datos: Las bases de datos proporcionan poderosos mecanismos de seguridad, incluyendo autenticacion de usuarios, control de acceso y cifrado de datos, para proteger los datos contra acceso, modificacion o destruccion no autorizada. Para hacer frente a situaciones imprevistas como fallas de hardware, errores humanos o ataques maliciosos, las bases de datos tambien ofrecen funciones de respaldo y recuperacion de datos. A traves de respaldos periodicos, los datos pueden recuperarse oportunamente en caso de perdida o dano, garantizando la continuidad del negocio.
1.3 Bases de datos relacionales y no relacionales
Anteriormente hemos entendido el valor central, los metodos de despliegue y las ventajas de escalabilidad de las bases de datos, y a la hora de elegir en la practica, lo primero que enfrentamos son las dos categorias principales: bases de datos relacionales y bases de datos no relacionales (NoSQL). Podemos entender sus diferencias con dos parrafos sencillos:
Las bases de datos relacionales son como tablas de Excel con una estructura rigurosa: todos los datos deben tener un formato predefinido (definir el contenido del Schema, por ejemplo, debe tener nombre y edad, donde el nombre debe ser texto y la edad debe ser un numero), y conectar diferentes tablas a traves de campos de relacion (identificadores usados para conectar diferentes tablas, como el numero de identidad). Su ventaja es que los datos son precisos y confiables, especialmente adecuados para escenarios donde no puede haber errores, como transferencias bancarias y gestion de inventario, pero la desventaja es que ajustar la estructura es bastante complicado, y el rendimiento se ve limitado con grandes volumenes de datos.
Las bases de datos no relacionales son como carpetas flexibles que pueden almacenar documentos, imagenes o pares clave-valor (similar a la estructura "palabra-definicion" de un diccionario) de formatos variados, sin necesidad de predefinir la estructura de cada conjunto de datos. Es mas facil hacer frente a requisitos que cambian rapidamente y a datos a gran escala (como las publicaciones masivas de redes sociales), y la escalabilidad (agregar servidores para mejorar el rendimiento) es mas conveniente, pero sacrifica parte de la capacidad de consulta relacional (la capacidad de organizar informacion a traves de diferentes tablas de datos) y la garantia de consistencia (asegurar que los datos sean siempre precisos y sin contradicciones), siendo adecuada para aplicaciones de Internet con mayores requisitos de tolerancia a fallos.
Entonces, como elegir una base de datos en aplicaciones practicas? Desde la perspectiva de la clasificacion de escenarios, las bases de datos relacionales son comunes en transacciones financieras, gestion de inventario, procesamiento de pedidos, sistemas contables y otros escenarios que requieren fuerte consistencia, procesamiento de transacciones complejas y acceso equilibrado de lectura-escritura frecuente; mientras que las bases de datos no relacionales son mas adecuadas para almacenamiento de contenido de redes sociales, analisis de registros en tiempo real, escritura masiva de datos IoT, sistemas de recomendacion con mucha lectura y escritura, y otros requisitos de alta concurrencia, patrones de lectura-escritura desequilibrados y estructura flexible.
Sin embargo, para las empresas, en la etapa inicial no es necesario dedicar mucho tiempo a pensar en que base de datos usar. Las bases de datos actuales ya son productos y servicios muy maduros, la forma mas directa es consultar a diferentes proveedores de servicios en la nube (proveedores que ofrecen recursos y servicios de TI como servidores, almacenamiento, bases de datos, software y capacidad de computo). Podemos contactar directamente a los equipos de ventas oficiales de los servicios en la nube para hacer coincidir soluciones de base de datos adecuadas segun las necesidades de negocio de nuestro propio producto; y la ruta conveniente para construir aplicaciones empresariales es priorizar la colaboracion con proveedores profesionales. (Nota: los precios de los servicios empresariales suelen ser altos, se recomienda investigar y comparar multiples opciones, y tambien se puede optar por comprar servidores y desplegar programas de bases de datos de codigo abierto como alternativa.)
Tambien podemos consultar las recomendaciones de seleccion de bases de datos de un proveedor de nube, donde podemos elegir diferentes tipos de bases de datos segun el escenario, y comparar las especificaciones de bases de datos de diferentes proveedores de nube para seleccionar la mas adecuada.
| Tipo de base de datos | Nombre de la base de datos | Precio | Escenarios aplicables |
|---|---|---|---|
| Base de datos relacional | RDS MySQL | Bajo | Version basica: aprendizaje y sitios web pequenos; Version de alta disponibilidad: escenarios de bases de datos medianas con cierta presion de negocio; Version de cluster: el negocio no permite interrupciones, presion de acceso elevada |
| RDS SQL Server | Alto | Version basica: pruebas y sitios web comerciales pequenos; Version de alta disponibilidad: sitios web comerciales empresariales; Version de cluster: el negocio empresarial no permite interrupciones, presion de acceso elevada | |
| RDS PostgreSQL | Minimo | Version basica: aprendizaje y sitios web pequenos; Version de alta disponibilidad: escenarios de bases de datos medianas con cierta presion de negocio; Version de cluster: escenarios donde el negocio no permite interrupciones y la presion de acceso es elevada, su rendimiento es superior al de MySQL general | |
| RDS PPAS | Alto | Tipo general: compatible con negocios Oracle, pero con presion de negocio moderada, la virtualizacion puede satisfacer sus necesidades; Tipo exclusivo: para negocios que requieren servidores fisicos dedicados, generalmente negocios Oracle de alta concurrencia | |
| DRDS | Medio | Version de entrada: 4 nucleos 8 GB, precio accesible, adecuada para negocios en linea de pequena y mediana escala; Version empresarial: 16 nucleos 32 GB, buena respuesta SQL compleja, adecuada para negocios en linea de ultra alta concurrencia; Version suprema: 32 nucleos 64 GB, la mejor respuesta de ejecucion SQL compleja, ofrece opciones de especificaciones ultra grandes | |
| Base de datos NoSQL | Redis | Medio | Redis de respaldo doble en caliente: generalmente utilizado como base de datos persistente para mejorar la disponibilidad del negocio; Version de cluster de Redis: generalmente utilizada como capa de cache para acelerar el acceso a la aplicacion, resolviendo la presion de lectura que las bases de datos generales no pueden soportar |
| MongoDB | Medio | Instancia de nodo unico: adecuada para desarrollo, pruebas y otros escenarios de almacenamiento de datos no nucleares empresariales; Instancia de conjunto de replicas: adecuada para escenarios de negocio con mayores requisitos de rendimiento de lectura, como sitios web de lectura, sistemas de consulta de pedidos con mas lectura que escritura o necesidades de negocio temporal; Instancia de cluster fragmentado: basada en multiples conjuntos de replicas compuesta por un cluster fragmentado, proporciona mayores requisitos de rendimiento de lectura, ofreciendo rendimiento de lectura de alta velocidad para negocios en linea en tiempo real |
Solo con palabras no es facil de entender, usemos un escenario concreto de "articulos de blog" para ver como se almacenan los mismos datos en una base de datos relacional (SQL) y diferentes tipos de bases de datos no relacionales (NoSQL).
Supongamos que tenemos una plataforma de blog que necesita almacenar la siguiente informacion:
- Usuarios (Users): ID de usuario, nombre de usuario, correo electronico
- Articulos (Posts): ID del articulo, titulo, contenido, ID del autor
- Comentarios (Comments): ID del comentario, contenido del comentario, ID del comentarista, ID del articulo al que pertenece
- Etiquetas (Tags): ID de la etiqueta, nombre de la etiqueta
- Relacion entre articulos y etiquetas: multiples etiquetas asociadas a un solo articulo, multiples articulos correspondientes a una sola etiqueta
Ejemplo de base de datos relacional (SQL)
En una base de datos SQL, almacenariamos diferentes tipos de datos en tablas separadas, y los conectariamos a traves de "claves foraneas". Esta estructura es clara y normalizada, reduciendo la redundancia de datos.
Tomando como ejemplo la "gestion de articulos de una plataforma de contenido", no mezclariamos "usuarios, articulos, comentarios, etiquetas", sino que los dividiriamos en 5 tablas con funciones unicas, cada una con "limites de responsabilidad" claros y definiciones de estructura estrictas (Schema):
- Tabla
users(almacena informacion de usuarios)
| user_id (clave primaria) | username | |
|---|---|---|
| 101 | Alice | alice@example.com |
| 102 | Bob | bob@example.com |
- Tabla
posts(almacena informacion de articulos)
| post_id (clave primaria) | title | content | author_id (clave foranea) |
|---|---|---|---|
| 1 | Introduccion a SQL | Un articulo sobre bases de datos SQL... | 101 |
| 2 | Introduccion a NoSQL | NoSQL ofrece un modelo de datos flexible... | 102 |
- Tabla
comments(almacena informacion de comentarios)
| comment_id (clave primaria) | body | commenter_id (clave foranea) | post_id (clave foranea) |
|---|---|---|---|
| 1001 | Excelente articulo! | 102 | 1 |
| 1002 | Aprendi algo nuevo. | 101 | 2 |
| 1003 | Hay mas ejemplos? | 101 | 1 |
- Tabla
tags(almacena etiquetas)
| tag_id (clave primaria) | tag_name |
|---|---|
| 51 | Base de datos |
| 52 | Tecnologia |
| 53 | Introduccion |
- Tabla
post_tags(almacena la relacion de muchos a muchos entre articulos y etiquetas, reflejando la caracteristica de union de tablas)
| post_id (clave foranea) | tag_id (clave foranea) |
|---|---|
| 1 | 51 |
| 1 | 52 |
| 2 | 51 |
| 2 | 52 |
| 2 | 53 |
Si necesitas consultar la "informacion completa del articulo 'Introduccion a SQL' (post_id=1) publicado por Alice (incluyendo contenido del articulo, autor, comentarios, etiquetas)", debes ejecutar una consulta de union de multiples tablas (JOIN), asociando 5 tablas a traves de claves foraneas y agregando datos. La declaracion SQL es la siguiente:
SELECT
p.title,
p.content,
u.username AS author,
c.body AS comment,
t.tag_name AS tag
FROM
posts p
JOIN
users u ON p.author_id = u.user_id
LEFT JOIN
comments c ON p.post_id = c.post_id
LEFT JOIN
post_tags pt ON p.post_id = pt.post_id
LEFT JOIN
tags t ON pt.tag_id = t.tag_id
WHERE
p.post_id = 1;Esta consulta abarca 5 tablas, reuniendo todos los datos relacionados en una sola respuesta. Esta es la ventaja central de las bases de datos relacionales: a traves de la normalizacion y operaciones de union, se pueden realizar de manera flexible todo tipo de consultas complejas, al tiempo que se garantiza la consistencia de los datos y la minima redundancia.
Ejemplo de base de datos no relacional (NoSQL)
Las bases de datos NoSQL (como MongoDB, Redis) tienen una filosofia de diseno opuesta a SQL: no enfatizan la division y normalizacion de datos, y generalmente empaquetan y agregan todos los datos relacionados en el negocio para reducir las operaciones de union en las consultas, mejorando asi el rendimiento de lectura.
Entre las bases de datos NoSQL, las bases de datos de documentos (Document Database) son uno de los tipos mas utilizados, y MongoDB es su representante tipico. Utiliza el "documento" como unidad basica de almacenamiento. Aqui, "documento" no se refiere a lo que comunmente entendemos como "articulo", sino a una estructura de datos similar a JSON (MongoDB usa el formato BSON, que soporta mas tipos de datos): no es necesario predefinir un Schema unificado (estructura de datos), los campos de cada documento pueden aumentarse o reducirse de manera flexible, y los tipos de campos tambien pueden ajustarse libremente, adaptandose perfectamente a escenarios con formatos de datos variables.
En las bases de datos de documentos, generalmente se almacena un articulo y toda su informacion relacionada (como comentarios, etiquetas) en un solo documento (el formato del documento es similar a JSON, se pueden definir campos de manera flexible sin necesidad de predefinir un Schema). La logica central es "almacenar la 'informacion completa de un escenario de negocio' en un solo documento", evitando la union de multiples fuentes de datos durante las consultas.
Ejemplo de un documento en la coleccion posts:
{
"_id": 1,
"title": "初识SQL",
"content": "这是关于SQL数据库的一篇文章...",
"author": {
"user_id": 101,
"username": "Alice",
"email": "alice@example.com"
},
"tags": [
"数据库",
"技术"
],
"comments": [
{
"comment_id": 1001,
"body": "写得很棒!",
"commenter": {
"user_id": 102,
"username": "Bob"
}
},
{
"comment_id": 1003,
"body": "有没有更多例子?",
"commenter": {
"user_id": 101,
"username": "Alice"
}
}
]
}La ventaja de este diseno es muy intuitiva: cuando necesitas obtener "la informacion completa del primer articulo (incluyendo autor, comentarios, etiquetas)", solo necesitas consultar este unico documento a traves de _id:1. La base de datos puede devolver todos los datos con una sola lectura, sin necesidad de ejecutar 3-4 operaciones de union de tablas como en SQL, mejorando enormemente la eficiencia de lectura.
Sin embargo, tambien tiene un trade-off (compromiso) evidente: dado que los datos se almacenan de forma "agregada", inevitablemente se produce redundancia de datos. Por ejemplo, el username de la autora "Alice" esta incrustado en cada documento de articulo que ella escribe. Si algun dia "Alice" cambia su nombre de usuario a "Alice_New", teoricamente seria necesario recorrer todos los documentos de articulos que contienen su informacion y actualizar el campo author.username uno por uno, lo cual no solo es tedioso, sino que tambien podria provocar que algunos documentos no se actualicen correctamente debido a problemas de red o del servidor, resultando en una situacion de "el mismo usuario con nombres de usuario inconsistentes en diferentes articulos".
Sin embargo, en la practica empresarial, esta redundancia suele ser "aceptable": para escenarios como blogs, noticias y detalles de productos de comercio electronico donde se lee mucho mas de lo que se escribe (los usuarios ven contenido muchas mas veces de las que los autores modifican sus nombres de usuario), intercambiar una pequena redundancia por un "rendimiento de lectura extremo" es la mejor opcion; mientras que en escenarios de "escritura frecuente y poca lectura" (como la modificacion frecuente de informacion de usuarios), es necesario sopesar segun las necesidades del negocio si usar una base de datos de documentos.
Lo anterior es una introduccion breve a las diferentes bases de datos. Si estas interesado en mas tipos especificos de bases de datos, puedes consultar los siguientes recursos para probar diferentes tipos.
Examples of SQL databases: Db2、MySQL、PostgreSQL、YugabyteDB、CockroachDB、Oracle Database、Azure SQL Database
Examples of NoSQL databases: Redis、CouchDB、MongoDB、Cassandra、Elasticsearch、BigTable、Neo4j、HBase
2. Supabase
Anteriormente hemos presentado varios tipos de bases de datos comunes y sus escenarios de uso adecuados. Sin embargo, en proyectos reales, la base de datos suele ser solo un modulo basico dentro del sistema backend: ademas de almacenar y consultar datos, tambien necesitas resolver un conjunto completo de problemas como registro e inicio de sesion de usuarios, verificacion de permisos, carga y almacenamiento de archivos, interfaces API externas e incluso tareas programadas y notificaciones en tiempo real. Simplemente elegir una buena base de datos no hace que tu aplicacion "este lista para produccion inmediatamente"; todavia hay un gran circulo de trabajo de ingenieria backend entre medias.
Por lo tanto, necesitamos considerar un contexto mas amplio: los servicios backend. Una aplicacion completa generalmente esta compuesta por "frontend + backend": el frontend se encarga de la visualizacion de paginas y la interaccion con el usuario, mientras que el backend se encarga del almacenamiento de datos, inicio de sesion de usuarios y procesamiento de logica de negocio. En el pasado, los desarrolladores a menudo tenian que construir sus propios servidores, configurar bases de datos, disenar e implementar APIs, y ademas gestionar manualmente la administracion de permisos, politicas de seguridad, escalabilidad y monitoreo de operaciones, un proceso repetitivo y que consumia mucho tiempo. Para resolver estas tareas repetitivas, la industria creo el concepto de BaaS (Backend as a Service, Backend como Servicio): empaquetando funciones backend comunes como bases de datos, autenticacion de usuarios, almacenamiento de archivos y capacidades en tiempo real en una plataforma en la nube, donde los desarrolladores pueden llamar directamente a estas capacidades a traves de SDK / API sin necesidad de construir y mantener la infraestructura desde cero.
En este contexto, Supabase puede considerarse como el representante de una nueva generacion de BaaS: utiliza PostgreSQL como base de datos central, integrando sobre ella un conjunto completo de capacidades backend como Auth, Storage, Realtime, Edge Functions y Vector, proporcionando a los desarrolladores una "plataforma backend integral centrada en Postgres". A continuacion, desde esta perspectiva, evolucionaremos de "solo elegir una base de datos" a "elegir una plataforma de desarrollo backend completa", para ver especificamente que trabajo nos puede ahorrar Supabase y como reduce drasticamente la distancia de un proyecto desde el prototipo hasta un producto utilizable.
2.1 Guia paso a paso
Despues de comprender claramente el posicionamiento general de Supabase, a continuacion desglosaremos las capacidades centrales que ofrece especificamente, siguiendo la ruta de operacion de la consola de Supabase, asi como las responsabilidades centrales correspondientes a cada capacidad. Presentaremos en detalle cada opcion involucrada en Supabase para ayudarte a comenzar rapidamente con las operaciones basicas.

Despues de visitar el sitio web oficial de Supabase e iniciar sesion, haz clic en New project en la pagina principal de la consola para ingresar al proceso de creacion;
Ingresa el contenido principal que necesita ser configurado: Project Name, contrasena de la base de datos; para la region, simplemente selecciona la mas cercana a los usuarios objetivo de tu programa.
Despues de crearlo exitosamente, la barra lateral izquierda de la consola mostrara todos los modulos de funciones centrales (Table Editor, SQL Editor, Database, Authentication, etc.), y las operaciones posteriores se desarrollaran en torno a estos modulos.
Editor de tablas
Table Editor puede considerarse como el editor visual de tablas de datos de Supabase, que te permite ver y modificar directamente los datos de la base de datos como si estuvieras operando Excel, sin necesidad de escribir declaraciones SQL; solo necesitas interactuar con el mouse para modificar el contenido de los datos.
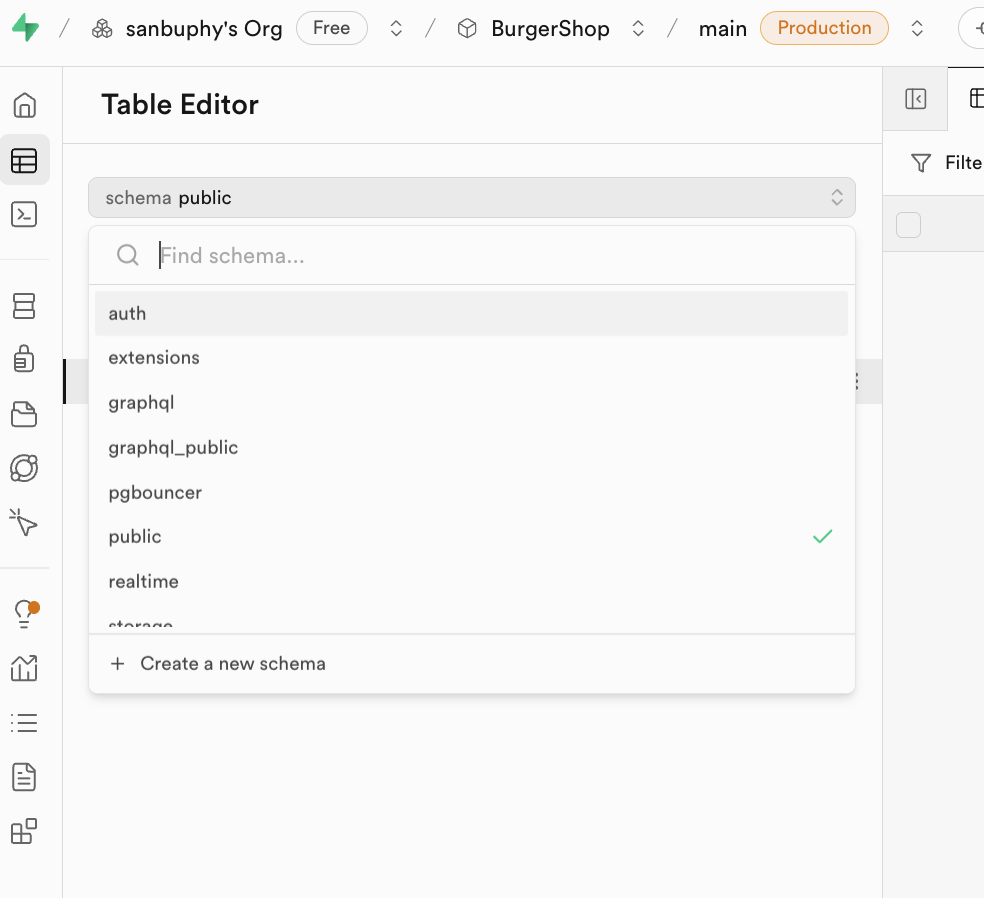
Lo que vale la pena destacar es Schema. Schema puede entenderse como un "contenedor de recursos" dentro de la base de datos, utilizado para la gestion agrupada de tablas, vistas, funciones, indices y otros recursos. Sus dos funciones principales son: primero, evitar conflictos de nombres (pueden existir tablas con el mismo nombre bajo diferentes Schemas); segundo, implementar aislamiento de permisos (como permitir solo a usuarios especificos acceder a tablas bajo cierto Schema);
Haz clic en el menu desplegable Schema en la parte superior del editor para cambiar entre diferentes contenedores. En el desarrollo diario, generalmente solo necesitas prestar atencion a dos categorias:
public: el contenedor de recursos publicos predeterminado, donde todas las tablas de negocio creadas por los desarrolladores (como "tabla de articulos", "tabla de comentarios") se almacenan;auth: el contenedor exclusivo de autenticacion de usuarios, donde la tablausersalmacena automaticamente toda la informacion de usuarios registrados (como ID de usuario, correo electronico, hora de inicio de sesion). No se recomienda modificar manualmente las tablas predeterminadas bajo este Schema para evitar afectar la funcionalidad de autenticacion;

Editor SQL
SQL Editor funciona como el ejecutor de declaraciones SQL de Supabase, permitiendote operar directamente la base de datos mediante codigo. Puedes hacer que un modelo grande genere directamente declaraciones SQL, introducirlas a la derecha y hacer clic en RUN para crear o modificar tablas con las declaraciones, o ver directamente los datos de las tablas filtrados en Results.
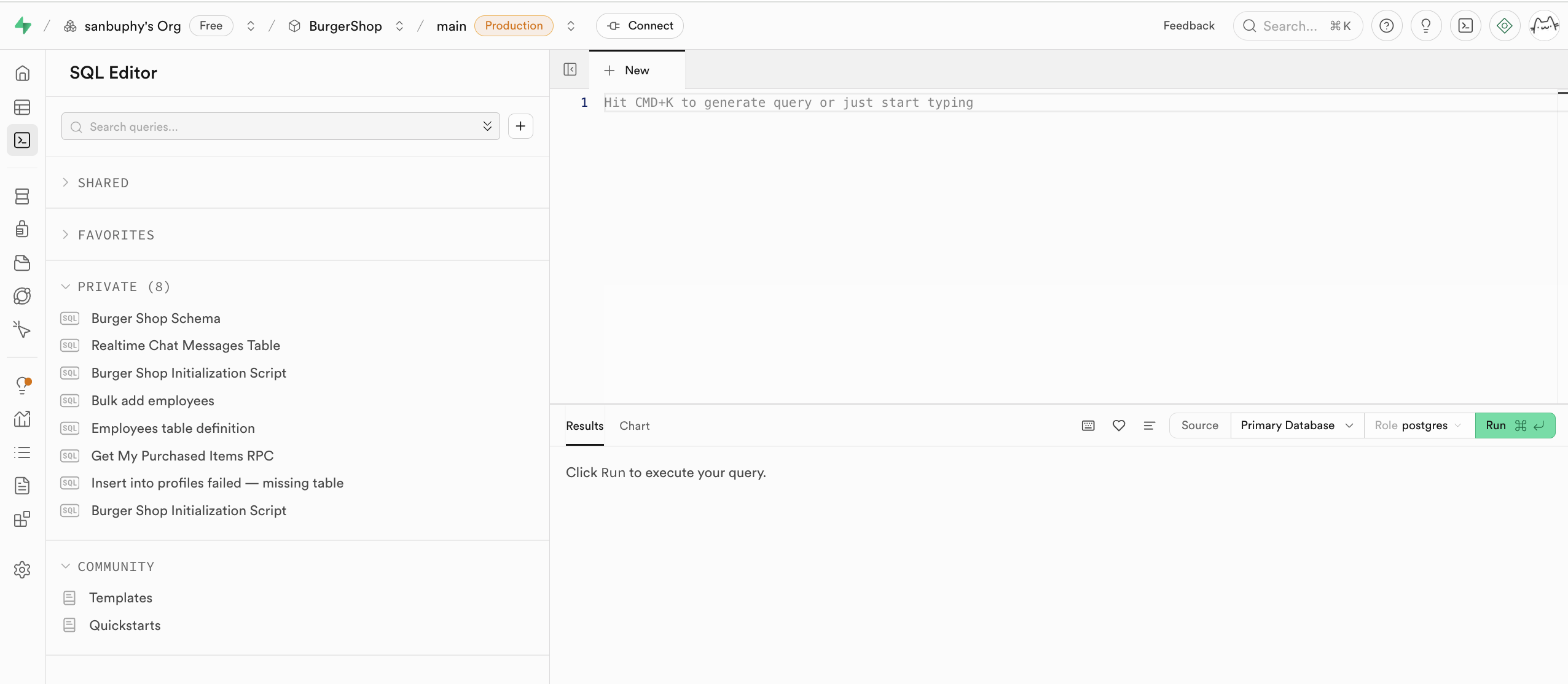
Despues de ejecutar RUN, puedes encontrar la tabla de datos recien creada en el schema public del Table Editor; ademas, las declaraciones ejecutadas se guardaran en la seccion PRIVATE del panel izquierdo, e incluso puedes hacer clic en el icono del corazon en la parte inferior para guardar como favorita esa consulta o declaracion de creacion.
Centro de gestion de bases de datos
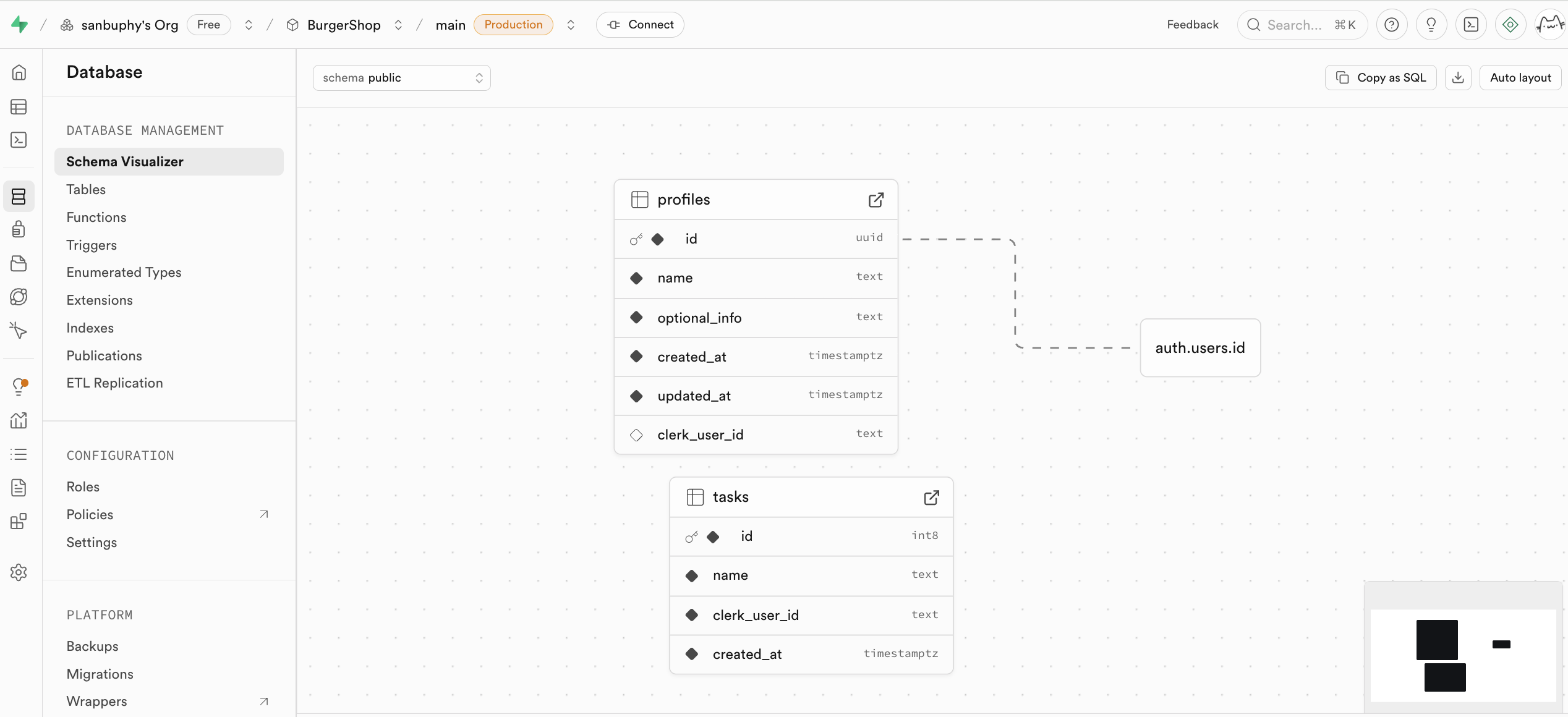
Database es el centro de gestion de bases de datos de Supabase, que permite ver y gestionar visualmente todas las tablas de datos, y entender las relaciones entre diferentes tablas a traves de las lineas de conexion entre ellas (es decir, restricciones de claves foraneas, que representan relaciones de referencia entre datos).
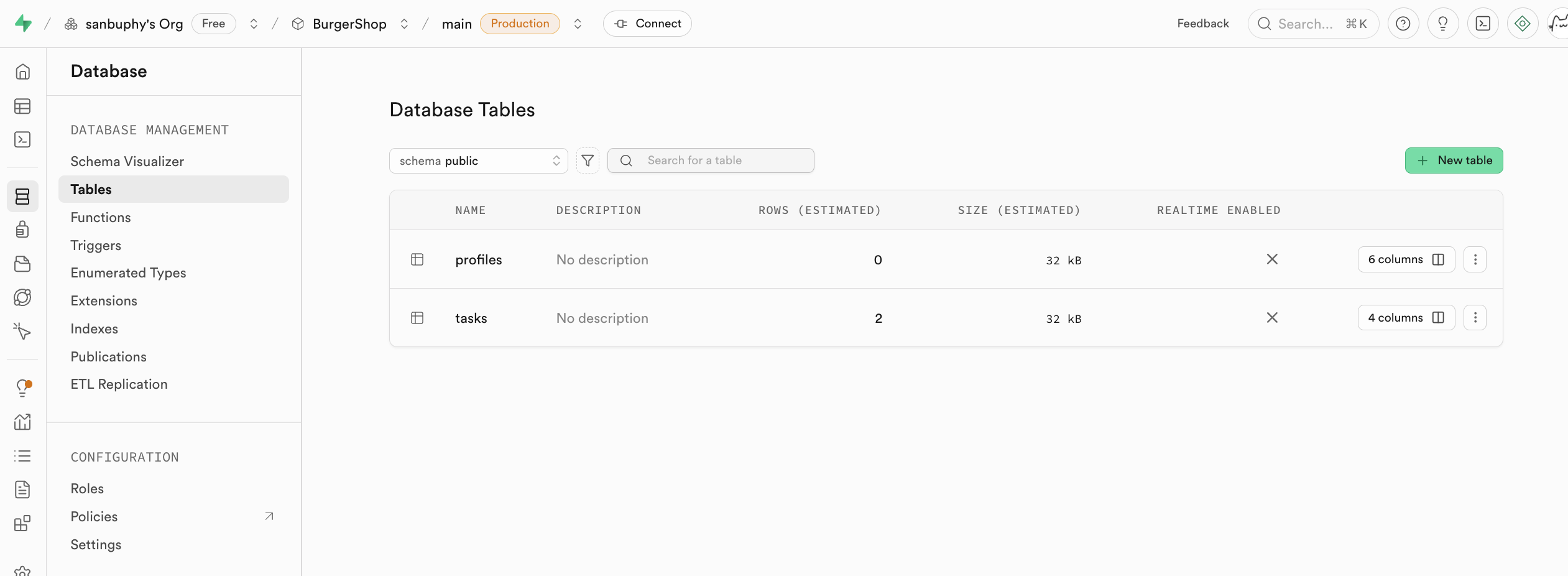
Si deseas crear manualmente una nueva tabla, puedes hacerlo directamente en la seccion Tables, explicaremos esto en detalle en tutoriales posteriores.
Autenticacion de identidad
Authentication gestiona el registro, inicio de sesion y permisos de los usuarios. Los datos del sistema de gestion de usuarios predeterminado se almacenan aqui, proporcionando funcionalidades listas para usar como registro de usuarios, inicio de sesion, restablecimiento de contrasena, verificacion por correo electronico, y soporte para inicio de sesion OAuth de terceros (como WeChat, GitHub, Google, etc.). Todos los datos de usuarios se sincronizan automaticamente con la tabla auth.users de la base de datos.
Puedes encontrar las diferentes entradas de inicio de sesion de informacion de usuario soportadas por Supabase en la opcion Provider; por defecto se usa Email. Si deseas usar cuentas de GitHub o Google para iniciar sesion, se necesita configuracion adicional de atributos, que explicaremos en detalle en las lecciones siguientes.
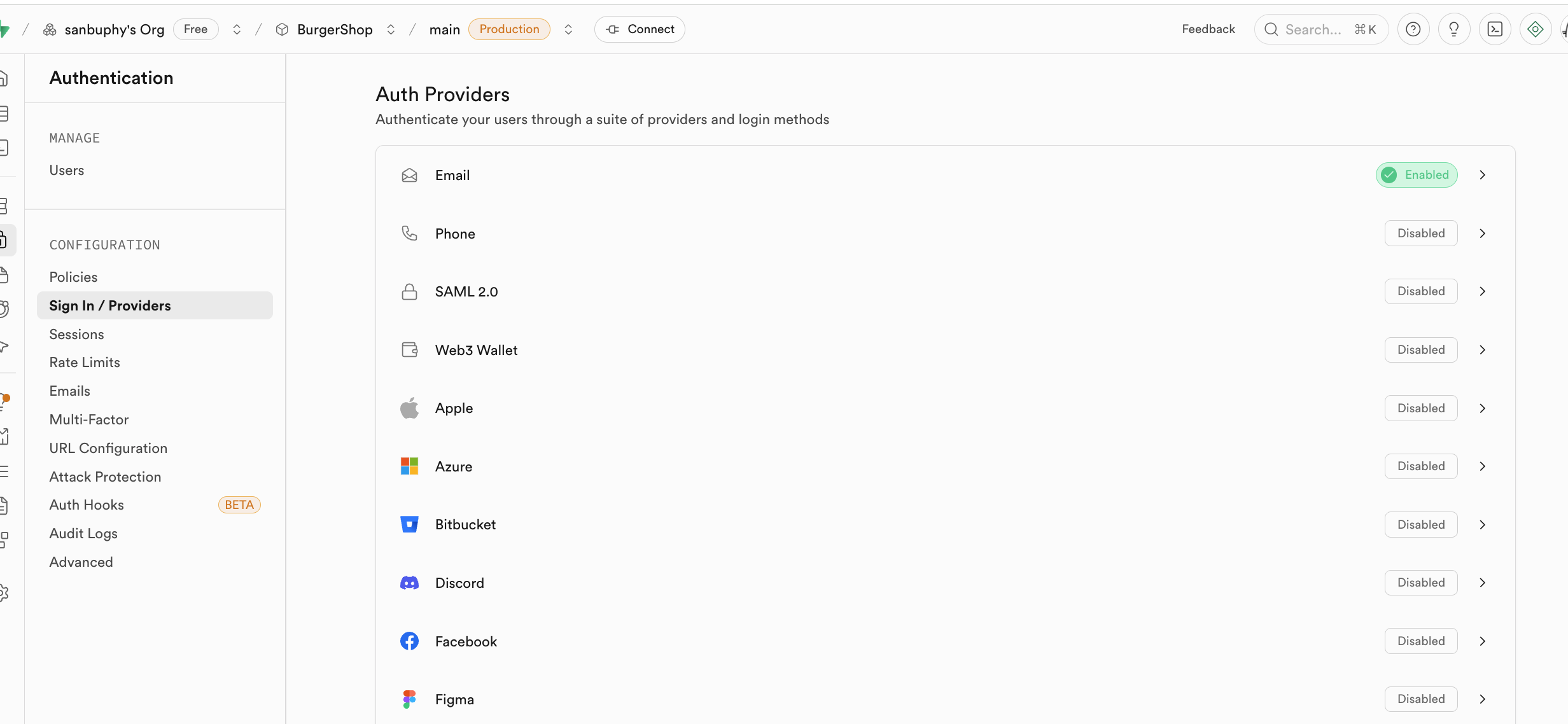
En Sign In / Providers tambien se incluye el control del comportamiento de registro por correo electronico. Si no deseas que cada registro por correo electronico requiera que el usuario acepte una invitacion antes de convertirse en usuario, puedes desactivar el requisito obligatorio de Confirm email.
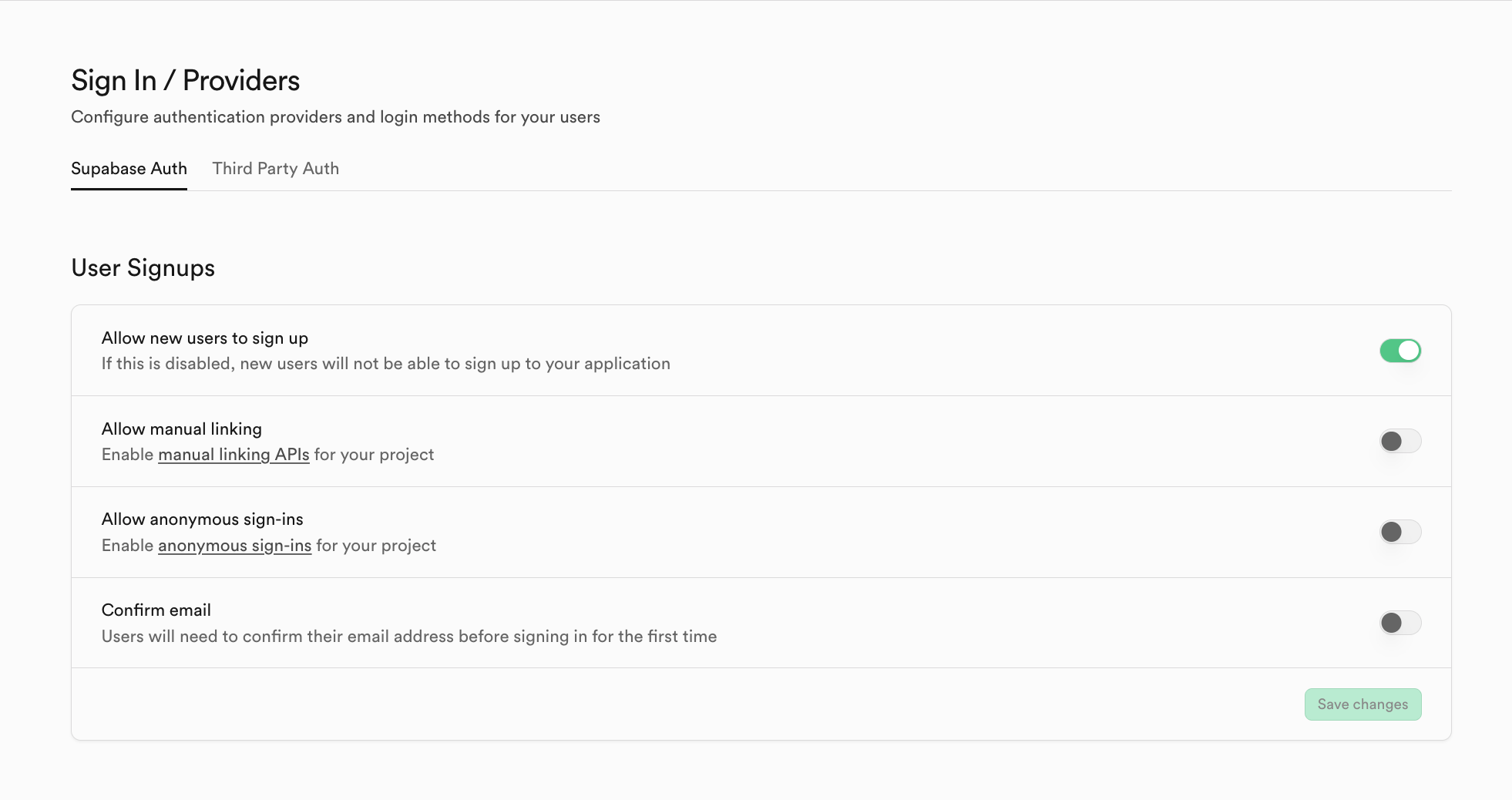
Si deseas cambiar a otro proveedor de sistema de autenticacion que no sea Supabase, puedes hacer clic en Third Party Auth, por ejemplo, aqui se usa Clerk como proveedor de sistema de terceros.
Si te preocupa que el volumen de acceso de usuarios registrados sea excesivo a corto plazo, puedes habilitar las politicas de limitacion de trafico correspondientes en Rate Limits:
Almacenamiento
Storage es el sistema de almacenamiento de Supabase, compatible con el concepto S3 de Amazon Cloud, que puede usarse para almacenar cualquier tipo de archivo (como imagenes, videos, documentos, audio, etc.), y proporciona gestion de permisos de acceso (publico o privado) y obtencion de enlaces de descarga (enlaces permanentes o temporales). Puedes gestionar convenientemente la carga y descarga de archivos relacionados con los usuarios en tu aplicacion, integrandose sin problemas con el sistema de autenticacion de Supabase para lograr un control de acceso preciso.
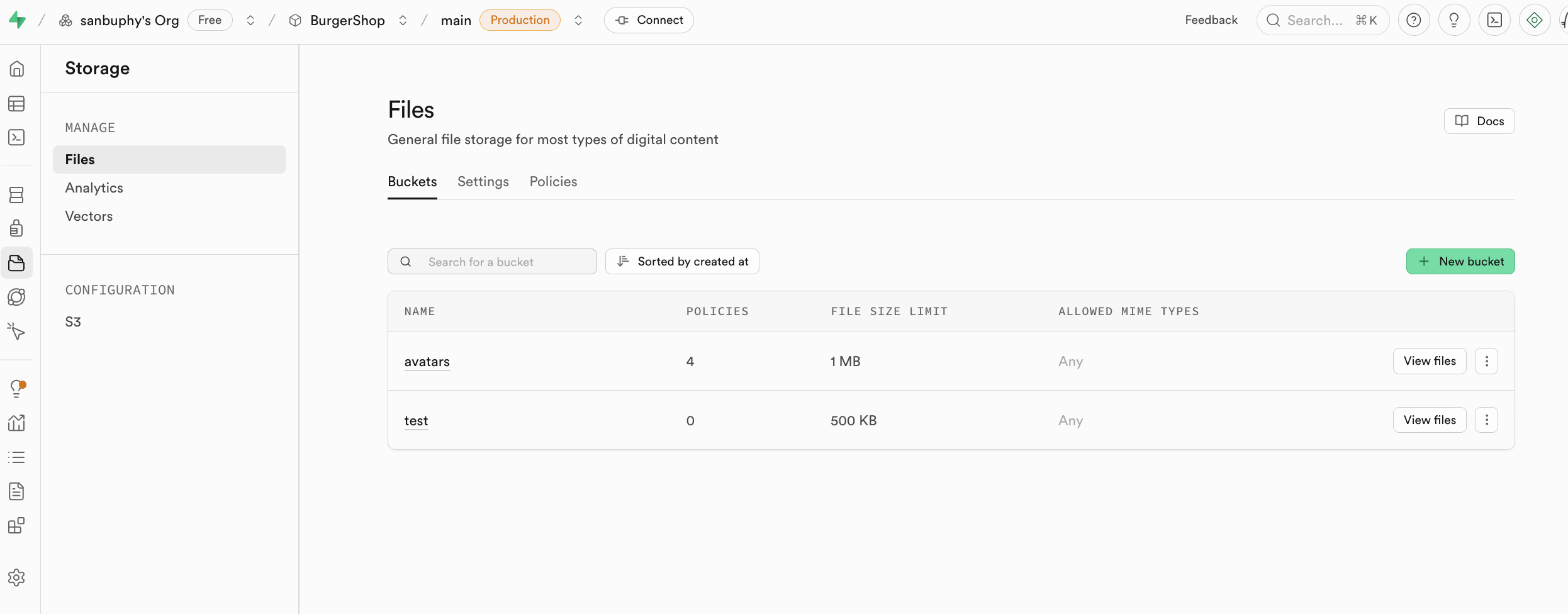
Explicaremos el uso especifico de storage en el proyecto avanzado de esta leccion.
Si deseas usar los protocolos relacionados de S3 para operar, puedes usar directamente la configuracion correspondiente:
Amazon Cloud (servicio en la nube de Amazon, o AWS) es la plataforma de computacion en la nube proporcionada por Amazon (como un gran centro de datos de red, donde puedes alquilar recursos de computo y almacenamiento segun lo necesites). S3 (Simple Storage Service) es el servicio dentro de AWS especificamente disenado para almacenar archivos (similar a un disco de red ilimitado, donde puedes guardar imagenes, videos, respaldos y otros archivos). Es actualmente el servicio de almacenamiento de objetos mas popular y se ha convertido en el estandar de facto de la industria.
Por que crear una API compatible con S3?: S3 ha existido por casi 20 anos, y hay una gran cantidad de herramientas, SDKs y documentacion disponibles en el mercado. Ser compatible con S3 significa que puedes usar directamente estos recursos sin tener que crear tus propias herramientas relacionadas desde cero, permitiendo satisfacer rapidamente las necesidades de poner en produccion tu negocio.
Funciones Edge
Si no quieres desplegar un backend pero deseas usar operaciones de base de datos y funciones, puedes usar Edge Functions para construir capacidades backend centrales sin necesidad de construir tus propios servidores. Son funciones de servidor distribuidas globalmente proporcionadas por Supabase. En terminos simples, te permiten escribir y desplegar codigo backend en la nube sin necesidad de comprar y gestionar tus propios servidores backend. Estas funciones se despliegan en nodos perifericos de la red global, ejecutandose automaticamente en la ubicacion mas cercana a tus usuarios, reduciendo drasticamente la latencia de red y proporcionando una velocidad de respuesta extrema. Puedes crear, editar y desplegar directamente desde el panel de Supabase, haciendo que todo el flujo de desarrollo sea muy conveniente.
Un uso central de Edge Functions es actuar como una capa intermedia segura para proteger tu informacion sensible y claves de autenticacion. Llamar directamente a servicios de terceros (como OpenAI, Stripe) desde el codigo frontend expondria tu API Key, conllevando un gran riesgo de seguridad. A traves de Edge Functions, tu aplicacion frontend solo se comunica con tu funcion de Supabase, y todos los secretos se mantienen solo en Supabase.
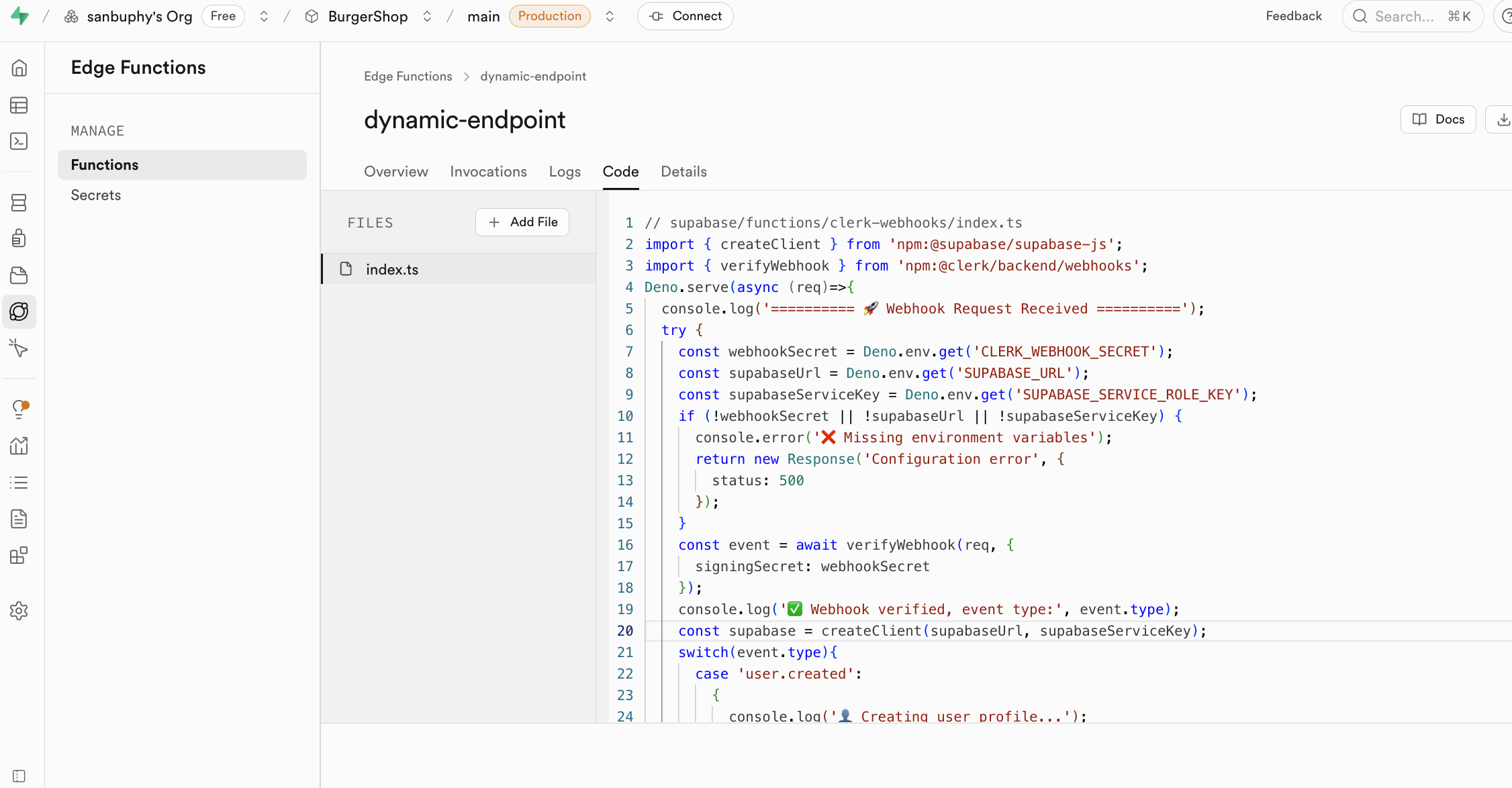
Las funciones de Edge Functions usan las claves expuestas en secrets como variables de entorno, cargandolas a traves de Deno.env.get para implementar llamadas a servicios de terceros. De esta manera, las claves sensibles nunca se expondran en el cliente (tu navegador), eliminando completamente el riesgo de ser robadas.
Al solicitar una Supabase Edge Function, debes incluir la clave Supabase correspondiente en los encabezados de la solicitud. A continuacion se muestra un ejemplo minimo:
// Configuracion central (reemplaza con tu informacion real)
const projectId = "Tu ID de proyecto Supabase";
const functionName = "Nombre de la Edge Function objetivo";
const supabaseKey = "Supabase anon_key";
// Llamar a la funcion
async function callEdgeFunction() {
const url = `https://${projectId}.supabase.co/functions/v1/${functionName}`;
try {
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
"Authorization": `Bearer ${supabaseKey}` // Clave: llevar la clave para completar la autenticacion
},
body: JSON.stringify({ order_id: "123", action: "refund" }) // Datos de solicitud personalizados
});
const result = await response.json();
console.log("Llamada exitosa:", result);
} catch (error) {
console.error("Llamada fallida:", error.message);
}
}
// Ejecutar la llamada
callEdgeFunction();Ademas, Edge Functions se integra sin problemas con el sistema de autenticacion de usuarios de Supabase. Cuando un usuario que ha iniciado sesion llama a una funcion, su informacion de identidad se transmite a la funcion. Esto te permite identificar facilmente al usuario actual dentro de la funcion y ejecutar controles de permisos basados en su identidad. Lo que es mas importante, cuando la funcion opera en la base de datos, seguira automaticamente las politicas de seguridad a nivel de fila (Row Level Security) que hayas configurado, asegurando que los usuarios solo puedan acceder y modificar los datos que tienen permitido operar, simplificando la construccion de aplicaciones multiusuario seguras.
Los escenarios de aplicacion de Edge Functions son muy amplios y pueden manejar diversas tareas backend. Son ideales para escuchar eventos Webhook de servicios de terceros (por ejemplo, pagos exitosos, envios de codigo) y ejecutar automaticamente la logica de procesamiento de datos correspondiente. Tambien puedes usarlas para enviar notificaciones por correo electronico, generar informes PDF, crear interfaces API personalizadas para encapsular logica de negocio compleja, o ejecutar cualquier tarea computacional que desees completar en el lado del servidor, expandiendo enormemente las capacidades de tu aplicacion.
Un ejemplo concreto: la herramienta de autenticacion Clerk. Clerk solo se usa para manejar operaciones relacionadas con la autenticacion como inicio de sesion, registro y actualizacion de informacion de usuarios, y no gestiona directamente tu base de datos de negocio. Si deseas sincronizar estas dinamicas de autenticacion con la base de datos de negocio, necesitas implementarlo a traves de la activacion de eventos Webhook que solicitan Edge Functions. Edge Functions puede escuchar las senales Webhook enviadas por Clerk, ejecutar automaticamente la logica de sincronizacion de datos, manteniendo la informacion de usuarios en la base de datos de Supabase alineada en tiempo real con el estado de inicio de sesion de Clerk, todo sin necesidad de desplegar un backend independiente.
Motor de sincronizacion de datos en tiempo real
Realtime es el motor de sincronizacion de datos en tiempo real de Supabase, que permite a tu aplicacion recibir notificaciones instantaneas de cambios en la base de datos sin necesidad de sondear repetidamente la API. Cuando se producen operaciones INSERT, UPDATE o DELETE en los datos de la base de datos, Realtime envia estos cambios en tiempo real a traves de WebSocket a todos los clientes conectados. Esto es crucial para construir aplicaciones que requieren interaccion en tiempo real.
Realtime incluye principalmente tres funciones centrales que cubren la mayoria de los escenarios en tiempo real:
- Postgres Changes: Escucha directamente los cambios en las tablas de la base de datos. Puedes suscribirte con precision a tablas especificas, eventos especificos (insercion, eliminacion, modificacion) e incluso recibir notificaciones basadas en condiciones de filtrado, integrandose perfectamente con las politicas de seguridad a nivel de fila (Row Level Security) para asegurar que los usuarios solo reciban cambios de datos que tienen permiso para ver.
- Broadcast: Permite enviar mensajes temporales de baja latencia entre clientes a traves de canales (Channel). Esto es ideal para implementar funciones como salas de chat, seguimiento de cursores en tiempo real y sincronizacion del estado de juegos en linea.
- Presence: Se usa para rastrear y sincronizar el estado de los usuarios en linea. Puedes usarlo para implementar facilmente funciones como "quien esta en linea" y "hay X personas viendo actualmente", muy adecuado para aplicaciones colaborativas.
Explicaremos esta seccion en detalle en el aprendizaje basado en proyectos posterior.
Configuracion del proyecto
Project Settings es la seccion de configuracion avanzada del proyecto de Supabase, donde puedes implementar la programacion profunda de recursos computacionales y la configuracion precisa de parametros subyacentes de diversas funciones.
En la etapa de introduccion, solo necesitamos enfocarnos en los siguientes dos paneles centrales. Uno es Data API, donde podemos obtener la clave "Supabase URL", que es un endpoint RESTful con el formato https://xxx.supabase.co, la "direccion de entrada" para todas las operaciones de consulta, insercion, modificacion y eliminacion de datos. El frontend o el servidor necesita usar esta URL para inicializar el cliente de Supabase y establecer la conexion con la base de datos.
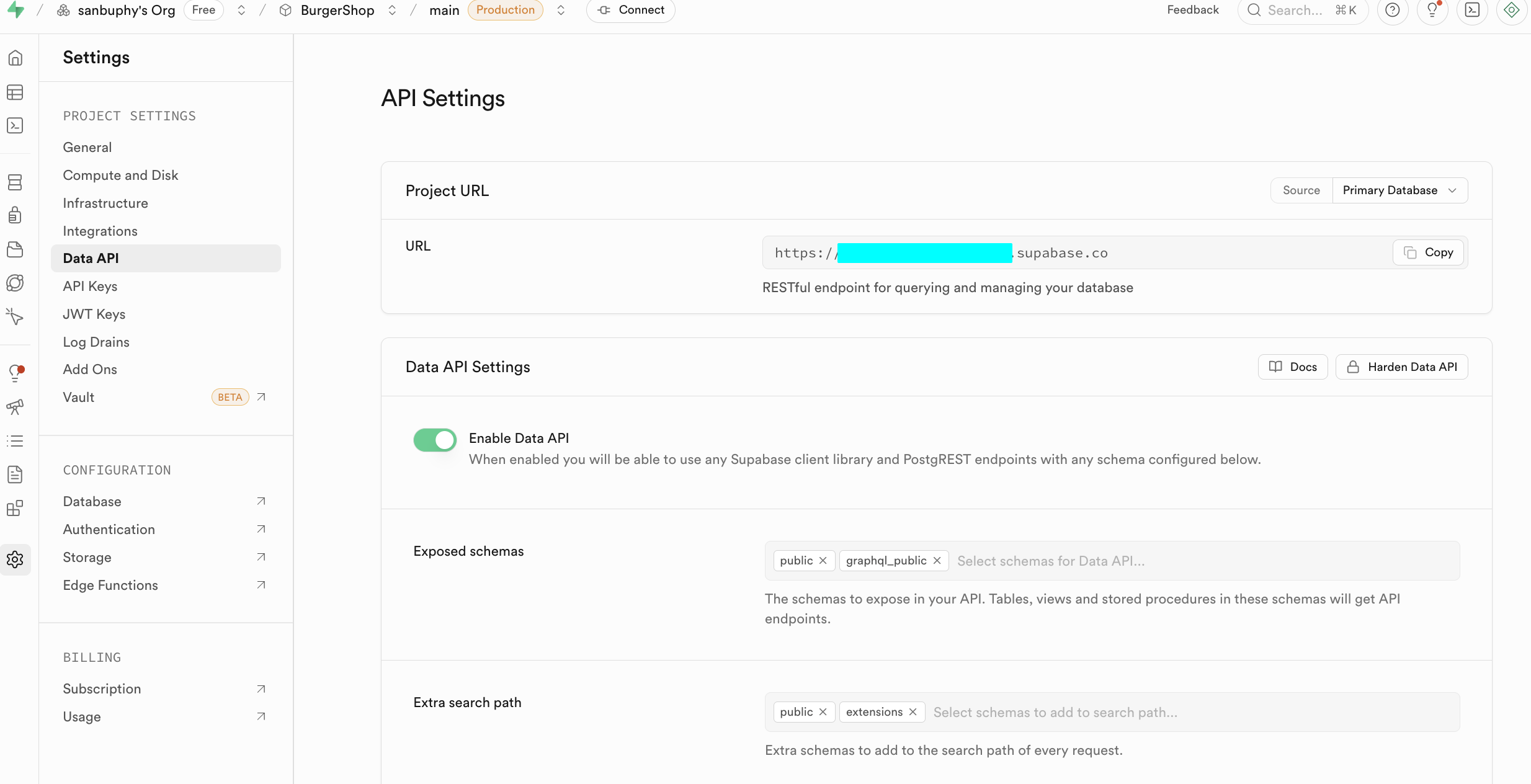
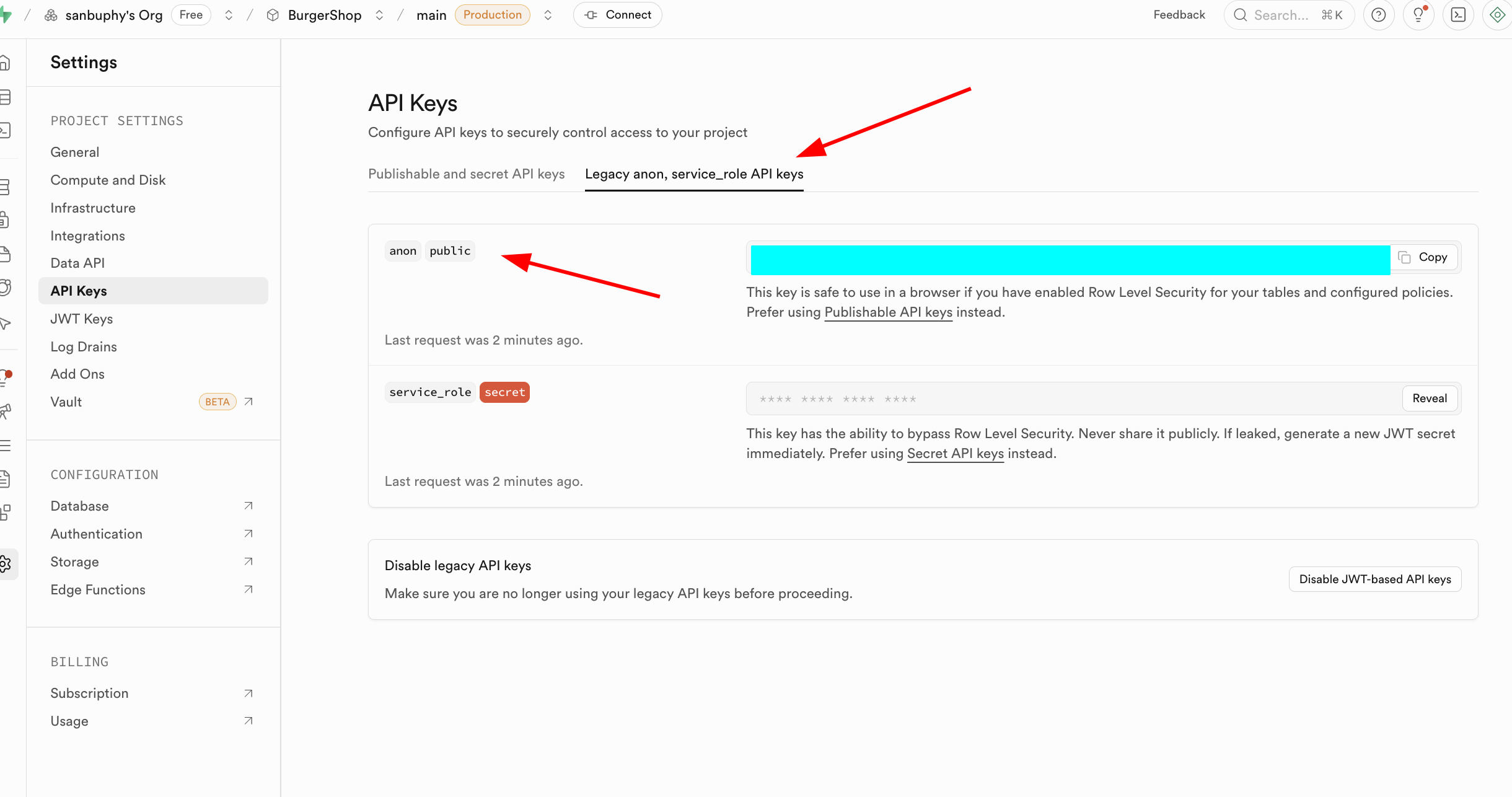
El otro punto importante es API Keys. Selecciona la pestana "Legacy anon, service_role API keys"; la clave anon public contenida en ella es una credencial de identidad importante para escenarios frontend, con permisos estrictamente limitados por RLS, y solo puede acceder a los datos autorizados para el usuario. La clave service_role es una "clave de alto permiso del servidor", con la capacidad de evadir la seguridad a nivel de fila, y puede ejecutar operaciones masivas de datos, configuraciones a nivel de sistema y otras operaciones sensibles. Esta absolutamente prohibido compartirla publicamente; si se filtra, genera inmediatamente una nueva clave y actualiza la configuracion del servidor.
Los demas elementos de configuracion no necesitan ser estudiados en profundidad en la etapa actual; podras explorarlos uno por uno cuando tengas necesidades de uso avanzado en el futuro.
2.1 Creando tu primera tabla de datos SQL
Lo anterior es la introduccion a la interfaz de Supabase. A continuacion, profundizaremos en la seccion de operaciones de la base de datos central de Supabase.
Para crear tablas de datos en Supabase, existen principalmente dos metodos comunes que puedes elegir segun tus necesidades:
- (Recomendado) Usar un modelo de lenguaje grande para generar declaraciones SQL adaptadas a Supabase, pegarlas y ejecutarlas directamente en el SQL Editor (el ejecutor de declaraciones SQL presentado anteriormente), de manera eficiente y rapida. Explicaremos este proceso operativo en detalle en la siguiente seccion.
- Crear a traves de operaciones visuales: encuentra el modulo Database en la barra lateral izquierda, haz clic para entrar, selecciona Tables en la barra lateral, y haz clic en el boton New Table a la derecha para crear tablas de datos a traves de la interfaz grafica.
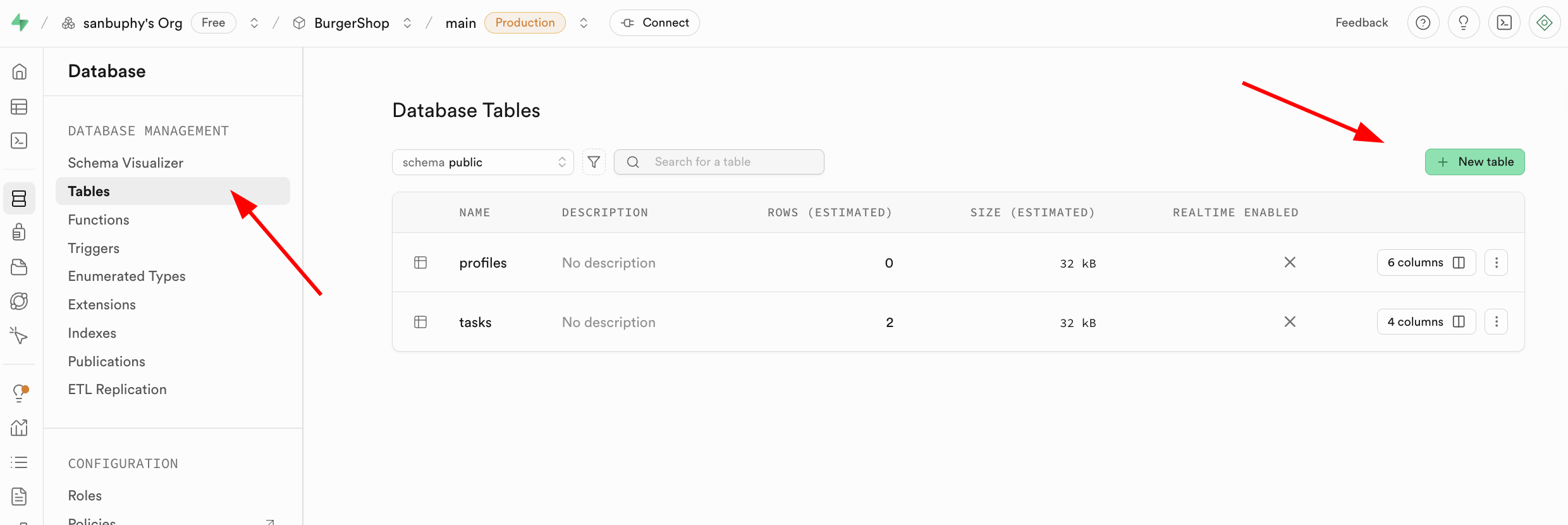
Cabe senalar que el nombre de la tabla de datos correspondiente y los tipos de datos almacenados se pueden especificar en la seccion Columns a continuacion.
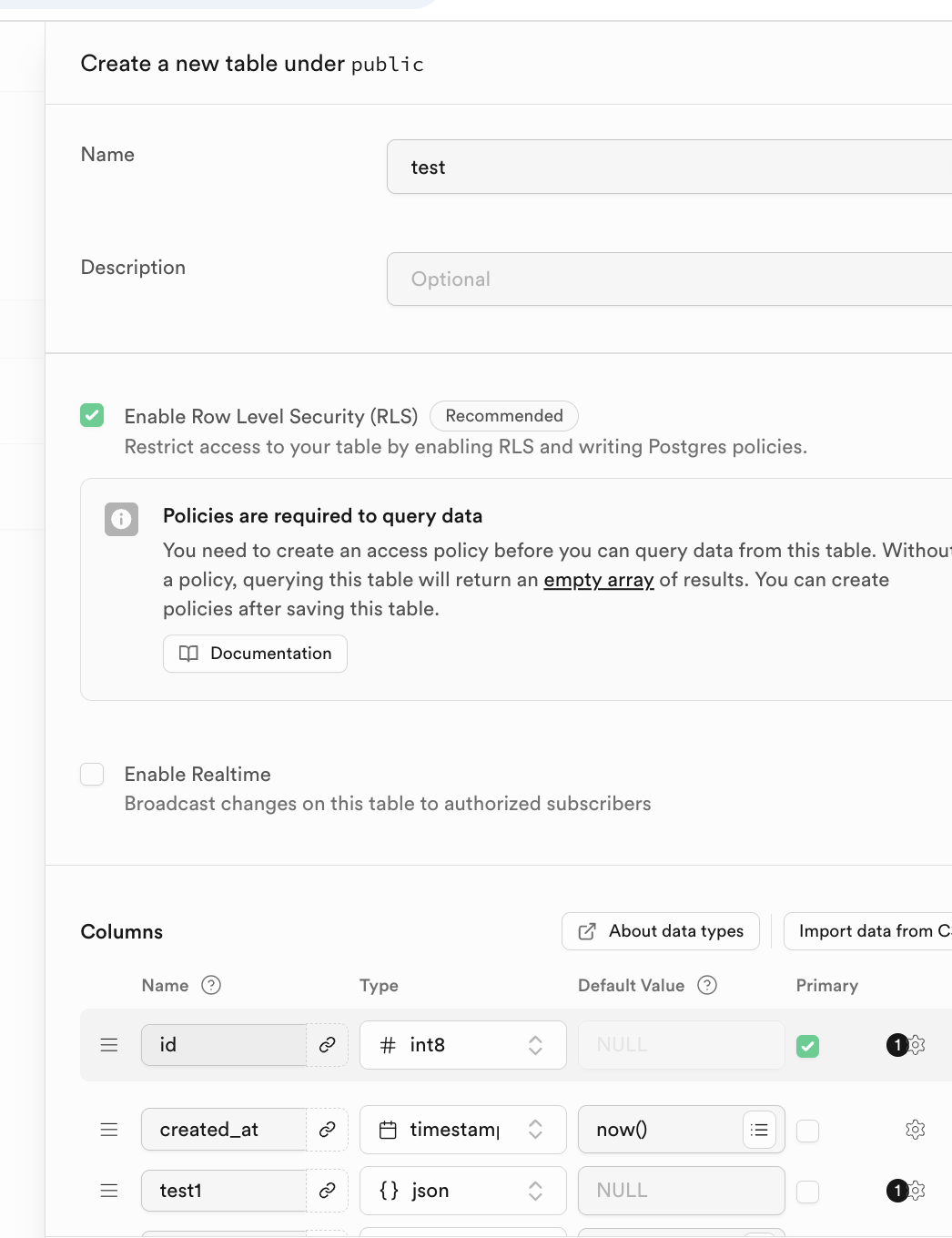
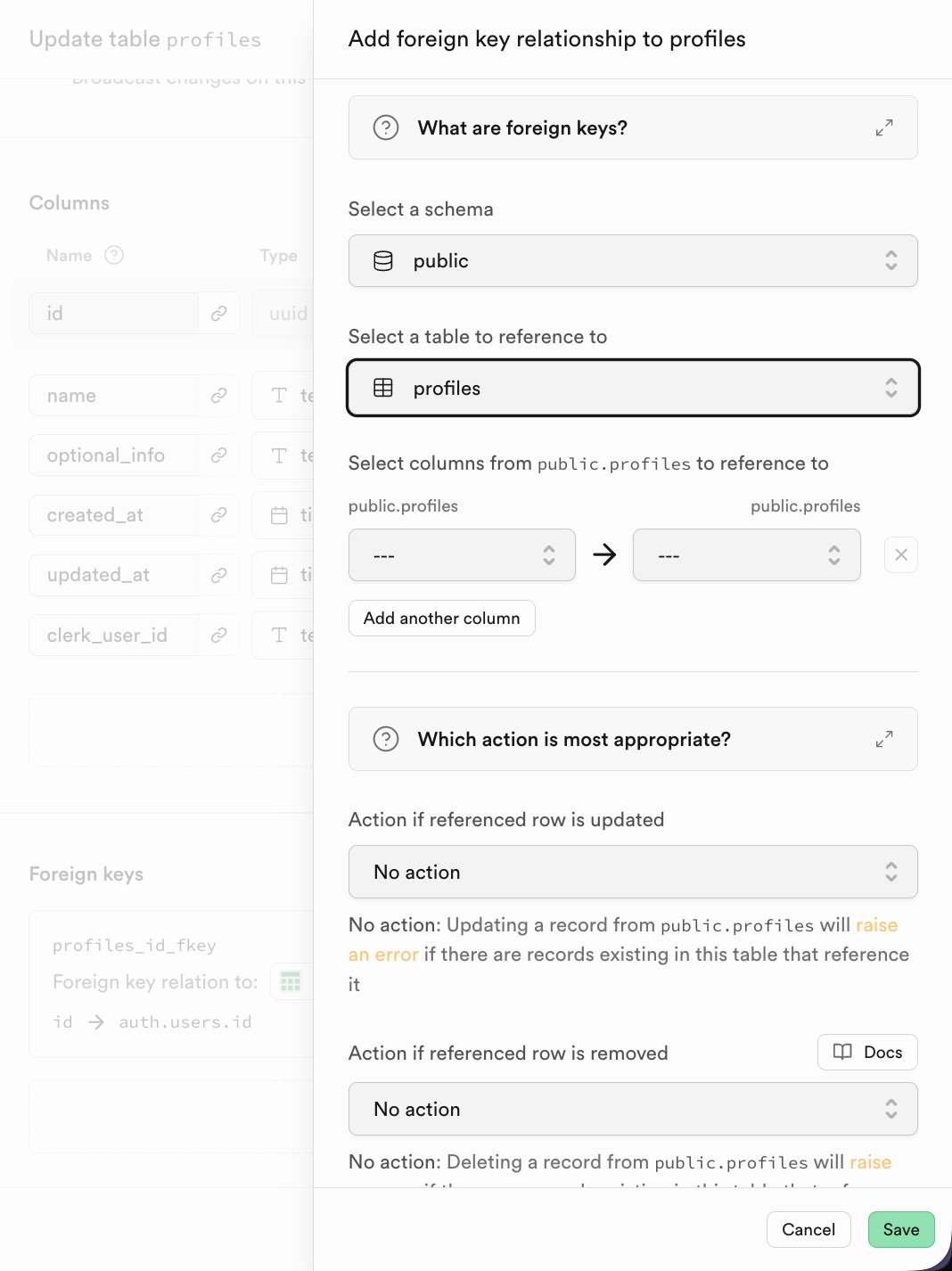
Para bases de datos relacionales, una caracteristica importante es la relacion entre tablas. Puedes encontrar Foreign keys a continuacion y hacer clic para crear la relacion correspondiente:
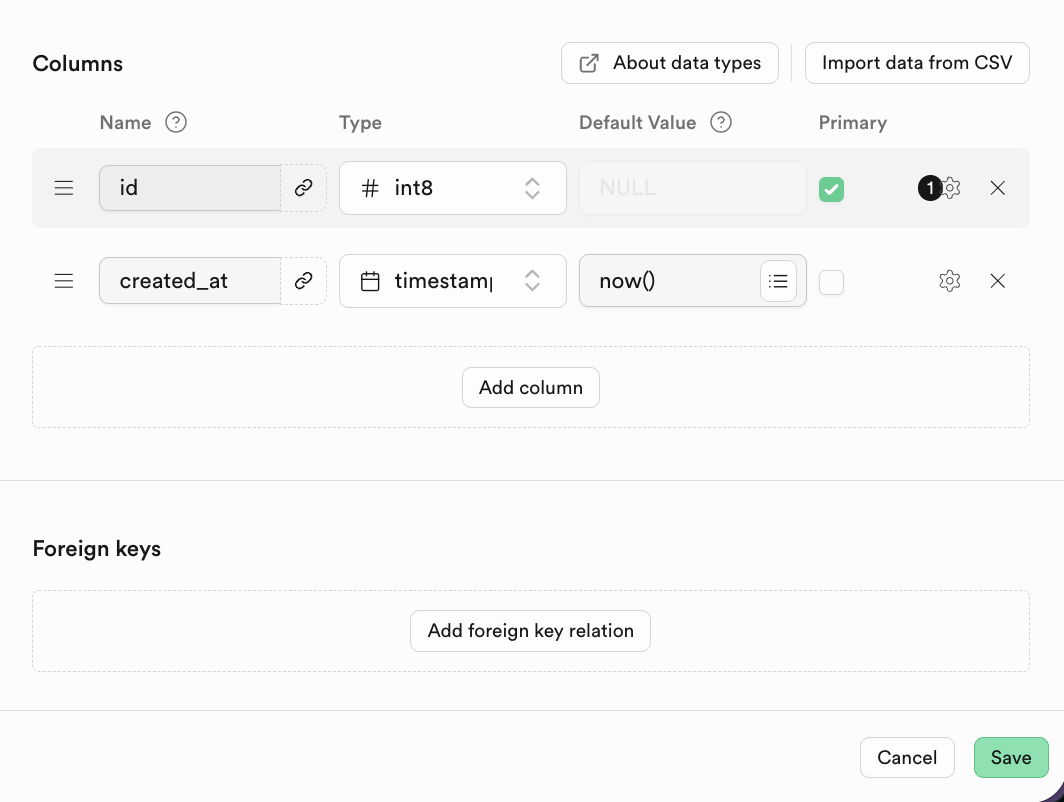
Foreign keys expresa la relacion entre tablas: un campo o conjunto de campos cuyo valor en la tabla actual (tabla hija) hace referencia al valor de la clave primaria en otra tabla (tabla padre).
Por ejemplo, al crear una tabla de estudiantes, podemos definir una clave foranea de esta manera: (la columna numero de clase al que pertenece es una clave foranea. Esta clave foranea hace referencia a la columna numero de clase en la tabla de clases.)
CREATE TABLE 学生表 (
学生学号 INT PRIMARY KEY,
学生姓名 VARCHAR(50),
所属班级编号 INT,
FOREIGN KEY (所属班级编号) REFERENCES 班级表(班级编号)
);Para un ejemplo mas concreto, podemos observar visualmente la estructura de las tablas correspondientes:
Tabla de clases: Esta tabla registra la informacion de todas las clases, cada clase tiene un numero de clase unico. El numero de clase es la clave primaria (Primary Key) de esta tabla, la identificacion unica de cada clase.
| Numero de clase | Nombre de la clase |
|---|---|
| 101 | Primer grado clase A |
| 102 | Primer grado clase B |
Tabla de estudiantes: Esta tabla registra la informacion de todos los estudiantes. Cada estudiante pertenece a una clase especifica, verdad? Entonces, como sabemos que estudiante esta en que clase?
Podemos agregar una columna a la tabla de estudiantes llamada numero de clase al que pertenece.
| Numero de estudiante | Nombre del estudiante | Numero de clase al que pertenece |
|---|---|---|
| 2024001 | Zhang San | 101 |
| 2024002 | Li Si | 102 |
| 2024003 | Wang Wu | 101 |
En este ejemplo, la columna numero de clase al que pertenece en la tabla de estudiantes es la clave foranea (Foreign Key).
En Supabase, despues de hacer clic para agregar Foreign Key, puedes seleccionar directamente la columna correspondiente de la tabla relacionada.
2.3 Introduccion al SQL Editor y operaciones basicas de bases de datos
A continuacion ejecutaremos paso a paso una serie de scripts SQL para familiarizarnos con las operaciones CRUD (Crear, Leer, Actualizar, Eliminar) comunes en SQL. Puedes copiar el codigo de cada paso al SQL Editor, ejecutarlo y observar los resultados.
Puedes obtener todos los archivos SQL de prueba en el siguiente directorio:
https://github.com/THU-SIGS-AIID/Project5-Supabase-Demos/tree/main/apps/sql-examples
2.3.1 CREATE - Crear estructura de tabla
La declaracion CREATE TABLE se usa para definir el esquema (Schema) de una nueva tabla, incluyendo sus columnas (Columns), tipos de datos correspondientes (Data Types) y cualquier restriccion (Constraints). En terminos simples, crea una tabla de datos.
-- Step 1: Create the 'orders' table
-- This file is fully independent and creates a sample table for later steps.
CREATE TABLE IF NOT EXISTS orders (
id serial PRIMARY KEY,
user_id int NOT NULL, -- User ID
status text NOT NULL, -- Order status (e.g. paid, pending)
amount numeric(10, 2) NOT NULL, -- Order total amount
details jsonb, -- Item and extra details as JSON
placed_at timestamptz DEFAULT now(), -- Order creation time
is_paid boolean DEFAULT false -- Paid flag
);
-- Expected Output:
-- Orders table created if it did not exist.
-- No data inserted. (Querying returns zero rows for now.)
-- If table already exists, no error occurs.Despues de ejecutarse exitosamente, el sistema indicara que el script se ha completado. Podras ver en el Table Editor que la tabla correspondiente ha sido creada:
2.3.2 INSERT - Rellenar datos iniciales
Una vez creada la estructura de la tabla, el siguiente paso es usar la declaracion INSERT INTO para agregar filas de datos a la tabla.
-- Step 2: Insert initial rows into the orders table
-- Provides realistic, varied data for demo/testing. All values are self-contained.
INSERT INTO orders (user_id, status, amount, details, placed_at, is_paid) VALUES
(2001, 'pending', 23.50, '{"items":[{"sku":"BGR001","name":"Beef Burger","qty":1,"price":12.00}]}', now() - interval '2 days', false),
(2002, 'paid', 50.00, '{"items":[{"sku":"BGR002","name":"Chicken Burger","qty":2,"price":10.00},{"sku":"DRK001","name":"Lemonade","qty":2,"price":5.00}]}', now() - interval '1 day', true),
(2003, 'cancelled', 15.00, '{"items":[{"sku":"FRY001","name":"French Fries","qty":3,"price":5.00}], "reason":"Not available"}', now() - interval '45 days', false),
(2004, 'paid', 22.98, '{"items":[{"sku":"BGR003","name":"Veggie Burger","qty":2,"price":9.99}], "promo":"SUMMER22"}', now() - interval '10 days', true),
(2005, 'pending', 18.75, '{"items":[{"sku":"SAL001","name":"Salad","qty":1,"price":6.75},{"sku":"BGR001","name":"Beef Burger","qty":1,"price":12.00}]}', now() - interval '7 hours', false),
(2006, 'paid', 8.00, '{"items":[{"sku":"DRK002","name":"Cola","qty":2,"price":4.00}]}', now() - interval '3 hours', true),
(2007, 'refunded', 14.50, '{"items":[{"sku":"BGR003","name":"Veggie Burger","qty":1,"price":9.99},{"sku":"FRY001","name":"French Fries","qty":1,"price":4.51}], "refund_reason":"Late delivery"}', now() - interval '15 days', false),
(2008, 'paid', 26.99, '{"items":[{"sku":"BGR002","name":"Chicken Burger","qty":2,"price":10.00},{"sku":"DRK001","name":"Lemonade","qty":1,"price":6.99}]}', now() - interval '12 days', true),
(2009, 'pending', 9.99, '{"items":[{"sku":"BGR003","name":"Veggie Burger","qty":1,"price":9.99}]}', now() - interval '30 minutes', false),
(2010, 'paid', 19.89, '{"items":[{"sku":"BGR001","name":"Beef Burger","qty":1,"price":12.00},{"sku":"DRK002","name":"Cola","qty":2,"price":3.95}]}', now() - interval '5 days', true),
(2011, 'cancelled', 0.00, '{"items":[], "reason":"User cancelled"}', now() - interval '2 days', false);
-- Expected Output:
-- After running this script, SELECT * FROM orders will show about 11 rows with varied user_id, status, amount, details (JSON), placed_at, and is_paid fields.
-- For example:
-- | id | user_id | status | amount | is_paid | placed_at |
-- |----|---------|-----------|--------|---------|---------------------|
-- | 1 | 2001 | pending | 23.50 | false | 2025-10-28 13:40:00Z|
-- | 2 | 2002 | paid | 50.00 | true | ... |
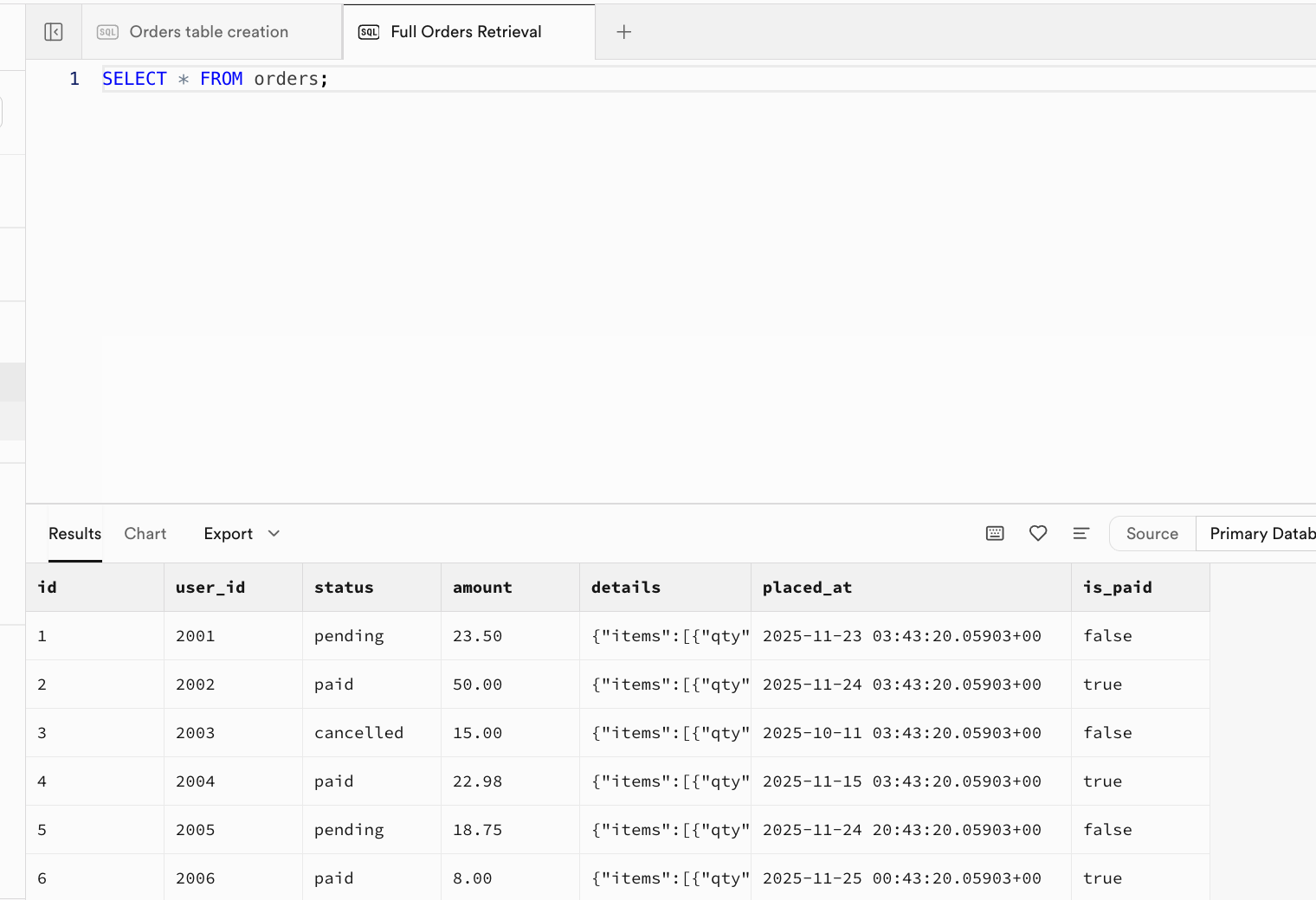
-- |... | ... | ... | ... | ... | ... |Despues de ejecutarse exitosamente, los datos iniciales ya se han insertado en la tabla. Puedes ir a la interfaz del Table Editor y actualizar para ver los resultados, o puedes abrir una nueva ventana directamente en la interfaz del SQL Editor y ejecutar la consulta SELECT * FROM orders; para ver los resultados:
2.3.3 SELECT - Leer y consultar datos
La sentencia SELECT se utiliza para recuperar datos de una tabla. Mediante el uso de diferentes clausulas, es posible lograr un filtrado preciso, ordenamiento y formateo de los datos. Podemos referirnos a las siguientes sentencias para ejecutarlas paso a paso y ver los resultados:
-- Step 3: SELECT query examples for the orders table
-- Example 1: Select all fields for all orders
SELECT * FROM orders;
-- Expected Output: Returns all rows and fields. Columns: id, user_id, status, amount, details, placed_at, is_paid.
-- Example 2: Select only pending orders
SELECT id, user_id, amount FROM orders WHERE status = 'pending';
-- Expected Output: All rows with status 'pending'; columns: id, user_id, amount.
-- Example 3: Select specific fields and filter by payment status
SELECT id, status, is_paid, amount FROM orders WHERE is_paid = true;
-- Expected Output: All rows where is_paid is true; columns: id, status, is_paid, amount.
-- Example 4: Extract all item names from the details (JSON) for each order
SELECT id, details -> 'items' AS item_list FROM orders;
-- Expected Output: Each row shows id and an array from JSON with item details.- Ejemplo 1: Devuelve todas las filas y columnas de la tabla
orders, similar a la salida del paso 2. - Ejemplo 2: Solo devuelve los pedidos con estado 'pending', y solo las columnas especificadas:
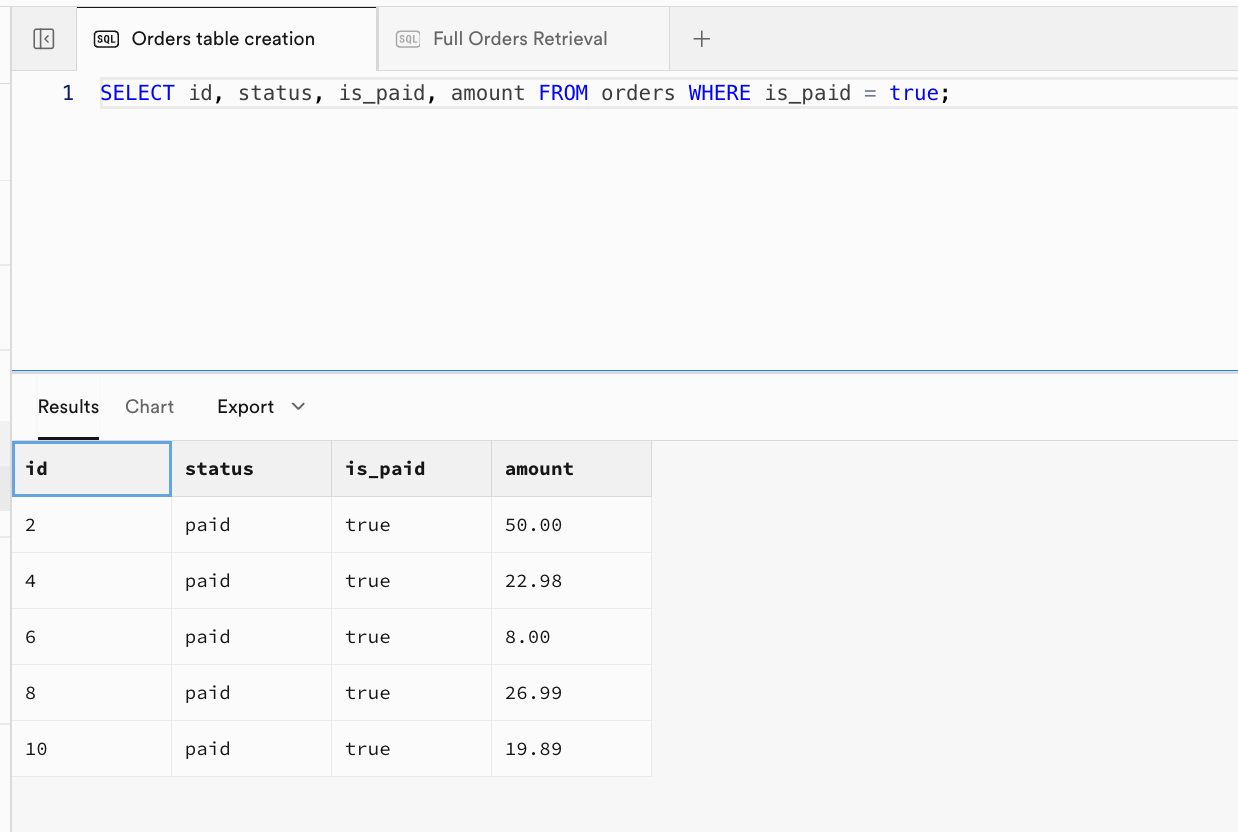
- Ejemplo 3: Solo devuelve los pedidos ya pagados, mostrando las columnas especificadas:
| id | status | is_paid | amount |
|---|---|---|---|
| 2 | paid | true | 50.00 |
| 4 | paid | true | 22.98 |
| 6 | paid | true | 8.00 |
| 8 | paid | true | 26.99 |
| 10 | paid | true | 19.89 |
- Ejemplo 4: Devuelve el
idde cada pedido y el arrayitemsextraido del campodetails:
| id | item_list |
|---|---|
| 1 | [{"qty":1,"sku":"BGR001","name":"Beef Burger","price":12}] |
| 2 | [{"qty":2,"sku":"BGR002","name":"Chicken Burger","price":10},{"qty":2,"sku":"DRK001","name":"Lemonade","price":5}] |
| 3 | [{"qty":3,"sku":"FRY001","name":"French Fries","price":5}] |
| ... | ... |
2.3.4 INSERT - Insertar un solo registro
En la seccion 2.3.2, demostramos la insercion masiva de datos durante la inicializacion. Ahora veremos como insertar un solo registro nuevo.
-- Step 4: INSERT a new order (single row)
-- Example: Add a new paid order for user 2012 with one Chicken Burger
INSERT INTO orders (user_id, status, amount, details, is_paid)
VALUES (
2012, 'paid', 9.99,
'{"items":[{"sku":"BGR002","name":"AIID Burger","qty":100,"price":1000}]}',
true
);
-- Expected Output:
-- Before (table fragment):
-- | id | user_id | status | amount | is_paid |
-- | ...| ... | ... | ... | ... |
--
-- After (last row):
-- | id | user_id | status | amount | is_paid |
-- | xx | 2012 | paid | 9.99 | true |
-- (where xx = next serial value)En este momento, si volvemos a consultar los datos con SELECT * FROM orders;, podemos ver que la tabla orders paso exitosamente de 11 registros a 12.
2.3.5 UPDATE - Modificar datos existentes
En el trabajo practico, necesitamos actualizar frecuentemente los datos de las tablas. Podemos usar la sentencia UPDATE para modificar registros existentes en una tabla.
-- Step 5: UPDATE example
-- Example: Mark order with id=1 as paid and update its status
UPDATE orders SET status = 'paid', is_paid = true WHERE id = 1;
-- Expected Output:
-- Before (row with id=1):
-- | id | status | is_paid |
-- | 1 | pending | false |
-- After (row with id=1):
-- | id | status | is_paid |
-- | 1 | paid | true |
-- All other rows remain unchanged.2.3.6 DELETE - Eliminar datos
La sentencia DELETE se puede utilizar para eliminar registros de una tabla, combinada con condiciones para eliminar solo los datos especificados.
-- Step 6: DELETE example
-- Example: Delete orders older than 2 days to clean up old data
DELETE FROM orders WHERE placed_at < now() - interval '2 days';
-- Expected Output:
-- Before (filtered for affected rows):
-- | id | status | placed_at |
-- | 3 | shipped | 2025-10-13 ... | <-- will be deleted
--
-- After:
-- No such rows remain. SELECT * FROM orders WHERE placed_at < now()-interval '2 days' yields zero rows.
-- Other rows in orders table are unaffected.Antes de ejecutarlo, puedes primero ejecutar SELECT id, status, placed_at FROM orders WHERE placed_at < now() - interval '2 days'; para ver los resultados filtrados de la tabla. Despues de ejecutar el comando DELETE, al ejecutar nuevamente la misma consulta SELECT id, status, placed_at FROM orders WHERE placed_at < now() - interval '2 days';, obtendras un resultado vacio, lo que indica que estas filas han sido eliminadas exitosamente.
2.4 Seguridad a nivel de fila (Row Level Security)
Despues de aprender las operaciones basicas de bases de datos, necesitamos profundizar en un concepto central que garantiza la seguridad de los datos: RLS (Row Level Security, Seguridad a Nivel de Fila).
Consideremos primero una pregunta clave en un escenario practico: como lograr el "acceso aislado" a los datos? Por ejemplo, permitir que el usuario A solo vea sus propios datos, sin poder ver la informacion del usuario B; o bien, incluso si un rol tiene permisos de acceso a la base de datos, como evitar que manipule por error o filtre datos sensibles de otros usuarios?
RLS nacio precisamente para resolver este tipo de necesidades de seguridad y aislamiento de datos. Permite a los desarrolladores definir politicas de seguridad granulares para las tablas de la base de datos, controlando con precision que usuarios pueden acceder y modificar que filas de datos, en funcion de la informacion de identidad del usuario (como el ID de usuario, permisos de rol, etc.).
Un ejemplo tipico: para la tabla de pedidos (orders), podemos definir una politica RLS: "solo cuando la columna user_id de un registro en la tabla orders coincida exactamente con el ID del usuario actualmente autenticado, ese usuario podra consultar los datos de ese pedido", cumpliendo asi con el requisito central de "cada usuario solo puede ver sus propios pedidos".
Cuando habilitas RLS para una tabla, todas las solicitudes de operaciones de datos sobre esa tabla (incluyendo consultas SELECT, inserciones INSERT, modificaciones UPDATE y eliminaciones DELETE) activaran la verificacion RLS: la operacion debe pasar la verificacion de al menos una politica de seguridad para poder ejecutarse. Si no existe una politica que permita la operacion, o si la solicitud no cumple con las condiciones de ninguna politica, la base de datos rechazara directamente la operacion, bloqueando el acceso no autorizado desde la capa inferior.
En Supabase, RLS esta profundamente integrado con el sistema de autenticacion de usuarios, lo que lo hace aun mas conveniente de usar. Supabase proporciona una funcion dedicada auth.uid(), que devuelve directamente el ID unico (en formato UUID) del "usuario autenticado que realiza la solicitud actual". Con esta funcion, podemos escribir facilmente politicas que logren una asociacion precisa entre "filas de datos e identidad del usuario" (como el ejemplo mencionado anteriormente de "el user_id del pedido coincide con el ID del usuario actual").
La forma de habilitar las politicas RLS es flexible. Puedes configurarlas y habilitarlas directamente en la interfaz de gestion de la base de datos de Supabase haciendo clic en el boton "RLS":
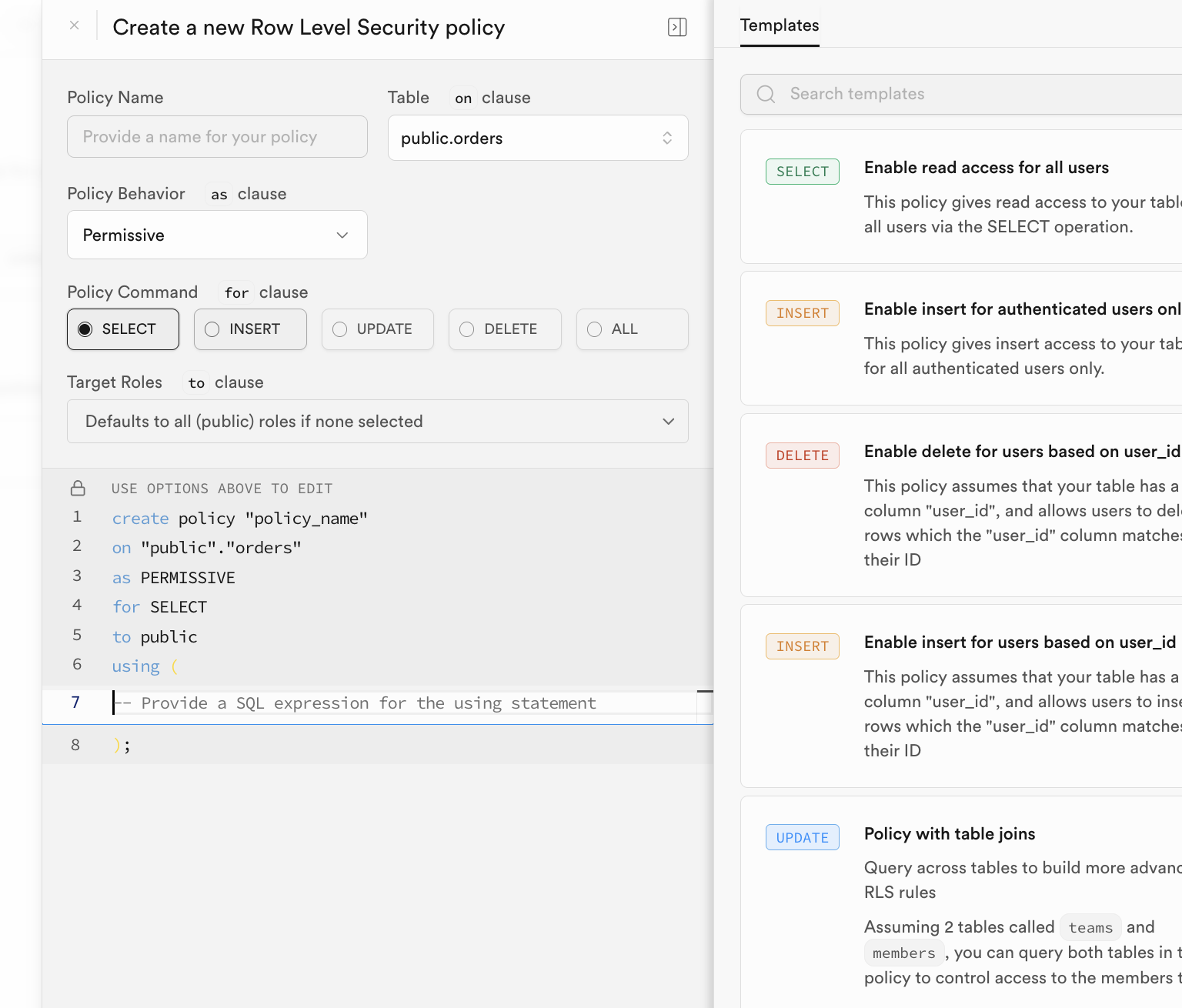
La configuracion manual puede resultar tediosa. Normalmente, al crear las sentencias de la tabla de datos y durante la inicializacion, ya se suelen incluir las politicas RLS correspondientes. Solo necesitamos ejecutar sentencias similares a la siguiente en el SQL Editor para habilitar automaticamente las politicas de seguridad a nivel de fila en la tabla correspondiente.

3. Primera aplicacion SQL
Habiendo dominado las operaciones basicas de bases de datos y la logica central de RLS, finalmente entramos en la seccion practica de este tutorial. Esta larga etapa de aprendizaje preliminar tiene como objetivo hacer que el proceso posterior de "construir una aplicacion de 0 a 1" sea mas claro. A continuacion, usaremos el escenario de "gestion de pedidos de una hamburgueseria" para demostrar paso a paso las operaciones comunes de Supabase: desde la configuracion de la conexion entre la aplicacion y Supabase, hasta la integracion de la base de datos y las funcionalidades de inicio de sesion, aprendiendo gradualmente diferentes logicas de operacion.
3.1 Clonar y ejecutar el proyecto de ejemplo de Supabase
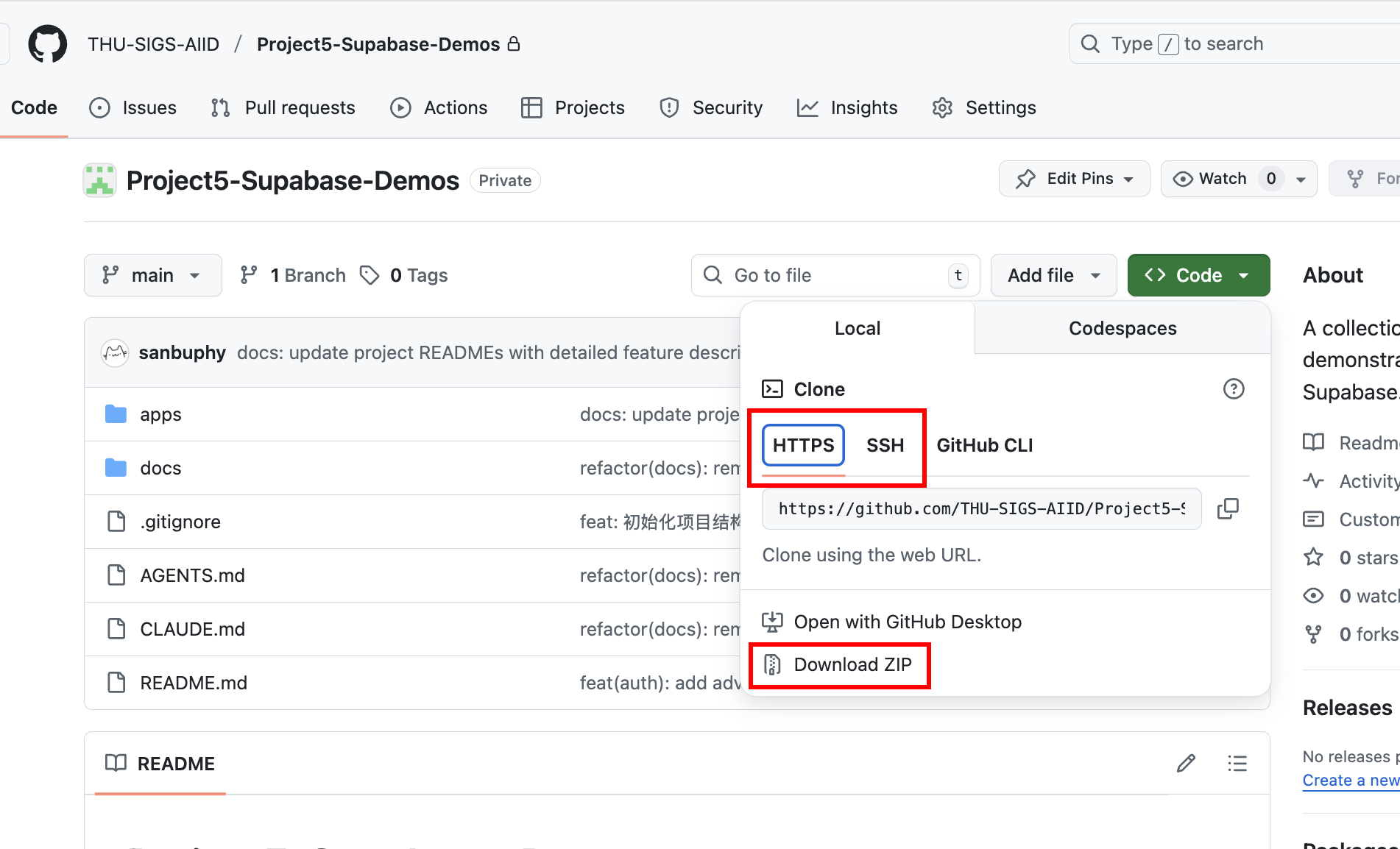
Para realizar las practicas, primero necesitas obtener el repositorio de codigo de demostracion correspondiente. Puedes pedirle a Trae o Claude Code que te ayude a clonar (git clone) el siguiente repositorio: https://github.com/THU-SIGS-AIID/Project5-Supabase-Demos
Si ya has configurado una clave SSH, se recomienda usar la direccion SSH para clonar (git@github.com:THU-SIGS-AIID/Project5-Supabase-Demos.git) para mayor seguridad; si encuentras problemas de red con SSH o HTTPS, puedes hacer clic directamente en "Download ZIP" en la pagina del repositorio, descomprimir el archivo descargado y tendras el codigo completo.
Despues de clonar, tambien puedes pedirle a Trae o Claude Code que te ayude a iniciar el proyecto, por ejemplo, indicando directamente en la interfaz del Agent: Ayudame a iniciar directamente el project 1 de este proyecto, o copiando la ruta absoluta del proyecto que deseas iniciar y pegandosela al modelo para que lo inicie directamente.
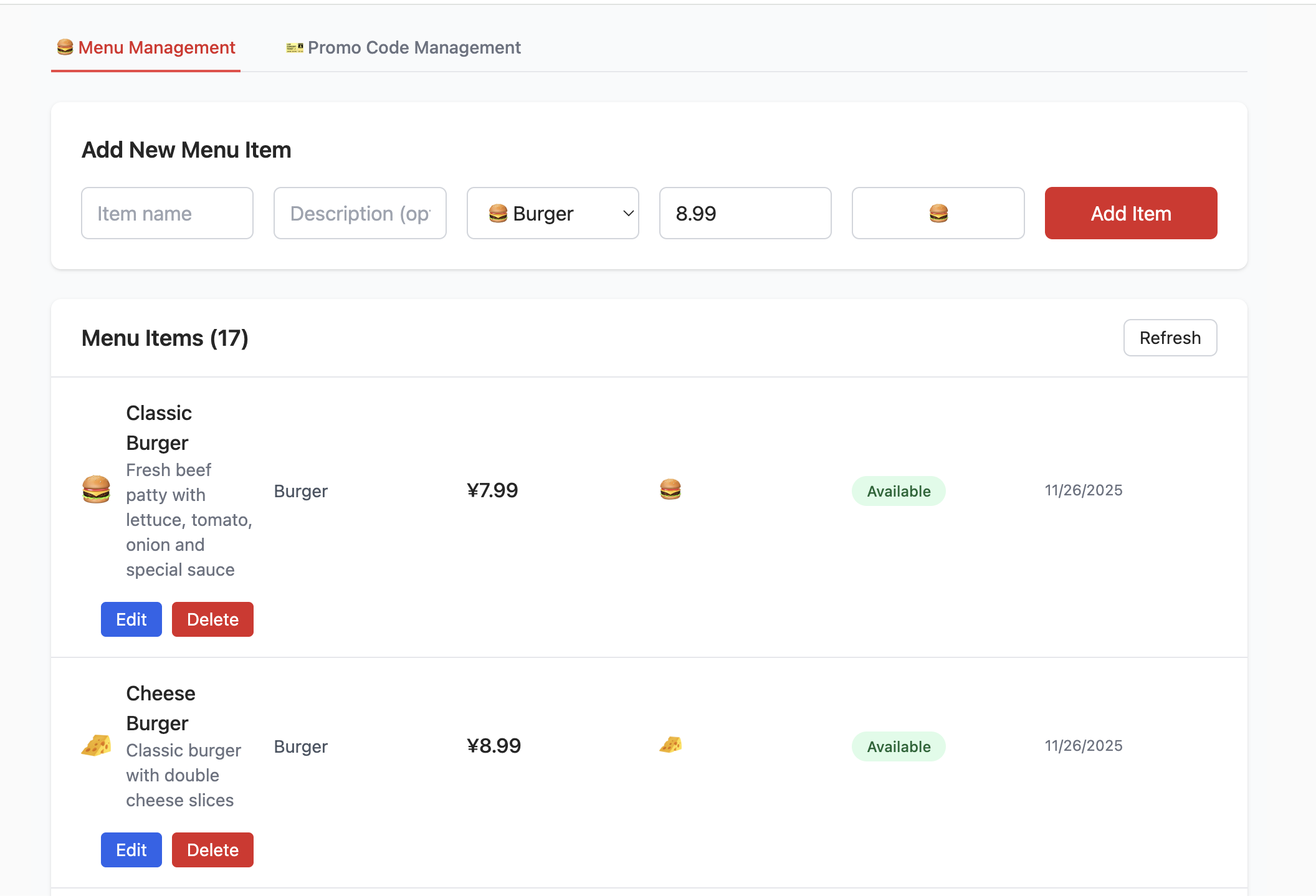
3.2 Proyecto 1 - CRUD del menu de una hamburgueseria
A continuacion entramos en la seccion practica: tomando project-burger-shop-menu-crud-1 como ejemplo, aprenderemos como inicializar la base de datos de Supabase con un solo clic a traves de un script SQL, y completar la configuracion de conexion entre el proyecto local y la base de datos de Supabase, para que el frontend pueda leer y escribir normalmente los datos del menu.
Crear la base de datos con un script
Primero, necesitamos crear el contenido relacionado con las tablas de datos necesarias en Supabase. Al entrar en el directorio del Proyecto 1, encontraras una carpeta llamada scripts, que contiene un archivo de script de base de datos init.sql. Este script nos ayuda a crear automaticamente todos los recursos relacionados con la base de datos (incluyendo estructura de tablas, datos iniciales, etc.), y lo usaremos frecuentemente para inicializar las tablas de la base de datos.
......
-- ============================================================================
-- 2. Create Menu Items Table
-- ============================================================================
create table if not exists public.menu_items (
id uuid primary key default gen_random_uuid(),
name text not null,
description text,
category text check (category in ('burger','side','drink')) default 'burger',
price_cents int not null check (price_cents > 0),
available boolean default true,
emoji text,
created_at timestamptz not null default now(),
updated_at timestamptz not null default now()
);
-- Comments for documentation
comment on table public.menu_items is 'Burger shop menu items for CRUD demo';
comment on column public.menu_items.id is 'Unique identifier for each menu item';
comment on column public.menu_items.name is 'Display name of the menu item';
comment on column public.menu_items.description is 'Detailed description of the menu item';
comment on column public.menu_items.category is 'Category: burger, side, or drink';
comment on column public.menu_items.price_cents is 'Price in cents (integer) to avoid floating point issues';
comment on column public.menu_items.available is 'Whether the item is currently available for order';
comment on column public.menu_items.emoji is 'Optional emoji representation of the menu item';
comment on column public.menu_items.created_at is 'Timestamp when the item was created';
comment on column public.menu_items.updated_at is 'Timestamp when the item was last updated';
......Despues de ejecutar el script SQL de inicializacion en el SQL Editor, podras ver las tablas de datos creadas en el Table Editor. La logica de ejecucion especifica del codigo de inicializacion de la base de datos es la siguiente:
- Crear la tabla menu_items:
- Esta tabla se usa para almacenar todos los elementos del menu de la hamburgueseria. Incluye campos como name (nombre del producto), description (descripcion), price_cents (precio en centavos, para evitar problemas de precision con numeros de punto flotante), category (categoria) y available (si esta disponible). Esto cubre basicamente toda la informacion necesaria para un elemento del menu.
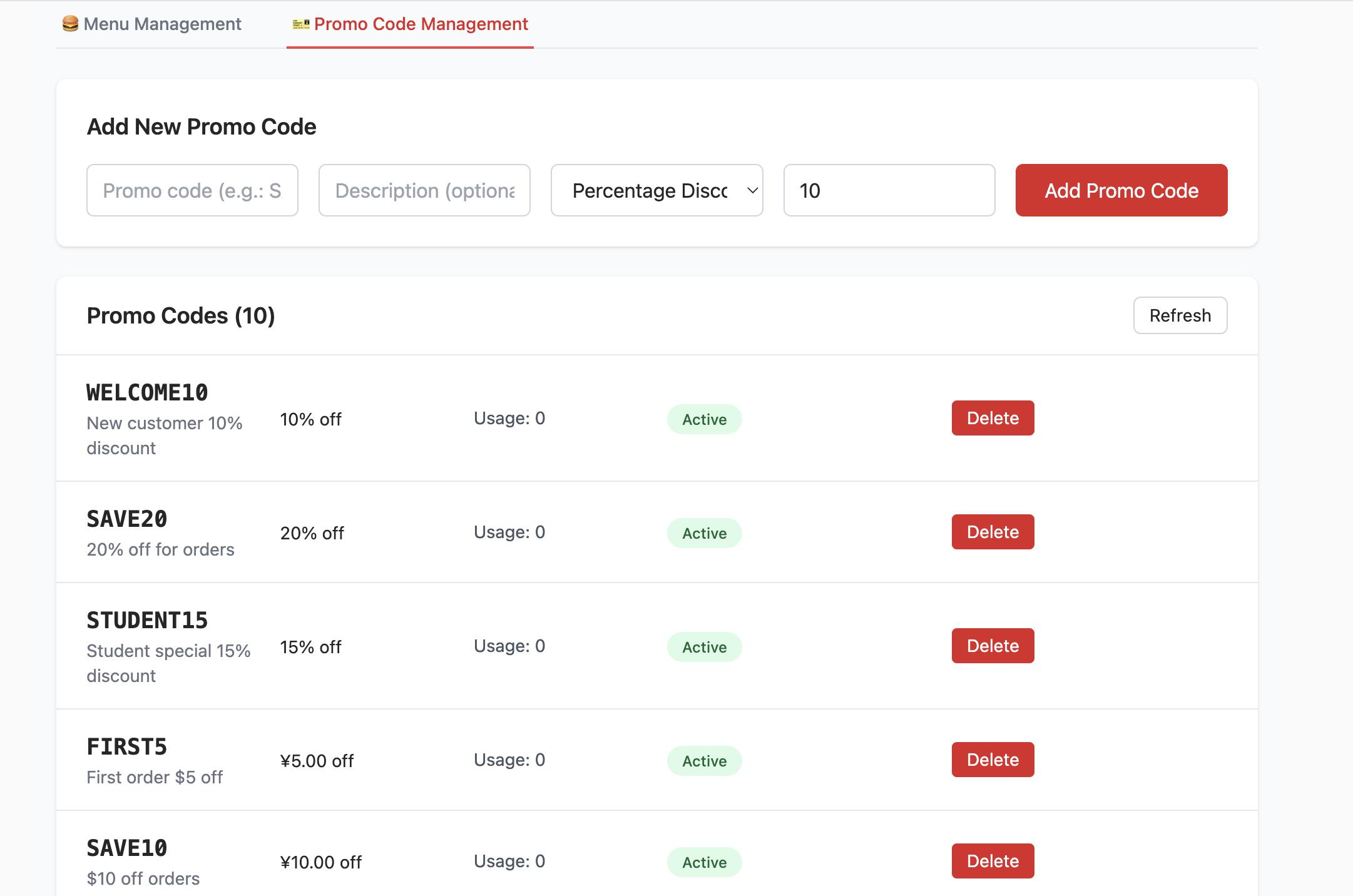
- Crear la tabla promo_codes:
- Esta tabla se usa para gestionar promociones, como codigos de descuento. Define campos como code (codigo de descuento), discount_type (tipo de descuento, como porcentaje o monto fijo), discount_value (valor del descuento), etc.
- Deshabilitar Row Level Security (RLS):
- Para facilitar el desarrollo y las pruebas, el script deshabilita explicitamente RLS. Pero, recordando la logica central de RLS que aprendimos anteriormente: RLS es una funcion clave de Supabase para garantizar la seguridad de los datos, capaz de controlar con precision a traves de politicas granulares "quien puede acceder/modificar que datos" (por ejemplo, solo permitir que los administradores editen codigos de promocion, mientras que los usuarios normales solo pueden ver el menu). Por lo tanto, en un entorno de produccion, es imprescindible habilitar RLS y configurar politicas razonables, bloqueando el acceso no autorizado desde la capa inferior (como evitar que usuarios malintencionados modifiquen menus creados por otros, o filtren reglas de codigos de promocion).
- Insertar datos semilla (Seed Data):
- Para que el proyecto frontend pueda mostrar datos reales de menu y promociones al iniciarse (sin necesidad de ingresar datos de prueba manualmente), el script
init.sqltambien inserta "datos semilla" (es decir, datos de ejemplo) en las tablasmenu_itemsypromo_codes. Por ejemplo, puedes ver diversas hamburguesas, aperitivos, bebidas y una gran variedad de codigos de descuento.
Configurar la conexion con la base de datos
Una vez que la base de datos esta lista, necesitamos conectar este proyecto frontend con Supabase para poder leer normalmente los datos de la base de datos. Necesitamos escribir la URL del proyecto de Supabase y la anon key en la configuracion correspondiente. Este proyecto ofrece dos metodos flexibles de configuracion:
- Configurar mediante variables de entorno
Crea un archivo .env en el directorio raiz del proyecto y completa tus credenciales de Supabase:
NEXT_PUBLIC_SUPABASE_URL=https://your-project.supabase.co
NEXT_PUBLIC_SUPABASE_ANON_KEY=your-anon-key- Configurar directamente en la pagina del proyecto
Para facilitar demostraciones rapidas y cambiar entre diferentes proyectos de Supabase, la pagina de inicio proporciona un boton de configuracion en la esquina superior derecha. Puedes hacer clic en el e ingresar o pegar directamente la URL de Supabase y la anon key en el modal que aparece.
Despues de hacer clic en "Save", esta informacion se utiliza para crear dinamicamente una instancia del cliente de Supabase, similar al siguiente codigo:
import { createClient, type SupabaseClient } from '@supabase/supabase-js';
// Optional client factory for demos: returns null when env is not set.
export function maybeCreateBrowserClient(): SupabaseClient | null {
const url = process.env.NEXT_PUBLIC_SUPABASE_URL;
const anon = process.env.NEXT_PUBLIC_SUPABASE_ANON_KEY;
if (!url || !anon) return null;
return createClient(url, anon);
}Despues de crear la base de datos y completar la configuracion de conexion con Supabase, podras ver la siguiente interfaz. Puedes intentar agregar, eliminar, consultar y modificar productos, y observar los cambios en las tablas de datos correspondientes en Supabase.
Ejercicios
- Intenta agregar y eliminar elementos existentes, y observa en el Table Editor como las operaciones de modificacion afectan el contenido de las tablas de datos.
3.4 Proyecto 2 - Autenticacion de usuarios en la hamburgueseria
El Proyecto 1 implemento "CRUD del menu + conexion a la base de datos". El Proyecto 2 introducira capacidades centrales mas cercanas a un negocio real: autenticacion de usuarios (Auth) y gestion de permisos con Row Level Security (RLS).
El Proyecto 2 incluye una pagina de inicio de sesion independiente que permite a los usuarios iniciar sesion mediante "correo electronico + contrasena". Su logica central consiste en llamar a los metodos nativos proporcionados por Supabase Auth para implementar rapidamente el flujo de autenticacion, sin necesidad de desarrollar manualmente una logica compleja de validacion de inicio de sesion:
const { error: err } = await supabaseClient.auth.signUp({
email,
password,
options: {
data: {
full_name: fullName || null,
birthday: birthday || null,
avatar_url: avatarUrl || null
}
}
});
Despues de iniciar sesion exitosamente, Supabase crea automaticamente una sesion (session) para el usuario y adjunta automaticamente la informacion de autenticacion en todas las solicitudes posteriores a la base de datos. Gracias a RLS, cada usuario solo puede ver la informacion de su propia cuenta (articulos comprados, saldo restante en la billetera) segun su informacion de autenticacion, y no puede ver la informacion de la cuenta de otros usuarios. Esto logra el aislamiento de datos despues del inicio de sesion de diferentes usuarios, donde cada persona solo puede ver su propio contenido.
Al igual que en el Proyecto 1, primero necesitas usar init.sql para inicializar las tablas de datos (nota: si encuentras errores durante la inicializacion, primero elimina las tablas de datos ya creadas en el Table Editor, o bien elimina directamente este proyecto de Supabase y crea uno nuevo).
Despues de registrar exitosamente una cuenta con correo electronico y confirmar el registro en tu correo, al iniciar sesion entraras a la interfaz de la tienda donde podras ver el siguiente contenido:
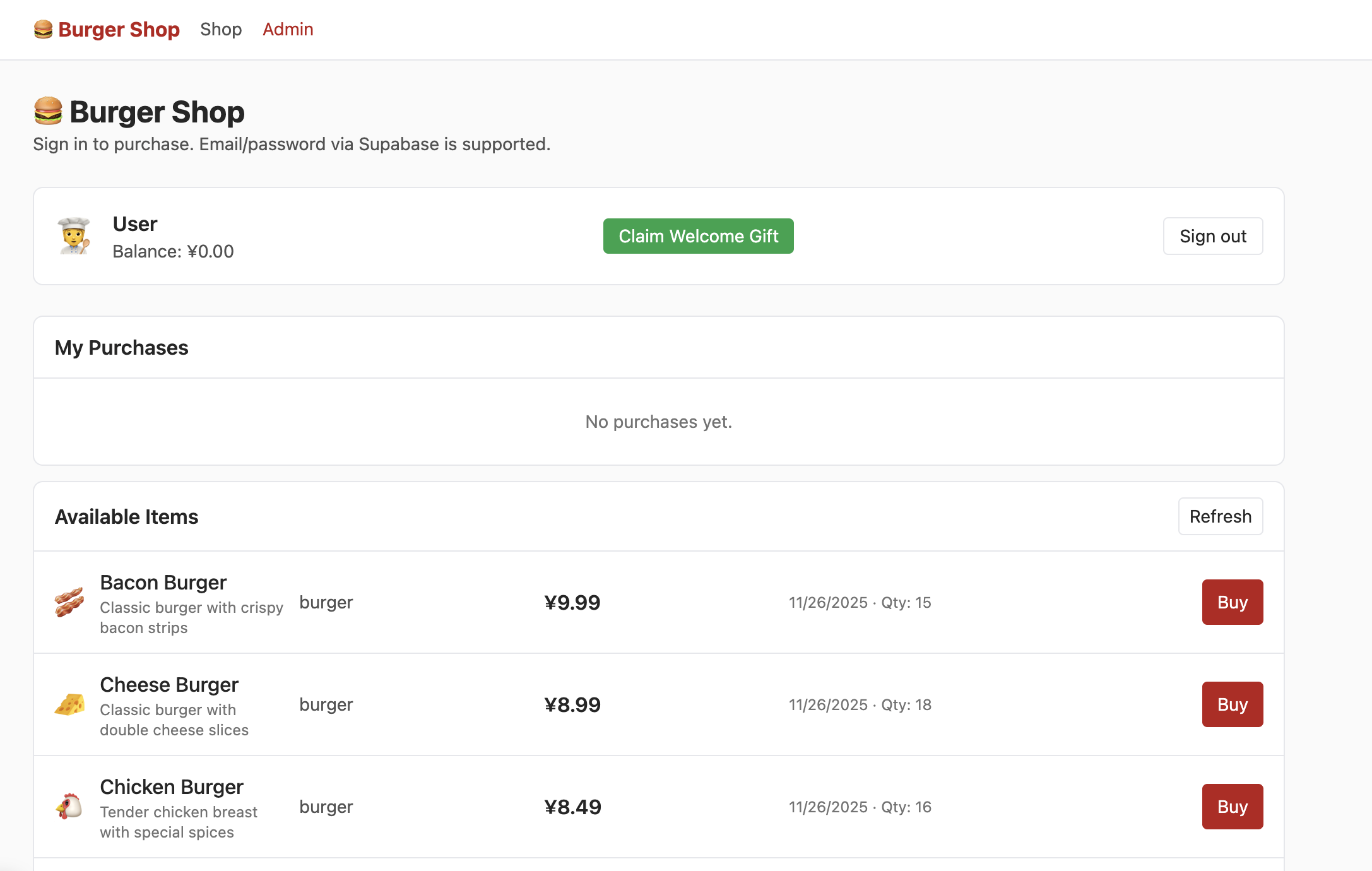
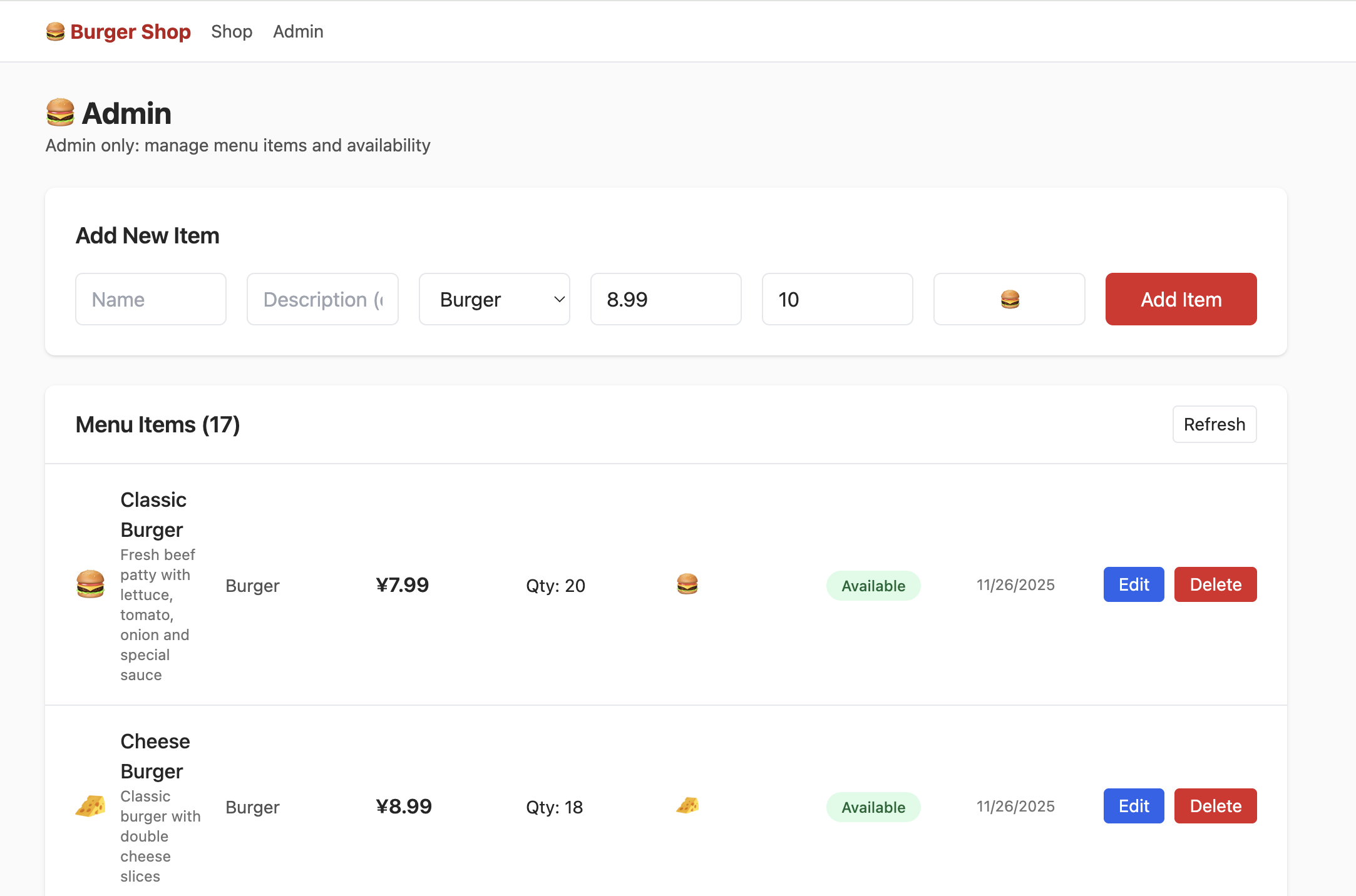
Sin embargo, al hacer clic en admin en este momento, no podras ver la siguiente interfaz. Necesitas intentar encontrar en las tablas de datos la seccion que controla los permisos de usuario y modificar los permisos a admin, para poder ver normalmente el siguiente contenido en la interfaz de administracion:
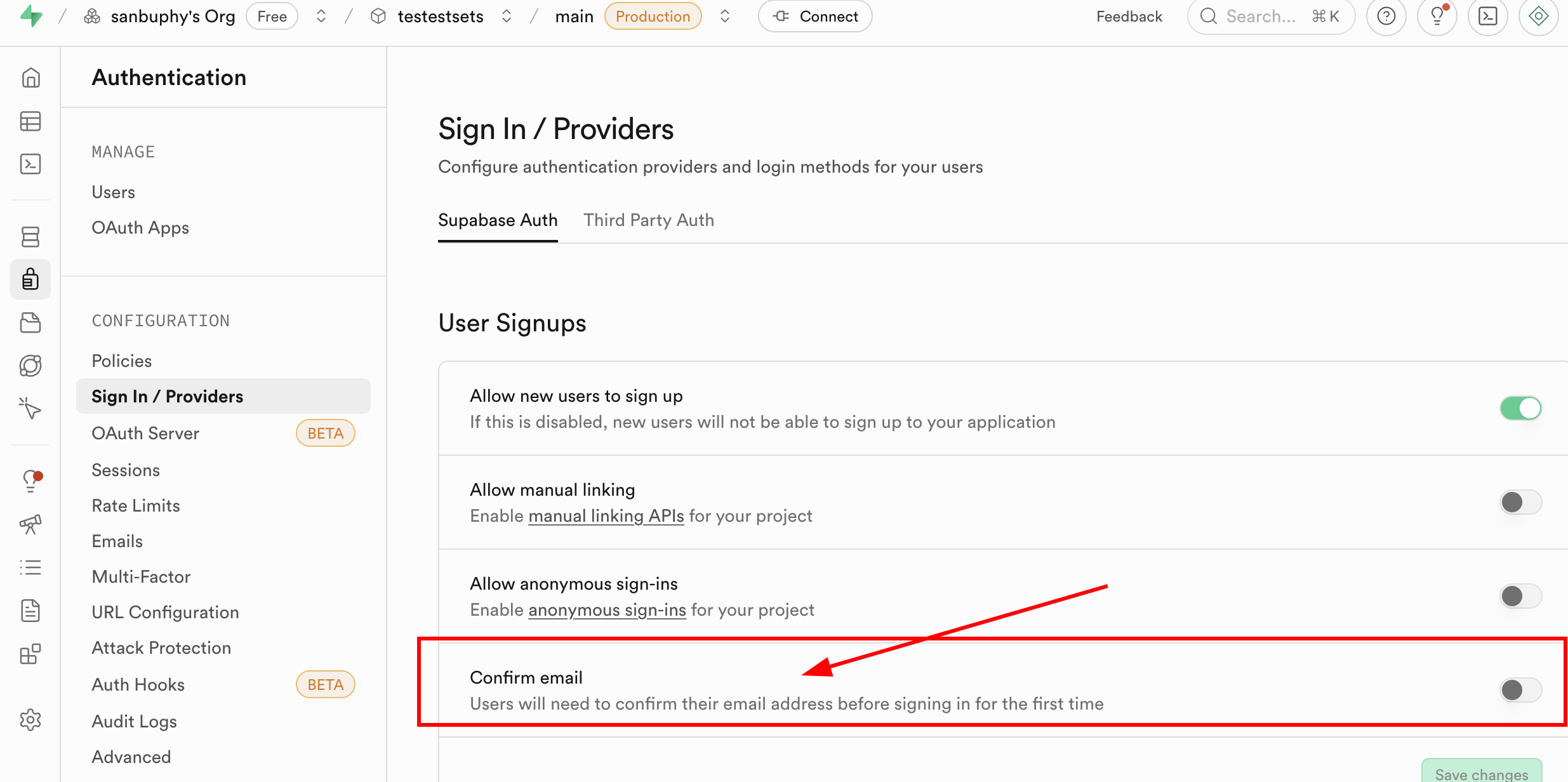
Cabe destacar que actualmente, cada vez que registras un nuevo correo electronico, necesitas confirmar el registro en tu correo electronico antes de poder iniciar sesion; pero este paso no es obligatorio. Puedes encontrar Sign In / Providers en la seccion Authentication de Supabase y hacer clic en Confirm email para desactivar la confirmacion obligatoria por correo electronico.
Ejercicios
- Primero reclama el regalo de nuevo usuario y completa las operaciones de compra de productos.
- Intenta encontrar la ubicacion de la tabla de datos donde se configuran los permisos de usuario, cambia los permisos a
admin, y modifica exitosamente la cantidad de productos en la interfaz de gestion de pedidos. - Intenta localizar en las tablas de datos la tabla relacionada con el saldo de la billetera, y modificala para aumentar el saldo restante.
4. Construye tu primera aplicacion con Supabase
Despues del aprendizaje sistematico anterior, ya dominas las capacidades centrales de Supabase (operaciones de base de datos, autenticacion de usuarios, politicas de seguridad RLS). Ahora es el momento de poner manos a la obra y construir tu primera aplicacion que incluya una base de datos y soporte un sistema de inicio de sesion de usuarios!
4.1 Flujo estandarizado para conectar cualquier aplicacion a una base de datos Supabase
Podemos usar un flujo estandarizado para conectar cualquier aplicacion a una base de datos Supabase:
- Primero, realiza un analisis de requisitos y sincronizacion de informacion, aclarando los objetivos y comunicandoselos a la IA
- Necesitas describir claramente a la IA las funciones centrales de tu aplicacion actual y los nuevos requisitos de base de datos. Ejemplo: "Tengo una aplicacion React Todo local, los datos solo se almacenan en el navegador, necesito agregar una funcion de 'sincronizacion de datos en la nube' y conectarla a una base de datos Supabase. Ayudame a analizar: que operaciones de datos involucra esta aplicacion (como agregar tareas, cambiar estados, eliminar tareas)? Que tablas de datos necesito crear para almacenar estos datos?"
- Agrega restricciones clave (opcional): por ejemplo, requisitos de formato de campos (timestamps con
timestamptz, montos en centavos como enteros), reglas de permisos de datos (solo visible para el propio usuario), para que el analisis de la IA se ajuste mejor a las necesidades reales. - Revisa los resultados devueltos por la IA; si el enfoque de la IA tiene omisiones (como no considerar el campo "fecha limite de la tarea"), agrega indicaciones para corregir: "Olvidaste considerar la fecha limite, ayudame a agregarla."
- Pide a la IA que genere un script
init.sqladaptado a Supabase basandose en la estructura de tablas confirmada: "Basandote en el enfoque y la estructura de tablas mencionados anteriormente, devuelveme un script init.sql que pueda inicializarse en Supabase". Luego necesitaras ejecutar el script en el SQL Editor; si se producen errores, retroalimentalos a la IA para que corrija el script. - Despues de ejecutar el script init.sql en Supabase, pide a la IA que reestructure el codigo actual basandose en el script, para que pueda interactuar normalmente con Supabase: "Por favor, reestructura el codigo del proyecto basandote en mi script SQL y la configuracion discutida anteriormente, para que pueda comunicarse con la base de datos correspondiente de Supabase y procesar datos".
- Una vez completada la reestructuracion, solo necesitas configurar correctamente los parametros de la direccion de Supabase y las claves (en proyectos formales normalmente solo se usa la configuracion por variables de entorno), y luego verificar. Si no hay problemas, habras conectado exitosamente la aplicacion a la base de datos de Supabase.
- Ejecuta el proyecto, prueba todas las funciones de interaccion con la base de datos, y verifica en tiempo real en el Supabase Table Editor si los datos se sincronizan;
- Si surgen problemas (como datos que no se pueden insertar, o solo se ve una parte de los datos), informa del problema a la IA para que identifique la causa y corrija el codigo.
Ademas, si el objetivo es desarrollar una pagina de inicio de sesion de usuarios, puedes pedir directamente a la IA que ayude a integrar la pagina de inicio de sesion: "Ahora necesitas que me ayudes a agregar el sistema de inicio de sesion de usuarios de Supabase a esta aplicacion, usando correo electronico para registro e inicio de sesion". Tambien necesitas especificar claramente a la IA la logica de redireccion y las rutas de las paginas (como redirigir a la pagina principal del sistema despues de un inicio de sesion exitoso, cual es la direccion de la pagina principal, permanecer en la pagina actual y mostrar un mensaje de error si el inicio de sesion falla). Una vez completada la integracion, debes intentar registrarte e iniciar sesion para verificar que puedas ver los nuevos datos de usuario en la seccion Authentication de Supabase, y que despues de iniciar sesion puedas acceder normalmente a las interfaces de la aplicacion que antes no eran accesibles sin iniciar sesion.
Por supuesto, tambien puedes pedir directamente a la IA que tome como referencia la implementacion de un proyecto determinado y migre las funcionalidades correspondientes de Supabase. Por ejemplo, si un proyecto utiliza funcionalidades avanzadas de base de datos y Edge Functions, puedes indicarle a la IA de la siguiente manera para que migre las funcionalidades similares: "Por favor, refiriendote a la logica de implementacion de las funcionalidades relacionadas con Supabase en este proyecto {pega aqui la ruta absoluta del proyecto de referencia}, anade una logica de implementacion similar al proyecto actual (como inicio de sesion de usuarios, gestion de base de datos, solicitudes de funciones, etc.)".
4.2 Caso de estudio: Construir un juego online de Snake
Siguiendo el SOP mencionado anteriormente, practiquemos con un caso concreto Project5-Supabase-Demos/apps_snakegame: agregar un ranking de puntuaciones a un proyecto de juego "Snake" existente, incluyendo inicio de sesion de usuarios y funcionalidades basicas de base de datos.
4.2.1 Analizar el proyecto e identificar los requisitos de datos
Primero, de manera similar al flujo estandarizado mencionado anteriormente, podemos comunicar los requisitos a la IA y pedirle que nos de un plan de modificacion basado en nuestro proyecto y necesidades. Posteriormente trabajaremos basandonos en este plan.
Puedes usar el siguiente prompt para guiar a la IA:
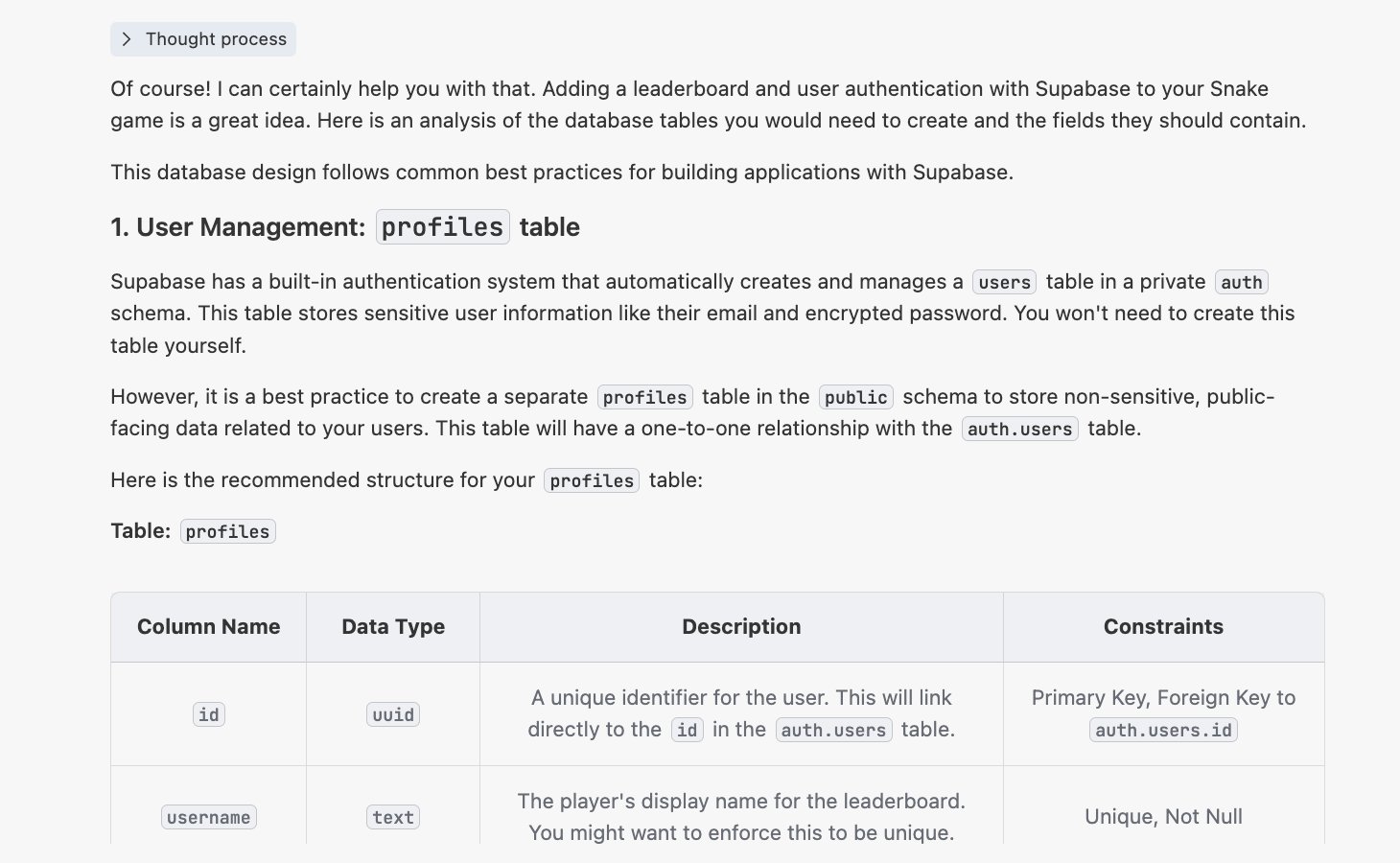
"Tengo un juego de Snake, el directorio esta en {pega aqui la ruta absoluta del juego de Snake}. Ahora quiero combinarlo con Supabase para agregarle una funcion de ranking online, y ademas soportar un sistema de inicio de sesion de usuarios. El ranking debe poder mostrar las posiciones segun nombre de usuario y correo electronico.
Por favor, ayudame a analizar: para implementar esta funcionalidad, que tablas de datos necesito crear? Que campos debe tener cada tabla?"
En este punto recibiras una respuesta similar a la siguiente:
4.2.2 Generar el script init.sql
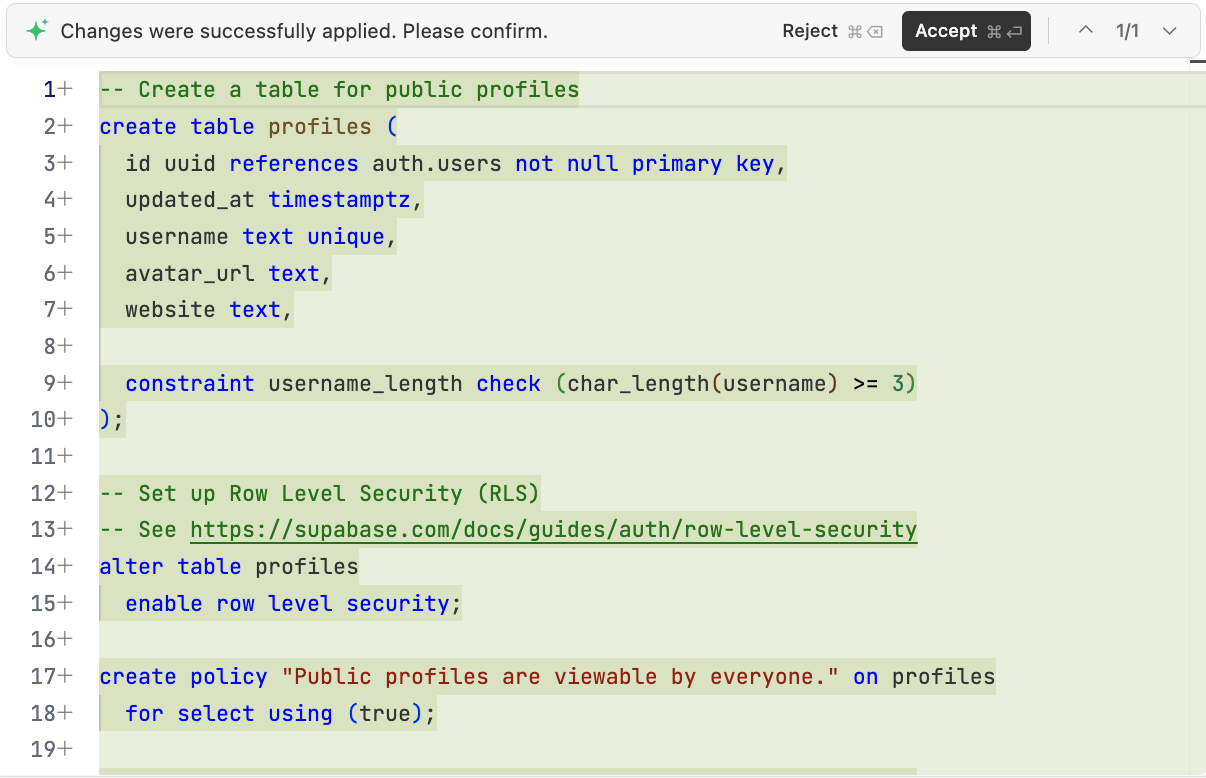
Una vez determinadas las partes necesarias, podemos pedir a la IA que genere el script de inicializacion de base de datos para ejecutar en Supabase: "Por favor, basandote en el analisis anterior, ayudame a generar el script scripts/init.sql en el proyecto para inicializar la base de datos necesaria en Supabase".
4.2.3 Modificar el codigo del proyecto
A continuacion, solo necesitamos pedir a la IA que reestructure el codigo actual del juego de Snake basandose en el contenido anterior: "Ahora, por favor, basandote en el contenido analizado anteriormente y las tablas SQL, ayudame a implementar la funcionalidad de ranking usando Supabase. El ranking debe ser una pagina independiente, debe poder distinguir las puntuaciones totales de diferentes usuarios por correo electronico y nombre de usuario, y tambien necesitas soportar un sistema de inicio de sesion de usuarios basado en correo electronico, donde los usuarios deben registrarse e iniciar sesion para poder jugar."
Si la conversacion actual con la IA tiene demasiadas iteraciones y deseas iniciar una nueva sesion para la reestructuracion del proyecto, puedes incluir el init.sql mencionado anteriormente como parte del contexto, para que la IA reestructre el proyecto basandose en el archivo SQL.
Si descubres que el sistema de inicio de sesion de usuarios implementado por la IA no funciona correctamente, puedes incluir directamente la direccion de Project5-Supabase-Demos/apps/project-burger-shop-auth-users-2 en el prompt, para que la IA implemente el sistema de inicio de sesion basandose en ese proyecto. Verifica tambien que se hayan configurado correctamente las condiciones necesarias para conectarse a Supabase, para evitar errores por configuracion incorrecta.
Durante el proceso de modificacion del codigo, si el resultado real no coincide con lo esperado (como datos del ranking que no se muestran, validacion de inicio de sesion que no funciona, etc.), simplemente documenta el fenomeno especifico y reporta la situacion a la IA, y podras acercarte gradualmente al resultado correcto. El criterio de exito para la modificacion es: los usuarios puedan completar exitosamente el registro e inicio de sesion, y despues de iniciar sesion puedan ver normalmente el ranking del juego.
Ejercicios del curso
- Integra el sistema de gestion de usuarios en la version de demostracion del juego de Snake
- Integra el sistema de gestion de usuarios en tu propia aplicacion (si ya has desarrollado una aplicacion anteriormente)
5. Conviertete en un experto de Supabase
Lo anterior cubre las operaciones basicas de Supabase. En el camino que sigue, entraremos en contacto con los principios avanzados y funcionalidades de Supabase. Comprenderas por que elegimos Supabase como caso de estudio, y como usar Supabase para implementar operaciones mas avanzadas, ayudandote a lograr funcionalidades interactivas mas complejas. Ademas, despues de aprender estas funcionalidades, incluso frente a otras herramientas similares a Supabase, podras extrapolar y comprender desde un nivel mas fundamental los principios centrales de los servicios backend. Por supuesto, no necesitas aprenderlo todo de una vez; quizas solo aprender a soportar inicio de sesion de terceros sea suficiente. Puedes revisar primero el siguiente contenido, y volver a estudiarlo en profundidad cuando tu proyecto encuentre necesidades correspondientes.
5.1 Por que elegimos Supabase
Antes de entrar en lo avanzado, reflexionemos nuevamente sobre esta pregunta: entre las muchas soluciones tecnologicas de backend, por que finalmente elegimos Supabase como base tecnologica?
Los equipos emergentes suelen enfrentar una contradiccion al seleccionar tecnologia: quieren tener control total del sistema backend, pero al mismo tiempo deben lanzar productos rapidamente. Construir un backend propio generalmente significa invertir meses en configurar bases de datos con sincronizacion en tiempo real, autenticacion de usuarios, servicios API, almacenamiento de archivos, tareas programadas, monitoreo y alertas, y otros componentes centrales, a menos que los miembros del equipo ya hayan acumulado rica experiencia practica en las areas correspondientes. Bajo la doble presion de fondos limitados y ventanas de mercado breves, una vez que se cae en el atolladero de la infraestructura, es facil que las iteraciones se retrasen y se pierdan oportunidades de crecimiento temprano.
Supabase empaqueta estas capacidades de backend como servicios listos para usar (base de datos PostgreSQL, suscripciones en tiempo real, autenticacion de identidad, almacenamiento de objetos, Edge Functions, generacion automatica de API, etc.), permitiendo a los equipos emergentes enfocar sus recursos escasos en el desarrollo de funciones centrales, evitando que la construccion de la infraestructura ralentice el lanzamiento. Esta se ha convertido en una estrategia de supervivencia pragmatica en el entorno actual de emprendimiento. Por supuesto, tambien podemos usar otros productos de backend integrales para el desarrollo, como PocketBase (ligero y minimalista) y Appwrite (adaptacion multiplataforma), pero considerando la integridad funcional, la madurez del ecosistema SQL y la atencion de la comunidad de GitHub, Supabase es mas adecuado para soportar el funcionamiento estable a largo plazo del negocio.
Entre productos similares, la estrategia de codigo abierto de Supabase ofrece mayores ventajas. Tomando como ejemplo Firebase, que tiene una mayor cuota de mercado: su naturaleza de codigo cerrado facilmente conduce a una vinculacion con la plataforma, con costos de migracion extremadamente altos. Supabase adopta un modelo completamente de codigo abierto, soportando despliegue privado, evitando el riesgo de bloqueo por parte del proveedor y permitiendo cambiar a otros competidores segun las necesidades.
En resumen, la seleccion tecnologica debe coincidir con la escala y los objetivos del negocio. Para proyectos personales o pruebas de alcance muy limitado, soluciones ultraligeras como PocketBase son suficientes; si una empresa necesita integrarse con sistemas de identidad complejos, o cumplir con requisitos de auditoria de cumplimiento para empresas que cotizan en bolsa, soluciones de gobernanza de identidad empresarial como WorkOS son mas apropiadas. Pero para validar un MVP y soportar los escenarios de negocio centrales con usuarios iniciales, la funcionalidad completa de Supabase es totalmente suficiente. No solo puede soportar de forma independiente al menos decenas de miles de usuarios, sino que tambien puede integrarse de manera flexible con servicios de terceros como Stripe (pagos), Resend (correo electronico), Cloudflare (CDN); incluso si el negocio se expande en el futuro hasta necesidades empresariales, la arquitectura de codigo abierto de Supabase puede desplegarse en paralelo con sistemas empresariales, eligiendo la plataforma mas adecuada para cada funcion. Esta flexibilidad progresiva permite a los equipos emergentes evitar invertir prematuramente en infraestructura pesada, manteniendo al mismo tiempo un espacio de evolucion a prueba de futuro.
5.2 Soporte para inicio de sesion con Google y GitHub
En los tutoriales anteriores, explicamos como usar directamente el correo electronico para registrarse e iniciar sesion, pero en la practica normalmente queremos simplificar el proceso de registro, por ejemplo usando el inicio de sesion de terceros Google y GitHub para un registro e inicio de sesion rapido en el sistema. Cubriremos cada detalle en esta seccion del tutorial; al mismo tiempo, un sistema de autenticacion completo tambien debe proporcionar una funcionalidad de restablecimiento de contrasena segura y confiable, la cual tambien integraremos en el proyecto de esta seccion.
Este proyecto (Project5-Supabase-Demos/apps/project-burger-shop-auth-advanced-supabase-6) demuestra completamente como implementar estas funcionalidades avanzadas.

5.2.1 Flujo OAuth: Como funciona el inicio de sesion de terceros?
El nucleo del inicio de sesion de terceros es el protocolo de autorizacion abierta OAuth 2.0. Su esencia es la "autorizacion delegada": permite a los usuarios autorizar a nuestra aplicacion (el proyecto de la hamburgueseria) a acceder a su informacion publica en una plataforma de terceros (como Google), como correo electronico y avatar, sin necesidad de exponer la contrasena de la plataforma de terceros a nuestra aplicacion, evitando fundamentalmente el riesgo de filtracion de contrasenas.
El flujo completo se puede descomponer en 5 pasos clave, tomando como ejemplo el inicio de sesion con Google:
- El usuario inicia la solicitud de autorizacion: el usuario hace clic en el boton "Sign in with Google" en la pagina, y nuestra aplicacion redirige automaticamente al usuario a la pagina de autorizacion oficial de Google (garantizando la seguridad del proceso de autorizacion, evitando riesgos de phishing).
- El usuario completa la autorizacion de terceros: el usuario inicia sesion en su cuenta de Google en la pagina de Google (verificando la identidad del usuario) y acepta los permisos solicitados por nuestra aplicacion (como "obtener la direccion de correo electronico").
- Google devuelve un codigo de autorizacion de un solo uso: despues de que se aprueba la autorizacion, Google redirige al usuario de vuelta a nuestra "URL de callback (Callback URL)" previamente acordada, adjuntando en los parametros de la URL un codigo de autorizacion de un solo uso y de corta duracion (en lugar de devolver directamente la informacion del usuario, lo que aumenta aun mas la seguridad).
- Supabase intercambia un Access Token (Token de Acceso): nuestro backend (alojado por Supabase, sin necesidad de construirlo) usa este codigo de autorizacion para hacer una solicitud a la interfaz oficial de Google y obtener un Access Token que permite acceder a la informacion del usuario (el codigo de autorizacion solo se usa para intercambiar el Token, evitando que el Token se transmita directamente en el frontend).
- Creacion de cuenta y establecimiento de sesion: Supabase usa el Access Token para obtener la informacion publica del usuario desde Google (como correo electronico, avatar), y crea automaticamente una cuenta para ese usuario en nuestro proyecto (si es el primer inicio de sesion) o asocia la cuenta existente, generando finalmente una sesion de usuario valida (Session), completando el inicio de sesion.
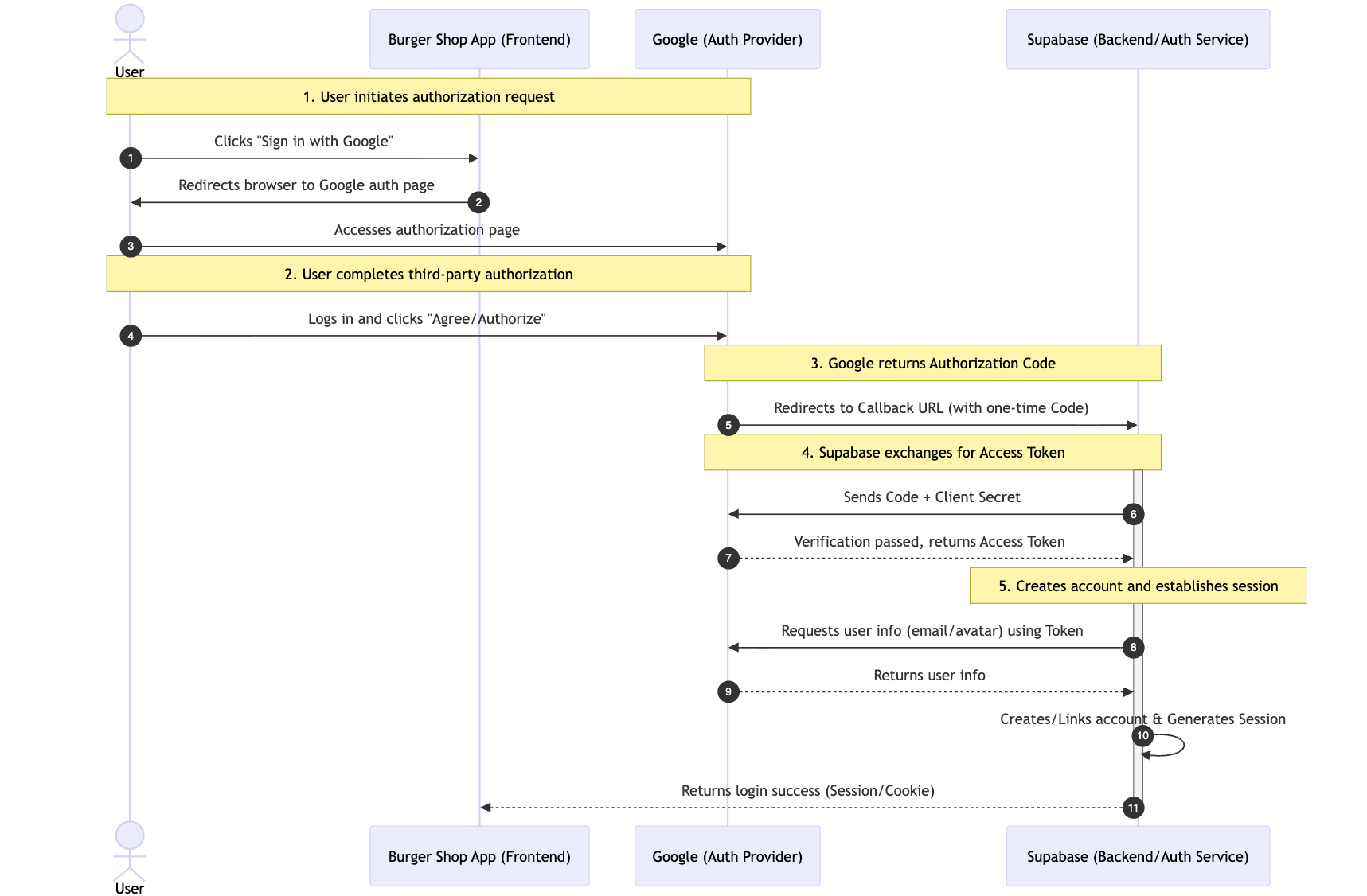
5.2.2 Configurar Google Cloud para obtener Client ID y Secret
Independientemente del metodo de inicio de sesion de terceros, generalmente necesitamos obtener un Client ID y un Secret para la configuracion. Para el inicio de sesion de terceros con Google, primero necesitas crear un OAuth 2.0 Client ID en Google Cloud Platform para obtener los parametros correspondientes.
- Acceder a Google Cloud Console:
- Visita Google Cloud Console.
- Crea un nuevo proyecto o selecciona uno existente.
- Configurar la pantalla de consentimiento OAuth (OAuth consent screen):
- En la barra de navegacion izquierda, encuentra "APIs & Services" -> "OAuth consent screen".
- Selecciona el tipo de usuario "External" y haz clic en "Create".
- Completa el nombre de la aplicacion, el correo electronico de soporte al usuario y otra informacion obligatoria.
- En la seccion "Authorized domains", agrega el dominio de tu proyecto de Supabase, con el formato
*.supabase.co. - Guarda y continua. En los pasos de "Scopes" y "Test users", puedes omitirlos temporalmente y guardar directamente.
- Crear credenciales (Create Credentials):
- Ve a "APIs & Services" -> "Credentials".
- Haz clic en "+ CREATE CREDENTIALS" y selecciona "OAuth client ID".
- En "Application type", selecciona "Web application".
- Dale un nombre, por ejemplo "Supabase Auth".
- En la seccion "Authorized redirect URIs", haz clic en "ADD URI" e ingresa la URL de callback de tu proyecto de Supabase. Puedes encontrar esta URL en el Supabase Dashboard en "Authentication" -> "Providers" -> "Google". Su formato suele ser
https://<tu-ID-de-proyecto>.supabase.co/auth/v1/callback.
- Haz clic en "CREATE".
- Obtener Client ID y Client Secret:
- Una vez creados exitosamente, una ventana emergente mostrara tu Client ID y Client Secret. Asegurate de copiarlos y guardarlos de forma segura inmediatamente.
5.2.3 Configurar GitHub para obtener Client ID y Secret
De manera similar, tambien necesitas registrar una aplicacion OAuth en GitHub.
Acceder a GitHub Developer Settings:
- Inicia sesion en tu cuenta de GitHub.
- Haz clic en tu avatar en la esquina superior derecha y ve a "Settings".
- En la parte inferior de la barra de navegacion izquierda, encuentra "Developer settings".
Registrar una nueva aplicacion (Register a new application):
Selecciona "OAuth Apps" y haz clic en "New OAuth App".
Completa el nombre de la aplicacion, por ejemplo "My Burger Shop".
Homepage URL: Ingresa la direccion en linea de tu aplicacion, o la direccion de desarrollo local
http://localhost:3000.Authorization callback URL: Ingresa la URL de callback de tu proyecto de Supabase. Igualmente, puedes encontrarla en el Supabase Dashboard en "Authentication" -> "Providers" -> "GitHub", con el formato
https://<tu-ID-de-proyecto>.supabase.co/auth/v1/callback.Haz clic en "Register application".
Obtener Client ID y Client Secret:
Una vez registrado exitosamente, la pagina mostrara tu Client ID.
Haz clic en "Generate a new client secret" para generar tu Client Secret. Nuevamente, copialo y guardalo inmediatamente.
5.2.4 Configurar el Provider en Supabase
Ahora, configuremos las credenciales obtenidas en Supabase.
- Acceder al Supabase Dashboard:
- Selecciona tu proyecto y ve a "Authentication" -> "Providers".
- Habilitar y configurar Google:
- Encuentra "Google" y habilita.
- Pega el Client ID y Client Secret obtenidos de Google Cloud en los campos correspondientes.
- Haz clic en "Save".
- Habilitar y configurar GitHub:
- Encuentra "GitHub" y habilita.
- Pega el Client ID y Client Secret obtenidos de GitHub en los campos correspondientes.
- Haz clic en "Save".

En este punto, ya puedes usar cuentas de terceros para iniciar sesion en el sitio web que has construido. Puedes pedir directamente a la IA que tome como referencia el proyecto Project5-Supabase-Demos/apps/project-burger-shop-auth-advanced-supabase-6 para soportar el sistema de inicio de sesion de usuarios en tu proyecto, integrando con un costo minimo una interfaz de inicio de sesion de usuarios que incluya autenticacion con GitHub y Google.
5.2.6 Implementacion del restablecimiento de contrasena
Como componente maduro de inicio de sesion de usuarios, el restablecimiento de contrasena tambien es una parte extremadamente importante. Este proyecto project-burger-shop-auth-advanced-supabase-6 tambien incluye la implementacion completa de esta funcionalidad. Puedes pedir directamente a la IA que replique el componente completo de restablecimiento de contrasena basandose en la funcionalidad de este proyecto. Se divide principalmente en los siguientes pasos:
- Enviar solicitud: el usuario ingresa su correo electronico en la pagina de contrasena olvidada, el frontend llama a la funcion
supabase.auth.resetPasswordForEmail()y especifica una URL de redireccion redirectTo (por ejemplo, /auth/reset). - Enviar correo electronico: Supabase envia al correo electronico un mensaje con un enlace unico de restablecimiento.
- Acceder al enlace: el usuario hace clic en el enlace del correo y es redirigido a la pagina de restablecimiento especificada dentro de la aplicacion.
- Actualizar contrasena: en la pagina de restablecimiento, el usuario ingresa la nueva contrasena. El frontend llama a
supabase.auth.updateUser(), enviando la nueva contrasena a Supabase. Supabase verifica automaticamente la validez del enlace y completa la actualizacion de la contrasena.
Finalmente, si crees que el correo electronico de restablecimiento de contrasena actual es demasiado simple, puedes personalizar la plantilla de correo "Reset Password" en Supabase Dashboard en Authentication -> Email Templates.
Ademas de la funcionalidad de Reset password, tambien podras ver muchas otras funcionalidades avanzadas relacionadas con la gestion de usuarios (como Invite user, etc.). Puedes agregar las funcionalidades correspondientes segun la documentacion de desarrollo de cada una, combinandolas con herramientas de Vibe coding.
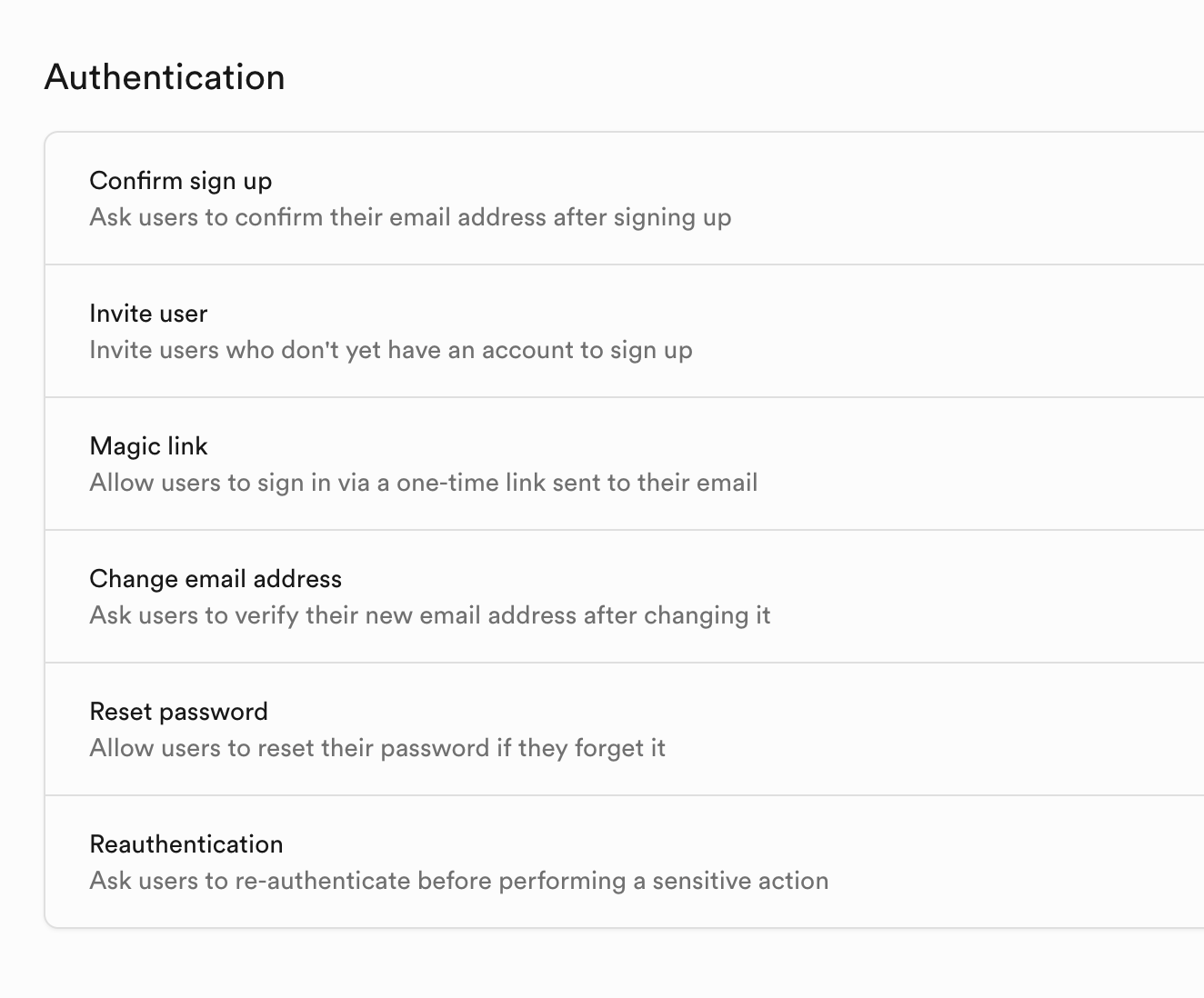
5.3 Funcionalidad en tiempo real
La funcionalidad en tiempo real de Supabase es una de sus caracteristicas mas potentes, proporcionando una gran comodidad para construir documentos colaborativos, dashboards en tiempo real, salas de juego o sistemas de atencion al cliente.
Este proyecto Project5-Supabase-Demos/apps/project-burger-shop-realtime-orders-3 demuestra, a traves de la construccion de una sala de chat multiusuario en tiempo real y una funcionalidad de compartir la posicion del cursor, las tres capacidades centrales de Supabase Realtime: escucha de cambios en la base de datos (Postgres Changes), Broadcast (Difusion) y Presence (Presencia en linea).
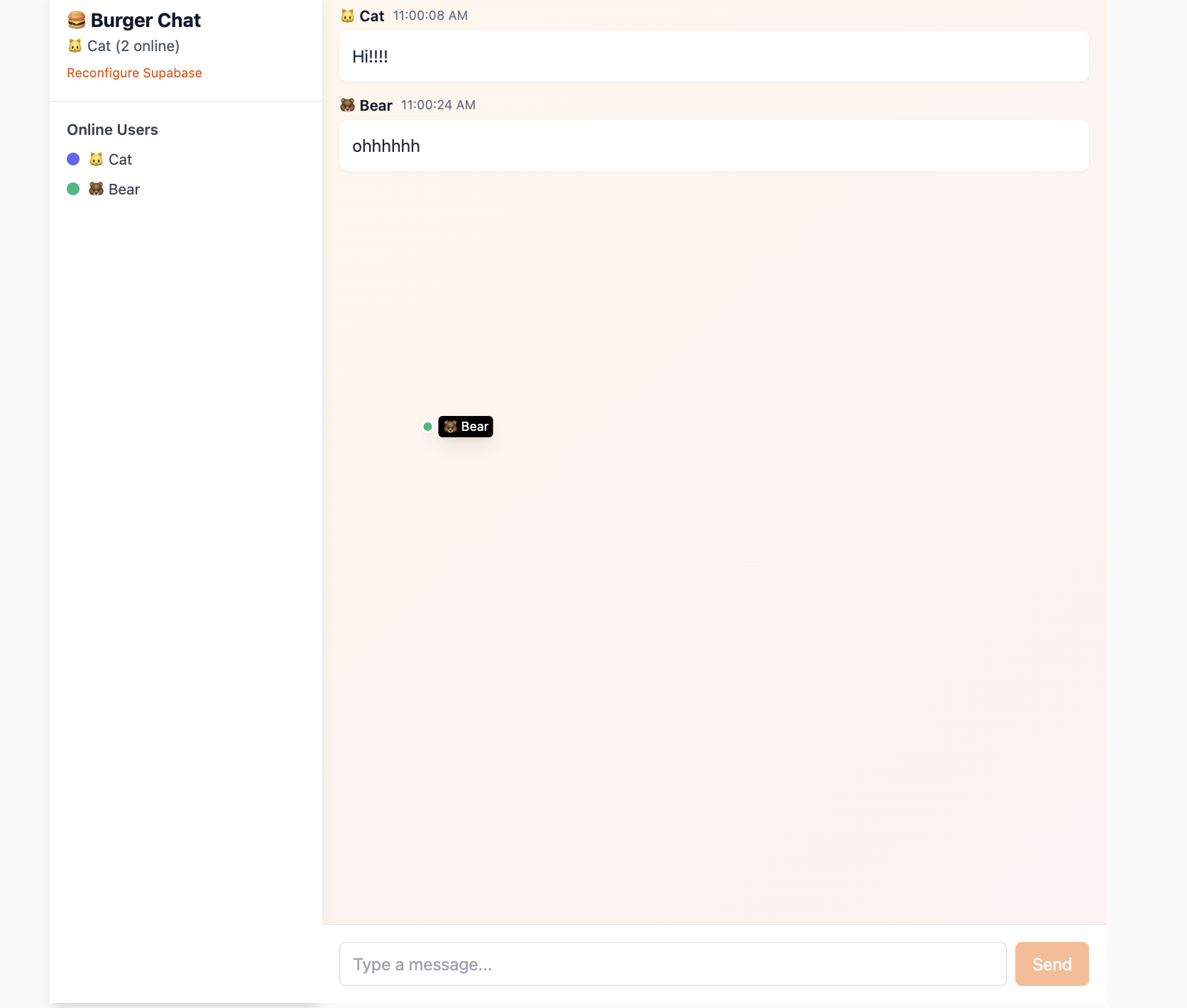
Si encuentras que algunas partes del codigo tienen cierta dificultad, puedes pedir directamente a la IA que tome como referencia esa parte de la documentacion para modificar tu programa.
5.3.1 Cambios en tiempo real en la base de datos: Postgres Changes
La funcionalidad de Realtime mas comun es la escucha en tiempo real de los cambios en la base de datos: Postgres Changes. Permite a los clientes suscribirse a eventos INSERT, UPDATE o DELETE en tablas especificas, filas especificas e incluso columnas especificas de la base de datos. Una vez que se produce un cambio en la base de datos (ya sea a traves de una llamada a la API, operaciones en el Supabase Dashboard o ejecucion de scripts SQL), Supabase utiliza el mecanismo de replicacion subyacente de PostgreSQL para enviar inmediatamente los datos modificados a todos los clientes frontend suscritos a ese canal a traves de WebSocket, sin necesidad de que el frontend realice sondeos repetidos (Polling).
Generalmente, esta funcionalidad se puede habilitar encontrando "Enable Realtime" en el Table Editor y haciendo clic, pero es mas conveniente ejecutarla a traves de la inicializacion con scripts SQL, por ejemplo:
-- Enable realtime replication
ALTER TABLE public.chat_messages REPLICA IDENTITY FULL;
DO $$
BEGIN
IF NOT EXISTS (
SELECT 1 FROM pg_publication_tables
WHERE pubname = 'supabase_realtime'
AND schemaname = 'public'
AND tablename = 'chat_messages'
) THEN
ALTER PUBLICATION supabase_realtime ADD TABLE public.chat_messages;
END IF;
END $$;Esta sentencia agrega la tabla chat_messages al supabase_realtime preconfigurado de Supabase. Una vez que una tabla se agrega a esta publication especial, el servidor en tiempo real de Supabase comienza a escuchar todos los cambios en sus datos.
Basandonos en la tabla de datos especial anterior, podemos usar codigo de escucha para monitorear en tiempo real los cambios en los datos de la tabla. Lo que necesitamos implementar es que cuando un usuario envia un mensaje, todos los demas usuarios en linea puedan verlo inmediatamente en sus pantallas. Esto se logra suscribiendose al evento INSERT de la tabla chat_messages.
const sub = supabase
.channel('chat_messages_channel')
.on('postgres_changes', {
event: 'INSERT',
schema: 'public',
table: 'chat_messages'
}, (payload: any) => {
console.log('New message received:', payload.new);
const newMessage = payload.new as Message;
// ... //
.subscribe((status: string) => {
console.log('Chat subscription status:', status);
});.channel('chat_messages_channel'): Crea un canal de comunicacion aislado..on('postgres_changes', ...): Este es el metodo central de suscripcion. Le decimos a Supabase que solo nos interesan los eventosINSERTde la tablachat_messages.payload.new: Cuando se inserta un nuevo mensaje en la base de datos, Supabase envia el contenido completo de los nuevos datos a todos los clientes suscritos a traves depayload.new..subscribe(): Inicia la suscripcion.
5.3.2 Sincronizacion de difusion de informacion: Broadcast y Presence
Para interacciones mas "inmediatas" que no necesitan almacenarse en la base de datos, como el movimiento del cursor o el estado en linea, Supabase proporciona las funcionalidades de Broadcast y Presence.
- Presence: Se usa para rastrear el estado compartido de todos los clientes en un canal. Ideal para implementar funcionalidades de "quien esta en linea".
- Broadcast: Se usa para enviar mensajes temporales de baja latencia a todos los demas clientes en el canal.
La idea central de Presence es: permitir que cada cliente declare su estado en linea, y que los servidores de Supabase se encarguen de sincronizar estos estados de forma fiable con todos los demas clientes del canal. La implementacion de Presence se divide en los siguientes pasos clave:
- Crear un canal que soporte Presence
Primero, creamos un canal lobby_presence dedicado a manejar estas interacciones, y especificamos en la configuracion una clave unica para identificar al usuario actual. Esta clave suele ser el ID del usuario.
const ch = supabase.channel
('lobby_presence', {
config: {
presence: { key: anonymousUser.id },
}
});- Suscribirse al canal y declarar "estoy en linea"
Una vez creado el canal, necesitamos suscribirnos. En el callback de suscripcion exitosa (status === 'SUBSCRIBED'), llamamos al metodo channel.track(). Este metodo transmite la informacion del usuario actual (por ejemplo, ID de usuario, nombre, color de avatar, etc.) a todos los demas clientes del canal, declarando su estado "en linea".
const me = {
id: anonymousUser.id,
name: anonymousUser.name,
color: anonymousUser.color
};
ch.subscribe(async (status) => {
if (status === 'SUBSCRIBED') {
await ch.track(me);
}
});- Sincronizar la lista completa de usuarios en linea
Cuando un nuevo usuario se une al canal, necesita obtener la lista de todos los usuarios que ya estan en linea. Esto se logra escuchando el evento sync de presence. El evento sync se activa cuando te unes al canal por primera vez, proporcionandote una "instantanea" completa.
El metodo channel.presenceState() devuelve un objeto que contiene la informacion de estado de todos los usuarios en linea actuales del canal. Lo procesamos y actualizamos en el state de la aplicacion, para asi renderizar la lista completa de usuarios en linea.
ch.on('presence', { event: 'sync' }, ()
=> {
const state = ch.presenceState();
const flat = {};
Object.values(state).forEach((arr) => {
arr.forEach((u) => { flat[u.id] =
{ ...u }; });
});
setOnline(flat);
});- Escuchar la union y salida de usuarios individuales
Ademas del evento sync, podemos escuchar los eventos join y leave para responder de forma inmediata cuando un nuevo usuario entra o sale, por ejemplo mostrando una notificacion de "User has joined".
ch.on('presence', { event: 'join' }, ({
key, newPresences }) => {
console.log('User joined:', key,
newPresences);
});
ch.on('presence', { event: 'leave' }, ({
key, leftPresences }) => {
console.log('User left:', key,
leftPresences);
});Con estos pasos, hemos construido un sistema de presencia en linea completo y funcional. Supabase gestiona automaticamente los casos de desconexion inesperada del usuario (como cerrar el navegador o perder la conexion a internet) y activa el evento leave en el momento adecuado, garantizando la precision de la lista de usuarios en linea.
Una vez que Presence nos permite saber "quien esta presente", Broadcast permite que estos usuarios mantengan una "conversacion", pero el contenido de la conversacion se almacena de forma efimera. Un ejemplo tipico es el seguimiento de cursores en tiempo real. Si cada movimiento del raton implicara una lectura o escritura en la base de datos, causaria un enorme desperdicio de rendimiento y latencia. Broadcast resuelve este problema a la perfeccion: permite que los mensajes se transmitan directamente entre los clientes a traves de WebSocket, sin pasar por la base de datos.
El modo de funcionamiento de Broadcast depende principalmente de dos metodos fundamentales: channel.send() para enviar y channel.on() para recibir.
- Emisor: difundir la posicion de mi cursor
Agregamos un listener al evento mousemove. Cuando el raton se mueve, construimos un payload que contiene el ID del usuario, las coordenadas y el color, y lo transmitimos a traves de channel.send() con el nombre de evento 'cursor'.
const handleMouseMove = (e) => {
const payload = {
id: anonymousUser.id,
x: e.clientX,
y: e.clientY,
name: anonymousUser.name,
color: anonymousUser.color
};
channelRef.current?.send({
type: 'broadcast',
event: 'cursor',
payload
});
};
document.addEventListener('mousemove', handleMouseMove);- Receptor: escuchar y renderizar los cursores de otros
Dentro del mismo canal, todos los clientes utilizan channel.on() para escuchar mensajes de tipo broadcast cuyo event sea 'cursor'. Una vez que se recibe un mensaje coincidente, se activa la funcion de callback. Extraemos los datos del emisor desde el payload y los usamos para actualizar el estado local online, renderizando asi en pantalla la posicion de los cursores de otros usuarios en tiempo real.
ch.on('broadcast', { event: 'cursor' }, ({ payload }) => {
setOnline((prev) => ({
...prev,
[payload.id]: {
...(prev[payload.id] || {}),
x: payload.x,
y: payload.y
}
}));
});De esta manera, Presence y Broadcast trabajan en conjunto: Presence mantiene la lista de usuarios en linea, mientras que Broadcast se encarga de transmitir estados temporales como las posiciones de los cursores entre esos usuarios, logrando finalmente una rica funcionalidad de interaccion en tiempo real con un costo reducido.
5.4 Storage
Ademas de los datos estructurados como la informacion de usuarios y pedidos, que se pueden definir de forma regular, una aplicacion completa generalmente necesita gestionar una gran cantidad de archivos no estructurados, por ejemplo, avatares de usuarios, imagenes de productos o documentos de pedidos subidos por los usuarios. La caracteristica de estos archivos es que sus tamanos varian mucho y su cantidad puede ser enorme (por ejemplo, las imagenes de productos en una plataforma de comercio electronico pueden llegar a decenas de miles o incluso cientos de miles). Si se almacenan directamente en el servidor de la aplicacion, aumentarian significativamente la carga de almacenamiento del servidor y podrian ralentizar la lectura y escritura de datos, afectando el rendimiento general de la aplicacion.
En el desarrollo real, estos archivos no estructurados se gestionan de manera uniforme mediante un "servicio de almacenamiento de objetos". OSS, Amazon S3 y otros pertenecen a este tipo de servicios; son "herramientas de almacenamiento especializadas" disenadas especificamente para el almacenamiento masivo de archivos, capaces de gestionar eficientemente las necesidades de almacenamiento, copia de seguridad y lectura rapida de archivos. Cuando obtenemos estos archivos en nuestra aplicacion, no los recuperamos directamente del "almacen subyacente" del servicio de almacenamiento de objetos, sino a traves de URLs: cada archivo almacenado en el almacenamiento de objetos recibe una URL unica (similar a una direccion como "https://xxx.oss.com/avatar/user123.jpg", que se puede entender simplemente como un "sitio web" que contiene solo una imagen). Esta URL es como la "direccion de acceso exclusiva" del archivo; la pagina frontend solo necesita usarla para descargar o cargar directamente el avatar o la imagen del producto, sin depender del servidor de la aplicacion como intermediario, mejorando la velocidad de carga de archivos y reduciendo la carga del servidor.
El proyecto project-burger-shop-storage-uploads-4 demuestra a traves de una funcionalidad de carga de avatares de usuario como utilizar Supabase Storage para construir un sistema moderno de carga de archivos, permitiendo a los desarrolladores comprender de forma intuitiva el flujo completo desde la carga de archivos no estructurados hasta su acceso via URL. Ademas, este proyecto utiliza la libreria Uppy para proporcionar una excelente interfaz de carga de archivos, combinada con el plugin Tus para implementar cargas reanudables, apuntando el endpoint de carga de Uppy al API estandar de Supabase (<supabaseUrl>/storage/v1/upload/resumable) para su funcionamiento. Puedes referirte a un enfoque similar para implementar tus propios componentes de carga.
5.4.1. Storage Bucket
La unidad basica de Supabase Storage es el Bucket (storage bucket). Puedes imaginarlo como una carpeta en el sistema operativo de tu computadora. Cada Bucket puede tener sus propias politicas de seguridad y configuracion independientes.
Todos los archivos dentro de Storage son accesibles directamente a traves de una URL publica, pero esto no significa que cualquiera pueda subir o modificar archivos libremente. Los permisos de acceso especificos se controlan mediante politicas mas granulares. Al igual que la base de datos, los permisos de Storage tambien se gestionan mediante Row Level Security (RLS). Las politicas SQL se escriben sobre las tablas especiales storage.objects y storage.buckets, permitiendo definir con precision quien puede leer (SELECT), subir (INSERT), actualizar (UPDATE) o eliminar (DELETE) archivos.
Por ejemplo, podemos crear una politica que solo permita a los usuarios subir archivos a una carpeta con su propio user_id, y que solo permita subir archivos de tipo imagen:
CREATE POLICY "Allow authenticated
uploads to avatars bucket"
ON storage.objects FOR INSERT
TO authenticated
WITH CHECK (
bucket_id = 'avatars' AND
auth.uid() = (storage.foldername(name))
[1]::uuid AND
(storage.extension(name) IN ('png',
'jpg', 'jpeg'))
);
CREATE POLICY "Allow public read access
to avatars"
ON storage.objects FOR SELECT
USING ( bucket_id = 'avatars' );5.4.2 Obtener la URL accesible del archivo
Este proyecto requiere que crees manualmente un bucket publico llamado avatars; todos los archivos se subiran y almacenaran en ese bucket. Una vez que el archivo se ha subido con exito, solo obtenemos su ruta de almacenamiento en Storage, por ejemplo public/avatar1.png. Esto es simplemente una cadena de texto almacenada en la base de datos; para que el navegador pueda renderizar esta imagen, necesitamos convertirla en una URL HTTP accesible.
Supabase ofrece dos estrategias fundamentalmente diferentes para obtener esta URL, que difieren en cuanto a seguridad, persistencia y control de costos.
1. Public URL - Enlace permanente
Esta es la forma mas directa. Si tu archivo se encuentra en un Public Bucket, puedes obtener un enlace publico fijo y permanente.
const { data } = supabase.storage
.from('avatars')
.getPublicUrl('public/avatar1.png');
const publicUrl = data.publicUrl;Este tipo de enlace tiene dos caracteristicas principales: primera, es simple y directo, con una estructura de URL fija que facilita su concatenacion y gestion en la practica, reduciendo la barrera tecnica de uso; segunda, favorece el almacenamiento en cache, ya que al ser un enlace permanente, puede ser almacenado eficientemente en cache por CDN (Content Delivery Network) y navegadores, mejorando significativamente la velocidad de acceso a los recursos y optimizando la experiencia del usuario. Gracias a estas caracteristicas, es adecuado para escenarios de recursos publicos en el sentido mas estricto, como logos de sitios web, imagenes de catalogos de productos o imagenes de articulos de blog.
Sin embargo, en entornos de produccion, este tipo de enlaces presenta un riesgo significativo de robo de ancho de banda (Hotlinking). Dado que los enlaces son permanentemente publicos, personas externas pueden facilmente incrustar los enlaces de tus imagenes en sus propios sitios web de alto trafico, lo que provoca que tu ancho de banda sea utilizado de forma no autorizada. Este comportamiento genera grandes costos de trafico innecesarios en tu proyecto de Supabase, y el trafico consumido no esta sirviendo a tu propia aplicacion, lo cual es un tipico desperdicio de costos que requiere atencion y prevencion en entornos de produccion; por lo tanto, necesitamos recurrir a las Signed URLs temporales para exponer recursos externos.
2. Signed URL - Enlace de autorizacion temporal
Para resolver los problemas de seguridad y costos de las Public URLs, Supabase ofrece la posibilidad de generar Signed URLs temporales. Esta es la mejor practica recomendada para la mayoria de las aplicaciones en produccion, como por ejemplo: aplicaciones de generacion de texto a imagen que generan enlaces de visualizacion con tiempo limitado para los usuarios, plataformas de comercio electronico que solo permiten a los usuarios que han realizado un pedido obtener una direccion temporal de descarga de facturas, o plataformas de contenido de pago que proporcionan a los suscriptores enlaces de reproduccion de cursos de corta duracion, previniendo tanto el uso no autorizado de archivos como el robo de ancho de banda, con una adaptabilidad muy alta.
const { data, error } = await supabase.storage
.from('avatars')
.createSignedUrl('private/user-invoice.pdf', 3600); // El enlace es valido por 3600 segundos (1 hora)
const signedUrl = data?.signedUrl;Las Signed URLs temporales tienen tres ventajas fundamentales: seguridad controlada significa que los enlaces llevan una marca de seguridad y tienen un periodo de validez, por lo que expiran y dejan de funcionar; la vinculacion de permisos es simple: solo quien puede ver el archivo puede generar el enlace, e incluso si el archivo esta en un almacenamiento privado (Private Bucket), con este enlace se puede abrir normalmente; y prevencion del robo de ancho de banda, ya que los enlaces son temporales y al copiarlos a otro lugar caducan rapidamente, evitando el uso malicioso del trafico. Gracias a estas ventajas, archivos que requieren gestion de permisos como avatares de usuarios, fotos privadas, contenido de pago y facturas de pedidos pueden utilizarlas.
Desde la perspectiva de la seguridad y el control de costos, se recomienda adquirir el habito de priorizar las Signed URLs temporales. Solo cuando un recurso necesita claramente ser permanente y publicamente accesible sin restricciones (como el logo publico de una aplicacion o imagenes de promocion de eventos publicos) se debe considerar el uso de Public URLs. De este modo se pueden satisfacer las necesidades especificas del negocio mientras se minimizan los riesgos y costos innecesarios.
5.5 Edge Functions
Edge Function es una de las formas mas destacadas dentro del ecosistema Serverless, proporcionando un soporte ligero y eficiente para la ejecucion de funciones en escenarios "sin backend propio".
Que es Serverless? Serverless no significa que realmente no haya servidores, sino que los desarrolladores no necesitan preocuparse por la compra, mantenimiento, configuracion y escalado de servidores. Solo necesitas escribir el codigo de negocio (funciones), y el proveedor de servicios en la nube asignara automaticamente los recursos para ejecutar tu codigo cuando se active un evento especifico, cobrando solo por el tiempo real de ejecucion.
Cuando tu aplicacion necesita ejecutar logica que no puede o no debe completarse en el cliente (navegador), por ejemplo, interactuar con APIs de terceros que requieren claves privadas, ejecutar tareas computacionalmente intensivas o hacer cumplir reglas de negocio complejas, las Edge Functions son la solucion. Las Supabase Edge Functions estan basadas en Deno y TypeScript, y se despliegan en nodos perifericos (edge nodes) a nivel mundial, fisicamente cerca de tus usuarios, proporcionando asi una latencia de ejecucion extremadamente baja.
Actualmente, los principales proveedores de nube ofrecen sus propios servicios de Edge Function, entre los mas comunes se encuentran:
- AWS Lambda@Edge: servicio de funciones perifericas basado en AWS Lambda, que puede integrarse con CloudFront CDN y soporta lenguajes como Node.js y Python;
- Cloudflare Workers: funciones perifericas de Cloudflare, desplegadas en mas de 275 nodos perifericos a nivel mundial, soportan JavaScript/TypeScript, con "latencia de milisegundos" como ventaja principal;
- Vercel Edge Functions: funciones perifericas adaptadas a proyectos frontend de Vercel, profundamente integradas con Next.js, soportan TypeScript, y se centran en la "conexion sin interrupciones entre el frontend y la logica periferica";
Volviendo a Supabase, cuando tu aplicacion necesita ejecutar logica que "no puede completarse en el cliente (navegador)", como llamar a una API de terceros con una clave privada (por ejemplo, la interfaz de un LLM), procesar tareas computacionalmente intensivas (como compresion de imagenes) o hacer cumplir la validacion de permisos (como reglas de acceso a archivos), las Supabase Edge Functions entran en accion. Estan construidas sobre Deno runtime y TypeScript, desplegadas en nodos perifericos a nivel mundial, y pueden lograr una latencia de ejecucion extremadamente baja gracias a la "proximidad fisica al usuario", siendo la herramienta principal para escribir logica del lado del servidor personalizada y confiable.
El proyecto Project5-Supabase-Demos/apps/project-burger-shop-edge-function-5 muestra el flujo de aplicacion mas simple de las Edge Functions a traves de una funcionalidad de对话 en streaming en tiempo real con un Large Language Model (LLM).
5.5.1 Analisis del caso LLM Chat
Supongamos que quieres integrar un chatbot similar a ChatGPT en tu aplicacion. Necesitas llamar a la API de OpenAI desde el lado del servidor, pero esto requiere una API Key privada. Esta Key nunca debe exponerse en el codigo frontend, de lo contrario cualquiera podria robarla revisando el codigo fuente de la pagina web y generar costos elevados. Aqui es precisamente donde Edge Function resulta util. Crearemos una funcion llamada llm-chat que actuara como un proxy seguro entre el frontend y la API de OpenAI.
Consulta el codigo en project-burger-shop-edge-function-5/scripts/llm-chat.ts para ver como funciona:
// scripts/llm-chat.ts
import "jsr:@supabase/functions-js/edge-runtime.d.ts";
import { OpenAI } from "npm:openai";
const OPENAI_API_KEY = Deno.env.get("OPENAI_API_KEY");
Deno.serve(async (req) => {
try {
const openai = new OpenAI({ apiKey: OPENAI_API_KEY });
const { prompt } = await req.json();
const stream = await openai.chat.completions.create({
model: "gpt-3.5-turbo",
messages: [{ role: "user", content: prompt }],
stream: true,
});
return new Response(stream.toReadableStream(), {
headers: { "Content-Type": "text/event-stream" },
});
} catch (err) {
}
});En este caso, en cuanto a la seguridad de la clave, OPENAI_API_KEY se almacena de forma segura como variable de entorno en los servidores de Supabase. El codigo frontend local no tiene acceso a la clave, garantizando asi su seguridad de manera efectiva.
5.5.2 Crear y desplegar una funcion
Supabase ofrece una interfaz muy amigable que te permite completar el despliegue sin necesidad de tocar la linea de comandos.
- Acceder al panel de Edge Functions:
- Inicia sesion en el Dashboard de tu proyecto Supabase.
- En la barra de navegacion izquierda, haz clic en el icono que parece codigo para acceder a "Edge Functions".
- Crear una nueva funcion:
- Haz clic en el boton "Create a new function".
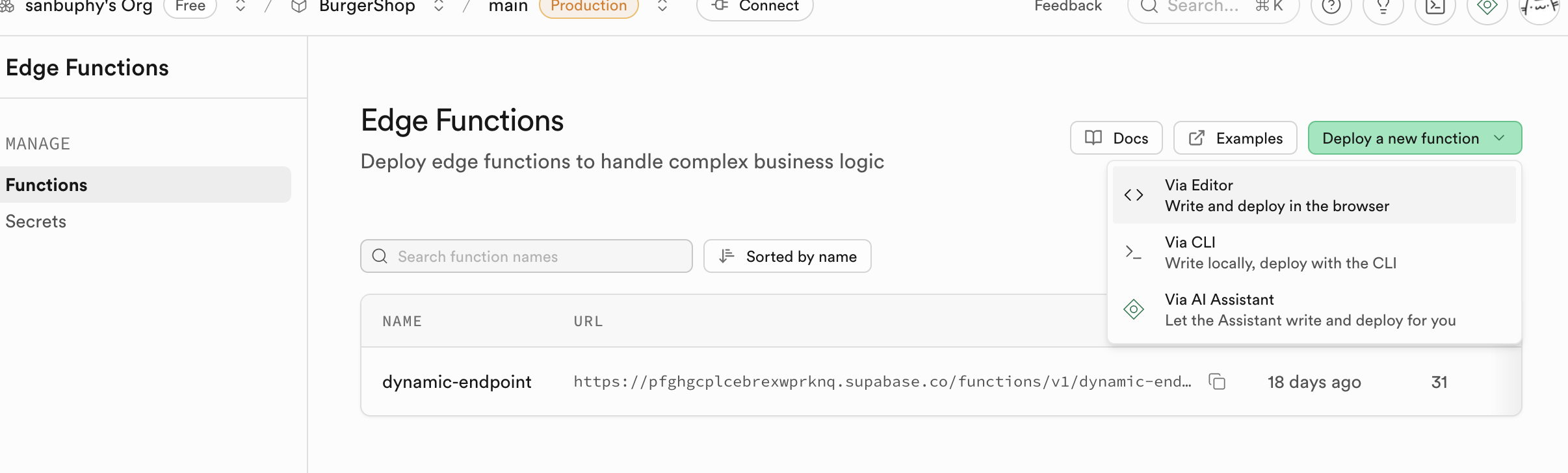
- Asigna un nombre a la funcion, por ejemplo
llm-chat. - Pegar el codigo:
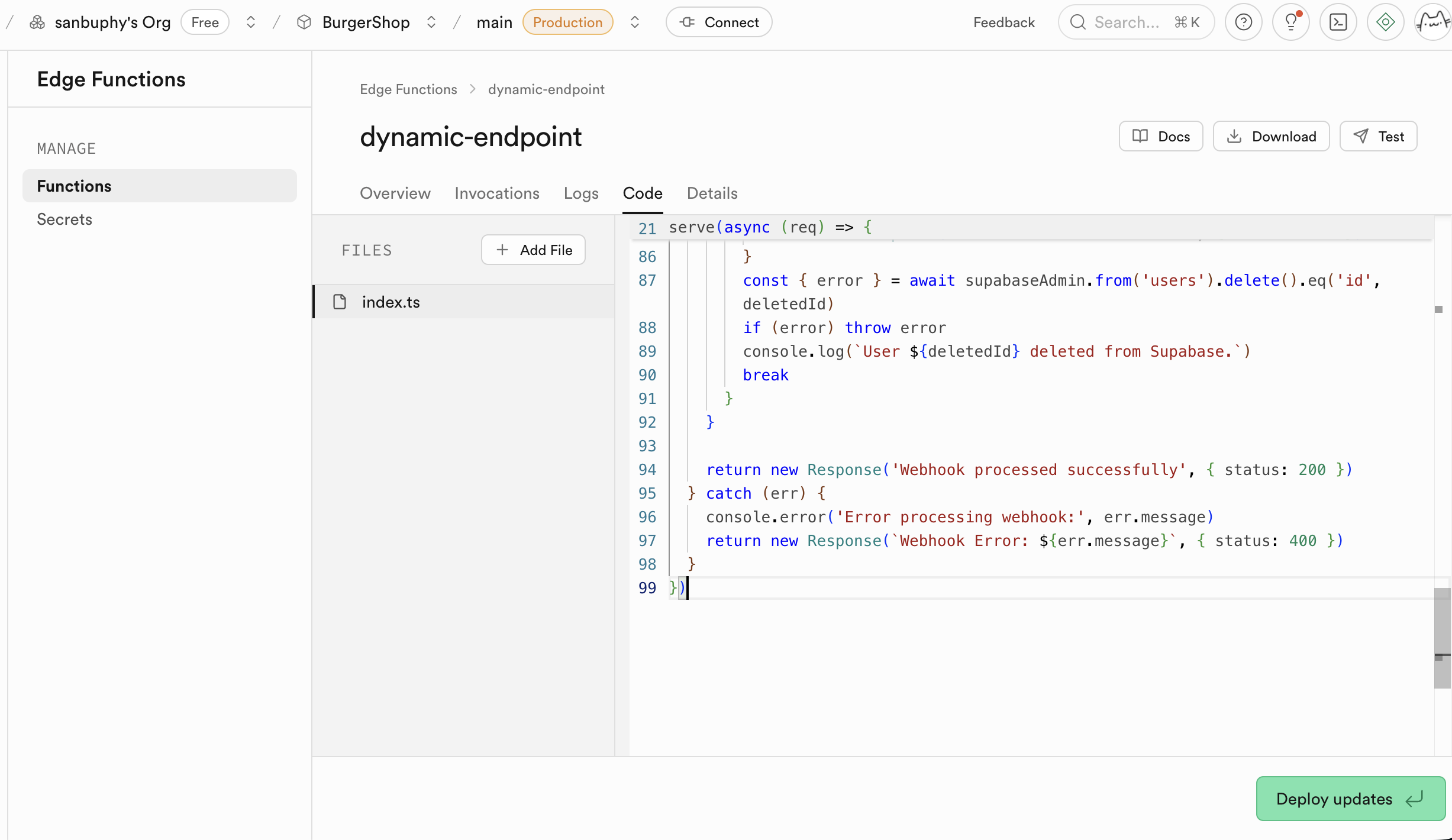
- En el editor en linea que aparece, elimina todo el codigo de marcador de posicion predeterminado.
- Abre tu archivo local
llm-chat.tsy copia todo su contenido. - Pega el codigo copiado en el editor en linea de Supabase.
- Configurar variables de entorno (Secrets):
- En la barra lateral encuentra Secrets.
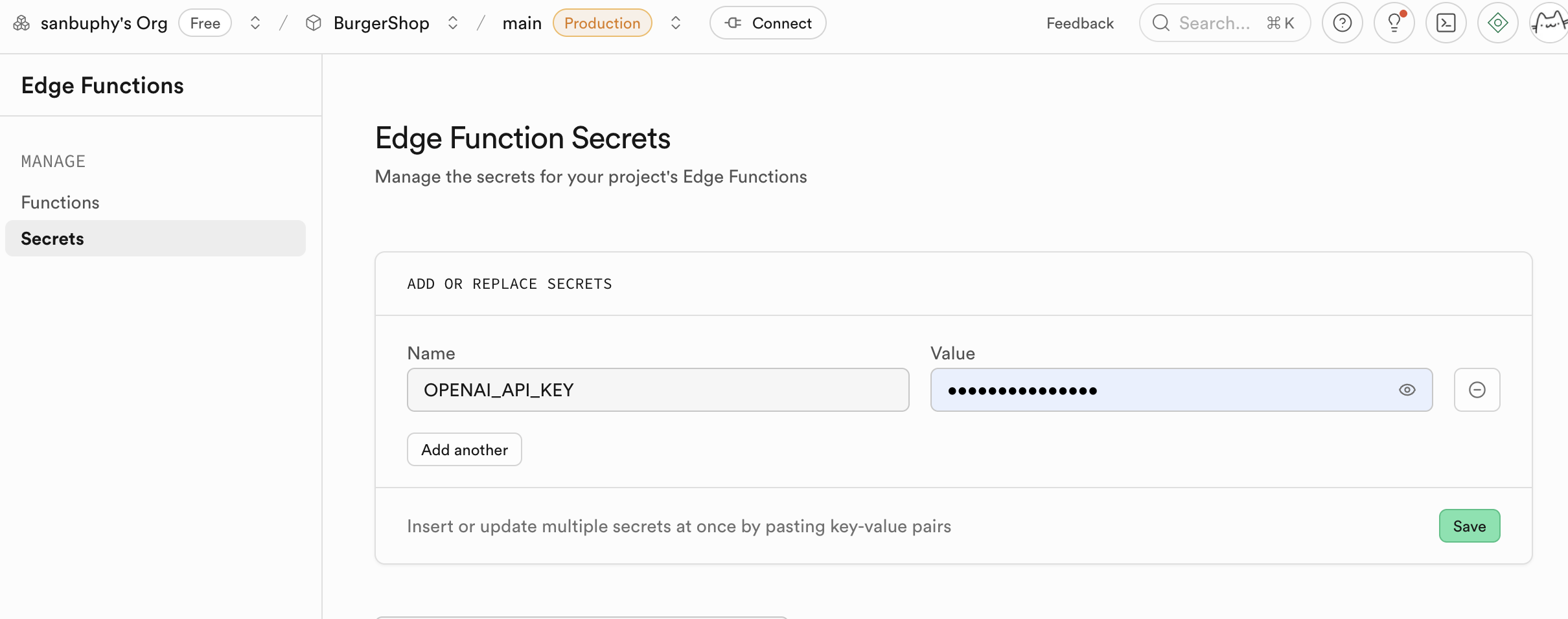
- Name: ingresa
OPENAI_API_KEY. - Value: pega tu propia OpenAI API Key.
- Haz clic en "Save". El Secret configurado aqui se almacenara encriptado y se inyectara de forma segura en el entorno de ejecucion de tu funcion.
- En la barra lateral encuentra Secrets.
Si necesitas actualizar la funcion, recuerda ejecutar Deploy updates en la seccion de Edge Functions. Supabase construira y desplegara la funcion en la nube por ti. En unos minutos, tu funcion estara accesible en linea.
Mas alla de funcionar como un proxy seguro para modelos de lenguaje, los casos de uso de las Edge Functions van mucho mas alla. En realidad, cualquier tarea que requiera procesamiento de logica del lado del servidor, ya sea una simple llamada a una API, validacion de datos o calculos mas complejos, puede implementarse a traves de Edge Functions. Te proporciona un backend ligero y escalable sin necesidad de gestionar ninguna infraestructura de servidores.
Si deseas explorar mas posibilidades, puedes consultar otros ejemplos en el proyecto. Por ejemplo:
- Generacion de imagenes (txt2img.ts): esta funcion muestra como utilizar Edge Function para llamar a una API de terceros de texto a imagen (Text-to-Image) (como Stability AI, Midjourney, etc.) para generar imagenes dinamicamente. Este es un escenario tipico computacionalmente intensivo o que requiere llamadas seguras a servicios externos. Al igual que en el caso de llm-chat, la clave API se almacena de forma segura en el backend de Supabase, y el frontend solo se encarga de enviar la descripcion de texto y luego recibir y mostrar la imagen generada; todo el proceso es seguro y eficiente.
- Envio de correos electronicos (send-email.ts): enviar correos de bienvenida, notificaciones de transacciones o correos de restablecimiento de contrasena es un requisito comun en las aplicaciones. El ejemplo send-email.ts demuestra como integrar un servicio de correo electronico (como Resend, SendGrid) a traves de Edge Function. No necesitas exponer la API Key del servicio de correo en el codigo del cliente; solo necesitas crear una funcion y dejar que el frontend active el envio del correo llamando a esta funcion.
5.6 Clerk Login
Clerk es una herramienta de desarrollo profesional enfocada en la autenticacion de identidad y la gestion de usuarios. Sus capacidades principales cubren todo el flujo de autenticacion: registro de usuarios, inicio de sesion, seguridad de cuentas con MFA, control de permisos y gestion de sesiones. Ayuda a los desarrolladores a construir rapidamente un sistema de usuarios seguro, flexible y conforme a los estandares de aplicaciones modernas, sin necesidad de desarrollar desde cero una logica de identidad compleja.
Esta seccion presentara como configurar el servicio Clerk desde cero e integrarlo con Supabase. Puedes experimentar el flujo completo en el proyecto project-burger-shop-auth-advanced-clerk-7.
5.6.1 Crear una aplicacion Clerk y obtener las claves
Antes de usar este proyecto, necesitas tener una cuenta de Clerk y crear una aplicacion.
- Registro y creacion:
- Visita dashboard.clerk.com y registrate para obtener una cuenta.
- Haz clic en "Create application".
- Ingresa el nombre de la aplicacion (por ejemplo "Burger Shop").
- En "How will your users sign in?", selecciona por defecto Email, Google y GitHub.
- Haz clic en Create application.
- Obtener las API Keys:
Despues de crearla con exito, seras redirigido a la pagina de API Keys.
Encuentra la Publishable key (que comienza con
pk_) y la Secret key (que comienza consk_).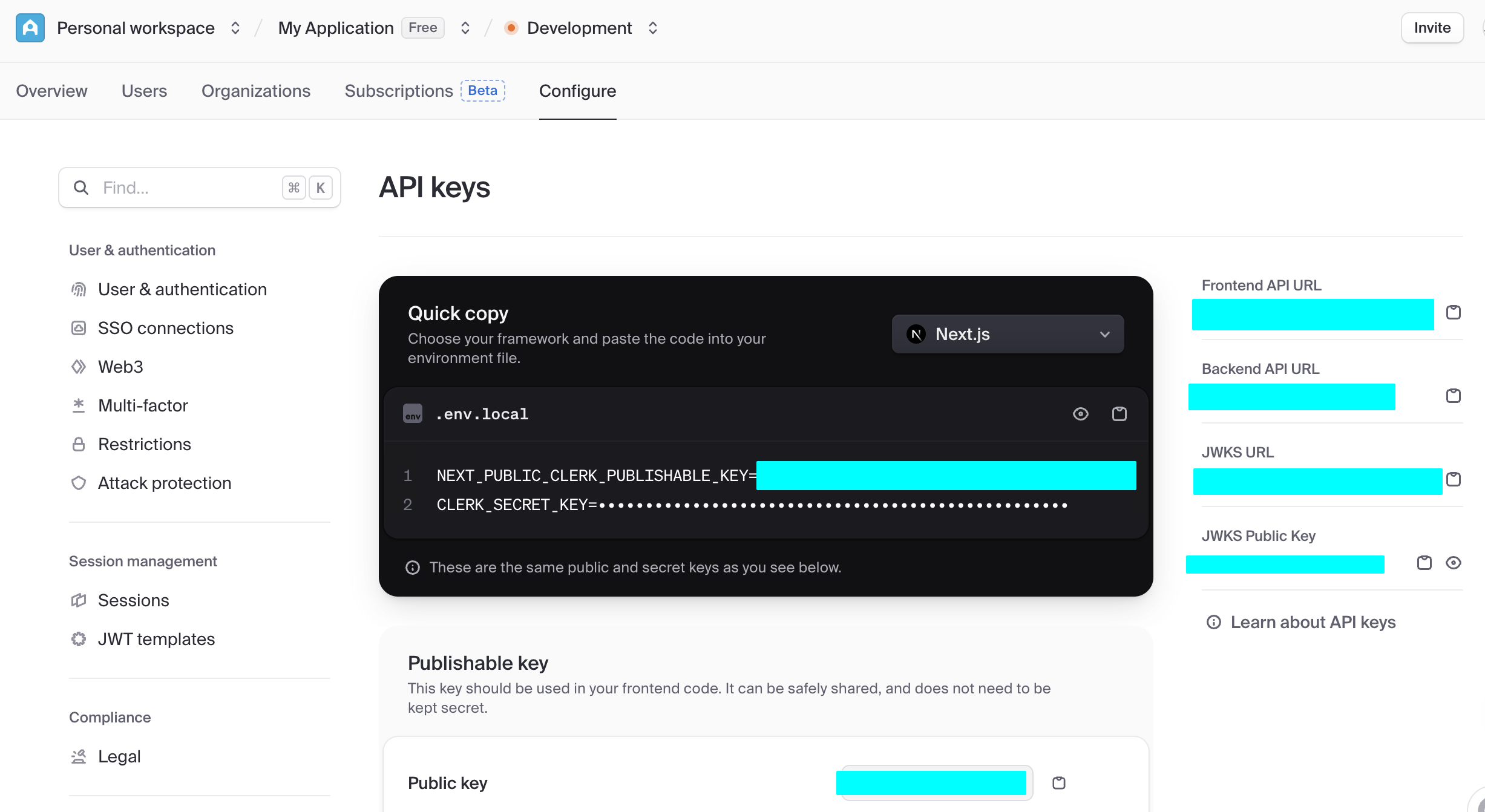
Copialas en tu archivo
.env.local(consulta el archivo.env.examplede este proyecto):bashNEXT_PUBLIC_CLERK_PUBLISHABLE_KEY=pk_test_... CLERK_SECRET_KEY=sk_test_...
5.6.2 Configurar la integracion nativa entre Supabase y Clerk
Antes de continuar, necesitamos integrar la relacion entre Supabase y Clerk, para facilitar la redireccion de autenticacion durante el inicio de sesion y controlar los permisos de acceso a bases de datos especificas. Supabase y Clerk ofrecen una capacidad de integracion oficial nativa que permite conectar rapidamente la autenticacion de ambas plataformas sin necesidad de configurar manualmente una logica de adaptacion compleja, simplificando enormemente el desarrollo de funciones como el inicio de sesion de usuarios y la validacion de permisos:
- Activar la integracion oficial con Supabase en Clerk
- Inicia sesion en Clerk Dashboard.
- En el menu de navegacion izquierdo, ve a Integrations.
- Encuentra y haz clic en Supabase en la lista.
- Activa el interruptor Enable Supabase (o haz clic en Activate integration).
- Paso clave: despues de activar con exito, la pagina mostrara tu Clerk Domain (el formato suele ser
https://<your-id>.clerk.accounts.devo tu dominio personalizado). Copia esta direccion de dominio, la necesitaras en el siguiente paso.
- Agregar Clerk como proveedor en Supabase
- Inicia sesion en Supabase Dashboard y entra en tu proyecto.
- En el menu de navegacion izquierdo, ve a Authentication > Sign In / Up (o haz clic directamente en Providers).
- Haz clic en el boton Add provider y selecciona Clerk de la lista desplegable.
- En el campo Clerk Domain que aparece, pega la direccion de dominio que copiaste de Clerk.
- Haz clic en Save para guardar la configuracion.
5.6.3 Sincronizar datos de usuarios a Supabase a traves de Webhooks
La integracion por si sola solo satisface la necesidad de verificar permisos, pero no sincroniza automaticamente la informacion de los usuarios ya registrados en Clerk hacia Supabase. Para facilitar la gestion, necesitamos mantener una copia de seguridad de los usuarios en la tabla public.users de Supabase, para poder realizar consultas asociadas o analisis de datos. Podemos implementar esta funcionalidad a traves de Clerk Webhooks; el proceso completo es el siguiente:
- Clerk envia una notificacion: cuando un usuario se registra o actualiza su perfil en Clerk, este envia una solicitud POST a la URL del Webhook que hemos configurado.
- Supabase recibe y escribe: la Edge Function recibe la solicitud, verifica la firma (para garantizar la seguridad) y luego actualiza los datos del usuario en la tabla de la base de datos de Supabase.
Antes de comenzar, necesitamos configurar las tablas de datos necesarias para la sincronizacion:
-- File: init.sql
-- 1. Create `users` table for synced Clerk users
-- This table will store user data pushed from Clerk Webhooks.
CREATE TABLE public.users (
id TEXT NOT NULL PRIMARY KEY, -- Corresponds to Clerk User ID
email TEXT,
first_name TEXT,
last_name TEXT,
image_url TEXT,
created_at TIMESTAMPTZ DEFAULT NOW(),
updated_at TIMESTAMPTZ DEFAULT NOW()
);
-- 2. Enable Row Level Security (RLS) on the table
-- This is an important security measure to ensure users cannot access any data by default.
ALTER TABLE public.users ENABLE ROW LEVEL SECURITY;
-- 3. Create RLS policies
-- Policy 1: Allow authenticated users to read their own user info.
-- `auth.jwt()->>'sub'` extracts the user ID from the JWT provided by Clerk.
CREATE POLICY "Authenticated users can view their own user record"
ON public.users FOR SELECT
TO authenticated
USING ( (SELECT auth.jwt()->>'sub') = id );
-- Policy 2: Allow users to update their own info.
CREATE POLICY "Authenticated users can update their own user record"
ON public.users FOR UPDATE
TO authenticated
USING ( (SELECT auth.jwt()->>'sub') = id );Y habilitar la Edge Function correspondiente en Supabase:
// File path: supabase/functions/clerk-webhooks/index.ts
import { serve } from 'https://deno.land/std@0.177.0/http/server.ts'
import { Webhook } from 'npm:svix'
import { createClient } from 'https://esm.sh/@supabase/supabase-js@2'
// Get Clerk Webhook signing secret from environment variables
const CLERK_WEBHOOK_SECRET = Deno.env.get('CLERK_WEBHOOK_SECRET')
if (!CLERK_WEBHOOK_SECRET) {
throw new Error('CLERK_WEBHOOK_SECRET is not set in environment variables')
}
const supabaseAdmin = createClient(
Deno.env.get('SUPABASE_URL')!,
Deno.env.get('SUPABASE_SERVICE_ROLE_KEY')!
)
serve(async (req) => {
try {
// 1. Get Svix signature info from request headers
const headers = Object.fromEntries(req.headers)
const svix_id = headers['svix-id']
const svix_timestamp = headers['svix-timestamp']
const svix_signature = headers['svix-signature']
if (!svix_id || !svix_timestamp || !svix_signature) {
return new Response('Missing Svix headers', { status: 400 })
}
const payload = await req.json()
const body = JSON.stringify(payload)
// 2. Verify Webhook signature validity using the secret
const wh = new Webhook(CLERK_WEBHOOK_SECRET)
const evt = wh.verify(body, {
'svix-id': svix_id,
'svix-timestamp': svix_timestamp,
'svix-signature': svix_signature,
})
const { id } = evt.data
const eventType = evt.type
console.log(`Received webhook event: ${eventType} for user: ${id}`)
// 3. Execute database operations based on event type
switch (eventType) {
case 'user.created': {
const { id, first_name, last_name, image_url, email_addresses } = evt.data
const { error } = await supabaseAdmin.from('users').insert({
id,
first_name,
last_name,
image_url,
email: email_addresses[0]?.email_address,
})
if (error) throw error
console.log(`User ${id} created in Supabase.`)
break
}
case 'user.updated': {
const { id, first_name, last_name, image_url, email_addresses } = evt.data
const { error } = await supabaseAdmin
.from('users')
.update({
first_name,
last_name,
image_url,
email: email_addresses[0]?.email_address,
updated_at: new Date().toISOString(), // Update timestamp
})
.eq('id', id)
if (error) throw error
console.log(`User ${id} updated in Supabase.`)
break
}
case 'user.deleted': {
// For delete events, ID might be at the top level
const deletedId = id
if (!deletedId) {
return new Response('Deleted user ID not found', { status: 400 })
}
const { error } = await supabaseAdmin.from('users').delete().eq('id', deletedId)
if (error) throw error
console.log(`User ${deletedId} deleted from Supabase.`)
break
}
}
return new Response('Webhook processed successfully', { status: 200 })
} catch (err) {
console.error('Error processing webhook:', err.message)
return new Response(`Webhook Error: ${err.message}`, { status: 400 })
}
})Despues de inicializar las tablas de datos y funciones de Supabase, tambien necesitas habilitar el soporte de Webhooks en Clerk:
- En Clerk Dashboard -> Webhooks, agrega un Endpoint e ingresa la URL de tu Supabase Edge Function.
- Selecciona los eventos
user.created,user.updated,user.deleted, etc.
Una vez configurado con exito, podras ver diferentes mensajes de solicitud en Message Attempts; haz clic en ellos para ver los resultados detallados de los parametros de respuesta. Si el webhook tiene problemas al solicitar la Edge Function, podras encontrar rapidamente la razon detallada en los valores devueltos. Te recomendamos comparar simultaneamente la informacion de los registros de solicitudes de Clerk y Supabase para analizar si la configuracion de cada funcion es correcta.
5.6.4 Soporte de inicio de sesion con terceros en Clerk
Antes de profundizar en como Clerk soporta el inicio de sesion con terceros, aclaremos dos conceptos fundamentales: entorno de desarrollo y entorno de produccion. Estos son las dos etapas clave desde el "desarrollo y pruebas" hasta el "lanzamiento en produccion" de un software, y sus posiciones, usos y requisitos de seguridad son completamente diferentes:
- Entorno de desarrollo: el entorno utilizado por los desarrolladores en sus servidores locales o de prueba, exclusivamente para desarrollo de funcionalidades, depuracion y verificacion interna (como un servicio local en localhost:3000), no esta abierto al publico.
- Entorno de produccion: el entorno publico orientado a usuarios reales despues del lanzamiento oficial de la aplicacion (como plataformas desplegadas en Vercel, Alibaba Cloud, etc., en https://my-app.com).
Clerk distingue entre estos dos entornos para el inicio de sesion social, equilibrando esencialmente la "eficiencia de desarrollo" con la "seguridad de produccion": en la fase de desarrollo se busca reducir configuraciones redundantes para validar funcionalidades rapidamente, mientras que en produccion se necesitan credenciales exclusivas para garantizar la seguridad de los datos, cumpliendo simultaneamente con las reglas de plataformas OAuth de terceros como Google y GitHub (las aplicaciones en produccion deben vincular dominios y credenciales exclusivos, no se permite el uso de recursos compartidos). A continuacion se detallan las diferencias de configuracion del inicio de sesion social de Clerk en ambos entornos:
- Verificacion rapida en entorno de desarrollo
En el entorno de desarrollo, Clerk ya tiene preconfiguradas credenciales OAuth compartidas y URIs de redireccion predeterminadas, sin necesidad de ir a GitHub/Google para solicitar credenciales exclusivas. Los pasos son los siguientes:
Inicia sesion en Clerk Dashboard y ve a la pagina SSO connections en la barra de navegacion izquierda.
Haz clic en Add connection y selecciona For all users.
En el menu desplegable Choose provider, selecciona GitHub o Google segun tus necesidades.
Haz clic directamente en Add connection; Clerk completara automaticamente la vinculacion con las credenciales compartidas.
Despues de la configuracion, inicia la aplicacion localmente (por ejemplo,
localhost:3000) y haz clic en "Sign in with GitHub/Google"; Clerk proxysara automaticamente la solicitud de inicio de sesion, verificando rapidamente que la funcionalidad funciona correctamente.
- Configuracion de credenciales personalizadas en entorno de produccion
(Nota: si encuentras alguna inconsistencia con lo esperado, se recomienda leer la documentacion oficial para probar los metodos mas recientes.)
Despues de desplegar la aplicacion (por ejemplo, en Vercel, Alibaba Cloud) y cambiar a la Clerk Production Instance, las credenciales compartidas dejan de funcionar, y es necesario configurar credenciales OAuth personalizadas para GitHub/Google (se recomienda tener abierto tanto el Clerk Dashboard como la pagina de la plataforma de terceros para facilitar la operacion simultanea):
- Operaciones previas generales (consola de Clerk):
- Ve a la pagina SSO connections de Clerk, haz clic en Add connection y selecciona For all users.
- Selecciona la plataforma objetivo (GitHub/Google), asegurandote de activar Enable for sign-up and sign-in y Use custom credentials.
- Copia la Authorization Callback URL (para GitHub) o Authorized Redirect URI (para Google) que aparece en la pagina, guardalas en un lugar seguro y no cierres la pagina/ventana actual.
- 2.1 Configuracion de la plataforma GitHub:
- Inicia sesion en GitHub y ve a Developer Settings (ruta: avatar -> Settings -> Developer settings -> OAuth Apps).
- Haz clic en New OAuth app y completa la informacion:
Application name(nombre de la aplicacion),Homepage URL(dominio de produccion, comohttps://my-app.com),Authorization Callback URL(pega la direccion copiada de Clerk). - Haz clic en Register application, luego en Generate a new client secret, y guarda el Client ID y Client Secret generados (el Secret solo se muestra una vez).
- Vuelve a la ventana emergente de Clerk, pega el Client ID y Client Secret, y haz clic en Add connection para completar la configuracion (si cerraste la ventana, puedes encontrar la conexion de GitHub en SSO connections y completar los datos en la seccion "Use custom credentials").
- 2.2 Configuracion de la plataforma Google:
- Inicia sesion en Google Cloud Console, selecciona un proyecto existente o crea uno nuevo (como "My App Production").
- Haz clic en el menu superior izquierdo -> APIs & Services -> Credentials, luego en Create Credentials -> OAuth client ID (para la primera configuracion necesitas completar la configuracion del OAuth consent screen, seleccionando "External" y llenando la informacion de la aplicacion).
- Selecciona Application type como Web application y configura:
Authorized JavaScript origins: agrega el dominio de produccion (comohttps://my-app.com,https://www.my-app.com); para verificacion local puedes agregarhttp://localhost:numero_de_puerto.Authorized Redirect URIs: pega la direccion copiada de Clerk.
- Haz clic en Create, guarda el Client ID y Client Secret de la ventana emergente, vuelve a la ventana de Clerk para pegarlos y haz clic en Add connection.
- Notas importantes:
- Prohibido el inicio de sesion WebView: Google OAuth no soporta el inicio de sesion en navegadores integrados en aplicaciones; consulta la documentacion oficial de Google para ajustar esto.
- Cambiar el estado de publicacion: el estado "Testing" predeterminado solo soporta 100 usuarios de prueba; necesitas cambiar el "Publishing status" a In production en el OAuth consent screen (requiere aprobacion de Google).
- Bloquear subdirecciones de correo: Clerk bloquea por defecto los correos de Google que contienen
+/=/#(comouser+alias@example.com); puedes activar o desactivar Block email subaddresses en la pagina de detalles de la conexion de Google (se recomienda activarlo para mejorar la seguridad). - Soporte para Google One Tap: una vez completada la configuracion, puedes integrar el componente
<GoogleOneTap />de Clerk para implementar un "inicio de sesion con un clic"; consulta la documentacion de componentes de Clerk.
- Probar la conexion de inicio de sesion con terceros
Despues de completar la configuracion, verifica la funcionalidad a traves del Account Portal integrado de Clerk:
- Ve al Clerk Dashboard y accede a la pagina Account Portal en la barra de navegacion izquierda.
- En el modulo "Sign-in", a la derecha, haz clic en el boton "visitar pagina de inicio de sesion" para ir a la pagina de inicio de sesion del entorno correspondiente:
- Entorno de desarrollo:
https://tu-dominio.accounts.dev/sign-in(comohttps://my-app.accounts.dev/sign-in). - Entorno de produccion:
https://accounts.tu-dominio.com/sign-in(comohttps://accounts.my-app.com/sign-in).
- Entorno de desarrollo:
- Haz clic en "Sign in with GitHub/Google" e inicia sesion con la cuenta de la plataforma correspondiente; si se redirige correctamente y vuelve a la aplicacion, significa que la conexion esta configurada correctamente.
6. De Supabase a mas componentes de desarrollo backend (Avanzado)
En las secciones anteriores, nos hemos centrado principalmente en la perspectiva de Supabase para ver que problemas puede resolver "una plataforma backend integral centrada en Postgres": autenticacion, base de datos, almacenamiento de archivos, comunicacion en tiempo real y funciones perifericas, todos integrados en una misma consola, listos para usar y con una experiencia unificada, ideal para arranques rapidos y proyectos medianos y pequenos.
Pero desde una perspectiva mas a largo plazo y mas orientada a la ingenieria, cada una de las capacidades que ofrece Supabase (Auth / Storage / Edge Functions / Realtime / Database) tiene alternativas profesionales correspondientes en la industria, incluyendo tanto plataformas BaaS similares como servicios en la nube y componentes de codigo abierto mas especializados. Como desarrolladores ambiciosos y equipos emergentes, conocer estas opciones alternativas tiene varios beneficios:
- Determinar si el proyecto actual es suficiente "usando solo Supabase" o si alguna area necesita un servicio especializado mas profesional, economico o facil de cumplir con normativas;
- Cuando el proyecto crece o los requisitos se vuelven mas complejos, si se puede reemplazar un modulo de Supabase (por ejemplo, cambiando a una plataforma de Auth especializada o almacenamiento de objetos) en lugar de quedar bloqueado por la plataforma desde el principio;
- Ampliar la vision de seleccion tecnica; incluso si no se cambia inmediatamente, poder tener una idea general de "si no uso la funcion X de Supabase, cuales son mis opciones habituales".
Esta seccion presentara las alternativas principales en el mercado para las capacidades que cubre Supabase, por ejemplo: autenticacion (Auth), almacenamiento de archivos (Storage), funciones perifericas (Edge Functions), comunicacion en tiempo real (Realtime) y hosting de bases de datos. Compararemos brevemente sus diferencias en caracteristicas funcionales, limites gratuitos/precios, facilidad de uso y popularidad en la comunidad, para que tengas una comprension mas completa del arsenal de herramientas de componentes backend.
Plataformas BaaS similares
Antes de comenzar, podemos revisar las plataformas BaaS similares; si sientes que Supabase no se ajusta bien a tus necesidades, puedes elegir diferentes alternativas segun tus requisitos.
| Plataforma/Servicio | Tipo | Limite gratuito/Precios | Caracteristicas / Escenarios de uso |
|---|---|---|---|
| Firebase (Google) | BaaS completamente gestionado (Auth + Firestore + Storage + Functions + Hosting) | Spark: limite gratuito ligero; Blaze: pago por uso (Firestore/Storage/Functions se facturan por separado) | La mas madura en la industria, buena documentacion, inicio rapido, fuerte capacidad en tiempo real. Adecuada para productos medianos y pequenos, equipos de movil/frontend. Desventajas: facturacion compleja, fuerte vinculacion, limitaciones de consultas (especialmente Firestore). |
| Supabase | BaaS de codigo abierto (Postgres + Auth + Storage + Edge Functions + Realtime) | Gratuito: 500MB DB, 1GB Storage, llamadas limitadas a funciones sin servidor; Pro: facturacion por instancia | La version SQL mas similar a Firebase; interfaz excelente, experiencia moderna, auto-hospedable. Adecuada para aplicaciones que necesitan SQL robusto, BI y capacidades transaccionales. Desventajas: costos mas altos para alta concurrencia o funciones complejas. |
| Appwrite Cloud | BaaS integral de codigo abierto (DB + Auth + Storage + Functions + Realtime) | Gratuito: DB/Storage/FaaS basicos incluidos; de pago por nivel de recursos | Experiencia moderna, API unificada, auto-hospedable; adecuado para iteracion rapida de aplicaciones amigables para desarrolladores. Desventajas: ecosistema menos maduro que Firebase/Supabase; rendimiento en aplicaciones grandes necesita pruebas. |
| Nhost | Postgres + GraphQL + Auth + Storage + Functions | Gratuito: 1GB DB, 1GB Storage, llamadas limitadas a funciones | Similar a "Supabase + Hasura"; GraphQL nativo; adecuado para equipos frontend y proyectos React/Next.js. Desventajas: ecosistema pequeno, costos aumentan con el uso. |
| AWS Amplify | Backend integral de AWS (Cognito + AppSync + DynamoDB + Storage + Functions + Hosting) | Gratuito: limite de Hosting + Cognito 10k MAU + limite parcial de funciones | Completo y exhaustivo, adecuado para equipos con base en AWS; confiabilidad de nivel empresarial. Desventajas: el mas dificil de aprender, servicios fragmentados; alto costo de mantenimiento para equipos emergentes. |
| Xata (crecimiento rapido en los ultimos anos) | Base de datos multimodelo + Auth + Edge Functions | Gratuito: 250k registros, 15GB de ancho de banda | Aunque es mas un "DB + API", proporciona Auth, archivos y logica, pudiendo servir como backend full-stack ligero. Excelente UI/experiencia de desarrollo. Desventajas: menos completo que Firebase/Supabase. |
| Convex (experiencia de desarrollador extremadamente fuerte) | Base de datos gestionada + Auth + Functions (frontend-first) | Version de desarrollo gratuita; de pago por volumen de solicitudes | Inicio extremadamente simple; no requiere schema; escribir funciones en el frontend es suficiente para usar el backend. Adecuado para MVPs/validacion rapida. Desventajas: alta vinculacion a la plataforma, costos de migracion elevados; no es un BaaS tradicional completo. |
Autenticacion (Auth)
| Herramienta/Plataforma | Caracteristicas funcionales | Limite gratuito/Precios | Escenarios de uso y pros/contras |
|---|---|---|---|
| Firebase Authentication | Servicio de autenticacion BaaS de Google, soporta email/contrasena, telefono, inicio de sesion social, anonimo, etc. Spark gratuito soporta hasta 50k MAU. | Spark (gratuito) 50k MAU; Blaze por uso | Integrado con el ecosistema Google, documentacion rica, inicio simple; funcionalidad completa (MFA, funciones de bloqueo, etc.), adecuado para desarrollo rapido. Pero esta vinculado a la plataforma Firebase; expandirse a otros servicios requiere configuracion adicional. |
| Auth0 (Okta) | Plataforma de autenticacion completamente gestionada, soporta inicio de sesion social, SSO empresarial, autenticacion multifactor, extensiones de reglas y funciones avanzadas. | Plan gratuito 25k MAU, de pago por MAU | Funcionalidad de nivel empresarial completa (RBAC, registros de auditoria, etc.), adecuada para aplicaciones medianas y grandes; interfaz amigable. Desventajas: costos altos cuando el MAU aumenta, version gratuita con funciones limitadas (por ejemplo, no incluye MFA/RBAC). Alta visibilidad en la comunidad, con muchos usuarios. |
| AWS Cognito | Servicio de identidad nativo de Amazon Cloud, soporta inicio de sesion social y SAML federado. Pool de usuarios con inicio de sesion directo ofrece 10k MAU gratuitos mensuales, el excedente se cobra a 0.0055 USD/MAU. | Gratuito 10k MAU/mes, excedente por uso | Profundamente integrado con el ecosistema AWS (puede integrarse sin problemas con API Gateway, Lambda, etc.), barrera de entrada ligeramente alta, documentacion compleja; limite gratuito limitado, adecuado para equipos acostumbrados a AWS. |
| Logto | Plataforma de autenticacion de codigo abierto, version auto-hospedada gratuita, plan de servicio en la nube gratuito hasta 50k MAU. Soporta multiples lenguajes, multi-tenant, OAuth/OIDC, etc. | Edicion comunitaria gratuita; Logto Cloud gratuito 50k MAU | Alternativa de codigo abierto a Auth0 de reciente popularidad, ya con mas de 10k Stars en GitHub. Facil de extender, auto-hospedaje reduce costos; desventajas: ecosistema y documentacion relativamente nuevos, tamano de la comunidad inferior a Firebase/Auth0. |
| Keycloak | Reconocida solucion IAM/SSO de codigo abierto, soporta usuario/contrasena, LDAP, SAML, OAuth2, etc. | Completamente gratuito, requiere auto-hospedaje | Funcionalidad potente y extensible (soporta control de permisos granular), funciones de nivel empresarial ricas; pero la complejidad de despliegue y mantenimiento es alta, con una curva de aprendizaje pronunciada para equipos pequenos. Requiere conocimientos de contenedores y operacion de clusters. |
Almacenamiento de archivos (Storage)
| Plataforma/Servicio | Tipo | Limite gratuito/Precios | Caracteristicas/Escenarios de uso |
|---|---|---|---|
| Amazon S3 | Almacenamiento de objetos en la nube (AWS) | AWS Free Tier ofrece 5GB de almacenamiento, 20k solicitudes GET/PUT/mes, excedente por uso | Almacenamiento de objetos estandar de la industria, alta confiabilidad, despliegue en multiples regiones globales. Funcionalidad completa, buena integracion con el ecosistema AWS; precios complejos, los nuevos usuarios necesitan entender las reglas de facturacion. |
| Google Cloud Storage (Firebase Storage) | Almacenamiento de objetos en la nube (Google) | Firebase Spark ofrece limite gratuito (1GB almacenamiento + limite de trafico), Blaze de pago | Estrechamente integrado con Firebase/Google Cloud, facil de gestionar; soporta aceleracion CDN, reglas de seguridad granulares. |
| Tencent Cloud COS / Alibaba Cloud OSS | Almacenamiento de objetos en la nube (China) | Pago por uso (cada uno ofrece creditos para nuevos usuarios, como OSS con 40GB gratis el primer ano) | Orientado al mercado chino, almacenamiento de objetos de alto rendimiento y gran escala; integrado con el ecosistema de nube chino, documentacion completa. Alibaba OSS es completo y con aceleracion global; Qiniu KODO se enfoca en procesamiento multimedia con costos mas bajos, adecuado para individuos y equipos pequenos. |
| MinIO | Almacenamiento compatible con S3 de codigo abierto | Codigo abierto gratuito (auto-hospedado) | Ligero, alto rendimiento, compatible con la API S3, adecuado para construir almacenamiento de objetos en nube privada o local. Documentacion y comunidad activas; requiere mantenimiento propio de la infraestructura. |
| Cloudinary / Imgix, etc. | Almacenamiento multimedia + CDN | Plan basico gratuito (como Cloudinary con 25GB/mes de ancho de banda gratuito) | Almacenamiento en la nube + CDN optimizado para imagenes/videos, con funciones avanzadas como transcodificacion y compresion en tiempo real. Adecuado para proyectos multimedia, pero la funcionalidad es muy especifica; usarlo como almacenamiento de archivos general tiene un costo mas alto. |
Edge Functions
| Plataforma/Servicio | Caracteristicas | Limite gratuito/Precios | Escenarios de uso y pros/contras |
|---|---|---|---|
| Cloudflare Workers | Entorno JavaScript/Wasmtime distribuido globalmente | Plan gratuito: 100k solicitudes/dia; plan estandar $5/mes con 10 millones de solicitudes | Ejecuta en nodos perifericos de Cloudflare con latencia extremadamente baja; adecuado para logica distribuida globalmente, renderizado de recursos estaticos, etc. Cuota gratuita relativamente pequena (equivalente a ~3 millones de solicitudes/mes), inicio simple. Desventajas: limitaciones del runtime (JS/Wasmtime) y herramientas de depuracion limitadas. |
| Vercel Edge Functions | Integracion sin interrupciones con Next.js/frameworks frontend, soporta JS/TS/Go | Hobby gratuito: 1 millon de llamadas a funciones/mes, 1 millon de solicitudes edge | Profundamente integrado con frameworks frontend, despliegue automatico; adecuado para aplicaciones web modernas. Cuota gratuita generosa, runtime predeterminado de 10s, ampliable a 60s. Desventajas: la version gratuita tiene funciones de colaboracion en equipo limitadas; dependencia de la plataforma Vercel. |
| Netlify Edge / Functions | Funciones Node.js en la nube + enrutamiento edge (NFT) | Gratuito: 300 tokens/mes (equivalente a ~1M solicitudes/mes); facturacion por creditos | Soporta funciones Node.js, procesamiento de enrutamiento en edge, etc. Cuota gratuita para construccion, funciones y ancho de banda, adecuado para despliegue full-stack frontend. Ventaja: facil de usar, integracion con despliegue Git; desventaja: la cuota gratuita requiere calculo (10k solicitudes = 3 puntos). |
| AWS Lambda@Edge / CloudFront Functions | Computacion edge sin servidor de AWS | AWS Lambda (1M solicitudes gratuitas/mes + 400k GB-s) + CloudFront desde $0.085/100k llamadas | Integrado con CloudFront, permite ejecutar codigo en el edge. Adecuado para quienes necesitan el ecosistema AWS (como permisos a nivel de nodo o tests A/B). Ventajas: flexible y potente; desventajas: configuracion compleja, latencia ligeramente mayor que Cloudflare/Vercel. |
Comunicacion en tiempo real (Realtime)
| Plataforma/Servicio | Caracteristicas funcionales | Limite gratuito/Precios | Escenarios de uso y pros/contras |
|---|---|---|---|
| Firebase Realtime Database / Firestore | Base de datos en tiempo real BaaS de Google; soporta notificacion de cambios en datos | Spark gratuito: 1GB de almacenamiento y limite en Realtime DB; Blaze por uso | Fuerte integracion con el ecosistema Firebase, escucha en tiempo real simple. Ventajas: inicio rapido con lo gratuito; desventajas: tipo de base de datos (JSON/NoSQL), capacidad de consultas complejas debil. |
| Ably | Plataforma de mensajes en tiempo real y pub/sub, soporta WebSocket, MQTT, etc. | Paquete gratuito: 6,000,000 mensajes/mes | Servicio de mensajes en tiempo real con funcionalidad completa, soporte de alta concurrencia; cuota gratuita de hasta 6 millones de mensajes/mes. Buena comunidad y documentacion, adecuado para distribucion global. |
| Pusher Channels | Servicio de push de eventos, soporta mecanismo de canales/eventos | Sandbox gratuito: 200k mensajes/dia, 100 conexiones concurrentes | Servicio WebSocket facil de usar, documentacion completa, adecuado para implementar rapidamente funcionalidades de chat y notificaciones. La version gratuita limita la cantidad de mensajes y conexiones; buena escalabilidad en la version de pago. |
| WebSocket/Socket.IO auto-construido | Construir tu propio servidor (Node.js, Elixir, Go, etc.) | Costo de auto-hospedaje (como gastos de servidor) | Maxima flexibilidad, permite personalizar protocolos y topologia segun las necesidades. Adecuado para equipos con control estricto de costos y madurez tecnica. Desventajas: requiere gestionar disponibilidad, escalabilidad y problemas entre dominios. |
Base de datos
| Plataforma/Herramienta | Tipo de base de datos | Limite gratuito/Precios | Caracteristicas principales |
|---|---|---|---|
| Neon (Serverless PostgreSQL) | Relacional (PostgreSQL) | Plan gratuito: 0.5GB almacenamiento, rama principal permanentemente en linea, 20h de computacion de ramas/mes | Postgres sin servidor nativo de la nube, soporta auto-escalado y ramificaciones (fork para pruebas). Cuota gratuita suficiente para proyectos pequenos, adecuado para flujos de desarrollo modernos. Funcionalidad de ramificacion potente, pero cuota gratuita pequena. |
| Aiven PostgreSQL | Relacional (PostgreSQL/MySQL) | Plan gratuito: 1GB almacenamiento, 1 vCPU, 1GB memoria | Servicio de base de datos gestionado, soporta migracion multi-region y multi-cloud. Ofrece MySQL, Redis y otros. Cuota gratuita adecuada para desarrollo y proyectos pequenos; version comercial soporta clusters de alta disponibilidad y monitoreo. |
| CockroachDB Cloud | SQL distribuido (compatible con PostgreSQL) | Plan gratuito: 10GB almacenamiento | Base de datos SQL distribuida similar a Google Spanner, con fragmentacion automatica y escalado. 10GB gratuitos bastante generosos; adecuado para aplicaciones que necesitan escalado horizontal y alta consistencia. Version comercial con SLA alto. |
| TiDB Cloud | Relacional distribuido (compatible con MySQL) | Plan gratuito: 5GB por nodo, maximo 25GB en total | Version en la nube del TiDB de codigo abierto, compatible con protocolo MySQL, arquitectura distribuida. Cuota gratuita generosa, adecuada para equipos familiarizados con MySQL, rendimiento excelente; desventajas: operacion relativamente compleja (para escenarios grandes). |
| MongoDB Atlas | Documental (NoSQL MongoDB) | Cluster M0 gratuito: 0.5GB almacenamiento | MongoDB en la nube, modelo de documentos flexible, soporta consultas ricas e indices. Base de datos gratuita de 0.5GB adecuada para pruebas y aplicaciones pequenas; escalado horizontal bajo demanda. Curva de aprendizaje ligeramente mas alta que bases de datos relacionales. |
| SQLPub | Multibase de datos (MySQL, PostgreSQL, Redis, etc.) | Plan gratuito: 36,000 solicitudes/hora, 30 conexiones concurrentes, 500MB almacenamiento | Plataforma de bases de datos integral, soporta multiples tipos de bases de datos. Version gratuita adecuada para aprendizaje y proyectos pequenos; ventaja: soporte de multiples DB, desventaja: cuota de almacenamiento pequena. |
Las alternativas anteriores tienen cada una sus puntos fuertes: las de codigo abierto son mas flexibles y controlables (Keycloak, MinIO, Socket.IO, Neon, CockroachDB, etc.), mientras que los servicios gestionados en la nube son mas faciles de usar (Firebase, Auth0, Cloudflare, Vercel, Netlify, AWS, Aiven, MongoDB Atlas, etc.). La eleccion debe basarse en los requisitos del proyecto, el stack tecnologico del equipo, el presupuesto y el ecosistema de la comunidad. Para proyectos personales, se recomienda priorizar servicios con cuotas gratuitas generosas y facil integracion (como la serie Firebase, Qiniu Storage, Cloudflare Workers, Neon, CockroachDB, etc.), mientras que para requisitos empresariales o de seguridad especificos, se pueden considerar soluciones mas completas pero mas costosas (Auth0, Alibaba/Tencent Cloud, AWS, TiDB/Aiven, etc.). Puedes seguir experimentando en aplicaciones reales hasta encontrar las herramientas de componentes de desarrollo backend mas adecuadas.
Resumen
En la leccion de hoy, hemos aprendido sistematicamente los conceptos basicos de las bases de datos, la definicion central de Supabase y los detalles de sus operaciones. Durante la practica posterior, puedes volver a consultar este documento como referencia en cualquier momento, segun los escenarios y necesidades reales de tu proyecto.
Recuerda siempre un principio importante: Primero completa, luego perfecciona! No es necesario lograr todo a la primera; podemos acercarnos progresivamente a mejores resultados a traves de iteracion continua. Te deseamos exito en tus futuros proyectos practicos!
Tareas posteriores a la leccion
- Desarrolla una aplicacion que incluya un sistema de gestion de usuarios y una base de datos. Idealmente, deberia incorporar mas funcionalidades de Supabase (Realtime / Cloud Storage / Edge Functions).