Desde NanoBanana: construye tu propio Agent de produccion de assets
Capitulo 1: Genera tu primer asset de imagen en 1 minuto
Antes de hablar de diseno, estilo o ingenieria de prompts, primero generemos una imagen con los minimos pasos posibles.
1.1 Conoce NanoBanana
Antes de hablar de estilo de diseno e ingenieria de prompts, resolvamos algo mas importante: confirmar que realmente puedes generar una imagen.
Los modelos grandes mainstream ya tienen capacidad de generacion y edicion de imagenes. Este tipo de modelos generalmente se llaman modelos generativos.
Para simplificar al maximo el proceso, este tutorial ha elegido un modelo que ya cuenta con capacidades estables de generacion y edicion de imagenes como ejemplo — NanoBanana. Es un modelo de generacion de imagenes lanzado por Google, con nombre oficial Gemini 3.1 Flash Image Preview, que soporta la generacion directa de imagenes a partir de lenguaje natural y tambien permite modificar imagenes existentes.

A nivel de capacidades, no hay diferencia fundamental con otros modelos que quizas hayas oido (como GPT-4o, Claude, Qwen, Midjourney, etc.): introduces una descripcion y el modelo genera el resultado.



Puedes entenderlo como un "pincel". En este capitulo solo nos importa una cosa: 👉 Si este pincel puede trazar la primera pincelada en tus manos.
En el uso practico, NanoBanana se puede utilizar directamente a traves de plataformas oficiales como Google AI Studio, o integrarse en el flujo de desarrollo mediante API. Este tutorial utiliza el metodo de llamada API. Ahora tambien se ha lanzado el modelo NanoBanana 2, puedes probar con el modelo mas reciente.
1.2 Generacion a nivel "Hello World"
Antes de comenzar, solo necesitas completar estos tres pasos:
- Crea una nueva carpeta en Trae
- Crea un nuevo archivo Python
- Copia y pega el siguiente codigo completo
Trae completara automaticamente el despliegue del entorno y la instalacion de dependencias necesarias, sin configuracion adicional.
El codigo necesitara el API Key de NanoBanana. Aqui no detallamos el proceso de solicitud — con que puedas obtener e ingresar los parametros correspondientes es suficiente. En esta etapa no buscamos entender cada linea de codigo, solo que se ejecute correctamente.
# /// script
# dependencies = [
# "gradio>=4.0.0",
# "pillow>=10.0.0",
# "requests>=2.31.0",
# ]
# ///
import gradio as gr
import requests
import base64
from PIL import Image
import io
import os
import time
import re
from typing import Optional, Dict, Any, List
# Configurar informacion del API
NANOBANANA_API_URL: str = "YOUR API URL"
NANOBANANA_API_KEY: str = "YOUR API KEY"
OUTPUT_DIR: str = "outputs"
# Asegurar que el directorio de salida existe
os.makedirs(OUTPUT_DIR, exist_ok=True)
def image_to_base64_data_uri(image: Image.Image) -> str:
"""
Convierte una imagen PIL a formato data URI compatible con OpenAI API.
"""
buffer = io.BytesIO()
# Convertir uniformemente a PNG para garantizar compatibilidad
image.save(buffer, format="PNG")
encoded = base64.b64encode(buffer.getvalue()).decode('utf-8')
return f"data:image/png;base64,{encoded}"
def base64_to_image(base64_str: str) -> Optional[Image.Image]:
"""
Convierte una cadena base64 pura a una imagen PIL.
"""
try:
image_bytes = base64.b64decode(base64_str)
return Image.open(io.BytesIO(image_bytes))
except Exception as e:
print(f"Error de decodificacion Base64: {e}")
return None
def extract_base64_from_response(content: Any) -> Optional[str]:
"""
Logica de analisis central: extrae datos Base64 de imagen del content devuelto por el API.
Compatible con formato Markdown y formato de lista estructurada.
"""
if not content:
return None
base64_data = None
# 1. Intento de extraccion estructurada (List)
# Formato de retorno correspondiente: [{"type": "image_url", "image_url": {"url": "data:..."}}]
if isinstance(content, list):
for part in reversed(content): # Busqueda en orden inverso, generalmente la imagen mas reciente esta al final
if isinstance(part, dict):
# Verificar campo image_url u output_image
img_field = part.get("image_url") or part.get("image") or part.get("output_image")
if isinstance(img_field, dict):
url = img_field.get("url", "")
if url.startswith("data:image/") and "," in url:
return url.split(",", 1)[1].strip()
# Si no hay imagen estructurada en la lista, intentar concatenar textos de la lista para buscar Markdown
text_parts = [
str(p.get("text", ""))
for p in content
if isinstance(p, dict) and p.get("type") in ["text", "input_text"]
]
content_str = "".join(text_parts)
else:
content_str = str(content)
# 2. Intento de extraccion con regex Markdown (String)
# Formato de retorno correspondiente: "Here is your image: "
pattern = re.compile(r"!\[.*?\]\((data:image/[^;]+;base64,[^)]+)\)", re.IGNORECASE)
match = pattern.search(content_str)
if match:
data_url = match.group(1)
if "," in data_url:
return data_url.split(",", 1)[1].strip()
return None
def synthesize(prompt: str, input_image: Optional[Image.Image]) -> Optional[Image.Image]:
"""
Llama al API de Nanobanana para generar.
"""
if not prompt or not prompt.strip():
gr.Warning("Por favor ingresa un prompt")
return None
print(f">>> Iniciando tarea: {prompt[:50]}...")
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {NANOBANANA_API_KEY}"
}
# Construir payload conforme al estandar OpenAI Vision / Chat
messages = []
if input_image is not None:
# Modo de entrada multimodal / imagen a imagen
print(">>> Imagen de entrada detectada, usando modo multimodal")
img_base64 = image_to_base64_data_uri(input_image)
messages.append({
"role": "user",
"content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": img_base64}}
]
})
else:
# Modo de texto a imagen puro
messages.append({
"role": "user",
"content": prompt
})
payload = {
"messages": messages,
# Usar el modelo verificado como disponible en el primer codigo
"model": "gemini-2.5-flash-image",
# Parametros opcionales, dependiendo del soporte del API
"stream": False
}
try:
# Aumentar tiempo de espera, la generacion de imagenes suele ser mas lenta
response = requests.post(NANOBANANA_API_URL, headers=headers, json=payload, timeout=120)
# Verificar estado HTTP
if response.status_code != 200:
error_msg = f"Error en solicitud API: {response.status_code} - {response.text}"
print(error_msg)
gr.Error(error_msg)
return None
result = response.json()
# Debug: imprimir parte de la respuesta, util para depuracion
print(f"Respuesta original del API (truncada): {str(result)[:200]}...")
# Extraer Content
content = None
if "choices" in result and len(result["choices"]) > 0:
content = result["choices"][0].get("message", {}).get("content")
if not content:
gr.Warning("La respuesta del API no contiene campo content")
return None
# Usar la logica verificada anteriormente para extraer Base64
base64_str = extract_base64_from_response(content)
if base64_str:
output_image = base64_to_image(base64_str)
if output_image:
return output_image
# Si no se extrajo imagen, puede que el modelo la haya rechazado o solo haya devuelto texto
text_content = str(content) if not isinstance(content, list) else " ".join([str(x) for x in content])
gr.Info(f"No se genero imagen, el modelo devolvio texto: {text_content[:100]}...")
return None
except requests.exceptions.Timeout:
gr.Error("Tiempo de espera agotado, intenta de nuevo mas tarde")
return None
except Exception as e:
import traceback
traceback.print_exc()
gr.Error(f"Error desconocido: {str(e)}")
return None
# Configuracion de la interfaz Gradio
with gr.Blocks(title="Nanobanana Image Generator") as app:
gr.Markdown("# 🍌 Nanobanana Text/Image to Image")
gr.Markdown("Basado en el modelo Gemini-2.5-Flash-Image, soporta texto a imagen e imagen a imagen.")
with gr.Row():
with gr.Column():
prompt_input = gr.Textbox(
label="Prompt (Indicacion)",
placeholder="Ejemplo: A cyberpunk cat holding a neon sign...",
lines=3
)
image_input = gr.Image(
label="Imagen de referencia (opcional, para imagen a imagen)",
type="pil",
height=300
)
submit_btn = gr.Button("Iniciar generacion", variant="primary")
with gr.Column():
image_output = gr.Image(label="Resultado generado", format="png")
submit_btn.click(
fn=synthesize,
inputs=[prompt_input, image_input],
outputs=image_output
)
if __name__ == "__main__":
app.launch(share=True)Cuando Trae indique que la ejecucion fue exitosa, haz clic en el enlace local que proporciona (generalmente http://127.0.0.1:7860).
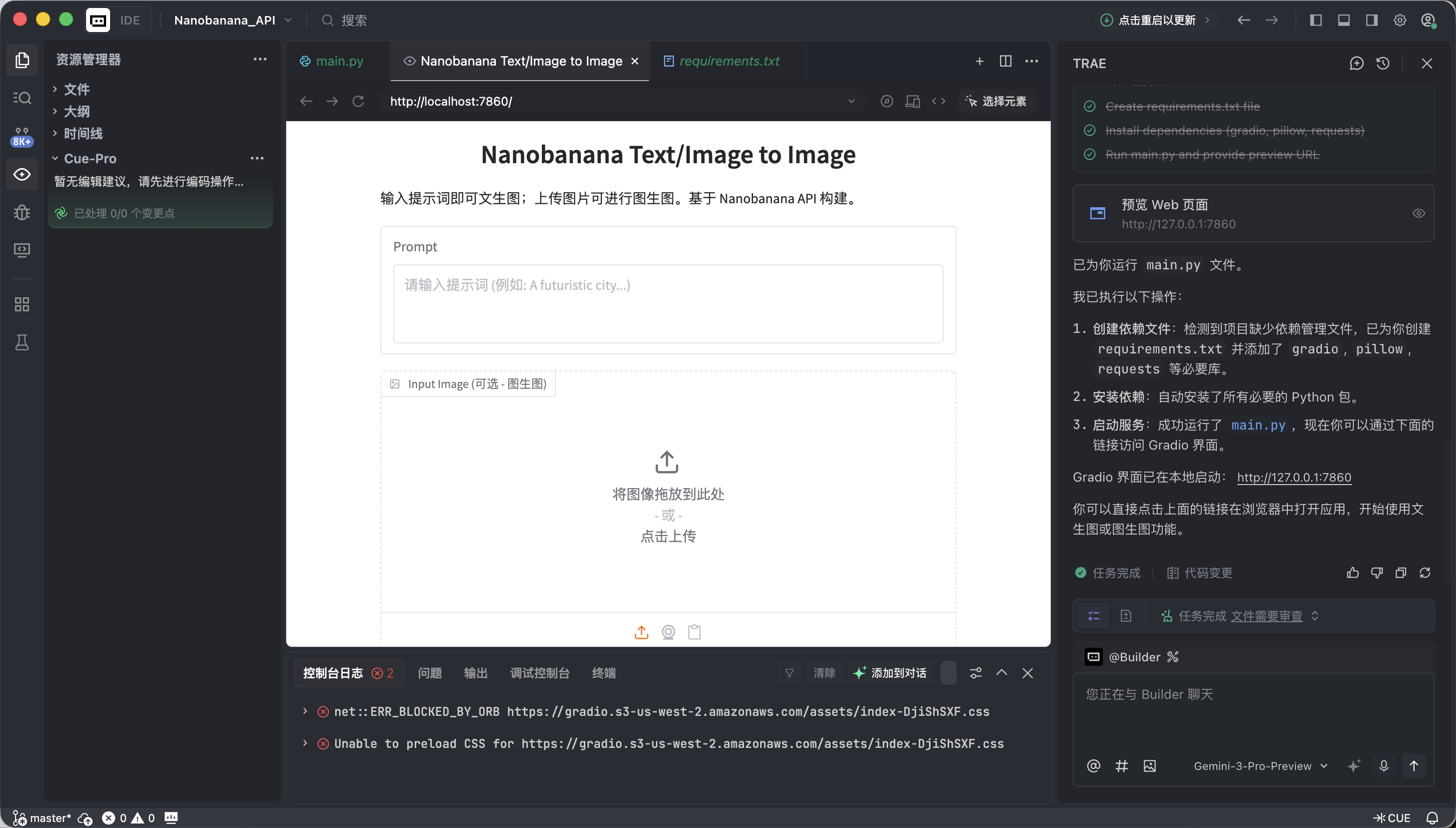
Si todo esta correcto, veras una interfaz de generacion de imagenes con IA que ya esta funcional.
Esta interfaz parece simple, pero ya cuenta con las dos capacidades mas centrales de las herramientas de generacion de imagenes de nivel comercial: texto a imagen e imagen a imagen.
- Izquierda: Zona de comandos (Input Zone) — aqui das las ordenes.
- Prompt (campo de indicacion): Ingresa tu descripcion creativa (se recomienda usar ingles).
- Input Image (campo de imagen de referencia):
- Modo texto a imagen: Manten este campo vacio.
- Modo imagen a imagen: Arrastra una imagen local aqui y la IA creara basandose en ella.
- Boton Submit: Haz clic para enviar la instruccion y comenzar la generacion.
- Derecha: Zona de resultados (Output Zone) — donde ocurre la magia, los resultados generados se mostraran aqui.
Ahora podemos intentar generar tu primera imagen!
El prompt utilizado en este ejemplo es:
A red apple
Este es un ejemplo deliberadamente simplificado, sin ninguna descripcion de estilo o parametros.
Flujo real
Despues de ejecutar el codigo, el flujo se puede resumir en tres pasos:
- Enviar la descripcion de texto al modelo
- El modelo genera la imagen correspondiente
- La imagen se guarda como archivo local
Despues de unos segundos, veras el resultado generado localmente. La generacion del modelo tiene aleatoriedad, por lo que el mismo prompt producira diferentes resultados. Puedes generar varias veces y elegir tu imagen favorita.
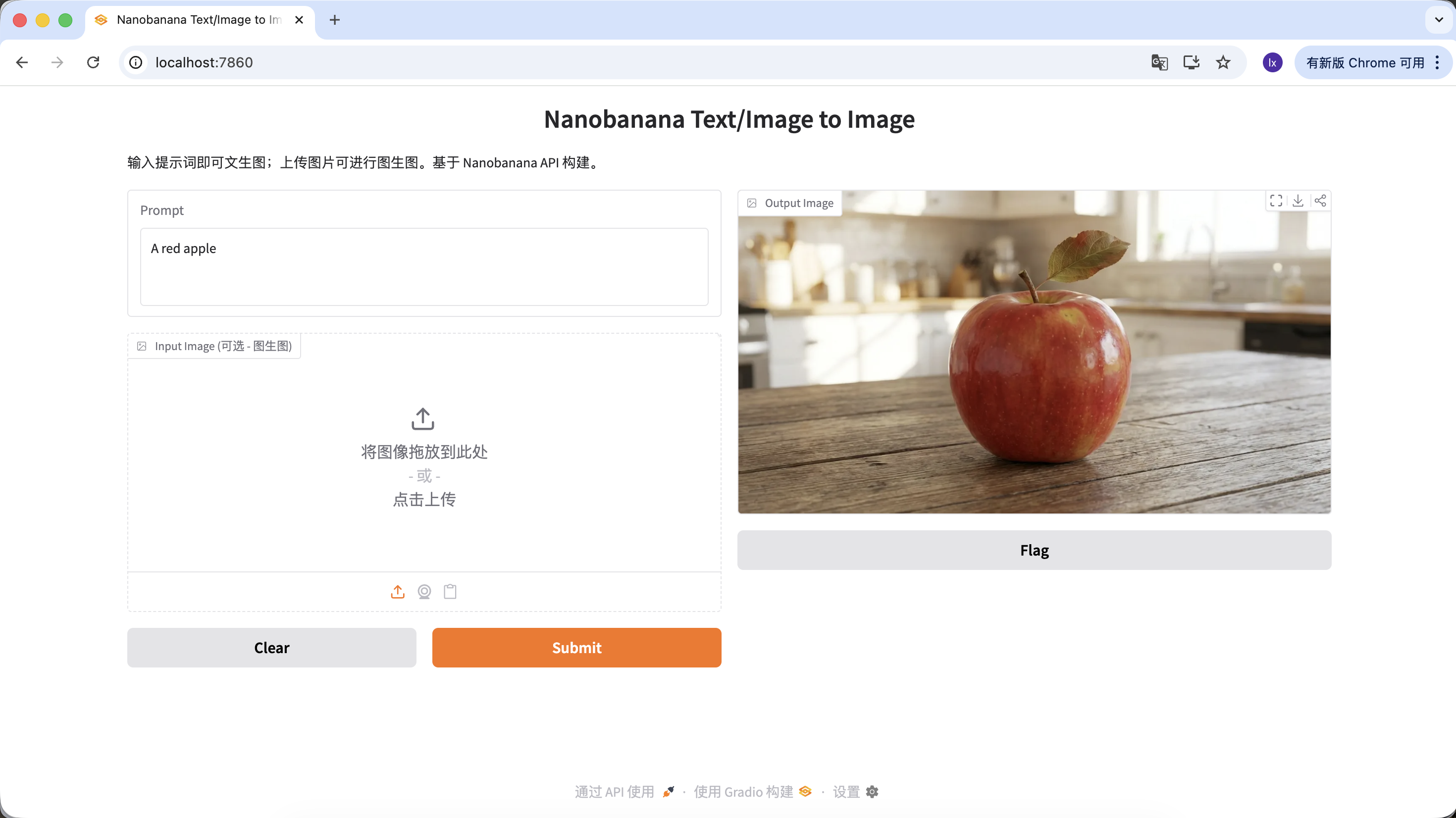
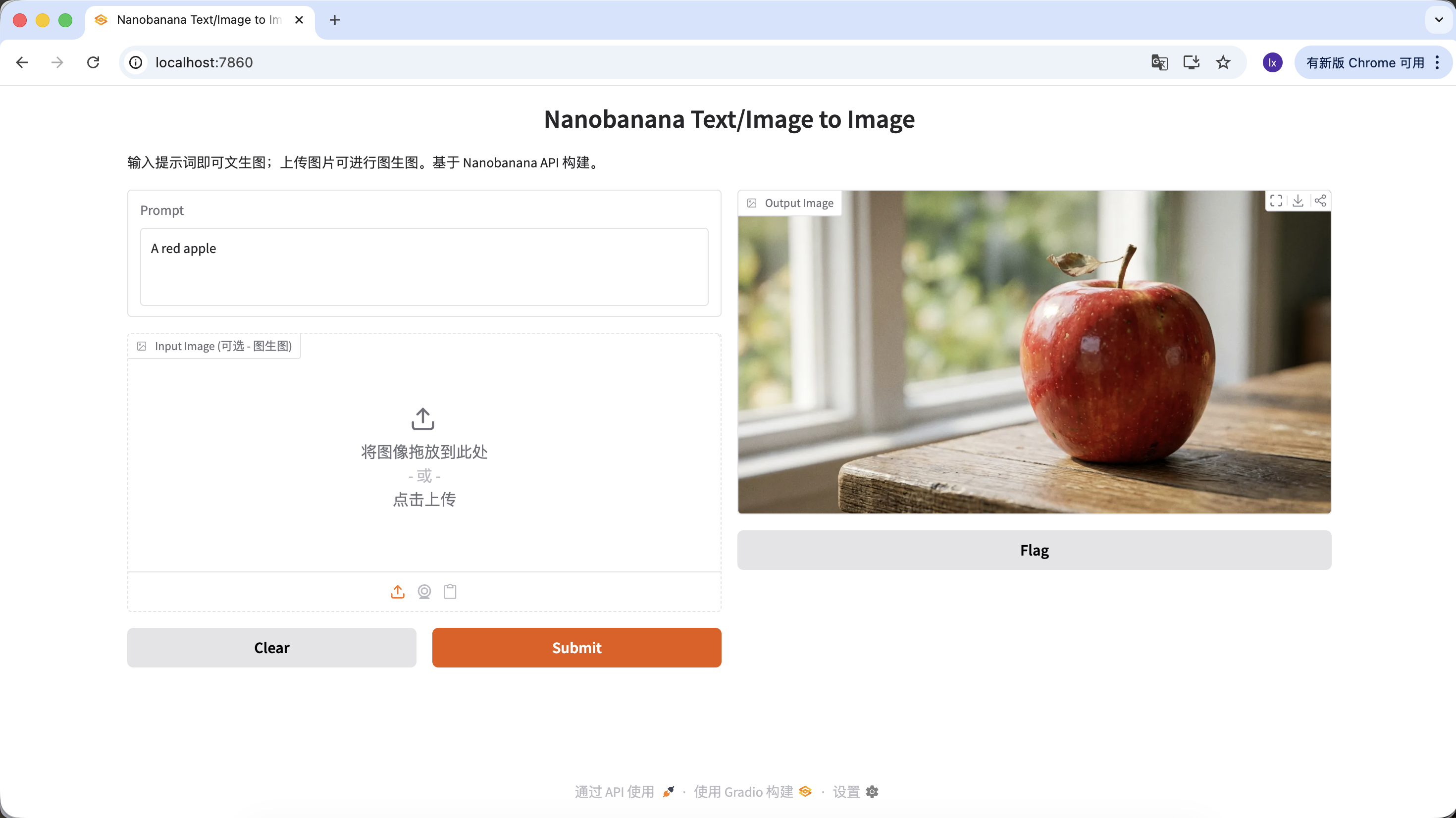
Tambien puedes enriquecer tu prompt, dandole mas descripcion y restricciones. Por ejemplo, con el siguiente prompt obtendras una imagen mas especial.
"A hyper-realistic close-up of a fresh red apple with water droplets on its skin, sitting on a dark rustic wooden table. Cinematic dramatic lighting, rim light, shallow depth of field, bokeh background, 8k resolution, macro photography."
(Un primer plano hiperrealista de una manzana roja fresca con gotas de agua en su piel, sobre una mesa de madera oscura y rustica. Iluminacion dramatica cinematografica, luz de contorno, poca profundidad de campo, fondo con efecto bokeh, resolucion 8k, fotografia macro.)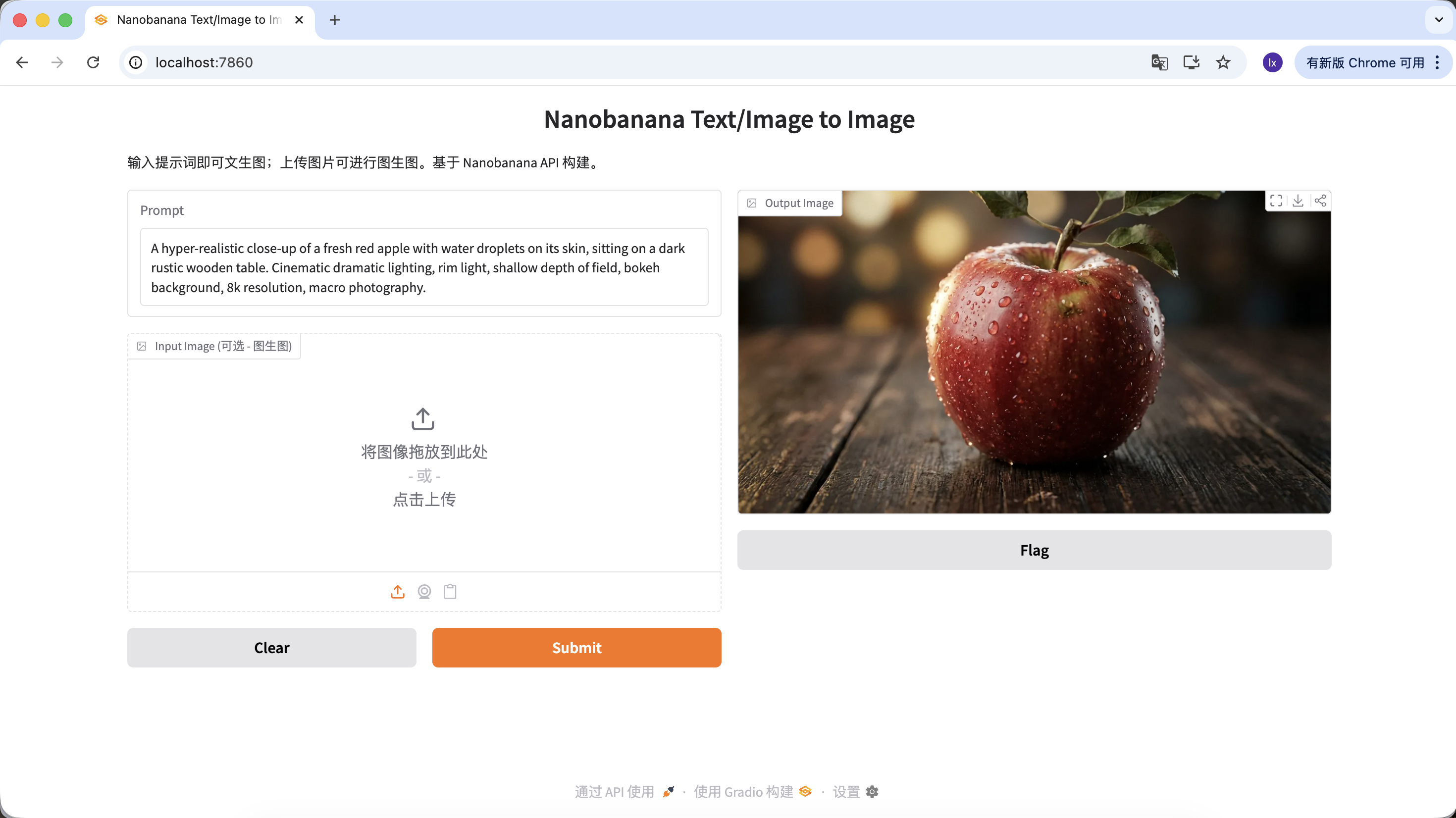
Haz clic en descargar en el area de Output Image para guardar la imagen localmente.
1.3 Escenarios comunes de generacion de assets con modelos de generacion de imagenes
En el trabajo practico, la generacion de imagenes con modelos grandes se usa mas para producir eficientemente assets de diseno que para crear obras de arte individuales.
Si observas los casos populares de cuentas de marketing de diseno, encontraras que su produccion se concentra principalmente en dos tipos de escenarios:
- Texto a imagen (de 0 a 1)
- Generacion con imagen de referencia (de 1 a N)
Primero: Texto a imagen — obtencion rapida de materiales de diseno
Este tipo de escenario se enfoca en la eficiencia. Cuando necesitas rellenar espacios vacios en el diseno (como estados vacios, avatares, ilustraciones), la IA actua esencialmente como una biblioteca de imagenes de generacion instantanea.
Generacion de assets de diseno UI
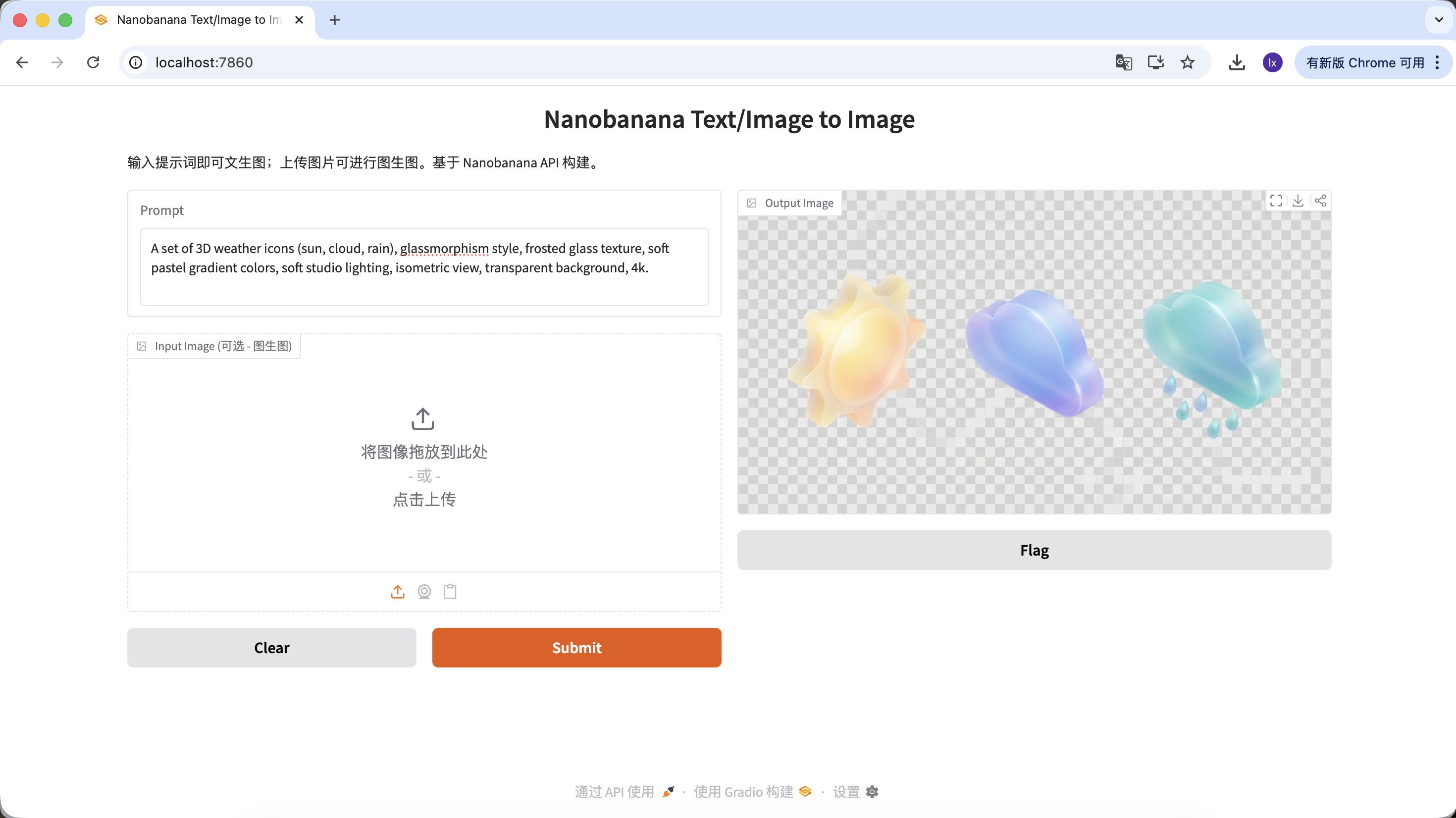
- Tendencia: Iconos 3D estilo glassmorphism o clay que se ven a menudo en Dribbble
- Manifestacion comun: Materiales transparentes, bordes luminosos, iconos de funciones o clima con colores de caramelo
Prompt de ejemplo:
A set of 3D weather icons (sun, cloud, rain), glassmorphism style, frosted glass texture, soft pastel gradient colors, soft studio lighting, isometric view, transparent background, 4k.
(Un conjunto de iconos 3D del clima, estilo glassmorphism, textura de cristal esmerilado, colores degradado pastel suaves, iluminacion de estudio, vista isometrica)
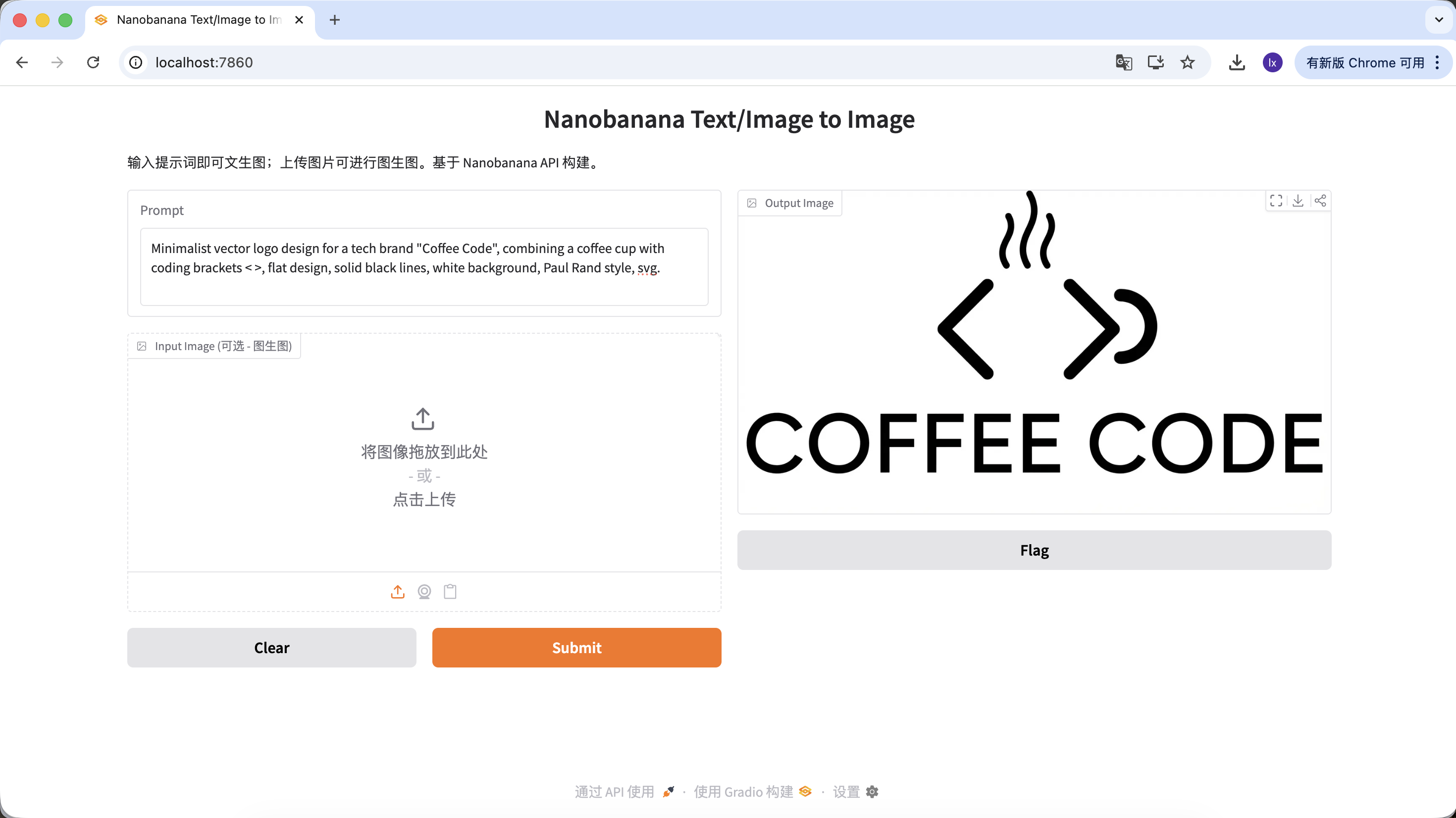
Generacion de logos
- Tendencia: Logos tecnologicos con lineas minimalistas y combinaciones geometricas
- Manifestacion comun: Esquema blanco y negro, diseno de espacio negativo, sensacion de marca clara
Prompt de ejemplo:
Minimalist vector logo design for a tech brand "Coffee Code", combining a coffee cup with coding brackets < >, flat design, solid black lines, white background, Paul Rand style, svg.
(Logo vectorial minimalista, combina taza de cafe con simbolos de codigo, diseno flat, lineas negras puras)
Generacion de imagenes de usuarios para sitios web
- Tendencia: Avatares 3D virtuales comunes en sitios web de SaaS, para evitar derechos de imagen de personas reales
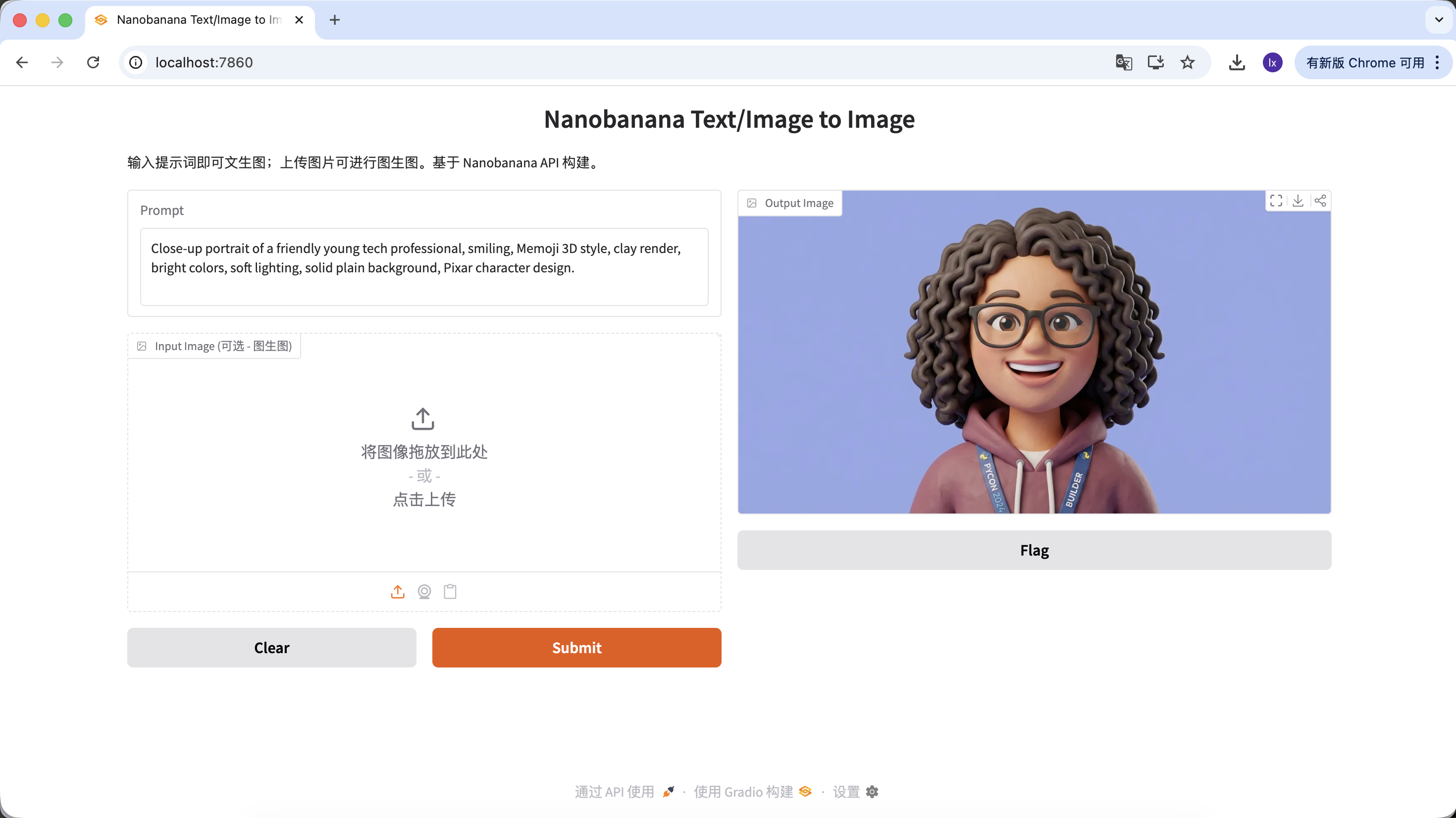
- Manifestacion comun: Expresion amigable, proporciones cartoon, estilo Pixar o Memoji
Prompt de ejemplo:
Close-up portrait of a friendly young tech professional, smiling, Memoji 3D style, clay render, bright colors, soft lighting, solid plain background, Pixar character design.
(Profesional tecnologico joven y amigable, estilo Memoji 3D, renderizado clay)
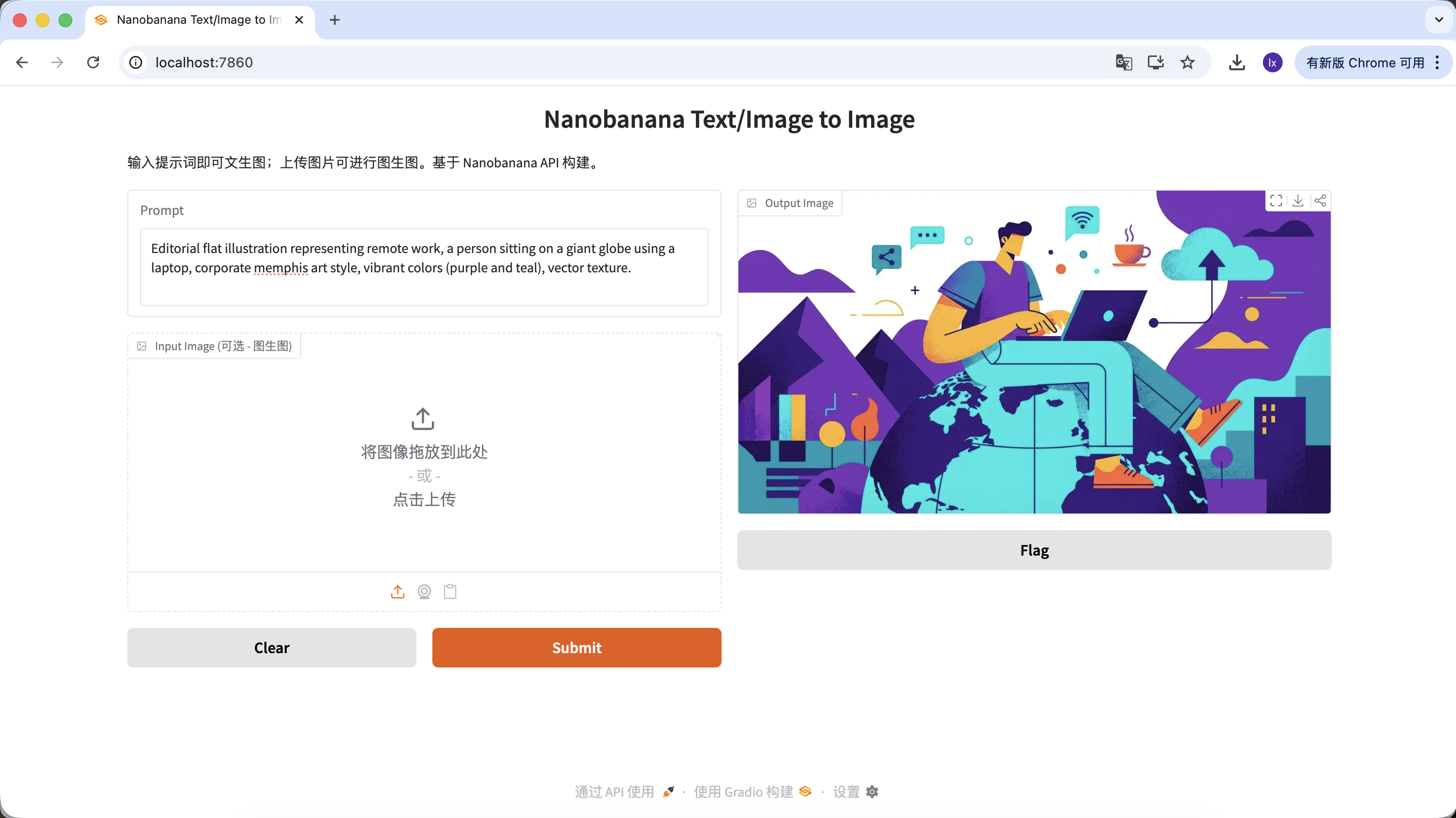
Generacion de ilustraciones para articulos
- Tendencia: Ilustraciones planas abstractas comunes en blogs de empresas tecnologicas
- Manifestacion comun: Esquema morado-azul, proporciones humanas exageradas, elementos UI flotantes
Prompt de ejemplo:
Editorial flat illustration representing remote work, a person sitting on a giant globe using a laptop, corporate memphis art style, vibrant colors (purple and teal), vector texture.
(Ilustracion plana de tema trabajo remoto, estilo memphis corporativo)
Segundo: Generacion con imagen de referencia — mantener la consistencia visual
Este tipo de escenario se enfoca mas en la escalabilidad. Se usa cuando ya tienes un visual principal satisfactorio y necesitas generar un conjunto completo de assets con estilo consistente.
Conjunto de botones o assets interactivos similares al visual principal
En el desarrollo de juegos, la consistencia de la UI es muy importante. Supongamos que ya tienes el boton "PLAY" de la pantalla principal y ahora necesitas expandir un conjunto completo de botones de funciones con estilo unificado (como pausa, configuracion, inicio). Solo con dibujo a mano es dificil garantizar que cada boton sea completamente consistente en brillo, perspectiva y valores de color.
Flujo de operacion basico:
- Guarda la imagen del boton azul "PLAY" existente

- Arrastralo al area Input Image de la interfaz, como referencia maestra para generaciones posteriores
- Manten la descripcion de estilo en el prompt sin cambios, solo modifica el contenido principal
En este flujo, con solo reemplazar la descripcion principal, puedes obtener botones con diferentes funciones pero estilo consistente.
Prompts de ejemplo:
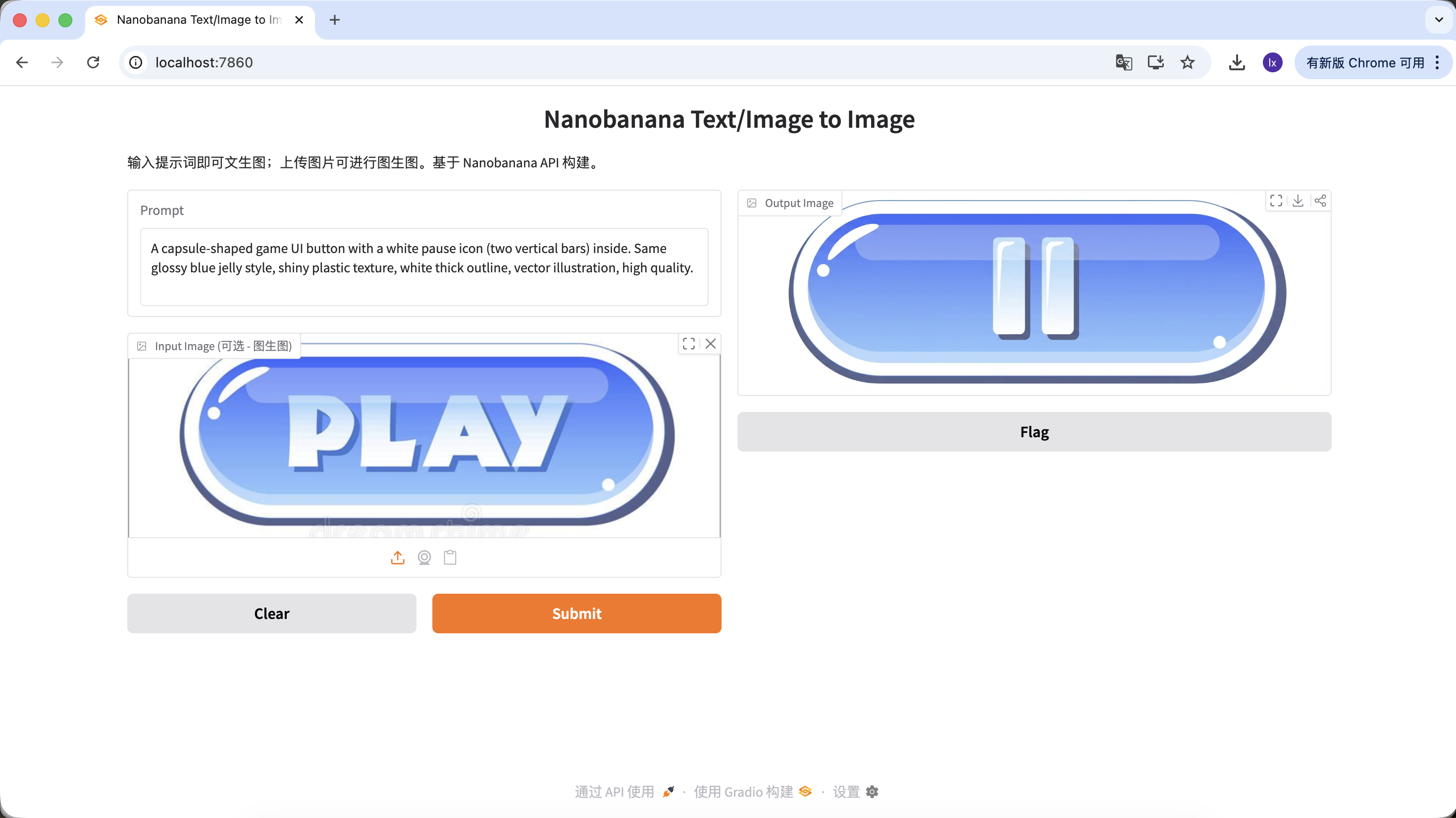
Variante A: Boton de pausa (tipo icono)
A capsule-shaped game UI button with a white pause icon (two vertical bars) inside. Same glossy blue jelly style, shiny plastic texture, white thick outline, vector illustration, high quality.
(Boton UI de juego en forma de capsula, icono de pausa blanco, textura jelly azul)
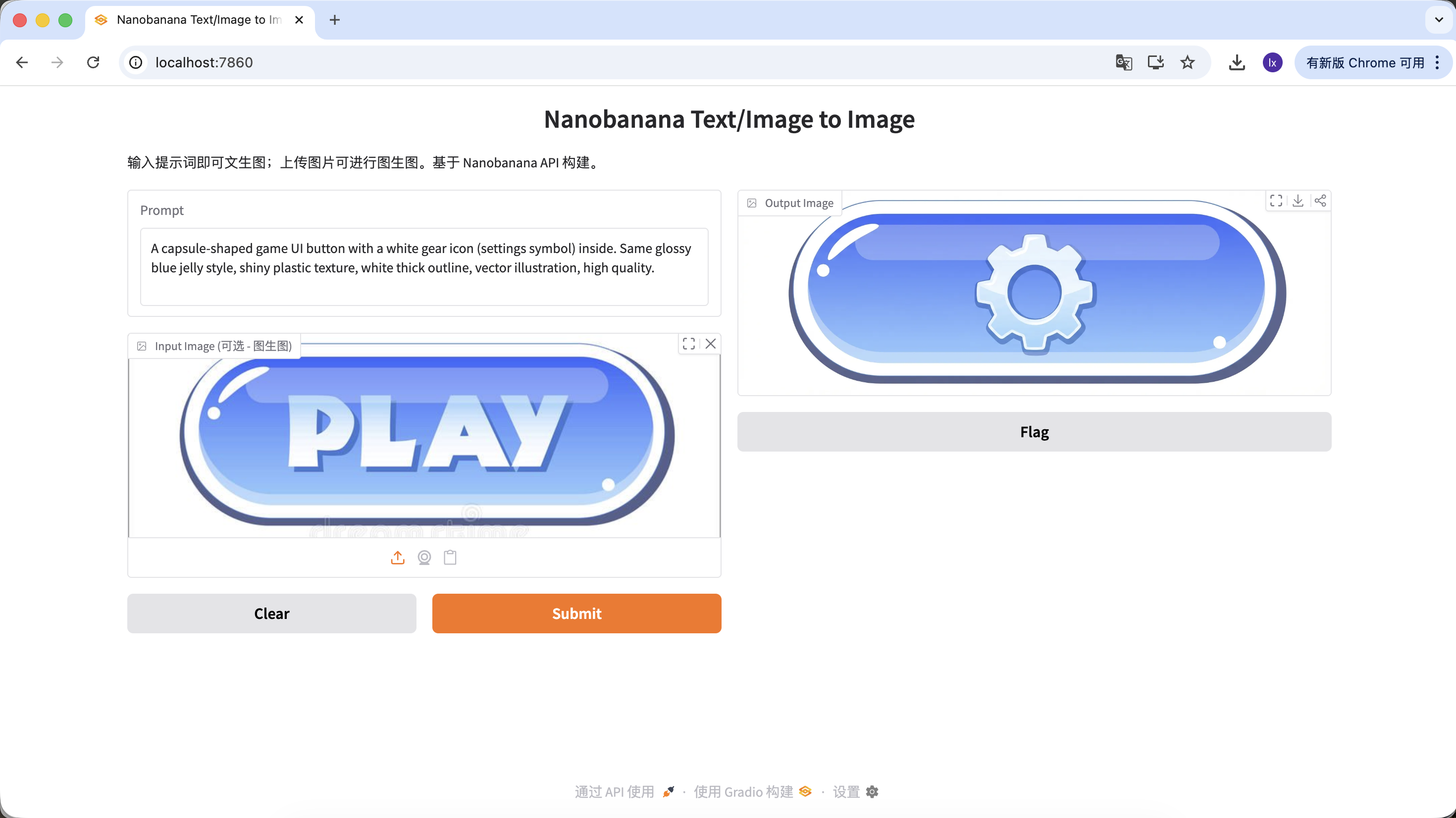
Variante B: Boton de configuracion (icono complejo)
A capsule-shaped game UI button with a white gear icon (settings symbol) inside. Same glossy blue jelly style, shiny plastic texture, white thick outline, vector illustration, high quality.
(Boton UI de juego en forma de capsula, icono de engranaje blanco, textura jelly azul)
Variante C: Boton de replay (cambio de forma)
Si necesitas ajustar la forma exterior del boton, puedes describir la forma directamente en el prompt. El modelo intentara cambiar la estructura mientras mantiene las caracteristicas del material.
A round game UI button with a white circular arrow icon (replay symbol) inside. Same glossy blue jelly style, shiny plastic texture, white thick outline, vector illustration, high quality.
(Boton UI de juego redondo, icono de flecha circular, textura jelly azul)

Con este conjunto de operaciones, no solo puedes reemplazar funciones e iconos de botones, sino incluso cambiar la forma del boton. Sin embargo, todos los resultados generados aun mantienen una alta consistencia en material, color e iluminacion. Este es precisamente el valor central de los modelos grandes en escenarios de derivacion de assets de diseno.
Capitulo 2: Un asistente de generacion de imagenes mas obediente — Ejemplo con Lovart
En la primera parte, llamamos directamente a NanoBanana a traves de codigo y experimentamos el flujo basico de "entrada y generacion inmediata". Este metodo no tiene problemas cuando los requisitos son simples. Pero cuando las tareas de generacion comienzan a incluir mas restricciones, como por ejemplo:
- Se necesitan multiples imagenes con estilo consistente
- Se necesitan ajustes iterativos sobre resultados existentes
- Se necesita modificar dinamicamente la direccion de generacion segun la entrada del usuario
El metodo de llamada unica se vuelve gradualmente insuficiente.
En este momento, es necesario introducir un AI Agent (agente inteligente). Esta seccion usa Lovart como ejemplo para mostrar como cambia el flujo de trabajo completo cuando el modelo de generacion de imagenes tiene una "capa de pensamiento". Nota! Esto no es publicidad, solo es para ayudar a todos a captar rapidamente la conveniencia de los AI Agents~
2.0 Primer encuentro con Lovart: tu agente de diseno AI
Lovart es una herramienta de diseno basada en Agent en la web. Comparada con las herramientas comunes de generacion de imagenes, tiene una capa adicional de "pensamiento y planificacion" antes de la generacion.
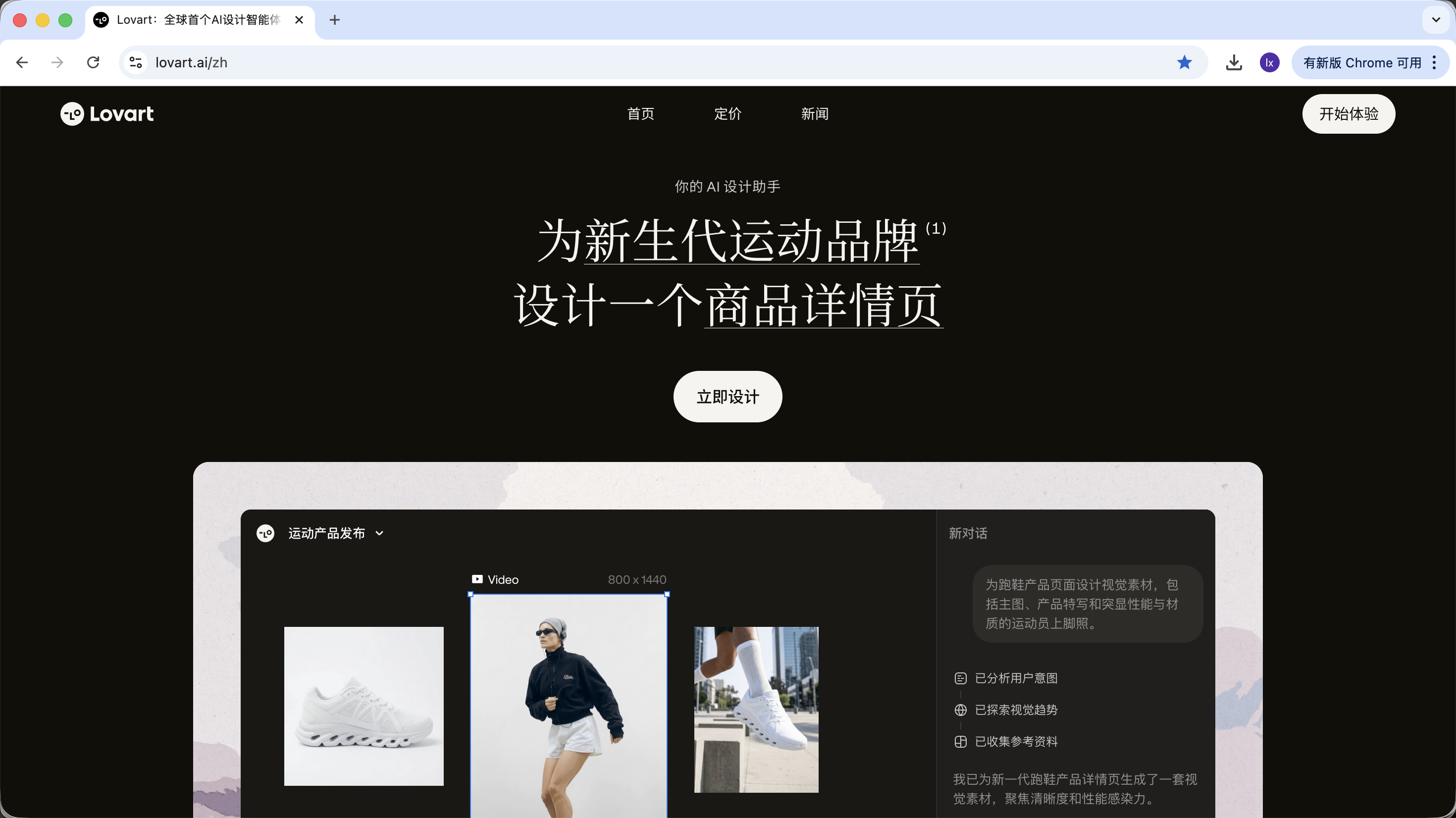
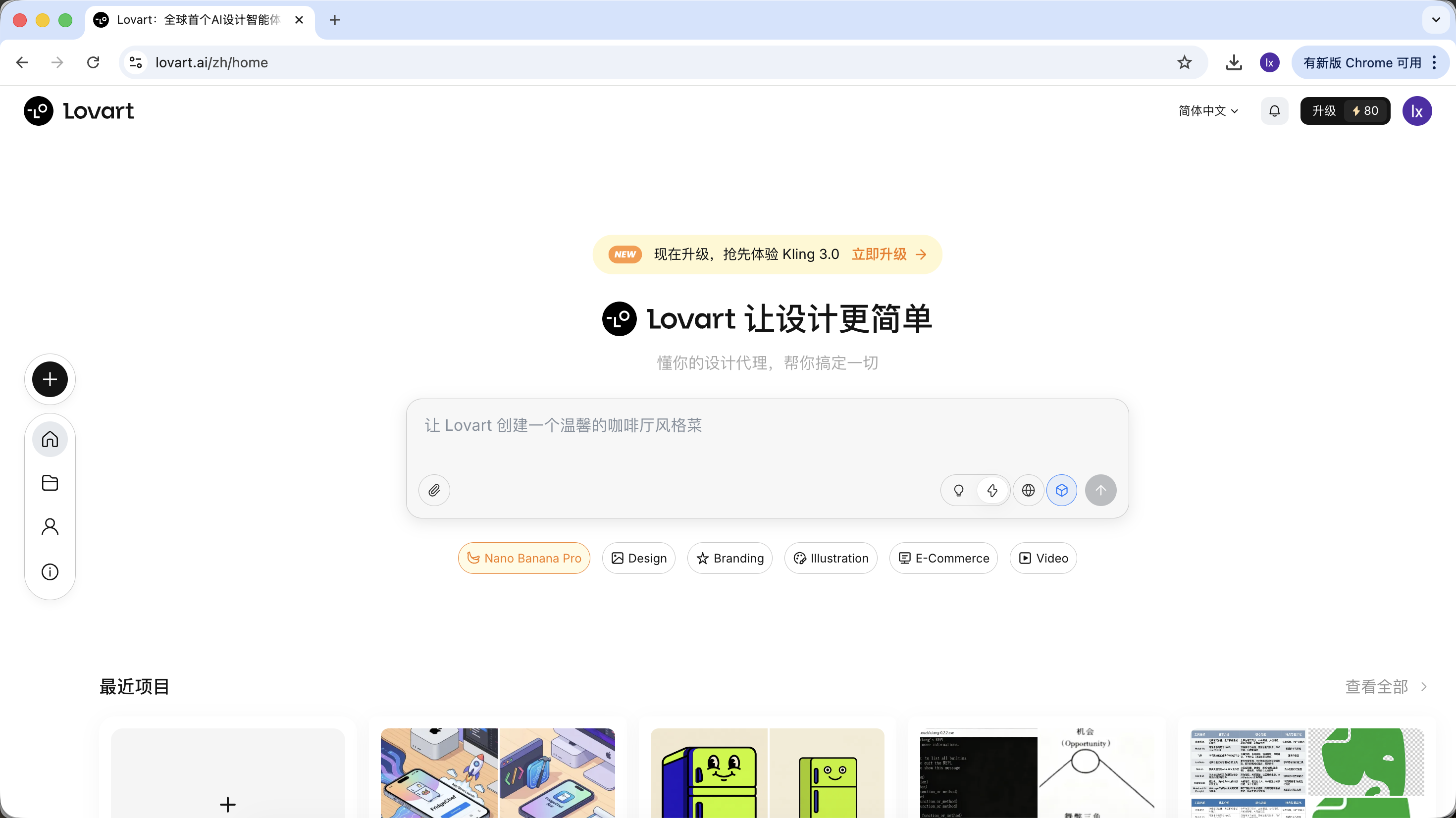
Despues de entrar a Lovart, principalmente necesitas conocer los siguientes controles:
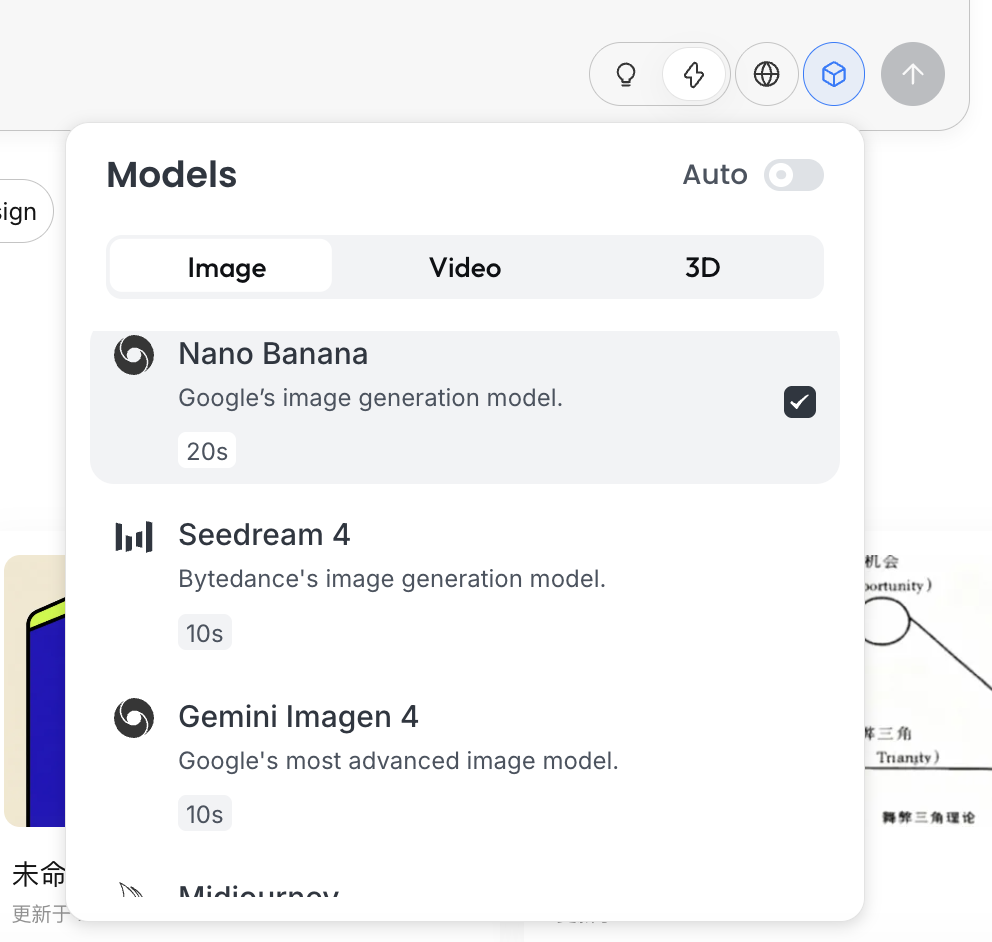
Seleccion de modelo
Haz clic en el icono del cubo debajo del campo de entrada para ver los modelos de generacion disponibles (como GPT Image, Flux, etc.).
Para mantener la coherencia con los ejemplos anteriores, esta seccion continua usando NanoBanana como modelo de generacion base.
Modo de pensamiento
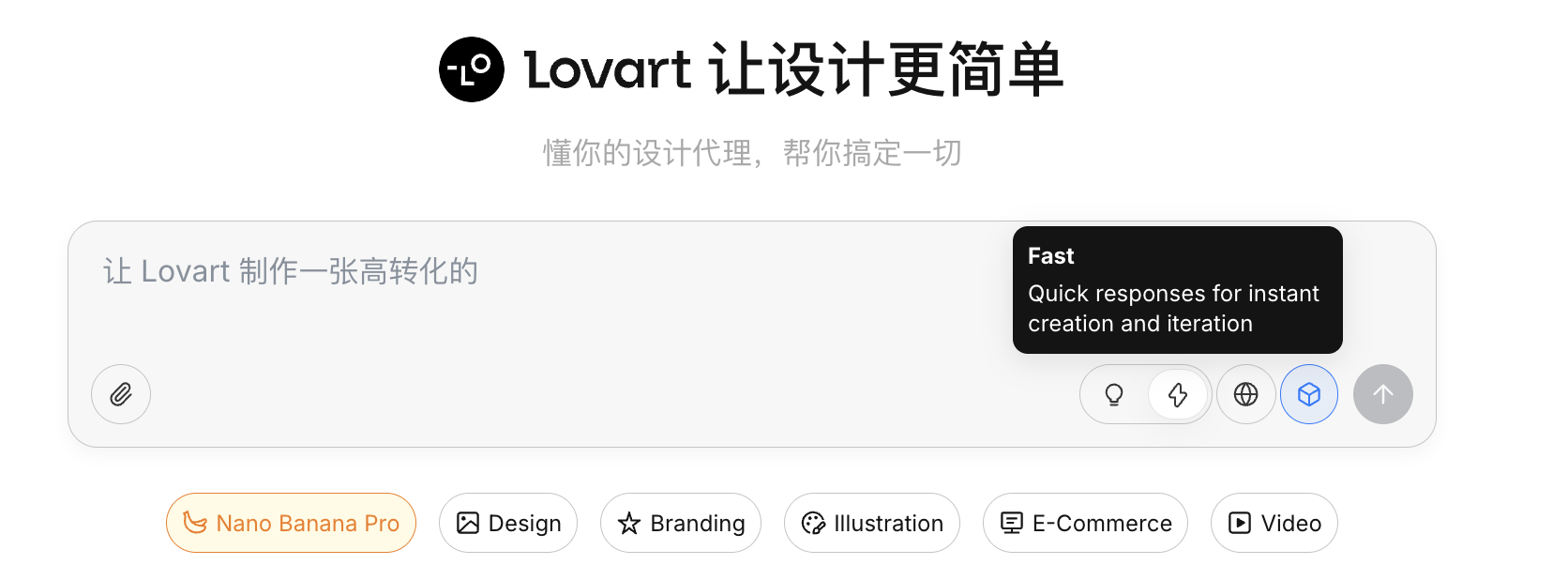
Este es el interruptor central de Lovart:
- Fast Mode (⚡): Similar al API nativo, respuesta rapida, adecuado para generacion de imagenes unicas con instrucciones claras
- Thinking Mode (💡): Modo Agent, la IA primero descompone los requisitos, reescribe el prompt y luego ejecuta la generacion
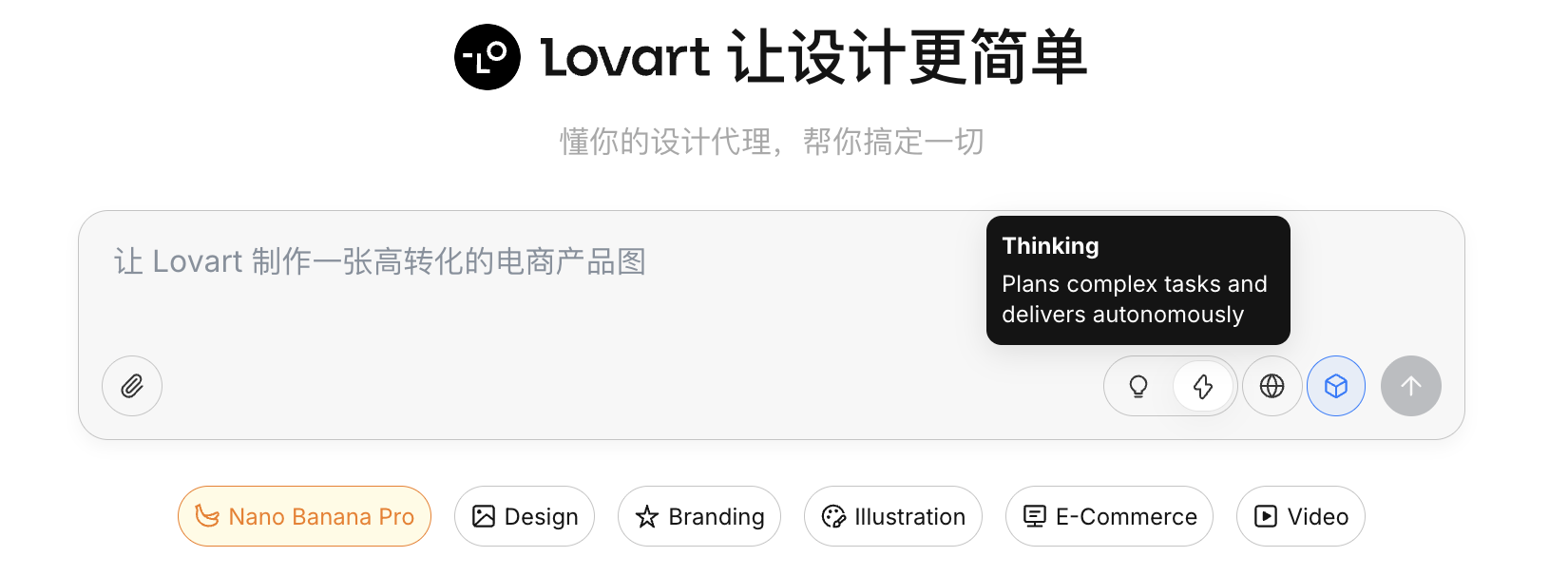
Capacidad de conexion a Internet
Al activar el icono del globo, el Agent puede buscar informacion en la web durante el proceso de generacion (como tendencias de diseno, esquemas de color) como entrada auxiliar.
2.1 Por que el API nativo no es suficiente?
Aunque ya es posible generar imagenes de buena calidad a traves de Python, el API nativo todavia tiene limitaciones en tareas complejas. La razon clave es: el API nativo es esencialmente imperativo. Cuando le pides que genere un objeto especifico, puede ejecutarlo directamente; pero cuando la entrada se convierte en "planificar un conjunto completo de assets de juego", no descompondra activamente el objetivo en multiples pasos ejecutables.
La diferencia central de Lovart esta en el mecanismo Agent. Entre la entrada del usuario y el modelo de generacion de imagenes, agrega una capa de logica para comprension y planificacion: primero identifica la intencion del usuario, luego descompone la tarea, reescribe el prompt y finalmente ejecuta la generacion.
2.2 Demostracion practica: Crea un set de stickers IP en 5 minutos
Tomemos como ejemplo "crear un set de stickers IP de pato programador" y veamos como participa el Agent en todo el proceso.
Fase 1: Planificacion (capacidad de pensamiento del Agent)
Problema del API nativo: Necesitas pensar por ti mismo en la configuracion del personaje, los estados emocionales y escribir prompts individuales para cada imagen.
El enfoque de Lovart:
- Activa 💡 Thinking Mode
- Ingresa una instruccion:
Disena un set de stickers IP de pato programador, con estilo flat y kawaii
La IA no dibuja inmediatamente, sino que primero busca en internet imagenes de diseno relacionadas con patos programadores. Genera un plan descompuesto, crea automaticamente escenarios como Debug, Coffee Break, Panic y genera multiples descripciones visuales correspondientes.
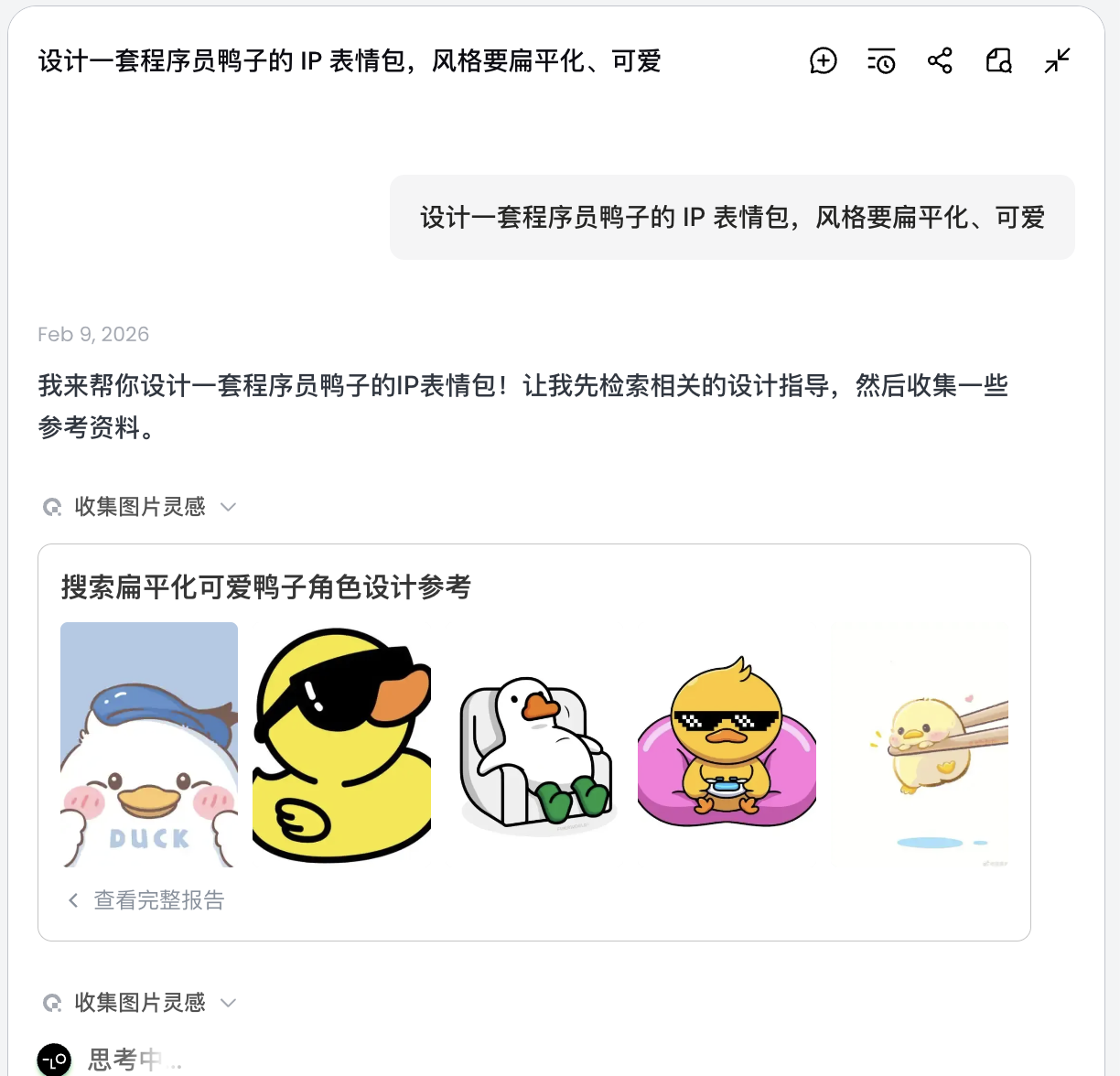

En este paso, la IA pasa de "ejecutor" a "planificador". Despues de que la IA analiza tus requisitos, puedes ver multiples imagenes de patos programadores con diferentes estilos y contenidos en el area del lienzo de Lovart. Puedes empezar a filtrar los estilos que te gusten.
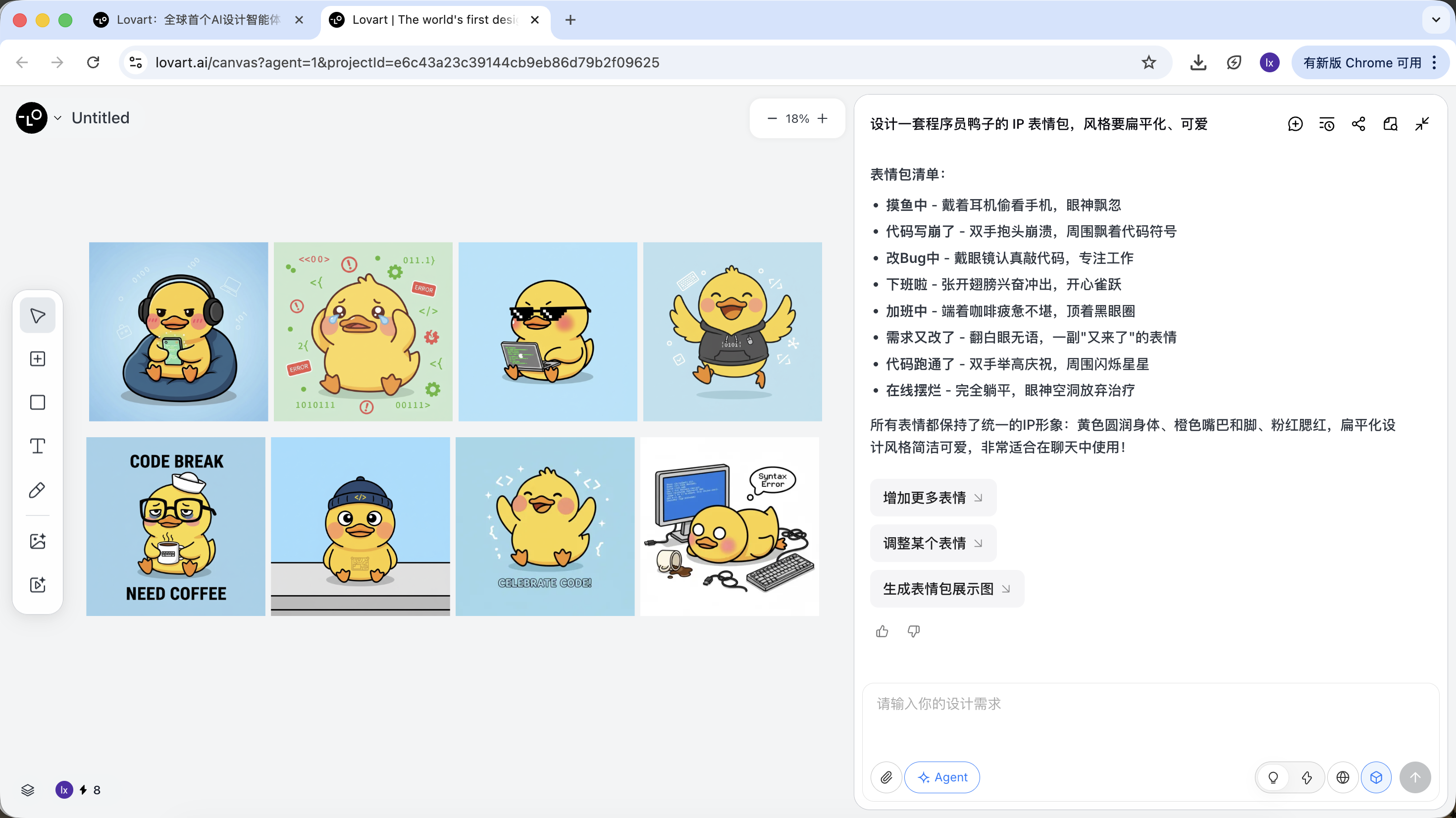
Fase 2: Consistencia (anclaje visual basado en referencias)
En Lovart, las imagenes no son solo resultados, tambien participan en generaciones posteriores.
Imagen de referencia completa
- Selecciona el "pato estandar" mas satisfactorio de los bocetos y haz clic en la imagen correspondiente en el area del lienzo
- La imagen aparecera automaticamente en el area de chat como Reference
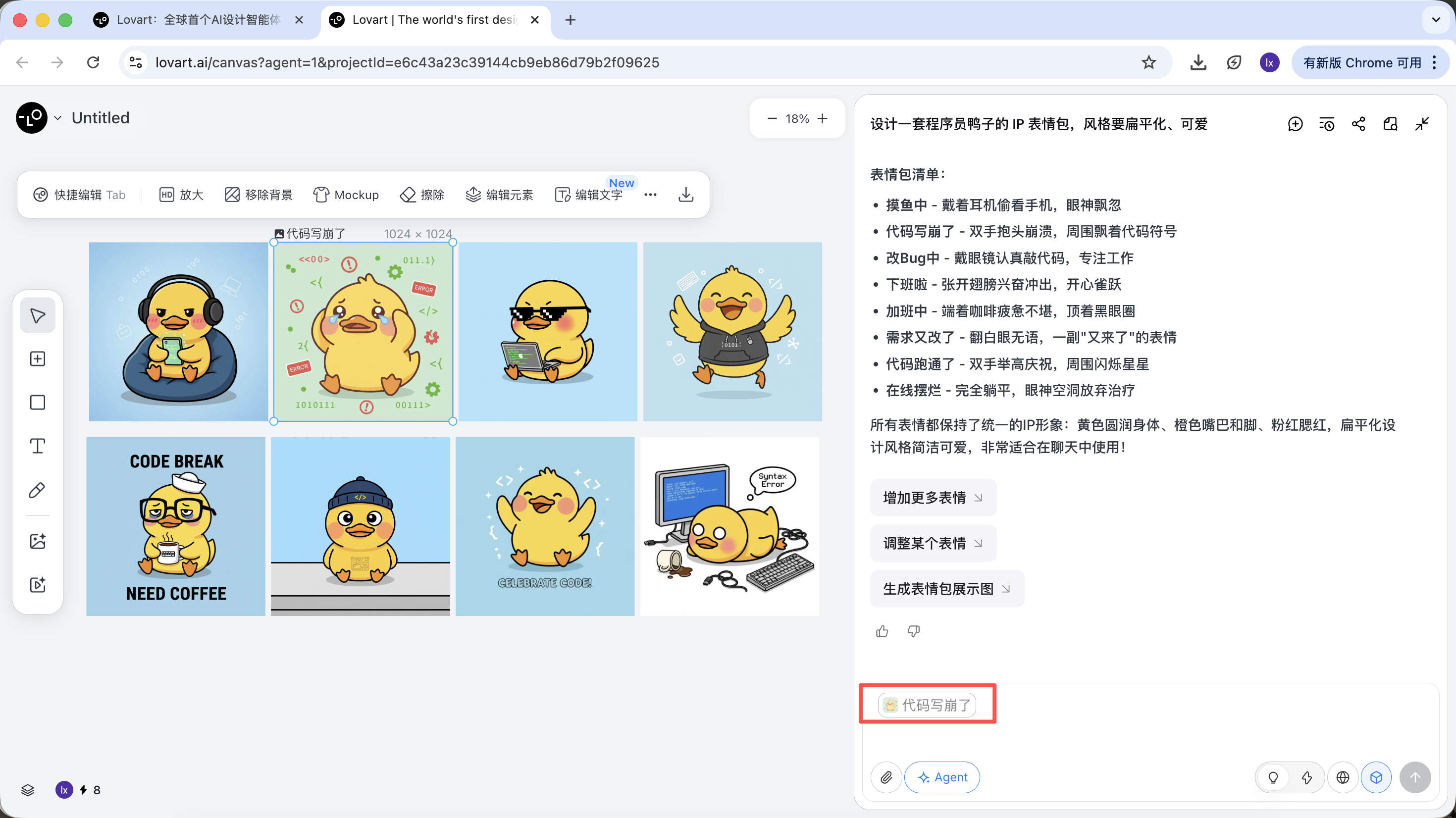
- Ingresa una nueva accion (como feliz) y genera
El resultado generado heredara la paleta de colores, proporciones y detalles de la imagen maestra.
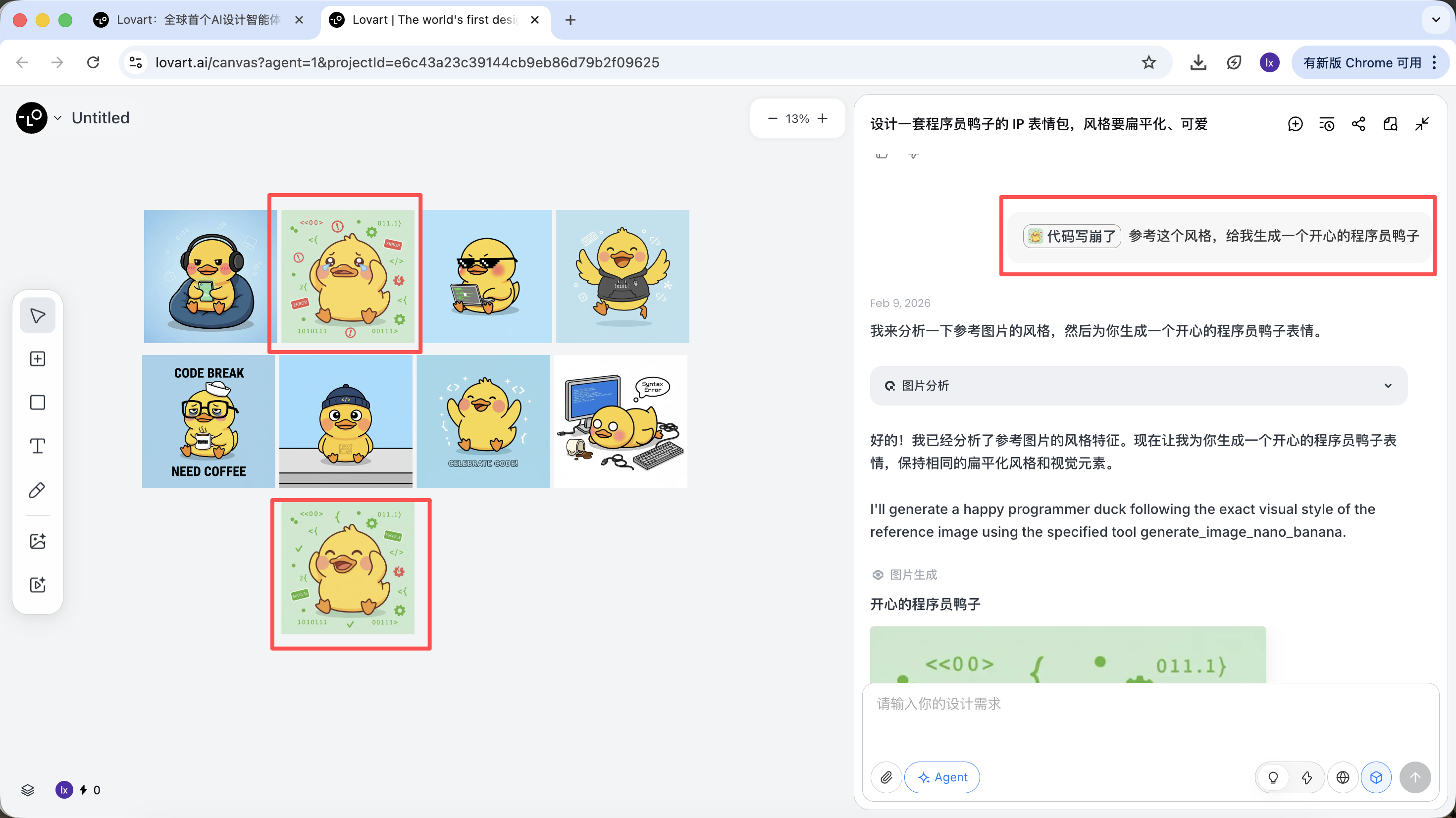
Referencia parcial / Integracion de multiples imagenes
Ademas de usar la imagen completa como referencia, Lovart tambien soporta:
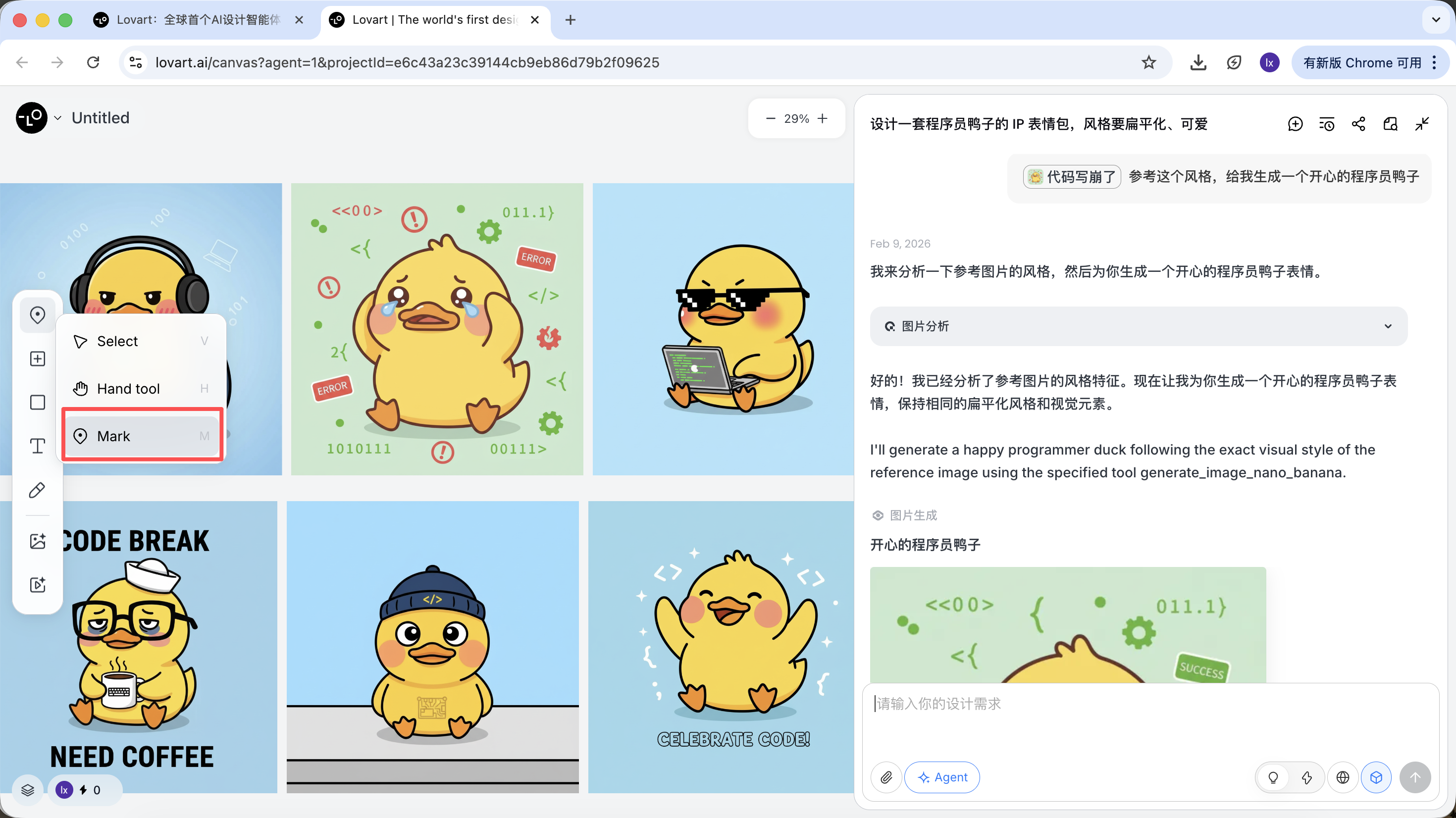
- Seleccionar solo un area parcial de la imagen (por ejemplo, solo referenciar el sombrero o la expresion)
Haz clic en la barra de pestañas del lado izquierdo del area del lienzo, selecciona la tecla "Mark" y marca el area parcial de la imagen objetivo. Esta parte del contenido se sincronizara automaticamente con el cuadro de dialogo. Por ejemplo, aqui podemos elegir modificar el color de fondo.
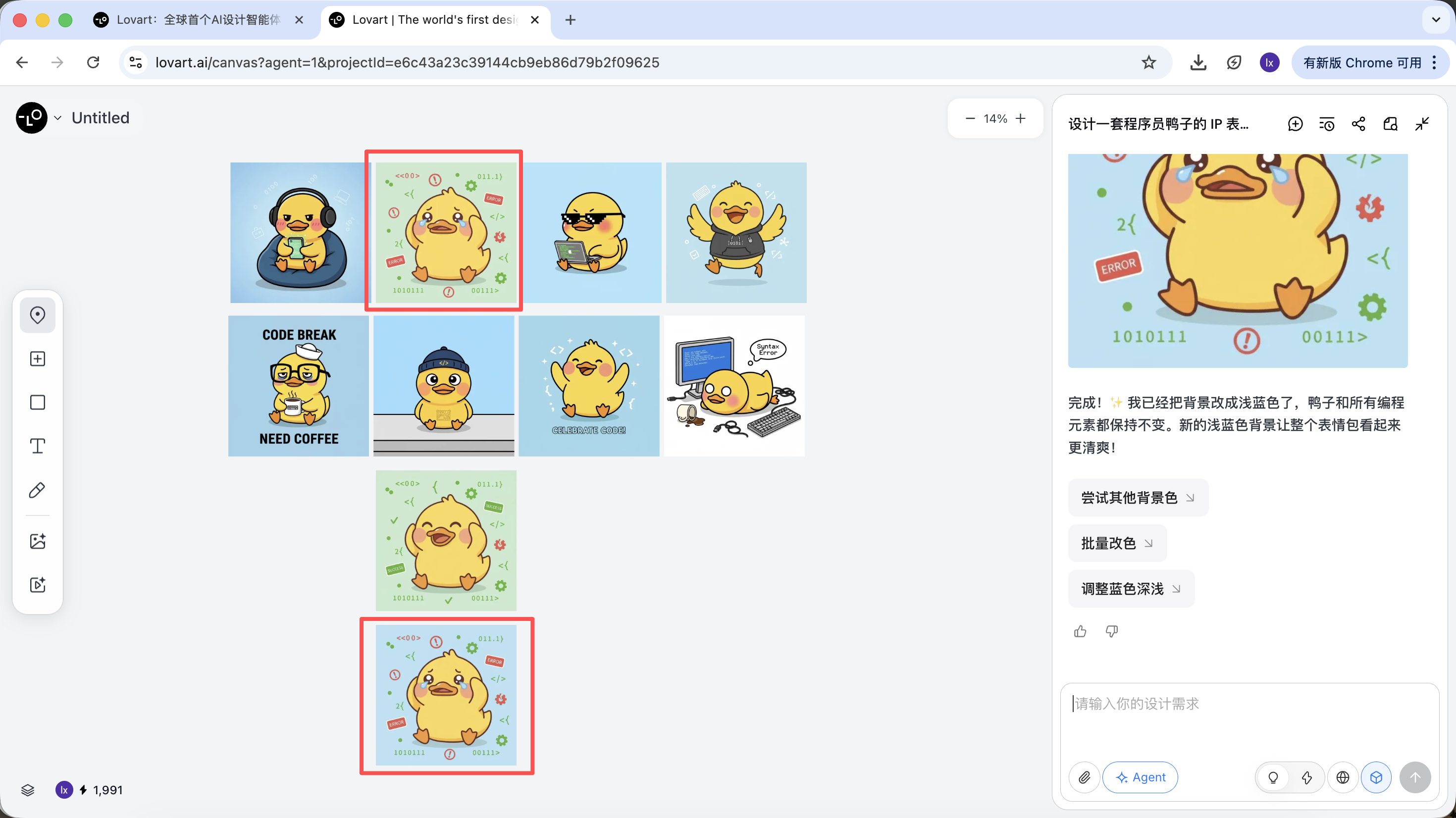
Se puede ver que la imagen recien generada solo cambio el color de fondo, lo cual tambien es coherente con nuestros requisitos de entrada.
- Referenciar sub-elementos de multiples imagenes por separado, luego combinarlos para generar un nuevo resultado
Por ejemplo: puedes mantener el sujeto del personaje de la imagen A mientras reemplazas solo el sombrero con el estilo de la imagen B. El Agent integrara automaticamente estas restricciones visuales en segundo plano.
Tomando el pato programador como ejemplo, podemos elegir mantener la figura del pato de la primera imagen y reemplazarla como elemento principal en la segunda imagen.
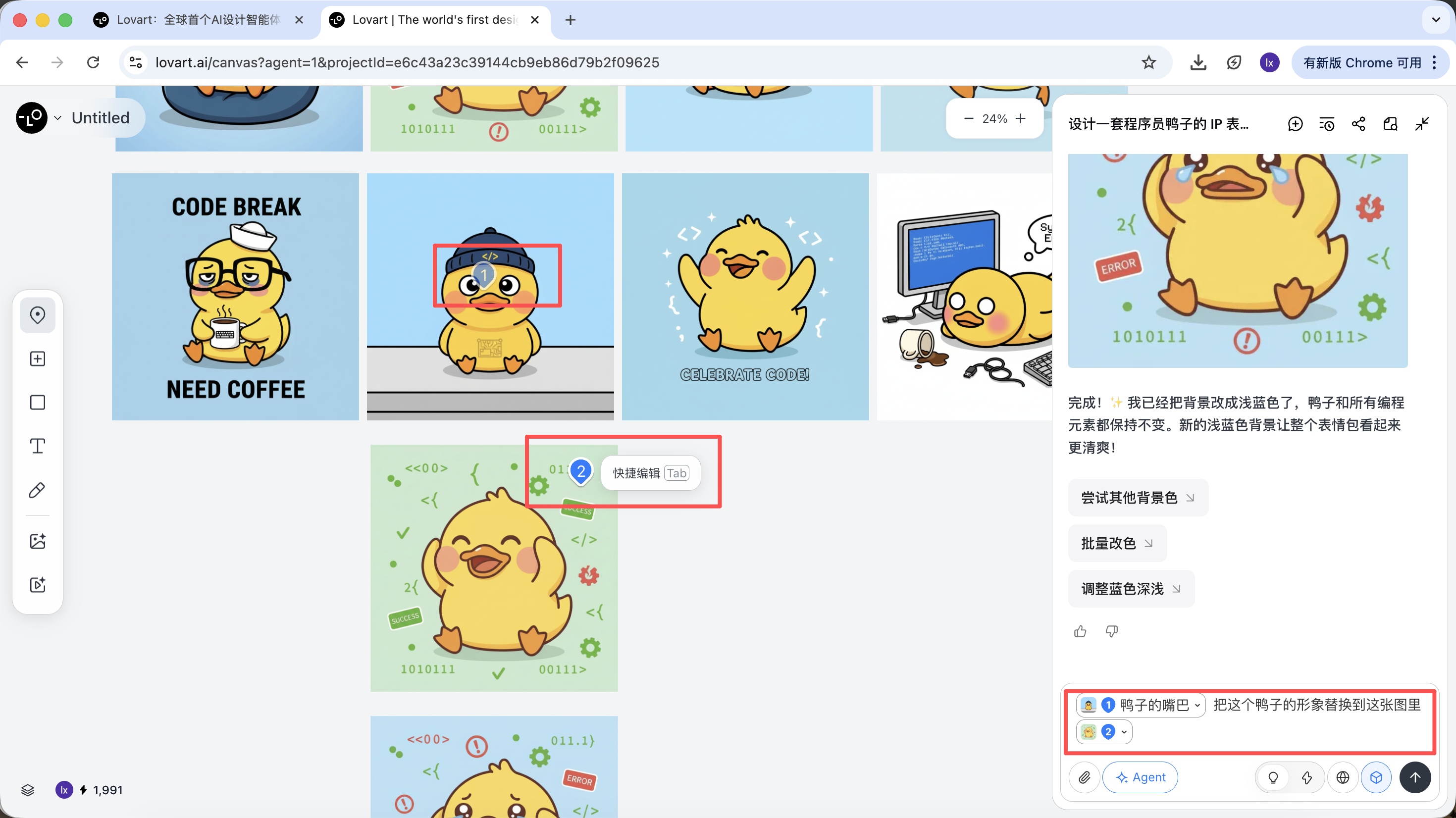
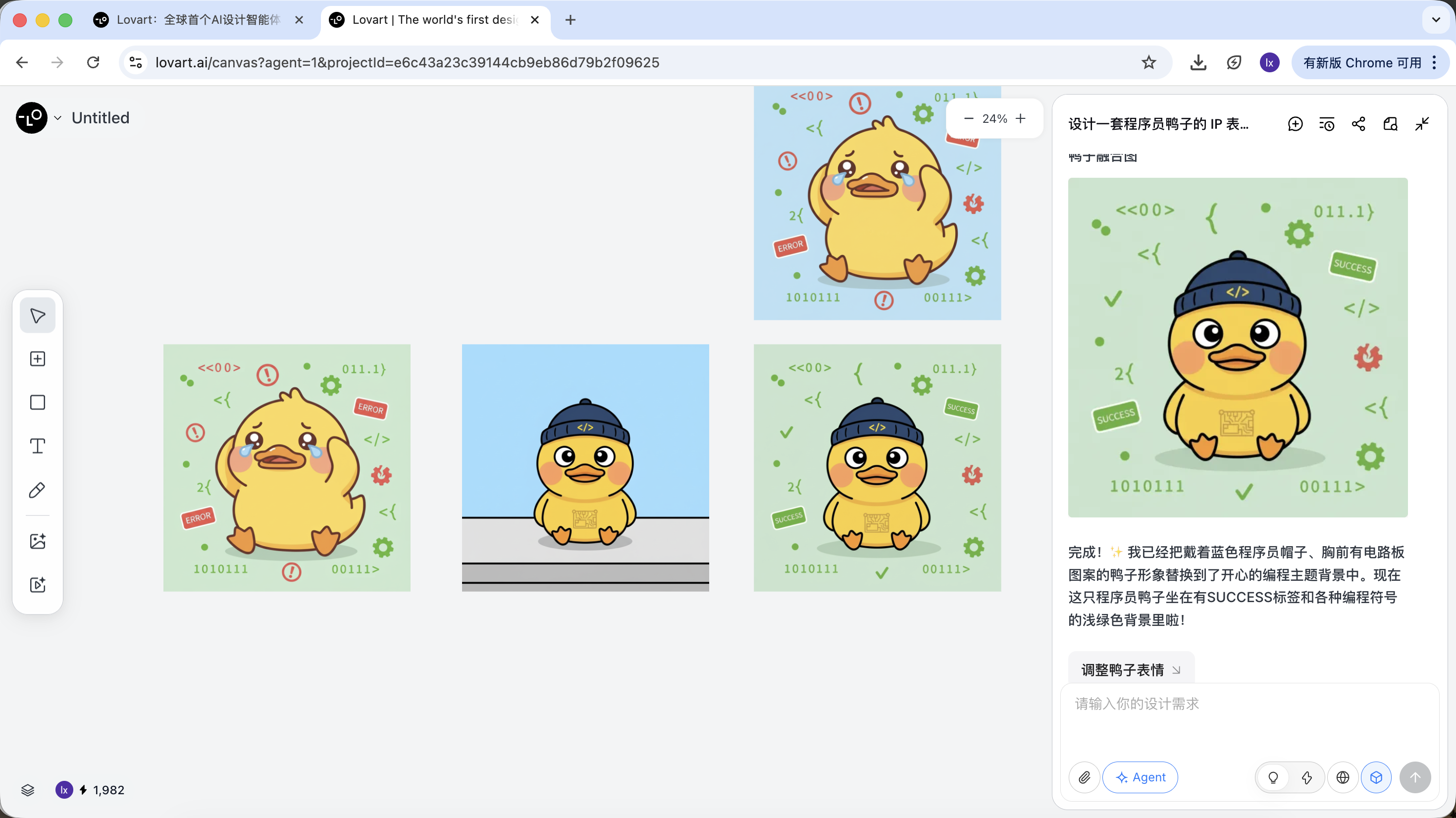
El efecto final tambien es muy notable. Prueba otras combinaciones!
Fase 3: Entrega (llamada a herramientas del Agent)
Una vez completada la generacion, puedes ejecutar directamente operaciones como: ampliar, eliminar fondo, borrar, etc.
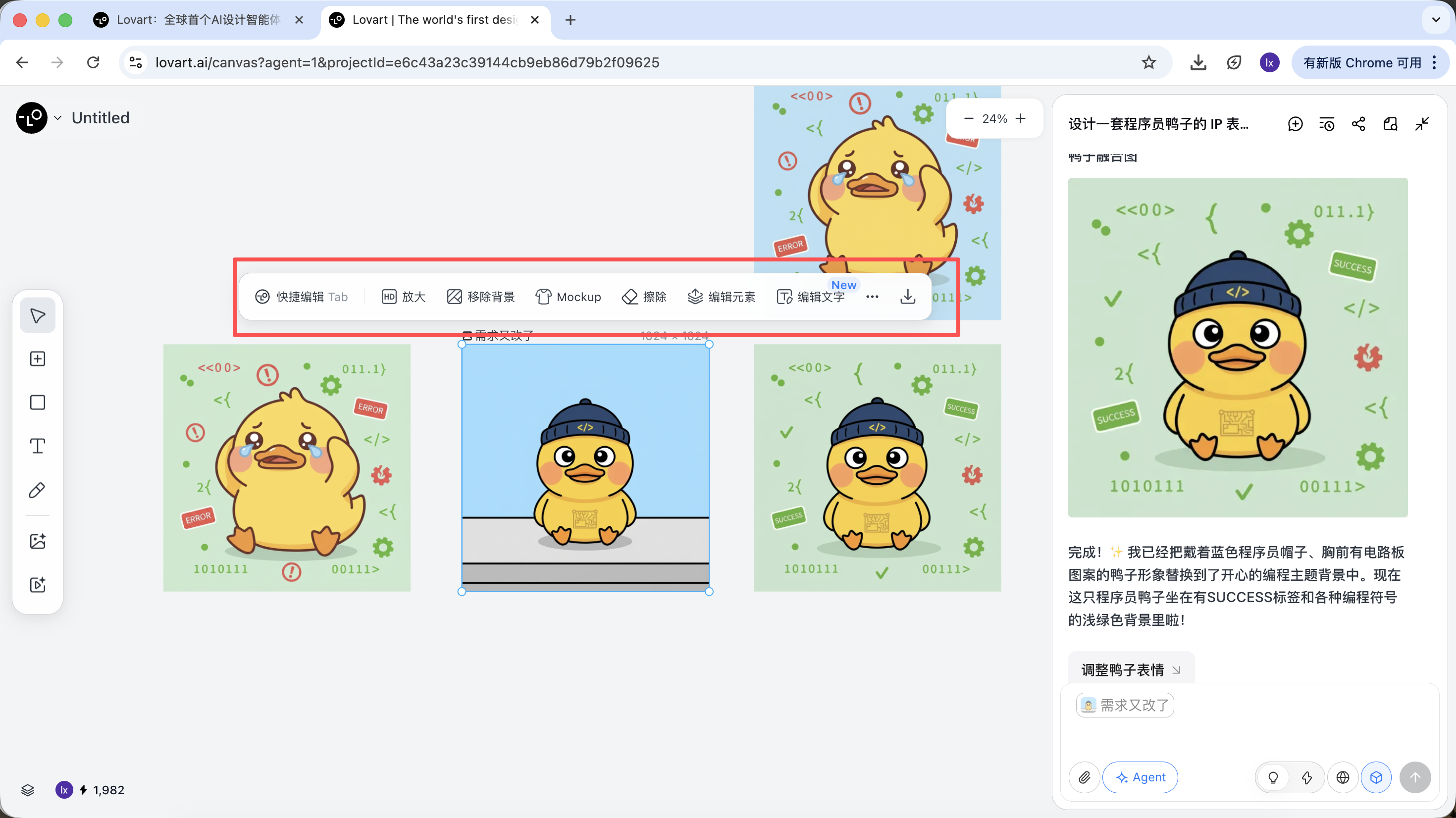
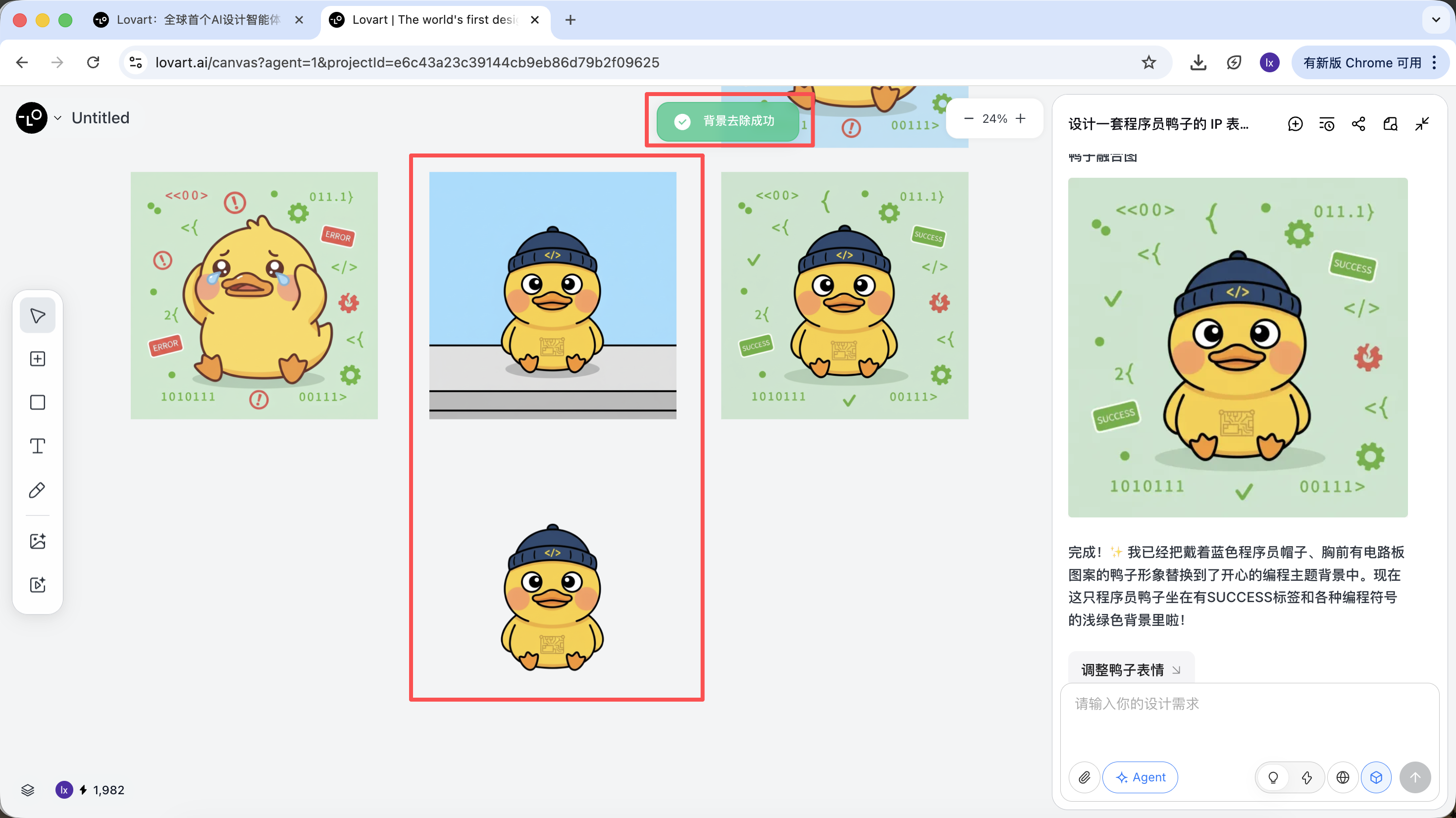
Estos no son simples filtros, sino resultados completados por el Agent que despacha automaticamente diferentes herramientas.
Una vez confirmado el estilo base, puedes generar rapidamente una serie de imagenes de stickers.
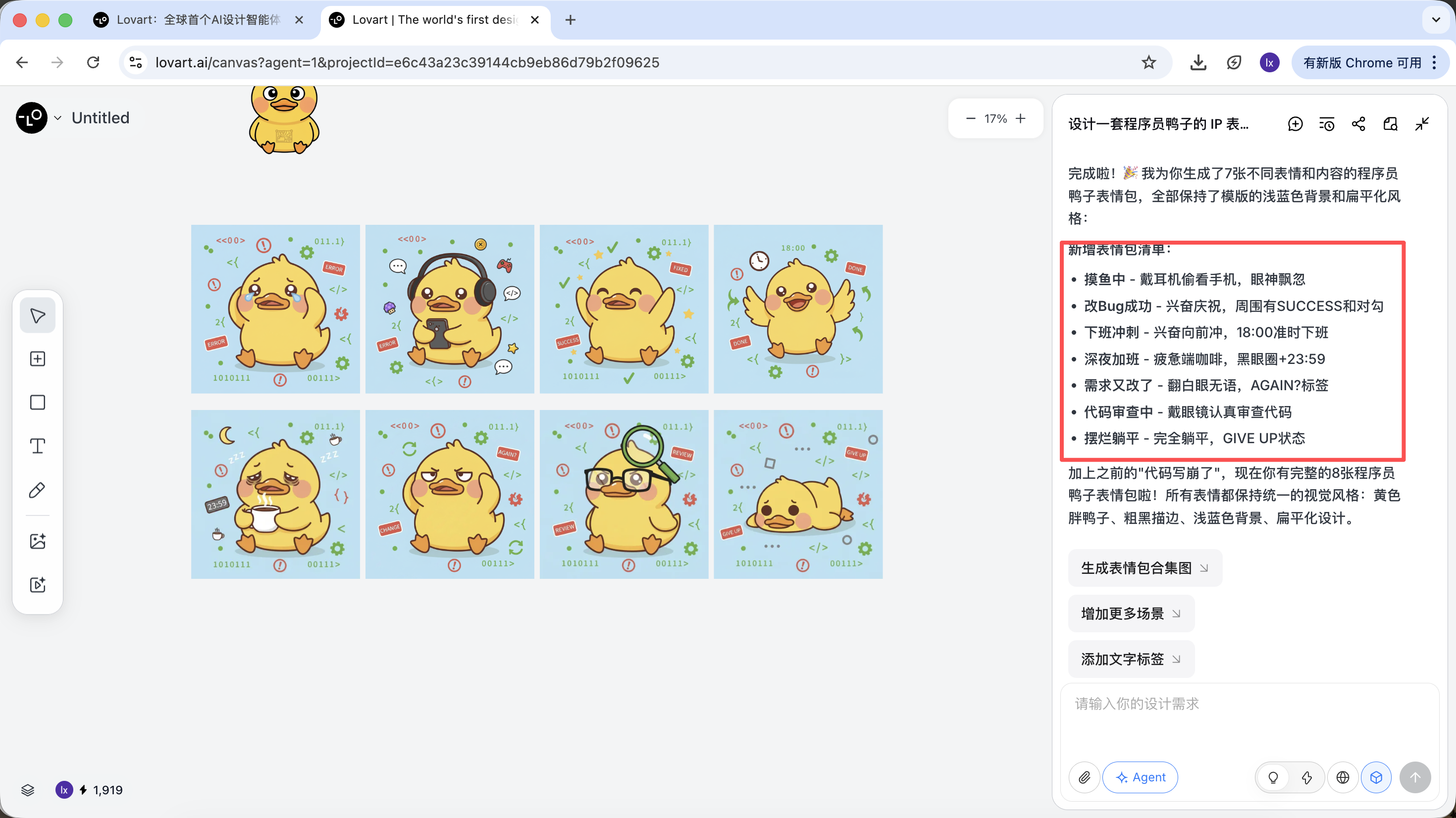
Lo que finalmente obtenemos son assets de nivel de produccion listos para entrega, no simplemente una imagen de demostracion.
2.3 Instrucciones de uso y tarifas
Lovart adopta un modelo de suscripcion, donde diferentes planes corresponden a diferentes limites de uso y permisos de funciones. Los detalles especificos estan sujetos a lo publicado en el sitio web oficial.
Este tutorial no recomienda ni compara ningun plan en particular. Si tienes necesidades en el uso practico, puedes elegir la actualizacion de pago segun tu situacion personal. Actualmente se soporta el pago a traves de Alipay y otros metodos.
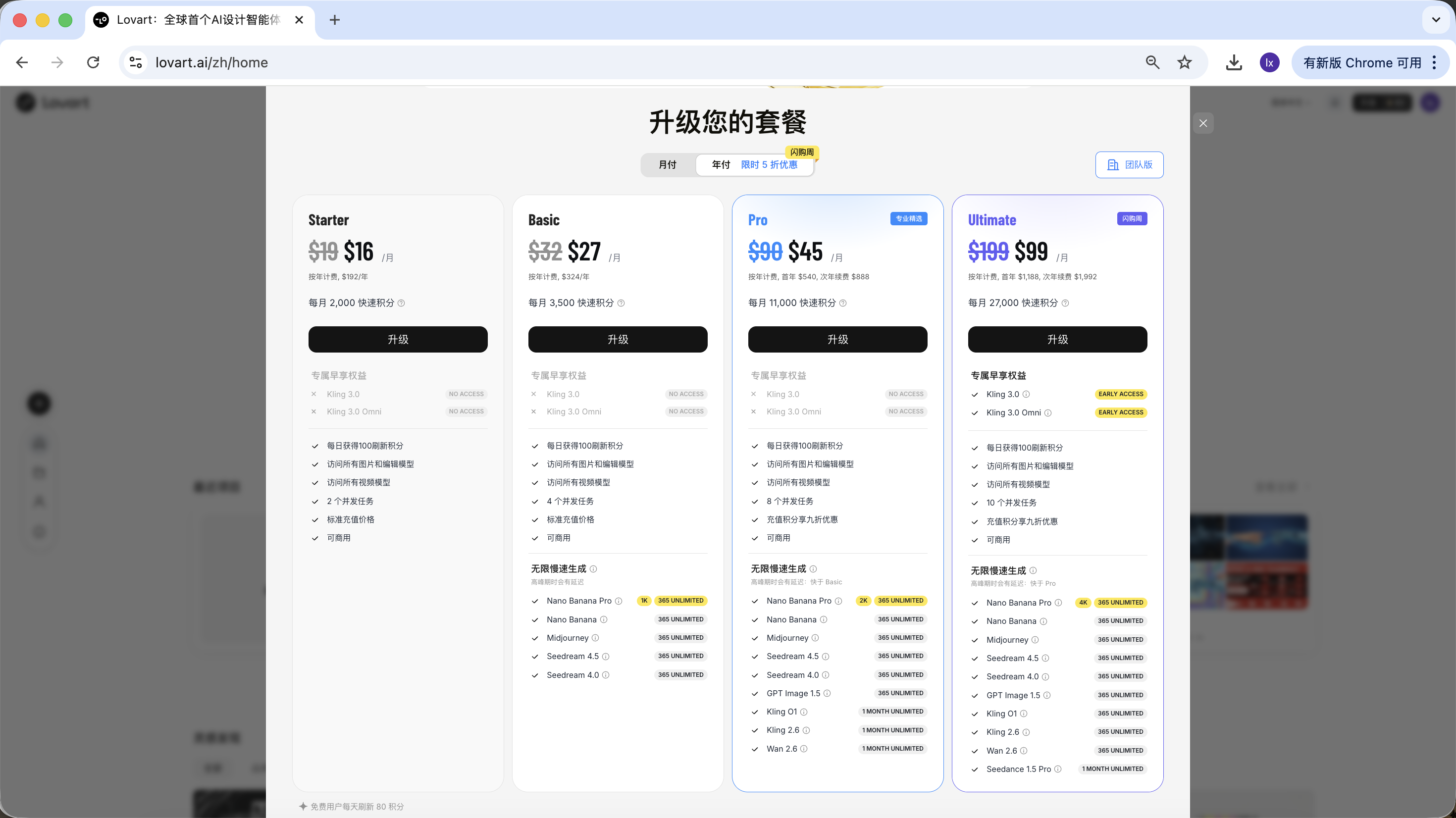
Resumen
Lovart no reemplaza el modelo base, sino que a traves del mecanismo Agent, actualiza la generacion de imagenes de "ejecucion unica" a "flujo de trabajo continuo".
Cuando las tareas comienzan a involucrar planificacion, consistencia y entrega, las ventajas de este tipo de herramientas se vuelven muy evidentes.
Capitulo 3: Construye tu propio asistente de generacion de imagenes inteligente
Ademas de usar Lovart directamente, tambien podemos implementar por nosotros mismos una version simplificada de un asistente de generacion de imagenes.
Este capitulo toma "ilustracion automatica de articulos" como ejemplo, partiendo de problemas reales y construyendo gradualmente un Agent con capacidad de pensamiento.
3.1 Introduccion al problema: Por que enviar directamente un articulo al modelo de generacion de imagenes no funciona?
Si envias un articulo largo a NanoBanana y pides que genere una ilustracion, generalmente es dificil obtener resultados satisfactorios. La razon no es que el modelo "no sepa dibujar", sino que no es bueno entendiendo textos largos.
Los modelos de generacion de imagenes son mas adecuados para procesar descripciones visuales breves y claras. Cuando la entrada se convierte en un articulo con estructura, puntos clave y relaciones contextuales, el modelo no puede juzgar que contenido es el que realmente necesita expresarse en la imagen. Esto a menudo resulta en que la salida generada se desvie del tema o solo capture detalles dispersos, sin capacidad de sintesis general.
Esencialmente, los modelos de imagen solo tienen capacidad de "ejecucion", pero carecen del proceso de analisis y seleccion de texto.
3.2 Enfoque de solucion: Separar "comprension" y "ejecucion" con un Agent
La clave para resolver este problema no son prompts mas complejos, sino pensar con claridad antes de generar la imagen. Por lo tanto, introducimos una "capa de pensamiento" independiente en el flujo de generacion y construimos con ella el Agent mas simple y util.
El objetivo central de este Agent es solo uno: hacer que la imagen final generada se acerque lo mas posible a la verdadera intencion de expresion del usuario.
El flujo general se puede resumir como: Entrada de texto largo → Comprension y juicio del modelo de lenguaje → Generacion de prompts visuales apropiados → Ejecucion de generacion por el modelo de imagen → Salida de imagen
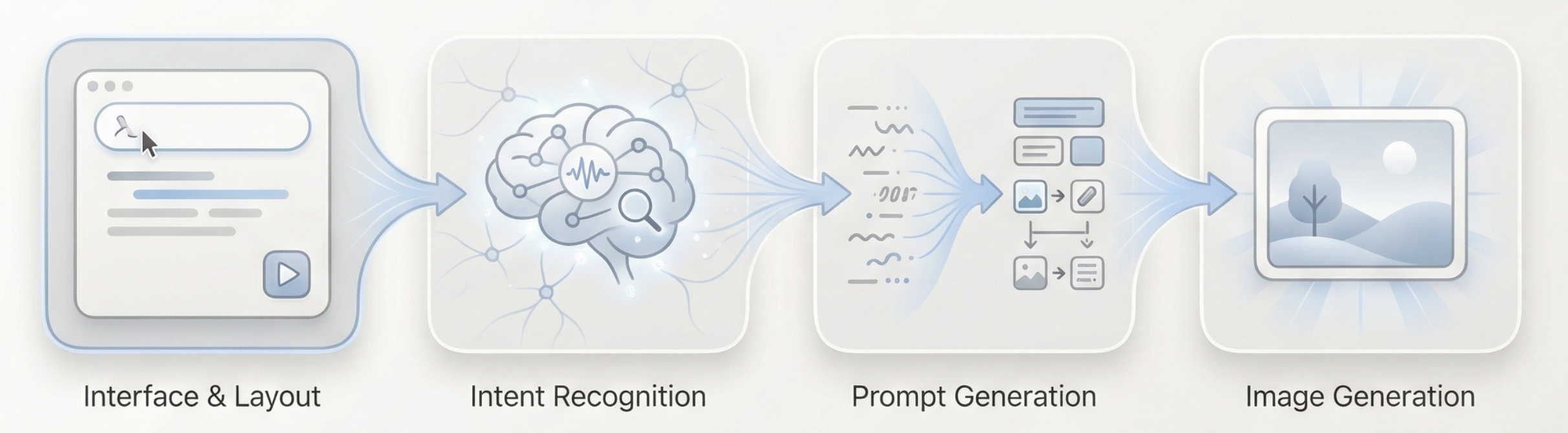
Entonces, como puede nuestro Agent entender la intencion del usuario?
Aqui elegimos hacer una "capa de pensamiento" simplificada. Hemos configurado tres intenciones diferentes: entrada invalida, generacion directa de imagen, texto largo que necesita comprension.
En este Agent, la division de roles se puede resumir en cuatro puntos:
- El modelo de lenguaje como nucleo de toma de decisiones Es responsable de entender el contenido del articulo, juzgar la intencion de la entrada del usuario y distribuir la tarea al camino de generacion apropiado, decidiendo "que hacer a continuacion" y como generar los prompts de imagen.
- El modelo de imagen como ejecutor El modelo de imagen no participa en la comprension y el juicio, solo recibe instrucciones visuales ya organizadas y se enfoca en completar el renderizado de la imagen.
- El usuario como guia intervinible Ademas de ingresar texto directamente, el usuario tambien puede ajustar manualmente los prompts generados durante el proceso, o agregar imagenes de referencia para auxiliar la generacion, guiando y refinando el resultado final.
- Gradio y el API backend como capa de soporte integral Son responsables de conectar la interfaz, las llamadas al modelo y la presentacion de resultados, garantizando que todo el Agent funcione de manera estable como una aplicacion web completa.
3.3 Preparacion practica: Obtener APIs
Parece muy interesante! Para ejecutar el flujo anterior, solo necesitamos preparar dos tipos de APIs.
Mano: API de NanoBanana (generacion de imagenes)
Usa directamente el API Key y API URL ya configurados en el Capitulo 1, sin necesidad de configuracion adicional.
Cerebro: API de SiliconFlow (pensamiento de texto)
Necesitamos un modelo de lenguaje grande para asumir el rol de "capa de pensamiento". Este tutorial utiliza el servicio de modelos proporcionado por SiliconFlow: https://cloud.siliconflow.cn
SiliconFlow proporciona interfaces compatibles con la especificacion OpenAI API, que se pueden llamar muy convenientemente a traves de solicitudes de red estandar en el proyecto. Aqui elegimos el modelo gratuito Qwen2.5-7B-Instruct. Todo lo necesario para la llamada ya esta escrito en el siguiente Prompt. Antes de comenzar, solo necesitas registrar una cuenta y crear un API Key en el sitio web oficial.
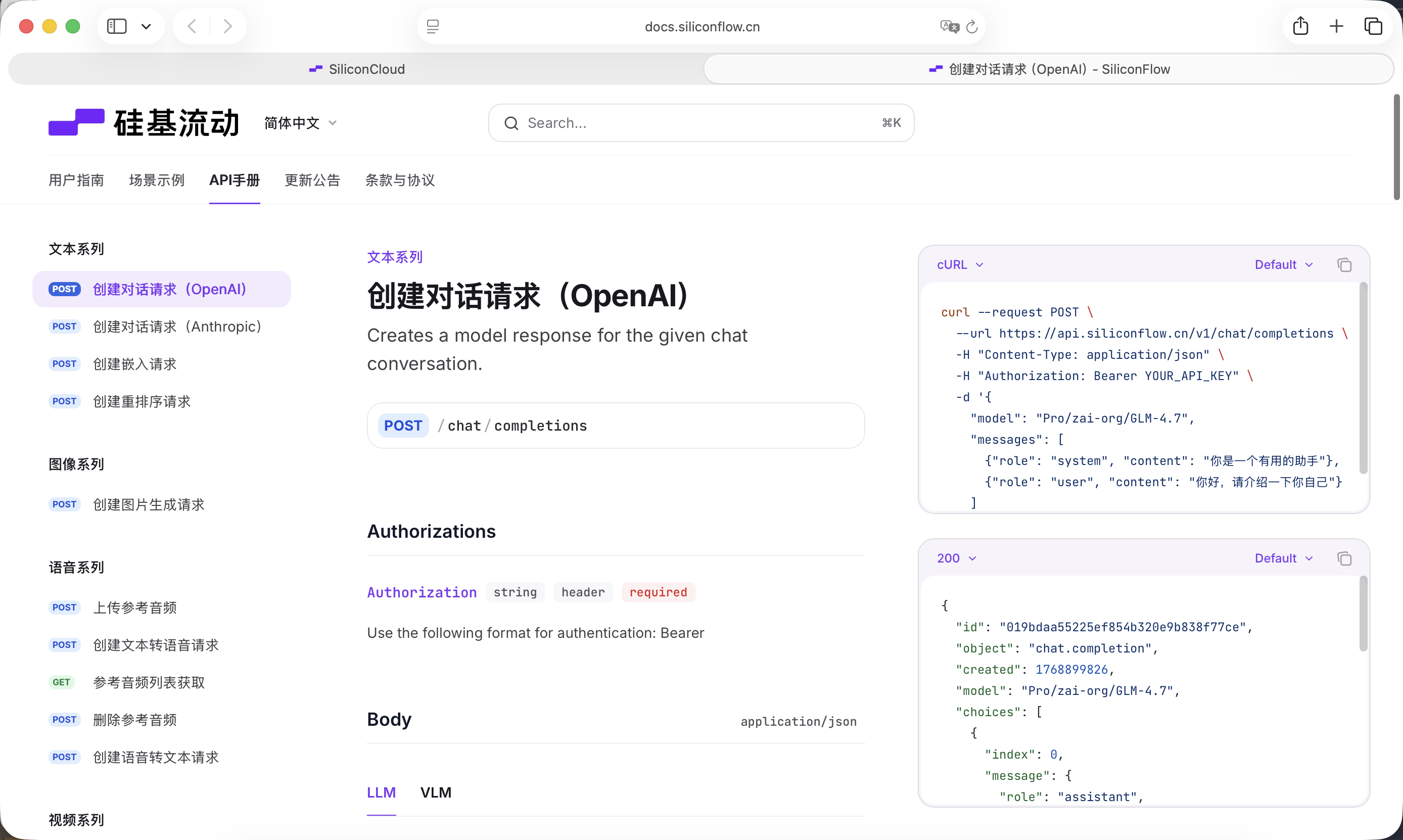
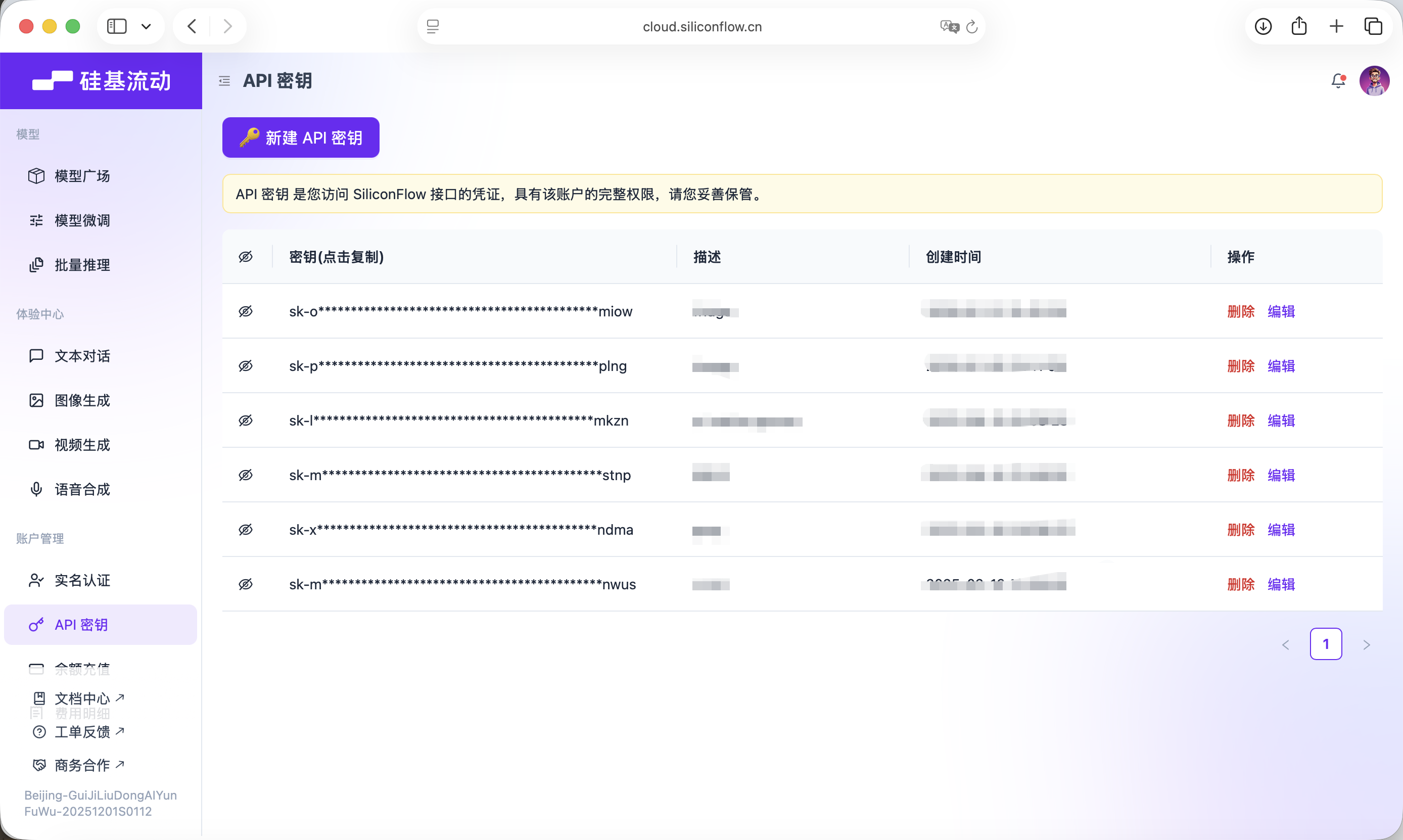
Esta Key se utilizara para las llamadas posteriores al modelo.
3.4 Construccion del Agent:
Este experimento utiliza principalmente Trae para escribir el codigo. El modelo elegido para este tutorial es Gemini-3-Pro-Preview. La idea general es crear un nuevo proyecto, copiar el Prompt completo a continuacion en el cuadro de dialogo, reemplazar gradualmente las API KEY, ejecutar el codigo y completar las pruebas.
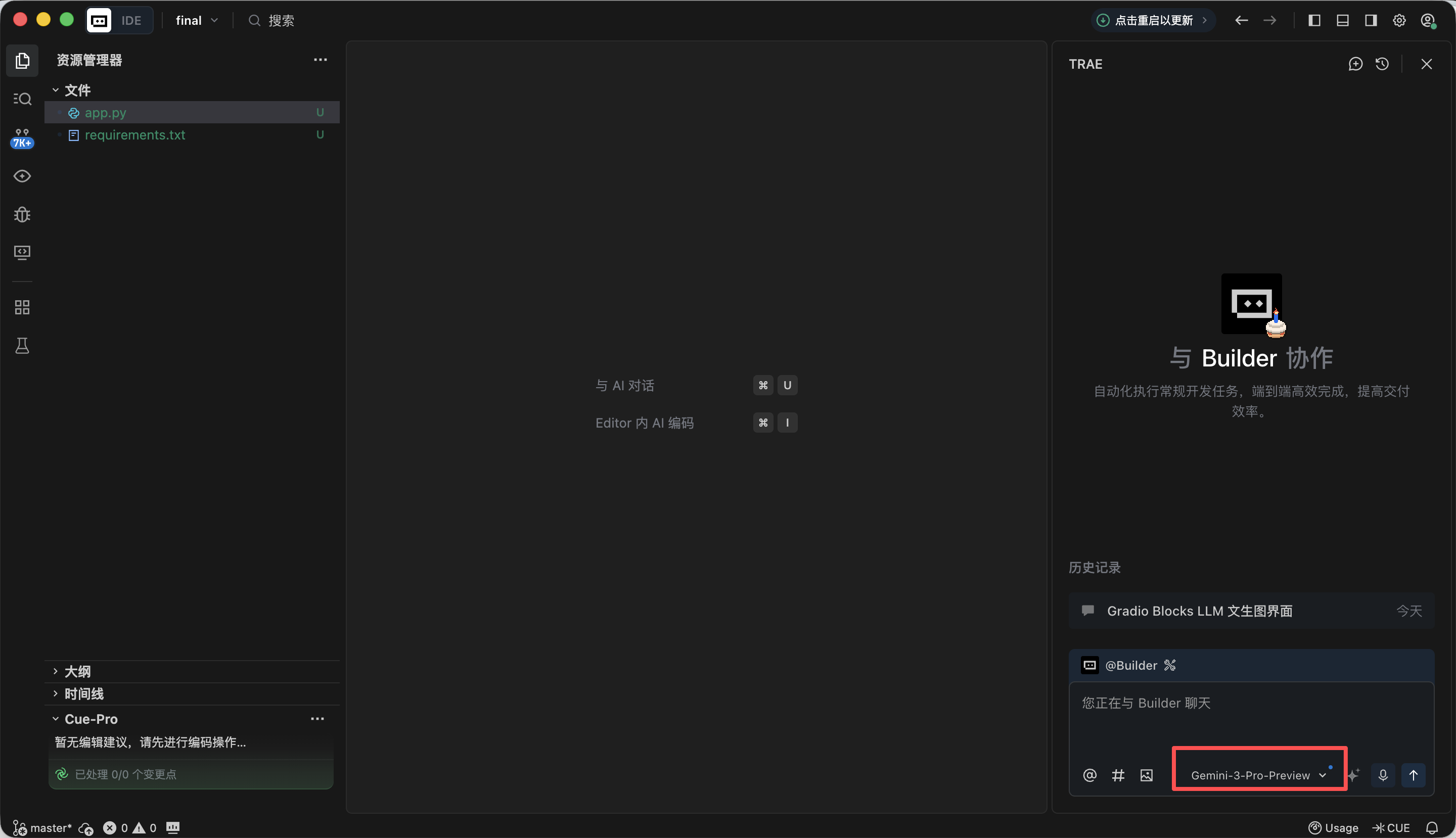
Fase 1️⃣: Framework basico de Gradio Blocks y diseno de interfaz
En esta fase, nuestro objetivo principal es construir primero el "aspecto" de todo el Agent, implementando el diseno de la pagina frontend. Despues de copiar el siguiente Prompt en el cuadro de dialogo de Trae e implementarlo, obtendras una URL local (generalmente http://127.0.0.1:7860) para ver la interfaz y verificar el resultado de la implementacion.
Modulo 1: Framework basico de Gradio Blocks y diseno de interfaz
1, Objetivo de la tarea
- Basado en el layout Blocks de Gradio 4.0.0+, implementar la interfaz basica del proyecto "LLM+Nanobanana texto a imagen", siguiendo estrictamente el layout fijo de division izquierda-derecha, inicializando todos los componentes UI y configurando los estados iniciales correctos.
2, Requisitos del stack tecnologico
- Debe desarrollarse usando el modo Blocks de Gradio 4.0.0+, esta prohibido usar el modo Interface;
- Dependencias: gradio>=4.0.0, pillow>=10.0.0 (solo importar, no implementar logica de procesamiento de imagenes por ahora);
- El codigo debe ser un archivo Python completo y ejecutable, incluyendo todas las declaraciones de importacion necesarias.
3, Reglas de layout de interfaz (restriccion central, fusion de detalles practicos)
- Layout general:
Titulo de pagina: Herramienta completa de texto a imagen impulsada por LLM;
Division fija izquierda-derecha: el lado izquierdo ocupa 60% del ancho, el lado derecho ocupa 40% del ancho, usando gr.Row y gr.Column para implementar el control de proporciones.
- Lista de componentes del lado izquierdo 60% (area de flujo de generacion de prompts):
input_text: gr.Textbox, etiqueta "Texto de entrada (parrafo de tutorial / instruccion de dibujo)", lines=6, placeholder "Ingresa el texto de tutorial que necesita ilustracion o una instruccion de dibujo directo...";
identify_intent_btn: gr.Button, value="Identificar intencion", estado inicial clickeable normalmente;
intent_status: gr.Textbox, etiqueta "Tipo de intencion / Estado de procesamiento", lines=2, interactive=False, valor inicial "Intencion no identificada";
system_prompt: gr.Textbox, etiqueta "System Prompt (solo editable para intencion de ilustracion de articulo)", lines=4, interactive=False, placeholder "Reglas de restriccion para la generacion de prompts por LLM...";
confirm_prompt_btn: gr.Button, value="Confirmar generacion de prompt de imagen", interactive=False (inicialmente deshabilitado para prevenir errores);
generation_prompt: gr.Textbox, etiqueta "Prompt de generacion (editable)", lines=3, interactive=True, valor inicial vacio, placeholder "El prompt de imagen en ingles generado se mostrara aqui, soporta modificacion manual...".
- Lista de componentes del lado derecho 40% (area de funcion de generacion de imagenes Nanobanana):
ref_image: gr.Image, etiqueta "Imagen de referencia (opcional, imagen a imagen)", type=filepath, height=300, permite subir;
generate_btn: gr.Button, value="Generar imagen", interactive=False (inicialmente deshabilitado, no se puede clickear sin prompt);
result_image: gr.Image, etiqueta "Resultado generado", type=pil, height=300, inicialmente vacio, interactive=False.
4, Requisitos de logica de interaccion
- El estado interactive inicial de todos los componentes debe seguir estrictamente la configuracion anterior, y se actualizara dinamicamente a traves de funciones posteriormente;
- El estado deshabilitado de los botones debe ser intuitivo (en gris), evitando operaciones erroneas del usuario.
5, Requisitos de salida
- Generar codigo Python completo, implementando solo el layout de interfaz y la inicializacion de componentes, sin incluir logica de negocio;
- Comentarios de codigo claros, nombres de componentes consistentes con la version practica (input_text/identify_intent_btn, etc.);
- El codigo debe ser directamente ejecutable, con la estructura de interfaz completamente consistente con la descripcion.Despues de abrir http://127.0.0.1:7860 en el navegador, puedes ver que Trae ha generado la siguiente pagina web segun nuestros requisitos, que es aproximadamente consistente con nuestros requisitos, por lo que podemos proceder al siguiente paso de generacion.
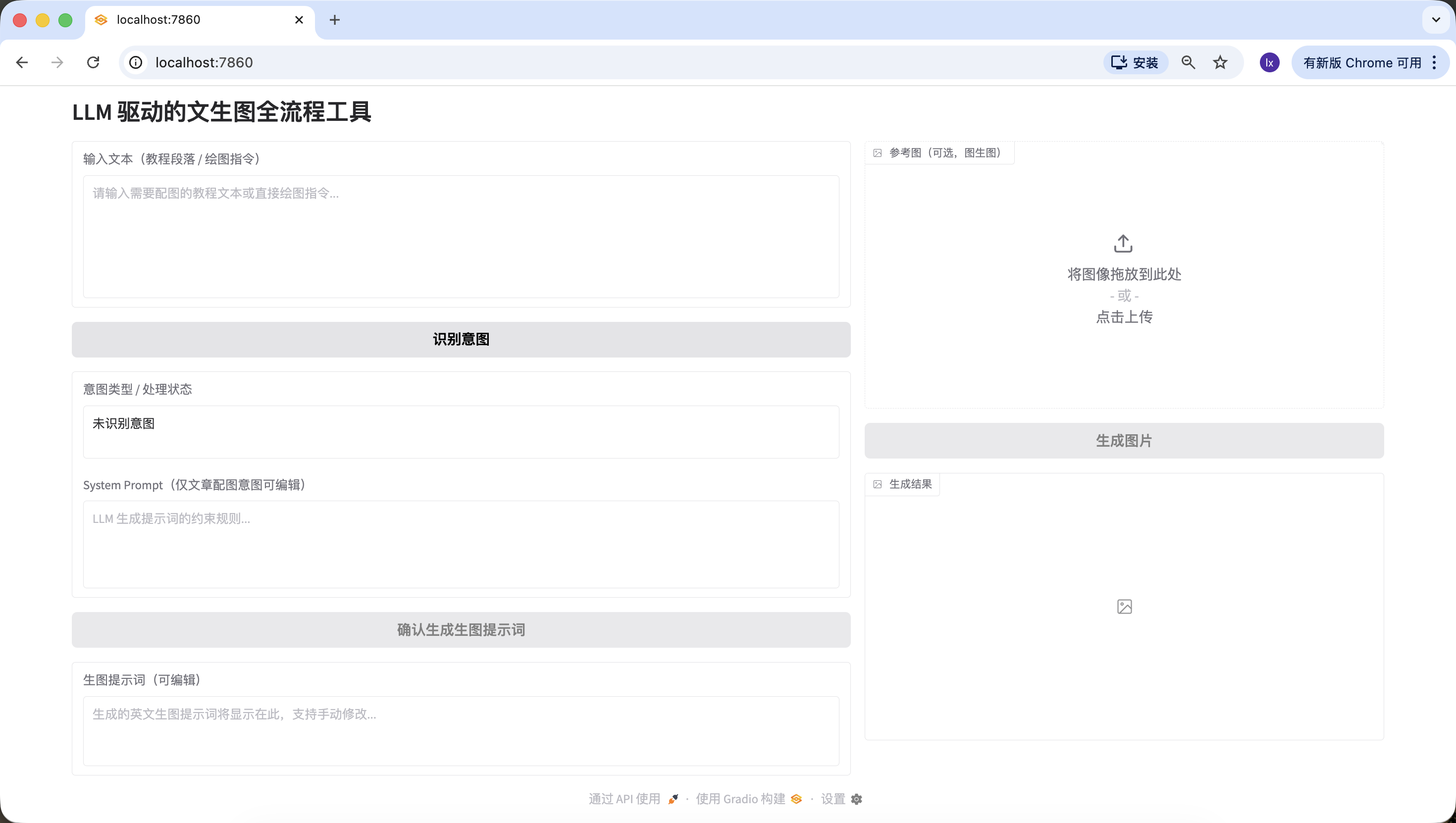
Fase 2️⃣: Modulo de identificacion de intencion LLM (API de Siliconflow)
Al usar VLM para dibujar en el dia a dia, pueden existir las siguientes tres situaciones de entrada comunes:
- Contenido sin sentido, como "hola", "ya comiste hoy?", no se puede dibujar la imagen correspondiente.
- Articulo/texto largo, con muchas palabras, como un articulo estructurado de unas 200 palabras, que requiere primero entender la estructura y el contenido del articulo, y luego considerar como generar una imagen que resuma completamente este texto.
- Instruccion de dibujo directa, como "dibujame un perro banandose", donde el requisito ya esta descrito con suficiente especificidad para generar la imagen directamente.
Igual que antes, copia el siguiente Prompt en el cuadro de dialogo de Trae para implementarlo, y agrega las APIs obtenidas en los pasos anteriores.
Modulo 2: Modulo de identificacion de intencion LLM (API de Siliconflow)
1, Objetivo de la tarea
Sobre la base de la interfaz Gradio ya implementada, agregar logica de clic al boton "Identificar intencion", llamar al API de Siliconflow para completar la identificacion de intencion y vincular el estado de los componentes.
2, Requisitos del stack tecnologico
Basado en Gradio 4.0.0+ Blocks;
Dependencias: requests>=2.31.0, openai;
Salida de archivo Python completo y ejecutable, incluyendo interfaz del Modulo 1 + logica de este modulo.
3, Reglas de negocio centrales (desviacion absoluta no permitida)
- Reglas de clasificacion de intencion (solo 3 categorias, retornar estrictamente numero + descripcion)
1 = Contenido sin sentido: solo charla, saludos, conversacion irrelevante, sin ninguna necesidad de dibujo o ilustracion (ej: "hola", "ya comiste?");
2 = Necesidad de ilustracion de articulo / texto largo: el usuario ingresa un articulo completo, tutorial, parrafo o texto descriptivo, con contenido orientado a narrativa/explicacion/docencia, implicando la intencion de generar una ilustracion para este contenido, sin necesidad de que el usuario diga explicitamente "ilustra este texto";
3 = Instruccion de dibujo directa: el usuario ingresa un comando de dibujo breve y claro, sin fondo de texto largo, pidiendo directamente dibujar algo especifico (ej: "dibuja un gato estilo Apple").
- Restricciones de llamada LLM (fusion con plantilla de version practica)
Direccion de interfaz: https://api.siliconflow.cn/v1/chat/completions;
Modelo: Qwen/Qwen2.5-7B-Instruct;
temperature=0.1;
Codigo de definicion unificada:
python
ejecutar
LLM_BASE_URL = "https://api.siliconflow.cn/v1"
LLM_API_KEY = "" # El usuario debe reemplazar
LLM_MODEL = "Qwen/Qwen2.5-7B-Instruct"# Plantilla de identificacion de intencion verificada en practica (fijada en el codigo)
INTENT_PROMPT_TEMPLATE = """Debes identificar la intencion del texto ingresado por el usuario, retornando solo uno de los siguientes 3 resultados (formato: numero + descripcion en espanol):
1 = Contenido sin sentido; 2 = Necesidad de ilustracion de articulo / texto largo; 3 = Instruccion de dibujo directa.
Entrada del usuario: {user_input}
Resultado de identificacion:
Extraer solo el numero y la descripcion del resultado retornado, contenido adicional prohibido."""Actualiza la direccion web anterior http://127.0.0.1:7860 y comienza a probar si puede detectar correctamente las tres situaciones.
- Contenido sin sentido, puedes intentar ingresar "hola", "gracias", y ver que se identifica correctamente.
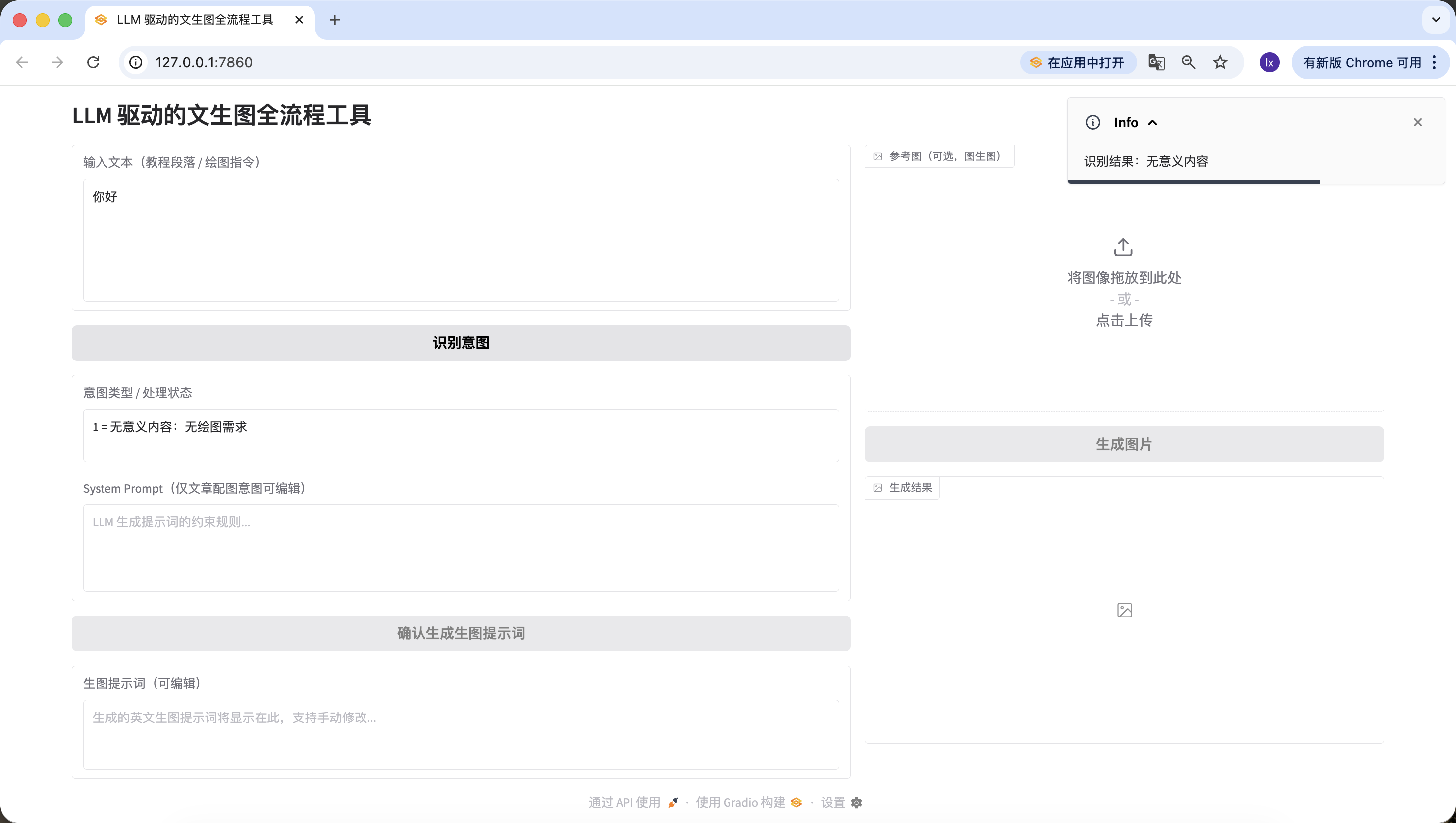
- Articulo/texto largo, aqui usamos un texto sobre inteligencia artificial generado por Doubao. Tambien puedes probar con tu propio parrafo de tesis.
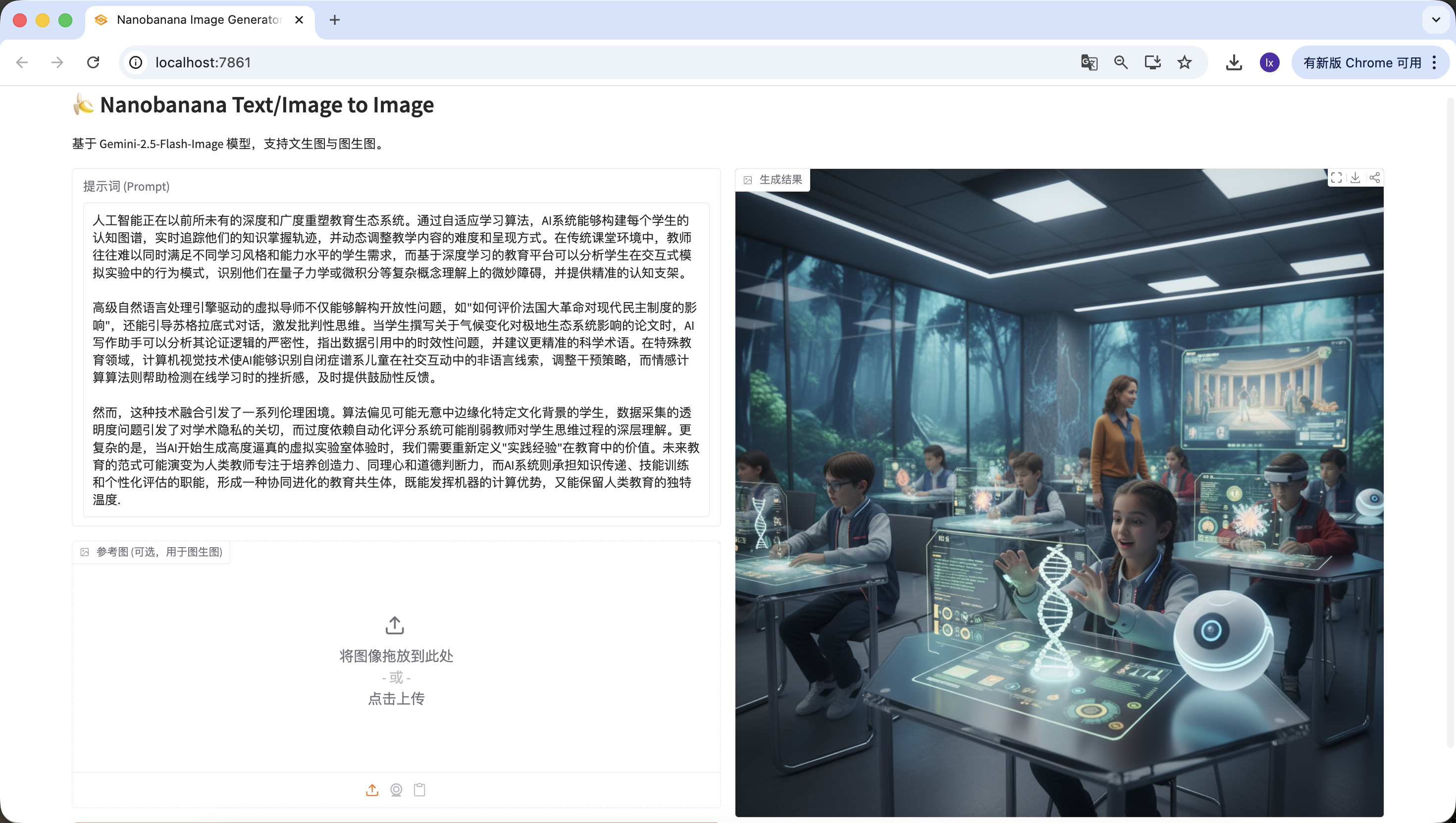
La inteligencia artificial esta reconfigurando el ecosistema educativo con una profundidad y amplitud sin precedentes. A traves de algoritmos de aprendizaje adaptativo, los sistemas de IA pueden construir el mapa cognitivo de cada estudiante, rastrear en tiempo real su trayectoria de adquisicion de conocimientos y ajustar dinamicamente la dificultad y forma de presentacion del contenido educativo. En entornos de aula tradicionales, los docentes a menudo tienen dificultades para satisfacer simultaneamente las necesidades de estudiantes con diferentes estilos de aprendizaje y niveles de habilidad, mientras que las plataformas educativas basadas en aprendizaje profundo pueden analizar los patrones de comportamiento de los estudiantes en simulaciones interactivas, identificar obstaculos sutiles en la comprension de conceptos complejos como la mecanica cuantica o el calculo, y proporcionar andamios cognitivos precisos.
Los tutores virtuales impulsados por motores avanzados de procesamiento de lenguaje natural no solo pueden deconstruir preguntas abiertas, sino tambien guiar dialogos socraticos que estimulen el pensamiento critico. Cuando un estudiante escribe un ensayo sobre el impacto del cambio climatico en los ecosistemas polares, el asistente de escritura de IA puede analizar la rigidez de su logica argumentativa, senalar problemas de vigencia en las citas de datos y sugerir terminos cientificos mas precisos. En el campo de la educacion especial, la tecnologia de vision por computadora permite a la IA identificar senales no verbales de ninos en el espectro autista durante las interacciones sociales, ajustando las estrategias de intervencion, mientras que los algoritmos de computacion afectiva ayudan a detectar la frustracion durante el aprendizaje en linea, proporcionando retroalimentacion de animacion oportuna.
Sin embargo, esta fusion tecnologica plantea una serie de dilemas eticos. Los sesgos algoritmicos pueden marginalizar inadvertidamente a estudiantes de ciertos contextos culturales, los problemas de transparencia en la recopilacion de datos generan preocupaciones sobre la privacidad academica, y la dependencia excesiva de sistemas de calificacion automatizada puede debilitar la comprension profunda del docente sobre los procesos de pensamiento del estudiante. Lo mas complejo es que, cuando la IA comienza a generar experiencias de laboratorio virtual altamente realistas, necesitamos redefinir el valor de la "experiencia practica" en la educacion. El paradigma educativo del futuro podria evolucionar hacia un modelo donde los docentes humanos se concentren en cultivar la creatividad, la empatia y el juicio moral, mientras que los sistemas de IA asumen las funciones de transmision de conocimientos, entrenamiento de habilidades y evaluacion personalizada, formando un simbionte educativo de coevolucion que aproveche las ventajas computacionales de las maquinas mientras preserva el calidez unica de la educacion humana.Igualmente detectado con exito~
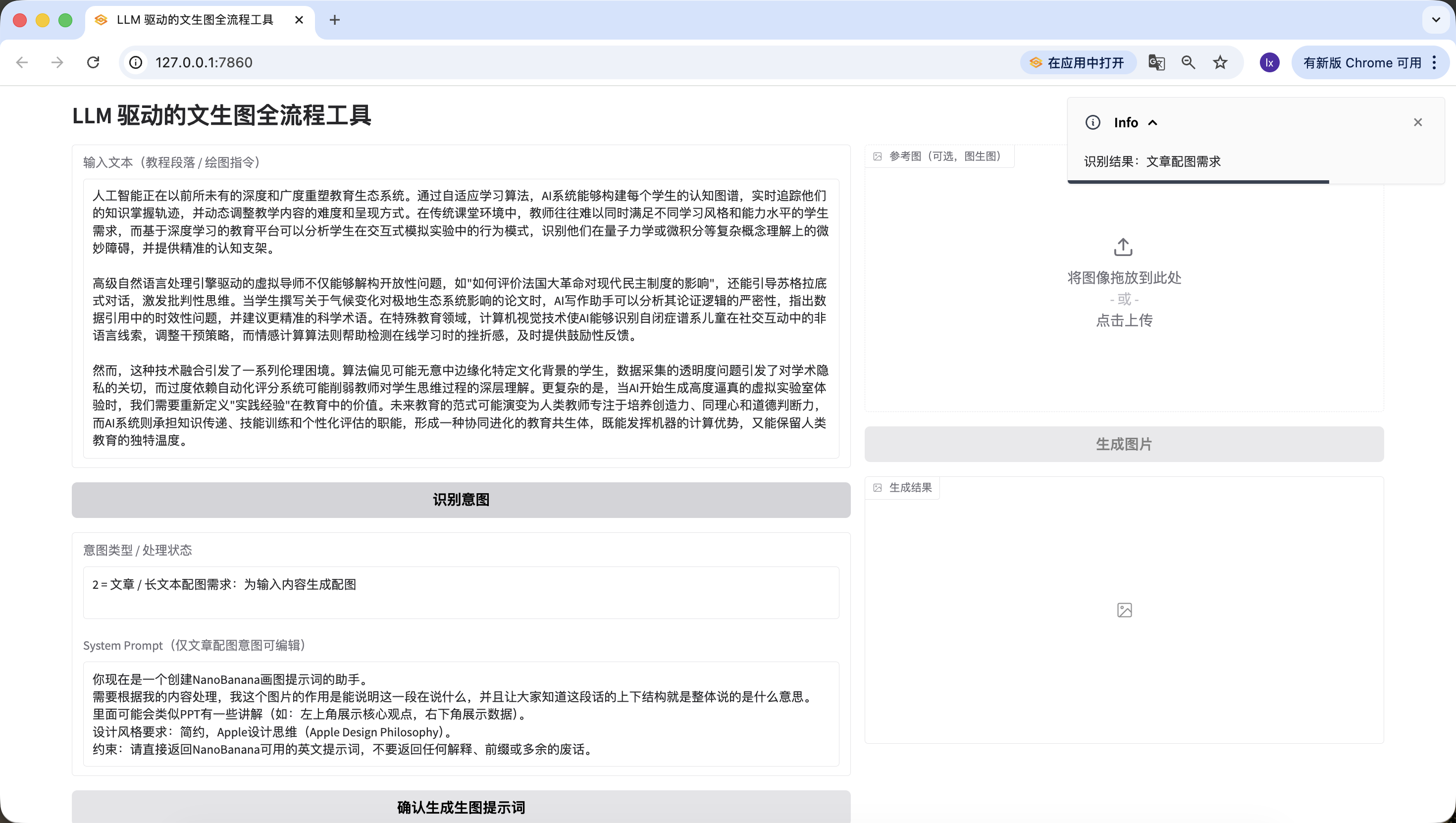
- Instruccion de dibujo directa, aqui se ingreso "quiero dibujar un gato", igualmente detectado con precision.
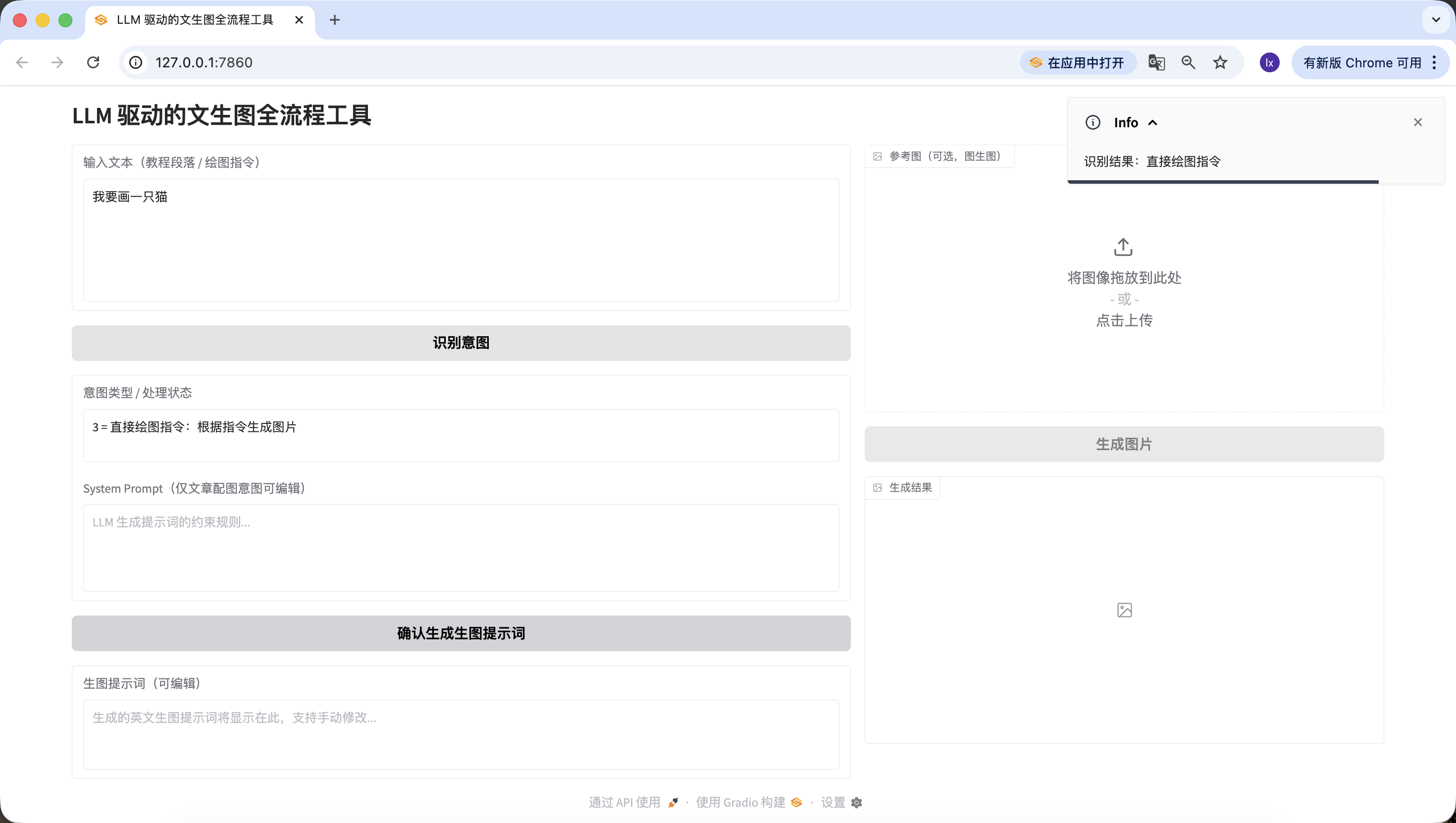
Con esto ya hemos implementado exitosamente la segunda fase — la identificacion de intencion.
Fase 3️⃣: Modulo de generacion de prompts de imagen (segunda llamada LLM)
Despues de la identificacion de intencion, para articulos o textos largos, hay un paso muy importante que es generar el prompt para dibujar, y este es precisamente el punto clave de este Agent.
Modulo 3: Modulo de generacion de prompts de imagen (segunda llamada LLM)
1, Objetivo de la tarea
Sobre la base de la identificacion de intencion, implementar la logica del boton "Confirmar generacion de prompt de imagen", llamar al LLM para optimizar el texto en un prompt visual en ingles adecuado para dibujo, rellenarlo en el campo de edicion y vincularlo con el boton "Generar imagen".
2, Requisitos del stack tecnologico
Igual que el Modulo 2, salida de codigo completo = Modulo 1 + Modulo 2 + este modulo;
Compartir LLM_BASE_URL, LLM_API_KEY, LLM_MODEL definidos en el Modulo 2, sin agregar nuevas claves.
3, Reglas de negocio centrales (fusion con logica de ensamblaje de prompt de version practica)
- Reglas de entrada para generacion de prompts (seguir estrictamente)
La generacion de prompts de imagen ya no es una simple concatenacion de cadenas, sino la construccion de una lista de mensajes Chat estandar. La estructura del codigo es la siguiente:
python
ejecutar
messages=[# Rol System: contenido de system_prompt final confirmado/editado por el usuario en la pagina web{"role": "system", "content": final_system_prompt},# Rol User: porta los datos a procesar, aclara el objetivo de la tarea{"role": "user", "content": f"Genera un prompt visual para el siguiente contenido:\n\n{user_input}"}]
Cuando la intencion es 2: El contenido de System toma la version final del system_prompt editado por el usuario;
Cuando la intencion es 3: El contenido de System toma la regla por defecto rellenada en estado deshabilitado
user_input es el texto original que el usuario ingreso inicialmente en el campo input_text.
- Preset de System Prompt verificado en practica (fijado en el codigo)
python
ejecutar
SYSTEM_PROMPT_DEFAULT = """Ahora eres un asistente que crea prompts de dibujo para NanoBanana.
Debes procesar segun mi contenido. El proposito de esta imagen es poder explicar lo que dice este parrafo y hacer que todos entiendan la estructura de contexto de este texto, es decir, lo que dice en general.
Puede haber explicaciones similares a PPT (ej: esquina superior izquierda muestra el punto clave, esquina inferior derecha muestra datos).
Requisitos de estilo de diseno: minimalista, filosofia de diseno Apple (Apple Design Philosophy).
Restriccion: retorna directamente prompts en ingles utilizables por NanoBanana, sin retornar ninguna explicacion, prefijo o palabras innecesarias."""
- Restricciones de llamada LLM
Compartir el mismo conjunto de LLM_BASE_URL, LLM_API_KEY, LLM_MODEL del Modulo 2;
temperature=0.7 (garantizar creatividad y adecuacion del prompt);
max_tokens=200 (limitar longitud de salida, coincidir con restricciones de prompt);
Usar estrictamente la estructura de lista de mensajes Chat estandar anterior, prohibida la concatenacion de cadenas.
- Ejemplo de entrada y salida (referencia central)
Ejemplo de entrada 1 (intencion de ilustracion de articulo): Texto original: "Como la IA cambia la educacion: Con el desarrollo de la tecnologia de inteligencia artificial, el rol del docente ha pasado de transmisor de conocimientos a guia, los asistentes de IA pueden auxiliar a los estudiantes en el aprendizaje personalizado, y la colaboracion humano-maquina en el aula se ha convertido en norma." System Prompt final: SYSTEM_PROMPT_DEFAULT (sin modificar) Salida esperada: "Minimalist illustration, Apple Design Philosophy, 1024x1024. Top left shows 'AI + Education' core concept, bottom right shows data of teacher-student-AI collaboration, soft color palette, clean lines, no redundant elements."
Ejemplo de entrada 2 (instruccion de dibujo directa): Texto original: "Dibuja un gato estilo Apple, sentado junto a un MacBook" System Prompt final: SYSTEM_PROMPT_DEFAULT (estado deshabilitado) Salida esperada: "Minimalist cat, Apple style, 1024x1024, sitting next to a silver MacBook, clean white background, soft shadows, geometric shapes, no extra details."
- Restriccion forzada de salida de prompt
Puramente en ingles, sin chino;
Debe incluir Apple Design Philosophy/Apple style + 1024x1024;
Longitud de 50-200 caracteres, verificacion en el codigo;
Sin explicacion adicional, prefijo o palabras innecesarias, retornar solo el prompt en si.
4, Reglas de vinculacion de componentes
Generacion exitosa: Rellenar el prompt en el campo generation_prompt, activar generate_btn, agregar a intent_status "Prompt generado exitosamente, puede modificar y generar imagen";
Generacion fallida: Indicar razon especifica (ej: fallo en llamada API, longitud insuficiente), generate_btn permanece deshabilitado, campo generation_prompt vacio;
El usuario modifica/vacia manualmente el campo generation_prompt:
Al vaciar, deshabilitar automaticamente generate_btn;
Cuando no este vacio, mantener generate_btn activado.
5, Manejo de excepciones
Fallo en llamada API: Mensaje amigable "Fallo en generacion de prompt: {mensaje de error especifico}", sin crashear;
Fallo en validacion de prompt: Indicar razon claramente (ej: "No incluye Apple style", "Longitud de solo 40 caracteres"), permitir reintentar;
Fallo en parseo de respuesta: Indicar "No se pudo parsear el resultado retornado por el LLM, por favor reintente".
6, Requisitos de salida
Codigo completo y ejecutable, solo reemplazar LLM_API_KEY para usar;
Estructura de codigo clara, comentarios completos, interfaz bonita y concisa;
Implementar estrictamente la estructura de lista de mensajes Chat estandar, parametros y logica de ejemplo consistentes;
Incluir logica de validacion de longitud y contenido del prompt, mensajes de error amigables.Igualmente copia el texto del segundo modulo para verificar.
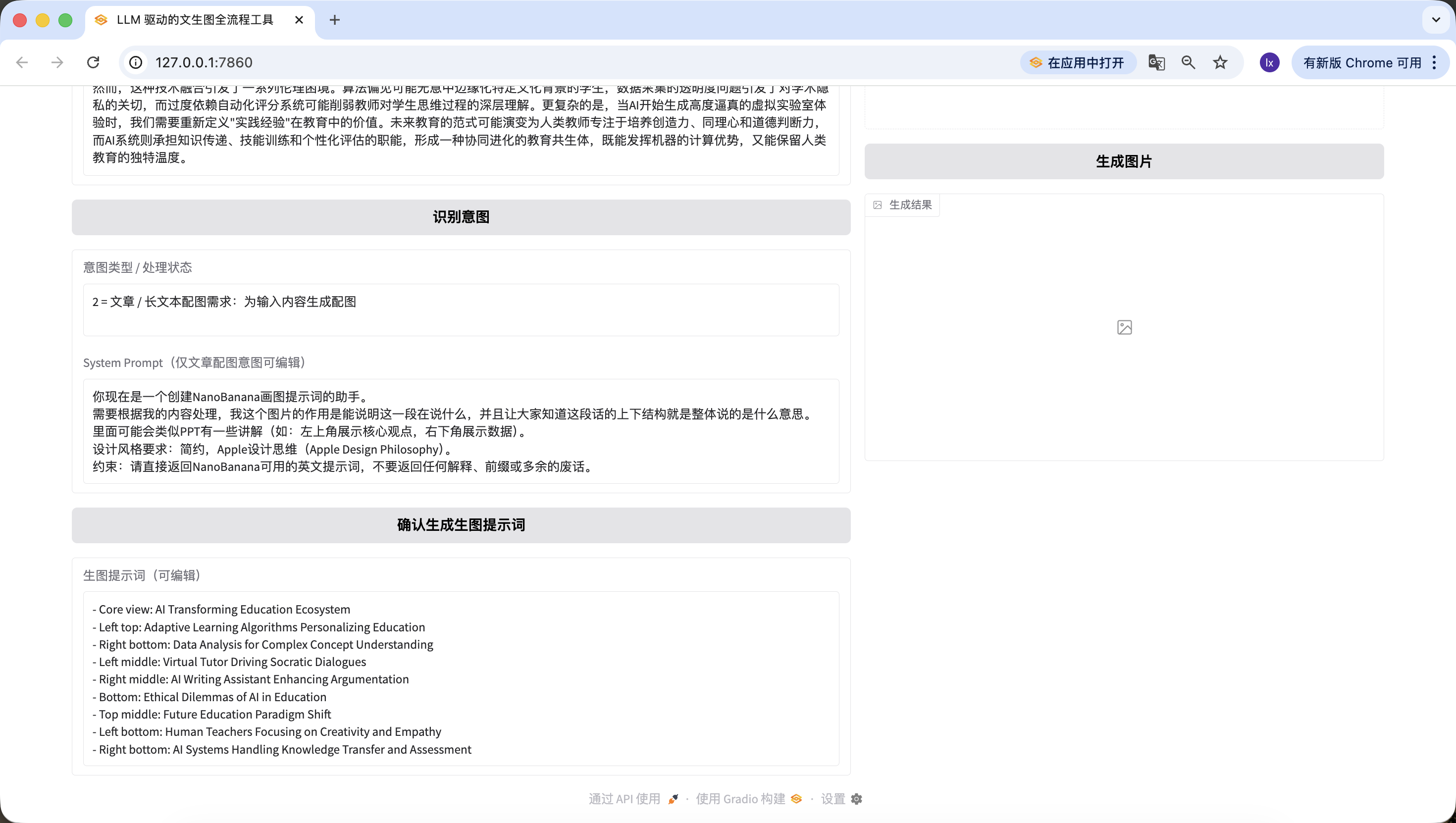
Cabe senalar que el System Prompt preset que configuramos aqui para la generacion de prompts de imagen es:
Ahora eres un asistente que crea prompts de dibujo para NanoBanana. Debes procesar segun mi contenido. El proposito de esta imagen es poder explicar lo que dice este parrafo y hacer que todos entiendan la estructura de contexto de este texto, es decir, lo que dice en general. Puede haber explicaciones similares a PPT (ej: esquina superior izquierda muestra el punto clave, esquina inferior derecha muestra datos). Requisitos de estilo de diseno: minimalista, filosofia de diseno Apple (Apple Design Philosophy). Restriccion: retorna directamente prompts en ingles utilizables por NanoBanana, sin retornar ninguna explicacion, prefijo o palabras innecesarias.
Si quieres cambiar a otra plantilla preset, puedes modificarla en el prompt anterior, o modificarla directamente en Trae a traves del dialogo.
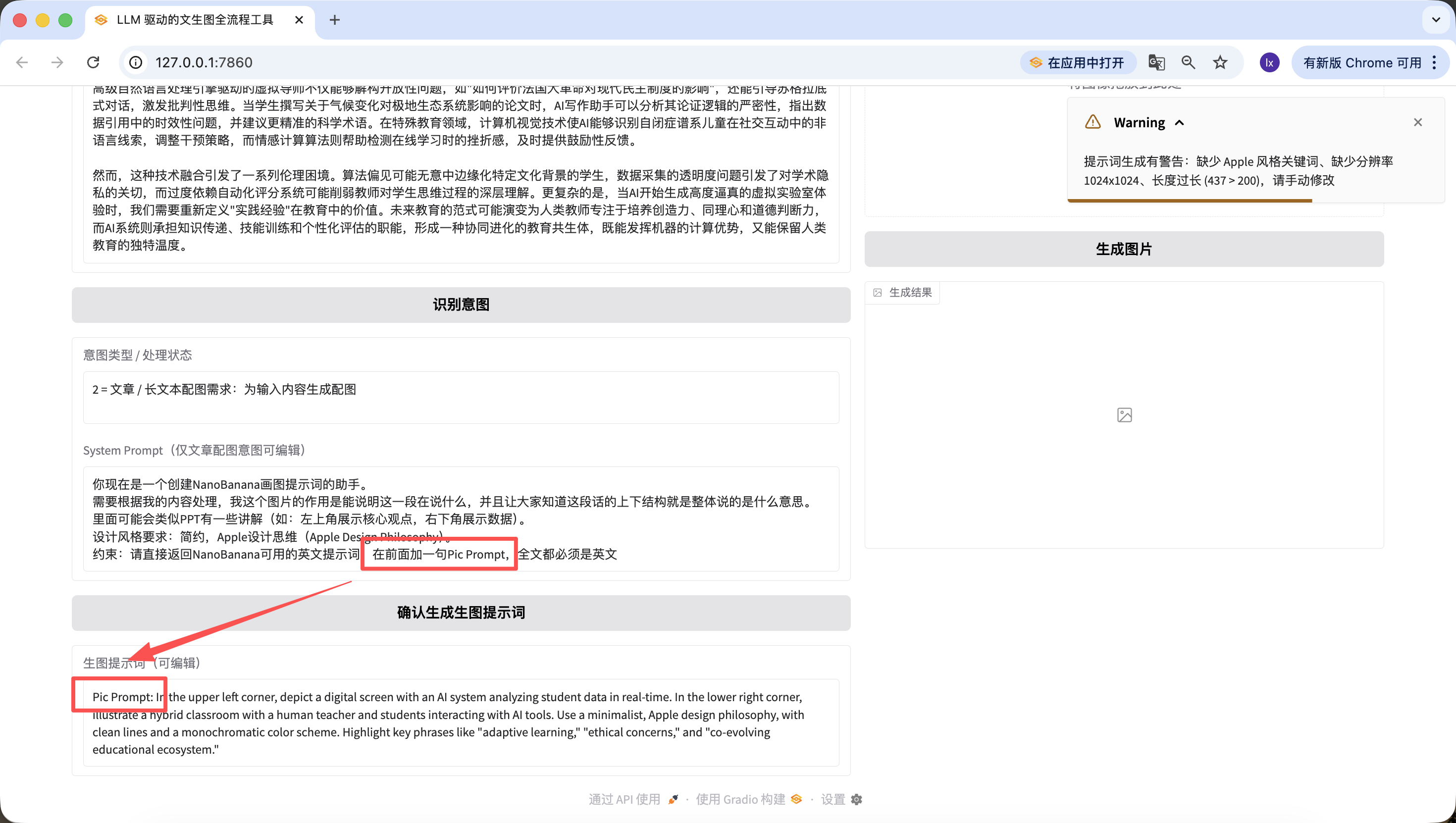
Ademas de modificar el codigo base, tambien podemos editar rapidamente en la pagina web. Por ejemplo, aqui agregue una frase, "agregar Pic Prompt al inicio", y puedes ver que el nuevo prompt generado tambien incluye esa frase al inicio~ Este diseno es para facilitar la modificacion rapida del System Prompt de generacion, ayudandonos a cambiar estilos rapidamente.
Fase 4️⃣: Modulo de texto a imagen / imagen a imagen de Nanobanana
Finalmente llegamos al ultimo paso. Sin conectar el modelo de generacion de imagenes, no es un Agent completo!
Modulo 4: Modulo de texto a imagen / imagen a imagen de Nanobanana (version final)
1, Objetivo de la tarea
Implementar la logica del boton "Generar imagen", llamar al API real de Nanobanana, soportar texto a imagen / imagen a imagen, analizar Base64 y mostrar la imagen.
2, Requisitos del stack tecnologico
Basado en Gradio 4.0.0+ Blocks;
Dependencias: requests, pillow, base64, io, re;
Codigo completo = Modulo 1+2+3 + este modulo.
3, Configuracion central del API (fijada y verificada en practica)
Configuracion de codigo fijada:
python
ejecutar
# Configuracion de API fijada en el codigo
NANOBANANA_API_URL = "https://api.zyai.online/v1/chat/completions"
NANOBANANA_MODEL = "gemini-2.5-flash-image"
NANOBANANA_API_KEY = "" # El usuario debe reemplazar
Metodo de autenticacion: Header Authorization: Bearer {NANOBANANA_API_KEY}.
4, Requisitos de preprocesamiento de imagen (debe implementarse) Implementar funcion image_to_base64_data_uri (ref_image_path), logica central:
Convertir imagen PIL a formato PNG;
Escalar automaticamente a resolucion 1024x1024;
Convertir canal transparente a fondo blanco;
Codificar como Base64, formato de retorno: data:image/png;base64,...
5, Reglas de construccion de solicitud (seguir estrictamente la logica de ramificacion de version practica)
- Definicion de funcion central Implementar funcion generate_image (prompt, ref_image_path):
Parametros de entrada: prompt (contenido del campo generation_prompt), ref_image_path (ruta del archivo subido a ref_image);
Retorno: PIL Image (mostrar en result_image) o mensaje de error.
- Rama logica 1: Texto a imagen puro (ref_image_path vacio)
python
ejecutar
messages = [{"role": "user", "content": prompt}]
- Rama logica 2: Imagen a imagen (ref_image_path tiene valor)
python
ejecutar
# Primero llamar a la funcion de preprocesamiento de imagen
image_base64 = image_to_base64_data_uri(ref_image_path)
messages = [{"role": "user","content": [{"type": "text", "text": prompt},{"type": "image_url", "image_url": {"url": image_base64}}]}]
6, Requisitos de analisis de respuesta (debe ser compatible con ambos formatos) Extraer imagen Base64 de choices [0].message.content, soportando:
Campo image_url de retorno JSON estructurado;
Formato Markdown
;
Extraer uniformemente la codificacion Base64, decodificar y convertir a PIL Image para retornar.
7, Vinculacion de componentes y manejo de excepciones
Generacion exitosa: Mostrar PIL Image en result_image, indicar en intent_status "Imagen generada exitosamente";
Fallo en generacion / analisis / subida: Mostrar indicacion de texto clara en intent_status (ej: "Fallo en analisis Base64", "Tiempo de espera agotado en llamada API"), sin crashear.
8, Requisitos de salida
Codigo completo y ejecutable, solo reemplazar LLM_API_KEY y NANOBANANA_API_KEY para ejecutar directamente, todo el flujo funcional, logica de ramificacion estrictamente coincidente con la version practica.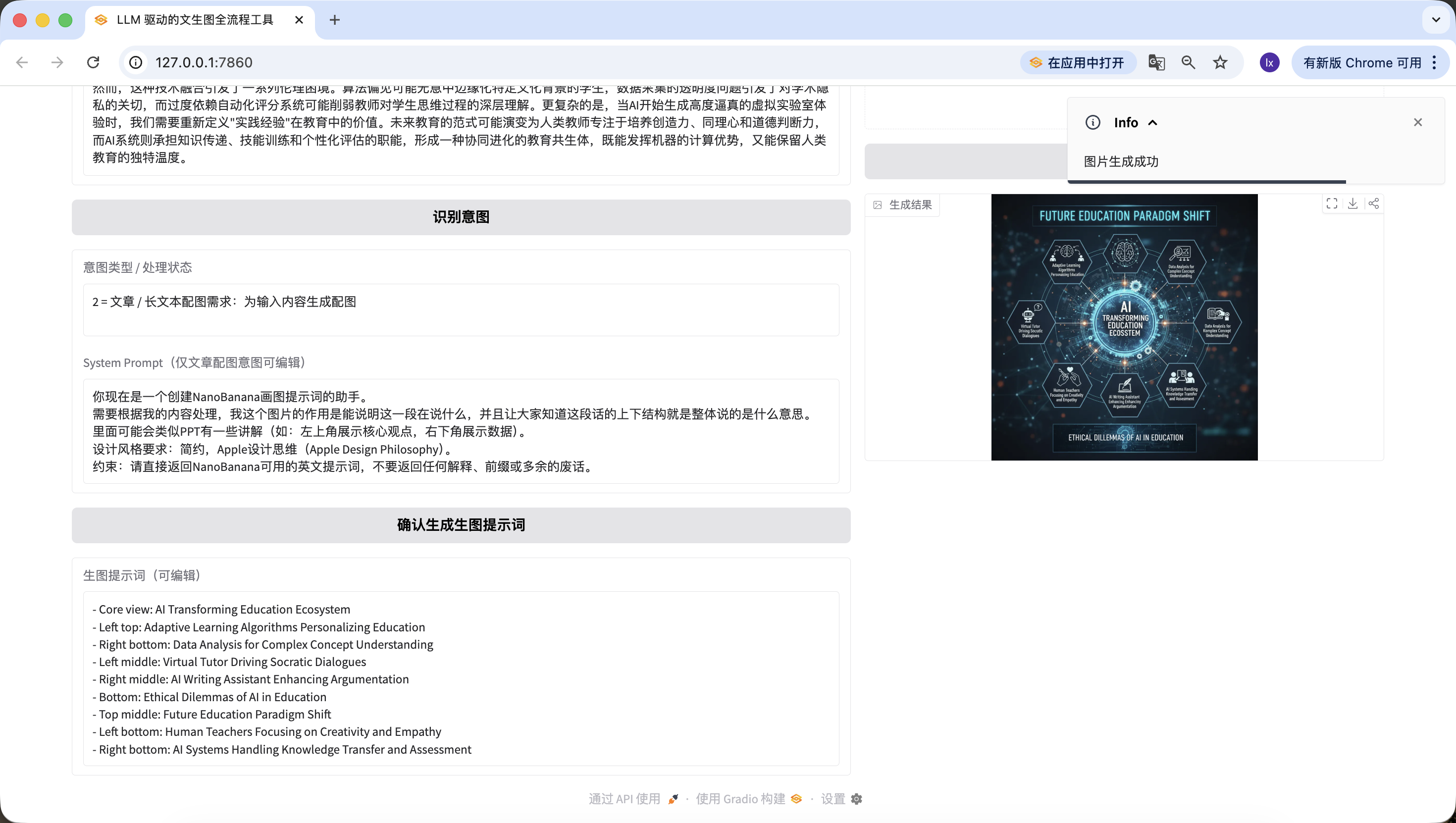
Que emocionante! Finalmente hemos generado exitosamente la primera imagen de este Agent. Si miras con cuidado la imagen generada, es coherente con nuestro texto y prompt. Con esto ya basicamente has implementado tu propio Agent!

Tambien agregamos la funcionalidad de imagen a imagen. Sube tu imagen favorita y la IA referenciara automaticamente el estilo.
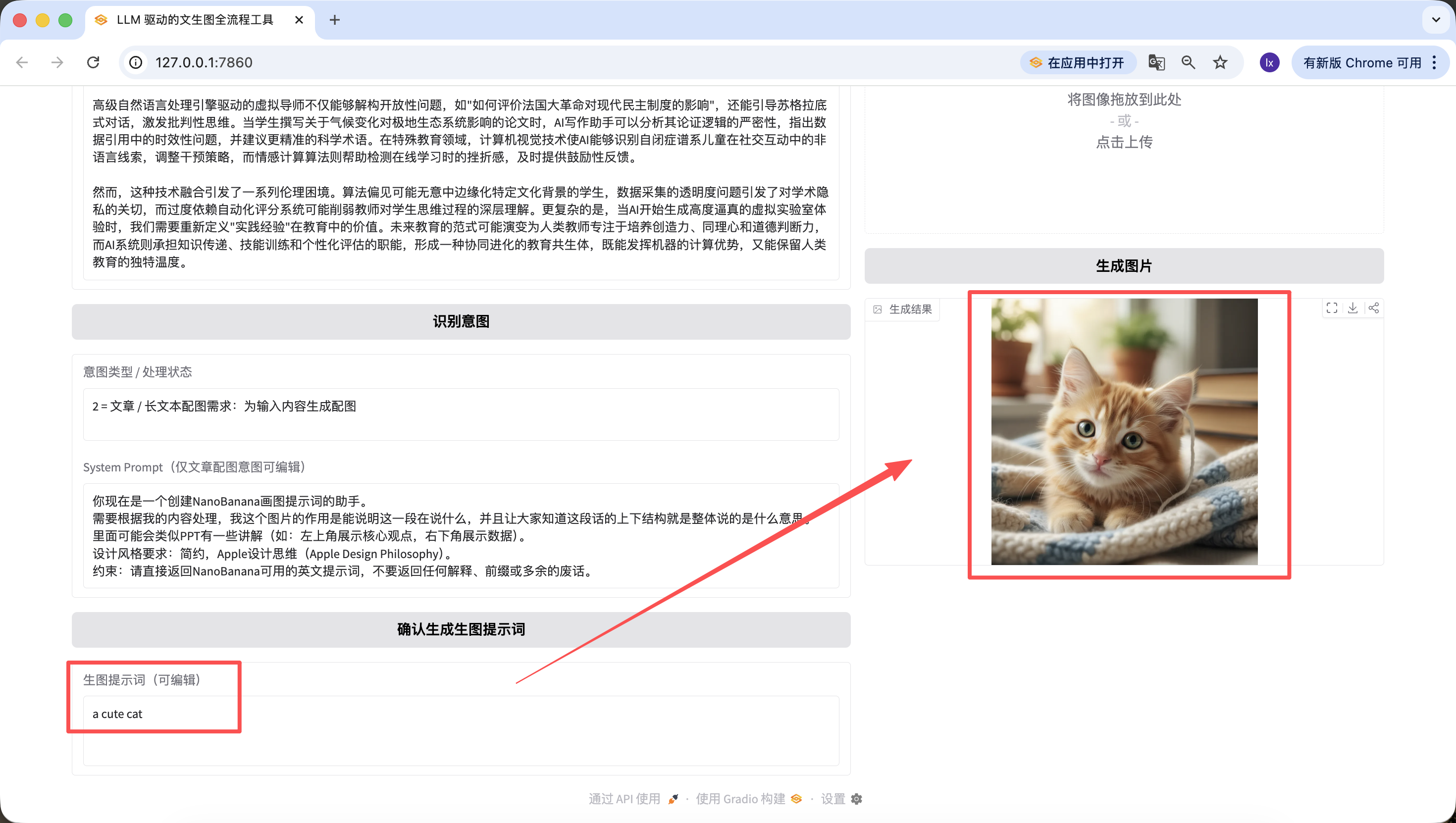
Cabe mencionar que los prompts generados en los pasos anteriores tambien son editables en la pagina web, y tomamos como referencia el prompt al momento de hacer clic final en el boton~ Incluso si lo cambias aqui por "a cute cat", la imagen final generada sera un lindo gatito.
Capitulo 4: Resumen

Por fin termino! Sinceramente, hasta yo suspire de alivio al escribir la ultima linea, sin mencionar a todos ustedes que han llegado hasta aqui. Haber completado todo este flujo de principio a fin ya es algo impresionante en si mismo. Esto demuestra que realmente pusieron las manos en el teclado y completaron las cosas paso a paso. Bravo 🎉 🥳 👏
Mientras escribia este contenido, estuve pensando: que es exactamente lo que queremos dejar? La respuesta en realidad no son los nombres de los modelos, los parametros o algun enfoque fijo, sino ayudarte a desarrollar gradualmente una sensibilidad: que cosas puedes confiar tranquilamente a la IA para que entienda y planifique, y en que lugares solo necesitas decidir la direccion. Una vez que esta division del trabajo se establece, muchos de los procesos de generacion que antes parecian complejos comenzaran a volverse mas fluidos.
En retrospectiva, este camino en realidad no es complicado. Piensa claramente en el problema que quieres resolver, entrega el texto largo al modelo de lenguaje para que lo descomponga, luego pasa la intencion visual ya organizada al modelo de generacion de imagenes para que la represente, y finalmente encapsula todo este flujo en tu propio asistente personal. Llegado a este punto, ya no estas "usando un modelo", sino construyendo un sistema que pueda acompanarte a trabajar a largo plazo. Y eso es precisamente lo que este tutorial mas quiere transmitirte.
Pero ya lo has hecho muy bien! Los que han aprendido hasta aqui ya tienen un dominio inicial de Vibe Coding. Date un pequeno descanso!