Từ Cơ sở dữ liệu đến Supabase
Trong bài học trước, chúng ta đã học cách sử dụng cơ bản các công cụ thiết kế UI là Mastergo và Figma, biết cách sử dụng github để lấy mã nguồn và quản lý phiên bản, đồng thời triển khai trang web thông qua Zeabur để đưa ứng dụng / trang web của mình đến với nhiều người dùng hơn.
Để giúp các bạn kết nối kiến thức tốt hơn, trước khi bắt đầu nội dung mới về công cụ thiết kế và triển khai trong bài học này, chúng ta hãy cùng ôn lại nhanh các kiến thức cốt lõi của bài trước thông qua một vài câu hỏi đơn giản:
- Công cụ thiết kế frontend là gì, định nghĩa và cách sử dụng Figma, MasterGo.
- Phương pháp cơ bản để chuyển đổi bản thiết kế thành mã nguồn.
- Github là gì, cách cấu hình SSH, cách tạo kho lưu trữ đầu tiên của bạn.
- Triển khai (deployment) nghĩa là gì, cách sử dụng Zeabur, cách triển khai mã nguồn từ Github hoặc local lên mạng công khai để mọi người truy cập.
Nếu bạn còn mơ hồ về bất kỳ câu hỏi nào ở trên, hãy xem lại tài liệu và bài giảng của bài học trước. Bạn cũng có thể đặt câu hỏi bất cứ lúc nào trong nhóm học tập WeChat.
Trong bài học này, chúng ta sẽ học cách biến một APP / trang web từ trạng thái "chạy được" thành sản phẩm thực tế gần hơn: ngoài việc sử dụng cơ sở dữ liệu để quản lý các thay đổi dữ liệu trong quá trình chạy ứng dụng, còn cần phải có hệ thống người dùng hoàn chỉnh (đăng ký, đăng nhập, phân quyền...) cùng các khả năng backend quan trọng khác. Chúng ta sẽ lấy nền tảng dịch vụ backend Supabase làm主线, đầu tiên sử dụng nó để thực hiện hai chức năng cơ bản là "cơ sở dữ liệu + hệ thống người dùng", sau đó tham khảo các thành phần do Supabase cung cấp để hiểu rõ hơn về các mô-đun cốt lõi mà dịch vụ backend đám mây hiện đại thường bao gồm, cũng như chức năng và logic hoạt động cụ thể của từng mô-đun.
Bạn sẽ học được gì
- Dữ liệu là gì, cơ sở dữ liệu là gì, các cơ sở dữ liệu phổ biến và cách sử dụng
- Supabase là gì, cách sử dụng Supabase để thực hiện các thao tác cơ sở dữ liệu cơ bản
- Cách sử dụng Supabase để thêm chức năng quản lý người dùng cơ bản cho ứng dụng
- Học các tính năng nâng cao của Supabase: realtime, storage, edge function
- Học cách thêm hỗ trợ đăng nhập Google và GitHub cho Supabase
- Một ứng dụng cơ bản hỗ trợ đăng ký / đăng nhập người dùng và có thể lưu trữ dữ liệu vào cơ sở dữ liệu trực tuyến
- Một bộ mẫu mã backend Supabase có thể tái sử dụng (quản lý cơ sở dữ liệu + người dùng, v.v.), để áp dụng trực tiếp cho các dự án tiếp theo
1. Cơ sở dữ liệu là gì
1.1 Dữ liệu là gì
Trong thế giới kỹ thuật số, dữ liệu (Data) có mặt ở khắp nơi. Nói một cách đơn giản, dữ liệu là载体 của thông tin. Thông tin liên lạc của bạn bè, một bài viết trên WeChat, một video ngắn, cấp độ nhân vật trong game - tất cả这些都是 dữ liệu. Trong ứng dụng của chúng ta, dữ liệu là mọi thông tin cần được ghi lại và quản lý, chẳng hạn như hồ sơ cá nhân của người dùng, lịch sử đơn hàng, cài đặt chương trình, v.v.
Nói chung, dữ liệu có nhiều dạng biểu diễn khác nhau trong chương trình, đơn giản nhất là biến. Chúng ta có thể dùng các biến khác nhau để ghi lại các con số đơn giản:
# Python variable definition examples
# Integer variable: stores age information
age = 30
# Boolean variable: stores status (whether active)
is_active = True # True means active, False means inactive
# List variable: stores a set of score data
scores = [85, 92, 78, 90] # Contains 4 integer elements representing different scores
# Dictionary variable: stores multiple related information of a user
user_info = {
"age": 30, # Key "age" corresponds to the value of age
"height": 1.80, # Key "height" corresponds to the value of height (unit: meter)
"login_count": 156 # Key "login_count" corresponds to the value of login times
}Đối với các dữ liệu phức tạp như hồ sơ cá nhân và lịch sử đơn hàng đã đề cập ở trên, chúng ta có thể sử dụng bảng biểu phức tạp hơn để biểu diễn dữ liệu:
| user_id | name | |
|---|---|---|
| 1001 | Alice | alice@example.com |
| 1002 | Bob | bob@example.com |
| order_id | user_id | amount | status |
|---|---|---|---|
| 901 | 1001 | 29.99 | completed |
| 902 | 1002 | 15.50 | pending |
Nhưng đối với các dữ liệu có cấu trúc phức tạp, có quan hệ phân cấp hoặc các trường không cố định, chúng ta có thể sử dụng định dạng JSON để mô tả — đây là định dạng trung gian dữ liệu phổ thông trên internet, hầu hết tất cả các chương trình đều có thể đọc và phân tích, rất tiện lợi khi truyền dữ liệu giữa các hệ thống. Ví dụ, một đơn hàng có thể chứa nhiều sản phẩm, mỗi sản phẩm lại có tên, số lượng và giá riêng. Việc biểu diễn bằng bảng truyền thống sẽ rất cồng kềnh: hoặc phải chia thành nhiều bảng "bảng đơn hàng" "bảng sản phẩm", dựa vào trường liên kết mới có thể thể hiện mối quan hệ "đơn hàng chứa sản phẩm"; hoặc sử dụng các trường thừa như "tên sản phẩm 1, giá sản phẩm 1, tên sản phẩm 2..." trong một bảng, hoàn toàn không thể thích ứng khi số lượng sản phẩm không cố định; trong khi JSON có thể sử dụng cấu trúc lồng nhau để làm rõ phân cấp "đơn hàng - sản phẩm - thuộc tính sản phẩm", vừa trực quan vừa linh hoạt.
{
"order_id": 901,
"user_id": 1001,
"amount": 29.99,
"status": "completed",
"items": [
{ "sku": "BG-001", "name": "Bò băm bub-gơ", "quantity": 1, "price": 18.00 },
{ "sku": "SD-003", "name": "Khoai tây chiên", "quantity": 1, "price": 6.99 },
{ "sku": "DK-002", "name": "Cola", "quantity": 1, "price": 5.00 }
],
"shipping_address": {
"street": "Công viên Khoa học và Công nghệ số 123",
"city": "Thâm Quyến",
"zip_code": "518057"
}
}Xa hơn nữa, nếu chúng ta xem xét dữ liệu được mã hóa thành vector (Vector), dữ liệu vector thường là biểu diễn số thu được sau khi dữ liệu phi cấu trúc như văn bản, hình ảnh hoặc âm thanh được xử lý qua mô hình AI (như mô hình Embedding). Dạng biểu diễn của nó có thể là:
[0.123, -0.456, 0.789, ..., -0.234] (một mảng gồm hàng trăm thậm chí hàng nghìn số dấu phẩy động)
Nhìn chung, trong thế giới thực có rất nhiều dữ liệu với nhiều hình thái và mục đích sử dụng khác nhau đáng để chúng ta phân tích chi tiết, mỗi loại dữ liệu có thể都需要 cơ sở dữ liệu chuyên dụng để lưu trữ, cụ thể có thể tham khảo sơ đồ dưới đây — có phải cảm thấy rất nhiều không?
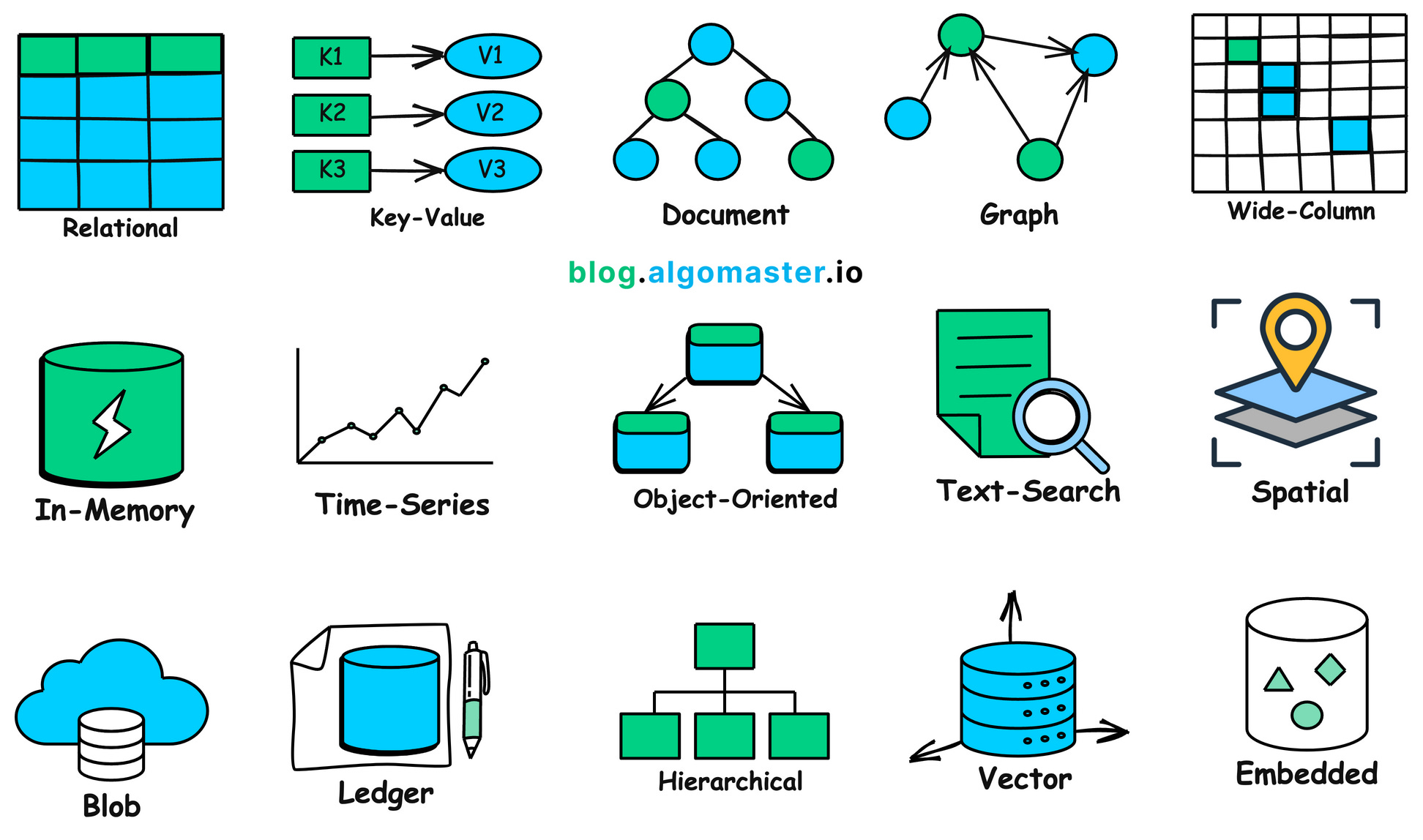
1.2 Tại sao chúng ta cần cơ sở dữ liệu
Chúng ta đã hiểu rằng dữ liệu trong thế giới thực thường có cấu trúc phức tạp, để lưu trữ và sử dụng dữ liệu này một cách hiệu quả, chúng ta cần một chương trình hoặc container chuyên dụng để quản lý chúng — đây chính là mục đích ra đời của cơ sở dữ liệu (Database). Về bản chất, cơ sở dữ liệu là một chương trình đặc biệt, có vai trò cốt lõi là tổ chức dữ liệu một cách chuẩn hóa, lưu trữ an toàn, quản lý có hệ thống và hỗ trợ truy vấn gọi hiệu quả.
Hãy tưởng tượng, nếu không có cơ sở dữ liệu, dữ liệu ứng dụng sẽ rơi vào tình trạng thế nào? Khi người dùng đóng trình duyệt hoặc thoát ứng dụng, tất cả thông tin được tải tạm thời sẽ bị mất trực tiếp; chúng ta không thể lưu trữ vĩnh viễn trạng thái sử dụng của người dùng (như thông tin đăng nhập, cài đặt cá nhân hóa), cũng không thể chia sẻ dữ liệu quan trọng giữa các người dùng (như tồn kho sản phẩm, hồ sơ đơn hàng). Chúng ta cần có một thiết bị giúp lưu trữ tất cả dữ liệu của mình!
Linh hoạt hơn, cách triển khai cơ sở dữ liệu có thể được chọn theo nhu cầu: có thể triển khai trên máy chủ cục bộ, đáp ứng nhu cầu quản lý dữ liệu tại chỗ; cũng có thể triển khai trên đám mây, cơ sở dữ liệu đám mây hỗ trợ mở rộng linh hoạt (Scale), có thể mở rộng năng lực theo sự gia tăng của lượng dữ liệu và lượng truy cập, chịu được lượng dữ liệu khổng lồ và đồng thời cao, ngay cả khi lượng người dùng tăng mạnh, vẫn đảm bảo trải nghiệm sử dụng bình thường của người dùng.
Tóm lại, cơ sở dữ liệu凭借 khả năng lưu trữ bền vững hiệu quả, quản lý tinh tế và truy vấn nhanh chóng, chủ yếu giải quyết các vấn đề cốt lõi sau:
- Lưu trữ bền vững dữ liệu: Nếu không có cơ sở dữ liệu, dữ liệu sẽ chỉ tồn tại trong bộ nhớ của ứng dụng, một khi ứng dụng đóng, dữ liệu sẽ bị mất. Cơ sở dữ liệu giải quyết vấn đề này, nó lưu trữ dữ liệu bền vững trên các phương tiện lưu trữ như ổ cứng, đảm bảo việc lưu trữ dài hạn dữ liệu, giảm nguy cơ mất mát.
- Truy vấn và phân tích dữ liệu tiện lợi: Cơ sở dữ liệu cung cấp ngôn ngữ truy vấn mạnh mẽ (như SQL), cho phép người dùng dễ dàng, hiệu quả thực hiện các truy vấn, lọc và phân tích phức tạp trên lượng dữ liệu khổng lồ, giúp doanh nghiệp đưa ra quyết định sáng suốt hơn. Nếu không có cơ sở dữ liệu, việc tìm kiếm thông tin cụ thể từ một lượng lớn tập tin không có thứ tự sẽ là một nhiệm vụ cực kỳ tốn thời gian và khó khăn.
- Hỗ trợ truy cập hiệu năng cao và đồng thời cao: Cơ sở dữ liệu thông qua các công nghệ như tối ưu hóa chỉ mục, bộ đệm truy vấn, pool kết nối và kiến trúc phân tán, có thể phản hồi yêu cầu truy vấn trong thời gian mili-giây và hỗ trợ hàng nghìn người dùng truy cập đồng thời. Điều này rất quan trọng đối với các ứng dụng internet hiện đại (như hoạt động flash sale trên nền tảng thương mại điện tử, feed thời gian thực trên mạng xã hội), đảm bảo tốc độ phản hồi của hệ thống và trải nghiệm người dùng. Nếu không có hỗ trợ hiệu năng cao của cơ sở dữ liệu, hệ thống sẽ gặp độ trễ nghiêm trọng hoặc thậm chí sập khi đối mặt với lượng yêu cầu khổng lồ từ người dùng.
- Đảm bảo tính toàn vẹn và nhất quán của dữ liệu: Cơ sở dữ liệu thông qua một loạt cơ chế (như ràng buộc, trigger) để đảm bảo tính chính xác và nhất quán của dữ liệu. Điều này có nghĩa là dữ liệu trong cơ sở dữ liệu phải tuân thủ các quy tắc được thiết lập trước, ví dụ, tuổi của người dùng phải là số, số đơn hàng phải là duy nhất, từ đó ngăn chặn hiệu quả việc tạo ra dữ liệu bất hợp pháp hoặc không hợp lệ.
- Đảm bảo bảo mật dữ liệu: Cơ sở dữ liệu cung cấp các cơ chế bảo mật mạnh mẽ, bao gồm xác thực danh tính người dùng, kiểm soát truy cập và mã hóa dữ liệu, để bảo vệ dữ liệu khỏi truy cập, sửa đổi hoặc phá hủy trái phép. Để đối phó với các tình huống bất ngờ như lỗi phần cứng, sai sót con người hoặc tấn công độc hại, cơ sở dữ liệu còn cung cấp chức năng sao lưu và khôi phục dữ liệu. Thông qua sao lưu định kỳ, có thể khôi phục kịp thời khi dữ liệu bị mất hoặc hỏng, đảm bảo tính liên tục của hoạt động kinh doanh.
1.3 Cơ sở dữ liệu quan hệ và cơ sở dữ liệu phi quan hệ
Ở trên chúng ta đã hiểu giá trị cốt lõi, cách triển khai và lợi thế linh hoạt của cơ sở dữ liệu, và trong thực tế lựa chọn, điều đầu tiên phải đối mặt là hai danh mục cốt lõi của cơ sở dữ liệu: cơ sở dữ liệu quan hệ và cơ sở dữ liệu phi quan hệ (NOSQL), chúng ta có thể hiểu sự khác biệt của chúng một cách đơn giản qua hai đoạn văn ngắn:
Cơ sở dữ liệu quan hệ giống như bảng Excel có cấu trúc nghiêm ngặt, tất cả dữ liệu phải được định nghĩa trước định dạng (nội dung Schema đã được định nghĩa, ví dụ phải có tên và tuổi, và tên phải là văn bản, tuổi phải là số), và thông qua trường liên kết (định danh dùng để kết nối các bảng khác nhau, như số CMND) kết nối các bảng khác nhau. Ưu điểm của nó là dữ liệu chính xác và đáng tin cậy, đặc biệt phù hợp với các tình huống không thể sai sót như chuyển khoản ngân hàng, quản lý tồn kho, nhưng nhược điểm là điều chỉnh cấu trúc khá phiền toái, hiệu suất sẽ bị hạn chế với lượng dữ liệu khổng lồ.
Cơ sở dữ liệu phi quan hệ thì giống như thư mục linh hoạt, có thể lưu trữ các tài liệu, hình ảnh hoặc cặp khóa-giá trị (cấu trúc "từ - giải thích" tương tự từ điển) có định dạng khác nhau, không cần quy định trước cấu trúc của từng dữ liệu. Nó dễ dàng đối phó hơn với các nhu cầu thay đổi nhanh chóng và dữ liệu siêu quy mô (như lượng bài viết khổng lồ trên mạng xã hội), mở rộng (thêm máy chủ để tăng hiệu suất) cũng thuận tiện hơn, nhưng hy sinh một phần khả năng truy vấn liên kết (khả năng tổng hợp thông tin từ các bảng dữ liệu khác nhau) và đảm bảo nhất quán (đảm bảo dữ liệu luôn chính xác không mâu thuẫn), phù hợp với các ứng dụng internet có yêu cầu chịu lỗi cao.
Vậy, trong ứng dụng thực tế nên chọn cơ sở dữ liệu nào? Từ góc độ phân loại tình huống, cơ sở dữ liệu quan hệ thường thấy trong các tình huống như giao dịch tài chính, quản lý tồn kho, xử lý đơn hàng, hệ thống kế toán cần tính nhất quán mạnh, xử lý giao dịch phức tạp và truy cập đọc ghi cân bằng thường xuyên; trong khi cơ sở dữ liệu phi quan hệ phù hợp hơn với các nhu cầu lưu trữ nội dung mạng xã hội, phân tích log thời gian thực, ghi dữ liệu khổng lồ IoT, hệ thống gợi ý đặc trưng đọc nhiều ghi nhiều có đồng thời cao, mô hình đọc ghi không cân bằng và cấu trúc linh hoạt.
Nhưng đối với doanh nghiệp, trong giai đoạn đầu không cần dành nhiều thời gian suy nghĩ về việc nên sử dụng cơ sở dữ liệu nào. Cơ sở dữ liệu hiện nay đã là sản phẩm dịch vụ rất trưởng thành, cách trực tiếp nhất là tham vấn các nhà cung cấp dịch vụ đám mây khác nhau (chỉ các nhà cung cấp dịch vụ tài nguyên IT và dịch vụ công nghệ như máy chủ, lưu trữ, cơ sở dữ liệu, phần mềm, năng lực tính toán, v.v.). Chúng ta có thể đối thoại trực tiếp với bộ phận bán hàng chính thức của dịch vụ đám mây, dựa trên nhu cầu kinh doanh sản phẩm của mình để phù hợp với giải pháp cơ sở dữ liệu thích ứng; và con đường thuận tiện để xây dựng ứng dụng cấp doanh nghiệp là ưu tiên hợp tác với các nhà cung cấp chuyên nghiệp. (Cần lưu ý: giá dịch vụ cấp doanh nghiệp thường cao, nên khảo sát và so sánh nhiều bên trước, cũng có thể chọn mua máy chủ để tự triển khai chương trình cơ sở dữ liệu mã nguồn mở sebagai giải pháp thay thế.)
Chúng ta cũng có thể tham khảo khuyến nghị chọn cơ sở dữ liệu của một nhà cung cấp đám mây, dựa trên tình huống có thể chọn các loại cơ sở dữ liệu khác nhau, bạn có thể so sánh thông số cơ sở dữ liệu của các nhà cung cấp đám mây khác nhau để chọn loại phù hợp nhất để sử dụng.
| Loại cơ sở dữ liệu | Tên cơ sở dữ liệu | Giá | Tình huống sử dụng |
|---|---|---|---|
| Cơ sở dữ liệu quan hệ | RDS MySQL版 | Thấp | Phiên bản cơ bản: học tập và trang web nhỏ Phiên bản cao khả dụng: tình huống cơ sở dữ liệu trung bình có áp lực kinh doanh nhất định Phiên bản cluster: kinh doanh không được gián đoạn, áp lực truy cập lớn |
| RDS SQL server版 | Cao | Phiên bản cơ bản: thử nghiệm và trang web thương mại nhỏ Phiên bản cao khả dụng: trang web thương mại cấp doanh nghiệp Phiên bản cluster: kinh doanh doanh nghiệp không được gián đoạn, áp lực truy cập lớn | |
| RDS PostgreSQL版 | Thấp nhất | Phiên bản cơ bản: học tập và trang web nhỏ Phiên bản cao khả dùng: tình huống cơ sở dữ liệu trung bình có áp lực kinh doanh nhất định Phiên bản cluster: kinh doanh không được gián đoạn, tình huống áp lực truy cập lớn, hiệu suất cao hơn MySQL thông thường | |
| RDS PPAS版 | Cao | Loại phổ thông: tương thích kinh doanh Oracle, nhưng áp lực kinh doanh Udacity, ảo hóa có thể đáp ứng nhu cầu Loại độc quyền: đối với kinh doanh cần máy vật lý độc quyền, thường là kinh doanh Oracle loại đồng thời cao | |
| DRDS | Trung bình | Phiên bản nhập môn: 4 Core 8 G, giá cả phải chăng, phù hợp doanh nghiệp kinh doanh trực tuyến nhỏ và vừa Phiên bản doanh nghiệp: 16 Core 32 G, phản hồi SQL phức tạp tốt, phù hợp kinh doanh trực tuyến đồng thời siêu cao Phiên bản tối thượng: 32 Core 64 G, phản hồi thực thi SQL phức tạp tốt nhất, cung cấp lựa chọn thông số siêu lớn | |
| Cơ sở dữ liệu NoSQL | Redis | Trung bình | Redis dự phòng nóng hai máy: thường dùng làm cơ sở dữ liệu bền vững để tăng tính khả dụng của kinh doanh Phiên bản cluster của Redis: thường dùng làm lớp bộ đệm, tăng tốc truy cập ứng dụng, giải quyết áp lực đọc mà cơ sở dữ liệu thông thường không thể chịu tải |
| MongoDB版 | Trung bình | Thực thể nút đơn: phù hợp cho phát triển, thử nghiệm và các tình huống lưu trữ dữ liệu không phải cốt lõi doanh nghiệp Thực thể replica set: phù hợp cho các tình huống kinh doanh có nhu cầu hiệu suất đọc cao hơn cho cơ sở dữ liệu, như trang web đọc, hệ thống tra cứu đơn hàng đọc nhiều ghi ít hoặc nhu cầu kinh doanh đột biến từ sự kiện tạm thời Thực thể sharded cluster: dựa trên nhiều replica set (mỗi replica set sử dụng mô hình ba replica) tạo thành thực thể sharded cluster, cung cấp nhu cầu hiệu suất đọc cao hơn, cung cấp hiệu suất đọc tốc độ cao cho kinh doanh trực tuyến thời gian thực |
Chỉ nói thì không dễ hiểu, chúng ta hãy xem xét một tình huống "bài viết blog" cụ thể, để xem cùng một dữ liệu được lưu trữ như thế nào trong cơ sở dữ liệu quan hệ (SQL) và các loại cơ sở dữ liệu phi quan hệ (NoSQL) khác nhau.
Giả sử chúng ta có một nền tảng blog, cần lưu trữ các thông tin sau:
- Người dùng (Users): ID người dùng, tên người dùng, email
- Bài viết (Posts): ID bài viết, tiêu đề, nội dung, ID tác giả
- Bình luận (Comments): ID bình luận, nội dung bình luận, ID người bình luận, ID bài viết thuộc về
- Thẻ (Tags): ID thẻ, tên thẻ
- Quan hệ bài viết và thẻ: nhiều thẻ liên kết với một bài viết, nhiều bài viết tương ứng với một thẻ
Ví dụ về cơ sở dữ liệu quan hệ (SQL)
Trong cơ sở dữ liệu SQL, chúng ta sẽ lưu trữ các loại dữ liệu khác nhau trong các bảng khác nhau, và liên kết chúng thông qua "khóa ngoại". Cấu trúc này rõ ràng, chuẩn hóa, giảm thiểu dư thừa dữ liệu.
Lấy ví dụ "quản lý bài viết trên nền tảng nội dung", chúng ta sẽ không trộn lẫn "người dùng, bài viết, bình luận, thẻ", mà chia thành 5 bảng có chức năng đơn nhất, mỗi bảng đều có "ranh giới trách nhiệm" rõ ràng và định nghĩa cấu trúc nghiêm ngặt (Schema):
- Bảng
users(lưu trữ thông tin người dùng)
| user_id (khóa chính) | username | |
|---|---|---|
| 101 | Alice | alice@example.com |
| 102 | Bob | bob@example.com |
- Bảng
posts(lưu trữ thông tin bài viết)
| post_id (khóa chính) | title | content | author_id (khóa ngoại) |
|---|---|---|---|
| 1 | Làm quen SQL | Đây là một bài viết về cơ sở dữ liệu SQL... | 101 |
| 2 | Nhập môn NoSQL | NoSQL cung cấp mô hình dữ liệu linh hoạt... | 102 |
- Bảng
comments(lưu trữ thông tin bình luận)
| comment_id (khóa chính) | body | commenter_id (khóa ngoại) | post_id (khóa ngoại) |
|---|---|---|---|
| 1001 | Viết rất hay! | 102 | 1 |
| 1002 | Đã học được. | 101 | 2 |
| 1003 | Có thêm ví dụ không? | 101 | 1 |
- Bảng
tags(lưu trữ thẻ)
| tag_id (khóa chính) | tag_name |
|---|---|
| 51 | Cơ sở dữ liệu |
| 52 | Công nghệ |
| 53 | Nhập môn |
- Bảng
post_tags(lưu trữ quan hệ nhiều-nhiều giữa bài viết và thẻ, thể hiện đặc điểm liên kết bảng)
| post_id (khóa ngoại) | tag_id (khóa ngoại) |
|---|---|
| 1 | 51 |
| 1 | 52 |
| 2 | 51 |
| 2 | 52 |
| 2 | 53 |
Nếu cần truy vấn "thông tin đầy đủ của bài viết 《Làm quen SQL》 (post_id=1) do Alice đăng (bao gồm nội dung bài viết, tác giả, bình luận, thẻ)", cần thực hiện truy vấn kết nối nhiều bảng (JOIN), liên kết 5 bảng thông qua khóa ngoại và tổng hợp dữ liệu, câu lệnh SQL như sau:
SELECT
p.title,
p.content,
u.username AS author,
c.body AS comment,
t.tag_name AS tag
FROM
posts p
JOIN
users u ON p.author_id = u.user_id
LEFT JOIN
comments c ON p.post_id = c.post_id
LEFT JOIN
post_tags pt ON p.post_id = pt.post_id
LEFT JOIN
tags t ON pt.tag_id = t.tag_id
WHERE
p.post_id = 1;Truy vấn này sẽ xuyên qua 5 bảng, tổng hợp tất cả dữ liệu liên quan và trả về. Đây là lợi thế cốt lõi của cơ sở dữ liệu quan hệ: thông qua chuẩn hóa và phép kết nối, có thể linh hoạt thực hiện nhiều loại truy vấn phức tạp, đồng thời đảm bảo tính nhất quán của dữ liệu và dư thừa tối thiểu.
Ví dụ về cơ sở dữ liệu phi quan hệ (NoSQL)
Ý tưởng thiết kế của cơ sở dữ liệu NoSQL (như MongoDB, Redis) ngược lại với SQL, nó không nhấn mạnh việc chia nhỏ và chuẩn hóa dữ liệu, thường sẽ đóng gói và tổng hợp tất cả dữ liệu liên quan về mặt kinh doanh lại với nhau, để giảm thiểu phép kết nối khi truy vấn, từ đó tăng hiệu suất đọc.
Trong cơ sở dữ liệu NoSQL, cơ sở dữ liệu tài liệu (Document Database) là một trong những loại phổ biến nhất, MongoDB là đại diện tiêu biểu. Nó sử dụng "tài liệu" làm đơn vị lưu trữ cơ bản, "tài liệu" ở đây không phải là "bài viết" như chúng ta hiểu thông thường, mà là một cấu trúc dữ liệu tương tự JSON (trong MongoDB thực tế sử dụng định dạng BSON, hỗ trợ nhiều loại dữ liệu hơn): không cần định nghĩa trước Schema thống nhất (cấu trúc dữ liệu), các trường của mỗi tài liệu có thể tăng giảm linh hoạt, loại trường cũng có thể điều chỉnh tự do, hoàn toàn phù hợp với các tình huống định dạng dữ liệu thay đổi đa dạng.
Trong cơ sở dữ liệu tài liệu, thường lưu trữ một bài viết và tất cả thông tin liên quan (như bình luận, thẻ) trong một tài liệu (định dạng tài liệu tương tự JSON, có thể định nghĩa trường linh hoạt, không cần Schema trước), logic cốt lõi là "lưu trữ 'thông tin hoàn chỉnh trong một tình huống kinh doanh' trong một tài liệu", tránh việc ghép nối nhiều nguồn dữ liệu khi truy vấn.
Ví dụ về một tài liệu trong bộ sưu tập posts:
{
"_id": 1,
"title": "Làm quen SQL",
"content": "Đây là một bài viết về cơ sở dữ liệu SQL...",
"author": {
"user_id": 101,
"username": "Alice",
"email": "alice@example.com"
},
"tags": [
"Cơ sở dữ liệu",
"Công nghệ"
],
"comments": [
{
"comment_id": 1001,
"body": "Viết rất hay!",
"commenter": {
"user_id": 102,
"username": "Bob"
}
},
{
"comment_id": 1003,
"body": "Có thêm ví dụ không?",
"commenter": {
"user_id": 101,
"username": "Alice"
}
}
]
}Ưu điểm của thiết kế này rất trực quan: khi bạn cần lấy "thông tin đầy đủ của bài viết đầu tiên (bao gồm tác giả, bình luận, thẻ)", chỉ cần truy vấn tài liệu này thông qua _id:1, cơ sở dữ liệu có thể trả về tất cả dữ liệu chỉ với một lần đọc, không cần thực hiện 3-4 phép kết nối bảng như SQL, hiệu suất đọc được cải thiện đáng kể.
Nhưng nó cũng存在 trade-off (sự đánh đổi) rõ ràng: do dữ liệu được "tổng hợp lưu trữ", sẽ không thể tránh khỏi việc tạo ra dư thừa dữ liệu — ví dụ username của tác giả "Alice" được nhúng vào mỗi tài liệu bài viết cô ấy viết, nếu một ngày nào đó "Alice" đổi tên người dùng thành "Alice_New", về lý thuyết cần duyệt qua tất cả tài liệu bài viết chứa thông tin của cô ấy, cập nhật trường author.username từng cái một, không chỉ phiền toạp mà còn có thể do vấn đề mạng hoặc máy chủ dẫn đến việc cập nhật một số tài liệu thất bại, xuất hiện tình trạng "cùng một người dùng có tên khác nhau trong các bài viết khác nhau".
Tuy nhiên trong kinh doanh thực tế, loại dư thừa này thường là "có thể chấp nhận được": đối với các tình huống "đọc nhiều ghi ít" như blog, tin tức, chi tiết sản phẩm thương mại điện tử (số lần người dùng xem nội dung nhiều hơn nhiều so với số lần tác giả sửa tên người dùng), việc sử dụng một lượng dư thừa nhỏ để đổi lấy "hiệu suất đọc cực đoan" là lựa chọn tốt hơn; còn nếu là tình huống "ghi nhiều đọc ít" (như sửa đổi thông tin người dùng thường xuyên), thì cần kết hợp nhu cầu kinh doanh để cân nhắc có nên sử dụng cơ sở dữ liệu tài liệu hay không.
Trên đây là giới thiệu đơn giản về các cơ sở dữ liệu khác nhau, nếu bạn quan tâm đến nhiều loại cơ sở dữ liệu cụ thể hơn, bạn có thể tham khảo các tài liệu sau để thử các loại cơ sở dữ liệu khác nhau.
Examples of SQL databases: Db2、MySQL、PostgreSQL、YugabyteDB、CockroachDB、Oracle Database、Azure SQL Database
Examples of NoSQL databases: Redis、CouchDB、MongoDB、Cassandra、Elasticsearch、BigTable、Neo4j、HBase
2. Supabase
Ở phần trước chúng ta đã giới thiệu một số loại cơ sở dữ liệu phổ biến và các tình huống sử dụng phù hợp của từng loại. Tuy nhiên trong dự án thực tế, cơ sở dữ liệu thường chỉ là một mô-đun cơ bản trong hệ thống backend: ngoài việc lưu trữ và truy vấn dữ liệu, bạn còn cần giải quyết một loạt vấn đề như đăng ký đăng nhập người dùng, xác thực phân quyền, tải lên và lưu trữ tệp, API giao diện bên ngoài , thậm chí tác vụ định kỳ, thông báo thời gian thực. Chỉ việc chọn cơ sở dữ liệu tốt không thể làm cho ứng dụng của bạn "ngay lập tức có thể chạy trực tuyến", ở giữa còn có một loạt công việc backend phức tạp.
Vì vậy, chúng ta cần xem xét một bối cảnh lớn hơn: dịch vụ backend. Một ứng dụng hoàn chỉnh, thường bao gồm "frontend + backend": frontend chịu trách nhiệm hiển thị trang và tương tác người dùng, backend chịu trách nhiệm lưu trữ dữ liệu, đăng nhập người dùng, xử lý logic kinh doanh, v.v. Trước đây, các nhà phát triển thường cần tự xây dựng máy chủ, cấu hình cơ sở dữ liệu, thiết kế và triển khai API, còn phải xử lý thủ công quản lý phân quyền, chính sách bảo mật, khả năng mở rộng và vận hành giám sát, toàn bộ quá trình vừa lặp lại vừa tốn thời gian. Để giải quyết các công việc lặp lại này, ngành đã xuất hiện BaaS (Backend as a Service, Backend dưới dạng dịch vụ): đóng gói các chức năng backend phổ biến như cơ sở dữ liệu, xác thực người dùng, lưu trữ tệp, khả năng thời gian thực thành một nền tảng đám mây, nhà phát triển có thể gọi trực tiếp các khả năng này thông qua SDK / API mà không cần xây dựng và vận hành cơ sở hạ tầng từ con số không.
Trong bối cảnh này, Supabase có thể được xem là đại diện BaaS thế hệ mới: nó sử dụng PostgreSQL làm cơ sở dữ liệu cốt lõi, tích hợp trên đó một bộ khả năng backend hoàn chỉnh bao gồm Auth, Storage, Realtime, Edge Functions, Vector, v.v., cung cấp cho nhà phát triển một "nền tảng backend一站式 lấy Postgres làm trung tâm". Tiếp theo, chúng ta sẽ đi từ góc độ này, từ "chỉ chọn cơ sở dữ liệu" nâng cấp lên "chọn nền tảng phát triển backend hoàn chỉnh", xem cụ thể Supabase có thể giúp chúng ta tiết kiệm những công việc nào, và làm thế nào để rút ngắn đáng kể khoảng cách từ nguyên mẫu đến sản phẩm可用.
2.1 Hướng dẫn từng bước
Sau khi nắm bắt rõ định vị tổng thể của Supabase, tiếp theo chúng ta sẽ đi theo đường dẫn thao tác trên bảng điều khiển Supabase, phân tích từng mục về các khả năng cốt lõi cụ thể mà nó cung cấp và trách nhiệm cốt lõi tương ứng của từng khả năng. Chúng ta sẽ giới thiệu chi tiết từng tùy chọn mà Supabase liên quan, giúp bạn nhanh chóng làm quen với các thao tác cơ bản của Supabase.

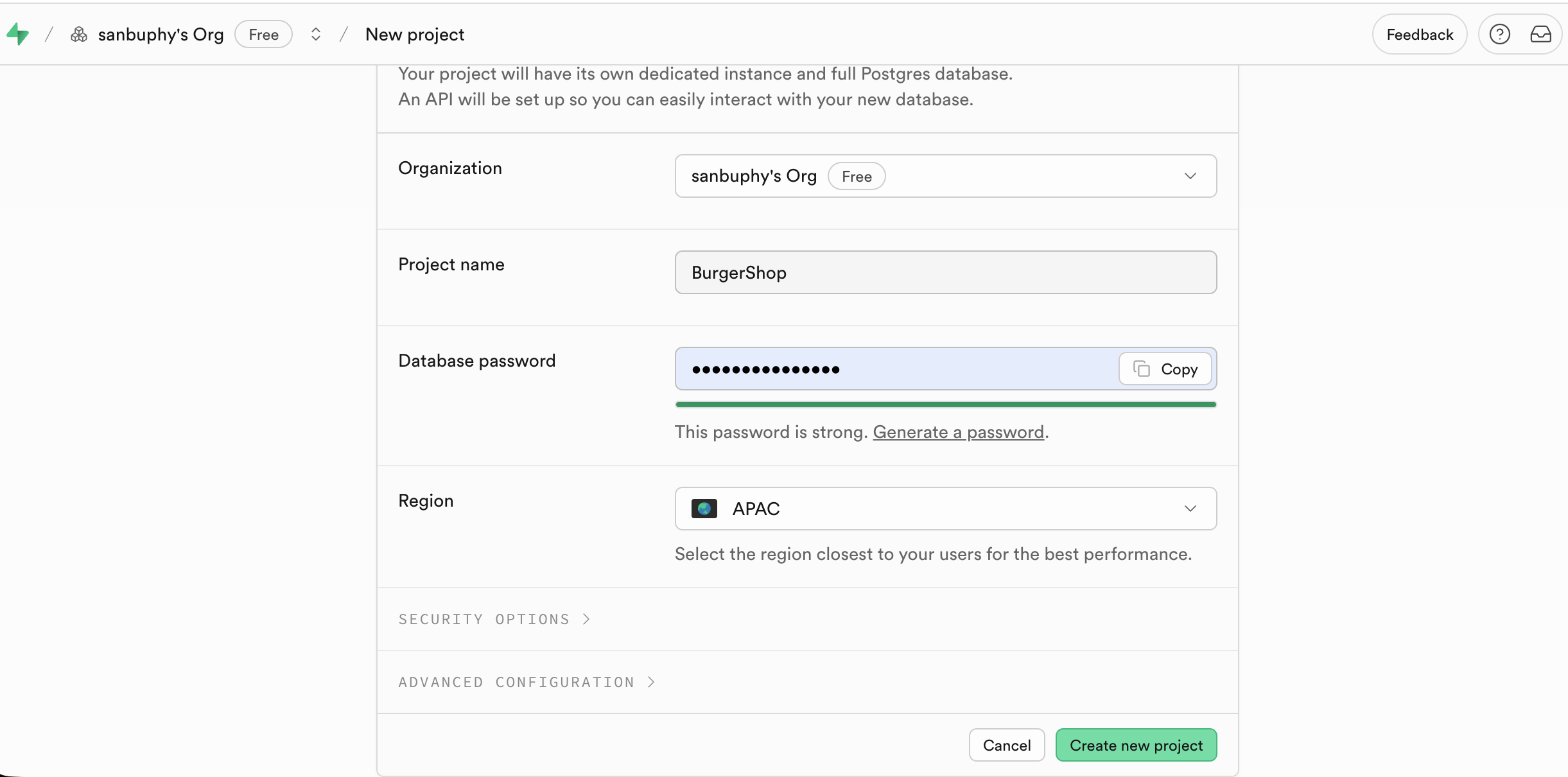
Sau khi truy cập trang web chính thức của Supabase và đăng nhập, tại trang chủ bảng điều khiển nhấn New project để vào quá trình tạo;
Nhập nội dung cấu hình chính cần thiết là Project Name, mật khẩu cơ sở dữ liệu, khu vực chỉ cần chọn khu vực gần nhất với người dùng mục tiêu của chương trình.
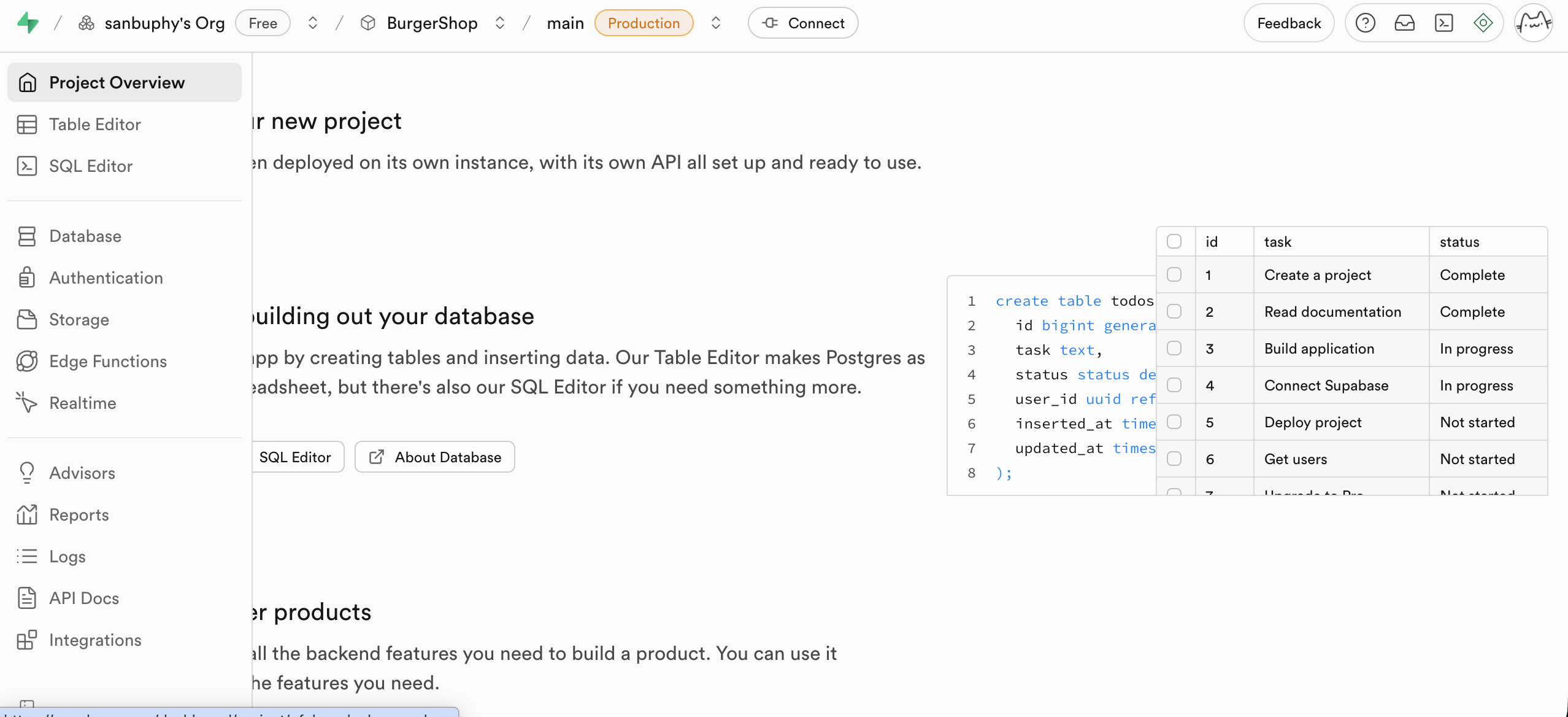
Sau khi tạo thành công, thanh bên trái của bảng điều khiển sẽ hiển thị tất cả các mô-đun chức năng cốt lõi (Table Editor, SQL Editor, Database, Authentication, v.v.), các thao tác tiếp theo sẽ xoay quanh các mô-đun này.
Trình soạn thảo bảng
Table Editor có thể được coi là trình soạn thảo bảng dữ liệu trực quan của Supabase, nó cho phép bạn xem và sửa đổi dữ liệu trong cơ sở dữ liệu trực tiếp như thao tác với Excel mà không cần viết câu lệnh SQL, chỉ cần tương tác bằng chuột là có thể sửa đổi nội dung dữ liệu.
Điều đáng chú ý là Schema, Schema có thể được hiểu là "container tài nguyên" trong cơ sở dữ liệu, dùng để quản lý phân nhóm các tài nguyên như bảng, view, hàm, chỉ mục, chủ yếu có hai tác dụng: một là tránh xung đột đặt tên (các bảng cùng tên có thể tồn tại dưới các Schema khác nhau), hai là thực hiện cách ly phân quyền (ví dụ chỉ cho phép người dùng cụ thể truy cập bảng dưới một Schema nhất định);
Nhấn vào dropdown Schema ở đầu trình soạn thảo để chuyển đổi giữa các container khác nhau, trong phát triển hàng ngày thường chỉ cần quan tâm hai loại:
public: container tài nguyên công khai mặc định, tất cả các bảng kinh doanh do nhà phát triển tạo mới (như "bảng bài viết" "bảng bình luận") đều được lưu trữ ở đây;auth: container chuyên dụng cho xác thực người dùng, bảnguserstrong đó tự động lưu trữ thông tin của tất cả người dùng đã đăng ký (như ID người dùng, email, thời gian đăng nhập), không nên sửa đổi thủ công các bảng mặc định dưới Schema này để tránh ảnh hưởng đến chức năng xác thực;

Trình soạn thảo SQL
SQL Editor là trình thực thi câu lệnh SQL của Supabase, cho phép bạn thao tác trực tiếp với cơ sở dữ liệu bằng mã. Bạn có thể để mô hình lớn tạo trực tiếp câu lệnh SQL, nhập ở bên phải sau đó nhấn RUN để tạo hoặc sửa đổi bảng bằng câu lệnh, cũng có thể xem trực tiếp dữ liệu bảng đã lọc trong Results.
Bạn có thể tìm thấy bảng dữ liệu mới tạo trong public schema của Table Editor sau khi chạy RUN; và câu lệnh đã chạy sẽ được lưu trong mục PRIVATE bên trái, thậm chí có thể nhấn vào biểu tượng trái tim ở dưới để thêm vào yêu thích cho câu truy vấn hoặc câu lệnh tạo này.
Trung tâm quản lý cơ sở dữ liệu
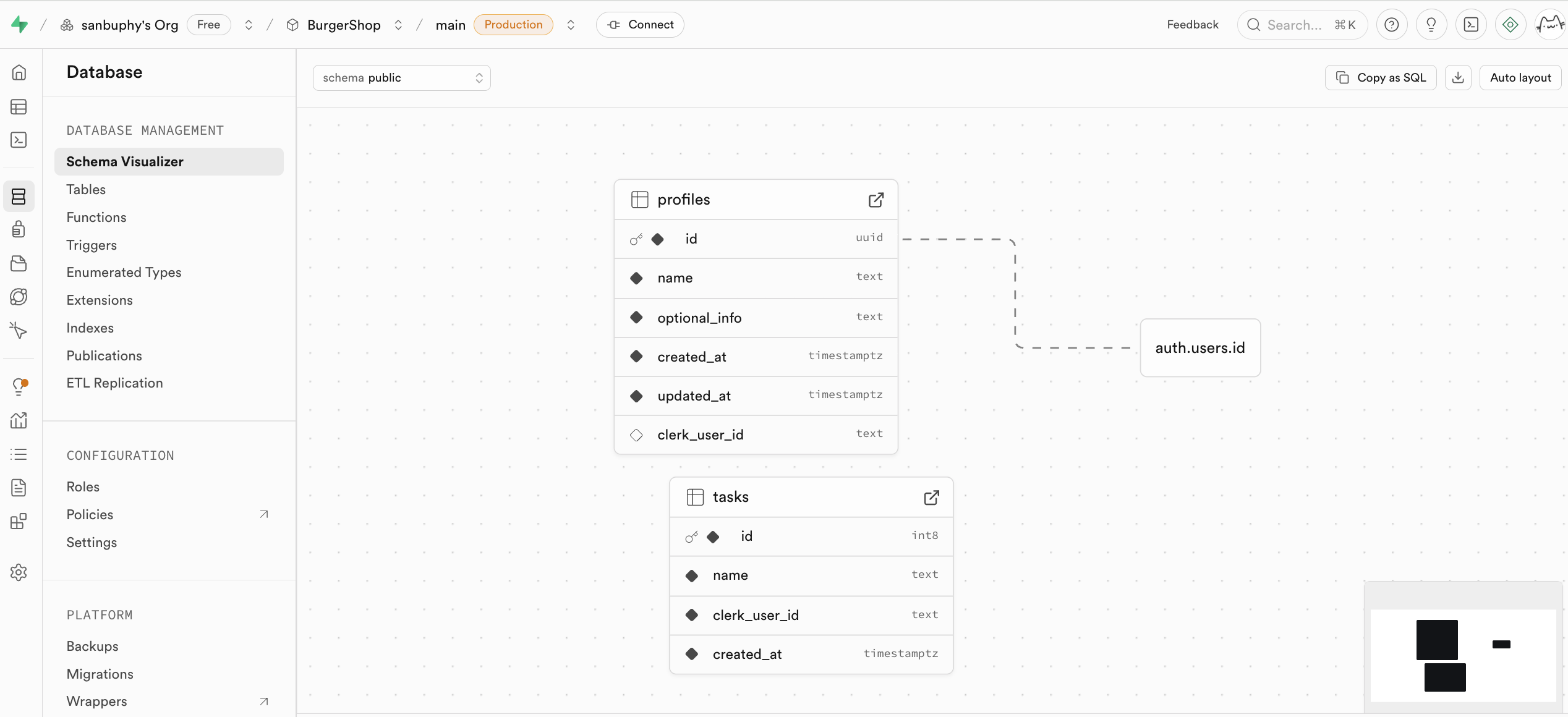
Database là trung tâm quản lý cơ sở dữ liệu của Supabase, hỗ trợ xem và quản lý tất cả các bảng dữ liệu một cách trực quan, và hiểu mối quan hệ liên kết giữa các bảng khác nhau thông qua các đường kết nối (tức là ràng buộc khóa ngoại, thể hiện mối quan hệ tham chiếu giữa dữ liệu).
Nếu bạn muốn tạo bảng mới thủ công, bạn có thể tạo bảng trực tiếp trong tables, chúng tôi sẽ hướng dẫn chi tiết trong hướng dẫn sau.
Xác thực danh tính
Authentication chịu trách nhiệm quản lý đăng ký, đăng nhập và phân quyền của người dùng. Dữ liệu hệ thống quản lý người dùng mặc định đều được lưu trữ tại đây, nó cung cấp các chức năng đăng ký, đăng nhập, đặt lại mật khẩu, xác thực email sẵn sàng sử dụng, và hỗ trợ đăng nhập OAuth bên thứ ba (như WeChat, GitHub, Google, v.v.). Tất cả dữ liệu người dùng sẽ tự động đồng bộ vào bảng auth.users của cơ sở dữ liệu.
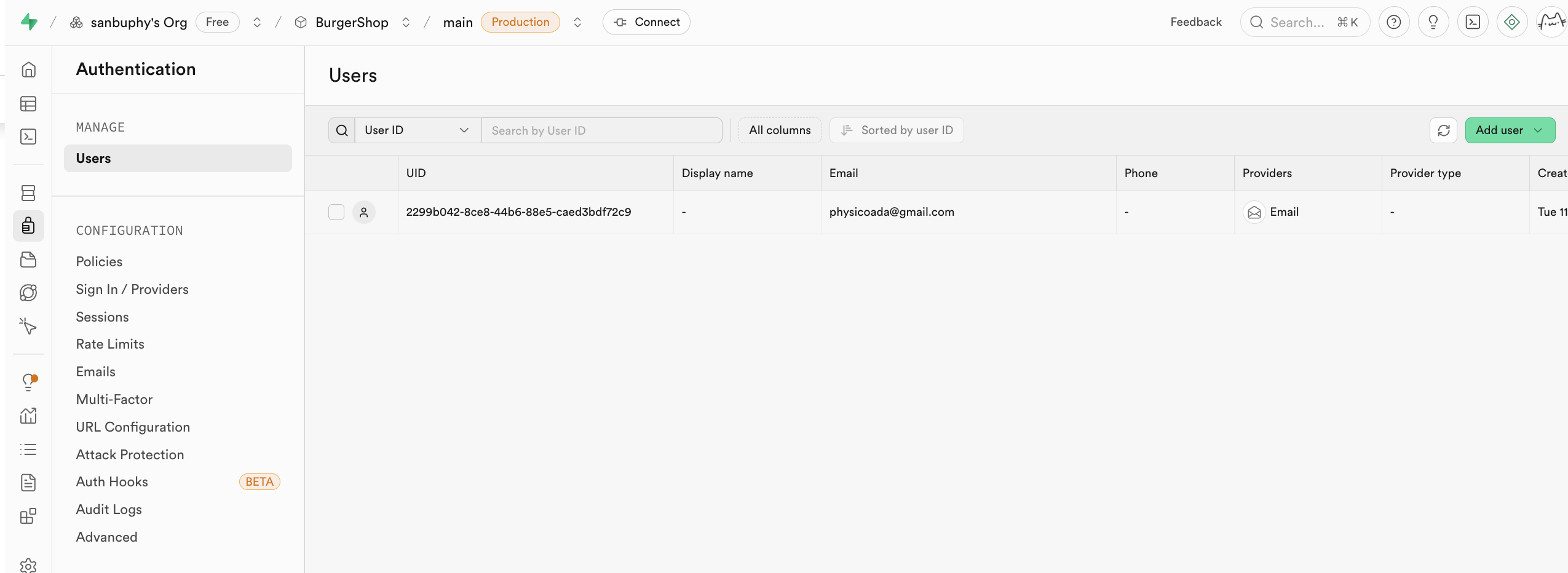
Bạn có thể tìm thấy các điểm đăng nhập thông tin người dùng được Supabase hỗ trợ khác nhau trong tùy chọn Provider, mặc định sử dụng Email; nếu bạn muốn sử dụng tài khoản Github hoặc Google để đăng nhập, cần thêm cấu hình thuộc tính, chúng tôi sẽ hướng dẫn chi tiết trong bài học dưới đây.
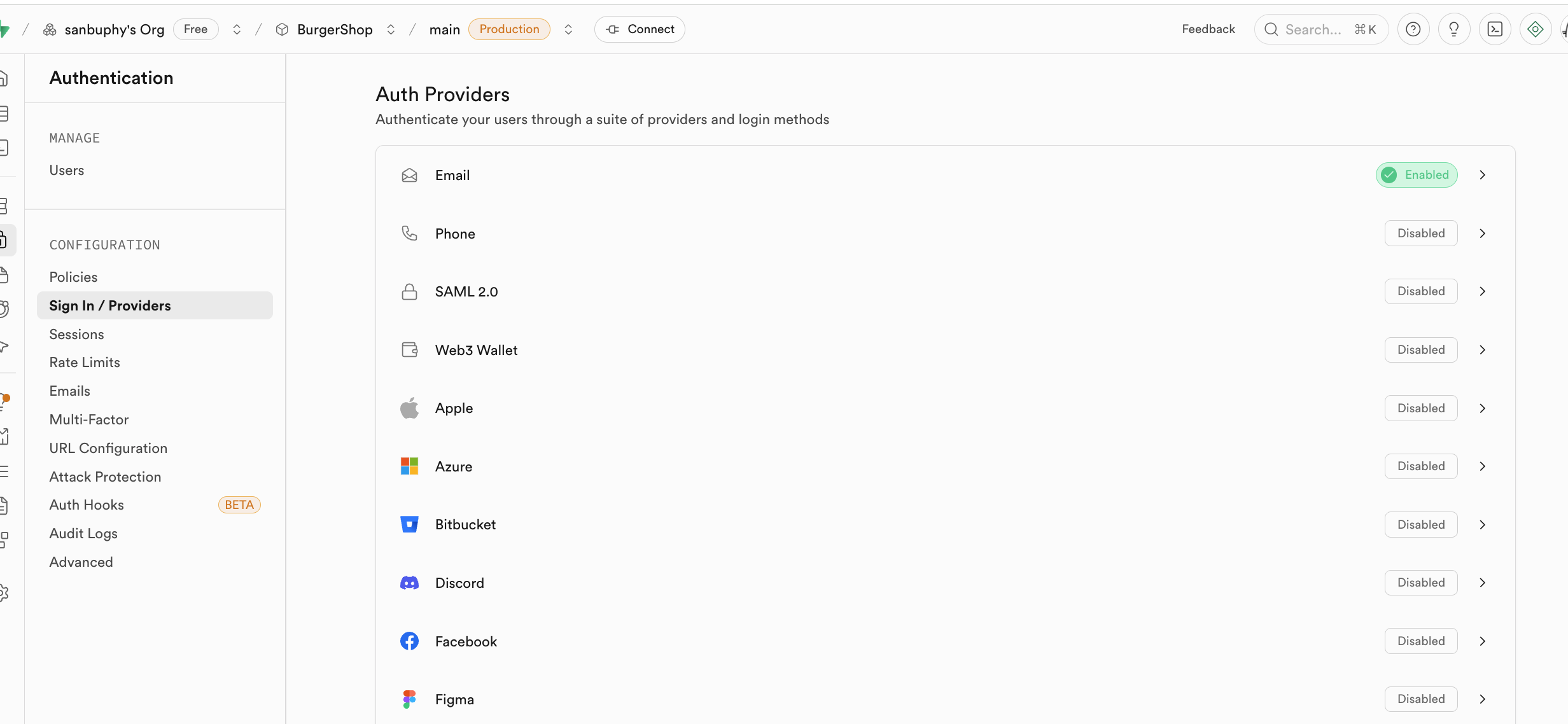
Trong Sign In / Providers còn bao gồm kiểm soát hành vi đăng ký email, nếu bạn không muốn mỗi lần đăng ký bằng email đều phải để người dùng chấp nhận lời mời rồi mới trở thành người dùng, bạn có thể hủy yêu cầu bắt buộc Confirm email.
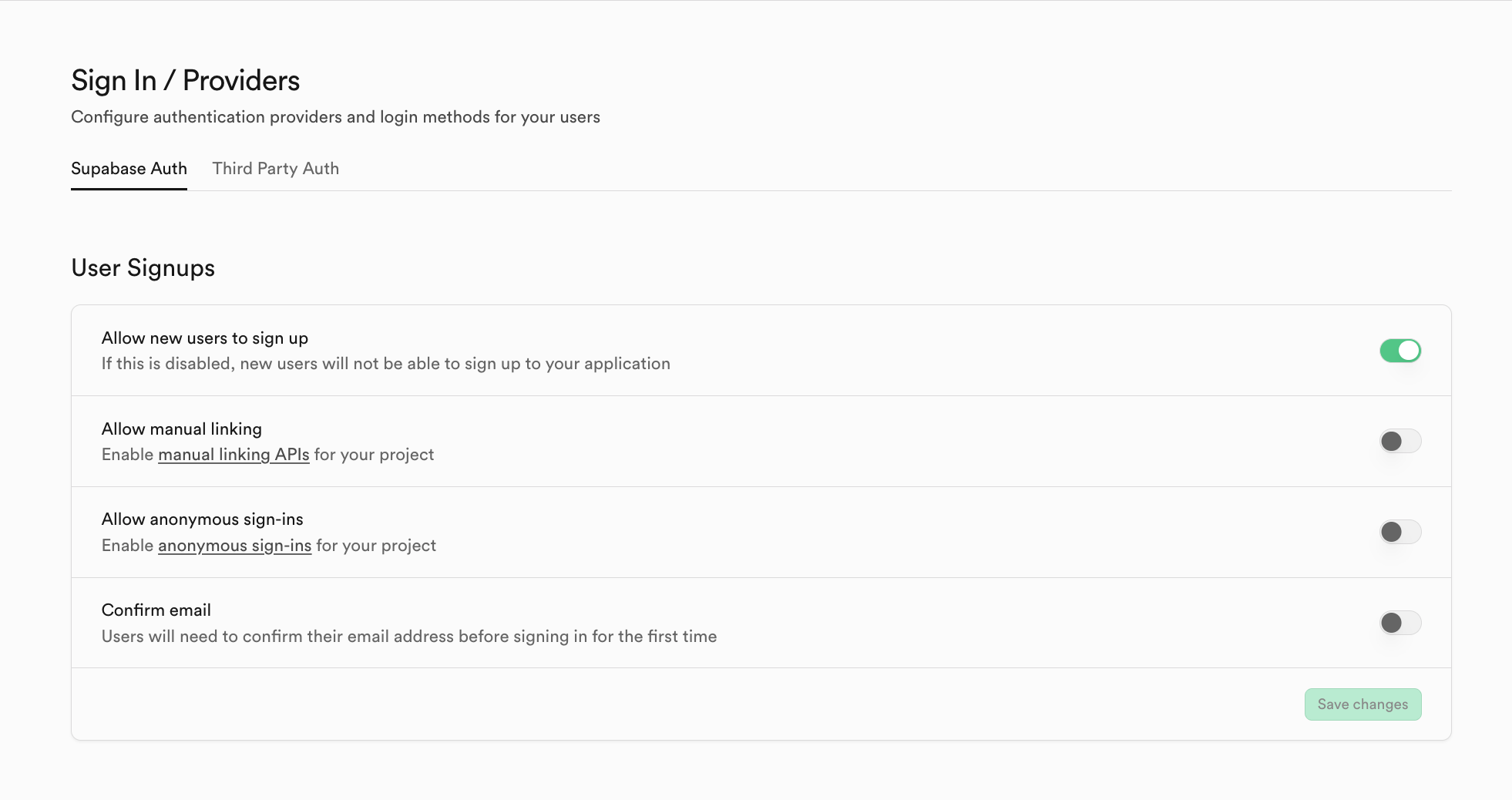
Nếu bạn muốn chuyển sang nhà cung cấp dịch vụ hệ thống auth khác không phải Supabase, bạn có thể nhấn vào Third Party Auth, ví dụ ở đây sử dụng Clerk làm nhà cung cấp dịch vụ bên thứ ba.
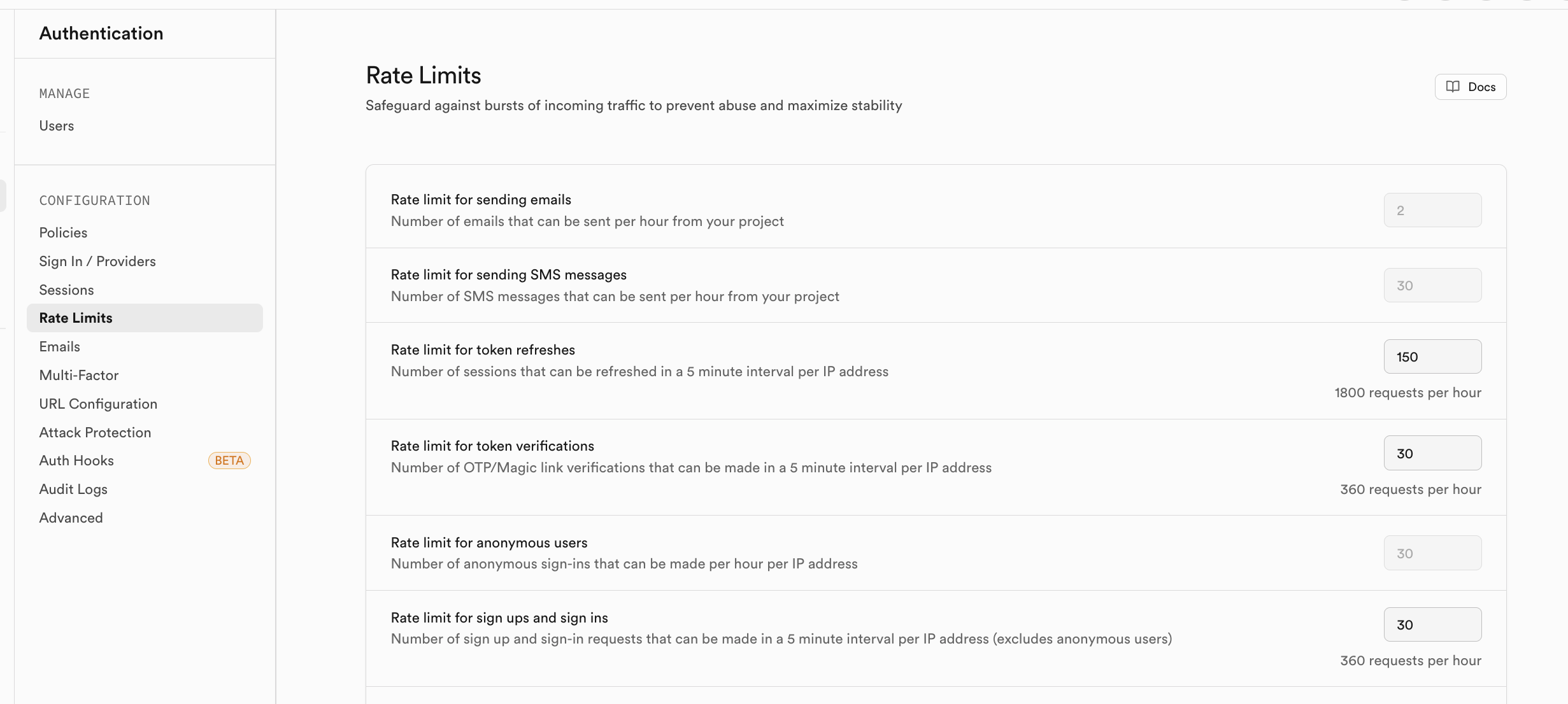
Nếu bạn lo ngại về lượng truy cập quá lớn của người dùng đã đăng ký trong thời gian ngắn, bạn có thể bật chính sách giới hạn lưu lượng tương ứng trong Rate Limits:
Lưu trữ
Storage là hệ thống lưu trữ của Supabase, tương thích với khái niệm s3 của amazon cloud, có thể được sử dụng để lưu trữ bất kỳ loại tệp nào (như hình ảnh, video, tài liệu, âm thanh, v.v.), và cung cấp quản lý phân quyền truy cập (công khai hoặc riêng tư) và lấy liên kết tải xuống (liên kết vĩnh viễn hoặc liên kết tạm thời), bạn có thể dễ dàng quản lý tải lên và tải xuống nội dung tệp liên quan đến người dùng trong ứng dụng, và tích hợp liền mạch với hệ thống xác thực của Supabase, thực hiện kiểm soát truy cập tinh tế.
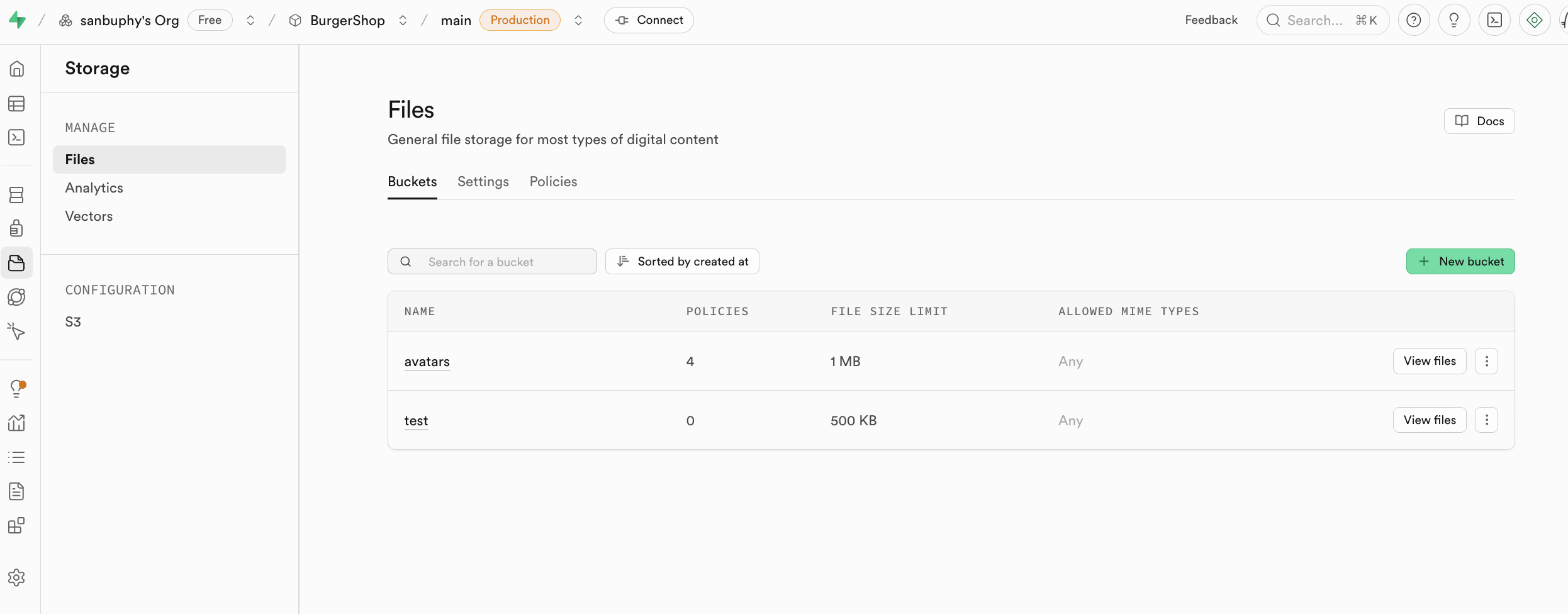
Chúng tôi sẽ giải thích cách sử dụng cụ thể của storage trong dự án nâng cao của bài học này.
Nếu bạn muốn sử dụng giao thức liên quan đến S3 để thao tác, có thể trực tiếp sử dụng cấu hình tương ứng:
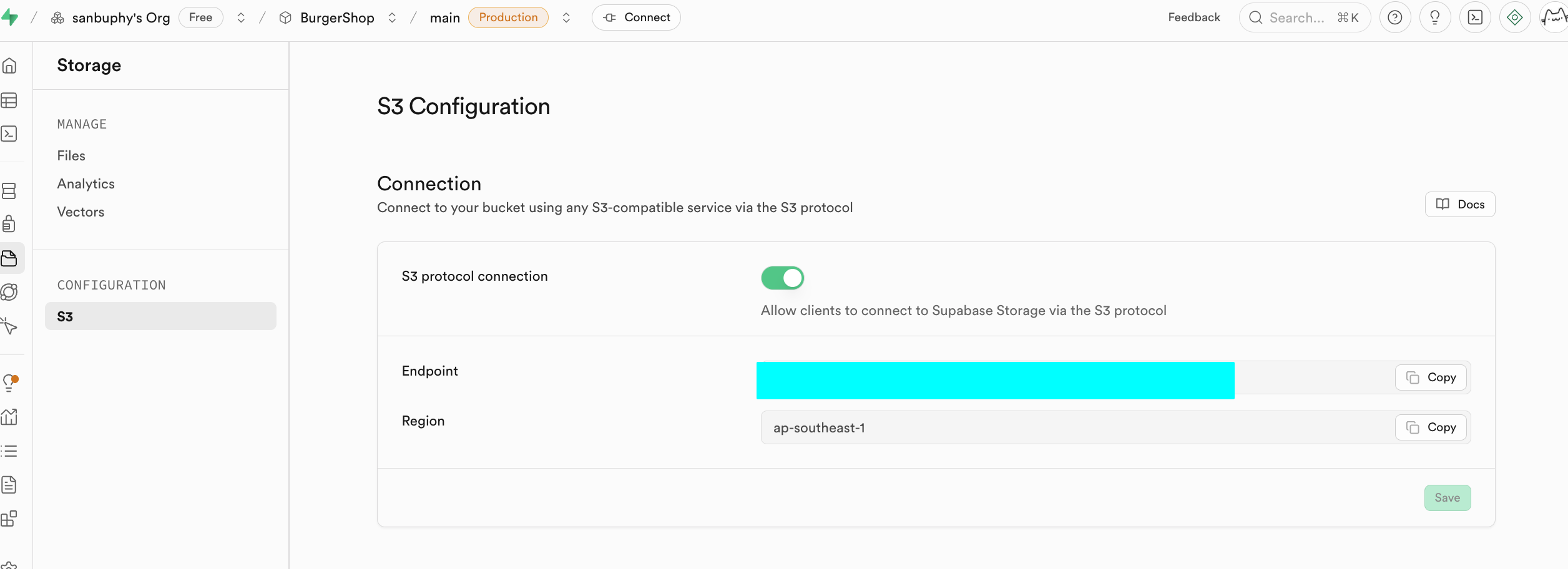
Amazon Cloud (dịch vụ đám mây Amazon, gọi tắt là AWS) là nền tảng điện toán đám mây do Amazon cung cấp (giống như một phòng máy mạng lớn, bạn có thể thuê tài nguyên tính toán và lưu trữ theo nhu cầu). S3 (Simple Storage Service) là dịch vụ chuyên dùng để lưu trữ tệp trong AWS (tương tự như một ổ đĩa mạng không giới hạn dung lượng, có thể lưu hình ảnh, video, sao lưu và nhiều loại tệp khác), đây là dịch vụ lưu trữ đối tượng phổ biến nhất hiện nay và đã trở thành tiêu chuẩn thực tế của ngành.
Tại sao phải làm thành S3 tương thích API?: S3 đã tồn tại gần 20 năm, thị trường có lượng lớn công cụ, SDK và tài liệu sẵn có, tương thích với S3 có nghĩa là bạn có thể sử dụng trực tiếp các tài nguyên này mà không cần tạo từ đầu các công cụ liên quan, có thể nhanh chóng đáp ứng nhu cầu kinh doanh đưa lên mạng.
Edge Functions
Nếu bạn không muốn triển khai backend nhưng muốn sử dụng cơ sở dữ liệu và thao tác hàm, bạn có thể sử dụng Edge Functions để xây dựng khả năng backend cốt lõi mà không cần tự xây dựng máy chủ, đây là hàm phía máy chủ phân tán toàn cầu do Supabase cung cấp. Nói một cách đơn giản, nó cho phép bạn viết và triển khai mã backend trên đám mây mà không cần mua và quản lý máy chủ backend riêng. Các hàm này được triển khai trên các nút cạnh của mạng lưới toàn cầu, sẽ tự động chạy ở vị trí gần người dùng của bạn nhất, từ đó giảm đáng kể độ trễ mạng, cung cấp tốc độ phản hồi cực nhanh. Bạn có thể tạo, chỉnh sửa và triển khai trực tiếp trong bảng điều khiển Supabase, toàn bộ quá trình phát triển rất thuận tiện.
Một công dụng cốt lõi của Edge Functions là đóng vai trò là lớp trung gian an toàn, bảo vệ thông tin nhạy cảm và khóa xác thực của bạn. Việc gọi trực tiếp dịch vụ bên thứ ba (như OpenAI, Stripe) trong mã frontend sẽ làm lộ API Key của bạn, mang lại rủi ro bảo mật rất lớn. Thông qua Edge Functions, ứng dụng frontend của bạn chỉ giao tiếp với hàm supabase của bạn, tất cả bí mật chỉ được lưu giữ trong supabase.
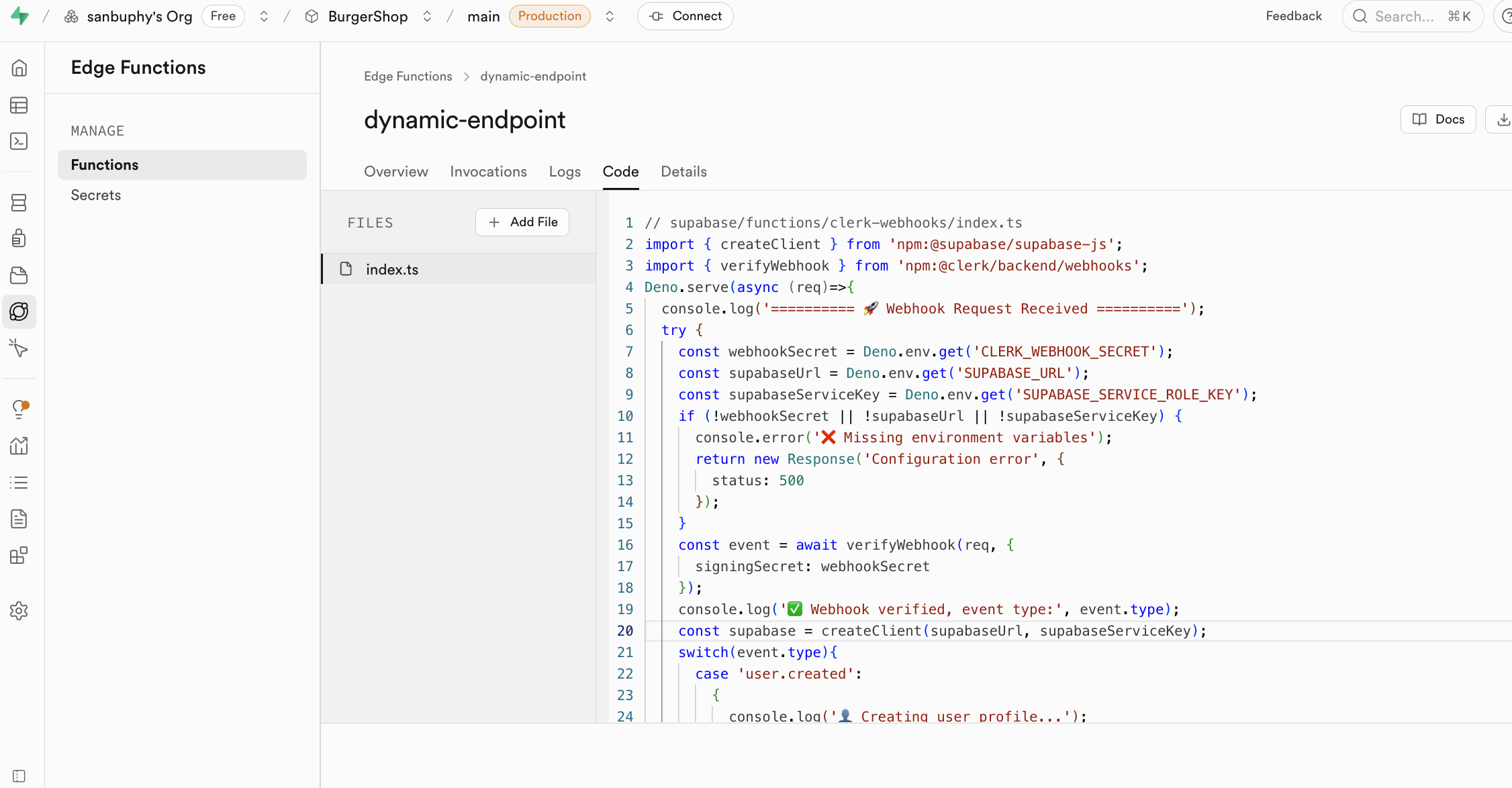
Các hàm của Edge Functions sử dụng khóa được tiết lộ trong secrets làm biến môi trường, tải thông qua Deno.env.get, từ đó thực hiện gọi dịch vụ bên thứ ba. Bằng cách này, khóa nhạy cảm sẽ không bao giờ bị lộ trên phía client (trình duyệt của bạn), triệt để loại bỏ nguy cơ bị đánh cắp.
Khi yêu cầu Supabase Edge Function, cần mang theo khóa Supabase tương ứng trong header yêu cầu, dưới đây là một ví dụ tối giản:
// Cấu hình cốt lõi (thay bằng thông tin thực tế của bạn)
const projectId = "ID dự án Supabase của bạn";
const functionName = "Tên Edge Function mục tiêu";
const supabaseKey = "Supabase anon_key";
// Gọi hàm
async function callEdgeFunction() {
const url = `https://${projectId}.supabase.co/functions/v1/${functionName}`;
try {
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
"Authorization": `Bearer ${supabaseKey}` // Quan trọng: mang theo khóa để hoàn tất xác thực
},
body: JSON.stringify({ order_id: "123", action: "refund" }) // Dữ liệu yêu cầu tùy chỉnh
});
const result = await response.json();
console.log("Gọi thành công:", result);
} catch (error) {
console.error("Gọi thất bại:", error.message);
}
}
// Thực hiện gọi
callEdgeFunction();Ngoài ra, Edge Functions tích hợp liền mạch với hệ thống xác thực người dùng của Supabase. Khi một người dùng đã đăng nhập gọi một hàm, thông tin danh tính của họ sẽ được truyền cho hàm. Điều này cho phép bạn dễ dàng nhận diện người dùng hiện tại trong hàm và thực hiện kiểm soát phân quyền dựa trên danh tính của họ. Quan trọng hơn, khi hàm thao tác với cơ sở dữ liệu, nó sẽ tự động tuân thủ chính sách bảo mật cấp hàng (Row Level Security) mà bạn đã thiết lập, đảm bảo người dùng chỉ có thể truy cập và sửa đổi dữ liệu họ có quyền thao tác, giúp việc xây dựng ứng dụng đa người dùng an toàn trở nên đơn giản.
Các tình huống ứng dụng của Edge Functions rất đa dạng, có thể xử lý nhiều loại tác vụ backend. Chúng rất phù hợp để lắng nghe sự kiện Webhook từ dịch vụ bên thứ ba (ví dụ thanh toán thành công, commit mã, v.v.) và tự động thực hiện logic xử lý dữ liệu tương ứng. Bạn cũng có thể sử dụng nó để gửi thông báo email, tạo báo cáo PDF, tạo giao diện API tùy chỉnh để đóng gói logic kinh doanh phức tạp, hoặc thực hiện bất kỳ tác vụ tính toán nào bạn muốn hoàn thành ở phía máy chủ, mở rộng đáng kể khả năng ứng dụng của bạn.
Cụ thể với một ví dụ phổ biến: công cụ xác thực danh tính Clerk. Clerk chỉ được sử dụng để xử lý các thao tác liên quan đến xác thực như đăng nhập, đăng ký, cập nhật thông tin người dùng, không trực tiếp quản lý cơ sở dữ liệu kinh doanh của bạn. Nếu bạn muốn đồng bộ các động thái xác thực này vào cơ sở dữ liệu kinh doanh, bạn cần thực hiện thông qua kích hoạt sự kiện Webhook yêu cầu Edge Functions. Edge Functions có thể lắng nghe tín hiệu Webhook do Clerk gửi, tự động thực hiện logic đồng bộ dữ liệu, làm cho thông tin người dùng trong cơ sở dữ liệu Supabase đồng bộ实时 với trạng thái đăng nhập Clerk, toàn bộ quá trình không cần bạn triển khai backend độc lập.
Công cụ đồng bộ dữ liệu thời gian thực
Realtime là công cụ đồng bộ dữ liệu thời gian thực của Supabase, nó cho phép ứng dụng của bạn nhận ngay thông báo thay đổi cơ sở dữ liệu mà không cần liên tục thăm dò API. Khi dữ liệu trong cơ sở dữ liệu thực hiện thao tác INSERT, UPDATE hoặc DELETE, Realtime sẽ đẩy các thay đổi này theo thời gian thực đến tất cả các client đã kết nối thông qua WebSocket. Điều này rất quan trọng đối với việc xây dựng các ứng dụng cần tương tác thời gian thực.
Realtime chủ yếu bao gồm ba chức năng cốt lõi, bao phủ phần lớn các tình huống thời gian thực:
- Postgres Changes: Lắng nghe trực tiếp các thay đổi của bảng cơ sở dữ liệu. Bạn có thể đăng ký chính xác các bảng cụ thể, sự kiện cụ thể (thêm, xóa, sửa), thậm chí có thể nhận thông báo dựa trên điều kiện lọc, và tích hợp hoàn hảo với chính sách bảo mật cấp hàng (Row Level Security), đảm bảo người dùng chỉ nhận được các thay đổi dữ liệu họ có quyền xem.
- Broadcast: Cho phép các client gửi tin nhắn tạm thời độ trễ thấp cho nhau thông qua kênh (Channel). Rất phù hợp để triển khai các chức năng như phòng chat, theo dõi con trỏ thời gian thực, đồng bộ trạng thái game trực tuyến, v.v.
- Presence: Dùng để theo dõi và đồng bộ trạng thái người dùng trực tuyến. Bạn có thể sử dụng nó để dễ dàng triển hiện các chức năng như "ai đang trực tuyến", "hiện có X người đang xem", rất phù hợp với các ứng dụng cộng tác.
Chúng tôi sẽ giới thiệu chi tiết nội dung của phần này trong học tập dự án sau này.
Cài đặt dự án
Project Settings là phần cấu hình cấp cao của dự án Supabase, bạn có thể thực hiện điều độ sâu tài nguyên tính toán tại đây, cũng như cấu hình tinh chỉnh các tham số nền tảng của các loại chức năng.
Trong giai đoạn nhập môn, chúng ta chỉ cần tập trung vào hai khu vực cốt lõi sau, một là Data API, tại đây chúng ta có thể lấy "Supabase URL" quan trọng, nó là endpoint RESTful có dạng https://xxx.supabase.co, là "địa chỉ入口" của tất cả các thao tác truy vấn, thêm mới, sửa đổi, xóa dữ liệu. Frontend hoặc phía máy chủ cần khởi tạo client Supabase thông qua URL này để thiết lập kết nối với cơ sở dữ liệu.
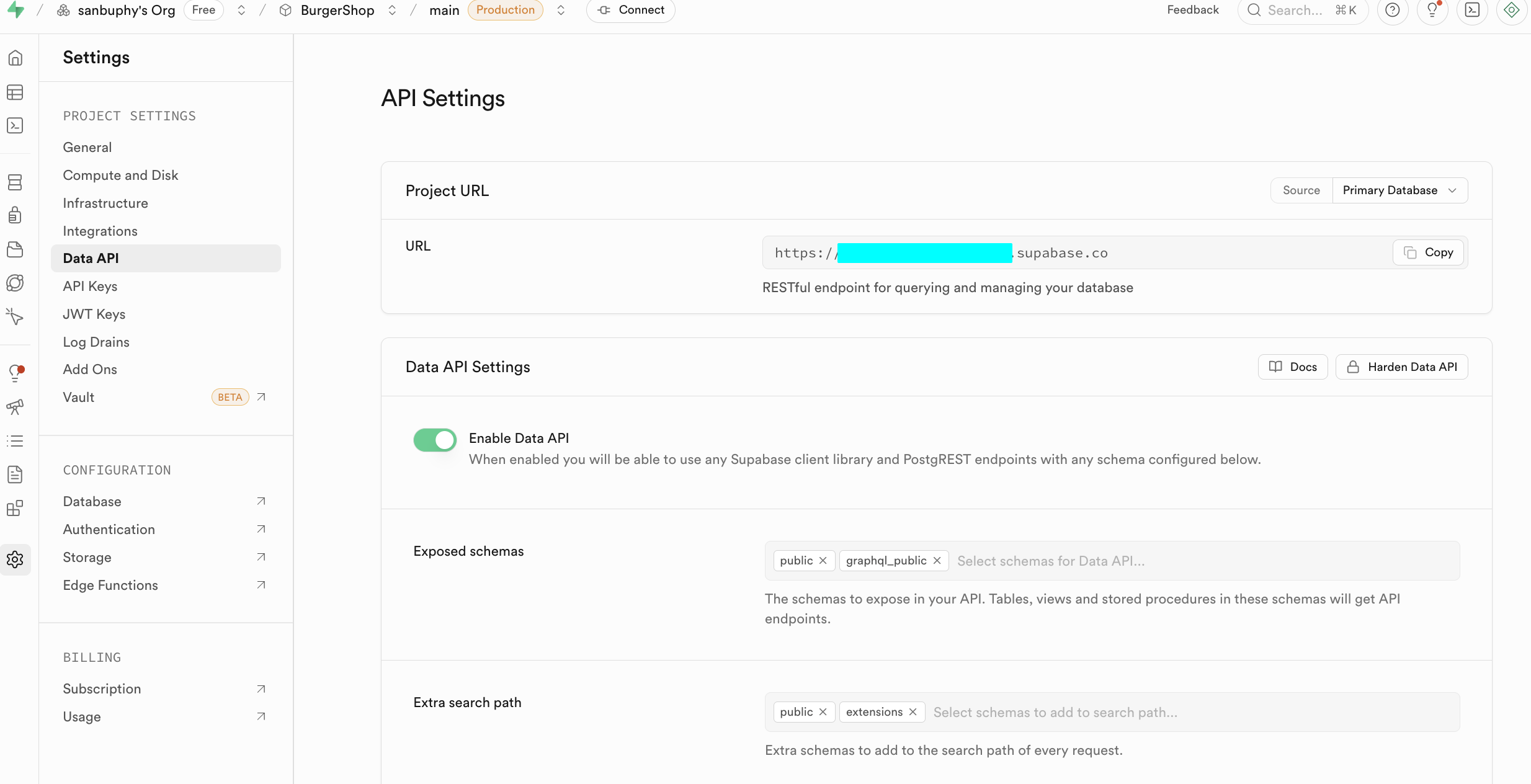
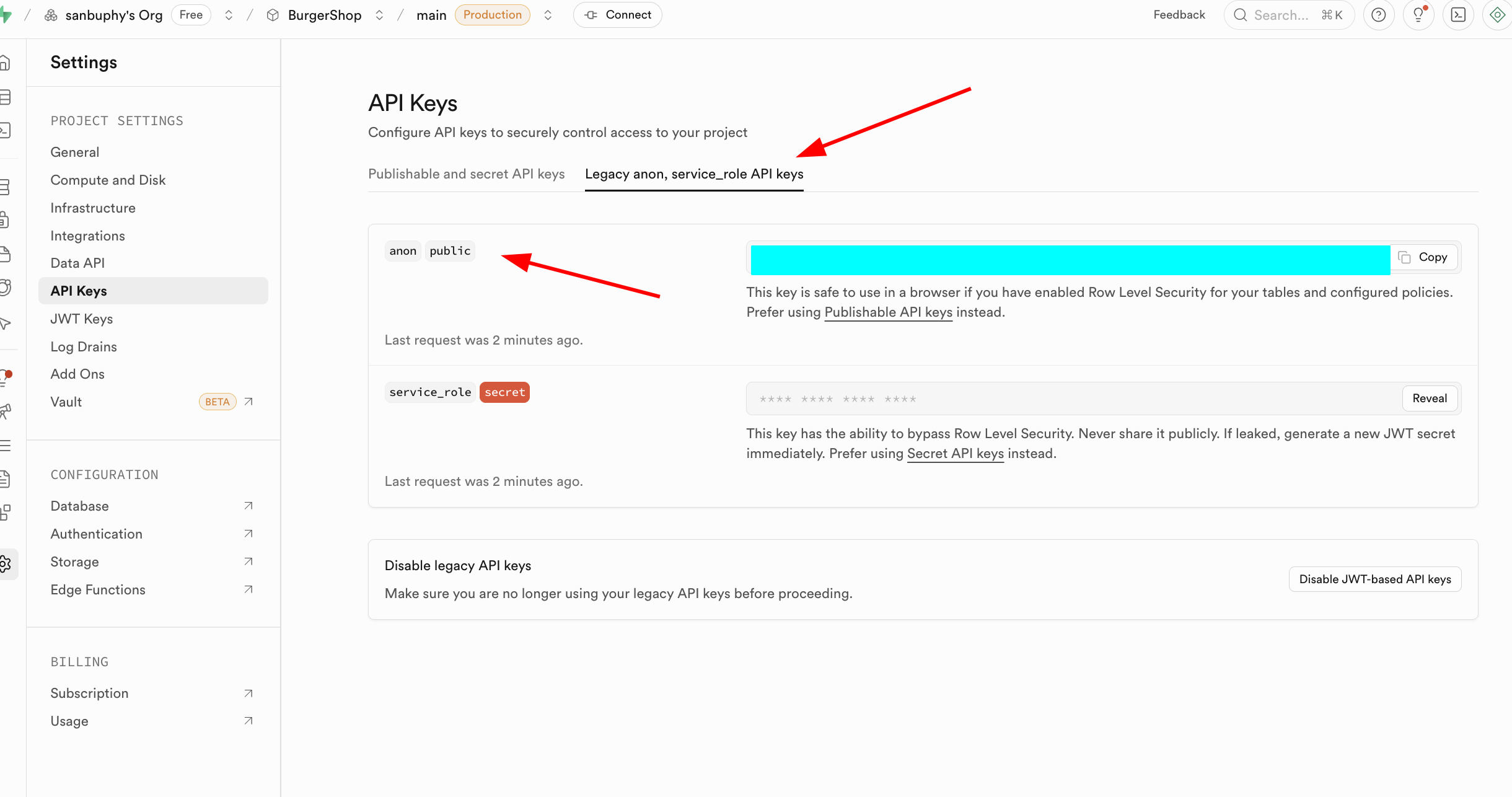
Một trọng điểm khác là API Keys, chọn tab "Legacy anon, service_role API keys", trong đó khóa anon public là chứng chỉ danh tính quan trọng trong tình huống frontend, quyền của nó bị RLS hạn chế nghiêm ngặt, chỉ có thể truy cập dữ liệu người dùng được ủy quyền. Còn khóa service_role thuộc về "khóa quyền cao phía máy chủ", có khả năng bỏ qua bảo mật cấp hàng, có thể thực hiện các thao tác dữ liệu hàng loạt, cấu hình cấp hệ thống và các thao tác nhạy cảm khác. Tuyệt đối cấm chia sẻ công khai, nếu bị lộ cần ngay lập tức tạo khóa mới và cập nhật cấu hình phía máy chủ.
Các mục cấu hình còn lại không cần nghiên cứu sâu ở giai đoạn hiện tại, khi có nhu cầu sử dụng nâng cao sau này thì khám phá từng cái một.
2.1 Tạo bảng dữ liệu SQL đầu tiên của bạn
Trên đây là giới thiệu về giao diện Supabase, tiếp theo chúng ta sẽ đi sâu vào phần thao tác cơ sở dữ liệu cốt lõi của Supabase.
Để tạo bảng dữ liệu trong Supabase, chủ yếu có hai cách phổ biến sau, bạn có thể chọn theo nhu cầu:
- (Khuyến nghị) Sử dụng mô hình ngôn ngữ lớn để tạo câu lệnh SQL phù hợp với Supabase, dán trực tiếp và thực thi trong SQL Editor (trình thực thi câu lệnh SQL đã giới thiệu ở trên), hiệu quả và nhanh chóng, chúng tôi sẽ giải thích chi tiết quá trình thao tác này trong phần tiếp theo.
- Tạo thông qua thao tác trực quan: tìm mô-đun Database trong thanh bên trái, nhấn vào sau đó chọn Tables trong thanh bên, nhấn nút New table ở bên phải, có thể tạo bảng dữ liệu thông qua giao diện đồ họa.
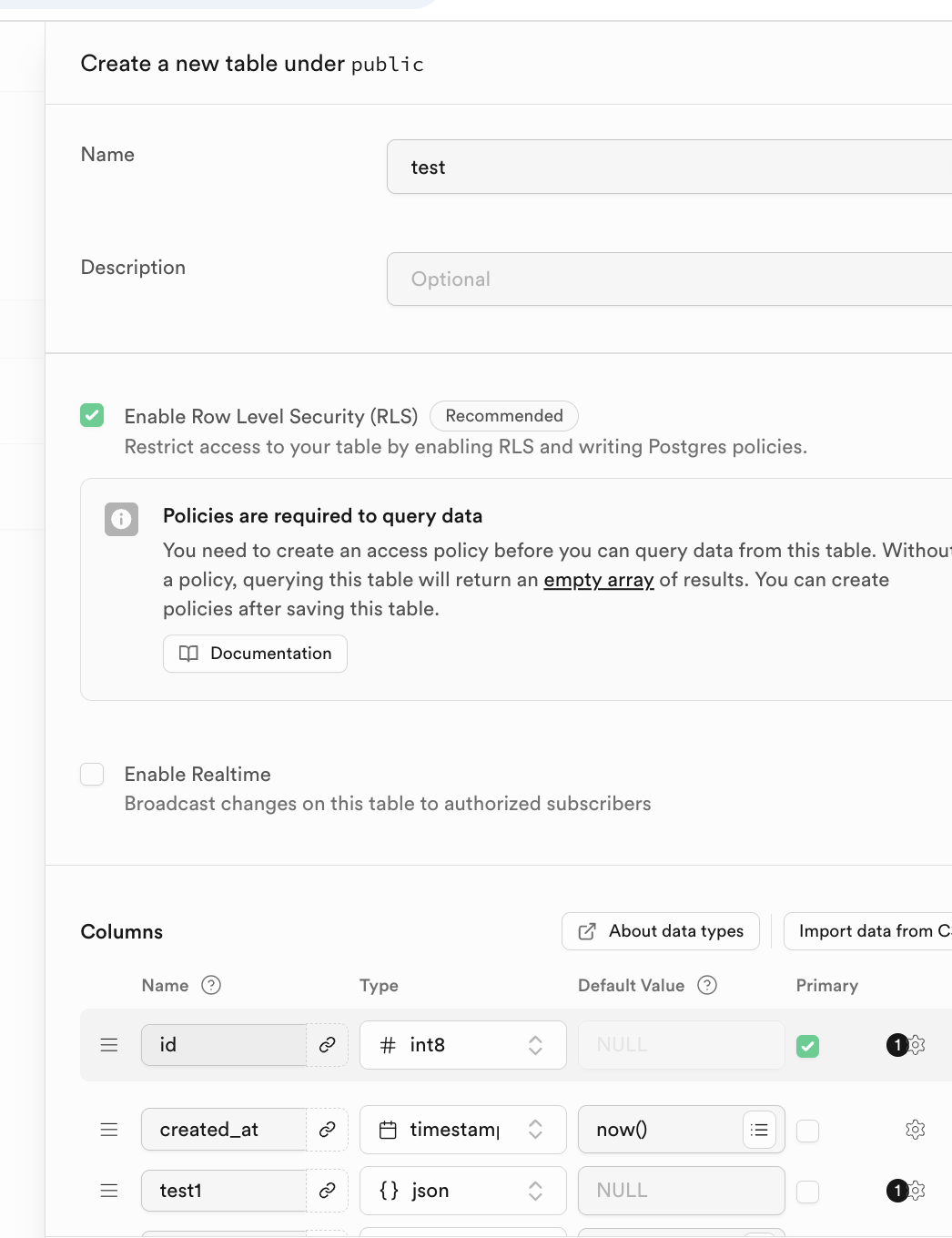
Đáng chú ý, tên bảng dữ liệu tương ứng và kiểu dữ liệu lưu trữ có thể được chỉ định trong Columns ở dưới.
Đối với cơ sở dữ liệu quan hệ, một đặc điểm rất quan trọng là mối quan hệ liên kết giữa các bảng, bạn có thể tìm thấy Foreign keys ở dưới, nhấn để tạo mối quan hệ liên kết tương ứng:
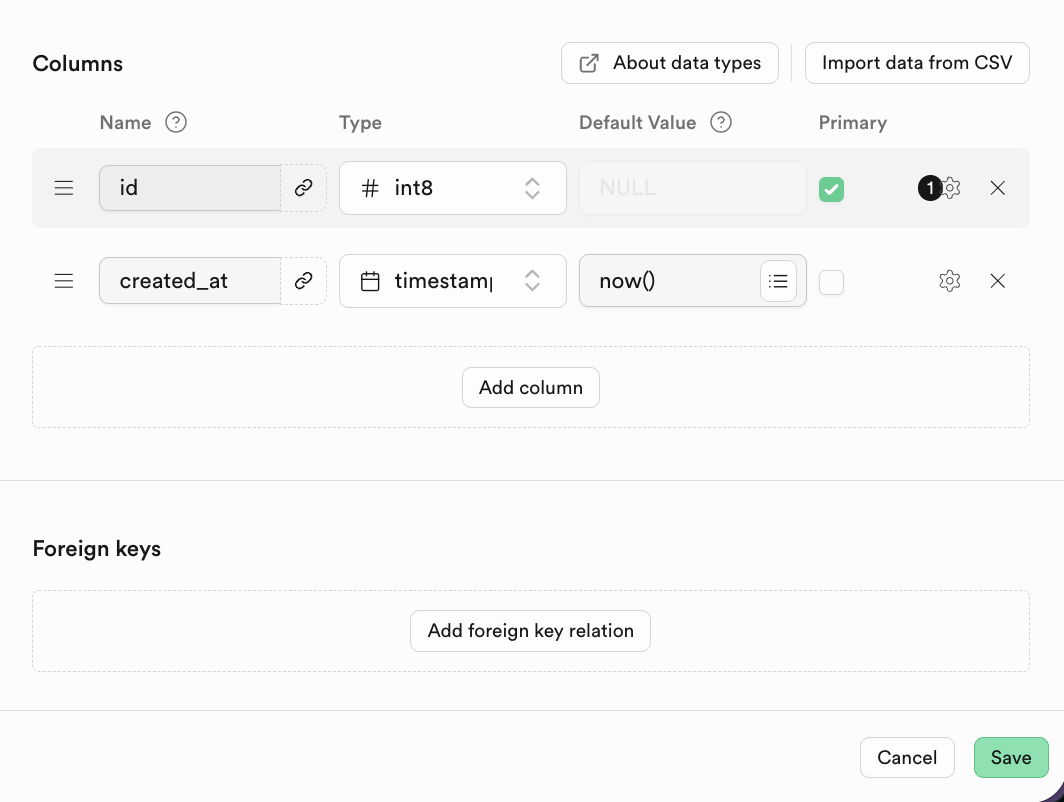
Trong đó Foreign keys thể hiện mối quan hệ liên kết giữa các bảng: một hoặc một nhóm trường, giá trị của nó trong bảng hiện tại (bảng con) sẽ tham chiếu đến giá trị khóa chính của bảng khác (bảng cha).
Ví dụ, khi tạo bảng học sinh, chúng ta có thể định nghĩa khóa ngoại như sau: (cột Mã lớp thuộc về là một khóa ngoại. Khóa ngoại này tham chiếu đến cột Mã lớp trong bảng lớp.)
CREATE TABLE Bảng_học_sinh (
Mã_học_sinh INT PRIMARY KEY,
Tên_học_sinh VARCHAR(50),
Mã_lóp_thuộc_về INT,
FOREIGN KEY (Mã_lóp_thuộc_về) REFERENCES Bảng_lớp(Mã_lớp)
);Cụ thể hơn, chúng ta có thể quan sát trực quan cấu trúc bảng tương ứng:
Bảng lớp: Bảng này ghi lại thông tin của tất cả các lớp, mỗi lớp đều có một mã lớp duy nhất. Mã lớp chính là khóa chính (Primary Key) của bảng này, là "chứng minh thư" duy nhất của mỗi lớp.
| Mã lớp | Tên lớp |
|---|---|
| 101 | Lớp 1A |
| 102 | Lớp 1B |
Bảng học sinh: Bảng này ghi lại thông tin của tất cả học sinh. Mỗi học sinh đều thuộc về một lớp cụ thể, đúng không? Vậy làm sao chúng ta biết học sinh nào ở lớp nào?
Chúng ta có thể thêm một cột trong bảng học sinh, gọi là Mã lớp thuộc về.
| Mã học sinh | Tên học sinh | Mã lớp thuộc về |
|---|---|---|
| 2024001 | Trương Tam | 101 |
| 2024002 | Lý Tứ | 102 |
| 2024003 | Vương Ngũ | 101 |
Trong ví dụ này, cột Mã lớp thuộc về trong bảng học sinh chính là khóa ngoại (Foreign Key).
Trong Supabase, sau khi nhấn thêm Foreign Key, bạn có thể trực tiếp chọn cột tương ứng của bảng liên kết
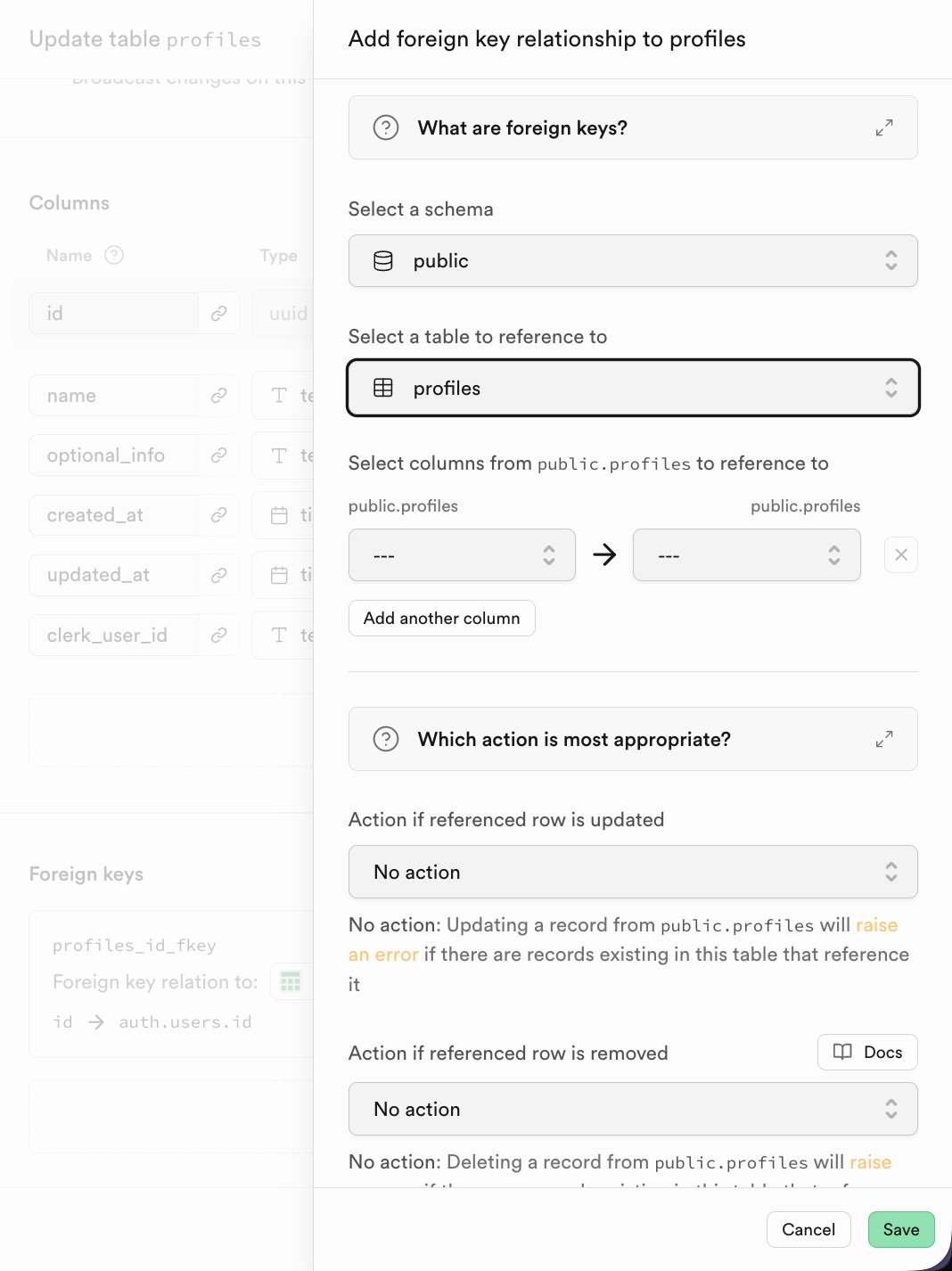
2.3 Giới thiệu SQL Editor và các thao tác cơ sở dữ liệu cơ bản
Tiếp theo chúng ta sẽ thực hiện từng bước một loạt script SQL, làm quen với các thao tác thêm, xóa, truy vấn, sửa đổi phổ biến trong SQL. Bạn có thể sao chép mã của mỗi bước vào SQL Editor, thực thi và quan sát kết quả.
Bạn có thể lấy tất cả các tệp SQL thử nghiệm tại thư mục sau:
https://github.com/THU-SIGS-AIID/Project5-Supabase-Demos/tree/main/apps/sql-examples
2.3.1 CREATE - Tạo cấu trúc bảng
Câu lệnh CREATE TABLE được sử dụng để định nghĩa schema (Schema) cho bảng mới, bao gồm các cột (Columns) của nó, các kiểu dữ liệu tương ứng (Data Types) và bất kỳ ràng buộc (Constraints) nào, hiểu đơn giản là tạo một bảng dữ liệu.
-- Step 1: Create the 'orders' table
-- This file is fully independent and creates a sample table for later steps.
CREATE TABLE IF NOT EXISTS orders (
id serial PRIMARY KEY,
user_id int NOT NULL, -- User ID
status text NOT NULL, -- Order status (e.g. paid, pending)
amount numeric(10, 2) NOT NULL, -- Order total amount
details jsonb, -- Item and extra details as JSON
placed_at timestamptz DEFAULT now(), -- Order creation time
is_paid boolean DEFAULT false -- Paid flag
);
-- Expected Output:
-- Orders table created if it did not exist.
-- No data inserted. (Querying returns zero rows for now.)
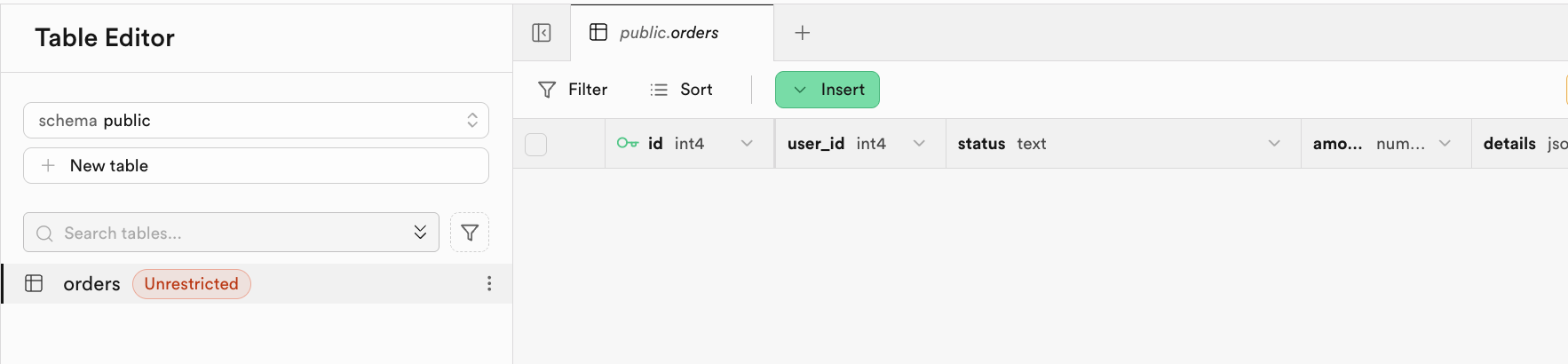
-- If table already exists, no error occurs.Sau khi thực thi thành công, hệ thống sẽ thông báo script đã hoàn tất. Bạn có thể thấy bảng tương ứng đã được tạo trong Table Editor:
2.3.2 INSERT - Điền dữ liệu ban đầu
Sau khi cấu trúc bảng được tạo xong, bước tiếp theo là sử dụng câu lệnh INSERT INTO để thêm hàng dữ liệu vào bảng.
-- Step 2: Insert initial rows into the orders table
-- Provides realistic, varied data for demo/testing. All values are self-contained.
INSERT INTO orders (user_id, status, amount, details, placed_at, is_paid) VALUES
(2001, 'pending', 23.50, '{"items":[{"sku":"BGR001","name":"Beef Burger","qty":1,"price":12.00}]}', now() - interval '2 days', false),
(2002, 'paid', 50.00, '{"items":[{"sku":"BGR002","name":"Chicken Burger","qty":2,"price":10.00},{"sku":"DRK001","name":"Lemonade","qty":2,"price":5.00}]}', now() - interval '1 day', true),
(2003, 'cancelled', 15.00, '{"items":[{"sku":"FRY001","name":"French Fries","qty":3,"price":5.00}], "reason":"Not available"}', now() - interval '45 days', false),
(2004, 'paid', 22.98, '{"items":[{"sku":"BGR003","name":"Veggie Burger","qty":2,"price":9.99}], "promo":"SUMMER22"}', now() - interval '10 days', true),
(2005, 'pending', 18.75, '{"items":[{"sku":"SAL001","name":"Salad","qty":1,"price":6.75},{"sku":"BGR001","name":"Beef Burger","qty":1,"price":12.00}]}', now() - interval '7 hours', false),
(2006, 'paid', 8.00, '{"items":[{"sku":"DRK002","name":"Cola","qty":2,"price":4.00}]}', now() - interval '3 hours', true),
(2007, 'refunded', 14.50, '{"items":[{"sku":"BGR003","name":"Veggie Burger","qty":1,"price":9.99},{"sku":"FRY001","name":"French Fries","qty":1,"price":4.51}], "refund_reason":"Late delivery"}', now() - interval '15 days', false),
(2008, 'paid', 26.99, '{"items":[{"sku":"BGR002","name":"Chicken Burger","qty":2,"price":10.00},{"sku":"DRK001","name":"Lemonade","qty":1,"price":6.99}]}', now() - interval '12 days', true),
(2009, 'pending', 9.99, '{"items":[{"sku":"BGR003","name":"Veggie Burger","qty":1,"price":9.99}]}', now() - interval '30 minutes', false),
(2010, 'paid', 19.89, '{"items":[{"sku":"BGR001","name":"Beef Burger","qty":1,"price":12.00},{"sku":"DRK002","name":"Cola","qty":2,"price":3.95}]}', now() - interval '5 days', true),
(2011, 'cancelled', 0.00, '{"items":[], "reason":"User cancelled"}', now() - interval '2 days', false);
-- Expected Output:
-- After running this script, SELECT * FROM orders will show about 11 rows with varied user_id, status, amount, details (JSON), placed_at, and is_paid fields.
-- For example:
-- | id | user_id | status | amount | is_paid | placed_at |
-- |----|---------|-----------|--------|---------|---------------------|
-- | 1 | 2001 | pending | 23.50 | false | 2025-10-28 13:40:00Z|
-- | 2 | 2002 | paid | 50.00 | true | ... |
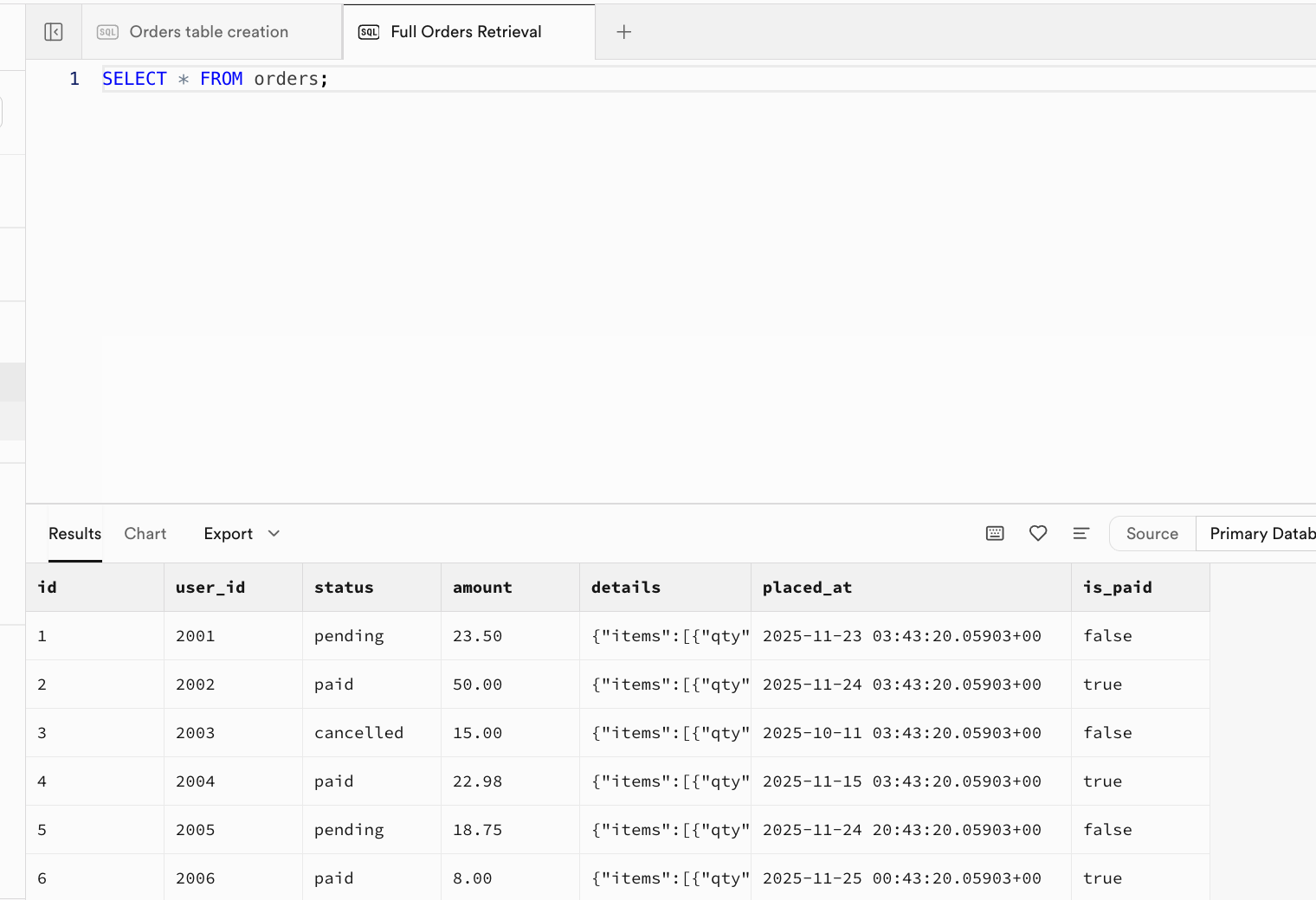
-- |... | ... | ... | ... | ... | ... |Sau khi thực thi thành công, lúc này dữ liệu gốc đã được chèn vào bảng, bạn có thể vào giao diện Table Editor làm mới để xem kết quả, cũng có thể trực tiếp tạo cửa sổ mới trong giao diện SQL Editor, thực thi câu lệnh truy vấn SELECT * FROM orders; để xem kết quả:
2.3.3 SELECT - Đọc và truy vấn dữ liệu
Câu lệnh SELECT được sử dụng để truy xuất dữ liệu từ bảng. Thông qua việc sử dụng các mệnh đề khác nhau, có thể thực hiện lọc chính xác, sắp xếp và định dạng dữ liệu, chúng ta có thể tham khảo các câu lệnh sau để thực hiện từng bước và xem kết quả:
-- Step 3: SELECT query examples for the orders table
-- Example 1: Select all fields for all orders
SELECT * FROM orders;
-- Expected Output: Returns all rows and fields. Columns: id, user_id, status, amount, details, placed_at, is_paid.
-- Example 2: Select only pending orders
SELECT id, user_id, amount FROM orders WHERE status = 'pending';
-- Expected Output: All rows with status 'pending'; columns: id, user_id, amount.
-- Example 3: Select specific fields and filter by payment status
SELECT id, status, is_paid, amount FROM orders WHERE is_paid = true;
-- Expected Output: All rows where is_paid is true; columns: id, status, is_paid, amount.
-- Example 4: Extract all item names from the details (JSON) for each order
SELECT id, details -> 'items' AS item_list FROM orders;
-- Expected Output: Each row shows id and an array from JSON with item details.- Ví dụ 1: Trả về tất cả các hàng và cột trong bảng
orders, tương tự như kết quả ở bước hai. - Ví dụ 2: Chỉ trả về các đơn hàng có trạng thái 'pending', và chỉ chứa các cột được chỉ định:
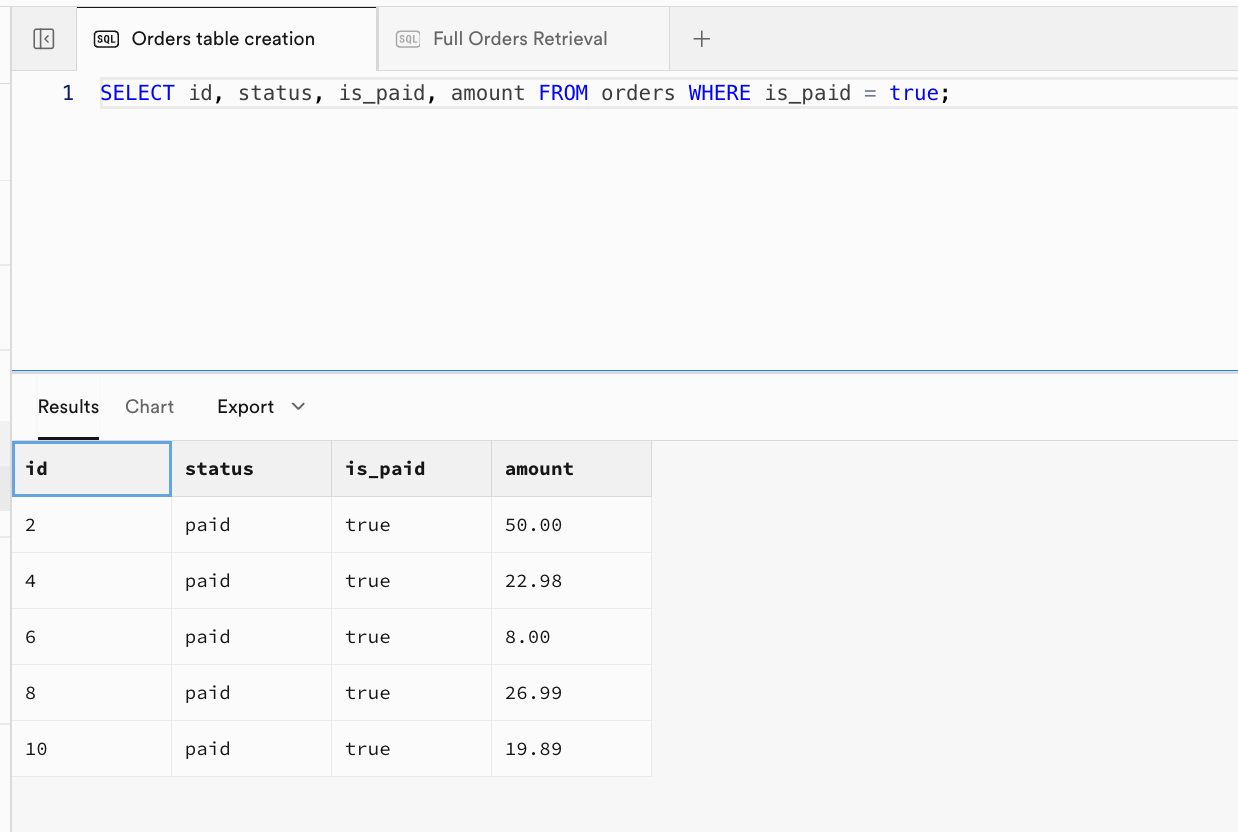
- Ví dụ 3: Chỉ trả về các đơn hàng đã thanh toán và hiển thị các cột được chỉ định:
| id | status | is_paid | amount |
|---|---|---|---|
| 2 | paid | true | 50.00 |
| 4 | paid | true | 22.98 |
| 6 | paid | true | 8.00 |
| 8 | paid | true | 26.99 |
| 10 | paid | true | 19.89 |
- Ví dụ 4: Trả về
idcủa mỗi đơn hàng và mảngitemsđược trích xuất từ trườngdetails:
| id | item_list |
|---|---|
| 1 | [{"qty":1,"sku":"BGR001","name":"Beef Burger","price":12}] |
| 2 | [{"qty":2,"sku":"BGR002","name":"Chicken Burger","price":10},{"qty":2,"sku":"DRK001","name":"Lemonade","price":5}] |
| 3 | [{"qty":3,"sku":"FRY001","name":"French Fries","price":5}] |
| ... | ... |
2.3.4 INSERT - Chèn một bản ghi duy nhất
Trong phần 2.3.2, chúng ta đã trình bày việc chèn hàng loạt dữ liệu khi khởi tạo ban đầu, bây giờ chúng ta sẽ xem cách chèn thêm một bản ghi đơn lẻ mới.
-- Step 4: INSERT a new order (single row)
-- Example: Add a new paid order for user 2012 with one Chicken Burger
INSERT INTO orders (user_id, status, amount, details, is_paid)
VALUES (
2012, 'paid', 9.99,
'{"items":[{"sku":"BGR002","name":"AIID Burger","qty":100,"price":1000}]}',
true
);
-- Expected Output:
-- Before (table fragment):
-- | id | user_id | status | amount | is_paid |
-- | ...| ... | ... | ... | ... |
--
-- After (last row):
-- | id | user_id | status | amount | is_paid |
-- | xx | 2012 | paid | 9.99 | true |
-- (where xx = next serial value)Sau đó, sử dụng SELECT * FROM orders; để truy vấn dữ liệu, chúng ta có thể thấy bảng orders đã tăng thành công từ 11 bản ghi lên 12 bản ghi.
2.3.5 UPDATE - Sửa đổi dữ liệu hiện có
Trong công việc thực tế, chúng ta cần thường xuyên cập nhật dữ liệu trong bảng, có thể sử dụng câu lệnh UPDATE để sửa đổi các bản ghi đã tồn tại trong bảng.
-- Step 5: UPDATE example
-- Example: Mark order with id=1 as paid and update its status
UPDATE orders SET status = 'paid', is_paid = true WHERE id = 1;
-- Expected Output:
-- Before (row with id=1):
-- | id | status | is_paid |
-- | 1 | pending | false |
-- After (row with id=1):
-- | id | status | is_paid |
-- | 1 | paid | true |
-- All other rows remain unchanged.2.3.6 DELETE - Xóa dữ liệu
Câu lệnh DELETE có thể được sử dụng để xóa các bản ghi khỏi bảng và kết hợp với điều kiện để xóa dữ liệu cụ thể.
-- Step 6: DELETE example
-- Example: Delete orders older than 2 days to clean up old data
DELETE FROM orders WHERE placed_at < now() - interval '2 days';
-- Expected Output:
-- Before (filtered for affected rows):
-- | id | status | placed_at |
-- | 3 | shipped | 2025-10-13 ... | <-- will be deleted
--
-- After:
-- No such rows remain. SELECT * FROM orders WHERE placed_at < now()-interval '2 days' yields zero rows.
-- Other rows in orders table are unaffected.Trước khi thực thi, bạn có thể chạy trước SELECT id, status, placed_at FROM orders WHERE placed_at < now() - interval '2 days'; để xem kết quả lọc của bảng dữ liệu. Sau khi chạy lệnh DELETE, thực thi lại cùng một câu truy vấn SELECT id, status, placed_at FROM orders WHERE placed_at < now() - interval '2 days';, kết quả trả về sẽ rỗng, cho thấy các hàng đó đã được xóa thành công.
2.4 Bảo mật cấp hàng (Row Level Security)
Sau khi học các thao tác cơ bản về cơ sở dữ liệu, chúng ta cần đi sâu hơn vào một khái niệm cốt lõi đảm bảo an toàn dữ liệu - RLS (Bảo mật cấp hàng, Row Level Security).
Trước hết, hãy suy nghĩ về một câu hỏi quan trọng trong tình huống thực tế: làm thế nào để thực hiện "truy cập cách ly" dữ liệu? Ví dụ, chỉ cho phép người dùng A xem dữ liệu của chính mình, mà không thể thấy thông tin của người dùng B; hoặc, ngay cả khi một vai trò nào đó có quyền truy cập cơ sở dữ liệu, làm thế nào để tránh việc vô tình thao tác hoặc làm lộ dữ liệu nhạy cảm của người dùng khác?
RLS chính là giải pháp sinh ra để giải quyết nhu cầu về bảo mật và cách ly dữ liệu này. Nó cho phép nhà phát triển định nghĩa các chính sách bảo mật tinh tế cho các bảng cơ sở dữ liệu, dựa trên thông tin danh tính của người dùng (như ID người dùng, quyền vai trò, v.v.), kiểm soát chính xác người dùng nào có thể truy cập, sửa đổi hàng dữ liệu nào trong bảng.
Lấy một ví dụ điển hình: đối với bảng đơn hàng (orders), chúng ta có thể định nghĩa một chính sách RLS như sau - "chỉ khi cột user_id của một bản ghi trong bảng orders hoàn toàn khớp với ID của người dùng hiện đang đăng nhập, người dùng đó mới có thể truy vấn được dữ liệu đơn hàng này", từ đó thực hiện nhu cầu cốt lõi "người dùng chỉ có thể xem đơn hàng của chính mình".
Khi bạn bật RLS cho một bảng, tất cả các yêu cầu thao tác dữ liệu trên bảng đó (bao gồm truy vấn SELECT, thêm mới INSERT, sửa đổi UPDATE, xóa DELETE) đều sẽ kích hoạt kiểm tra RLS: phải vượt qua kiểm tra của ít nhất một chính sách bảo mật thì thao tác mới được thực thi. Nếu không tồn tại chính sách nào cho phép thao tác đó, hoặc yêu cầu không đáp ứng điều kiện của bất kỳ chính sách nào, cơ sở dữ liệu sẽ trực tiếp từ chối thao tác này, ngăn chặn truy cập trái phép từ cấp nền tảng.
Trong Supabase, RLS được liên kết sâu với hệ thống xác thực người dùng, khiến việc sử dụng trở nên thuận tiện hơn. Supabase cung cấp một hàm chuyên dụng auth.uid(), nó có thể trực tiếp trả về ID duy nhất (định dạng UUID) của "người dùng đã đăng nhập hiện đang gửi yêu cầu". Thông qua hàm này, chúng ta có thể dễ dàng viết các chính sách, thực hiện liên kết chính xác giữa "hàng dữ liệu và danh tính người dùng" (như "user_id của đơn hàng khớp với ID người dùng hiện tại" đã đề cập ở trên).
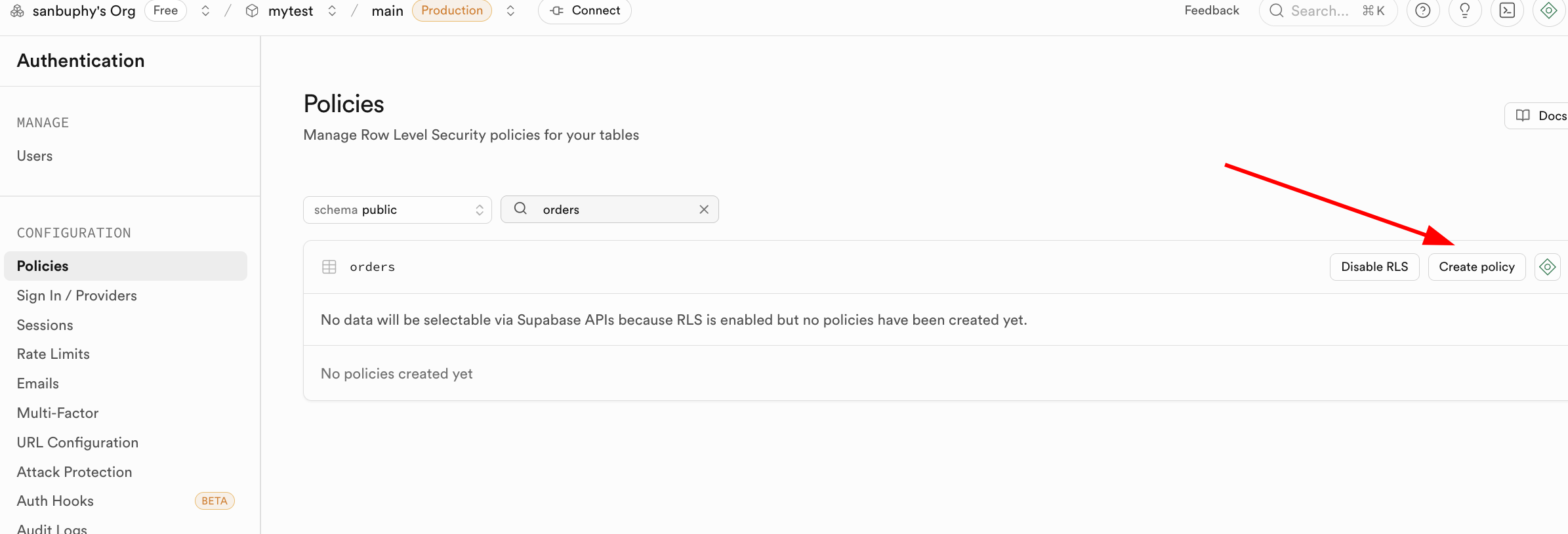
Cách bật chính sách RLS rất linh hoạt, bạn có thể nhấn nút "RLS" trong giao diện quản lý cơ sở dữ liệu Supabase để trực tiếp cấu hình và bật chính sách:
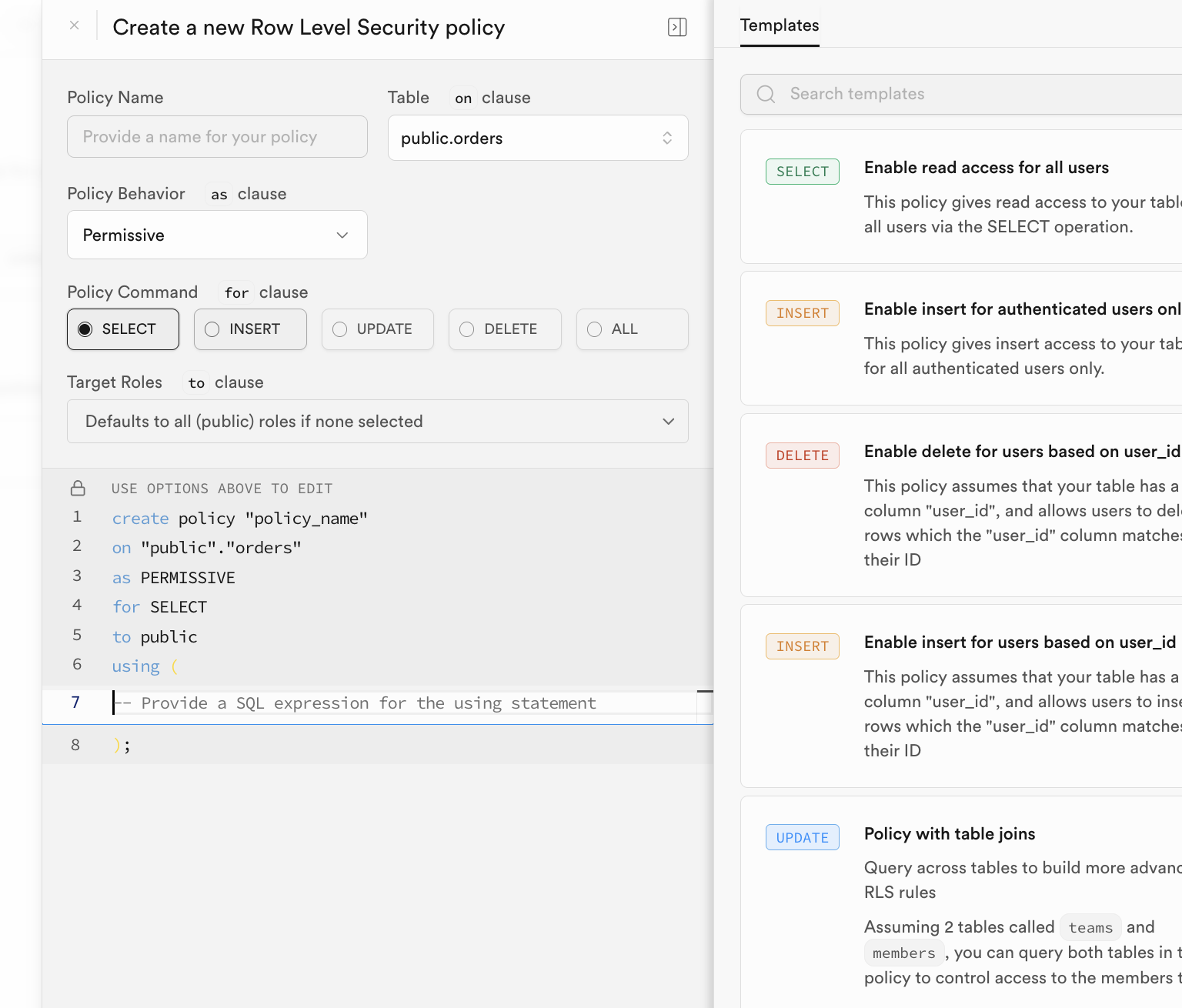
Việc cấu hình thủ công khá phiền toái, thông thường chúng ta sẽ tự động xem xét việc nhúng các chính sách RLS tương ứng khi tạo câu lệnh bảng dữ liệu và khởi tạo. Chúng ta chỉ cần thực thi các câu lệnh tương tự như sau trong SQL Editor để tự động bật chính sách bảo mật cấp hàng cho bảng dữ liệu tương ứng.

3. Ứng dụng SQL đầu tiên của bạn
Sau khi nắm vững các thao tác cơ bản về cơ sở dữ liệu và logic cốt lõi của RLS, chúng ta cuối cùng đã bước vào phần thực hành của hướng dẫn này. Quá trình học tập kéo dài phía trước là để làm cho quá trình "xây dựng ứng dụng từ 0 đến 1" phía sau trở nên rõ ràng hơn. Tiếp theo, chúng ta sẽ lấy "quản lý đơn hàng cửa hàng hamburger" làm kịch bản, hướng dẫn từng bước các thao tác phổ biến của Supabase: từ cấu hình liên kết giữa ứng dụng và Supabase, đến tích hợp cơ sở dữ liệu và chức năng đăng nhập, từng bước học các logic thao tác khác nhau.
3.1 Clone và chạy dự án mẫu Supabase
Để tiến hành thực hành, trước tiên cần lấy kho mã demo đi kèm. Bạn có thể yêu cầu Trae hoặc Claude Code hỗ trợ git clone kho lưu trữ sau: https://github.com/THU-SIGS-AIID/Project5-Supabase-Demos
Nếu đã cấu hình khóa SSH, nên sử dụng địa chỉ SSH để clone (git@github.com:THU-SIGS-AIID/Project5-Supabase-Demos.git) để tăng tính bảo mật; nếu kết nối SSH hoặc HTTPS gặp vấn đề mạng, bạn có thể trực tiếp nhấn "Download ZIP" trên trang kho lưu trữ, sau khi giải nén tệp nén sẽ thấy mã nguồn hoàn chỉnh.
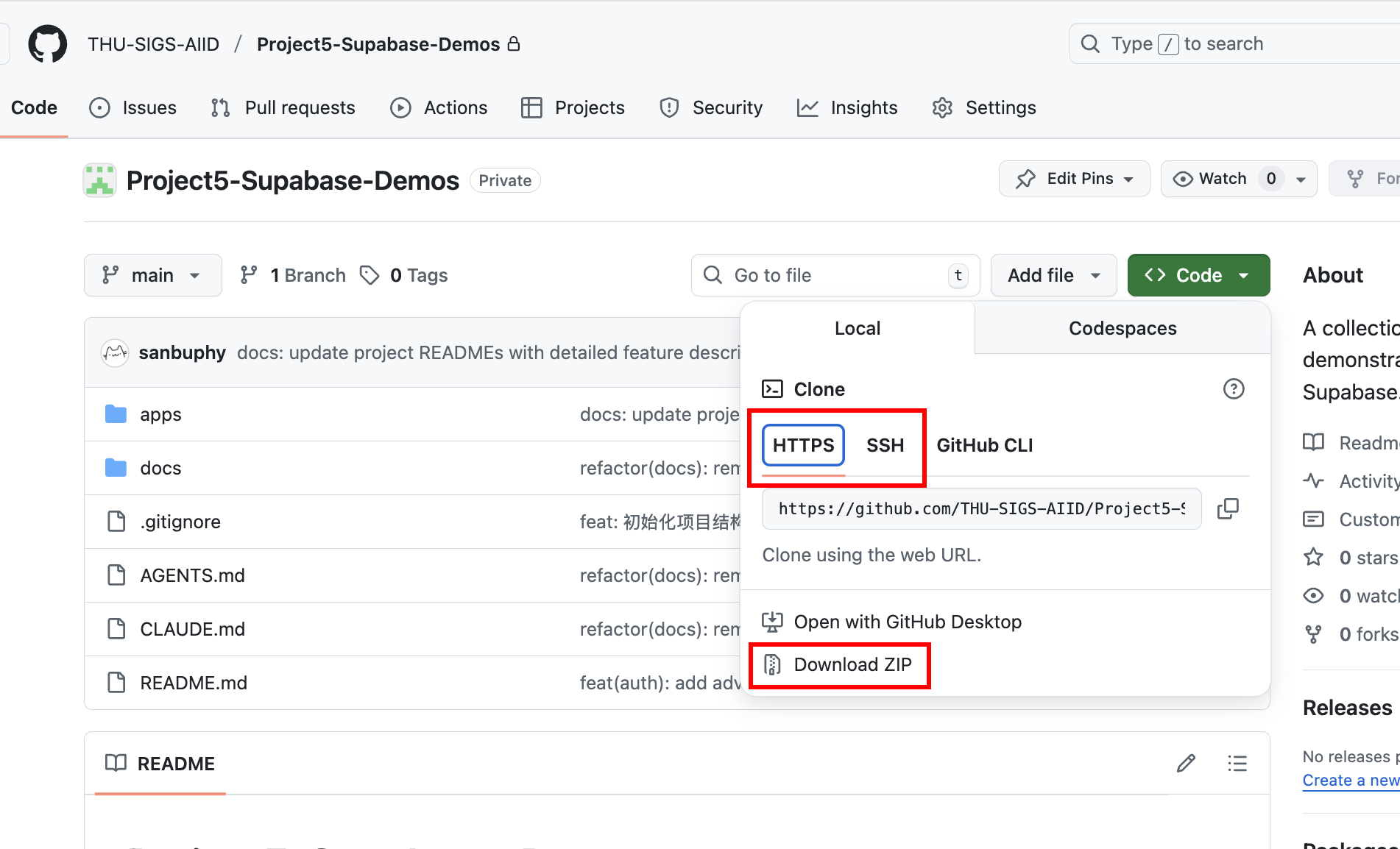
Sau khi clone, bạn cũng có thể để Trae hoặc Claude Code giúp bạn khởi chạy dự án, ví dụ trực tiếp mô tả trong giao diện Agent: Hãy giúp tôi khởi chạy project 1 trong dự án này, hoặc sao chép đường dẫn tuyệt đối của project muốn khởi chạy, dán vào cho mô hình lớn để mô hình lớn khởi chạy trực tiếp.
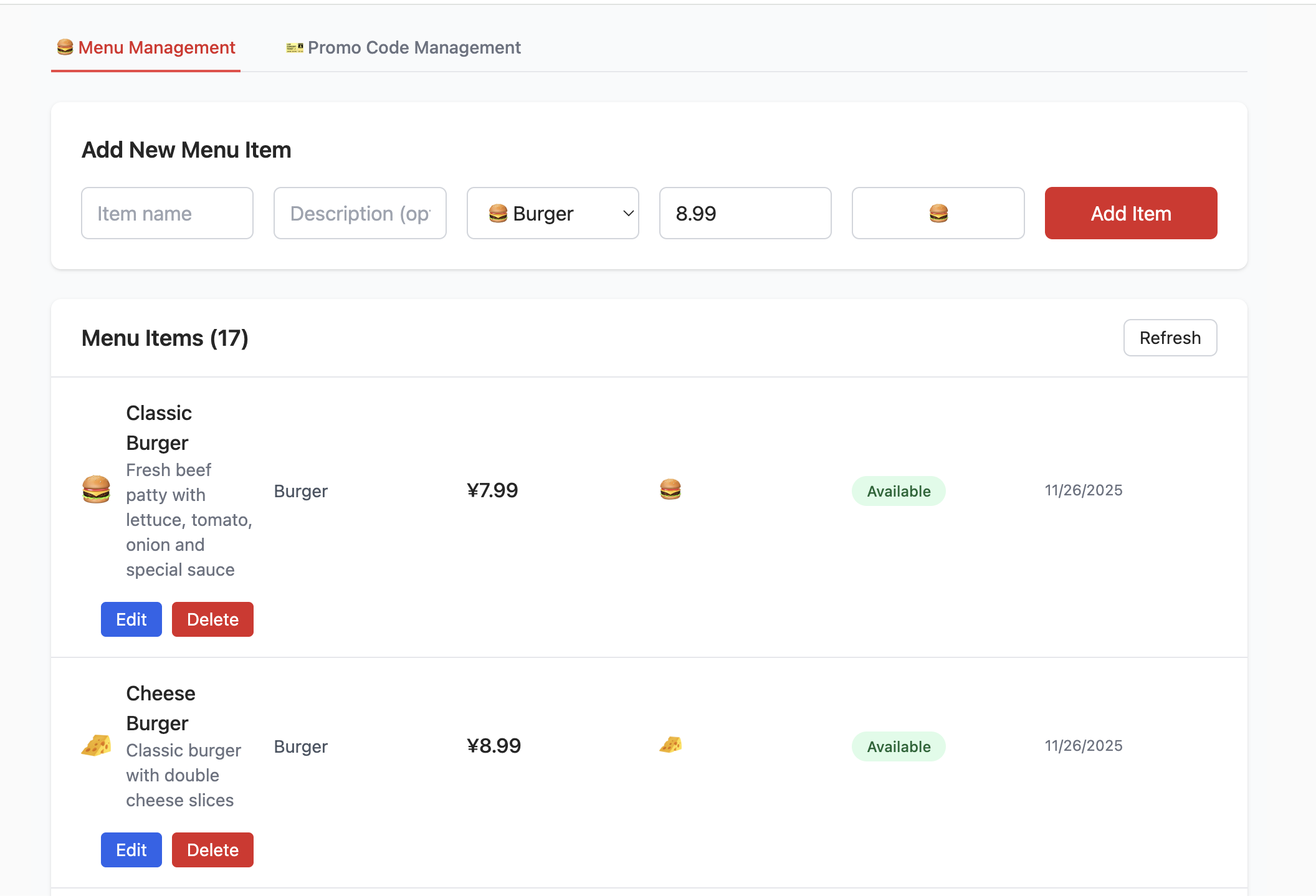
3.2 Dự án 1 - Thêm, xóa, sửa, tra cứu menu cửa hàng hamburger
Tiếp theo chúng ta bước vào phần thực hành - lấy project-burger-shop-menu-crud-1 làm ví dụ, chúng ta sẽ học cách khởi tạo cơ sở dữ liệu Supabase chỉ bằng một cú click thông qua script SQL, và hoàn tất cấu hình liên kết giữa dự án cục bộ và cơ sở dữ liệu Supabase, để frontend có thể đọc ghi dữ liệu menu bình thường.
Sử dụng script để tạo cơ sở dữ liệu
Đầu tiên, chúng ta cần tạo các nội dung liên quan đến bảng dữ liệu cần thiết trong Supabase. Vào thư mục dự án Project1, bạn sẽ thấy một thư mục tên là scripts, trong đó chứa 1 tệp script cơ sở dữ liệu init.sql, nó có thể giúp chúng ta tự động hoàn tất việc tạo tất cả các tài nguyên liên quan đến cơ sở dữ liệu (bao gồm cấu trúc bảng, dữ liệu ban đầu, v.v.), sau này chúng ta sẽ thường xuyên sử dụng tệp này để khởi tạo bảng trong cơ sở dữ liệu.
......
-- ============================================================================
-- 2. Create Menu Items Table
-- ============================================================================
create table if not exists public.menu_items (
id uuid primary key default gen_random_uuid(),
name text not null,
description text,
category text check (category in ('burger','side','drink')) default 'burger',
price_cents int not null check (price_cents > 0),
available boolean default true,
emoji text,
created_at timestamptz not null default now(),
updated_at timestamptz not null default now()
);
-- Comments for documentation
comment on table public.menu_items is 'Burger shop menu items for CRUD demo';
comment on column public.menu_items.id is 'Unique identifier for each menu item';
comment on column public.menu_items.name is 'Display name of the menu item';
comment on column public.menu_items.description is 'Detailed description of the menu item';
comment on column public.menu_items.category is 'Category: burger, side, or drink';
comment on column public.menu_items.price_cents is 'Price in cents (integer) to avoid floating point issues';
comment on column public.menu_items.available is 'Whether the item is currently available for order';
comment on column public.menu_items.emoji is 'Optional emoji representation of the menu item';
comment on column public.menu_items.created_at is 'Timestamp when the item was created';
comment on column public.menu_items.updated_at is 'Timestamp when the item was last updated';
......Sau khi thực thi script khởi tạo SQL trong SQL Editor, bạn có thể thấy bảng dữ liệu đã được tạo trong Table Editor. Logic thực thi cụ thể của mã khởi tạo cơ sở dữ liệu như sau:
- Tạo bảng menu_items:
- Bảng này được sử dụng để lưu trữ tất cả các mục trong menu cửa hàng hamburger. Nó bao gồm các trường như name (tên sản phẩm), description (mô tả), price_cents (giá tính bằng xu, tránh vấn đề độ chính xác số thực), category (phân loại) và available (có còn bán không). Về cơ bản bao gồm tất cả thông tin cần thiết cho một mục menu.
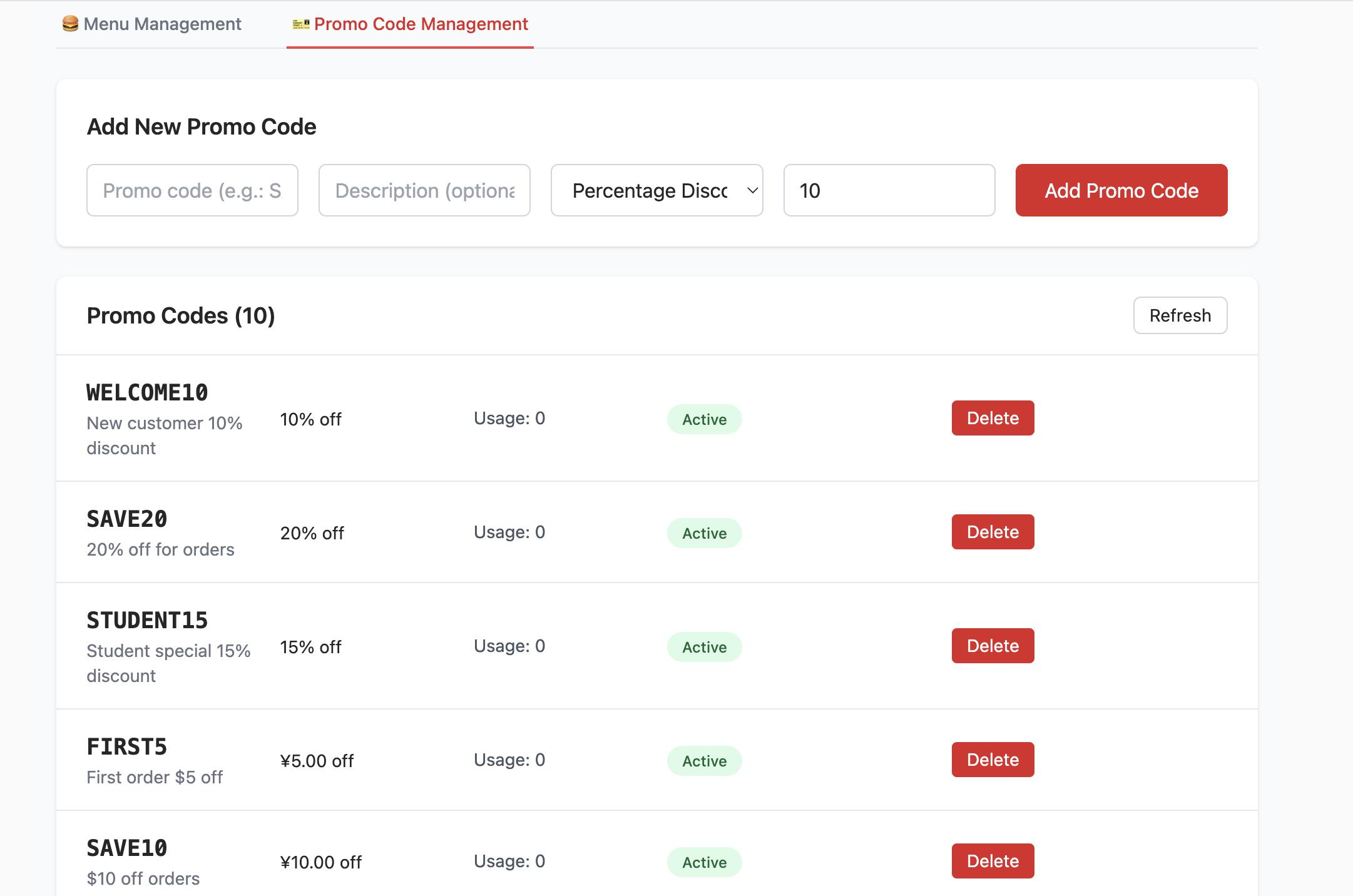
- Tạo bảng promo_codes:
- Bảng này được sử dụng để quản lý các chương trình khuyến mãi, ví dụ như mã giảm giá. Nó định nghĩa các trường như code (mã giảm giá), discount_type (loại giảm giá, như phần trăm hoặc số tiền cố định), discount_value (giá trị giảm giá), v.v.
- Vô hiệu hóa Bảo mật cấp hàng (Row Level Security - RLS):
- Để thuận tiện cho việc phát triển và kiểm thử, script đã tắt RLS một cách rõ ràng. Nhưng kết hợp với logic cốt lõi của RLS mà chúng ta đã học trước đó: RLS là tính năng then chốt của Supabase để đảm bảo an toàn dữ liệu, có thể thông qua chính sách tinh tế để kiểm soát "ai có thể truy cập / sửa đổi dữ liệu nào" (ví dụ chỉ cho phép quản trị viên chỉnh sửa mã khuyến mãi, người dùng thông thường chỉ có thể xem menu). Do đó trong môi trường sản xuất, bắt buộc phải bật RLS và cấu hình chính sách hợp lý, ngăn chặn truy cập trái phép từ cấp nền tảng (như ngăn người dùng độc ý sửa đổi menu do người khác tạo, hoặc làm lộ quy tắc mã khuyến mãi).
- Chèn dữ liệu hạt giống (Seed Data):
- Để dự án frontend có thể hiển thị dữ liệu menu và khuyến mãi thực tế ngay sau khi khởi động (không cần nhập thủ công dữ liệu kiểm thử), script
init.sqlcũng sẽ chèn "dữ liệu hạt giống" (tức là dữ liệu mẫu) vào các bảngmenu_itemsvàpromo_codes. Ví dụ, bạn có thể thấy nhiều loại hamburger, đồ ăn nhẹ, đồ uống cũng như nhiều loại mã giảm giá khác nhau.
Thiết lập kết nối với cơ sở dữ liệu
Sau khi chuẩn bị cơ sở dữ liệu xong, chúng ta cần kết nối dự án frontend này với Supabase, từ đó có thể đọc dữ liệu trong cơ sở dữ liệu bình thường. Chúng ta cần ghi URL dự án Supabase và anon key vào cấu hình được chỉ định, dự án này cung cấp hai phương pháp cấu hình linh hoạt:
- Cấu hình qua biến môi trường
Tạo một tệp .env trong thư mục gốc của dự án và điền thông tin đăng nhập Supabase của bạn:
NEXT_PUBLIC_SUPABASE_URL=https://your-project.supabase.co
NEXT_PUBLIC_SUPABASE_ANON_KEY=your-anon-key- Cấu hình trực tiếp trên trang dự án
Để thuận tiện cho việc demo nhanh và chuyển đổi giữa các dự án Supabase khác nhau, trang chủ có một nút Cài đặt ở góc trên bên phải. Bạn có thể nhấn vào nó và nhập hoặc dán URL Supabase và anon key trực tiếp trong hộp thoại modal hiện ra.
Sau khi nhấn "Save", thông tin này sẽ được sử dụng để tạo instance client Supabase động, tương tự như mã dưới đây:
import { createClient, type SupabaseClient } from '@supabase/supabase-js';
// Optional client factory for demos: returns null when env is not set.
export function maybeCreateBrowserClient(): SupabaseClient | null {
const url = process.env.NEXT_PUBLIC_SUPABASE_URL;
const anon = process.env.NEXT_PUBLIC_SUPABASE_ANON_KEY;
if (!url || !anon) return null;
return createClient(url, anon);
}Sau khi tạo cơ sở dữ liệu và điền xong cấu hình liên kết Supabase, bạn có thể thấy giao diện như sau, bạn có thể thử thêm, xóa, tra cứu, sửa đổi sản phẩm và quan sát sự thay đổi của bảng dữ liệu tương ứng trong Supabase.
📚 Bài tập
- Thử thêm và xóa các mục hiện có, xem tác động của thao tác sửa đổi đối với nội dung bảng dữ liệu trong Table Editor.
3.4 Dự án 2 - Xác thực người dùng cửa hàng hamburger
Dự án 1 đã thực hiện "CRUD menu + kết nối cơ sở dữ liệu", Dự án 2 sẽ giới thiệu khả năng cốt lõi gần gũi với nghiệp vụ thực tế hơn: xác thực người dùng (Auth) và quản lý quyền Bảo mật cấp hàng (RLS).
Dự án 2 bao gồm trang đăng nhập độc lập, hỗ trợ người dùng đăng nhập qua "email + mật khẩu". Logic cốt lõi là gọi các phương thức gốc do Supabase Auth cung cấp, nhanh chóng thực hiện quy trình xác thực, không cần tự phát triển logic kiểm tra đăng nhập phức tạp:
const { error: err } = await supabaseClient.auth.signUp({
email,
password,
options: {
data: {
full_name: fullName || null,
birthday: birthday || null,
avatar_url: avatarUrl || null
}
}
});
Sau khi đăng nhập thành công, Supabase sẽ tự động tạo một phiên (session) cho người dùng và tự động mang theo thông tin xác thực trong tất cả các yêu cầu cơ sở dữ liệu tiếp theo; thông qua tác dụng của RLS, mỗi người dùng dựa trên thông tin xác thực tương ứng chỉ có thể thấy thông tin tài khoản của chính mình (các sản phẩm đã mua, số dư ví còn lại), không thể thấy thông tin tài khoản của người dùng khác, điều này thực hiện cách ly dữ liệu sau khi các người dùng khác nhau đăng nhập, mỗi người chỉ có thể thấy nội dung của chính mình.
Giống như Dự án 1, bạn cần sử dụng init.sql để khởi tạo bảng dữ liệu trước (lưu ý: nếu phát hiện lỗi khởi tạo, hãy xóa bảng dữ liệu đã tạo trong Table Editor trước, hoặc trực tiếp xóa dự án Supabase này và tạo lại một Project mới).
Sau khi đăng ký tài khoản bằng email thành công và xác nhận đăng ký trong email, đăng nhập và vào giao diện Shop để thấy nội dung như sau:
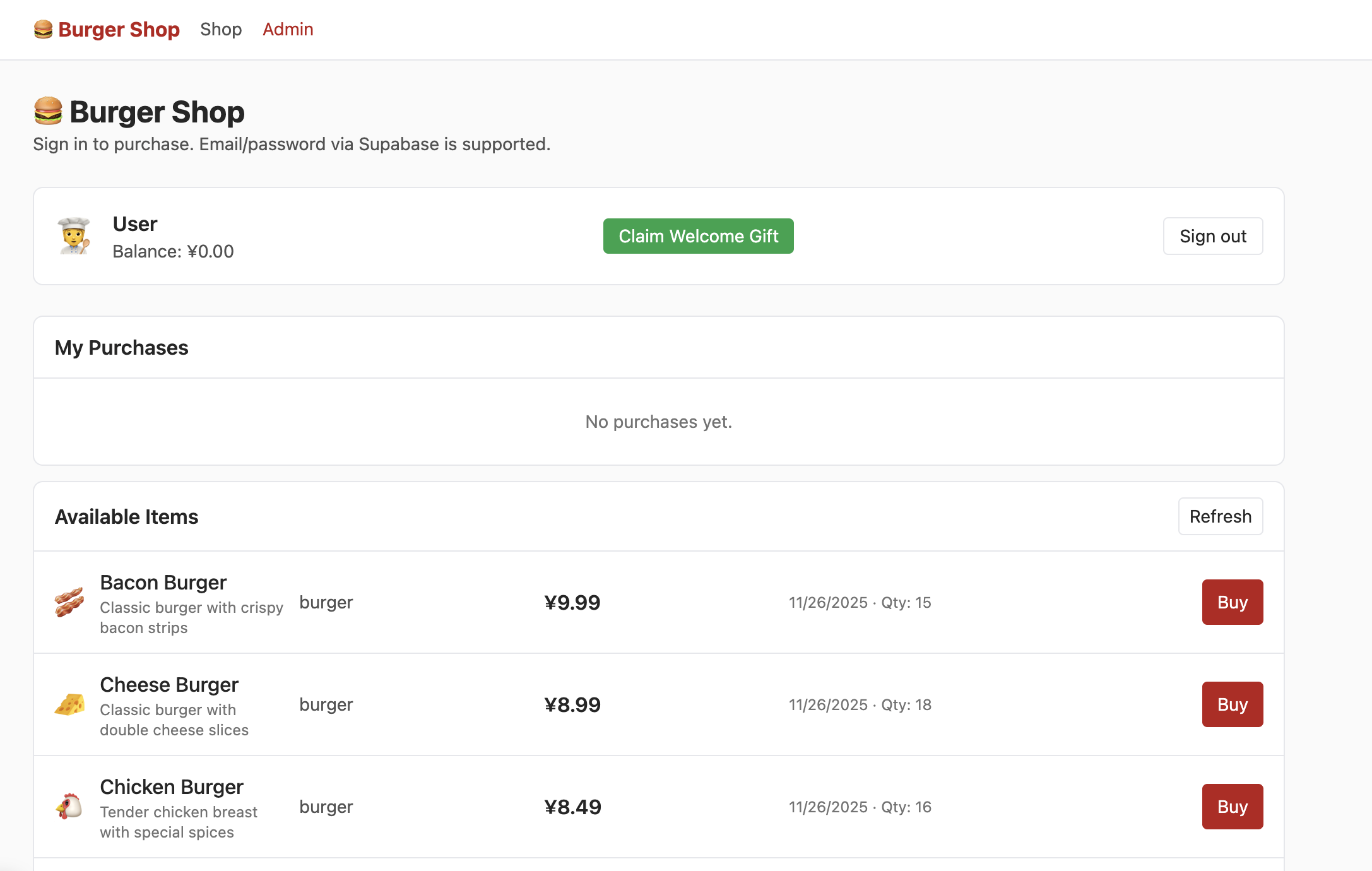
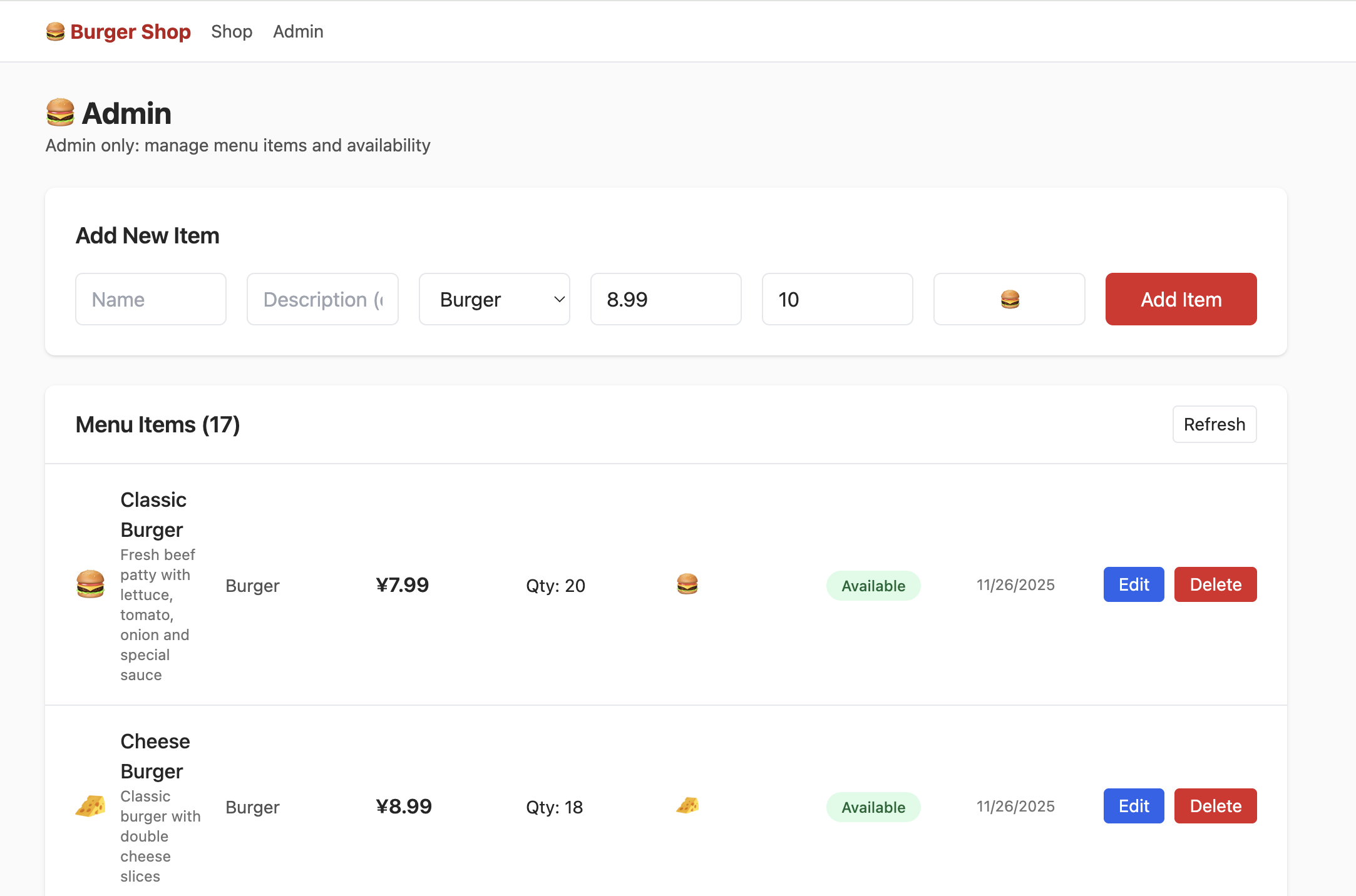
Nhưng lúc này nhấn vào admin, bạn sẽ không thấy giao diện sau, bạn cần thử tìm phần kiểm soát quyền người dùng trong bảng dữ liệu, sửa quyền thành admin, từ đó có thể thấy nội dung như sau trong giao diện Admin:
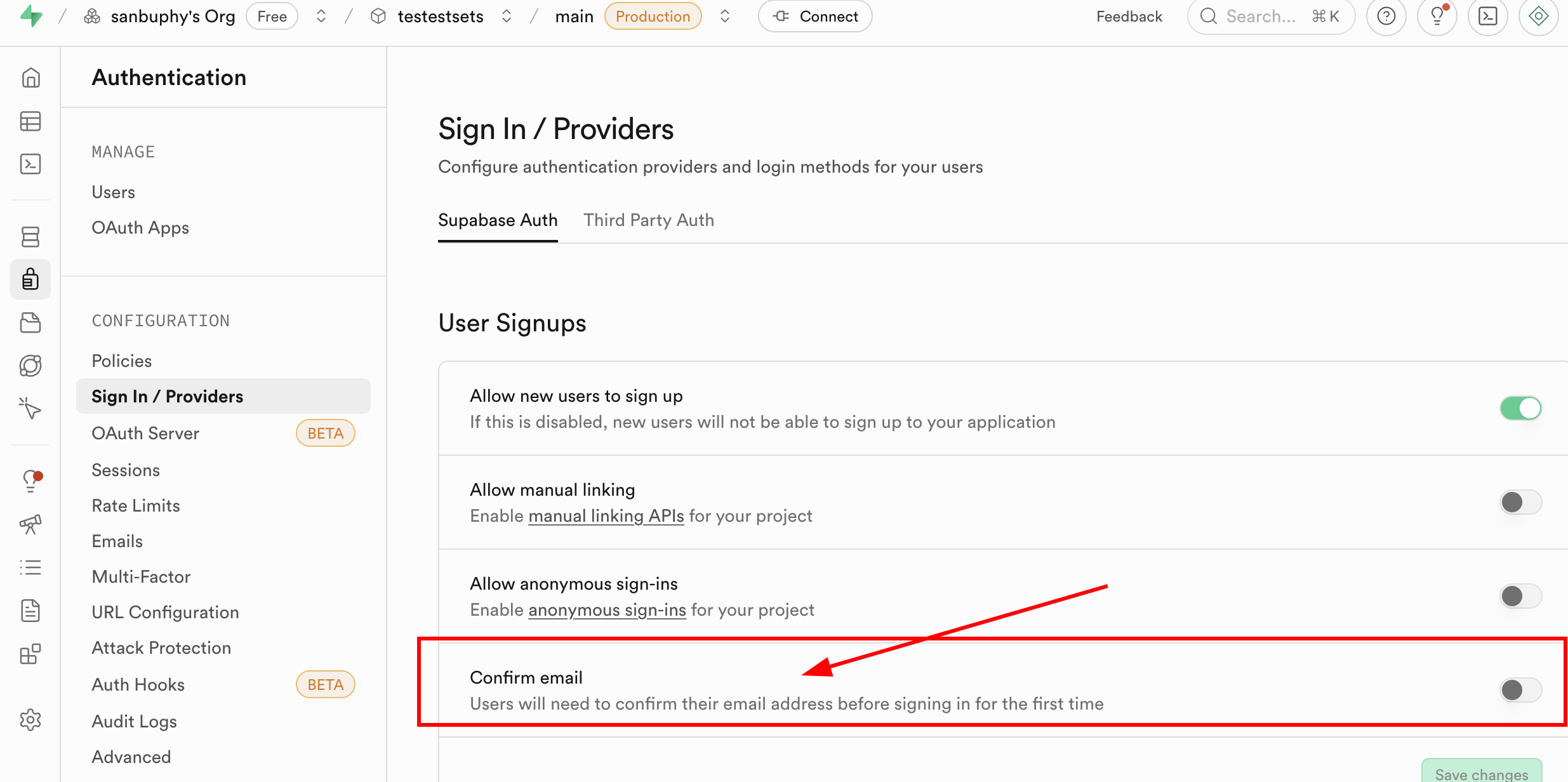
Đáng lưu ý, hiện tại mỗi lần đăng ký email mới, bạn đều cần xác nhận đăng ký trong email mới có thể đăng nhập; nhưng bước này không phải là bắt buộc, bạn có thể tìm Sign In / Providers trong mục Authentication của Supabase, nhấn Confirm email để hủy yêu cầu xác nhận email bắt buộc.
📚 Bài tập
- Hãy nhận quà tặng người mới trước, hoàn tất thao tác mua sản phẩm.
- Thử tìm vị trí bảng dữ liệu thiết lập quyền người dùng, sửa quyền thành
admin, và sửa đổi số lượng sản phẩm thành công trong giao diện quản lý đơn hàng. - Thử định vị bảng liên quan đến số dư ví trong bảng dữ liệu, thông qua sửa đổi để tăng số dư ví còn lại.
4. Xây dựng ứng dụng Supabase đầu tiên của bạn
Sau khi học tập hệ thống phía trước, bạn đã nắm vững các khả năng cốt lõi của Supabase (thao tác cơ sở dữ liệu, xác thực người dùng, chính sách bảo mật RLS), bây giờ là lúc tự tay xây dựng ứng dụng đầu tiên của bạn bao gồm cơ sở dữ liệu và hỗ trợ hệ thống đăng nhập người dùng!
4.1 Quy trình chuẩn hóa để kết nối bất kỳ ứng dụng nào với cơ sở dữ liệu Supabase
Chúng ta có thể sử dụng quy trình chuẩn hóa để kết nối bất kỳ ứng dụng nào với cơ sở dữ liệu Supabase:
- Trước tiên thực hiện sắp xếp nhu cầu và đồng bộ thông tin, làm rõ mục tiêu và thông báo cho AI
- Bạn cần mô tả rõ ràng cho AI về các chức năng cốt lõi của ứng dụng hiện tại và nhu cầu cơ sở dữ liệu mới cần thêm. Ví dụ: "Tôi hiện có một ứng dụng React Todo cục bộ, dữ liệu chỉ được lưu trong bộ nhớ trình duyệt cục bộ, cần thêm chức năng 'đồng bộ dữ liệu đám mây' và kết nối cơ sở dữ liệu Supabase. Hãy giúp tôi phân tích: ứng dụng này liên quan đến những thao tác dữ liệu nào (như thêm việc cần làm, sửa trạng thái, xóa việc cần làm)? Cần tạo những bảng dữ liệu nào để lưu trữ các dữ liệu này?"
- Bổ sung các điều kiện ràng buộc quan trọng (tùy chọn): ví dụ yêu cầu định dạng trường (dấu thời gian dùng
timestamptz, số tiền dùng số nguyên lưu theo xu), quy tắc quyền dữ liệu (chỉ mình tôi có thể thấy việc cần làm), để phân tích của AI phù hợp hơn với nhu cầu thực tế. - Xem xét kết quả AI trả về, nếu có thiếu sót trong tư duy của AI (như chưa xem xét trường "hạn chót của việc cần làm"), hãy bổ sung nhắc nhở sửa đổi: "Bạn đã bỏ sót hạn chót, hãy giúp tôi thêm vào."
- Để AI dựa trên cấu trúc bảng bạn đã xác nhận, tạo script
init.sqlphù hợp với Supabase: "Dựa trên những ý tưởng và cấu trúc bảng đã nói ở trên, hãy trả về cho tôi script init.sql có thể khởi tạo trong Supabase", sau đó bạn cần thực thi script trong SQL Editor; nếu thực thi báo lỗi, phản hồi thông tin lỗi cho AI để sửa script. - Sau khi chạy script init.sql trong Supabase, để AI dựa trên script tái cấu trúc mã hiện tại, để có thể tương tác dữ liệu bình thường với Supabase: "Hãy dựa trên script sql và các thiết lập đã thảo luận ở trên, tái cấu trúc mã dự án để nó hỗ trợ giao tiếp và xử lý dữ liệu với cơ sở dữ liệu Supabase tương ứng".
- Sau khi tái cấu trúc xong, lúc này chỉ cần cấu hình tham số địa chỉ Supabase và key (dự án chính thức thường chỉ cần cấu hình biến môi trường), sau đó kiểm tra, nếu không có vấn đề thì đã kết nối thành công ứng dụng với cơ sở dữ liệu Supabase.
- Chạy dự án, kiểm tra tất cả các chức năng tương tác cơ sở dữ liệu, vào Supabase Table Editor xem dữ liệu có được đồng bộ theo thời gian thực không;
- Nếu có vấn đề (như không thể chèn dữ liệu, chỉ thấy một phần dữ liệu), hãy phản hồi hiện tượng vấn đề cho AI để AI xác định nguyên nhân và sửa mã.
Ngoài ra, nếu mục tiêu là phát triển trang đăng nhập người dùng, bạn có thể trực tiếp để AI hỗ trợ tích hợp trang đăng nhập: "Bây giờ bạn cần giúp tôi thêm hệ thống đăng nhập người dùng Supabase vào ứng dụng này, có thể sử dụng email để đăng ký và đăng nhập". Ngoài ra, bạn còn cần làm rõ với AI về logic và đường dẫn chuyển hướng trang (như sau khi đăng nhập thành công chuyển đến trang chủ hệ thống, địa chỉ trang chủ chuyển đến là gì, khi đăng nhập thất bại ở lại trang hiện tại và hiển thị thông báo lỗi). Sau khi tích hợp xong, bạn cần thử đăng ký và đăng nhập, có thể thấy dữ liệu người dùng mới được thêm trong mục Authentication của Supabase, và sau khi đăng nhập có thể vào bình thường giao diện ứng dụng trước đó không thể vào khi chưa đăng nhập.
Tất nhiên, bạn cũng có thể trực tiếp để AI tham khảo triển khai của một project nào đó để trực tiếp chuyển đổi các chức năng Supabase tương ứng, ví dụ một Project nào đó sử dụng cơ sở dữ liệu và các chức năng nâng cao của Edge Function, bạn có thể làm theo cách sau để trực tiếp yêu cầu AI chuyển đổi các chức năng tương tự: "Hãy tham khảo logic triển khai chức năng Supabase trong dự án {dán đường dẫn tuyệt đối của dự án tham khảo tại đây} và thêm logic triển khai tương tự cho dự án hiện tại (như đăng nhập người dùng, quản lý cơ sở dữ liệu, yêu cầu hàm, v.v.)."
4.2 Nghiên cứu tình huống: Xây dựng một trò chơi rắn ăn mảnh trực tuyến
Dựa trên SOP đã đề cập ở trên, chúng ta hãy thực hành thông qua một tình huống cụ thể Project5-Supabase-Demos/apps_snakegame: thêm bảng xếp hạng điểm số cho một dự án trò chơi "rắn ăn mảnh" hiện có, bao gồm chức năng đăng nhập người dùng và các chức năng cơ sở dữ liệu cơ bản.
4.2.1 Phân tích dự án, xác định nhu cầu dữ liệu
Đầu tiên, tương tự như quy trình chuẩn hóa đã đề cập trước đó, chúng ta có thể làm rõ nhu cầu cho AI trước, để AI đưa ra phương án sửa đổi tương ứng dựa trên dự án và nhu cầu của chúng ta, sau đó chúng ta sẽ dựa trên phương án sửa đổi này.
Bạn có thể sử dụng câu hỏi gợi ý sau để hướng dẫn AI:
"Tôi có một trò chơi rắn ăn mảnh, thư mục ở {dán đường dẫn tuyệt đối của trò chơi rắn ăn mảnh tại đây}. Bây giờ tôi muốn kết hợp Supabase để thêm chức năng bảng xếp hạng trực tuyến, đồng thời hỗ trợ hệ thống đăng nhập người dùng, bảng xếp hạng có thể hiển thị thứ hạng dựa trên tên người dùng và email.
Hãy giúp tôi phân tích, để thực hiện chức năng này, tôi cần tạo những bảng dữ liệu nào? Mỗi bảng nên bao gồm những trường nào?"
Lúc này bạn sẽ nhận được phản hồi tương tự như sau:
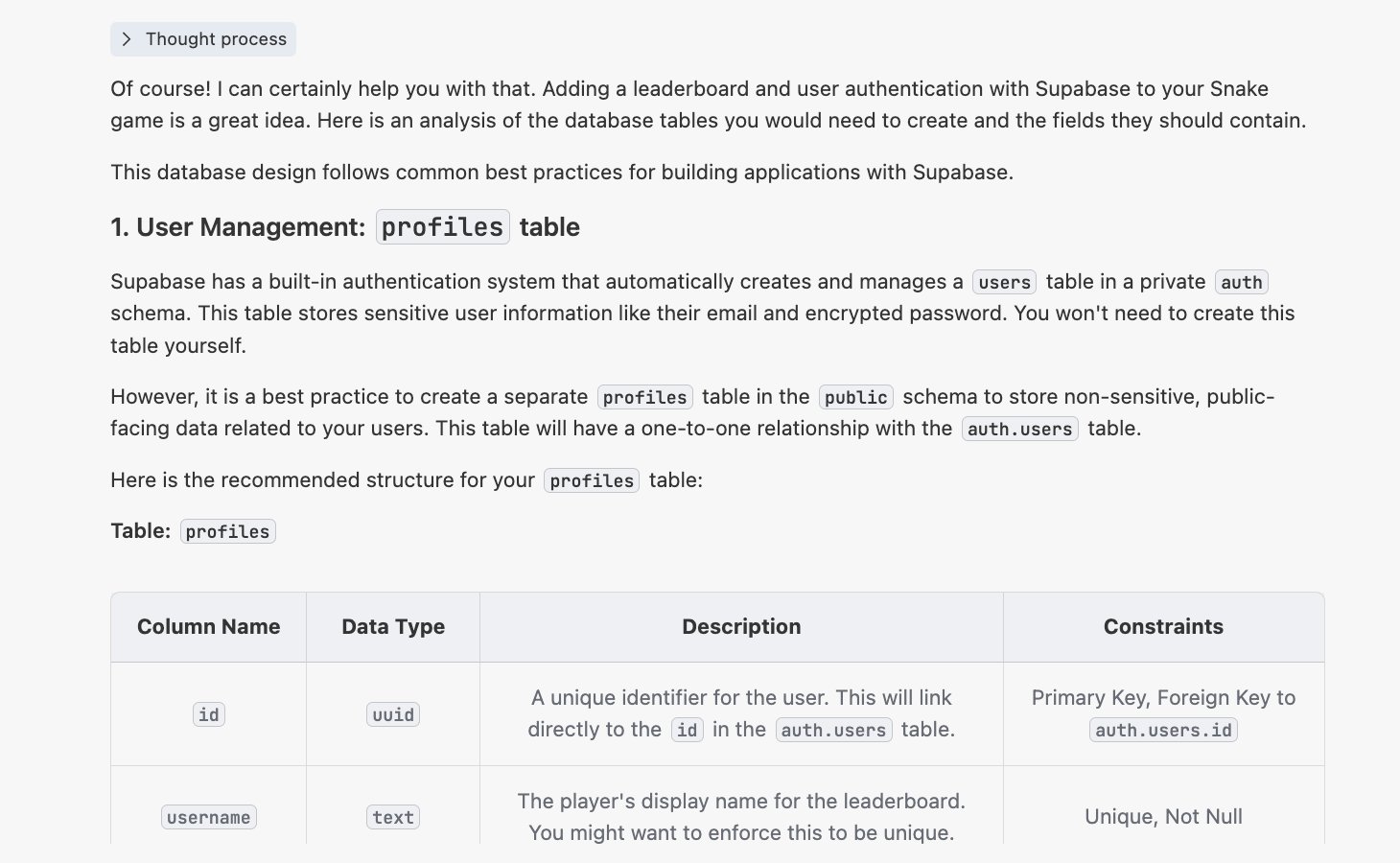
4.2.2 Tạo script init.sql
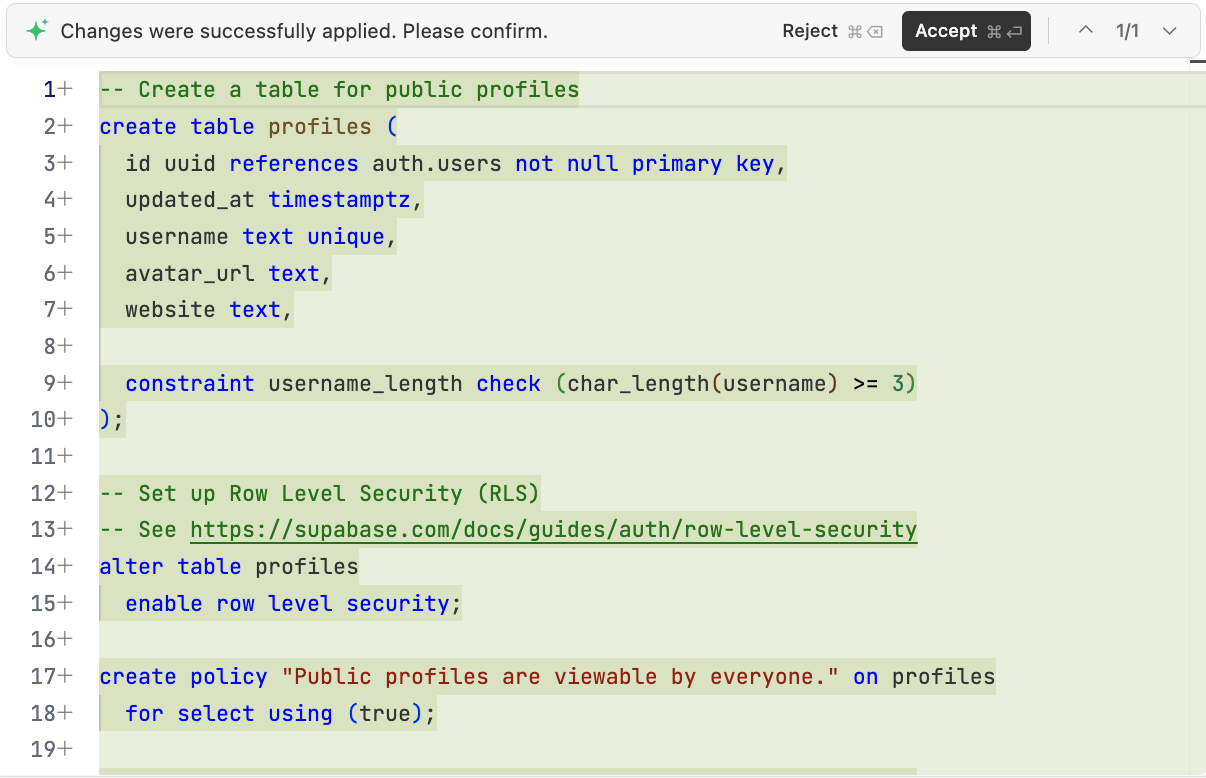
Sau khi xác định các phần cần thiết, chúng ta có thể yêu cầu AI tạo script khởi tạo cơ sở dữ liệu cần thực thi trong Supabase: "Hãy dựa trên phân tích ở trên, giúp tôi tạo script scripts/init.sql trong dự án để khởi tạo cơ sở dữ liệu cần thiết trong Supabase".
4.2.3 Cải tạo mã dự án
Tiếp theo chúng ta chỉ cần yêu cầu AI dựa trên nội dung phía trước tái cấu trúc mã trò chơi rắn ăn mảnh hiện tại: "Tiếp theo hãy dựa trên nội dung đã suy nghĩ ở trên và bảng sql, sử dụng Supabase giúp tôi thực hiện chức năng bảng xếp hạng, bảng xếp hạng là một trang riêng biệt, cần có thể phân biệt tổng điểm của các người dùng khác nhau dựa trên email và tên người dùng, bạn còn cần hỗ trợ hệ thống đăng nhập người dùng dựa trên email, phải đăng ký đăng nhập mới có thể chơi trò chơi này."
Nếu phiên hội thoại AI hiện tại có quá nhiều vòng, bạn muốn mở một phiên hội thoại mới để tái cấu trúc dự án, bạn có thể đưa init.sql đã đề cập ở trên vào nội dung ngữ cảnh, để AI dựa trên tệp sql để tái cấu trúc dự án.
Nếu phát hiện hệ thống đăng nhập người dùng do AI triển khai không đủ bình thường, bạn có thể trực tiếp đưa địa chỉ của Project5-Supabase-Demos/apps/project-burger-shop-auth-users-2 đã viết trước đó vào câu hỏi gợi ý, để AI dựa trên dự án triển khai trực tiếp hệ thống đăng nhập người dùng. Và kiểm tra xem đã thiết lập đúng các điều kiện cần thiết để kết nối với Supabase chưa, ngăn ngừa lỗi do cấu hình Supabase không đúng.
Trong quá trình sửa đổi mã, nếu hiệu quả thực tế không khớp với mong đợi (như dữ liệu bảng xếp hạng không hiển thị, xác thực đăng nhập không hoạt động, v.v.), chỉ cần ghi lại đầy đủ hiện tượng cụ thể và phản hồi cho AI, là có thể dần dần tiếp cận kết quả chính xác. Tiêu chuẩn cải tạo thành công là: người dùng có thể hoàn tất thao tác đăng ký và đăng nhập, và sau khi đăng nhập có thể xem bảng xếp hạng trò chơi tương ứng bình thường.
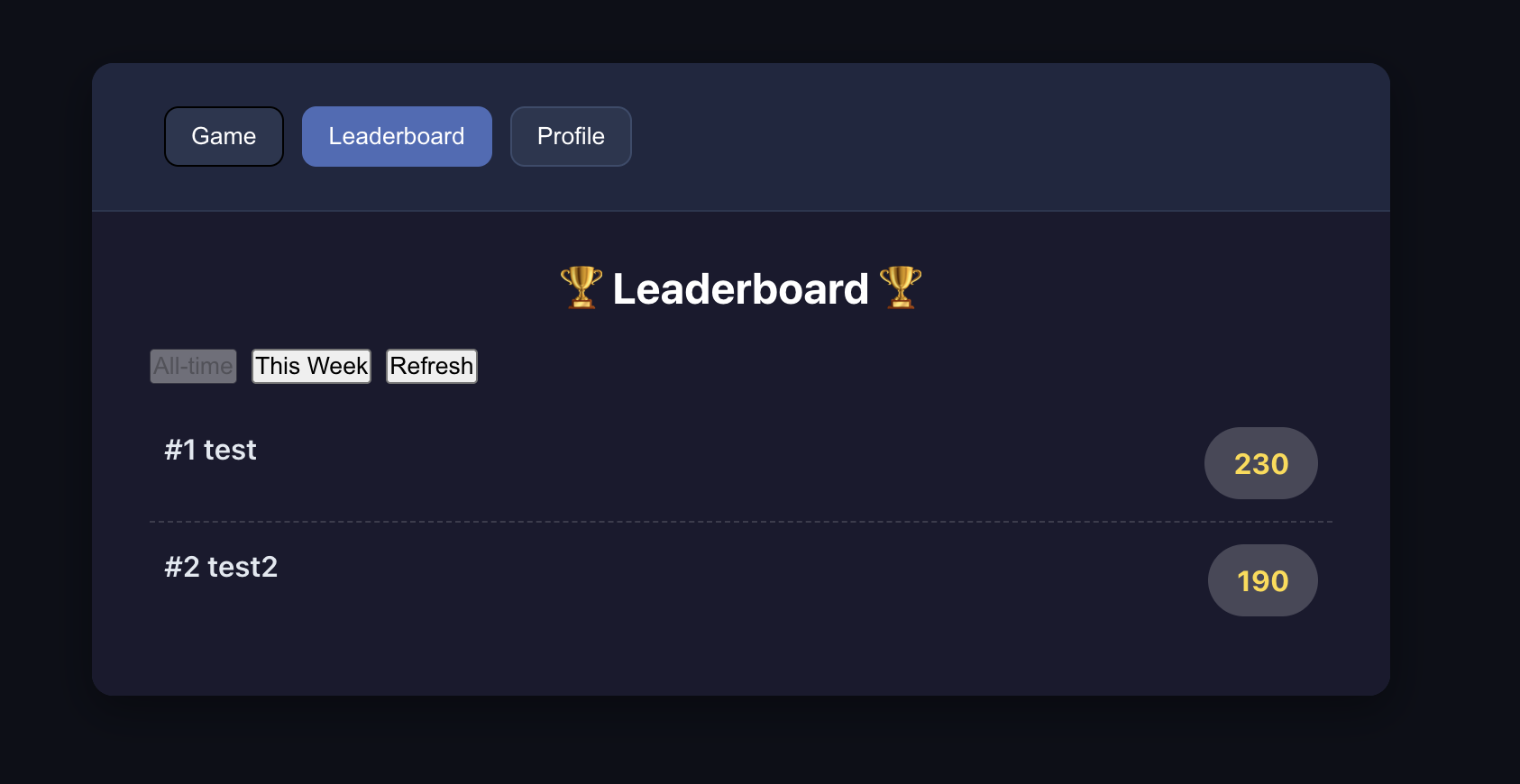
📚 Bài tập khóa học
- Tích hợp hệ thống quản lý người dùng vào phiên bản demo trò chơi rắn ăn mảnh
- Tích hợp hệ thống quản lý người dùng vào ứng dụng của bạn (nếu trước đó đã phát triển một ứng dụng)
5. Trở thành chuyên gia Supabase
Trên đây là các thao tác cơ bản của Supabase, trong hành trình tiếp theo chúng ta sẽ tiếp xúc với các nguyên lý và chức năng nâng cao của Supabase, bạn sẽ hiểu tại sao chúng ta chọn Supabase làm tình huống giảng dạy, cũng như cách sử dụng Supabase để thực hiện các thao tác nâng cao hơn, hỗ trợ bạn thực hiện các chức năng tương tác phức tạp hơn, và sau khi học các chức năng này, ngay cả khi đối mặt với các công cụ tương tự khác ngoài Supabase, bạn cũng có thể liên hệ tương tự, hiểu nguyên lý cốt lõi của dịch vụ backend từ cấp độ sâu hơn. Tất nhiên, bạn không cần phải học tất cả trong thời gian ngắn, có lẽ chỉ cần học hỗ trợ đăng nhập bên thứ ba là đã đủ, bạn có thể duyệt qua các nội dung dưới đây trước, quay lại học sâu khi dự án gặp nhu cầu tương ứng.
5.1 Tại sao chúng ta chọn Supabase
Trước khi bắt đầu phần nâng cao, chúng ta hãy suy nghĩ lại câu hỏi này: trong nhiều giải pháp công nghệ backend, tại sao chúng ta cuối cùng chọn Supabase làm nền tảng công nghệ?
Các đội ngũ khởi nghiệp thường đối mặt với một mâu thuẫn khi chọn công nghệ: vừa muốn kiểm soát hoàn toàn hệ thống backend, lại phải ra mắt sản phẩm nhanh chóng - việc tự xây dựng backend thường có nghĩa là phải dành hàng tháng để xây dựng các thành phần cốt lõi như cơ sở dữ liệu và đồng bộ thời gian thực, xác thực người dùng, dịch vụ API, lưu trữ tệp, tác vụ định kỳ, giám sát cảnh báo, v.v., trừ khi thành viên đội ngũ đã có kinh nghiệm thực chiến phong phú trong lĩnh vực tương ứng. Dưới áp lực kép từ thiếu vốn và cửa sổ thị trường ngắn, một khi sa lầy vào cơ sở hạ tầng, rất dễ dẫn đến lặp lại chậm trễ, bỏ lỡ không gian tăng trưởng ban đầu.
Supabase đóng gói các khả năng backend này thành các dịch vụ sẵn sàng sử dụng (cơ sở dữ liệu PostgreSQL, đăng ký thời gian thực, xác thực danh tính, lưu trữ đối tượng, hàm Edge, tự động tạo API, v.v.), cho phép đội ngũ khởi nghiệp tập trung nguồn lực hạn chế vào phát triển chức năng cốt lõi, tránh việc xây dựng cấp nền tảng làm chậm tốc độ ra mắt - điều này đã trở thành chiến lược sinh tồt thực tế trong bối cảnh đầu tư mạo hiểm hiện tại. Tất nhiên, chúng ta cũng có thể sử dụng các sản phẩm backend toàn ngăn xếp khác để phát triển, ví dụ PocketBase (nhẹ và tối giản) và Appwrite (thích ứng đa nền tảng), nhưng xét về tính đầy đủ chức năng, độ trưởng thành hệ sinh thái SQL và mức độ quan tâm cộng đồng Github, Supabase phù hợp hơn để hỗ trợ vận hành ổn định lâu dài của nghiệp vụ.
Trong số các sản phẩm cùng loại, chiến lược mã nguồn mở của Supabase có lợi thế hơn. Lấy Firebase có thị phần cao làm ví dụ: đặc tính mã nguồn đóng dễ dẫn đến ràng buộc nền tảng, chi phí di chuyển rất cao. Supabase áp dụng mô hình mã nguồn mở hoàn toàn, hỗ trợ triển khai riêng tư, tránh rủi ro khóa nhà cung cấp, có thể chuyển sang các sản phẩm cạnh tranh khác theo nhu cầu.
Tóm lại, việc chọn công nghệ cần phù hợp với quy mô và mục tiêu nghiệp vụ. Đối với các dự án cá nhân hoặc kiểm thử quy mô rất nhỏ, các giải pháp siêu nhẹ như PocketBase là đủ; nếu doanh nghiệp cần kết nối với hệ thống danh tính phức tạp, hoặc cần đáp ứng yêu cầu kiểm toán tuân thủ của công ty niêm yết, các giải pháp quản lý danh tính cấp doanh nghiệp như WorkOS phù hợp hơn. Nhưng đối với việc xác thực MVP, hỗ trợ nghiệp vụ cốt lõi của người dùng ban đầu, chức năng đầy đủ của Supabase là hoàn toàn đủ, nó không chỉ có thể độc lập hỗ trợ quy mô người dùng ít nhất hàng nghìn, mà còn có thể tích hợp linh hoạt các dịch vụ bên thứ ba như Stripe (thanh toán), Resend (email), Cloudflare (CDN); ngay cả khi nghiệp vụ mở rộng đến nhu cầu cấp doanh nghiệp trong tương lai, kiến trúc mã nguồn mở của Supabase cũng có thể triển khai song song với hệ thống doanh nghiệp, chọn nền tảng phù hợp nhất cho các chức năng khác nhau để sử dụng. Tính linh hoạt tiệm tiến này giúp đội ngũ khởi nghiệp không cần đầu tư quá sớm vào cơ sở hạ tầng nặng, mà vẫn giữ được không gian phát triển future-proof.
5.2 Hỗ trợ đăng nhập Google và GitHub
Trong hướng dẫn phía trước, chúng ta đã giải thích cách đăng ký và đăng nhập trực tiếp bằng email, nhưng trong thực tế chúng ta thường muốn đơn giản hóa quy trình đăng ký, ví dụ sử dụng đăng nhập bên thứ ba Google và GitHub để đăng ký và đăng nhập nhanh chóng hệ thống, chúng ta sẽ trình bày chi tiết từng bước trong phần hướng dẫn này; đồng thời, một hệ thống xác thực hoàn chỉnh cũng phải cung cấp chức năng đặt lại mật khẩu an toàn và đáng tin cậy, chúng ta cũng sẽ tích hợp chức năng đặt lại mật khẩu vào dự án của phần hướng dẫn này.
Dự án này Project5-Supabase-Demos/apps/project-burger-shop-auth-advanced-supabase-6) trình bày đầy đủ cách triển khai các chức năng nâng cao này.

5.2.1 Quy trình OAuth: Đăng nhập bên thứ ba hoạt động như thế nào?
Cốt lõi của đăng nhập bên thứ ba là giao thức ủy quyền mở OAuth 2.0, bản chất của nó là "ủy quyền đại diện": cho phép người dùng ủy quyền ứng dụng của chúng ta (dự án cửa hàng hamburger) truy cập thông tin công khai của họ trên nền tảng bên thứ ba (như Google) (như email, ảnh đại diện), mà không cần tiết lộ mật khẩu của nền tảng bên thứ ba cho ứng dụng của chúng ta,从根本上 ngăn ngừa rủi ro rò rỉ mật khẩu.
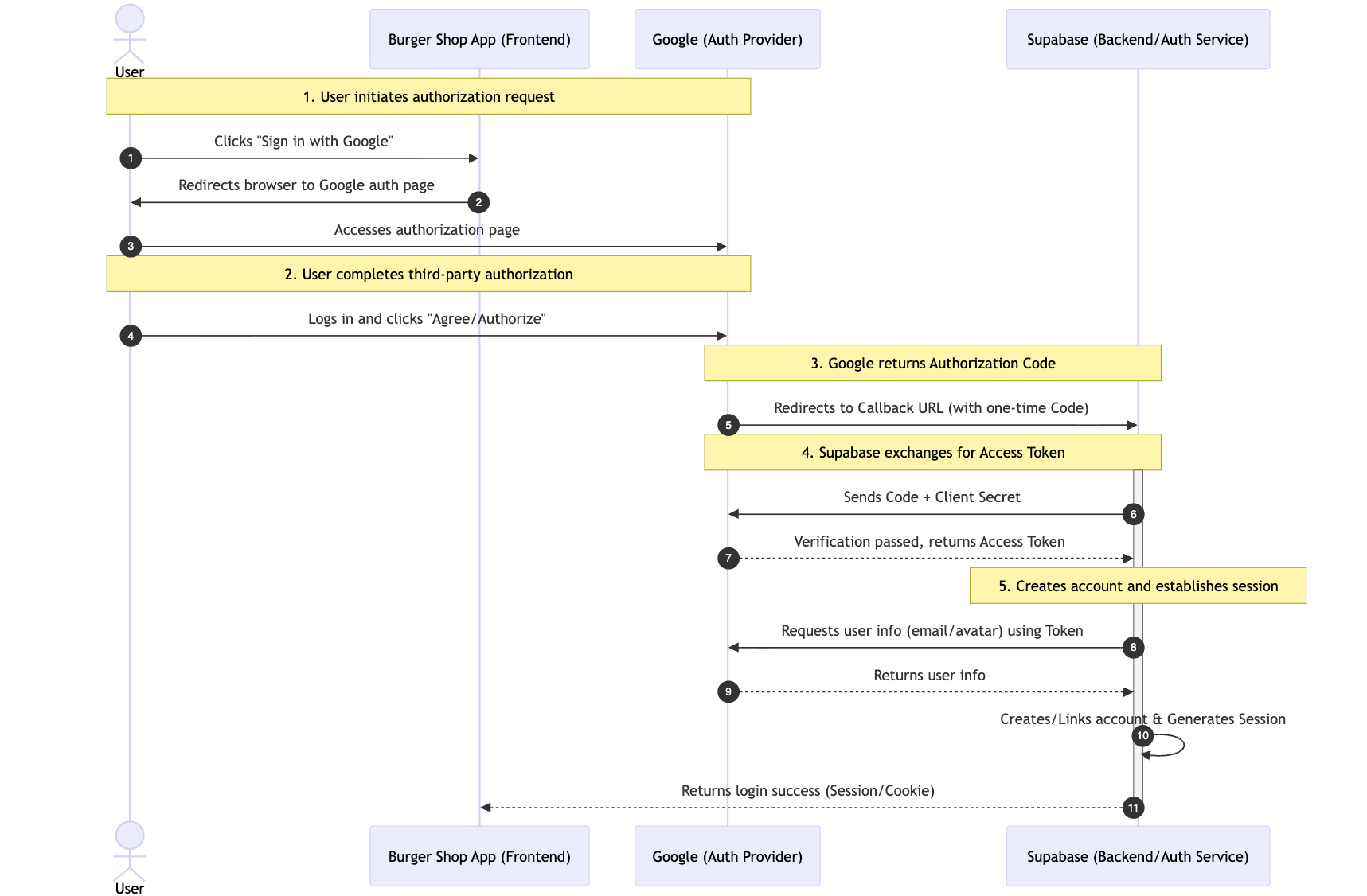
Quy trình hoàn chỉnh có thể được chia thành 5 bước chính, lấy đăng nhập Google làm ví dụ:
- Người dùng gửi yêu cầu ủy quyền: Người dùng nhấn nút "Sign in with Google" trên trang, ứng dụng của chúng ta sẽ tự động chuyển hướng người dùng đến trang ủy quyền chính thức của Google (đảm bảo tính bảo mật của quá trình ủy quyền, tránh rủi ro lừa đảo).
- Người dùng hoàn tất ủy quyền bên thứ ba: Người dùng đăng nhập vào tài khoản của mình trên trang Google (xác minh danh tính người dùng), và đồng ý với quyền mà ứng dụng của chúng ta yêu cầu (như "lấy địa chỉ email").
- Google trả về mã ủy quyền một lần: Sau khi ủy quyền thành công, Google sẽ chuyển hướng người dùng trở lại "URL gọi lại (Callback URL)" đã thỏa thuận trước của chúng ta, và đính kèm một mã ủy quyền một lần, có hiệu lực ngắn trong tham số URL (thay vì trực tiếp trả về thông tin người dùng,进一步提升 tính bảo mật).
- Supabase trao đổi Mã truy cập (Access Token): Backend của chúng ta (do Supabase lưu trữ, không cần tự xây dựng) sẽ dùng mã ủy quyền này, gửi yêu cầu đến giao diện chính thức của Google để đổi lấy Access Token có thể sử dụng để lấy thông tin người dùng (mã ủy quyền chỉ dùng để đổi Token, tránh Token truyền trực tiếp trên frontend).
- Tạo tài khoản và thiết lập phiên: Supabase sử dụng Access Token để kéo thông tin công khai của người dùng từ Google (như email, ảnh đại diện), và tự động tạo tài khoản cho người dùng này trong dự án của chúng ta (nếu đăng nhập lần đầu) hoặc trực tiếp liên kết với tài khoản hiện có, cuối cùng tạo một phiên người dùng (Session) hợp lệ, hoàn tất đăng nhập.
5.2.2 Cấu hình Google Cloud để lấy Client ID và Secret
Bất kể là phương thức đăng nhập bên thứ ba nào, chúng ta thường cần lấy Client ID và Secret để cấu hình; đối với đăng nhập bên thứ ba của Google, trước tiên bạn cần tạo một OAuth 2.0 Client ID trong Google Cloud Platform để lấy các tham số tương ứng.
- Vào Google Cloud Console:
- Truy cập Google Cloud Console.
- Tạo một dự án mới hoặc chọn một dự án hiện có.
- Cấu hình Màn hình đồng ý OAuth (OAuth consent screen):
- Trong thanh điều hướng bên trái, tìm "APIs & Services" -> "OAuth consent screen".
- Chọn loại người dùng "External", sau đó nhấn "Create".
- Điền tên ứng dụng, email hỗ trợ người dùng và các thông tin bắt buộc khác.
- Trong phần "Authorized domains", thêm tên miền dự án Supabase của bạn, định dạng là
*.supabase.co. - Lưu và tiếp tục. Trong các bước "Scopes" và "Test users", bạn có thể tạm thời bỏ qua, trực tiếp lưu.
- Tạo thông tin xác thực (Create Credentials):
- Vào "APIs & Services" -> "Credentials".
- Nhấn "+ CREATE CREDENTIALS", chọn "OAuth client ID".
- Trong "Application type" chọn "Web application".
- Đặt tên cho nó, ví dụ "Supabase Auth".
- Trong phần "Authorized redirect URIs", nhấn "ADD URI", và điền URL gọi lại của dự án Supabase. Bạn có thể tìm URL này trong Supabase Dashboard tại "Authentication" -> "Providers" -> "Google", định dạng thường là
https://<ID-dự-án-của-bạn>.supabase.co/auth/v1/callback.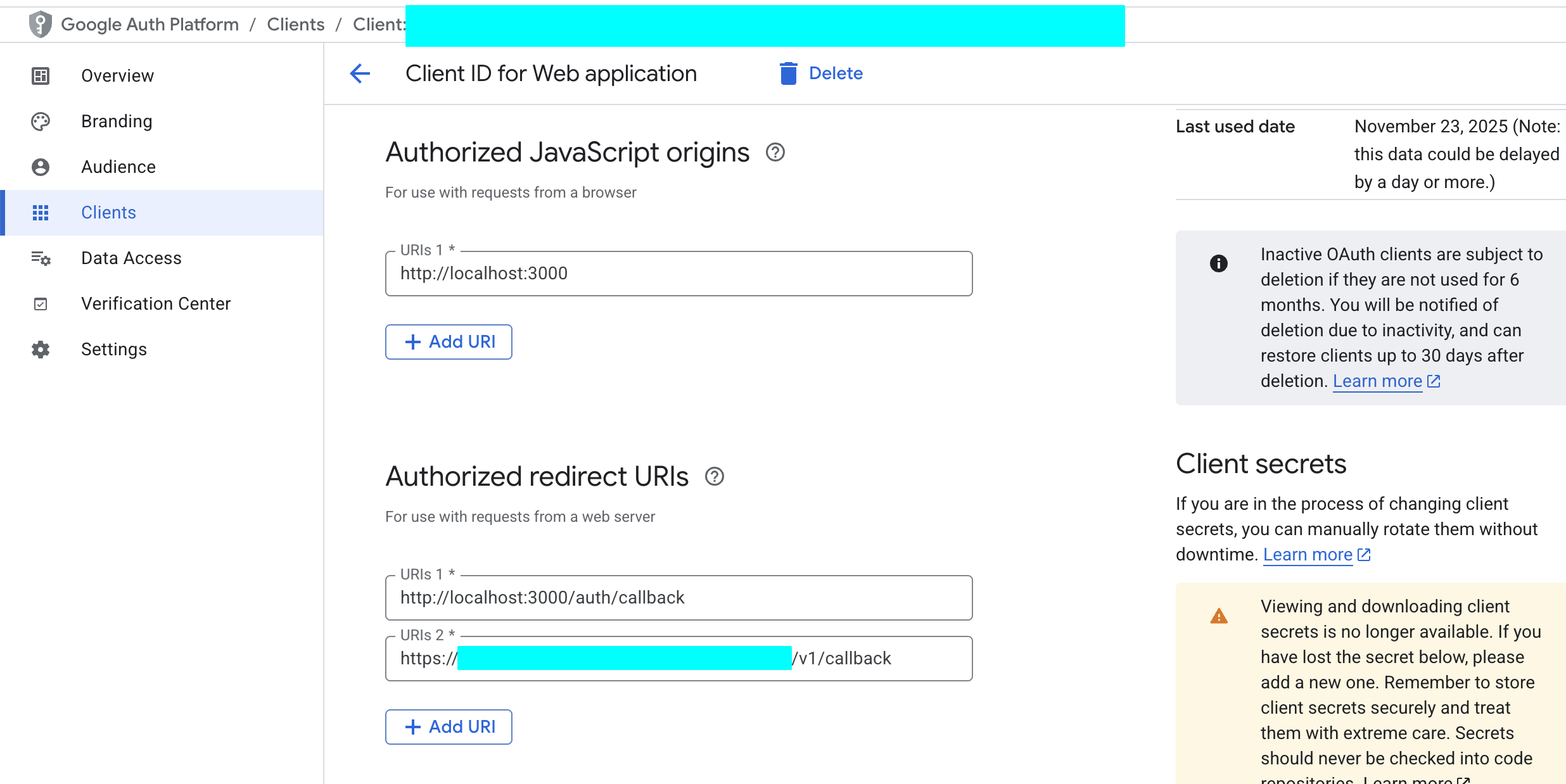
- Nhấn "CREATE".
- Lấy Client ID và Client Secret:
- Sau khi tạo thành công, một hộp thoại sẽ hiển thị Client ID và Client Secret của bạn. Hãy ngay lập tức sao chép và lưu trữ cẩn thận chúng.
5.2.3 Cấu hình GitHub để lấy Client ID và Secret
Tương tự, bạn cũng cần đăng ký một ứng dụng OAuth trên GitHub.
Vào Developer Settings của GitHub::
- Đăng nhập vào tài khoản GitHub của bạn.
- Nhấn vào ảnh đại diện ở góc trên bên phải, vào "Settings".
- Ở cuối thanh điều hướng bên trái, tìm "Developer settings".
Đăng ký ứng dụng mới (Register a new application):
Chọn "OAuth Apps", sau đó nhấn "New OAuth App".
Điền tên ứng dụng, ví dụ "My Burger Shop".
Homepage URL: Điền địa chỉ trực tuyến của ứng dụng, hoặc địa chỉ phát triển cục bộ
http://localhost:3000.Authorization callback URL: Điền URL gọi lại của dự án Supabase. Tương tự, bạn có thể tìm nó trong Supabase Dashboard tại "Authentication" -> "Providers" -> "GitHub", định dạng là
https://<ID-dự-án-của-bạn>.supabase.co/auth/v1/callback.Nhấn "Register application".
Lấy Client ID và Client Secret:
Sau khi đăng ký thành công, trang sẽ hiển thị Client ID của bạn.
Nhấn "Generate a new client secret" để tạo Client Secret của bạn. Tương tự, hãy ngay lập tức sao chép và lưu trữ nó.
5.2.4 Cấu hình Provider trong Supabase
Bây giờ, hãy cấu hình thông tin xác thực đã lấy được vào Supabase.
- Vào Supabase Dashboard:
- Chọn dự án của bạn, vào "Authentication" -> "Providers".
- Bật và cấu hình Google:
- Tìm "Google" và bật nó.
- Dán Client ID và Client Secret lấy từ Google Cloud vào các ô nhập tương ứng.
- Nhấn "Save".
- Bật và cấu hình GitHub::
- Tìm "GitHub" và bật nó.
- Dán Client ID và Client Secret lấy từ GitHub vào các ô nhập tương ứng.
- Nhấn "Save".

Đến đây, bạn đã có thể sử dụng tài khoản bên thứ ba để đăng nhập vào trang web đã xây dựng, bạn có thể trực tiếp yêu cầu AI dựa trên dự án Project5-Supabase-Demos/apps/project-burger-shop-auth-advanced-supabase-6 làm tham chiếu, hỗ trợ hệ thống đăng nhập người dùng trên nền tảng dự án của bạn, với chi phí thấp nhất tích hợp giao diện đăng nhập người dùng bao gồm xác thực github và google.
5.2.6 Triển khai đặt lại mật khẩu
Là một thành phần đăng nhập người dùng trưởng thành, đặt lại mật khẩu cũng là một phần cực kỳ quan trọng, dự án project-burger-shop-auth-advanced-supabase-6 này cũng bao gồm triển khai đầy đủ chức năng này, bạn có thể trực tiếp yêu cầu AI dựa trên chức năng đặt lại mật khẩu của dự án này để sao chép thành phần đặt lại mật khẩu hoàn chỉnh. Nó chủ yếu chia thành các bước sau:
- Gửi yêu cầu: Người dùng nhập email trên trang quên mật khẩu, frontend gọi hàm
supabase.auth.resetPasswordForEmail(), và chỉ định URL chuyển hướng redirectTo (ví dụ /auth/reset). - Gửi email: Supabase sẽ gửi một email chứa liên kết đặt lại duy nhất đến email đó.
- Truy cập liên kết: Người dùng nhấn liên kết trong email, được chuyển hướng đến trang đặt lại được chỉ định trong ứng dụng.
- Cập nhật mật khẩu: Trên trang đặt lại, người dùng nhập mật khẩu mới. Frontend gọi
supabase.auth.updateUser(), gửi mật khẩu mới cho Supabase. Supabase sẽ tự động xác minh tính hợp lệ của liên kết và hoàn tất cập nhật mật khẩu.
Cuối cùng, nếu bạn cảm thấy email đặt lại mật khẩu hiện tại quá đơn giản, bạn có thể tùy chỉnh mẫu email "Reset Password" trong Supabase Dashboard tại Authentication -> Email Templates.
Ngoài chức năng Reset password, bạn còn có thể thấy nhiều cài đặt chức năng nâng cao khác liên quan đến quản lý người dùng (ví dụ Invite user, v.v.), bạn có thể dựa trên tài liệu phát triển của từng chức năng, kết hợp công cụ Vibe coding để tự thêm các chức năng tương ứng.
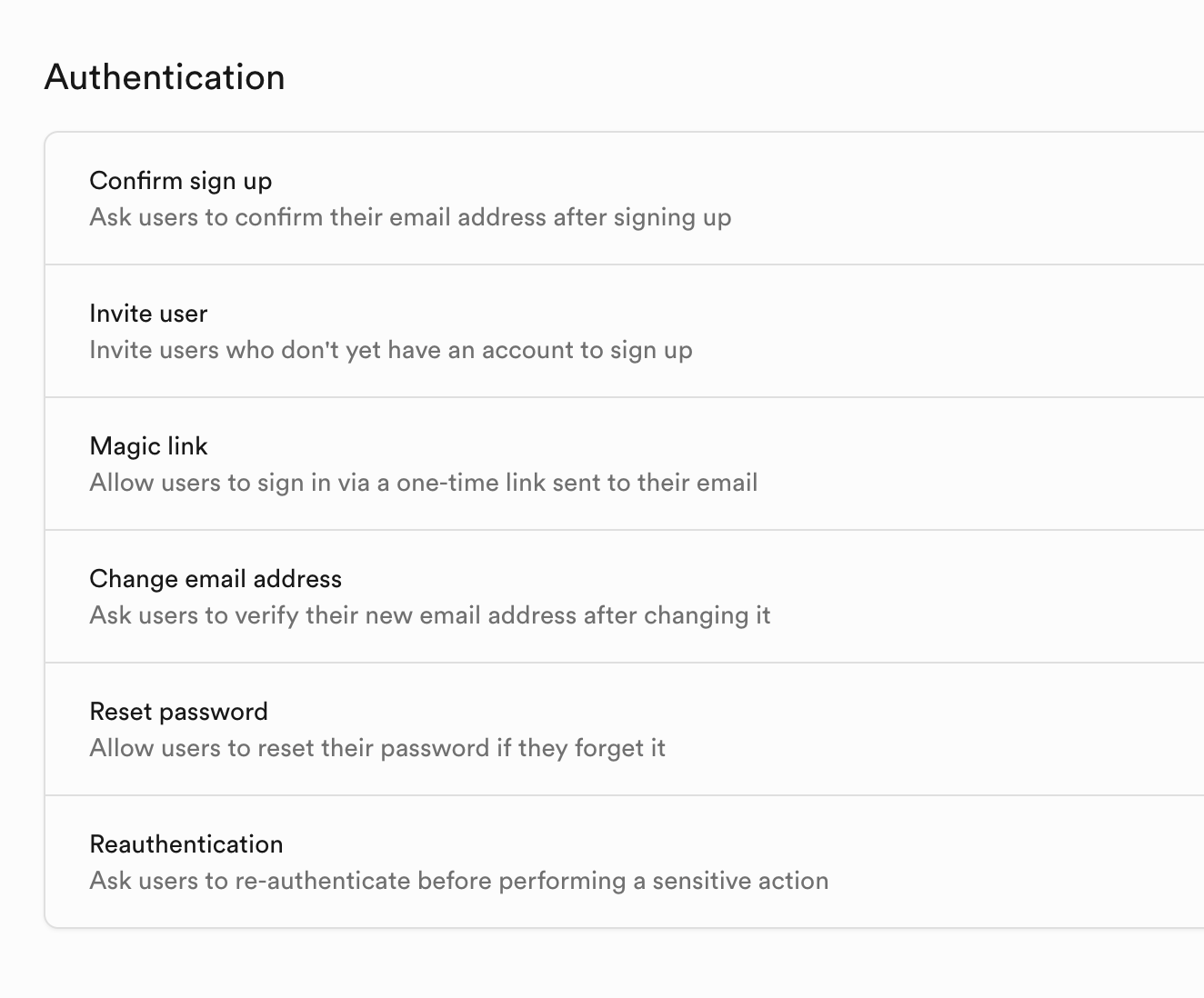
5.3 Chức năng thời gian thực
Chức năng thời gian thực của Supabase là một trong những đặc điểm mạnh nhất, cung cấp sự thuận tiện lớn cho việc xây dựng tài liệu cộng tác, bảng điều khiển thời gian thực, sảnh game hoặc hệ thống chăm sóc khách hàng.
Dự án này Project5-Supabase-Demos/apps/project-burger-shop-realtime-orders-3 thông qua việc xây dựng một phòng chat thời gian thực nhiều người, chức năng chia sẻ vị trí con trỏ, trình bày ba khả năng cốt lõi mà Supabase Realtime liên quan: Lắng nghe thay đổi cơ sở dữ liệu (Postgres Changes), Phát sóng (Broadcast) và Trạng thái trực tuyến (Presence).
Nếu bạn cảm thấy phần mã liên quan có độ khó nhất định, bạn có thể trực tiếp yêu cầu AI tham khảo nội dung tài liệu phần này để sửa đổi chương trình của bạn.
5.3.1 Thay đổi cơ sở dữ liệu thời gian thực Postgres Changes
Chức năng Realtime phổ biến nhất là lắng nghe thời gian thực các thay đổi của cơ sở dữ liệu Postgres Changes. Nó cho phép client đăng ký các sự kiện INSERT, UPDATE hoặc DELETE của các bảng cụ thể, hàng cụ thể thậm chí cột cụ thể trong cơ sở dữ liệu. Một khi cơ sở dữ liệu có thay đổi (dù thông qua gọi API, thao tác Supabase Dashboard, hay thực thi script SQL), Supabase sẽ sử dụng cơ chế sao chép cấp dưới của PostgreSQL, ngay lập tức đẩy dữ liệu thay đổi đến tất cả các client frontend đã đăng ký kênh thông qua WebSocket, mà không cần frontend liên tục thăm dò (Polling).
Nói chung, chức năng này có thể được bật bằng cách nhấn Enable Realtime trong Table Editor, nhưng thuận tiện hơn là thực thi khởi tạo thông qua script SQL, ví dụ:
-- Enable realtime replication
ALTER TABLE public.chat_messages REPLICA IDENTITY FULL;
DO $$
BEGIN
IF NOT EXISTS (
SELECT 1 FROM pg_publication_tables
WHERE pubname = 'supabase_realtime'
AND schemaname = 'public'
AND tablename = 'chat_messages'
) THEN
ALTER PUBLICATION supabase_realtime ADD TABLE public.chat_messages;
END IF;
END $$;Câu lệnh này thêm bảng chat_messages vào supabase_realtime được Supabase thiết lập sẵn, và một khi một bảng được thêm vào publication đặc biệt này, máy chủ thời gian thực của Supabase sẽ bắt đầu lắng nghe tất cả các thay đổi dữ liệu của nó.
Dựa trên bảng dữ liệu đặc biệt ở trên, chúng ta có thể sử dụng mã lắng nghe để theo dõi thời gian thực các thay đổi dữ liệu trong bảng. Điều chúng ta cần thực hiện là khi một người dùng gửi tin nhắn, tất cả người dùng trực tuyến khác đều có thể ngay lập tức thấy tin nhắn này trên màn hình. Điều này có thể được thực hiện thông qua việc đăng ký sự kiện INSERT của bảng chat_messages.
const sub = supabase
.channel('chat_messages_channel')
.on('postgres_changes', {
event: 'INSERT',
schema: 'public',
table: 'chat_messages'
}, (payload: any) => {
console.log('New message received:', payload.new);
const newMessage = payload.new as Message;
// ... //
.subscribe((status: string) => {
console.log('Chat subscription status:', status);
});.channel('chat_messages_channel'): Tạo một kênh liên lạc cách ly..on('postgres_changes', ...): Đây là phương thức đăng ký cốt lõi. Chúng ta cho Supabase biết chúng ta chỉ quan tâm đến sự kiệnINSERTcủa bảngchat_messages.payload.new: Khi có tin nhắn mới được chèn vào cơ sở dữ liệu, Supabase sẽ đẩy nội dung đầy đủ của dữ liệu mới này đến tất cả client đã đăng ký thông quapayload.new..subscribe(): Khởi động đăng ký.
5.3.2 Đồng bộ phát sóng thông tin Broadcast & Presence
Đối với các tương tác "tức thời" hơn không cần lưu vào cơ sở dữ liệu, như di chuyển con trỏ, trạng thái trực tuyến, v.v., Supabase cung cấp chức năng Broadcast và Presence.
- Presence: Dùng để theo dõi trạng thái chia sẻ của tất cả các client trong kênh. Phù hợp để triển khai chức năng "ai đang trực tuyến".
- Broadcast: Dùng để gửi tin nhắn tạm thời độ trễ thấp đến tất cả các client khác trong kênh.
Ý tưởng cốt lõi của Presence là: để mỗi client khai báo trạng thái trực tuyến của mình, và máy chủ Supabase chịu trách nhiệm đồng bộ các trạng thái này một cách đáng tin cậy cho tất cả các client khác trong kênh. Việc triển khai Presence chia thành các bước chính sau:
- Tạo một kênh hỗ trợ Presence
Đầu tiên, chúng ta tạo một kênh lobby_presence để xử lý riêng các tương tác này, và chỉ định một key duy nhất để xác định người dùng hiện tại trong cấu hình. Key này thường là ID của người dùng.
const ch = supabase.channel
('lobby_presence', {
config: {
presence: { key: anonymousUser.id },
}
});- Đăng ký kênh để thông báo thông tin "tôi đang trực tuyến"
Sau khi kênh được tạo thành công, chúng ta cần đăng ký nó. Trong callback khi đăng ký thành công (status === 'SUBSCRIBED'), chúng ta gọi phương thức channel.track(). Phương thức này sẽ phát sóng thông tin của người dùng hiện tại (ví dụ ID người dùng, tên, màu ảnh đại diện, v.v.) cho tất cả các client khác trong kênh, thông báo trạng thái "trực tuyến" của mình.
const me = {
id: anonymousUser.id,
name: anonymousUser.name,
color: anonymousUser.color
};
ch.subscribe(async (status) => {
if (status === 'SUBSCRIBED') {
await ch.track(me);
}
});- Đồng bộ danh sách trực tuyến đầy đủ
Khi một người dùng mới tham gia kênh, họ cần lấy danh sách tất cả người dùng đã trực tuyến. Điều này được thực hiện thông qua việc lắng nghe sự kiện sync của presence. Sự kiện sync sẽ được kích hoạt khi bạn lần đầu tham gia kênh, cung cấp cho bạn một "ảnh chụp" đầy đủ.
Phương thức channel.presenceState() sẽ trả về một đối tượng, chứa thông tin trạng thái của tất cả người dùng trực tuyến hiện tại trong kênh. Chúng ta xử lý nó và cập nhật vào state của ứng dụng, từ đó render danh sách người dùng trực tuyến đầy đủ.
ch.on('presence', { event: 'sync' }, ()
=> {
const state = ch.presenceState();
const flat = {};
Object.values(state).forEach((arr) => {
arr.forEach((u) => { flat[u.id] =
{ ...u }; });
});
setOnline(flat);
});- Lắng nghe việc tham gia và rời đi của từng người dùng
Ngoài sự kiện sync, chúng ta còn có thể lắng nghe các sự kiện join và leave, để phản hồi ngay lập tức khi có người dùng mới vào hoặc rời đi, ví dụ hiển thị thông báo "User has joined".
ch.on('presence', { event: 'join' }, ({
key, newPresences }) => {
console.log('User joined:', key,
newPresences);
});
ch.on('presence', { event: 'leave' }, ({
key, leftPresences }) => {
console.log('User left:', key,
leftPresences);
});Thông qua các bước trên, chúng ta đã xây dựng một hệ thống trạng thái trực tuyến hoàn chỉnh về mặt chức năng. Supabase tự động xử lý trường hợp người dùng ngắt kết nối bất ngờ (như đóng trình duyệt hoặc mất mạng), và kích hoạt sự kiện leave vào thời điểm thích hợp, đảm bảo tính chính xác của danh sách trực tuyến.
Khi Presence cho chúng ta biết "ai đang có mặt", Broadcast cho phép họ "trò chuyện" với nhau, nhưng nội dung trò chuyện được lưu trữ tạm thời. Một ví dụ điển hình là theo dõi con trỏ thời gian thực. Nếu mỗi lần di chuyển chuột đều đọc ghi cơ sở dữ liệu, sẽ gây lãng phí hiệu suất và độ trễ rất lớn. Broadcast giải quyết hoàn hảo vấn đề này, nó cho phép tin nhắn truyền trực tiếp giữa các client thông qua WebSocket, bỏ qua hoàn toàn cơ sở dữ liệu.
Chế độ làm việc của Broadcast chủ yếu dựa vào hai phương thức cốt lõi: channel.send() dùng để gửi, channel.on() dùng để nhận.
- Phía gửi: Phát sóng vị trí con trỏ của tôi
Chúng ta thêm một trình lắng nghe cho sự kiện mousemove. Khi chuột di chuyển, chúng ta tạo payload chứa ID người dùng, tọa độ và màu sắc, sau đó phát sóng nó thông qua channel.send(), và chỉ định tên sự kiện là 'cursor'.
const handleMouseMove = (e) => {
const payload = {
2. Đầu nhận: Lắng nghe và hiển thị con trỏ của người khác
Trong cùng một kênh, tất cả các client đều sử dụng `channel.on()` để lắng nghe các tin nhắn kiểu `broadcast` có `event` là `'cursor'`. Khi nhận được tin nhắn phù hợp, hàm callback sẽ được kích hoạt. Chúng ta phân tích dữ liệu của người gửi từ `payload` và sử dụng nó để cập nhật trạng thái `online` cục bộ, từ đó hiển thị vị trí con trỏ của các người dùng khác trên màn hình theo thời gian thực.
```typescript
ch.on('broadcast', { event: 'cursor' }, ({ payload }) => {
setOnline((prev) => ({
...prev,
[payload.id]: {
...(prev[payload.id] || {}),
x: payload.x,
y: payload.y
}
}));
});Thông qua cách này, Presence và Broadcast hoạt động phối hợp với nhau; Presence duy trì danh sách người dùng trực tuyến, trong khi Broadcast chịu trách nhiệm truyền tải các trạng thái tạm thời như vị trí con trỏ giữa các người dùng, cuối cùng đạt được chức năng tương tác thời gian thực phong phú với chi phí thấp.
5.4 Lưu trữ
Bên cạnh các dữ liệu có cấu trúc có thể định nghĩa rõ ràng như thông tin người dùng, đơn hàng, một ứng dụng hoàn chỉnh thường còn cần xử lý lượng lớn tệp không có cấu trúc -- ví dụ như avatar người dùng, hình ảnh hiển thị sản phẩm, tài liệu đơn hàng do người dùng tải lên, v.v. Đặc điểm của các tệp này là dung lượng chênh lệch lớn, số lượng có thể cực nhiều (ví dụ hình ảnh sản phẩm trên nền tảng thương mại điện tử có thể lên đến hàng chục nghìn甚至 hàng trăm nghìn张), nếu lưu trữ trực tiếp trên máy chủ nghiệp vụ của ứng dụng, sẽ làm tăng đáng kể tải lưu trữ của máy chủ, còn có thể làm chậm tốc độ đọc ghi dữ liệu, ảnh hưởng đến hiệu suất tổng thể của ứng dụng.
Trong phát triển thực tế, các tệp không có cấu trúc này sẽ được quản lý thống nhất bởi "dịch vụ lưu trữ đối tượng". OSS, Amazon S3 đều thuộc loại dịch vụ này, chúng là "công cụ lưu trữ chuyên nghiệp" được thiết kế riêng cho việc lưu trữ tệp số lượng lớn, có thể xử lý hiệu quả nhu cầu lưu trữ, sao lưu và đọc nhanh tệp. Và khi chúng ta lấy các tệp này trong ứng dụng, sẽ không truy xuất trực tiếp từ "kho lưu trữ cơ sở" của dịch vụ lưu trữ đối tượng, mà thông qua địa chỉ URL: mỗi tệp được lưu trữ trong lưu trữ đối tượng sẽ được gán một URL duy nhất (tương tự như địa chỉ "https://xxx.oss.com/avatar/user123.jpg", có thể hiểu đơn giản là "trang web" này chỉ có một hình ảnh), URL này giống như "địa chỉ truy cập riêng" của tệp, trang front-end chỉ cần thông qua địa chỉ này, có thể trực tiếp tải xuống hoặc tải avatar, hình ảnh sản phẩm, mà không cần dựa vào máy chủ nghiệp vụ của ứng dụng làm trung gian, vừa tăng tốc độ tải tệp, vừa giảm áp lực cho máy chủ nghiệp vụ.
Dự án project-burger-shop-storage-uploads-4 này thông qua chức năng tải lên avatar người dùng, trình diễn chuyên sâu cách sử dụng Supabase Storage để xây dựng hệ thống tải tệp hiện đại, giúp nhà phát triển hiểu rõ toàn bộ quy trình từ tải lên tệp không có cấu trúc đến truy cập qua URL. Ngoài ra, dự án này sử dụng thư viện Uppy để cung cấp giao diện tải tệp xuất sắc, kết hợp plugin Tus để thực hiện tải có thể tiếp tục, bằng cách trỏ điểm cuối tải của Uppy đến API tiêu chuẩn của Supabase (<supabaseUrl>/storage/v1/upload/resumable) để hoạt động, bạn có thể tham khảo cách tương tự để thực hiện thành phần chức năng tải lên.
5.4.1. Bucket lưu trữ
Đơn vị cấu thành của Supabase Storage là Bucket (thùng lưu trữ). Bạn có thể hình dung nó như một thư mục trong hệ điều hành máy tính. Mỗi Bucket có thể có chính sách bảo mật và cấu hình độc lập riêng.
Tất cả các tệp trong Storage đều có thể được truy cập trực tiếp thông qua một URL công khai, nhưng điều đó không có nghĩa là bất kỳ ai cũng có thể tùy ý tải lên hoặc sửa đổi, quyền truy cập cụ thể sẽ được kiểm soát bởi các chính sách chi tiết hơn. Giống như cơ sở dữ liệu, quyền truy cập Storage cũng được quản lý thông qua chính sách bảo mật cấp hàng. Chính sách SQL được viết trên hai bảng đặc biệt là storage.objects và storage.buckets, có thể định nghĩa chính xác ai có thể đọc (SELECT), tải lên (INSERT), cập nhật (UPDATE) hoặc xóa (DELETE) tệp.
Ví dụ, chúng ta có thể tạo một chính sách chỉ cho phép người dùng tải lên thư mục được đặt tên theo user_id của chính họ, và chỉ được tải các tệp kiểu hình ảnh:
CREATE POLICY "Allow authenticated
uploads to avatars bucket"
ON storage.objects FOR INSERT
TO authenticated
WITH CHECK (
bucket_id = 'avatars' AND
auth.uid() = (storage.foldername(name))
[1]::uuid AND
(storage.extension(name) IN ('png',
'jpg', 'jpeg'))
);
CREATE POLICY "Allow public read access
to avatars"
ON storage.objects FOR SELECT
USING ( bucket_id = 'avatars' );5.4.2 Lấy URL tệp có thể truy cập
Dự án này yêu cầu bạn tạo thủ công một Bucket công khai có tên là avatars, tất cả các tệp sẽ được tải lên và lưu trữ dưới Bucket công khai này. Sau khi tệp được tải thành công, chúng ta chỉ nhận được đường dẫn lưu trữ của nó trong Storage, ví dụ public/avatar1.png. Đây chỉ là một chuỗi được lưu trữ trong cơ sở dữ liệu, để trình duyệt có thể hiển thị hình ảnh này, chúng ta cần chuyển đổi nó thành một HTTP URL có thể truy cập được.
Supabase cung cấp hai chiến lược hoàn toàn khác nhau để lấy URL này, chúng có sự khác biệt bản chất về bảo mật, tính bền vững và kiểm soát chi phí.
1. URL công khai (Public URL) - Liên kết vĩnh viễn
Đây là cách trực tiếp nhất. Nếu tệp của bạn được lưu trữ trong một Public Bucket, bạn có thể lấy một liên kết công khai cố định, vĩnh viễn.
const { data } = supabase.storage
.from('avatars')
.getPublicUrl('public/avatar1.png');
const publicUrl = data.publicUrl;Loại liên kết này có hai đặc điểm cốt lõi: một là đơn giản và trực tiếp, cấu trúc URL cố định, trong thực tế dễ nối và quản lý, giảm thiểu rào cản sử dụng kỹ thuật; hai là có lợi cho bộ nhớ đệm, với tư cách là liên kết vĩnh viễn, nó có thể được bộ nhớ đệm hiệu quả bởi CDN (Mạng phân phối nội dung) và trình duyệt, từ đó cải thiện đáng kể tốc độ truy cập tài nguyên, tối ưu hóa trải nghiệm người dùng. Dựa trên các đặc điểm này, nó phù hợp với các kịch bản tài nguyên công khai thực sự, ví dụ như Logo trang web, hình ảnh danh mục sản phẩm, hình ảnh minh họa bài viết blog, v.v., có thể đáp ứng tốt nhu cầu truy cập và quản lý các tài nguyên loại này.
Tuy nhiên trong môi trường sản xuất, loại liên kết này có rủi ro rõ ràng về bị đánh cắp băng thông (Hotlinking). Do liên kết là vĩnh viễn công khai, người bên ngoài có thể dễ dàng nhúng liên kết hình ảnh của bạn vào trang web có lưu lượng truy cập cao của họ, dẫn đến băng thông bị sử dụng trái phép. Hành vi này sẽ tạo ra lượng lớn chi phí băng thông không cần thiết cho dự án Supabase của bạn, mà lượng băng thông tiêu thụ này không phục vụ cho ứng dụng của chính bạn, là sự lãng phí chi phí điển hình, là vấn đề cần cảnh giác cao độ và phòng ngừa trong môi trường sản xuất; do đó, chúng ta cần chuyển sang URL ký tạm thời để thực hiện việc phơi bày tài nguyên ra bên ngoài.
2. URL được ký (Signed URL) - Liên kết ủy quyền tạm thời
Để giải quyết vấn đề bảo mật và chi phí của URL công khai, Supabase cung cấp cách tạo URL ký tạm thời. Đây là phương pháp thực hành tốt nhất được khuyến nghị cho hầu hết các ứng dụng trực tuyến, ví dụ như ứng dụng tạo ảnh từ văn bản cung cấp cho người dùng liên kết xem ảnh có thời hạn, nền tảng thương mại điện tử chỉ cho phép người dùng đã đặt hàng nhận địa chỉ tải hóa đơn tạm thời, nền tảng nội dung trả phí cung cấp liên kết phát khóa học có hiệu lực ngắn hạn cho người dùng đăng ký, vừa chống sao chép tệp trái phép vừa tránh đánh cắp băng thông, khả năng thích ứng cực kỳ mạnh mẽ.
const { data, error } = await supabase.storage
.from('avatars')
.createSignedUrl('private/user-invoice.pdf', 3600); // Thời gian hiệu lực của liên kết là 3600 giây (1 giờ)
const signedUrl = data?.signedUrl;URL ký tạm thời (Signed URL) có ba lợi thế cốt lõi: an toàn và kiểm soát được nghĩa là liên kết mang đánh dấu bảo mật, có thời gian hiệu lực, hết hạn thì không sử dụng được; ràng buộc quyền hạn rất đơn giản -- chỉ những người có thể xem tệp này mới có thể tạo liên kết này, ngay cả khi tệp ẩn trong lưu trữ riêng tư (Private Bucket), sử dụng liên kết này cũng có thể mở bình thường; ngăn chặn đánh cắp băng thông vì liên kết là tạm thời, sao chép sang nơi khác sẽ nhanh chóng hết hiệu lực, không bị lạm dụng băng thông. Nhờ những lợi thế này, các tệp cần quản lý quyền truy cập như avatar người dùng, ảnh cá nhân, nội dung trả phí, hóa đơn đơn hàng đều có thể sử dụng nó.
Từ góc độ bảo đảm an toàn và kiểm soát chi phí, đề nghị hình thành thói quen ưu tiên sử dụng URL ký tạm thời. Chỉ khi một tài nguyên rõ ràng cần công khai vĩnh viễn, truy cập không hạn chế (ví dụ như Logo công khai của ứng dụng, hình ảnh tuyên truyền sự kiện công cộng, v.v.) thì mới cân nhắc sử dụng Public URL. Như vậy vừa đáp ứng nhu cầu nghiệp vụ cụ thể, vừa tối đa hóa việc tránh rủi ro và tiêu hao chi phí không cần thiết.
5.5 Hàm Edge
Edge Function là một trong những hình thái có giá trị cốt lõi trong hệ sinh thái Serverless (kiến trúc không máy chủ), nó cung cấp hỗ trợ chạy hàm nhẹ, hiệu quả cho các kịch bản "không có backend tự xây dựng".
Serverless là gì? Serverless (kiến trúc không máy chủ) không có nghĩa là thực sự không có máy chủ, mà là nhà phát triển không cần quan tâm đến việc mua sắm, vận hành, cấu hình và mở rộng máy chủ. Bạn chỉ cần viết mã nghiệp vụ (hàm), nhà cung cấp dịch vụ đám mây sẽ tự động phân bổ tài nguyên để chạy mã khi có sự kiện cụ thể kích hoạt, và tính phí theo thời gian chạy thực tế.
Khi ứng dụng của bạn cần thực thi một số logic không thể hoặc không nên hoàn thành trên client (trình duyệt) -- ví dụ như tương tác với API bên thứ ba cần khóa bí mật, thực thi tác vụ tính toán chuyên sâu, hoặc thực thi bắt buộc các quy tắc nghiệp vụ phức tạp -- Edge Functions sẽ phát huy tác dụng. Supabase Edge Functions dựa trên Deno và TypeScript, chúng được triển khai trên các nút edge toàn cầu, gần người dùng về mặt khoảng cách vật lý, từ đó cung cấp độ trễ thực thi hàm cực thấp.
Hiện nay các nhà cung cấp đám mây chính đều đã ra mắt dịch vụ Edge Function riêng, thường thấy bao gồm:
- AWS Lambda@Edge: Dịch vụ hàm edge mở rộng dựa trên AWS Lambda, có thể liên kết với CloudFront CDN, hỗ trợ các ngôn ngữ như Node.js, Python, v.v.;
- Cloudflare Workers: Hàm edge do Cloudflare推出的, triển khai trên hơn 275 nút edge toàn cầu, hỗ trợ JavaScript/TypeScript, với "độ trễ cấp mili-giây" là lợi thế cốt lõi;
- Vercel Edge Functions: Hàm edge thích ứng với dự án front-end Vercel, tích hợp sâu với Next.js, hỗ trợ TypeScript, chủ đạo "kết nối liền mạch giữa front-end và logic edge";
Quay lại Supabase, khi ứng dụng của bạn cần thực thi logic "không thể hoàn thành trên client (trình duyệt)", ví dụ như gọi API bên thứ ba bằng khóa bí mật (như giao diện LLM), xử lý tác vụ tính toán chuyên sâu (như nén hình ảnh), hoặc thực thi bắt buộc kiểm tra quyền (như quy tắc truy cập tệp), Supabase Edge Functions sẽ phát huy tác dụng. Nó được xây dựng dựa trên Deno runtime và TypeScript, triển khai trên các nút edge toàn cầu, có thể đạt được độ trễ thực thi cực thấp bằng "khoảng cách vật lý gần người dùng", là công cụ cốt lõi để viết logic phía máy chủ tùy chỉnh, đáng tin cậy.
Dự án Project5-Supabase-Demos/apps/project-burger-shop-edge-function-5 này thông qua một chức năng đối thoại luồng thời gian thực với mô hình ngôn ngữ lớn (LLM), trình diễn quy trình ứng dụng đơn giản nhất của Edge Functions.
5.5.1 Phân tích trường hợp LLM Chat
Giả sử bạn muốn tích hợp một chatbot tương tự ChatGPT vào ứng dụng. Bạn cần gọi API của OpenAI trên phía máy chủ, nhưng điều này đòi hỏi một API Key bí mật. Key này tuyệt đối không được phơi bày trong mã front-end, nếu không bất kỳ ai cũng có thể xem mã nguồn trang web để đánh cắp Key của bạn, tạo ra chi phí cao. Đây chính là nơi Edge Function phát huy tác dụng. Chúng ta sẽ tạo một hàm có tên llm-chat, nó đóng vai trò như một proxy bảo mật giữa front-end và OpenAI API.
Tham khảo mã của project-burger-shop-edge-function-5/scripts/llm-chat.ts, chúng ta hãy xem cách nó hoạt động:
// scripts/llm-chat.ts
import "jsr:@supabase/functions-js/edge-runtime.d.ts";
import { OpenAI } from "npm:openai";
const OPENAI_API_KEY = Deno.env.get("OPENAI_API_KEY");
Deno.serve(async (req) => {
try {
const openai = new OpenAI({ apiKey: OPENAI_API_KEY });
const { prompt } = await req.json();
const stream = await openai.chat.completions.create({
model: "gpt-3.5-turbo",
messages: [{ role: "user", content: prompt }],
stream: true,
});
return new Response(stream.toReadableStream(), {
headers: { "Content-Type": "text/event-stream" },
});
} catch (err) {
}
});Trong trường hợp này, đối với bảo mật khóa, OPENAI_API_KEY được lưu trữ an toàn dưới dạng biến môi trường trên máy chủ Supabase. Mã front-end cục bộ hoàn toàn không thể tiếp xúc với khóa này, từ đó đảm bảo hiệu quả tính bảo mật của khóa.
5.5.2 Tạo và triển khai hàm
Supabase cung cấp giao diện rất thân thiện, cho phép bạn hoàn tất triển khai mà không cần chạm đến dòng lệnh.
- Vào bảng Edge Functions :
- Đăng nhập vào Dashboard dự án Supabase của bạn.
- Trong thanh điều hướng bên trái, nhấp vào biểu tượng giống mã, vào "Edge Functions".
- Tạo hàm mới :
- Nhấp vào nút "Create a new function".
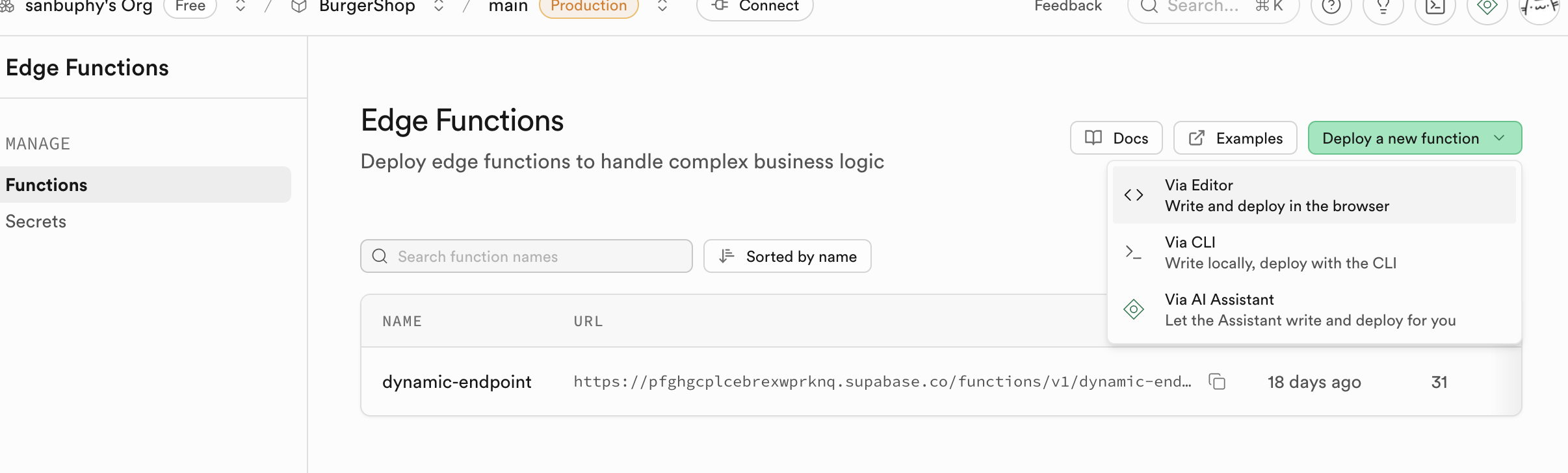
- Đặt tên cho hàm, ví dụ
llm-chat. - Dán mã :
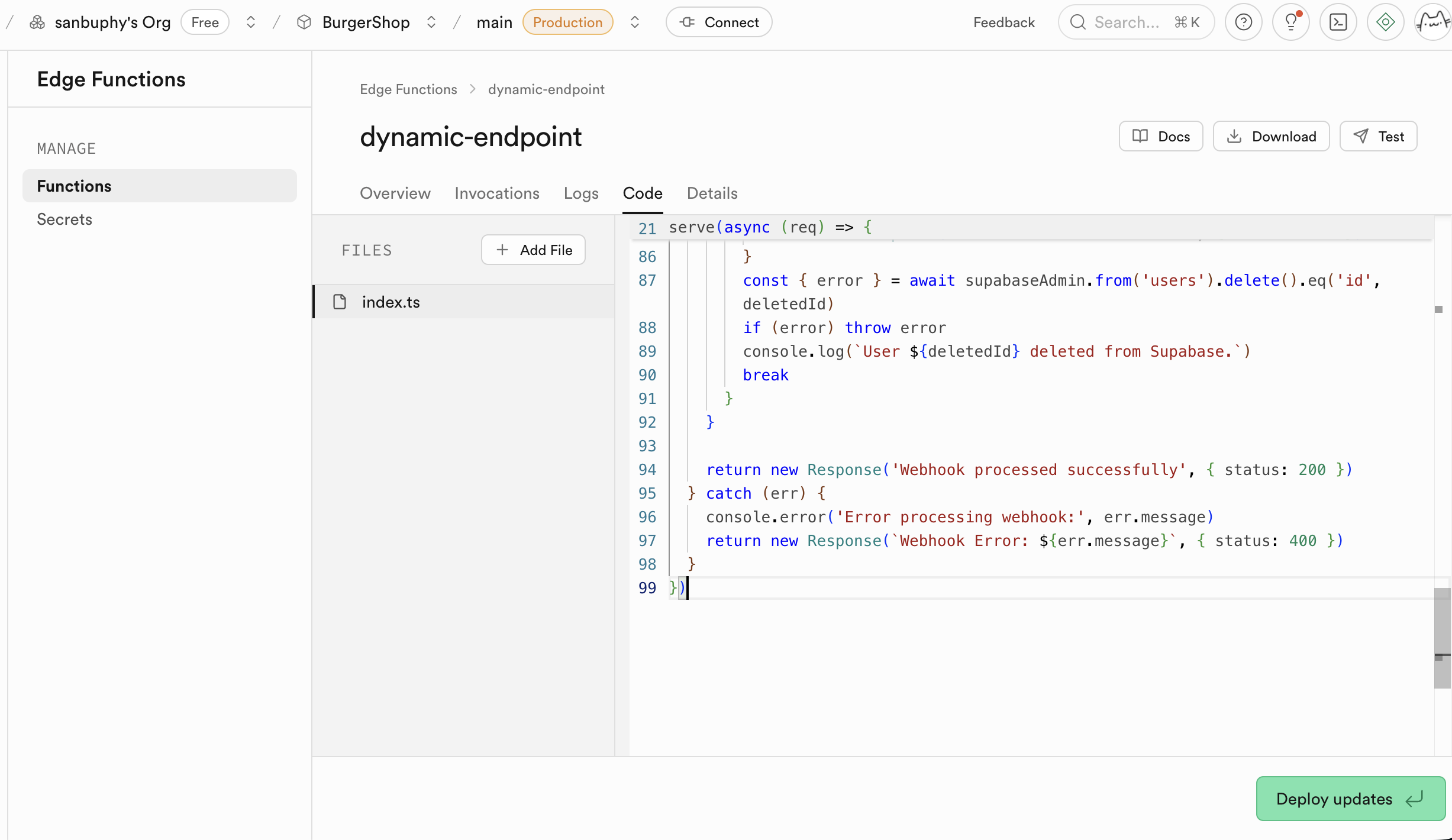
- Trong trình soạn thảo trực tuyến hiện ra, xóa tất cả mã giữ chỗ mặc định.
- Mở tệp
llm-chat.tscục bộ của bạn, sao chép toàn bộ nội dung của nó. - Dán mã đã sao chép vào trình soạn thảo trực tuyến của Supabase.
- Cấu hình biến môi trường ** (Secrets)** :
- Tìm Secrets trong thanh bên.
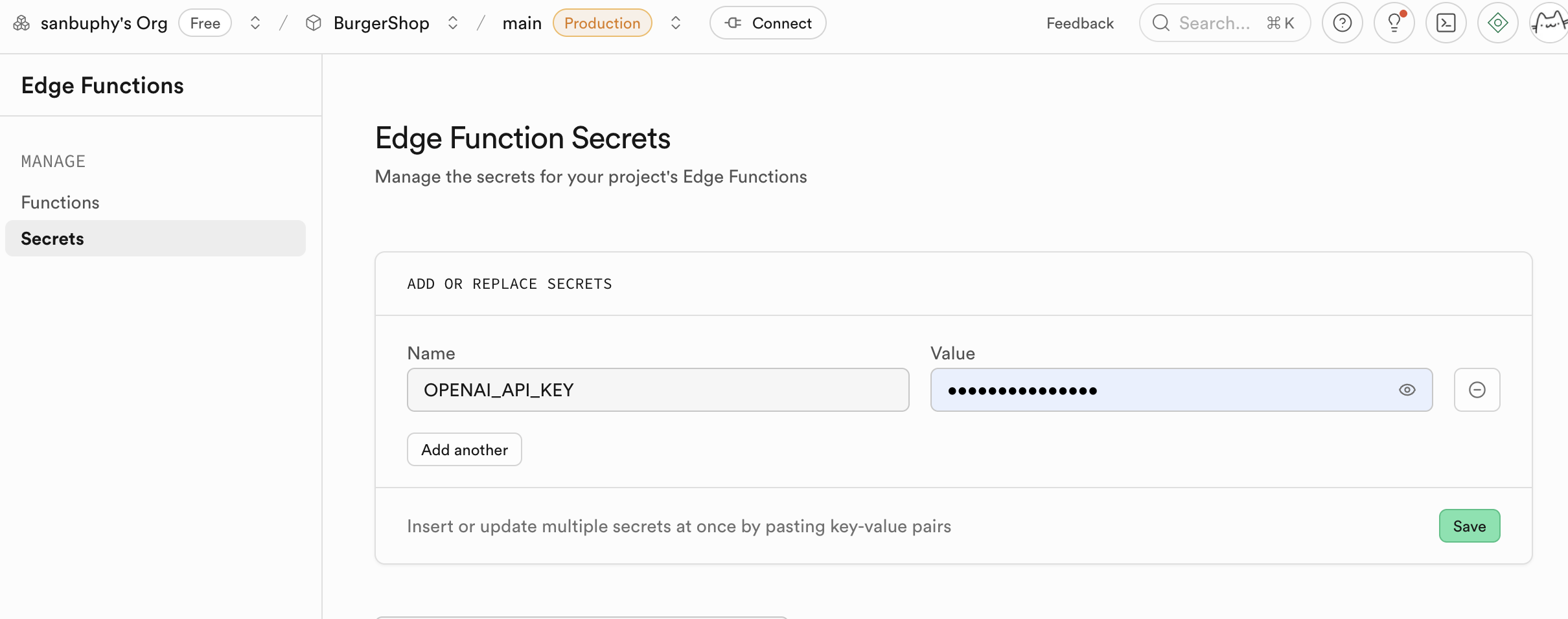
- Name: Nhập
OPENAI_API_KEY. - Value: Dán OpenAI API Key của bạn.
- Nhấp vào "Save". Secret được đặt ở đây sẽ được mã hóa và lưu trữ, đồng thời được tiêm an toàn vào môi trường chạy hàm của bạn.
- Tìm Secrets trong thanh bên.
Nếu hàm cần được cập nhật, hãy nhớ thực thi Deploy updates trong phần Edge Function. Supabase sẽ xây dựng và triển khai hàm này trên đám mây cho bạn. Sau vài phút, hàm của bạn có thể được truy cập trực tuyến.
Bên cạnh việc làm proxy bảo mật cho mô hình ngôn ngữ, các kịch bản ứng dụng của Edge Functions còn nhiều hơn thế. Trên thực tế, bất kỳ tác vụ nào cần xử lý logic phía máy chủ, dù là gọi API đơn giản, xác thực dữ liệu, hay các tính toán phức tạp hơn, đều có thể thực hiện thông qua Edge Function. Nó cung cấp cho bạn một backend nhẹ, có thể mở rộng mà không cần quản lý bất kỳ cơ sở hạ tầng máy chủ nào.
Nếu bạn muốn khám phá thêm nhiều khả năng, có thể tham khảo các ví dụ khác trong dự án. Ví dụ:
- Tạo hình ảnh (txt2img.ts): Hàm này trình diễn cách sử dụng Edge Function để gọi API tạo ảnh từ văn bản (Text-to-Image) bên thứ ba (như Stability AI, Midjourney, v.v.) để tạo hình ảnh động. Đây là một kịch bản điển hình về tính toán chuyên sâu hoặc cần gọi dịch vụ bên ngoài một cách an toàn. Giống như trường hợp llm-chat, khóa API được lưu trữ an toàn ở backend Supabase, front-end chỉ chịu trách nhiệm gửi mô tả văn bản, sau đó nhận và hiển thị hình ảnh đã tạo, toàn bộ quá trình an toàn, hiệu quả.
- Gửi email (send-email.ts): Gửi email chào mừng, thông báo giao dịch hoặc email đặt lại mật khẩu trong ứng dụng là nhu cầu phổ biến. Ví dụ send-email.ts trình diễn cách tích hợp dịch vụ email (như Resend, SendGrid) thông qua Edge Function. Bạn không cần phơi bày khóa API dịch vụ email nhạy cảm trong mã client, chỉ cần tạo một hàm, để front-end kích hoạt gửi email thông qua việc gọi hàm này.
5.6 Đăng nhập Clerk
Clerk là một công cụ phát triển chuyên nghiệp tập trung vào xác thực danh tính và quản lý người dùng, năng lực cốt lõi bao gồm đăng ký người dùng, đăng nhập, bảo mật tài khoản MFA, kiểm soát quyền, quản lý phiên, v.v., toàn bộ chuỗi nhu cầu liên quan đến xác thực danh tính, có thể giúp nhà phát triển nhanh chóng xây dựng hệ thống người dùng an toàn, linh hoạt và tuân thủ tiêu chuẩn ứng dụng hiện đại mà không cần phát triển logic xác thực phức tạp từ đầu.
Phần này sẽ giới thiệu cách cấu hình dịch vụ Clerk từ đầu và tích hợp nó với Supabase. Bạn có thể trải nghiệm toàn bộ quy trình trong dự án project-burger-shop-auth-advanced-clerk-7.
5.6.1 Tạo ứng dụng Clerk và lấy khóa
Trước khi sử dụng dự án này, bạn cần có tài khoản Clerk và tạo một ứng dụng.
- Đăng ký và tạo:
- Truy cập dashboard.clerk.com và đăng ký tài khoản.
- Nhấp vào "Create application".
- Nhập tên ứng dụng (ví dụ "Burger Shop").
- Trong "How will your users sign in?", mặc định chọn Email, Google, GitHub.
- Nhấp vào Create application.
- Lấy API Keys:
Sau khi tạo thành công, bạn sẽ được hướng dẫn đến trang API Keys.
Tìm Publishable key (bắt đầu bằng
pk_) và Secret key (bắt đầu bằngsk_).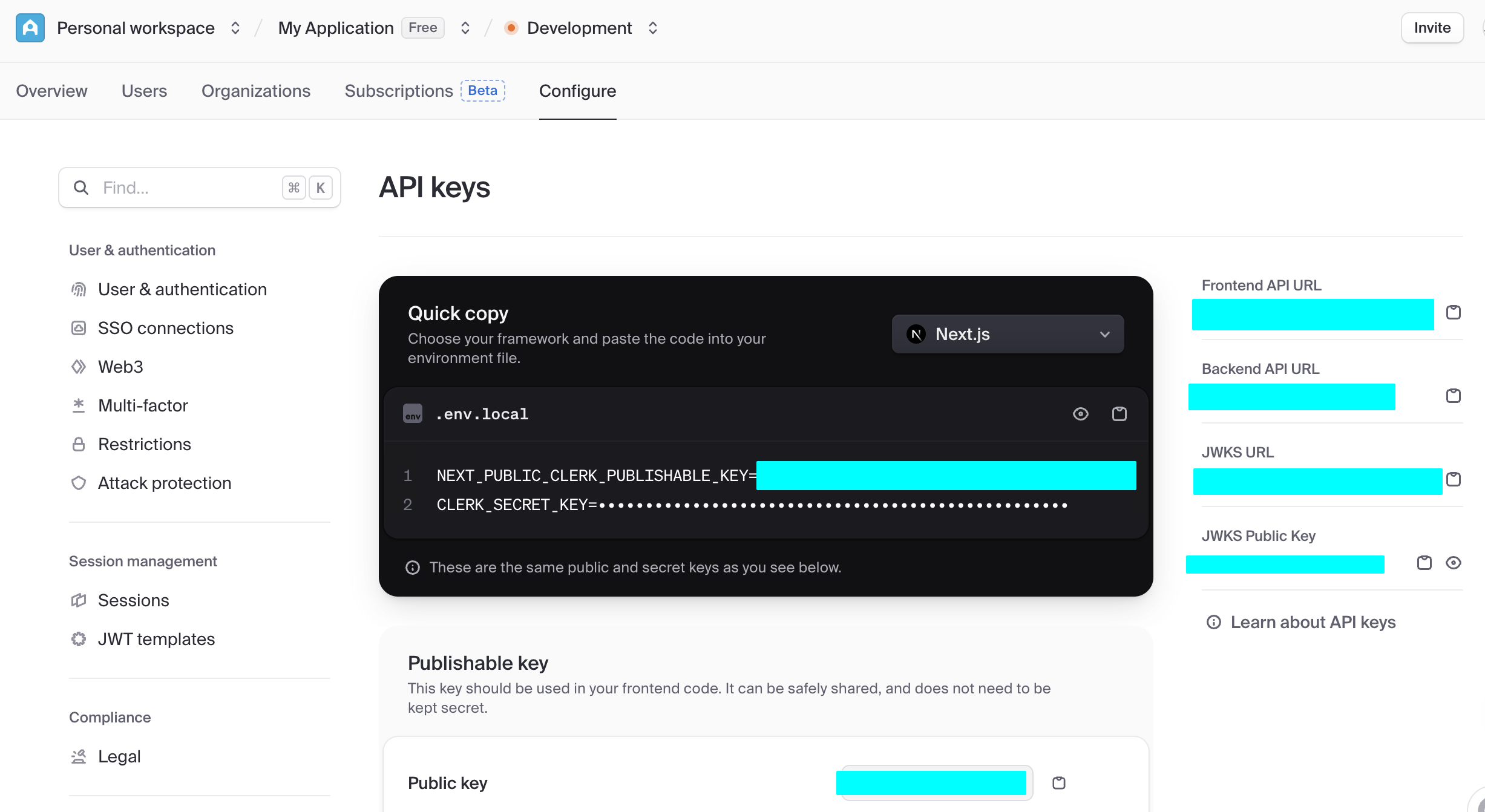
Sao chép chúng vào tệp
.env.localcủa bạn (tham khảo.env.examplecủa dự án này):bashNEXT_PUBLIC_CLERK_PUBLISHABLE_KEY=pk_test_... CLERK_SECRET_KEY=sk_test_...
5.6.2 Cấu hình tích hợp nguyên bản giữa Supabase và Clerk
Trước khi sử dụng sâu hơn, chúng ta cần tích hợp mối quan hệ giữa Supabase và Clerk, thuận tiện cho việc chuyển hướng xác thực đăng nhập và kiểm soát quyền truy cập cơ sở dữ liệu cụ thể sau này. Supabase và Clerk cung cấp khả năng tích hợp nguyên bản chính thức, thông qua tích hợp này có thể nhanh chóng thực hiện kết nối xác thực danh tính giữa hai bên mà không cần cấu hình thủ thích phức tạp, đơn giản hóa đáng kể quy trình phát triển các chức năng như đăng nhập người dùng, kiểm tra quyền:
- Kích hoạt tích hợp chính thức Supabase trong Clerk
- Đăng nhập vào Clerk Dashboard.
- Trong menu điều hướng bên trái, đi đến Integrations (Tích hợp).
- Tìm và nhấp vào Supabase trong danh sách.
- Bật công tắc Enable Supabase (hoặc nhấp vào Activate integration).
- Bước quan trọng: Sau khi kích hoạt thành công, trang sẽ hiển thị Clerk Domain của bạn (định dạng thường là
https://<your-id>.clerk.accounts.devhoặc tên miền tùy chỉnh của bạn). Vui lòng sao chép địa chỉ Domain này, sẽ sử dụng ở bước tiếp theo.
- Thêm nhà cung cấp Clerk trong Supabase
- Đăng nhập vào Supabase Dashboard và vào dự án của bạn.
- Trong menu điều hướng bên trái, đi đến Authentication > Sign In / Up (hoặc nhấp trực tiếp vào Providers).
- Nhấp vào nút Add provider, chọn Clerk từ danh sách thả xuống.
- Trong hộp nhập Clerk Domain hiện ra, dán địa chỉ Domain bạn vừa sao chép từ Clerk.
- Nhấp vào Save để lưu cấu hình.
5.6.3 Đồng bộ dữ liệu người dùng sang Supabase thông qua Webhook
Chỉ tích hợp là chỉ đáp ứng nhu cầu xác định quyền, nhưng điều này sẽ không đồng bộ thông tin người dùng đã đăng ký trong Clerk sang Supabase. Để thuận tiện cho việc quản lý, chúng ta còn cần giữ một bản sao người dùng trong bảng public.users của Supabase, để thực hiện truy vấn liên kết hoặc phân tích dữ liệu. Chúng ta có thể thực hiện chức năng này thông qua Clerk Webhooks, toàn bộ quy trình như sau:
- Clerk gửi thông báo: Khi người dùng đăng ký hoặc cập nhật thông tin trong Clerk, Clerk sẽ gửi một yêu cầu POST đến URL Webhook mà chúng ta đã cấu hình.
- Supabase nhận và ghi入: Edge Function nhận yêu cầu, xác minh chữ ký (đảm bảo an toàn), sau đó cập nhật dữ liệu người dùng vào bảng cơ sở dữ liệu của Supabase.
Trước khi bắt đầu, chúng ta cần cấu hình bảng dữ liệu cần thiết để đồng bộ thông tin:
-- File: init.sql
-- 1. Create `users` table for synced Clerk users
-- This table will store user data pushed from Clerk Webhooks.
CREATE TABLE public.users (
id TEXT NOT NULL PRIMARY KEY, -- Corresponds to Clerk User ID
email TEXT,
first_name TEXT,
last_name TEXT,
image_url TEXT,
created_at TIMESTAMPTZ DEFAULT NOW(),
updated_at TIMESTAMPTZ DEFAULT NOW()
);
-- 2. Enable Row Level Security (RLS) on the table
-- This is an important security measure to ensure users cannot access any data by default.
ALTER TABLE public.users ENABLE ROW LEVEL SECURITY;
-- 3. Create RLS policies
-- Policy 1: Allow authenticated users to read their own user info.
-- `auth.jwt()->>'sub'` extracts the user ID from the JWT provided by Clerk.
CREATE POLICY "Authenticated users can view their own user record"
ON public.users FOR SELECT
TO authenticated
USING ( (SELECT auth.jwt()->>'sub') = id );
-- Policy 2: Allow users to update their own info.
CREATE POLICY "Authenticated users can update their own user record"
ON public.users FOR UPDATE
TO authenticated
USING ( (SELECT auth.jwt()->>'sub') = id );Và kích hoạt Edge function tương ứng trong Supabase:
// File path: supabase/functions/clerk-webhooks/index.ts
import { serve } from 'https://deno.land/std@0.177.0/http/server.ts'
import { Webhook } from 'npm:svix'
import { createClient } from 'https://esm.sh/@supabase/supabase-js@2'
// Get Clerk Webhook signing secret from environment variables
const CLERK_WEBHOOK_SECRET = Deno.env.get('CLERK_WEBHOOK_SECRET')
if (!CLERK_WEBHOOK_SECRET) {
throw new Error('CLERK_WEBHOOK_SECRET is not set in environment variables')
}
const supabaseAdmin = createClient(
Deno.env.get('SUPABASE_URL')!,
Deno.env.get('SUPABASE_SERVICE_ROLE_KEY')!
)
serve(async (req) => {
try {
// 1. Get Svix signature info from request headers
const headers = Object.fromEntries(req.headers)
const svix_id = headers['svix-id']
const svix_timestamp = headers['svix-timestamp']
const svix_signature = headers['svix-signature']
if (!svix_id || !svix_timestamp || !svix_signature) {
return new Response('Missing Svix headers', { status: 400 })
}
const payload = await req.json()
const body = JSON.stringify(payload)
// 2. Verify Webhook signature validity using the secret
const wh = new Webhook(CLERK_WEBHOOK_SECRET)
const evt = wh.verify(body, {
'svix-id': svix_id,
'svix-timestamp': svix_timestamp,
'svix-signature': svix_signature,
})
const { id } = evt.data
const eventType = evt.type
console.log(`Received webhook event: ${eventType} for user: ${id}`)
// 3. Execute database operations based on event type
switch (eventType) {
case 'user.created': {
const { id, first_name, last_name, image_url, email_addresses } = evt.data
const { error } = await supabaseAdmin.from('users').insert({
id,
first_name,
last_name,
image_url,
email: email_addresses[0]?.email_address,
})
if (error) throw error
console.log(`User ${id} created in Supabase.`)
break
}
case 'user.updated': {
const { id, first_name, last_name, image_url, email_addresses } = evt.data
const { error } = await supabaseAdmin
.from('users')
.update({
first_name,
last_name,
image_url,
email: email_addresses[0]?.email_address,
updated_at: new Date().toISOString(), // Update timestamp
})
.eq('id', id)
if (error) throw error
console.log(`User ${id} updated in Supabase.`)
break
}
case 'user.deleted': {
// For delete events, ID might be at the top level
const deletedId = id
if (!deletedId) {
return new Response('Deleted user ID not found', { status: 400 })
}
const { error } = await supabaseAdmin.from('users').delete().eq('id', deletedId)
if (error) throw error
console.log(`User ${deletedId} deleted from Supabase.`)
break
}
}
return new Response('Webhook processed successfully', { status: 200 })
} catch (err) {
console.error('Error processing webhook:', err.message)
return new Response(`Webhook Error: ${err.message}`, { status: 400 })
}
})Sau khi khởi tạo bảng dữ liệu và hàm Supabase, bạn còn cần kích hoạt hỗ trợ Webhooks trong Clerk:
- Trong Clerk Dashboard -> Webhooks, thêm Endpoint, điền URL của Supabase Edge Function.
- Chọn các sự kiện
user.created,user.updated,user.deleted, v.v.
Sau khi thiết lập thành công, bạn có thể xem các thông tin yêu cầu khác nhau trong Message Attempts, nhấp vào có thể thấy kết quả tham số trả về chi tiết của yêu cầu; nếu webhook gặp vấn đề khi yêu cầu Edge function, bạn có thể nhanh chóng tìm thấy nguyên nhân chi tiết trong giá trị trả về. Đề xuất bạn đồng thời đối chiếu thông tin nhật ký yêu cầu của Clerk và Supabase, để phân tích xem các hàm đã thiết lập có chính xác hay không.
5.6.4 Hỗ trợ đăng nhập bên thứ ba trong Clerk
Trước khi tìm hiểu sâu về cách Clerk hỗ trợ đăng nhập bên thứ ba, chúng ta hãy làm rõ hai khái niệm cốt lõi: môi trường phát triển và môi trường sản xuất, đây là hai giai đoạn quan trọng từ "phát triển thử nghiệm" đến "trực tuyến có thể sử dụng" của phần mềm, định vị, mục đích sử dụng và yêu cầu bảo mật của hai môi trường này hoàn toàn khác nhau:
- Môi trường phát triển: Môi trường sử dụng trên máy cục bộ của nhà phát triển hoặc máy chủ thử nghiệm, chỉ dành cho phát triển tính năng, gỡ lỗi và xác minh nội bộ (như dịch vụ localhost:3000 cục bộ), không mở ra bên ngoài
- Môi trường sản xuất: Sau khi ứng dụng chính thức trực tuyến, môi trường công khai hướng đến người dùng thực (như triển khai trên các nền tảng Vercel, Alibaba Cloud, v.v. tại https://my-app.com)
Và Clerk phân biệt hai môi trường này đối với đăng nhập xã hội, bản chất là cân bằng "hiệu suất phát triển" và "bảo mật sản xuất": giai đoạn phát triển cần giảm cấu hình dư thừa để nhanh chóng xác minh chức năng, giai đoạn sản xuất cần đảm bảo bảo mật dữ liệu thông qua thông tin xác thực chuyên dụng, đồng thời tuân thủ quy tắc của các nền tảng OAuth bên thứ ba như Google, GitHub (ứng dụng trực tuyến phải liên kết tên miền và thông tin xác thực chuyên dụng, không được phép sử dụng tài nguyên dùng chung). Dưới đây là mô tả cụ thể về cấu hình khác biệt của đăng nhập xã hội Clerk trong hai môi trường:
- Xác minh nhanh trong môi trường phát triển
Trong môi trường phát triển, Clerk đã được cấu hình sẵn thông tin xác thực OAuth dùng chung và URI chuyển hướng mặc định, không cần đến GitHub/Google để nộp đơn xin thông tin xác thực chuyên dụng, các bước thao tác như sau:
Đăng nhập vào Clerk Dashboard, trong thanh điều hướng bên trái vào trang SSO connections (Kết nối SSO).
Nhấp vào Add connection (Thêm kết nối), chọn For all users (Có hiệu lực cho tất cả người dùng).
Trong menu thả xuống Choose provider (Chọn nhà cung cấp), chọn GitHub hoặc Google theo nhu cầu.
Nhấp trực tiếp vào Add connection (Thêm kết nối), Clerk sẽ tự động sử dụng thông tin xác thực dùng chung để hoàn tất liên kết.
Sau khi cấu hình, khởi động ứng dụng cục bộ (như
localhost:3000) và nhấp vào "Sign in with GitHub/Google", Clerk sẽ tự động proxy yêu cầu đăng nhập, nhanh chóng xác minh xem chức năng có bình thường hay không.
- Cấu hình thông tin xác thực tùy chỉnh trong môi trường sản xuất
(Lưu ý: Nếu phát hiện có khâu không nhất quán với dự kiến, đề xuất đọc tài liệu chính thức để thử cách mới nhất)
Sau khi ứng dụng được triển khai trực tuyến (như Vercel, Alibaba Cloud) và chuyển sang Clerk Production Instance, thông tin xác thực dùng chung sẽ hết hiệu lực, cần cấu hình thông tin xác thực OAuth tùy chỉnh cho GitHub/Google (đề xuất đồng thời mở Clerk Dashboard và trang nền tảng bên thứ ba, thuận tiện cho thao tác đồng bộ):
- Thao tác chung trước (Bảng điều khiển Clerk):
- Vào trang Clerk SSO connections, nhấp Add connection -> chọn For all users.
- Chọn nền tảng mục tiêu (GitHub/Google), đảm bảo bật Enable for sign-up and sign-in (Cho phép đăng ký đăng nhập) và Use custom credentials (Sử dụng thông tin xác thực tùy chỉnh).
- Sao chép Authorization Callback URL (GitHub) hoặc Authorized Redirect URI (Google) trên trang, lưu vào vị trí an toàn, không đóng trang/cửa sổ hiện tại.
- 2.1 Cấu hình nền tảng GitHub:
- Đăng nhập GitHub, vào Developer Settings (Đường dẫn: Avatar -> Settings -> Developer settings -> OAuth Apps).
- Nhấp vào New OAuth app, điền thông tin:
Application name(Tên ứng dụng),Homepage URL(Tên miền sản xuất, nhưhttps://my-app.com),Authorization Callback URL(Dán địa chỉ đã sao chép từ Clerk). - Nhấp Register application, sau đó nhấp Generate a new client secret, lưu Client ID và Client Secret đã tạo (Secret chỉ hiển thị một lần).
- Quay lại cửa sổ Clerk, dán Client ID và Client Secret, nhấp Add connection để hoàn tất cấu hình (Nếu đã đóng cửa sổ, có thể tìm kết nối GitHub trong SSO connections, điền bổ sung trong phần "Use custom credentials").
- 2.2 Cấu hình nền tảng Google:
- Đăng nhập Google Cloud Console, chọn dự án hiện có hoặc tạo dự án mới (như "My App Production").
- Nhấp vào menu góc trên bên trái -> APIs & Services -> Credentials, nhấp Create Credentials -> OAuth client ID (Cấu hình lần đầu cần hoàn tất thiết lập OAuth consent screen trước, chọn "External" và điền thông tin ứng dụng).
- Chọn Application type là Web application, cấu hình:
Authorized JavaScript origins: Thêm tên miền sản xuất (nhưhttps://my-app.com,https://www.my-app.com), để xác minh cục bộ có thể bổ sunghttp://localhost:số_cổng.Authorized Redirect URIs: Dán địa chỉ đã sao chép từ Clerk.
- Nhấp Create, lưu Client ID và Client Secret trong cửa sổ hiện ra, quay lại cửa sổ Clerk dán và nhấp Add connection.
- Lưu ý quan trọng:
- Cấm đăng nhập WebView: Google OAuth không hỗ trợ đăng nhập qua trình duyệt trong ứng dụng, cần tham khảo tài liệu chính thức Google để điều chỉnh.
- Chuyển đổi trạng thái xuất bản: Trạng thái "Testing" mặc định chỉ hỗ trợ 100 người dùng thử nghiệm, cần thay đổi "Publishing status" thành In production trong OAuth consent screen (cần thông qua đánh giá của Google).
- Chặn email con: Clerk mặc định chặn email Google chứa
+/=/#(nhưuser+alias@example.com), có thể bật/tắt Block email subaddresses trong trang chi tiết kết nối Google (đề xuất bật để tăng bảo mật). - Hỗ trợ Google One Tap: Sau khi cấu hình hoàn tất, có thể tích hợp thành phần
<GoogleOneTap />của Clerk để thực hiện "đăng nhập một chạm", tham khảo tài liệu thành phần Clerk.
- Kiểm tra kết nối đăng nhập bên thứ ba
Sau khi cấu hình hoàn tất, xác minh chức năng thông qua Account Portal tích hợp sẵn của Clerk:
- Vào Clerk Dashboard, trong thanh điều hướng bên trái vào trang Account Portal.
- Trong phần "Sign-in" bên phải, nhấp vào nút "Truy cập trang đăng nhập", chuyển đến trang đăng nhập môi trường tương ứng:
- Môi trường phát triển:
https://tên-miền-của-bạn.accounts.dev/sign-in(nhưhttps://my-app.accounts.dev/sign-in). - Môi trường sản xuất:
https://accounts.tên-miền-của-bạn.com/sign-in(nhưhttps://accounts.my-app.com/sign-in).
- Môi trường phát triển:
- Nhấp vào "Sign in with GitHub/Google", đăng nhập bằng tài khoản nền tảng tương ứng, nếu có thể chuyển hướng thành công và quay lại ứng dụng,说明 kết nối đã được cấu hình bình thường.
6. Từ Supabase đến nhiều thành phần phát triển backend hơn (Nâng cao)
Trong phần trên, chúng ta chủ yếu đứng từ góc nhìn của Supabase, xem "một nền tảng backend tất cả trong một lấy Postgres làm cốt lõi" có thể giúp chúng ta giải quyết những vấn đề nào: xác thực, cơ sở dữ liệu, lưu trữ tệp, giao tiếp thời gian thực, hàm edge, v.v., đều được tích hợp trong cùng một bảng điều khiển, sẵn sàng sử dụng, trải nghiệm thống nhất, rất phù hợp để bắt đầu nhanh chóng và các dự án vừa và nhỏ.
Nhưng từ góc độ dài hạn và kỹ thuật hơn, mỗi khả năng mà Supabase cung cấp (Auth / Storage / Edge Functions / Realtime / Database), trong ngành đều hầu như có giải pháp thay thế chuyên nghiệp tương ứng -- bao gồm cả các nền tảng BaaS同类, cũng như các dịch vụ đám mây và thành phần mã nguồn mở "đột phá đơn điểm" hơn. Với tư cách là nhà phát triển cá nhân và đội ngũ khởi nghiệp có tham vọng, việc hiểu các lựa chọn thay thế này có một số lợi ích:
- Đánh giá xem dự án hiện tại có "chỉ dùng Supabase là đủ" hay không, hay một khía cạnh nào đó cần dịch vụ chuyên dụng chuyên nghiệp hơn / rẻ hơn / dễ tuân thủ hơn;
- Khi quy mô dự án lớn lên hoặc nhu cầu phức tạp hơn, có thể thay thế một module nào đó từ Supabase ra ngoài (ví dụ chuyển sang nền tảng Auth chuyên dụng hoặc lưu trữ đối tượng), thay vì bị khóa chặt bởi nền tảng ngay từ đầu;
- Mở rộng tầm nhìn lựa chọn kỹ thuật, ngay cả khi tạm thời không thay đổi, cũng có thể biết đại khái "nếu không sử dụng tính năng X của Supabase, tôi còn những lựa chọn phổ biến nào".
Phần này sẽ giới thiệu riêng biệt các giải pháp thay thế phổ biến trên thị trường cho một số khả năng chính mà Supabase bao phủ, ví dụ: xác thực (Auth), lưu trữ tệp (Storage), hàm edge (Edge Functions), giao tiếp thời gian thực (Realtime), lưu trữ cơ sở dữ liệu, v.v. Đơn giản so sánh sự khác biệt của chúng về đặc tính chức năng, hạn mức miễn phí/định giá, tính dễ sử dụng và mức độ phổ biến của cộng đồng, giúp bạn có hiểu biết toàn diện hơn về bộ công cụ thành phần backend.
Nền tảng Baas tương tự
Trước khi bắt đầu, chúng ta có thể duyệt qua các nền tảng Baas tương tự, nếu cảm thấy Supabase không đủ tốt, bạn có thể chọn các sản phẩm thay thế khác nhau để thử nghiệm theo nhu cầu.
| Nền tảng/Dịch vụ | Loại | Hạn mức miễn phí/Định giá | Đặc điểm / Kịch bản áp dụng |
|---|---|---|---|
| Firebase (Google) | BaaS quản lý hoàn toàn (Auth + Firestore + Storage + Functions + Hosting) | Spark: hạn mức nhẹ miễn phí; Blaze: tính phí theo lượng sử dụng (Firestore/Storage/Functions tính riêng) | Thành thục nhất trong ngành, tài liệu tốt, nhanh chóng làm quen, khả năng thời gian thực mạnh. Phù hợp cho sản phẩm vừa và nhỏ, đội ngũ chủ đạo mobile/front-end. Nhược điểm: tính phí phức tạp, mức độ khóa cao, nhiều hạn chế truy vấn (đặc biệt Firestore). |
| Supabase | BaaS mã nguồn mở (Postgres + Auth + Storage + Edge Functions + Realtime) | Miễn phí: 500MB DB, 1GB Storage, vài lệnh gọi hàm không máy chủ; Pro: tính phí theo instance | Phiên bản SQL giống Firebase nhất; giao diện xuất sắc, trải nghiệm hiện đại, có thể tự lưu trữ. Phù hợp cho ứng dụng cần SQL mạnh, BI, khả năng giao dịch. Nhược điểm: chi phí cao cho đồng thời cao hoặc hàm phức tạp. |
| Appwrite Cloud | BaaS tất cả trong một mã nguồn mở (DB + Auth + Storage + Functions + Realtime) | Miễn phí: bao gồm DB/Storage/FaaS cơ bản; trả phí theo cấp tài nguyên | Trải nghiệm hiện đại, API thống nhất, có thể tự lưu trữ; phù hợp cho phát triển nhanh ứng dụng thân thiện với nhà phát triển. Nhược điểm: hệ sinh thái chưa trưởng thành bằng Firebase/Supabase; hiệu suất cần thử nghiệm trong ứng dụng lớn. |
| Nhost | Postgres + GraphQL + Auth + Storage + Functions | Miễn phí: 1GB DB, 1GB Storage, vài lệnh gọi hàm | Tương tự "Supabase + Hasura"; GraphQL tự nhiên; phù hợp cho đội ngũ front-end và dự án React/Next.js. Nhược điểm: hệ sinh thái nhỏ, chi phí tăng theo lượng sử dụng. |
| AWS Amplify | Backend tất cả trong một của AWS (Cognito + AppSync + DynamoDB + Storage + Functions + Hosting) | Miễn phí: hạn mức Hosting + Cognito 10k MAU + một phần hạn mức hàm | Lớn và toàn diện, phù hợp cho đội ngũ đã có nền tảng AWS; độ tin cậy cấp doanh nghiệp. Nhược điểm: khó tiếp cận nhất, dịch vụ phân mảnh; chi phí bảo trì cao cho đội ngũ khởi nghiệp. |
| Xata (tăng trưởng nhanh trong gần hai năm) | Cơ sở dữ liệu đa mô hình + Auth + Edge Functions | Miễn phí: 250k bản ghi, 15GB băng thông | Mặc dù thiên về "DB + API" hơn, nhưng cung cấp Auth, tệp, logic, có thể sử dụng như backend toàn ngăn xếp nhẹ. UI/trải nghiệm phát triển cực tốt. Nhược điểm: chức năng không toàn diện bằng Firebase/Supabase. |
| Convex (Trải nghiệm nhà phát triển cực mạnh) | Cơ sở dữ liệu được quản lý + Auth + Functions (Ưu tiên front-end) | Phiên bản phát triển miễn phí; trả phí tính theo lượng yêu cầu | Cực kỳ dễ tiếp cận; không cần schema; front-end viết hàm là có thể sử dụng backend. Phù hợp cho MVP/xác minh nhanh. Nhược điểm: liên kết chặt với nền tảng, chi phí di chuyển cao; không hoàn toàn là BaaS truyền thống. |
Xác thực (Auth)
| Công cụ/Nền tảng | Đặc điểm chức năng | Hạn mức miễn phí/Định giá | Kịch bản áp dụng và Ưu nhược điểm |
|---|---|---|---|
| Firebase Authentication | Dịch vụ xác thực BaaS do Google cung cấp, hỗ trợ các phương thức phổ biến như email/mật khẩu, điện thoại, đăng nhập xã hội, ẩn danh, v.v. Gói miễn phí Spark hỗ trợ tối đa 50k MAU. | Spark (miễn phí) 50k MAU; Blaze tính phí theo lượng sử dụng | Tích hợp hệ sinh thái Google, tài liệu phong phú, đơn giản để bắt đầu; chức năng toàn diện (MFA, hàm chặn, v.v.), phù hợp cho phát triển nhanh. Nhưng liên kết với nền tảng Firebase, mở rộng sang dịch vụ khác cần cấu hình bổ sung. |
| Auth0 (Okta) | Nền tảng xác thực danh tính được quản lý hoàn toàn, hỗ trợ đăng nhập xã hội, SSO doanh nghiệp, xác thực đa yếu tố, mở rộng quy tắc, v.v. | Gói miễn phí 25k MAU, trả phí tính theo MAU | Chức năng cấp doanh nghiệp toàn diện (RBAC, nhật ký kiểm toán, v.v.), phù hợp cho ứng dụng vừa và lớn; giao diện thân thiện. Nhược điểm là chi phí cao khi MAU tăng, phiên miễn phí có chức năng hạn chế (như không bao gồm MFA/RBAC). Độ知名度 trong cộng đồng cao, người dùng đông đảo. |
| AWS Cognito | Dịch vụ xác thực gốc của Amazon Cloud, hỗ trợ đăng nhập xã hội và SAML liên hợp. User Pool đăng nhập trực tiếp cung cấp miễn phí 10k MAU mỗi tháng, vượt quá tính phí 0.0055 USD/MAU. | Miễn phí 10k MAU/tháng, vượt quá trả phí theo lượng | Tích hợp sâu với hệ sinh thái AWS (có thể phối hợp liền mạch với API Gateway, Lambda, v.v.), rào cản vào cửa hơi cao, tài liệu khá phức tạp; hạn mức miễn phí hạn chế, phù hợp cho đội ngũ đã có thói quen sử dụng AWS. |
| Logto | Nền tảng xác thực danh tính mã nguồn mở, phiên bản tự lưu trữ miễn phí, gói dịch vụ đám mây miễn phí 50k MAU. Hỗ trợ đa ngôn ngữ, đa tenant, OAuth/OIDC, v.v. | Phiên bản cộng đồng miễn phí; Logto Cloud miễn phí 50k MAU | Giải pháp thay thế mã nguồn mở Auth0 phổ biến gần đây, GitHub đã có 10k+ Stars. Dễ mở rộng, tự lưu trữ giảm chi phí; nhược điểm là hệ sinh thái và tài liệu còn tương đối mới, quy mô cộng đồng kém hơn Firebase/Auth0. |
| Keycloak | Giải pháp IAM/SSO mã nguồn mở nổi tiếng, hỗ trợ tên người dùng/mật khẩu, LDAP, SAML, OAuth2, v.v. | Hoàn toàn miễn phí, cần tự lưu trữ | Chức năng mạnh mẽ, có thể mở rộng (hỗ trợ kiểm soát quyền chi tiết), chức năng cấp doanh nghiệp phong phú; nhưng độ phức tạp triển khai và bảo trì cao, đường cong học tập dốc đối với đội ngũ nhỏ. Nhược điểm là yêu cầu cao về container hóa và vận hành cụm. |
Lưu trữ tệp (Storage)
| Nền tảng/Dịch vụ | Loại | Hạn mức miễn phí/Định giá | Đặc điểm/Kịch bản áp dụng |
|---|---|---|---|
| Amazon S3 | Lưu trữ đối tượng đám mây (AWS) | Gói miễn phí AWS cung cấp 5GB lưu trữ, 20k yêu cầu GET/PUT/tháng, vượt quá trả phí theo lượng sử dụng | Lưu trữ đối tượng tiêu chuẩn ngành, độ tin cậy cao, triển khai đa khu vực toàn cầu. Chức năng toàn diện, tích hợp tốt với hệ sinh thái AWS; định giá khá phức tạp, người dùng mới cần tìm hiểu quy tắc tính phí. |
| Google Cloud Storage (Firebase Storage) | Lưu trữ đối tượng đám mây (Google) | Gói Firebase Spark cung cấp hạn mức miễn phí (1GB lưu trữ + giới hạn băng thông), Blaze trả phí | Tích hợp chặt chẽ với Firebase/Google Cloud, dễ quản lý; hỗ trợ tăng tốc CDN, quy tắc bảo mật chi tiết. |
| Tencent Cloud COS / Alibaba Cloud OSS | Lưu trữ đối tượng đám mây (trong nước) | Trả phí theo lượng (mỗi nền tảng có hạn mức tặng người dùng mới, như OSS có 40GB miễn phí năm đầu, v.v.) | Hướng đến thị trường nội địa, lưu trữ đối tượng hiệu suất cao, quy mô lớn; tích hợp với hệ sinh thái đám mây Trung Quốc, tài liệu khá hoàn thiện. Alibaba OSS chức năng toàn diện, tăng tốc toàn cầu; Qiniu KODO tập trung xử lý đa phương tiện, chi phí thấp, phù hợp cho cá nhân và đội ngũ nhỏ. |
| MinIO | Lưu trữ tương thích S3 mã nguồn mở | Mã nguồn mở miễn phí (tự xây dựng) | Nhẹ, hiệu suất cao, tương thích với API S3, phù hợp để xây dựng lưu trữ đối tượng trên đám mây riêng hoặc cục bộ. Tài liệu và cộng đồng hoạt động; cần tự bảo trì cơ sở hạ tầng. |
| Cloudinary / Imgix, v.v. | Lưu trữ phương tiện + CDN | Gói miễn phí cơ bản (như Cloudinary miễn phí 25GB/tháng băng thông) | Dịch vụ lưu trữ đám mây + CDN được tối ưu cho hình ảnh/video, cung cấp các chức năng nâng cao như chuyển mã thời gian thực, nén, v.v. Phù hợp cho dự án phương tiện, nhưng chức năng khá chuyên biệt, chi phí cao nếu sử dụng làm lưu trữ tệp thông dụng. |
Hàm Edge (Edge Functions)
| Nền tảng/Dịch vụ | Đặc điểm | Hạn mức miễn phí/Định giá | Kịch bản áp dụng và Ưu nhược điểm |
|---|---|---|---|
| Cloudflare Workers | Môi trường JavaScript/Wasmtime phân tán toàn cầu | Gói miễn phí: 100k yêu cầu mỗi ngày; gói tiêu chuẩn $5/tháng bao gồm 10 triệu yêu cầu | Chạy trên các nút edge của Cloudflare, độ trễ cực thấp; phù hợp cho logic phân phối toàn cầu, hiển thị tài nguyên tĩnh, v.v. Hạn mức miễn phí ít (tương đương khoảng 3 triệu yêu cầu mỗi tháng), dễ tiếp cận. Nhược điểm là giới hạn runtime (JS/Wasmtime) và công cụ gỡ lỗi hạn chế. |
| Vercel Edge Functions | Tích hợp liền mạch với Next.js/framework front-end, hỗ trợ JS/TS/Go | Hobby miễn phí: 1 triệu lệnh gọi hàm mỗi tháng, 1 triệu yêu cầu edge | Tích hợp sâu framework front-end, triển khai tự động; phù hợp cho ứng dụng Web hiện đại. Hạn mức miễn phí dồi dào, runtime mặc định 10s, có thể nâng lên 60s. Nhược điểm là phiên miễn phí hạn chế chức năng cộng tác nhóm; phụ thuộc nền tảng Vercel. |
| Netlify Edge / Functions | Hàm đám mây Node.js + định tuyến edge (NFT) | Miễn phí: 300 token/tháng (tương đương khoảng 1M yêu cầu mỗi tháng); tính phí theo điểm tín dụng | Hỗ trợ hàm Node.js, xử lý định tuyến edge, v.v. Hạn mức miễn phí dùng cho xây dựng, hàm và băng thông, phù hợp cho triển khai toàn ngăn xếp front-end. Ưu điểm là dễ sử dụng, tích hợp triển khai Git; nhược điểm là cần tính toán hạn mức miễn phí (10k yêu cầu = 3 điểm). |
| AWS Lambda@Edge / CloudFront Functions | Tính toán edge không máy chủ của AWS | AWS Lambda (1M yêu cầu miễn phí/tháng + 400k GB-s) + CloudFront $0.085/mỗi 100k lệnh gọi trở lên | Tích hợp với CloudFront, có thể thực thi mã ở edge. Phù hợp khi cần hệ sinh thái AWS (như làm quyền hoặc kiểm thử A/B ở cấp nút). Ưu điểm là linh hoạt và mạnh mẽ; nhược điểm là cấu hình phức tạp, độ trễ hơi cao hơn Cloudflare/Vercel. |
Giao tiếp thời gian thực (Realtime)
| Nền tảng/Dịch vụ | Đặc điểm chức năng | Hạn mức miễn phí/Định giá | Kịch bản áp dụng và Ưu nhược điểm |
|---|---|---|---|
| Firebase Realtime Database / Firestore | Cơ sở dữ liệu thời gian thực BaaS của Google; hỗ trợ đẩy thông báo thay đổi dữ liệu | Spark miễn phí: Realtime Database 1GB lưu trữ & hạn mức; Blaze tính phí theo lượng | Tích hợp mạnh hệ sinh thái Firebase, lắng nghe thời gian thực đơn giản. Ưu điểm là bắt đầu nhanh với gói miễn phí; nhược điểm là loại cơ sở dữ liệu (JSON/NoSQL), khả năng truy vấn phức tạp yếu. |
| Ably | Nền tảng tin nhắn thời gian thực và pub/sub, hỗ trợ WebSocket, MQTT, v.v. | Gói miễn phí: 6.000.000 tin nhắn mỗi tháng | Dịch vụ tin nhắn thời gian thực toàn diện, hỗ trợ đồng thời cao; hạn mức miễn phí có thể đạt 6 triệu tin nhắn/tháng. Cộng đồng và tài liệu tốt, phù hợp cho phân phối toàn cầu. |
| Pusher Channels | Dịch vụ đẩy sự kiện, hỗ trợ cơ chế kênh/sự kiện | Sandbox miễn phí: 200k tin nhắn mỗi ngày, 100 kết nối đồng thời | Dịch vụ WebSocket dễ sử dụng, tài liệu đầy đủ, phù hợp để nhanh chóng thực hiện chức năng chat và thông báo. Phiên miễn phí giới hạn lượng tin nhắn và số kết nối; sau khi trả phí khả năng mở rộng tốt. |
| Tự xây dựng WebSocket/Socket.IO | Tự xây dựng máy chủ (Node.js, Elixir hoặc Go, v.v.) | Chi phí tự lưu trữ (như phí máy chủ) | Mức độ linh hoạt cao nhất, có thể tùy chỉnh giao thức và cấu trúc liên kết theo nhu cầu. Phù hợp cho đội ngũ kiểm soát chi phí nghiêm ngặt và kỹ thuật trưởng thành. Nhược điểm là cần tự xử lý tính sẵn sàng, mở rộng và các vấn đề cross-origin, v.v. |
Cơ sở dữ liệu
| Nền tảng/Công cụ | Loại cơ sở dữ liệu | Hạn mức miễn phí/Định giá | Đặc điểm chính |
|---|---|---|---|
| Neon (Serverless PostgreSQL) | Quan hệ (PostgreSQL) | Gói miễn phí: 0.5GB lưu trữ, nhánh chính trực tuyến vĩnh viễn, 20h tính toán nhánh/tháng | Postgres không máy chủ gốc đám mây, hỗ trợ tự động mở rộng và phân nhánh (fork thử nghiệm). Hạn mức miễn phí đủ cho dự án nhỏ, phù hợp cho quy trình phát triển hiện đại. Chức năng phân nhánh mạnh mẽ, nhưng hạn mức miễn phí khá nhỏ. |
| Aiven PostgreSQL | Quan hệ (PostgreSQL/MySQL) | Gói miễn phí: 1GB lưu trữ, 1 vCPU, 1GB bộ nhớ | Dịch vụ cơ sở dữ liệu được quản lý, hỗ trợ di chuyển đa vùng đa đám mây. Cung cấp MySQL, Redis, v.v. có thể chọn. Hạn mức miễn phí phù hợp cho phát triển và dự án nhỏ; phiên bản thương mại hỗ trợ cụm tính sẵn sàng cao và giám sát. |
| CockroachDB Cloud | SQL phân tán (Tương thích PostgreSQL) | Gói miễn phí: 10GB lưu trữ | Cơ sở dữ liệu SQL phân tán tương tự Google Spanner, tự động phân mảnh mở rộng. 10GB miễn phí khá hào phóng; phù hợp cho ứng dụng cần mở rộng ngang và tính nhất quán cao. Phiên bản thương mại SLA cao. |
| TiDB Cloud | Quan hệ phân tán (Tương thích MySQL) | Gói miễn phí: 5GB mỗi nút, tổng cộng tối đa 25GB | Phiên bản đám mây của TiDB mã nguồn mở, tương thích giao thức MySQL, kiến trúc phân tán. Hạn mức miễn phí dồi dào, phù hợp cho đội ngũ quen MySQL, hiệu suất xuất sắc; nhược điểm là vận hành khá phức tạp (đối với kịch bản quy mô lớn). |
| MongoDB Atlas | Tài liệu (NoSQL MongoDB) | Cụm M0 miễn phí: 0.5GB lưu trữ | MongoDB trên đám mây, mô hình tài liệu linh hoạt, hỗ trợ truy vấn và chỉ mục phong phú. Cơ sở dữ liệu 0.5GB miễn phí phù hợp cho thử nghiệm và ứng dụng nhỏ; có thể mở rộng ngang theo nhu cầu. Đường cong học tập hơi cao hơn cơ sở dữ liệu quan hệ. |
| SQLPub | Đa cơ sở dữ liệu (MySQL, PostgreSQL, Redis, v.v.) | Gói miễn phí: 36.000 yêu cầu/giờ, 30 kết nối đồng thời, 500MB lưu trữ | Nền tảng cơ sở dữ liệu tất cả trong một, hỗ trợ nhiều loại cơ sở dữ liệu. Phiên bản miễn phí phù hợp cho học tập và dự án nhỏ; ưu điểm là hỗ trợ nhiều DB, nhược điểm là hạn mức lưu trữ nhỏ. |
Các giải pháp thay thế trên đều có trọng tâm khác nhau: mã nguồn mở linh hoạt và kiểm soát được hơn (Keycloak, MinIO, Socket.IO, Neon, CockroachDB, v.v.), dịch vụ đám mây quản lý dễ tiếp cận hơn (Firebase, Auth0, Cloudflare, Vercel, Netlify, AWS, Aiven, MongoDB Atlas, v.v.). Khi lựa chọn có thể cân nhắc dựa trên nhu cầu dự án, ngăn xếp kỹ thuật đội ngũ, ngân sách và hệ sinh thái cộng đồng. Dự án cá nhân có thể ưu tiên sử dụng các dịch vụ có hạn mức miễn phí dồi dào, dễ tích hợp (như loạt Firebase, lưu trữ Qiniu, Cloudflare Workers, Neon, CockroachDB, v.v.), còn đối với nhu cầu cấp doanh nghiệp hoặc bảo mật cụ thể, có thể cân nhắc các giải pháp chức năng phong phú hơn nhưng tính phí cao hơn (Auth0, Alibaba/Tencent Cloud, AWS, TiDB/Aiven, v.v.). Bạn có thể liên tục thử nghiệm trong ứng dụng thực tế, cho đến khi chọn được thành phần công cụ phát triển backend phù hợp nhất.
Tổng kết
Trong bài học hôm nay, chúng ta đã hệ thống học các khái niệm cơ bản về cơ sở dữ liệu, định nghĩa cốt lõi của Supabase và chi tiết thao tác của nó. Trong quá trình thực hành sau này, bạn có thể dựa trên kịch bản ứng dụng và nhu cầu thực tế của dự án, quay lại tham khảo tài liệu này bất cứ lúc nào.
Xin hãy luôn ghi nhớ một nguyên tắc quan trọng: Hoàn thành trước, hoàn thiện sau! Không cần theo đuổi hoàn hảo ngay từ đầu, chúng ta hoàn toàn có thể thông qua lặp lại tối ưu hóa liên tục, từng bước tiến gần đến kết quả tốt hơn. Chúc bạn mọi việc thuận lợi trong thực hành dự án sau này!
📚 Bài tập về nhà
- Phát triển một ứng dụng bao gồm hệ thống quản lý người dùng và cơ sở dữ liệu. Tốt nhất là bao gồm nhiều chức năng Supabase hơn (Realtime / cloud storage / Edge function).