Từ NanoBanana, xây dựng Agent sản xuất tài sản của riêng bạn
Chương 1: Tạo tài sản hình ảnh đầu tiên trong 1 phút
Trước khi bắt đầu thảo luận về thiết kế, phong cách hoặc prompt, chúng ta hãy dùng ít bước nhất để tạo hình ảnh đầu tiên.
1.1 Tìm hiểu về NanoBanana
Trước khi thảo luận về phong cách thiết kế, prompt engineering, chúng ta hãy giải quyết một việc quan trọng hơn: Xác nhận rằng bạn thực sự có thể tạo ra một hình ảnh.
Các mô hình lớn hiện tại đã có khả năng tạo và chỉnh sửa hình ảnh, loại mô hình này thường được gọi là mô hình tạo sinh.
Để đơn giản hóa quy trình nhất có thể, hướng dẫn này chọn một mô hình đã có khả năng tạo và chỉnh sửa hình ảnh ổn định làm ví dụ -- NanoBanana. Đây là mô hình tạo hình ảnh do Google phát triển, tên chính thức là Gemini 3.1 Flash Image Preview, hỗ trợ tạo hình ảnh trực tiếp qua ngôn ngữ tự nhiên, cũng hỗ trợ chỉnh sửa dựa trên hình ảnh có sẵn.

Về mặt khả năng, nó không khác biệt bản chất so với các mô hình khác mà bạn có thể biết (như GPT-4o, Claude, Qwen, Midjourney, v.v.): Nhập mô tả, mô hình chịu trách nhiệm tạo kết quả.



Bạn có thể hiểu nó như một "cây cọ vẽ". Trong chương này, chúng ta chỉ quan tâm một điều: Chúng ta chỉ quan tâm một điều: Cây cọ này có thể vẽ nét đầu tiên trong tay bạn hay không.
Trong thực tế sử dụng, NanoBanana có thể được sử dụng trực tiếp qua các nền tảng chính thức như Google AI Studio, hoặc tích hợp vào quy trình phát triển thông qua API. Hướng dẫn này sử dụng cách gọi API. Hiện tại đã ra mắt mô hình NanoBanana 2, bạn có thể sử dụng mô hình lớn mới nhất để thử nghiệm.
1.2 Tạo hình ảnh cấp độ "Hello World"
Trước khi bắt đầu, bạn chỉ cần hoàn thành ba bước sau:
- Tạo một thư mục mới trong Trae
- Tạo một tệp Python mới
- Dán toàn bộ mã dưới đây vào
Trae sẽ tự động hoàn thành việc triển khai môi trường và cài đặt dependency cần thiết, không cần cấu hình thêm.
Mã sẽ sử dụng API Key của NanoBanana. Ở đây không trình bày chi tiết quy trình đăng ký -- miễn là bạn có thể lấy và điền tham số tương ứng. Giai đoạn này không cần hiểu từng dòng mã, miễn là nó chạy thành công.
# /// script
# dependencies = [
# "gradio>=4.0.0",
# "pillow>=10.0.0",
# "requests>=2.31.0",
# ]
# ///
import gradio as gr
import requests
import base64
from PIL import Image
import io
import os
import time
import re
from typing import Optional, Dict, Any, List
# Cấu hình API
NANOBANANA_API_URL: str = "YOUR API URL"
NANOBANANA_API_KEY: str = "YOUR API KEY"
OUTPUT_DIR: str = "outputs"
# Đảm bảo thư mục đầu ra tồn tại
os.makedirs(OUTPUT_DIR, exist_ok=True)
def image_to_base64_data_uri(image: Image.Image) -> str:
"""
Chuyển đổi hình ảnh PIL sang định dạng data URI tương thích với OpenAI API.
"""
buffer = io.BytesIO()
# Chuyển đổi thống nhất sang PNG để đảm bảo tương thích
image.save(buffer, format="PNG")
encoded = base64.b64encode(buffer.getvalue()).decode('utf-8')
return f"data:image/png;base64,{encoded}"
def base64_to_image(base64_str: str) -> Optional[Image.Image]:
"""
Chuyển đổi chuỗi base64 thuần túy sang PIL Image.
"""
try:
image_bytes = base64.b64decode(base64_str)
return Image.open(io.BytesIO(image_bytes))
except Exception as e:
print(f"Giải mã Base64 thất bại: {e}")
return None
def extract_base64_from_response(content: Any) -> Optional[str]:
"""
Logic phân tích cốt lõi: Trích xuất dữ liệu Base64 hình ảnh từ content API trả về.
Tương thích với cả định dạng Markdown và định dạng danh sách có cấu trúc.
"""
if not content:
return None
base64_data = None
# 1. Thử trích xuất có cấu trúc (List)
if isinstance(content, list):
for part in reversed(content):
if isinstance(part, dict):
img_field = part.get("image_url") or part.get("image") or part.get("output_image")
if isinstance(img_field, dict):
url = img_field.get("url", "")
if url.startswith("data:image/") and "," in url:
return url.split(",", 1)[1].strip()
text_parts = [
str(p.get("text", ""))
for p in content
if isinstance(p, dict) and p.get("type") in ["text", "input_text"]
]
content_str = "".join(text_parts)
else:
content_str = str(content)
# 2. Thử trích xuất regex Markdown (String)
pattern = re.compile(r"!\[.*?\]\((data:image/[^;]+;base64,[^)]+)\)", re.IGNORECASE)
match = pattern.search(content_str)
if match:
data_url = match.group(1)
if "," in data_url:
return data_url.split(",", 1)[1].strip()
return None
def synthesize(prompt: str, input_image: Optional[Image.Image]) -> Optional[Image.Image]:
"""
Gọi Nanobanana API để tạo hình ảnh.
"""
if not prompt or not prompt.strip():
gr.Warning("Vui lòng nhập prompt")
return None
print(f">>> Bắt đầu tác vụ: {prompt[:50]}...")
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {NANOBANANA_API_KEY}"
}
messages = []
if input_image is not None:
print(">>> Phát hiện hình ảnh đầu vào, sử dụng chế độ đa phương thức")
img_base64 = image_to_base64_data_uri(input_image)
messages.append({
"role": "user",
"content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": img_base64}}
]
})
else:
messages.append({
"role": "user",
"content": prompt
})
payload = {
"messages": messages,
"model": "gemini-2.5-flash-image",
"stream": False
}
try:
response = requests.post(NANOBANANA_API_URL, headers=headers, json=payload, timeout=120)
if response.status_code != 200:
error_msg = f"Yêu cầu API thất bại: {response.status_code} - {response.text}"
print(error_msg)
gr.Error(error_msg)
return None
result = response.json()
print(f"Phản hồi API gốc (cắt bớt): {str(result)[:200]}...")
content = None
if "choices" in result and len(result["choices"]) > 0:
content = result["choices"][0].get("message", {}).get("content")
if not content:
gr.Warning("Không có trường content trong kết quả API trả về")
return None
base64_str = extract_base64_from_response(content)
if base64_str:
output_image = base64_to_image(base64_str)
if output_image:
return output_image
text_content = str(content) if not isinstance(content, list) else " ".join([str(x) for x in content])
gr.Info(f"Không tạo được hình ảnh, mô hình trả về văn bản: {text_content[:100]}...")
return None
except requests.exceptions.Timeout:
gr.Error("Yêu cầu quá thời gian, vui lòng thử lại sau")
return None
except Exception as e:
import traceback
traceback.print_exc()
gr.Error(f"Lỗi không xác định: {str(e)}")
return None
# Cấu hình giao diện Gradio
with gr.Blocks(title="Nanobanana Image Generator") as app:
gr.Markdown("# 🍌 Nanobanana Text/Image to Image")
gr.Markdown("Dựa trên mô hình Gemini-2.5-Flash-Image, hỗ trợ tạo ảnh từ văn bản và tạo ảnh từ ảnh.")
with gr.Row():
with gr.Column():
prompt_input = gr.Textbox(
label="Prompt",
placeholder="Ví dụ: A cyberpunk cat holding a neon sign...",
lines=3
)
image_input = gr.Image(
label="Hình ảnh tham khảo (tùy chọn, dùng để tạo ảnh từ ảnh)",
type="pil",
height=300
)
submit_btn = gr.Button("Bắt đầu tạo", variant="primary")
with gr.Column():
image_output = gr.Image(label="Kết quả tạo", format="png")
submit_btn.click(
fn=synthesize,
inputs=[prompt_input, image_input],
outputs=image_output
)
if __name__ == "__main__":
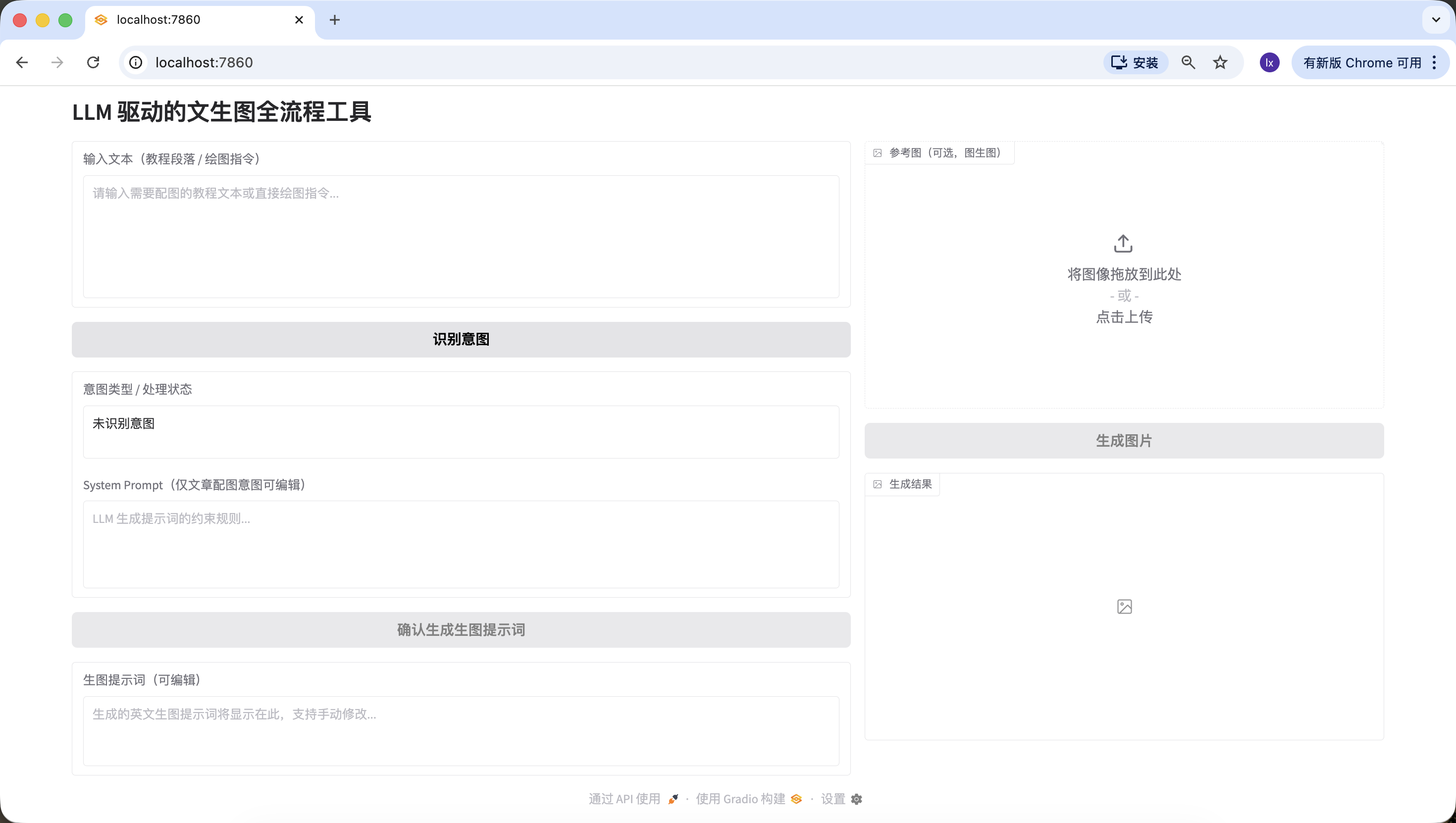
app.launch(share=True)Khi Trae thông báo chạy thành công, nhấp vào liên kết cục bộ mà nó cung cấp (thường là http://127.0.0.1:7860).
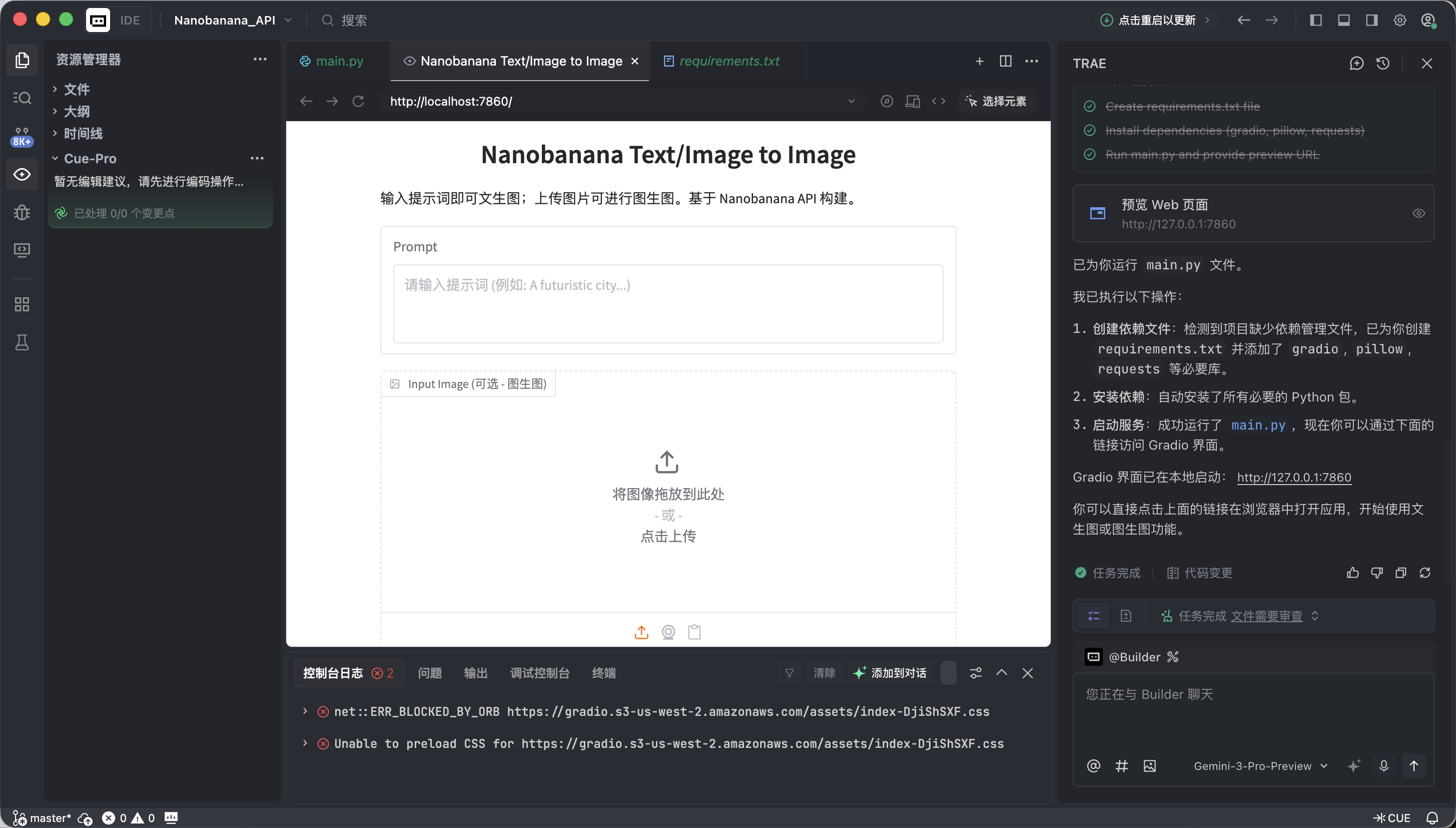
Nếu mọi thứ bình thường, bạn sẽ thấy một giao diện vẽ AI đã có thể hoạt động.
Giao diện này trông rất đơn giản, nhưng nó đã có hai khả năng cốt lõi trong công cụ vẽ cấp thương mại, đó là tạo ảnh từ văn bản và tạo ảnh từ ảnh.
- Bên trái: Vùng chỉ thị (Input Zone) -- Bạn ra lệnh tại đây.
- Prompt (ô nhập): Nhập mô tả sáng tạo của bạn (khuyến nghị sử dụng tiếng Anh).
- Input Image (ô tham khảo):
- Chế độ tạo ảnh từ văn bản: Giữ trống.
- Chế độ tạo ảnh từ ảnh: Kéo hình ảnh cục bộ vào đây, AI sẽ sáng tạo dựa trên nó.
- Nút Submit: Nhấp để gửi chỉ thị, bắt đầu tạo.
- Bên phải: Vùng hiển thị (Output Zone) -- Nơi chứng kiến phép màu, kết quả tạo sẽ hiển thị tại đây.
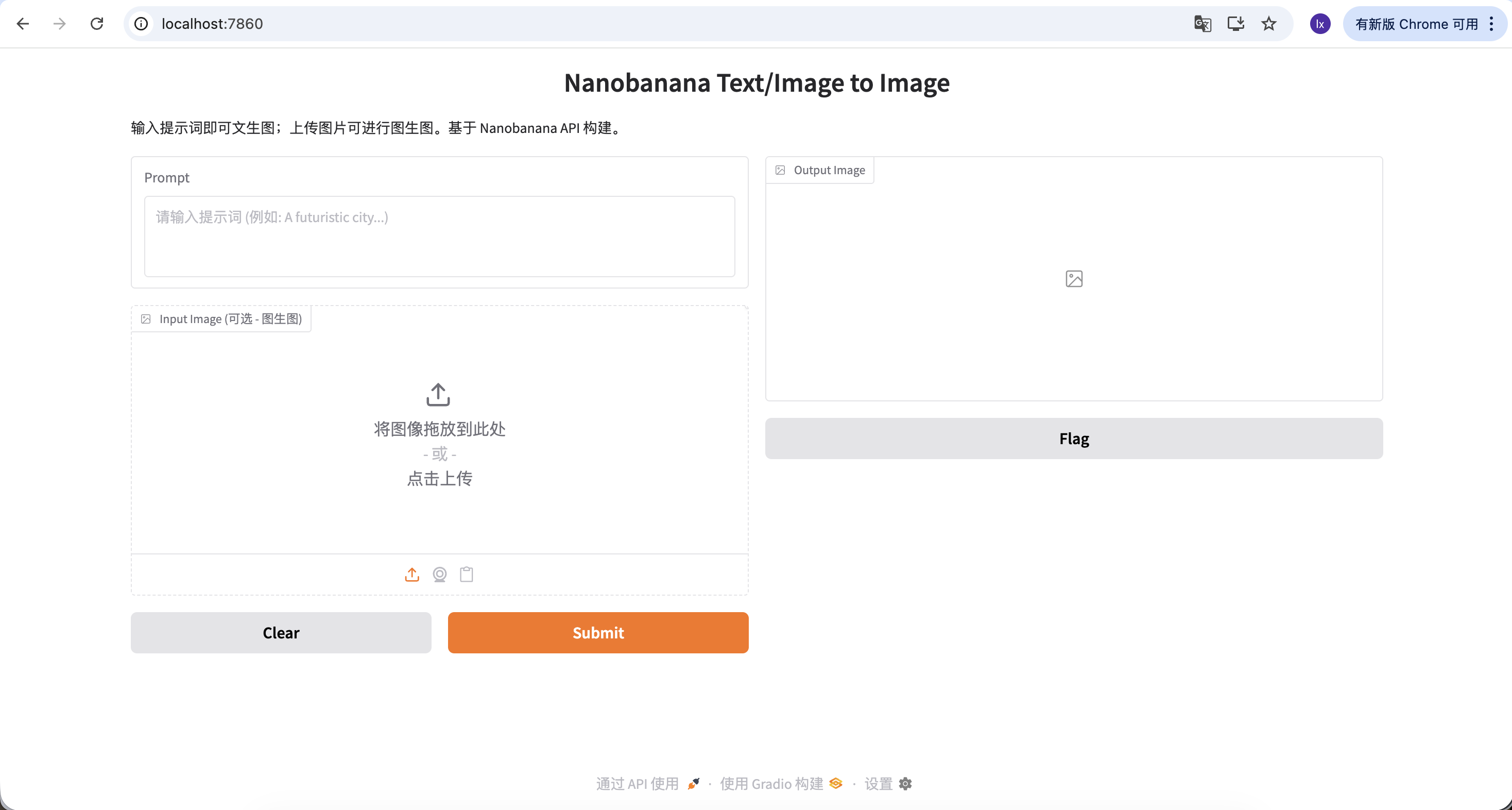
Bây giờ chúng ta có thể thử tạo hình ảnh đầu tiên của bạn!
Prompt sử dụng trong ví dụ này như sau:
A red apple
Đây là một ví dụ được đơn giản hóa có chủ ý, không chứa bất kỳ mô tả phong cách hay tham số nào.
Quy trình thực tế
Sau khi chạy mã, quy trình có thể tóm tắt thành ba bước:
- Gửi mô tả văn bản cho mô hình
- Mô hình tạo hình ảnh tương ứng
- Hình ảnh được lưu dưới dạng tệp cục bộ
Vài giây sau, bạn sẽ thấy kết quả tạo tại máy cục bộ. Việc tạo hình ảnh bởi mô hình có tính ngẫu nhiên, nên cùng một prompt sẽ có kết quả tạo khác nhau, bạn có thể tạo nhiều lần và chọn hình ảnh ưng ý.
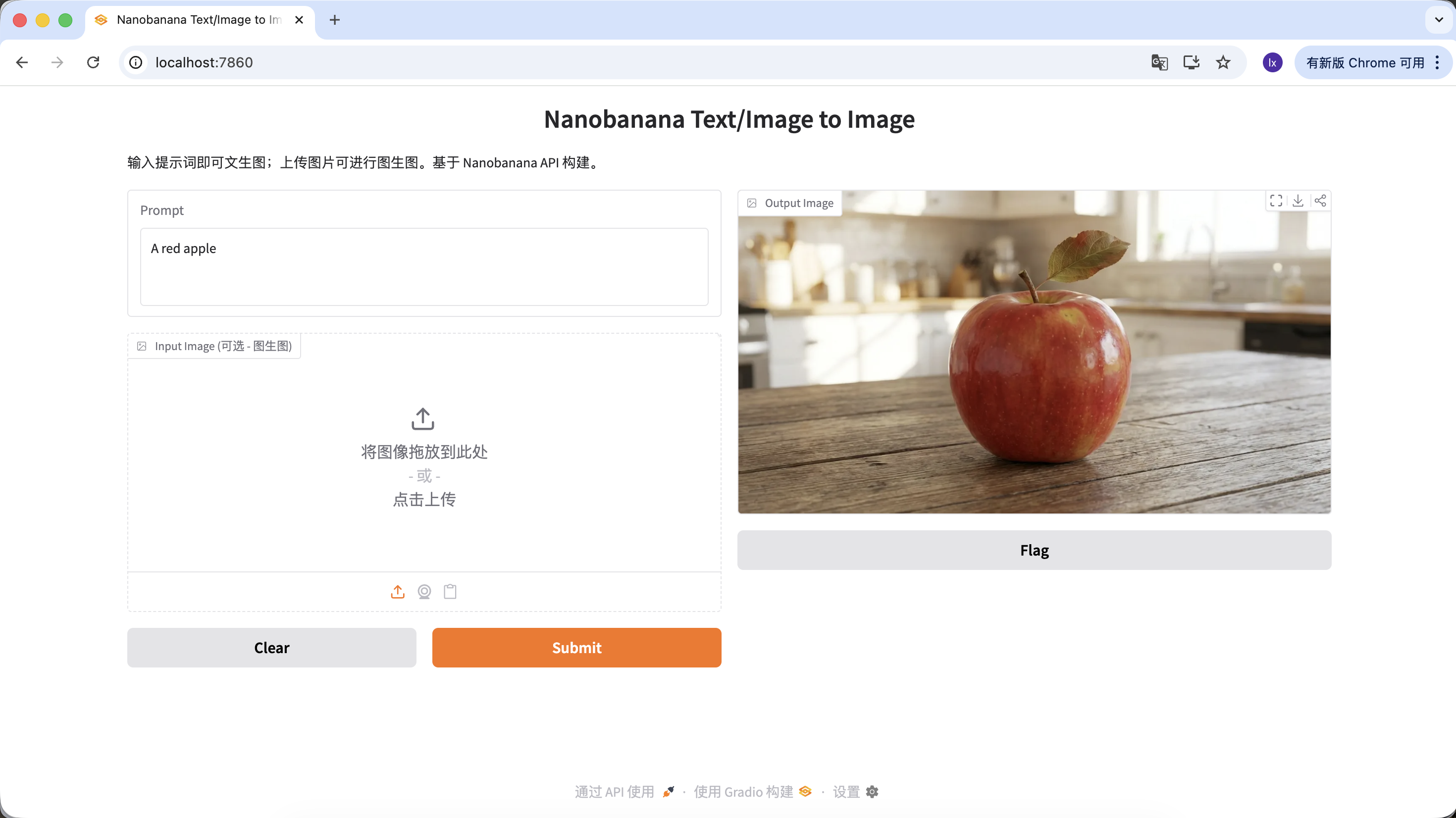
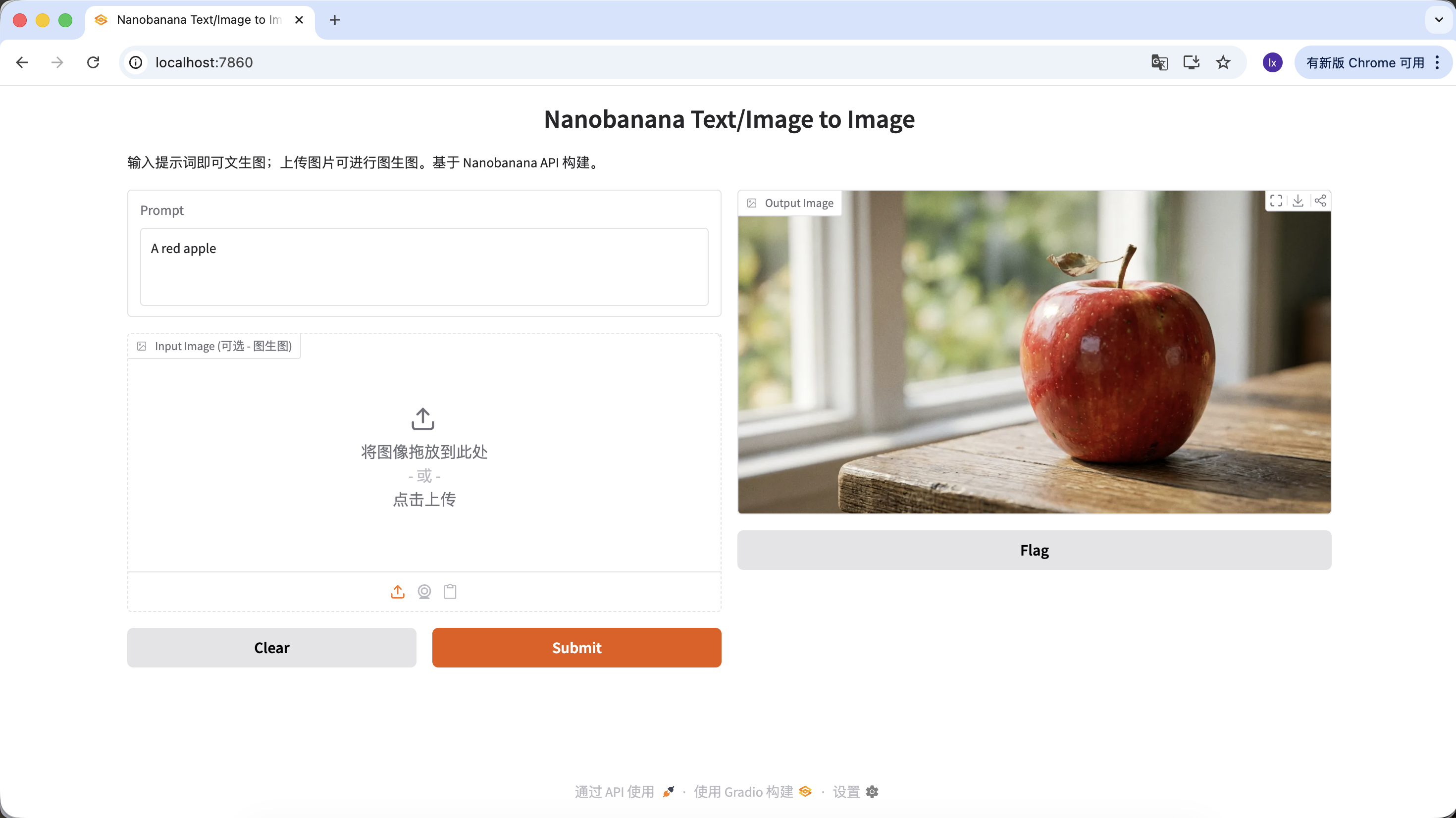
Bạn cũng có thể làm phong phú prompt của mình, đưa thêm nhiều mô tả và giới hạn. Ví dụ với prompt sau, hình ảnh nhận được sẽ đặc biệt hơn.
"A hyper-realistic close-up of a fresh red apple with water droplets on its skin, sitting on a dark rustic wooden table. Cinematic dramatic lighting, rim light, shallow depth of field, bokeh background, 8k resolution, macro photography."
(Một quả táo đỏ tươi siêu chân thực có giọt nước trên vỏ, đặt trên bàn gỗ thô tối màu. Ánh sáng kịch tính điện ảnh, ánh sáng viền, độ sâu trường ảnh nông, nền mờ, độ phân giải 8k, nhiếp ảnh macro.)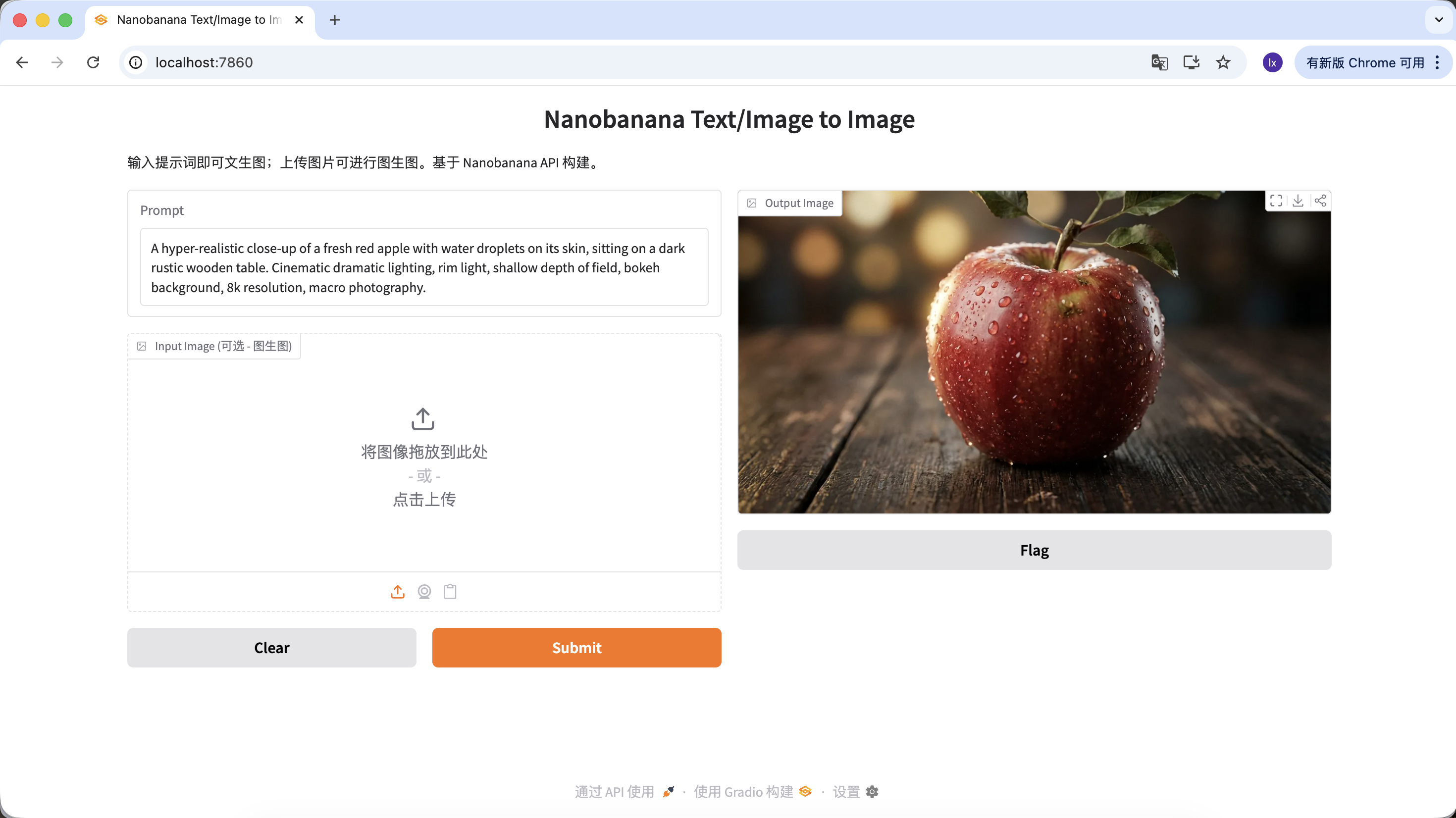
Nhấp vào tải xuống hình ảnh trong vùng Output Image để lưu về máy.
1.3 Các kịch bản tạo tài sản phổ biến của mô hình tạo ảnh
Trong công việc thực tế, việc mô hình lớn tạo hình ảnh chủ yếu dùng để sản xuất tài sản thiết kế hiệu quả, chứ không phải tạo ra một tác phẩm nghệ thuật đơn lẻ.
Khi bạn quan sát các case được thích nhiều trên các tài khoản marketing về thiết kế, bạn sẽ thấy sản phẩm của họ tập trung vào hai loại kịch bản:
- Tạo ảnh từ văn bản (từ 0 đến 1)
- Tạo ảnh từ ảnh tham khảo (từ 1 đến N)
1. Tạo ảnh từ văn bản: Nhanh chóng có tài sản thiết kế
Loại kịch bản này tập trung vào hiệu quả. Khi cần lấp khoảng trống trong thiết kế (như trạng thái trống, avatar, hình minh họa), AI về bản chất đóng vai trò là một kho hình ảnh tạo tức thì.
Tạo tài sản thiết kế UI
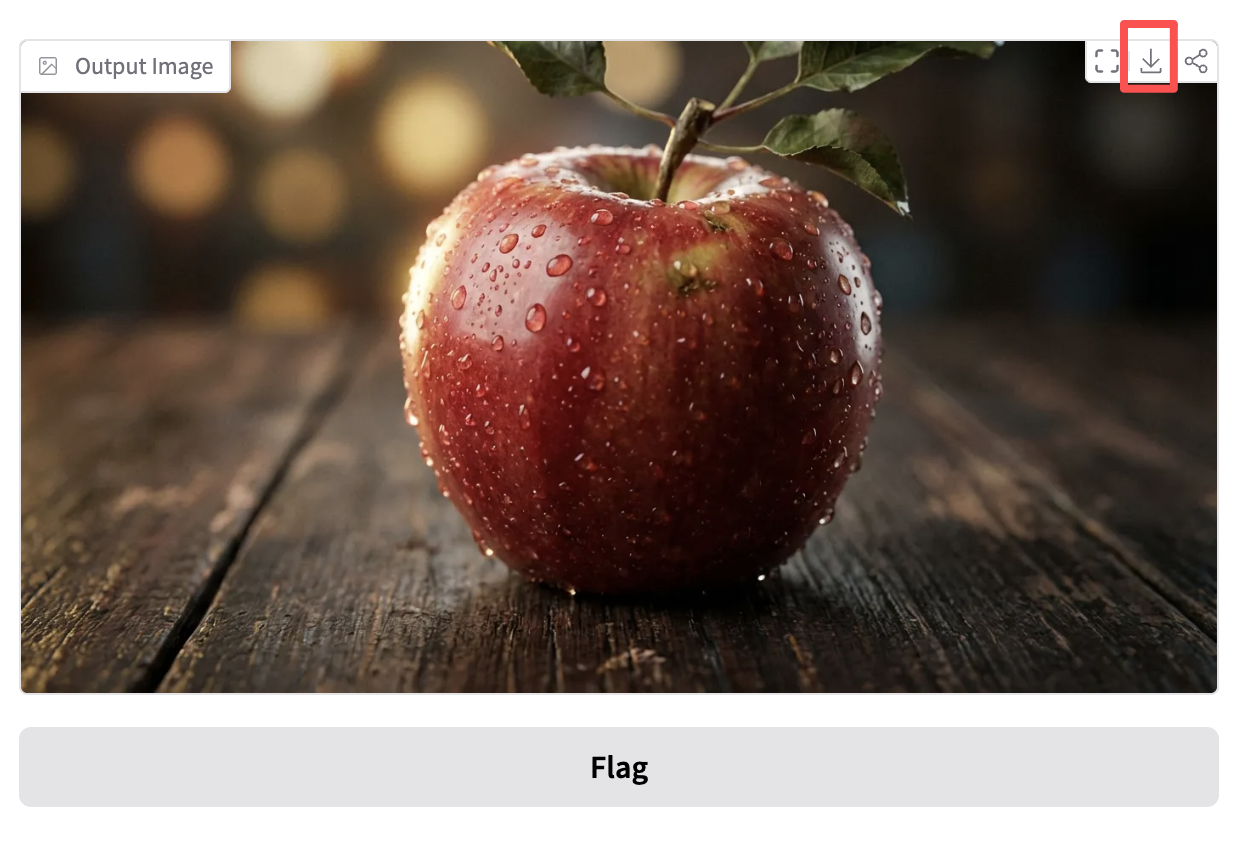
- Xu hướng phổ biến: Icon 3D phong cách kính mờ, phong cách đất sét trên Dribbble
- Biểu hiện phổ biến: Chất liệu trong suốt, phát sáng ở viền, icon chức năng hoặc thời tiết với màu kẹo pastel
Prompt ví dụ:
A set of 3D weather icons (sun, cloud, rain), glassmorphism style, frosted glass texture, soft pastel gradient colors, soft studio lighting, isometric view, transparent background, 4k.
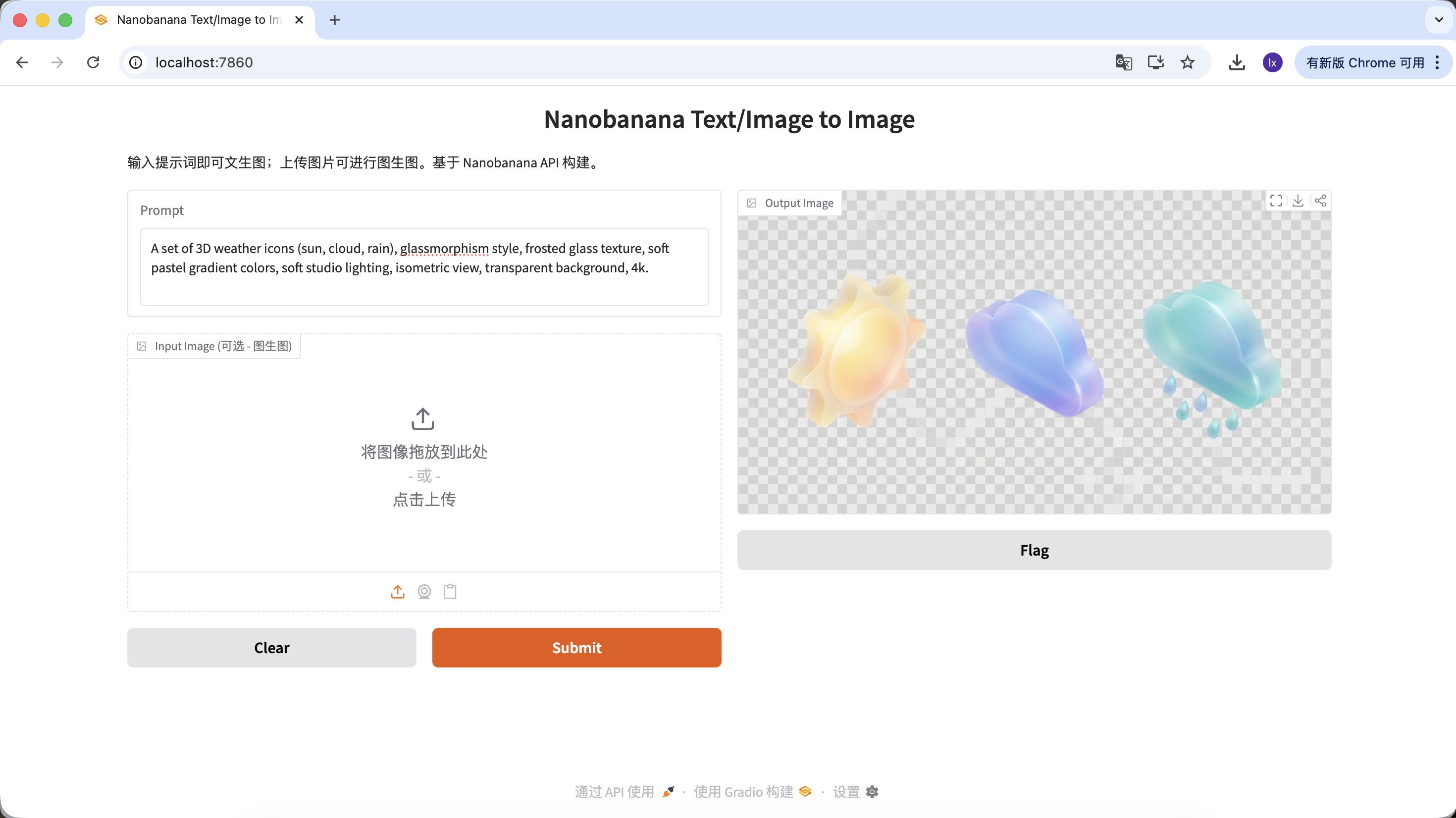
Tạo Logo
- Xu hướng phổ biến: Logo công nghệ cảm với đường nét tối giản, kết hợp hình học
- Biểu hiện phổ biến: Phối màu đen trắng, thiết kế không gian âm, nhận diện thương hiệu rõ ràng
Prompt ví dụ:
Minimalist vector logo design for a tech brand "Coffee Code", combining a coffee cup with coding brackets < >, flat design, solid black lines, white background, Paul Rand style, svg.
Tạo hình ảnh người dùng cho trang web
- Xu hướng phổ biến: Avatar 3D ảo phổ biến trên trang SaaS, để tránh bản quyền chân dung
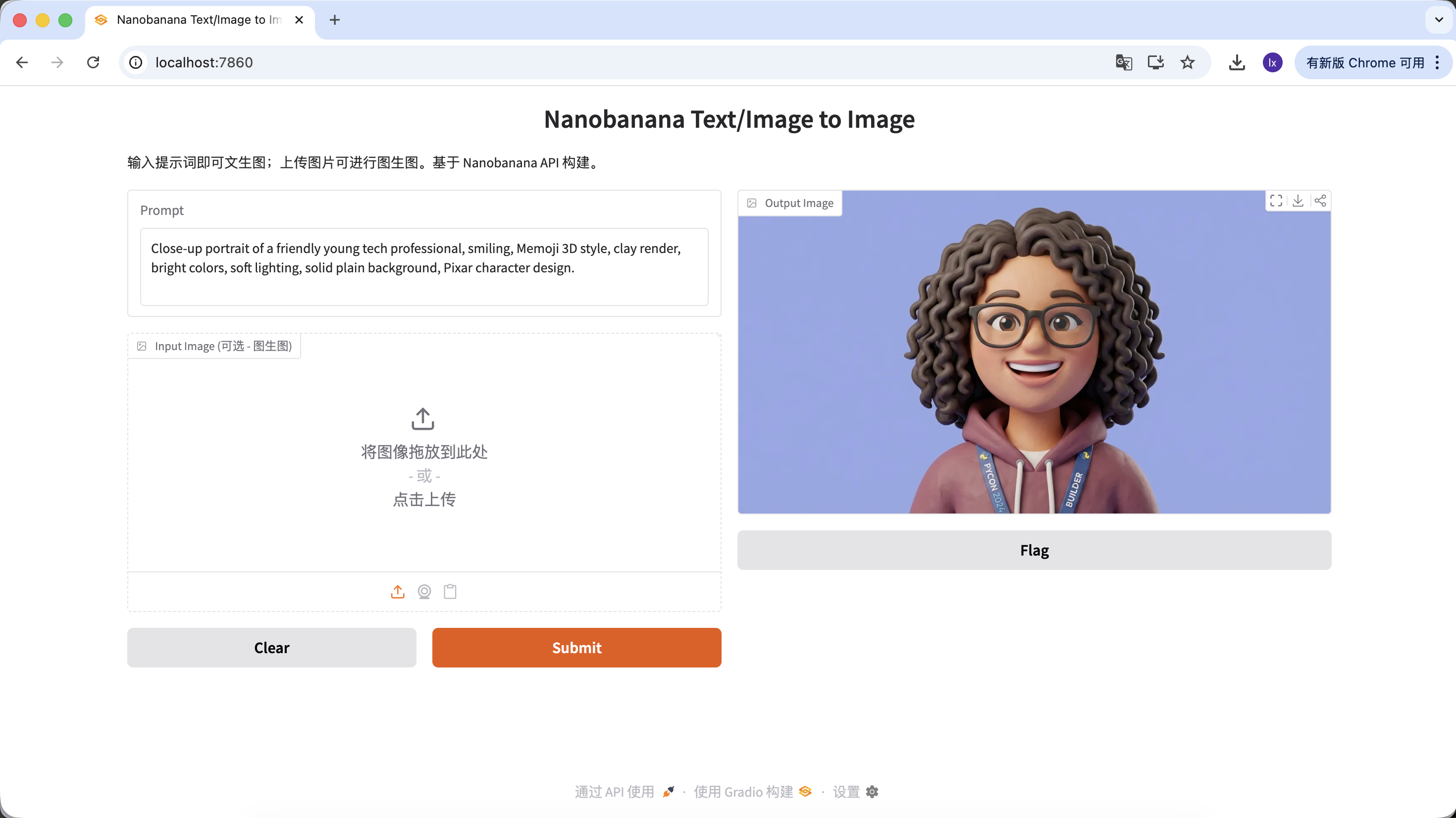
- Biểu hiện phổ biến: Biểu cảm thân thiện, tỷ lệ hoạt hình, phong cách gần Pixar hoặc Memoji
Prompt ví dụ:
Close-up portrait of a friendly young tech professional, smiling, Memoji 3D style, clay render, bright colors, soft lighting, solid plain background, Pixar character design.
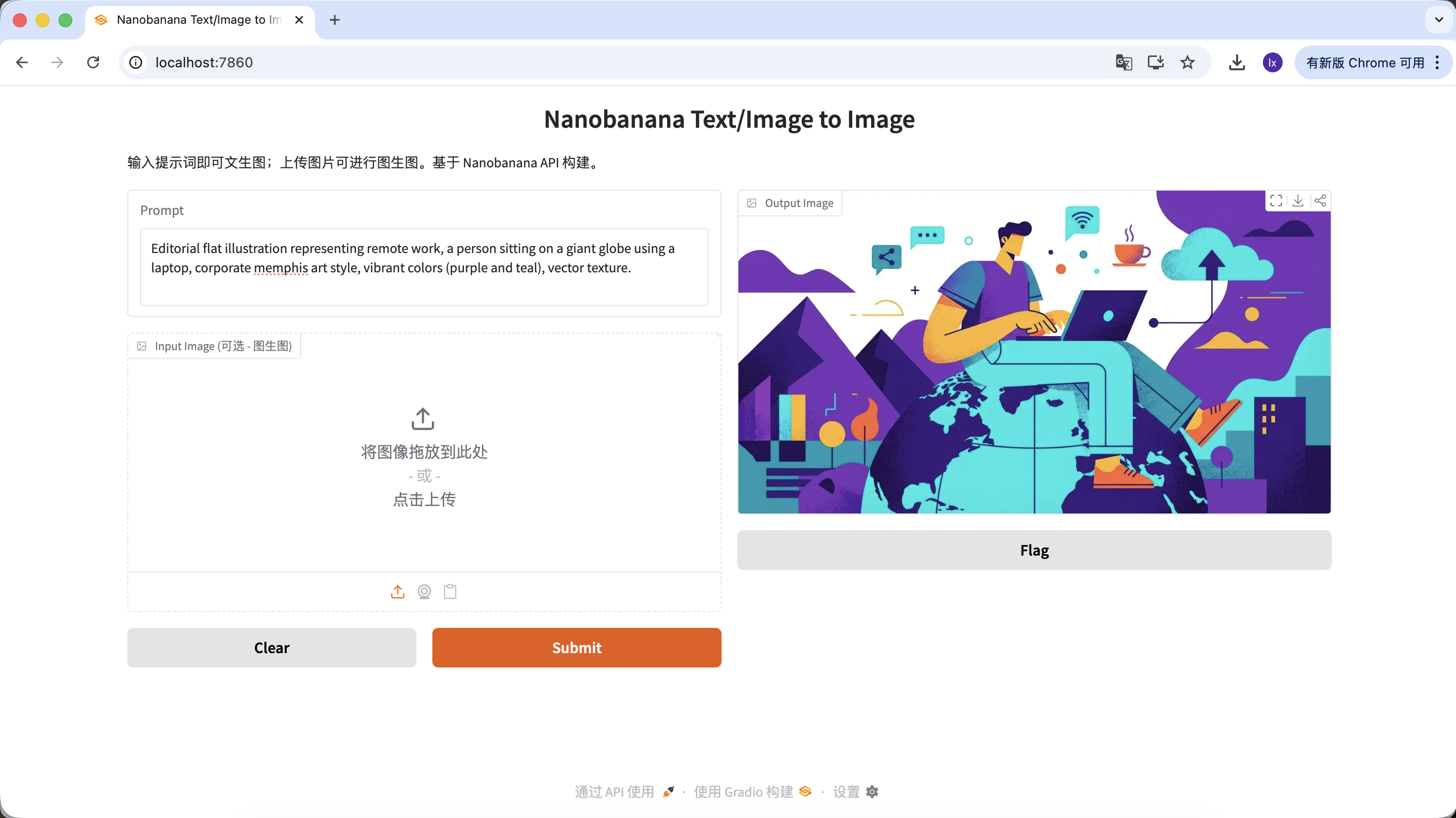
Tạo hình ảnh minh họa bài viết
- Xu hướng phổ biến: Minh họa phẳng trừu tượng phổ biến trên blog công ty công nghệ
- Biểu hiện phổ biến: Phối màu tím xanh, tỷ lệ nhân vật phóng đại, yếu tố UI trôi nổi
Prompt ví dụ:
Editorial flat illustration representing remote work, a person sitting on a giant globe using a laptop, corporate memphis art style, vibrant colors (purple and teal), vector texture.
2. Tạo ảnh từ ảnh tham khảo: Giữ nhất quán thị giác
Loại kịch bản này quan tâm nhiều hơn đến khả năng mở rộng. Khi bạn đã có một hình ảnh chính hài lòng và cần tạo một bộ tài sản cùng phong cách.
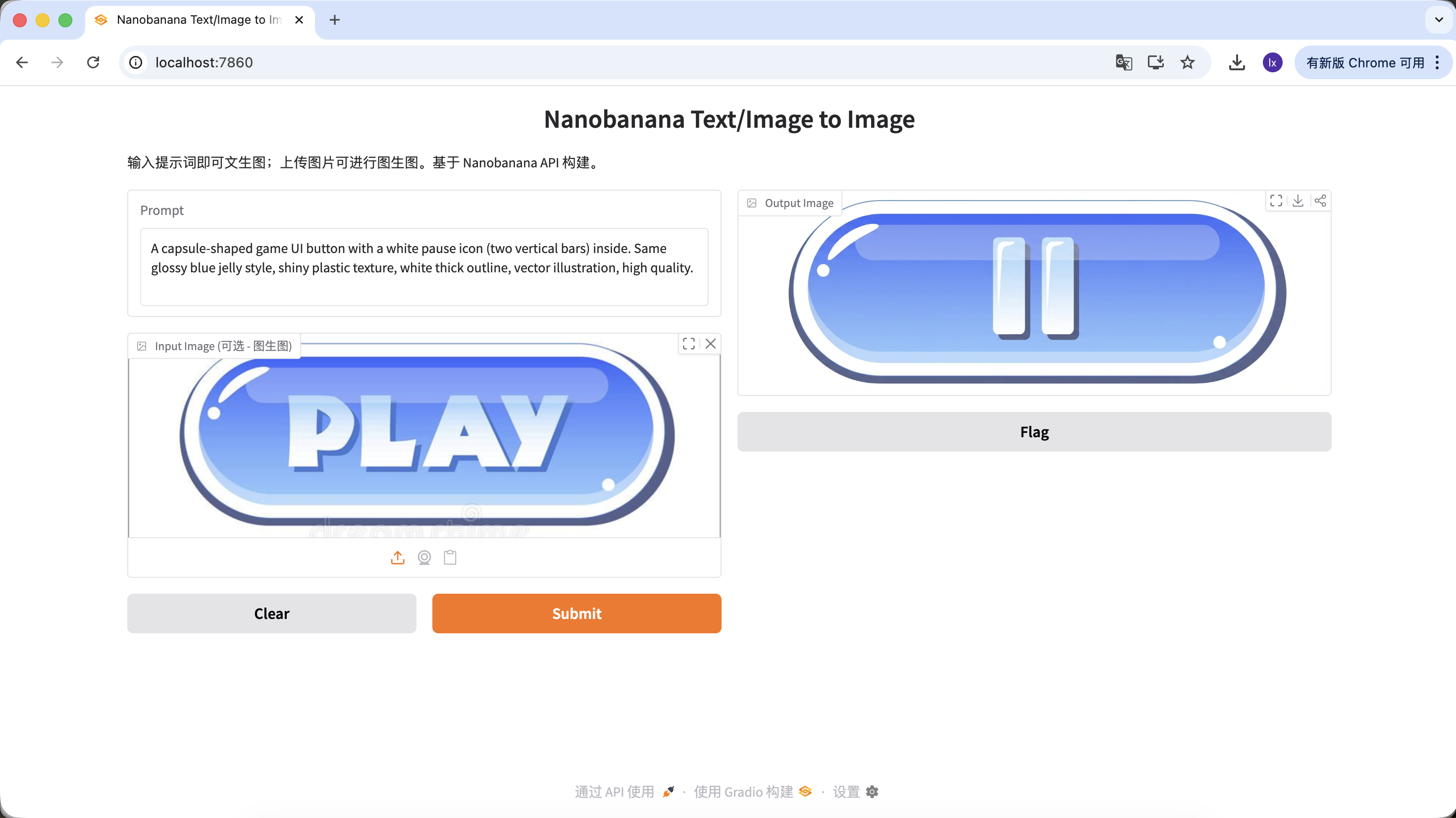
Bộ nút hoặc tài sản tương tác tương tự hình ảnh chính
Trong phát triển game, nhất quán UI rất quan trọng. Giả sử bạn đã có nút "PLAY" của giao diện chính, nay cần mở rộng thành một bộ nút chức năng cùng phong cách (như tạm dừng, cài đặt, trang chủ). Chỉ dựa vào vẽ tay rất khó đảm bảo mỗi nút hoàn toàn nhất quán về độ bóng, phối cảnh và giá trị màu.
Quy trình thao tác cơ bản:
- Lưu hình ảnh nút "PLAY" màu xanh đã có

- Kéo nó vào vùng Input Image của giao diện, làm ảnh tham khảo mẫu
- Giữ nguyên mô tả phong cách trong prompt, chỉ thay đổi nội dung chính thể
Với quy trình này, miễn là thay mô tả chính thể, bạn có thể nhận được các nút chức năng khác nhau nhưng cùng phong cách.
Prompt ví dụ:
Biến thể A: Nút tạm dừng (loại icon)
A capsule-shaped game UI button with a white pause icon (two vertical bars) inside. Same glossy blue jelly style, shiny plastic texture, white thick outline, vector illustration, high quality.
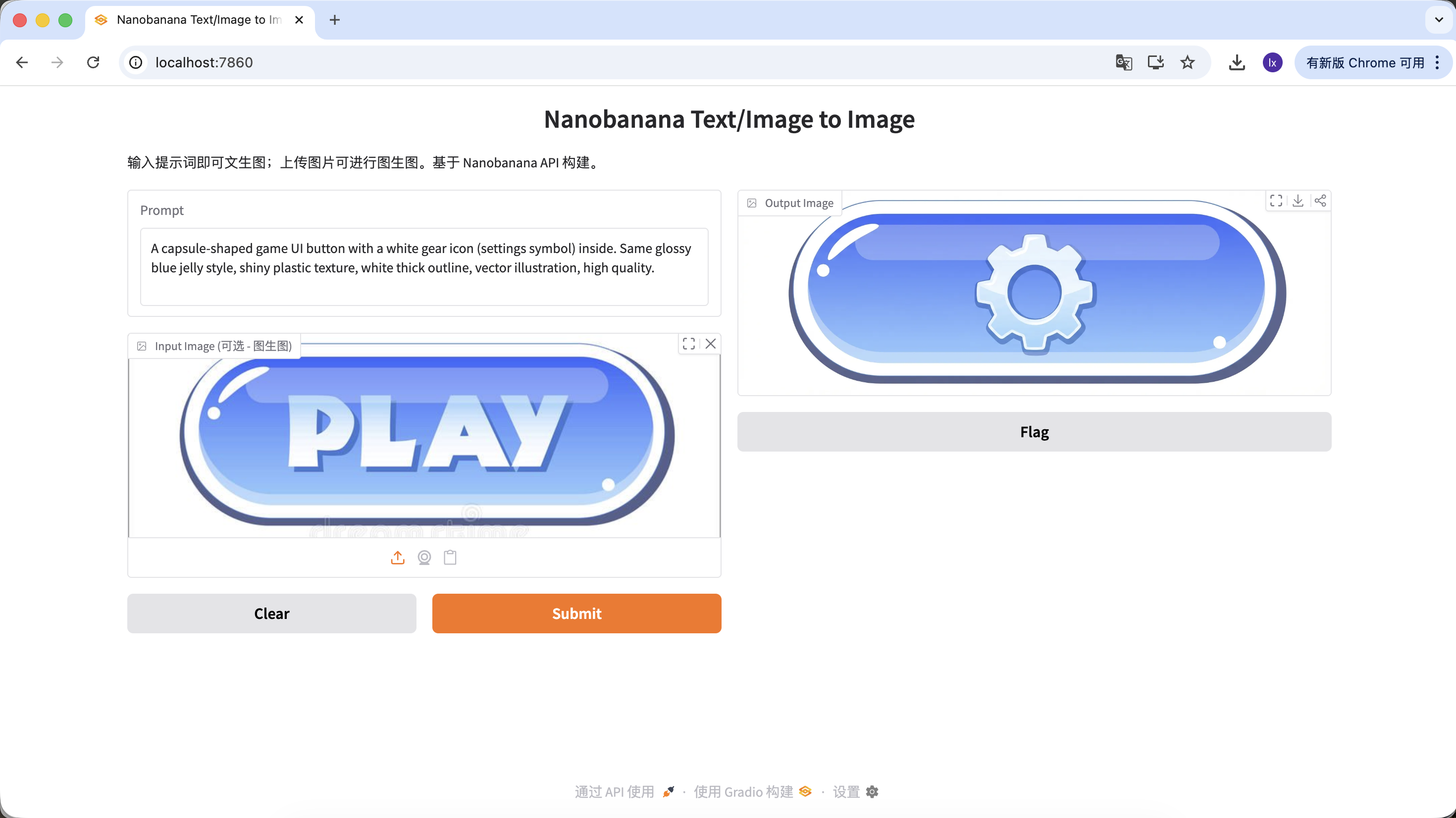
Biến thể B: Nút cài đặt (icon phức tạp)
A capsule-shaped game UI button with a white gear icon (settings symbol) inside. Same glossy blue jelly style, shiny plastic texture, white thick outline, vector illustration, high quality.
Biến thể C: Nút chơi lại (thay đổi hình dạng)
Nếu cần thay đổi hình dáng nút, bạn có thể mô tả trực tiếp hình dạng trong prompt, mô hình sẽ cố gắng thay đổi cấu trúc trong khi giữ nguyên đặc trưng chất liệu.
A round game UI button with a white circular arrow icon (replay symbol) inside. Same glossy blue jelly style, shiny plastic texture, white thick outline, vector illustration, high quality.

Thông qua tập thao tác này, bạn không chỉ thay đổi chức năng và icon của nút, mà thậm chí thay đổi hình dáng nút, nhưng tất cả kết quả tạo vẫn giữ nhất quán cao về chất liệu, phối màu và ánh sáng. Đây chính là giá trị cốt lõi của mô hình lớn trong kịch bản nhân giống tài sản thiết kế.
Chương 2: Trợ lý tạo hình ảnh nghe lời hơn -- Ví dụ với Lovart
Trong phần đầu, chúng ta đã gọi NanoBanana trực tiếp qua mã, trải nghiệm quy trình cơ bản "nhập là tạo". Cách này không có vấn đề khi nhu cầu đơn giản. Nhưng khi tác vụ tạo bắt đầu bao gồm nhiều ràng buộc hơn, ví dụ:
- Cần nhiều hình ảnh cùng phong cách
- Cần điều chỉnh liên tục dựa trên kết quả có sẵn
- Cần thay đổi hướng tạo động theo đầu vào của người dùng
Cách gọi đơn lẻ sẽ dần trở nên không đủ dùng.
Lúc này, cần giới thiệu AI Agent (trí năng thể). Phần này lấy Lovart làm ví dụ, cho thấy khi mô hình tạo hình ảnh có "lớp tư duy", toàn bộ quy trình làm việc sẽ thay đổi ra sao. Lưu ý! Đây không phải quảng cáo, chỉ là giúp mọi người nhanh chóng cảm nhận sự tiện lợi của AI Agent~
2.0 Giới thiệu Lovart: Đại lý thiết kế AI của bạn
Lovart là một công cụ thiết kế dựa trên Agent Web. So với công cụ tạo ảnh thông thường, nó thêm một lớp "tư duy và lập kế hoạch" trước khi tạo.
Sau khi vào Lovart, chủ yếu cần hiểu các điều khiển sau:
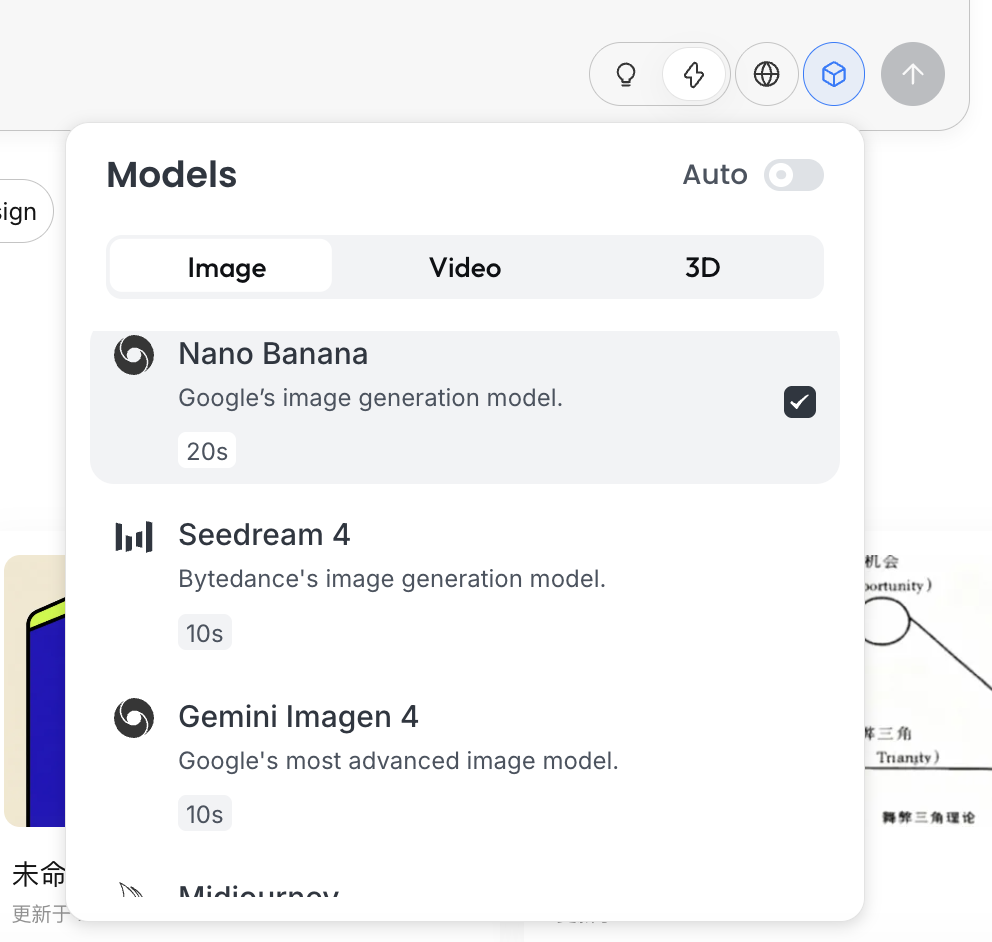
Chọn mô hình
Nhấp vào biểu tượng khối bên dưới ô nhập, có thể xem các mô hình tạo hiện có (như GPT Image, Flux, v.v.).
Để nhất quán với ví dụ trước, phần này vẫn sử dụng NanoBanana làm mô hình tạo cơ sở.
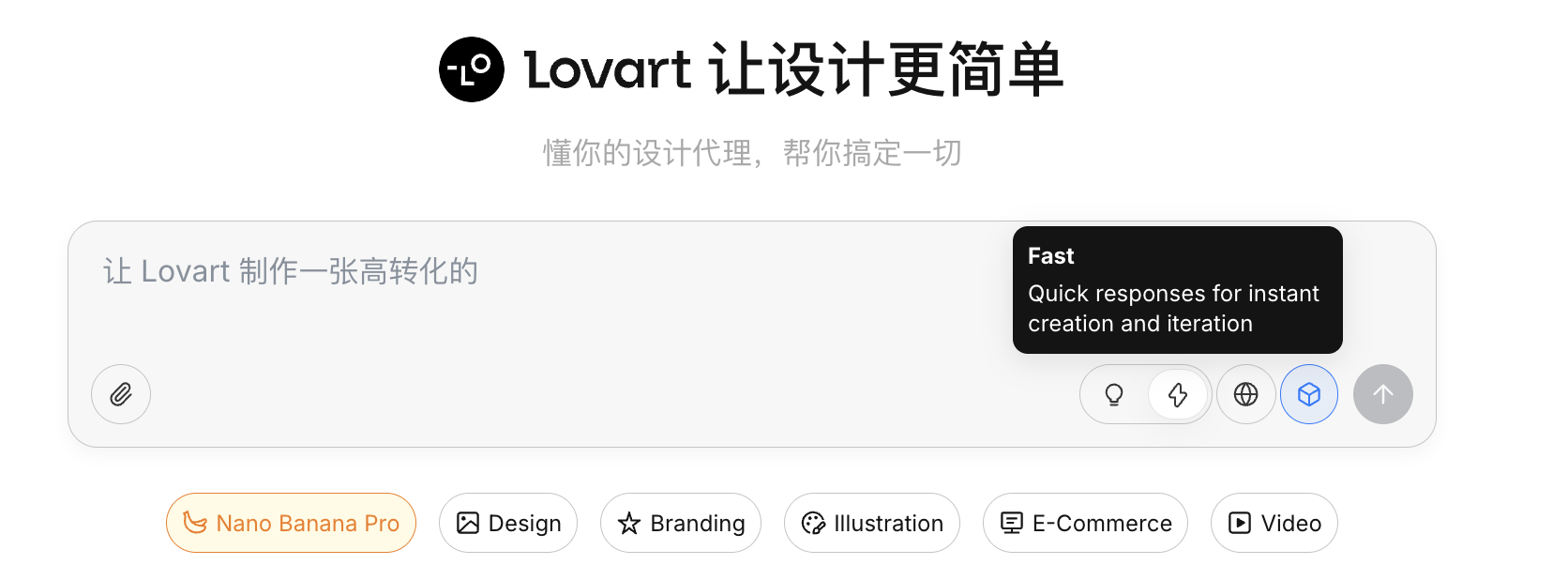
Chế độ tư duy
Đây là công tắc cốt lõi của Lovart:
- Fast Mode: Gần như API gốc, phản hồi nhanh, phù hợp tạo đơn lẻ, chỉ thị rõ ràng
- Thinking Mode: Chế độ Agent, AI sẽ phân tích nhu cầu trước, viết lại prompt, sau đó mới thực hiện tạo
Khả năng truy cập mạng
Sau khi bật biểu tượng trái đất, Agent có thể tìm kiếm thông tin mạng (như xu hướng thiết kế, phong cách phối màu) trong quá trình tạo, làm đầu vào phụ trợ.
2.1 Tại sao API gốc chưa đủ?
Kể cả khi đã có thể tạo hình ảnh chất lượng tốt qua Python, API gốc vẫn có giới hạn trong tác vụ phức tạp. Nguyên nhân chính là: API gốc về bản chất là kiểu mệnh lệnh. Khi bạn yêu cầu nó tạo một đối tượng cụ thể, nó có thể thực hiện trực tiếp; nhưng khi đầu vào trở thành "lập kế hoạch một bộ tài sản game hoàn chỉnh", nó sẽ không chủ động phân tích mục tiêu thành nhiều bước thực hiện.
Điểm khác biệt cốt lõi của Lovart nằm ở cơ chế Agent. Giữa đầu vào người dùng và mô hình tạo hình ảnh, nó thêm một lớp logic để hiểu và lập kế hoạch: nhận diện ý định người dùng trước, sau đó phân tích tác vụ, viết lại prompt, cuối cùng mới thực hiện tạo.
2.2 Demo thực tế: 5 phút tạo bộ sticker IP
Lấy ví dụ "Tạo một bộ sticker IP vịt lập trình viên", xem Agent tham gia vào toàn bộ quy trình như thế nào.
Giai đoạn 1: Lập kế hoạch (Khả năng tư duy của Agent)
Vấn đề của API gốc: Bạn cần tự suy nghĩ thiết kế nhân vật, trạng thái cảm xúc, và viết prompt riêng cho mỗi hình.
Cách làm của Lovart:
- Bật chế độ Thinking Mode
- Nhập một câu lệnh:
Thiết kế một bộ sticker IP vịt lập trình viên, phong cách phẳng, dễ thương
AI sẽ không vẽ ngay mà tìm kiếm hình ảnh thiết kế vịt lập trình viên liên quan trên mạng. Xuất một kế hoạch đã phân tích, tự động tạo các cảnh Debug, Coffee Break, Panic, v.v., và tạo nhiều mô tả thị giác tương ứng.
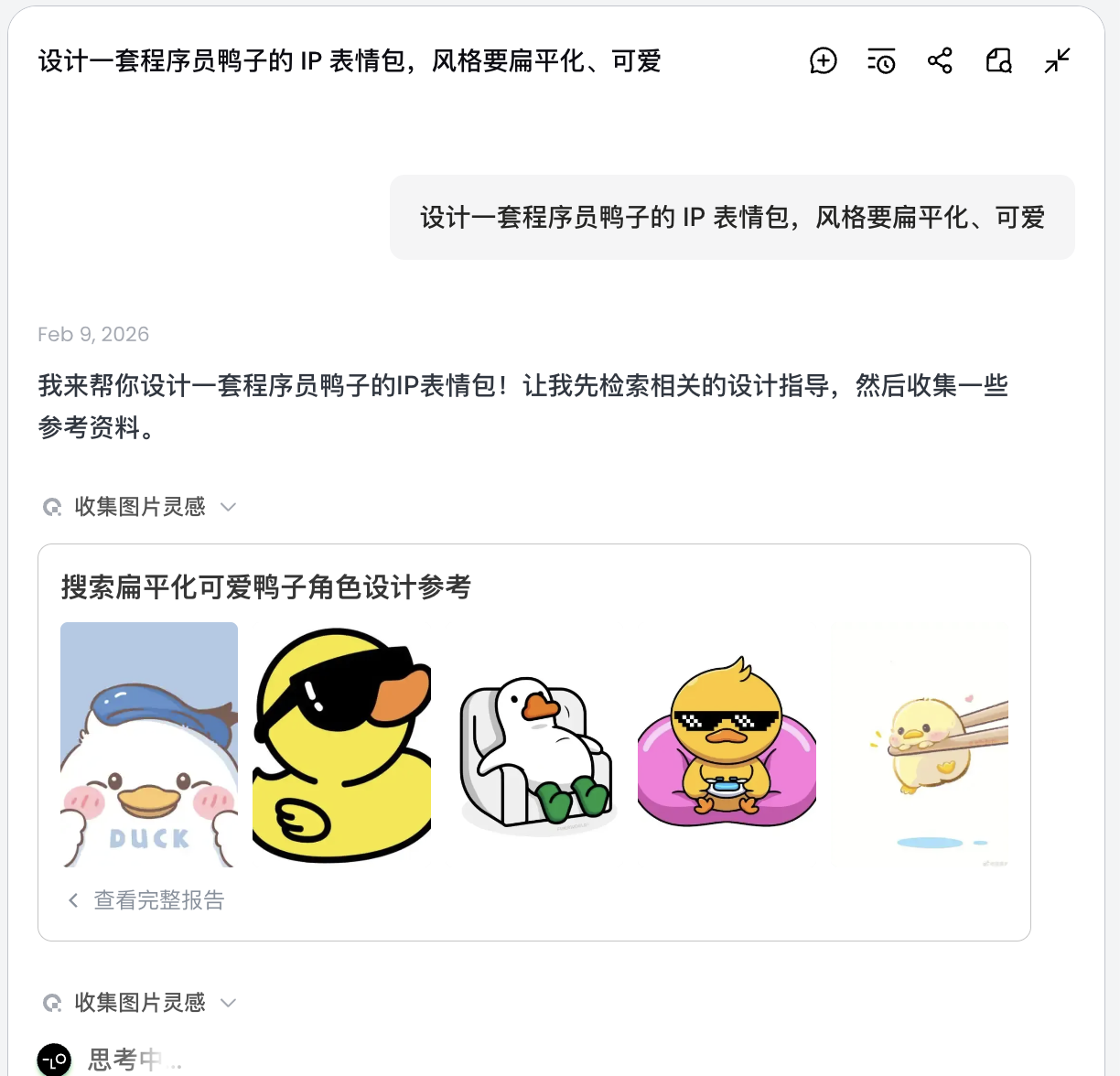

Trong bước này, AI chuyển từ "người thực thi" thành "người lập kế hoạch". Sau khi AI phân tích xong nhu cầu, bạn có thể xem nhiều hình ảnh vịt lập trình viên với phong cách và nội dung khác nhau trong vùng canvas của Lovart. Có thể bắt đầu chọn phong cách bạn thích.
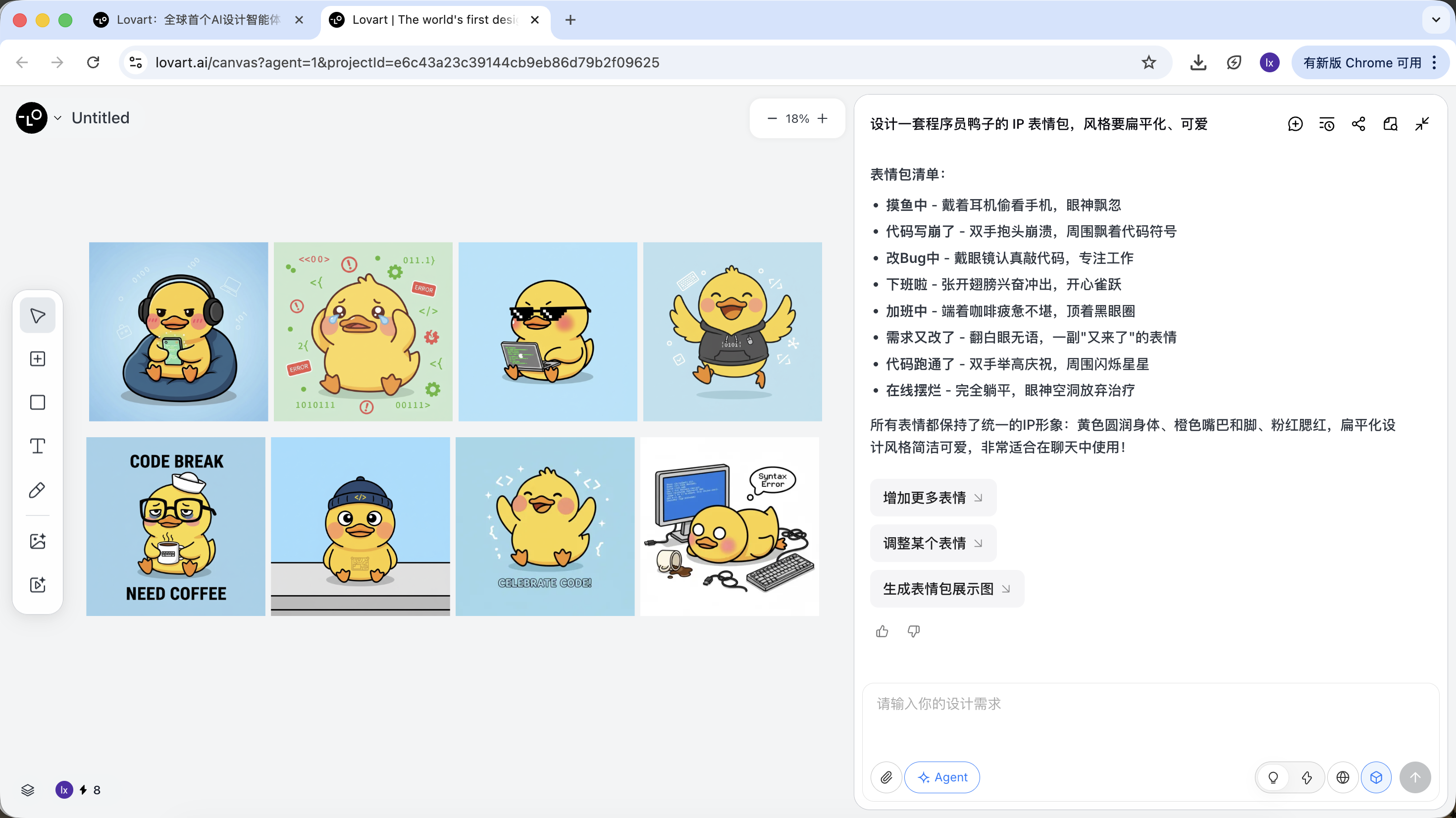
Giai đoạn 2: Nhất quán (Neo thị giác dựa trên tham chiếu)
Hình ảnh trong Lovart không chỉ là kết quả, mà còn tham gia vào việc tạo tiếp theo.
Tham chiếu hình ảnh hoàn chỉnh
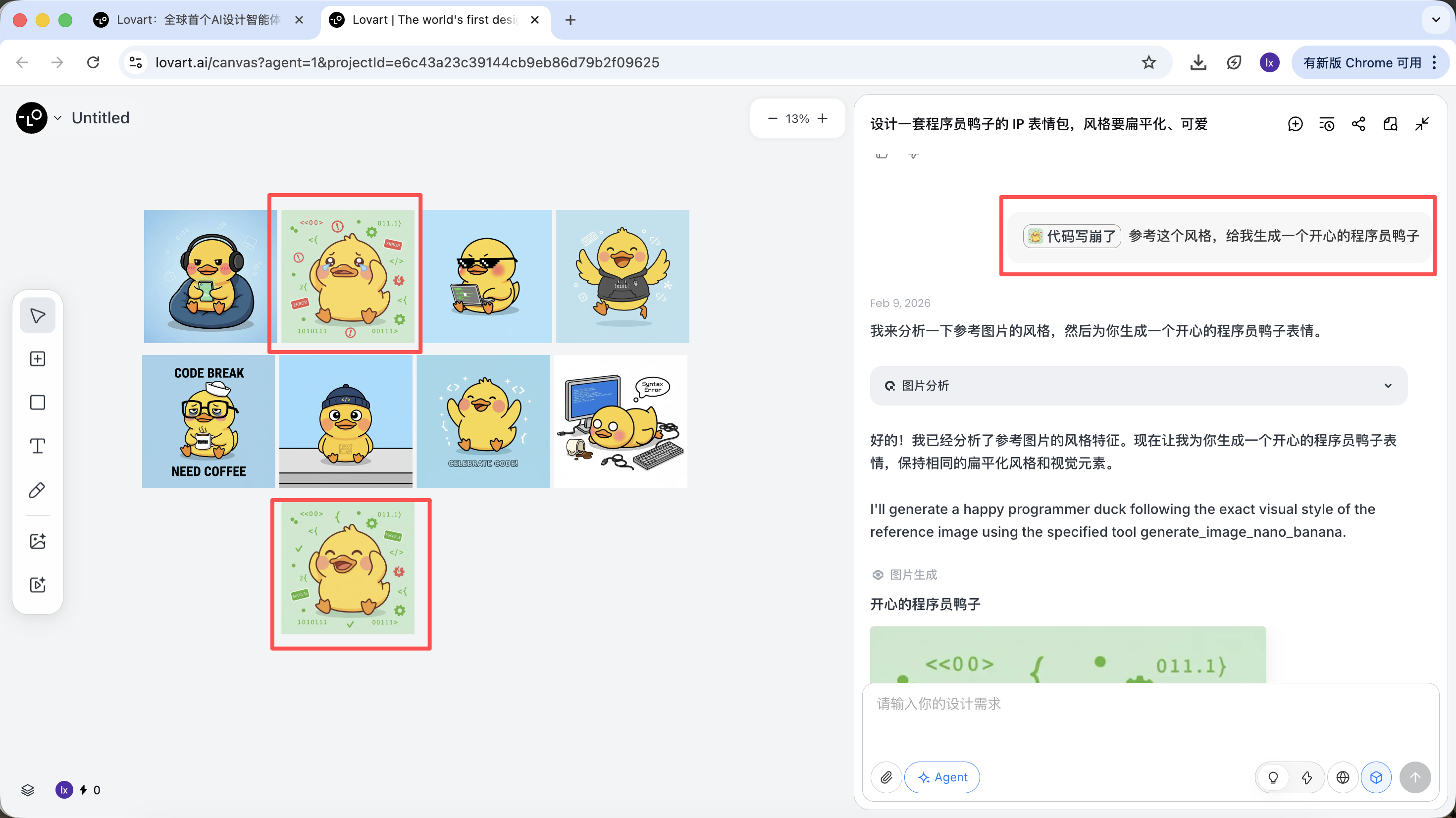
- Chọn một "vịt tiêu chuẩn" hài lòng nhất từ bản nháp, nhấp vào hình ảnh tương ứng trong vùng canvas
- Hình ảnh này sẽ tự động xuất hiện trong vùng hội thoại, làm Reference
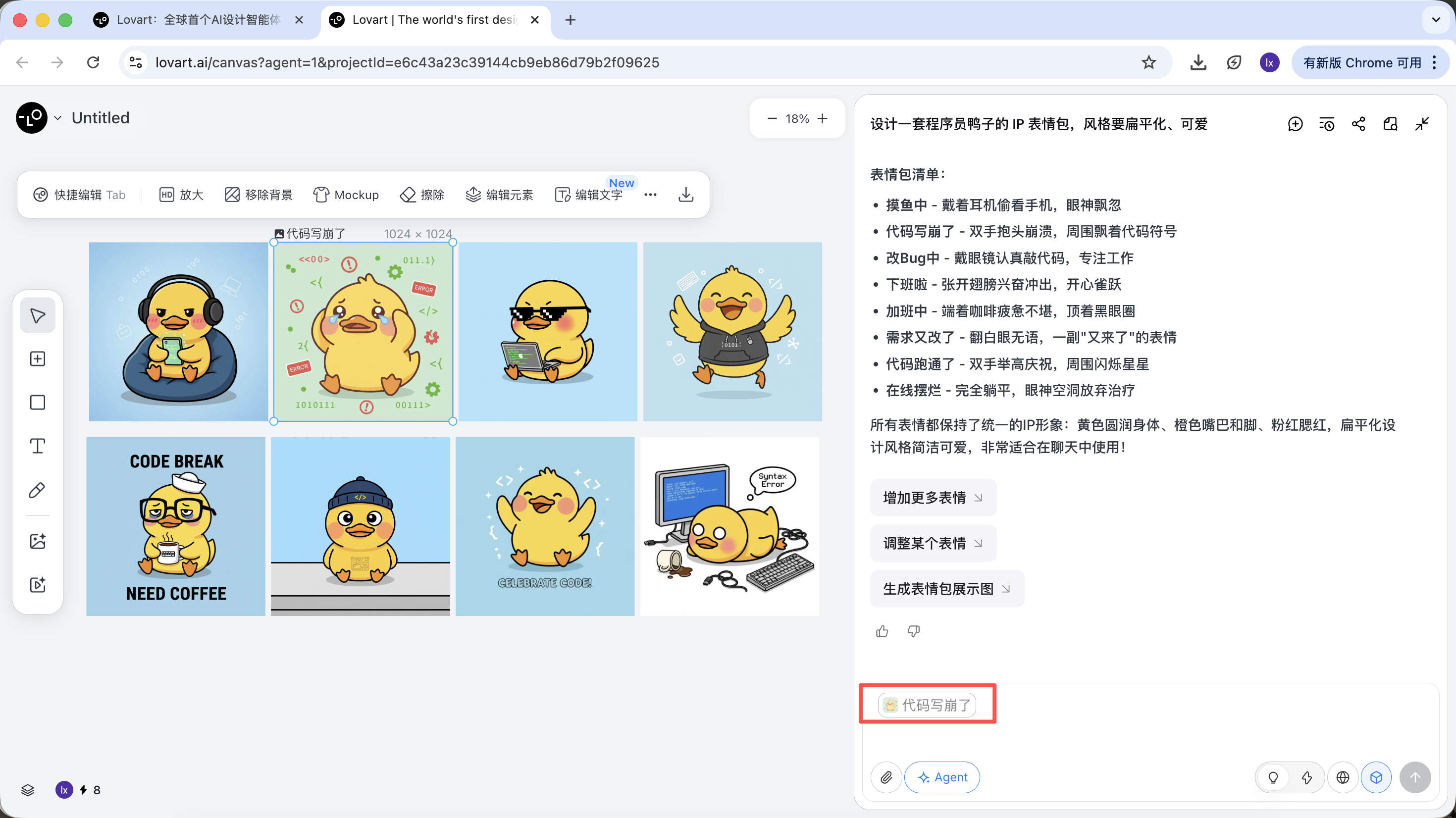
- Nhập hành động mới (như vui vẻ) và tạo
Kết quả tạo sẽ kế thừa phối màu, tỷ lệ và chi tiết của ảnh mẫu.
Tham chiếu cục bộ / Kết hợp đa ảnh
Ngoài việc dùng cả ảnh làm tham chiếu, Lovart còn hỗ trợ:
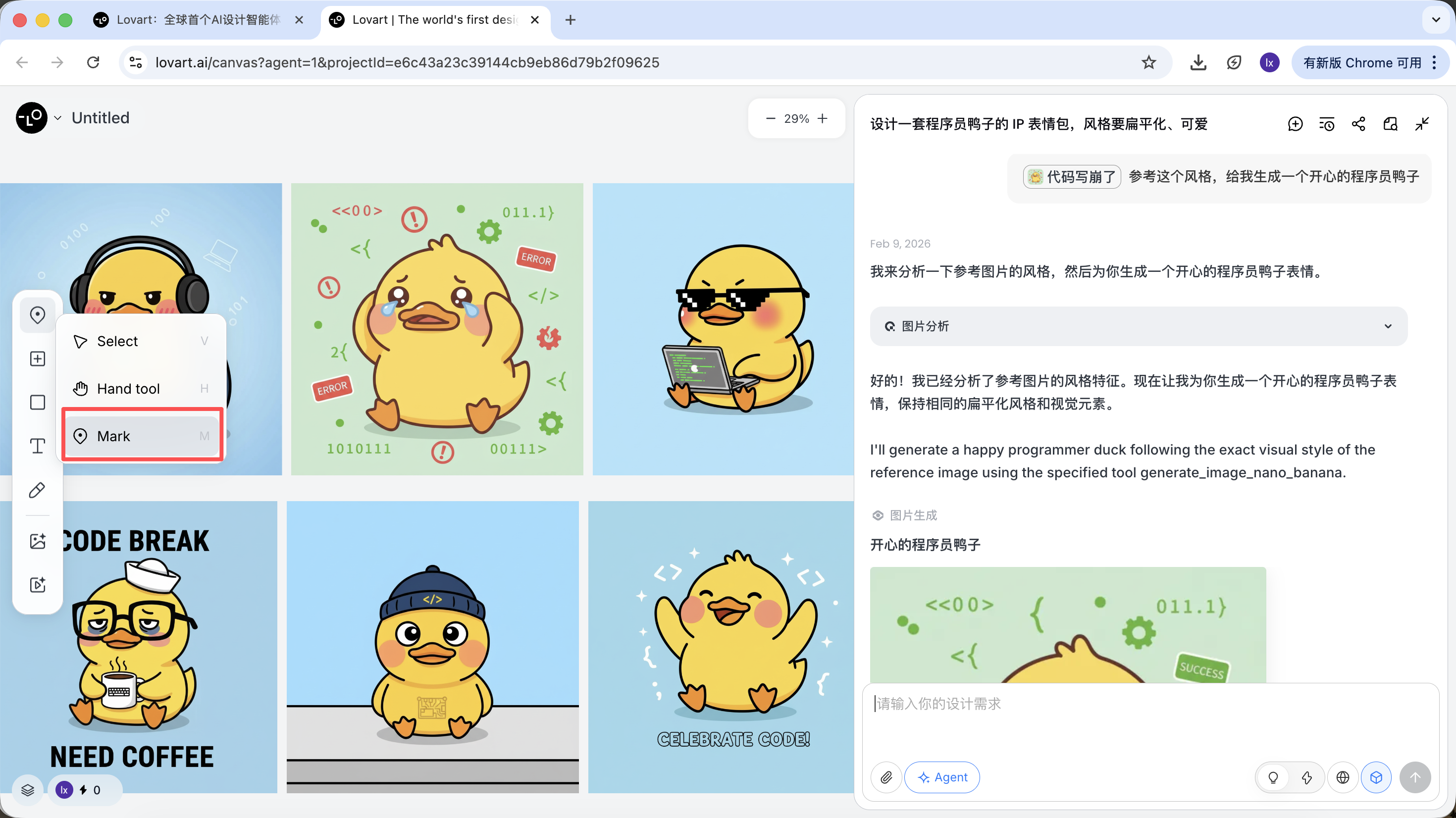
- Chỉ chọn vùng cục bộ của hình ảnh (ví dụ chỉ tham chiếu mũ hoặc biểu cảm)
Nhấp vào tab bên trái vùng canvas, chọn phím 「Mark」, đánh dấu vùng cục bộ trên hình ảnh mục tiêu, nội dung phần này sẽ tự động đồng bộ vào ô hội thoại. Ví dụ ở đây chúng ta có thể chọn thay đổi màu nền.
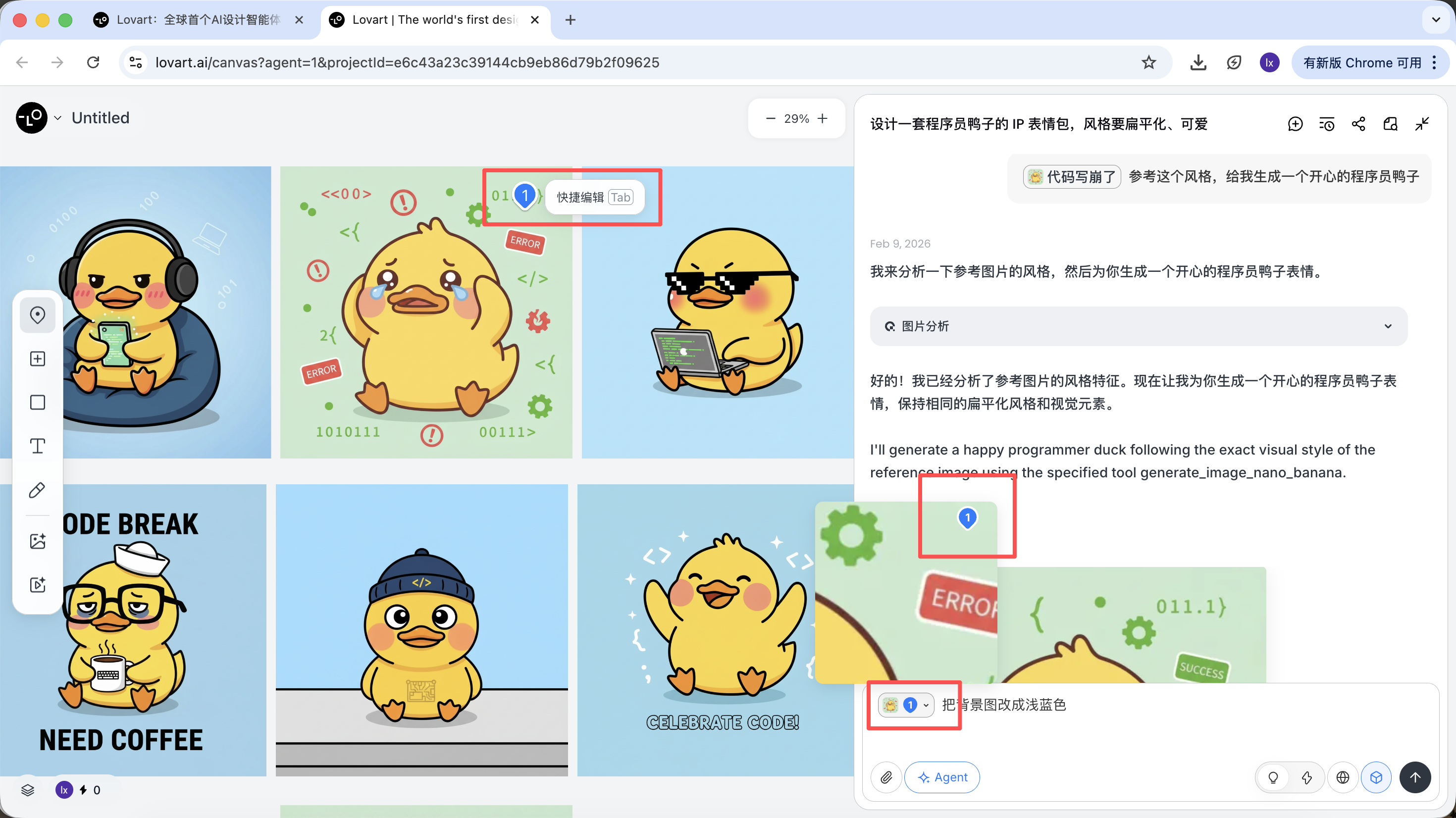
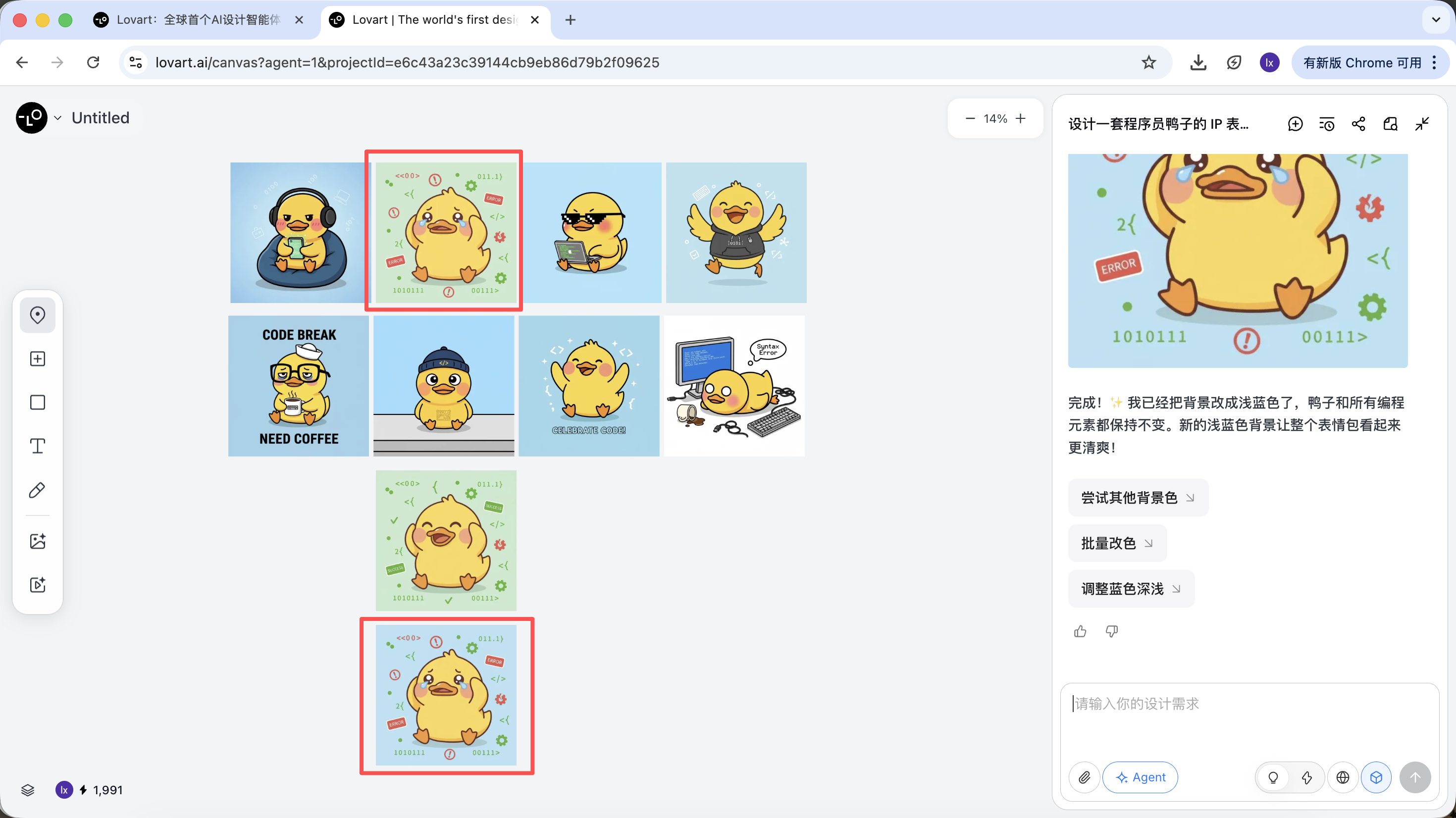
Có thể thấy hình ảnh mới tạo chỉ thay đổi màu nền, điều này cũng nhất quán với yêu cầu chúng ta nhập.
- Trích dẫn tử phần tử từ nhiều hình ảnh khác nhau, sau đó kết hợp tạo kết quả mới
Ví dụ: bạn có thể giữ phần thân nhân vật từ ảnh A, đồng thời chỉ thay mũ thành phong cách từ ảnh B, Agent sẽ tự động tích hợp các ràng buộc thị giác này ở backend.
Lấy vịt lập trình viên làm ví dụ, chúng ta có thể chọn giữ hình tượng vịt từ ảnh đầu tiên, và thay nó vào ảnh thứ hai làm phần tử chính thể.
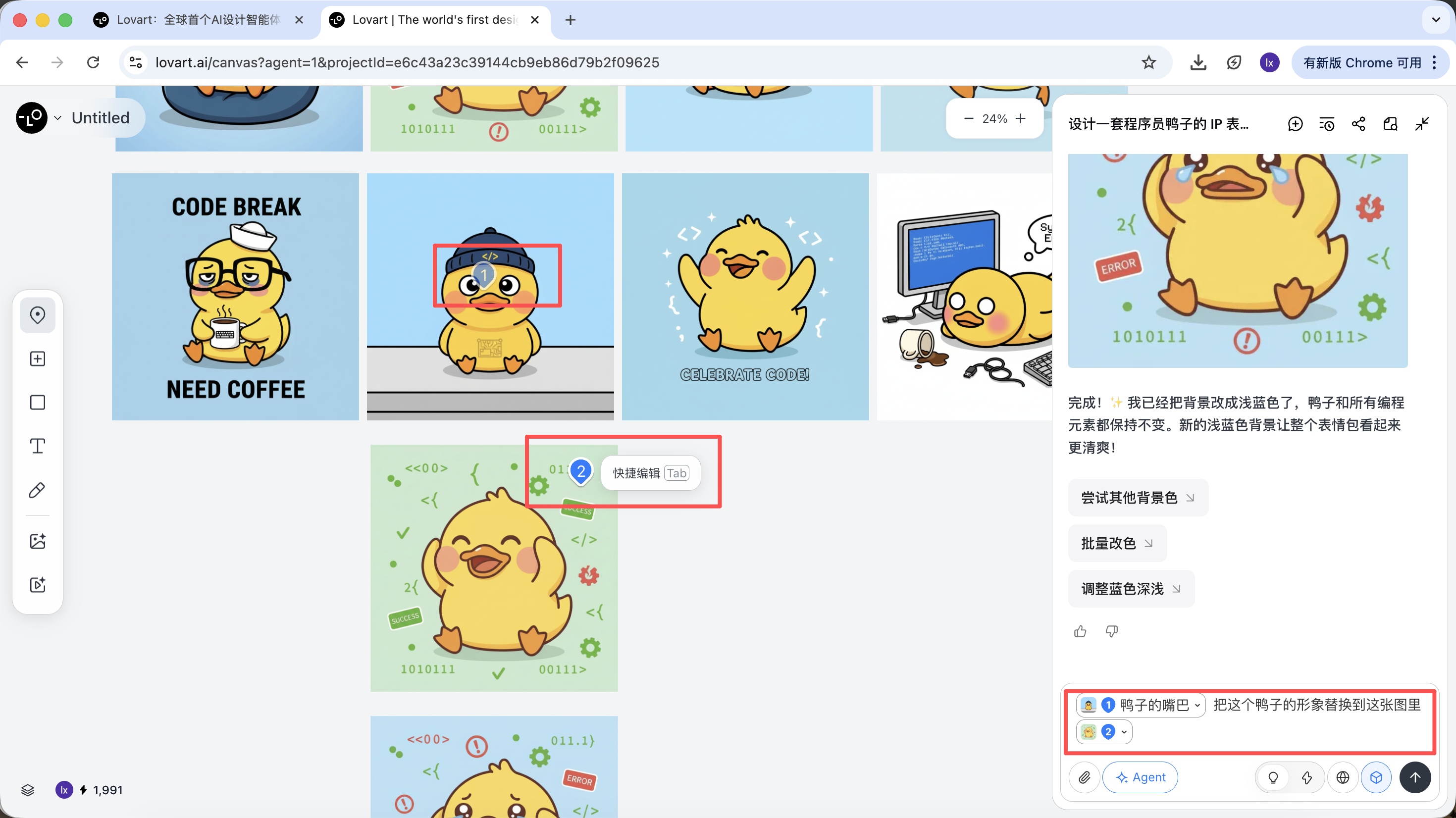
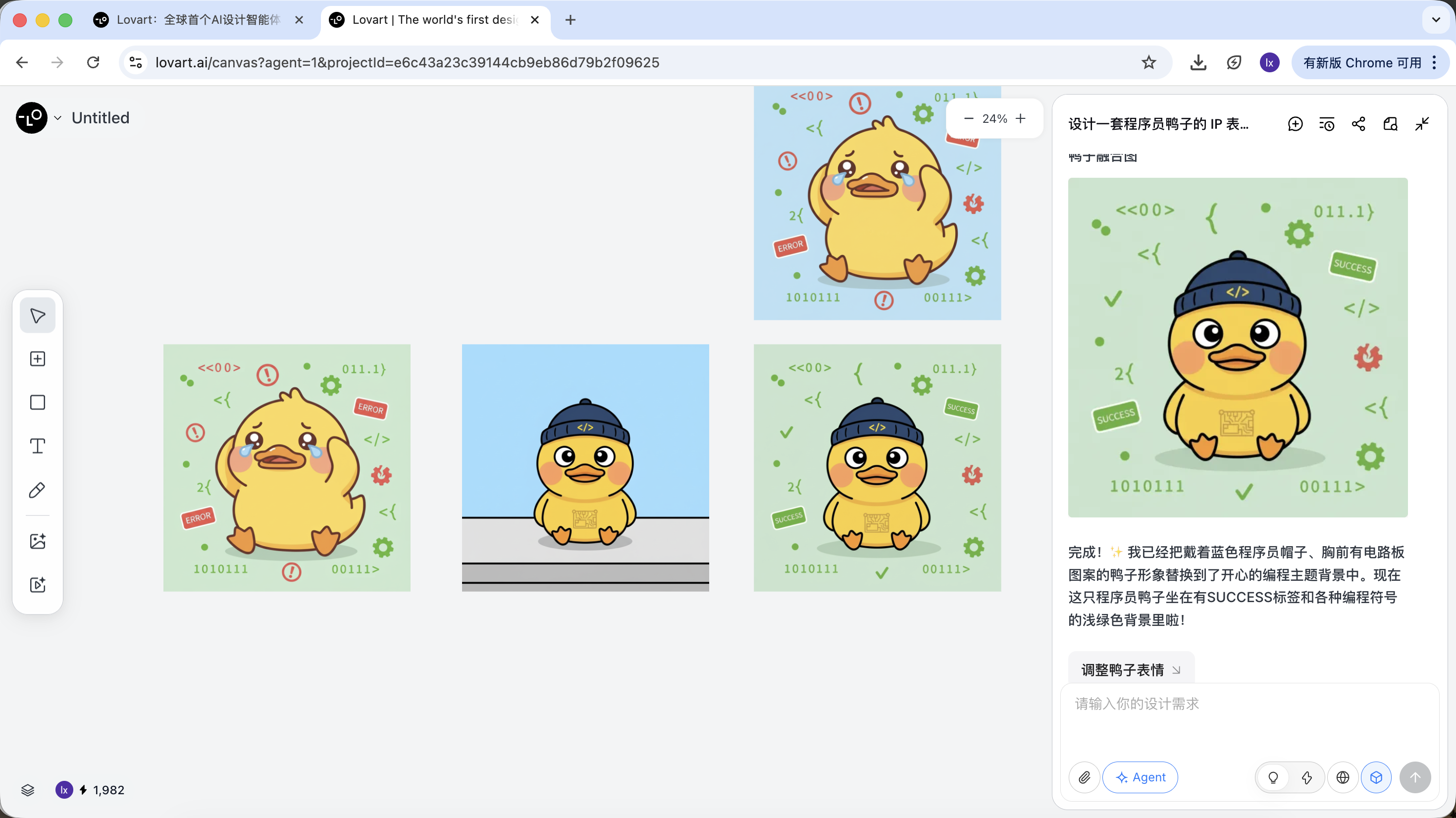
Hiệu quả cuối cùng cũng rất rõ rệt. Bạn cũng có thể thử các kết hợp khác!
Giai đoạn 3: Triển khai (Gọi công cụ của Agent)
Sau khi tạo xong, có thể trực tiếp thực hiện: phóng to, xóa nền, xóa bỏ, v.v.
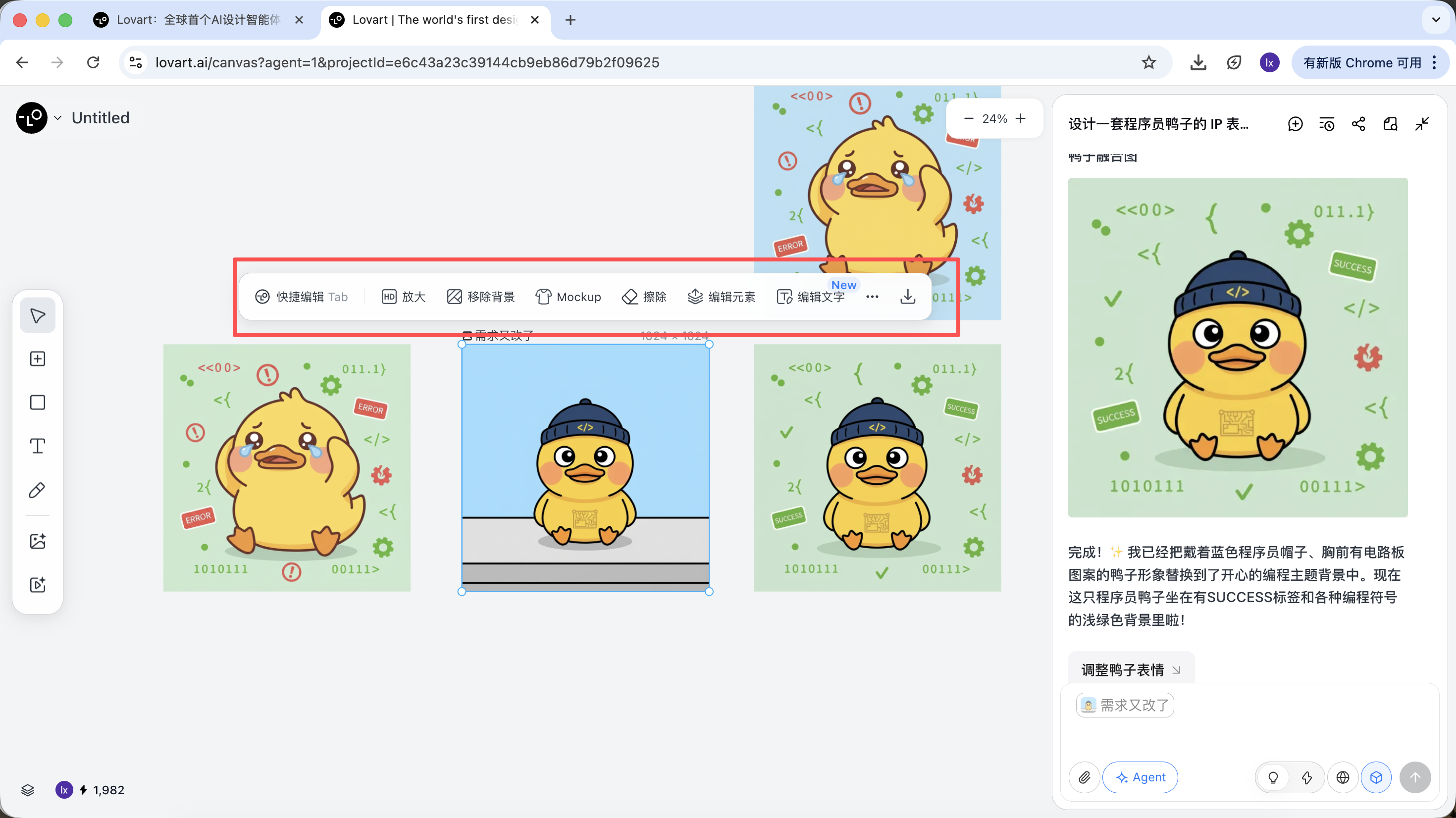
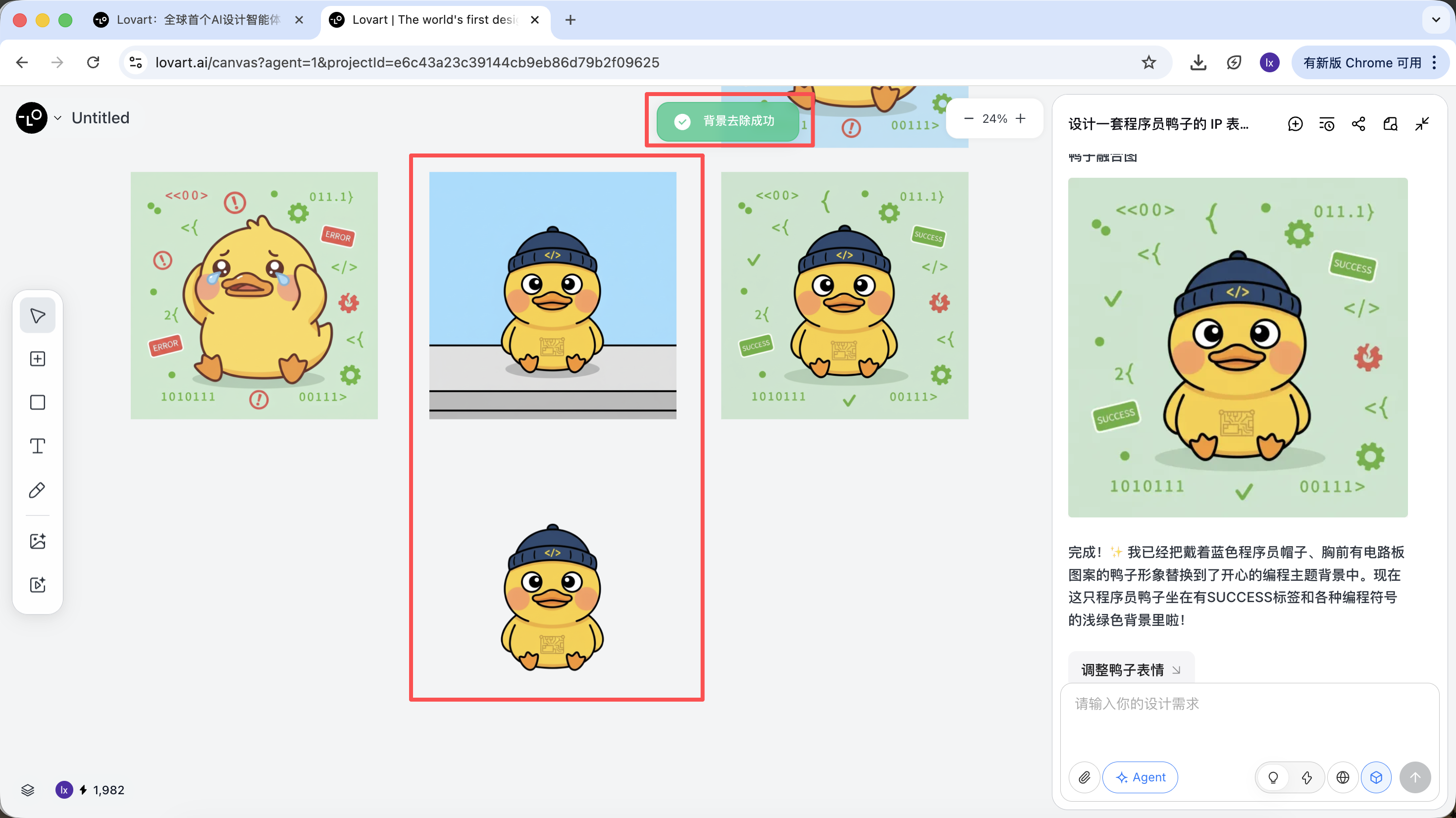
Đây không phải là bộ lọc đơn giản, mà là kết quả do Agent tự động điều phối các công cụ khác nhau.
Sau khi xác định xong phong cách nền tảng, có thể rất nhanh chóng tạo một loạt hình ảnh sticker.
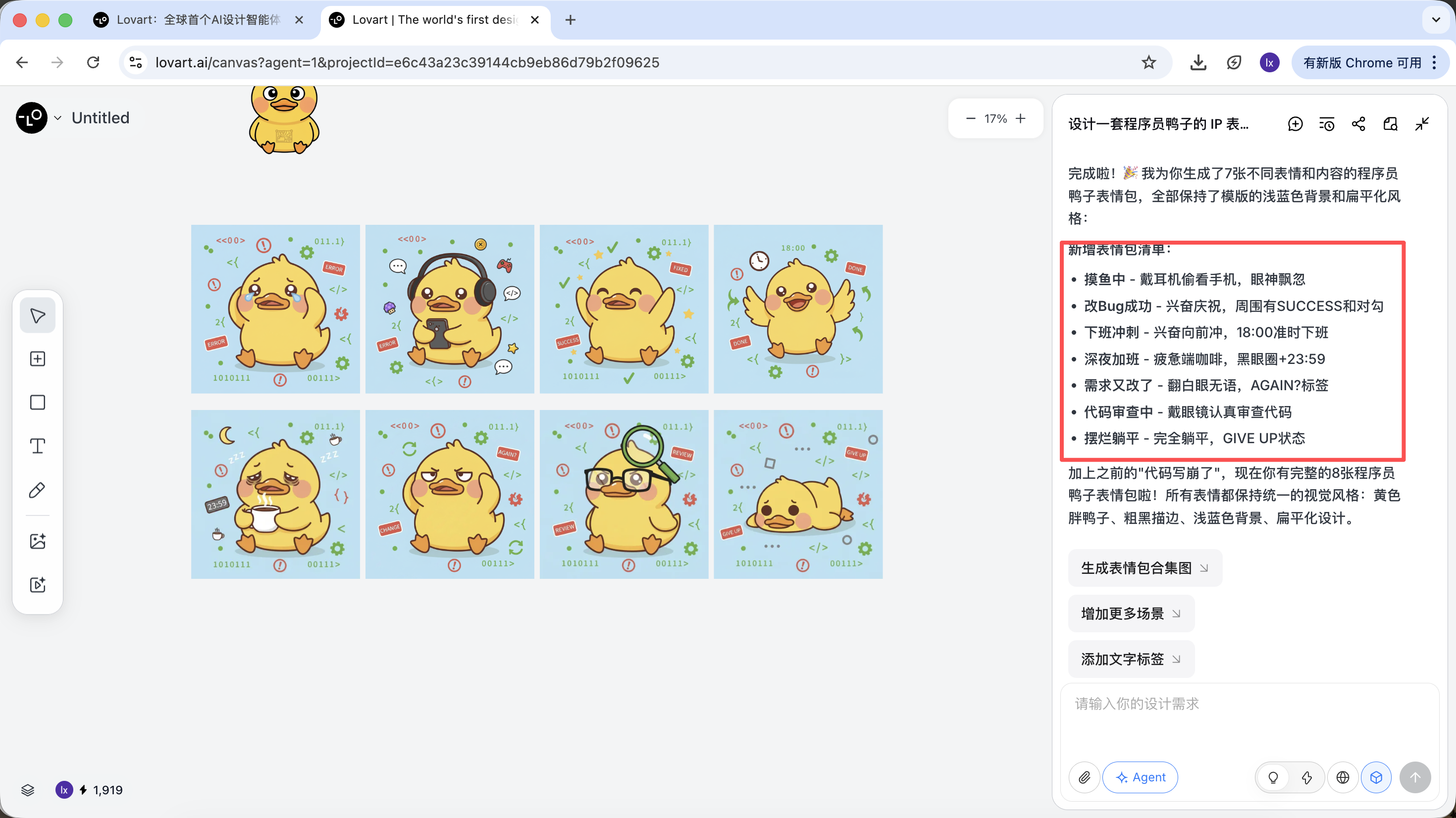
Cuối cùng chúng ta nhận được là tài sản cấp sản xuất có thể giao ngay, chứ không chỉ là một hình ảnh trình diễn.
2.3 Hướng dẫn sử dụng và tính phí
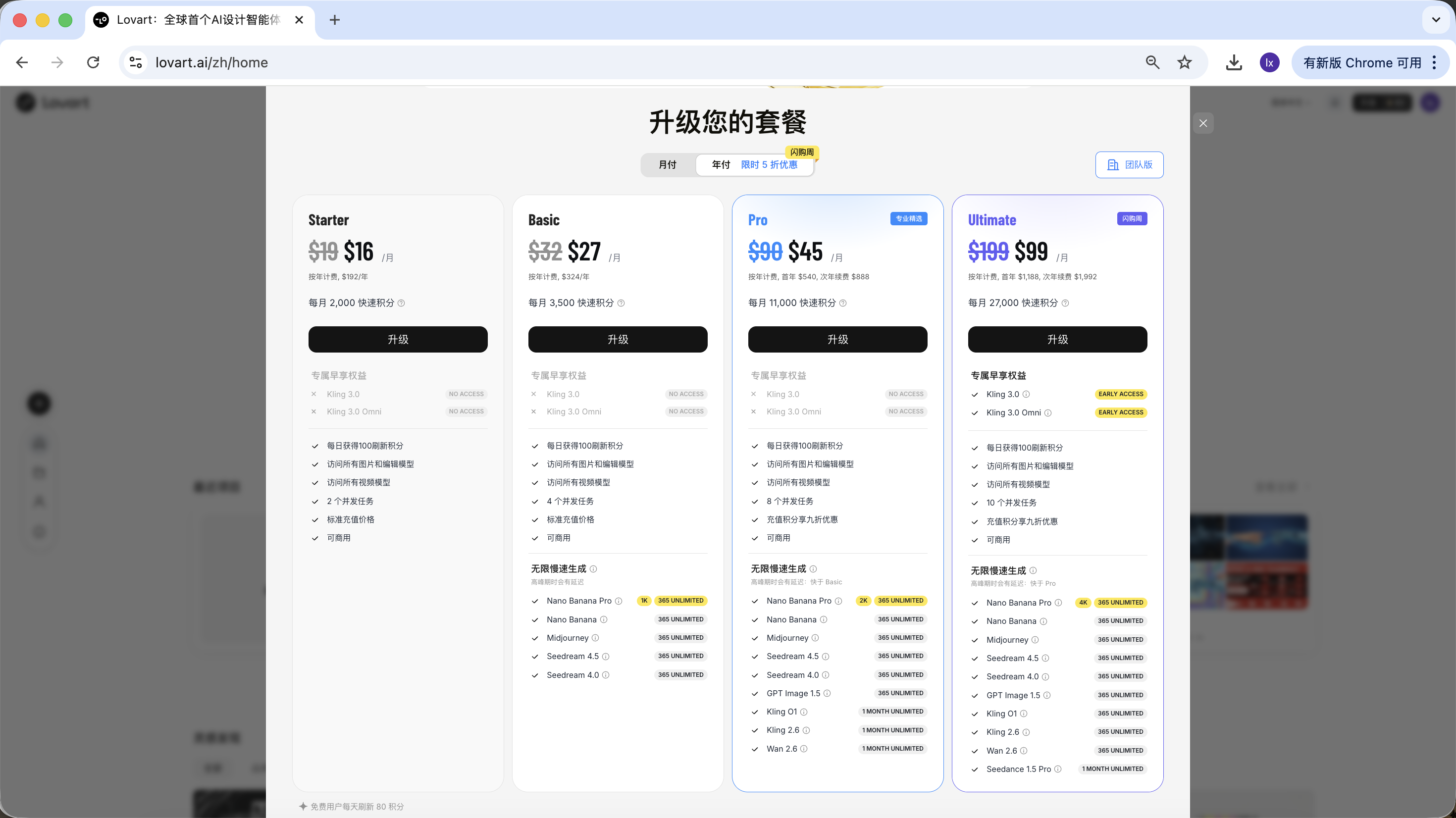
Lovart áp dụng mô hình tính phí theo gói đăng ký, các gói khác nhau tương ứng với hạn mức sử dụng và quyền chức năng khác nhau, cụ thể dựa trên hiển thị trên trang chủ chính thức.
Hướng dẫn này không giới thiệu hoặc so sánh bất kỳ gói nào; nếu có nhu cầu trong sử dụng thực tế, bạn có thể chọn nâng cấp trả phí theo tình hình cá nhân. Hiện tại hỗ trợ thanh toán qua Alipay và các phương thức khác.
Tóm tắt
Lovart không phải thay thế mô hình cơ sở, mà thông qua cơ chế Agent, nâng cấp tạo hình ảnh từ "thực thi đơn lẻ" thành "quy trình làm việc liên tục".
Khi tác vụ bắt đầu liên quan đến lập kế hoạch, nhất quán và giao hàng, ưu điểm của loại công cụ này sẽ trở nên rất rõ rệt.
Chương 3: Tự tay làm một trợ lý vẽ thông minh
Ngoài việc sử dụng trực tiếp Lovart, chúng ta cũng có thể tự triển khai một trợ lý vẽ phiên bản đơn giản hóa.
Chương này lấy "tự động tạo hình minh họa bài viết" làm ví dụ, từ vấn đề thực tế出发, từng bước xây dựng một Agent có khả năng tư duy.
3.1 Nỗi đau: Tại sao gửi trực tiếp bài viết cho mô hình vẽ không hiệu quả?
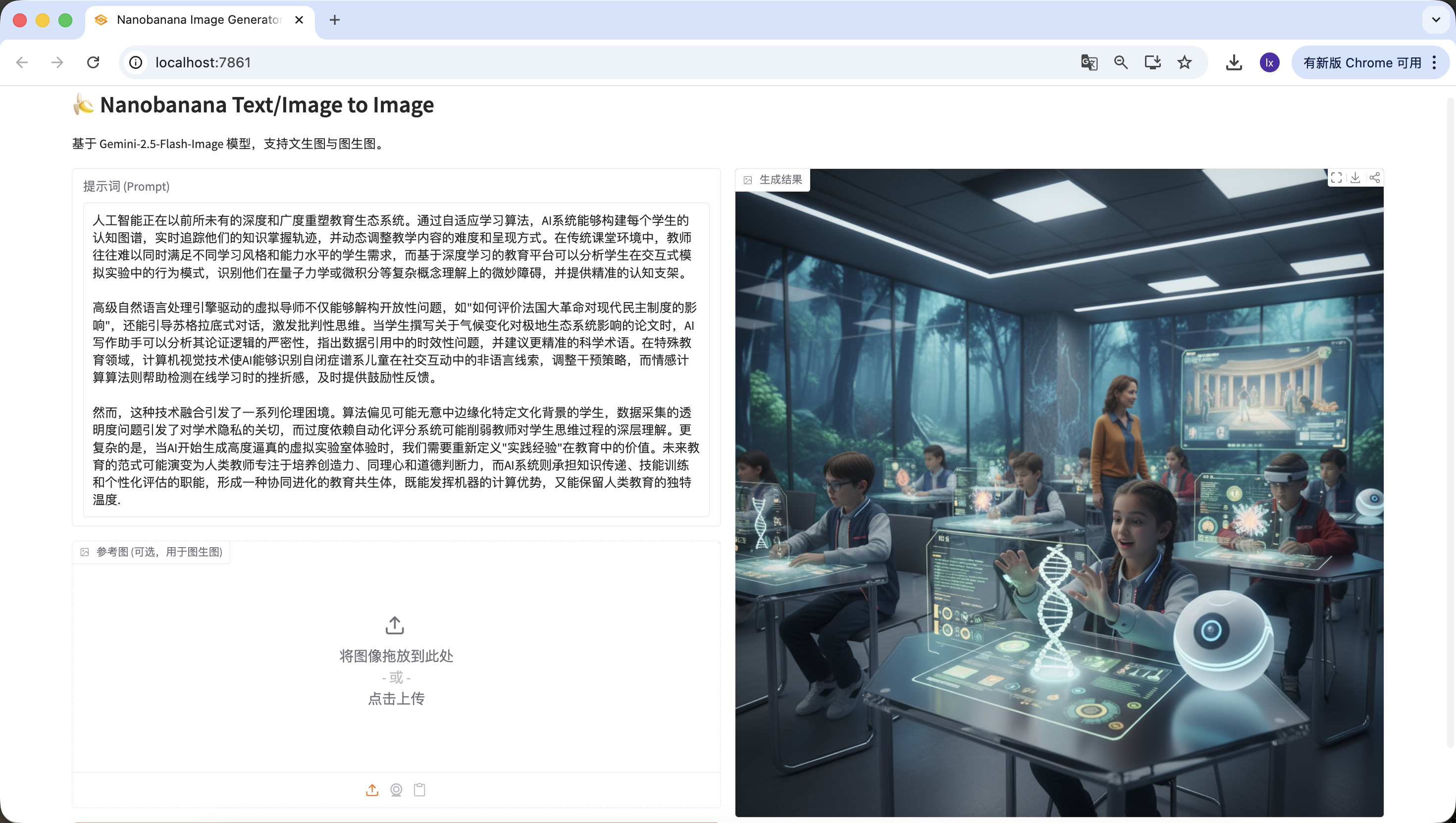
Gửi trực tiếp một bài viết dài cho NanoBanana và yêu cầu tạo hình minh họa thường khó nhận được kết quả lý tưởng. Nguyên nhân không phải mô hình "vẽ không tốt", mà là nó không giỏi hiểu văn bản dài.
Mô hình tạo hình ảnh phù hợp hơn để xử lý mô tả thị giác ngắn gọn, rõ ràng, và khi đầu vào trở thành một bài viết có cấu trúc, trọng điểm và bối cảnh, mô hình không thể phân biệt nội dung nào mới thực sự cần thể hiện trong hình. Điều này thường dẫn đến kết quả tạo lệch chủ đề, hoặc chỉ nắm bắt được chi tiết rời rạc, thiếu khả năng khái quát tổng thể.
Về bản chất, mô hình hình ảnh chỉ có khả năng "thực thi", nhưng thiếu quá trình phân tích và lựa chọn văn bản.
3.2 Hướng giải quyết: Dùng Agent tách "hiểu" và "thực thi"
Để giải quyết vấn đề này, điểm mấu chốt không phải prompt phức tạp hơn, mà là suy nghĩ kỹ trước khi vẽ. Do đó, chúng ta giới thiệu một "lớp tư duy" độc lập vào quy trình tạo, và dựa trên đó xây dựng một Agent đơn giản có thể sử dụng.
Mục tiêu cốt lõi của Agent này chỉ có một: Làm cho hình ảnh cuối cùng tạo ra, gần nhất với ý định biểu đạt thực sự của người dùng.
Toàn bộ quy trình có thể tóm tắt: Đầu vào văn bản dài -> Mô hình ngôn ngữ hiểu và phán đoán -> Tạo prompt thị giác phù hợp -> Mô hình hình ảnh thực thi tạo -> Xuất hình ảnh
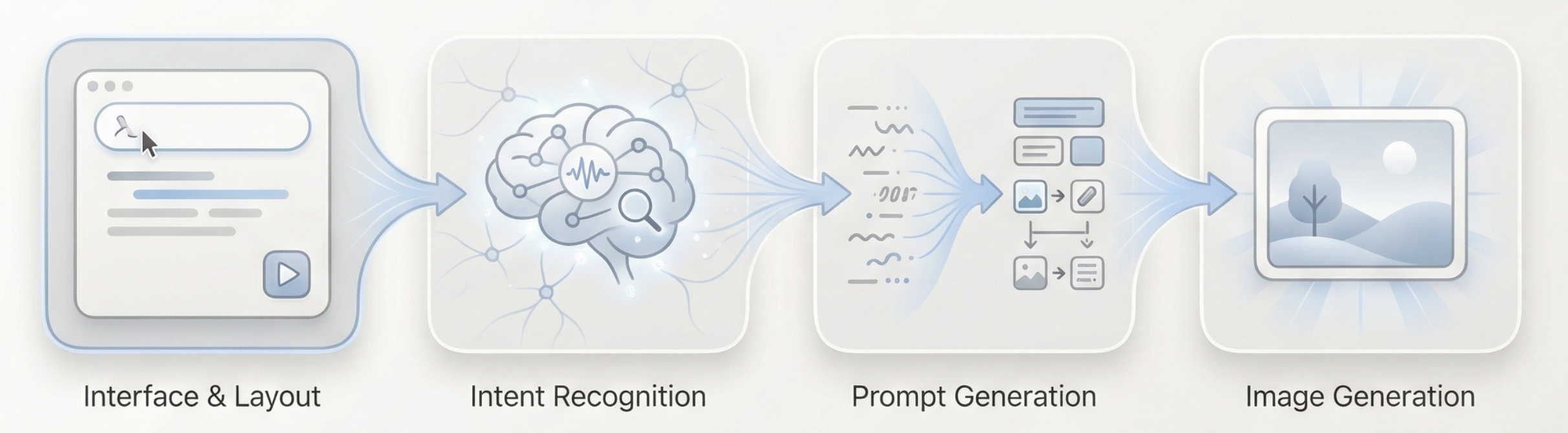
Vậy Agent chúng ta xây dựng làm thế nào để hiểu ý định người dùng?
Ở đây chọn làm một "lớp tư duy" đơn giản hóa, chúng ta thiết lập ba loại ý định khác nhau: đầu vào vô nghĩa, tạo ảnh trực tiếp, văn bản dài cần hiểu.
Trong Agent này, phân công vai trò của từng thành phần có thể tóm tắt thành bốn điểm:
- Mô hình ngôn ngữ làm lõi ra quyết định Nó chịu trách nhiệm hiểu nội dung bài viết, phán đoán ý định đầu vào của người dùng, và phân phối tác vụ vào đường dẫn tạo phù hợp, quyết định "tiếp theo làm gì" và cách tạo prompt tạo ảnh.
- Mô hình hình ảnh làm người thực thi Mô hình hình ảnh không tham gia hiểu và phán đoán, chỉ nhận chỉ dẫn thị giác đã được sắp xếp, tập trung hoàn thành render hình ảnh.
- Người dùng làm người hướng dẫn có thể can thiệp Ngoài việc nhập văn bản trực tiếp, người dùng cũng có thể điều chỉnh prompt đã tạo trong quá trình, hoặc thêm ảnh tham khảo để hỗ trợ tạo, từ đó hướng dẫn và tinh chỉnh kết quả cuối cùng.
- Gradio và API backend làm lớp承载 tổng thể Chúng chịu trách nhiệm kết nối giao diện, gọi mô hình và hiển thị kết quả, đảm bảo toàn bộ Agent có thể vận hành ổn định dưới dạng một ứng dụng Web hoàn chỉnh.
3.3 Chuẩn bị thực hành: Lấy API
Có vẻ rất thú vị phải không! Để chạy thông quy trình trên, chúng ta chỉ cần chuẩn bị hai loại API.
Tay: NanoBanana API (tạo hình ảnh)
Sử dụng trực tiếp API Key và API URL đã cấu hình ở Chương 1, không cần thiết lập thêm.
Não: SiliconFlow API (tư duy văn bản)
Chúng ta cần một mô hình ngôn ngữ lớn để đảm nhận vai trò "lớp tư duy". Hướng dẫn này sử dụng dịch vụ mô hình do SiliconFlow cung cấp: https://cloud.siliconflow.cn
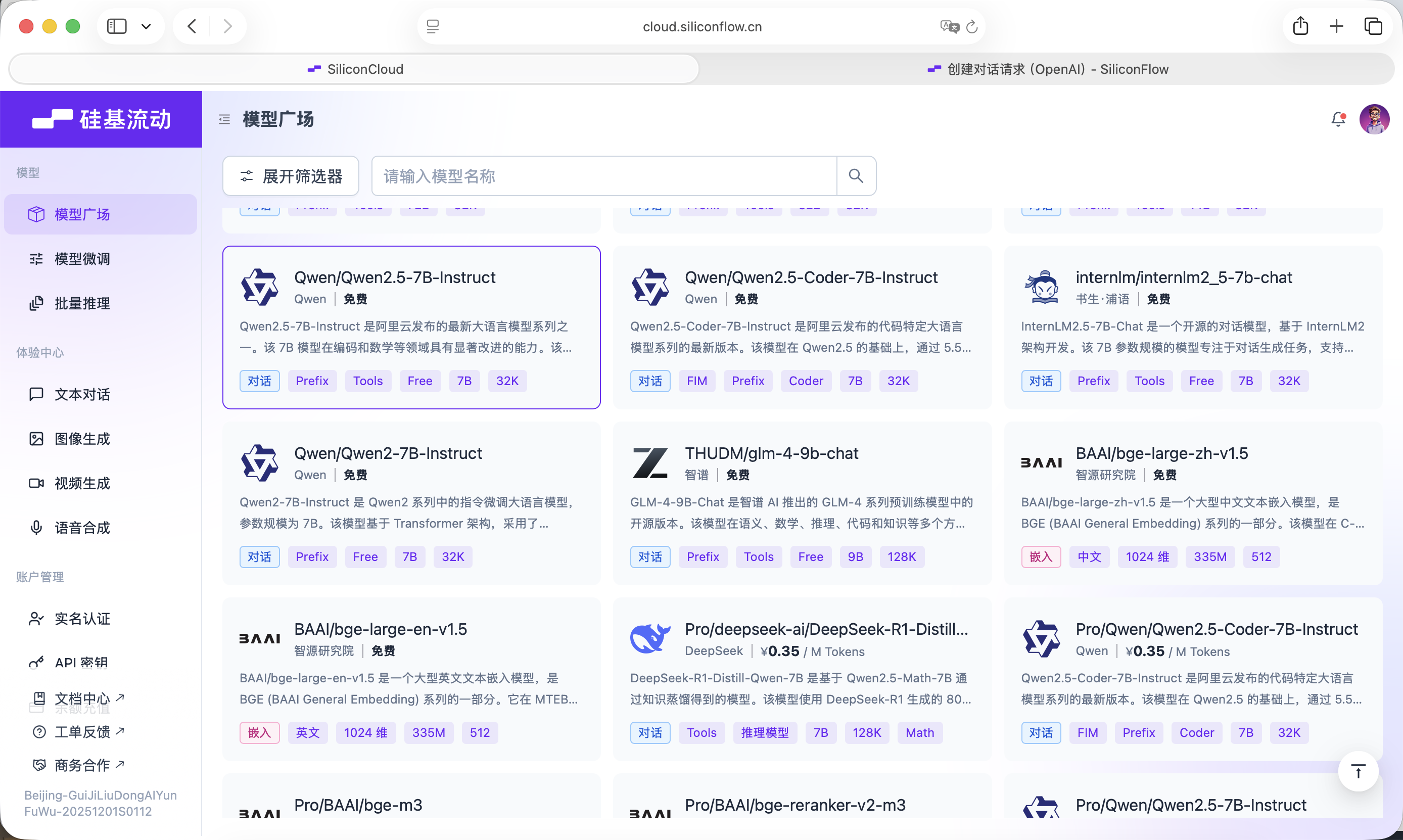
SiliconFlow cung cấp giao diện tương thích với quy cách OpenAI API, có thể rất tiện lợi gọi trong dự án thông qua yêu cầu mạng tiêu chuẩn. Ở đây chúng ta chọn mô hình Qwen2.5-7B-Instruct miễn phí, nội dung cần gọi đã được viết trong Prompt dưới đây. Trước khi bắt đầu, bạn chỉ cần đăng ký tài khoản và tạo API Key trên trang chủ chính thức.
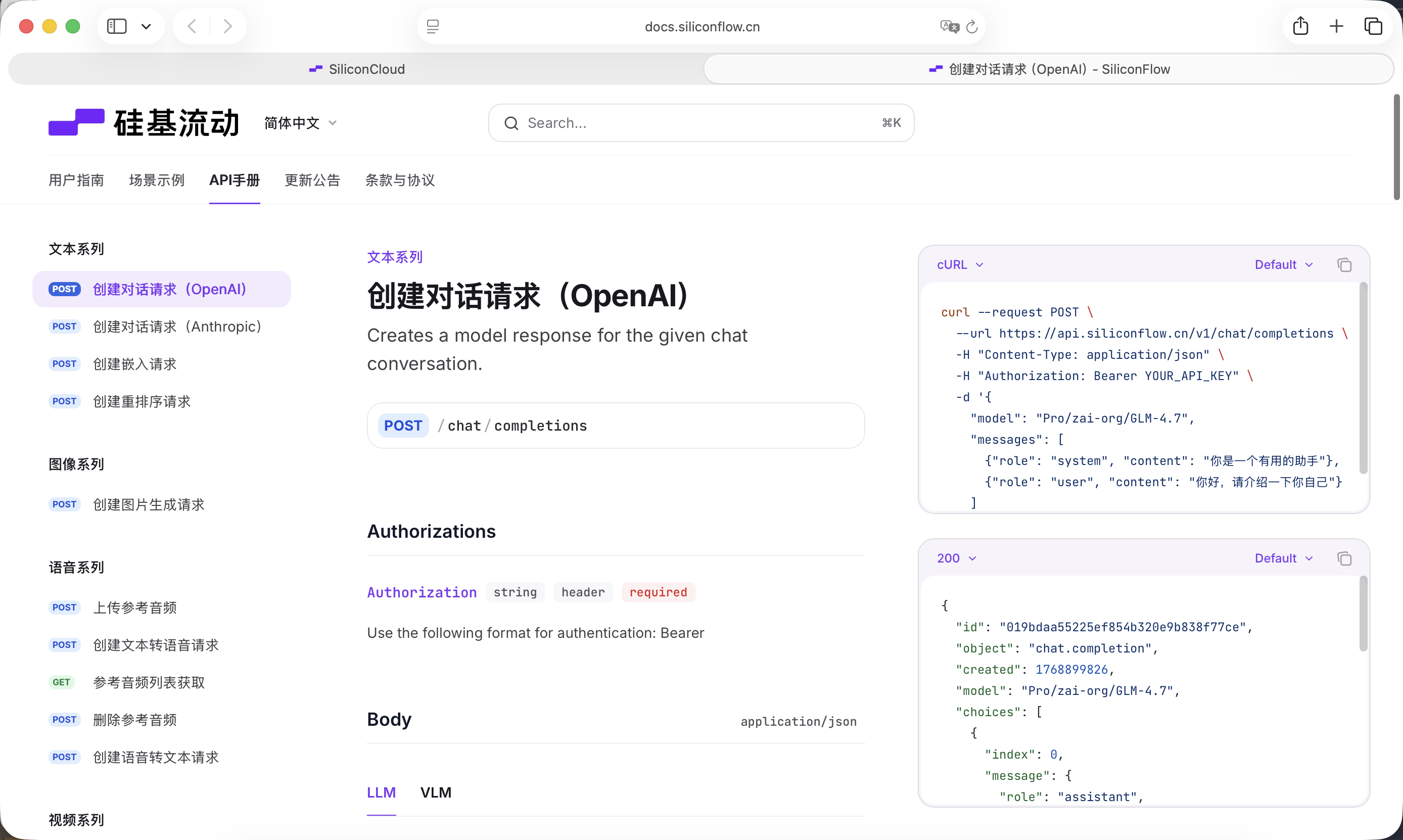
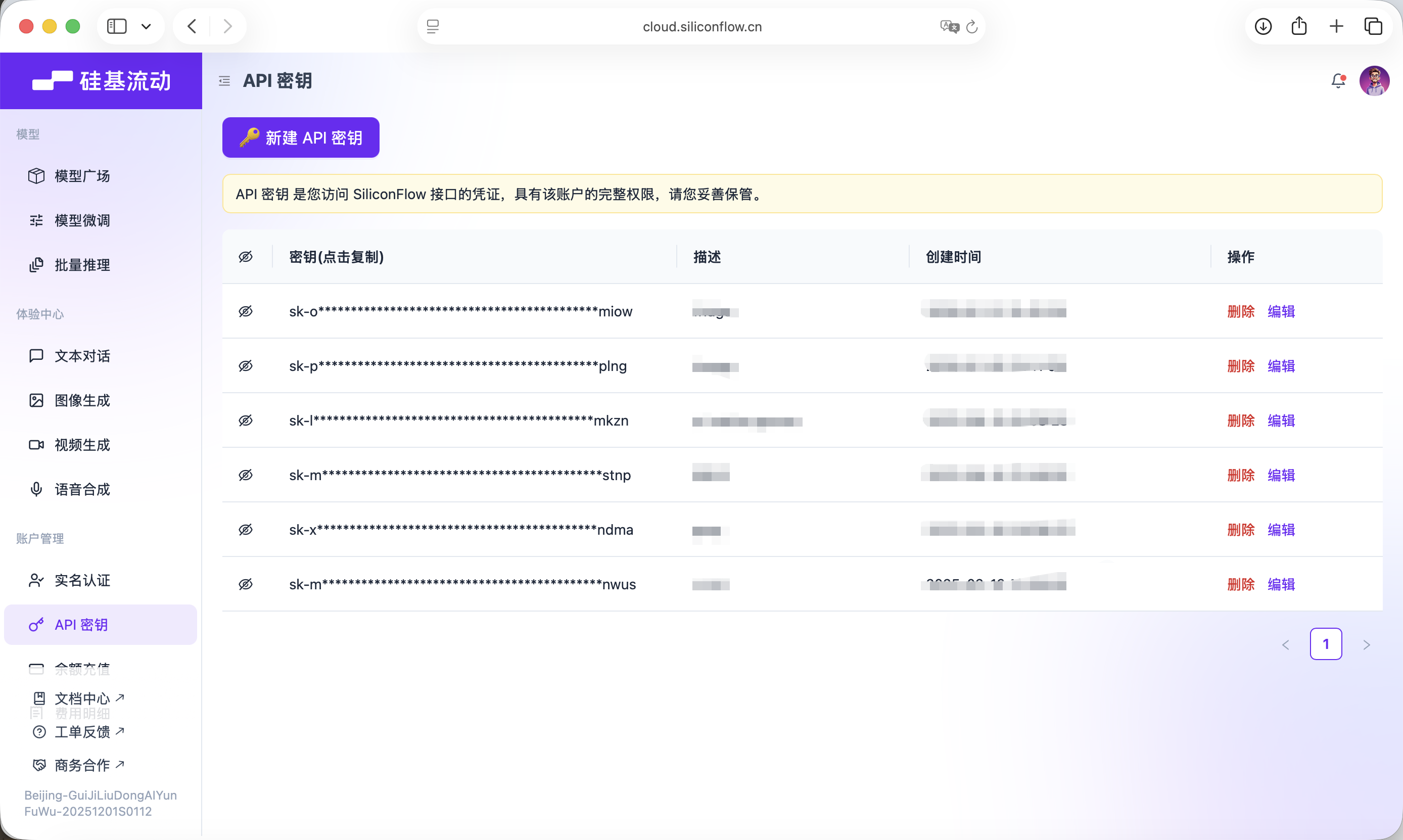
Key này sẽ được sử dụng cho việc gọi mô hình tiếp theo.
3.4 Xây dựng Agent:
Thí nghiệm này chủ yếu sử dụng Trae để giúp chúng ta viết mã, hướng dẫn này chọn mô hình Gemini-3-Pro-Preview. Tổng thể tư duy là, sau khi tạo dự án mới, sao chép Prompt hoàn chỉnh dưới đây vào ô hội thoại và nhập, thay thế API KEY từng bước rồi chạy mã, hoàn thành kiểm tra.
Giai đoạn 1: Khung cơ bản Gradio Blocks và bố cục giao diện
Trong giai đoạn này, mục tiêu chính của chúng ta là xây dựng "ngoại hình" cho toàn bộ Agent, triển khai thiết kế trang frontend. Sao chép Prompt dưới đây vào ô hội thoại Trae để triển khai, bạn sẽ nhận được một URL cục bộ (thường là http://127.0.0.1:7860) để xem giao diện và kiểm tra hiệu quả.
Mục 1: Khung cơ bản Gradio Blocks và bố cục giao diện
1. Mục tiêu tác vụ
·Dựa trên bố cục Blocks của Gradio 4.0.0+, triển khai giao diện cơ bản của dự án "LLM+Nanobanana tạo ảnh từ văn bản", tuân thủ nghiêm ngặt bố cục chia trái phải cố định, khởi tạo tất cả thành phần UI và đặt trạng thái ban đầu đúng.
2. Yêu cầu công nghệ
·Phải sử dụng chế độ Blocks của Gradio 4.0.0+ để phát triển, cấm sử dụng chế độ Interface;
·Dependency: gradio>=4.0.0, pillow>=10.0.0 (chỉ import, tạm thời không triển khai logic xử lý ảnh);
·Mã phải là tệp Python hoàn chỉnh có thể chạy, bao gồm tất cả câu lệnh import cần thiết.
3. Quy tắc bố cục giao diện (ràng buộc cốt lõi)
·Bố cục tổng thể:
Tiêu đề trang: Công cụ tạo ảnh từ văn bản toàn quy trình do LLM điều khiển;
Chia trái phải cố định: Bên trái chiếm 60% chiều rộng, bên phải chiếm 40% chiều rộng, sử dụng gr.Row và gr.Column để kiểm soát tỷ lệ.
·Bên trái 60% (Vùng quy trình tạo prompt) danh sách thành phần:
input_text: gr.Textbox, label "Nhập văn bản (đoạn hướng dẫn / chỉ thị vẽ)", lines=6, placeholder "Vui lòng nhập văn bản hướng dẫn cần tạo hình minh họa hoặc chỉ thị vẽ trực tiếp...";
identify_intent_btn: gr.Button, value="Nhận diện ý định", trạng thái ban đầu có thể nhấp;
intent_status: gr.Textbox, label "Loại ý định / Trạng thái xử lý", lines=2, interactive=False, giá trị ban đầu "Chưa nhận diện ý định";
system_prompt: gr.Textbox, label "System Prompt (chỉ ý định tạo hình minh họa bài viết mới có thể chỉnh sửa)", lines=4, interactive=False, placeholder "Quy tắc ràng buộc để LLM tạo prompt...";
confirm_prompt_btn: gr.Button, value="Xác nhận tạo prompt tạo ảnh", interactive=False (vô hiệu hóa ban đầu để tránh nhầm);
generation_prompt: gr.Textbox, label="Prompt tạo ảnh (có thể chỉnh sửa)", lines=3, interactive=True, giá trị ban đầu rỗng, placeholder "Prompt tiếng Anh tạo ảnh sẽ hiển thị tại đây, hỗ trợ sửa thủ công...".
·Bên phải 40% (Vùng chức năng tạo ảnh Nanobanana) danh sách thành phần:
ref_image: gr.Image, label "Ảnh tham khảo (tùy chọn, tạo ảnh từ ảnh)", type=filepath, height=300, cho phép tải lên;
generate_btn: gr.Button, value="Tạo hình ảnh", interactive=False (vô hiệu hóa ban đầu, không có prompt không thể nhấp);
result_image: gr.Image, label "Kết quả tạo", type=pil, height=300, ban đầu rỗng, interactive=False.
4. Yêu cầu logic tương tác
·Trạng thái interactive ban đầu của tất cả thành phần tuân thủ nghiêm ngặt cấu hình trên, cập nhật động qua hàm sau;
·Trạng thái vô hiệu hóa nút cần trực quan (làm mờ), tránh người dùng nhầm.
5. Yêu cầu đầu ra
·Tạo mã Python hoàn chỉnh, chỉ triển khai bố cục giao diện và khởi tạo thành phần, không chứa bất kỳ logic nghiệp vụ nào;
·Comment mã rõ ràng, tên thành phần nhất quán với phiên bản thực tế (input_text/identify_intent_btn, v.v.);
·Mã có thể chạy trực tiếp, cấu trúc giao diện hoàn toàn nhất quán với mô tả.Sau khi mở http://127.0.0.1:7860 trong trình duyệt, bạn có thể thấy Trae đã tạo trang web theo yêu cầu của chúng ta, cơ bản phù hợp yêu cầu, có thể tiếp tục bước tạo tiếp theo.
Giai đoạn 2: Module nhận diện ý định LLM (Siliconflow API)
Khi sử dụng VLM để vẽ trong cuộc sống hàng ngày, có thể có ba loại đầu vào phổ biến sau:
- Nội dung vô nghĩa, như "xin chào", "hôm nay bạn ăn chưa", không thể vẽ hình tương ứng.
- Bài viết/văn bản dài, nhiều chữ, khoảng 200 chữ một bài có cấu trúc, cần hiểu cấu trúc và nội dung bài viết trước, sau đó mới xem xét tạo hình ảnh có thể tóm tắt hoàn chỉnh đoạn văn này.
- Chỉ thị vẽ trực tiếp, như "giúp tôi vẽ một con chó đang tắm", yêu cầu đã trình bày rất cụ thể, có thể tạo hình ảnh trực tiếp.
Giống như trước, sao chép Prompt dưới đây vào ô hội thoại Trae để triển khai, và bổ sung API lấy ở bước trước.
Mục 2: Module nhận diện ý định LLM (Siliconflow API)
1. Mục tiêu tác vụ
Trên cơ sở giao diện Gradio đã triển khai, thêm logic nhấp cho nút "Nhận diện ý định", gọi Siliconflow API hoàn thành nhận diện ý định, và liên kết trạng thái thành phần.
2. Yêu cầu công nghệ
Dựa trên Blocks Gradio 4.0.0+;
Dependency: requests>=2.31.0, openai;
Xuất tệp Python hoàn chỉnh có thể chạy, bao gồm giao diện Mục 1 + logic module này.
3. Quy tắc nghiệp vụ cốt lõi (tuyệt đối không được sai lệch)
·Quy tắc phân loại ý định (chỉ 3 loại, trả về nghiêm ngặt số + mô tả)
1 = Nội dung vô nghĩa: Chỉ nói chuyện phiếm, chào hỏi, hội thoại không liên quan, không có nhu cầu vẽ hoặc tạo hình minh họa (như "xin chào" "hôm nay ăn chưa");
2 = Nhu cầu tạo hình minh họa bài viết/văn bản dài: Người dùng nhập một bài viết hoàn chỉnh, hướng dẫn, đoạn văn, văn bản mô tả, nội dung thiên về tường thuật/mô tả/giảng giải, ẩn chứa ý định cần tạo hình minh họa cho nội dung này, không cần người dùng nói rõ "tạo hình minh họa cho đoạn văn này";
3 = Chỉ thị vẽ trực tiếp: Người dùng nhập lệnh vẽ ngắn gọn, rõ ràng, không có bối cảnh văn bản dài, yêu cầu trực tiếp vẽ một nội dung nào đó (như "vẽ một con mèo phong cách Apple").
·Ràng buộc gọi LLM (tích hợp mẫu phiên bản thực tế)
Địa chỉ giao diện: https://api.siliconflow.cn/v1/chat/completions;
Mô hình: Qwen/Qwen2.5-7B-Instruct;
temperature=0.1;
4. Quy tắc liên kết thành phần
·Kết quả là 1: intent_status hiển thị "1 = Nội dung vô nghĩa: Không có nhu cầu vẽ", system_prompt giữ vô hiệu, confirm_prompt_btn vô hiệu;
·Kết quả là 2: intent_status hiển thị "2 = Nhu cầu tạo hình minh họa bài viết/văn bản dài: Tạo hình minh họa cho nội dung đầu vào", bật system_prompt và điền quy tắc mặc định, kích hoạt confirm_prompt_btn;
·Kết quả là 3: intent_status hiển thị "3 = Chỉ thị vẽ trực tiếp: Tạo hình ảnh theo chỉ thị", system_prompt vô hiệu và điền quy tắc mặc định, kích hoạt confirm_prompt_btn.
5. Xử lý ngoại lệ
Lỗi API, lỗi phân tích đều đưa ra prompt thân thiện, không sập, thành phần trở về trạng thái ban đầu.
6. Yêu cầu đầu ra
Tạo mã hoàn chỉnh có thể chạy, thay LLM_API_KEY là có thể sử dụng, logic rõ ràng comment đầy đủ, mẫu nhận diện ý định sử dụng nghiêm ngặt phiên bản thực tế.Làm mới trang http://127.0.0.1:7860 trước đó, bắt đầu kiểm tra xem có thể nhận diện đúng ba trường hợp hay không.
- Nội dung vô nghĩa, có thể thử nhập "xin chào", "cảm ơn", phát hiện có thể nhận diện bình thường.
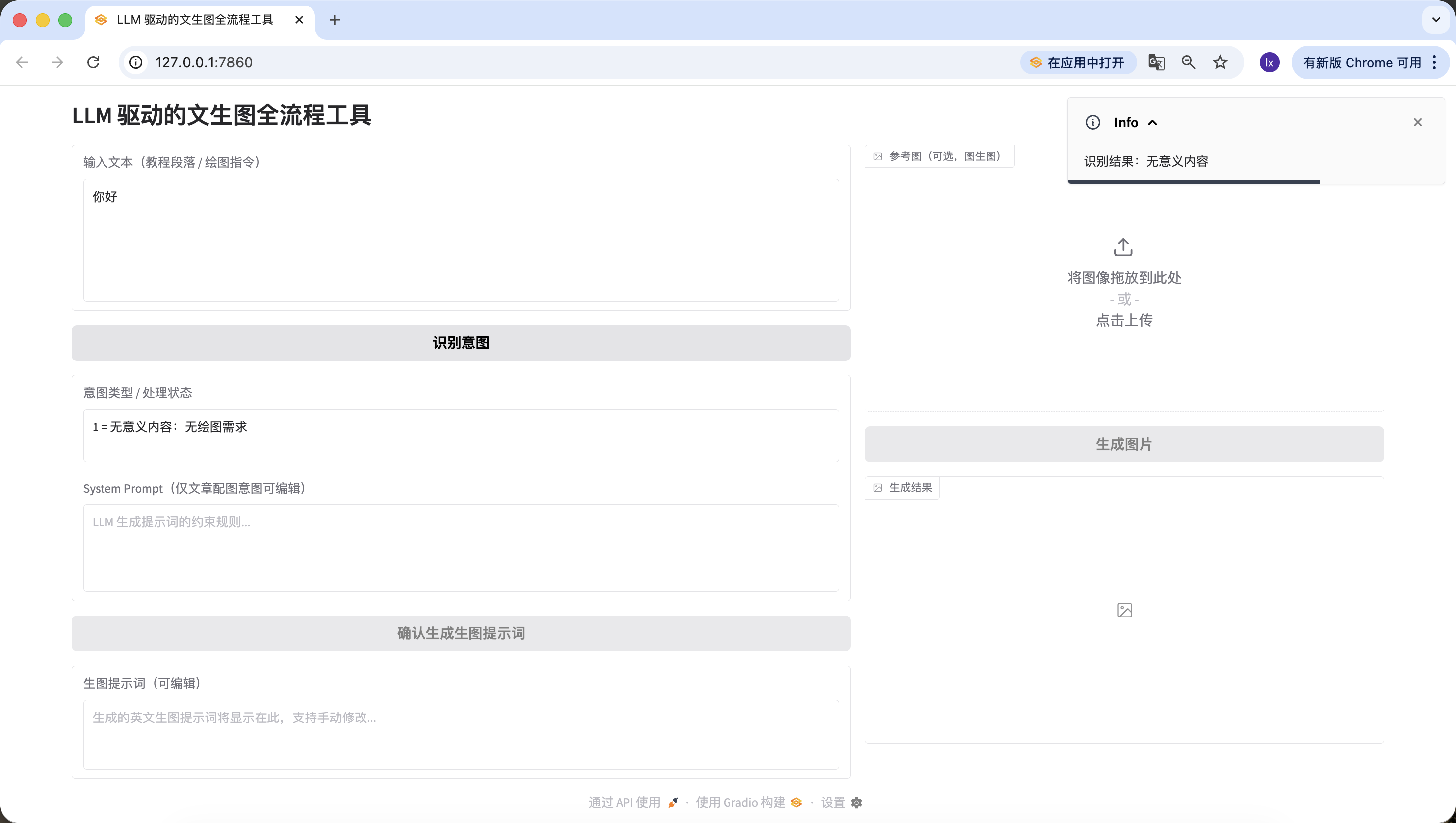
- Bài viết/văn bản dài, ở đây chúng ta dùng một đoạn văn bản do Doubao tạo mô tả trí tuệ nhân tạo. Bạn cũng có thể thử sử dụng đoạn luận văn của mình để kiểm tra.
Trí tuệ nhân tạo đang định hình lại hệ sinh thái giáo dục với độ sâu và breadth chưa từng có...Cũng kiểm tra thành công~
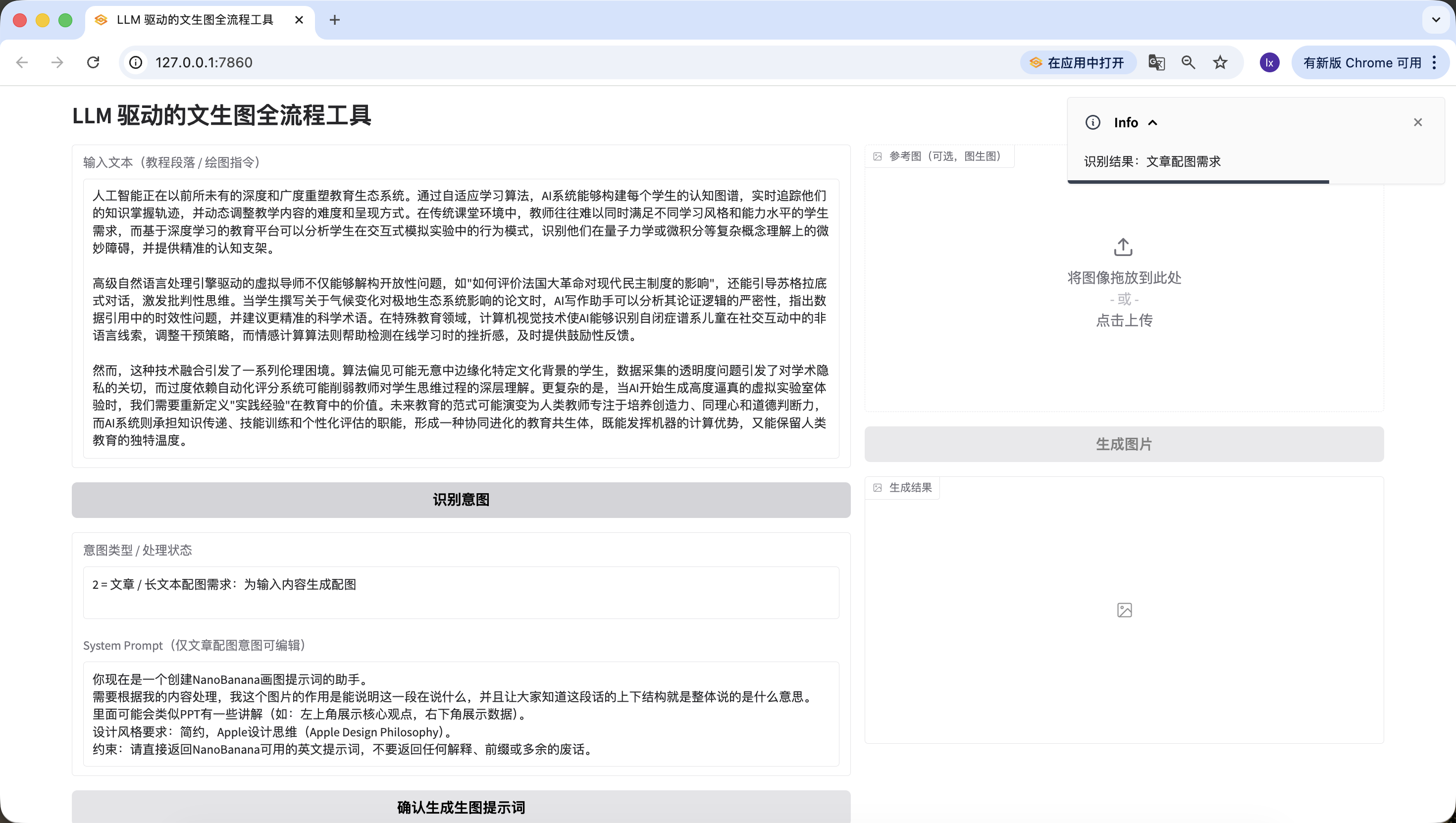
- Chỉ thị vẽ trực tiếp, ở đây nhập "tôi muốn vẽ một con mèo", cũng nhận diện chính xác.
Đến đây chúng ta đã hoàn thành thuận lợi giai đoạn thứ hai -- nhận diện ý định.
Giai đoạn 3: Module tạo prompt tạo ảnh (Gọi LLM lần hai)
Sau khi nhận diện ý định, đối với bài viết hoặc văn bản dài, còn một bước rất quan trọng là tạo prompt vẽ, đây chính là trọng điểm của Agent này.
Mục 3: Module tạo prompt tạo ảnh (Gọi LLM lần hai)
1. Mục tiêu tác vụ
Trên cơ sở nhận diện ý định, triển khai logic nút "Xác nhận tạo prompt tạo ảnh", gọi LLM tối ưu hóa văn bản thành prompt thị giác tiếng Anh phù hợp để vẽ, điền vào ô chỉnh sửa và liên kết nút "Tạo hình ảnh".
2. Yêu cầu công nghệ
Giống Mục 2, xuất mã hoàn chỉnh = Mục 1 + Mục 2 + module này;
Sử dụng chung LLM_BASE_URL, LLM_API_KEY, LLM_MODEL đã định nghĩa ở Mục 2, không thêm key mới.
3. Quy tắc nghiệp vụ cốt lõi
·Quy tắc đầu vào tạo prompt (phải tuân thủ nghiêm ngặt)
Tạo prompt tạo ảnh không còn là nối chuỗi đơn giản, mà là xây dựng danh sách tin nhắn Chat tiêu chuẩn.
·Ràng buộc gọi LLM
Sử dụng chung bộ LLM_BASE_URL, LLM_API_KEY, LLM_MODEL với Mục 2;
temperature=0.7;
max_tokens=200;
Sử dụng nghiêm ngặt cấu trúc danh sách tin nhắn Chat tiêu chuẩn, cấm nối chuỗi.
·Ràng buộc bắt buộc đầu ra prompt
Tiếng Anh thuần, không có tiếng Trung;
Phải bao gồm Apple Design Philosophy/Apple style + 1024x1024;
Độ dài 50-200 ký tự, kiểm tra trong mã;
Không có giải thích thêm, tiền tố hoặc lời thừa, chỉ trả về prompt.
4. Quy tắc liên kết thành phần
Tạo thành công: Điền prompt vào ô generation_prompt, kích hoạt generate_btn, intent_status thêm "Tạo prompt thành công, có thể sửa rồi tạo hình ảnh";
Tạo thất bại: Prompt lý do cụ thể, generate_btn giữ vô hiệu, ô generation_prompt rỗng;
Người dùng sửa/xóa ô generation_prompt:
Xóa tự động vô hiệu generate_btn;
Không rỗng thì giữ generate_btn kích hoạt.
5. Xử lý ngoại lệ
Gọi API thất bại: Prompt thân thiện, không sập;
Kiểm tra prompt thất bại: Nêu rõ lý do, cho thử lại;
Phân tích phản hồi thất bại: Prompt "Không thể phân tích kết quả LLM trả về, vui lòng thử lại".
6. Yêu cầu đầu ra
Mã hoàn chỉnh có thể chạy, thay LLM_API_KEY là có thể sử dụng;
Cấu trúc mã rõ ràng, comment đầy đủ, giao diện đẹp简洁;
Triển khai nghiêm ngặt cấu trúc danh sách tin nhắn Chat tiêu chuẩn, tham số và logic mẫu nhất quán;
Bao gồm logic kiểm tra độ dài, nội dung prompt, prompt lỗi thân thiện.Cũng sao chép văn bản của giai đoạn thứ hai để kiểm tra.
Đáng chú ý, System Prompt tạo prompt tạo ảnh mà chúng ta đặt trước ở đây là:
Bạn hiện là trợ giúp tạo prompt vẽ NanoBanana. Cần xử lý dựa trên nội dung của tôi, hình ảnh này có tác dụng giải thích đoạn này đang nói gì, và để mọi người biết cấu trúc bối cảnh của đoạn này nói chung là có ý nghĩa gì. Có thể có phần giải thích tương tự PPT (như: góc trên bên trái thể hiện quan điểm cốt lõi, góc dưới bên phải thể hiện dữ liệu). Yêu cầu phong cách thiết kế: Tối giản, tư duy thiết kế Apple (Apple Design Philosophy). Ràng buộc: Vui lòng trả về trực tiếp prompt tiếng Anh có thể sử dụng cho NanoBanana, không trả về bất kỳ giải thích, tiền tố hoặc lời thừa nào.
Nếu bạn muốn đổi mẫu mặc định khác, có thể sửa trong prompt trước đó, hoặc trực tiếp sửa qua hội thoại trong Trae.
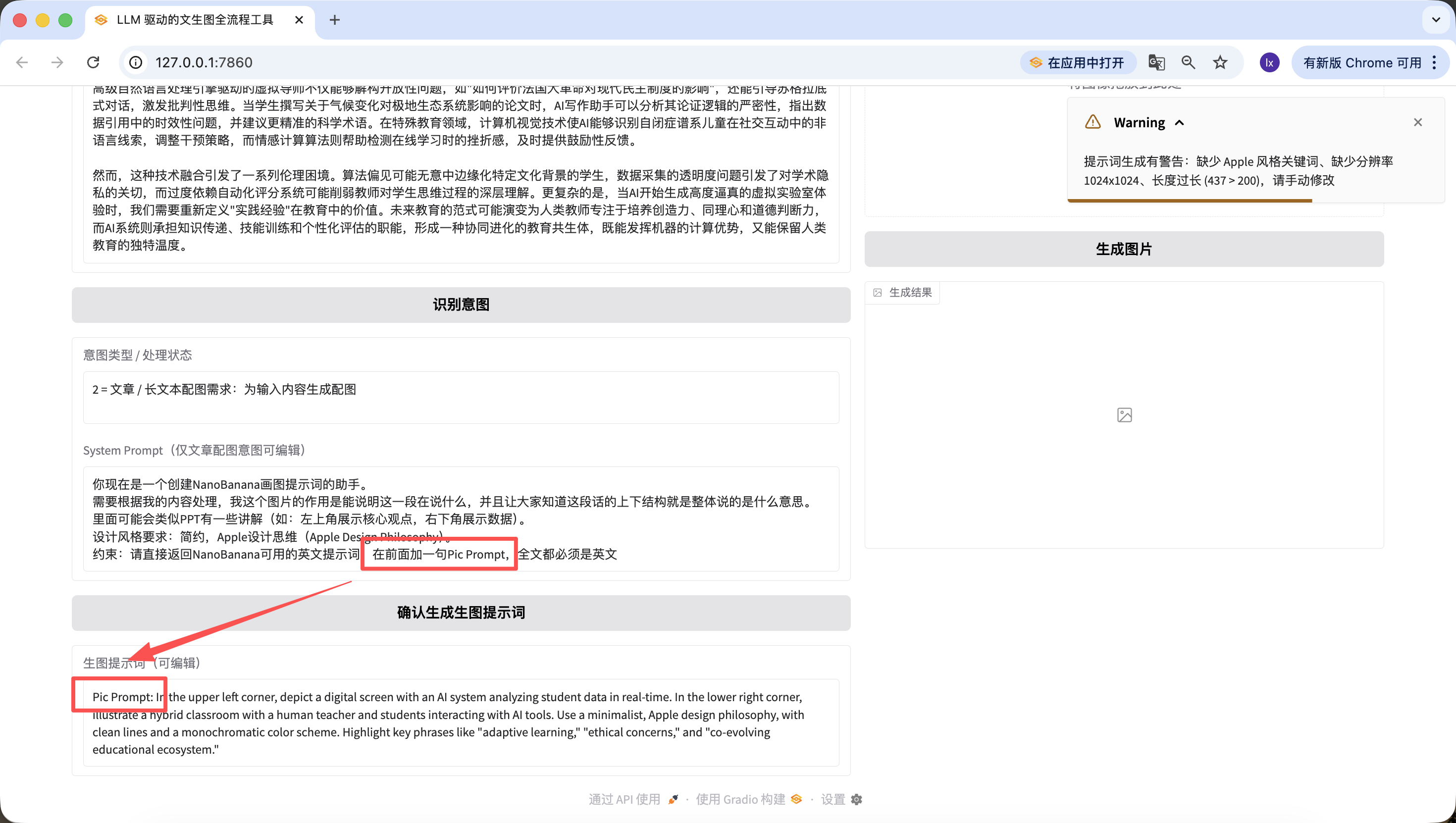
Ngoài việc sửa mã cơ sở, chúng ta cũng có thể chỉnh sửa nhanh trên trang web. Ví dụ, tôi thêm một câu ở đây, "thêm câu Pic Prompt ở phía trước", có thể thấy prompt mới tạo cũng bao gồm ở phía trước~ Thiết kế này là để dễ dàng sửa System Prompt tạo prompt, giúp chúng ta nhanh chóng chuyển đổi phong cách.
Giai đoạn 4: Module tạo ảnh từ văn bản/tạo ảnh từ ảnh Nanobanana
Cuối cùng đã đến bước cuối cùng, không kết nối mô hình tạo ảnh thì không phải Agent hoàn chỉnh!
Mục 4: Module tạo ảnh từ văn bản/tạo ảnh từ ảnh Nanobanana (phiên bản cuối)
1. Mục tiêu tác vụ
Triển khai logic nút "Tạo hình ảnh", gọi API Nanobanana thực tế, hỗ trợ tạo ảnh từ văn bản/tạo ảnh từ ảnh, phân tích Base64 và hiển thị hình ảnh.
2. Yêu cầu công nghệ
Dựa trên Blocks Gradio 4.0.0+;
Dependency: requests, pillow, base64, io, re;
Mã hoàn chỉnh = Mục 1+2+3 + module này.
3. Cấu hình API cốt lõi
Cấu hình mã cố định:
NANOBANANA_API_URL = "https://api.zyai.online/v1/chat/completions"
NANOBANANA_MODEL = "gemini-2.5-flash-image"
NANOBANANA_API_KEY = "" # Người dùng tự thay
4. Yêu cầu tiền xử lý hình ảnh (phải triển khai)
Triển khai hàm image_to_base64_data_uri (ref_image_path), logic cốt lõi:
Chuyển hình ảnh PIL sang định dạng PNG;
Tự động thu nhỏ về độ phân giải 1024x1024;
Kênh trong suốt chuyển sang nền trắng;
Mã hóa Base64, trả về định dạng: data:image/png;base64,...
5. Quy tắc xây yêu cầu (theo logic phân nhánh phiên bản thực tế)
·Hàm cốt lõi
Triển khai hàm generate_image (prompt, ref_image_path):
Tham số: prompt (nội dung ô generation_prompt), ref_image_path (đường dẫn tệp tải lên ref_image);
Trả về: PIL Image (hiển thị vào result_image) hoặc prompt lỗi.
·Nhánh logic 1: Tạo ảnh từ văn bản thuần (ref_image_path rỗng)
messages = [{"role": "user", "content": prompt}]
·Nhánh logic 2: Tạo ảnh từ ảnh (ref_image_path có giá trị)
Gọi hàm tiền xử lý hình ảnh trước, sau đó xây messages với image_url.
6. Yêu cầu phân tích phản hồi (phải tương thích hai định dạng)
Trích xuất Base64 hình ảnh từ choices[0].message.content, hỗ trợ:
Trường image_url trả về JSON có cấu trúc;
Định dạng Markdown;
Trích xuất thống nhất mã hóa Base64, giải mã sau chuyển đổi thành PIL Image trả về.
7. Liên kết thành phần và xử lý ngoại lệ
Tạo thành công: Hiển thị PIL Image vào result_image, intent_status prompt "Tạo hình ảnh thành công";
Tạo/phân tích/tải lên thất bại: Hiển thị prompt văn bản rõ ràng trong intent_status, không sập.
8. Yêu cầu đầu ra
Mã hoàn chỉnh có thể chạy, thay LLM_API_KEY và NANOBANANA_API_KEY là có thể chạy trực tiếp, toàn bộ quy trình sử dụng được, logic phân nhánh khớp nghiêm ngặt phiên bản thực tế.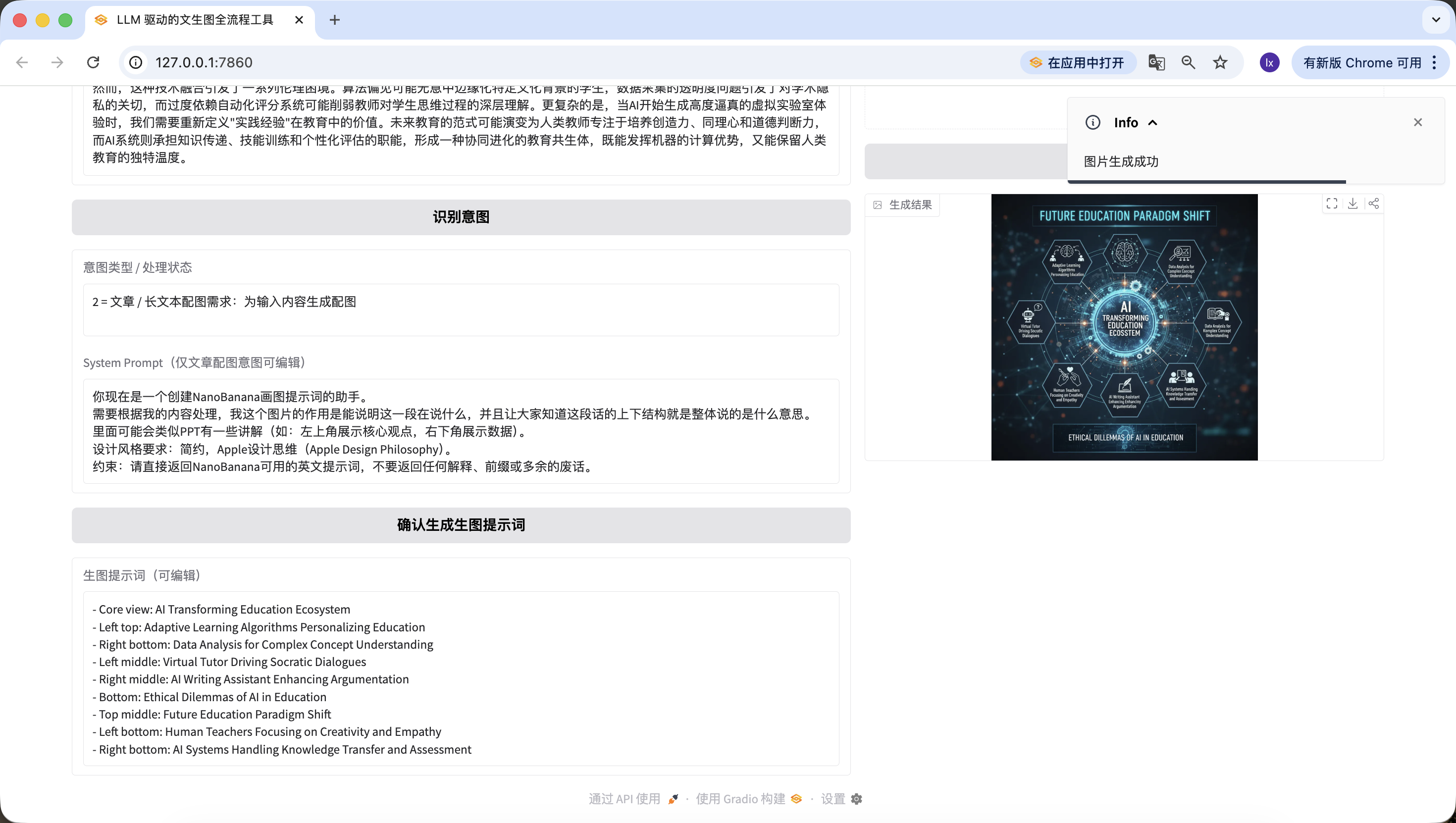
Thật thú vị! Chúng ta đã tạo thành công hình ảnh đầu tiên của Agent này, nhìn kỹ hình ảnh tạo ra, nó khớp với văn bản và prompt của chúng ta. Đến đây bạn đã cơ bản triển khai xong Agent của riêng mình!

Chúng ta còn thêm chức năng tạo ảnh từ ảnh, tải lên hình ảnh bạn thích, AI sẽ tự động tham khảo phong cách.
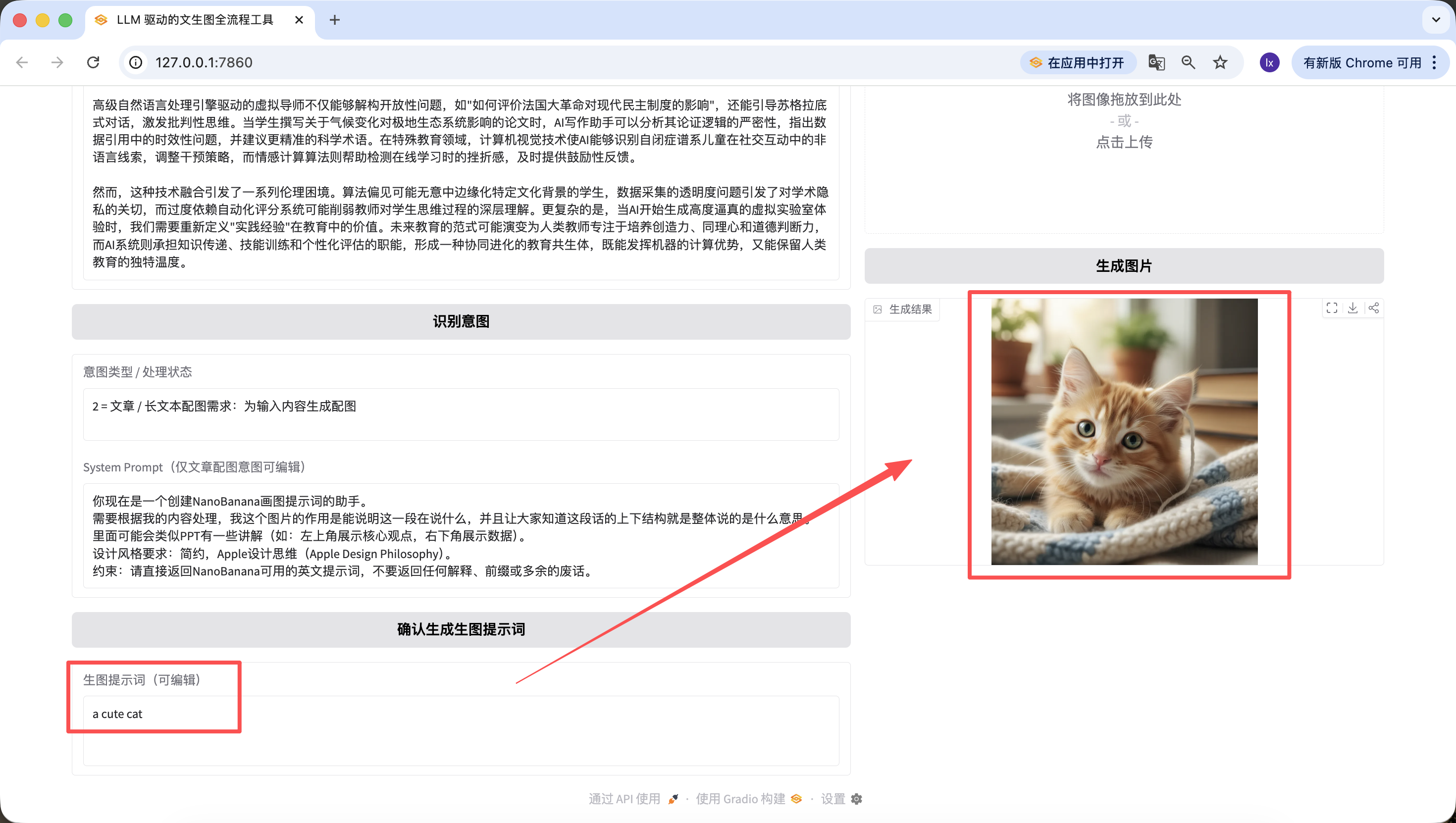
Đáng nhắc là, prompt tạo ở bước trước cũng có thể chỉnh sửa trên trang web, và chúng ta lấy prompt khi nhấp nút cuối cùng làm chuẩn~ Ngay cả khi tôi đổi thành "a cute cat" ở đây, hình ảnh cuối cùng tạo ra cũng chỉ là chú mèo dễ thương.
Chương 4: Tổng kết

Tuyệt vời! Cuối cùng cũng viết xong.
Thành thật mà nói, ngay cả bản thân tôi khi viết xong dòng cuối cùng cũng không khỏi thở phào nhẹ nhõm, chưa nói đến bạn đã theo dõi đến đây. Có thể chạy hoàn chỉnh toàn bộ quy trình này đã rất giỏi rồi, điều này chứng tỏ bạn thực sự đã đặt tay lên bàn phím, hoàn thành từng bước. Tuyệt vời!
Trong quá trình viết nội dung này, tôi luôn suy nghĩ, chúng ta thực sự muốn để lại điều gì? Câu trả lời thực chất không phải tên mô hình, tham số hoặc một phương pháp cố định nào, mà là giúp bạn dần dần xây dựng một cảm giác: những việc nào có thể yên tâm giao cho AI để hiểu và lập kế hoạch, những chỗ nào chỉ cần bạn quyết định hướng. Một khi sự phân công này được thiết lập, nhiều quy trình tạo ban đầu trông phức tạp sẽ bắt đầu trôi chảy hơn.
Nhìn lại, con đường này thực chất không phức tạp. Suy nghĩ kỹ vấn đề bạn muốn giải quyết, giao văn bản dài cho mô hình ngôn ngữ để phân tích, sau đó giao ý định thị giác đã sắp xếp cho mô hình vẽ để trình bày, cuối cùng đóng gói toàn bộ quy trình này thành một trợ lý nhỏ của riêng bạn. Đến đây, bạn không chỉ "đang dùng mô hình", mà đang xây dựng một hệ thống có thể đồng hành cùng bạn làm việc lâu dài, và đây mới là điều mà bộ hướng dẫn này muốn mang đến cho bạn.
Bạn đã làm rất tốt rồi! Tin rằng học đến đây bạn đã nắm bắt cơ bản Vibe Coding, hãy cho mình một kỳ nghỉ nhỏ nghỉ ngơi nhé!