00 QuickStart:CTR 预测(DeepFM)
- 场景:排序/精排中的点击率预估(CTR Prediction)
- 模型:DeepFM
- 数据:Criteo 广告点击样例数据
- 目标:从环境安装开始,跑通
DataFrame -> Feature -> DataGenerator -> DeepFM -> CTRTrainer -> AUC的完整链路
这篇是整组教程的入口,尽量把第一次运行会卡住的地方都写在 notebook 里。你不需要同时打开 README 或文档才能理解代码;后面的教程会默认你已经看过这里的环境、Feature、DataGenerator 和 Trainer 基础概念。
参考资料
- DeepFM 论文:DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
- Torch-RecHub DeepFM 代码:
torch_rechub/models/ranking/deepfm.py - 中文模型教程:
docs/zh/tutorials/models/ranking/deepfm.md - Criteo 样例数据:
examples/ranking/data/criteo/criteo_sample.csv
数据集介绍
Criteo 是 CTR 预测里很常见的广告点击数据集。每一行代表一次广告曝光样本:
label:是否点击,1表示点击,0表示未点击。I1到I13:连续数值特征,也叫 dense feature,例如计数、价格、时长、统计量等。C1到C26:类别/ID 特征,也叫 sparse feature,例如用户分桶、广告位、广告主、设备、上下文类别等。
仓库内置的是 sample 数据,目的是让你快速跑通 API;指标不能代表完整 Criteo 数据集上的模型效果。真实业务数据通常还会包含更多用户、物品、上下文和统计特征,但会落到同一套 DenseFeature / SparseFeature 表达方式里。
环境安装:AMD GPU 专用
PyTorch 与 ROCm、驱动和硬件型号强相关,安装前建议先查看 AMD ROCm / PyTorch 版本适配文档。
如果你使用的是 Ryzen AI Max+ 395/390/385 等 gfx1151 设备,可以使用下面的 ROCm wheel 源安装 ROCm 和 PyTorch:
pip install --index-url https://repo.amd.com/rocm/whl/gfx1151/ "rocm[libraries,devel]" torch torchvision torchaudio方案 A:从当前仓库源码运行教程(推荐给开发者)
在仓库根目录执行:
conda create -n torch-rechub python=3.10 -y
conda activate torch-rechub
# AMD GPU (ROCm, gfx1151 = Ryzen AI Max+ 395/390/385)
pip install --index-url https://repo.amd.com/rocm/whl/gfx1151/ "rocm[libraries,devel]" torch torchvision torchaudio
# 再安装当前仓库为可编辑包
pip install -e .
# Notebook 必需依赖
pip install notebook ipykernel scikit-learn tqdm
python -m ipykernel install --user --name torch-rechub-amd --display-name "Python (torch-rechub-amd)"如果你使用 README 里的 uv 工作流,也可以:
pip install uv
uv pip install --index-url https://repo.amd.com/rocm/whl/gfx1151/ "rocm[libraries,devel]" torch torchvision torchaudio # AMD GPU (ROCm, gfx1151 = Ryzen AI Max+ 395/390/385)
uv sync方案 B:只使用稳定版包
如果你不准备改源码,只想试用,也同样先装 AMD GPU 对应的 PyTorch,再装发布包:
pip install --index-url https://repo.amd.com/rocm/whl/gfx1151/ "rocm[libraries,devel]" torch torchvision torchaudio # AMD GPU (ROCm, gfx1151 = Ryzen AI Max+ 395/390/385)
pip install torch-rechub
pip install notebook ipykernel scikit-learn tqdm按需安装可选能力
README 里把可选依赖拆成 extras。教程里常用的是:
pip install "torch-rechub[tracking]" # WandB / SwanLab / TensorBoardX
pip install "torch-rechub[onnx]" # ONNX 导出、ONNXRuntime、FP16 转换
pip install "torch-rechub[visualization]" # torchview / graphviz Python 包
pip install "torch-rechub[annoy]" # 召回向量检索示例如果本机没有配置 Graphviz 系统程序,模型可视化还需要额外安装:
# Ubuntu: sudo apt-get install graphviz
# macOS: brew install graphviz
# Windows: choco install graphviz第一次运行建议先用单卡 AMD GPU,EPOCH=1~3,确认代码链路能跑通;不要一开始就把 epoch、batch size、ONNX、可视化和日志平台全部打开。
学习路线
00:CTR 基础训练,理解 Feature、DataGenerator、Trainer。01:加入用户历史序列,学习 DIN 的 target attention。02:从精排打分切换到召回检索,学习 DSSM 双塔和向量 topk。03:从单目标切换到多目标,学习 MMOE。04:给训练流程接入 WandB / SwanLab / TensorBoardX 实验记录。05:把训练好的模型导出成 ONNX,并做最小推理验证和量化演示。
import os
from pathlib import Path
import numpy as np
import pandas as pd
import torch
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
from tqdm import tqdm
from torch_rechub.basic.features import DenseFeature, SparseFeature
from torch_rechub.models.ranking import DeepFM
from torch_rechub.trainers import CTRTrainer
from torch_rechub.utils.data import DataGenerator
# 可选:实验跟踪(默认关闭)
# from torch_rechub.basic.tracking import WandbLogger, SwanLabLogger, TensorBoardXLogger
SEED = 2022
DEVICE = "cuda:0" # AMD ROCm 通常通过 cuda:0 设备名访问
# 数据路径:按 tutorials/ 目录为基准的相对路径。
# 如果你从仓库根目录启动 Jupyter,把这一行改成:
# DATASET_PATH = Path("examples/ranking/data/criteo/criteo_sample.csv")
DATASET_PATH = Path("../examples/ranking/data/criteo/criteo_sample.csv")
# 训练配置:尽量保持 5-10 分钟内可跑通
EPOCH = 2
BATCH_SIZE = 2048
LR = 1e-3
WEIGHT_DECAY = 1e-3
EARLYSTOP_PATIENCE = 4
# 可选开关
USE_TRACKING = False
LOGGER_TYPE = None # "wandb" | "swanlab" | "tensorboard" | None
PROJECT_NAME = "criteo-ctr"
EXPORT_ONNX = False
ONNX_PATH = "deepfm.onnx"
torch.manual_seed(SEED)
print("DATASET_PATH:", DATASET_PATH)
print("DATASET_PATH exists:", DATASET_PATH.exists())
print("DEVICE:", DEVICE)运行前检查
执行下面的配置 cell 后,请先确认:
DATASET_PATH指向../examples/ranking/data/criteo/criteo_sample.csvDATASET_PATH exists: TrueDEVICE建议为cuda:0;AMD ROCm 的 PyTorch 通常也通过cuda:0设备名访问
这份 notebook 默认你在 tutorials/ 目录下运行,所以数据路径使用 ../examples/...。如果你从仓库根目录启动 Jupyter,请把配置 cell 里的路径改为:
DATASET_PATH = Path("examples/ranking/data/criteo/criteo_sample.csv")几个参数可以先这样理解:
DEVICE:AMD ROCm 的 PyTorch 通常也通过cuda:0设备名访问;如果不可用则先检查 ROCm/PyTorch 安装。BATCH_SIZE:一次送进模型多少行样本,sample 数据很小,不需要调大。EPOCH:完整遍历训练集的轮数;教程默认很小,只为了快速跑通。EMBED_DIM:每个 sparse/id 特征映射成多长的 embedding。EXPORT_ONNX:部署相关,第一次运行保持False。
如果你想看更稳定的指标,可以逐步增大 EPOCH、调小学习率并替换为更完整的数据;但调参不是这篇的重点。
from typing import Union
def convert_numeric_feature(val: Union[float, int]) -> int:
"""与 examples/ranking/run_criteo.py 保持一致:把 dense 值离散化成一个新 sparse 特征。"""
v = int(val)
if v > 2:
return int(np.log(v) ** 2)
else:
return v - 2
def get_criteo_data_dict(data_path: str | Path):
"""复用并对齐仓库现有 Criteo 预处理风格。"""
data_path = Path(data_path)
if not data_path.exists():
raise FileNotFoundError(
f"Criteo 样例数据不存在:{data_path}\n"
"请确认当前工作目录是否为 tutorials/;如果从仓库根目录运行,请把 DATASET_PATH 改成 "
"Path(\"examples/ranking/data/criteo/criteo_sample.csv\")。"
)
data = pd.read_csv(data_path, compression="gzip") if data_path.suffix == ".gz" else pd.read_csv(data_path)
print("data load finished, shape=", data.shape)
dense_features = [f for f in data.columns.tolist() if f.startswith("I")]
sparse_features = [f for f in data.columns.tolist() if f.startswith("C")]
data[sparse_features] = data[sparse_features].fillna("0")
data[dense_features] = data[dense_features].fillna(0)
# dense → dense(归一化) + dense_cat(离散化后作为 sparse)
for feat in tqdm(dense_features, desc="discretize dense"):
sparse_features.append(feat + "_cat")
data[feat + "_cat"] = data[feat].apply(lambda x: convert_numeric_feature(x))
sca = MinMaxScaler()
data[dense_features] = sca.fit_transform(data[dense_features]).astype(np.float32)
for feat in tqdm(sparse_features, desc="label encode sparse"):
lbe = LabelEncoder()
data[feat] = lbe.fit_transform(data[feat])
dense_feas = [DenseFeature(feature_name) for feature_name in dense_features]
sparse_feas = [
SparseFeature(feature_name, vocab_size=data[feature_name].nunique(), embed_dim=16)
for feature_name in sparse_features
]
y = data["label"]
x = data.drop(columns=["label"])
return dense_feas, sparse_feas, x, yDeepFM 在做什么
DeepFM 是 CTR 精排模型,输入是一条曝光样本,输出“用户是否会点击”的概率。论文的核心点是:FM 分支和 Deep 分支共享同一套 embedding,同时学习低阶和高阶特征交互。
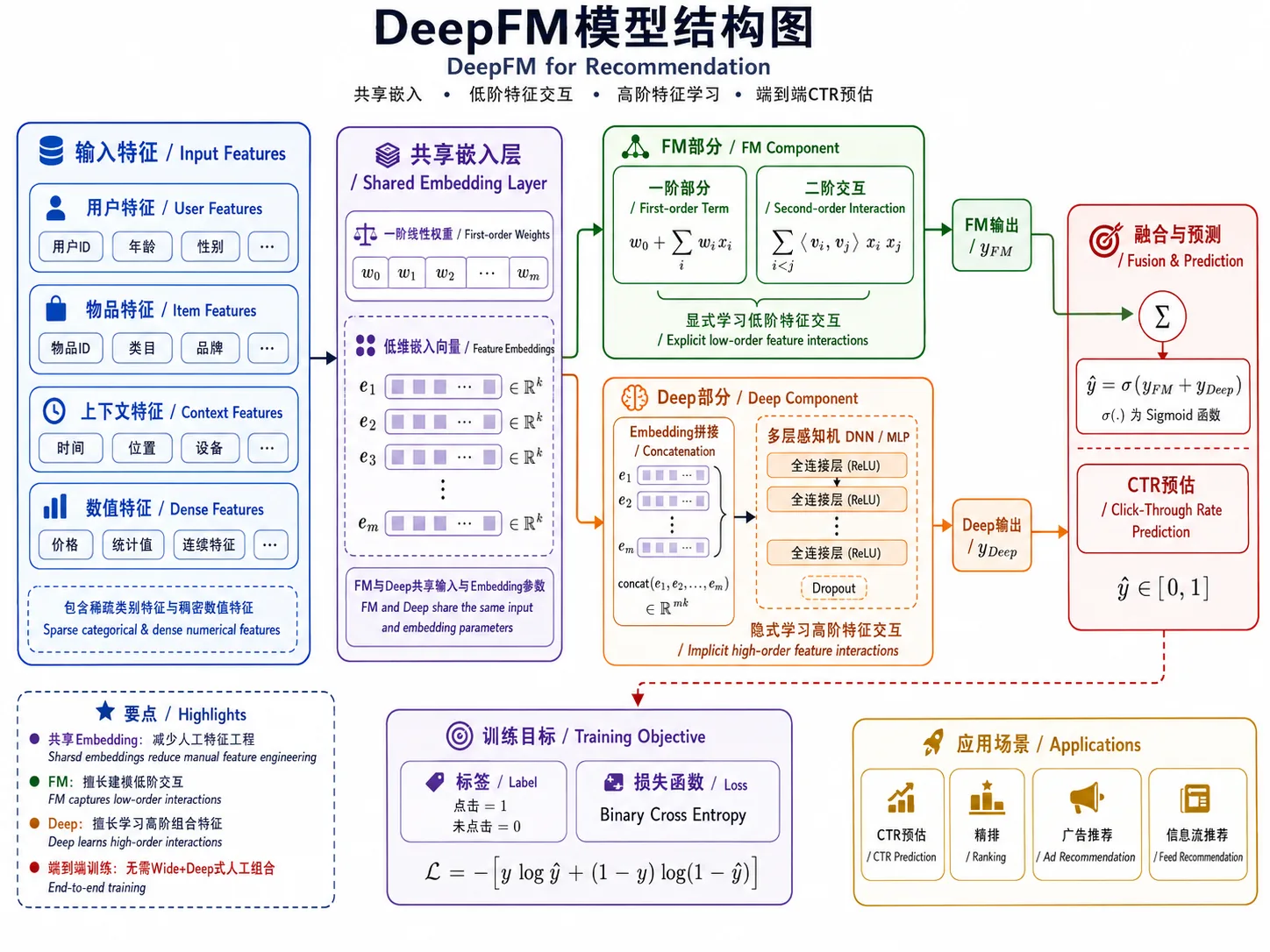
模型推理直觉
设一条样本的特征为 x,模型输出点击概率:
FM 分支负责显式二阶交互:
其中 <v_i, v_j> 表示两个特征 embedding 的内积。它能直接学习“广告类目 × 用户分桶”“广告位 × 设备类型”这类低阶组合。
Deep 分支把所有 dense 值和 sparse embedding 拼接后送入 MLP:
它负责学习更复杂的非线性组合。FM 擅长记忆稳定的二阶共现,DNN 擅长泛化高阶模式;两者联合训练,因此不需要像传统 Wide&Deep 那样手工构造大量交叉特征。
本教程里的特征配置
fm_features进入 LR/FM,通常放 sparse/id 类特征,用来学习显式低阶交互。deep_features进入 MLP,可以放 dense + sparse。这里把所有 dense 和 sparse 都放入 Deep 部分,更接近常见 CTR 配置。DenseFeature:数值列,通常先填缺失值、缩放,再以float32输入。SparseFeature:类别/ID 列,需要先编码成整数,并指定vocab_size和embed_dim。DataGenerator:把x字典和y标签包装成 PyTorchDataLoader,并切分训练/验证/测试集。
如果修改特征名,务必同步修改 x 字典里的列名;Feature 的 name 必须和输入字典的 key 一一对应。
dense_feas, sparse_feas, x, y = get_criteo_data_dict(DATASET_PATH)
dg = DataGenerator(x, y)
train_dl, val_dl, test_dl = dg.generate_dataloader(split_ratio=[0.7, 0.1], batch_size=BATCH_SIZE)
model = DeepFM(
deep_features=dense_feas + sparse_feas,
fm_features=sparse_feas,
mlp_params={"dims": [256, 128], "dropout": 0.2, "activation": "relu"},
)
# 默认不启用 logger
model_logger = None
# 如需启用:把 USE_TRACKING=True 并设置 LOGGER_TYPE
# if USE_TRACKING:
# loggers = []
# if LOGGER_TYPE == "wandb":
# loggers.append(WandbLogger(project=PROJECT_NAME, name=f"deepfm-{SEED}", config={"lr": LR, "batch_size": BATCH_SIZE, "seed": SEED}, tags=["criteo", "ctr", "deepfm"]))
# elif LOGGER_TYPE == "swanlab":
# loggers.append(SwanLabLogger(project=PROJECT_NAME, experiment_name=f"deepfm-{SEED}", config={"lr": LR, "batch_size": BATCH_SIZE, "seed": SEED}))
# elif LOGGER_TYPE == "tensorboard":
# loggers.append(TensorBoardXLogger(log_dir=f"./runs/deepfm-{SEED}"))
# model_logger = loggers if loggers else None
ctr_trainer = CTRTrainer(
model,
optimizer_params={"lr": LR, "weight_decay": WEIGHT_DECAY},
n_epoch=EPOCH,
earlystop_patience=EARLYSTOP_PATIENCE,
device=DEVICE,
model_path="./",
model_logger=model_logger,
)
ctr_trainer.fit(train_dl, val_dl)
auc = ctr_trainer.evaluate(ctr_trainer.model, test_dl)
print(f"test auc: {auc}")# 可选:导出 ONNX(默认关闭)
# 说明:需要 onnx>=1.20.0,且某些环境需要额外安装 onnxruntime 做推理验证。
if EXPORT_ONNX:
try:
ctr_trainer.export_onnx(ONNX_PATH, verbose=False, device=DEVICE)
print("exported:", ONNX_PATH)
except Exception as e:
print("ONNX export failed:", repr(e))换个排序模型再跑
跑通 DeepFM 后,下面会在同一套 Criteo 数据处理、DataGenerator 和 CTRTrainer 上继续训练 WideDeep 和 DCN,并输出各自测试集 AUC。
这类对照实验建议一次只换模型,其他训练参数先保持一致,这样更容易判断差异来自模型结构,而不是学习率、batch size 或训练轮数。
# 换 WideDeep / DCN 再跑一遍
from torch_rechub.models.ranking import DCN, WideDeep
ranking_models = {
"WideDeep": WideDeep(
wide_features=sparse_feas,
deep_features=dense_feas + sparse_feas,
mlp_params={"dims": [256, 128], "dropout": 0.2, "activation": "relu"},
),
"DCN": DCN(
features=dense_feas + sparse_feas,
n_cross_layers=3,
mlp_params={"dims": [256, 128], "dropout": 0.2, "activation": "relu"},
),
}
baseline_results = {}
for model_name, candidate_model in ranking_models.items():
print(f"\n===== Train {model_name} =====")
candidate_model_path = Path(f"./{model_name.lower()}")
candidate_model_path.mkdir(parents=True, exist_ok=True)
candidate_trainer = CTRTrainer(
candidate_model,
optimizer_params={"lr": LR, "weight_decay": WEIGHT_DECAY},
n_epoch=EPOCH,
earlystop_patience=EARLYSTOP_PATIENCE,
device=DEVICE,
model_path=str(candidate_model_path),
model_logger=None,
)
candidate_trainer.fit(train_dl, val_dl)
baseline_results[model_name] = candidate_trainer.evaluate(candidate_trainer.model, test_dl)
print("baseline_results:", baseline_results)