01 序列兴趣建模:DIN(Amazon-Electronics)
- 场景:带用户行为序列的 CTR 精排
- 模型:DIN(Deep Interest Network)
- 数据:Amazon-Electronics 样例数据
- 目标:理解历史行为序列如何变成
SequenceFeature,以及 DIN 如何用候选物品对历史兴趣做 attention
这一篇默认你已经跑过 00_QuickStart_CTR_DeepFM.ipynb,因此不再重复环境安装、dense/sparse 基础预处理和 CTRTrainer 的通用用法。
参考资料
- DIN 论文:Deep Interest Network for Click-Through Rate Prediction
- Torch-RecHub DIN 代码:
torch_rechub/models/ranking/din.py - 中文模型教程:
docs/zh/tutorials/models/ranking/din.md - Amazon 数据说明:
examples/ranking/data/amazon-electronics/
数据集介绍
Amazon-Electronics 数据记录用户在电子商品上的行为,教程用仓库里的轻量 sample。原始列主要包括:
user_id:用户 ID。item_id:商品 ID。cate_id:商品类目 ID。time:行为时间,用来按时间顺序构造历史序列。
DIN 不是把每条样本看成孤立的静态特征,而是把“当前候选物品”和“用户过去行为”一起建模。例如候选物品是耳机时,历史里的手机、音箱可能更相关;候选物品是图书时,这些电子商品历史的注意力权重就可能降低。
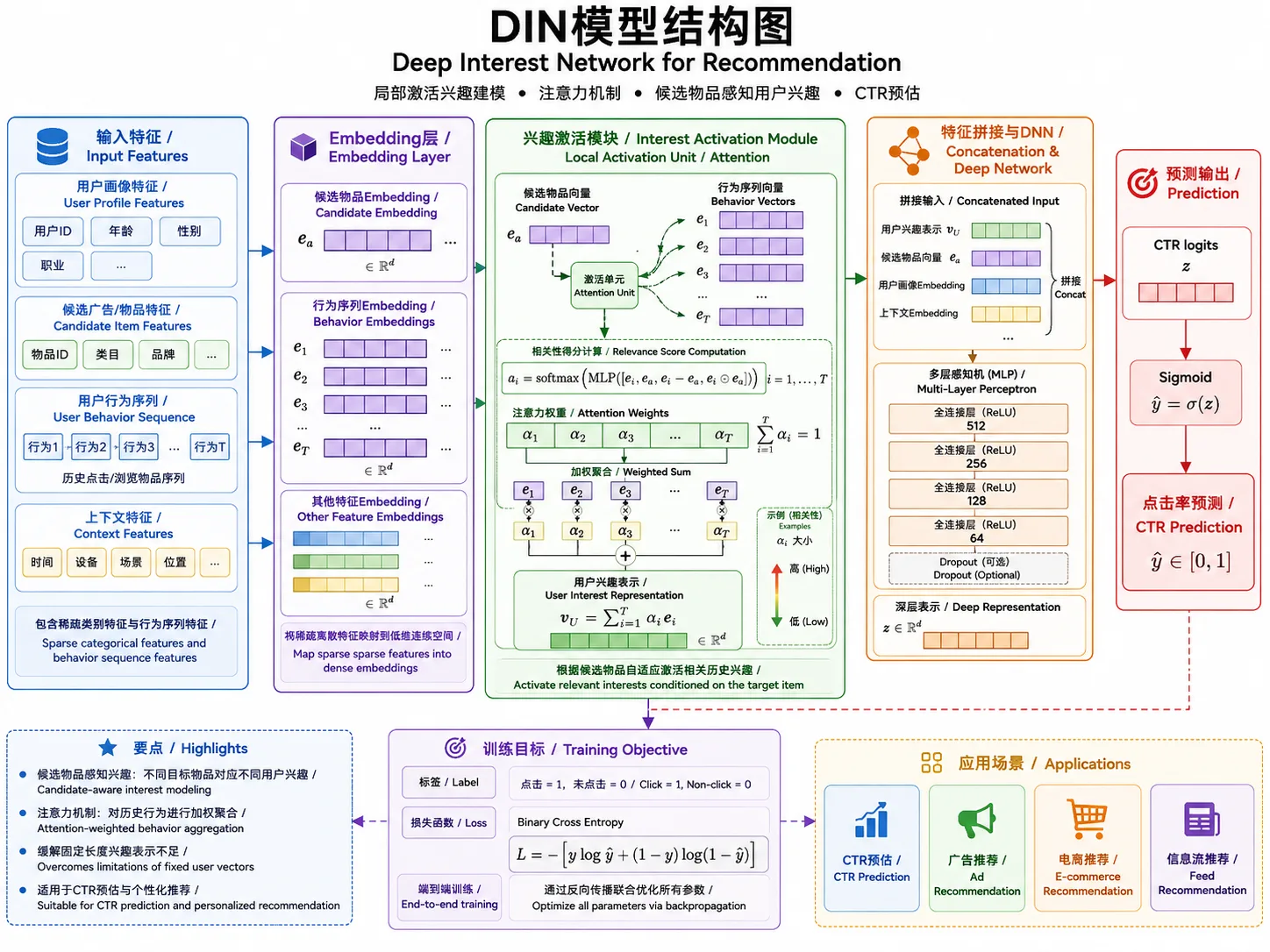
DIN 的数学直觉
DIN 的关键不是把历史序列平均成一个固定用户向量,而是对每个候选物品动态计算历史权重。设候选物品 embedding 为 q,第 i 个历史行为 embedding 为 h_i:
a_i 越大,说明当前候选物品越激活这段历史兴趣。这个机制适合用户兴趣很多样、候选物品差异很大的电商推荐场景。
DIN 输入约定
本篇会构造三组输入:
features:最终进入 MLP 的上下文特征,例如user_id、target_item、target_cate。history_features:用户历史序列,例如history_item、history_cate,通常是二维[batch_size, seq_len]。target_features:候选物品特征,例如target_item、target_cate,DIN 的 attention 用它们去匹配历史序列。
这里新增的是 SequenceFeature。它和普通 SparseFeature 的区别是输入不再是单个 id,而是一段 id 序列;padding 位置要使用 padding_idx=0,这样模型在 attention 或 pooling 时可以把补齐位置屏蔽掉。
import os
from pathlib import Path
import numpy as np
import pandas as pd
import torch
from torch_rechub.basic.features import SparseFeature, SequenceFeature
from torch_rechub.models.ranking import DIN
from torch_rechub.trainers import CTRTrainer
from torch_rechub.utils.data import DataGenerator, create_seq_features, df_to_dict
# 可选:实验跟踪(默认关闭)
# from torch_rechub.basic.tracking import WandbLogger, SwanLabLogger, TensorBoardXLogger
SEED = 2022
DEVICE = "cuda:0" # AMD ROCm 通常通过 cuda:0 设备名访问
PROJECT_ROOT = Path.cwd() if (Path.cwd() / "examples").exists() else Path.cwd().parent
DATASET_PATH = PROJECT_ROOT / "examples/ranking/data/amazon-electronics/amazon_electronics_sample.csv"
SEQ_MAX_LEN = 50
DROP_SHORT = 0 # sample 数据较小,通常不丢弃
EPOCH = 2
BATCH_SIZE = 4096
LR = 1e-3
WEIGHT_DECAY = 1e-3
EARLYSTOP_PATIENCE = 4
USE_TRACKING = False
LOGGER_TYPE = None # "wandb" | "swanlab" | "tensorboard" | None
PROJECT_NAME = "amazon-electronics-din"
EXPORT_ONNX = False
ONNX_PATH = "din.onnx"
torch.manual_seed(SEED)
print("DATASET_PATH:", DATASET_PATH.resolve())data = pd.read_csv(DATASET_PATH)
print("raw shape:", data.shape)
print(data.head())
# 严格对齐 tutorials/DIN.ipynb:用 create_seq_features 构造滑窗样本与序列特征
train_df, val_df, test_df = create_seq_features(
data=data,
seq_feature_col=["item_id", "cate_id"],
max_len=SEQ_MAX_LEN,
drop_short=DROP_SHORT,
shuffle=True,
)
print("train/val/test:", train_df.shape, val_df.shape, test_df.shape)
# vocab_size 取各列的最大 id(create_seq_features 已经 LabelEncode +1,0 留给 padding)
# history_* 是 list,需要从 list-of-lists 取最大值。
def max_from_list_col(df: pd.DataFrame, col: str) -> int:
arr = np.asarray(df[col].tolist())
return int(arr.max())
n_users = int(max(train_df["user_id"].max(), val_df["user_id"].max(), test_df["user_id"].max()))
n_items = int(max(
train_df["target_item"].max(), val_df["target_item"].max(), test_df["target_item"].max(),
max_from_list_col(train_df, "history_item"),
max_from_list_col(val_df, "history_item"),
max_from_list_col(test_df, "history_item"),
))
n_cates = int(max(
train_df["target_cate"].max(), val_df["target_cate"].max(), test_df["target_cate"].max(),
max_from_list_col(train_df, "history_cate"),
max_from_list_col(val_df, "history_cate"),
max_from_list_col(test_df, "history_cate"),
))
print({"n_users": n_users, "n_items": n_items, "n_cates": n_cates})
# 转成模型输入 dict
train = df_to_dict(train_df)
val = df_to_dict(val_df)
test = df_to_dict(test_df)
train_y, val_y, test_y = train["label"], val["label"], test["label"]
for d in (train, val, test):
del d["label"]
train_x, val_x, test_x = train, val, test输出:
raw shape: (100, 4)
user_id item_id time cate_id
0 0 13179 1400457600 584
1 0 29247 1400457600 339
2 0 28326 1400457600 587
3 0 17993 1400457600 513
4 0 62275 1400457600 115
train/val/test: (134, 6) (32, 6) (32, 6)
{'n_users': 16, 'n_items': 99, 'n_cates': 67}特征构造说明
create_seq_features 会把每个用户按时间排序后的行为切成训练样本:
history_item/history_cate:当前行为之前的定长历史序列,不足处用 0 padding。target_item/target_cate:当前要预测的候选物品和类目。label:是否发生目标行为。
这里最容易错的是 vocab size。下面的 n_items/n_cates 会同时扫描 target 列和 history 列;不要只看 target 列,否则历史序列里出现更大的 id 时会导致 embedding 越界。
SEQ_MAX_LEN 越大,历史信息越多,但显存和计算也越高。sample 教程用较短序列保证能快速运行;真实业务里需要结合行为密度、线上延迟和指标收益一起调。
# 构造特征:目标物品/类目 + 用户 id + 历史序列(与 target 共享 embedding)
target_features = [
SparseFeature("target_item", vocab_size=n_items + 1, embed_dim=64, padding_idx=0),
SparseFeature("target_cate", vocab_size=n_cates + 1, embed_dim=64, padding_idx=0),
]
features = target_features + [
SparseFeature("user_id", vocab_size=n_users + 1, embed_dim=64),
]
history_features = [
SequenceFeature(
"history_item",
vocab_size=n_items + 1,
embed_dim=64,
pooling="concat",
shared_with="target_item",
padding_idx=0,
),
SequenceFeature(
"history_cate",
vocab_size=n_cates + 1,
embed_dim=64,
pooling="concat",
shared_with="target_cate",
padding_idx=0,
),
]
# dataloader
dg = DataGenerator(train_x, train_y)
train_dl, val_dl, test_dl = dg.generate_dataloader(
x_val=val_x,
y_val=val_y,
x_test=test_x,
y_test=test_y,
batch_size=BATCH_SIZE,
)
model = DIN(
features=features,
history_features=history_features,
target_features=target_features,
mlp_params={"dims": [256, 128]},
attention_mlp_params={"dims": [256, 128]},
)
model_logger = None
# if USE_TRACKING:
# ... 参见 04_Experiment_Tracking_Light.ipynb 的统一演示
ctr_trainer = CTRTrainer(
model,
optimizer_params={"lr": LR, "weight_decay": WEIGHT_DECAY},
n_epoch=EPOCH,
earlystop_patience=EARLYSTOP_PATIENCE,
device=DEVICE,
model_path="./",
# model_logger=model_logger,
)
ctr_trainer.fit(train_dl, val_dl)
auc = ctr_trainer.evaluate(ctr_trainer.model, test_dl)
print(f"test auc: {auc}")输出:
epoch: 0输出:
train: 100%|██████████| 1/1 [00:00<00:00, 8.02it/s]
validation: 100%|██████████| 1/1 [00:00<00:00, 108.23it/s]输出:
epoch: 0 validation: auc: 0.12890625
epoch: 1输出:
train: 100%|██████████| 1/1 [00:00<00:00, 10.17it/s]
validation: 100%|██████████| 1/1 [00:00<00:00, 101.12it/s]输出:
epoch: 1 validation: auc: 0.1171875输出:
validation: 100%|██████████| 1/1 [00:00<00:00, 146.95it/s]输出:
test auc: 0.876953125DIN 训练说明
features 是最终 MLP 的上下文输入,这里包含 target item、target cate 和 user id;target_features 会额外传给 attention 层。也就是说 target 特征既参与 attention,也作为显式特征进入最后的 MLP,这是 DIN 教程中的常见写法。
DIN 关注的是“候选物品相关的兴趣”,不是简单地把历史行为平均成一个用户向量。训练完成后,AUC 仍然是 CTR 任务的离线指标;如果要在线部署,通常还会继续放进排序链路,和召回、粗排、规则、重排共同工作。
如果你想加用户画像或上下文特征,例如年龄、城市、设备类型,把它们加到 features 里即可;不要加到 history_features,除非它本身是一段随时间变化的序列。
# 可选:导出 ONNX(默认关闭)
if EXPORT_ONNX:
try:
ctr_trainer.export_onnx(ONNX_PATH, verbose=False, device=DEVICE)
print("exported:", ONNX_PATH)
except Exception as e:
print("ONNX export failed:", repr(e))换个序列排序模型再跑
DIN 跑通后,下面会在同一套 Amazon-Electronics 序列样本上继续训练一个 BST。这样读者可以直接比较 DIN 的 target attention 和 BST 的 Transformer 序列建模,不需要再手动打开开关。
DIEN 还需要额外构造负历史序列(neg_history_features),不适合在这里用几行代码硬塞进去;等 DIN 和 BST 的序列输入跑明白后,再单独看 DIEN 教程更稳。
# 换 BST 再跑一遍
# 这里默认直接运行,用同一套序列样本比较 DIN 的 target attention 和 BST 的 Transformer 序列建模。
from torch_rechub.models.ranking import BST
bst_model = BST(
features=features,
history_features=history_features,
target_features=target_features,
mlp_params={"dims": [256, 128]},
nhead=4,
dropout=0.2,
num_layers=1,
)
bst_model_path = Path("./bst")
bst_model_path.mkdir(parents=True, exist_ok=True)
bst_trainer = CTRTrainer(
bst_model,
optimizer_params={"lr": LR, "weight_decay": WEIGHT_DECAY},
n_epoch=EPOCH,
earlystop_patience=EARLYSTOP_PATIENCE,
device=DEVICE,
model_path=str(bst_model_path),
)
bst_trainer.fit(train_dl, val_dl)
bst_auc = bst_trainer.evaluate(bst_trainer.model, test_dl)
print(f"BST test auc: {bst_auc}")输出:
epoch: 0输出:
train: 100%|██████████| 1/1 [00:00<00:00, 2.61it/s]
validation: 100%|██████████| 1/1 [00:00<00:00, 71.77it/s]输出:
epoch: 0 validation: auc: 0.3984375
epoch: 1输出:
train: 100%|██████████| 1/1 [00:00<00:00, 2.71it/s]
validation: 100%|██████████| 1/1 [00:00<00:00, 90.86it/s]输出:
epoch: 1 validation: auc: 0.3515625输出:
validation: 100%|██████████| 1/1 [00:00<00:00, 83.62it/s]输出:
BST test auc: 0.6953125