03 多任务学习:MMOE(Ali-CCP)
- 场景:精排中的多目标建模
- 模型:MMOE(Multi-gate Mixture-of-Experts)
- 数据:Ali-CCP 样例数据
- 目标:用
MTLTrainer跑通多任务训练,并理解 expert、gate、tower 如何服务不同任务
前面几篇都是单目标:CTR 预测点击,DSSM 学用户和物品是否匹配。真实推荐系统往往同时关心点击、收藏、加购、购买、停留时长等目标。把每个目标都训练成独立模型会浪费特征和样本,也容易让多目标之间的关系被忽略。
参考资料
- MMOE 论文:Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
- Torch-RecHub MMOE 代码:
torch_rechub/models/multi_task/mmoe.py - 中文模型教程:
docs/zh/tutorials/models/multi_task/mmoe.md - Ali-CCP 数据集官网:天池 Ali-CCP
数据集介绍
Ali-CCP 是广告/推荐多任务学习中常见的数据集,典型目标包括:
click:用户是否点击。purchase:用户是否购买或转化。
仓库里的 sample 已经做过基础预处理,适合演示 API。真实业务数据如果还保留字符串 ID,需要先把 ID 编码成整数;连续特征则应先处理缺失值、异常值和尺度。
MMOE 适合解决什么问题
MMOE 的思路是:多个 expert 学共享表达,每个任务有自己的 gate,决定更依赖哪些 expert,然后接各自的 task tower 输出任务预测。
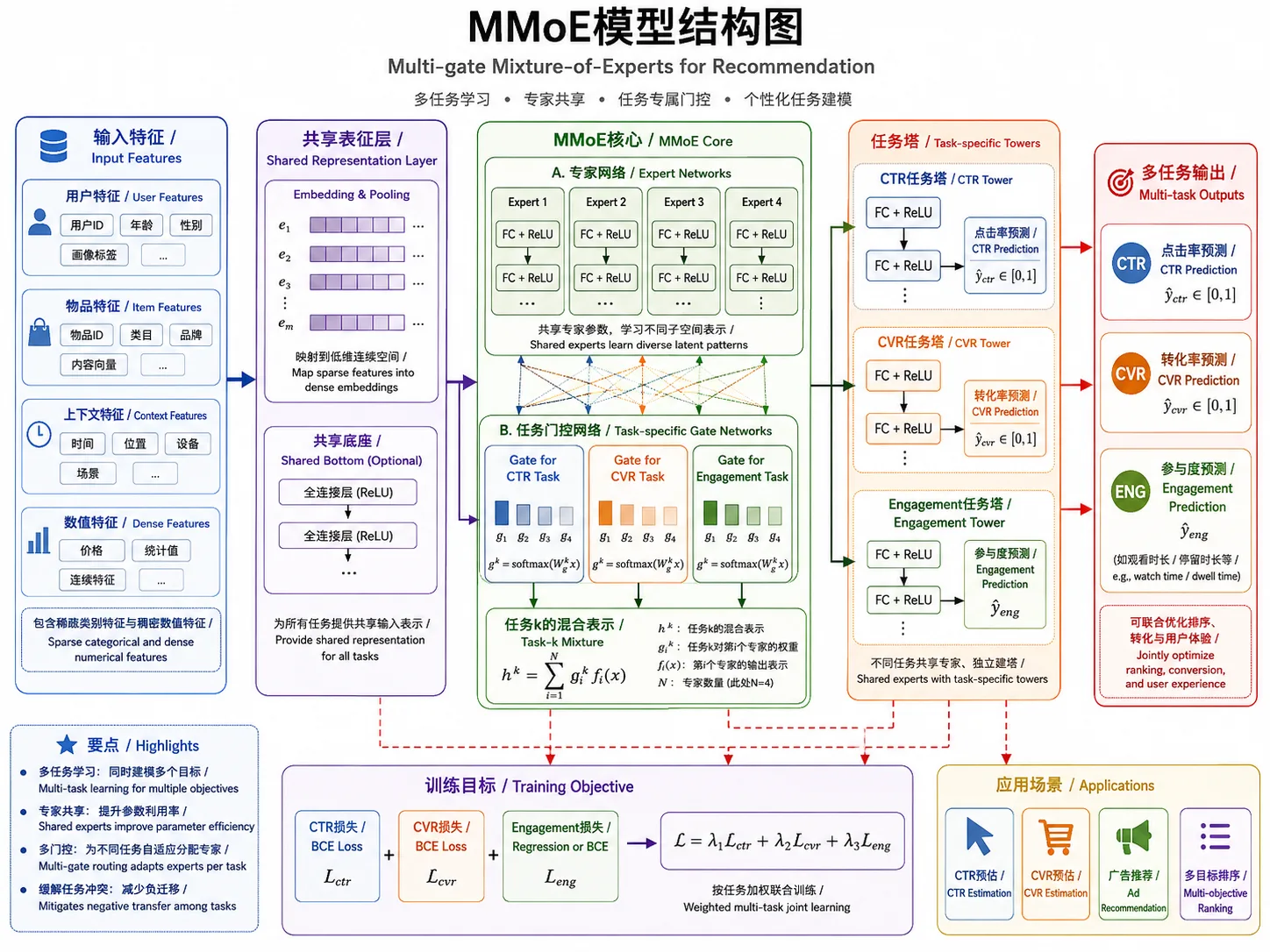
MMOE 的数学直觉
设第 k 个 expert 的输出为 e_k(x),第 t 个任务的 gate 输出为 g_t(x),其中 g_t 是对 expert 的 softmax 权重:
每个任务都能用不同的权重组合专家。点击任务可能更依赖曝光/兴趣类 expert,购买任务可能更依赖价格/转化倾向类 expert。这样既共享底层信息,又允许任务之间保持差异,缓解负迁移。
import os
from pathlib import Path
import pandas as pd
import torch
from torch_rechub.basic.features import DenseFeature, SparseFeature
from torch_rechub.models.multi_task import MMOE
from torch_rechub.trainers import MTLTrainer
from torch_rechub.utils.data import DataGenerator
SEED = 2022
DEVICE = "cuda:0" # AMD ROCm 通常通过 cuda:0 设备名访问
PROJECT_ROOT = Path.cwd() if (Path.cwd() / "examples").exists() else Path.cwd().parent
DATA_DIR = PROJECT_ROOT / "examples/ranking/data/ali-ccp"
EPOCH = 1
BATCH_SIZE = 1024
LR = 1e-3
WEIGHT_DECAY = 1e-4
EARLYSTOP_PATIENCE = 30
# 可选:自适应权重(默认关闭)
USE_ADAPTIVE_WEIGHT = False
ADAPTIVE_METHOD = "uwl" # "uwl" | "gradnorm" | ...(以实现为准)
torch.manual_seed(SEED)
print("DATA_DIR:", DATA_DIR.resolve())数据列说明
Ali-CCP 的 sample 已经完成基础预处理,因此这里不再做 LabelEncoder。D* 列作为 dense 特征,其余业务 id 列作为 sparse 特征。真实业务数据如果还保留字符串 id,需要先编码成从 0 或 1 开始的整数 id。
多任务数据最容易出现两个问题:
- 标签缺失或口径不一致:例如某些样本有点击标签但没有购买标签,需要明确如何过滤或填充。
- 任务正负样本极不平衡:购买通常比点击更稀疏,训练时可能需要调 loss weight、采样或自适应权重。
# 严格对齐 examples/ranking/run_ali_ccp_multi_task.py 的数据处理与列划分
df_train = pd.read_csv(DATA_DIR / "ali_ccp_train_sample.csv")
df_val = pd.read_csv(DATA_DIR / "ali_ccp_val_sample.csv")
df_test = pd.read_csv(DATA_DIR / "ali_ccp_test_sample.csv")
print("train : val : test = %d %d %d" % (len(df_train), len(df_val), len(df_test)))
train_idx, val_idx = df_train.shape[0], df_train.shape[0] + df_val.shape[0]
data = pd.concat([df_train, df_val, df_test], axis=0)
# task 1: purchase (cvr), task 2: click (ctr)
data.rename(columns={"purchase": "cvr_label", "click": "ctr_label"}, inplace=True)
col_names = data.columns.values.tolist()
dense_cols = ["D109_14", "D110_14", "D127_14", "D150_14", "D508", "D509", "D702", "D853"]
sparse_cols = [c for c in col_names if c not in dense_cols and c not in ["cvr_label", "ctr_label", "ctcvr_label"]]
# MMOE 只用两任务标签
label_cols = ["cvr_label", "ctr_label"]
used_cols = sparse_cols + dense_cols
print("sparse cols:", len(sparse_cols), "dense cols:", len(dense_cols))
features = [SparseFeature(col, int(data[col].max() + 1), embed_dim=4) for col in sparse_cols] + [DenseFeature(col) for col in dense_cols]
x_train = {name: data[name].values[:train_idx] for name in used_cols}
y_train = data[label_cols].values[:train_idx]
x_val = {name: data[name].values[train_idx:val_idx] for name in used_cols}
y_val = data[label_cols].values[train_idx:val_idx]
x_test = {name: data[name].values[val_idx:] for name in used_cols}
y_test = data[label_cols].values[val_idx:]
print("y_train shape:", y_train.shape, "y_val shape:", y_val.shape, "y_test shape:", y_test.shape)输出:
train : val : test = 100 50 50
sparse cols: 23 dense cols: 8
y_train shape: (100, 2) y_val shape: (50, 2) y_test shape: (50, 2)MMOE 训练说明
MMOE 使用多个 expert 和每个任务独立的 gate/tower。这里两个任务都是二分类,所以 task_types=["classification", "classification"]。
MTLTrainer 会接收多列标签,并分别计算各任务指标。日志里通常会看到类似 task_0、task_1 的指标;实际项目里建议把任务名映射清楚,例如 click_auc、purchase_auc,方便实验追踪和汇报。
如果打开自适应权重,先从 USE_ADAPTIVE_WEIGHT=True 且 ADAPTIVE_METHOD="uwl" 开始。其他方法对模型结构、梯度和训练稳定性更敏感,不建议在第一次跑教程时启用。
如果你增加第三个任务,需要同步改三处:label_cols、task_types、tower_params_list。三者长度必须一致。
task_types = ["classification", "classification"]
model = MMOE(
features=features,
task_types=task_types,
n_expert=8,
expert_params={"dims": [16]},
tower_params_list=[{"dims": [8]}, {"dims": [8]}],
)
dg = DataGenerator(x_train, y_train)
train_dl, val_dl, test_dl = dg.generate_dataloader(
x_val=x_val,
y_val=y_val,
x_test=x_test,
y_test=y_test,
batch_size=BATCH_SIZE,
)
adaptive_params = {"method": ADAPTIVE_METHOD} if USE_ADAPTIVE_WEIGHT else None
mtl_trainer = MTLTrainer(
model,
task_types=task_types,
optimizer_params={"lr": LR, "weight_decay": WEIGHT_DECAY},
adaptive_params=adaptive_params,
n_epoch=EPOCH,
earlystop_patience=EARLYSTOP_PATIENCE,
device=DEVICE,
model_path="./",
)
mtl_trainer.fit(train_dl, val_dl)
auc = mtl_trainer.evaluate(mtl_trainer.model, test_dl)
print("test auc:", auc)输出:
train: 100%|██████████| 1/1 [00:00<00:00, 38.21it/s]输出:
train loss: {'task_0:': np.float64(0.5873538255691528), 'task_1:': np.float64(0.6726336479187012)}输出:
validation: 100%|██████████| 1/1 [00:00<00:00, 166.94it/s]输出:
epoch: 0 validation scores: [0.22448979591836737, 0.5460992907801419]输出:
validation: 100%|██████████| 1/1 [00:00<00:00, 166.71it/s]输出:
test auc: [0.10204081632653061, 0.71875]换个多任务模型再跑
MMOE 跑通后,下面会继续用同一套 Ali-CCP 特征和标签训练一个 SharedBottom,作为更简单的多任务基线。
ESMM / PLE / AITM 也值得继续比较,但它们的输入假设和任务关系更具体,建议单独放到后续教程里展开。
# 换 SharedBottom 再跑一遍
from torch_rechub.models.multi_task import SharedBottom
shared_bottom_model = SharedBottom(
features=features,
task_types=task_types,
bottom_params={"dims": [32, 16], "activation": "relu", "dropout": 0.2},
tower_params_list=[
{"dims": [8], "activation": "relu", "dropout": 0.2},
{"dims": [8], "activation": "relu", "dropout": 0.2},
],
)
shared_bottom_model_path = Path("./shared_bottom")
shared_bottom_model_path.mkdir(parents=True, exist_ok=True)
shared_bottom_trainer = MTLTrainer(
shared_bottom_model,
task_types=task_types,
optimizer_params={"lr": LR, "weight_decay": WEIGHT_DECAY},
n_epoch=EPOCH,
earlystop_patience=EARLYSTOP_PATIENCE,
device=DEVICE,
model_path=str(shared_bottom_model_path),
)
shared_bottom_trainer.fit(train_dl, val_dl)
shared_bottom_auc = shared_bottom_trainer.evaluate(shared_bottom_trainer.model, test_dl)
print("SharedBottom test auc:", shared_bottom_auc)输出:
train: 100%|██████████| 1/1 [00:00<00:00, 53.82it/s]输出:
train loss: {'task_0:': np.float64(0.7585865259170532), 'task_1:': np.float64(0.667772114276886)}输出:
validation: 100%|██████████| 1/1 [00:00<00:00, 155.21it/s]输出:
epoch: 0 validation scores: [0.9795918367346939, 0.5886524822695035]输出:
validation: 100%|██████████| 1/1 [00:00<00:00, 249.53it/s]输出:
SharedBottom test auc: [0.40816326530612246, 0.7291666666666667]