02 匹配/召回:DSSM(MovieLens-1M) + Annoy 轻量检索
- 场景:召回(Matching / Retrieval)
- 模型:DSSM 双塔
- 数据:MovieLens-1M 样例数据
- 目标:跑通
MatchDataGenerator -> MatchTrainer -> user/item tower -> item embedding topk的召回链路
这一篇从 CTR 精排切换到召回。00/01 的任务是“给一个候选物品打分”,这里的任务是“从大量物品里先找出一批候选”。在线推荐通常不能对全量物品逐个跑精排模型,召回模型会先把候选空间缩小。
参考资料
- DSSM 论文:Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
- Torch-RecHub DSSM 代码:
torch_rechub/models/matching/dssm.py - 中文模型教程:
docs/zh/tutorials/models/matching/dssm.md - MovieLens 样例数据:
examples/matching/data/ml-1m/
数据集介绍
MovieLens-1M 是电影推荐常用数据集。样例数据通常包含:
- 用户侧:
user_id、性别、年龄、职业、历史观看序列等。 - 物品侧:
movie_id、电影类型等。 - 行为侧:评分或隐式反馈,以及时间顺序。
在召回训练里,我们把用户和物品分别编码成向量。
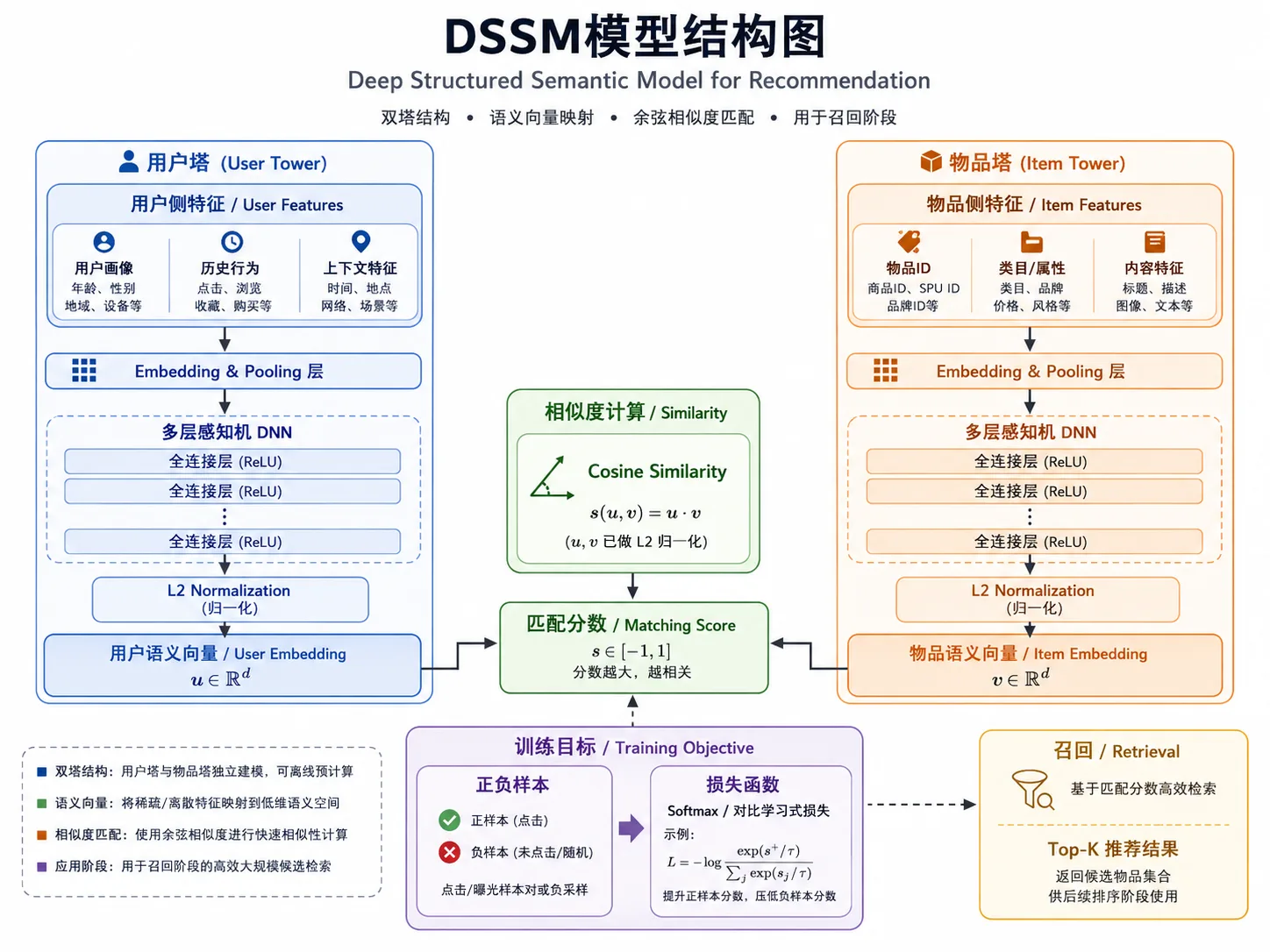
DSSM 的数学直觉
DSSM 的目标是把用户和物品映射到同一个向量空间:
训练时让正样本 user-item 的相似度更高,负样本相似度更低。推理时 item tower 可以离线批量计算所有物品向量,线上只算 user tower,再用 Annoy/FAISS/Milvus 查 topk。
训练时会用负采样构造“用户-正样本-负样本”的学习信号;检索时则把物品向量提前建成 ANN 索引,线上只需要计算用户向量并查询 topk。
import os
from pathlib import Path
import numpy as np
import pandas as pd
import torch
from sklearn.preprocessing import LabelEncoder
from torch_rechub.basic.features import SparseFeature, SequenceFeature
from torch_rechub.models.matching import DSSM
from torch_rechub.trainers import MatchTrainer
from torch_rechub.utils.data import MatchDataGenerator, df_to_dict
from torch_rechub.utils.match import Annoy, gen_model_input, generate_seq_feature_match
SEED = 2022
DEVICE = "cuda:0" # AMD ROCm 通常通过 cuda:0 设备名访问
PROJECT_ROOT = Path.cwd() if (Path.cwd() / "examples").exists() else Path.cwd().parent
DATASET_PATH = PROJECT_ROOT / "examples/matching/data/ml-1m/ml-1m_sample.csv" # 或 ml-1m.csv
SAVE_DIR = PROJECT_ROOT / "examples/matching/data/ml-1m/saved"
RAW_ID_MAPS_PATH = SAVE_DIR / "raw_id_maps.npy"
SEQ_MAX_LEN = 50
NEG_RATIO = 3
MODE = 0
EPOCH = 2
BATCH_SIZE = 4096
LR = 1e-4
WEIGHT_DECAY = 1e-6
EXPORT_ONNX = False
torch.manual_seed(SEED)
SAVE_DIR.mkdir(parents=True, exist_ok=True)
print("DATASET_PATH:", DATASET_PATH.resolve())
print("SAVE_DIR:", SAVE_DIR.resolve())# 严格对齐 tutorials/Matching.ipynb / examples/matching/run_ml_dssm.py:
# - genres -> cate_id(取第一个 genre)
# - LabelEncoder +1(0 留给 padding)
# - 保存 raw_id_maps.npy
data = pd.read_csv(DATASET_PATH)
print("raw shape:", data.shape)
# genres -> cate_id
data["cate_id"] = data["genres"].apply(lambda x: str(x).split("|")[0])
sparse_features = ["user_id", "movie_id", "gender", "age", "occupation", "zip", "cate_id"]
user_col, item_col = "user_id", "movie_id"
feature_max_idx = {}
user_map, item_map = None, None
for feature in sparse_features:
lbe = LabelEncoder()
data[feature] = lbe.fit_transform(data[feature]) + 1
feature_max_idx[feature] = int(data[feature].max() + 1)
if feature == user_col:
user_map = {encode_id + 1: raw_id for encode_id, raw_id in enumerate(lbe.classes_)}
if feature == item_col:
item_map = {encode_id + 1: raw_id for encode_id, raw_id in enumerate(lbe.classes_)}
np.save(RAW_ID_MAPS_PATH, np.array((user_map, item_map), dtype=object))
print("saved raw_id_maps:", RAW_ID_MAPS_PATH)
user_profile = data[["user_id", "gender", "age", "occupation", "zip"]].drop_duplicates("user_id")
item_profile = data[["movie_id", "cate_id"]].drop_duplicates("movie_id")
print("user_profile:", user_profile.shape, "item_profile:", item_profile.shape)输出:
raw shape: (100, 10)
saved raw_id_maps
user_profile: (2, 5) item_profile: (93, 2)样本生成说明
generate_seq_feature_match 会基于用户行为时间顺序生成召回训练样本。mode=0 时最后一列是 label,neg_ratio 控制负样本数量。随后 gen_model_input 会把用户画像、物品画像和历史序列拼成模型需要的输入字典。
召回训练和 CTR 训练的关键差异是:负样本非常重要。真实线上没有点击/观看的物品不一定都是负反馈,所以负采样策略会明显影响模型学到的相似度。
本篇最后用 Annoy 做轻量向量检索演示。Annoy 是内存友好的近似最近邻库,适合本地教学和中小规模检索;中文 Serving 文档还介绍了 FAISS 和 Milvus,分别更适合高性能单机检索和向量数据库场景。
注意:召回模型训练出的 AUC 只衡量 point-wise 打分,不等同于最终线上召回效果;实际系统还要看 topk 命中率、召回率和后续排序链路。
# 生成训练/测试样本(滑窗 + 负采样)
# 注意:generate_seq_feature_match 会生成包含 label 的 df_train/df_test
df_train, df_test = generate_seq_feature_match(
data,
user_col=user_col,
item_col=item_col,
time_col="timestamp",
item_attribute_cols=[],
sample_method=1,
mode=MODE,
neg_ratio=NEG_RATIO,
min_item=0,
)
x_train = gen_model_input(df_train, user_profile, user_col, item_profile, item_col, seq_max_len=SEQ_MAX_LEN)
y_train = x_train["label"]
x_test = gen_model_input(df_test, user_profile, user_col, item_profile, item_col, seq_max_len=SEQ_MAX_LEN)
y_test = x_test["label"]
# 训练数据字典里保留 label 以外的字段
x_train = {k: v for k, v in x_train.items() if k != "label"}
all_item = df_to_dict(item_profile)
test_user = x_test # test_user 中仍包含 label/movie_id 等,用于生成 test dataloader & 评估
print("x_train keys:", list(x_train.keys())[:10], "...", "len=", len(x_train))
print("test_user keys:", list(test_user.keys())[:10], "...", "len=", len(test_user))
print("y_train shape:", np.asarray(y_train).shape, "y_test shape:", np.asarray(y_test).shape)输出:
preprocess data输出:
generate sequence features: 100%|██████████| 2/2 [00:00<00:00, 809.95it/s]输出:
n_train: 384, n_test: 2
0 cold start user dropped
x_train keys: ['user_id', 'movie_id', 'hist_movie_id', 'histlen_movie_id', 'gender', 'age', 'occupation', 'zip', 'cate_id'] ... len= 9
test_user keys: ['user_id', 'movie_id', 'hist_movie_id', 'histlen_movie_id', 'label', 'gender', 'age', 'occupation', 'zip', 'cate_id'] ... len= 10
y_train shape: (384,) y_test shape: (2,)双塔特征说明
hist_movie_id 放在 user tower 中,并通过 shared_with="movie_id" 和 item tower 的 movie_id 共用 embedding 表。这样历史电影 id 和候选电影 id 位于同一个向量空间,适合做用户兴趣聚合。
双塔模型有一个重要约束:user tower 和 item tower 最后的输出维度必须一致,因为后面要做点积或余弦相似度。这里两个 tower 的 MLP 最后一层都是 64 维。
部署时通常会把 item tower 离线批量跑完,得到所有物品 embedding,并保存到 Annoy/FAISS/Milvus;user tower 在线实时计算当前用户 embedding,再查向量索引拿到候选电影。这个流程会在 05_Model_Export_and_Serving.ipynb 里继续展开。
# 构造双塔特征(与 examples/matching/run_ml_dssm.py 对齐)
user_cols = ["user_id", "gender", "age", "occupation", "zip"]
item_cols = ["movie_id", "cate_id"]
user_features = [SparseFeature(name, vocab_size=feature_max_idx[name], embed_dim=16) for name in user_cols]
user_features += [
SequenceFeature(
"hist_movie_id",
vocab_size=feature_max_idx["movie_id"],
embed_dim=16,
pooling="mean",
shared_with="movie_id",
)
]
item_features = [SparseFeature(name, vocab_size=feature_max_idx[name], embed_dim=16) for name in item_cols]
model = DSSM(
user_features,
item_features,
temperature=0.02,
user_params={"dims": [128, 64], "activation": "prelu"},
item_params={"dims": [128, 64], "activation": "prelu"},
)
trainer = MatchTrainer(
model,
mode=MODE,
optimizer_params={"lr": LR, "weight_decay": WEIGHT_DECAY},
n_epoch=EPOCH,
device=DEVICE,
model_path=SAVE_DIR,
)
dg = MatchDataGenerator(x=x_train, y=y_train)
# 注意:MatchDataGenerator.generate_dataloader 的签名是 (x_test_user, x_all_item, batch_size, ...)
train_dl, test_dl, item_dl = dg.generate_dataloader(test_user, all_item, batch_size=BATCH_SIZE, num_workers=0)
trainer.fit(train_dl)
print("inference embedding...")
user_emb = trainer.inference_embedding(model=model, mode="user", data_loader=test_dl, model_path=SAVE_DIR)
item_emb = trainer.inference_embedding(model=model, mode="item", data_loader=item_dl, model_path=SAVE_DIR)
print("user_emb:", tuple(user_emb.shape), "item_emb:", tuple(item_emb.shape))输出:
epoch: 0输出:
train: 100%|██████████| 1/1 [00:00<00:00, 29.10it/s]输出:
epoch: 1输出:
train: 100%|██████████| 1/1 [00:00<00:00, 62.52it/s]输出:
inference embedding...输出:
user inference: 100%|██████████| 1/1 [00:00<00:00, 1000.31it/s]
item inference: 100%|██████████| 1/1 [00:00<00:00, 689.40it/s]输出:
user_emb: (2, 64) item_emb: (93, 64)# 可选:基于 Annoy 做本地 topk 检索演示
# - 用 item tower embedding 建索引
# - 用 user embedding 做 topk query
# - 如未安装 annoy,会自动跳过;需要时执行 pip install annoy
try:
annoy = Annoy(n_trees=10)
annoy.fit(item_emb)
user_map, item_map = np.load(RAW_ID_MAPS_PATH, allow_pickle=True)
TOPK = 10
N_SHOW = 5
hits = 0
for i in range(min(N_SHOW, len(test_user[user_col]))):
uid_enc = int(test_user[user_col][i])
true_item_enc = int(test_user[item_col][i])
idx, scores = annoy.query(v=user_emb[i], n=TOPK)
rec_item_enc = all_item[item_col][idx]
hit = int(true_item_enc in set(rec_item_enc.tolist()))
hits += hit
rec_raw = [item_map[int(x)] for x in rec_item_enc.tolist()]
print(f"user(raw)={user_map[uid_enc]} true_item(raw)={item_map[true_item_enc]} hit@{TOPK}={hit}")
print("rec:", rec_raw)
shown = min(N_SHOW, len(test_user[user_col]))
print(f"sample hit@{TOPK} over {shown} users: {hits}/{shown}")
except ImportError as e:
print("Annoy not installed, skip topk demo:", e)输出:
Annoy not installed, skip topk demo: Annoy is not available. To use Annoy engine, please install it first:
pip install annoy
Or use other available engines like Faiss or Milvus# 可选:导出 ONNX(默认关闭)
# - 双塔:分别导出 user_tower / item_tower
if EXPORT_ONNX:
try:
user_onnx = str(SAVE_DIR / "user_tower.onnx")
item_onnx = str(SAVE_DIR / "item_tower.onnx")
trainer.export_onnx(user_onnx, mode="user")
trainer.export_onnx(item_onnx, mode="item")
print("exported:", user_onnx)
print("exported:", item_onnx)
except Exception as e:
print("ONNX export failed:", repr(e))换个召回模型再跑
DSSM 是 point-wise 双塔召回基线。下面会继续训练一个 YouTubeDNN 对照模型,训练方式切换到 mode=2 list-wise,并重新生成带 neg_items 的样本。
这个 cell 会复用前面已经完成的 MovieLens 编码、用户画像、物品画像和 all_item,只重新生成 YouTubeDNN 需要的 list-wise 训练样本。
# 换 YoutubeDNN 再跑一遍
# YoutubeDNN 使用 list-wise loss,需要重新生成包含 neg_items 的训练样本。
from torch_rechub.models.matching import YoutubeDNN
youtube_train_df, youtube_test_df = generate_seq_feature_match(
data,
user_col=user_col,
item_col=item_col,
time_col="timestamp",
item_attribute_cols=[],
sample_method=1,
mode=2,
neg_ratio=NEG_RATIO,
min_item=0,
)
youtube_x_train = gen_model_input(
youtube_train_df,
user_profile,
user_col,
item_profile,
item_col,
seq_max_len=SEQ_MAX_LEN,
)
# list-wise: label=0 表示第 0 列是正样本,其余列是负样本。
youtube_y_train = np.zeros(youtube_train_df.shape[0], dtype=np.int64)
youtube_test_user = gen_model_input(
youtube_test_df,
user_profile,
user_col,
item_profile,
item_col,
seq_max_len=SEQ_MAX_LEN,
)
youtube_user_features = [SparseFeature(name, vocab_size=feature_max_idx[name], embed_dim=16) for name in user_cols]
youtube_user_features += [
SequenceFeature(
"hist_movie_id",
vocab_size=feature_max_idx["movie_id"],
embed_dim=16,
pooling="mean",
shared_with="movie_id",
)
]
youtube_item_features = [SparseFeature("movie_id", vocab_size=feature_max_idx["movie_id"], embed_dim=16)]
youtube_neg_item_feature = [
SequenceFeature(
"neg_items",
vocab_size=feature_max_idx["movie_id"],
embed_dim=16,
pooling="concat",
shared_with="movie_id",
)
]
youtube_model = YoutubeDNN(
youtube_user_features,
youtube_item_features,
youtube_neg_item_feature,
user_params={"dims": [128, 64, 16]},
temperature=0.02,
)
youtube_model_path = SAVE_DIR / "youtube_dnn"
youtube_model_path.mkdir(parents=True, exist_ok=True)
youtube_trainer = MatchTrainer(
youtube_model,
mode=2,
optimizer_params={"lr": LR, "weight_decay": WEIGHT_DECAY},
n_epoch=EPOCH,
device=DEVICE,
model_path=youtube_model_path,
)
youtube_dg = MatchDataGenerator(x=youtube_x_train, y=youtube_y_train)
youtube_train_dl, youtube_test_dl, youtube_item_dl = youtube_dg.generate_dataloader(
youtube_test_user,
all_item,
batch_size=BATCH_SIZE,
num_workers=0,
)
youtube_trainer.fit(youtube_train_dl)
youtube_user_emb = youtube_trainer.inference_embedding(
model=youtube_model,
mode="user",
data_loader=youtube_test_dl,
model_path=youtube_model_path,
)
youtube_item_emb = youtube_trainer.inference_embedding(
model=youtube_model,
mode="item",
data_loader=youtube_item_dl,
model_path=youtube_model_path,
)
print("YoutubeDNN user_emb:", tuple(youtube_user_emb.shape), "item_emb:", tuple(youtube_item_emb.shape))输出:
preprocess data输出:
generate sequence features: 100%|██████████| 2/2 [00:00<00:00, 473.48it/s]输出:
n_train: 96, n_test: 2
0 cold start user dropped
epoch: 0输出:
train: 100%|██████████| 1/1 [00:00<00:00, 60.20it/s]输出:
epoch: 1输出:
train: 100%|██████████| 1/1 [00:00<00:00, 73.44it/s]
user inference: 100%|██████████| 1/1 [00:00<00:00, 499.92it/s]
item inference: 100%|██████████| 1/1 [00:00<00:00, 499.62it/s]输出:
YoutubeDNN user_emb: (2, 16) item_emb: (93, 16)