🚀 Happy-LLM - 从零训练大模型 AMD ROCm 版本
Happy-LLM 是一套完整的大语言模型(LLM)学习与实践教程,由 Datawhale 社区发起,从零开始讲解大模型的核心原理和实现方法,包含模型结构设计、预训练、微调、应用等全流程。
🎯 本模块(AMD ROCm 版)仅包含原项目的第 5、6 章,因为这两章涉及 GPU 实际训练,需要针对 AMD ROCm 平台做适配和优化。如果你尚未学习大模型基础理论,建议先阅读原项目的前 4 章(见下方原项目章节概览)。
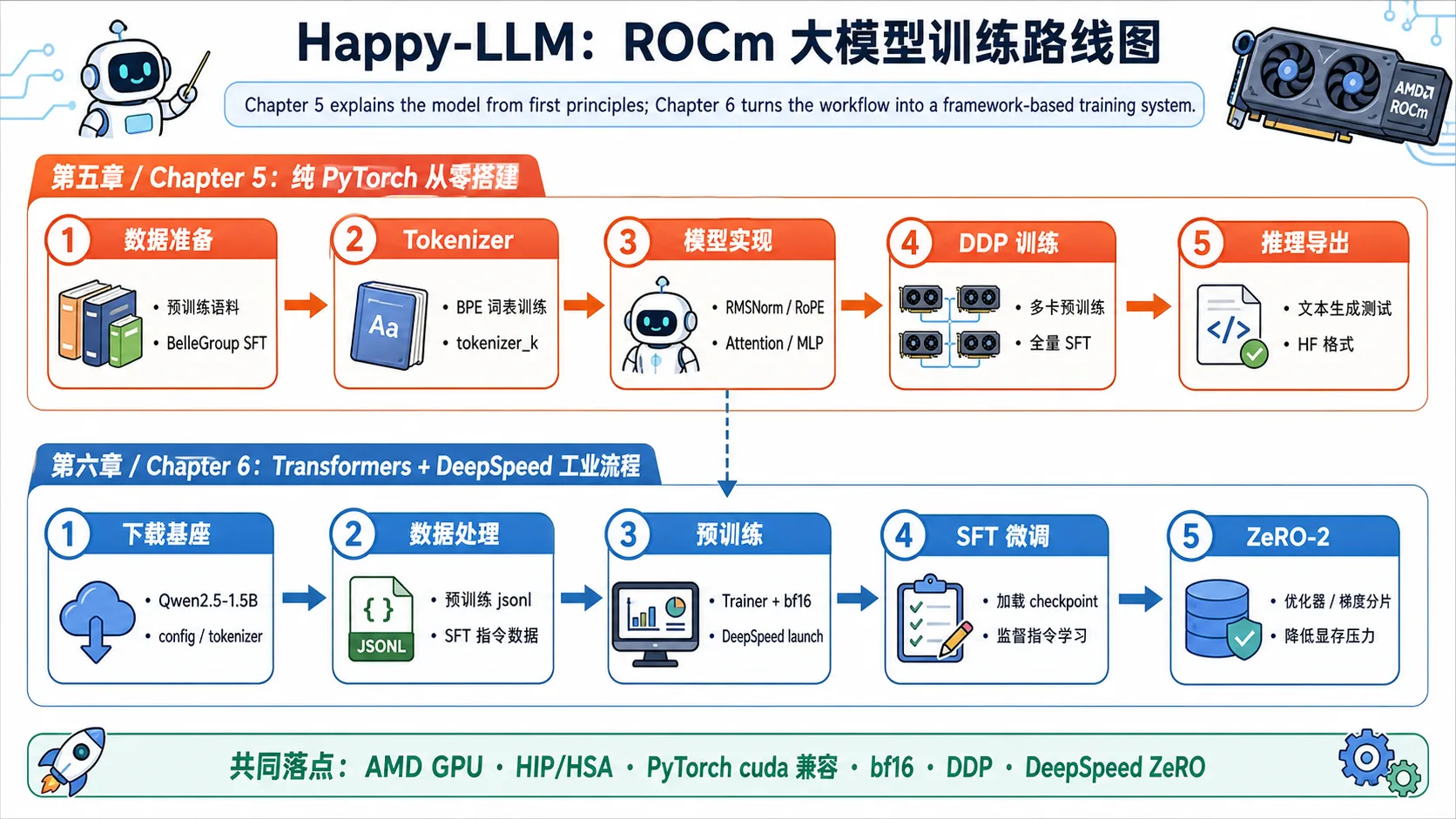
Happy-LLM ROCm 训练路线
原项目章节概览
Happy-LLM 完整教程共 7 章 + 1 个扩展篇,分为 基础理论 和 实战应用 两大部分:
📘 基础理论篇(第 1-4 章)
以下章节为纯理论知识,不涉及 GPU 训练,可直接查看原项目学习,本模块未做修改。
| 章节 | 内容 | 链接 |
|---|---|---|
| 第 1 章 — NLP 基础概念 | NLP 发展历程、任务分类、文本表示演进(从词袋到 Word2Vec) | 原项目第1章 |
| 第 2 章 — Transformer 架构 | 注意力机制原理、Encoder-Decoder 结构、手把手搭建 Transformer | 原项目第2章 |
| 第 3 章 — 预训练语言模型 | BERT / T5 / GPT 架构对比、预训练范式演进 | 原项目第3章 |
| 第 4 章 — 大语言模型 | LLM 定义、训练策略(预训练 → SFT → RLHF)、涌现能力分析 | 原项目第4章 |
🛠️ 实战应用篇(第 5-7 章)
第 5、6 章已适配 AMD ROCm,可直接在本模块运行。第 7 章为通用应用知识,可在原项目查阅。
| 章节 | 内容 | 本模块状态 |
|---|---|---|
| 第 5 章 — 动手搭建大模型 🟢 | 纯 PyTorch 从零实现 LLaMA2(8000万参数),完成预训练 + SFT 微调 | ✅ ROCm 已适配 |
| 第 6 章 — 大模型训练流程实践 🟢 | 基于 Transformers + DeepSpeed 框架,复现工业级预训练与 SFT 流程 | ✅ ROCm 已适配 |
| 第 7 章 — 大模型应用 | 模型评测、RAG 检索增强生成、Agent 智能体 | 原项目第7章 |
| Extra Chapter — LLM Blog | 社区贡献的优秀大模型学习笔记 | 扩展篇 |
💡 学习路线建议:如果你是大模型新手,建议按 1 → 2 → 3 → 4 → 5 → 6 的顺序学习。第 1-4 章在原项目阅读,第 5-6 章回本模块动手实践。有经验者可跳过前 4 章,直接进入第 5 章。
本模块章节导航
📚 第五章:动手搭建大模型
使用纯 PyTorch 从零实现 LLaMA2 模型(8000万参数),并在 AMD ROCm 上完成预训练与 SFT 微调,无需依赖任何训练框架。
🔧 第六章:大模型训练流程实践
基于 Transformers + DeepSpeed 框架,复现工业级预训练与 SFT 流程,支持 AMD ROCm 多卡分布式训练与 ZeRO 优化。
环境要求
硬件要求
- GPU:AMD RDNA 2/3 系列(如 RX 6700 XT、RX 7900 XTX)或 MI 系列(如 MI300X)
- 显存:建议 64GB+ 以上
- 系统内存:128GB+ 推荐
- 存储空间:300GB+(用于模型和数据集)
软件要求
- 操作系统:Linux (Ubuntu 22.04 LTS / 24.04 LTS 推荐)
- ROCm 版本:7.12.0 或更高版本
- Python 版本:3.10~3.12
快速开始
第一步:环境准备
📖 ROCm + PyTorch 基础环境安装请参考 00-Environment,完成后再继续以下步骤。
cd 04-happy-llm
# 激活虚拟环境后,安装项目专用依赖
uv pip install -r ./chapter5/code/requirements.txt
uv pip install -r ./chapter6/code/requirements.txt本项目使用 4×AMD Radeon™ AI PRO R9700(gfx1201)运行测试,其他架构请在 00-Environment 中替换对应的
--index-url。
第二步:选择学习路径
初学者推荐路线:
- 先完成第五章第一节,理解 LLaMA2 的完整结构
- 按顺序完成第五章,掌握从零实现大模型
- 进入第六章,学习使用主流框架训练模型
进阶开发者路线:
- 跳过第五章基础部分,从第五章第二节开始
- 重点学习第六章的分布式训练和优化技术
- 完成性能基准测试和优化案例
第三步:运行示例
# 运行第五章模型实现示例
cd chapter5/code
# 运行第六章预训练脚本
cd chapter6/code关键技术点
模型架构
| 组件 | 说明 |
|---|---|
| Token Embedding | 词嵌入层 |
| RMSNorm | 根均方范数归一化 |
| Attention | 多头自注意力机制,支持 FlashAttention2 |
| FFN | 前馈网络 (MLP) |
| Rotary Embedding | 旋转位置编码 |
训练优化
| 技术 | 用途 |
|---|---|
| DDP | 数据并行分布式训练 |
| DeepSpeed ZeRO | 内存优化与参数分片 |
| FlashAttention | 降低注意力计算复杂度 |
| PEFT/LoRA | 参数高效微调 |
| 梯度累积 | 增大有效批大小 |
| 混合精度训练 | 降低显存占用 |
常见问题
Q: ROCm 找不到 GPU 怎么办?
A: 按以下步骤排查:
验证 GPU 和驱动:
bashrocminfo rocm-smi检查环境变量:
bashecho $LD_LIBRARY_PATH export HSA_OVERRIDE_GFX_VERSION=gfx90a # 对某些 GPU 可能需要重新安装 PyTorch ROCm 版本,注意 gpu 对应架构:
bashpip install torch torchvision torchaudio --index-url https://repo.amd.com/rocm/whl/gfx120X-all/如果问题仍存在,请查看 ROCm 官方指南
Q: 显存不足(OOM)如何解决?
A: 尝试以下方法(优先级从高到低):
- 减小批大小 - 在配置文件中设置
per_device_train_batch_size = 1 - 启用梯度累积 - 设置
gradient_accumulation_steps = 8 - 使用混合精度 - 设置
fp16 = true或bf16 = true - 启用 DeepSpeed ZeRO-3 - 完整参数分片
- 使用 LoRA 微调 - 而不是全量微调
- 启用 FlashAttention - 降低注意力显存占用
Q: 多卡训练速度不理想怎么办?
A: 检查和优化:
验证多卡识别:
bashrocm-smi # 查看所有 GPU检查通信带宽:
bashrocm-bandwidth-test在训练脚本中启用 distributed debug:
bashexport NCCL_DEBUG=INFO # 或 HIP 的等价环境变量尝试增加
num_train_epochs和logging_steps以平衡通信开销
Q: 如何在服务器上实际运行这些项目?
A: 推荐流程:
环境准备(第一次运行)
- 运行
code/install_rocm_deps.sh安装所有依赖 - 运行
code/setup_environment.sh配置环境变量
- 运行
验证环境
- 运行
code/performance_benchmark.py进行性能测试 - 查看输出的 GPU 利用率和吞吐量
- 运行
选择模型
- 根据硬件显存选择合适的模型大小
- 参考"性能参考"表格调整超参数
开始训练
- 从 chapter5 开始学习基础概念
- 按 chapter6 的脚本进行实际训练
监控和优化
- 使用
rocm-smi实时监控 GPU 状态 - 根据训练日志调整超参数
- 使用
详细的运行指南见各章节文档。
Q: 第五章和第六章有什么区别?
A:
- 第五章:纯 PyTorch 实现,从零搭建 LLaMA2,适合理解模型原理
- 第六章:使用 Transformers 框架,重点在于工业级训练和优化,适合实际应用
如果想快速上手训练,可以直接进入第六章。如果想深入理解模型原理,建议先完成第五章。
项目结构
src/amd-yes/happy-llm/
├── chapter5/ # 第五章:从零搭建 LLaMA2 模型
│ └── code/
│ ├── 00_download_dataset.sh # 步骤 0:下载数据集(Linux)
│ ├── 00_windows_download_dataset.sh # 步骤 0:下载数据集(Windows)
│ ├── 01_deal_dataset.py # 步骤 1:预处理数据集
│ ├── 02_train_tokenizer.py # 步骤 2:训练 BPE Tokenizer
│ ├── 03_ddp_pretrain.py # 步骤 3:DDP 多卡预训练
│ ├── 04_ddp_sft_full.py # 步骤 4:DDP 多卡 SFT 微调
│ ├── 05_model_sample.py # 步骤 5:推理测试
│ ├── 06_export_model.py # 步骤 6:导出 HuggingFace 格式
│ ├── k_model.py # 模型定义(库文件)
│ ├── dataset.py # 数据集类(库文件)
│ ├── tokenizer_k/ # 预训练好的 Tokenizer
│ │ ├── special_tokens_map.json
│ │ ├── tokenizer.json
│ │ └── tokenizer_config.json
│ └── requirements.txt
└── chapter6/ # 第六章:基于 Transformers 的 LLM 训练
└── code/
├── 00_download_model.py # 步骤 0:下载基础模型
├── 01_download_dataset.py # 步骤 1a:下载数据集
├── 01_process_dataset.ipynb # 步骤 1b:数据集处理(Notebook)
├── 02_pretrain.py # 步骤 2:预训练脚本
├── 02_pretrain.sh # 步骤 2:DeepSpeed 启动脚本
├── 02_pretrain.ipynb # 步骤 2:预训练(Notebook)
├── 03_finetune.py # 步骤 3:SFT 微调脚本
├── 03_finetune.sh # 步骤 3:DeepSpeed 启动脚本
├── ds_config_zero2.json # DeepSpeed ZeRO-2 配置
├── whole.ipynb # 完整流程 Notebook
└── requirements.txt参考资源
- 📚 Happy-LLM 原始项目
- 📖 ROCm 官方文档
- 📖 ROCm 官方 preview 文档
- 🤗 Hugging Face Transformers
- ⚡ DeepSpeed 官方文档
- 🔧 PyTorch 官方文档
贡献与反馈
欢迎提交 Issue 和 Pull Request!
- 📝 改进文档和教程
- 🐛 报告 Bug
- 💡 分享优化技巧
- 📊 补充性能测试结果
开始学习大模型,从零构建 LLM! 🎓
Made with ❤️ by the hello-rocm community