Von der Datenbank zu Supabase
In der letzten Lektion haben wir die grundlegende Verwendung der UI-Design-Tools MasterGo und Figma kennengelernt, konnten Code ueber GitHub abrufen und版本 verwalten sowie Websites ueber Zeabur bereitstellen, um unsere Anwendungen einer breiteren Nutzergemeinde zugaenglich zu machen.
Um den Wissenstransfer zu erleichtern, lassen Sie uns vor Beginn der neuen Inhalte zu Design-Tools und Bereitstellung einige der Kernpunkte der letzten Lektion anhand einiger einfacher Fragen kurz wiederholen:
- Was sind Frontend-Design-Tools, Figma und MasterGo - Definition und Verwendung.
- Grundlegende Methoden zur Umsetzung von Designentwuerfen in Code.
- Was ist GitHub, wie konfiguriert man SSH und wie erstellt man sein erstes Repository.
- Was bedeutet Bereitstellung (Deployment), wie verwendet man Zeabur und wie stellt man GitHub- oder lokalen Code oeffentlich zugaenglich bereit.
Wenn dir bei einer dieser Fragen noch Unklarheiten bleiben, empfiehlt es sich, die Dokumente und Unterlagen der letzten Lektion noch einmal durchzugehen. Du kannst jederzeit Fragen in der WeChat-Lerngruppe stellen.
In dieser Lektion werden wir lernen, wie eine App oder Website von einem lauffaehigen Zustand zu einem echten Online-Produkt wird: Neben der Verwaltung verschiedener Datenveraenderungen waehrend des Programmablaufs durch eine Datenbank benoetigen wir auch ein vollstaendiges Benutzersystem (Registrierung, Anmeldung, Berechtigungen usw.) sowie weitere wichtige Backend-Faehigkeiten. Wir werden Supabase als Backend-Service-Plattform als Leitfaden verwenden und damit zunaechst die beiden Grundfunktionen "Datenbank + Benutzersystem" implementieren. Anschliessend werden wir die von Supabase bereitgestellten Komponenten als Referenz nutzen, um die Kernmodule moderner Cloud-Backend-Dienste besser zu verstehen sowie deren spezifische Funktionen und Wirkungsweise.
Was du lernen wirst
- Was sind Daten, was ist eine Datenbank sowie haeufige Datenbanken und deren Verwendung
- Was ist Supabase und wie man grundlegende Datenbankoperationen mit Supabase durchfuehrt
- Wie man Supabase nutzt, um einer App grundlegende Benutzerverwaltungsfunktionen hinzuzufuegen
- Supabase-Erweiterungsfunktionen erlernen: Realtime, Storage, Edge Functions
- Google- und GitHub-Login-Unterstützung fuer Supabase hinzufuegen
- Eine Basisanwendung, die Benutzerregistrierung/-anmeldung unterstuetzt und Daten in einer Online-Datenbank speichern kann
- Eine wiederverwendbare Supabase-Backend-Codevorlage (Datenbank, Benutzerverwaltung usw.) fuer die direkte Verwendung in spaeteren Projekten
1. Was ist eine Datenbank
1.1 Was sind Daten
In der digitalen Welt sind Daten (Data) ueberall präsent. Kurz gesagt: Daten sind Traeger von Informationen. Die Kontaktdaten deiner Freunde, ein WeChat-Artikel, ein kurzes Video, der Charakterlevel in einem Spiel - all dies sind Daten. In unserer Anwendung sind Daten alle Informationen, die aufgezeichnet und verwaltet werden muessen, wie z. B. Benutzerprofile, Bestellverlaufe, Programmeinstellungen usw.
Im Allgemeinen haben Daten in einem Programm unterschiedliche Darstellungsformen. Die einfachste Form ist die Variable. Wir koennen verschiedene Variablen verwenden, um einfache Zahlen aufzuzeichnen:
# Python variable definition examples
# Integer variable: stores age information
age = 30
# Boolean variable: stores status (whether active)
is_active = True # True means active, False means inactive
# List variable: stores a set of score data
scores = [85, 92, 78, 90] # Contains 4 integer elements representing different scores
# Dictionary variable: stores multiple related information of a user
user_info = {
"age": 30, # Key "age" corresponds to the value of age
"height": 1.80, # Key "height" corresponds to the value of height (unit: meter)
"login_count": 156 # Key "login_count" corresponds to the value of login times
}Fuer komplexe Daten wie persoenliche Profile oder Bestellverlaufe koennen wir diese in ausfuehrlicheren Tabellen darstellen:
| user_id | name | |
|---|---|---|
| 1001 | Alice | alice@example.com |
| 1002 | Bob | bob@example.com |
| order_id | user_id | amount | status |
|---|---|---|---|
| 901 | 1001 | 29.99 | completed |
| 902 | 1002 | 15.50 | pending |
Fuer Daten mit komplexer Struktur, hierarchischen Beziehungen oder variablen Feldern koennen wir das JSON-Format zur Beschreibung verwenden. Es ist das universelle Zwischenformat des Internets, das von fast allen Programmen gelesen und geparst werden kann, was den Datenaustausch zwischen Systemen sehr bequem macht.
{
"order_id": 901,
"user_id": 1001,
"amount": 29.99,
"status": "completed",
"items": [
{ "sku": "BG-001", "name": "Rindfleisch-Burger", "quantity": 1, "price": 18.00 },
{ "sku": "SD-003", "name": "Pommes frites", "quantity": 1, "price": 6.99 },
{ "sku": "DK-002", "name": "Cola", "quantity": 1, "price": 5.00 }
],
"shipping_address": {
"street": "Technologiepark-Strasse 123",
"city": "Shenzhen",
"zip_code": "518057"
}
}Darueber hinaus koennen Daten auch als Vektoren (Vectors) codiert werden. Vektordaten sind in der Regel numerische Darstellungen, die durch KI-Modelle (wie Embedding-Modelle) aus unstrukturierten Daten wie Text, Bildern oder Audio generiert werden.
[0.123, -0.456, 0.789, ..., -0.234] (ein Array aus Hunderten oder Tausenden von Gleitkommazahlen)
Insgesamt gibt es in der realen Welt viele verschiedene Datenformen und Verwendungszwecke, die eine detaillierte Analyse erfordern. Jede Datenart benoetigt moeglicherweise eine spezielle Datenbank zur Speicherung.
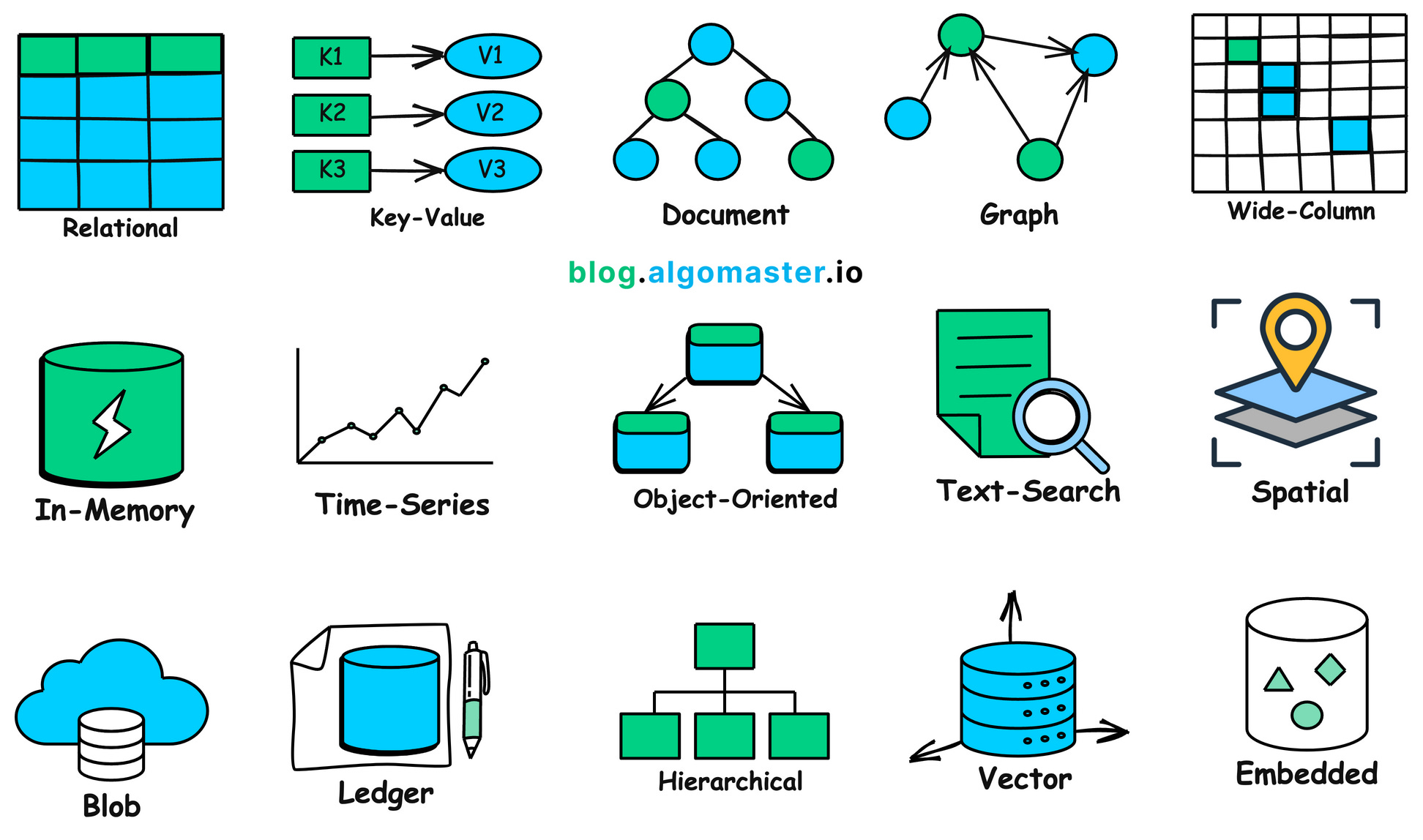
1.2 Warum wir Datenbanken brauchen
Wir haben bereits gelernt, dass Daten in der realen Welt oft komplex strukturiert sind. Um diese Daten effizient zu speichern und zu nutzen, benoetigen wir ein spezielles Programm oder einen Container zu ihrer Verwaltung - dies war der urspruengliche Grund fuer die Entstehung von Datenbanken (Databases). Eine Datenbank ist im Kern ein spezielles Programm, dessen Hauptaufgabe darin besteht, Daten zu standardisieren, sicher zu speichern, systematisch zu verwalten und effiziente Abfragen zu ermoeglichen.
Stell dir vor, was ohne Datenbanken passieren wuerde: Wenn Benutzer den Browser schliessen oder die App verlassen, gehen alle temporaer geladenen Informationen verloren. Wir koennen weder den Nutzungsstatus (wie Anmeldedaten, personalisierte Einstellungen) dauerhaft speichern noch Schluesseldaten zwischen verschiedenen Benutzern teilen (wie Produktbestaende, Bestellaufzeichnungen). Wir brauchen ein System, das alle unsere Daten speichert!
Flexibler ist die Bereitstellung der Datenbank: Sie kann auf einem lokalen Server fuer lokale Datenverwaltung bereitgestellt werden oder in der Cloud. Cloud-Datenbanken unterstuetzen elastische Skalierung (Scale) und koennen mit wachsenden Datenmengen und Zugriffszahlen erweitert werden, um massive Daten und hohe Parallelitaet zu bewaeltigen. Selbst bei stark steigenden Benutzerzahlen bleibt eine gute Nutzungserfahrung gewaehrleistet.
Zusammenfassend loesen Datenbanken durch effiziente dauerhafte Speicherung, feinkoernige Verwaltung und schnelle Abfragefaehigkeiten die folgenden Kernprobleme:
- Dauerhafte Datenspeicherung: Ohne Datenbank wuerden Daten nur im Arbeitsspeicher der Anwendung existieren und beim Schliessen der Anwendung verloren gehen. Eine Datenbank loest dieses Problem, indem sie Daten dauerhaft auf Festplatten und anderen Speichermedien ablegt und so die langfristige Aufbewahrung sicherstellt.
- Komfortable Datenabfrage und -analyse: Datenbanken bieten leistungsstarke Abfragesprachen (wie SQL), mit denen Benutzer umfangreiche Daten einfach, effizient und komplex abfragen, filtern und analysieren koennen, um informiertere Geschaeftsentscheidungen zu treffen.
- Hochleistung und gleichzeitigen Zugriff: Durch Indizierung, Abfrage-Caching, Verbindungspools und verteilte Architekturen koennen Datenbanken Abfragen in Millisekunden beantworten und tausende gleichzeitige Benutzerzugriffe unterstuetzen.
- Datenintegritaet und -konsistenz: Datenbanken stellen durch Mechanismen wie Einschraenkungen (Constraints) und Trigger sicher, dass Daten genau und konsistent sind.
- Datensicherheit: Datenbanken bieten starke Sicherheitsmechanismen einschliesslich Benutzerauthentifizierung, Zugriffskontrolle und Datenverschluesselung.
1.3 Relationale und nicht-relationale Datenbanken
Wir haben bereits den Kernwert, die Bereitstellungsoptionen und die elastischen Vorteile von Datenbanken kennengelernt. Bei der tatsaechlichen Auswahl stehen wir zunaechst vor zwei Hauptkategorien: relationale und nicht-relationale Datenbanken (NoSQL).
Relationale Datenbanken sind wie streng strukturierte Excel-Tabellen: Alle Daten muessen im Voraus ein Format definiert haben (Schema). Sie werden durch Verknuepfungsfelder (wie Ausweisnummern) miteinander verbunden. Ihr Vorteil ist praezise und zuverlaessige Datenverarbeitung, besonders geeignet fuer Bankueberweisungen, Bestandsverwaltung und andere fehlerkritische Szenarien. Der Nachteil ist, dass Strukturaenderungen aufwaendig sind und die Leistung bei riesigen Datenmengen begrenzt sein kann.
Nicht-relationale Datenbanken sind wie flexible Ordner, die Dokumente, Bilder oder Schluessel-Wert-Paare in unterschiedlichen Formaten speichern koennen, ohne die Struktur jedes Datensatzes vorab festzulegen. Sie eignen sich besser fuer sich schnell aendernde Anforderungen und extrem grosse Datenmengen.
| Datenbanktyp | Name | Preis | Anwendungsbereich |
|---|---|---|---|
| Relationale Datenbank | RDS MySQL | Niedrig | Lern- und kleine Website-Projekte; mittlere Datenbank-Szenarien; Cluster fuer hohe Zugriffsauslastung |
| RDS SQL Server | Hoch | Test- und kleine kommerzielle Websites; kommerzielle Websites auf Unternehmensebene; Cluster fuer unterbrechungsfreien Betrieb | |
| RDS PostgreSQL | Niedrigste | Lern- und kleine Website-Projekte; mittlere Datenbank-Szenarien; hochperformante Cluster | |
| NoSQL-Datenbank | Redis | Mittel | Persistenz-Datenbank fuer hohe Verfuegbarkeit; Cache-Beschleunigungsschicht |
| MongoDB | Mittel | Einzelknoten fuer Entwicklung/Tests; Replikat-Sets fuer hoehere Leseleistung; Sharded Cluster fuer Echtzeit-Online-Geschaeft |
Beispiel: Relationale Datenbank (SQL)
In einer SQL-Datenbank speichern wir verschiedene Datentypen in separaten Tabellen, die durch "Fremdschluessel" (Foreign Keys) miteinander verknuepft sind.
usersTabelle:
| user_id ( Primaerschluessel) | username | |
|---|---|---|
| 101 | Alice | alice@example.com |
| 102 | Bob | bob@example.com |
postsTabelle:
| post_id ( Primaerschluessel) | title | content | author_id ( Fremdschluessel) |
|---|---|---|---|
| 1 | SQL kennenlernen | Ein Artikel ueber SQL-Datenbanken... | 101 |
| 2 | NoSQL-Einfuehrung | NoSQL bietet flexible Datenmodelle... | 102 |
commentsTabelle:
| comment_id ( Primaerschluessel) | body | commenter_id ( Fremdschluessel) | post_id ( Fremdschluessel) |
|---|---|---|---|
| 1001 | Sehr gut geschrieben! | 102 | 1 |
| 1002 | Gelernt. | 101 | 2 |
tagsTabelle:
| tag_id ( Primaerschluessel) | tag_name |
|---|---|
| 51 | Datenbank |
| 52 | Technologie |
| 53 | Einfuehrung |
post_tagsTabelle (fuer die Viele-zu-Viele-Beziehung):
| post_id ( Fremdschluessel) | tag_id ( Fremdschluessel) |
|---|---|
| 1 | 51 |
| 1 | 52 |
| 2 | 51 |
| 2 | 52 |
| 2 | 53 |
Um "alle Informationen zu Alices Artikel (post_id=1)" abzufragen, ist eine JOIN-Abfrage ueber mehrere Tabellen erforderlich:
SELECT
p.title,
p.content,
u.username AS author,
c.body AS comment,
t.tag_name AS tag
FROM
posts p
JOIN
users u ON p.author_id = u.user_id
LEFT JOIN
comments c ON p.post_id = c.post_id
LEFT JOIN
post_tags pt ON p.post_id = pt.post_id
LEFT JOIN
tags t ON pt.tag_id = t.tag_id
WHERE
p.post_id = 1;Beispiel: Nicht-relationale Datenbank (NoSQL)
NoSQL-Datenbanken (wie MongoDB) buendeln alle relevanten Daten in einem einzigen Dokument:
{
"_id": 1,
"title": "SQL kennenlernen",
"content": "Ein Artikel ueber SQL-Datenbanken...",
"author": {
"user_id": 101,
"username": "Alice",
"email": "alice@example.com"
},
"tags": [
"Datenbank",
"Technologie"
],
"comments": [
{
"comment_id": 1001,
"body": "Sehr gut geschrieben!",
"commenter": {
"user_id": 102,
"username": "Bob"
}
}
]
}Der Vorteil: Alle Daten koennen mit einer einzigen Abfrage abgerufen werden, ohne JOINs. Der Nachteil: Datenredundanz kann zu Konsistenzproblemen fuehren.
2. Supabase
Nachdem wir verschiedene Datenbanktypen vorgestellt haben, muessen wir ein groesseres Bild betrachten: Backend-Services. Eine vollstaendige Anwendung besteht in der Regel aus "Frontend + Backend". Das Frontend ist fuer die Seitenanzeige und Benutzerinteraktion zustaendig, waehrend das Backend Datenverwaltung, Benutzeranmeldung, Geschaeftslogik und mehr uebernimmt.
Um diese wiederkehrenden Aufgaben zu vereinfachen, entstand BaaS (Backend as a Service): Datenbank, Benutzerauthentifizierung, Dateispeicher, Echtzeitfaehigkeiten und weitere gängige Backend-Funktionen werden als Cloud-Plattform gebuendelt, die Entwickler ueber SDK/API direkt nutzen koennen, ohne Infrastruktur von Grund auf neu aufzubauen.
Supabase kann als repraesentative Plattform der neuen BaaS-Generation betrachtet werden: Sie nutzt PostgreSQL als Kern-Datenbank und integriert Auth, Storage, Realtime, Edge Functions, Vector und weitere Backend-Faehigkeiten zu einer "Postgres-zentrierten All-in-One-Backend-Plattform".
2.1 Schritt-fuer-Schritt-Anleitung
Nachdem wir die Positionierung von Supabase verstanden haben, werden wir nun die Kernfunktionen der Supabase-Konsole Schritt fuer Schritt erklaeren.

Besuche die Supabase-Website, melde dich an und klicke auf der Konsole-Startseite auf "New project".
Nach erfolgreicher Erstellung zeigt die linke Seitenleiste alle Kernfunktionsmodule an.
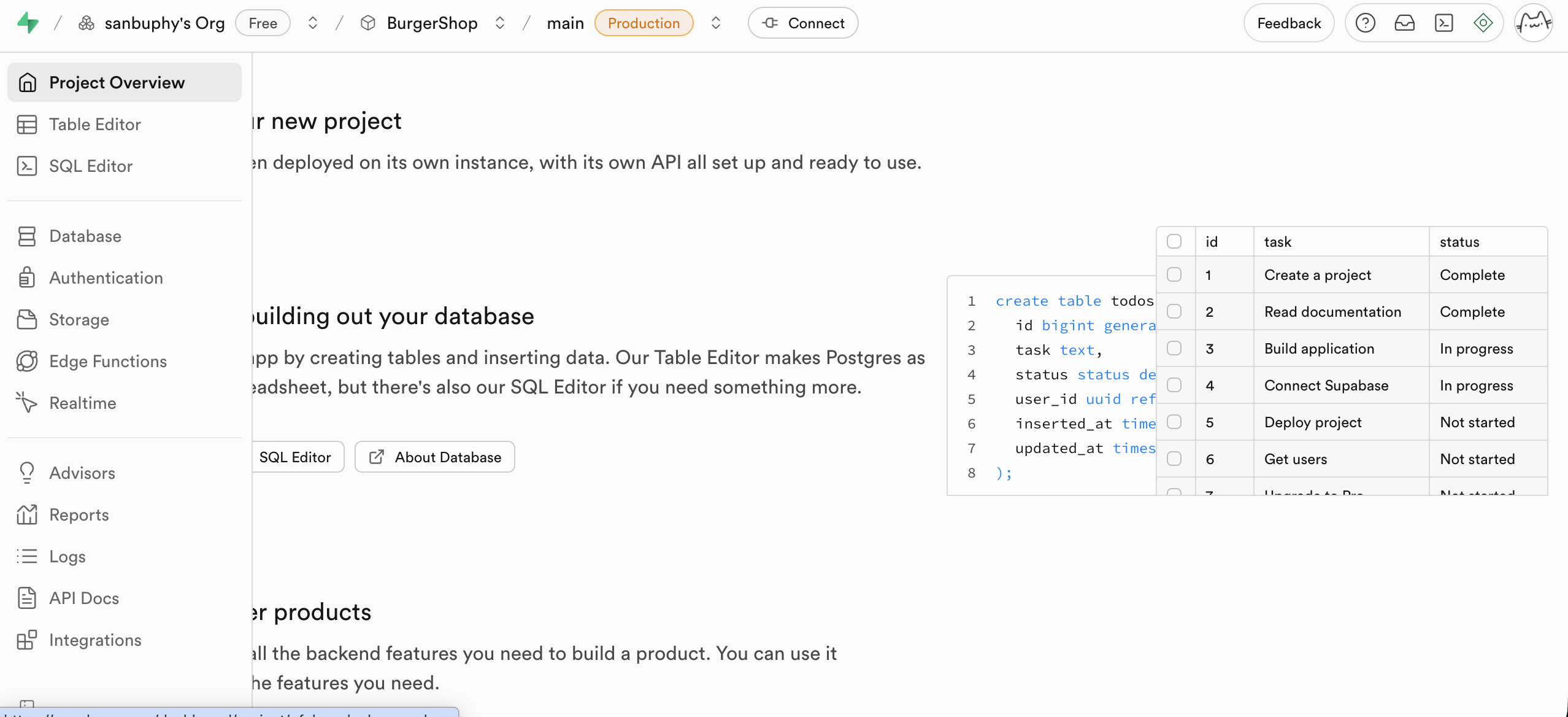
Tabellen-Editor (Table Editor)
Der Tabellen-Editor ist der visuelle Datentabellen-Editor von Supabase. Er ermoeglicht es dir, Daten in der Datenbank direkt wie in Excel anzuzeigen und zu aendern, ohne SQL-Statements schreiben zu muessen.
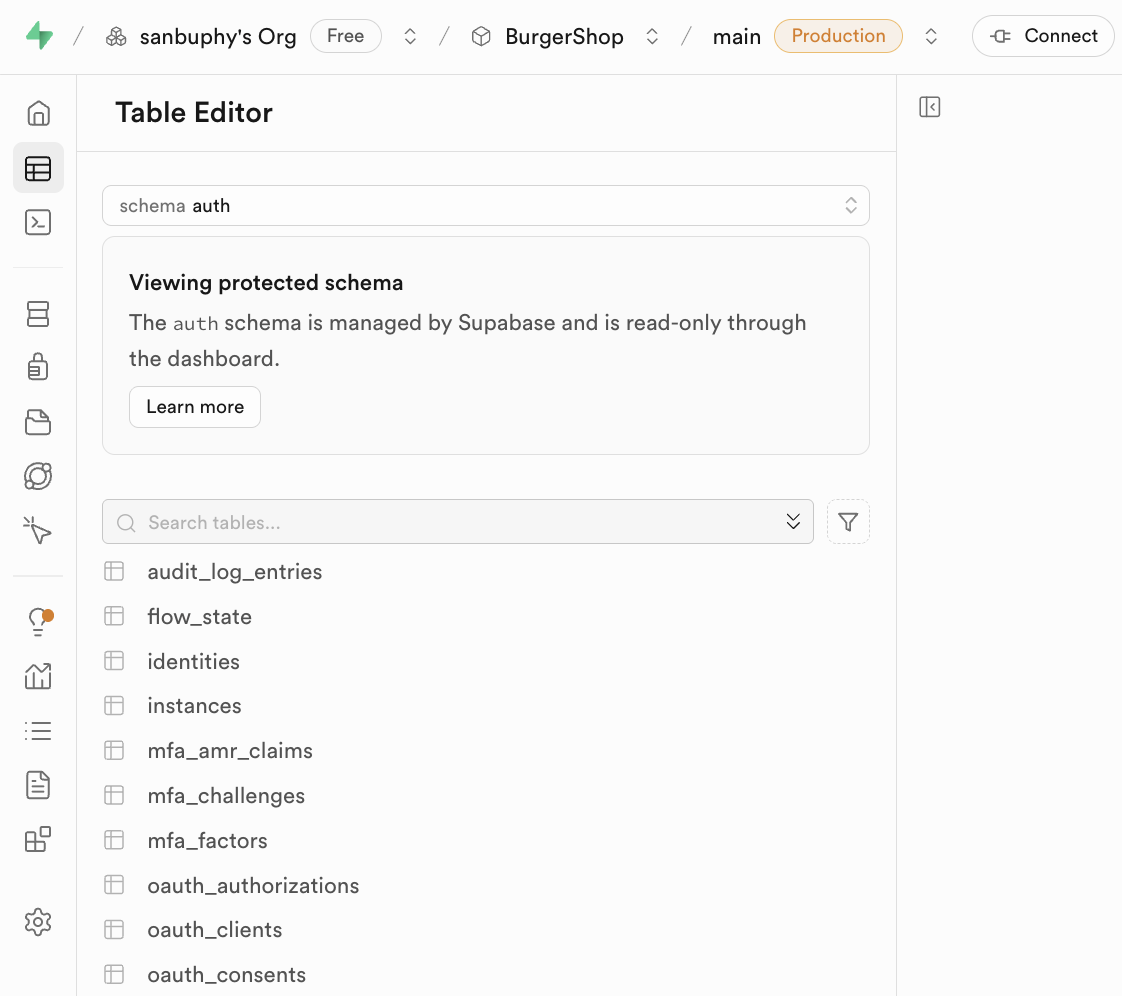
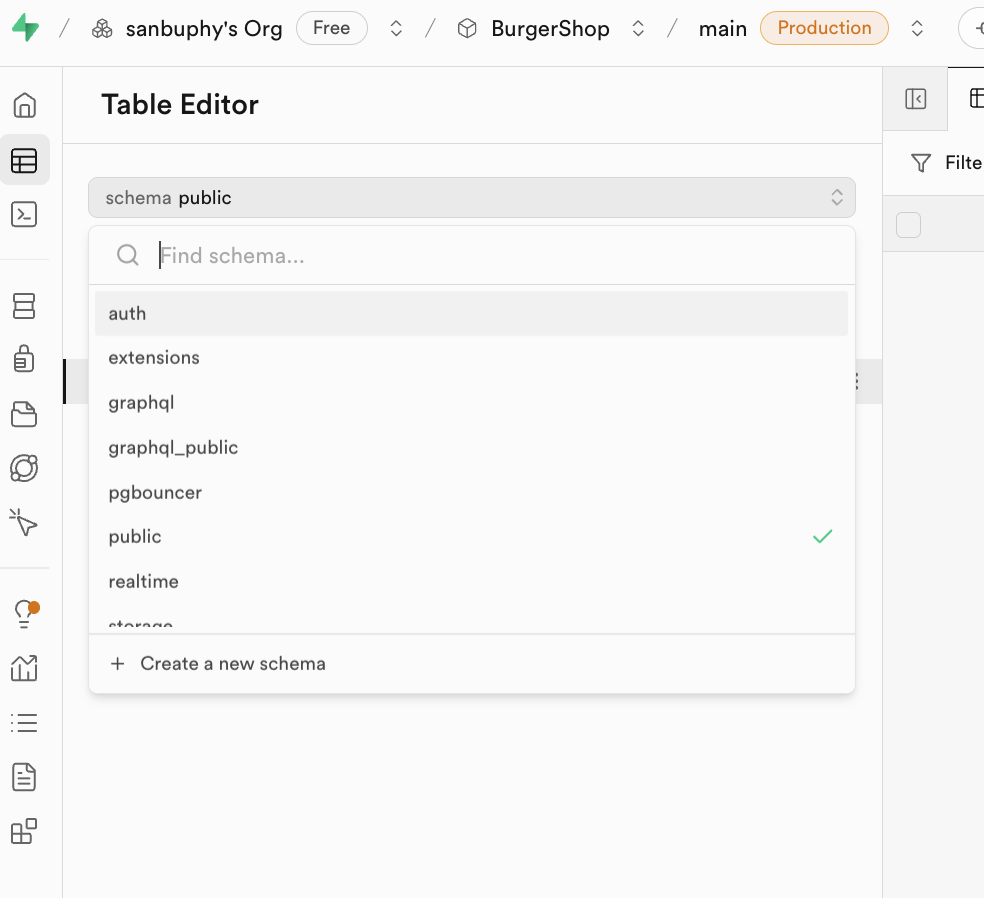
Bemerkenswert ist das Schema-Konzept. Schema kann als "Ressourcen-Container" innerhalb der Datenbank verstanden werden. Klicke auf das Dropdown-Menue "Schema" oben im Editor, um zwischen verschiedenen Containern zu wechseln. Im Alltag sind zwei Schemas besonders relevant:
public: Der Standard-Container fuer oeffentliche Ressourcen. Alle von Entwicklern erstellten Geschaeftstabellen werden hier gespeichert.auth: Der exklusive Container fuer die Benutzerauthentifizierung.

SQL-Editor
Der SQL-Editor ist der SQL-Ausfuehrungsbereich von Supabase. Du kannst grosse Sprachmodelle SQL-Statements generieren lassen, diese rechts eingeben und auf "RUN" klicken.
Datenbankverwaltung (Database)
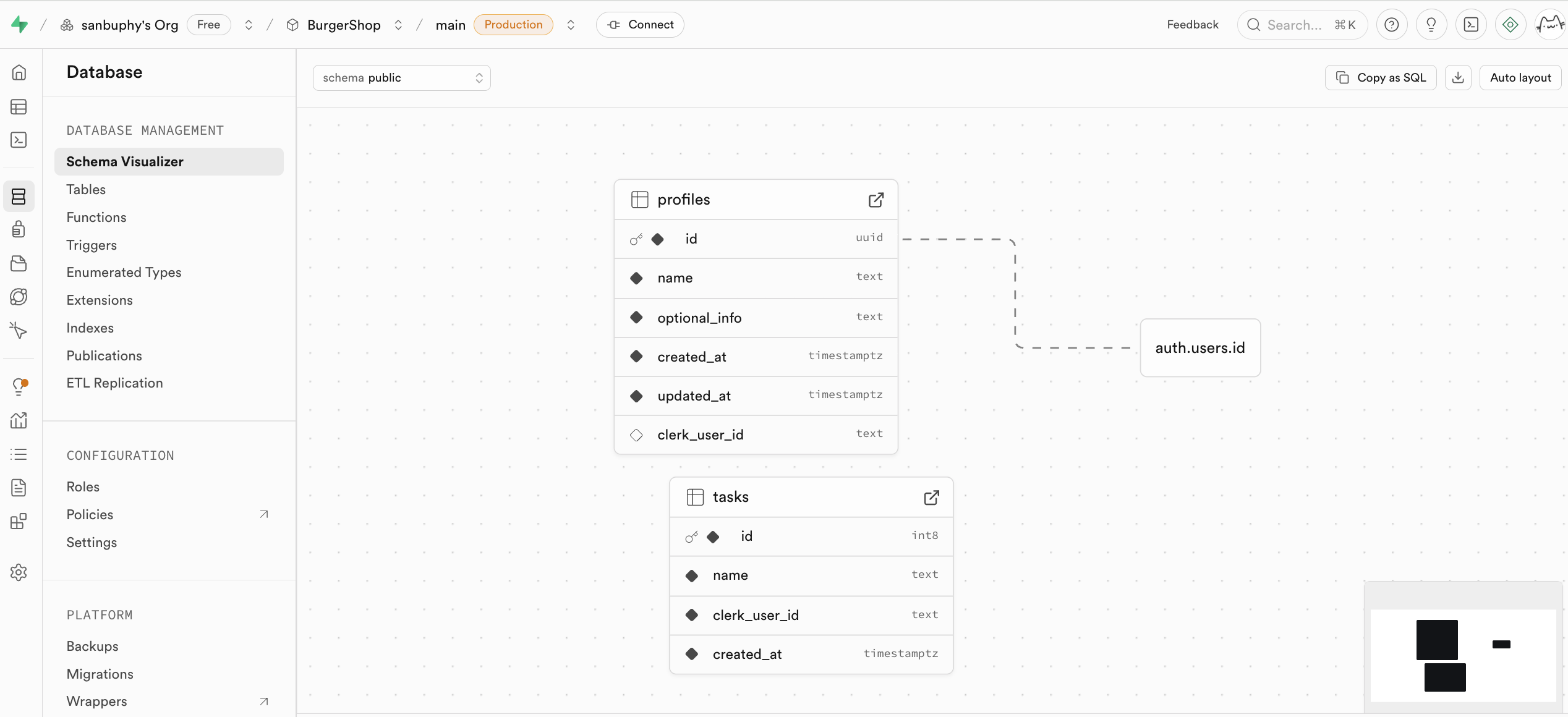
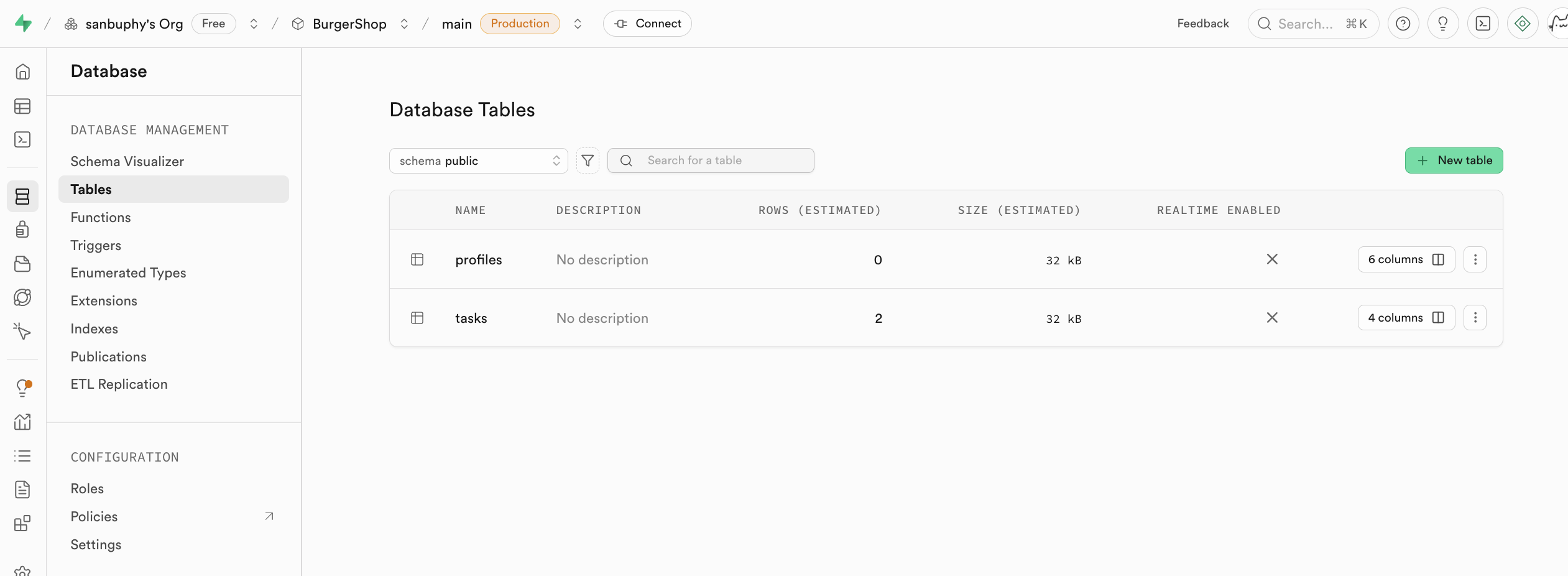
Database ist das Datenbankverwaltungszentrum von Supabase. Es ermoeglicht die visuelle Verwaltung aller Datentabellen und zeigt Beziehungen zwischen Tabellen an (Fremdschluessel-Beziehungen).
Authentifizierung (Authentication)
Authentication verwaltet Benutzerregistrierung, Anmeldung und Berechtigungen. Es bietet sofort einsatzbereite Funktionen fuer Registrierung, Anmeldung, Passwort-Zuruecksetzen, E-Mail-Verifizierung und unterstuetzt OAuth-Anmeldung von Drittanbietern (wie WeChat, GitHub, Google). Alle Benutzerdaten werden automatisch in der Tabelle auth.users gespeichert.
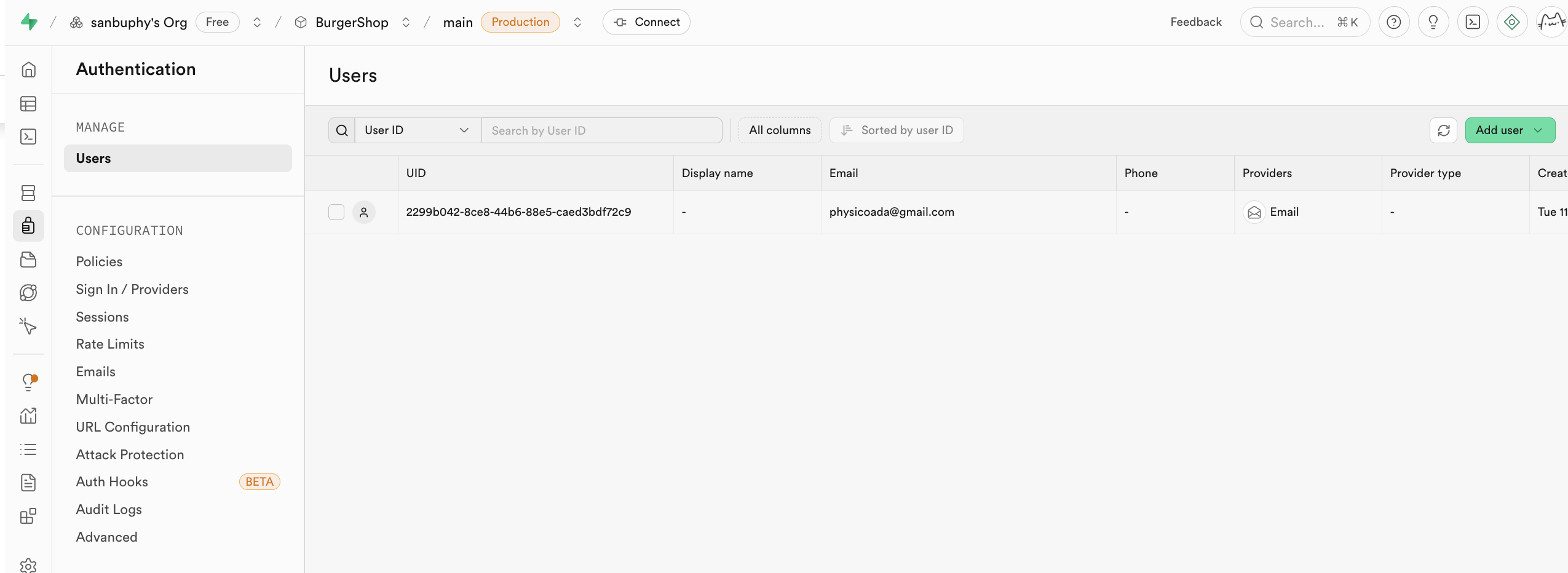
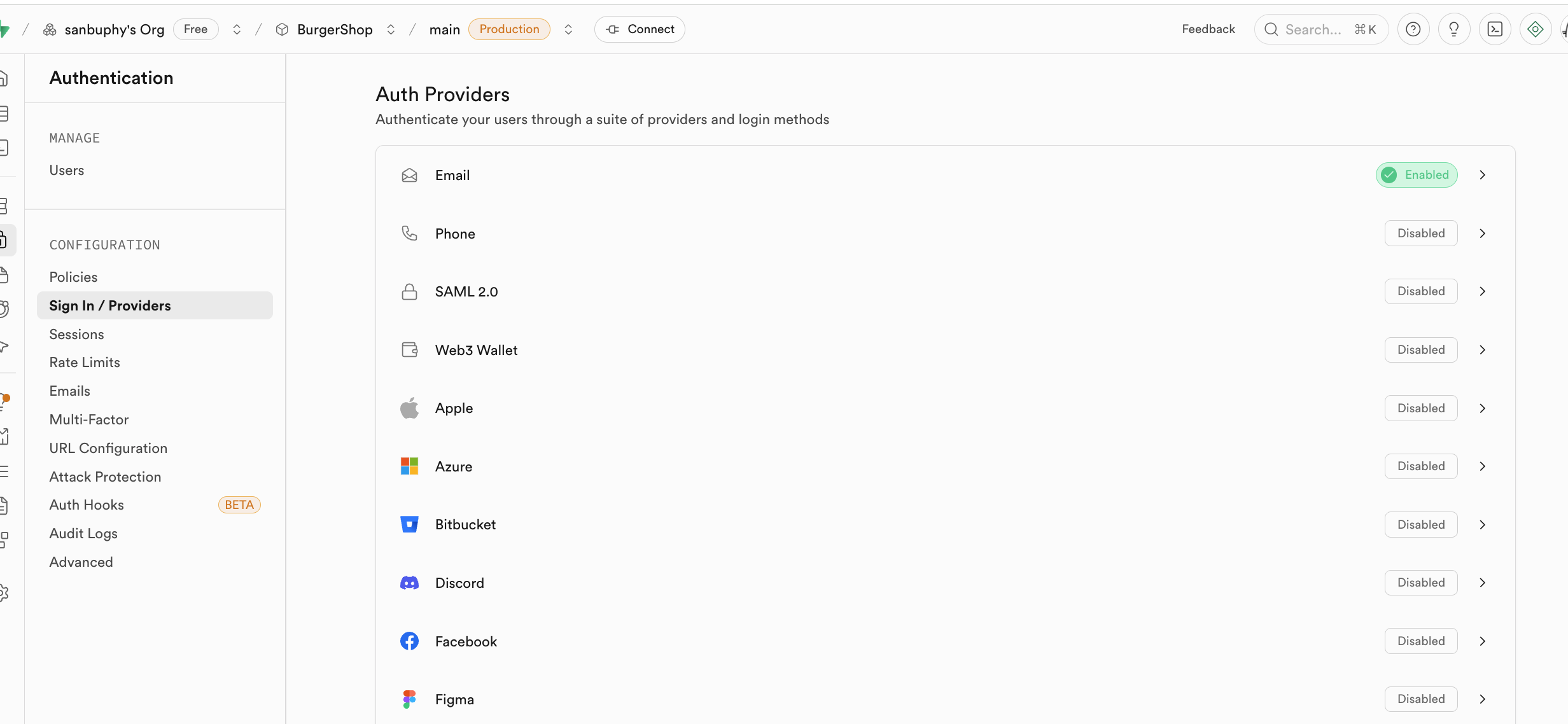
Speicher (Storage)
Storage ist das Speichersystem von Supabase, kompatibel mit dem S3-Konzept von Amazon Cloud. Es kann beliebige Dateitypen speichern (Bilder, Videos, Dokumente, Audio usw.) und bietet Zugriffsberechtigungsverwaltung und Download-Links.
Edge Functions
Wenn du kein Backend bereitstellen moechtest, aber Datenbank- und Funktionsoperationen nutzen willst, kannst du Edge Functions verwenden. Sie sind global verteilte serverseitige Funktionen von Supabase, die auf Deno und TypeScript basieren.
Ein Kernanwendungsfall von Edge Functions ist die Funktion als sichere Zwischenschicht zum Schutz vertraulicher Informationen und Authentifizierungsschluessel.
// Kernkonfiguration (mit deinen tatsaechlichen Daten ersetzen)
const projectId = "Deine Supabase-Projekt-ID";
const functionName = "Name der Ziel-Edge-Function";
const supabaseKey = "Supabase anon_key";
// Funktion aufrufen
async function callEdgeFunction() {
const url = `https://${projectId}.supabase.co/functions/v1/${functionName}`;
try {
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
"Authorization": `Bearer ${supabaseKey}`
},
body: JSON.stringify({ order_id: "123", action: "refund" })
});
const result = await response.json();
console.log("Aufruf erfolgreich:", result);
} catch (error) {
console.error("Aufruf fehlgeschlagen:", error.message);
}
}
callEdgeFunction();Echtzeit-Datensynchronisation (Realtime)
Realtime ist die Echtzeit-Datensynchronisations-Engine von Supabase. Sie ermoeglicht deiner Anwendung, sofortige Benachrichtigungen ueber Datenbankaenderungen zu empfangen, ohne wiederholt APIs abfragen zu muessen.
Projekteinstellungen (Project Settings)
Project Settings ist der Bereich fuer erweiterte Konfiguration deines Supabase-Projekts.
Im Einstiegsbereich fokussieren wir uns auf zwei Kernbereiche: Data API (fuer die Supabase URL) und API Keys (fuer anon public und service_role Schluessel).
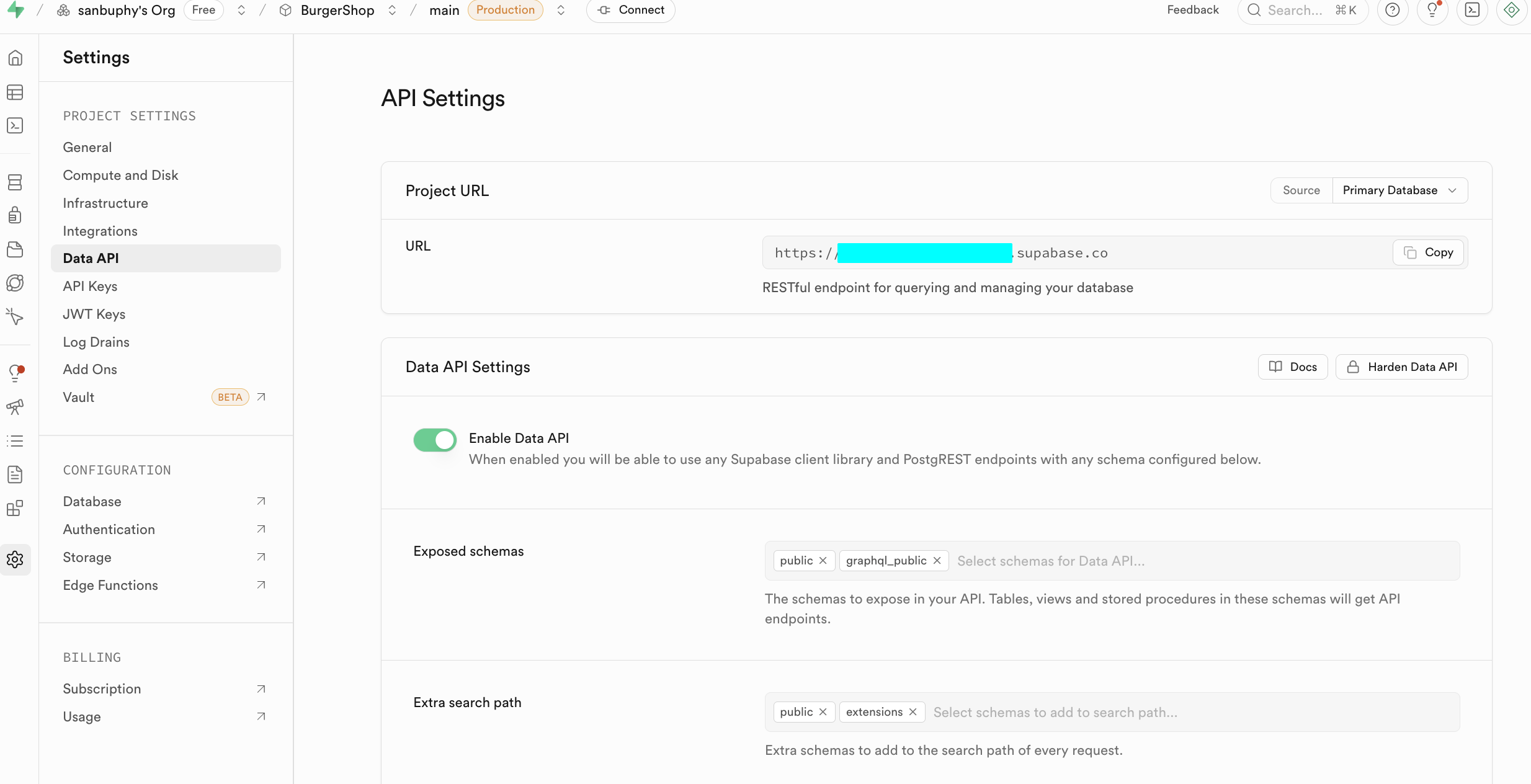
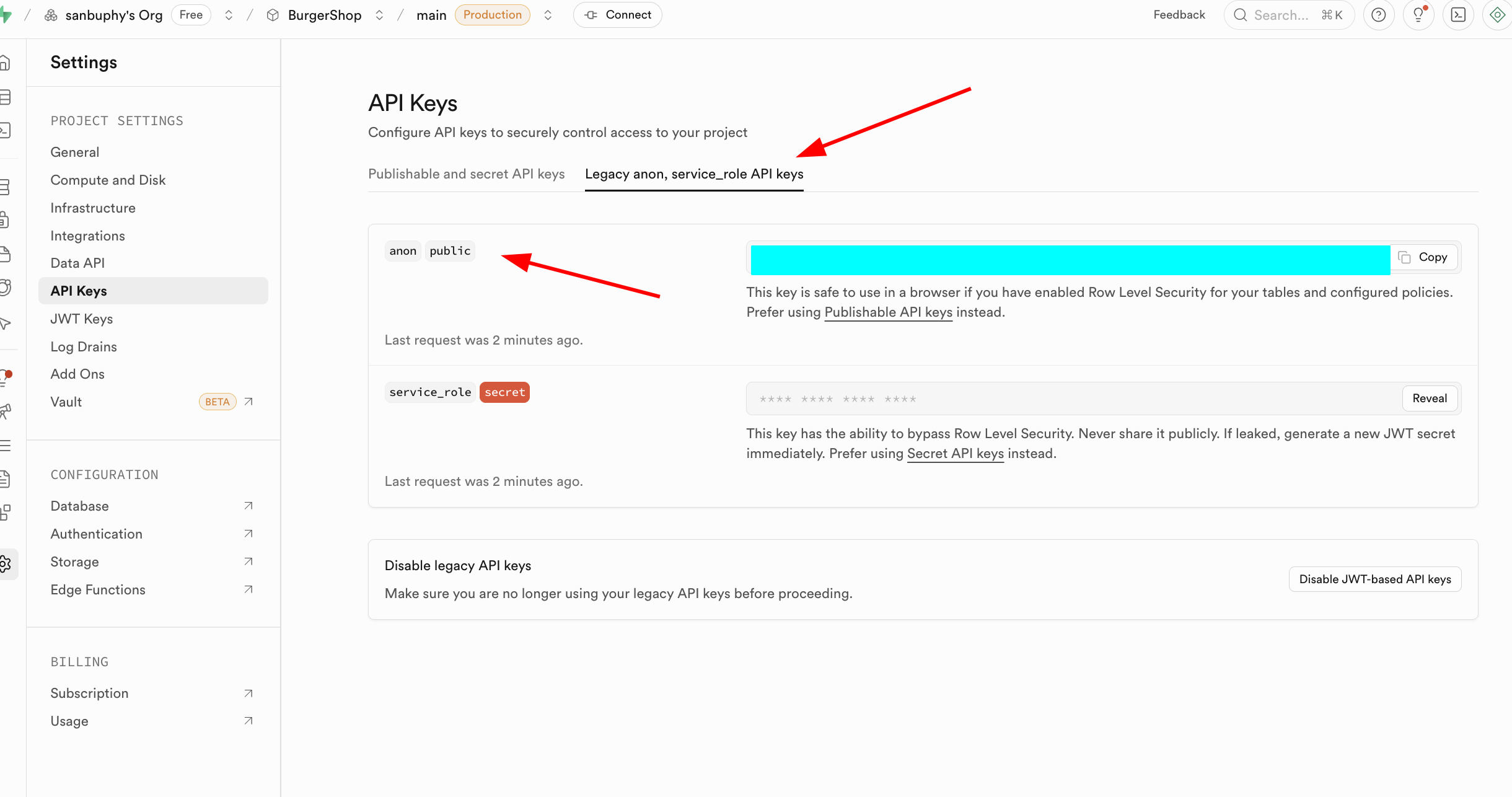
2.1 Erstelle deine erste SQL-Datentabelle
Es gibt zwei gängige Methoden zum Erstellen von Datentabellen in Supabase:
- (Empfohlen) Lass dir von einem grossen Sprachmodell SQL-Statements fuer Supabase generieren und fuehre sie im SQL-Editor aus.
- Ueber visuelle Operationen: Navigiere zu Database > Tables und klicke auf "New table".
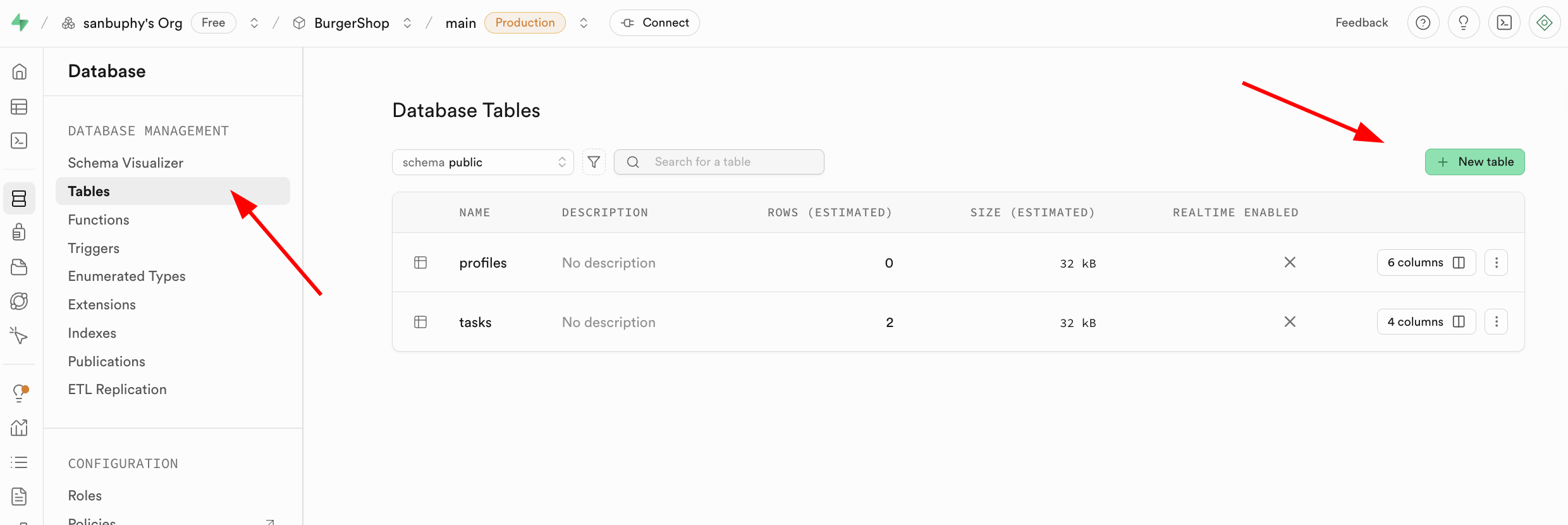
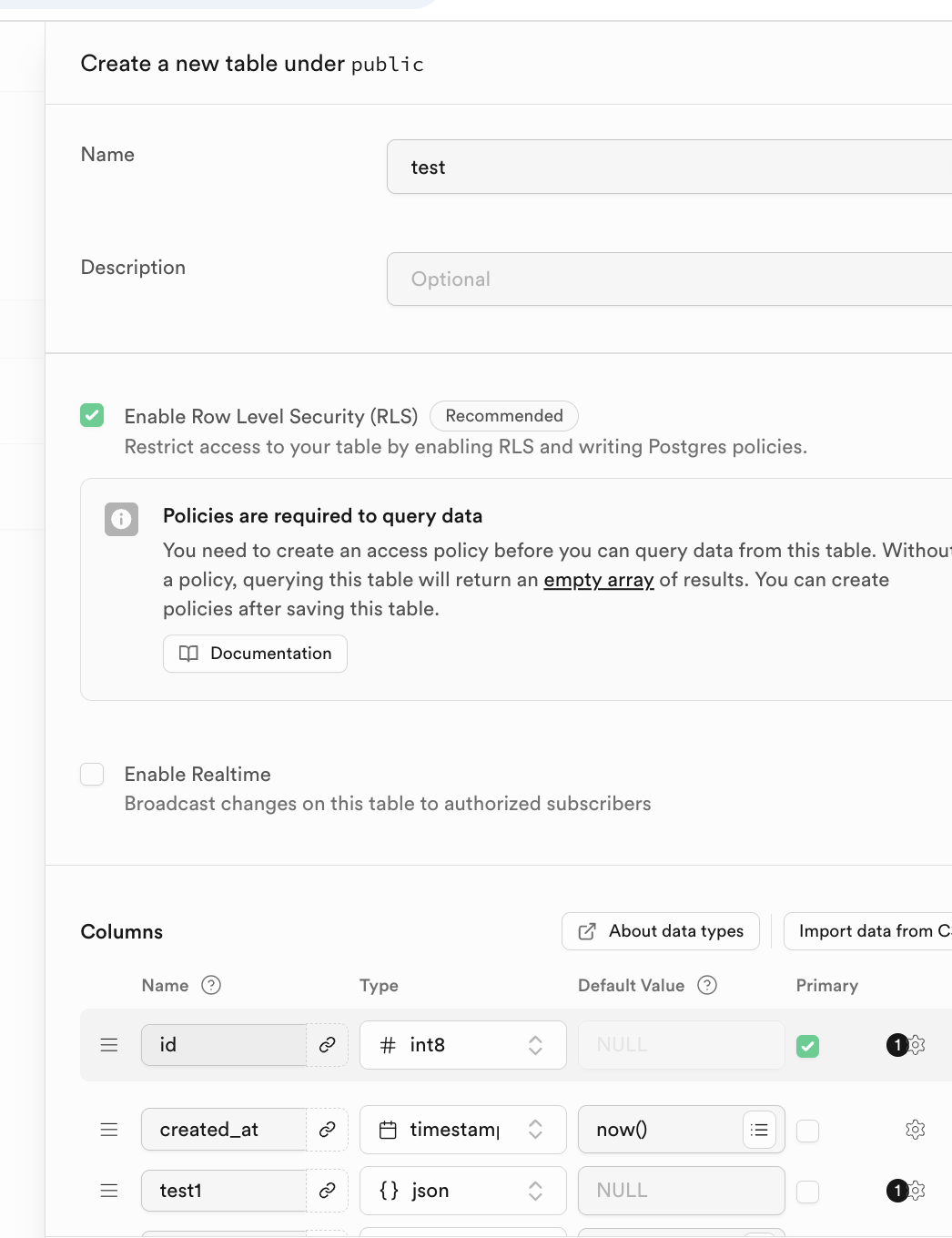
Fuer relationale Datenbanken ist die Verknuepfung zwischen Tabellen wichtig. Du kannst Fremdschluessel (Foreign Keys) unten hinzufuegen:
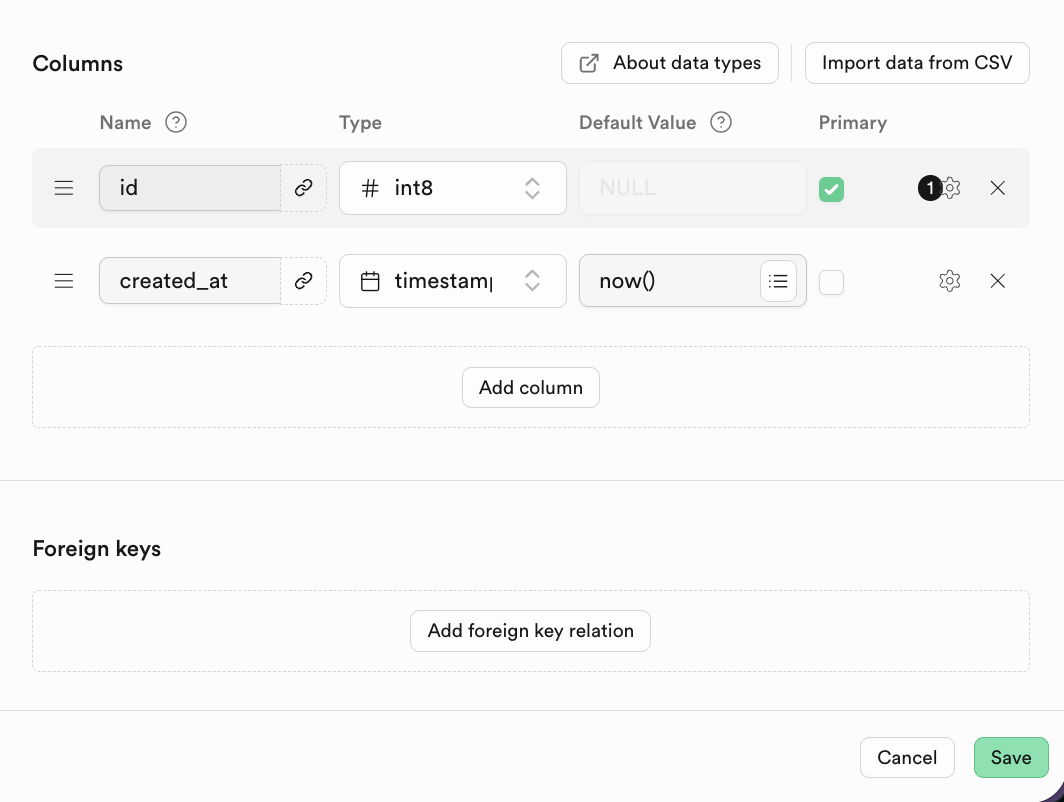
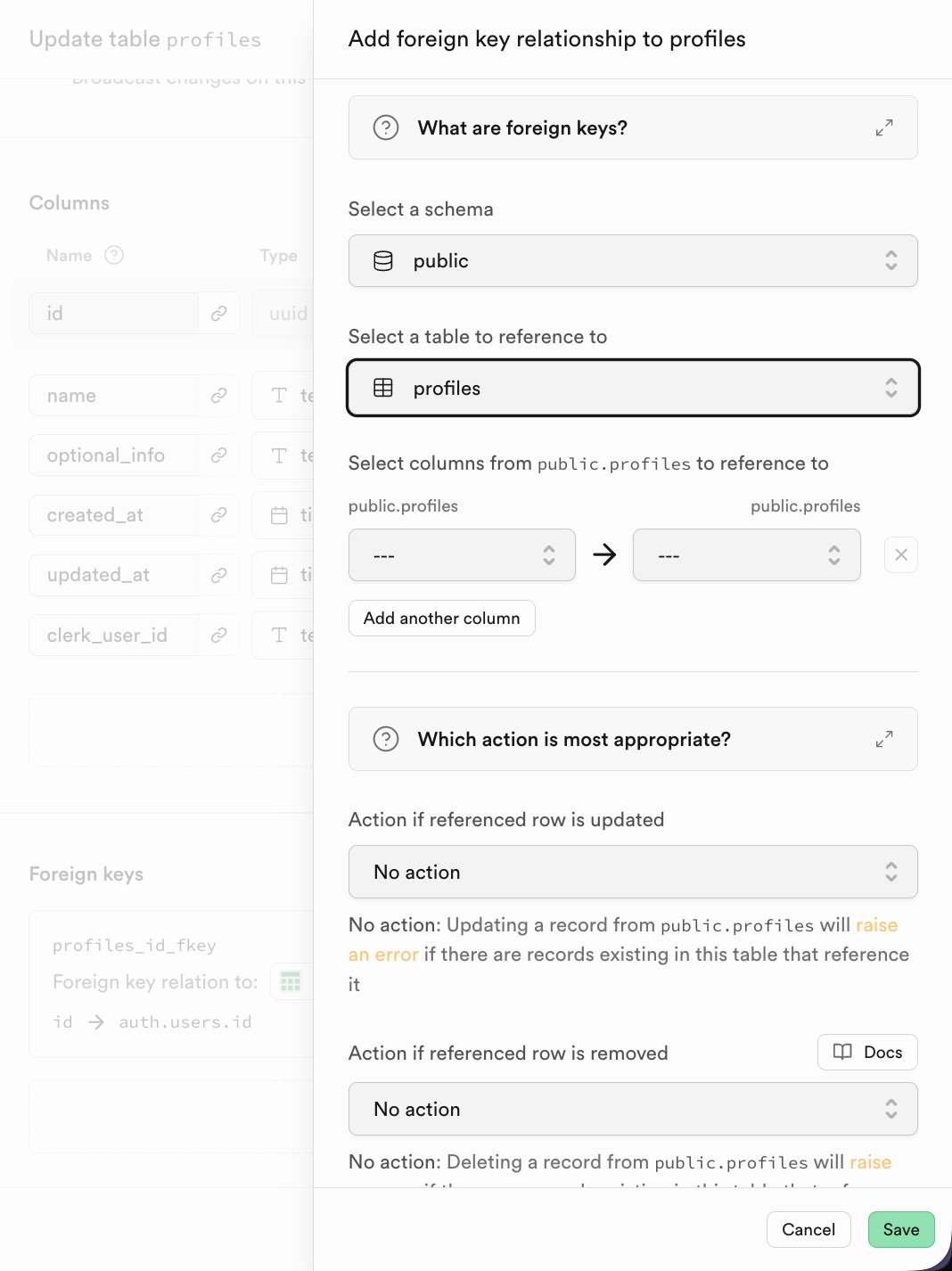
2.3 SQL-Editor und grundlegende Datenbankoperationen
Wir werden nun eine Reihe von SQL-Skripten schrittweise ausfuehren und die gängigen CRUD-Operationen (Create, Read, Update, Delete) kennenlernen.
2.3.1 CREATE - Tabellenstruktur erstellen
CREATE TABLE IF NOT EXISTS orders (
id serial PRIMARY KEY,
user_id int NOT NULL,
status text NOT NULL,
amount numeric(10, 2) NOT NULL,
details jsonb,
placed_at timestamptz DEFAULT now(),
is_paid boolean DEFAULT false
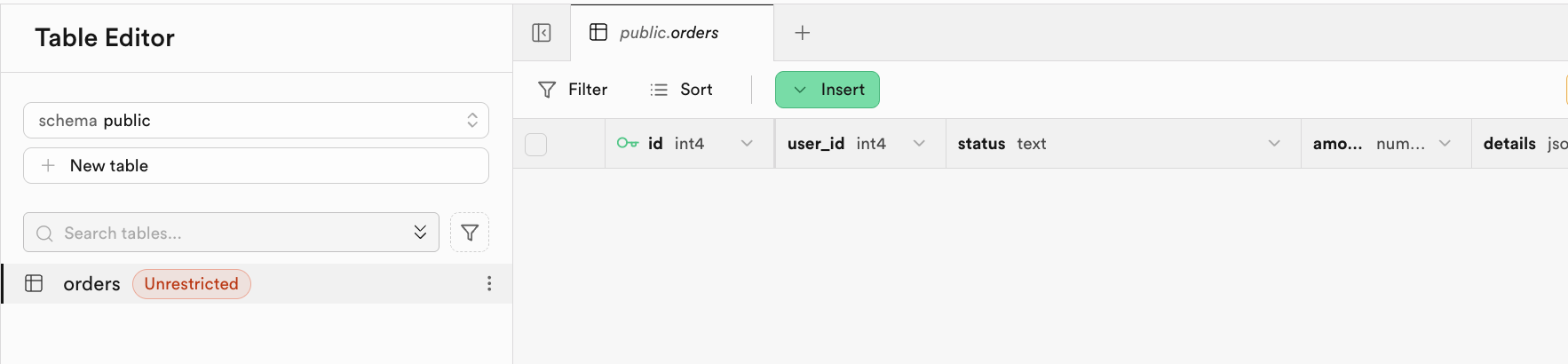
);Nach erfolgreicher Ausfuehrung siehst du die erstellte Tabelle im Tabellen-Editor:
2.3.2 INSERT - Anfangsdaten einfuegen
INSERT INTO orders (user_id, status, amount, details, placed_at, is_paid) VALUES
(2001, 'pending', 23.50, '{"items":[{"sku":"BGR001","name":"Beef Burger","qty":1,"price":12.00}]}', now() - interval '2 days', false),
(2002, 'paid', 50.00, '{"items":[{"sku":"BGR002","name":"Chicken Burger","qty":2,"price":10.00}]}', now() - interval '1 day', true);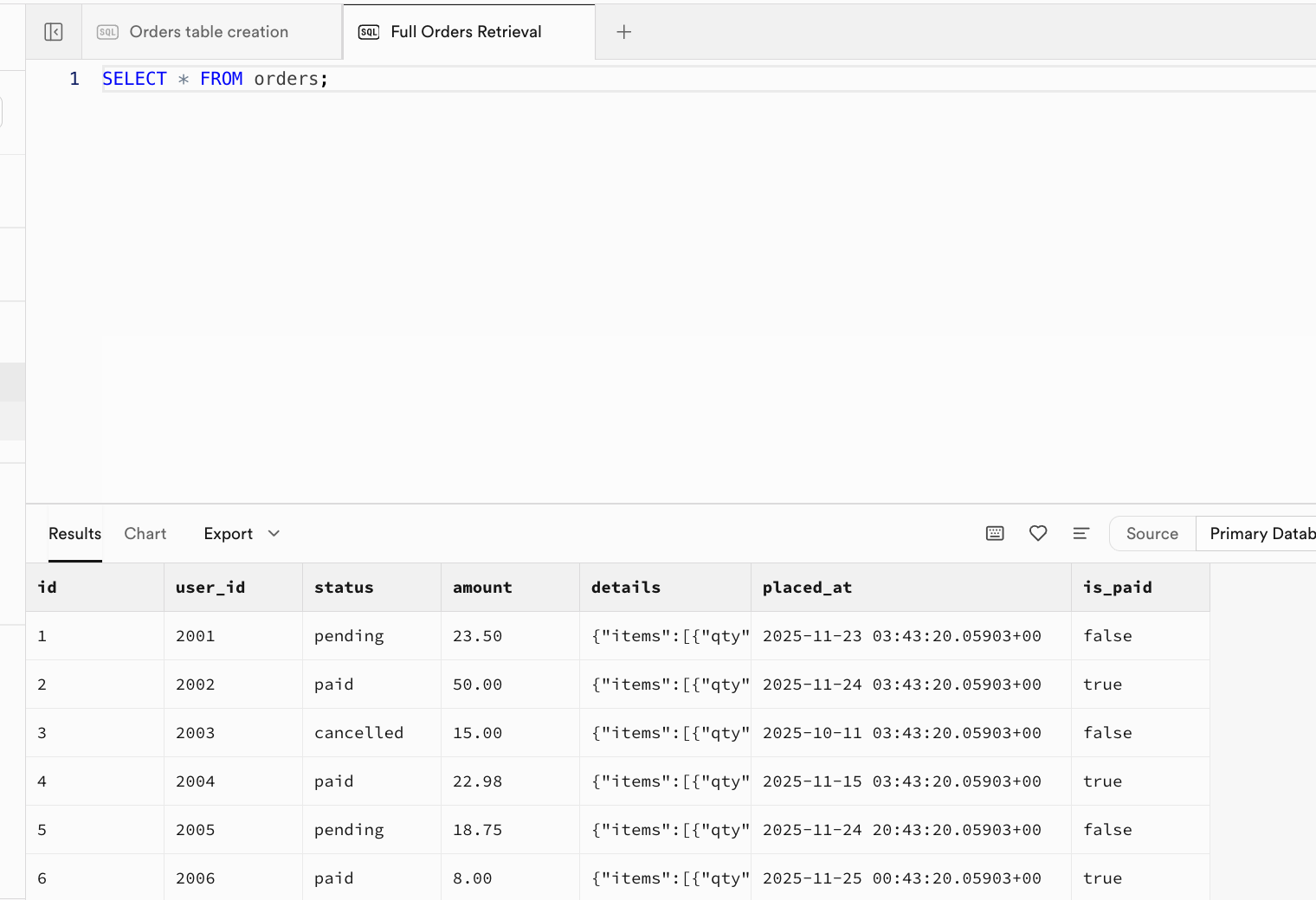
2.3.3 SELECT - Daten lesen und abfragen
-- Alle Felder aller Bestellungen abfragen
SELECT * FROM orders;
-- Nur ausstehende Bestellungen
SELECT id, user_id, amount FROM orders WHERE status = 'pending';
-- Nur bezahlte Bestellungen
SELECT id, status, is_paid, amount FROM orders WHERE is_paid = true;
-- Artikelliste aus JSON extrahieren
SELECT id, details -> 'items' AS item_list FROM orders;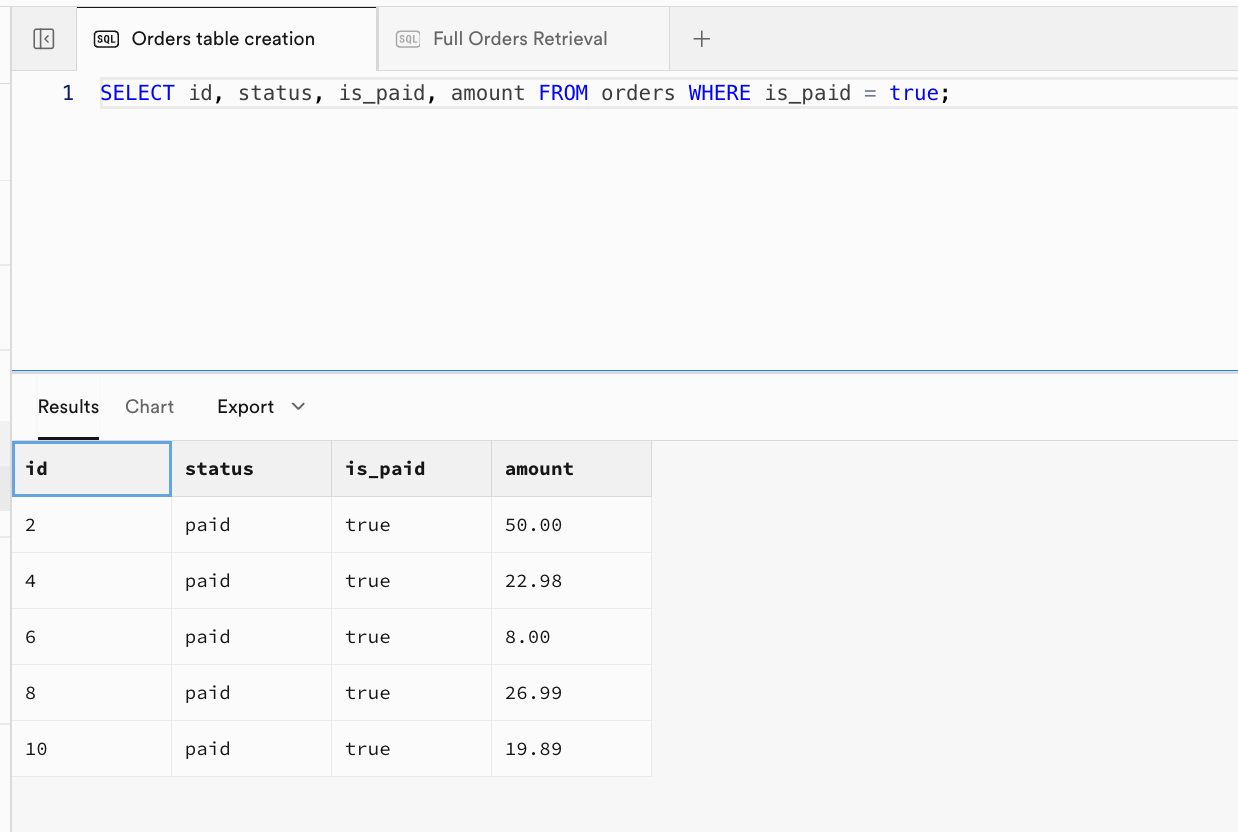
2.3.4 INSERT - Einzelnen Datensatz einfuegen
INSERT INTO orders (user_id, status, amount, details, is_paid)
VALUES (
2012, 'paid', 9.99,
'{"items":[{"sku":"BGR002","name":"AIID Burger","qty":100,"price":1000}]}',
true
);2.3.5 UPDATE - Vorhandene Daten aendern
UPDATE orders SET status = 'paid', is_paid = true WHERE id = 1;2.3.6 DELETE - Daten loeschen
DELETE FROM orders WHERE placed_at < now() - interval '2 days';2.4 Zeilensicherheit (Row Level Security - RLS)
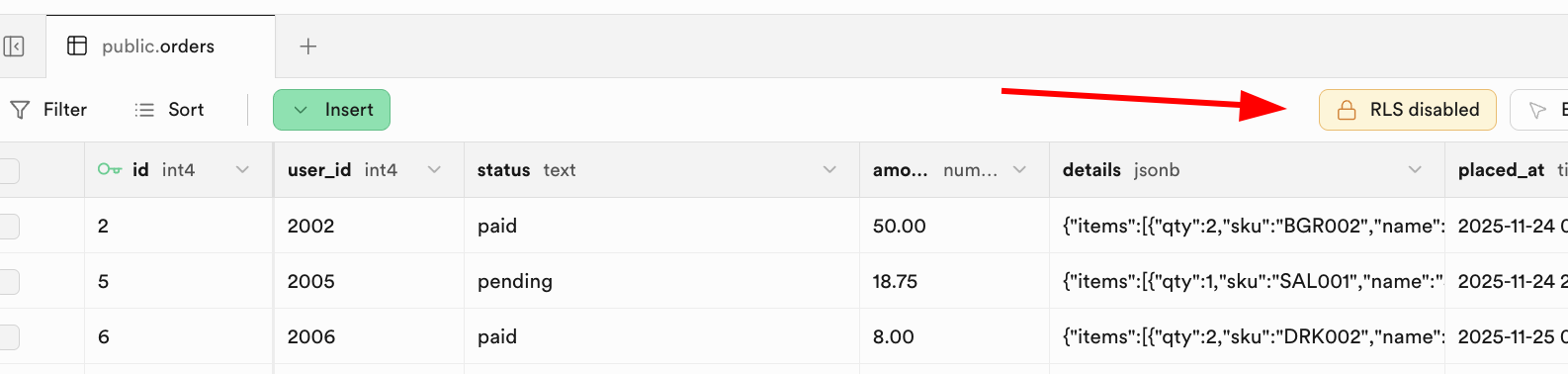
Nachdem wir die grundlegenden Datenbankoperationen gelernt haben, muessen wir ein Kernkonzept fuer die Datensicherheit vertiefen: RLS (Row Level Security).
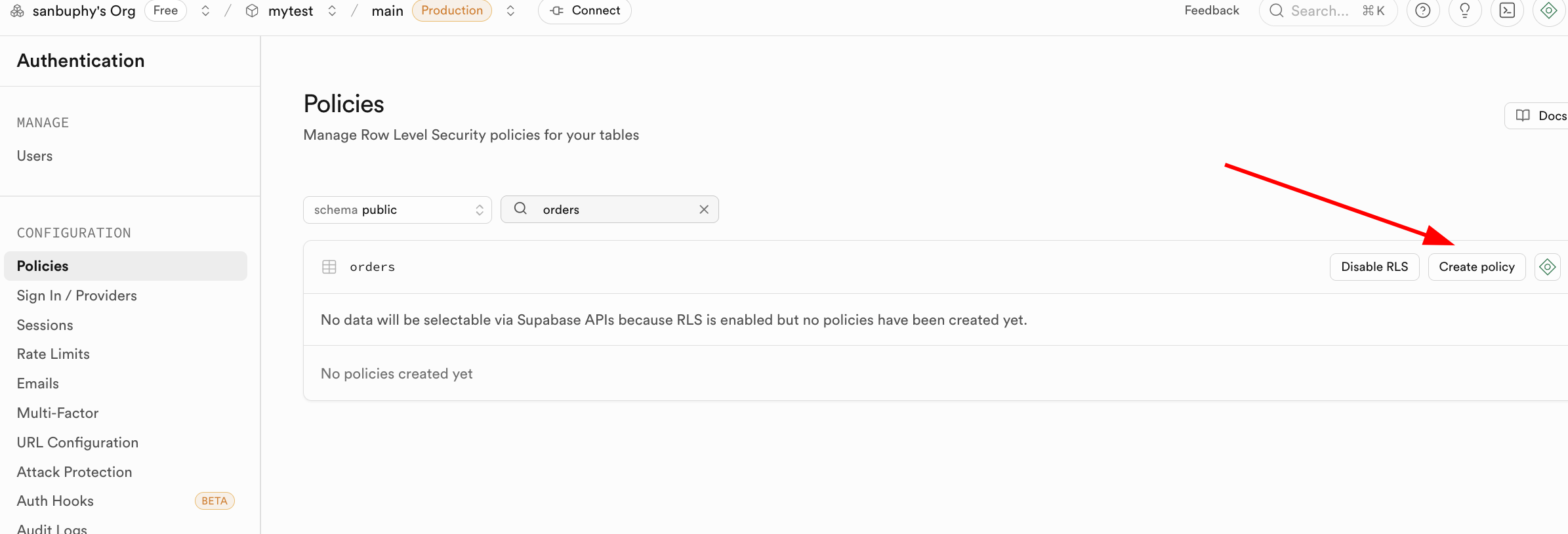
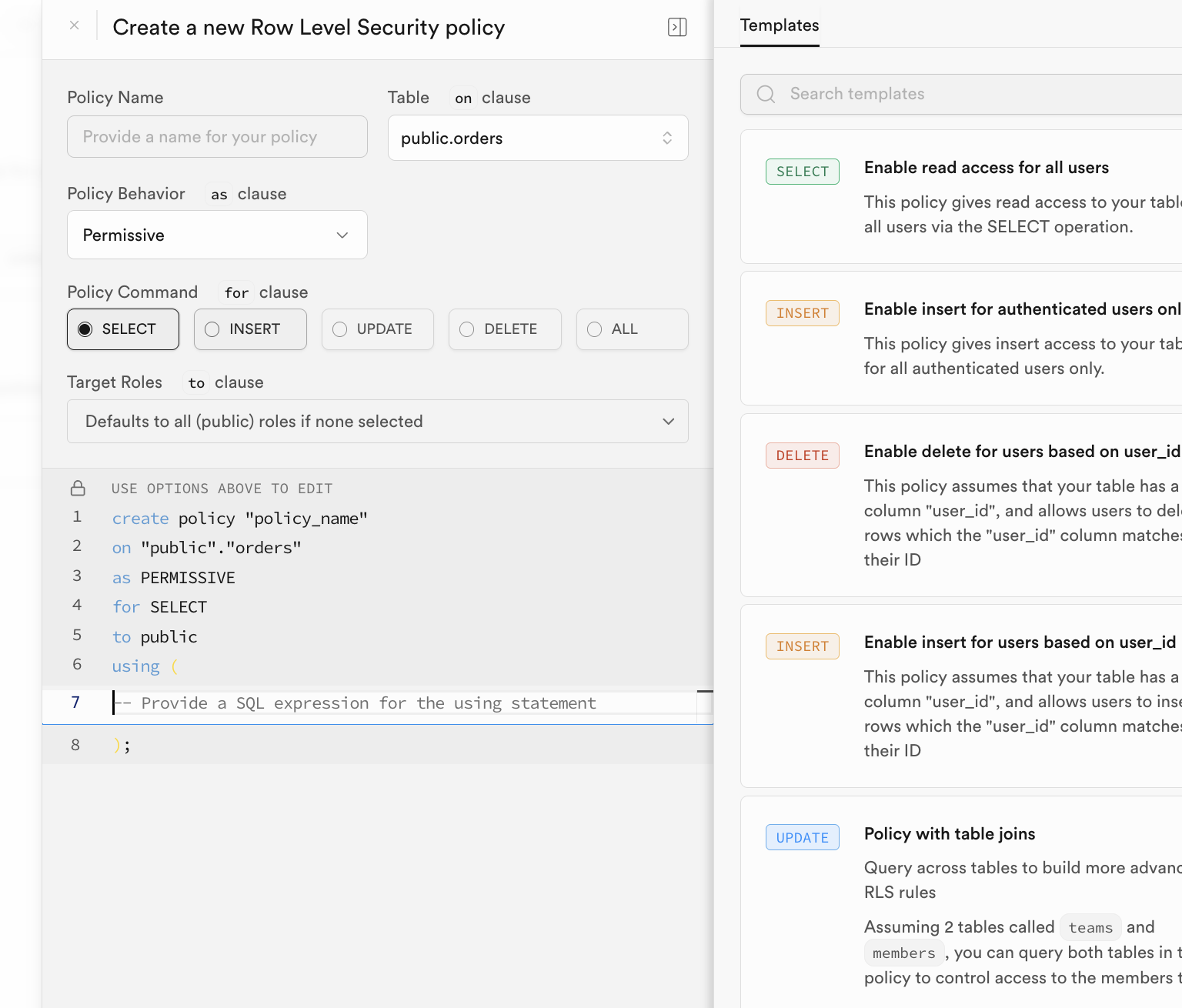
RLS wurde entwickelt, um Datensicherheits- und Isolationsanforderungen zu loesen. Es ermoeglicht Entwicklern, feinkoernige Sicherheitsrichtlinien fuer Datenbanktabellen zu definieren und praezise zu steuern, welche Benutzer auf welche Zeilen einer Tabelle zugreifen koennen.
In Supabase ist RLS eng mit dem Benutzerauthentifizierungssystem verknuepft. Supabase stellt eine spezielle Funktion auth.uid() zur Verfuegung, die direkt die eindeutige ID des aktuell angemeldeten Benutzers zurueckgibt.

3. Erste SQL-Anwendung
Nachdem wir die grundlegenden Datenbankoperationen und die RLS-Kernlogik gemeistert haben, betreten wir nun den praktischen Teil dieses Tutorials. Wir werden das Szenario "Bestellverwaltung fuer ein Burger-Restaurant" verwenden, um die haeufigsten Supabase-Operationen Schritt fuer Schritt zu demonstrieren.
3.1 Supabase-Beispielprojekt klonen und starten
Du kannst Trae oder Claude Code verwenden, um folgendes Repository zu klonen: https://github.com/THU-SIGS-AIID/Project5-Supabase-Demos
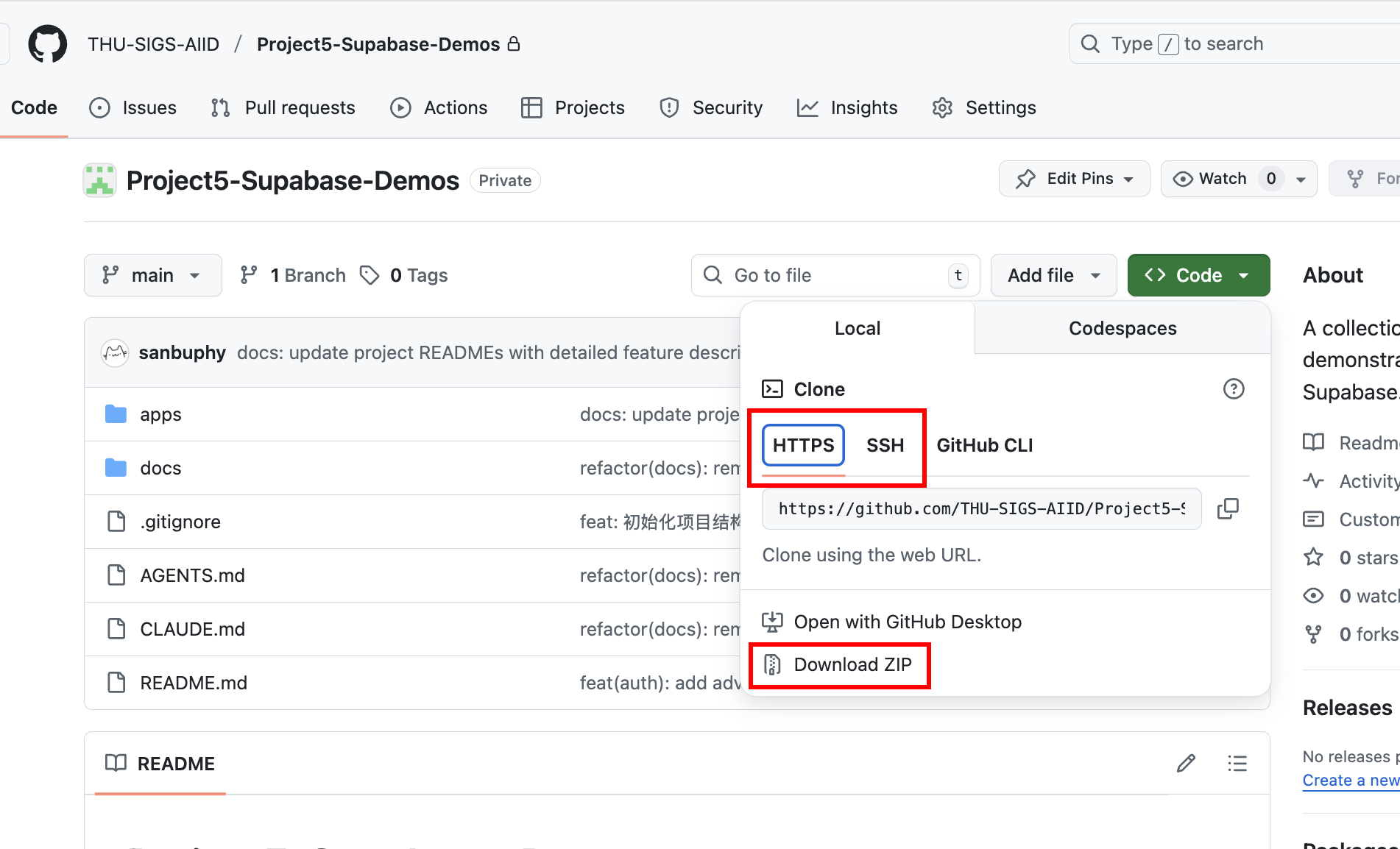
3.2 Projekt 1 - Burger-Restaurant Menue CRUD
Wir nehmen project-burger-shop-menu-crud-1 als Beispiel und lernen, wie man eine Datenbank mit SQL-Skripten initialisiert und das lokale Projekt mit Supabase verbindet.
Datenbank mit Skript erstellen
Im Projektverzeichnis befindet sich ein Ordner scripts mit einer Datei init.sql, die automatisch alle datenbankbezogenen Ressourcen erstellt.
Verbindung zur Datenbank einrichten
Es gibt zwei Methoden:
- Ueber Umgebungsvariablen in einer
.env-Datei:
NEXT_PUBLIC_SUPABASE_URL=https://your-project.supabase.co
NEXT_PUBLIC_SUPABASE_ANON_KEY=your-anon-key- Direkt auf der Projektseite ueber den Einstellungs-Button.
import { createClient, type SupabaseClient } from '@supabase/supabase-js';
export function maybeCreateBrowserClient(): SupabaseClient | null {
const url = process.env.NEXT_PUBLIC_SUPABASE_URL;
const anon = process.env.NEXT_PUBLIC_SUPABASE_ANON_KEY;
if (!url || !anon) return null;
return createClient(url, anon);
}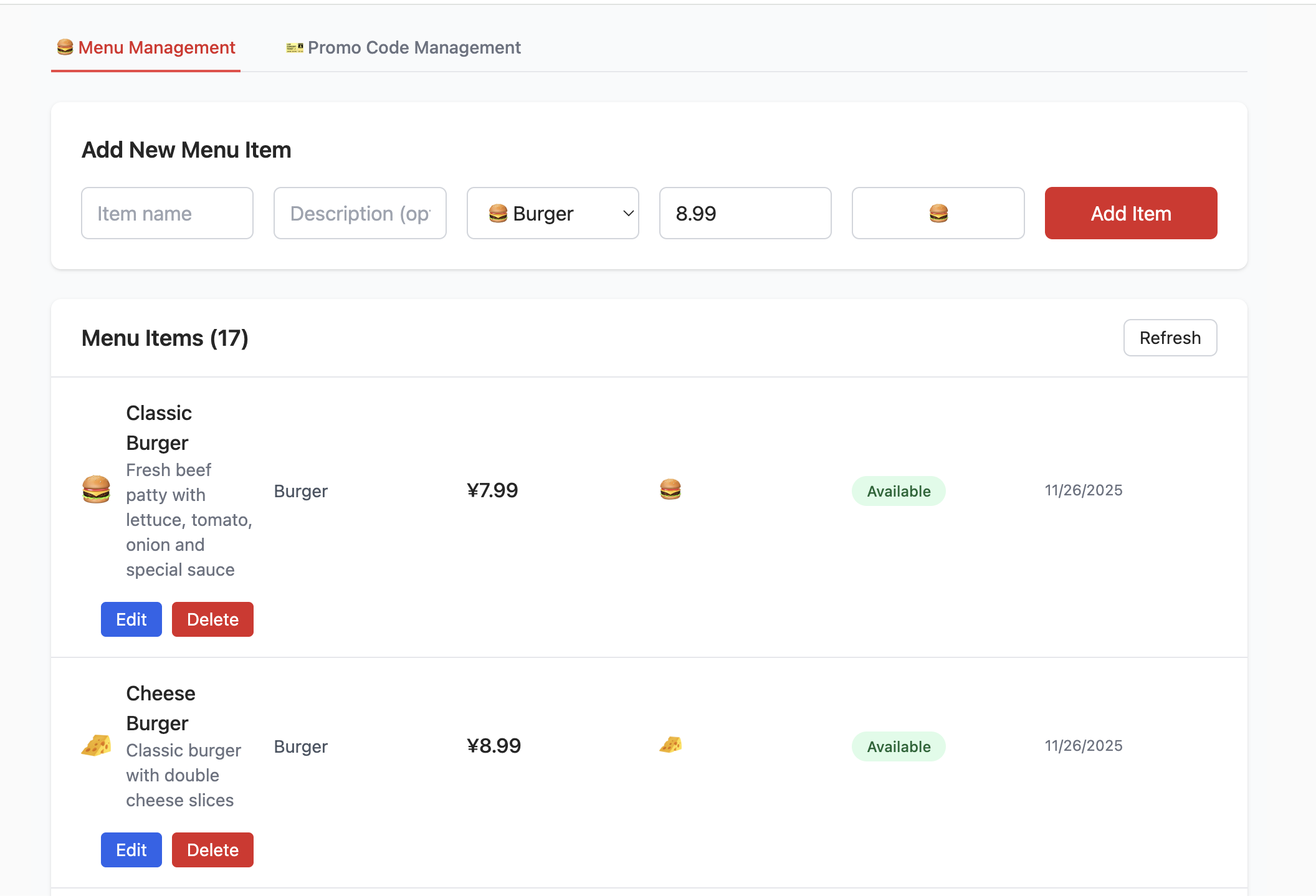
Hausaufgabe
- Versuche, Elemente hinzuzufuegen und zu loeschen, und beobachte die Auswirkungen auf die Datentabelle im Tabellen-Editor.
3.4 Projekt 2 - Burger-Restaurant mit Benutzerauthentifizierung
Projekt 2 fuegt die Kernfaehigkeiten Benutzerauthentifizierung (Auth) und RLS-Berechtigungsverwaltung hinzu.
const { error: err } = await supabaseClient.auth.signUp({
email,
password,
options: {
data: {
full_name: fullName || null,
birthday: birthday || null,
avatar_url: avatarUrl || null
}
}
});
Nach erfolgreicher Registrierung und Anmeldung gelangst du zur Shop-Oberflaeche:
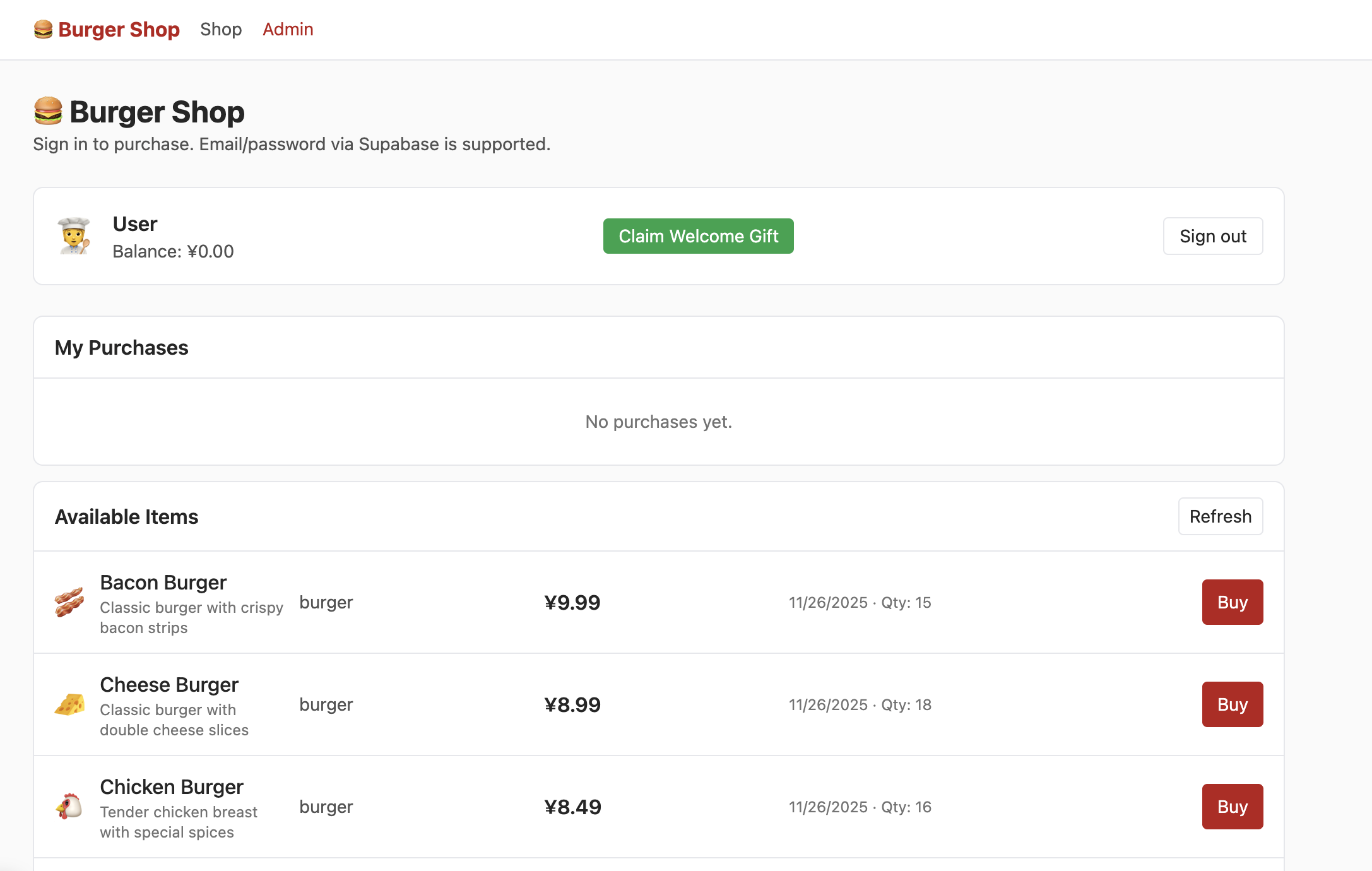
Um den Admin-Bereich zu sehen, musst du die Benutzerberechtigungen in der Datentabelle auf admin aendern:
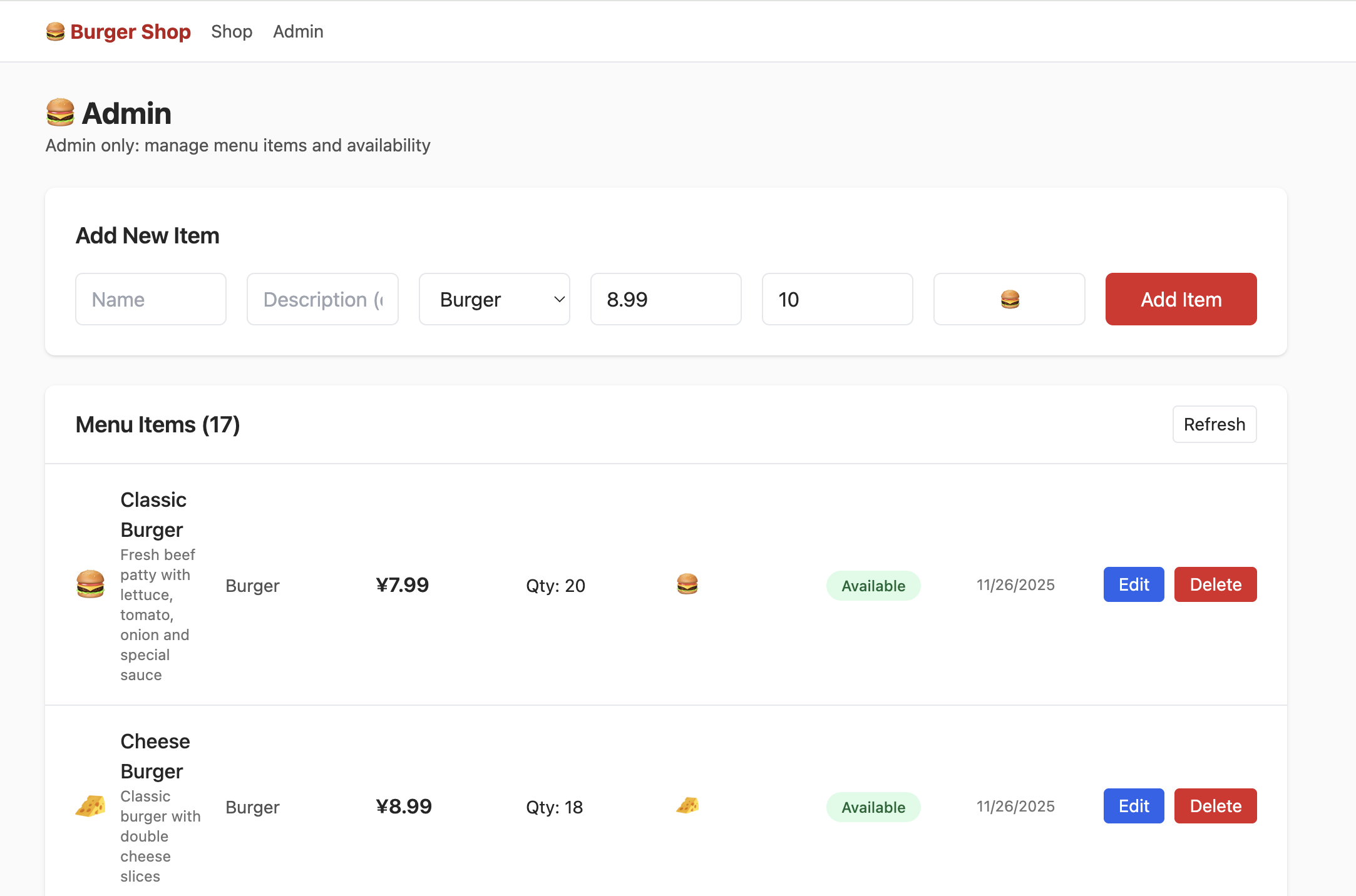
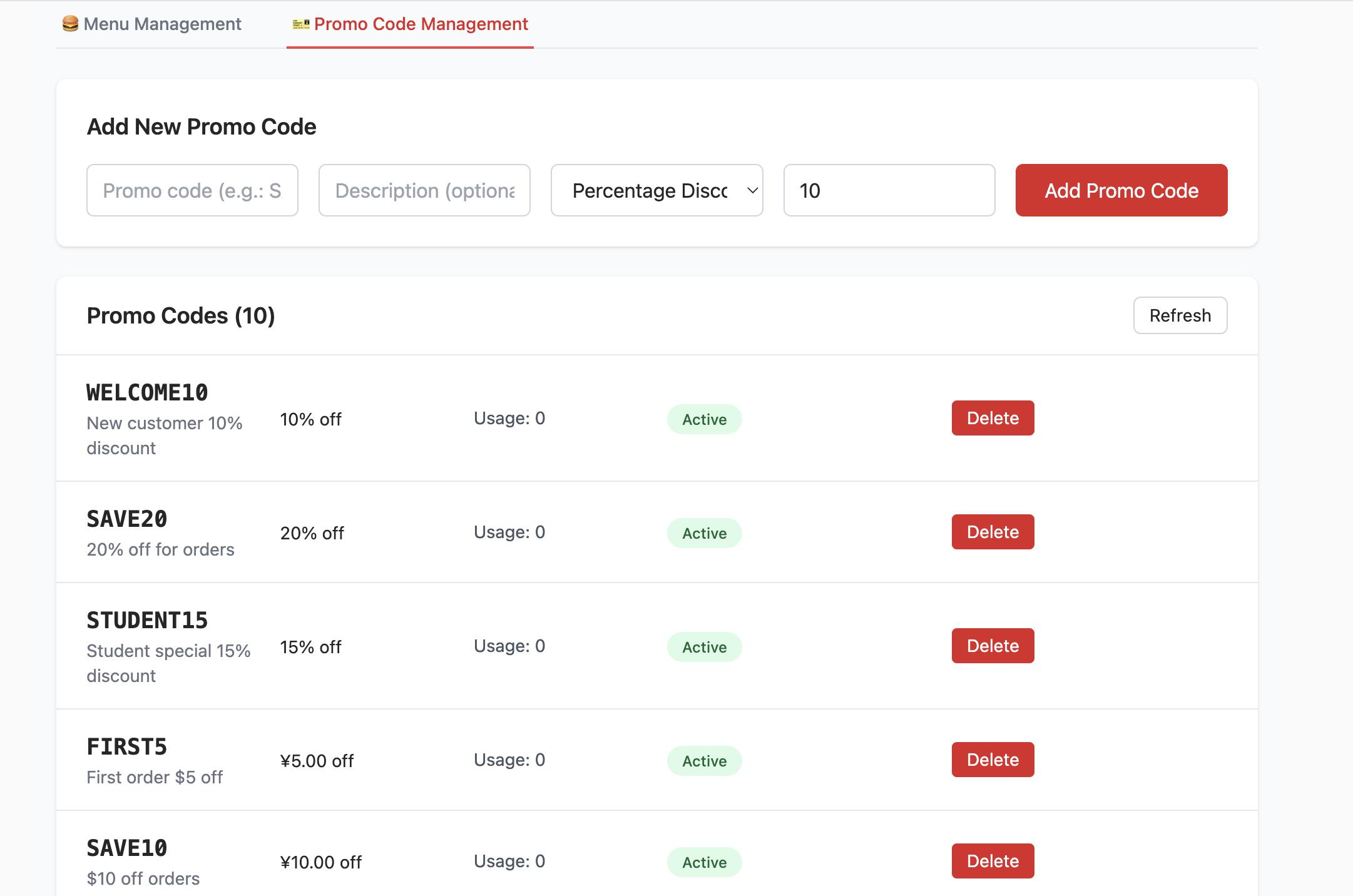
Hausaufgabe
- Hole das Neukunden-Geschenk ab und schliesse einen Kauf ab.
- Finde die Position der Benutzerberechtigungs-Datentabelle und aendere die Berechtigung auf
admin. - Lokalisiere die Geldboersen-Tabelle und erhoeehe den Restbetrag.
4. Baue deine erste Supabase-Anwendung
Nach dem systematischen Lernen hast du die Kernfaehigkeiten von Supabase gemeistert. Jetzt ist es an der Zeit, deine erste Anwendung mit Datenbank und Benutzeranmeldung selbst zu erstellen!
4.1 Standardisierter Prozess zur Anbindung einer Supabase-Datenbank
- Anforderungsanalyse: Beschreibe der KI klar die Kernfunktionen und neuen Datenbankanforderungen deiner App.
- SQL-Skript generieren: Lass die KI ein
init.sql-Skript generieren und fuehre es im SQL-Editor aus. - Code restrukturieren: Lass die KI den Projektcode so umschreiben, dass er mit der Supabase-Datenbank kommunizieren kann.
- Konfiguration und Tests: Konfiguriere die Supabase-URL und Schluessel, teste alle Datenbankinteraktionen.
4.2 Fallstudie: Ein Online-Schlangenspiel
Wir praktizieren den Standardprozess an einem konkreten Beispiel: Einem Schlangenspiel, dem wir einen Online-Bestenliste und Benutzeranmeldung hinzufuegen.
4.2.1 Projekt analysieren und Datenanforderungen identifizieren
Prompts fuer die KI:
"Ich habe ein Schlangenspiel im Verzeichnis {Pfad}. Ich moechte eine Online-Bestenliste mit Benutzeranmeldung hinzufuegen. Welche Datentabellen und Felder brauche ich?"
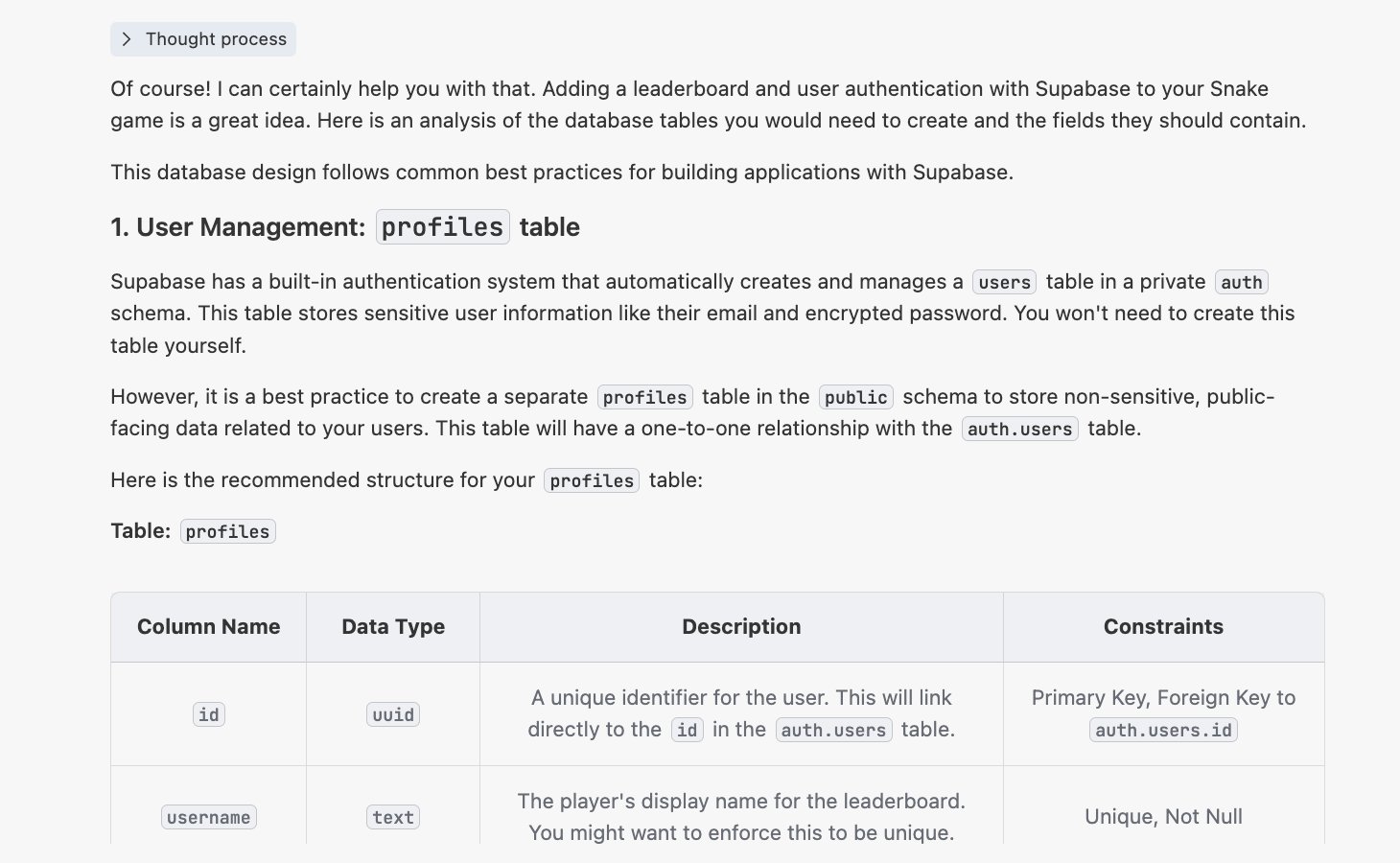
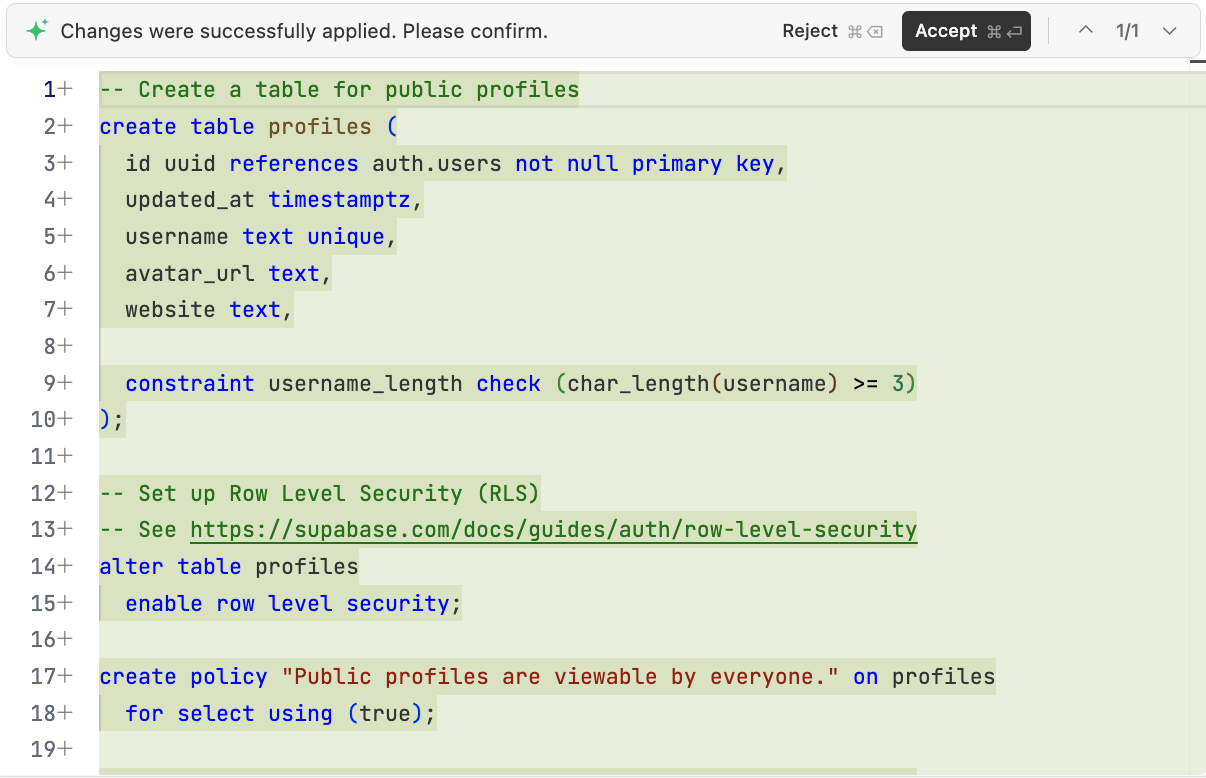
4.2.2 init.sql-Skript generieren
Lass die KI ein scripts/init.sql-Skript generieren.
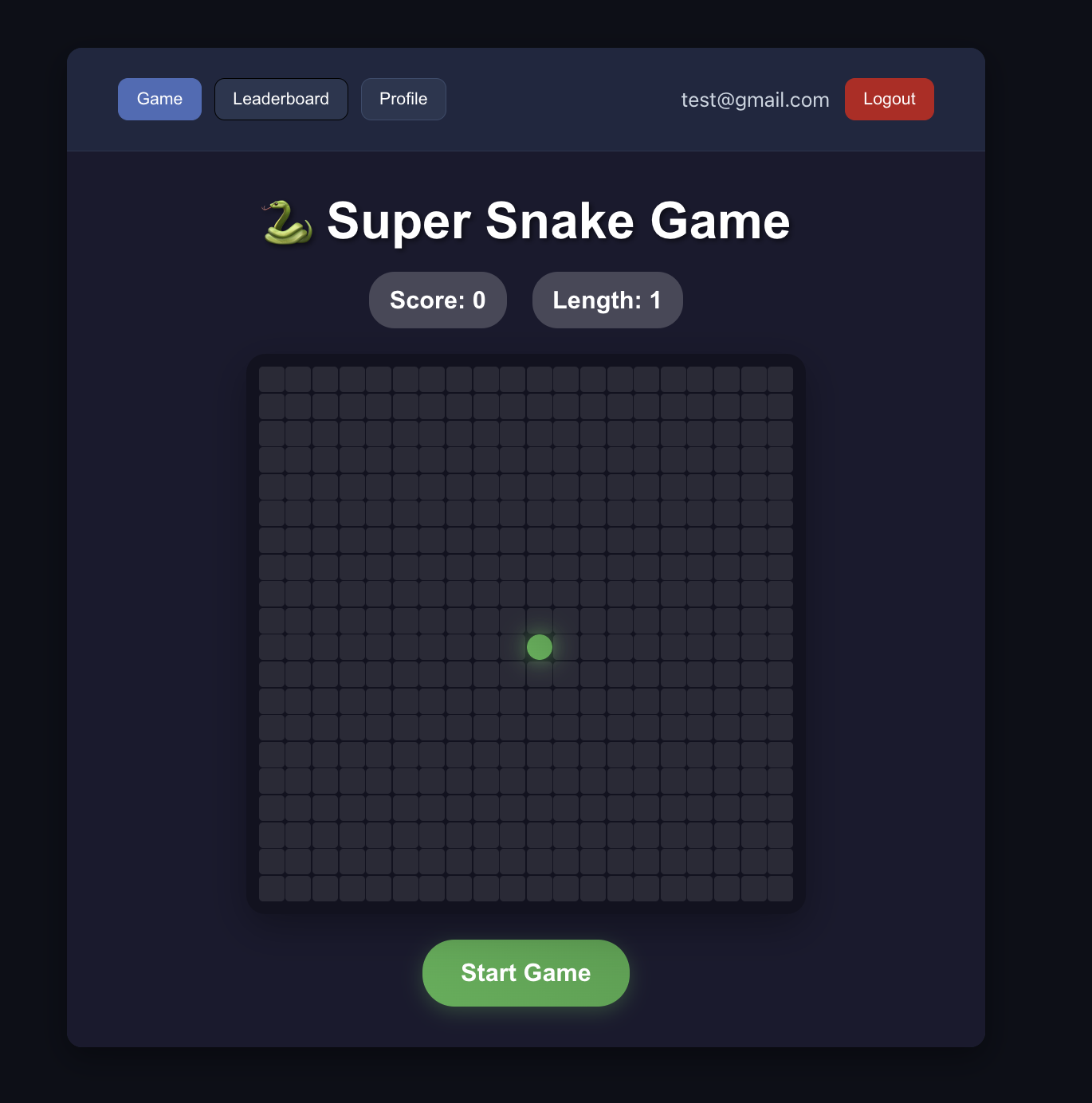
4.2.3 Projektcode restrukturieren
Lass die KI den Spielcode mit Supabase-Integration umschreiben.
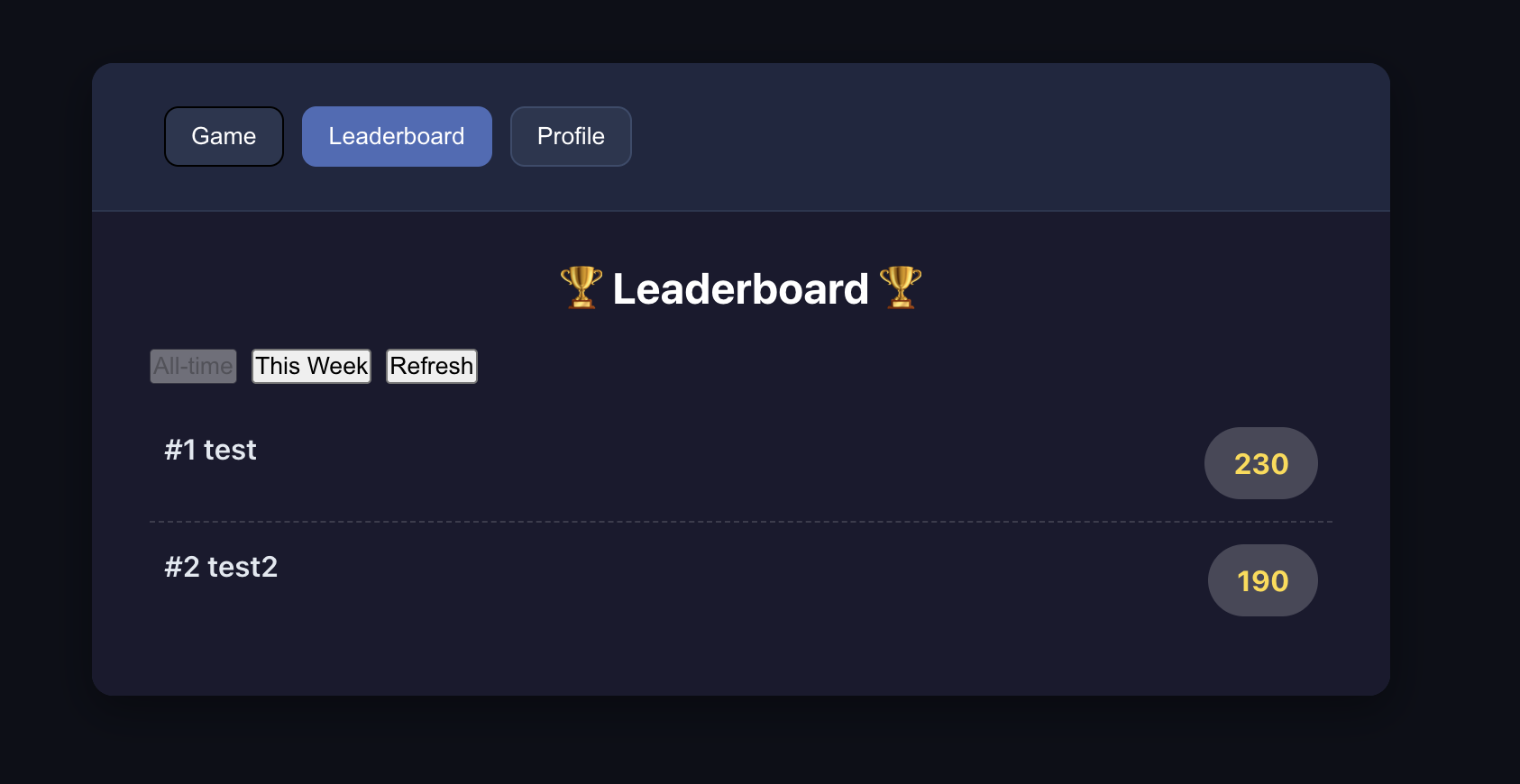
Hausaufgabe
- Integriere das Benutzermanagement-System in die Schlangenspiel-Demoversion.
- Integriere das Benutzermanagement-System in deine eigene Anwendung.
5. Supabase-Meister werden
Die oben genannten Inhalte decken die Grundoperationen von Supabase ab. Im weiteren Verlauf werden wir die erweiterten Prinzipien und Funktionen von Supabase kennenlernen.
5.1 Warum wir Supabase gewaehlt haben
Bei der Technologieauswahl stehen Startups vor einem Dilemma: Sie wollen volle Kontrolle ueber das Backend-System, muessen aber gleichzeitig schnell Produkte auf den Markt bringen. Supabase buendelt diese Backend-Faehigkeiten als sofort einsatzbereite Dienste (PostgreSQL-Datenbank, Echtzeit-Abos, Authentifizierung, Objektspeicher, Edge Functions, automatisch generierte APIs usw.).
Im Vergleich zu Konkurrenzprodukten wie dem geschlossenen Firebase bietet Supabase eine vollstaendig quelloffene Strategie, die Private-Deployment unterstuetzt und das Risiko von Vendor-Lock-in vermeidet.
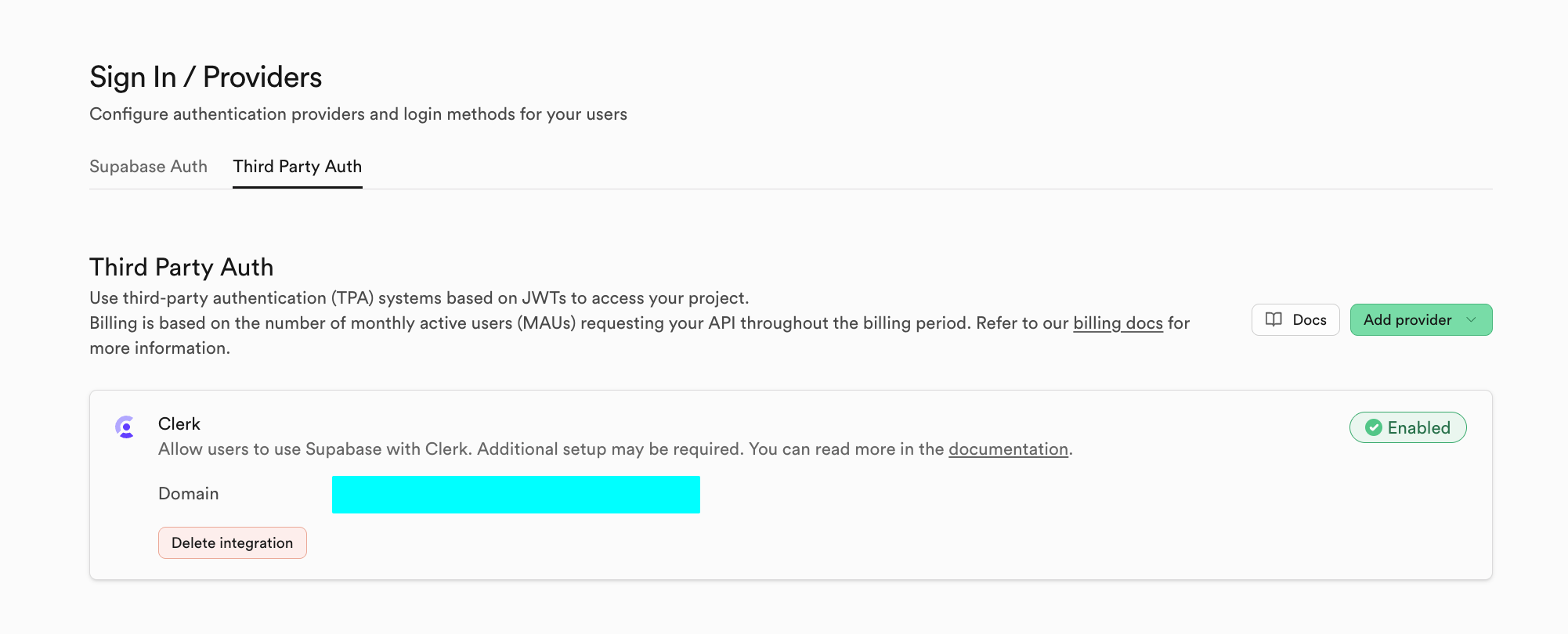
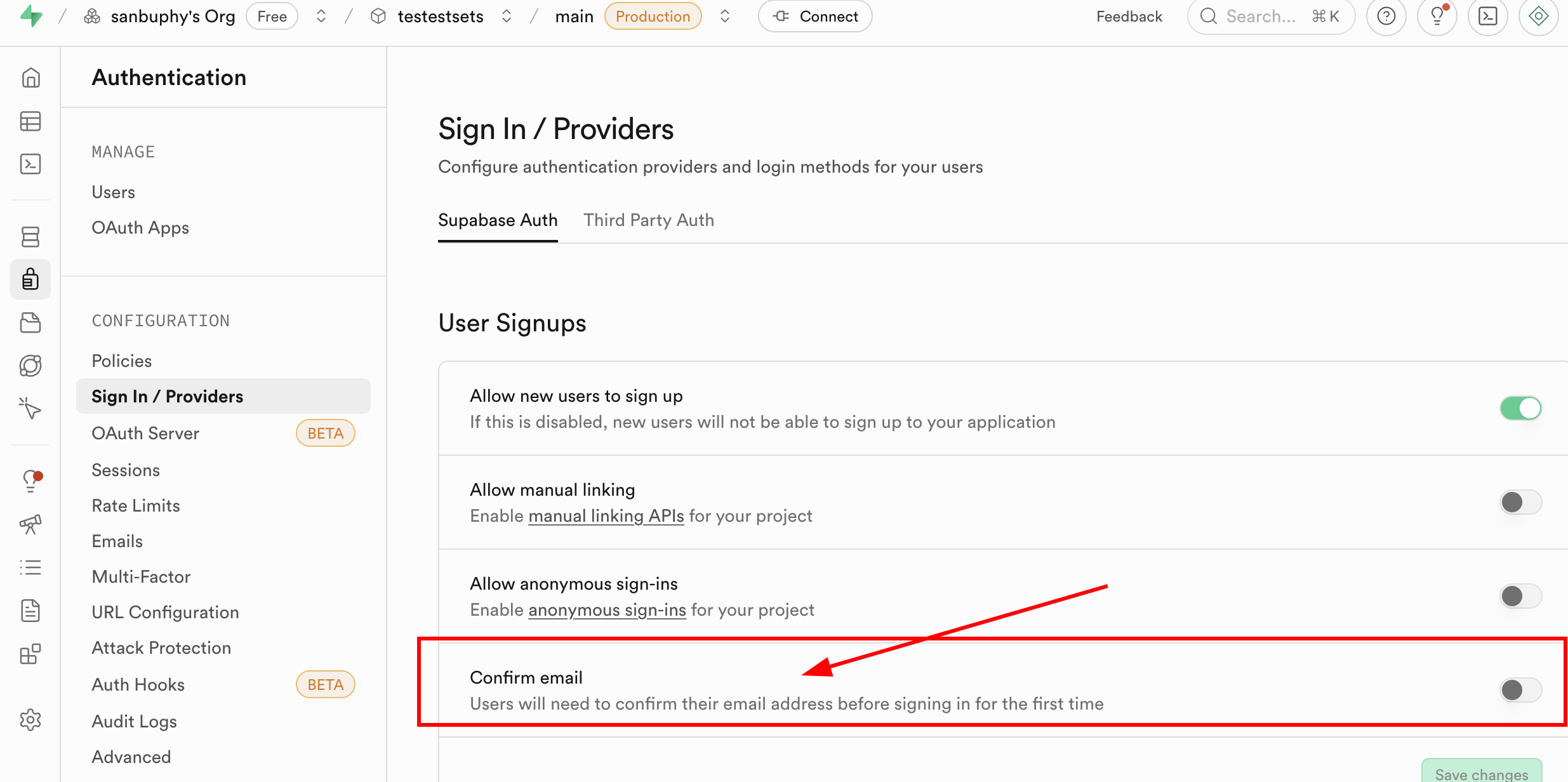
5.2 Google- und GitHub-Login-Unterstützung
Dieses Projekt project-burger-shop-auth-advanced-supabase-6 demonstriert vollstaendig die Implementierung dieser erweiterten Funktionen.

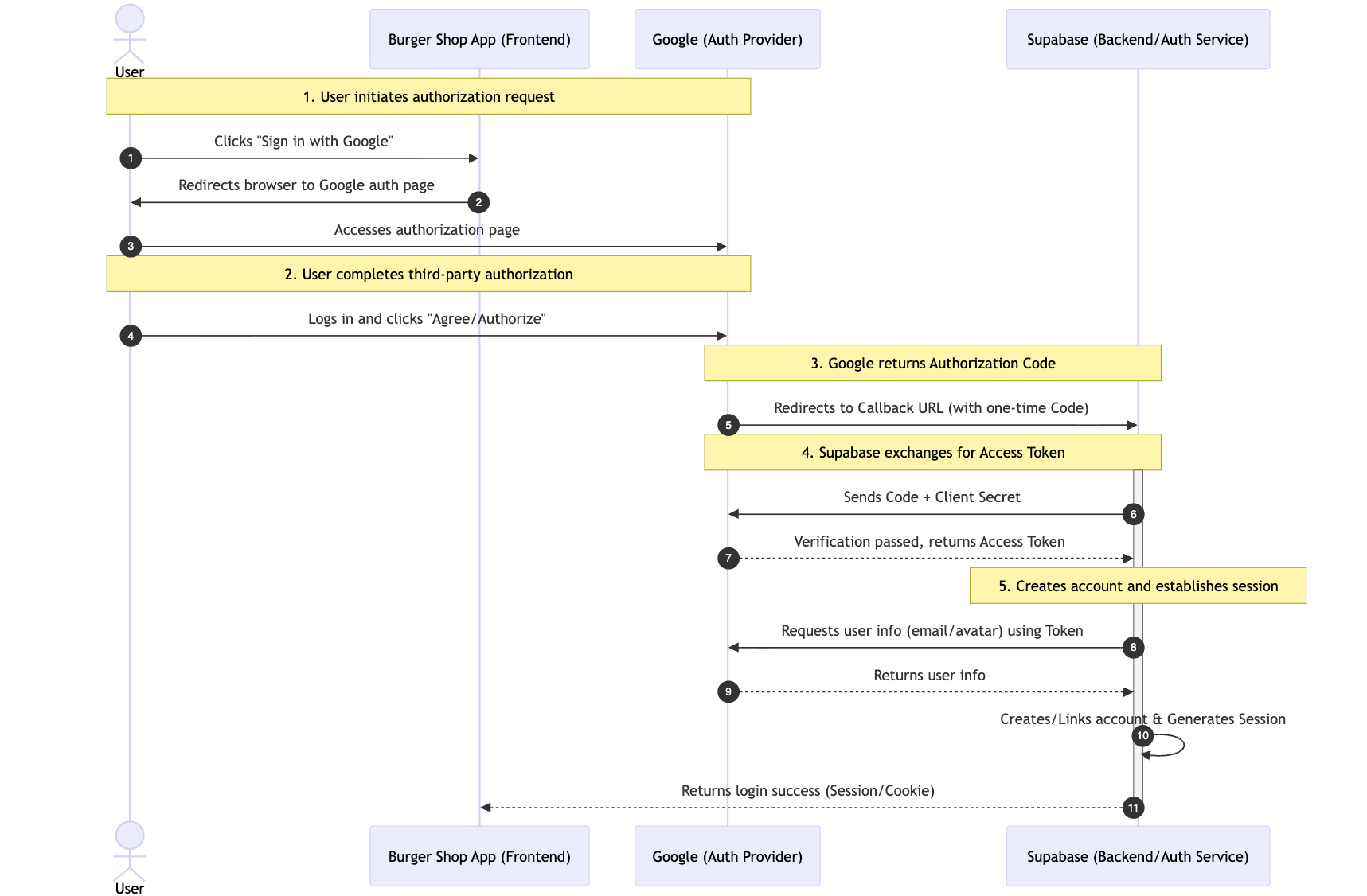
5.2.1 OAuth-Ablauf: Wie funktioniert Drittanbieter-Login?
Der Kern des Drittanbieter-Logins ist das OAuth 2.0-Protokoll. Es ermoeglicht Benutzern, unsere App zu autorisieren, auf ihre oeffentlichen Informationen (wie E-Mail, Avatar) bei einem Drittanbieter (wie Google) zuzugreifen, ohne das Passwort des Drittanbieters preiszugeben.
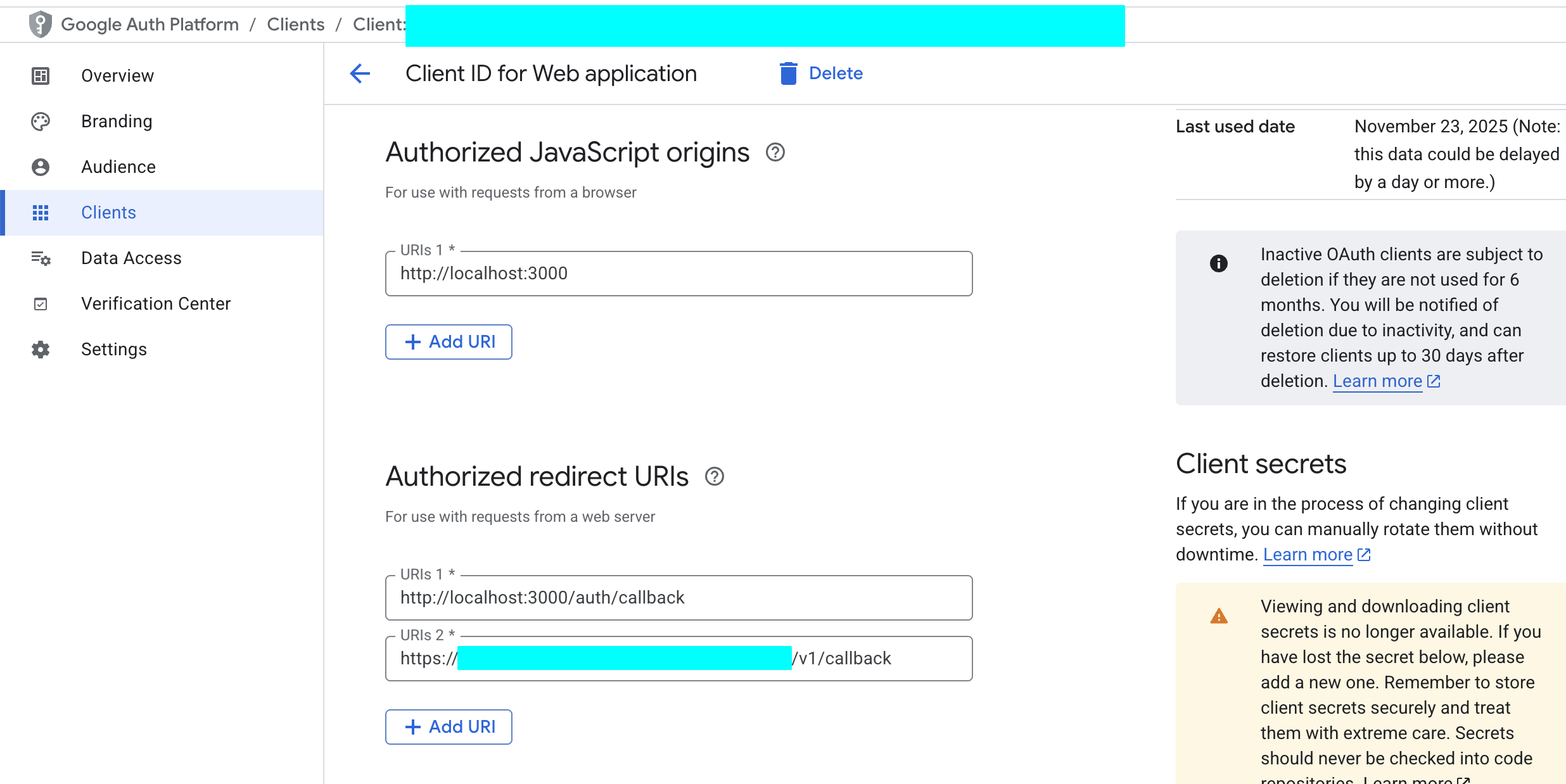
5.2.2 Google Cloud fuer Client ID und Secret konfigurieren
- Gehe zu Google Cloud Console.
- Konfiguriere den OAuth-Zustimmungsbildschirm.
- Erstelle OAuth 2.0-Client-Anmeldeinformationen.
- Trage die Supabase-Callback-URL ein:
https://<Deine-Projekt-ID>.supabase.co/auth/v1/callback.
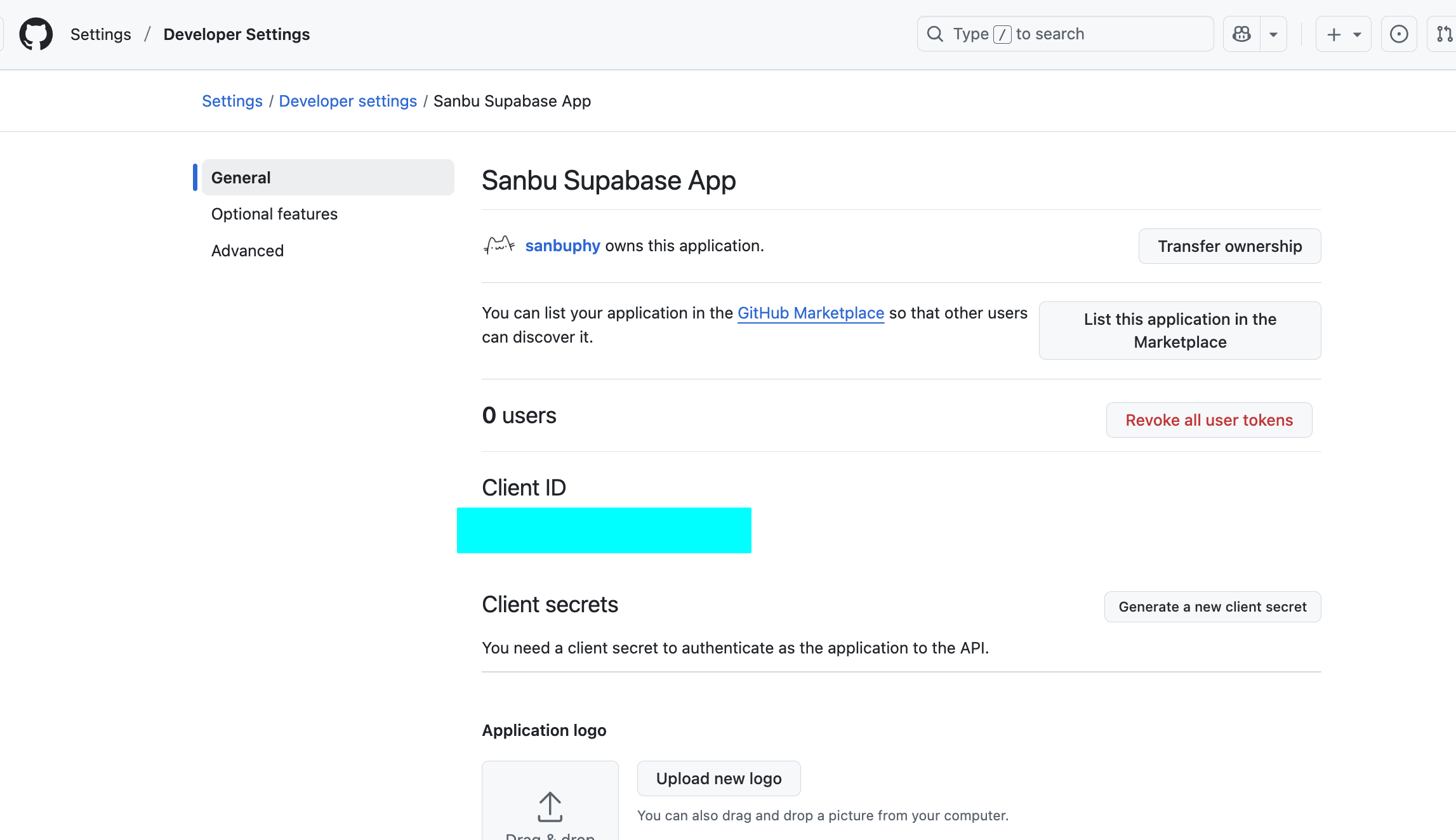
5.2.3 GitHub fuer Client ID und Secret konfigurieren
- Gehe zu GitHub Developer Settings.
- Registriere eine neue OAuth-App.
- Trage die Supabase-Callback-URL ein.
- Generiere ein Client Secret.
5.2.4 Provider in Supabase konfigurieren
- Gehe zu Supabase Dashboard > Authentication > Providers.
- Aktiviere Google und trage Client ID und Client Secret ein.
- Aktiviere GitHub und trage Client ID und Client Secret ein.

5.2.6 Passwort-Zuruecksetzen implementieren
- Benutzer gibt E-Mail ein, Frontend ruft
supabase.auth.resetPasswordForEmail()auf. - Supabase sendet E-Mail mit einzigartigem Reset-Link.
- Benutzer klickt auf Link und wird zurueckgeleitet.
- Benutzer gibt neues Passwort ein, Frontend ruft
supabase.auth.updateUser()auf.
5.3 Echtzeit-Funktionen
Dieses Projekt project-burger-shop-realtime-orders-3 demonstriert die drei Kernfaehigkeiten von Supabase Realtime: Datenbankaenderungen ueberwachen (Postgres Changes), Broadcast und Presence.
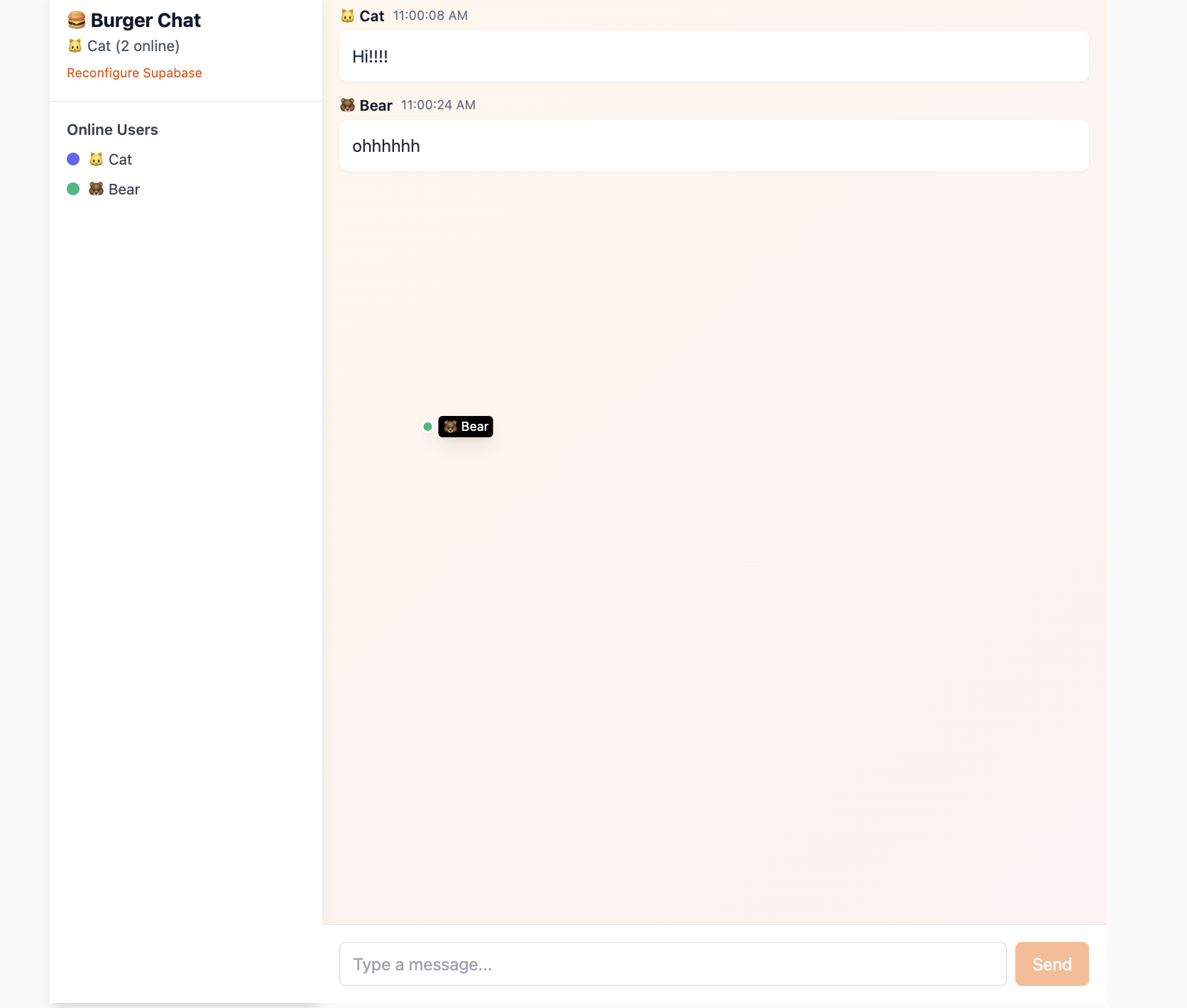
5.3.1 Datenbank-Echtzeitaenderungen (Postgres Changes)
Die haeufigste Realtime-Funktion ist das Ueberwachen von Datenbankaenderungen. Kunden koennen spezifische Tabellen, Zeilen oder Spalten auf INSERT-, UPDATE- oder DELETE-Ereignisse abonnieren.
-- Echtzeit-Replikation aktivieren
ALTER TABLE public.chat_messages REPLICA IDENTITY FULL;
DO $$
BEGIN
IF NOT EXISTS (
SELECT 1 FROM pg_publication_tables
WHERE pubname = 'supabase_realtime'
AND schemaname = 'public'
AND tablename = 'chat_messages'
) THEN
ALTER PUBLICATION supabase_realtime ADD TABLE public.chat_messages;
END IF;
END $$;const sub = supabase
.channel('chat_messages_channel')
.on('postgres_changes', {
event: 'INSERT',
schema: 'public',
table: 'chat_messages'
}, (payload: any) => {
console.log('Neue Nachricht empfangen:', payload.new);
})
.subscribe((status: string) => {
console.log('Chat-Abonnementstatus:', status);
});5.3.2 Broadcast und Presence
- Presence: Verfolgt den Online-Status aller Clients in einem Kanal.
- Broadcast: Sendet temporäre Nachrichten mit niedriger Latenz zwischen Clients.
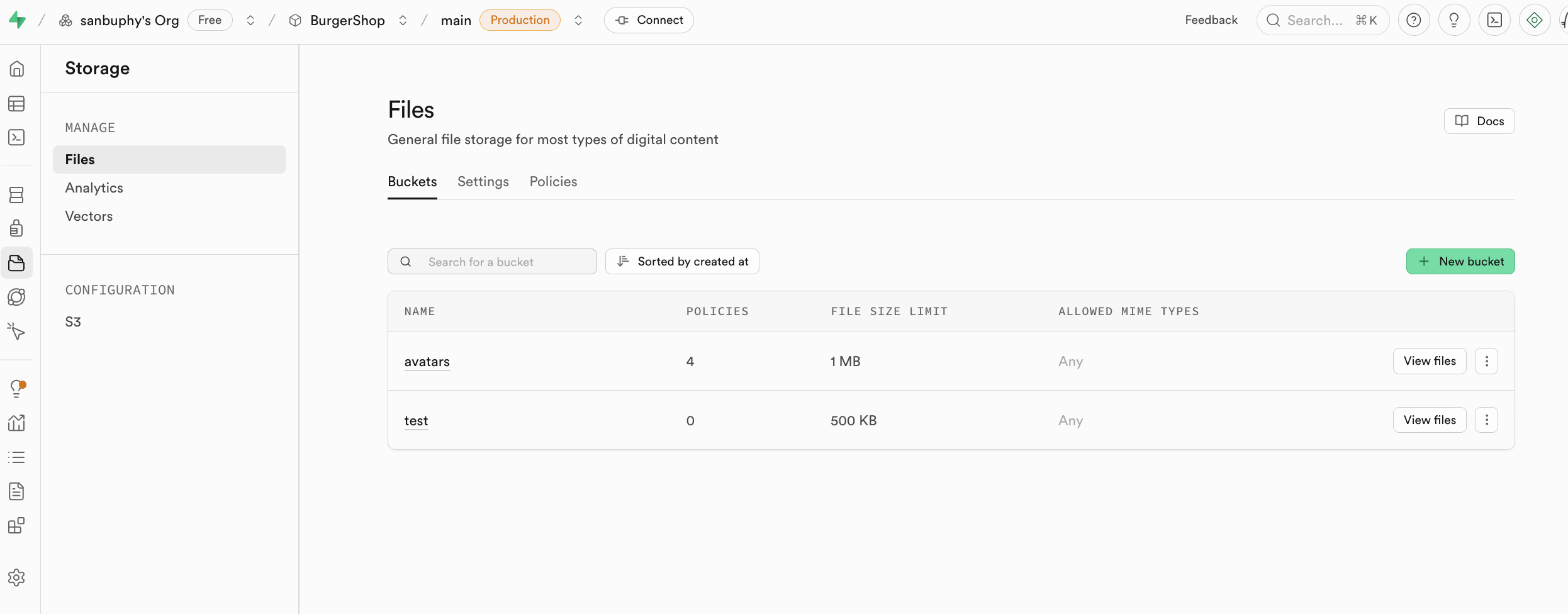
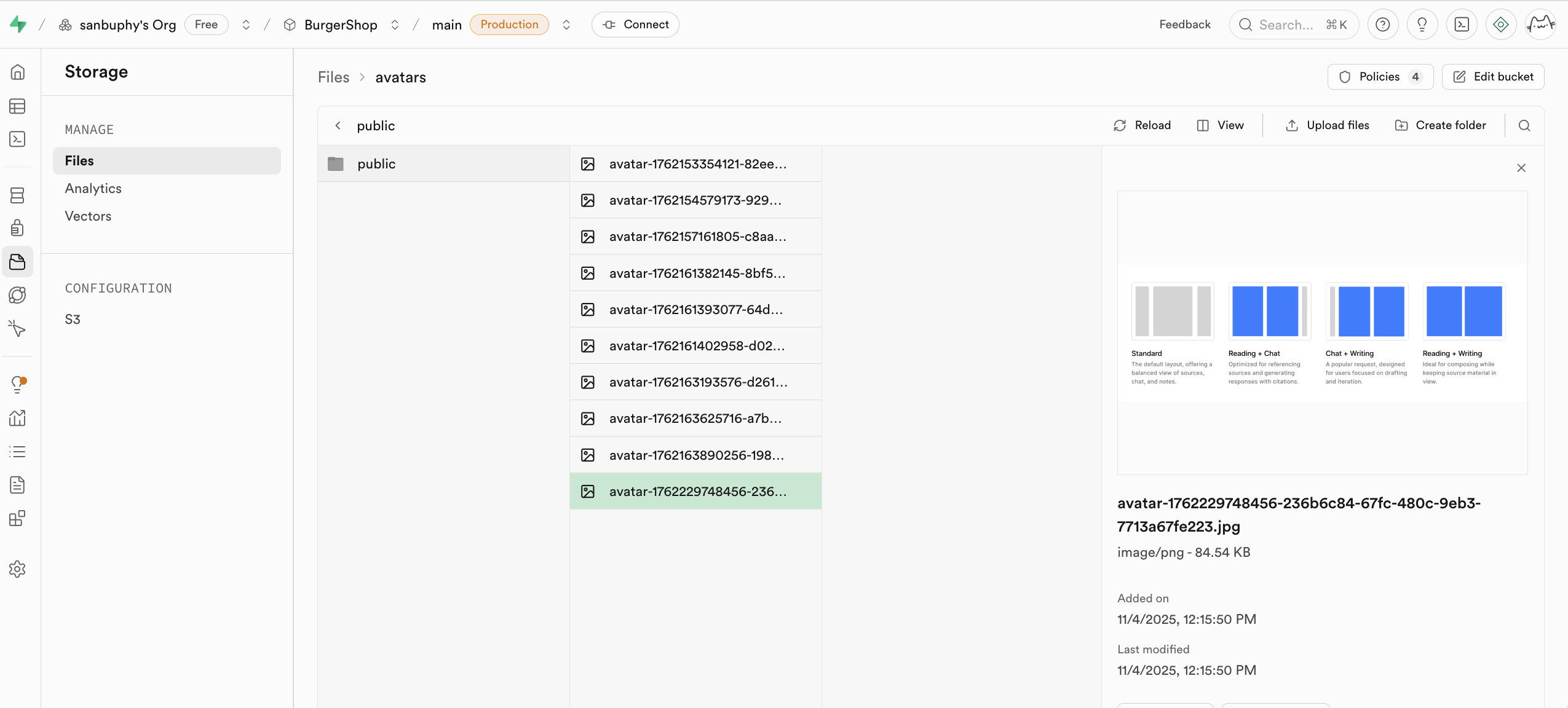
5.4 Speicher (Storage)
Dieses Projekt project-burger-shop-storage-uploads-4 demonstriert den Aufbau eines modernen Datei-Upload-Systems mit Supabase Storage.
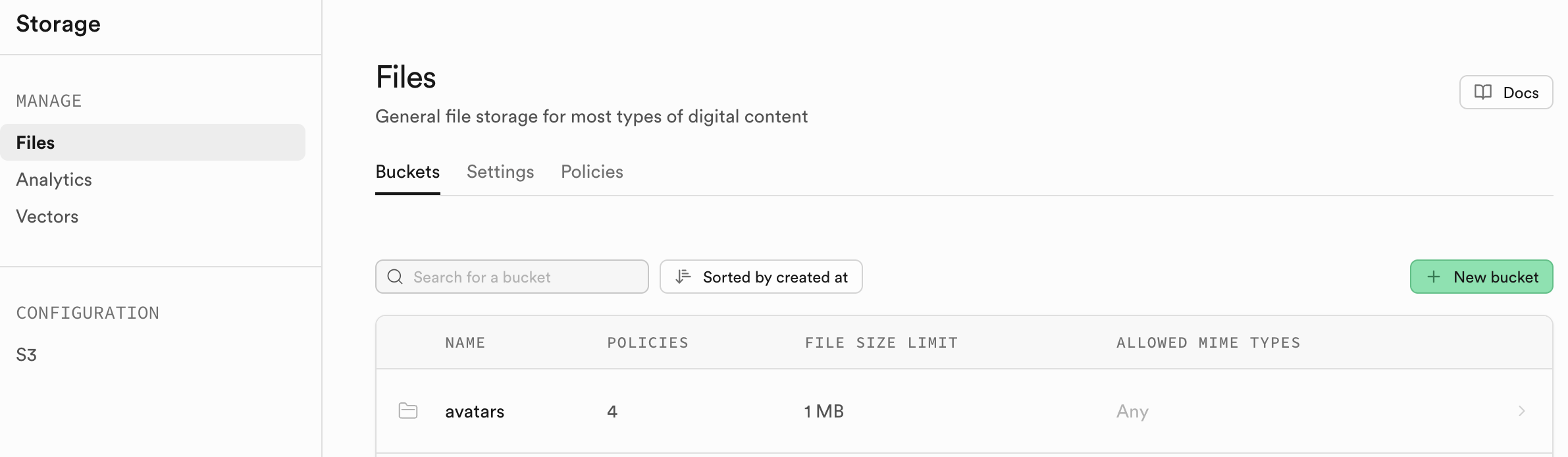
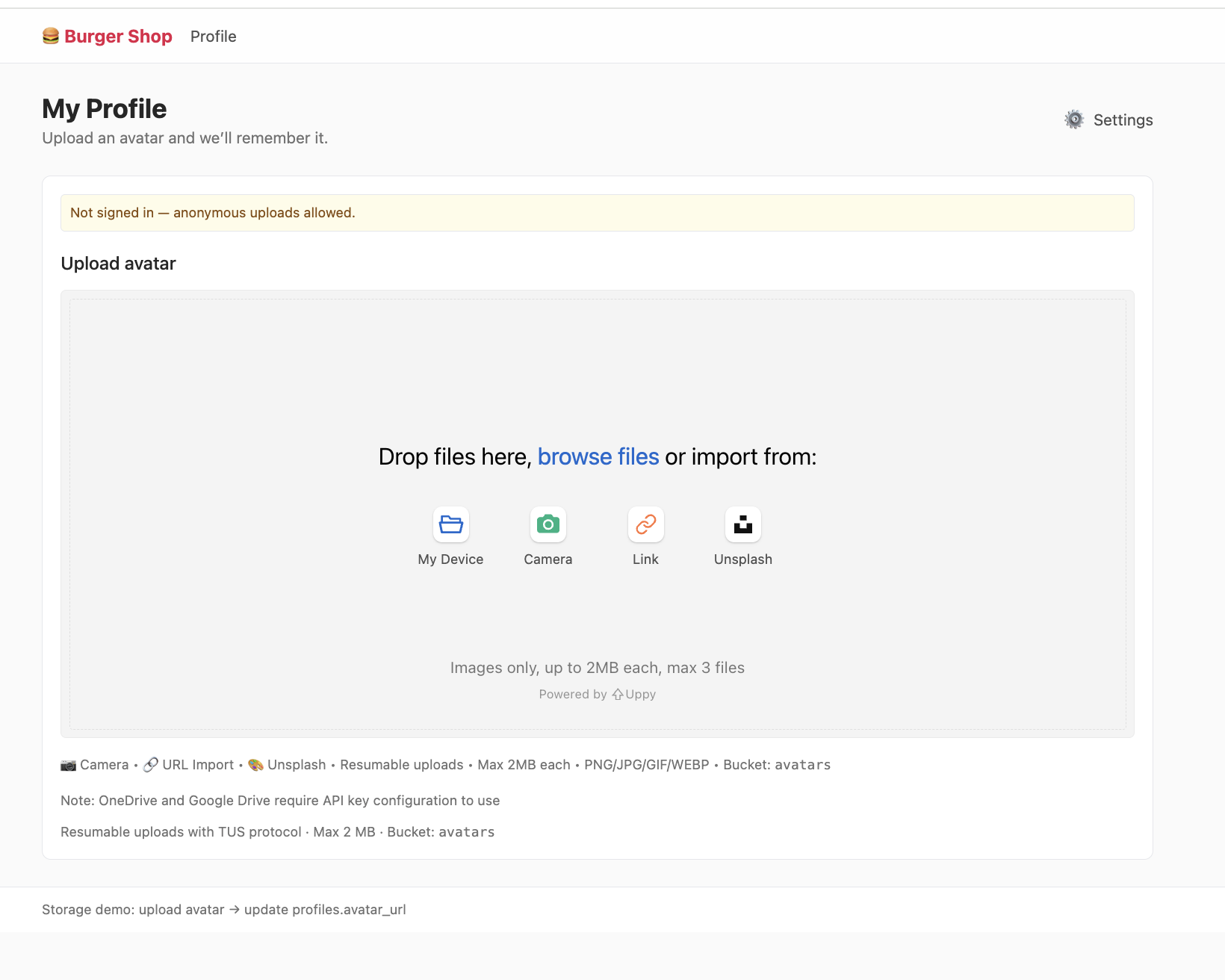
5.4.1 Speicher-Buckets (Storage Buckets)
Supabase Storage besteht aus Speicher-Buckets (Buckets). Jeder Bucket kann eigene Sicherheitsrichtlinien und Konfigurationen haben.
CREATE POLICY "Allow authenticated uploads to avatars bucket"
ON storage.objects FOR INSERT
TO authenticated
WITH CHECK (
bucket_id = 'avatars' AND
auth.uid() = (storage.foldername(name))[1]::uuid AND
(storage.extension(name) IN ('png', 'jpg', 'jpeg'))
);
CREATE POLICY "Allow public read access to avatars"
ON storage.objects FOR SELECT
USING ( bucket_id = 'avatars' );5.4.2 Zugaengliche Datei-URLs abrufen
Oeffentliche URL (Public URL) - Permanenter Link
const { data } = supabase.storage
.from('avatars')
.getPublicUrl('public/avatar1.png');
const publicUrl = data.publicUrl;Signierte URL (Signed URL) - Temporaerer Link
const { data, error } = await supabase.storage
.from('avatars')
.createSignedUrl('private/user-invoice.pdf', 3600);
const signedUrl = data?.signedUrl;5.5 Edge Functions
Dieses Projekt project-burger-shop-edge-function-5 demonstriert den einfachsten Anwendungsprozess von Edge Functions anhand einer Echtzeit-Streaming-Chat-Funktion mit einem grossen Sprachmodell (LLM).
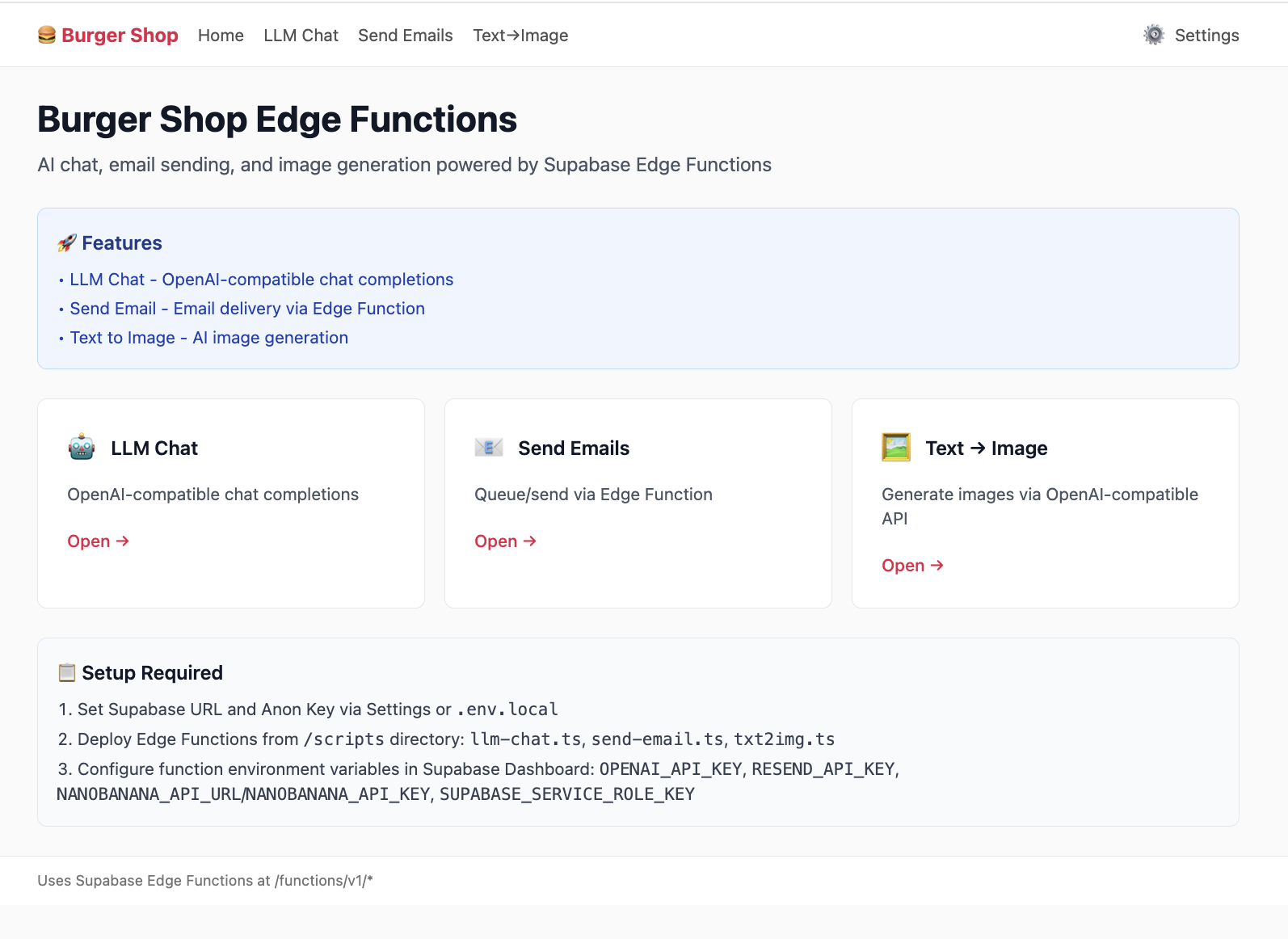
5.5.1 LLM-Chat-Fallanalyse
// scripts/llm-chat.ts
import "jsr:@supabase/functions-js/edge-runtime.d.ts";
import { OpenAI } from "npm:openai";
const OPENAI_API_KEY = Deno.env.get("OPENAI_API_KEY");
Deno.serve(async (req) => {
try {
const openai = new OpenAI({ apiKey: OPENAI_API_KEY });
const { prompt } = await req.json();
const stream = await openai.chat.completions.create({
model: "gpt-3.5-turbo",
messages: [{ role: "user", content: prompt }],
stream: true,
});
return new Response(stream.toReadableStream(), {
headers: { "Content-Type": "text/event-stream" },
});
} catch (err) {
}
});5.5.2 Funktion erstellen und bereitstellen
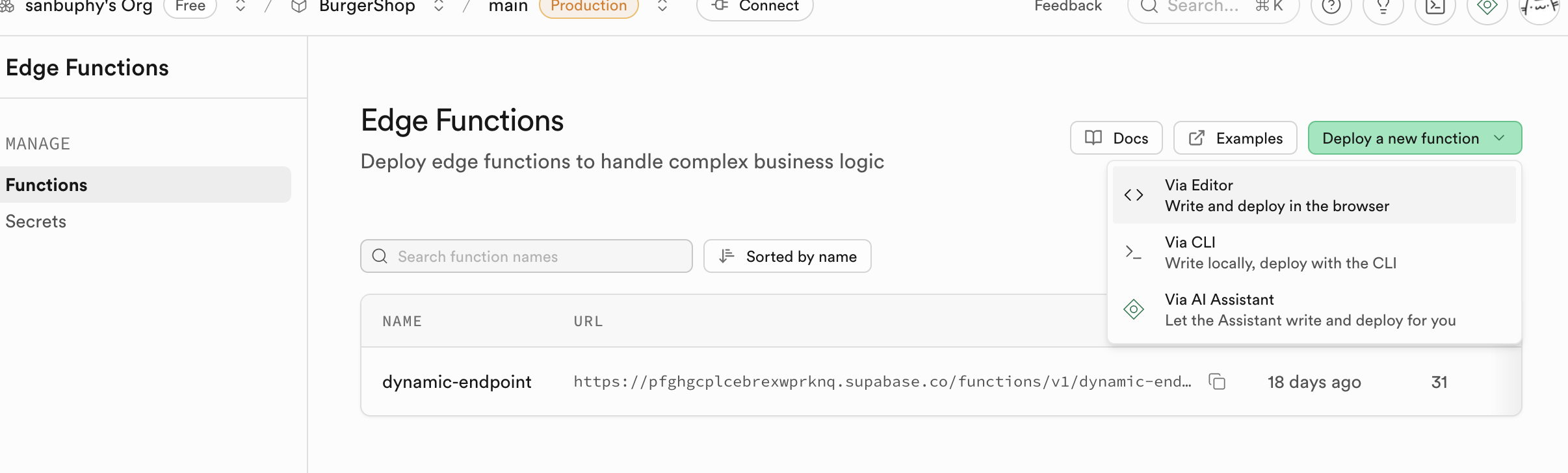
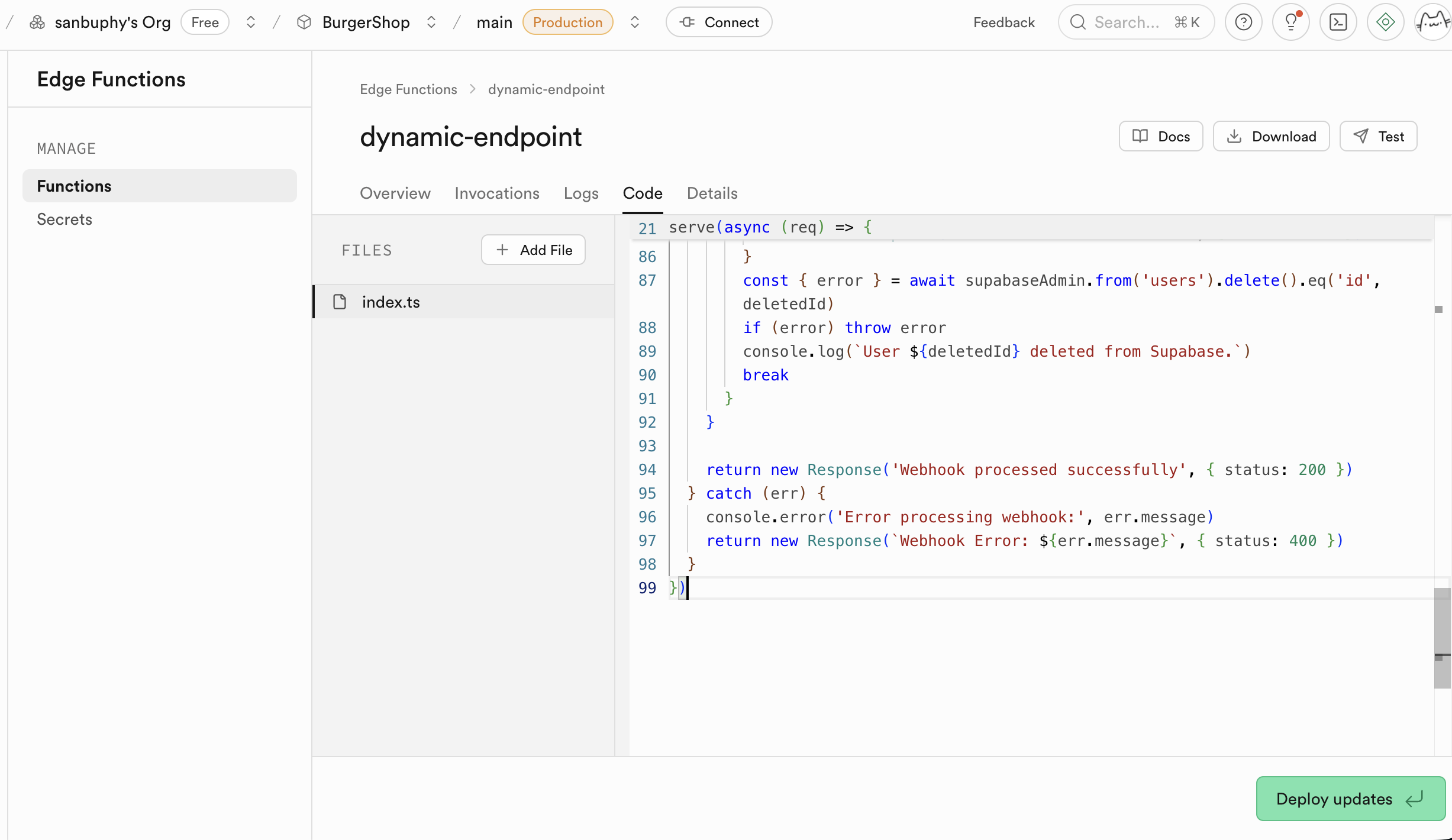
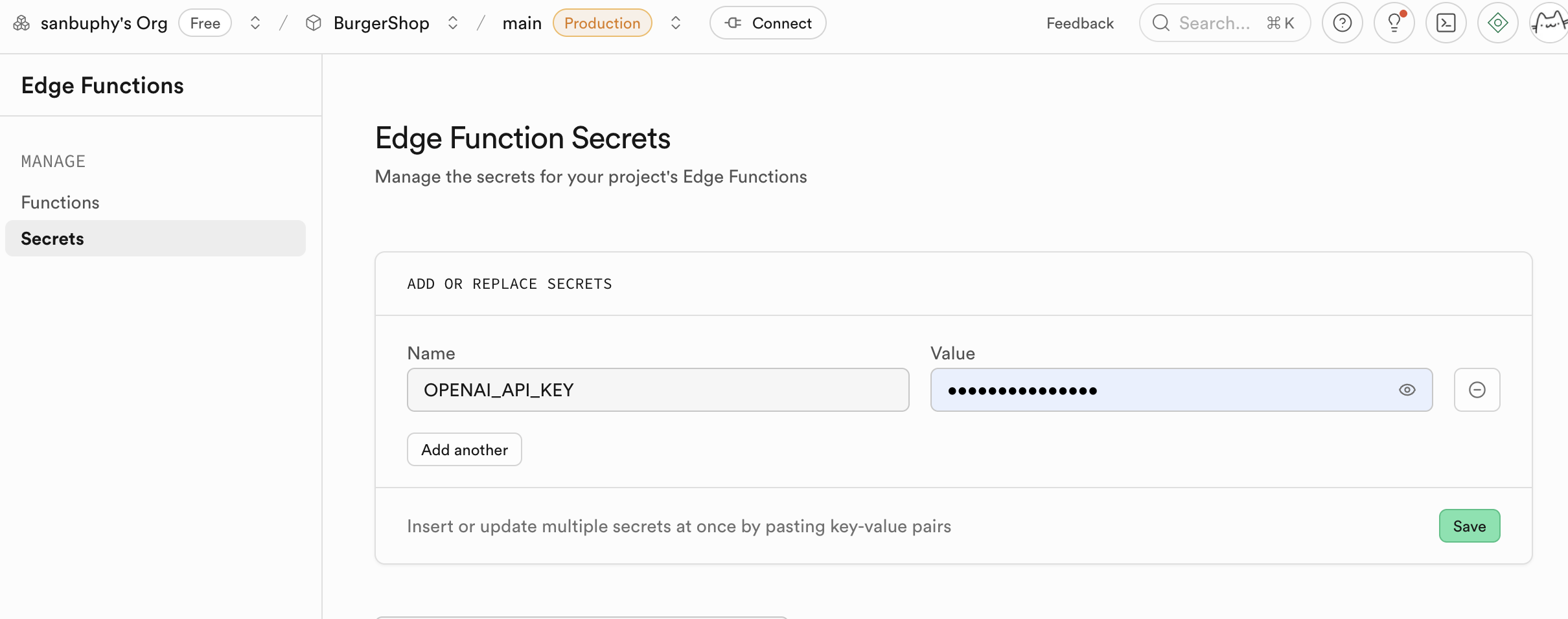
5.6 Clerk-Login
Clerk ist ein professionelles Entwicklungstool fuer Identitaetsauthentifizierung und Benutzerverwaltung.
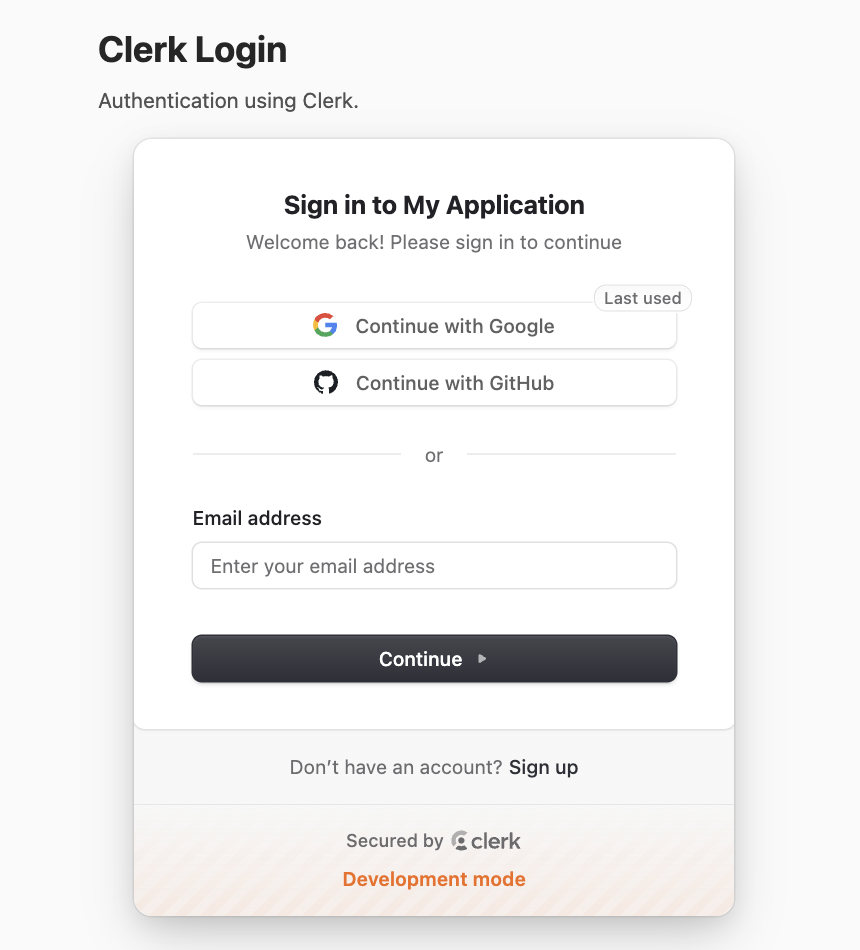
5.6.1 Clerk-App erstellen und Schluessel abrufen
5.6.2 Supabase und Clerk nativ integrieren
- Aktiviere die offizielle Supabase-Integration in Clerk.
- Fuege Clerk als Provider in Supabase hinzu.
5.6.3 Benutzerdaten ueber Webhook mit Supabase synchronisieren
CREATE TABLE public.users (
id TEXT NOT NULL PRIMARY KEY,
email TEXT,
first_name TEXT,
last_name TEXT,
image_url TEXT,
created_at TIMESTAMPTZ DEFAULT NOW(),
updated_at TIMESTAMPTZ DEFAULT NOW()
);
ALTER TABLE public.users ENABLE ROW LEVEL SECURITY;
CREATE POLICY "Authenticated users can view their own user record"
ON public.users FOR SELECT
TO authenticated
USING ( (SELECT auth.jwt()->>'sub') = id );
5.6.4 Drittanbieter-Login in Clerk
Clerk unterscheidet zwischen Entwicklungs- und Produktionsumgebung fuer Social-Login.
6. Von Supabase zu weiteren Backend-Entwicklungskomponenten (Fortgeschritten)
Supabase bietet eine umfassende Plattform, aber jede einzelne Faehigkeit (Auth / Storage / Edge Functions / Realtime / Database) hat professionelle Alternativen auf dem Markt.
Vergleichbare BaaS-Plattformen
| Plattag/Service | Typ | Kostenloseinheit/Preisgestaltung |
|---|---|---|
| Firebase (Google) | Voll verwaltetes BaaS | Spark: kostenlose Leichtversion; Blaze: nutzungsabhaengig |
| Supabase | Open-Source BaaS | Kostenlos: 500MB DB, 1GB Storage; Pro: nach Instanz |
| Appwrite Cloud | Open-Source All-in-One BaaS | Kostenlos: Basis DB/Storage/FaaS |
| Nhost | Postgres + GraphQL + Auth + Storage + Functions | Kostenlos: 1GB DB, 1GB Storage |
| AWS Amplify | AWS All-in-One Backend | Kostenlos: Hosting + Cognito 10k MAU |
Authentifizierung (Auth)
| Tool/Plattform | Kostenloseinheit |
|---|---|
| Firebase Authentication | Spark: 50k MAU kostenlos |
| Auth0 (Okta) | 25k MAU kostenlos |
| AWS Cognito | 10k MAU/Monat kostenlos |
| Logto | Community Edition kostenlos |
| Keycloak | Vollstaendig kostenlos (selbst gehostet) |
Dateispeicher (Storage)
| Plattform/Service | Kostenloseinheit |
|---|---|
| Amazon S3 | 5GB Speicher im kostenlosen AWS-Kontingent |
| Google Cloud Storage (Firebase Storage) | 1GB Speicher in Spark-Plan |
| Tencent Cloud COS / Alibaba Cloud OSS | Nutzungsabhaengig |
| MinIO | Open-Source kostenlos (selbst gehostet) |
Edge Functions
| Plattform/Service | Kostenloseinheit |
|---|---|
| Cloudflare Workers | 100k Anfragen/Tag kostenlos |
| Vercel Edge Functions | 1M Funktionsaufrufe/Monat kostenlos |
| Netlify Edge / Functions | 300 Credits/Monat kostenlos |
| AWS Lambda@Edge / CloudFront Functions | 1M kostenlose Anfragen/Monat |
Zusammenfassung
In der heutigen Lektion haben wir systematisch die Grundkonzepte von Datenbanken sowie die Kerndefinition und Bedienungsdetails von Supabase gelernt. Waehrend der weiteren Praxis kannst du jederzeit auf dieses Dokument zurueckgreifen.
Bitte denke immer an einen wichtigen Grundsatz: Zuerst fertigstellen, dann perfektionieren! Es ist nicht noetig, alles auf einmal perfekt zu machen. Durch kontinuierliche Iteration und Optimierung koennen wir uns schrittweise besseren Ergebnissen naehern.
Hausaufgabe
- Entwickle eine Anwendung mit Benutzermanagement-System und Datenbank. Idealerweise mit weiteren Supabase-Funktionen (Realtime / Cloud Storage / Edge Functions).