Von NanoBanana ausgehend: deinen eigenen Asset-Produktions-Agenten aufbauen
Kapitel 1: In 1 Minute das erste Bild-Asset generieren
Bevor wir ueber Design, Stil oder Prompts diskutieren, generieren wir zuerst mit den minimalsten Schritten das erste Bild.
1.1 NanoBanana kennenlernen
Bevor wir ueber Designstile und Prompt-Engineering diskutieren, moechten wir zuerst eine wichtigere Frage klaeren: Sicherstellen, dass du wirklich ein Bild generieren kannst.
Aktuelle Mainstream-Grossmodelle verfügen bereits ueber Bildgenerierungs- und Bearbeitungsfaehigkeiten. Diese Modelle werden normalerweise als generative Modelle bezeichnet.
Um den Prozess so einfach wie moeglich zu halten, waehlt dieses Tutorial ein Modell, das bereits stabile Bildgenerierungs- und Bearbeitungsfaehigkeiten besitzt, als Beispiel -- NanoBanana. Es ist ein von Google herausgegebenes Bildgenerierungsmodell mit dem offiziellen Namen Gemini 3.1 Flash Image Preview, das die direkte Bildgenerierung ueber natuerliche Sprache unterstuetzt und auch die Bearbeitung vorhandener Bilder ermoeglicht.

Auf der Faehigkeitsebene gibt es keinen wesentlichen Unterschied zu anderen Modellen, die du vielleicht kennst (wie GPT-4o, Claude, Qwen, Midjourney etc.): Beschreibung eingeben, das Modell generiert das Ergebnis.



Du kannst es dir als einen "Pinsel" vorstellen. In diesem Kapitel interessiert uns nur eine Frage: Kann dieser Pinsel in deiner Hand den ersten Strich ziehen.
In der praktischen Verwendung kann NanoBanana direkt ueber offizielle Plattformen wie Google AI Studio verwendet werden oder ueber API in den Entwicklungsprozess integriert werden. Dieses Tutorial verwendet die API-Aufrufmethode. Mittlerweile ist auch das NanoBanana 2-Modell verfuegbar, und du kannst die neuesten Grossmodelle ausprobieren.
1.2 "Hello World"-Level-Generierung
Bevor du beginnst, musst du nur die folgenden drei Schritte abschliessen:
- Erstelle einen neuen Ordner in Trae
- Erstelle eine neue Python-Datei
- Den folgenden Code vollstaendig einfuegen
Trae schliesst automatisch die erforderliche Umgebungsbereitstellung und Abhaengigkeitsinstallation ab, ohne zusaetzliche Konfiguration.
Der Code verwendet den API-Key von NanoBanana. Hier wird der Antragsprozess nicht im Detail erlaeutert -- solange du den entsprechenden Parameter abrufen und eingeben kannst. In dieser Phase geht es nicht darum, jede Codezeile zu verstehen, sondern dass er erfolgreich ausgefuehrt wird.
# /// script
# dependencies = [
# "gradio>=4.0.0",
# "pillow>=10.0.0",
# "requests>=2.31.0",
# ]
# ///
import gradio as gr
import requests
import base64
from PIL import Image
import io
import os
import time
import re
from typing import Optional, Dict, Any, List
# API-Informationen konfigurieren
NANOBANANA_API_URL: str = "YOUR API URL"
NANOBANANA_API_KEY: str = "YOUR API KEY"
OUTPUT_DIR: str = "outputs"
# Sicherstellen, dass das Ausgabeverzeichnis existiert
os.makedirs(OUTPUT_DIR, exist_ok=True)
def image_to_base64_data_uri(image: Image.Image) -> str:
"""
Konvertiert ein PIL-Bild in ein OpenAI-API-kompatibles data URI-Format.
"""
buffer = io.BytesIO()
# Einheitlich nach PNG konvertieren fuer Kompatibilitaet
image.save(buffer, format="PNG")
encoded = base64.b64encode(buffer.getvalue()).decode('utf-8')
return f"data:image/png;base64,{encoded}"
def base64_to_image(base64_str: str) -> Optional[Image.Image]:
"""
Konvertiert einen reinen Base64-String in ein PIL-Bild.
"""
try:
image_bytes = base64.b64decode(base64_str)
return Image.open(io.BytesIO(image_bytes))
except Exception as e:
print(f"Base64-Decodierung fehlgeschlagen: {e}")
return None
def extract_base64_from_response(content: Any) -> Optional[str]:
"""
Kern-Parselogik: Extrahiert Bild-Base64-Daten aus dem von der API zurueckgegebenen content.
Kompatibel mit Markdown-Format und strukturiertem Listenformat.
"""
if not content:
return None
base64_data = None
# 1. Versuch der strukturierten Extraktion (List)
if isinstance(content, list):
for part in reversed(content):
if isinstance(part, dict):
img_field = part.get("image_url") or part.get("image") or part.get("output_image")
if isinstance(img_field, dict):
url = img_field.get("url", "")
if url.startswith("data:image/") and "," in url:
return url.split(",", 1)[1].strip()
text_parts = [
str(p.get("text", ""))
for p in content
if isinstance(p, dict) and p.get("type") in ["text", "input_text"]
]
content_str = "".join(text_parts)
else:
content_str = str(content)
# 2. Versuch der Markdown-Regex-Extraktion (String)
pattern = re.compile(r"!\[.*?\]\((data:image/[^;]+;base64,[^)]+)\)", re.IGNORECASE)
match = pattern.search(content_str)
if match:
data_url = match.group(1)
if "," in data_url:
return data_url.split(",", 1)[1].strip()
return None
def synthesize(prompt: str, input_image: Optional[Image.Image]) -> Optional[Image.Image]:
"""
Ruft die Nanobanana-API fuer die Generierung auf.
"""
if not prompt or not prompt.strip():
gr.Warning("Bitte gib einen Prompt ein")
return None
print(f">>> Aufgabe starten: {prompt[:50]}...")
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {NANOBANANA_API_KEY}"
}
messages = []
if input_image is not None:
print(">>> Eingabebild erkannt, multimodaler Modus wird verwendet")
img_base64 = image_to_base64_data_uri(input_image)
messages.append({
"role": "user",
"content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": img_base64}}
]
})
else:
messages.append({
"role": "user",
"content": prompt
})
payload = {
"messages": messages,
"model": "gemini-2.5-flash-image",
"stream": False
}
try:
response = requests.post(NANOBANANA_API_URL, headers=headers, json=payload, timeout=120)
if response.status_code != 200:
error_msg = f"API-Anfrage fehlgeschlagen: {response.status_code} - {response.text}"
print(error_msg)
gr.Error(error_msg)
return None
result = response.json()
print(f"API-Rohantwort (gekuerzt): {str(result)[:200]}...")
content = None
if "choices" in result and len(result["choices"]) > 0:
content = result["choices"][0].get("message", {}).get("content")
if not content:
gr.Warning("Kein content-Feld in der API-Antwort")
return None
base64_str = extract_base64_from_response(content)
if base64_str:
output_image = base64_to_image(base64_str)
if output_image:
return output_image
text_content = str(content) if not isinstance(content, list) else " ".join([str(x) for x in content])
gr.Info(f"Kein Bild generiert, Modell gab Text zurueck: {text_content[:100]}...")
return None
except requests.exceptions.Timeout:
gr.Error("Anfrage-Zeitueberschreitung, bitte versuche es spaeter erneut")
return None
except Exception as e:
import traceback
traceback.print_exc()
gr.Error(f"Ein unbekannter Fehler ist aufgetreten: {str(e)}")
return None
# Gradio-Oberflaechenkonfiguration
with gr.Blocks(title="Nanobanana Image Generator") as app:
gr.Markdown("# Nanobanana Text/Image to Image")
gr.Markdown("Basierend auf dem Gemini-2.5-Flash-Image-Modell, unterstuetzt Text-zu-Bild und Bild-zu-Bild.")
with gr.Row():
with gr.Column():
prompt_input = gr.Textbox(
label="Prompt (Eingabe)",
placeholder="z.B.: A cyberpunk cat holding a neon sign...",
lines=3
)
image_input = gr.Image(
label="Referenzbild (optional, fuer Bild-zu-Bild)",
type="pil",
height=300
)
submit_btn = gr.Button("Generierung starten", variant="primary")
with gr.Column():
image_output = gr.Image(label="Generierungsergebnis", format="png")
submit_btn.click(
fn=synthesize,
inputs=[prompt_input, image_input],
outputs=image_output
)
if __name__ == "__main__":
app.launch(share=True)Wenn Trae eine erfolgreiche Ausführung anzeigt, klicke auf den bereitgestellten lokalen Link (normalerweise http://127.0.0.1:7860).
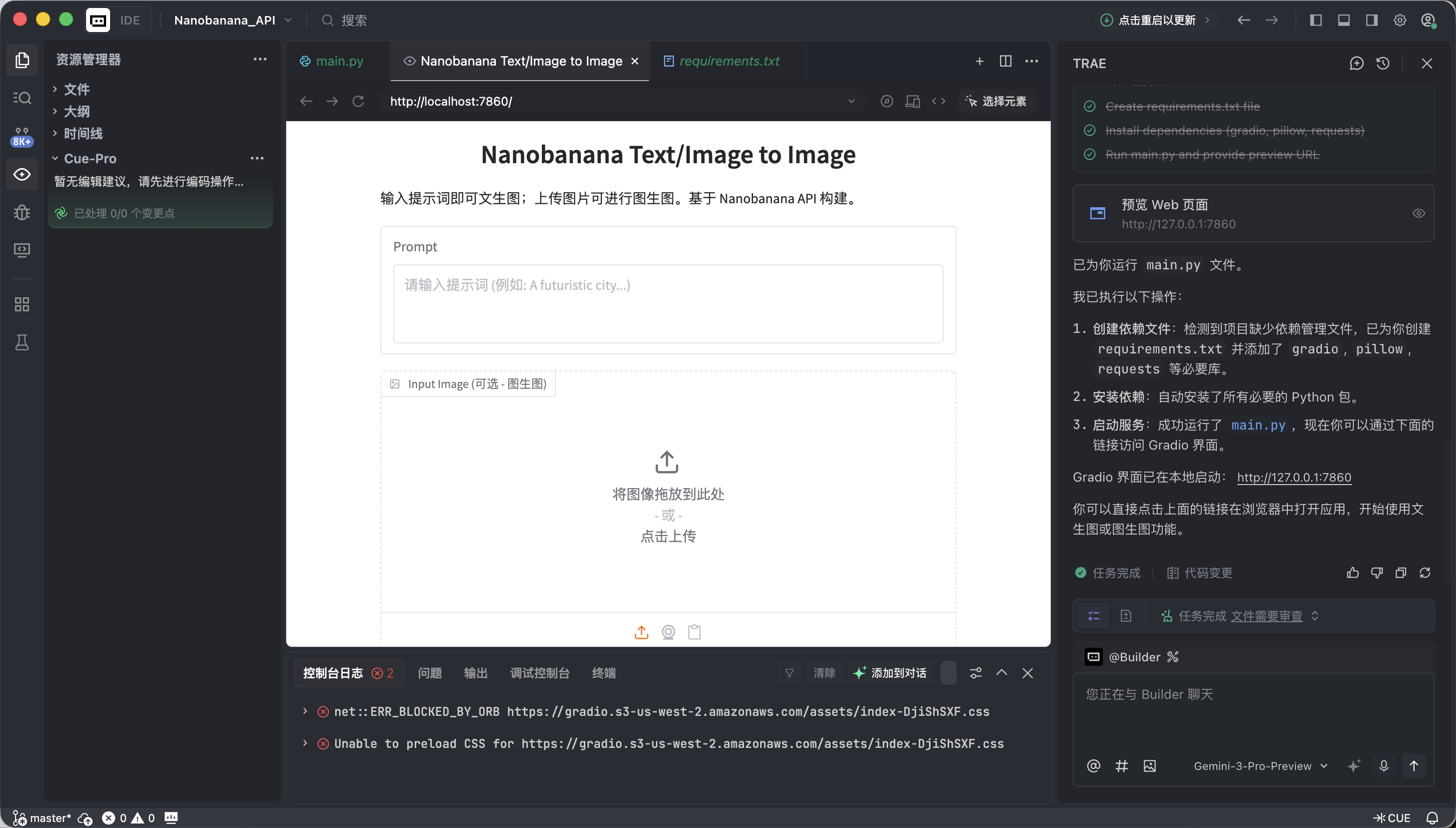
Wenn alles funktioniert, siehst du bereits eine funktionsfaehige KI-Zeichenoberflaeche.
Diese Oberflaeche sieht einfach aus, aber sie besitzt bereits die zwei wichtigsten Faehigkeiten von kommerziellen Zeichenwerkzeugen: Text-zu-Bild und Bild-zu-Bild.
- Links: Eingabebereich (Input Zone) -- Hier gibst du Anweisungen.
- Prompt (Eingabefeld): Gib deine kreative Beschreibung ein (Englisch empfohlen).
- Input Image (Referenzbildfeld):
- Text-zu-Bild-Modus: Hier leer lassen.
- Bild-zu-Bild-Modus: Ein lokales Bild hierher ziehen, die KI wird es als Grundlage fuer die Erstellung verwenden.
- Submit-Button: Klicken, um die Anweisung zu senden und die Generierung zu starten.
- Rechts: Anzeigebereich (Output Zone) -- Hier wird das Wunder sichtbar, die generierten Ergebnisse werden hier angezeigt.
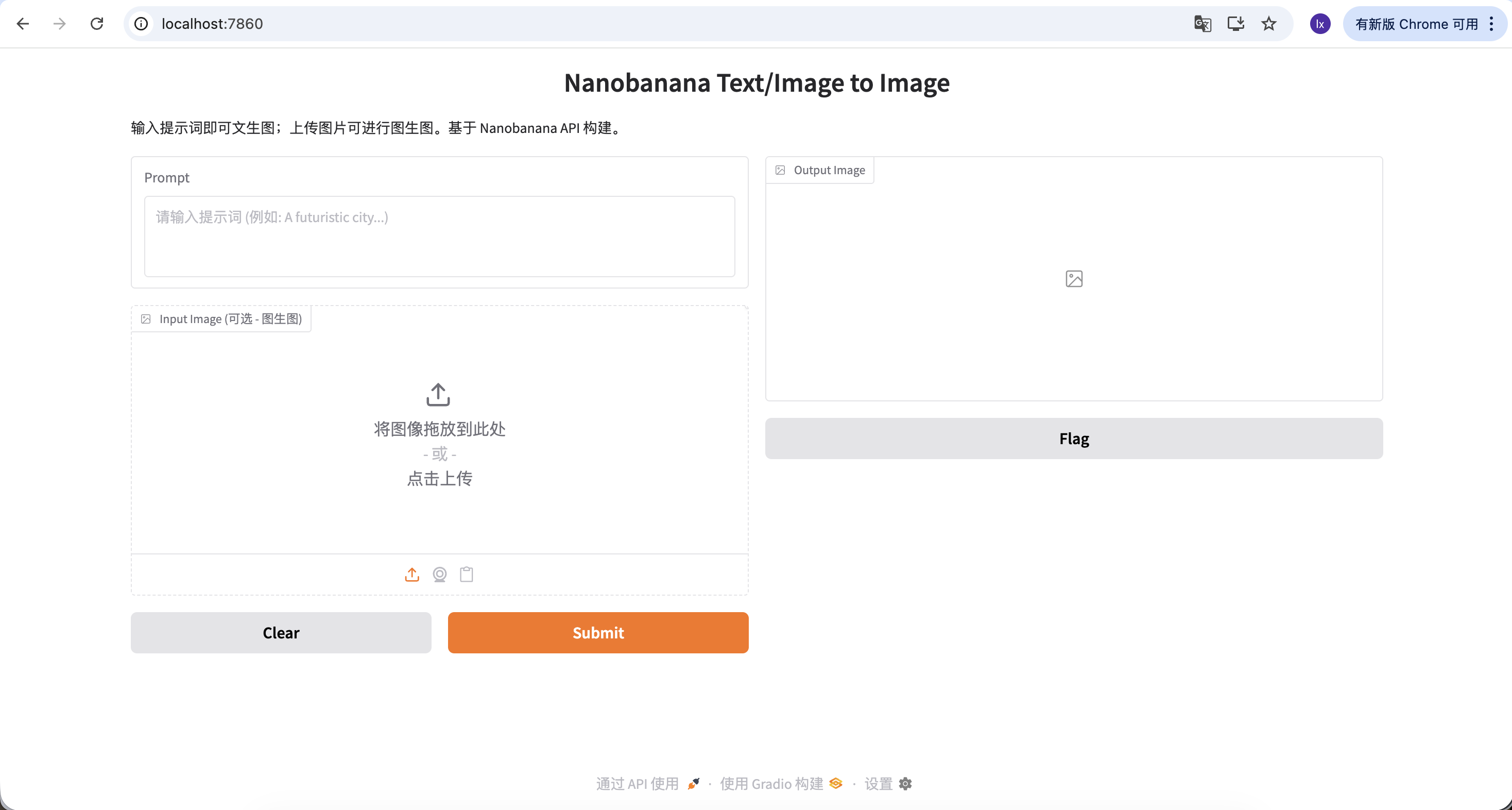
Jetzt koennen wir versuchen, dein erstes Bild zu generieren!
Der in diesem Beispiel verwendete Prompt lautet:
A red apple
Dies ist ein bewusst vereinfachtes Beispiel ohne Stil- oder Parameterbeschreibungen.
Tatsaechlicher Ablauf
Nach dem Ausfuehren des Codes kann der Prozess in drei Schritte zusammengefasst werden:
- Textbeschreibung an das Modell senden
- Modell generiert das entsprechende Bild
- Bild wird als lokale Datei gespeichert
Nach einigen Sekunden siehst du das generierte Ergebnis lokal. Da die Modellgenerierung zufaellig ist, werden gleiche Prompts unterschiedliche Ergebnisse liefern. Du kannst mehrmals generieren und dein bevorzugtes Bild auswaehlen.
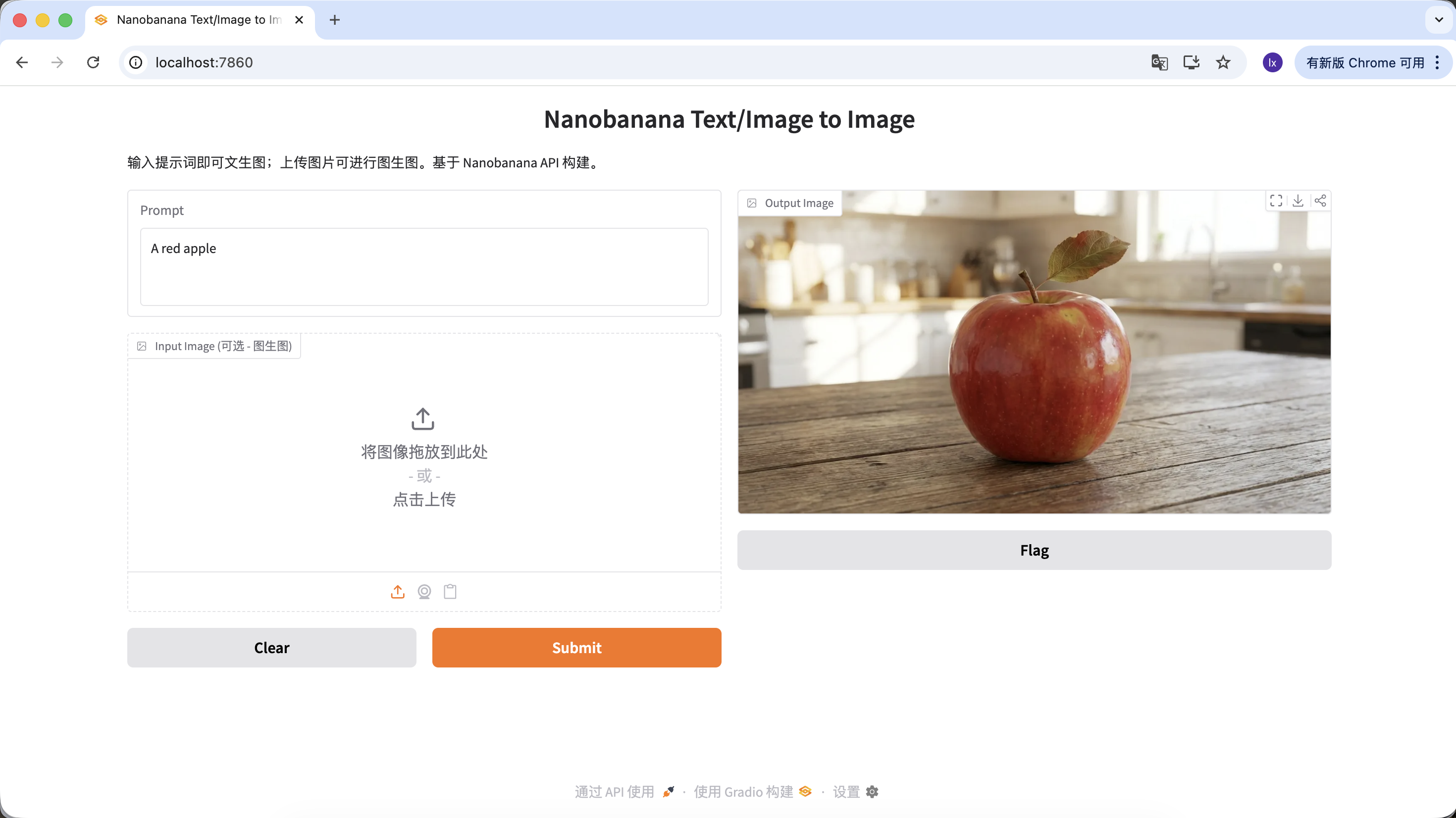
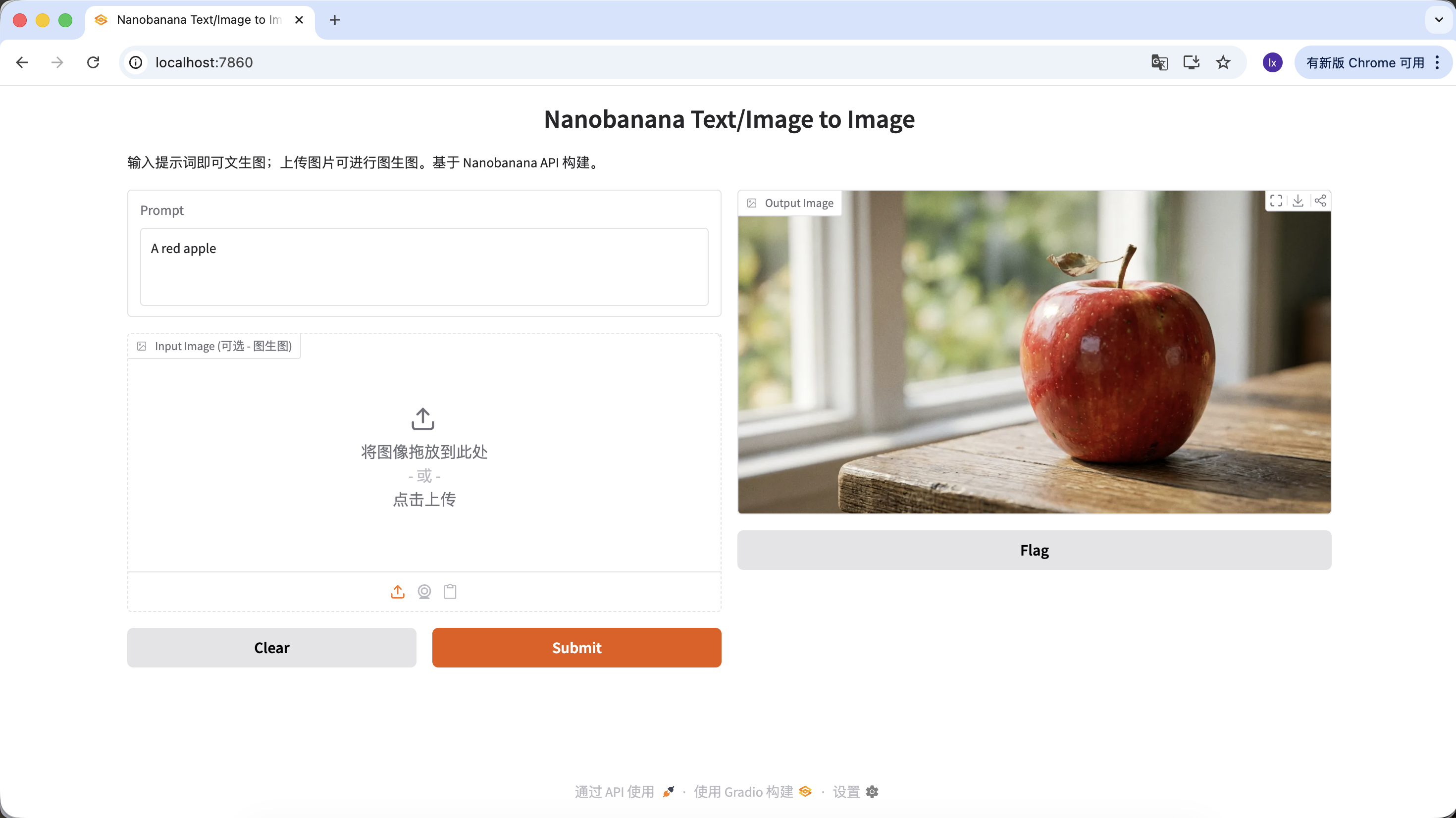
Du kannst auch deinen Prompt anreichern und ihm mehr Beschreibungen und Einschraenkungen geben. Mit dem folgenden Prompt wird das erhaltene Bild beispielsweise etwas besonderer.
"A hyper-realistic close-up of a fresh red apple with water droplets on its skin, sitting on a dark rustic wooden table. Cinematic dramatic lighting, rim light, shallow depth of field, bokeh background, 8k resolution, macro photography."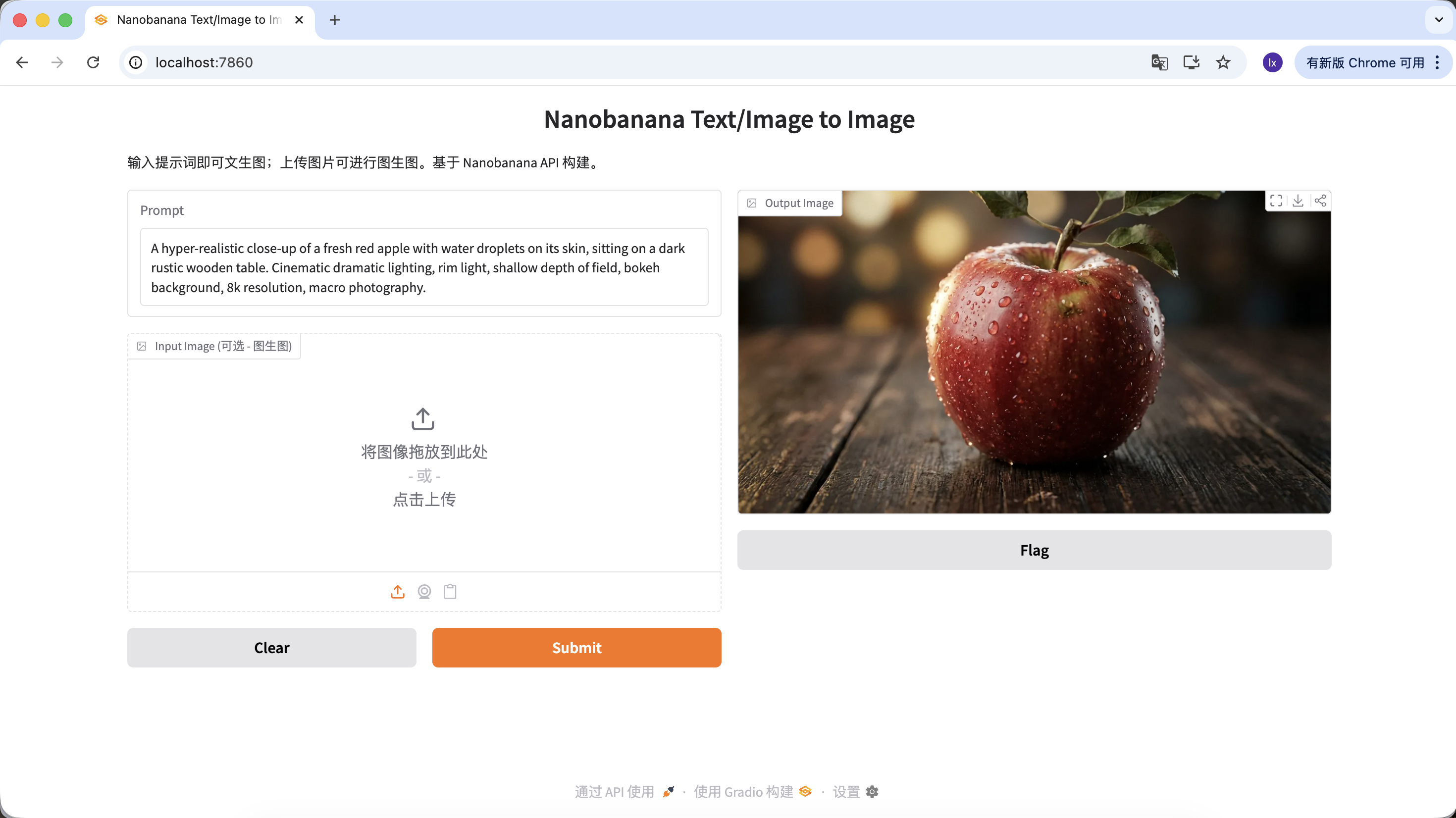
Klicke im Output Image-Bereich auf Herunterladen, um das Bild lokal zu speichern.
1.3 Haeufige Asset-Generierungsszenarien fuer Bildgenerierungsmodelle
In der praktischen Arbeit werden Grossmodelle eher zur effizienten Produktion von Design-Assets eingesetzt als zur Erstellung einzelner Kunstwerke.
Wenn du die beliebtesten Beitraege von Design-Marketing-Accounts betrachtest, wirst du feststellen, dass sich ihre Produktion hauptsaechlich auf zwei Arten von Szenarien konzentriert:
- Text-zu-Bild (von 0 auf 1)
- Bildreferenz-Generierung (von 1 auf N)
1. Text-zu-Bild: Design-Materialien schnell abrufen
Diese Art von Szenario fokussiert sich auf Effizienz. Wenn Luecken im Design gefuellt werden muessen (wie Leerrojekte, Avatare, Illustrationen), fungiert die KI im Wesentlichen als eine sofort generierende Bilddatenbank.
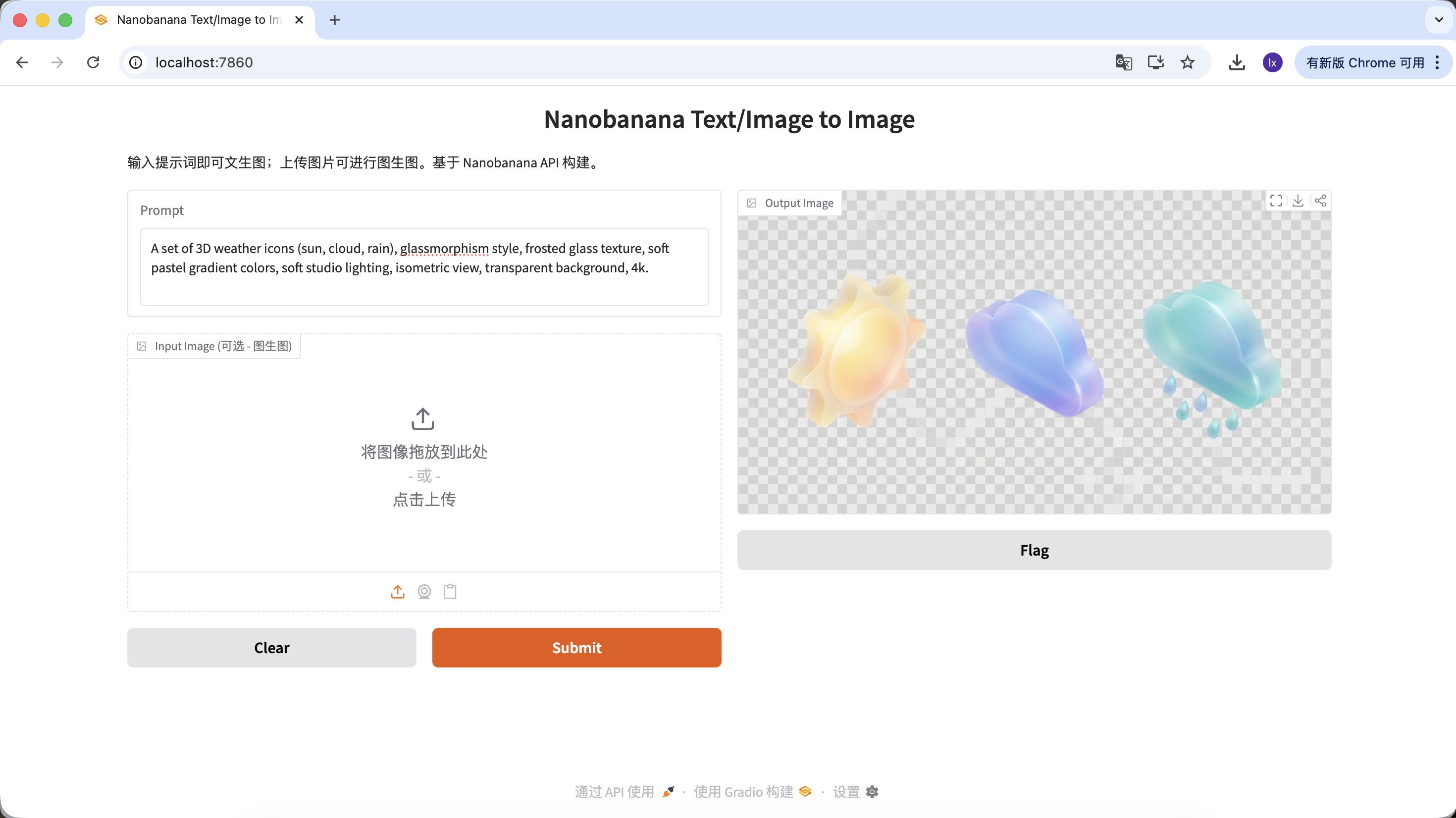
UI-Design-Materialien generieren
- Aktueller Trend: Glas-morphismus, Clay-Stil 3D-Icons auf Dribbble
- Haeufige Darstellung: Transparente Materialien, leuchtende Raender, Bonbon-farbene Funktions- oder Wetter-Icons
Beispiel-Prompt:
A set of 3D weather icons (sun, cloud, rain), glassmorphism style, frosted glass texture, soft pastel gradient colors, soft studio lighting, isometric view, transparent background, 4k.
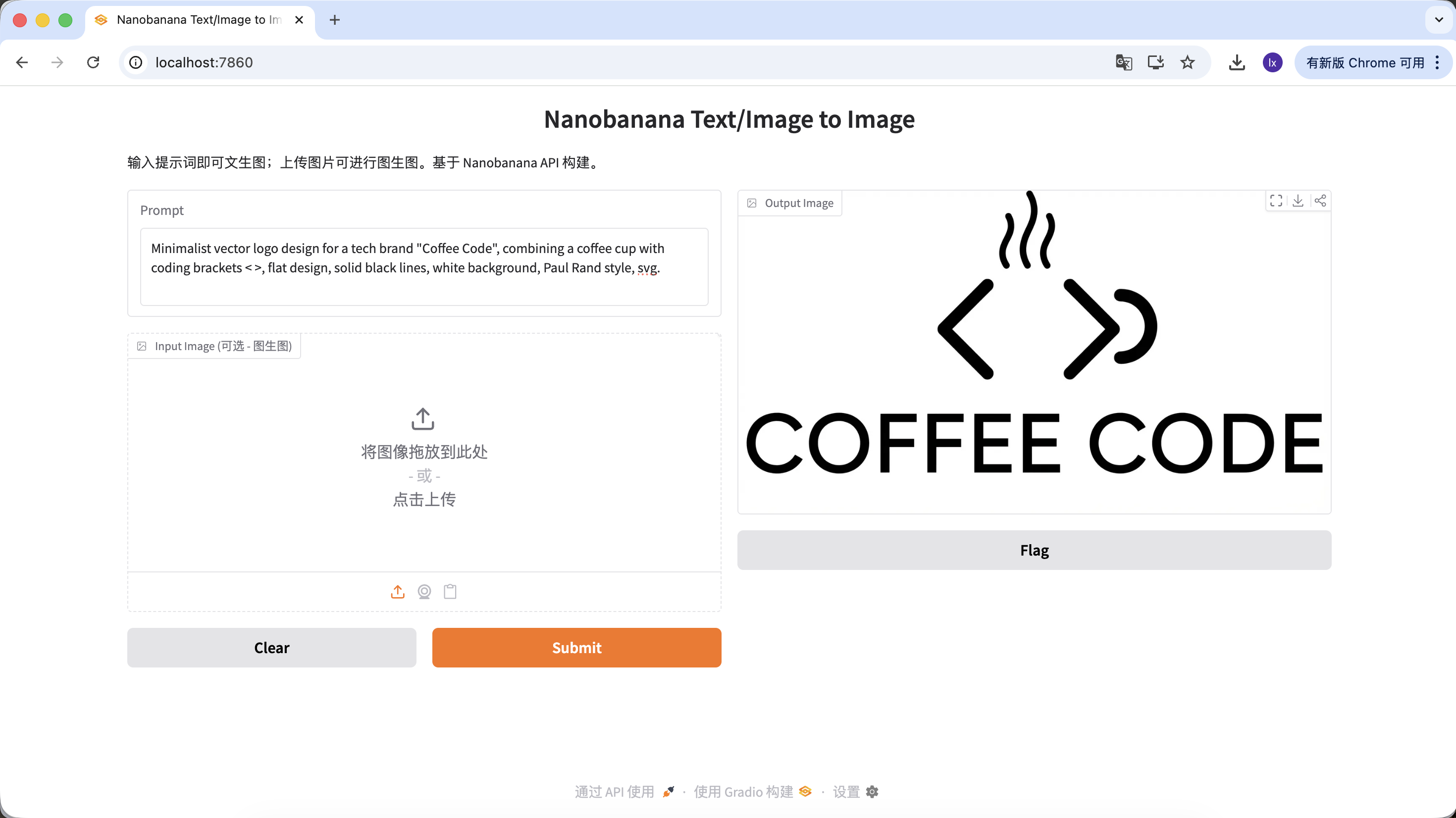
Logo generieren
- Aktueller Trend: Minimalistische Linien, geometrische Kombinationen fuer technologische Logos
- Haeufige Darstellung: Schwarz-Weiss-Farbgebung, Negativraum-Design, klares Branding
Beispiel-Prompt:
Minimalist vector logo design for a tech brand "Coffee Code", combining a coffee cup with coding brackets < >, flat design, solid black lines, white background, Paul Rand style, svg.
Benutzerbilder fuer die Website generieren
- Aktueller Trend: 3D-Virtual-Avatare auf SaaS-Websites, um Urheberrechtprobleme mit echten Personen zu vermeiden
- Haeufige Darstellung: Freundliche Ausdruecke, Cartoon-Proportionen, Pixar- oder Memoji-Stil
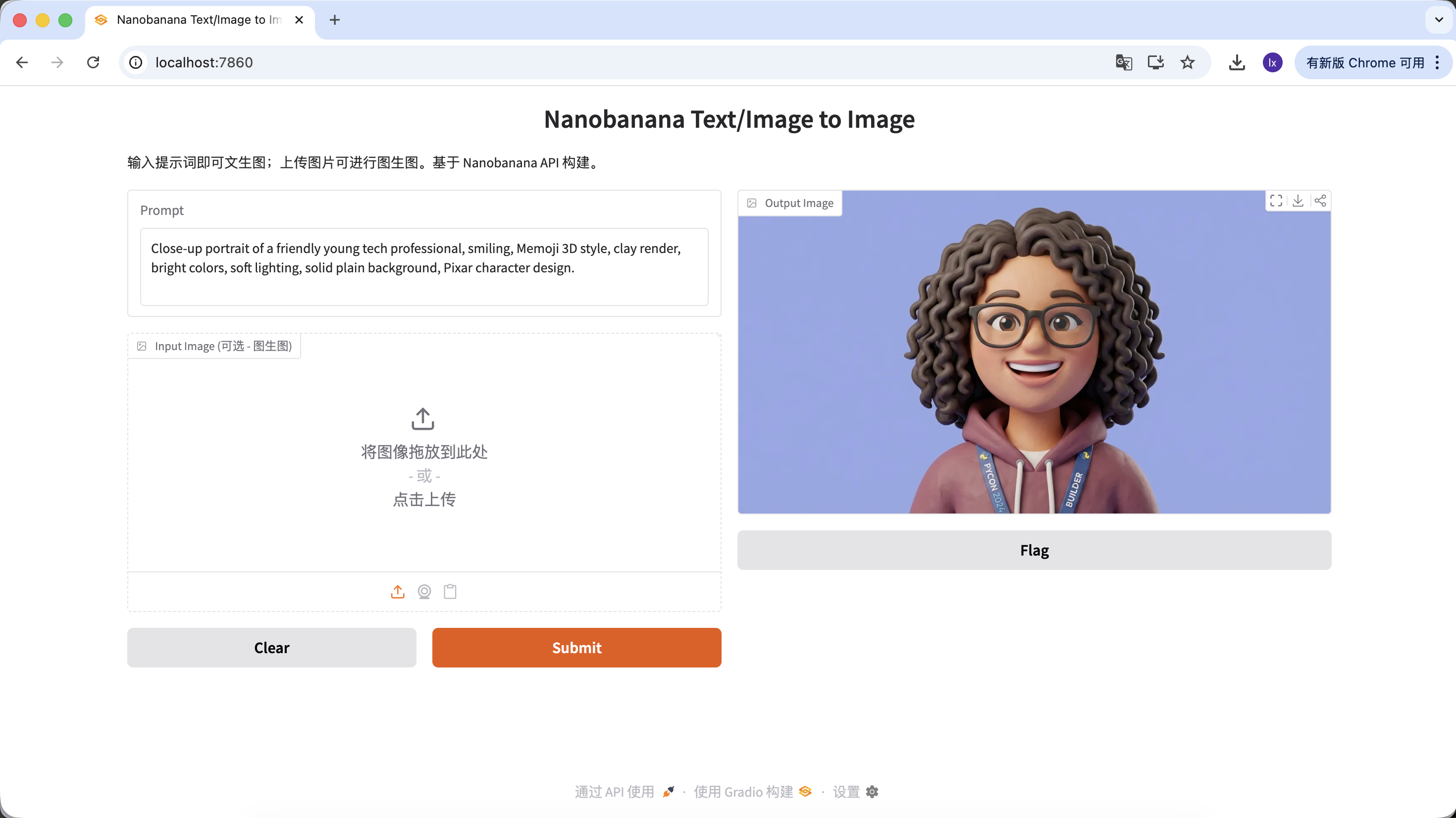
Beispiel-Prompt:
Close-up portrait of a friendly young tech professional, smiling, Memoji 3D style, clay render, bright colors, soft lighting, solid plain background, Pixar character design.
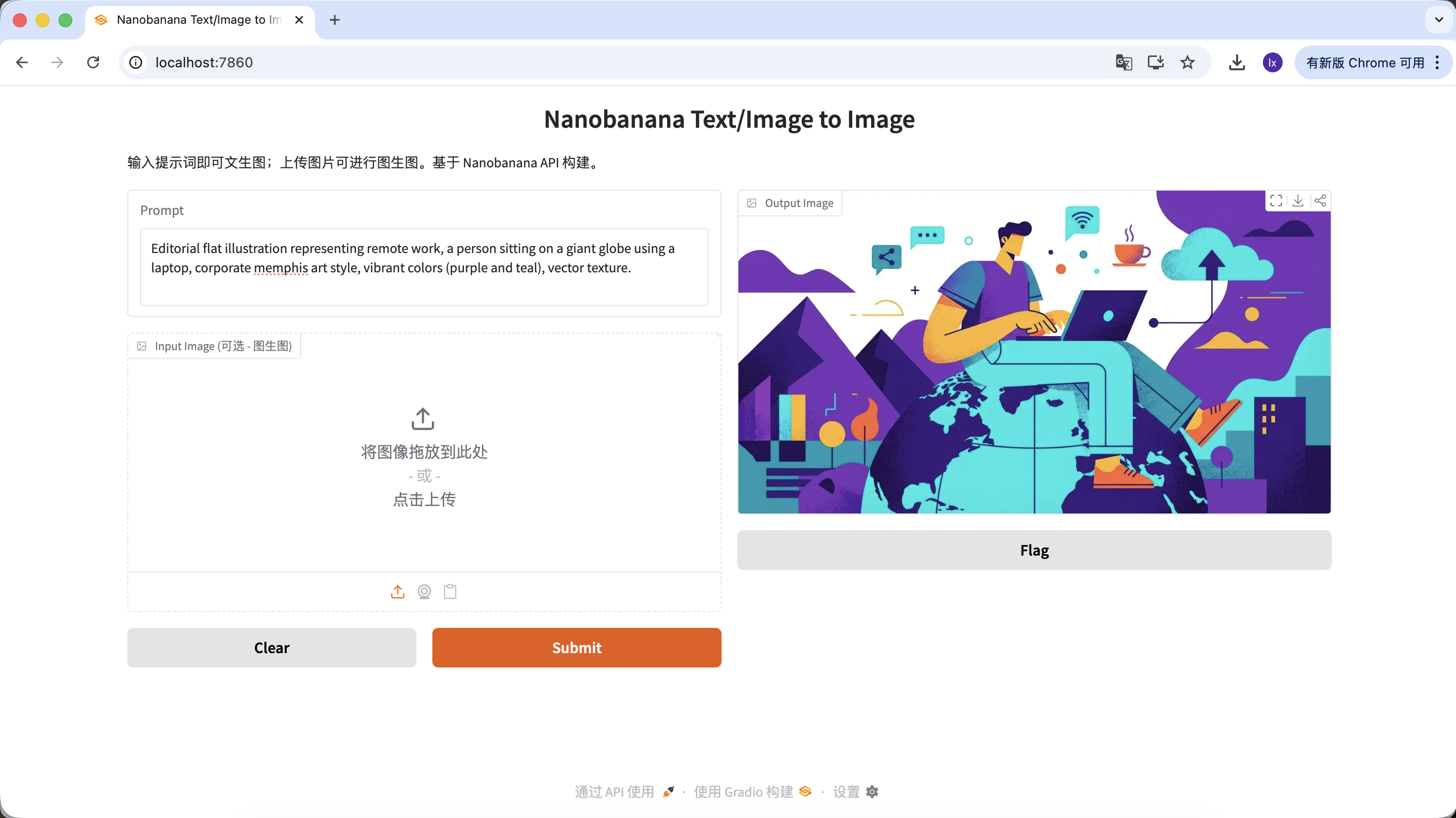
Artikelillustrationen generieren
- Aktueller Trend: Abstrakte flache Illustrationen, haeufig in Technologie-Unternehmensblogs
- Haeufige Darstellung: Lila-Blaue Farbgebung, uebertriebene Koerperproportionen, schwebende UI-Elemente
Beispiel-Prompt:
Editorial flat illustration representing remote work, a person sitting on a giant globe using a laptop, corporate memphis art style, vibrant colors (purple and teal), vector texture.
2. Bildreferenz-Generierung: Visuelle Konsistenz wahren
Diese Art von Szenario konzentriert sich mehr auf Skalierbarkeit. Wenn du bereits ein zufriedenstellendes Hauptvisual hast und einen ganzen Satz stilistisch einheitlicher Assets generieren musst.
Ein Satz von Buttons oder interaktiven Asset-Bildern im gleichen Stil wie das Hauptvisual
In der Spieleentwicklung ist die Konsistenz der UI sehr wichtig. Angenommen, du hast bereits den "PLAY"-Button des Hauptbildschirms und musst nun einen ganzen Satz stilistisch einheitlicher Funktions-Buttons erstellen (wie Pause, Einstellungen, Startseite). Nur durch manuelles Zeichnen ist es schwierig, die vollstaendige Konsistenz von Glanz, Perspektive und Farbwert jedes Buttons zu gewaehrleisten.
Grundlegender Arbeitsablauf:
- Das vorhandene blaue "PLAY"-Button-Bild speichern

- In den Input Image-Bereich der Oberflaeche ziehen, als Referenzvorlage fuer nachfolgende Generierungen
- Die Stilbeschreibung im Prompt beibehalten, nur den Hauptinhalt aendern
In diesem Arbeitsablauf kannst du durch einfaches Ersetzen der Hauptbeschreibung verschiedene, aber stilistisch konsistente Buttons erhalten.
Beispiel-Prompt:
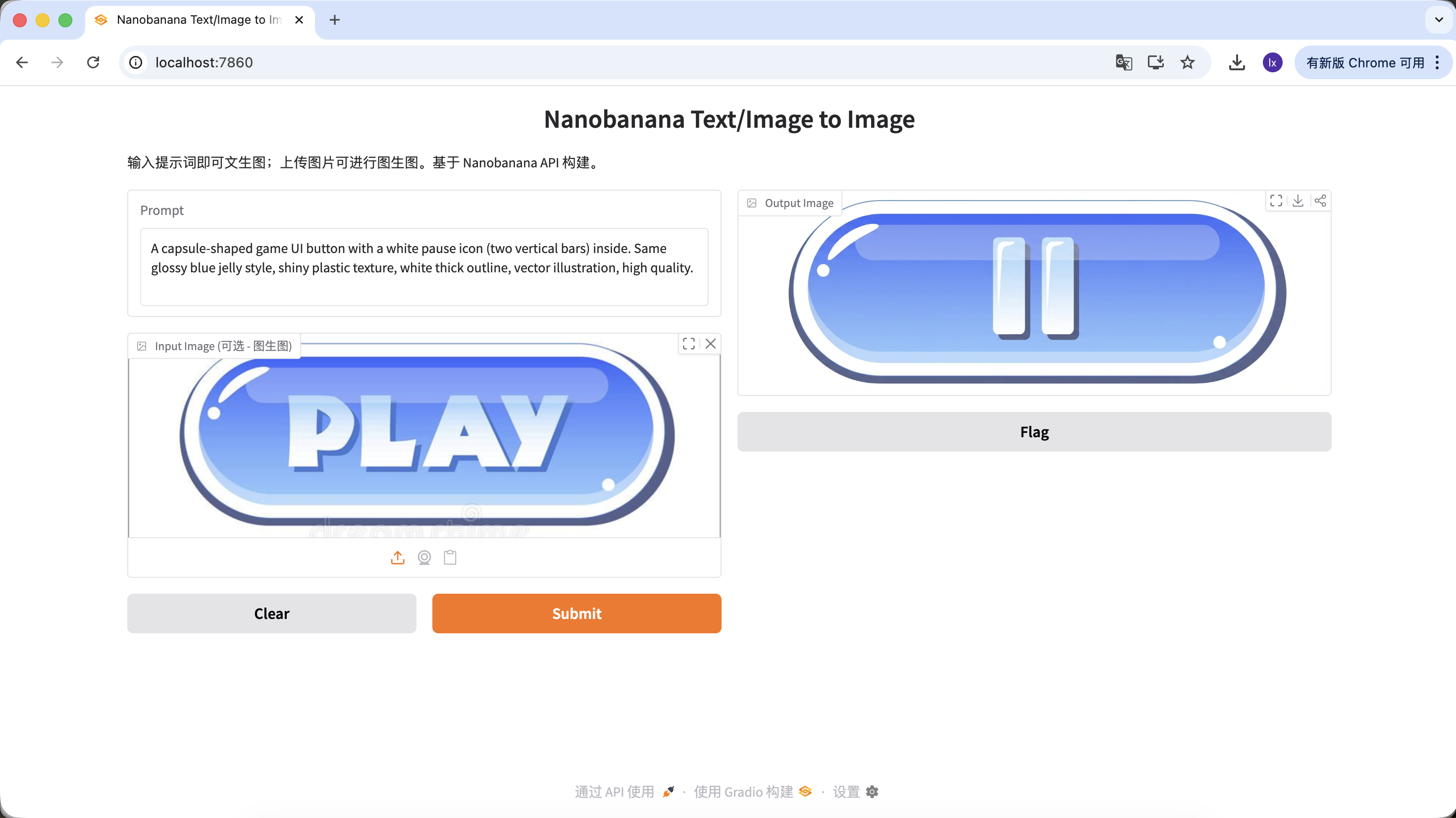
Variante A: Pause-Button (Symboltyp)
A capsule-shaped game UI button with a white pause icon (two vertical bars) inside. Same glossy blue jelly style, shiny plastic texture, white thick outline, vector illustration, high quality.
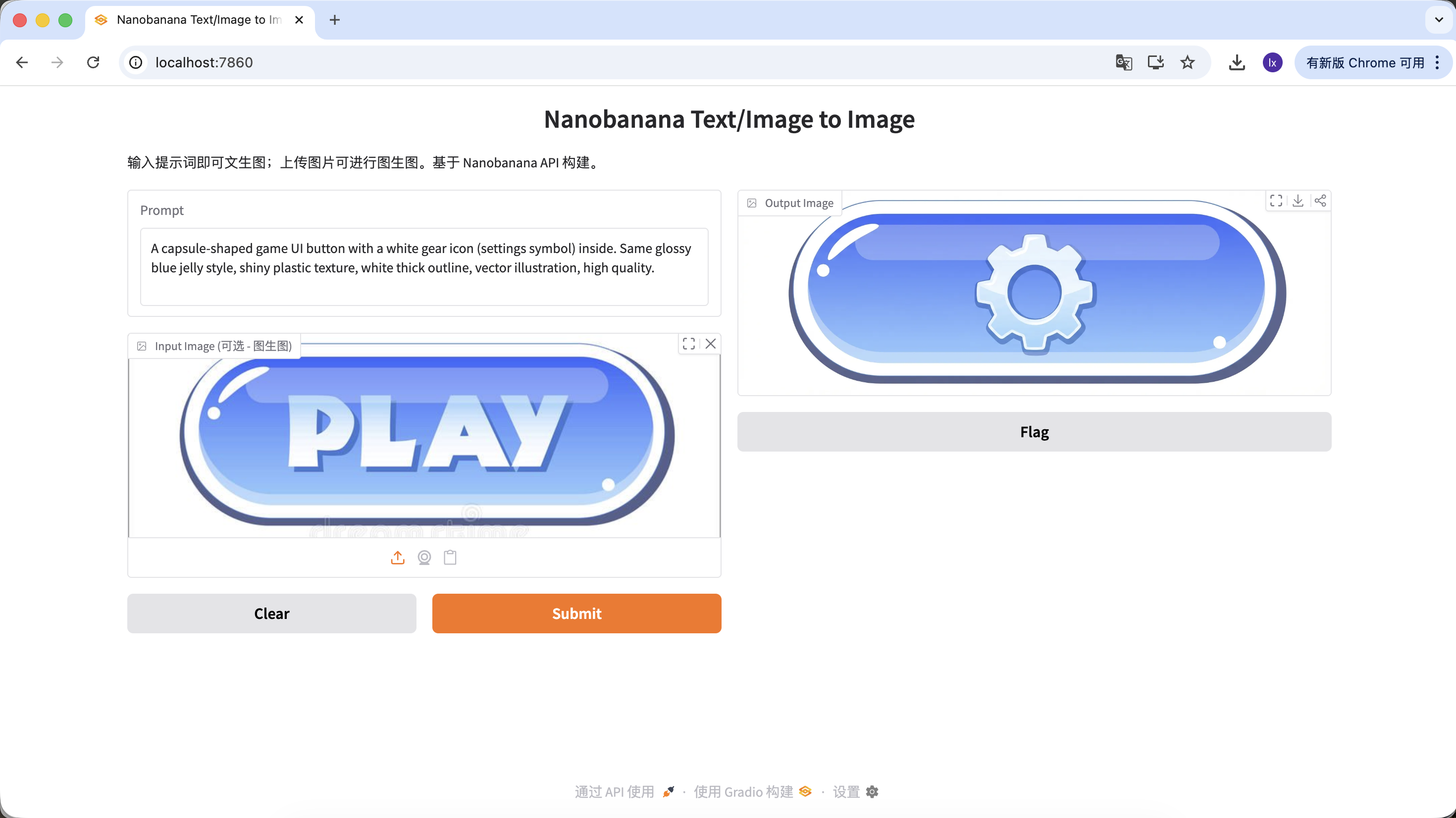
Variante B: Einstellungs-Button (komplexes Symbol)
A capsule-shaped game UI button with a white gear icon (settings symbol) inside. Same glossy blue jelly style, shiny plastic texture, white thick outline, vector illustration, high quality.
Variante C: Replay-Button (Formaenderung)
Wenn du die Button-Form anpassen moechtest, kannst du die Form direkt im Prompt beschreiben, und das Modell wird versuchen, die Struktur zu aendern, während die Materialeigenschaften beibehalten werden.
A round game UI button with a white circular arrow icon (replay symbol) inside. Same glossy blue jelly style, shiny plastic texture, white thick outline, vector illustration, high quality.

Durch diese Reihe von Operationen koennen nicht nur Button-Funktion und Symbol ersetzt, sondern sogar die Button-Form geaendert werden, wobei alle generierten Ergebnisse in Material, Farbgebung und Licht/Schatten hochgradig konsistent bleiben. Dies ist der Kernwert von Grossmodellen in Szenarien der Design-Asset-Vervielfaeltigung.
Kapitel 2: Ein gehorsameres Bildgenerierungs-Assistent -- Am Beispiel von Lovart
Im ersten Teil haben wir NanoBanana direkt ueber Code aufgerufen und den grundlegenden Prozess "Eingabe gleich Generierung" erlebt. Diese Methode funktioniert gut bei einfachen Anforderungen. Wenn die Generierungsaufgabe jedoch mehr Einschraenkungen enthaelt, wie zum Beispiel:
- Mehrere stilistisch konsistente Bilder erforderlich
- Mehrfache Anpassungen an vorhandenen Ergebnissen noetig
- Dynamische Aenderung der Generierungsrichtung basierend auf Benutzereingabe
wird die Einzelaufruf-Methode allmaehlich unzureichend.
Hier muss ein AI Agent (intelligenter Agent) eingefuehrt werden. Dieser Abschnitt zeigt am Beispiel von Lovart, wie sich der gesamte Workflow veraendert, wenn dem Bildgenerierungsmodell eine "Denkschicht" hinzugefuegt wird. Hinweis! Hier geht es nicht um Werbung, sondern nur darum, die Bequemlichkeit von AI-Agenten schnell zu vermitteln~
2.0 Lovart kennenlernen: Dein KI-Design-Agent
Lovart ist ein agentenbasiertes Design-Tool im Web. Im Vergleich zu normalen Bildgenerierungstools hat es vor der Generierung eine zusaetzliche "Denk- und Planungsschicht".
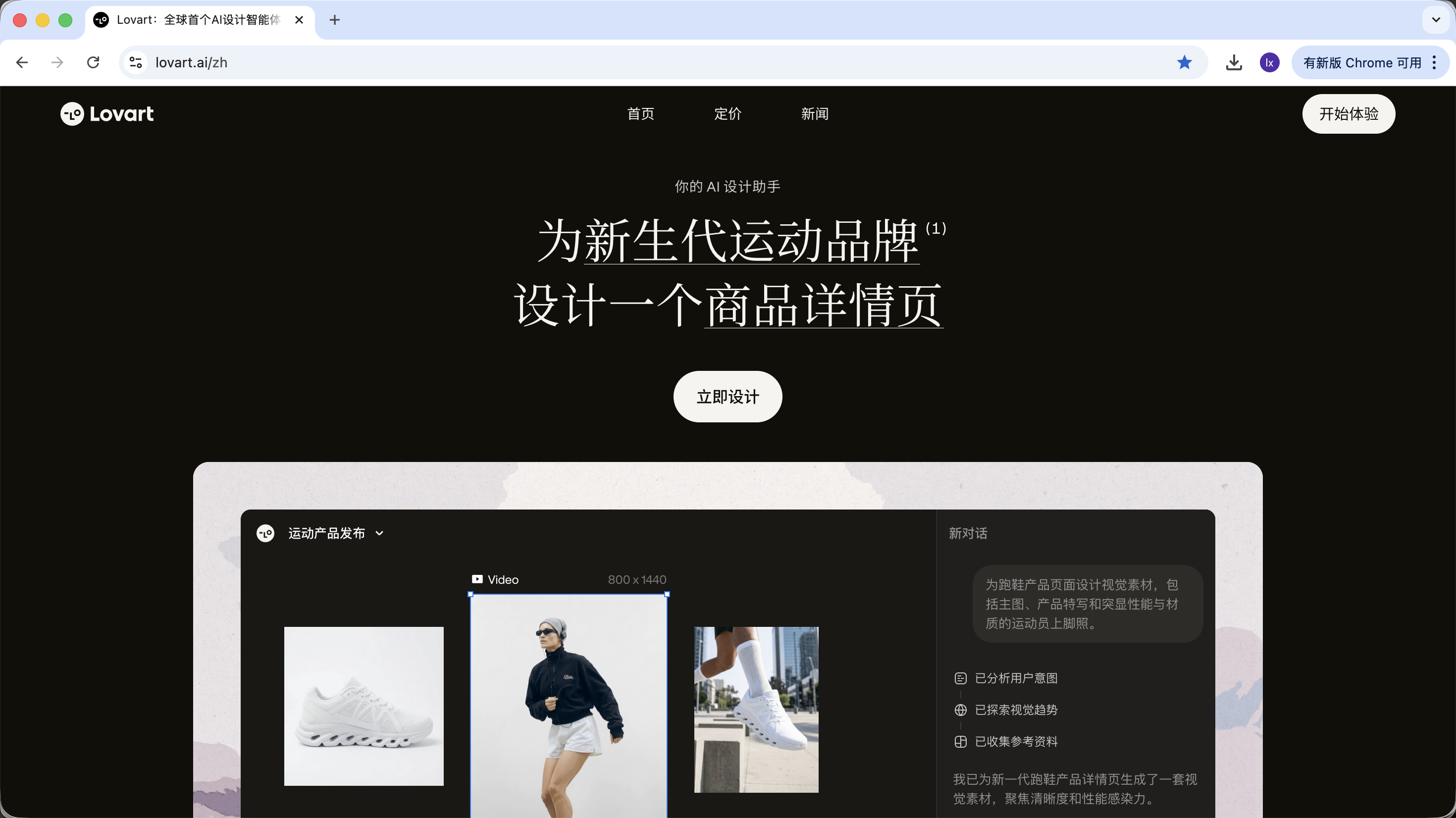
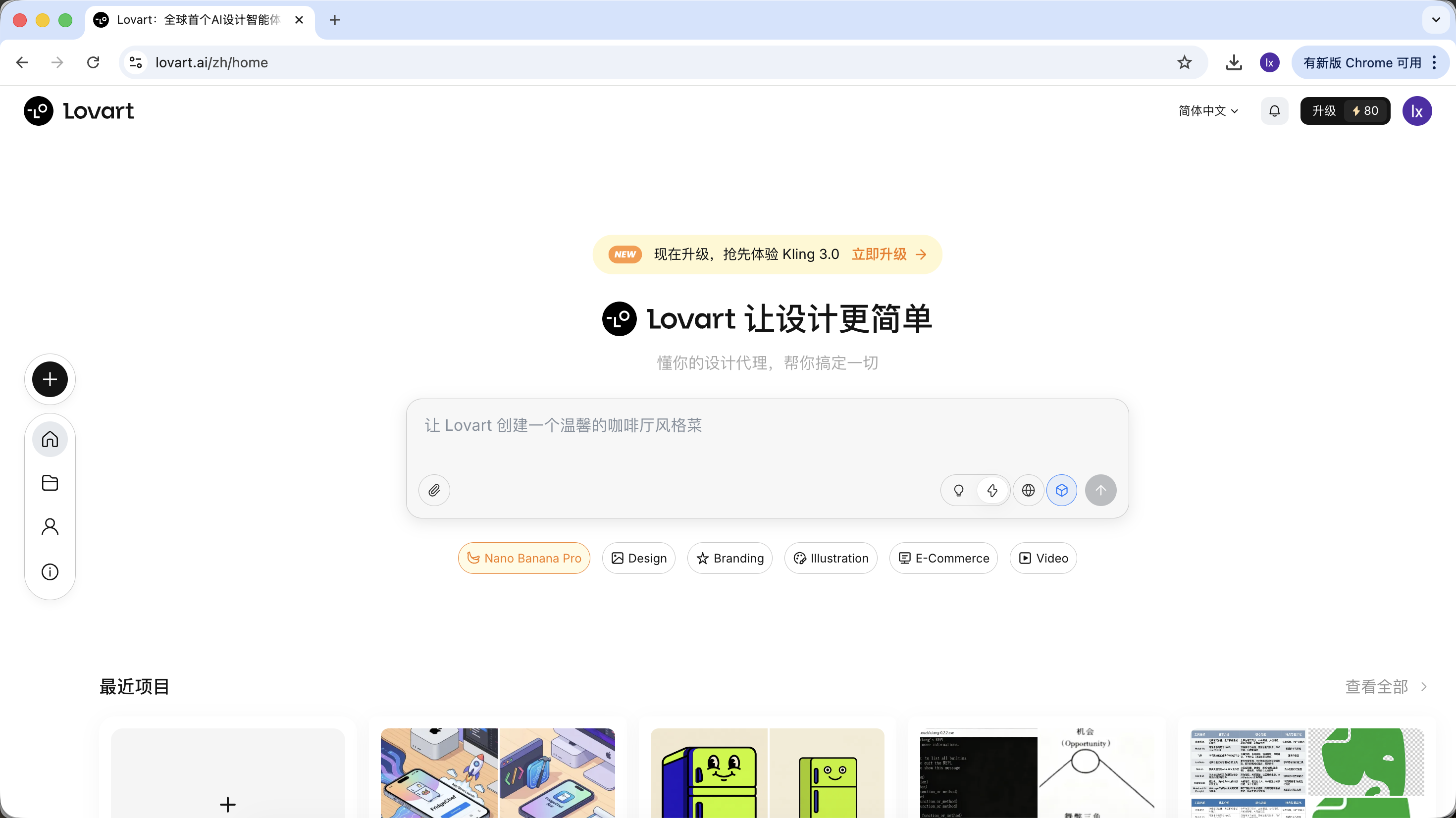
Nach dem Einloggen bei Lovart musst du hauptsaechlich die folgenden Steuerungselemente kennenlernen:
Modellauswahl
Klicke auf das Wuerfel-Symbol unterhalb des Eingabefelds, um die aktuell verfuegbaren Generierungsmodelle (wie GPT Image, Flux etc.) anzuzeigen.
Um mit dem vorherigen Beispiel konsistent zu bleiben, verwendet dieser Abschnitt weiterhin NanoBanana als zugrundeliegendes Generierungsmodell.
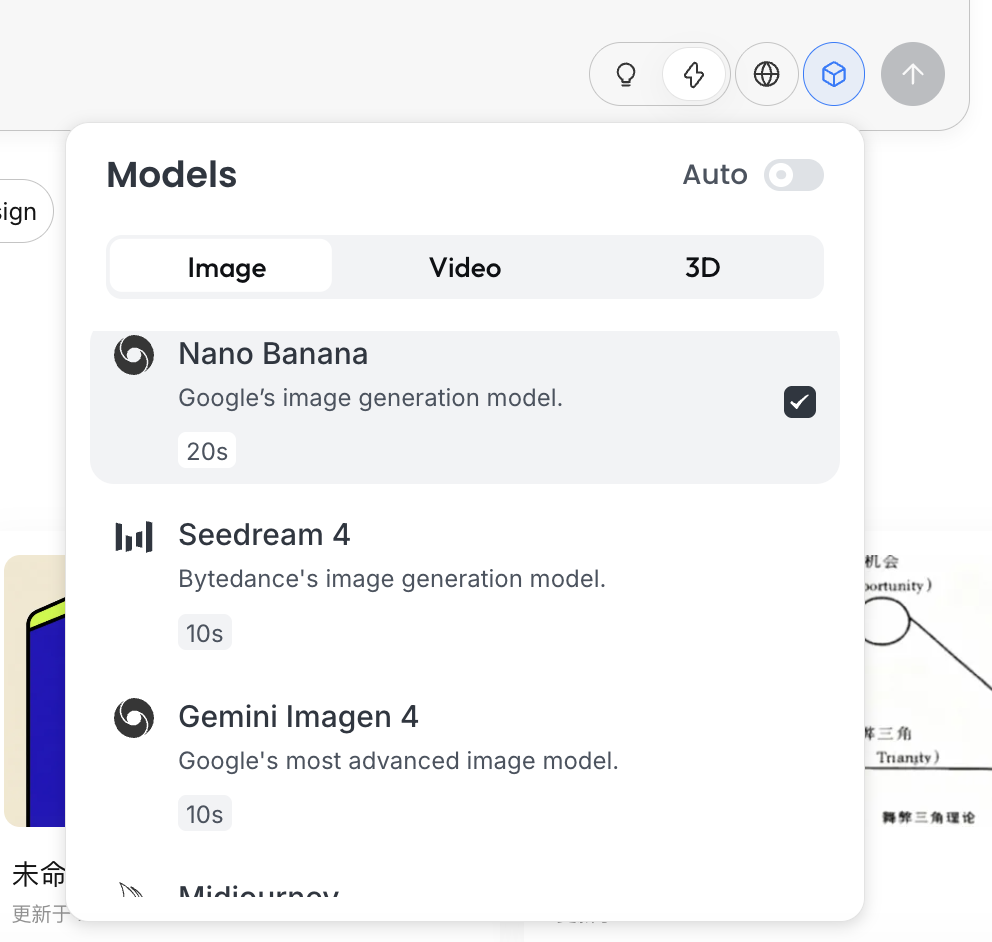
Denkmodus
Dies ist der Kern-Schalter von Lovart:
- Fast Mode: Nahe an nativer API, schnelle Antwort, geeignet fuer Einzel-, klar formulierte Generierungen
- Thinking Mode: Agent-Modus, die KI analysiert zuerst die Anforderungen, schreibt den Prompt um und fuehrt dann die Generierung aus
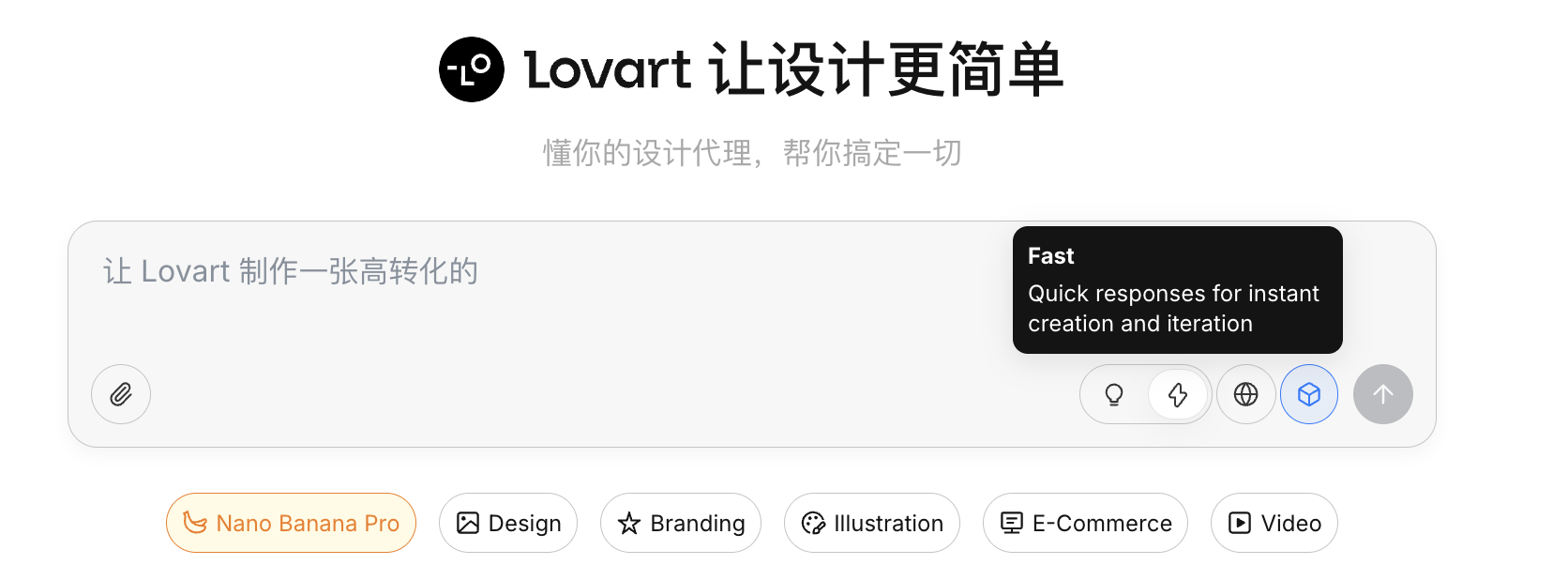
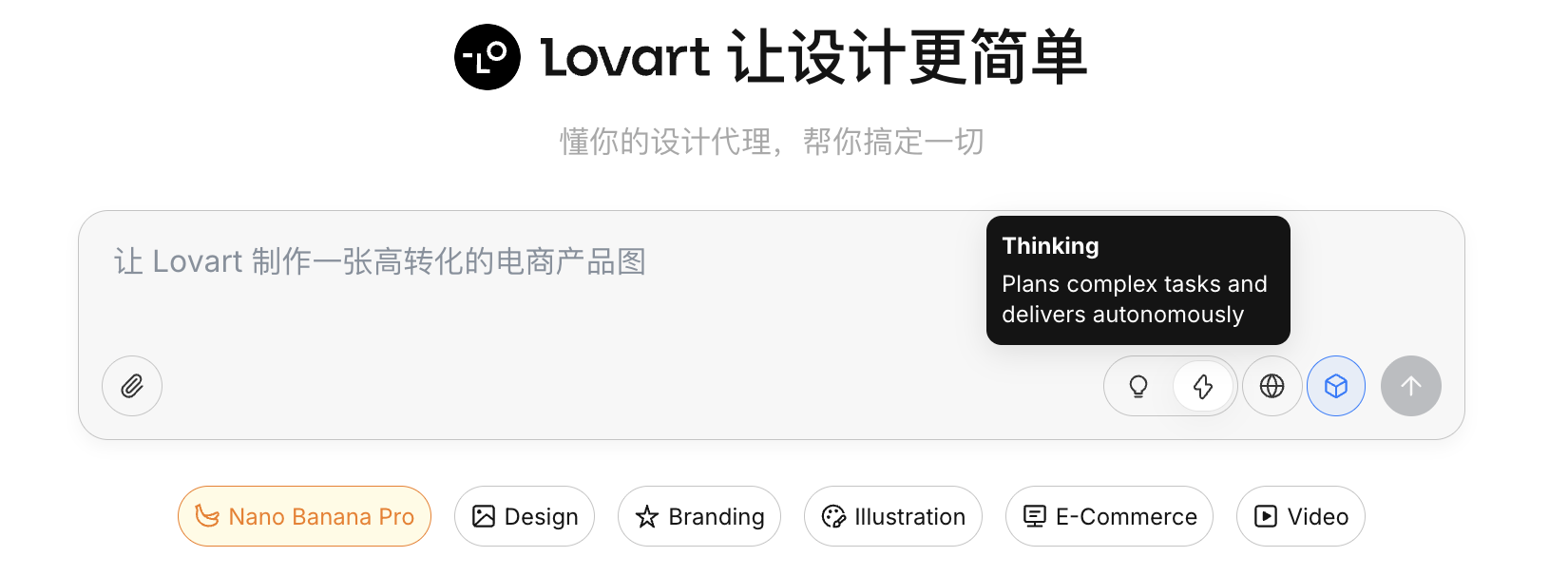
Internet-Faehigkeit
Nach Aktivierung des Globus-Symbols kann der Agent waehrend der Generierung Web-Informationen abrufen (z.B. Designtrends, Farbschemata) als zusatzliche Eingabe.
2.1 Warum die native API nicht ausreicht?
Auch wenn du bereits ueber Python qualitativ hochwertige Bilder generieren kannst, gibt es weiterhin Einschraenkungen der nativen API bei komplexen Aufgaben. Der Hauptgrund dafuer ist: Die native API ist im Wesentlichen imperativ. Wenn du sie aufforderst, ein bestimmtes Objekt zu generieren, kann sie es direkt ausfuehren; aber wenn die Eingabe zu "einem vollstaendigen Satz von Spiel-Assets planen" wird, wird sie das Ziel nicht aktiv in mehrere ausfuehrbare Schritte aufteilen.
Der Kernunterschied von Lovart liegt im Agent-Mechanismus. Zwischen der Benutzereingabe und dem Bildgenerierungsmodell fuegt es eine Logik-Schicht zum Verstehen und Planen hinzu: Zunaechst die Benutzerabsicht erkennen, dann die Aufgabe aufteilen, den Prompt umschreiben und schliesslich die Generierung ausfuehren.
2.2 Praxisdemonstration: In 5 Minuten einen IP-Sticker-Satz erstellen
Am Beispiel von "Einen IP-Sticker-Satz fuer Programmierer-Enten erstellen" sehen wir, wie der Agent am gesamten Prozess teilnimmt.
Phase 1: Planung (Die Denkfaehigkeit des Agenten)
Problem der nativen API: Du musst selbst das Charakterdesign, emotionale Zustaende denken und fuer jedes Bild einen separaten Prompt schreiben.
Lovarts Vorgehen:
- Den Thinking Mode aktivieren
- Eine Anweisung eingeben:
Entwirf einen IP-Sticker-Satz fuer Programmierer-Enten im flachen, niedlichen Stil
Die KI wird nicht sofort zeichnen, sondern zuerst im Internet nach aehnlichen Programmierer-Enten-Designs suchen. Sie gibt eine analysierte Loesung aus, generiert automatisch Szenarien wie Debug, Coffee Break, Panic und erstellt entsprechende visuelle Beschreibungen.
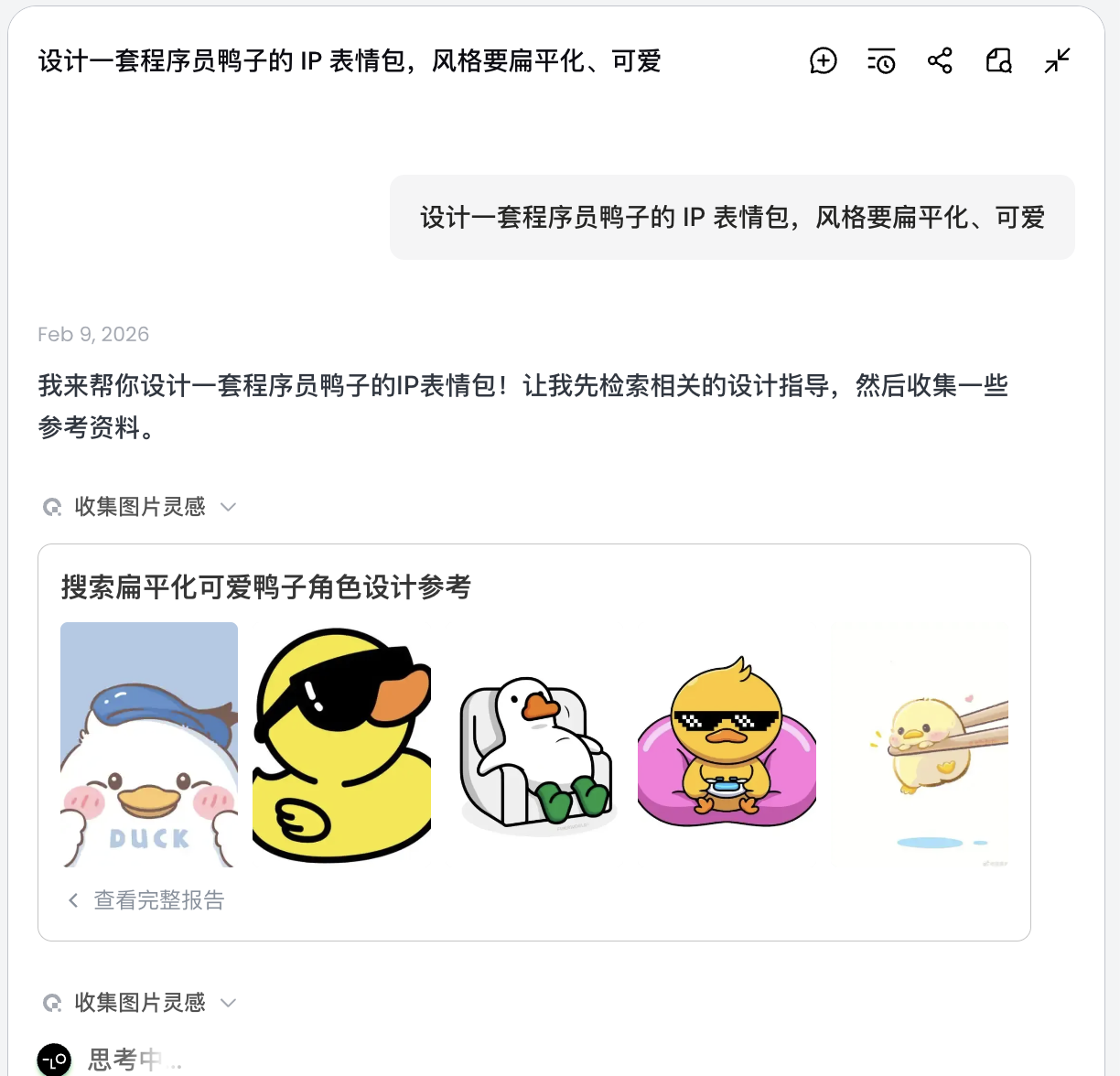

In diesem Schritt wechselt die KI von der "Ausfuehrerin" zur "Planerin". Nachdem die KI deine Anforderungen analysiert hat, kannst du im Lovart-Canvas-Bereich verschiedene Stile und Inhalte von Programmierer-Enten-Bildern sehen. Du kannst beginnen, deinen bevorzugten Stil auszuwaehlen.
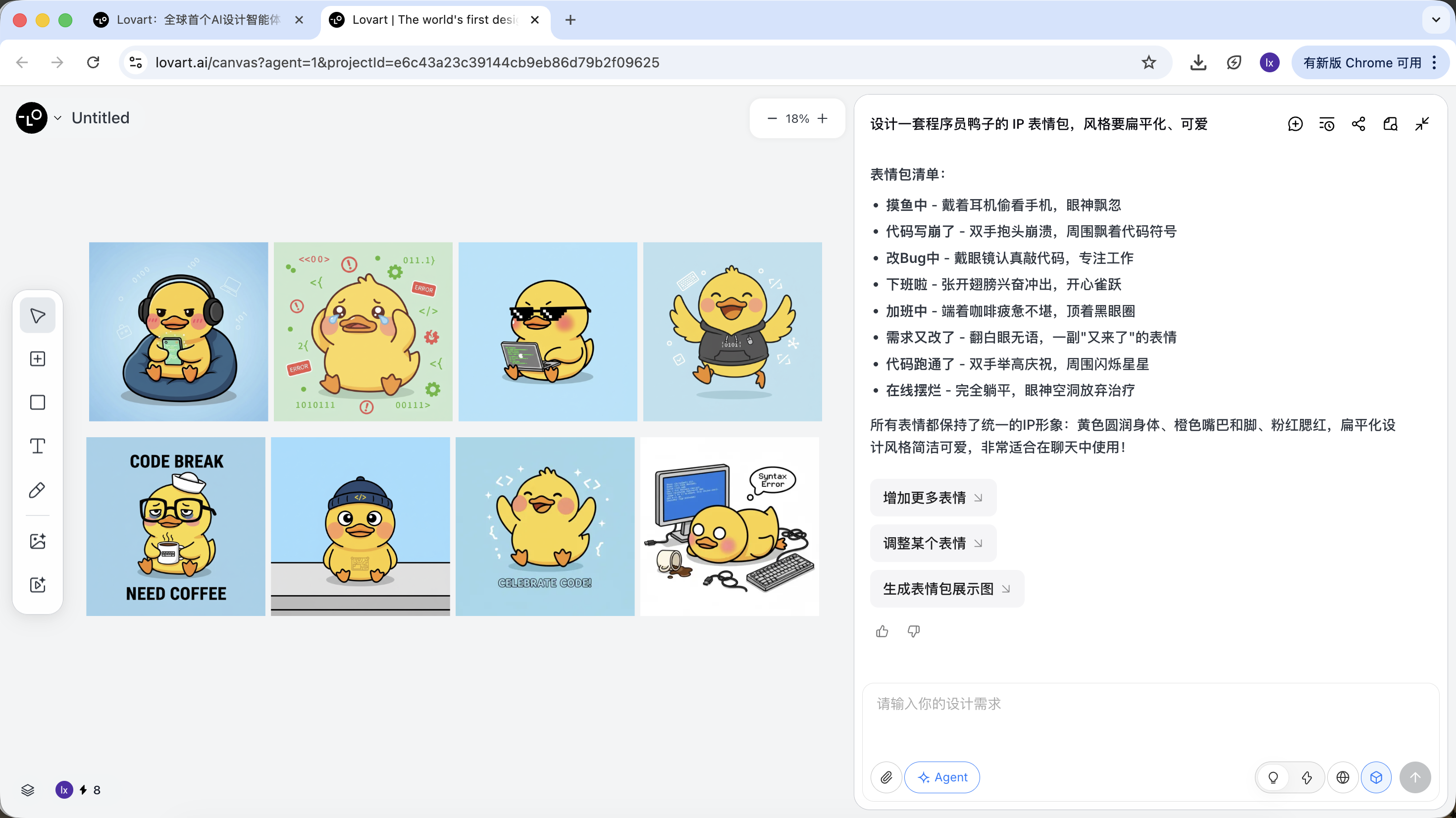
Phase 2: Konsistenz (Referenzbasierte visuelle Verankerung)
Bilder in Lovart sind nicht nur Ergebnisse, sondern nehmen auch an nachfolgenden Generierungen teil.
Vollstaendiges Referenzbild
- Waehle aus den Skizzen die zufriedenstellendste "Standard-Ente" und klicke auf das entsprechende Bild im Canvas-Bereich
- Das Bild wird automatisch im Chat-Bereich als Referenz angezeigt
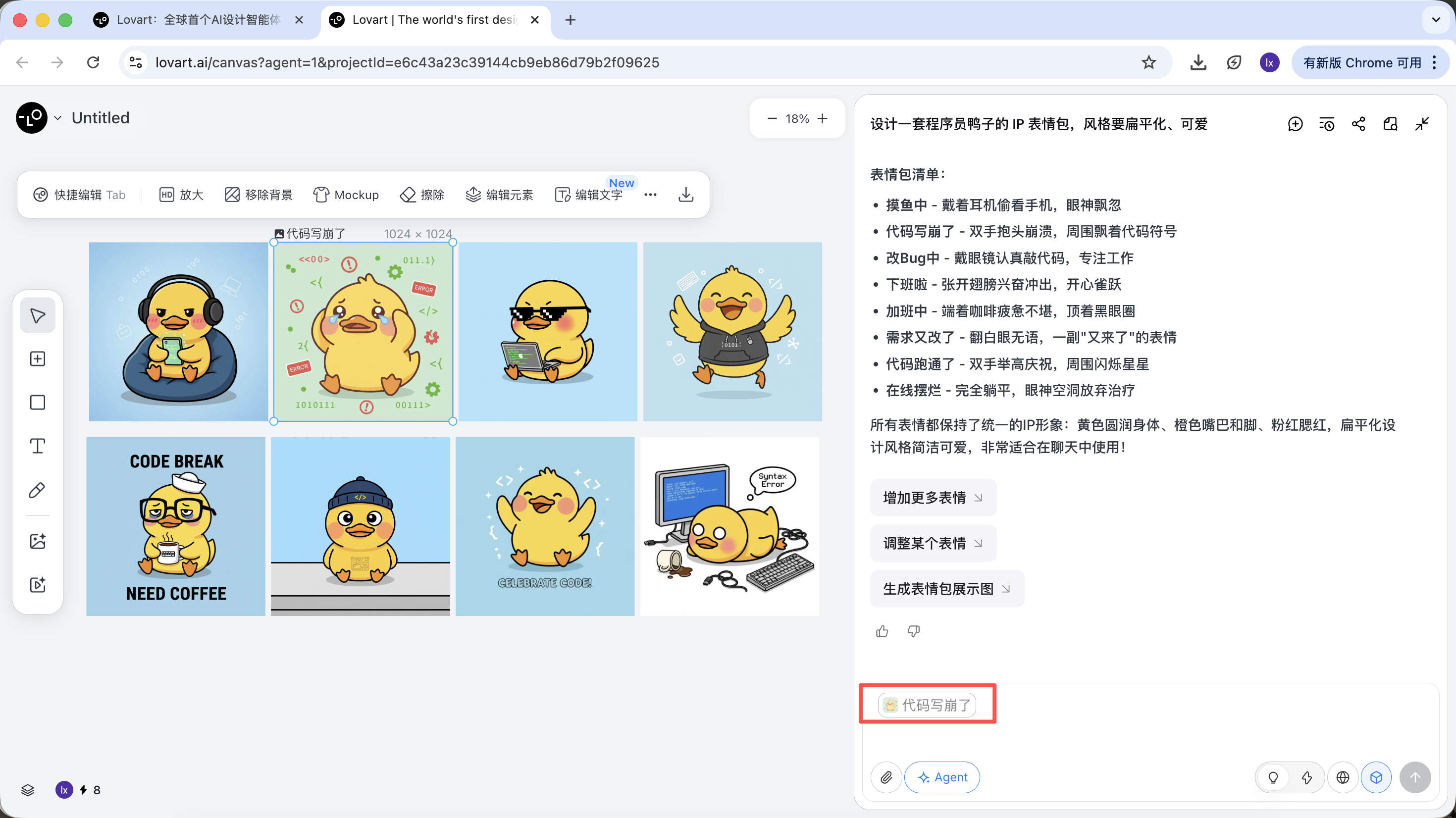
- Neue Aktion eingeben (z.B. gluecklich) und generieren
Das generierte Ergebnis erbt Farbgebung, Proportionen und Details der Vorlage.
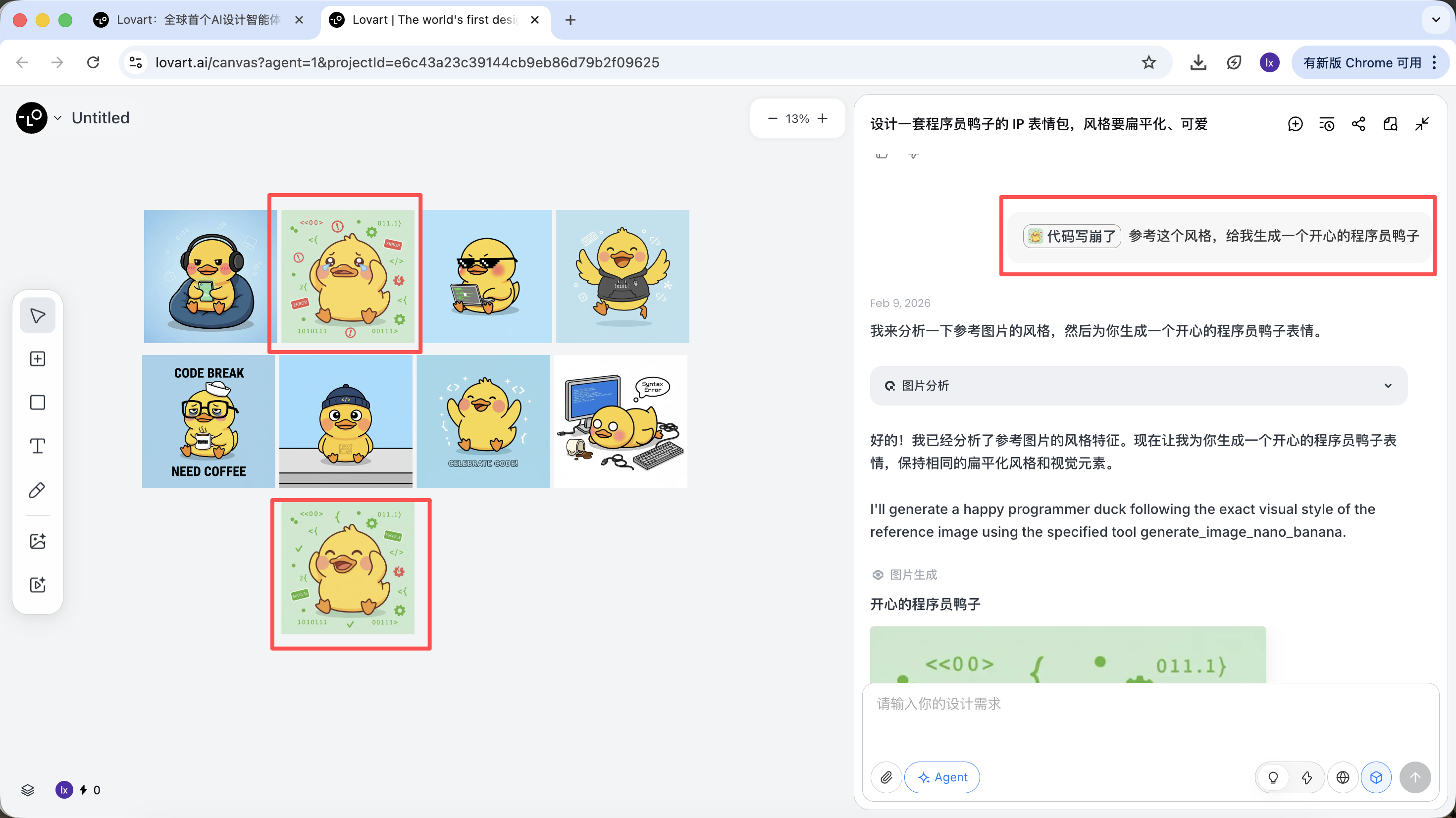
Teilreferenz / Multi-Bild-Integration
Zusaetzlich zur Verwendung eines ganzen Bildes als Referenz unterstuetzt Lovart auch:
- Nur einen Teilbereich des Bildes auswaehlen (z.B. nur den Hut oder Ausdruck referenzieren)
Klicke auf den linken Tab im Canvas-Bereich, waehle "Mark" und markiere den Teilbereich des Zielbildes. Dieser Inhalt wird automatisch in das Chat-Feld synchronisiert. Hier koennen wir z.B. die Hintergrundfarbe aendern.
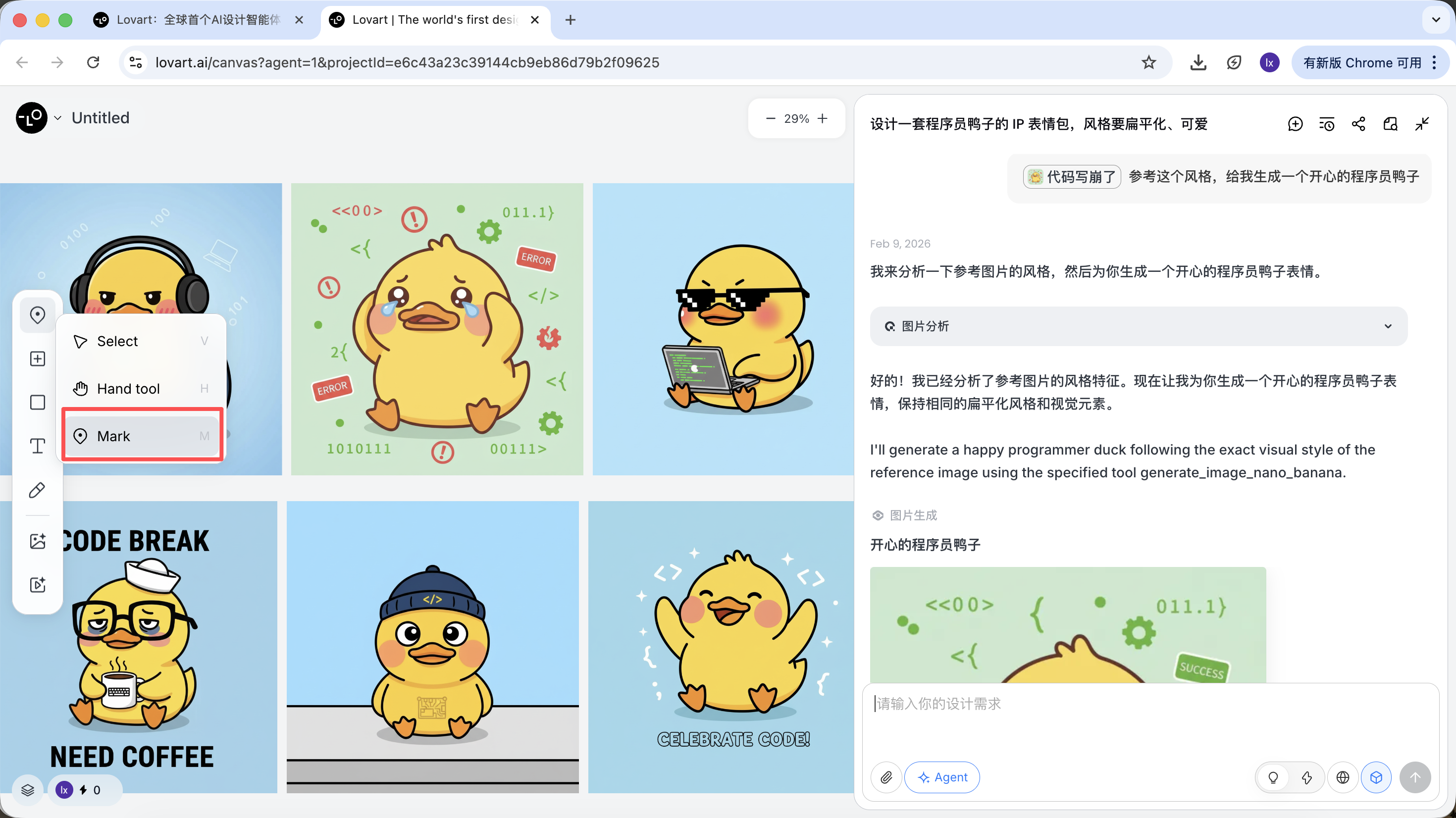
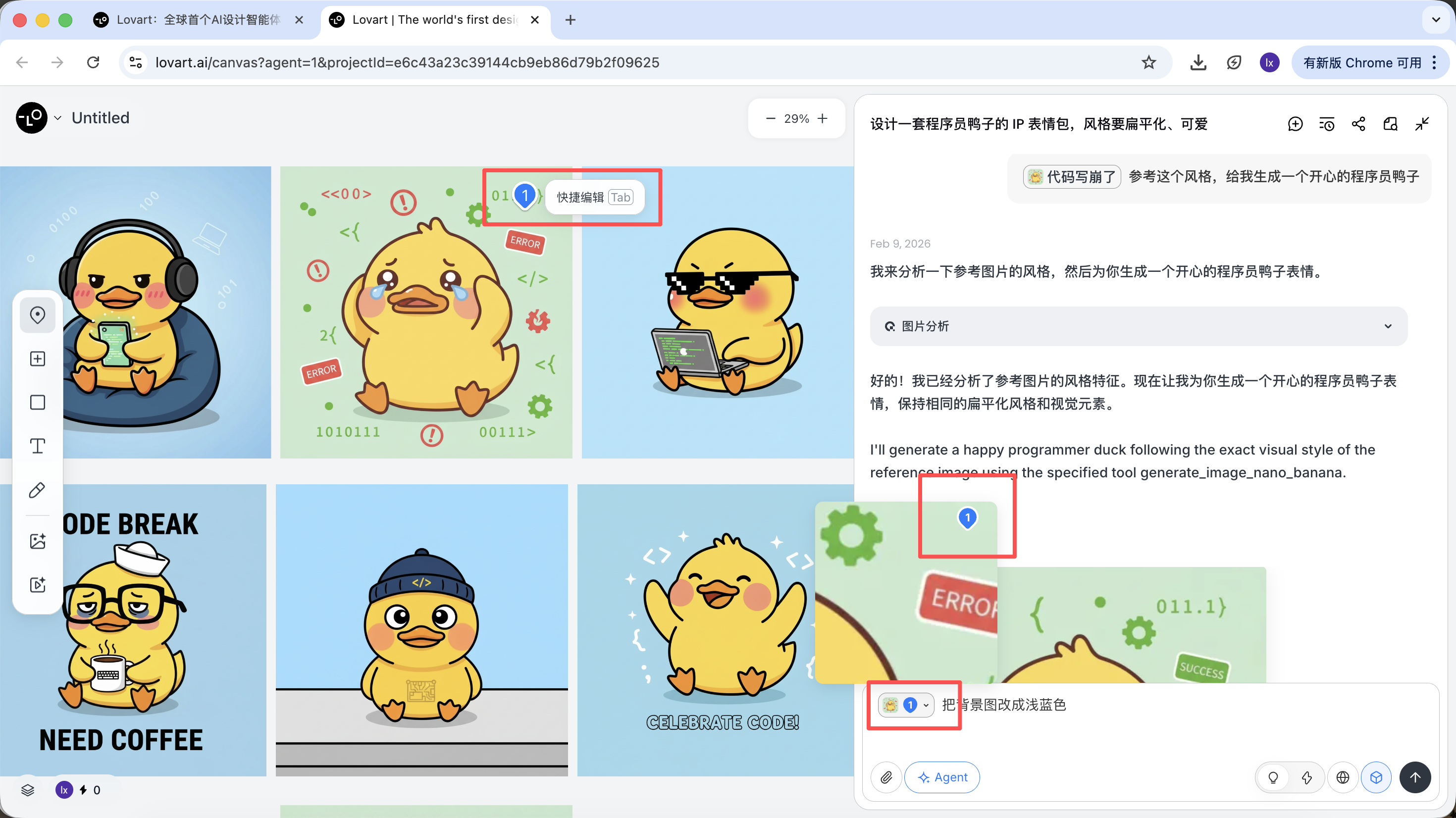
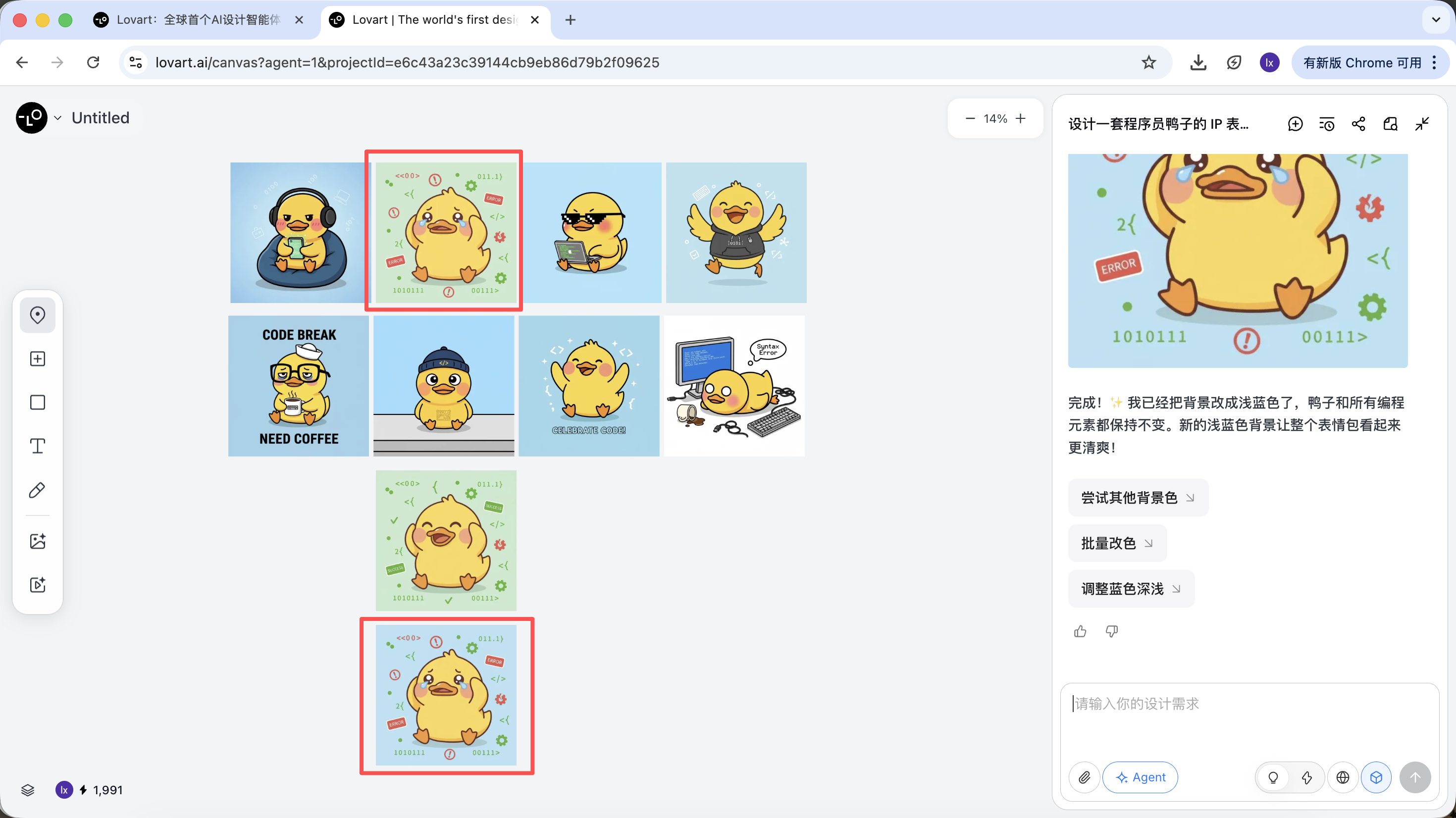
Man sieht, dass das neu generierte Bild nur die Hintergrundfarbe geaendert hat, was unserer Eingabe entspricht.
- Unterschiedliche Unterelemente aus mehreren Bildern referenzieren und zu einem neuen Ergebnis kombinieren
Zum Beispiel: Du kannst den Charakterkoerper aus Bild A beibehalten und gleichzeitig den Hut durch den Stil aus Bild B ersetzen. Der Agent wird diese visuellen Einschraenkungen im Hintergrund automatisch integrieren.
Am Beispiel der Programmierer-Ente koennen wir waehlen, das Enten-Design aus dem ersten Bild beizubehalten und es als Hauptelement im zweiten Bild zu ersetzen.
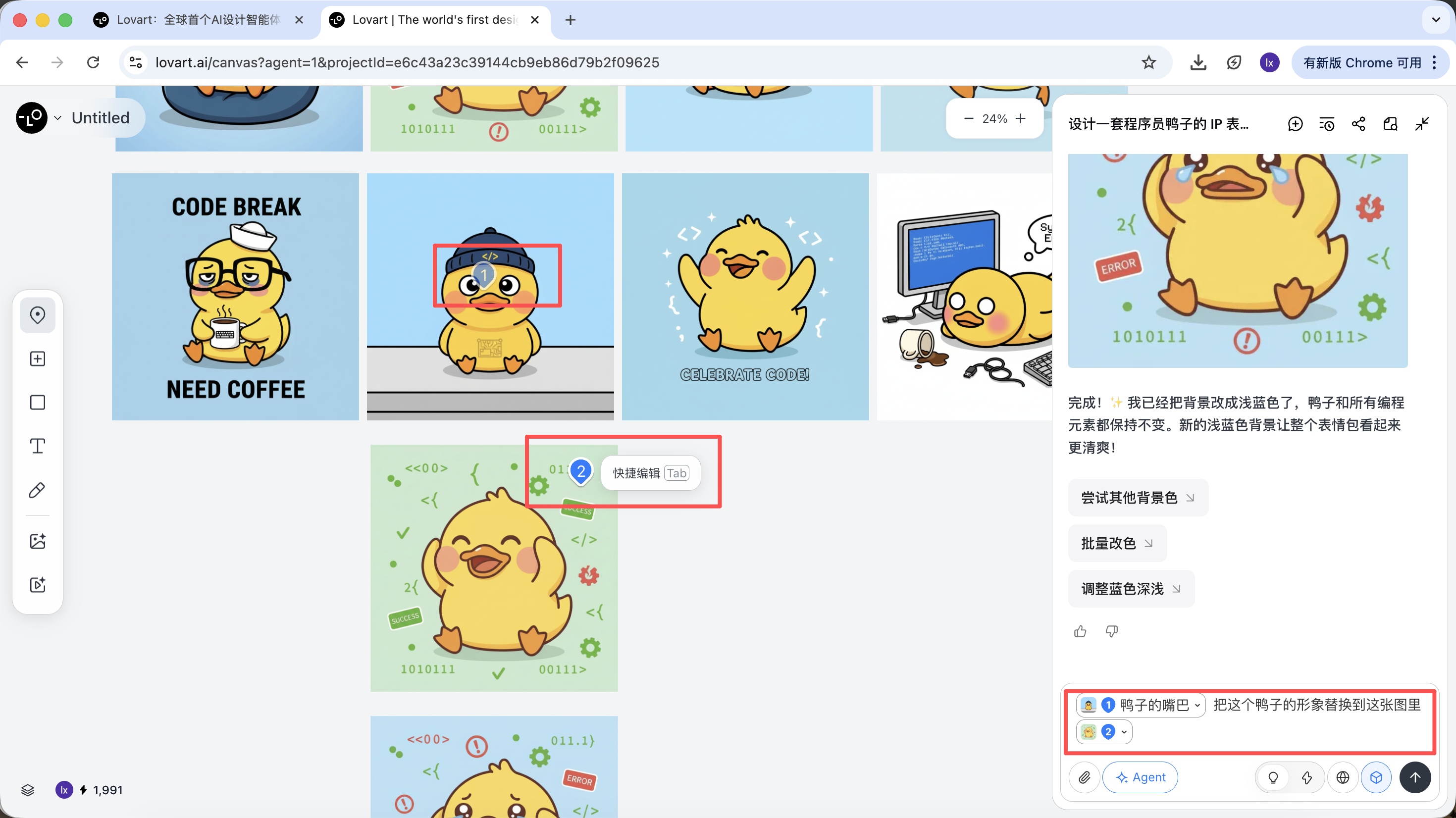
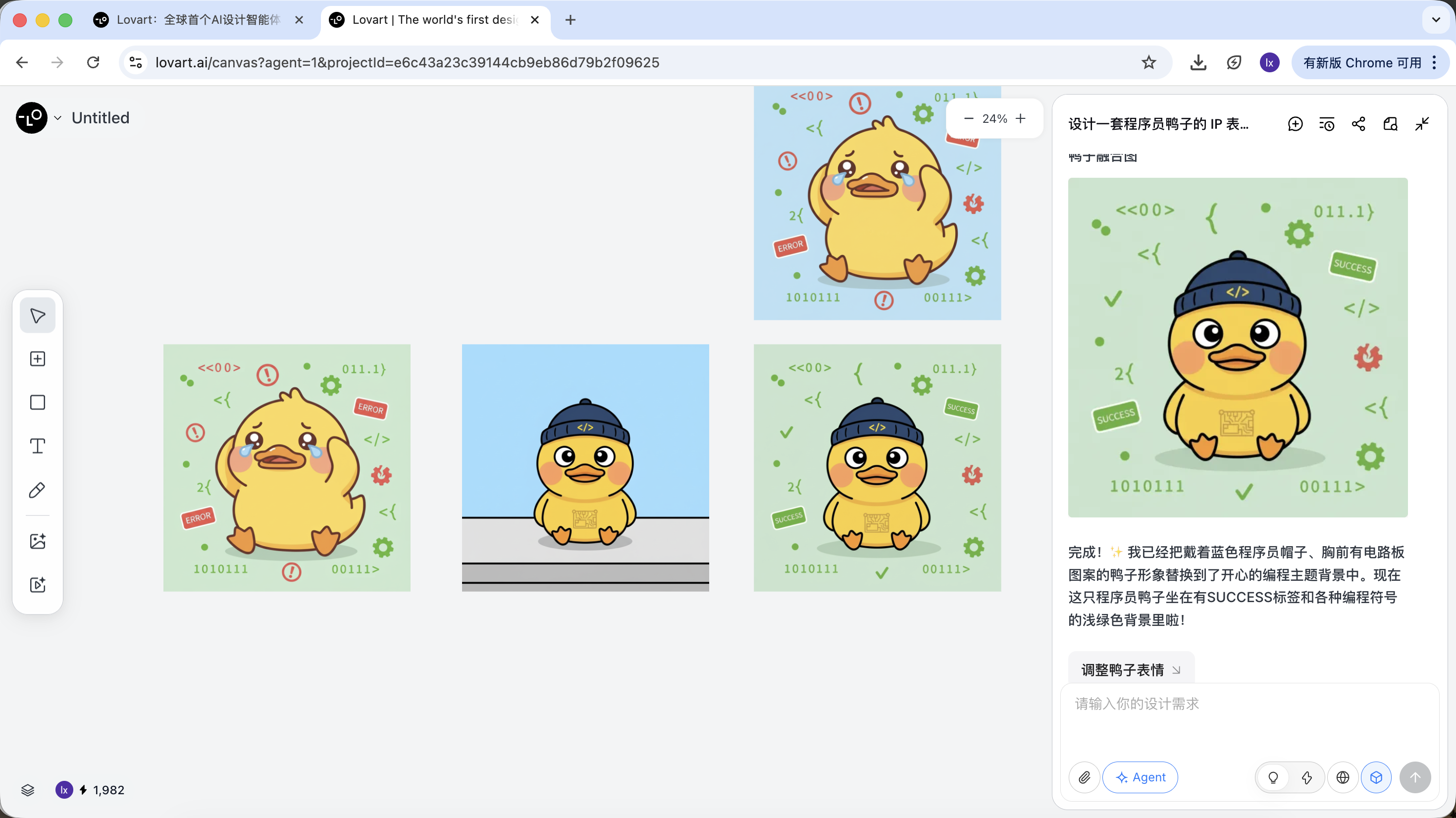
Der finale Effekt ist sehr deutlich. Du kannst auch andere Kombinationen ausprobieren!
Phase 3: Umsetzung (Werkzeugaufruf des Agenten)
Nach Abschluss der Generierung koennen direkt folgende Operationen ausgefuehrt werden: Vergroessern, Hintergrund entfernen, Radieren etc.
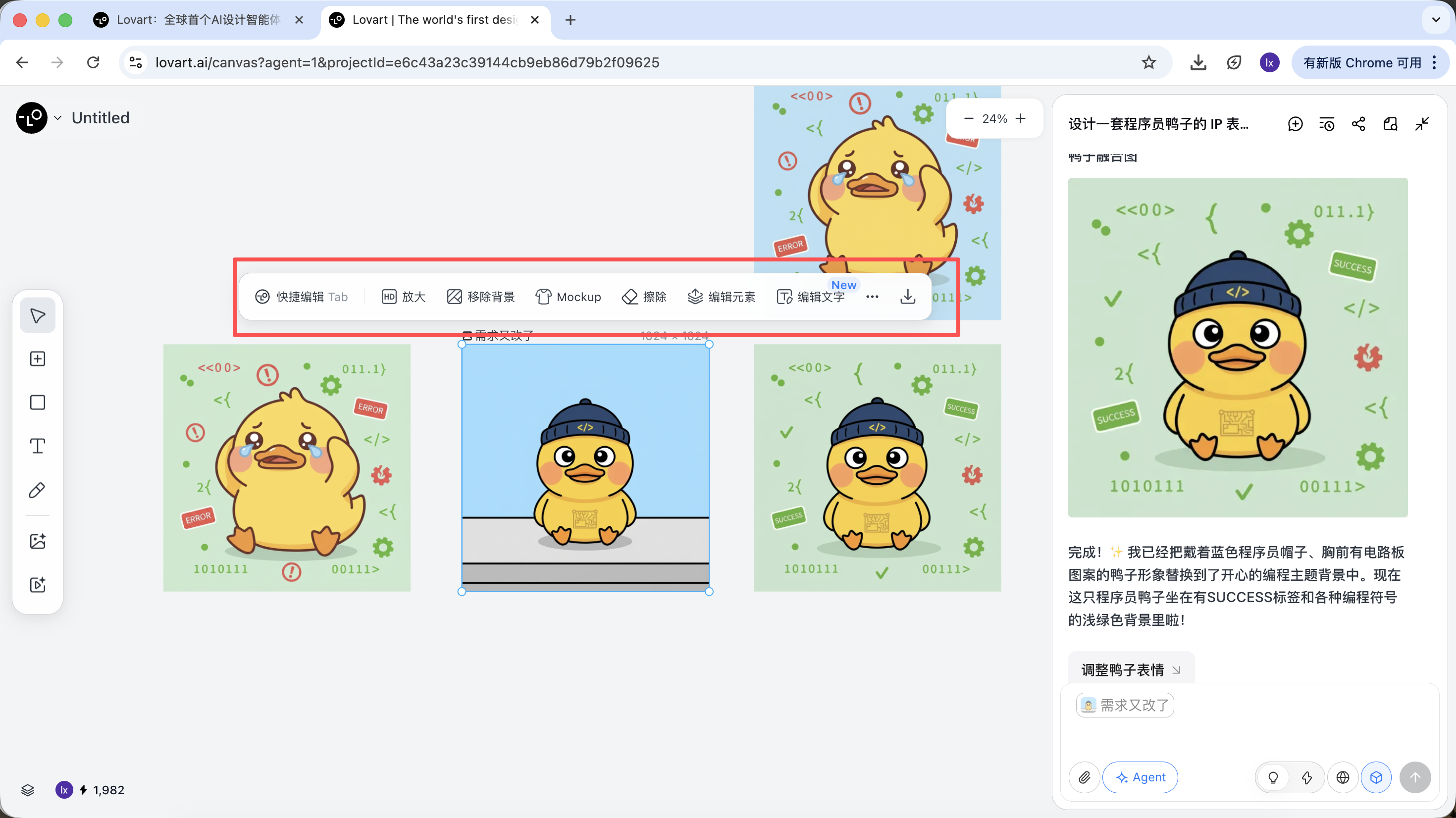
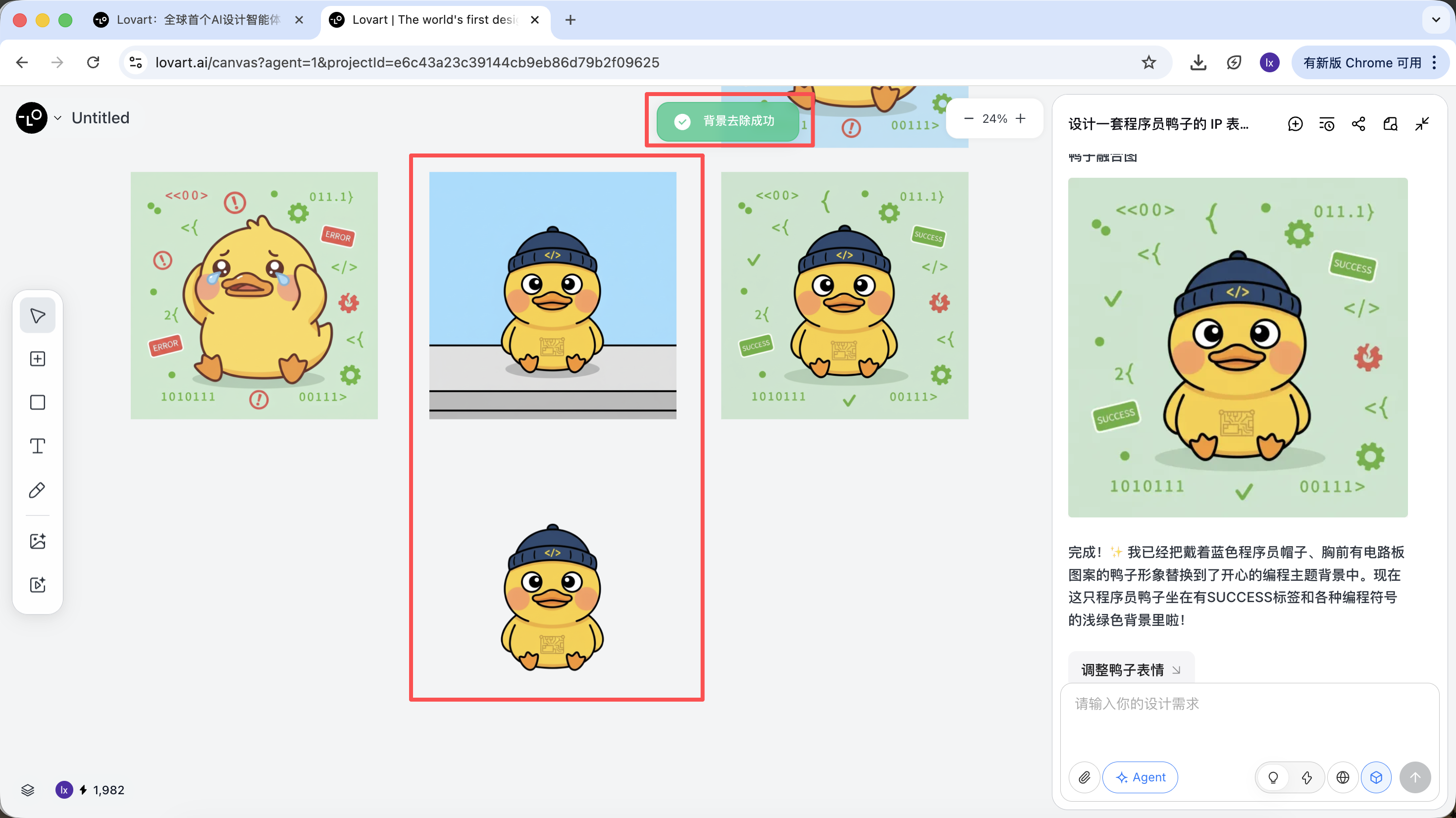
Diese sind keine einfachen Filter, sondern Ergebnisse, die der Agent automatisch durch den Einsatz verschiedener Werkzeuge erzielt.
Nachdem der Grundstil festgelegt wurde, koennen sehr schnell eine Reihe von Sticker-Bildern generiert werden.
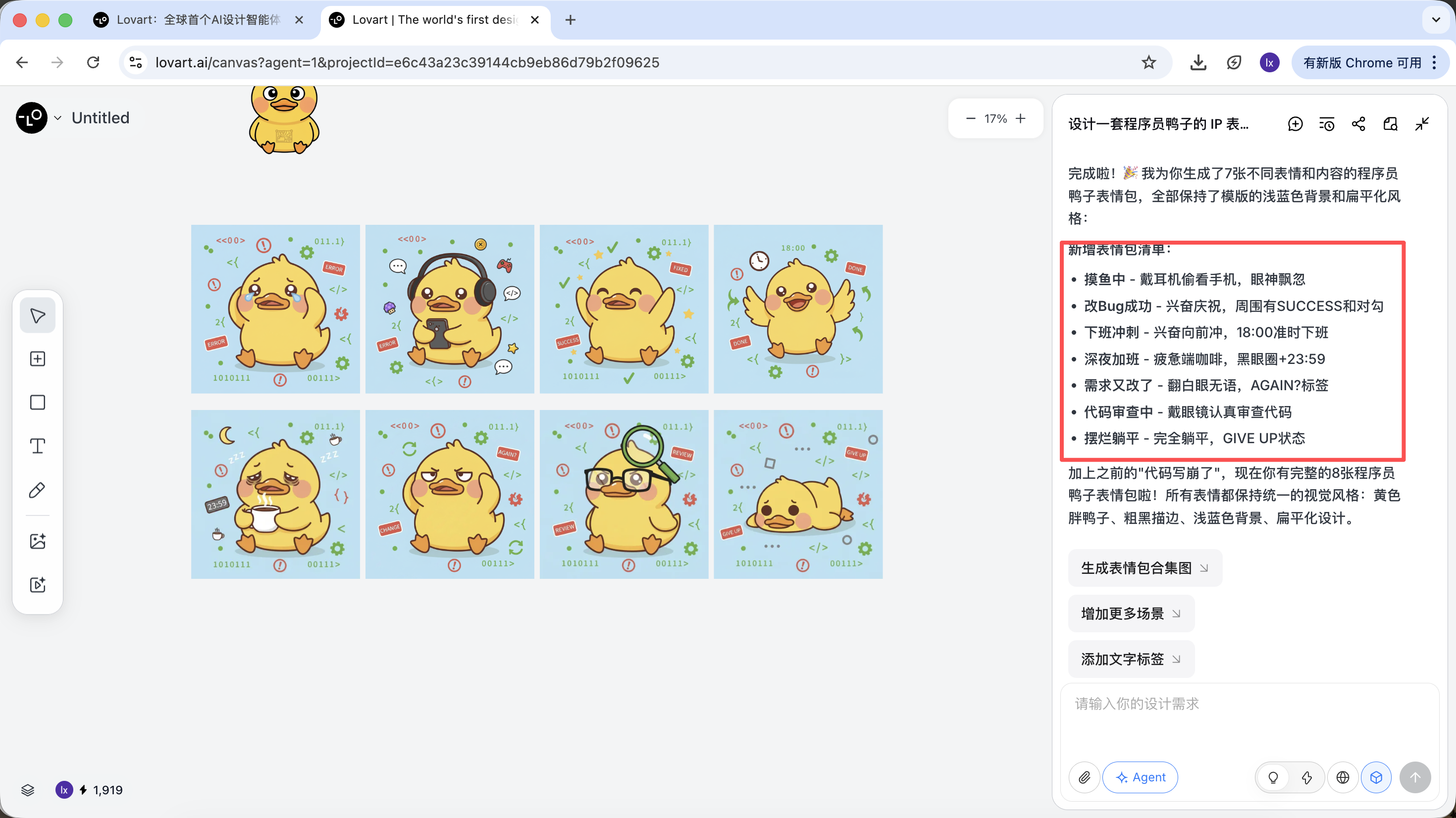
Am Ende erhalten wir produktionsfaehige Assets, die direkt geliefert werden koennen, und nicht nur ein Präsentationsbild.
2.3 Hinweise zur Nutzung und Preisgestaltung
Lovart verwendet ein Abonnement-Preismodell mit unterschiedlichen Kontingenten und Funktionsberechtigungen fuer verschiedene Pakete. Massgeblich sind die auf der offiziellen Website angezeigten Informationen.
Dieses Tutorial empfiehlt oder vergleicht keine Pakete; bei tatsaechlichem Bedarf kannst du je nach persoenlicher Situation ein kostenpflichtiges Upgrade waehlen. Aktuell wird die Bezahlung ueber Alipay und andere Methoden unterstuetzt.
Zusammenfassung
Lovart ersetzt nicht das zugrundeliegende Modell, sondern aktualisiert die Bildgenerierung durch den Agent-Mechanismus von "einmaliger Ausfuehrung" zu "kontinuierlichem Workflow".
Wenn die Aufgabe Planung, Konsistenz und Lieferung umfasst, werden die Vorteile dieser Art von Werkzeug sehr deutlich.
Kapitel 3: Selbst einen intelligenten Zeichenassistenten bauen
Anstatt Lovart direkt zu verwenden, koennen wir auch eine vereinfachte Version eines Zeichenassistenten selbst implementieren.
Dieses Kapitel verwendet "automatische Artikelillustration" als Beispiel, um schrittweise einen Agenten mit Denkfaehigkeit aus einem praktischen Problem heraus aufzubauen.
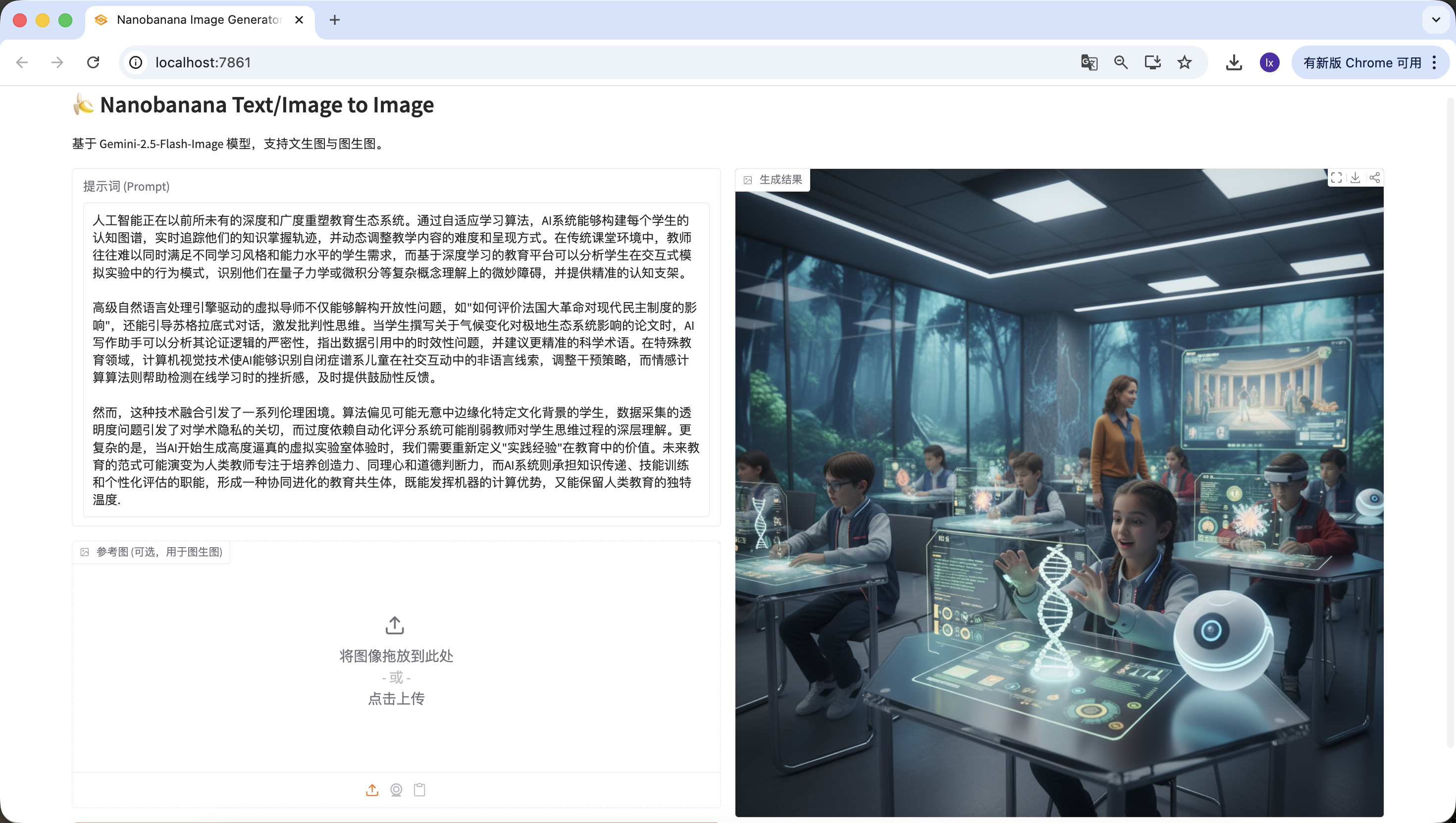
3.1 Problemstellung: Warum es nicht funktioniert, Artikel direkt an ein Bildgenerierungsmodell zu senden
Wenn du einen laengeren Artikel an NanoBanana sendest und um eine Illustration bittest, erhaeltst du normalerweise keine zufriedenstellenden Ergebnisse. Der Grund liegt nicht darin, dass das Modell "nicht gut zeichnen kann", sondern daran, dass es nicht gut darin ist, lange Texte zu verstehen.
Bildgenerierungsmodelle sind besser geeignet fuer kurze, eindeutige visuelle Beschreibungen. Wenn die Eingabe zu einem Artikel mit Struktur, Schwerpunkten und Kontextbeziehungen wird, kann das Modell nicht beurteilen, welche Inhalte im Bild wirklich dargestellt werden muessen. Dies fuehrt oft dazu, dass die generierten Ergebnisse vom Thema abweichen oder nur vereinzelte Details erfassen, ohne eine gesamthafte Zusammenfassung zu liefern.
Im Wesentlichen haben Bildmodelle nur die Faehigkeit zur "Ausfuehrung", aber keinen Prozess zur Analyse und Auswahl von Text.
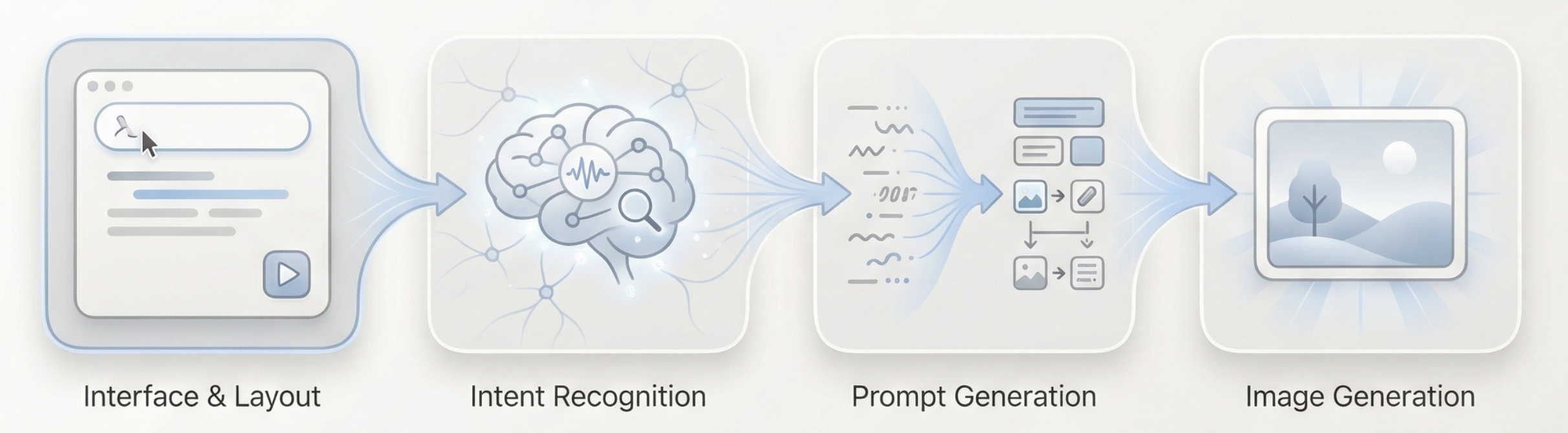
3.2 Loesungsansatz: "Verstehen" und "Ausfuehren" mit einem Agenten aufteilen
Um dieses Problem zu loesen, ist der Schluessel nicht komplexere Prompts, sondern vor dem Zeichnen zuerst klar zu denken. Daher fuehren wir eine unabhaengige "Denkschicht" in den Generierungsprozess ein und bauen damit einen einfach verwendbaren Agenten.
Das einzige Kernziel dieses Agenten: Das endgueltig generierte Bild so nahe wie moeglich an der tatsaechlichen Ausdrucksabsicht des Benutzers ausrichten.
Der Gesamtprozess kann wie folgt zusammengefasst werden: Lange Texteingabe -> Sprachmodell-Verstehen und Beurteilung -> Geeignete visuelle Prompts generieren -> Bildmodell fuehrt die Generierung aus -> Bild ausgeben
Wie kann unser Agent die Absicht des Benutzers verstehen?
Hier waehlen wir eine vereinfachte "Denkschicht" mit drei verschiedenen Intentionen: ungueltige Eingabe, direkte Bildgenerierung und lange Texte, die Verstaendnis erfordern.
In diesem Agenten kann die Arbeitsteilung der einzelnen Rollen in vier Punkte zusammengefasst werden:
- Sprachmodell als Entscheidungszentrum Es ist verantwortlich fuer das Verstehen von Artikelinhalten, die Beurteilung der Benutzerabsicht und die Weiterleitung der Aufgabe an den entsprechenden Generierungspfad, um zu entscheiden, "wie als naechstes vorzugehen ist" und wie der Prompt zur Bildgenerierung erstellt wird.
- Bildmodell als Ausfuehrer Das Bildmodell nimmt nicht am Verstehen und Beurteilen teil, sondern erhaelt nur bereits aufbereitete visuelle Anweisungen und konzentriert sich auf die Bilddarstellung.
- Benutzer als intervenierender Leiter Neben der direkten Texteingabe koennen Benutzer waehrend des Prozesses manuell generierte Prompts anpassen oder Referenzbilder hinzufuegen, um das Endergebnis zu leiten und feinzuaeinen.
- Gradio und Backend-API als Gesamttraegerschicht Sie sind verantwortlich fuer die Verkettung von Oberflaeche, Modellaufrufen und Ergebnisanzeige, um sicherzustellen, dass der gesamte Agent als stabile Web-Anwendung laeuft.
3.3 Praktische Vorbereitung: API abrufen
Das sieht doch interessant aus! Um den obigen Prozess zum Laufen zu bringen, muessen wir nur zwei Arten von APIs vorbereiten.
Hand: NanoBanana API (Bildgenerierung)
Direkte Wiederverwendung der in Kapitel 1 bereits konfigurierten API-Key und API-URL, keine zusaetzliche Einrichtung noetig.
Gehirn: SiliconFlow API (Textdenken)
Wir benoetigen ein Grosssprachenmodell fuer die "Denkschicht". Dieses Tutorial verwendet den von SiliconFlow bereitgestellten Modelldienst: https://cloud.siliconflow.cn
SiliconFlow bietet eine mit der OpenAI-API-Spezifikation kompatible Schnittstelle, die sehr einfach ueber Standard-Netzwerkanfragen in Projekten aufgerufen werden kann. Hier waehlen wir das kostenlose Qwen2.5-7B-Instruct-Modell. Alle fuer den Aufruf erforderlichen Inhalte sind bereits in den folgenden Prompt integriert. Vor dem Start musst du nur ein Konto auf der offiziellen Website registrieren und einen API-Key erstellen.
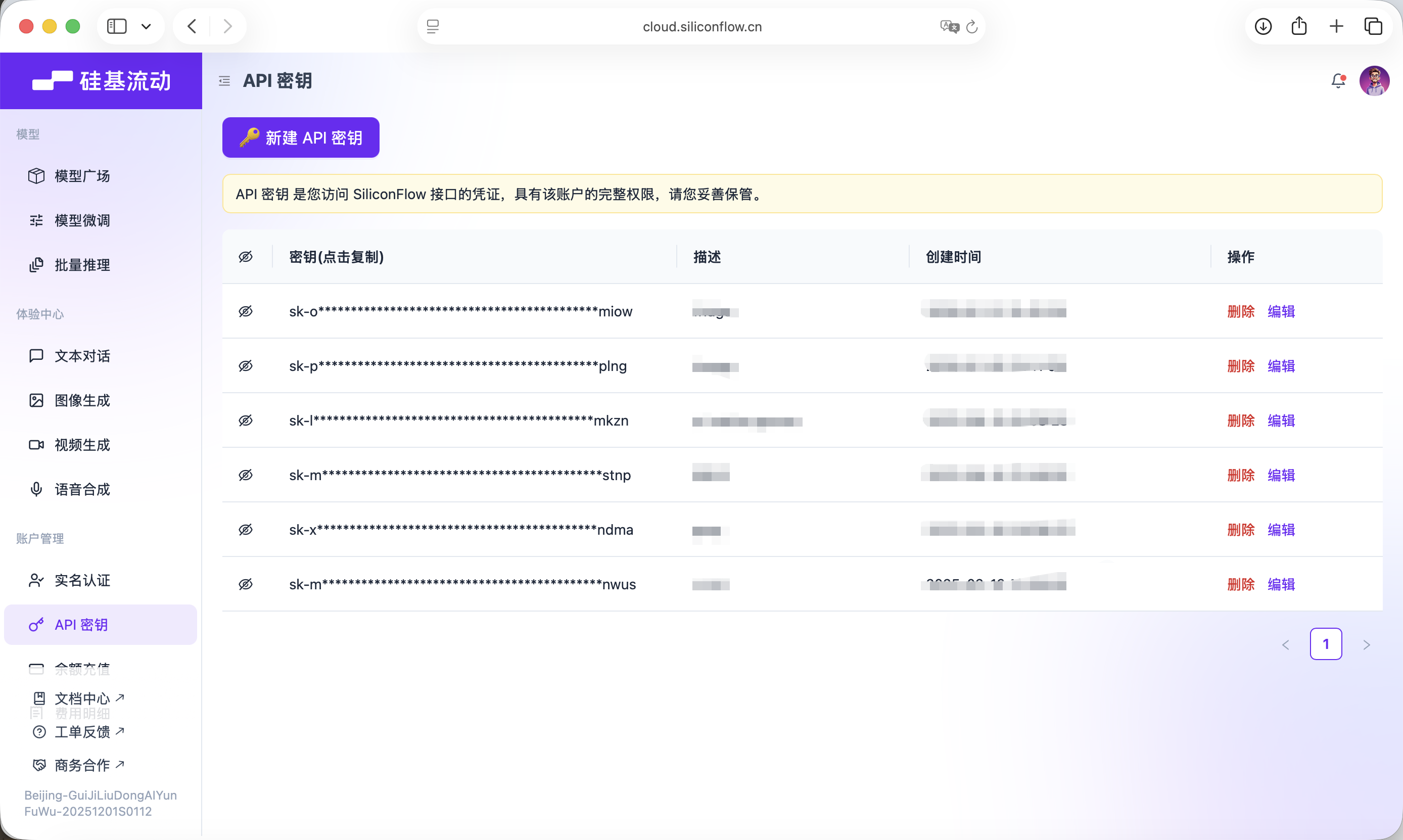
Dieser Key wird fuer nachfolgende Modellaufrufe verwendet.
3.4 Den Agenten aufbauen:
Dieses Experiment verwendet hauptsaechlich Trae beim Schreiben von Code. Dieses Tutorial waehlt das Gemini-3-Pro-Preview-Modell. Der Gesamtansatz ist: Nach dem Erstellen eines neuen Projekts den folgenden vollstaendigen Prompt in das Chat-Feld kopieren und eingeben, schrittweise die API-Key ersetzen, den Code ausfuehren und den Test abschliessen.
Phase 1: Gradio Blocks Grundgeruest und Oberflaechenlayout
In dieser Phase ist unser Hauptziel, zunaechst ein "Aeusseres" fuer den gesamten Agenten zu erstellen und das Frontend-Seiten-Design zu implementieren. Nach dem Kopieren des folgenden Prompts in das Trae-Chat-Feld wirst du eine lokale URL (normalerweise http://127.0.0.1:7860) erhalten, um die Oberflaeche zu sehen und die Implementierung zu pruefen.
Block 1: Gradio Blocks Grundgeruest und Oberflaechenlayout
1. Aufgabenziel
Basierend auf dem Gradio 4.0.0+ Blocks-Layout, die Basisoberflaeche fuer das "LLM+Nanobanana Text-zu-Bild"-Projekt implementieren, streng dem festen Links-Rechts-Spalten-Layout folgen, alle UI-Komponenten initialisieren und den korrekten Anfangszustand setzen.
2. Technologie-Stack-Anforderungen
Muss den Gradio 4.0.0+ Blocks-Modus verwenden, Interface-Modus ist verboten;
Abhaengigkeiten: gradio>=4.0.0, pillow>=10.0.0 (nur importieren, Bildverarbeitungslogik noch nicht implementieren);
Der Code muss eine vollstaendig ausfuehrbare Python-Datei mit allen erforderlichen Import-Anweisungen sein.
3. Oberflaechenlayout-Regeln (Kernbeschraenkung)
Gesamtlayout:
Seitentitel: LLM-gesteuertes Text-zu-Bild-Vollprozess-Tool;
Festes Links-Rechts-Spalten-Layout: Links 60% Breite, Rechts 40% Breite, mit gr.Row und gr.Column die Proportionen steuern.
Links 60% (Prompt-Generierungsprozess-Bereich) Komponentenliste:
input_text: gr.Textbox, Label "Text eingeben (Tutorial-Abschnitt / Zeichenanweisung)", lines=6, Platzhalter "Bitte gib den Tutorial-Text oder direkte Zeichenanweisung ein...";
identify_intent_btn: gr.Button, value="Intent erkennen", Anfangszustand normal klickbar;
intent_status: gr.Textbox, Label "Intent-Typ / Verarbeitungsstatus", lines=2, interactive=False, Anfangswert "Intent nicht erkannt";
system_prompt: gr.Textbox, Label "System Prompt (nur fuer Artikel-Illustrations-Intent bearbeitbar)", lines=4, interactive=False, Platzhalter "LLM-Generierungs-Prompt-Regeln...";
confirm_prompt_btn: gr.Button, value="Bildgenerierungs-Prompt bestaetigen", interactive=False (anfaenglich deaktiviert);
generation_prompt: gr.Textbox, Label="Generierungs-Prompt (bearbeitbar)", lines=3, interactive=True, Anfangswert leer, Platzhalter "Der generierte englische Prompt wird hier angezeigt, manuelle Bearbeitung moeglich...".
Rechts 40% (Nanobanana Bildgenerierungsfunktion-Bereich) Komponentenliste:
ref_image: gr.Image, Label="Referenzbild (optional, Bild-zu-Bild)", type=filepath, height=300, Upload erlauben;
generate_btn: gr.Button, value="Bild generieren", interactive=False (anfaenglich deaktiviert);
result_image: gr.Image, Label="Generierungsergebnis", type=pil, height=300, Anfangswert leer, interactive=False.
4. Interaktionslogik-Anforderungen
Alle interactive-Anfangszustaende strikt nach obiger Konfiguration, spaeter dynamisch durch Funktionen aktualisieren;
Deaktivierter Button-Zustand muss sichtbar sein (ausgegraut), um Fehlbedienungen zu vermeiden.
5. Ausgabeanforderungen
Vollstaendigen Python-Code generieren, nur Oberflaechenlayout und Komponenteninitialisierung implementieren, keine Geschaeftslogik;
Klare Code-Kommentare, Komponentenbenennung konsistent mit der praktischen Version;
Code direkt ausfuehrbar, Oberflaechenstruktur vollstaendig wie beschrieben.Nach dem Oeffnen von http://127.0.0.1:7860 im Browser kannst du sehen, dass Trae bereits die folgende Webseite nach unseren Anforderungen generiert hat, die unseren Anforderungen weitgehend entspricht, und du kannst mit der naechsten Generierung fortfahren.
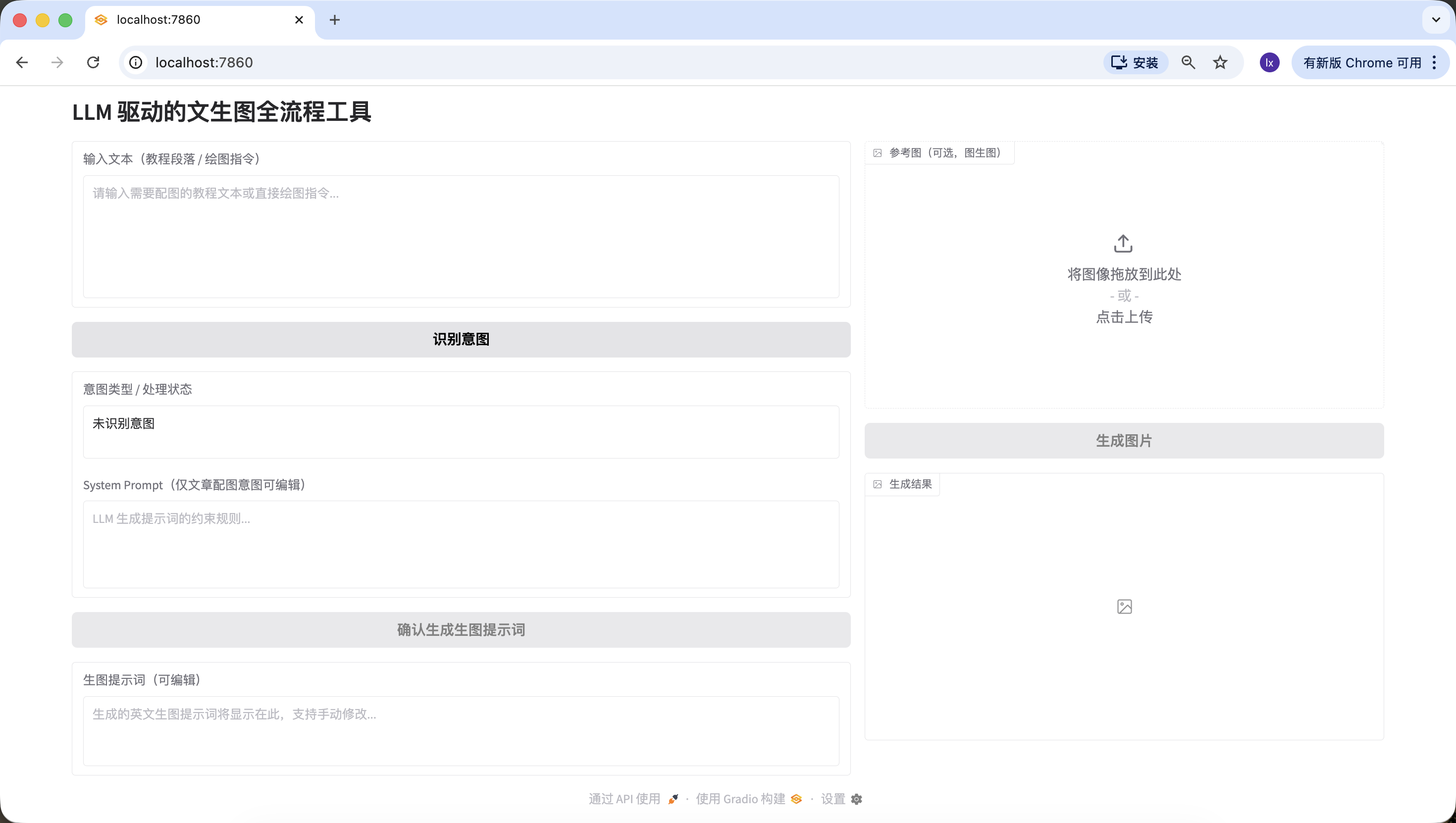
Phase 2: LLM Intent-Erkennungsmodul (Siliconflow API)
Bei der taeglichen Verwendung von VLM zum Zeichnen koennen drei haeufige Eingabesituationen auftreten:
- Bedeutungsloser Inhalt wie "Hallo", "Hast du heute schon gegessen?" etc., fuer den keine entsprechenden Bilder gezeichnet werden koennen.
- Artikel/lange Texte mit mehr Woertern, z.B. ein strukturierter Artikel von ca. 200 Woertern, bei dem zunaechst die Struktur und der Inhalt des Artikels verstanden werden muessen, bevor entschieden werden kann, wie ein Bild generiert werden soll, das den gesamten Text zusammenfasst.
- Direkte Zeichenanweisungen wie "Zeichne mir eine badende Katze", bei denen die Anforderungen bereits sehr konkret formuliert sind und direkt ein Bild generiert werden kann.
Wie zuvor den folgenden Prompt in das Trae-Chat-Feld kopieren und implementieren, und die in den vorherigen Schritten erhaltene API ergaenzen.
Block 2: LLM Intent-Erkennungsmodul (Siliconflow API)
1. Aufgabenziel
Auf Basis der bereits implementierten Gradio-Oberflaeche die Klick-Logik fuer den "Intent erkennen"-Button hinzufuegen, Siliconflow-API fuer Intent-Erkennung aufrufen und Komponentenzustaende verknuepfen.
2. Technologie-Stack-Anforderungen
Basierend auf Gradio 4.0.0+ Blocks;
Abhaengigkeiten: requests>=2.31.0, openai;
Vollstaendig ausfuehrbare Python-Datei ausgeben, einschliesslich Block 1 Oberflaeche + dieses Moduls Logik.
3. Kern-Geschaeftsregeln
Intent-Klassifizierungsregeln (nur 3 Kategorien, strikt Zahl + Beschreibung zurueckgeben)
1 = Bedeutungsloser Inhalt: Nur Plauderei, Begruessung, irrelevante Konversation ohne Zeichen- oder Illustrationsbedarf;
2 = Artikel/langer Text Illustrationsbedarf: Benutzer gibt einen vollstaendigen Artikel, Tutorial, Absatz, erklaerenden Text ein, der eher narrativ/erklaerend/instruktiv ist, mit der impliziten Absicht, eine Illustration fuer diesen Inhalt zu erstellen;
3 = Direkte Zeichenanweisung: Benutzer gibt eine kurze, eindeutige Zeichenanweisung ohne langen Text-Hintergrund ein (z.B. "Zeichne eine Apple-Stil Katze").
LLM-Aufrufbeschraenkungen
Schnittstellenadresse: https://api.siliconflow.cn/v1/chat/completions;
Modell: Qwen/Qwen2.5-7B-Instruct;
temperature=0.1;
4. Komponentenverknuepfungsregeln
Ergebnis 1: intent_status zeigt "1 = Bedeutungsloser Inhalt: Kein Zeichenbedarf", system_prompt bleibt deaktiviert, confirm_prompt_btn deaktiviert;
Ergebnis 2: intent_status zeigt "2 = Artikel/langer Text Illustrationsbedarf: Illustration fuer Eingabe generieren", system_prompt aktivieren und Standardregeln ausfuellen, confirm_prompt_btn aktivieren;
Ergebnis 3: intent_status zeigt "3 = Direkte Zeichenanweisung: Bild gemaess Anweisung generieren", system_prompt deaktiviert und Standardregeln ausfuellen, confirm_prompt_btn aktivieren.
5. Fehlerbehandlung
API-Fehler, Parsing-Fehler alle freundliche Hinweise geben, kein Absturz, Komponenten in Anfangszustand zuruecksetzen.
6. Ausgabeanforderungen
Vollstaendig ausfuehrbaren Code generieren, LLM_API_KEY ersetzen und verwenden, klare Kommentare, Intent-Erkennungs-Template strikt verwenden.Die vorherige URL http://127.0.0.1:7860 aktualisieren und testen, ob die drei Situationen korrekt erkannt werden.
- Bedeutungsloser Inhalt: Versuche "Hallo", "Danke" einzugeben und stelle fest, dass es korrekt erkannt wird.
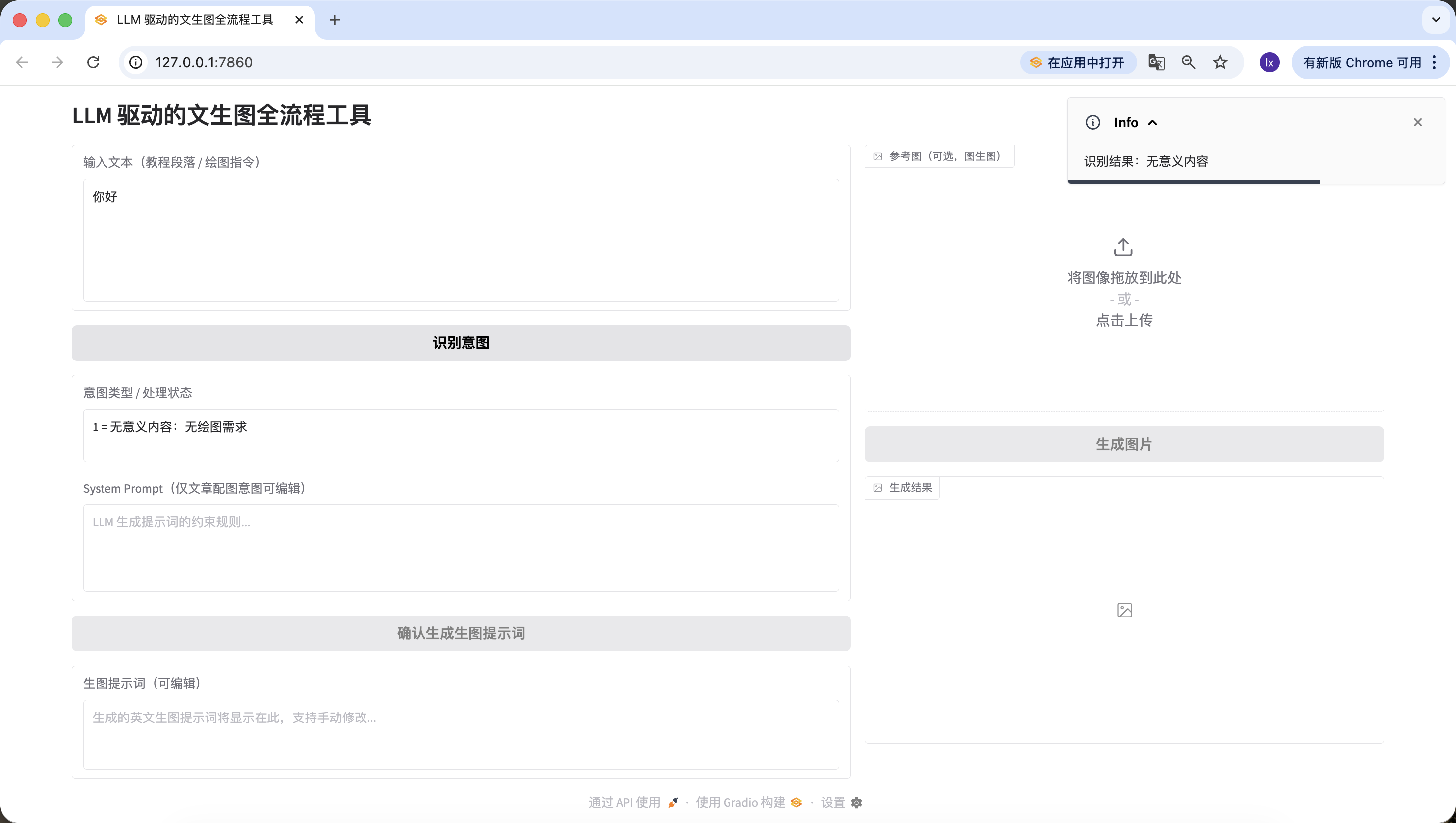
- Artikel/langer Text: Hier wurde ein von Doubao generierter Text ueber kuenstliche Intelligenz verwendet. Du kannst auch eigene Aufsatzabschnitte zum Testen verwenden.
Ebenfalls erfolgreich erkannt~
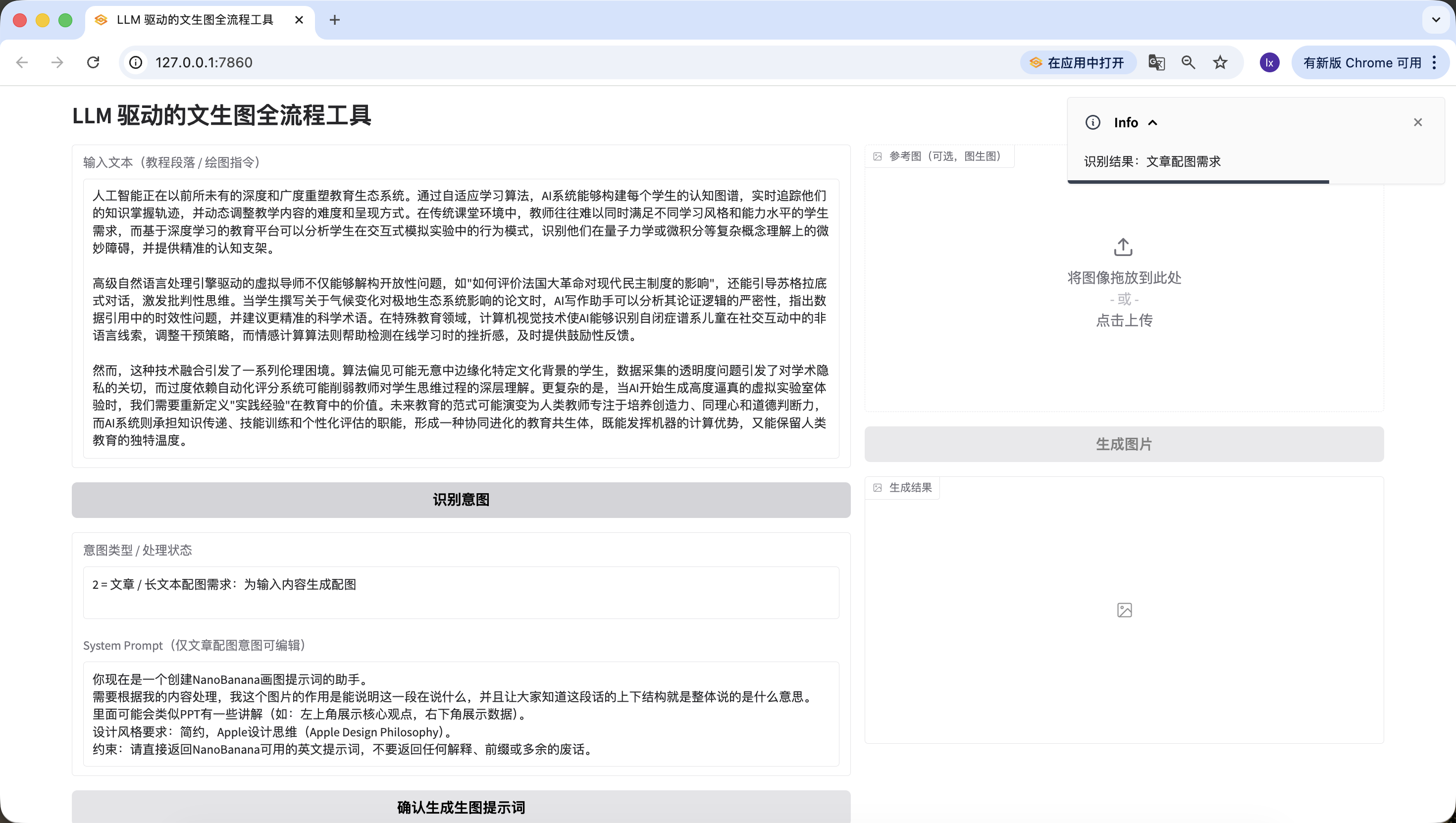
- Direkte Zeichenanweisung: Hier wurde "Ich moechte eine Katze zeichnen" eingegeben, ebenfalls korrekt erkannt.
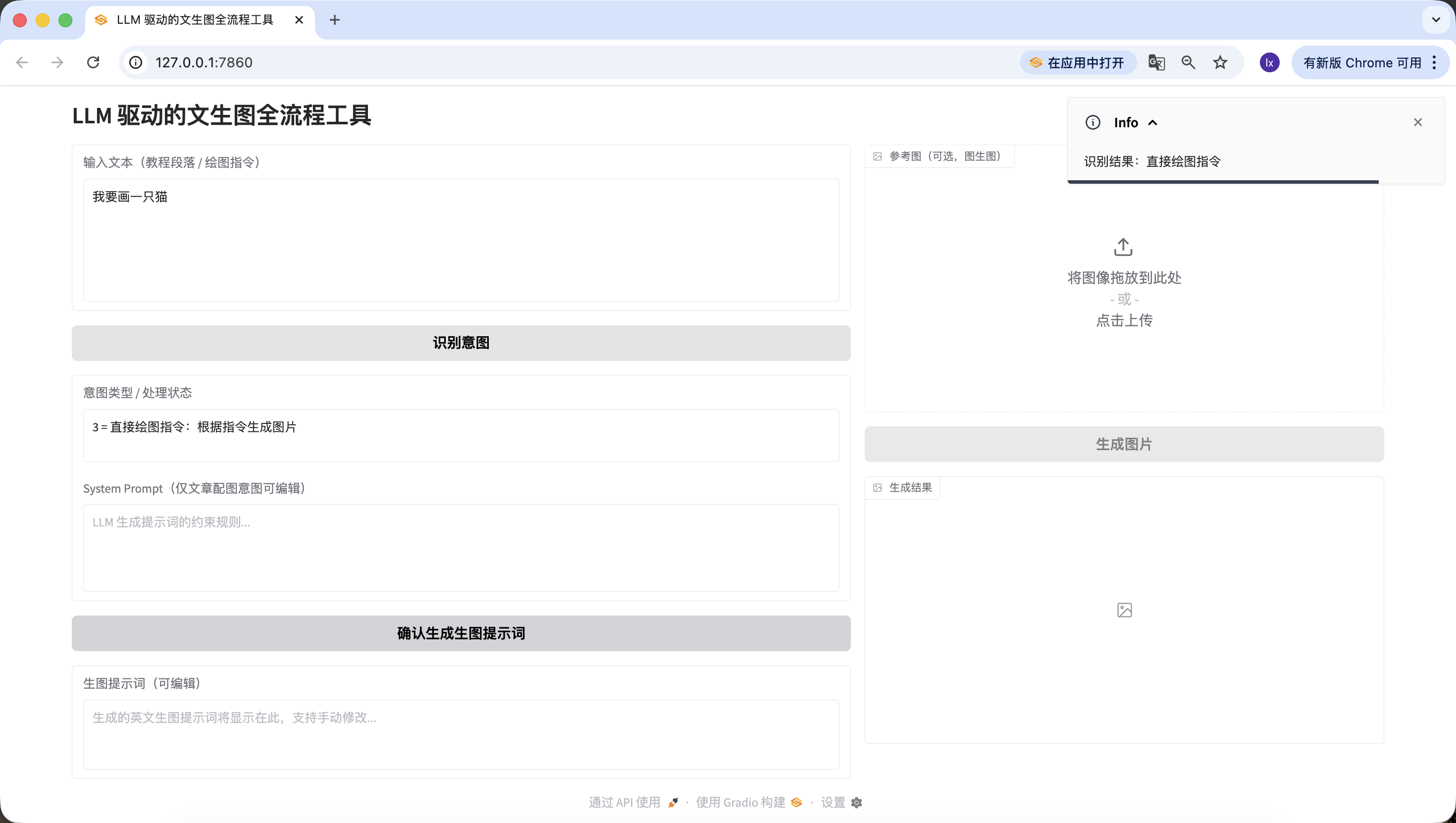
Damit haben wir erfolgreich die zweite Phase implementiert -- Intent-Erkennung.
Phase 3: Bildgenerierungs-Prompt-Generierungsmodul (LLM-Zweitaufruf)
Nach der Intent-Erkennung gibt es fuer Artikel oder lange Texte einen sehr wichtigen weiteren Schritt: die Generierung des Zeichen-Prompts, und genau das ist der Schwerpunkt dieses Agenten.
Block 3: Bildgenerierungs-Prompt-Generierungsmodul (LLM-Zweitaufruf)
1. Aufgabenziel
Auf Basis der Intent-Erkennung die Logik fuer den "Bildgenerierungs-Prompt bestaetigen"-Button implementieren, LLM aufrufen, um Text in einen fuer die Bildgenerierung geeigneten englischen visuellen Prompt umzuwandeln, das Bearbeitungsfeld ausfuellen und den "Bild generieren"-Button verknuepfen.
2. Technologie-Stack-Anforderungen
Wie Block 2, vollstaendigen Code ausgeben = Block 1 + Block 2 + dieses Modul;
Gemeinsame Nutzung der in Block 2 definierten LLM_BASE_URL, LLM_API_KEY, LLM_MODEL, kein neuer Schluessel.
3. Kern-Geschaeftsregeln
Prompt-Generierungs-Eingaberegeln
Die Prompt-Generierung ist keine einfache String-Verkettung, sondern erstellt eine Standard-Chat-Nachrichtenliste.
4. Komponentenverknuepfungsregeln
Erfolgreiche Generierung: Prompt in das generation_prompt-Feld eintragen, generate_btn aktivieren, intent_status "Prompt erfolgreich generiert, kann nach Bearbeitung Bild generieren" anhaengen;
Fehlgeschlagene Generierung: Spezifischen Grund anzeigen, generate_btn deaktiviert lassen, generation_prompt-Feld leer;
Benutzer manuelle Bearbeitung/Leerung des generation_prompt-Felds:
Leerung deaktiviert automatisch generate_btn;
Nicht-leer haelt generate_btn aktiv.
5. Fehlerbehandlung
API-Aufruf fehlgeschlagen: Freundlicher Hinweis "Prompt-Generierung fehlgeschlagen: {spezifische Fehlermeldung}", kein Absturz;
Prompt-Ueberpruefung fehlgeschlagen: Grund klar angeben, erneuten Versuch erlauben;
Antwort-Parsing fehlgeschlagen: Hinweis "LLM-Antwort kann nicht geparst werden, bitte erneut versuchen".
6. Ausgabeanforderungen
Vollstaendig ausfuehrbaren Code, LLM_API_KEY ersetzen und verwenden;
Klare Code-Struktur, vollstaendige Kommentare, schoene und einfache Oberflaeche;
Strikt die Standard-Chat-Nachrichtenlisten-Struktur implementieren, Parameter und Beispielelogik konsistent;
Prompt-Laenge und Inhaltsueberpruefungslogik enthalten, freundliche Fehlermeldungen.Ebenso den Text aus der zweiten Phase kopieren und testen.
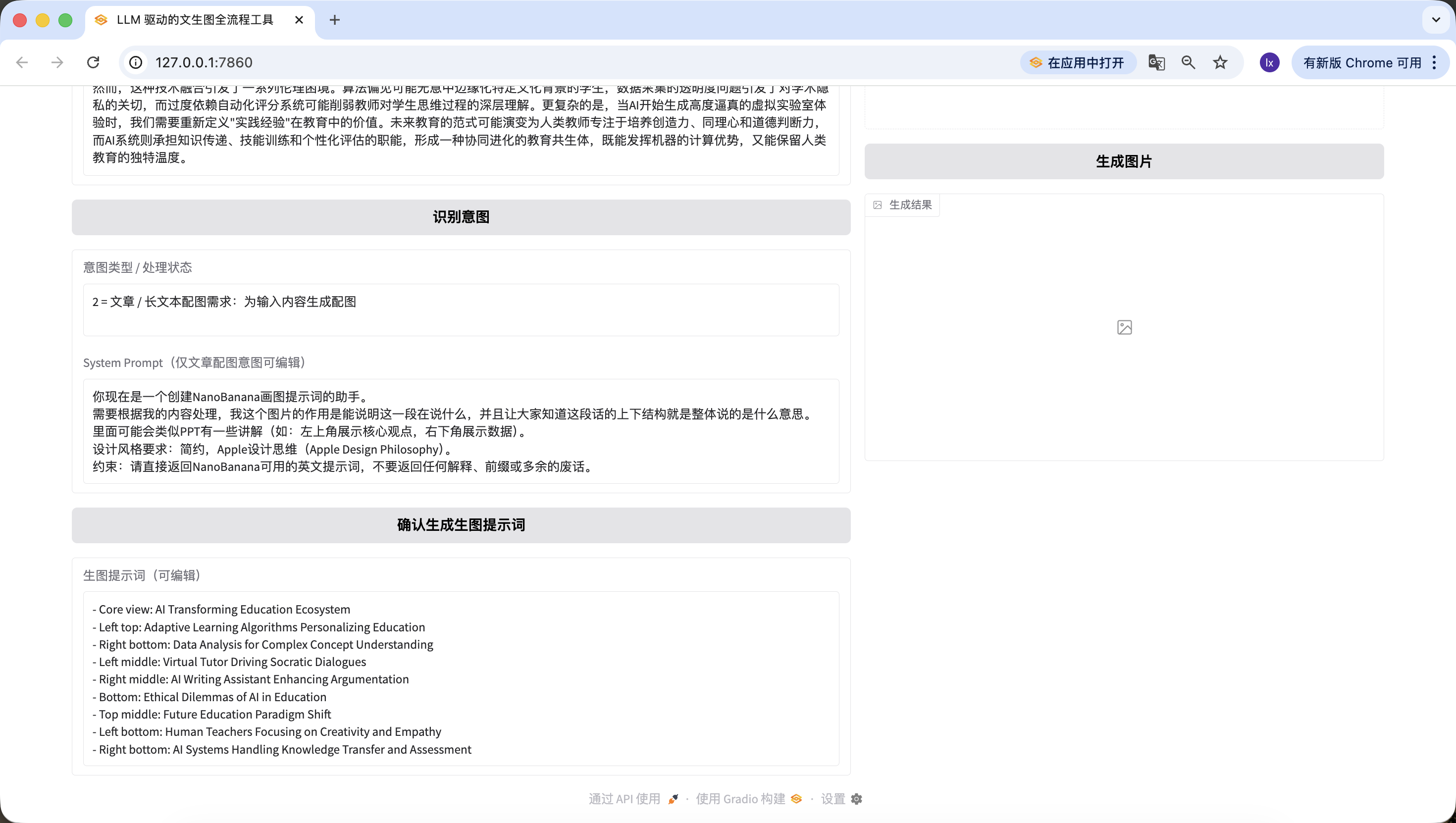
Es ist erwähnenswert, dass der hier voreingestellte System-Prompt fuer die Bildgenerierung lautet:
Du bist jetzt ein Assistent zum Erstellen von NanoBanana-Zeichen-Prompts. Du musst basierend auf meinem Inhalt verarbeiten. Der Zweck dieses Bildes ist zu veranschaulichen, was dieser Abschnitt sagt, und den Leuten zu zeigen, was die Kontextstruktur des gesamten Textes bedeutet. Es koennte aehnlich wie in einer Praesentation einige Erklaerungen enthalten (z.B. oben links die Kernansicht, unten rechts die Daten). Designstilanforderung: Minimalistisch, Apple Design Philosophy. Einschraenkung: Bitte gib nur den fuer NanoBanana verwendbaren englischen Prompt zurueck, ohne Erklaerungen, Praefixe oder ueberfluessigen Text.
Wenn du ein anderes voreingestelltes Template verwenden moechtest, kannst du es im vorherigen Prompt aendern oder direkt in Trae durch Konversation anpassen.
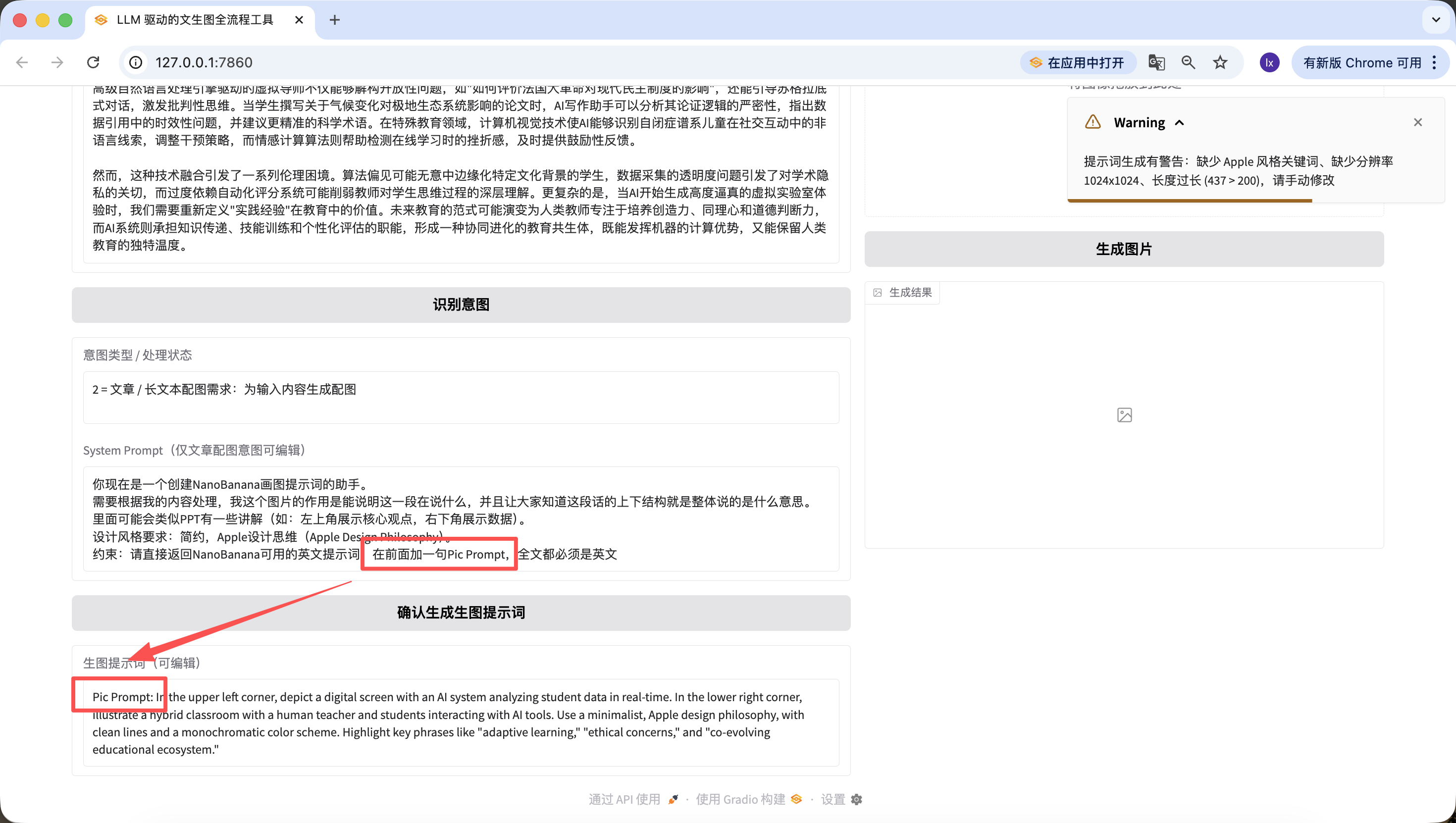
Zusaetzlich zur Aenderung des unterliegenden Codes koennen wir auch auf der Webseite schnell bearbeiten. Zum Beispiel habe ich hier den Satz "Pic Prompt am Anfang hinzufuegen" ergaenzt, und man sieht, dass der neu generierte Prompt ebenfalls diesen enthaelt. Dieses Design ist gedacht, um das schnelle Aendern des System-Prompts fuer die Prompt-Generierung zu ermoeglichen und uns beim schnellen Wechsel von Stilen zu helfen.
Phase 4: Nanobanana Text-zu-Bild / Bild-zu-Bild-Modul
Endlich der letzte Schritt -- ohne Anschluss an ein Bildgenerierungsmodell ist es kein vollstaendiger Agent!
Block 4: Nanobanana Text-zu-Bild / Bild-zu-Bild-Modul (Finalversion)
1. Aufgabenziel
Die Logik fuer den "Bild generieren"-Button implementieren, die echte Nanobanana-API aufrufen, Text-zu-Bild/Bild-zu-Bild unterstuetzen, Base64 parsen und Bild anzeigen.
2. Technologie-Stack-Anforderungen
Basierend auf Gradio 4.0.0+ Blocks;
Abhaengigkeiten: requests, pillow, base64, io, re;
Vollstaendiger Code = Block 1+2+3 + dieses Modul.
3. Kern-API-Konfiguration
Code-Konfiguration fixieren:
NANOBANANA_API_URL = "https://api.zyai.online/v1/chat/completions"
NANOBANANA_MODEL = "gemini-2.5-flash-image"
NANOBANANA_API_KEY = "" # Benutzer ersetzt selbst
4. Bildvorverarbeitung
Funktion image_to_base64_data_uri(ref_image_path) implementieren: PIL-Bild nach PNG konvertieren, automatisch auf 1024x1024 skalieren, transparenten Kanal zu weissem Hintergrund, als Base64 kodieren.
5. Anforderungskonstruktion
Funktion generate_image(prompt, ref_image_path) implementieren;
Logik-Zweig 1: Reines Text-zu-Bild (ref_image_path leer);
Logik-Zweig 2: Bild-zu-Bild (ref_image_path vorhanden).
6. Antwort-Parsing
Aus choices[0].message.content Bild-Base64 extrahieren, strukturiertes JSON und Markdown-Format unterstuetzen.
7. Komponentenverknuepfung und Fehlerbehandlung
Erfolgreiche Generierung: PIL-Bild in result_image anzeigen;
Fehlgeschlagene Generierung/Parsing/Upload: Klare Textmeldung in intent_status anzeigen, kein Absturz.
8. Ausgabeanforderungen
Vollstaendig ausfuehrbaren Code, LLM_API_KEY und NANOBANANA_API_KEY ersetzen und direkt ausfuehren.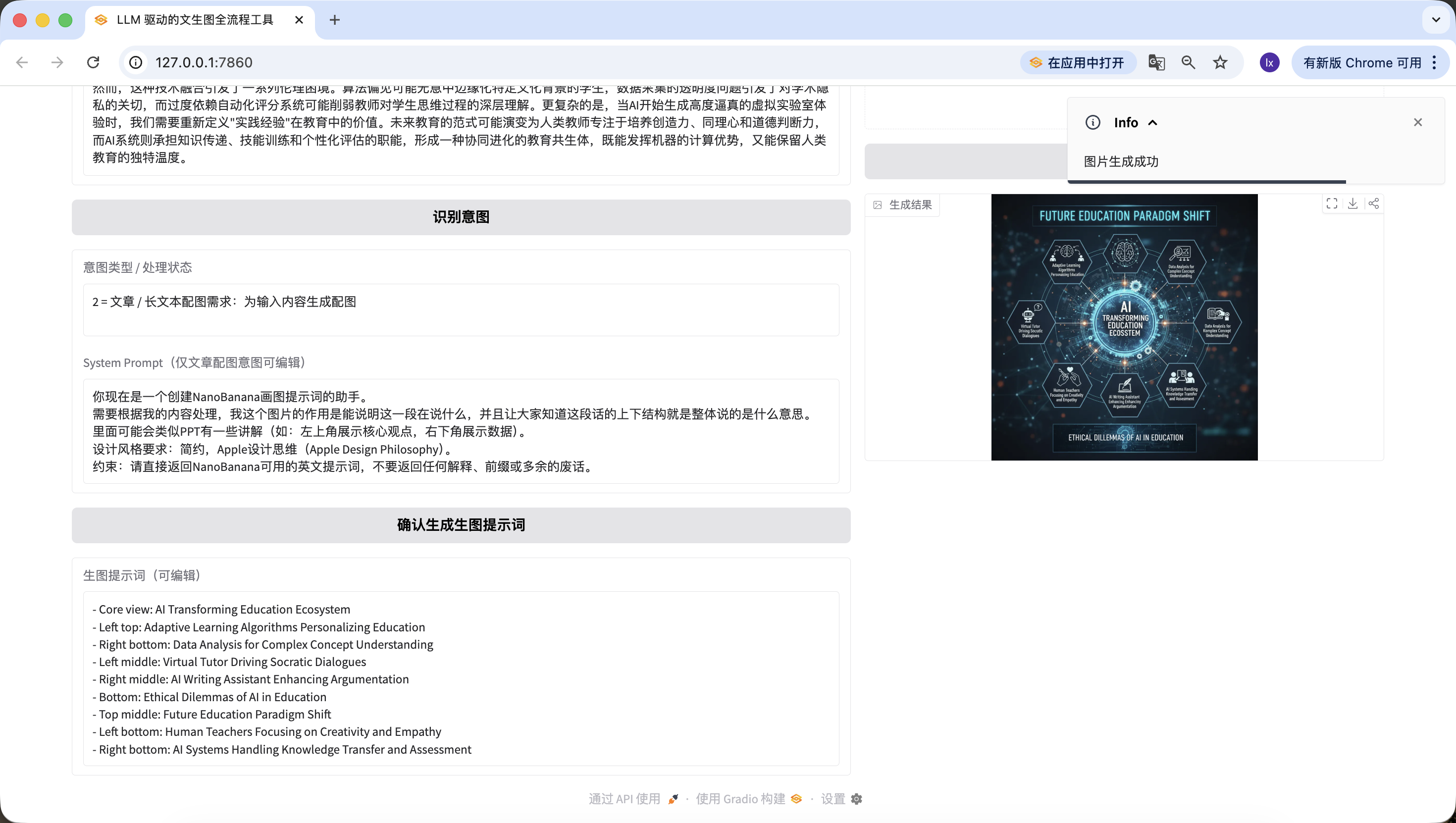
Wie aufregend! Wir haben endlich das erste Bild dieses Agenten erfolgreich generiert. Wenn du das generierte Bild genau betrachtest, siehst du, dass es mit unserem Text und dem Prompt uebereinstimmt. Hier hast du im Wesentlichen deinen eigenen Agenten implementiert!

Wir haben auch eine Bild-zu-Bild-Funktion hinzugefuegt. Lade dein Lieblingsbild hoch, und die KI wird automatisch den Stil uebernehmen.
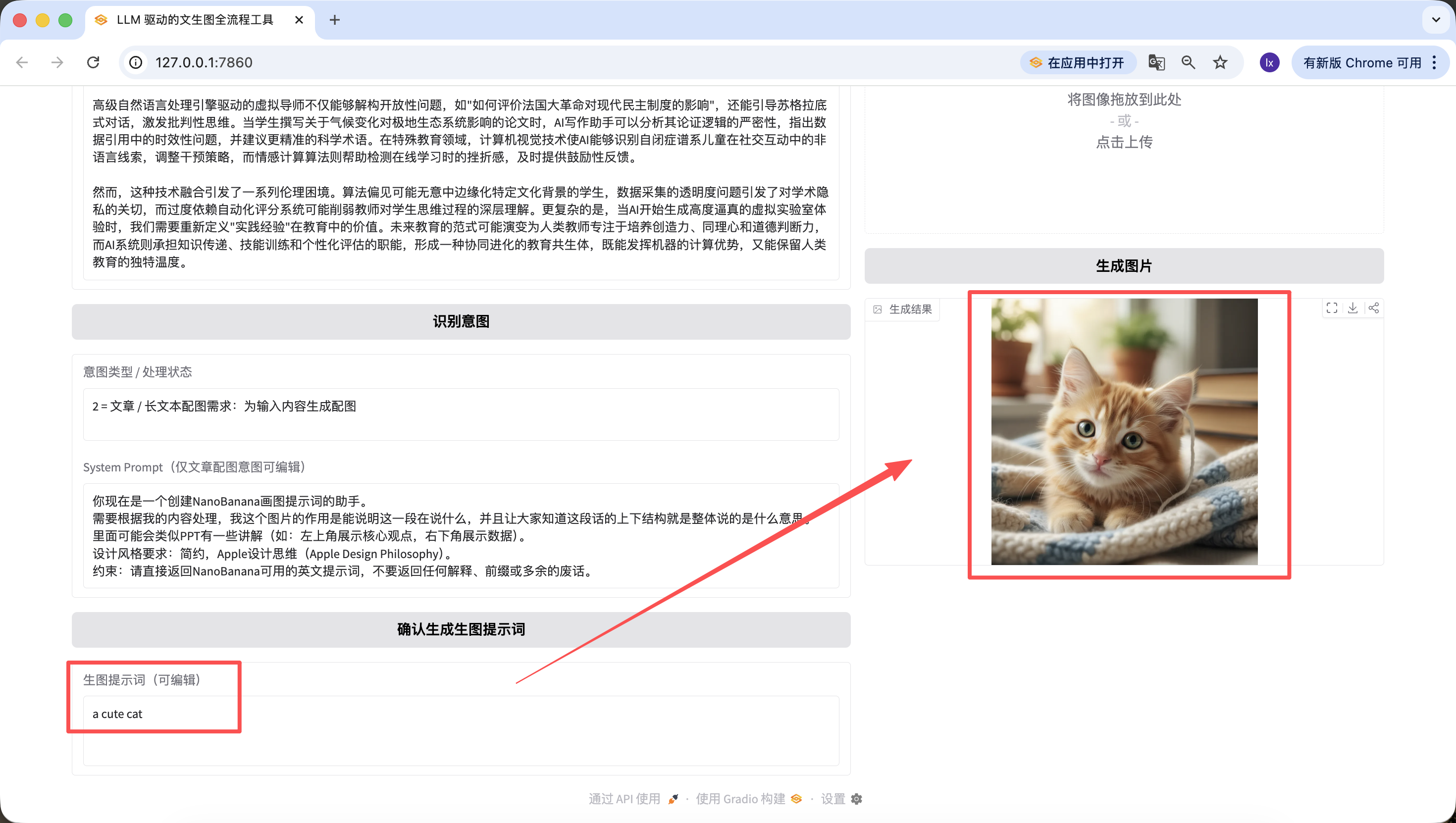
Es ist erwähnenswert, dass die in den vorherigen Schritten generierten Prompts auch auf der Webseite bearbeitet werden koennen, und wir den Prompt zum Zeitpunkt des endgueltigen Klicks als Massstab nehmen. Selbst wenn du hier "a cute cat" eingibst, wird das endgueltig generierte Bild nur eine suesse kleine Katze sein.
Kapitel 4: Zusammenfassung

Hurra! Endlich fertig! Um ehrlich zu sein, selbst ich habe beim Schreiben der letzten Zeile tief durchgeatmet, ganz zu schweigen von dir, der bis hierhin mitgemacht hat. Diesen gesamten Prozess komplett durchlaufen zu koennen, ist bereits sehr beeindruckend. Es zeigt, dass du wirklich die Haende auf die Tastatur gelegt und die Dinge Schritt fuer Schritt erledigt hast.
Waehrend ich diesen Inhalt geschrieben habe, habe ich immer wieder darueber nachgedacht, was wir eigentlich hinterlassen wollen. Die Antwort ist nicht der Modellname, die Parameter oder ein bestimmter fester Ansatz, sondern dir allmaehlich ein Gefuehl zu vermitteln: welche Dinge beruhigt der KI zum Verstehen und Planen uebergeben werden koennen und wo du nur die Richtung vorgeben musst. Sobald diese Arbeitsteilung steht, werden viele urspruenglich komplex erscheinende Generierungsprozesse fluessiger.
Im Rueckblick war dieser Weg gar nicht so kompliziert. Klar werden, welches Problem du loesen moechtest, den langen Text dem Sprachmodell zur Analyse uebergeben, dann die aufbereitete visuelle Absicht dem Bildgenerierungsmodell zur Darstellung uebergeben und schliesslich diesen gesamten Prozess als deinen eigenen kleinen Assistenten verpacken. Hier bist du nicht mehr nur "beim Modell-Nutzen", sondern beim Aufbau eines Systems, das dich langfristig bei der Arbeit begleiten kann. Und genau das ist es, was dieses Tutorial dir am meisten vermitteln moechte.
Aber du hast schon sehr Gutes geleistet! Wer bis hierhin gelernt hat, hat bereits eine grundlegende Beherrschung von Vibe Coding. Goenn dir eine kleine Pause!