データベースから Supabase へ
前回のレッスンでは、UI デザインツールである Mastergo と Figma の基本的な使い方を学び、GitHub を使ったコードの取得とバージョン管理ができるようになり、Zeabur を使ってウェブサイトをデプロイすることで、自分のアプリやウェブサイトをより多くの人に使ってもらえるようになりました。
知識のつながりを深めるため、今回のレッスンで取り上げる設計ツールとデプロイの新しい内容に入る前に、簡単な問題を通して前回のレッスンの重要なポイントを振り返りましょう。
- フロントエンドデザインツール、Figma、MasterGo の定義と使い方。
- デザインカンプをコードに変換する基本的な方法。
- GitHub とは何か、SSH の設定方法、最初のリポジトリの作り方。
- デプロイとは何か、Zeabur の使い方、GitHub やローカルコードをパブリックネットワークにデプロイして他の人にアクセスしてもらう方法。
もし上記のいずれかの問題について曖昧な部分があれば、前回のレッスンのドキュメントや資料を見直すことをお勧めします。WeChat 学習グループでいつでも質問してください。
今回のレッスンでは、APP やウェブサイトを「動く状態」から「実際のオンライン製品」に近づける方法を学びます。データベースを使ってプログラムの実行中のさまざまなデータ変化を管理するだけでなく、ユーザー体系(登録、ログイン、権限など)やその他の重要なバックエンド能力も備える必要があります。Supabase というバックエンドサービスプラットフォームをメインのテーマとして、まず「データベース+ユーザーシステム」という2つの基本機能を実現し、その後、Supabase が提供するコンポーネントを参考にしながら、モダンなクラウドサービスのバックエンドが通常含むコアモジュール、および各モジュールの具体的な役割と動作原理について理解を深めていきます。
学ぶ内容
- データとは何か、データベースとは何か、一般的なデータベースとその使い方
- Supabase とは何か、Supabase を使った基本的なデータベース操作方法
- Supabase を使ってアプリケーションに基本的なユーザー管理機能を追加する方法
- Supabase の高度な機能を学ぶ:Realtime、Storage、Edge Function
- Supabase に Google と GitHub のログインサポートを追加する方法
- ユーザーの登録/ログインをサポートし、データをオンラインデータベースに保存できる基本アプリケーション
- 再利用可能な Supabase バックエンドコードテンプレート(データベース+ユーザー管理など)、後続のプロジェクトにそのまま適用可能
1. データベースとは
1.1 データとは
デジタルの世界では、データ(Data)はどこにでも存在します。簡単に言えば、データは情報の担い手です。友人の連絡先、WeChat の記事、ショート動画、ゲーム内のキャラクターレベル、これらはすべてデータです。私たちのアプリケーションでは、データとは記録・管理すべきすべての情報であり、ユーザーのプロフィール、注文履歴、プログラムの設定などです。
一般的に、データはプログラム内でさまざまな形で表現されます。最も単純なものは変数であり、異なる変数を使って簡単な数値を記録できます。
# Python variable definition examples
# Integer variable: stores age information
age = 30
# Boolean variable: stores status (whether active)
is_active = True # True means active, False means inactive
# List variable: stores a set of score data
scores = [85, 92, 78, 90] # Contains 4 integer elements representing different scores
# Dictionary variable: stores multiple related information of a user
user_info = {
"age": 30, # Key "age" corresponds to the value of age
"height": 1.80, # Key "height" corresponds to the value of height (unit: meter)
"login_count": 156 # Key "login_count" corresponds to the value of login times
}上記の個人情報や注文履歴のような複雑なデータについては、より複雑なテーブルを使ってデータを表現できます。
| user_id | name | |
|---|---|---|
| 1001 | Alice | alice@example.com |
| 1002 | Bob | bob@example.com |
| order_id | user_id | amount | status |
|---|---|---|---|
| 901 | 1001 | 29.99 | completed |
| 902 | 1002 | 15.50 | pending |
しかし、構造が複雑で階層関係がある、あるいはフィールドが固定されていないデータについては、JSON 形式で記述できます。JSON はインターネットで共通のデータ中間フォーマットであり、ほぼすべてのプログラムが読み取り・解析でき、異なるシステム間でのデータ伝送に非常に便利です。例えば、1つの注文に複数の商品が含まれ、各商品に名前、数量、価格がある場合、従来のテーブルで表現すると非常に不格好になります。「注文テーブル」「商品テーブル」など複数のテーブルに分割し、関連フィールドで「注文に商品が含まれる」関係を表現するか、1つのテーブルで「商品1の名前、商品1の価格、商品2の名前...」のような冗長なフィールドを使う必要があります。商品数が固定されていない場合には対応できません。一方、JSON はネスト構造を使って「注文 - 商品 - 商品属性」の階層を明確に表現でき、直感的かつ柔軟です。
{
"order_id": 901,
"user_id": 1001,
"amount": 29.99,
"status": "completed",
"items": [
{ "sku": "BG-001", "name": "牛肉ハンバーガー", "quantity": 1, "price": 18.00 },
{ "sku": "SD-003", "name": "フライドポテト", "quantity": 1, "price": 6.99 },
{ "sku": "DK-002", "name": "コーラ", "quantity": 1, "price": 5.00 }
],
"shipping_address": {
"street": "科技園路123号",
"city": "深圳",
"zip_code": "518057"
}
}さらに一歩進んで、ベクトル(Vector)としてエンコードされたデータを考えると、ベクトルデータは通常、テキスト、画像、音声などの非構造化データを AI モデル(Embedding モデルなど)で処理して得られる数値表現です。その表現形式は次のようになります。
[0.123, -0.456, 0.789, ..., -0.234] (数百から数千の浮動小数点数で構成される配列)
まとめると、現実世界には非常に多くの異なる形態や用途のデータがあり、それぞれに専用のデータベースが必要になる場合があります。詳しくは下の図を参照してください。非常に多く感じられますよね?
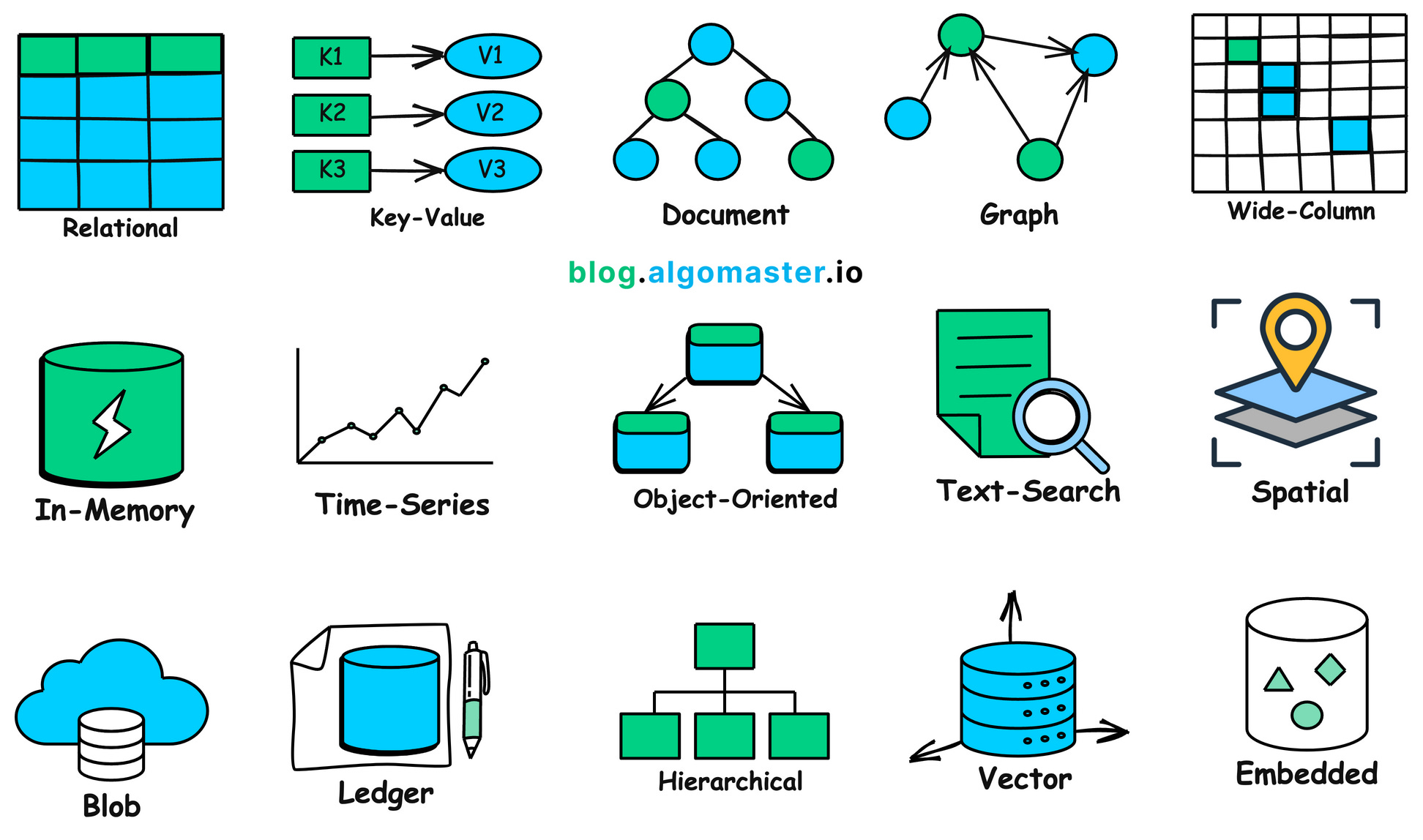
1.2 なぜデータベースが必要なのか
現実世界のデータは構造が複雑であることをすでに理解しました。これらのデータを効率的に保存・利用するためには、データを管理する専用のプログラムやコンテナが必要です。これがデータベース(Database)誕生の初衷です。データベースは本質的に特殊なプログラムであり、コアとなる役割はデータを標準化して整理し、安全に保存し、体系的に管理し、効率的なクエリと呼び出しをサポートすることです。
データベースがない場合、アプリケーションのデータはどうなるか想像してみてください。ユーザーがブラウザを閉じたりアプリを終了したりすると、一時的に読み込まれたすべての情報がそのまま失われます。ユーザーの利用状態(ログイン情報やカスタマイズ設定など)を永久に保存することもできず、異なるユーザー間で重要なデータ(商品在庫や注文記録など)を共有することもできません。すべてのデータを保存する仕組みが必要です!
さらに柔軟なことに、データベースのデプロイ方法は必要に応じて選択できます。ローカルサーバーにデプロイしてデータのローカル管理のニーズに応えることもできますし、クラウドにデプロイすることもできます。クラウドデータベースは弾力的なスケーリング(Scale)をサポートし、データ量やアクセス量の増加に伴って能力を拡張し、大量のデータと高トラフィックに対応できます。ユーザー数が大幅に増加しても、ユーザーの正常な利用体験を保証できます。
まとめると、データベースは効率的な永続ストレージ、精細な管理、高速なクエリ能力により、主に次のコアとなる問題を解決します。
- データの永続的な保存 :データベースがない場合、データはアプリケーションのメモリにのみ存在し、アプリケーションを閉じるとデータが失われます。データベースはこの問題を解決し、データをハードディスクなどの記憶媒体に永続的に保存し、データの長期保存を確保し、紛失のリスクを低減します。
- 便利なデータクエリと分析 :データベースは強力なクエリ言語(SQL など)を提供し、ユーザーが膨大なデータに対して複雑なクエリ、フィルタリング、分析を簡単かつ効率的に行えるようにします。これにより、企業はより賢明な意思決定を行えます。データベースがない場合、大量の無秩序なファイルから特定の情報を探し出すことは非常に時間がかかり困難な作業となります。
- 高性能と高トラフィックアクセスのサポート :データベースはインデックス最適化、クエリキャッシュ、接続プール、分散アーキテクチャなどの技術により、ミリ秒単位でクエリリクエストに応答し、数千から数万人のユーザーの同時アクセスをサポートできます。これは現代のインターネットアプリケーション(ECサイトのセールイベント、ソーシャルネットワークのリアルタイムフィードなど)にとって極めて重要であり、システムの応答速度とユーザー体験を確保します。データベースの高性能なサポートがなければ、大量のユーザーリクエストに直面した際、システムに深刻な遅延が発生したりクラッシュしたりする可能性があります。
- データの完全性と一貫性の保証 :データベースは一連のメカニズム(制約、トリガーなど)を通じて、データの正確性と一貫性を確保します。これは、データベース内のデータが事前に定義されたルールに従わなければならないことを意味します。例えば、ユーザーの年齢は数値でなければならず、注文番号は一意でなければなりません。これにより、不正または無効なデータの発生を効果的に防止します。
- データのセキュリティの確保 :データベースは強力なセキュリティメカニズムを提供し、ユーザー認証、アクセス制御、データ暗号化などを含み、データを不正なアクセス、変更、破壊から保護します。ハードウェア障害、人的ミス、悪意ある攻撃などの予期せぬ事態に対応するため、データベースはデータバックアップと復元機能も提供しています。定期的なバックアップにより、データの紛失や破損時に迅速に復元でき、ビジネスの継続性を確保します。
1.3 リレーショナルデータベースと非リレーショナルデータベース
前述の通り、データベースのコアとなる価値、デプロイ方法、弾力的な利点について理解しました。実際の選択において、まず直面するのはデータベースの2つの主要カテゴリー、リレーショナルデータベースと非リレーショナルデータベース(NoSQL)です。簡単な2つの段落でその違いを理解しましょう。
リレーショナルデータベースは構造が厳格な Excel テーブルのようなもので、すべてのデータは事前にフォーマットを定義する必要があります(Schema の内容を定義、例えば氏名と年齢が必要で、氏名は文字列、年齢は数値でなければならないなど)。異なるテーブルは関連フィールド(異なるテーブルを接続する識別子、例えばID番号)を通じて結びつけられます。その利点はデータが正確で信頼性が高いことで、銀行の送金、在庫管理などのエラーが許されない場面に特に適していますが、欠点は構造の変更が面倒で、大量のデータではパフォーマンスが制限される可能性があることです。
非リレーショナルデータベースは柔軟なフォルダのようなもので、形式の異なるドキュメント、画像、キーと値のペア(辞書の「見出し - 説明」構造に似たもの)を保存でき、事前にデータ構造を規定する必要はありません。急速に変化する要件や超大規模なデータ(ソーシャルメディアの大量の投稿など)により対応しやすく、スケーリング(サーバーを追加してパフォーマンスを向上)も容易ですが、一部の関連クエリ能力(異なるデータテーブルにまたがる情報の整理能力)と一貫性の保証(データが常に正確で矛盾ないことを確保)を犠牲にしており、フォールトトレランスが高いインターネットアプリケーションに適しています。
では、実際の応用ではどのようにデータベースを選ぶべきでしょうか。シナリオ別にまとめると、リレーショナルデータベースは金融取引、在庫管理、注文処理、会計システムなど、強い一貫性、複雑なトランザクション処理、および頻繁な読み書きのバランスのとれたアクセスが必要なシーンでよく使われます。非リレーショナルデータベースは、ソーシャルメディアコンテンツの保存、リアルタイムログ分析、IoT の大量データ書き込み、推薦システムの特徴読み書きなど、高トラフィックで読み書きのパターンが不均衡、構造が柔軟なニーズに適しています。
ただし企業にとって、初期段階ではどのデータベースを使うべきか考えるために大量の時間を費やす必要はありません。現在のデータベースは非常に成熟した製品サービスであり、最も直接的な方法は異なるクラウドサービスプロバイダー(サーバー、ストレージ、データベース、ソフトウェア、コンピューティングリソースなどの IT リソースと技術サービスを提供する事業者)に相談することです。クラウドサービスの公式営業に直接連絡し、自社の製品ビジネス要件に合ったデータベースソリューションをマッチングしてもらえます。エンタープライズアプリケーションを構築する便利な方法は、専門的なプロバイダーと優先的に協力することです。(注意:エンタープライズサービスは通常価格が高いため、まず複数のプロバイダーを調査・比較することをお勧めします。サーバーを購入してオープンソースのデータベースプログラムを自前でデプロイする代替案もあります。)
あるクラウドプロバイダーのデータベース選定ガイドも参考にできます。シナリオに応じて異なるデータベースタイプを選択でき、異なるクラウドプロバイダーのデータベース仕様を比較して最適なものを選べます。
| データベースタイプ | データベース名 | 価格 | 適用シナリオ |
|---|---|---|---|
| リレーショナルデータベース | RDS MySQL版 | 低 | 基本版:学習および小規模ウェブサイト 高可用版:ある程度ビジネス負荷のある中型データベースシナリオ クラスタ版:ビジネスの中断が許されず、アクセス負荷が大きい |
| RDS SQL Server版 | 高 | 基本版:テストおよび小規模商用ウェブサイト 高可用版:エンタープライズ級商用ウェブサイト クラスタ版:エンタープライズビジネスの中断が許されず、アクセス負荷が大きい | |
| RDS PostgreSQL版 | 最低 | 基本版:学習および小規模ウェブサイト 高可用版:ある程度ビジネス負荷のある中型データベースシナリオ クラスタ版:ビジネスの中断が許されず、アクセス負荷が大きいシナリオ、一般的な MySQL より高性能 | |
| RDS PPAS版 | 高 | 汎用型:Oracle 互換ビジネス、ただしビジネス負荷は低く、仮想化でニーズを満たせる 専有型:専有物理サーバーが必要なビジネス向け、通常は高トラフィックの Oracle 系ビジネス | |
| DRDS | 中 | エントリー版:4 Core 8 G、価格が手頃で中小規模オンラインビジネスに適している エンタープライズ版:16 Core 32 G、複雑な SQL の応答が良く、超高トラフィックのオンラインビジネスに適している アルティメット版:32 Core 64 G、複雑な SQL の実行応答が最も良く、超大規模仕様の選択肢を提供 | |
| NoSQLデータベース | Redis | 中 | デュアルマシン ホットスタンバイ Redis:通常、永続的データベースとしてビジネスの可用性を向上させる クラスタ版 Redis:通常、キャッシュレイヤーとしてアプリケーションのアクセスを高速化し、一般的なデータベースでは対応できない読み取り負荷を解決 |
| MongoDB版 | 中 | シングルノードインスタンス:開発、テストおよびその他のエンタープライズコアデータ以外の保存シナリオに適している レプリカセットインスタンス:一部のビジネスシナリオでデータベースの読み取り性能を高める要件(読み物系ウェブサイト、注文照会システムなどの読み多用少シーンや一時イベントなどの突発的ビジネス要件)に適している シャードクラスタインスタンス:複数のレプリカセット(各レプリカセットは3レプリカモード)で構成されるシャードクラスタインスタンスを基に、より高い読み取り性能要件を提供し、リアルタイムオンラインビジネスに高速読み取り性能を提供 |
言葉だけでは分かりにくいので、具体的な「ブログ記事」シナリオを使って、同じデータがリレーショナルデータベース(SQL)と異なるタイプの非リレーショナルデータベース(NoSQL)でどのように保存されるかを見てみましょう。
ブログプラットフォームがあり、以下の情報を保存する必要があるとします。
- ユーザー(Users):ユーザー ID、ユーザー名、メールアドレス
- 記事(Posts):記事 ID、タイトル、内容、著者 ID
- コメント(Comments):コメント ID、コメント内容、投稿者 ID、所属記事 ID
- タグ(Tags):タグ ID、タグ名
- 記事とタグの関係:1つの記事に複数のタグが関連付けられ、1つのタグに複数の記事が関連付けられる
リレーショナルデータベース (SQL) の例
SQL データベースでは、異なるタイプのデータをそれぞれ異なるテーブルに保存し、「外部キー」で関連付けます。この構造は明確で規範的であり、データの冗長性を減らします。
「コンテンツプラットフォームの記事管理」を例にすると、「ユーザー、記事、コメント、タグ」を混在させるのではなく、5つの機能が単一なテーブルに分割され、各テーブルには明確な「責任範囲」と厳格な構造定義(Schema)があります。
usersテーブル (ユーザー情報の保存)
| user_id (主キー) | username | |
|---|---|---|
| 101 | Alice | alice@example.com |
| 102 | Bob | bob@example.com |
postsテーブル (記事情報の保存)
| post_id (主キー) | title | content | author_id (外部キー) |
|---|---|---|---|
| 1 | SQL入門 | これはSQLデータベースに関する記事です... | 101 |
| 2 | NoSQL入門 | NoSQLは柔軟なデータモデルを提供します... | 102 |
commentsテーブル (コメント情報の保存)
| comment_id (主キー) | body | commenter_id (外部キー) | post_id (外部キー) |
|---|---|---|---|
| 1001 | 素晴らしい! | 102 | 1 |
| 1002 | 勉強になりました。 | 101 | 2 |
| 1003 | もっと例はありますか? | 101 | 1 |
tagsテーブル (タグの保存)
| tag_id (主キー) | tag_name |
|---|---|
| 51 | データベース |
| 52 | 技術 |
| 53 | 入門 |
post_tagsテーブル (記事とタグの多対多の関係を保存、テーブル結合の特徴を示す)
| post_id (外部キー) | tag_id (外部キー) |
|---|---|
| 1 | 51 |
| 1 | 52 |
| 2 | 51 |
| 2 | 52 |
| 2 | 53 |
「Alice が投稿した『SQL入門』(post_id=1)の完全な情報(記事内容、著者、コメント、タグを含む)」をクエリする場合、複数テーブルの結合(JOIN)クエリを実行し、外部キーで5つのテーブルを関連付け、データを集計する必要があります。SQL 文は以下の通りです。
SELECT
p.title,
p.content,
u.username AS author,
c.body AS comment,
t.tag_name AS tag
FROM
posts p
JOIN
users u ON p.author_id = u.user_id
LEFT JOIN
comments c ON p.post_id = c.post_id
LEFT JOIN
post_tags pt ON p.post_id = pt.post_id
LEFT JOIN
tags t ON pt.tag_id = t.tag_id
WHERE
p.post_id = 1;このクエリは5つのテーブルにまたがり、関連するすべてのデータを集計して返します。これがリレーショナルデータベースのコアの利点です。正規化と結合操作により、さまざまな複雑なクエリを柔軟に実行しながら、データの一貫性と最小の冗長性を保証します。
非リレーショナルデータベース (NoSQL) の例
NoSQL データベース(MongoDB、Redis など)の設計思想は SQL とは逆で、データの分割と正規化を重視せず、通常はビジネス上関連するすべてのデータをまとめて集約し、クエリ時の結合操作を減らすことで読み取り性能を向上させます。
NoSQL データベースの中で、ドキュメントデータベース(Document Database)は最もよく使われるタイプの一つであり、MongoDB がその代表的な例です。基本保存単位として「ドキュメント」を使用します。ここでの「ドキュメント」は日常的な「文書」ではなく、JSON に似たデータ構造です(MongoDB では実際に BSON 形式を使用し、より多くのデータ型をサポート)。事前に統一の Schema(データ構造)を定義する必要はなく、各ドキュメントのフィールドを柔軟に増減でき、フィールドの型も自由に調整でき、データ形式が変動しやすいシーンに完璧に適応します。
ドキュメントデータベースでは、通常、1つの記事とその関連情報(コメント、タグなど)を1つのドキュメントに保存します(ドキュメント形式は JSON に似ており、フィールドを柔軟に定義でき、事前の Schema の制定は不要)。コアとなる考え方は「1つのビジネスシナリオにおける完全な情報を1つのドキュメントに保存する」ことで、クエリ時の複数データソースの結合を避けることです。
posts コレクション内の1つのドキュメント例:
{
"_id": 1,
"title": "SQL入門",
"content": "これはSQLデータベースに関する記事です...",
"author": {
"user_id": 101,
"username": "Alice",
"email": "alice@example.com"
},
"tags": [
"データベース",
"技術"
],
"comments": [
{
"comment_id": 1001,
"body": "素晴らしい!",
"commenter": {
"user_id": 102,
"username": "Bob"
}
},
{
"comment_id": 1003,
"body": "もっと例はありますか?",
"commenter": {
"user_id": 101,
"username": "Alice"
}
}
]
}この設計の利点は非常に直感的です。「最初の記事の完全な情報(著者、コメント、タグを含む)」を取得したい場合、_id:1 でこの1つのドキュメントをクエリするだけで、データベースは1回の読み取りですべてのデータを返します。SQL のように3〜4回のテーブル結合操作を行う必要はなく、読み取り効率が大幅に向上します。
しかし、明らかなトレードオフ(Trade-off)もあります。データが「集約保存」されるため、避けられないデータの冗長性が生じます。例えば、著者「Alice」の username は彼女が書いたすべての記事のドキュメントに組み込まれています。ある日「Alice」がユーザー名を「Alice_New」に変更した場合、理論上は彼女の情報を含むすべての記事ドキュメントを走査し、author.username フィールドを1つずつ更新する必要があります。操作が煩雑なだけでなく、ネットワークやサーバーの問題により一部のドキュメントの更新に失敗し、「同じユーザーが異なる記事でユーザー名が一致しない」という状況が発生する可能性があります。
ただし実際のビジネスでは、この冗長性は「許容可能」なことが多いです。ブログ、ニュース、EC商品詳細などの「読み多用少」シーン(ユーザーがコンテンツを閲覧する回数が、著者がユーザー名を変更する回数よりはるかに多い)では、少量の冗長性で「極限の読み取り性能」を得る方がより良い選択です。一方、「書き多用少」(ユーザー情報の頻繁な変更など)のシーンでは、ビジネス要件に応じてドキュメントデータベースを使用するかどうかを検討する必要があります。
以上が異なるデータベースの簡単な紹介です。より具体的なデータベースタイプに興味がある場合は、以下の資料を参照して異なるタイプのデータベースを試してみてください。
Examples of SQL databases: Db2、MySQL、PostgreSQL、YugabyteDB、CockroachDB、Oracle Database、Azure SQL Database
Examples of NoSQL databases: Redis、CouchDB、MongoDB、Cassandra、Elasticsearch、BigTable、Neo4j、HBase
2. Supabase
前述の通り、いくつかの一般的なデータベースとそれぞれに適した使用シーンについて紹介しました。しかし実際のプロジェクトでは、データベースは通常、バックエンド体系の基礎的なモジュールの1つに過ぎません。データの保存とクエリに加えて、ユーザー登録・ログイン、権限検証、ファイルアップロードと保存、外部 API インターフェース、さらには定時タスクやリアルタイム通知など、一連の問題を解決する必要があります。適切なデータベースを選ぶだけでは、アプリケーションが「すぐにオンラインで稼働」するわけではありません。その間には大量の煩雑なバックエンドエンジニアリング作業があります。
そこで、より大きな背景としてバックエンドサービスを考える必要があります。完全なアプリケーションは通常「フロントエンド+バックエンド」で構成されています。フロントエンドはページの表示とユーザーインタラクションを担当し、バックエンドはデータの保存、ユーザーログイン、ビジネスロジックの処理などを担当します。かつて、開発者は自らサーバーを構築し、データベースを設定し、API を設計・実装し、さらに権限管理、セキュリティポリシー、スケーラビリティや監視・運用保守などを手動で処理する必要があり、全体のプロセスは反復的で時間がかかるものでした。このような重複作業を解決するため、業界ではBaaS(Backend as a Service、バックエンド・アズ・ア・サービス)が登場しました。データベース、ユーザー認証、ファイル保存、リアルタイム能力などの一般的なバックエンド機能をクラウドプラットフォームにパッケージ化し、開発者は SDK / API を通じてこれらの能力を直接呼び出すことができ、インフラストラクチャをゼロから構築・運用する必要がなくなります。
この背景の下で、Supabase は新しい世代の BaaS の代表と見なすことができます。PostgreSQL をコアデータベースとし、その上に Auth、Storage、Realtime、Edge Functions、Vector など一連のバックエンド能力を統合し、開発者に「Postgres を中心としたワンストップバックエンドプラットフォーム」を提供しています。では、「データベースだけを選ぶ」から「完全なバックエンド開発プラットフォームを選ぶ」へと視点を広げ、Supabase がどのような作業を省いてくれるのか、そしてプロジェクトをプロトタイプから利用可能な製品までの距離をどのように大幅に短縮するのかを見ていきましょう。
2.1 ステップバイステップガイド
Supabase の全体的な位置づけを明確に把握した後、Supabase コンソールの操作パスに沿って、具体的にどのコア能力を提供しているか、そして各能力のコアとなる責務を1つずつ紐解いていきます。Supabase に関わる各オプションについて詳しく説明し、Supabase の基本操作を素早く身につけられるようサポートします。

Supabase の公式サイトにアクセスしてログインした後、コンソールのホームページで New project をクリックして作成フローに入ります。
設定する主な内容は Project Name、データベースパスワードを入力します。リージョンはプログラムのターゲットユーザーに最も近い地域を選ぶだけで済みます。
作成が成功すると、コンソール左側のサイドバーにすべてのコア機能モジュール(Table Editor、SQL Editor、Database、Authentication など)が表示されます。以降の操作はこれらのモジュールを中心に展開します。
テーブルエディタ
Table Editor は Supabase のビジュアルデータテーブルエディタと見なせます。Excel を操作するように、SQL 文を書かずにマウスのインタラクションだけでデータベース内のデータを直接閲覧・修正できます。
注目すべきは Schema です。Schema はデータベース内の「リソースコンテナ」として理解でき、テーブル、ビュー、関数、インデックスなどのリソースをグループ管理するために使用されます。主な役割は2つあります。1つは名前の競合を避けること(異なる Schema 下で同名のテーブルが存在可能)、もう1つは権限の分離を実現すること(特定のユーザーのみが特定 Schema 下のテーブルにアクセスできるようにするなど)。
エディタ上部の Schema ドロップダウンボックスをクリックして異なるコンテナに切り替えられます。日常の開発では通常、次の2種類に注目すれば十分です。
public:デフォルトのパブリックリソースコンテナ。開発者が新規作成したビジネス用テーブル(「記事テーブル」「コメントテーブル」など)はすべてここに保存されます。auth:ユーザー認証専用コンテナ。その中のusersテーブルはすべての登録ユーザー情報(ユーザー ID、メールアドレス、ログイン時間など)を自動的に保存します。この Schema 下のデフォルトテーブルは手動で変更しないことをお勧めします。認証機能に影響を与える可能性があります。
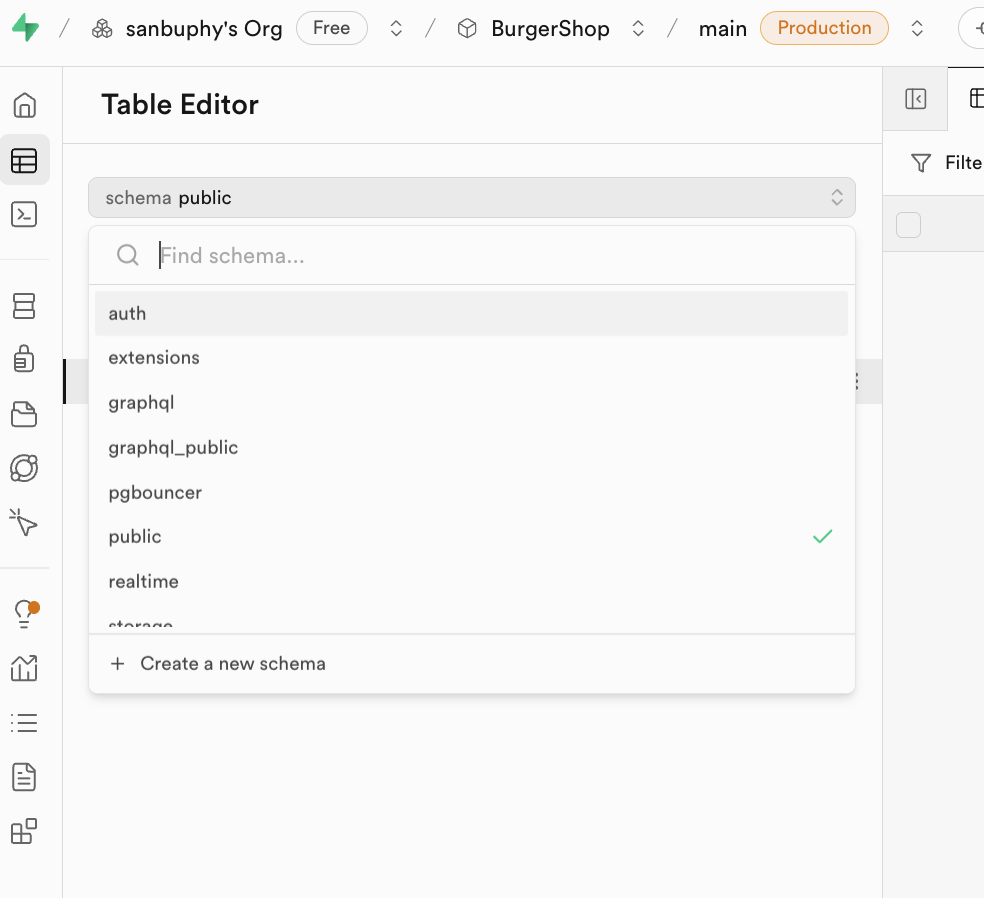

SQL エディタ
SQL Editor は Supabase の SQL 文実行ツールで、コードを使ってデータベースを直接操作できます。大規模言語モデルに直接 SQL 文を生成させ、右側に入力後 RUN をクリックすれば文でテーブルを作成・変更できます。また、Results で絞り込まれたテーブルデータを直接確認できます。
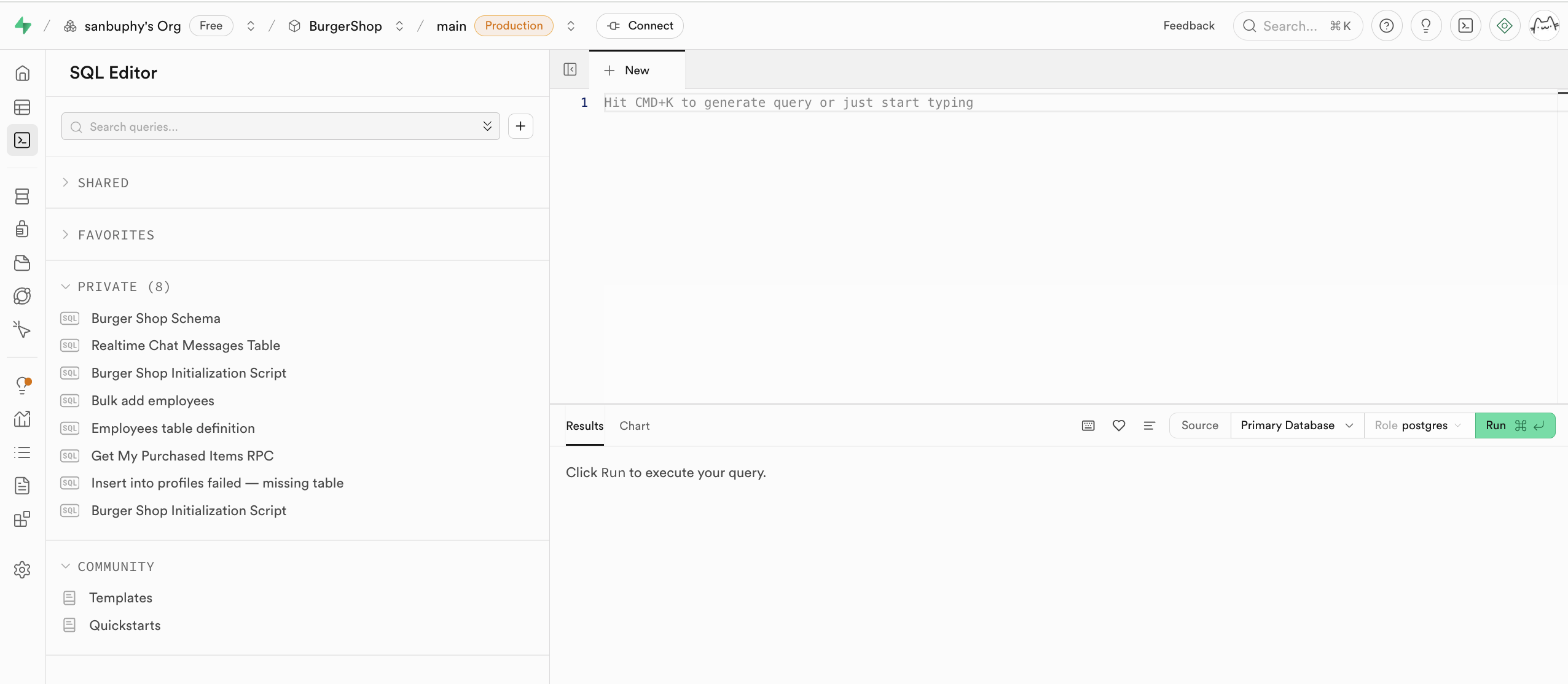
RUN を実行した後、Table Editor の public schema で新しく作成されたデータテーブルを確認できます。実行された文は左側の PRIVATE 欄に保存され、下部のハートマークをクリックしてそのクエリや作成文をお気に入りに追加することもできます。
データベース管理センター
Database は Supabase のデータベース管理センターで、すべてのデータテーブルをビジュアルに閲覧・管理し、テーブル間の相互接続線を通じて異なるテーブル間の関連関係(つまり外部キー制約、データ間の参照関係を示す)を理解できます。
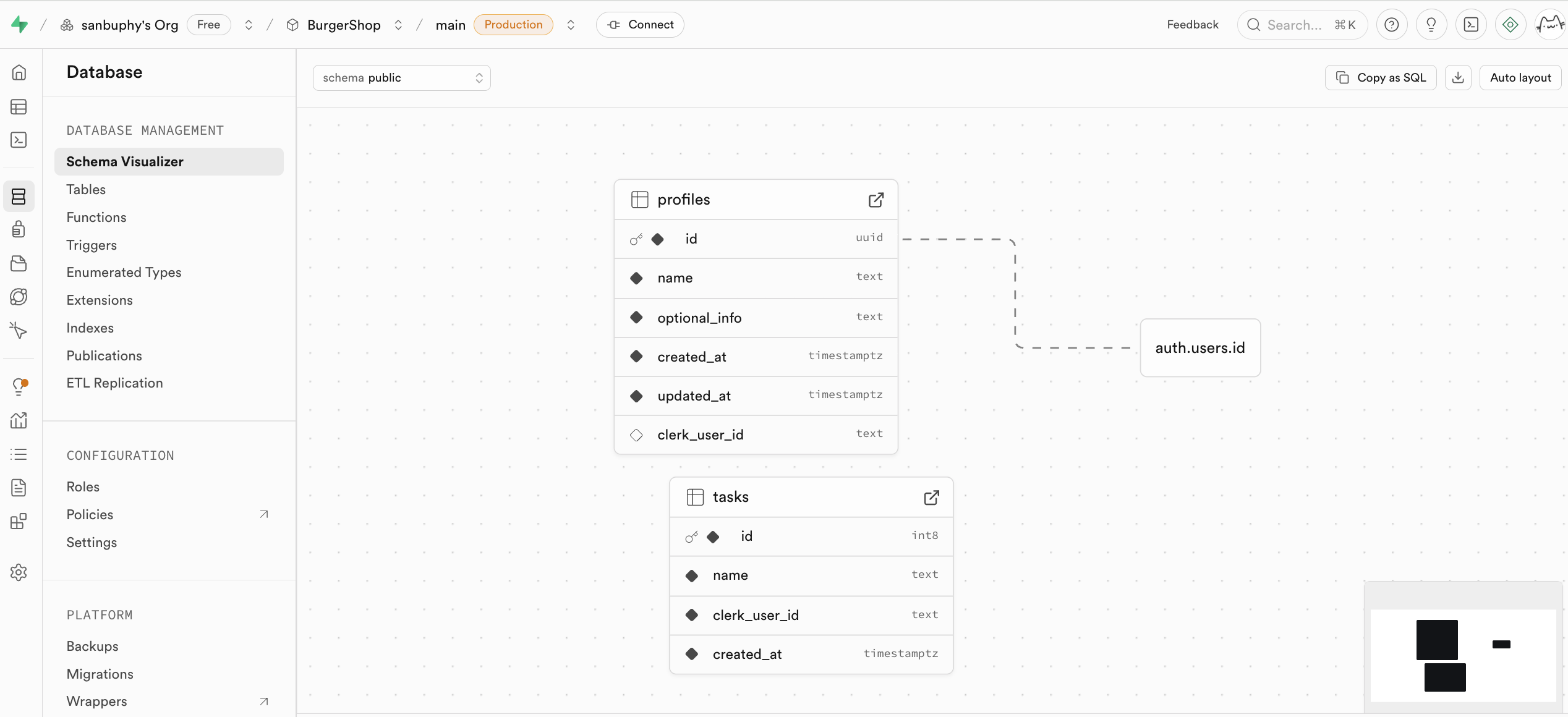
テーブルを手動で新規作成したい場合、tables 内で直接新しいテーブルを作成できます。詳細は後のチュートリアルで説明します。
認証
Authentication はユーザーの登録、ログイン、権限を管理します。デフォルトのユーザー管理システムのデータはすべてここに保存されます。すぐに使えるユーザー登録、ログイン、パスワードリセット、メール確認などの機能を提供し、サードパーティの OAuth ログイン(WeChat、GitHub、Google など)もサポートしています。すべてのユーザーデータは自動的にデータベースの auth.users テーブルに同期されます。
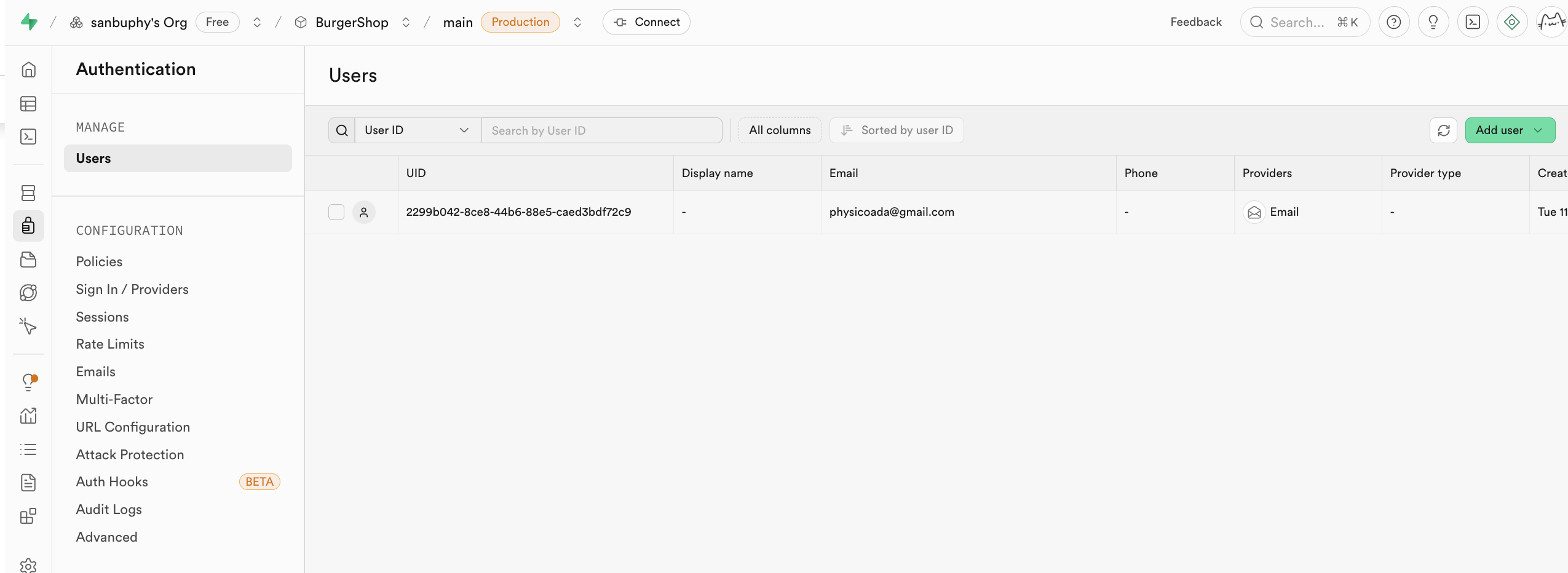
Provider オプションで Supabase がサポートする異なるユーザー情報ログインエントリを見つけられます。デフォルトでは Email が使用されます。GitHub や Google アカウントでログインしたい場合は、さらに多くの属性設定が必要です。以下のレッスンで詳しく説明します。
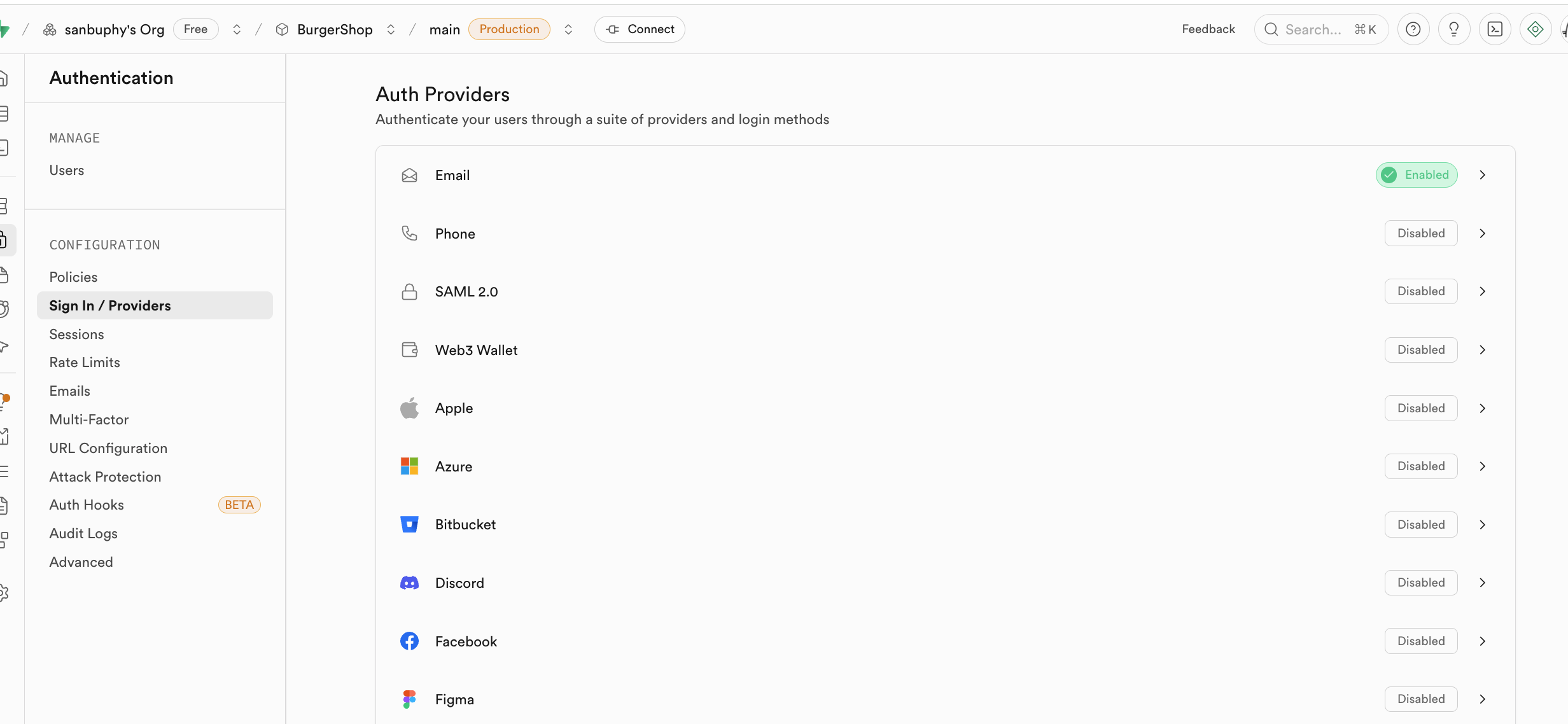
Sign In / Providers には登録メール動作の制御も含まれています。メール登録のたびにユーザーが招待を受け入れてからユーザーになる必要がないようにしたい場合、Confirm email の強制要件を解除できます。
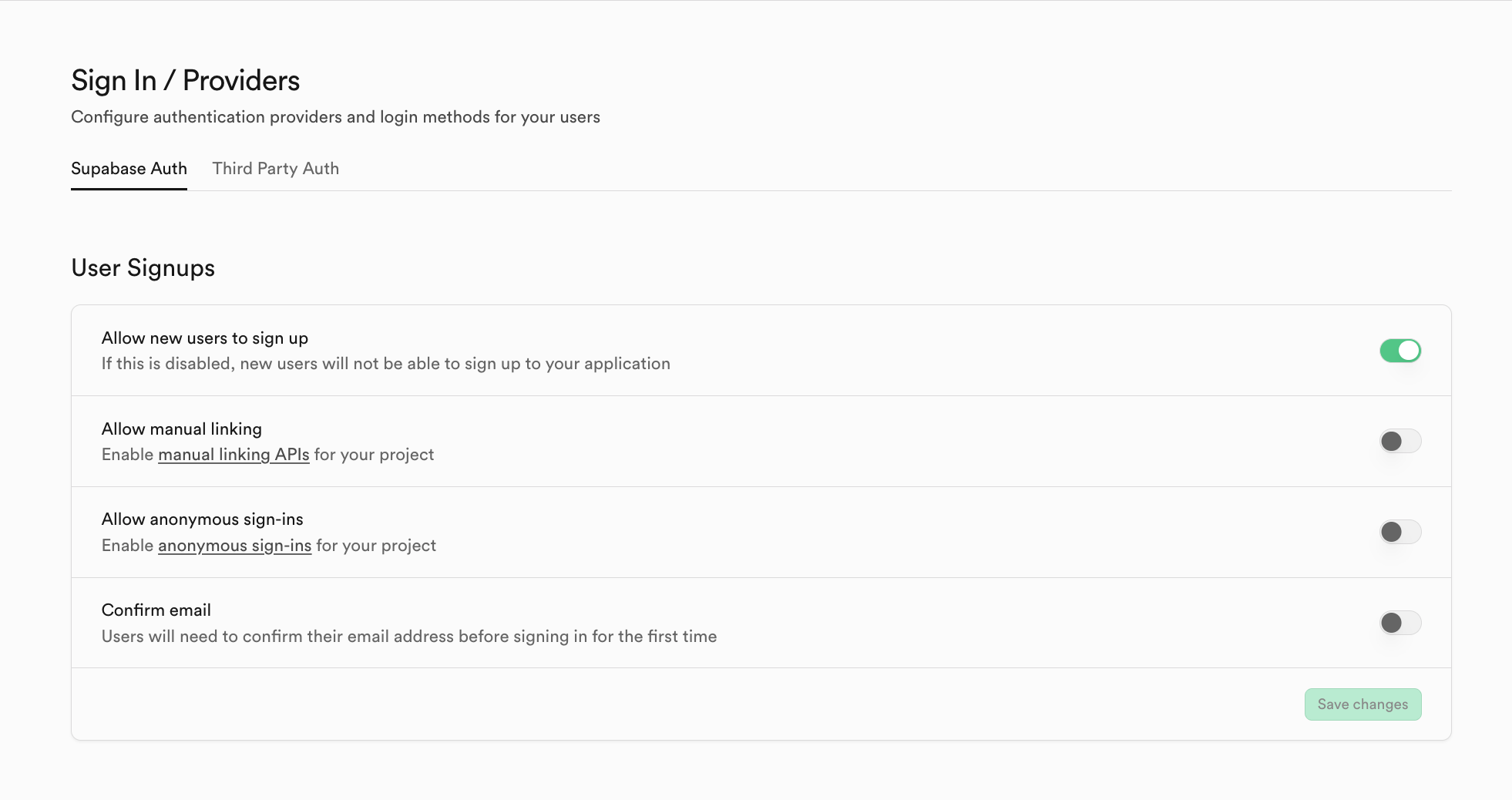
Supabase 以外の他の Auth システムプロバイダーに切り替えたい場合、Third Party Auth をクリックできます。例えば、ここでは Clerk をサードパーティのシステムプロバイダーとして使用しています。
登録ユーザーの短期間のアクセス急増が心配な場合、Rate Limits で対応するトラフィック制限ポリシーを有効にできます。
ストレージ
Storage は Supabase のストレージシステムで、Amazon Cloud の S3 コンセプトと互換性があり、あらゆるタイプのファイル(画像、動画、ドキュメント、音声など)の保存に使用でき、アクセス権管理(公開または非公開)とダウンロードリンクの取得(永久リンクまたは一時リンク)を提供します。アプリケーション内でユーザーに関連するファイルコンテンツのアップロードとダウンロード管理を簡単に行え、Supabase の認証システムとシームレスに統合され、精細なアクセス制御を実現します。
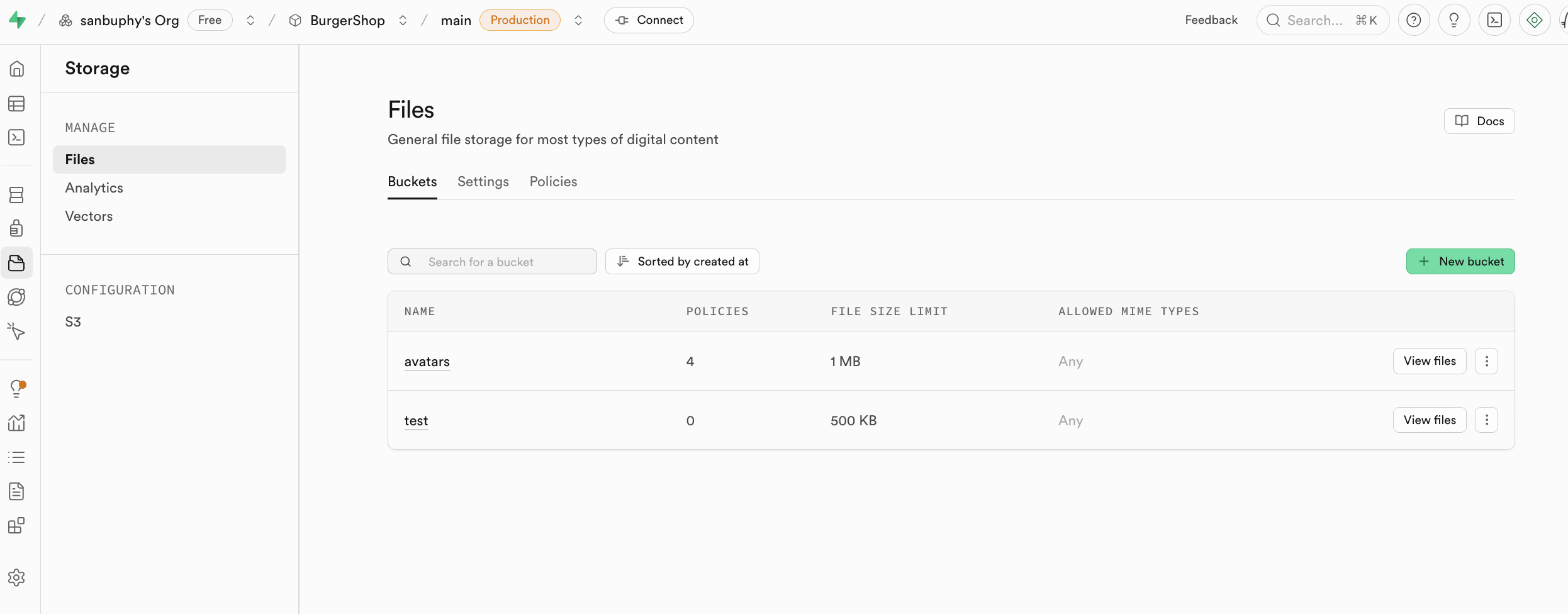
今回のレッスンの高度なプロジェクトで Storage の具体的な使い方を説明します。
S3 の関連プロトコルを使用して操作したい場合、対応する設定を直接使用できます。
Amazon Cloud(Amazon クラウドサービス、略称 AWS)は Amazon が提供するクラウドコンピューティングプラットフォームです(大規模なネットワークサーバールームのようなもので、必要に応じてコンピューティングとストレージリソースをレンタルできます)。S3(Simple Storage Service)は AWS 内でファイルの保存に特化したサービスです(無限の大きさのオンラインストレージのようなもので、画像、動画、バックアップなど各種ファイルを保存できます)。現在、最も人気のあるオブジェクトストレージサービスであり、事実上の業界標準となっています。
なぜ S3 互換 API にするのか? :S3 はほぼ20年間存在しており、市場には大量の既存ツール、SDK、ドキュメントがあります。S3 との互換性は、これらのリソースを直接活用でき、各種関連ツールをゼロから作る必要がないことを意味し、ビジネスのオンライン化要件を迅速に満たせます。
エッジ関数
バックエンドをデプロイしたくないが、データベースと関数の操作を使いたい場合、Edge Functions を使って独自サーバーなしのバックエンドコア能力を構築できます。これは Supabase が提供するグローバル分散型サーバーサイド関数です。簡単に言えば、独自のバックエンドサーバーを購入・管理することなく、クラウド上で実行されるバックエンドコードを直接書いてデプロイできます。これらの関数はグローバルネットワークのエッジノードにデプロイされ、ユーザーに最も近い場所で自動的に実行されるため、ネットワーク遅延を大幅に削減し、究極の応答速度を提供します。Supabase のダッシュボードで直接作成、編集、デプロイが可能で、開発フロー全体が非常に便利です。
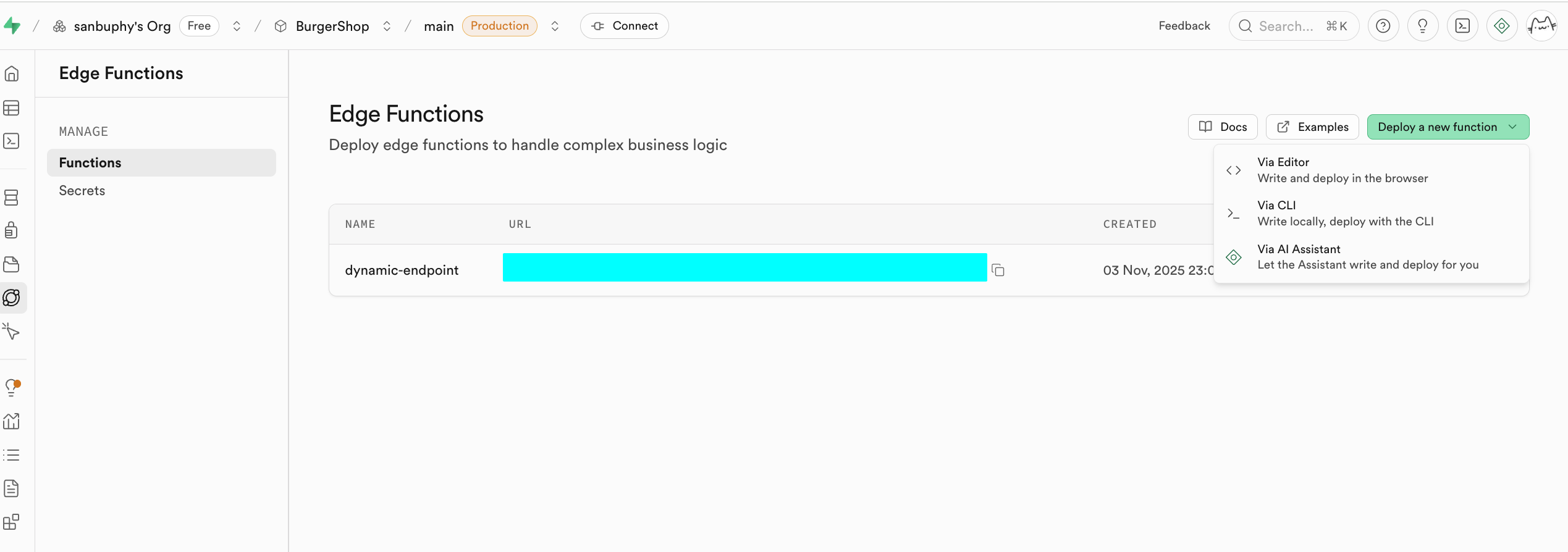
Edge Functions のコアとなる用途の一つは、セキュアな中間層として機能し、機密情報と認証キーを保護することです。フロントエンドコードでサードパーティサービス(OpenAI、Stripe など)を直接呼び出すと、API Key が露出し、大きなセキュリティリスクをもたらします。Edge Functions を通じて、フロントエンドアプリケーションは Supabase の関数とのみ通信し、すべての秘密は Supabase 内で保管されます。
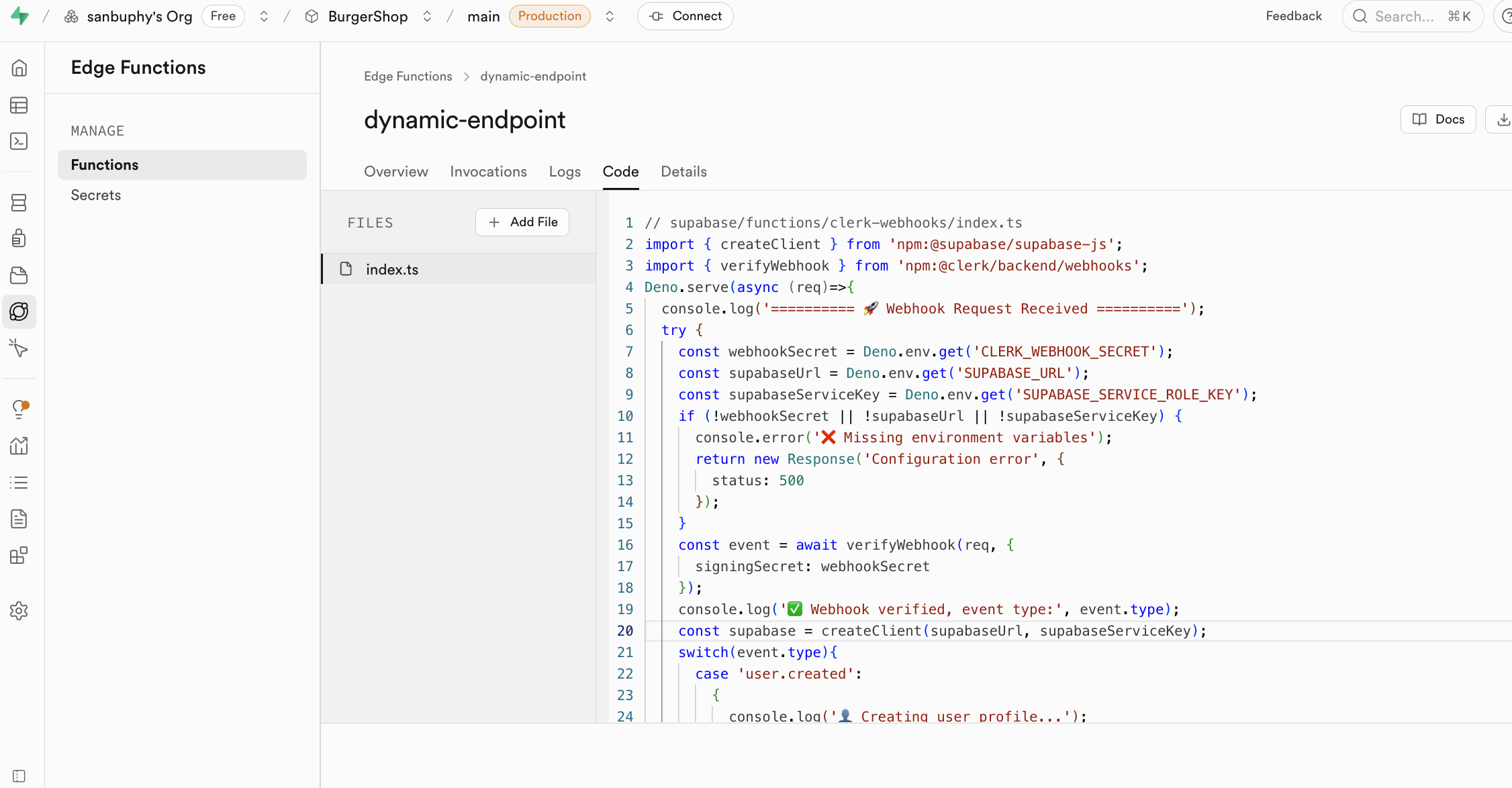
Edge Functions の関数は、secrets で公開されたキーを環境変数として使用し、Deno.env.get で読み込むことで、サードパーティサービスの呼び出しを実現します。これにより、機密キーはクライアント(ブラウザ)に決して露出せず、不正利用のリスクを完全に排除します。
Supabase Edge Function をリクエストする際、リクエストヘッダーに対応する Supabase キーを含める必要があります。以下は最小限の例です。
// 核心配置(替换为你的实际信息)
const projectId = "あなたの Supabase プロジェクトID";
const functionName = "対象 Edge Function 名";
const supabaseKey = "Supabase anon_key";
// 调用函数
async function callEdgeFunction() {
const url = `https://${projectId}.supabase.co/functions/v1/${functionName}`;
try {
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
"Authorization": `Bearer ${supabaseKey}` // 关键:携带密钥完成认证
},
body: JSON.stringify({ order_id: "123", action: "refund" }) // 自定义请求数据
});
const result = await response.json();
console.log("调用成功:", result);
} catch (error) {
console.error("调用失败:", error.message);
}
}
// 执行调用
callEdgeFunction();さらに、Edge Functions は Supabase のユーザー認証システムとシームレスに統合されています。ログイン済みのユーザーが関数を呼び出すと、その身元情報が関数に渡されます。これにより、関数内で現在のユーザーを簡単に識別し、身元に基づいて権限制御を実行できます。さらに重要なのは、関数がデータベースを操作する際、設定済みの行レベルセキュリティポリシー(Row Level Security)に自動的に従い、ユーザーが操作権限のあるデータのみにアクセス・変更できることを保証します。これにより、セキュアなマルチユーザーアプリケーションの構築が簡単になります。
Edge Functions の応用シーンは非常に広く、さまざまなバックエンドタスクを処理できます。サードパーティサービスからの Webhook イベント(決済完了、コードコミットなど)のリッスンや、対応するデータ処理ロジックの自動実行に非常に適しています。メール通知の送信、PDF レポートの生成、複雑なビジネスロジックをカプセル化するカスタム API インターフェースの作成、またはサーバーサイドで実行したいあらゆる計算タスクに使用でき、アプリケーションの能力を大幅に拡張します。
具体的な一般的な例として、認証ツールの Clerk があります。Clerk はユーザーのログイン、登録、情報更新など認証関連の操作の処理にのみ使用され、ビジネスデータベースを直接管理するものではありません。これらの認証動的データをビジネスデータベースに同期したい場合、Webhook イベントを通じて Edge Functions をリクエストすることで実現する必要があります。Edge Functions は Clerk が発信する Webhook シグナルをリッスンし、自動的にデータ同期ロジックを実行して、Supabase データベース内のユーザー情報と Clerk のログイン状態をリアルタイムに同期させます。独立したバックエンドをデプロイする必要はありません。
リアルタイムデータ同期エンジン
Realtime は Supabase のリアルタイムデータ同期エンジンで、アプリケーションが API を繰り返しポーリングすることなく、データベースの変更通知を即座に受け取れるようにします。データベース内のデータで INSERT、UPDATE、DELETE 操作が発生すると、Realtime は WebSocket を通じてこれらの変更をすべての接続済みクライアントにリアルタイムでプッシュします。これはリアルタイムインタラクションを必要とするアプリケーションの構築に不可欠です。
Realtime は主に3つのコア機能を含み、大部分のリアルタイムシナリオをカバーしています。
- Postgres Changes: データベーステーブルの変更を直接リッスンします。特定のテーブル、特定のイベント(挿入、削除、更新)を正確にサブスクライブでき、フィルタ条件に基づいて通知を受け取ることも可能です。行レベルセキュリティポリシー(Row Level Security)と完璧に統合され、ユーザーが権限のあるデータ変更のみを受け取れることを保証します。
- Broadcast: クライアント間でチャンネル(Channel)を通じて低遅延の一時メッセージを送信できます。チャットルーム、リアルタイムカーソル追跡、オンラインゲームの状態同期などの機能の実装に非常に適しています。
- Presence: オンラインユーザーの状態を追跡・同期するために使用します。「誰がオンラインか」「現在 X 人が閲覧中」などの機能を簡単に実装でき、コラボレーション系アプリケーションに非常に適しています。
後続のプロジェクトベース学習でこの内容について詳しく説明します。
プロジェクト設定
Project Settings は Supabase プロジェクトの高度な設定セクションで、コンピューティングリソースの深いスケジューリングや、各種機能の基盤パラメータの精細な設定を実現できます。
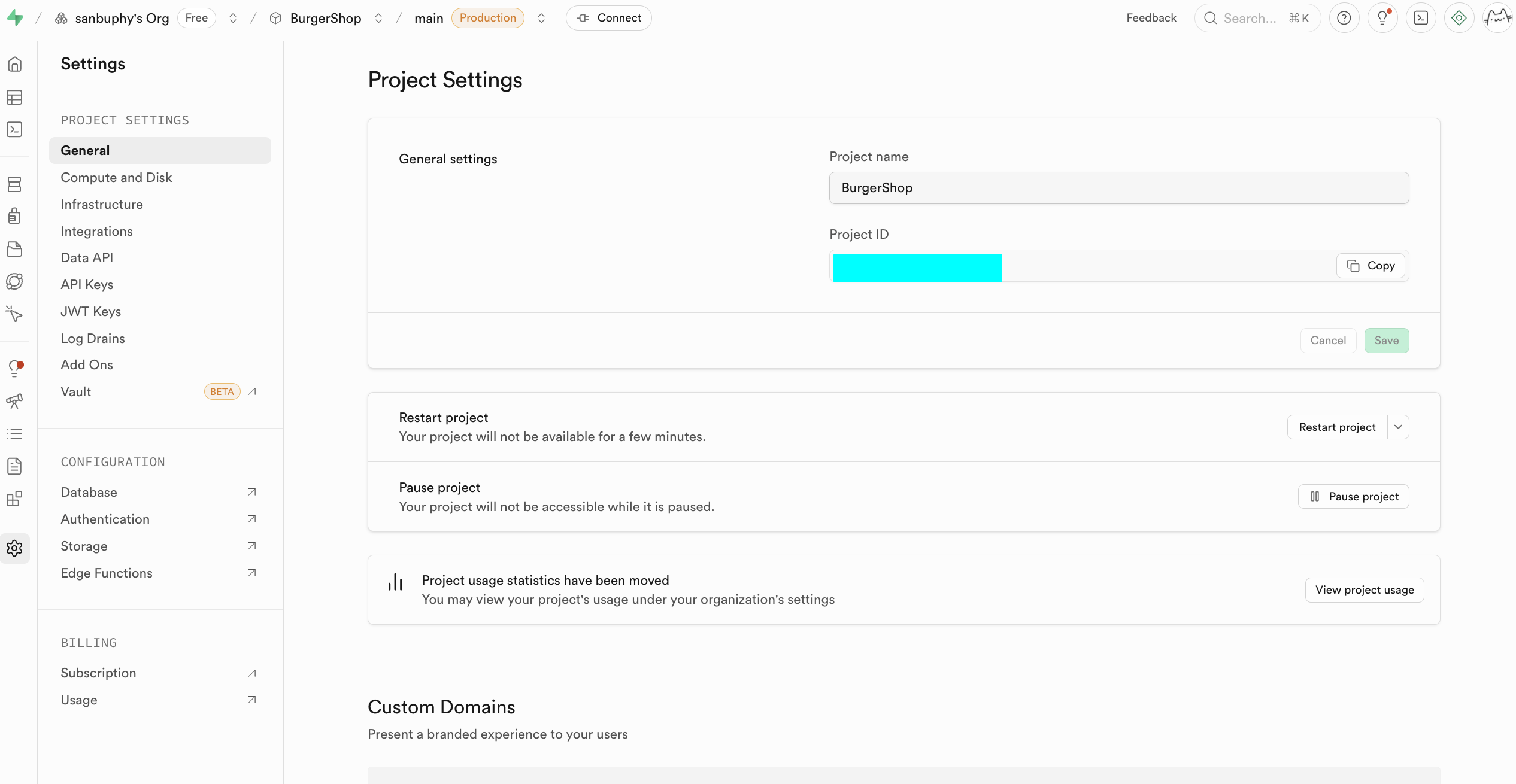
入門段階では、以下の2つのコアセクションに注目するだけで十分です。1つは Data API で、ここで重要な「Supabase URL」を取得できます。これは https://xxx.supabase.co 形式の RESTful エンドポイントであり、すべてのデータクエリ、追加、変更、削除操作の「エントリアドレス」です。フロントエンドまたはサーバーサイドはこの URL を通じて Supabase クライアントを初期化し、データベースとの接続を確立する必要があります。
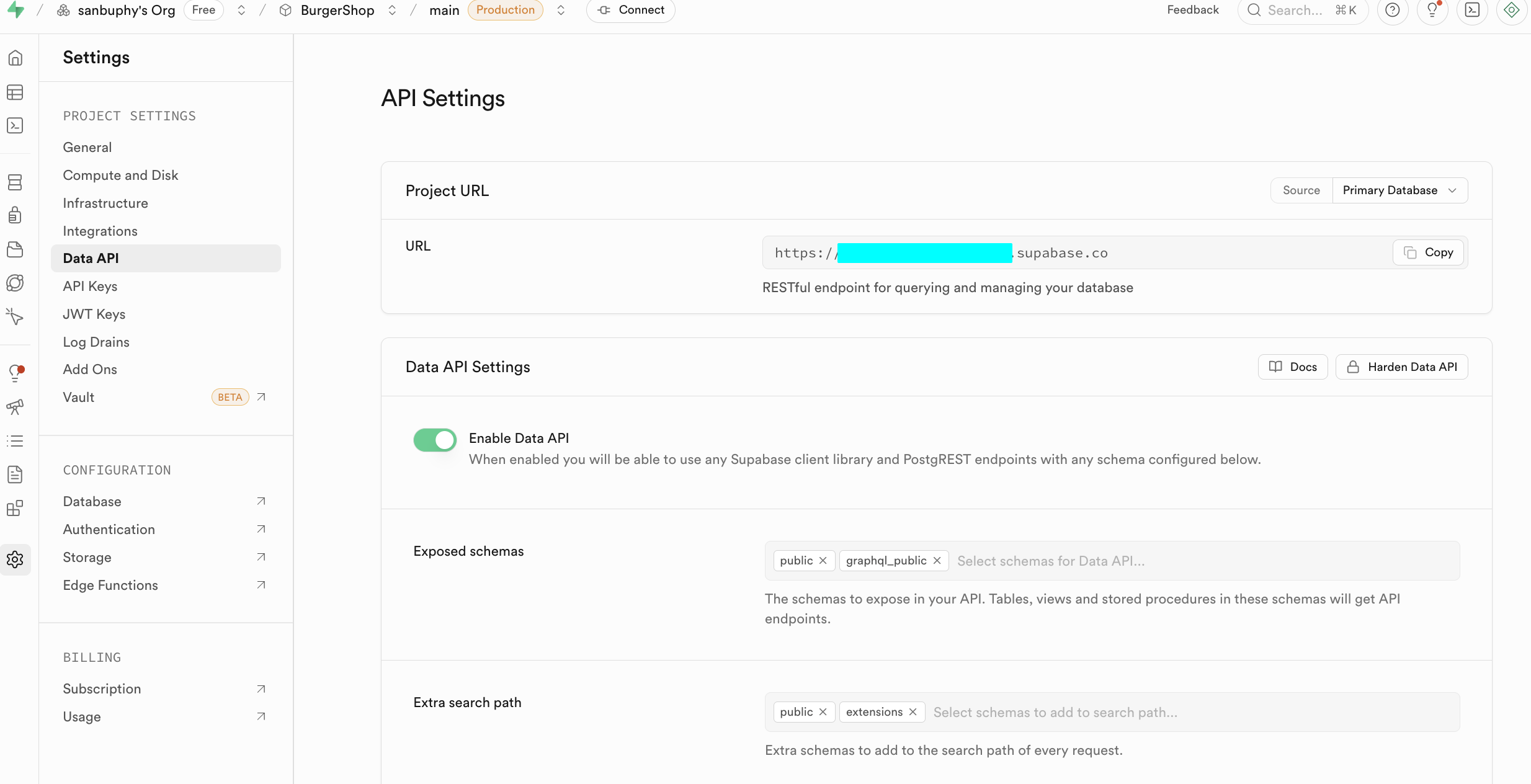
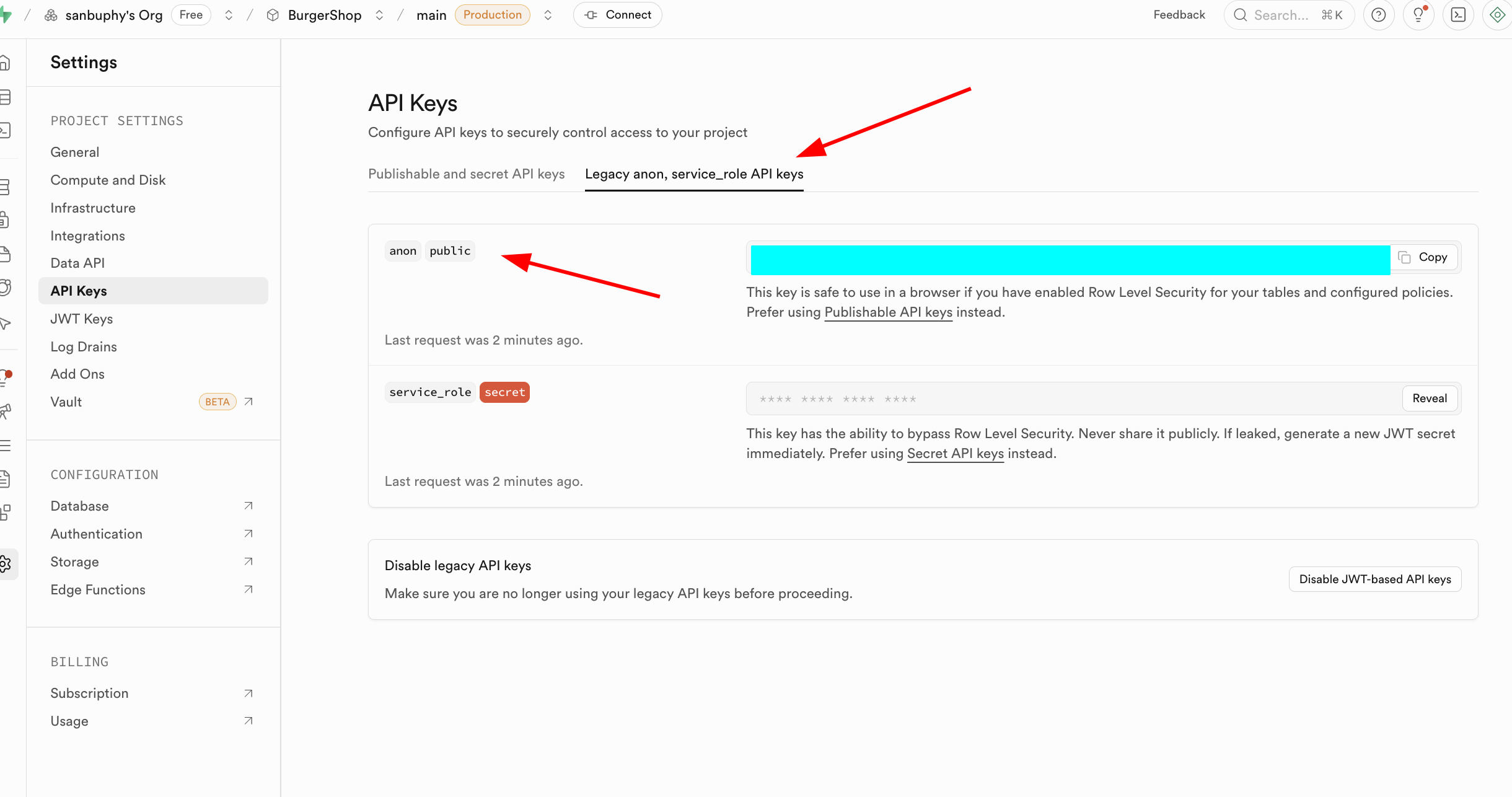
もう1つの重要ポイントは API Keys で、「Legacy anon, service_role API keys」タブを選択します。その中の anon public キーはフロントエンドシーンにおける重要な認証情報で、権限は RLS によって厳格に制限されており、ユーザーが権限を与えられたデータにのみアクセスできます。service_role キーは「サーバーサイド高権限キー」に属し、行レベルセキュリティをバイパスする能力を持ち、バッチデータ操作、システムレベルの設定などの機密操作を実行できます。絶対に公開共有しないでください。漏洩した場合は直ちに新しいキーを生成し、サーバー側の設定を更新する必要があります。
その他の設定項目は現在の段階では深く掘り下げる必要はありません。将来高度な使用ニーズが生じた際に1つずつ探求してください。
2.1 最初の SQL データテーブルの作成
以上が Supabase のインターフェースの紹介です。次に、Supabase のコアデータベースの操作に入ります。
Supabase でデータテーブルを作成するには、主に次の2つの一般的な方法があり、ニーズに応じて選択できます。
- (推奨)大規模言語モデルを使って Supabase に適合した SQL 文を生成し、SQL Editor(前述の SQL 文実行ツール)に直接貼り付けて実行する方法。効率的で迅速です。次のセクションでこの操作プロセスについて重点的に説明します。
- ビジュアル操作による作成:左側のサイドバーで Database モジュールを見つけ、クリックして入った後、サイドバーの Tables を選択し、右側で New table ボタンをクリックすると、グラフィカルインターフェースでデータテーブルを作成できます。
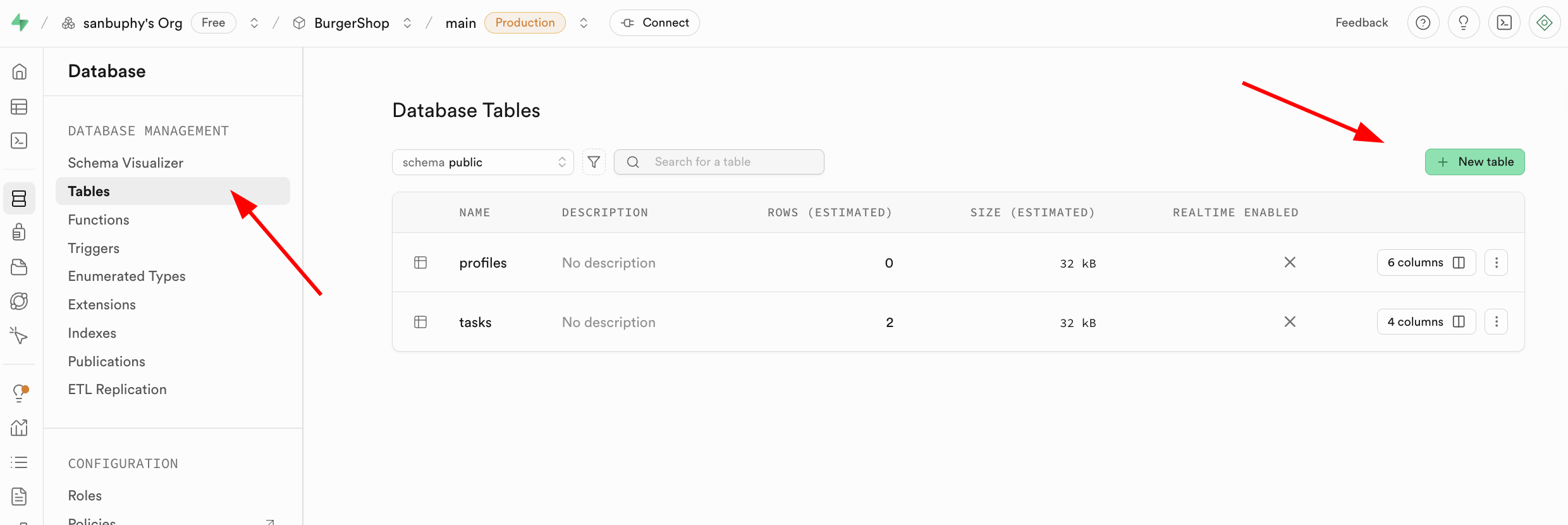
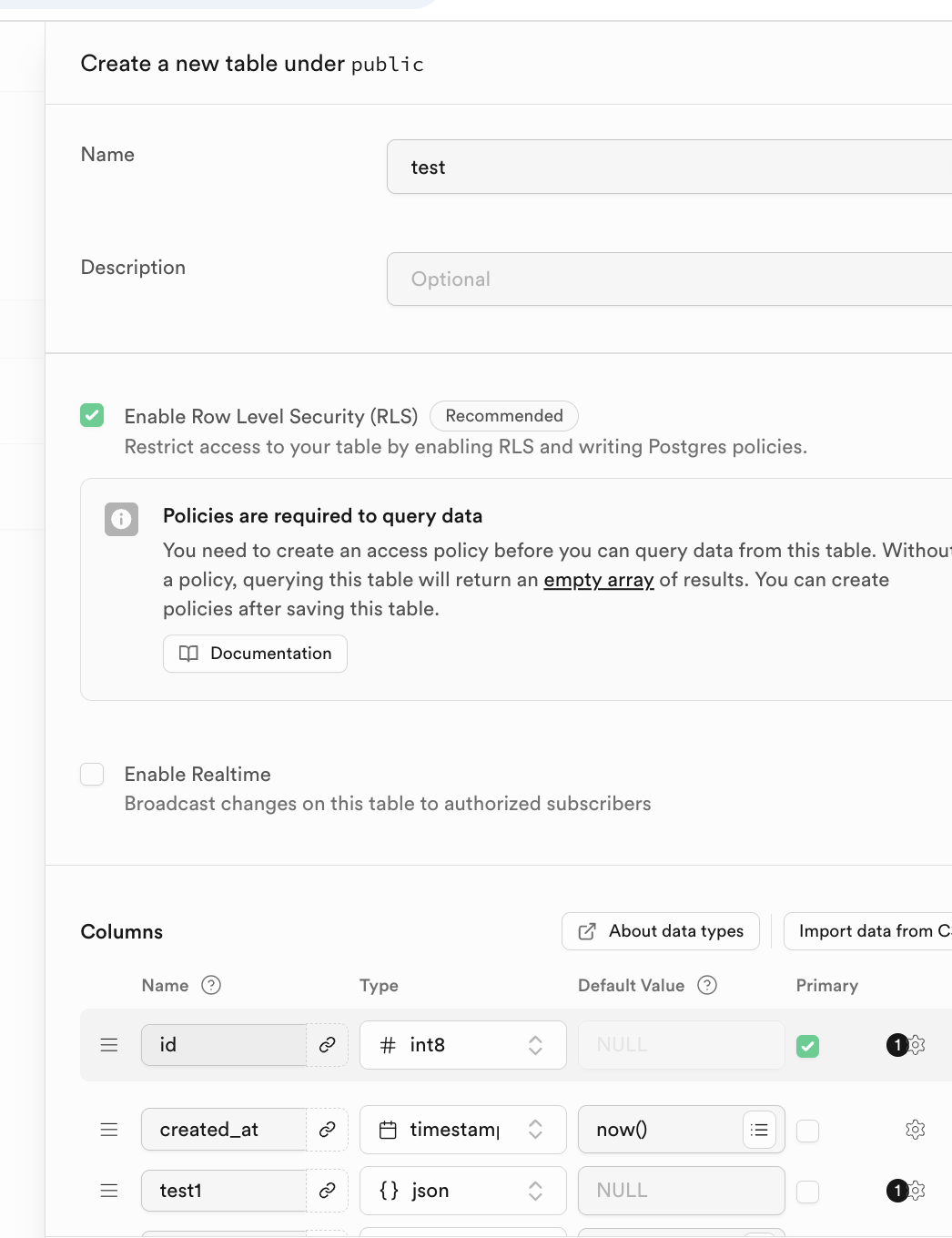
なお、対応するデータテーブルの名前と保存するデータ型は、下部の Columns で指定できます。
リレーショナルデータベースの重要な特徴はテーブル間の関連付けです。下部に Foreign keys があり、クリックして対応する関連関係を作成できます。
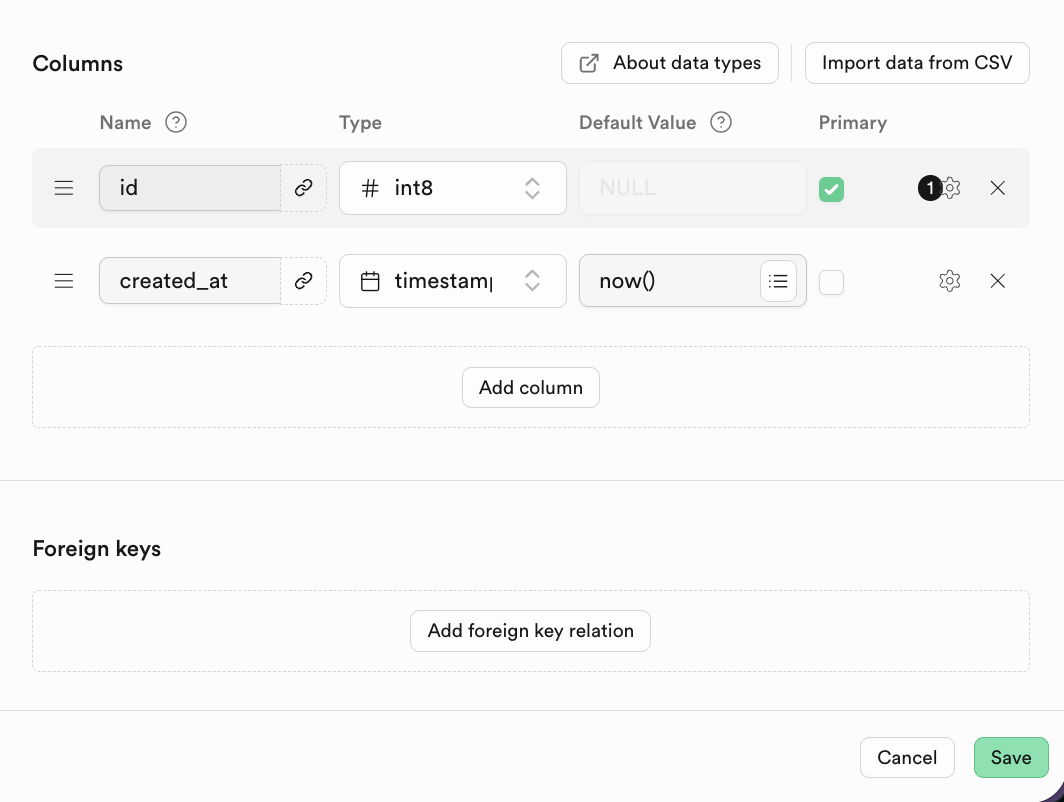
Foreign keys はテーブル間の関連関係を表現します。現在のテーブル(子テーブル)の1つまたは一連のフィールドの値が、別のテーブル(親テーブル)の主キーの値を参照するものです。
例えば、学生テーブルを作成する際、次のように外部キーを定義できます。(所属クラス番号 という列は外部キーです。この外部キーは クラステーブル の クラス番号 という列を参照しています。)
CREATE TABLE 学生テーブル (
学生番号 INT PRIMARY KEY,
学生氏名 VARCHAR(50),
所属クラス番号 INT,
FOREIGN KEY (所属クラス番号) REFERENCES クラステーブル(クラス番号)
);より具体的な例として、対応するテーブルの構造をビジュアルに観察できます。
クラステーブル: このテーブルにはすべてのクラスの情報が記録されており、各クラスには一意のクラス番号があります。クラス番号がこのテーブルの主キー(Primary Key)であり、各クラスの一意のIDです。
| クラス番号 | クラス名称 |
|---|---|
| 101 | 1年1組 |
| 102 | 1年2組 |
学生テーブル: このテーブルにはすべての学生の情報が記録されています。各学生は特定のクラスに所属していますよね?では、どの学生がどのクラスにいるかどうやって知るのでしょうか?
学生テーブルに 所属クラス番号 という列を追加できます。
| 学生番号 | 学生氏名 | 所属クラス番号 |
|---|---|---|
| 2024001 | 張三 | 101 |
| 2024002 | 李四 | 102 |
| 2024003 | 王五 | 101 |
この例では、学生テーブルの 所属クラス番号 列が外部キー(Foreign Key)です。
Supabase では、Add Foreign Key をクリックした後、関連テーブルの対応列を直接選択できます。
2.3 SQL Editor の紹介とデータベースの基本操作
次に、一連の SQL スクリプトを段階的に実行し、一般的な SQL における CRUD(作成、読み取り、更新、削除)操作に慣れます。各ステップのコードを SQL Editor にコピーして実行し、結果を確認できます。
すべてのテスト SQL ファイルは以下のディレクトリで入手できます。
https://github.com/THU-SIGS-AIID/Project5-Supabase-Demos/tree/main/apps/sql-examples
2.3.1 CREATE - テーブル構造の作成
CREATE TABLE 文は新しいテーブルのスキーマ(Schema)を定義するために使用されます。列(Columns)、対応するデータ型(Data Types)、および制約(Constraints)を含みます。簡単に言えば、データテーブルを作成します。
-- Step 1: Create the 'orders' table
-- This file is fully independent and creates a sample table for later steps.
CREATE TABLE IF NOT EXISTS orders (
id serial PRIMARY KEY,
user_id int NOT NULL, -- User ID
status text NOT NULL, -- Order status (e.g. paid, pending)
amount numeric(10, 2) NOT NULL, -- Order total amount
details jsonb, -- Item and extra details as JSON
placed_at timestamptz DEFAULT now(), -- Order creation time
is_paid boolean DEFAULT false -- Paid flag
);
-- Expected Output:
-- Orders table created if it did not exist.
-- No data inserted. (Querying returns zero rows for now.)
-- If table already exists, no error occurs.正常に実行されると、スクリプトが完了したことが示されます。Table Editor で対応するテーブルが作成されたことを確認できます。
2.3.2 INSERT - 初期データの挿入
テーブル構造の作成が完了したら、次に INSERT INTO 文を使ってテーブルにデータ行を追加します。
-- Step 2: Insert initial rows into the orders table
-- Provides realistic, varied data for demo/testing. All values are self-contained.
INSERT INTO orders (user_id, status, amount, details, placed_at, is_paid) VALUES
(2001, 'pending', 23.50, '{"items":[{"sku":"BGR001","name":"Beef Burger","qty":1,"price":12.00}]}', now() - interval '2 days', false),
(2002, 'paid', 50.00, '{"items":[{"sku":"BGR002","name":"Chicken Burger","qty":2,"price":10.00},{"sku":"DRK001","name":"Lemonade","qty":2,"price":5.00}]}', now() - interval '1 day', true),
(2003, 'cancelled', 15.00, '{"items":[{"sku":"FRY001","name":"French Fries","qty":3,"price":5.00}], "reason":"Not available"}', now() - interval '45 days', false),
(2004, 'paid', 22.98, '{"items":[{"sku":"BGR003","name":"Veggie Burger","qty":2,"price":9.99}], "promo":"SUMMER22"}', now() - interval '10 days', true),
(2005, 'pending', 18.75, '{"items":[{"sku":"SAL001","name":"Salad","qty":1,"price":6.75},{"sku":"BGR001","name":"Beef Burger","qty":1,"price":12.00}]}', now() - interval '7 hours', false),
(2006, 'paid', 8.00, '{"items":[{"sku":"DRK002","name":"Cola","qty":2,"price":4.00}]}', now() - interval '3 hours', true),
(2007, 'refunded', 14.50, '{"items":[{"sku":"BGR003","name":"Veggie Burger","qty":1,"price":9.99},{"sku":"FRY001","name":"French Fries","qty":1,"price":4.51}], "refund_reason":"Late delivery"}', now() - interval '15 days', false),
(2008, 'paid', 26.99, '{"items":[{"sku":"BGR002","name":"Chicken Burger","qty":2,"price":10.00},{"sku":"DRK001","name":"Lemonade","qty":1,"price":6.99}]}', now() - interval '12 days', true),
(2009, 'pending', 9.99, '{"items":[{"sku":"BGR003","name":"Veggie Burger","qty":1,"price":9.99}]}', now() - interval '30 minutes', false),
(2010, 'paid', 19.89, '{"items":[{"sku":"BGR001","name":"Beef Burger","qty":1,"price":12.00},{"sku":"DRK002","name":"Cola","qty":2,"price":3.95}]}', now() - interval '5 days', true),
(2011, 'cancelled', 0.00, '{"items":[], "reason":"User cancelled"}', now() - interval '2 days', false);
-- Expected Output:
-- After running this script, SELECT * FROM orders will show about 11 rows with varied user_id, status, amount, details (JSON), placed_at, and is_paid fields.
-- For example:
-- | id | user_id | status | amount | is_paid | placed_at |
-- |----|---------|-----------|--------|---------|---------------------|
-- | 1 | 2001 | pending | 23.50 | false | 2025-10-28 13:40:00Z|
-- | 2 | 2002 | paid | 50.00 | true | ... |
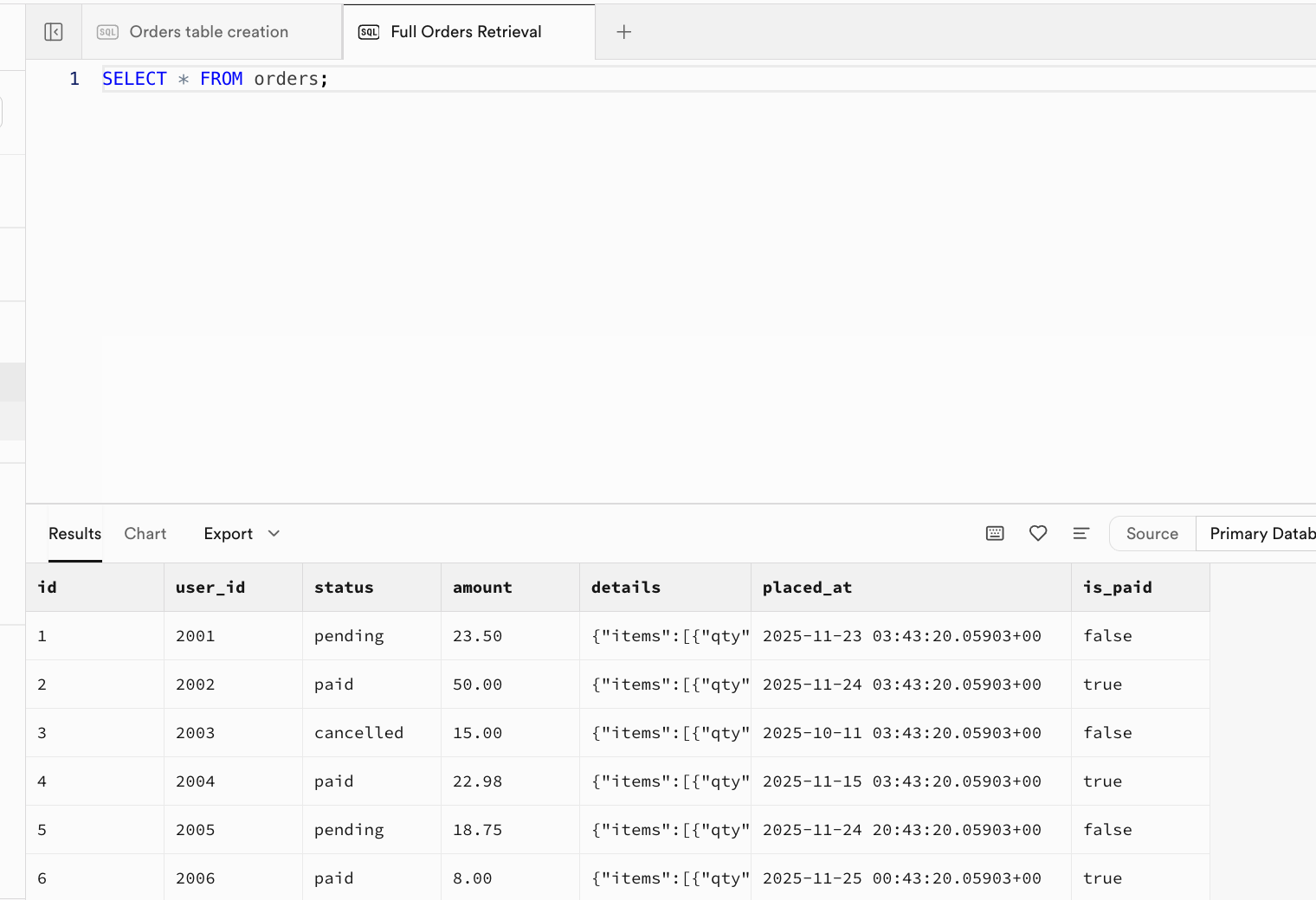
-- |... | ... | ... | ... | ... | ... |正常に実行されると、テーブルに元データが挿入されています。Table Editor 画面に移動してリフレッシュして結果を確認するか、SQL Editor 画面で新しいウィンドウを作成し、クエリ文 SELECT * FROM orders; を実行して結果を確認できます。
2.3.3 SELECT - データの読み取りとクエリ
SELECT 文はテーブルからデータを取得するために使用されます。異なる句を使用することで、データの正確なフィルタリング、並べ替え、フォーマットが実現できます。以下の文を参考に段階的に実行して結果を確認しましょう。
-- Step 3: SELECT query examples for the orders table
-- Example 1: Select all fields for all orders
SELECT * FROM orders;
-- Expected Output: Returns all rows and fields. Columns: id, user_id, status, amount, details, placed_at, is_paid.
-- Example 2: Select only pending orders
SELECT id, user_id, amount FROM orders WHERE status = 'pending';
-- Expected Output: All rows with status 'pending'; columns: id, user_id, amount.
-- Example 3: Select specific fields and filter by payment status
SELECT id, status, is_paid, amount FROM orders WHERE is_paid = true;
-- Expected Output: All rows where is_paid is true; columns: id, status, is_paid, amount.
-- Example 4: Extract all item names from the details (JSON) for each order
SELECT id, details -> 'items' AS item_list FROM orders;
-- Expected Output: Each row shows id and an array from JSON with item details.- 例 1:
ordersテーブルのすべての行と列を返します。ステップ2の出力と同様です。 - 例 2: ステータスが 'pending' の注文のみを返し、指定された列のみを含みます。
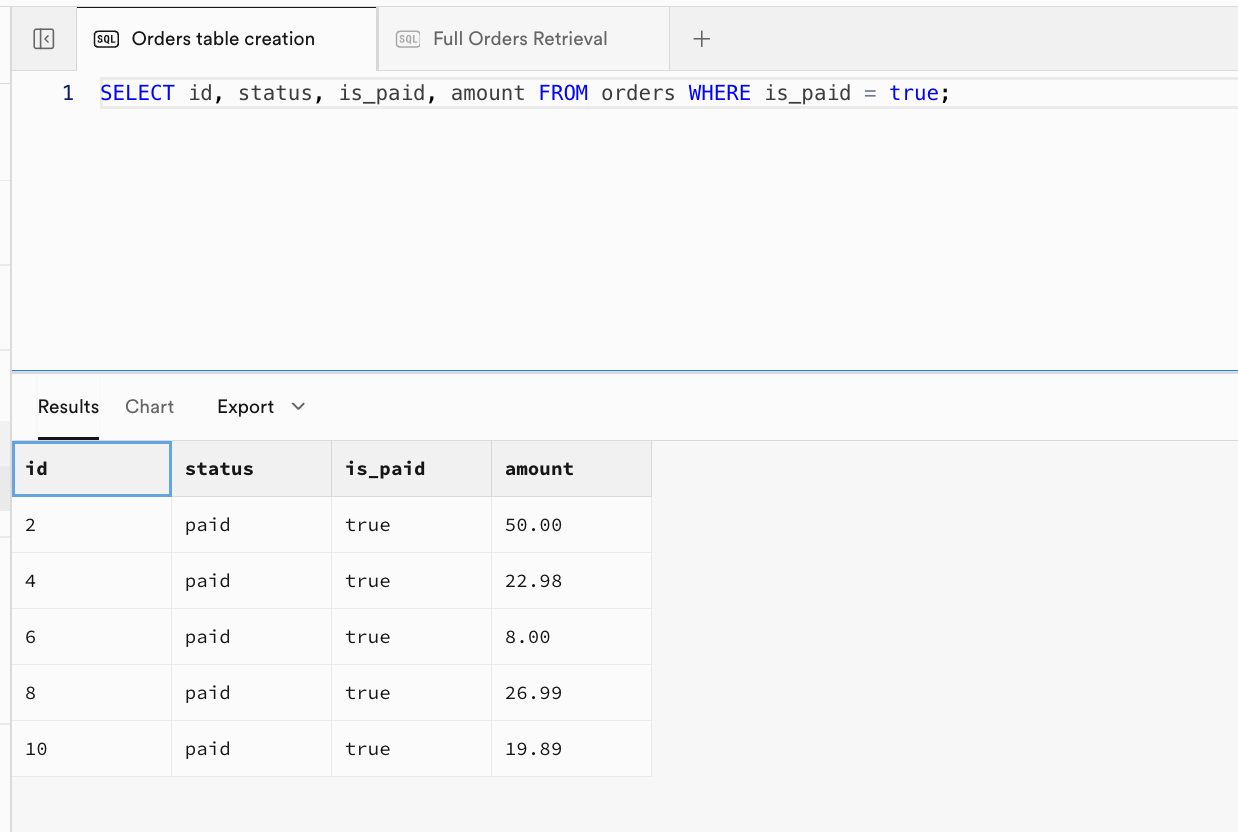
- 例 3: 支払い済みの注文のみを返し、指定された列を表示します。
| id | status | is_paid | amount |
|---|---|---|---|
| 2 | paid | true | 50.00 |
| 4 | paid | true | 22.98 |
| 6 | paid | true | 8.00 |
| 8 | paid | true | 26.99 |
| 10 | paid | true | 19.89 |
- 例 4: 各注文の
idとdetailsフィールドから抽出されたitems配列を返します。
| id | item_list |
|---|---|
| 1 | [{"qty":1,"sku":"BGR001","name":"Beef Burger","price":12}] |
| 2 | [{"qty":2,"sku":"BGR002","name":"Chicken Burger","price":10},{"qty":2,"sku":"DRK001","name":"Lemonade","price":5}] |
| 3 | [{"qty":3,"sku":"FRY001","name":"French Fries","price":5}] |
| ... | ... |
2.3.4 INSERT - 単一レコードの挿入
2.3.2 では、初期段階でのバルクデータ挿入をデモしました。ここでは、単一データの新規挿入方法を見てみましょう。
-- Step 4: INSERT a new order (single row)
-- Example: Add a new paid order for user 2012 with one Chicken Burger
INSERT INTO orders (user_id, status, amount, details, is_paid)
VALUES (
2012, 'paid', 9.99,
'{"items":[{"sku":"BGR002","name":"AIID Burger","qty":100,"price":1000}]}',
true
);
-- Expected Output:
-- Before (table fragment):
-- | id | user_id | status | amount | is_paid |
-- | ...| ... | ... | ... | ... |
--
-- After (last row):
-- | id | user_id | status | amount | is_paid |
-- | xx | 2012 | paid | 9.99 | true |
-- (where xx = next serial value)ここで SELECT * FROM orders; でデータをクエリすると、orders テーブルが正常に11件から12件になったことが確認できます。
2.3.5 UPDATE - 既存データの変更
実際の業務では、データテーブルの頻繁な更新が必要です。UPDATE 文を使ってテーブル内の既存レコードを変更できます。
-- Step 5: UPDATE example
-- Example: Mark order with id=1 as paid and update its status
UPDATE orders SET status = 'paid', is_paid = true WHERE id = 1;
-- Expected Output:
-- Before (row with id=1):
-- | id | status | is_paid |
-- | 1 | pending | false |
-- After (row with id=1):
-- | id | status | is_paid |
-- | 1 | paid | true |
-- All other rows remain unchanged.2.3.6 DELETE - データの削除
DELETE 文はテーブルからレコードを削除するために使用され、条件を組み合わせて指定部分のデータを変更できます。
-- Step 6: DELETE example
-- Example: Delete orders older than 2 days to clean up old data
DELETE FROM orders WHERE placed_at < now() - interval '2 days';
-- Expected Output:
-- Before (filtered for affected rows):
-- | id | status | placed_at |
-- | 3 | shipped | 2025-10-13 ... | <-- will be deleted
--
-- After:
-- No such rows remain. SELECT * FROM orders WHERE placed_at < now()-interval '2 days' yields zero rows.
-- Other rows in orders table are unaffected.実行前に、まず SELECT id, status, placed_at FROM orders WHERE placed_at < now() - interval '2 days'; を実行してデータテーブルのフィルタリング結果を確認できます。DELETE コマンドを実行した後、同じ SELECT クエリ SELECT id, status, placed_at FROM orders WHERE placed_at < now() - interval '2 days'; を再度実行すると、空の結果が返され、これらの行が正常に削除されたことが示されます。
2.4 行レベルセキュリティ
データベースの基本操作を学んだ後、データセキュリティを保障するコア概念である RLS(行レベルセキュリティ、Row Level Security)についてさらに深く掘り下げる必要があります。
まず、実際のシーンにおける重要な問題を考えてみましょう。データの「分離アクセス」をどうやって実現するかです。例えば、ユーザー A に自分のデータのみを閲覧させ、ユーザー B の情報を見られないようにするにはどうすればよいか。また、ある役割がデータベースへのアクセス権を持っている場合でも、他のユーザーの機密データの誤操作や漏洩をどうやって防ぐか。
RLS はまさにこのようなデータセキュリティと分離のニーズを解決するために生まれました。開発者がデータベーステーブルに精細なセキュリティポリシーを定義できるようにし、ユーザーの身元情報(ユーザー ID、役割権限など)に基づいて、どのユーザーがテーブル内のどの行データにアクセス・変更できるかを正確に制御します。 典型的な例として、注文テーブル(orders)に対して、次のような RLS ポリシーを定義できます。「orders テーブルの特定レコードの user_id 列が、現在ログインしているユーザーの ID と完全に一致する場合のみ、そのユーザーはこの注文データをクエリできる」とし、「ユーザーは自分の注文のみを見られる」というコア要件を実現します。
あるテーブルに対して RLS を有効にすると、そのテーブルのすべてのデータ操作リクエスト(SELECT クエリ、INSERT 挿入、UPDATE 変更、DELETE 削除を含む)が RLS 検証をトリガーします。少なくとも1つのセキュリティポリシーのチェックを通過しなければ、操作は実行できません。その操作を許可するポリシーが存在しない場合や、リクエストがいかなるポリシーの条件も満たさない場合、データベースは直接その操作を拒否し、基盤レベルで不正アクセスをブロックします。
Supabase では、RLS はユーザー認証システムと深く統合されており、使用がより便利です。Supabase は専用関数 auth.uid() を提供し、「現在リクエストを発行しているログイン済みユーザー」の一意の ID(UUID 形式)を直接返します。この関数を使って、ポリシーを簡単に作成し、「データ行とユーザー身元」の正確な関連付けを実現できます(前述の「注文の user_id が現在のユーザー ID と一致する」など)。
RLS ポリシーを有効にする方法は柔軟です。Supabase データベース管理画面の「RLS」ボタンで、直接ポリシーを設定・有効化できます。
手動設定はどうしても面倒です。通常、データテーブルの作成・初期化時に対応する RLS ポリシーを自動的に組み込むことを考えます。SQL Editor で以下のような文を実行するだけで、対応するデータテーブルの行レベルセキュリティポリシーを自動的に有効にできます。

3. 最初の SQL アプリケーション
データベースの基本操作と RLS のコアロジックを習得し、いよいよ今回のチュートリアルの実践パートに入ります。長い学習の準備は、その後の「ゼロからアプリを構築する」プロセスをより明確にするためでした。次に、「ハンバーガーショップの注文管理」をシーンとして、Supabase の一般的な操作をステップバイステップでデモンストレーションします。アプリケーションと Supabase の関連設定から、データベースとログイン機能の統合まで、異なる操作ロジックを段階的に学びます。
3.1 Supabase サンプルプロジェクトのクローンと実行
実践を始めるには、まず対応するデモコードリポジトリを取得する必要があります。Trae または Claude Code に以下のリポジトリを git clone させることができます。https://github.com/THU-SIGS-AIID/Project5-Supabase-Demos
SSH キーが設定済みの場合は、セキュリティ向上のため SSH アドレス(git@github.com:THU-SIGS-AIID/Project5-Supabase-Demos.git)を使用して clone することをお勧めします。SSH または HTTPS 接続でネットワークの問題が発生した場合、リポジトリページの「Download ZIP」を直接クリックし、圧縮パッケージを取得して解凍すれば完全なコードが確認できます。
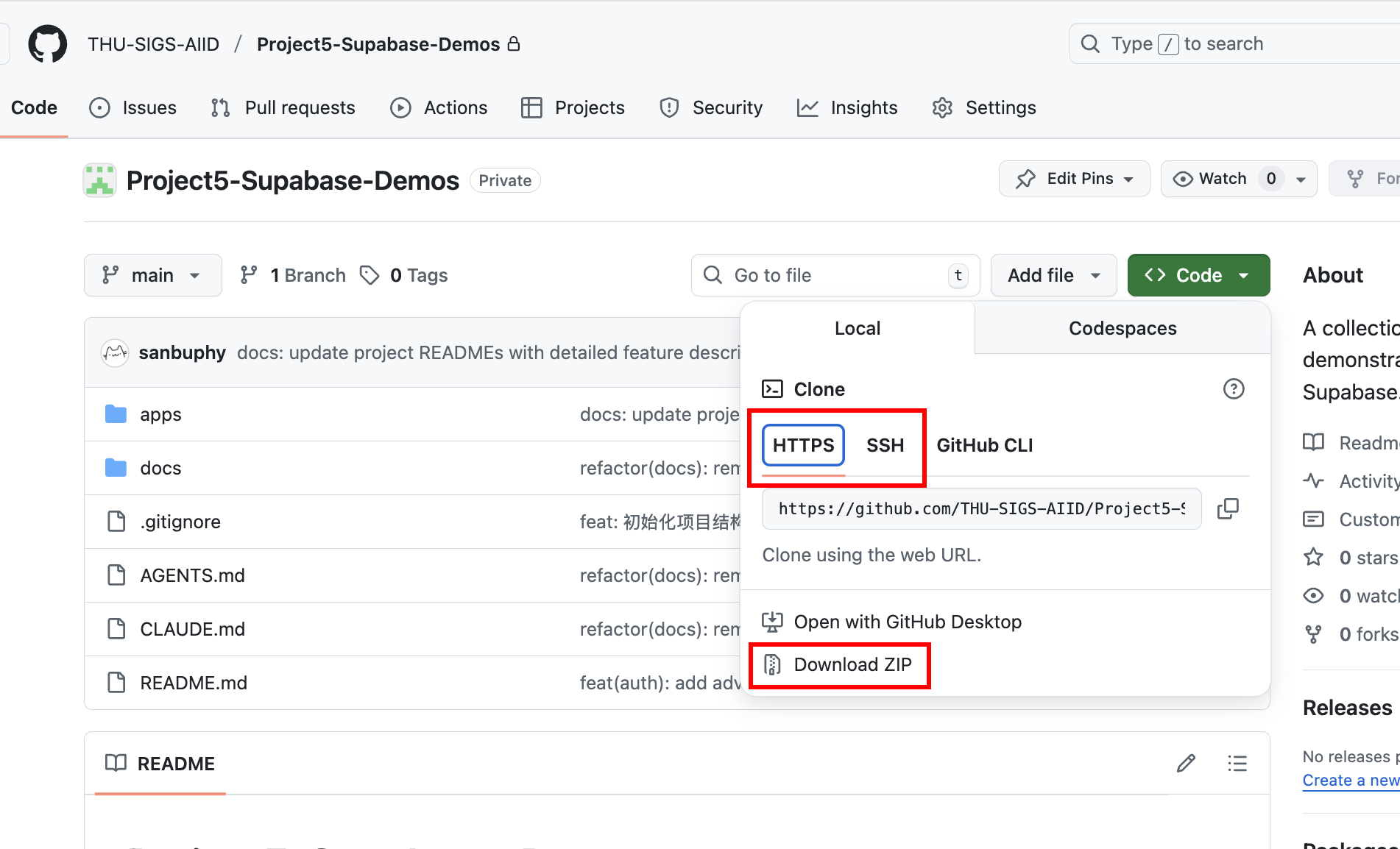
Clone 後、同様に Trae または Claude Code にプロジェクトを起動させることができます。例えば、Agent 画面で直接 このプロジェクトの中の project 1 を直接起動して と指示するか、起動したい project の絶対パスをコピーして、大規模言語モデルに貼り付けて直接起動させます。
3.2 プロジェクト1 - ハンバーガーショップメニュー CRUD
次に実践パートに入ります。project-burger-shop-menu-crud-1 を例に、SQL スクリプトを使って Supabase データベースをワンクリックで初期化し、ローカルプロジェクトと Supabase データベースの関連設定を完了して、フロントエンドがメニューデータを正常に読み書きできるようにする方法を学びます。
スクリプトを使ったデータベースの作成
まず、Supabase で必要なデータテーブル関連の内容を作成する必要があります。Project1 プロジェクトディレクトリに入ると scripts というフォルダがあり、その中に1つの init.sql データベーススクリプトファイルが含まれています。これはデータベース関連リソース(テーブル構造、初期データなど)の作成を自動的に完了してくれます。以降、データベース内のテーブルの初期化にこのファイルを頻繁に使用します。
......
-- ============================================================================
-- 2. Create Menu Items Table
-- ============================================================================
create table if not exists public.menu_items (
id uuid primary key default gen_random_uuid(),
name text not null,
description text,
category text check (category in ('burger','side','drink')) default 'burger',
price_cents int not null check (price_cents > 0),
available boolean default true,
emoji text,
created_at timestamptz not null default now(),
updated_at timestamptz not null default now()
);
-- Comments for documentation
comment on table public.menu_items is 'Burger shop menu items for CRUD demo';
comment on column public.menu_items.id is 'Unique identifier for each menu item';
comment on column public.menu_items.name is 'Display name of the menu item';
comment on column public.menu_items.description is 'Detailed description of the menu item';
comment on column public.menu_items.category is 'Category: burger, side, or drink';
comment on column public.menu_items.price_cents is 'Price in cents (integer) to avoid floating point issues';
comment on column public.menu_items.available is 'Whether the item is currently available for order';
comment on column public.menu_items.emoji is 'Optional emoji representation of the menu item';
comment on column public.menu_items.created_at is 'Timestamp when the item was created';
comment on column public.menu_items.updated_at is 'Timestamp when the item was last updated';
......SQL Editor で初期化 SQL スクリプトを実行した後、Table Editor で作成されたデータテーブルを確認できます。データベース初期化コードの具体的な実行ロジックは以下の通りです。
- menu_items テーブルの作成 :
- このテーブルはハンバーガーショップメニューの全項目を保存するために使用されます。name(商品名)、description(説明)、price_cents(セント単位の価格、浮動小数点精度の問題を回避)、category(分類)、available(販売可否)などのフィールドが含まれています。これでメニュー項目に必要なほぼすべての情報をカバーしています。
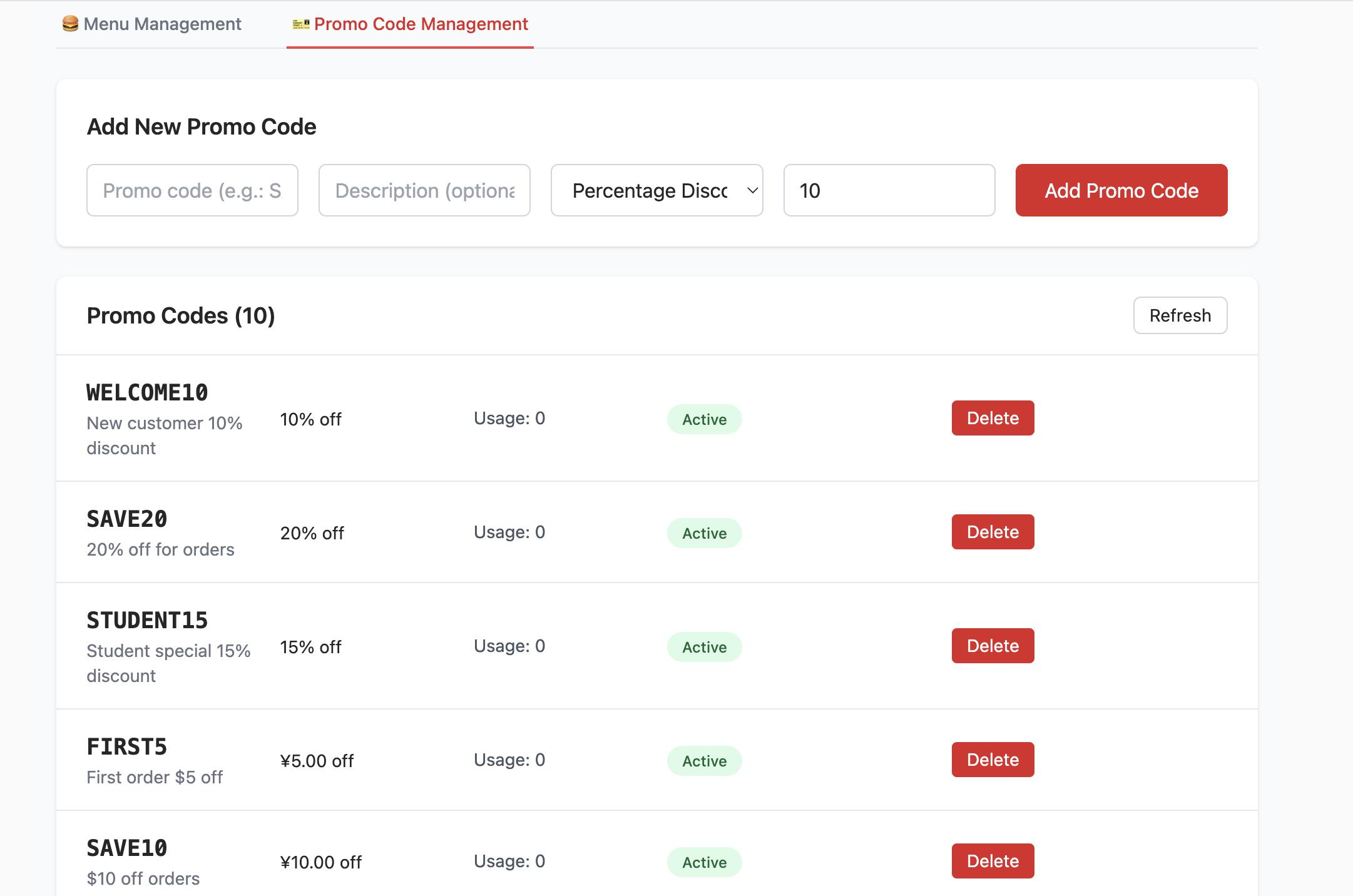
- promo_codes テーブルの作成 :
- このテーブルはプロモーション活動、例えば割引コードを管理するために使用されます。code(割引コード)、discount_type(割引タイプ、パーセンテージや固定金額など)、discount_value(割引数値)などのフィールドが定義されています。
- 行レベルセキュリティ(Row Level Security - RLS)の無効化 :
- 開発とテストの便宜のため、スクリプトでは明示的に RLS を無効にしています。しかし、以前に学習した RLS のコアロジックを思い出してください。RLS は Supabase がデータセキュリティを保障する重要な機能であり、精細なポリシーで「誰がどのデータにアクセス/変更できるか」を制御できます(例えば、管理者のみがプロモーションコードを編集でき、一般ユーザーはメニューの閲覧のみ)。したがって、本番環境では RLS を有効にし、適切なポリシーを設定して、基盤レベルで不正アクセスをブロックする必要があります(ユーザーが他人の作成したメニューを悪意を持って変更したり、プロモーションコードルールが漏洩したりするのを防ぐなど)。
- シードデータ(Seed Data)の挿入 :
- フロントエンドプロジェクト起動後に実際のメニューとプロモーションデータをすぐに閲覧できるようにするため(テストデータの手動入力が不要)、
init.sqlスクリプトはmenu_itemsとpromo_codesテーブルに「シードデータ」(つまりサンプルデータ)を挿入します。例えば、各種ハンバーガー、サイドメニュー、ドリンク、および多様な割引コードが含まれています。
データベースとの接続設定
データベースの準備が完了したら、このフロントエンドプロジェクトと Supabase を接続して、データベース内のデータを正常に読み取れるようにする必要があります。Supabase プロジェクトの URL と anon key を指定の設定に書き込む必要があります。本プロジェクトでは2つの柔軟な設定方法を提供しています。
- 環境変数による設定
プロジェクトのルートディレクトリに .env ファイルを作成し、Supabase の認証情報を入力します。
NEXT_PUBLIC_SUPABASE_URL=https://your-project.supabase.co
NEXT_PUBLIC_SUPABASE_ANON_KEY=your-anon-key- プロジェクトページでの直接設定
異なる Supabase プロジェクトを素早くデモ・切り替えするため、ホームページの右上隅に設定ボタンが用意されています。クリックして、ポップアップモーダルで Supabase URL と anon key を直接入力または貼り付けます。
「Save」をクリックした後、これらの情報は Supabase クライアントインスタンスを動的に作成するために使用されます。以下のコードに似ています。
import { createClient, type SupabaseClient } from '@supabase/supabase-js';
// Optional client factory for demos: returns null when env is not set.
export function maybeCreateBrowserClient(): SupabaseClient | null {
const url = process.env.NEXT_PUBLIC_SUPABASE_URL;
const anon = process.env.NEXT_PUBLIC_SUPABASE_ANON_KEY;
if (!url || !anon) return null;
return createClient(url, anon);
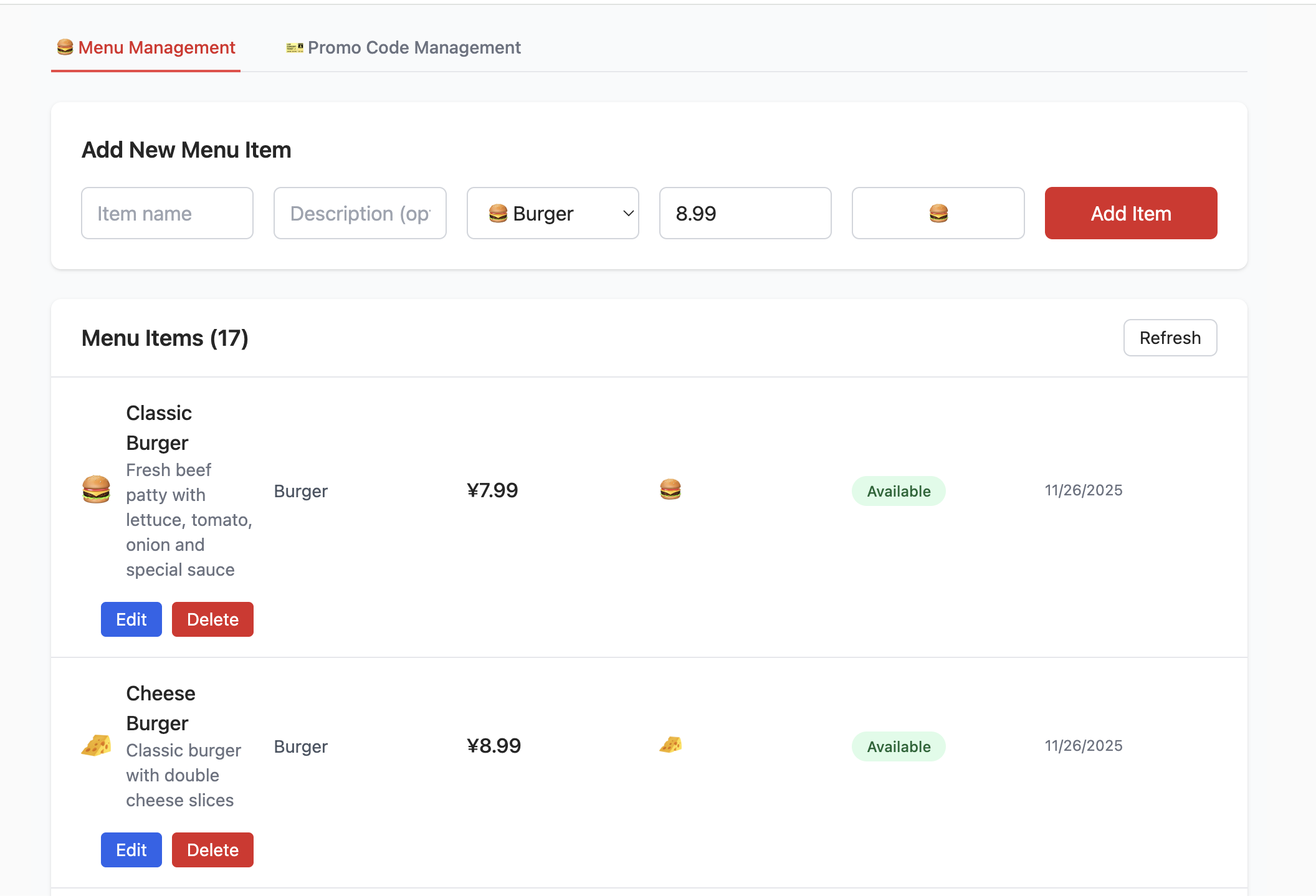
}データベースの作成と、対応する Supabase Link 関連設定の入力が完了すると、次の画面が表示されます。商品の追加・削除・閲覧・変更を試し、Supabase 内の対応部分のデータテーブルの変化を観察できます。
📚 宿題
- 既存項目の追加と削除を試し、Table Editor で変更操作がデータテーブル内容の変動に与える影響を確認してください。
3.4 プロジェクト2 - ハンバーガーショップ認証ユーザー
Project1 は「メニュー CRUD+データベース接続」を実現しました。Project2 では、実際のビジネスに近いコア能力であるユーザー認証(Auth)と行レベルセキュリティ(RLS)権限管理を導入します。
Project2 には独立したログインページが含まれ、ユーザーが「メールアドレス+パスワード」でログインできるようにサポートしています。そのコアロジックは、Supabase Auth が提供するネイティブメソッドを呼び出して、認証フローを迅速に実現することです。複雑なログイン検証ロジックを手動で開発する必要はありません。
const { error: err } = await supabaseClient.auth.signUp({
email,
password,
options: {
data: {
full_name: fullName || null,
birthday: birthday || null,
avatar_url: avatarUrl || null
}
}
});
ログインが成功すると、Supabase は自動的にユーザーのセッション(session)を作成し、以降のすべてのデータベースリクエストに認証情報を自動的に含めます。RLS の作用により、各ユーザーは対応する認証情報に基づいて自分のアカウント情報(購入済み項目、ウォレット残高)のみを閲覧でき、他のユーザーのアカウント情報を見ることはできません。これにより、異なるユーザーがログインした後のデータ分離が実現され、各人は自分のコンテンツのみを見られます。
Project1 と同様に、まず init.sql を使ってデータテーブルの初期化を行う必要があります(注:初期化エラーが発生した場合、まず Table Editor で既に作成されたデータテーブルを削除するか、この Supabase Project を直接削除して、新しい Project を新規作成してください)。
メールアドレスでアカウントを正常に登録し、メールで登録を確認した後、ログインして Shop 画面に入ると次の内容が表示されます。
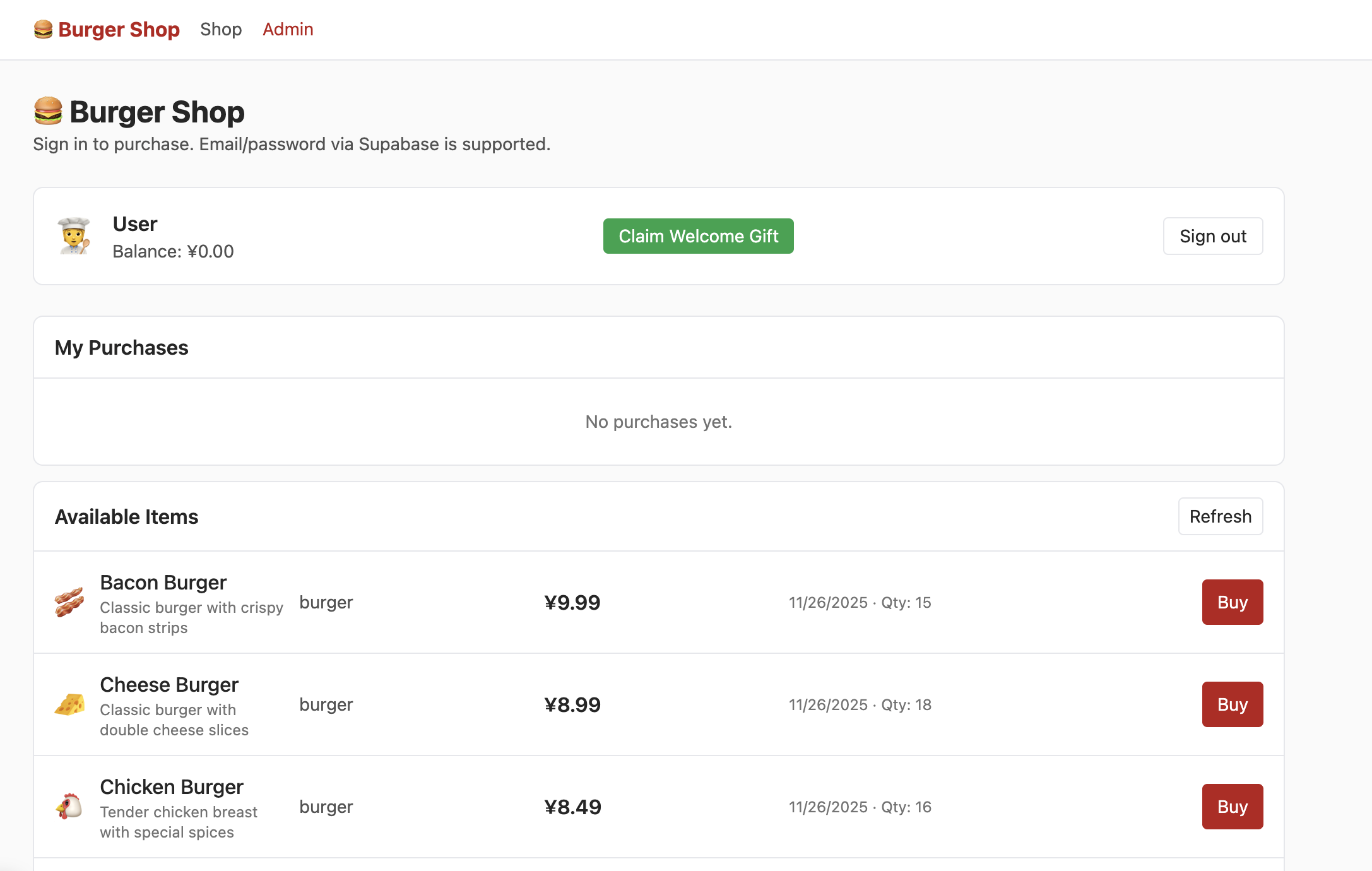
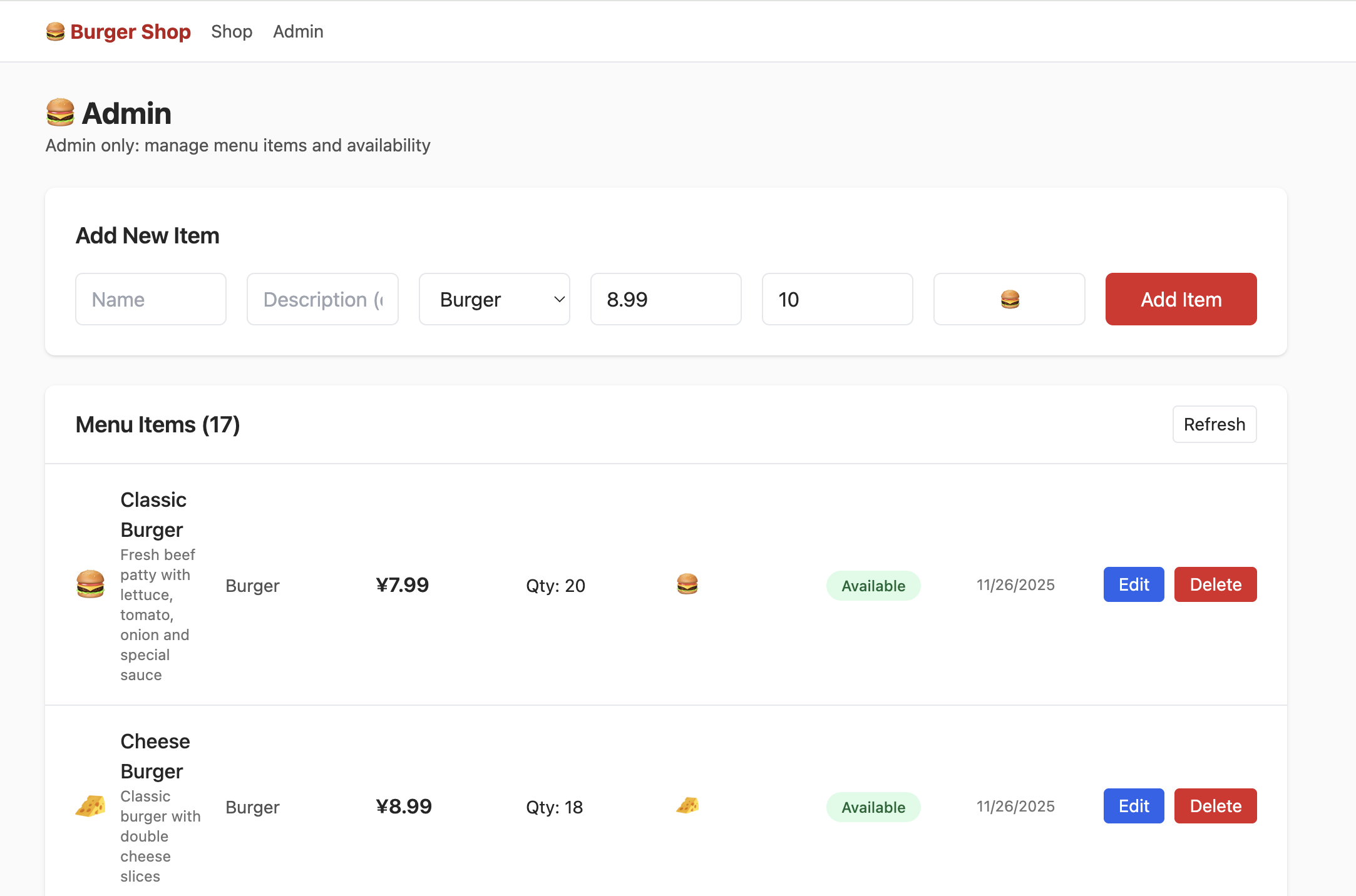
しかし、この時点で admin をクリックしても次の画面は表示されません。データテーブル内でユーザー権限を制御する部分を見つけ、権限を admin に変更する必要があります。そうすることで Admin 画面で次の内容を正常に閲覧できます。
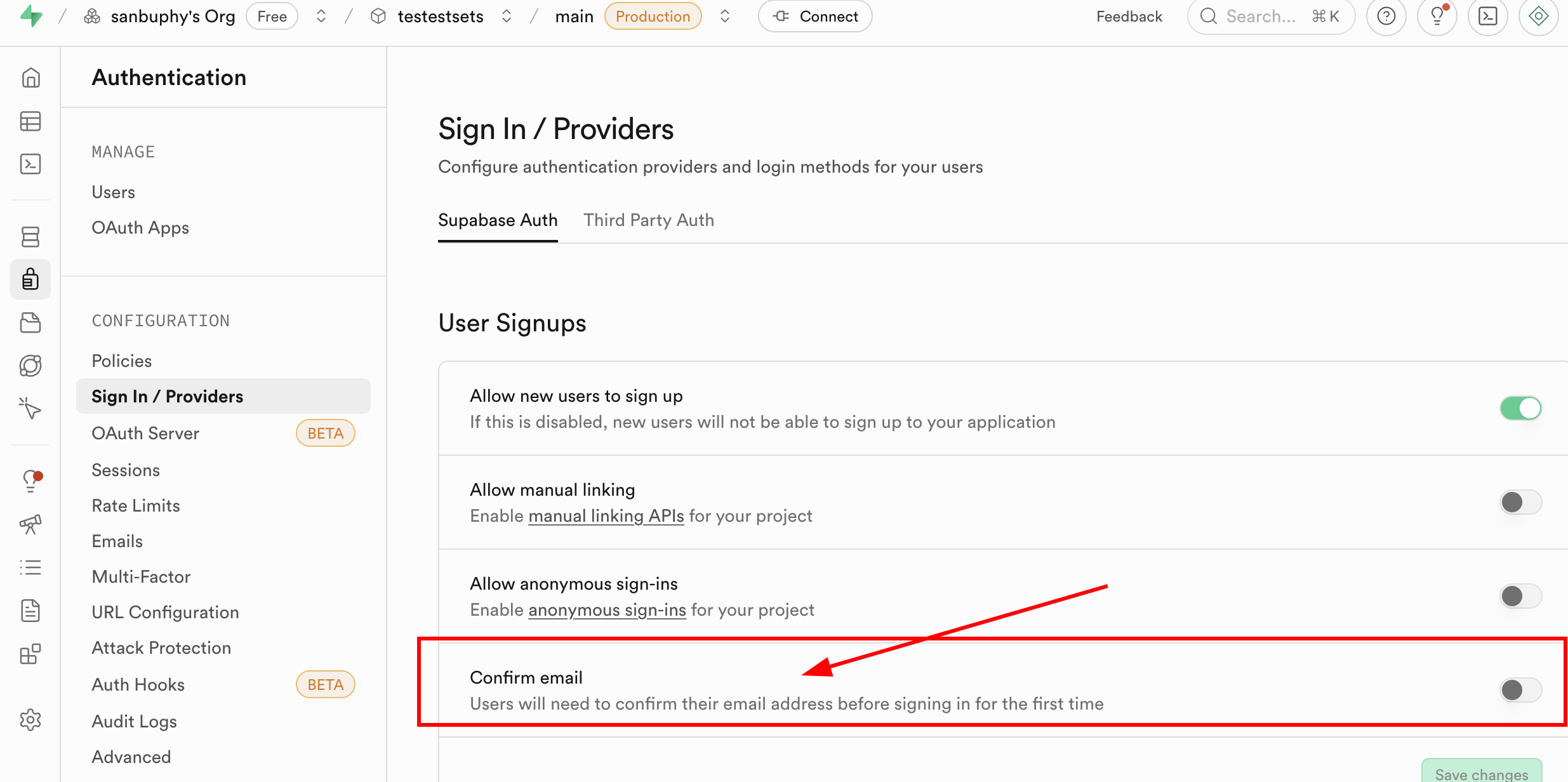
参考までに、現在は新しいメールアドレスを登録するたびに、メールで登録確認を行わなければログインできない点に留意してください。しかし、このステップは必須ではありません。Supabase の Authentication セクションで Sign In / Providers を見つけ、Confirm email をクリックしてメールの強制確認を解除できます。
📚 宿題
- まず初心者ギフトを受け取り、商品購入操作を完了してください。
- ユーザー権限の設定データテーブルの場所を見つけ、権限を
adminに変更して、注文管理画面で商品数量の変更に成功してみてください。 - データテーブル内でウォレット金額関連のテーブルを見つけ、修正してウォレット残高を増やしてみてください。
4. 最初の Supabase アプリケーションの構築
前述の体系的な学習を通じて、Supabase のコア能力(データベース操作、ユーザー認証、RLS セキュリティポリシー)をすでに習得しました。ここからは実際に手を動かして、データベースを含み、ユーザーログインシステムをサポートする最初のアプリケーションを構築しましょう!
4.1 任意のアプリケーションを Supabase データベースに接続する標準フロー
標準フローを使って任意のアプリケーションを Supabase データベースに接続できます。
- まず要件の整理と情報の同期を行い、目標を明確にして AI に伝える
- 現在のアプリケーションのコア機能と、新たに追加するデータベース要件を AI に明確に説明する必要があります。例:「現在ローカルに React Todo アプリがあり、データはブラウザのローカルストレージにのみ保存されています。"データのクラウド同期"機能を追加し、Supabase データベースに接続したいです。このアプリケーションに関わるデータ操作(新しい Todo の追加、ステータス変更、Todo の削除など)は何ですか?これらのデータを保存するためにどのようなデータテーブルを作成する必要がありますか?」
- 追加の制約条件(オプション):フィールド形式の要件(タイムスタンプは
timestamptz、金額は整数でセント単位で保存)、データ権限ルール(自分の Todo のみ閲覧可能)など。これにより AI の分析が実際の要件により合致します。 - AI から返された結果を確認し、AI の考えに漏れがあれば(「Todo の締め切り」フィールドを考慮していないなど)、補足して修正を促します。「締め切りを見落としていますね。追加してください。」
- AI に確認したテーブル構造に基づいて、Supabase に適合した
init.sqlスクリプトを生成させます。「上記の考え方とテーブル構造に基づいて、Supabase で初期化できる init.sql スクリプトを返してください」。その後 SQL Editor でスクリプトを実行します。実行時にエラーが発生した場合、エラー情報を AI にフィードバックしてスクリプトを修正させます。 - Supabase で init.sql スクリプトを実行した後、AI にスクリプトに基づいて現在のコードをリファクタリングさせ、Supabase との正常なデータインタラクションができるようにします。「SQL スクリプトと上記の議論に基づいて、プロジェクトのコードをリファクタリングして、Supabase の対応データベースとの通信とデータ処理をサポートするようにしてください」。
- リファクタリングが完了したら、Supabase のアドレスとキーのパラメータを設定するだけです(本番プロジェクトでは通常、環境変数による設定のみを使用)。その後、確認を行い、問題がなければアプリケーションの Supabase データベースへの接続が完了します。
- プロジェクトを実行し、すべてのデータベースインタラクション機能をテストし、Supabase Table Editor でデータが同期されているかをリアルタイムで確認します。
- 問題が発生した場合(データが挿入できない、一部のデータしか見えないなど)、問題の現象を AI にフィードバックし、原因を特定してコードを修正させます。
さらに、ユーザーログインページの開発を目標とする場合、AI に直接ログインページの統合を支援させることができます。「このアプリケーションに Supabase のユーザーログインシステムを追加してください。メールアドレスで登録とログインができるようにしてください」。また、ページの遷移ロジックとパス(ログイン成功後のシステムホームへの遷移、ホームのアドレス、ログイン失敗時は現在のページに留まりエラーメッセージを表示するなど)を AI に明確に伝える必要があります。統合が完了したら、登録・ログイン後に Supabase の Authentication セクションで新規ユーザーデータを確認できることと、ログイン後にログイン前はアクセスできなかったアプリケーション画面に正常に入れることを確認してください。
もちろん、AI に特定のプロジェクトの実装を参考にして、対応する Supabase 機能を直接移行させることもできます。例えば、ある Project でデータベースと Edge Function の高度な機能が使われている場合、次のように AI に直接類似機能の移行を依頼できます。「プロジェクト {ここに参考プロジェクトの絶対パスを貼り付け} の Supabase 関連機能の実装ロジックを参考に、現在のプロジェクトに同様の実装ロジック(ユーザーログイン、データベース管理、関数リクエストなど)を追加してください」。
4.2 ケーススタディ:オンラインスネークゲームの構築
上記で言及した標準フローに基づいて、具体的な実例 Project5-Supabase-Demos/apps_snakegame を通して実践しましょう。既存の「スネークゲーム」プロジェクトに、ユーザーログインとデータベースの基本機能を含むスコアランキングを追加します。
4.2.1 プロジェクトの分析、データ要件の特定
まず、前述の標準フローと同様に、要件を AI に明確に伝え、AI にプロジェクトと要件に基づいた変更案を提示させます。その後、この変更案に基づいて作業を進めます。
次のようなプロンプトを使って AI に指示できます。
「スネークゲームがあります。ディレクトリは {ここにスネークゲームの絶対パスを貼り付け} です。今回は Supabase を組み合わせてオンラインランキング機能を追加し、ユーザーログインシステムもサポートしたいです。ランキングはユーザー名とメールアドレスに基づいて順位を表示できるようにします。
この機能を実現するために、どのようなデータテーブルを作成する必要があるか分析してください。各テーブルにはどのようなフィールドを含めるべきですか?」
この場合、次のような回答が得られます。
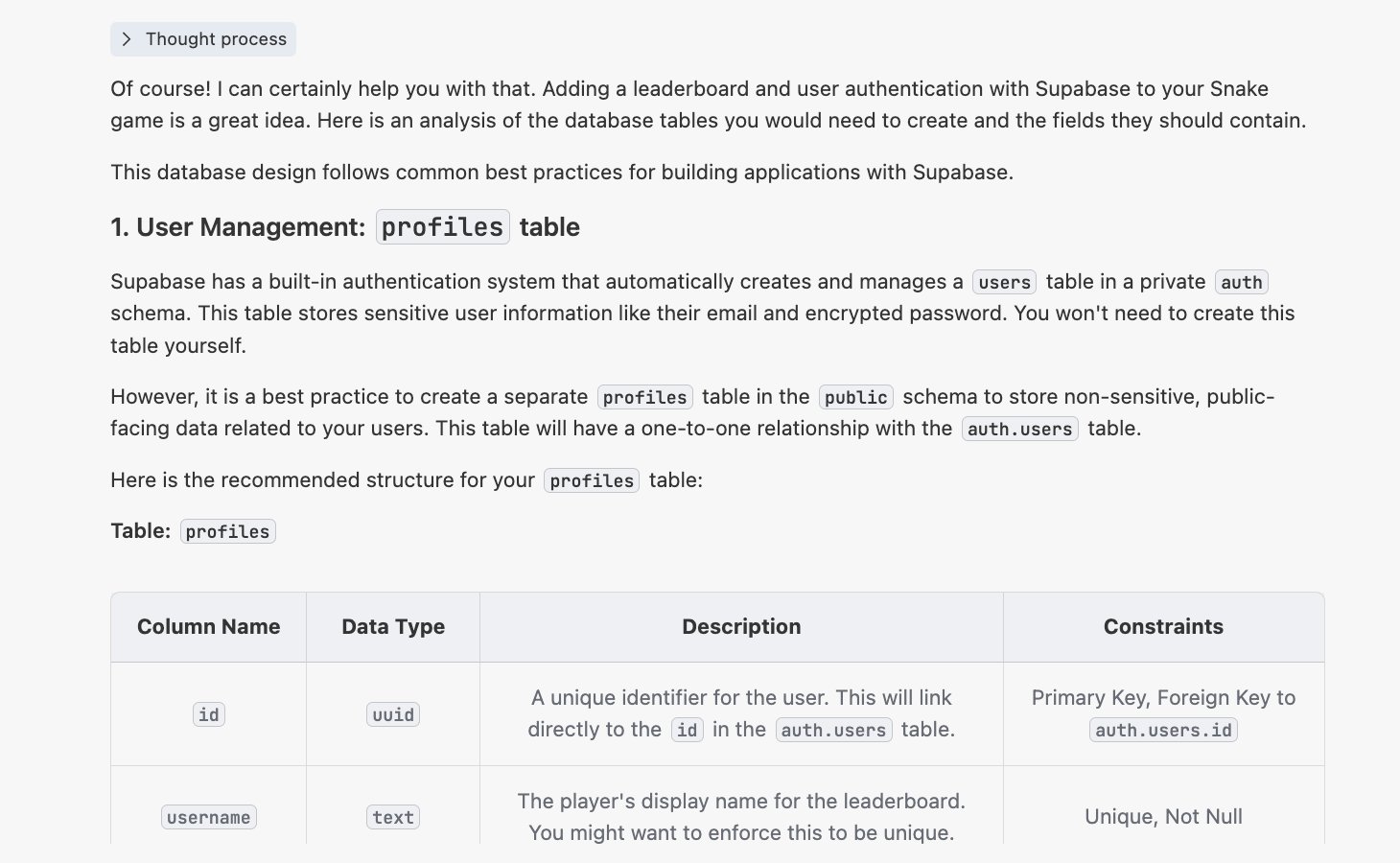
4.2.2 init.sql スクリプトの生成
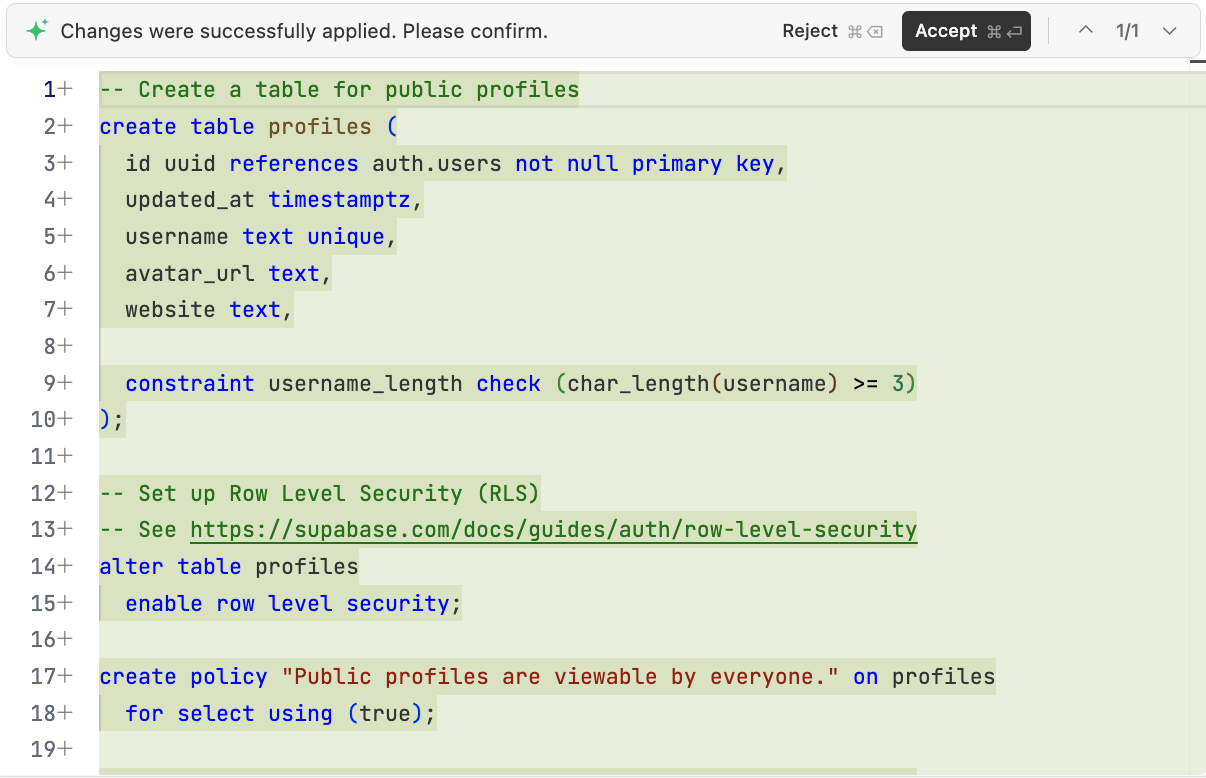
必要な部分を確定したら、AI に Supabase で実行するデータベース初期化スクリプトを生成させます。「上記の分析に基づいて、プロジェクトに scripts/init.sql スクリプトを生成し、Supabase で必要なデータベースを初期化できるようにしてください」。
4.2.3 プロジェクトコードのリファクタリング
次に、AI に前述の内容に基づいて現在のスネークゲームコードをリファクタリングさせるだけです。「これまでの検討内容と SQL テーブルに基づいて、Supabase を使ってランキング機能を実装してください。ランキングは独立したページとし、メールアドレスとユーザー名で異なるユーザーの合計スコアを区別できるようにしてください。また、メールアドレスベースのユーザーログインシステムもサポートし、登録・ログインしないとゲームをプレイできないようにしてください。」
現在の AI の会話ターンが多すぎる場合、新しいセッションを開いてプロジェクトのリファクタリングを行いたい場合は、前述の init.sql をコンテキストに含め、AI に SQL ファイルに基づいてプロジェクトをリファクタリングさせることができます。
AI が実装したユーザーログインシステムが正常に動作しない場合、前回作成した Project5-Supabase-Demos/apps/project-burger-shop-auth-users-2 のアドレスをプロンプトに含め、AI にプロジェクトをベースにユーザーログインシステムを直接実装させることができます。また、Supabase への接続に必要な条件が正しく設定されているか確認し、Supabase の設定エラーによるエラーを防いでください。
コードの修正過程で、実際の動作が期待と異なる場合(ランキングデータが表示されない、ログイン認証が機能しないなど)、具体的な現象を完全に記録して AI にフィードバックすれば、徐々に正しい結果に近づけます。リファクタリング成功の基準は、ユーザーが登録とログイン操作をスムーズに完了でき、ログイン後に対応するゲームのランキングを正常に閲覧できることです。
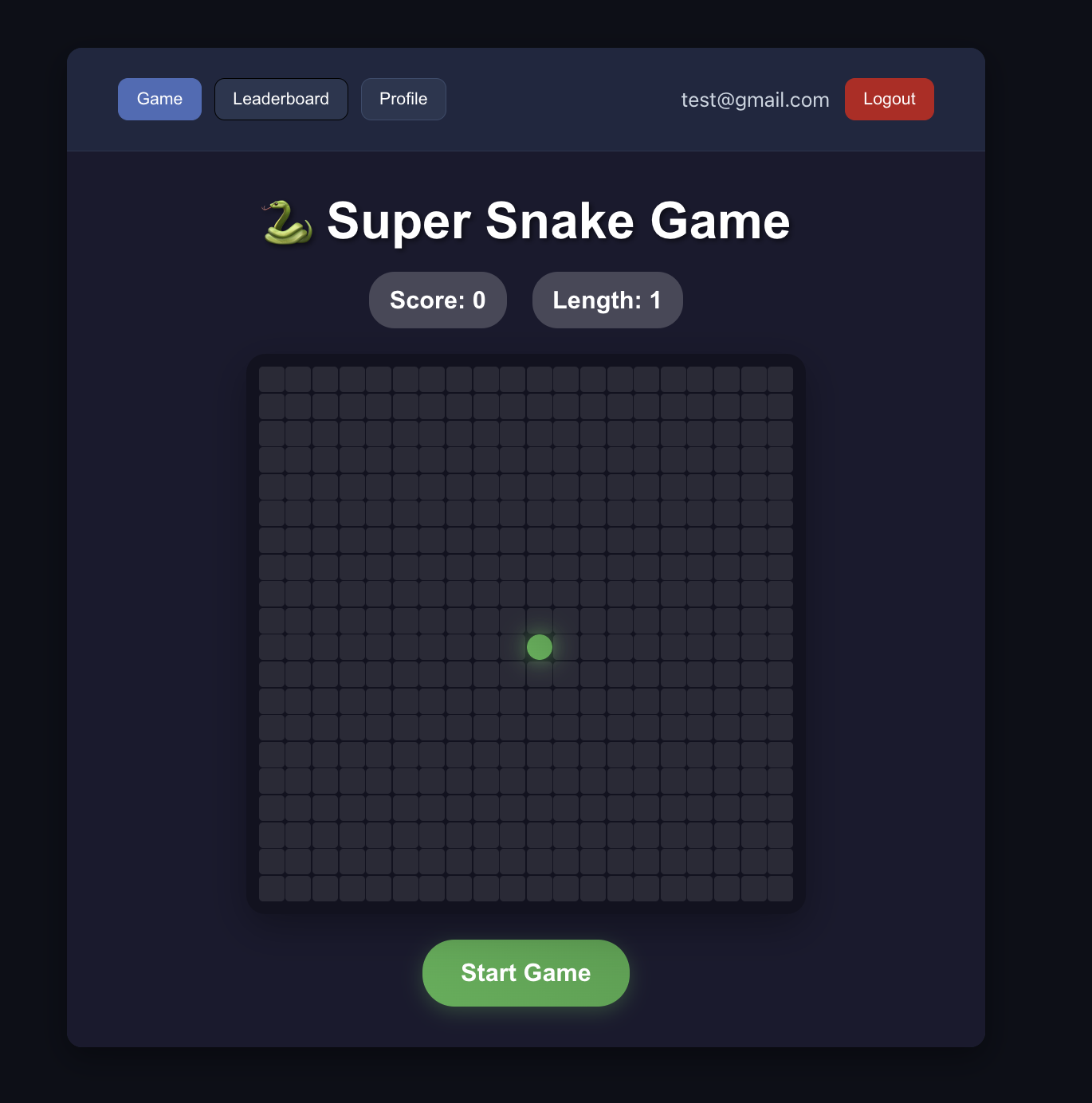
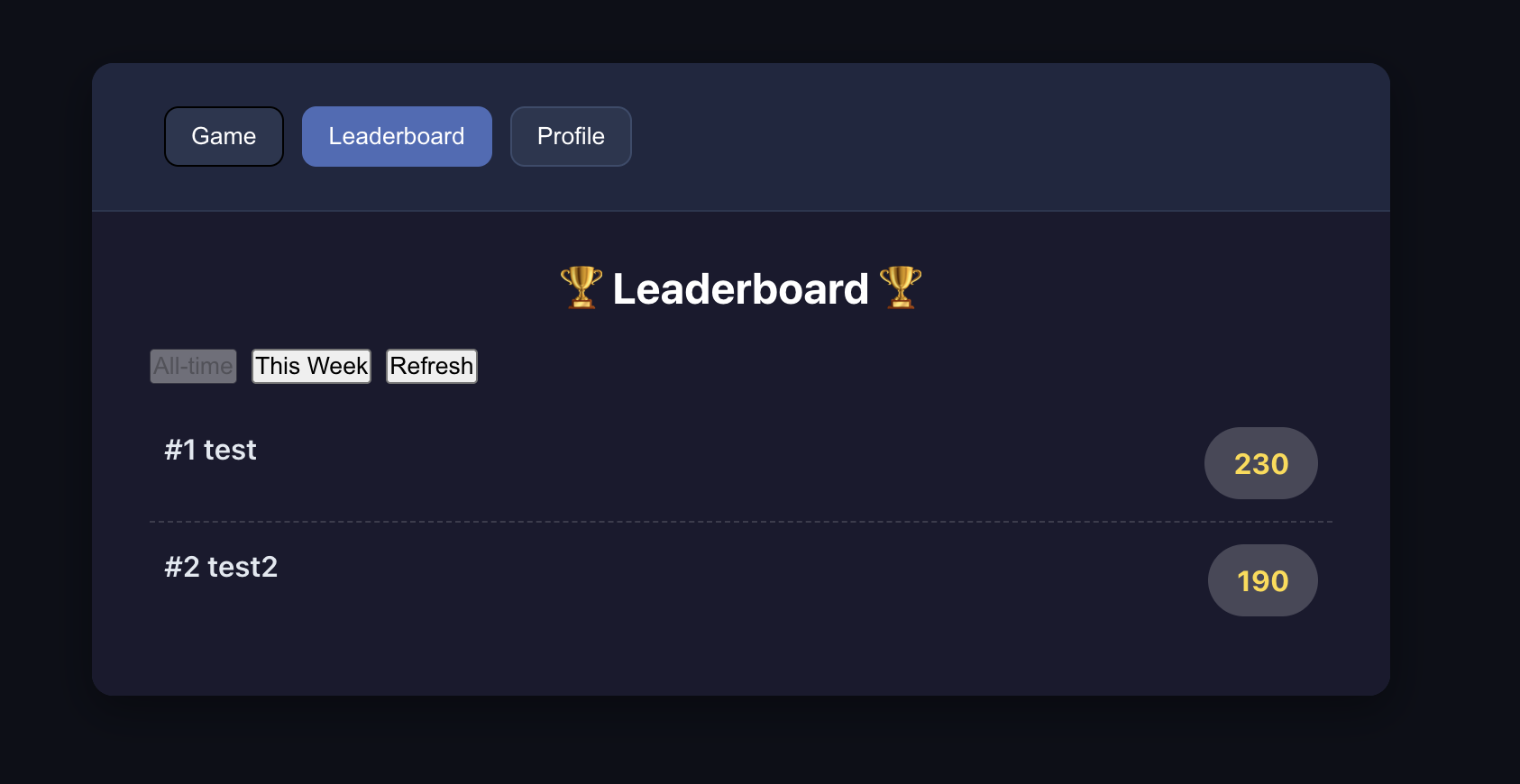
📚 课程作业
- ユーザー管理システムをスネークゲームのデモ版に統合してください
- ユーザー管理システムをあなたのアプリケーションに統合してください(以前にアプリケーションを開発済みの場合)
5. Supabase マスターへの道
以上が Supabase の基本操作です。次の旅では、Supabase の高度な原理と機能に触れます。なぜ Supabase を学習ケースとして選んだのか、そして Supabase を使ってより高度な操作を実現し、より複雑なインタラクション機能を実現する方法を理解します。さらに、これらの機能を学んだ後は、Supabase 以外の同種ツールに対しても応用が効き、より本質的なレベルでバックエンドサービスのコア原理を理解できるようになります。もちろん、短期間ですべてを習得する必要はありません。サードパーティログインサポートだけでも十分かもしれません。まずは以下の内容をざっと目を通し、プロジェクトで対応するニーズが生じた際に戻ってきて深く学ぶだけで大丈夫です。
5.1 なぜ Supabase を選んだのか
高度な内容に入る前に、もう一度この問題を考えましょう。多くのバックエンド技術ソリューションの中で、なぜ最終的に Supabase を技術基盤として選んだのでしょうか。
スタートアップチームが技術選定を行う際、一般的に直面するジレンマがあります。バックエンドシステムを完全に掌握したいと考えつつ、製品を迅速にリリースしなければならないという矛盾です。自社でバックエンドを構築する場合、通常、データベースとリアルタイム同期、ユーザー認証、API サービス、ファイル保存、定時タスク、監視・アラートなどのコアコンポーネントを構築するのに数ヶ月を要します。ただし、チームメンバーが対応分野で豊富な実戦経験を蓄積している場合は別です。資金不足と短い市場の窓という二重の圧力の下で、インフラストラクチャの泥沼に陥ると、イテレーションの遅れや早期の成長機会の喪失を招きやすくなります。
Supabase は、これらのバックエンド能力をすぐに使えるサービスとしてパッケージ化しています(PostgreSQL データベース、リアルタイムサブスクリプション、認証、オブジェクトストレージ、エッジ関数、自動生成 API など)。スタートアップチームは限られたリソースをコア機能の開発に集中でき、基盤構築によるリリース遅延を回避できます。これは現在の投資・起業環境において現実的な生存戦略となっています。もちろん、他のオールインワンバックエンド製品を使って開発することも可能です。例えば PocketBase(軽量・ミニマル)や Appwrite(クロスプラットフォーム対応)などの選択肢もありますが、機能の完全性、SQL エコシステムの成熟度、GitHub コミュニティの注目度を総合的に考慮すると、Supabase はビジネスの長期的かつ安定した稼働を支えるにより適しています。
同種製品の中で、Supabase のオープンソース戦略はさらに優位性があります。市場シェアの高い Firebase を例に挙げると、クローズドソースの特性によりプラットフォームロックインが発生しやすく、移行コストが非常に高くなります。Supabase は完全なオープンソースモデルを採用し、プライベートデプロイをサポートし、ベンダーロックインのリスクを回避し、必要に応じて他の競合製品に切り替えることができます。
まとめると、技術選定はビジネスの規模と目標に合致させる必要があります。個人プロジェクトや非常に小規模なテストの場合、PocketBase などの超軽量ソリューションで十分です。企業が複雑な認証システムと連携する必要がある場合や、上場企業のコンプライアンス監査要件を満たす必要がある場合は、WorkOS のようなエンタープライズ級の全認証ガバナンスソリューションがより適しています。しかし、MVP の検証や初期ユーザーを抱えるコアビジネスシナリオにおいては、Supabase の完全な機能で十分です。少なくとも万ユーザー規模まで単独で対応でき、さらに Stripe(決済)、Resend(メール)、Cloudflare(CDN)などのサードパーティサービスと柔軟に統合できます。将来的にビジネスがエンタープライズ級の要件に拡大した場合でも、Supabase のオープンソースアーキテクチャはエンタープライズシステムと並行してデプロイでき、異なる機能には最適なプラットフォームを選択して使用できます。この段階的な柔軟性により、スタートアップチームは重厚なインフラストラクチャに早すぎる投資を避けつつ、将来にわたって進化できる余裕を確保できます。
5.2 Google と GitHub のログインサポート
前のチュートリアルでは、メールアドレスを使って直接登録・ログインする方法について説明しました。しかし実際の操作では、登録フローを簡略化したいケースがよくあります。例えば、Google や GitHub などのサードパーティログインを使って、システムに素早く登録・ログインできるようにしたい場合です。このセクションでは、各詳細について説明します。また、完全な認証システムは安全で信頼性の高いパスワードリセット機能も提供する必要があり、パスワードリセット機能もこのセクションのプロジェクトに統合されます。
本プロジェクト(Project5-Supabase-Demos/apps/project-burger-shop-auth-advanced-supabase-6)は、これらの高度な機能を実装する方法を完全にデモしています。

5.2.1 OAuth フロー:サードパーティログインはどのように機能するのか
サードパーティログインのコアは OAuth 2.0 オープン認可プロトコルです。その本質は「認可の代理」です。ユーザーが私たちのアプリケーション(ハンバーガーショッププロジェクト)に対して、サードパーティプラットフォーム(Google など)の公開情報(メールアドレス、アバターなど)へのアクセスを許可しつつ、サードパーティプラットフォームのパスワードを私たちのアプリケーションに露出させる必要がない仕組みで、パスワード漏洩のリスクを根本から回避します。
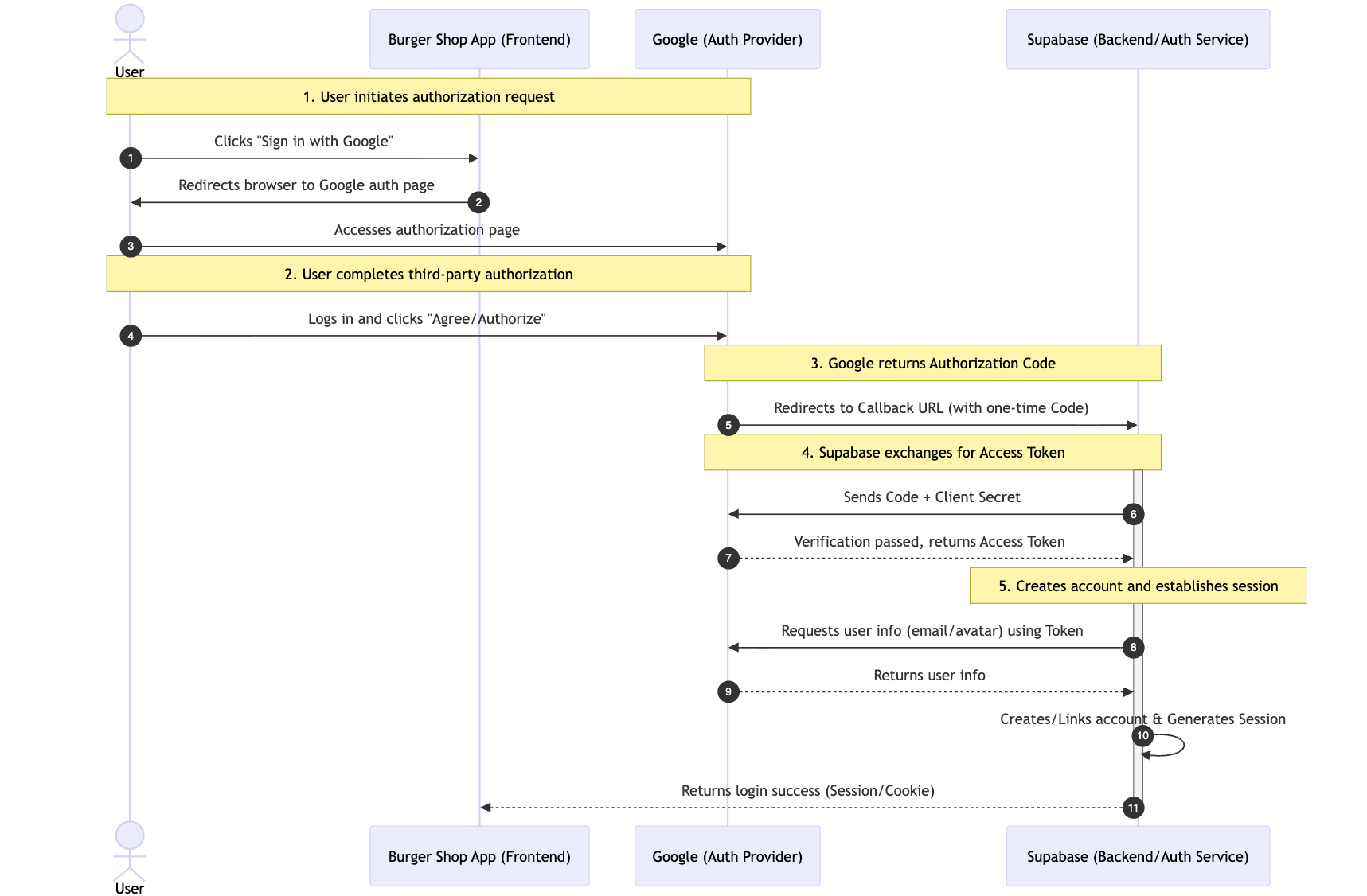
完全なフローは5つの重要なステップに分解でき、Google ログインを例に説明します。
- ユーザーが認可リクエストを発行:ユーザーがページ上の「Sign in with Google」ボタンをクリックすると、私たちのアプリケーションは自動的にユーザーを Google の公式認可ページにリダイレクトします(認可プロセスのセキュリティを確保し、フィッシングのリスクを回避します)。
- ユーザーがサードパーティの認可を完了:ユーザーが Google のページで自分のアカウントにログインし(ユーザーの身元を確認)、私たちのアプリケーションが要求する権限(「メールアドレスの取得」など)に同意します。
- Google が使い捨て認可コードを返す:認可が通ると、Google はユーザーを事前に取り決めた「コールバック URL(Callback URL)」にリダイレクトし、URL パラメータに使い捨てで短期間有効な認可コードを付加します(ユーザー情報を直接返すのではなく、セキュリティをさらに向上させます)。
- Supabase がアクセストークン(Access Token)を交換:私たちのバックエンド(Supabase がホストするため、自前の構築は不要)がこの認可コードを使って Google の公式インターフェースにリクエストを送り、ユーザー情報の取得に使用できる Access Token と交換します(認可コードは Token との交換にのみ使用し、Token がフロントエンドで直接伝送されるのを回避します)。
- アカウント作成とセッション確立:Supabase が Access Token を使って Google からユーザーの公開情報(メールアドレス、アバターなど)を取得し、私たちのプロジェクトでそのユーザーのアカウントを自動作成(初回ログイン時)するか、既存のアカウントに直接関連付け、最終的に有効なユーザーセッション(Session)を生成してログインを完了します。
5.2.2 Google Cloud の設定で Client ID と Secret を取得
サードパーティログインの方式に関わらず、通常は Client ID と Secret を取得して設定する必要があります。Google のサードパーティログインの場合、まず Google Cloud Platform で OAuth 2.0 クライアント ID を作成して、対応するパラメータを取得する必要があります。
- Google Cloud Console にアクセス :
- Google Cloud Console にアクセスします。
- 新しいプロジェクトを作成するか、既存のプロジェクトを選択します。
- OAuth 同意画面(OAuth consent screen)の設定 :
- 左側のナビゲーションで「APIs & Services」->「OAuth consent screen」を見つけます。
- 「External」ユーザータイプを選択し、「Create」をクリックします。
- アプリケーション名、ユーザーサポートメールアドレスなどの必須情報を入力します。
- 「Authorized domains」セクションで、Supabase プロジェクトのドメインを
*.supabase.coの形式で追加します。 - 保存して続行します。「Scopes」と「Test users」のステップは、とりあえずスキップしてそのまま保存します。
- 認証情報の作成(Create Credentials) :
- 「APIs & Services」->「Credentials」に入ります。
- 「+ CREATE CREDENTIALS」をクリックし、「OAuth client ID」を選択します。
- 「Application type」で「Web application」を選択します。
- 名前を付けます(例:「Supabase Auth」)。
- 「Authorized redirect URIs」セクションで、「ADD URI」をクリックし、Supabase プロジェクトのコールバック URL を入力します。この URL は Supabase Dashboard の「Authentication」->「Providers」->「Google」で確認できます。形式は通常
https://<あなたのプロジェクトID>.supabase.co/auth/v1/callbackです。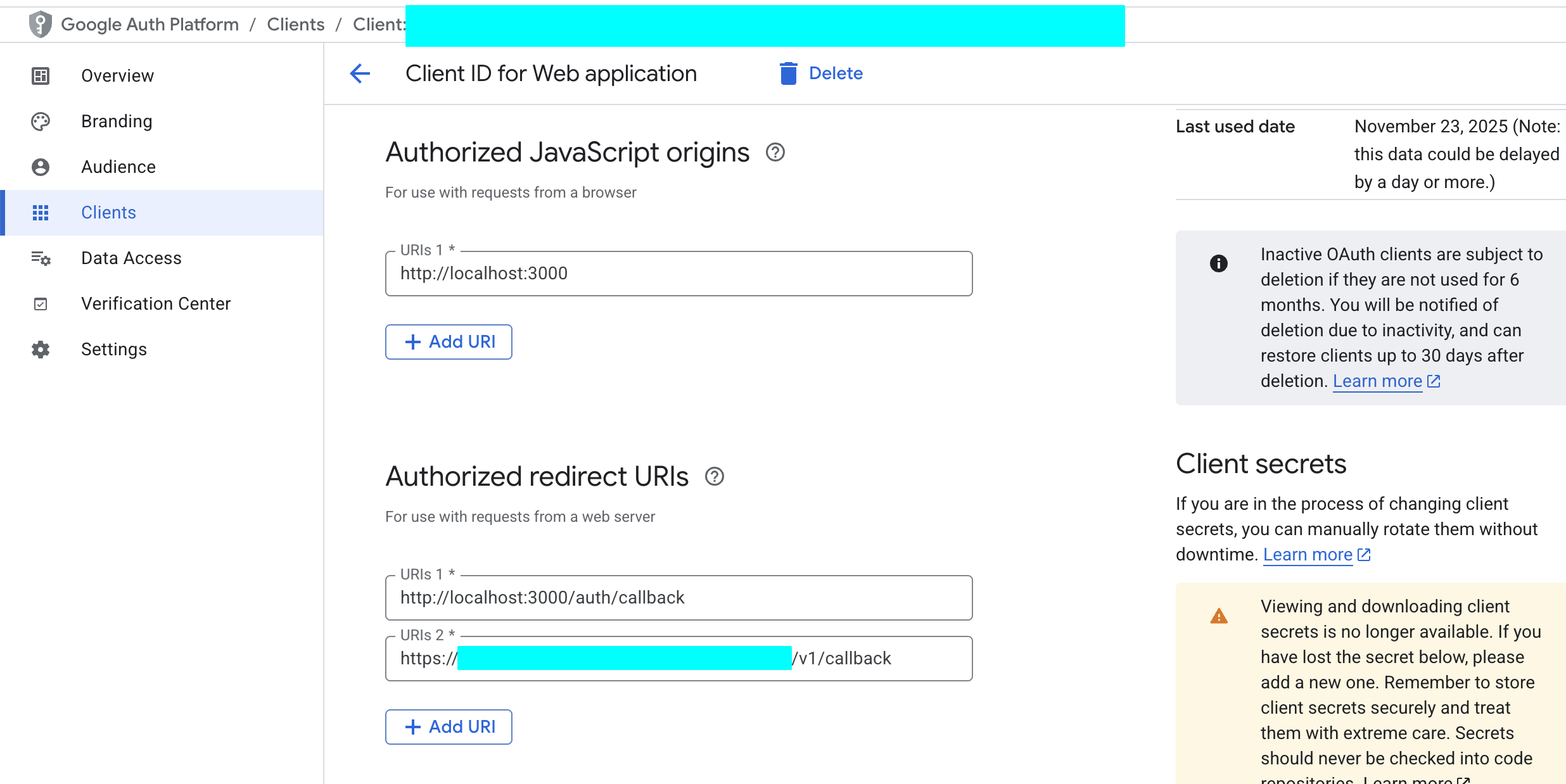
- 「CREATE」をクリックします。
- Client ID と Client Secret の取得 :
- 作成が成功すると、ポップアップに Client ID と Client Secret が表示されます。必ずすぐにコピーして安全に保管してください。
5.2.3 GitHub の設定で Client ID と Secret を取得
同様に、GitHub でも OAuth アプリケーションを登録する必要があります。
GitHub Developer Settings にアクセス :
- GitHub アカウントにログインします。
- 右上のアバターをクリックし、「Settings」に入ります。
- 左側ナビゲーションの下部にある「Developer settings」を見つけます。
新しいアプリケーションの登録(Register a new application) :
「OAuth Apps」を選択し、「New OAuth App」をクリックします。
アプリケーション名を入力します(例:「My Burger Shop」)。
Homepage URL :アプリケーションのオンラインアドレス、またはローカル開発アドレス
http://localhost:3000を入力します。Authorization callback URL :Supabase プロジェクトのコールバック URL を入力します。これも Supabase Dashboard の「Authentication」->「Providers」->「GitHub」で確認でき、形式は
https://<あなたのプロジェクトID>.supabase.co/auth/v1/callbackです。「Register application」をクリックします。
Client ID と Client Secret の取得 :
登録が成功すると、ページに Client ID が表示されます。
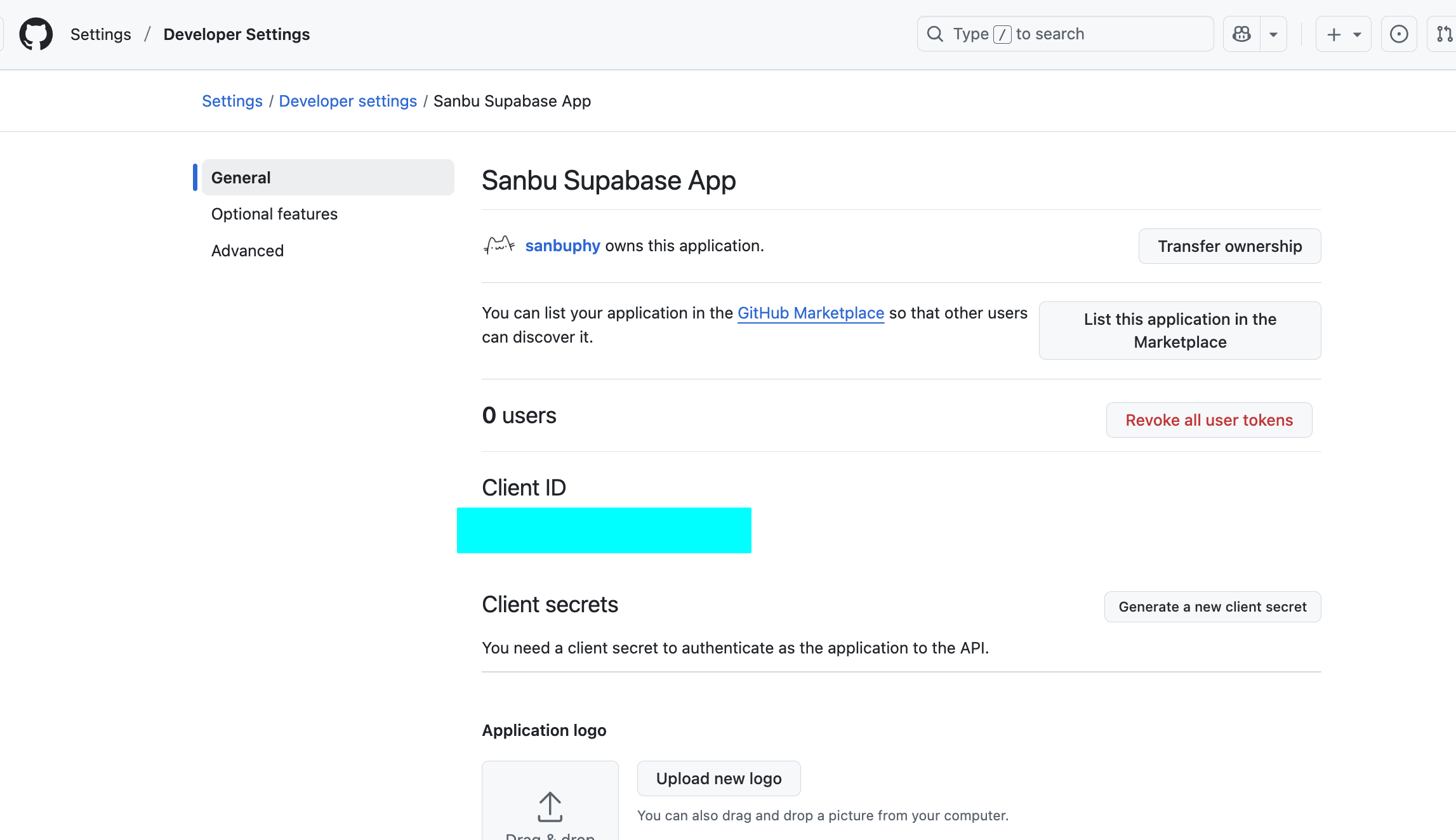
「Generate a new client secret」をクリックして Client Secret を生成します。同様に、必ずすぐにコピーして保存してください。
5.2.4 Supabase での Provider の設定
次に、取得した認証情報を Supabase に設定します。
- Supabase Dashboard にアクセス :
- プロジェクトを選択し、「Authentication」->「Providers」に入ります。
- Google の有効化と設定 :
- 「Google」を見つけて有効にします。
- Google Cloud から取得した Client ID と Client Secret を対応する入力欄に貼り付けます。
- 「Save」をクリックします。
- GitHub の有効化と設定 :
- 「GitHub」を見つけて有効にします。
- GitHub から取得した Client ID と Client Secret を対応する入力欄に貼り付けます。
- 「Save」をクリックします。

これで、構築したウェブサイトでサードパーティアカウントを使ってログインできるようになりました。AI に Project5-Supabase-Demos/apps/project-burger-shop-auth-advanced-supabase-6 プロジェクトを参考にして、あなたのプロジェクトにユーザーログインシステムをサポートさせ、GitHub と Google 認証を含むユーザーログイン画面を最小コストで統合させることができます。
5.2.6 パスワードリセットの実装
成熟したユーザーログインコンポーネントとして、パスワードリセットも極めて重要な要素です。本プロジェクト project-burger-shop-auth-advanced-supabase-6 にはこの機能の完全な実装も含まれています。AI に本プロジェクトのパスワードリセット機能をベースに完全なパスワードリセットコンポーネントを複製させることができます。主なステップは以下の通りです。
- リクエストの発行 :ユーザーがパスワード忘れページでメールアドレスを入力し、フロントエンドが
supabase.auth.resetPasswordForEmail()関数を呼び出し、リダイレクト先の redirectTo URL(例:/auth/reset)を指定します。 - メールの送信 :Supabase がそのメールアドレスに固有のリセットリンクを含むメールを送信します。
- リンクへのアクセス :ユーザーがメール内のリンクをクリックし、アプリケーション内の指定されたリセットページにリダイレクトされます。
- パスワードの更新 :リセットページでユーザーが新しいパスワードを入力します。フロントエンドが
supabase.auth.updateUser()を呼び出し、新しいパスワードを Supabase に送信します。Supabase は自動的にリンクの有効性を検証し、パスワードの更新を完了します。
最後に、現在のパスワードリセットメールが簡素すぎると感じる場合、Supabase Dashboard の Authentication -> Email Templates で「Reset Password」メールテンプレートをカスタマイズできます。
Reset password 機能の他にも、ユーザー管理に関連する多くの高度な機能設定(例えば Invite user など)があります。それぞれの機能の開発ドキュメントを参照し、Vibe coding ツールと組み合わせて対応機能を追加してください。
5.3 リアルタイム機能
Supabase のリアルタイム機能は最も強力な特性の一つであり、コラボレーションドキュメント、リアルタイムダッシュボード、ゲームロビー、カスタマーサポートシステムの構築に大きな利便性をもたらします。
本プロジェクト Project5-Supabase-Demos/apps/project-burger-shop-realtime-orders-3 は、マルチユーザー リアルタイムチャットルーム、カーソル位置共有機能を構築することで、Supabase Realtime に関わる3つのコア能力、データベース変更リッスン(Postgres Changes)、ブロードキャスト(Broadcast)、オンライン状態(Presence)をデモしています。
関連コード部分が難しいと感じる場合、AI にこのドキュメントの内容を参考にして、あなたのプログラムを修正させることができます。
5.3.1 データベースリアルタイム変更 Postgres Changes
最も一般的な Realtime 機能は、データベースの変更に対するリアルタイムリッスンである Postgres Changes です。クライアントがデータベース内の特定のテーブル、特定の行、さらには特定の列の INSERT、UPDATE、DELETE イベントをサブスクライブできるようにします。データベースに変更が発生すると(API 呼び出し、Supabase Dashboard の操作、SQL スクリプトの実行のいずれであっても)、Supabase は PostgreSQL の基盤レプリケーションメカニズムを利用して、変更されたデータを WebSocket 経由ですべてのサブスクライブ済みフロントエンドクライアントに即座にプッシュします。フロントエンドがポーリング(Polling)で繰り返しクエリする必要はありません。
一般的に、この機能は Table Editor で Enable Realtime をクリックして有効にできますが、SQL スクリプトによる初期化実行の方が便利です。例えば以下のようになります。
-- Enable realtime replication
ALTER TABLE public.chat_messages REPLICA IDENTITY FULL;
DO $$
BEGIN
IF NOT EXISTS (
SELECT 1 FROM pg_publication_tables
WHERE pubname = 'supabase_realtime'
AND schemaname = 'public'
AND tablename = 'chat_messages'
) THEN
ALTER PUBLICATION supabase_realtime ADD TABLE public.chat_messages;
END IF;
END $$;この文は chat_messages テーブルを Supabase に事前設定された supabase_realtime に追加します。テーブルがこの特別な publication に追加されると、Supabase のリアルタイムサーバーはそのテーブルのすべてのデータ変更のリッスンを開始します。
上記の特別なデータテーブルに基づいて、リッスンコードを使ってテーブル内のデータ変更をリアルタイムにリッスンできます。実現したいのは、あるユーザーがメッセージを送信した際、他のすべてのオンラインユーザーが直ちに画面でそのメッセージを見られるようにすることです。chat_messages テーブルの INSERT イベントをサブスクライブすることでこれが実現できます。
const sub = supabase
.channel('chat_messages_channel')
.on('postgres_changes', {
event: 'INSERT',
schema: 'public',
table: 'chat_messages'
}, (payload: any) => {
console.log('New message received:', payload.new);
const newMessage = payload.new as Message;
// ... //
.subscribe((status: string) => {
console.log('Chat subscription status:', status);
});.channel('chat_messages_channel'): 分離された通信チャンネルを作成します。.on('postgres_changes', ...): コアのサブスクライブメソッドです。chat_messagesテーブルのINSERTイベントのみを関心対象として Supabase に伝えます。payload.new: 新しいメッセージがデータベースに挿入されると、Supabase は新しいデータの完全な内容をpayload.newを通じてすべてのサブスクライブ済みクライアントにプッシュします。.subscribe(): サブスクリプションを開始します。
5.3.2 情報ブロードキャスト同期 Broadcast & Presence
データベースに保存する必要のない、より「即時的な」インタラクション(カーソル移動、オンライン状態など)については、Supabase は Broadcast と Presence 機能を提供しています。
- Presence: チャンネル内のすべてのクライアントの共有状態を追跡するために使用します。「誰がオンラインか」の機能の実装に適しています。
- Broadcast: チャンネル内の他のすべてのクライアントに低遅延の一時メッセージを送信するために使用します。
Presence のコアとなる考え方は、各クライアントが自分のオンライン状態を宣言し、Supabase のサーバーがこれらの状態をチャンネル内の他のすべてのクライアントに確実に同期させることです。Presence の実装は以下の重要なステップに分かれます。
- Presence をサポートするチャンネルの作成
まず、チャンネル lobby_presence を作成し、これらのインタラクションを専用に処理させます。設定で一意のキーを指定して現在のユーザーを識別します。このキーは通常、ユーザーの ID です。
const ch = supabase.channel
('lobby_presence', {
config: {
presence: { key: anonymousUser.id },
}
});- チャンネルのサブスクライブと「オンライン」の宣言
チャンネルが作成されたら、それをサブスクライブする必要があります。サブスクライブ成功のコールバック(status === 'SUBSCRIBED')で、channel.track() メソッドを呼び出します。このメソッドは現在のユーザーの情報(ユーザー ID、名前、アバターの色など)をチャンネル内の他のすべてのクライアントにブロードキャストし、自分の「オンライン」状態を宣言します。
const me = {
id: anonymousUser.id,
name: anonymousUser.name,
color: anonymousUser.color
};
ch.subscribe(async (status) => {
if (status === 'SUBSCRIBED') {
await ch.track(me);
}
});- 完全なオンラインリストの同期
新しいユーザーがチャンネルに参加する際、現在すでにオンラインの全ユーザーのリストを取得する必要があります。これは presence の sync イベントをリッスンすることで実現します。sync イベントは初めてチャンネルに参加した際にトリガーされ、完全な「スナップショット」を提供します。
channel.presenceState() メソッドはオブジェクトを返し、現在のチャンネル内のすべてのオンラインユーザーの状態情報を含みます。これを処理してアプリケーションの state に更新し、完全なオンラインユーザーリストをレンダリングします。
ch.on('presence', { event: 'sync' }, ()
=> {
const state = ch.presenceState();
const flat = {};
Object.values(state).forEach((arr) => {
arr.forEach((u) => { flat[u.id] =
{ ...u }; });
});
setOnline(flat);
});- 個別ユーザーの参加と離脱のリッスン
sync イベントに加えて、join と leave イベントもリッスンでき、新しいユーザーが入退室する際に即座に対応できます。例えば「User has joined」の通知を表示するなど。
ch.on('presence', { event: 'join' }, ({
key, newPresences }) => {
console.log('User joined:', key,
newPresences);
});
ch.on('presence', { event: 'leave' }, ({
key, leftPresences }) => {
console.log('User left:', key,
leftPresences);
});以上のステップにより、機能完備なオンライン状態システムを構築しました。Supabase はユーザーの予期せぬ切断(ブラウザの閉鎖やネットワーク切断など)を自動的に処理し、適切なタイミングで leave イベントをトリガーして、オンラインリストの正確性を確保します。
Presence により「誰がいるか」が分かった後、Broadcast が彼らの間で「会話」を可能にしますが、会話の内容は一時的に保存されます。典型的な例はリアルタイムカーソル追跡です。マウスの移動のたびにデータベースの読み書きを行うと、多大なパフォーマンスの無駄と遅延が生じます。Broadcast はこの問題を完璧に解決し、メッセージが各クライアント間で WebSocket を通じて直接伝達され、データベースを完全にバイパスします。
Broadcast の動作モードは主に2つのコアメソッドに依存します。channel.send() が送信に使用され、channel.on() が受信に使用されます。
- 送信側:自分のカーソル位置のブロードキャスト
mousemove イベントにリスナーを追加します。マウスが移動した際、ユーザー ID、座標、色を含む payload を構築し、channel.send() でブロードキャストし、イベント名を 'cursor' として指定します。
const handleMouseMove = (e) => {
const payload = {
id: anonymousUser.id,
x: e.clientX,
y: e.clientY,
name: anonymousUser.name,
color: anonymousUser.color
};
channelRef.current?.send({
type: 'broadcast',
event: 'cursor',
payload
});
};
document.addEventListener('mousemove', handleMouseMove);- 受信側:他人のカーソルのリッスンとレンダリング
同じチャンネル内で、すべてのクライアントが channel.on() を使って broadcast タイプで、イベントが 'cursor' のメッセージをリッスンします。一致するメッセージを受信すると、コールバック関数がトリガーされます。payload から送信側のデータを解析し、ローカルの online 状態を更新して、画面上に他のユーザーのカーソル位置をリアルタイムにレンダリングします。
ch.on('broadcast', { event: 'cursor' }, ({ payload }) => {
setOnline((prev) => ({
...prev,
[payload.id]: {
...(prev[payload.id] || {}),
x: payload.x,
y: payload.y
}
}));
});この方式により、Presence と Broadcast が連携して動作します。Presence はオンラインユーザーリストを維持し、Broadcast はこれらのユーザー間でカーソル位置のような一時状態の伝達を担当し、最終的に低コストで豊富なリアルタイムインタラクション機能を実現します。
5.4 ストレージ
ユーザー情報や注文のように規則的に定義できる構造化データに加えて、完全なアプリケーションは通常、大量の非構造化ファイルも処理する必要があります。例えば、ユーザーのアバター、商品画像、ユーザーがアップロードした注文ドキュメントなどです。この種のファイルの特徴は、サイズのばらつきが大きく、数が非常に多くなる可能性があることです(ECプラットフォームの商品画像は数万から数十万枚に達する可能性があります)。アプリケーション自身のビジネスサーバーに直接保存すると、サーバーのストレージ負荷が著しく増加し、データの読み書き速度が低下し、アプリケーション全体のパフォーマンスに影響を与える可能性があります。
実際の開発では、この種の非構造化ファイルは「オブジェクトストレージサービス」に一元管理されます。OSS、Amazon S3 はいずれもこの種のサービスに属し、大量ファイルの保存に特化して設計された「プロフェッショナルなストレージツール」で、ファイルの保存、バックアップ、高速読み取りの要件に効率的に対応できます。そして、アプリケーションでこれらのファイルを取得する際、オブジェクトストレージサービスの「基盤ストレージ」から直接取り出すのではなく、URL アドレスを通じて実現します。オブジェクトストレージに保存された各ファイルには一意の URL が割り当てられ(「https://xxx.oss.com/avatar/user123.jpg」のようなアドレスで、この「ウェブサイト」には画像が1枚だけあると簡単に理解できます)。この URL はファイルの「専用アクセスアドレス」であり、フロントエンドページはこのアドレスを通じて直接アバターや商品画像をダウンロードまたは読み込むことができ、アプリケーションのビジネスサーバーを経由する必要がありません。ファイルの読み込み速度が向上するだけでなく、ビジネスサーバーの負荷も軽減されます。
本プロジェクト project-burger-shop-storage-uploads-4 は、ユーザーアバターアップロード機能を通して、Supabase Storage を活用したモダンなファイルアップロードシステムの構築方法を深くデモし、非構造化ファイルがアップロードから URL アクセスまでの完全なフローを直感的に理解させます。また、本プロジェクトは Uppy ライブラリを使用して優れたファイルアップロードインターフェースを提供し、Tus プラグインと組み合わせてレジューム可能なアップロードを実現し、Uppy のアップロードエンドポイントを Supabase の標準 API(<supabaseUrl>/storage/v1/upload/resumable)に向けて動作させます。同様の方法でアップロード機能コンポーネントを実装できます。
5.4.1. ストレージバケット
Supabase Storage の構成単位はストレージバケット(Bucket)です。コンピュータのオペレーティングシステムにおけるフォルダと考えてください。各 Bucket は独立したセキュリティポリシーと設定を持つことができます。
Storage 内のすべてのファイルは公開 URL を通じて直接アクセスできますが、誰でも自由にアップロードや変更ができるわけではありません。具体的なアクセス権限はより精細なポリシーによって制御されます。データベースと同様に、Storage のアクセス権限も行レベルセキュリティポリシーによって管理されます。SQL ポリシーは storage.objects と storage.buckets という2つの特別なテーブルに記述され、誰がファイルを読み取り(SELECT)、アップロード(INSERT)、更新(UPDATE)、削除(DELETE)できるかを正確に定義できます。
例えば、ユーザーが自分の user_id で名付けられたフォルダにのみアップロードでき、かつ画像タイプのファイルのみをアップロードできるポリシーを作成できます。
CREATE POLICY "Allow authenticated
uploads to avatars bucket"
ON storage.objects FOR INSERT
TO authenticated
WITH CHECK (
bucket_id = 'avatars' AND
auth.uid() = (storage.foldername(name))
[1]::uuid AND
(storage.extension(name) IN ('png',
'jpg', 'jpeg'))
);
CREATE POLICY "Allow public read access
to avatars"
ON storage.objects FOR SELECT
USING ( bucket_id = 'avatars' );5.4.2 アクセス可能なファイル URL の取得
本プロジェクトでは、avatars という名前のパブリックバケットを手動で作成する必要があります。すべてのファイルはこのパブリックバケットにアップロードされて保存されます。ファイルのアップロードが成功すると、Storage 内の保存パス(例:public/avatar1.png)のみが得られます。これはデータベースに保存されている文字列に過ぎず、ブラウザがこの画像をレンダリングするには、アクセス可能な HTTP URL に変換する必要があります。
Supabase はこの URL を取得するための2つの異なる戦略を提供しており、セキュリティ、永続性、コスト管理の面で本質的な違いがあります。
1. 公開 URL(Public URL) - 永久リンク
最も直接的な方法です。ファイルがPublic Bucketに保存されている場合、固定で永続的な公開リンクを取得できます。
const { data } = supabase.storage
.from('avatars')
.getPublicUrl('public/avatar1.png');
const publicUrl = data.publicUrl;この種のリンクには2つのコアの特徴があります。1つ目はシンプルで直接的なことで、URL 構造が固定されており、実際の操作で継ぎ足しや管理が容易で、技術的な利用のハードルを下げます。2つ目はキャッシュに有利なことで、永久リンクとして、CDN(コンテンツ配信ネットワーク)やブラウザに効果的にキャッシュされ、リソースのアクセス速度を大幅に向上させ、ユーザー体験を最適化します。これらの特徴に基づき、真の意味でのパブリックリソースシーン(ウェブサイトのロゴ、製品カタログ画像、ブログ記事の画像など)に適しており、これらのリソースのアクセスと管理の要件にうまく対応できます。
ただし本番環境では、この種のリンクにはトラフィックの不正利用(Hotlinking)のリスクが明確に存在します。リンクが永久に公開されているため、外部の人物があなたの画像リンクを自分の高トラフィックウェブサイトに容易に埋め込むことができ、トラフィックが不正に占有されます。この行為により、あなたの Supabase プロジェクトに大量の不要なトラフィック費用が発生し、これらのトラフィックはあなた自身のアプリケーションにサービスを提供するものではなく、典型的なコストの無駄であり、本番環境で高度に警戒・防止すべき問題です。したがって、外部リソースの公開には一時的な署名 URL への転換が必要です。
2. 署名付き URL(Signed URL) - 一時認可リンク
公開 URL のセキュリティとコストの問題を解決するため、Supabase は一時署名付き URL の生成方法を提供しています。これは大部分のオンラインアプリケーションで推奨されるベストプラクティスです。例えば、画像生成 AI アプリケーションがユーザーに期限付きの画像閲覧リンクを生成する場合、ECプラットフォームが注文済みユーザーのみに一時的な請求書ダウンロードアドレスを提供する場合、有料コンテンツプラットフォームが購読ユーザーに短期間有効なコース再生リンクを提供する場合など、ファイルの不正利用を防ぎつつトラフィックの盗用も回避でき、適応性が非常に高いです。
const { data, error } = await supabase.storage
.from('avatars')
.createSignedUrl('private/user-invoice.pdf', 3600); // リンクの有効期間は 3600 秒(1時間)
const signedUrl = data?.signedUrl;一時署名付き URL(Signed URL)には3つのコアの利点があります。セキュアで制御可能とは、リンクにセキュリティマークが付いており有効期限があり、期限切れになると使用できなくなることです。権限バインディングが簡単とは、このファイルを見られる人だけがこのリンクを生成でき、たとえファイルがプライベートストレージ(Private Bucket)に隠されていても、このリンクを使えば正常に開けることです。盗用防止とは、リンクが一時的であり、他の場所にコピーされてもすぐに無効になるため、悪意のあるトラフィック消費を防げることです。これらの利点により、ユーザーのアバター、プライベート写真、有料コンテンツ、注文の請求書など、権限管理が必要なファイルに適しています。
セキュリティの確保とコスト管理の観点から、まず一時署名付き URL を使用する習慣を身につけることをお勧めします。あるリソースが明確に永続的に公開され、無制限のアクセスが必要な場合(アプリケーションの公開ロゴ、公開イベントの宣伝画像など)にのみ、Public URL の使用を検討してください。これにより、特定のビジネス要件を満たしつつ、不要なリスクとコストの浪費を最大限に回避できます。
5.5 エッジ関数
Edge Function は Serverless(サーバーレスアーキテクチャ)エコシステムにおいて極めてコアとなる形態の一つであり、「自前バックエンドなし」のシーンに軽量で効率的な関数実行サポートを提供します。
Serverless とは何か?Serverless(サーバーレスアーキテクチャ)は、本当にサーバーがないという意味ではなく、開発者がサーバーの購入、運用保守、設定、スケーリングを気にする必要がないことを指します。ビジネスコード(関数)を書くだけで、クラウドサービスプロバイダーが特定のイベントのトリガー時に自動的にリソースを割り当ててコードを実行し、実際の実行時間に応じて課金します。
アプリケーションがクライアント(ブラウザ)では完了できない、あるいは完了すべきでないロジックを実行する必要がある場合(例えば、秘密鍵が必要なサードパーティ API とのインタラクション、計算集約型タスクの実行、複雑なビジネスルールの強制など)、Edge Functions が活躍します。Supabase Edge Functions は Deno と TypeScript に基づいており、グローバルのエッジノードにデプロイされ、物理的にユーザーに近い距離で実行されるため、極めて低い関数実行遅延を提供します。
現在、主要なクラウドプロバイダーはそれぞれの Edge Function サービスを提供しています。一般的なものは以下の通りです。
- AWS Lambda@Edge:AWS Lambda を拡張したエッジ関数サービスで、CloudFront CDN と連携し、Node.js、Python などの言語をサポート。
- Cloudflare Workers:Cloudflare が提供するエッジ関数で、グローバル 275+ のエッジノードにデプロイされ、JavaScript/TypeScript をサポートし、「ミリ秒級の遅延」をコアの利点とする。
- Vercel Edge Functions:Vercel のフロントエンドプロジェクトに適合するエッジ関数で、Next.js と深く統合され、TypeScript をサポートし、「フロントエンドとエッジロジックのシームレスな連携」を特徴とする。
Supabase に戻ると、アプリケーションが「クライアント(ブラウザ)では完了できない」ロジックを実行する必要がある場合、例えば秘密鍵を使ったサードパーティ API(LLM インターフェースなど)の呼び出し、計算集約型タスクの処理(画像圧縮など)、権限検証の強制(ファイルアクセスルールなど)の際、Supabase Edge Functions が力を発揮します。Deno runtime と TypeScript に基づいて構築され、グローバルのエッジノードにデプロイされ、「ユーザーに近い物理的距離」で極めて低い実行遅延を実現し、カスタムで信頼性の高いサーバーサイドロジックを記述するためのコアツールです。
本プロジェクト Project5-Supabase-Demos/apps/project-burger-shop-edge-function-5 は、大規模言語モデル(LLM)とのリアルタイムストリーミング対話機能を通して、Edge Functions の最もシンプルな応用フローをデモしています。
5.5.1 LLM Chat ケースの分析
アプリケーションに ChatGPT のようなチャットボットを統合したいとします。OpenAI の API をサーバーサイドで呼び出す必要がありますが、これには秘密の API Key が必要です。この Key は絶対にフロントエンドコードに露出させてはいけません。そうしないと、誰もがウェブページのソースコードを閲覧してあなたの Key を盗用し、高額な費用が発生する可能性があります。これこそが Edge Function の出番です。llm-chat という名前の関数を作成し、フロントエンドと OpenAI API の間のセキュアなプロキシとして機能させます。
project-burger-shop-edge-function-5/scripts/llm-chat.ts のコードを参考に、その仕組みを見てみましょう。
// scripts/llm-chat.ts
import "jsr:@supabase/functions-js/edge-runtime.d.ts";
import { OpenAI } from "npm:openai";
const OPENAI_API_KEY = Deno.env.get("OPENAI_API_KEY");
Deno.serve(async (req) => {
try {
const openai = new OpenAI({ apiKey: OPENAI_API_KEY });
const { prompt } = await req.json();
const stream = await openai.chat.completions.create({
model: "gpt-3.5-turbo",
messages: [{ role: "user", content: prompt }],
stream: true,
});
return new Response(stream.toReadableStream(), {
headers: { "Content-Type": "text/event-stream" },
});
} catch (err) {
}
});このケースでは、キーセキュリティに関して、OPENAI_API_KEY は環境変数として Supabase のサーバーに安全に保存されています。ローカルのフロントエンドコードはこのキーに全くアクセスできず、キーのセキュリティを効果的に保障しています。
5.5.2 関数の作成とデプロイ
Supabase は非常に使いやすいインターフェースを提供し、コマンドラインに触れることなくデプロイを完了できます。
- Edge Functions パネルにアクセス :
- Supabase プロジェクト Dashboard にログインします。
- 左側のナビゲーションでコードのようなアイコンをクリックし、「Edge Functions」に入ります。
- 新しい関数の作成 :
- 「Create a new function」ボタンをクリックします。
- 関数に名前を付けます(例:
llm-chat)。 - コードの貼り付け :
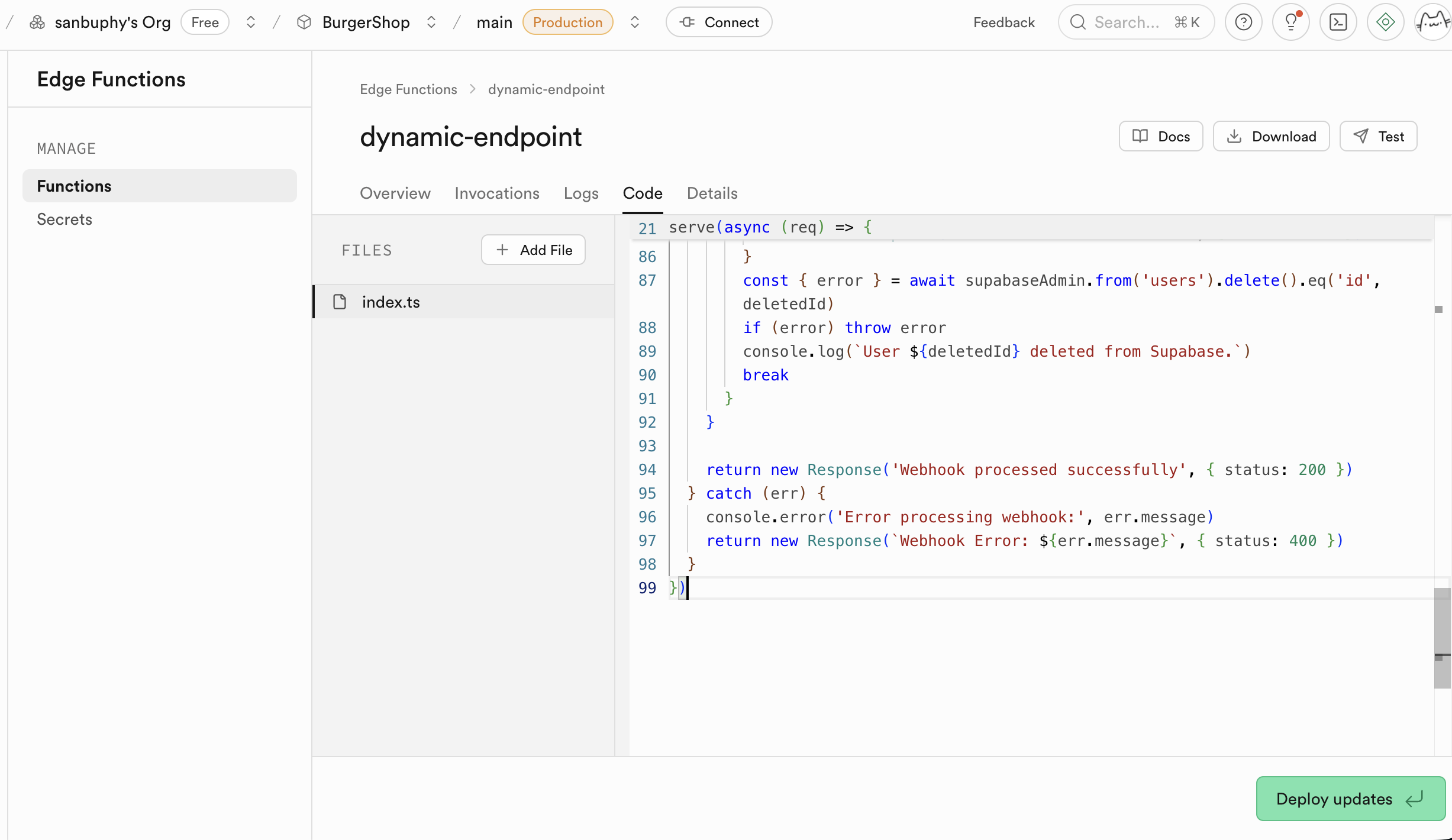
- ポップアップしたオンラインエディタで、すべてのデフォルトのプレースホルダーコードを削除します。
- ローカルの
llm-chat.tsファイルを開き、全内容をコピーします。 - コピーしたコードを Supabase のオンラインエディタに貼り付けます。
- 環境変数(Secrets)の設定 :
- サイドバーで Secrets を見つけます。
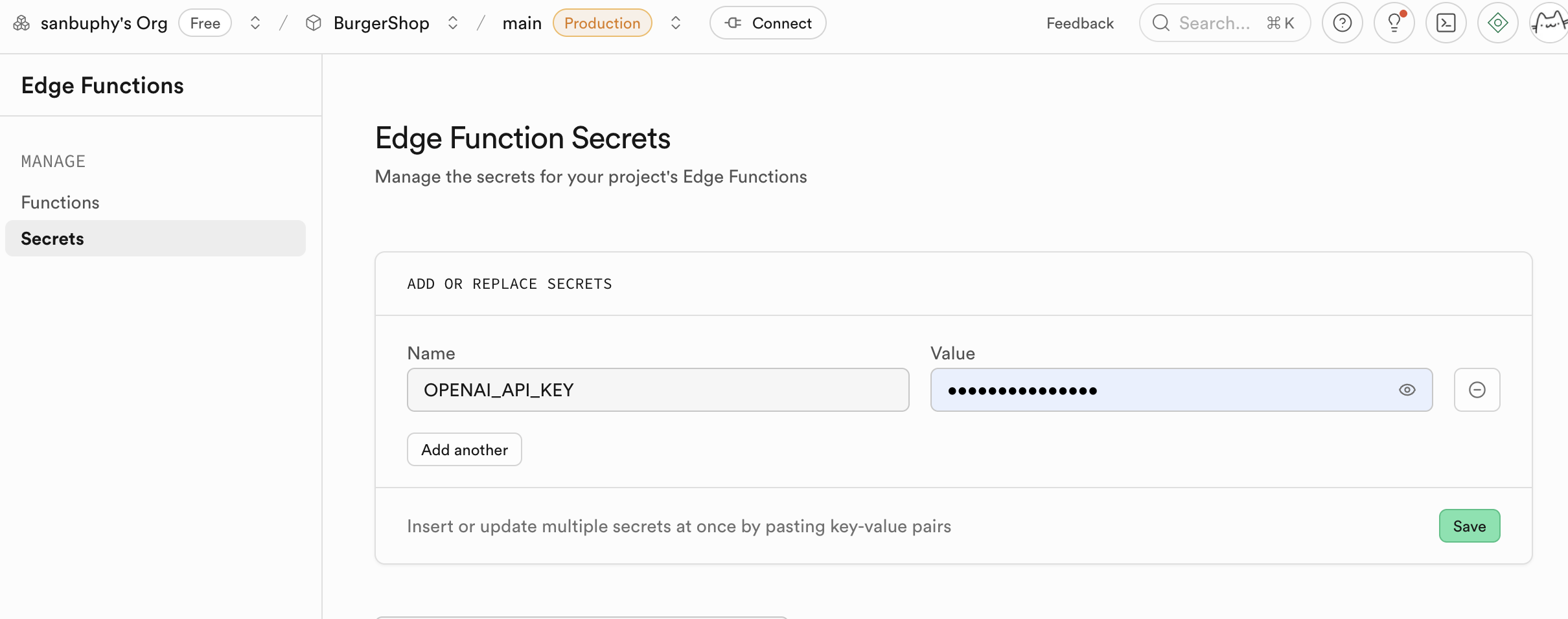
- Name:
OPENAI_API_KEYを入力します。 - Value:自分の OpenAI API Key を貼り付けます。
- 「Save」をクリックします。ここで設定した Secret は暗号化して保存され、関数のランタイム環境に安全に注入されます。
- サイドバーで Secrets を見つけます。
関数の更新が必要な場合、Edge Function セクションで Deploy updates を実行してください。Supabase はクラウド上でこの関数をビルドし、デプロイします。数分後、関数はオンラインでアクセス可能になります。
言語モデルのセキュアなプロキシとしてだけでなく、Edge Functions の応用シーンはこれにとどまりません。実際、サーバーサイドロジックの処理が必要なタスクであれば、単純な API 呼び出し、データ検証から、より複雑な計算まで、すべて Edge Function で実現できます。サーバーインフラストラクチャを管理することなく、軽量でスケーラブルなバックエンドを提供します。
さらに多くの可能性を探求したい場合、プロジェクト内の他のサンプルを参照できます。例えば以下の通りです。
- 画像生成(txt2img.ts):この関数は、Edge Function を使ってサードパーティのテキストから画像への(Text-to-Image)API(Stability AI、Midjourney など)を呼び出し、動的に画像を生成する方法をデモしています。これは典型的な計算集約型またはセキュアな外部サービス呼び出しが必要なシーンです。llm-chat のケースと同様に、API キーは Supabase バックエンドに安全に保存され、フロントエンドはテキストの説明を送信するだけで、生成された画像を受信して表示します。全体のプロセスは安全かつ効率的です。
- メール送信(send-email.ts):アプリケーションでウェルカムメール、取引通知、パスワードリセットメールの送信は一般的な要件です。send-email.ts のサンプルは、Edge Function を通じてメールサービス(Resend、SendGrid など)を統合する方法をデモしています。クライアントコードに機密性の高いメールサービスの API Key を露出させる必要はなく、関数を作成するだけで、フロントエンドはこの関数を呼び出してメールの送信をトリガーできます。
5.6 Clerk ログイン
Clerk は認証とユーザー管理に特化したプロフェッショナルな開発ツールで、コア能力はユーザー登録、ログイン、アカウントセキュリティ MFA、権限制御、セッション管理など、認証に関連する全プロセスの要件をカバーし、開発者が複雑な認証ロジックをゼロから開発することなく、安全で柔軟かつモダンなアプリケーション標準に準拠したユーザー体系を迅速に構築できるようにします。
このセクションでは、Clerk サービスのゼロからの設定と、Supabase との統合方法について紹介します。プロジェクト project-burger-shop-auth-advanced-clerk-7 で全プロセスを体験できます。
5.6.1 Clerk アプリケーションの作成とキーの取得
本プロジェクトを使用する前に、Clerk アカウントを持ち、アプリケーションを作成する必要があります。
- 登録と作成:
- dashboard.clerk.com にアクセスし、アカウントを登録します。
- "Create application" をクリックします。
- アプリケーション名を入力します(例:"Burger Shop")。
- "How will your users sign in?" で、デフォルトの Email、Google、GitHub にチェックを入れます。
- Create application をクリックします。
- API Keys の取得:
作成が成功すると、API Keys ページにリダイレクトされます。
Publishable key(
pk_で始まるもの)と Secret key(sk_で始まるもの)を見つけます。
これらを
.env.localファイルにコピーします(本プロジェクトの.env.exampleを参照)。bashNEXT_PUBLIC_CLERK_PUBLISHABLE_KEY=pk_test_... CLERK_SECRET_KEY=sk_test_...
5.6.2 Supabase と Clerk のネイティブ統合の設定
さらに使用を進める前に、Supabase と Clerk の関連関係を統合し、後のログイン時の認可リダイレクトと特定のデータベースへのアクセス権の制御を容易にする必要があります。Supabase と Clerk は公式のネイティブ統合能力を提供しており、この統合により両者の認証を迅速に連携させ、複雑な適応ロジックを手動で設定することなく、ユーザーログインや権限検証などの機能の開発プロセスを大幅に簡素化できます。
- Clerk で Supabase の公式統合を有効化
- Clerk Dashboard にログインします。
- 左側のメニューで Integrations(統合)に移動します。
- リストから Supabase を見つけてクリックします。
- Enable Supabase スイッチをオンにします(または Activate integration をクリックします)。
- 重要なステップ:有効化が成功すると、ページに Clerk Domain が表示されます(形式は通常
https://<your-id>.clerk.accounts.devまたはカスタムドメイン)。この Domain アドレスをコピーしてください。次のステップで使用します。
- Supabase で Clerk プロバイダーを追加
- Supabase Dashboard にログインし、プロジェクトに入ります。
- 左側のメニューで Authentication > Sign In / Up(または直接 Providers をクリック)に移動します。
- Add provider ボタンをクリックし、ドロップダウンリストから Clerk を選択します。
- ポップアップされた Clerk Domain 入力欄に、先ほど Clerk からコピーした Domain アドレスを貼り付けます。
- Save をクリックして設定を保存します。
5.6.3 Webhook 経由でのユーザーデータの Supabase への同期
統合だけでは権限検証の要件を満たすに過ぎず、Clerk に登録されたユーザー情報が Supabase に同期されるわけではありません。管理の便宜のため、関連クエリやデータ分析のために、Supabase の public.users テーブルにユーザーのバックアップを保持する必要があります。Clerk Webhooks を通じてこの機能を実現できます。完全なプロセスは以下の通りです。
- Clerk が通知を送信 :ユーザーが Clerk で登録またはプロフィールを更新する際、Clerk は設定された Webhook URL に POST リクエストを送信します。
- Supabase が受信して書き込み :Edge Function がリクエストを受信し、署名を検証し(セキュリティの確保)、その後ユーザーデータを Supabase のデータベーステーブルに更新します。
開始する前に、同期情報に必要なデータテーブルを設定する必要があります。
-- File: init.sql
-- 1. Create `users` table for synced Clerk users
-- This table will store user data pushed from Clerk Webhooks.
CREATE TABLE public.users (
id TEXT NOT NULL PRIMARY KEY, -- Corresponds to Clerk User ID
email TEXT,
first_name TEXT,
last_name TEXT,
image_url TEXT,
created_at TIMESTAMPTZ DEFAULT NOW(),
updated_at TIMESTAMPTZ DEFAULT NOW()
);
-- 2. Enable Row Level Security (RLS) on the table
-- This is an important security measure to ensure users cannot access any data by default.
ALTER TABLE public.users ENABLE ROW LEVEL SECURITY;
-- 3. Create RLS policies
-- Policy 1: Allow authenticated users to read their own user info.
-- `auth.jwt()->>'sub'` extracts the user ID from the JWT provided by Clerk.
CREATE POLICY "Authenticated users can view their own user record"
ON public.users FOR SELECT
TO authenticated
USING ( (SELECT auth.jwt()->>'sub') = id );
-- Policy 2: Allow users to update their own info.
CREATE POLICY "Authenticated users can update their own user record"
ON public.users FOR UPDATE
TO authenticated
USING ( (SELECT auth.jwt()->>'sub') = id );また、Supabase で対応する Edge function を有効にします。
// File path: supabase/functions/clerk-webhooks/index.ts
import { serve } from 'https://deno.land/std@0.177.0/http/server.ts'
import { Webhook } from 'npm:svix'
import { createClient } from 'https://esm.sh/@supabase/supabase-js@2'
// Get Clerk Webhook signing secret from environment variables
const CLERK_WEBHOOK_SECRET = Deno.env.get('CLERK_WEBHOOK_SECRET')
if (!CLERK_WEBHOOK_SECRET) {
throw new Error('CLERK_WEBHOOK_SECRET is not set in environment variables')
}
const supabaseAdmin = createClient(
Deno.env.get('SUPABASE_URL')!,
Deno.env.get('SUPABASE_SERVICE_ROLE_KEY')!
)
serve(async (req) => {
try {
// 1. Get Svix signature info from request headers
const headers = Object.fromEntries(req.headers)
const svix_id = headers['svix-id']
const svix_timestamp = headers['svix-timestamp']
const svix_signature = headers['svix-signature']
if (!svix_id || !svix_timestamp || !svix_signature) {
return new Response('Missing Svix headers', { status: 400 })
}
const payload = await req.json()
const body = JSON.stringify(payload)
// 2. Verify Webhook signature validity using the secret
const wh = new Webhook(CLERK_WEBHOOK_SECRET)
const evt = wh.verify(body, {
'svix-id': svix_id,
'svix-timestamp': svix_timestamp,
'svix-signature': svix_signature,
})
const { id } = evt.data
const eventType = evt.type
console.log(`Received webhook event: ${eventType} for user: ${id}`)
// 3. Execute database operations based on event type
switch (eventType) {
case 'user.created': {
const { id, first_name, last_name, image_url, email_addresses } = evt.data
const { error } = await supabaseAdmin.from('users').insert({
id,
first_name,
last_name,
image_url,
email: email_addresses[0]?.email_address,
})
if (error) throw error
console.log(`User ${id} created in Supabase.`)
break
}
case 'user.updated': {
const { id, first_name, last_name, image_url, email_addresses } = evt.data
const { error } = await supabaseAdmin
.from('users')
.update({
first_name,
last_name,
image_url,
email: email_addresses[0]?.email_address,
updated_at: new Date().toISOString(), // Update timestamp
})
.eq('id', id)
if (error) throw error
console.log(`User ${id} updated in Supabase.`)
break
}
case 'user.deleted': {
// For delete events, ID might be at the top level
const deletedId = id
if (!deletedId) {
return new Response('Deleted user ID not found', { status: 400 })
}
const { error } = await supabaseAdmin.from('users').delete().eq('id', deletedId)
if (error) throw error
console.log(`User ${deletedId} deleted from Supabase.`)
break
}
}
return new Response('Webhook processed successfully', { status: 200 })
} catch (err) {
console.error('Error processing webhook:', err.message)
return new Response(`Webhook Error: ${err.message}`, { status: 400 })
}
})Supabase データテーブルと関数の初期化が完了したら、Clerk で Webhooks のサポートも有効にする必要があります。
- Clerk Dashboard -> Webhooks で Endpoint を追加し、Supabase Edge Function の URL を入力します。
user.created、user.updated、user.deletedなどのイベントにチェックを入れます。
設定が成功すると、Message Attempts で異なるリクエスト情報を確認でき、クリックすると詳細なリクエスト返却パラメータの結果が表示されます。Webhook が Edge function をリクエストする際に問題が発生した場合、返却値で詳細な原因をすばやく見つけられます。Clerk と Supabase のリクエストログ情報を同時に比較して、各関数設定が正しいかを分析することをお勧めします。
5.6.4 Clerk でのサードパーティログインサポート
Clerk でのサードパーティログインサポートについて深く理解する前に、まず2つのコア概念を明確にしましょう。開発環境と本番環境です。これはソフトウェアが「開発テスト」から「オンライン利用可能」までの2つの重要な段階であり、両者の位置づけ、用途、セキュリティ要件は全く異なります。
- 開発環境:開発者のローカルやテストサーバーで使用される環境で、機能開発、デバッグ、内部検証にのみ使用されます(ローカル localhost:3000 サービスなど)。外部には公開されません。
- 本番環境:アプリケーションが正式にリリースされた後、実際のユーザー向けの公開環境です(Vercel、Alibaba Cloud などのプラットフォームにデプロイされた https://my-app.com など)。
Clerk がソーシャルログインをこれら2つの環境で区別するのは、本質的には「開発効率」と「本番セキュリティ」のバランスを取るためです。開発段階では冗長な設定を減らして機能を迅速に検証する必要があり、本番段階では専用の認証情報によるデータセキュリティの保障が必要です。同時に、Google、GitHub などのサードパーティ OAuth プラットフォームのルール(オンラインアプリケーションは専用ドメインと認証情報をバインドする必要があり、共有リソースの使用は不可)にも準拠する必要があります。以下に、2つの環境下での Clerk ソーシャルログインの差異設定について具体的に説明します。
- 開発環境での迅速な検証
開発環境では、Clerk は共有 OAuth 認証情報とデフォルトのリダイレクト URI を事前に設定しているため、GitHub/Google に専用認証情報を申請しに行く必要はありません。操作ステップは以下の通りです。
Clerk Dashboard にログインし、左側のナビゲーションで SSO connections(SSO 接続)ページに入ります。
Add connection(接続追加)をクリックし、For all users(全ユーザーに適用)を選択します。
Choose provider(プロバイダー選択)のドロップダウンメニューから、必要に応じて GitHub または Google を選択します。
そのまま Add connection(接続追加)をクリックすると、Clerk が自動的に共有認証情報でバインディングを完了します。
設定後、ローカルでアプリケーションを起動(例:
localhost:3000)し、「Sign in with GitHub/Google」をクリックすると、Clerk が自動的にログインリクエストをプロキシし、機能が正常かどうかを迅速に検証できます。
- 本番環境でのカスタム認証情報設定
(注:予期しない動作が見つかった場合、公式ドキュメントを参照して最新の方法を試すことをお勧めします)
アプリケーションがデプロイされ(Vercel、Alibaba Cloud など)、Clerk Production Instance に切り替わると、共有認証情報は無効になり、GitHub/Google のカスタム OAuth 認証情報を設定する必要があります(Clerk Dashboard とサードパーティプラットフォームのページを同時に開いておくことをお勧めします)。
- 事前の共通操作(Clerk コンソール):
- Clerk SSO connections ページに入り、Add connection -> For all users を選択します。
- 対象プラットフォーム(GitHub/Google)を選択し、Enable for sign-up and sign-in(登録・ログインを許可)と Use custom credentials(カスタム認証情報を使用)が有効になっていることを確認します。
- ページ内の Authorization Callback URL(GitHub)または Authorized Redirect URI(Google)をコピーし、安全な場所に保存して、現在のページ/ポップアップを閉じないでください。
- 2.1 GitHub プラットフォームの設定:
- GitHub にログインし、Developer Settings(パス:アバター -> Settings -> Developer settings -> OAuth Apps)に入ります。
- New OAuth app をクリックし、情報を入力します:
Application name(アプリケーション名)、Homepage URL(本番ドメイン、例:https://my-app.com)、Authorization Callback URL(Clerk からコピーしたアドレスを貼り付け)。 - Register application をクリックし、次に Generate a new client secret をクリックして、生成された Client ID と Client Secret を保存します(Secret は1回のみ表示されます)。
- Clerk のポップアップに戻り、Client ID と Client Secret を貼り付けて、Add connection をクリックして設定を完了します(ポップアップを閉じた場合は、SSO connections で GitHub 接続を見つけ、「Use custom credentials」モジュールで追加入力できます)。
- 2.2 Google プラットフォームの設定:
- Google Cloud Console にログインし、既存のプロジェクトを選択するか新しいプロジェクトを作成します(例:「My App Production」)。
- 左上のメニュー -> APIs & Services -> Credentials をクリックし、Create Credentials -> OAuth client ID をクリックします(初回設定時はまず OAuth consent screen の設定を完了し、「External」を選択してアプリケーション情報を入力する必要があります)。
- Application type を Web application に選択し、設定します:
Authorized JavaScript origins:本番ドメインを追加(例:https://my-app.com、https://www.my-app.com)。ローカル検証のためにhttp://localhost:ポート番号も追加可能。Authorized Redirect URIs:Clerk からコピーしたアドレスを貼り付けます。
- Create をクリックし、ポップアップの Client ID と Client Secret を保存し、Clerk のポップアップに戻って貼り付け、Add connection をクリックします。
- 重要な注意事項:
- WebView ログインの禁止:Google OAuth はアプリ内ブラウザでのログインをサポートしていません。Google 公式ドキュメントを参照して調整してください。
- 公開ステータスの切り替え:デフォルトの「Testing」ステータスでは100人のテストユーザーのみサポートしています。OAuth consent screen で「Publishing status」を In production に変更する必要があります(Google の審査が必要)。
- サブメールアドレスのブロック:Clerk はデフォルトで
+/=/#を含む Google メールアドレス(例:user+alias@example.com)をブロックします。Google 接続の詳細ページで Block email subaddresses のオン/オフを切り替えられます(オンにすることでセキュリティ向上を推奨)。 - Google One Tap のサポート:設定完了後、Clerk の
<GoogleOneTap />コンポーネントを統合して「ワンタップログイン」を実現できます。Clerk コンポーネントドキュメントを参照してください。
- サードパーティログイン接続のテスト
設定完了後、Clerk 内蔵の Account Portal で機能を検証します。
- Clerk Dashboard に入り、左側のナビゲーションで Account Portal ページに移動します。
- 「Sign-in」モジュールの右側にある「ログインページにアクセス」ボタンをクリックし、対応する環境のログインページに移動します。
- 開発環境:
https://あなたのドメイン.accounts.dev/sign-in(例:https://my-app.accounts.dev/sign-in)。 - 本番環境:
https://accounts.あなたのドメイン.com/sign-in(例:https://accounts.my-app.com/sign-in)。
- 開発環境:
- 「Sign in with GitHub/Google」をクリックし、対応するプラットフォームのアカウントでログインします。正常にリダイレクトしてアプリケーションに戻れば、接続設定は正常です。
6. Supabase からさらなるバックエンド開発コンポーネントへ(高度編)
上記では主に Supabase の視点から、「Postgres を中心としたワンストップバックエンドプラットフォーム」がどのような問題を解決できるかを見てきました。認証、データベース、ファイルストレージ、リアルタイム通信、エッジ関数などがすべて同じコンソールに統合され、すぐに使え、統一された体験を提供し、迅速なスタートアップや中小規模プロジェクトに非常に適しています。
しかし、より長期的でエンジニアリングの観点から見ると、Supabase が提供する各能力(Auth / Storage / Edge Functions / Realtime / Database)には、業界でほぼ対応するプロフェッショナルな代替ソリューションが存在します。同種の BaaS プラットフォームもあれば、より「単点突破」のクラウドサービスやオープンソースコンポーネントもあります。向上心のある個人開発者やスタートアップチームとして、これらの代替選択肢を理解することにはいくつかの利点があります。
- 現在のプロジェクトが「Supabase だけで十分か」、それとも特定の部分でよりプロフェッショナル/より安価/よりコンプライアンスに適した専用サービスが必要かを判断できる。
- プロジェクトの規模が大きくなり、要件が複雑になった際、特定のモジュールを Supabase から切り離して(例えば専用の Auth プラットフォームやオブジェクトストレージに変更)できるかどうかを判断し、最初からプラットフォームに完全にロックインされるのを防ぐ。
- 技術選定の視野を広げ、Supabase の X 機能を使わない場合に、他にどのような一般的な選択肢があるかを大まかに把握する。
本節では、Supabase がカバーするいくつかの主要能力について、市場における主流の代替ソリューションをそれぞれ紹介します。例えば、認証(Auth)、ファイルストレージ(Storage)、エッジ関数(Edge Functions)、リアルタイム通信(Realtime)、データベースホスティングなどです。機能特性、無料枠/料金、使いやすさ、コミュニティの人気度などの面での違いを簡単に比較し、バックエンドコンポーネントツールキットの理解をより全面的にします。
同種の BaaS プラットフォーム
始める前に、同種の BaaS プラットフォームを閲覧できます。Supabase が使いにくいと感じる場合、ニーズに応じて異なる代替品を選んで試すことができます。
| プラットフォーム/サービス | タイプ | 無料枠/料金 | 特徴 / 適用シナリオ |
|---|---|---|---|
| Firebase(Google) | フルマネージド BaaS(Auth + Firestore + Storage + Functions + Hosting) | Spark:無料軽量枠;Blaze:従量課金(Firestore/Storage/Functions それぞれ計算) | 業界で最も成熟、ドキュメントが良好、スタートが早い、リアルタイム能力が強力。中小規模製品、モバイル/フロントエンド主導チームに適しています。欠点:課金が複雑、ロックインが強い、クエリ制限が多い(特に Firestore)。 |
| Supabase | オープンソース BaaS(Postgres + Auth + Storage + Edge Functions + Realtime) | 無料:500MB DB、1GB Storage、サーバーレス関数少量呼び出し;Pro:インスタンス単位課金 | Firebase の SQL 版に最も近い;インターフェースが優秀、体験がモダン、自己ホスト可能。強力な SQL、BI、トランザクション能力が必要なアプリケーションに適しています。欠点:高トラフィックや複雑な関数のコストが高い。 |
| Appwrite Cloud | オープンソース ワンストップ BaaS(DB + Auth + Storage + Functions + Realtime) | 無料:基本 DB/Storage/FaaS を含む;有料はリソースレベル別課金 | 体験がモダン、API が統一、自己ホスト可能;開発者フレンドリーなアプリケーションの迅速なイテレーションに適しています。欠点:エコシステムは Firebase/Supabase ほど成熟していない;大規模アプリでのパフォーマンスはテストが必要。 |
| Nhost | Postgres + GraphQL + Auth + Storage + Functions | 無料:1GB DB、1GB Storage、少量関数呼び出し | 「Supabase + Hasura」に類似;ネイティブ GraphQL;フロントエンドチームと React/Next.js プロジェクトに適しています。欠点:エコシステムが小さい、使用量に伴いコストが上昇。 |
| AWS Amplify | AWS ワンストップバックエンド(Cognito + AppSync + DynamoDB + Storage + Functions + Hosting) | 無料:Hosting 枠 + Cognito 10k MAU + 一部関数枠 | 大規模で包括的、AWS 基盤のあるチームに適しています;エンタープライズ級の信頼性。欠点:スタートが最も難しく、サービスが断片化;スタートアップのメンテナンスコストが高い。 |
| Xata(近年急速成長) | マルチモデルデータベース + Auth + Edge Functions | 無料:250k レコード、15GB 帯域 | より「DB + API」に近いが、Auth、ファイル、ロジックを提供し、軽量なフルスタックバックエンドとして使用可能。UI/開発体験が非常に優れています。欠点:Firebase/Supabase ほど機能が全面的ではない。 |
| Convex(開発者体験が極めて強い) | マネージドデータベース + Auth + Functions(フロントエンド優先) | 無料開発版;有料はリクエスト量課金 | 極めてシンプルなスタートアップ;Schema 不要;フロントエンドで関数を書くだけでバックエンドが利用可能。MVP/迅速検証に適しています。欠点:プラットフォームへの結合度が高く、移行コストが高い;完全な従来 BaaS とは言えない。 |
認証 (Auth)
| ツール/プラットフォーム | 機能の特徴 | 無料枠/料金 | 適用シナリオと長所・短所 |
|---|---|---|---|
| Firebase Authentication | Google が提供する BaaS 認証サービス。メール/パスワード、電話、ソーシャルログイン、匿名などの一般的な方式をサポート。Spark 無料プランは最大50k MAU をサポート。 | Spark(無料)50k MAU;Blaze 従量課金 | Google エコシステムとの統合、豊富なドキュメント、簡単なスタートアップ;機能が包括的(MFA、ブロッキング関数など)、迅速な開発に適しています。ただし Firebase プラットフォームにバインドされ、他サービスへの拡張には追加設定が必要。 |
| Auth0 (Okta) | フルマネージド認証プラットフォーム。ソーシャルログイン、エンタープライズ SSO、多要素認証、ルール拡張などの強力な機能をサポート。 | 無料プラン25k MAU、有料は MAU 課金 | エンタープライズ級の機能が充実(RBAC、監査ログなど)、中〜大規模アプリケーションに適しています;インターフェースが使いやすい。欠点は MAU 増加時にコストが高く、無料版の機能が限定的(MFA/RBAC なし)。コミュニティ知名度が高く、ユーザーが多数。 |
| AWS Cognito | Amazon クラウドネイティブ認証サービス。ソーシャルおよび SAML フェデレーションログインをサポート。ダイレクトログインユーザープールは月10k MAU 無料、超過分は 0.0055 USD/MAU。 | 無料10k MAU/月、超過分は従量課金 | AWS エコシステムと深く統合(API Gateway、Lambda などとシームレスに連携)、導入ハードルはやや高く、ドキュメントが複雑;無料枠が限られており、AWS の利用実績があるチームに適しています。 |
| Logto | オープンソース認証プラットフォーム。自己ホスト版は無料、クラウドサービスプランは50k MAU 無料。多言語、マルチテナント、OAuth/OIDC などをサポート。 | コミュニティ版無料;Logto Cloud は50k MAU 無料 | 最近人気の Auth0 オープンソース代替。GitHub で 10k+ Stars。拡張が容易、自己ホストでコスト削減;欠点はエコシステムとドキュメントが比較的新しく、コミュニティ規模が Firebase/Auth0 より小さい。 |
| Keycloak | 有名なオープンソース IAM/SSO ソリューション。ユーザー名/パスワード、LDAP、SAML、OAuth2 などをサポート。 | 完全無料、自己ホスト必要 | 機能が強力、拡張可能(細粒度権限制御をサポート)、エンタープライズ級機能が豊富;ただしデプロイとメンテナンスの複雑さが高く、小規模チームにとって学習曲線が急。コンテナ化とクラスタ運用スキルが求められる。 |
ファイルストレージ (Storage)
| プラットフォーム/サービス | タイプ | 無料枠/料金 | 特徴/適用シナリオ |
|---|---|---|---|
| Amazon S3 | クラウドオブジェクトストレージ(AWS) | AWS 無料枠で 5GB ストレージ、20k GET/PUT リクエスト/月、超過分は従量課金 | 業界標準のオブジェクトストレージ。信頼性が高く、グローバルにマルチリージョンデプロイ。機能が包括的で AWS エコシステムと統合が良好;料金体系が複雑で、新規ユーザーは課金ルールの理解が必要。 |
| Google Cloud Storage(Firebase Storage) | クラウドオブジェクトストレージ(Google) | Firebase Spark プランで無料枠(1GB ストレージ + 帯域制限)、Blaze 有料 | Firebase/Google Cloud と緊密に統合、管理が容易;CDN 高速化、細粒度セキュリティルールをサポート。 |
| Tencent Cloud COS / Alibaba Cloud OSS | クラウドオブジェクトストレージ(中国国内) | 従量課金(各社新規ユーザー特典あり、例:OSS は初年度40GB 無料など) | 中国市場向け、高性能、大規模オブジェクトストレージ;中国クラウドエコシステムと統合、ドキュメントが充実。Alibaba OSS は機能が包括的、グローバルアクセラレーションあり;Qiniu KODO はマルチメディア処理に特化、コストが低く、個人や小チームに適しています。 |
| MinIO | オープンソース S3 互換ストレージ | オープンソース無料(自己構築) | 軽量、高性能、S3 API と互換、プライベートクラウドやローカルでのオブジェクトストレージ構築に適しています。ドキュメントとコミュニティが活発;インフラストラクチャの自己メンテナンスが必要。 |
| Cloudinary / Imgix など | メディアストレージ+CDN | 基本無料プラン(例:Cloudinary は月25GB 帯域無料) | 画像/動画に最適化されたクラウドストレージ+CDN サービス。リアルタイムトランスコード、圧縮などの高度な機能を提供。メディアプロジェクトに適していますが、汎用的なファイルストレージとして使用するとコストが比較的高い。 |
エッジ関数 (Edge Functions)
| プラットフォーム/サービス | 特徴 | 無料枠/料金 | 適用シナリオと長所・短所 |
|---|---|---|---|
| Cloudflare Workers | グローバル分散型 JavaScript/Wasmtime 環境 | 無料プラン:毎日 100k リクエスト;標準プラン $5/月で1,000万リクエスト | Cloudflare エッジノードで実行、遅延が極めて低い;グローバルに分散するロジック、静的リソースレンダリングなどに適しています。無料枠が少なめ(月約300万リクエストに相当)、スタートが簡単。欠点はランタイム(JS/Wasmtime)の制限とデバッグツールが限定的。 |
| Vercel Edge Functions | Next.js/フロントエンドフレームワークとシームレスに統合、JS/TS/Go サポート | Hobby 無料:月100万関数呼び出し、100万エッジリクエスト | フロントエンドフレームワークと深く統合、自動デプロイ;モダンウェブアプリケーションに適しています。無料枠が十分、デフォルトランタイム 10s、最大 60s まで拡張可能。欠点は無料版のチームコラボ機能が制限的;Vercel プラットフォームへの依存。 |
| Netlify Edge / Functions | Node.js クラウド関数+エッジルーティング(NFT) | 無料:300 クレジット/月(約月 1M リクエストに相当);クレジット単位課金 | Node.js 関数、エッジ処理ルーティングなどをサポート。無料枠はビルド、関数、帯域に使用可能、フロントエンド フルスタックデプロイに適しています。利点は使いやすさと Git デプロイの統合;欠点は無料枠の管理が必要(10k リクエスト = 3 クレジット)。 |
| AWS Lambda@Edge / CloudFront Functions | AWS サーバーレスエッジコンピューティング | AWS Lambda(月1M 無料リクエスト + 400k GB-s)+ CloudFront $0.085/10万呼び出しから | CloudFront と統合し、エッジでコードを実行可能。AWS エコシステムが必要な場合(ノードレベルでの権限や A/B テストなど)に適しています。利点は柔軟で強力;欠点は設定が複雑で、Cloudflare/Vercel より遅延がやや高い。 |
リアルタイム通信 (Realtime)
| プラットフォーム/サービス | 機能の特徴 | 無料枠/料金 | 適用シナリオと長所・短所 |
|---|---|---|---|
| Firebase Realtime Database / Firestore | Google BaaS リアルタイムデータベース;データ変更のプッシュをサポート | Spark 無料:リアルタイム DB 1GB ストレージ & 制限あり;Blaze 従量課金 | Firebase エコシステムとの強力な統合、リアルタイムリッスンがシンプル。利点は無料で素早くスタート可能;欠点はデータベースタイプ(JSON/NoSQL)で、複雑なクエリ能力が弱い。 |
| Ably | リアルタイムメッセージングと pub/sub プラットフォーム。WebSocket、MQTT などをサポート | 無料プラン:月 6,000,000 メッセージ | 機能が包括的なリアルタイムメッセージサービス、高トラフィック対応;無料枠で月600万メッセージまで可能。コミュニティとドキュメントが良好で、グローバル配信に適しています。 |
| Pusher Channels | イベントプッシュサービス。チャンネル/イベントメカニズムをサポート | Sandbox 無料:毎日 200k メッセージ、100 同時接続 | 使いやすい WebSocket サービス、ドキュメントが充実し、チャットや通知機能の迅速な実装に適しています。無料版はメッセージ量と接続数に制限あり;有料後は拡張性が良い。 |
| 自己構築 WebSocket/Socket.IO | 自前でサーバーを構築(Node.js、Elixir、Go など) | 自己ホストコスト(サーバー費用など) | 柔軟性が最も高く、要件に応じてプロトコルやトポロジーをカスタマイズ可能。コスト管理が厳しく技術的に成熟したチームに適しています。欠点は可用性、スケーリング、クロスドメインなどを自己管理する必要がある。 |
データベース
| プラットフォーム/ツール | データベースタイプ | 無料枠/料金 | 主な特徴 |
|---|---|---|---|
| Neon (Serverless PostgreSQL) | リレーショナル(PostgreSQL) | 無料プラン:0.5GB ストレージ、メインブランチ常時稼働、月20h ブランチ計算 | クラウドネイティブ サーバーレス Postgres。自動スケーリングとブランチ(テスト用フォーク)をサポート。無料枠は小規模プロジェクトに十分で、モダン開発フローに適しています。ブランチ機能が強力だが、無料枠はやや小さい。 |
| Aiven PostgreSQL | リレーショナル(PostgreSQL/MySQL) | 無料プラン:1GB ストレージ、1 vCPU、1GB メモリ | マネージドデータベースサービス。クラウド横断 マルチリージョン移行をサポート。MySQL、Redis などの選択肢もあり。無料枠は開発や小規模プロジェクトに適しています;商用版は高可用クラスタとモニタリングをサポート。 |
| CockroachDB Cloud | 分散 SQL(PostgreSQL 互換) | 無料プラン:10GB ストレージ | Google Spanner に類似した分散 SQL データベース。自動シャーディングでスケーリング。無料 10GB は比較的寛大;水平スケーリングと強い一貫性が必要なアプリケーションに適しています。商用版の SLA が高い。 |
| TiDB Cloud | 分散リレーショナル(MySQL 互換) | 無料プラン:ノードあたり5GB、合計最大25GB | オープンソース TiDB のクラウド版。MySQL プロトコル互換、分散アーキテクチャ。無料枠が十分で、MySQL に慣れたチームに適しており、パフォーマンスが優秀;欠点は運用がやや複雑(大規模シナリオ)。 |
| MongoDB Atlas | ドキュメント型(NoSQL MongoDB) | 無料 M0 クラスタ:0.5GB ストレージ | クラウド版 MongoDB。柔軟なドキュメントモデル、豊富なクエリとインデックスをサポート。無料 0.5GB データベースはテストや小規模アプリに適しています;必要に応じて水平スケーリング可能。学習曲線はリレーショナルデータベースよりやや高い。 |
| SQLPub | マルチデータベース(MySQL、PostgreSQL、Redis など) | 無料プラン:36,000 リクエスト/時間、30 同時接続、500MB ストレージ | ワンストップデータベースプラットフォーム。複数のデータベースタイプをサポート。無料版は学習や小規模プロジェクトに適しています;利点は複数 DB のサポート、欠点はストレージ枠が小さい。 |
以上の代替ソリューションはそれぞれ異なる重点を持っています。オープンソースの方が柔軟で制御しやすく(Keycloak、MinIO、Socket.IO、Neon、CockroachDB など)、クラウドマネージドサービスの方がスタートしやすいです(Firebase、Auth0、Cloudflare、Vercel、Netlify、AWS、Aiven、MongoDB Atlas など)。選択の際は、プロジェクトの要件、チームの技術スタック、予算、コミュニティエコシステムなどを考慮して判断してください。個人プロジェクトでは、無料枠が豊富で統合しやすいサービスを優先的に選ぶことができます(Firebase シリーズ、Qiniu ストレージ、Cloudflare Workers、Neon、CockroachDB など)。エンタープライズ級や特定のセキュリティ要件がある場合は、機能がより豊富だが料金が高いソリューションを検討できます(Auth0、Alibaba/Tencent Cloud、AWS、TiDB/Aiven など)。実際のアプリケーションで継続的に試し、最適なバックエンド開発ツールコンポーネントを見つけてください。
まとめ
今日のレッスンでは、データベースの基本概念、Supabase のコア定義とその操作の詳細について体系的に学びました。今後の実践過程では、プロジェクトの実際の応用シーンと要件に応じて、いつでもこのドキュメントに戻って参照として活用してください。
常に覚えておいてください。重要な原則は まず完成させ、それから完璧にする! ということです。一度に完璧を目指す必要はありません。継続的なイテレーションと改善を通じて、より良い成果に段階的に近づけることができます。今後のプロジェクト実践がすべて順調に進むことを願っています!
📚 授業後の課題
- ユーザー管理システムとデータベースを含むアプリケーションを開発してください。より多くの Supabase 機能(Realtime / Cloud Storage / Edge Function)を含めることをお勧めします。