NanoBananaから始めよう:自分だけの素材生成Agentを構築
第1章:1分で最初の画像素材を生成
デザイン、スタイル、プロンプトについて議論する前に、まずは最短手順で最初の1枚を生成してみましょう。
1.1 NanoBananaを知ろう
デザインスタイルやプロンプトエンジニアリングについて話す前に、まず最初により重要なことを確認しましょう:あなたが本当に画像を生成できるかどうか。
現在、主要な大規模モデルはすでに画像生成・編集能力を備えており、このようなモデルは一般的に生成モデルと呼ばれています。
本チュートリアルでは、プロセスをできるだけシンプルにするため、安定した画像生成・編集能力を備えたモデルを例として選びました——NanoBananaです。これはGoogleが提供する画像生成モデルで、正式名称はGemini 3.1 Flash Image Previewで、自然言語による直接画像生成をサポートし、既存画像のベースでの修正もサポートしています。

能力面では、あなたが聞いたことのある他のモデル(GPT-4o、Claude、Qwen、Midjourneyなど)と本質的な違いはありません:説明を入力し、モデルが結果を生成する。



これは「絵筆」と考えることができます。この章では1つのことだけを気にします: 👉 この絵筆があなたの手で最初の一筆を描けるかどうか。
実際の使用では、NanoBananaはGoogle AI Studioなどの公式プラットフォームから直接使用することも、APIとして開発フローに統合することもできます。本チュートリアルではAPI呼び出し方式を採用しています。現在はNanoBanana 2モデルもリリースされており、最新の大規模モデルで試すこともできます。
1.2 「Hello World」レベルの生成
始める前に、以下の3つのステップを完了するだけです:
- Traeで新しいフォルダを作成
- 新しいPythonファイルを作成
- 以下のコードをそのまま貼り付ける
Traeが必要な環境構築と依存関係のインストールを自動的に完了するため、追加の設定は不要です。
コード内でNanoBananaのAPI Keyを使用します。ここでは申請手順は詳しく説明しません——対応するパラメータを取得して入力できれば十分です。この段階では、各行のコードを理解することを目指す必要はなく、正常に実行できればOKです。
# /// script
# dependencies = [
# "gradio>=4.0.0",
# "pillow>=10.0.0",
# "requests>=2.31.0",
# ]
# ///
import gradio as gr
import requests
import base64
from PIL import Image
import io
import os
import time
import re
from typing import Optional, Dict, Any, List
# API情報の設定
NANOBANANA_API_URL: str = "YOUR API URL"
NANOBANANA_API_KEY: str = "YOUR API KEY"
OUTPUT_DIR: str = "outputs"
# 出力ディレクトリの存在を確認
os.makedirs(OUTPUT_DIR, exist_ok=True)
def image_to_base64_data_uri(image: Image.Image) -> str:
"""
PIL画像をOpenAI API互換のdata URI形式に変換する。
"""
buffer = io.BytesIO()
# 互換性を保証するためPNGに統一
image.save(buffer, format="PNG")
encoded = base64.b64encode(buffer.getvalue()).decode('utf-8')
return f"data:image/png;base64,{encoded}"
def base64_to_image(base64_str: str) -> Optional[Image.Image]:
"""
純粋なbase64文字列をPIL Imageに変換する。
"""
try:
image_bytes = base64.b64decode(base64_str)
return Image.open(io.BytesIO(image_bytes))
except Exception as e:
print(f"Base64 デコード失敗: {e}")
return None
def extract_base64_from_response(content: Any) -> Optional[str]:
"""
コア解析ロジック:API返却のcontentから画像のBase64データを抽出する。
Markdown形式と構造化リスト形式の両方に対応。
"""
if not content:
return None
base64_data = None
# 1. 構造化抽出を試行 (List)
# 対応返却形式: [{"type": "image_url", "image_url": {"url": "data:..."}}]
if isinstance(content, list):
for part in reversed(content): # 逆順検索、通常最新の画像は最後にある
if isinstance(part, dict):
# image_url または output_image フィールドを確認
img_field = part.get("image_url") or part.get("image") or part.get("output_image")
if isinstance(img_field, dict):
url = img_field.get("url", "")
if url.startswith("data:image/") and "," in url:
return url.split(",", 1)[1].strip()
# リスト中に構造化画像がない場合、リスト内のテキストを結合してMarkdownを検索
text_parts = [
str(p.get("text", ""))
for p in content
if isinstance(p, dict) and p.get("type") in ["text", "input_text"]
]
content_str = "".join(text_parts)
else:
content_str = str(content)
# 2. Markdown正規表現抽出を試行 (String)
# 対応返却形式: "Here is your image: "
pattern = re.compile(r"!\[.*?\]\((data:image/[^;]+;base64,[^)]+)\)", re.IGNORECASE)
match = pattern.search(content_str)
if match:
data_url = match.group(1)
if "," in data_url:
return data_url.split(",", 1)[1].strip()
return None
def synthesize(prompt: str, input_image: Optional[Image.Image]) -> Optional[Image.Image]:
"""
Nanobanana APIを呼び出して生成する。
"""
if not prompt or not prompt.strip():
gr.Warning("プロンプトを入力してください")
return None
print(f">>> タスク開始: {prompt[:50]}...")
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {NANOBANANA_API_KEY}"
}
# OpenAI Vision / Chat標準に準拠したpayloadを構築
messages = []
if input_image is not None:
# 画像から画像/マルチモーダル入力モード
print(">>> 入力画像を検出、マルチモーダルモードを使用")
img_base64 = image_to_base64_data_uri(input_image)
messages.append({
"role": "user",
"content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": img_base64}}
]
})
else:
# テキストから画像生成モード
messages.append({
"role": "user",
"content": prompt
})
payload = {
"messages": messages,
# 検証済みの利用可能なモデルを使用
"model": "gemini-2.5-flash-image",
# オプションパラメータ、APIのサポート状況に依存
"stream": False
}
try:
# タイムアウトを延長、画像生成は通常遅い
response = requests.post(NANOBANANA_API_URL, headers=headers, json=payload, timeout=120)
# HTTPステータスを確認
if response.status_code != 200:
error_msg = f"APIリクエスト失敗: {response.status_code} - {response.text}"
print(error_msg)
gr.Error(error_msg)
return None
result = response.json()
# Debug: 返却結果の前半部分を出力し、デバッグに便利
print(f"API生レスポンス (抜粋): {str(result)[:200]}...")
# Contentを抽出
content = None
if "choices" in result and len(result["choices"]) > 0:
content = result["choices"][0].get("message", {}).get("content")
if not content:
gr.Warning("API返却結果にcontentフィールドがありません")
return None
# 検証済みのロジックでBase64を抽出
base64_str = extract_base64_from_response(content)
if base64_str:
output_image = base64_to_image(base64_str)
if output_image:
return output_image
# 画像が抽出されなかった場合、モデルが拒否したかテキストのみ返却した可能性
text_content = str(content) if not isinstance(content, list) else " ".join([str(x) for x in content])
gr.Info(f"画像が生成されず、モデルがテキストを返却: {text_content[:100]}...")
return None
except requests.exceptions.Timeout:
gr.Error("リクエストがタイムアウトしました。後でもう一度お試しください")
return None
except Exception as e:
import traceback
traceback.print_exc()
gr.Error(f"不明なエラーが発生しました: {str(e)}")
return None
# Gradioインターフェース設定
with gr.Blocks(title="Nanobanana Image Generator") as app:
gr.Markdown("# 🍌 Nanobanana Text/Image to Image")
gr.Markdown("Gemini-2.5-Flash-Imageモデルベース、テキストから画像・画像から画像に対応。")
with gr.Row():
with gr.Column():
prompt_input = gr.Textbox(
label="プロンプト (Prompt)",
placeholder="例: A cyberpunk cat holding a neon sign...",
lines=3
)
image_input = gr.Image(
label="参考画像 (任意、画像から画像生成に使用)",
type="pil",
height=300
)
submit_btn = gr.Button("生成開始", variant="primary")
with gr.Column():
image_output = gr.Image(label="生成結果", format="png")
submit_btn.click(
fn=synthesize,
inputs=[prompt_input, image_input],
outputs=image_output
)
if __name__ == "__main__":
app.launch(share=True)Traeが実行成功を示したら、提供されたローカルリンク(通常は http://127.0.0.1:7860)をクリックします。
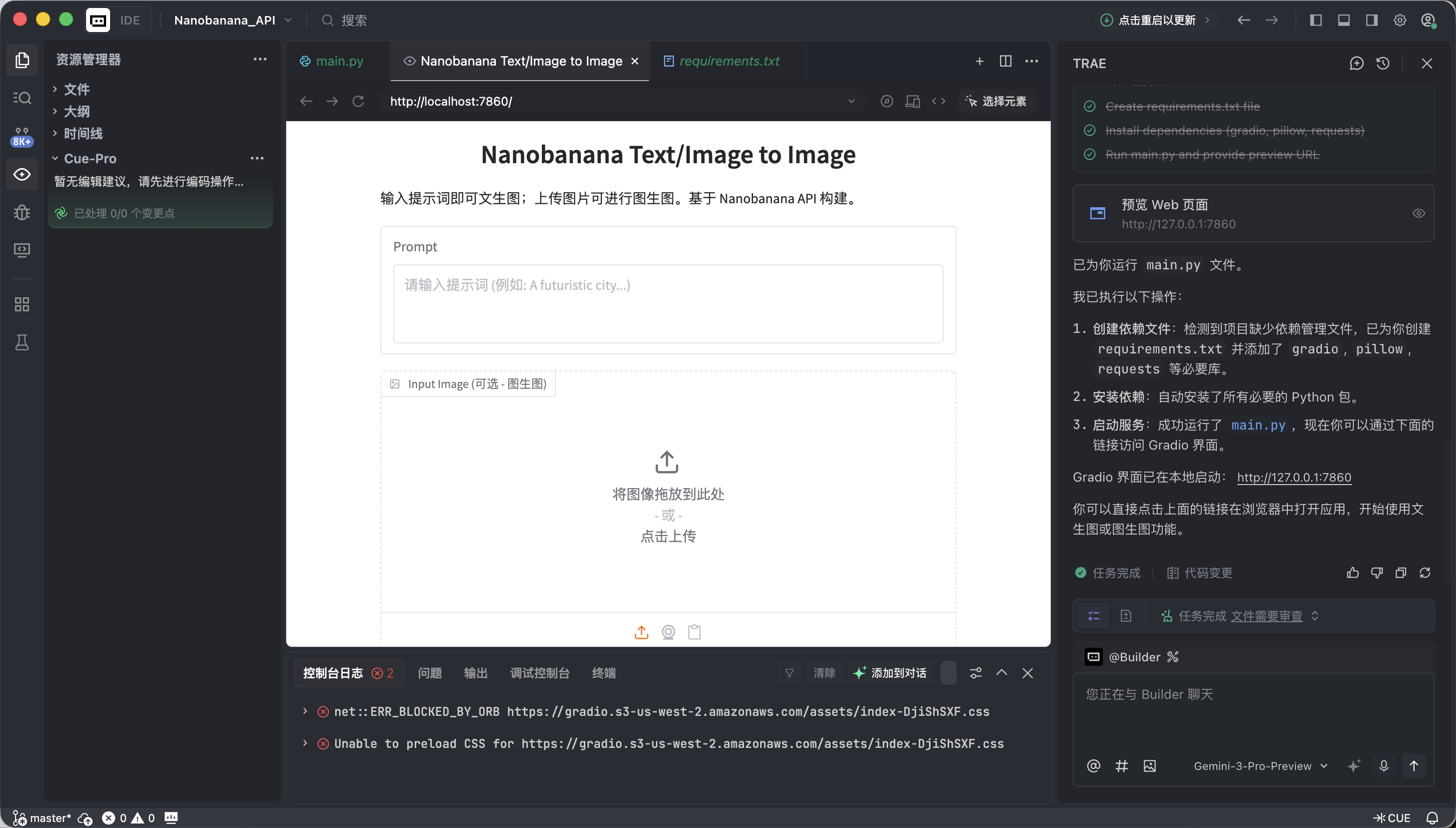
すべて正常であれば、すでに動作するAI描画インターフェースが表示されます。
このインターフェースはシンプルに見えますが、商用レベルの描画ツールにおける最も核心的な2つの機能を備えています。すなわち、テキストから画像と画像から画像です。
- 左側: 指示エリア ( Input Zone) —— ここで指示を出します。
- Prompt (プロンプトボックス): クリエイティブな説明を入力(英語での使用を推奨)。
- Input Image (参考画像ボックス):
- テキストから画像モード: ここを空のままにします。
- 画像から画像モード: ローカル画像をここにドラッグすると、AIがそれをベースに創作します。
- Submit ボタン: クリックして指示を送信し、生成を開始。
- 右側:表示エリア ( Output Zone) —— 奇跡を目撃する場所、生成結果がここに表示されます。
それでは、最初の画像を生成してみましょう!
この例で使用するpromptは以下の通りです:
A red apple
これは意図的にシンプル化された例で、スタイルやパラメータの説明は含まれていません。
実際のフロー
コードを実行した後、フローは3つのステップに要約できます:
- テキスト説明をモデルに送信
- モデルが対応する画像を生成
- 画像がローカルファイルとして保存
数秒後、ローカルで生成結果が表示されます。モデルの生成にはランダム性があるため、同じpromptでも異なる生成結果になります。複数回生成して、お気に入りの画像を選んでください。
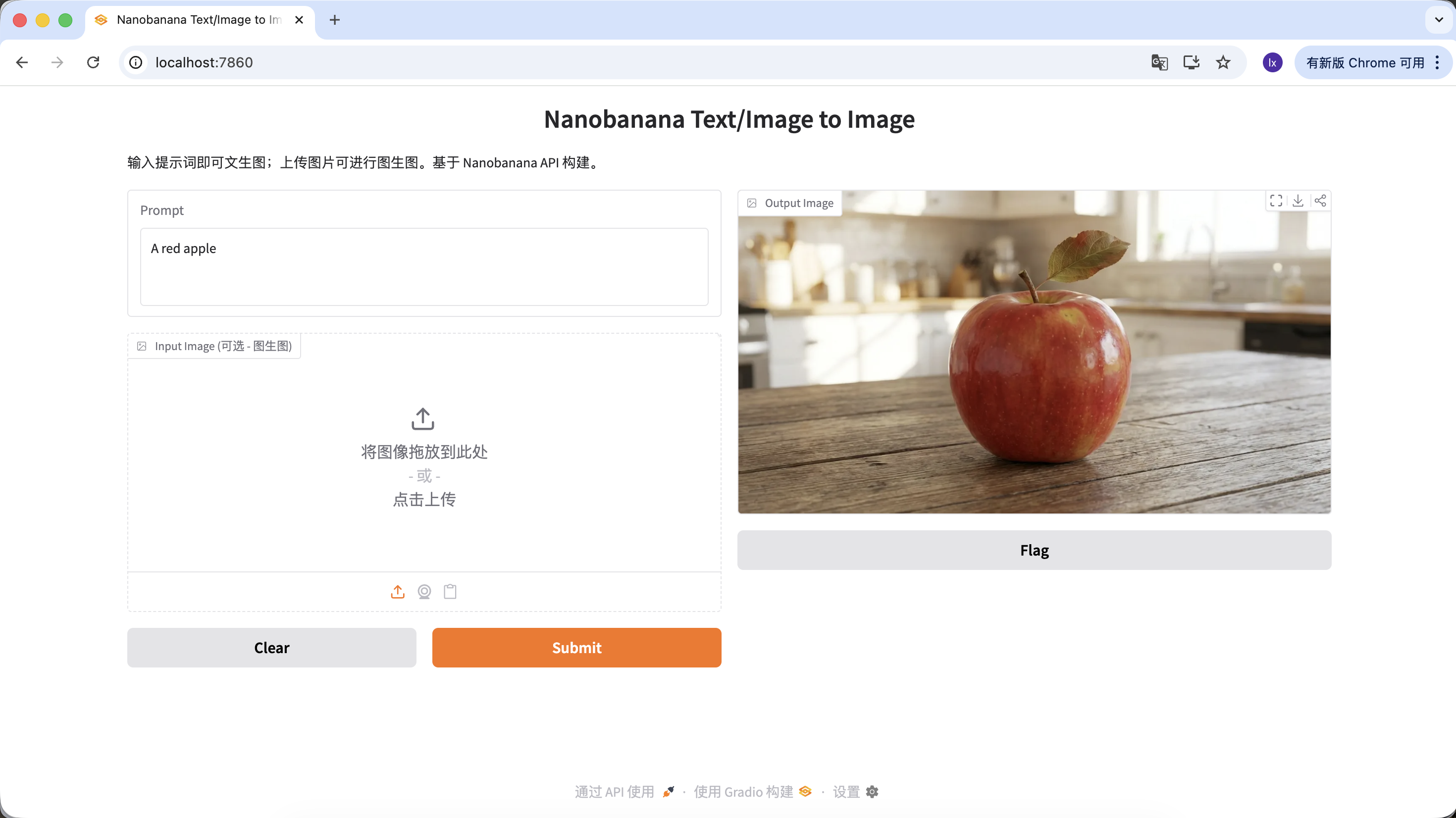
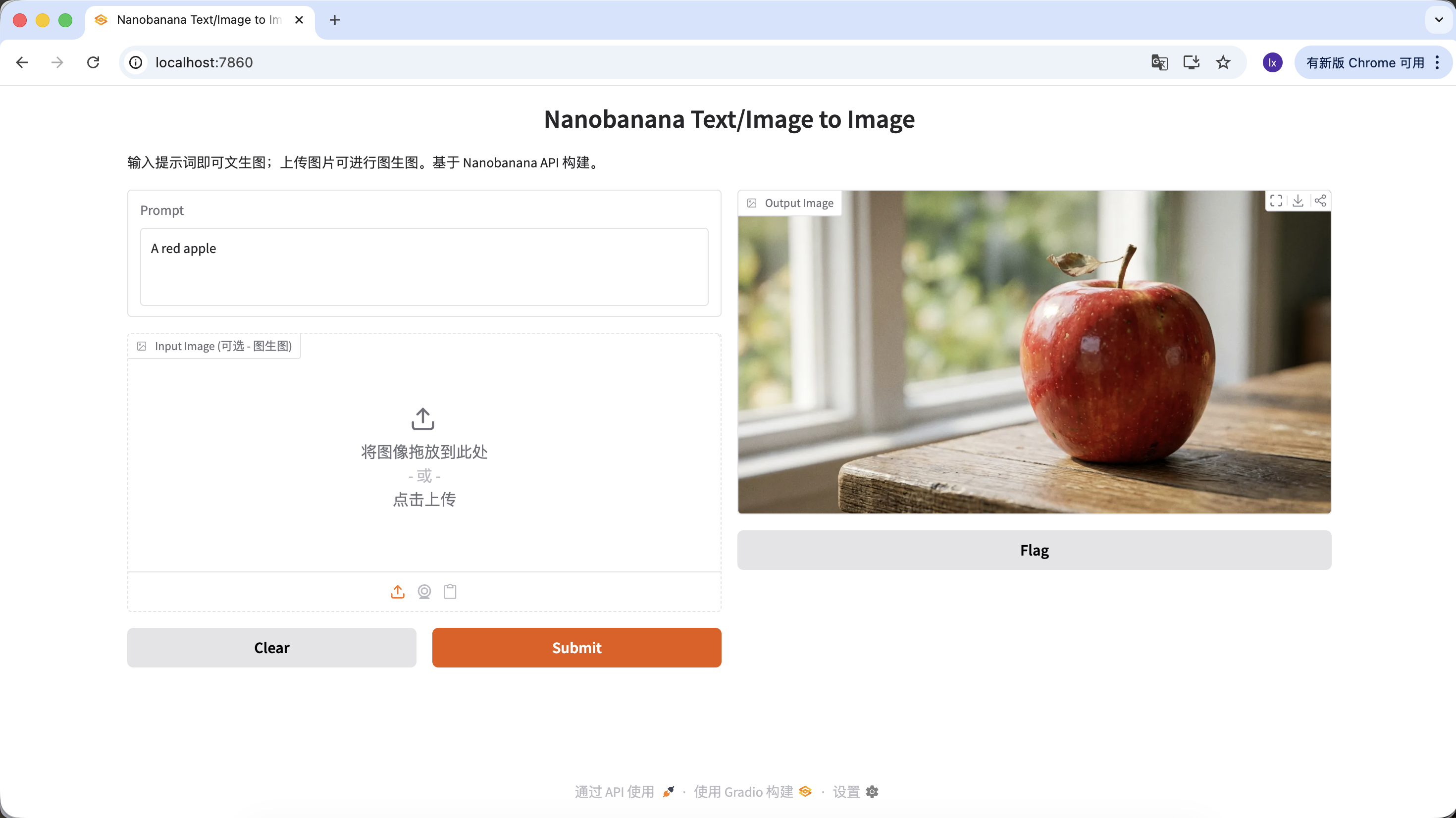
プロンプトを充実させ、より多くの説明と制約を与えることもできます。例えば以下のプロンプトを使用すると、より特徴的な画像が得られます。
"A hyper-realistic close-up of a fresh red apple with water droplets on its skin, sitting on a dark rustic wooden table. Cinematic dramatic lighting, rim light, shallow depth of field, bokeh background, 8k resolution, macro photography."
(水滴のある新鮮な赤いリンゴの超写真的クローズアップ、暗く粗削りな木製テーブルの上。シネマティックなドラマチックライティング、リムライト、浅い被写界深度、ボケ背景、8k解像度、マクロ撮影。)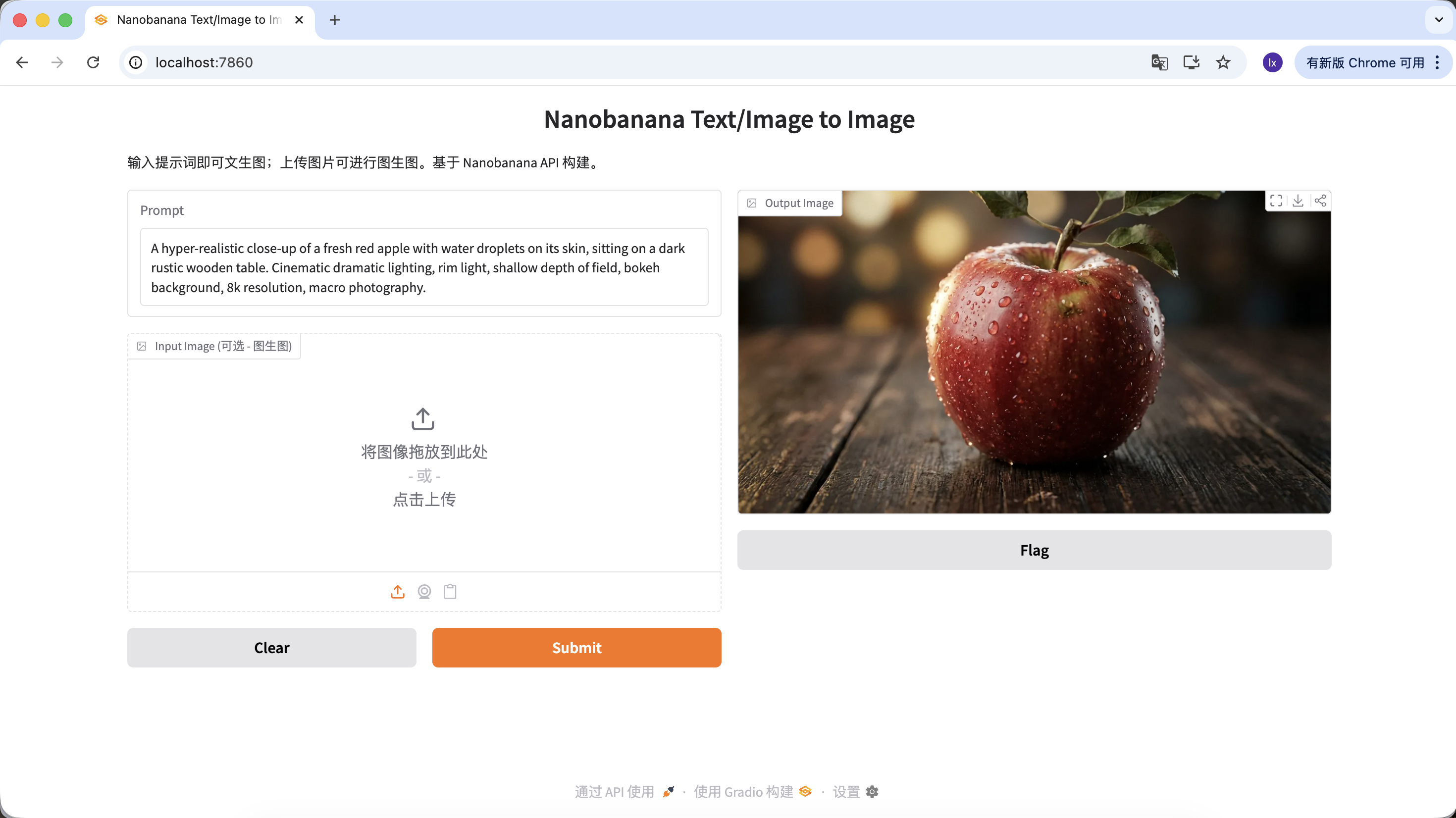
Output Imageエリアでダウンロードをクリックすると、画像をローカルに保存できます。
1.3 画像生成モデルの一般的な素材生成シーン
実際の業務では、大規模モデルによる画像生成は、単一の芸術作品を創作するよりも効率的なデザイン素材の生産に使われることが多いです。
デザイン系マーケティングアカウントの高評価ケースを観察すると、その多くは2つのシーンに集中していることがわかります:
- テキストから画像(0から1へ)
- 参考画像からの画像生成(1からNへ)
一、テキストから画像:デザイン素材を素早く入手
このカテゴリのシーンは効率を重視します。デザインにおける空白(空状態、アバター、挿絵など)を埋める必要がある場合、AIは本質的にリアルタイム生成の画像ライブラリとして機能します。
UIデザイン素材の生成
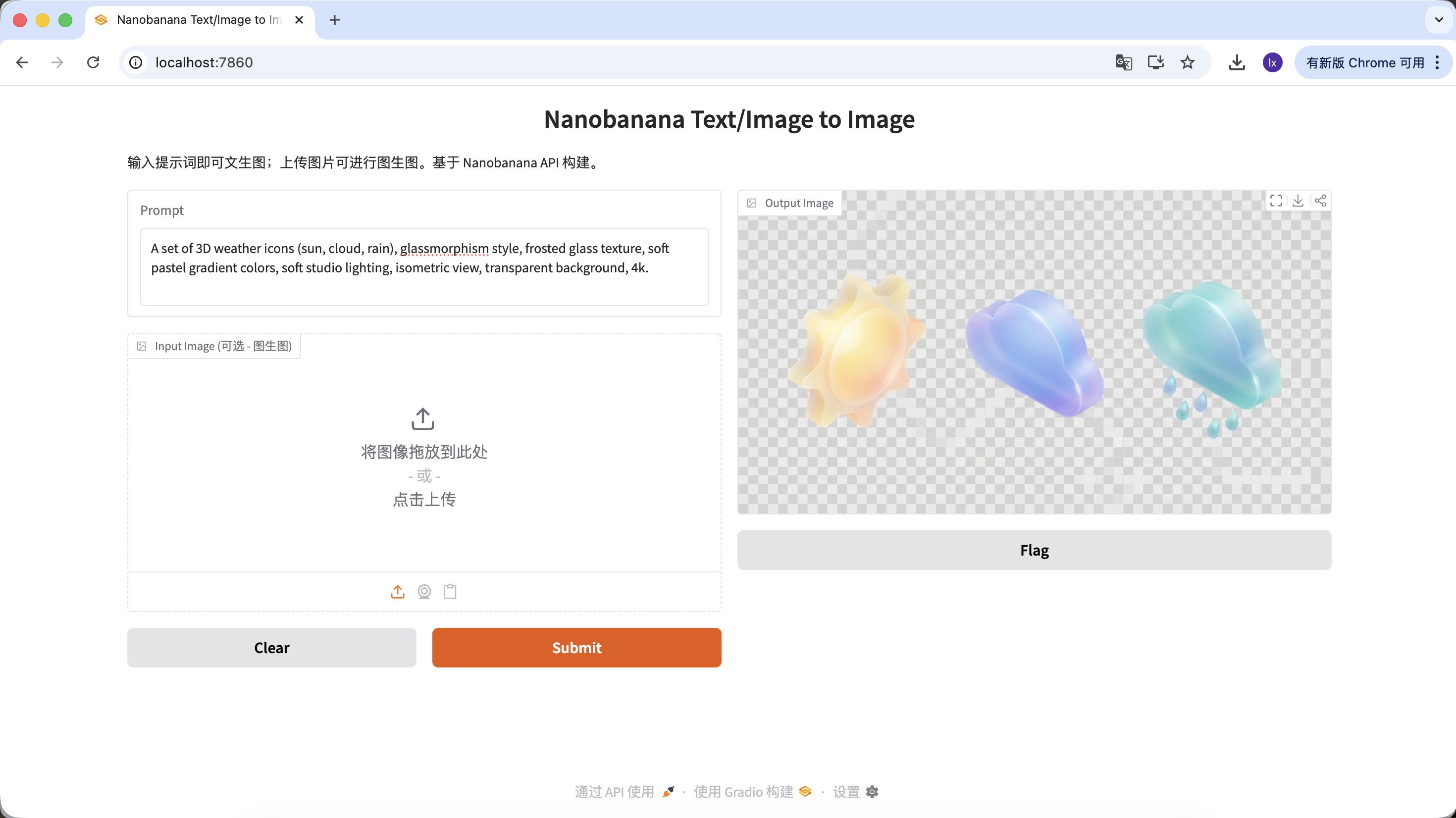
- トレンド:Dribbbleでよく見かけるグラスモーフィズム、クレイスタイルの3Dアイコン
- よくある表現:透明感のある素材、縁の発光、キャンディカラーの機能や天気アイコン
サンプル Prompt:
A set of 3D weather icons (sun, cloud, rain), glassmorphism style, frosted glass texture, soft pastel gradient colors, soft studio lighting, isometric view, transparent background, 4k.
(3D天気アイコンセット、グラスモーフィズムスタイル、すりガラスのテクスチャ、柔らかなパステルグラデーションカラー、スタジオライティング、アイソメトリックビュー)
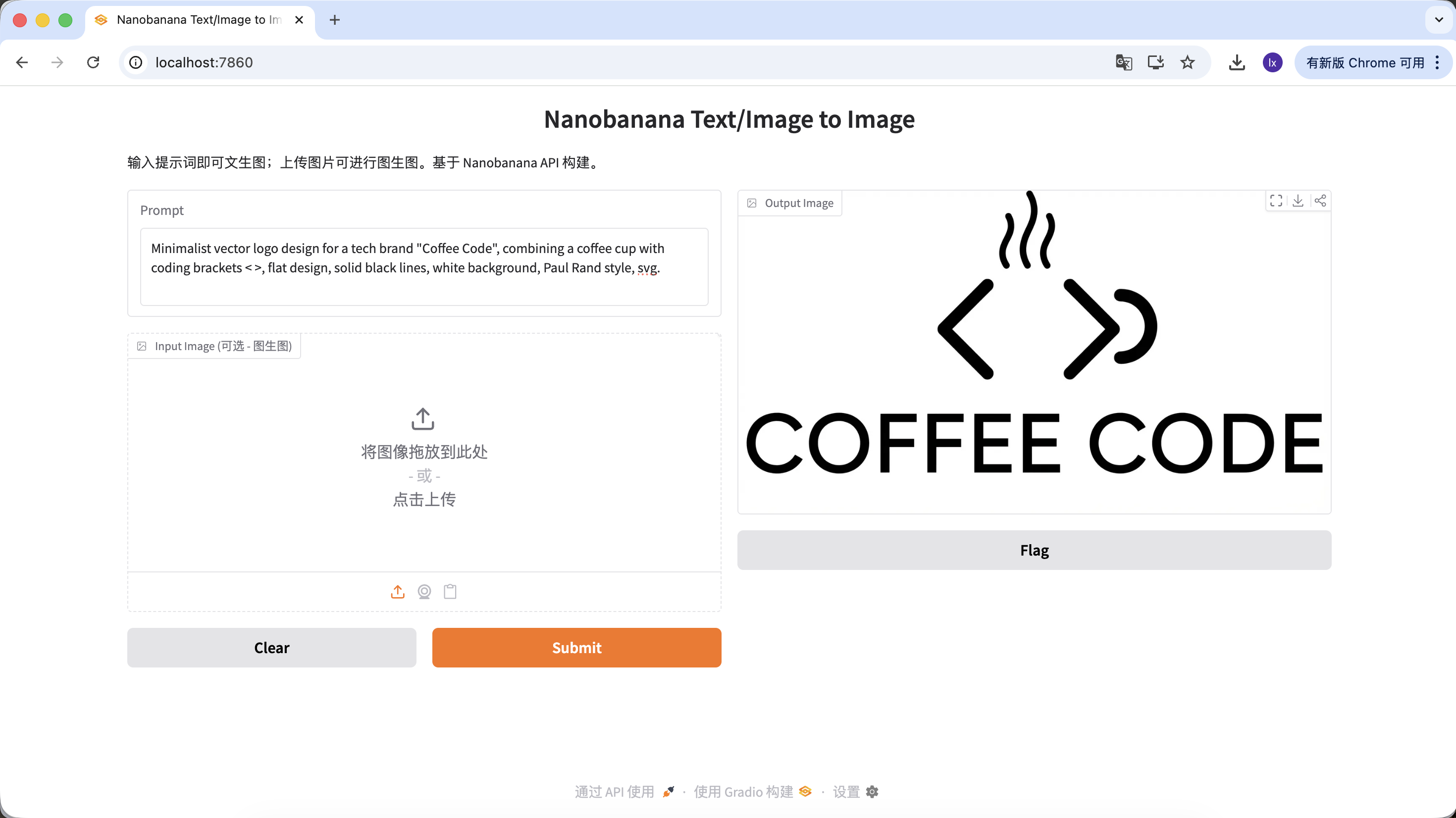
ロゴの生成
- トレンド:ミニマルなライン、幾何学的な組み合わせのテクノロジー感のあるロゴ
- よくある表現:白黒配色、ネガティブスペースデザイン、ブランド感が明確
サンプル Prompt:
Minimalist vector logo design for a tech brand "Coffee Code", combining a coffee cup with coding brackets < >, flat design, solid black lines, white background, Paul Rand style, svg.
(ミニマルなベクターロゴ、コーヒーカップとコーディング括弧の組み合わせ、フラットデザイン、純黒ライン)
公式サイトのユーザー画像生成
- トレンド:SaaS公式サイトでよく使われる3Dバーチャルアバター、実写の著作権問題を回避
- よくある表現:フレンドリーな表情、カートゥーン比率、PixarやMemojiスタイル寄り
サンプル Prompt:
Close-up portrait of a friendly young tech professional, smiling, Memoji 3D style, clay render, bright colors, soft lighting, solid plain background, Pixar character design.
(フレンドリーな若手テックプロフェッショナル、3D Memojiスタイル、クレイレンダリング)
記事の挿絵生成
- トレンド:テック企業ブログでよく見かける抽象的なフラットイラスト
- よくある表現:紫と青の配色、誇張された人物比率、浮遊するUI要素
サンプル Prompt:
Editorial flat illustration representing remote work, a person sitting on a giant globe using a laptop, corporate memphis art style, vibrant colors (purple and teal), vector texture.
(リモートワークをテーマにしたフラットイラスト、コーポレートメンフィススタイル)
二、参考画像からの画像生成:視覚的一貫性の維持
このカテゴリのシーンは拡張性に焦点を当てています。満足のいくメインビジュアルが1つあり、それとスタイルが一致する一連の素材を生成する必要がある場合に使用します。
メインビジュアルに類似した一連のボタンやインタラクション素材画像
ゲーム開発では、UIの一貫性が非常に重要です。メイン画面の「PLAY」ボタンがすでにあると仮定し、スタイルが統一された一連の機能ボタン(一時停止、設定、ホームなど)を追加で生成する必要があるとします。手描きだけで各ボタンの光沢、パースペクティブ、色味の完全な一致性を保証するのは困難です。
基本的な操作フロー:
- 既存の青色「PLAY」ボタン画像を保存

- インターフェースのInput Imageエリアにドラッグし、以降の生成の参考マスターとする
- promptのスタイル説明は変更せず、メインコンテンツのみを変更
このフローでは、メインの説明を置き換えるだけで、機能は異なるがスタイルが一致したボタンを得ることができます。
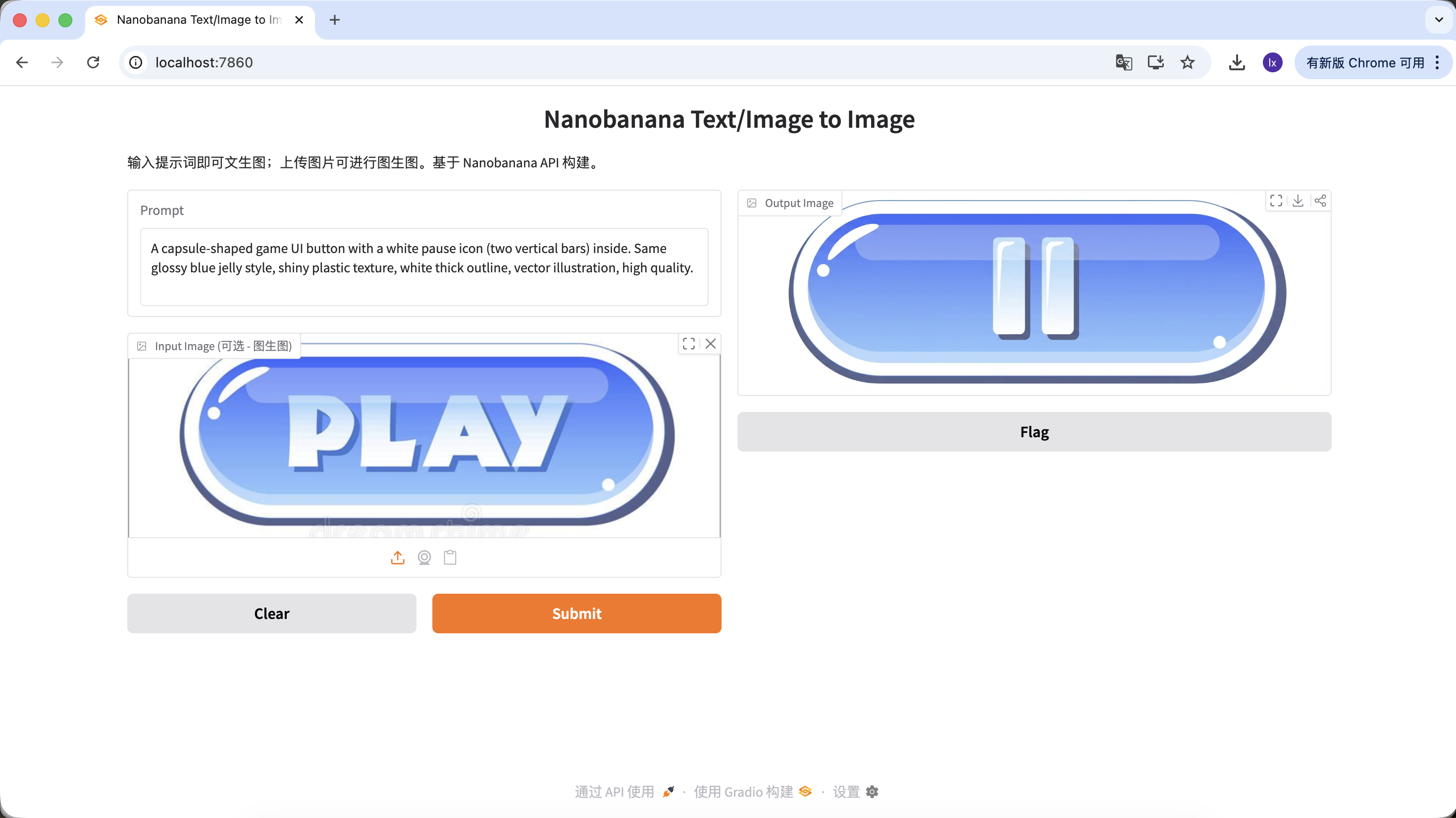
サンプル Prompt:
バリアント A:一時停止ボタン(アイコンタイプ)
A capsule-shaped game UI button with a white pause icon (two vertical bars) inside. Same glossy blue jelly style, shiny plastic texture, white thick outline, vector illustration, high quality.
(カプセル型ゲームUIボタン、白色の一時停止アイコン、ブルーのゼリー質感)
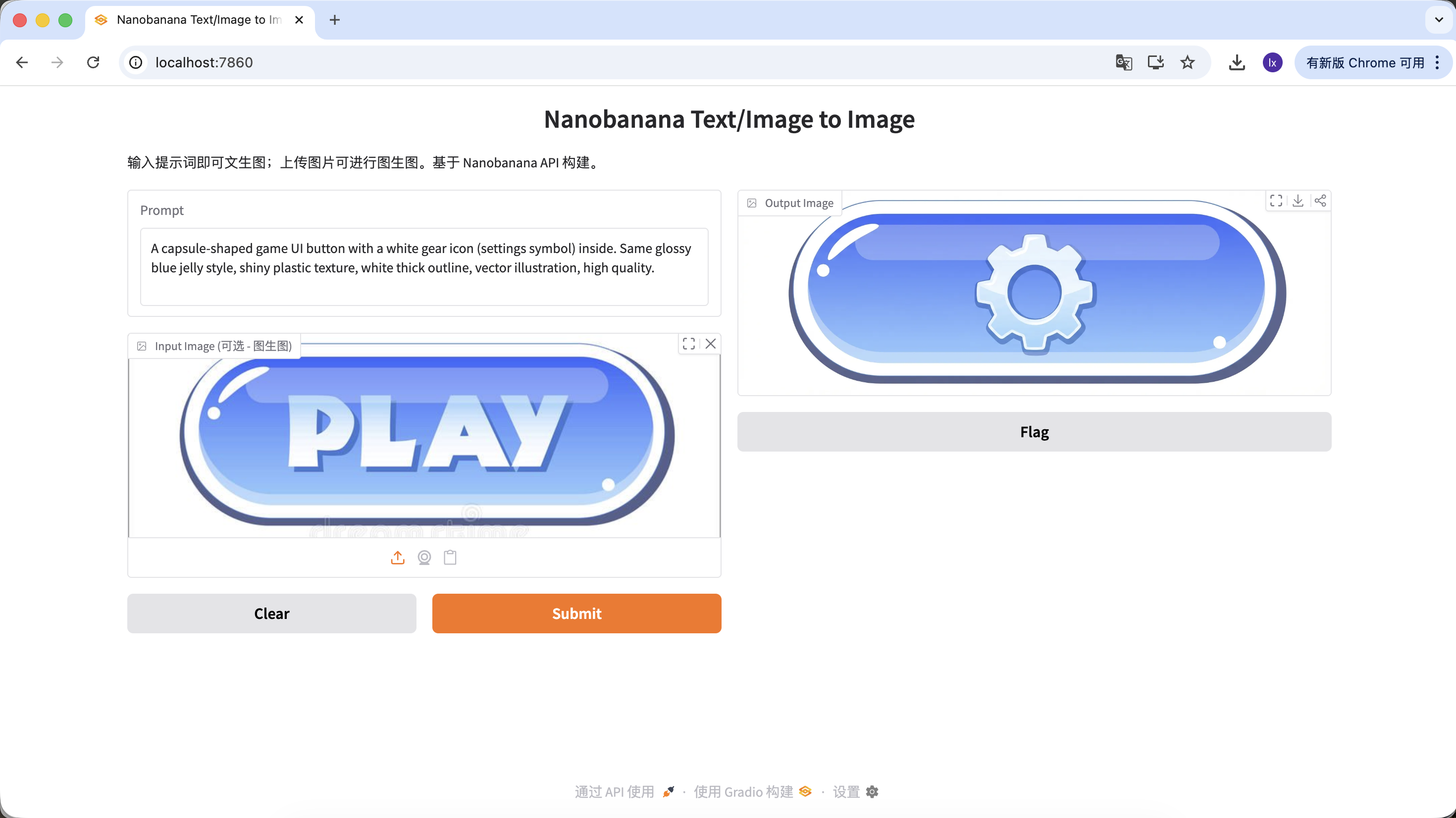
バリアント B:設定ボタン(複雑なアイコン)
A capsule-shaped game UI button with a white gear icon (settings symbol) inside. Same glossy blue jelly style, shiny plastic texture, white thick outline, vector illustration, high quality.
(カプセル型ゲームUIボタン、白色の歯車アイコン、ブルーのゼリー質感)
バリアント C:リプレイボタン(形状変更)
ボタンの外形を調整する必要がある場合、promptで直接形状を説明すると、モデルは素材の特徴を維持しながら構造の変更を試みます。
A round game UI button with a white circular arrow icon (replay symbol) inside. Same glossy blue jelly style, shiny plastic texture, white thick outline, vector illustration, high quality.
(円形ゲームUIボタン、循環矢印アイコン、ブルーのゼリー質感)

この一連の操作により、ボタンの機能やアイコンを置き換えるだけでなく、ボタンの形状を変えることさえできますが、すべての生成結果は素材、カラーリング、光と影において高い一貫性を保ちます。これこそが、大規模モデルがデザイン素材の派生シーンにおいて持つ核心的な価値です。
第2章:より従順な画像生成アシスタント —— Lovartを例に
第1部では、コードを通じて直接NanoBananaを呼び出し、「入力すれば生成」という基本フローを体験しました。この方法はニーズがシンプルな場合には問題ありません。しかし、生成タスクにさらに多くの制約が含まれるようになると、例えば:
- 複数のスタイルが一致した画像が必要
- 既存の結果に基づいて繰り返し調整が必要
- ユーザー入力に基づいて生成方向を動的に変更する必要がある
単一呼び出しの方式では次第に対応が困難になります。
ここで、AI Agent(エージェント)の導入が必要になります。本節ではLovartを例に、画像生成モデルに「思考層」が備わった後、全体的なワークフローがどのように変化するかを示します。注意!ここは広告ではなく、皆さんにAI Agentの利便性を素早く理解してもらうためのものです~
2.0 Lovart入門:あなたのAIデザインエージェント
LovartはAgentベースのデザインツールWebです。通常の画像生成ツールと比較して、生成の前に「思考と計画」の層が1つ追加されています。
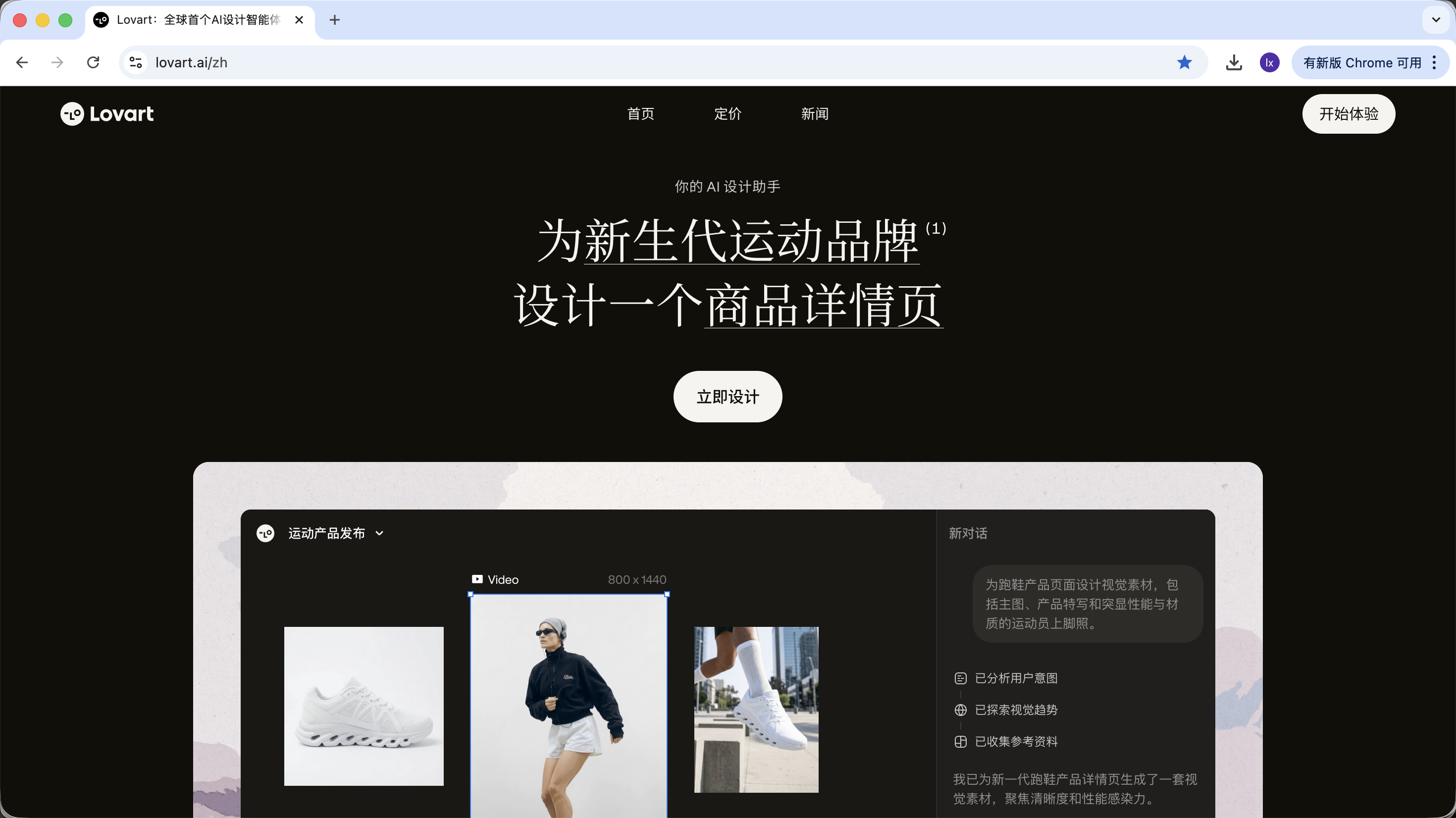
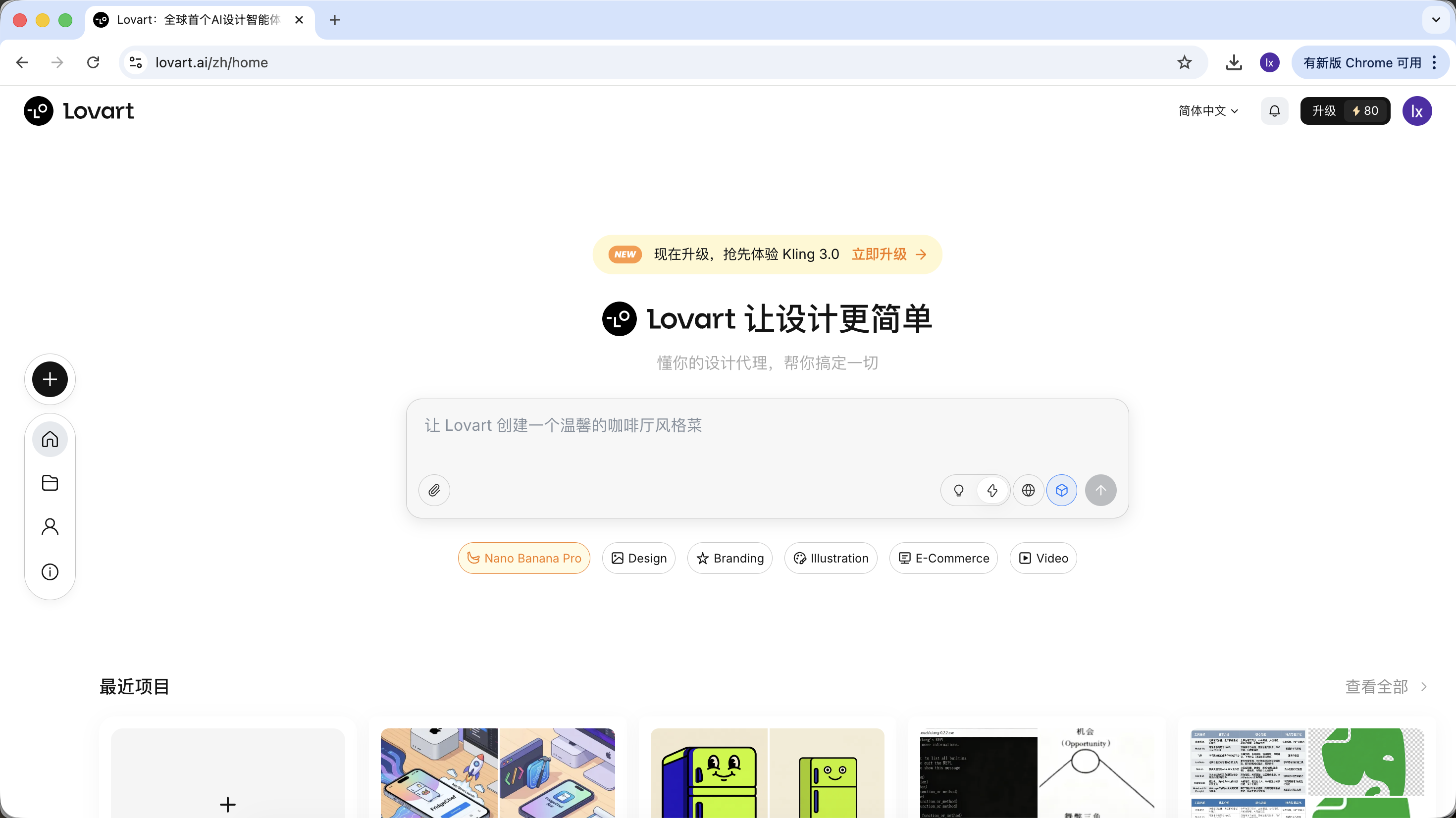
Lovartに入った後、主に以下の制御項目を理解する必要があります:
モデル選択
入力ボックスの下にある立方体アイコンをクリックすると、現在利用可能な生成モデル(GPT Image、Fluxなど)を確認できます。
前述の例との一貫性を保つため、本節では引き続きNanoBananaを基盤生成モデルとして使用します。
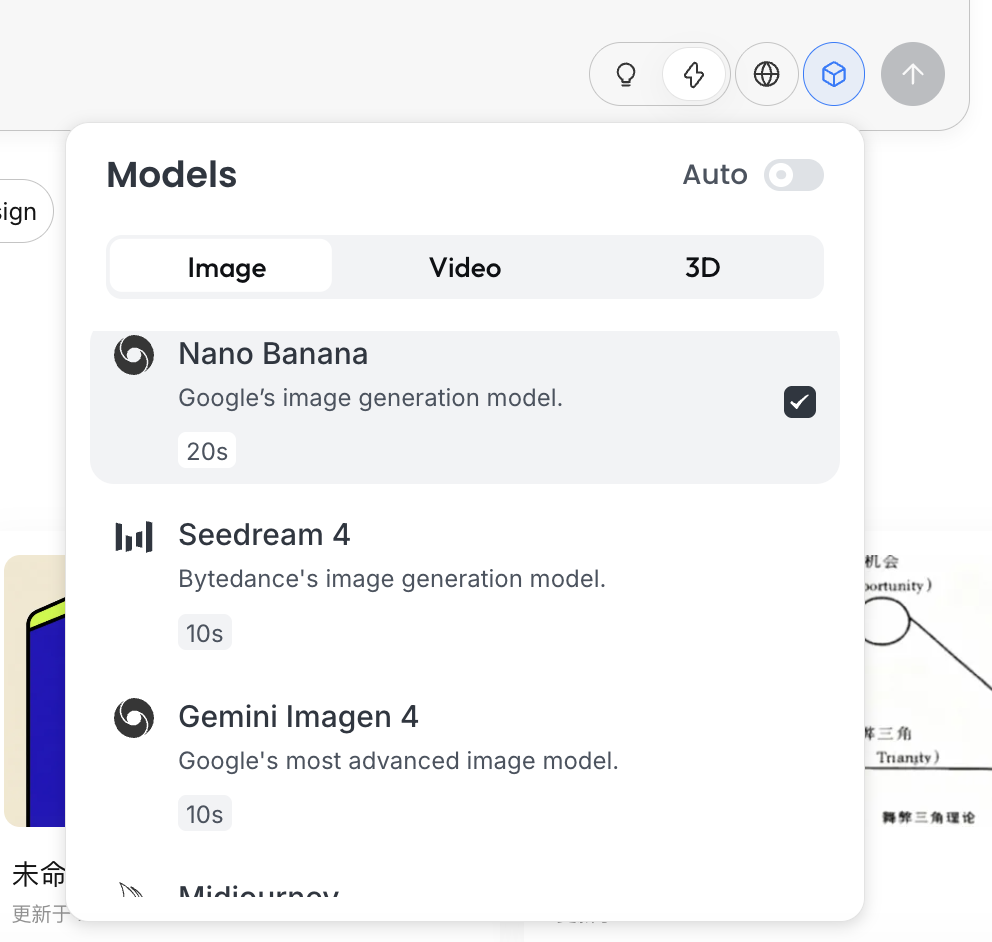
思考モード
これがLovartの核心的なスイッチです:
- Fast Mode(⚡):ネイティブAPIに近く、レスポンスが速く、単一で明確な指示の生成に適している
- Thinking Mode(💡):Agentモード、AIがまずニーズを分解し、promptを書き直してから生成を実行
インターネット接続機能
地球儀アイコンをオンにすると、Agentは生成過程でネットワーク情報(デザイントレンド、カラーパレットなど)を検索し、補助入力として利用できます。
2.1 なぜネイティブAPIだけでは不十分なのか?
Pythonで品質の良い画像を生成できるようになっても、ネイティブAPIは複雑なタスクでは依然として制限があります。重要な理由は、ネイティブAPIが本質的に命令型であることです。具体的なオブジェクトの生成を要求された場合、直接実行できますが、入力が「完全なゲーム素材セットの企画」になると、目標を複数の実行可能なステップに自発的に分解することはありません。
Lovartの核心的な違いはAgentメカニズムにあります。ユーザー入力と画像生成モデルの間に、理解と計画のためのロジック層を追加します:まずユーザーの意図を識別し、次にタスクを分解し、promptを書き直し、最後に生成を実行します。
2.2 実践デモ:5分でIPスタンプセットを作る
「プログラマー鸭のIPスタンプセットを作る」を例に、Agentがプロセス全体にどのように関与するかを見てみましょう。
ステップ1:企画(Agentの思考能力)
ネイティブAPIの問題点: 自分でキャラクター設定、感情状態を考え、各画像ごとに個別にpromptを書く必要があります。
Lovartのアプローチ:
- 💡 Thinking Modeを点灯
- 1つの指示を入力:
プログラマー鸭のIPスタンプセットをデザインして、スタイルはフラットで可愛く
AIはすぐに絵を描くのではなく、まずネットで関連するプログラマー鸭のデザイン画像を検索します。分解されたプランを出力し、Debug、Coffee Break、Panicなどのシーンを自動生成し、対応する複数の視覚説明を生成します。
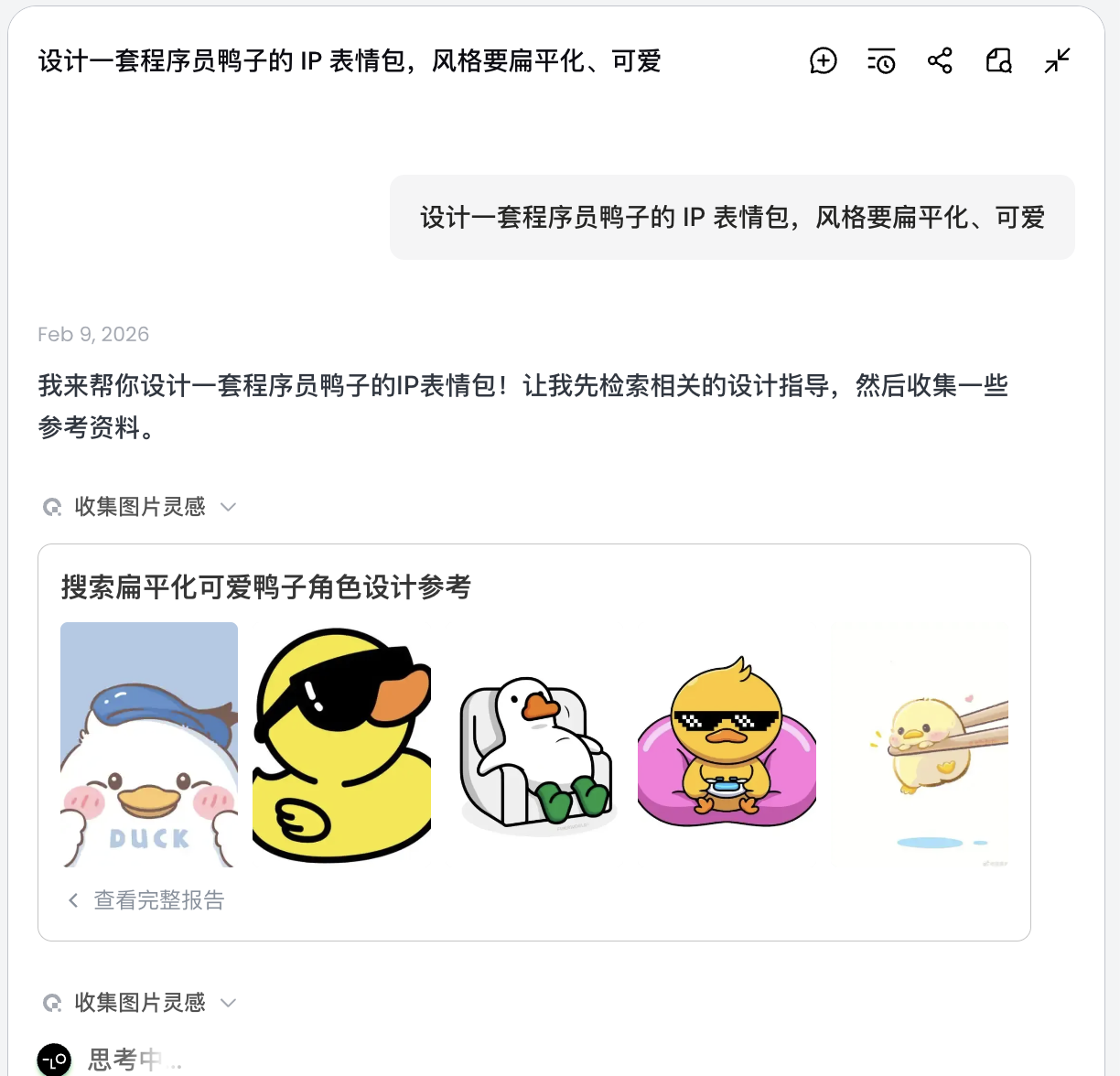

このステップで、AIは「実行者」から「企画者」へと変わります。AIがニーズの分析を完了した後、Lovartのキャンバスエリアで様々なスタイルとコンテンツのプログラマー鸭画像を見ることができます。お気に入りのスタイルを選び始めることができます。
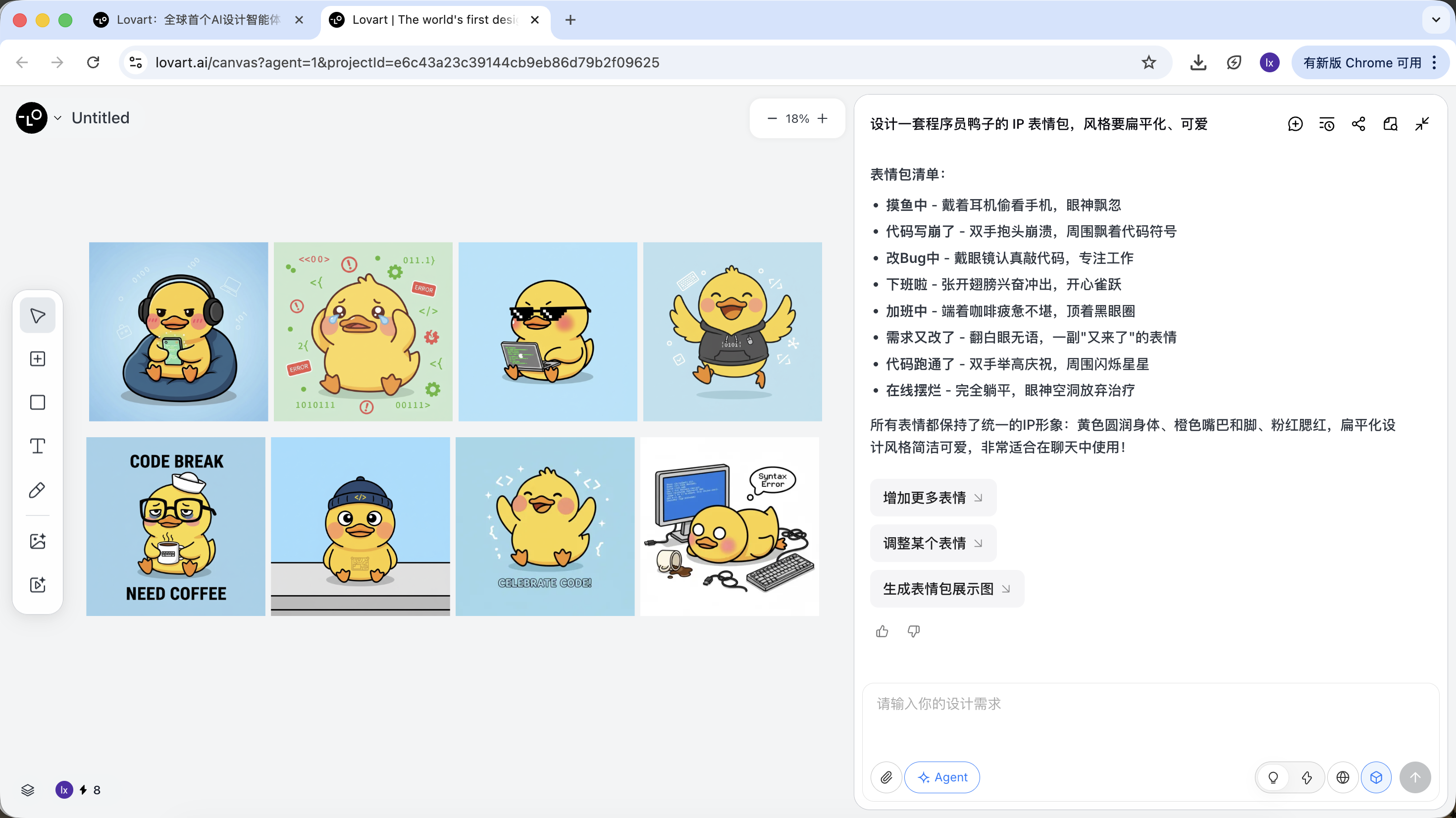
ステップ2:一貫性(参考に基づく視覚的アンカー)
Lovartの画像は結果であるだけでなく、以降の生成にも参加します。
完全な参考画像
- スケッチから最も満足のいく「標準的な鸭」を1枚選び、キャンバスエリアで対応する画像をクリック
- その画像は自動的に対話エリアにReferenceとして表示されます
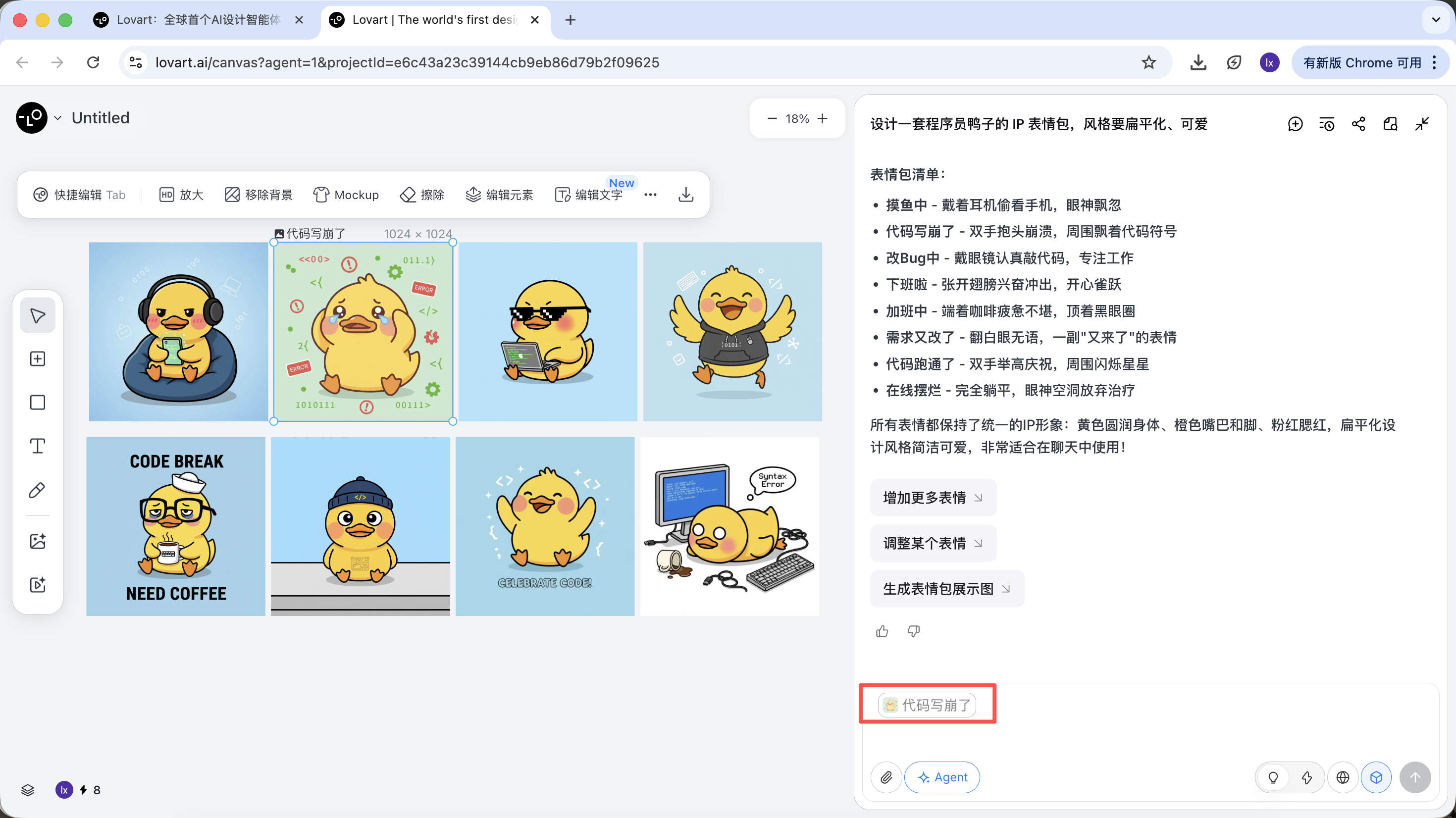
- 新しい動作(例:嬉しい)を入力して生成
生成結果はマスター画像のカラーリング、比率、ディテールを継承します。
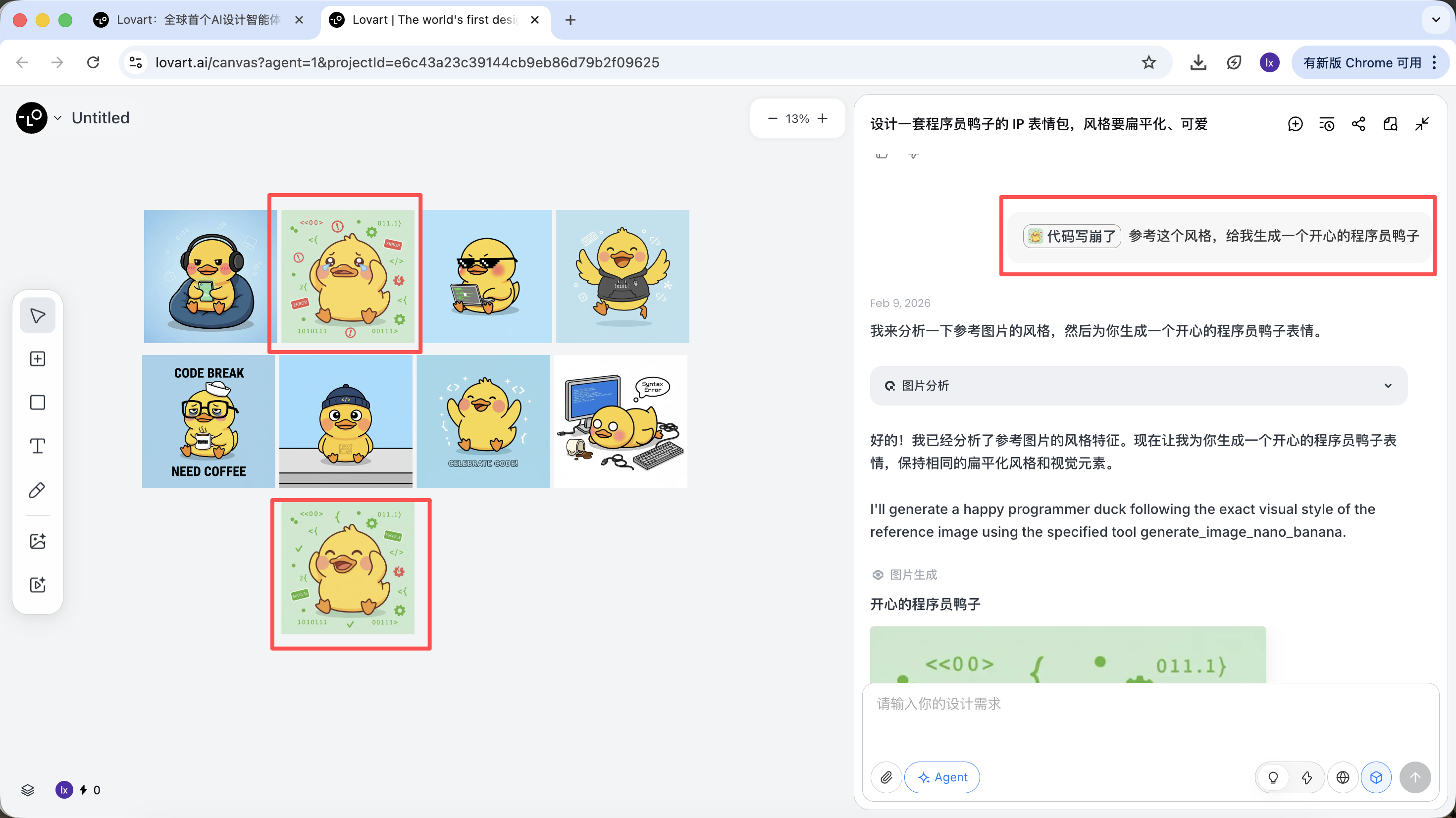
部分参考 / 複数画像の統合
画像全体を参考にするだけでなく、Lovartは以下もサポートしています:
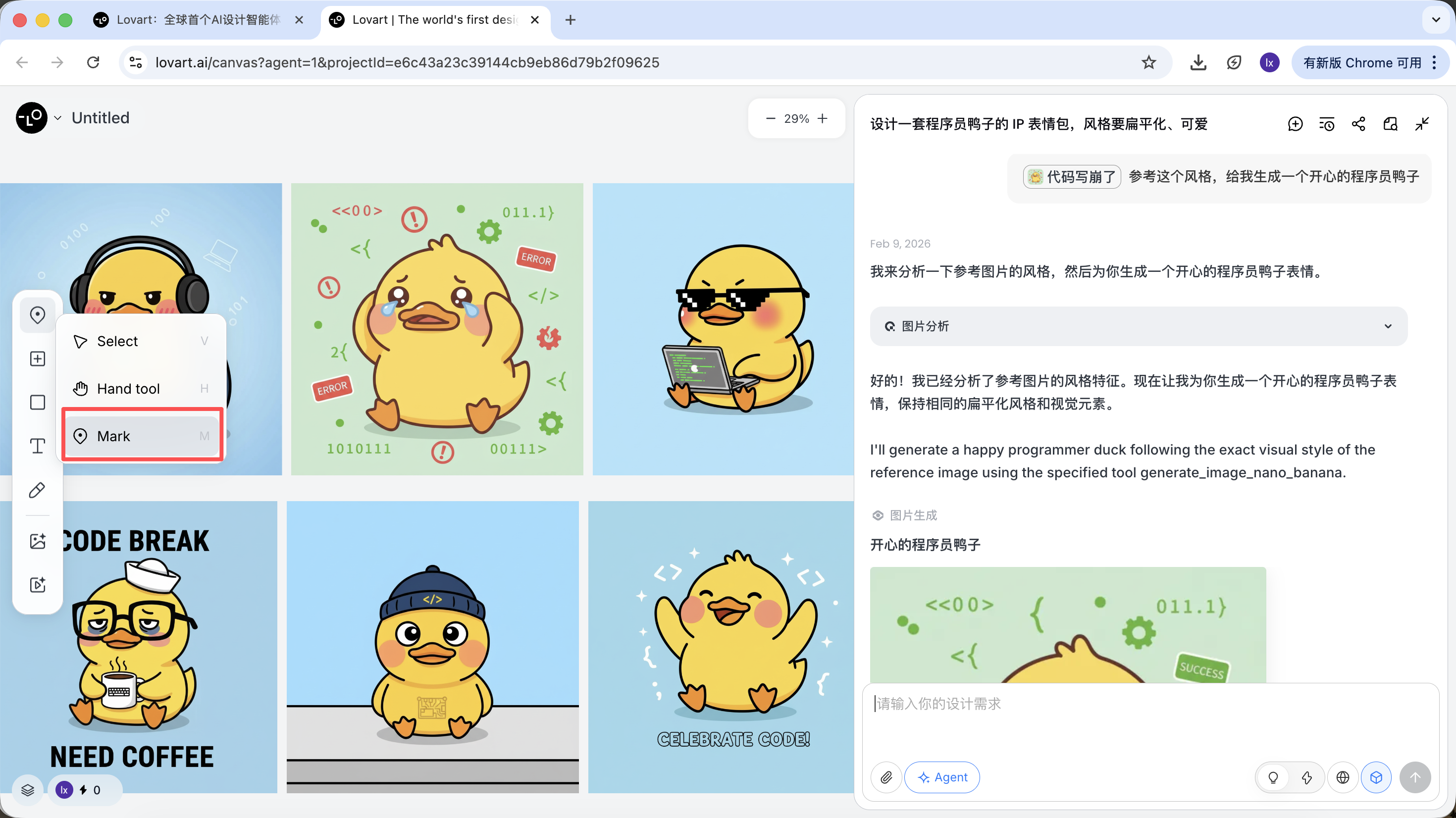
- 画像の部分的な領域のみを選択(例:帽子や表情のみを参考にする)
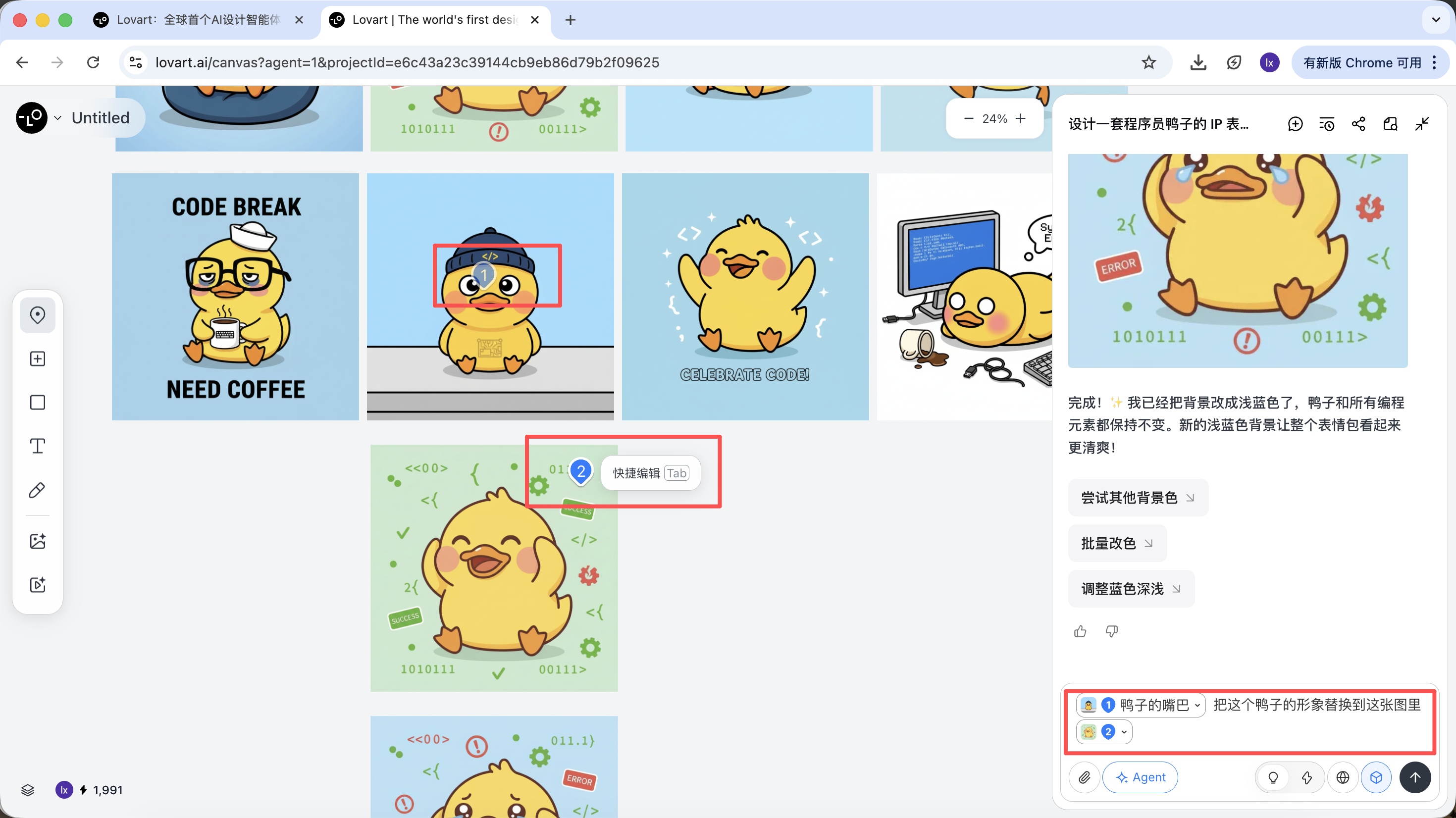
キャンバスエリア左側のタブバーをクリックし、「Mark」キーを選択し、ターゲット画像の部分領域をマークすると、この部分の内容が自動的に対話ボックスに同期されます。例えば、ここでは背景の色を変更するよう選択できます。
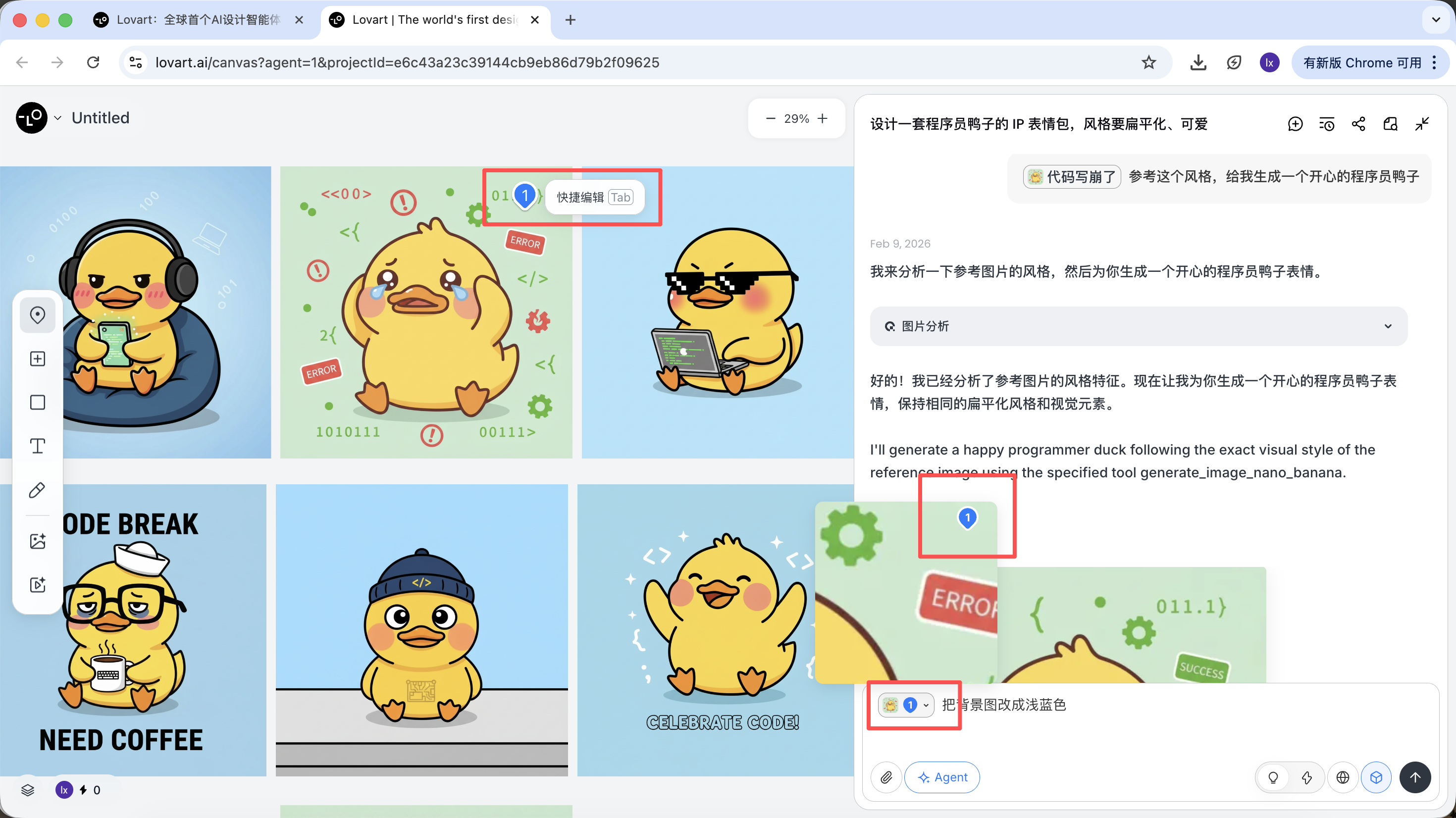
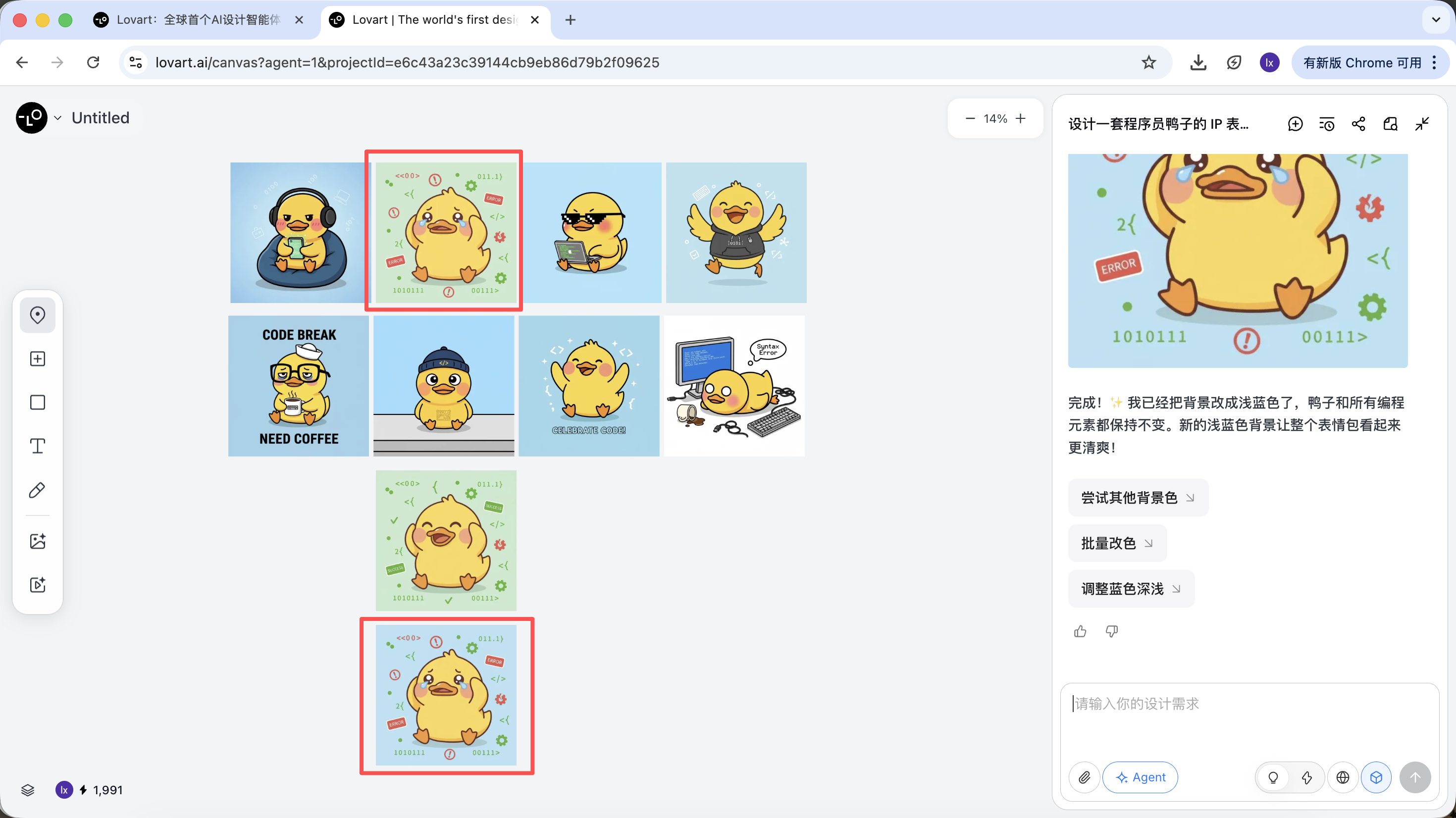
新しく生成された画像が背景の色のみを変更しており、これは入力した要求とも一致していることがわかります。
- 複数の画像からそれぞれサブ要素を引用し、組み合わせて新しい結果を生成
例えば:画像Aのキャラクター本体を保持しつつ、帽子だけを画像Bのスタイルに置き換えることができ、Agentはバックグラウンドでこれらの視覚的制約を自動的に統合します。
プログラマー鸭を例にすると、最初の画像の鸭のキャラクターを保持し、それを2枚目の画像のメイン要素として置き換えることができます。
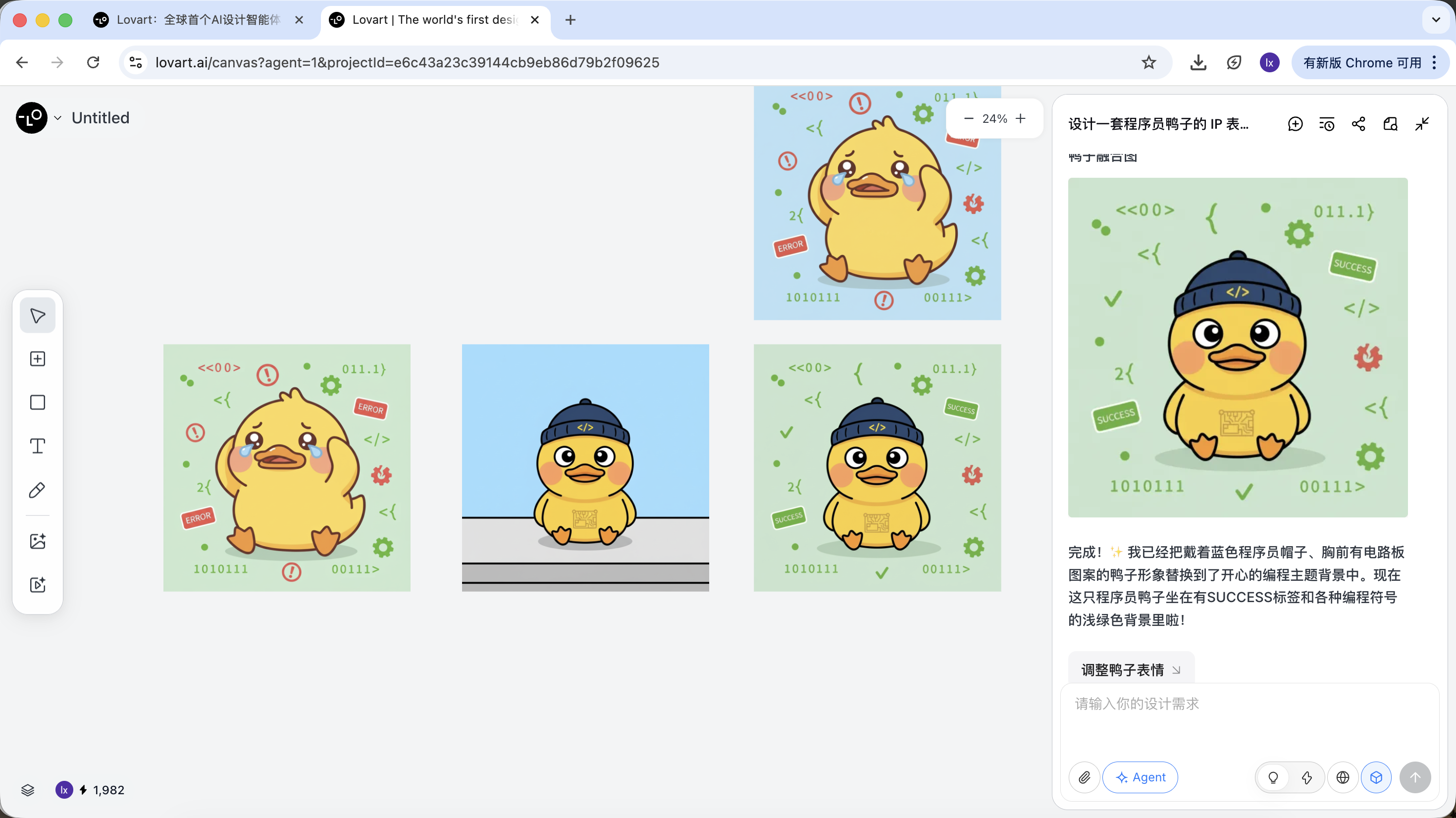
最終的な効果も非常に顕著です。他の組み合わせも試してみてください!
ステップ3:仕上げ(Agentのツール呼び出し)
生成が完了したら、直接実行できます:拡大、背景除去、消去などの操作
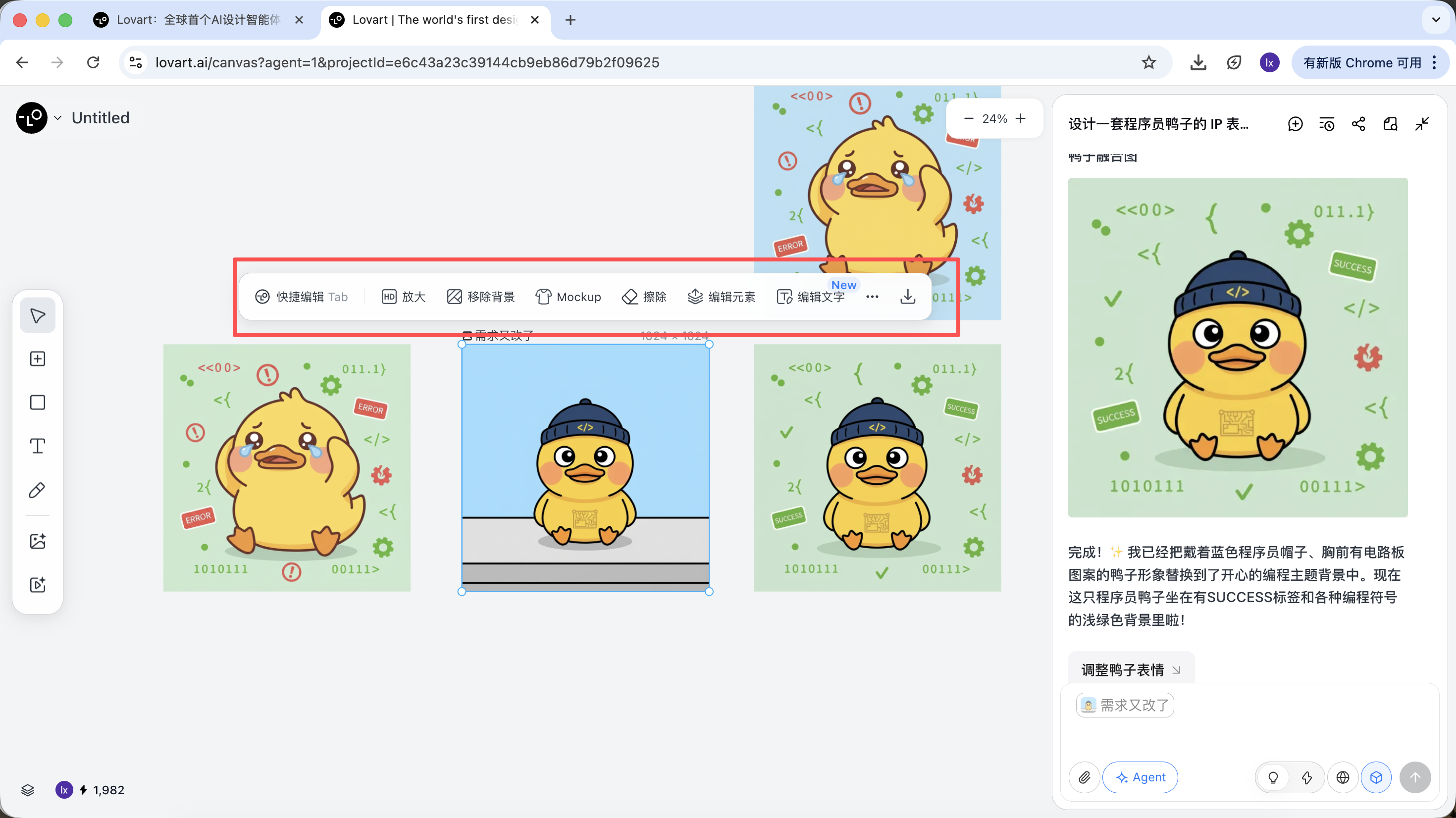
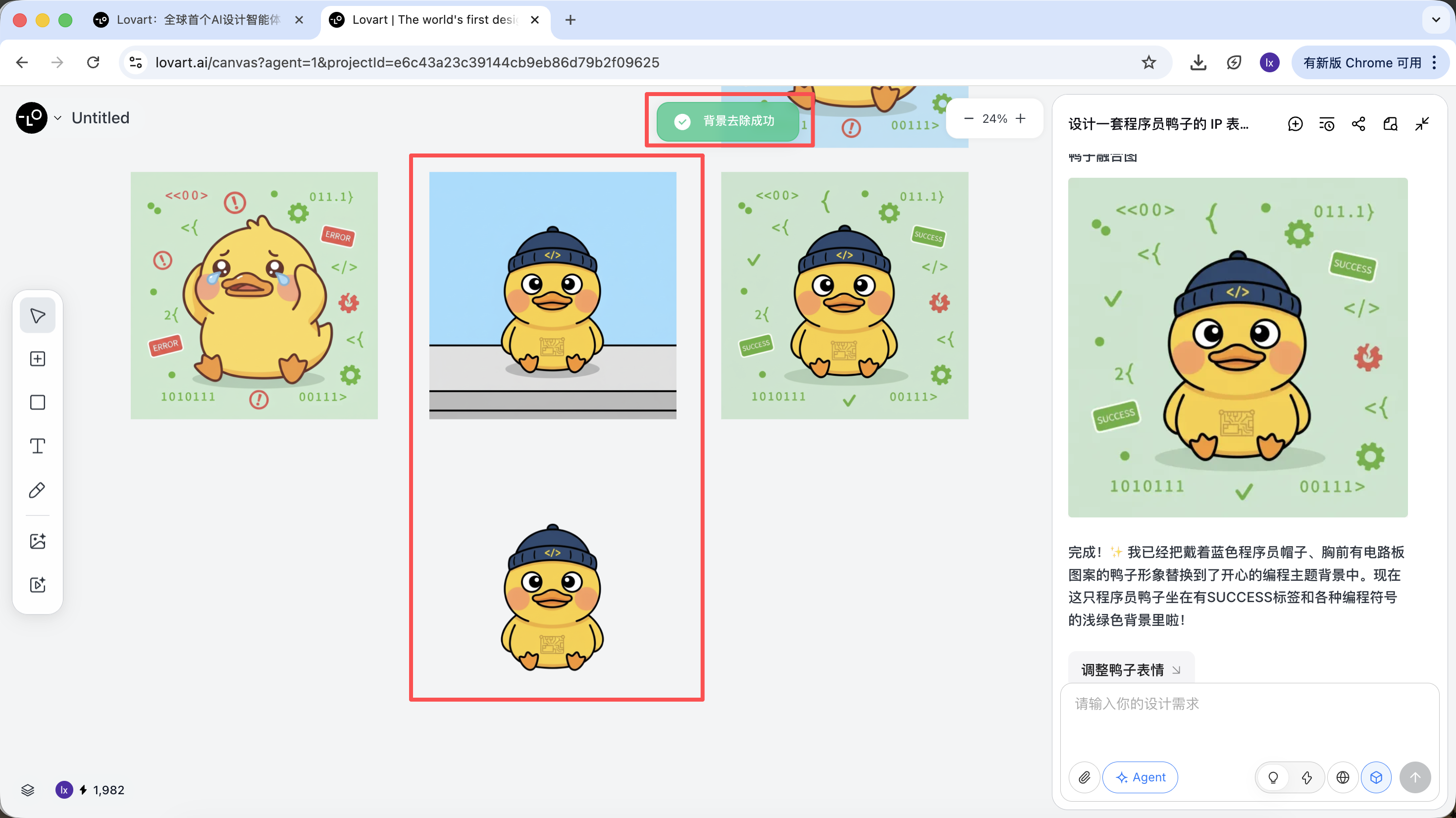
これらは単純なフィルターではなく、Agentが異なるツールを自動的に呼び出して完成させた結果です。
基調スタイルが確定した後、一連のスタンプ画像を非常に速く生成できます。
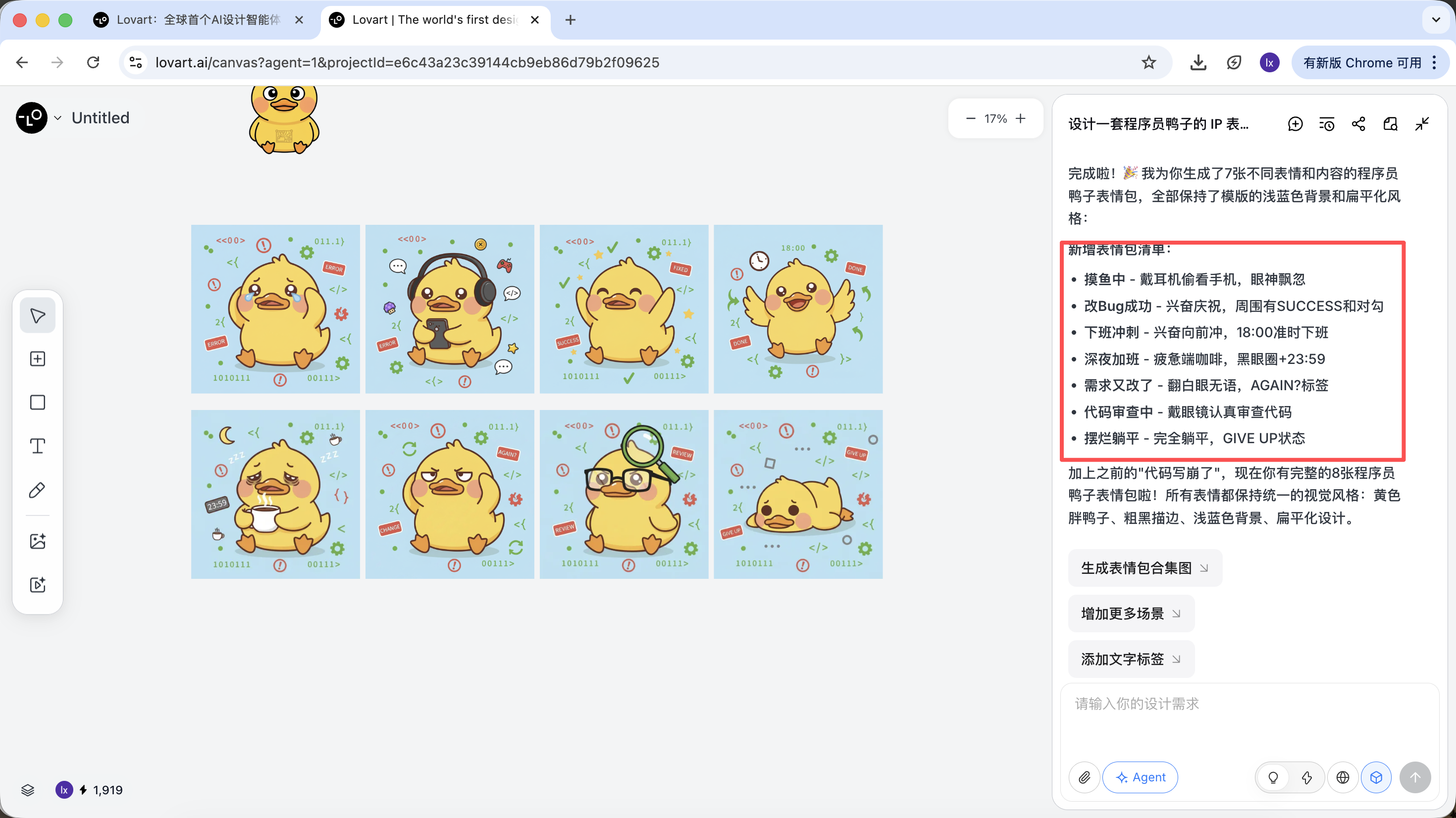
最終的に得られるのは、直接納品可能な本番レベルの素材であり、単なる展示画像ではありません。
2.3 利用料金について
Lovartはサブスクリプション制の課金モデルを採用しており、異なるプランは異なる使用量と機能権限に対応しています。詳細は公式サイトの表示をご確認ください。
本チュートリアルはいかなるプランの推奨や比較も行いません。実際の使用で必要がある場合は、個人の状況に応じて有料アップグレードを選択できます。 現在はAlipayなどでの支払いに対応しています。
まとめ
Lovartは基盤モデルを代替するものではなく、Agentメカニズムを通じて、画像生成を「単一実行」から「連続ワークフロー」へとアップグレードします。
タスクが企画、一貫性、納品に関わり始めると、この種のツールの利点が非常に明確になります。
第3章:自分でスマート描画アシスタントを作ろう
Lovartを直接使用するだけでなく、自分で簡易版の描画アシスタントを実装することもできます。
本章では「記事の自動挿絵」を例に、実際の問題から出発し、段階的に思考能力を持つAgentを構築します。
3.1 課題の導入:なぜ記事をそのまま画像生成モデルに送ってもうまくいかないのか?
長い記事をNanoBananaに直接入力して挿絵を求めても、通常は理想的な結果が得られません。理由はモデルが「描くのが下手」だからではなく、長いテキストの理解が得意ではないからです。
画像生成モデルは短く明確な視覚的説明を処理するのに適しており、入力が構造、要点、文脈関係を含む記事になると、モデルはどの内容が画像で表現すべき部分なのかを判断できません。これにより、生成結果がテーマから逸脱したり、断片的なディテールしか捉えられず、全体的な要約力が欠如することになります。
本質的に、画像モデルには「実行」する能力はあっても、テキストを分析し取捨選択するプロセスが欠けています。
3.2 解決アプローチ:Agentで「理解」と「実行」を分ける
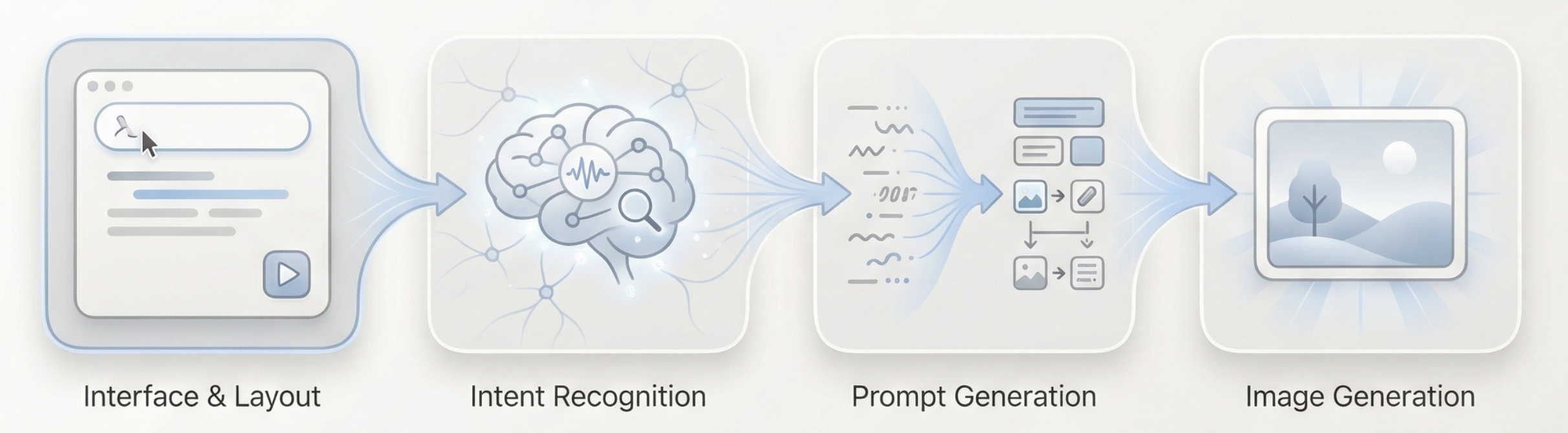
この問題を解決するための鍵は、より複雑なプロンプトではなく、画像生成の前にまず考えることです。したがって、生成フローに独立した「思考層」を導入し、それを使って最もシンプルな利用可能なAgentを構築します。
このAgentの核心的な目標は1つだけです:最終的に生成される画像が、ユーザーの真の表現意図にできるだけ近づくこと。
全体のフローは次のように要約できます:長いテキスト入力 → 言語モデルによる理解と判断 → 適切な視覚プロンプトの生成 → 画像モデルによる生成の実行 → 画像の出力
では、私たちが構築するAgentはどうやってユーザーの意図を理解するのでしょうか?
ここでは簡略化された「思考層」を作ることを選択し、3つの異なる意図を設定しました:無効な入力、直接画像生成、理解が必要な長いテキスト。
このAgentでは、各役割の分担は4つのポイントに要約できます:
- 言語モデルが意思決定の核心として 記事の内容を理解し、ユーザー入力の意図を判断し、タスクを適切な生成パスに配信し、「次にどうすべきか」および画像生成プロンプトの生成方法を決定する役割を担います。
- 画像モデルが実行者として 画像モデルは理解と判断には参加せず、すでに整理された視覚的指示のみを受け取り、画像レンダリングの完成に集中します。
- ユーザーが介入可能なガイドとして テキストを直接入力するだけでなく、プロセス中に生成されたプロンプトを手動で調整したり、参考画像を追加して生成を補助し、最終結果をガイド・微調整することもできます。
- GradioとバックエンドAPIが全体のサポート層として インターフェース、モデル呼び出し、結果表示を連携し、Agent全体が完全なWebアプリケーションとして安定して動作できるようにします。
3.3 実践準備:APIの取得
とても面白そうですね!上記のフローを実行するために、必要なAPIは2種類だけです。
手:NanoBanana API(画像生成)
第1章で既に設定済みのAPI KeyとAPI URLをそのまま使用し、追加の設定は不要です。
脳:SiliconFlow API(テキスト思考)
「思考層」の役割を担う大規模言語モデルが必要です。本チュートリアルではSiliconFlowが提供するモデルサービスを使用します:https://cloud.siliconflow.cn
SiliconFlowはOpenAI API仕様と互換性のあるインターフェースを提供しており、標準的なネットワークリクエストでプロジェクトに非常に便利に統合できます。ここで選択したのは無料のQwen2.5-7B-Instructモデルで、呼び出しに必要な内容は以下のPromptにすべて記載されています。始める前に、公式サイトでアカウントを登録しAPI Keyを作成するだけです。
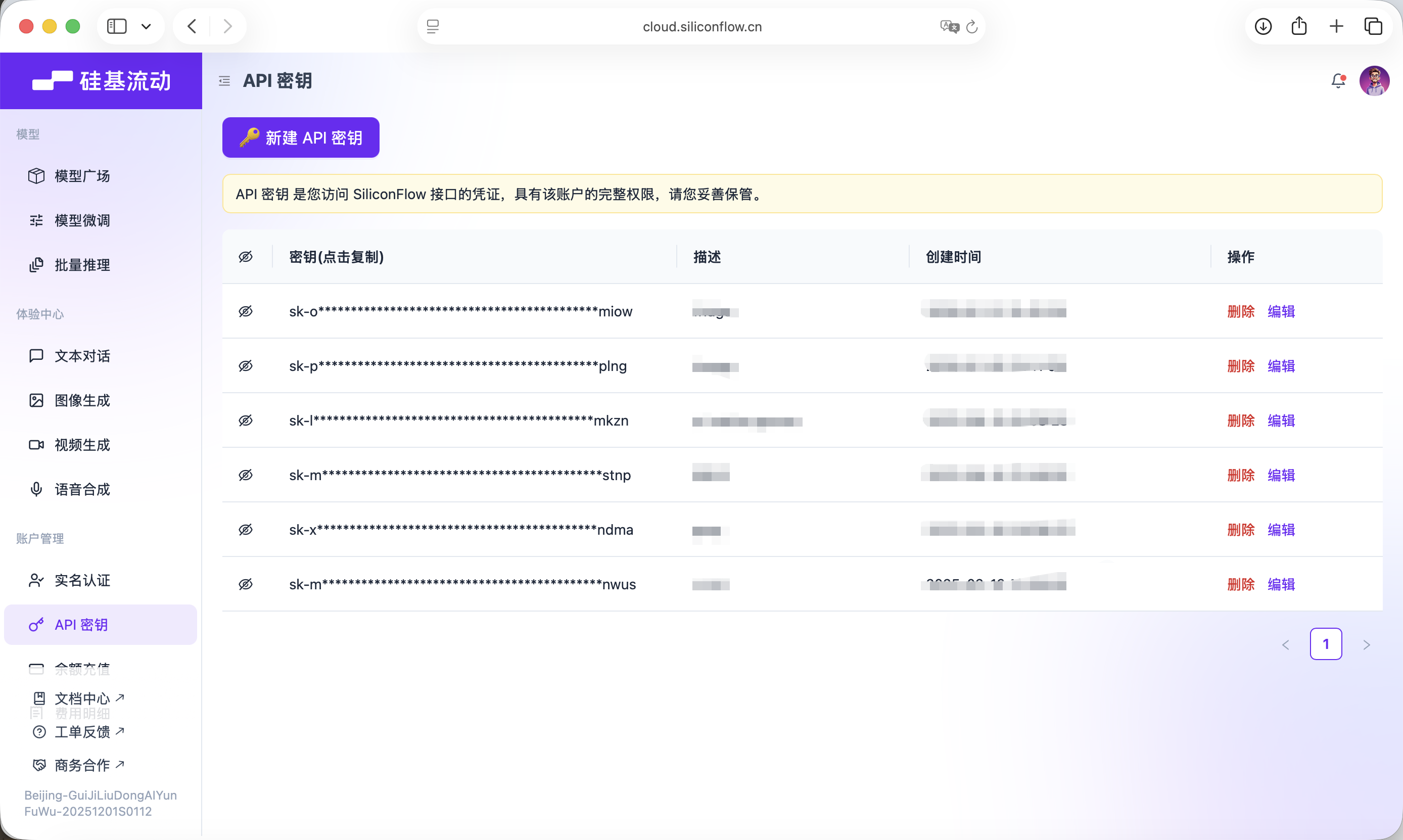
このKeyは以降のモデル呼び出しに使用されます。
3.4 Agentの構築:
今回の実験では主にTraeを使用してコードを記述します。本チュートリアルで選択したのはGemini-3-Pro-Previewモデルです。全体的なアプローチは、新しいプロジェクトを作成した後、以下の完全なPromptを対話ボックスにコピーして入力し、段階的にAPI KEYを置き換えた後コードを実行し、テストを完了します。
ステップ1️⃣:Gradio Blocks基本フレームワークとインターフェースレイアウト
このステップでは、Agent全体の「外観」を構築し、フロントエンドのページデザインを実現することが主な目標です。以下のPromptをコピーしてTraeの対話ボックスで実装すると、ローカルのURL(通常は http://127.0.0.1:7860)が取得でき、インターフェースを確認し、実装効果を検証できます。
セクション 1:Gradio Blocks基本フレームワークとインターフェースレイアウト
1、タスク目標
· Gradio 4.0.0+のBlocksレイアウトに基づいて、「LLM+Nanobananaテキストから画像」プロジェクトの基本インターフェースを実装し、固定左右分割レイアウトを厳格に遵守し、すべてのUIコンポーネントを初期化し正しい初期状態を設定。
2、技術スタック要件
· Gradio 4.0.0+のBlocksモードでの開発を使用、Interfaceモードの使用は禁止;
· 依存関係:gradio>=4.0.0、pillow>=10.0.0(インポートのみ、画像処理ロジックは一時未実装);
· コードは完全に実行可能なPythonファイルで、すべての必要なインポート文を含む。
3、インターフェースレイアウトルール(核心制約、実践的詳細を統合)
·全体レイアウト:
ページタイトル:LLM駆動のテキストから画像全プロセスツール;
固定左右分割:左側60%幅、右側40%幅、gr.Rowとgr.Columnで比率制御を実現。
·左側60%(プロンプト生成プロセスエリア)コンポーネント一覧:
input_text:gr.Textbox、ラベル「入力テキスト(チュートリアル段落 / 描画指示)」、lines=6、プレースホルダー「画像挿絵用のチュートリアルテキストまたは直接描画指示を入力...」;
identify_intent_btn:gr.Button、value="意図を識別"、初期状態は通常クリック可能;
intent_status:gr.Textbox、ラベル「意図タイプ / 処理ステータス」、lines=2、interactive=False、初期値「意図未識別」;
system_prompt:gr.Textbox、ラベル「System Prompt(記事挿絵意図のみ編集可能)」、lines=4、interactive=False、プレースホルダー「LLMがプロンプトを生成する際の制約ルール...」;
confirm_prompt_btn:gr.Button、value="画像生成プロンプトを確認"、interactive=False(誤操作防止のため初期無効);
generation_prompt:gr.Textbox、ラベル「画像生成プロンプト(編集可能)」、lines=3、interactive=True、初期値は空、プレースホルダー「生成された英語の画像生成プロンプトがここに表示されます、手動での修正に対応...」。
·右側40%(Nanobanana画像生成機能エリア)コンポーネント一覧:
ref_image:gr.Image、ラベル「参考画像(任意、画像から画像生成)」、type=filepath、height=300、アップロード許可;
generate_btn:gr.Button、value="画像を生成"、interactive=False(初期無効、プロンプトがないとクリック不可);
result_image:gr.Image、ラベル="生成結果"、type=pil、height=300、初期は空、interactive=False。
4、インタラクションロジック要件
·すべてのコンポーネントのinteractive初期状態は上記設定に厳格に従い、その後関数で動的に更新;
·ボタンの無効状態は直感的に(グレーアウト)、ユーザーの誤操作を防止。
5、出力要件
·完全なPythonコードを生成、インターフェースレイアウトとコンポーネントの初期化のみを実装、ビジネスロジックは含まない;
·コードコメントは明確、コンポーネント名は実践版と一致(input_text/identify_intent_btnなど);
·コードは直接実行可能、インターフェース構造は説明と完全に一致。ブラウザでhttp://127.0.0.1:7860を開くと、Traeが要件に従って以下のWebページを生成していることが確認できます。要求とほぼ一致しており、次の生成ステップに進めます。
ステップ2️⃣:LLM意図認識モジュール(Siliconflow API)
日常的にVLMで画像を描く際、以下の3つの一般的な入力パターンがあります:
- 無意味な内容、「こんにちは」「今日ご飯食べた?」など、対応する画像が描けない。
- 記事/長文、文字数が多く、例えば200字程度の構造化された記事で、まず文章の構造と内容を理解してから、この文章全体を要約できる画像の生成方法を考える必要がある。
- 直接的な描画指示、「お風呂に入っている犬を描いて」など、要求がすでに非常に具体的で、直接画像を生成できる。
前と同様に、以下のPromptをコピーしてTraeの対話ボックスで実装し、前のステップで取得したAPIを追加します。
セクション 2:LLM意図認識モジュール(Siliconflow API)
1、タスク目標
実装済みのGradioインターフェースを基に、「意図を識別」ボタンにクリックロジックを追加し、Siliconflow APIを呼び出して意図認識を完了し、コンポーネント状態と連動。
2、技術スタック要件
Gradio 4.0.0+ Blocksに基づく;
依存関係:requests>=2.31.0、openai;
セクション1インターフェース + 本モジュールロジックを含む完全な実行可能Pythonファイルを出力。
3、核心ビジネスルール(絶対に逸脱不可)
·意図分類ルール(3種類のみ、数字 + 説明を厳格に返却)
1 = 無意味な内容:雑談、挨拶、無関係な会話のみで、描画や挿絵のニーズが全くない(例:「こんにちは」「今日食べた?」);
2 = 記事 / 長文の挿絵ニーズ:ユーザーが完全な記事、チュートリアル、段落、説明文を入力し、内容は叙述 / 説明 / 解説に偏り、この内容に挿絵を生成する意図が暗黙的に含まれる。ユーザーが「この文章に挿絵をつけて」と明示的に言う必要はない;
3 = 直接的な描画指示:ユーザーが短く明確な描画コマンドを入力し、長文の背景がなく、直接特定の内容を描くよう要求(例:「Apple風の猫を描いて」)。
·LLM呼び出し制約(実践版テンプレートを統合)
インターフェースURL:https://api.siliconflow.cn/v1/chat/completions;
モデル:Qwen/Qwen2.5-7B-Instruct;
temperature=0.1;
統一定義コード:
python
実行
LLM_BASE_URL = "https://api.siliconflow.cn/v1"
LLM_API_KEY = "" # ユーザーが各自入力
LLM_MODEL = "Qwen/Qwen2.5-7B-Instruct"# 実践検証済み意図認識テンプレート(コードに固定)
INTENT_PROMPT_TEMPLATE = """ユーザー入力テキストの意図を識別する必要があります。以下の3種類の結果のうち1つのみを返却(形式:数字 + 中国語の説明):
1 = 無意味な内容;2 = 記事 / 長文の挿絵ニーズ;3 = 直接的な描画指示。
ユーザー入力:{user_input}
認識結果:
結果中の数字と説明のみを抽出して返却し、余分な内容は禁止。"""
4、コンポーネント連動ルール
·結果が1:intent_statusに「1 = 無意味な内容:描画ニーズなし」と表示、system_promptは無効状態を維持、confirm_prompt_btnは無効;
·結果が2:intent_statusに「2 = 記事 / 長文の挿絵ニーズ:入力内容に挿絵を生成」と表示、system_promptを有効化しデフォルトルールを充填、confirm_prompt_btnを有効化;
·結果が3:intent_statusに「3 = 直接的な描画指示:指示に基づいて画像を生成」と表示、system_promptは無効状態でデフォルトルールを充填、confirm_prompt_btnを有効化。
5、例外処理
API例外、解析例外はすべてフレンドリーなプロンプトを表示し、クラッシュせず、コンポーネントは初期状態に復帰。
6、出力要件
LLM_API_KEYを置き換えるだけで使用可能な完全な実行可能コードを生成、ロジックは明確でコメントは完全、意図認識テンプレートは実践版を厳格に使用。以前のhttp://127.0.0.1:7860のURLをリフレッシュし、3つのケースを正しく認識できるかテストを開始します。
- 無意味な内容、「こんにちは」「ありがとう」などを入力して試すと、正常に認識できることが確認できます。
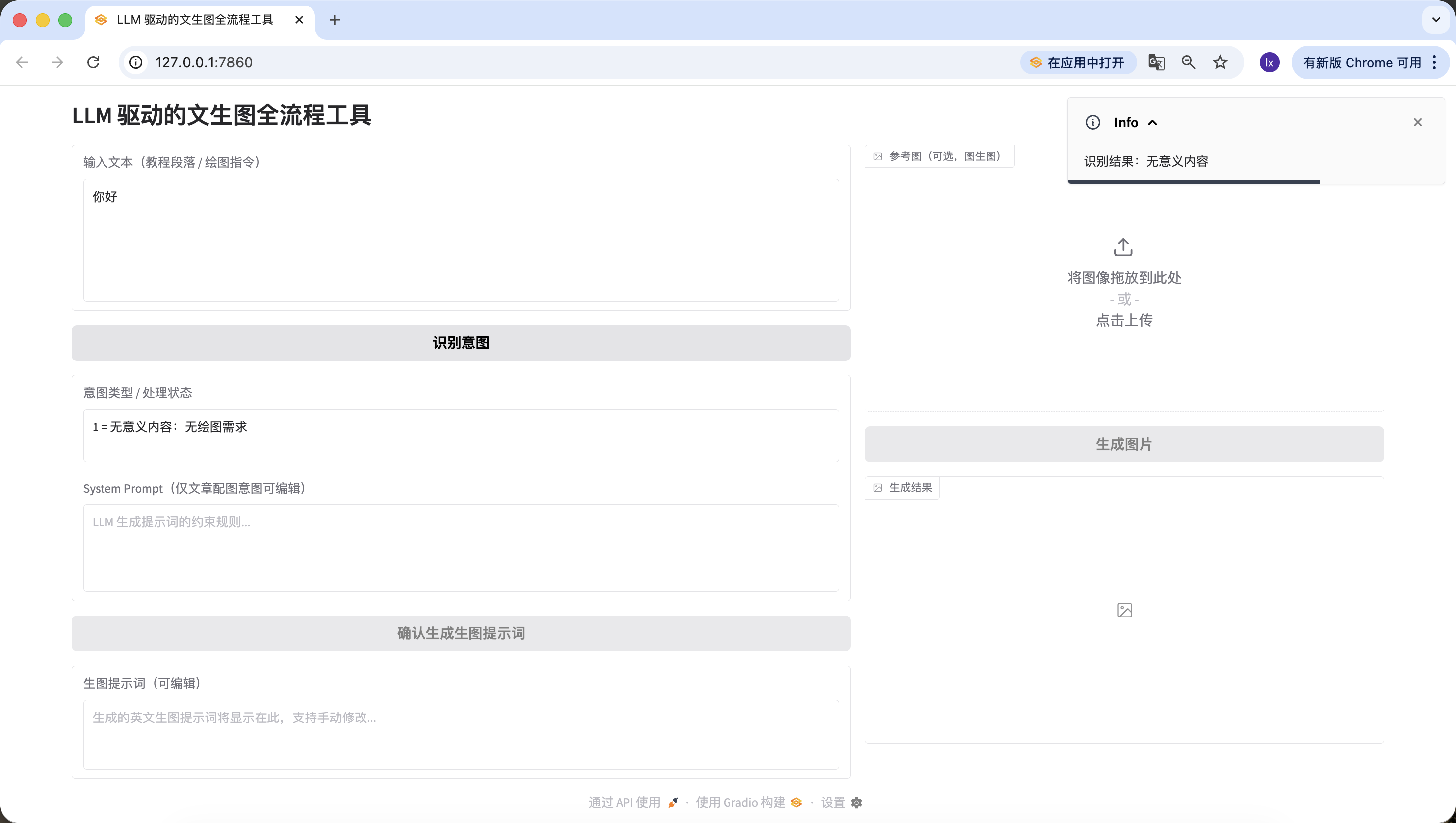
- 記事/長文、ここではDoubaoが生成した人工知能に関する文章を使用しました。自分の論文の段落を使ってテストすることもできます。
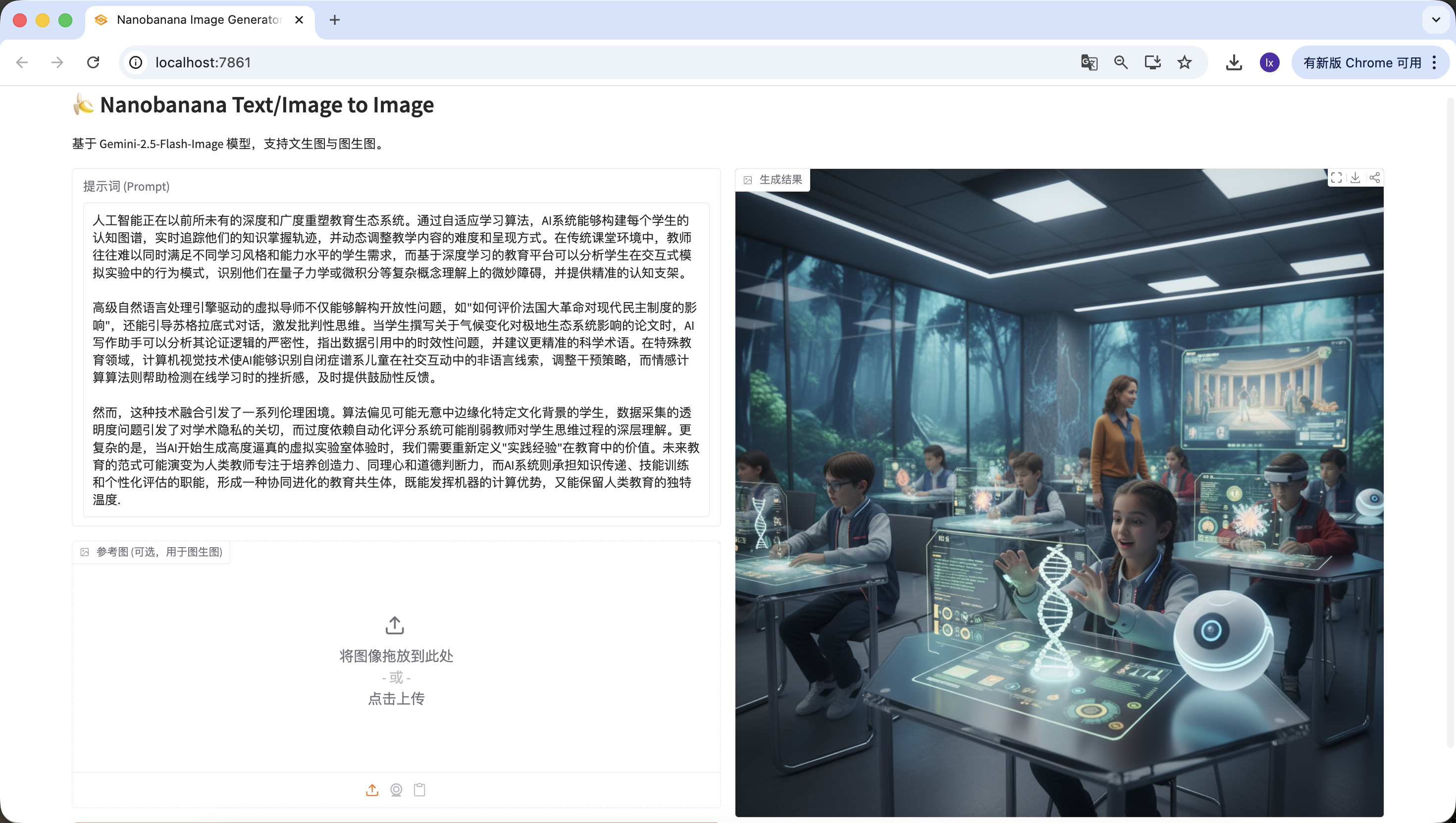
人工知能はかつてない深さと広がりで教育エコシステムを再構築しています。適応型学習アルゴリズムにより、AIシステムは各学生の認知マップを構築し、知識習得軌跡をリアルタイムで追跡し、教育内容の難易度と提示方法を動的に調整できます。従来の教室環境では、教師は異なる学習スタイルや能力レベルの学生のニーズに同時に対応することが困難ですが、ディープラーニングに基づく教育プラットフォームは、インタラクティブなシミュレーション実験における学生の行動パターンを分析し、量子力学や微積分などの複雑な概念理解における微妙な障害を特定し、的確な認知スキャフォールドを提供できます。
高度な自然言語処理エンジンによるバーチャルチューターは、「フランス革命が現代民主制度に与えた影響をどう評価するか」のようなオープンな質問を分解できるだけでなく、ソクラテス式対話を通じてクリティカルシンキングを促進します。学生が気候変動が極地生態系に与える影響に関する論文を執筆する際、AI執筆アシスタントはその論証の厳密さを分析し、データ引用のタイムリーな問題を指摘し、より正確な科学用語を提案できます。特別教育の分野では、コンピュータビジョン技術により、AIは自閉スペクトラムの児童の社会的インタラクションにおける非言語的手がかりを認識し、介入戦略を調整でき、感情コンピューティングアルゴリズムはオンライン学習時の挫折感を検出し、タイムリーに励ましのフィードバックを提供します。
しかし、このような技術統合は一連の倫理的ジレンマを引き起こしています。アルゴリズムの偏見が意図せず特定の文化的背景を持つ学生を周縁化する可能性があり、データ収集の透明性の問題は学術的プライバシーへの懸念を引き起こし、自動採点システムへの過度の依存は学生の思考プロセスに対する教師の深い理解を弱める可能性があります。さらに複雑なのは、AIが高度にリアルなバーチャル実験体験を生成し始めた時、教育における「実践的経験」の価値を再定義する必要があることです。未来の教育パラダイムは、人間の教師が創造性、共感力、道徳的判断力の育成に集中し、AIシステムが知識伝達、スキル訓練、個別化評価の機能を担う、協調進化する教育共生体へと進化する可能性があり、機械の計算優位性を発揮しつつ、人間教育の独自の温かさも保持できるでしょう。同様に認識成功~
- 直接的な描画指示、ここでは「猫を描きたい」と入力し、同様に正確に認識されました。
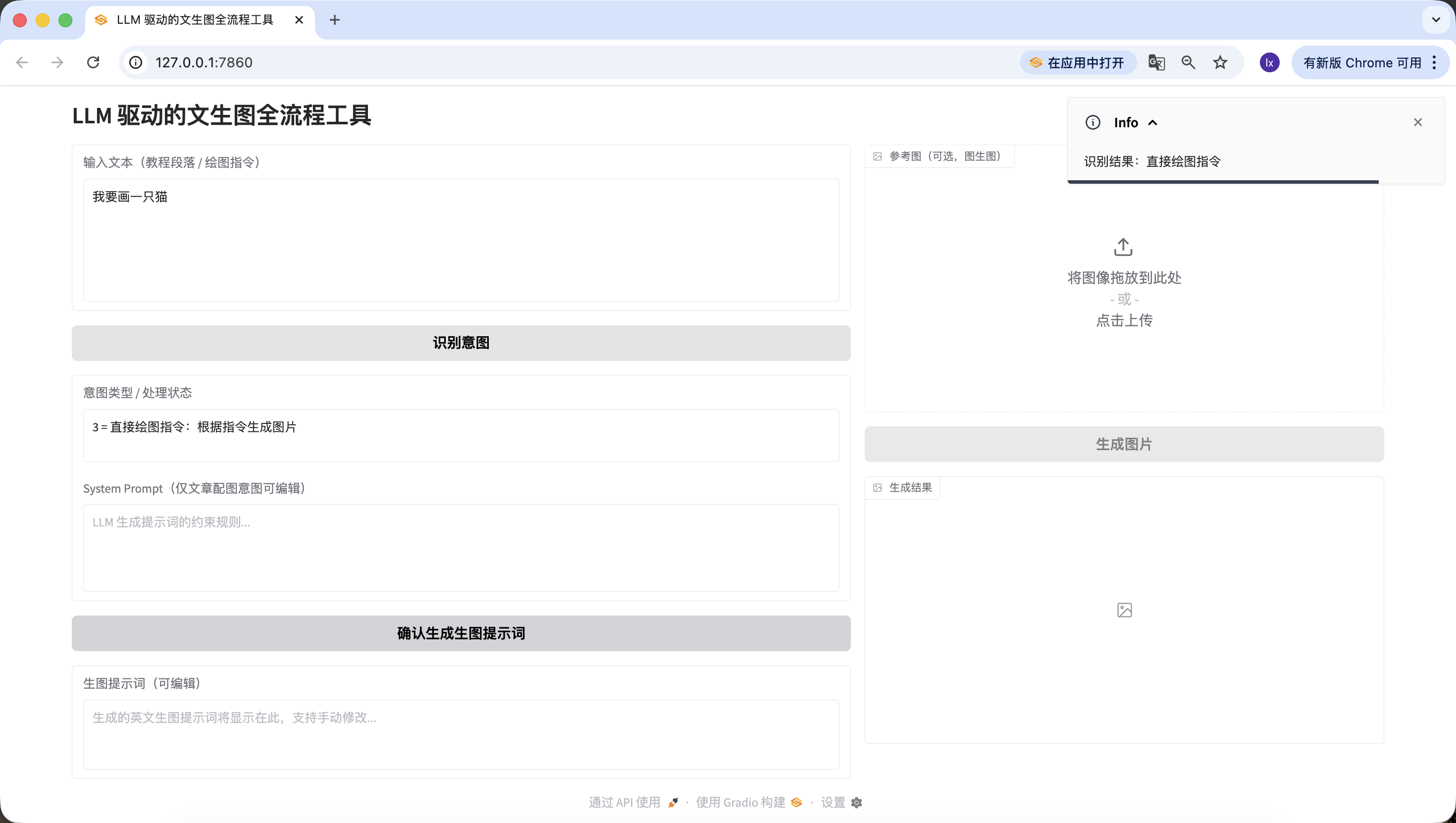
ここまでで、第2のステップ——意図認識を無事に実装できました。
ステップ3️⃣:画像生成プロンプト生成モジュール(LLM二次呼び出し)
意図認識後、記事や長文に対しては、画像生成のプロンプトを生成する重要なステップがあります。これこそが本Agentのポイントです。
セクション 3:画像生成プロンプト生成モジュール(LLM二次呼び出し)
1、タスク目標
意図認識を基に、「画像生成プロンプトを確認」ボタンのロジックを実装し、LLMを呼び出してテキストを画像生成に適した英語の視覚プロンプトに最適化し、編集ボックスに充填し「画像を生成」ボタンと連動。
2、技術スタック要件
セクション2と同様、完全コード = セクション1 + セクション2 + 本モジュールを出力;
セクション2で定義したLLM_BASE_URL、LLM_API_KEY、LLM_MODELを共有、新しいキーは追加しない。
3、核心ビジネスルール(実践版Prompt組み立てロジックを統合)
·プロンプト生成入力ルール(厳格に遵守必須)
画像生成プロンプト生成はもはや単純な文字列連結ではなく、標準Chatメッセージリストを構築する。コード構造は以下:
python
実行
messages=[# System役割:Web上でユーザーが最終確認/編集したsystem_promptの内容{"role": "system", "content": final_system_prompt},# User役割:処理対象データを保持し、タスク目標を明確化{"role": "user", "content": f"以下の内容に視覚プロンプトを生成:\n\n{user_input}"}]
意図が2の場合:System内容はユーザーが編集したsystem_promptの最終版を取得;
意図が3の場合:System内容は無効状態で充填されたデフォルトルールを取得
user_inputはユーザーがinput_textボックスに最初に入力した元のテキスト。
·実践検証済みSystem Promptプリセット(コードに固定)
python
実行
SYSTEM_PROMPT_DEFAULT = """あなたはNanoBanana描画プロンプトを作成するアシスタントです。
私の内容に基づいて処理する必要があります。この画像の役割は、この文章が何を言っているかを説明し、皆にこの文章の文脈構造全体の意味を理解させることです。
PPTのような説明が含まれる場合があります(例:左上に核心的観点、右下にデータ)。
デザインスタイル要件:シンプル、Apple Design Philosophy(Apple設計哲学)。
制約:NanoBananaで使用可能な英語プロンプトのみを直接返却し、説明、プレフィックス、余計な内容は一切返却しないでください。"""
·LLM呼び出し制約
セクション2と同じLLM_BASE_URL、LLM_API_KEY、LLM_MODELを共有;
temperature=0.7(プロンプトの創造性と適合性を保証);
max_tokens=200(出力長を制限し、プロンプト制約にマッチ);
上記標準Chatメッセージリスト構造を厳格に使用、文字列連結は禁止。
·サンプル入出力(核心参考)
入力例1(記事挿絵意図):元のテキスト:「AIがいかに教育を変えるか:AI技術の発展に伴い、教師の役割は知識伝授者からガイドへと変わり、AIアシスタントが学生の個別化学習を支援し、教室での人機協働が常態化する。」最終System Prompt:SYSTEM_PROMPT_DEFAULT(未修正)出力予想:"Minimalist illustration, Apple Design Philosophy, 1024x1024. Top left shows 'AI + Education' core concept, bottom right shows data of teacher-student-AI collaboration, soft color palette, clean lines, no redundant elements."
入力例2(直接的描画指示):元のテキスト:「Apple風の猫を描いて、MacBookの隣に座っている」最終System Prompt:SYSTEM_PROMPT_DEFAULT(無効状態)出力予想:"Minimalist cat, Apple style, 1024x1024, sitting next to a silver MacBook, clean white background, soft shadows, geometric shapes, no extra details."
·プロンプト出力強制制約
純粋な英語、中国語なし;
Apple Design Philosophy/Apple style + 1024x1024を必ず含む;
長さ50–200文字、コード内で検証;
余分な説明、プレフィックス、無駄な内容は一切なし、プロンプト自体のみ返却。
4、コンポーネント連動ルール
生成成功:プロンプトをgeneration_promptボックスに充填、generate_btnを有効化、intent_statusに「プロンプト生成成功、修正後に画像生成可能」を追加;
生成失敗:具体的な理由をプロンプト表示(例:API呼び出し失敗、長さ不適格)、generate_btnは無効状態を維持、generation_promptボックスは空;
ユーザーがgeneration_promptボックスを手動修正 / クリア:
クリア時は自動的にgenerate_btnを無効化;
空でない場合はgenerate_btnを有効状態に維持。
5、例外処理
API呼び出し失敗:フレンドリーなプロンプト「プロンプト生成失敗:{具体的なエラー情報}」、クラッシュしない;
プロンプト検証失敗:明確に原因をプロンプト表示(例:「Apple styleが含まれていない」「長さが40文字しかない」)、リトライを許可;
レスポンス解析失敗:プロンプト「LLM返却結果を解析できません、リトライしてください」。
6、出力要件
LLM_API_KEYを置き換えるだけで使用可能な完全な実行可能コード;
コード構造は明確、コメントは完備、インターフェースは美しくシンプル;
標準Chatメッセージリスト構造を厳格に実装、パラメータと例のロジックは一致;
プロンプト長、内容検証ロジックを含み、エラープロンプトはフレンドリー。同様に第2ステップのテキストをコピーして検証します。
注目すべきは、ここでプリセットした画像生成プロンプト生成用のSystem Promptは以下の通りです:
あなたはNanoBanana描画プロンプトを作成するアシスタントです。 私の内容に基づいて処理する必要があります。この画像の役割は、この文章が何を言っているかを説明し、皆にこの文章の文脈構造全体の意味を理解させることです。 PPTのような説明が含まれる場合があります(例:左上に核心的観点、右下にデータ)。 デザインスタイル要件:シンプル、Apple Design Philosophy(Apple設計哲学)。 制約:NanoBananaで使用可能な英語プロンプトのみを直接返却し、説明、プレフィックス、余計な内容は一切返却しないでください。
他のプリセットテンプレートに変更したい場合は、前のpromptで修正するか、Traeで対話を通じて修正できます。
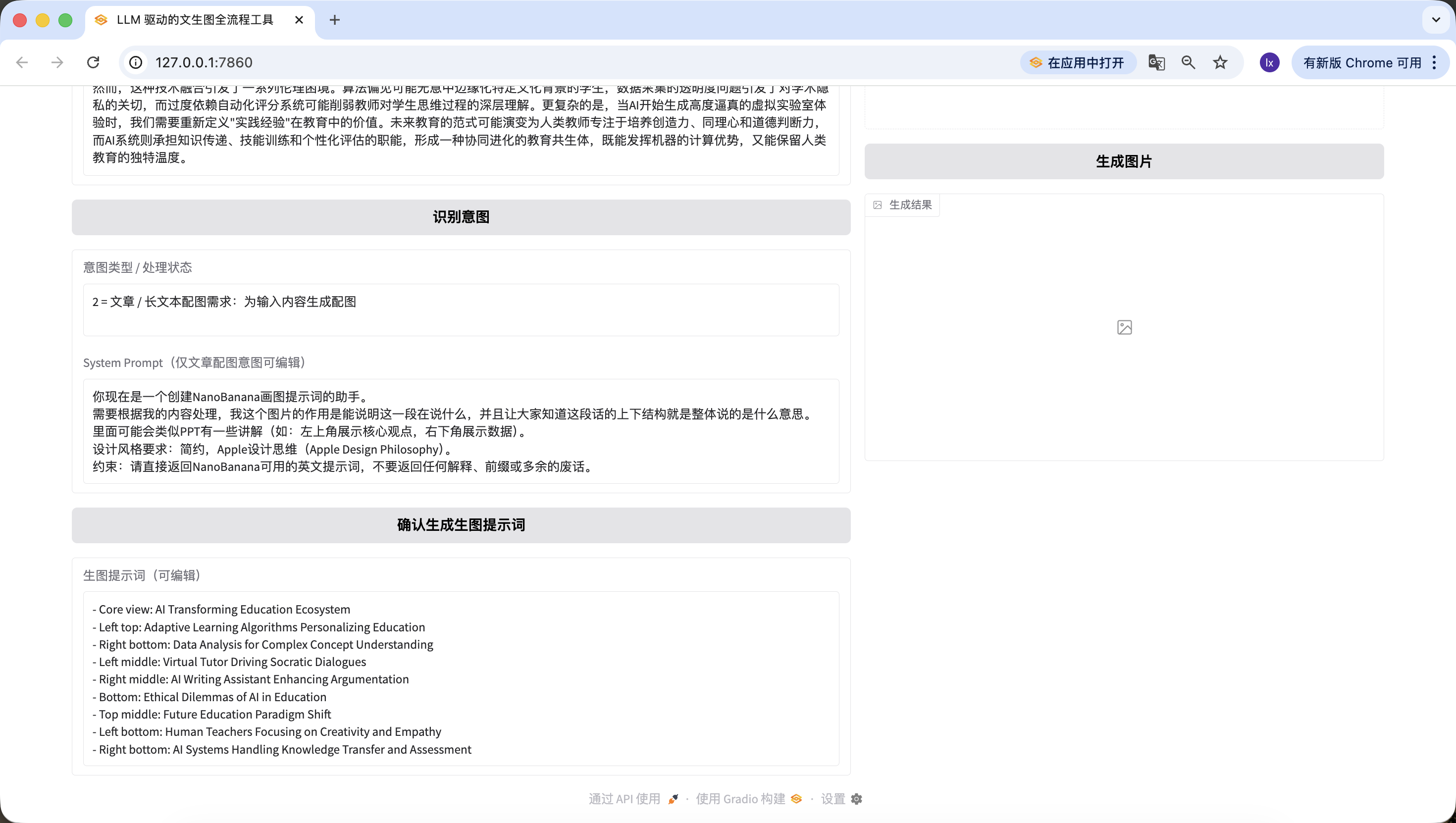
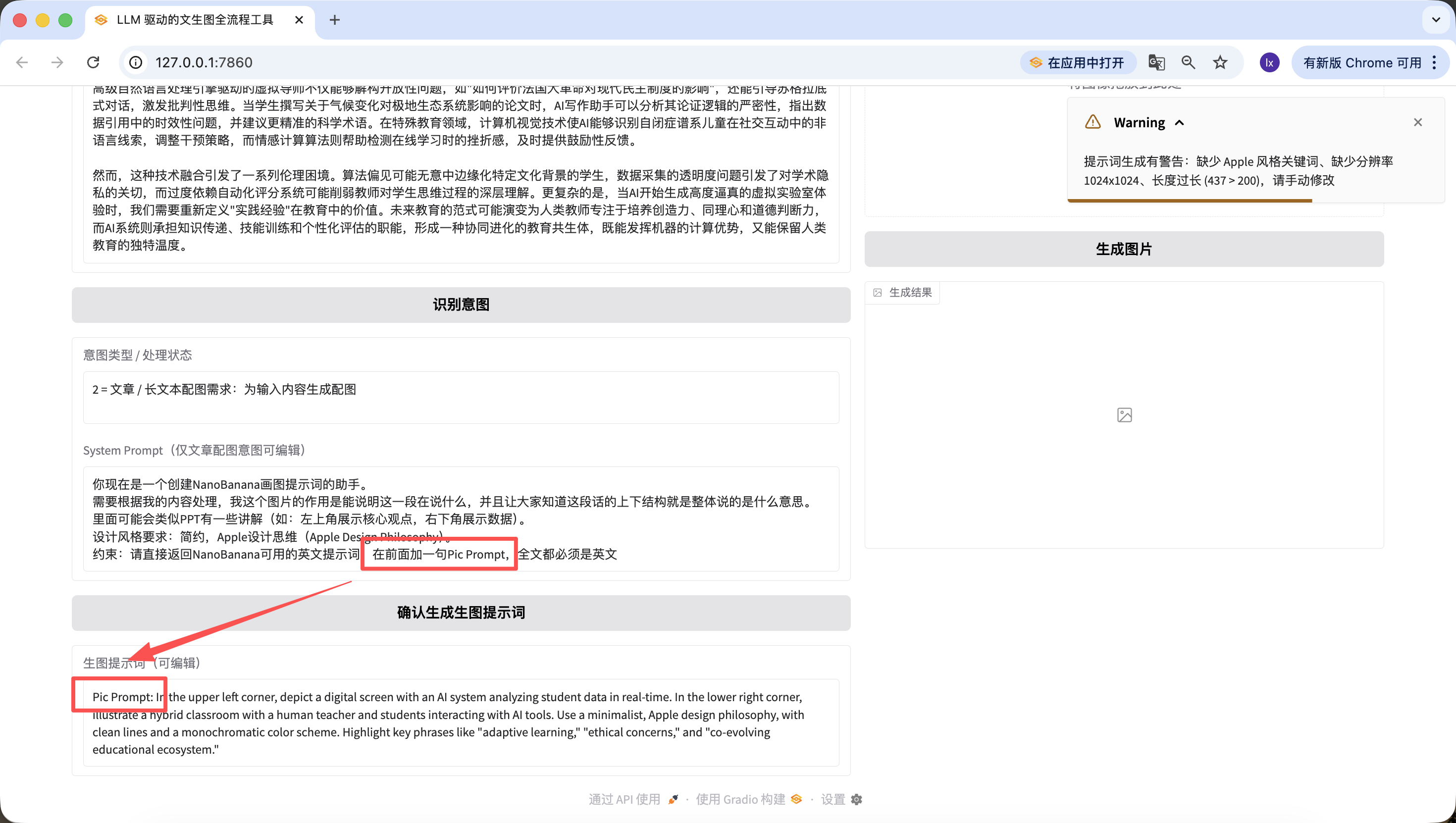
基盤コードを修正するだけでなく、Web上でも素早く編集できます。例えば、ここで「先頭にPic Promptという一文を追加」という一文を追加すると、新しく生成されたプロンプトの先頭にもそれが含まれていることがわかります~この設計は、画像生成プロンプトのSystem Promptを素早く修正し、スタイルの迅速な切り替えを支援するためのものです。
ステップ4️⃣:Nanobananaテキストから画像 / 画像から画像モジュール
ついに最後のステップです。画像生成モデルを接続しなければ、完全なAgentとは言えません!
セクション 4:Nanobananaテキストから画像 / 画像から画像モジュール(最終版)
1、タスク目標
「画像を生成」ボタンのロジックを実装し、実際のNanobanana APIを呼び出し、テキストから画像 / 画像から画像をサポートし、Base64を解析して画像を表示。
2、技術スタック要件
Gradio 4.0.0+ Blocksに基づく;
依存関係:requests, pillow, base64, io, re;
完全コード = セクション1+2+3 + 本モジュール。
3、核心API設定(実践検証済み固定)
固定コード設定:
python
実行
# コードに固定されたAPI設定
NANOBANANA_API_URL = "https://api.zyai.online/v1/chat/completions"
NANOBANANA_MODEL = "gemini-2.5-flash-image"
NANOBANANA_API_KEY = "" # ユーザーが各自入力
認証方式:Header Authorization: Bearer {NANOBANANA_API_KEY}。
4、画像前処理要件(実装必須)関数image_to_base64_data_uri (ref_image_path)を実装、核心ロジック:
PIL画像をPNG形式に変換;
1024x1024解像度に自動リサイズ;
透明チャンネルを白色背景に変換;
Base64にエンコード、返却形式:data:image/png;base64,...。
5、リクエスト構築ルール(実践版分岐ロジックに厳格に従う)
·核心関数の定義関数generate_image (prompt, ref_image_path)を実装:
引数:prompt(generation_promptボックスの内容)、ref_image_path(ref_imageにアップロードされたファイルパス);
返却:PIL Image(result_imageに表示)またはエラープロンプト。
·分岐1:純テキストから画像(ref_image_pathが空)
python
実行
messages = [{"role": "user", "content": prompt}]
·分岐2:画像から画像(ref_image_pathに値あり)
python
実行
# まず画像前処理関数を呼び出し
image_base64 = image_to_base64_data_uri(ref_image_path)
messages = [{"role": "user","content": [{"type": "text", "text": prompt},{"type": "image_url", "image_url": {"url": image_base64}}]}]
6、レスポンス解析要件(2つの形式に互換必須)choices[0].message.contentから画像Base64を抽出し、サポート:
構造化JSON返却のimage_urlフィールド;
Markdown形式
;
統一的にBase64エンコードを抽出、デコード後PIL Imageに変換して返却。
7、コンポーネント連動と例外処理
生成成功:PIL Imageをresult_imageに表示、intent_statusに「画像生成成功」をプロンプト;
生成 / 解析 / アップロード失敗:intent_statusに明確なテキストプロンプトを表示(例:「Base64解析失敗」「API呼び出しタイムアウト」)、クラッシュしない。
8、出力要件
LLM_API_KEYとNANOBANANA_API_KEYを置き換えるだけで直接実行可能な完全コード、全プロセス利用可能、分岐ロジックは実践版に厳格にマッチ。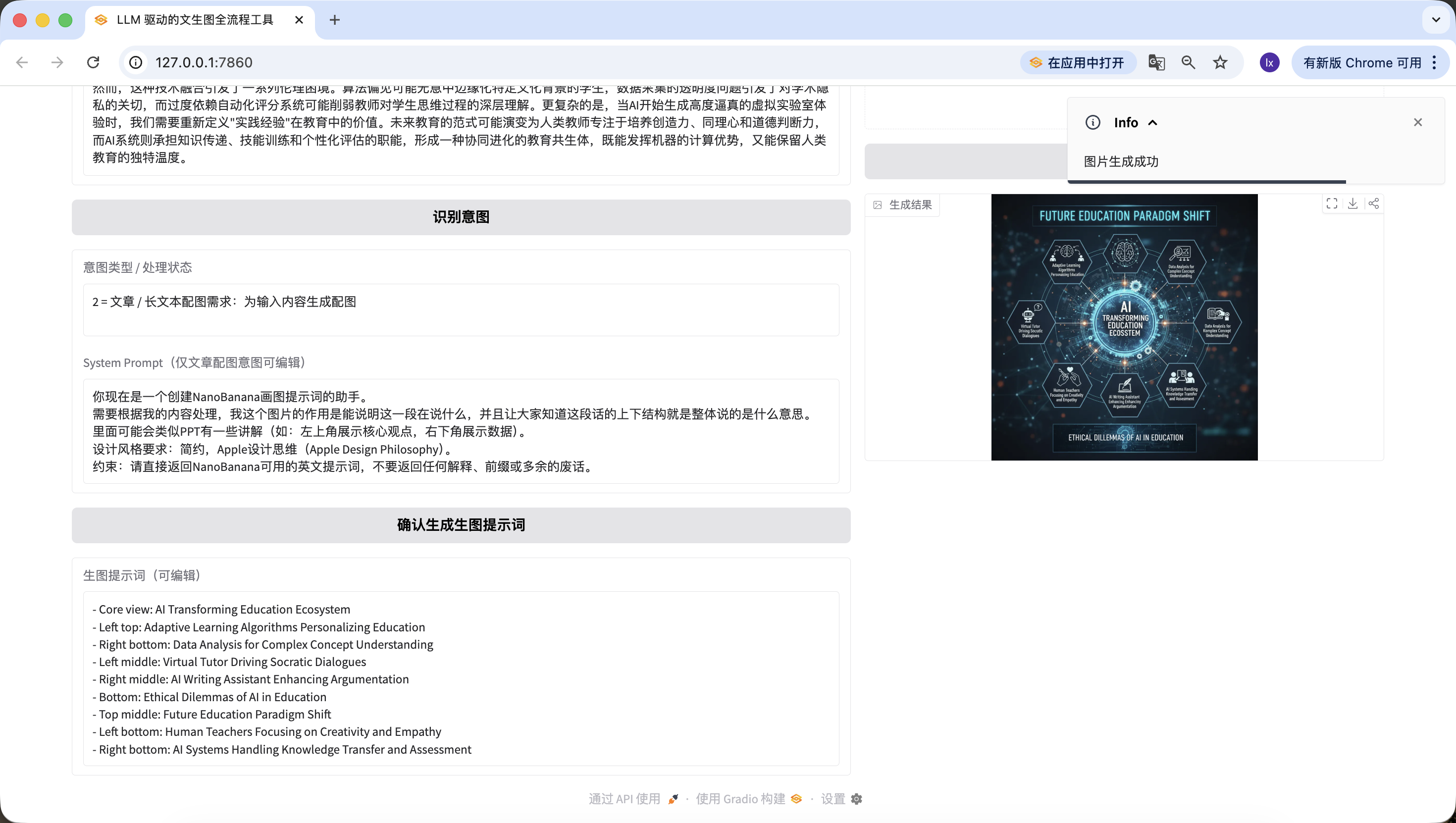
とてもエキサイティングですね!ついにこのAgentの最初の画像を正常に生成しました。生成された画像をよく見ると、テキストとプロンプトにマッチしていることがわかります。ここまでで、基本的にあなた自身のAgentが実装できました!

画像から画像機能も追加しており、お気に入りの画像をアップロードすると、AIが自動的にスタイルを参考にします。
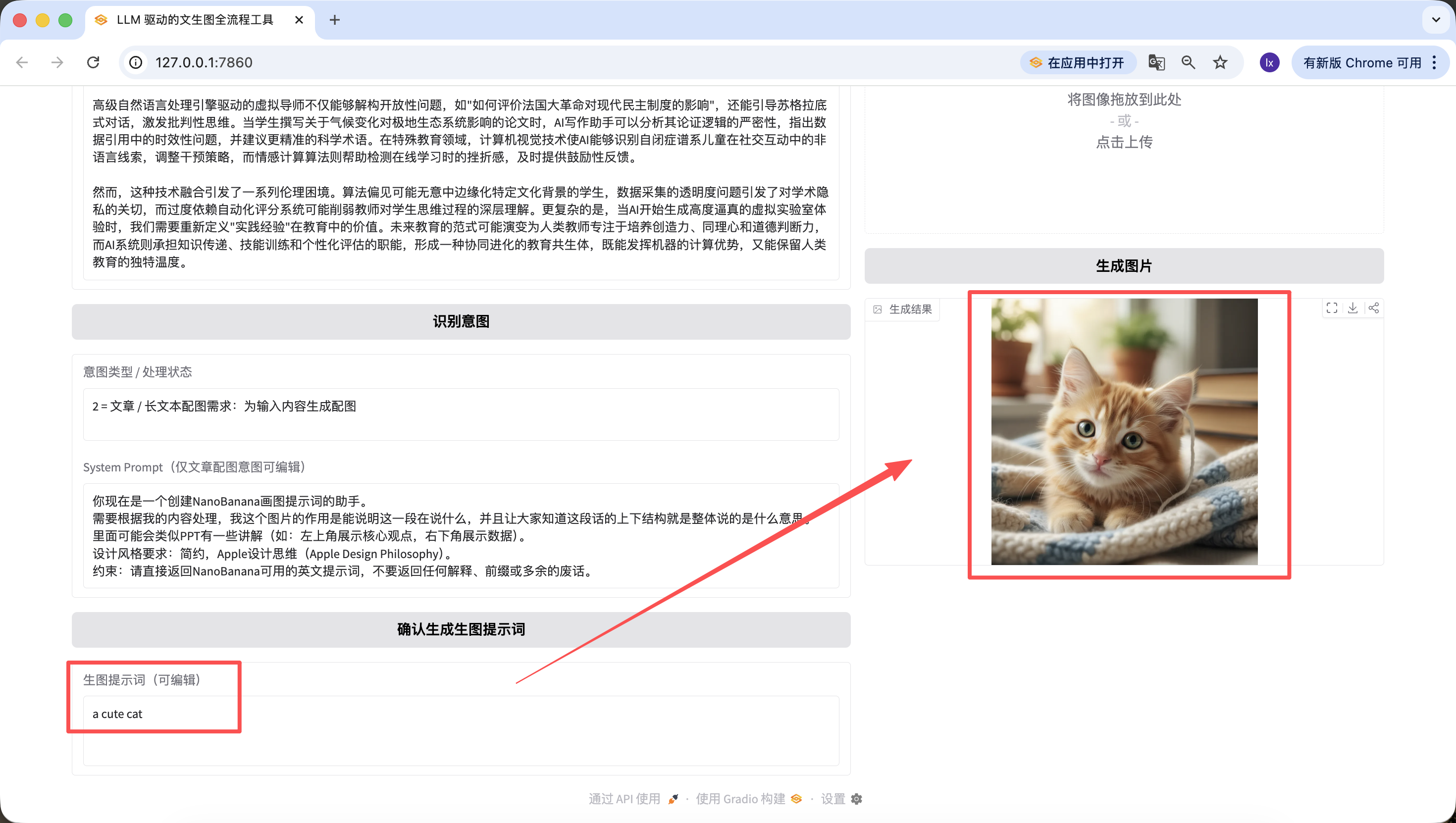
特筆すべきは、前のステップで生成されたプロンプトもWeb上で編集可能であり、最終的にボタンをクリックした時のプロンプトが基準となることです~例えばここで「a cute cat」に変更した場合、最終的に生成される画像も可愛い子猫になります。
第4章:まとめ

ついに完成しました! 正直なところ、私自身も最後の一行を書き終えた時、思わず深く息を吐きました。ましてやここまでやり遂げたあなたはなおさらです。この一連のフローを完全に実行できたこと自体が、本当に素晴らしいことです。それはあなたが本当にキーボードに手を置き、一歩ずつやり遂げたことを意味しています。Bravo 🎉 🥳 👏
この内容を書く過程で、私はずっと考え続けていました——私たちは一体何を残すべきなのか?答えは実はモデルの名前、パラメータ、あるいは特定の固定手法ではなく、あなたに徐々に一つの感覚を身につけさせることです:どのようなことを安心してAIに理解と計画を任せ、どのような部分ではあなたが方向を決めるだけでよいのか。この分担関係が成立すれば、元々複雑に見えた生成プロセスの多くが、自然とスムーズに進むようになります。
振り返ってみると、この道は実はそれほど複雑ではありません。解決したい問題を明確に考え、長文は言語モデルに分解させ、整理された視覚的意図を画像生成モデルに表現させ、最後にこの一連のフローをあなただけの小さなアシスタントとしてパッケージ化します。ここまで来ると、あなたはもはや「モデルを使っている」だけでなく、長期的にあなたの仕事をサポートするシステムを構築しています。これこそが、このチュートリアルが最も伝えたかったことです。
しかし、あなたはすでに素晴らしい成果を上げています!ここまで学んできたあなたはVibe Codingの基礎をすでに身につけています。少し休憩してリフレッシュしましょう!