انطلق من NanoBanana: ابنِ وكيلك الخاص لإنتاج الأصول
الفصل الأول: أنشئ أول أصل صورة في دقيقة واحدة
قبل أن نناقش التصميم أو الأسلوب أو هندسة الأوامر (Prompts)، لنبدأ أولاً بإنشاء صورة بأقل عدد من الخطوات الممكنة.
1.1 تعرّف على NanoBanana
قبل أن نناقش أسلوب التصميم وهندسة الأوامر، دعنا نحل أمراً أكثر أهمية أولاً: التأكد من أنك قادر فعلاً على إنشاء صورة.
النماذج الكبيرة السائدة تمتلك بالفعل قدرات إنشاء وتحرير الصور، وعادة ما تُسمى هذه النماذج النماذج التوليدية.
لتبسيط العملية قدر الإمكان، اختار هذا البرنامج التعليمي نموذجاً يمتلك بالفعل قدرات إنشاء وتحرير صور مستقرة كمثال — NanoBanana. وهو نموذج إنشاء صور أطلقته Google، واسمه الرسمي Gemini 3.1 Flash Image Preview، ويدعم إنشاء الصور مباشرة من اللغة الطبيعية، كما يدعم التعديل على الصور الموجودة.

على مستوى القدرات، لا يوجد فرق جوهري بينه وبين النماذج الأخرى التي ربما سمعت عنها (مثل GPT-4o، Claude، Qwen، Midjourney وغيرها): أدخل وصفاً، والنموذج يُنشئ النتيجة.



يمكنك فهمه على أنه "فرشاة رسم". في هذا الفصل نهتم بأمر واحد فقط: 👉 هل يمكن لهذه الفرشاة أن ترسم أول ضربة في يدك.
في الاستخدام العملي، يمكن استخدام NanoBanana مباشرة من خلال المنصات الرسمية مثل Google AI Studio، أو دمجه في سير العمل التطويري عبر API. يستخدم هذا البرنامج التعليمي طريقة استدعاء API. تم الآن إطلاق نموذج NanoBanana 2 أيضاً، يمكنك تجربة أحدث نموذج كبير.
1.2 إنشاء بمستوى "Hello World"
قبل البدء، تحتاج فقط إلى إكمال الخطوات الثلاث التالية:
- أنشئ مجلداً جديداً في Trae
- أنشئ ملف Python جديد
- انسخ الكود التالي بالكامل والصقه
سيُكمل Trae تلقائياً نشر البيئة المطلوبة وتثبيت التبعيات، دون الحاجة إلى إعدادات إضافية.
سيحتاج الكود إلى NanoBanana API Key. لن نتوسع هنا في عملية التقديم — يكفي أن تحصل على المعلمات المناسبة وتُدخلها. في هذه المرحلة لا نسعى لفهم كل سطر من الكود، المهم أن يعمل بنجاح.
# /// script
# dependencies = [
# "gradio>=4.0.0",
# "pillow>=10.0.0",
# "requests>=2.31.0",
# ]
# ///
import gradio as gr
import requests
import base64
from PIL import Image
import io
import os
import time
import re
from typing import Optional, Dict, Any, List
# تكوين معلومات API
NANOBANANA_API_URL: str = "YOUR API URL"
NANOBANANA_API_KEY: str = "YOUR API KEY"
OUTPUT_DIR: str = "outputs"
# التأكد من وجود مجلد الإخراج
os.makedirs(OUTPUT_DIR, exist_ok=True)
def image_to_base64_data_uri(image: Image.Image) -> str:
"""
تحويل صورة PIL إلى تنسيق data URI متوافق مع OpenAI API.
"""
buffer = io.BytesIO()
# التحويل الموحد إلى PNG لضمان التوافق
image.save(buffer, format="PNG")
encoded = base64.b64encode(buffer.getvalue()).decode('utf-8')
return f"data:image/png;base64,{encoded}"
def base64_to_image(base64_str: str) -> Optional[Image.Image]:
"""
تحويل سلسلة base64 نقية إلى صورة PIL.
"""
try:
image_bytes = base64.b64decode(base64_str)
return Image.open(io.BytesIO(image_bytes))
except Exception as e:
print(f"فشل فك تشفير Base64: {e}")
return None
def extract_base64_from_response(content: Any) -> Optional[str]:
"""
منطق التحليل الأساسي: استخراج بيانات Base64 للصورة من المحتوى المُعاد بواسطة API.
متوافق مع تنسيق Markdown وتنسيق القائمة المهيكلة.
"""
if not content:
return None
base64_data = None
# 1. محاولة الاستخراج المهيكل (List)
# تنسيق الإرجاع المقابل: [{"type": "image_url", "image_url": {"url": "data:..."}}]
if isinstance(content, list):
for part in reversed(content): # البحث بترتيب عكسي، عادةً تكون أحدث صورة في النهاية
if isinstance(part, dict):
# التحقق من حقل image_url أو output_image
img_field = part.get("image_url") or part.get("image") or part.get("output_image")
if isinstance(img_field, dict):
url = img_field.get("url", "")
if url.startswith("data:image/") and "," in url:
return url.split(",", 1)[1].strip()
# إذا لم تكن هناك صورة مهيكلة في القائمة، حاول تجميع النصوص للبحث عن Markdown
text_parts = [
str(p.get("text", ""))
for p in content
if isinstance(p, dict) and p.get("type") in ["text", "input_text"]
]
content_str = "".join(text_parts)
else:
content_str = str(content)
# 2. محاولة الاستخراج بتعبير Markdown regex (String)
# تنسيق الإرجاع المقابل: "Here is your image: "
pattern = re.compile(r"!\[.*?\]\((data:image/[^;]+;base64,[^)]+)\)", re.IGNORECASE)
match = pattern.search(content_str)
if match:
data_url = match.group(1)
if "," in data_url:
return data_url.split(",", 1)[1].strip()
return None
def synthesize(prompt: str, input_image: Optional[Image.Image]) -> Optional[Image.Image]:
"""
استدعاء API Nanobanana للإنشاء.
"""
if not prompt or not prompt.strip():
gr.Warning("يرجى إدخال أمر (Prompt)")
return None
print(f">>> بدء المهمة: {prompt[:50]}...")
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {NANOBANANA_API_KEY}"
}
# بناء payload يتوافق مع معيار OpenAI Vision / Chat
messages = []
if input_image is not None:
# وضع الإدخال متعدد الوسائط / صورة إلى صورة
print(">>> تم اكتشاف صورة إدخال، استخدام الوضع متعدد الوسائط")
img_base64 = image_to_base64_data_uri(input_image)
messages.append({
"role": "user",
"content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": img_base64}}
]
})
else:
# وضع نص إلى صورة فقط
messages.append({
"role": "user",
"content": prompt
})
payload = {
"messages": messages,
# استخدام النموذج المُتحقق من توفره في الكود الأول
"model": "gemini-2.5-flash-image",
# معلمات اختيارية، حسب دعم API
"stream": False
}
try:
# زيادة وقت الانتظار، إنشاء الصور عادةً أبطأ
response = requests.post(NANOBANANA_API_URL, headers=headers, json=payload, timeout=120)
# التحقق من حالة HTTP
if response.status_code != 200:
error_msg = f"فشل طلب API: {response.status_code} - {response.text}"
print(error_msg)
gr.Error(error_msg)
return None
result = response.json()
# تصحيح: طباعة جزء من الاستجابة الأصلية، مفيد للتصحيح
print(f"استجابة API الأصلية (مقتطعة): {str(result)[:200]}...")
# استخراج المحتوى
content = None
if "choices" in result and len(result["choices"]) > 0:
content = result["choices"][0].get("message", {}).get("content")
if not content:
gr.Warning("استجابة API لا تحتوي على حقل content")
return None
# استخدام المنطق المُتحقق منه سابقاً لاستخراج Base64
base64_str = extract_base64_from_response(content)
if base64_str:
output_image = base64_to_image(base64_str)
if output_image:
return output_image
# إذا لم يتم استخراج صورة، ربما رفض النموذج أو أعاد نصاً فقط
text_content = str(content) if not isinstance(content, list) else " ".join([str(x) for x in content])
gr.Info(f"لم يتم إنشاء صورة، أعاد النموذج نصاً: {text_content[:100]}...")
return None
except requests.exceptions.Timeout:
gr.Error("انتهت مهلة الطلب، يرجى المحاولة لاحقاً")
return None
except Exception as e:
import traceback
traceback.print_exc()
gr.Error(f"حدث خطأ غير معروف: {str(e)}")
return None
# تكوين واجهة Gradio
with gr.Blocks(title="Nanobanana Image Generator") as app:
gr.Markdown("# 🍌 Nanobanana Text/Image to Image")
gr.Markdown("يعتمد على نموذج Gemini-2.5-Flash-Image، يدعم النص إلى صورة والصورة إلى صورة.")
with gr.Row():
with gr.Column():
prompt_input = gr.Textbox(
label="الأمر (Prompt)",
placeholder="مثال: A cyberpunk cat holding a neon sign...",
lines=3
)
image_input = gr.Image(
label="صورة مرجعية (اختيارية، للصورة إلى صورة)",
type="pil",
height=300
)
submit_btn = gr.Button("بدء الإنشاء", variant="primary")
with gr.Column():
image_output = gr.Image(label="النتيجة المُنشأة", format="png")
submit_btn.click(
fn=synthesize,
inputs=[prompt_input, image_input],
outputs=image_output
)
if __name__ == "__main__":
app.launch(share=True)عندما يُشير Trae إلى نجاح التشغيل، انقر على الرابط المحلي الذي يوفره (عادةً http://127.0.0.1:7860).
إذا كان كل شيء طبيعياً، سترى واجهة إنشاء صور بالذكاء الاصطناعي تعمل بالفعل.
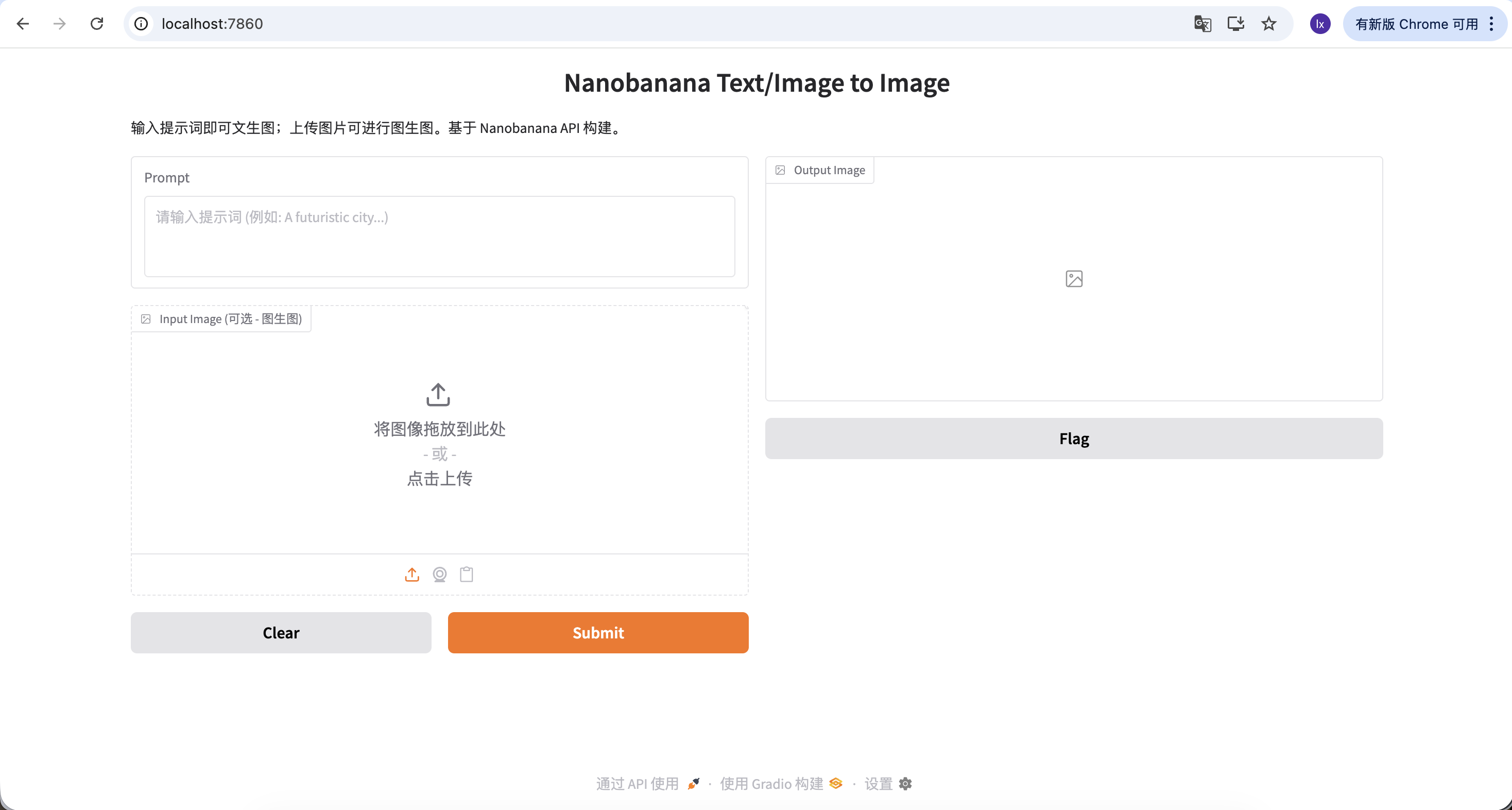
تبدو هذه الواجهة بسيطة، لكنها تمتلك بالفعل القدرتين الأكثر أهمية في أدوات إنشاء الصور التجارية: النص إلى صورة والصورة إلى صورة.
- اليسار: منطقة الأوامر (Input Zone) — هنا تصدر التعليمات.
- Prompt (حقل الأمر): أدخل وصفك الإبداعي (يُنصح باستخدام الإنجليزية).
- Input Image (حقل الصورة المرجعية):
- وضع النص إلى صورة: أبقِ هذا فارغاً.
- وضع الصورة إلى صورة: اسحب صورة محلية إلى هنا، وستقوم الذكاء الاصطناعي بالإبداع بناءً عليها.
- زر Submit: انقر لإرسال التعليمات وبدء الإنشاء.
- اليمين: منطقة عرض النتائج (Output Zone) — حيث تحدث المعجزة، ستُعرض النتائج المُنشأة هنا.
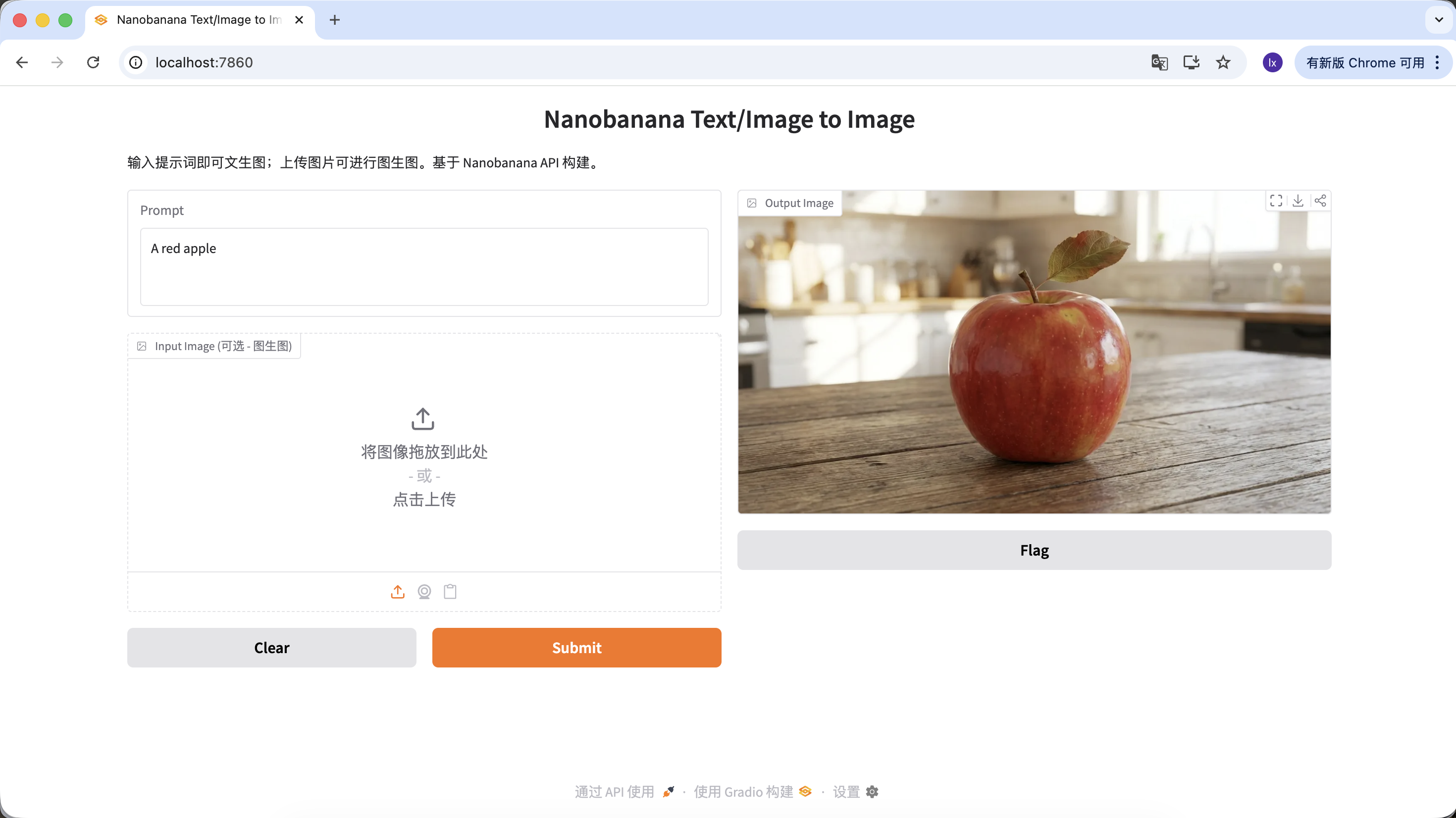
الآن يمكننا تجربة إنشاء صورتك الأولى!
الأمر (Prompt) المستخدم في هذا المثال هو:
A red apple
هذا مثال مُبسط عمداً، لا يتضمن أي وصف للأسلوب أو المعلمات.
العملية الفعلية
بعد تشغيل الكود، يمكن تلخيص العملية في ثلاث خطوات:
- إرسال الوصف النصي إلى النموذج
- يقوم النموذج بإنشاء الصورة المقابلة
- تُحفظ الصورة كملف محلي
بعد بضع ثوانٍ، سترى نتيجة الإنشاء محلياً. إنشاء النموذج عشوائي، لذا فإن نفس الأمر (Prompt) سينتج نتائج مختلفة. يمكنك الإنشاء عدة مرات واختيار الصورة التي تعجبك.
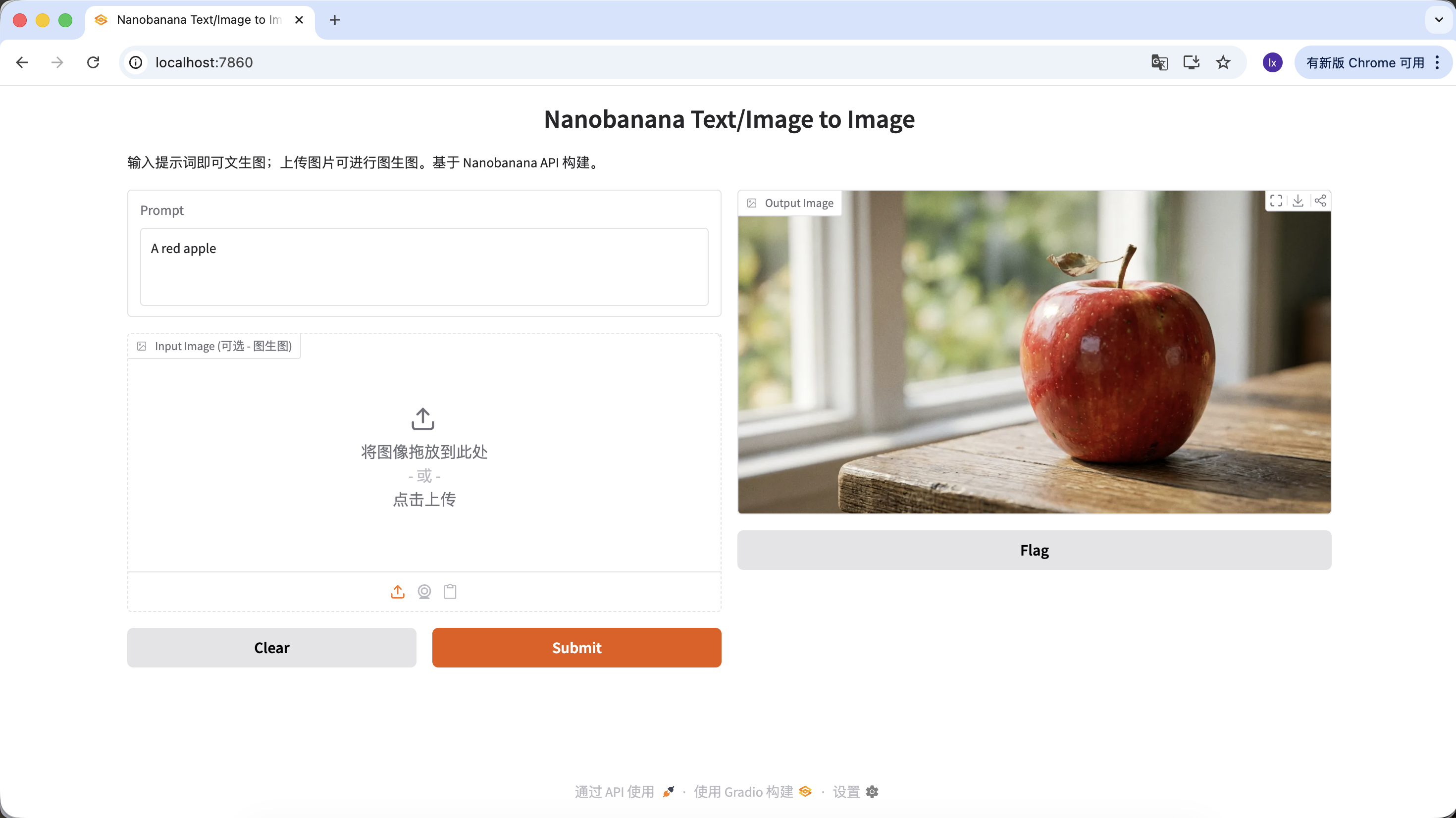
يمكنك أيضاً إثراء أمرك (Prompt) وإضافة المزيد من الوصف والقيود. على سبيل المثال، مع الأمر التالي ستحصل على صورة أكثر تميزاً.
"A hyper-realistic close-up of a fresh red apple with water droplets on its skin, sitting on a dark rustic wooden table. Cinematic dramatic lighting, rim light, shallow depth of field, bokeh background, 8k resolution, macro photography."
(لقطة مقربة فائقة الواقعية لتفاحة حمراء طازجة مع قطرات ماء على قشرتها، موضوعة على طاولة خشبية داكنة خشنة. إضاءة سينمائية درامية، إضاءة حافة، عمق ميدان ضحل، خلفية ضبابية، دقة 8k، تصوير ماكرو.)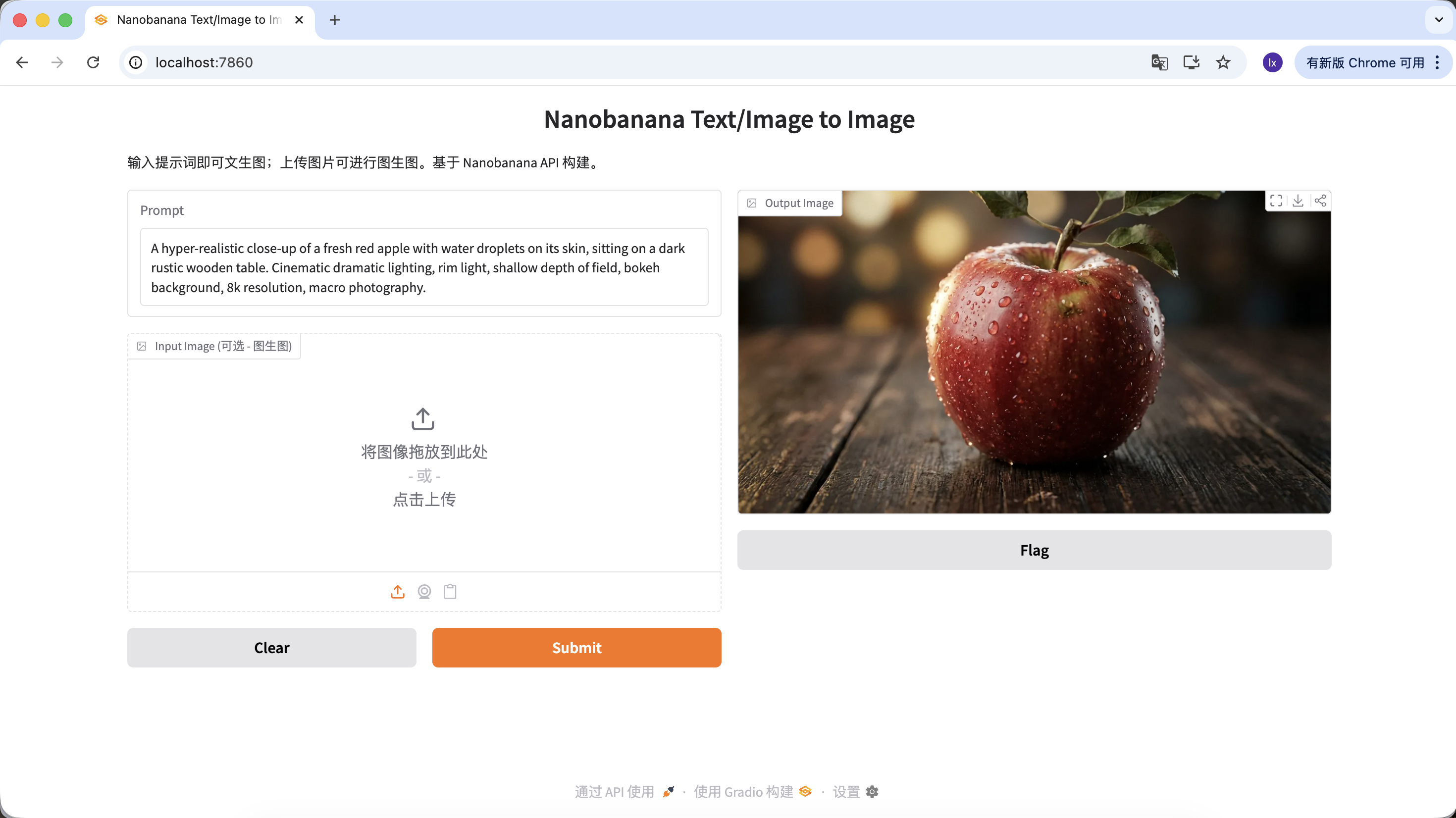
انقر على التنزيل في منطقة Output Image للحفظ محلياً.
1.3 سيناريوهات إنشاء الأصول الشائعة مع نماذج إنشاء الصور
في العمل العملي، يُستخدم إنشاء الصور بالنماذج الكبيرة أكثر لإنتاج أصول التصميم بكفاءة بدلاً من إنشاء أعمال فنية فردية.
عند مراقبة الحالات الشائعة في حسابات التسويق المتعلقة بالتصميم، ستجد أن منتجاتها تتركز أساساً في نوعين من السيناريوهات:
- النص إلى صورة (من 0 إلى 1)
- إنشاء بصورة مرجعية (من 1 إلى N)
أولاً: النص إلى صورة — الحصول السريع على أصول التصميم
يركز هذا النوع من السيناريوهات على الكفاءة. عندما تحتاج إلى ملء الفراغات في التصميم (مثل الحالات الفارغة، الصور الشخصية، الرسوم التوضيحية)، تعمل الذكاء الاصطناعي بشكل أساسي كمكتبة صور تُنشأ فوراً.
إنشاء أصول تصميم واجهة المستخدم
- الاتجاه السائد: أيقونات ثلاثية الأبعاد بتأثير الزجاج المطفأ أو الأسلوب الطيني الشائعة على Dribbble
- المظاهر الشائعة: مواد شفافة، حواف متوهجة، أيقونات وظيفية أو مناخية بألوان الحلوى
أمر (Prompt) مثال:
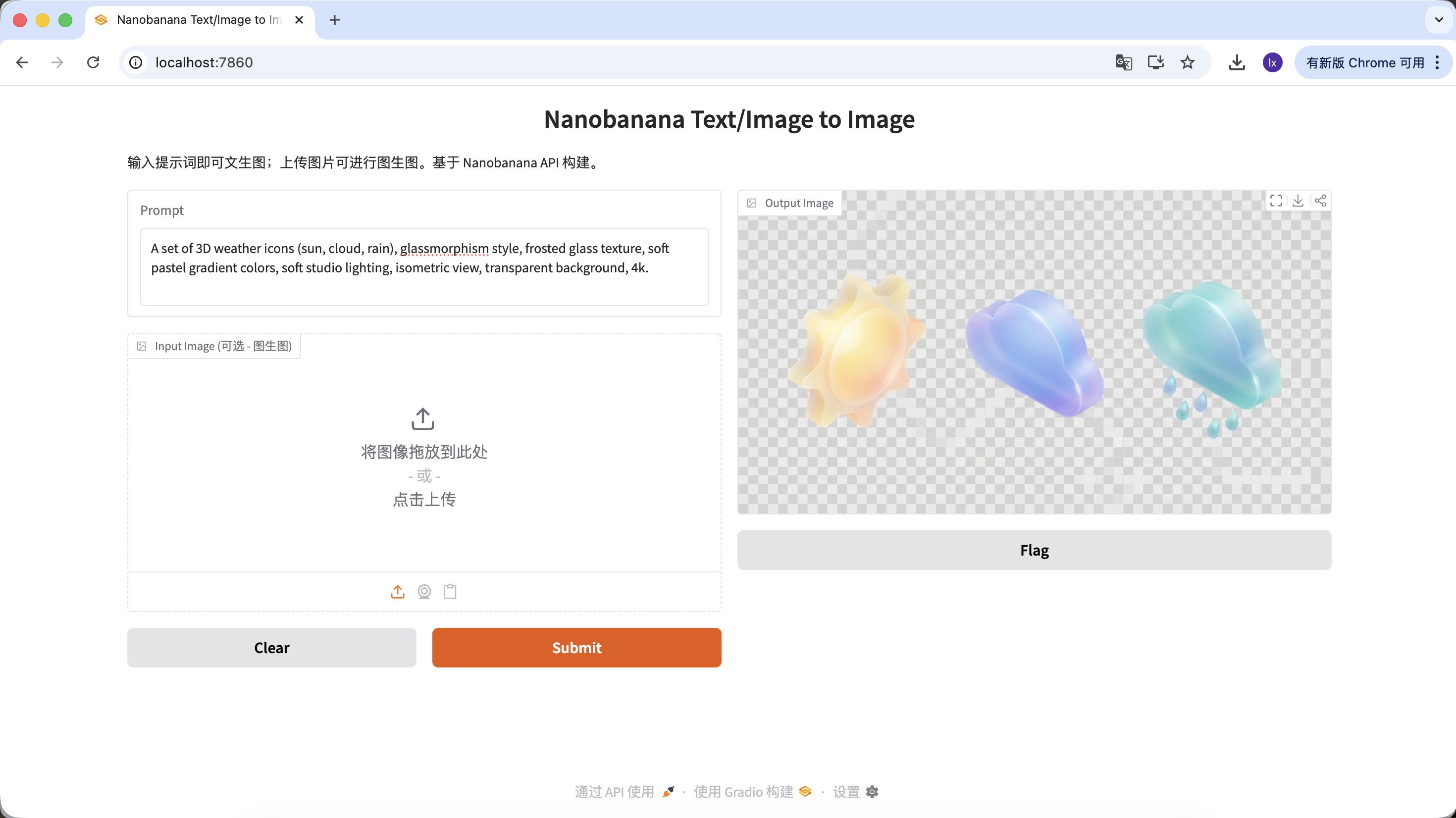
A set of 3D weather icons (sun, cloud, rain), glassmorphism style, frosted glass texture, soft pastel gradient colors, soft studio lighting, isometric view, transparent background, 4k.
(مجموعة أيقونات طقس ثلاثية الأبعاد، أسلوب glassmorphism، ملمس زجاج مطفأ، ألوان تدرج باستيل ناعمة، إضاءة استوديو، عرض isometric)
إنشاء شعارات (Logos)
- الاتجاه السائد: شعارات تقنية بخطوط بسيطة وتركيبات هندسية
- المظاهر الشائعة: ألوان أبيض وأسود، تصميم المساحة السلبية، إحساس واضح بالعلامة التجارية
أمر (Prompt) مثال:
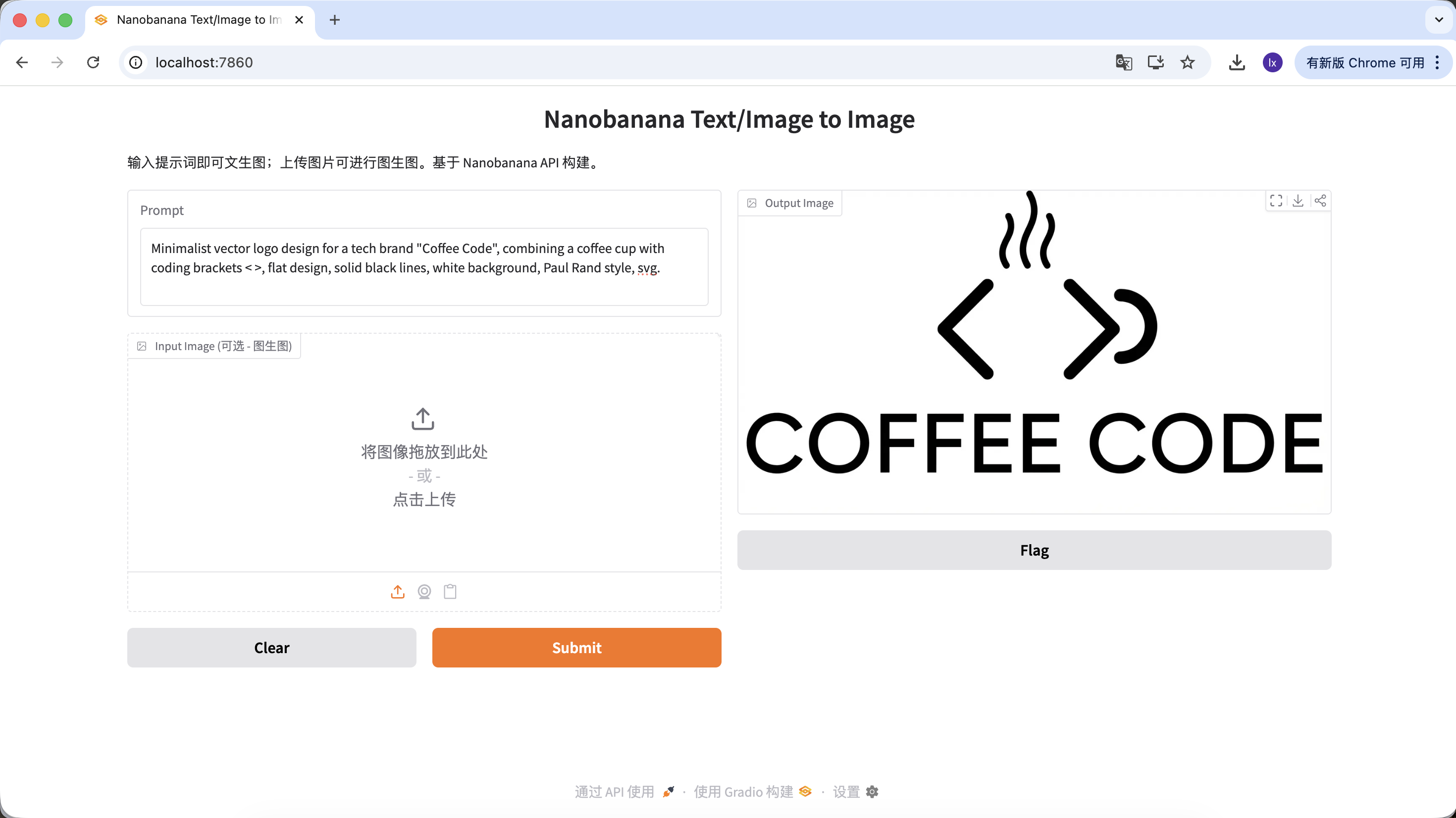
Minimalist vector logo design for a tech brand "Coffee Code", combining a coffee cup with coding brackets < >, flat design, solid black lines, white background, Paul Rand style, svg.
(شعار متجه بسيط، يجمع بين كوب قهوة وأقواس البرمجة، تصميم مسطح، خطوط سوداء صلبة)
إنشاء صور المستخدمين للمواقع الرسمية
- الاتجاه السائد: صور رمزية ثلاثية الأبعاد افتراضية شائعة في مواقع SaaS الرسمية، لتجنب حقوق صور الأشخاص الحقيقيين
- المظاهر الشائعة: تعبيرات ودية، نسب كرتونية، أسلوب Pixar أو Memoji
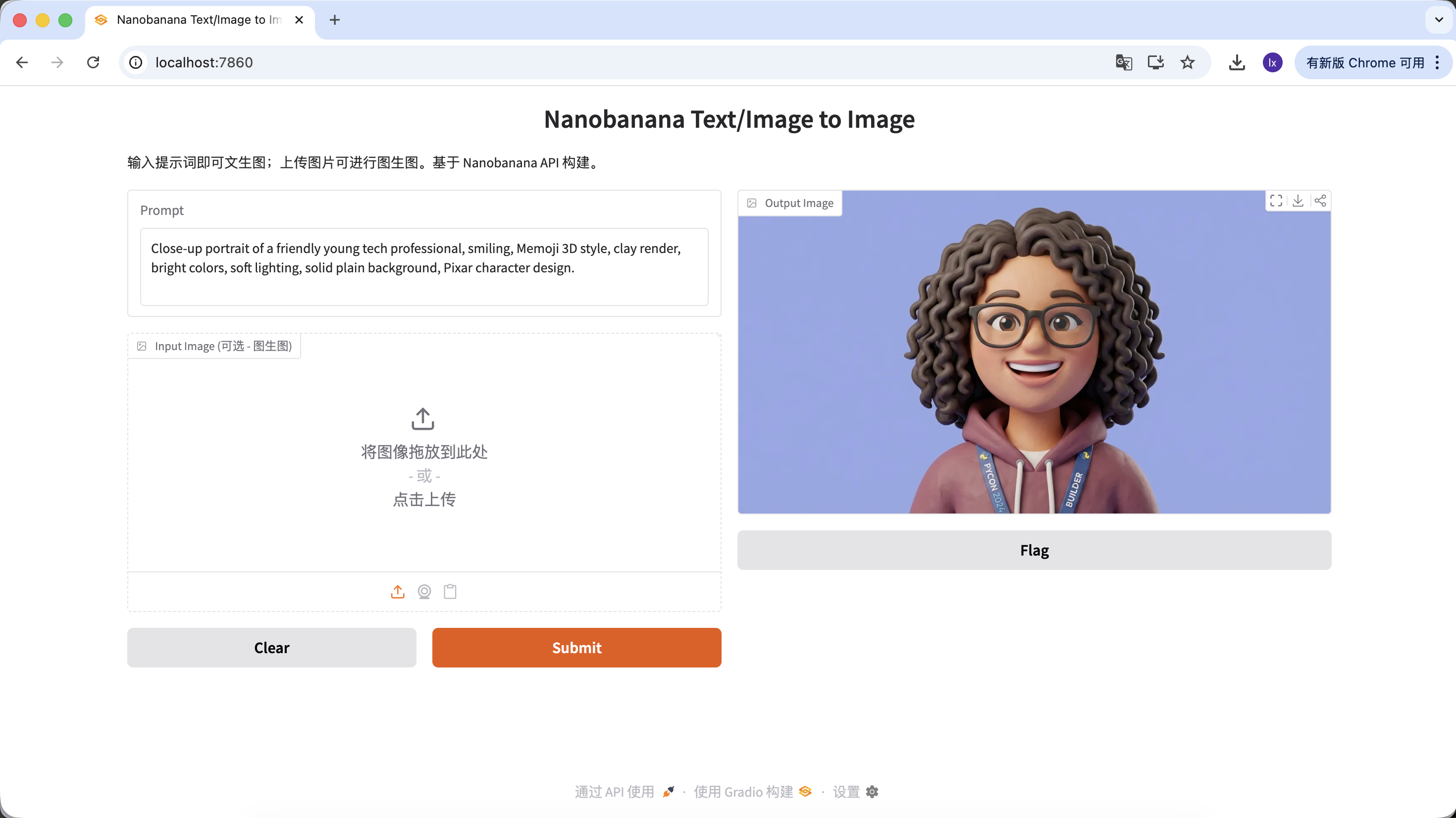
أمر (Prompt) مثال:
Close-up portrait of a friendly young tech professional, smiling, Memoji 3D style, clay render, bright colors, soft lighting, solid plain background, Pixar character design.
(محترف تقني شاب ودود، أسلوب Memoji ثلاثي الأبعاد، عرض clay)
إنشاء رسوم توضيحية للمقالات
- الاتجاه السائد: رسوم توضيحية مسطحة مجردة شائعة في مدونات شركات التقنية
- المظاهر الشائعة: ألوان بنفسجية-زرقاء، نسب بشرية مبالغ فيها، عناصر UI عائمة
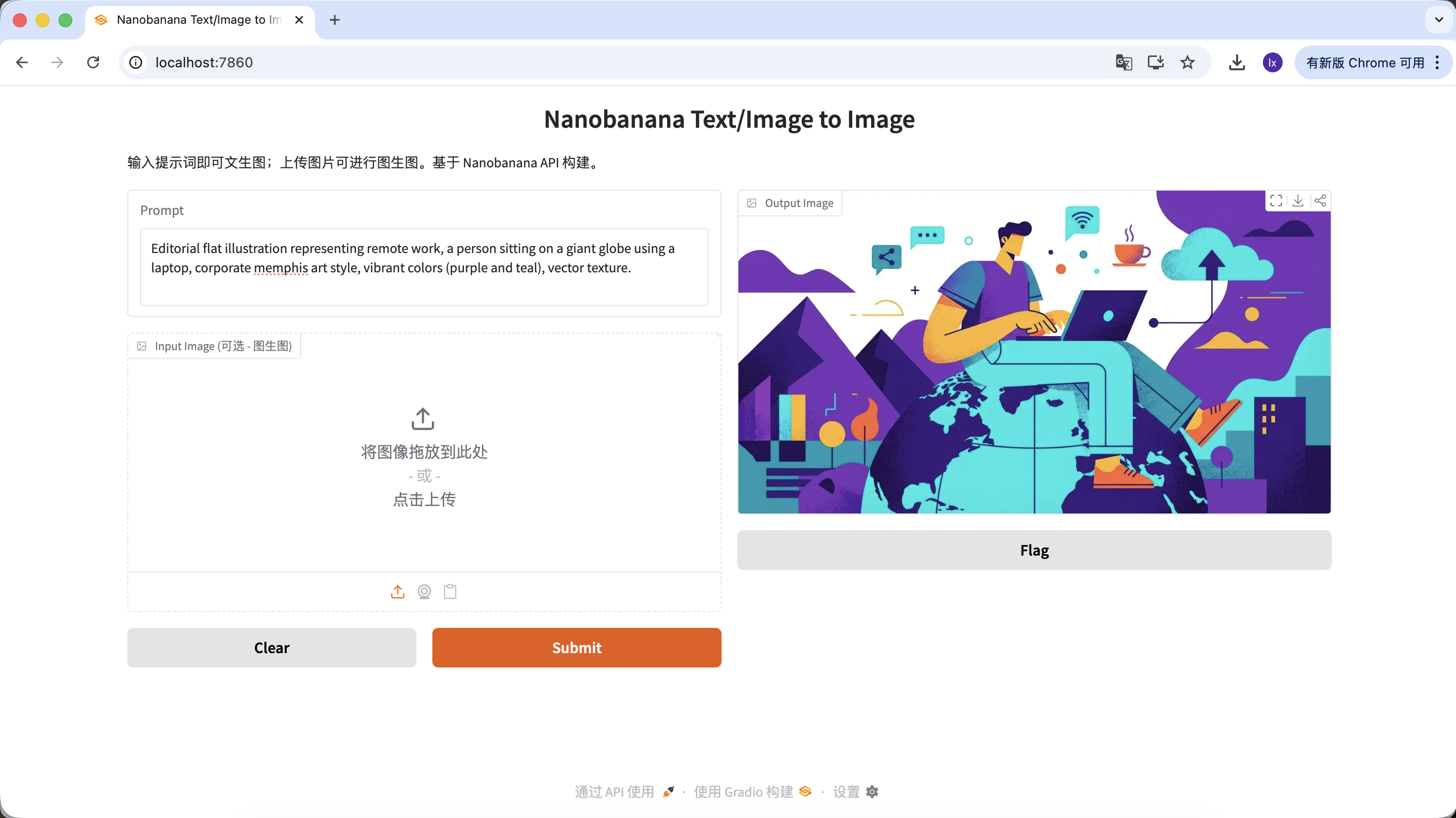
أمر (Prompt) مثال:
Editorial flat illustration representing remote work, a person sitting on a giant globe using a laptop, corporate memphis art style, vibrant colors (purple and teal), vector texture.
(رسم توضيحي مسطح لموضوع العمل عن بُعد، أسلوب memphis المؤسسي)
ثانياً: إنشاء بصورة مرجعية — الحفاظ على التناسق البصري
يركز هذا النوع من السيناريوهات أكثر على قابلية التوسع. يُستخدم عندما يكون لديك بالفعل صورة رئيسية مرضية وتحتاج إلى إنشاء مجموعة كاملة من الأصول بأسلوب متناسق.
مجموعة أزرار أو أصول تفاعلية مشابهة للصورة الرئيسية
في تطوير الألعاب، التناسق في واجهة المستخدم أمر بالغ الأهمية. لنفترض أن لديك بالفعل زر "PLAY" في الشاشة الرئيسية وتحتاج الآن إلى توسيع مجموعة كاملة من أزرار الوظائف بأسلوب موحد (مثل إيقاف مؤقت، إعدادات، رئيسي). من الصعب جداً ضمان تطابق كل زر تماماً في اللمعان والمنظور وقيم الألوان من خلال الرسم اليدوي فقط.
سير العمل الأساسي:
- احفظ صورة زر "PLAY" الأزرق الموجود

- اسحبه إلى منطقة Input Image في الواجهة، كقالب مرجعي للأجيال اللاحقة
- أبقِ وصف الأسلوب في الأمر (Prompt) بدون تغيير، وعدّل المحتوى الرئيسي فقط
في هذا التدفق، مع استبدال الوصف الرئيسي فقط، يمكنك الحصول على أزرار بوظائف مختلفة ولكن بأسلوب متناسق.
أوامر (Prompts) مثال:
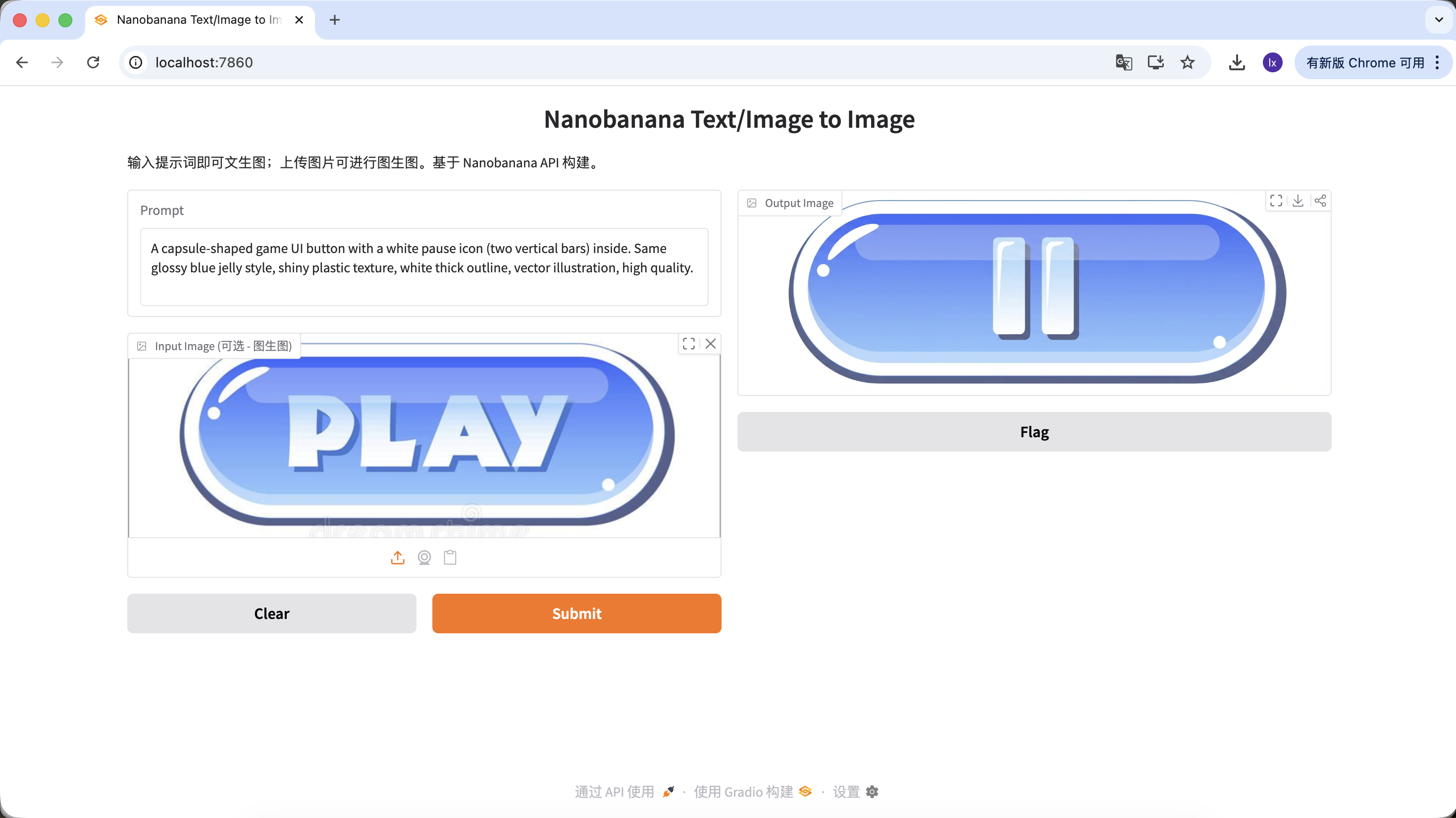
المتغير A: زر الإيقاف المؤقت (نوع أيقونة)
A capsule-shaped game UI button with a white pause icon (two vertical bars) inside. Same glossy blue jelly style, shiny plastic texture, white thick outline, vector illustration, high quality.
(زر واجهة مستخدم لعبة بشكل كبسولة، أيقونة إيقاف مؤقت بيضاء، ملمس jelly أزرق)
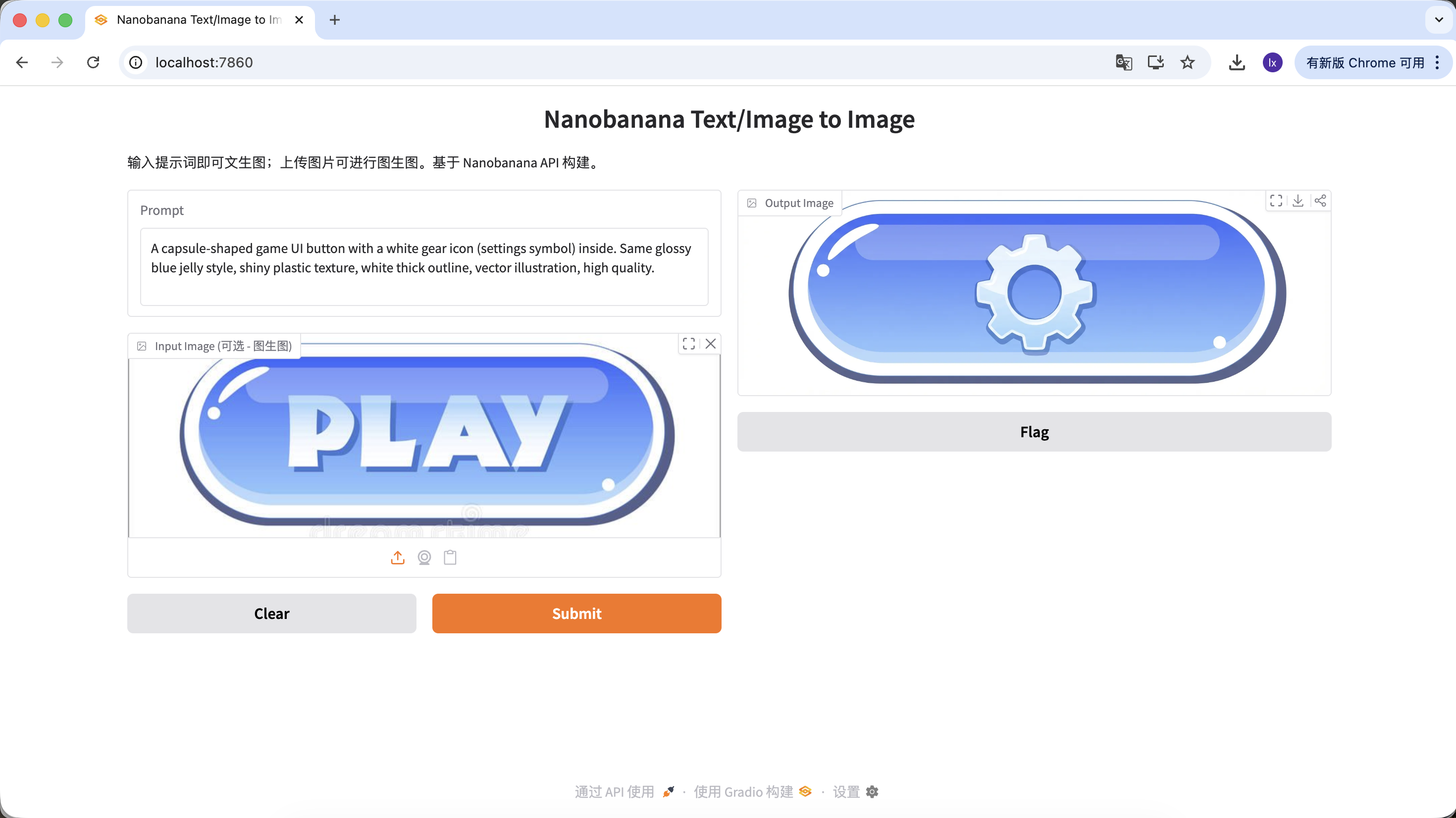
المتغير B: زر الإعدادات (أيقونة معقدة)
A capsule-shaped game UI button with a white gear icon (settings symbol) inside. Same glossy blue jelly style, shiny plastic texture, white thick outline, vector illustration, high quality.
(زر واجهة مستخدم لعبة بشكل كبسولة، أيقونة ترس بيضاء، ملمس jelly أزرق)
المتغير C: زر إعادة اللعب (تغيير الشكل)
إذا كنت بحاجة إلى تعديل الشكل الخارجي للزر، يمكنك وصف الشكل مباشرة في الأمر (Prompt). سيحاول النموذج تغيير الهيكل مع الحفاظ على خصائص المادة.
A round game UI button with a white circular arrow icon (replay symbol) inside. Same glossy blue jelly style, shiny plastic texture, white thick outline, vector illustration, high quality.
(زر واجهة مستخدم لعبة دائري، أيقونة سهم دائري، ملمس jelly أزرق)

من خلال هذه المجموعة من العمليات، لا يمكنك فقط استبدال وظائف وأيقونات الأزرار، بل حتى تغيير شكل الزر. ومع ذلك، تظل جميع النتائج المُنشأة متناسقة للغاية في المادة والألوان والإضاءة. وهذه هي القيمة الأساسية للنماذج الكبيرة في سيناريوهات اشتقاق أصول التصميم.
الفصل الثاني: مساعد إنشاء صور أكثر طاعة — مثال Lovart
في الجزء الأول، استدعينا NanoBanana مباشرة من خلال الكود وجربنا التدفق الأساسي لـ "الإدخال والإنشاء الفوري". هذه الطريقة لا مشكلة فيها عندما تكون المتطلبات بسيطة. لكن عندما تبدأ مهام الإنشاء بتضمين المزيد من القيود، مثل:
- الحاجة إلى صور متعددة بأسلوب متناسق
- الحاجة إلى تعديلات متكررة على النتائج الموجودة
- الحاجة إلى تعديل اتجاه الإنشاء ديناميكياً بناءً على إدخال المستخدم
طريقة الاستدعاء الواحد تصبح تدريجياً غير كافية.
في هذه المرحلة، يجب إدخال وكيل ذكاء اصطناعي (AI Agent). يستخدم هذا القسم Lovart كمثال لإظهار كيف يتغير سير العمل بالكامل عندما يمتلك نموذج إنشاء الصور "طبقة تفكير". ملاحظة! هذا ليس إعلاناً، بل只是为了 مساعدة الجميع على فهم سهولة وكلاء الذكاء الاصطناعي بسرعة~
2.0 التعرف الأول على Lovart: وكيل تصميم الذكاء الاصطناعي الخاص بك
Lovart هو أداة تصميم قائمة على الوكيل (Agent) على الويب. مقارنة بأدوات إنشاء الصور العادية، يضيف طبقة "تفكير وتخطيط" قبل الإنشاء.
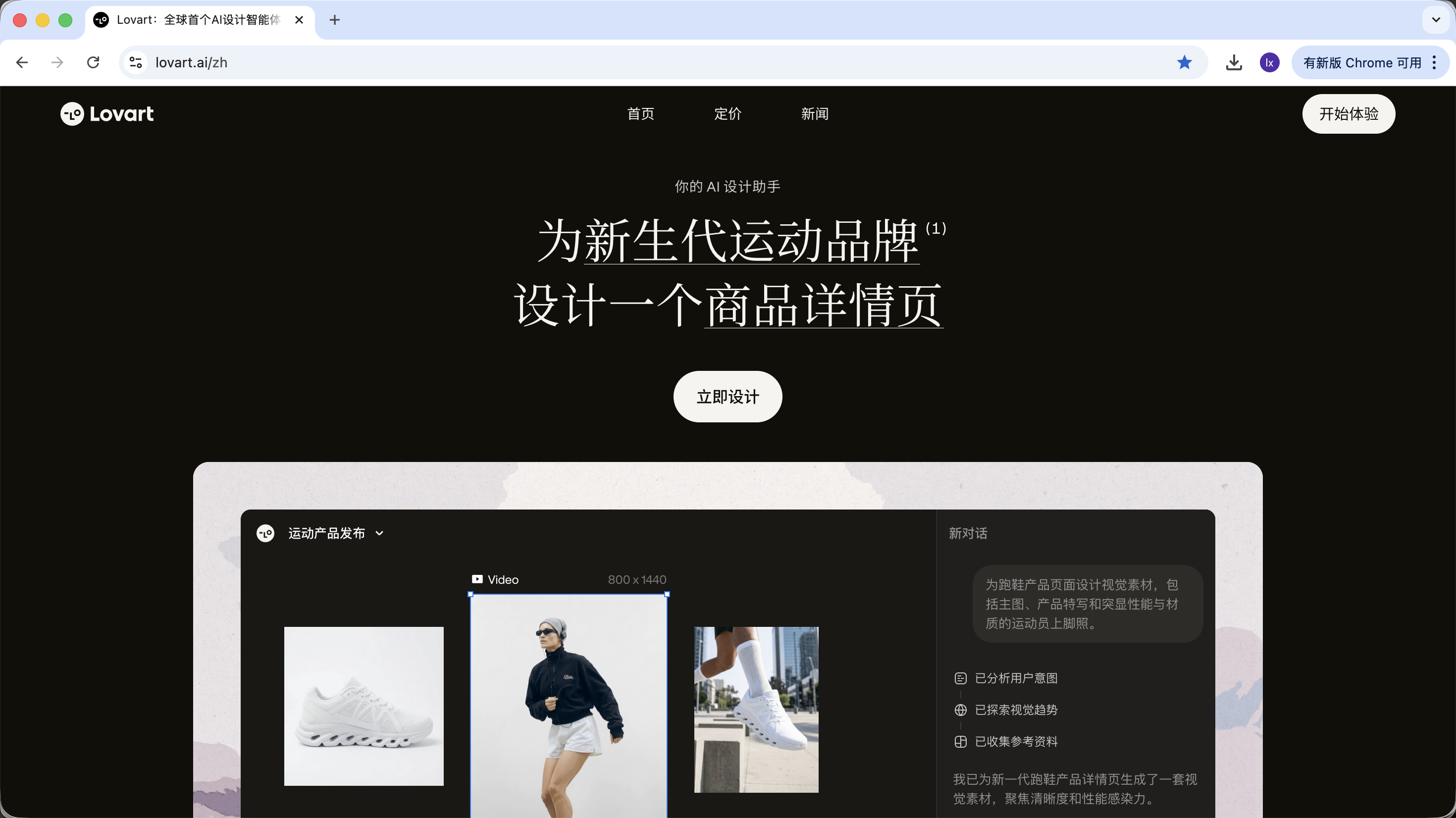
بعد الدخول إلى Lovart، تحتاج أساساً إلى فهم عناصر التحكم التالية:
اختيار النموذج
انقر على أيقونة المكعب أسفل مربع الإدخال لعرض نماذج الإنشاء المتاحة (مثل GPT Image، Flux، إلخ).
للحفاظ على التناسق مع الأمثلة السابقة، يستمر هذا القسم في استخدام NanoBanana كنموذج إنشاء أساسي.
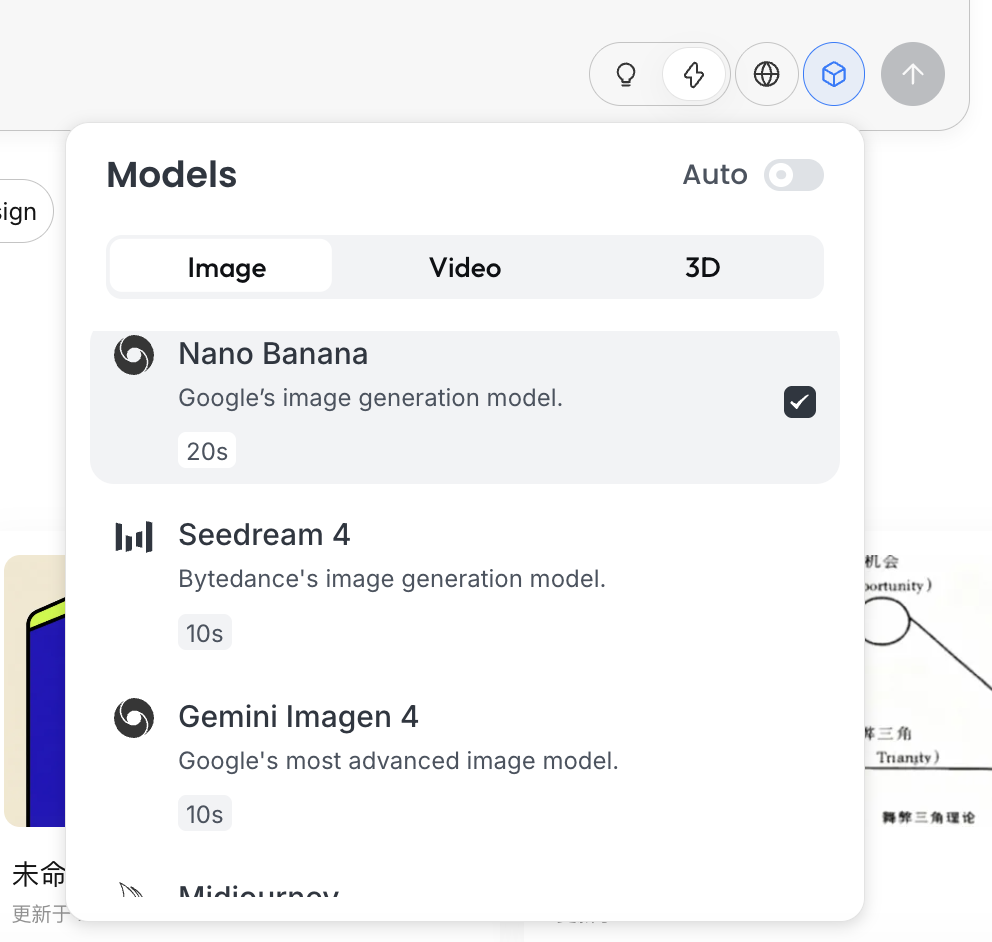
وضع التفكير
هذا هو المفتاح الرئيسي في Lovart:
- الوضع السريع (⚡): قريب من API الأصلي، استجابة سريعة، مناسب لإنشاء صور فردية بتعليمات واضحة
- وضع التفكير (💡): وضع الوكيل، يقوم الذكاء الاصطناعي أولاً بتفكيك المتطلبات وإعادة كتابة الأمر ثم ينفذ الإنشاء
القدرة على الاتصال بالإنترنت
عند تفعيل أيقونة الكرة الأرضية، يمكن للوكيل البحث عن معلومات الويب أثناء عملية الإنشاء (مثل اتجاهات التصميم، أنماط الألوان) كمدخل مساعد.
2.1 لماذا API الأصلي غير كافٍ؟
على الرغم من أنه يمكن بالفعل إنشاء صور بجودة جيدة من خلال Python، لا يزال API الأصلي محدوداً في المهام المعقدة. السبب الرئيسي هو: API الأصلي إلزامي (imperative) بطبيعته. عندما تطلب منه إنشاء كائن محدد، يمكنه التنفيذ مباشرة؛ لكن عندما يصبح الإدخال "تخطيط مجموعة كاملة من أصول اللعبة"، لن يقوم تلقائياً بتفكيك الهدف إلى خطوات قابلة للتنفيذ.
الفرق الجوهري في Lovart يكمن في آلية الوكيل. بين إدخال المستخدم ونموذج إنشاء الصور، يضيف طبقة منطقية للفهم والتخطيط: يتعرف أولاً على نية المستخدم، ثم يفكك المهمة، يعيد كتابة الأمر، وأخيراً ينفذ الإنشاء.
2.2 عرض عملي: إنشاء مجموعة ملصقات IP في 5 دقائق
لنأخذ "إنشاء مجموعة ملصقات IP بطة مبرمج" كمثال، لنرى كيف يشارك الوكيل في العملية بالكامل.
المرحلة الأولى: التخطيط (قدرة التفكير للوكيل)
مشكلة API الأصلي: تحتاج إلى التفكير بنفسك في إعداد الشخصية والحالات العاطفية، وكتابة أوامر (Prompts) منفصلة لكل صورة.
نهج Lovart:
- فعّل 💡 وضع التفكير
- أدخل تعليمة واحدة:
صمم مجموعة ملصقات IP بطة مبرمج، بأسلوب مسطح ولطيف
لا يرسم الذكاء الاصطناعي فوراً، بل يبحث أولاً على الإنترنت عن صور تصميم بطات مبرمجين ذات صلة. يُخرج خطة مفككة، وينشئ تلقائياً مشاهد مثل التصحيح (Debug)، استراحة القهوة (Coffee Break)، الهلع (Panic)، ويولد أوصافاً بصرية متعددة لكل مشهد.
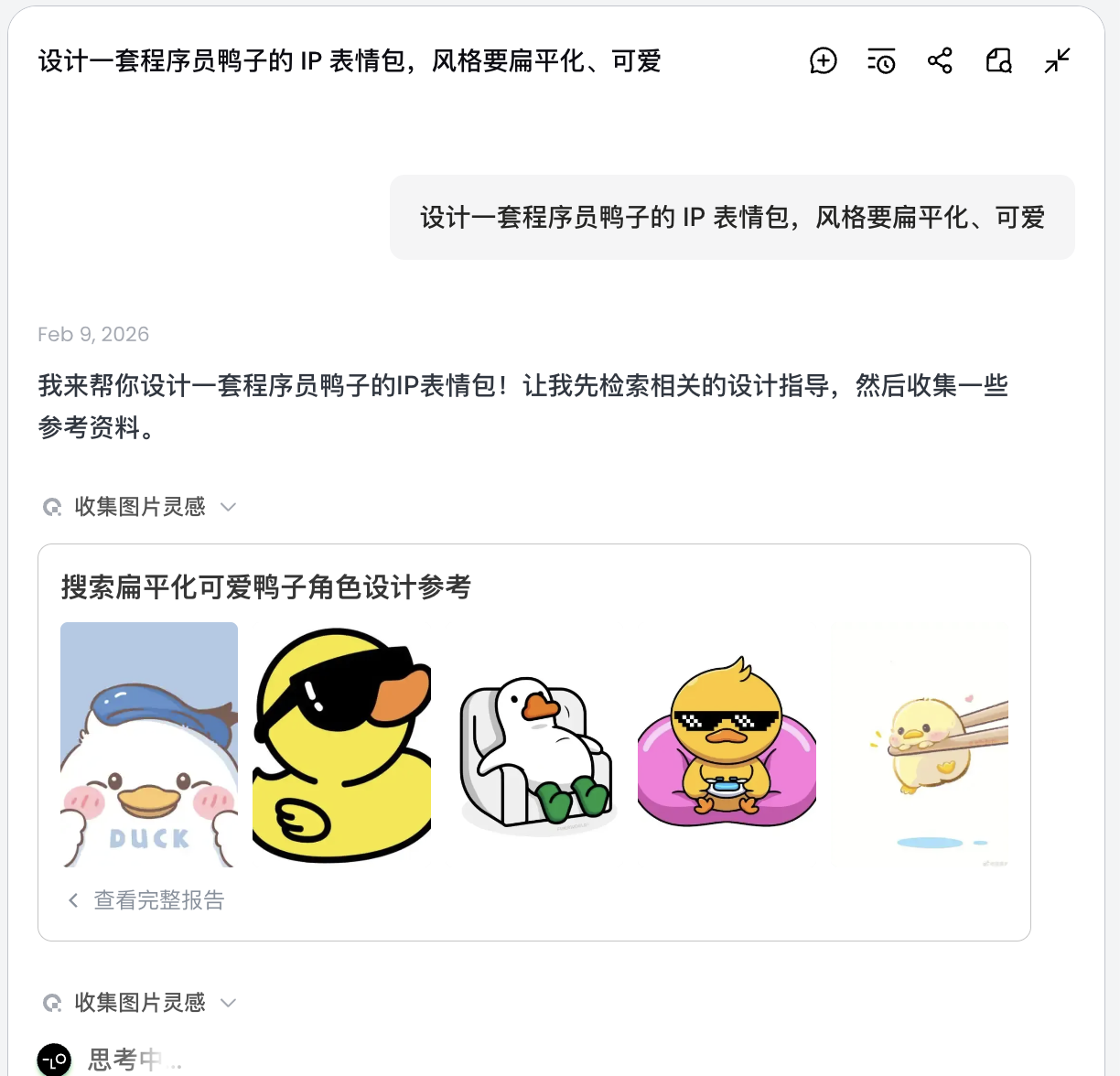

في هذه الخطوة، يتحول الذكاء الاصطناعي من "منفذ" إلى "مخطط". بعد أن يحلل الذكاء الاصطناعي متطلباتك، يمكنك رؤية صور متعددة لبطات مبرمجين بأنماط ومحتويات مختلفة في منطقة اللوحة في Lovart. يمكنك البدء في فرز الأساليب التي تعجبك.
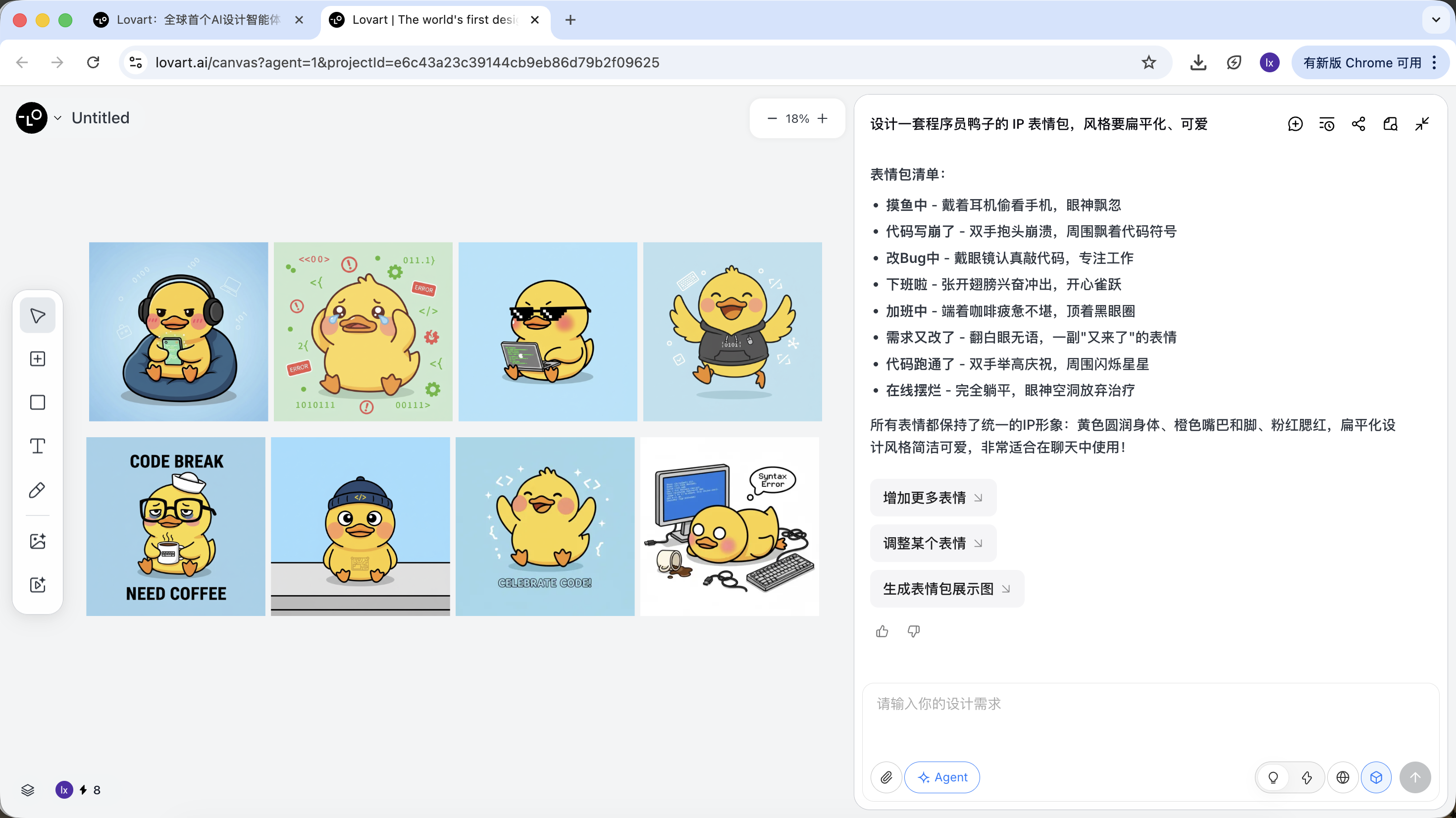
المرحلة الثانية: التناسق (التثبيت البصري القائم على المرجع)
في Lovart، الصور ليست مجرد نتائج، بل تشارك أيضاً في الإنشاء اللاحق.
صورة مرجعية كاملة
- اختر "البطة القياسية" الأكثر إرضاءً من الرسومات، وانقر على الصورة المقابلة في منطقة اللوحة
- ستظهر الصورة تلقائياً في منطقة المحادثة كمرجع (Reference)
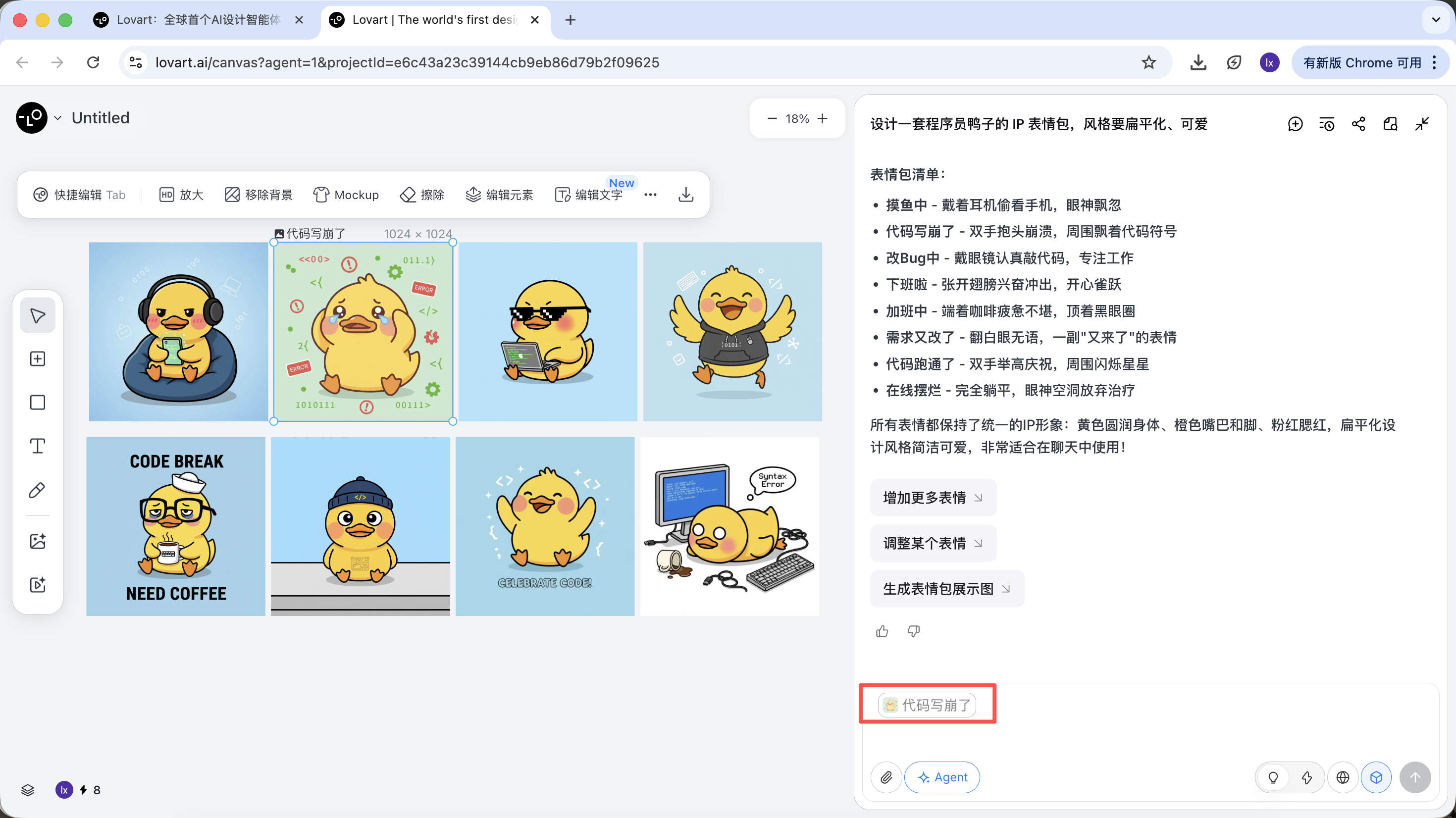
- أدخل حركة جديدة (مثل سعيد) وأنشئ
سترث النتيجة المُنشأة الألوان والنسب والتفاصيل من الصورة الرئيسية.
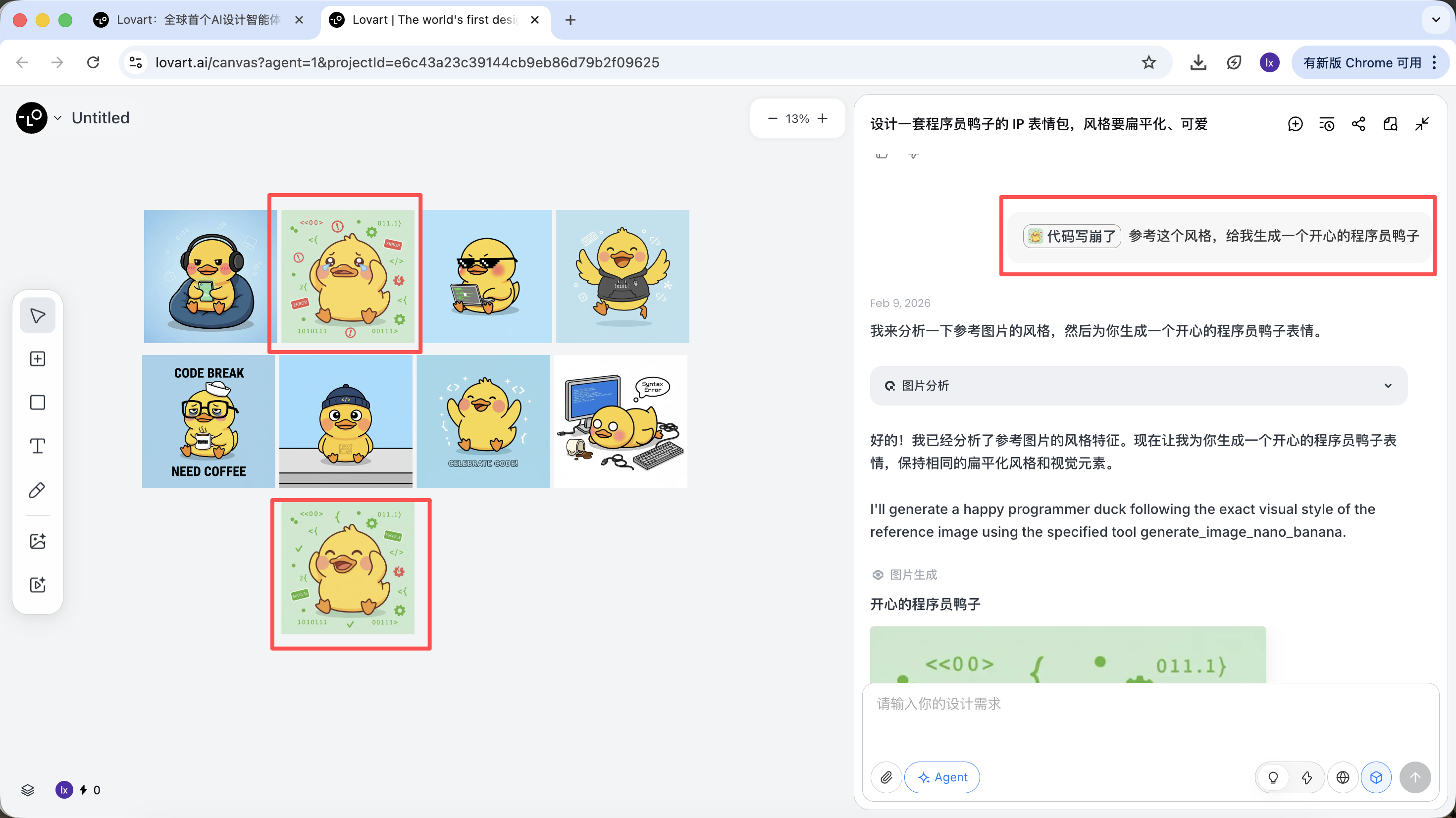
مرجع جزئي / تكامل صور متعددة
بالإضافة إلى استخدام الصورة الكاملة كمرجع، يدعم Lovart أيضاً:
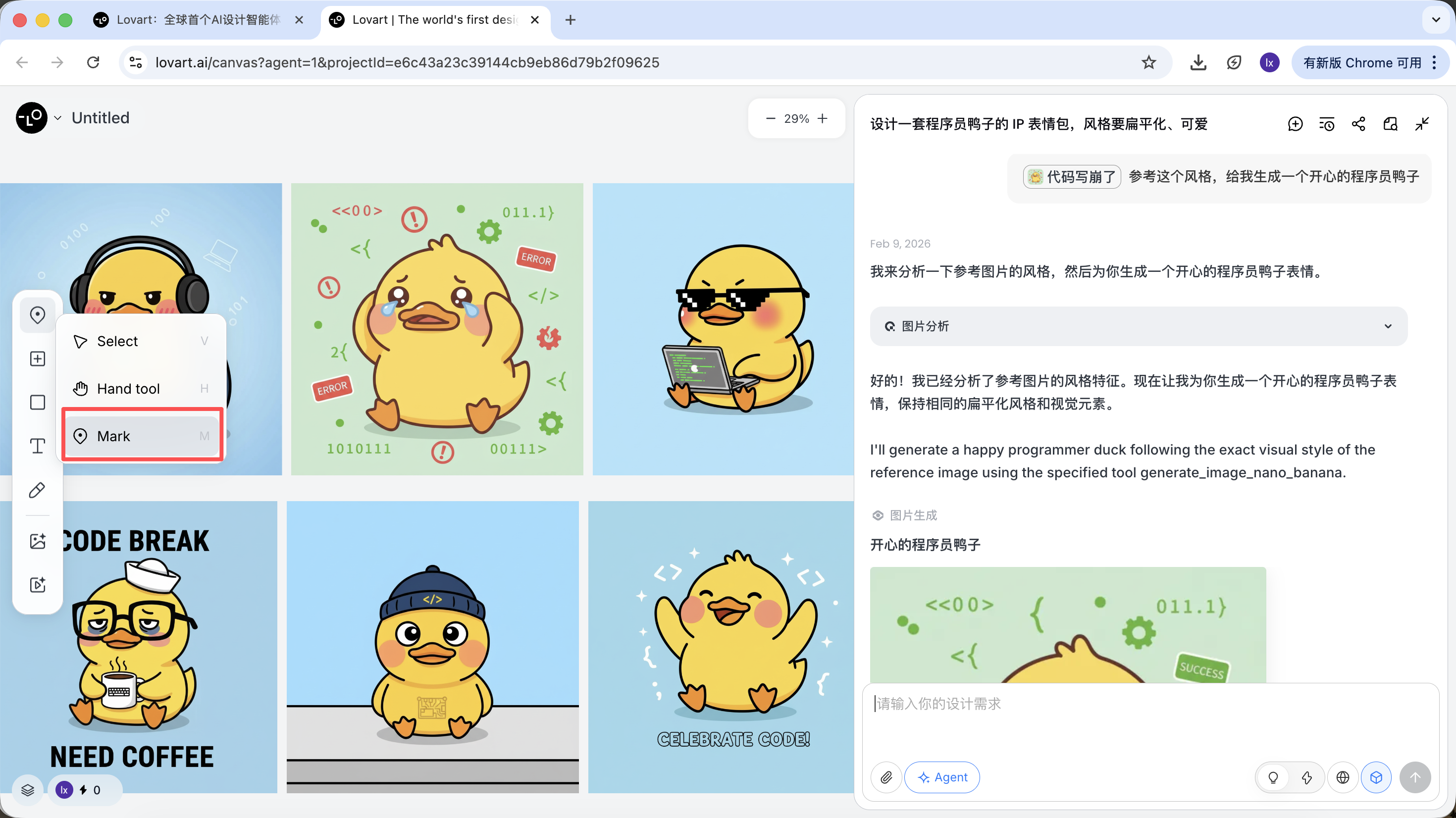
- تحديد منطقة جزئية فقط من الصورة (مثل الإشارة إلى القبعة أو التعبير فقط)
انقر على شريط التبويب الأيسر في منطقة اللوحة، اختر مفتاح "Mark"، وحدد المنطقة الجزئية من الصورة المستهدفة. ستتم مزامنة هذا المحتوى تلقائياً مع مربع الحوار. على سبيل المثال، هنا يمكننا اختيار تعديل لون الخلفية.
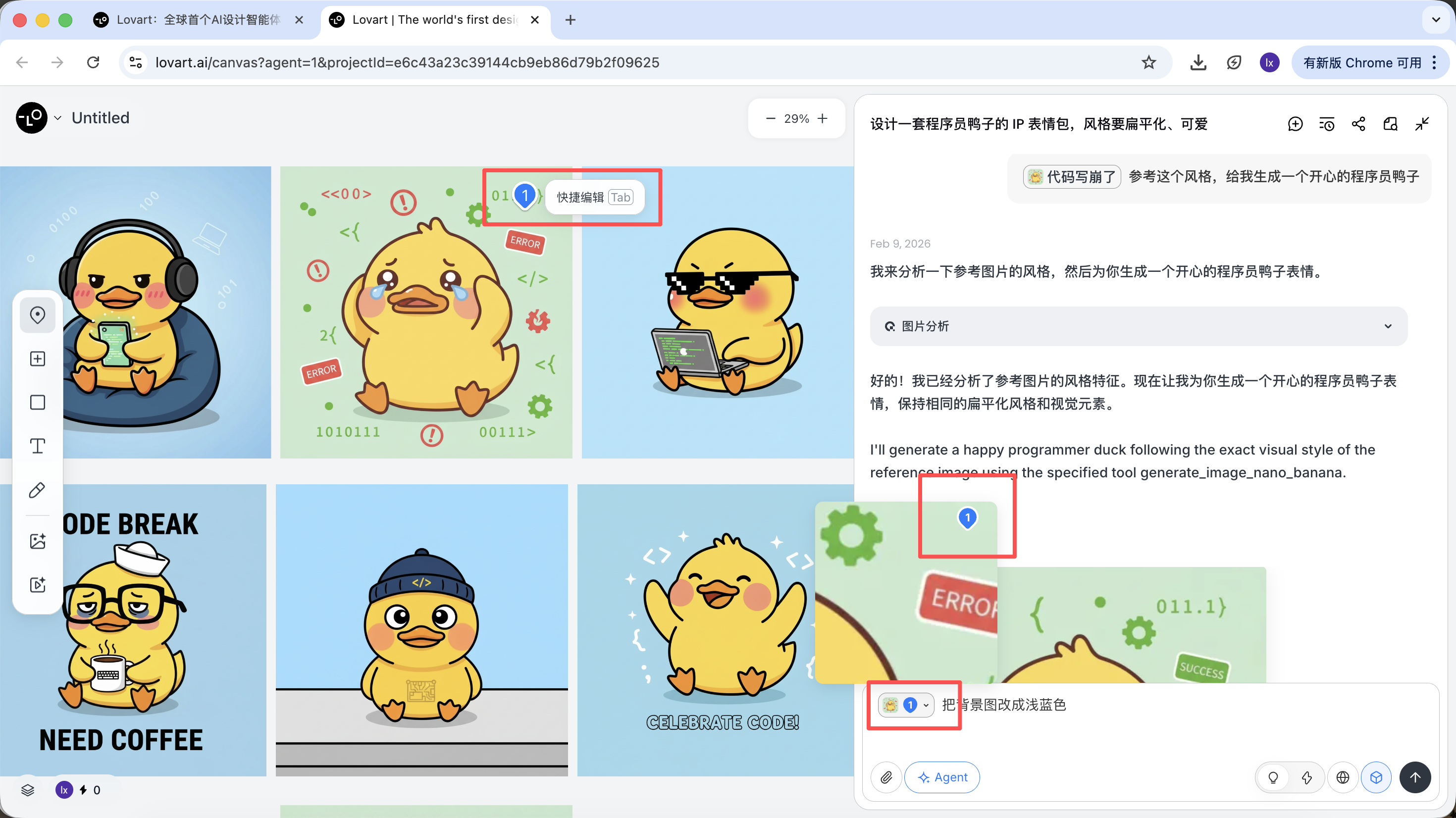
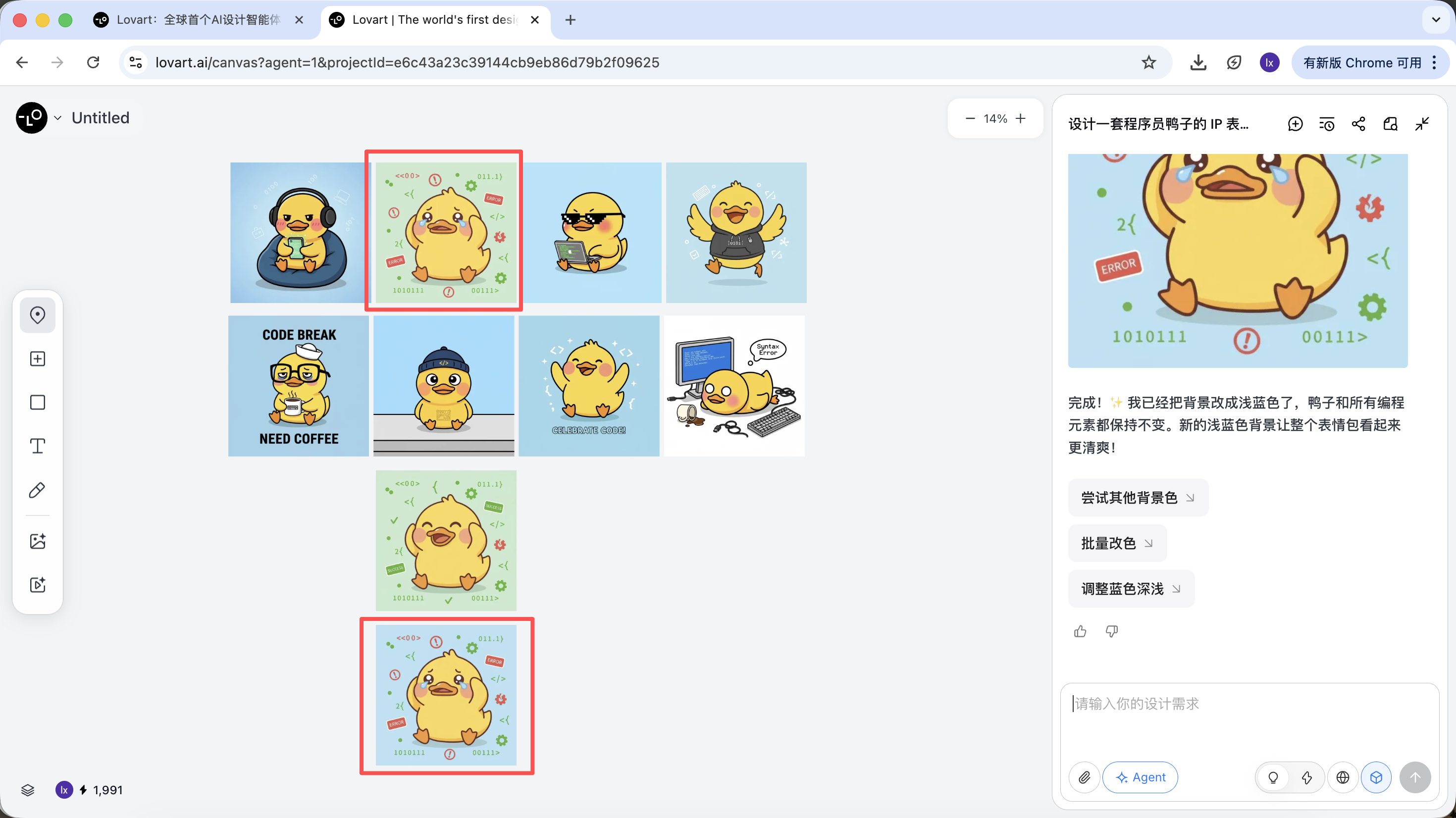
يمكنك رؤية أن الصورة المُنشأة حديثاً تغيّر لون الخلفية فقط، وهو ما يتوافق أيضاً مع متطلبات الإدخال الخاصة بنا.
- الإشارة إلى عناصر فرعية من صور متعددة على حدة، ثم دمجها لإنشاء نتيجة جديدة
على سبيل المثال: يمكنك الاحتفاظ بشخصية الصورة A، واستبدال القبعة فقط بأسلوب الصورة B. سيقوم الوكيل بدمج هذه القيود البصرية تلقائياً في الخلفية.
بأخذ البطة المبرمج كمثال، يمكننا اختيار الاحتفاظ بشكل البطة من الصورة الأولى واستبدالها كعنصر رئيسي في الصورة الثانية.
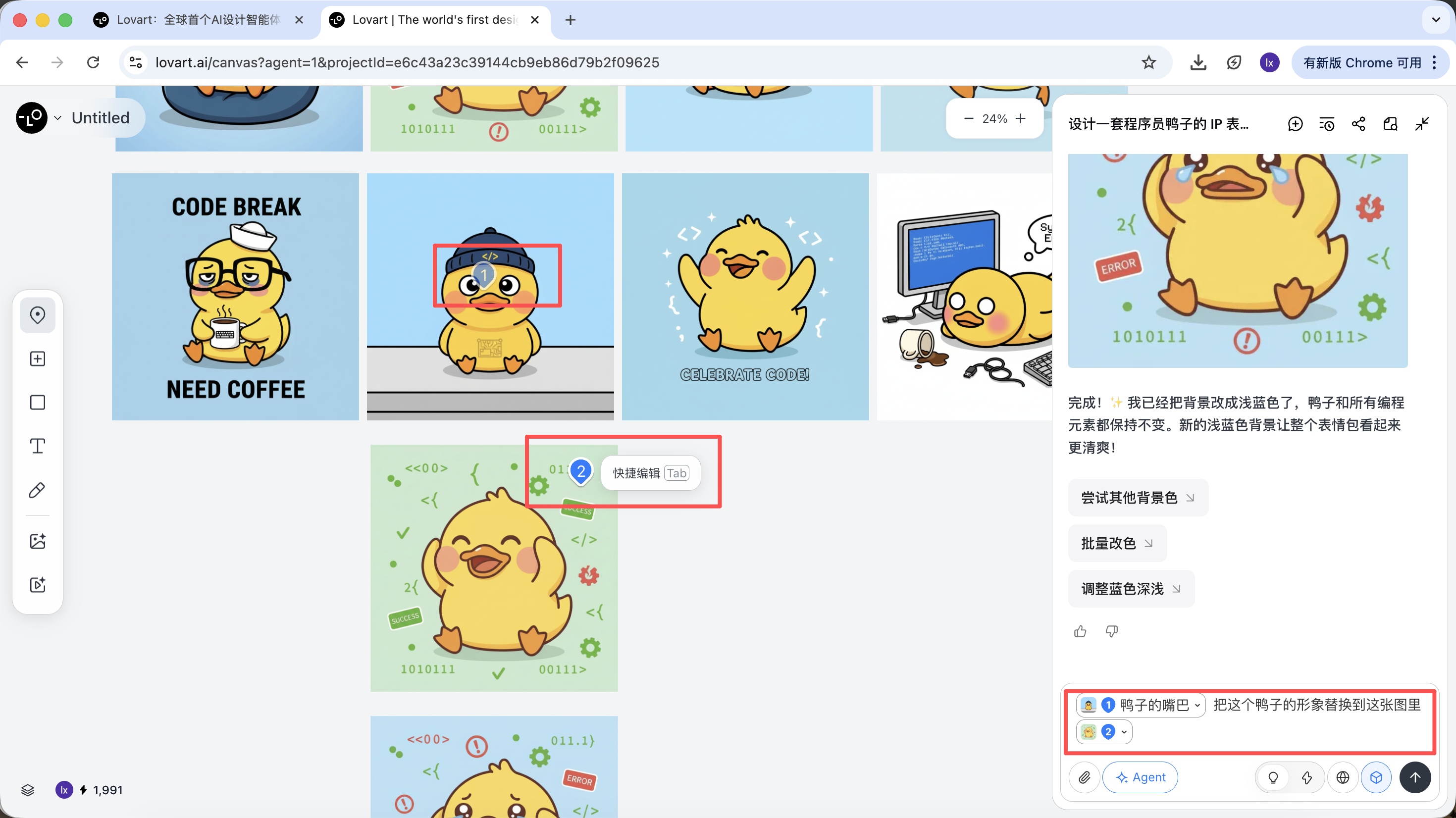
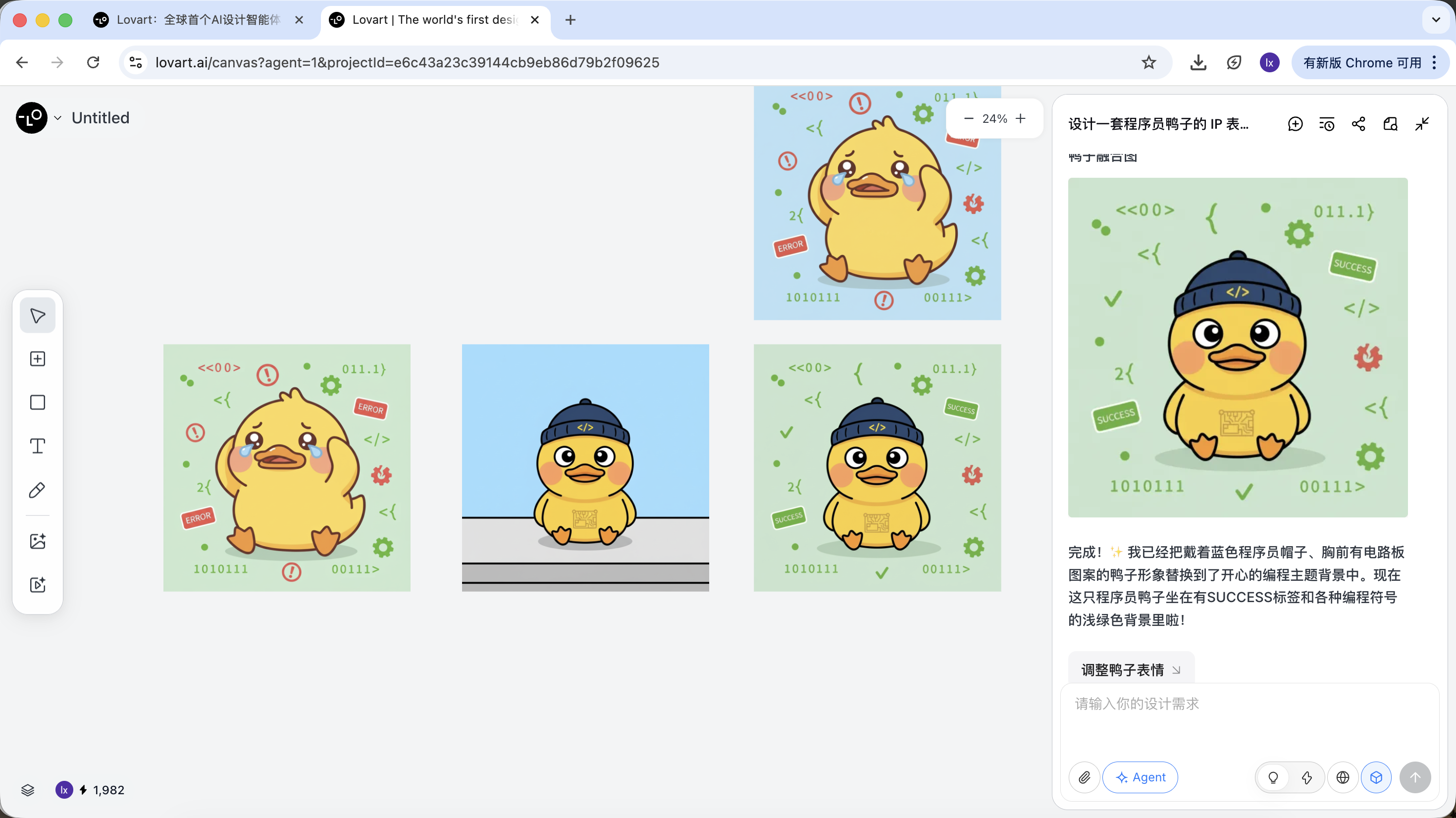
التأثير النهائي أيضاً ملحوظ جداً. جرب مجموعات أخرى!
المرحلة الثالثة: التسليم (استدعاء أدوات الوكيل)
بعد اكتمال الإنشاء، يمكنك تنفيذ عمليات مثل: التكبير، إزالة الخلفية، المسح، إلخ مباشرة.
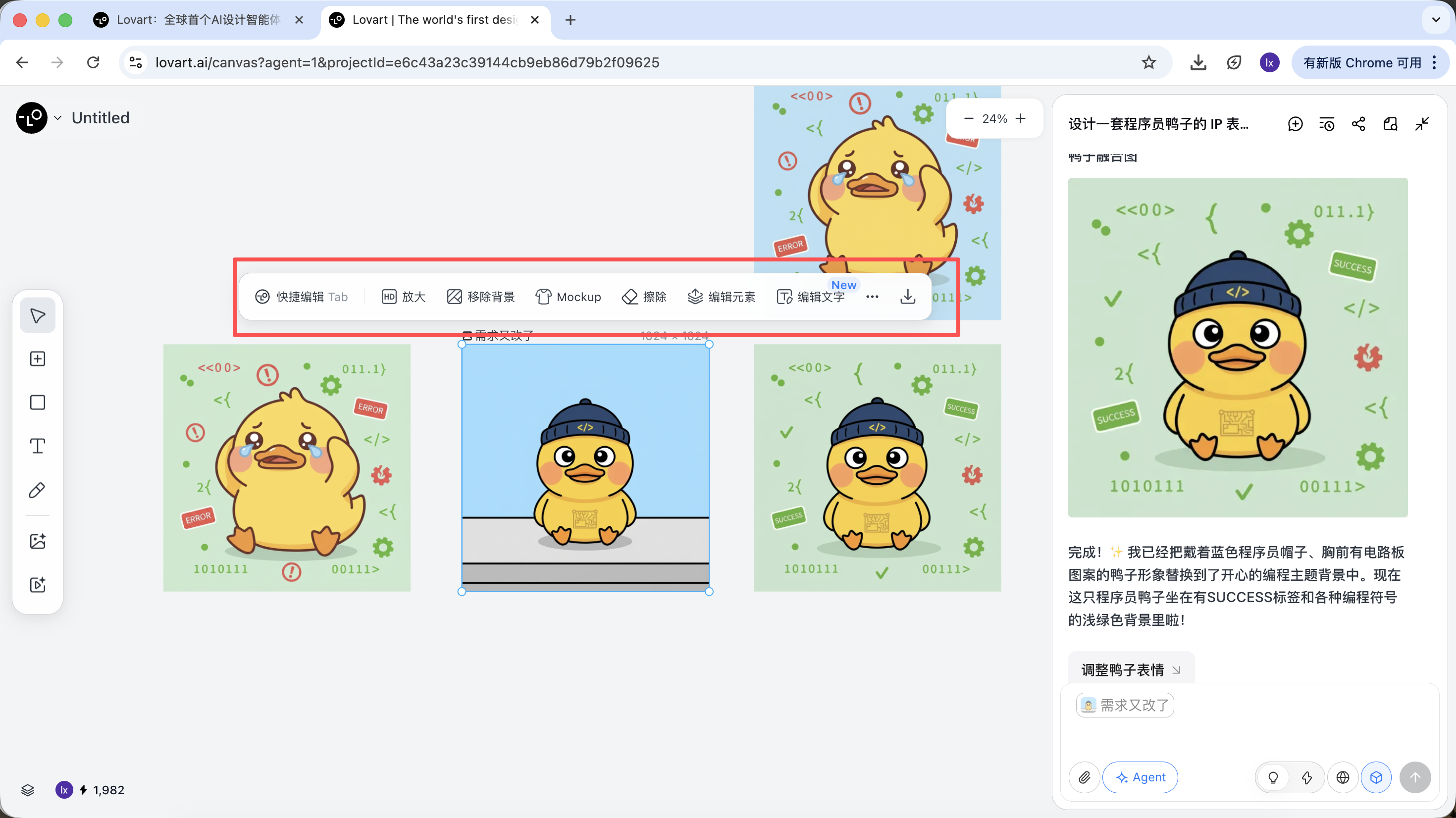
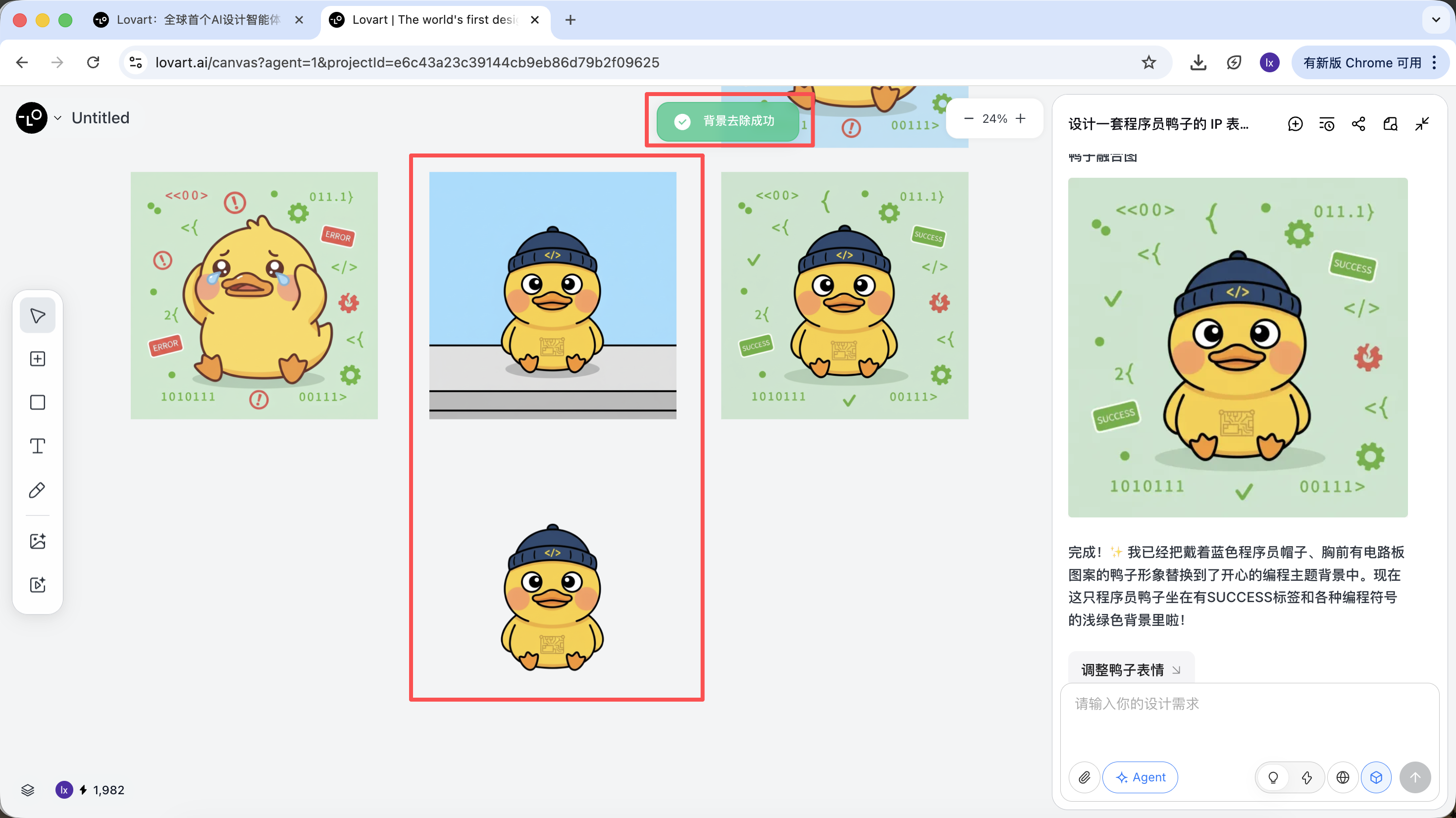
هذه ليست فلاتر بسيطة، بل نتائج أنجزها الوكيل عن طريق استدعاء أدوات مختلفة تلقائياً.
بعد تأكيد الأسلوب الأساسي، يمكنك إنشاء سلسلة من صور الملصقات بسرعة كبيرة.
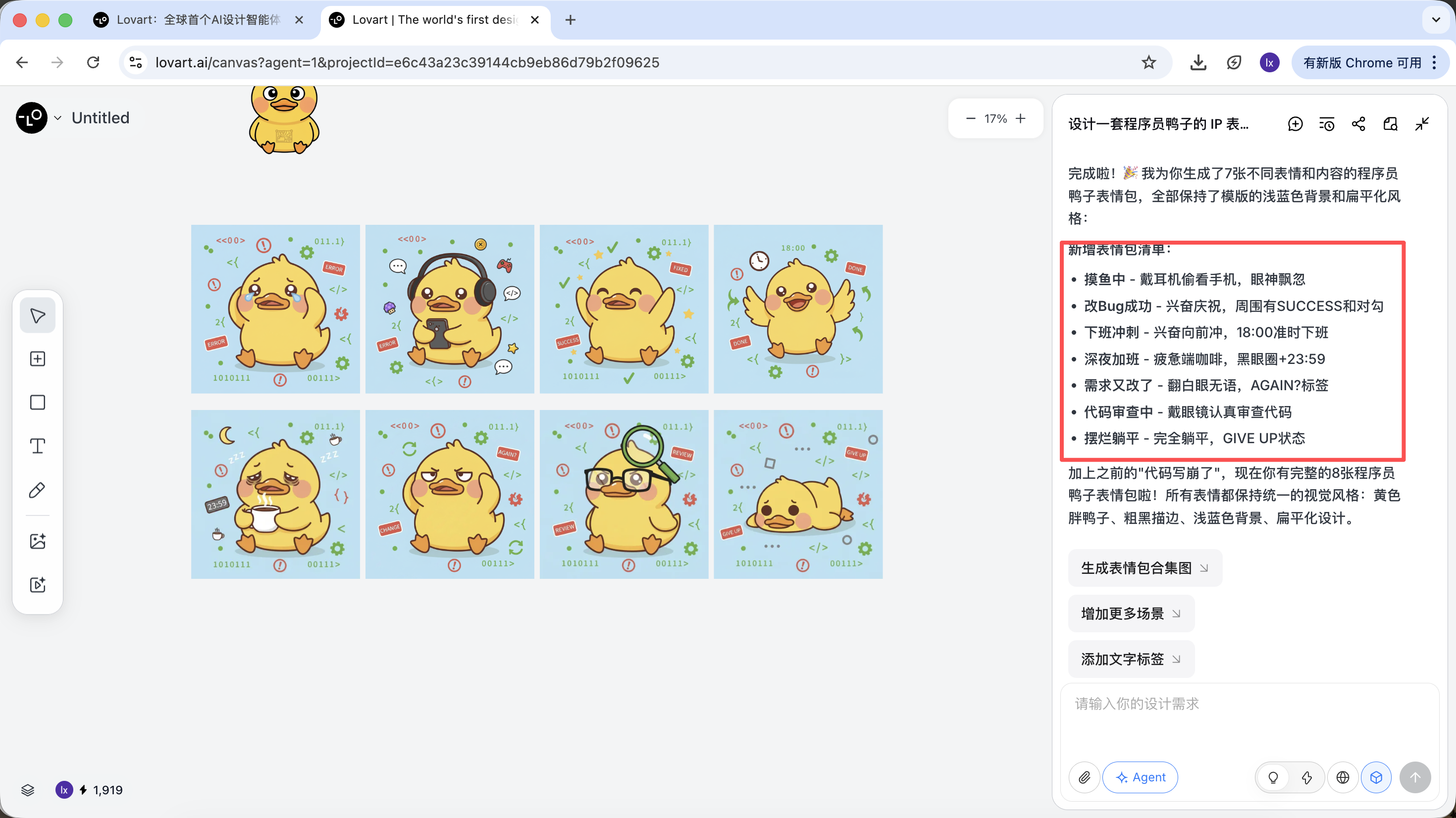
ما نحصل عليه في النهاية هو أصول بمستوى الإنتاج جاهزة للتسليم، وليس مجرد صورة عرض.
2.3 تعليمات الاستخدام والرسوم
يعتمد Lovart نموذج اشتراك، حيث تتوافق الخطط المختلفة مع حدود استخدام وصلاحيات وظيفية مختلفة. التفاصيل المحددة خاضعة لما هو منشور على الموقع الرسمي.
لا يوصي هذا البرنامج التعليمي أو يقارن أي خطة معينة. إذا كانت لديك احتياجات في الاستخدام العملي، يمكنك اختيار الترقية المدفوعة حسب وضعك الشخصي. حالياً يدعم الدفع عبر Alipay وطرق أخرى.
ملخص
Lovart لا يحل محل النموذج الأساسي، بل من خلال آلية الوكيل، يرتقي بإنشاء الصور من "تنفيذ واحد" إلى "سير عمل مستمر".
عندما تبدأ المهام بتضمين التخطيط والتناسق والتسليم، تصبح مزايا هذا النوع من الأدوات واضحة جداً.
الفصل الثالث: ابنِ مساعد إنشاء صور ذكي بنفسك
بالإضافة إلى استخدام Lovart مباشرة، يمكننا أيضاً تنفيذ نسخة مبسطة من مساعد إنشاء الصور بأنفسنا.
يتخذ هذا الفصل "الرسوم التوضيحية التلقائية للمقالات" كمثال، ينطلق من مشاكل فعلية ويبني تدريجياً وكيلاً يمتلك قدرة التفكير.
3.1 تقديم المشكلة: لماذا لا ينفع إرسال المقال مباشرة إلى نموذج إنشاء الصور؟
إذا أدخلت مقالاً طويلاً في NanoBanana وطلبت إنشاء رسم توضيحي، فمن الصعب عادةً الحصول على نتيجة مرضية. السبب ليس أن النموذج "لا يعرف كيف يرسم"، بل لأنه ليس بارعاً في فهم النصوص الطويلة.
نماذج إنشاء الصور أكثر ملاءمة لمعالجة الأوصاف البصرية القصيرة والواضحة. عندما يصبح الإدخال مقالاً يحتوي على هيكل ونقاط رئيسية وعلاقات سياقية، لا يستطيع النموذج الحكم على أي محتوى هو الذي يحتاج فعلاً إلى التعبير عنه في الصورة. هذا غالباً ما يؤدي إلى انحراف النتائج المُنشأة عن الموضوع، أو التقاط تفاصيل متفرقة فقط دون قدرة على التلخيص الشامل.
في الجوهر، نموذج الصور يمتلك قدرة "التنفيذ" فقط، لكنه يفتقر إلى عملية تحليل النص واختياره.
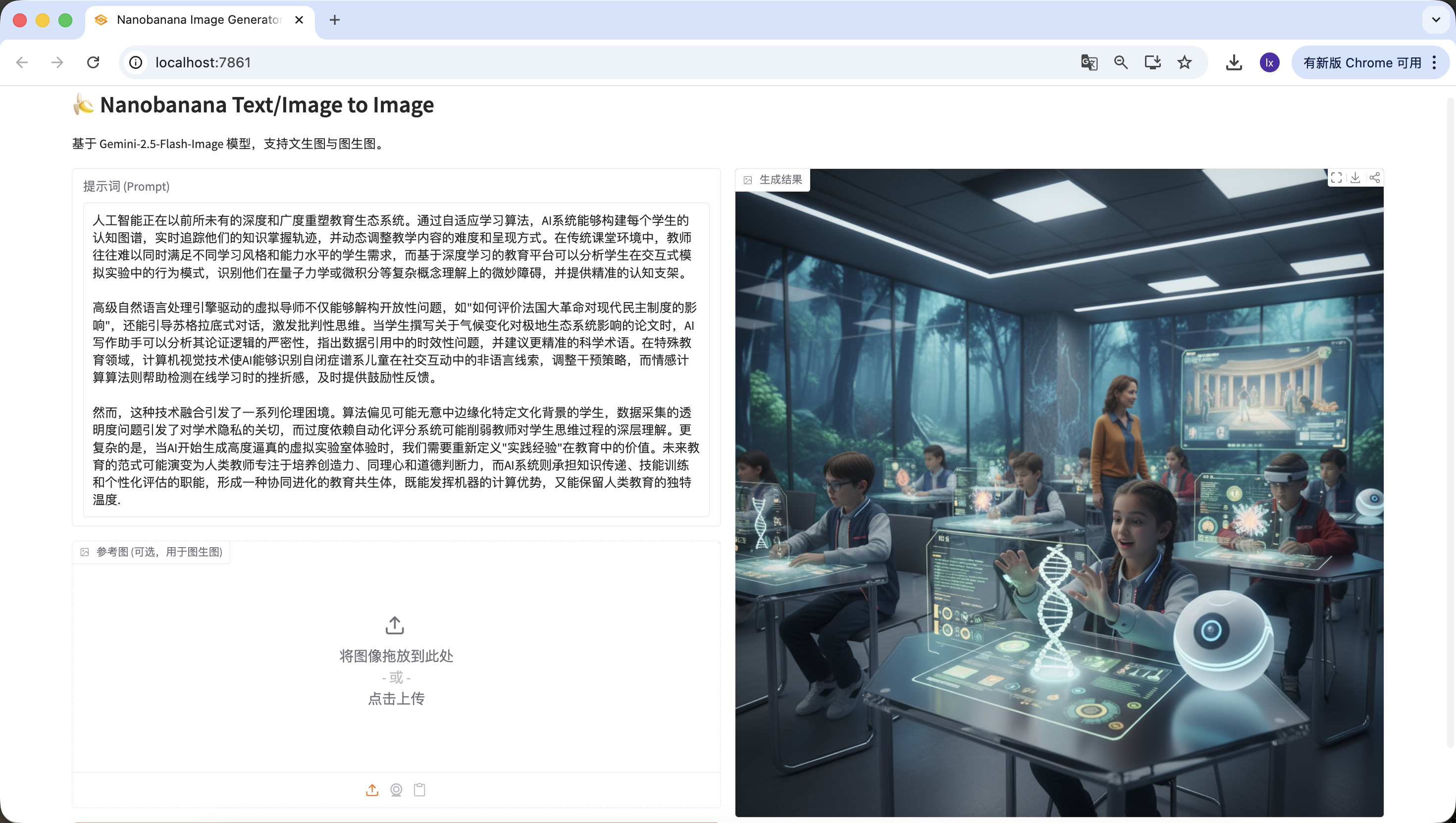
3.2 نهج الحل: فصل "الفهم" و"التنفيذ" باستخدام وكيل
المفتاح لحل هذه المشكلة ليس أوامر (Prompts) أكثر تعقيداً، بل التفكير بوضوح قبل إنشاء الصورة. لذلك، نقدم "طبقة تفكير" مستقلة في تدفق الإنشاء ونبني معها أبسط وكيل عملي.
الهدف الأساسي لهذا الوكيل هو شيء واحد فقط: جعل الصورة النهائية المُنشأة أقرب ما يمكن إلى نية التعبير الحقيقية للمستخدم.
يمكن تلخيص التدفق الكامل كالتالي: إدخال نص طويل → فهم وحكم نموذج اللغة → إنشاء أوامر بصرية مناسبة → تنفيذ الإنشاء بنموذج الصورة → إخراج الصورة
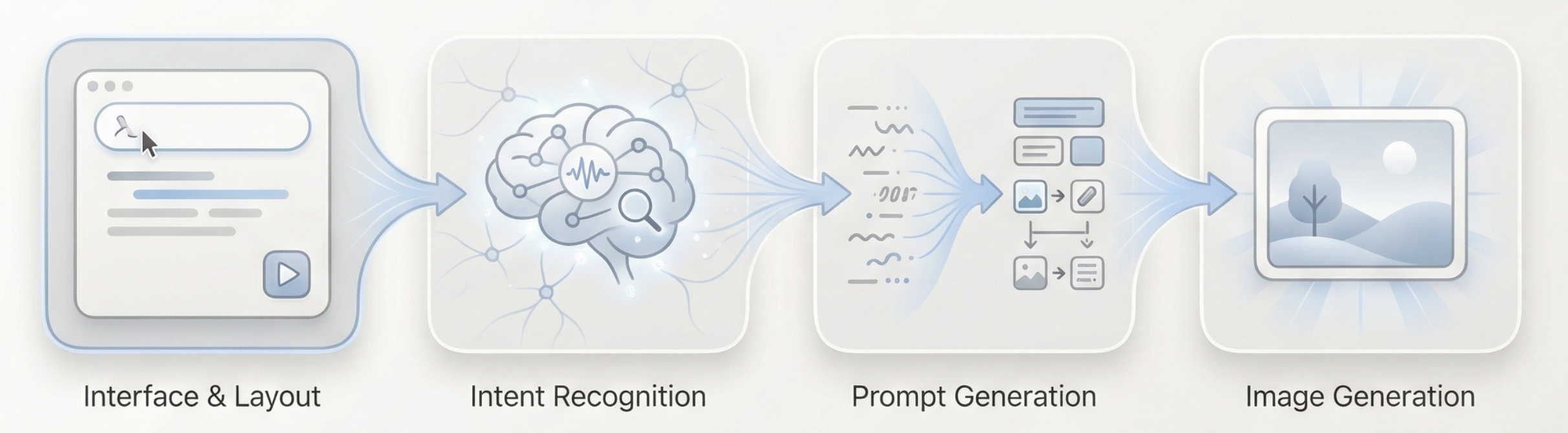
إذن، كيف يمكن لوكيلنا أن يفهم نية المستخدم؟
هنا اخترنا إنشاء "طبقة تفكير" مبسطة. قمنا بإعداد ثلاث نيات مختلفة: إدخال غير صالح، إنشاء صورة مباشر، نص طويل يحتاج إلى فهم.
في هذا الوكيل، يمكن تلخيص تقسيم الأدوار في أربعة نقاط:
- نموذج اللغة كنواة لصنع القرار مسؤول عن فهم محتوى المقال، الحكم على نية إدخال المستخدم، وتوزيع المهمة على مسار الإنشاء المناسب، وتحديد "ما يجب فعله بعد ذلك" وكيفية إنشاء أوامر الصور.
- نموذج الصور كمنفذ لا يشارك نموذج الصور في الفهم والحكم، بل يستقبل التعليمات البصرية المُجهزة فقط ويركز على إكمال عرض الصورة.
- المستخدم كمرشد قابل للتدخل بالإضافة إلى إدخال النص مباشرة، يمكن للمستخدم أيضاً تعديل الأوامر المُنشأة يدوياً أثناء العملية، أو إضافة صور مرجعية للمساعدة في الإنشاء، وبالتالي توجيه النتيجة النهائية وضبطها بدقة.
- Gradio و API الخلفي كطبقة دعم شاملة مسؤولة عن ربط الواجهة، واستدعاءات النموذج، وعرض النتائج، لضمان تشغيل الوكيل بالكامل بشكل مستقر كتطبيق ويب متكامل.
3.3 التحضير العملي: الحصول على APIs
يبدو ممتعاً جداً! لتشغيل التدفق أعلاه، نحتاج فقط إلى إعداد نوعين من APIs.
اليد: API NanoBanana (إنشاء الصور)
استخدم مباشرة API Key و API URL الذي تم تكوينه بالفعل في الفصل الأول، دون الحاجة إلى إعدادات إضافية.
العقل: API SiliconFlow (التفكير النصي)
نحتاج إلى نموذج لغة كبير ليضطلع بدور "طبقة التفكير". يستخدم هذا البرنامج التعليمي خدمة النماذج التي توفرها SiliconFlow: https://cloud.siliconflow.cn
توفر SiliconFlow واجهات متوافقة مع مواصفات OpenAI API، يمكن استدعاؤها بسهولة كبيرة من خلال طلبات الشبكة القياسية في المشروع. هنا اخترنا نموذج Qwen2.5-7B-Instruct المجاني. كل ما يلزم للاستدعاء مكتوب بالفعل في الأمر (Prompt) أدناه. قبل البدء، تحتاج فقط إلى تسجيل حساب وإنشاء API Key على الموقع الرسمي.
سيُستخدم هذا المفتاح لاستدعاءات النموذج اللاحقة.
3.4 بناء الوكيل:
تستخدم هذه التجربة بشكل أساسي Trae لكتابة الكود، والنموذج المختار في هذا البرنامج التعليمي هو Gemini-3-Pro-Preview. الفكرة العامة هي إنشاء مشروع جديد، ثم نسخ الأمر (Prompt) الكامل أدناه إلى مربع الحوار وإدخاله، واستبدال API KEY تدريجياً، ثم تشغيل الكود وإكمال الاختبار.
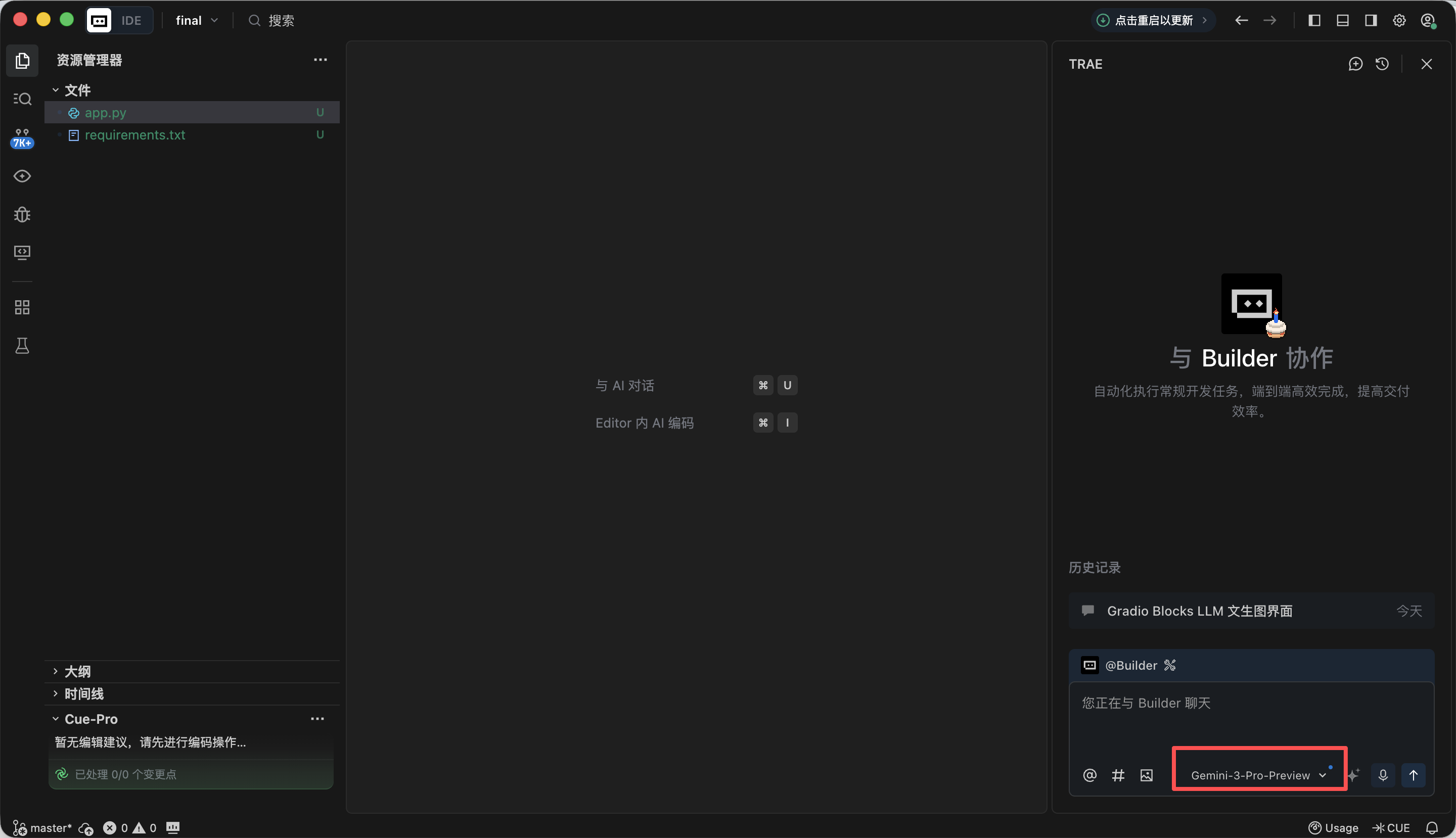
المرحلة 1️⃣: إطار عمل Gradio Blocks الأساسي وتصميم الواجهة
في هذه المرحلة، هدفنا الرئيسي هو بناء "المظهر" للوكيل أولاً، أي تنفيذ تصميم الصفحة الأمامية. بعد نسخ الأمر (Prompt) التالي في مربع حوار Trae وتنفيذه، ستحصل على عنوان URL محلي (عادةً http://127.0.0.1:7860) لعرض الواجهة والتحقق من نتيجة التنفيذ.
الوحدة 1: إطار عمل Gradio Blocks الأساسي وتصميم الواجهة
1، هدف المهمة
- بناءً على تخطيط Blocks في Gradio 4.0.0+، تنفيذ الواجهة الأساسية لمشروع "LLM+Nanobanana نص إلى صورة"، مع الالتزام الصارم بتخطيط القسمة الثابتة يسار-يمين، وتهيئة جميع مكونات واجهة المستخدم وإعداد الحالات الأولية الصحيحة.
2، متطلبات المجموعة التقنية
- يجب التطوير باستخدام وضع Blocks في Gradio 4.0.0+، يُمنع استخدام وضع Interface;
- التبعيات: gradio>=4.0.0، pillow>=10.0.0 (استيراد فقط، عدم تنفيذ منطق معالجة الصور مؤقتاً);
- يجب أن يكون الكود ملف Python كامل وقابل للتشغيل، يتضمن جميع عبارات الاستيراد الضرورية.
3، قواعد تخطيط الواجهة (القيد الأساسي، دمج تفاصيل عملية)
- التخطيط العام:
عنوان الصفحة: أداة كاملة لتحويل النص إلى صورة مدعومة بـ LLM;
قسمة ثابتة يسار-يمين: الجانب الأيسر يشغل 60% من العرض، الجانب الأيمن يشغل 40% من العرض، باستخدام gr.Row و gr.Column لتنفيذ التحكم في النسب.
- قائمة مكونات الجانب الأيسر 60% (منطقة تدفق إنشاء الأوامر):
input_text: gr.Textbox، التسمية "إدخال نص (فقرة تعليمية / أمر رسم)"، lines=6، placeholder "أدخل النص التعليمي الذي يحتاج إلى رسم توضيحي أو أمر رسم مباشر...";
identify_intent_btn: gr.Button، value="تحديد النية"، الحالة الأولية قابلة للنقر بشكل طبيعي;
intent_status: gr.Textbox، التسمية "نوع النية / حالة المعالجة"، lines=2، interactive=False، القيمة الأولية "نية غير محددة";
system_prompt: gr.Textbox، التسمية "System Prompt (قابل للتعديل لنية الرسم التوضيحي للمقال فقط)"، lines=4، interactive=False، placeholder "قواعد القيد لإنشاء الأوامر بواسطة LLM...";
confirm_prompt_btn: gr.Button، value="تأكيد إنشاء أمر الصورة"، interactive=False (معطل مبدئياً لمنع الأخطاء);
generation_prompt: gr.Textbox، التسمية "أمر إنشاء الصورة (قابل للتعديل)"، lines=3، interactive=True، القيمة الأولية فارغة، placeholder "سيُعرض أمر إنشاء الصورة بالإنجليزية هنا، يدعم التعديل اليدوي...".
- قائمة مكونات الجانب الأيمن 40% (منطقة وظيفة إنشاء صور Nanobanana):
ref_image: gr.Image، التسمية "صورة مرجعية (اختيارية، صورة إلى صورة)"، type=filepath، height=300، يسمح بالرفع;
generate_btn: gr.Button، value="إنشاء صورة"، interactive=False (معطل مبدئياً، لا يمكن النقر بدون أمر);
result_image: gr.Image، التسمية "النتيجة المُنشأة"، type=pil، height=300، القيمة الأولية فارغة، interactive=False.
4، متطلبات منطق التفاعل
- الحالة التفاعلية الأولية لجميع المكونات يجب أن تتبع التكوين أعلاه بدقة، وسيتم تحديثها ديناميكياً من خلال الوظائف لاحقاً;
- حالة تعطيل الأزرار يجب أن تكون بديهية (رمادية)، لتجنب العمليات الخاطئة من المستخدم.
5، متطلبات الإخراج
- إنشاء كود Python كامل، ينفذ تخطيط الواجهة وتهيئة المكونات فقط، دون تضمين أي منطق أعمال;
- تعليقات الكود واضحة، تسمية المكونات متسقة مع النسخة العملية (input_text/identify_intent_btn، إلخ);
- الكود قابل للتشغيل مباشرة، هيكل الواجهة متطابق تماماً مع الوصف.بعد فتح http://127.0.0.1:7860 في المتصفح، يمكنك رؤية أن Trae أنشأ صفحة الويب التالية وفقاً لمتطلباتنا، وهي متوافقة تقريباً مع متطلباتنا، لذا يمكننا الانتقال إلى خطوة الإنشاء التالية.
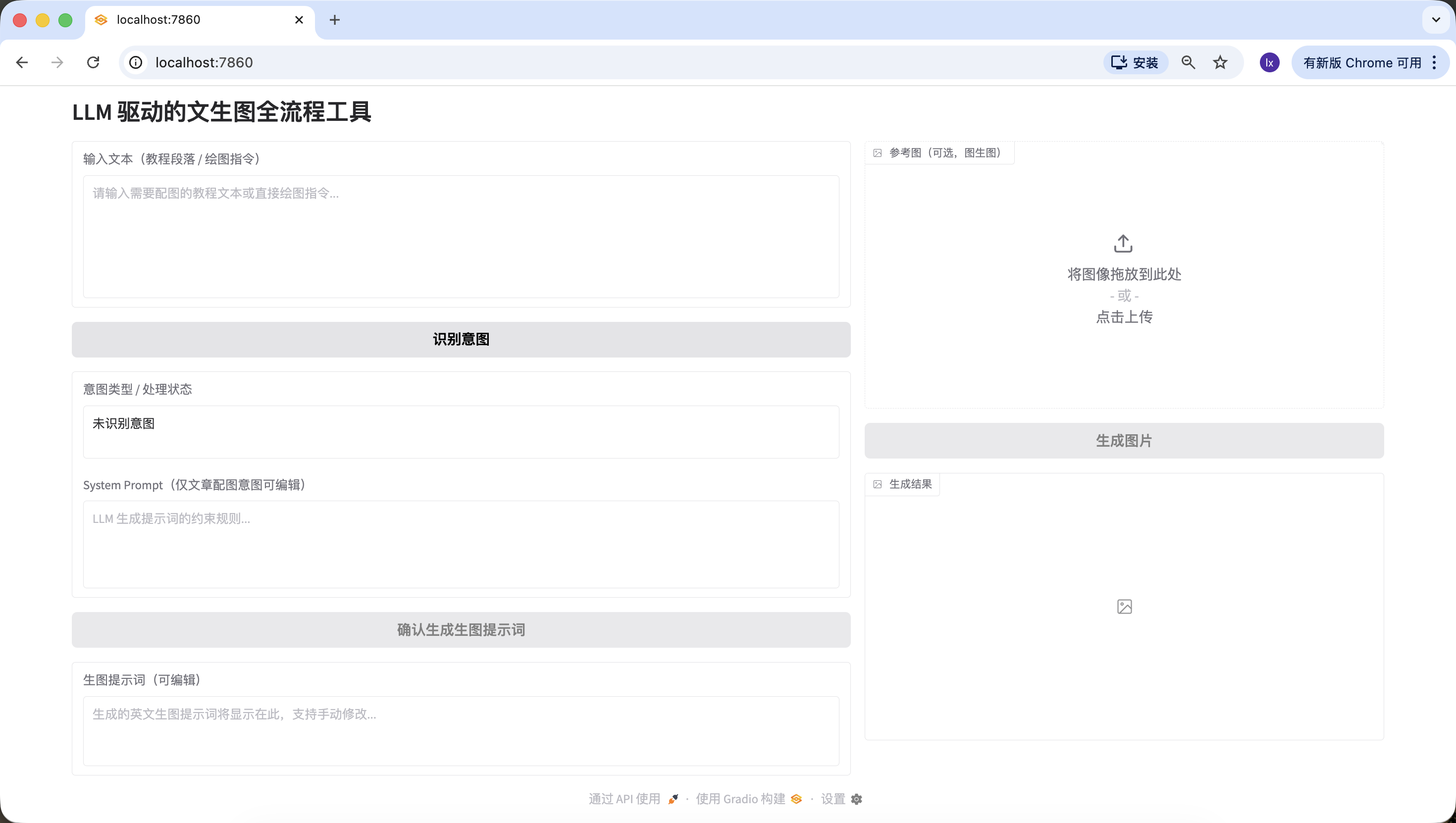
المرحلة 2️⃣: وحدة تحديد نية LLM (API Siliconflow)
عند استخدام VLM للرسم في الحياة اليومية، قد تكون هناك حالات الإدخال الشائعة الثلاث التالية:
- محتوى بلا معنى، مثل "مرحباً"، "هل أكلت اليوم؟"، لا يمكن رسم الصورة المقابلة.
- مقال/نص طويل، بعدد كلمات كبير، مثل مقال مهيكل بحوالي 200 كلمة، يحتاج أولاً إلى فهم هيكل المقال ومحتواه، ثم التفكير في كيفية إنشاء صورة تلخص هذا النص بالكامل.
- أمر رسم مباشر، مثل "ارسم لي كلباً يستحم"، حيث المتطلبات موصوفة بالتفصيل بالفعل ويمكن إنشاء الصورة مباشرة.
كما في السابق، انسخ الأمر (Prompt) التالي في مربع حوار Trae للتنفيذ، وأضف الـ APIs التي حصلت عليها في الخطوات السابقة.
الوحدة 2: وحدة تحديد نية LLM (API Siliconflow)
1، هدف المهمة
على أساس واجهة Gradio المنفذة، إضافة منطق النقر لزر "تحديد النية"، واستدعاء API Siliconflow لإكمال تحديد النية، وربط حالة المكونات.
2، متطلبات المجموعة التقنية
بناءً على Gradio 4.0.0+ Blocks;
التبعيات: requests>=2.31.0، openai;
إخراج ملف Python كامل قابل للتشغيل، يتضمن واجهة الوحدة 1 + منطق هذه الوحدة.
3، قواعد العمل الأساسية (الانحراف المطلق غير مسموح)
- قواعد تصنيف النية (3 فئات فقط، إرجاع رقم + وصف بدقة)
1 = محتوى بلا معنى: دردشة فقط، تحيات، حوار غير ذي صلة، بدون أي حاجة للرسم أو الرسم التوضيحي (مثل "مرحباً"، "هل أكلت؟");
2 = حاجة لرسم توضيحي لمقال / نص طويل: يدخل المستخدم مقالاً كاملاً، أو تعليمي، أو فقرة، أو نصاً توضيحياً، المحتوى يميل للسرد/الشرح/التدريس، يحتوي على نية ضمنية لإنشاء رسم توضيحي لهذا المحتوى، لا يحتاج المستخدم أن يقول صراحةً "أضف رسم توضيحي لهذا النص";
3 = أمر رسم مباشر: يدخل المستخدم أمر رسم قصير وواضح، بدون خلفية نص طويل، يطلب مباشرة رسم شيء محدد (مثل "ارسم قطة بأسلوب Apple").
- قيود استدعاء LLM (دمج مع قالب النسخة العملية)
عنوان الواجهة: https://api.siliconflow.cn/v1/chat/completions;
النموذج: Qwen/Qwen2.5-7B-Instruct;
temperature=0.1;
كود التعريف الموحد:
python
تشغيل
LLM_BASE_URL = "https://api.siliconflow.cn/v1"
LLM_API_KEY = "" # المستخدم يستبدل بنفسه
LLM_MODEL = "Qwen/Qwen2.5-7B-Instruct"# قالب تحديد النية المُتحقق عملياً (مُثبت في الكود)
INTENT_PROMPT_TEMPLATE = """يجب عليك تحديد نية النص الذي أدخله المستخدم، إرجاع واحد فقط من النتائج الثلاث التالية (التنسيق: رقم + وصف بالعربية):
1 = محتوى بلا معنى; 2 = حاجة لرسم توضيحي لمقال / نص طويل; 3 = أمر رسم مباشر.
إدخال المستخدم: {user_input}
نتيجة التحديد:
استخرج الرقم والوصف فقط من نتيجة الإرجاع، المحتوى الإضافي ممنوع."""حدّث عنوان الويب السابق http://127.0.0.1:7860 وابدأ في اختبار ما إذا كان يمكنه الكشف عن الحالات الثلاث بشكل صحيح.
- محتوى بلا معنى، يمكنك تجربة إدخال "مرحباً"، "شكراً"، وسترى أنه يتم تحديده بشكل طبيعي.
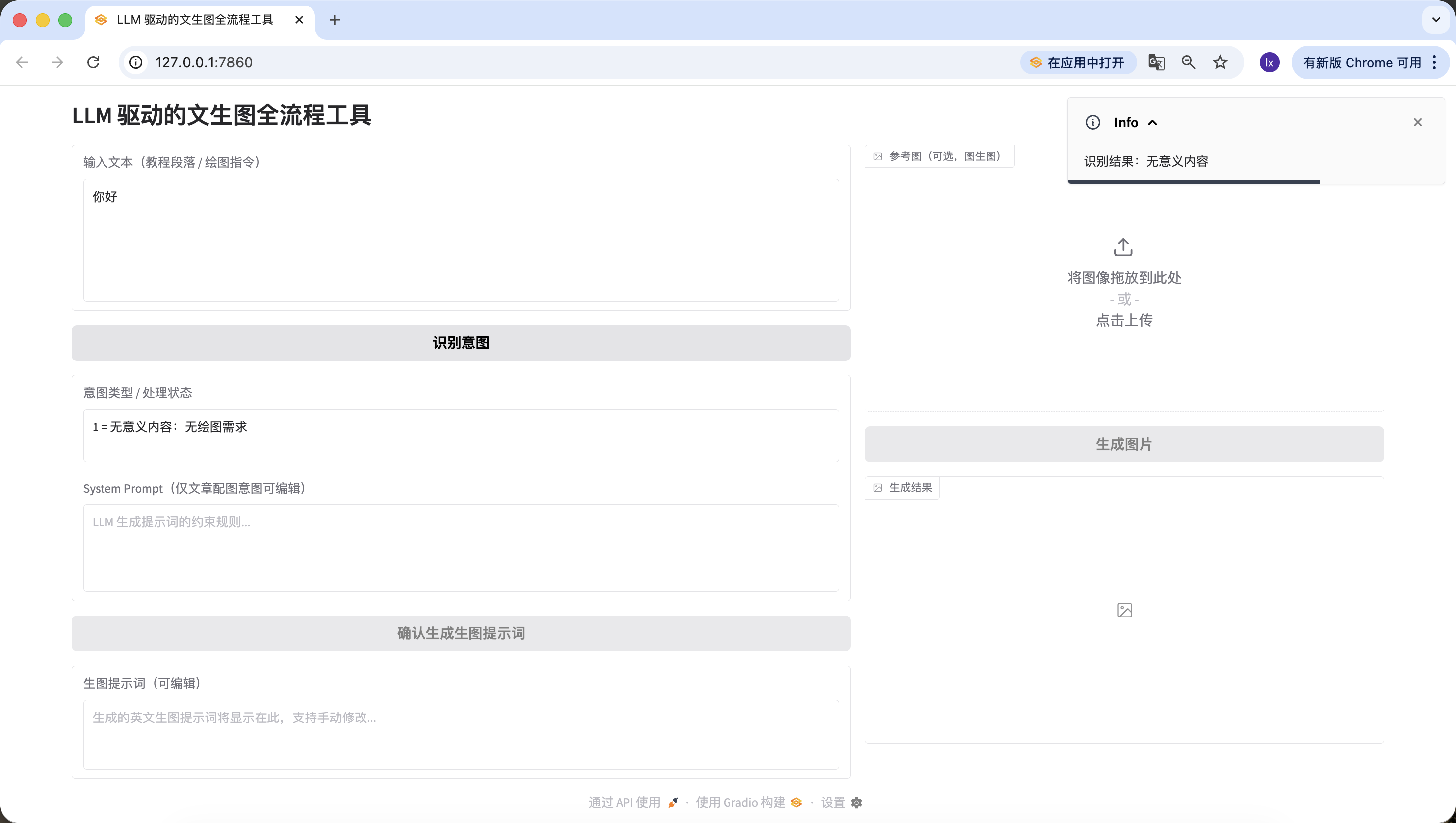
- مقال/نص طويل، هنا استخدمنا نصاً عن الذكاء الاصطناعي أنشأه Doubao. يمكنك أيضاً تجربة فقرة من أطروحتك للاختبار.
يعيد الذكاء الاصطناعي تشكيل النظام البيئي التعليمي بعمق واتساع غير مسبوقين. من خلال خوارزميات التعلم التكيفي، يمكن لأنظمة الذكاء الاصطناعي بناء خريطة معرفية لكل طالب، وتتبع مسار اكتساب المعرفة في الوقت الفعلي، وتعديل صعوبة وطريقة عرض المحتوى التعليمي ديناميكياً. في بيئات الفصول التقليدية، غالباً ما يجد المعلمون صعوبة في تلبية احتياجات الطلاب ذوي أساليب التعريب ومستويات القدرة المختلفة في وقت واحد، بينما يمكن للمنصات التعليمية القائمة على التعلم العميق تحليل أنماط سلوك الطلاب في المحاكاة التفاعلية، وتحديد العوائق الدقيقة في فهم المفاهيم المعقدة مثل ميكانيكا الكم أو التفاضل والتكامل، وتقديم سقالات معرفية دقيقة.
المعلمون الافتراضيون المدعومون بمحركات متقدمة لمعالجة اللغة الطبيعية لا يمكنهم فقط تفكيك الأسئلة المفتوحة، بل يمكنهم أيضاً توجيه حوارات سقراطية تحفز التفكير النقدي. عندما يكتب طالب مقالاً عن تأثير تغير المناخ على النظم البيئية القطبية، يمكن لمساعد الكتابة بالذكاء الاصطناعي تحليل صرامة حجته المنطقية، والإشارة إلى مشاكل الحداثة في اقتباسات البيانات، واقتراح مصطلحات علمية أكثر دقة. في مجال التربية الخاصة، تتيح تقنية رؤية الحاسوب للذكاء الاصطناعي التعرف على الإشارات غير اللفظية لدى الأطفال في طيف التوحد أثناء التفاعلات الاجتماعية، وتعديل استراتيجيات التدخل، بينما تساعد خوارزميات الحوسبة العاطفية في اكتشاف الإحباط أثناء التعلم عبر الإنترنت، وتقديم تغذية راجعة تشجيعية في الوقت المناسب.
ومع ذلك، يثير هذا الاندماج التقني سلسلة من المعضلات الأخلاقية. قد تهمش التحيزات الخوارزمية عن غير قصد الطلاب من خلفيات ثقافية معينة، وتثير مشاكل الشفافية في جمع البيانات مخاوف تتعلق بالخصوصية الأكاديمية، وقد يؤدي الاعتماد المفرط على أنظمة التقييم الآلية إلى إضعاف فهم المعلم العميق لعمليات تفكير الطلاب. والأكثر تعقيداً أنه عندما يبدأ الذكاء الاصطناعي في إنشاء تجارب مختبر افتراضية واقعية للغاية، نحتاج إلى إعادة تعريف قيمة "الخبرة العملية" في التعليم. قد يتطور نموذج التعليم المستقبلي إلى نموذج يركز فيه المعلمون البشريون على تنمية الإبداع والتعاطف والحكم الأخلاقي، بينما تتولى أنظمة الذكاء الاصطناعي وظائف نقل المعارف وتدريب المهارات والتقييم الشخصي، مشكلة كائناً تعليمياً متعايشاً يتطور بشكل مشترك يستفيد من مزايا الحوسبة الآلية مع الحفاظ على الدفء الفريد للتعليم البشري.تم الكشف بنجاح أيضاً~
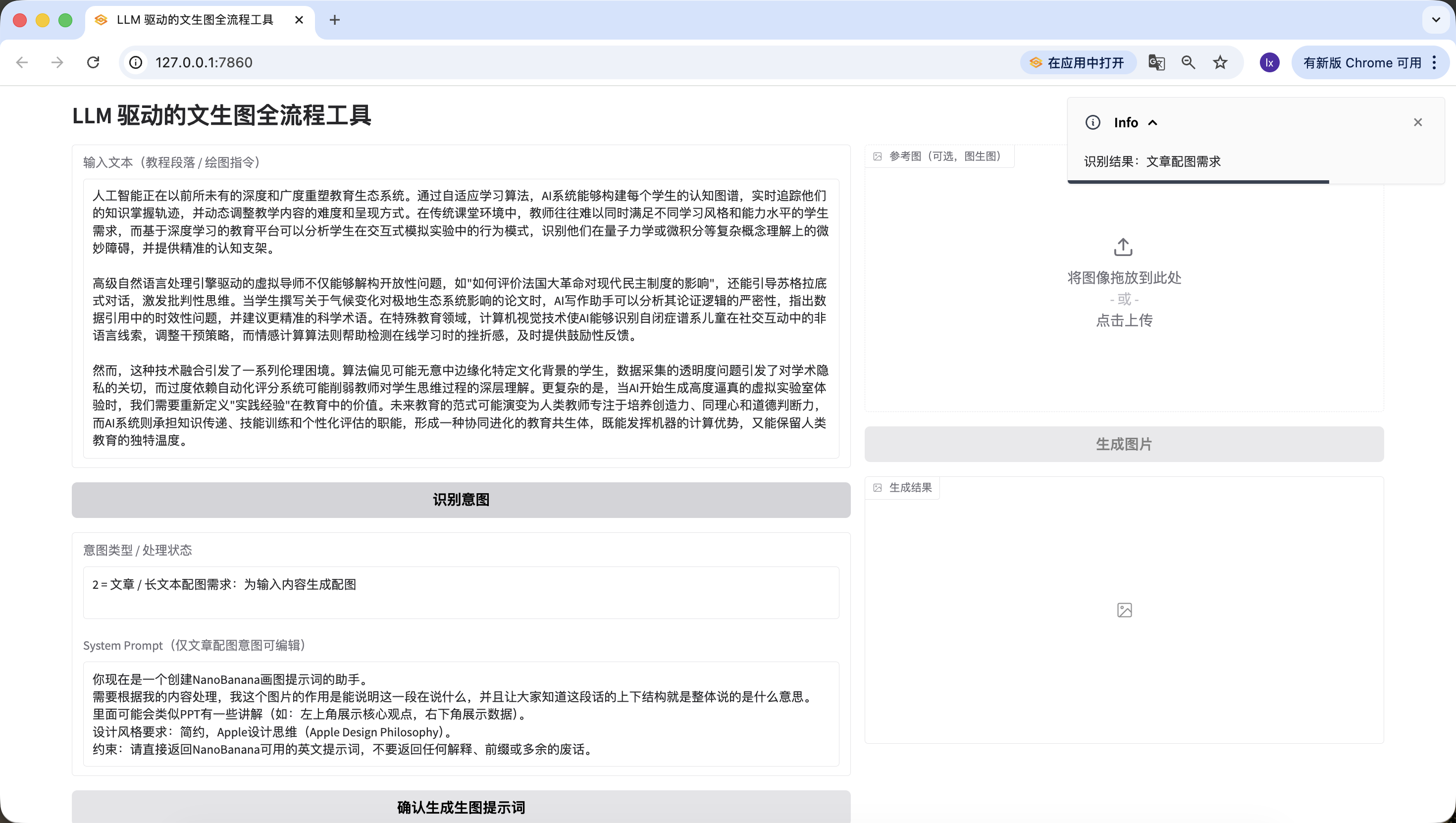
- أمر رسم مباشر، هنا تم إدخال "أريد رسم قطة"، وتم الكشف عنه بدقة أيضاً.
إلى هنا نكون قد نفذنا بنجاح المرحلة الثانية — تحديد النية.
المرحلة 3️⃣: وحدة إنشاء أوامر إنشاء الصور (استدعاء LLM الثاني)
بعد تحديد النية، بالنسبة للمقالات أو النصوص الطويلة، هناك خطوة مهمة جداً وهي إنشاء أمر الرسم، وهذا هو بالضبط النقطة الأساسية في هذا الوكيل.
الوحدة 3: وحدة إنشاء أوامر إنشاء الصور (استدعاء LLM الثاني)
1، هدف المهمة
على أساس تحديد النية، تنفيذ منطق زر "تأكيد إنشاء أمر الصورة"، واستدعاء LLM لتحسين النص إلى أمر بصري بالإنجليزية مناسب للرسم، وتعبئته في مربع التحرير وربطه بزر "إنشاء صورة".
2، متطلبات المجموعة التقنية
مثل الوحدة 2، إخراج كود كامل = الوحدة 1 + الوحدة 2 + هذه الوحدة;
مشاركة LLM_BASE_URL، LLM_API_KEY، LLM_MODEL المعرفة في الوحدة 2، بدون إضافة مفاتيح جديدة.
3، قواعد العمل الأساسية (دمج منطق تجميع الأوامر للنسخة العملية)
- قواعد إدخال إنشاء الأوامر (يجب اتباعها بدقة)
إنشاء أوامر إنشاء الصور لم يعد مجرد ربط سلاسل بسيط، بل هو بناء قائمة رسائل Chat قياسية. هيكل الكود كالتالي:
python
تشغيل
messages=[# دور النظام: محتوى system_prompt النهائي الذي أكده/حرره المستخدم على صفحة الويب{"role": "system", "content": final_system_prompt},# دور المستخدم: يحمل البيانات المراد معالجتها، يوضح هدف المهمة{"role": "user", "content": f"أنشئ أمراً بصرياً للمحتوى التالي:\n\n{user_input}"}]
عندما تكون النية 2: محتوى System يأخذ النسخة النهائية من system_prompt التي حررها المستخدم;
عندما تكون النية 3: محتوى System يأخذ القاعدة الافتراضية المعبأة في الحالة المعطلة
user_input هو النص الأصلي الذي أدخله المستخدم مبدئياً في مربع input_text.
- إعداد System Prompt المُتحقق عملياً (مُثبت في الكود)
python
تشغيل
SYSTEM_PROMPT_DEFAULT = """أنت الآن مساعد ينشئ أوامر رسم لـ NanoBanana.
يجب المعالجة وفقاً لمحتواي. الغرض من هذه الصورة هو توضيح ما يقوله هذه الفقرة وجعل الجميع يفهمون بنية السياق لهذا النص، أي ما يعنيه بشكل عام.
قد تكون هناك شروحات مشابهة لـ PPT (مثل: الزاوية العلوية اليسرى تعرض النقطة الرئيسية، الزاوية السفلية اليمنى تعرض البيانات).
متطلبات أسلوب التصميم: بسيط، فلسفة تصميم Apple (Apple Design Philosophy).
القيد: أرجع مباشرة أوامر بالإنجليزية قابلة للاستخدام في NanoBanana، بدون إرجاع أي تفسير أو بادئة أو كلام زائد."""
- قيود استدعاء LLM
مشاركة نفس مجموعة LLM_BASE_URL، LLM_API_KEY، LLM_MODEL من الوحدة 2;
temperature=0.7 (ضمان إبداعية وملاءمة الأوامر);
max_tokens=200 (تحديد طول الإخراج، مطابق لقيود الأوامر);
استخدام هيكل قائمة رسائل Chat القياسي أعلاه بدقة، ربط السلاسل ممنوع.
- مثال الإدخال والإخراج (مرجع أساسي)
مثال إدخال 1 (نية رسم توضيحي للمقال): النص الأصلي: "كيف تغير الذكاء الاصطناعي التعليم: مع تطور تكنولوجيا الذكاء الاصطناعي، تحول دور المعلم من ناقل معرفة إلى مرشد، يمكن لمساعدي الذكاء الاصطناعي مساعدة الطلاب في التعلم الشخصي، وأصبح التعاون بين الإنسان والآلة في الفصل هو القاعدة." System Prompt النهائي: SYSTEM_PROMPT_DEFAULT (بدون تعديل) الإخراج المتوقع: "Minimalist illustration, Apple Design Philosophy, 1024x1024. Top left shows 'AI + Education' core concept, bottom right shows data of teacher-student-AI collaboration, soft color palette, clean lines, no redundant elements."
مثال إدخال 2 (أمر رسم مباشر): النص الأصلي: "ارسم قطة بأسلوب Apple، تجلس بجانب MacBook" System Prompt النهائي: SYSTEM_PROMPT_DEFAULT (حالة معطلة) الإخراج المتوقع: "Minimalist cat, Apple style, 1024x1024, sitting next to a silver MacBook, clean white background, soft shadows, geometric shapes, no extra details."
- قيود إجبارية على إخراج الأوامر
إنجليزية بحتة، بدون صينية;
يجب أن يتضمن Apple Design Philosophy/Apple style + 1024x1024;
الطول 50-200 حرف، تحقق في الكود;
بدون تفسير إضافي أو بادئة أو كلام زائد، إرجاع الأمر فقط.
4، قواعد ربط المكونات
إنشاء ناجح: تعبئة الأمر في مربع generation_prompt، تنشيط generate_btn، إضافة "تم إنشاء الأمر بنجاح، يمكن التعديل ثم إنشاء الصورة" إلى intent_status;
إنشاء فاشل: عرض السبب المحدد (مثل فشل استدعاء API، طول غير كافٍ)، بقاء generate_btn معطلاً، مربع generation_prompt فارغ;
المستخدم يعدّل/يفرّغ مربع generation_prompt يدوياً:
عند التفريغ، تعطيل generate_btn تلقائياً;
عند عدم التفريغ، البقاء على generate_btn في حالة التنشيط.
5، معالجة الاستثناءات
فشل استدعاء API: رسالة ودية "فشل إنشاء الأمر: {رسالة الخطأ المحددة}"، بدون انهيار;
فشل التحقق من الأمر: عرض السبب بوضوح (مثل "لا يتضمن Apple style"، "الطول 40 حرفاً فقط")، السماح بإعادة المحاولة;
فشل تحليل الاستجابة: عرض "تعذر تحليل نتيجة الإرجاع من LLM، يرجى إعادة المحاولة".
6، متطلبات الإخراج
كود كامل قابل للتشغيل، فقط استبدل LLM_API_KEY للاستخدام;
هيكل كود واضح، تعليقات كاملة، واجهة جميلة ومختصرة;
تنفيذ هيكل قائمة رسائل Chat القياسي بدقة، المعلمات ومنطق المثال متسقة;
تضمين منطق التحقق من طول ومحتوى الأوامر، رسائل خطأ ودية.بنفس الطريقة، انسخ نص المرحلة الثانية للتحقق.
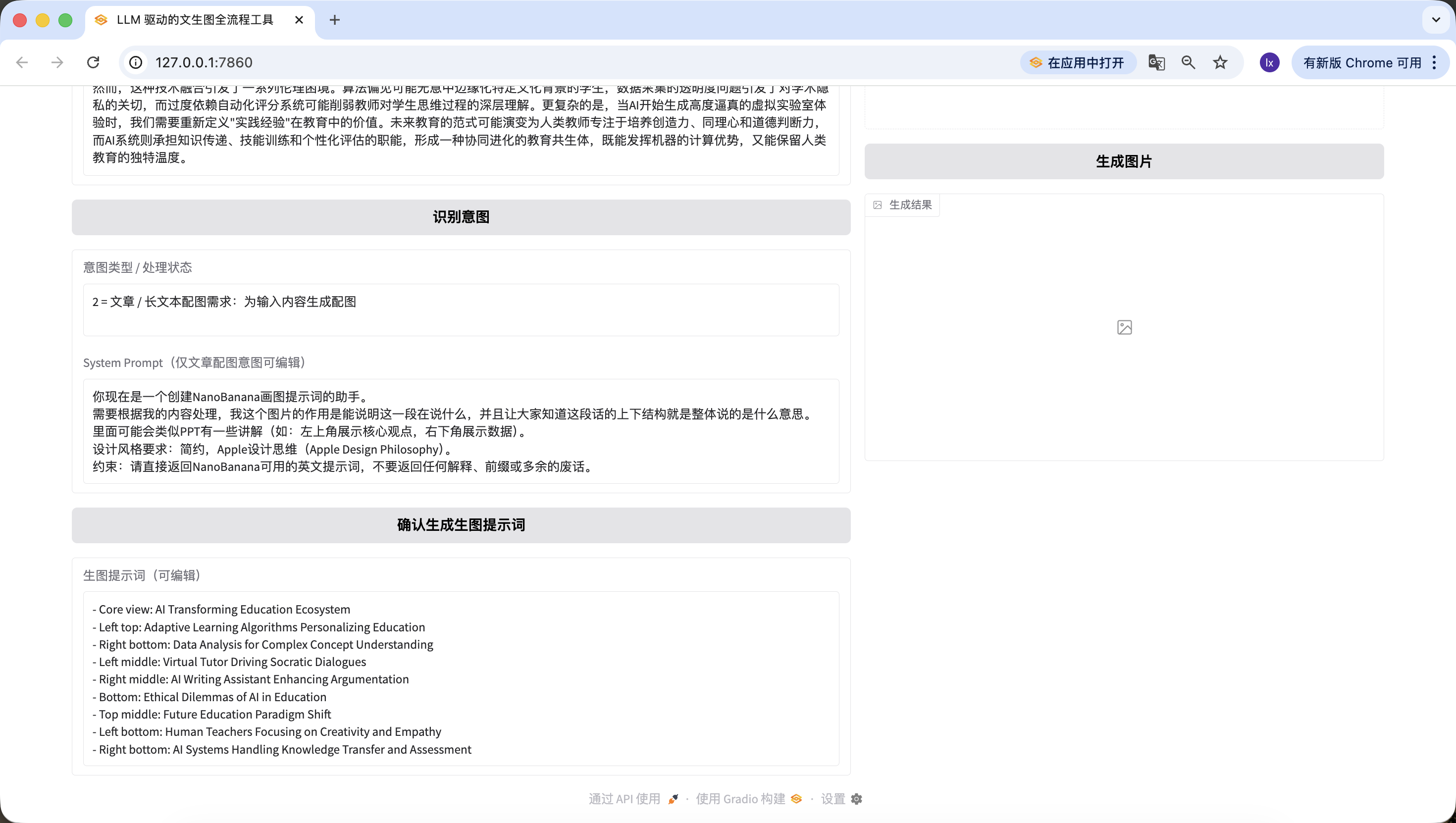
الجدير بالملاحظة أن System Patrol المُعد مسبقاً الذي قمنا بإعداده هنا لإنشاء أوامر إنشاء الصور هو:
أنت الآن مساعد ينشئ أوامر رسم لـ NanoBanana. يجب المعالجة وفقاً لمحتواي. الغرض من هذه الصورة هو توضيح ما يقوله هذه الفقرة وجعل الجميع يفهمون بنية السياق لهذا النص، أي ما يعنيه بشكل عام. قد تكون هناك شروحات مشابهة لـ PPT (مثل: الزاوية العلوية اليسرى تعرض النقطة الرئيسية، الزاوية السفلية اليمنى تعرض البيانات). متطلبات أسلوب التصميم: بسيط، فلسفة تصميم Apple (Apple Design Philosophy). القيد: أرجع مباشرة أوامر بالإنجليزية قابلة للاستخدام في NanoBanana، بدون إرجاع أي تفسير أو بادئة أو كلام زائد.
إذا كنت تريد التغيير إلى قالب مُعد مسبقاً آخر، يمكنك تعديله في الأمر السابق، أو تعديله مباشرة من خلال المحادثة في Trae.
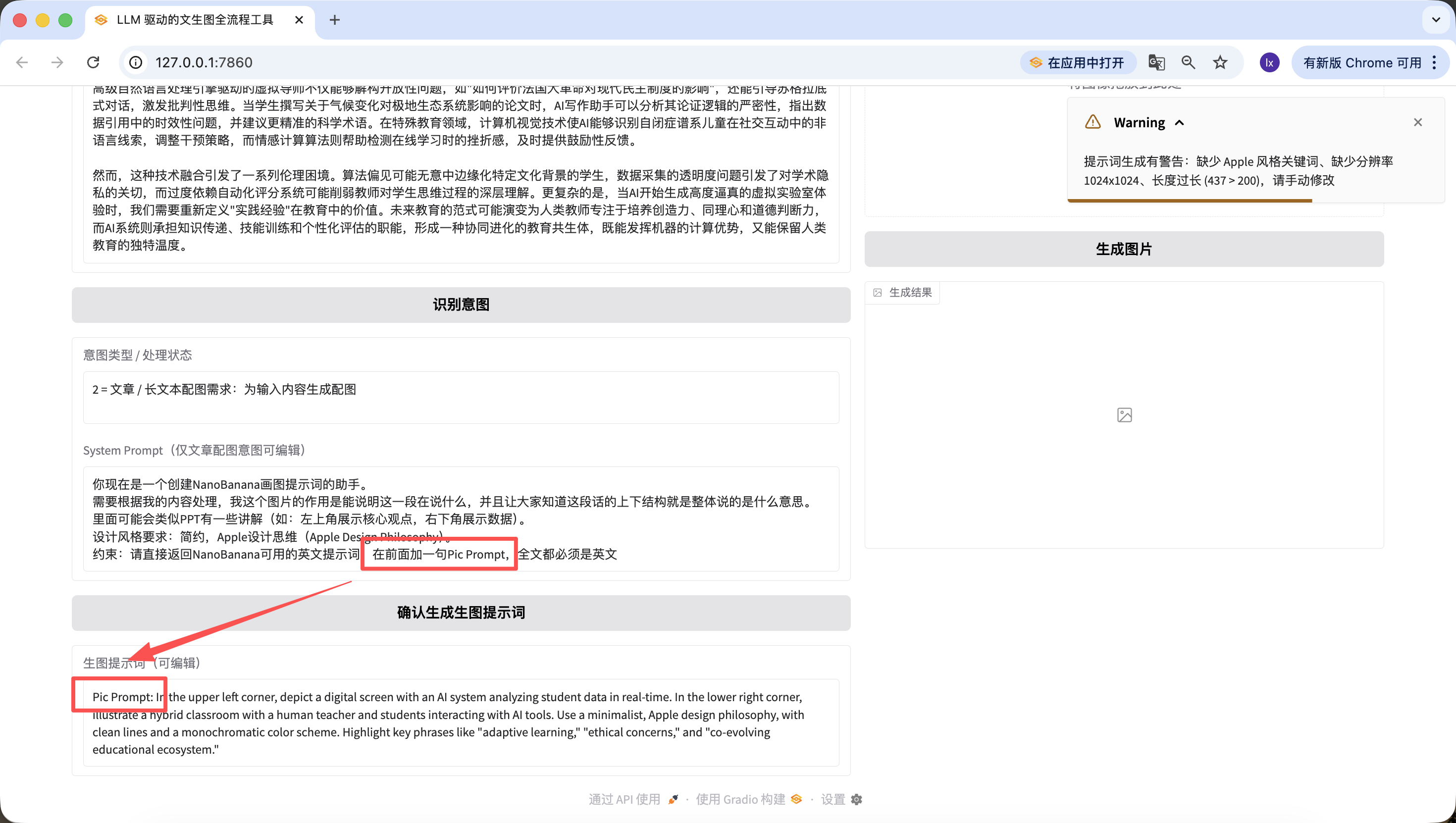
بالإضافة إلى تعديل الكود الأساسي، يمكننا أيضاً التحرير بسرعة على صفحة الويب. على سبيل المثال، أضفت هنا جملة "أضف Pic Prompt في البداية"، ويمكنك أن ترى أن الأمر الجديد المُنشأ يتضمن هذه الجملة في البداية أيضاً~ هذا التصميم هو لتسهيل التعديل السريع لـ System Patrol لإنشاء الأوامر، ومساعدتنا على تبديل الأساليب بسرعة.
المرحلة 4️⃣: وحدة النص إلى صورة / الصورة إلى صورة من Nanobanana
أخيراً وصلنا إلى الخطوة الأخيرة. بدون ربط نموذج إنشاء الصور، هذا ليس وكيلاً كاملاً!
الوحدة 4: وحدة النص إلى صورة / الصورة إلى صورة من Nanobanana (النسخة النهائية)
1، هدف المهمة
تنفيذ منطق زر "إنشاء صورة"، واستدعاء API الحقيقي لـ Nanobanana، ودعم النص إلى صورة / الصورة إلى صورة، وتحليل Base64 وعرض الصورة.
2، متطلبات المجموعة التقنية
بناءً على Gradio 4.0.0+ Blocks;
التبعيات: requests، pillow، base64، io، re;
الكود الكامل = الوحدة 1+2+3 + هذه الوحدة.
3، تكوين API الأساسي (مُثبت ومُتحقق عملياً)
تكوين الكود المُثبت:
python
تشغيل
# تكوين API المُثبت في الكود
NANOBANANA_API_URL = "https://api.zyai.online/v1/chat/completions"
NANOBANANA_MODEL = "gemini-2.5-flash-image"
NANOBANANA_API_KEY = "" # المستخدم يستبدل بنفسه
طريقة المصادقة: Header Authorization: Bearer {NANOBANANA_API_KEY}.
4، متطلبات المعالجة المسبقة للصورة (يجب تنفيذها) تنفيذ دالة image_to_base64_data_uri (ref_image_path)، المنطق الأساسي:
تحويل صورة PIL إلى تنسيق PNG;
التحجيم التلقائي إلى دقة 1024x1024;
تحويل القناة الشفافة إلى خلفية بيضاء;
الترميز كـ Base64، تنسيق الإرجاع: data:image/png;base64,...
5، قواعد بناء الطلب (اتباع منطق التفرع للنسخة العملية بدقة)
- تعريف الدالة الأساسية تنفيذ دالة generate_image (prompt، ref_image_path):
معلمات الإدخال: prompt (محتوى مربع generation_prompt)، ref_image_path (مسار الملف المرفوع إلى ref_image);
الإرجاع: PIL Image (عرض في result_image) أو رسالة خطأ.
- الفرع المنطقي 1: نص إلى صورة بحت (ref_image_path فارغ)
python
تشغيل
messages = [{"role": "user", "content": prompt}]
- الفرع المنطقي 2: صورة إلى صورة (ref_image_path له قيمة)
python
تشغيل
# استدعاء دالة المعالجة المسبقة للصورة أولاً
image_base64 = image_to_base64_data_uri(ref_image_path)
messages = [{"role": "user","content": [{"type": "text", "text": prompt},{"type": "image_url", "image_url": {"url": image_base64}}]}]
6، متطلبات تحليل الاستجابة (يجب التوافق مع كلا التنسيقين) استخراج صورة Base64 من choices [0].message.content، دعم:
حقل image_url من إرجاع JSON المهيكل;
تنسيق Markdown
;
استخراج ترميز Base64 بشكل موحد، فك الترميز والتحويل إلى PIL Image للإرجاع.
7، ربط المكونات ومعالجة الاستثناءات
إنشاء ناجح: عرض PIL Image في result_image، إشعار في intent_status "تم إنشاء الصورة بنجاح";
فشل الإنشاء / التحليل / الرفع: عرض إشعار نصي واضح في intent_status (مثل "فشل تحليل Base64"، "انتهت مهلة استدعاء API")، بدون انهيار.
8، متطلبات الإخراج
كود كامل قابل للتشغيل، فقط استبدل LLM_API_KEY و NANOBANANA_API_KEY للتشغيل مباشرة، التدفق الكامل قابل للاستخدام، منطق التفرع متطابق بدقة مع النسخة العملية.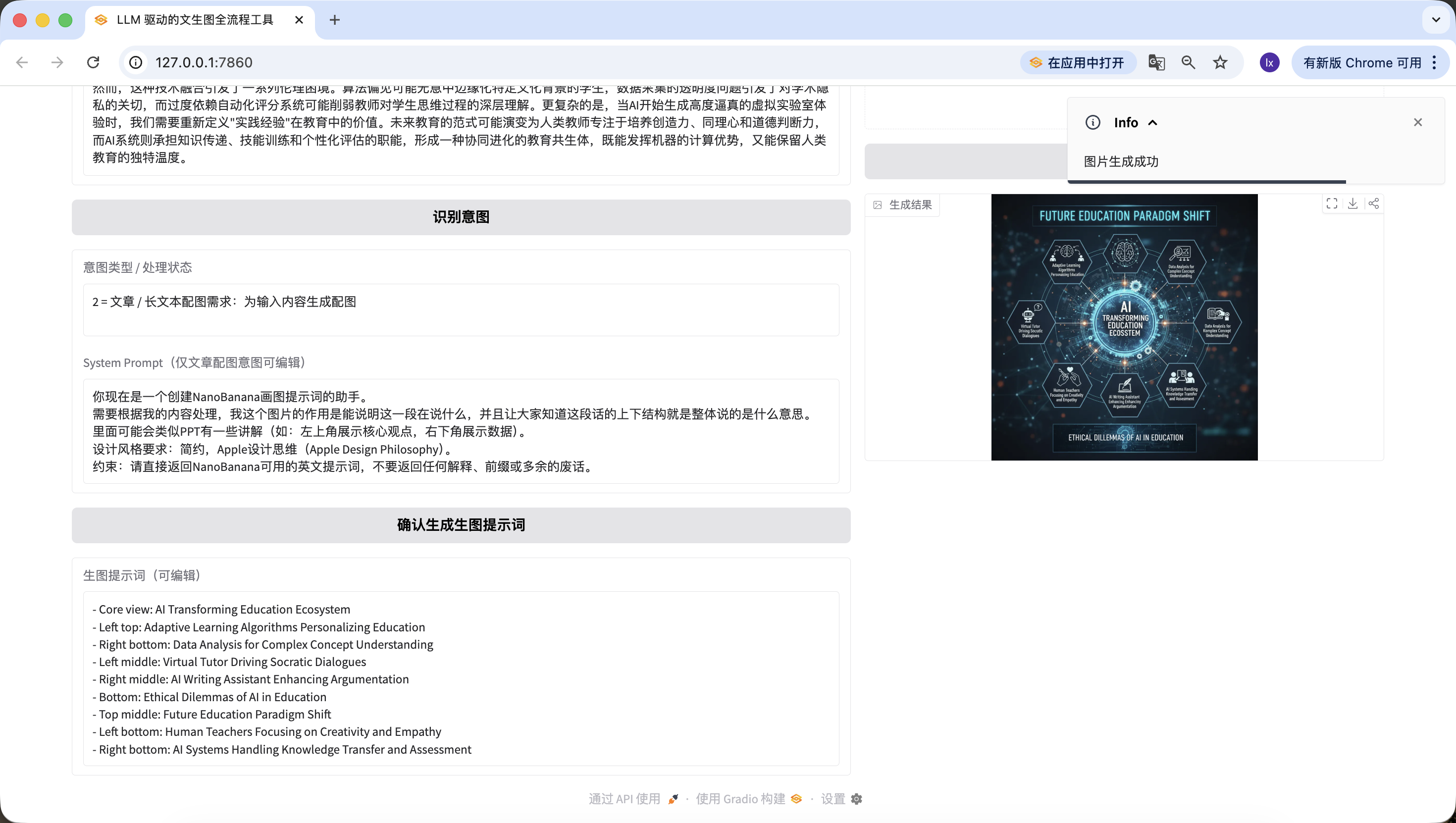
كم هو مثير! أخيراً أنشأنا بنجاح الصورة الأولى من هذا الوكيل. انظر بعناية إلى الصورة المُنشأة، إنها متطابقة مع نصنا وأمرنا. إلى هنا تكون قد نفذت وكيلك الخاص بشكل أساسي!

أضفنا أيضاً وظيفة الصورة إلى صورة. ارفع صورتك المفضلة وسيشير الذكاء الاصطناعي تلقائياً إلى الأسلوب.
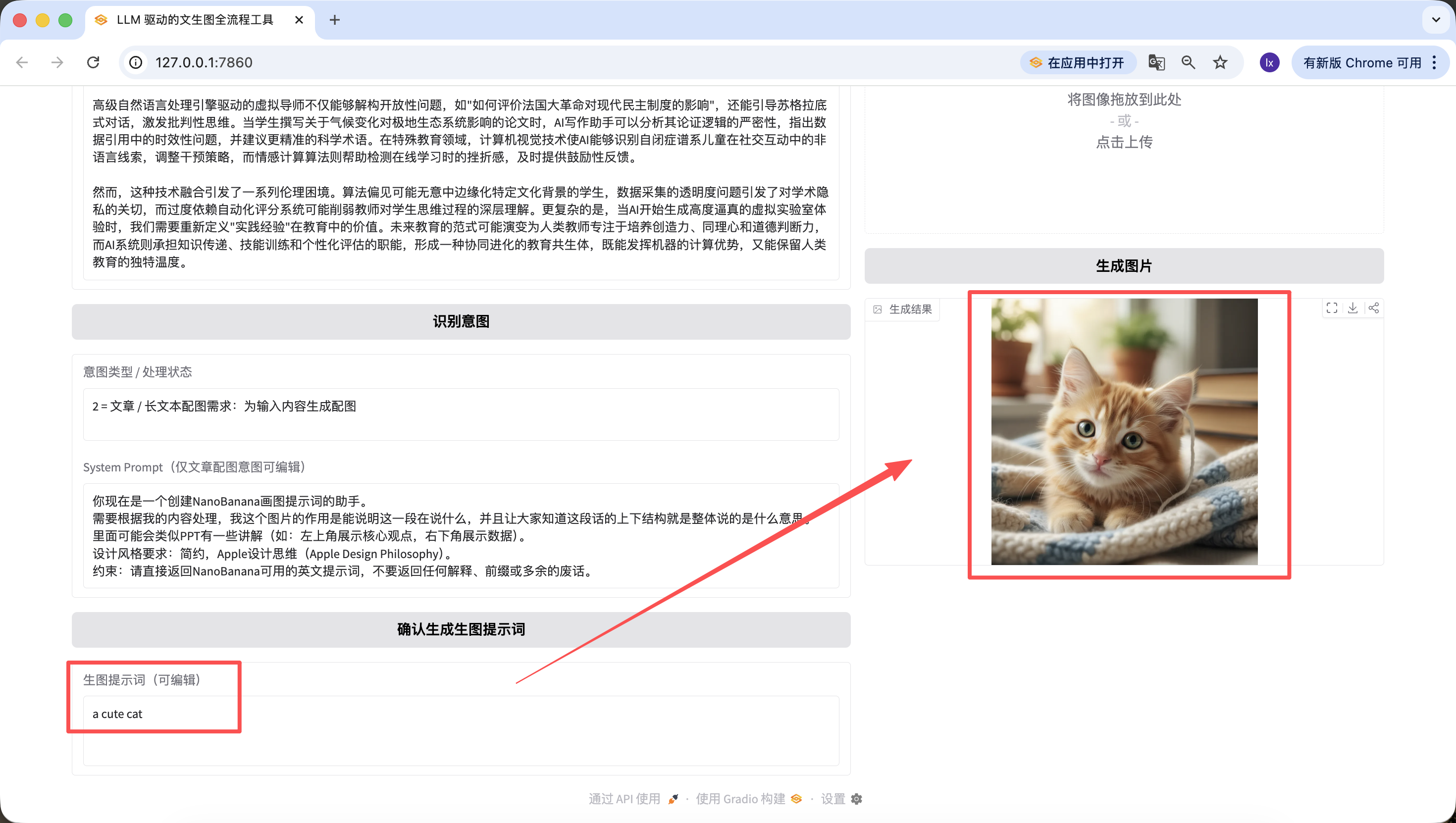
الجدير بالإشارة أن الأوامر المُنشأة في الخطوات السابقة قابلة للتحرير أيضاً على صفحة الويب، ونحن نعتمد على الأمر عند النقر النهائي على الزر~ حتى لو قمت بتغييره هنا إلى "a cute cat"، ستكون الصورة النهائية المُنشأة قطة لطيفة.
الفصل الرابع: ملخص

أخيراً انتهينا! بصراحة، حتى أنا تنفست الصعداء عندما كتبت السطر الأخير، فما بالك بمن تبعني حتى هنا. إنجاز هذا التدفق الكامل من البداية إلى النهاية أمر رائع في حد ذاته. هذا يدل على أنك وضعت يديك فعلاً على لوحة المفاتيح وأنجزت الأمور خطوة بخطوة. Bravo 🎉 🥳 👏
أثناء كتابة هذا المحتوى، كنت أفكر دائماً: ما الذي نريد تركه بالضبط؟ الإجابة في الحقيقة ليست أسماء النماذج أو المعلمات أو أسلوباً ثابتاً، بل مساعدتك على بناء إحساس تدريجياً: أي الأشياء يمكنك أن تثق فيها الذكاء الاصطناعي ليفهم ويخطط، وأي الأماكن تحتاج فقط أنت لتحديد الاتجاه. بمجرد أن تؤسس هذه القسمة للعمل، ستبدأ العديد من عمليات الإنشاء التي كانت تبدو معقدة في السابق بالانسياب.
بالنظر إلى الوراء، هذا الطريق ليس معقداً في الحقيقة. فكر بوضوح في المشكلة التي تريد حلها، سلم النص الطويل لنموذج اللغة لتفكيكه، ثم مرر النية البصرية المرتبة لنموذج إنشاء الصور للتعبير عنها، وأخيراً غلف هذا التدفق بالكامل كمساعد صغير خاص بك. عند هذه النقطة، لم تعد "تستخدم نموذجاً"، بل تبني نظاماً يمكنه مرافقتك في العمل على المدى الطويل. وهذا هو بالضبط ما يريد هذا البرنامج التعليمي أن يقدمه لك.
لكنك قمت بعمل رائع بالفعل! من تعلموا حتى هنا لديهم بالفعل فهم مبدئي لـ Vibe Coding. خذ استراحة قصيرة!