من قاعدة البيانات إلى Supabase
في الدرس السابق، تعلمنا الاستخدام الأساسي لأدوات تصميم واجهة المستخدم MasterGo وFigma، وكيفية استخدام GitHub للحصول على الكود وإدارة الإصدارات، ونشر مواقعنا الإلكترونية عبر Zeabur لتوصيل تطبيقاتنا ومواقعنا إلى المزيد من المستخدمين.
لمساعدتكم على ربط المعرفة بشكل أفضل، قبل أن نبدأ المحتوى الجديد حول أدوات التصميم والنشر في هذا الدرس، دعونا نراجع بسرعة النقاط المعرفية الأساسية من الدرس السابق من خلال بعض الأسئلة البسيطة:
- ما هي أدوات تصميم الواجهة الأمامية، تعريف Figma وMasterGo وطرق استخدامهما.
- الطرق الأساسية لتحويل التصاميم إلى كود.
- ما هو GitHub، كيفية تهيئة SSH، وكيفية إنشاء مستودعك الأول.
- ماذا يعني النشر، كيفية استخدام Zeabur، وكيفية نشر كود GitHub أو الكود المحلي إلى الشبكة العامة ليتمكن الجميع من الوصول إليه.
إذا كانت هناك أي نقطة من النقاط المذكورة أعلاه لا تزال غامضة، ننصحك بمراجعة وثائق وملاحظات الدرس السابق أولاً. مرحب بك دائماً لطرح أسئلتك في مجموعة التعلم عبر WeChat.
في هذا الدرس، سنتعلم كيفية تحويل تطبيق/موقع إلكتروني من مجرد تطبيق يعمل إلى تطبيق أقرب إلى المنتج الحقيقي المتاح عبر الإنترنت: بالإضافة إلى استخدام قاعدة بيانات لإدارة التغيرات المختلفة في البيانات أثناء تشغيل البرنامج، يجب أن يتضمن أيضاً نظام مستخدمين متكامل (التسجيل، تسجيل الدخول، الصلاحيات، إلخ) وقدرات خلفية أساسية أخرى. سنتخذ من منصة الخدمات الخلفية Supabase كخط رئيسي، وسنستخدمها أولاً لتحقيق وظيفتي "قاعدة البيانات + نظام المستخدمين" كقدرتين أساسيتين، ثم سنتخذ من المكونات التي توفرها Supabase كمرجع لفهم أعمق للوحدات الأساسية التي تتضمنها خدمات الخلفية السحابية الحديثة عادةً، والوظائف المحددة والمنطق التشغيلي لكل وحدة.
ما ستتعلمه
- ما هي البيانات، ما هي قاعدة البيانات، قواعد البيانات الشائعة وطرق استخدامها
- ما هو Supabase، وكيفية استخدام Supabase لإجراء عمليات قاعدة البيانات الأساسية
- كيفية استخدام Supabase لإضافة وظائف إدارة المستخدمين الأساسية للتطبيق
- تعلم الوظائف المتقدمة في Supabase: Realtime، Storage، Edge Function
- تعلم كيفية إضافة دعم تسجيل الدخول عبر Google وGitHub إلى Supabase
- تطبيق أساسي يدعم تسجيل/تسجيل دخول المستخدمين، ويمكنه تخزين البيانات في قاعدة بيانات عبر الإنترنت
- قالب كود خلفي قابل لإعادة الاستخدام لـ Supabase (قاعدة بيانات + إدارة المستخدمين، إلخ)، يمكن استخدامه مباشرة في المشاريع اللاحقة
1. ما هي قاعدة البيانات
1.1 ما هي البيانات
في العالم الرقمي، البيانات (Data) موجودة في كل مكان. ببساطة، البيانات هي حاملة المعلومات. بيانات الاتصال لصديقك، مقالة على WeChat، مقطع فيديو قصير، مستوى الشخصية في لعبة - كل هذه بيانات. في تطبيقنا، البيانات هي كل المعلومات التي تحتاج إلى تسجيلها وإدارتها، مثل الملفات الشخصية للمستخدمين، وسجل الطلبات، وإعدادات البرنامج.
بشكل عام، تأخذ البيانات أشكالاً مختلفة في البرنامج، وأبسطها هو المتغير، حيث يمكننا استخدام متغيرات مختلفة لتسجيل أرقام بسيطة:
# Python variable definition examples
# Integer variable: stores age information
age = 30
# Boolean variable: stores status (whether active)
is_active = True # True means active, False means inactive
# List variable: stores a set of score data
scores = [85, 92, 78, 90] # Contains 4 integer elements representing different scores
# Dictionary variable: stores multiple related information of a user
user_info = {
"age": 30, # Key "age" corresponds to the value of age
"height": 1.80, # Key "height" corresponds to the value of height (unit: meter)
"login_count": 156 # Key "login_count" corresponds to the value of login times
}أما بالنسبة للبيانات المعقدة مثل الملفات الشخصية وسجل الطلبات المذكورة أعلاه، فيمكننا استخدام جداول أكثر تعقيداً لتمثيل البيانات:
| user_id | name | |
|---|---|---|
| 1001 | Alice | alice@example.com |
| 1002 | Bob | bob@example.com |
| order_id | user_id | amount | status |
|---|---|---|---|
| 901 | 1001 | 29.99 | completed |
| 902 | 1002 | 15.50 | pending |
ولكن بالنسبة للبيانات ذات الهيكل المعقد أو ذات العلاقات الهرمية أو الحقول غير الثابتة، يمكننا استخدام تنسيق JSON للوصف - فهو تنسيق بيانات وسيط عام على الإنترنت، يمكن لجميع البرامج تقريباً قراءته وتحليله، وهو مريح جداً لنقل البيانات بين الأنظمة. على سبيل المثال، قد يحتوي طلب واحد على منتجات متعددة، ولكل منتج اسمه وكميته وسعره. سيكون تمثيل ذلك بجدول تقليدي مرهقاً: إما تقسيمه إلى جداول متعددة مثل "جدول الطلبات" و"جدول المنتجات"، والاعتماد على حقول الربط لإظهار علاقة "الطلب يحتوي على منتجات"؛ أو استخدام حقول مكررة مثل "اسم المنتج 1، سعر المنتج 1، اسم المنتج 2..." في جدول واحد، وهو ما لا يمكن تكييفه عندما يكون عدد المنتجات غير ثابت؛ بينما JSON يمكنه استخدام هيكل متداخل لتوضيح المستوى الهرمي لـ "الطلب - المنتج - خصائص المنتج" بشكل مباشر ومرن.
{
"order_id": 901,
"user_id": 1001,
"amount": 29.99,
"status": "completed",
"items": [
{ "sku": "BG-001", "name": "برجر لحم بقري", "quantity": 1, "price": 18.00 },
{ "sku": "SD-003", "name": "بطاطس مقلية", "quantity": 1, "price": 6.99 },
{ "sku": "DK-002", "name": "كولا", "quantity": 1, "price": 5.00 }
],
"shipping_address": {
"street": "123 طريق حديقة التكنولوجيا",
"city": "شنتشن",
"zip_code": "518057"
}
}علاوة على ذلك، إذا فكرنا في بيانات مشفرة على شكل متجه (Vector)، فبيانات المتجه عادةً ما تكون تمثيلاً رقمياً للبيانات غير المهيكلة مثل النصوص والصور والصوتيات بعد معالجتها بواسطة نماذج الذكاء الاصطناعي (مثل نماذج Embedding). قد يكون شكلها التمثيلي:
[0.123, -0.456, 0.789, ..., -0.234] (مصفوفة تتكون من مئات أو حتى آلاف الأرقام العشرية)
بشكل عام، هناك العديد من البيانات ذات الأشكال والاستخدامات المختلفة في العالم الحقيقي التي تستحق تحليلاً مفصلاً، وكل نوع من البيانات قد يحتاج إلى قاعدة بيانات مخصصة لتخزينه، ويمكن الرجوع إلى الشكل التالي - ألا تشعر أنها كثيرة جداً؟
1.2 لماذا نحتاج إلى قاعدة بيانات
لقد تعلمنا بالفعل أن البيانات في العالم الحقيقي غالباً ما تكون ذات هيكل معقد. من أجل تخزين واستخدام هذه البيانات بكفاءة، نحتاج إلى برنامج أو حاوية مخصصة لإدارتها - وهذا هو الغرض الأصلي من إنشاء قاعدة البيانات (Database). قاعدة البيانات في جوهرها هي برنامج خاص، وظيفتها الأساسية هي تنظيم البيانات بشكل موحد، وتخزينها بأمان، وإدارتها بشكل منهجي، ودعم الاستعلام والاستدعاء بكفاءة.
تخيل، بدون قاعدة بيانات، ما هي المأزق الذي ستواجهه بيانات التطبيق؟ عندما يغلق المستخدم المتصفح أو يخرج من التطبيق، ستضيع جميع المعلومات المحملة مؤقتاً مباشرةً؛ لا يمكننا حفظ حالة استخدام المستخدم بشكل دائم (مثل معلومات تسجيل الدخول، والإعدادات المخصصة)، ولا يمكننا مشاركة البيانات الأساسية بين المستخدمين المختلفين (مثل مخزون المنتجات، وسجل الطلبات). نحتاج إلى جهاز يساعدنا في تخزين جميع بياناتنا!
ما هو أكثر مرونة هو أن طريقة نشر قاعدة البيانات يمكن اختيارها حسب الحاجة: يمكن نشرها على خادم محلي لتلبية احتياجات إدارة البيانات المحلية؛ ويمكن أيضاً نشرها على السحابة، حيث تدعم قواعد البيانات السحابية التوسع المرن (Scale)، ويمكنها توسيع قدراتها مع نمو حجم البيانات وحجم الوصول لتحمل كميات هائلة من البيانات والتزامن العالي، وحتى مع زيادة كبيرة في عدد المستخدمين، يمكنها ضمان تجربة استخدام طبيعية للمستخدمين.
بشكل موجز، تعتمد قواعد البيانات على قدرات التخزين المستمر الفعال، والإدارة الدقيقة، والاستعلام السريع، وتحل بشكل أساسي المشاكل الأساسية التالية:
- التخزين المستمر للبيانات: بدون قاعدة بيانات، ستوجد البيانات فقط في ذاكرة التطبيق، وبمجرد إغلاق التطبيق، ستضيع البيانات. تحل قاعدة البيانات هذه المشكلة من خلال تخزين البيانات بشكل مستمر على وسائط تخزين مثل الأقراص الصلبة، مما يضمن الحفظ طويل المدى للبيانات ويقلل من خطر الفقدان.
- الاستعلام والتحليل المريح للبيانات: توفر قواعد البيانات لغات استعلام قوية (مثل SQL)، مما يتيح للمستخدمين إجراء استعلامات وتصفية وتحليل معقدة للبيانات الضخمة بسهولة وفعالية، وبالتالي مساعدة المؤسسات على اتخاذ قرارات أكثر حكمة. بدون قاعدة بيانات، سيكون البحث عن معلومات محددة من عدد كبير من الملفات غير المرتبة مهمة مستهلكة للوقت وصعبة للغاية.
- دعم الأداء العالي والوصول المتزامن العالي: من خلال تقنيات مثل تحسين الفهارس، والتخزين المؤقت للاستعلامات، وتجمعات الاتصال، والبنية الموزعة، يمكن لقواعد البيانات الاستجابة لطلبات الاستعلام في غضون أجزاء من الثانية، ودعم الوصول المتزامن لآلاف المستخدمين. هذا أمر حاسم للتطبيقات الحديثة (مثل أنشطة البيع السريع على منصات التجارة الإلكترونية، والتحديثات الفورية على الشبكات الاجتماعية)، مما يضمن سرعة استجابة النظام وتجربة المستخدم. بدون الدعم عالي الأداء لقواعد البيانات، سيعاني النظام من تأخيرات خطيرة أو حتى انهيار عند مواجهة طلبات المستخدمين الضخمة.
- ضمان تكامل واتساق البيانات: تضمن قواعد البيانات دقة واتساق البيانات من خلال سلسلة من الآليات (مثل القيود والمحفزات). هذا يعني أن البيانات في قاعدة البيانات يجب أن تتوافق مع القواعد المحددة مسبقاً، على سبيل المثال، يجب أن يكون عمر المستخدم رقماً، ويجب أن يكون رقم الطلب فريداً، مما يمنع بشكل فعال إنشاء بيانات غير قانونية أو غير صالحة.
- ضمان أمان البيانات: توفر قواعد البيانات آليات أمنية قوية، بما في ذلك مصادقة هوية المستخدم، والتحكم في الوصول، وتشفير البيانات، لحماية البيانات من الوصول أو التعديل أو التخريب غير المصرح به. للتعامل مع الحوادث مثل أعطال الأجهزة، أو الأخطاء البشرية، أو الهجمات الخبيثة، توفر قواعد البيانات أيضاً وظائف النسخ الاحتياطي للبيانات واستعادتها. من خلال النسخ الاحتياطي المنتظم، يمكن استعادة البيانات في الوقت المناسب عند فقدانها أو تلفها، مما يضمن استمرارية الأعمال.
1.3 قواعد البيانات العلائقية وقواعد البيانات غير العلائقية
لقد تعلمنا بالفعل عن القيمة الأساسية لقواعد البيانات، وطرق نشرها، ومزاياها المرنة. وعند الاختيار الفعلي، أول شيء نواجهه هو الفئتان الأساسيتان لقواعد البيانات: قواعد البيانات العلائقية وقواعد البيانات غير العلائقية (NoSQL). يمكننا فهم الفرق بينهما ببساطة من خلال فقرتين:
قواعد البيانات العلائقية تشبه جداول Excel المنظمة بدقة، حيث يجب تحديد تنسيق جميع البيانات مسبقاً (تحديد محتوى Schema، مثل ضرورة وجود الاسم والعمر، ويجب أن يكون الاسم نصاً والعمر رقماً)، وربط الجداول المختلفة من خلال حقول الارتباط (معرفات تُستخدم لربط الجداول المختلفة، مثل رقم الهوية). ميزتها أن البيانات دقيقة وموثوقة، ومناسبة بشكل خاص للمشاهد التي لا تحتمل الأخطاء مثل التحويلات المصرفية وإدارة المخزون، لكن عيبها هو أن تعديل الهيكل أمر مرهق، والأداء محدود في ظل كميات البيانات الضخمة.
قواعد البيانات غير العلائقية تشبه المجلدات المرنة، حيث يمكن تخزين مستندات وصور وأزواج من القيم والمفاتيح (هيكل "كلمة - تفسير" مشابه للقاموس) بتنسيقات مختلفة، دون الحاجة إلى تحديد هيكل كل بيانات مسبقاً. إنها أكثر قدرة على التعامل مع المتطلبات سريعة التغيير والبيانات فائقة الحجم (مثل المنشورات الضخمة على وسائل التواصل الاجتماعي)، والتوسع (إضافة خوادم لتحسين الأداء) أسهل، لكنها تضحي ببعض قدرات الاستعلام العلائقي (القدرة على تنظيم المعلومات عبر جداول بيانات مختلفة) وضمانات الاتساق (التأكد من دقة البيانات وعدم تناقضها في جميع الأوقات)، وهي مناسبة للتطبيقات الإلكترونية التي تتطلب مستوى عالٍ من التسامح مع الأخطاء.
إذن، كيف تختار قاعدة البيانات في التطبيقات العملية؟ من حيث تقسيم المشاهد، تُستخدم قواعد البيانات العلائقية بشكل شائع في المعاملات المالية، وإدارة المخزون، ومعالجة الطلبات، والأنظمة المحاسبية التي تتطلب اتساقاً قوياً، ومعالجة المعاملات المعقدة، والوصول المتوازن المتكرر للقراءة والكتابة؛ بينما قواعد البيانات غير العلائقية أكثر ملاءمة لتخزين محتوى وسائل التواصل الاجتماعي، وتحليل السجلات الفورية، وكتابة البيانات الضخمة لإنترنت الأشياء، والقراءة والكتابة المكثفة لميزات أنظمة التوصية وغيرها من المشاهد عالية التزامن ذات أنماط القراءة والكتابة غير المتوازنة والهيكل المرن.
ولكن بالنسبة للمؤسسات، في المرحلة الأولية لا داعي لقضاء الكثير من الوقت في التفكير في قاعدة البيانات التي يجب استخدامها. قواعد البيانات الحالية هي خدمات منتجات ناضجة جداً، وأكثر الطرق مباشرة هو استشارة مزودي الخدمات السحابية المختلفين (يشيرون إلى مزودي الخدمات الذين يوفرون موارد وتقنيات تقنية المعلومات مثل الخوادم والتخزين وقواعد البيانات والبرمجيات وقوة الحوسبة). يمكننا التواصل مباشرة مع منصات المبيعات الرسمية للخدمات السحابية لمطابقة حلول قواعد البيانات المناسبة وفقاً لمتطلبات أعمال منتجاتنا؛ والمسار المناسب لبناء التطبيقات على مستوى المؤسسات هو إعطاء الأولوية للتعاون مع مزودين محترفين. (يرجى الملاحظة: أسعار الخدمات على مستوى المؤسسات عادة ما تكون مرتفعة، يُنصح بإجراء بحث ومقارنة من مصادر متعددة أولاً، ويمكن أيضاً اختيار شراء خوادم ونشر برامج قواعد البيانات مفتوحة المصدر بنفسك كبديل.)
يمكننا أيضاً الرجوع إلى توصيات اختيار قاعدة البيانات من أحد مزودي الخدمات السحابية، حيث يمكن اختيار أنواع قواعد بيانات مختلفة وفقاً للمشهد، ويمكنك مقارنة مواصفات قواعد البيانات من مزودين سحابيين مختلفين لاختيار الأنسب للاستخدام.
| نوع قاعدة البيانات | اسم قاعدة البيانات | السعر | المشاهد المناسبة |
|---|---|---|---|
| قاعدة بيانات علائقية | RDS MySQL | منخفض | الإصدار الأساسي: التعلم والمواقع الصغيرة؛ إصدار التوافر العالي: مشاهد قواعد البيانات المتوسطة ذات الضغط التشغيلي المعتدل؛ إصدار الكتلة: الأعمال التي لا تسمح بالانقطاع وضغط الوصول الكبير |
| RDS SQL Server | مرتفع | الإصدار الأساسي: الاختبار والمواقع التجارية الصغيرة؛ إصدار التوافر العالي: المواقع التجارية على مستوى المؤسسات؛ إصدار الكتلة: أعمال المؤسسات التي لا تسمح بالانقطاع وضغط الوصول الكبير | |
| RDS PostgreSQL | الأدنى | الإصدار الأساسي: التعلم والمواقع الصغيرة؛ إصدار التوافر العالي: مشاهد قواعد البيانات المتوسطة ذات الضغط التشغيلي المعتدل؛ إصدار الكتلة: المشاهد التي لا تسمح بانقطاع الأعمال وضغط الوصول الكبير، أداؤها أعلى من MySQL العادي | |
| RDS PPAS | مرتفع | النوع العام: متوافق مع أعمال Oracle، لكن ضغط الأعمال منخفض، والافتراضية يمكن تلبيته؛ النوع الحصري: للأعمال التي تتطلب خادماً مادياً حصرياً، عادة ما تكون أعمال Oracle عالية التزامن | |
| DRDS | متوسط | إصدار الدخول: 4 نوى 8 جيجابايت، سعر مناسب، مناسب للأعمال الإلكترونية الصغيرة والمتوسطة؛ إصدار المؤسسات: 16 نواة 32 جيجابايت، استجابة SQL المعقدة جيدة، مناسب للأعمال الإلكترونية ذات التزامن الفائق؛ الإصدار الأعلى: 32 نواة 64 جيجابايت، أفضل استجابة لتنفيذ SQL المعقد | |
| قاعدة بيانات NoSQL | Redis | متوسط | Redis الاحتياطي السريع المزدوج: عادة كقاعدة بيانات ثابتة لتحسين توافر الأعمال؛ إصدار الكتلة من Redis: عادة كطبقة تخزين مؤقت لتسريع وصول التطبيقات وحل ضغط القراءة الذي لا يمكن لقواعد البيانات العادية تحمله |
| MongoDB | متوسط | مثيل العقدة المفردة: مناسب للتطوير والاختبار ومشاهد تخزين البيانات غير الأساسية للمؤسسات؛ مثيل مجموعة النسخ: مناسب للمشاهد التي تتطلب أداء قراءة أعلى لقاعدة البيانات؛ مثيل الكتلة المجزأة: يوفر متطلبات أداء قراءة أعلى للأعمال الفورية عبر الإنترنت |
الكلام وحده ليس كافياً للفهم، دعونا نأخذ مشهد "مقالات المدونة" كمثال محدد لنرى كيف يتم تخزين نفس البيانات في قاعدة البيانات العلائقية (SQL) وأنواع مختلفة من قواعد البيانات غير العلائقية (NoSQL).
لنفترض أن لدينا منصة مدونة تحتاج إلى تخزين المعلومات التالية:
- المستخدمون (Users): معرف المستخدم، اسم المستخدم، البريد الإلكتروني
- المقالات (Posts): معرف المقالة، العنوان، المحتوى، معرف المؤلف
- التعليقات (Comments): معرف التعليق، محتوى التعليق، معرف المعلق، معرف المقالة المنتمي إليها
- الوسوم (Tags): معرف الوسم، اسم الوسم
- علاقة المقالات بالوسوم: الوسوم المتعددة المرتبطة بمقالة واحدة، المقالات المتعددة المرتبطة بوسم واحد
مثال على قاعدة البيانات العلائقية (SQL)
في قاعدة بيانات SQL، سنقوم بتخزين أنواع مختلفة من البيانات في جداول منفصلة، وربطها من خلال "المفاتيح الخارجية". هذا الهيكل واضح ومنظم ويقلل من تكرار البيانات.
باستخدام "إدارة مقالات منصة المحتوى" كمثال، لن نقوم بخلط "المستخدمين، المقالات، التعليقات، الوسوم" معاً، بل نقسمها إلى 5 جداول بوظائف فردية، لكل جدول "حدود مسؤولية" واضحة وتعريف هيكلي صارم (Schema):
- جدول
users(تخزين معلومات المستخدمين)
| user_id (مفتاح أساسي) | username | |
|---|---|---|
| 101 | Alice | alice@example.com |
| 102 | Bob | bob@example.com |
- جدول
posts(تخزين معلومات المقالات)
| post_id (مفتاح أساسي) | title | content | author_id (مفتاح خارجي) |
|---|---|---|---|
| 1 | مقدمة إلى SQL | هذه مقالة عن قواعد بيانات SQL... | 101 |
| 2 | مدخل إلى NoSQL | NoSQL توفر نموذج بيانات مرناً... | 102 |
- جدول
comments(تخزين معلومات التعليقات)
| comment_id (مفتاح أساسي) | body | commenter_id (مفتاح خارجي) | post_id (مفتاح خارجي) |
|---|---|---|---|
| 1001 | مكتوب بشكل رائع! | 102 | 1 |
| 1002 | تعلمت منه. | 101 | 2 |
| 1003 | هل هناك أمثلة أخرى؟ | 101 | 1 |
- جدول
tags(تخزين الوسوم)
| tag_id (مفتاح أساسي) | tag_name |
|---|---|
| 51 | قاعدة بيانات |
| 52 | تقنية |
| 53 | مدخل |
- جدول
post_tags(تخزين علاقة العديد للعديد بين المقالات والوسوم، يعكس خصائص ربط الجداول)
| post_id (مفتاح خارجي) | tag_id (مفتاح خارجي) |
|---|---|
| 1 | 51 |
| 1 | 52 |
| 2 | 51 |
| 2 | 52 |
| 2 | 53 |
إذا كنت بحاجة إلى الاستعلام عن "المعلومات الكاملة لمقالة (مقدمة إلى SQL) (post_id=1) المنشورة من قبل Alice (بما في ذلك محتوى المقالة، المؤلف، التعليقات، الوسوم)"، فستحتاج إلى تنفيذ استعلام ربط جداول متعددة (JOIN)، وربط 5 جداول من خلال المفاتيح الخارجية وتجميع البيانات. بيان SQL كالتالي:
SELECT
p.title,
p.content,
u.username AS author,
c.body AS comment,
t.tag_name AS tag
FROM
posts p
JOIN
users u ON p.author_id = u.user_id
LEFT JOIN
comments c ON p.post_id = c.post_id
LEFT JOIN
post_tags pt ON p.post_id = pt.post_id
LEFT JOIN
tags t ON pt.tag_id = t.tag_id
WHERE
p.post_id = 1;هذا الاستعلام سيعبر 5 جداول، ويعيد جميع البيانات ذات الصلة مجمعة معاً. هذه هي الميزة الأساسية لقواعد البيانات العلائقية: من خلال التطبيع وعمليات الربط، يمكن إجراء استعلامات معقدة متنوعة بمرونة، مع ضمان اتساق البيانات والحد الأدنى من التكرار.
مثال على قاعدة البيانات غير العلائقية (NoSQL)
فكرة تصميم قواعد بيانات NoSQL (مثل MongoDB، Redis) معاكسة لـ SQL، فهي لا تؤكد على تقسيم البيانات وتطبيعها، وعادة ما تقوم بتجميع جميع البيانات المرتبطة أعمالياً معاً لتقليل عمليات الربط أثناء الاستعلام، وبالتالي تحسين أداء القراءة.
في قواعد بيانات NoSQL، قواعد البيانات الوثائقية (Document Database) هي واحدة من الأنواع الأكثر استخداماً، وMongoDB هي ممثل نموذجي. تستخدم "المستند" كوحدة تخزين أساسية، وهنا "المستند" ليس ما نفهمه عادةً من "مقالة"، بل هو بنية بيانات مشابهة لـ JSON (في MongoDB يتم استخدام تنسيق BSON فعلياً، والذي يدعم المزيد من أنواع البيانات): لا حاجة لتعريف Schema موحد (هيكل البيانات) مسبقاً، يمكن زيادة أو تقليل حقول كل مستند بمرونة، ويمكن تعديل أنواع الحقول بحرية، مما يتناسب بشكل مثالي مع المشاهد ذات تنسيقات البيانات المتغيرة.
في قاعدة بيانات المستندات، عادة ما يتم تخزين مقالة واحدة وجميع المعلومات ذات الصلة (مثل التعليقات، الوسوم) في مستند واحد (تنسيق المستند مشابه لـ JSON، يمكن تعريف الحقول بمرونة، دون الحاجة لصياغة Schema مسبقاً). المنطق الأساسي هو "تخزين 'المعلومات الكاملة تحت سيناريو أعمال واحد' في مستند واحد"، لتجنب ربط مصادر بيانات متعددة أثناء الاستعلام.
مثال على مستند في مجموعة posts:
{
"_id": 1,
"title": "مقدمة إلى SQL",
"content": "هذه مقالة عن قواعد بيانات SQL...",
"author": {
"user_id": 101,
"username": "Alice",
"email": "alice@example.com"
},
"tags": [
"قاعدة بيانات",
"تقنية"
],
"comments": [
{
"comment_id": 1001,
"body": "مكتوب بشكل رائع!",
"commenter": {
"user_id": 102,
"username": "Bob"
}
},
{
"comment_id": 1003,
"body": "هل هناك أمثلة أخرى؟",
"commenter": {
"user_id": 101,
"username": "Alice"
}
}
]
}ميزة هذا التصميم بديهية جداً: عندما تحتاج إلى الحصول على "المعلومات الكاملة للمقالة الأولى (بما في ذلك المؤلف والتعليقات والوسوم)"، تحتاج فقط إلى الاستعلام عن هذا المستند الواحد من خلال _id:1، وستعيد قاعدة البيانات جميع البيانات بقراءة واحدة، دون الحاجة لتنفيذ 3-4 عمليات ربط جداول كما في SQL، مما يحسن كفاءة القراءة بشكل كبير.
لكن هناك أيضاً مقايضة (trade-off) واضحة: نظراً لأن البيانات "مخزنة بشكل تجميعي"، سيحدث تكرار في البيانات حتماً - على سبيل المثال، اسم المستخدم username للمؤلفة "Alice" مدمج في كل مستند مقالة كتبتها، وإذا قامت "Alice" بتغيير اسم المستخدم إلى "Alice_New" يوماً ما، فستحتاج نظرياً إلى المرور على جميع مستندات المقالات التي تحتوي على معلوماتها، وتحديث حقل author.username واحداً تلو الآخر، وهو أمر مرهق في التشغيل، وقد يؤدي أيضاً إلى فشل تحديث بعض المستندات بسبب مشاكل في الشبكة أو الخادم، مما يؤدي إلى ظهور "نفس المستخدم باسم مستخدم مختلف في مقالات مختلفة".
لكن في الممارسة العملية، هذا التكرار غالباً ما يكون "مقبولاً": بالنسبة للمشاهد التي تكون فيها القراءة أكثر من الكتابة (القراءة المتكررة) (مثل المدونات، والأخبار، وتفاصيل منتجات التجارة الإلكترونية)، حيث يكون عدد مرات مشاهدة المستخدمين للمحتوى أكبر بكثير من عدد مرات تعديل المؤلفين لأسماء المستخدمين، فالتضحية بقليل من التكرار مقابل "أداء قراءة فائق" هو الخيار الأفضل؛ أما إذا كان المشهد "كتابة أكثر من القراءة" (مثل التعديلات المتكررة لمعلومات المستخدم)، فستحتاج إلى الموازنة بين متطلبات العمل لتحديد ما إذا كنت ستستخدم قاعدة بيانات المستندات.
ما سبق هو مقدمة بسيطة لقواعد البيانات المختلفة، إذا كنت مهتماً بأنواع محددة أكثر من قواعد البيانات، يمكنك الرجوع إلى الموارد التالية لتجربة أنواع مختلفة من قواعد البيانات.
أمثلة على قواعد بيانات SQL: Db2، MySQL، PostgreSQL، YugabyteDB، CockroachDB، Oracle Database، Azure SQL Database
أمثلة على قواعد بيانات NoSQL: Redis، CouchDB، MongoDB، Cassandra، Elasticsearch، BigTable، Neo4j، HBase
2. Supabase
فيما سبق قدمنا عدة أنواع شائعة من قواعد البيانات ومشاهد الاستخدام المناسبة لكل منها. لكن في المشاريع الحقيقية، قاعدة البيانات عادة ما تكون مجرد وحدة أساسية في نظام الخلفية: بالإضافة إلى تخزين البيانات واستعلامها، تحتاج أيضاً إلى حل مجموعة كاملة من المشاكل مثل تسجيل المستخدمين وتسجيل الدخول، والتحقق من الصلاحيات، ورفع الملفات وتخزينها، واجهات API الخارجية، وحتى المهام المجدولة والإشعارات الفورية. مجرد اختيار قاعدة بيانات جيدة لا يجعل تطبيقك "جاهزاً للإطلاق فوراً"، فهناك لا يزال الكثير من أعمال الهندسة الخلفية المرهقة بينهما.
لذا، نحتاج إلى النظر في سياق أوسع: خدمات الخلفية. التطبيق الكامل يتكون عادةً من "واجهة أمامية + خلفية": الواجهة الأمامية مسؤولة عن عرض الصفحات وتفاعل المستخدم، بينما الخلفية مسؤولة عن تخزين البيانات، وتسجيل دخول المستخدمين، ومعالجة منطق الأعمال. في الماضي، كان المطورون يحتاجون في كثير من الأحيان إلى بناء خوادمهم الخاصة، وتهيئة قواعد البيانات، وتصميم وتنفيذ API، والتعامل يدوياً مع إدارة الصلاحيات، واستراتيجيات الأمان، والقابلية للتوسع، والمراقبة والصيانة، وكانت العملية بأكملها متكررة وتستغرق وقتاً طويلاً. لحل هذه الأعمال المتكررة، ظهرت في الصناعة BaaS (Backend as a Service، الخلفية كخدمة): التي تحزم وظائف الخلفية الشائعة مثل قواعد البيانات، ومصادقة المستخدمين، وتخزين الملفات، والقدرات الفورية في منصة سحابية، ويمكن للمطورين استدعاء هذه القدرات مباشرة من خلال SDK/API، دون الحاجة لبناء وصيانة البنية التحتية من الصفر.
في هذا السياق، يمكن النظر إلى Supabase كممثل للجيل الجديد من BaaS: تستخدم PostgreSQL كقاعدة بيانات أساسية، وتدمج فوقها مجموعة كاملة من قدرات الخلفية مثل Auth وStorage وRealtime وEdge Functions وVector، مما يوفر للمطورين "منصة خلفية شاملة تتمحور حول Postgres". بعد ذلك، سنتخذ من هذه الزاوية، وننتقل من "اختيار قاعدة بيانات فقط" إلى "اختيار منصة تطوير خلفية كاملة"، لنرى بالتحديد أي الأعمال يمكن لـ Supabase أن توفرها علينا، وكيف يمكنها تقصير المسافة من النموذج الأولي إلى المنتج القابل للاستخدام بشكل كبير.
2.1 دليل خطوة بخطوة
بعد الفهم الواضح للتموضع العام لـ Supabase، سنقوم بعد ذلك بتفكيك القدرات الأساسية التي يوفرها بالتحديد على طول مسار عمليات لوحة تحكم Supabase، والمسؤوليات الأساسية لكل قدرة. سنقدم بالتفصيل كل خيار يتضمنه Supabase لمساعدتك على البدء بسرعة في العمليات الأساسية لـ Supabase.

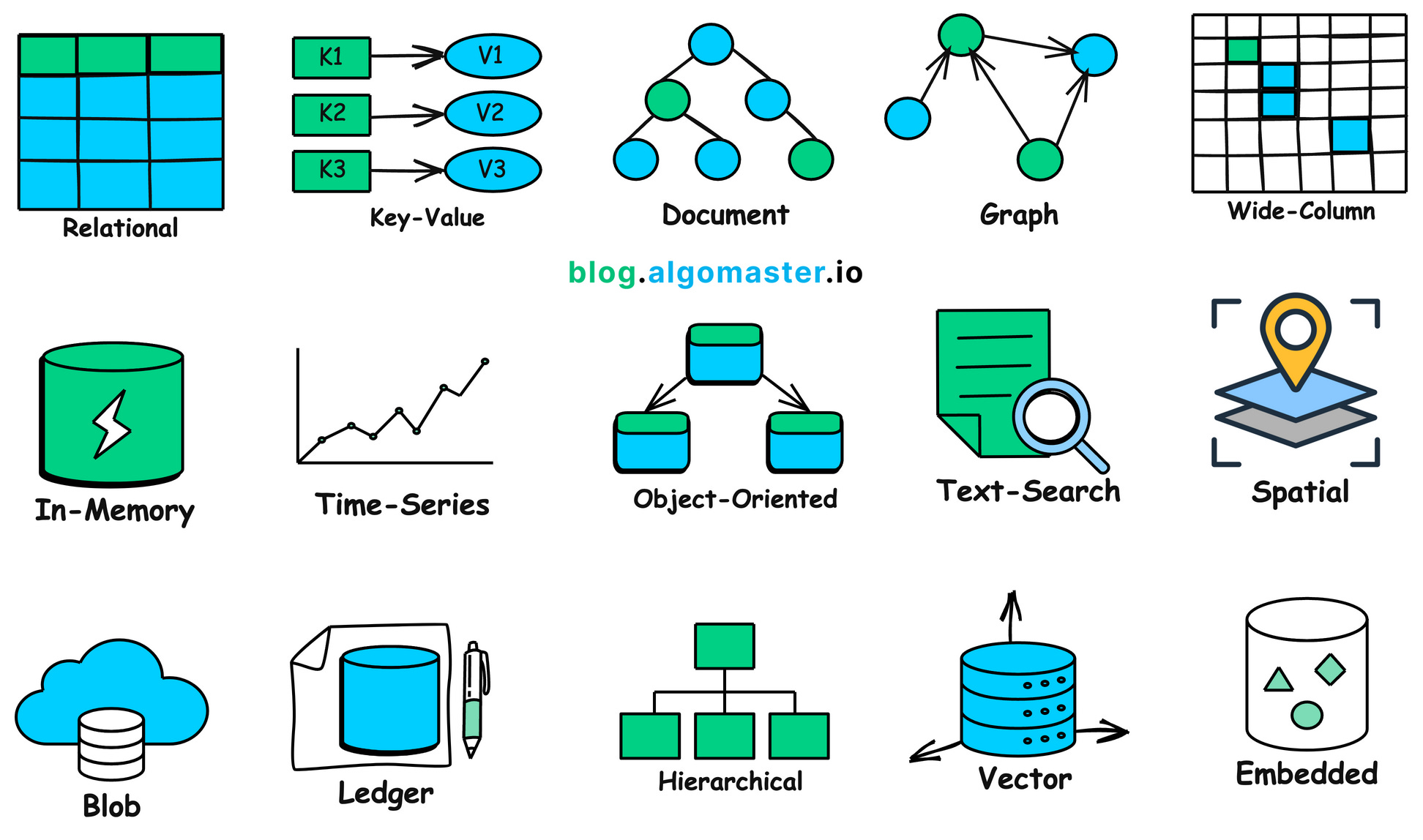
بعد زيارة الموقع الرسمي لـ Supabase وتسجيل الدخول، انقر على New project في الصفحة الرئيسية للوحة التحكم للدخول في عملية الإنشاء؛
أدخل المحتوى الرئيسي الذي يحتاج إلى تهيئة: اسم المشروع Project Name، وكلمة مرور قاعدة البيانات. أما المنطقة فيكفي اختيار الأقرب للمستخدمين المستهدفين لبرنامجك.
بعد الإنشاء الناجح، ستعرض الشريط الجانبي الأيسر في لوحة التحكم جميع وحدات الوظائف الأساسية (Table Editor، SQL Editor، Database، Authentication، إلخ)، وستتمحور العمليات اللاحقة حول هذه الوحدات.
محرر الجداول
يمكن اعتبار Table Editor كمحرر جداول بيانات مرئي في Supabase، يتيح لك عرض وتعديل البيانات في قاعدة البيانات مباشرة كما تعمل مع Excel، دون الحاجة لكتابة عبارات SQL، حيث يمكنك تعديل محتوى البيانات من خلال تفاعل الماوس فقط.
من بين ما يجدر الانتباه إليه Schema، والذي يمكن فهمه كـ "حاوية موارد" داخل قاعدة البيانات، تُستخدم لإدارة مجموعات من الجداول، والطراف، والدوال، والفهارس، ووظيفتها الأساسية اثنتان: الأولى هي تجنب تعارض الأسماء (يمكن وجود جدول بنفس الاسم تحت Schema مختلف)، والثانية是实现 عزل الصلاحيات (مثل السماح فقط لمستخدمين محددين بالوصول إلى الجداول تحت Schema معين)؛
يمكنك النقر على القائمة المنسدلة Schema في أعلى المحرر للتبديل بين الحاويات المختلفة، وفي التطوير اليومي تحتاج عادةً فقط للانتباه إلى نوعين:
public: حاوية الموارد العامة الافتراضية، حيث يتم تخزين جميع جداول الأعمال التي أنشأها المطورون (مثل "جدول المقالات" و"جدول التعليقات")؛auth: حاوية مخصصة لمصادقة المستخدمين، حيث يقوم جدولusersتلقائياً بتخزين معلومات جميع المستخدمين المسجلين (مثل معرف المستخدم، البريد الإلكتروني، وقت تسجيل الدخول)، ولا يُنصح بتعديل الجداول الافتراضية تحت هذا Schema يدوياً، لتجنب التأثير على وظائف المصادقة؛
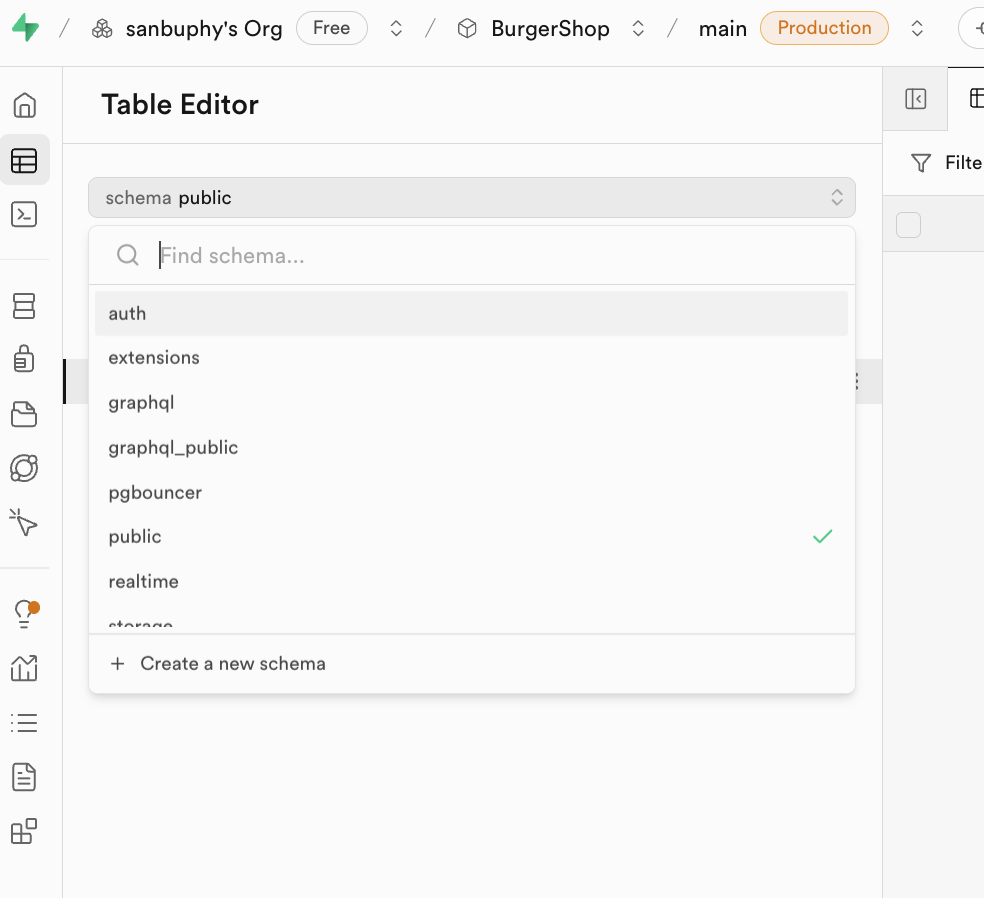

محرر SQL
يعمل SQL Editor كمنفذ لتنفيذ عبارات SQL في Supabase، ويتيح لك تشغيل قاعدة البيانات مباشرة من خلال الكود. يمكنك جعل النماذج الكبيرة تولد عبارات SQL مباشرة، وإدخالها على اليمين والنقر على RUN لإنشاء أو تعديل الجداول، ويمكنك أيضاً رؤية بيانات الجداول المفلترة مباشرة في Results.
يمكنك بعد تشغيل RUN، العثور على جدول البيانات المنشأ حديثاً في public schema في Table Editor؛ وسيتم حفظ العبارات المنفذة في عمود PRIVATE على اليسار، ويمكنك حتى النقر على رمز القلب أدناه لإضافة عبارة الاستعلام أو الإنشاء هذه إلى المفضلة.
مركز إدارة قاعدة البيانات
Database هو مركز إدارة قاعدة البيانات في Supabase، يدعم عرض وإدارة جميع جداول البيانات بصرياً، وفهم العلاقات بين الجداول المختلفة من خلال خطوط الربط (أي قيود المفاتيح الخارجية، التي تمثل علاقات المرجعية بين البيانات).
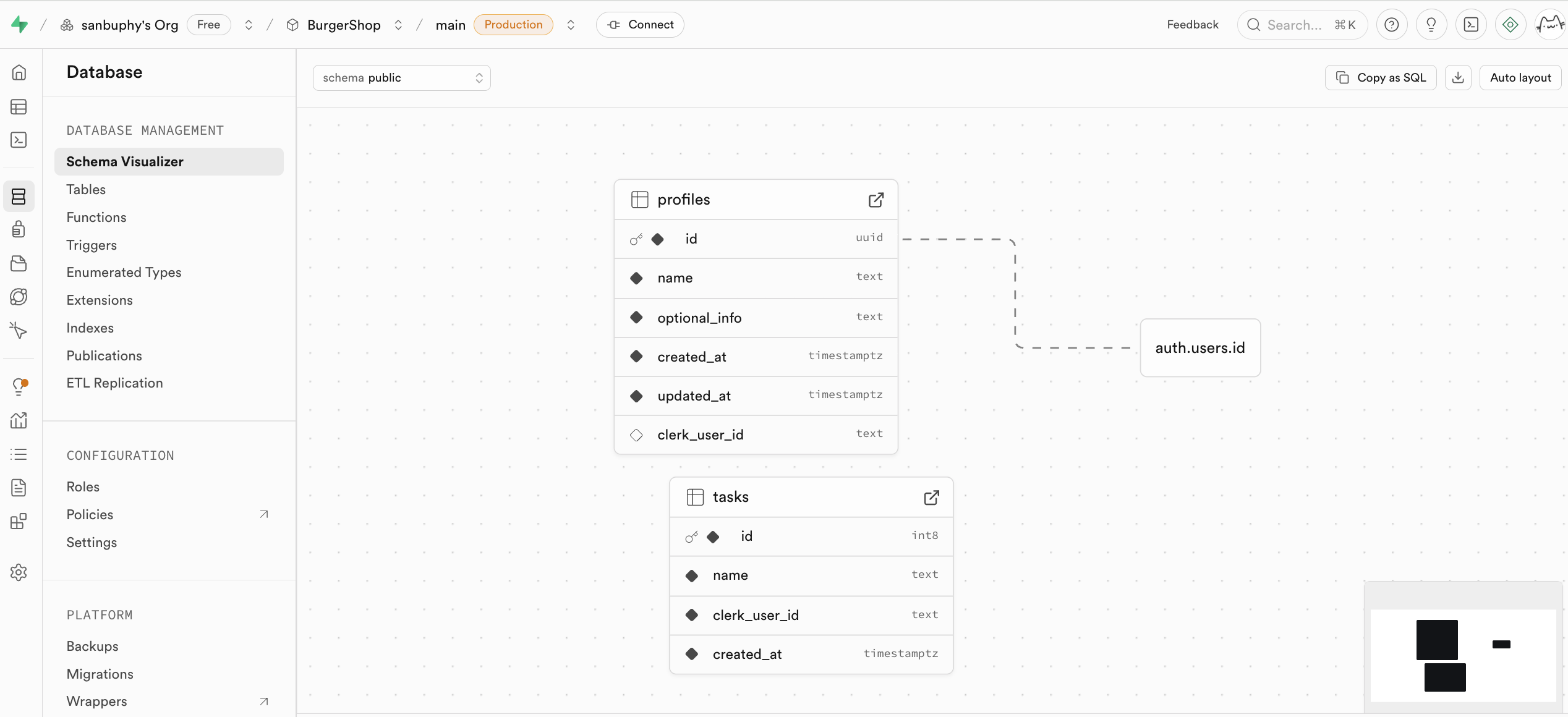
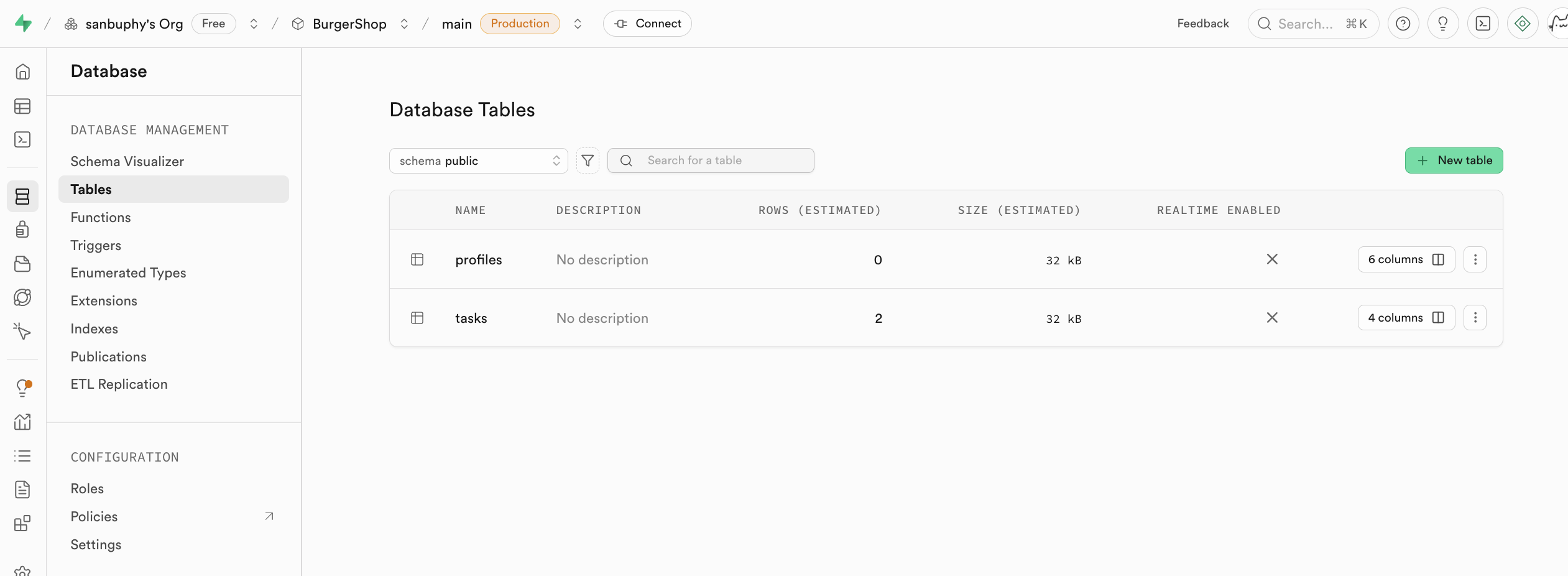
إذا كنت ترغب في إنشاء جدول جديد يدوياً، يمكنك إنشاء الجدول مباشرة في tables، وسنشرح ذلك بالتفصيل في البرنامج التعليمي اللاحق.
المصادقة
يدير Authentication تسجيل المستخدمين وتسجيل الدخول والصلاحيات. يتم تخزين بيانات نظام إدارة المستخدمين الافتراضي هنا، ويوفر وظائف جاهزة للاستخدام مثل تسجيل المستخدمين، وتسجيل الدخول، وإعادة تعيين كلمة المرور، والتحقق من البريد الإلكتروني، ويدعم تسجيل الدخول عبر OAuth لطرف ثالث (مثل WeChat، GitHub، Google، إلخ). ستتم مزامنة جميع بيانات المستخدمين تلقائياً مع جدول auth.users في قاعدة البيانات.
يمكنك العثور على مداخل تسجيل الدخول بمعلومات المستخدم المختلفة التي يدعمها Supabase في خيار Provider، حيث يتم استخدام البريد الإلكتروني Email بشكل افتراضي؛ إذا كنت ترغب في استخدام حساب GitHub أو Google لتسجيل الدخول، فستحتاج إلى تهيئة خصائص إضافية، وسنشرح ذلك بالتفصيل في الدروس أدناه.
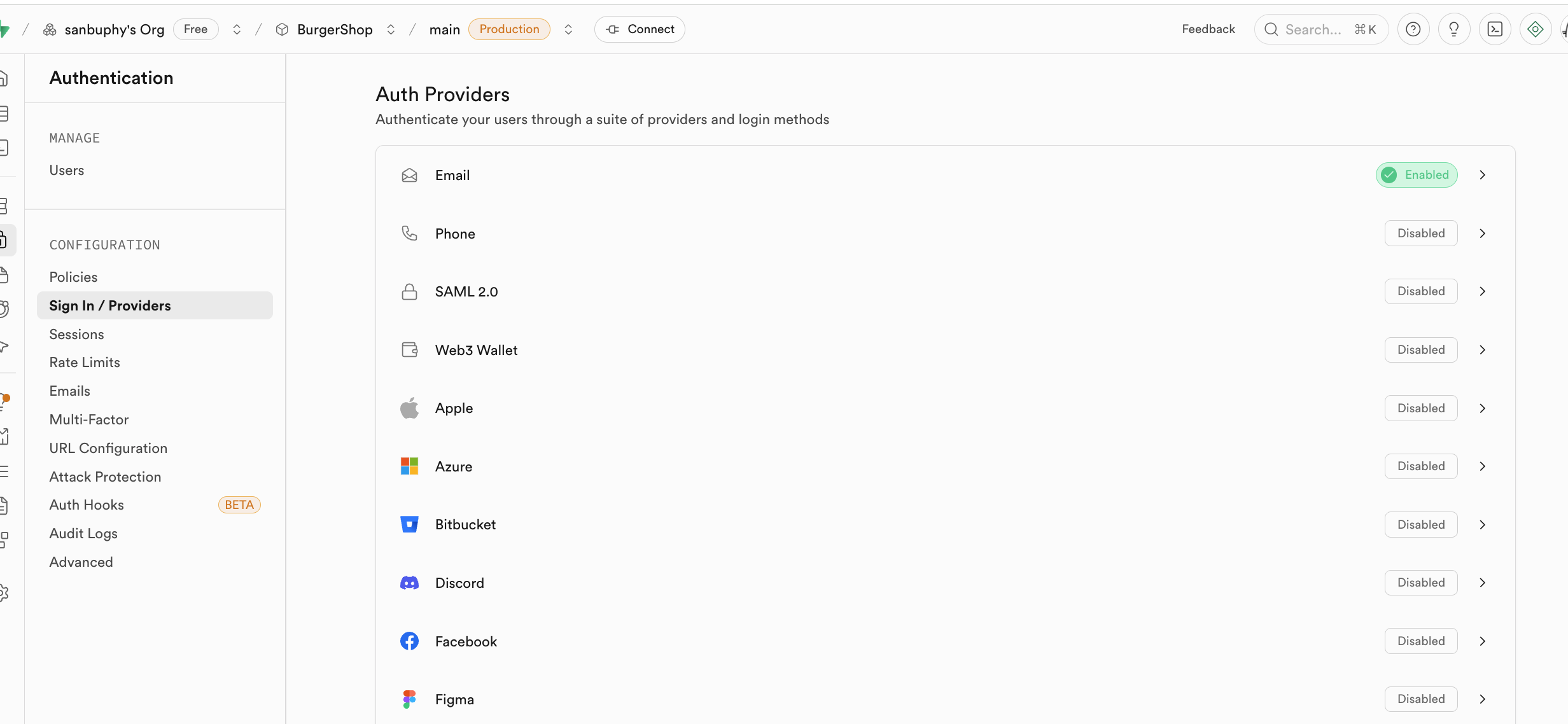
يتضمن Sign In / Providers أيضاً التحكم في سلوك تسجيل البريد الإلكتروني، إذا كنت لا تريد أن يكون تأكيد البريد الإلكتروني إلزامياً في كل مرة يسجل فيها المستخدم، يمكنك إلغاء متطلب Confirm email الإلزامي.
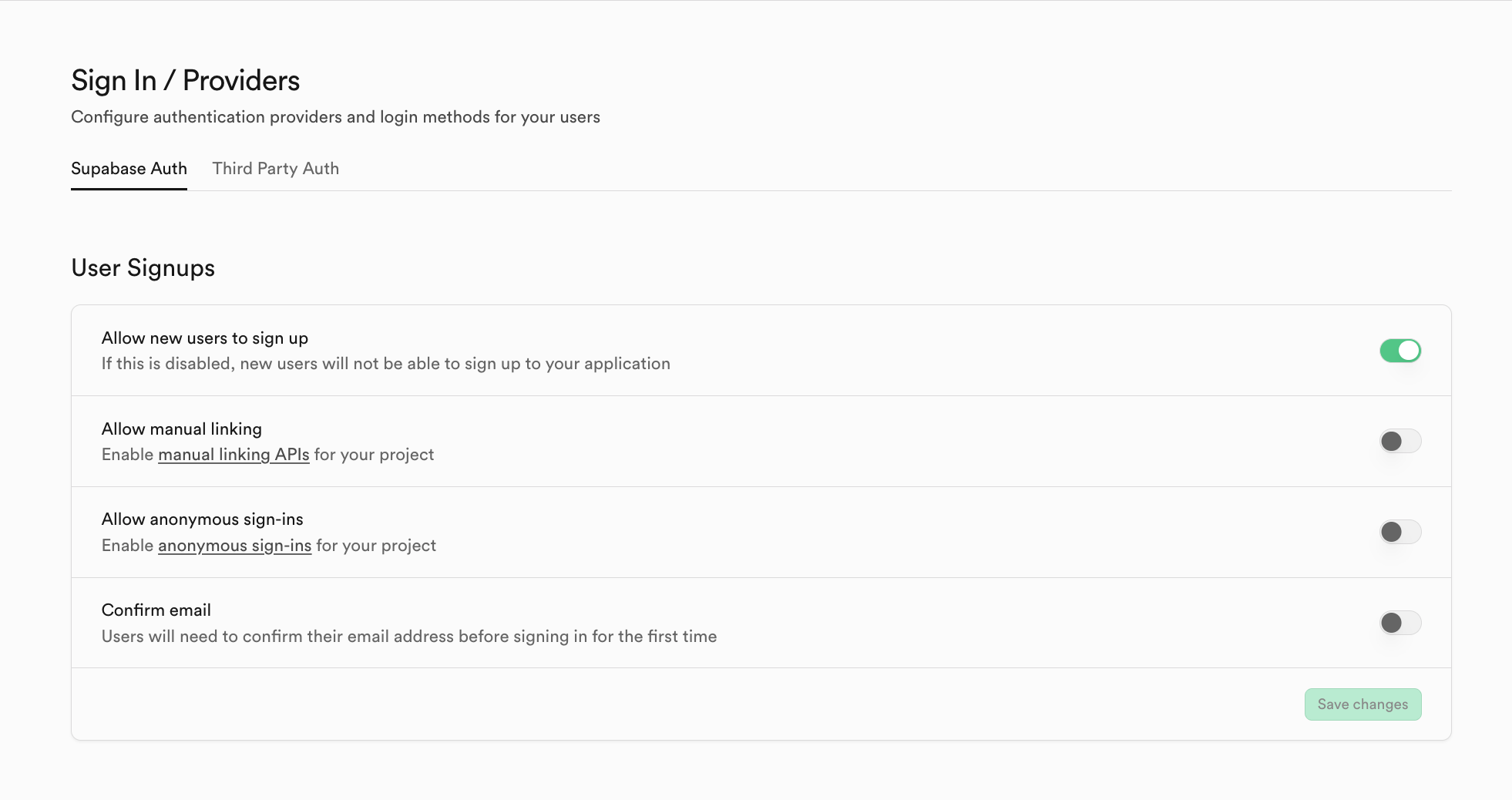
إذا كنت ترغب في التبديل إلى مزود خدمة auth آخر غير Supabase، يمكنك النقر على Third Party Auth، على سبيل المثال هنا يتم استخدام Clerk كمزود خدمة طرف ثالث.
إذا كنت قلقاً من أن حجم الوصول للمستخدمين المسجلين سيكون كبيراً جداً على المدى القصير، يمكنك تمكين سياسة تحديد حركة المرور المقابلة في Rate Limits:
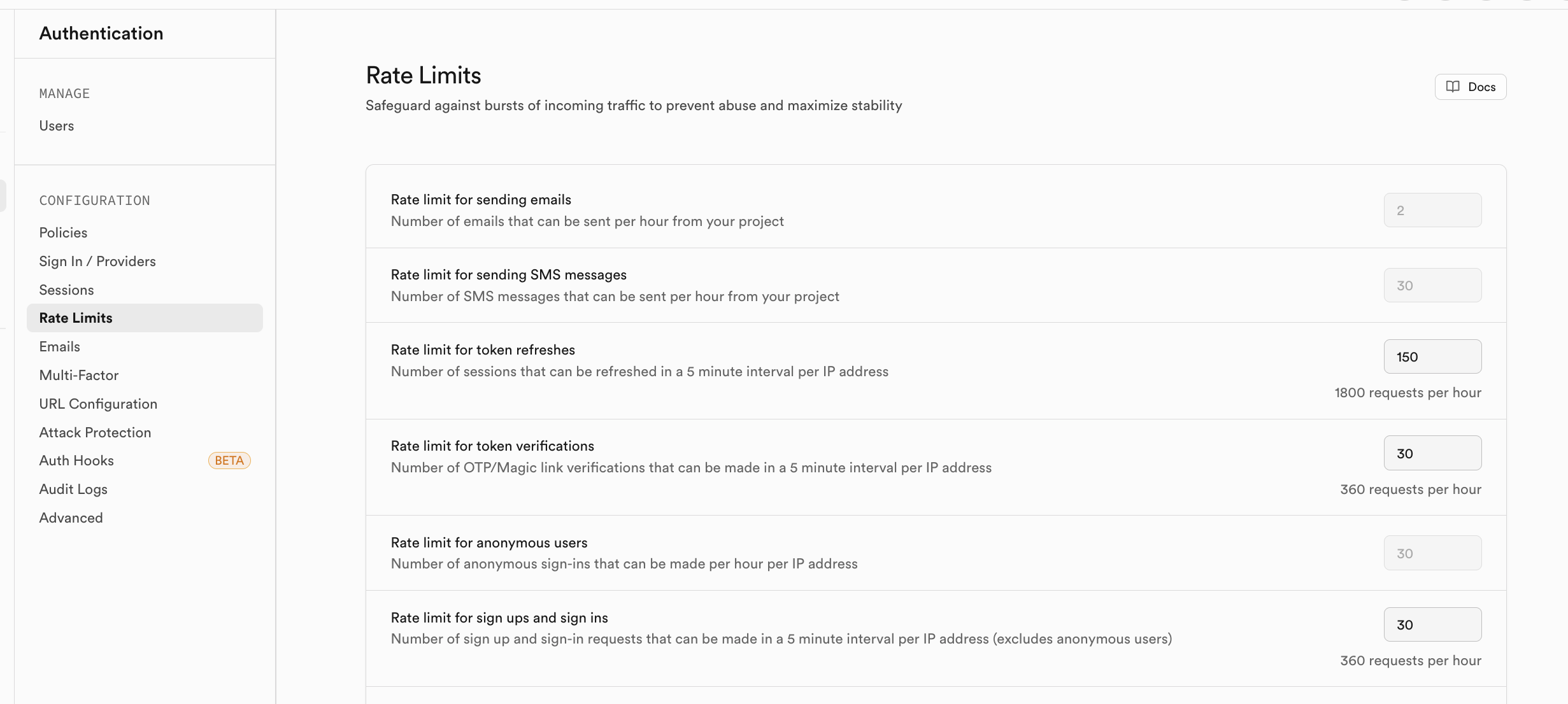
التخزين
Storage هو نظام التخزين في Supabase، متوافق مع مفهوم S3 من Amazon Cloud، ويمكن استخدامه لتخزين أي نوع من الملفات (مثل الصور، الفيديو، المستندات، الصوتيات، إلخ)، ويوفر إدارة صلاحيات الوصول (عامة أو خاصة) والحصول على روابط التحميل (روابط دائمة أو مؤقتة)، ويمكنك بسهولة إدارة رفع وتحميل الملفات المتعلقة بالمستخدمين في التطبيق، والتكامل بسلاسة مع نظام المصادقة في Supabase لتحقيق تحكم دقيق في الوصول.
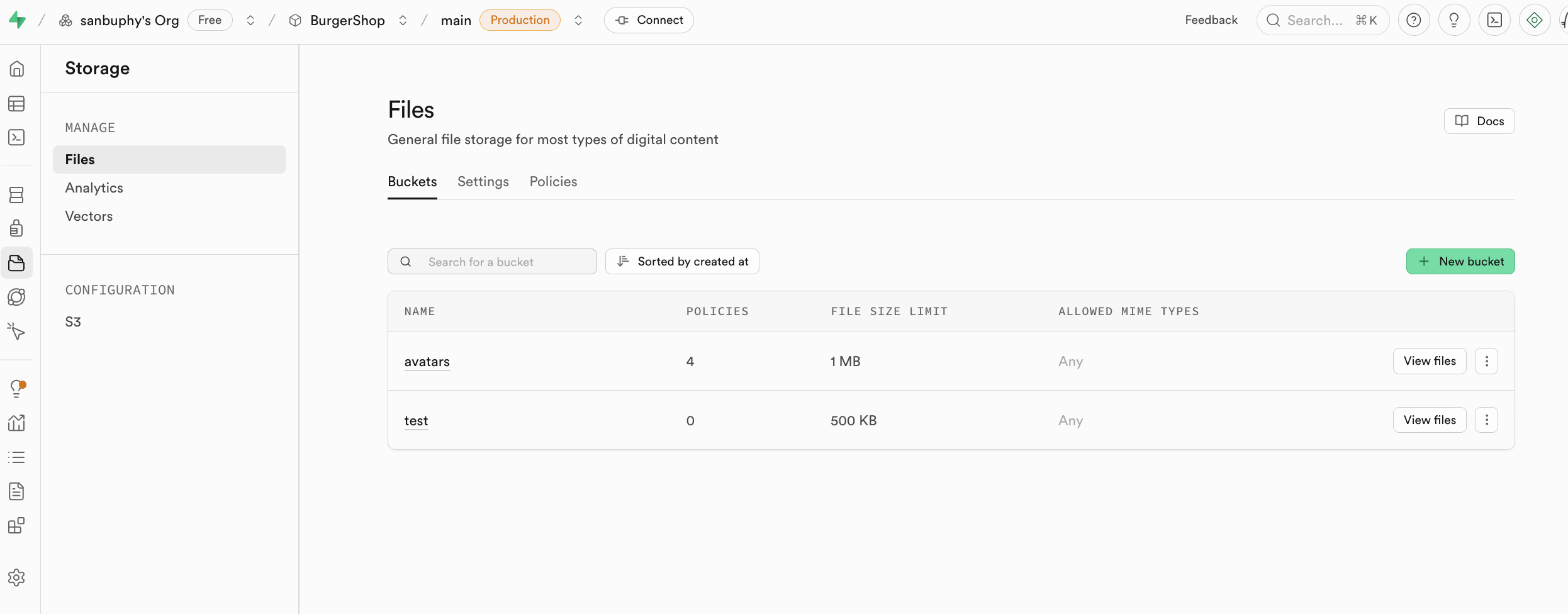
سنشرح الاستخدام المحدد لـ storage في مشروعنا المتقدم في هذا الدرس.
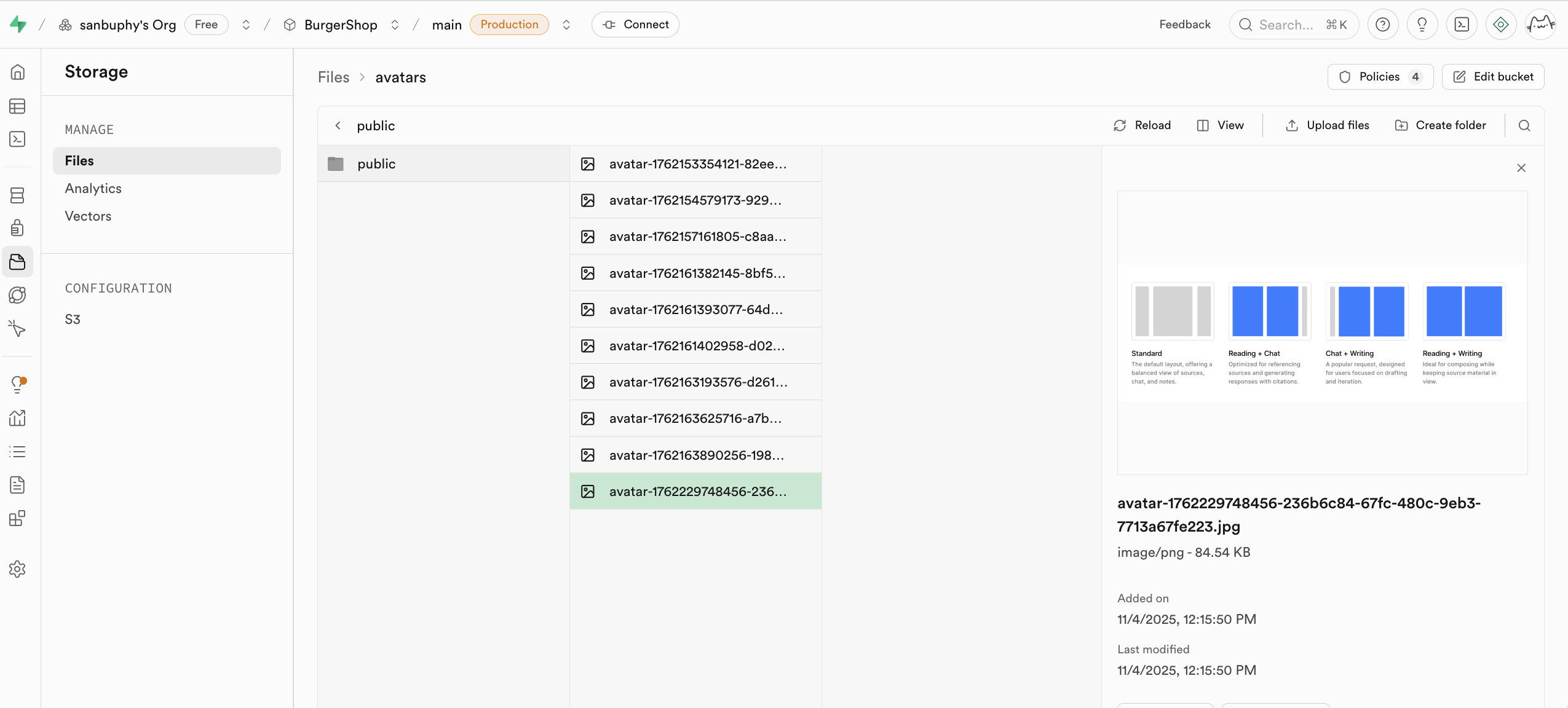
إذا كنت ترغب في استخدام بروتوكولات S3 ذات الصلة للعمليات، يمكنك استخدام التهيئة المقابلة مباشرة:
Amazon Cloud (خدمات Amazon السحابية، أو AWS باختصار) هي منصة حوسبة سحابية توفرها Amazon (مثل غرفة خوادم شبكية كبيرة، يمكنك استئجار موارد الحوسبة والتخزين حسب الحاجة). S3 (Simple Storage Service) هي خدمة في AWS مخصصة لتخزين الملفات (مشابهة لقرص شبكة كبير بلا حدود، يمكنه تخزين الصور والفيديو والنسخ الاحتياطية وأنواع الملفات المختلفة)، وهي خدمة تخزين الكائنات الأكثر شعبية حالياً، وأصبحت معياراً فعلياً في الصناعة.
لماذا يجب أن تكون متوافقة مع S3 API؟: S3 موجود منذ ما يقارب 20 عاماً، وهناك عدد كبير من الأدوات وSDKs والوثائق الجاهزة في السوق، والتوافق مع S3 يعني أنه يمكنك استخدام هذه الموارد مباشرة دون الحاجة لبدء صنع أنواع مختلفة من الأدوات ذات الصلة من الصفر، مما يلبي احتياجات إطلاق الأعمال بسرعة.
الدوال الحدية (Edge Functions)
إذا كنت لا ترغب في نشر خلفية لكنك تريد استخدام قاعدة البيانات وعمليات الدوال، يمكنك استخدام Edge Functions لبناء قدرات خلفية أساسية دون الحاجة لإنشاء خادم خاص بك. إنها دوال خادمية موزعة عالمياً يوفرها Supabase. ببساطة، تتيح لك كتابة ونشر كود خلفي على السحابة دون الحاجة لشراء وإدارة خادم خلفي خاص بك. يتم نشر هذه الدوال على العقد الحدية في الشبكة العالمية، وتعمل تلقائياً في الموقع الأقرب لمستخدميك، مما يقلل من زمن استجابة الشبكة بشكل كبير ويوفر سرعة استجابة فائقة. يمكنك إنشاء وتحرير ونشر الدوال مباشرة من لوحة تحكم Supabase، وعملية التطوير بأكملها مريحة جداً.
أحد الاستخدامات الأساسية لـ Edge Functions هو العمل كطبقة وسيطة آمنة لحماية معلوماتك الحساسة ومفاتيح المصادقة. استدعاء خدمات الطرف الثالث (مثل OpenAI، Stripe) مباشرة من كود الواجهة الأمامية سيكشف مفتاح API الخاص بك، مما يجلب مخاطر أمنية كبيرة. من خلال Edge Functions، يتواصل تطبيقك الأمامي فقط مع دوال Supabase الخاصة بك، وجميع الأسرار تُحفظ فقط في Supabase.
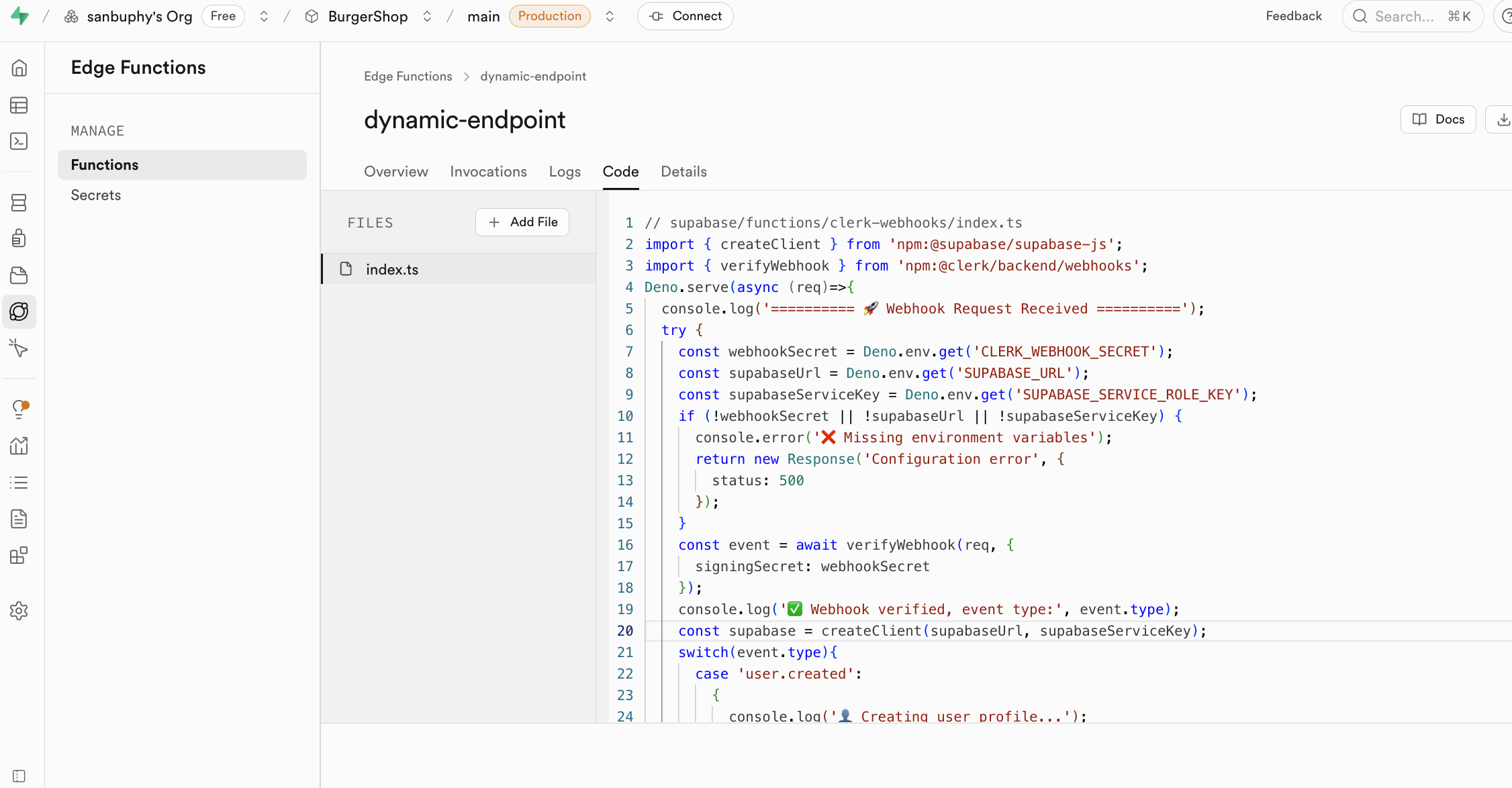
تستخدم دوال Edge Functions المفاتيح المكشوفة في secrets كمتغيرات بيئة، وتُحمّل من خلال Deno.env.get لتحقيق استدعاء خدمات الطرف الثالث. بهذه الطريقة، لن تتعرض المفاتيح الحساسة أبداً على العميل (متصفحك)، مما يقضي تماماً على خطر سرقتها.
عند طلب Supabase Edge Function، يجب حمل مفتاح Supabase المقابل في رأس الطلب، إليك مثال مبسط:
// التهيئة الأساسية (استبدل بمعلوماتك الفعلية)
const projectId = "معرف مشروع Supabase الخاص بك";
const functionName = "اسم Edge Function المستهدف";
const supabaseKey = "Supabase anon_key";
// استدعاء الدالة
async function callEdgeFunction() {
const url = `https://${projectId}.supabase.co/functions/v1/${functionName}`;
try {
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
"Authorization": `Bearer ${supabaseKey}` // المفتاح: حمل المفتاح لإكمال المصادقة
},
body: JSON.stringify({ order_id: "123", action: "refund" }) // بيانات الطلب المخصصة
});
const result = await response.json();
console.log("نجح الاستدعاء:", result);
} catch (error) {
console.error("فشل الاستدعاء:", error.message);
}
}
// تنفيذ الاستدعاء
callEdgeFunction();بالإضافة إلى ذلك، تتكامل Edge Functions بسلاسة مع نظام مصادقة المستخدمين في Supabase. عندما يقوم مستخدم مسجل الدخول باستدعاء دالة، يتم تمرير معلومات هويتها إلى الدالة. هذا يتيح لك التعرف بسهولة على المستخدم الحالي داخل الدالة، وتنفيذ التحكم في الصلاحيات بناءً على هويته. والأهم من ذلك، أن الدوال ستتبع تلقائياً سياسات الأمان على مستوى الصف (Row Level Security) التي قمت بإعدادها عند تشغيل قاعدة البيانات، مما يضمن أن المستخدمين يمكنهم فقط الوصول إلى وتعديل البيانات التي يملكون صلاحية تشغيلها، مما يجعل بناء تطبيقات متعددة المستخدمين آمنة أمراً بسيطاً.
مشاهد تطبيق Edge Functions واسعة جداً، وقادرة على معالجة مهام خلفية متنوعة. إنها مناسبة جداً للاستماع إلى أحداث Webhook من خدمات الطرف الثالث (مثل نجاح الدفع، وإرسال الكود، إلخ)، وتنفيذ منطق معالجة البيانات المقابل تلقائياً. يمكنك أيضاً استخدامها لإرسال إشعارات البريد الإلكتروني، وإنشاء تقارير PDF، وإنشاء واجهات API مخصصة لتغليف منطق الأعمال المعقد، أو تنفيذ أي مهام حسابية ترغب في إكمالها على جانب الخادم، مما يوسع قدرات تطبيقك بشكل كبير.
بالنسبة لمثال شائع محدد: أداة المصادقة Clerk. يُستخدم Clerk فقط لمعالجة العمليات المتعلقة بالمصادقة مثل تسجيل دخول المستخدمين، والتسجيل، وتحديث المعلومات، ولا يدير قاعدة بيانات أعمالك مباشرة. إذا كنت ترغب في مزامنة ديناميكيات المصادقة هذه إلى قاعدة بيانات الأعمال، فستحتاج إلى تحقيق ذلك من خلال تشغيل أحداث Webhook لطلب Edge Functions. يمكن لـ Edge Functions الاستماع إلى إشارات Webhook المرسلة من Clerk، وتنفيذ منطق مزامنة البيانات تلقائياً، بحيث تتوافق معلومات المستخدمين في قاعدة بيانات Supabase مع حالة تسجيل الدخول في Clerk في الوقت الفعلي، دون الحاجة لنشر خلفية مستقلة.
محرك مزامنة البيانات الفورية
Realtime هو محرك مزامنة البيانات الفورية في Supabase، والذي يتيح لتطبيقك تلقي إشعارات بتغييرات قاعدة البيانات فوراً، دون الحاجة لاستطلاع API بشكل متكرر. عندما تحدث عمليات INSERT أو UPDATE أو DELETE على البيانات في قاعدة البيانات، يقوم Realtime بدفع هذه التغييرات في الوقت الفعلي إلى جميع العملاء المتصلين عبر WebSocket. هذا أمر حاسم لبناء التطبيقات التي تتطلب تفاعلاً فورياً.
يحتوي Realtime بشكل أساسي على ثلاث وظائف أساسية تغطي الغالبية العظمى من المشاهد الفورية:
- Postgres Changes: الاستماع المباشر لتغييرات جداول قاعدة البيانات. يمكنك الاشتراك بدقة في جداول محددة، وأحداث محددة (إضافة، حذف، تعديل)، وحتى تلقي الإشعارات بناءً على شروط التصفية، مع تكامل مثالي مع سياسات الأمان على مستوى الصف (Row Level Security)، مما يضمن أن المستخدمين يتلقون فقط تغييرات البيانات التي يملكون صلاحية عرضها.
- Broadcast: يتيح للعملاء إرسال رسائل مؤقتة منخفضة التأخير فيما بينهم عبر القنوات (Channel). هذا مناسب جداً لتنفيذ غرف الدردشة، وتتبع المؤشر الفوري، ومزامنة حالة الألعاب عبر الإنترنت ووظائف أخرى.
- Presence: يُستخدم لتتبع ومزامنة حالة المستخدمين المتصلين. يمكنك استخدامه لتنفيذ وظائف مثل "من متصل" و"هناك X أشخاص يشاهدون حالياً" بسهولة، وهو مناسب جداً للتطبيقات التعاونية.
سنقدم هذا الجزء بالتفصيل في التعلم القائم على المشاريع اللاحقة.
إعدادات المشروع
Project Settings هو قسم التهيئة المتقدمة لمشروع Supabase، حيث يمكنك تحقيق الجدولة العميقة لموارد الحوسبة، والتهيئة الدقيقة لمعلمات الطبقة السفلية للوظائف المختلفة.
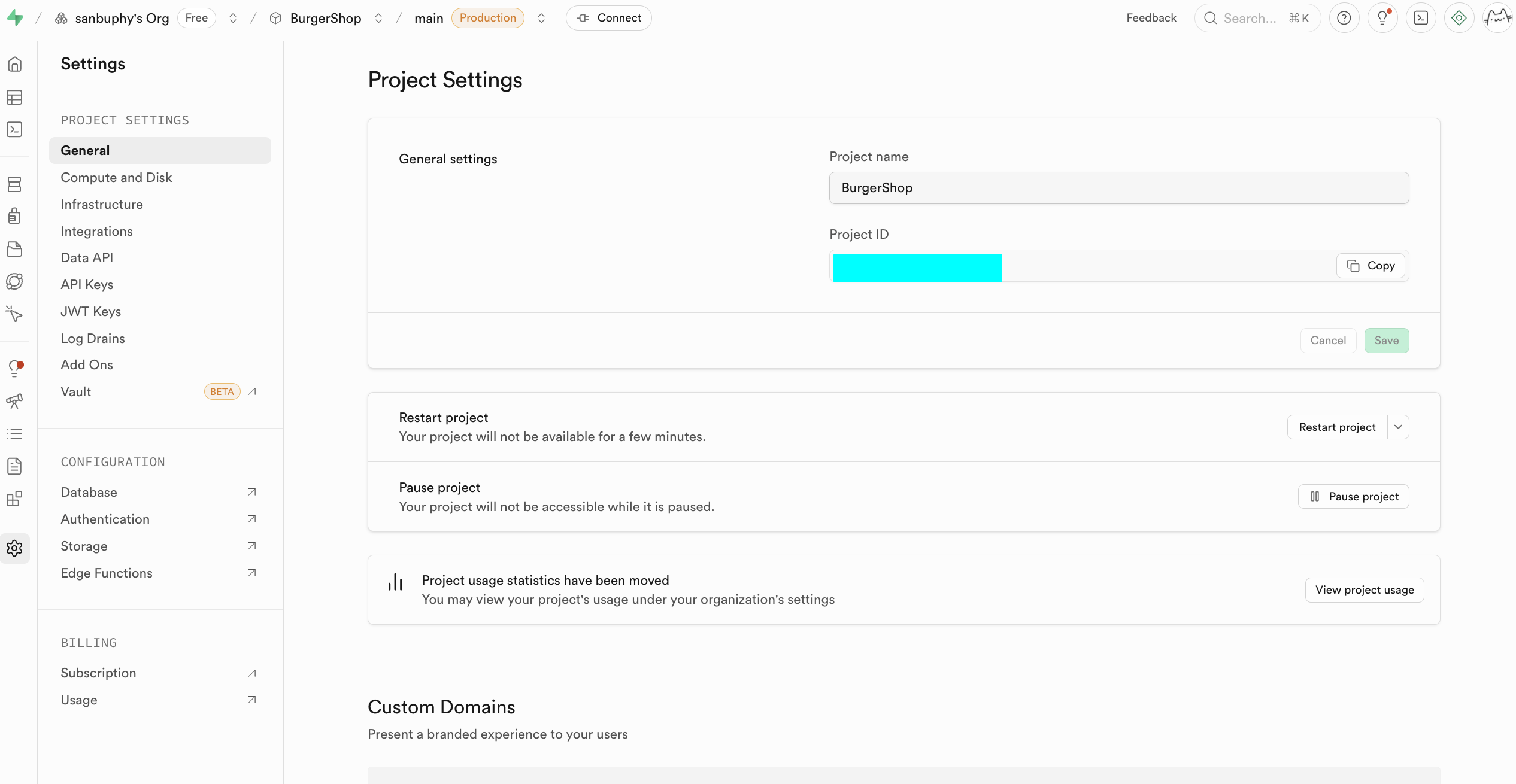
في مرحلة البدء، نحتاج فقط للتركيز على لوحتين أساسيتين التاليتين. الأولى هي Data API، حيث يمكننا الحصول على "Supabase URL" الأساسي، وهو نقطة نهاية RESTful بشكل https://xxx.supabase.co، ويمثل "عنوان المدخل" لجميع عمليات استعلام البيانات، وإضافتها، وتعديلها، وحذفها. تحتاج الواجهة الأمامية أو جانب الخادم إلى تهيئة عميل Supabase من خلال هذا URL لإنشاء اتصال بقاعدة البيانات.
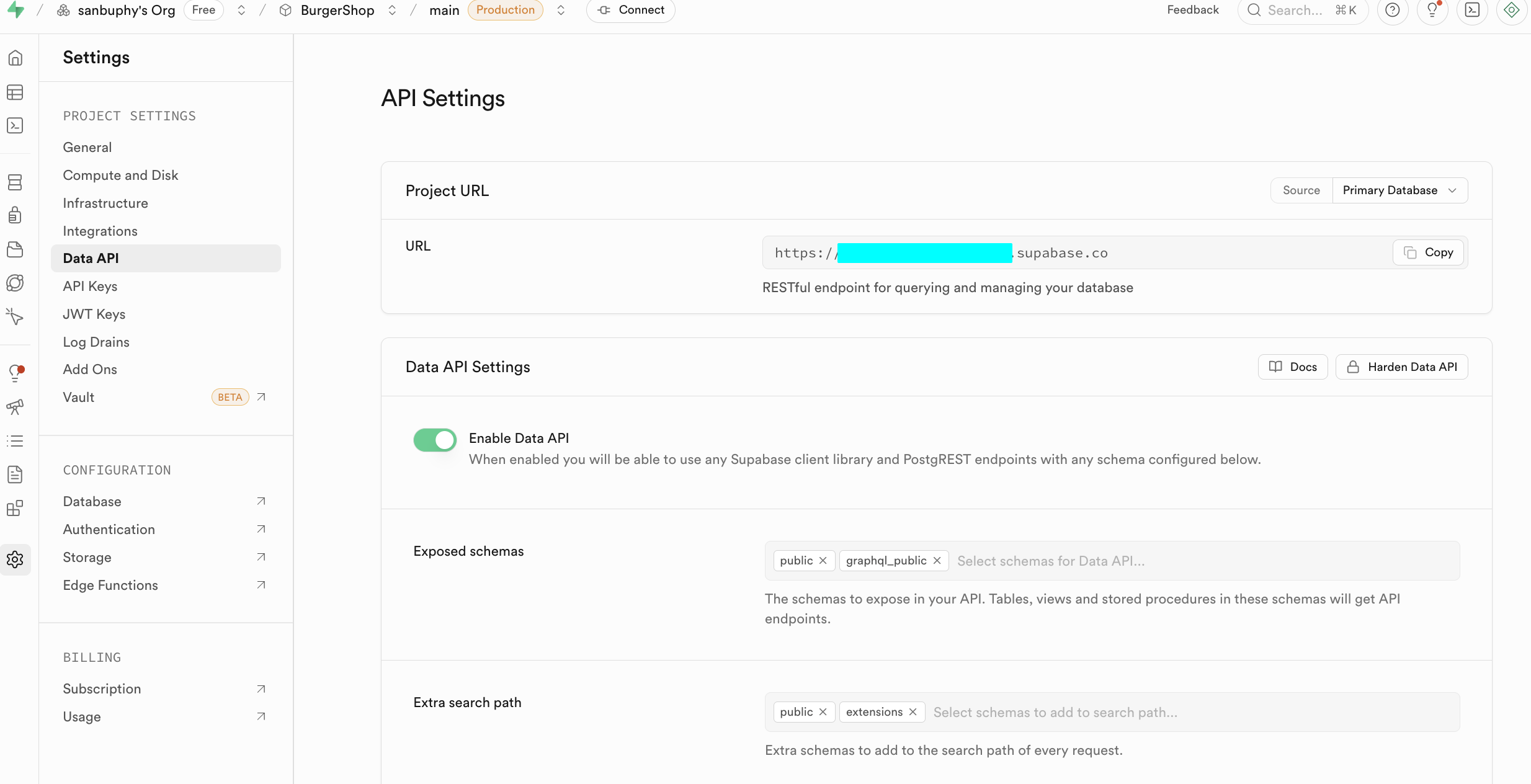
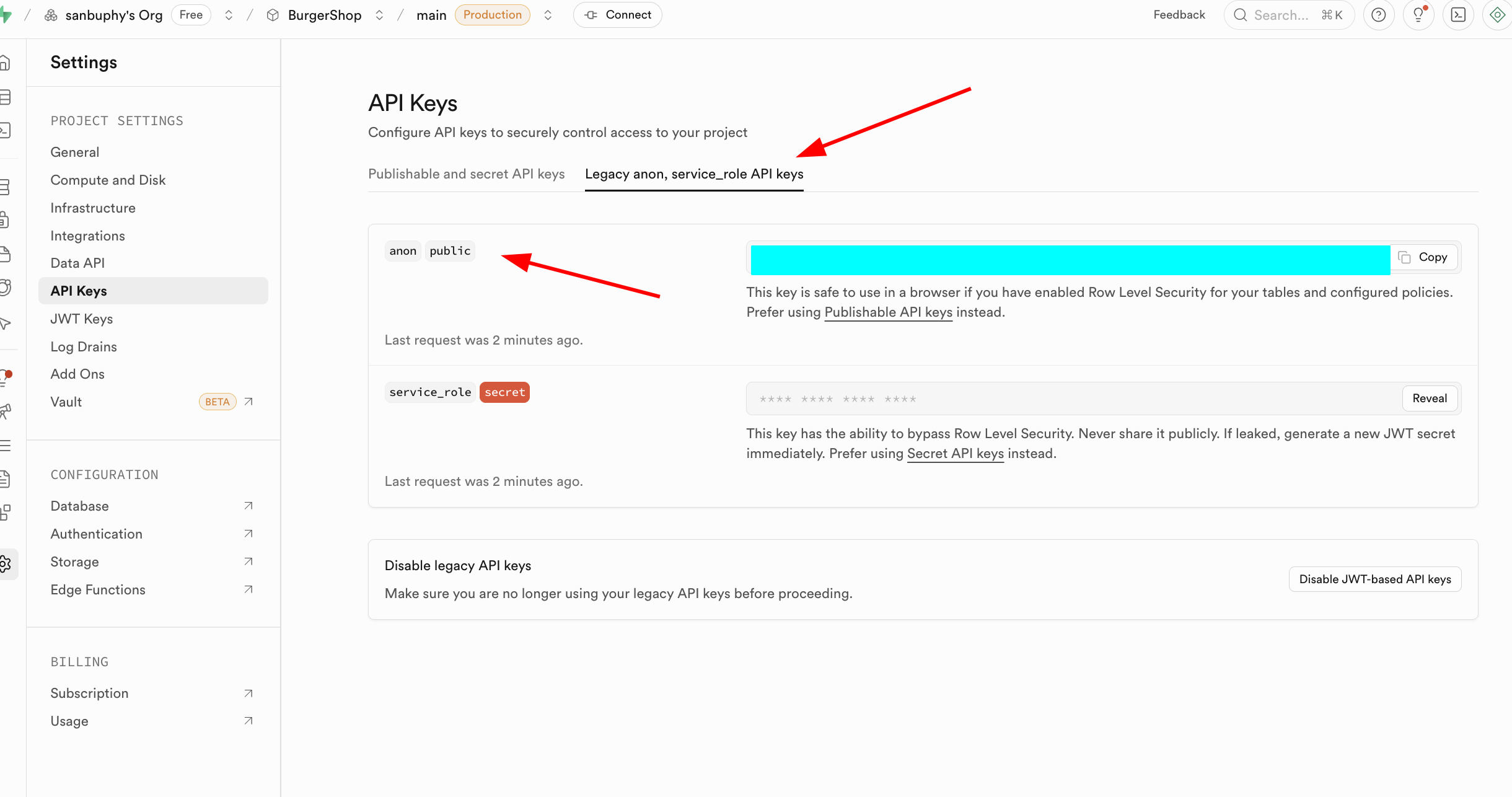
والنقطة المهمة الأخرى هي API Keys، اختر علامة التبويب "Legacy anon, service_role API keys"، حيث يكون مفتاح anon public هو بيانات اعتماد الهوية المهمة في مشاهد الواجهة الأمامية، وصلاحياته محدودة بشكل صارم بواسطة RLS، ويمكنه فقط الوصول إلى البيانات المصرح بها للمستخدم. أما مفتاح service_role فهو ينتمي إلى "مفتاح صلاحيات عالية من جانب الخادم"، ولديه القدرة على تجاوز الأمان على مستوى الصف، ويمكنه تنفيذ عمليات بيانات مجمعة، وتهيئات على مستوى النظام وعمليات حساسة أخرى. يُمنع منعاً باتاً مشاركته علنياً، وإذا تم تسريبه، يجب إنشاء مفتاح جديد فوراً وتحديث تهيئة الخادم.
باقي عناصر التهيئة لا تحتاج إلى دراسة معمقة في المرحلة الحالية، ويمكن استكشافها واحدة تلو الأخرى عند وجود متطلبات استخدام متقدمة لاحقاً.
2.1 إنشاء جدول بيانات SQL الأول الخاص بك
ما سبق كان مقدمة لواجهة Supabase، وبعد ذلك سنتعمق في جزء عمليات قاعدة البيانات الأساسية في Supabase.
لإنشاء جدول بيانات في Supabase، هناك طريقتان شائعتان رئيسيتان، ويمكنك الاختيار بناءً على احتياجاتك:
- (مُوصى به) استخدام نموذج اللغة الكبيرة لتوليد عبارات SQL متوافقة مع Supabase، ولصقها وتنفيذها مباشرة في SQL Editor (منفذ تنفيذ عبارات SQL المقدم سابقاً)، وهي طريقة فعالة وسريعة، وسنشرح عملية التشغيل هذه بالتفصيل في الجزء التالي.
- الإنشاء من خلال العمليات المرئية: ابحث عن وحدة Database في الشريط الجانبي الأيسر، وانقر للدخول ثم حدد Tables في الشريط الجانبي، وانقر على زر New table على اليمين، ويمكنك إنشاء جدول بيانات من خلال الواجهة الرسومية.
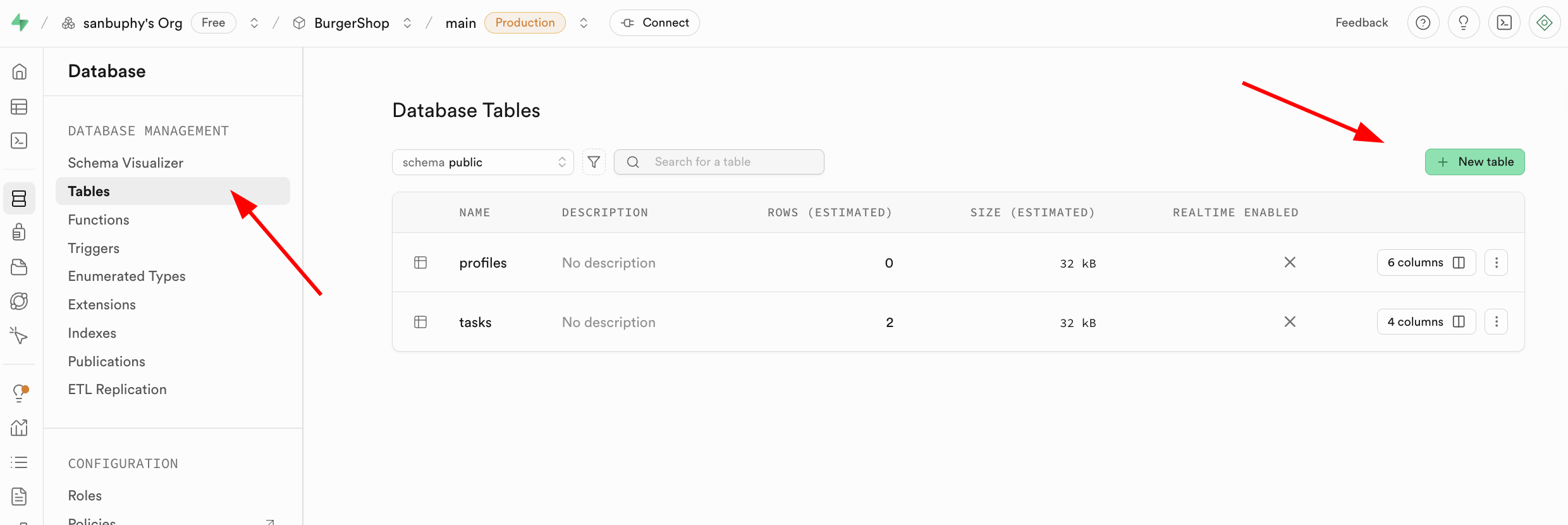
تجدر الإشارة إلى أنه يمكن تحديد اسم جدول البيانات المقابل وأنواع البيانات المخزنة في Columns أدناه.
بالنسبة لقواعد البيانات العلائقية، من الخصائص المهمة جداً الارتباط بين الجداول، ويمكنك العثور على Foreign keys أدناه، والنقر لإنشاء علاقات الارتباط المقابلة:
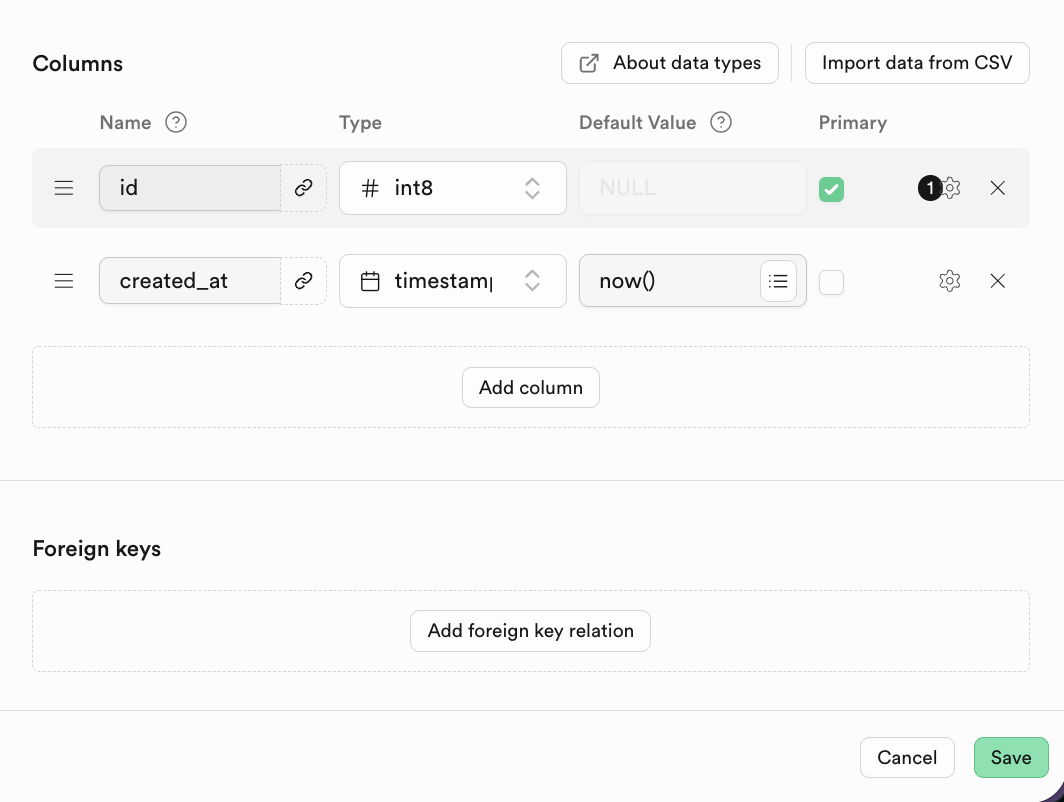
يعبر Foreign keys عن علاقة الارتباط بين الجداول: حقل أو مجموعة حقول، قيمته في الجدول الحالي (الجدول الفرعي) تشير إلى قيمة المفتاح الأساسي في جدول آخر (الجدول الأصلي).
على سبيل المثال، عند إنشاء جدول الطلاب، يمكننا تعريف المفتاح الخارجي كما يلي: (عمود رقم الفصل المنتمي هو مفتاح خارجي. يشير هذا المفتاح الخارجي إلى عمود رقم الفصل في جدول الفصول.)
CREATE TABLE جدول_الطلاب (
رقم_الطالب INT PRIMARY KEY,
اسم_الطالب VARCHAR(50),
رقم_الفصل_المنتمي INT,
FOREIGN KEY (رقم_الفصل_المنتمي) REFERENCES جدول_الفصول(رقم_الفصل)
);بشكل أكثر تحديداً، يمكننا مراقبة هيكل الجدول المقابل بصرياً:
جدول الفصول: يسجل هذا الجدول معلومات جميع الفصول، وكل فصل له رقم فصل فريد. رقم الفصل هو المفتاح الأساسي (Primary Key) لهذا الجدول، وهو بطاقة الهوية الفريدة لكل فصل.
| رقم الفصل | اسم الفصل |
|---|---|
| 101 | الصف الأول الفصل الأول |
| 102 | الصف الأول الفصل الثاني |
جدول الطلاب: يسجل هذا الجدول معلومات جميع الطلاب. كل طالب ينتمي إلى فصل محدد، أليس كذلك؟ فكيف نعرف أي طالب في أي فصل؟
يمكننا إضافة عمود في جدول الطلاب يسمى رقم الفصل المنتمي.
| رقم الطالب | اسم الطالب | رقم الفصل المنتمي |
|---|---|---|
| 2024001 | أحمد | 101 |
| 2024002 | محمد | 102 |
| 2024003 | خالد | 101 |
في هذا المثال، عمود رقم الفصل المنتمي في جدول الطلاب هو المفتاح الخارجي (Foreign Key).
في Supabase، بعد النقر لإضافة Foreign Key، يمكنك اختيار العمود المقابل في الجدول المرتبط مباشرة
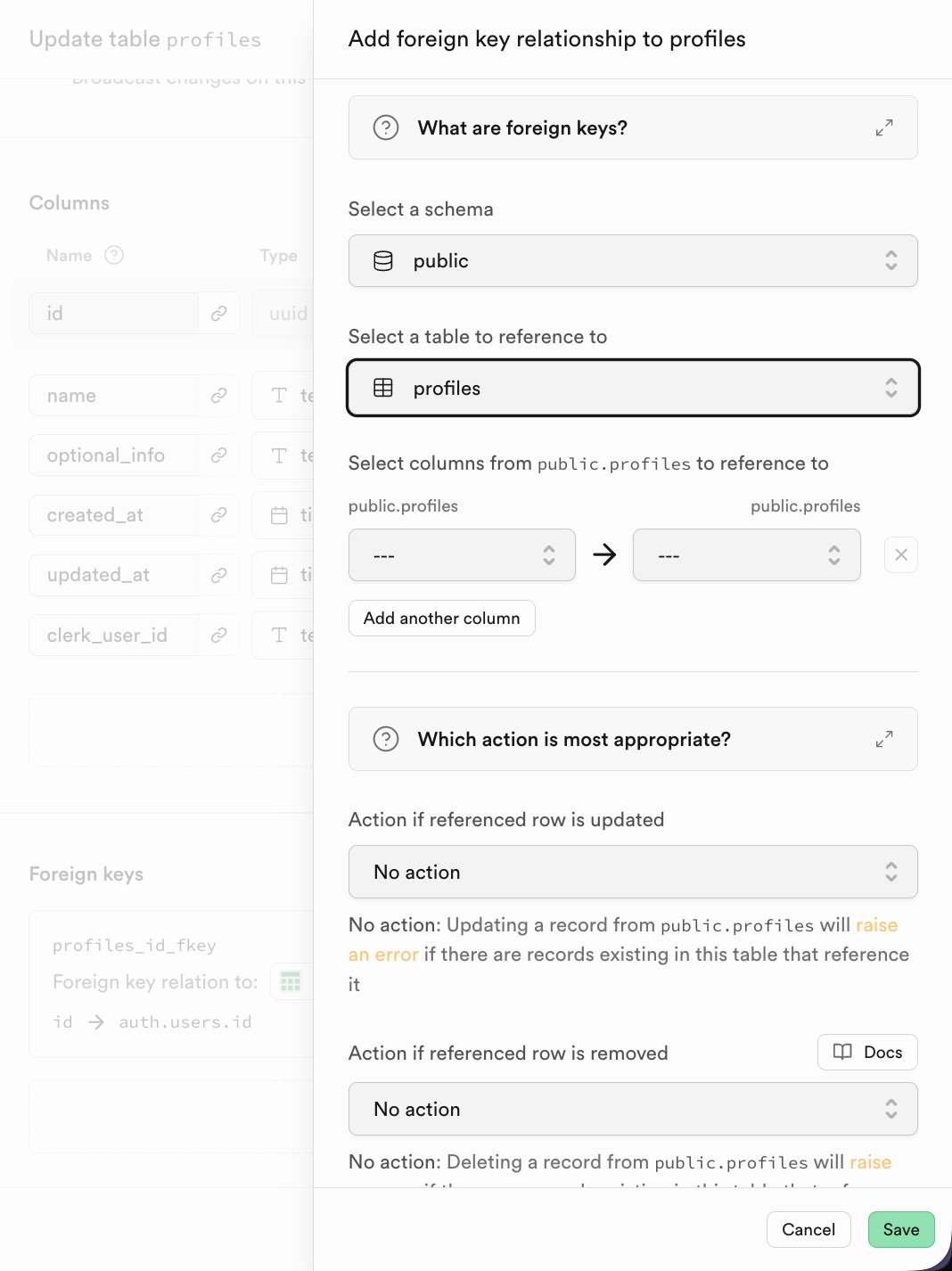
2.3 مقدمة في SQL Editor والعمليات الأساسية لقاعدة البيانات
بعد ذلك سنقوم بتنفيذ سلسلة من برامج SQL النصية خطوة بخطوة، للتعرف على عمليات الإضافة والحذف والاستعلام والتعديل الشائعة في SQL. يمكنك نسخ كود كل خطوة إلى SQL Editor، وتنفيذه ومراقبة النتائج.
يمكنك الحصول على جميع ملفات SQL الاختبارية في هذا الدليل:
https://github.com/THU-SIGS-AIID/Project5-Supabase-Demos/tree/main/apps/sql-examples
2.3.1 CREATE - إنشاء هيكل الجدول
تُستخدم عبارة CREATE TABLE لتعريف Schema للجدول الجديد، بما في ذلك أعمدته (Columns)، وأنواع البيانات المقابلة (Data Types)، وأي قيود (Constraints)، وببساطة يتم إنشاء جدول بيانات.
-- Step 1: Create the 'orders' table
-- This file is fully independent and creates a sample table for later steps.
CREATE TABLE IF NOT EXISTS orders (
id serial PRIMARY KEY,
user_id int NOT NULL, -- User ID
status text NOT NULL, -- Order status (e.g. paid, pending)
amount numeric(10, 2) NOT NULL, -- Order total amount
details jsonb, -- Item and extra details as JSON
placed_at timestamptz DEFAULT now(), -- Order creation time
is_paid boolean DEFAULT false -- Paid flag
);
-- Expected Output:
-- Orders table created if it did not exist.
-- No data inserted. (Querying returns zero rows for now.)
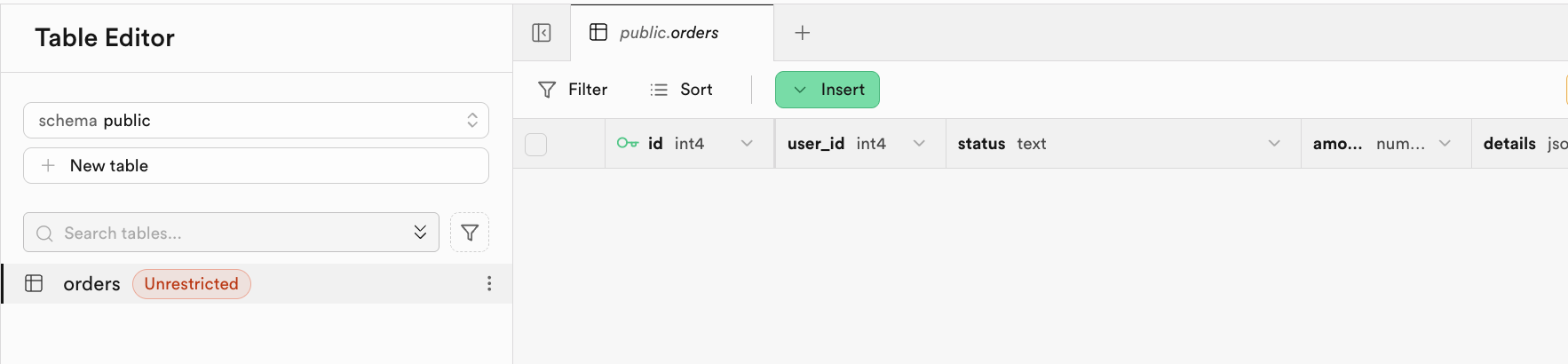
-- If table already exists, no error occurs.بعد التنفيذ الناجح، سيشير النظام إلى اكتمال البرنامج النصي. يمكنك رؤية الجدول المقابل الذي تم إنشاؤه في Table Editor:
2.3.2 INSERT - تعبئة البيانات الأولية
بعد إنشاء هيكل الجدول، الخطوة التالية هي إضافة صفوف البيانات إلى الجدول باستخدام عبارة INSERT INTO.
-- Step 2: Insert initial rows into the orders table
-- Provides realistic, varied data for demo/testing. All values are self-contained.
INSERT INTO orders (user_id, status, amount, details, placed_at, is_paid) VALUES
(2001, 'pending', 23.50, '{"items":[{"sku":"BGR001","name":"Beef Burger","qty":1,"price":12.00}]}', now() - interval '2 days', false),
(2002, 'paid', 50.00, '{"items":[{"sku":"BGR002","name":"Chicken Burger","qty":2,"price":10.00},{"sku":"DRK001","name":"Lemonade","qty":2,"price":5.00}]}', now() - interval '1 day', true),
(2003, 'cancelled', 15.00, '{"items":[{"sku":"FRY001","name":"French Fries","qty":3,"price":5.00}], "reason":"Not available"}', now() - interval '45 days', false),
(2004, 'paid', 22.98, '{"items":[{"sku":"BGR003","name":"Veggie Burger","qty":2,"price":9.99}], "promo":"SUMMER22"}', now() - interval '10 days', true),
(2005, 'pending', 18.75, '{"items":[{"sku":"SAL001","name":"Salad","qty":1,"price":6.75},{"sku":"BGR001","name":"Beef Burger","qty":1,"price":12.00}]}', now() - interval '7 hours', false),
(2006, 'paid', 8.00, '{"items":[{"sku":"DRK002","name":"Cola","qty":2,"price":4.00}]}', now() - interval '3 hours', true),
(2007, 'refunded', 14.50, '{"items":[{"sku":"BGR003","name":"Veggie Burger","qty":1,"price":9.99},{"sku":"FRY001","name":"French Fries","qty":1,"price":4.51}], "refund_reason":"Late delivery"}', now() - interval '15 days', false),
(2008, 'paid', 26.99, '{"items":[{"sku":"BGR002","name":"Chicken Burger","qty":2,"price":10.00},{"sku":"DRK001","name":"Lemonade","qty":1,"price":6.99}]}', now() - interval '12 days', true),
(2009, 'pending', 9.99, '{"items":[{"sku":"BGR003","name":"Veggie Burger","qty":1,"price":9.99}]}', now() - interval '30 minutes', false),
(2010, 'paid', 19.89, '{"items":[{"sku":"BGR001","name":"Beef Burger","qty":1,"price":12.00},{"sku":"DRK002","name":"Cola","qty":2,"price":3.95}]}', now() - interval '5 days', true),
(2011, 'cancelled', 0.00, '{"items":[], "reason":"User cancelled"}', now() - interval '2 days', false);
-- Expected Output:
-- After running this script, SELECT * FROM orders will show about 11 rows with varied user_id, status, amount, details (JSON), placed_at, and is_paid fields.
-- For example:
-- | id | user_id | status | amount | is_paid | placed_at |
-- |----|---------|-----------|--------|---------|---------------------|
-- | 1 | 2001 | pending | 23.50 | false | 2025-10-28 13:40:00Z|
-- | 2 | 2002 | paid | 50.00 | true | ... |
-- |... | ... | ... | ... | ... | ... |بعد نجاح التنفيذ، تم إدراج البيانات الأولية في الجدول بالفعل، يمكنك الدخول إلى واجهة Table Editor والتحديث لرؤية النتائج، أو يمكنك إنشاء نافذة جديدة مباشرة في واجهة SQL Editor وتنفيذ عبارة الاستعلام SELECT * FROM orders; لعرض النتائج:
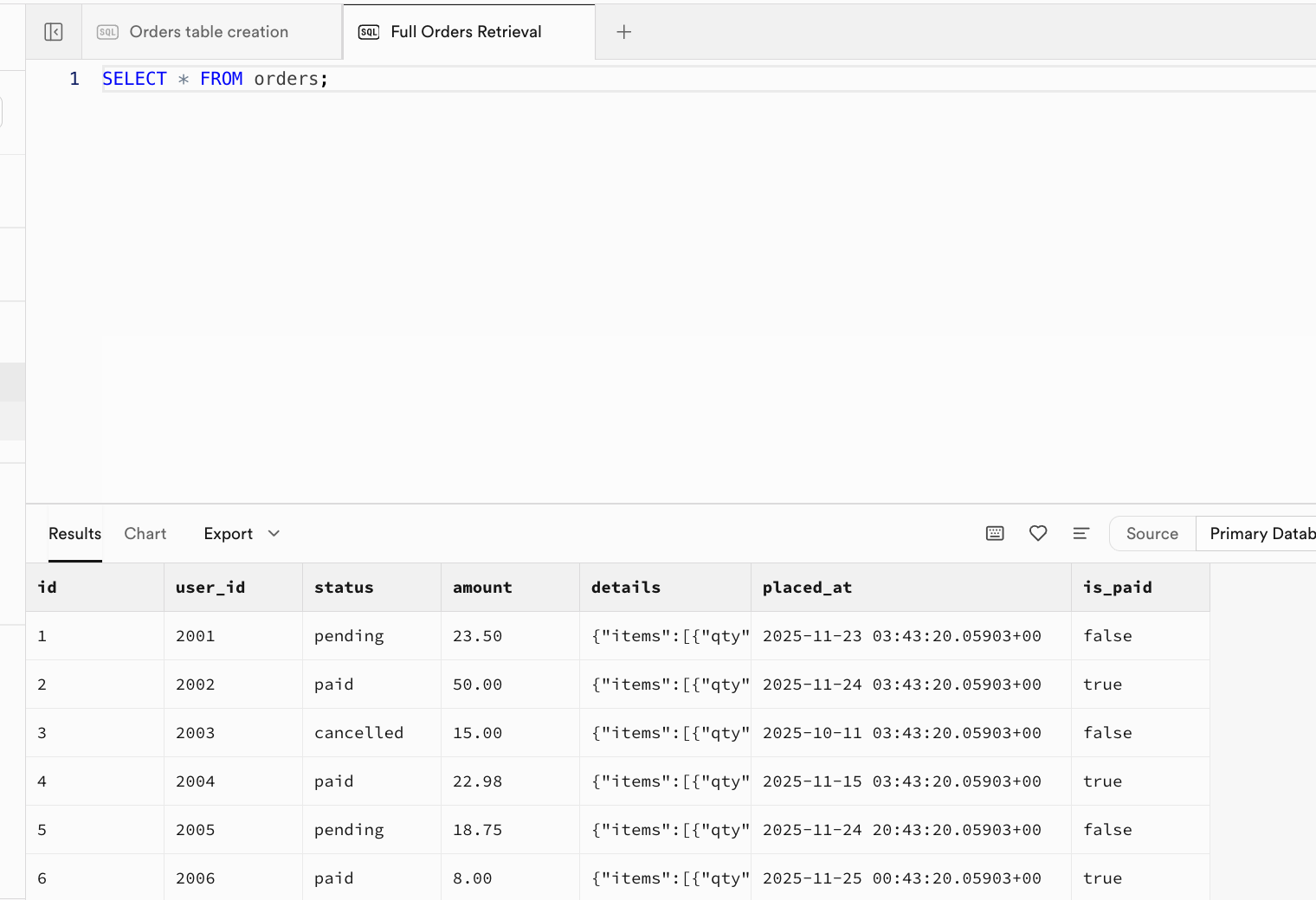
2.3.3 SELECT - قراءة البيانات والاستعلام عنها
تُستخدم عبارة SELECT لاسترجاع البيانات من الجدول. من خلال استخدام بنود مختلفة، يمكن تحقيق تصفية دقيقة للبيانات وفرزها وتنسيقها. يمكننا الرجوع إلى العبارات التالية وتنفيذها خطوة بخطوة لعرض النتائج:
-- Step 3: SELECT query examples for the orders table
-- Example 1: Select all fields for all orders
SELECT * FROM orders;
-- Expected Output: Returns all rows and fields. Columns: id, user_id, status, amount, details, placed_at, is_paid.
-- Example 2: Select only pending orders
SELECT id, user_id, amount FROM orders WHERE status = 'pending';
-- Expected Output: All rows with status 'pending'; columns: id, user_id, amount.
-- Example 3: Select specific fields and filter by payment status
SELECT id, status, is_paid, amount FROM orders WHERE is_paid = true;
-- Expected Output: All rows where is_paid is true; columns: id, status, is_paid, amount.
-- Example 4: Extract all item names from the details (JSON) for each order
SELECT id, details -> 'items' AS item_list FROM orders;
-- Expected Output: Each row shows id and an array from JSON with item details.- مثال 1: يُرجع جميع الصفوف والأعمدة في جدول
orders، مشابه لمخرجات الخطوة الثانية. - مثال 2: يُرجع فقط الطلبات ذات الحالة 'pending'، ويحتوي فقط على الأعمدة المحددة:
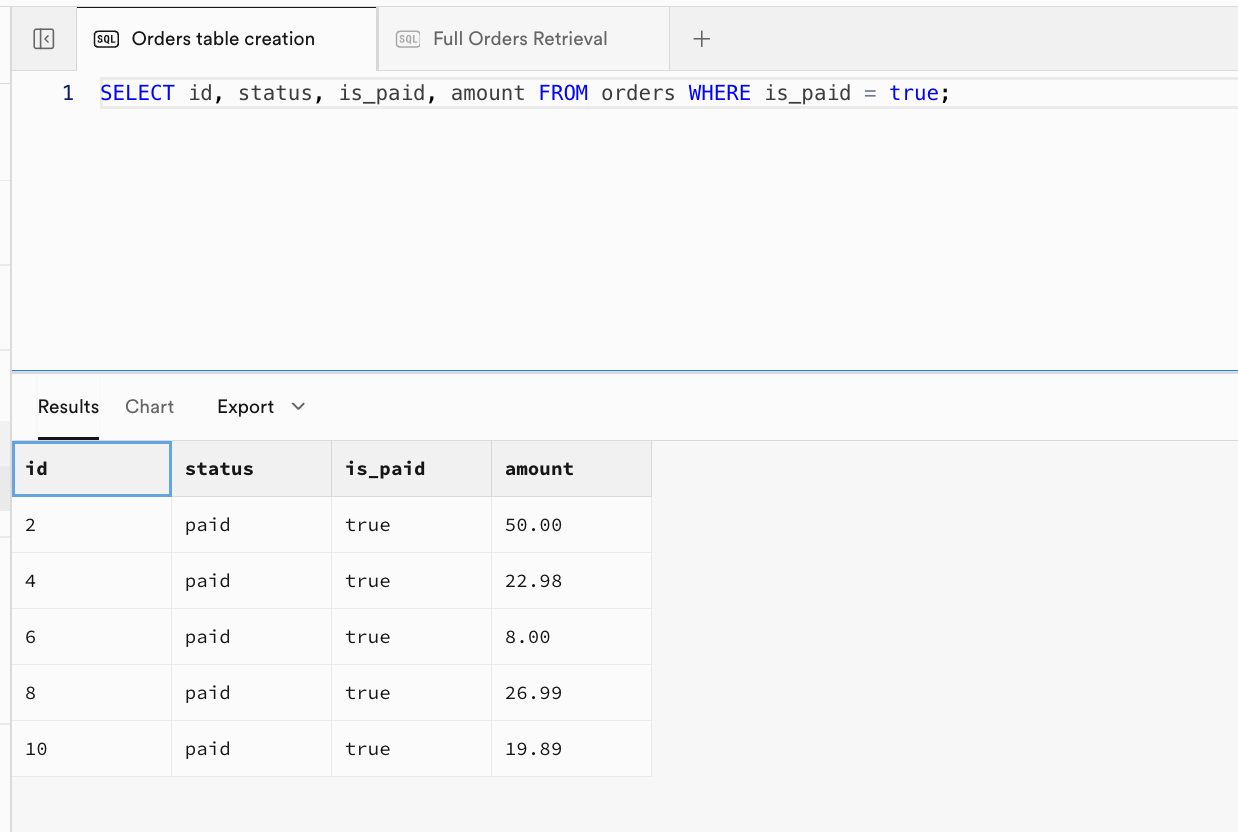
- مثال 3: يُرجع فقط الطلبات المدفوعة ويعرض الأعمدة المحددة:
| id | status | is_paid | amount |
|---|---|---|---|
| 2 | paid | true | 50.00 |
| 4 | paid | true | 22.98 |
| 6 | paid | true | 8.00 |
| 8 | paid | true | 26.99 |
| 10 | paid | true | 19.89 |
- مثال 4: يُرجع
idلكل طلب ومصفوفةitemsالمستخرجة من حقلdetails:
| id | item_list |
|---|---|
| 1 | [{"qty":1,"sku":"BGR001","name":"Beef Burger","price":12}] |
| 2 | [{"qty":2,"sku":"BGR002","name":"Chicken Burger","price":10},{"qty":2,"sku":"DRK001","name":"Lemonade","price":5}] |
| 3 | [{"qty":3,"sku":"FRY001","name":"French Fries","price":5}] |
| ... | ... |
2.3.4 INSERT - إدراج سجل واحد
في 2.3.2، أوضحنا كيفية إدراج البيانات بشكل مبدئي عند البداية. الآن سنرى كيفية إضافة وإدراج بيانات مفردة.
-- Step 4: INSERT a new order (single row)
-- Example: Add a new paid order for user 2012 with one Chicken Burger
INSERT INTO orders (user_id, status, amount, details, is_paid)
VALUES (
2012, 'paid', 9.99,
'{"items":[{"sku":"BGR002","name":"AIID Burger","qty":100,"price":1000}]}',
true
);
-- Expected Output:
-- Before (table fragment):
-- | id | user_id | status | amount | is_paid |
-- | ...| ... | ... | ... | ... |
--
-- After (last row):
-- | id | user_id | status | amount | is_paid |
-- | xx | 2012 | paid | 9.99 | true |
-- (where xx = next serial value)في هذا الوقت، باستخدام SELECT * FROM orders; للاستعلام عن البيانات، يمكننا أن نرى أن جدول orders قد زاد بنجاح من 11 بيانة إلى 12 بيانة.
2.3.5 UPDATE - تعديل البيانات الموجودة
في العمل الفعلي، نحتاج إلى تحديث البيانات في جداول البيانات بشكل متكرر. يمكننا استخدام عبارة UPDATE لتعديل السجلات الموجودة في الجدول.
-- Step 5: UPDATE example
-- Example: Mark order with id=1 as paid and update its status
UPDATE orders SET status = 'paid', is_paid = true WHERE id = 1;
-- Expected Output:
-- Before (row with id=1):
-- | id | status | is_paid |
-- | 1 | pending | false |
-- After (row with id=1):
-- | id | status | is_paid |
-- | 1 | paid | true |
-- All other rows remain unchanged.2.3.6 DELETE - حذف البيانات
يمكن استخدام عبارة DELETE لإزالة السجلات من الجدول، مع إمكانية دمج الشروط لتعديل أجزاء محددة من البيانات.
-- Step 6: DELETE example
-- Example: Delete orders older than 2 days to clean up old data
DELETE FROM orders WHERE placed_at < now() - interval '2 days';
-- Expected Output:
-- Before (filtered for affected rows):
-- | id | status | placed_at |
-- | 3 | shipped | 2025-10-13 ... | <-- will be deleted
--
-- After:
-- No such rows remain. SELECT * FROM orders WHERE placed_at < now()-interval '2 days' yields zero rows.
-- Other rows in orders table are unaffected.قبل التنفيذ، يمكنك أولاً تنفيذ SELECT id, status, placed_at FROM orders WHERE placed_at < now() - interval '2 days'; لعرض نتائج تصفية جدول البيانات. عند تشغيل أمر DELETE، قم بتنفيذ نفس استعلام SELECT مرة أخرى SELECT id, status, placed_at FROM orders WHERE placed_at < now() - interval '2 days';، وسيُرجع نتيجة فارغة، مما يدل على أنه تم حذف هذه الصفوف بنجاح.
2.4 الأمان على مستوى الصف
بعد تعلم العمليات الأساسية لقاعدة البيانات، نحتاج إلى التعمق أكثر في مفهوم أساسي يضمن أمان البيانات - RLS (الأمان على مستوى الصف، Row Level Security).
لنبدأ بالتفكير في سؤال رئيسي في سيناريو عملي: كيف يمكن تحقيق "الوصول المعزول" للبيانات؟ على سبيل المثال، السماح فقط للمستخدم A بعرض بياناته الخاصة، دون القدرة على رؤية معلومات المستخدم B؛ ومثال آخر، حتى لو كان لدى دور ما صلاحية الوصول إلى قاعدة البيانات، كيف يمكن تجنب تشغيله الخاطئ أو تسريب البيانات الحساسة لمستخدمين آخرين؟
تم إنشاء RLS خصيصاً لحل احتياجات أمن البيانات والعزل هذه. فهو يتيح للمطورين تعريف سياسات أمنية دقيقة لجداول قاعدة البيانات، وبناءً على معلومات هوية المستخدم (مثل معرف المستخدم، وصلاحيات الدور، إلخ)، التحكم بدقة في المستخدمين الذين يمكنهم الوصول إلى وتعديل صفوف بيانات محددة في الجدول.
لنأخذ مثالاً نموذجياً: بالنسبة لجدول الطلبات (orders)، يمكننا تعريف سياسة RLS كالتالي - "فقط عندما يتطابق عمود user_id في سجل معين في جدول orders تماماً مع معرف المستخدم المسجل دخوله حالياً، يمكن لهذا المستخدم الاستعلام عن بيانات هذا الطلب"، وبالتالي تحقيق المتطلب الأساسي المتمثل في "يمكن للمستخدم رؤية طلباته فقط".
عندما تقوم بتفعيل RLS لجدول ما، فإن جميع طلبات عمليات البيانات على هذا الجدول (بما في ذلك استعلامات SELECT، وإضافة INSERT، وتعديل UPDATE، وحذف DELETE) ستقوم بتشغيل تحقق RLS: يجب اجتياز فحص سياسة أمنية واحدة على الأقل لتنفيذ العملية. في حال عدم وجود سياسة تسمح بهذه العملية، أو إذا لم يستوفِ الطلب شروط أي سياسة، سترفض قاعدة البيانات هذه العملية مباشرة، مما يمنع الوصول غير المصرح به من المستوى الأساسي.
في Supabase، يرتبط RLS بشكل عميق بنظام مصادقة المستخدمين، مما يجعل استخدامه أكثر سهولة. يوفر Supabase دالة مخصصة auth.uid()، والتي يمكنها إرجاع المعرف الفريد (بتنسيق UUID) لـ "المستخدم المسجل دخوله الذي يقدم الطلب حالياً" مباشرة. باستخدام هذه الدالة، يمكننا بسهولة كتابة سياسات لتحقيق الارتباط الدقيق بين "صفوف البيانات وهوية المستخدم" (مثل ما ذكرناه سابقاً من "مطابقة user_id للطلب مع معرف المستخدم الحالي").
طريقة تفعيل سياسات RLS مرنة، حيث يمكنك تهيئة وتفعيل السياسات مباشرة من خلال زر "RLS" في واجهة إدارة قاعدة بيانات Supabase:
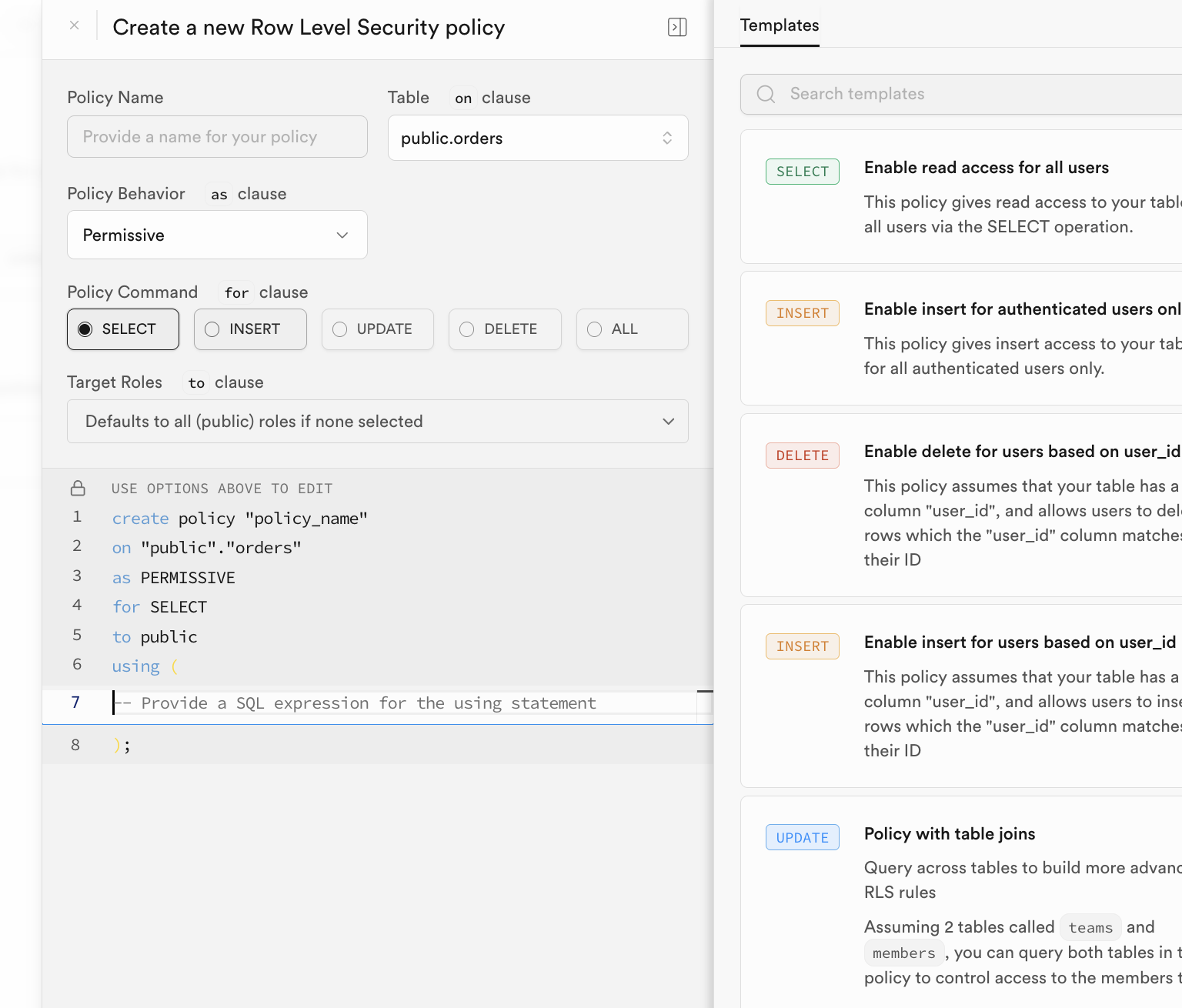
قد يبدو التهيئة اليدوية مرهقة، وعادة ما نأخذ استراتيجيات RLS في الاعتبار تلقائياً عند إنشاء جداول البيانات وتهيئتها بعبارات SQL. نحتاج فقط إلى تنفيذ عبارات مشابهة لما يلي في SQL Editor لتفعيل سياسات الأمان على مستوى الصف تلقائياً لجدول البيانات المقابل.

3. أول تطبيق SQL
بعد إتقان العمليات الأساسية لقاعدة البيانات والمنطق الأساسي لـ RLS، دخلنا أخيراً الجزء العملي من هذا الدرس التعليمي. كان التعلم الطويل والم preparations目的是make عملية "بناء تطبيق من الصفر" أكثر وضوحاً لاحقاً. بعد ذلك، سنتخذ من "إدارة طلبات متجر البرجر" كسيناريو، لنشرح خطوة بخطوة العمليات الشائعة في Supabase: من تهيئة الارتباط بين التطبيق وSupabase، إلى تكامل قاعدة البيانات ووظائف تسجيل الدخول، والتعلم التدريجي لمنطق العمليات المختلفة.
3.1 استنساخ وتشغيل مشروع Supabase التجريبي
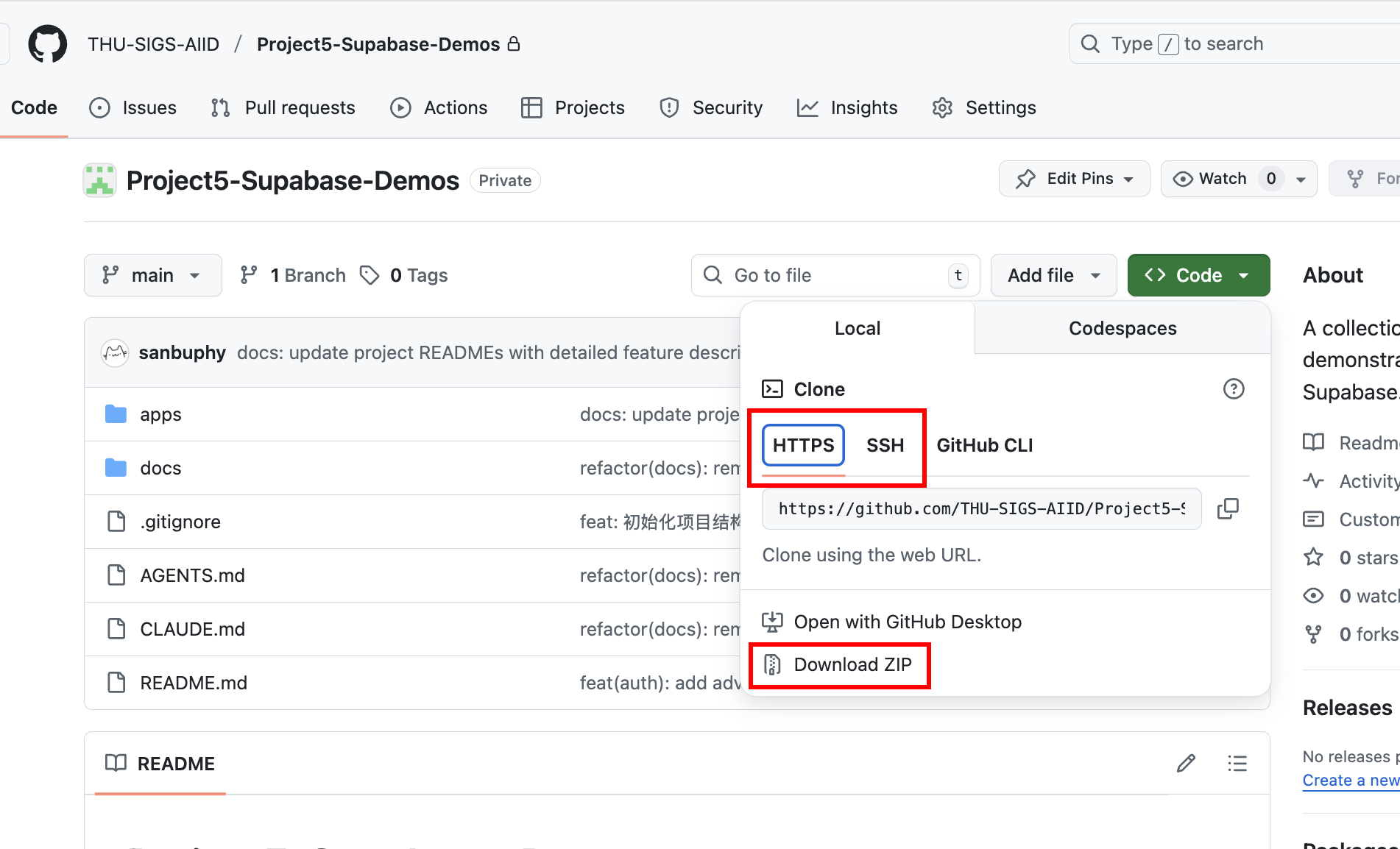
للبدء في التطبيق العملي، تحتاج أولاً إلى الحصول على مستودع الكود التجريبي المصاحب. يمكنك جعل Trae أو Claude Code يساعدك في git clone المستودع التالي: https://github.com/THU-SIGS-AIID/Project5-Supabase-Demos
إذا كنت قد قمت بتهيئة مفاتيح SSH، يُنصح باستخدام عنوان SSH للنسخ (git@github.com:THU-SIGS-AIID/Project5-Supabase-Demos.git) لتحسين الأمان؛ إذا واجهت مشاكل في الشبكة مع SSH أو HTTPS، يمكنك النقر مباشرة على زر "Download ZIP" في صفحة المستودع، والحصول على الملف المضغوط ثم فك ضغطه لرؤية الكود الكامل.
بعد الاستنساخ، يمكنك أيضاً جعل Trae أو Claude Code يساعدك في تشغيل المشروع، على سبيل المثال بالشرح مباشرة في واجهة Agent: ساعدني في تشغيل المشروع 1 في هذا المشروع مباشرة، أو نسخ المسار المطلق للمشروع الذي تريد تشغيله ولصقه للنموذج الكبير ليقوم بتشغيله مباشرة.
3.2 المشروع 1 - إضافة وحذف وتعديل واستعلام قائمة متجر البرجر
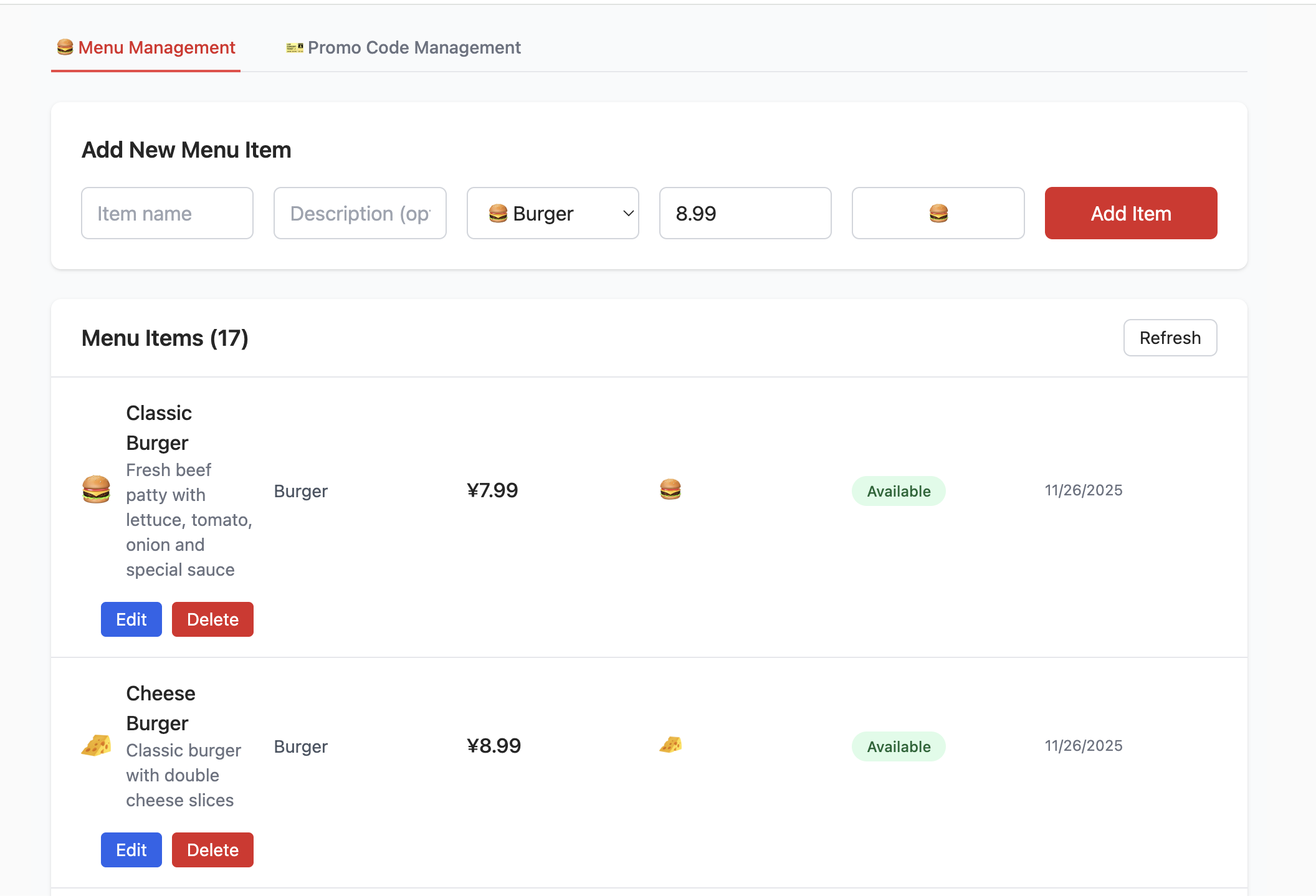
بعد ذلك ندخل الجزء العملي - باستخدام project-burger-shop-menu-crud-1 كمثال، سنتعلم كيفية تهيئة قاعدة بيانات Supab بنقرة واحدة من خلال برامج SQL النصية، وإكمال تهيئة الارتباط بين المشروع المحلي وقاعدة بيانات Supabase، بحيث يمكن للواجهة الأمامية قراءة وكتابة بيانات القائمة بشكل طبيعي.
إنشاء قاعدة البيانات باستخدام البرنامج النصي
أولاً، نحتاج إلى إنشاء المحتوى ذي الصلة بجداول البيانات المطلوبة في Supabase. بالدخول إلى دليل المشروع 1، ستجد مجلداً باسم scripts يحتوي على ملف برنامج SQL نصي واحد باسم init.sql، والذي يمكنه مساعدتنا تلقائياً في إنشاء جميع الموارد ذات الصلة بقاعدة البيانات (بما في ذلك هيكل الجداول، والبيانات الأولية، إلخ)، وسنستخدم هذا الملف كثيراً لاحقاً لتهيئة الجداول في قاعدة البيانات.
......
-- ============================================================================
-- 2. Create Menu Items Table
-- ============================================================================
create table if not exists public.menu_items (
id uuid primary key default gen_random_uuid(),
name text not null,
description text,
category text check (category in ('burger','side','drink')) default 'burger',
price_cents int not null check (price_cents > 0),
available boolean default true,
emoji text,
created_at timestamptz not null default now(),
updated_at timestamptz not null default now()
);
-- Comments for documentation
comment on table public.menu_items is 'Burger shop menu items for CRUD demo';
comment on column public.menu_items.id is 'Unique identifier for each menu item';
comment on column public.menu_items.name is 'Display name of the menu item';
comment on column public.menu_items.description is 'Detailed description of the menu item';
comment on column public.menu_items.category is 'Category: burger, side, or drink';
comment on column public.menu_items.price_cents is 'Price in cents (integer) to avoid floating point issues';
comment on column public.menu_items.available is 'Whether the item is currently available for order';
comment on column public.menu_items.emoji is 'Optional emoji representation of the menu item';
comment on column public.menu_items.created_at is 'Timestamp when the item was created';
comment on column public.menu_items.updated_at is 'Timestamp when the item was last updated';
......بعد تنفيذ البرنامج النصي لتهيئة SQL في SQL Editor، يمكنك رؤية جداول البيانات المنشأة في Table Editor. المنطق التنفيذي المحدد لكود تهيئة قاعدة البيانات هو كالتالي:
- إنشاء جدول menu_items:
- يُستخدم هذا الجدول لتخزين جميع عناصر قائمة متجر البرجر. يحتوي على حقول مثل name (اسم المنتج)، description (الوصف)، price_cents (السعر بالسنتات لتجنب مشاكل دقة الأرقام العشرية)، category (الفئة) وavailable (هل هو متاح للبيع). هذا يغطي بشكل أساسي جميع المعلومات المطلوبة لعنصر قائمة واحد.
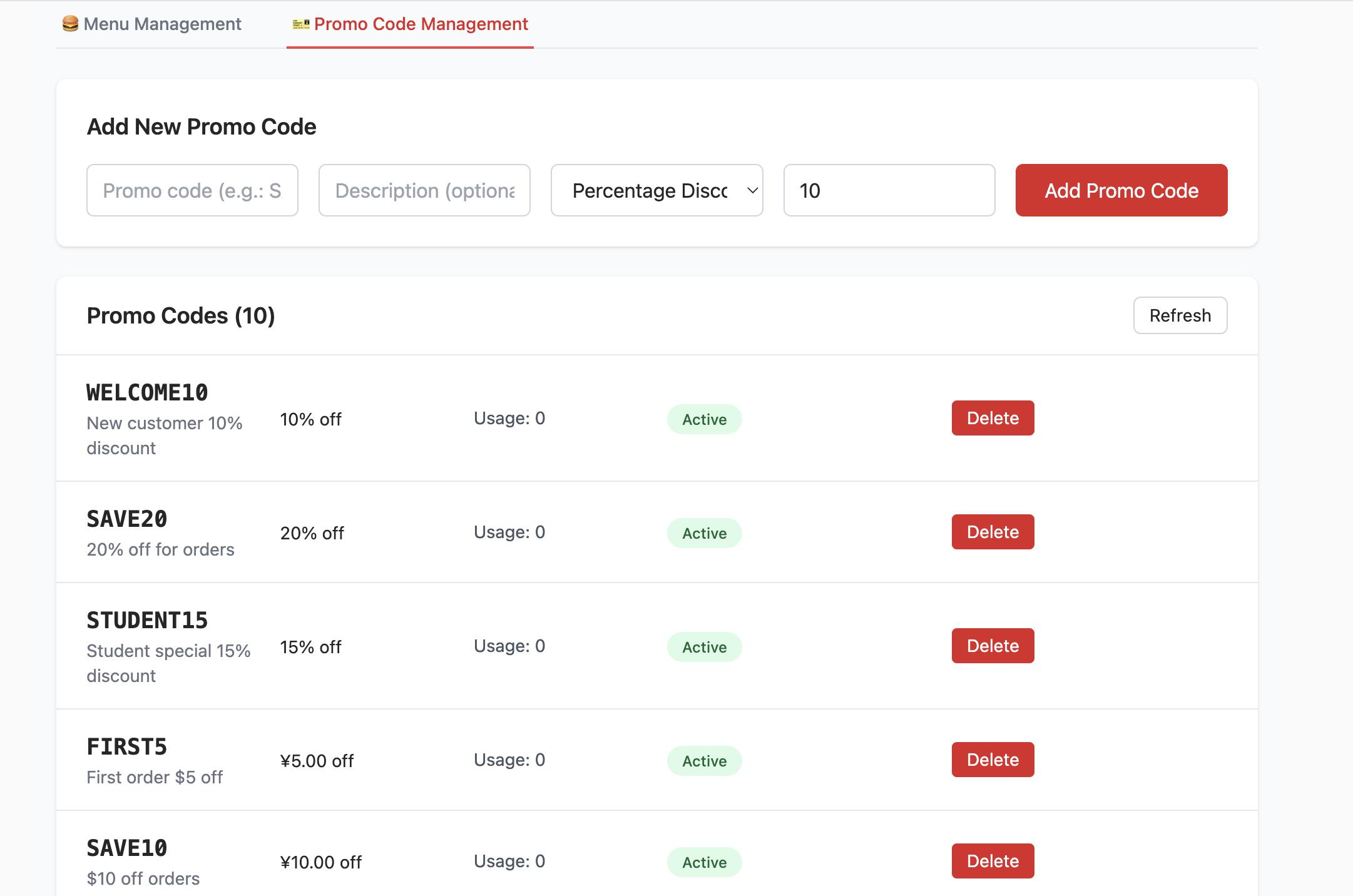
- إنشاء جدول promo_codes:
- يُستخدم هذا الجدول لإدارة الأنشطة الترويجية، مثل أكواد الخصم. يحدد حقولاً مثل code (كود الخصم)، discount_type (نوع الخصم، مثل نسبة مئوية أو مبلغ ثابت)، discount_value (قيمة الخصم).
- تعطيل الأمان على مستوى الصف (Row Level Security - RLS):
- لتسهيل التطوير والاختبار، يقوم البرنامج النصي بتعطيل RLS بشكل صريح. لكن بالنظر إلى المنطق الأساسي لـ RLS الذي تعلمناه سابقاً: RLS هي وظيفة أساسية في Supabase لضمان أمان البيانات، ويمكنها التحكم من خلال سياسات دقيقة في "من يمكنه الوصول/تعديل أي بيانات" (مثل السماح فقط للمسؤولين بتعديل أكواد الخصم، والمستخدمين العاديين يمكنهم فقط عرض القائمة). لذلك في بيئة الإنتاج، يجب تفعيل RLS وتهيئة سياسات معقولة، لمنع الوصول غير المصرح به من المستوى الأساسي (مثل منع المستخدمين من التعديل الخبيث لقوائم أنشأها آخرون، أو تسريب قواعد أكواد الخصم).
- إدراج بيانات البذور (Seed Data):
- لكي يتمكن المشروع الأمامي من رؤية بيانات القائمة والعروض الترويجية الحقيقية بعد التشغيل (دون الحاجة لإدخال بيانات اختبار يدوياً)، سيقوم البرنامج النصي
init.sqlأيضاً بإدراج "بيانات البذور" (أي بيانات نموذجية) في جداولmenu_itemsوpromo_codes. على سبيل المثال، يمكنك رؤية أنواع مختلفة من البرجر والوجبات الخفيفة والمشروبات ومجموعة متنوعة من أكواد الخصم.
إعداد الاتصال بقاعدة البيانات
بعد الانتهاء من تهيئة قاعدة البيانات، نحتاج إلى ربط مشروع الواجهة الأمامية هذا مع Supabase لقراءة البيانات من قاعدة البيانات بشكل طبيعي. نحتاج إلى كتابة URL ومفتاح anon الخاص بمشروع Supabase في التهيئة المحددة. يوفر هذا المشروع طريقتين مرنتين للتهيئة:
- التهيئة من خلال متغيرات البيئة
أنشئ ملف .env في الدليل الجذري للمشروع، وأدخل بيانات اعتماد Supabase الخاصة بك:
NEXT_PUBLIC_SUPABASE_URL=https://your-project.supabase.co
NEXT_PUBLIC_SUPABASE_ANON_KEY=your-anon-key- الإعداد مباشرة في صفحة المشروع
لتسهيل العرض السريع والتبديل بين مشاريع Supabase المختلفة، توفر صفحة الرئيسية زر إعداد في الزاوية العلوية اليمنى. يمكنك النقر عليه، وإدخال أو لصق Supabase URL ومفتاح anon مباشرة في مربع الحوار المنبثق.
بعد النقر على "Save"، ستُستخدم هذه المعلومات لإنشاء مثيل عميل Supabase ديناميكياً، كما هو موضح في الكود التالي:
import { createClient, type SupabaseClient } from '@supabase/supabase-js';
// Optional client factory for demos: returns null when env is not set.
export function maybeCreateBrowserClient(): SupabaseClient | null {
const url = process.env.NEXT_PUBLIC_SUPABASE_URL;
const anon = process.env.NEXT_PUBLIC_SUPABASE_ANON_KEY;
if (!url || !anon) return null;
return createClient(url, anon);
}بعد إنشاء قاعدة البيانات وملء تهيئة رابط Supabase ذات الصلة، يمكنك رؤية الواجهة التالية. يمكنك تجربة إضافة وحذف والاستعلام عن المنتجات وتعديلها، ومراقبة التغييرات في جزء جدول البيانات المقابل في Supabase.
واجب
- حاول إضافة وحذف العناصر الموجودة، واعرض تأثير عمليات التعديل على محتوى جدول البيانات في Table Editor.
3.4 المشروع 2 - مستخدمو مصادقة متجر البرجر
حقق المشروع 1 "إضافة وحذف واستعلام وتعديل القائمة + اتصال قاعدة البيانات"، وسيقدم المشروع 2 قدرات أساسية أقرب إلى الأعمال الحقيقية: مصادقة المستخدمين (Auth) وإدارة صلاحيات الأمان على مستوى الصف (RLS).
يحتوي المشروع 2 على صفحة تسجيل دخول مستقلة، ويد تسجيل دخول المستخدمين عبر "البريد الإلكتروني + كلمة المرور". المنطق الأساسي هو استدعاء الأساليب الأصلية التي يوفرها Supabase Auth لتحقيق عملية المصادقة بسرعة، دون الحاجة لتطوير منطق التحقق من تسجيل الدخول المعقد يدوياً:
const { error: err } = await supabaseClient.auth.signUp({
email,
password,
options: {
data: {
full_name: fullName || null,
birthday: birthday || null,
avatar_url: avatarUrl || null
}
}
});
بعد نجاح تسجيل الدخول، سينشئ Supabase تلقائياً جلسة (session) للمستخدم، ويحمل معلومات المصادقة تلقائياً في جميع طلبات قاعدة البيانات اللاحقة؛ من خلال تأثير RLS، يمكن لكل مستخدم رؤية معلومات حسابه فقط (المشاريع المشتراة، الرصيد المتبقي في المحفظة) بناءً على معلومات المصادقة المقابلة، ولا يمكنه رؤية معلومات حساب المستخدمين الآخرين. هذا يحقق عزل البيانات بعد تسجيل دخول مستخدمين مختلفين، حيث يمكن لكل شخص رؤية محتواه فقط.
كما في المشروع 1، تحتاج أولاً إلى استخدام init.sql لتهيئة جداول البيانات (ملاحظة: إذا وجدت خطأ في التهيئة، يرجى حذف جداول البيانات المنشأة بالفعل في Table Editor أولاً، أو حذف مشروع Supabase هذا مباشرة وإنشاء مشروع جديد)
بعد التسجيل بنجاح باستخدام البريد الإلكتروني وتأكيد التسجيل في البريد الإلكتروني، بعد تسجيل الدخول وال دخول إلى واجهة Shop يمكنك رؤية المحتوى التالي:
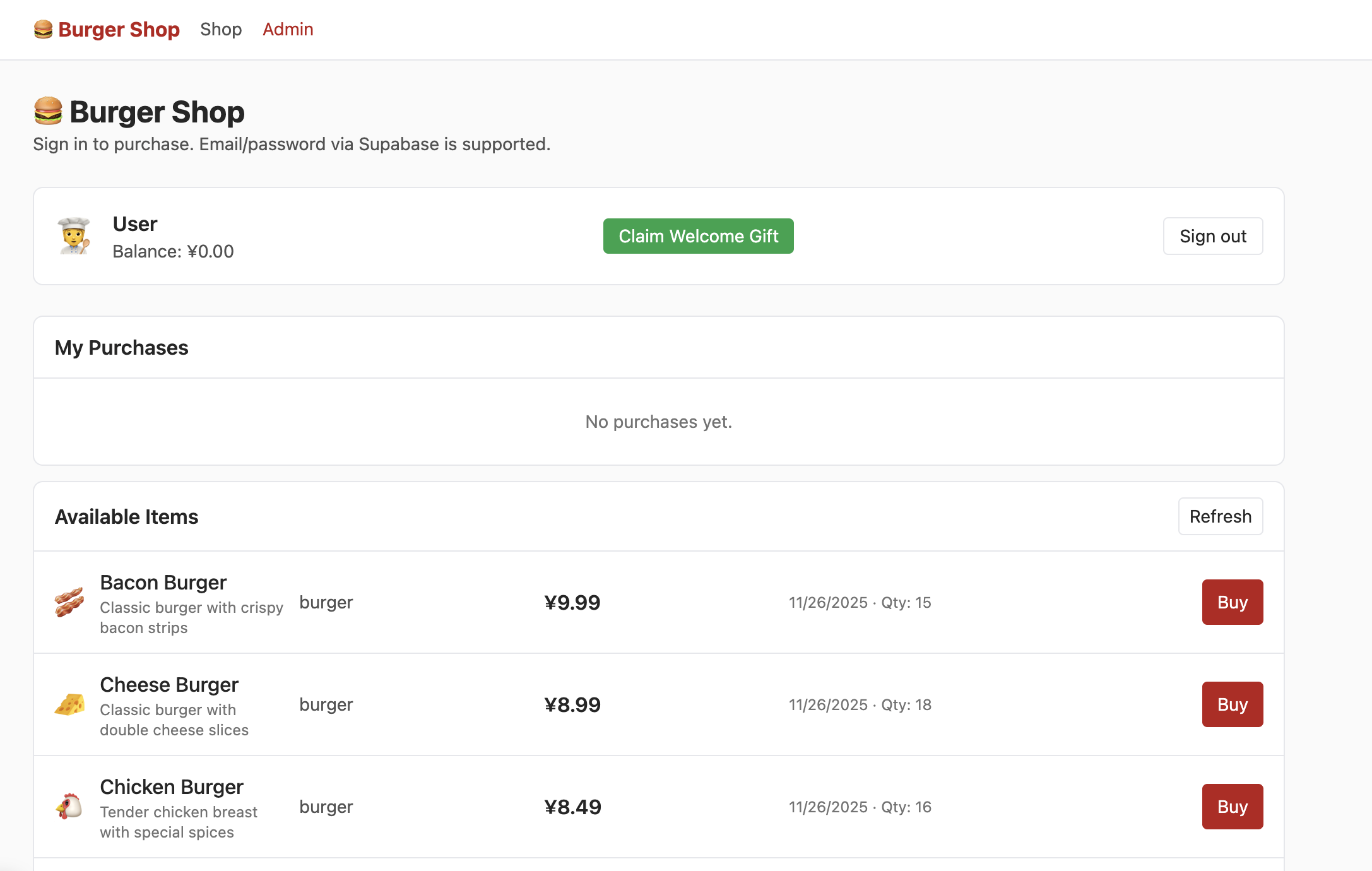
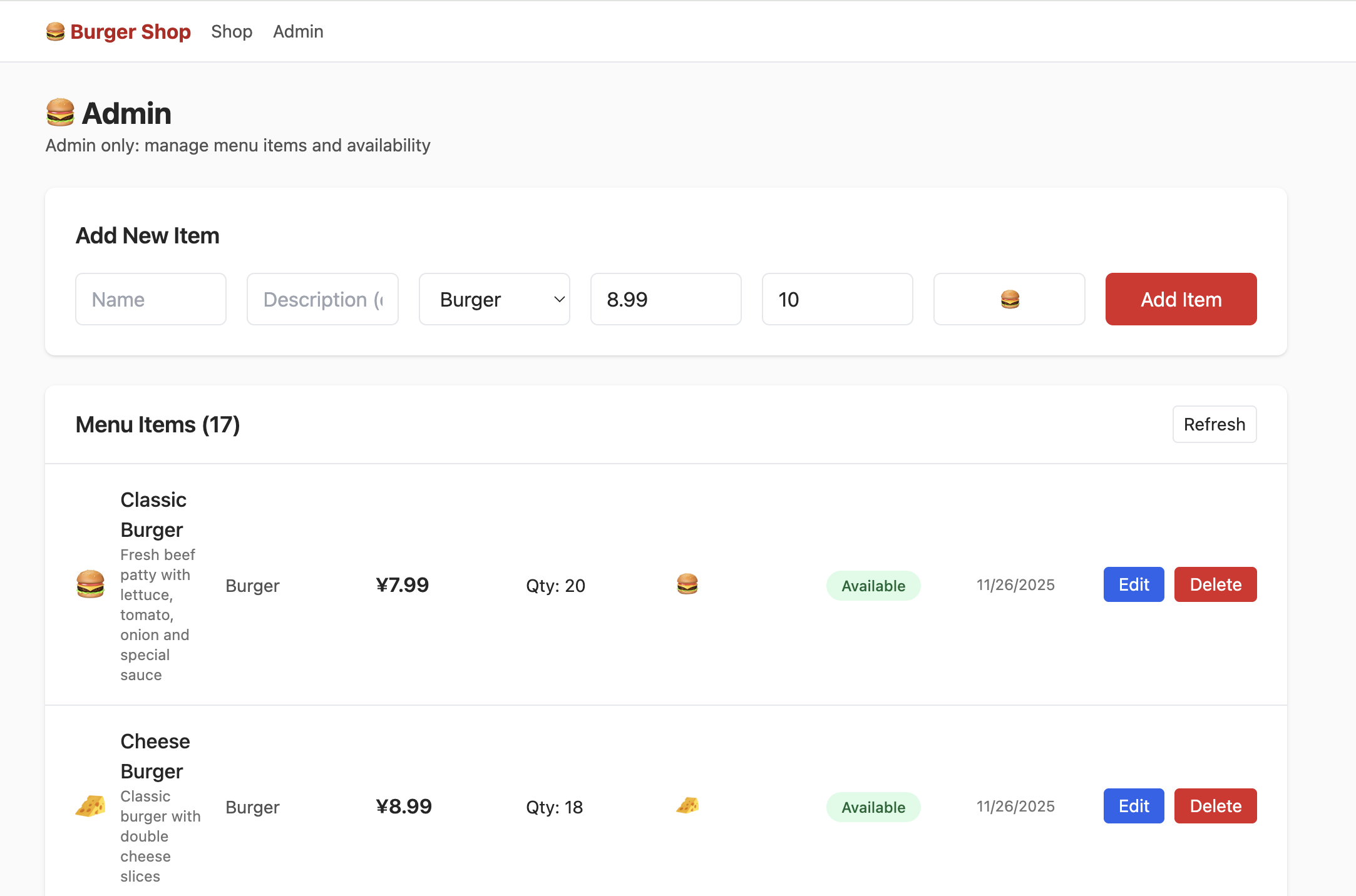
لكن في هذا الوقت عند النقر على admin، لن تتمكن من رؤية الواجهة التالية. تحتاج إلى محاولة العثور على جزء التحكم في صلاحيات المستخدم في جدول البيانات، وتعديل الصلاحيات إلى admin، حتى تتمكن من رؤية المحتوى التالي بشكل طبيعي في واجهة Admin:
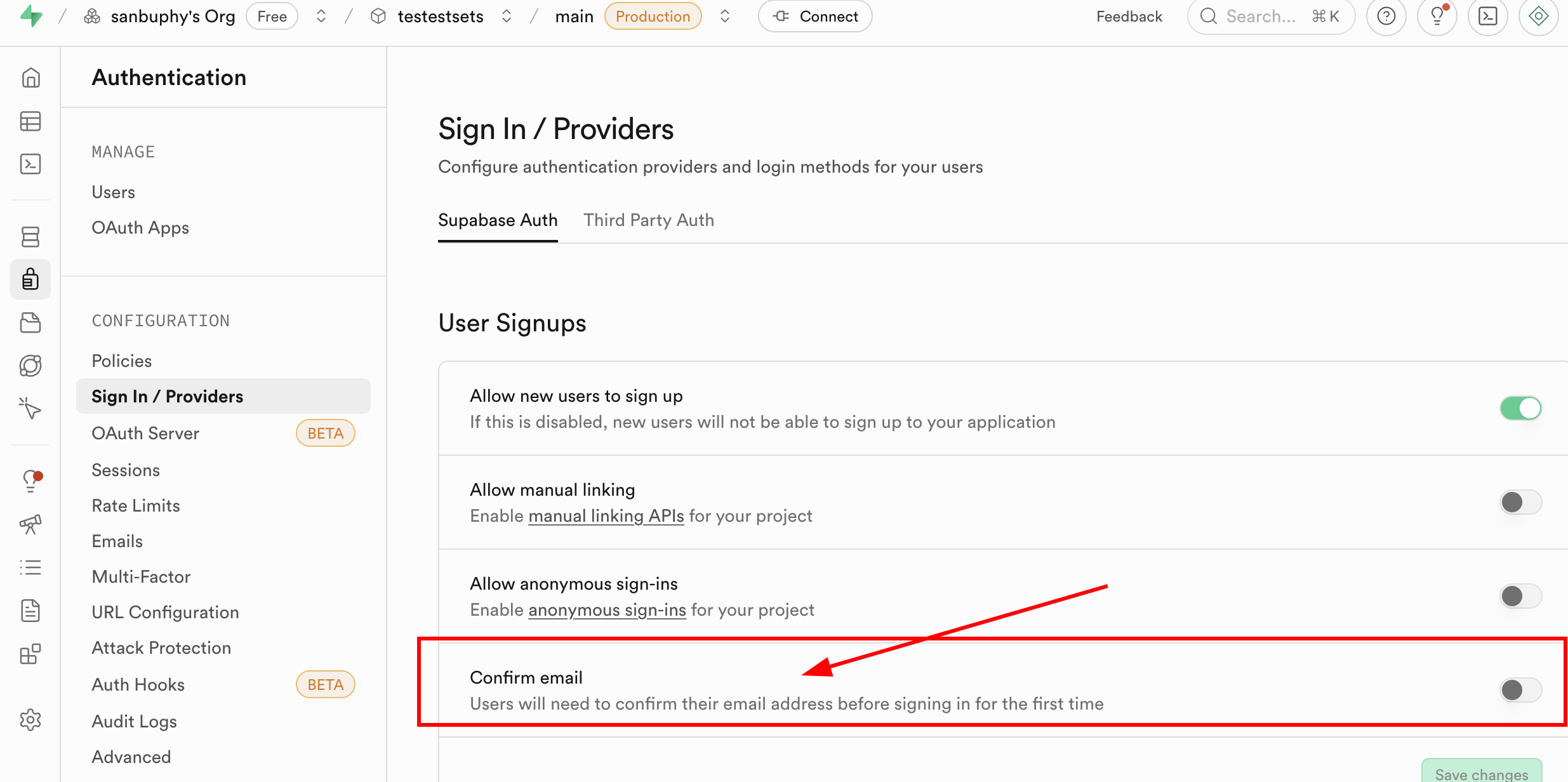
تجدر الإشارة إلى أنه حالياً في كل مرة تسجل فيها بريداً إلكترونياً جديداً، تحتاج إلى تأكيد التسجيل في البريد الإلكتروني قبل أن تتمكن من تسجيل الدخول؛ لكن هذه الخطوة ليست إلزامية، يمكنك العثور على Sign In / Providers في قسم Authentication في Supabase، والنقر على Confirm email لإلغاء التأكيد الإلزامي للبريد الإلكتروني.
واجب
- يرجى استلام حزمة المبتدئين أولاً، وإكمال عملية شراء المنتج.
- حاول العثور على موقع جدول بيانات إعدادات صلاحيات المستخدم، وقم بتعديل الصلاحيات إلى
admin، وقم بنجاح بتعديل كمية المنتجات في واجهة إدارة الطلبات. - حاول تحديد موقع جدول رصيد المحفظة في جدول البيانات، ومن خلال التعديل قم بزيادة الرصيد المتبقي في المحفظة.
4. بناء تطبيق Supabase الأول الخاص بك
بعد التعلم المنهجي السابق، أتقنت القدرات الأساسية لـ Supabase (عمليات قاعدة البيانات، مصادقة المستخدمين، سياسات أمان RLS). حان الوقت الآن للبدء بنفسك وبناء أول تطبيق لك يتضمن قاعدة بيانات ويدعم نظام تسجيل دخول المستخدمين!
4.1 العملية الموحدة لتوصيل أي تطبيق بقاعدة بيانات Supabase
يمكننا استخدام عملية موحدة لتوصيل أي تطبيق بقاعدة بيانات Supabase:
- أولاً قم بترتيب المتطلبات ومزامنة المعلومات، وتوضيح الهدف وإخبار الذكاء الاصطناعي
- تحتاج إلى وصف الوظائف الأساسية لتطبيقك الحالي بوضوح للذكاء الاصطناعي، ومتطلبات قاعدة البيانات الجديدة المراد إضافتها. مثال: "لدي حالياً تطبيق React Todo محلي، البيانات مخزنة فقط في وحدة التخزين المحلية للمتصفح، أحتاج إلى إضافة وظيفة 'مزامنة البيانات السحابية' وتوصيل قاعدة بيانات Supabase. ساعدني في ترتيب: ما هي عمليات البيانات التي يتضمنها هذا التطبيق (مثل إضافة مهام، تعديل الحالة، حذف المهام)؟ ما هي جداول البيانات التي يجب إنشاؤها لتخزين هذه البيانات؟"
- أضف قيوداً رئيسية (اختياري): مثل متطلبات تنسيق الحقول (استخدم
timestamptzللطوابع الزمنية، استخدم أعداد صحيحة بالسنتات للمبالغ)، قواعد صلاحيات البيانات (المهام مرئية فقط لنفسك)، لجعل تحليل الذكاء الاصطناعي أكثر ملاءمة للاحتياجات الفعلية. - راجع النتائج التي أرجعها الذكاء الاصطناعي، إذا كان هناك نقص في تفكير الذكاء الاصطناعي (مثل عدم مراعاة حقل "موعد انتهاء المهمة")، أضف تلميحات للتصحيح: "لقد نسيت موعد الانتهاء، ساعدني في إضافته."
- دع الذكاء الاصطناعي ينشئ بنية الجداول التي أكدت عليها، ويولد برنامج
init.sqlالنصي المتوافق مع Supabase: "بناءً على الأفكار المذكورة أعلاه وبنية الجداول، أرجع لي برنامج init.sql النصي الذي يمكن تهيئته في Supabase"، وبعد ذلك تحتاج إلى تنفيذ البرنامج النصي في SQL Editor؛ إذا حدث خطأ أثناء التنفيذ، أرسل رسالة الخطأ إلى الذكاء الاصطناعي ليقوم بتصحيح البرنامج النصي. - بعد تشغيل برنامج init.sql النصي في Supabase، دع الذكاء الاصطناعي يعيد هيكلة الكود الحالي بناءً على البرنامج النصي، بحيث يمكنه التفاعل مع البيانات بشكل طبيعي مع Supabase: "يرجى إعادة هيكلة كود المشروع بناءً على برنامج SQL النصي والإعدادات المناقشة أعلاه ليدعم الاتصال بقاعدة بيانات Supabase المقابلة ومعالجة البيانات".
- بعد إعادة الهيكلة، تحتاج فقط إلى تهيئة معلمات عنوان Supabase والمفتاح (عادة ما تستخدم المشاريع الرسمية فقط تهيئة متغيرات البيئة)، ثم قم بالتحقق، وإذا لم تكن هناك مشاكل فقد تم توصيل التطبيق بقاعدة بيانات Supabase بنجاح.
- قم بتشغيل المشروع، واختبر جميع وظائف التفاعل مع قاعدة البيانات، واذهب إلى Supabase Table Editor لعرض البيانات في الوقت الفعلي لمعرفة ما إذا كانت متزامنة؛
- في حالة حدوث مشاكل (مثل عدم القدرة على إدراج البيانات، أو رؤية جزء فقط من البيانات)، أرسل ظاهرة المشكلة إلى الذكاء الاصطناعي ليقوم بتحديد السبب وتصحيح الكود.
بالإضافة إلى ذلك، إذا كان الهدف هو تطوير صفحة تسجيل دخول المستخدمين، يمكنك جعل الذكاء الاصطناعي يساعدك مباشرة في دمج صفحة تسجيل الدخول: "الآن تحتاج إلى مساعدتي في إضافة نظام تسجيل دخول مستخدمي Supabase إلى هذا التطبيق، بحيث يمكن التسجيل وتسجيل الدخول باستخدام البريد الإلكتروني". بالإضافة إلى ذلك، تحتاج أيضاً إلى توضيح منطق التنقل والمسارات للذكاء الاصطناعي (مثل الانتقال إلى الصفحة الرئيسية للنظام بعد نجاح تسجيل الدخول، وما هو عنوان الصفحة الرئيسية، والبقاء في الصفحة الحالية وعرض رسالة خطأ عند فشل تسجيل الدخول). بعد اكتمال الدمج، تحتاج إلى محاولة التسجيل وتسجيل الدخول ثم التحقق من أنه يمكنك رؤية بيانات المستخدمين الجديدة في قسم Authentication في Supabase، وأنه يمكنك الدخول بشكل طبيعي إلى واجهات التطبيق التي لم تكن متاحة قبل تسجيل الدخول.
بالطبع، يمكنك أيضاً جعل الذكاء الاصطناعي يشير مباشرة إلى تنفيذ مشروع معين لترحيل وظائف Supabase المقابلة، على سبيل المثال يستخدم مشروع معين وظائف متقدمة لقاعدة البيانات وEdge Function، يمكنك جعل الذكاء الاصطناعي يرحيل الوظائف المماثلة مباشرة بالطريقة التالية: "يرجى الرجوع إلى منطق تنفيذ وظائف Supabase ذات الصلة في هذا المشروع {الصق المسار المطلق للمشروع المرجعي هنا} وأضف منطق تنفيذ مشابه للمشروع الحالي (مثل تسجيل دخول المستخدمين، إدارة قاعدة البيانات، طلبات الدوال، إلخ)".
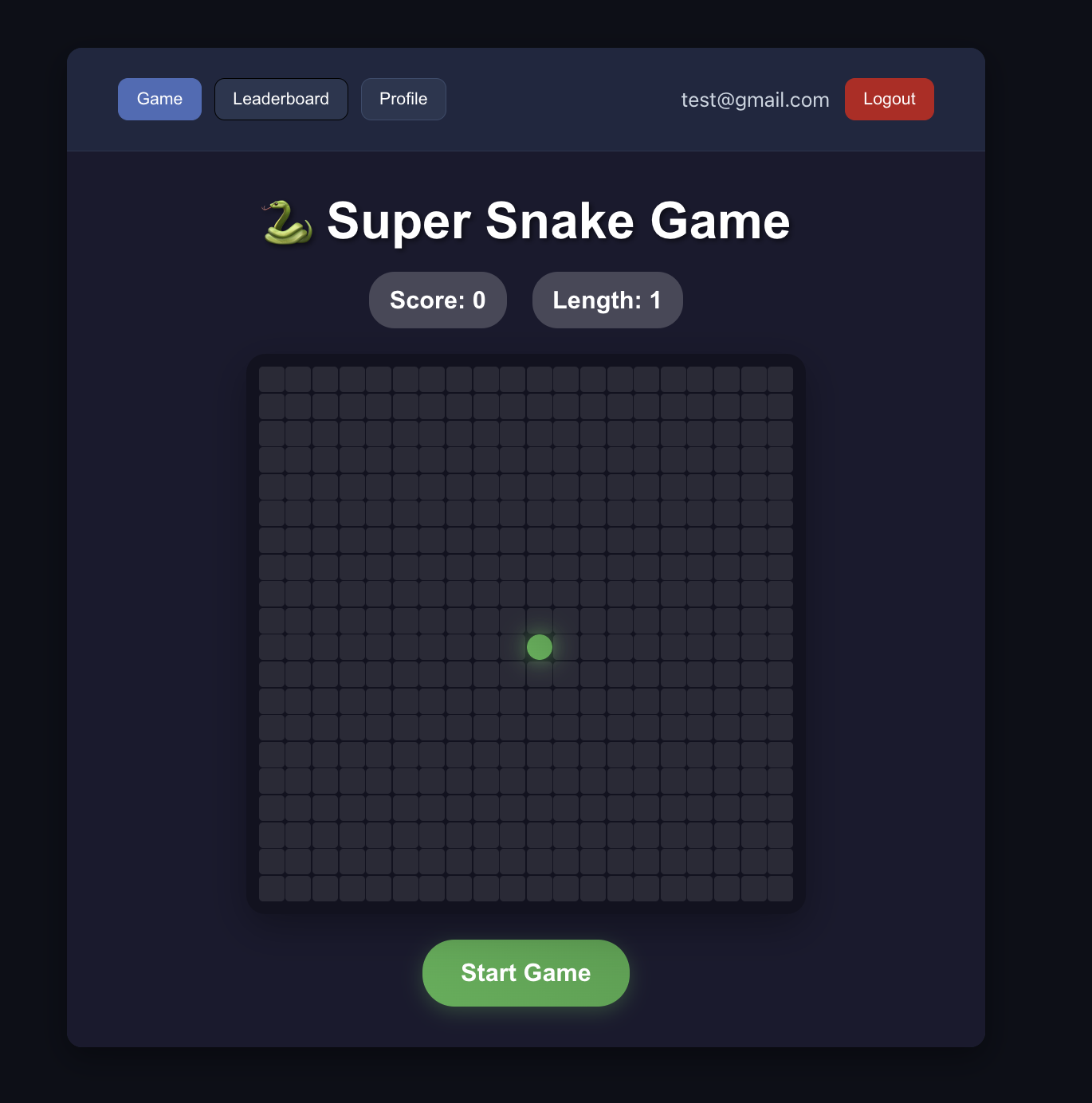
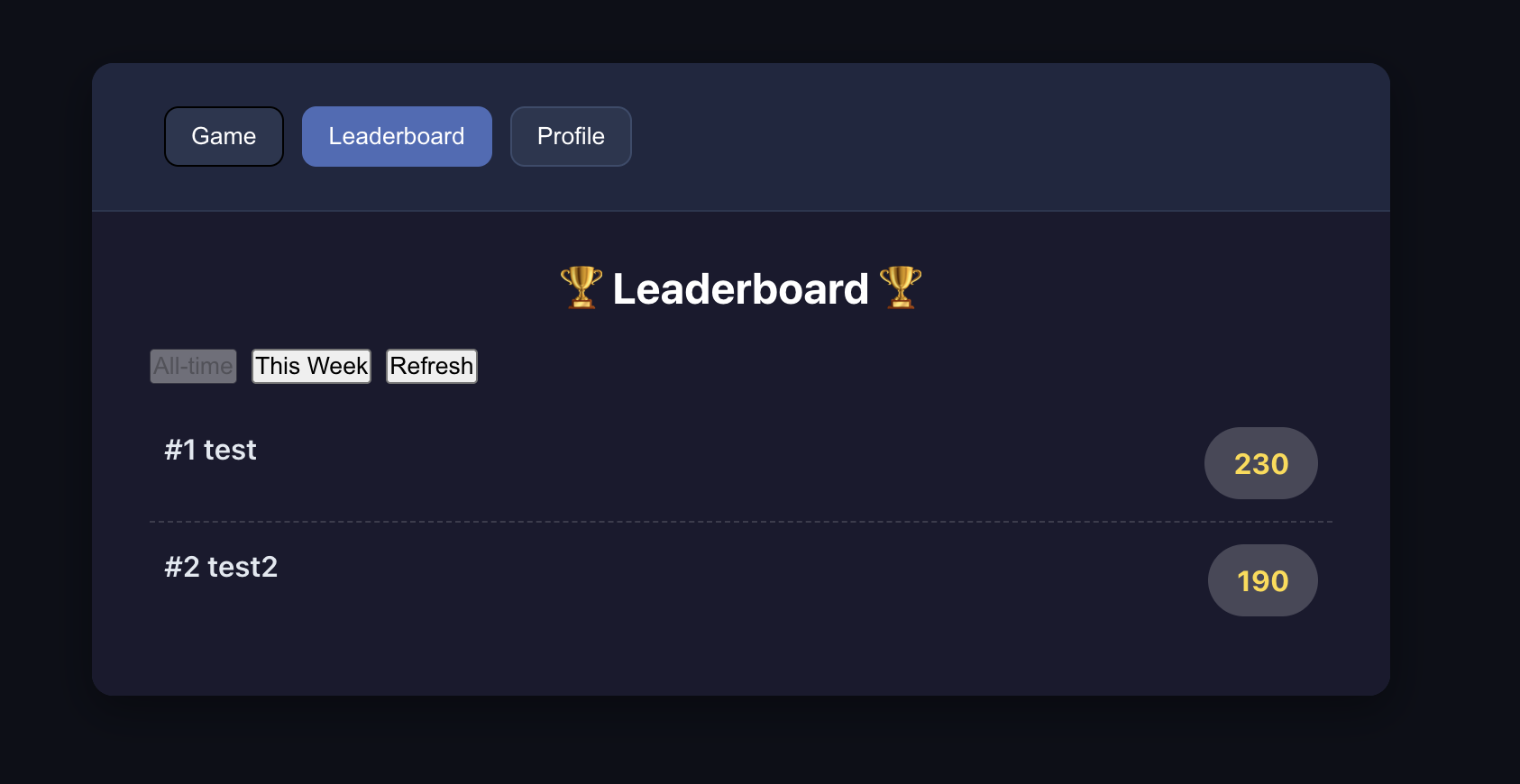
4.2 دراسة حالة: بناء لعبة ثعبان جشع عبر الإنترنت
بناءً على SOP المذكور أعلاه، دعنا نتدرب من خلال حالة عملية محددة Project5-Supabase-Demos/apps_snakegame: إضافة لوحة ص.points لتصنيف تطبيق "لعبة الثعبان الجشع" الموجود، بما في ذلك تسجيل دخول المستخدمين ووظائف قاعدة البيانات الأساسية.
4.2.1 تحليل المشروع، وتحديد متطلبات البيانات
أولاً، كما في العملية الموحدة المذكورة سابقاً، يمكننا توضيح المتطلبات للذكاء الاصطناعي أولاً، وجعله يعطي خطة التعديل المقابلة بناءً على مشروعنا ومتطلباتنا، ثم سنعمل بناءً على خطة التعديل هذه.
يمكنك استخدام الموجه التالي لتوجيه الذكاء الاصطناعي:
"لدي لعبة ثعبان جشع، الدليل في {الصق المسار المطلق للعبة الثعبان الجشع هنا}. أريد الآن دمج Supabase لإضافة وظيفة لوحة تصنيف عبر الإنترنت، ودعم نظام تسجيل دخول المستخدمين، ويمكن أن تعرض لوحة التصنيف الترتيب بناءً على اسم المستخدم والبريد الإلكتروني.
ساعدني في تحليل: لتحقيق هذه الوظيفة، ما هي جداول البيانات التي أحتاج إلى إنشائها؟ ما هي الحقول التي يجب أن يتضمنها كل جدول؟"
في هذا الوقت ستحصل على إجابة مشابهة لما يلي:
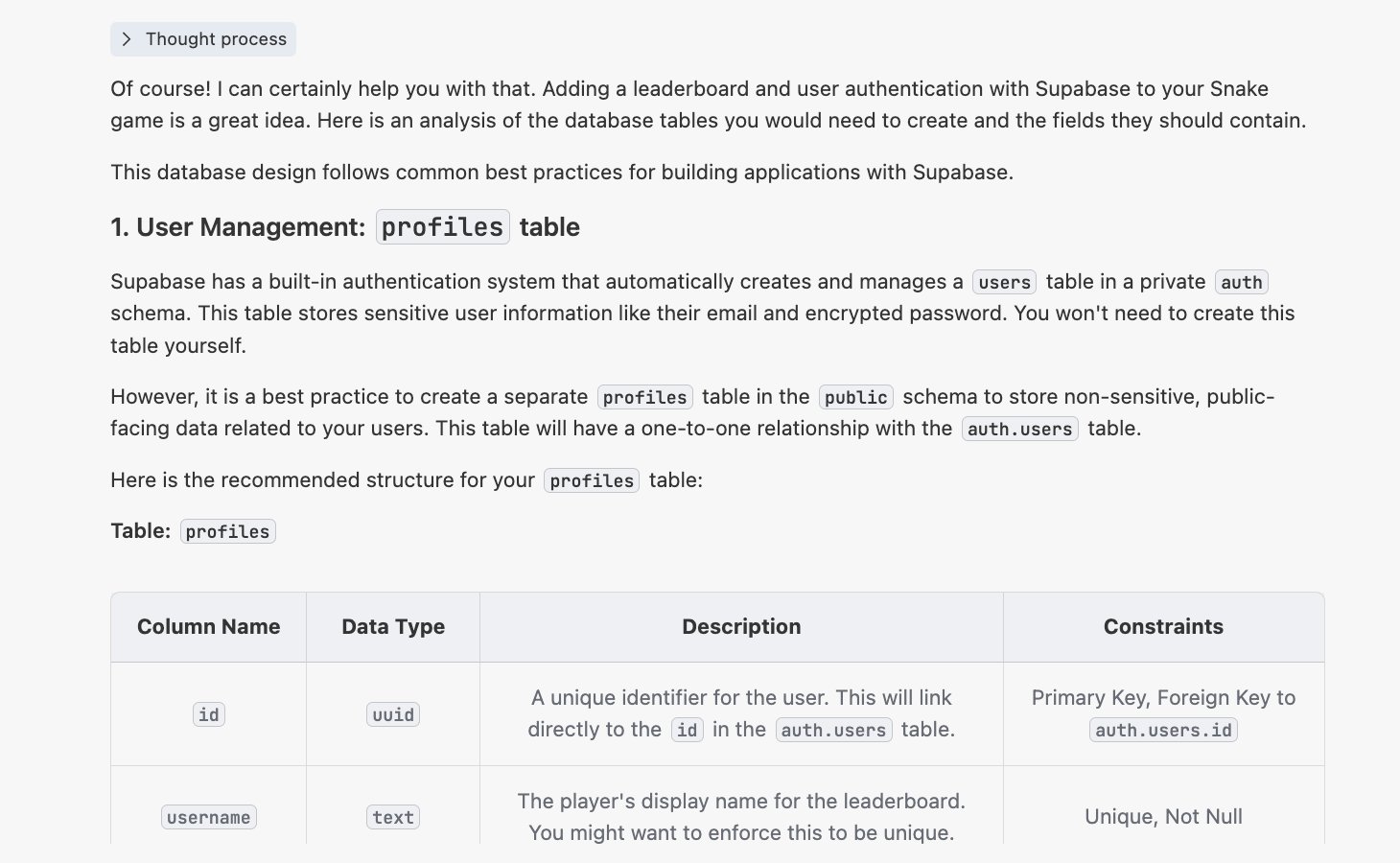
4.2.2 إنشاء برنامج init.sql النصي
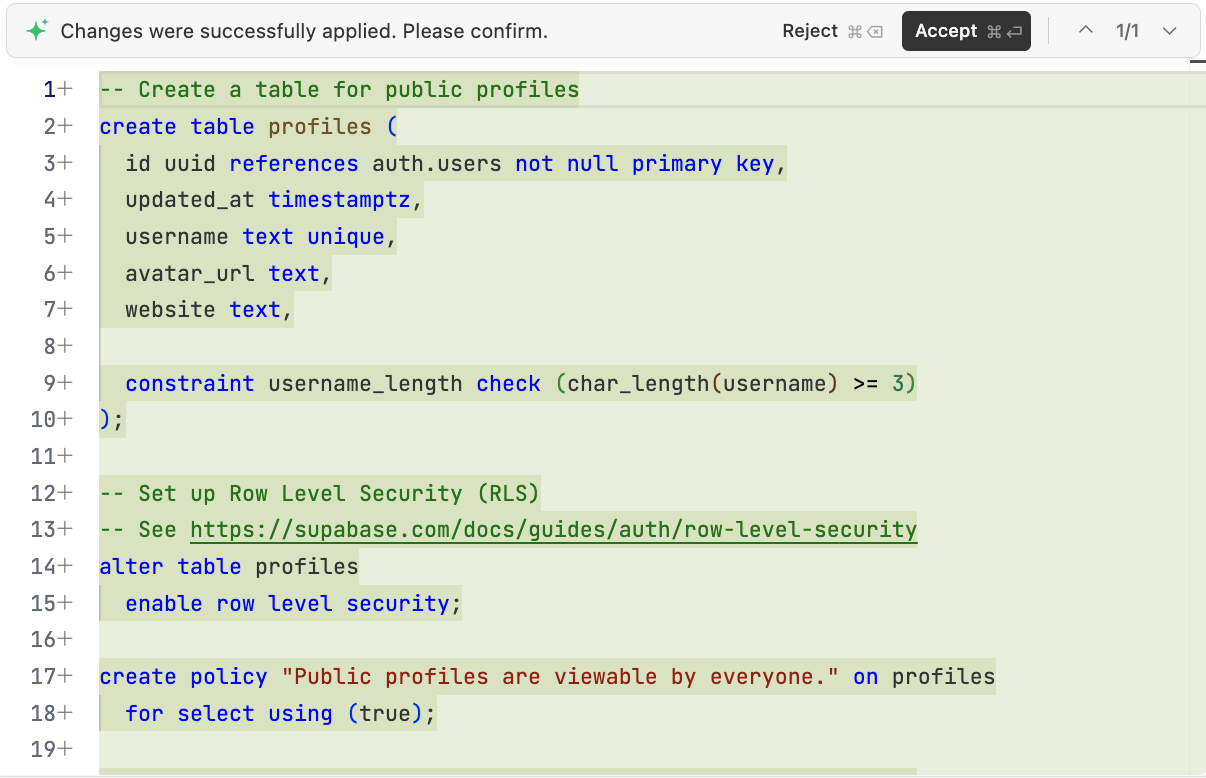
بعد تحديد الأجزاء المطلوبة، يمكننا جعل الذكاء الاصطناعي ينشئ برنامج تهيئة قاعدة البيانات النصي الذي يجب تنفيذه في Supabase: "يرجى إنشاء برنامج scripts/init.sql نصي في المشروع بناءً على التحليل أعلاه لتهيئة قاعدة البيانات المطلوبة في Supabase".
4.2.3 تعديل كود المشروع
بعد ذلك نحتاج فقط إلى جعل الذكاء الاصطناعي يعيد هيكلة كود لعبة الثعبان الجشع الحالي بناءً على المحتوى السابق: "بعد ذلك، يرجى استخدام Supabase بناءً على المحتوى الذي فكرنا فيه سابقاً وجداول SQL لمساعدتي في تنفيذ وظيفة لوحة التصنيف. لوحة التصنيف هي صفحة منفصلة، ويجب أن تكون قادرة على التمييز بين النقاط الإجمالية للمستخدمين المختلفين بناءً على البريد الإلكتروني واسم المستخدم، كما تحتاج إلى دعم نظام تسجيل دخول المستخدمين عبر البريد الإلكتروني، حيث يجب التسجيل وتسجيل الدخول للعب هذه اللعبة."
إذا كان عدد جولات المحادثة الحالية مع الذكاء الاصطناعي كبيراً جداً وتريد بدء جلسة جديدة لإعادة هيكلة المشروع، يمكنك وضع init.sql المذكور أعلاه كمحتوى في السياق، وجعل الذكاء الاصطناعي يعيد هيكلة المشروع بناءً على ملف SQL.
إذا وجدت أن نظام تسجيل دخول المستخدمين الذي نفذه الذكاء الاصطناعي غير طبيعي بما فيه الكفاية، يمكنك وضع عنوان Project5-Supabase-Demos/apps/project-burger-shop-auth-users-2 الذي كتبناه سابقاً مباشرة في الموجه، وجعل الذكاء الاصطناعي ينفذ نظام تسجيل دخول المستخدمين بناءً على المشروع مباشرة. وتحقق من أنه تم تعيين شروط الاتصال الضرورية بـ Supabase بشكل صحيح، لمنع الأخطاء الناتجة عن تهيئة Supabase الخاطئة.
أثناء عملية تعديل الكود، إذا كانت النتائج الفعلية لا تتوافق مع التوقعات (مثل عدم عرض بيانات لوحة التصنيف، أو فشل التحقق من تسجيل الدخول، إلخ)، فقط سجل الظاهرة المحددة بالكامل وأرسلها إلى الذكاء الاصطناعي، ويمكنك الاقتراب تدريجياً من النتيجة الصحيحة. معيار نجاح التعديل هو: أن يتمكن المستخدم من إكمال عمليات التسجيل وتسجيل الدخول بنجاح، وبعد تسجيل الدخول يمكنه عرض لوحة تصنيف اللعبة المقابلة بشكل طبيعي.
واجب الدرس
- دمج نظام إدارة المستخدمين في نسخة العرض التجريبي للعبة الثعبان الجشع
- دمج نظام إدارة المستخدمين في تطبيقك (إذا كنت قد طورت تطبيقاً سابقاً)
5. كن خبيراً في Supabase
ما سبق كان العمليات الأساسية لـ Supabase، في الرحلة التالية سنتعرض للمبادئ والوظائف المتقدمة لـ Supabase. ستفهم لماذا اخترنا Supabase كحالة دراسية تعليمية، وكيفية استخدام Supabase لتحقيق عمليات أكثر تقدماً، لمساعدتك في تحقيق وظائف تفاعلية أكثر تعقيداً. وبعد تعلم هذه الوظائف، حتى عند مواجهة أدوات أخرى مشابهة لـ Supabase، ستتمكن من التفكير بشكل أوسع وفهم المبادئ الأساسية لخدمات الخلفية من مستوى أعمق. بالطبع، لا تحتاج إلى تعلم كل شيء في وقت قصير، ربما يكفي تعلم دعم تسجيل الدخول عبر طرف ثالث فقط. يمكنك تصفح المحتوى التالي أولاً، ثم العودة للتعمق عند مواجهة متطلبات مقابلة في المشروع.
5.1 لماذا اخترنا Supabase
قبل البدء في المحتوى المتقدم، دعنا نفكر في هذا السؤال مرة أخرى: من بين العديد من الحلول التقنية للخلفية، لماذا اخترنا Supabase في النهاية كقاعدة تقنية؟
تواجه الفرق الناشئة تناقضاً شائعاً عند الاختيار التقني: فمن ناحية تريد التحكم الكامل في نظام الخلفية، ومن ناحية أخرى يجب إطلاق المنتج بسرعة - وبناء الخلفية بنفسك عادة ما يعني استثمار أشهر في بناء قواعد البيانات والمزامنة الفورية، ومصادقة المستخدمين، وخدمات API، وتخزين الملفات، والمهام المجدولة، والمراقبة والتنبيه وغيرها من المكونات الأساسية، ما لم يكن أعضاء الفريق قد اكتسبوا خبرة عملية غنية في المجالات المقابلة. تحت الضغط المزدوج لنقص التمويل وضيق نافذة السوق، بمجرد الوقوع في مستنعد البنية التحتية، من السهل جداً أن يؤدي ذلك إلى تأخر التكرار وفقدان مساحة النمو المبكرة.
يقوم Supabase بتعبئة قدرات الخلفية هذه كخدمات جاهزة للاستخدام (قاعدة بيانات PostgreSQL، اشتراكات فورية، مصادقة الهوية، تخزين الكائنات، الدوال الحدية، إنشاء API تلقائي، إلخ)، مما يتيح للفرق الناشئة التركيز على تطوير الوظائف الأساسية بمواردها المحدودة، وتجنب إبطاء سرعة الإطلاق بسبب البناء الأساسي - وقد أصبح هذا استراتيجية بقاء عملية في بيئة الاستثمار الحالية. بالطبع، يمكننا أيضاً استخدام منتجات خلفية متكاملة أخرى للتطوير، مثل PocketBase (خفيف وبسيط) وAppwrite (متوافق عبر المنصات) وغيرها من الحلول، لكن بالنظر إلى اكتمال الوظائف، ونضوج نظام SQL البيئي، واهتمام مجتمع GitHub، فإن Supabase أكثر ملاءمة لدعم التشغيل المستقر طويل الأمد للأعمال.
من بين المنتجات المماثلة، تتميز استراتيجية المصدر المفتوح لـ Supabase بمزايا أكبر. خذ Firebase الذي يتمتع بحصة سوقية أعلى كمثال: طبيعته المغلقة المصدر تؤدي بسهولة إلى الارتباط بالمنصة، وتكاليف الانتقال مرتفعة جداً. يعتمد Supabase نموذج مصدر مفتوح بالكامل، ويدعم النشر الخاص، مما يتجنب مخاطر الاعتماد على مورد واحد، ويمكن التبديل إلى منافسين آخرين حسب الحاجة.
باختصار، يجب أن يتطابق الاختيار التقني مع حجم الأعمال وأهدافها. بالنسبة للمشاريع الشخصية أو الاختبار في نطاق صغير جداً، فإن الحلول فائقة الخفة مثل PocketBase كافية؛ إذا كانت المؤسسة بحاجة إلى التكامل مع أنظمة هوية معقدة، أو تحتاج إلى تلبية متطلبات التدقيق الامتثالي للشركات المدرجة، فإن حلول إدارة الهوية الشاملة على مستوى المؤسسات مثل WorkOS أكثر ملاءمة. لكن للتحقق من MVP، وتحمل الأعمال الأساسية للمستخدمين الأوائل، الوظائف الكاملة لـ Supabase كافية تماماً، حيث يمكنها ليس فقط دعم حجم مستخدمين يصل إلى عشرات الآلاف بشكل مستقل، بل يمكن أيضاً التكامل بمرونة مع خدمات طرف ثالث مثل Stripe (المدفوعات) وResend (البريد الإلكتروني) وCloudflare (CDN)؛ وحتى لو توسعت الأعمال مستقبلاً إلى متطلبات على مستوى المؤسسات، يمكن للبنية المفتوحة المصدر لـ Supabase أن تُنشر بالتوازي مع أنظمة المؤسسات، مع اختيار المنصة الأكثر ملاءمة لكل وظيفة. هذه المرونة التدريجية تتيح للفرق الناشئة عدم الاستثمار المبكر في البنية التحتية الثقيلة، مع الاحتفاظ بمساحة تطور مستقبلية.
5.2 دعم تسجيل الدخول عبر Google وGitHub
في الدروس التعليمية السابقة، شرحنا كيفية استخدام البريد الإلكتروني مباشرة للتسجيل وتسجيل الدخول، لكن في الممارسة العملية نريد عادة تبسيط عملية التسجيل، مثل استخدام تسجيل الدخول عبر طرف ثالث Google وGitHub للتسجيل وتسجيل الدخول السريع للنظام. سنتناول في هذا الدرس التعليمي كل تفصيلة؛ وفي الوقت نفسه، يجب أن يوفر نظام المصادقة الكامل أيضاً وظيفة إعادة تعيين كلمة المرور الآمنة والموثوقة، وسنقوم بدمج وظيفة إعادة تعيين كلمة المرور في مشروع هذا الدرس التعليمي أيضاً.
يقدم هذا المشروع Project5-Supabase-Demos/apps/project-burger-shop-auth-advanced-supabase-6) عرضاً كاملاً لكيفية تنفيذ هذه الوظائف المتقدمة.

5.2.1 عملية OAuth: كيف يعمل تسجيل الدخول عبر طرف ثالث؟
جوهر تسجيل الدخول عبر طرف ثالث هو بروتوكول OAuth 2.0 للتفويض المفتوح، وطبيعته هي "وكيل التفويض": يسمح للمستخدمين بتفويض تطبيقنا (مشروع متجر البرجر) للوصول إلى معلوماتهم العامة (مثل البريد الإلكتروني، الصورة الرمزية) على منصة طرف ثالث (مثل Google)، دون الحاجة لكشف كلمة مرور المنصة الثالثة لتطبيقنا، مما يتجنب مخاطر تسريب كلمة المرور بشكل أساسي.
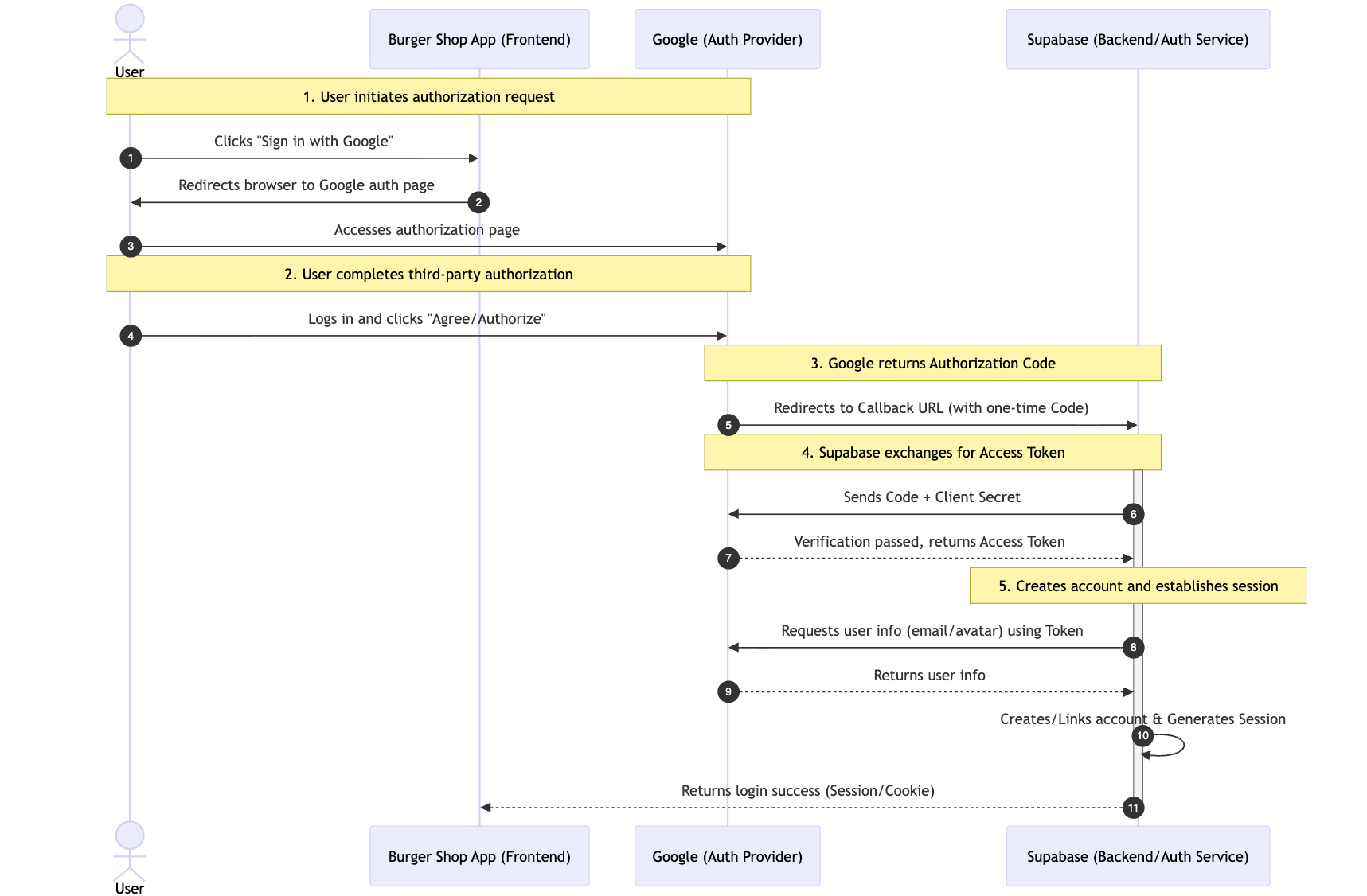
يمكن تفكيك العملية الكاملة إلى 5 خطوات رئيسية، مع أخذ تسجيل الدخول عبر Google كمثال:
- يبدأ المستخدم طلب التفويض: ينقر المستخدم على زر "Sign in with Google" في الصفحة، وسيقوم تطبيقنا تلقائياً بإعادة توجيه المستخدم إلى صفحة التفويض الرسمية من Google (لضمان أمان عملية التفويض، وتجنب مخاطر التصيد).
- يكمل المستخدم التفويض عبر الطرف الثالث: يسجل المستخدم الدخول إلى حسابه على صفحة Google (للتحقق من هوية المستخدم)، ويوافق على الأذونات التي يطلبها تطبيقنا (مثل "الحصول على عنوان البريد الإلكتروني").
- تعيد Google رمز تفويض لمرة واحدة: بعد اجتياز التفويض، ستقوم Google بإعادة توجيه المستخدم إلى "URL الاستدعاء (Callback URL)" الذي اتفقنا عليه مسبقاً، وتُرفق معامل URL برمز تفويض لمرة واحدة وقصير الأجل (بدلاً من إرجاع معلومات المستخدم مباشرة، مما يعزز الأمان بشكل أكبر).
- يتبادل Supabase رمز الوصول (Access Token): ستحمل خلفيتنا (التي يستضيفها Supabase، دون الحاجة لبنائها بنفسك) رمز التفويض هذا، وتطلب من واجهة Google الرسمية للحصول على Access Token يمكن استخدامه للحصول على معلومات المستخدم (يُستخدم رمز التفويض فقط لاستبدال Token، مما يتجنب نقل Token مباشرة في الواجهة الأمامية).
- إنشاء حساب وإنشاء جلسة: يستخدم Supabase رمز الوصول لسحب المعلومات العامة للمستخدم من Google (مثل البريد الإلكتروني، الصورة الرمزية)، وإنشاء حساب لهذا المستخدم تلقائياً في مشروعنا (إذا كان تسجيل الدخول الأول) أو ربط الحساب الموجود مباشرة، وفي النهاية إنشاء جلسة مستخدم صالحة (Session)، لإكمال تسجيل الدخول.
5.2.2 تهيئة Google Cloud للحصول على Client ID وSecret
بغض النظر عن طريقة تسجيل الدخول عبر طرف ثالث، نحتاج عادةً إلى الحصول على Client ID وSecret للتهيئة؛ بالنسبة لتسجيل الدخول عبر طرف ثالث من Google، تحتاج أولاً إلى إنشاء OAuth 2.0 Client ID في Google Cloud Platform للحصول على المعلمات المقابلة.
- الدخول إلى Google Cloud Console:
- قم بزيارة Google Cloud Console.
- أنشئ مشروعاً جديداً أو اختر مشروعاً موجوداً.
- تهيئة شاشة موافقة OAuth (OAuth consent screen):
- في شريط التنقل الأيسر، ابحث عن "APIs & Services" -> "OAuth consent screen".
- اختر نوع المستخدم "External"، ثم انقر على "Create".
- املأ اسم التطبيق، والبريد الإلكتروني لدعم المستخدم وغيرها من المعلومات المطلوبة.
- في قسم "Authorized domains"، أضف نطاق مشروع Supabase الخاص بك، بالتنسيق
*.supabase.co. - احفظ وتابع. في خطوتي "Scopes" و"Test users"، يمكنك التخطي مؤقتاً والحفظ مباشرة.
- إنشاء بيانات الاعتماد (Create Credentials):
- انتقل إلى "APIs & Services" -> "Credentials".
- انقر على "+ CREATE CREDENTIALS"، واختر "OAuth client ID".
- في "Application type"، اختر "Web application".
- أعطه اسماً، مثل "Supabase Auth".
- في قسم "Authorized redirect URIs"، انقر على "ADD URI"، وأدخل URL الاستدعاء لمشروع Supabase الخاص بك. يمكنك العثور على هذا URL في "Authentication" -> "Providers" -> "Google" في لوحة تحكم Supabase، وتنسيقه عادةً يكون
https://<معرف-مشروعك>.supabase.co/auth/v1/callback.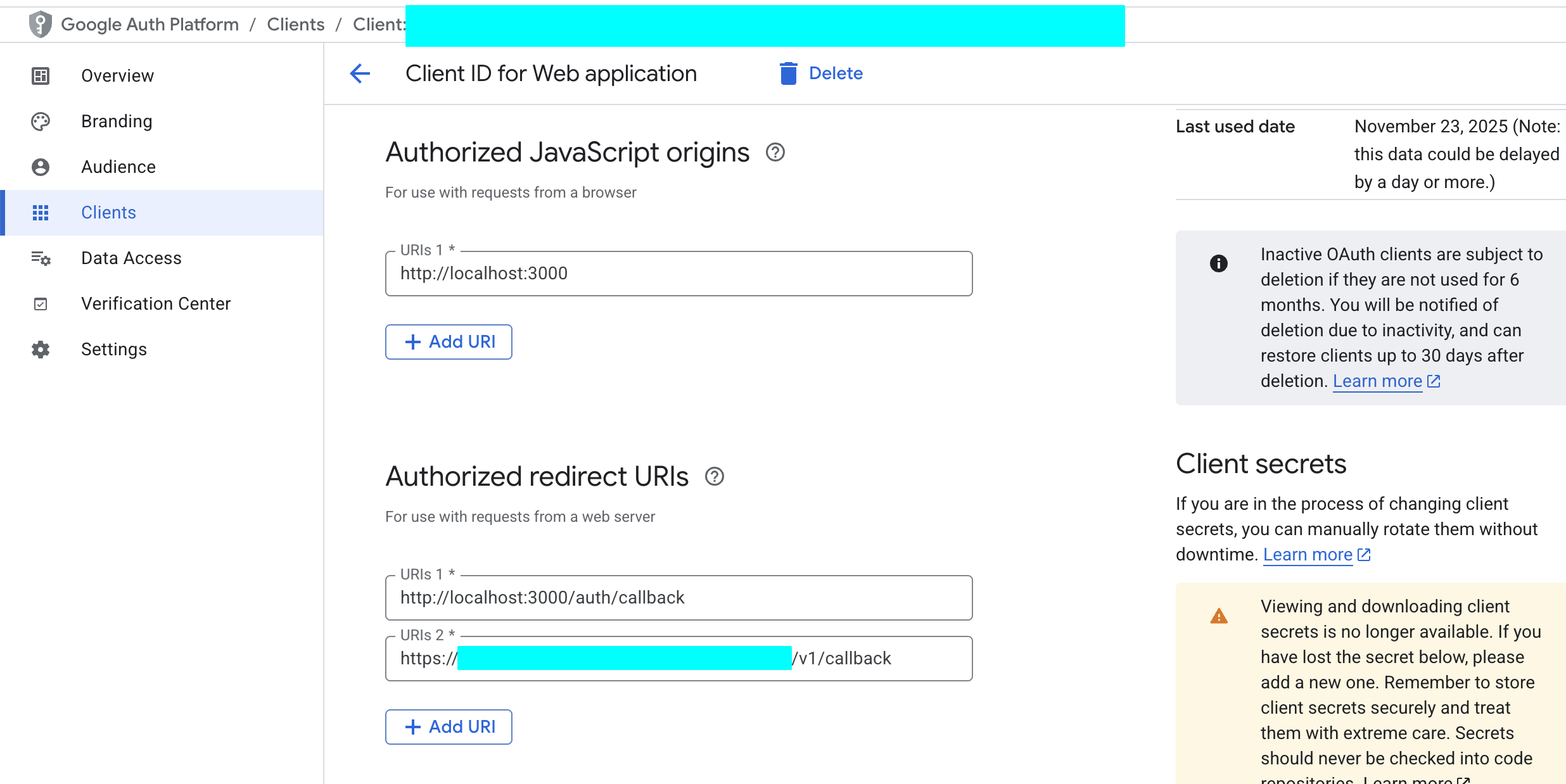
- انقر على "CREATE".
- الحصول على Client ID وClient Secret:
- بعد الإنشاء الناجح، ستعرض نافذة منبثقة Client ID وClient Secret الخاصين بك. يرجى نسخهما وحفظهما بشكل آمن فوراً.
5.2.3 تهيئة GitHub للحصول على Client ID وSecret
وبالمثل، تحتاج أيضاً إلى تسجيل تطبيق OAuth على GitHub.
الدخول إلى إعدادات مطور GitHub (Developer Settings):
- سجل الدخول إلى حسابك على GitHub.
- انقر على الصورة الرمزية في الزاوية العلوية اليمنى، وانتقل إلى "Settings".
- في أسفل شريط التنقل الأيسر، ابحث عن "Developer settings".
تسجيل تطبيق جديد (Register a new application):
اختر "OAuth Apps"، ثم انقر على "New OAuth App".
املأ اسم التطبيق، مثل "My Burger Shop".
Homepage URL: أدخل العنوان الإلكتروني لتطبيقك، أو عنوان التطوير المحلي
http://localhost:3000.Authorization callback URL: أدخل URL الاستدعاء لمشروع Supabase الخاص بك. وبالمثل، يمكنك العثور عليه في "Authentication" -> "Providers" -> "GitHub" في لوحة تحكم Supabase، وتنسيقه هو
https://<معرف-مشروعك>.supabase.co/auth/v1/callback.انقر على "Register application".
الحصول على Client ID وClient Secret:
بعد التسجيل الناجح، ستعرض الصفحة Client ID الخاص بك.
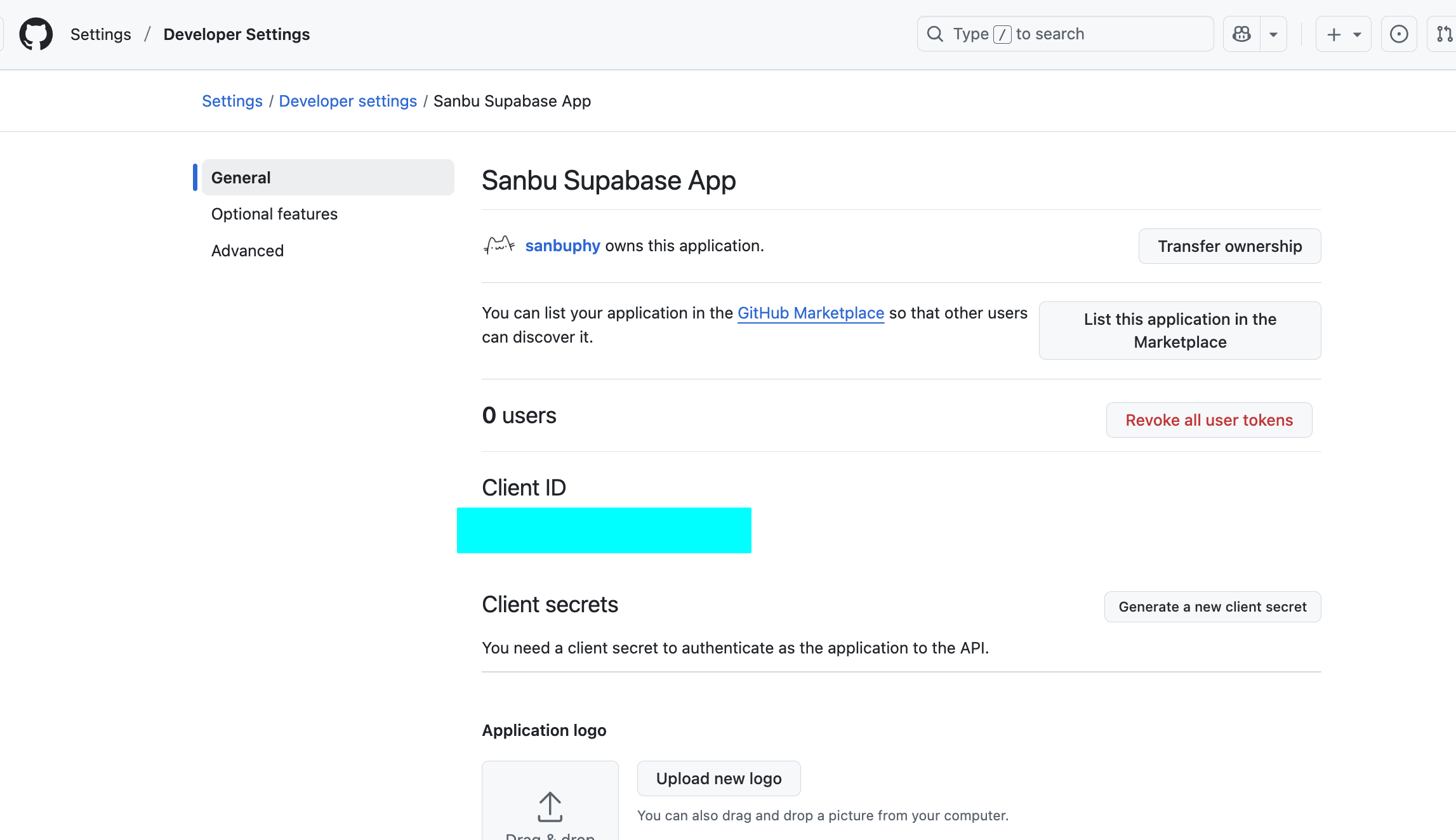
انقر على "Generate a new client secret" لإنشاء Client Secret الخاص بك. وبالمثل، يرجى نسخه وحفظه فوراً.
5.2.4 تهيئة Provider في Supabase
الآن، دعنا نقوم بتهيئة بيانات الاعتماد التي حصلنا عليها في Supabase.
- الدخول إلى لوحة تحكم Supabase:
- اختر مشروعك، وانتقل إلى "Authentication" -> "Providers".
- تفعيل وتهيئة Google:
- ابحث عن "Google" وقم بتفعيله.
- الصق Client ID وClient Secret اللذين حصلت عليهما من Google Cloud في مربعات الإدخال المقابلة.
- انقر على "Save".
- تفعيل وتهيئة GitHub:
- ابحث عن "GitHub" وقم بتفعيله.
- الصق Client ID وClient Secret اللذين حصلت عليهما من GitHub في مربعات الإدخال المقابلة.
- انقر على "Save".

بعد ذلك، ستتمكن من استخدام حسابات الطرف الثالث لتسجيل الدخول في الموقع الذي أنشأته. يمكنك جعل الذكاء الاصطناعي يشير مباشرة إلى مشروع Project5-Supabase-Demos/apps/project-burger-shop-auth-advanced-supabase-6 كمرجع، ودعم نظام تسجيل دخول المستخدمين في مشروعك، مع تكامل واجهة تسجيل دخول المستخدمين بما في ذلك مصادقة GitHub وGoogle بأقل تكلفة.
5.2.6 تنفيذ إعادة تعيين كلمة المرور
كمكون تسجيل دخول مستخدمين ناضج، تعد إعادة تعيين كلمة المرور أيضاً جزءاً مهماً للغاية. يحتوي هذا المشروع project-burger-shop-auth-advanced-supabase-6 أيضاً على التنفيذ الكامل لهذه الوظيفة. يمكنك جعل الذكاء الاصطناعي ينسخ مكون إعادة تعيين كلمة المرور الكامل بناءً على وظيفة إعادة تعيين كلمة المرور في هذا المشروع. وتنقسم بشكل أساسي إلى الخطوات التالية:
- بدء الطلب: يدخل المستخدم البريد الإلكتروني في صفحة نسيت كلمة المرور، وتستدعي الواجهة الأمامية دالة
supabase.auth.resetPasswordForEmail()، وتحدد URL إعادة توجيه redirectTo (مثلاً /auth/reset). - إرسال البريد الإلكتروني: سيرسل Supabase رسالة بريد إلكتروني تحتوي على رابط إعادة تعيين فريد إلى هذا البريد الإلكتروني.
- زيارة الرابط: ينقر المستخدم على الرابط في البريد الإلكتروني، ويتم إعادة توجيهه إلى صفحة إعادة التعيين المحددة داخل التطبيق.
- تحديث كلمة المرور: في صفحة إعادة التعيين، يدخل المستخدم كلمة المرور الجديدة. تستدعي الواجهة الأمامية
supabase.auth.updateUser()، لإرسال كلمة المرور الجديدة إلى Supabase. سيقوم Supabase تلقائياً بالتحقق من صلاحية الرابط وإكمال تحديث كلمة المرور.
أخيراً، إذا شعرت أن رسالة إعادة تعيين كلمة المرور الحالية بسيطة جداً، يمكنك تخصيص قالب رسالة "Reset Password" في Supabase Dashboard في Authentication -> Email Templates.
بالإضافة إلى وظيفة Reset password، يمكنك أيضاً رؤية العديد من الوظائف المتقدمة الأخرى المتعلقة بإدارة المستخدمين (مثل Invite user وغيرها)، ويمكنك إضافة الوظائف المقابلة بنفسك بناءً على وثائق التطوير الخاصة بكل وظيفة، بالاقتران مع أدوات Vibe coding.
5.3 الوظائف الفورية
تُعد الوظائف الفورية في Supabase واحدة من أقوى خصائصها، وتوفر راحة كبيرة لبناء المستندات التعاونية، ولوحات المعلومات الفورية، وقاعات الألعاب، أو أنظمة خدمة العملاء.
يقدم هذا المشروع Project5-Supabase-Demos/apps/project-burger-shop-realtime-orders-3 من خلال بناء غرفة دردشة فورية متعددة المستخدمين، ووظيفة مشاركة موقع المؤشر، القدرات الأساسية الثلاث التي يتضمنها Supabase Realtime: مراقبة تغييرات قاعدة البيانات (Postgres Changes)، والبث (Broadcast)، والحالة المتصلة (Presence).
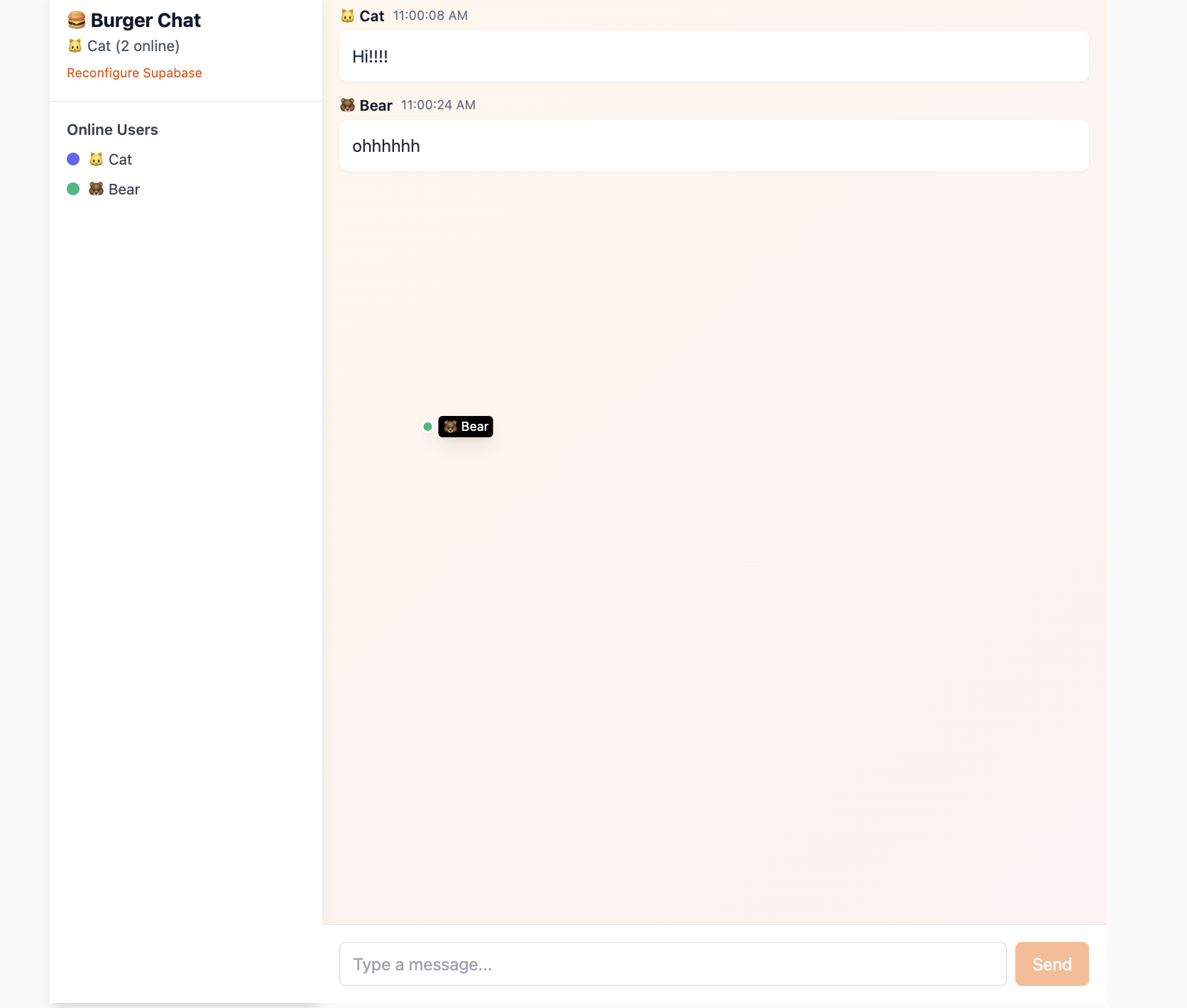
إذا شعرت أن جزء الكود ذو صعوبة معينة، يمكنك جعل الذكاء الاصطناعي يشير مباشرة إلى محتوى التوثيق في هذا الجزء لتعديل برنامجك.
5.3.1 التغييرات الفورية لقاعدة البيانات Postgres Changes
أكثر وظائف Realtime شيوعاً هي المراقبة الفورية لتغييرات قاعدة البيانات Postgres Changes. فهي تسمح للعميل بالاشتراك في أحداث INSERT أو UPDATE أو DELETE لجداول محددة أو صفوف محددة أو حتى أعمدة محددة في قاعدة البيانات. بمجرد حدوث تغيير في قاعدة البيانات (سواء من خلال استدعاء API، أو عمليات لوحة تحكم Supabase، أو تنفيذ برامج SQL النصية)، سيستخدم Supabase آلية النسخ المتماثل الأساسية في PostgreSQL لدفع البيانات المتغيرة فوراً إلى جميع عملاء الواجهة الأمامية المشتركين في هذه القناة عبر WebSocket، دون الحاجة للعميل للاستطلاع (Polling) بشكل متكرر.
بشكل عام، يمكن العثور على هذه الوظيفة في Table Editor بالنقر على Enable Realtime لبدء التشغيل، لكن الأكثر راحة هو التنفيذ من خلال برامج SQL النصية للتهيئة، على سبيل المثال:
-- Enable realtime replication
ALTER TABLE public.chat_messages REPLICA IDENTITY FULL;
DO $$
BEGIN
IF NOT EXISTS (
SELECT 1 FROM pg_publication_tables
WHERE pubname = 'supabase_realtime'
AND schemaname = 'public'
AND tablename = 'chat_messages'
) THEN
ALTER PUBLICATION supabase_realtime ADD TABLE public.chat_messages;
END IF;
END $$;تضيف هذه العبارة جدول chat_messages إلى supabase_realtime المعرف مسبقاً في Supabase، وبمجرد إضافة جدول إلى هذا publication الخاص، سيبدأ خادم Supabase الفوري في مراقبة جميع تغييرات بياناته.
بناءً على جدول البيانات الخاص أعلاه، يمكننا استخدام كود المراقبة للمراقبة الفورية لتغييرات البيانات داخل الجدول. ما نحتاج لتحقيقه هو أنه عندما يرسل مستخدم رسالة، يمكن لجميع المستخدمين الآخرين المتصلين رؤية هذه الرالة على شاشتهم فوراً. يمكن تحقيق ذلك من خلال الاشتراك في حدث INSERT لجدول chat_messages.
const sub = supabase
.channel('chat_messages_channel')
.on('postgres_changes', {
event: 'INSERT',
schema: 'public',
table: 'chat_messages'
}, (payload: any) => {
console.log('New message received:', payload.new);
const newMessage = payload.new as Message;
// ... //
.subscribe((status: string) => {
console.log('Chat subscription status:', status);
});.channel('chat_messages_channel'): إنشاء قناة اتصال معزولة..on('postgres_changes', ...): هذه هي طريقة الاشتراك الأساسية. نخبر Supabase أننا نهتم فقط بحدثINSERTلجدولchat_messages.payload.new: عند إدراج رسالة جديدة في قاعدة البيانات، سيدفع Supabase المحتوى الكامل لهذه البيانات الجديدة إلى جميع العملاء المشتركين عبرpayload.new..subscribe(): بدء الاشتراك.
5.3.2 مزامنة البث والمعلومات Broadcast & Presence
بالنسبة للتفاعلات "الفورية" التي لا تحتاج إلى تخزينها في قاعدة البيانات، مثل حركة المؤشر، والحالة المتصلة، إلخ، يوفر Supabase وظائف Broadcast وPresence.
- Presence: يُستخدم لتتبع الحالة المشتركة لجميع العملاء داخل القناة. مناسب لتنفيذ وظيفة "من متصل".
- Broadcast: يُستخدم لإرسال رسائل مؤقتة منخفضة التأخير إلى جميع العملاء الآخرين داخل القناة.
الفكرة الأساسية لـ Presence هي: جعل كل عميل يعلن عن حالته المتصلة، ويتحمل خادم Supabase مسؤولية مزامنة هذه الحالات بشكل موثوق مع جميع العملاء الآخرين داخل القناة. يتم تنفيذ Presence في الخطوات الأساسية التالية:
- إنشاء قناة تدعم Presence
أولاً، أنشأنا قناة lobby_presence للتعامل حصرياً مع هذه التفاعلات، وحددنا في التهيئة مفتاحاً فريداً لتحديد المستخدم الحالي. هذا المفتاح عادةً هو معرف المستخدم.
const ch = supabase.channel
('lobby_presence', {
config: {
presence: { key: anonymousUser.id },
}
});- الاشتراك في القناة والإعلان عن معلومات "أنا متصل"
بمجرد إنشاء القناة بنجاح، نحتاج للاشتراك فيها. في رد الاشتراك الناجح (status === 'SUBSCRIBED')، نستدعي طريقة channel.track(). هذه الطريقة ستقوم ببث معلومات المستخدم الحالي (مثل معرف المستخدم، والاسم، ولون الصورة الرمزية، إلخ) إلى جميع العملاء الآخرين داخل القناة، للإعلان عن حالته "المتصلة".
const me = {
id: anonymousUser.id,
name: anonymousUser.name,
color: anonymousUser.color
};
ch.subscribe(async (status) => {
if (status === 'SUBSCRIBED') {
await ch.track(me);
}
});- مزامنة قائمة المتصلين الكاملة
عند انضمام مستخدم جديد إلى القناة، يحتاجون للحصول على قائمة بجميع المستخدمين المتصلين حالياً. يتم تحقيق ذلك من خلال الاستماع لحدث sync الخاص بـ presence. يتم تشغيل حدث sync عند انضمامك للقناة لأول مرة، ويوفر لك "لقطة" كاملة.
طريقة channel.presenceState() تُرجع كائناً يحتوي على معلومات حالة جميع المستخدمين المتصلين حالياً داخل القناة. نقوم بمعالجتها وتحديثها في حالة التطبيق، مما يسمح بعرض قائمة المستخدمين المتصلين الكاملة.
ch.on('presence', { event: 'sync' }, ()
=> {
const state = ch.presenceState();
const flat = {};
Object.values(state).forEach((arr) => {
arr.forEach((u) => { flat[u.id] =
{ ...u }; });
});
setOnline(flat);
});- مراقبة انضمام ومغادرة المستخدمين الفرديين
بالإضافة إلى حدث sync، يمكننا أيضاً الاستماع لأحداث join وleave، للرد فوراً عند دخول مستخدم جديد أو مغادرة آخر، مثل عرض إشعار "انضم مستخدم".
ch.on('presence', { event: 'join' }, ({
key, newPresences }) => {
console.log('User joined:', key,
newPresences);
});
ch.on('presence', { event: 'leave' }, ({
key, leftPresences }) => {
console.log('User left:', key,
leftPresences);
});من خلال الخطوات المذكورة أعلاه، قمنا ببناء نظام حالة متصلة كامل الوظائف. يتعامل Supabase تلقائياً مع حالات انقطاع اتصال المستخدم غير المتوقع (مثل إغلاق المتصفح أو انقطاع الشبكة)، ويقوم بتشغيل حدث leave في الوقت المناسب، مما يضمن دقة قائمة المتصلين.
عندما يجعلنا Presence نعرف "من موجود"، فإن Broadcast يتيح لهم "التحدث" فيما بينهم، لكن محتوى الحديث يتم تخزينه مؤقتاً فقط. مثال نموذجي هو تتبع المؤشر الفوري. إذا تمت قراءة وكتابة قاعدة البيانات في كل مرة يتحرك فيها الماوس، فسيؤدي ذلك إلى هدر كبير في الأداء وتأخير. يحل Broadcast هذه المشكلة بشكل مثالي، فهو يسمح للرسائل بالمرور مباشرة بين العملاء عبر WebSocket، متجاوزاً قاعدة البيانات تماماً.
يعتمد وضع عمل Broadcast بشكل أساسي على طريقتين أساسيتين: channel.send() للإرسال، وchannel.on() للاستلام.
- جانب الإرسال: بث موقع المؤشر الخاص بي
أضفنا مستمعاً لحدث mousemove. عند تحرك الماوس، نبني payload يحتوي على معرف المستخدم، والإحداثيات، واللون، ثم ن بثه عبر channel.send()، ونحدد اسم الحدث كـ 'cursor'.
const handleMouseMove = (e) => {
const payload = {
id: anonymousUser.id,
x: e.clientX,
y: e.clientY,
name: anonymousUser.name,
color: anonymousUser.color
};
channelRef.current?.send({
type: 'broadcast',
event: 'cursor',
payload
});
};
document.addEventListener('mousemove', handleMouseMove);- جانب الاستلام: الاستماع وعرض مؤشرات الآخرين
ضمن نفس القناة، يستخدم جميع العملاء channel.on() للاستماع لرسائل نوع broadcast، وبحيث يكون الحدث 'cursor'. بمجرد استلام رسالة مطابقة، يتم تشغيل دالة الاستدعاء. نقوم بتحليل بيانات المرسل من payload، ونستخدمها لتحديث الحالة المحلية المتصلة، مما يسمح بعرض موقع مؤشرات المستخدمين الآخرين في الوقت الفعلي على الشاشة.
ch.on('broadcast', { event: 'cursor' }, ({ payload }) => {
setOnline((prev) => ({
...prev,
[payload.id]: {
...(prev[payload.id] || {}),
x: payload.x,
y: payload.y
}
}));
});من خلال هذه الطريقة، يعمل Presence وBroadcast معاً؛ حيث يحافظ Presence على قائمة المستخدمين المتصلين، بينما يتحمل Broadcast مسؤولية نقل الحالات المؤقتة مثل مواقع المؤشرات بين هؤلاء المستخدمين، وفي النهاية يتم تحقيق وظائف تفاعل فوري غنية بتكلفة منخفضة.
5.4 التخزين
بالإضافة إلى البيانات المهيكلة مثل معلومات المستخدمين والطلبات التي يمكن تعريفها بشكل منظم، يحتاج التطبيق الكامل عادةً أيضاً للتعامل مع عدد كبير من الملفات غير المهيكلة - مثل صور المستخدمين الرمزية، وصور عرض المنتجات، ومستندات الطلبات التي رفعها المستخدمون، إلخ. ما يميز هذه الملفات هو أن أحجامها تتفاوت بشكل كبير، وعددها قد يكون كبيراً جداً (مثلاً صور منتجات منصة التجارة الإلكترونية قد تصل إلى عشرات الآلاف أو حتى مئات الآلاف)، وإذا تم تخزينها مباشرة في خادم الأعمال الخاص بالتطبيق، فسيزيد ذلك بشكل كبير من حمل التخزين على الخادم، وقد يبطئ أيضاً سرعة قراءة وكتابة البيانات، مما يؤثر على أداء التطبيق بشكل عام.
في التطوير الفعلي، يتم تسليم هذه الملفات غير المهيكلة بشكل موحد إلى "خدمة تخزين الكائنات" لإدارتها، وOSS وAmazon S3 كلاهما ينتميان إلى هذا النوع من الخدمات، وهي "أدوات تخزين متخصصة" مصممة خصيصاً لتخزين الملفات الضخمة، ويمكنها التعامل بكفاءة مع متطلبات التخزين والنسخ الاحتياطي والقراءة السريعة للملفات. وعندما نحصل على هذه الملفات في التطبيق، لا نقوم باستدعائها مباشرة من "المستودع الأساسي" لخدمة تخزين الكائنات، بل من خلال عناوين URL: يتم تعيين عنوان URL فريد لكل ملف مخزن في تخزين الكائنات (مثل عنوان "https://xxx.oss.com/avatar/user123.jpg"، والذي يمكن فهمه ببساطة على أن هذا "الموقع" يحتوي على صورة واحدة فقط)، هذا عنوان URL مثل "عنوان الوصول الحصري" للملف، تحتاج صفحة الواجهة الأمامية فقط إلى استخدام هذا العنوان لتحميل أو عرض الصورة الرمزية وصورة المنتج مباشرة، دون الاعتماد على خادم أعمال التطبيق كوسيط، مما يحسن سرعة تحميل الملفات ويقلل أيضاً من الضغط على خادم الأعمال.
يقدم هذا المشروع project-burger-shop-storage-uploads-4 من خلال وظيفة رفع صورة المستخدم الرمزية، عرضاً معمقاً لكيفية استخدام Supabase Storage لبناء نظام رفع ملفات حديث، مما يتيح للمطورين فهم العملية الكاملة من رفع الملفات غير المهيكلة إلى الوصول إليها عبر URL. بالإضافة إلى ذلك، يستخدم هذا المشروع مكتبة Uppy لتوفير واجهة رفع ملفات ممتازة، ويدمج البرنامج المساعد Tus لتنفيذ رفع قابل للاستئناف، من خلال توجيه نقطة نهاية رفع Uppy إلى واجهة API القياسية في Supabase (<supabaseUrl>/storage/v1/upload/resumable) للعمل، ويمكنك الرجوع إلى طريقة مشابهة لتنفيذ مكون وظيفة الرفع.
5.4.1 حاويات التخزين
وحدة التكوين الأساسية في Supabase Storage هي حاوية التخزين Bucket. يمكنك تخيلها كمجلد في نظام تشغيل الكمبيوتر. يمكن أن يكون لكل Bucket سياسات أمان وتهيئة مستقلة خاصة به.
جميع الملفات داخل Storage يمكن الوصول إليها مباشرة من خلال URL عام، لكن هذا لا يعني أن أي شخص يمكنه الرفع أو التعديل بشكل عشوائي، حيث يتم التحكم في صلاحيات الوصول المحددة من خلال سياسات أكثر دقة. كما في قاعدة البيانات، يتم إدارة صلاحيات الوصول إلى Storage أيضاً من خلال سياسات الأمان على مستوى الصف. تُكتب سياسات SQL على جدولين خاصين هما storage.objects وstorage.buckets، ويمكن تعريف بدقة من يمكنه القراءة (SELECT)، والرفع (INSERT)، والتحديث (UPDATE)، أو الحذف (DELETE) للملفات.
على سبيل المثال، يمكننا إنشاء سياسة تسمح فقط للمستخدمين بالرفع إلى مجلد يحمل اسم user_id الخاص بهم، ورفع ملفات من نوع صور فقط:
CREATE POLICY "Allow authenticated
uploads to avatars bucket"
ON storage.objects FOR INSERT
TO authenticated
WITH CHECK (
bucket_id = 'avatars' AND
auth.uid() = (storage.foldername(name))
[1]::uuid AND
(storage.extension(name) IN ('png',
'jpg', 'jpeg'))
);
CREATE POLICY "Allow public read access
to avatars"
ON storage.objects FOR SELECT
USING ( bucket_id = 'avatars' );5.4.2 الحصول على URL ملف قابل للوصول
يتطلب منك هذا المشروع إنشاء حاوية عامة باسم avatars يدوياً، وسيتم رفع جميع الملفات وتخزينها تحت هذه الحاوية العامة. بعد نجاح رفع الملف، حصلنا فقط على مسار تخزينه في Storage، مثلاً public/avatar1.png. هذا مجرد سلسلة نصية مخزنة في قاعدة البيانات، ولجعل المتصفح قادراً على عرض هذه الصورة، نحتاج لتحويلها إلى عنوان HTTP URL قابل للوصول.
يوفر Supabase استراتيجيتين مختلفتين تماماً للحصول على هذا URL، وهما تختلفان اختلافاً جوهرياً من حيث الأمان، والديمومة، والتحكم في التكاليف.
1. URL العام (Public URL) - رابط دائم
هذه هي الطريقة الأكثر مباشرة. إذا كان ملفك مخزناً في Public Bucket، يمكنك الحصول على رابط عام ثابت ودائم.
const { data } = supabase.storage
.from('avatars')
.getPublicUrl('public/avatar1.png');
const publicUrl = data.publicUrl;تتميز هذه الروابط بخصائص أساسيتين: الأولى هي البساطة والمباشرة، حيث يكون هيكل URL ثابتاً، مما يسهل تجميعه وإدارته في الممارسة العملية، ويقلل من عتبة الاستخدام التقني؛ والثانية هي ملاءمة التخزين المؤقت، كونها رابط دائم، يمكن تخزينها مؤقتاً بشكل فعال من قبل CDN (شبكة توصيل المحتوى) والمتصفح، مما يحسن بشكل كبير من سرعة الوصول إلى الموارد ويحسن تجربة المستخدم. بناءً على هذه الخصائص، فهي مناسبة لسيناريوهات الموارد العامة الحقيقية، مثل شعار الموقع، وصور كتالوج المنتجات، وصور مقالات المدونة، إلخ، وتلبي احتياجات الوصول وإدارة هذه الموارد بشكل جيد.
لكن في بيئة الإنتاج، تحمل هذه الروابط مخاطر واضحة لسرقة حركة المرور (Hotlinking). نظراً لأن الروابط عامة ودائمة، يمكن للأشخاص الخارجيين بسهولة تضمين رابط صورتك في مواقعهم ذات الحركة العالية، مما يؤدي إلى استخدام حركتك بشكل غير قانوني. هذا السلوك سيجعل مشروع Supabase الخاص بك ينتج رسوم حركة كبيرة غير ضرورية، وهذه الحركة المستهلكة لا تخدم تطبيقك الخاص، وهي نموذجي لهدر التكاليف ويجب الحذر منه والوقاية منه بشدة في بيئة الإنتاج؛ لذلك، نحتاج للتحول إلى عنوان URL الموقع المؤقت لتعريض الموارد الخارجية.
2. عنوان URL الموقع (Signed URL) - رابط تفويض مؤقت
لحل مشاكل الأمان والتكلفة في URL العام، يوفر Supabase طريقة لإنشاء عنوان URL موقّع مؤقت. هذه هي أفضل الممارسات الموصى بها لمعظم التطبيقات عبر الإنترنت، مثل تطبيقات توليد الصور من النص التي توفر للمستخدمين روابط عرض صور محدودة الوقت، ومنصات التجارة الإلكترونية التي تتيح فقط للمستخدمين الذين قدموا طلبات الحصول على عنوان تحميل فاتورة مؤقت، ومنصات المحتوى المدفوعة التي توفر للمشتركين روابط تشغيل دورات قصيرة الأجل، مما يمنع سرقة الملفات ويتجنب سرقة حركة المرور، مع توافق عالي.
const { data, error } = await supabase.storage
.from('avatars')
.createSignedUrl('private/user-invoice.pdf', 3600); // فترة صلاحية الرابط 3600 ثانية (ساعة واحدة)
const signedUrl = data?.signedUrl;لعنوان URL الموقع المؤقت (Signed URL) ثلاث مزايا أساسية: التحكم الآمن يعني أن الرابط يحمل علامة أمنية وله فترة صلاحية، وبعد انتهائها لا يمكن استخدامه؛ ربط الصلاحيات بسيط - فقط الشخص الذي يمكنه رؤية هذا الملف يمكنه إنشاء هذا الرابط، حتى لو كان الملف مخفياً في تخزين خاص (Private Bucket)، يمكنه فتحه بشكل طبيعي باستخدام هذا الرابط؛ ومنع سرقة حركة المرور لأن الرابط مؤقت، وعند نسخه إلى مكان آخر يصبح غير صالح بسرعة، ولن يتم استخدامه لاستنزاف حركة المرور بشكل خبيث. وبفضل هذه المزايا، يمكن استخدامه للملفات التي تحتاج إلى إدارة صلاحيات مثل صور المستخدمين الرمزية، والصور الخاصة، والمحتوى المدفوع، وفواتير الطلبات.
من منظور ضمان الأمان والتحكم في التكاليف، يُنصح بتبني عادة استخدام عنوان URL الموقع المؤقت أولاً. فقط عندما يحتاج مورد معين بشكل واضح إلى أن يكون عاماً بشكل دائم وبدون قيود على الوصول (مثل شعار التطبيق العام، أو صور ترويج الأنشطة العامة، إلخ)، يمكن النظر في استخدام Public URL. بهذه الطريقة يمكن تلبية احتياجات العمل المحددة، مع تجنب المخاطر وهدر التكاليف غير الضرورية إلى أقصى حد.
5.5 الدوال الحدية
Edge Function هي واحدة من الأشكال الأساسية في نظام Serverless (البنية بدون خادم)، فهي توفر دعم تشغيل دوال خفيف وفعال لسيناريوهات "بدون خلفية ذاتية البناء".
ما هو Serverless؟ Serverless (البنية بدون خادم) لا يعني حقاً عدم وجود خادم، بل يعني أن المطورين لا يحتاجون للقلق بشأن شراء الخوادم وصيانتها وتهيئتها وتوسيعها. تحتاج فقط إلى كتابة كود الأعمال (الدوال)، وسيقوم مزود الخدمة السحابية تلقائياً بتخصيص الموارد لتشغيل الكود عند تشغيل أحداث معينة، ويحسب التكلفة بناءً على وقت التشغيل الفعلي.
عندما يحتاج تطبيقك لتنفيذ بعض المنطق الذي لا يمكن أو لا يجب تنفيذه على العميل (المتصفح) - مثل التفاعل مع واجهات API لطرف ثالث تتطلب مفاتيح سرية، أو تنفيذ مهام حسابية مكثفة، أو فرض قواعد أعمال معقدة - هنا تأتي أهمية Edge Functions. وظائف Supabase Edge Functions مبنية على Deno وTypeScript، ويتم نشرها على العقد الحدية حول العالم، وقريبة فعلياً من المستخدمين، مما يوفر تأخيراً منخفضاً جداً في تنفيذ الدوال.
الشركات السحابية الرئيسية حالياً أطلقت خدمات Edge Function الخاصة بها، وتشمل الشائعة:
- AWS Lambda@Edge: خدمة دوال حدية ممتدة من AWS Lambda، يمكن ربطها مع CloudFront CDN، وتدعم لغات مثل Node.js وPython؛
- Cloudflare Workers: دوال حدية أطلقتها Cloudflare، منشورة على أكثر من 275 عقدة حدية حول العالم، وتدعم JavaScript/TypeScript، وتتميز بـ "تأخير على مستوى المللي ثانية" كميزة أساسية؛
- Vercel Edge Functions: دوال حدية متوافقة مع مشاريع الواجهة الأمامية من Vercel، مدمجة بعمق مع Next.js، وتدعم TypeScript، وتتمحور حول "الربط السلس بين الواجهة الأمامية والمنطق الحدي"؛
بالعودة إلى Supabase، عندما يحتاج تطبيقك لتنفيذ منطق "لا يمكن إكماله على العميل (المتصفح)"، مثل استدعاء واجهات API لطرف ثالث بمفاتيح سرية (مثل واجهة LLM)، أو معالجة مهام حسابية مكثفة (مثل ضغط الصور)، أو فرض التحقق من الصلاحيات (مثل قواعد الوصول للملفات)، يمكن لـ Supabase Edge Functions أن تلعب دورها. وهي مبنية على Deno runtime وTypeScript، ومنشورة على العقد الحدية حول العالم، ويمكنها تحقيق تأخير تنفيذ منخفض للغاية بـ "المسافة الفيزيائية القريبة من المستخدم"، وهي الأداة الأساسية لكتابة منطق مخصص وموثوق من جانب الخادم.
يقدم هذا المشروع Project5-Supabase-Demos/apps/project-burger-shop-edge-function-5 من خلال وظيفة محادثة فورية مع نموذج لغة كبير (LLM)، عرضاً لأبسط عملية تطبيق لـ Edge Functions.
5.5.1 تحليل حالة LLM Chat
لنفترض أنك تريد دمج روبوت محادثة مشابه لـ ChatGPT في تطبيقك. تحتاج إلى استدعاء واجهة API الخاصة بـ OpenAI على جانب الخادم، لكن هذا يتطلب مفتاح API سري. يجب عدم كشف هذا المفتاح في كود الواجهة الأمامية أبداً، وإلا يمكن لأي شخص سرقة مفتاحك من خلال عرض الكود المصدري لصفحة الويب، مما ينتج عنه تكاليف مرتفعة. هذا بالضبط مجال تطبيق Edge Function. سنقوم بإنشاء دالة باسم llm-chat تعمل كوكيل آمن بين الواجهة الأمامية وواجهة OpenAI API.
بالرجوع إلى كود project-burger-shop-edge-function-5/scripts/llm-chat.ts، دعنا نرى كيف يعمل:
// scripts/llm-chat.ts
import "jsr:@supabase/functions-js/edge-runtime.d.ts";
import { OpenAI } from "npm:openai";
const OPENAI_API_KEY = Deno.env.get("OPENAI_API_KEY");
Deno.serve(async (req) => {
try {
const openai = new OpenAI({ apiKey: OPENAI_API_KEY });
const { prompt } = await req.json();
const stream = await openai.chat.completions.create({
model: "gpt-3.5-turbo",
messages: [{ role: "user", content: prompt }],
stream: true,
});
return new Response(stream.toReadableStream(), {
headers: { "Content-Type": "text/event-stream" },
});
} catch (err) {
}
});في هذه الحالة، بالنسبة لأمان المفاتيح، يتم تخزين OPENAI_API_KEY بشكل آمن كمتغير بيئة على خادم Supabase. لا يمكن لكود الواجهة الأمامية المحلية الوصول إلى هذا المفتاح على الإطلاق، مما يضمن أمان المفتاح بشكل فعال.
5.5.2 إنشاء ونشر الدوال
يوفر Supabase واجهة سهلة الاستخدام جداً، تتيح لك إكمال النشر دون الحاجة لاستخدام سطر الأوامر.
- الدخول إلى لوحة Edge Functions:
- سجل الدخول إلى لوحة تحكم مشروع Supabase الخاص بك.
- في شريط التنقل الأيسر، انقر على أيقونة تشبه الكود للدخول إلى "Edge Functions".
- إنشاء دالة جديدة:
- انقر على زر "Create a new function".
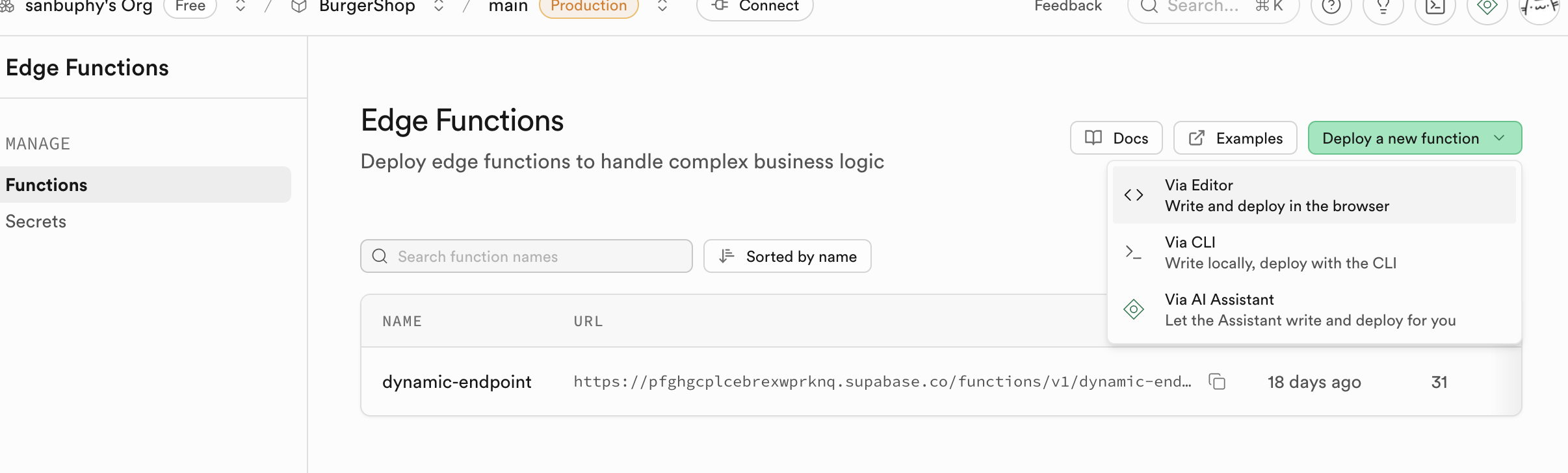
- قم بتسمية الدالة، مثلاً
llm-chat. - لصق الكود:
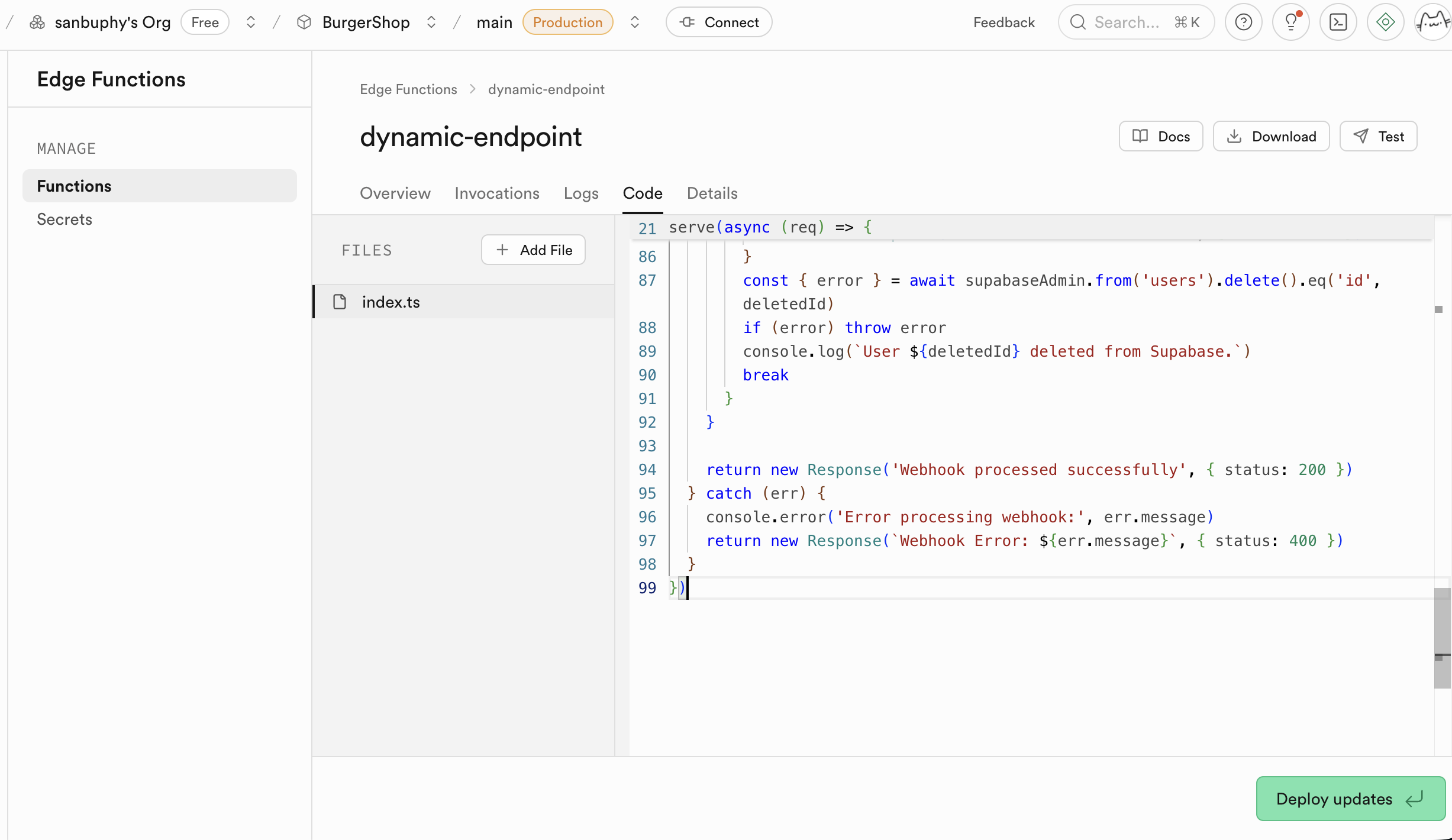
- في المحرر عبر الإنترنت المنبثق، احذف جميع الكود الافتراضي المؤقت.
- افتح ملف
llm-chat.tsالمحلي الخاص بك، وانسخ محتواه بالكامل. - الصق الكود المنسوخ في محرر Supabase عبر الإنترنت.
- تهيئة متغيرات البيئة (Secrets):
- ابحث عن Secrets في الشريط الجانبي.
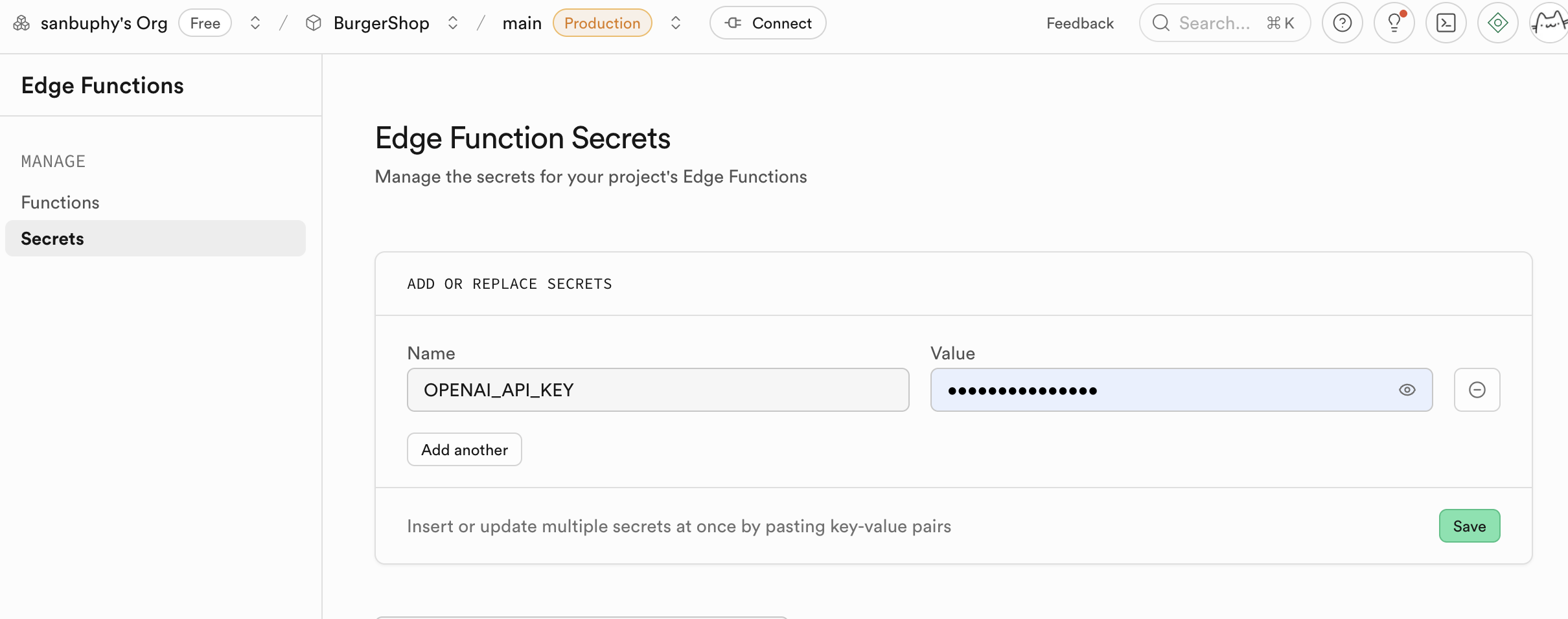
- Name: أدخل
OPENAI_API_KEY. - Value: الصق مفتاح OpenAI API الخاص بك.
- انقر على "Save". سيتم تشفير Secret المُعد هنا وتخزينه، وحقنه بشكل آمن في بيئة تشغيل الدالة الخاصة بك.
- ابحث عن Secrets في الشريط الجانبي.
إذا كانت هناك حاجة لتحديث الدالة، تذكر تنفيذ Deploy updates في قسم Edge Function. سيقوم Supabase ببناء ونشر هذه الدالة لك على السحابة. بعد بضع دقائق، ستكون دالتك متاحة للوصول عبر الإنترنت.
بالإضافة إلى كونها وكيل آمن لنموذج اللغة، فإن مجالات تطبيق Edge Functions تتجاوز ذلك بكثير. في الواقع، أي مهمة تتطلب معالجة منطقية من جانب الخادم، سواء كانت استدعاء API بسيط، أو التحقق من البيانات، أو حسابات أكثر تعقيداً، يمكن تحقيقها من خلال Edge Function. فهي توفر لك خلفية خفيفة وقابلة للتوسع، دون الحاجة لإدارة أي بنية تحتية للخوادم.
إذا كنت ترغب في استكشاف المزيد من الاحتمالات، يمكنك الرجوع إلى الأمثلة الأخرى في المشروع. على سبيل المثال:
- توليد الصور (txt2img.ts): توضح هذه الدالة كيفية استخدام Edge Function لاستدعاء واجهة API لطرف ثالث لتوليد الصور من النص (Text-to-Image) (مثل Stability AI، Midjourney، إلخ) لإنشاء صور ديناميكياً. هذا سيناريو نموذجي للحسابات المكثفة أو الذي يتطلب استدعاء آمن لخدمات خارجية. كما في حالة llm-chat، يتم تخزين مفتاح API بشكل آمن في خلفية Supabase، والواجهة الأمامية مسؤولة فقط عن إرسال وصف نصي، ثم استقبال وعرض الصور المولدة، العملية بأكملها آمنة وفعالة.
- إرسال البريد الإلكتروني (send-email.ts): إرسال رسائل ترحيب، أو إشعارات المعاملات، أو رسائل إعادة تعيين كلمة المرور في التطبيق هو متطلب شائع. يوضح مثال send-email.ts كيفية دمج خدمات البريد الإلكتروني (مثل Resend، SendGrid) من خلال Edge Function. لا تحتاج لكشف مفتاح API الخاص بخدمة البريد الإلكتروني الحساس في كود العميل، فقط أنشئ دالة، واجعل الواجهة الأمامية تستدعي هذه الدالة لتشغيل إرسال البريد الإلكتروني.
5.6 تسجيل الدخول عبر Clerk
Clerk هي أداة تطوير متخصصة تركز على مصادقة الهوية وإدارة المستخدمين، وتغطي قدراتها الأساسية مسار مصادقة الهوية الكامل بما في ذلك تسجيل المستخدمين، وتسجيل الدخول، وأمان الحسابات MFA، والتحكم في الصلاحيات، وإدارة الجلسات، ويمكنها مساعدة المطورين في بناء نظام مستخدمين آمن ومرن يتوافق مع معايير التطبيقات الحديثة بسرعة، دون الحاجة لتطوير منطق هوية معقد من الصفر.
سيقدم هذا الجزء كيفية تهيئة خدمة Clerk من الصفر ودمجها مع Supabase. يمكنك تجربة العملية الكاملة في مشروع project-burger-shop-auth-advanced-clerk-7.
5.6.1 إنشاء تطبيق Clerk والحصول على المفاتيح
قبل استخدام هذا المشروع، تحتاج إلى امتلاك حساب Clerk وإنشاء تطبيق.
- التسجيل والإنشاء:
- قم بزيارة dashboard.clerk.com وسجل حساباً.
- انقر على "Create application".
- أدخل اسم التطبيق (مثلاً "Burger Shop").
- في "How will your users sign in?"، اختر Email، Google، GitHub بشكل افتراضي.
- انقر على Create application.
- الحصول على API Keys:
بعد الإنشاء الناجح، سيتم توجيهك إلى صفحة API Keys.
ابحث عن Publishable key (يبدأ بـ
pk_) وSecret key (يبدأ بـsk_).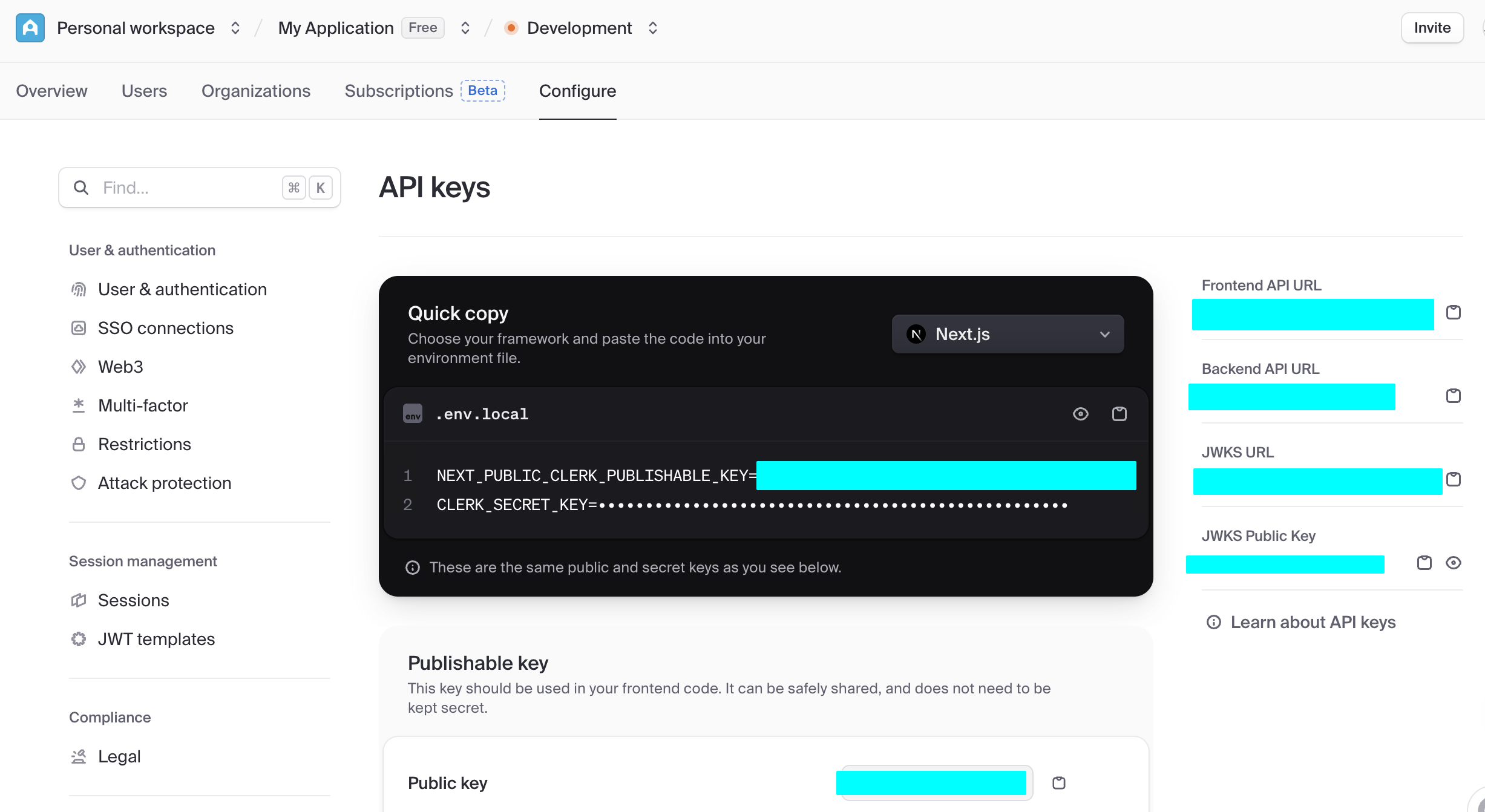
انسخها إلى ملف
.env.localالخاص بك (راجع.env.exampleفي هذا المشروع):bashNEXT_PUBLIC_CLERK_PUBLISHABLE_KEY=pk_test_... CLERK_SECRET_KEY=sk_test_...
5.6.2 تهيئة التكامل الأصلي بين Supabase وClerk
قبل الاستخدام الإضافي، نحتاج لدمج علاقة الارتباط بين Supabase وClerk، لتسهيل انتقال المصادقة والتحكم في صلاحيات الوصول إلى قواعد بيانات محددة لاحقاً. يوفر Supabase وClerk قدرة تكامل أصلي رسمية، ومن خلال هذا التكامل يمكن تحقيق ربط مصادقة الهوية بين الاثنين بسرعة، دون الحاجة لتهيئة منطق تكييف معقد يدوياً، مما يبسط بشكل كبير تطوير وظائف مثل تسجيل دخول المستخدمين والتحقق من الصلاحيات:
- تفعيل التكامل الرسمي لـ Supabase في Clerk
- سجل الدخول إلى Clerk Dashboard.
- في القائمة اليسرى انتقل إلى Integrations (التكاملات).
- ابحث عن وانقر على Supabase في القائمة.
- قم بتشغيل مفتاح Enable Supabase (أو انقر على Activate integration).
- خطوة مهمة: بعد التفعيل الناجح، ستعرض الصفحة Clerk Domain الخاص بك (التنسيق عادةً
https://<your-id>.clerk.accounts.devأو نطاقك المخصص). يرجى نسخ عنوان Domain هذا، وستحتاج إليه في الخطوة التالية.
- إضافة مزود Clerk في Supabase
- سجل الدخول إلى Supabase Dashboard وادخل مشروعك.
- في القائمة اليسرى انتقل إلى Authentication > Sign In / Up (أو انقر مباشرة على Providers).
- انقر على زر Add provider، واختر Clerk من القائمة المنسدلة.
- في مربع إدخال Clerk Domain المنبثق، الصق عنوان Domain الذي نسخته من Clerk.
- انقر على Save لحفظ التهيئة.
5.6.3 مزامنة بيانات المستخدم إلى Supabase من خلال Webhook
التكامل وحده يلبي فقط الحاجة للتحقق من الصلاحيات، لكنه لن يقوم بمزامنة معلومات المستخدمين المسجلين بالفعل في Clerk إلى Supabase. لتسهيل الإدارة، نحتاج أيضاً إلى الاحتفاظ بنسخة احتياطية من المستخدمين في جدول public.users في Supabase، لتمكين الاستعلامات المرتبطة أو تحليل البيانات. يمكننا تحقيق هذه الوظيفة من خلال Clerk Webhooks، والعملية الكاملة كالتالي:
- يرسل Clerk إشعاراً: عندما يقوم مستخدم بالتسجيل أو تحديث بياناته في Clerk، سيرسل Clerk طلب POST إلى عنوان URL الخاص بـ Webhook الذي قمنا بتهيئته.
- يستقبل Supabase ويكتب: تستقبل Edge Function الطلب، وتتحقق من التوقيع (لضمان الأمان)، ثم تقوم بتحديث بيانات المستخدم في جدول قاعدة بيانات Supabase.
قبل البدء، نحتاج لتهيئة جداول البيانات المطلوبة لمزامنة المعلومات:
-- File: init.sql
-- 1. Create `users` table for synced Clerk users
-- This table will store user data pushed from Clerk Webhooks.
CREATE TABLE public.users (
id TEXT NOT NULL PRIMARY KEY, -- Corresponds to Clerk User ID
email TEXT,
first_name TEXT,
last_name TEXT,
image_url TEXT,
created_at TIMESTAMPTZ DEFAULT NOW(),
updated_at TIMESTAMPTZ DEFAULT NOW()
);
-- 2. Enable Row Level Security (RLS) on the table
-- This is an important security measure to ensure users cannot access any data by default.
ALTER TABLE public.users ENABLE ROW LEVEL SECURITY;
-- 3. Create RLS policies
-- Policy 1: Allow authenticated users to read their own user info.
-- `auth.jwt()->>'sub'` extracts the user ID from the JWT provided by Clerk.
CREATE POLICY "Authenticated users can view their own user record"
ON public.users FOR SELECT
TO authenticated
USING ( (SELECT auth.jwt()->>'sub') = id );
-- Policy 2: Allow users to update their own info.
CREATE POLICY "Authenticated users can update their own user record"
ON public.users FOR UPDATE
TO authenticated
USING ( (SELECT auth.jwt()->>'sub') = id );وكذلك تفعيل Edge function المقابلة في Supabase:
// File path: supabase/functions/clerk-webhooks/index.ts
import { serve } from 'https://deno.land/std@0.177.0/http/server.ts'
import { Webhook } from 'npm:svix'
import { createClient } from 'https://esm.sh/@supabase/supabase-js@2'
// Get Clerk Webhook signing secret from environment variables
const CLERK_WEBHOOK_SECRET = Deno.env.get('CLERK_WEBHOOK_SECRET')
if (!CLERK_WEBHOOK_SECRET) {
throw new Error('CLERK_WEBHOOK_SECRET is not set in environment variables')
}
const supabaseAdmin = createClient(
Deno.env.get('SUPABASE_URL')!,
Deno.env.get('SUPABASE_SERVICE_ROLE_KEY')!
)
serve(async (req) => {
try {
// 1. Get Svix signature info from request headers
const headers = Object.fromEntries(req.headers)
const svix_id = headers['svix-id']
const svix_timestamp = headers['svix-timestamp']
const svix_signature = headers['svix-signature']
if (!svix_id || !svix_timestamp || !svix_signature) {
return new Response('Missing Svix headers', { status: 400 })
}
const payload = await req.json()
const body = JSON.stringify(payload)
// 2. Verify Webhook signature validity using the secret
const wh = new Webhook(CLERK_WEBHOOK_SECRET)
const evt = wh.verify(body, {
'svix-id': svix_id,
'svix-timestamp': svix_timestamp,
'svix-signature': svix_signature,
})
const { id } = evt.data
const eventType = evt.type
console.log(`Received webhook event: ${eventType} for user: ${id}`)
// 3. Execute database operations based on event type
switch (eventType) {
case 'user.created': {
const { id, first_name, last_name, image_url, email_addresses } = evt.data
const { error } = await supabaseAdmin.from('users').insert({
id,
first_name,
last_name,
image_url,
email: email_addresses[0]?.email_address,
})
if (error) throw error
console.log(`User ${id} created in Supabase.`)
break
}
case 'user.updated': {
const { id, first_name, last_name, image_url, email_addresses } = evt.data
const { error } = await supabaseAdmin
.from('users')
.update({
first_name,
last_name,
image_url,
email: email_addresses[0]?.email_address,
updated_at: new Date().toISOString(), // Update timestamp
})
.eq('id', id)
if (error) throw error
console.log(`User ${id} updated in Supabase.`)
break
}
case 'user.deleted': {
// For delete events, ID might be at the top level
const deletedId = id
if (!deletedId) {
return new Response('Deleted user ID not found', { status: 400 })
}
const { error } = await supabaseAdmin.from('users').delete().eq('id', deletedId)
if (error) throw error
console.log(`User ${deletedId} deleted from Supabase.`)
break
}
}
return new Response('Webhook processed successfully', { status: 200 })
} catch (err) {
console.error('Error processing webhook:', err.message)
return new Response(`Webhook Error: ${err.message}`, { status: 400 })
}
})بعد الانتهاء من تهيئة جداول بيانات Supabase والدوال، تحتاج أيضاً إلى تفعيل دعم Webhooks في Clerk:
- في Clerk Dashboard -> Webhooks أضف Endpoint، وأدخل URL الخاص بـ Supabase Edge Function.
- حدد الأحداث
user.created،user.updated،user.deletedوغيرها.
بمجرد نجاح الإعداد، ستتمكن من رؤية معلومات الطلبات المختلفة في Message Attempts، وبعد النقر يمكنك رؤية معلمات نتيجة الطلب التفصيلية؛ إذا واجهت مشاكل عندما يقوم webhook بطلب Edge function، يمكنك العثور بسرعة على السبب التفصيلي في القيمة المرجعة. يُنصح بمقارنة سجلات الطلبات من Clerk وSupabase في نفس الوقت، لتحليل ما إذا كانت إعدادات الدوال المختلفة صحيحة.
5.6.4 دعم تسجيل الدخول عبر طرف ثالث في Clerk
قبل التعمق في كيفية دعم تسجيل الدخول عبر طرف ثالث في Clerk، دعنا نوضح مفهومين أساسيين أولاً: بيئة التطوير وبيئة الإنتاج، وهما المرحلتان الرئيسيتان من "التطوير والاختبار" إلى "الإطلاق والتوفر" للبرنامج، ولهما موقع واستخدام ومتطلبات أمان مختلفة تماماً:
- بيئة التطوير: البيئة المستخدمة على الخادم المحلي أو خادم الاختبار من قبل المطورين، وتستخدم فقط لتطوير الوظائف والتصحيح والتحقق الداخلي (مثل خدمة localhost:3000 المحلية)، ولا تكون مفتوحة للجمهور
- بيئة الإنتاج: البيئة العامة الموجهة للمستخدمين الحقيقيين بعد إطلاق التطبيق رسمياً (مثل النشر على Vercel، أو Alibaba Cloud، وغيرها من المنصات على https://my-app.com)
ويميز Clerk بين بيئتين لتسجيل الدخول الاجتماعي، والجوهر هو الموازنة بين "كفاءة التطوير" و"أمان الإنتاج": في مرحلة التطوير يجب تقليل التهيئة الزائدة للتحقق من الوظائف بسرعة، وفي مرحلة الإنتاج يجب ضمان أمان البيانات من خلال بيانات اعتماد مخصصة، مع الامتثال لقواعد منصات OAuth لطرف ثالث مثل Google وGitHub (يجب أن ترتبط التطبيقات عبر الإنترنت بنطاق مخصص وبيانات اعتماد، ولا يسمح باستخدام الموارد المشتركة). فيما يلي شرح تفصيلي للاختلافات في تهيئة تسجيل الدخول الاجتماعي في Clerk في البيئتين:
- التحقق السريع في بيئة التطوير
في بيئة التطوير، قام Clerk مسبقاً بتعيين بيانات اعتماد OAuth المشتركة وعناوين URI لإعادة التوجيه الافتراضية، دون الحاجة للذهاب إلى GitHub/Google للتقدم ببيانات اعتماد مخصصة، خطوات العمل كالتالي:
سجل الدخول إلى Clerk Dashboard، وانتقل إلى صفحة SSO connections (اتصالات SSO) من شريط التنقل الأيسر.
انقر على Add connection (إضافة اتصال)، واختر For all users (لجميع المستخدمين).
في القائمة المنسدلة Choose provider (اختيار المزود)، اختر GitHub أو Google حسب الحاجة.
انقر مباشرة على Add connection (إضافة اتصال)، وسيقوم Clerk تلقائياً بالربط باستخدام بيانات الاعتماد المشتركة.
بعد التهيئة، قم بتشغيل التطبيق محلياً (مثل
localhost:3000) وانقر على "Sign in with GitHub/Google"، وسيقوم Clerk تلقائياً بوكالة طلب تسجيل الدخول للتحقق بسرعة مما إذا كانت الوظيفة تعمل بشكل طبيعي.
- تهيئة بيانات اعتماد مخصصة لبيئة الإنتاج
(ملاحظة: إذا وجدت أن هناك ارتباطاً لا يتوافق مع التوقعات، يُنصح بقراءة الوثائق الرسمية لتجربة أحدث الطرق)
بعد نشر التطبيق عبر الإنترنت (مثل Vercel، أو Alibaba Cloud) والتحول إلى Clerk Production Instance، تصبح بيانات الاعتماد المشتركة غير صالحة، وتحتاج لتهيئة بيانات اعتماد OAuth مخصصة لـ GitHub/Google (يُنصح بفتح Clerk Dashboard وصفحة المنصة الثالثة في نفس الوقت لتسهيل العمليات المتزامنة):
- العمليات العامة المسبقة (لوحة تحكم Clerk):
- انتقل إلى صفحة Clerk SSO connections، وانقر على Add connection -> اختر For all users.
- اختر المنصة المستهدفة (GitHub/Google)، وتأكد من تفعيل Enable for sign-up and sign-in (السماح بالتسجيل وتسجيل الدخول) وUse custom credentials (استخدام بيانات اعتماد مخصصة).
- انسخ Authorization Callback URL (لـ GitHub) أو Authorized Redirect URI (لـ Google) من الصفحة، واحفظها في مكان آمن، لا تغلق الصفحة/النافذة المنبثقة الحالية.
- 2.1 تهيئة منصة GitHub:
- سجل الدخول إلى GitHub، وانتقل إلى Developer Settings (المسار: الصورة الرمزية -> Settings -> Developer settings -> OAuth Apps).
- انقر على New OAuth app، واملأ المعلومات:
Application name(اسم التطبيق)،Homepage URL(النطاق الإنتاجي، مثلhttps://my-app.com)،Authorization Callback URL(الصق العنوان المنسوخ من Clerk). - انقر على Register application، ثم انقر على Generate a new client secret، واحفظ Client ID وClient Secret المولدين (يظهر Secret مرة واحدة فقط).
- عد إلى النافذة المنبثقة في Clerk، الصق Client ID وClient Secret، وانقر على Add connection لإكمال التهيئة (إذا أغلقت النافذة المنبثقة، يمكنك العثور على اتصال GitHub في SSO connections، وملء حقول "Use custom credentials").
- 2.2 تهيئة منصة Google:
- سجل الدخول إلى Google Cloud Console، واختر مشروعاً حالياً أو أنشئ مشروعاً جديداً (مثل "My App Production").
- انقر على القائمة في الزاوية العلوية اليسرى -> APIs & Services -> Credentials، وانقر على Create Credentials -> OAuth client ID (في التهيئة الأولى تحتاج لإكمال إعداد OAuth consent screen أولاً، اختر "External" واملأ معلومات التطبيق).
- اختر Application type كـ Web application، وقم بالتهيئة:
Authorized JavaScript origins: أضف النطاق الإنتاجي (مثلhttps://my-app.com،https://www.my-app.com)، للتحقق المحلي يمكنك إضافةhttp://localhost:رقم_المنفذ.Authorized Redirect URIs: الصق العنوان المنسوخ من Clerk.
- انقر على Create، واحفظ Client ID وClient Secret من النافذة المنبثقة، ثم عد إلى النافذة المنبثقة في Clerk للصق وانقر على Add connection.
- ملاحظات مهمة:
- منع تسجيل الدخول عبر WebView: Google OAuth لا يدعم تسجيل الدخول عبر متصفح داخل التطبيق، راجع وثائق Google الرسمية للتعديل.
- تغيير حالة النشر: حالة "Testing" الافتراضية تدعم فقط 100 مستخدم اختبار، تحتاج لتغيير "Publishing status" إلى In production في OAuth consent screen (يتطلب اجتياز مراجعة Google).
- منع البريد الإلكتروني الفرعي: يعترض Clerk افتراضياً رسائل Google الإلكترونية التي تحتوي على
+/=/#(مثلuser+alias@example.com)، يمكنك تفعيل/إلغاء Block email subaddresses في صفحة تفاصيل اتصال Google (يُنصح بالتفعيل لتحسين الأمان). - دعم Google One Tap: بعد اكتمال التهيئة، يمكنك دمج مكون Clerk
<GoogleOneTap />لتحقيق "تسجيل الدخول بنقرة واحدة"، راجع توثيق مكونات Clerk.
- اختبار اتصال تسجيل الدخول عبر طرف ثالث
بعد اكتمال التهيئة، تحقق من الوظيفة من خلال Account Portal المدمج في Clerk:
- انتقل إلى Clerk Dashboard، ومن شريط التنقل الأيسر انتقل إلى صفحة Account Portal.
- في وحدة "Sign-in" على اليمين، انقر على زر "زيارة صفحة تسجيل الدخول" للانتقال إلى صفحة تسجيل الدخول في البيئة المقابلة:
- بيئة التطوير:
https://your-domain.accounts.dev/sign-in(مثلhttps://my-app.accounts.dev/sign-in). - بيئة الإنتاج:
https://accounts.your-domain.com/sign-in(مثلhttps://accounts.my-app.com/sign-in).
- بيئة التطوير:
- انقر على "Sign in with GitHub/Google"، وسجل الدخول بحساب المنصة المقابلة، وإذا تمت إعادة التوجيه بنجاح والعودة إلى التطبيق، فهذا يعني أن تهيئة الاتصال طبيعية.
6. من Supabase إلى المزيد من مكونات تطوير الخلفية (متقدم)
فيما سبق، كنا نقف بشكل أساسي من منظور Supabase لنرى "ما هي المشاكل التي يمكن لمنصة خلفية شاملة تتمحور حول Postgres أن تساعدنا في حلها": المصادقة، وقواعد البيانات، وتخزين الملفات، والاتصال الفوري، والدوال الحدية، وغيرها، كلها مدمجة في لوحة تحكم واحدة، جاهزة للاستخدام، وتجربة موحدة، ومناسبة جداً للبدء السريع والمشاريع الصغيرة والمتوسطة.
لكن من منظور طويل الأمد وأكثر هندسية، كل قدرة يوفرها Supabase (Auth / Storage / Edge Functions / Realtime / Database)، لها تقريباً حلول بديلة متخصصة مقابلة في الصناعة - تشمل منصات BaaS المماثلة، وكذلك الخدمات السحابية والمكونات مفتوحة المصدر الأكثر "اختراقاً في نقطة واحدة". كمطورين أفراد طموحين وفرق ناشئة، فإن فهم هذه الخيارات البديلة له عدة فوائد:
- الحكم على ما إذا كان المشروع الحالي "يكفي استخدام Supabase بالكامل"، أم أن هناك حاجة لخدمة متخصصة/أرخص/أسهل في الامتثال في جزء معين؛
- عندما يكبر حجم المشروع أو تصبح المتطلبات أكثر تعقيداً، هل يمكن استبدال وحدة معينة من Supabase (مثلاً التغيير إلى منصة Auth متخصصة أو تخزين كائنات)، بدلاً من الارتباط بالمنصة بالكامل منذ البداية؛
- توسيع آفاق الاختيار التقني، حتى لو لم تقم بالتغيير مؤقتاً، يمكنك معرفة "إذا لم أستخدم وظيفة X في Supabase، ما هي الخيارات الشائعة الأخرى المتاحة لي".
سيقدم هذا القسم البدائل السائدة في السوق للقدرات الرئيسية التي يغطيها Supabase، مثل: المصادقة (Auth)، وتخزين الملفات (Storage)، والدوال الحدية (Edge Functions)، والاتصال الفوري (Realtime)، واستضافة قواعد البيانات. مع مقارنة بسيطة للاختلافات في خصائص الوظائف، والحصة المجانية/التسعير، وسهولة الاستخدام، وشعبية المجتمع، لمنحك فهماً أشمل لمكتبة أدوات مكونات الخلفية.
منصات BaaS المماثلة
قبل البدء، يمكننا تصفح منصات BaaS المماثلة، وإذا شعرت أن Supabase ليست جيدة بما فيه الكفاية، يمكنك اختيار بدائل مختلفة للتجربة بناءً على احتياجاتك.
| المنصة/الخدمة | النوع | الحصة المجانية/التسعير | الخصائص / سيناريوهات الاستخدام المناسبة |
|---|---|---|---|
| Firebase (Google) | BaaS مُدار بالكامل (Auth + Firestore + Storage + Functions + Hosting) | Spark: حصة مجانية خفيفة؛ Blaze: الدفع حسب الاستخدام (Firestore/Storage/Functions محسوبة بشكل منفصل) | الأكثر نضجاً في الصناعة، توثيق جيد، سهل البدء، قدرات فورية قوية. مناسب للمنتجات الصغيرة والمتوسطة، والفرق التي تقودها الأجهزة المحمولة/الواجهة الأمامية. العيوب: تسعير معقد، ارتباط قوي، قيود كثيرة على الاستعلام (خاصة Firestore). |
| Supabase | BaaS مفتوح المصدر (Postgres + Auth + Storage + Edge Functions + Realtime) | مجاني: 500 ميجابايت DB، 1 جيجابايت Storage، عدد قليل من استدعاءات الدوال بدون خادم؛ Pro: الدفع حسب المثيل | الأكثر شبهاً بنسخة SQL من Firebase؛ واجهة ممتازة، تجربة حديثة، يمكن الاستضافة الذاتية. مناسب للتطبيقات التي تحتاج SQL قوي، وBI، وقدرات المعاملات. العيوب: تكلفة عالية في التزامن العالي أو الدوال المعقدة. |
| Appwrite Cloud | BaaS شامل مفتوح المصدر (DB + Auth + Storage + Functions + Realtime) | مجاني: يتضمن DB/Storage/FaaS أساسي؛ المدفوع حسب مستوى الموارد | تجربة حديثة، API موحد، يمكن الاستضافة الذاتية؛ مناسب للتكرار السريع للتطبيقات الصديقة للمطورين. العيوب: النظام البيئي ليس ناضجاً مثل Firebase/Supabase؛ الأداء يحتاج للاختبار في التطبيقات الكبيرة. |
| Nhost | Postgres + GraphQL + Auth + Storage + Functions | مجاني: 1 جيجابايت DB، 1 جيجابايت Storage، عدد قليل من استدعاءات الدوال | مشابه لـ "Supabase + Hasura"؛ GraphQL طبيعي؛ مناسب لفرق الواجهة الأمامية ومشاريع React/Next.js. العيوب: نظام بيئي صغير، التكلفة ترتفع مع الاستخدام. |
| AWS Amplify | خلفية شاملة من AWS (Cognito + AppSync + DynamoDB + Storage + Functions + Hosting) | مجاني: حصة Hosting + Cognito 10k MAU + جزء من حصة الدوال | كبير وشامل، مناسب للفرق التي لديها بالفعل بنية AWS أساسية؛ موثوقية على مستوى المؤسسات. العيوب: الأصعب في البدء، خدمات مجزأة؛ تكلفة صيانة عالية للفرق الناشئة. |
| Xata (نمو سريع في السنتين الأخيرتين) | قاعدة بيانات متعددة النماذج + Auth + Edge Functions | مجاني: 250 ألف سجل، 15 جيجابايت عرض نطاق | رغم أنه أقرب لـ "DB + API"، لكنه يوفر Auth، وملفات، ومنطق، ويمكن استخدامه كخلفية كاملة خفيفة. UI/تجربة تطوير ممتازة. العيوب: الوظائف ليست شاملة مثل Firebase/Supabase. |
| Convex (تجربة مطورين قوية جداً) | قاعدة بيانات مُستضافة + Auth + Functions (الواجهة الأمامية أولاً) | إصدار تطوير مجاني؛ المدفوع يحسب حسب حجم الطلبات | سهل البدء بشكل كبير؛ لا حاجة لـ schema؛ الواجهة الأمامية تكتب الدوال ويمكنها استخدام الخلفية. مناسب لـ MVP/التحقق السريع. العيوب: ارتباط عالٍ بالمنصة، تكلفة الانتقال عالية؛ لا يُعتبر BaaS تقليدي بالكامل. |
المصادقة (Auth)
| الأداة/المنصة | خصائص الوظائف | الحصة المجانية/التسعير | سيناريوهات الاستخدام والمزايا/العيوب |
|---|---|---|---|
| Firebase Authentication | خدمة مصادقة هوية BaaS من Google، تدعم البريد الإلكتروني/كلمة المرور، الهاتف، تسجيل الدخول الاجتماعي، مجهول وغيرها من الطرق الشائعة. خطة Spark المجانية تدعم حتى 50 ألف مستخدم نشط شهرياً. | Spark (مجاني) 50k MAU؛ Blaze الدفع حسب الاستخدام | متكامل مع نظام Google البيئي، توثيق غني، سهل البدء؛ وظائف شاملة (MFA، دوال الحظر، إلخ)، مناسب للتطوير السريع. لكنه مرتبط بمنصة Firebase، والتوسع لخدمات أخرى يتطلب تهيئة إضافية. |
| Auth0 (Okta) | منصة مصادقة هوية مُدارة بالكامل، تدعم تسجيل الدخول الاجتماعي، وSSO للمؤسسات، والمصادقة متعددة العوامل، وتوسيع القواعد ووظائف قوية أخرى. | خطة مجانية 25k MAU، المدفوع يحسب حسب MAU | وظائف على مستوى المؤسسات كاملة (RBAC، سجلات التدقيق، إلخ)، مناسب للتطبيقات المتوسطة والكبيرة؛ واجهة سهلة الاستخدام. العيب هو أن التكلفة ترتفع عند زيادة MAU، والنسخة المجانية محدودة الوظائف (مثل عدم تضمين MFA/RBAC). شهرة عالية في المجتمع، مستخدمون كثيرون. |
| AWS Cognito | خدمة هوية أصلية من Amazon Cloud، تدعم تسجيل الدخول الاجتماعي وSAML الموحد. تسجيل دخول مستخدم مباشر يوفر 10k MAU مجاناً شهرياً، والزيادة تُحسب بسعر 0.0055 دولار/MAU. | مجاني 10k MAU/شهر، الزيادة الدفع حسب الاستخدام | متكامل بعمق مع نظام AWS البيئي (يمكن العمل بسلاسة مع API Gateway، Lambda، إلخ)، عتبة الدخول مرتفعة قليلاً، التوثيق معقد؛ الحصة المجانية محدودة، مناسب للفرق المعتادة على استخدام AWS. |
| Logto | منصة مصادقة هوية مفتوحة المصدر، النسخة المستضافة ذاتياً مجانية، خطة الخدمة السحابية مجانية لـ 50k MAU. تدعم لغات متعددة، ومستأجرين متعددين، وOAuth/OIDC وغيرها. | نسخة المجتمع مجانية؛ Logto Cloud مجاني 50k MAU | بديل مفتوح المصدر شائع حديثاً لـ Auth0، GitHub لديه بالفعل أكثر من 10k نجمة. سهل التوسع، الاستضافة الذاتية تقلل التكلفة؛ العيب هو أن النظام البيئي والتوثيق لا يزالان جديدين نسبياً، وحجم المجتمع أقل من Firebase/Auth0. |
| Keycloak | حل IAM/SSO مفتوح المصدر معروف، يدعم اسم المستخدم وكلمة المرور، وLDAP، وSAML، وOAuth2 وغيرها. | مجاني بالكامل، يتطلب استضافة ذاتية | وظائف قوية، قابل للتوسع (يدعم التحكم الدقيق في الصلاحيات)، وظائف على مستوى المؤسسات غنية؛ لكن تعقيد النشر والصيانة عالي، ومنحنى التعلم حاد للفرق الصغيرة. العيب هو متطلبات عالية للحاويات والتشغيل والصيانة العنقودية. |
تخزين الملفات (Storage)
| المنصة/الخدمة | النوع | الحصة المجانية/التسعير | الخصائص/سيناريوهات الاستخدام |
|---|---|---|---|
| Amazon S3 | تخزين كائنات سحابي (AWS) | حزمة AWS المجانية توفر 5 جيجابايت تخزين، 20 ألف طلب GET/PUT شهرياً، الزيادة الدفع حسب الاستخدام | معيار الصناعة لتخزين الكائنات، موثوقية عالية، نشر متعدد المناطق عالمياً. وظائف شاملة، تكامل جيد مع نظام AWS البيئي؛ التسعير معقد نسبياً، يحتاج المستخدمون الجدد لفهم قواعد الفوترة. |
| Google Cloud Storage (Firebase Storage) | تخزين كائنات سحابي (Google) | خطة Firebase Spark توفر حصة مجانية (1 جيجابايت تخزين + قيود حركة)، Blaze مدفوع | تكامل وثيق مع Firebase/Google Cloud، سهل الإدارة؛ يدعم تسريع CDN، قواعد أمان دقيقة. |
| Tencent Cloud COS / Alibaba Cloud OSS | تخزين كائنات سحابي (محلي) | الدفع حسب الاستخدام (لكل مزود هدايا للمستخدمين الجدد، مثل OSS لديه 40 جيجابايت مجاناً في السنة الأولى) | موجه للسوق المحلي، تخزين كائنات عالي الأداء و كبير الحجم؛ تكامل مع النظام البيئي السحابي الصيني، توثيق جيد. Alibaba OSS وظائف شاملة، تسريع عالمي؛ Qiniu KODO يركز على معالجة الوسائط المتعددة، تكلفة منخفضة، مناسب للأفراد والفرق الصغيرة. |
| MinIO | تخزين متوافق مع S3 مفتوح المصدر | مفتوح المصدر مجاني (ذاتي البناء) | خفيف، عالي الأداء، متوافق مع S3 API، مناسب لبناء تخزين كائنات في سحابة خاصة أو محلياً. توثيق ومجتمع نشطان؛ يحتاج لصيانة البنية التحتية بنفسك. |
| Cloudinary / Imgix وغيرها | تخزين وسائط + CDN | خطة مجانية أساسية (مثل Cloudinary مجاني 25 جيجابايت/شهر عرض نطاق) | خدمة تخزين سحابي + CDN محسنة للصور/الفيديو، توفر وظائف متقدمة مثل التحويل في الوقت الفعلي، والضغط، إلخ. مناسبة لمشاريع الوسائط، لكن الوظائف متخصصة نسبياً، والتكلفة مرتفعة عند استخدامها كتخزين ملفات عام. |
الدوال الحدية (Edge Functions)
| المنصة/الخدمة | الخصائص | الحصة المجانية/التسعير | سيناريوهات الاستخدام والمزايا/العيوب |
|---|---|---|---|
| Cloudflare Workers | بيئة JavaScript/Wasmtime موزعة عالمياً | خطة مجانية: 100 ألف طلب يومياً؛ الخطة القياسية $5/شهر تتضمن 10 ملايين طلب | تعمل على عقد Cloudflare الحدية، تأخير منخفض جداً؛ مناسب للمنطق الموزع عالمياً، وعرض الموارد الثابتة، إلخ. الحصة المجانية قليلة نسبياً (ما يعادل حوالي 3 ملايين طلب شهرياً)، سهل البدء. العيب هو قيود وقت التشغيل (JS/Wasmtime) وأدوات التصحيح المحدودة. |
| Vercel Edge Functions | تكامل سلس مع Next.js/أطر الواجهة الأمامية، يدعم JS/TS/Go | Hobby مجاني: مليون استدعاء دالة شهرياً، مليون طلب حدي | تكامل عميق مع أطر الواجهة الأمامية، نشر تلقائي؛ مناسب لتطبيقات الويب الحديثة. حصة مجانية كافية، وقت التشغيل الافتراضي 10 ثوانٍ، يمكن رفعه إلى 60 ثانية. العيب هو أن النسخة المجانية محدودة في وظائف التعاون الجماعي؛ الاعتماد على منصة Vercel. |
| Netlify Edge / Functions | دوال Node.js السحابية + توجيه حدي (NFT) | مجاني: 300 رمز/شهر (ما يعادل تقريباً مليون طلب شهري)؛ الدفع حسب نقاط الائتمان | يدعم دوال Node.js، ومعالجة التوجيه الحدية، إلخ. الحصة المجانية للبناء والدوال وعرض النطاق، مناسب لنشر الواجهة الأمامية الشامل. الميزة هي سهولة الاستخدام، تكامل نشر Git؛ العيب هو أن الحصة المجانية تحتاج حساباً (10 آلاف طلب = 3 نقاط). |
| AWS Lambda@Edge / CloudFront Functions | حوسبة حدية بدون خادم من AWS | AWS Lambda (مليون طلب مجاني/شهر + 400 ألف GB-s) + CloudFront $0.085/لكل 100 ألف استدعاء | متكامل مع CloudFront، يمكن تنفيذ الكود على الحافة. مناسب لمن يحتاج نظام AWS البيئي (مثل إجراء صلاحيات أو اختبارات A/B على مستوى العقدة). الميزة هي المرونة والقوة؛ العيب هو التهيئة المعقدة، والتأخير أعلى قليلاً من Cloudflare/Vercel. |
الاتصال الفوري (Realtime)
| المنصة/الخدمة | خصائص الوظائف | الحصة المجانية/التسعير | سيناريوهات الاستخدام والمزايا/العيوب |
|---|---|---|---|
| Firebase Realtime Database / Firestore | قاعدة بيانات فورية BaaS من Google؛ تدعم دفع تغييرات البيانات | Spark مجاني: قاعدة البيانات الفورية 1 جيجابايت تخزين وحدود؛ Blaze الدفع حسب الاستخدام | تكامل قوي مع نظام Firebase البيئي، الاستماع الفوري بسيط. الميزة هي البدء السريع مجاناً؛ العيب هو نوع قاعدة البيانات (JSON/NoSQL)، قدرات الاستعلام المعقدة ضعيفة. |
| Ably | منصة رسائل فورية وpub/sub، تدعم WebSocket، MQTT وغيرها | حزمة مجانية: 6,000,000 رسالة شهرياً | خدمة رسائل فورية شاملة الوظائف، دعم التزامن العالي؛ الحصة المجانية يمكن أن تصل إلى 6 ملايين رسالة/شهر. مجتمع وتوثيق جيدان، مناسب للتوزيع العالمي. |
| Pusher Channels | خدمة دفع الأحداث، تدعم آلية القنوات/الأحداث | Sandbox مجاني: 200 ألف رسالة يومياً، 100 اتصال متزامن | خدمة WebSocket سهلة الاستخدام، توثيق كامل، مناسب لتنفيذ الدردشة والإشعارات بسرعة. النسخة المجانية محدودة في عدد الرسائل والاتصالات؛ بعد الدفع قابلية التوسع جيدة. |
| WebSocket/Socket.IO ذاتي البناء | بناء خادم بنفسك (Node.js، Elixir أو Go وغيرها) | تكلفة الاستضافة الذاتية (مثل رسوم الخادم) | أعلى مرونة، يمكن تخصيص البروتوكول والطوبولوجيا حسب الحاجة. مناسب للفرق ذات التحكم الصارم في التكلفة والناضجة تقنياً. العيب هو الحاجة لمعالجة التوفر والتوسع والمشاكل عبر النطاقات وغيرها بنفسك. |
قواعد البيانات
| المنصة/الأداة | نوع قاعدة البيانات | الحصة المجانية/التسعير | الخصائص الرئيسية |
|---|---|---|---|
| Neon (Serverless PostgreSQL) | علائقية (PostgreSQL) | خطة مجانية: 0.5 جيجابايت تخزين، الفرع الرئيسي متصل دائماً، 20 ساعة حساب فروع/شهر | Postgres بدون خادم سحابي أصلي، يدعم التوسع التلقائي والتفرع (fork للاختبار). الحصة المجانية كافية للمشاريع الصغيرة، مناسبة لسير العمل التطويري الحديث. وظيفة التفرع قوية، لكن الحصة المجانية صغيرة. |
| Aiven PostgreSQL | علائقية (PostgreSQL/MySQL) | خطة مجانية: 1 جيجابايت تخزين، 1 vCPU، 1 جيجابايت ذاكرة | خدمة قاعدة بيانات مُدارة، تدعم الترحيل متعدد المناطق عبر السحب. توفر MySQL، Redis وخيارات أخرى. الحصة المجانية مناسبة للتطوير والمشاريع الصغيرة؛ النسخة التجارية تدعم الكتل عالية التوافر والمراقبة. |
| CockroachDB Cloud | SQL موزعة (متوافقة مع PostgreSQL) | خطة مجانية: 10 جيجابايت تخزين | قاعدة بيانات SQL موزعة مشابهة لـ Google Spanner، تقسيم وتوسع تلقائي. 10 جيجابايت مجانية سخية؛ مناسب للتطبيقات التي تحتاج توسع أفقي واتساق عالي. النسخة التجارية SLA عالي. |
| TiDB Cloud | علائقية موزعة (متوافقة مع MySQL) | خطة مجانية: 5 جيجابايت لكل عقدة، بإجمالي يصل إلى 25 جيجابايت | النسخة السحابية من TiDB مفتوح المصدر، متوافقة مع بروتوكول MySQL، بنية موزعة. حصة مجانية كافية، مناسب للفرق المعتادة على MySQL، أداء ممتاز؛ العيب هو أن التشغيل والصيانة معقد نسبياً (للسيناريوهات الكبيرة). |
| MongoDB Atlas | مستندية (NoSQL MongoDB) | كتلة M0 مجانية: 0.5 جيجابايت تخزين | MongoDB على السحابة، نموذج مستندات مرن، يدعم استعلامات وفهارس غنية. قاعدة بيانات 0.5 جيجابايت مجانية مناسبة للاختبار والتطبيقات الصغيرة؛ يمكن التوسع الأفقي حسب الحاجة. منحنى التعلم أعلى قليلاً من قواعد البيانات العلائقية. |
| SQLPub | متعددة قواعد البيانات (MySQL، PostgreSQL، Redis وغيرها) | خطة مجانية: 36,000 طلب/ساعة، 30 اتصال متزامن، 500 ميجابايت تخزين | منصة قواعد بيانات شاملة، تدعم أنواع قواعد بيانات متعددة. النسخة المجانية مناسبة للتعلم والمشاريع الصغيرة؛ الميزة هي دعم أنواع DB متعددة، العيب هو أن حصة التخزين صغيرة. |
البدائل المذكورة أعلاه لكل منها تركيز مختلف: المصدر المفتوح أكثر مرونة وتحكماً (Keycloak، MinIO، Socket.IO، Neon، CockroachDB، إلخ)، والخدمات السحابية المُدارة أسهل في البدء (Firebase، Auth0، Cloudflare، Vercel، Netlify، AWS، Aiven، MongoDB Atlas، إلخ). عند الاختيار يمكن الموازنة بناءً على متطلبات المشروع، والبنية التقنية للفريق، والميزانية، والنظام البيئي للمجتمع. للمشاريع الشخصية يمكن إعطاء الأولوية للخدمات ذات الحصة المجانية الكافية والسهلة التكامل (مثل سلسلة Firebase، وتخزين Qiniu، وCloudflare Workers، وNeon، وCockroachDB، إلخ)، أما للاحتياجات على مستوى المؤسسات أو الأمنية المحددة، فيمكن النظر في الحلول الأكثر ثراءً في الوظائف والأعلى تكلفة (Auth0، وAlibaba/Tencent Cloud، وAWS، وTiDB/Aiven، إلخ). يمكنك التجربة المستمرة في التطبيقات العملية حتى تختار أنسب مكونات أدوات تطوير الخلفية.
الملخص
في درس اليوم، تعلمنا بشكل منهجي المفاهيم الأساسية لقواعد البيانات، والتعريف الأساسي لـ Supabase وتفاصيل عملياته. لاحقاً في عملية الممارسة، يمكنك الرجوع إلى هذه الوثيقة في أي وقت كمرجع بناءً على سيناريوهات التطبيق الفعلية ومتطلبات مشروعك.
يرجى تذكر دائماً مبدأ مهماً: أكمل أولاً، ثم أتقن! لا حاجة للسعي لتحقيق الكمال من الخطوة الأولى، يمكننا التحسن بشكل تدريجي من خلال التكرار المستمر، والاقتراب تدريجياً من نتائج أفضل. نتمنى لك كل التوفيق في ممارسات مشروعك اللاحقة!
واجب ما بعد الدرس
- تطوير تطبيق يتضمن نظام إدارة المستخدمين وقاعدة بيانات. يُفضل أن يتضمن المزيد من وظائف Supabase (Realtime / التخزين السحابي / Edge function).