De la base de données à Supabase
Lors du cours précédent, nous avons appris les bases de l'utilisation des outils de conception UI MasterGo et Figma, la récupération de code et la gestion de versions avec GitHub, et le déploiement d'applications et de sites web via Zeabur pour les rendre accessibles au plus grand nombre.
Pour vous aider à mieux consolider vos connaissances, avant d'aborder les nouveaux contenus de ce cours sur les outils de conception et le déploiement, revoyons ensemble les points clés du cours précédent à travers quelques questions simples :
- Qu'est-ce qu'un outil de conception frontend, définition et utilisation de Figma, MasterGo.
- Les méthodes de base pour convertir des maquettes de design en code.
- Qu'est-ce que GitHub, comment configurer SSH, comment créer votre premier dépôt.
- Que signifie le déploiement, comment utiliser Zeabur, comment déployer du code GitHub ou local sur le réseau public pour le rendre accessible.
Si l'un de ces points reste flou, nous vous recommandons de revoir d'abord les documents et supports du cours précédent. N'hésitez pas à poser vos questions dans le groupe de discussion WeChat.
Dans ce cours, nous apprendrons comment faire passer une application ou un site web d'un simple état fonctionnel à un produit plus proche d'un véritable service en ligne : non seulement nous utiliserons une base de données pour gérer les différentes évolutions des données de l'application, mais nous mettrons aussi en place un système utilisateur complet (inscription, connexion, permissions) ainsi que d'autres capacités backend essentielles. Nous prendrons Supabase comme plateforme de services backend pour fil conducteur, en l'utilisant d'abord pour implémenter les deux fonctionnalités fondamentales que sont « base de données + système utilisateur », puis en nous appuyant sur les composants fournis par Supabase pour mieux comprendre les modules clés généralement inclus dans les services backend cloud modernes, ainsi que leurs fonctions et logiques spécifiques.
Ce que vous allez apprendre
- Qu'est-ce qu'une donnée, qu'est-ce qu'une base de données, les bases de données courantes et leurs méthodes d'utilisation
- Qu'est-ce que Supabase, comment utiliser Supabase pour les opérations de base sur une base de données
- Comment utiliser Supabase pour ajouter une gestion basique des utilisateurs à votre application
- Maîtriser les fonctionnalités avancées de Supabase : Realtime, Storage, Edge Functions
- Ajouter la prise en charge de la connexion Google et GitHub à Supabase
- Une application de base prenant en charge l'inscription/connexion des utilisateurs et le stockage des données dans une base de données en ligne
- Un modèle de code backend Supabase réutilisable (base de données + gestion des utilisateurs, etc.) pour vos projets ultérieurs
1. Qu'est-ce qu'une base de données
1.1 Qu'est-ce qu'une donnée
Dans le monde numérique, les données (Data) sont omniprésentes. En termes simples, les données sont le support de l'information. Les coordonnées de vos amis, un article WeChat, une courte vidéo, le niveau d'un personnage dans un jeu -- tout cela constitue des données. Dans notre application, les données représentent toute information qui doit être enregistrée et gérée, comme les profils utilisateurs, l'historique des commandes, les paramètres du programme, etc.
En général, les données se présentent sous différentes formes dans un programme. La forme la plus simple est la variable, que nous pouvons utiliser pour stocker des nombres simples :
# Python variable definition examples
# Integer variable: stores age information
age = 30
# Boolean variable: stores status (whether active)
is_active = True # True means active, False means inactive
# List variable: stores a set of score data
scores = [85, 92, 78, 90] # Contains 4 integer elements representing different scores
# Dictionary variable: stores multiple related information of a user
user_info = {
"age": 30, # Key "age" corresponds to the value of age
"height": 1.80, # Key "height" corresponds to the value of height (unit: meter)
"login_count": 156 # Key "login_count" corresponds to the value of login times
}Pour les données plus complexes telles que les profils personnels ou l'historique des commandes, nous pouvons utiliser des tableaux plus élaborés pour représenter les données :
| user_id | name | |
|---|---|---|
| 1001 | Alice | alice@example.com |
| 1002 | Bob | bob@example.com |
| order_id | user_id | amount | status |
|---|---|---|---|
| 901 | 1001 | 29.99 | completed |
| 902 | 1002 | 15.50 | pending |
Mais pour les données à la structure complexe, présentant des relations hiérarchiques ou des champs variables, nous pouvons utiliser le format JSON pour les décrire -- il s'agit d'un format intermédiaire de données universel sur Internet, compréhensible par presque tous les programmes, ce qui facilite les échanges de données entre systèmes. Par exemple, une commande peut contenir plusieurs articles, chacun ayant son propre nom, sa quantité et son prix. Représenter cela dans un tableau traditionnel serait fastidieux : il faudrait soit diviser les données en plusieurs tables (« table des commandes », « table des articles ») reliées par des champs d'association ; soit utiliser une seule table avec des champs redondants du type « nom article 1, prix article 1, nom article 2... », ce qui est impossible à adapter quand le nombre d'articles varie ; le JSON, quant à lui, permet de représenter directement la hiérarchie « commande - articles - propriétés des articles » de façon intuitive et flexible.
{
"order_id": 901,
"user_id": 1001,
"amount": 29.99,
"status": "completed",
"items": [
{ "sku": "BG-001", "name": "牛肉汉堡", "quantity": 1, "price": 18.00 },
{ "sku": "SD-003", "name": "炸薯条", "quantity": 1, "price": 6.99 },
{ "sku": "DK-002", "name": "可乐", "quantity": 1, "price": 5.00 }
],
"shipping_address": {
"street": "科技园路123号",
"city": "深圳",
"zip_code": "518057"
}
}Allons plus loin : si nous considérons une donnée encodée sous forme de vecteur (Vector), il s'agit généralement d'une représentation numérique obtenue en traitant des données non structurées (texte, images ou audio) via un modèle IA (comme un modèle d'Embedding). Sa représentation peut ressembler à ceci :
[0.123, -0.456, 0.789, ..., -0.234] (un tableau de plusieurs centaines, voire milliers de nombres à virgule flottante)
En résumé, le monde réel regorge de données de formes et d'usages très variés qui méritent une analyse détaillée. Chaque type de données peut nécessiter une base de données spécifique pour son stockage, comme le montre l'illustration ci-dessous -- n'est-ce pas impressionnant ?
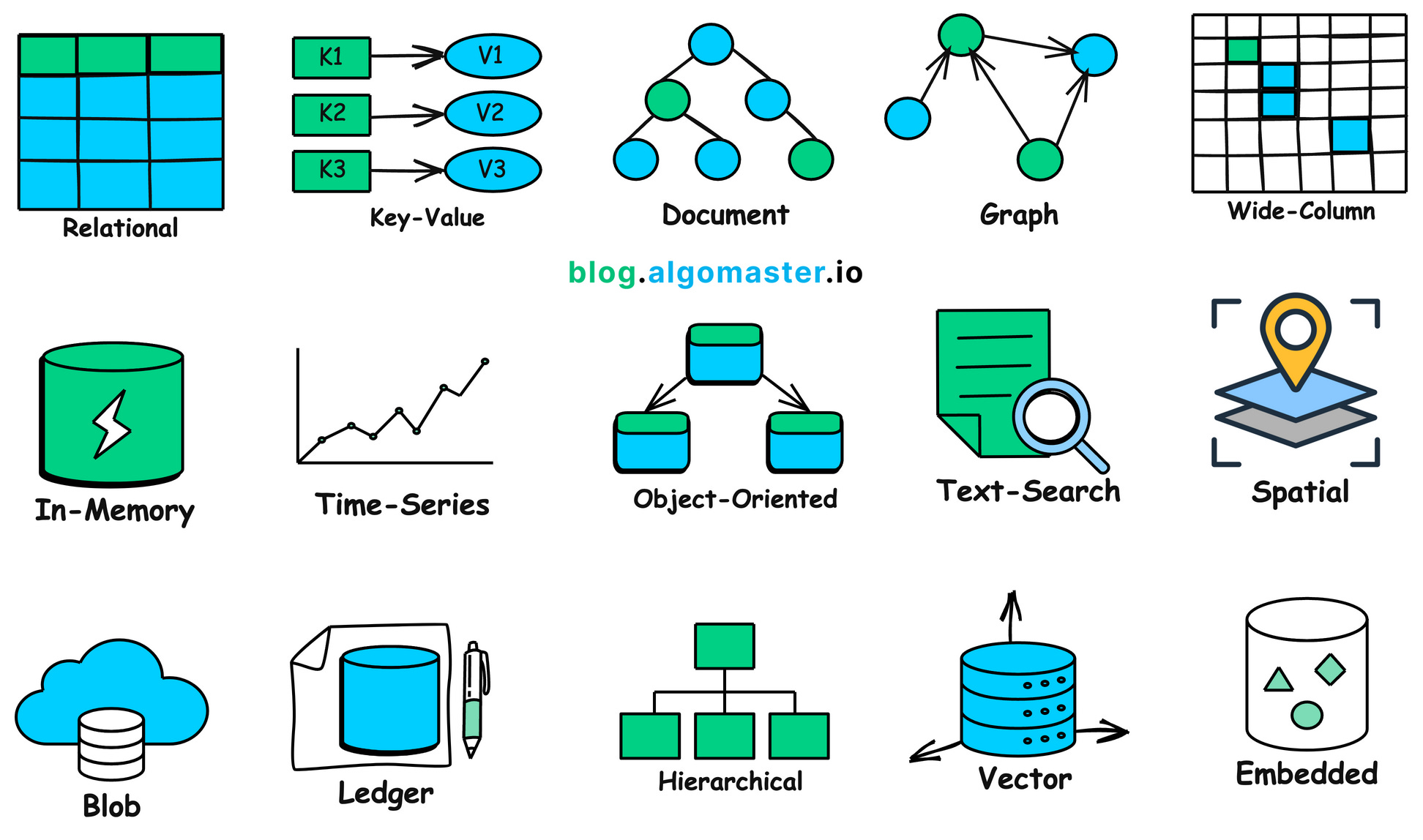
1.2 Pourquoi avons-nous besoin d'une base de données
Nous avons vu que les données du monde réel ont souvent une structure complexe. Pour stocker et utiliser efficacement ces données, nous avons besoin d'un programme ou d'un conteneur spécialisé pour les gérer -- c'est précisément la raison d'être des bases de données (Database). Une base de données est fondamentalement un programme spécialisé dont le rôle principal est d'organiser, de stocker en toute sécurité et de gérer systématiquement les données, tout en prenant en charge des requêtes efficaces.
Imaginez un instant : sans base de données, que deviendraient les données de votre application ? Lorsque l'utilisateur ferme le navigateur ou quitte l'application, toutes les informations temporairement chargées sont immédiatement perdues ; nous ne pouvons ni sauvegarder durablement l'état d'utilisation (comme les informations de connexion, les paramètres personnalisés), ni partager de données clés entre les utilisateurs (comme le stock de produits, l'historique des commandes). Nous avons absolument besoin d'un dispositif pour stocker toutes nos données !
Plus souplement encore, le mode de déploiement d'une base de données peut être adapté aux besoins : elle peut être déployée sur un serveur local pour répondre aux exigences de gestion locale des données ; ou déployée dans le cloud, les bases de données cloud prenant en charge la mise à l'échelle élastique (Scale), capable de s'étendre en fonction de la croissance du volume de données et du trafic, et de supporter des données massives et une forte concurrence, garantissant une expérience utilisateur fluide même avec une forte croissance du nombre d'utilisateurs.
En résumé, grâce à leur stockage persistant efficace, leur gestion fine et leurs capacités de requête rapide, les bases de données résolvent principalement les problèmes suivants :
- Stockage persistant des données : Sans base de données, les données n'existeraient que dans la mémoire de l'application et seraient perdues à sa fermeture. La base de données résout ce problème en stockant les données de manière persistante sur des supports comme les disques durs, assurant leur conservation à long terme et réduisant le risque de perte.
- Requêtes et analyse pratiques des données : Les bases de données offrent des langages de requête puissants (comme SQL) permettant d'effectuer facilement et efficacement des requêtes, des filtres et des analyses complexes sur des données massives, aidant ainsi les entreprises à prendre de meilleures décisions. Sans base de données, trouver une information spécifique dans une masse de fichiers non organisés serait une tâche extrêmement chronophage et difficile.
- Prise en charge de performances élevées et d'un accès concurrentiel massif : Grâce à des techniques telles que l'optimisation des index, le cache de requêtes, les pools de connexions et l'architecture distribuée, les bases de données peuvent répondre aux requêtes en quelques millisecondes et supporter des milliers, voire des millions d'utilisateurs simultanés. C'est crucial pour les applications Internet modernes (flash sales e-commerce, flux en temps réel des réseaux sociaux), garantissant la réactivité du système et l'expérience utilisateur. Sans les hautes performances des bases de données, face à un afflux massif de requêtes, le système subirait des retards sévères, voire des pannes.
- Garantie de l'intégrité et de la cohérence des données : Les bases de données assurent l'exactitude et la cohérence des données grâce à divers mécanismes (contraintes, déclencheurs). Cela signifie que les données de la base doivent respecter des règles prédéfinies : par exemple, l'âge d'un utilisateur doit être un nombre, le numéro de commande doit être unique, empêchant ainsi efficacement la création de données illégales ou invalides.
- Sécurité des données : Les bases de données fournissent des mécanismes de sécurité robustes, notamment l'authentification des utilisateurs, le contrôle d'accès et le chiffrement des données, pour protéger celles-ci contre les accès, modifications ou destructions non autorisés. Pour faire face aux pannes matérielles, erreurs humaines ou attaques malveillantes, les bases de données proposent également des fonctions de sauvegarde et de restauration. Grâce à des sauvegardes régulières, les données perdues ou endommagées peuvent être restaurées en temps utile, assurant la continuité des activités.
1.3 Bases de données relationnelles et non relationnelles
Nous avons déjà abordé la valeur essentielle, les modes de déploiement et les avantages d'élasticité des bases de données. Lorsqu'il s'agit de choisir concrètement, la première distinction à opérer est entre les deux grandes catégories : les bases de données relationnelles et les bases de données non relationnelles (NoSQL). Voici une explication simple en quelques phrases :
Les bases de données relationnelles sont comme des tableaux Excel rigoureusement structurés. Toutes les données doivent avoir un format prédéfini (un Schema défini, par exemple : il faut un nom et un âge, le nom doit être du texte, l'âge un nombre), et les différentes tables sont reliées par des champs d'association (un identifiant servant à connecter les tables, comme un numéro de sécurité sociale). Leur avantage est la précision et la fiabilité des données, idéales pour les virements bancaires, la gestion de stocks et autres scénarios où l'erreur est interdite. L'inconvénient est que la modification de la structure est assez contraignante, et que les performances peuvent être limitées avec des volumes de données massifs.
Les bases de données non relationnelles (NoSQL) sont comme des dossiers flexibles, capables de stocker des documents, des images ou des paires clé-valeur (une structure de type « mot-définition » similaire à un dictionnaire) dans des formats variés, sans avoir à définir la structure à l'avance. Elles s'adaptent plus facilement aux besoins changeants et aux données à très grande échelle (comme les publications massives des réseaux sociaux), et la mise à l'échelle (ajout de serveurs pour améliorer les performances) est plus simple, mais au prix d'une perte partielle des capacités de requêtes associatives (capacité à consolider des informations de différentes tables) et des garanties de cohérence (assurance que les données restent exactes et non contradictoires), ce qui les rend adaptées aux applications Internet tolérant un certain niveau d'erreur.
Alors, comment choisir une base de données en pratique ? En résumé, les bases de données relationnelles sont couramment utilisées pour les transactions financières, la gestion de stocks, le traitement de commandes, les systèmes comptables -- des scénarios nécessitant une forte cohérence, des transactions complexes et un équilibre lecture/écriture. Les bases de données non relationnelles conviennent mieux au stockage de contenu de réseaux sociaux, à l'analyse de logs en temps réel, à l'ingestion massive de données IoT, aux systèmes de recommandation avec forte lecture et écriture -- des scénarios à forte concurrence, avec des modes de lecture/écriture déséquilibrés et une structure flexible.
Mais pour les entreprises, aux premiers stades il n'est pas nécessaire de consacrer beaucoup de temps à réfléchir au choix de la base de données. Les bases de données actuelles sont des produits et services très matures. L'approche la plus directe est de consulter différents fournisseurs de services cloud (des prestataires offrant des ressources et services IT comme des serveurs, du stockage, des bases de données, des logiciels et de la puissance de calcul). Vous pouvez contacter directement les équipes commerciales des fournisseurs cloud pour obtenir une solution de base de données adaptée à vos besoins métier ; et le moyen le plus pratique de construire une application d'entreprise est de privilégier la collaboration avec des fournisseurs spécialisés. (Note : les services d'entreprise sont généralement plus onéreux, il est recommandé de comparer plusieurs offres et, éventuellement, d'acheter des serveurs pour déployer soi-même une base de données open source comme alternative.)
Vous pouvez également vous référer aux recommandations de sélection de base de données d'un fournisseur cloud, qui permettent de choisir différents types de bases de données selon les scénarios, et comparer les spécifications de différents fournisseurs pour trouver la plus adaptée.
| Type de base de données | Nom | Prix | Scénarios d'utilisation |
|---|---|---|---|
| Relationnelle | RDS MySQL | Faible | Version de base : apprentissage et petits sites ; version haute disponibilité : scénarios de bases de données de taille moyenne avec une certaine pression métier ; version cluster : métier ne tolérant pas les interruptions, forte pression d'accès |
| RDS SQL Server | Élevé | Version de base : tests et petits sites commerciaux ; version haute disponibilité : sites commerciaux d'entreprise ; version cluster : métier d'entreprise ne tolérant pas les interruptions, forte pression d'accès | |
| RDS PostgreSQL | Le plus bas | Version de base : apprentissage et petits sites ; version haute disponibilité : scénarios de bases de données de taille moyenne avec une certaine pression métier ; version cluster : métier ne tolérant pas les interruptions, performances généralement supérieures à MySQL | |
| RDS PPAS | Élevé | Usage général : compatible avec les métiers Oracle, pression modérée ; version dédiée : pour les métiers nécessitant un serveur physique dédié, généralement des métiers Oracle à forte concurrence | |
| DRDS | Moyen | Version d'entrée : 4 cœurs 8 Go, prix abordable, adapté aux PME en ligne ; version entreprise : 16 cœurs 32 Go, bonne réponse SQL complexe, adaptée aux activités en ligne à très forte concurrence ; version ultime : 32 cœurs 64 Go, meilleure réponse SQL complexe, offre de très grandes capacités | |
| NoSQL | Redis | Moyen | Redis double actif-standby : généralement utilisé comme base de données persistante pour améliorer la disponibilité ; version cluster Redis : généralement utilisée comme couche de cache pour accélérer les accès applicatifs, résolvant la pression de lecture que les bases de données classiques ne peuvent supporter |
| MongoDB | Moyen | Instance mono-nœud : adaptée au développement, aux tests et au stockage de données non critiques ; instance répliquée : adaptée aux scénarios nécessitant de meilleures performances de lecture, comme les sites de lecture, les systèmes de requête de commandes, ou les pics d'activité temporaires ; instance shardée : cluster basé sur plusieurs réplicas offrant des performances de lecture encore supérieures pour les activités en ligne en temps réel |
La théorie seule étant parfois difficile à saisir, illustrons avec un scénario concret de « articles de blog » comment les mêmes données sont stockées différemment dans une base de données relationnelle (SQL) et dans différents types de bases de données non relationnelles (NoSQL).
Supposons que nous ayons une plateforme de blog stockant les informations suivantes :
- Utilisateurs (Users) : ID utilisateur, nom d'utilisateur, email
- Articles (Posts) : ID article, titre, contenu, ID de l'auteur
- Commentaires (Comments) : ID commentaire, contenu du commentaire, ID du commentateur, ID de l'article associé
- Tags (Tags) : ID tag, nom du tag
- Relations articles-tags : plusieurs tags associés à un article, plusieurs articles correspondant à un même tag
Exemple de base de données relationnelle (SQL)
Dans une base de données SQL, nous stockons les différents types de données dans des tables séparées, reliées par des « clés étrangères ». Cette structure est claire, normalisée et réduit la redondance.
Prenons l'exemple de la « gestion d'articles d'une plateforme de contenu » : au lieu de stocker ensemble « utilisateurs, articles, commentaires, tags », nous les répartissons en 5 tables aux fonctions bien délimitées, chacune avec un « périmètre de responsabilité » clair et une définition de structure stricte (Schema) :
- Table
users(stockage des informations utilisateurs)
| user_id (clé primaire) | username | |
|---|---|---|
| 101 | Alice | alice@example.com |
| 102 | Bob | bob@example.com |
- Table
posts(stockage des articles)
| post_id (clé primaire) | title | content | author_id (clé étrangère) |
|---|---|---|---|
| 1 | 初识SQL | 这是关于SQL数据库的一篇文章... | 101 |
| 2 | NoSQL入门 | NoSQL提供了灵活的数据模型... | 102 |
- Table
comments(stockage des commentaires)
| comment_id (clé primaire) | body | commenter_id (clé étrangère) | post_id (clé étrangère) |
|---|---|---|---|
| 1001 | 写得很棒! | 102 | 1 |
| 1002 | 学习了。 | 101 | 2 |
| 1003 | 有没有更多例子? | 101 | 1 |
- Table
tags(stockage des tags)
| tag_id (clé primaire) | tag_name |
|---|---|
| 51 | 数据库 |
| 52 | 技术 |
| 53 | 入门 |
- Table
post_tags(stockage des relations plusieurs-à-plusieurs entre articles et tags)
| post_id (clé étrangère) | tag_id (clé étrangère) |
|---|---|
| 1 | 51 |
| 1 | 52 |
| 2 | 51 |
| 2 | 52 |
| 2 | 53 |
Pour interroger les « informations complètes de l'article "初识 SQL" (post_id=1) d'Alice (contenu, auteur, commentaires, tags) », il faut exécuter une requête multi-table (JOIN), en reliant les 5 tables via les clés étrangères et en agrégeant les données. La requête SQL est la suivante :
SELECT
p.title,
p.content,
u.username AS author,
c.body AS comment,
t.tag_name AS tag
FROM
posts p
JOIN
users u ON p.author_id = u.user_id
LEFT JOIN
comments c ON p.post_id = c.post_id
LEFT JOIN
post_tags pt ON p.post_id = pt.post_id
LEFT JOIN
tags t ON pt.tag_id = t.tag_id
WHERE
p.post_id = 1;Cette requête traverse 5 tables et agrège toutes les données associées dans un seul résultat. C'est l'avantage central des bases de données relationnelles : grâce à la normalisation et aux opérations de jointure, il est possible d'effectuer toutes sortes de requêtes complexes tout en garantissant la cohérence et une redondance minimale.
Exemple de base de données non relationnelle (NoSQL)
Les bases de données NoSQL (comme MongoDB, Redis) adoptent une philosophie de conception inverse : elles n'insistent pas sur le découpage et la normalisation des données, et regroupent généralement toutes les données associées dans un même agrégat afin de réduire les jointures lors des requêtes et d'améliorer les performances de lecture.
Dans les bases de données NoSQL, les bases de données orientées documents (Document Database) sont parmi les plus courantes, avec MongoDB comme représentant typique. Elles utilisent le « document » comme unité de stockage de base -- un « document » n'est pas un article au sens habituel, mais une structure de données similaire à JSON (MongoDB utilise le format BSON, qui supporte davantage de types de données) : pas besoin de définir un Schema unifié à l'avance, les champs de chaque document peuvent être ajoutés ou supprimés flexiblement, et les types de champs peuvent être librement ajustés, parfaitement adaptés aux scénarios où les formats de données sont très variables.
Dans une base de données orientée documents, un article et toutes ses informations associées (commentaires, tags) sont généralement stockés dans un seul document (au format similaire à JSON, avec des champs librement définis, sans Schema prédéfini). La logique centrale est de « stocker l'information complète d'un scénario métier dans un seul document », évitant la concaténation de multiples sources de données lors des requêtes.
Exemple de document dans la collection posts :
{
"_id": 1,
"title": "初识SQL",
"content": "这是关于SQL数据库的一篇文章...",
"author": {
"user_id": 101,
"username": "Alice",
"email": "alice@example.com"
},
"tags": [
"数据库",
"技术"
],
"comments": [
{
"comment_id": 1001,
"body": "写得很棒!",
"commenter": {
"user_id": 102,
"username": "Bob"
}
},
{
"comment_id": 1003,
"body": "有没有更多例子?",
"commenter": {
"user_id": 101,
"username": "Alice"
}
}
]
}L'avantage de cette conception est très intuitive : pour obtenir « les informations complètes du premier article (auteur, commentaires, tags inclus) », il suffit de requêter ce seul document via _id:1. La base de données retourne toutes les données en une seule lecture, sans avoir à effectuer les 3-4 jointures de tables comme en SQL -- l'efficacité de lecture est considérablement améliorée.
Mais cette approche présente aussi un trade-off (compromis) évident : comme les données sont « stockées par agrégation », une redondance de données est inévitable -- par exemple, le username de l'auteur « Alice » est intégré dans chaque document d'article qu'elle a écrit. Si un jour « Alice » change son nom d'utilisateur en « Alice_New », il faudrait en théorie parcourir tous les documents d'articles contenant ses informations et mettre à jour le champ author.username un par un -- non seulement l'opération est fastidieuse, mais des problèmes de réseau ou de serveur peuvent aussi entraîner l'échec de la mise à jour de certains documents, créant une situation où « le même utilisateur a un nom différent selon les articles ».
En pratique, cependant, cette redondance est souvent « acceptable » : pour les scénarios de type blogs, médias, fiches produits e-commerce où l'on lit beaucoup et écrit peu (les consultations de contenu sont bien plus fréquentes que les modifications de nom d'utilisateur), échanger un peu de redondance contre des « performances de lecture extrêmes » est un choix judicieux. En revanche, pour les scénarios où l'on « écrit beaucoup et lit peu » (comme les modifications fréquentes des informations utilisateurs), il faut pondérer les besoins métier pour déterminer si une base de données orientée documents est pertinente.
Ce qui précède constitue une introduction simple aux différents types de bases de données. Si vous souhaitez en savoir plus sur les types de bases de données spécifiques, vous pouvez consulter les ressources suivantes pour essayer différentes bases de données.
Examples of SQL databases : Db2, MySQL, PostgreSQL, YugabyteDB, CockroachDB, Oracle Database, Azure SQL Database
Examples of NoSQL databases : Redis, CouchDB, MongoDB, Cassandra, Elasticsearch, BigTable, Neo4j, HBase
2. Supabase
Nous venons de présenter plusieurs types de bases de données courantes et leurs scénarios d'utilisation respectifs. Cependant, dans un projet réel, la base de données n'est généralement qu'un module fondamental de l'infrastructure backend : au-delà du stockage et de la recherche de données, il faut aussi résoudre tout un ensemble de problèmes, notamment l'inscription et la connexion des utilisateurs, la vérification des permissions, le téléchargement et le stockage de fichiers, les API publiques, voire les tâches planifiées et les notifications en temps réel. Simplement choisir une bonne base de données ne permet pas à votre application d'« être immédiatement opérationnelle en ligne » -- il reste tout un pan de travail backend fastidieux entre les deux.
Il faut donc prendre en compte un contexte plus large : les services backend. Une application complète est généralement composée d'un « frontend + backend » : le frontend gère l'affichage des pages et les interactions utilisateur, tandis que le backend se charge du stockage des données, de la connexion des utilisateurs, du traitement de la logique métier, etc. Autrefois, les développeurs devaient installer leurs propres serveurs, configurer les bases de données, concevoir et implémenter les API, et gérer manuellement les permissions, les stratégies de sécurité, l'évolutivité et la supervision -- un processus à la fois répétitif et chronophage. Pour résoudre ces tâches répétitives, l'industrie a vu apparaître le BaaS (Backend as a Service) : une plateforme cloud regroupant les fonctionnalités backend courantes -- base de données, authentification des utilisateurs, stockage de fichiers, capacités temps réel -- que les développeurs peuvent appeler directement via SDK/API, sans avoir à construire et maintenir l'infrastructure depuis zéro.
Dans ce contexte, Supabase peut être considéré comme un représentant de nouvelle génération du BaaS : il prend PostgreSQL comme base de données centrale et y intègre un ensemble complet de capacités backend -- Auth, Storage, Realtime, Edge Functions, Vector -- offrant aux développeurs une « plateforme backend tout-en-un centrée sur Postgres ». Abordons maintenant ce sujet en passant de « choisir uniquement une base de données » à « choisir une plateforme complète de développement backend », et voyons concrètement ce que Supabase permet d'éviter et comment il réduit considérablement la distance entre un prototype et un produit utilisable.
2.1 Guide pas à pas
Après avoir bien compris le positionnement global de Supabase, nous allons suivre le parcours de la console Supabase pour détailler les capacités centrales qu'il offre et les responsabilités de chacune. Nous présenterons en détail chaque option de Supabase pour vous aider à prendre en main rapidement ses opérations de base.

Après vous être connecté sur le site officiel de Supabase, cliquez sur « New project » sur la page d'accueil de la console pour lancer la création ;
Saisissez les informations principales requises : Project Name, mot de passe de la base de données, et choisissez comme région celle qui est la plus proche des utilisateurs cibles de votre application.
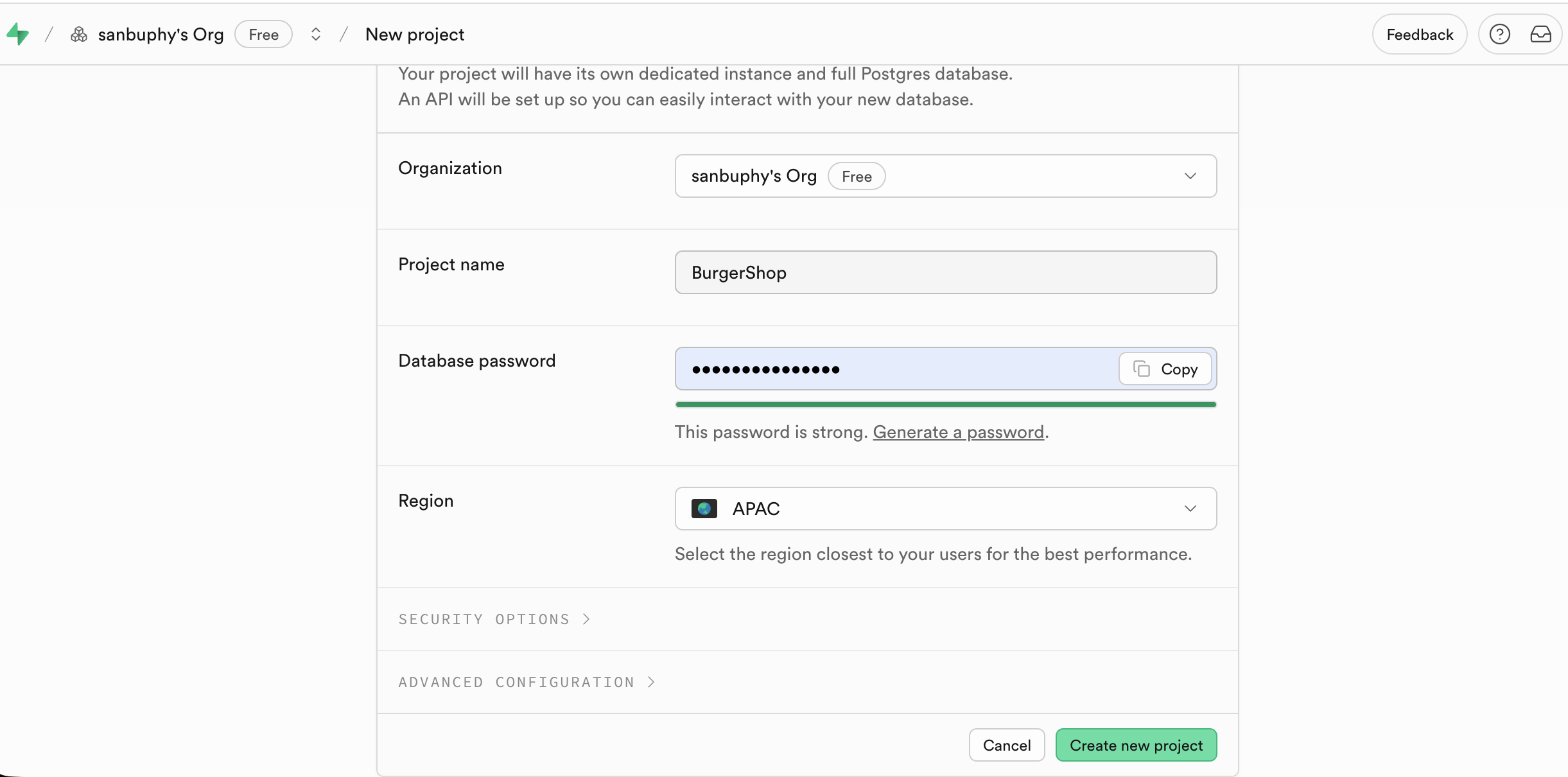
Une fois la création réussie, la barre latérale gauche de la console affichera tous les modules fonctionnels clés (Table Editor, SQL Editor, Database, Authentication, etc.). Les opérations suivantes s'articuleront autour de ces modules.
Éditeur de tables (Table Editor)
Table Editor est l'éditeur visuel de tables de données de Supabase. Il vous permet de visualiser et modifier directement les données de la base de données comme sur Excel, sans écrire de SQL -- il suffit d'interagir à la souris pour modifier le contenu des données.
Un point notable est le Schema. Le Schema peut être compris comme un « conteneur de ressources » au sein de la base de données, utilisé pour organiser en groupes les tables, vues, fonctions, index et autres ressources. Ses deux rôles principaux sont : éviter les conflits de nommage (des tables de même nom peuvent exister dans différents Schémas) et mettre en place une isolation de permissions (par exemple n'autoriser que certains utilisateurs à accéder aux tables d'un Schema donné).
Cliquez sur la liste déroulante Schema en haut de l'éditeur pour basculer entre les différents conteneurs. En développement quotidien, vous n'avez généralement besoin de vous concentrer que sur deux catégories :
public: le conteneur de ressources publiques par défaut. Les tables métier créées par les développeurs (comme « table des articles », « table des commentaires ») y sont stockées ;auth: le conteneur dédié à l'authentification des utilisateurs. Sa tableusersstocke automatiquement les informations de tous les utilisateurs inscrits (ID utilisateur, email, heure de connexion, etc.). Il n'est pas recommandé de modifier manuellement les tables par défaut de ce Schema pour ne pas affecter les fonctionnalités d'authentification ;

Éditeur SQL (SQL Editor)
Le SQL Editor est l'exécuteur d'instructions SQL de Supabase, vous permettant de manipuler directement la base de données par du code. Vous pouvez demander à un grand modèle de générer des instructions SQL, les saisir à droite puis cliquer sur RUN pour créer ou modifier des tables, et visualiser directement les données filtrées dans la section Results.
Après avoir exécuté RUN, vous retrouverez les nouvelles tables créées dans le Schema public du Table Editor ; les requêtes exécutées sont sauvegardées dans la section PRIVATE à gauche, et vous pouvez même cliquer sur l'icône cœur sous la requête pour l'ajouter en favoris.
Centre de gestion de la base de données (Database)
Database est le centre de gestion de la base de données de Supabase, permettant de visualiser et gérer toutes les tables de données, et de comprendre les relations entre les tables grâce à des lignes de connexion (contraintes de clé étrangère, représentant les relations de référence entre les données).
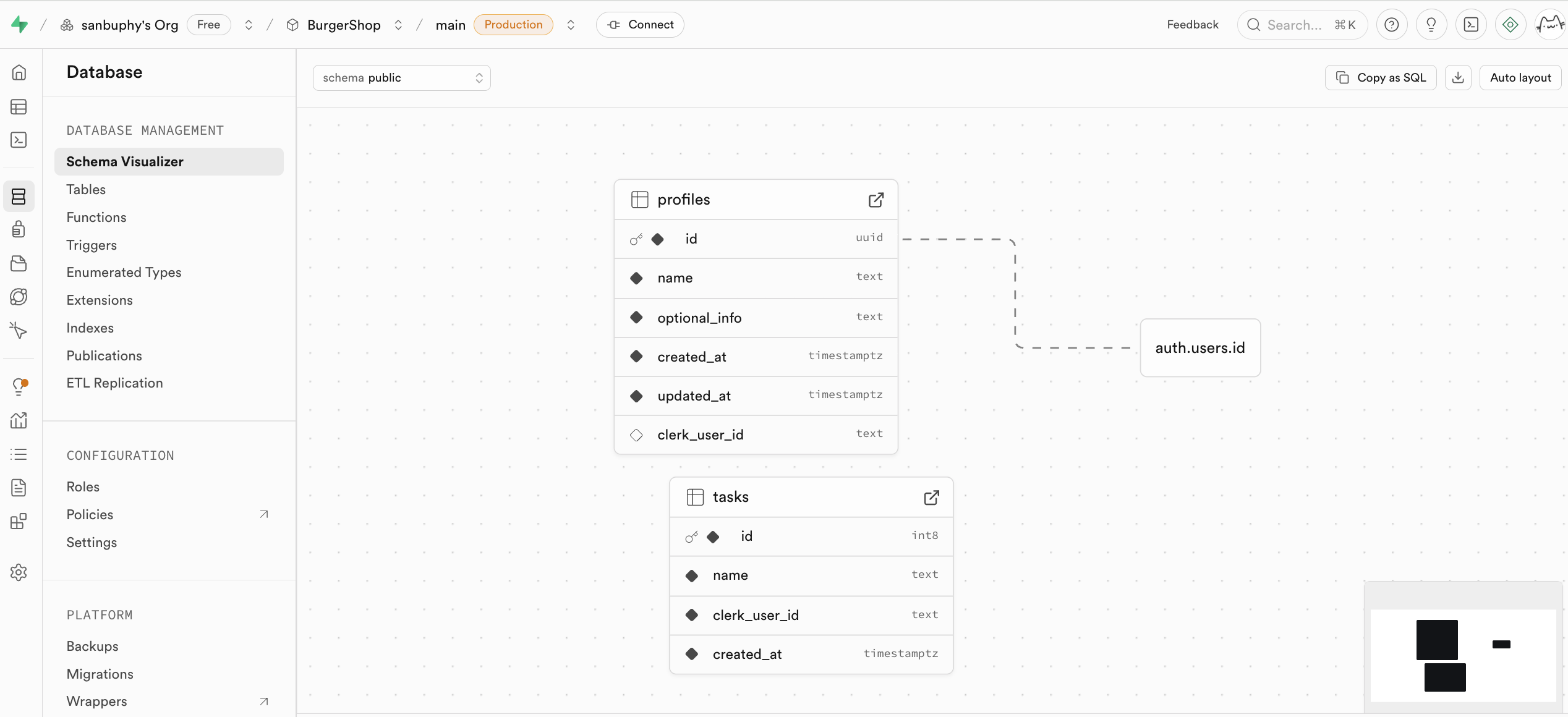
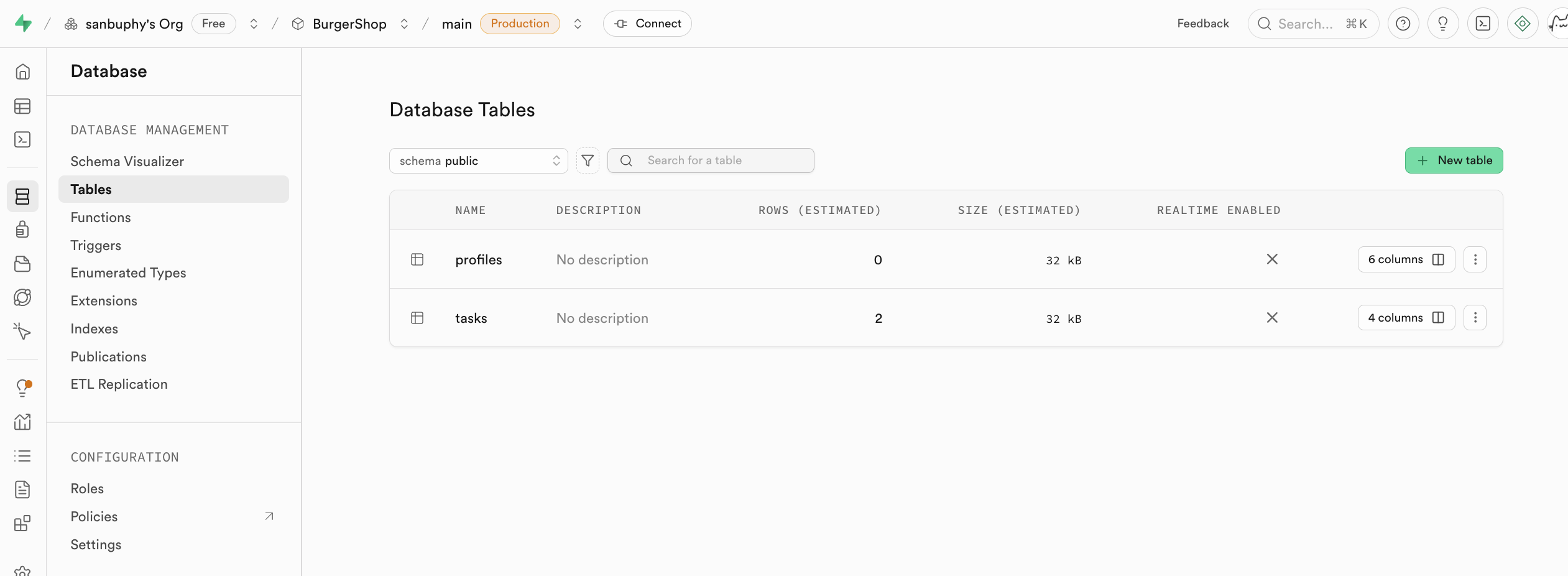
Si vous souhaitez créer manuellement une nouvelle table, vous pouvez le faire directement dans la section tables. Nous détaillerons cette opération dans les tutoriels suivants.
Authentification (Authentication)
Authentication gère l'inscription, la connexion et les permissions des utilisateurs. Les données du système de gestion des utilisateurs par défaut y sont stockées. Il offre des fonctionnalités prêtes à l'emploi : inscription, connexion, réinitialisation du mot de passe, vérification par email, et prend en charge la connexion OAuth tiers (WeChat, GitHub, Google, etc.). Toutes les données utilisateurs sont automatiquement synchronisées dans la table auth.users de la base de données.
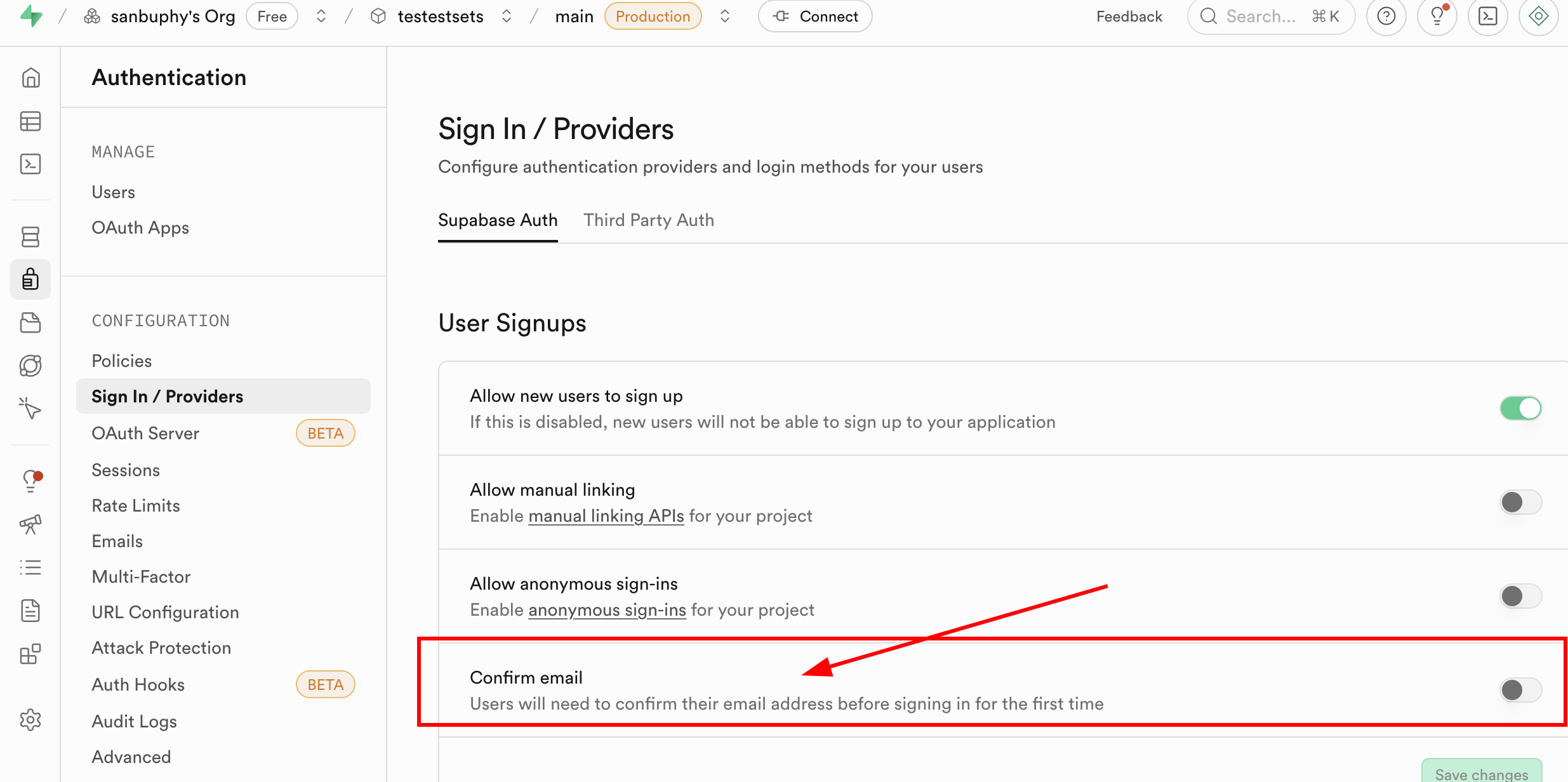
Vous trouverez dans l'option Provider les différentes entrées de connexion prises en charge par Supabase. Par défaut, l'email est utilisé ; si vous souhaitez utiliser GitHub ou Google pour la connexion, une configuration supplémentaire est nécessaire, que nous détaillerons dans les cours suivants.
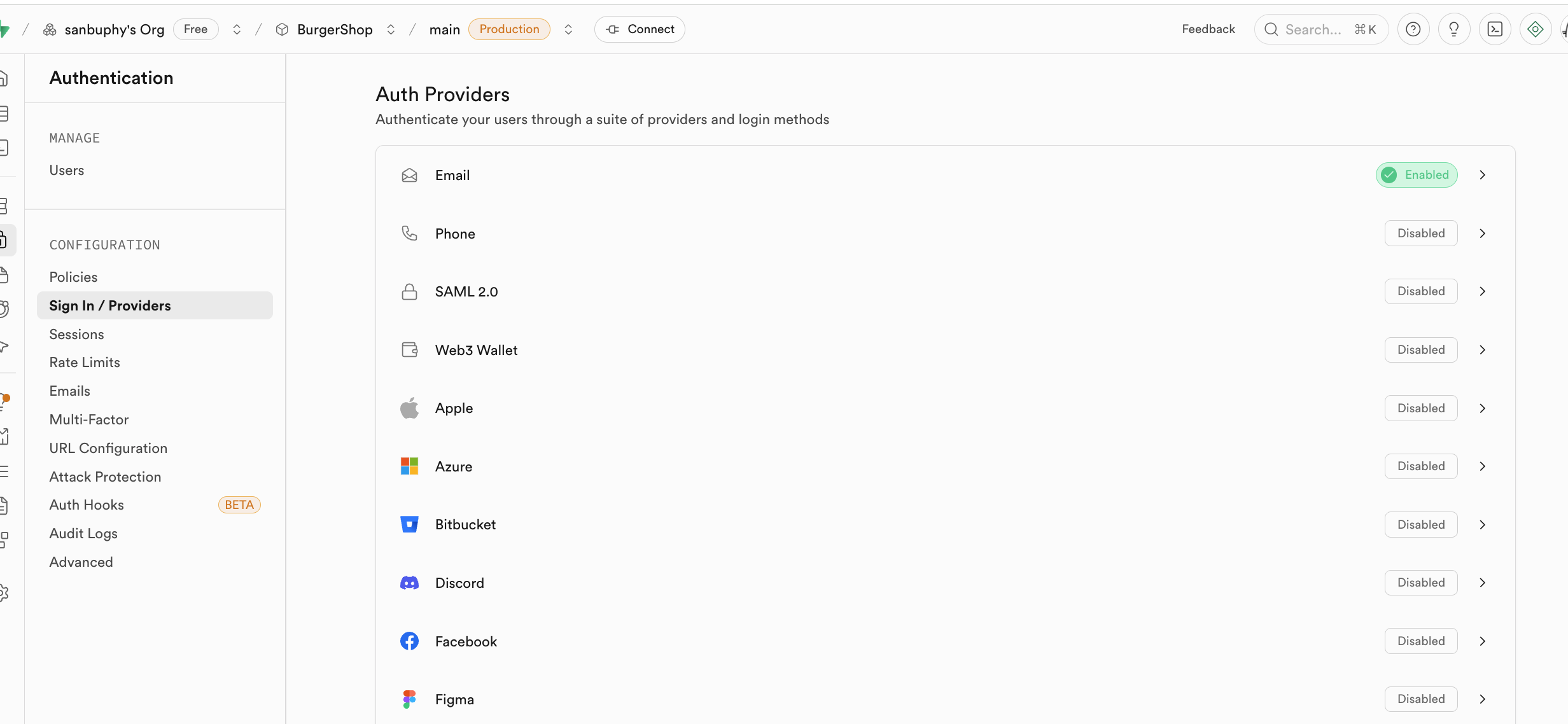
La section Sign In / Providers inclut également le contrôle du comportement d'inscription par email. Si vous ne souhaitez pas que chaque inscription par email nécessite une confirmation préalable de l'utilisateur, vous pouvez désactiver l'obligation de confirmer l'email.
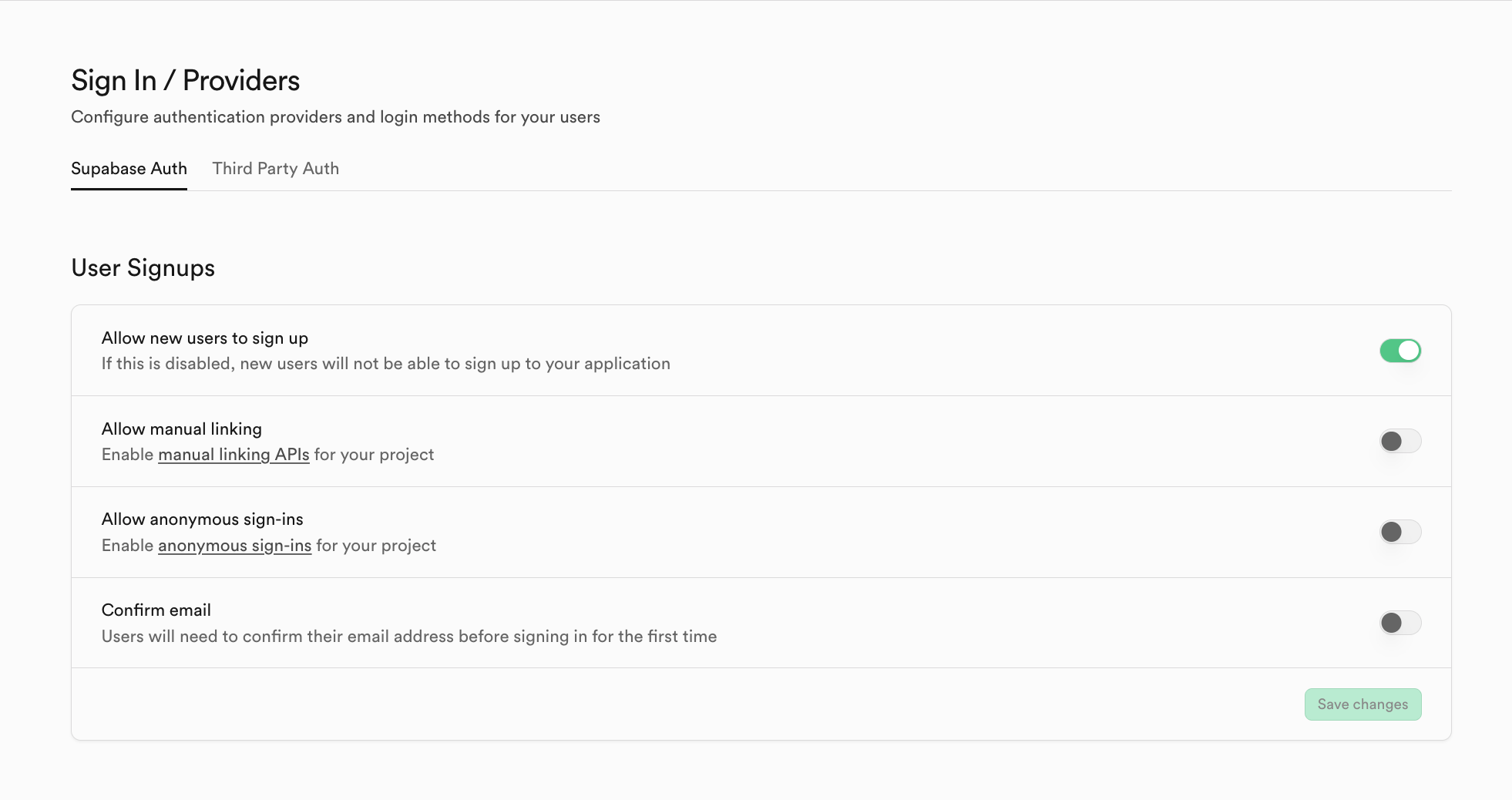
Si vous souhaitez utiliser un autre fournisseur de services d'authentification que Supabase, vous pouvez cliquer sur Third Party Auth -- par exemple, utiliser Clerk comme fournisseur tiers.
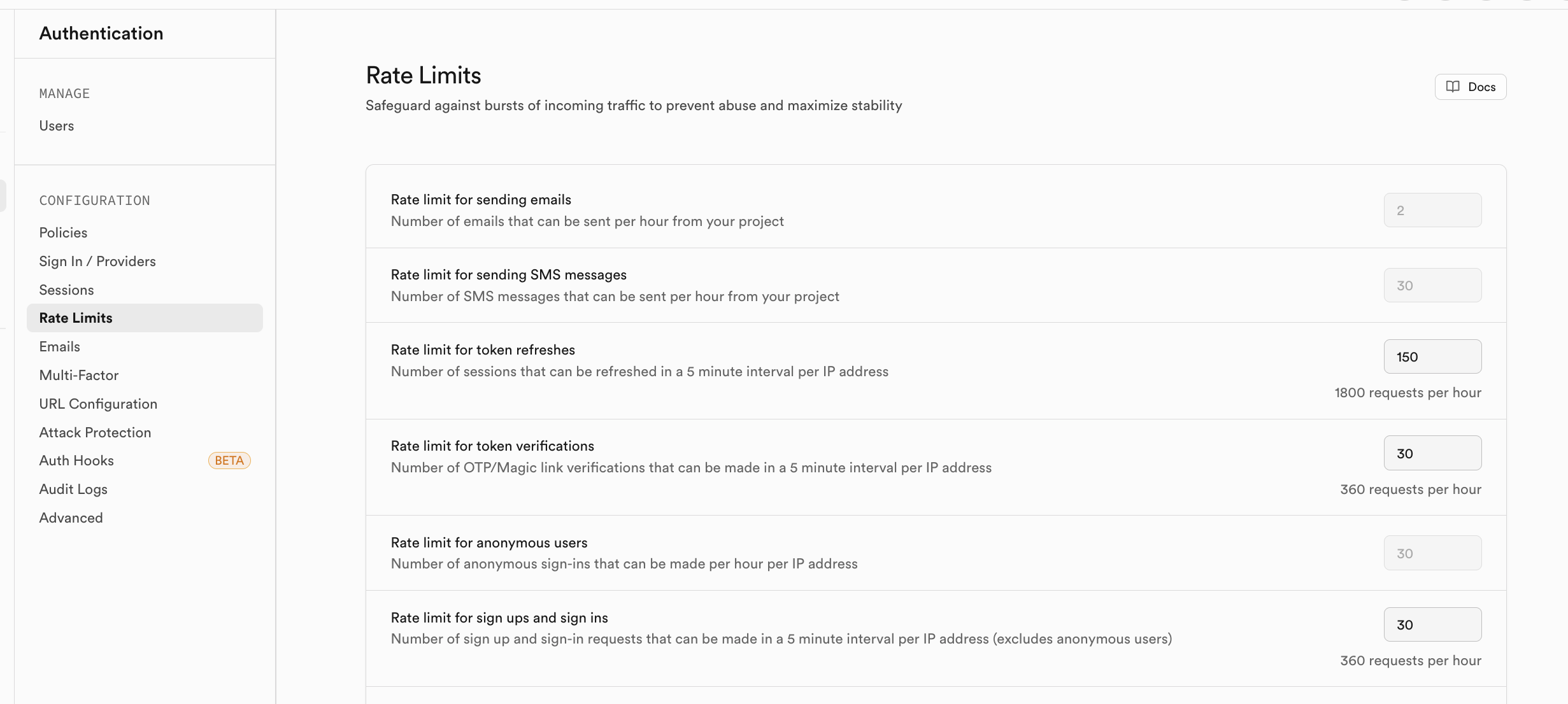
Si vous craignez un afflux d'utilisateurs inscrits à court terme, vous pouvez activer les stratégies de limitation de débit dans Rate Limits :
Stockage (Storage)
Storage est le système de stockage de Supabase, compatible avec le concept S3 d'Amazon Cloud. Il permet de stocker tout type de fichiers (images, vidéos, documents, audio, etc.) et offre une gestion des permissions d'accès (public ou privé) ainsi que des liens de téléchargement (permanents ou temporaires). Vous pouvez facilement gérer les fichiers des utilisateurs dans votre application et intégrer le système d'authentification de Supabase pour un contrôle d'accès fin.
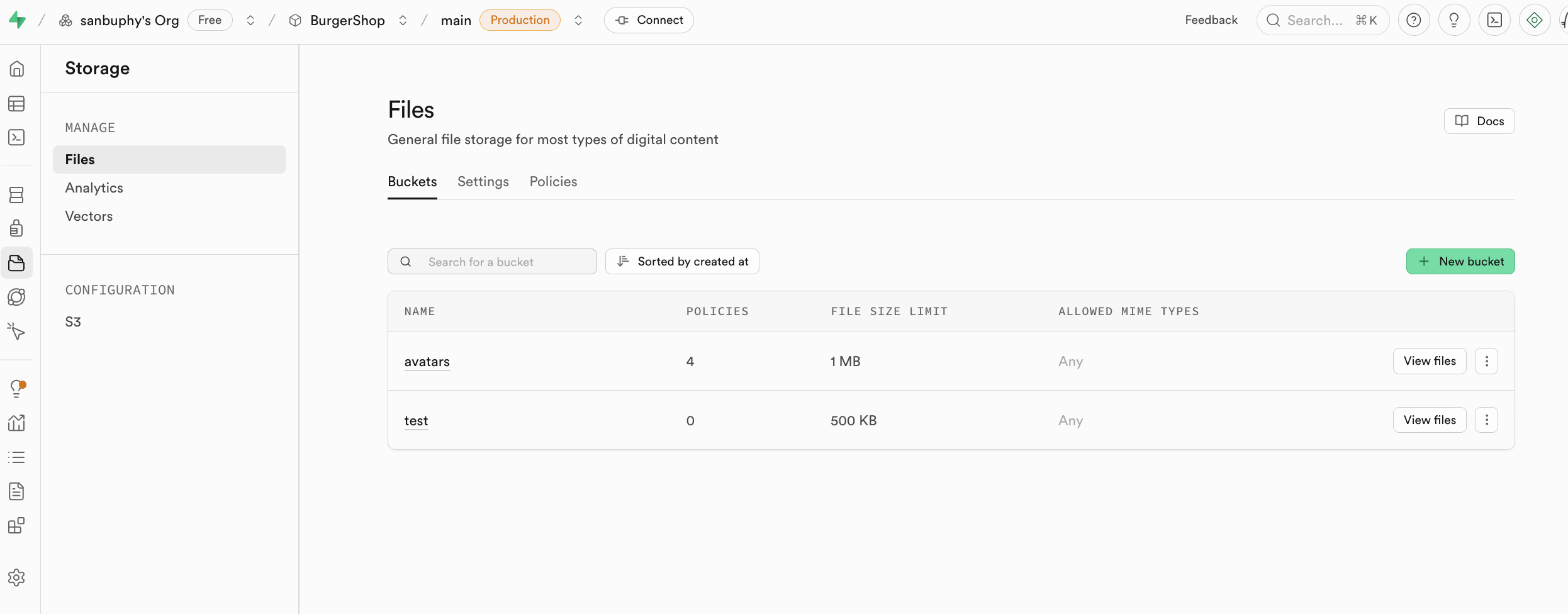
Nous présenterons l'utilisation concrète de Storage dans le projet avancé de ce cours.
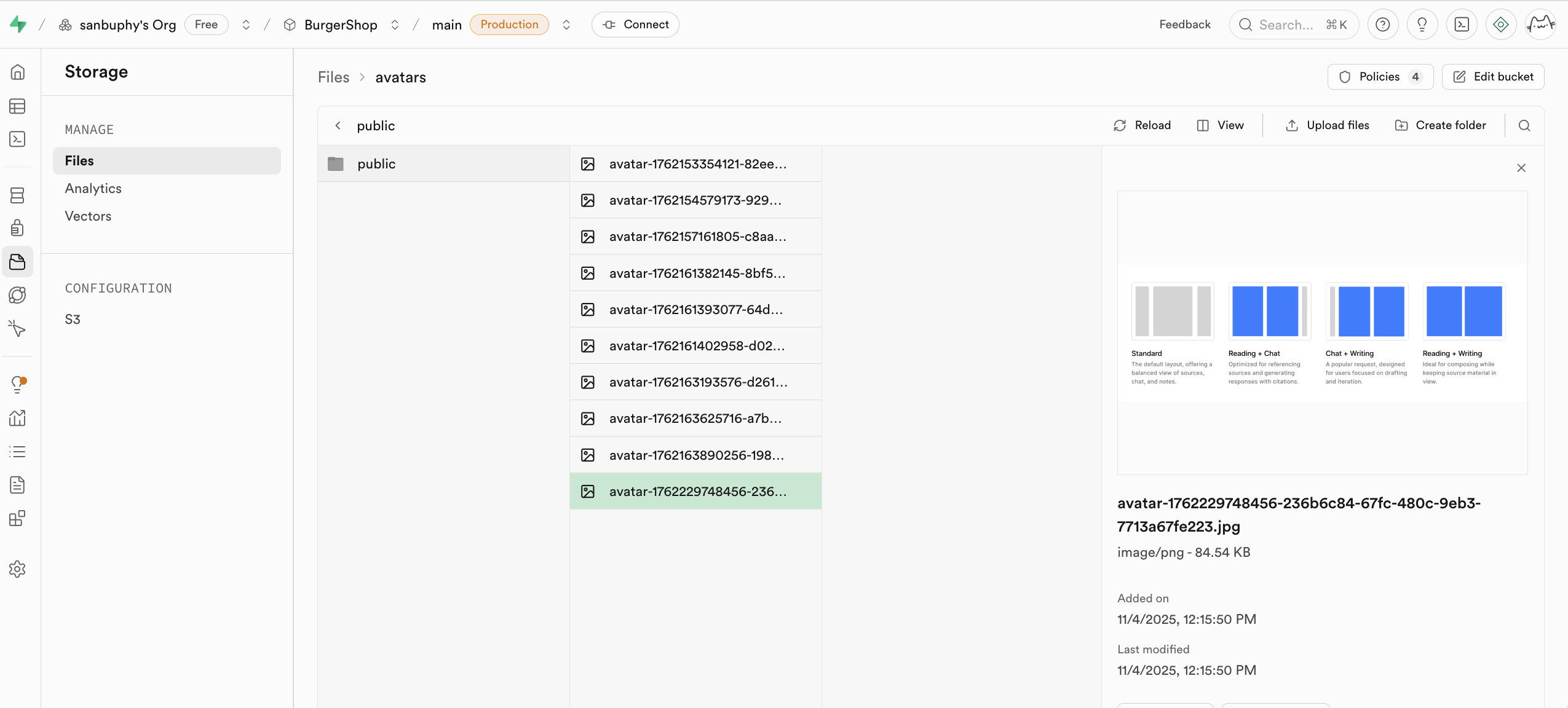
Si vous souhaitez utiliser les protocoles S3 pour vos opérations, vous pouvez utiliser directement la configuration correspondante :
Amazon Cloud (Amazon Web Services, ou AWS) est la plateforme de cloud computing d'Amazon (comme une immense salle serveur en ligne où vous pouvez louer à la demande des ressources de calcul et de stockage). S3 (Simple Storage Service) est le service d'AWS dédié au stockage de fichiers (similaire à un disque dur en ligne illimité, pour stocker images, vidéos, sauvegardes et autres fichiers). C'est aujourd'hui le service de stockage d'objets le plus populaire, devenu un standard de facto dans l'industrie.
Pourquoi proposer une API compatible S3 ? : S3 existe depuis près de 20 ans. Il existe de nombreux outils, SDK et documentations prêts à l'emploi. La compatibilité S3 signifie que vous pouvez utiliser directement ces ressources sans avoir à tout recréer, ce qui accélère la mise en production.
Edge Functions
Si vous ne souhaitez pas déployer de backend mais avez besoin d'opérations sur la base de données et de fonctions, vous pouvez utiliser les Edge Functions pour bénéficier de capacités backend sans serveur. Ce sont des fonctions côté serveur distribuées globalement fournies par Supabase. En termes simples, elles vous permettent d'écrire et déployer du code backend dans le cloud sans avoir à acheter ni gérer vos propres serveurs. Ces fonctions sont déployées sur les nœuds de périphérie du réseau mondial et s'exécutent automatiquement au plus près de vos utilisateurs, réduisant ainsi considérablement la latence réseau pour une vitesse de réponse optimale. Vous pouvez créer, éditer et déployer directement depuis le tableau de bord Supabase -- le flux de développement est très pratique.
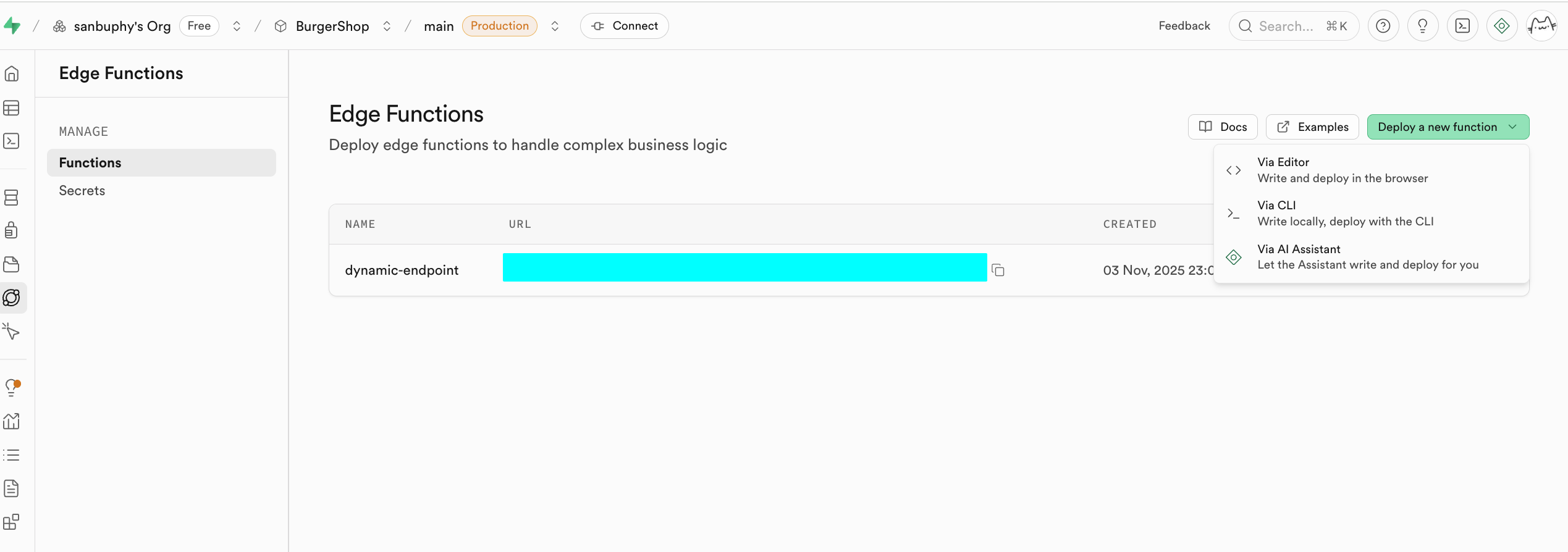
Un usage clé des Edge Functions est de servir d'intercouche sécurisée pour protéger vos informations sensibles et vos clés d'authentification. Appeler directement des services tiers (comme OpenAI, Stripe) depuis le code frontend expose votre clé API, avec tous les risques de sécurité que cela implique. Grâce aux Edge Functions, votre application frontend ne communique qu'avec votre fonction Supabase, et tous les secrets sont conservés uniquement dans Supabase.
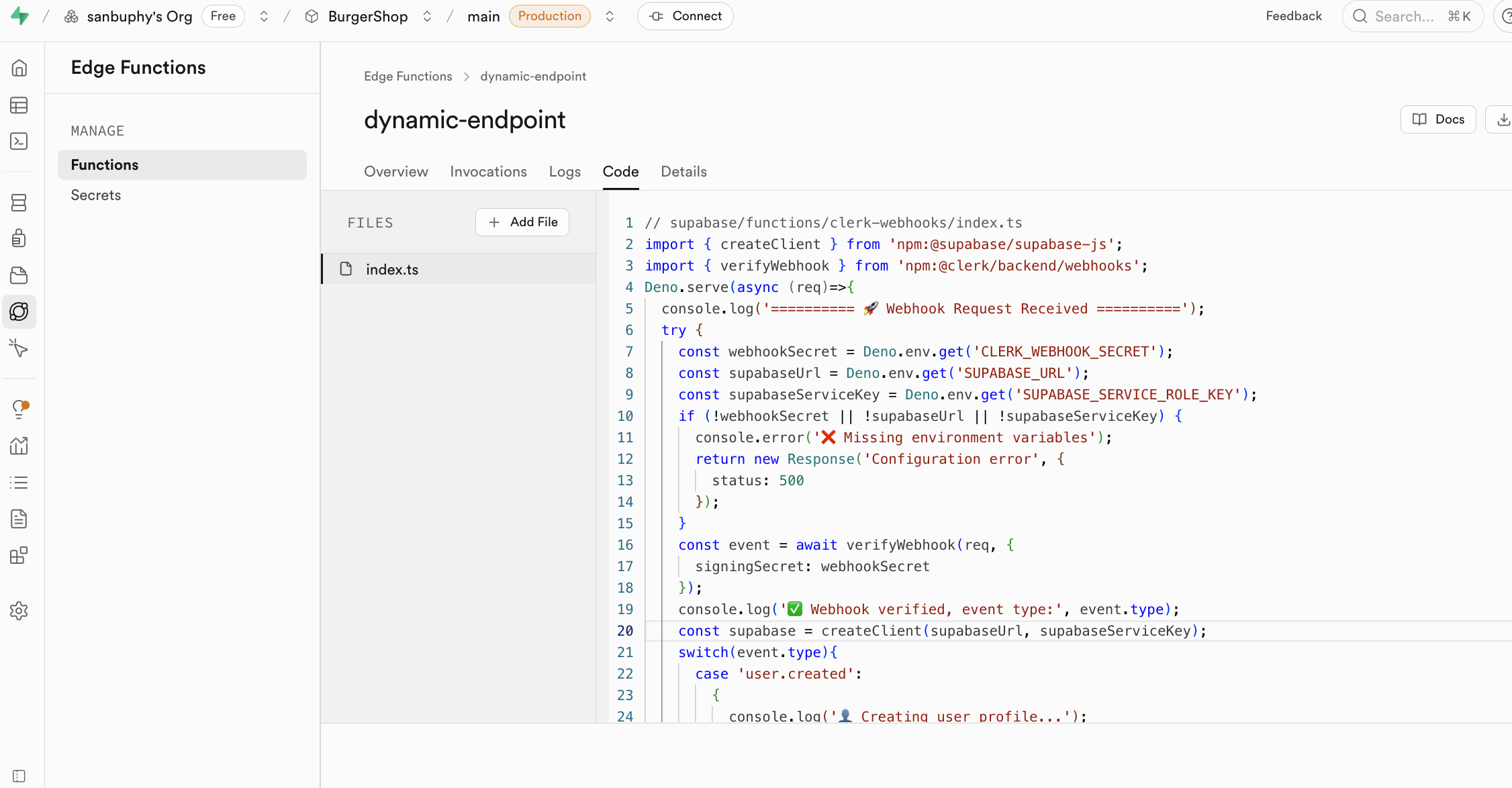
Les Edge Functions utilisent les clés exposées dans les secrets comme variables d'environnement, chargées via Deno.env.get, pour réaliser les appels aux services tiers. Ainsi, les clés sensibles ne sont jamais exposées côté client (votre navigateur), éliminant définitivement le risque de vol.
Lors d'une requête à une Edge Function Supabase, la clé Supabase correspondante doit être incluse dans l'en-tête de la requête. Voici un exemple minimal :
// Configuration principale (remplacez par vos informations réelles)
const projectId = "Votre ID de projet Supabase";
const functionName = "Nom de l'Edge Function cible";
const supabaseKey = "Clé anon_key Supabase";
// Appel de la fonction
async function callEdgeFunction() {
const url = `https://${projectId}.supabase.co/functions/v1/${functionName}`;
try {
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
"Authorization": `Bearer ${supabaseKey}` // Clé : authentification via la clé
},
body: JSON.stringify({ order_id: "123", action: "refund" }) // Données de requête personnalisées
});
const result = await response.json();
console.log("Appel réussi :", result);
} catch (error) {
console.error("Échec de l'appel :", error.message);
}
}
// Exécuter l'appel
callEdgeFunction();En outre, les Edge Functions s'intègrent parfaitement au système d'authentification des utilisateurs de Supabase. Lorsqu'un utilisateur connecté appelle une fonction, ses informations d'identité sont transmises à la fonction. Vous pouvez ainsi identifier facilement l'utilisateur courant dans la fonction et appliquer des contrôles de permissions en fonction de son identité. Plus important encore, lors des opérations sur la base de données, les fonctions respectent automatiquement les politiques de sécurité au niveau des lignes (Row Level Security) que vous avez définies, garantissant que les utilisateurs ne peuvent accéder et modifier que les données qu'ils sont autorisés à manipuler -- simplifiant la création d'applications multi-utilisateurs sécurisées.
Les cas d'usage des Edge Functions sont très variés et couvrent toutes sortes de tâches backend. Elles sont idéales pour écouter les événements Webhook de services tiers (paiement réussi, commit de code, etc.) et exécuter automatiquement la logique de traitement correspondante. Vous pouvez aussi les utiliser pour envoyer des notifications par email, générer des rapports PDF, créer des interfaces API personnalisées encapsulant une logique métier complexe, ou exécuter toute tâche de calcul que vous souhaitez réaliser côté serveur -- étendant considérablement les capacités de votre application.
Prenons un exemple concret : l'outil d'authentification Clerk. Clerk ne gère que les opérations liées à l'authentification (connexion, inscription, mise à jour des informations), sans gérer directement votre base de données métier. Pour synchroniser ces informations d'authentification avec votre base de données métier, il faut passer par des événements Webhook qui déclenchent des Edge Functions. Celles-ci écoutent les signaux Webhook de Clerk et exécutent automatiquement la logique de synchronisation, alignant en temps réel les informations utilisateur dans la base Supabase avec l'état de connexion Clerk -- le tout sans déployer un backend indépendant.
Moteur de synchronisation de données en temps réel (Realtime)
Realtime est le moteur de synchronisation de données en temps réel de Supabase, qui permet à votre application de recevoir instantanément les notifications de modifications de la base de données sans avoir à interroger l'API de manière répétée. Lorsqu'une opération INSERT, UPDATE ou DELETE est effectuée sur les données, Realtime pousse ces modifications en temps réel à tous les clients connectés via WebSocket. C'est essentiel pour les applications nécessitant des interactions en temps réel.
Realtime comprend principalement trois fonctionnalités clés, couvrant la plupart des scénarios temps réel :
- Postgres Changes : écoute directement les modifications des tables de la base de données. Vous pouvez vous abonner avec précision à des tables spécifiques, à des événements spécifiques (insertion, suppression, modification), voire filtrer les notifications selon des critères, le tout parfaitement intégré aux politiques de sécurité au niveau des lignes (Row Level Security) pour garantir que les utilisateurs ne reçoivent que les modifications auxquelles ils ont accès.
- Broadcast : permet aux clients d'envoyer des messages temporaires à faible latence via des canaux (Channel). Idéal pour les salons de discussion, le suivi de curseurs en temps réel, la synchronisation d'état dans les jeux en ligne, etc.
- Presence : utilisé pour suivre et synchroniser l'état des utilisateurs en ligne. Vous pouvez facilement implémenter des fonctionnalités comme « qui est en ligne » ou « X personnes consultent actuellement cette page », parfaitement adapté aux applications collaboratives.
Nous détaillerons cette partie dans les projets avancés.
Paramètres du projet (Project Settings)
Project Settings est la section de configuration avancée de votre projet Supabase, où vous pouvez gérer finement les ressources de calcul et configurer les paramètres basiques des différentes fonctionnalités.
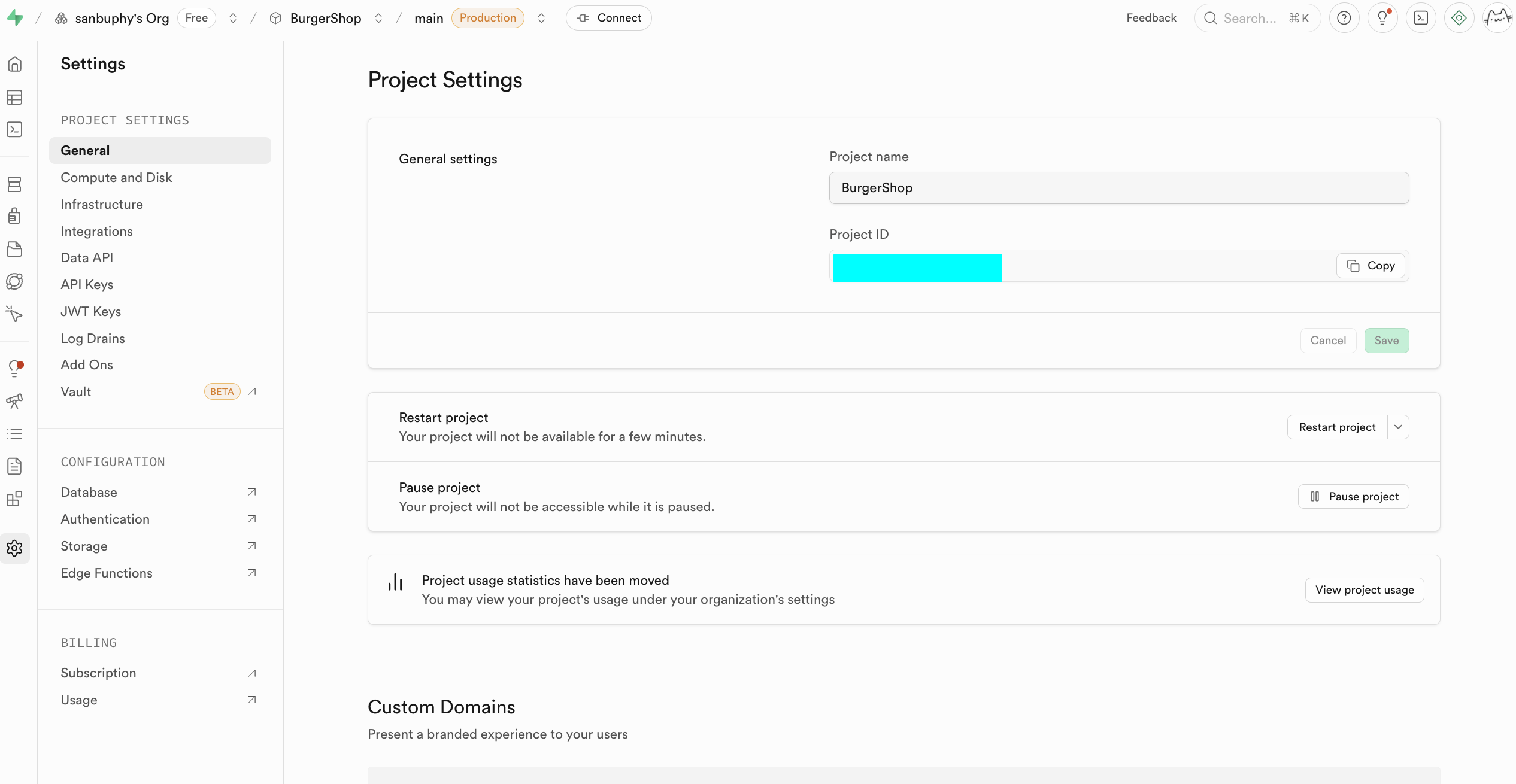
Au stade débutant, concentrons-nous sur deux sections clés. La première est Data API, où vous obtenez le « Supabase URL » clé -- un point de terminaison RESTful au format https://xxx.supabase.co, qui est l'« adresse d'entrée » pour toutes les opérations de création, lecture, mise à jour et suppression de données. Le frontend ou le serveur doit utiliser cette URL pour initialiser le client Supabase et établir la connexion à la base de données.
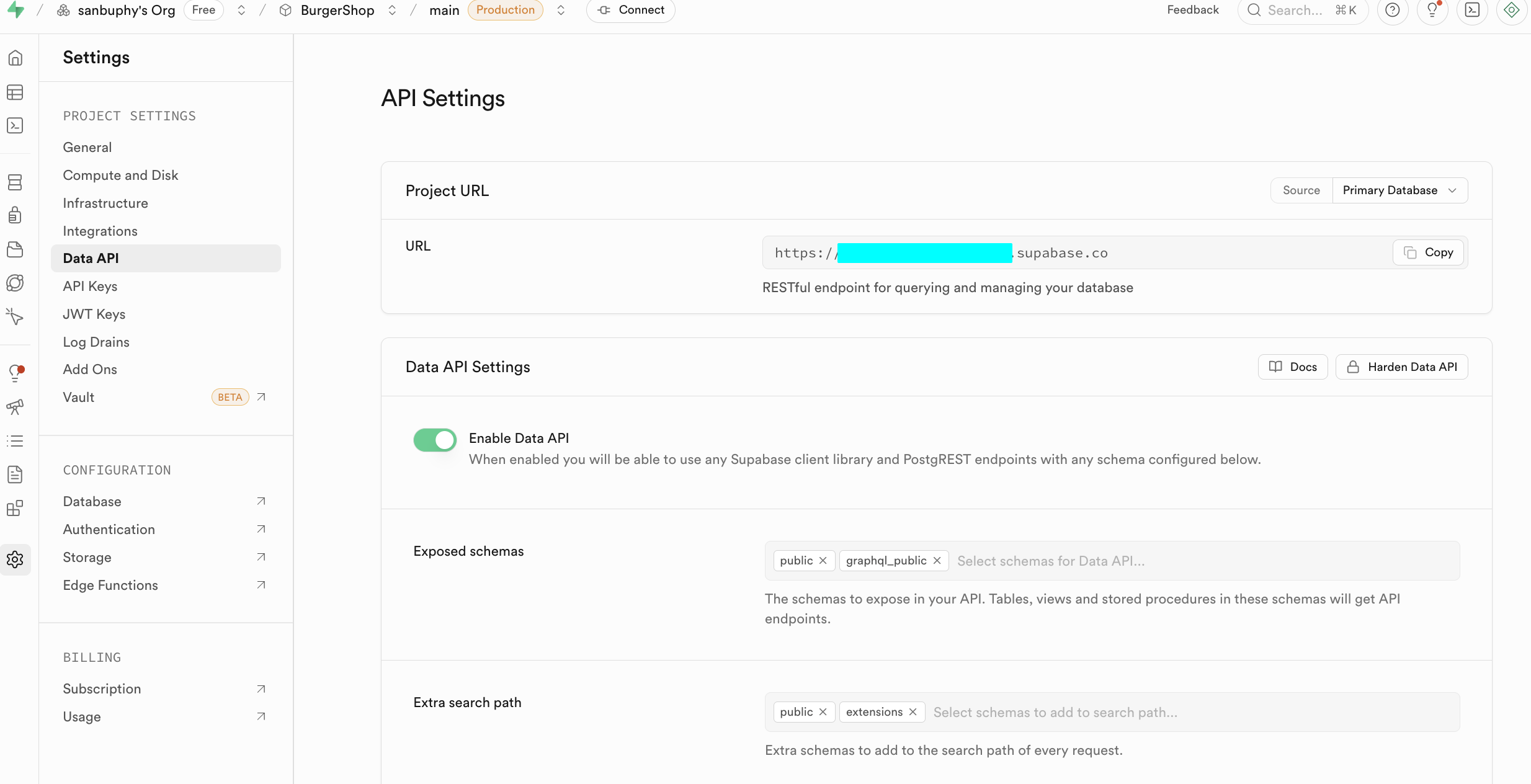
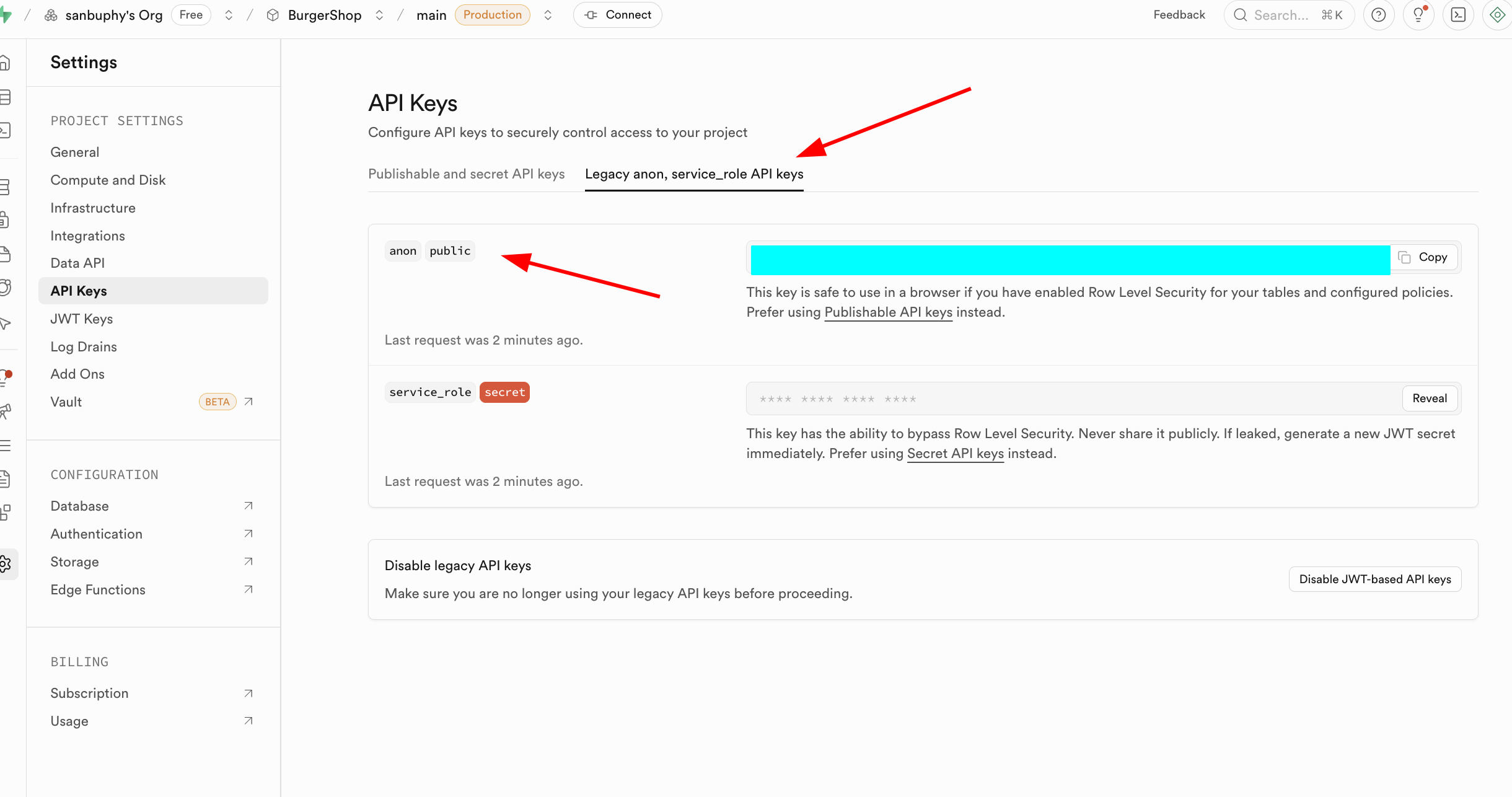
L'autre point important est API Keys. Sélectionnez l'onglet « Legacy anon, service_role API keys ». La clé anon public est un identifiant essentiel pour les scénarios frontend, dont les permissions sont strictement limitées par les politiques RLS, n'autorisant l'accès qu'aux données que l'utilisateur est autorisé à consulter. La clé service_role est une « clé de haute permissions côté serveur », capable de contourner la sécurité au niveau des lignes pour exécuter des opérations de données en lot ou des configurations système. Elle ne doit jamais être partagée publiquement ; en cas de fuite, générez immédiatement une nouvelle clé et mettez à jour la configuration côté serveur.
Les autres paramètres n'ont pas besoin d'être approfondis à ce stade. Vous pourrez les explorer au fur et à mesure de vos besoins avancés.
2.1 Créer votre première table de données SQL
Voici pour la présentation de l'interface Supabase. Passons maintenant aux opérations sur la base de données centrale de Supabase.
Pour créer une table de données dans Supabase, il existe principalement deux méthodes courantes, au choix selon vos besoins :
- (Recommandé) Utiliser un grand modèle de langage pour générer des instructions SQL adaptées à Supabase, puis les coller et exécuter directement dans le SQL Editor (l'exécuteur SQL présenté précédemment) -- rapide et efficace. Nous détaillerons ce processus dans la section suivante.
- Créer via des opérations visuelles : dans la barre latérale de gauche, trouvez le module Database, cliquez dessus, sélectionnez Tables dans la barre latérale, puis cliquez sur le bouton New table à droite pour créer une table via l'interface graphique.
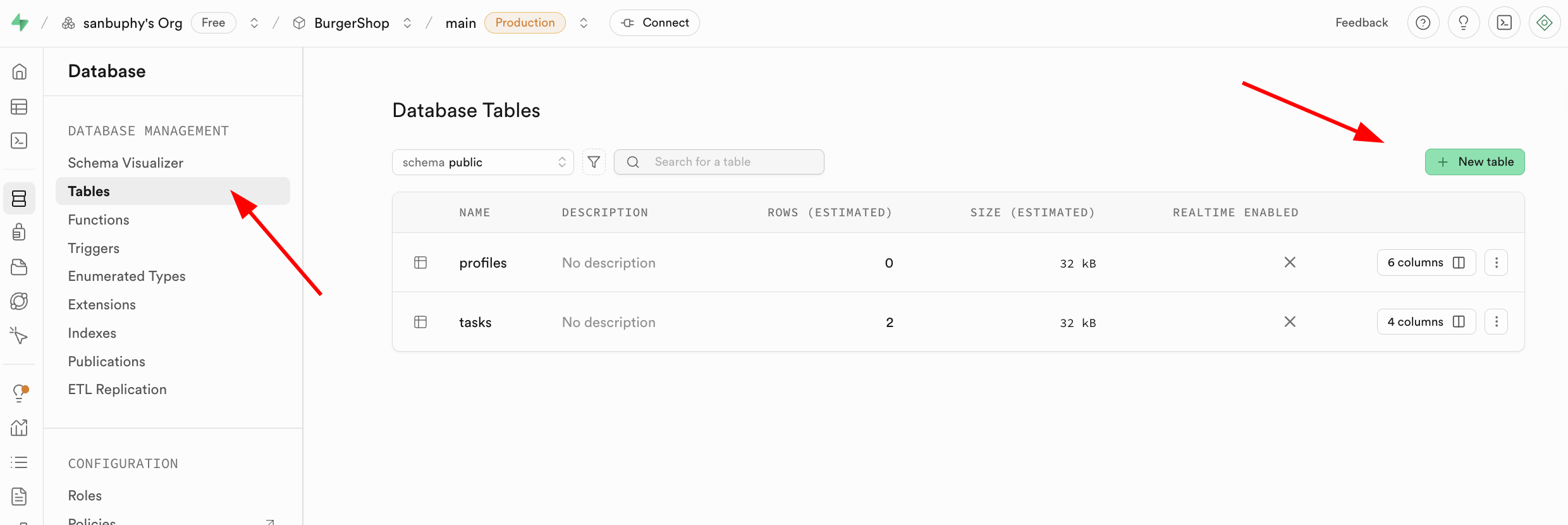
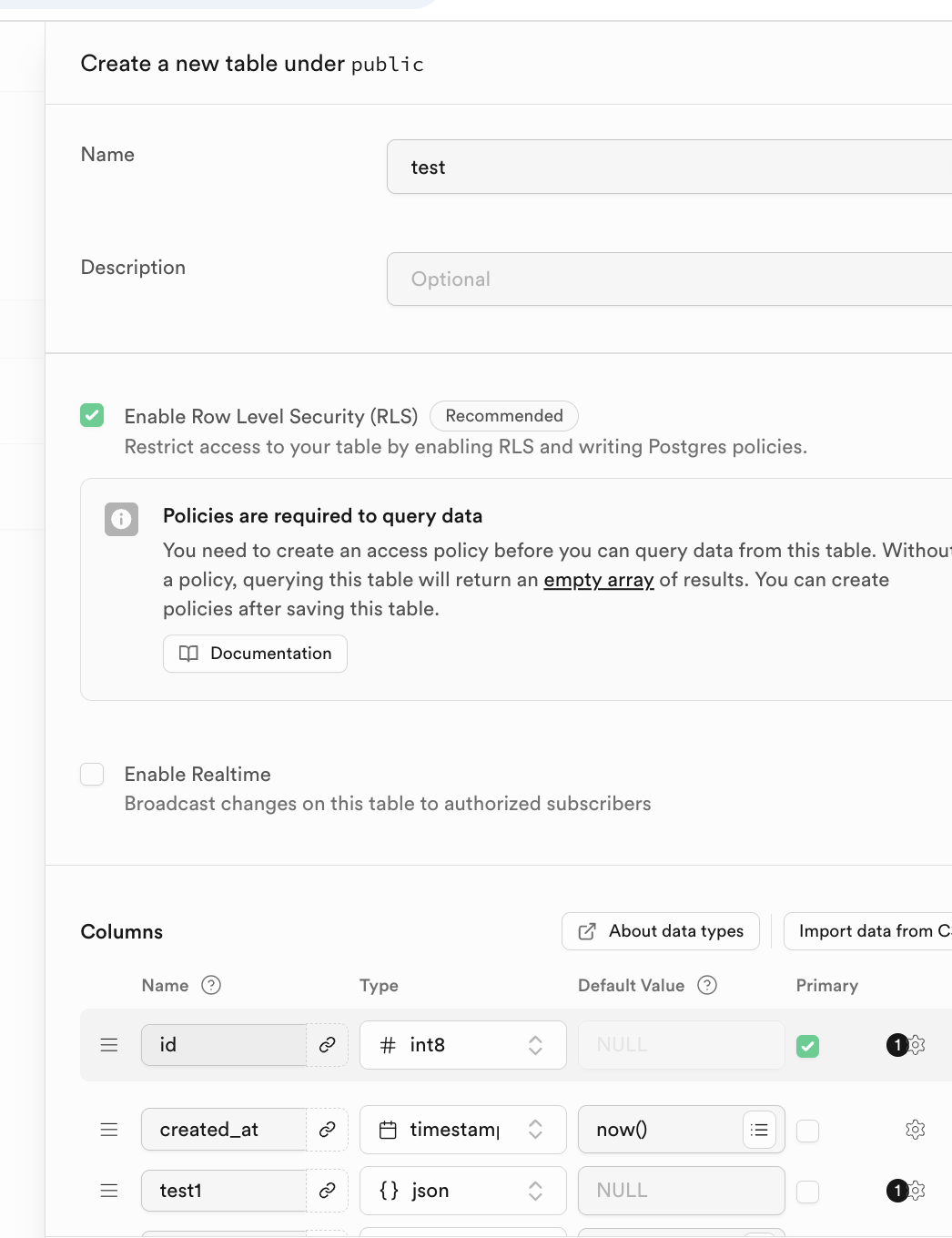
Il est à noter que le nom de la table et les types de données peuvent être spécifiés dans la section Columns située en dessous.
Pour les bases de données relationnelles, un aspect important est les relations entre les tables. Vous trouverez ci-dessous la section Foreign keys, où vous pouvez créer les relations correspondantes :
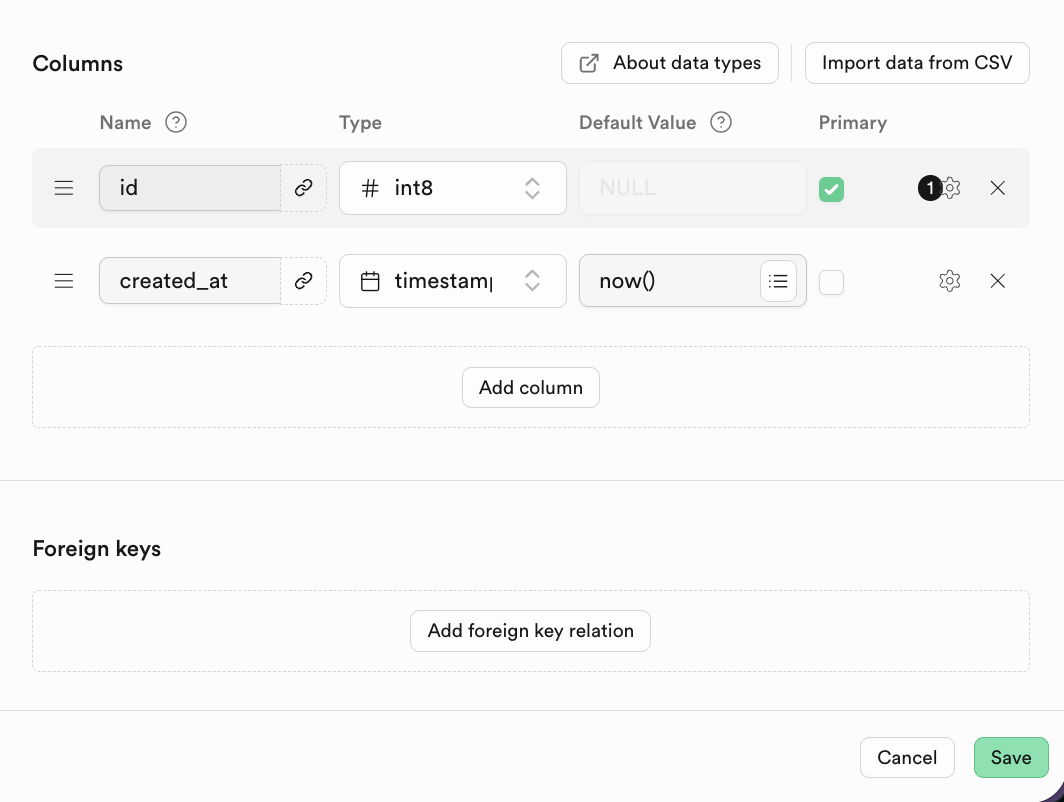
Un Foreign key exprime la relation d'association entre les tables : un ou plusieurs champs de la table actuelle (table enfant) dont les valeurs référencent la clé primaire d'une autre table (table parent).
Par exemple, lors de la création d'une table étudiants, nous pouvons définir la clé étrangère ainsi : (la colonne Numéro de classe est une clé étrangère qui référence la colonne Numéro de classe de la table classes.)
CREATE TABLE 学生表 (
学生学号 INT PRIMARY KEY,
学生姓名 VARCHAR(50),
所属班级编号 INT,
FOREIGN KEY (所属班级编号) REFERENCES 班级表(班级编号)
);Pour être plus concret, observons visuellement la structure des tables correspondantes :
Table des classes : Cette table enregistre les informations de toutes les classes, chacune ayant un numéro de classe unique. Le numéro de classe est la clé primaire (Primary Key) de cette table, l'identifiant unique de chaque classe.
| 班级编号 | 班级名称 |
|---|---|
| 101 | 一年级一班 |
| 102 | 一年级二班 |
Table des étudiants : Cette table enregistre les informations de tous les étudiants. Chaque étudiant appartient à une classe spécifique, n'est-ce pas ? Comment savoir quel étudiant est dans quelle classe ?
Nous pouvons ajouter une colonne dans la table des étudiants, appelée Numéro de classe.
| 学生学号 | 学生姓名 | 所属班级编号 |
|---|---|---|
| 2024001 | 张三 | 101 |
| 2024002 | 李四 | 102 |
| 2024003 | 王五 | 101 |
Dans cet exemple, la colonne Numéro de classe de la table des étudiants est la clé étrangère (Foreign Key).
Dans Supabase, après avoir cliqué sur « Add Foreign Key », vous pouvez directement sélectionner la table et la colonne associées.
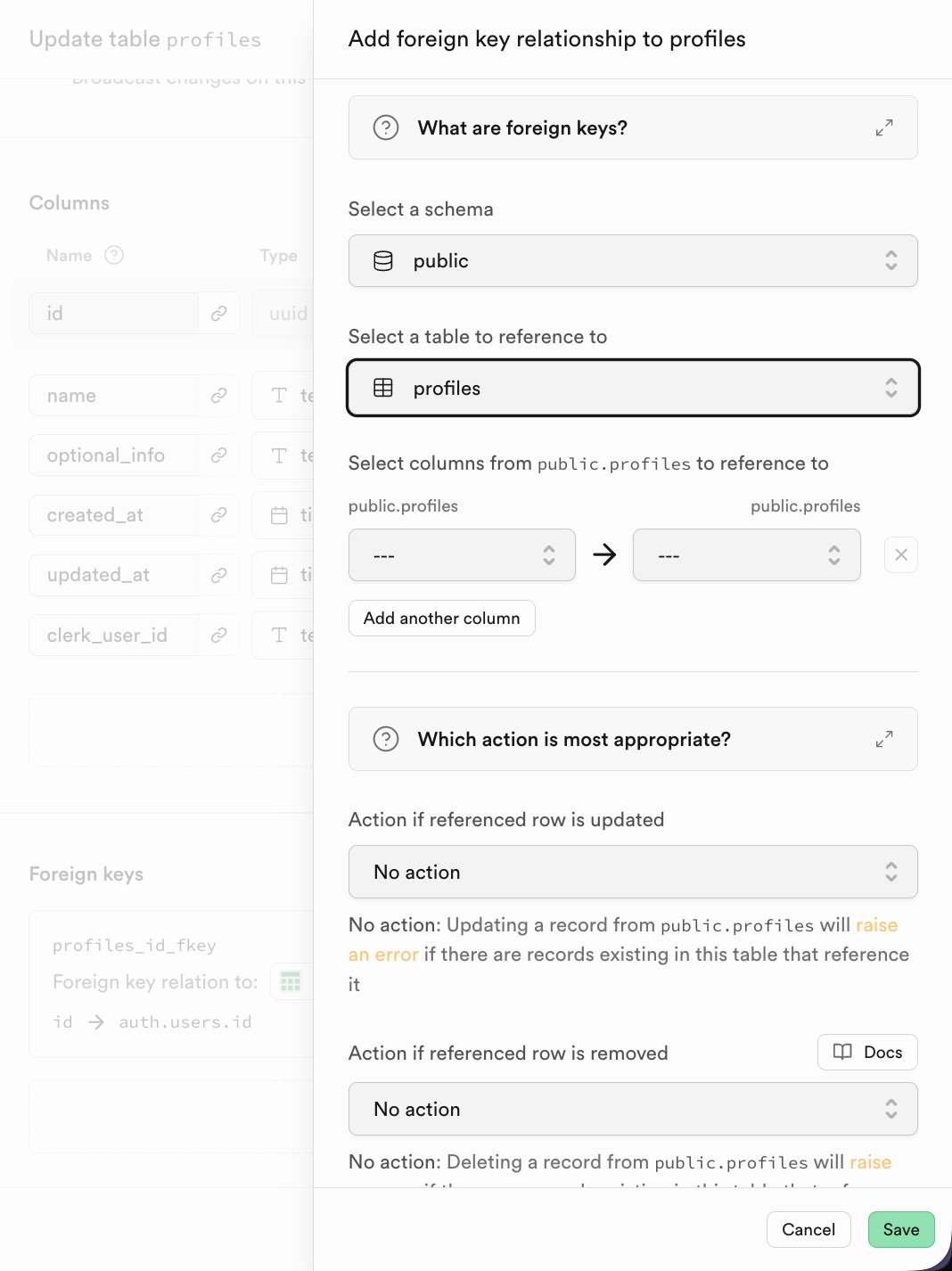
2.3 Présentation du SQL Editor et opérations de base sur la base de données
Nous allons maintenant exécuter pas à pas une série de scripts SQL pour nous familiariser avec les opérations courantes de CRUD (création, lecture, mise à jour, suppression) en SQL. Vous pouvez copier le code de chaque étape dans le SQL Editor, l'exécuter et observer les résultats.
Vous trouverez tous les fichiers SQL de test dans ce répertoire :
https://github.com/THU-SIGS-AIID/Project5-Supabase-Demos/tree/main/apps/sql-examples
2.3.1 CREATE -- Créer la structure d'une table
L'instruction CREATE TABLE sert à définir le schéma (Schema) d'une nouvelle table, incluant ses colonnes (Columns), les types de données correspondants (Data Types) et les éventuelles contraintes (Constraints). En termes simples, cela crée une table de données.
-- Step 1: Create the 'orders' table
-- This file is fully independent and creates a sample table for later steps.
CREATE TABLE IF NOT EXISTS orders (
id serial PRIMARY KEY,
user_id int NOT NULL, -- User ID
status text NOT NULL, -- Order status (e.g. paid, pending)
amount numeric(10, 2) NOT NULL, -- Order total amount
details jsonb, -- Item and extra details as JSON
placed_at timestamptz DEFAULT now(), -- Order creation time
is_paid boolean DEFAULT false -- Paid flag
);
-- Expected Output:
-- Orders table created if it did not exist.
-- No data inserted. (Querying returns zero rows for now.)
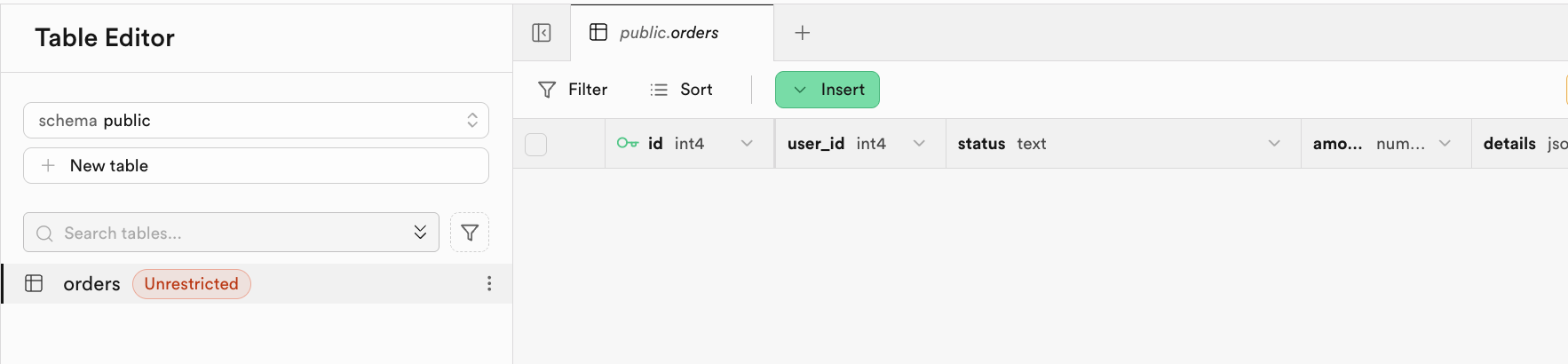
-- If table already exists, no error occurs.Après une exécution réussie, le système indiquera que le script est terminé. Vous pourrez voir la table nouvellement créée dans le Table Editor :
2.3.2 INSERT -- Insérer des données initiales
Une fois la structure de la table créée, l'étape suivante consiste à utiliser l'instruction INSERT INTO pour ajouter des lignes de données à la table.
-- Step 2: Insert initial rows into the orders table
-- Provides realistic, varied data for demo/testing. All values are self-contained.
INSERT INTO orders (user_id, status, amount, details, placed_at, is_paid) VALUES
(2001, 'pending', 23.50, '{"items":[{"sku":"BGR001","name":"Beef Burger","qty":1,"price":12.00}]}', now() - interval '2 days', false),
(2002, 'paid', 50.00, '{"items":[{"sku":"BGR002","name":"Chicken Burger","qty":2,"price":10.00},{"sku":"DRK001","name":"Lemonade","qty":2,"price":5.00}]}', now() - interval '1 day', true),
(2003, 'cancelled', 15.00, '{"items":[{"sku":"FRY001","name":"French Fries","qty":3,"price":5.00}], "reason":"Not available"}', now() - interval '45 days', false),
(2004, 'paid', 22.98, '{"items":[{"sku":"BGR003","name":"Veggie Burger","qty":2,"price":9.99}], "promo":"SUMMER22"}', now() - interval '10 days', true),
(2005, 'pending', 18.75, '{"items":[{"sku":"SAL001","name":"Salad","qty":1,"price":6.75},{"sku":"BGR001","name":"Beef Burger","qty":1,"price":12.00}]}', now() - interval '7 hours', false),
(2006, 'paid', 8.00, '{"items":[{"sku":"DRK002","name":"Cola","qty":2,"price":4.00}]}', now() - interval '3 hours', true),
(2007, 'refunded', 14.50, '{"items":[{"sku":"BGR003","name":"Veggie Burger","qty":1,"price":9.99},{"sku":"FRY001","name":"French Fries","qty":1,"price":4.51}], "refund_reason":"Late delivery"}', now() - interval '15 days', false),
(2008, 'paid', 26.99, '{"items":[{"sku":"BGR002","name":"Chicken Burger","qty":2,"price":10.00},{"sku":"DRK001","name":"Lemonade","qty":1,"price":6.99}]}', now() - interval '12 days', true),
(2009, 'pending', 9.99, '{"items":[{"sku":"BGR003","name":"Veggie Burger","qty":1,"price":9.99}]}', now() - interval '30 minutes', false),
(2010, 'paid', 19.89, '{"items":[{"sku":"BGR001","name":"Beef Burger","qty":1,"price":12.00},{"sku":"DRK002","name":"Cola","qty":2,"price":3.95}]}', now() - interval '5 days', true),
(2011, 'cancelled', 0.00, '{"items":[], "reason":"User cancelled"}', now() - interval '2 days', false);
-- Expected Output:
-- After running this script, SELECT * FROM orders will show about 11 rows with varied user_id, status, amount, details (JSON), placed_at, and is_paid fields.
-- For example:
-- | id | user_id | status | amount | is_paid | placed_at |
-- |----|---------|-----------|--------|---------|---------------------|
-- | 1 | 2001 | pending | 23.50 | false | 2025-10-28 13:40:00Z|
-- | 2 | 2002 | paid | 50.00 | true | ... |
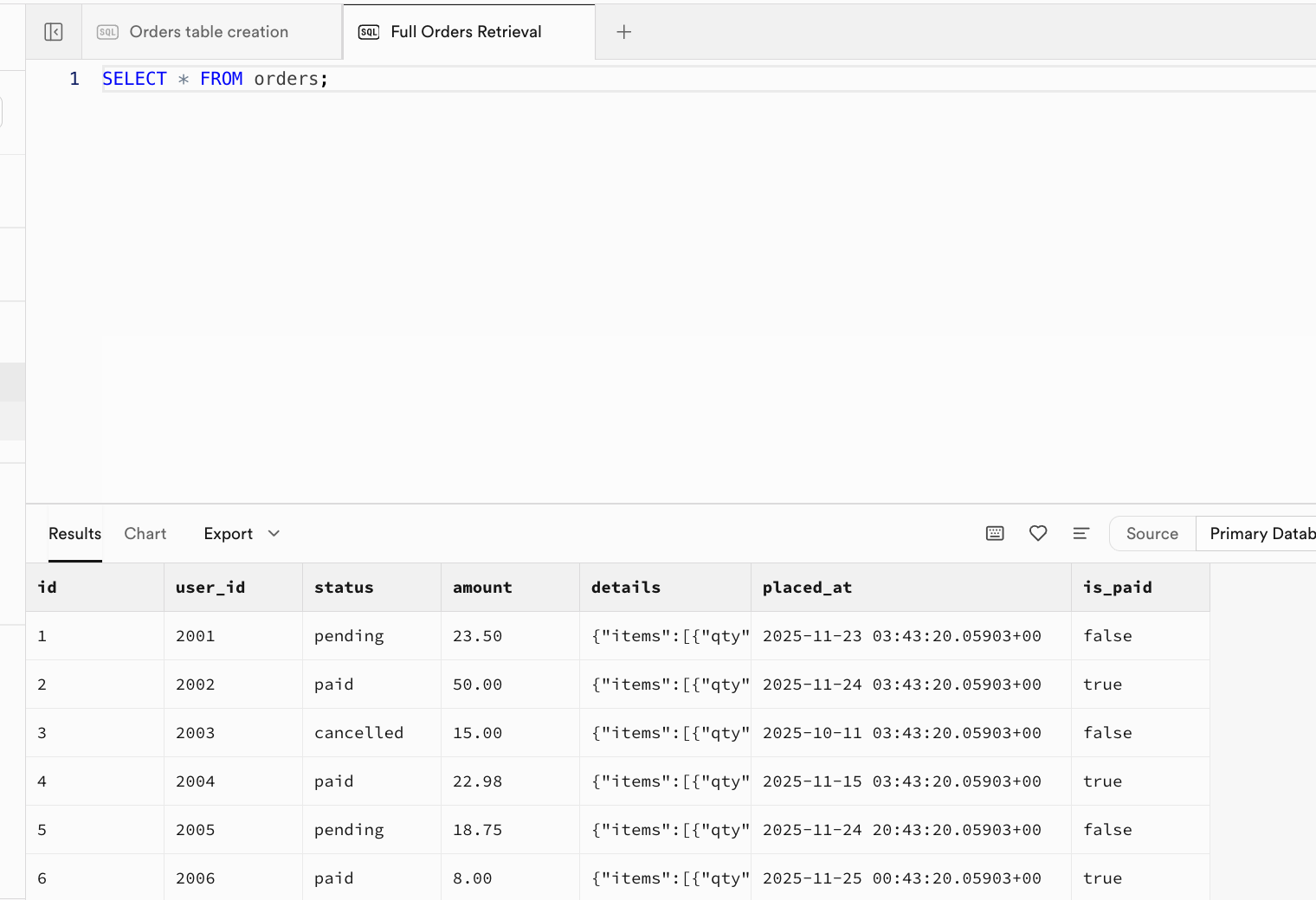
-- |... | ... | ... | ... | ... | ... |Après exécution, les données initiales ont été insérées dans la table. Vous pouvez accéder à l'interface du Table Editor, actualiser et voir les résultats, ou ouvrir une nouvelle fenêtre dans le SQL Editor et exécuter la requête SELECT * FROM orders; pour visualiser les résultats :
2.3.3 SELECT -- Lire et interroger les données
L'instruction SELECT permet de récupérer des données depuis une table. En combinant différentes clauses, il est possible de filtrer, trier et formater les données avec précision. Voici quelques exemples à exécuter pas à pas :
-- Step 3: SELECT query examples for the orders table
-- Example 1: Select all fields for all orders
SELECT * FROM orders;
-- Expected Output: Returns all rows and fields. Columns: id, user_id, status, amount, details, placed_at, is_paid.
-- Example 2: Select only pending orders
SELECT id, user_id, amount FROM orders WHERE status = 'pending';
-- Expected Output: All rows with status 'pending'; columns: id, user_id, amount.
-- Example 3: Select specific fields and filter by payment status
SELECT id, status, is_paid, amount FROM orders WHERE is_paid = true;
-- Expected Output: All rows where is_paid is true; columns: id, status, is_paid, amount.
-- Example 4: Extract all item names from the details (JSON) for each order
SELECT id, details -> 'items' AS item_list FROM orders;
-- Expected Output: Each row shows id and an array from JSON with item details.- Exemple 1 : Retourne toutes les lignes et colonnes de la table
orders, similaire à la sortie de l'étape 2. - Exemple 2 : Retourne uniquement les commandes au statut 'pending', avec les colonnes spécifiées :
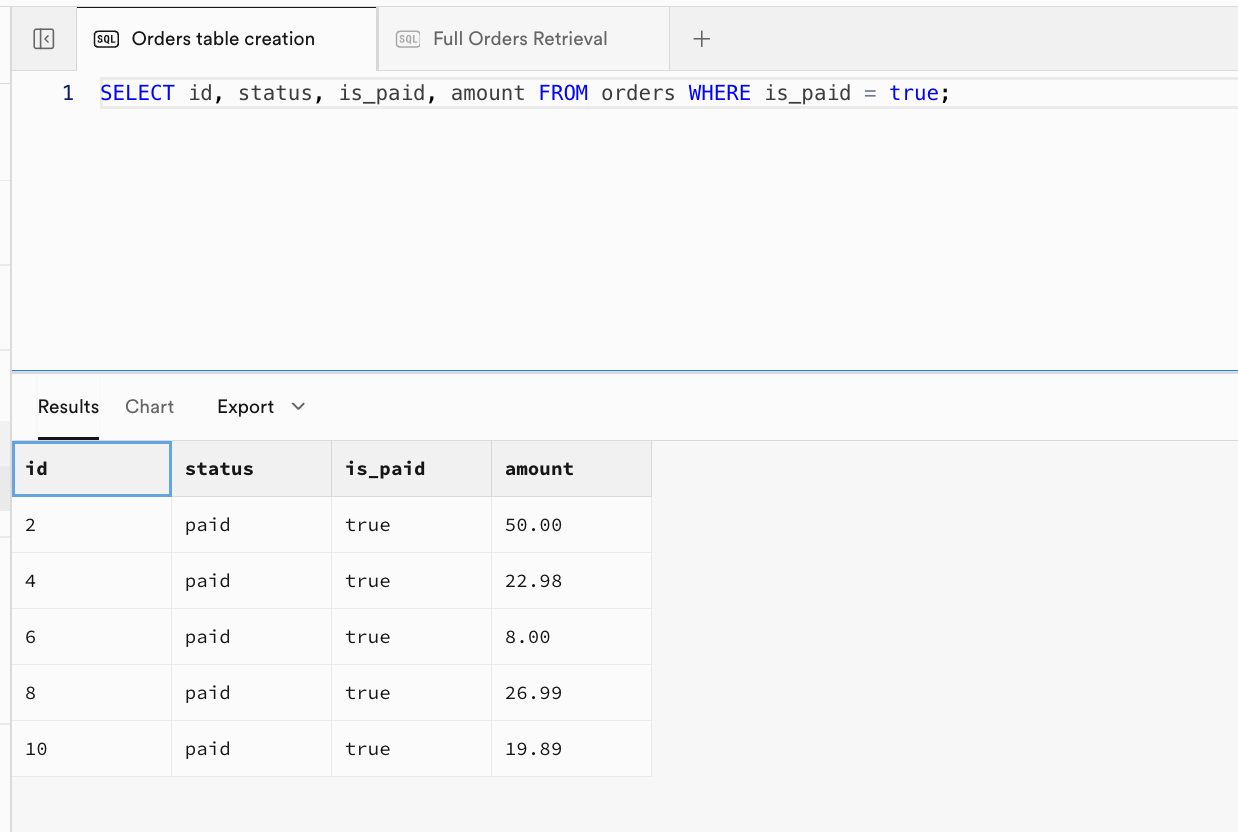
- Exemple 3 : Retourne uniquement les commandes payées, avec les colonnes spécifiées :
| id | status | is_paid | amount |
|---|---|---|---|
| 2 | paid | true | 50.00 |
| 4 | paid | true | 22.98 |
| 6 | paid | true | 8.00 |
| 8 | paid | true | 26.99 |
| 10 | paid | true | 19.89 |
- Exemple 4 : Retourne l'
idde chaque commande et le tableauitemsextrait du champdetails:
| id | item_list |
|---|---|
| 1 | [{"qty":1,"sku":"BGR001","name":"Beef Burger","price":12}] |
| 2 | [{"qty":2,"sku":"BGR002","name":"Chicken Burger","price":10},{"qty":2,"sku":"DRK001","name":"Lemonade","price":5}] |
| 3 | [{"qty":3,"sku":"FRY001","name":"French Fries","price":5}] |
| ... | ... |
2.3.4 INSERT -- Insérer un enregistrement unique
Dans la section 2.3.2, nous avons démontré l'insertion de données en lot au moment de l'initialisation. Voyons maintenant comment insérer une seule donnée.
-- Step 4: INSERT a new order (single row)
INSERT INTO orders (user_id, status, amount, details, is_paid)
VALUES (
2012, 'paid', 9.99,
'{"items":[{"sku":"BGR002","name":"AIID Burger","qty":100,"price":1000}]}',
true
);En interrogeant ensuite avec SELECT * FROM orders;, nous pouvons constater que la table orders est passée de 11 à 12 enregistrements.
2.3.5 UPDATE -- Modifier des données existantes
L'instruction UPDATE permet de modifier les enregistrements existants dans une table.
-- Step 5: UPDATE example
UPDATE orders SET status = 'paid', is_paid = true WHERE id = 1;2.3.6 DELETE -- Supprimer des données
L'instruction DELETE permet de supprimer des enregistrements d'une table.
-- Step 6: DELETE example
DELETE FROM orders WHERE placed_at < now() - interval '2 days';Avant l'exécution, vous pouvez d'abord exécuter SELECT id, status, placed_at FROM orders WHERE placed_at < now() - interval '2 days'; pour visualiser les données qui seront supprimées. Après avoir exécuté la commande DELETE, réexécutez la même requête -- le résultat sera vide, confirmant que ces lignes ont été supprimées.
2.4 Sécurité au niveau des lignes (RLS)
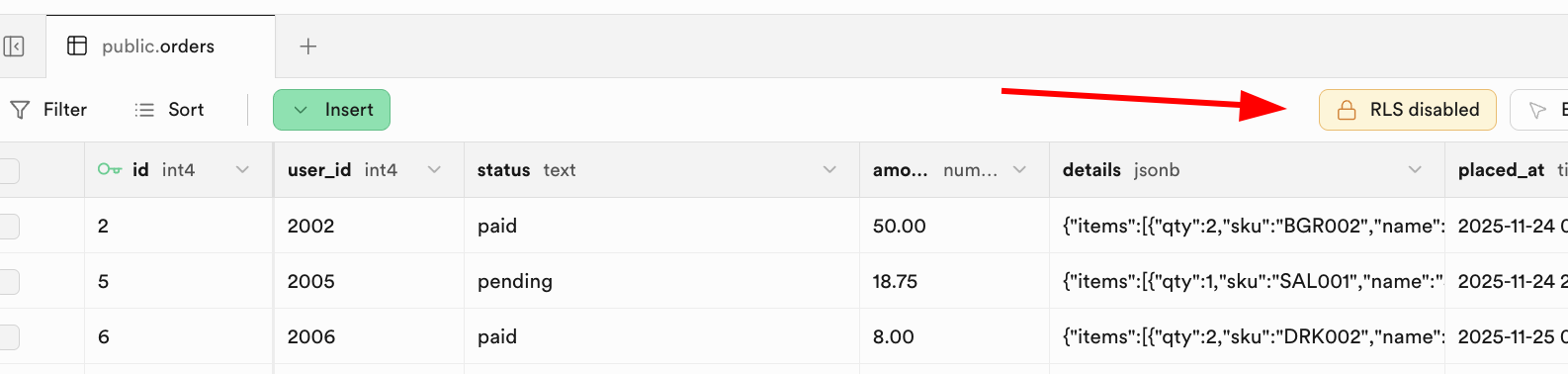
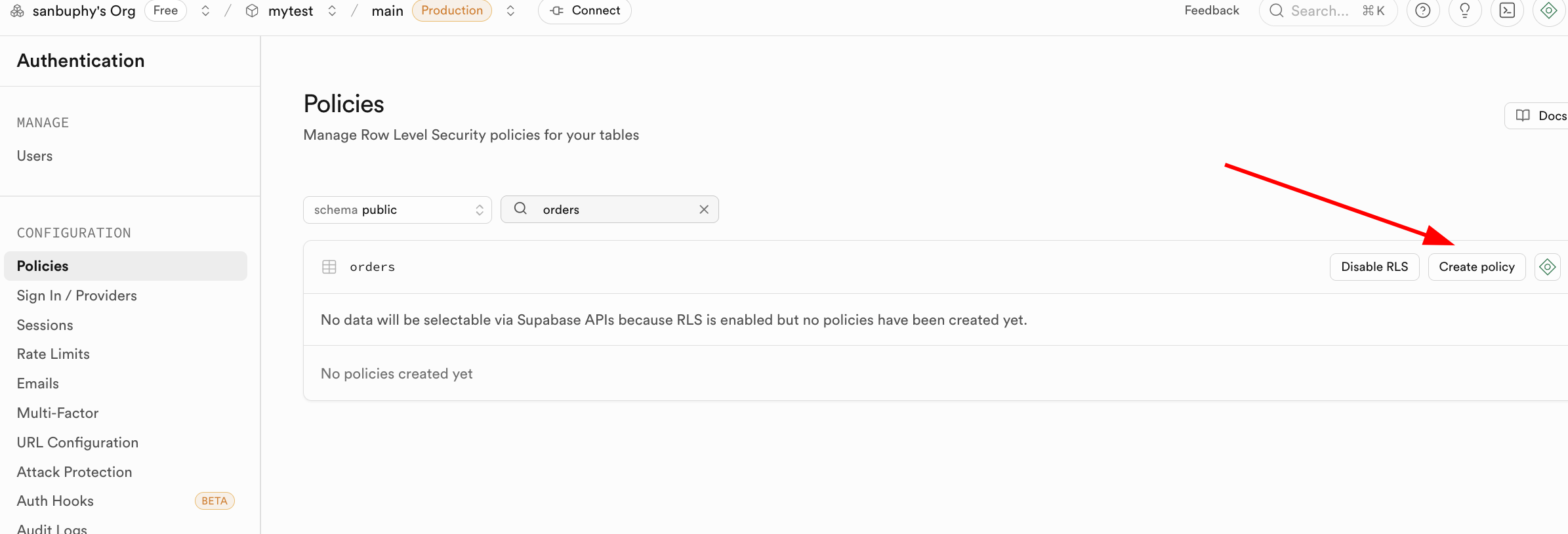
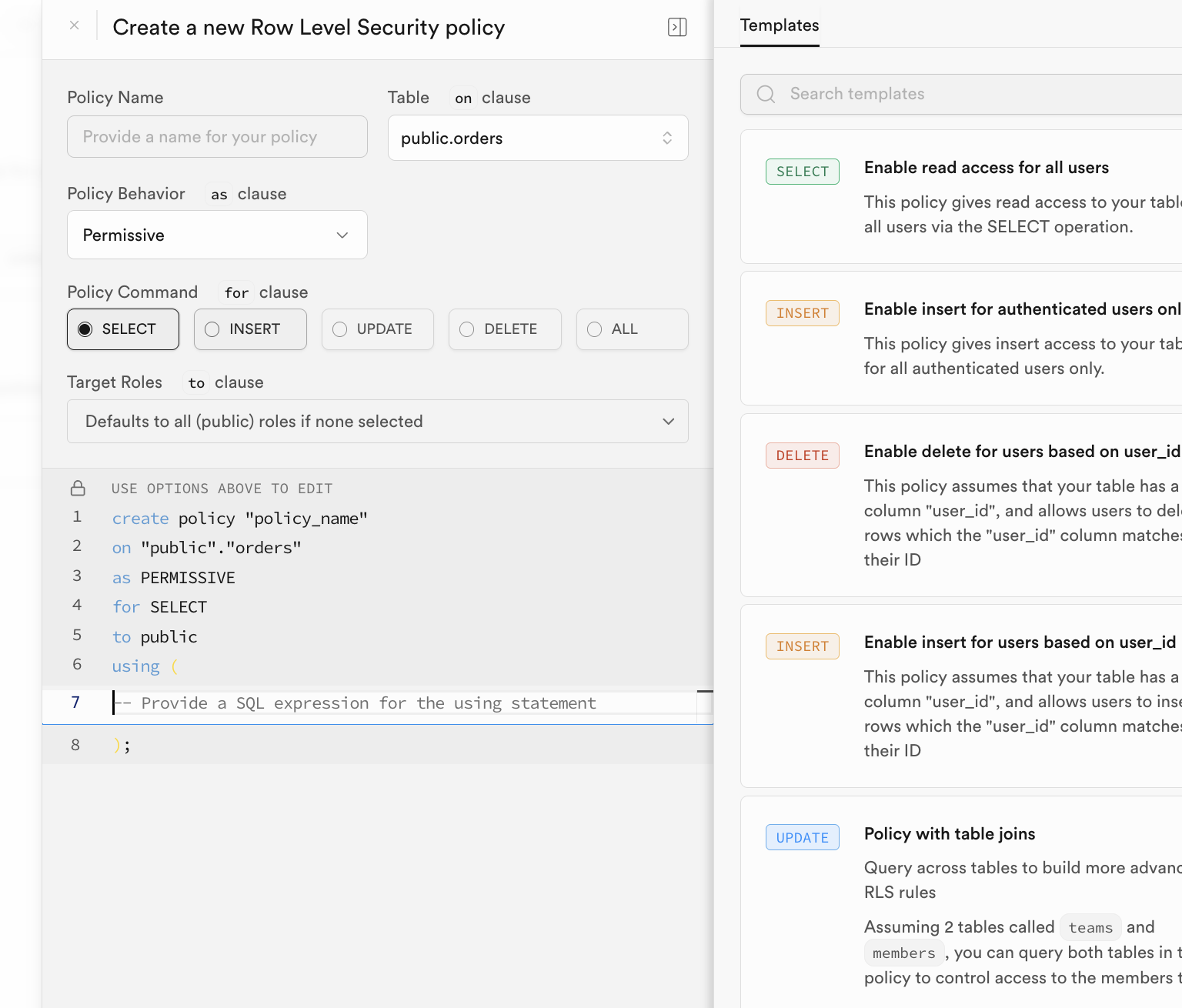
Après avoir appris les opérations de base sur les bases de données, nous devons approfondir un concept central de sécurité des données : RLS (Row Level Security, sécurité au niveau des lignes).
RLS permet aux développeurs de définir des politiques de sécurité fines sur les tables de la base de données, en contrôlant avec précision, selon l'identité de l'utilisateur, quelles lignes de données il peut consulter ou modifier.
Lorsque vous activez RLS sur une table, toutes les requêtes de données déclenchent une vérification RLS : l'opération ne peut être exécutée que si elle passe avec succès au moins une politique de sécurité.
Dans Supabase, RLS est profondément intégré au système d'authentification des utilisateurs. La fonction dédiée auth.uid() retourne directement l'identifiant unique de l'utilisateur connecté, permettant d'associer précisément les lignes de données à l'identité de l'utilisateur.

3. Première application SQL
Après avoir maîtrisé les opérations de base sur les bases de données et RLS, nous entamons la phase pratique avec le scénario « gestion des commandes d'un restaurant de hamburgers ».
3.1 Cloner et exécuter le projet exemple Supabase
Clonez le dépôt suivant : https://github.com/THU-SIGS-AIID/Project5-Supabase-Demos
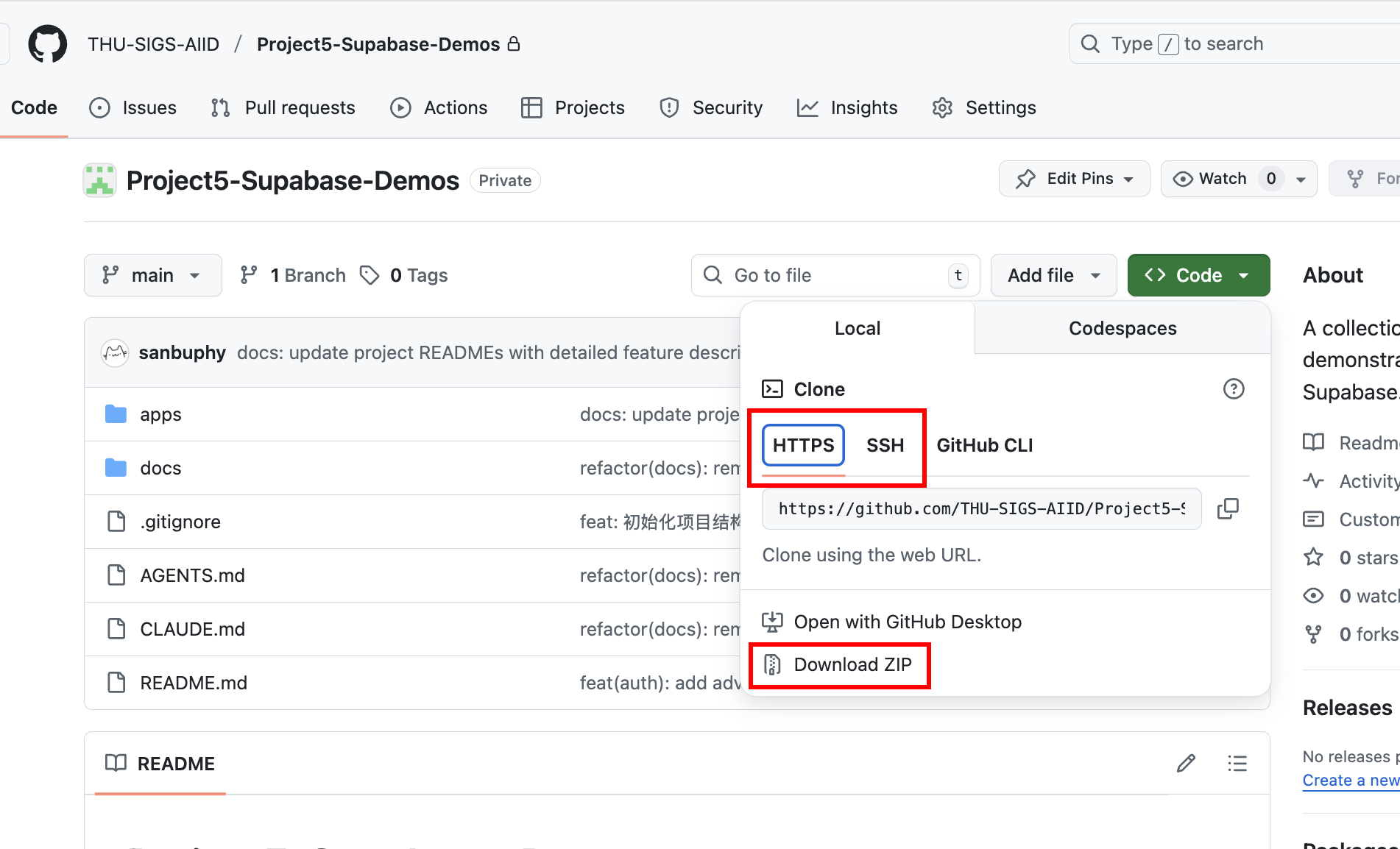
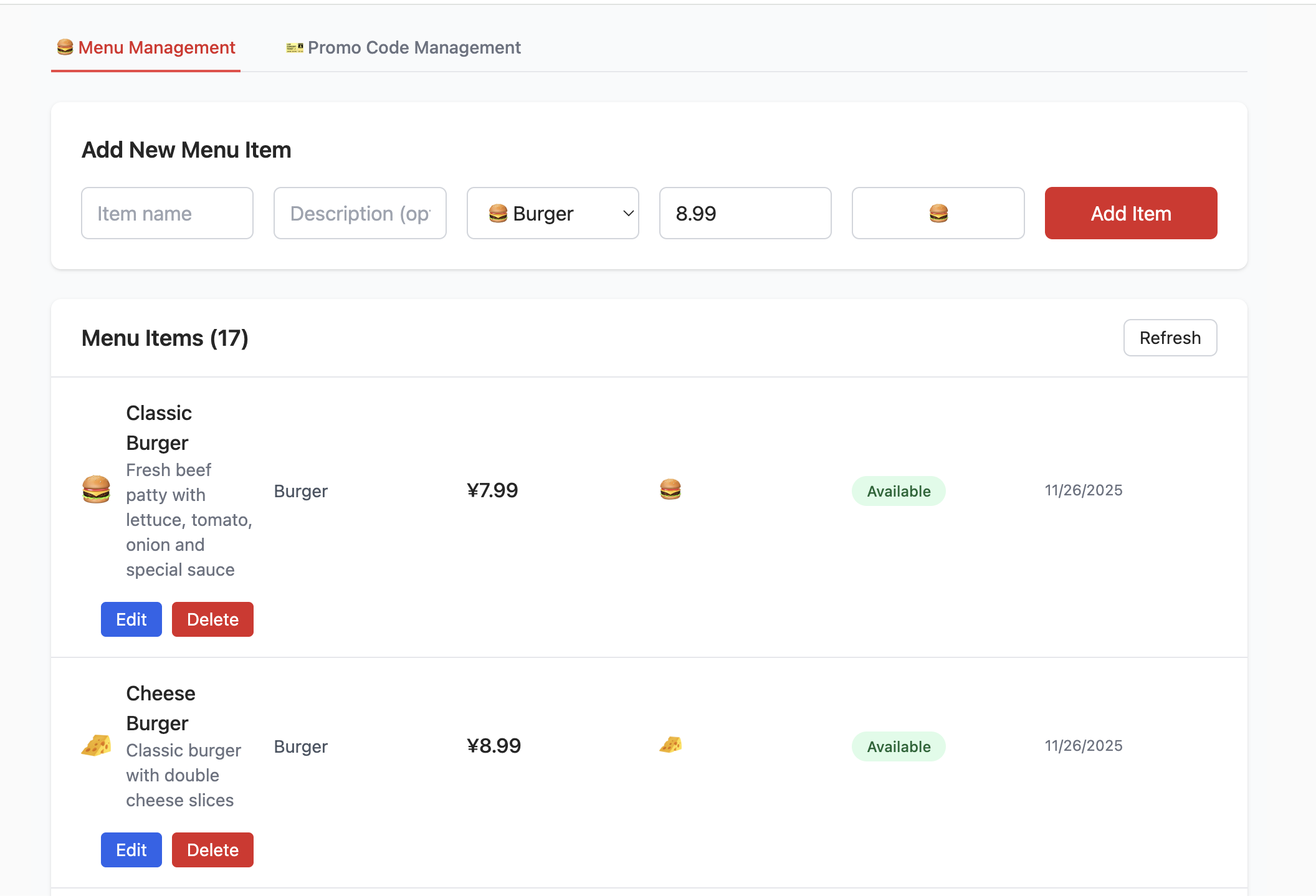
3.2 Projet 1 -- CRUD du menu du restaurant de hamburgers
Apprenez à initialiser la base de données via un script SQL et à connecter le projet frontend à Supabase.
Créer la base de données avec un script
Exécutez le script init.sql du dossier scripts dans le SQL Editor.
Configurer la connexion à la base de données
- Via les variables d'environnement : créez un fichier
.envavecNEXT_PUBLIC_SUPABASE_URLetNEXT_PUBLIC_SUPABASE_ANON_KEY. - Via la page du projet : cliquez sur le bouton Paramètres en haut à droite.
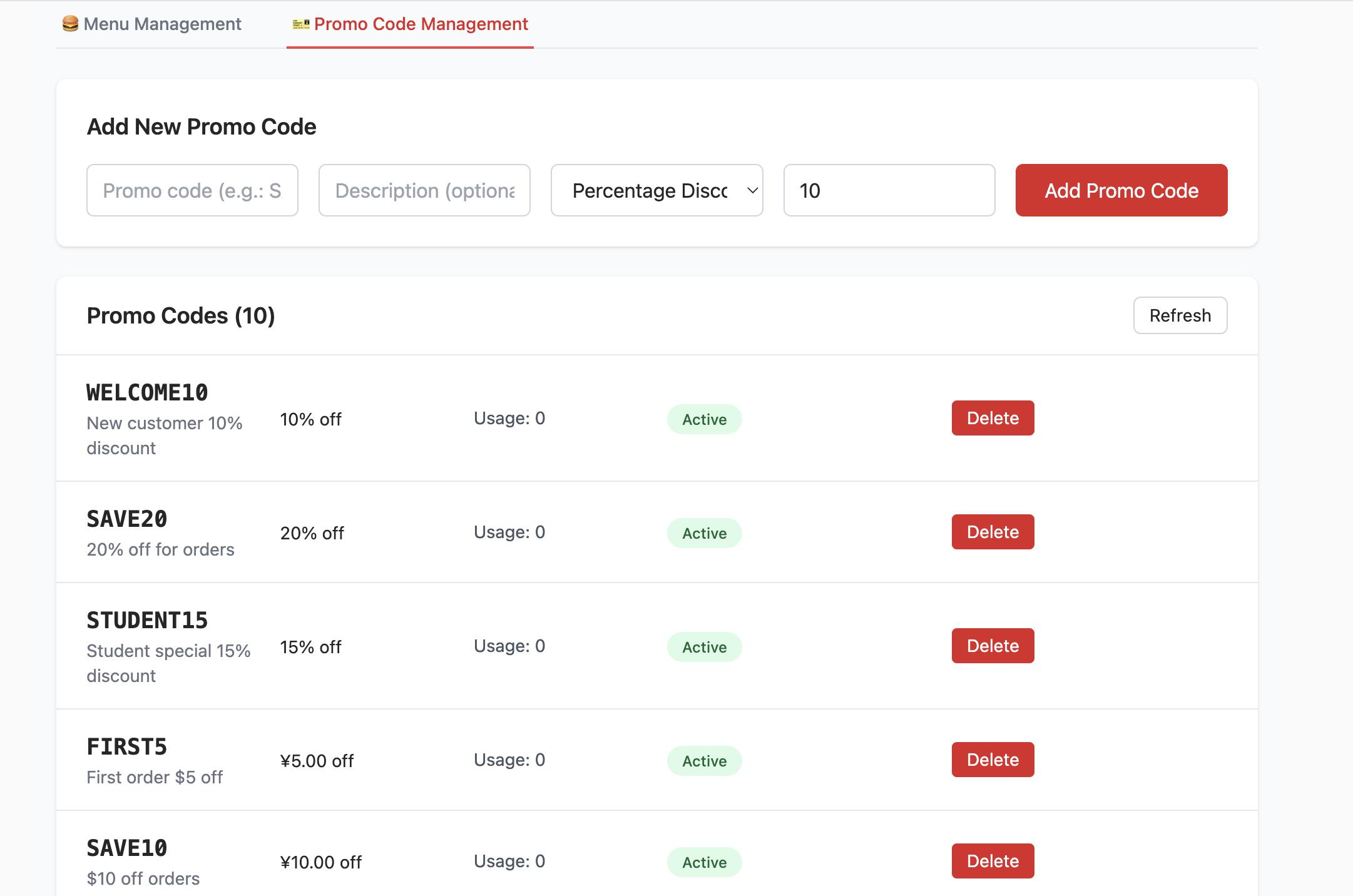
📚 Exercice
- Essayez d'ajouter et de supprimer des éléments existants, observez les changements dans le Table Editor.
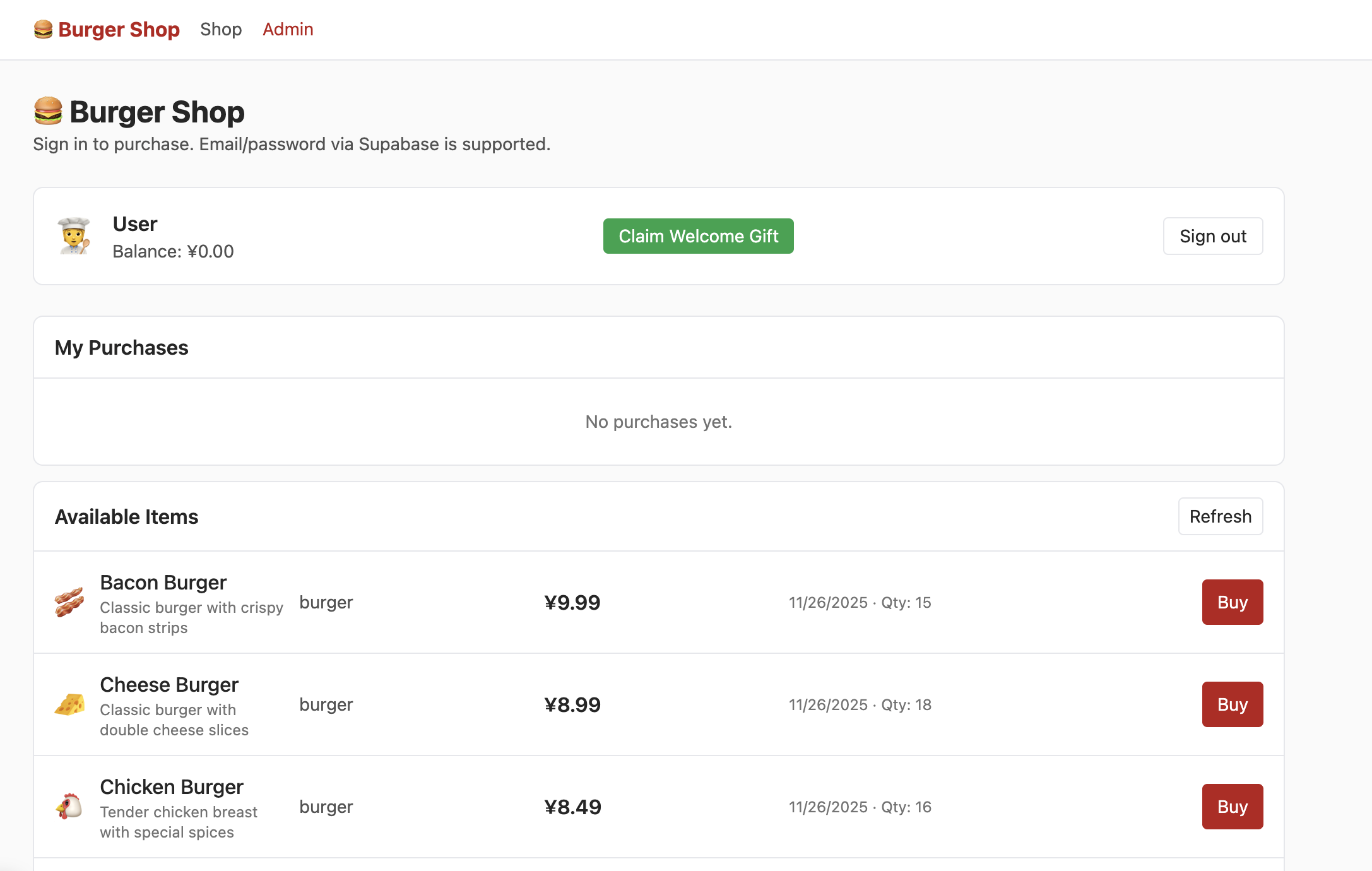
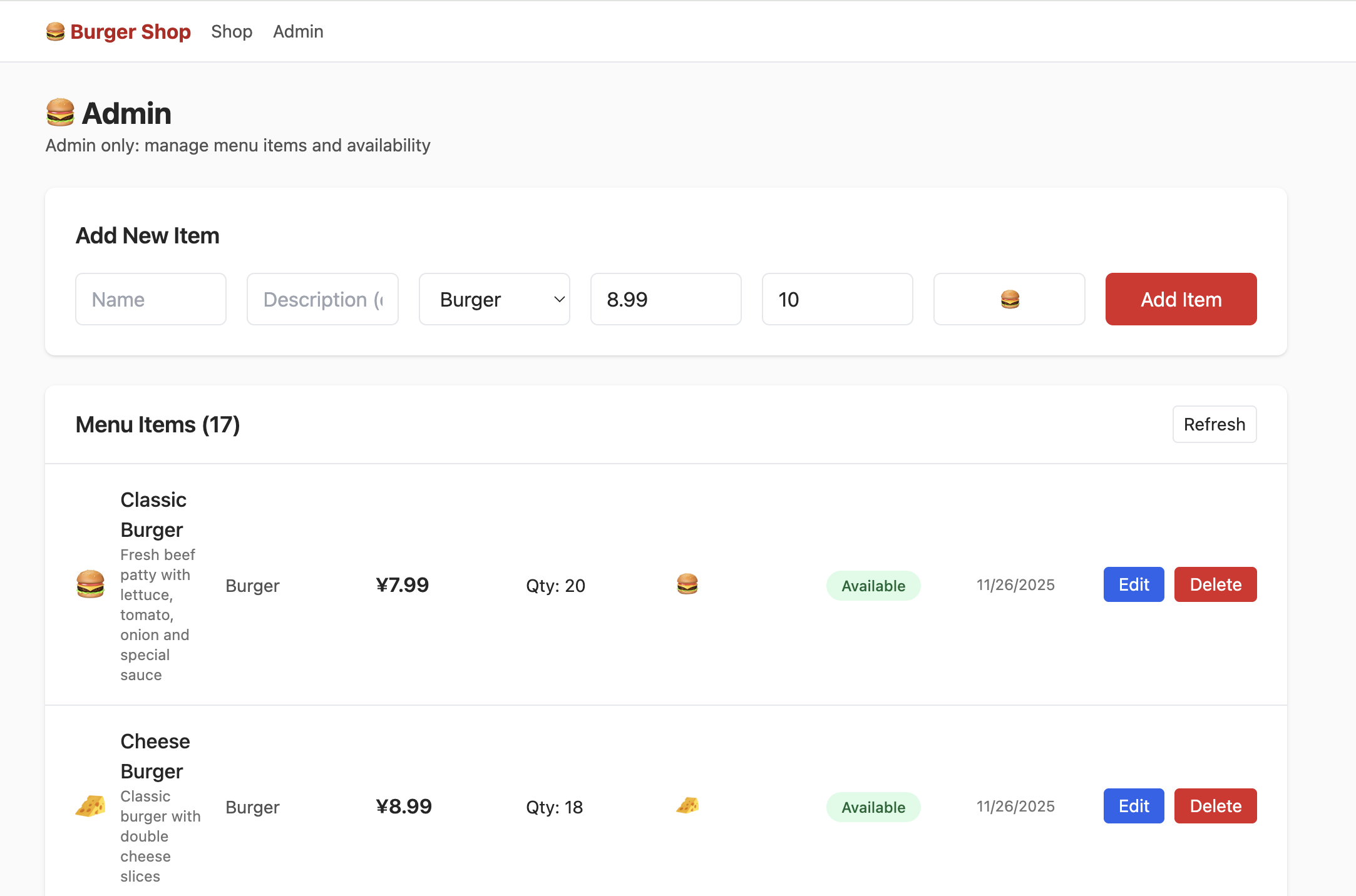
3.4 Projet 2 -- Restaurant de hamburgers avec authentification des utilisateurs
Le Projet 2 introduit l'authentification (Auth) et la gestion des permissions RLS, avec une page de connexion indépendante supportant « email + mot de passe ».
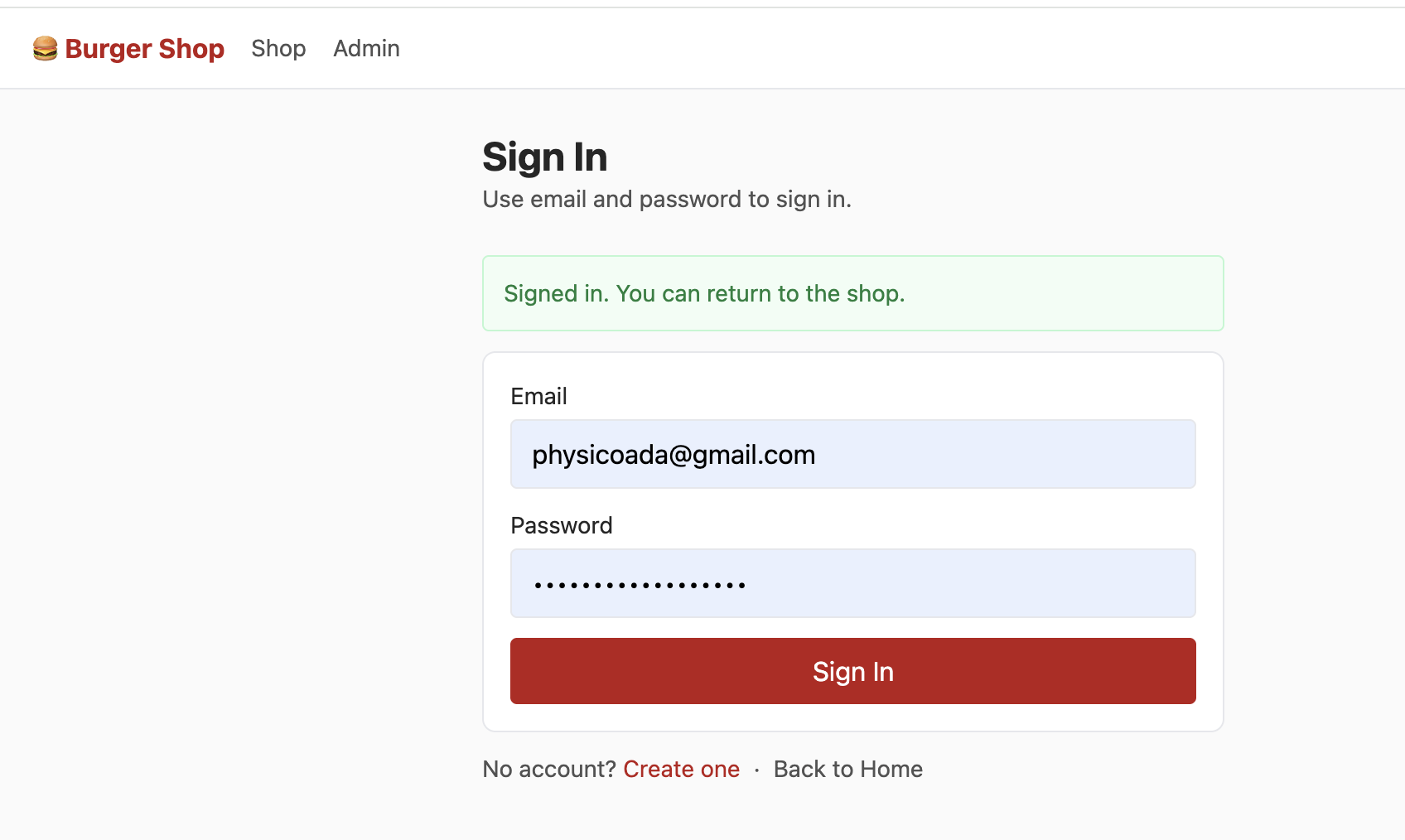
📚 Exercice
- Récupérez le cadeau de bienvenue, effectuez un achat.
- Trouvez la table des permissions utilisateur et modifiez-les en
admin. - Localisez la table du portefeuille et augmentez le solde.
4. Construire votre première application Supabase
4.1 Processus standardisé pour connecter n'importe quelle application à Supabase
- Clarifiez les besoins et décrivez-les à l'IA.
- Générez un script
init.sqladapté à Supabase. - Restructurez le code pour interagir avec Supabase.
- Configurez les paramètres de connexion et testez.
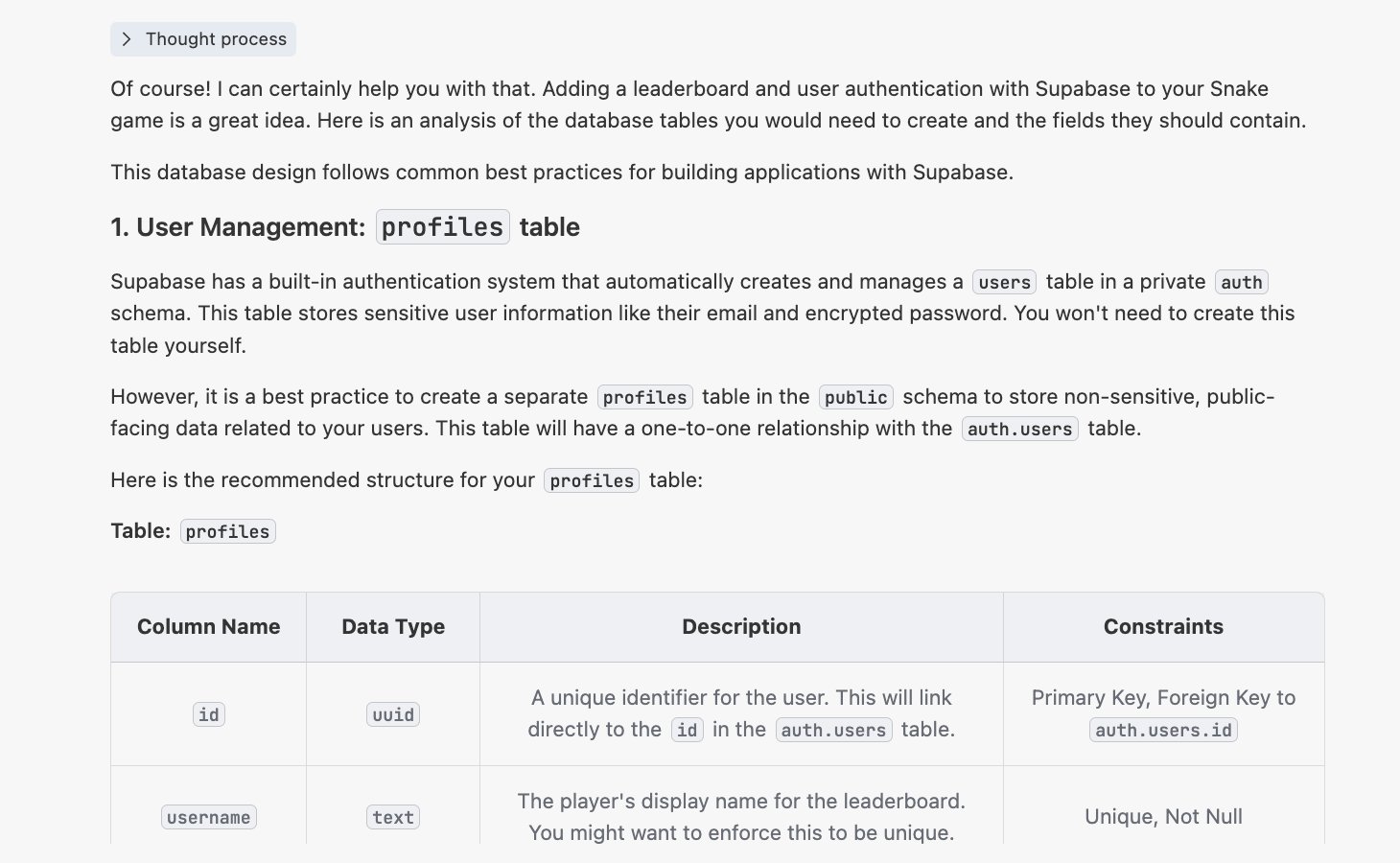
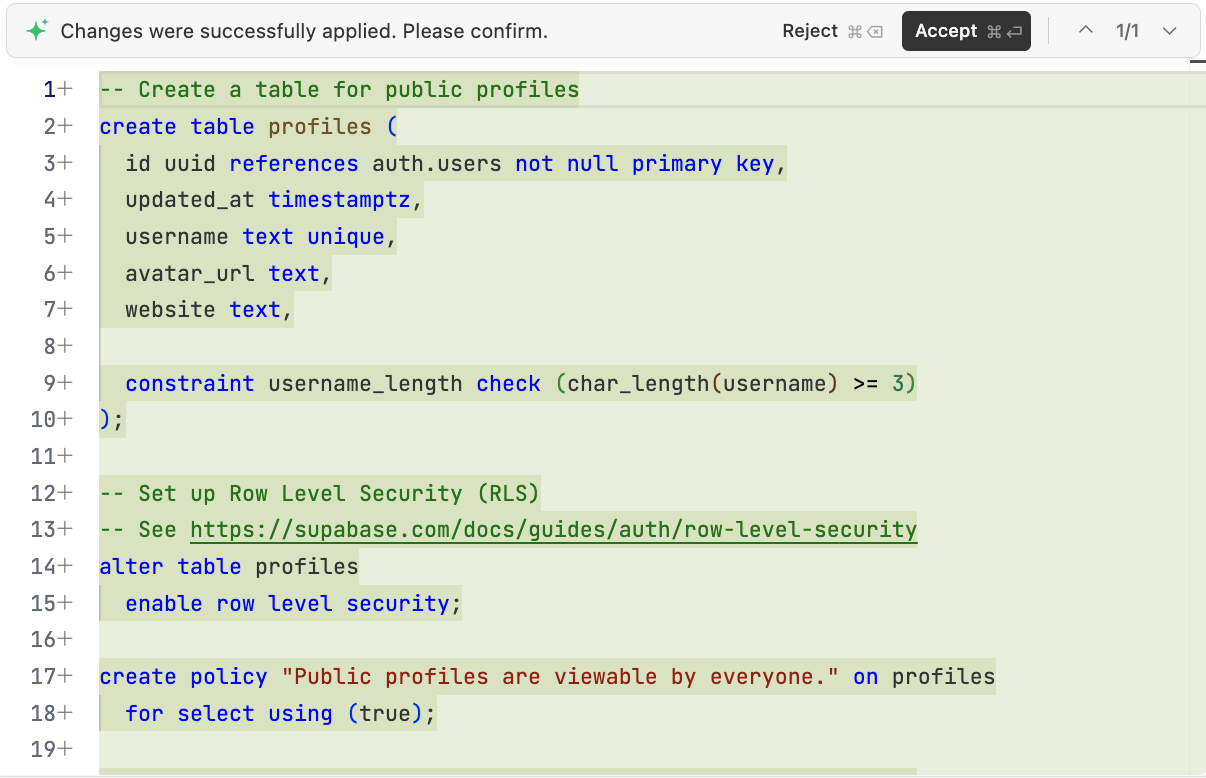
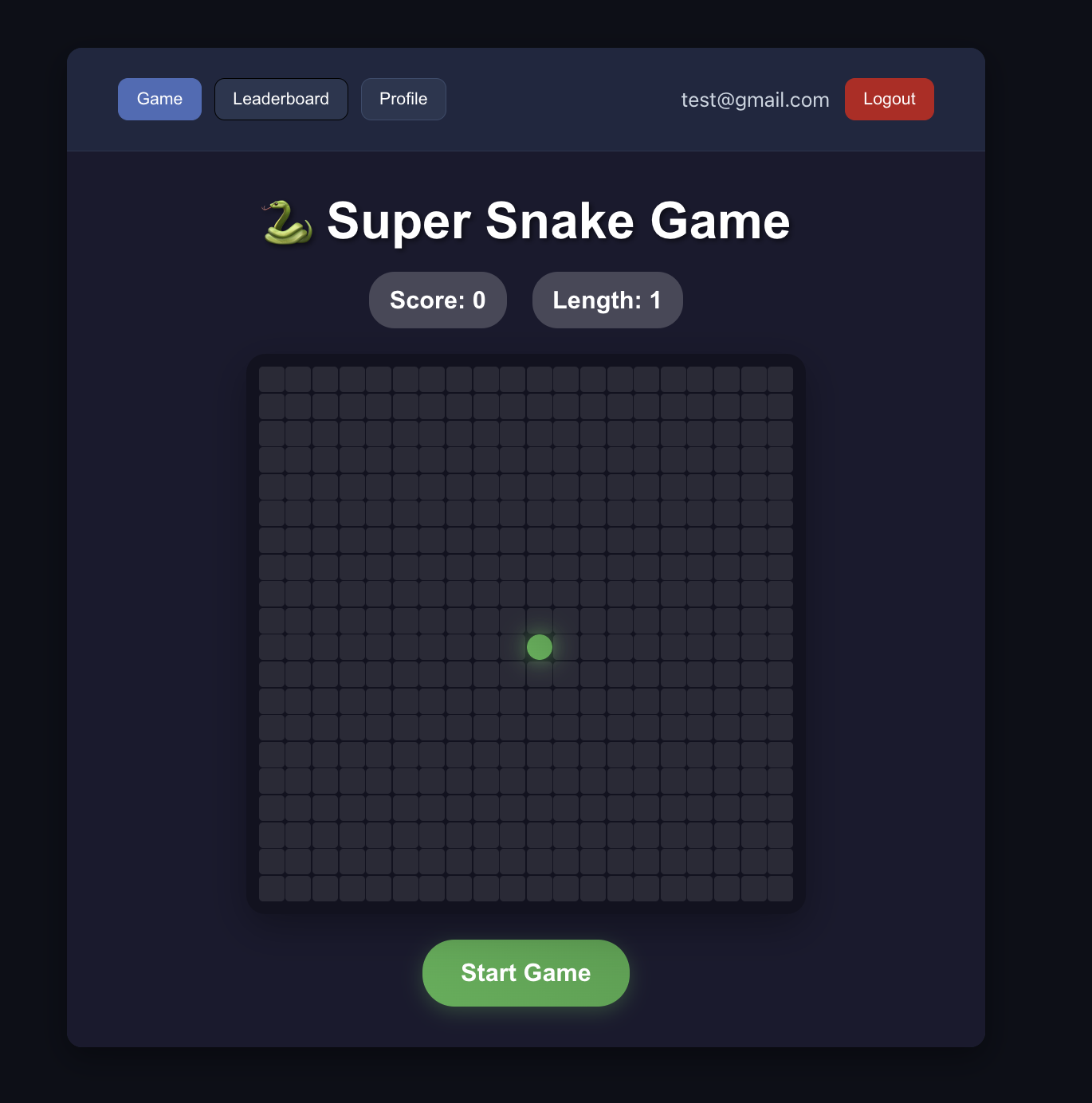
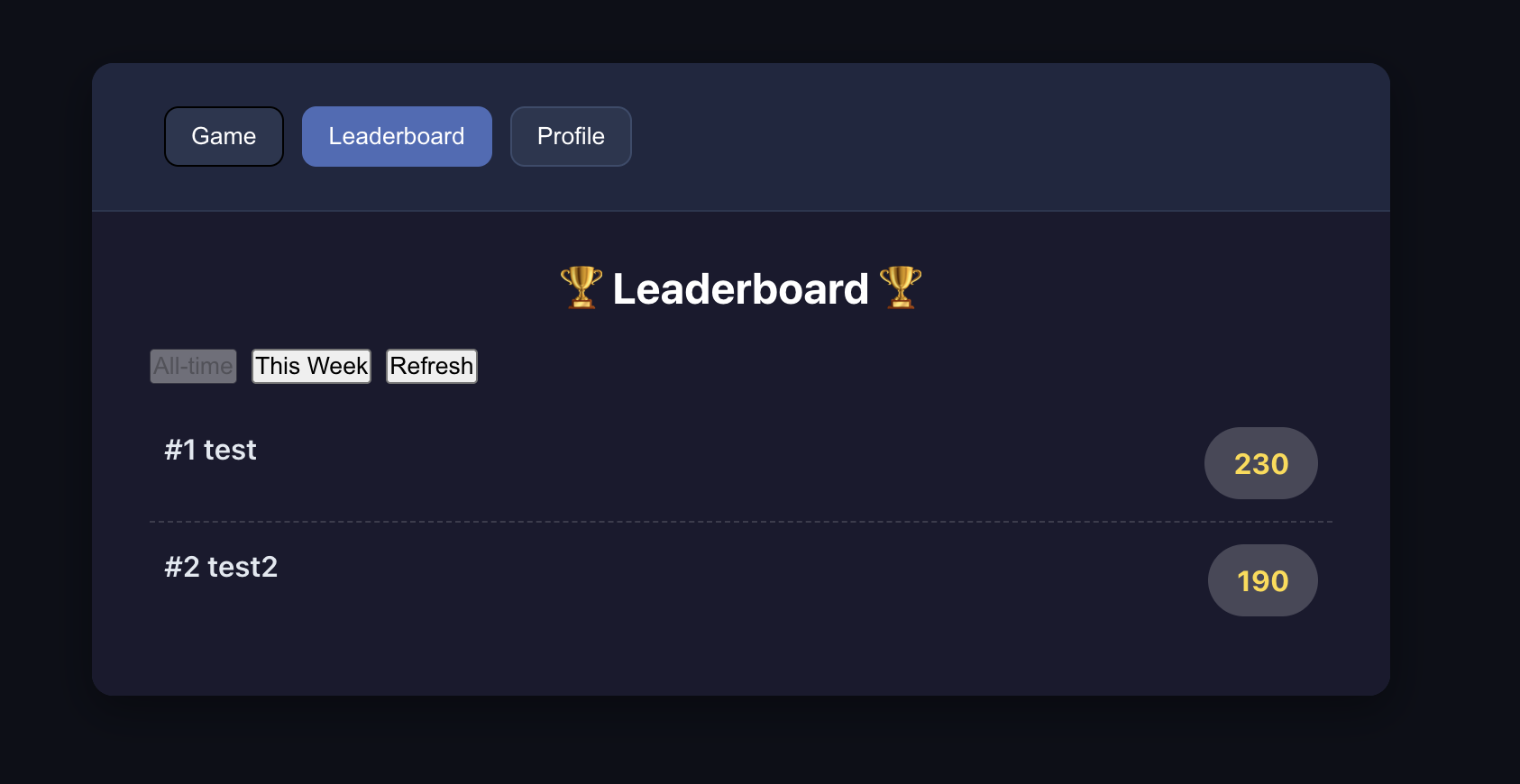
4.2 Étude de cas : construire un jeu du serpent en ligne
Pratiquez avec le projet Project5-Supabase-Demos/apps_snakegame : ajoutez un classement des scores avec connexion utilisateur.
📚 Exercice
- Intégrez le système de gestion des utilisateurs dans le jeu du serpent.
- Intégrez le système de gestion des utilisateurs dans votre propre application.
5. Devenir un expert Supabase
5.1 Pourquoi avons-nous choisi Supabase
Supabase empaquette les capacités backend en services prêts à l'emploi (PostgreSQL, Realtime, Auth, Storage, Edge Functions, API auto-générées), permettant aux équipes de se concentrer sur le développement des fonctionnalités clés. Sa stratégie entièrement open source, avec support du déploiement privé, évite le verrouillage fournisseur.
5.2 Connexion Google et GitHub
Le projet project-burger-shop-auth-advanced-supabase-6 démontre ces fonctionnalités avancées.

5.2.1 Flux OAuth : comment fonctionne la connexion tierce
Le protocole OAuth 2.0 permet à l'utilisateur d'autoriser notre application à accéder à ses informations publiques sur une plateforme tierce sans exposer son mot de passe.
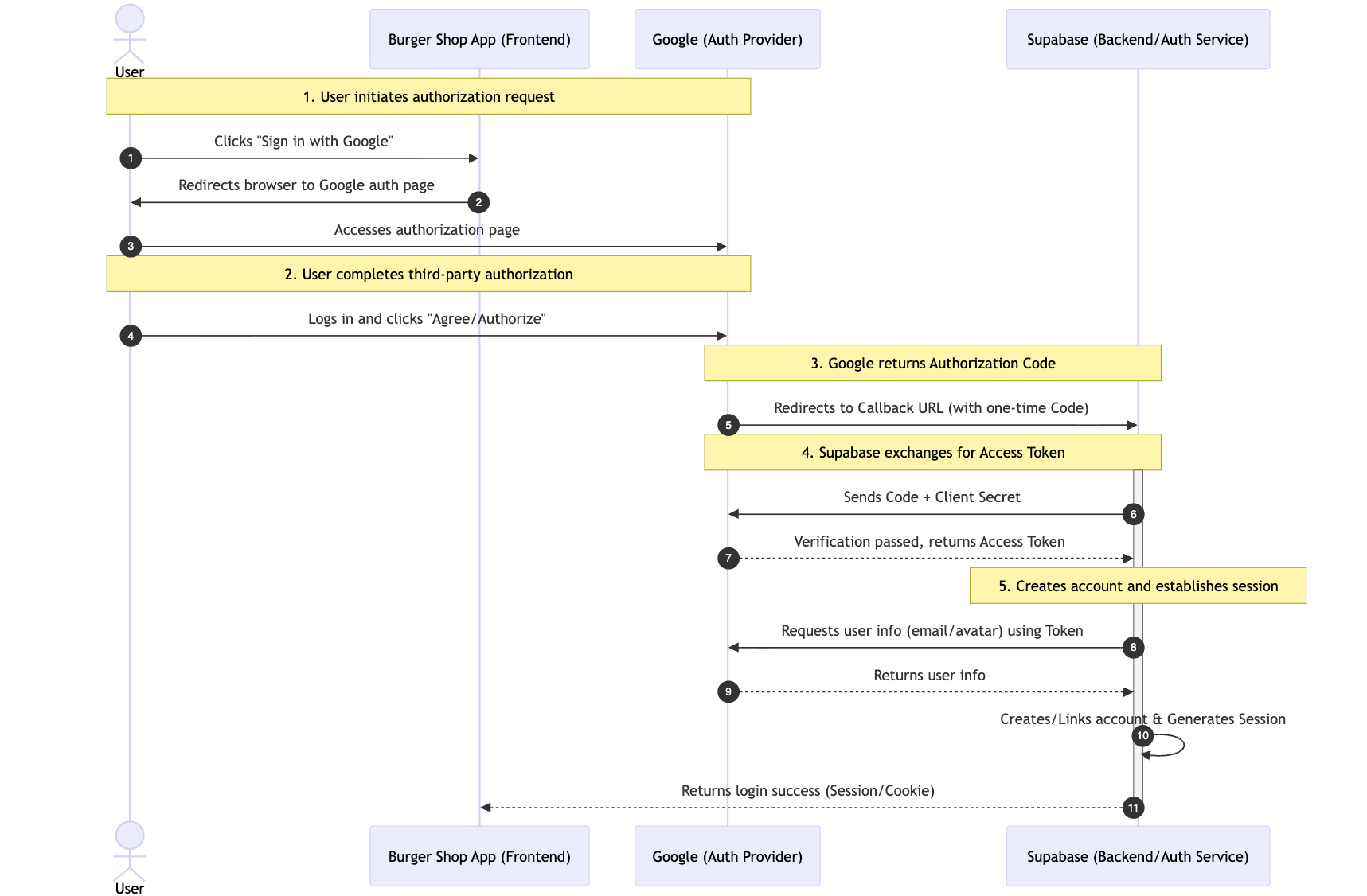
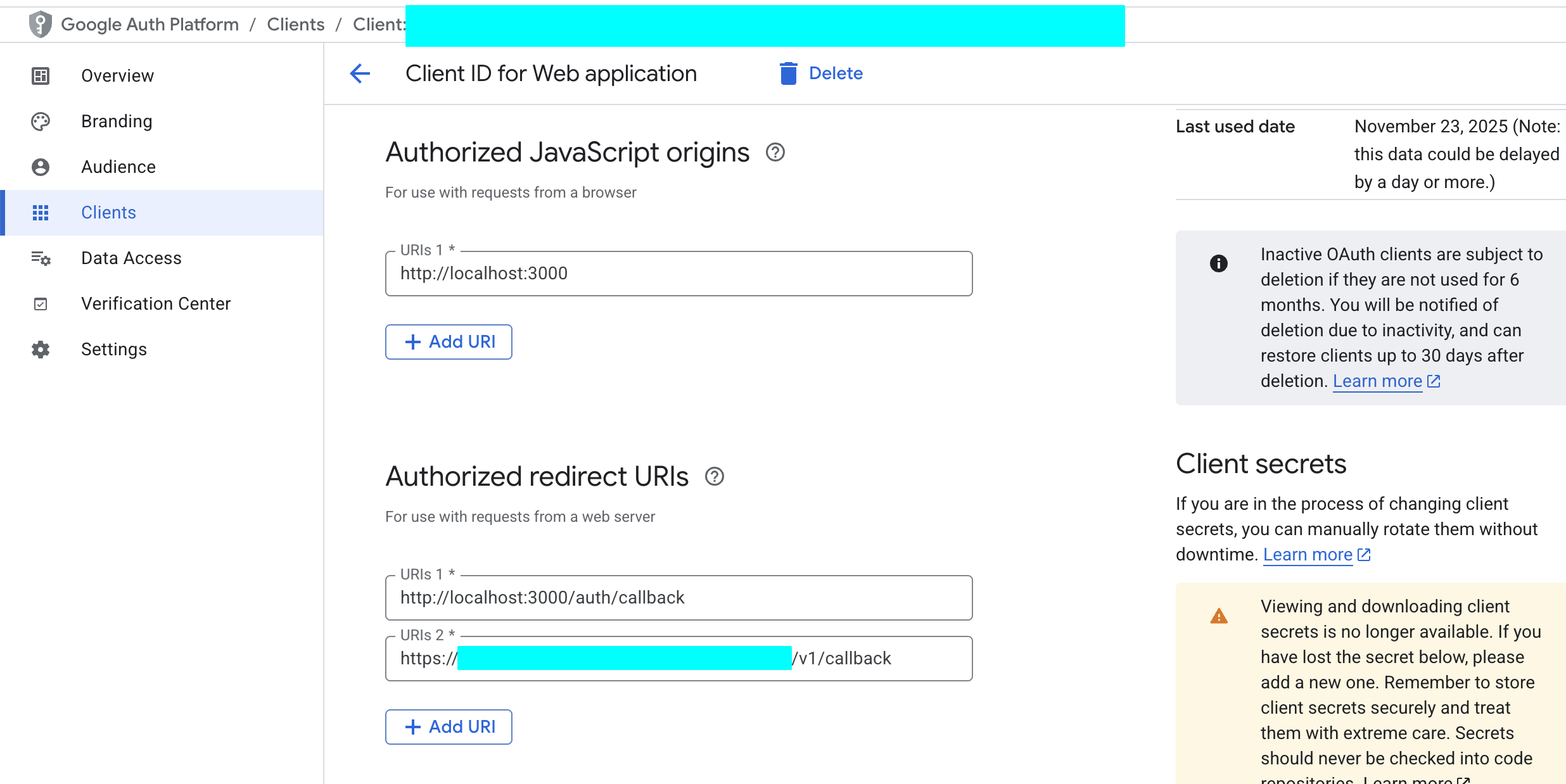
5.2.2 Configurer Google Cloud
Créez un OAuth 2.0 Client ID dans Google Cloud Console.
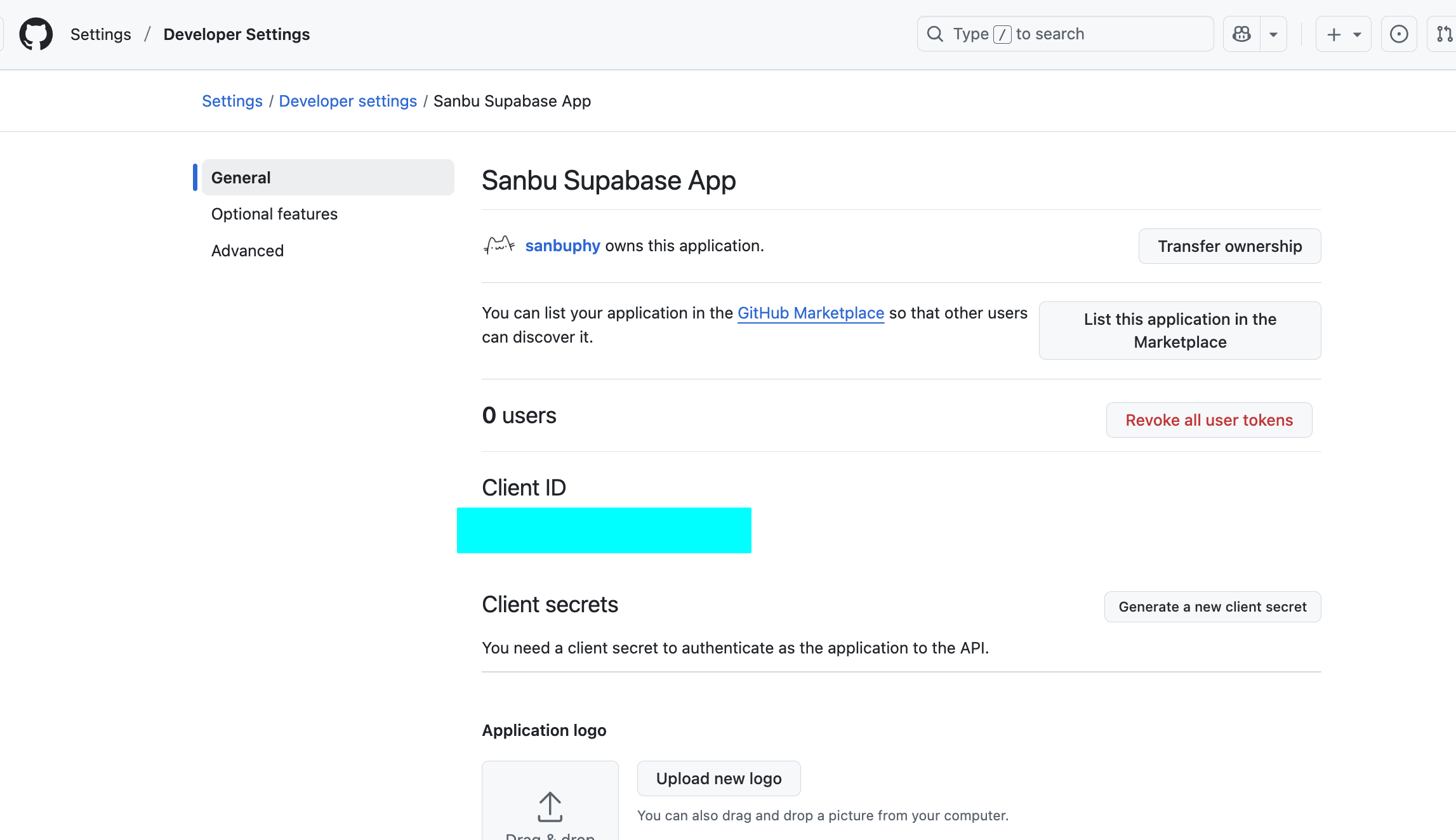
5.2.3 Configurer GitHub
Enregistrez une application OAuth dans GitHub Developer Settings.
5.2.4 Configurer les Providers dans Supabase
Activez Google et GitHub dans Authentication > Providers.

5.2.6 Réinitialisation du mot de passe
Le projet inclut la réinitialisation de mot de passe via supabase.auth.resetPasswordForEmail().
5.3 Fonctionnalités temps réel
Le projet project-burger-shop-realtime-orders-3 illustre les capacités Realtime : Postgres Changes, Broadcast et Presence.
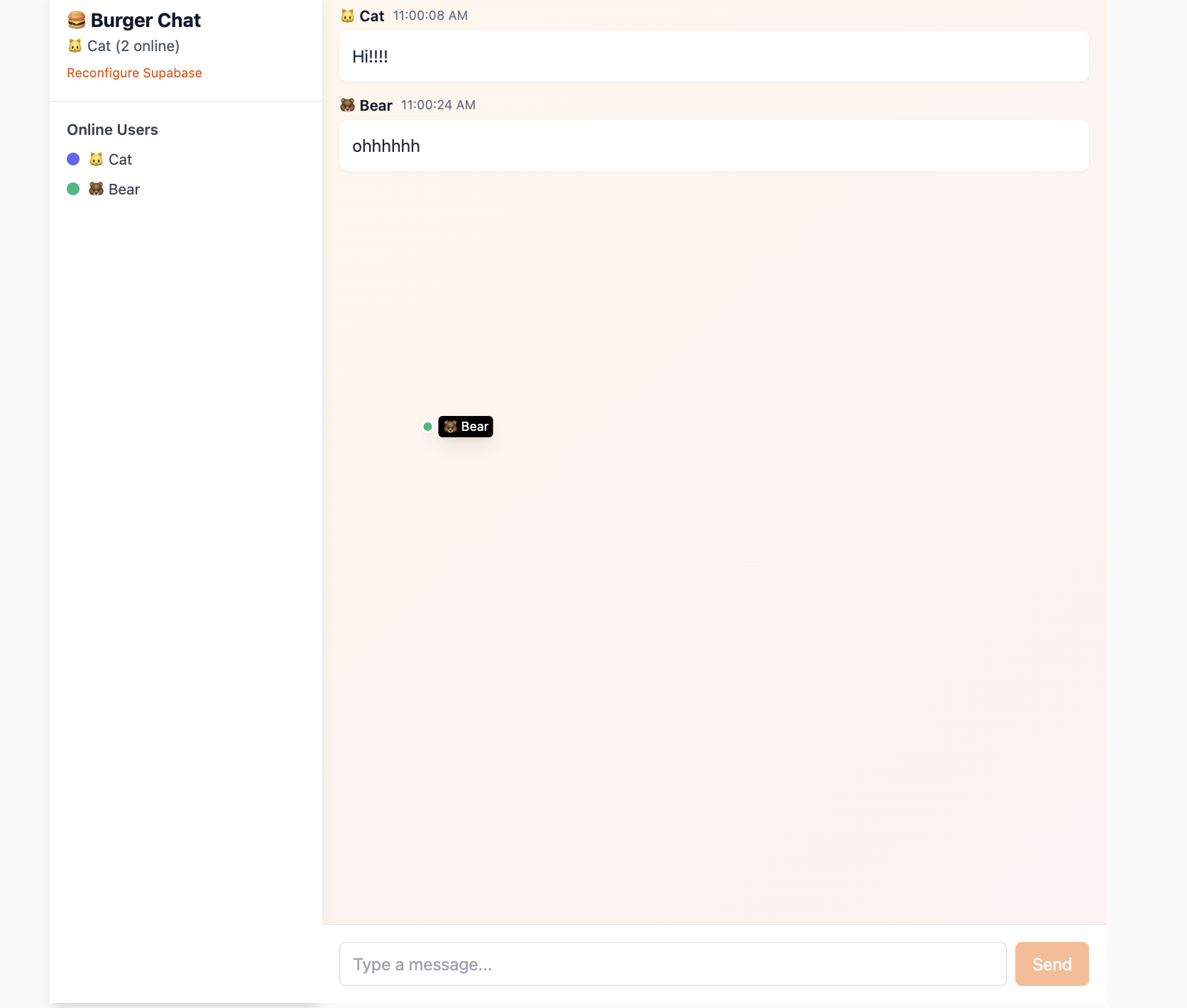
5.3.1 Postgres Changes -- Modifications en temps réel
Permet de s'abonner aux événements INSERT, UPDATE, DELETE sur des tables spécifiques.
5.3.2 Broadcast & Presence
- Presence : suivi des utilisateurs en ligne.
- Broadcast : messages temporaires à faible latence entre clients.
5.4 Stockage (Storage)
Le projet project-burger-shop-storage-uploads-4 démontre le système de fichiers avec Supabase Storage.
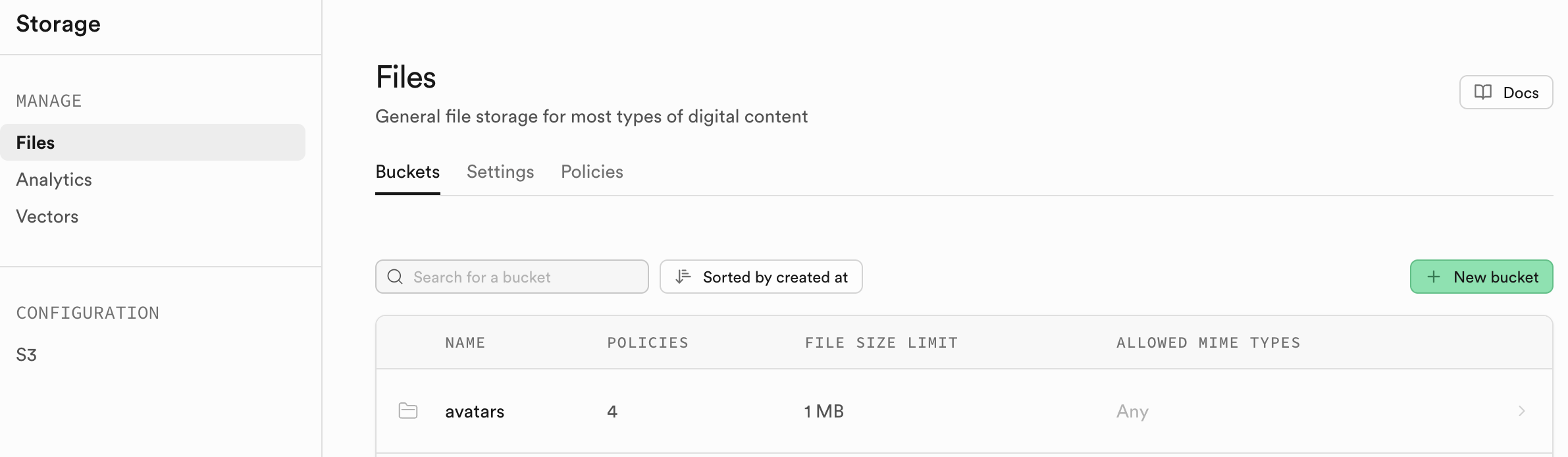
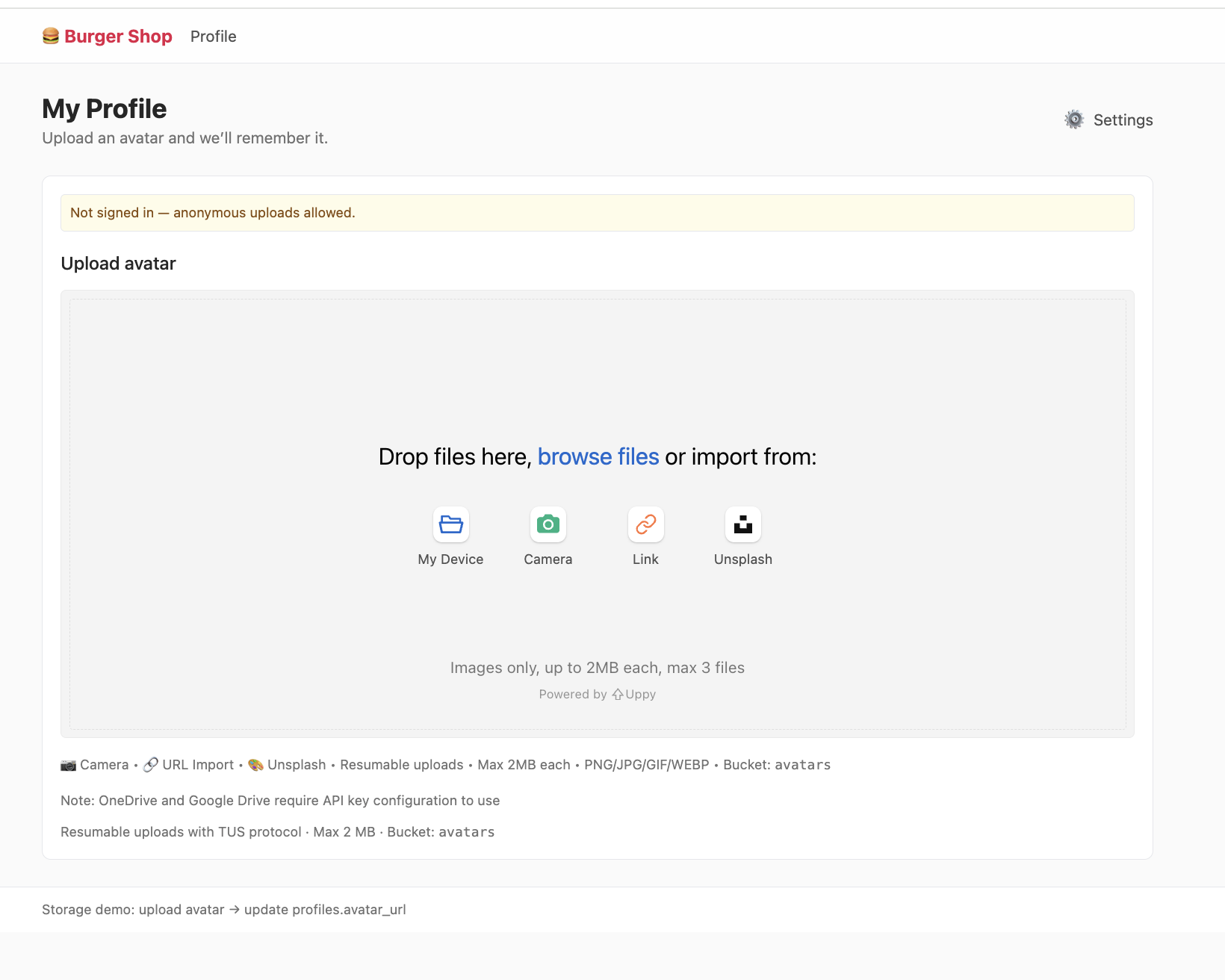
5.4.1 Buckets de stockage
Les fichiers sont organisés en Buckets avec des politiques de sécurité.
5.4.2 URLs de fichiers
- Public URL : lien permanent pour les ressources publiques.
- Signed URL : lien temporaire sécurisé (recommandé en production).
5.5 Edge Functions
Le projet project-burger-shop-edge-function-5 montre une conversation LLM en streaming via Edge Functions.
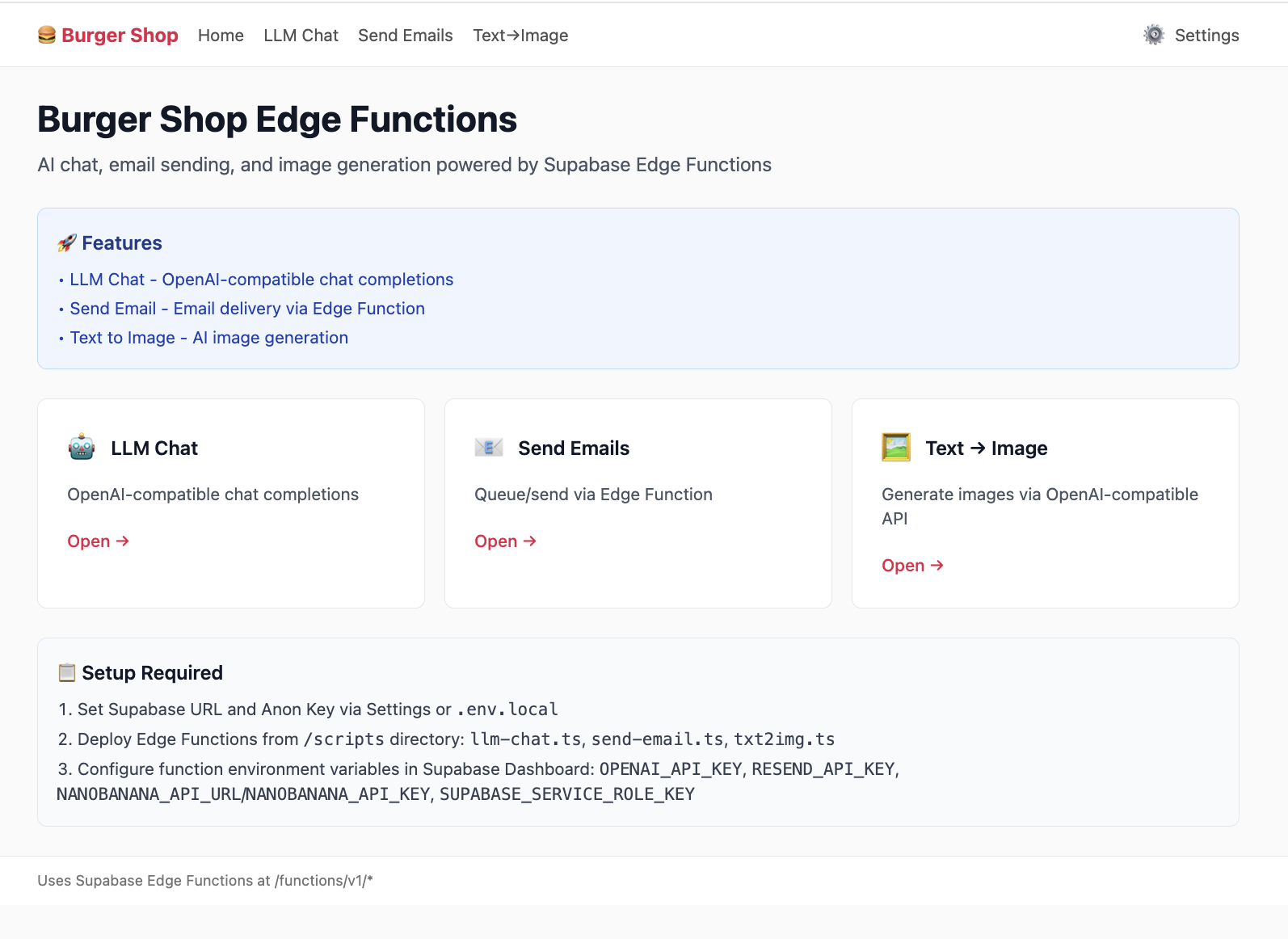
5.5.1 Cas LLM Chat
L'Edge Function agit comme proxy sécurisé entre le frontend et l'API OpenAI.
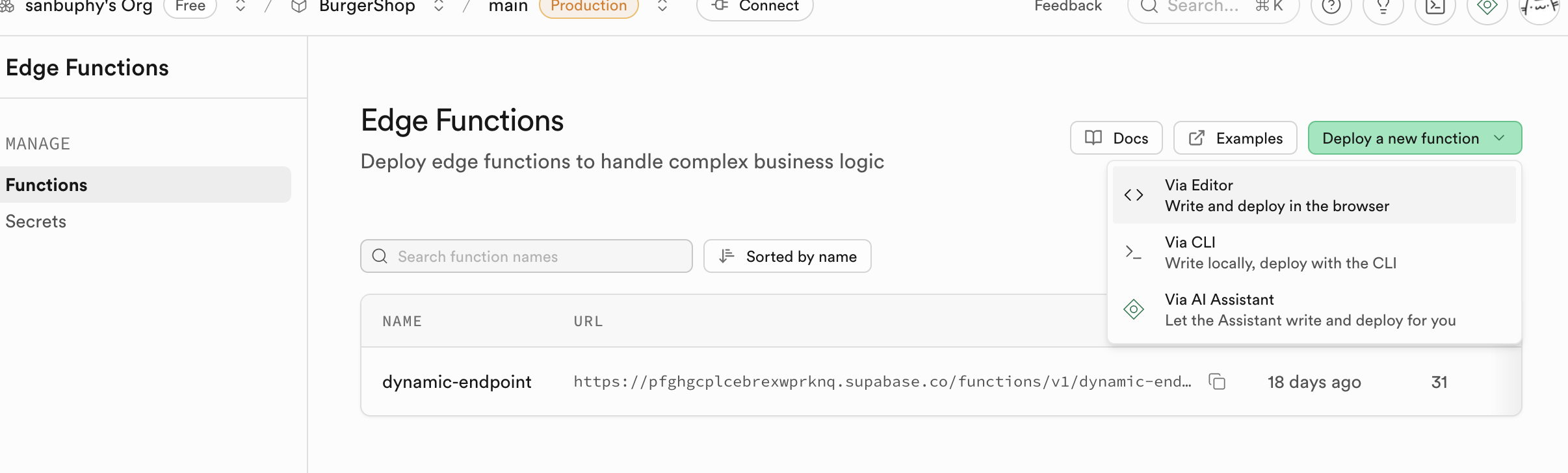
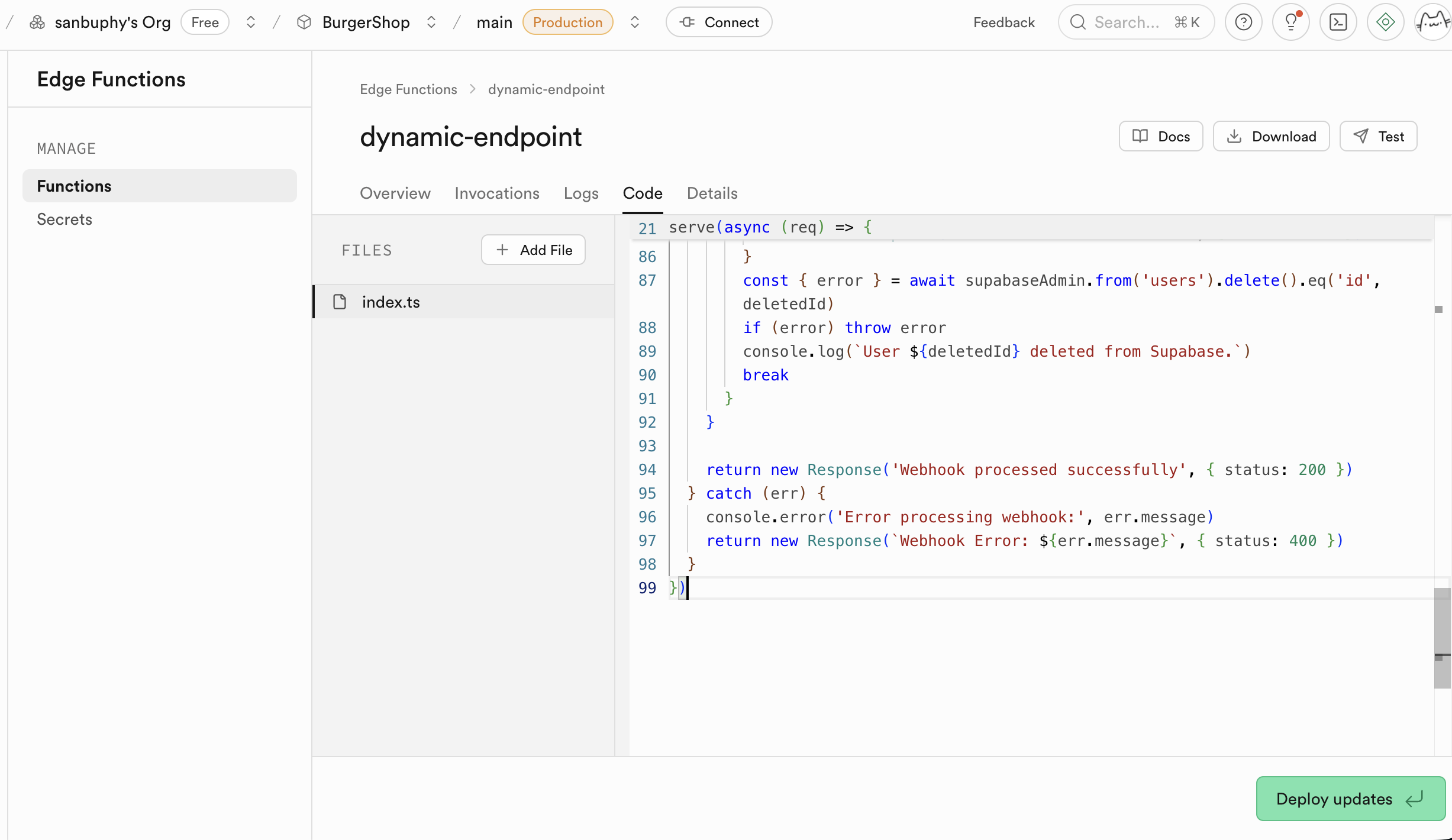
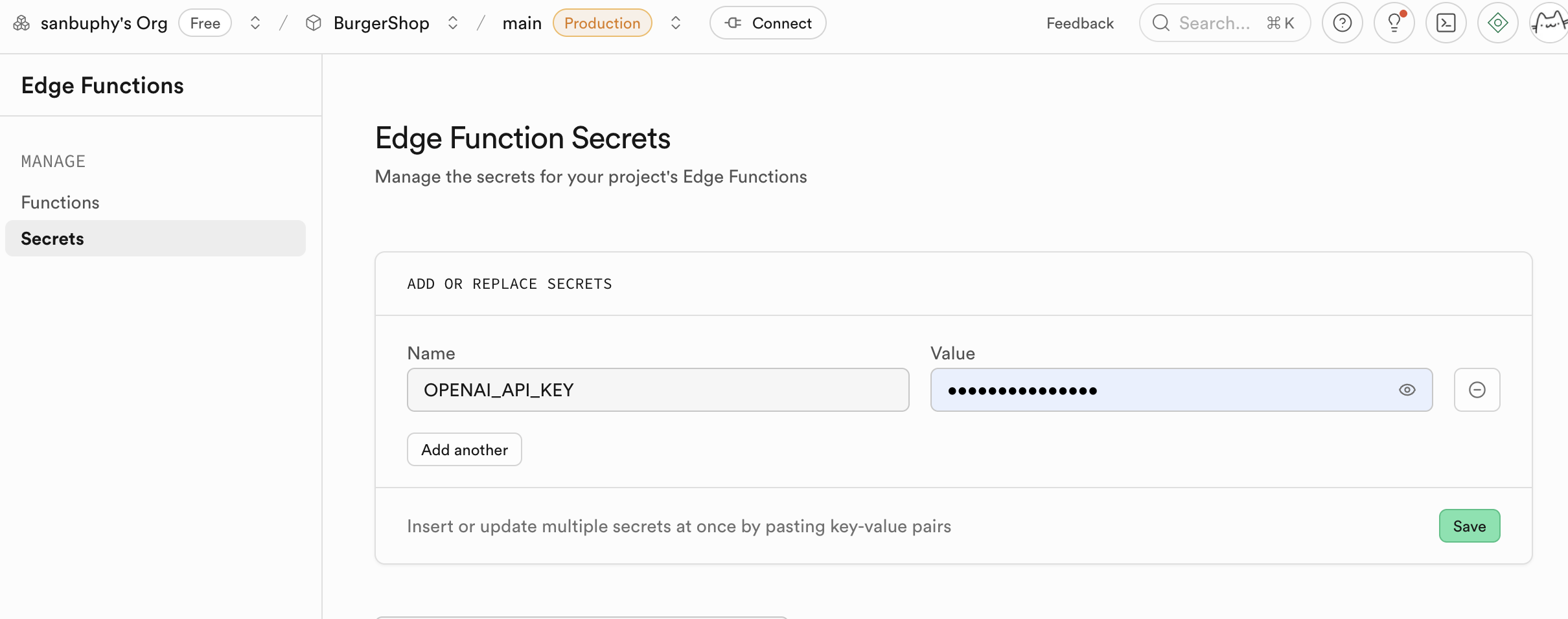
5.6 Connexion Clerk
Clerk est un outil d'authentification professionnelle. Le projet project-burger-shop-auth-advanced-clerk-7 illustre son intégration avec Supabase.
5.6.1 Créer une application Clerk
Visitez dashboard.clerk.com pour créer votre application.
5.6.2 Intégration native Supabase-Clerk
Configurez l'intégration dans Clerk Dashboard > Integrations > Supabase.
5.6.3 Synchronisation des utilisateurs via Webhook
Utilisez un Edge Function Supabase pour recevoir les Webhooks Clerk et synchroniser les utilisateurs.
5.6.4 Connexion tierce avec Clerk
Clerk différencie les environnements de développement et de production pour les connexions sociales.
6. De Supabase aux autres composants backend (avancé)
Supabase couvre l'essentiel, mais chaque capacité (Auth, Storage, Edge Functions, Realtime, Database) a des alternatives spécialisées sur le marché.
Plateformes BaaS similaires
| Plateforme | Type | Gratuité/Prix | Caractéristiques |
|---|---|---|---|
| Firebase | BaaS complet | Spark gratuit, Blaze à l'usage | Le plus mature, bonne documentation |
| Supabase | BaaS open source | 500Mo DB, 1Go Storage | Le plus proche de Firebase en SQL |
| Appwrite Cloud | BaaS open source | Basique gratuit | Moderne, auto-hébergeable |
| Nhost | Postgres + GraphQL | 1Go DB, 1Go Storage | Type « Supabase + Hasura » |
| AWS Amplify | BaaS AWS | Hosting + Cognito 10k MAU | Complet mais complexe |
Authentification (Auth)
| Outil | Caractéristiques | Gratuité |
|---|---|---|
| Firebase Auth | Google BaaS, 50k MAU | Spark gratuit |
| Auth0 (Okta) | Entreprise, SSO, MFA | 25k MAU gratuit |
| AWS Cognito | AWS natif | 10k MAU/mois |
| Logto | Open source | 50k MAU cloud gratuit |
| Keycloak | Open source IAM | Entièrement gratuit (auto-hébergé) |
Stockage de fichiers (Storage)
| Plateforme | Type | Gratuité |
|---|---|---|
| Amazon S3 | Stockage cloud AWS | 5Go, 20k requêtes/mois |
| Google Cloud Storage | Stockage cloud Google | 1Go via Firebase |
| MinIO | S3 compatible open source | Gratuit (auto-hébergé) |
| Cloudinary | Média + CDN | 25Go bande passante/mois |
Edge Functions
| Plateforme | Caractéristiques | Gratuité |
|---|---|---|
| Cloudflare Workers | Distribué mondial | 100k requêtes/jour |
| Vercel Edge Functions | Intégration Next.js | 1M appels/mois |
| Netlify Edge | Node.js + Edge | ~1M requêtes/mois |
| AWS Lambda@Edge | AWS Serverless | 1M requêtes/mois |
Temps réel (Realtime)
| Plateforme | Caractéristiques | Gratuité |
|---|---|---|
| Firebase Realtime DB | Google BaaS temps réel | 1Go stockage |
| Ably | Pub/sub temps réel | 6M messages/mois |
| Pusher Channels | WebSocket service | 200k messages/jour |
| Socket.IO (auto-hébergé) | Flexibilité maximale | Coût serveur |
Bases de données
| Plateforme | Type | Gratuité |
|---|---|---|
| Neon | Serverless PostgreSQL | 0.5Go, branches |
| Aiven PostgreSQL | PostgreSQL managé | 1Go stockage |
| CockroachDB Cloud | SQL distribué | 10Go stockage |
| TiDB Cloud | MySQL compatible distribué | 25Go max |
| MongoDB Atlas | NoSQL document | 0.5Go stockage |
Résumé
Dans ce cours, nous avons systématiquement appris les concepts fondamentaux des bases de données, la définition et les opérations détaillées de Supabase. Vous pourrez vous référer à ce document à tout moment lors de vos projets ultérieurs.
Rappelez-vous toujours un principe important : Terminez d'abord, perfectionnez ensuite ! Nul besoin de viser la perfection du premier coup -- nous pouvons toujours nous améliorer par itérations successives. Bonne chance dans vos projets pratiques !
📚 Exercice final
- Développez une application intégrant un système de gestion des utilisateurs et une base de données. Idéalement avec davantage de fonctionnalités Supabase (Realtime / Cloud Storage / Edge Function).