데이터베이스에서 Supabase 까지
이전 강의에서는 UI 디자인 도구인 Mastergo와 Figma의 기본 사용법을 배우고, GitHub을 통해 코드를 가져오고 버전을 관리하며, Zeabur를 사용하여 웹사이트를 배포하여 더 많은 사람들이 우리의 앱/웹사이트를 사용할 수 있도록 하는 방법을 배웠어요.
지식을 더 잘 연결할 수 있도록, 이번 강의의 새로운 내용을 시작하기 전에 몇 가지 간단한 질문을 통해 이전 강의의 핵심 포인트를 빠르게 복습해 볼게요:
- 프론트엔드 디자인 도구, Figma, MasterGo의 정의와 사용 방법
- 디자인 시안을 코드로 변환하는 기본 방법
- GitHub이란 무엇인가, SSH를 어떻게 설정하는가, 첫 번째 저장소를 어떻게 만드는가
- 배포란 무엇인가, Zeabur를 어떻게 사용하는가, GitHub 또는 로컬 코드를 공개 네트워크에 배포하여 다른 사람들이 접속할 수 있게 하는 방법
위 질문 중 하나라도 기억이 흐릿하다면, 먼저 이전 강의의 문서와 강의 자료를 다시 확인해 보세요. 언제든지 위챗 학습 그룹에서 질문해 주셔도 좋아요.
이번 강의에서는 APP/웹사이트가 단순히 실행되는 것을 넘어, 실제 온라인 제품에 더 가까워지도록 만드는 방법을 배울 거예요: 데이터베이스로 프로그램 실행 중 다양한 데이터 변화를 관리하는 것 외에도, 완성도 높은 사용자 시스템(회원가입, 로그인, 권한 등)과 다른 핵심 백엔드 역량을 갖추어야 해요. Supabase라는 백엔드 서비스 플랫폼을 주축으로, 먼저 "데이터베이스 + 사용자 시스템"이라는 두 가지 기본 기능을 구현하고, Supabase가 제공하는 컴포넌트를 참고하여 현대 클라우드 서비스 백엔드가 일반적으로 포함하는 핵심 모듈과 각 모듈의 구체적인 역할 및 작동 논리를 더 깊이 이해할 거예요.
배울 내용
- 데이터란 무엇인가, 데이터베이스란 무엇인가, 일반적인 데이터베이스와 사용 방법
- Supabase란 무엇인가, Supabase를 사용하여 기본 데이터베이스 작업을 수행하는 방법
- Supabase를 사용하여 앱에 기본 사용자 관리 기능을 추가하는 방법
- Supabase 고급 기능 배우기: realtime, storage, edge function
- Supabase에 Google과 GitHub 로그인 지원 추가하기
- 사용자 회원가입/로그인을 지원하고, 데이터를 온라인 데이터베이스에 저장할 수 있는 기본 앱
- 후속 프로젝트에 바로 적용할 수 있는 재사용 가능한 Supabase 백엔드 코드 템플릿 (데이터베이스 + 사용자 관리 등)
1. 데이터베이스란 무엇인가
1.1 데이터란 무엇인가
디지털 세계에서 데이터(Data)는 어디에나 존재해요. 간단히 말해, 데이터는 정보의 담체예요. 친구의 연락처, 위챗 글 하나, 짧은 동영상, 게임 속 캐릭터 레벨 — 이 모든 것이 데이터랍니다. 우리 앱에서 데이터란 기록되고 관리되어야 하는 모든 정보를 말해요. 예를 들어 사용자의 개인 프로필, 주문 기록, 프로그램 설정 등이 있죠.
일반적으로 데이터는 프로그램에서 다양한 형태로 표현되며, 가장 간단한 것은 변수예요. 우리는 다양한 변수를 사용하여 간단한 숫자를 기록할 수 있어요:
# Python variable definition examples
# Integer variable: stores age information
age = 30
# Boolean variable: stores status (whether active)
is_active = True # True means active, False means inactive
# List variable: stores a set of score data
scores = [85, 92, 78, 90] # Contains 4 integer elements representing different scores
# Dictionary variable: stores multiple related information of a user
user_info = {
"age": 30, # Key "age" corresponds to the value of age
"height": 1.80, # Key "height" corresponds to the value of height (unit: meter)
"login_count": 156 # Key "login_count" corresponds to the value of login times
}앞서 언급한 개인 프로필, 주문 기록 같은 복잡한 데이터의 경우, 더 복잡한 표를 사용하여 데이터를 표현할 수 있어요:
| user_id | name | |
|---|---|---|
| 1001 | Alice | alice@example.com |
| 1002 | Bob | bob@example.com |
| order_id | user_id | amount | status |
|---|---|---|---|
| 901 | 1001 | 29.99 | completed |
| 902 | 1002 | 15.50 | pending |
하지만 구조가 복잡하고 계층적 관계가 있거나 필드가 고정되지 않은 데이터의 경우, JSON 형식으로 설명할 수 있어요 — JSON은 인터넷에서 통용되는 데이터 중간 형식으로, 거의 모든 프로그램이 읽고 파싱할 수 있어서 시스템 간 데이터 전송에 매우 편리해요. 예를 들어, 하나의 주문에 여러 상품이 포함될 수 있고, 각 상품에는 이름, 수량, 가격이 있죠. 전통적인 표로 나타내려면 매우 번거로워요: "주문 테이블"과 "상품 테이블" 등 여러 테이블로 나누어 연결 필드로 "주문에 상품이 포함된다"는 관계를 나타내야 하거나, 한 테이블에 "상품 1 이름, 상품 1 가격, 상품 2 이름..."과 같은 중복 필드를 사용해야 하는데, 상품 수가 고정되지 않으면 적응할 수 없어요. 반면 JSON은 중첩 구조를 사용하여 "주문 - 상품 - 상품 속성"의 계층을 직접적으로 명확하게 보여줘요. 직관적이면서도 유연하죠.
{
"order_id": 901,
"user_id": 1001,
"amount": 29.99,
"status": "completed",
"items": [
{ "sku": "BG-001", "name": "소고기 버거", "quantity": 1, "price": 18.00 },
{ "sku": "SD-003", "name": "감자튀김", "quantity": 1, "price": 6.99 },
{ "sku": "DK-002", "name": "콜라", "quantity": 1, "price": 5.00 }
],
"shipping_address": {
"street": "과학공원로 123번지",
"city": "선전",
"zip_code": "518057"
}
}더 나아가, 벡터(Vector)로 인코딩된 데이터를 생각해 볼 수 있어요. 벡터 데이터는 일반적으로 텍스트, 이미지 또는 오디오와 같은 비정형 데이터가 AI 모델(예: Embedding 모델)에 의해 처리된 후 얻어지는 수치 표현이에요. 그 표현 형태는 다음과 같을 수 있어요:
[0.123, -0.456, 0.789, ..., -0.234] (수백에서 수천 개의 부동소수점 숫자로 구성된 배열)
요약하자면, 현실 세계에는 다양한 형태와 용도의 데이터가 너무 많아서 각각의 데이터 유형에 맞는 전문 데이터베이스가 필요해요. 아래 이미지를 참조해 보세요 — 정말 많죠?
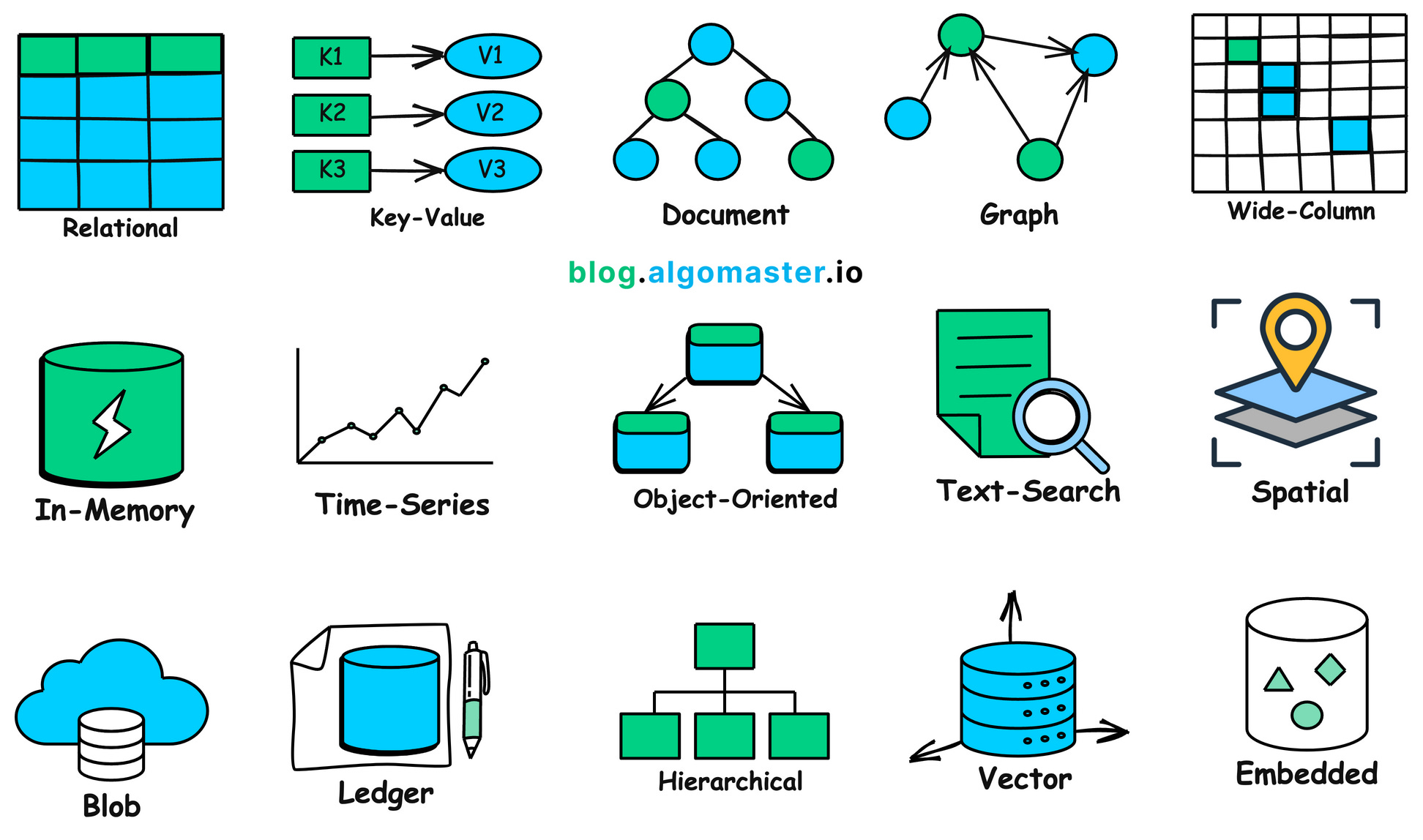
1.2 왜 데이터베이스가 필요한가
우리는 이미 현실 세계의 데이터가 종종 복잡한 구조를 가진다는 것을 알고 있어요. 이러한 데이터를 효율적으로 저장하고 사용하기 위해, 데이터를 관리하는 전용 프로그램이나 컨테이너가 필요해요 — 이것이 바로 데이터베이스(Database)가 탄생한 이유예요. 데이터베이스는 본질적으로 특수한 프로그램으로, 핵심 역할은 데이터를 체계적으로 조직화하고, 안전하게 저장하며, 체계적으로 관리하고, 효율적인 조회와 호출을 지원하는 거예요.
상상해 보세요. 데이터베이스가 없다면 앱 데이터는 어떤困境에 빠질까요? 사용자가 브라우저를 닫거나 앱을 종료하면 일시적으로 로드된 모든 정보가 그대로 손실돼요. 사용자의 사용 상태(예: 로그인 정보, 개인화 설정)를 영구적으로 저장할 수도 없고, 다른 사용자 간에 핵심 데이터(예: 상품 재고, 주문 기록)를 공유할 수도 없어요. 모든 데이터를 저장해 줄 장치가 필요해요!
더 유연한 점은, 데이터베이스의 배포 방식을 필요에 따라 선택할 수 있다는 거예요. 로컬 서버에 배포하여 데이터의 로컬 관리 요구를 충족할 수도 있고, 클라우드에 배포할 수도 있어요. 클라우드 데이터베이스는 탄력적 확장(Scale)을 지원하여 데이터 양과 액세스량이 증가함에 따라 용량을 확장하고 대량의 데이터와 높은 동시성을 처리할 수 있어, 사용자 수가 크게 증가하더라도 정상적인 사용자 경험을 보장해요.
요약하자면, 데이터베이스는 효율적인 영구 저장, 정밀한 관리 및 빠른 조회 능력을 통해 다음과 같은 핵심 문제를 주로 해결해요:
- 데이터의 영구 저장: 데이터베이스가 없다면 데이터는 앱의 메모리에만 존재하게 되고, 앱이 종료되면 데이터가 손실돼요. 데이터베이스는 이 문제를 해결하여 데이터를 하드 디스크 등의 저장 매체에 영구적으로 저장하여 장기 보존을 보장하고 손실 위험을 줄여줘요.
- 편리한 데이터 조회 및 분석: 데이터베이스는 강력한 쿼리 언어(예: SQL)를 제공하여, 사용자가 대량의 데이터에 대해 복잡한 조회, 필터링 및 분석을 쉽고 효율적으로 수행할 수 있게 해줘요. 이를 통해 기업은 더 현명한 의사결정을 내릴 수 있어요. 데이터베이스가 없다면 많은 양의 정렬되지 않은 파일에서 특정 정보를 찾는 것은 매우 시간이 많이 걸리고 어려운 작업이 될 거예요.
- 고성능 및 높은 동시성 액세스 지원: 데이터베이스는 인덱스 최적화, 쿼리 캐싱, 연결 풀 및 분산 아키텍처 등의 기술을 통해 밀리초 단위로 쿼리 요청에 응답하고, 수천 명의 사용자 동시 액세스를 지원할 수 있어요. 이는 현대 인터넷 애플리케이션(예: 전자상거래 플랫폼의 플래시 세일, 소셜 네트워크의 실시간 피드)에 매우 중요하며, 시스템의 응답 속도와 사용자 경험을 보장해요. 데이터베이스의 고성능 지원이 없다면, 대량의 사용자 요청에 직면했을 때 시스템에 심각한 지연이 발생하거나 충돌할 수 있어요.
- 데이터의 무결성과 일관성 보장: 데이터베이스는 일련의 메커니즘(예: 제약 조건, 트리거)을 통해 데이터의 정확성과 일관성을 보장해요. 이는 데이터베이스의 데이터가 미리 설정된 규칙을 준수해야 한다는 것을 의미해요. 예를 들어, 사용자의 나이는 숫자여야 하고, 주문 번호는 고유해야 하며, 이를 통해 불법적이거나 유효하지 않은 데이터의 생성을 효과적으로 방지해요.
- 데이터 보안 보장: 데이터베이스는 사용자 인증, 액세스 제어 및 데이터 암호화 등을 포함한 강력한 보안 메커니즘을 제공하여, 데이터를 무단 액세스, 수정 또는 파괴로부터 보호해요. 하드웨어 고장, 인적 오류 또는 악의적인 공격 등의 예상치 못한 상황에 대비하여, 데이터베이스는 데이터 백업 및 복구 기능도 제공해요. 정기적인 백업을 통해 데이터 손실이나 손상 시 적시에 복구할 수 있어, 비즈니스의 연속성을 보장해요.
1.3 관계형 데이터베이스와 비관계형 데이터베이스
앞서 데이터베이스의 핵심 가치, 배포 방식 및 탄력적 장점에 대해 알아보았고, 실제 선택 시 가장 먼저 직면하는 것은 데이터베이스의 두 가지 핵심 카테고리예요: 관계형 데이터베이스와 비관계형 데이터베이스(NoSQL). 두 가지의 차이를 간단한 두 문장으로 이해해 볼 수 있어요:
관계형 데이터베이스는 구조가 엄격한 Excel 표와 같아요. 모든 데이터는 미리 형식을 정의해야 하고 (Schema의 내용을 정의, 예를 들어 이름과 나이가 있어야 하며, 이름은 텍스트, 나이는 숫자여야 함), 연결 필드(다른 테이블을 연결하는 데 사용되는 식별자, 예: 주민등록번호)를 통해 다른 테이블을 연결해요. 장점은 데이터가 정확하고 신뢰할 수 있으며, 은행 이체, 재고 관리 등 오류가 허용되지 않는 시나리오에 특히 적합하다는 거예요. 단점은 구조 조정이 번거롭고, 대량의 데이터에서 성능이 제한될 수 있다는 거예요.
비관계형 데이터베이스는 유연한 폴더와 같아요. 형식이 다른 문서, 이미지 또는 키-값 쌍(사전의 "단어-설명" 구조와 유사)을 저장할 수 있으며, 각 데이터의 구조를 미리 규정할 필요가 없어요. 빠르게 변화하는 요구와 초대규모 데이터(예: 소셜 미디어의 수많은 게시물)에 더 쉽게 대응할 수 있고, 확장(서버를 추가하여 성능 향상)도 더 편리해요. 하지만 일부 연결 쿼리 능력(다른 데이터 테이블 간 정보를 정리하는 능력)과 일관성 보장(데이터가 항상 정확하고 모순되지 않도록 보장)을 희생하며, 내결함성 요구가 높은 인터넷 애플리케이션에 적합해요.
그렇다면 실제 응용에서 데이터베이스를 어떻게 선택해야 할까요? 시나리오별로 요약하면, 관계형 데이터베이스는 금융 거래, 재고 관리, 주문 처리, 회계 시스템 등 강력한 일관성, 복잡한 트랜잭션 처리 및 빈번한 읽기-쓰기 균형 액세스가 필요한 시나리오에서 흔히 사용돼요. 반면 비관계형 데이터베이스는 소셜 미디어 콘텐츠 저장, 실시간 로그 분석, 사물인터넷 대량 데이터 쓰기, 추천 시스템 특성의 읽기/쓰기가 많은 등 높은 동시성, 불균형한 읽기-쓰기 패턴 및 유연한 구조의 요구에 더 적합해요.
하지만 기업의 경우 초기 단계에서 어떤 데이터베이스를 사용해야 할지 고민하는 데 많은 시간을 들일 필요가 없어요. 현재 데이터베이스는 이미 매우 성숙한 제품 서비스이며, 가장 직접적인 방법은 다양한 클라우드 서비스 제공업체(서버, 스토리지, 데이터베이스, 소프트웨어, 컴퓨팅 파워 등 IT 리소스와 기술 서비스를 제공하는 서비스 제공업체를 의미)에 문의하는 거예요. 클라우드 서비스 공식 영업팀과 직접 소통하여 자체 제품 비즈니스 요구에 맞는 데이터베이스 솔루션을 매칭할 수 있어요. 기업급 애플리케이션을 구축하는 편리한 경로는 전문 업체와 우선 협력하는 거예요. (주의: 기업급 서비스는 일반적으로 가격이 높으므로, 먼저 여러 곳을 조사하고 비교하는 것이 좋아요. 서버를 구매하여 오픈소스 데이터베이스 프로그램을 직접 배포하는 것도 대안으로 선택할 수 있어요.)
특정 클라우드 제공업체의 데이터베이스 선택 추천을 참조할 수도 있어요. 시나리오에 따라 다양한 데이터베이스 유형을 선택할 수 있고, 다양한 클라우드 제공업체의 데이터베이스 사양을 비교하여 가장 적합한 것을 선택할 수 있어요.
| 데이터베이스 유형 | 데이터베이스 이름 | 가격 | 적용 시나리오 |
|---|---|---|---|
| 관계형 데이터베이스 | RDS MySQL 버전 | 낮음 | 기본 버전: 학습 및 소규모 웹사이트 / 고가용성 버전: 일정한 비즈니스 부담이 있는 중형 데이터베이스 시나리오 / 클러스터 버전: 비즈니스 중단이 허용되지 않고 액세스 압력이 큰 경우 |
| RDS SQL Server 버전 | 높음 | 기본 버전: 테스트 및 소규모 상업 웹사이트 / 고가용성 버전: 기업급 상업 웹사이트 / 클러스터 버전: 기업 비즈니스 중단이 허용되지 않고 액세스 압력이 큰 경우 | |
| RDS PostgreSQL 버전 | 최저 | 기본 버전: 학습 및 소규모 웹사이트 / 고가용성 버전: 일정한 비즈니스 부담이 있는 중형 데이터베이스 시나리오 / 클러스터 버전: 비즈니스 중단이 허용되지 않고 액세스 압력이 큰 시나리오, 일반 MySQL보다 성능이 높음 | |
| RDS PPAS 버전 | 높음 | 범용형: Oracle 호환 비즈니스, 비즈니스 부담이 낮고 가상화로 요구 충족 가능 / 독점형: 독점 물리 서버가 필요한 비즈니스, 일반적으로 높은 동시성 Oracle 유형 비즈니스 | |
| DRDS | 중간 | 입문 버전: 4 Core 8G, 가격이 합리적이고 중소규모 온라인 비즈니스에 적합 / 기업 버전: 16 Core 32G, 복잡한 SQL 응답이 좋고 초고동시성 온라인 비즈니스에 적합 / 최고급 버전: 32 Core 64G, 복잡한 SQL 실행 응답이 가장 좋고 초대형 사양 선택 제공 | |
| NoSQL 데이터베이스 | Redis | 중간 | 듀얼 머신 핫 스탠바이 Redis: 일반적으로 영구 데이터베이스로 비즈니스 가용성 향상 / 클러스터 버전 Redis: 일반적으로 캐시 레이어로 애플리케이션 액세스 가속화, 일반 데이터베이스가 감당할 수 없는 읽기 압력 해결 |
| MongoDB 버전 | 중간 | 단일 노드 인스턴스: 개발, 테스트 및 기업 핵심 데이터가 아닌 저장 시나리오에 적합 / 레플리카 셋 인스턴스: 읽기 성능 요구가 높은 비즈니스 시나리오(예: 읽기 중심 웹사이트, 주문 조회 시스템) 또는 임시 이벤트 등 급증 비즈니스 요구에 적합 / 샤딩 클러스터 인스턴스: 더 높은 읽기 성능 요구 제공 |
말로만 설명하면 이해하기 어려우니, 구체적인 "블로그 글" 시나리오를 통해 동일한 데이터가 관계형 데이터베이스(SQL)와 다양한 유형의 비관계형 데이터베이스(NoSQL)에서 어떻게 저장되는지 살펴볼게요.
블로그 플랫폼이 있고 다음 정보를 저장해야 한다고 가정해 볼게요:
- 사용자(Users): 사용자 ID, 사용자 이름, 이메일
- 글(Posts): 글 ID, 제목, 내용, 작성자 ID
- 댓글(Comments): 댓글 ID, 댓글 내용, 댓글 작성자 ID, 소속 글 ID
- 태그(Tags): 태그 ID, 태그 이름
- 글과 태그의 관계: 단일 글에 연결된 여러 태그, 단일 태그에 해당하는 여러 글
관계형 데이터베이스 (SQL) 예시
SQL 데이터베이스에서는 다양한 유형의 데이터를 각각 다른 테이블에 저장하고, "외래 키(Foreign Key)"를 통해 연결해요. 이 구조는 명확하고 체계적이며, 데이터 중복을 줄여줘요.
"콘텐츠 플랫폼의 글 관리"를 예로 들면, "사용자, 글, 댓글, 태그"를 섞어서 저장하지 않고 5개의 기능이 단일화된 테이블로 나누어요. 각 테이블에는 명확한 "역할 경계"와 엄격한 구조 정의(Schema)가 있어요:
users테이블 (사용자 정보 저장)
| user_id (기본 키) | username | |
|---|---|---|
| 101 | Alice | alice@example.com |
| 102 | Bob | bob@example.com |
posts테이블 (글 정보 저장)
| post_id (기본 키) | title | content | author_id (외래 키) |
|---|---|---|---|
| 1 | SQL 입문 | SQL 데이터베이스에 대한 글입니다... | 101 |
| 2 | NoSQL 입문 | NoSQL은 유연한 데이터 모델을 제공해요... | 102 |
comments테이블 (댓글 정보 저장)
| comment_id (기본 키) | body | commenter_id (외래 키) | post_id (외래 키) |
|---|---|---|---|
| 1001 | 정말 좋아요! | 102 | 1 |
| 1002 | 배웠어요. | 101 | 2 |
| 1003 | 더 많은 예시가 있나요? | 101 | 1 |
tags테이블 (태그 저장)
| tag_id (기본 키) | tag_name |
|---|---|
| 51 | 데이터베이스 |
| 52 | 기술 |
| 53 | 입문 |
post_tags테이블 (글과 태그의 다대다 관계 저장, 조인 테이블 특징 반영)
| post_id (외래 키) | tag_id (외래 키) |
|---|---|
| 1 | 51 |
| 1 | 52 |
| 2 | 51 |
| 2 | 52 |
| 2 | 53 |
"Alice가 작성한 'SQL 입문'(post_id=1)의 전체 정보(글 내용, 작성자, 댓글, 태그 포함)"을 조회하려면, 다중 테이블 조인(JOIN) 쿼리를 실행하여 외래 키로 5개의 테이블을 연결하고 데이터를 집계해야 해요. SQL 문은 다음과 같아요:
SELECT
p.title,
p.content,
u.username AS author,
c.body AS comment,
t.tag_name AS tag
FROM
posts p
JOIN
users u ON p.author_id = u.user_id
LEFT JOIN
comments c ON p.post_id = c.post_id
LEFT JOIN
post_tags pt ON p.post_id = pt.post_id
LEFT JOIN
tags t ON pt.tag_id = t.tag_id
WHERE
p.post_id = 1;이 쿼리는 5개의 테이블을 가로질러 모든 관련 데이터를 집계하여 반환해요. 이것이 관계형 데이터베이스의 핵심 장점이에요: 정규화와 조인 작업을 통해 다양한 복잡한 쿼리를 유연하게 수행할 수 있으면서도 데이터 일관성과 최소 중복을 보장해요.
비관계형 데이터베이스 (NoSQL) 예시
NoSQL 데이터베이스(예: MongoDB, Redis)의 설계 철학은 SQL과 반대예요. 데이터의 분할과 정규화를 강조하지 않고, 비즈니스적으로 관련된 모든 데이터를 하나로 묶어 저장하여 쿼리 시 조인 작업을 줄이고 읽기 성능을 높여요.
NoSQL 데이터베이스에서 문서 데이터베이스(Document Database)는 가장 일반적으로 사용되는 유형 중 하나이며, MongoDB가 대표적인 예예요. "문서"를 기본 저장 단위로 사용하며, 여기서 "문서"는 우리가 일상적으로 이해하는 "글"이 아니라 JSON과 유사한 데이터 구조(MongoDB에서는 BSON 형식을 실제로 사용하여 더 많은 데이터 유형을 지원)를 말해요. 통일된 Schema(데이터 구조)를 미리 정의할 필요가 없고, 각 문서의 필드를 유연하게 추가하거나 줄일 수 있으며, 필드 유형도 자유롭게 조정할 수 있어 데이터 형식이 변화하는 시나리오에 완벽하게 적응해요.
문서 데이터베이스에서는 일반적으로 하나의 글과 그에 관련된 모든 정보(예: 댓글, 태그)를 하나의 문서에 저장해요(문서 형식은 JSON과 유사하며, 필드를 유연하게 정의할 수 있고 Schema를 미리 정할 필요가 없어요). 핵심 논리는 "'하나의 비즈니스 시나리오에서의 완전한 정보'를 하나의 문서에 저장한다"는 것이며, 쿼리 시 여러 데이터 소스를 연결하는 것을 방지해요.
posts 컬렉션의 문서 예시:
{
"_id": 1,
"title": "SQL 입문",
"content": "SQL 데이터베이스에 대한 글입니다...",
"author": {
"user_id": 101,
"username": "Alice",
"email": "alice@example.com"
},
"tags": [
"데이터베이스",
"기술"
],
"comments": [
{
"comment_id": 1001,
"body": "정말 좋아요!",
"commenter": {
"user_id": 102,
"username": "Bob"
}
},
{
"comment_id": 1003,
"body": "더 많은 예시가 있나요?",
"commenter": {
"user_id": 101,
"username": "Alice"
}
}
]
}이 설계의 장점은 매우 직관적이에요: "첫 번째 글의 전체 정보(작성자, 댓글, 태그 포함)"를 가져오려면 _id:1로 이 문서 하나만 쿼리하면 돼요. 데이터베이스 한 번의 읽기로 모든 데이터를 반환할 수 있어서, SQL처럼 3-4번의 테이블 조인 작업을 수행할 필요가 없으며, 읽기 효율이 크게 향상돼요.
하지만 명백한 trade-off(절충안)도 있어요: 데이터가 "집계 저장"되기 때문에 불가피하게 데이터 중복이 발생해요. 예를 들어, 작성자 "Alice"의 username이 그녀가 작성한 모든 글 문서에 포함되어 있어요. 만약 어느 날 "Alice"가 사용자 이름을 "Alice_New"로 변경한다면, 이론적으로 그녀의 정보가 포함된 모든 글 문서를 순회하며 author.username 필드를 하나씩 업데이트해야 해요. 이는 번거로울 뿐만 아니라, 네트워크나 서버 문제로 일부 문서 업데이트가 실패하여 "동일한 사용자가 다른 글에서 사용자 이름이 일치하지 않는" 상황이 발생할 수 있어요.
하지만 실제 비즈니스에서 이러한 중복은 종종 "수용 가능"해요. 블로그, 뉴스, 전자상거래 상품 상세 페이지 등 "읽기가 많고 쓰기가 적은" 시나리오(사용자가 콘텐츠를 보는 횟수가 작성자가 사용자 이름을 수정하는 횟수보다 훨씬 많음)에서는, 약간의 중복으로 "극한의 읽기 성능"을 얻는 것이 더 나은 선택이에요. 반면 "쓰기가 많고 읽기가 적은"(예: 사용자 정보를 자주 수정하는) 시나리오에서는 비즈니스 요구에 따라 문서 데이터베이스 사용 여부를 고려해야 해요.
이상이 다양한 데이터베이스에 대한 간단한 소개였어요. 더 많은 구체적인 데이터베이스 유형에 관심이 있다면, 다음 자료를 참고하여 다양한 유형의 데이터베이스를 사용해 볼 수 있어요.
Examples of SQL databases: Db2, MySQL, PostgreSQL, YugabyteDB, CockroachDB, Oracle Database, Azure SQL Database
Examples of NoSQL databases: Redis, CouchDB, MongoDB, Cassandra, Elasticsearch, BigTable, Neo4j, HBase
2. Supabase
앞서 몇 가지 일반적인 데이터베이스와 각각에 적합한 사용 시나리오를 소개했어요. 하지만 실제 프로젝트에서 데이터베이스는 보통 백엔드 시스템의 기본 모듈 중 하나일 뿐이에요. 데이터를 저장하고 조회하는 것 외에도 사용자 회원가입/로그인, 권한 검증, 파일 업로드 및 저장, 외부 API 인터페이스, 심지어 예약 작업, 실시간 알림 등 일련의 문제를 해결해야 해요. 단순히 데이터베이스를 잘 선택하는 것만으로는 앱이 "즉시 온라인에 출시될 수" 없으며, 그 사이에는 많은 번거로운 백엔드 엔지니어링 작업이 있어요.
따라서 우리는 더 큰 배경을 고려해야 해요: 백엔드 서비스. 완전한 앱은 일반적으로 "프론트엔드 + 백엔드"로 구성돼요. 프론트엔드는 페이지 표시와 사용자 상호작용을 담당하고, 백엔드는 데이터 저장, 사용자 로그인, 비즈니스 로직 처리 등을 담당해요. 과거에는 개발자가 직접 서버를 구축하고, 데이터베이스를 설정하며, API를 설계하고 구현해야 했고, 권한 관리, 보안 정책, 확장성 및 모니터링/운영 등도 수동으로 처리해야 했어요. 전체 과정이 반복적이고 시간이 많이 소요됐어요. 이러한 반복 노동을 해결하기 위해 업계에서는 BaaS(Backend as a Service, 백엔드 as a Service) 가 등장했어요: 데이터베이스, 사용자 인증, 파일 저장, 실시간 기능 등 일반적인 백엔드 기능을 하나의 클라우드 플랫폼으로 패키징하여, 개발자가 SDK/API를 통해 이러한 기능을 직접 호출할 수 있게 하고, 인프라를 처음부터 구축하고 운영할 필요가 없도록 해줘요.
이러한 배경에서 Supabase는 새로운 세대의 BaaS 대표주자로 볼 수 있어요. PostgreSQL을 핵심 데이터베이스로 사용하고, 그 위에 Auth, Storage, Realtime, Edge Functions, Vector 등 완전한 백엔드 역량을 통합하여, 개발자에게 "Postgres 중심의 원스톱 백엔드 플랫폼"을 제공해요. 이제 이 관점에서 출발하여, "데이터베이스만 선택하는 것"에서 "완전한 백엔드 개발 플랫폼을 선택하는 것"으로 업그레이드하여, Supabase가 어떤 작업을 줄여줄 수 있는지, 그리고 어떻게 프로젝트가 프로토타입에서 사용 가능한 제품까지의 거리를 크게 단축할 수 있는지 구체적으로 살펴볼게요.
2.1 단계별 가이드
Supabase의 전체적인 포지셔닝을 명확히 파악한 후, Supabase 콘솔의 작업 경로를 따라 구체적으로 어떤 핵심 역량을 제공하는지, 그리고 각 역량에 해당하는 핵심 책임은 무엇인지 하나씩 살펴볼게요. Supabase와 관련된 각 옵션을 자세히 소개하여, Supabase의 기본 작업에 빠르게 입문할 수 있도록 도와줄게요.

Supabase 공식 웹사이트에 접속하여 로그인한 후, 콘솔 홈페이지에서 New project를 클릭하여 생성 프로세스에 진입해요.
입력해야 하는 주요 내용은 Project Name, 데이터베이스 비밀번호이며, 지역은 프로그램 대상 사용자와 가장 가까운 곳으로 선택하면 돼요.
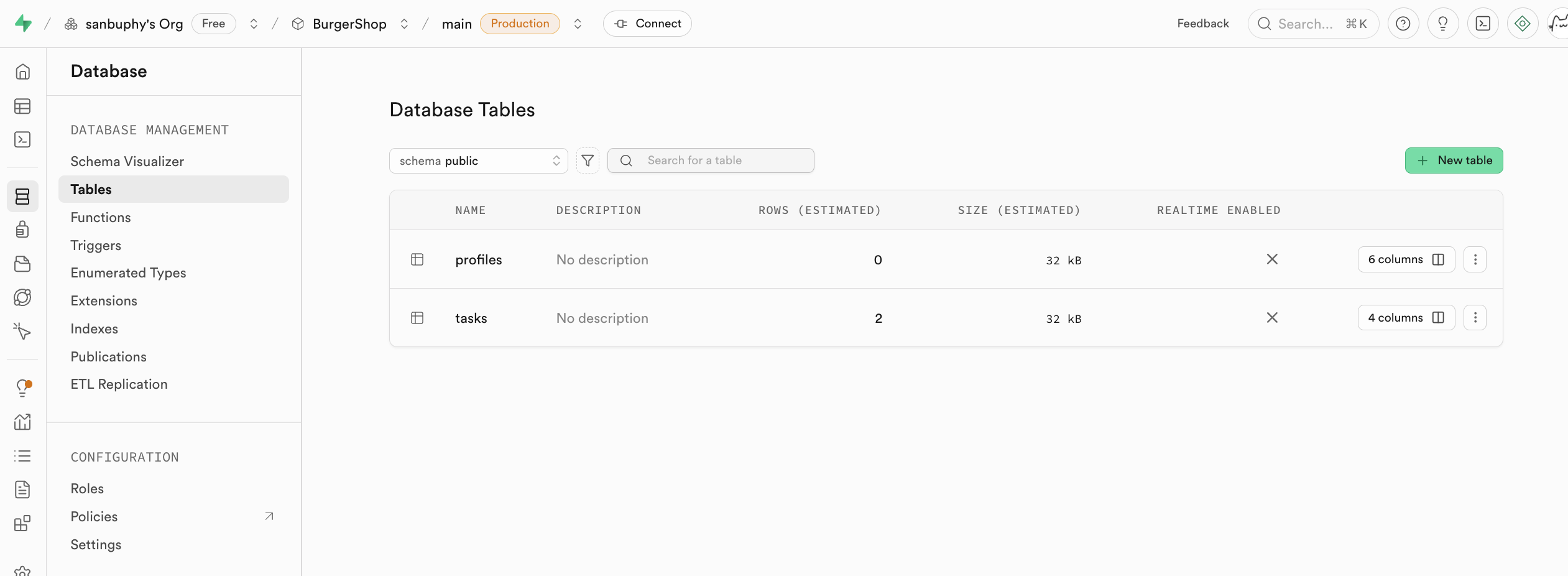
생성이 완료되면, 콘솔 왼쪽 사이드바에 모든 핵심 기능 모듈(Table Editor, SQL Editor, Database, Authentication 등)이 표시되며, 후속 작업은 이러한 모듈을 중심으로 진행돼요.
테이블 편집기
Table Editor는 Supabase의 시각적 데이터 테이블 편집기로 생각할 수 있어요. Excel을 조작하는 것처럼 SQL 문을 작성할 필요 없이 마우스 상호작용만으로 데이터베이스의 데이터를 직접 보고 수정할 수 있어요.
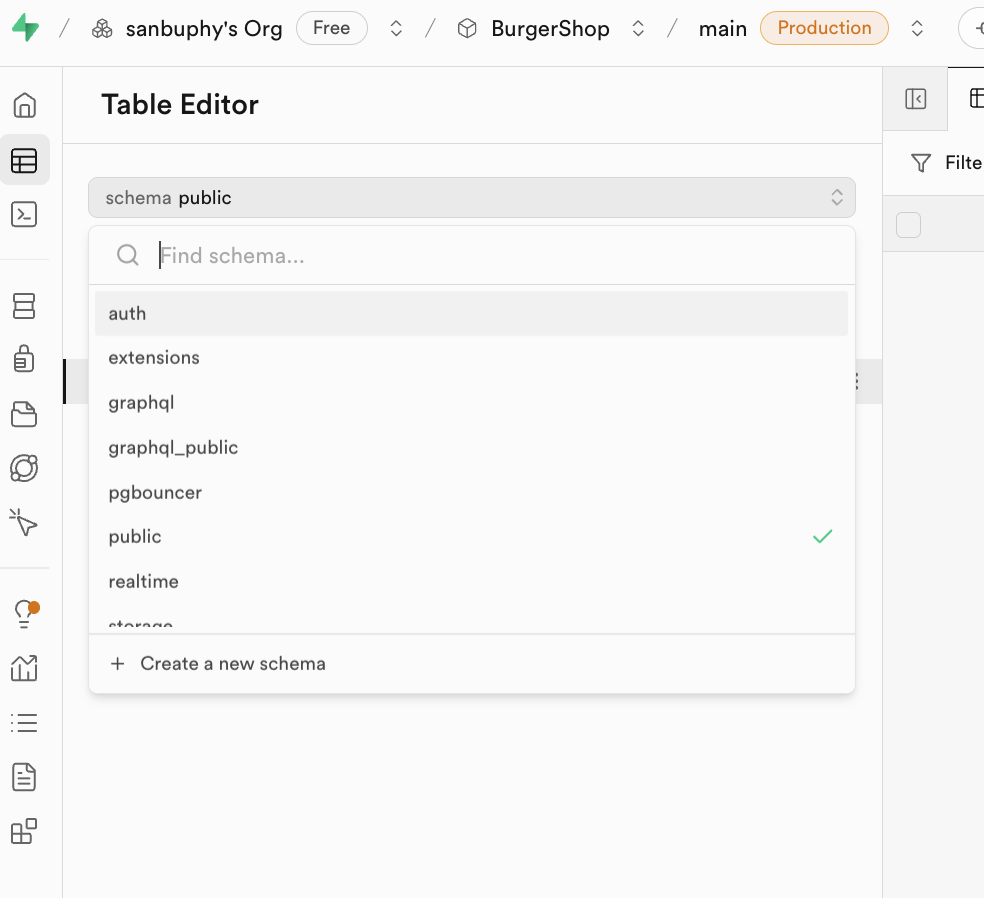
주목할 만한 것은 Schema예요. Schema는 데이터베이스 내의 "리소스 컨테이너"로 이해할 수 있으며, 테이블, 뷰, 함수, 인덱스 등의 리소스를 그룹별로 관리하는 데 사용돼요. 주요 역할은 두 가지예요: 첫째, 이름 충돌을 피하는 것(다른 Schema 아래에 동일한 이름의 테이블이 존재할 수 있음)이고, 둘째, 권한 격리를 실현하는 것(예: 특정 사용자만 특정 Schema의 테이블에 액세스하도록 허용)이에요.
편집기 상단의 Schema 드롭다운을 클릭하면 다른 컨테이너로 전환할 수 있어요. 일상적인 개발에서는 일반적으로 두 가지 유형만 주의하면 돼요:
public: 기본 공개 리소스 컨테이너. 개발자가 새로 만드는 비즈니스 테이블(예: "글 테이블", "댓글 테이블")이 모두 여기에 저장돼요.auth: 사용자 인증 전용 컨테이너. 여기의users테이블에는 모든 등록된 사용자 정보(예: 사용자 ID, 이메일, 로그인 시간)가 자동으로 저장돼요. 인증 기능에 영향을 주지 않도록 이 Schema의 기본 테이블을 수동으로 수정하는 것은 권장하지 않아요.

SQL 편집기
SQL Editor는 Supabase의 SQL 문 실행기로, 코드를 통해 데이터베이스를 직접 조작할 수 있게 해줘요. 대형 언어 모델이 SQL 문을 직접 생성하게 한 후, 오른쪽에 입력하고 RUN을 클릭하면 문을 사용하여 테이블을 생성하거나 수정할 수 있고, Results에서 필터링된 테이블 데이터를 직접 볼 수도 있어요.
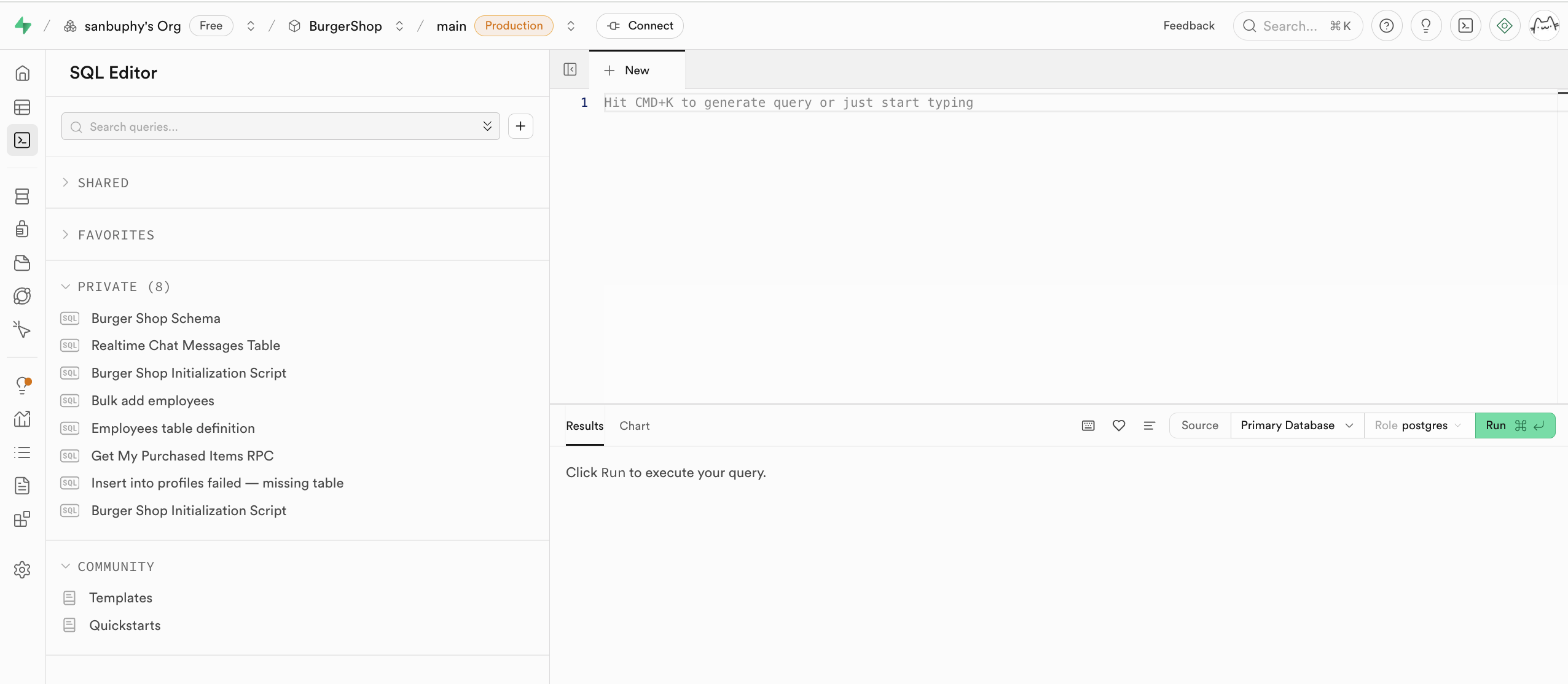
RUN을 실행한 후, Table Editor의 public schema에서 새로 생성된 데이터 테이블을 찾을 수 있어요. 그리고 실행된 문은 왼쪽의 PRIVATE 탭에 저장되며, 하단의 하트 아이콘을 클릭하여 해당 쿼리나 생성 문을 즐겨찾기에 추가할 수도 있어요.
데이터베이스 관리 센터
Database는 Supabase의 데이터베이스 관리 센터로, 모든 데이터 테이블을 시각적으로 보고 관리할 수 있으며, 테이블 간의 상호 연결을 통해 다른 테이블 간의 연결 관계(즉, 외래 키 제약 조건, 데이터 간의 참조 관계를 나타냄)를 이해할 수 있어요.
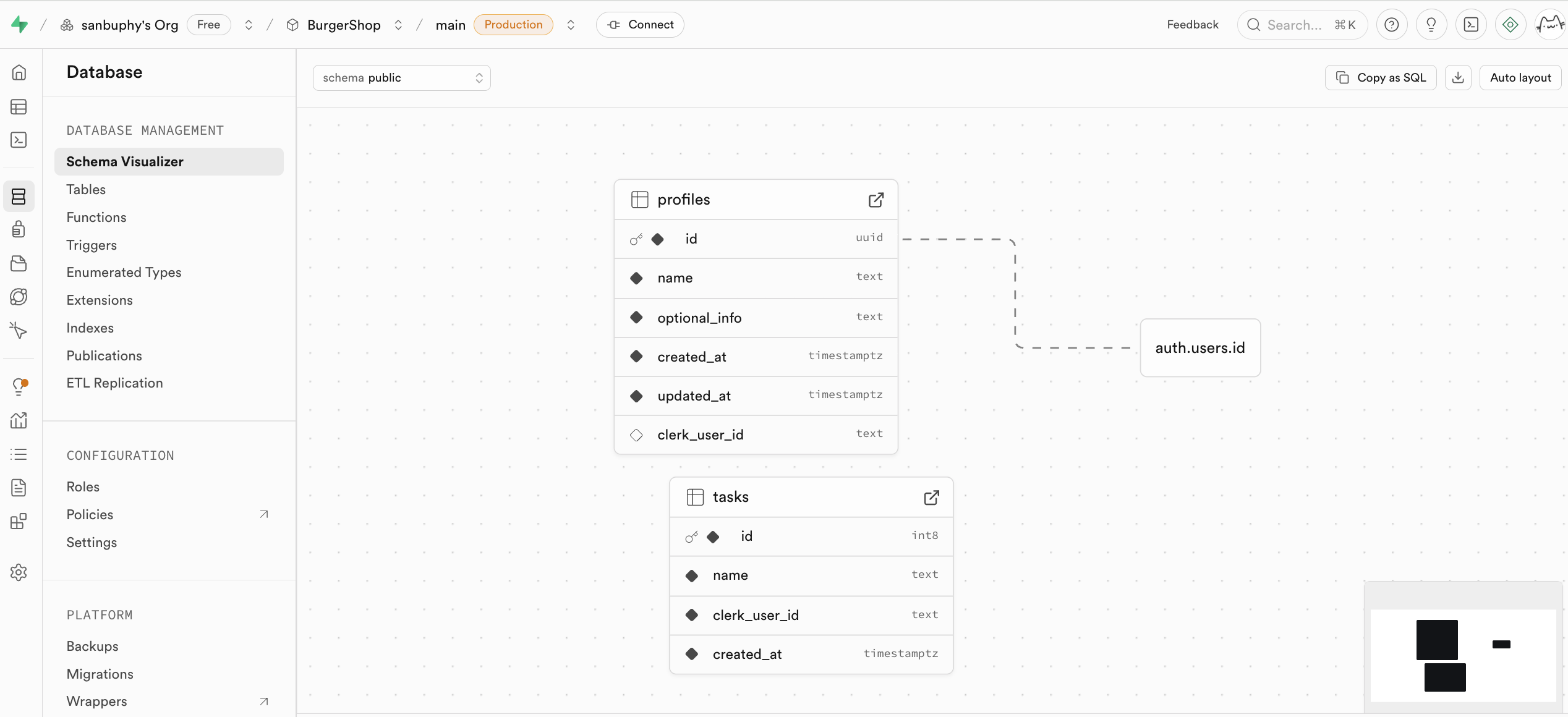
수동으로 새로운 테이블을 만들고 싶다면, tables에서 직접 새로운 테이블을 만들 수 있어요. 이후 튜토리얼에서 자세히 설명할게요.
인증
Authentication은 사용자의 회원가입, 로그인 및 권한 관리를 담당해요. 기본 사용자 관리 시스템 데이터가 모두 여기에 저장돼요. 바로 사용할 수 있는 사용자 회원가입, 로그인, 비밀번호 재설정, 이메일 인증 등의 기능을 제공하며, 타사 OAuth 로그인(예: WeChat, GitHub, Google 등)도 지원해요. 모든 사용자 데이터는 자동으로 데이터베이스의 auth.users 테이블에 동기화돼요.
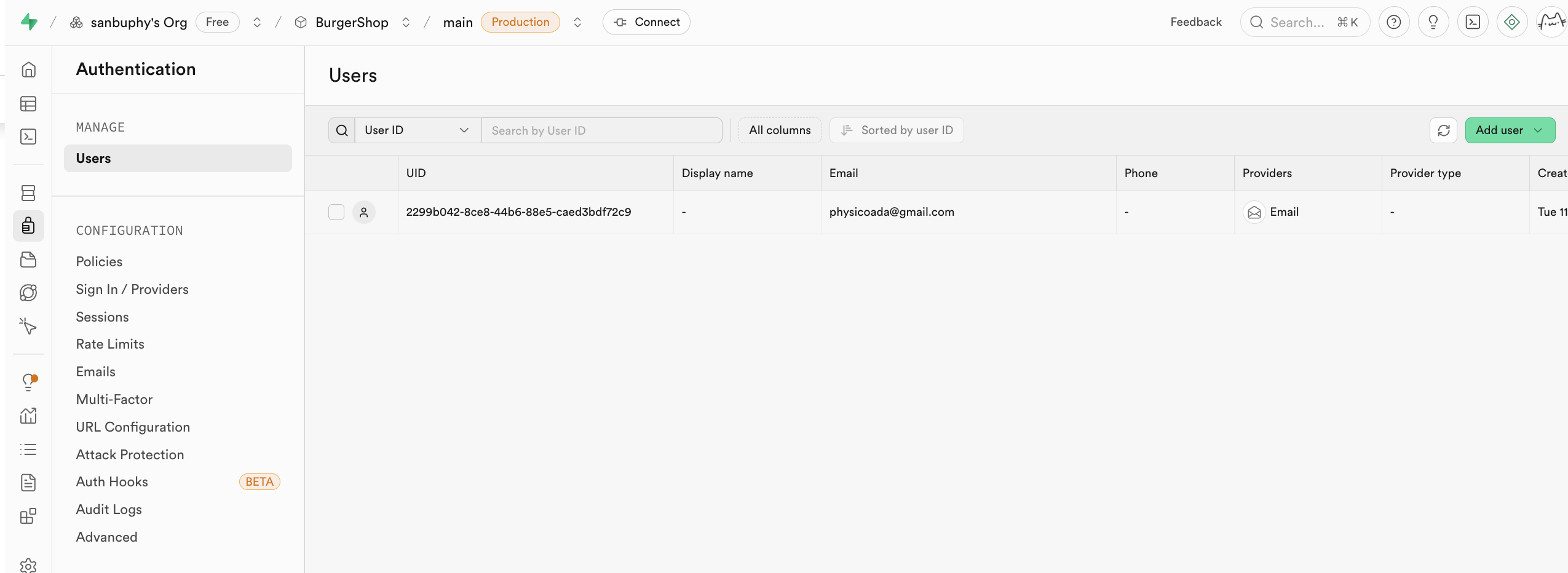
Provider 옵션에서 Supabase가 지원하는 다양한 사용자 정보 로그인 입구를 찾을 수 있어요. 기본적으로 Email을 사용해요. GitHub나 Google 계정으로 로그인하려면 더 많은 속성 설정이 필요하며, 이에 대해서는 아래 강의에서 자세히 설명할게요.
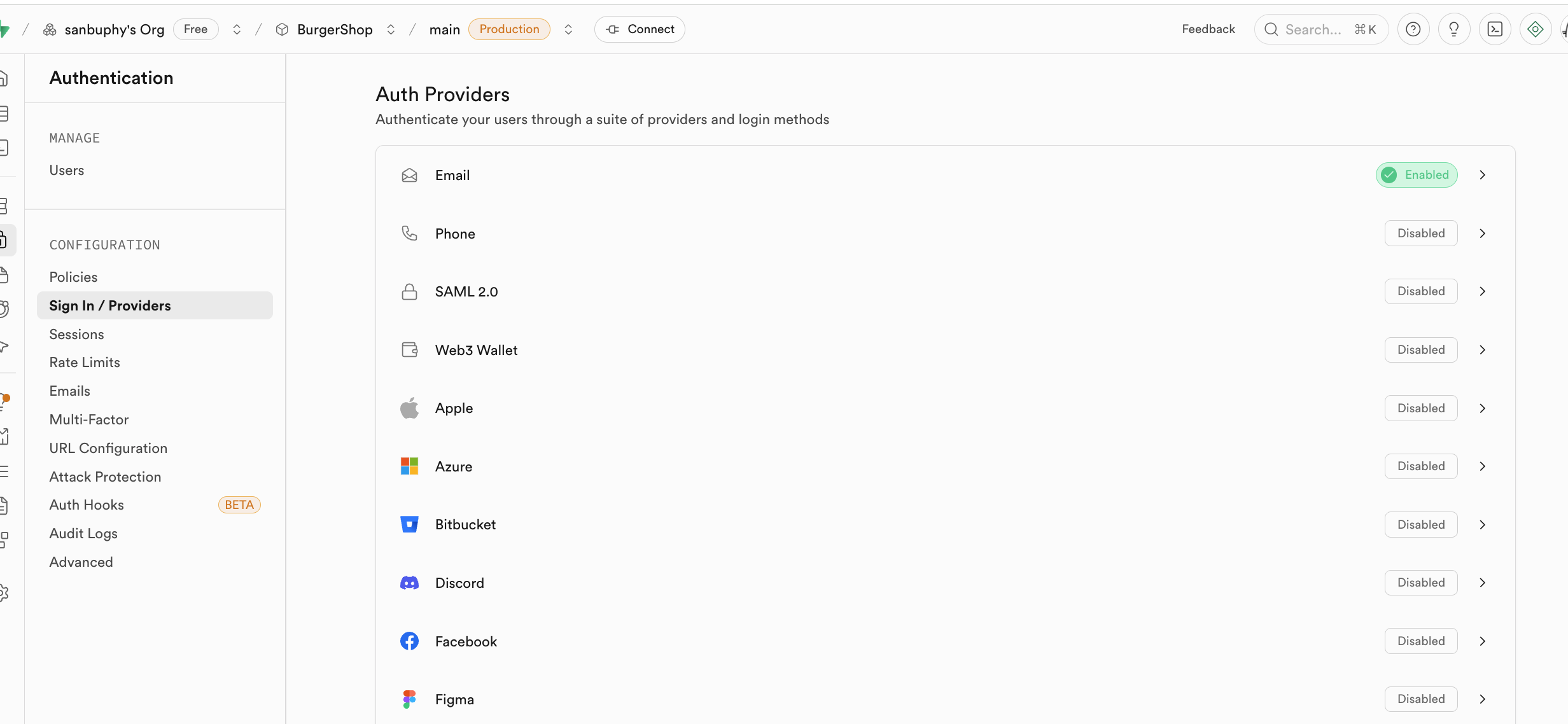
Sign In / Providers에는 등록 이메일 동작에 대한 제어도 포함되어 있어요. 이메일 등록 시마다 사용자가 초대를 수락해야만 사용자가 될 수 있도록 강제하고 싶지 않다면, Confirm email의 필수 요구 사항을 해제할 수 있어요.
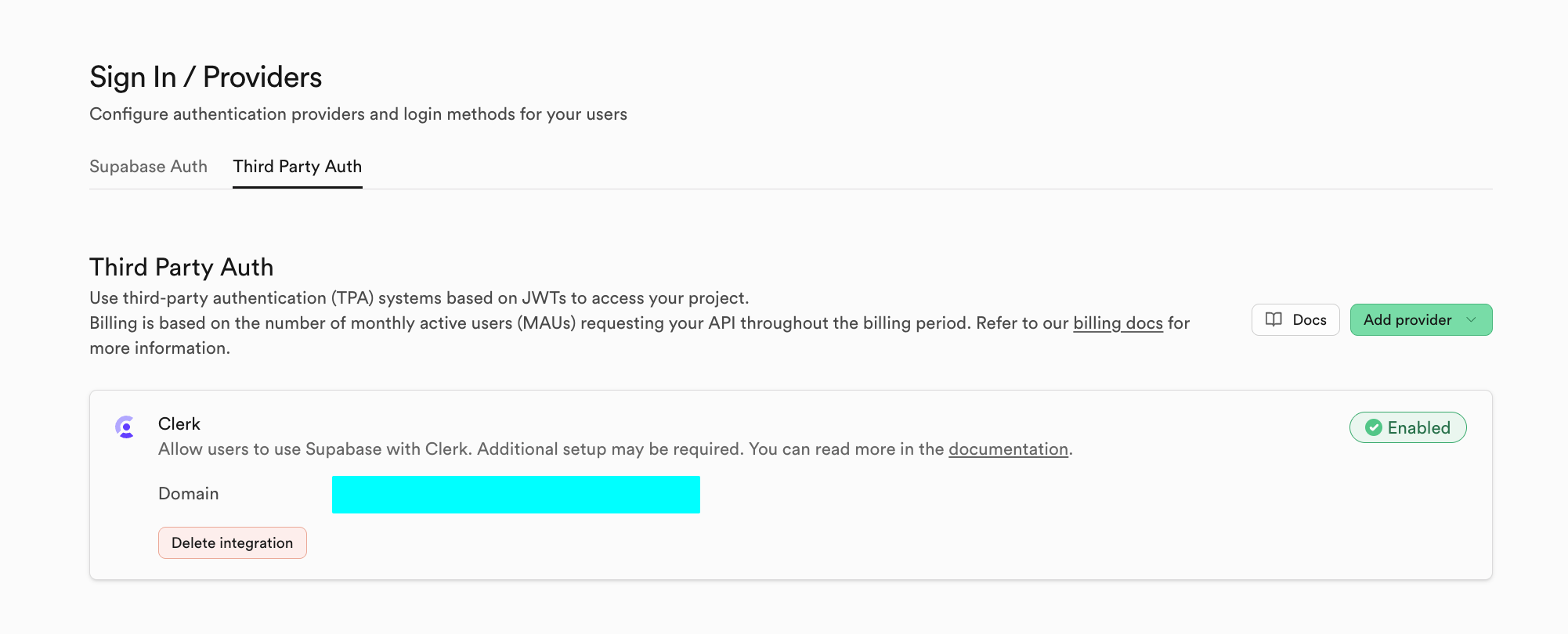
Supabase가 아닌 다른 auth 시스템 제공업체로 전환하고 싶다면, Third Party Auth를 클릭할 수 있어요. 예를 들어 여기서는 Clerk를 타사 시스템 제공업체로 사용해요.
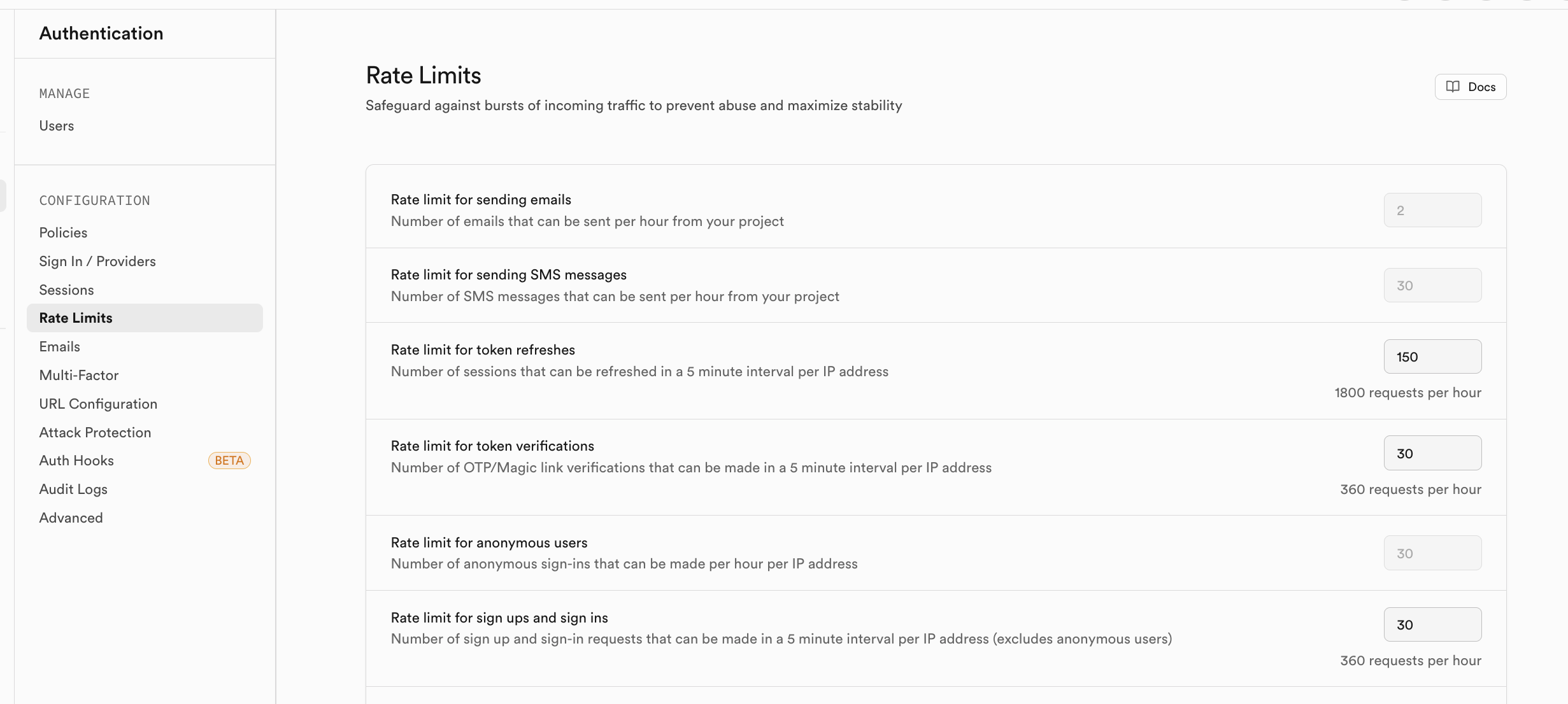
등록된 사용자의 단기간 액세스량이 너무 많을 것이 우려된다면, Rate Limits에서 해당 트래픽 제한 정책을 활성화할 수 있어요:
스토리지
Storage는 Supabase의 스토리지 시스템으로, Amazon Cloud의 S3 개념과 호환되며, 모든 유형의 파일(예: 이미지, 동영상, 문서, 오디오 등)을 저장하는 데 사용할 수 있어요. 액세스 권한 관리(공개 또는 비공개)와 다운로드 링크 획득(영구 링크 또는 임시 링크)을 제공하며, 애플리케이션에서 사용자와 관련된 파일 콘텐츠를 편리하게 업로드 및 다운로드 관리할 수 있고, Supabase의 인증 시스템과 원활하게 통합되어 세밀한 액세스 제어를 실현해요.
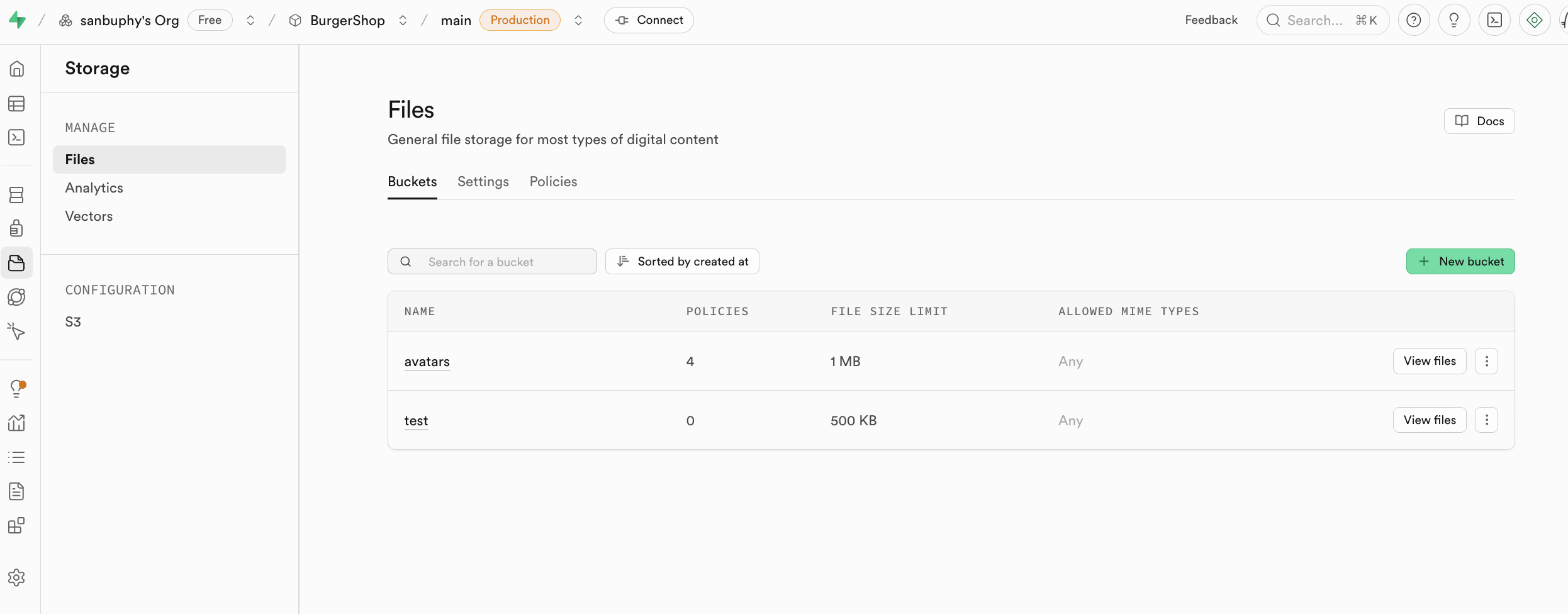
이번 강의의 고급 프로젝트에서 storage의 구체적인 사용법을 설명할 거예요.
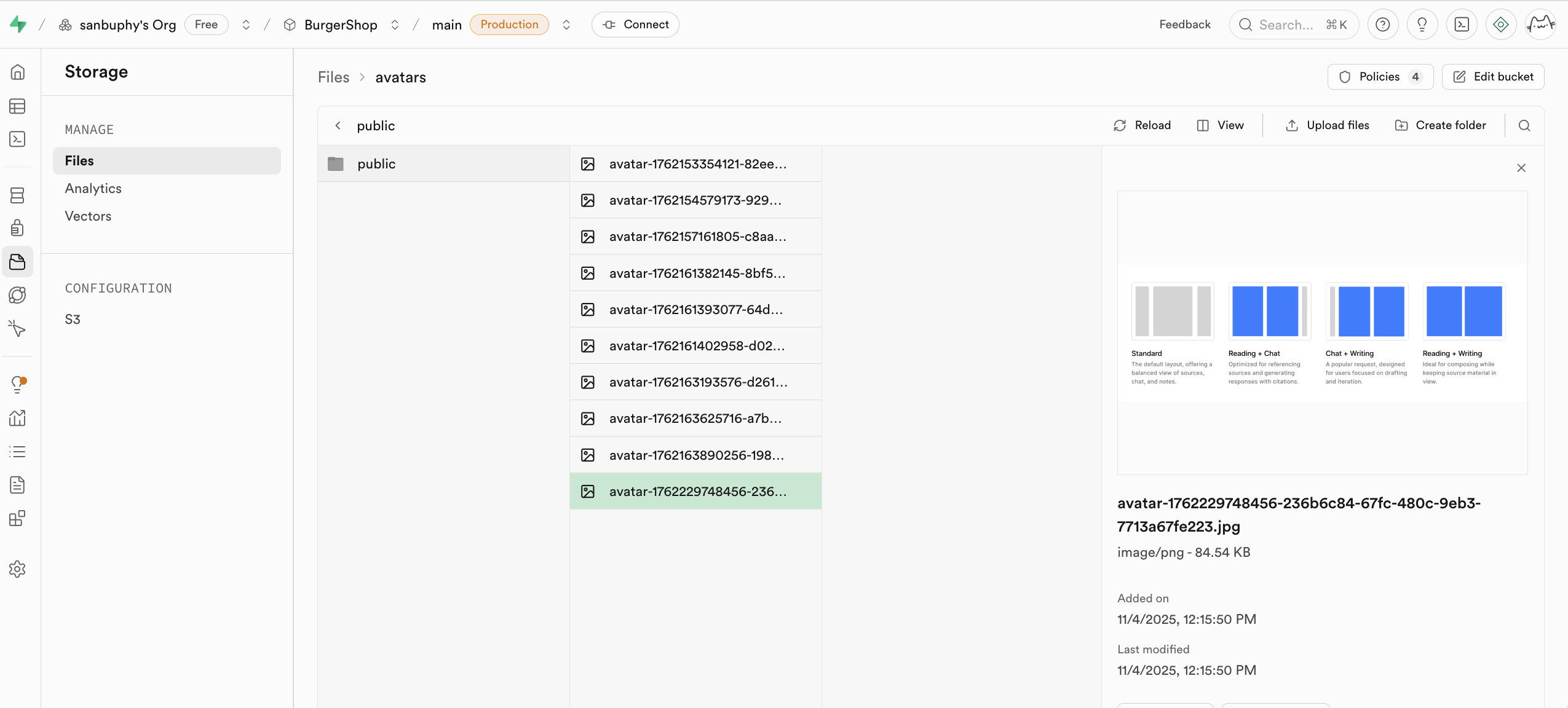
S3 관련 프로토콜을 사용하여 작업하고 싶다면, 해당 설정을 직접 사용할 수 있어요:
Amazon Cloud(AWS, Amazon Web Services)는 Amazon이 제공하는 클라우드 컴퓨팅 플랫폼이에요(대형 네트워크 서버실과 같아서, 필요에 따라 컴퓨팅 및 스토리지 리소스를 대여할 수 있어요). S3(Simple Storage Service)는 AWS에서 파일을 전문적으로 저장하는 서비스예요(무한한 크기의 네트워크 드라이브와 유사하며, 이미지, 동영상, 백업 등 다양한 파일을 저장할 수 있어요). 현재 가장 인기 있는 객체 스토리지 서비스이자 사실상의 업계 표준이 되었어요.
왜 S3 호환 API로 만들어야 하나요?: S3는 거의 20년 동안 존재해 왔고, 시장에 이미 많은 도구, SDK 및 문서가 있어요. S3와 호환된다는 것은 이러한 리소스를 직접 사용할 수 있다는 것을 의미하며, 관련 도구를 처음부터 만들 필요 없이 비즈니스 출시 요구를 빠르게 충족할 수 있어요.
엣지 함수
백엔드를 배포하고 싶지 않지만 데이터베이스와 함수 작업을 사용하고 싶다면, Edge Functions를 사용하여 자체 서버 없이 백엔드 핵심 역량을 구축할 수 있어요. 이는 Supabase가 제공하는 글로벌 분산 서버 측 함수예요. 간단히 말해, 자체 백엔드 서버를 구매하고 관리할 필요 없이 클라우드에서 실행되는 백엔드 코드를 직접 작성하고 배포할 수 있게 해줘요. 이러한 함수는 글로벌 네트워크의 엣지 노드에 배포되어, 사용자와 가장 가까운 위치에서 자동으로 실행되어 네트워크 지연을 크게 줄이고 극한의 응답 속도를 제공해요. Supabase 대시보드에서 직접 생성, 편집 및 배포할 수 있으며, 전체 개발 프로세스가 매우 편리해요.
Edge Functions의 핵심 용도 중 하나는 안전한 미들웨어 역할을 하여 민감한 정보와 인증 키를 보호하는 거예요. 프론트엔드 코드에서 타사 서비스(예: OpenAI, Stripe)를 직접 호출하면 API Key가 노출되어 큰 보안 위험이 발생해요. Edge Functions를 통해 프론트엔드 애플리케이션은 Supabase 함수와만 통신하고, 모든 비밀은 Supabase에서만 보관돼요.
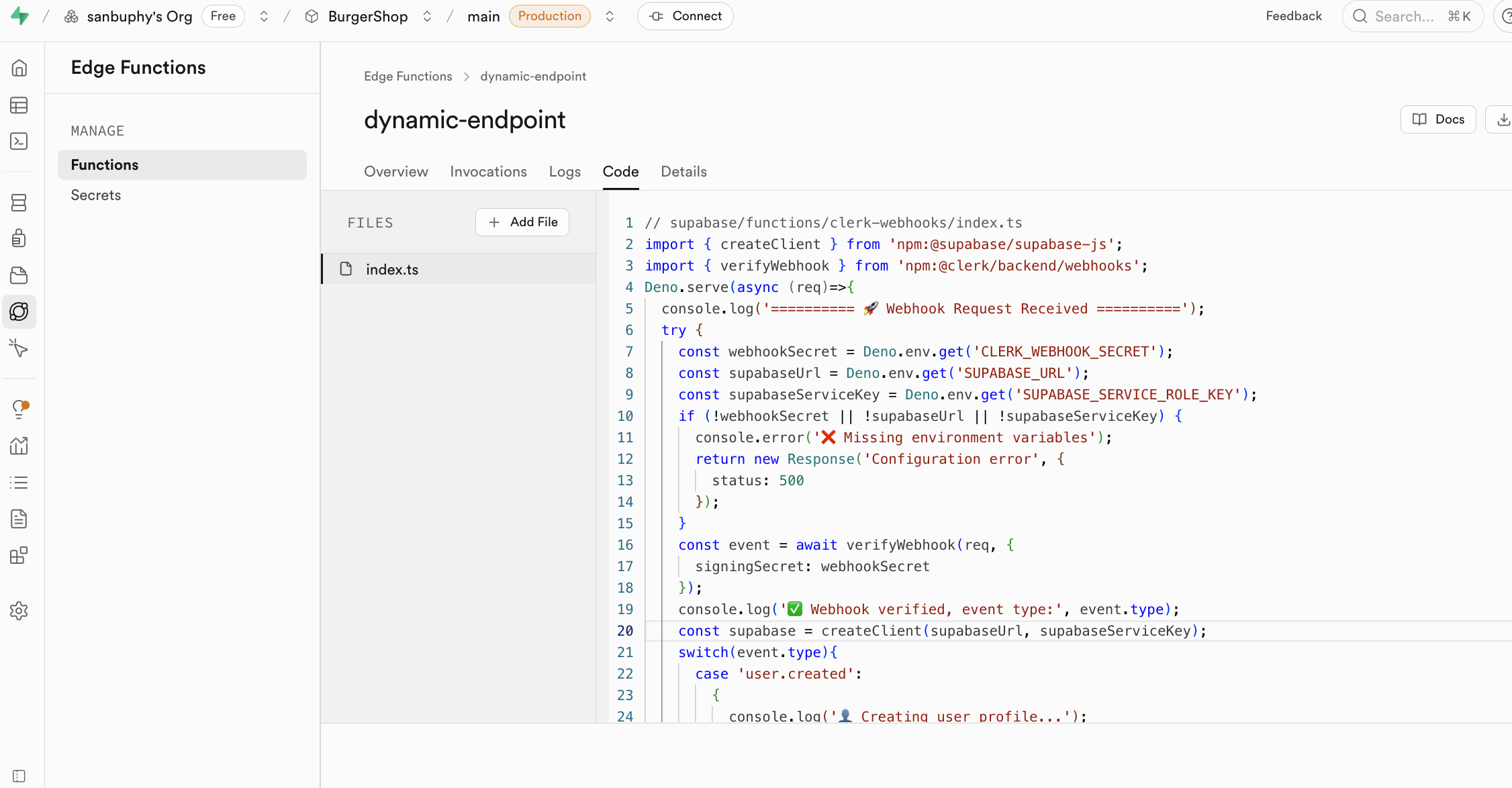
Edge Functions의 함수는 secrets에 노출된 키를 환경 변수로 사용하며, Deno.env.get을 통해 로드하여 타사 서비스 호출을 실현해요. 이렇게 하면 민감한 키가 클라이언트(브라우저)에 절대 노출되지 않아, 도용 위험을 완전히 제거해요.
Supabase Edge Function을 요청할 때, 요청 헤더에 해당 Supabase 키를 포함해야 해요. 다음은 간단한 예시예요:
// 핵심 설정 (실제 정보로 교체하세요)
const projectId = "당신의 Supabase 프로젝트 ID";
const functionName = "대상 Edge Function 이름";
const supabaseKey = "Supabase anon_key";
// 함수 호출
async function callEdgeFunction() {
const url = `https://${projectId}.supabase.co/functions/v1/${functionName}`;
try {
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
"Authorization": `Bearer ${supabaseKey}` // 핵심: 키를 휴대하여 인증 완료
},
body: JSON.stringify({ order_id: "123", action: "refund" }) // 커스텀 요청 데이터
});
const result = await response.json();
console.log("호출 성공:", result);
} catch (error) {
console.error("호출 실패:", error.message);
}
}
// 호출 실행
callEdgeFunction();또한, Edge Functions는 Supabase의 사용자 인증 시스템과 원활하게 통합돼요. 로그인한 사용자가 함수를 호출하면 해당 사용자의 신원 정보가 함수에 전달돼요. 이를 통해 함수 내부에서 현재 사용자를 쉽게 식별하고, 해당 신원에 따라 권한 제어를 수행할 수 있어요. 더 중요한 것은, 함수가 데이터베이스를 조작할 때 설정한 행 수준 보안 정책(Row Level Security)을 자동으로 준수하여, 사용자가 권한이 있는 데이터에만 액세스하고 수정할 수 있도록 보장하여, 안전한 다중 사용자 애플리케이션 구축을 간단하게 만들어줘요.
Edge Functions의 응용 시나리오는 매우 광범위하며, 다양한 백엔드 작업을 처리할 수 있어요. 타사 서비스의 Webhook 이벤트(예: 결제 완료, 코드 커밋 등)를 수신하고 자동으로 해당 데이터 처리 로직을 실행하는 데 매우 적합해요. 이메일 알림 발송, PDF 보고서 생성, 복잡한 비즈니스 로직을 캡슐화하는 커스텀 API 인터페이스 생성, 또는 서버 측에서 완료하고자 하는 모든 계산 작업을 실행하는 데 사용할 수도 있어요. 애플리케이션의 역량을 크게 확장해줘요.
구체적인 일반적인 예시: 인증 도구 Clerk. Clerk은 사용자 로그인, 회원가입, 정보 업데이트 등 인증 관련 작업만 처리하며, 비즈니스 데이터베이스를 직접 관리하지 않아요. 이러한 인증 동적 정보를 비즈니스 데이터베이스에 동기화하려면, Webhook 이벤트를 통해 Edge Functions를 요청하여 구현해야 해요. Edge Functions는 Clerk이 보낸 Webhook 신호를 수신하고, 자동으로 데이터 동기화 로직을 실행하여, Supabase 데이터베이스의 사용자 정보와 Clerk 로그인 상태를 실시간으로 정렬해줘요. 전체 과정에서 독립적인 백엔드를 배포할 필요가 없어요.
실시간 데이터 동기화 엔진
Realtime은 Supabase의 실시간 데이터 동기화 엔진으로, 애플리케이션이 API를 반복적으로 폴링하지 않고도 데이터베이스의 변화 알림을 즉시 수신할 수 있게 해줘요. 데이터베이스의 데이터에 INSERT, UPDATE 또는 DELETE 작업이 발생하면, Realtime은 WebSocket을 통해 이러한 변화를 모든 연결된 클라이언트에 실시간으로 푸시해요. 이는 실시간 상호작용이 필요한 애플리케이션을 구축하는 데 매우 중요해요.
Realtime은 주로 세 가지 핵심 기능을 포함하며, 대부분의 실시간 시나리오를 커버해요:
- Postgres Changes: 데이터베이스 테이블의 변화를 직접 수신해요. 특정 테이블, 특정 이벤트(추가, 삭제, 수정)를 정확하게 구독할 수 있고, 필터 조건에 따라 알림을 받을 수도 있으며, 행 수준 보안 정책(Row Level Security)과 완벽하게 통합되어 사용자가 권한이 있는 데이터 변경 사항만 수신할 수 있도록 보장해요.
- Broadcast: 클라이언트 간에 채널(Channel)을 통해 낮은 지연의 임시 메시지를 보낼 수 있게 해줘요. 채팅방, 실시간 커서 추적, 온라인 게임 상태 동기화 등의 기능 구현에 매우 적합해요.
- Presence: 온라인 사용자 상태를 추적하고 동기화하는 데 사용돼요. "누가 온라인인가", "현재 X명이 보고 있습니다" 등의 기능을 쉽게 구현할 수 있어요. 협업 유형의 애플리케이션에 매우 적합해요.
후속 프로젝트 기반 학습에서 이 부분의 내용을 자세히 소개할 거예요.
프로젝트 설정
Project Settings는 Supabase 프로젝트의 고급 설정 섹션으로, 컴퓨팅 리소스의 심층 스케줄링과 다양한 기능의 기본 파라미터를 세밀하게 설정할 수 있어요.
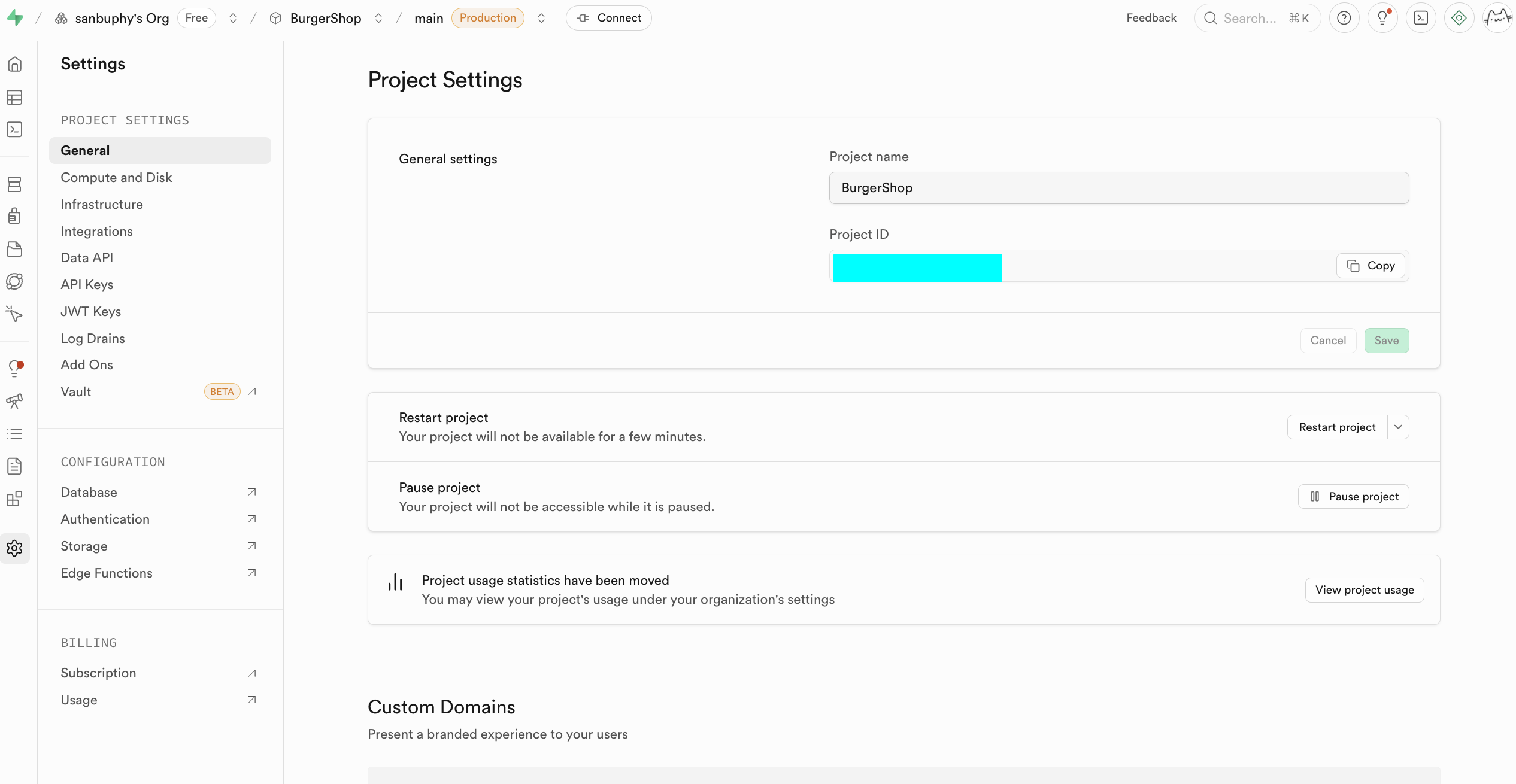
입문 단계에서는 다음 두 가지 핵심 영역에만 집중하면 돼요. 하나는 Data API로, 여기서 핵심적인 "Supabase URL"을 얻을 수 있어요. 이것은 https://xxx.supabase.co 형태의 RESTful 엔드포인트로, 모든 데이터 쿼리, 추가, 수정, 삭제 작업의 "입구 주소"예요. 프론트엔드나 서버 측은 이 URL을 통해 Supabase 클라이언트를 초기화하고 데이터베이스와의 연결을 설정해야 해요.
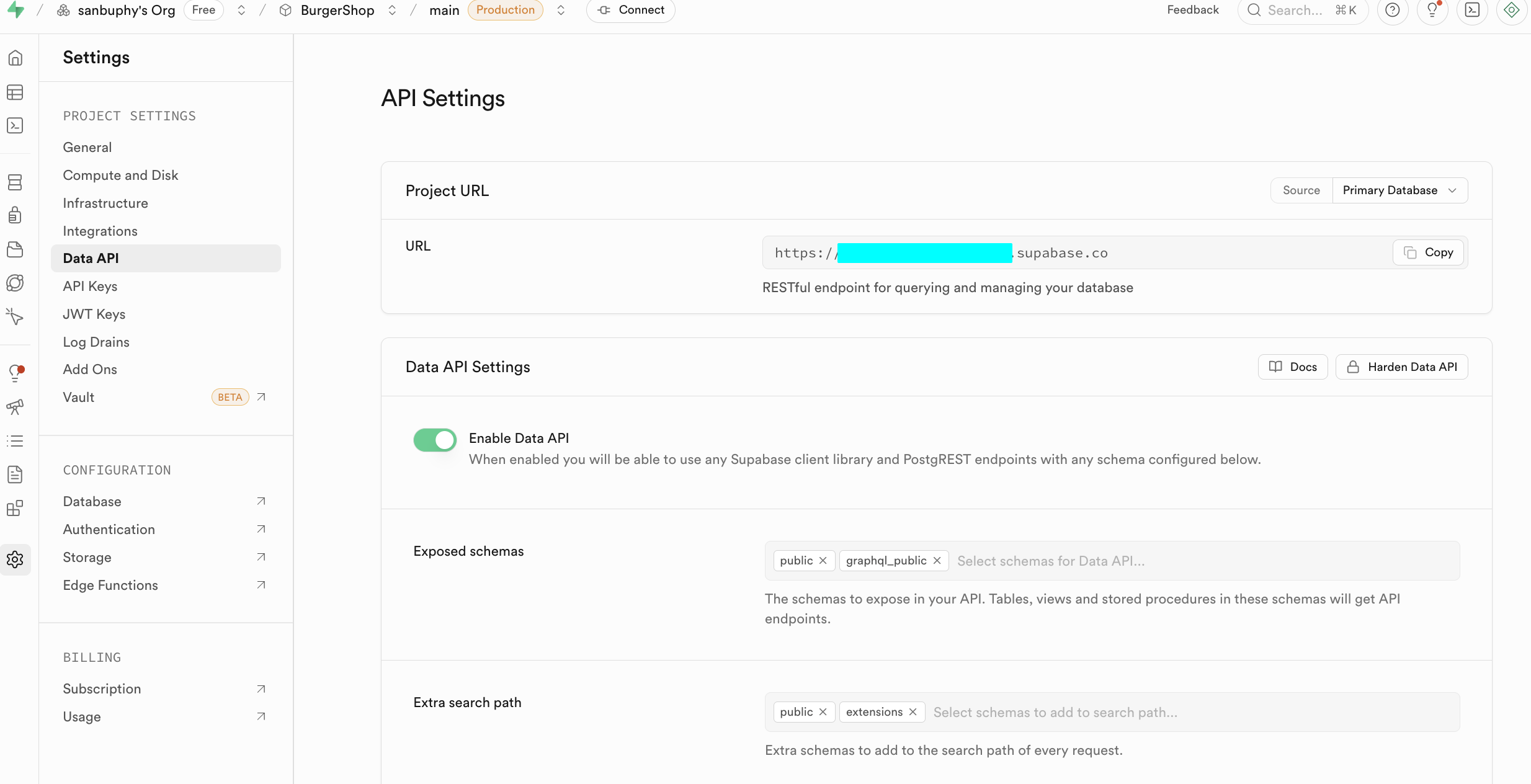
또 다른 중요한 것은 API Keys예요. "Legacy anon, service_role API keys" 탭을 선택하면, 그중 anon public 키는 프론트엔드 시나리오의 중요한 신원 증명이에요. 권한이 RLS에 의해 엄격히 제한되어, 사용자가 권한을 부여받은 데이터에만 액세스할 수 있어요. 반면 service_role 키는 "서버 측 고권한 키"에 속하며, 행 수준 보안을 우회할 수 있는 능력을 가지고 있어 대량 데이터 작업, 시스템 수준 설정 등 민감한 작업을 수행할 수 있어요. 공개적으로 공유하는 것은 절대 금지되며, 유출된 경우 즉시 새 키를 생성하고 서버 측 설정을 업데이트해야 해요.
나머지 설정 항목은 현재 단계에서 깊이 파고들 필요가 없어요. 향후 고급 사용 요구가 있을 때 하나씩 탐색하면 돼요.
2.1 첫 번째 SQL 데이터 테이블 만들기
이상이 Supabase의 인터페이스 소개였으며, 다음으로 Supabase의 핵심 데이터베이스 작업 단계로 들어갈게요.
Supabase에서 데이터 테이블을 만드는 방법은 주로 다음 두 가지가 있어요. 요구에 따라 선택할 수 있어요:
- (권장) 대형 언어 모델을 사용하여 Supabase에 적합한 SQL 문을 생성하고, SQL Editor(앞서 소개한 SQL 문 실행기)에 직접 붙여넣어 실행. 효율적이고 빠르며, 다음 부분에서 이 작업 과정을 중점적으로 설명할 거예요.
- 시각적 작업으로 생성: 왼쪽 사이드바에서 Database 모듈을 찾아 클릭한 후 사이드바의 Tables를 선택하고, 오른쪽에서 New Table 버튼을 클릭하면 그래픽 인터페이스를 통해 데이터 테이블을 만들 수 있어요.
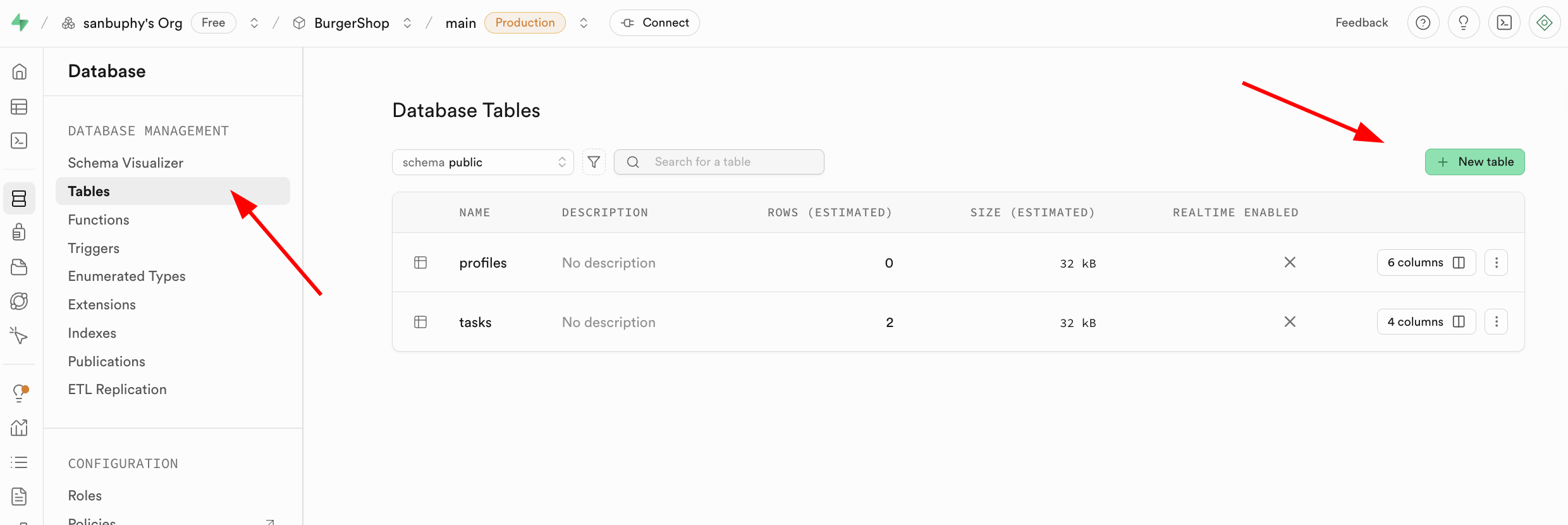
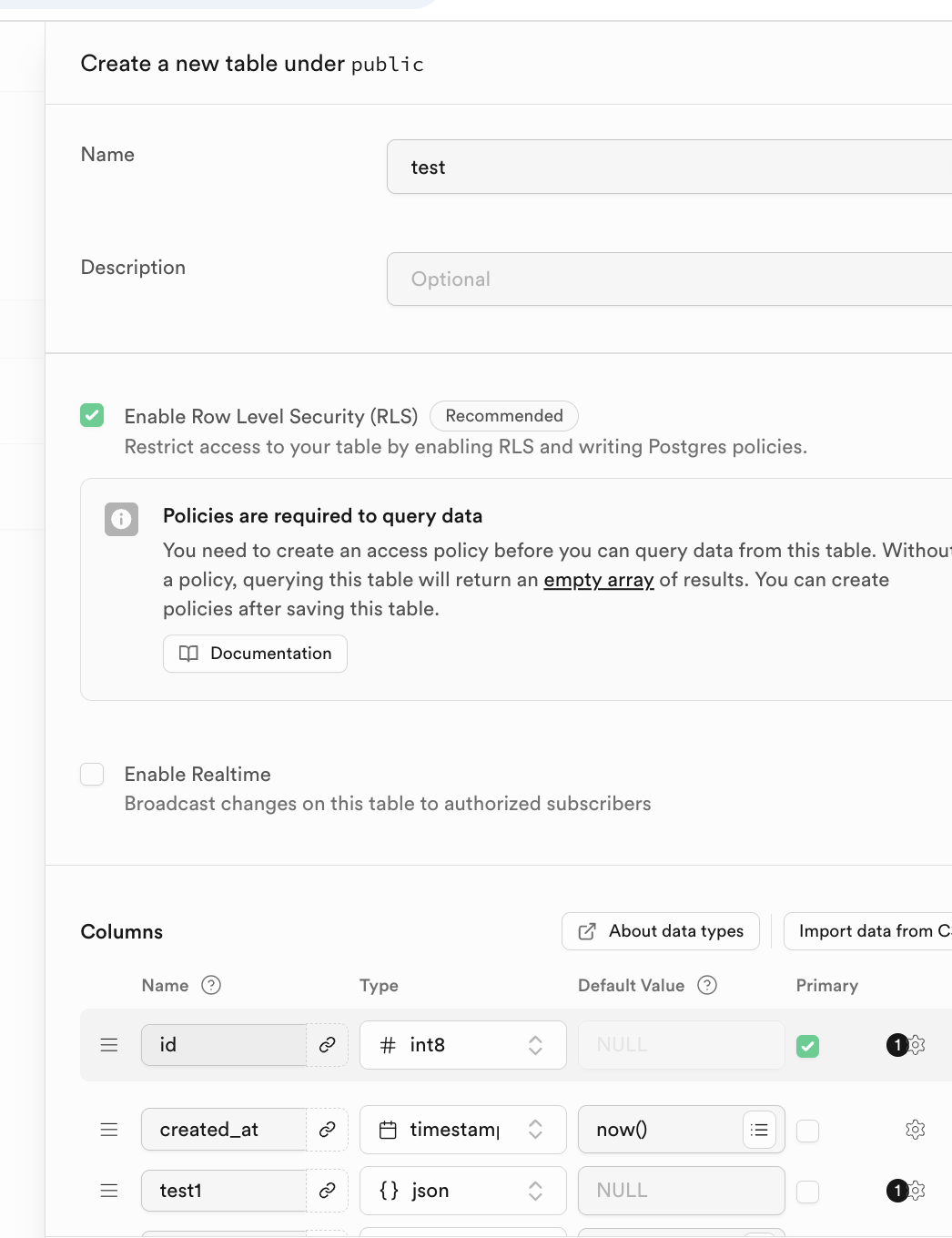
주목할 점은, 해당 데이터 테이블의 이름과 저장할 데이터 유형은 하단의 Columns에서 지정할 수 있다는 거예요.
관계형 데이터베이스의 중요한 특징은 테이블 간의 연결이에요. 하단에서 Foreign keys를 찾아 해당 연결 관계를 생성할 수 있어요:
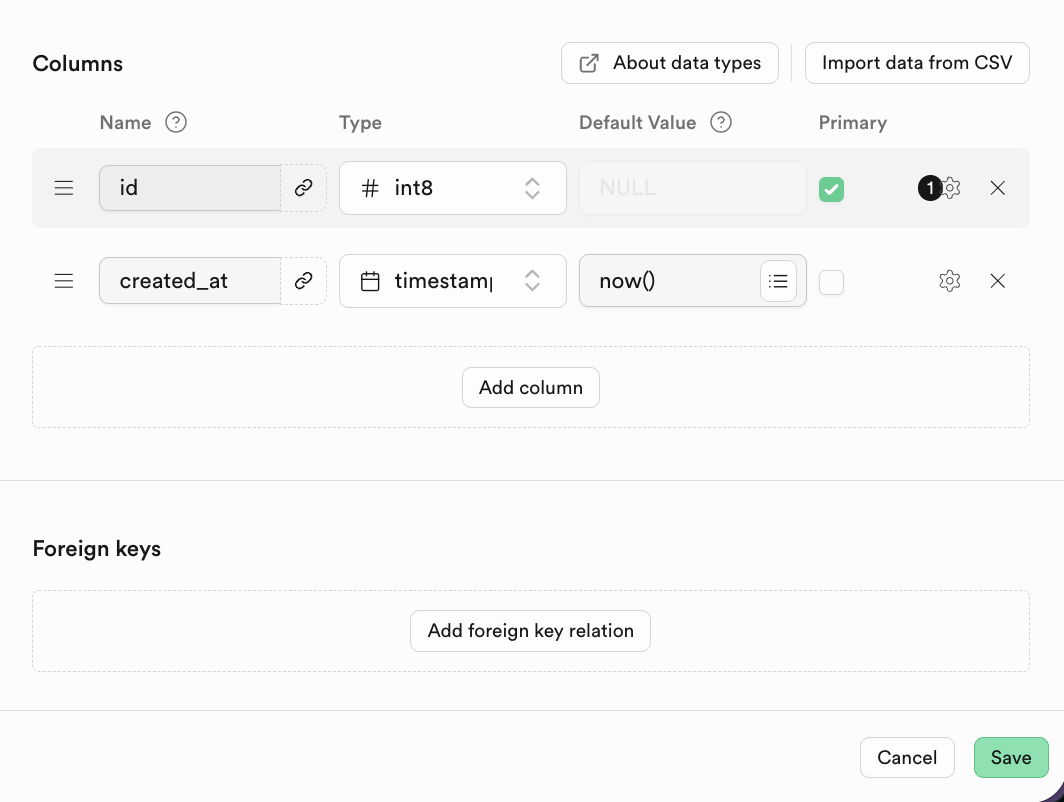
Foreign keys는 테이블 간의 연결 관계를 표현해요: 하나 또는一组 필드로, 현재 테이블(자식 테이블)의 값이 다른 테이블(부모 테이블)의 기본 키 값을 참조해요.
예를 들어, 학생 테이블을 만들 때 외래 키를 다음과 같이 정의할 수 있어요: (소속 반 번호 열은 외래 키이며, 이 외래 키는 반 테이블의 반 번호 열을 참조해요.)
CREATE TABLE 학생_테이블 (
학생_학번 INT PRIMARY KEY,
학생_이름 VARCHAR(50),
소속_반_번호 INT,
FOREIGN KEY (소속_반_번호) REFERENCES 반_테이블(반_번호)
);더 구체적인 예로, 해당 테이블의 구조를 시각적으로 살펴볼 수 있어요:
반 테이블: 이 테이블에는 모든 반의 정보가 기록되어 있으며, 각 반에는 고유한 반 번호가 있어요. 반 번호가 이 테이블의 기본 키(Primary Key)이며, 각 반의 유일한 신분증이에요.
| 반_번호 | 반_이름 |
|---|---|
| 101 | 1학년 1반 |
| 102 | 1학년 2반 |
학생 테이블: 이 테이블은 모든 학생의 정보를 기록해요. 각 학생은 특정 반에 속해 있죠. 그렇다면 어떤 학생이 어느 반에 있는지 어떻게 알 수 있을까요?
학생 테이블에 소속 반 번호라는 열을 추가할 수 있어요.
| 학생_학번 | 학생_이름 | 소속_반_번호 |
|---|---|---|
| 2024001 | 김철수 | 101 |
| 2024002 | 이영희 | 102 |
| 2024003 | 박민수 | 101 |
이 예시에서 학생 테이블의 소속 반 번호 열이 외래 키(Foreign Key)예요.
Supabase에서 Add Foreign Key를 클릭한 후, 연결 테이블의 해당 열을 직접 선택할 수 있어요.
2.3 SQL Editor 소개 및 데이터베이스 기본 작업
다음으로 일련의 SQL 스크립트를 단계별로 실행하면서, 일반적인 SQL의 CRUD(생성, 읽기, 수정, 삭제) 작업에 익숙해질 거예요. 각 단계의 코드를 SQL Editor에 복사하여 실행하고 결과를 확인할 수 있어요.
모든 테스트 SQL 파일은 다음 디렉토리에서 얻을 수 있어요:
https://github.com/THU-SIGS-AIID/Project5-Supabase-Demos/tree/main/apps/sql-examples
2.3.1 CREATE - 테이블 구조 만들기
CREATE TABLE 문은 새 테이블의 스키마(Schema)를 정의하는 데 사용돼요. 열(Columns), 해당 데이터 유형(Data Types) 및 제약 조건(Constraints)을 포함하며, 간단히 말해 데이터 테이블을 하나 만드는 거예요.
-- Step 1: Create the 'orders' table
-- This file is fully independent and creates a sample table for later steps.
CREATE TABLE IF NOT EXISTS orders (
id serial PRIMARY KEY,
user_id int NOT NULL, -- User ID
status text NOT NULL, -- Order status (e.g. paid, pending)
amount numeric(10, 2) NOT NULL, -- Order total amount
details jsonb, -- Item and extra details as JSON
placed_at timestamptz DEFAULT now(), -- Order creation time
is_paid boolean DEFAULT false -- Paid flag
);
-- Expected Output:
-- Orders table created if it did not exist.
-- No data inserted. (Querying returns zero rows for now.)
-- If table already exists, no error occurs.성공적으로 실행되면 시스템이 스크립트가 완료되었음을 알려줘요. Table Editor에서 해당 테이블이 생성된 것을 볼 수 있어요:
2.3.2 INSERT - 초기 데이터 채우기
테이블 구조가 생성된 후, 다음 단계는 INSERT INTO 문을 사용하여 테이블에 데이터 행을 추가하는 거예요.
-- Step 2: Insert initial rows into the orders table
-- Provides realistic, varied data for demo/testing. All values are self-contained.
INSERT INTO orders (user_id, status, amount, details, placed_at, is_paid) VALUES
(2001, 'pending', 23.50, '{"items":[{"sku":"BGR001","name":"Beef Burger","qty":1,"price":12.00}]}', now() - interval '2 days', false),
(2002, 'paid', 50.00, '{"items":[{"sku":"BGR002","name":"Chicken Burger","qty":2,"price":10.00},{"sku":"DRK001","name":"Lemonade","qty":2,"price":5.00}]}', now() - interval '1 day', true),
(2003, 'cancelled', 15.00, '{"items":[{"sku":"FRY001","name":"French Fries","qty":3,"price":5.00}], "reason":"Not available"}', now() - interval '45 days', false),
(2004, 'paid', 22.98, '{"items":[{"sku":"BGR003","name":"Veggie Burger","qty":2,"price":9.99}], "promo":"SUMMER22"}', now() - interval '10 days', true),
(2005, 'pending', 18.75, '{"items":[{"sku":"SAL001","name":"Salad","qty":1,"price":6.75},{"sku":"BGR001","name":"Beef Burger","qty":1,"price":12.00}]}', now() - interval '7 hours', false),
(2006, 'paid', 8.00, '{"items":[{"sku":"DRK002","name":"Cola","qty":2,"price":4.00}]}', now() - interval '3 hours', true),
(2007, 'refunded', 14.50, '{"items":[{"sku":"BGR003","name":"Veggie Burger","qty":1,"price":9.99},{"sku":"FRY001","name":"French Fries","qty":1,"price":4.51}], "refund_reason":"Late delivery"}', now() - interval '15 days', false),
(2008, 'paid', 26.99, '{"items":[{"sku":"BGR002","name":"Chicken Burger","qty":2,"price":10.00},{"sku":"DRK001","name":"Lemonade","qty":1,"price":6.99}]}', now() - interval '12 days', true),
(2009, 'pending', 9.99, '{"items":[{"sku":"BGR003","name":"Veggie Burger","qty":1,"price":9.99}]}', now() - interval '30 minutes', false),
(2010, 'paid', 19.89, '{"items":[{"sku":"BGR001","name":"Beef Burger","qty":1,"price":12.00},{"sku":"DRK002","name":"Cola","qty":2,"price":3.95}]}', now() - interval '5 days', true),
(2011, 'cancelled', 0.00, '{"items":[], "reason":"User cancelled"}', now() - interval '2 days', false);
-- Expected Output:
-- After running this script, SELECT * FROM orders will show about 11 rows with varied user_id, status, amount, details (JSON), placed_at, and is_paid fields.
-- For example:
-- | id | user_id | status | amount | is_paid | placed_at |
-- |----|---------|-----------|--------|---------|---------------------|
-- | 1 | 2001 | pending | 23.50 | false | 2025-10-28 13:40:00Z|
-- | 2 | 2002 | paid | 50.00 | true | ... |
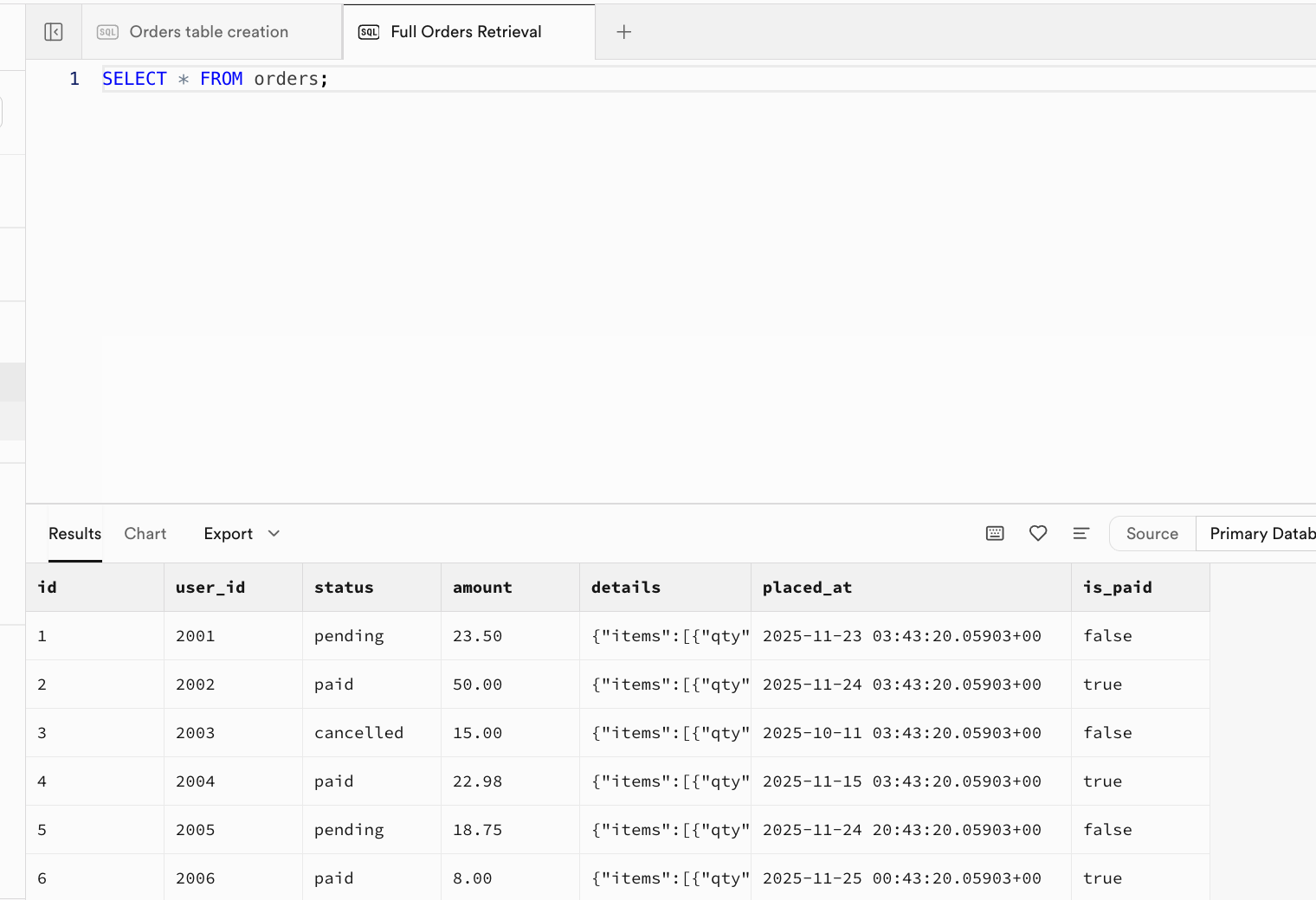
-- |... | ... | ... | ... | ... | ... |실행이 성공하면, 테이블에 원본 데이터가 삽입된 상태예요. Table Editor 인터페이스로 이동하여 새로고침한 후 결과를 볼 수도 있고, SQL Editor 인터페이스에서 새 창을 열고 쿼리 문 SELECT * FROM orders;를 실행하여 결과를 확인할 수도 있어요:
2.3.3 SELECT - 데이터 읽기와 쿼리
SELECT 문은 테이블에서 데이터를 검색할 때 사용해요. 다양한 절(clause)을 활용하면 데이터의 정밀한 필터링, 정렬, 포맷팅이 가능해요. 다음 문장들을 참고하여 단계별로 실행하고 결과를 확인해 볼 수 있어요:
-- Step 3: SELECT query examples for the orders table
-- Example 1: Select all fields for all orders
SELECT * FROM orders;
-- Expected Output: Returns all rows and fields. Columns: id, user_id, status, amount, details, placed_at, is_paid.
-- Example 2: Select only pending orders
SELECT id, user_id, amount FROM orders WHERE status = 'pending';
-- Expected Output: All rows with status 'pending'; columns: id, user_id, amount.
-- Example 3: Select specific fields and filter by payment status
SELECT id, status, is_paid, amount FROM orders WHERE is_paid = true;
-- Expected Output: All rows where is_paid is true; columns: id, status, is_paid, amount.
-- Example 4: Extract all item names from the details (JSON) for each order
SELECT id, details -> 'items' AS item_list FROM orders;
-- Expected Output: Each row shows id and an array from JSON with item details.- 예시 1:
orders테이블의 모든 행과 열을 반환하며, 두 번째 단계의 출력과 유사해요. - 예시 2: 상태가 'pending'인 주문만 반환하며, 지정된 열만 포함돼요:
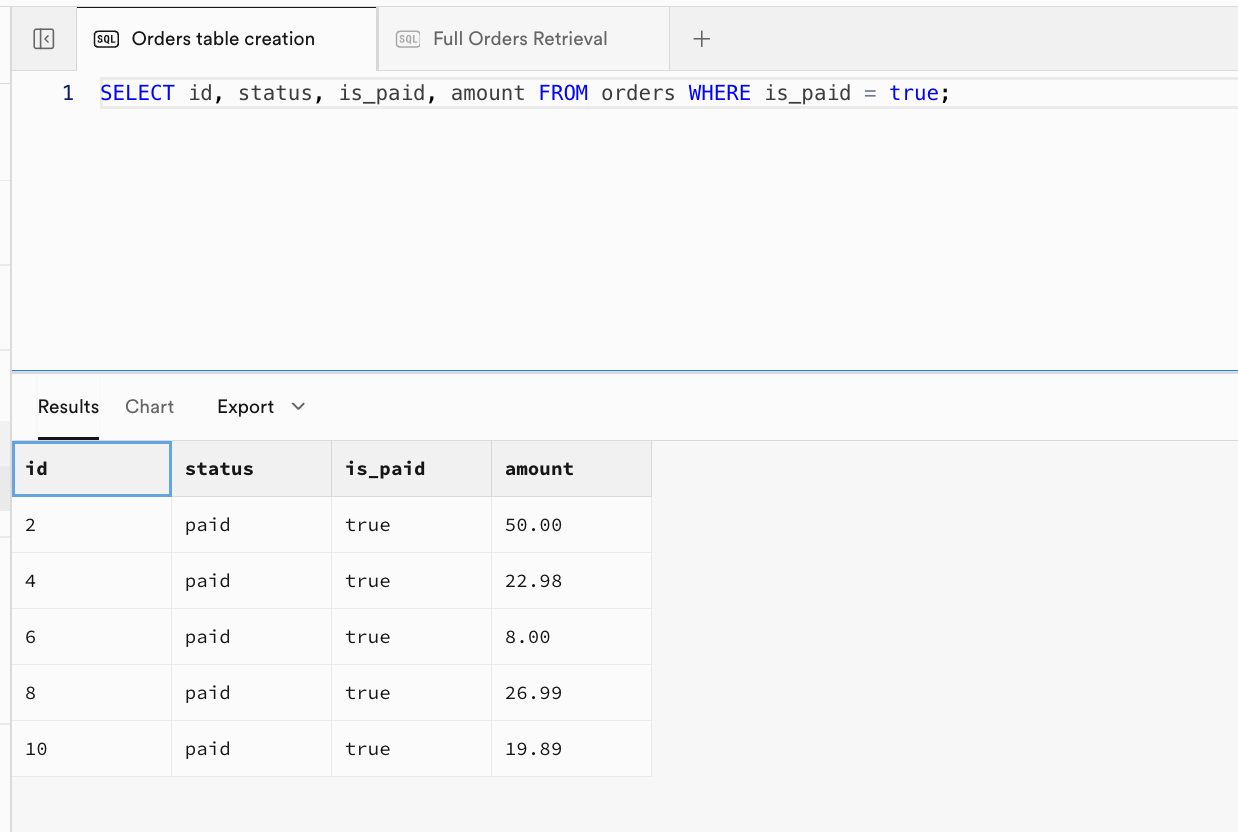
- 예시 3: 결제가 완료된 주문만 반환하며, 지정된 열을 표시해요:
| id | status | is_paid | amount |
|---|---|---|---|
| 2 | paid | true | 50.00 |
| 4 | paid | true | 22.98 |
| 6 | paid | true | 8.00 |
| 8 | paid | true | 26.99 |
| 10 | paid | true | 19.89 |
- 예시 4: 각 주문의
id와details필드에서 추출한items배열을 반환해요:
| id | item_list |
|---|---|
| 1 | [{"qty":1,"sku":"BGR001","name":"Beef Burger","price":12}] |
| 2 | [{"qty":2,"sku":"BGR002","name":"Chicken Burger","price":10},{"qty":2,"sku":"DRK001","name":"Lemonade","price":5}] |
| 3 | [{"qty":3,"sku":"FRY001","name":"French Fries","price":5}] |
| ... | ... |
2.3.4 INSERT - 단일 레코드 삽입
2.3.2에서는 초기 대량 데이터를 일괄 삽입하는 방법을 보여드렸는데요, 이제 단일 데이터를 새로 삽입하는 방법을 살펴볼게요.
-- Step 4: INSERT a new order (single row)
-- Example: Add a new paid order for user 2012 with one Chicken Burger
INSERT INTO orders (user_id, status, amount, details, is_paid)
VALUES (
2012, 'paid', 9.99,
'{"items":[{"sku":"BGR002","name":"AIID Burger","qty":100,"price":1000}]}',
true
);
-- Expected Output:
-- Before (table fragment):
-- | id | user_id | status | amount | is_paid |
-- | ...| ... | ... | ... | ... |
--
-- After (last row):
-- | id | user_id | status | amount | is_paid |
-- | xx | 2012 | paid | 9.99 | true |
-- (where xx = next serial value)이후 다시 SELECT * FROM orders;로 데이터를 조회해 보면, orders 테이블의 데이터가 성공적으로 11개에서 12개로 늘어난 것을 확인할 수 있어요.
2.3.5 UPDATE - 기존 데이터 수정
실무에서는 데이터 테이블에 대한 빈번한 업데이트가 필요해요. UPDATE 문을 사용하면 테이블에 이미 존재하는 레코드를 수정할 수 있어요.
-- Step 5: UPDATE example
-- Example: Mark order with id=1 as paid and update its status
UPDATE orders SET status = 'paid', is_paid = true WHERE id = 1;
-- Expected Output:
-- Before (row with id=1):
-- | id | status | is_paid |
-- | 1 | pending | false |
-- After (row with id=1):
-- | id | status | is_paid |
-- | 1 | paid | true |
-- All other rows remain unchanged.2.3.6 DELETE - 데이터 삭제
DELETE 문은 테이블에서 레코드를 제거할 때 사용하며, 조건을 결합하여 지정된 부분의 데이터만 삭제할 수 있어요.
-- Step 6: DELETE example
-- Example: Delete orders older than 2 days to clean up old data
DELETE FROM orders WHERE placed_at < now() - interval '2 days';
-- Expected Output:
-- Before (filtered for affected rows):
-- | id | status | placed_at |
-- | 3 | shipped | 2025-10-13 ... | <-- will be deleted
--
-- After:
-- No such rows remain. SELECT * FROM orders WHERE placed_at < now()-interval '2 days' yields zero rows.
-- Other rows in orders table are unaffected.실행하기 전에 먼저 SELECT id, status, placed_at FROM orders WHERE placed_at < now() - interval '2 days';를 실행하여 삭제 대상 데이터를 미리 확인해 볼 수 있어요. DELETE 명령을 실행한 후, 동일한 SELECT 쿼리 SELECT id, status, placed_at FROM orders WHERE placed_at < now() - interval '2 days';를 다시 실행하면 빈 결과가 반환되며, 이는 해당 행들이 성공적으로 삭제되었음을 의미해요.
2.4 행 수준 보안
데이터베이스 기본 조작을 배운 후, 데이터 보안을 보장하는 핵심 개념인 RLS(Row Level Security, 행 수준 보안)에 대해 더 깊이 알아볼게요.
먼저 실제 시나리오에서의 핵심 질문을 생각해 볼까요? 어떻게 데이터의 "격리된 접근"을 구현할 수 있을까요? 예를 들어, 사용자 A는 자신의 데이터만 볼 수 있고 사용자 B의 정보는 볼 수 없게 하려면 어떻게 해야 할까요? 또는 특정 역할이 데이터베이스 접근 권한을 가지고 있더라도, 다른 사용자의 민감한 데이터에 대한 오조작이나 유출을 어떻게 방지할 수 있을까요?
RLS는 바로 이러한 데이터 보안과 격리 요구를 해결하기 위해 만들어졌어요. 개발자가 데이터베이스 테이블에 대해 세밀한 보안 정책을 정의할 수 있게 해주며, 사용자의 신원 정보(예: 사용자 ID, 역할 권한 등)를 기반으로 어떤 사용자가 테이블의 어떤 행 데이터에 접근하고 수정할 수 있는지를 정확하게 제어할 수 있어요. 전형적인 예시로, 주문 테이블(orders)에 대해 "orders 테이블의 어떤 레코드의 user_id 열이 현재 로그인한 사용자의 ID와 완전히 일치할 때만, 해당 사용자가 이 주문 데이터를 조회할 수 있다"는 RLS 정책을 정의하면 "사용자는 자신의 주문만 볼 수 있다"는 핵심 요구를 구현할 수 있어요.
특정 테이블에 RLS를 활성화하면, 해당 테이블의 모든 데이터 조작 요청(SELECT 조회, INSERT 추가, UPDATE 수정, DELETE 삭제 포함)이 RLS 검증을 트리거해요. 적어도 하나 이상의 보안 정책 검사를 통과해야만 조작이 실행될 수 있어요. 해당 조작을 허용하는 정책이 존재하지 않거나, 요청이 어떤 정책의 조건도 충족하지 못하면, 데이터베이스는 즉시 이번 조작을 거부하고 비인가 접근을 근본적으로 차단해요.
Supabase에서는 RLS가 사용자 인증 시스템과 깊게 연동되어 있어 사용이 더 편리해요. Supabase는 전용 함수 auth.uid()를 제공하는데, 이 함수는 "현재 요청을 보낸 로그인된 사용자"의 고유 ID(UUID 형식)를 직접 반환해요. 이 함수를 활용하면 "데이터 행과 사용자 신원"의 정확한 연결을 쉽게 구현할 수 있어요(예를 들어 앞서 언급한 "주문의 user_id가 현재 사용자 ID와 일치").
RLS 정책을 활성화하는 방법은 유연해요. Supabase 데이터베이스 관리 인터페이스의 "RLS" 버튼에서 직접 정책을 구성하고 활성화할 수 있어요:
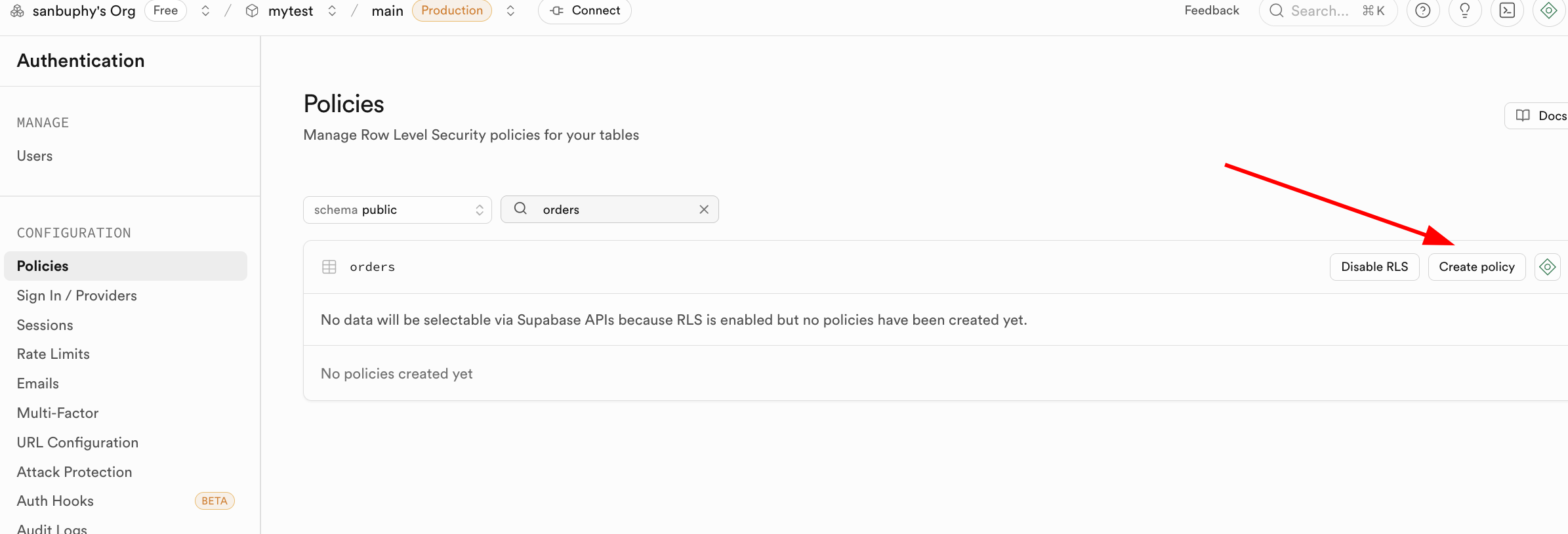
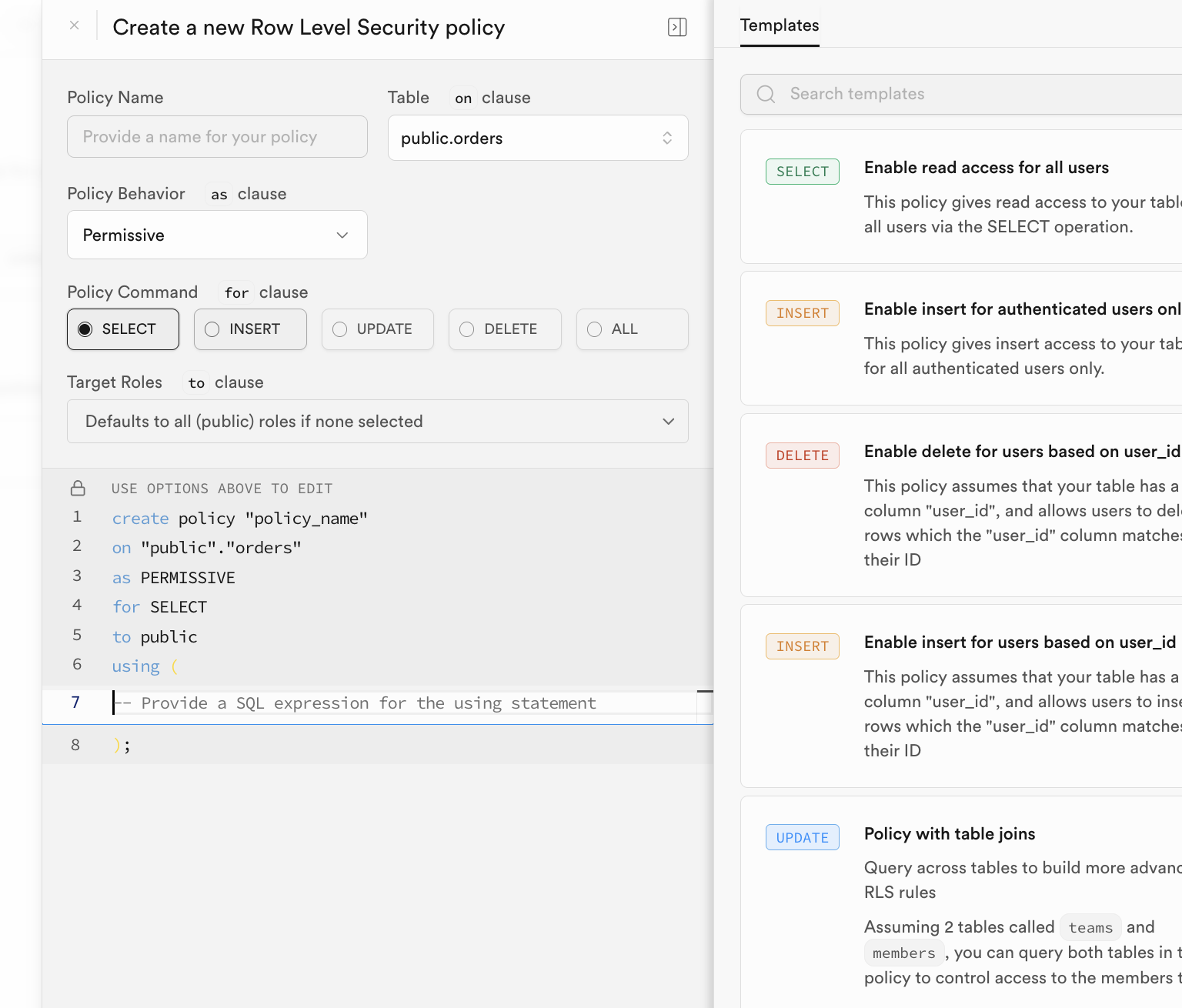
수동 구성은 다소 번거로울 수 있어요. 보통은 데이터 테이블 문장을 생성하고 초기화할 때 해당 RLS 정책을 함께 포함시키는 방식을 사용해요. SQL Editor에서 다음과 비슷한 문장을 실행하면, 해당 데이터 테이블의 행 수준 보안 정책이 자동으로 활성화돼요.

3. 첫 번째 SQL 애플리케이션
데이터베이스 기본 조작과 RLS 핵심 로직을 마스터한 후, 드디어 이번 튜토리얼의 실습 단계에 진입해요. 긴 학습 준비 과정은 이후 "0부터 1까지 애플리케이션 구축" 과정을 더 명확하게 만들기 위한 것이었어요. 다음으로 "햄버거 가게 주문 관리"를 시나리오로 삼아, Supabase의 일반적인 조작을 단계별로 보여드릴게요: 애플리케이션과 Supabase의 연결 설정부터, 데이터베이스와 로그인 기능의 통합까지, 다양한 조작 로직을 점진적으로 학습해요.
3.1 Supabase 예제 프로젝트 클론 및 실행
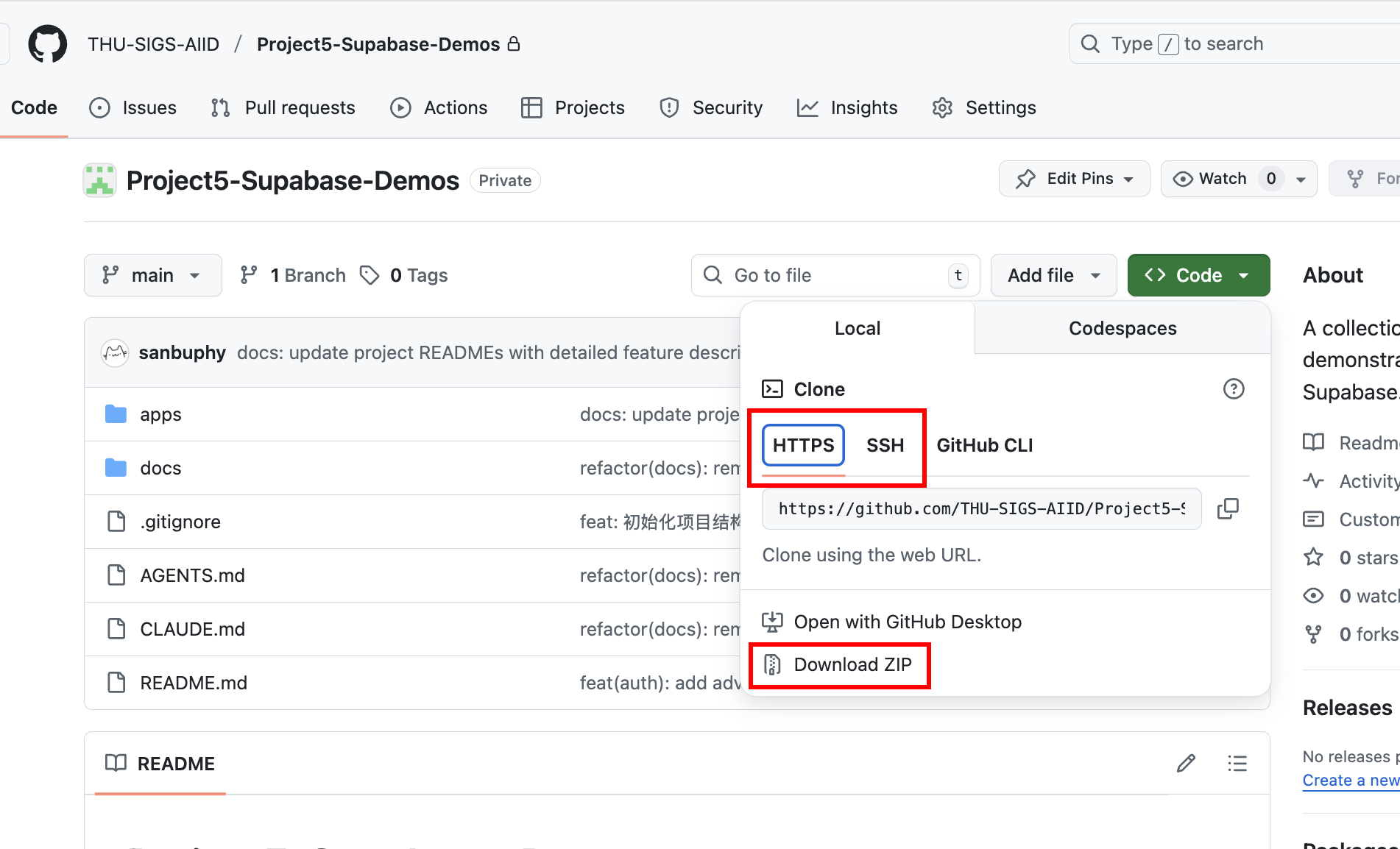
실습을 시작하려면 먼저 해당 데모 코드 저장소를 가져와야 해요. Trae나 Claude Code를 사용하여 다음 저장소를 git clone할 수 있어요: https://github.com/THU-SIGS-AIID/Project5-Supabase-Demos
SSH 키가 이미 설정되어 있다면 보안 향상을 위해 SSH 주소(git@github.com:THU-SIGS-AIID/Project5-Supabase-Demos.git)를 사용하는 것을 권장해요. SSH나 HTTPS 연결에서 네트워크 문제가 발생하면, 저장소 페이지의 "Download ZIP"을 직접 클릭하여 압축 파일을 다운로드하고 풀면 전체 코드를 확인할 수 있어요.
Clone이 완료되면, 마찬가지로 Trae나 Claude Code를 사용해 프로젝트를 시작할 수 있어요. 예를 들어 Agent 인터페이스에서 帮我直接启动这个项目里面的 project 1이라고 입력하거나, 시작하고자 하는 project의 절대 경로를 복사하여 대형 언어 모델에 붙여넣어 직접 시작할 수도 있어요.
3.2 프로젝트 1 - 햄버거 가게 메뉴 CRUD
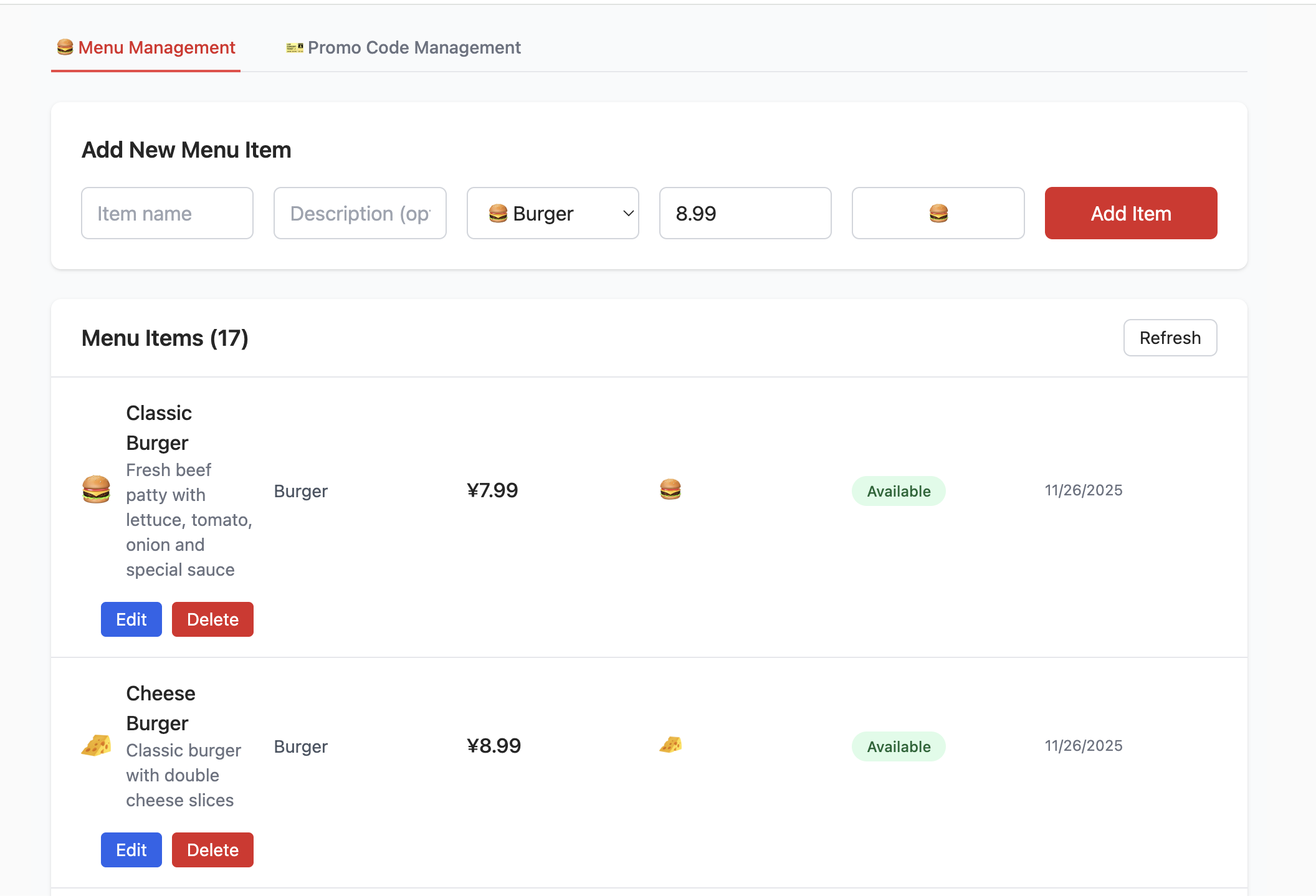
이제 실습 단계에 들어갈게요. project-burger-shop-menu-crud-1을 예로 들어, SQL 스크립트로 Supabase 데이터베이스를 원클릭 초기화하는 방법과 로컬 프로젝트를 Supabase 데이터베이스와 연결하여 프론트엔드에서 메뉴 데이터를 정상적으로 읽고 쓸 수 있도록 설정하는 방법을 배워볼 거예요.
스크립트로 데이터베이스 생성하기
먼저 Supabase에서 필요한 데이터 테이블 관련 내용을 생성해야 해요. Project1 프로젝트 디렉토리로 들어가면 scripts라는 폴더를 볼 수 있는데, 여기에는 init.sql 데이터베이스 스크립트 파일 1개가 들어 있어요. 이 파일은 데이터베이스 관련 리소스(테이블 구조, 초기 데이터 등)의 생성을 자동으로 완료해 주며, 이후 데이터베이스 테이블 초기화에 자주 사용하게 될 파일이에요.
......
-- ============================================================================
-- 2. Create Menu Items Table
-- ============================================================================
create table if not exists public.menu_items (
id uuid primary key default gen_random_uuid(),
name text not null,
description text,
category text check (category in ('burger','side','drink')) default 'burger',
price_cents int not null check (price_cents > 0),
available boolean default true,
emoji text,
created_at timestamptz not null default now(),
updated_at timestamptz not null default now()
);
-- Comments for documentation
comment on table public.menu_items is 'Burger shop menu items for CRUD demo';
comment on column public.menu_items.id is 'Unique identifier for each menu item';
comment on column public.menu_items.name is 'Display name of the menu item';
comment on column public.menu_items.description is 'Detailed description of the menu item';
comment on column public.menu_items.category is 'Category: burger, side, or drink';
comment on column public.menu_items.price_cents is 'Price in cents (integer) to avoid floating point issues';
comment on column public.menu_items.available is 'Whether the item is currently available for order';
comment on column public.menu_items.emoji is 'Optional emoji representation of the menu item';
comment on column public.menu_items.created_at is 'Timestamp when the item was created';
comment on column public.menu_items.updated_at is 'Timestamp when the item was last updated';
......SQL Editor에서 초기화 SQL 스크립트를 실행하면, Table Editor에서 생성된 데이터 테이블을 볼 수 있어요. 데이터베이스 초기화 코드의 구체적인 실행 로직은 다음과 같아요:
- menu_items 테이블 생성:
- 이 테이블은 햄버거 가게 메뉴의 모든 항목을 저장하는 데 사용돼요. name(상품명), description(설명), price_cents(센트 단위의 가격, 부동소수점 정밀도 문제 회피), category(분류), available(판매 가능 여부) 등의 필드가 포함되어 있어요. 메뉴 항목에 필요한 모든 정보를 기본적으로 다루고 있어요.
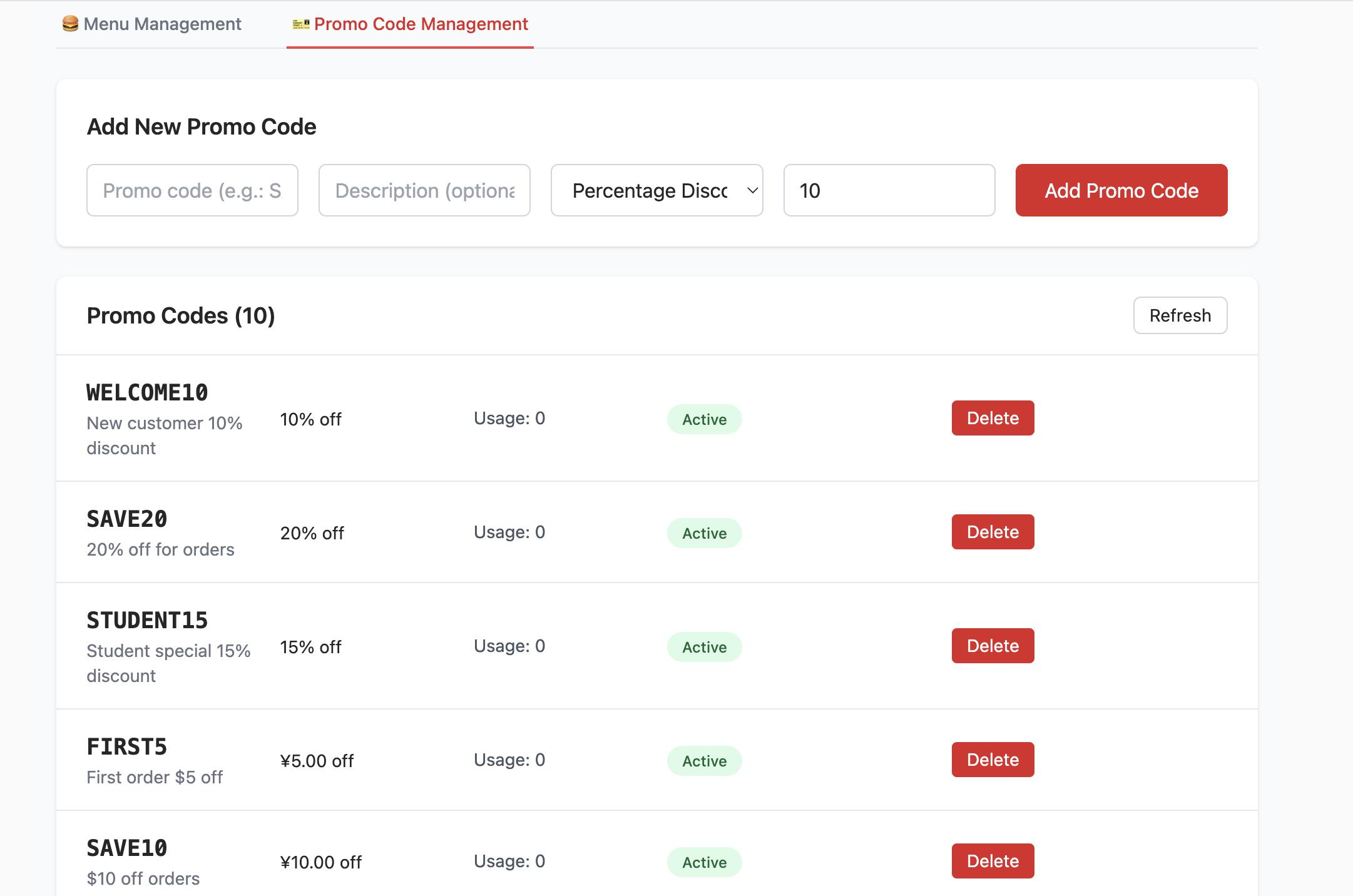
- promo_codes 테이블 생성:
- 이 테이블은 할인 코드와 같은 프로모션을 관리하는 데 사용돼요. code(할인 코드), discount_type(할인 유형, 예: 퍼센트 또는 고정 금액), discount_value(할인 수치) 등의 필드를 정의해요.
- 행 수준 보안(Row Level Security - RLS) 비활성화:
- 개발과 테스트를 편리하게 하기 위해 스크립트에서 RLS를 명시적으로 비활성화했어요. 하지만 앞서 학습한 RLS 핵심 로직을 떠올려 보면, RLS는 Supabase에서 데이터 보안을 보장하는 핵심 기능으로, 세밀한 정책을 통해 "누가 어떤 데이터에 접근/수정할 수 있는지"를 제어할 수 있어요(예: 관리자만 프로모션 코드를 편집할 수 있고, 일반 사용자는 메뉴만 볼 수 있게 제한). 따라서 프로덕션 환경에서는 반드시 RLS를 활성화하고 합리적인 정책을 구성하여, 비인가 접근(예: 사용자가 다른 사람이 만든 메뉴를 악의적으로 수정하거나 프로모션 코드 규칙을 유출하는 것)을 근본적으로 차단해야 해요.
- 시드 데이터(Seed Data) 삽입:
- 프론트엔드 프로젝트 시작 후 바로 실제 메뉴와 프로모션 데이터를 볼 수 있도록(테스트 데이터를 수동으로 입력할 필요 없이),
init.sql스크립트는menu_items와promo_codes테이블에 "시드 데이터"(샘플 데이터)를 삽입해요. 예를 들어 다양한 버거, 사이드, 음료 및 여러 가지 할인 코드를 볼 수 있어요.
데이터베이스 연결 설정
데이터베이스 준비가 완료되면, 이 프론트엔드 프로젝트를 Supabase와 연결하여 데이터베이스 내의 데이터를 정상적으로 읽어올 수 있도록 해야 해요. Supabase 프로젝트의 URL과 anon key를 지정된 설정에 입력해야 하며, 이 프로젝트는 두 가지 유연한 설정 방법을 제공해요:
- 환경 변수를 통한 설정
프로젝트 루트 디렉토리에 .env 파일을 생성하고, Supabase 자격 증명을 입력해요:
NEXT_PUBLIC_SUPABASE_URL=https://your-project.supabase.co
NEXT_PUBLIC_SUPABASE_ANON_KEY=your-anon-key- 프로젝트 페이지에서 직접 설정
빠른 데모와 다른 Supabase 프로젝트 간 전환을 편리하게 하기 위해, 홈페이지 우측 상단에 설정 버튼이 있어요. 클릭하면 나타나는 모달 창에서 Supabase URL과 anon key를 직접 입력하거나 붙여넣을 수 있어요.
"Save"를 클릭하면, 이 정보는 다음 코드와 유사한 방식으로 Supabase 클라이언트 인스턴스를 동적으로 생성하는 데 사용돼요:
import { createClient, type SupabaseClient } from '@supabase/supabase-js';
// Optional client factory for demos: returns null when env is not set.
export function maybeCreateBrowserClient(): SupabaseClient | null {
const url = process.env.NEXT_PUBLIC_SUPABASE_URL;
const anon = process.env.NEXT_PUBLIC_SUPABASE_ANON_KEY;
if (!url || !anon) return null;
return createClient(url, anon);
}데이터베이스 생성 후, 해당 Supabase Link 관련 설정을 완료하면 다음 인터페이스를 볼 수 있어요. 상품에 대한 추가, 삭제, 조회, 수정을 시도하고, Supabase에서 해당 데이터 테이블의 변화를 관찰해 보세요.
📚 과제
- 기존 항목을 추가하고 삭제해 보며, Table Editor에서 수정 조작이 데이터 테이블 내용에 미치는 변화를 확인해 보세요.
3.4 프로젝트 2 - 햄버거 가게 사용자 인증
Project 1은 "메뉴 CRUD + 데이터베이스 연결"을 구현했고, Project 2에서는 실제 비즈니스에 더 가까운 핵심 기능인 사용자 인증(Auth)과 행 수준 보안(RLS) 권한 관리를 도입해요.
Project 2에는 독립된 로그인 페이지가 포함되어 있으며, 사용자가 "이메일 + 비밀번호" 방식으로 로그인할 수 있도록 지원해요. 핵심 로직은 Supabase Auth에서 제공하는 네이티브 메서드를 호출하여 복잡한 로그인 검증 로직을 직접 개발할 필요 없이 빠르게 인증 흐름을 구현하는 것이에요:
const { error: err } = await supabaseClient.auth.signUp({
email,
password,
options: {
data: {
full_name: fullName || null,
birthday: birthday || null,
avatar_url: avatarUrl || null
}
}
});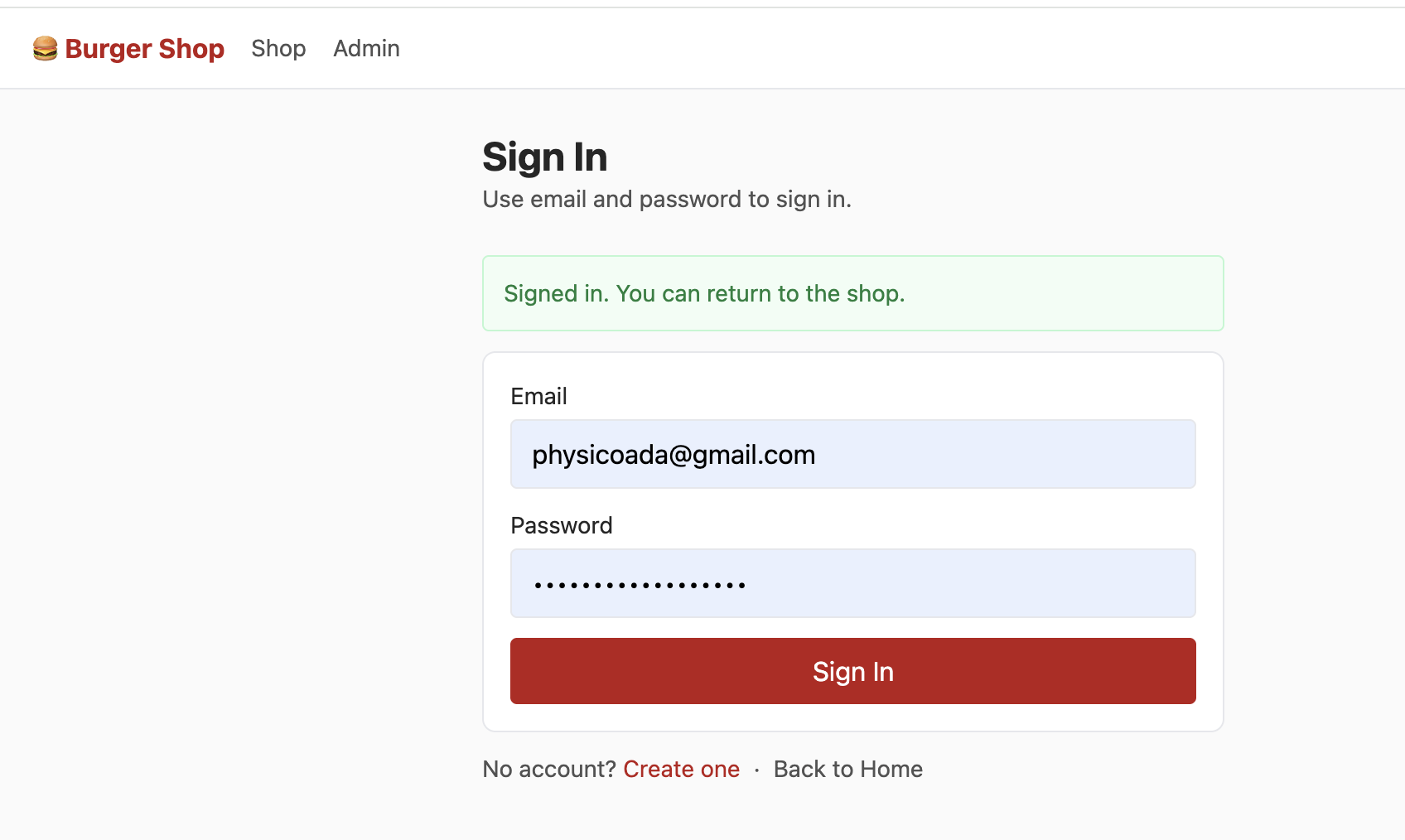
로그인에 성공하면, Supabase는 사용자를 위한 세션(session)을 자동으로 생성하고, 이후 모든 데이터베이스 요청에 인증 정보를 자동으로 포함해요. RLS의 역할 덕분에 각 사용자는 자신의 인증 정보에 따라 자신의 계정 정보(구매한 항목, 지갑 잔액)만 볼 수 있으며, 다른 사용자의 계정 정보는 볼 수 없어요. 이를 통해 다른 사용자가 로그인한 후의 데이터 격리가 실현되며, 각자 자신의 콘텐츠만 볼 수 있어요.
Project 1과 마찬가지로, 먼저 init.sql을 사용하여 데이터 테이블을 초기화해야 해요(참고: 초기화 중 오류가 발생하면, 먼저 Table Editor에서 이미 생성된 데이터 테이블을 삭제하거나, 이 Supabase Project를 직접 삭제하고 새 Project를 생성하세요).
이메일로 계정을 성공적으로 등록하고, 이메일에서 계정 등록을 확인한 후 로그인하면 Shop 인터페이스에서 다음 내용을 볼 수 있어요:
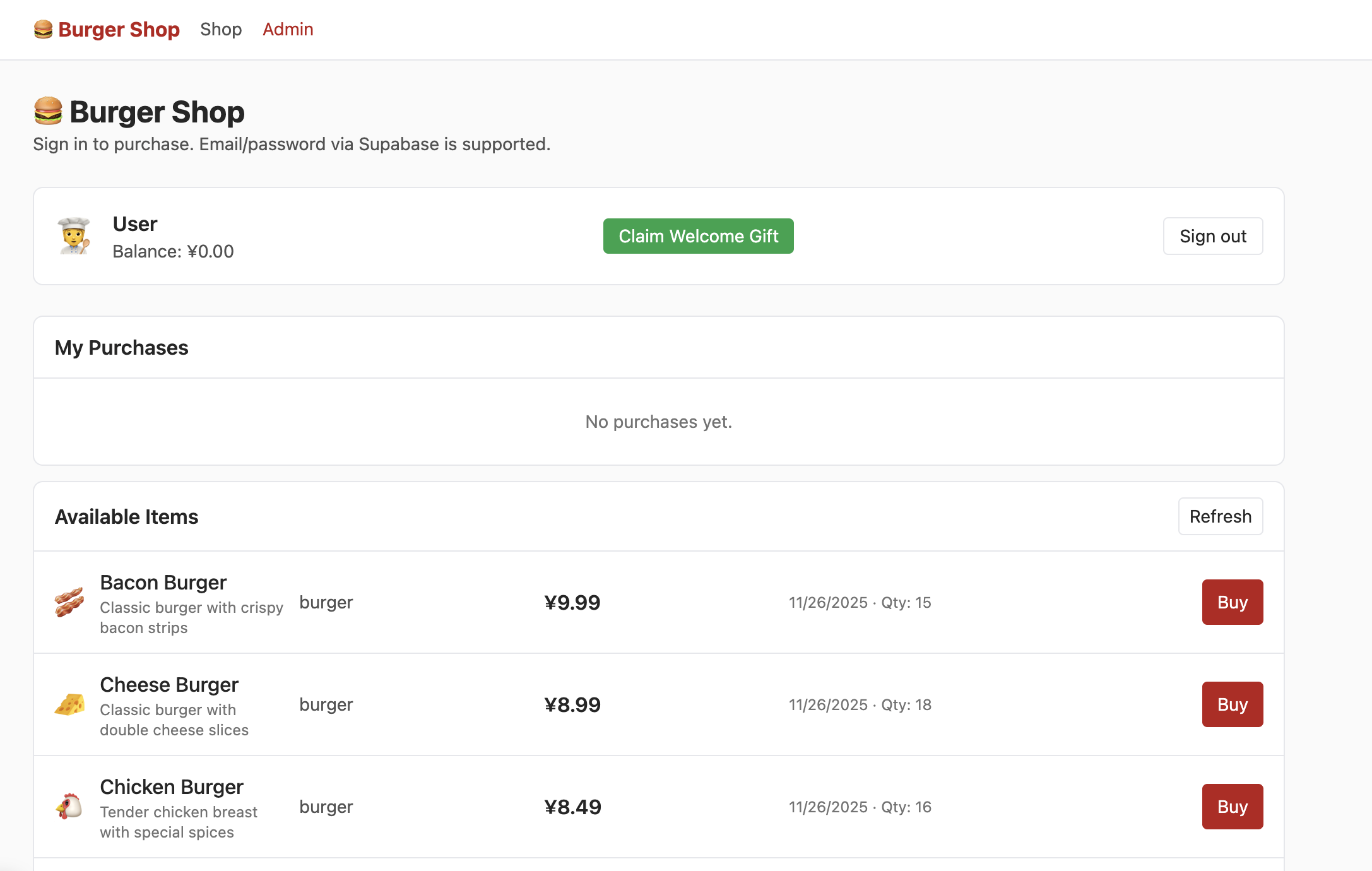
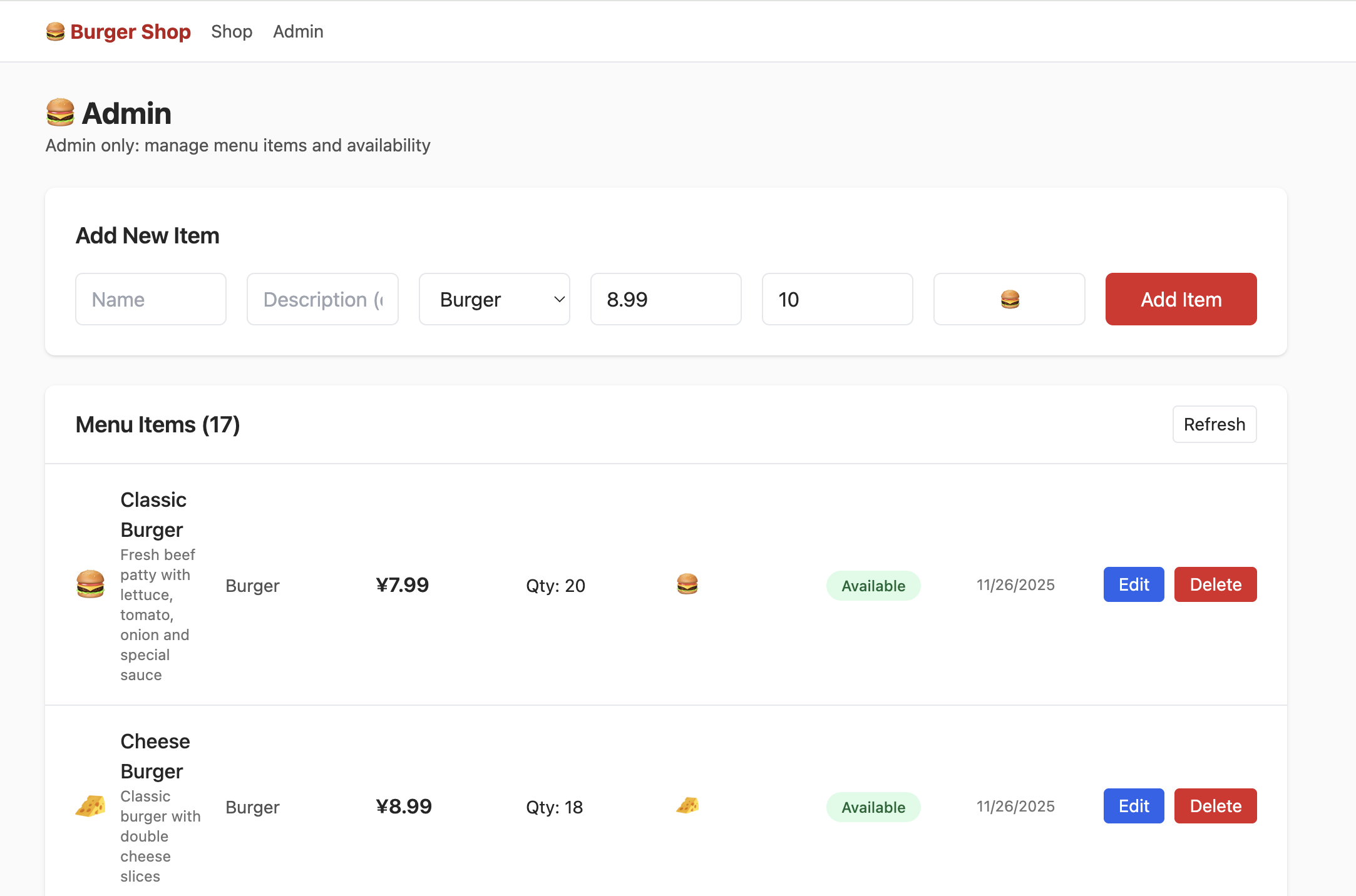
하지만 이때 admin을 클릭해도 다음 인터페이스를 볼 수 없어요. 데이터 테이블에서 사용자 권한을 제어하는 부분을 찾아 권한을 admin으로 수정하면, Admin 인터페이스에서 다음 내용을 정상적으로 볼 수 있어요:
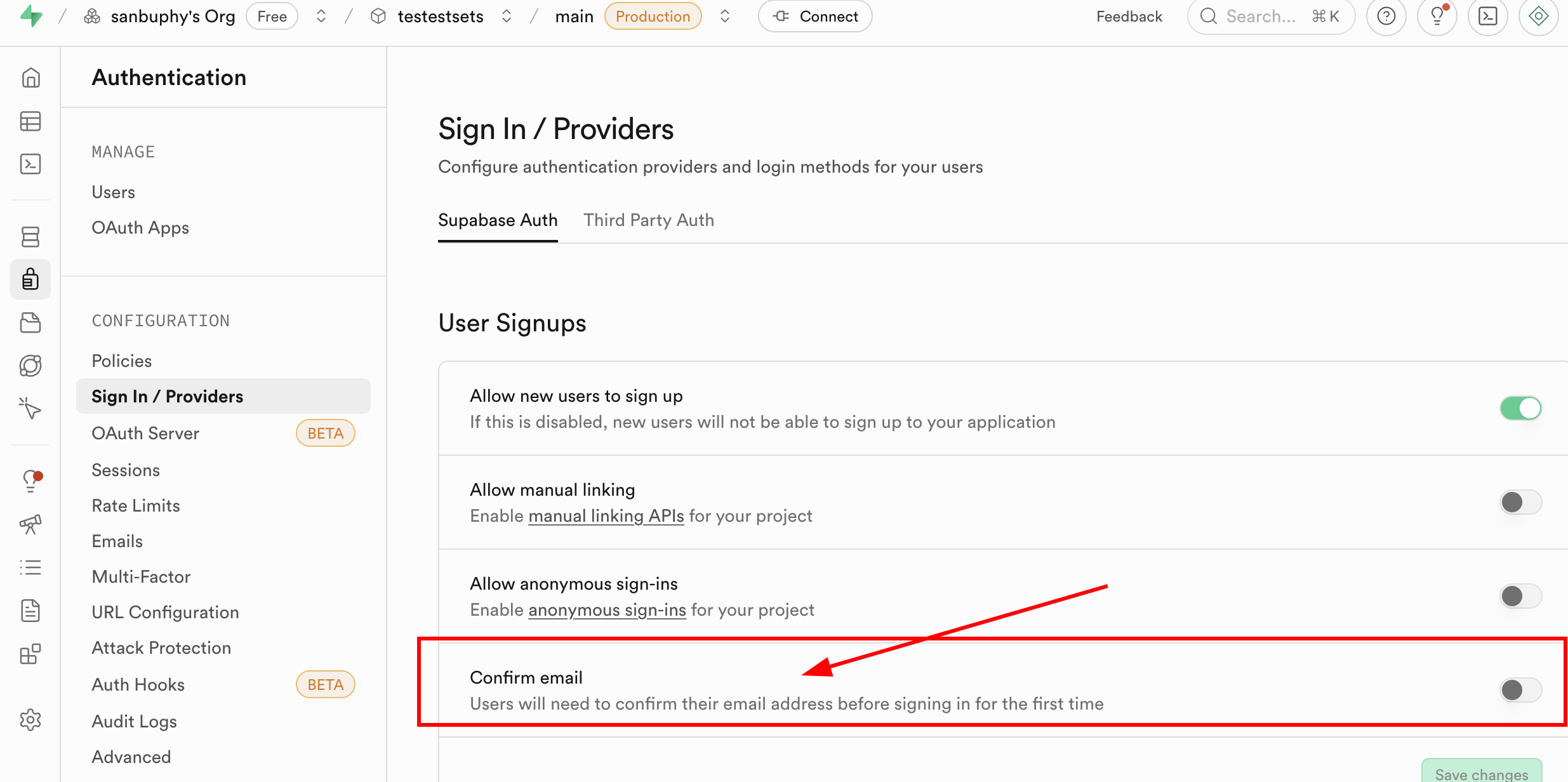
참고로, 현재 새 이메일로 등록할 때마다 이메일에서 등록 확인을 해야만 로그인할 수 있어요. 하지만 이 단계가 필수는 아니에요. Supabase의 Authentication 섹션에서 Sign In / Providers를 찾아, Confirm email을 클릭하여 이메일 강제 확인을 해제할 수 있어요.
📚 과제
- 먼저 신규 사용자 선물 팩을 수령하고, 상품 구매 조작을 완료해 보세요.
- 사용자 권한 설정 데이터 테이블 위치를 찾아 권한을
admin으로 수정하고, 주문 관리 인터페이스에서 상품 수량을 성공적으로 수정해 보세요. - 데이터 테이블 내에서 지갑 금액 관련 테이블을 찾아, 수정을 통해 남은 지갑 금액을 증가시켜 보세요.
4. 첫 번째 Supabase 애플리케이션 구축하기
앞선 체계적인 학습을 통해 Supabase의 핵심 역량(데이터베이스 조작, 사용자 인증, RLS 보안 정책)을 마스터했어요. 이제 직접 데이터베이스가 포함되고 사용자 로그인 시스템을 지원하는, 나만의 첫 번째 애플리케이션을 구축해 볼 차례예요!
4.1 임의의 애플리케이션에 Supabase 데이터베이스를 연결하는 표준화된 프로세스
표준화된 프로세스를 사용하여 임의의 애플리케이션을 Supabase 데이터베이스에 연결할 수 있어요:
- 먼저 요구사항을 정리하고 정보를 동기화하여 목표를 명확히 하고 AI에 알려요
- 현재 애플리케이션의 핵심 기능과 새로 추가할 데이터베이스 요구사항을 AI에게 명확하게 설명해야 해요. 예시: "현재 로컬 React Todo 애플리케이션이 있는데, 데이터가 브라우저 로컬 저장소에만 있어요. '데이터 클라우드 동기화' 기능을 새로 추가하고 Supabase 데이터베이스에 연결하고 싶어요. 이 애플리케이션에 어떤 데이터 조작이 있는지(예: 할 일 추가, 상태 수정, 할 일 삭제) 분석해 주세요. 이 데이터를 저장하려면 어떤 데이터 테이블을 만들어야 하나요?"
- 핵심 제약 조건을 추가해요(선택사항): 예를 들어 필드 형식 요구사항(타임스탬프에
timestamptz사용, 금액은 정수로 센트 단위 저장), 데이터 권한 규칙(자신의 할 일만 볼 수 있음) 등을 명시하면, AI의 분석이 실제 요구사항에 더 부합해요. - AI가 반환한 결과를 검토하고, AI의 분석에 누락이 있으면(예: "할 일 마감 시간" 필드를 고려하지 않은 경우) 보완 프롬프트로 수정해요: "마감 시간을 놓쳤어요, 추가해 주세요."
- 확인한 테이블 구조를 바탕으로 AI가 Supabase에 맞는
init.sql스크립트를 생성하도록 해요: "위에서 논의한 내용과 테이블 구조를 바탕으로, Supabase에서 초기화할 수 있는 init.sql 스크립트를 만들어 주세요." 이후 SQL Editor에서 스크립트를 실행해요. 실행 중 오류가 발생하면 오류 메시지를 AI에 피드백하여 스크립트를 수정받아요. - Supabase에서 init.sql 스크립트를 실행한 후, AI가 스크립트를 바탕으로 현재 코드를 리팩토링하여 Supabase와 정상적인 데이터 상호작용이 가능하도록 해요: "SQL 스크립트와 위에서 논의한 설정을 바탕으로, 프로젝트 코드를 리팩토링하여 Supabase의 해당 데이터베이스와 통신하고 데이터를 처리할 수 있도록 해 주세요."
- 리팩토링이 완료되면, Supabase 주소와 key 파라미터만 설정하면 돼요(실제 프로젝트는 보통 환경 변수 설정만 사용). 이후 검사를 진행하고, 문제가 없다면 애플리케이션을 Supabase 데이터베이스에 성공적으로 연결한 것이에요.
- 프로젝트를 실행하고 모든 데이터베이스 상호작용 기능을 테스트하며, Supabase Table Editor에서 데이터가 동기화되었는지 실시간으로 확인해요.
- 문제가 발생하면(예: 데이터 삽입 불가, 일부 데이터만 보이는 경우) 현상을 AI에 피드백하여 원인을 파악하고 코드를 수정받아요.
또한, 사용자 로그인 페이지 개발이 목표라면 AI에게 직접 로그인 페이지 통합을 도와달라고 요청할 수 있어요: "이 애플리케이션에 Supabase 사용자 로그인 시스템을 추가해 주세요. 이메일로 가입하고 로그인할 수 있게 해 주세요." 또한, 페이지 전환 로직과 경로(예: 로그인 성공 후 시스템 홈페이지로 이동, 홈페이지 주소는 무엇인지, 로그인 실패 시 현재 페이지에 머물며 오류 메시지 표시)를 AI에게 명확히 알려줘야 해요. 통합이 완료되면, 가입 후 로그인하여 Supabase의 Authentication 항목에서 새 사용자 데이터를 확인할 수 있고, 로그인 후 원래 접근할 수 없었던 애플리케이션 인터페이스에 정상적으로 진입할 수 있어야 해요.
물론, AI에게 특정 프로젝트의 구현을 참고하여 해당 Supabase 기능을 직접 마이그레이션하도록 할 수도 있어요. 예를 들어 어떤 Project가 데이터베이스와 Edge Function의 고급 기능을 사용하고 있다면, 다음과 같이 AI에게 유사한 기능을 직접 마이그레이션하도록 요청할 수 있어요: "{여기에 참조 프로젝트의 절대 경로를 복사하여 붙여넣기} 이 프로젝트의 Supabase 관련 기능 구현 로직을 참고하여, 현재 프로젝트에 유사한 구현 로직(예: 사용자 로그인, 데이터베이스 관리, 함수 요청 등)을 추가해 주세요."
4.2 사례 연구: 온라인 뱀 게임 구축하기
위에서 언급한 SOP에 따라, 구체적인 실제 사례인 Project5-Supabase-Demos/apps_snakegame를 통해 실습해 볼게요: 이미 있는 "뱀" 게임 프로젝트에 사용자 로그인과 데이터베이스 기본 기능이 포함된 점수 랭킹보드를 추가해 볼 거예요.
4.2.1 프로젝트 분석, 데이터 요구사항 식별
먼저, 앞서 언급한 표준화된 프로세스와 유사하게 요구사항을 AI에게 전달하여, AI가 우리 프로젝트와 요구사항을 바탕으로 해당 수정 방안을 제시하도록 해요. 이후 이 수정 방안을 바탕으로 작업을 진행할 거예요.
다음과 같은 프롬프트를 사용하여 AI를 안내할 수 있어요:
"뱀 게임이 있는데, 디렉토리는 {여기에 뱀 게임의 절대 경로를 붙여넣기}이에요. 이제 Supabase를 결합하여 온라인 리더보드 기능을 추가하고, 사용자 로그인 시스템도 지원하고 싶어요. 리더보드는 사용자 이름과 이메일로 순위를 표시할 수 있어야 해요.
이 기능을 구현하려면 어떤 데이터 테이블을 만들어야 할지 분석해 주세요. 각 테이블에는 어떤 필드가 포함되어야 하나요?"
그러면 다음과 비슷한 응답을 받을 수 있어요:
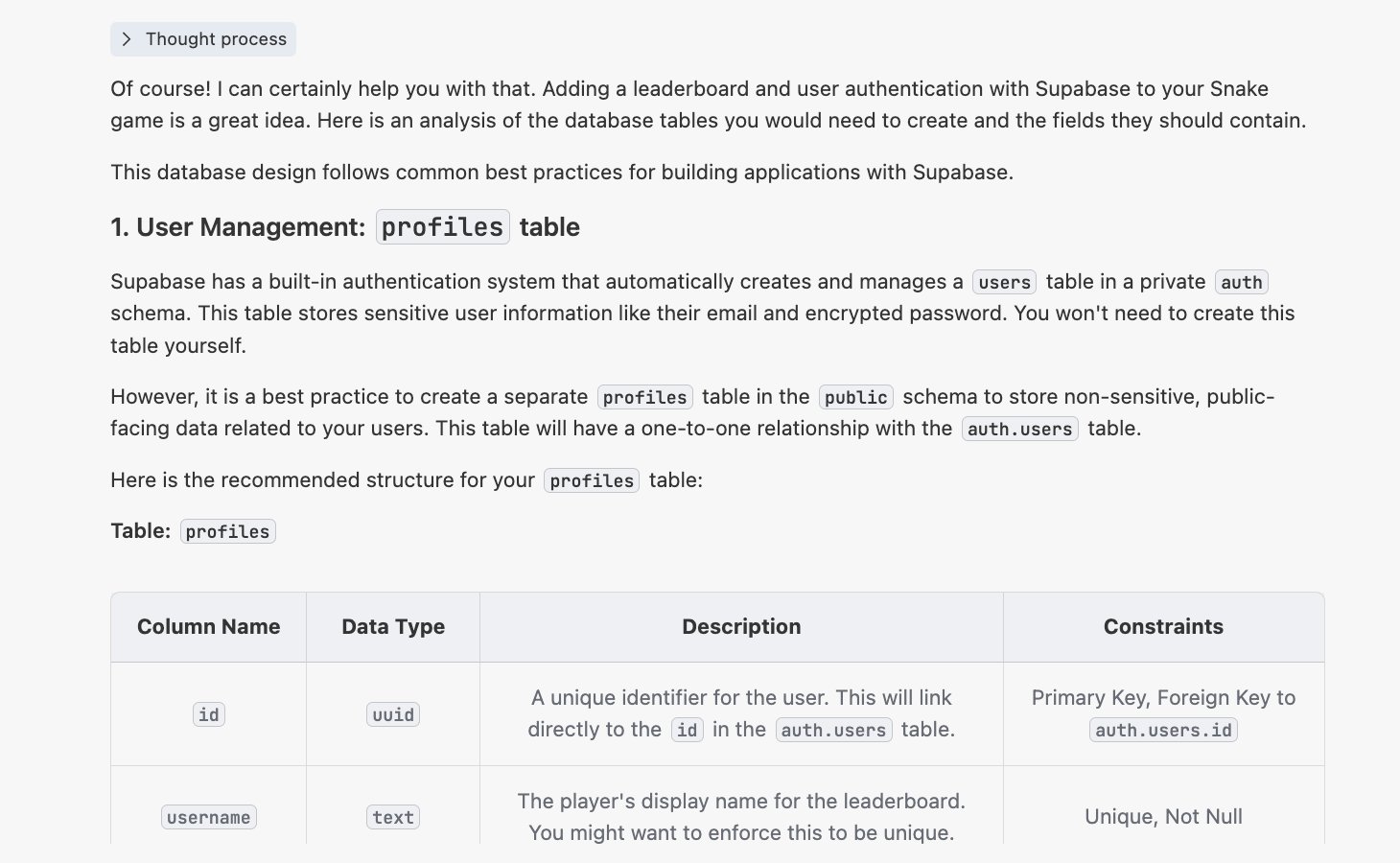
4.2.2 init.sql 스크립트 생성
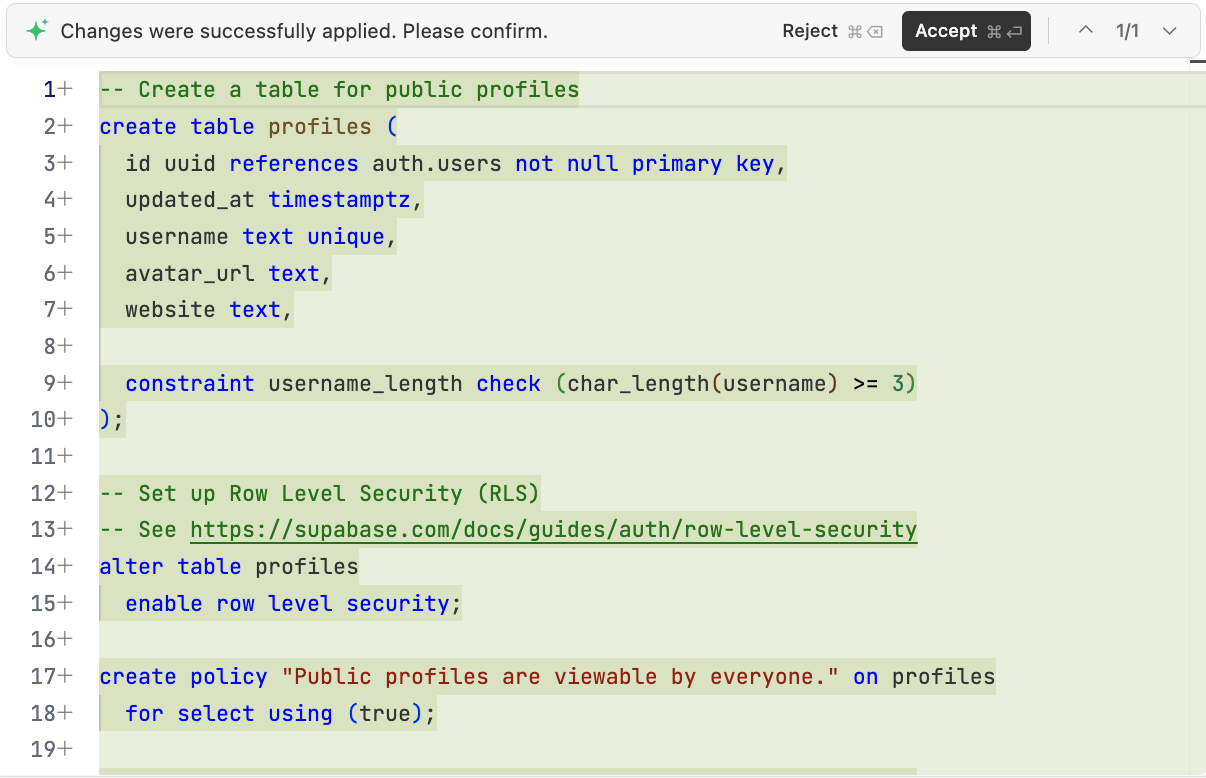
필요한 부분이 확인되면, AI에게 Supabase에서 실행할 데이터베이스 초기화 스크립트를 생성하도록 요청해요: "위 분석을 바탕으로, 프로젝트에 scripts/init.sql 스크립트를 생성하여 Supabase에서 필요한 데이터베이스를 초기화할 수 있도록 해 주세요."
4.2.3 프로젝트 코드 리팩토링
다음으로, AI에게 앞선 내용을 바탕으로 현재 뱀 게임 코드를 리팩토링하도록 해요: "앞서 고민한 내용과 SQL 테이블을 바탕으로, Supabase를 사용하여 리더보드 기능을 구현해 주세요. 리더보드는 별도의 페이지로, 이메일과 사용자 이름으로 다른 사용자의 총점을 구분할 수 있어야 하고, 이메일 기반 사용자 로그인 시스템도 지원해야 해요. 가입하고 로그인해야만 게임을 플레이할 수 있어야 해요."
현재 AI 대화 차수가 너무 많아 새 세션을 열어 프로젝트를 리팩토링하고 싶다면, 앞서 언급한 init.sql을 컨텍스트의 내용으로 포함시켜, AI가 SQL 파일을 바탕으로 프로젝트를 리팩토링하도록 할 수 있어요.
AI가 구현한 사용자 로그인 시스템이 정상적으로 작동하지 않는다면, 이전에 작성된 Project5-Supabase-Demos/apps/project-burger-shop-auth-users-2의 주소를 프롬프트에 함께 포함시켜, AI가 프로젝트를 바탕으로 사용자 로그인 시스템을 직접 구현하도록 할 수 있어요. 그리고 Supabase에 연결하기 위한 필수 조건이 올바르게 설정되었는지 확인하여, Supabase 설정 오류로 인한 에러를 방지해야 해요.
코드 수정 과정에서 실제 효과가 예상과 다른 경우(예: 리더보드 데이터가 표시되지 않음, 로그인 검증이 작동하지 않음 등), 구체적인 현상을 자세히 기록하고 AI에 피드백하면 점진적으로 올바른 결과에 도달할 수 있어요. 리팩토링 성공의 기준은: 사용자가 가입과 로그인 조작을 순조롭게 완료할 수 있고, 로그인 후 해당 게임 리더보드를 정상적으로 볼 수 있어야 해요.
📚 과제
- 사용자 관리 시스템을 뱀 게임 데모 버전에 통합해 보세요.
- 사용자 관리 시스템을 여러분의 애플리케이션에 통합해 보세요(이전에 애플리케이션을 개발한 적이 있다면).
5. Supabase 마스터 되기
지금까지 Supabase의 기본 조작에 대해 알아보았고, 다음 여정에서는 Supabase의 고급 원리와 기능을 접하게 될 거예요. 왜 우리가 Supabase를 교육 사례로 선택했는지, 그리고 Supabase를 사용하여 더 고급 조작을 어떻게 구현하는지 이해하게 될 거예요. 더 복잡한 상호작용 기능을 실현하는 데 도움이 될 거예요. 또한 이러한 기능을 학습한 후에는 Supabase 외의 다른 유사 도구를 만나더라도 유추할 수 있고, 백엔드 서비스의 핵심 원리를 더 근본적인 수준에서 이해할 수 있게 돼요. 물론, 단시간에 모든 것을 배울 필요는 없어요. 서드파티 로그인 지원만 학습해도 충분할 수 있어요. 먼저 아래 내용을 훑어보고, 프로젝트에서 해당 요구사항이 생겼을 때 다시 돌아와 깊이 학습해도 좋아요.
5.1 왜 Supabase를 선택했나요
고급 내용으로 들어가기 전에, 다시 한 번 이 질문을 생각해 봐요: 수많은 백엔드 기술 솔루션 중 왜 최종적으로 Supabase를 기술 기반으로 선택했을까요?
초기 창업팀이 기술 선정을 할 때 흔히 직면하는 딜레마가 있어요: 백엔드 시스템을 완전히 통제하고 싶으면서도 제품을 빠르게 출시해야 한다는 것이에요. 하지만 자체 백엔드 구축은 보통 데이터베이스와 실시간 동기화, 사용자 인증, API 서비스, 파일 저장, 정기 작업, 모니터링/알림 등 핵심 컴포넌트를 구축하는 데 수개월이 소요돼요. 단, 팀원이 해당 분야에서 풍부한 실무 경험을 축적한 경우는 예외예요. 자금 부족과 짧은 시장 기회라는 이중 압박 속에서 인프라 구축의 늪에 빠지면, 반복 주기가 지연되어 초기 성장 기회를 놓치기 쉬워요.
Supabase는 이러한 백엔드 역량을 바로 사용 가능한 서비스로 패키징해요(PostgreSQL 데이터베이스, 실시간 구독, 인증, 객체 스토리지, 엣지 함수, 자동 API 생성 등). 초기 창업팀이 부족한 자원을 핵심 기능 개발에 집중할 수 있게 해주며, 기반 인프라 구축으로 인한 출시 지연을 방지해요. 이는 현재 벤처 투자 환경에서 실용적인 생존 전략이 되었어요. 물론 PocketBase(경량 미니멀)나 Appwrite(크로스 플랫폼 지원) 등 다른 올인원 백엔드 제품으로도 개발할 수 있지만, 기능 완성도, SQL 생태계 성숙도, Github 커뮤니티 관심도를 종합적으로 고려하면 Supabase가 비즈니스의 장기 안정 운영을 지원하는 데 더 적합해요.
동류 제품 중에서 Supabase의 오픈소스 전략이 더욱 우위에 있어요. 시장 점유율이 높은 Firebase를 예로 들면: 폐쇄소스 특성상 플랫폼 종속성이 발생하기 쉽고, 마이그레이션 비용이 매우 높아요. Supabase는 완전한 오픈소스 모델을 채택하여, 사설 배포를 지원하고 벤더 종속(lock-in) 위험을 회피하며, 필요에 따라 다른 경쟁 제품으로 전환할 수 있어요.
요약하자면, 기술 선정은 비즈니스 규모와 목표에 부합해야 해요. 개인 프로젝트나 극소규모 테스트의 경우 PocketBase 같은 초경량 솔루션으로 충분해요. 기업이 복잡한 ID 시스템과 연동해야 하거나 상장 기업의 컴플라이언스 감사 요구를 충족해야 하는 경우, WorkOS 같은 엔터프라이즈급 전체 ID 거버넌스 솔루션이 더 적합해요. 하지만 MVP 검증과 초기 사용자를 수용하는 핵심 비즈니스 시나리오에서는 Supabase의 완전한 기능이 충분해요. 최소 만 명 수준의 사용자 규모를 독자적으로 지원할 수 있을 뿐만 아니라, Stripe(결제), Resend(이메일), Cloudflare(CDN) 등 서드파티 서비스와 유연하게 통합할 수 있어요. 향후 비즈니스가 엔터프라이즈급 요구사항으로 확장되더라도, Supabase의 오픈소스 아키텍처는 엔터프라이즈 시스템과 병렬 배포가 가능하며, 각 기능에 가장 적합한 플랫폼을 선택하여 사용할 수 있어요. 이러한 점진적 유연성 덕분에 초기 창업팀은 과도한 중량급 인프라에 조기 투자할 필요가 없으면서도, 미래 지향적인 진화 공간을 보존할 수 있어요.
5.2 Google 및 GitHub 로그인 지원
앞선 튜토리얼에서는 이메일을 사용한 직접 가입과 로그인 방법을 설명했어요. 하지만 실제로는 가입 절차를 간소화하고 싶을 때가 많아요. 예를 들어 Google이나 GitHub 같은 서드파티 로그인을 사용하여 빠른 가입과 로그인을 구현하고 싶을 수 있어요. 이번 섹션에서는 각 세부 사항을 다룰 거예요. 또한, 완전한 인증 시스템은 안전하고 신뢰할 수 있는 비밀번호 재설정 기능도 제공해야 하며, 비밀번호 재설정 기능도 이번 섹션의 프로젝트에 통합할 거예요.
이 프로젝트(Project5-Supabase-Demos/apps/project-burger-shop-auth-advanced-supabase-6)는 이러한 고급 기능을 구현하는 방법을 완전히 보여줘요.

5.2.1 OAuth 흐름: 서드파티 로그인은 어떻게 작동하나요?
서드파티 로그인의 핵심은 OAuth 2.0 개방형 인가 프로토콜이에요. 그 본질은 "인가 대리"예요: 사용자가 우리 애플리케이션(햄버거 가게 프로젝트)이 서드파티 플랫폼(예: Google)의 공개 정보(예: 이메일, 프로필 사진)에 접근하도록 승인할 수 있게 하되, 서드파티 플랫폼의 비밀번호를 우리 애플리케이션에 노출할 필요가 없어요. 이를 통해 근본적으로 비밀번호 유출 위험을 회피해요.
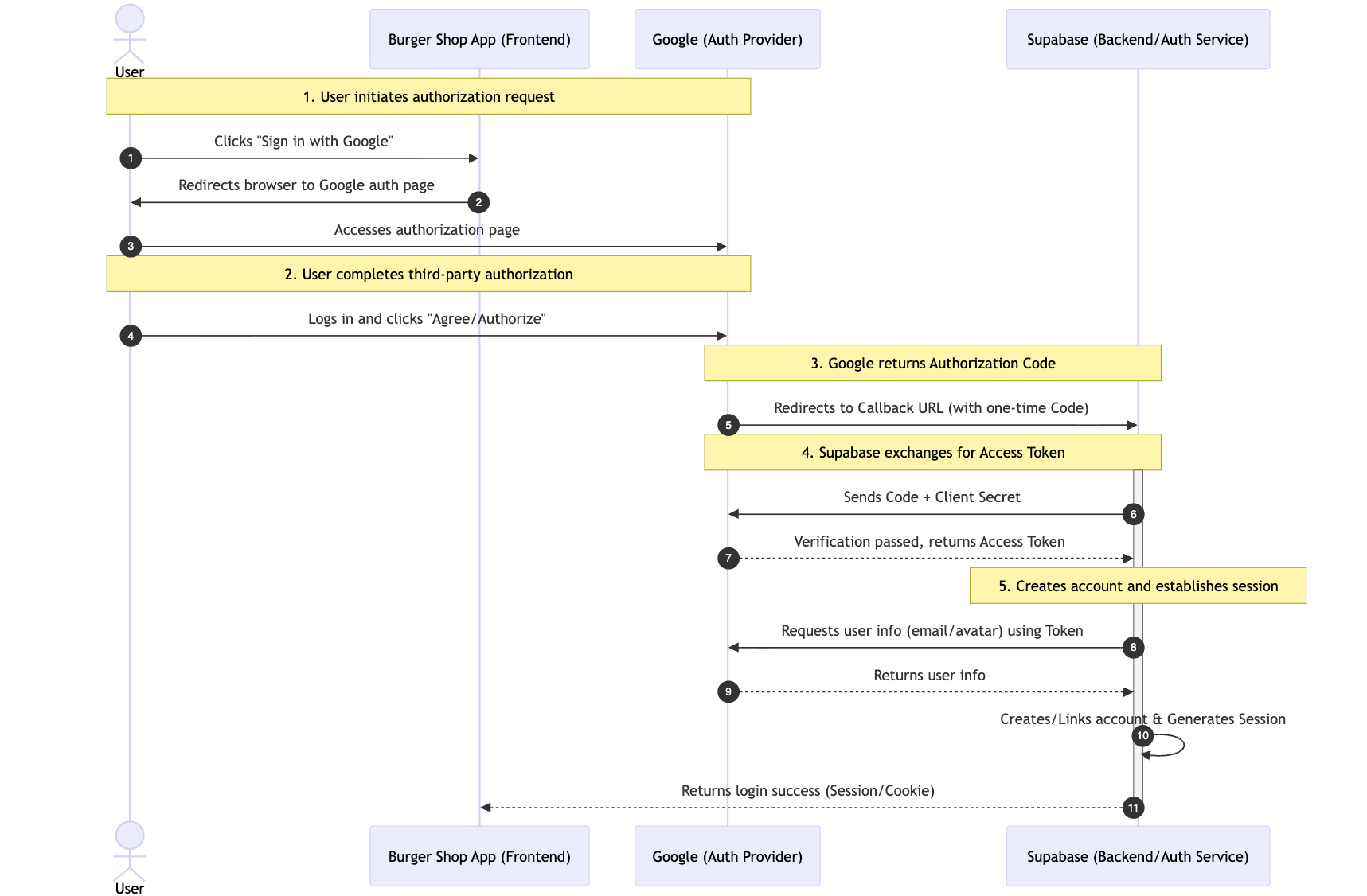
전체 흐름은 Google 로그인을 예로 들어 5개의 핵심 단계로 나눌 수 있어요:
- 사용자가 인가 요청 시작: 사용자가 페이지의 "Sign in with Google" 버튼을 클릭하면, 우리 애플리케이션은 사용자를 Google 공식 인가 페이지로 자동 리다이렉트해요(인가 과정의 보안을 보장하고 피싱 위험을 방지).
- 사용자가 서드파티 인가 완료: 사용자가 Google 페이지에서 자신의 계정에 로그인하고(사용자 신원 확인), 우리 애플리케이션이 요청한 권한(예: "이메일 주소 가져오기")에 동의해요.
- Google이 일회용 인가 코드 반환: 인가가 통과되면, Google은 사용자를 사전에 합의된 "콜백 URL(Callback URL)"로 리다이렉트하고, URL 파라미터에 일회용이며 단기 유효한 인가 코드를 포함해요(사용자 정보를 직접 반환하지 않고, 보안을 한층 더 강화).
- Supabase가 Access Token 교환: 우리 백엔드(Supabase가 호스팅하므로 자체 구축 불필요)는 이 인가 코드를 가지고 Google 공식 인터페이스에 요청을 보내, 사용자 정보를 가져오는 데 사용할 수 있는 Access Token으로 교환해요(인가 코드는 Token 교환에만 사용되며, Token이 프론트엔드에서 직접 전송되는 것을 방지).
- 계정 생성 및 세션 구축: Supabase가 Access Token을 사용하여 Google에서 사용자의 공개 정보(예: 이메일, 프로필 사진)를 가져오고, 해당 사용자의 계정을 자동으로 생성(첫 로그인 시)하거나 기존 계정에 직접 연결한 후, 최종적으로 유효한 사용자 세션(Session)을 생성하여 로그인을 완료해요.
5.2.2 Google Cloud 설정하여 Client ID와 Secret 얻기
어떤 서드파티 로그인 방식이든, 보통 Client ID와 Secret을 얻어 설정해야 해요. Google 서드파티 로그인의 경우, 먼저 Google Cloud Platform에서 OAuth 2.0 클라이언트 ID를 생성하여 해당 파라미터를 얻어야 해요.
- Google Cloud Console 진입 :
- Google Cloud Console에 접속해요.
- 새 프로젝트를 만들거나 기존 프로젝트를 선택해요.
- OAuth 동의 화면(OAuth consent screen) 설정 :
- 왼쪽 탐색 바에서 "APIs & Services" -> "OAuth consent screen"을 찾아요.
- "External" 사용자 유형을 선택한 후 "Create"를 클릭해요.
- 애플리케이션 이름, 사용자 지원 이메일 등 필수 정보를 입력해요.
- "Authorized domains" 섹션에 Supabase 프로젝트 도메인을 추가해요. 형식은
*.supabase.co예요. - 저장하고 계속 진행해요. "Scopes" 및 "Test users" 단계는 일단 건너뛰고 바로 저장해도 돼요.
- 자격 증명 생성(Create Credentials) :
- "APIs & Services" -> "Credentials"로 들어가요.
- "+ CREATE CREDENTIALS"를 클릭하고 "OAuth client ID"를 선택해요.
- "Application type"에서 "Web application"을 선택해요.
- 이름을 지정해요. 예를 들어 "Supabase Auth"라고 해요.
- "Authorized redirect URIs" 섹션에서 "ADD URI"를 클릭하고, Supabase 프로젝트의 콜백 URL을 입력해요. 이 URL은 Supabase Dashboard의 "Authentication" -> "Providers" -> "Google"에서 찾을 수 있어요. 형식은 보통
https://<프로젝트ID>.supabase.co/auth/v1/callback이에요.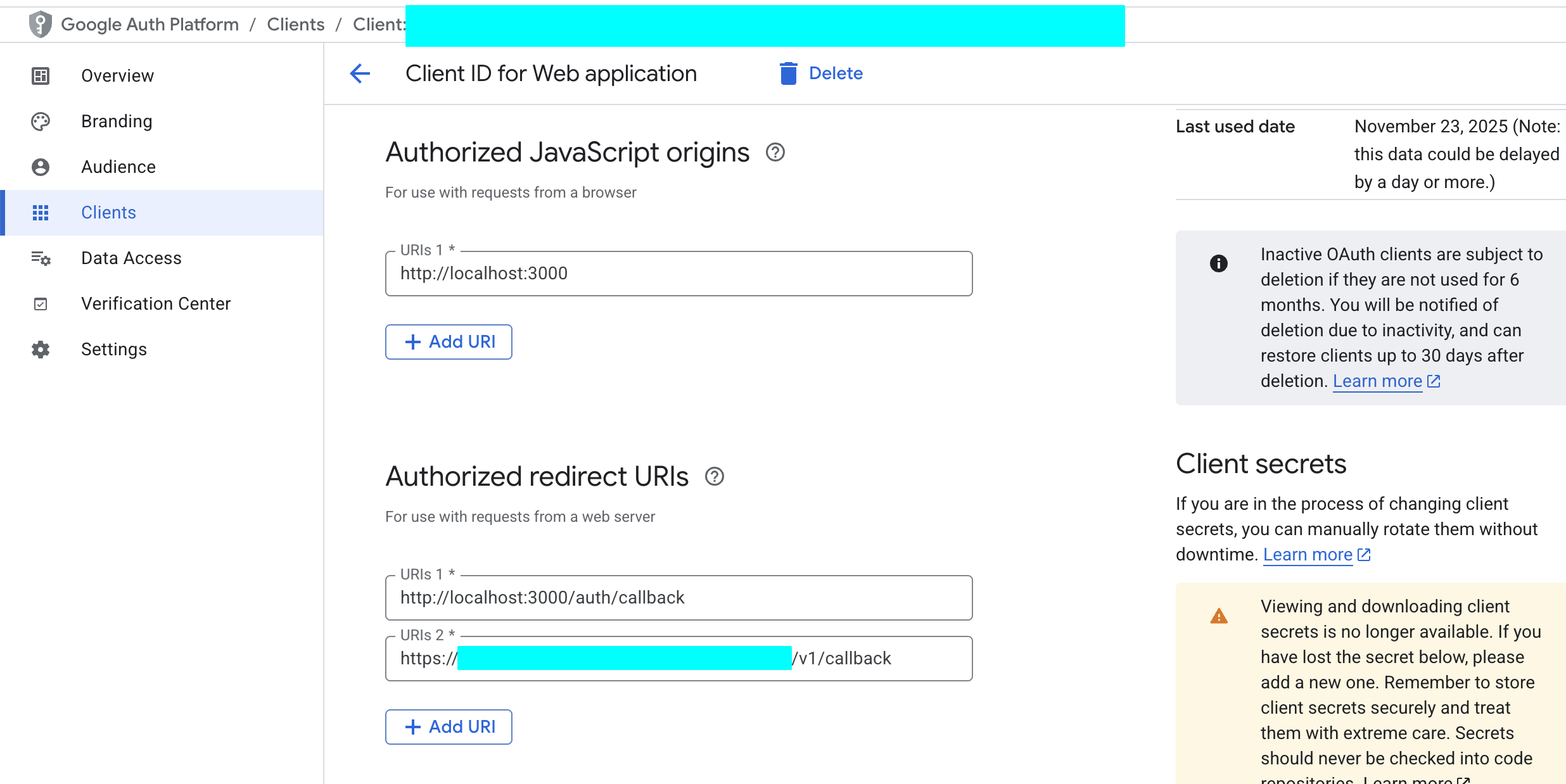
- "CREATE"를 클릭해요.
- Client ID와 Client Secret 얻기 :
- 생성이 완료되면 팝업 창에 Client ID와 Client Secret이 표시돼요. 즉시 복사하여 안전하게 보관하세요.
5.2.3 GitHub 설정하여 Client ID와 Secret 얻기
마찬가지로 GitHub에도 OAuth 애플리케이션을 등록해야 해요.
GitHub Developer Settings 진입 :
- GitHub 계정에 로그인해요.
- 우측 상단 프로필 사진을 클릭하고 "Settings"로 들어가요.
- 왼쪽 탐색 바 하단에서 "Developer settings"를 찾아요.
새 애플리케이션 등록(Register a new application) :
"OAuth Apps"를 선택한 후 "New OAuth App"을 클릭해요.
애플리케이션 이름을 입력해요. 예를 들어 "My Burger Shop"이라고 해요.
Homepage URL : 애플리케이션의 온라인 주소 또는 로컬 개발 주소
http://localhost:3000을 입력해요.Authorization callback URL : Supabase 프로젝트의 콜백 URL을 입력해요. 마찬가지로 Supabase Dashboard의 "Authentication" -> "Providers" -> "GitHub"에서 찾을 수 있으며, 형식은
https://<프로젝트ID>.supabase.co/auth/v1/callback이에요."Register application"을 클릭해요.
Client ID와 Client Secret 얻기 :
등록이 완료되면 페이지에 Client ID가 표시돼요.
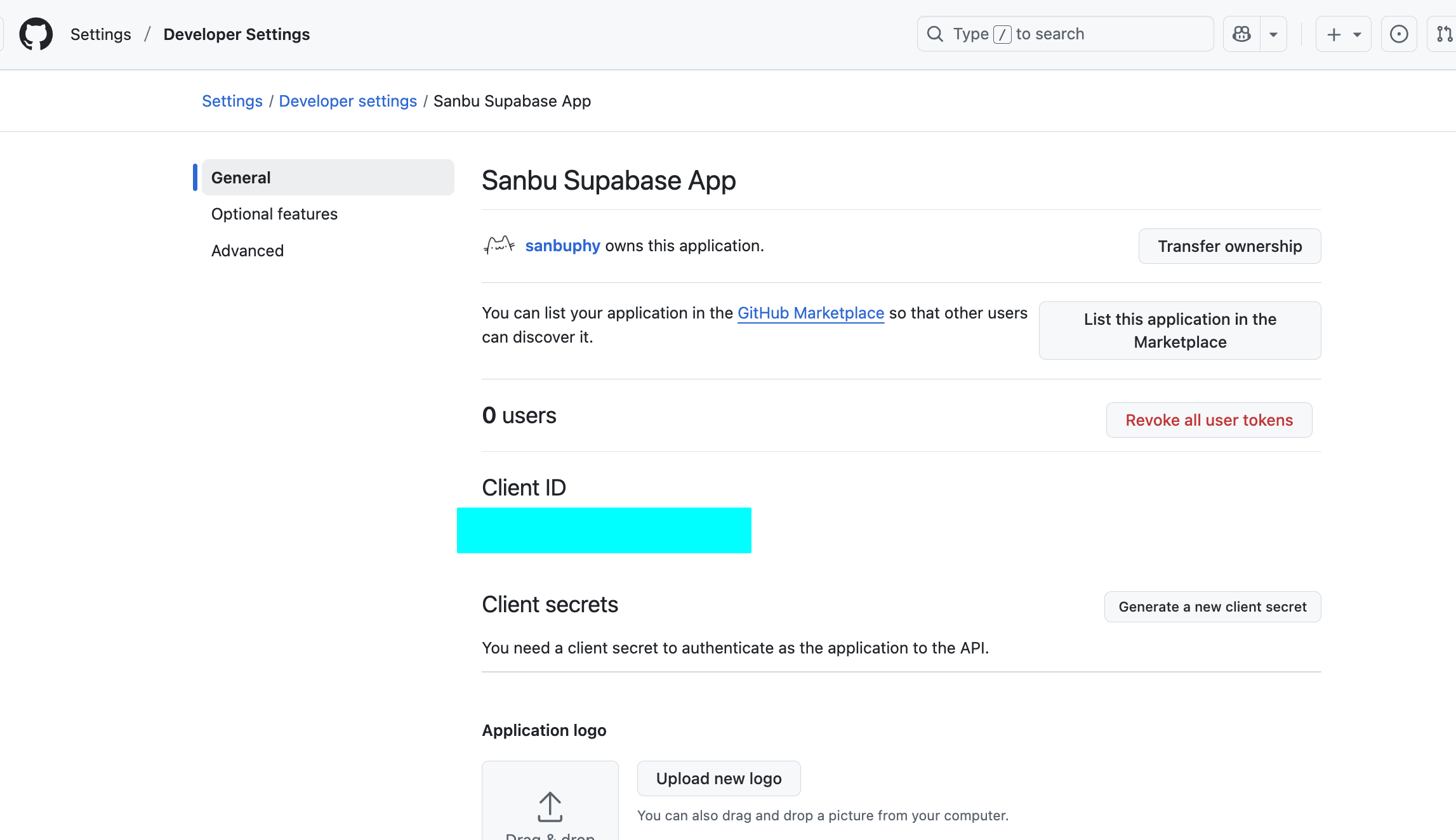
"Generate a new client secret"을 클릭하여 Client Secret을 생성해요. 마찬가지로 즉시 복사하여 저장하세요.
5.2.4 Supabase에서 Provider 설정하기
이제 얻은 자격 증명을 Supabase에 설정해요.
- Supabase Dashboard 진입 :
- 프로젝트를 선택하고 "Authentication" -> "Providers"로 들어가요.
- Google 활성화 및 설정 :
- "Google"을 찾아 활성화해요.
- Google Cloud에서 얻은 Client ID와 Client Secret을 해당 입력란에 붙여넣어요.
- "Save"를 클릭해요.
- GitHub 활성화 및 설정 :
- "GitHub"을 찾아 활성화해요.
- GitHub에서 얻은 Client ID와 Client Secret을 해당 입력란에 붙여넣어요.
- "Save"를 클릭해요.

이제 서드파티 계정을 사용하여 구축한 웹사이트에 로그인할 수 있어요. AI에게 Project5-Supabase-Demos/apps/project-burger-shop-auth-advanced-supabase-6 프로젝트를 참고하여, 여러분의 프로젝트에 사용자 로그인 시스템을 지원하도록 하여 최소 비용으로 GitHub와 Google 인증이 포함된 사용자 로그인 인터페이스를 통합할 수 있어요.
5.2.6 비밀번호 재설정 구현
성숙한 사용자 로그인 컴포넌트로서 비밀번호 재설정도 매우 중요한 부분이에요. 이 프로젝트 project-burger-shop-auth-advanced-supabase-6에는 해당 기능의 완전한 구현도 포함되어 있어요. AI에게 이 프로젝트의 비밀번호 재설정 기능을 바탕으로 완전한 비밀번호 재설정 컴포넌트를 복제하도록 요청할 수 있어요. 주요 단계는 다음과 같아요:
- 요청 시작: 사용자가 비밀번호 찾기 페이지에서 이메일을 입력하면, 프론트엔드가
supabase.auth.resetPasswordForEmail()함수를 호출하고, 리다이렉트 redirectTo URL(예: /auth/reset)을 지정해요. - 이메일 발송: Supabase가 해당 이메일로 고유한 재설정 링크가 포함된 이메일을 발송해요.
- 링크 접속: 사용자가 이메일의 링크를 클릭하면, 애플리케이션 내의 지정된 재설정 페이지로 리다이렉트돼요.
- 비밀번호 업데이트: 재설정 페이지에서 사용자가 새 비밀번호를 입력해요. 프론트엔드는
supabase.auth.updateUser()를 호출하여 새 비밀번호를 Supabase에 제출해요. Supabase가 링크의 유효성을 자동으로 검증하고 비밀번호 업데이트를 완료해요.
마지막으로, 현재 비밀번호 재설정 이메일이 너무 단조롭다고 생각되면, Supabase Dashboard의 Authentication -> Email Templates에서 "Reset Password" 이메일 템플릿을 커스터마이징할 수 있어요.
Reset password 기능 외에도, 사용자 관리와 관련된 많은 고급 기능 설정(예: Invite user 등)을 볼 수 있어요. 각 기능의 개발 문서를 참고하여, Vibe coding 도구와 결합해 해당 기능을 직접 추가할 수 있어요.
5.3 실시간 기능
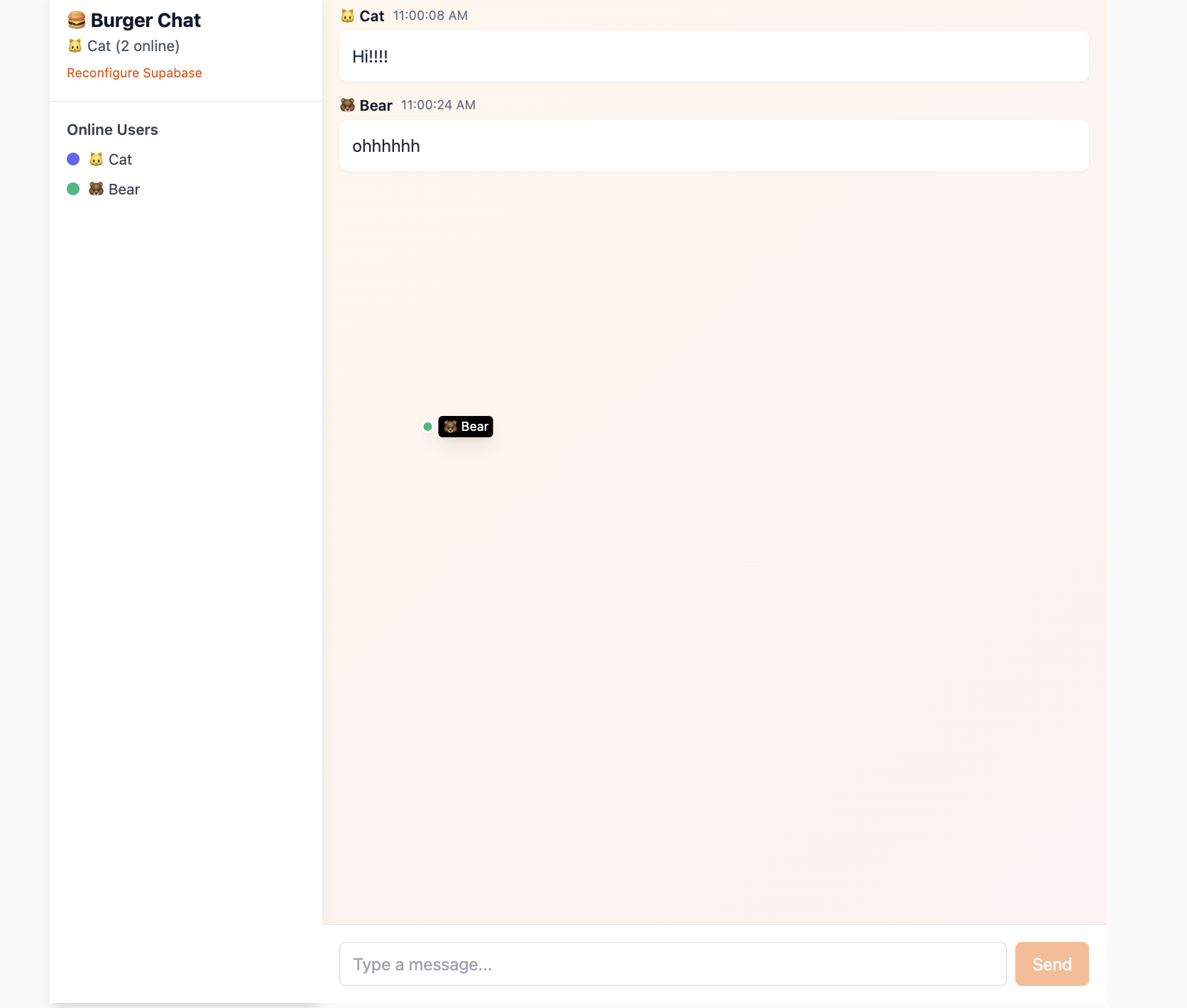
Supabase의 실시간 기능은 가장 강력한 특징 중 하나로, 협업 문서, 실시간 대시보드, 게임 로비 또는 고객 서비스 시스템 구축에 매우 편리해요.
이 프로젝트 Project5-Supabase-Demos/apps/project-burger-shop-realtime-orders-3는 다인 실시간 채팅방과 커서 위치 공유 기능을 구현하여, Supabase Realtime과 관련된 세 가지 핵심 역량인 데이터베이스 변경 감시(Postgres Changes), 브로드캐스트(Broadcast), 온라인 상태(Presence)를 보여줘요.
관련 코드 부분이 다소 어렵게 느껴진다면, AI에게 이 문서의 내용을 참고하여 프로그램을 수정하도록 직접 요청할 수 있어요.
5.3.1 데이터베이스 실시간 변동 Postgres Changes
가장 일반적인 Realtime 기능은 데이터베이스 변경을 실시간으로 감시하는 Postgres Changes예요. 클라이언트가 데이터베이스의 특정 테이블, 특정 행, 심지어 특정 열의 INSERT, UPDATE, DELETE 이벤트를 구독할 수 있게 해줘요. 데이터베이스에 변경이 발생하면(API 호출, Supabase Dashboard 조작, SQL 스크립트 실행 등 어떤 방식이든), Supabase는 PostgreSQL의 기본 복제 메커니즘을 활용하여, 즉시 WebSocket을 통해 변경된 데이터를 해당 채널을 구독 중인 모든 프론트엔드 클라이언트에 푸시해요. 프론트엔드에서 폴링(Polling)으로 반복 조회할 필요가 없어요.
일반적으로 이 기능은 Table Editor에서 Enable Realtime을 클릭하여 시작할 수 있지만, SQL 스크립트를 통한 초기화 실행이 더 편리해요. 예를 들어:
-- Enable realtime replication
ALTER TABLE public.chat_messages REPLICA IDENTITY FULL;
DO $$
BEGIN
IF NOT EXISTS (
SELECT 1 FROM pg_publication_tables
WHERE pubname = 'supabase_realtime'
AND schemaname = 'public'
AND tablename = 'chat_messages'
) THEN
ALTER PUBLICATION supabase_realtime ADD TABLE public.chat_messages;
END IF;
END $$;이 문장은 chat_messages 테이블을 Supabase에 사전 설정된 supabase_realtime에 추가해요. 테이블이 이 특수한 publication에 추가되면, Supabase의 실시간 서버가 해당 테이블의 모든 데이터 변경을 감시하기 시작해요.
위 특수 데이터 테이블을 바탕으로, 감시 코드를 사용하여 테이블 내 데이터 변동을 실시간으로 감시할 수 있어요. 구현해야 할 것은 한 사용자가 메시지를 보낼 때, 다른 모든 온라인 사용자가 즉시 화면에서 이 메시지를 볼 수 있도록 하는 것이에요. chat_messages 테이블의 INSERT 이벤트를 구독하면 이를 구현할 수 있어요.
const sub = supabase
.channel('chat_messages_channel')
.on('postgres_changes', {
event: 'INSERT',
schema: 'public',
table: 'chat_messages'
}, (payload: any) => {
console.log('New message received:', payload.new);
const newMessage = payload.new as Message;
// ... //
.subscribe((status: string) => {
console.log('Chat subscription status:', status);
});.channel('chat_messages_channel'): 격리된 통신 채널을 생성해요..on('postgres_changes', ...): 핵심 구독 메서드예요.chat_messages테이블의INSERT이벤트만 관심 있다고 Supabase에 알려주는 것이에요.payload.new: 새 메시지가 데이터베이스에 삽입되면, Supabase가 이 새 데이터의 전체 내용을payload.new를 통해 모든 구독 클라이언트에 푸시해요..subscribe(): 구독을 시작해요.
5.3.2 정보 브로드캐스트 동기화 Broadcast & Presence
데이터베이스에 저장할 필요가 없는 더 "즉각적인" 상호작용, 예를 들어 커서 이동, 온라인 상태 등에 대해서는 Supabase가 Broadcast와 Presence 기능을 제공해요.
- Presence: 채널 내 모든 클라이언트의 공유 상태를 추적하는 데 사용해요. "누가 온라인인지" 기능을 구현하는 데 적합해요.
- Broadcast: 채널 내 다른 모든 클라이언트에게 저지연의 임시 메시지를 보내는 데 사용해요.
Presence의 핵심 아이디어는: 각 클라이언트가 자신의 온라인 상태를 선언하고, Supabase 서버가 이 상태들을 채널 내 다른 모든 클라이언트에 안정적으로 동기화하는 것이에요. Presence 구현은 다음 핵심 단계로 나뉘어요:
- Presence를 지원하는 채널 생성
먼저 이러한 상호작용을 전담하는 채널 lobby_presence를 만들고, 설정에서 현재 사용자를 식별하는 고유 key를 지정해요. 이 key는 보통 사용자의 ID예요.
const ch = supabase.channel
('lobby_presence', {
config: {
presence: { key: anonymousUser.id },
}
});- 채널을 구독하고 "온라인" 상태를 알려요
채널이 성공적으로 생성되면, 이를 구독해야 해요. 구독 성공 콜백(status === 'SUBSCRIBED')에서 channel.track() 메서드를 호출해요. 이 메서드는 현재 사용자의 정보(예: 사용자 ID, 이름, 프로필 색상 등)를 채널 내 다른 모든 클라이언트에 브로드캐스트하여 자신의 "온라인" 상태를 알려요.
const me = {
id: anonymousUser.id,
name: anonymousUser.name,
color: anonymousUser.color
};
ch.subscribe(async (status) => {
if (status === 'SUBSCRIBED') {
await ch.track(me);
}
});- 전체 온라인 목록 동기화
새 사용자가 채널에 참여하면, 현재 이미 온라인인 모든 사용자 목록을 가져와야 해요. 이는 presence의 sync 이벤트를 감시하여 구현해요. sync 이벤트는 채널에 처음 참여할 때 트리거되어, 전체 "스냅샷"을 제공해요.
channel.presenceState() 메서드는 현재 채널 내 모든 온라인 사용자의 상태 정보가 포함된 객체를 반환해요. 이를 처리하여 애플리케이션의 state에 업데이트하면, 전체 온라인 사용자 목록을 렌더링할 수 있어요.
ch.on('presence', { event: 'sync' }, ()
=> {
const state = ch.presenceState();
const flat = {};
Object.values(state).forEach((arr) => {
arr.forEach((u) => { flat[u.id] =
{ ...u }; });
});
setOnline(flat);
});- 개별 사용자의 참여와 퇴장 감시
sync 이벤트 외에도, 새 사용자가 들어오거나 나갈 때 즉각적으로 반응할 수 있도록 join과 leave 이벤트를 감시할 수 있어요. 예를 들어 "User has joined" 알림을 표시할 수 있어요.
ch.on('presence', { event: 'join' }, ({
key, newPresences }) => {
console.log('User joined:', key,
newPresences);
});
ch.on('presence', { event: 'leave' }, ({
key, leftPresences }) => {
console.log('User left:', key,
leftPresences);
});위 단계를 통해 기능이 완전한 온라인 상태 시스템을 구축했어요. Supabase는 사용자가 예기치 않게 연결이 끊어진 경우(예: 브라우저를 닫거나 네트워크가 끊어진 경우)를 자동으로 처리하고, 적절한 시점에 leave 이벤트를 트리거하여 온라인 목록의 정확성을 보장해요.
Presence가 "누가 접속 중인지" 알려준 후, Broadcast는 그들 사이에서 "대화"를 가능하게 하지만, 대화의 내용은 임시로 저장돼요. 전형적인 예시가 실시간 커서 추적이에요. 마우스가 움직일 때마다 데이터베이스에 읽기/쓰기를 하면 엄청난 성능 낭비와 지연이 발생해요. Broadcast는 이 문제를 완벽하게 해결하여, 메시지가 각 클라이언트 간에 WebSocket을 통해 직접 전달되도록 하며, 데이터베이스를 완전히 우회해요.
Broadcast의 작동 모드는 주로 두 가지 핵심 메서드에 의존해요: channel.send()는 전송에, channel.on()은 수신에 사용돼요.
- 송신 측: 내 커서 위치 브로드캐스트
mousemove 이벤트에 리스너를 추가했어요. 마우스가 이동하면 사용자 ID, 좌표 및 색상이 포함된 payload를 구성한 다음, channel.send()를 통해 브로드캐스트하고 이벤트 이름을 'cursor'로 지정해요.
const handleMouseMove = (e) => {
const payload = {
id: anonymousUser.id,
x: e.clientX,
y: e.clientY,
name: anonymousUser.name,
color: anonymousUser.color
};
channelRef.current?.send({
type: 'broadcast',
event: 'cursor',
payload
});
};
document.addEventListener('mousemove', handleMouseMove);- 수신 측: 다른 사람의 커서 감시 및 렌더링
동일한 채널 내에서 모든 클라이언트는 channel.on()을 사용하여 broadcast 유형이면서 event가 'cursor'인 메시지를 감시해요. 일치하는 메시지가 수신되면 콜백 함수가 트리거돼요. payload에서 송신자의 데이터를 파싱하고, 이를 사용하여 로컬 online 상태를 업데이트하여 화면에 다른 사용자 커서의 위치를 실시간으로 렌더링해요.
ch.on('broadcast', { event: 'cursor' }, ({ payload }) => {
setOnline((prev) => ({
...prev,
[payload.id]: {
...(prev[payload.id] || {}),
x: payload.x,
y: payload.y
}
}));
});이러한 방식으로 Presence와 Broadcast가 협력하여 작동해요. Presence는 온라인 사용자 목록을 유지하고, Broadcast는 커서 위치와 같은 임시 상태를 이들 사용자 간에 전달하여, 낮은 비용으로 풍부한 실시간 상호작용 기능을 구현해요.
5.4 스토리지
사용자 정보, 주문과 같이 규격화하여 정의할 수 있는 구조화된 데이터 외에도, 완전한 애플리케이션은 일반적으로 대량의 비정형 파일을 처리해야 해요. 예를 들어 사용자 아바타, 상품 전시 이미지, 사용자가 업로드한 주문 문서 등이 있어요. 이러한 파일의 특징은 크기 편차가 크고 수량이 매우 많을 수 있다는 거예요(예: 전자상거래 플랫폼의 상품 이미지는 수만 장에서 수십만 장에 달할 수 있어요). 이를 애플리케이션 자체의 비즈니스 서버에 직접 저장하면 서버의 스토리지 부하가 크게 증가하고, 데이터 읽기/쓰기 속도가 느려져 애플리케이션의 전반적인 성능에 영향을 미칠 수 있어요.
실제 개발에서는 이러한 비정형 파일이 "객체 스토리지 서비스"에 의해 통합 관리돼요. OSS, Amazon S3가 모두 이러한 서비스에 속하며, 대량의 파일 저장을 위해 특별히 설계된 "전문 스토리지 도구"로 파일의 저장, 백업 및 빠른 읽기 요구를 효율적으로 처리할 수 있어요. 애플리케이션에서 이러한 파일을 가져올 때 객체 스토리지 서비스의 "기본 저장소"에서 직접 호출하는 것이 아니라 URL 주소를 통해 이루어져요. 객체 스토리지에 저장된 각 파일에는 고유한 URL이 할당돼요(예: "https://xxx.oss.com/avatar/user123.jpg"와 같은 주소로, 이 "웹사이트"에는 이미지가 하나만 있다고 간단히 이해할 수 있어요). 이 URL은 파일의 "전용 액세스 주소"와 같아서, 프론트엔드 페이지는 이 주소를 통해 아바타나 상품 이미지를 직접 다운로드하거나 로드할 수 있어요. 애플리케이션 비즈니스 서버를 거칠 필요가 없어 파일 로딩 속도가 향상되고 비즈니스 서버의 부하가 줄어들어요.
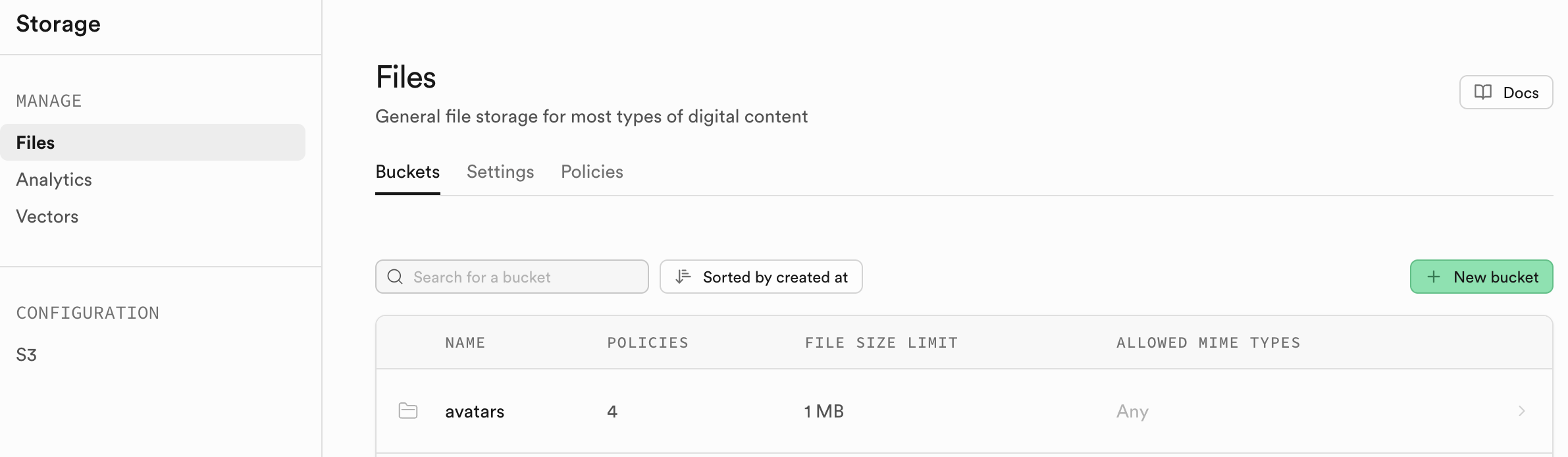
이 프로젝트 project-burger-shop-storage-uploads-4는 사용자 아바타 업로드 기능을 통해 Supabase Storage를 활용하여 현대적인 파일 업로드 시스템을 구축하는 방법을 깊이 있게 시연하여, 개발자가 비정형 파일이 업로드에서 URL 액세스까지의 전체 과정을 직관적으로 이해할 수 있도록 해줘요. 또한 이 프로젝트는 Uppy 라이브러리를 사용하여 우수한 파일 업로드 인터페이스를 제공하고, Tus 플러그인과 결합하여 재개 가능한 업로드를 구현하며, Uppy의 업로드 엔드포인트를 Supabase의 표준 API(supabaseUrl>/storage/v1/upload/resumable)로 지정하여 작동해요. 유사한 방식으로 업로드 기능 컴포넌트를 구현할 수 있어요.
5.4.1. 스토리지 버킷
Supabase Storage의 구성 단위는 스토리지 버킷(Bucket)이에요. 컴퓨터 운영 체제의 폴더로 생각할 수 있어요. 각 Bucket은 자체적인 보안 정책과 설정을 가질 수 있어요.
Storage 내의 모든 파일은 공개 URL을 통해 직접 액세스할 수 있지만, 이것이 누구나 마음대로 업로드하거나 수정할 수 있다는 의미는 아니에요. 구체적인 액세스 권한은 더 세밀한 정책에 의해 제어돼요. 데이터베이스와 마찬가지로 Storage의 액세스 권한도 행 수준 보안 정책을 통해 관리돼요. SQL 정책은 storage.objects와 storage.buckets라는 두 특수 테이블에 작성되며, 누가 파일을 읽고(SELECT), 업로드하고(INSERT), 업데이트하고(UPDATE), 삭제할 수(DELETE) 있는지 정확하게 정의할 수 있어요.
예를 들어, 사용자가 자신의 user_id로 명명된 폴더에만 업로드할 수 있고, 이미지 유형의 파일만 업로드할 수 있도록 하는 정책을 만들 수 있어요:
CREATE POLICY "Allow authenticated
uploads to avatars bucket"
ON storage.objects FOR INSERT
TO authenticated
WITH CHECK (
bucket_id = 'avatars' AND
auth.uid() = (storage.foldername(name))
[1]::uuid AND
(storage.extension(name) IN ('png',
'jpg', 'jpeg'))
);
CREATE POLICY "Allow public read access
to avatars"
ON storage.objects FOR SELECT
USING ( bucket_id = 'avatars' );5.4.2 액세스 가능한 파일 URL 획득
이 프로젝트에서는 avatars라는 공개 버킷을 수동으로 생성해야 해요. 모든 파일이 해당 공개 버킷 아래에 업로드되어 저장돼요. 파일 업로드가 성공하면 Storage 내의 저장 경로(예: public/avatar1.png)만 얻게 돼요. 이는 데이터베이스에 저장된 문자열일 뿐이며, 브라우저가 이 이미지를 렌더링할 수 있으려면 이를 액세스 가능한 HTTP URL로 변환해야 해요.
Supabase는 이 URL을 얻기 위해 두 가지 서로 다른 전략을 제공하며, 보안, 지속성 및 비용 제어 측면에서 본질적인 차이가 있어요.
1. 공개 URL (Public URL) - 영구 링크
가장 직접적인 방법이에요. 파일이 Public Bucket에 저장된 경우, 고정되고 영구적인 공개 링크를 얻을 수 있어요.
const { data } = supabase.storage
.from('avatars')
.getPublicUrl('public/avatar1.png');
const publicUrl = data.publicUrl;이러한 링크에는 두 가지 핵심 특징이 있어요. 첫째, 간단하고 직접적이며, URL 구조가 고정되어 있어 실제 운영에서 조립하고 관리하기 쉬워 기술적 사용 임계값이 낮아요. 둘째, 캐싱에 유리하며, 영구 링크로서 CDN(콘텐츠 전송 네트워크)과 브라우저에 의해 효과적으로 캐시될 수 있어 리소스의 액세스 속도를 크게 향상시키고 사용자 경험을 최적화해요. 이러한 특징을 바탕으로 웹사이트 로고, 제품 카탈로그 이미지, 블로그 글 삽화 등 진정한 의미의 공개 리소스 시나리오에 적합하며, 이러한 리소스의 액세스 및 관리 요구를 잘 충족할 수 있어요.
하지만 프로덕션 환경에서 이러한 링크는 트래픽 도용(Hotlinking)의 위험이 뚜렷해요. 링크가 영구적으로 공개되어 있기 때문에 외부 사람들이 귀하의 이미지 링크를 자신의 트래픽이 많은 웹사이트에 쉽게 삽입할 수 있어, 트래픽이 불법적으로 점유될 수 있어요. 이러한 행위는 Supabase 프로젝트에 불필요한 트래픽 비용을大量으로 발생시키며, 이 트래픽은 귀하의 애플리케이션을 위해 서비스되는 것이 아니라 전형적인 비용 낭비예요. 프로덕션 환경에서 높은 경계와 방지가 필요한 문제이므로, 임시 서명 URL을 통해 외부 리소스 노출을 구현해야 해요.
2. 서명 URL (Signed URL) - 임시 인증 링크
공개 URL의 보안 및 비용 문제를 해결하기 위해, Supabase는 임시 서명 URL을 생성하는 방법을 제공해요. 이는 대부분의 온라인 애플리케이션에 권장되는 모범 사례예요. 예를 들어 텍스트-이미지 생성 앱이 사용자에게 제한 시간 내 이미지 보기 링크를 생성해 주거나, 전자상거래 플랫폼이 주문한 사용자에게만 임시 송장 다운로드 주소를 제공하거나, 유료 콘텐츠 플랫폼이 구독 사용자에게 단기 유효 코스 재생 링크를 제공하는 경우 등, 파일 도용을 방지하면서 트래픽 도용도 방지할 수 있어 적용성이 매우 높아요.
const { data, error } = await supabase.storage
.from('avatars')
.createSignedUrl('private/user-invoice.pdf', 3600); // 링크 유효 기간은 3600초 (1시간)
const signedUrl = data?.signedUrl;임시 서명 URL(Signed URL)에는 세 가지 핵심 장점이 있어요. 보안 통제는 링크에 보안 마크가 포함되어 있고 유효 기간이 있어 만료되면 사용할 수 없다는 것을 의미해요. 권한 바인딩이 간단하여 이 파일을 볼 수 있는 사람만 이 링크를 생성할 수 있으며, 파일이 프라이빗 스토리지(Private Bucket)에 숨겨져 있어도 이 링크를 통해 정상적으로 열 수 있어요. 도용 방지는 링크가 임시적이어서 다른 곳에 복사하면 곧 만료되어 악의적인 트래픽 소모를 방지할 수 있어요. 이러한 장점 덕분에 사용자 아바타, 개인 사진, 유료 콘텐츠, 주문 송장 등 권한 관리가 필요한 파일에 모두 사용할 수 있어요.
보안 보장 및 비용 제어의 관점에서 임시 서명 URL을 우선적으로 사용하는 습관을 들이는 것이 좋아요. 특정 리소스가 영구적으로 공개되고 무제한 액세스가 명확히 필요한 경우(예: 애플리케이션의 공개 로고, 공개 행사 홍보 이미지 등)에만 Public URL 사용을 고려하세요. 이렇게 하면 특정 비즈니스 요구를 충족하면서 불필요한 위험과 비용 소모를 최대한 피할 수 있어요.
5.5 엣지 함수
Edge Function은 Serverless(서버리스 아키텍처) 생태계에서 핵심 가치가 높은 형태 중 하나로, "자체 백엔드 구축 없이" 시나리오에 가볍고 효율적인 함수 실행 지원을 제공해요.
Serverless란 무엇인가요? Serverless(서버리스 아키텍처)는 실제로 서버가 없다는 의미가 아니라, 개발자가 서버의 구매, 운영 유지보수, 구성 및 확장에 신경 쓸 필요가 없다는 것을 의미해요. 비즈니스 코드(함수)만 작성하면, 클라우드 서비스 제공업체가 특정 이벤트가 트리거될 때 자동으로 리소스를 할당하여 코드를 실행하고, 실제 실행 시간에 따라 요금을 청구해요.
애플리케이션이 클라이언트(브라우저)에서 완료할 수 없거나 완료해서는 안 되는 로직을 실행해야 할 때 — 예를 들어 비밀 키가 필요한 타사 API와의 상호작용, 컴퓨팅 집약적 작업 실행, 또는 복잡한 비즈니스 규칙 강제 실행 — Edge Functions가 유용해요. Supabase Edge Functions는 Deno와 TypeScript를 기반으로 하며, 전역 엣지 노드에 배포되어 사용자와 물리적으로 가까운 위치에서 극히 낮은 함수 실행 지연을 제공해요.
현재 주류 클라우드 제공업체들은 각자의 Edge Function 서비스를 출시했으며, 일반적인 것들은 다음과 같아요:
- AWS Lambda@Edge: AWS Lambda를 기반으로 확장된 엣지 함수 서비스로, CloudFront CDN과 연동되며 Node.js, Python 등의 언어를 지원해요.
- Cloudflare Workers: Cloudflare가 출시한 엣지 함수로, 전 세계 275개 이상의 엣지 노드에 배포되며 JavaScript/TypeScript를 지원하고 "밀리초 단위 지연"을 핵심 장점으로 해요.
- Vercel Edge Functions: Vercel 프론트엔드 프로젝트에 적합한 엣지 함수로, Next.js와 깊게 통합되고 TypeScript를 지원하며, "프론트엔드와 엣지 로직의 원활한 연결"을 강조해요.
Supabase로 돌아와서, 애플리케이션이 "클라이언트(브라우저)에서 완료할 수 없는" 로직을 실행해야 할 때, 예를 들어 비밀 키로 타사 API(예: LLM 인터페이스) 호출, 컴퓨팅 집약적 작업(예: 이미지 압축) 처리, 또는 권한 검증(예: 파일 액세스 규칙) 강제 실행 등의 경우 Supabase Edge Functions가 역할을 발휘해요. Deno 런타임과 TypeScript를 기반으로 구축되어 전역 엣지 노드에 배포되며, "사용자와 가까운 물리적 거리"로 극히 낮은 실행 지연을 실현하여, 커스텀하고 신뢰할 수 있는 서버 측 로직을 작성하는 핵심 도구예요.
이 프로젝트 Project5-Supabase-Demos/apps/project-burger-shop-edge-function-5는 대형 언어 모델(LLM)과의 실시간 스트리밍 대화 기능을 통해 Edge Functions의 가장 간단한 응용 프로세스를 보여줘요.
5.5.1 LLM Chat 사례 분석
애플리케이션에 ChatGPT와 유사한 챗봇을 통합하고 싶다고 가정해 볼게요. OpenAI의 API를 서버 측에서 호출해야 하지만, 이것은 비밀 API Key가 필요해요. 이 Key는 프론트엔드 코드에 절대 노출되어서는 안 돼요. 그렇지 않으면 누구나 웹페이지 소스 코드를 보고 귀하의 Key를 도용하여 높은 비용을 발생시킬 수 있어요. 이것이 바로 Edge Function이 필요한 이유예요. llm-chat이라는 함수를 만들어서 프론트엔드와 OpenAI API 사이의 보안 프록시 역할을 하게 할 거예요.
project-burger-shop-edge-function-5/scripts/llm-chat.ts의 코드를 참고하여 어떻게 작동하는지 살펴볼게요:
// scripts/llm-chat.ts
import "jsr:@supabase/functions-js/edge-runtime.d.ts";
import { OpenAI } from "npm:openai";
const OPENAI_API_KEY = Deno.env.get("OPENAI_API_KEY");
Deno.serve(async (req) => {
try {
const openai = new OpenAI({ apiKey: OPENAI_API_KEY });
const { prompt } = await req.json();
const stream = await openai.chat.completions.create({
model: "gpt-3.5-turbo",
messages: [{ role: "user", content: prompt }],
stream: true,
});
return new Response(stream.toReadableStream(), {
headers: { "Content-Type": "text/event-stream" },
});
} catch (err) {
}
});이 사례에서 키 보안 측면을 보면, OPENAI_API_KEY는 환경 변수로 Supabase 서버에 안전하게 저장돼요. 로컬 프론트엔드 코드는 이 키에 전혀 접근할 수 없어, 키의 보안성을 효과적으로 보장해요.
5.5.2 함수 생성 및 배포
Supabase는 명령줄에 접촉하지 않고도 배포를 완료할 수 있는 매우 친근한 인터페이스를 제공해요.
- Edge Functions 패널 진입:
- Supabase 프로젝트 Dashboard에 로그인해요.
- 왼쪽 탐색 모음에서 코드 아이콘을 클릭하여 "Edge Functions"에 들어가요.
- 새 함수 만들기:
- "Create a new function" 버튼을 클릭해요.
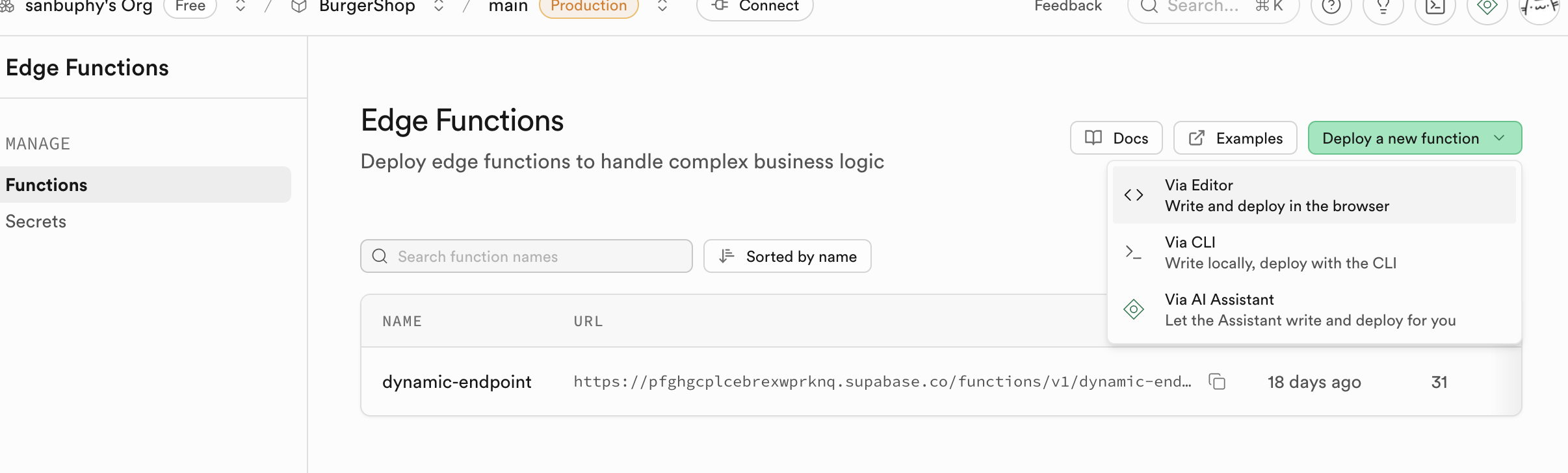
- 함수에 이름을 지정해요. 예:
llm-chat. - 코드 붙여넣기:
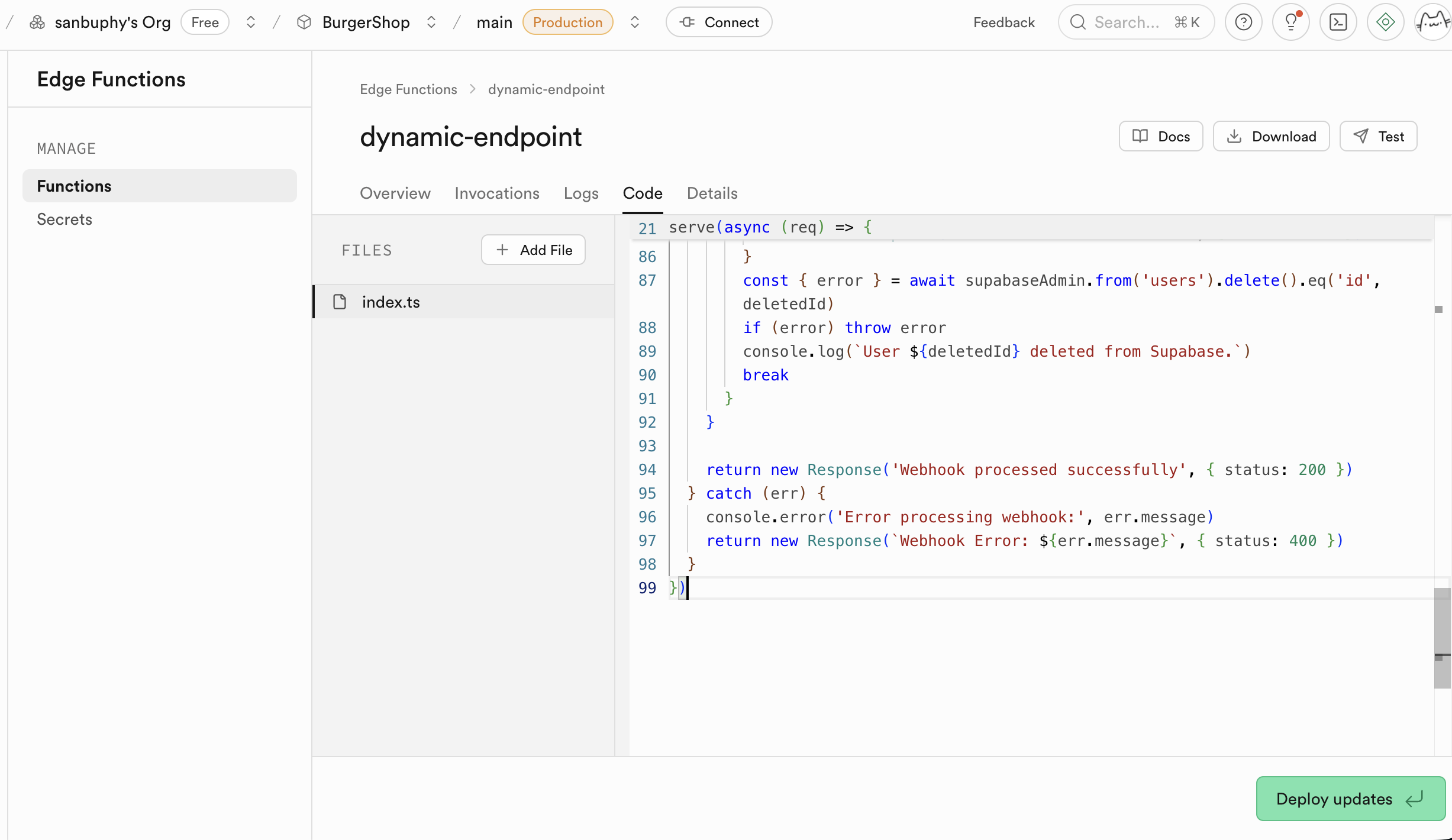
- 팝업된 온라인 편집기에서 모든 기본 자리 표시자 코드를 삭제해요.
- 로컬
llm-chat.ts파일을 열고, 전체 내용을 복사해요. - 복사한 코드를 Supabase의 온라인 편집기에 붙여넣기해요.
- 환경 변수(Secrets) 설정:
- 사이드바에서 Secrets를 찾아요.
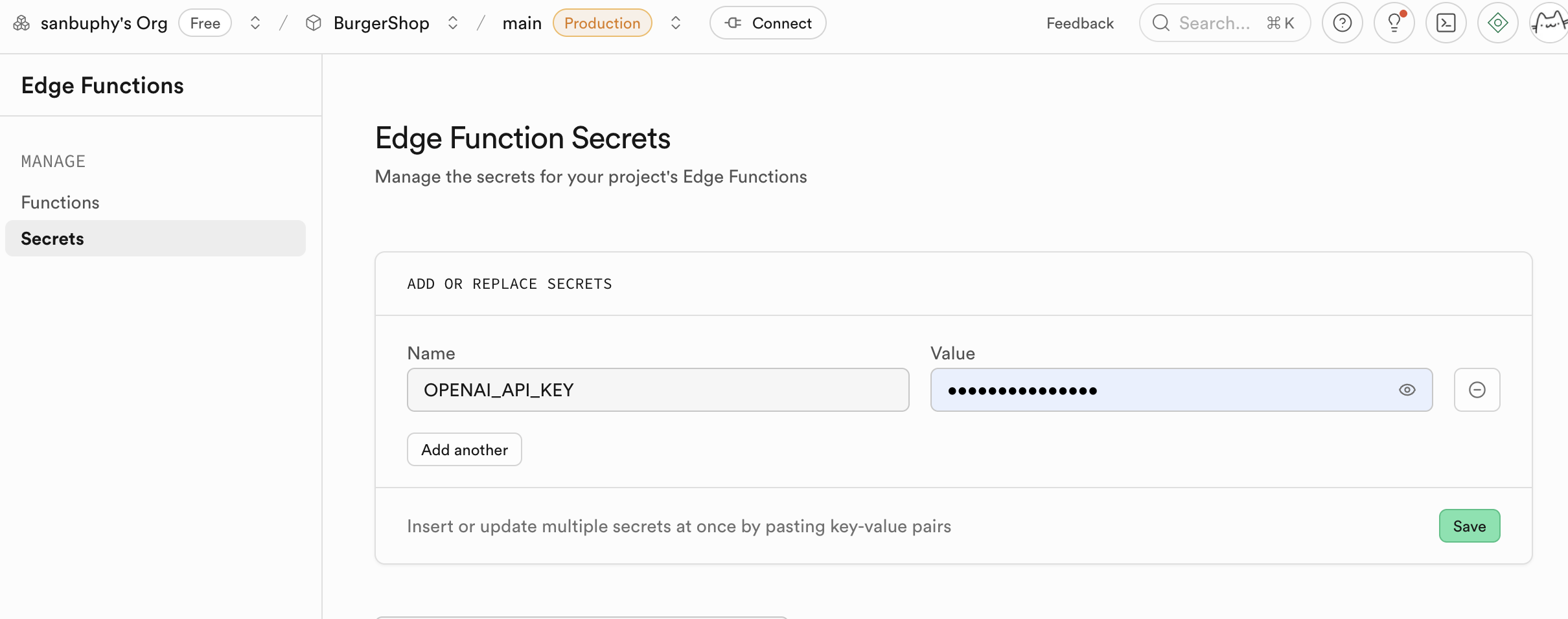
- Name:
OPENAI_API_KEY를 입력해요. - Value: 자신의 OpenAI API Key를 붙여넣기 해요.
- "Save"를 클릭해요. 여기서 설정한 Secret은 암호화되어 저장되며, 함수 런타임 환경에 안전하게 주입돼요.
- 사이드바에서 Secrets를 찾아요.
함수를 업데이트해야 하는 경우, Edge Function 섹션에서 Deploy updates를 실행하는 것을 잊지 마세요. Supabase가 클라우드에서 함수를 빌드하고 배포해요. 몇 분 후 함수가 온라인에서 액세스할 수 있게 돼요.
언어 모델의 보안 프록시 역할 외에도, Edge Functions의 응용 시나리오는 이것에 국한되지 않아요. 실제로 서버 측 로직 처리가 필요한 모든 작업, 간단한 API 호출, 데이터 검증부터 더 복잡한 컴퓨팅까지 Edge Function을 통해 구현할 수 있어요. 서버 인프라를 관리할 필요 없이 경량화되고 확장 가능한 백엔드를 제공해요.
더 많은 가능성을 탐색하고 싶다면 프로젝트의 다른 예시를 참고할 수 있어요. 예를 들어:
- 이미지 생성(txt2img.ts): 이 함수는 Edge Function을 활용하여 타사 텍스트-이미지(Text-to-Image) API(예: Stability AI, Midjourney 등)를 호출하여 동적으로 이미지를 생성하는 방법을 보여줘요. 이는 전형적인 컴퓨팅 집약적이거나 외부 서비스를 안전하게 호출해야 하는 시나리오예요. llm-chat 사례와 마찬가지로 API 키가 Supabase 백엔드에 안전하게 저장되고, 프론트엔드는 텍스트 설명을 보낸 다음 생성된 이미지를 수신하고 표시하는 역할만 하며, 전체 과정이 안전하고 효율적이에요.
- 이메일 발송(send-email.ts): 애플리케이션에서 환영 이메일, 거래 알림 또는 비밀번호 재설정 이메일을 보내는 것은 일반적인 요구 사항이에요. send-email.ts 예시는 Edge Function을 통해 이메일 서비스(예: Resend, SendGrid)를 통합하는 방법을 시연해요. 클라이언트 코드에서 민감한 이메일 서비스 API Key를 노출할 필요 없이, 함수를 생성하고 프론트엔드가 이 함수를 호출하여 이메일 발송을 트리거하도록 하면 돼요.
5.6 Clerk 로그인
Clerk은 신원 인증 및 사용자 관리에 특화된 전문 개발 도구로, 핵심 역량이 사용자 회원가입, 로그인, 계정 보안 MFA, 권한 제어, 세션 관리 등 전체 링크의 신원 인증 관련 요구를 포괄하여, 개발자가 복잡한 신원 로직을 처음부터 개발할 필요 없이 안전하고 유연하며 현대 애플리케이션 표준에 부합하는 사용자 시스템을 빠르게 구축할 수 있도록 도와줘요.
이 섹션에서는 Clerk 서비스를 처음부터 구성하고 Supabase와 통합하는 방법을 소개해요. 프로젝트 project-burger-shop-auth-advanced-clerk-7에서 전체 프로세스를 체험할 수 있어요.
5.6.1 Clerk 애플리케이션 생성 및 키 획득
이 프로젝트를 사용하기 전에 Clerk 계정을 가지고 있어야 하고 애플리케이션을 생성해야 해요.
- 등록 및 생성:
- dashboard.clerk.com에 접속하여 계정을 등록해요.
- "Create application"을 클릭해요.
- 애플리케이션 이름을 입력해요(예: "Burger Shop").
- "How will your users sign in?"에서 기본 선택된 Email, Google, GitHub를 유지해요.
- Create application을 클릭해요.
- API Keys 획득:
생성이 완료되면 API Keys 페이지로 이동해요.
Publishable key(
pk_로 시작)와 Secret key(sk_로 시작)를 찾아요.
이들을
.env.local파일에 복사해요(이 프로젝트의.env.example참조):bashNEXT_PUBLIC_CLERK_PUBLISHABLE_KEY=pk_test_... CLERK_SECRET_KEY=sk_test_...
5.6.2 Supabase와 Clerk의 네이티브 통합 구성
추가로 사용하기 전에 Supabase와 Clerk의 연결 관계를 통합하여, 이후 로그인 시 인증 리디렉션 및 특정 데이터베이스에 대한 액세스 권한 제어를 편리하게 해야 해요. Supabase와 Clerk은 공식 네이티브 통합 기능을 제공하며, 이 통합을 통해 두 시스템의 신원 인증을 빠르게 연결할 수 있어 복잡한 적응 로직을 수동으로 구성할 필요가 없으며, 사용자 로그인, 권한 검증 등 기능의 개발 프로세스를 크게 간소화해요:
- Clerk에서 Supabase 공식 통합 활성화
- Clerk Dashboard에 로그인해요.
- 왼쪽 메뉴에서 Integrations(통합)로 이동해요.
- 목록에서 Supabase를 찾아 클릭해요.
- Enable Supabase 스위치를 켜요(또는 Activate integration 클릭).
- 핵심 단계: 활성화가 성공하면 페이지에 Clerk Domain이 표시돼요(형식은 일반적으로
https://<your-id>.clerk.accounts.dev또는 커스텀 도메인). 이 Domain 주소를 복사하세요. 다음 단계에서 사용해요.
- Supabase에서 Clerk 제공업체 추가
- Supabase Dashboard에 로그인하고 프로젝트에 들어가요.
- 왼쪽 메뉴에서 Authentication > Sign In / Up(또는 Providers 직접 클릭)으로 이동해요.
- Add provider 버튼을 클릭하고, 드롭다운 목록에서 Clerk를 선택해요.
- 팝업된 Clerk Domain 입력 상자에 Clerk에서 복사한 Domain 주소를 붙여넣기 해요.
- Save를 클릭하여 구성을 저장해요.
5.6.3 Webhook을 통해 사용자 데이터를 Supabase에 동기화
통합만으로는 권한 검증의 요구를 충족할 뿐, Clerk에 이미 등록된 사용자 정보를 Supabase에 동기화하지는 않아요. 관리를 편리하게 하기 위해 Supabase의 public.users 테이블에 사용자 백업을 보관하여 연결 쿼리나 데이터 분석에 사용할 수 있도록 해야 해요. Clerk Webhooks를 통해 이 기능을 구현할 수 있으며, 전체 과정은 다음과 같아요:
- Clerk가 알림 전송: 사용자가 Clerk에서 등록하거나 프로필을 업데이트하면, Clerk이 구성한 Webhook URL로 POST 요청을 보내요.
- Supabase가 수신 및 쓰기: Edge Function이 요청을 수신하고, 서명을 검증(보안 보장)한 다음, 사용자 데이터를 Supabase의 데이터베이스 테이블에 업데이트해요.
시작하기 전에 동기화 정보에 필요한 데이터 테이블을 구성해야 해요:
-- File: init.sql
-- 1. Create `users` table for synced Clerk users
-- This table will store user data pushed from Clerk Webhooks.
CREATE TABLE public.users (
id TEXT NOT NULL PRIMARY KEY, -- Corresponds to Clerk User ID
email TEXT,
first_name TEXT,
last_name TEXT,
image_url TEXT,
created_at TIMESTAMPTZ DEFAULT NOW(),
updated_at TIMESTAMPTZ DEFAULT NOW()
);
-- 2. Enable Row Level Security (RLS) on the table
-- This is an important security measure to ensure users cannot access any data by default.
ALTER TABLE public.users ENABLE ROW LEVEL SECURITY;
-- 3. Create RLS policies
-- Policy 1: Allow authenticated users to read their own user info.
-- `auth.jwt()->>'sub'` extracts the user ID from the JWT provided by Clerk.
CREATE POLICY "Authenticated users can view their own user record"
ON public.users FOR SELECT
TO authenticated
USING ( (SELECT auth.jwt()->>'sub') = id );
-- Policy 2: Allow users to update their own info.
CREATE POLICY "Authenticated users can update their own user record"
ON public.users FOR UPDATE
TO authenticated
USING ( (SELECT auth.jwt()->>'sub') = id );그리고 Supabase에서 해당 Edge function을 활성화해요:
// File path: supabase/functions/clerk-webhooks/index.ts
import { serve } from 'https://deno.land/std@0.177.0/http/server.ts'
import { Webhook } from 'npm:svix'
import { createClient } from 'https://esm.sh/@supabase/supabase-js@2'
// Get Clerk Webhook signing secret from environment variables
const CLERK_WEBHOOK_SECRET = Deno.env.get('CLERK_WEBHOOK_SECRET')
if (!CLERK_WEBHOOK_SECRET) {
throw new Error('CLERK_WEBHOOK_SECRET is not set in environment variables')
}
const supabaseAdmin = createClient(
Deno.env.get('SUPABASE_URL')!,
Deno.env.get('SUPABASE_SERVICE_ROLE_KEY')!
)
serve(async (req) => {
try {
// 1. Get Svix signature info from request headers
const headers = Object.fromEntries(req.headers)
const svix_id = headers['svix-id']
const svix_timestamp = headers['svix-timestamp']
const svix_signature = headers['svix-signature']
if (!svix_id || !svix_timestamp || !svix_signature) {
return new Response('Missing Svix headers', { status: 400 })
}
const payload = await req.json()
const body = JSON.stringify(payload)
// 2. Verify Webhook signature validity using the secret
const wh = new Webhook(CLERK_WEBHOOK_SECRET)
const evt = wh.verify(body, {
'svix-id': svix_id,
'svix-timestamp': svix_timestamp,
'svix-signature': svix_signature,
})
const { id } = evt.data
const eventType = evt.type
console.log(`Received webhook event: ${eventType} for user: ${id}`)
// 3. Execute database operations based on event type
switch (eventType) {
case 'user.created': {
const { id, first_name, last_name, image_url, email_addresses } = evt.data
const { error } = await supabaseAdmin.from('users').insert({
id,
first_name,
last_name,
image_url,
email: email_addresses[0]?.email_address,
})
if (error) throw error
console.log(`User ${id} created in Supabase.`)
break
}
case 'user.updated': {
const { id, first_name, last_name, image_url, email_addresses } = evt.data
const { error } = await supabaseAdmin
.from('users')
.update({
first_name,
last_name,
image_url,
email: email_addresses[0]?.email_address,
updated_at: new Date().toISOString(), // Update timestamp
})
.eq('id', id)
if (error) throw error
console.log(`User ${id} updated in Supabase.`)
break
}
case 'user.deleted': {
// For delete events, ID might be at the top level
const deletedId = id
if (!deletedId) {
return new Response('Deleted user ID not found', { status: 400 })
}
const { error } = await supabaseAdmin.from('users').delete().eq('id', deletedId)
if (error) throw error
console.log(`User ${deletedId} deleted from Supabase.`)
break
}
}
return new Response('Webhook processed successfully', { status: 200 })
} catch (err) {
console.error('Error processing webhook:', err.message)
return new Response(`Webhook Error: ${err.message}`, { status: 400 })
}
})Supabase 데이터 테이블과 함수 초기화가 완료된 후, Clerk에서 Webhooks 지원도 활성화해야 해요:
- Clerk Dashboard -> Webhooks에서 Endpoint를 추가하고, Supabase Edge Function의 URL을 입력해요.
user.created,user.updated,user.deleted등의 이벤트를 체크해요.
설정이 성공하면 Message Attempts에서 다양한 요청 정보를 볼 수 있고, 클릭하면 상세한 요청 반환 파라미터 결과를 확인할 수 있어요. Webhook이 Edge function을 요청할 때 문제가 발생하면 반환 값에서 상세한 원인 결과를 빠르게 찾을 수 있어요. Clerk과 Supabase의 요청 로그 정보를 함께 비교하여 각 함수 설정이 올바른지 분석하는 것을 추천해요.
5.6.4 Clerk에서의 타사 로그인 지원
Clerk에 타사 로그인을 지원하는 방법을 깊이 이해하기 전에, 먼저 두 가지 핵심 개념을 명확히 해요: 개발 환경과 프로덕션 환경이에요. 이것은 소프트웨어가 "개발 테스트"에서 "온라인 사용 가능"에 이르는 두 가지 핵심 단계로, 두 환경의 포지셔닝, 용도 및 보안 요구 사항이 완전히 달라요:
- 개발 환경: 개발자의 로컬 또는 테스트 서버에서 사용하는 환경으로, 기능 개발, 디버깅 및 내부 검증에만 사용돼요(예: 로컬 localhost:3000 서비스). 외부에 공개되지 않아요.
- 프로덕션 환경: 애플리케이션이 정식으로 출시된 후 실제 사용자를 위한 공개 환경이에요(예: Vercel, Alibaba Cloud 등의 플랫폼에 배포된 https://my-app.com).
Clerk은 소셜 로그인에서 이 두 가지 환경을 구분하며, 그 본질은 "개발 효율성"과 "프로덕션 보안"의 균형이에요. 개발 단계에서는 기능을 빠르게 검증하기 위해 불필요한 구성을 줄여야 하고, 프로덕션 단계에서는 전용 자격 증명을 통해 데이터 보안을 보장해야 하며, 동시에 Google, GitHub 등 타사 OAuth 플랫폼의 규칙을 준수해야 해요(온라인 애플리케이션은 전용 도메인과 자격 증명에 바인딩되어야 하며, 공유 리소스 사용이 허용되지 않아요). 아래에서 두 가지 환경에서 Clerk 소셜 로그인의 차이점 구성을 구체적으로 설명해요:
- 개발 환경 빠른 검증
개발 환경에서 Clerk은 공유 OAuth 자격 증명과 기본 리디렉션 URI를 사전 구성해 두어, GitHub/Google에 가서 전용 자격 증명을 신청할 필요가 없어요. 작업 단계는 다음과 같아요:
Clerk Dashboard에 로그인하고, 왼쪽 탐색 모음에서 SSO connections(SSO 연결) 페이지로 들어가요.
Add connection(연결 추가)을 클릭하고, For all users(모든 사용자에게 적용)를 선택해요.
Choose provider(제공업체 선택) 드롭다운 메뉴에서 필요에 따라 GitHub 또는 Google을 선택해요.
Add connection(연결 추가)을 직접 클릭하면, Clerk이 자동으로 공유 자격 증명으로 바인딩을 완료해요.
구성 후 로컬에서 애플리케이션(예:
localhost:3000)을 시작하고 "Sign in with GitHub/Google"을 클릭하면, Clerk이 자동으로 로그인 요청을 프록시하여 기능이 정상인지 빠르게 검증해요.
- 프로덕션 환경 커스텀 자격 증명 구성
(참고: 특정 단계가 예상과 다른 경우, 공식 문서를 읽고 최신 방법을 시도하는 것이 좋아요)
애플리케이션이 온라인에 배포되고(예: Vercel, Alibaba Cloud) Clerk Production Instance로 전환되면 공유 자격 증명이 만료되어, GitHub/Google에 커스텀 OAuth 자격 증명을 구성해야 해요(Clerk Dashboard와 타사 플랫폼 페이지를 동시에 열어 두고 동기적으로 작업하는 것이 좋아요):
- 공통 사전 작업(Clerk 콘솔):
- Clerk SSO connections 페이지로 들어가서, Add connection 클릭 -> For all users 선택.
- 대상 플랫폼(GitHub/Google)을 선택하고, Enable for sign-up and sign-in(가입 및 로그인 허용)과 Use custom credentials(커스텀 자격 증명 사용)이 켜져 있는지 확인해요.
- 페이지의 Authorization Callback URL(GitHub) 또는 Authorized Redirect URI(Google)을 복사하여 안전한 곳에 보관하고, 현재 페이지/팝업을 닫지 마세요.
- 2.1 GitHub 플랫폼 구성:
- GitHub에 로그인하고, Developer Settings로 들어가요(경로: 프로필 사진 -> Settings -> Developer settings -> OAuth Apps).
- New OAuth app을 클릭하고 정보를 입력해요:
Application name(애플리케이션 이름),Homepage URL(프로덕션 도메인, 예:https://my-app.com),Authorization Callback URL(Clerk에서 복사한 주소 붙여넣기). - Register application을 클릭한 다음 Generate a new client secret을 클릭하고, 생성된 Client ID와 Client Secret을 저장해요(Secret은 한 번만 표시돼요).
- Clerk 팝업으로 돌아가서 Client ID와 Client Secret을 붙여넣고 Add connection을 클릭하여 구성을 완료해요(팝업을 닫은 경우 SSO connections에서 GitHub 연결을 찾아 "Use custom credentials" 모듈에서 보완 입력 가능).
- 2.2 Google 플랫폼 구성:
- Google Cloud Console에 로그인하고, 기존 프로젝트를 선택하거나 새 프로젝트를 만들어요(예: "My App Production").
- 왼쪽 상단 메뉴 클릭 -> APIs & Services -> Credentials, Create Credentials 클릭 -> OAuth client ID(처음 구성 시 먼저 OAuth consent screen 설정을 완료해야 하며, "External"을 선택하고 애플리케이션 정보 입력).
- Application type을 Web application으로 선택하고 구성:
Authorized JavaScript origins: 프로덕션 도메인 추가(예:https://my-app.com,https://www.my-app.com), 로컬 검증을 위해http://localhost:포트번호도 추가 가능.Authorized Redirect URIs: Clerk에서 복사한 주소를 붙여넣기.
- Create를 클릭하고, 팝업의 Client ID와 Client Secret을 저장한 다음 Clerk 팝업으로 돌아가 붙여넣고 Add connection을 클릭해요.
- 핵심 주의 사항:
- WebView 로그인 금지: Google OAuth는 인앱 브라우저 로그인을 지원하지 않아요. Google 공식 문서를 참조하여 조정해야 해요.
- 게시 상태 전환: 기본 "Testing" 상태에서는 테스트 사용자 100명만 지원돼요. OAuth consent screen에서 "Publishing status"를 In production으로 변경해야 해요(Google 심사 통과 필요).
- 하위 이메일 차단: Clerk은 기본적으로
+/=/#이 포함된 Google 이메일(예:user+alias@example.com)을 차단해요. Google 연결 상세 페이지에서 Block email subaddresses를 켜거나 끌 수 있어요(보안 강화를 위해 켜는 것을 권장). - Google One Tap 지원: 구성 완료 후 Clerk
<GoogleOneTap />컴포넌트를 통합하여 "원클릭 로그인"을 구현할 수 있어요. Clerk 컴포넌트 문서 참조.
- 타사 로그인 연결 테스트
구성 완료 후, Clerk 내장 Account Portal을 통해 기능을 검증해요:
- Clerk Dashboard로 들어가서, 왼쪽 탐색 모음에서 Account Portal 페이지로 이동해요.
- "Sign-in" 모듈 오른쪽의 "로그인 페이지 방문" 버튼을 클릭하여 해당 환경의 로그인 페이지로 이동:
- 개발 환경:
https://도메인.accounts.dev/sign-in(예:https://my-app.accounts.dev/sign-in). - 프로덕션 환경:
https://accounts.도메인.com/sign-in(예:https://accounts.my-app.com/sign-in).
- 개발 환경:
- "Sign in with GitHub/Google"을 클릭하고, 해당 플랫폼 계정으로 로그인하여 성공적으로 리디렉션되고 애플리케이션으로 돌아오면 연결 구성이 정상임을 확인할 수 있어요.
6. Supabase에서 더 많은 백엔드 개발 컴포넌트로 (고급)
위에서는 주로 Supabase의 관점에서 "Postgres를 핵심으로 하는 원스톱 백엔드 플랫폼"이 어떤 문제를 해결할 수 있는지 살펴보았어요. 인증, 데이터베이스, 파일 스토리지, 실시간 통신, 엣지 함수 등이 모두 동일한 콘솔에 통합되어 있어 바로 사용할 수 있고 경험이 통일되어 있어, 빠른 시작과 중소규모 프로젝트에 매우 적합해요.
하지만 더 장기적이고 엔지니어링 관점에서 보면, Supabase가 제공하는 각 역량(Auth / Storage / Edge Functions / Realtime / Database)은 업계에서 거의 모두 해당하는 전문 대안이 있어요. 유사한 BaaS 플랫폼도 포함하고, 더 "단일 기능에 집중"하는 클라우드 서비스와 오픈소스 컴포넌트도 포함해요. 야심 찬 개인 개발자와 스타트업 팀으로서 이러한 대안을 이해하는 것에는 몇 가지 장점이 있어요:
- 현재 프로젝트가 "Supabase만으로 충분한지" 아니면 특정 부분에 더 전문적이고/저렴하고/규정 준수하기 쉬운 전용 서비스가 필요한지 판단;
- 프로젝트 규모가 커지거나 요구 사항이 복잡해질 때 특정 모듈을 Supabase에서 교체할 수 있는지(예: 전문 Auth 플랫폼이나 객체 스토리지로 전환) 판단하여, 처음부터 플랫폼에 완전히 종속되지 않도록;
- 기술 선택의 시야를 넓혀서, 당장 교체하지 않더라도 "Supabase의 X 기능을 사용하지 않는다면 어떤 일반적인 대안이 있는지" 대략적으로 알 수 있도록.
이 섹션에서는 Supabase가 포괄하는 주요 역량에 대한 시장의 주류 대안을 각각 소개해요. 예를 들어: 인증(Auth), 파일 스토리지(Storage), 엣지 함수(Edge Functions), 실시간 통신(Realtime), 데이터베이스 호스팅 등이에요. 기능 특성, 무료 한도/가격, 사용 편의성 및 커뮤니티 인기도 측면에서의 차이를 간단히 비교하여, 백엔드 컴포넌트 도구에 대한 이해를 더 포괄적으로 만들어 줄게요.
유사한 Baas 플랫폼
시작하기 전에 유사한 BaaS 플랫폼을 살펴볼 수 있어요. Supabase가 충분히 좋지 않다고 느끼면, 요구에 따라 다른 대안을 선택하여 시도해 볼 수 있어요.
| 플랫폼/서비스 | 유형 | 무료 한도/가격 | 특징 / 적용 시나리오 |
|---|---|---|---|
| Firebase(Google) | 완전 관리형 BaaS(Auth + Firestore + Storage + Functions + Hosting) | Spark: 무료 경량 한도; Blaze: 사용량 기준 과금(Firestore/Storage/Functions 각각 계산) | 업계에서 가장 성숙하고, 문서가 좋고, 시작이 빠르며, 실시간 기능이 강해요. 중소형 제품, 모바일/프론트엔드 중심 팀에 적합해요. 단점: 과금이 복잡하고, 종속성이 강하며, 쿼리 제한이 많아요(특히 Firestore). |
| Supabase | 오픈소스 BaaS(Postgres + Auth + Storage + Edge Functions + Realtime) | 무료: 500MB DB, 1GB Storage, 서버리스 함수 소량 호출; Pro: 인스턴스별 과금 | 가장 Firebase와 유사한 SQL 버전; 인터페이스가 우수하고, 경험이 현대적이며, 자체 호스팅 가능. 강력한 SQL, BI, 트랜잭션 기능이 필요한 앱에 적합해요. 단점: 높은 동시성이나 복잡한 함수에서 비용이较高. |
| Appwrite Cloud | 오픈소스 원스톱 BaaS(DB + Auth + Storage + Functions + Realtime) | 무료: 기본 DB/Storage/FaaS 포함; 유료는 리소스 등급별 과금 | 경험이 현대적이고, API가 통일되어 있으며, 자체 호스팅 가능; 개발자 친화적인 애플리케이션의 빠른 반복에 적합해요. 단점: 생태계가 Firebase/Supabase만큼 성숙하지 않음; 대규모 애플리케이션에서는 성능 테스트 필요. |
| Nhost | Postgres + GraphQL + Auth + Storage + Functions | 무료: 1GB DB, 1GB Storage, 소량 함수 호출 | "Supabase + Hasura"와 유사; 자연스러운 GraphQL; 프론트엔드 팀과 React/Next.js 프로젝트에 적합해요. 단점: 생태계가 작고, 사용량이 증가하면 비용이 높아져요. |
| AWS Amplify | AWS 원스톱 백엔드(Cognito + AppSync + DynamoDB + Storage + Functions + Hosting) | 무료: Hosting 한도 + Cognito 10k MAU + 일부 함수 한도 | 포괄적이며, 이미 AWS 기반이 있는 팀에 적합; 기업급 신뢰성. 단점: 시작하기 가장 어렵고, 서비스가 분산되어 있음; 스타트업 팀의 유지보수 비용이 높아요. |
| Xata(최근 2년간 빠른 성장) | 다중 모델 데이터베이스 + Auth + Edge Functions | 무료: 250k 레코드, 15GB 대역폭 | 'DB + API'에 더 가깝지만 Auth, 파일, 로직을 제공하여 경량 풀스택 백엔드로 사용 가능. UI/개발 경험이 매우 뛰어나요. 단점: Firebase/Supabase만큼 기능이 포괄적이지 않음. |
| Convex(개발자 경험이 매우 강함) | 관리형 데이터베이스 + Auth + Functions(프론트엔드 우선) | 무료 개발 버전; 유료는 요청량 기준 과금 | 극도로 간단한 시작; 스키마 불필요; 프론트엔드에서 함수를 작성하면 백엔드를 사용할 수 있어요. MVP/빠른 검증에 적합해요. 단점: 플랫폼에 고도로 종속되어 마이그레이션 비용이 높음; 전통적인 BaaS라고 보기는 어려워요. |
인증 (Auth)
| 도구/플랫폼 | 기능 특징 | 무료 한도/가격 | 적용 시나리오와 장단점 |
|---|---|---|---|
| Firebase Authentication | Google이 제공하는 BaaS 신원 인증 서비스로, 이메일/비밀번호, 전화번호, 소셜 로그인, 익명 등 일반적인 방식을 지원해요. Spark 무료 플랜은 최대 50k 월 활성 사용자를 지원해요. | Spark(무료) 50k MAU; Blaze 사용량 기준 과금 | Google 생태계와 통합되고, 문서가 풍부하며, 시작이 간단해요; 기능이 포괄적(MFA, 차단 함수 등)이며 빠른 개발에 적합해요. 하지만 Firebase 플랫폼에 종속되어 다른 서비스로 확장하려면 추가 구성이 필요해요. |
| Auth0 (Okta) | 완전 관리형 신원 인증 플랫폼으로, 소셜 로그인, 기업 SSO, 다중 인증, 규칙 확장 등 강력한 기능을 지원해요. | 무료 플랜 25k MAU, 유료는 MAU 기준 과금 | 기업급 기능이 완비(RBAC, 감사 로그 등)되어 중대형 애플리케이션에 적합해요; 인터페이스가 친근해요. 단점은 MAU가 증가하면 비용이 높아지고, 무료 버전의 기능이 제한적(예: MFA/RBAC 미포함)이에요. 커뮤니티 인지도가 높고 사용자가 많아요. |
| AWS Cognito | Amazon 클라우드 네이티브 신원 서비스로, 소셜 및 SAML 연합 로그인을 지원해요. 직접 로그인 사용자 풀은 매월 10k MAU 무료 제공, 초과분은 0.0055 USD/MAU 부과. | 무료 10k MAU/월, 초과분 사용량 기준 과금 | AWS 생태계와 깊게 통합(API Gateway, Lambda 등과 원활하게 연동 가능), 진입 장벽이 약간 높고 문서가 복잡해요; 무료 한도가 제한적이며, 이미 AWS 사용 습관이 있는 팀에 적합해요. |
| Logto | 오픈소스 신원 인증 플랫폼으로, 자체 호스팅 버전은 무료, 클라우드 서비스 플랜은 50k MAU 무료. 다국어, 다중 테넌트, OAuth/OIDC 등을 지원해요. | 커뮤니티 버전 무료; Logto Cloud 무료 50k MAU | 최근 인기 있는 Auth0 오픈소스 대안으로, GitHub에 이미 10k+ Stars를 보유하고 있어요. 확장이 쉽고, 자체 호스팅으로 비용 절감; 단점은 생태계와 문서가 비교적 새로우며, 커뮤니티 규모가 Firebase/Auth0보다 작아요. |
| Keycloak | 유명한 오픈소스 IAM/SSO 솔루션으로, 사용자 이름/비밀번호, LDAP, SAML, OAuth2 등을 지원해요. | 완전 무료, 자체 호스팅 필요 | 기능이 강력하고 확장 가능하며(세밀한 권한 제어 지원), 기업급 기능이 풍부해요; 하지만 배포와 유지보수의 복잡도가 높아 소규모 팀에게는 학습 곡선이 가파르고, 컨테이너화 및 클러스터 운영 요구가 높아요. |
파일 스토리지 (Storage)
| 플랫폼/서비스 | 유형 | 무료 한도/가격 | 특징/적용 시나리오 |
|---|---|---|---|
| Amazon S3 | 클라우드 객체 스토리지(AWS) | AWS 무료 티어에서 5GB 스토리지, 20k GET/PUT 요청/월 제공, 초과분은 사용량 기준 과금 | 업계 표준의 객체 스토리지로, 신뢰성이 높고 글로벌 다중 리전 배포를 지원해요. 기능이 포괄적이며 AWS 생태계와 잘 통합돼요; 가격 구조가 복잡하여 새 사용자는 과금 규칙을 이해해야 해요. |
| Google Cloud Storage(Firebase Storage) | 클라우드 객체 스토리지(Google) | Firebase Spark 플랜에서 무료 한도 제공(1GB 스토리지 + 트래픽 제한), Blaze 유료 | Firebase/Google Cloud와 긴밀하게 통합되어 관리가 쉬워요; CDN 가속, 세밀한 보안 규칙을 지원해요. |
| Tencent Cloud COS / Alibaba Cloud OSS | 클라우드 객체 스토리지(중국 내수용) | 사용량 기준 과금(각 신규 사용자에게 한도 부여, 예: OSS는 첫 해 40GB 무료 등) | 중국 시장을 겨냥한 고성능, 대규모 객체 스토리지; 중국 클라우드 생태계와 통합되어 문서가 잘 되어 있어요. Alibaba OSS는 기능이 포괄적이고 글로벌 가속을 지원해요; Qiniu KODO는 멀티미디어 처리에 집중하여 비용이 낮고 개인 및 소규모 팀에 적합해요. |
| MinIO | 오픈소스 S3 호환 스토리지 | 오픈소스 무료(자체 구축) | 경량, 고성능, S3 API 호환으로 프라이빗 클라우드나 로컬에 객체 스토리지를 구축하는 데 적합해요. 문서와 커뮤니티가 활발해요; 인프라를 직접 유지보수해야 해요. |
| Cloudinary / Imgix 등 | 미디어 스토리지+CDN | 기본 무료 플랜(예: Cloudinary 무료 25GB/월 대역폭) | 이미지/비디오에 최적화된 클라우드 스토리지+CDN 서비스로, 실시간 트랜스코딩, 압축 등 고급 기능을 제공해요. 미디어 프로젝트에 적합하지만, 범용 파일 스토리지로 사용하면 비용이 높아요. |
엣지 함수 (Edge Functions)
| 플랫폼/서비스 | 특징 | 무료 한도/가격 | 적용 시나리오와 장단점 |
|---|---|---|---|
| Cloudflare Workers | 글로벌 분산 JavaScript/Wasmtime 환경 | 무료 플랜: 매일 100k 요청; 표준 플랜 $5/월에 1,000만 요청 포함 | Cloudflare 엣지 노드에서 실행되어 지연이 극도로 낮아요; 전역 분산 로직, 정적 리소스 렌더링 등에 적합해요. 무료 한도가 적어(월 약 300만 요청 상당), 시작은 간단해요. 단점은 런타임(JS/Wasmtime) 제한과 디버깅 도구가 제한적이에요. |
| Vercel Edge Functions | Next.js/프론트엔드 프레임워크와 원활하게 통합, JS/TS/Go 지원 | Hobby 무료: 매월 100만 함수 호출, 100만 엣지 요청 | 프론트엔드 프레임워크와 깊게 통합되어 자동 배포; 현대 웹 애플리케이션에 적합해요. 무료 한도가 충분하고, 기본 런타임 10초, 최대 60초까지 향상 가능해요. 단점은 무료 버전의 팀 협업 기능이 제한적; Vercel 플랫폼에 종속돼요. |
| Netlify Edge / Functions | Node.js 클라우드 함수 + 엣지 라우팅(NFT) | 무료: 300 토큰/월(약 월 1M 요청 상당); 크레딧 기반 과금 | Node.js 함수, 엣지 처리 라우팅 등을 지원해요. 무료 한도는 빌드, 함수 및 대역폭에 사용되며 프론트엔드 풀스택 배포에 적합해요. 장점은 사용이 간편하고 Git 배포 통합; 단점은 무료 한도 사용을 잘 계산해야 해요(10k 요청 = 3 포인트). |
| AWS Lambda@Edge / CloudFront Functions | AWS 서버리스 엣지 컴퓨팅 | AWS Lambda(월 1M 무료 요청+400k GB-s) + CloudFront 10만 호출당 $0.085부터 | CloudFront와 통합되어 엣지에서 코드를 실행할 수 있어요. AWS 생태계가 필요한 경우(예: 노드 레벨에서 권한 또는 A/B 테스트 수행)에 적합해요. 장점은 유연하고 강력; 단점은 구성이 복잡하고 지연이 Cloudflare/Vercel보다 약간 높아요. |
실시간 통신 (Realtime)
| 플랫폼/서비스 | 기능 특징 | 무료 한도/가격 | 적용 시나리오와 장단점 |
|---|---|---|---|
| Firebase Realtime Database / Firestore | Google BaaS 실시간 데이터베이스; 데이터 변경 푸시 지원 | Spark 무료: 실시간 데이터베이스 1GB 스토리지 & 한도; Blaze 사용량 기준 과금 | Firebase 생태계와 강력하게 통합되어 실시간 리스닝이 간단해요. 장점은 무료로 빠르게 시작 가능; 단점은 데이터베이스 유형(JSON/NoSQL)으로 복잡한 쿼리 능력이 약해요. |
| Ably | 실시간 메시징 및 pub/sub 플랫폼, WebSocket, MQTT 등 지원 | 무료 패키지: 월 6,000,000 메시지 | 기능이 포괄적인 실시간 메시징 서비스로 높은 동시성을 지원해요; 무료 한도로 월 600만 메시지까지 가능해요. 커뮤니티와 문서가 양호하며 글로벌 분산에 적합해요. |
| Pusher Channels | 이벤트 푸시 서비스, 채널/이벤트 메커니즘 지원 | Sandbox 무료: 일일 200k 메시지, 100 동시 연결 | 사용하기 쉬운 WebSocket 서비스로 문서가 잘 되어 있어 채팅 및 알림 기능을 빠르게 구현하는 데 적합해요. 무료 버전은 메시지 양과 연결 수가 제한적; 유료 전환 후 확장성이 좋아요. |
| 자체 구축 WebSocket/Socket.IO | 자체 서버 구축(Node.js, Elixir 또는 Go 등) | 자체 호스팅 비용(예: 서버 비용) | 유연성이 가장 높아 요구에 맞게 프로토콜과 토폴로지를 커스터마이징할 수 있어요. 비용 통제가 엄격하고 기술이 성숙한 팀에 적합해요. 단점은 가용성, 확장 및 크로스 도메인 등을 직접 처리해야 해요. |
데이터베이스
| 플랫폼/도구 | 데이터베이스 유형 | 무료 한도/가격 | 주요 특징 |
|---|---|---|---|
| Neon (Serverless PostgreSQL) | 관계형(PostgreSQL) | 무료 플랜: 0.5GB 스토리지, 메인 브랜치 영구 온라인, 월 20시간 브랜치 컴퓨팅 | 클라우드 네이티브 서버리스 Postgres로, 자동 스케일링과 브랜치(fork 테스트)를 지원해요. 무료 한도로 소규모 프로젝트에 충분하며 현대 개발 워크플로에 적합해요. 브랜치 기능이 강력하지만 무료 한도가 작아요. |
| Aiven PostgreSQL | 관계형(PostgreSQL/MySQL) | 무료 플랜: 1GB 스토리지, 1 vCPU, 1GB 메모리 | 관리형 데이터베이스 서비스로, 크로스 클라우드 다중 리전 마이그레이션을 지원해요. MySQL, Redis 등의 선택지도 제공해요. 무료 한도는 개발 및 소규모 프로젝트에 적합; 상업 버전은 고가용성 클러스터와 모니터링을 지원해요. |
| CockroachDB Cloud | 분산 SQL(PostgreSQL 호환) | 무료 플랜: 10GB 스토리지 | Google Spanner와 유사한 분산 SQL 데이터베이스로, 자동 샤딩 확장을 지원해요. 무료 10GB 공간이 관대해요; 수평 확장과 강력한 일관성이 필요한 애플리케이션에 적합해요. 상업 버전의 SLA가 높아요. |
| TiDB Cloud | 분산 관계형(MySQL 호환) | 무료 플랜: 노드당 5GB, 최대 총 25GB | 오픈소스 TiDB의 클라우드 버전으로, MySQL 프로토콜과 호환되는 분산 아키텍처예요. 무료 한도가 충분하고 MySQL에 익숙한 팀에 적합하며 성능이 우수해요; 단점은 대규모 시나리오에서 운영이 비교적 복잡해요. |
| MongoDB Atlas | 문서형(NoSQL MongoDB) | 무료 M0 클러스터: 0.5GB 스토리지 | 클라우드 MongoDB로 유연한 문서 모델을 제공하며, 풍부한 쿼리와 인덱스를 지원해요. 무료 0.5GB 데이터베이스는 테스트 및 소규모 애플리케이션에 적합해요; 필요에 따라 수평 확장 가능해요. 학습 곡선이 관계형 데이터베이스보다 약간 높아요. |
| SQLPub | 다중 데이터베이스(MySQL, PostgreSQL, Redis 등) | 무료 플랜: 시간당 36,000 요청, 30 동시 연결, 500MB 스토리지 | 원스톱 데이터베이스 플랫폼으로, 다양한 데이터베이스 유형을 지원해요. 무료 버전은 학습 및 소규모 프로젝트에 적합해요; 장점은 다양한 DB 지원, 단점은 스토리지 한도가 작아요. |
이상의 대안들은 각기 장점이 있어요: 오픈소스는 더 유연하고 통제 가능하며(Keycloak, MinIO, Socket.IO, Neon, CockroachDB 등), 클라우드 관리형 서비스는 시작이 더 쉬워요(Firebase, Auth0, Cloudflare, Vercel, Netlify, AWS, Aiven, MongoDB Atlas 등). 선택 시 프로젝트 요구 사항, 팀 기술 스택, 예산 및 커뮤니티 생태계 등을 고려하여 균형을 잡을 수 있어요. 개인 프로젝트는 무료 한도가 충분하고 통합이 쉬운 서비스를 우선 선택할 수 있어요(Firebase 시리즈, Qiniu 스토리지, Cloudflare Workers, Neon, CockroachDB 등). 반면 기업급 또는 특정 보안 요구 사항의 경우 기능이 더 풍부하지만 비용이 높은 솔루션을 고려할 수 있어요(Auth0, Alibaba/Tencent Cloud, AWS, TiDB/Aiven 등). 실제 애플리케이션에서 계속 시도해 보면서 가장 적합한 백엔드 개발 도구 컴포넌트를 선택할 수 있어요.
요약
오늘 강의에서는 데이터베이스의 기본 개념, Supabase의 핵심 정의 및 조작 세부 사항을 체계적으로 학습했어요. 후속 실습 과정에서 프로젝트의 실제 응용 시나리오와 요구에 따라 언제든지 이 문서를 다시 참고할 수 있어요.
항상 기억해야 할 중요한 원칙: 먼저 완성하고, 그 다음에 완벽하게 만들어요! 한 번에 완벽하게 해내려고 할 필요 없어요. 지속적인 반복 최적화를 통해 점차 더 나은 결과에 가까워질 수 있어요. 후속 프로젝트 실습에서 모든 것이 순조롭기를 바라요!
과제
- 사용자 관리 시스템과 데이터베이스가 포함된 애플리케이션을 개발하세요. 더 많은 Supabase 기능(Realtime / 클라우드 스토리지 / Edge function)을 포함하면 더 좋아요.