Construire votre propre Agent de production d'assets avec NanoBanana
Chapitre 1 : Générer vos premiers assets graphiques en 1 minute
Avant de discuter de design, de style ou de prompts, commençons par générer une première image avec le minimum d'étapes.
1.1 Découvrir NanoBanana
Avant de discuter de styles de design et de prompt engineering, réglons d'abord une question plus importante : vérifier que vous pouvez vraiment générer une image.
Les grands modèles actuels possèdent déjà des capacités de génération et d'édition d'images. Ce type de modèle est généralement appelé modèle génératif.
Pour simplifier au maximum le processus, ce tutoriel choisit comme exemple un modèle disposant déjà de capacités stables de génération et d'édition d'images — NanoBanana. Il s'agit d'un modèle de génération d'images proposé par Google, dont le nom officiel est Gemini 3.1 Flash Image Preview. Il supporte la génération d'images directement en langage naturel, ainsi que la modification d'images existantes.

En termes de capacités, il n'y a pas de différence fondamentale avec d'autres modèles que vous connaissez peut-être (comme GPT-4o, Claude, Qwen, Midjourney, etc.) : vous saisissez une description, le modèle génère le résultat.



Vous pouvez le considérer comme un « pinceau ». Dans ce chapitre, nous ne nous intéressons qu'à une seule chose : 👉 Ce pinceau peut-il tracer le premier coup dans vos mains.
En pratique, NanoBanana peut être utilisé directement via des plateformes officielles comme Google AI Studio, ou intégré dans un flux de développement via API. Ce tutoriel utilise l'approche par appel API. Le modèle NanoBanana 2 est maintenant disponible, vous pouvez essayer avec les derniers grands modèles.
1.2 Une génération de niveau « Hello World »
Avant de commencer, vous n'avez besoin que de trois étapes :
- Créer un nouveau dossier dans Trae
- Créer un nouveau fichier Python
- Coller le code ci-dessous en entier
Trae se chargera automatiquement du déploiement de l'environnement et de l'installation des dépendances, sans configuration supplémentaire.
Le code utilisera la clé API de NanoBanana. Nous ne détaillons pas ici le processus de demande — il vous suffit de l'obtenir et de renseigner les paramètres correspondants. À ce stade, l'objectif n'est pas de comprendre chaque ligne de code, mais simplement de le faire fonctionner avec succès.
# /// script
# dependencies = [
# "gradio>=4.0.0",
# "pillow>=10.0.0",
# "requests>=2.31.0",
# ]
# ///
import gradio as gr
import requests
import base64
from PIL import Image
import io
import os
import time
import re
from typing import Optional, Dict, Any, List
# Configuration API
NANOBANANA_API_URL: str = "YOUR API URL"
NANOBANANA_API_KEY: str = "YOUR API KEY"
OUTPUT_DIR: str = "outputs"
# S'assurer que le répertoire de sortie existe
os.makedirs(OUTPUT_DIR, exist_ok=True)
def image_to_base64_data_uri(image: Image.Image) -> str:
"""
Convertir une image PIL en format data URI compatible avec l'API OpenAI.
"""
buffer = io.BytesIO()
# Convertir en PNG pour garantir la compatibilité
image.save(buffer, format="PNG")
encoded = base64.b64encode(buffer.getvalue()).decode('utf-8')
return f"data:image/png;base64,{encoded}"
def base64_to_image(base64_str: str) -> Optional[Image.Image]:
"""
Convertir une chaîne base64 pure en image PIL.
"""
try:
image_bytes = base64.b64decode(base64_str)
return Image.open(io.BytesIO(image_bytes))
except Exception as e:
print(f"Échec du décodage Base64 : {e}")
return None
def extract_base64_from_response(content: Any) -> Optional[str]:
"""
Logique d'analyse principale : extraire les données Base64 de l'image depuis le content renvoyé par l'API.
Compatible avec les formats Markdown et les formats de liste structurée.
"""
if not content:
return None
base64_data = None
# 1. Tentative d'extraction structurée (List)
# Format de retour correspondant : [{"type": "image_url", "image_url": {"url": "data:..."}}]
if isinstance(content, list):
for part in reversed(content): # Recherche inversée, les images les plus récentes sont généralement à la fin
if isinstance(part, dict):
# Vérifier le champ image_url ou output_image
img_field = part.get("image_url") or part.get("image") or part.get("output_image")
if isinstance(img_field, dict):
url = img_field.get("url", "")
if url.startswith("data:image/") and "," in url:
return url.split(",", 1)[1].strip()
# Si aucune image structurée dans la liste, essayer de concaténer le texte pour trouver du Markdown
text_parts = [
str(p.get("text", ""))
for p in content
if isinstance(p, dict) and p.get("type") in ["text", "input_text"]
]
content_str = "".join(text_parts)
else:
content_str = str(content)
# 2. Tentative d'extraction par regex Markdown (String)
# Format de retour correspondant : "Here is your image: "
pattern = re.compile(r"!\[.*?\]\((data:image/[^;]+;base64,[^)]+)\)", re.IGNORECASE)
match = pattern.search(content_str)
if match:
data_url = match.group(1)
if "," in data_url:
return data_url.split(",", 1)[1].strip()
return None
def synthesize(prompt: str, input_image: Optional[Image.Image]) -> Optional[Image.Image]:
"""
Appeler l'API Nanobanana pour la génération.
"""
if not prompt or not prompt.strip():
gr.Warning("Veuillez entrer un prompt")
return None
print(f">>> Début de la tâche : {prompt[:50]}...")
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {NANOBANANA_API_KEY}"
}
# Construire le payload conforme au standard OpenAI Vision / Chat
messages = []
if input_image is not None:
# Mode image à image / entrée multimodale
print(">>> Image d'entrée détectée, utilisation du mode multimodal")
img_base64 = image_to_base64_data_uri(input_image)
messages.append({
"role": "user",
"content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": img_base64}}
]
})
else:
# Mode texte à image
messages.append({
"role": "user",
"content": prompt
})
payload = {
"messages": messages,
# Utiliser le modèle validé dans le premier extrait de code
"model": "gemini-2.5-flash-image",
# Paramètres optionnels, selon le support de l'API
"stream": False
}
try:
# Augmenter le timeout, la génération d'images est généralement plus lente
response = requests.post(NANOBANANA_API_URL, headers=headers, json=payload, timeout=120)
# Vérifier le statut HTTP
if response.status_code != 200:
error_msg = f"Échec de la requête API : {response.status_code} - {response.text}"
print(error_msg)
gr.Error(error_msg)
return None
result = response.json()
# Debug : afficher le début de la réponse pour faciliter le débogage
print(f"Réponse brute de l'API (tronquée) : {str(result)[:200]}...")
# Extraire le Content
content = None
if "choices" in result and len(result["choices"]) > 0:
content = result["choices"][0].get("message", {}).get("content")
if not content:
gr.Warning("Aucun champ content dans le résultat de l'API")
return None
# Utiliser la logique précédemment validée pour extraire le Base64
base64_str = extract_base64_from_response(content)
if base64_str:
output_image = base64_to_image(base64_str)
if output_image:
return output_image
# Si aucune image extraite, le modèle a peut-être refusé ou ne renvoyé que du texte
text_content = str(content) if not isinstance(content, list) else " ".join([str(x) for x in content])
gr.Info(f"Aucune image générée, le modèle a renvoyé du texte : {text_content[:100]}...")
return None
except requests.exceptions.Timeout:
gr.Error("Délai d'attente dépassé, veuillez réessayer plus tard")
return None
except Exception as e:
import traceback
traceback.print_exc()
gr.Error(f"Erreur inconnue : {str(e)}")
return None
# Configuration de l'interface Gradio
with gr.Blocks(title="Nanobanana Image Generator") as app:
gr.Markdown("# Nanobanana Text/Image to Image")
gr.Markdown("Basé sur le modèle Gemini-2.5-Flash-Image, supporte texte vers image et image vers image.")
with gr.Row():
with gr.Column():
prompt_input = gr.Textbox(
label="Prompt",
placeholder="Exemple : A cyberpunk cat holding a neon sign...",
lines=3
)
image_input = gr.Image(
label="Image de référence (optionnel, pour image vers image)",
type="pil",
height=300
)
submit_btn = gr.Button("Lancer la génération", variant="primary")
with gr.Column():
image_output = gr.Image(label="Résultat de la génération", format="png")
submit_btn.click(
fn=synthesize,
inputs=[prompt_input, image_input],
outputs=image_output
)
if __name__ == "__main__":
app.launch(share=True)Lorsque Trae indique que l'exécution a réussi, cliquez sur le lien local qu'il fournit (généralement http://127.0.0.1:7860).
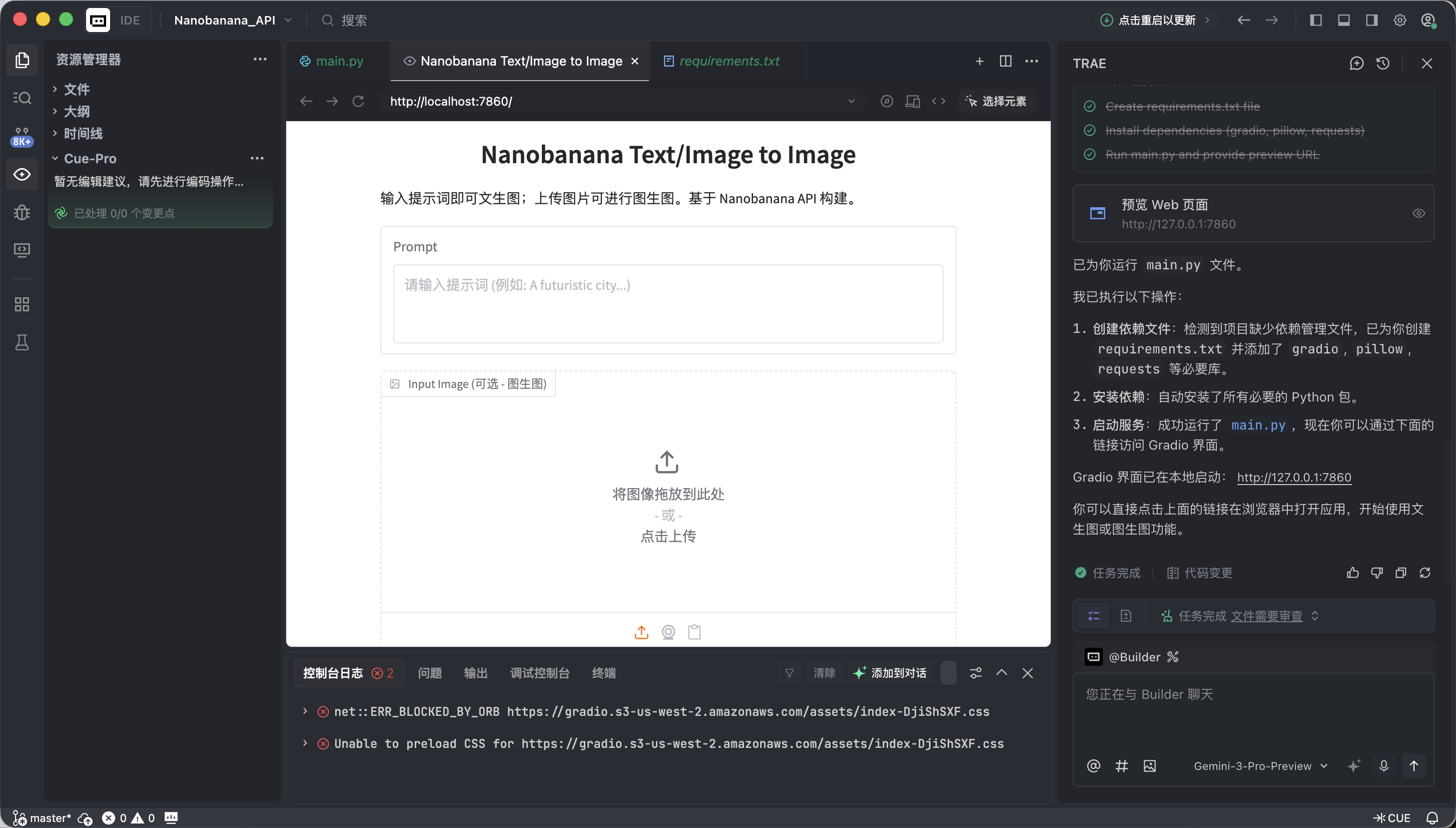
Si tout se passe bien, vous verrez une interface de dessin AI déjà fonctionnelle.
Cette interface peut sembler simple, mais elle possède déjà les deux capacités les plus fondamentales des outils de dessin de niveau commercial : texte vers image et image vers image.
- Gauche : Zone d'instructions (Input Zone) — c'est ici que vous donnez vos ordres.
- Prompt (champ de prompt) : saisissez votre description créative (l'anglais est recommandé).
- Input Image (champ d'image de référence) :
- Mode texte vers image : laissez ce champ vide.
- Mode image vers image : glissez-déposez une image locale ici, l'IA créera en s'en inspirant.
- Bouton Submit : cliquez pour envoyer l'instruction et lancer la génération.
- Droite : Zone d'affichage (Output Zone) — c'est ici que la magie opère, les résultats générés seront affichés ici.
Maintenant, essayons de générer votre première image !
Le prompt utilisé dans cet exemple est :
A red apple
C'est un exemple délibérément simplifié, sans aucune description de style ou de paramètres.
Processus réel
Après l'exécution du code, le processus se résume en trois étapes :
- Envoyer la description textuelle au modèle
- Le modèle génère l'image correspondante
- L'image est sauvegardée en tant que fichier local
Quelques secondes plus tard, vous verrez le résultat généré localement. La génération du modèle étant aléatoire, le même prompt donnera des résultats différents. Vous pouvez générer plusieurs fois pour choisir l'image qui vous plaît.
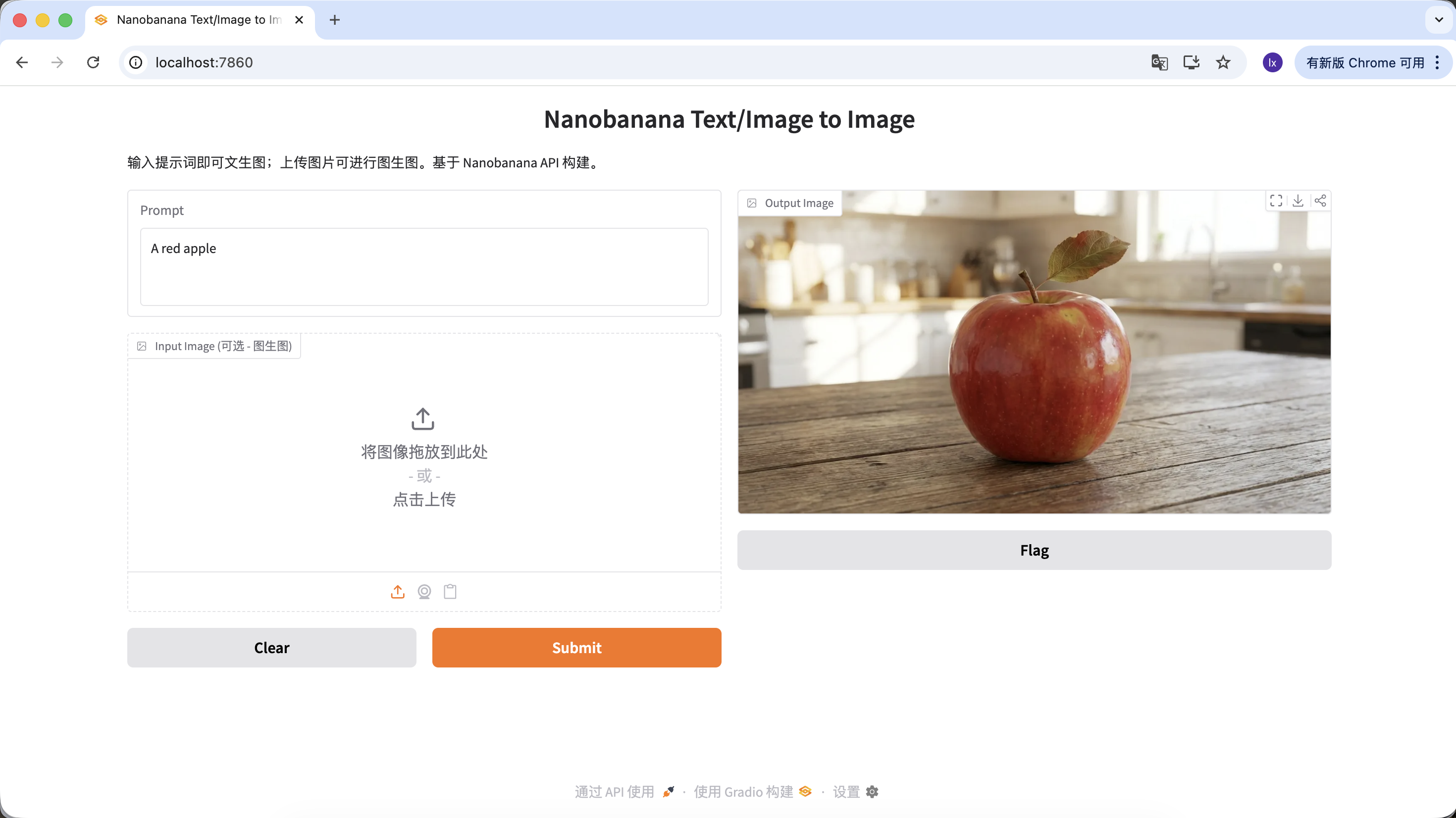
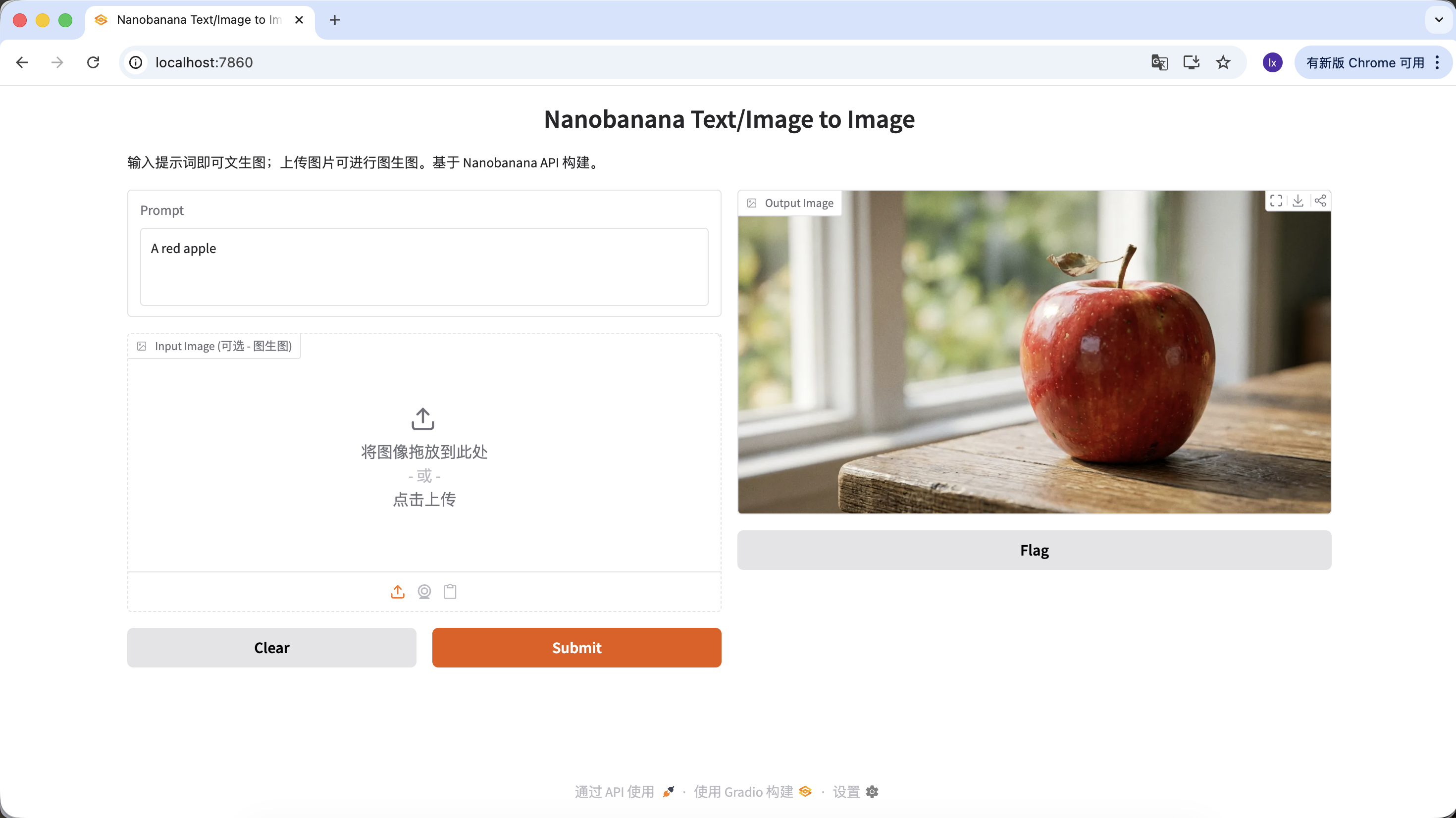
Vous pouvez aussi enrichir votre prompt avec plus de descriptions et de contraintes. Par exemple, avec le prompt suivant, l'image obtenue sera plus spécifique.
"A hyper-realistic close-up of a fresh red apple with water droplets on its skin, sitting on a dark rustic wooden table. Cinematic dramatic lighting, rim light, shallow depth of field, bokeh background, 8k resolution, macro photography."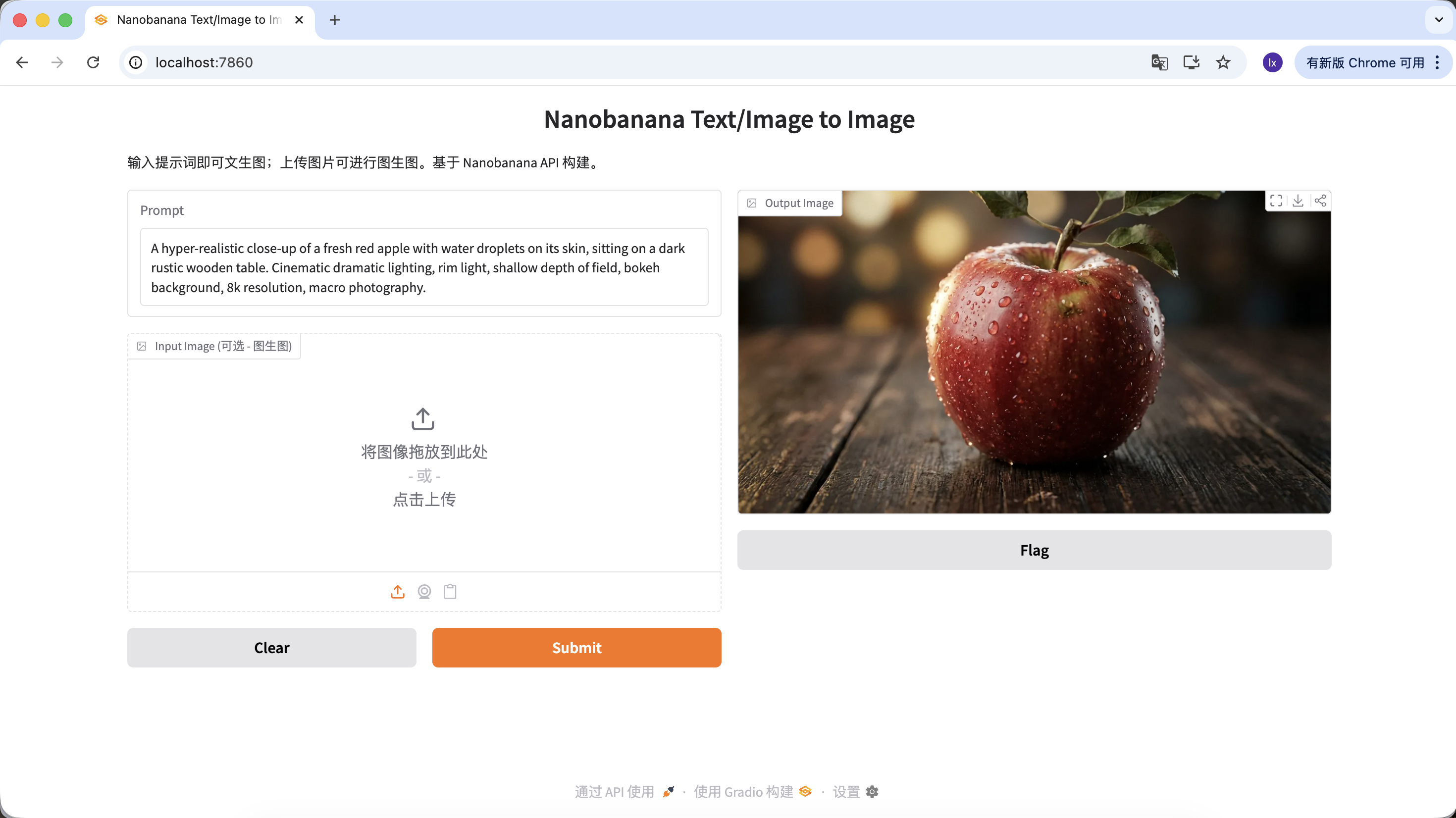
Cliquez sur download dans la zone Output Image pour sauvegarder l'image localement.
1.3 Scénarios courants de génération d'assets avec les modèles de génération d'images
Dans la pratique professionnelle, la génération d'images par grands modèles est davantage utilisée pour produire efficacement des assets de design que pour créer des œuvres d'art uniques.
En observant les cas les plus populaires sur certains comptes de marketing liés au design, on constate que leur production se concentre principalement sur deux catégories de scénarios :
- Texte vers image (de 0 à 1)
- Image avec référence (de 1 à N)
I. Texte vers image : obtenir rapidement du matériel de design
Cette catégorie de scénarios se concentre sur l'efficacité. Quand il faut combler des vides dans un design (états vides, avatars, illustrations), l'IA sert essentiellement de banque d'images à génération instantanée.
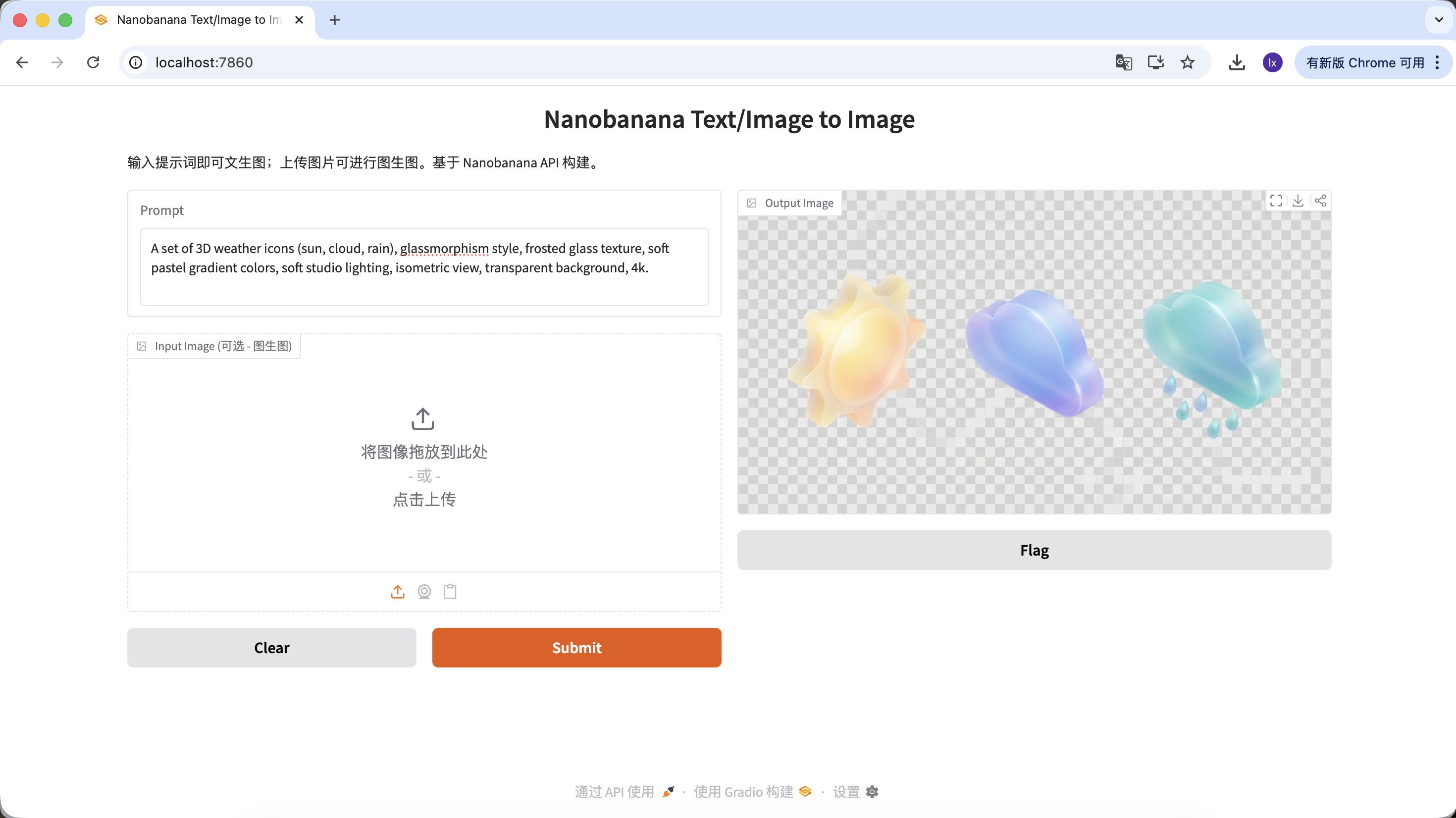
Générer des assets de design UI
- Tendance : icônes 3D style glassmorphisme ou argile sur Dribbble
- Manifestation courante : matériaux translucides, bords lumineux, icônes fonctionnelles ou météo aux couleurs bonbon
Exemple de Prompt :
A set of 3D weather icons (sun, cloud, rain), glassmorphism style, frosted glass texture, soft pastel gradient colors, soft studio lighting, isometric view, transparent background, 4k.
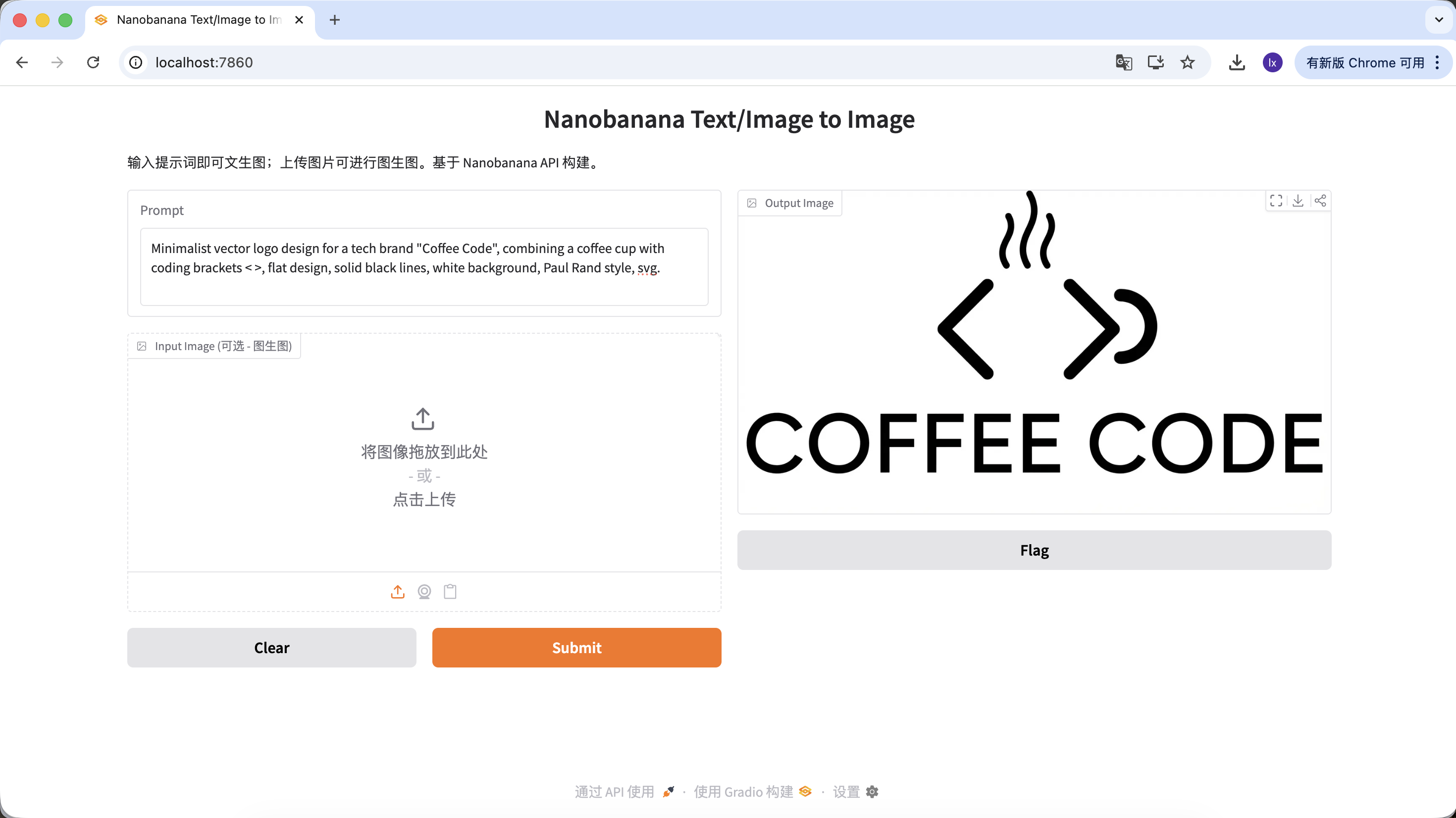
Générer des logos
- Tendance : logos tech minimalistes aux lignes épurées et combinaisons géométriques
- Manifestation courante : palette noir et blanc, design en espace négatif, identité de marque affirmée
Exemple de Prompt :
Minimalist vector logo design for a tech brand "Coffee Code", combining a coffee cup with coding brackets < >, flat design, solid black lines, white background, Paul Rand style, svg.
Générer des images d'utilisateurs pour un site
- Tendance : avatars 3D virtuels courants sur les sites SaaS, pour éviter les problèmes de droits d'image de personnes réelles
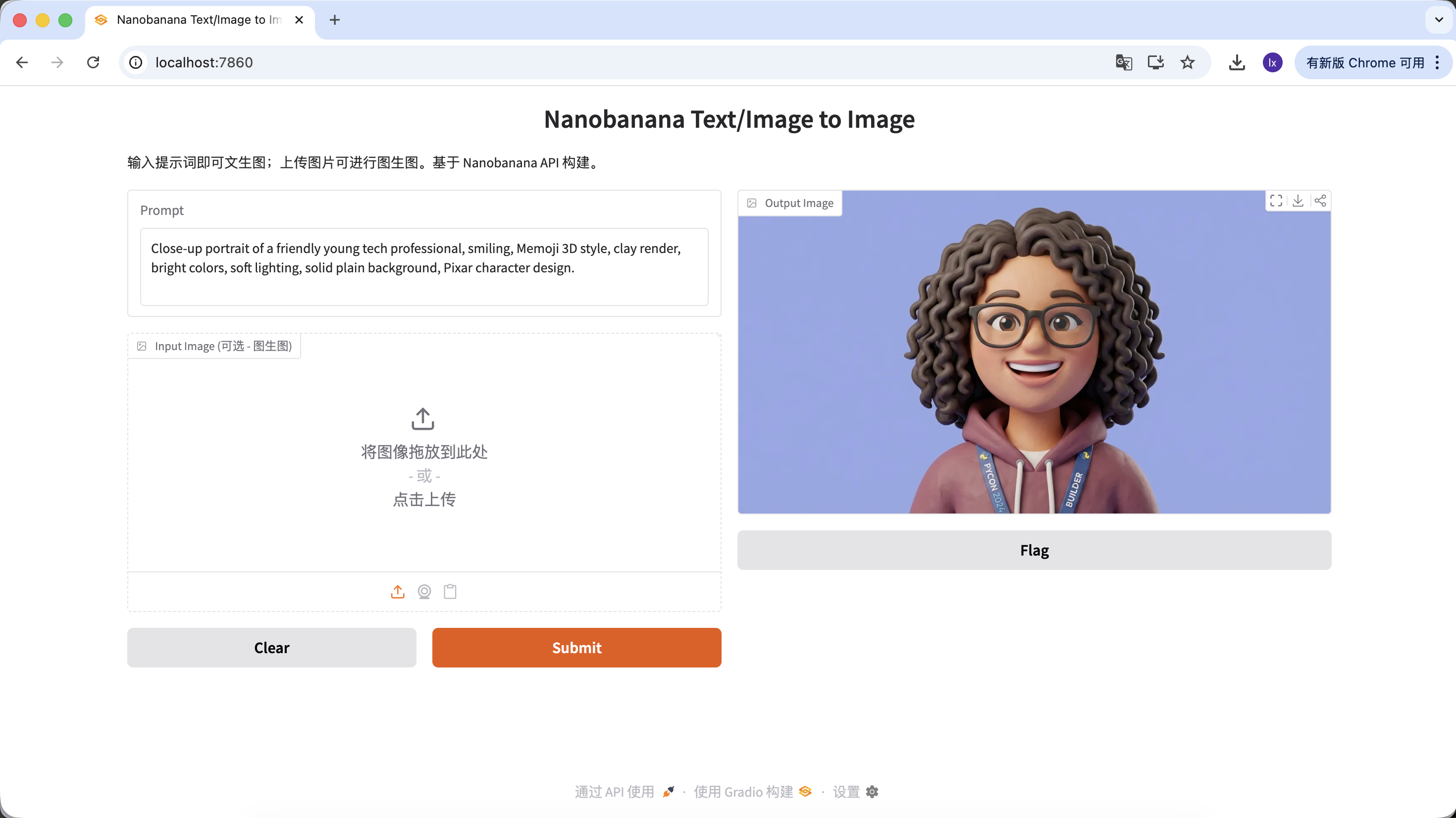
- Manifestation courante : expressions amicales, proportions cartoon, style Pixar ou Memoji
Exemple de Prompt :
Close-up portrait of a friendly young tech professional, smiling, Memoji 3D style, clay render, bright colors, soft lighting, solid plain background, Pixar character design.
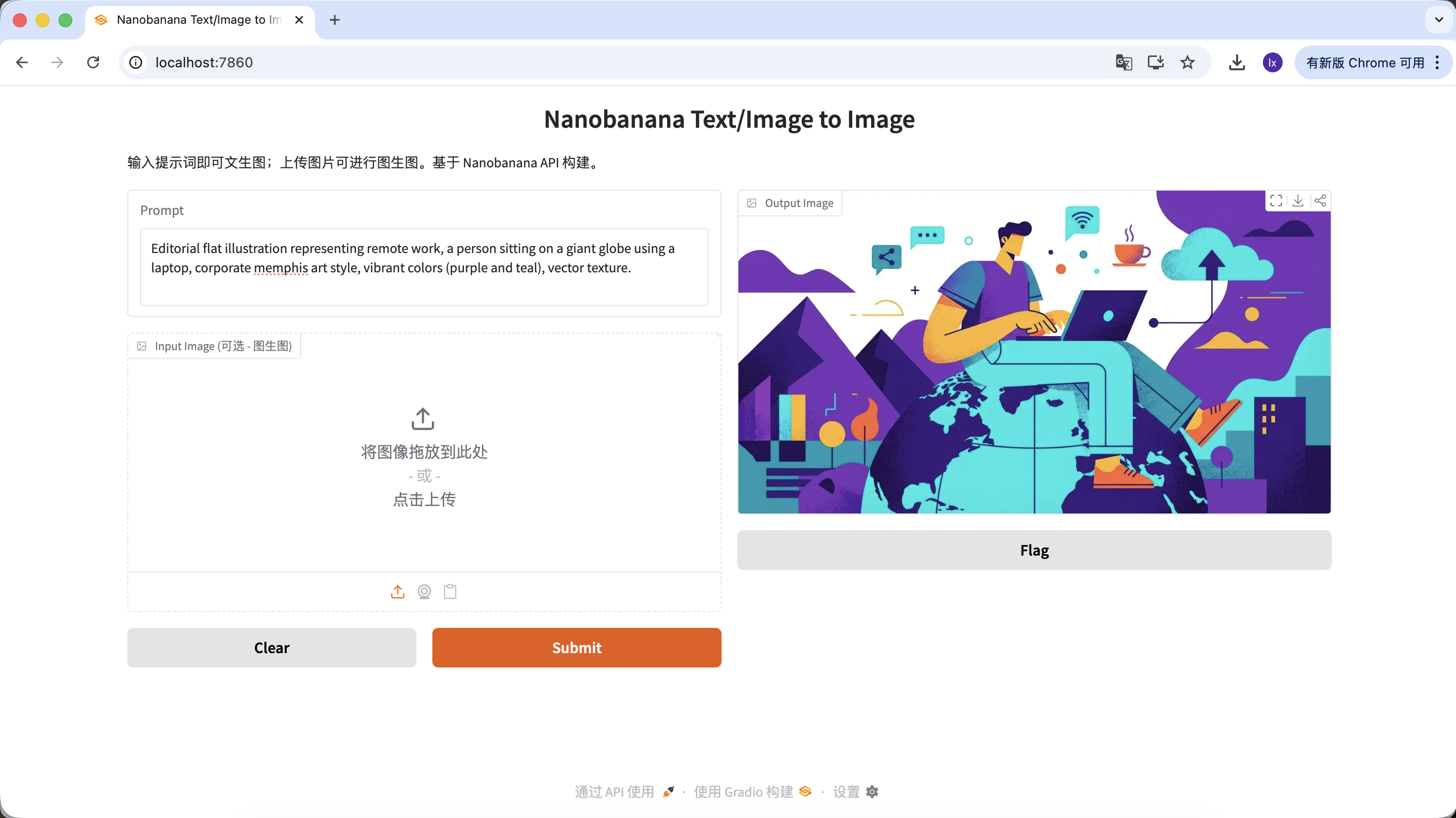
Générer des illustrations d'articles
- Tendance : illustrations plates abstraites courantes dans les blogs d'entreprises tech
- Manifestation courante : palette violet-bleu, proportions de personnages exagérées, éléments UI flottants
Exemple de Prompt :
Editorial flat illustration representing remote work, a person sitting on a giant globe using a laptop, corporate memphis art style, vibrant colors (purple and teal), vector texture.
II. Image avec référence : maintenir la cohérence visuelle
Cette catégorie de scénarios se concentre davantage sur l'extensibilité. Quand vous avez déjà une image clé satisfaisante et devez générer un ensemble complet d'assets au style cohérent.
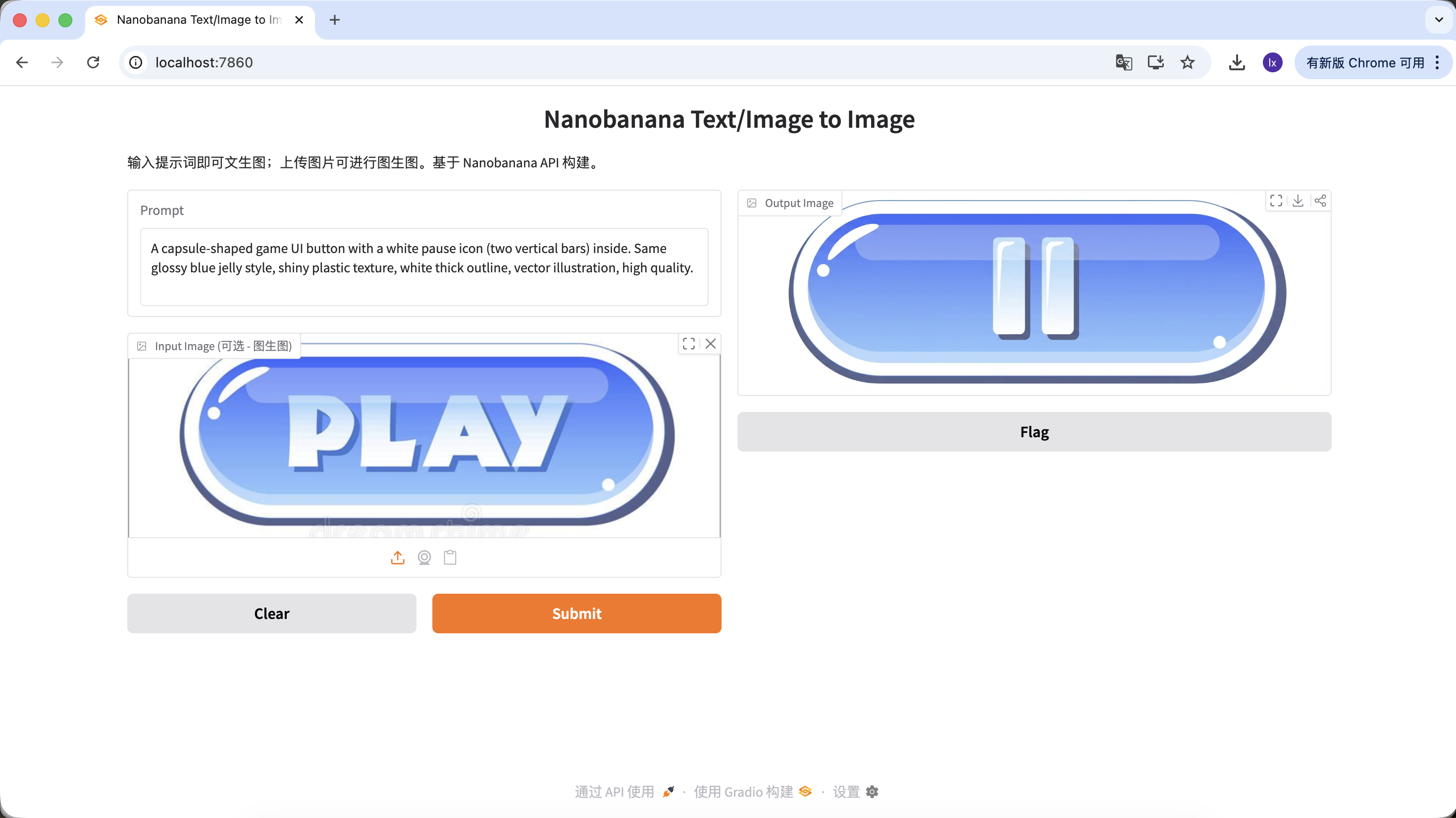
Un ensemble de boutons ou d'assets d'interaction cohérents avec l'image principale
Dans le développement de jeux, la cohérence de l'UI est cruciale. Supposons que vous ayez déjà le bouton « PLAY » de l'interface principale et deviez maintenant créer un ensemble complet de boutons fonctionnels au style unifié (pause, paramètres, accueil). Dessiner à la main chaque bouton pour garantir une cohérence parfaite en termes de brillance, perspective et valeurs de couleur est très difficile.
Processus de base :
- Sauvegarder l'image du bouton bleu « PLAY » existant

- La glisser dans la zone Input Image comme modèle de référence pour les générations suivantes
- Garder la description de style du prompt inchangée, modifier uniquement le contenu principal
Avec ce processus, il suffit de remplacer la description du contenu pour obtenir des boutons aux fonctionnalités différentes mais au style cohérent.
Exemple de Prompt :
Variante A : Bouton pause (icône)
A capsule-shaped game UI button with a white pause icon (two vertical bars) inside. Same glossy blue jelly style, shiny plastic texture, white thick outline, vector illustration, high quality.
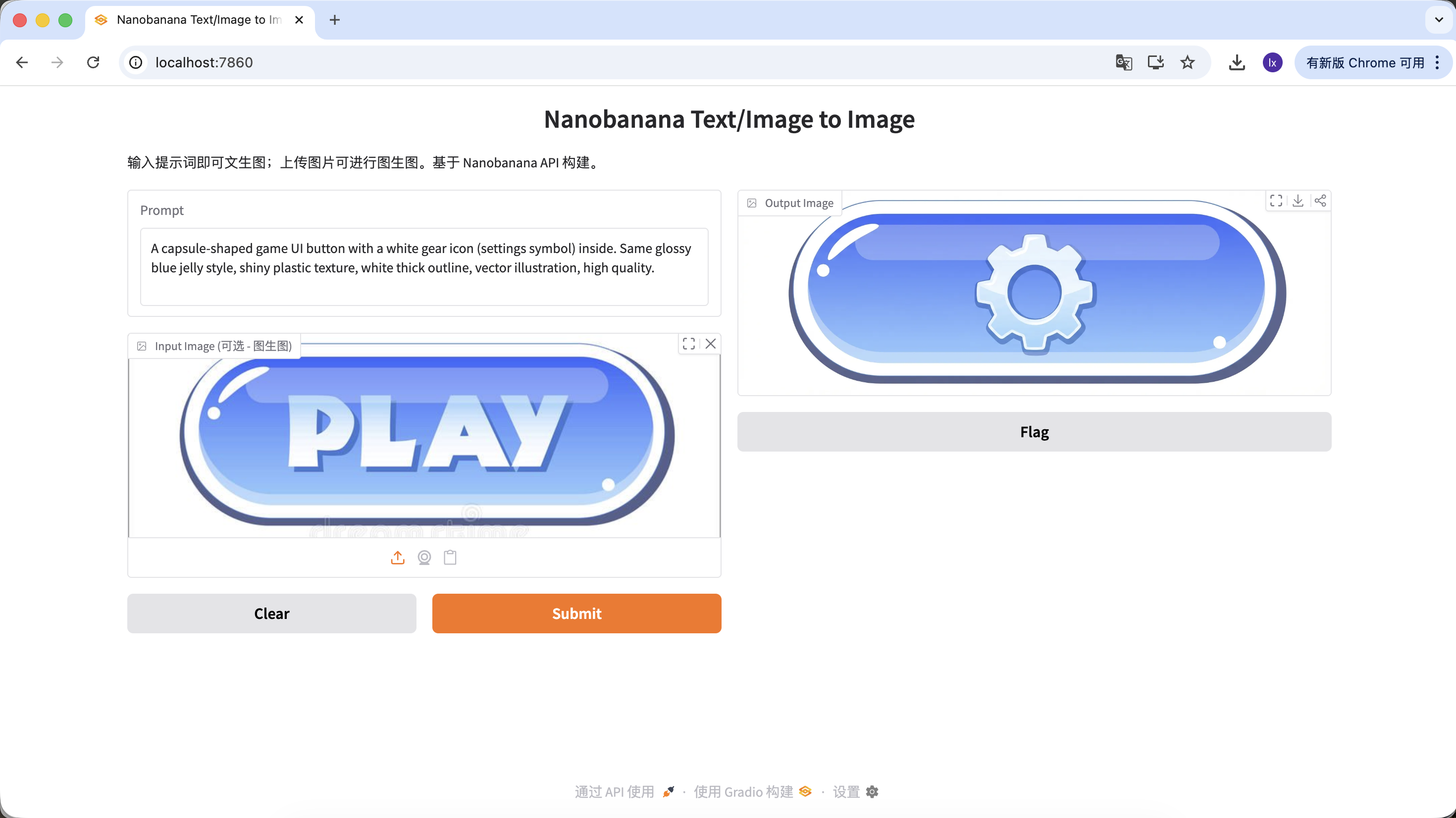
Variante B : Bouton paramètres (icône complexe)
A capsule-shaped game UI button with a white gear icon (settings symbol) inside. Same glossy blue jelly style, shiny plastic texture, white thick outline, vector illustration, high quality.
Variante C : Bouton rejouer (changement de forme)
Si vous devez ajuster la forme du bouton, décrivez-la directement dans le prompt — le modèle tentera de changer la structure tout en préservant les caractéristiques de matériau.
A round game UI button with a white circular arrow icon (replay symbol) inside. Same glossy blue jelly style, shiny plastic texture, white thick outline, vector illustration, high quality.

Avec cette série d'opérations, vous pouvez non seulement remplacer la fonction et l'icône du bouton, mais même changer sa forme, tout en conservant une cohérence élevée en termes de matériau, de palette et de lumière parmi tous les résultats générés. C'est précisément la valeur centrale des grands modèles dans les scénarios de déclinaison d'assets de design.
Chapitre 2 : Un assistant de génération d'images plus obéissant — l'exemple de Lovart
Dans la première partie, nous avons appelé NanoBanana directement via le code et avons expérimenté le flux de base « saisie = génération ». Cette approche fonctionne bien quand les besoins sont simples. Mais quand la tâche de génération commence à inclure plus de contraintes, par exemple :
- Besoin de plusieurs images au style cohérent
- Besoin d'ajustements itératifs sur les résultats existants
- Besoin de modifier dynamiquement la direction de génération en fonction des entrées utilisateur
L'approche par appel unique devient progressivement insuffisante.
C'est là qu'il faut introduire un Agent AI (Intelligence artificielle). Cette section prend Lovart comme exemple pour montrer comment le flux de travail change lorsque le modèle de génération d'images acquiert une « couche de réflexion ». Notez bien ! Il ne s'agit pas de publicité, mais simplement de vous aider à comprendre rapidement la praticité des Agents AI.
2.0 Découvrir Lovart : votre agent de design AI
Lovart est un outil de design basé sur des Agents, disponible en web. Comparé aux outils de génération d'images classiques, il ajoute une couche de « réflexion et planification » avant la génération.
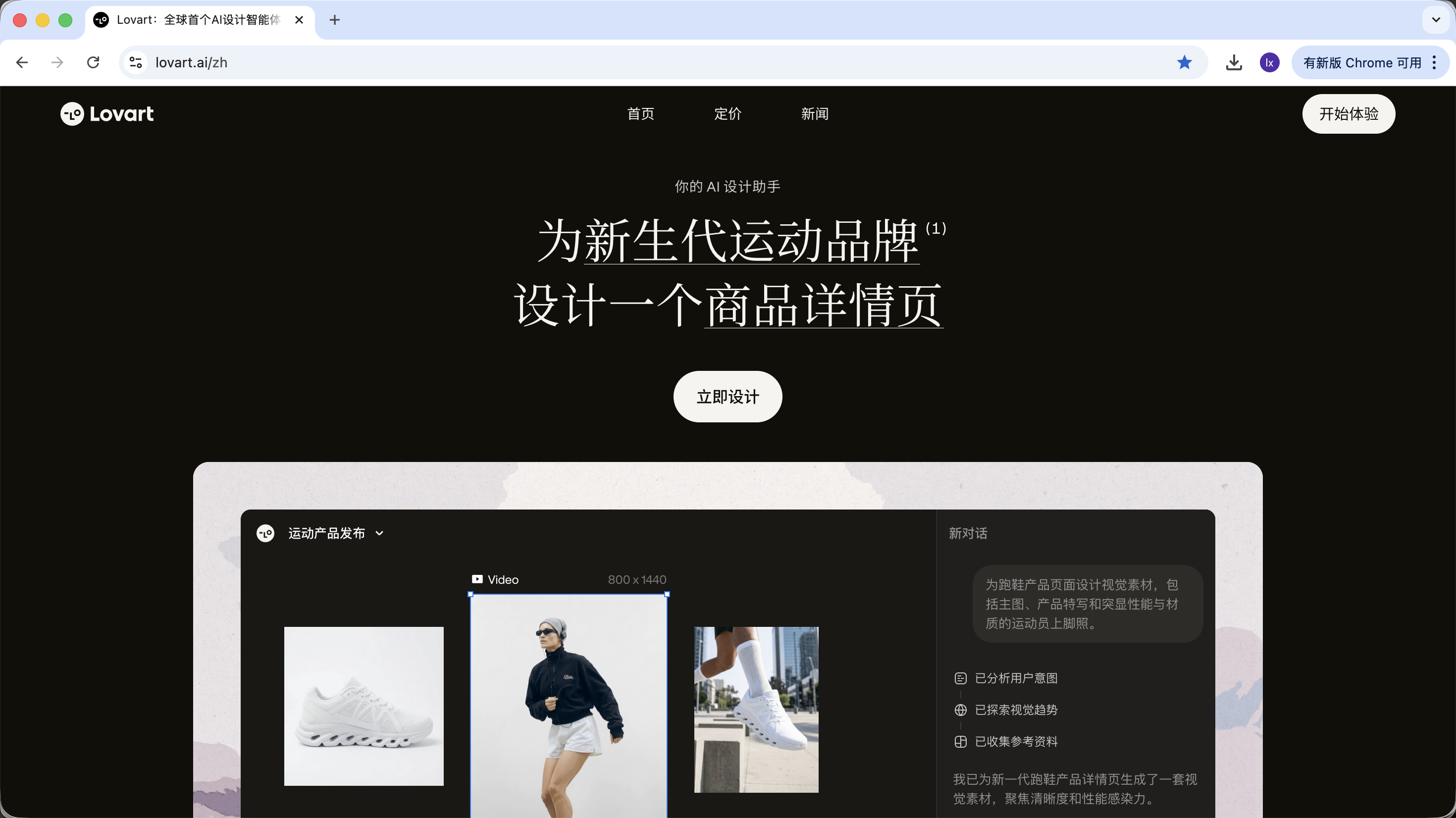
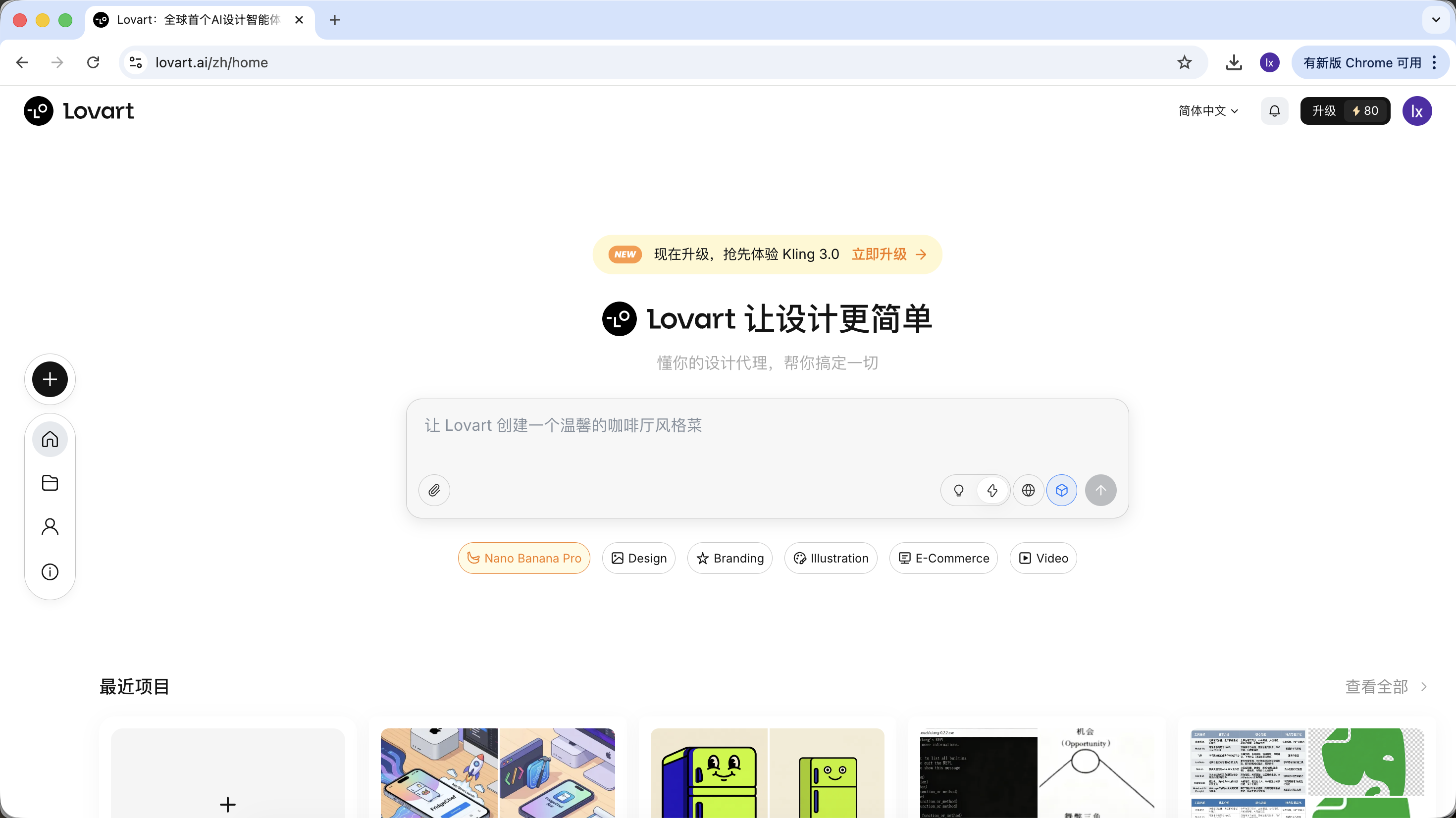
Une fois dans Lovart, voici les principaux éléments de contrôle à connaître :
Sélection du modèle
Cliquez sur l'icône du cube sous le champ de saisie pour voir les modèles de génération disponibles (comme GPT Image, Flux, etc.).
Pour rester cohérent avec l'exemple précédent, cette section utilise toujours NanoBanana comme modèle de génération sous-jacent.
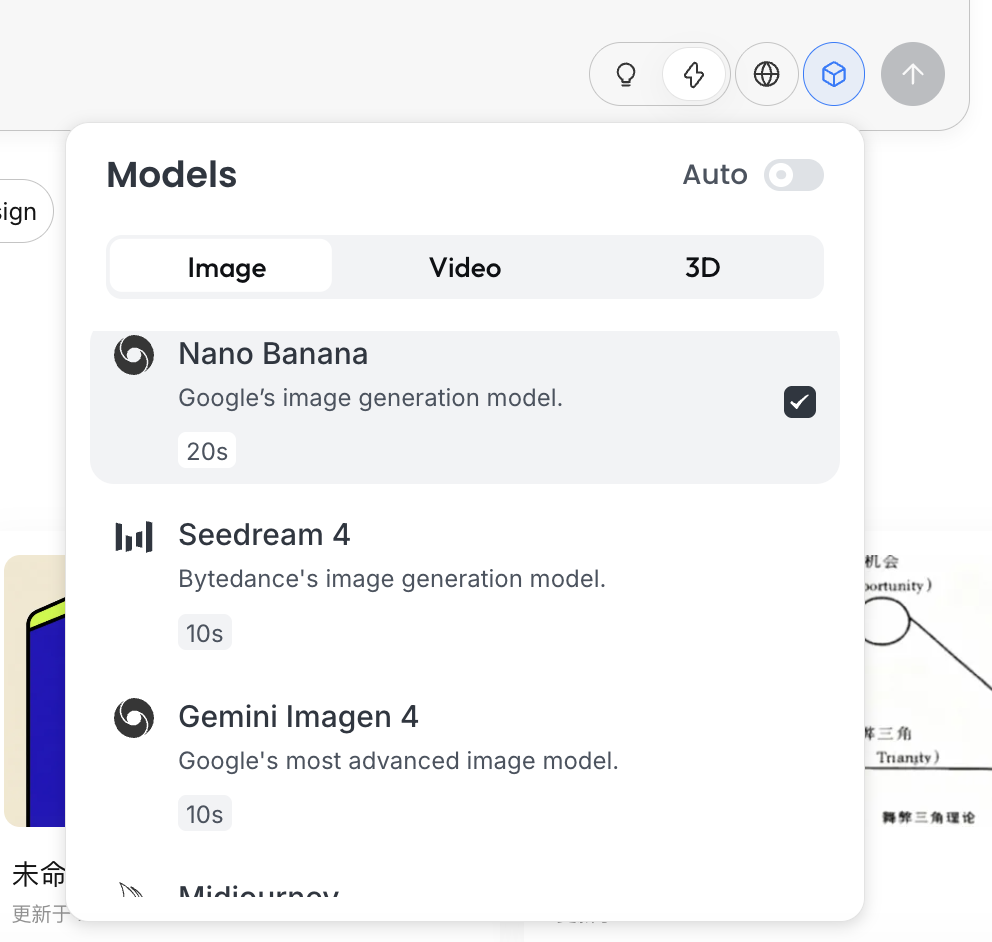
Mode de réflexion
C'est le commutateur central de Lovart :
- Fast Mode (⚡) : proche de l'API native, réponse rapide, adapté à la génération d'images uniques avec des instructions claires
- Thinking Mode (💡) : mode Agent, l'IA décompose d'abord le besoin, réécrit le prompt, puis exécute la génération
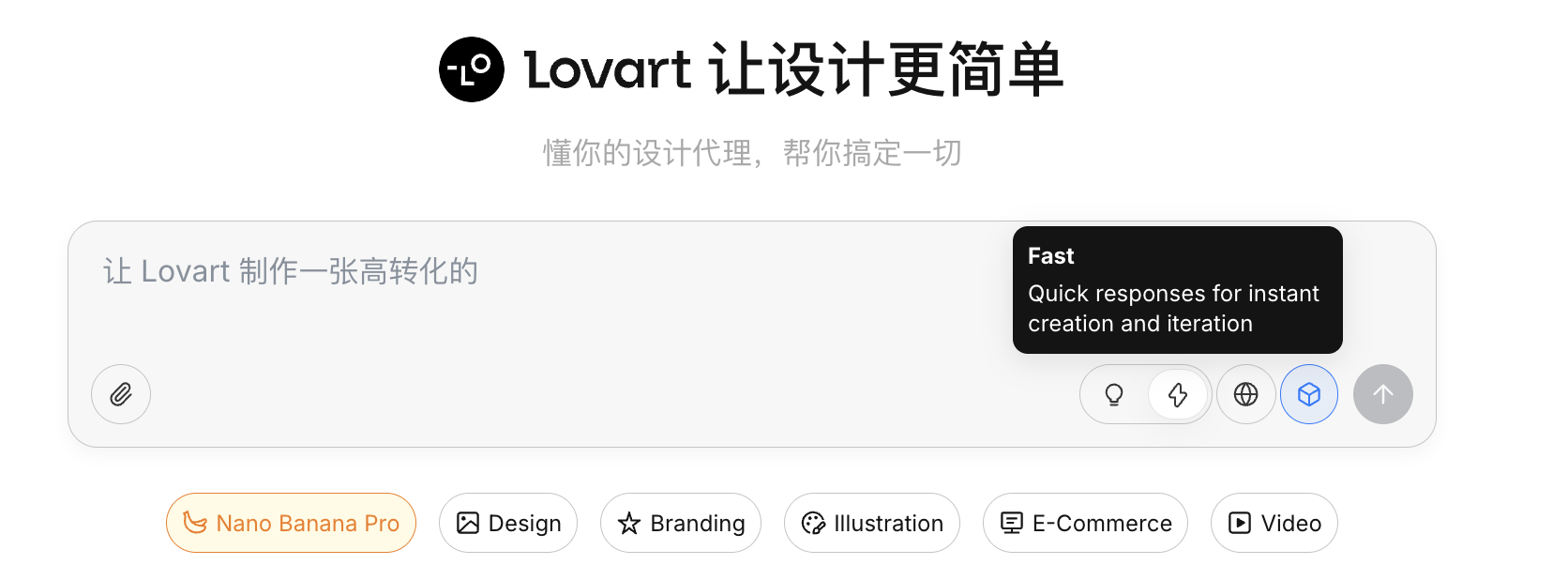
Capacité de connexion Internet
En activant l'icône du globe, l'Agent peut rechercher des informations en ligne pendant la génération (tendances de design, palettes de couleurs, etc.) comme entrée complémentaire.
2.1 Pourquoi l'API native ne suffit-elle pas ?
Même s'il est déjà possible de générer des images de bonne qualité via Python, l'API native reste limitée pour les tâches complexes. La raison principale est que l'API native est fondamentalement impérative. Quand vous lui demandez de générer un objet spécifique, elle peut l'exécuter directement ; mais quand l'entrée devient « concevoir un ensemble complet d'assets de jeu », elle ne décompose pas spontanément l'objectif en étapes exécutables.
La différence fondamentale de Lovart réside dans le mécanisme d'Agent. Entre l'entrée utilisateur et le modèle de génération d'images, elle ajoute une couche de logique de compréhension et de planification : identifier d'abord l'intention de l'utilisateur, puis décomposer la tâche, réécrire le prompt, et enfin exécuter la génération.
2.2 Démonstration pratique : créer un ensemble de stickers d'IP en 5 minutes
Prenons l'exemple de « créer un ensemble de stickers d'IP de canard programmeur » pour voir comment l'Agent participe à l'ensemble du processus.
Phase 1 : Planification (capacité de réflexion de l'Agent)
Problème de l'API native : Vous devez penser vous-même au design du personnage, aux états émotionnels et écrire un prompt séparé pour chaque image.
L'approche de Lovart :
- Activer le 💡 Thinking Mode
- Saisir une seule instruction :
Concevoir un ensemble de stickers d'IP de canard programmeur, style flat design, mignon
L'IA ne dessine pas immédiatement. Elle va d'abord chercher sur Internet des images de design de canards programmeurs. Puis elle produit un plan décomposé, générant automatiquement des scènes comme Debug, Coffee Break, Panic, avec les descriptions visuelles correspondantes.
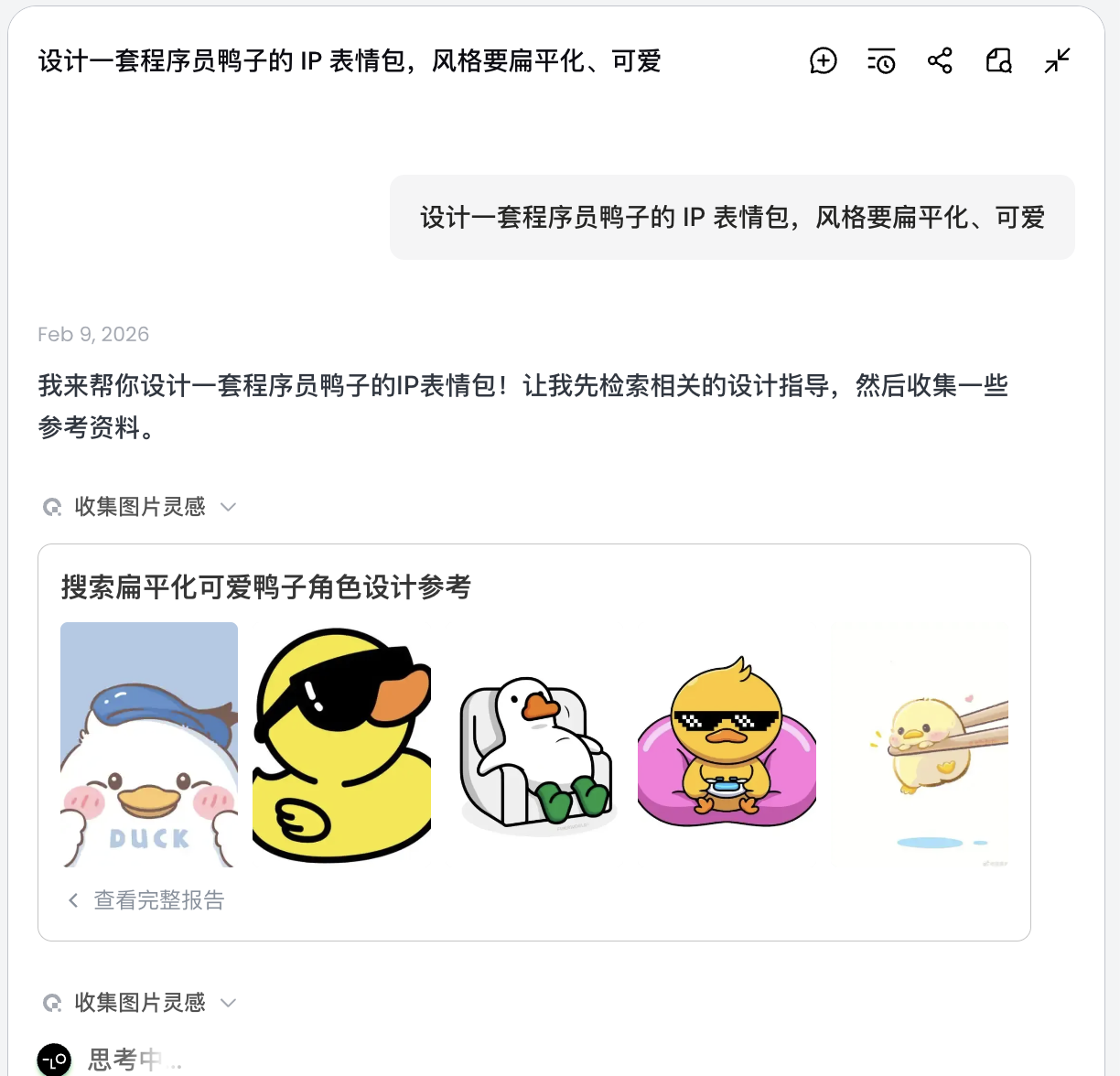

À cette étape, l'IA passe du rôle d'« exécutant » à celui de « planificateur ». Une fois que l'IA a analysé vos besoins, vous pouvez voir plusieurs styles et contenus d'images de canards programmeur dans la zone de canevas de Lovart. Vous pouvez commencer à filtrer les styles qui vous plaisent.
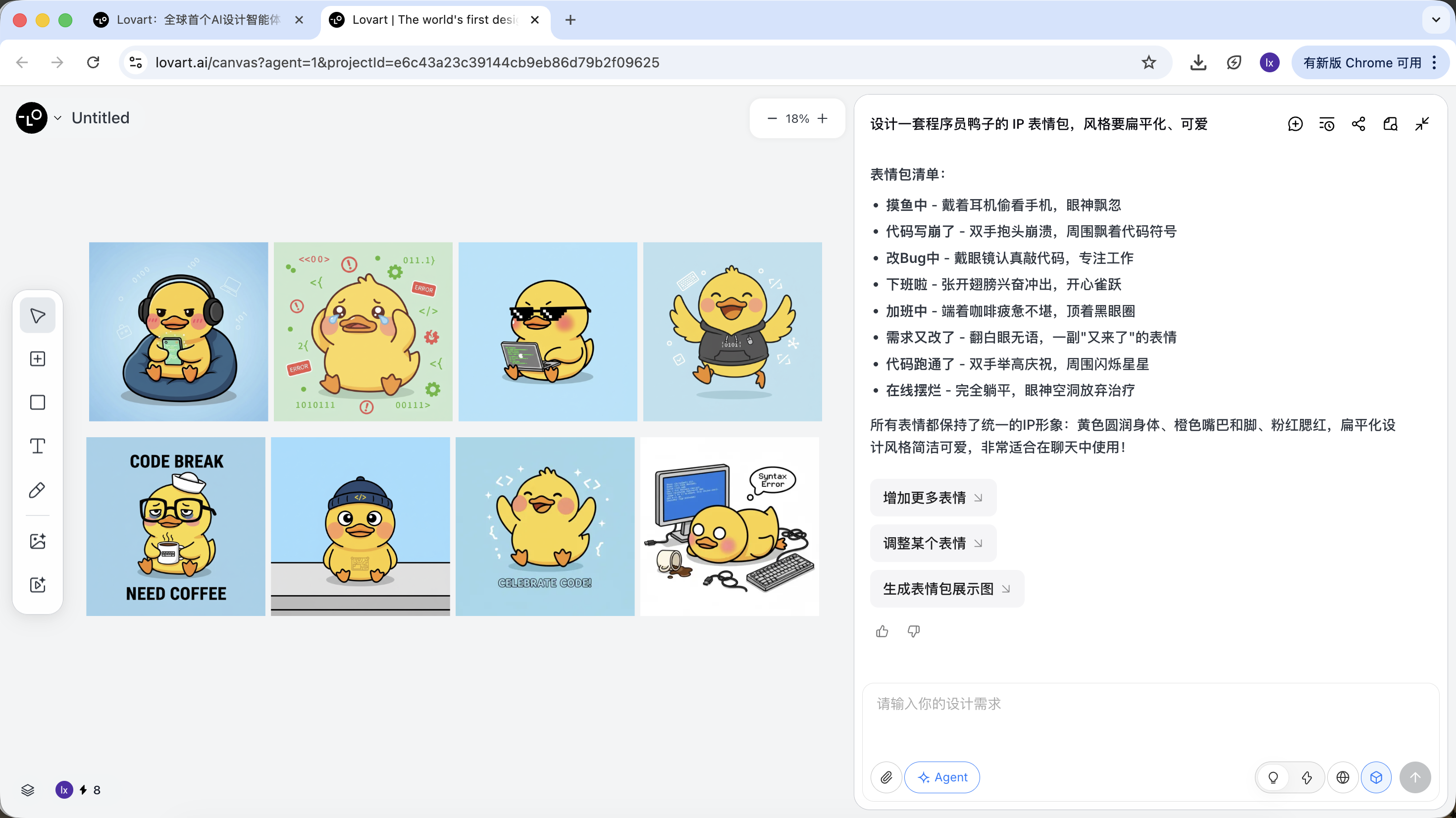
Phase 2 : Cohérence (ancrage visuel basé sur la référence)
Les images dans Lovart ne sont pas seulement des résultats, elles participent aussi aux générations suivantes.
Image de référence complète
- Sélectionnez le « canard standard » qui vous satisfait le plus dans les esquisses, cliquez sur l'image correspondante dans la zone de canevas
- L'image apparaîtra automatiquement dans la zone de dialogue comme Reference
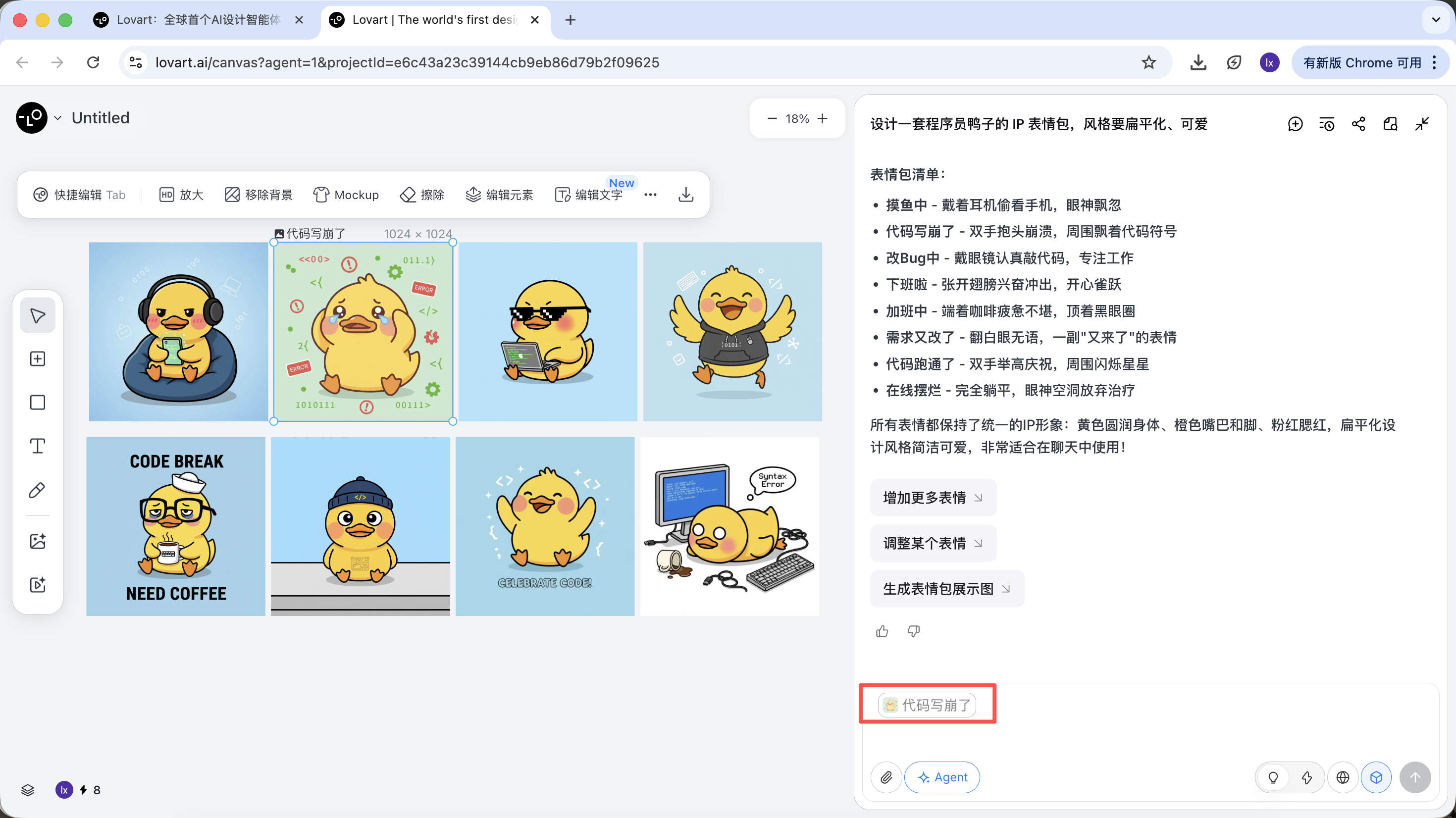
- Saisissez une nouvelle action (comme « heureux ») et générez
Le résultat généré héritera de la palette, des proportions et des détails du modèle original.
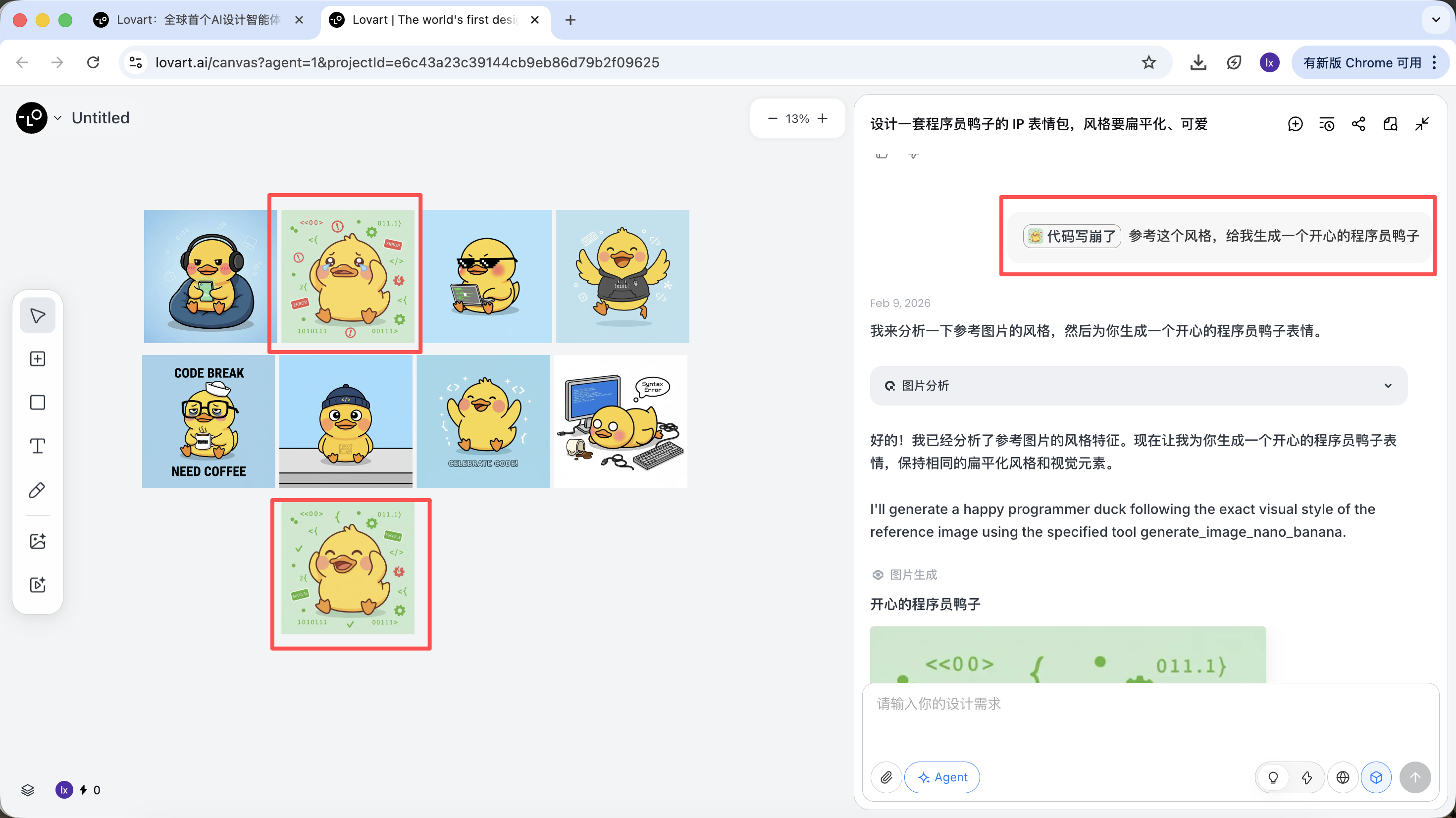
Référence partielle / Intégration multi-images
Outre l'utilisation d'une image complète comme référence, Lovart supporte aussi :
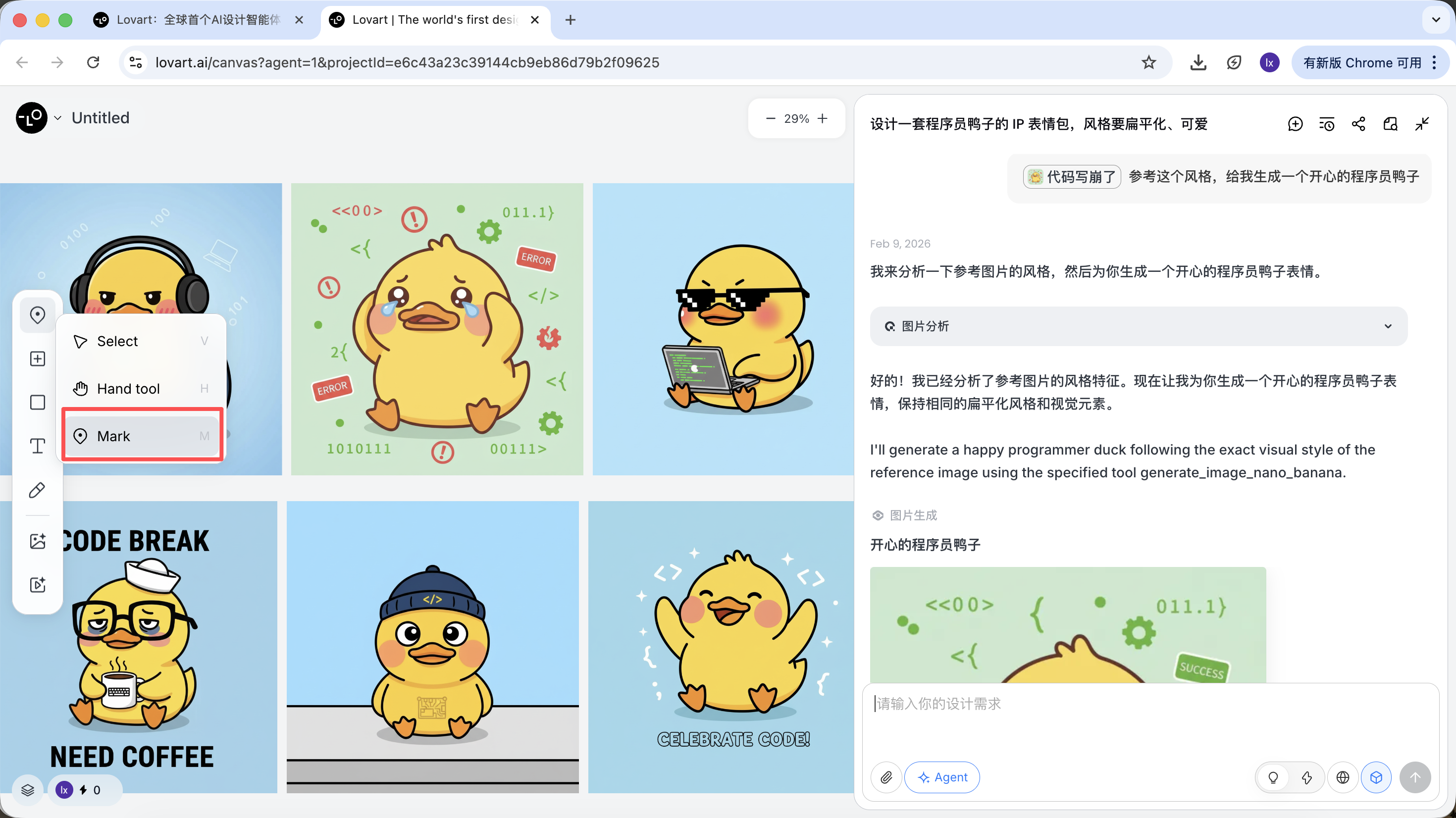
- Sélectionner uniquement une zone partielle de l'image (par exemple uniquement le chapeau ou l'expression)
Cliquez sur l'onglet à gauche de la zone de canevas, sélectionnez la touche « Mark », et marquez la zone partielle souhaitée sur l'image cible. Cette partie sera automatiquement synchronisée dans la zone de dialogue. Par exemple, ici nous pouvons choisir de modifier la couleur de fond.
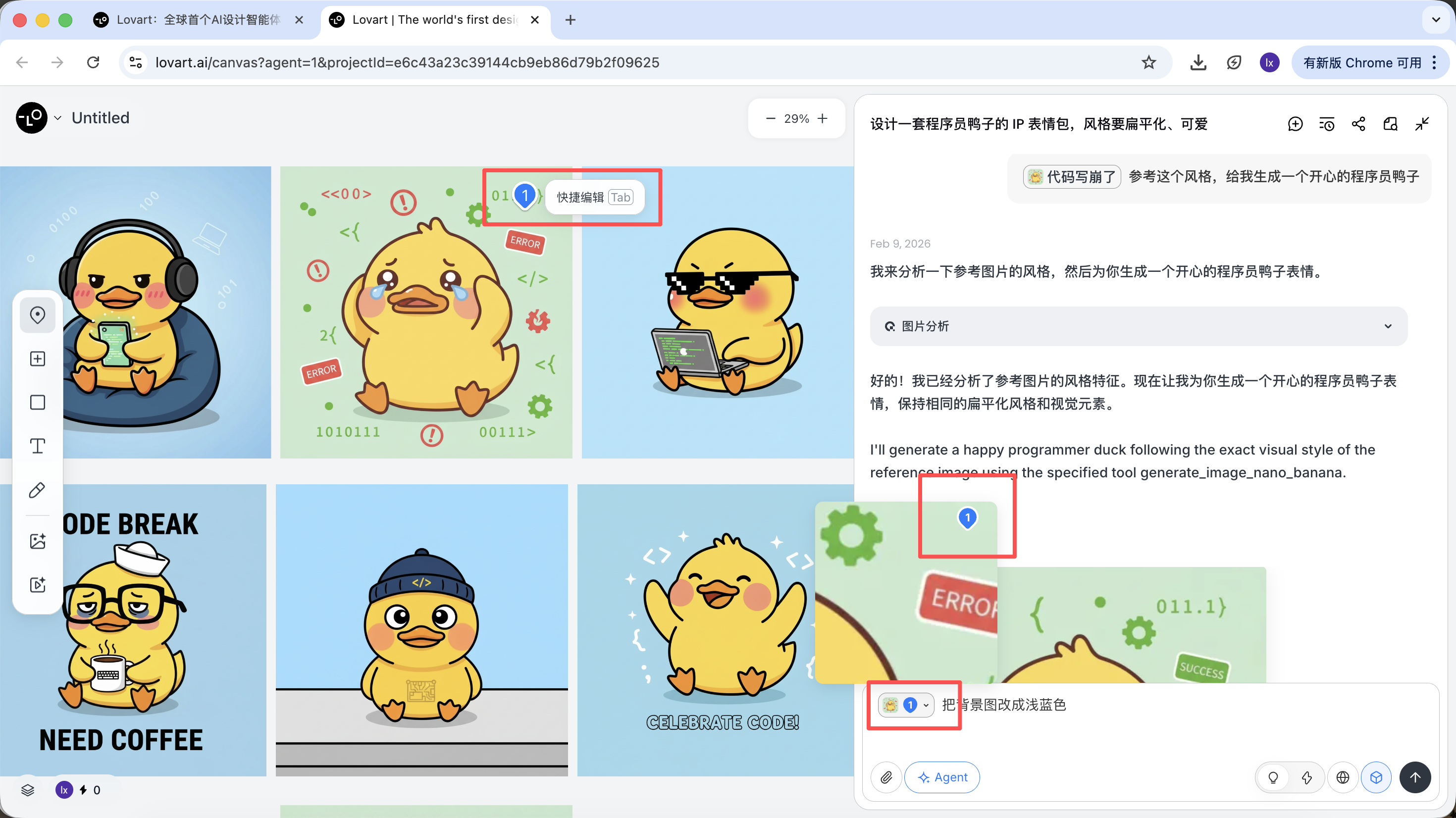
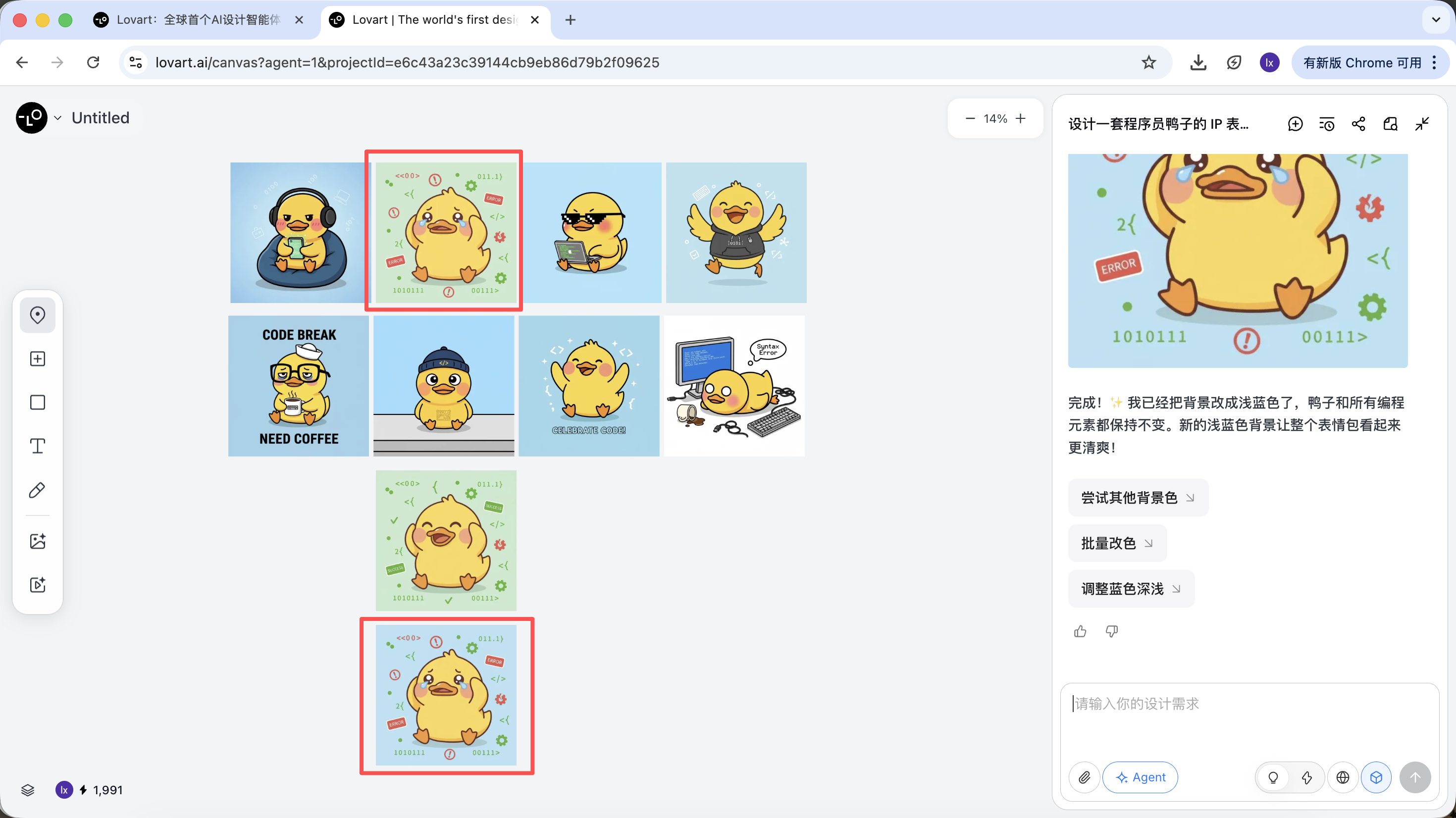
On peut voir que la nouvelle image générée n'a changé que la couleur de fond, ce qui correspond bien à notre demande.
- Référencer des sous-éléments de plusieurs images et les combiner pour générer un nouveau résultat
Par exemple : vous pouvez conserver le personnage principal de l'image A tout en remplaçant uniquement le chapeau par le style de l'image B. L'Agent intégrera automatiquement ces contraintes visuelles en arrière-plan.
Prenons l'exemple du canard programmeur : nous pouvons choisir de conserver l'image du canard de la première image et la remplacer dans la deuxième image comme élément principal.
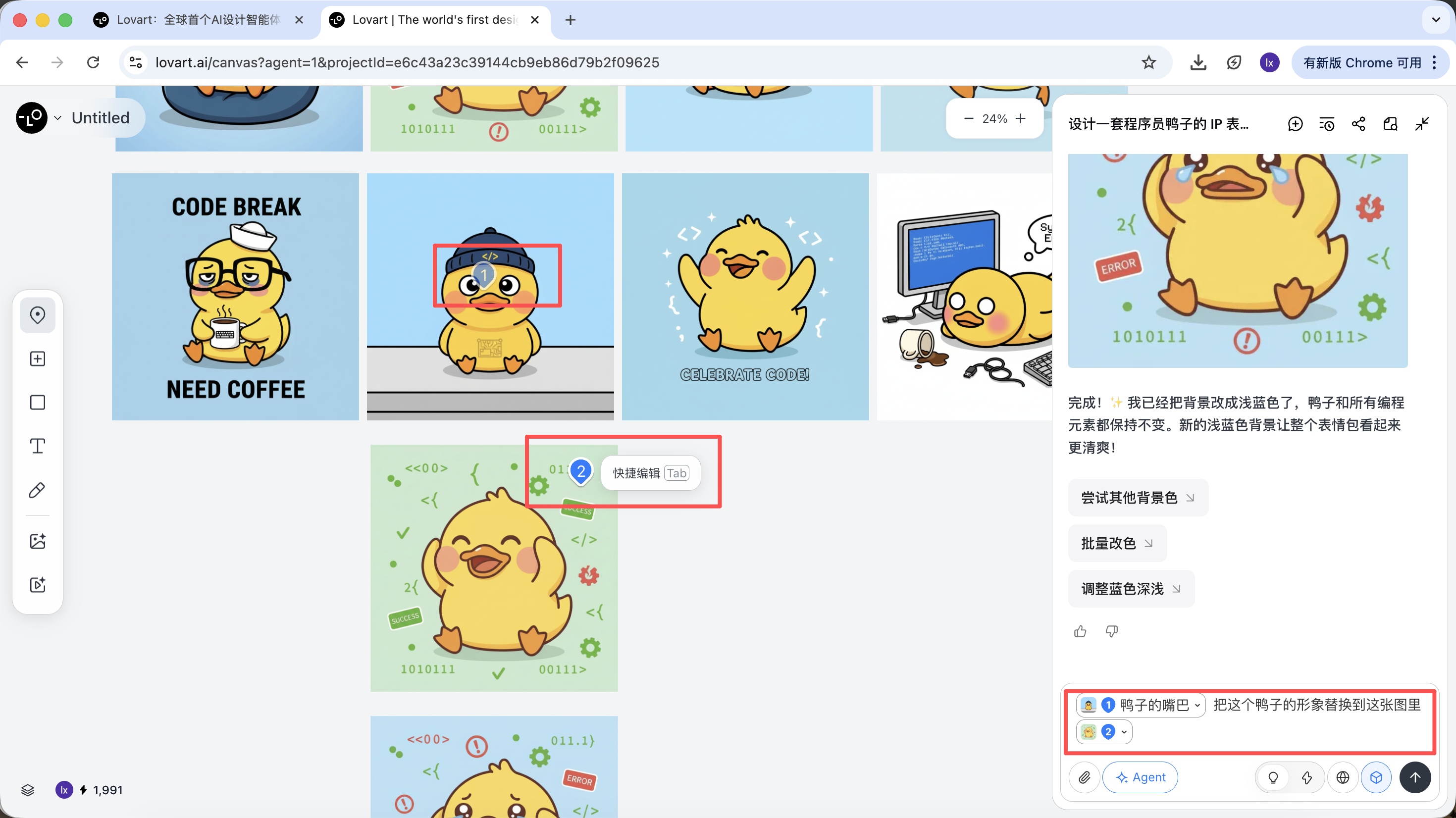
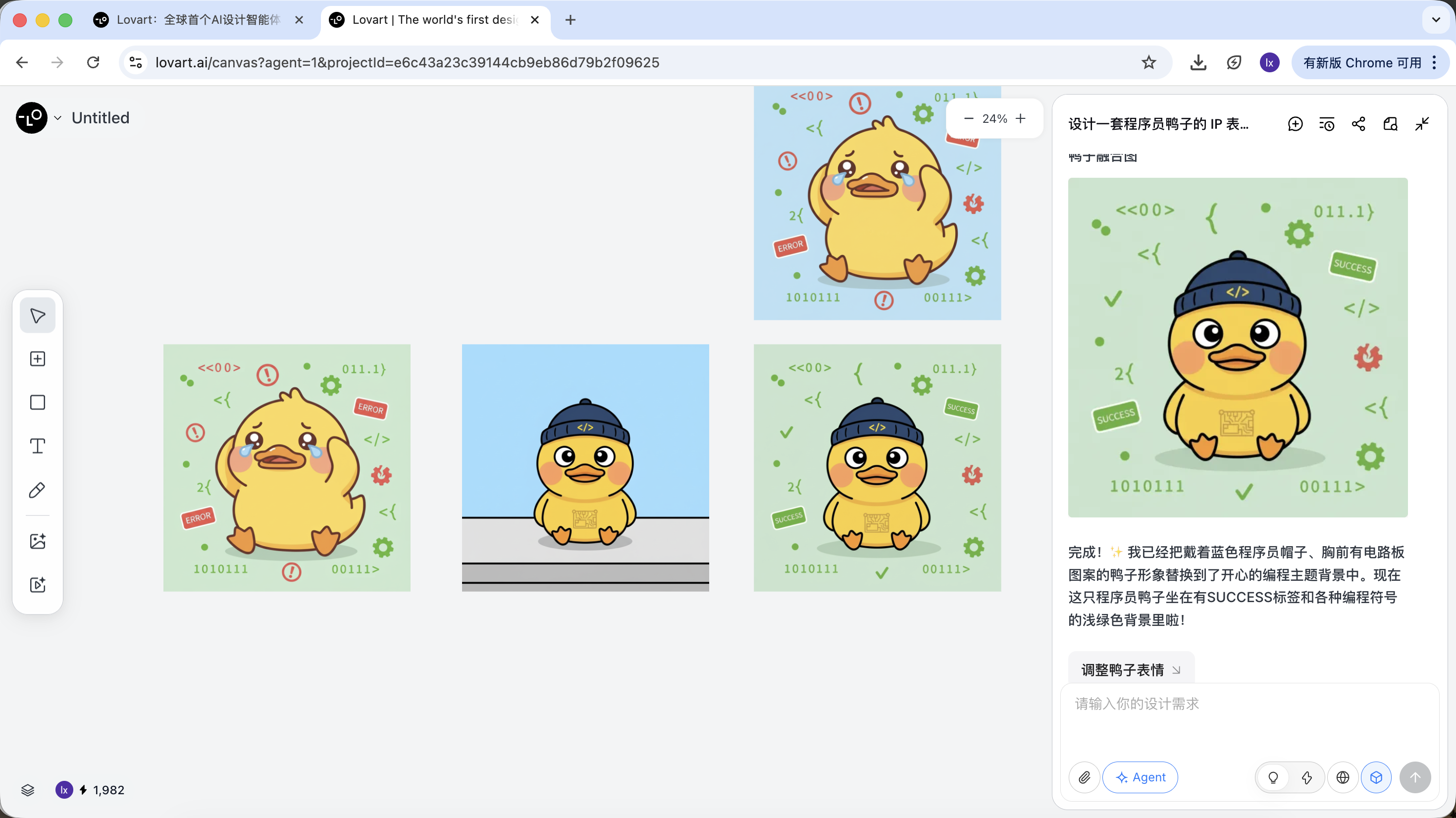
L'effet final est très significatif. Vous pouvez aussi essayer d'autres combinaisons !
Phase 3 : Livraison (appels d'outils de l'Agent)
Une fois la génération terminée, vous pouvez directement exécuter : agrandissement, suppression d'arrière-plan, effacement, etc.
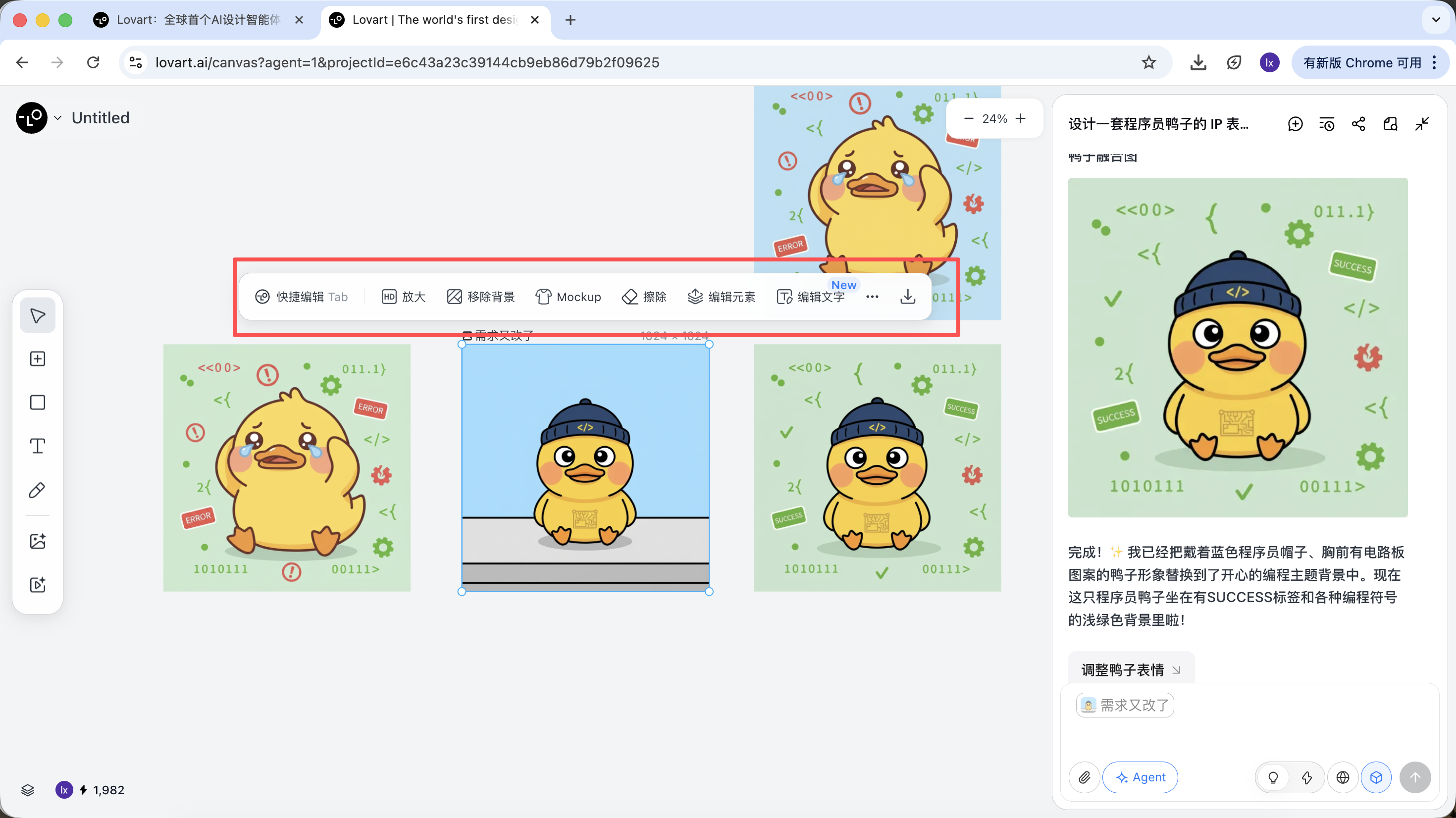
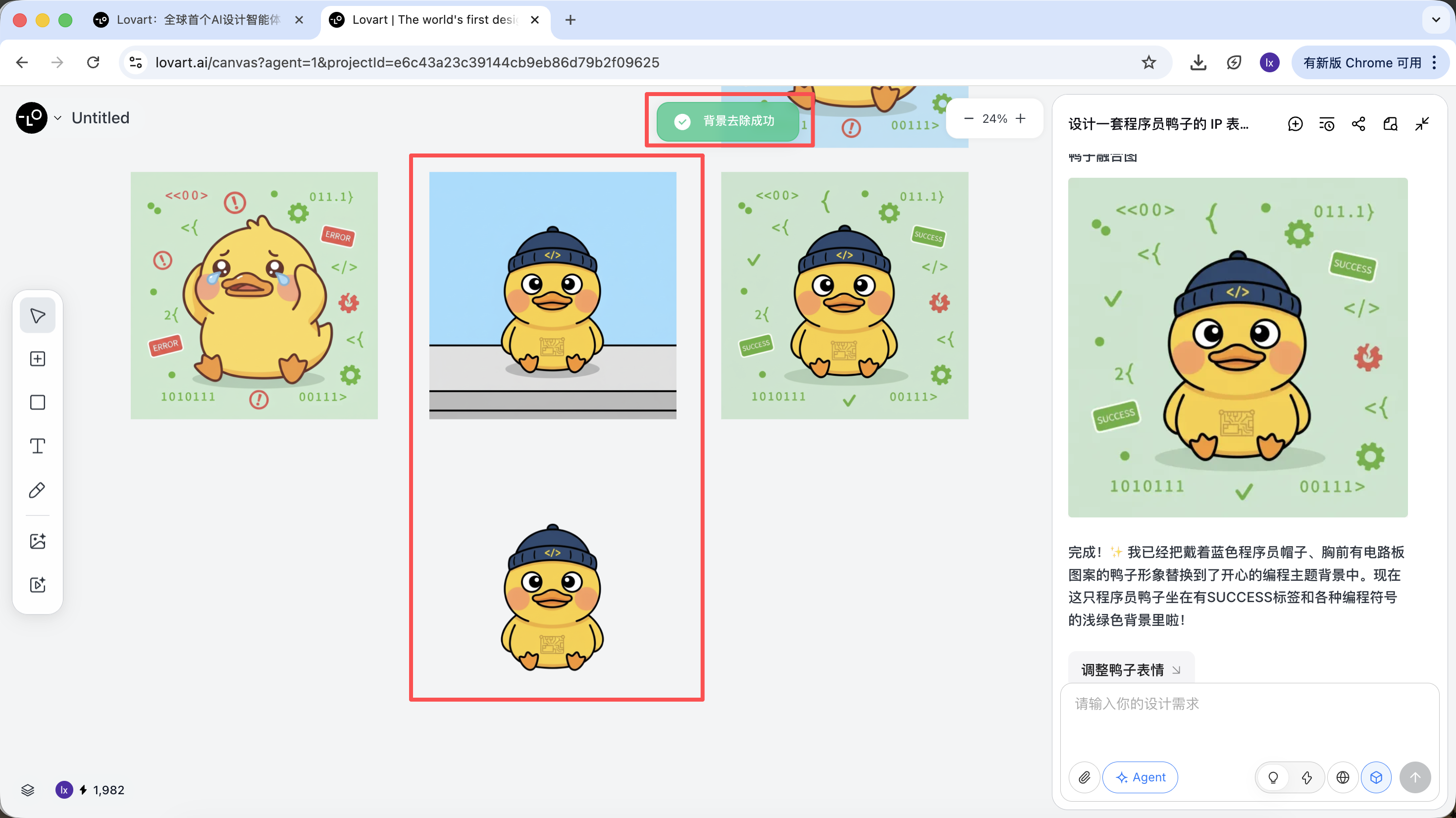
Il ne s'agit pas de simples filtres, mais de résultats obtenus par l'Agent en调度ant automatiquement différents outils.
Une fois le style de base défini, il est très rapide de générer toute une série d'images de stickers.
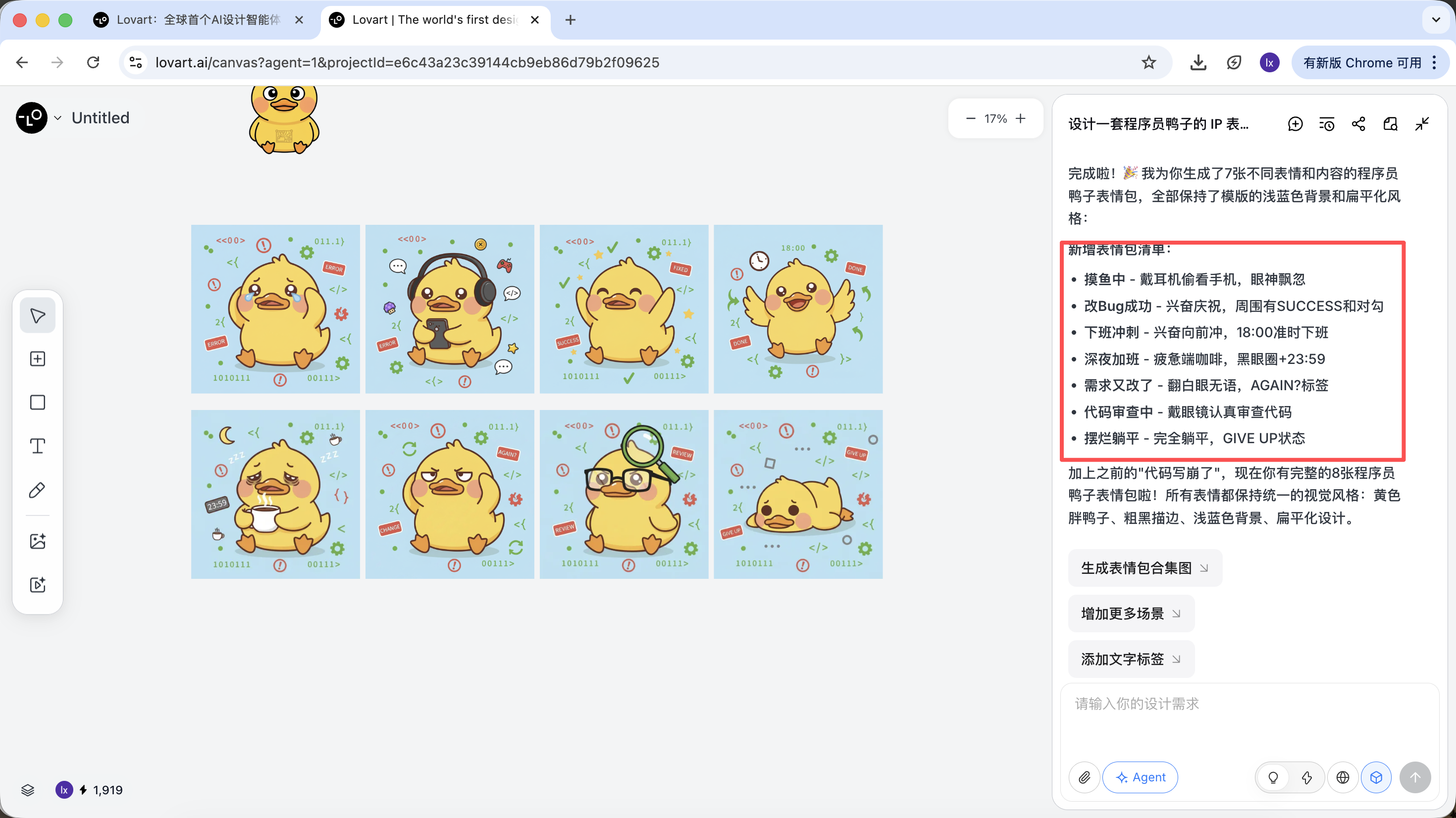
Au final, nous obtenons des assets de qualité production directement livrables, et non pas de simples images de démonstration.
2.3 Informations sur l'utilisation et la tarification
Lovart utilise un modèle de tarification par abonnement, avec différents forfaits correspondant à différentes allocations d'utilisation et droits de fonctionnalité. Les détails sont disponibles sur le site officiel.
Ce tutoriel ne fait aucune recommandation ni comparaison de forfaits ; si vous avez un besoin en usage réel, vous pouvez choisir de passer à un forfait payant selon votre situation personnelle. Le paiement est actuellement possible via Alipay et d'autres méthodes.
Résumé
Lovart ne remplace pas le modèle sous-jacent, mais grâce au mécanisme d'Agent, fait évoluer la génération d'images de « l'exécution unique » vers un « flux de travail continu ».
Quand la tâche commence à impliquer de la planification, de la cohérence et de la livraison, l'avantage de ce type d'outils devient très évident.
Chapitre 3 : Créer vous-même un assistant de dessin intelligent
Outre l'utilisation directe de Lovart, nous pouvons aussi implémenter nous-mêmes une version simplifiée d'un assistant de dessin.
Ce chapitre prend l'exemple de « l'illustration automatique d'articles » et construit progressivement un Agent avec des capacités de réflexion, en partant d'un problème concret.
3.1 Le problème : pourquoi envoyer directement un article à un modèle de dessin ne fonctionne pas ?
Envoyer directement un article long à NanoBanana en demandant une illustration donne rarement des résultats satisfaisants. La raison n'est pas que le modèle « dessine mal », mais qu'il n'est pas doué pour comprendre les textes longs.
Les modèles de génération d'images sont plus adaptés aux descriptions visuelles courtes et précises. Quand l'entrée devient un article avec sa structure, ses points clés et son contexte, le modèle ne peut pas déterminer quelles parties doivent vraiment être représentées dans l'image. Cela conduit souvent à des résultats hors sujet ou ne capturant que des détails épars, sans capacité de synthèse globale.
Fondamentalement, le modèle d'images n'a que la capacité d'« exécuter », mais manque d'un processus d'analyse et de sélection du texte.
3.2 Approche de résolution : séparer « compréhension » et « exécution » avec un Agent
Pour résoudre ce problème, la clé n'est pas des prompts plus complexes, mais de réfléchir avant de dessiner. Nous introduisons donc une « couche de réflexion » indépendante dans le flux de génération, et construisons un Agent minimal mais fonctionnel.
L'objectif principal de cet Agent est simple : que l'image finale générée soit la plus proche possible de la véritable intention expressive de l'utilisateur.
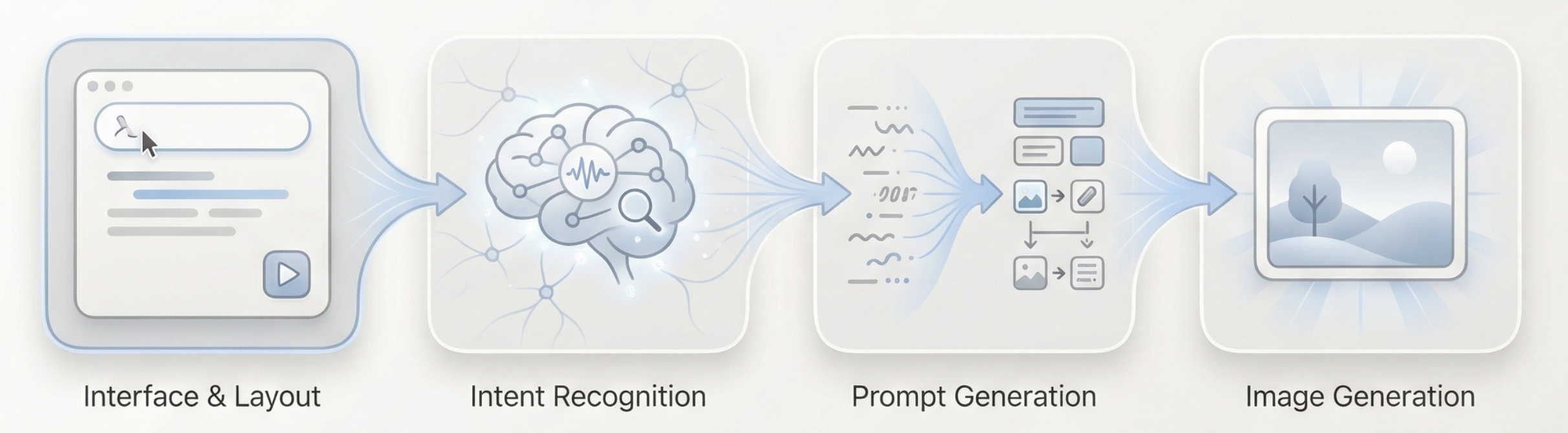
Le flux global peut se résumer ainsi : Texte long en entrée → Modèle de langage pour compréhension et jugement → Génération d'un prompt visuel approprié → Modèle d'images pour la génération → Image en sortie
Comment notre Agent peut-il comprendre l'intention de l'utilisateur ?
Nous choisissons de créer une « couche de réflexion » simplifiée, avec trois types d'intentions : entrée invalide, génération directe, texte long nécessitant compréhension.
Dans cet Agent, la répartition des rôles se résume en quatre points :
- Le modèle de langage comme cœur décisionnel Il est responsable de la compréhension du contenu de l'article, du jugement de l'intention de l'entrée utilisateur, et de la répartition de la tâche vers le chemin de génération approprié, décidant « que faire ensuite » et comment générer le prompt de dessin.
- Le modèle d'images comme exécutant Le modèle d'images ne participe pas à la compréhension ni au jugement, il reçoit uniquement les instructions visuelles déjà préparées et se concentre sur le rendu d'image.
- L'utilisateur comme guide intervenant Outre la saisie directe de texte, l'utilisateur peut ajuster manuellement le prompt généré pendant le processus, ou ajouter une image de référence pour guider la génération, orientant et affinant ainsi le résultat final.
- Gradio et l'API backend comme couche d'hébergement global Ils sont responsables de la liaison entre l'interface, les appels de modèle et l'affichage des résultats, garantissant que l'Agent fonctionne de manière stable comme une application web complète.
3.3 Préparation pratique : obtenir les API
Cela a l'air intéressant, n'est-ce pas ! Pour exécuter le flux ci-dessus, nous n'avons besoin que de deux types d'API.
La main : API NanoBanana (génération d'images)
Réutilisez directement la clé API et l'URL API déjà configurées au chapitre 1, sans configuration supplémentaire.
Le cerveau : API SiliconFlow (réflexion textuelle)
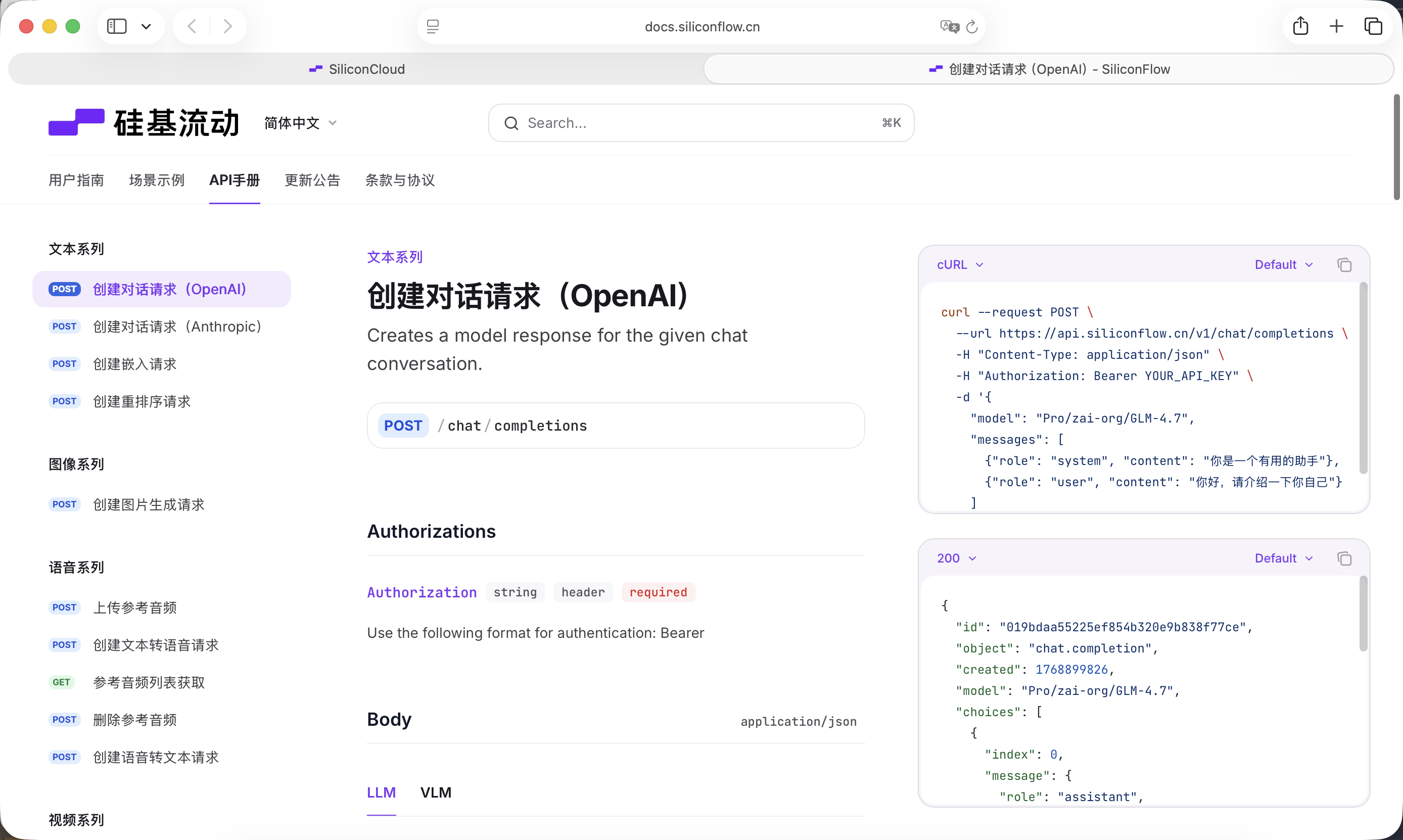
Nous avons besoin d'un grand modèle de langage pour assurer la « couche de réflexion ». Ce tutoriel utilise le service de modèle fourni par SiliconFlow : https://cloud.siliconflow.cn
SiliconFlow fournit une interface compatible avec la spécification API OpenAI, très facile à appeler via des requêtes réseau standard dans votre projet. Nous choisissons ici le modèle gratuit Qwen2.5-7B-Instruct. Le contenu nécessaire pour l'appel est déjà intégré dans le Prompt ci-dessous. Avant de commencer, il vous suffit de créer un compte sur le site officiel et de générer une clé API.
Cette clé sera utilisée pour les appels de modèle ultérieurs.
3.4 Construire l'Agent :
Cette expérience utilise principalement Trae pour vous aider à écrire le code. Ce tutoriel utilise le modèle Gemini-3-Pro-Preview. L'idée générale est de créer un nouveau projet, de copier le Prompt complet ci-dessous dans la boîte de dialogue et de l'envoyer, de remplacer progressivement les clés API, puis d'exécuter le code et effectuer les tests.
Phase 1 : Framework de base Gradio Blocks et mise en page de l'interface
Dans cette phase, notre objectif principal est de construire d'abord une « apparence » pour l'Agent entier, en réalisant la conception de la page frontend. Copiez le Prompt ci-dessous dans la boîte de dialogue de Trae, et après implémentation, vous obtiendrez une URL locale (généralement http://127.0.0.1:7860) pour voir l'interface et vérifier le résultat.
Bloc 1 : Framework de base Gradio Blocks et mise en page de l'interface
1. Objectif de la tâche
· Basé sur la mise en page Blocks de Gradio 4.0.0+, implémenter l'interface de base du projet « LLM + Nanobanana texte vers image », en suivant strictement une disposition fixe gauche-droite, en initialisant tous les composants UI et en définissant les états initiaux corrects.
2. Exigences de la stack technique
· Doit utiliser le mode Blocks de Gradio 4.0.0+, interdit le mode Interface ;
· Dépendances : gradio>=4.0.0, pillow>=10.0.0 (import uniquement, pas encore de logique de traitement d'image) ;
· Le code doit être un fichier Python complet et exécutable, incluant toutes les instructions d'import nécessaires.
3. Règles de mise en page de l'interface (contrainte principale, intégrant les détails pratiques)
· Mise en page globale :
Titre de la page : Outil complet de texte vers image piloté par LLM ;
Disposition fixe gauche-droite : gauche occupe 60% de la largeur, droite 40%, utiliser gr.Row et gr.Column pour le contrôle des proportions.
· Gauche 60% (zone du processus de génération de prompts) liste des composants :
input_text : gr.Textbox, label « Texte d'entrée (paragraphe de tutoriel / instruction de dessin) », lines=6, placeholder « Veuillez entrer le texte de tutoriel nécessitant une illustration ou une instruction de dessin direct... » ;
identify_intent_btn : gr.Button, value="Identifier l'intention", état initial normal cliquable ;
intent_status : gr.Textbox, label « Type d'intention / Statut de traitement », lines=2, interactive=False, valeur initiale « Intention non identifiée » ;
system_prompt : gr.Textbox, label « System Prompt (éditable uniquement pour l'intention d'illustration d'article) », lines=4, interactive=False, placeholder « Règles de contrainte pour la génération de prompts par le LLM... » ;
confirm_prompt_btn : gr.Button, value="Confirmer la génération du prompt de dessin", interactive=False (désactivé initialement pour éviter les erreurs) ;
generation_prompt : gr.Textbox, label « Prompt de dessin (éditable) », lines=3, interactive=True, valeur initiale vide, placeholder « Le prompt de dessin en anglais généré s'affichera ici, modification manuelle possible... ».
· Droite 40% (zone de génération d'images Nanobanana) liste des composants :
ref_image : gr.Image, label « Image de référence (optionnel, image vers image) », type=filepath, height=300, autorise l'upload ;
generate_btn : gr.Button, value="Générer l'image", interactive=False (désactivé initialement, pas de prompt = pas de clic) ;
result_image : gr.Image, label="Résultat de la génération", type=pil, height=300, initialement vide, interactive=False.
4. Exigences de logique d'interaction
· L'état interactive initial de tous les composants suit strictement la configuration ci-dessus, mis à jour dynamiquement via des fonctions par la suite ;
· L'état désactivé des boutons doit être visuel (grisé), pour éviter les erreurs de manipulation.
5. Exigences de sortie
· Générer un code Python complet, implémentant uniquement la mise en page de l'interface et l'initialisation des composants, sans aucune logique métier ;
· Commentaires de code clairs, noms de composants cohérents avec la version pratique (input_text/identify_intent_btn etc.) ;
· Le code doit être directement exécutable, la structure de l'interface doit correspondre exactement à la description.Après avoir ouvert http://127.0.0.1:7860 dans le navigateur, vous verrez que Trae a généré la page web suivante selon nos exigences, globalement conforme — vous pouvez passer à l'étape suivante de génération.
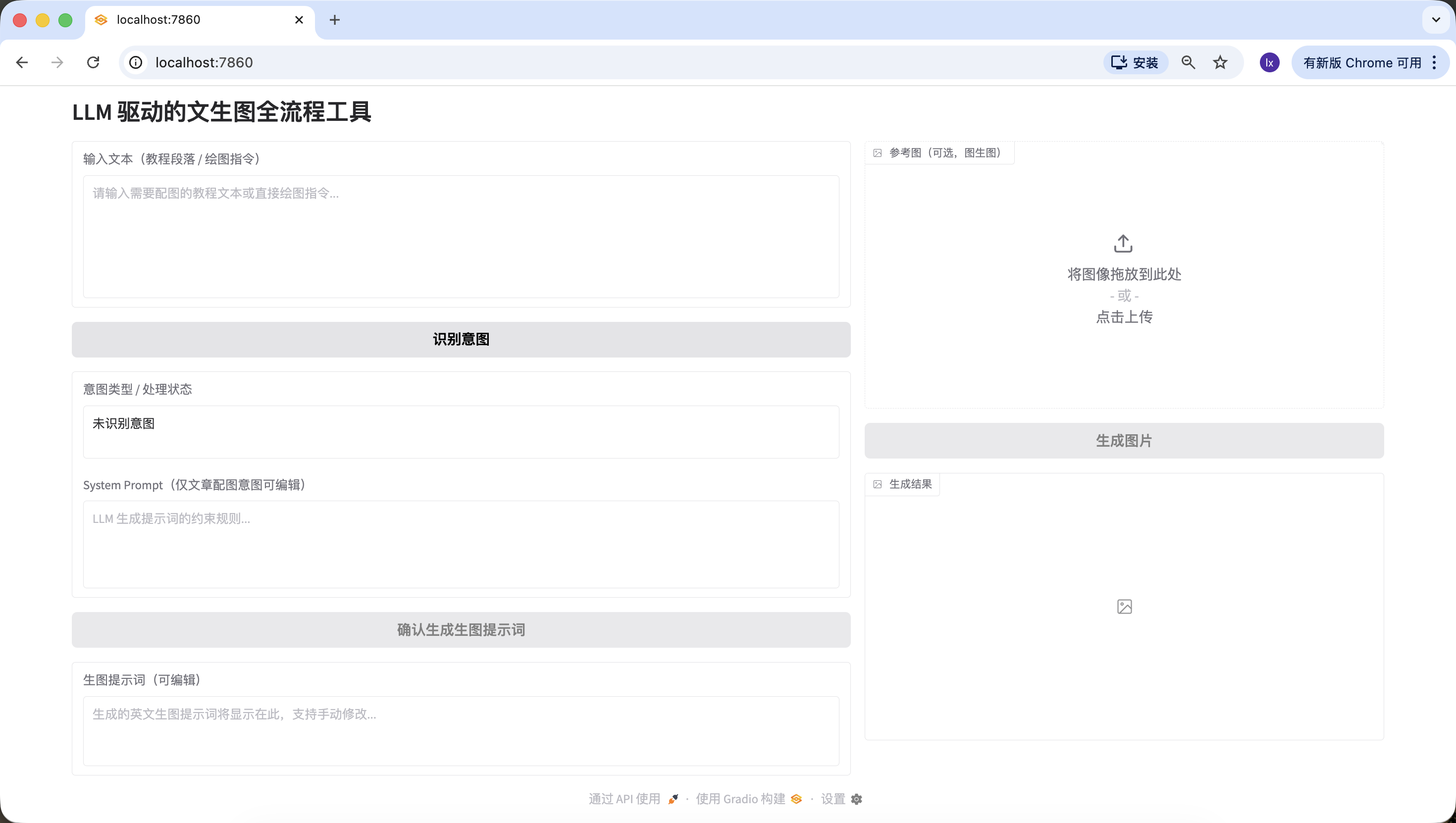
Phase 2 : Module d'identification d'intention par LLM (API Siliconflow)
Dans l'utilisation quotidienne de VLM pour le dessin, il existe trois types d'entrées courantes :
- Contenu sans signification, comme « bonjour », « as-tu mangé aujourd'hui », impossible d'en tirer une image.
- Article/texte long, avec un nombre de mots important, comme un article structuré d'environ 200 mots, nécessitant d'abord de comprendre la structure et le contenu de l'article avant de réfléchir à la génération d'une image résumant ce texte.
- Instruction de dessin direct, comme « dessine-moi un chien qui prend un bain », où la demande est déjà très spécifique et l'image peut être générée directement.
Comme précédemment, copiez le Prompt ci-dessous dans la boîte de dialogue de Trae et ajoutez les API obtenues aux étapes précédentes.
Bloc 2 : Module d'identification d'intention par LLM (API Siliconflow)
1. Objectif de la tâche
Sur la base de l'interface Gradio déjà implémentée, ajouter la logique de clic au bouton « Identifier l'intention », appeler l'API Siliconflow pour l'identification d'intention et lier l'état des composants.
2. Exigences de la stack technique
Basé sur Gradio 4.0.0+ Blocks ;
Dépendances : requests>=2.31.0, openai ;
Sortie : fichier Python complet et exécutable, incluant l'interface du Bloc 1 + la logique de ce module.
3. Règles métier principales (à ne jamais transgresser)
· Règles de classification d'intention (3 types uniquement, retourner strictement un nombre + description)
1 = Contenu sans signification : simple bavardage, salutations, conversation hors sujet, sans aucun besoin de dessin ou d'illustration (comme « bonjour » « as-tu mangé ») ;
2 = Besoin d'illustration pour article/texte long : l'utilisateur entre un article complet, un tutoriel, un paragraphe, un texte explicatif, au contenu plutôt narratif/explicatif/pédagogique, impliquant implicitement la nécessité de générer une illustration pour ce contenu, sans que l'utilisateur dise explicitement « illustre ce texte » ;
3 = Instruction de dessin direct : l'utilisateur entre une commande de dessin courte et claire, sans contexte de texte long, demandant directement de dessiner quelque chose (comme « dessine un chat style Apple »).
· Contraintes d'appel LLM (intégrant le template de la version pratique)
URL de l'interface : https://api.siliconflow.cn/v1/chat/completions ;
Modèle : Qwen/Qwen2.5-7B-Instruct ;
temperature=0.1 ;
Définition uniforme du code :
python
LLM_BASE_URL = "https://api.siliconflow.cn/v1"
LLM_API_KEY = "" # L'utilisateur remplace lui-même
LLM_MODEL = "Qwen/Qwen2.5-7B-Instruct"
# Template d'identification d'intention validé en pratique (figé dans le code)
INTENT_PROMPT_TEMPLATE = """Vous devez identifier l'intention du texte saisi par l'utilisateur, ne retourner qu'un des 3 types de résultats suivants (format : nombre + description en français) :
1 = Contenu sans signification ; 2 = Besoin d'illustration pour article/texte long ; 3 = Instruction de dessin direct.
Texte de l'utilisateur : {user_input}
Résultat de l'identification :
Extraire uniquement le nombre et la description du résultat, interdit tout contenu supplémentaire."""
4. Règles de liaison des composants
· Résultat 1 : intent_status affiche « 1 = Contenu sans signification : aucun besoin de dessin », system_prompt reste désactivé, confirm_prompt_btn désactivé ;
· Résultat 2 : intent_status affiche « 2 = Besoin d'illustration pour article/texte long : générer une illustration pour le contenu saisi », activer system_prompt et remplir la règle par défaut, activer confirm_prompt_btn ;
· Résultat 3 : intent_status affiche « 3 = Instruction de dessin direct : générer une image selon l'instruction », system_prompt désactivé et rempli avec la règle par défaut, activer confirm_prompt_btn.
5. Gestion des exceptions
Exceptions API, exceptions de parsing : afficher un message convivial, pas de crash, les composants reviennent à l'état initial.
6. Exigences de sortie
Générer un code complet et exécutable, il suffit de remplacer LLM_API_KEY pour l'utiliser, logique claire et commentaires complets, template d'identification d'intention strictement conforme à la version pratique.Rafraîchissez l'URL http://127.0.0.1:7860 précédente et commencez à tester si les trois cas sont correctement détectés.
- Contenu sans signification : essayez de saisir « bonjour », « merci », etc. — la détection fonctionne correctement.
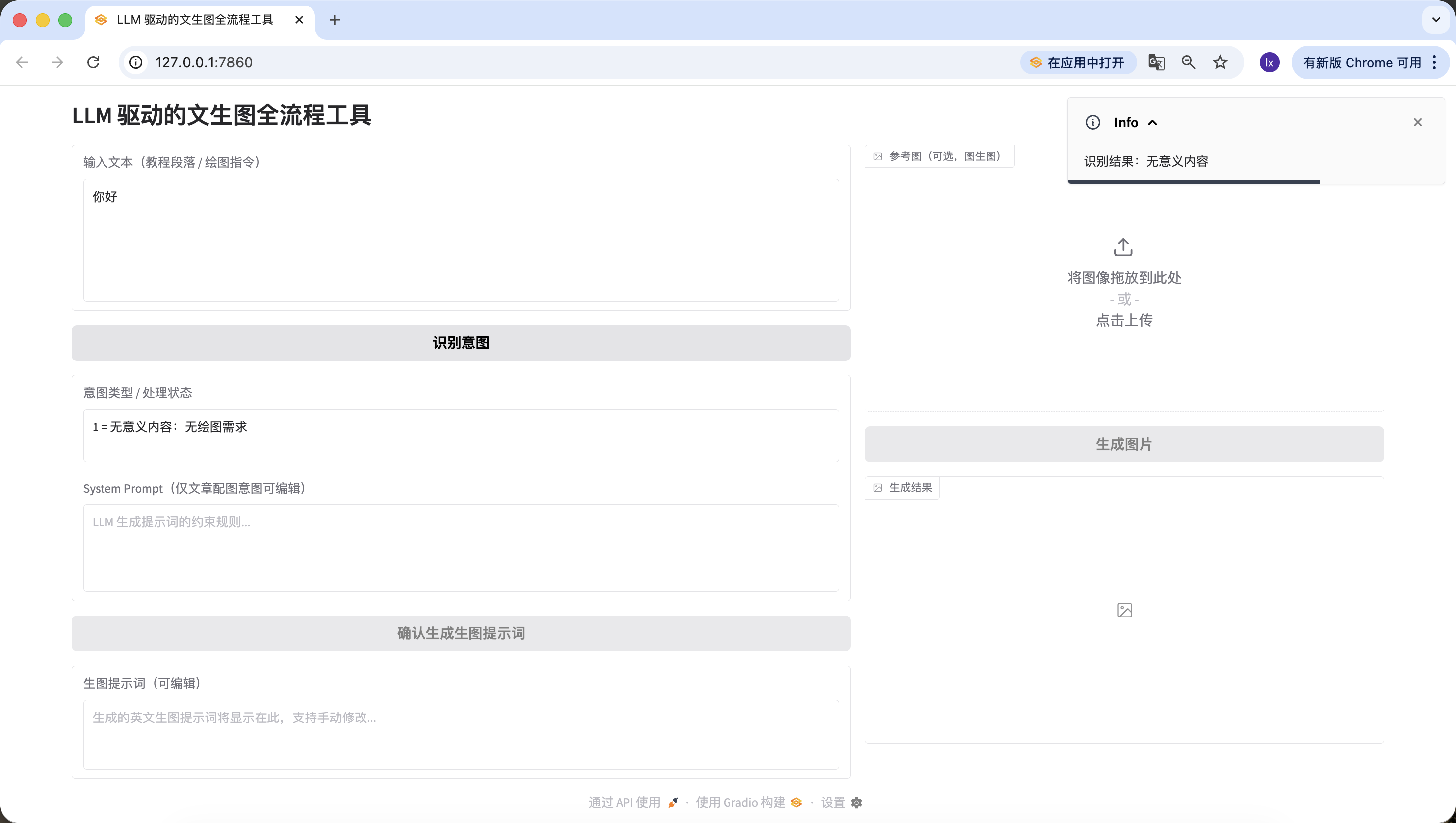
- Article/texte long : ici nous avons utilisé un texte généré par Doubao décrivant l'intelligence artificielle. Vous pouvez aussi tester avec vos propres paragraphes de thèse.
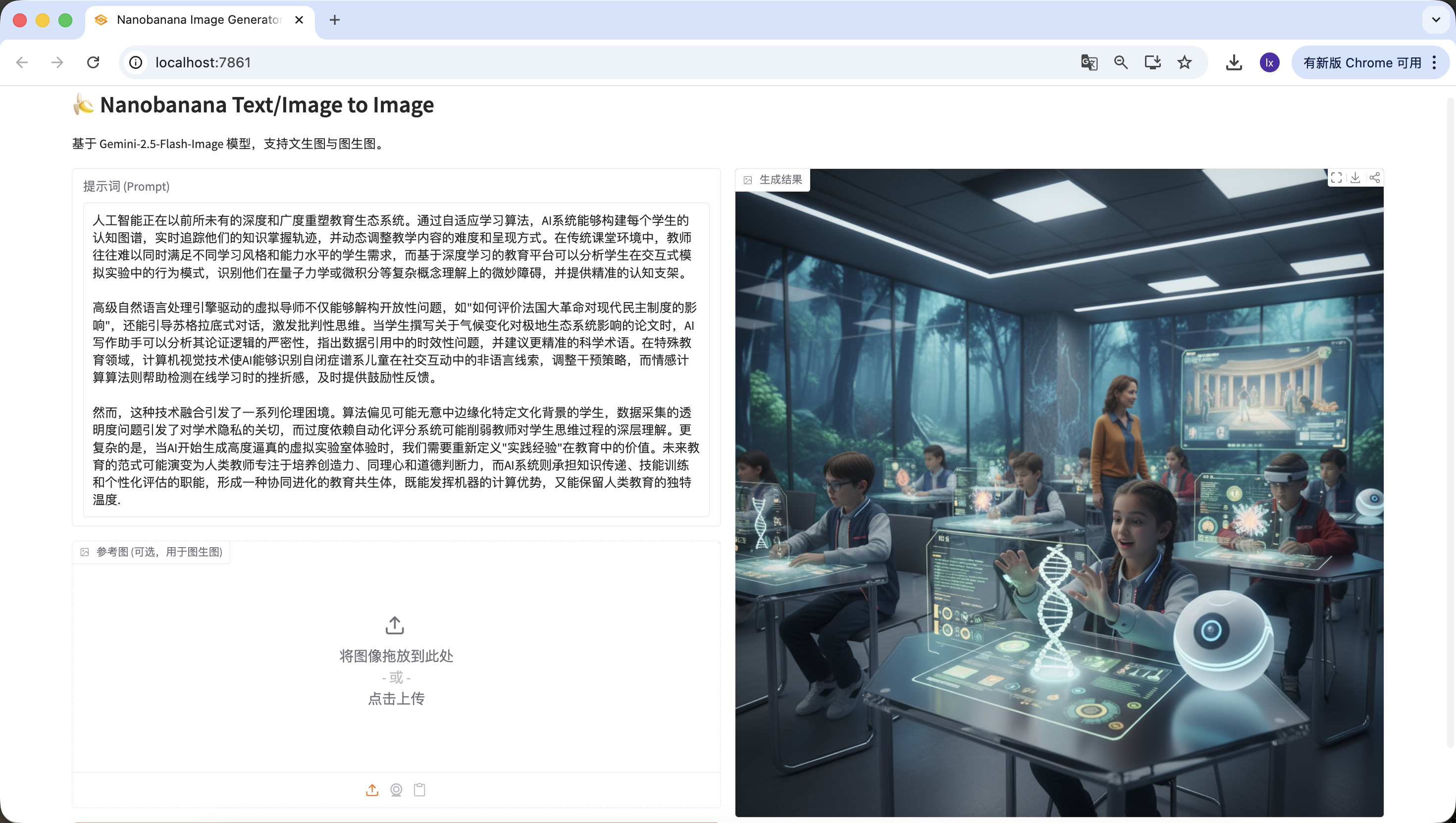
L'intelligence artificielle remodelle l'écosystème éducatif avec une profondeur et une ampleur sans précédent. Grâce à des algorithmes d'apprentissage adaptatif, les systèmes IA peuvent construire la carte cognitive de chaque étudiant, suivre en temps réel la trajectoire de maîtrise des connaissances, et ajuster dynamiquement le niveau de difficulté et le mode de présentation du contenu pédagogique. Dans un environnement de classe traditionnel, les enseignants peinent souvent à satisfaire simultanément les besoins d'étudiants aux styles d'apprentissage et niveaux de capacité différents, tandis que les plateformes éducatives basées sur l'apprentissage profond peuvent analyser les schémas de comportement des étudiants dans les simulations interactives, identifier les obstacles subtils dans la compréhension de concepts complexes comme la mécanique quantique ou le calcul, et fournir des échafaudages cognitifs précis.
Les tuteurs virtuels pilotés par des moteurs avancés de traitement du langage naturel peuvent non seulement déconstruire des questions ouvertes, comme « comment évaluer l'impact de la Révolution française sur les systèmes démocratiques modernes », mais aussi guider des dialogues socratiques stimulant la pensée critique. Lorsqu'un étudiant rédige un essai sur l'impact du changement climatique sur les écosystèmes polaires, l'assistant d'écriture IA peut analyser la rigueur logique de son argumentation, pointer les problèmes d'actualité dans les références de données, et suggérer des termes scientifiques plus précis. Dans le domaine de l'éducation spécialisée, la vision par ordinateur permet à l'IA d'identifier les indices non verbaux des enfants du spectre autistique dans les interactions sociales, ajuster les stratégies d'intervention, tandis que les algorithmes de calcul affectif aident à détecter la frustration lors de l'apprentissage en ligne, fournissant en temps utile des retours encourageants.
Cependant, cette intégration technologique soulève une série de dilemmes éthiques. Les biais algorithmiques peuvent involontairement marginaliser les étudiants de certains contextes culturels, les questions de transparence dans la collecte de données soulèvent des préoccupations concernant la vie privée académique, et la dépendance excessive aux systèmes de notation automatisés peut affaiblir la compréhension approfondie des enseignants sur le processus de pensée des étudiants. Plus complexe encore, quand l'IA commence à générer des expériences de laboratoire virtuel hautement réalistes, nous devons redéfinir la valeur de « l'expérience pratique » dans l'éducation. Le paradigme éducatif futur pourrait évoluer vers des enseignants humains se concentrant sur le développement de la créativité, de l'empathie et du jugement moral, tandis que les systèmes IA assumeraient les fonctions de transmission des connaissances, d'entraînement aux compétences et d'évaluation personnalisée, formant un symbiote éducatif en co-évolution, exploitant à la fois les avantages computationnels des machines et conservant la chaleur unique de l'éducation humaine.Détection réussie également !
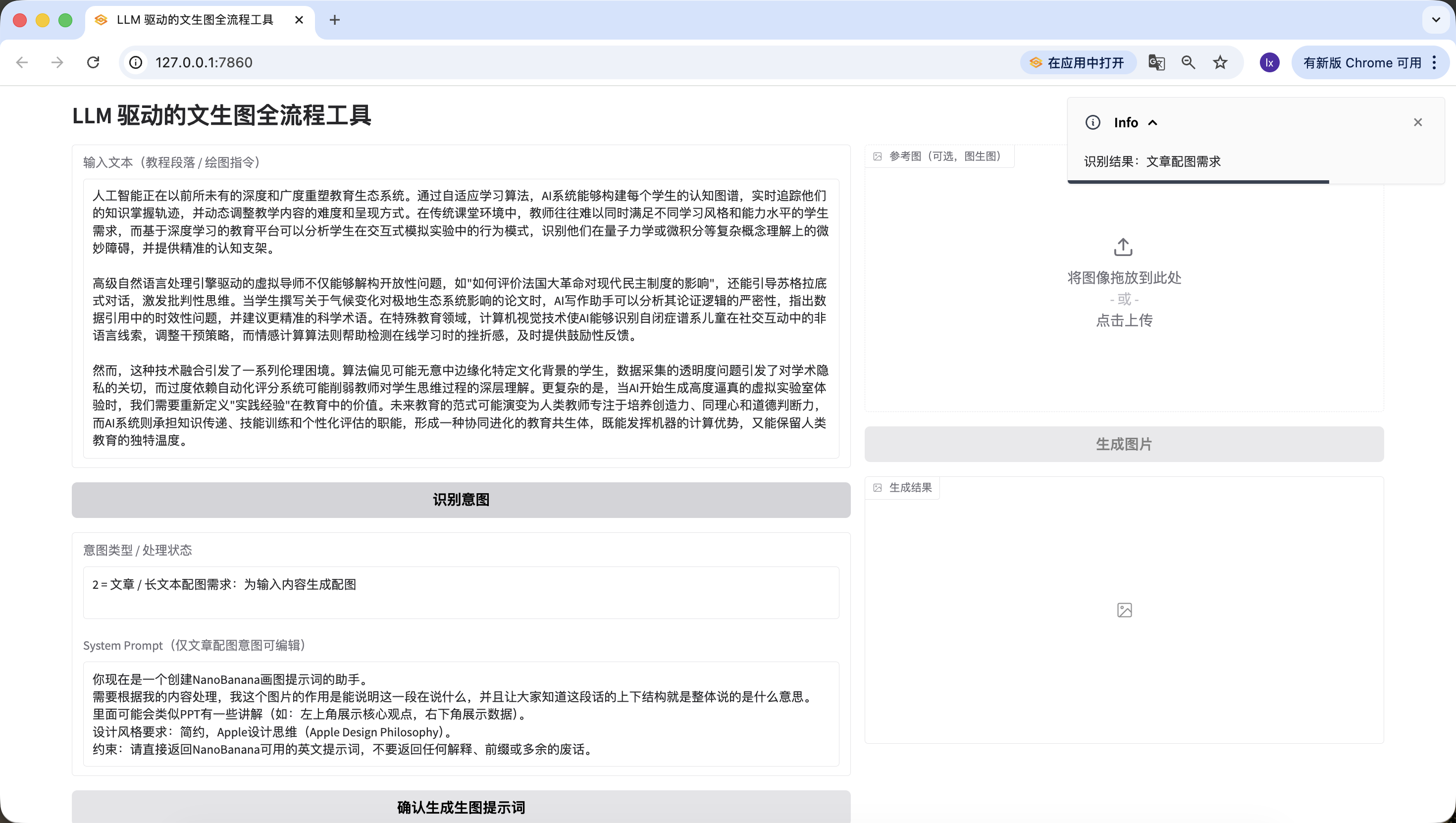
- Instruction de dessin direct : ici nous avons saisi « je veux dessiner un chat », détecté avec précision.
Nous avons ainsi réussi à implémenter la deuxième phase — l'identification d'intention.
Phase 3 : Module de génération de prompts de dessin (second appel LLM)
Après l'identification d'intention, pour les articles ou textes longs, il reste une étape très importante : générer le prompt de dessin, et c'est précisément le point clé de cet Agent.
Bloc 3 : Module de génération de prompts de dessin (second appel LLM)
1. Objectif de la tâche
Sur la base de l'identification d'intention, implémenter la logique du bouton « Confirmer la génération du prompt de dessin », appeler le LLM pour optimiser le texte en un prompt visuel en anglais adapté au dessin, remplir la zone d'édition et lier le bouton « Générer l'image ».
2. Exigences de la stack technique
Identiques au Bloc 2, sortie : code complet = Bloc 1 + Bloc 2 + ce module ;
Partage les LLM_BASE_URL, LLM_API_KEY, LLM_MODEL définis au Bloc 2, pas de nouvelle clé.
3. Règles métier principales (intégrant la logique d'assemblage de Prompt de la version pratique)
· Règles d'entrée pour la génération de prompts (à suivre strictement)
La génération de prompts de dessin n'est plus une simple concaténation de chaînes, mais construit une liste standard de messages Chat, la structure du code est la suivante :
python
messages=[
# Rôle System : contenu system_prompt final confirmé/édité par l'utilisateur sur la page
{"role": "system", "content": final_system_prompt},
# Rôle User : porte les données à traiter, clarifie l'objectif de la tâche
{"role": "user", "content": f"Veuillez générer un prompt visuel pour le contenu suivant :\n\n{user_input}"}
]
Intention 2 : le contenu System prend la version finale du system_prompt édité par l'utilisateur ;
Intention 3 : le contenu System prend la règle par défaut remplie en état désactivé ;
user_input est le texte original entré par l'utilisateur dans la zone input_text.
· Preset System Prompt validé en pratique (figé dans le code)
python
SYSTEM_PROMPT_DEFAULT = """Vous êtes maintenant un assistant créant des prompts de dessin pour NanoBanana.
Vous devez traiter en fonction de mon contenu, l'image doit pouvoir expliquer ce dont parle ce passage, et faire comprendre à tous la structure globale et le sens général du texte.
Il peut y avoir des éléments similaires à des présentations PPT (par exemple : le coin supérieur gauche montre l'idée centrale, le coin inférieur droit montre les données).
Exigences de style de design : minimaliste, philosophie de design Apple (Apple Design Philosophy).
Contrainte : retournez uniquement le prompt en anglais utilisable par NanoBanana, sans aucune explication, préfixe ou texte superflu."""
· Contraintes d'appel LLM
Partage les mêmes LLM_BASE_URL, LLM_API_KEY, LLM_MODEL que le Bloc 2 ;
temperature=0.7 (pour garantir la créativité et l'adaptabilité du prompt) ;
max_tokens=200 (limiter la longueur de sortie, en adéquation avec la contrainte de prompt) ;
Utiliser strictement la structure de liste de messages Chat standard ci-dessus, interdire la concaténation de chaînes.
· Contraintes forcées de sortie du prompt
Uniquement en anglais, pas de chinois ;
Doit inclure Apple Design Philosophy/Apple style + 1024x1024 ;
Longueur 50–200 caractères, validation dans le code ;
Pas d'explication supplémentaire, préfixe ou texte superflu, retourner uniquement le prompt lui-même.
4. Règles de liaison des composants
Génération réussie : remplir le prompt dans la zone generation_prompt, activer generate_btn, intent_status ajoute « Prompt généré avec succès, modifiable avant génération d'image » ;
Échec de génération : indiquer la raison spécifique (comme échec d'appel API, longueur insuffisante), generate_btn reste désactivé, zone generation_prompt vide ;
Modification/vidage manuel de la zone generation_prompt par l'utilisateur :
Si vidé, generate_btn est automatiquement désactivé ;
Si non vide, generate_btn reste activé.
5. Gestion des exceptions
Échec d'appel API : message convivial « Échec de génération du prompt : {message d'erreur spécifique} », pas de crash ;
Échec de validation du prompt : indiquer clairement la raison (comme « ne contient pas Apple style », « longueur de seulement 40 caractères »), permettre de réessayer ;
Échec de parsing de réponse : indiquer « Impossible d'analyser le résultat du LLM, veuillez réessayer ».
6. Exigences de sortie
Code complet et exécutable, il suffit de remplacer LLM_API_KEY pour l'utiliser ;
Structure de code claire, commentaires complets, interface belle et épurée ;
Implémenter strictement la structure de liste de messages Chat standard, paramètres et logique d'exemple cohérents ;
Inclure la logique de validation de longueur et de contenu du prompt, messages d'erreur conviviaux.Testez de la même manière avec le texte de la deuxième phase.
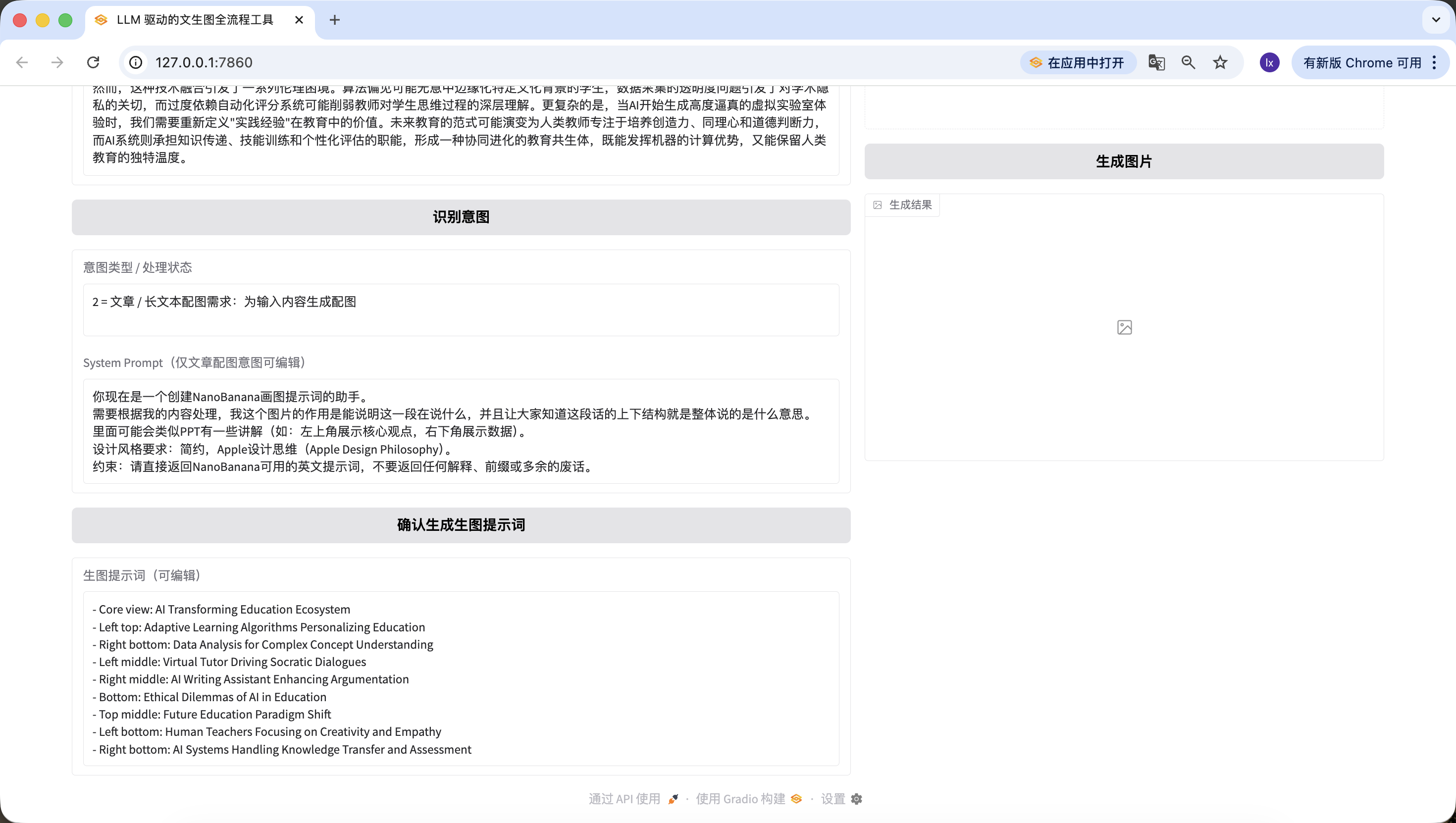
Notez que le System Prompt prédéfini pour la génération de prompts de dessin est le suivant :
Vous êtes maintenant un assistant créant des prompts de dessin pour NanoBanana. Vous devez traiter en fonction de mon contenu, l'image doit pouvoir expliquer ce dont parle ce passage, et faire comprendre à tous la structure globale et le sens général du texte. Il peut y avoir des éléments similaires à des présentations PPT (par exemple : le coin supérieur gauche montre l'idée centrale, le coin inférieur droit montre les données). Exigences de style de design : minimaliste, philosophie de design Apple (Apple Design Philosophy). Contrainte : retournez uniquement le prompt en anglais utilisable par NanoBanana, sans aucune explication, préfixe ou texte superflu.
Si vous souhaitez changer de template prédéfini, vous pouvez modifier le prompt précédent, ou le modifier directement dans Trae via le dialogue.
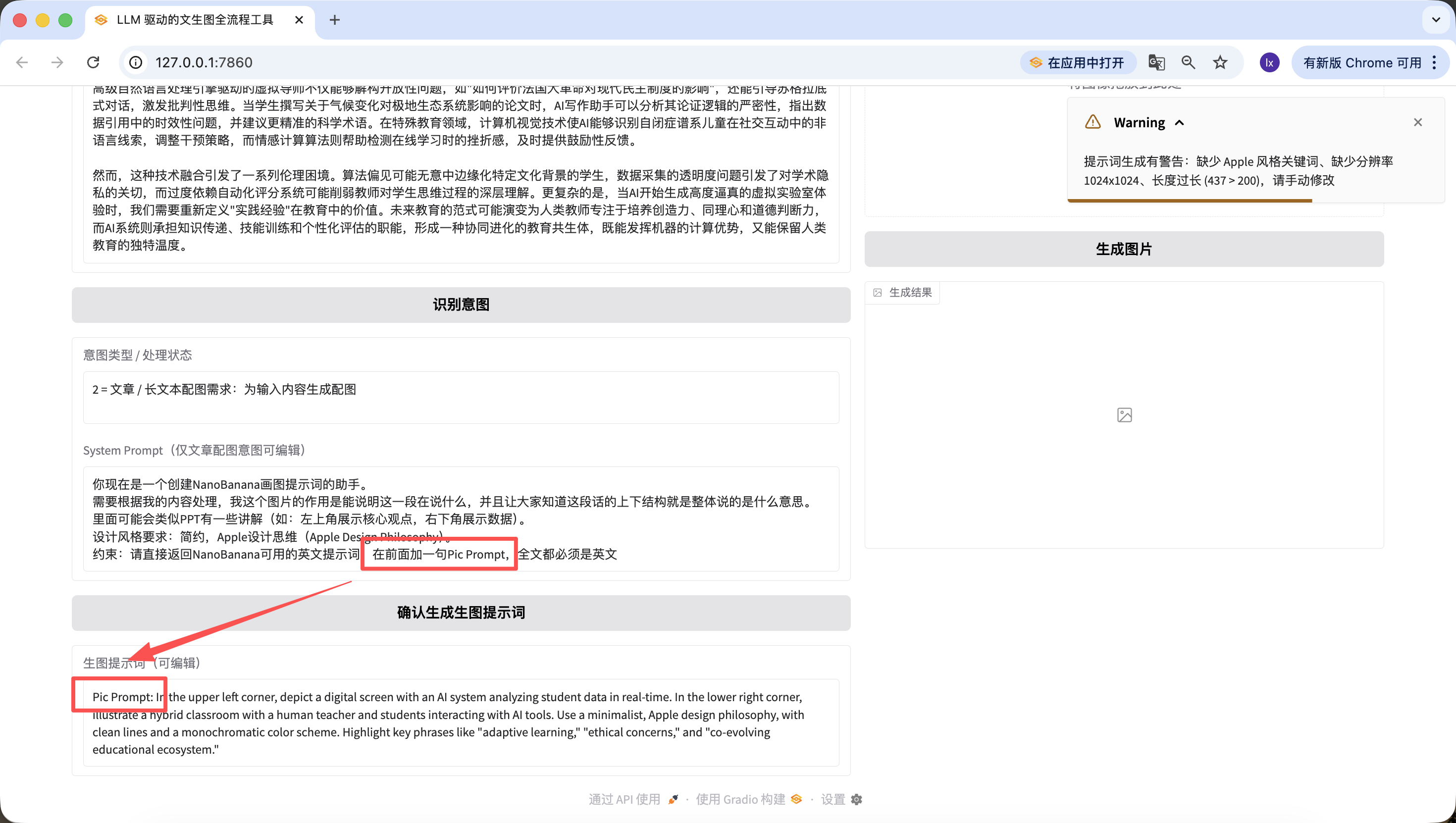
Outre la modification du code sous-jacent, vous pouvez aussi éditer rapidement sur la page web. Par exemple, j'ai ajouté ici « ajoutez "Pic Prompt" au début », et on peut voir que le nouveau prompt généré inclut bien ce préfixe. Cette conception permet de modifier rapidement le System Prompt de génération de prompts, facilitant les changements de style.
Phase 4 : Module de génération texte vers image / image vers image Nanobanana
Enfin la dernière étape — sans intégrer le modèle de génération d'images, ce n'est pas un Agent complet !
Bloc 4 : Module de génération texte vers image / image vers image Nanobanana (version finale)
1. Objectif de la tâche
Implémenter la logique du bouton « Générer l'image », appeler la véritable API Nanobanana, supporter texte vers image / image vers image, parser le Base64 et afficher l'image.
2. Exigences de la stack technique
Basé sur Gradio 4.0.0+ Blocks ;
Dépendances : requests, pillow, base64, io, re ;
Code complet = Bloc 1+2+3 + ce module.
3. Configuration API principale (figée et validée en pratique)
Configuration figée dans le code :
python
# Configuration API figée dans le code
NANOBANANA_API_URL = "https://api.zyai.online/v1/chat/completions"
NANOBANANA_MODEL = "gemini-2.5-flash-image"
NANOBANANA_API_KEY = "" # L'utilisateur remplace lui-même
Méthode d'authentification : Header Authorization: Bearer {NANOBANANA_API_KEY}.
4. Exigences de prétraitement d'image (obligatoire)
Implémenter la fonction image_to_base64_data_uri (ref_image_path), logique principale :
Convertir l'image PIL en format PNG ;
Mise à l'échelle automatique en résolution 1024x1024 ;
Canal transparent converti en fond blanc ;
Encoder en Base64, format retourné : data:image/png;base64,...
5. Règles de construction de la requête (suivre strictement la logique de branchement de la version pratique)
· Définition de la fonction principale
Implémenter la fonction generate_image (prompt, ref_image_path) :
Paramètres d'entrée : prompt (contenu de la zone generation_prompt), ref_image_path (chemin du fichier uploadé dans ref_image) ;
Retour : PIL Image (affichée dans result_image) ou message d'erreur.
· Branche logique 1 : texte vers image pur (ref_image_path vide)
python
messages = [{"role": "user", "content": prompt}]
· Branche logique 2 : image vers image (ref_image_path non vide)
python
# D'abord appeler la fonction de prétraitement d'image
image_base64 = image_to_base64_data_uri(ref_image_path)
messages = [{"role": "user","content": [{"type": "text", "text": prompt},{"type": "image_url", "image_url": {"url": image_base64}}]}]
6. Exigences de parsing de réponse (doit être compatible avec deux formats)
Extraire l'image Base64 depuis choices[0].message.content, supporter :
Champ image_url du retour JSON structuré ;
Format Markdown ;
Extraire uniformément l'encodage Base64, décoder puis convertir en PIL Image pour le retour.
7. Liaison des composants et gestion des exceptions
Génération réussie : afficher la PIL Image dans result_image, intent_status indique « Image générée avec succès » ;
Échec de génération/parsing/upload : afficher un message textuel clair dans intent_status (comme « Échec du parsing Base64 », « Délai d'attente de l'appel API dépassé »), pas de crash.
8. Exigences de sortie
Code complet et exécutable, il suffit de remplacer LLM_API_KEY et NANOBANANA_API_KEY pour l'exécuter directement, flux complet utilisable, logique de branchement strictement conforme à la version pratique.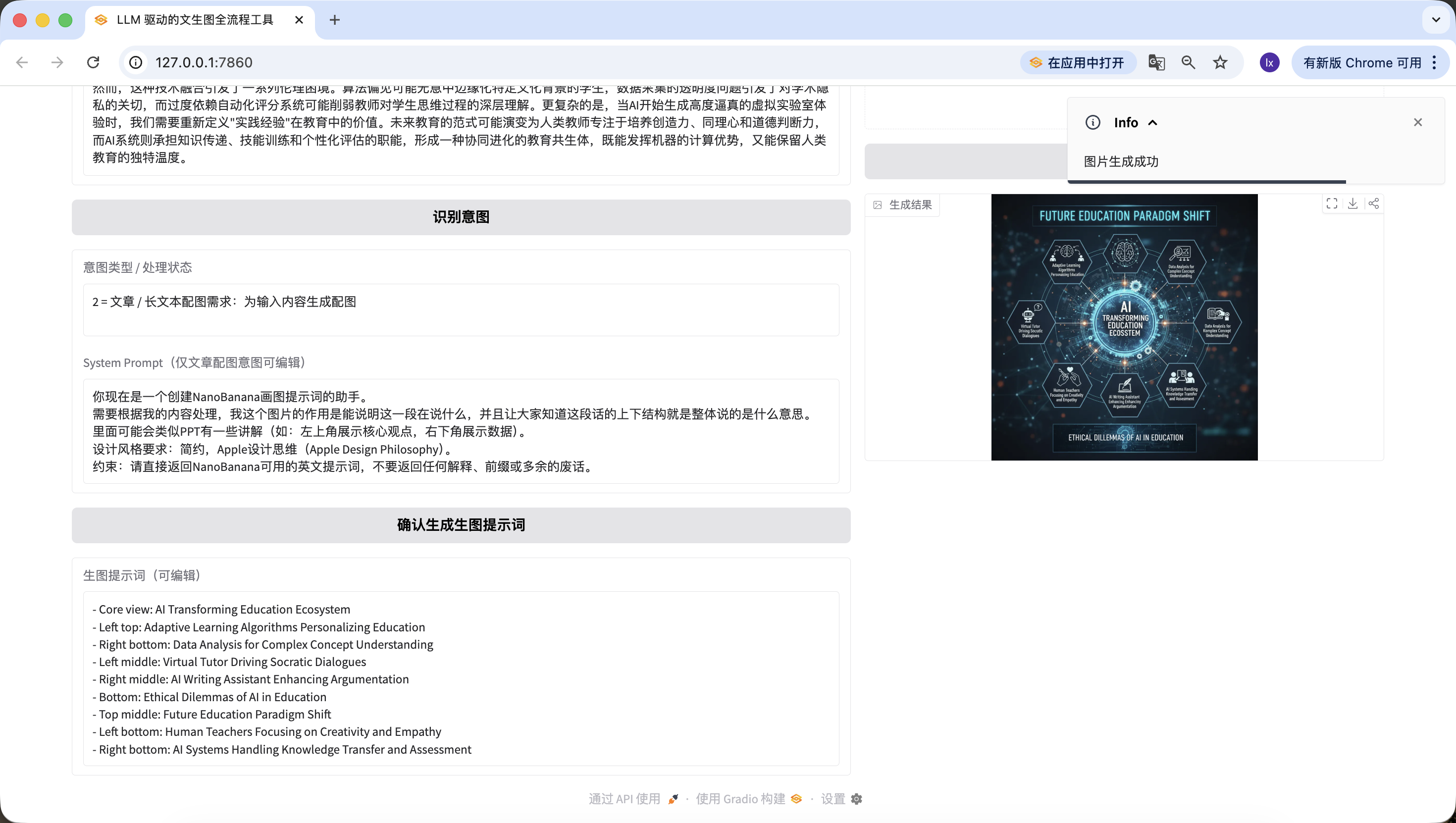
C'est vraiment passionnant ! Nous avons enfin réussi à générer la première image de cet Agent. Regardez attentivement l'image générée — elle correspond bien à notre texte et à notre prompt. Vous avez maintenant pratiquement implémenté votre propre Agent !

Nous avons aussi ajouté la fonctionnalité image vers image : uploadez une image que vous aimez et l'IA s'en inspirera automatiquement pour le style.
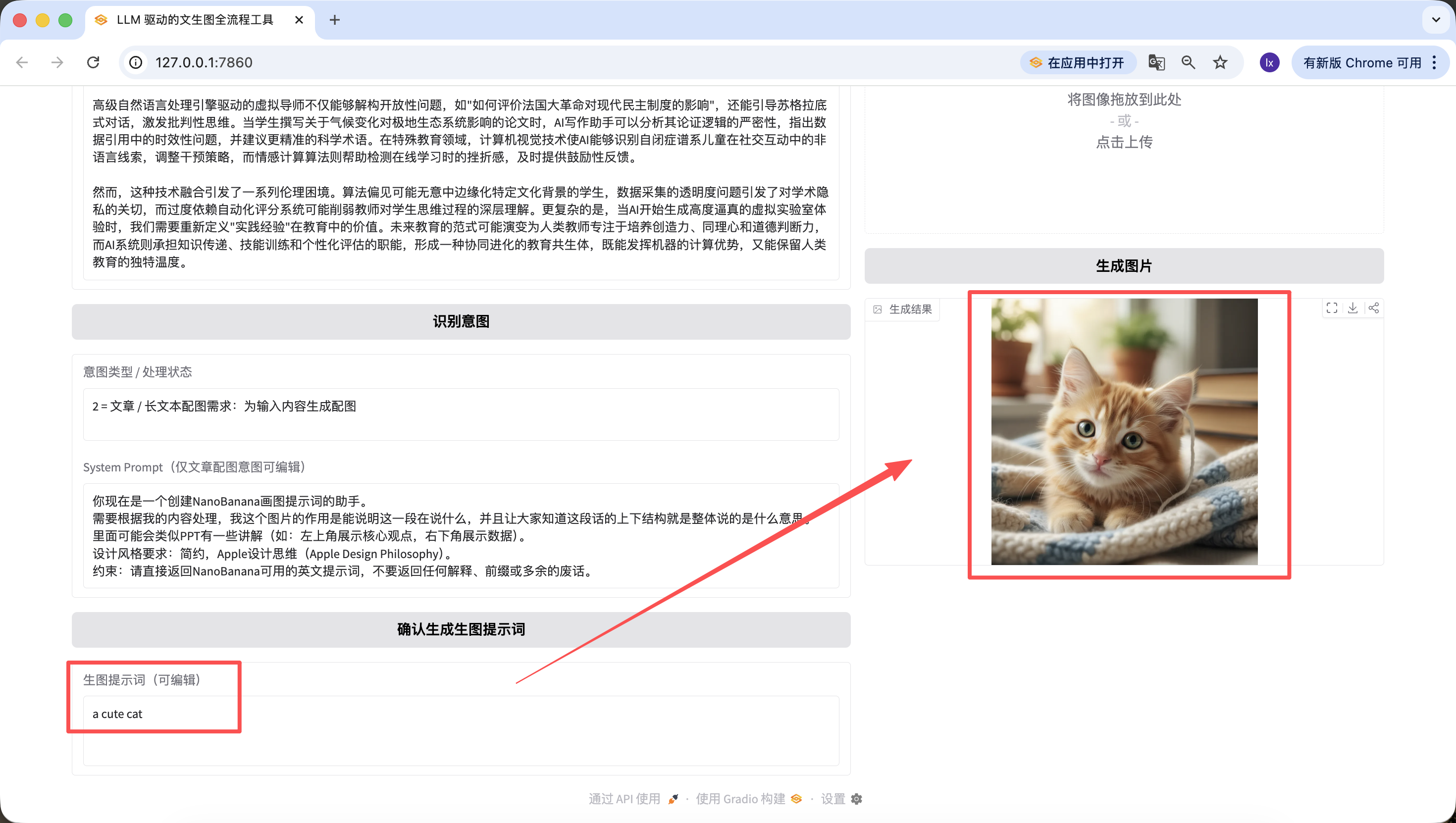
Il convient de mentionner que les prompts générés aux étapes précédentes sont également éditables sur la page web, et c'est le prompt au moment du clic final sur le bouton qui fait foi. Même si je remplace ici par « a cute cat », l'image finale générée ne sera qu'un mignon petit chat.
Chapitre 4 : Résumé

Hourra ! C'est enfin terminé. Honnêtement, même moi j'ai poussé un soupir de soulagement en écrivant la dernière ligne, alors imaginez pour vous qui avez suivi jusqu'au bout. Réussir à exécuter ce flux complet en entier est déjà très impressionnant — cela prouve que vous avez vraiment mis les mains sur le clavier et accompli les choses étape par étape. Bravo !
En écrivant ce contenu, je me suis toujours demandé ce que nous devions laisser derrière nous. La réponse n'est ni le nom des modèles, ni les paramètres ou une approche fixe, mais plutôt de vous aider à développer progressivement un ressenti : quelles tâches peut-on confier en toute sécurité à l'IA pour la compréhension et la planification, et où avez-vous simplement besoin de décider de la direction. Une fois cette répartition des rôles établie, de nombreux flux de génération qui semblaient complexes commencent à devenir plus fluides.
En y regardant en arrière, le chemin n'est pas si complexe. Réfléchissez clairement au problème que vous voulez résoudre, confiez les textes longs au modèle de langage pour les décomposer, puis transmettez l'intention visuelle organisée au modèle de dessin pour le rendu, et enfin encapsulez l'ensemble de ce flux dans votre propre petit assistant. À ce stade, vous ne faites plus qu'« utiliser un modèle » — vous construisez un système qui peut vous accompagner durablement dans votre travail. C'est exactement ce que ce tutoriel voulait vous transmettre avant tout.
Mais vous avez déjà fait du excellent travail ! Si vous êtes arrivé jusqu'ici, vous maîtrisez probablement les bases du Vibe Coding. Accordez-vous une petite pause bien méritée !